- 投稿日:2020-09-26T23:40:33+09:00
二つのテーブルを繋ぐ存在、中間テーブル
中間テーブルとは
二つのアソシエーションしたいテーブル同士が「多対多」の関係のときに、テーブルの間を受け持つ、便利なやつ。
具体例
LINEを思い浮かべると、一人のユーザーはいくつものグループに所属している。また、一つのグループには、何人ものユーザーが招待されている。このとき、ユーザーとグループは「多対多」の関係と言える。
問題点
「多対多」のテーブルをそのままアソシエーションすることが困難である。
解決策
先の例で言えば、ユーザーとグループの間に組み合わせを記録するテーブルをかませる。それが、中間テーブル。ユーザーとグループの組み合わせを記録するというのがポイントで、カラムにはユーザーidとグループidが必要となる。
記述
アソシエーションをするため、「has_manyメソッド」「belongs_toメソッド」を使う。
そのモデル(テーブル)ファイルの目線になって、繋がりを持ちたいモデル(テーブル)にはが複数か単数か考える。
ex) user(モデル) has_many groups
ここは、もはや英語の話。group.rbhas_many :user_groups has_many :users, through: :user_groupsuser.rbhas_many :user_groups has_many :groups, through: :user_groupsuser_group.rbbelongs_to :user belongs_to :group注意
直接的に繋がっていないモデルには、「throughオプション」を使う。
ポイント
- 中間テーブルは必ず「belongs_toメソッド」で、後に続くモデル名は単数形。
- アソシエーションしたいテーブル同士は間接的に多対多の関係になる。
- 中間テーブルではないテーブルは必ず「has_manyメソッド」で、後に続くモデル名は複数形。
- 「throughオプション」を使って、経由しているモデル名を複数形で記述。
最後に
人生で初めてQiitaに投稿します。自分のアウトプットを目的としていますが、お気づきの点があれば、ご指摘ください。
- 投稿日:2020-09-26T22:38:36+09:00
【Rails】devise関連のルーティングまとめ
deviseも便利な機能が故、それぞれ独自のメソッドが自動で生成してくれるルーティングについて、こんがらがってしまいます。
そんな同じお悩みの方はぜひ。devise_for
routes.rbdevise_for :users$ rails routes Prefix Verb URI Pattern Controller#Action new_user_session GET /users/sign_in(.:format) devise/sessions#new user_session POST /users/sign_in(.:format) devise/sessions#create destroy_user_session DELETE /users/sign_out(.:format) devise/sessions#destroy user_password POST /users/password(.:format) devise/passwords#create new_user_password GET /users/password/new(.:format) devise/passwords#new edit_user_password GET /users/password/edit(.:format) devise/passwords#edit PATCH /users/password(.:format) devise/passwords#update PUT /users/password(.:format) devise/passwords#update cancel_user_registration GET /users/cancel(.:format) devise/registrations#cancel user_registration POST /users(.:format) devise/registrations#create new_user_registration GET /users/sign_up(.:format) devise/registrations#new edit_user_registration GET /users/edit(.:format) devise/registrations#edit PATCH /users(.:format) devise/registrations#update PUT /users(.:format) devise/registrations#update DELETE /users(.:format) devise/registrations#destroyresources :usersとの比較
アクション名 リクエスト resources devise_for new GET /users/new /users/sign_up(.:format) edit GET /users/:id/edit /users/edit(.:format) show GET /users/:id なし index GET /users なし create POST /users /users(.:format) update PATCH / PUT /users /users(.:format) destroy DELETE /users /users(.:format) devise_scope
routes.rbdevise_scope :user do get 'signin' => 'devise_token_auth/sessions#new' post 'signin' => 'devise_token_auth/sessions#create' post 'signup' => 'users#create' put 'update' => 'users#update' end$ rails routes Prefix Verb URI Pattern Controller#Action signin GET /signin(.:format) devise_token_auth/sessions#new POST /signin(.:format) devise_token_auth/sessions#create signup POST /signup(.:format) users#create update PUT /update(.:format) users#updatemount_devise_token_auth_for
routes.rbmount_devise_token_auth_for 'User', controllers: { registrations: 'users' }$ rails routes Prefix Verb URI Pattern Controller#Action signin GET /signin(.:format) devise_token_auth/sessions#new POST /signin(.:format) devise_token_auth/sessions#create signup POST /signup(.:format) users#create update PUT /update(.:format) users#update
- 投稿日:2020-09-26T21:37:34+09:00
undefined method `**_path'のエラー
記事の目的
初学者の為、間違っているところはご指摘頂けると幸いです。
備忘録・アウトプット目的で投稿です。エラー内容
new.html.slim= form_with model: @review, local: true do |f| .form-group = f.label :purpose = f.text_field :purpose, class:'form-control', id: 'review_purpose'において、以下の「undefined method `reviews_path'」というエラーが発生。
そもそもreviews_path定義していないけどな。ActionView::Template::Error (undefined method `reviews_path' for #<#<Class:0x00007fb7553f5138>:0x00007fb7553fc9b0>):調べると、以上の「= form_with model: @review, local: true do |f|」のコードにおいては、form_with model: @review の箇所が内部的にpolymorphic_path(@review)というメソッドを実行しているそうで、 その実行結果がreviews_pathとなるのでそこでエラーが起きているらしい。
対処法
記事をみてみると、以下のように「form_forでしっかりどこに飛ばすのか指定してあげれば解決するらしい。解決。
new.html.slim= form_for @review,:url => {:action => :create} do |f|こちらに関しては、urlのオプションから実行しているコントローラーのnewアクションに該当するpathを作り出しており、このパスは存在するのでエラーとならないようです。
- 投稿日:2020-09-26T20:47:43+09:00
docker-composeを用いたRailsのAPIサーバー環境構築
筆者について
ProgateのRuby, Railsコースを一通りやった。
その後Dockerで環境作ってRailsでAPIサーバー作った。本記事について
Progateではviewを含んだrailsの書き方を学んだが、APIサーバーとしてのみRailsを使いたかった。
また、dockerで開発したかったため公式のクイックスタートを参考にRailsの開発環境を作った。
その過程で得られたノウハウをまとめる。APIサーバーの開発で使うGemについては別記事で書く。
前提
Docker, docker-composeの使い方がわかること
環境
Ruby 2.7
MySQL 5.7
VSCode
Mac 10.14.5
Sequel Pro データベース見る用Rails new するまで
まずはプロジェクトフォルダを作成。ここではrails-sampleとした。
そして、この直下に Dockerfileを作成FROM ruby:2.7 RUN apt-get update -qq && apt-get install -y RUN mkdir /myapp WORKDIR /myapp COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install # Add a script to be executed every time the container starts. COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"]次にrailsをインストールするためのGemfileを用意
source 'https://rubygems.org' gem 'rails', '~>5'空のGemfile.lockを作る
touch Gemfile.lockDockerfileに記載されている
entrypoint.shを作るentrypoint.sh#!/bin/bash set -e # Remove a potentially pre-existing server.pid for Rails. rm -f /myapp/tmp/pids/server.pid # Then exec the container's main process (what's set as CMD in the Dockerfile). exec "$@"なぜこれらのファイルを作るのかはDocker 公式クイックスタートの方を見ていただければ。
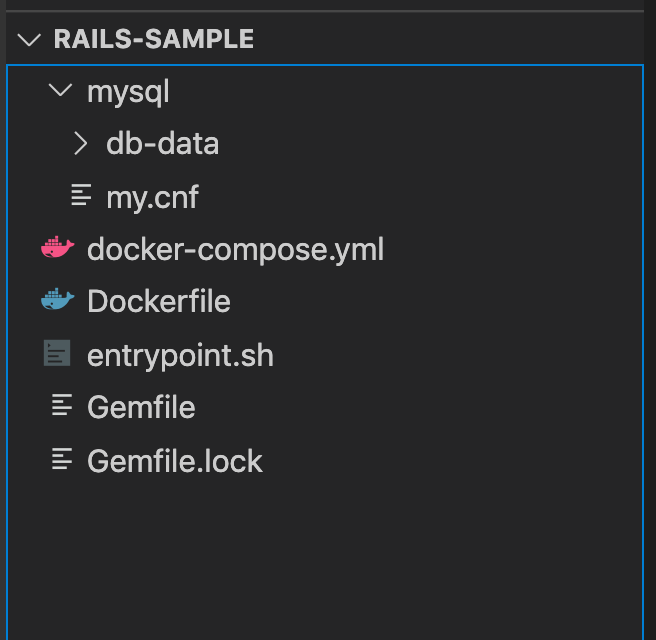
docker-compose.ymlを作るdocker-compose.ymlversion: '3' services: server: build: . tty: true volumes: - .:/myapp working_dir: /myapp ports: - "3000:3000" depends_on: - mysql command: bash # command: > # bash -c "rm -f tmp/pids/server.pid && # bundle exec rails s -p 3000 -b '0.0.0.0'" mysql: image: mysql:5.7 ports: - "3306:3306" environment: MYSQL_ROOT_PASSWORD: mysql volumes: - "./mysql/db-data/:/var/lib/mysql" # データ永続化 - "./mysql/my.cnf:/etc/mysql/conf.d/my.cnf" # 日本語をデータとして使うために必要MySQLのデータの永続化と日本語対応のために
rails-sample > mysql > db-data フォルダを作成。
mysqlフォルダ以下にmy.cnfを作成my.cnf[mysqld] character-set-server=utf8ここまででこのような構成になる。
それができたら
rails newする。docker-compose run server rails new . -MC --force --api --database=mysql --skip-active-storagerailsコマンドやコマンドのヘルプでオプションを調べ、不要そうなものを省いている。
重要なオプションは以下--force // rails new 時にファイルを上書き --api // api開発に不要なviewとかを生成しない --database=myql // デフォルトではsqliteだがmysqlを指定するこれでいろいろ作られる。
で、ここで
GemfileとGemfile.lockが上書きされて新しくなっている。
これをイメージのほうに反映させるために、docker-compose buildする必要がある。
事前に必要なgemがわかっている場合にはここでGemfileに書いておく。
これでrails new完了
mysqlに繋がるように設定ファイルを書く。
config > database.yml
database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: mysql development: <<: *default host: mysql database: myapp_development ... test: <<: *default host: mysql database: myapp_testproductionは不要なのでまるっとコメントアウトした
host名はdocker-compose.ymlのサービス名
passwordもdocker-compose.ymlで指定したものできたら
docker-compose up -dでコンテナを起動し、VSCodeのAttach Shellで中に入るrails db:createでDBを作る
root@dc075120af8a:/myapp# rails db:create ... Created database 'myapp_development' Created database 'myapp_test'これでデータベースが作れた。
Sequel Proで接続すればデータベースができていることが確認できるあとはProgateで学んだ通りモデル作ってマイグレーションすればテーブルができる。
参考
Docker 公式クイックスタート 英語
日本語の方は内容が古いので注意。
- 投稿日:2020-09-26T19:05:37+09:00
配列内の任意の文字を探す判定するメソッドの作り方
【概要】
1.結論
2.includeメソッドとは何か
3.どのようにプログラムしたか
1.結論
include?メソッドを使う!
