- 投稿日:2020-09-26T23:53:09+09:00
【ポアンカレ再帰定理】蛇振り子を100個・長周期に拡張して遊んでみた♬
マスゲームだから、意味ない(当たり前)かなと思いつつ、でも惑星直列などを考えると、こういう計算も実は意味のあるものかなと思い、まとめておくこととします。
なんといってもポアンカレの再帰定理。
「力学系は、ある種の条件が満たされれば、その任意の初期状態に有限時間内にほぼ回帰する」の具体的な事例としての意味があるということだと思いなおしました。
なお、惑星直列の計算とシミュレーションは今回はやりません。
ということで、今回は前回の式を個数と周期を自由に変更したいと思います。
※コード全体はおまけに載せました。
また、gifアニメーションがエラーが出て貼れないのでYoutubeに載せました100個を1ダンス120秒のシミュレーション
そして、100個の場合に拡張です。
これだと、前回の式では無理なので、以下のように変更します。N = 60 z0 =500 L0=980*(120/130)**2/(2*np.pi)**2 Fc0=1.0 Fc=[] fc=1 Fc.append(fc) for i in range(1,100,1): fc=fc*((131-i)/(130-i)) Fc.append(fc)あと、120secで元に戻るようにしたので、結果は以下のようになります。
15個を1ダンス120秒のシミュレーション
今度は、15個の振り子を120秒という長さの周期のダンスをさせてみる。
これで、実質的にあらゆる振り子の個数、長さ、周期のものが設計できることが分かる。
【蛇の振り子】15個を1ダンス120秒のシミュレーション作成して遊んでみた♬
主要なコードは、以下で実現できた。N = 60 L0=980*(120/65)**2/(2*np.pi)**2 #ここの120/65の120が重要 print(L0, 2*np.pi/np.sqrt(980/L0)) Fc0=1.0 z0 =150 Fc=[] fc=1 Fc.append(fc) for i in range(1,15,1): fc=fc*((66-i)/(65-i)) #65/64で1個1個のずらしを調整 Fc.append(fc) dataz=[] linez=[] y=0 for j in range(15): y += 2 #振り子のy軸方向の間隔 dataz0 = np.array(list(genxy(N,L=L0*Fc[j]**2,z0=z0,y0=y))).T linez0, = ax.plot(dataz0[0, 0:1], dataz0[1, 0:1], dataz0[2, 0:1],'o') dataz.append(dataz0) linez.append(linez0)generatorは前回のものと比べると、以下のようにy軸方向に配置できるように拡張している。
def genxy(n,L=20,z0=0,y0=0): phi = 0 g = 980 x0=5 #2.5 omega = np.sqrt(g/L) theta0 = np.arcsin(x0/L) while phi < 600: yield np.array([L*np.sin(np.sin(phi*omega+np.pi/2)*theta0), y0,z0-L+L*(1-np.cos(np.sin(phi*omega+np.pi/2)*theta0))]) phi += 1/nまとめ
・蛇振り子の個数や長さを自由を変更できるように拡張した
・100個の圧倒的な迫力と、120秒周期という長周期は鑑賞という意味で面白い・惑星直列など自然界にあるポアンカレの再帰定理の具現化をシミュレーションしたいと思う
・現実の蛇振り子を自由な周期で実現したいと思うおまけ
from matplotlib import pyplot as plt import numpy as np import mpl_toolkits.mplot3d.axes3d as p3 from matplotlib import animation fig, ax = plt.subplots(1,1,figsize=(1.6180 * 4, 4*1),dpi=200) ax = p3.Axes3D(fig) def genxy(n,L=20,z0=0,y0=0): phi = 0 g = 980 x0=5 omega = np.sqrt(g/L) theta0 = np.arcsin(x0/L) while phi < 600: yield np.array([L*np.sin(np.sin(phi*omega+np.pi/2)*theta0), y0,z0-L+L*(1-np.cos(np.sin(phi*omega+np.pi/2)*theta0))]) phi += 1/n def update(num, data, line,s): line.set_data(data[:2,num-1 :num]) line.set_3d_properties(data[2,num-1 :num]) ax.set_xticklabels([]) ax.grid(False) N = 60 L0=980*(120/65)**2/(2*np.pi)**2 print(L0, 2*np.pi/np.sqrt(980/L0)) #84.6cm 1.846sec Fc0=1.0 #omega=2pi/T z0 =150 Fc=[] fc=1 Fc.append(fc) for i in range(1,15,1): fc=fc*((66-i)/(65-i)) Fc.append(fc) dataz=[] linez=[] y=0 for j in range(15): y += 2 dataz0 = np.array(list(genxy(N,L=L0*Fc[j]**2,z0=z0,y0=y))).T linez0, = ax.plot(dataz0[0, 0:1], dataz0[1, 0:1], dataz0[2, 0:1],'o') dataz.append(dataz0) linez.append(linez0) # Setting the axes properties ax.set_xlim3d([-10., 10]) ax.set_xlabel('X') ax.set_ylim3d([0.0, 30.0]) ax.set_ylabel('Y') ax.set_zlim3d([0.0, z0-L0]) ax.set_zlabel('Z') elev=0 #20. azim=90 #35. ax.view_init(elev, azim) frames =60*120 fr0=60 s0=0 s=s0 while 1: s+=1 num = s for j in range(15): update(num,dataz[j],linez[j],s0) """ if s%fr0==0: print(s/fr0, s) plt.pause(0.001) """ if s%(fr0/10)==0: ax.set_title("s={}_sec".format(int(10*s/fr0)/10),loc='center') plt.pause(0.001) print(s/fr0) plt.savefig('./pendulum/'+str(int(10*s/fr0))+'.png') if s>=s0+frames: break s0=30*120 s=s0+30*120 fr0=60 from PIL import Image,ImageFilter images = [] for n in range(1,1201,1): exec('a'+str(n)+'=Image.open("./pendulum/'+str(n)+'.png")') images.append(eval('a'+str(n))) images[0].save('./pendulum/pendulum_{}_.gif'.format(100), save_all=True, append_images=images[1:], duration=100, loop=1)動画保存
gifアニメーションが貼れないので以下のコードでmp4ファイルを保存し、youtubeにアップします。
from matplotlib import pyplot as plt import numpy as np import mpl_toolkits.mplot3d.axes3d as p3 import cv2 def cv_fourcc(c1, c2, c3, c4): return (ord(c1) & 255) + ((ord(c2) & 255) << 8) + \ ((ord(c3) & 255) << 16) + ((ord(c4) & 255) << 24) OUT_FILE_NAME = "output_video.mp4" fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v') dst = cv2.imread('./pendulum/1.png') rows,cols,channels = dst.shape out = cv2.VideoWriter(OUT_FILE_NAME, int(fourcc), int(10), (int(cols), int(rows))) from PIL import Image,ImageFilter for n in range(1,1201,1): dst = cv2.imread('./pendulum/'+str(n)+'.png') out.write(dst) #mp4やaviに出力します

- 投稿日:2020-09-26T23:03:09+09:00
pythonでのAtCoderのチートシート(自分のため)
目的
チートシートを作らないと厳しくなってきたので整理用に。
c++ならかなりコードが公知になってるものが多いようですが、pythonは暗黙知っぽい書き方とかがあるように感じます。
解答をみると、みんなが当たり前に使っているライブラリやデータ構造などが多いです。
これらの暗黙知っぽいものをメモを取りながらやってますが、頭が混乱してきたので自分用にまとめます。
Atcoderをpythonでスタートするときにこういう前提知識のまとめが欲しかったです。。。間違っているところも多いでしょうが多めにみてください。
前提となるチートシート
Python 競技プログラミング チートシート自分用
入力の仕方はいつもここをみて入力しています。
競プロチートシート(python3)
約数と累乗はここをみる。約数のライブラリは意味わからないけど使えばすごい便利。
Python標準ライブラリ:順序維持のbisect
bisectはここをみる
Pythonでリストをソートするsortとsortedの違い
ソートはここをみる
pythonのsorted関数で使われるlambdaとは何なのか
lamda関数はこれがわかりやすかった。
Python, set型で集合演算(和集合、積集合や部分集合の判定など)
set,len,add,discard(), remove(), pop(), clear()
【Python】スライス操作についてまとめ
スライスはここをみる
Pythonで最大公約数と最小公倍数を算出・取得
gcd(最大公約数)、lcm(最小公倍数)はここをみる。数字が3つでも4つでも出せる。
Pythonのdivmodで割り算の商と余りを同時に取得
商とあまりはここをみる
Pythonのfor文によるループ処理(range, enumerate, zipなど)
range, enumerate, zipはここをみる
([式 for 変数名 in イテラブルオブジェクト]みたいな内包表現とか、
多重ループ: itertools.product()とか、
自分では使わないけど他人のコード読む時に使えるやつもここ)
PythonのCounterでリストの各要素の出現個数をカウント
今の自分には厳しいが、配列やらどこかの要素をサーチしてくるのに無茶苦茶便利小技
10^0.5
n**0.5
カウントする
l.count('a')
かぶりをなくす
set([1,1,2,2,3,3]) ⇨[1,2,3]
if X not in p: #pのリストにXがない
大文字小文字変換
str.upper(): すべての文字を大文字に変換
str.lower(): すべての文字を小文字に変換
絶対値:abs()
総和:sum(list)
大きい方:max(,)
小さい方:min(,)
count.values()
逆順: reversed()
forで複数列での循環:enumerate()
forで複数列での循環:zip()
modは大抵、mod=10**9+7
10^12の試行回数は結構厳し目だから、枝カリとか工夫とかしがち。
10^6は、2乗でかなりギリギリになるから、O(N^2)はギリギリになりがちで工夫が必要。
print("".join(lis)):これで、リストをジョインできる
print(list(itertools.permutations([1, 2, 3])))
-> [(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1)]
c = collections.Counter(l)
⇨Counter({'a': 4, 'c': 2, 'b': 1})
⇨c.keys()は['a', 'b', 'c']
⇨c.values()は[4, 1, 2]
⇨c.items()は[('a', 4), ('b', 1), ('c', 2)]
⇨c.most_common()は('a', 4), ('c', 2), ('b', 1)
⇨c.most_common()[::-1]は[('b', 1), ('c', 2), ('a', 4)] つまり、[::-1]は反対から並べるの意味
(引用: PythonのCounterでリストの各要素の出現個数をカウント)
a = lambda x : x*x
print(a(4)) #16
(aに無名関数λを挿入し、xに4を入れるとx^2)
コードテストで、挙動が良くわからない時は、print(変数)で変数がどのようになっているかチェックするとデバッグが楽
さらに前提となるpythonの基本文法
for _ in range(N):
これは 0~N-1を出力
末尾に":"をつける
for文の次の行はインデント(スペース4つなりtabなりでスペースをあける)
for文の次の行でtabとスペースを混用しているとエラーになることがある。
for c in l[2:5]:みたいに、スライスしてその分だけcを代入していくこともできる。
for i in range(1:N):にすれば、1からスタートもできる
if s == 1:
=は1つではなく、2つでつながないと条件にならない(=だけだと代入になる)
末尾に":"をつける
if文の次の行はインデント(スペース4つなりtabなりでスペースをあける)
if文の次の行でtabとスペースを混用しているとエラーになることがある。
while n!=1:
while文の次の行はインデント(スペース4つなりtabなりでスペースをあける)
while は、「この条件式が成立している間」やりますって意味。
個人的に今後理解する予定のもの
dfs,bfs,Union Findのプログラム
レッドコーダーが教える、競プロ・AtCoder上達のガイドライン【中級編:目指せ水色コーダー!】
100問で水色、それどころか青色が狙える内容らしいです。
手法ごとに問題が分類されているので、苦手手法を鍛えるのに良さげです。
こちらの記事をpythonで解いている記事が
【Python】初中級者が解くべき過去問精選 100 問を解いてみた【Part4/22】
- 投稿日:2020-09-26T22:50:17+09:00
ACL Beginner Contest 参戦記
ACL Beginner Contest 参戦記
ABLA - Repeat ACL
1分で突破. 書くだけ.