2.include?メソッドとは何か
include?は配列の中に指定した要素が、あるかを判定するメソッドです!
3.どのようにプログラムしたか
def array_hello(strs) if strs.include?(hello) puts "True" else puts "False" end end"strs"の引数から"hello"という文字を探したいので、
strs.include?(hello)という書き方にしています!
引数.include?(探したい配列内の文字)で適用できます!
- 投稿日:2020-09-26T19:03:43+09:00
(ECサイト)注文情報入力時におけるバリデーション
前提条件
ECサイトでECサイトで注文情報入力 ==> 注文確認画面の間に注文情報入力でバリデーションをかけたい
1.よく使うバリデーション
app/models/book.rbvalidates :title, presence: trueなどの普段よく使うバリデーションは
booksテーブルにtitleというカラムがあり
データベースに保存される時、つまり @book.save(book_params)の時にtitleカラムが空白だとバリデーションがかかる。
しかし、ECサイトで注文情報入力 ==> 注文確認画面
==> 注文確定(ここで.saveが行われる)というフローで実装する際、注文情報入力 ==> 注文確認画面の間に.saveが発生しない為、モデルにかけるバリデーションをrenderで呼び出すことができない為if文で条件分岐を書いてflash[:notice]を使う必要がある。2.if文の実装
app/controllers/order_controllers.rbwhen 3 if params[:order][:new_add][:postal_code] == "" && params[:order][:new_add][:address] == "" && params[:order][:new_add][:name] == "" flash[:notice] = "新しいお届け先が全て入力されていません" redirect_to new_order_path elsif params[:order][:new_add][:postal_code] == "" flash[:notice] = "郵便番号が入力されていません" redirect_to new_order_path elsif params[:order][:new_add][:address] == "" flash[:notice] = "住所が入力されていません" redirect_to new_order_path elsif params[:order][:new_add][:name] == "" flash[:notice] = "宛名が入力されていません" redirect_to new_order_path else @order.postal_code = params[:order][:new_add][:postal_code] @order.address = params[:order][:new_add][:address] @order.name = params[:order][:new_add][:name] end end3.コードの説明
まず、case文を使い、ラジオボタンを3個order/new.html.erbに書きwhenで3パターン分岐させている。
そして、3個目のラジオボタンを選ぶと注文情報入力時に新しいお届け先を入力できるように実装している。
[:new_add] は注文情報入力時に新しいお届け先を入力する際のパラメータ。app/controllers/order_controllers.rbparams[:フォームで送られてくる値] == "" flash[:notice] = ”ホニャホニャ"と書くことで空欄の時にフラッシュメッセージを出せる。
4.今回の実装を終えて
当初 == nil にしており値が返ってきていなかったがターミナルを見ると""になっていたので条件文を変えるとうまくいった。
&&で条件文を繋ぐ時に最後に一個だけイコールを入れるのではなく毎回イコールが必要である。5.参考サイト
https://qiita.com/GreenFingers_tk/items/ed5219e1e0cdd5e5d1b1#new
- 投稿日:2020-09-26T18:52:42+09:00
Railsにフォントを導入するまで
はじめに
ネット上には素晴らしいフリーフォントがたくさんあります。
デザインの表現の幅を広げるために是非、活用していきたいところ。
そこで、フリーフォントをRailsに導入していきます。フォントファイルの導入
ここでは導入したいフォントファイルを
smog.otfとします。
publicフォルダにfontsフォルダを作り、そこにフォントファイルを配置。- public - fonts - smog.otf使用するcssファイル(ここでは
sample.css)に以下のコードを追加します。
font-familyの名前は自由に設定できます、今回は'Smog'としましょう。
またformatはファイルのフォーマットに合わせます。
フォーマット 拡張子 format('woff') .woff format('truetype') .ttf format('opentype') .otf または .ttf format('embedded-opentype') .eot format('svg') .svg または .svgz sample.css@font-face { font-family: "Smog"; src: asset-url('/fonts/smog.otf') format('opentype'); font-weight: normal; font-style: normal; }あとはいつも通りcssでフォントを指定すれば使えます。
以下は例です。sample.css.foo h1 { font-family: 'Smog'; }index.html.erb<div class="foo"> <h1>hello!</h1> </div>以上です、お疲れ様でした!
- 投稿日:2020-09-26T17:12:22+09:00
【Rails】【bootstrap】レスポンシブに文字の大きさを変更したい
前提
gem bootstrapを使用
やりたいこと
Railsを使ってレスポンシブな画面を作る。
その際に文字の大きさをいい感じに大きくしたり小さくしたりしたい。結論
app/assets/stylesheets/application.scssbody, html { font-size: 30px; } @media screen and (min-width: 576px) and (max-width: 768px) { body, html { font-size: 30px; } } @media screen and (min-width: 769px) and (max-width: 992px) { body, html { font-size: 30px; } } @media screen and (min-width: 993px) and (max-width: 1200px) { body, html { font-size: 16px; } } @media screen and (min-width: 1201px) { body, html { font-size: 20px; } }上記のサイズを変更すればOK
色々見ているとpxで設定しない方がよいというのもあるので、他の方法も検討中
今回はRailsというよりはscssの書き方になる
- 投稿日:2020-09-26T16:40:51+09:00
sidekiqのリトライ上限を設定して死んだキューをslackで通知する方法
はじめに
非同期でjobを処理してくれるsidekiqを導入する中で、利便性を生かしつつも自分のアプリ専用にカスタマイズしたい、そんな時に役に立った設定をまとめています。
sidekiqとは
sidekiqとは、非同期処理を可能にしてくれるライブラリです。複数のジョブを同時に実行させる時などに、各ジョブのqueueの名称を分けることで、処理の優先順位を指定することができます。似たようなライブラリにresqueやdelayed_jobなどがあるかと思います。
簡単に導入できるのですが、つまづいてしまったキューをデフォルトで25回だか26回だかリトライするとか、その後はDEADとなって実行していたキューのログが見られないなどといった面倒な点もあります。
そこでこの記事では、例外を投げた時などにいつまでもリトライせず上限を設定してDEADとし、その際にslackにキューの内容とエラーメッセージを投げるという設定をする方法についてお話しします。環境
Ruby 2.6.6
Rails 6.0.2
sidekiqにはredisが必要になります。# On OSX brew update brew install redis brew services start redis失敗したキューをダッシュボードで確認する
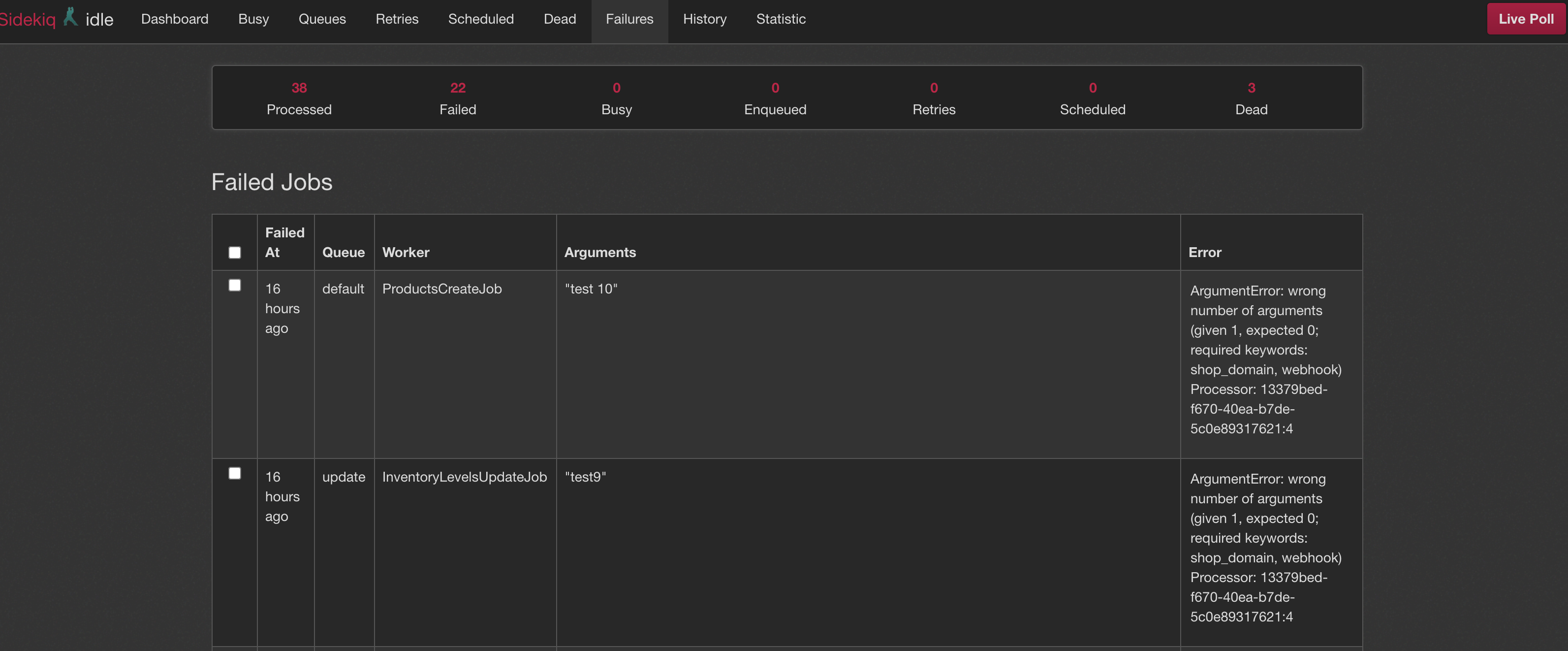
gemにsidekiq-failuresを追加することでダッシュボードで確認することができ、失敗したキュー全てをリトライさせることもできます。
gem 'sidekiq-failures'
failuresの一覧でもエラーの詳細が確認できます。
他にも投げられたキューを知る&分析するなどでたくさんgemがあるようですので参考までに載せておきます
リトライの上限を設定する
sidekiqは確かデフォルトで25,6回程度リトライをしてからキューを殺すといった仕様になっていたかと思います。