K = int(input()) print('ACL' * K)ABLB - Integer Preference
2分半で突破、WA1 orz. A < B < C < D のパターンを見落とした.
A, B, C, D = map(int, input().split()) if A <= C <= B or A <= D <= B or C <= A <= D or C <= B <= D: print('Yes') else: print('No')ABLC - Connect Cities
3分半で突破. Union Find して Union 数 - 1 が答え.
from sys import setrecursionlimit, stdin def find(parent, i): t = parent[i] if t < 0: return i t = find(parent, t) parent[i] = t return t def unite(parent, i, j): i = find(parent, i) j = find(parent, j) if i == j: return parent[j] += parent[i] parent[i] = j readline = stdin.readline setrecursionlimit(10 ** 6) N, M = map(int, readline().split()) parent = [-1] * N for _ in range(M): A, B = map(lambda x: int(x) - 1, readline().split()) unite(parent, A, B) print(sum(1 for i in range(N) if parent[i] < 0) - 1)ABLD - Flat Subsequence
32分で突破、WA1 orz. Go のコードを Python で提出した、アホすぎる. それまでの各値の最大経由数を記録しておけば SegmentTree で O(logN) で現値の最大経由数が求まるので O(NlogN) になり解ける.
package main import ( "bufio" "fmt" "os" "strconv" ) func min(x, y int) int { if x < y { return x } return y } func max(x, y int) int { if x > y { return x } return y } type segmentTree struct { offset int data []int op func(x, y int) int e int } func newSegmentTree(n int, op func(x, y int) int, e int) segmentTree { var result segmentTree t := 1 for t < n { t *= 2 } result.offset = t - 1 result.data = make([]int, 2*t-1) for i := 0; i < len(result.data); i++ { result.data[i] = e } result.op = op result.e = e return result } func (st segmentTree) update(index, value int) { i := st.offset + index st.data[i] = value for i >= 1 { i = (i - 1) / 2 st.data[i] = st.op(st.data[i*2+1], st.data[i*2+2]) } } func (st segmentTree) query(start, stop int) int { result := st.e l := start + st.offset r := stop + st.offset for l < r { if l&1 == 0 { result = st.op(result, st.data[l]) } if r&1 == 0 { result = st.op(result, st.data[r-1]) } l = l / 2 r = (r - 1) / 2 } return result } const ( maxA = 300000 ) func main() { defer flush() N := readInt() K := readInt() st := newSegmentTree(maxA+1, max, 0) for i := 0; i < N; i++ { A := readInt() st.update(A, st.query(max(A-K, 0), min(A+K+1, maxA+1))+1) } println(st.query(0, maxA+1)) } const ( ioBufferSize = 1 * 1024 * 1024 // 1 MB ) var stdinScanner = func() *bufio.Scanner { result := bufio.NewScanner(os.Stdin) result.Buffer(make([]byte, ioBufferSize), ioBufferSize) result.Split(bufio.ScanWords) return result }() func readString() string { stdinScanner.Scan() return stdinScanner.Text() } func readInt() int { result, err := strconv.Atoi(readString()) if err != nil { panic(err) } return result } var stdoutWriter = bufio.NewWriter(os.Stdout) func flush() { stdoutWriter.Flush() } func println(args ...interface{}) (int, error) { return fmt.Fprintln(stdoutWriter, args...) }追記: Python では TLE になってしまうが、PyPy なら AC した.
class SegmentTree: def __init__(self, size, op, e): self._op = op self._e = e self._size = size t = 1 while t < size: t *= 2 self._offset = t - 1 self._data = [e] * (t * 2 - 1) def update(self, index, value): op = self._op data = self._data i = self._offset + index data[i] = value while i >= 1: i = (i - 1) // 2 data[i] = op(data[i * 2 + 1], data[i * 2 + 2]) def query(self, start, stop): def iter_segments(data, l, r): while l < r: if l & 1 == 0: yield data[l] if r & 1 == 0: yield data[r - 1] l = l // 2 r = (r - 1) // 2 op = self._op it = iter_segments(self._data, start + self._offset, stop + self._offset) result = self._e for v in it: result = op(result, v) return result max_A = 300000 N, K, *A = map(int, open(0).read().split()) st = SegmentTree(max_A + 1, max, 0) for a in A: st.update(a, st.query(max(a - K, 0), min(a + K + 1, max_A + 1)) + 1) print(st.query(0, max_A + 1))ABLE - Replace Digits
突破できず. Lazy Segtree なんだろうなとは思ったけど、ACL の lazy_segtree の mapping, composition, id が理解できなくて利用できなかった.
- 投稿日:2020-09-26T22:22:45+09:00
ReactとPython flaskを使ってWebアプリを作りたい
はじめに
仕事でReactによるフロント開発に携わり始めたので、アウトプットの練習も兼ねて簡易webアプリを作成しました。
どんなアプリにするかアイデアはまったく思い浮かばなかったので、手元にあったmecabを使った分かち書きスクリプトを使って、フロントで受け取った入力テキストをサーバー側で分かち書きをし、その結果をフロントで表示するという非常にシンプルなアプリです。
(主目的はreactとflaskをつなぐ部分を勉強することだったため、アプリの見た目や機能は全然作り込んでいませんのであしからず。)表題の通り、フロント側はReact、サーバー側はpython flaskで実装しています。
今回実装したスクリプトはこちらで公開しています。
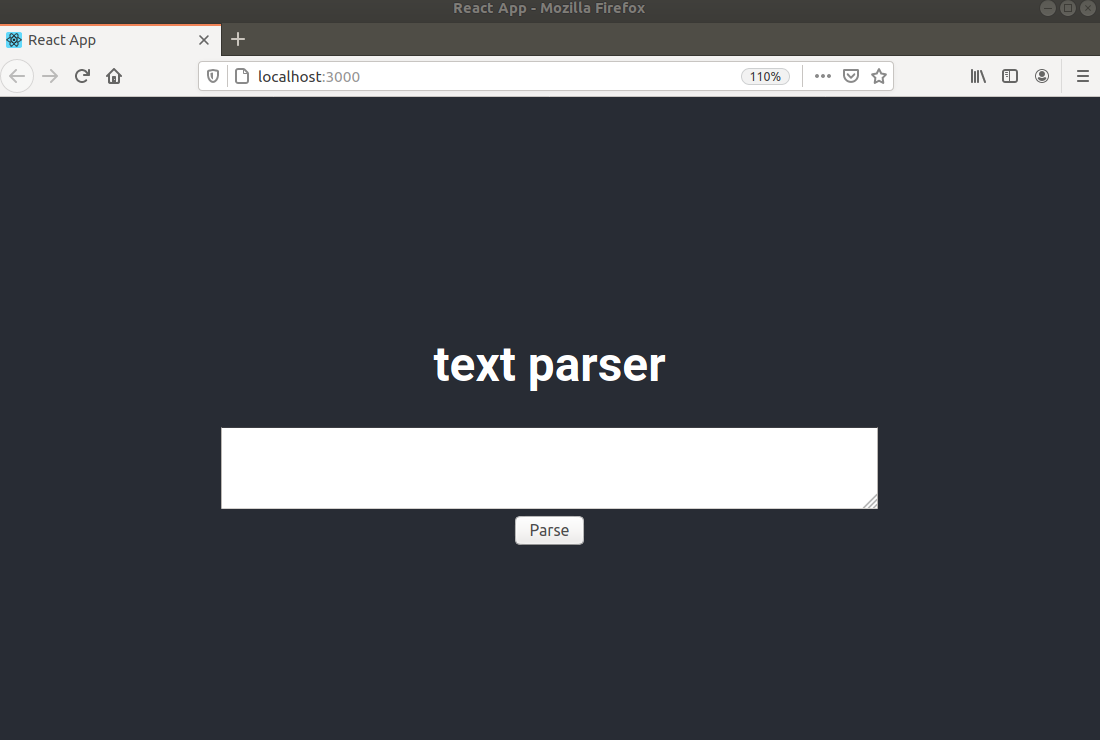
完成品
画面
分かち書きしてみる
実装環境
OS: Ubuntu 18.04.2 LTS Python: 3.6 flask==1.0.2 npm: 6.14.7reactの環境構築については今回触れませんが、公式チュートリアルが日本語でも充実していて非常に参考になりました。
- https://ja.reactjs.org/こちらもすごくおすすめです。
- https://mae.chab.in/archives/2529実装する
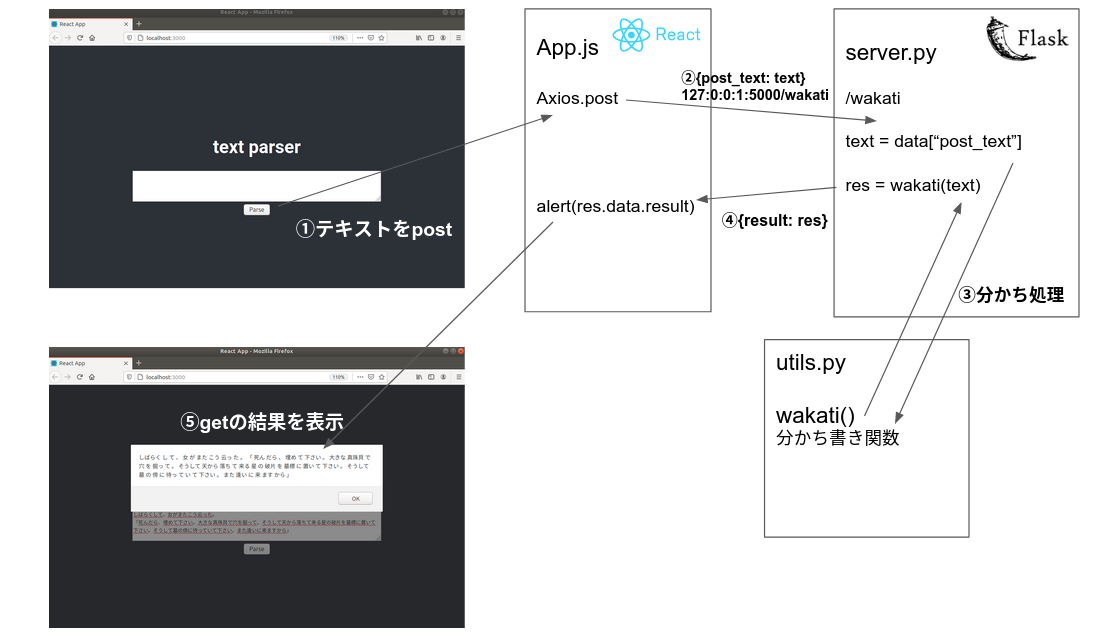
構成図
今回実装したアプリの構成は以下のようになっています(主要部分のみ)。
サーバー側
サーバー側は以下のような構成になっています。
backend/ ├─ requirements.txt ├─ server.py └─ utils.py
server.pyはflaskサーバーを立ち上げるコードです。アドレスやポートは一番下、
app.run(host='127.0.0.1', port=5000)で指定します。server.pyfrom flask import Flask from flask import request, make_response, jsonify from flask_cors import CORS from utils import wakati app = Flask(__name__, static_folder="./build/static", template_folder="./build") CORS(app) #Cross Origin Resource Sharing @app.route("/", methods=['GET']) def index(): return "text parser:)" @app.route("/wakati", methods=['GET','POST']) def parse(): #print(request.get_json()) # -> {'post_text': 'テストテストテスト'} data = request.get_json() text = data['post_text'] res = wakati(text) response = {'result': res} #print(response) return make_response(jsonify(response)) if __name__ == "__main__": app.debug = True app.run(host='127.0.0.1', port=5000)
@app.route("/wakati", methods=['GET','POST')部分でフロントからテキストを受け取り、分かち書き処理した後、フロントへ返す処理をしています。
data = request.get_json()によってフロントからポストされてきた内容をjson形式で取得します。
ここから必要なデータを取り出して、何らかの処理(関数にかけたり、DBに入れたりし)をし、response = {'result': res}のようにjson形式にしてフロントに返します。(補足:CORSとは)
別リソースへアクセス(=クロスサイトHTTPリクエスト)できるようにするために必要なルールです。これがないとフロント側から立ち上げたflaskサーバへアクセスできません。
- 参考:https://aloerina01.github.io/blog/2016-10-13-1フロント側
今回は
create-react-appの雛形を用いました。
(create-react-appの設定および使い方はこちらが非常にわかりやすいです!)フロント側は以下のような構成になっています(主要ファイルのみ掲載)。
frontend/app/ ├─ node_modules/ ├─ public/ ├─ src/ | ├─ App.css | ├─ App.js | ├─ index.js | └─ ... └─ ...自動生成された雛形の中の
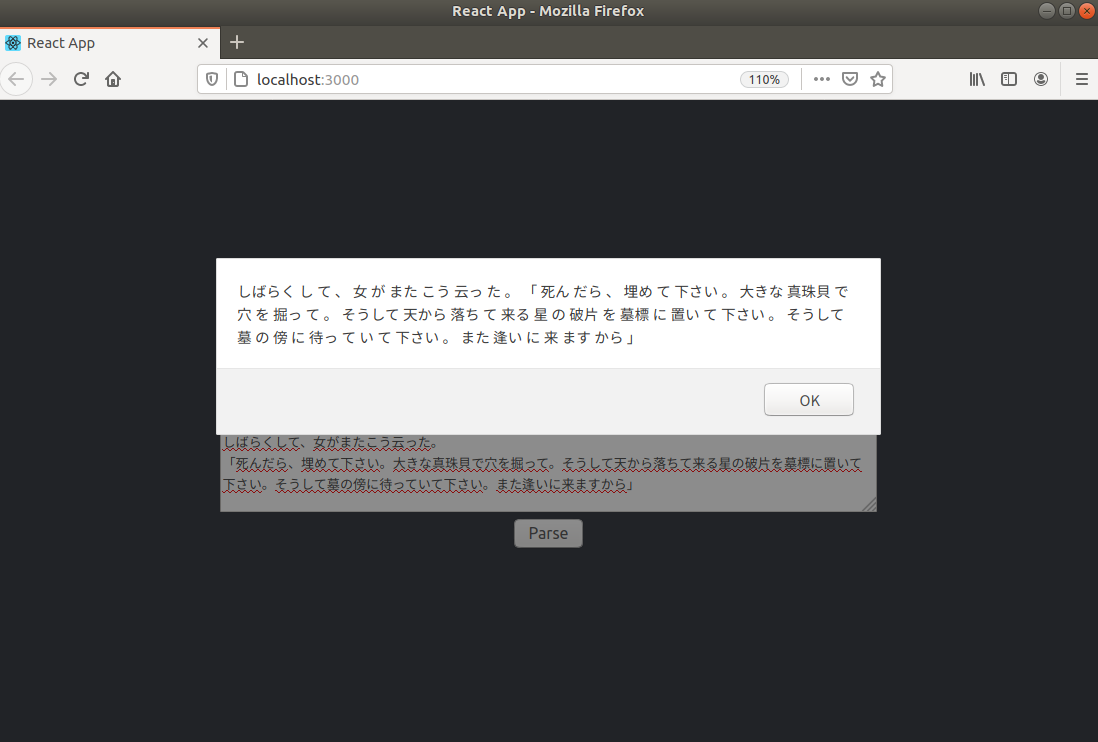
App.jsを以下のように書き換えました。App.jsimport React from 'react'; import './App.css'; import Axios from 'axios'; //function App() { export class App extends React.Component { constructor(props) { super(props); this.state = {value: ''}; this.handleChange = this.handleChange.bind(this); this.handleSubmit = this.handleSubmit.bind(this); } render() { return ( <div className="App"> <header className="App-header"> <h1>text parser</h1> <form onSubmit={this.handleSubmit}> <label> <textarea name="text" cols="80" rows="4" value={this.state.value} onChange={this.handleChange} /> </label> <br/> <input type="submit" value="Parse" /> </form> </header> </div> ); } wakati = text => { //console.log("input text >>"+text) Axios.post('http://127.0.0.1:5000/wakati', { post_text: text }).then(function(res) { alert(res.data.result); }) }; handleSubmit = event => { this.wakati(this.state.value) event.preventDefault(); }; handleChange = event => { this.setState({ value: event.target.value }); }; } export default App;この中の以下の部分でサーバー側とのやり取りを行なっています。
wakati = text => { //console.log("input text >>"+text) Axios.post('http://127.0.0.1:5000/wakati', { post_text: text }).then(function(res) { alert(res.data.result); }) };
server.pyで立てたhttp://127.0.0.1:5000/wakatiにthis.state.valueの値をポストします。
サーバー側で処理された後、返ってきたresultの値がalert(res.data.result);によってブラウザに表示されます。動かす
フロントエンド/バックエンド用にそれぞれターミナルを立ち上げて以下のコマンドを実行します。
サーバー側
$ cd backend $ python server.pyフロント側
$ cd frontend/app $ yarn startブラウザから
localhost:3000にアクセスすることでアプリを利用できます(yarn startで自動で立ち上がります)。おわりに
今回はReactとPython flaskを用いて簡易的なWebアプリを実装しました。
簡易的とはいえ、短時間で楽にWebアプリを実装できるので素晴らしいですね。フロント修行中の身なので、見た目や機能についてはまだまだなのでご意見、アドバイス等いただければ幸いです。
最後まで読んでいただきありがとうございました!
- 投稿日:2020-09-26T21:50:18+09:00
カメラ起動させて人の顔にモザイクかけようぜ(OpenCV)
1.はじめに
皆さんこんにちは!今回はpythonとOpenCVを扱って、カメラを起動させてリアルタイムで人の顔にモザイクを書けるプログラムを作成しました。
もしかしたら、すでに他の人が記事を書いているかもしれませんが…多分出ています。
とにかくやってみよう!2.手順
プログラムの流れはこちらになります。
1.カメラを起動させる。
2.人の顔を認識する。(Haar-like特徴分類器)
3.人の顔があるところをモザイク処理をする。
以上です。3.カメラを起動させる。
OpenCVを用いてカメラを起動させます。
kido.pyimport cv2 cap = cv2.VideoCapture(0) while True: ret, img = cap.read() cv2.imshow('video image', img)#'video image'はカメラのウィンドウの名前 key = cv2.waitKey(10) if key == 27: # ESCキーで終了 break cap.release() cv2.destroyAllWindows()
これでカメラの軌道はできますEscキーを押せばウィンドウが閉じてくれます。
4.人の顔を認識させる(Haar-like特徴分類器)
OpenCVではHaar-like特徴分類器があらかじめ用意されています。便利です!