そこで、たくさんのジョブを一気に処理させる時など、そこまでリトライしなくていいからダメになった何度かチャレンジしてダメになったら教えて・・・という人のために、リトライの上限をjobファイルに記載します。app/jobs/your_job.rbclass YourJob < ActiveJob::Base ... queue_as :default sidekiq_options retry: 5 ... endこれで5回トライしてダメだったキューはDEADキューとなります。
キューの死亡をslackで通知
Railsアプリにおいてslack通知をとても簡単にしてくれるgemがslack-incoming-webhooksです。
gem 'slack-incoming-webhooks'通知させるチャネルのURL取得はこのページを確認してください。
initializerでキューが死亡した場合の処理を設定(チャネルのURLは.envに保存します)
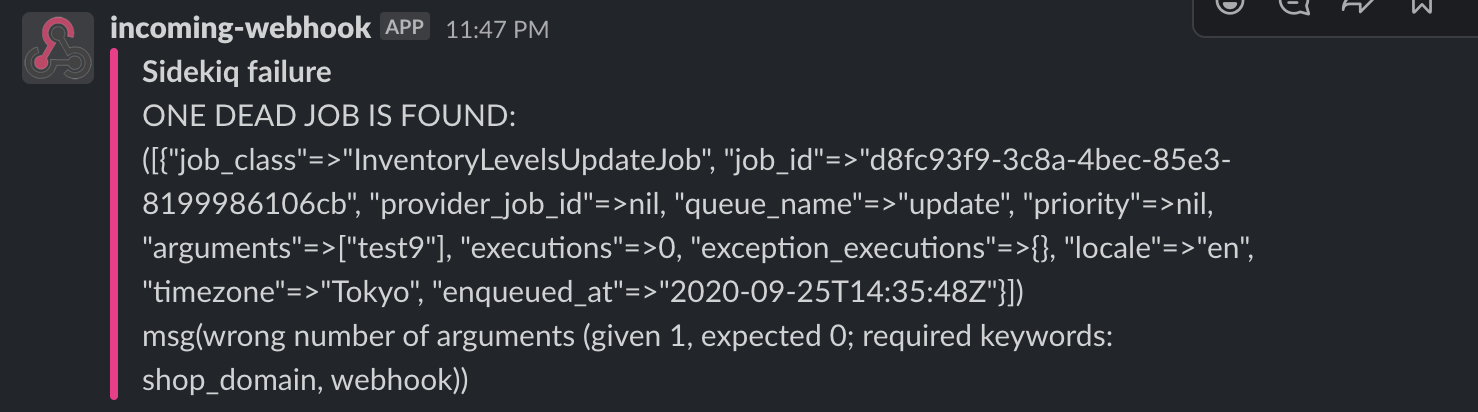
app/config/initializers/sidekiq.rbSidekiq.configure_server do |config| config.death_handlers << ->(job, ex) do slack = Slack::Incoming::Webhooks.new(ENV['SLACK_WEBHOOK_URL']) attachments = [{ title: "Sidekiq failure", text: "ONE DEAD JOB IS FOUND:\n (#{job['args']}) \n msg(#{job['error_message']})", color: "#fb2489" }] slack.post "", attachments: attachments end endこれで自然とDEADになってしまったキューはslack通知されるようになります。
注意点
sidekiqのダッシュボード上でキューを殺しても通知は来ない
config.death_handlersに通知の設定をする場合、ダッシュボード上でマニュアルにキューを死亡させた場合には通知が来ません。なのでリトライ上限の5回を超えた場合にのみ通知が来るようになります。rescure_from Exceptionで通知設定するとリトライしてくれない
例外処理なので一度ジョブを処理してエラーとなると死亡と看做され、slack通知はしてくれますがリトライはしてくれません。なんらかの事情で処理されずそれでもリトライして欲しい場合には、上記の通りconfig.death_handlersでslack通知の設定をおすすめします。
- 投稿日:2020-09-26T16:40:51+09:00
sidekiqのリトライ上限を設定して死んだjobをslackで通知する方法
はじめに
非同期でjobを処理してくれるsidekiqを導入する中で、利便性を生かしつつも自分のアプリ専用にカスタマイズしたい、そんな時に役に立った設定をまとめています。
sidekiqとは
sidekiqとは、非同期処理を可能にしてくれるライブラリです。複数のジョブを同時に実行させる時などに、各ジョブのqueueの名称を分けることで、処理の優先順位を指定することができます。似たようなライブラリにresqueやdelayed_jobなどがあるかと思います。
簡単に導入できるのですが、つまづいてしまったキューをデフォルトで25回だか26回だかリトライするとか、その後はDEADとなって実行していたキューのログが見られないなどといった面倒な点もあります。
そこでこの記事では、例外を投げた時などにいつまでもリトライせず上限を設定してDEADとし、その際にslackにキューの内容とエラーメッセージを投げるという設定をする方法についてお話しします。環境
Ruby 2.6.6
Rails 6.0.2
sidekiqにはredisが必要になります。# On OSX brew update brew install redis brew services start redis失敗したキューをダッシュボードで確認する
gemにsidekiq-failuresを追加することでダッシュボードで確認することができ、失敗したキュー全てをリトライさせることもできます。
gem 'sidekiq-failures'
failuresの一覧でもエラーの詳細が確認できます。
他にも投げられたキューを知る&分析するなどでたくさんgemがあるようですので参考までに載せておきます
リトライの上限を設定する
sidekiqは確かデフォルトで25,6回程度リトライをしてからキューを殺すといった仕様になっていたかと思います。
そこで、たくさんのジョブを一気に処理させる時など、そこまでリトライしなくていいからダメになった何度かチャレンジしてダメになったら教えて・・・という人のために、リトライの上限をjobファイルに記載します。app/jobs/your_job.rbclass YourJob < ActiveJob::Base ... queue_as :default sidekiq_options retry: 5 ... endこれで5回トライしてダメだったキューはDEADキューとなります。
キューの死亡をslackで通知
Railsアプリにおいてslack通知をとても簡単にしてくれるgemがslack-incoming-webhooksです。
gem 'slack-incoming-webhooks'通知させるチャネルのURL取得はこのページを確認してください。
initializerでキューが死亡した場合の処理を設定(チャネルのURLは.envに保存します)
app/config/initializers/sidekiq.rbSidekiq.configure_server do |config| config.death_handlers << ->(job, ex) do slack = Slack::Incoming::Webhooks.new(ENV['SLACK_WEBHOOK_URL']) attachments = [{ title: "Sidekiq failure", text: "ONE DEAD JOB IS FOUND:\n (#{job['args']}) \n msg(#{job['error_message']})", color: "#fb2489" }] slack.post "", attachments: attachments end endこれで自然とDEADになってしまったキューはslack通知されるようになります。
注意点
sidekiqのダッシュボード上でキューを殺しても通知は来ない
config.death_handlersに通知の設定をする場合、ダッシュボード上でマニュアルにキューを死亡させた場合には通知が来ません。なのでリトライ上限の5回を超えた場合にのみ通知が来るようになります。rescure_from Exceptionで通知設定するとリトライしてくれない
例外処理なので一度ジョブを処理してエラーとなると死亡と看做され、slack通知はしてくれますがリトライはしてくれません。なんらかの事情で処理されずそれでもリトライして欲しい場合には、上記の通りconfig.death_handlersでslack通知の設定をおすすめします。
- 投稿日:2020-09-26T14:45:56+09:00
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) のエラー対処法
記事の目的
初学者の為、間違っているところはご指摘頂けると幸いです。
備忘録・アウトプット目的で投稿です。Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
初学者の私は、こちらのエラーに何度も苦しみました。
このエラー以外にもCan't connect to local MySQL server through socket '/tmp/mysql.sock'(38)だとか、ERROR! The server quit without updating PID fileというエラーにも悩まされました。記事をみてみると、対処法として①PIDファイルの作成②権限の変更③再インストール対応が挙げられていましたが、色んな記事を試してもダメでした。(初学者なので、記事の理解・原因の理解ができていないからだと思います。)
同じように悩まれている初学者の方が私の解決策が参考となればと思い、残したいと思います。
(原因の理解はまだできていないので、解説抜きです。)
なので、試す場合は自己責任でお願いします。対処法
私の場合、mysql8.0をインストールしており、それで不都合が出るようでした。
なのでアンインストール対応します。brew uninstall mysqlこちらのコマンドを打ちます。
sudo rm -rf /usr/local/Cellar/mysql* sudo rm -rf /usr/local/bin/mysql* sudo rm -rf /usr/local/var/mysql* sudo rm -rf /usr/local/etc/my.cnf sudo rm -rf /usr/local/share/mysql* sudo rm -rf /usr/local/opt/mysql* sudo rm -rf /etc/my.cnf次にmysql@5.7をインストールして下さい。
brew install mysql@5.7その後、パスを通すので、以下のようにexportかけます。
export PATH="/usr/local/opt/apr-util/bin:$PATH" >> ~/.bash_profile export PATH="/usr/local/opt/mysql@5.7/bin:$PATH" >> ~/.bash_profile source ~/.bash_profileその後、mysql.server startを打ちます。
mysql.server startStarting MySQL..SUCCESS!となるでしょうか?