しかし、ファイルを保存しないと扱えないです。今回は人の顔を認識したいのでこちらのhaarcascade_frontalface_alt.xmlを扱います。ちなみに、Haar-like特徴分類器とは画像の特徴をとられる特徴量から明暗差に着目したHaar-like特徴とアダブーストによってHaar-likeフィルタのサイズを変えながら特徴量を抽出し顔を検出しています。
では、カメラを起動して人の顔を認識させてみましょう。ninsiki.pyimport cv2 #Haar-like特徴分類器を扱えるようにする。 face_cascade_path="haarcascade_frontalface_alt.xml" #pathを指定してください。 face_cascade = cv2.CascadeClassifier(face_cascade_path) cap = cv2.VideoCapture(0) while True: ret, img = cap.read() gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=5) #人の顔を矩形的に囲む for x, y, w, h in faces: cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2) face = img[y: y + h, x: x + w] face_gray = gray[y: y + h, x: x + w] cv2.imshow('video image', img) key = cv2.waitKey(10) if key == 27: # ESCキーで終了 break cap.release() cv2.destroyAllWindows()
これで人の顔を検出できました。5.モザイクをかける
モザイク処理は難しいことは考えずに顔画像を一旦縮小してから拡大して顔画像に張り付けます。
mozaic.pyimport cv2 #Haar-like特徴分類器を扱えるようにする。 face_cascade_path="haarcascade_frontalface_alt.xml" face_cascade = cv2.CascadeClassifier(face_cascade_path) ratio = 0.07 #ここの値を変えるとモザイクの粗さが変わる。 cap = cv2.VideoCapture(0) while True: ret, img = cap.read() gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=5) for x, y, w, h in faces: #モザイクの処理を個々の二行でしている。 small = cv2.resize(img[y: y+h, x: x+w], None,fy=ratio, fx=ratio,interpolation=cv2.INTER_NEAREST) img[y: y + h, x: x + w] = cv2.resize(small, (w, h), interpolation=cv2.INTER_NEAREST) cv2.imshow('video image', img) key = cv2.waitKey(10) if key == 27: # ESCキーで終了 break cap.release() cv2.destroyAllWindows()
完成しました。6.まとめ
今回は、リアルタイムで顔認識して顔にモザイク加工を施しました。明暗差で分類しているため、似顔絵でも反応してしまいます。(誤検知も結構ある)ですが、短いコードで顔検出(顔認識)が試せるのでOpenCV楽しいです。
今までブログなどの情報発信をしたことがないためわかりにくい文章になっているかもしれません。
これから、情報発信をしていき文章力をつけていきたいと思います、また技術で遊べる人間になるのが僕の夢なので温かい目で見守っててください。
これから、よろしくお願いします。
それでは!


- 投稿日:2020-09-26T21:30:19+09:00
Pythonの抽象クラス(ABCmeta)を詳しく説明したい
0.はじめに
Pythonの抽象クラスが思いのほか特殊だったので
メタクラスの説明も踏まえて少しばかり丁寧に解説したい1.ABCmetaの基本的な使い方
PythonのAbstract(抽象クラス)は少し特殊で、メタクラスと呼ばれるものに
ABCmetaを指定してクラスを定義する(メタクラスについては後ほど説明)from abc import ABC, ABCMeta, abstractmethod class Person(metaclass = ABCMeta): passちなみにABCクラスというのもあってこちらはmetaclassを指定せず
継承するだけなので基本こっちの方が分かりやすいclass Person(ABC): pass抽象化したいメソッドに@abstractmethodを付ける
@abstractmethod def greeting(self): pass継承したクラスで実装する
class Yamada(Person): def greeting(self): print("こんにちわ、山田です。")もちろん実装しないで、インスタンス化するとエラー
class Yamada(Person): pass yamada = Yamada() --------------------------------------------------------------------------------------------------------------- TypeError: Can't instantiate abstract class Yamada with abstract methods greeting以上が、基本的な抽象クラスの使い方
1.1そもそもメタクラスとはなんなのか
ここから少しそれてメタクラスの話、興味なかったら飛ばしてください
メタクラスとは
オブジェクト指向プログラミングにおいてメタクラスとは、インスタンスがクラスとなるクラスのことである。通常のクラスがそのインスタンスの振る舞いを定義するように、メタクラスはそのインスタンスであるクラスを、そして更にそのクラスのインスタンスの振る舞いを定義する。
【出典】: メタクラス - wikipedia
とまあよくわからないので、実例を出すと
実は、Pythonの隠し機能(?)でtypeからクラスを動的に定義できてしまうdef test_init(self): pass Test_Class = type('Test_Class', (object, ), dict(__init__ = test_init, ))もちろん、このクラスをインスタンス化できる
Test_Class_instance = Test_Class() print(type(Test_Class_instance)) ------------------------------------------------------------------------------------------------------------------- <class '__main__.Test_Class'>このときtypeで生成したTest_Classは、インスタンスともクラスの定義ともいえる
これが、狭義的な意味でのメタクラス驚きなのは、Pythonにおいて普段何気なく定義しているclassは
type型のインスタンスだったりするのだclass define_class: pass print(type(define_class)) ------------------------------------------------------------------------------------------------------------------- <class 'type'>結局のところ、Pythonはclassを定義すると内部で
type('classname', ...)が自動で呼び出されるという仕組みになっている
ということになるこの自動で呼び出せれるクラスを変えてしまえという
超強力な機能が__metaclass__ の正体で、
ABCmetaというのはtypeを継承したクラスということになる
ABCmetaのソースコードちなみに、metaclassは強力すぎて言語の仕様自体変えてしまう
黒魔術のため乱用しないほうがいいです2.classmethod、staticmethod、propertyの抽象化
@abstractclassmethod、@abstractstaticmethod、@abstractproperty
がともに非推奨になってしまったので、デコレータを重ねる必要がある抽象クラス
class Person(ABC): @staticmethod @abstractmethod def age_fudging(age): pass @classmethod @abstractmethod def weight_fudging(cls, weight): pass @property @abstractmethod def age(self): pass @age.setter @abstractmethod def age(self, val): pass @property @abstractmethod def weight(self): pass @weight.setter @abstractmethod def weight(self, val): pass実装
class Yamada(Person): def __init__(self): self.__age = 30 self.__weight = 120 #10歳サバ読み @staticmethod def age_fudging(age): return age - 10 #20kgサバ読み @classmethod def weight_fudging(cls, weight): return weight - 20 @property def age(self): return Yamada.age_fudging(self.__age) @age.setter def age(self): return @property def weight(self): return self.weight_fudging(self.__weight) @weight.setter def weight(self): return y = Yamada() print("名前:山田 年齢:{0} 体重:{1}".format(y.age, y.weight)) ----------------------------------------------------------------------------------------------------------------- 名前:山田 年齢:20 体重:100多少長くなってしまったが、基本的な使い方は同じ
ただ、@abstractmethodが下に来るようにしないとエラーを吐くので注意ちなみに、Pythonではメンバ変数の前に「__」を付けるとプライベート化できます
3.抽象クラスの多重継承
Pythonでは多重継承が使えるが、抽象クラスではどうでしょう
ご存じの通り、多重継承はいろいろと問題があるので(菱形継承問題、名前衝突)
基本的に多重継承は使わない方が無難だが、使う場合はMixinなクラスであることが求められる3.1Mixinとは?
mixin とはオブジェクト指向プログラミング言語において、
サブクラスによって継承されることにより機能を提供し、単体で動作することを意図しないクラスである。言語によっては、
その言語でクラスや継承と呼ぶものとは別のシステムとして mixin がある場合もある(#バリエーションの節で詳述)。【出典】: Mixin - wikipedia
またWikipediaからの引用だが要するに
継承しないとまともに動かないクラスのことで
抽象クラスやインターフェイスもMixinなクラスといえるということで、猫と人間を継承した獣人クラスを作っていく
class Cat(ABC): @abstractmethod def mew(self): pass #Personにもある @abstractmethod def sleep(self): pass class Person(ABC): @abstractmethod def greeting(self): pass #Catにもある @abstractmethod def sleep(self): pass class Therianthrope(Person, Cat): def greeting(self): print("こんにちわ") def mew(self): print("にゃー") def sleep(self): print("zzz…") cat_human = Therianthrope() cat_human.greeting() cat_human.mew() cat_human.sleep() ----------------------------------------------------------------------------------------------------------------- こんにちわ にゃー zzz…ABCmetaでも難なく動作することがわかる
今回は、sleepというメソッドを名前衝突させているが
継承元で実装されているわけではないので、問題がない最後にPythonの公式サイトにも書いてある通り
メタクラス同士の衝突には十分注意したほうがいい4.抽象クラスの多段継承
多段継承で懸念になるのはABCmetaは継承すると引き継ぐのか
言い換えると、Pythonは抽象クラスを継承すると抽象クラスに
なってしまうのかという点結論から言うとABCmetaは引き継ぐし、抽象クラスを継承すると抽象クラスになります
class Animal(metaclass=ABCMeta): pass class Person(Animal): pass class Yamada(Person): pass print(type(Person)) print(type(Yamada)) ------------------------------------------------------------------------------------------------------------------- <class 'abc.ABCMeta'> <class 'abc.ABCMeta'>つまるところ抽象メソッドはどこかしらで
実装すればよいということになるclass Animal(metaclass=ABCMeta): @abstractmethod def run(self): pass class Person(Animal): pass class Yamada(Person): def run(self): print("時速12km") y = Yamada() y.run() ------------------------------------------------------------------------------------------------------------------- 時速12km5.仮引数に抽象クラスをとる
だいぶ長くなってしまったが、最後に抽象クラスのざっくりとした
Pythonでも使える使用法の一例を紹介実は、Pythonでも仮引数、戻り値の型を指定することができるので
先ほど作った親クラスであり抽象クラスでもある「Person」を仮引数の型に指定した
fall_asleepという関数を作っていきましょうfrom abstract import Person import time def fall_asleep(p:Person): sleep_time = p.sleep() time.sleep(sleep_time) print("!")class Person(ABC): @abstractmethod def greeting(self): pass @abstractmethod def sleep(self) -> float: pass抽象クラスやら型指定やらと、もはやPythonではなくなって来てますが
この様なテクニックは、Pythonで少し規模が大きいソフトフェアを作るとき
なんかに役に立ちます。例えばfall_asleepを作っている人は、具象クラスの実態(YamadaなのかIkedaなのかYosidaなのか)を
気にせず(知らず)、またいくら変更しようともsleepという関数が要件さえ満たしてれば
完成させられるので、fall_asleepは具象クラスではなく抽象クラス(Person)に依存しているといえるこのことをアーキテクチャでは「依存関係逆転の原則(DIP)」なんて
言ったりしますDIPは以下の物が該当
- (変化しやすい)具象クラスを参照しない
- (変化しやすい)具象クラスを継承しない
- 具象関数をオーバーライドしない
結局のところ抽象クラスに依存したほうが、
強固なアーキテクチャを実現できるというわけですy = Yamada() fall_asleep(y) ------------------------------------------------------------------------------------------------------------------- zzz… !