パソコンを再起動すると、毎回このエラーが出ますが、私の場合は上記の対処法でエラーを解決することができます。
- 投稿日:2020-09-26T14:43:47+09:00
Rails6でActiveStorage導入でNameError: uninitialized constant ::Analyzableエラーが発生した対処
エラー内容
NameError: uninitialized constant #<Class:0x0000000000000000>::Analyzable from /bundle/ruby/2.7.0/gems/activestorage-6.0.3.3/app/models/active_storage/blob.rb:26:in `<class:Blob>'発生した環境
- rails 6.0.3.3
- ruby 2.7
対処
https://railsguides.jp/upgrading_ruby_on_rails.html#rails-6でclassicモードのオートローダーを使う方法
# config/environments/development.rb config.autoloader = :classic関連 Issue
- 投稿日:2020-09-26T14:28:03+09:00
バリデーションメッセージを Decorator で加工する
のっぴきならない事情があり、フォームの入力パターンに応じて、バリデーションメッセージを生成後に加工したかったのでメモ。
例えば、下記のようなフォームがあったとする。new.slim= form_for post_form, url: confirm_post_path do |f| - if post_form.errors.present? ul - post_form.errors.full_messages.each do |msg| li = msgしかし、フォーム内の特定の選択肢を選んだ場合に、バリデーションメッセージを変えるという要件が加わったとする。
この場合、errors.full_messages は Array なので、Decorator で中身を1件ずつチェックして力技で置換した。new.slim= form_for post_form, url: confirm_post_path do |f| - post_form_decorator = ::PostFormDecorator.new(f.object) - if post_form.errors.present? ul - post_form_decorator.post_error_display(post_form.errors.full_messages).each do |msg| li = msgpost_form_decorator.rbclass PostFormDecorator delegate_missing_to :@post_form def initialize(post_form) @post_form = post_form end def post_error_display(error_full_messages) error_full_messages.each do |msg| if @post_form.category == 'music' msg.gsub!(/#{@post_form.model.class.human_attribute_name(:author)}/, '歌手') end end end end破壊的メソッドで中身を入れ替えているので、「!」を付けなければgsubで置換されないので注意。
- 投稿日:2020-09-26T13:21:50+09:00
(Ruby on Rails6) 投稿された内容を"消去" する
まえがき
ここでは、RubyonRails6を使用して、投稿内容を 編集(内容の消去) を行う忘却録を記録します。
以前の投稿で 編集機能の実装 を行いました。編集機能の実装はそちらで記録しているので確認されたい方は、そちらでご確認ください。投稿された内容を"消去" する
この投稿を実装するためには、アクション に データの消去(クリック)・投稿一覧への転送 を行います。
routes の設定
routes に deleteアクション を作成します。
form/:id/delete で、消去したいidのURLを特定させています。
また、データベースを変更する場合はroutes上で "get" ではなく "post" で設定します。config/routes・ ・ ・ post "form/:id/delete" => "form#delete"View へのリンク設定
app/views/任意.html.erb・ ・ ・ <%= link_to("削除", "/form/#{@post.id}/delete", {method: "post"}) %>link_to を用いて、先ほど作成した deleteアクション へリンクしています。
注意: get と post の違い
{method: "post"}) をつけることで、routesのpostと紐づけることができます。
ややこしい!!app/views/任意.html.erbpostでは↓エラー <%= link_to("削除", "/form/#{@forms.id}/delete") %> ↓が正しい <%= link_to("削除", "/form/#{@forms.id}/delete", {method: "post"}) %>データを取り出して削除する
app/controllers/任意.rbdef delete @forms = Form.find_by(id: params[:id]) @forms.destroy redirect_to("/") end↑の詳細
app/controllers/任意.rbdef delete # find_byメソッドで、データを取得する @forms = Form.find_by(id: params[:id]) endapp/controllers/任意.rbdef delete # @テーブル名.destroy で削除する @forms.destroy endapp/controllers/任意.rbdef delete # redirect_toメソッド でリダイレクトを設定する redirect_to("/") end以上が、完了しエラーが怒らなければ、削除機能が出来上がっているはずです。
いかがでしたか?あとがき
ここまで読んでいただき、ありがとうございました。
データベースの設定から表示・修正の機能を実装していて、投稿に削除機能をつけると本格的なサイトみたいですね。
でも、投稿機能が無事に削除された時は嬉しいけど切ない気持ちになります(Why?)データーベースの作成・編集・デリート と基本機能を今までで実装しました。
セキュリティーや詳細機能を今後は学びたいと思います。参考リンク
Myリンク
また、Twitter・Portfolio のリンクがありますので、気になった方は
ぜひ繋がってください。プログラミング学習を共有できるフレンドが出来るととても嬉しいです。
- 投稿日:2020-09-26T13:03:00+09:00
ConoHa VPS(CentOS 8.2)に Rails 6 + PostgreSQL + Nginx + Unicorn + Capistrano でデプロイする
*この記事は自分のブログに投稿していた内容からの転載です。日頃、Qiitaの記事には大変お世話になっているため、私のブログ記事の中でもよくアクセスされる(=つまり参考にされていると思われる)ページをQiitaに投稿してわずかばかりでも恩返しとなればと思っています。では以下、早速スタートです。
前置き
初デプロイ時に相当苦労し、調べに調べてなんとかデプロイ完了まで漕ぎ着けました(デプロイするのに数日間…)。作業中は手順を逐一記録しており、それらをデプロイ完了後に改めて整理したのが本記事の手順です。本手順を作成した後で一度VPSを削除し、改めてゼロから本手順に通りに作業したところ、無事にデプロイができました。そのため、ある程度信頼できる手順になっているのではないかと思います。なおローカル環境についてはMacでターミナルを使用して作業を進めています。
また、パッケージのインストール部分について補足しておきます。
パッケージ(PostgreSQLなど)をインストールする部分では、CentOS (今回は8.2)の標準リポジトリからインストールできるバージョンを利用しています。つまり、パッケージのバージョンは特に指定せず、その時にCentOSが標準でインストールするものを導入する形です。ただしこの場合、必ずしも最新版のパッケージがインストールされるわけではありません。例えば、本記事作成時点のPostgreSQL最新版は12ですが、CentOS 8.2の標準だと10がインストールされます。
パッケージ開発元のリポジトリから最新版を指定してインストールすることもできるのですが、その場合はバージョンを明示する必要があったりと、今後さらにバージョンが変わっていった時に、手順の内容が使えない(古い)ものになったために不用意なエラーが起こる可能性があります。今回は手順の汎用性を考慮して全てCentOS標準のバージョンをインストールしています。
CentOS標準のバージョンで困ることは無いと考えていますが、もしも最新版を使いたい場合は、一度本手順に沿ってデプロイまで済ませた後、個別にバージョンを変更するのが安定しているかと思います。いずれにせよ、初学者にとってはデプロイするというハードルを超えるのが一苦労なので、そこまでたどり着くことが本手順の第一目的です。
以上、前置きでした。それでは以下が手順です。
1.ConoHaのVPSを契約する
メモリ等のプランは任意。私は以下を選択。
- リージョン:東京、メモリ:1GB、CPU:2Core、SSD:100GB、880円/月
- イメージタイプ:CentOS 8.2(64bit)
- rootパスワード:任意のパスワード
- ネームタグ:任意のネーム
- 追加オプション:全てデフォルトのまま(例:SSH Key 使用しない)
以降、VPSのことをサーバと記載。
2.サーバにログインする
1で作成したサーバの詳細ページを開き、IPアドレスを確認。その後、ターミナルから以下のコマンドでサーバに接続。
ssh root@IPアドレスその後、
The authenticity of host IPアドレス can't be established. ECDSA key fingerprint is SHA256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx. Are you sure you want to continue connecting (yes/no/[fingerprint])?上記のように、known hostsに追加するかと聞かれるので、yesと入力し回答。
これでローカルの「~/.ssh/known_hosts」にあるknown hostsファイルに追記される。
その後パスワードを求められるので、1で設定したrootパスワードを入力してログイン。
3.作業用ユーザを作成する
今後のために、ここで作業用ユーザを作成。
以下コマンドで新規ユーザ作成。
adduser ユーザ名ここで作成したユーザのことを、以降は作業用ユーザと記載する。
その後、パスワードを設定。
passwd 作業用ユーザ名root権限(sudo権限)を付与するために、設定ファイルを開く。
visudo以下の部分を探す。
## Allow root to run any commands anywhere root ALL=(ALL) ALLキーボードのiを押下して挿入モードに移行し、上記を下記の通り更新。
## Allow root to run any commands anywhere root ALL=(ALL) ALL 作業用ユーザ名 ALL=(ALL) ALLESCキーを押下してコマンドモードに戻り、その後、:wqを入力しエンターで、ファイルを保存。
sudo実行時に、パスワード入力を求められないように設定を変えるため、再び設定ファイルを開く。
visudo以下の部分を探す。
## Same thing without a password # %wheel ALL=(ALL) NOPASSWD: ALL先ほどと同様に操作し、上記を下記の通り更新して保存。
## Same thing without a password # %wheel ALL=(ALL) NOPASSWD: ALL %作業用ユーザ名 ALL=(ALL) NOPASSWD: ALLここまでの設定ができているかを確認する。作成したユーザにスイッチしてから、sudoコマンドを使用してみる。
su 作成したユーザ名sudo echo test上記実行後、パスワード入力を求められずに、testとだけ表示されればOK.
ここまで完了したら、exitで一度サーバから抜けて、作成したユーザでログインできることを確認する。
exitexitssh 作成したユーザ名@IPアドレスユーザ作成後に設定したパスワードを入力し、ログインする。
その後、rootによるログインを不許可にしておくため、下記で設定ファイルを開く。
sudo vi /etc/ssh/sshd_config下記の記載を探す。
/etc/ssh/sshd_config# Authentication: #LoginGraceTime 2m PermitRootLogin yes #StrictModes yes #MaxAuthTries 6 #MaxSessions 10上記のうち、PermitRootLoginの部分をnoに変えて、下記の通りとして保存する。
/etc/ssh/sshd_config# Authentication: #LoginGraceTime 2m PermitRootLogin no #StrictModes yes #MaxAuthTries 6 #MaxSessions 10設定を反映させるためにsshdのデーモンを再起動し、設定を読み込ませる。以下のコマンドを実行。
sudo systemctl restart sshd一度サーバから抜けて、rootでログインを試してみると、正しいパスワードを入力しても、Permission deniedとなってログインできなくなっている。
4.Gitをインストールする
3で作業用ユーザをせっかく作成したわけだが、一回一回sudoするのが手間のため、以降はrootユーザで作業をしていく。
作業用ユーザでサーバにログイン後、rootユーザへスイッチ。
su rootその後、サーバで下記を実行し、Gitをインストール。
*メモ:CentOS 8では、パッケージ管理システムとしてYumではなくDNFが使われている(DNFはYumの事実上の後継)。現状、引き続きyumコマンドを使用することもできるが、yumコマンドを入力しても内部的には dnf が呼び出されており、将来的にyumは廃止されるため、以降使用するのはdnfコマンドに統一しておく。(といっても、yumと打つところをdnfと打つだけの違い。)
dnf -y install gitちゃんとインストールできたか確認する。下記のコマンドを実行。
git --versiongit version 2.18.4などとバージョンが表示されればOK.
5.rbenvをインストールする
下記を実行。リモートのrbenvリポジトリを/usr/local/rbenvというディレクトリにクローンしている。
git clone https://github.com/rbenv/rbenv.git /usr/local/rbenv次にパスを通す(環境変数を設定する)ため、ファイルを作成する。
vi /etc/profile.d/rbenv.shファイルが作られ、開かれるので下記を記述する。
/etc/profile.d/rbenv.shexport RBENV_ROOT=/usr/local/rbenv export PATH="$RBENV_ROOT/bin:$PATH" eval "$(rbenv init -)"そして、設定ファイルを読み込ませるために以下を実行。
source /etc/profile.d/rbenv.shその後、ちゃんとインストールできたか確認する。
rbenv --versionrbenv 1.1.2などとバージョンが表示されればOK.
6.ruby-buildをインストールする
rootユーザで下記を実行。ruby-buildは、rbenvでインストールを実行するときに必要なプラグイン。
git clone https://github.com/rbenv/ruby-build.git /usr/local/rbenv/plugins/ruby-build7.開発パッケージをインストールする
Rubyをインストールするために必要なパッケージをインストールする。
dnf -y groupinstall "Development Tools"dnf -y install gcc gcc-c++ glibc-headers openssl-devel readline readline-devel zlib zlib-devel libffi-devel libxml2 libxml2-devel libxslt libxslt-devel mysql-devel bzip22つ目のコマンドの中で、1つ目のコマンドでインストールしたものと重複するものが含まれている場合があるが、その場合は未インストールのものだけを自動的にインストールしてくれるので、そこまで気にしなくても大丈夫。
8.Rubyをインストールする
以下を入力して、rbenvでインストールできるRubyのバージョン一覧を表示する。
rbenv install -list表示される結果例は下記の通り。
2.5.8 2.6.6 2.7.1 jruby-9.2.13.0 maglev-1.0.0 mruby-2.1.2 rbx-5.0 truffleruby-20.2.0 truffleruby+graalvm-20.2.0Rubyをインストールする。バージョンはローカルで使っているものを指定。私の場合は2.7.1をインストールする。下記を実行。
rbenv install 2.7.1インストールにはそれなりに時間がかかるので、気長に。
ちゃんとインストールされたかを確認する。
rbenv versions2.7.1などと表示されればOK.
次にサーバで利用するRubyの使用バージョンを設定する。
rbenv global 2.7.1rbenv rehash設定できているか確認する。
ruby -v2.7.1と表示されていればOK.
次に、作業用ユーザでも同様のことを行う。作業用ユーザに戻す。
exitさらに以下を入力し、ディレクトリを移動。
cd /usr/local/rbenv/事前確認のため、以下を実行。
ls -laファイルやフォルダの所有者が全てrootになっていることを確認。続いて、以下を実行。
sudo chown 作業用ユーザ名 versionsudo chown 作業用ユーザ名 shimsその後、再度以下を実行。
ls -laversionとshimsの所有ユーザが作業用ユーザ名に変更されていることを確認する。
一度サーバからログアウトし、改めて作業用ユーザでログインする。その後、さらに以下を実行。
rbenv global 2.7.1rbenv rehash最後に、以下を入力し、設定を確認。
ruby -v2.7.1と表示されていればOK.
9.Bundlerをインストールする
rootユーザにスイッチする。
su rootそして以下のコマンドを実行。
rbenv exec gem install bundlerrbenv rehashインストールできているか確認する。
which bundler上記入力後、/usr/local/rbenv/shims/bundler と返ってくればOK.
10.Node.jsをインストールする
以降、引き続きrootユーザのまま。インストールを実行。
dnf install -y nodejsインストールできていることを確認する。
node -vv10.21.0などとバージョンが表示されればOK.
11.Yarnをインストールする
以下を実行。
npm install -g yarnインストールできていることを確認する。
yarn -v1.22.5 などとバージョンが表示されればOK.
12.PostgreSQLをインストールする
以下を実行。
dnf install -y postgresql postgresql-server postgresql-devel postgresql-contrib postgresql-docspostgresql-setup initdbOS起動時にPostgreSQLも自動起動するように設定。
systemctl enable postgresql自動起動設定できたことを確認。
systemctl is-enabled postgresqlenabledであればOK.
現時点ではPostgreSQLは起動していないため、起動させる。
systemctl start postgresqlインストールできたことを確認。
psql --versionpsql (PostgreSQL) 10.6などと表示されればOK.
さらに、PostgreSQLが起動していることを確認する。
systemctl status postgresqlactive (running)になっていればOK.