- 投稿日:2020-09-26T21:11:46+09:00
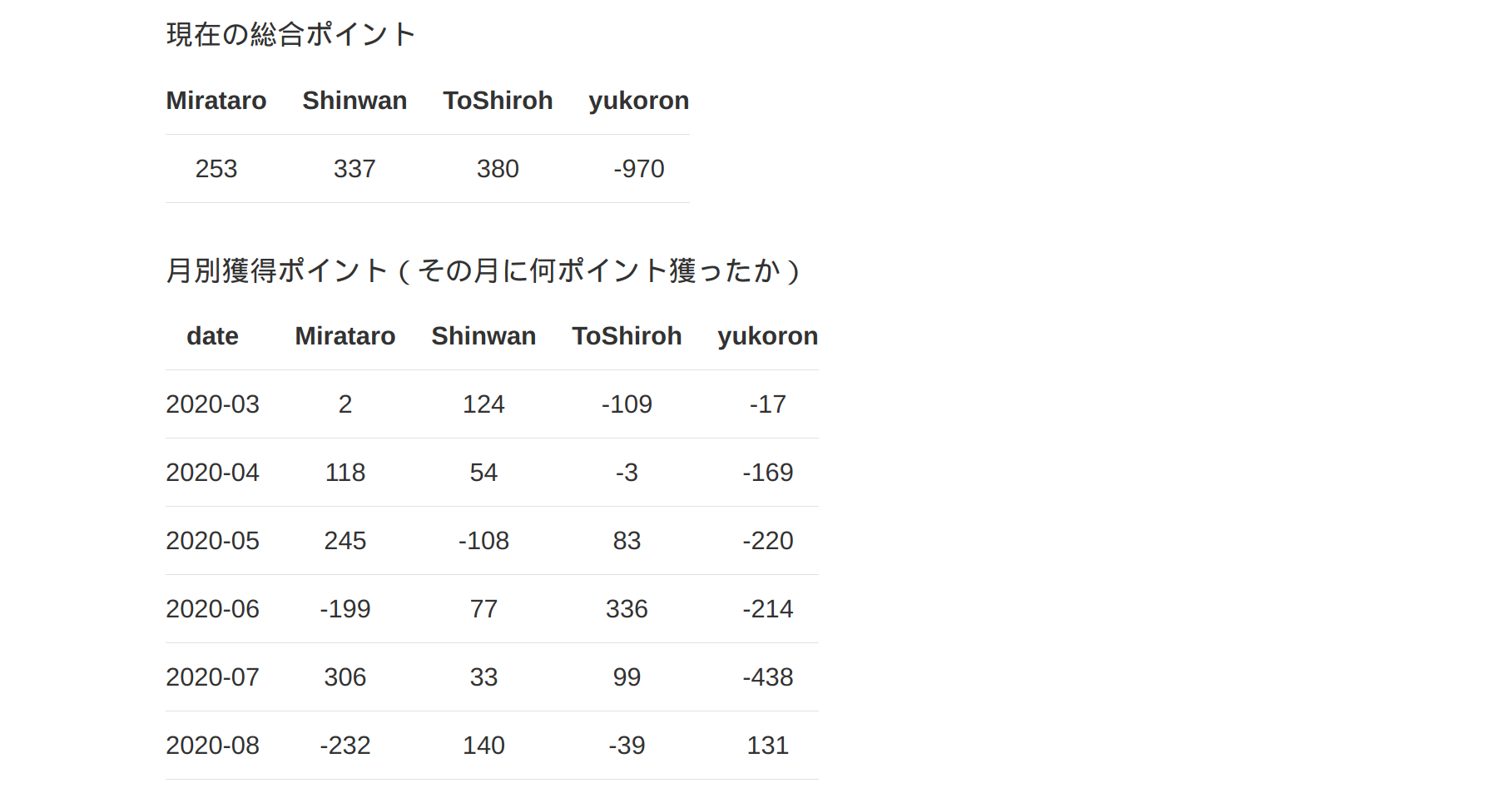
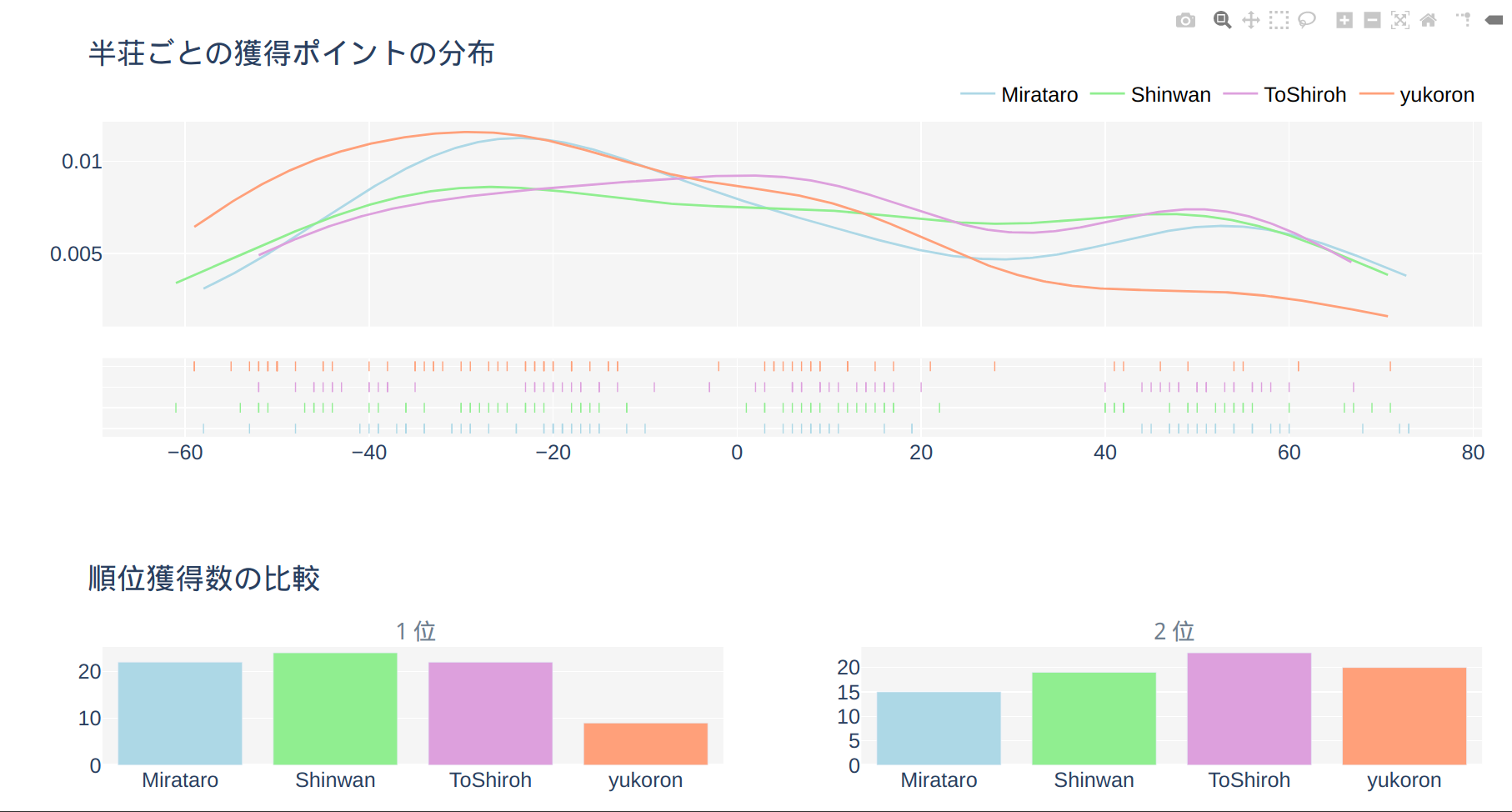
オンライン家族麻雀をPythonを使って解析してみる(PART 1: DATAを取る)
概要
最近家族とオンライン麻雀サイト天鳳で週に1回2時間ほど楽しんでいます。
今回は対戦成績の分析を家族が皆がウェブ上で見れるようにしたのでその解説です。
プロセスとしては:
- Pythonで分析
- Dashを使って可視化
- HerokuとGithubを使ってデブロイ
こんな感じに仕上がりました↓
https://drmahjong.herokuapp.com/
Codeは以下のGithubで見ることができます。
https://github.com/mottoki/mahjan-scoreデータを取る
天鳳のデータはログから取ることができます。requestというModuleを使用してデータを取ります。
python.pyimport requests import datetime new_date = datetime.datetime.now().strftime('%Y%m%d') url = "https://tenhou.net/sc/raw/dat/"+f"sca{new_date}.log.gz" filename = f"sca{new_date}.log.gz" # Download gz file from the url with open(filename, "wb") as f: r = requests.get(url) f.write(r.content)PythonとPandasを使ってデータ処理
Rawデータをプレイヤーの名前でフィルターをかけて、splitを使用してプレイヤーの名前とポイントだけのデータフレームを摘出します。
new_data.pyimport os import pickle import pandas as pd # プレイヤーの名前 playercol = ['date', 'Mirataro', 'Shinwan', 'ToShiroh', 'yukoron'] # Pandasのデータフレームに変換 df = pd.read_csv(filename, usecols=[0], error_bad_lines=False, header=None) df[len(df.columns)] = new_date # プレイヤーの名前でフィルターをかける df = df[(df[0].str.contains(playercol[1])) & (df[0].str.contains(playercol[2])) & (df[0].str.contains(playercol[3])) & (df[0].str.contains(playercol[4]))] # データフレームの処理を行う df[['one','two','three','four']] = df[0].str.split('|', 3, expand=True) df.columns = ['original', 'date', 'room', 'time', 'type', 'name1'] df['date'] = pd.to_datetime(df['date'], format='%Y%m%d') df[['empty', 'n1', 'n2', 'n3', 'n4']] = df.name1.str.split(" ", n=4, expand=True) # 重要なコラムだけ使用 df = df[['date', 'n1', 'n2', 'n3', 'n4']] # スコアと名前についているカギカッコを取り去りデータフレーム化する new_score = pd.DataFrame(columns=playercol) k=0 for i, j in df.iterrows(): dd = j[0] new_score.loc[k, 'date'] = dd for name in df.columns[1:]: s = j[name] player = s.split('(')[0] score = [p.split(')')[0] for p in s.split('(') if ')' in p][0] score = int(float(score.replace('+', ''))) new_score.loc[k, player] = score k += 1 # 古いデータをPickleから呼ぶ current_dir = os.getcwd() old_score = pd.read_pickle(f"{current_dir}/players_score.pkl") # 新しいデータと古いデータを合わせる concat_score = pd.concat([old_score, new_score], ignore_index=True) concat_score.to_pickle(f"{current_dir}/players_score.pkl")Dashを使って可視化する
Dashというライブラリを使って素早くデータの可視化を行います。
Dashのチュートリアルが一番わかりやすいです。(参考:Dash Documentation & User Guide)
Dashで引っかかるところのはCallbackという機能ですが、Pythonの可視化ライブラリDashを使う 2 Callbackをみるなど詳しく説明されている方がいますのでそちらを参照してください。
1. Front側(ウェブに見えるもの)
全てのコードを説明すると長くなってしまうので、コアとなる部分を例として説明します。
基本的に最初の
app.layout=の中に書かれているものは全てウェブサイトで表示されるものです。表示したくないもの(例えば何度も使うデータ「intermediate-values」)は
style={'display': 'none'}と入れるとウェブ上で見えなくなります。# フロントエンドはこのなかに書く app.layout = html.Div([ # データに反映される日付をユーザーが選べるようにする html.Div([ html.H2("DR.麻雀"), dcc.DatePickerRange( id='my-date-picker-range', min_date_allowed=dt(2020, 3, 1), max_date_allowed=dt.today(), end_date=dt.today() ), ], className="mytablestyle"), # 何度も使うデータ:style={'display': 'none'}で見えなくする html.Div(id='intermediate-value', style={'display': 'none'}), # ポイントの推移(グラフ) dcc.Graph(id='mygraph'), # 総合ポイント(テーブル) html.Div([ html.Div(html.P('現在の総合ポイント')), html.Div(id='totalscore'), ], className="mytablestyle"), ])2. CallbackでデータをJson化する
データをpandasのread_pickleで読み込み、日付でフィルターをかけ、json化して戻します。
こうすることによって同じデータをグラフやテーブルに何度も使えるようになります。