次にPostgreSQLの設定を変える。下記を実行してファイルを開く。
vi /var/lib/pgsql/data/postgresql.confCONNECTIONS AND AUTHENTICATIONの項目にある以下
/var/lib/pgsql/data/postgresql.conf#listen_addresses = 'localhost'のコメントアウトを解除して下記の通り変更する。
/var/lib/pgsql/data/postgresql.conflisten_addresses = '*'変更後、さらにもう1つファイルを開く。
vi /var/lib/pgsql/data/pg_hba.confファイル下部にある以下を、
/var/lib/pgsql/data/pg_hba.conf# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all peer # IPv4 local connections: host all all 127.0.0.1/32 ident # IPv6 local connections: host all all ::1/128 ident # Allow replication connections from localhost, by a user with the # replication privilege. local replication all peer host replication all 127.0.0.1/32 ident host replication all ::1/128 ident次のように変更する。(途中3行をコメントアウト、最終行に2行の記載追加)
/var/lib/pgsql/data/pg_hba.conf# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only # local all all peer # IPv4 local connections: # host all all 127.0.0.1/32 ident # IPv6 local connections: # host all all ::1/128 ident # Allow replication connections from localhost, by a user with the # replication privilege. local replication all peer host replication all 127.0.0.1/32 ident host replication all ::1/128 ident local all all trust host all all 0.0.0.0/0 md5設定を反映させるため、PostgreSQLを再起動する。
systemctl restart postgresql13.Railsアプリで使用するDBを作成する
一度ターミナルから目を離し、デプロイしたいRailsアプリの config/database.yml を開いてファイル内の以下の記述を確認する。
/config/database.ymlproduction: <<: *default database: test_production username: test password: <%= ENV['TEST_DATABASE_PASSWORD'] %>“test”の部分はrails newした時のプロジェクト名が設定されている。
その後、ターミナルに戻って以下の作業。
PostgreSQLにデフォルトで作られている、postgresというユーザを使ってPostgreSQLに接続する。
psql -U postgresと入力し、プロンプトが postgres=# となったことを確認する。
その後、以下コマンドによりロールを作成したいのだが、
CREATE ROLE "ロール名" WITH SUPERUSER LOGIN;“ロール名”の部分には、config/database.ymlのusernameに書いてある名称を記述する。今回の例ではtestなので、
CREATE ROLE "test" WITH SUPERUSER LOGIN;となる。これを入力して実行する。
次に、以下コマンドによりデータベースを作成したいのだが、
CREATE DATABASE "データベース名"“データベース名”の部分には、config/database.ymlのdatabaseに書いてある名称を記述する。今回の例ではtest_productionなので、
CREATE DATABASE "test_production";となる。これを入力して実行する。
データベースの操作はこれで終わりなので、
\qと入力して、PostgreSQLから抜ける。
最後に、PostgreSQLを再起動しておく。
systemctl restart postgresql14.Nginxをインストールする
以下のコマンドを実行。
dnf -y install nginxインストールされていることを確認。
nginx -vnginx version: nginx/1.14.1などと表示されればOK.
次に以下を実行して、OS起動時にNginxも自動起動するよう設定しておく。
systemctl enable nginx自動起動設定できたことを確認。
systemctl is-enabled nginxenabledであればOK.
次に以下を実行して、Nginxを起動する。
systemctl start nginxNginxが起動していることを確認する。
systemctl status nginxactive (running)になっていればOK.
次に、Nginxにhttpで接続できるように、firewalldの80番ポートを開放する。
firewall-cmd --add-service=http --permanentfirewalldをリロードする。
firewall-cmd --reloadその後、ウェブブラウザを開いてサーバのIPアドレスを入力して接続し、「Welcome to nginx」が出ればOK.
15.Capistranoでデプロイできるようにする
15−1.サーバとGitHubでSSH接続できるようにする
Capistranoを使うために、サーバとGitHub間でSSH接続できるようにする。
ここで作業用ユーザに戻る。
exitホームディレクトリに移動。
cdその後、以下で公開鍵と秘密鍵を作成。
ssh-keygen -t rsaこの時、
Enter file in which to save the key (/home/devsup/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again:と聞かれるが、全てそのままEngerを押下すればOK.
次に、以下を入力し、公開鍵の中身を表示する。
cat ~/.ssh/id_rsa.pubすると、
ssh-rsa XXXX...= ユーザ名@IPアドレスといったものが表示されるので、ssh-rsaから最後のIPアドレスまで全てをコピー。
その後、GitHubにログインし、SSHキーの登録ページ(https://github.com/settings/keys)からNew SSH Keyを押下して、コピーした内容をペーストし登録。
これで、サーバとGitHub間でSSH接続できるようになった。
次に、サーバにアプリ公開用のディレクトリを作成する。
まずディレクトリを移動。
cd /varwwwディレクトリを作成。
sudo mkdir wwwwwwディレクトリの所有ユーザとグループをrootから変更する。
sudo chown -R 作業用ユーザ名:作業用ユーザ名 www所有が変わったことを確認する。
ls -lrootではなく、作業用ユーザの所有に変わっていればOK.
15−2.Capistrano、Unicornをインストールする
ローカルでRailsアプリを開き、Gemfileに以下を追記。
/Gemfilegem 'dotenv-rails' gem 'unicorn' gem 'mini_racer', platforms: :ruby group :development, :test do gem 'capistrano' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano-rbenv' gem 'capistrano3-unicorn' endGemfile更新後、ローカルでbundle install実行。
bundle install次に、Capistranoの設定ファイルを作成する。ローカルで実行。
bundle exec cap install/Capfileが作成されるので、そのファイルに以下を追記。
/Capfilerequire 'capistrano/setup' require 'capistrano/deploy' require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn'デフォルトで記載されているものもあるため、不足しているものについて、上記となるように追記する。
次に、/config/deploy/production.rbを開き、以下を追記。
/config/deploy/production.rbserver 'サーバのIPアドレス', user: 'サーバの作業用ユーザ名', roles: %w{app db web} set :ssh_options, keys: 'ローカルの秘密鍵のパス'ローカルの秘密鍵のパスは、’/Users/ユーザ名/.ssh/id_rsa’ といった感じになる。
次に、Gemfile.lockを開き、インストールされたCapistranoのバージョンを確認。
/Gemfile.lockcapistrano (3.14.1) airbrussh (>= 1.0.0) i18n rake (>= 10.0.0) sshkit (>= 1.9.0)capistranoの右の3.14.1がバージョンを示している。
次に、/config/deploy.rbを開き、既存の記述を全て削除した後、下記を記載。
/config/deploy.rb# config valid only for current version of Capistrano lock "~> 3.14.1" # Capistranoのバージョン set :application, 'アプリケーション名' # アプリケーション名 set :repo_url, 'https://github.com/xxxx/yyyy' # クローンするGitHubリポジトリ(xxxxはユーザ名、yyyyはアプリ名) set :deploy_to, '/var/www/アプリケーション名' # デプロイ先のディレクトリ set :linked_files, %w{.env config/secrets.yml} # シンボリックリンクを貼るファイル set :linked_dirs, %w{log tmp/pids tmp/cache tmp/sockets public/uploads} # シンボリックリンクを貼るディレクトリ set :keep_releases, 3 # 保持するバージョンの数 set :rbenv_ruby, '2.7.1' # Rubyのバージョン set :rbenv_type, :system set :log_level, :debug # 出力するログのレベル 概要レベルにしたければ :info とする namespace :deploy do desc 'Restart application' task :restart do invoke 'unicorn:restart' end desc 'Create database' task :db_create do on roles(:db) do |host| with rails_env: fetch(:rails_env) do within current_path do execute :bundle, :exec, :rails, 'db:create' end end end end desc 'Run seed' task :seed do on roles(:app) do with rails_env: fetch(:rails_env) do within current_path do execute :bundle, :exec, :rails, 'db:seed' end end end end after :publishing, :restart after :restart, :clear_cache do on roles(:web), in: :groups, limit: 3, wait: 10 do end end endアプリケーション名、CapistranoやRubyのバージョン、GitHubのリポジトリは環境(人)によって異なるので、適宜変更。アプリケーション名は、Rails newした時のプロジェクト名に合わせておけば適当かと。
次に、config直下にunicornディレクトリを作成し、その直下にproduction.rbを作成する(/config/unicorn/production.rb)。作成したproduction.rbに以下を記載。
/config/unicorn/production.rb$worker = 2 $timeout = 30 $app_dir = "/var/www/アプリケーション名/current" $listen = File.expand_path 'tmp/sockets/unicorn.sock', $app_dir $pid = File.expand_path 'tmp/pids/unicorn.pid', $app_dir $std_log = File.expand_path 'log/unicorn.log', $app_dir worker_processes $worker working_directory $app_dir stderr_path $std_log stdout_path $std_log timeout $timeout listen $listen pid $pid preload_app true before_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.connection.disconnect! old_pid = "#{server.config[:pid]}.oldbin" if old_pid != server.pid begin Process.kill "QUIT", File.read(old_pid).to_i rescue Errno::ENOENT, Errno::ESRCH end end end after_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.establish_connection endアプリケーション名の部分は、/config/deploy.rb内で記述したアプリケーション名を記載する。
ここまで終わったら、更新内容をコミットして、GitHubにプッシュする。
15−3.Unicornの自動起動設定をする
サーバに戻り、以下を実行。
sudo vi /usr/lib/systemd/system/unicorn_アプリケーション名.service作成されたファイルに以下を記載。
/usr/lib/systemd/system/unicorn_アプリケーション名.service[Unit] Description=unicorn アプリケーション名 service After=network.target [Service] User=作業用ユーザ名 Environment=RAILS_ENV=production WorkingDirectory=/var/www/アプリケーション名/current PIDFile=/var/www/アプリケーション名/current/tmp/pids/unicorn.pid ExecStart=/usr/local/rbenv/shims/bundle exec unicorn -c /var/www/アプリケーション名/current/config/unicorn/production.rb -D Restart=always [Install] WantedBy=multi-user.target記述の書式が正しいことをチェック。
sudo systemd-analyze verify /usr/lib/systemd/system/unicorn_アプリケーション名.service何も表示されなければ問題ないということなのでOK.