@app.callback(Output("intermediate-value", "children"), [Input("my-date-picker-range", "start_date"), Input("my-date-picker-range", "end_date")]) def update_output(start_date, end_date): players = pd.read_pickle('players_score.pkl') if start_date is not None: start_date = dt.strptime(re.split('T| ', start_date)[0], '%Y-%m-%d') players = players.loc[(players['date'] >= start_date)] if end_date is not None: end_date = dt.strptime(re.split('T| ', end_date)[0], '%Y-%m-%d') players = players.loc[(players['date'] <= end_date)] return players.to_json(date_format='iso', orient='split')3. Callbackでデータをグラフ化&テーブル化
json化したデータをPandasのデータフレームに戻し、グラフ化とテーブル化していきます。
グラフ化はPlotlyの様式に乗っ取り、go.Figure()で表します。
テーブル化はhtml.Tableで表しました。テーブルはdash_tableというライブラリもあるのですが、今回のテーブルは簡易なものだったので必要ないろ思いこのスタイルにしました。
@app.callback([Output('mygraph', 'figure'), Output('totalscore', 'children')], [Input('intermediate-value', 'children'), Input('datatype', 'value')]) def update_fig(jsonified_df, data_type): # Json化したデータをPandasでもとに戻す。 players = pd.read_json(jsonified_df, orient='split') # グラフ化 fig = go.Figure() for i, name in enumerate(players.columns[1:]): fig.add_trace(go.Scatter(x=players.date, y=np.array(players[name]).cumsum(), mode='lines', name=name, line=dict(color=colors[i], width=4))) fig.update_layout(plot_bgcolor='whitesmoke', title='合計ポイントの推移', legend=dict( orientation="h", yanchor="bottom", y=1.02, xanchor="right", x=1,) ) # 総合ポイントを計算 summed = players.sum() # グラフと表を返す return fig, html.Table([ html.Thead( html.Tr([html.Th(col) for col in summed.index]) ), html.Tbody( html.Tr([html.Td(val) for val in summed]) ), ])HerokuとGithubを使ってデプロイ
最後にHerokuとGithubを使ってデプロイしていきます。
公式サイト(Deploying Dash Apps)にはGitとHerokuのやりかたが詳しく載っているので、ほとんどやり方は一緒です。
プロセスはこんな感じです:
- Githubのアカウントにサインアップする
- Githubの新しいレポジトリを作成する
- GithubにSSH接続する。(オプショナルですが、やったほうが楽。参照:GitHubにssh接続できるようにする)
- デプロイに必要なファイル(
.ignore,Procfile,requirements.txt)を作成する。gunicornも必要なのでpip install gunicornでインストールする。Gitコマンドで上記のファイルと
app.pyやplayers_score.pklのデータファイルをGithubにプッシュする。git init git add . git commit -m "メッセージ" git remote add origin git@github.com:<ユーザー名>/<レポジトリ名> git push origin masterGithubにプッシュされているのを確認したらHerokuのアカウントを作成して
New > create new appのボタンで新しいアプリを作成(Regionは日本がないので、United Statesを選択)。作成されたアプリのDeployのタブをクリックし、
Deployment methodをGithubにし、2.で作成したレポジトリに接続します。最後に
Manual deployのDeploy Branchという黒いボタンを押すと勝手にデプロイしてくれます。最後に
いかかでしたでしょうか。
cronとHerokuのAutomatic Deployを使えば天鳳から取ってくる新しいデータのアップデートを自動化することも可能です。(参考:cronでGithubにPushするプロセスを自動化する)
参考

- 投稿日:2020-09-26T21:11:07+09:00
機械学習の初心者がpythonで競馬予測モデルを作ってみた
最近では機械学習を取り入れたサービス開発も増え始め、私自身もそのディレクションをすることがあります。
ただ、データサイエンティスト、MLエンジニアと呼ばれる人々が作る学習モデルを盲目的に利用するだけの簡単なお仕事です、というのは否めず、初心者(私)が、機械学習の知識レベルを上げるために、簡単な学習モデルを作れるようになるまでの過程をまとめてみました。
今回のゴール
pythonによる環境構築からスタートして、一番手っ取り早いと思われるロジスティック回帰による分類モデルを構築してみるところまで実施してみます。題材は趣味と実益を兼ねて、競馬予測モデルに挑戦してみます。
※なお、競馬の専門用語を使用してますが、不明な点は調べて頂ければと思います。
環境構築
前提
実施した環境は以下の通りです。
- Python:3.7.7
- pip:20.2.2
pipenvインストール
pythonの実行環境をpipenvを使って構築していくことにします。
$ pip install pipenvpythonを実行する仮想環境を構築します。
$ export PIPENV_VENV_IN_PROJECT=true $ cd <project_dir> $ pipenv --python 3.7
PIPENV_VENV_IN_PROJECTは仮想環境をプロジェクトのディレクトリ配下(./.venv/)に構築する設定です。ライブラリインストール
ここでは、最低限必要なライブラリをインストールしていきます。
$ pipenv install pandas $ pipenv install sklearn $ pipenv install matplotlib $ pipenv install jupyterインストール後、カレントディレクトリのPipfileとPipfile.lockが更新されています。
これらの4ライブラリは必須アイテムと言えるので、有無を言わさずインストールしましょう。
ライブラリ 用途 pandas データの格納と前処理(クレンジング、統合、変換など) sklearn 様々な機械学習アルゴリズムを使用した学習と予測 matplotlib グラフ描画によるデータ可視化 jupyter ブラウザ上で対話形式のプログラミング jupyter notebookの起動方法