OS起動時にUnicornも自動起動するように設定。
sudo systemctl enable unicorn_アプリケーション名.service自動起動設定できているか確認。
sudo systemctl is-enabled unicorn_アプリケーション名.serviceenabledであればOK.
なおUnicornはこの後デプロイする中で起動されるので、今は起動しない。
15−4.Nginxの設定ファイルを作成
以下を実行。
sudo vi /etc/nginx/conf.d/アプリケーション名.conf作成されたファイルに以下を記載。
/etc/nginx/conf.d/アプリケーション名.confupstream unicorn_アプリケーション名 { server unix:/var/www/アプリケーション名/current/tmp/sockets/unicorn.sock; } server { listen 80; server_name サーバのIPアドレス; root /var/www/アプリケーション名/current/public; access_log /var/log/nginx/アプリケーション名_access.log; error_log /var/log/nginx/アプリケーション名_error.log; location / { try_files $uri @unicorn; } location @unicorn { proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_pass http://unicorn_アプリケーション名; } }設定ファイル作成後、以下のコマンドで設定ファイルに問題ないかをテストする。
sudo nginx -t下記のメッセージが表示され、テストに成功していることが確認できればOK.
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successfulその後、設定を反映させるためにNginxを再起動する。
sudo systemctl restart nginx15−5.デプロイできる状態か確認する
ローカル(のアプリのプロジェクトディレクトリ)で以下を実行する。
bundle exec cap production deploy:checkなお、デプロイチェックにあたり、GitHubについて、以下の点に留意。
- ローカルとGitHubでSSH接続できる(GitHubに鍵が登録されている)状態となっていること。
- GitHubのリポジトリがパブリックとなっていること。
GitHubのプライベートリポジトリでデプロイしたい場合は、本記事下部の「80−2.GitHubのプライベートリポジトリからデプロイする」を参照して設定しておく。
デプロイチェック実行後、
ERROR linked file /var/www/アプリケーション名/shared/.env does not exist on IPアドレスというエラーが出るが想定内なので大丈夫。
上記処理内ではデプロイできるかのチェックだけでなく、サーバで先ほど作成したwwwディレクトリ配下にアプリ用のディレクトリも作っている。
15−6.環境変数を設定する
ローカルで以下を実行し、乱数を生成する。
bundle exec rake secret出力された乱数をコピーしておく。
次にサーバで、secrets.ymlファイルを作成する。
sudo vi /var/www/アプリケーション名/shared/config/secrets.ymlファイルが開いたら、下記の通り、ローカルで生成した乱数をペーストして保存する。
/var/www/アプリケーション名/shared/config/secrets.ymlproduction: secret_key_base: 生成した乱数次に、.envファイルを作成する。
sudo vi /var/www/アプリケーション名/shared/.envファイルが開いたら、Railsアプリで.envに記述していた環境変数をコピーして、上記の.envファイルにペーストする。
15−7.改めてデプロイできる状態か確認する
改めてローカル(のアプリのプロジェクトディレクトリ)で以下を実行する。
bundle exec cap production deploy:check今度はエラーが発生しないことを確認する。これでデプロイできる状態となった。
16.デプロイを実行する
ローカルで以下を実行する。
bundle exec cap production deploybundler:installのところで時間がかかるため、固まったのか…?という不安と戦いながらじっと耐えるべし。
もし本当に固まったように思われた場合、Ctrl + Cでデプロイを中止し、もう一度デプロイコマンドを実行すると、次はうまくいくことが多い。
これでようやくデプロイ完了。アクセスしてみる。
http://IPアドレス(トップページを設定していないのであれば、http://IPアドレス/blogsなど存在するページを指定)Railsアプリのページが表示されることを確認する。
80.その他設定編
これまででデプロイはできたわけだが、以降、追加の設定について。
80−1.SSHのポート番号を変更する
セキュリティの観点から実施しておく。
rootユーザで作業する。
su rootまずは、SELinux(Linuxカーネルのセキュリティ機能のひとつ)の状態を確認する。
getenforceCentOS 8.2では、デフォルトがDisabledとなっていることを確認。そのままにしておく。
ファイルを開き、
vi /etc/ssh/sshd_config以下の部分を見つけ、
/etc/ssh/sshd_config# If you want to change the port on a SELinux system, you have to tell # SELinux about this change. # semanage port -a -t ssh_port_t -p tcp #PORTNUMBER # #Port 22 #AddressFamily any #ListenAddress 0.0.0.0 #ListenAddress ::#Port 22の部分のコメントアウトを外し、適当な番号を設定する。下記は例。
/etc/ssh/sshd_config# If you want to change the port on a SELinux system, you have to tell # SELinux about this change. # semanage port -a -t ssh_port_t -p tcp #PORTNUMBER # Port 50022 #AddressFamily any #ListenAddress 0.0.0.0 #ListenAddress ::ポート番号は自由に決めることができるが、自分のサーバ内で他のサービスが使っているポート番号と被ると問題になるので注意。とりあえず49152〜65535の間で適当に決めるのが良い。
どんなサービスがどんなポート番号を使っているかは、参考までに下記を参照。
TCPやUDPにおけるポート番号の一覧 – Wikipedia
また、設定ファイル内に、「# If you want to change the port on a SELinux system, you have to tell …」と記載がある通り、先に確認したSELinuxがDisabledではなく有効になっていると、SELinuxの設定も変える必要がある。
次に、Firewalldのデフォルト設定の格納場所である「/usr/lib/firewalld/services/」直下にある「ssh.xml」を、カスタム設定の格納場所である「/etc/firewalld/services/」直下へコピーする。
cp /usr/lib/firewalld/services/ssh.xml /etc/firewalld/services/ssh.xmlコピーして作成したファイルを開いて編集する。
vi /etc/firewalld/services/ssh.xml以下部分のポート番号を、
/etc/firewalld/services/ssh.xml<port protocol="tcp" port="22"/>先ほど設定したポート番号に変える。
/etc/firewalld/services/ssh.xml<port protocol="tcp" port="50022"/>設定を反映させるため、Firewalldをリロード、SSHDを再起動する。
firewall-cmd --reloadsystemctl restart sshdここまで終わったら、ターミナルをもう一つ立ち上げる。この時、上記作業に使ったターミナルはサーバに接続したままにしておき、決して閉じないように。万が一設定がうまくいっていないままターミナルを閉じると、二度と繋げなくなってしまう。
新たに立ち上げたターミナルで以下を実行。
ssh 作業用ユーザ名@IPアドレス結果、
ssh: connect to host IPアドレス port 22: Operation timed outになっていればOK. 22番ポートは閉じられている。
次に以下で接続。以下はSSHのポート番号を50022にしている場合。
ssh 作業用ユーザ名@IPアドレス -p 50022接続できることを確認。
ここまでの作業でSSHのポート番号が変わったわけだが、それと同時に、Capistranoでデプロイする時にもそのポート番号を使うように設定しておかないといけない。
ローカルでRailsアプリの/config/deploy/production.rbを開き、
/config/deploy/production.rbserver 'サーバのIPアドレス', user: 'サーバの作業用ユーザ名', roles: %w{app db web} set :ssh_options, keys: 'ローカルの秘密鍵のパス'上記に、ポート番号の設定を追加する。下記はポート番号が5022の場合。
/config/deploy/production.rbserver 'サーバのIPアドレス', user: 'サーバの作業用ユーザ名', port: '50022', roles: %w{app db web} set :ssh_options, keys: 'ローカルの秘密鍵のパス'変更後は、コミットしてGitHubへプッシュ。
最後にローカルで、
bundle exec cap production deploy:checkを実行して、ちゃんとデプロイできるようになっているか確認しておく。
80−2.GitHubのプライベートリポジトリからデプロイする
GitHubのリポジトリをプライベートにする場合は、デプロイの設定にも手を入れる必要がある。
まず、GitHubの以下ページから、
https://github.com/settings/tokens
Generate new tokenを押下し、repo項目のFull control of private repositoriesをチェックして生成。トークンが表示されたらコピーしておく。
その後、Railsアプリの/config/deploy.rbを開き、
/config/deploy.rbset :repo_url, 'https://github.com/xxxx/yyyy' # クローンするGitHubリポジトリ(xxxxはユーザ名、yyyyはアプリ名)上記となっているset :repo_urlを、以下のように編集。
/config/deploy.rbset :repo_url, 'https://トークン:@github.com/xxxx/yyyy' # クローンするGitHubリポジトリ(xxxxはユーザ名、yyyyはアプリ名)
https://github.com/の部分を、https://トークン:@github.com/に変える。最後にローカルで下記を実行し、
bundle exec cap production deploy:checkデプロイできる状態となっていることを確認しておく。
80−3.タイムゾーンを日本時間で統一する
必要であれば実施。
アプリ内で時刻を使用する場合、OS(CentOS)、DB(PostgreSQL)、Railsの時刻基準を合わせておくと良さそう。
まず、CentOSのタイムゾーンを変更する。サーバ上で、rootユーザにて以下を実行。
timedatectl set-timezone Asia/Tokyo上記後、以下で確認。
timedatectl statusTime zone: Asia/Tokyo (JST, +0900) となっていればOK.