$ cd <project_dir> $ pipenv run jupyter notebook ... To access the notebook, open this file in a browser: file:///Users/katayamk/Library/Jupyter/runtime/nbserver-4261-open.html Or copy and paste one of these URLs: http://localhost:8888/?token=f809cb2bcb716ba5726912d43738dd51992d3d7f20942d71 or http://127.0.0.1:8888/?token=f809cb2bcb716ba5726912d43738dd51992d3d7f20942d71ターミナルに出力されたlocalhostのURLにアクセスすることで、ローカルサーバでjupyter notebookをブラウジングできるようになります。
以上で、環境構築は完了です。
モデル構築
機械学習と一言で言っても、教師あり学習、教師なし学習、強化学習、ディープラーニングと種類は様々ありますが、今回は冒頭でも記載したように、簡単な学習モデルを作れるようになるために、教師あり学習の分類モデルを構築します。
機会学習のワークフロー
AWSの記事が分かりやすかったので、こちらを参照するといいと思います。
機械学習のワークフローってどうなっているの ? AWS の機械学習サービスをグラレコで解説
簡単にまとめると上記の流れになるかと思いますので、この順番で、学習モデルを構築していきます。1. データの取得
競馬予測モデルを構築するということで、まずは過去の競馬データが必要になります。
インターネット上には競馬情報サイトをスクレイピングする方法なども紹介されてますが、将来的な運用を見据えて、JRAの公式データを購入して取得することにします。
取得データ:JRA-VAN データラボ自分でデータを取得するプログラムを作るのもいいですが、あらかじめ提供されている無料の競馬ソフトを使ってデータをファイル出力する方法も可能です。(本筋の話じゃないので詳細は省きます。)
今回は以下の2種類のデータファイルを取得しました。データの対象期間は2015年〜2019年の5年分です。
ファイル名 データ種別 データ説明 syutsuba_data.csv 出馬表データ 開催されるレースの出走馬などが記載された番組表データ seiseki_data.csv 成績データ 開催されたレースの着順などが記載された成績データ 2. データの前処理
データの前処理とは
機械学習において、一番重要とも言われるステップがこちらです。取得したデータに合わせて、以下の処理を実施します。
データクレンジング
ノイズとなるデータを取り除いたり、欠損値を違う値で埋める作業などを行います。
データ統合
学習に必要なデータが、最初から一つにまとまっていることは稀であり、分散したデータを統合することで一貫したデータを生成します。
データ変換
モデルの品質を向上させるため、データを指定のフォーマットに変換するプロセスです。例えば、数値データを-1から1の範囲に収まるデータに標準化したり、犬か猫のどちらかが選択されているようなカテゴリーデータをダミー変数化して数値に変換するなど、様々なデータの加工を実施します。
競馬データの前処理
ここから実際に競馬データの前処理を実装してきますが、起動したjupyter notebookを使用すると、対話形式でデータの状態を確認しながらのプログラミングが可能です。
まずは、取得した競馬データをpandasのDataFrameにロードしますが、データの前処理を実施した結果、最終的には以下の構造にデータを加工しようと思います。
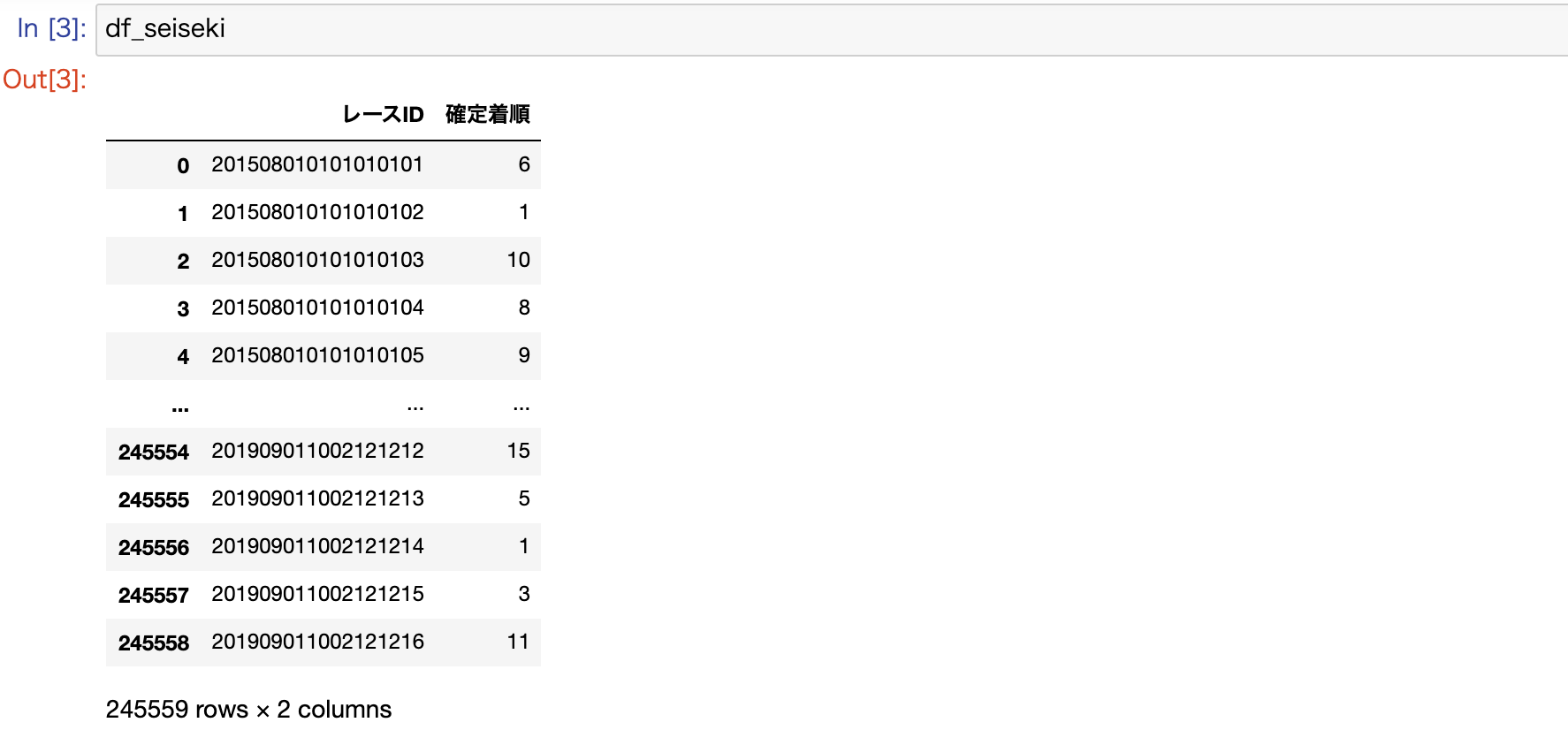
データ項目 用途 データ説明 race_index index 開催されるレースを特定した識別ID 本賞金 説明変数 出走馬の獲得賞金の合計金額 騎手名 説明変数 騎手名をダミー変数化して使用 3着以内 目的変数 出走馬の着順を3着以内なら1、4着以下なら0に変換 今回は出走馬の実力を測る特徴量として、各馬がこれまでに獲得した賞金の合計金額を使用します。また、騎手の手腕による差も大きいと考え、騎手名も採用しました。この二つの説明変数だけで、どの程度の予測精度になるか試してみます。
build.ipynbimport os import pandas as pd # 出馬表データ syutsuba_path = './data/sample/syutsuba_data.csv' df_syutsuba = pd.read_csv(syutsuba_path, encoding='shift-jis') df_syutsuba = df_syutsuba[['レースID', '本賞金', '騎手名']] # 成績データ seiseki_path = './data/sample/seiseki_data.csv' df_seiseki = pd.read_csv(seiseki_path, encoding='shift-jis') df_seiseki = df_seiseki[['レースID', '確定着順']]DataFrameでは、以下のようにデータが構成されています。
参考) レースIDのデータフォーマット
添字(レンジ) データ長 項目説明 0〜3 4byte 年 4〜5 2byte 月 6〜7 2byte 日 8〜9 2byte 競馬場コード 10〜11 2byte 開催回次 12〜13 2byte 開催日次 14〜15 2byte レース番号 16〜17 2byte 馬番 続いて、取得データを統合して、データのクレンジングや変換などを実施していきます。
build.ipynb# 出馬表データと成績データをマージ df = pd.merge(df_syutsuba, df_seiseki, on = 'レースID') # 欠損値があるレコードは除去 df.dropna(how='any', inplace=True) # 着順が3着以内かどうかのカラムを追加する f_ranking = lambda x: 1 if x in [1, 2, 3] else 0 df['3着以内'] = df['確定着順'].map(f_ranking) # ダミー変数を生成 df = pd.get_dummies(df, columns=['騎手名']) # インデックスを設定(レースだけを特定する場合は、16バイト目までを使用) df['race_index'] = df['レースID'].astype(str).str[0:16] df.set_index('race_index', inplace=True) # 不要なカラムを削除 df.drop(['レースID', '確定着順'], axis=1, inplace=True)DataFrameを確認すると、ダミー変数化したカラムは、そこに所属するカテゴリー数分の新たなカラムに置き換わって、0か1のフラグが設定されているのが分かります。
騎手名をダミー変数化したことで、カラム数が295まで増えてますが、カテゴリー数の多いカラムをダミー変数化すると過学習の原因にもなりますので、注意してください。3. モデルの学習
続いてモデルの学習を行っていきましょう。
まず、データを説明変数と目的変数ごとに学習用データと評価用データに分割します。build.ipynbfrom sklearn.model_selection import train_test_split # 説明変数をdataXに格納 dataX = df.drop(['3着以内'], axis=1) # 目的変数をdataYに格納 dataY = df['3着以内'] # データの分割を行う(学習用データ 0.8 評価用データ 0.2) X_train, X_test, y_train, y_test = train_test_split(dataX, dataY, test_size=0.2, stratify=dataY)要は以下の4種類のデータに分割しています。
変数名 データ種別 用途 X_train 説明変数 学習データ X_test 説明変数 評価データ y_train 目的変数 学習データ y_test 目的変数 評価データ 今回は、train_test_splitを使用して、簡易的に学習データと評価データを分割してますが、競馬のように、時系列の概念があるデータに関しては、(過去)-> 学習データ -> 評価データ ->(現在)という並びになるように、データを分割した方が、精度も上がると思われます。