次にPostgreSQLのタイムゾーンを変更。DBにアクセスし、
psql -U postgresプロンプトが、postgres=# となったのを確認して、DB一覧を確認。
\lタイムテーブルを変更したいDBの名前をコピーしておき、一度DBから抜ける。
\qそしてタイムゾーンを変更したいDBに接続する。
psql -U postgres -d DB名プロンプトが、DB名=# となったのを確認して、以下でタイムゾーンを変更。
ALTER DATABASE "DB名" SET timezone TO 'Asia/Tokyo';その後以下を実行し、
SELECT CURRENT_TIMESTAMP;日本時間で現在時刻が表示されていればOK、DBから抜ける。
\qなお、上記ではDB単位でタイムゾーンを設定しているため、他のDBのタイムゾーンは変わっていないことに注意。
最後にRailsのタイムゾーン設定を変える。
ローカルでRailsアプリの、config/application.rbを開く。
そして、class Application < Rails::Applicationブロックの中に以下2行を追記。
/config/application.rbmodule XXXX class Application < Rails::Application ......... ...... ... config.time_zone = 'Tokyo' #追記 config.active_record.default_timezone = :local #追記 end end最後に忘れずコミット&プッシュ&デプロイしておくこと。
80−4.ログローテーションの設定
放っておくと際限なくログファイルが膨れ上がってしまうため、自動的に削除するように設定しておく。
まず、Nginxのログについてはデフォルトでログローテーションされるようになっているため対応不要。
次に、Unicornのログについて設定。/etc/logrotate.d/の下に設定ファイルを作る。サーバ上でrootユーザにて以下を実行。
vim /etc/logrotate.d/アプリケーション名_unicorn開いたファイルに以下を記載。
/etc/logrotate.d/アプリケーション名_unicorn/var/www/アプリケーション名/current/log/*unicorn.log { create 0664 作業用ユーザ名 作業用ユーザ名 daily rotate 10 missingok notifempty compress postrotate pid=/var/www/アプリケーション名/current/tmp/pids/unicorn.pid test -s $pid && kill -USR1 "$(cat $pid)" endscript }上記では、1日1ファイルを作成、10世代保存という設定にしている。
最後に、Railsのログについて設定。ローカルでRailsアプリのconfig/environments/production.rbを開き、下記を追加する。設定内容の意味はコメントに記載している通り。
/config/environments/production.rb# production.0, production.1, production.2 の3世代保持 10Mを超えるとローテーション config.logger = Logger.new('log/production.log', 3, 10 * 1024 * 1024)その後、コミット&プッシュ&デプロイを忘れずに。
90.その他知っておくこと編
90−1.再度デプロイする場合
資産を更新しデプロイする場合は、GitHubにプッシュした後、ローカルで再度、
bundle exec cap production deployを実行すればOK.
90−2.サーバで本番環境のRails cを使う方法
サーバ内の、
var/www/アプリケーション名/currentにて、下記を実行する。
bundle exec rails console -e production-e productionを付けずに行うと、開発環境(development)のコンソールが開かれるので注意。
コンソール上で以下を入力するとその時の環境が表示されるので、確認することも可能。
Rails.env本番環境で開けていれば、”production”と表示される。
90−3.サーバで本番環境のRails dbコマンドを使う方法
サーバ内の以下で実施。
var/www/アプリケーション名/currentコマンドの後ろに、RAILS_ENV=productionを付ける。例えば、rails db:seedなら以下。
bundle exec rails db:seed RAILS_ENV=productionただし、本番環境のRails db:resetしたいときは以下ではダメ。
bundle exec rails db:reset RAILS_ENV=production上記を実行すると、「ActiveRecord::ProtectedEnvironmentError: You are attempting to run a destructive action against your ‘production’ database.」というエラーが出る。
本番環境でRails db:resetする場合は下記を入力する。
bundle exec rails db:reset RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1他にも、本番環境のDBに破壊的なコマンドを発行するときには、DISABLE_DATABASE_ENVIRONMENT_CHECK=1が必要。
90−4.ログの場所
本手順で構築した場合のログの格納場所。
Nginxのログはサーバ内の以下。
/var/log/nginx/
- アクセスログ
- /var/log/nginx/アプリケーション名_access.log
- エラーログ
- /var/log/nginx/アプリケーション名_error.log
UnicornおよびRailsのログはサーバ内の以下。
/var/www/アプリケーション名/shared/log/
- Unicornのログ
- /var/www/アプリケーション名/shared/log/unicorn.log
- Railsのログ
- /var/www/アプリケーション名/shared/log/production.log
以上
長くなったがようやく終わり。めでたしめでたし。
*追記:本記事の続きにあたるものとして、独自ドメイン適用およびSSL(https)化の手順に関する記事を投稿しました。ご参考ください。
「VPSのRailsに独自ドメインを適用し、SSL(https)化する(CentOS 8.2 / Nginx)」
補足
記事をお読みいただきありがとうございました。少しでも参考になりましたら幸いです。
一応、元のブログ記事へのリンクを以下に貼っておきますが、記載内容は本記事と同じため、特に参照いただく必要はないです(…むしろ、Qiitaのシンタックスハイライト機能があるため、Qiitaで記事を読んだ方がわかりやすいはずです)。
knmts.com | ConoHa VPS(CentOS 8.2)に Rails 6 + PostgreSQL + Nginx + Unicorn + Capistrano でデプロイする
- 投稿日:2020-09-26T09:56:48+09:00
Rails6.0ルーティングまとめ
はじめに
Rails6.0のルーティングのパス名 resouces resourceなどを忘備録を兼ねてまとめます。
明示的なルーティング指定
routes.rb# ルートへアクセスするルーティング root 'users#show' root to 'users#show' root '/', to: 'users#show'routes.rb# '/users/:id'でusersコントローラのshowアクションにルーティング get '/users/:id', to: 'users#show'routes.rb# 'hoge'でusersコントローラのshowにルーティング # as:オプションを使うとルーティングに名前を指定可能 get '/users/:id', to: 'users#show', as: 'hoge'<%= form_with %><%= link_to %>などでurlを指定する際に、直接/posts/:idなどのurlのように指定可能ですが、変更の際に修正箇所が多くなり得策ではありません。
as:で名前を付けることで、修正しやすくなり、コードも読みやすくなります。resourcesとresouceの違い
resources(複数)...7つのアクションがid付きで生成されます。
resource(単数) ...indexアクションを除いた6つのアクションがidなしで生成されます。
「写真」「ユーザー」「商品」のようにアプリケーションに複数存在する場合はresources(複数)
「自身のプロフィール」のように一つしか存在せず、idやindexが必要ない場合はresource(単数)resources(複数)
routes.rbresources :photosのような記述で、以下の7つのルーティングが生成されます。この場合、いずれもPhotosコントローラに対応します。
動詞 パス コントローラ#アクション 目的 GET /photos photos#index すべての写真の一覧を表示 GET /photos/new photos#new 写真を1つ作成するためのHTMLフォームを返す POST /photos photos#create 写真を1つ作成する GET /photos/:id photos#show 特定の写真を表示する GET /photos/:id/edit photos#edit 写真編集用のHTMLフォームを1つ返す PATCH/PUT /photos/:id photos#update 特定の写真を更新する DELETE /photos/:id photos#destroy 特定の写真を削除する resource(単数)
routes.rbresource :geocoder以上の記述で以下の6つのルーティングが生成されます。この場合、いずれもgeocoderに対応します。
動詞 パス コントローラ#アクション 目的 GET /geocoder/new geocoders#new geocoder作成用のHTMLフォームを返す POST /geocoder geocoders#create geocoderを作成する GET /geocoder geocoders#show 1つしかないgeocoderリソースを表示する GET /geocoder/edit geocoders#edit geocoder編集用のHTMLフォームを返す PATCH/PUT /geocoder geocoders#update 1つしかないgeocoderリソースを更新する DELETE /geocoder geocoders#destroy geocoderリソースを削除する 注意点
Railsのルーティングはルーティングファイルの上から順に実行します。そのため、同じ条件のルーティングが複数存在する場合、上のルーティングのみ有効になります。なお、無関係なURLの場合は順番は関係ありません。
参考
Railsのルーティング - Railsガイド v6.0
https://railsguides.jp/routing.html
- 投稿日:2020-09-26T00:33:39+09:00
Safari で disable_with オプションを付けても変わらない場合
Railsでフォームを作る際、送信ボタンに disable_with オプションを付けることで、二重送信を防ぐことができる。
= f.button '送信する', data: { disable_with: '送信中…' }しかし、Safariに限って、なぜかボタンの文言が変化しなかった。GitHub上でも、多々報告されている。
disable_with doesn't work with link in Safari #306解決策
結論から書くと、JSで送信処理をあえて遅らせることで、とりいそぎは回避できた。
Issue内ではバニラJSで書かれた例が出てくるので、jQueryを使っていなけば、そちらを参考にした方が早いかもしれない。= f.button '送信する', data: { disable_with: '送信中…' }, class: 'disable_with_safari'$('.disable-with-safari').click(function (event) { if ($(this).data('disableWith')) { $(this).prop('disabled', true); $(this).text($(this).data('disableWith')); var form = $(this).closest('form'); if (form.length) { event.preventDefault(); setTimeout(() => form.submit(), 300); } } });備考
冒頭のIssueでも議論されていたが、Safariの独特な仕様で、一度submitが走った後はDOMの更新が行われなくなるようだ。(あくまでもIssue上でのコメントなので、正確な仕様は一次情報を参照してください)
そのため、disable_withをつけても、ボタンの文言は変わらなかった。ちなみに、今回の問題について検索すると以下の解決策が出てきていたが、わたしの場合は効果がなかった。
- cursor: pointer; をつける
- 空のclickイベントを設定する
- 空のtouchstartイベントを設定する
- バインドを$(document)に変更する