続いて、用意したデータを学習させていきます。基本的なアルゴリズムならsklearnに内包されており、今回はロジスティック回帰を使用します。
build.ipynbfrom sklearn.linear_model import LogisticRegression # 分類器を作成(ロジスティック回帰) clf = LogisticRegression() # 学習 clf.fit(X_train, y_train)これだけで完了です。とても簡単ですね。
4. モデルの評価
まずは、評価データを予測して、その結果をもとに正解率を確認してみましょう。
build.ipynb# 予測 y_pred = clf.predict(X_test) # 正解率を表示 from sklearn.metrics import accuracy_score print(accuracy_score(y_test, y_pred)) 0.7874043003746538正解率は
0.7874043003746538と78%も正しく予測できていることになります。
一見、「おーすげー!めっちゃ儲かるやん!」と喜んでしまいそうですが、このaccuracy_scoreには要注意です。続いて以下のコードを実行してみます。build.ipynb# 混同行列を表示 from sklearn.metrics import confusion_matrix print(confusion_matrix(y_test, y_pred, labels=[1, 0])) [[ 339 10031] [ 410 38332]]この2次元配列は混同行列と言いますが、以下を表しています。
予測:3着以内 予測:4着以下 実際:3着以内 339 10031 実際:4着以下 410 38332 このうち、正解率は予測:3着以内 × 実際:3着以内と予測:4着以下 × 実際:4着以下の合算値になります。
正解率:0.78 = (339 + 38332) / (339 + 38332 + 410 + 10031)
予測:3着以内 予測:4着以下 実際:3着以内 339 10031 実際:4着以下 410 38332 この結果から、3着以内と予測した件数がそもそも少なすぎて、大半を4着以下と予測していることで、正解率が押し上げられていることが分かります。
正解率には要注意というのが分かったところで、では何を基準にモデルの精度を評価すればいいかですが、この混同行列を活用した方法としては、F値を確認するという方法があります。
F値とは
以下の1と2を合わせたものになります。
1)3着以内と予測した出走馬のうち、正解した割合(適合率と言います)
2)実際に3着以内だった出走馬のうち、正解した割合(再現率と言います)適合率:0.45 = 339 / (339 + 410)
再現率:0.03 = 339 / (339 + 10031)
予測:3着以内 予測:4着以下 実際:3着以内 339 10031 実際:4着以下 410 38332 build.ipynb# F値を表示 from sklearn.metrics import f1_score print(f1_score(y_test, y_pred)) 0.06097670653835776今回のF値を確認したところ、
0.06097670653835776でした。F値ですが、ランダムに0と1に振り分けたケースの場合、0.5に収束する性質のものであるため、今回の0.06という値は極めて低い数値であるというのが分かります。データ不均衡を修正
build.ipynbprint(df['3着以内'].value_counts()) 0 193711 1 51848目的変数の3着以内と4着以下のデータ比率は1:4で、ややデータに偏りが見られますので、ここを少し是正してみます。
まず、追加で以下のライブラリをインストールします。
$ pipenv install imbalanced-learn学習データの3着以内と4着以下のデータ比率を1:2にアンダーサンプリングします。アンダーサンプリングとは、少数データに合わせて多数データの件数をランダムに絞ることを意味します。
build.ipynbfrom imblearn.under_sampling import RandomUnderSampler # 学習データをアンダーサンプリング f_count = y_train.value_counts()[1] * 2 t_count = y_train.value_counts()[1] rus = RandomUnderSampler(sampling_strategy={0:f_count, 1:t_count}) X_train_rus, y_train_rus = rus.fit_sample(X_train, y_train)これで、データ不均衡を少し是正したので、再度モデルの学習と評価を実施します。
build.ipynb# 学習 clf.fit(X_train_rus, y_train_rus) # 予測 y_pred = clf.predict(X_test) # 正解率を表示 print(accuracy_score(y_test, y_pred)) 0.7767958950969214 # 混同行列を表示 print(confusion_matrix(y_test, y_pred, labels=[1, 0])) [[ 1111 9259] [ 1703 37039]] # F値を表示 print(f1_score(y_test, y_pred)) 0.1685376213592233F値が
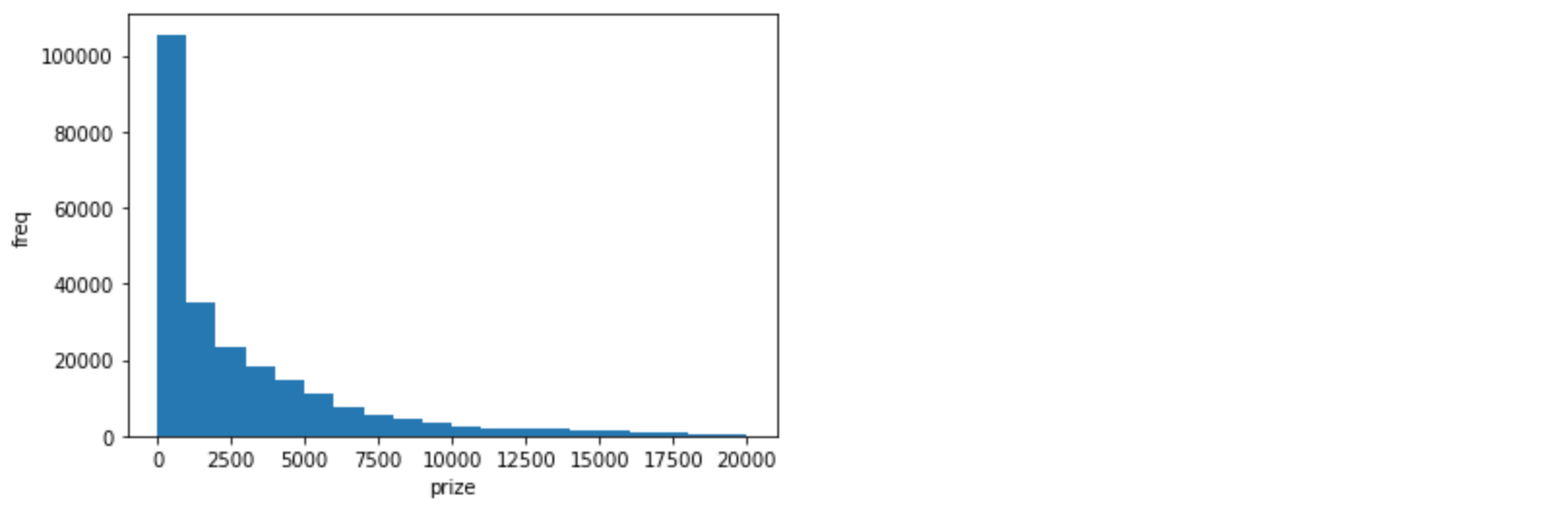
0.1685376213592233となり、かなり改善されましたね。説明変数を標準化
説明変数が本賞金と騎手名の二つですが、騎手名はダミー変数化により0か1の値、一方で本賞金は以下のような特徴量の分布になっています。
build.ipynbimport matplotlib.pyplot as plt plt.xlabel('prize') plt.ylabel('freq') plt.hist(dataX['本賞金'], range=(0, 20000), bins=20)
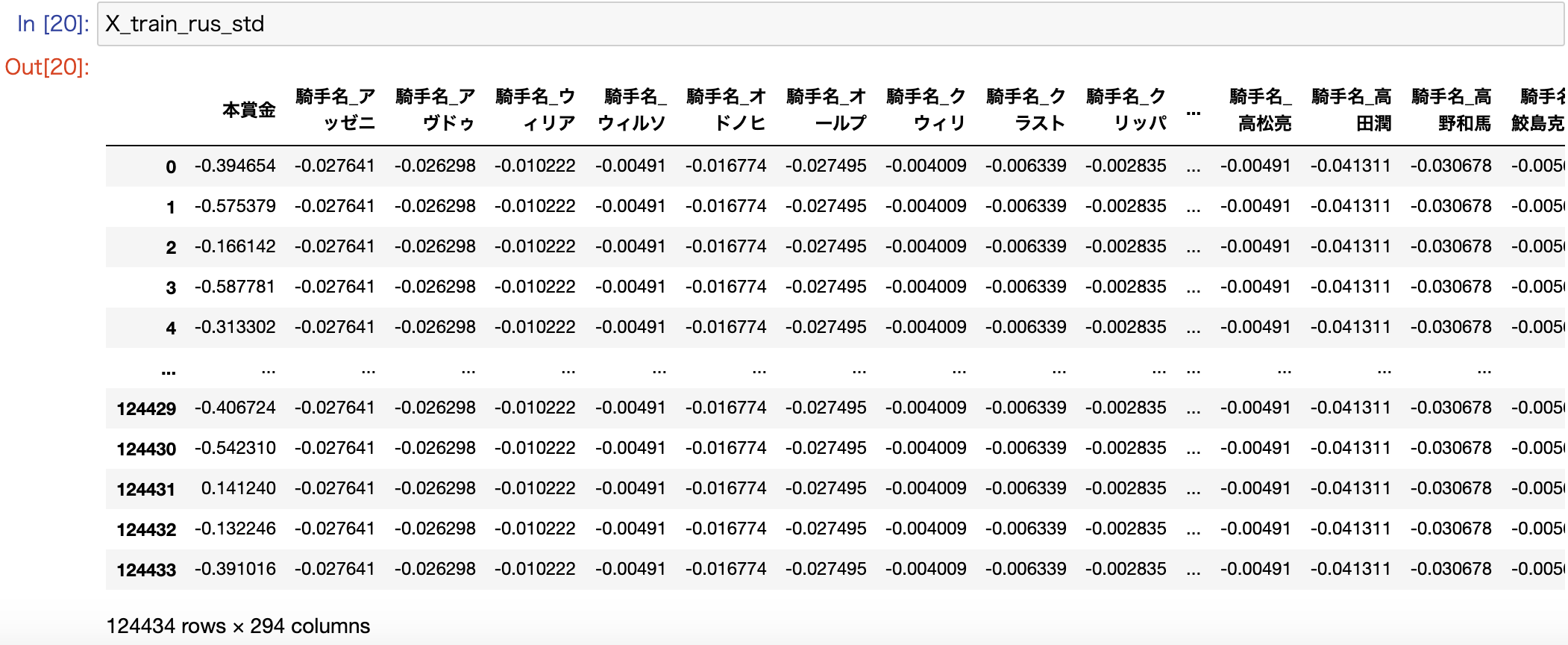
値の大きさが違いすぎるため、本賞金と騎手名を対等に比較できない可能性が高く、それぞれの特徴量を同じ範囲にスケールしてあげる必要があります。その手法の一つが標準化になります。build.ipynbfrom sklearn.preprocessing import StandardScaler # 説明変数を標準化 sc = StandardScaler() X_train_rus_std = pd.DataFrame(sc.fit_transform(X_train_rus), columns=X_train_rus.columns) X_test_std = pd.DataFrame(sc.transform(X_test), columns=X_test.columns)
標準化することで、全ての説明変数の値が一定の範囲内に収まるように変換されたので、再度モデルの学習と評価を実施します。build.ipynb# 学習 clf.fit(X_train_rus_std, y_train_rus) # 予測 y_pred = clf.predict(X_test_std) # 正解率を表示 print(accuracy_score(y_test, y_pred)) 0.7777732529727969 # 混同行列を表示 print(confusion_matrix(y_test, y_pred, labels=[1, 0])) [[ 2510 7860] [ 3054 35688]] # F値を表示 print(f1_score(y_test, y_pred)) 0.3150495795155014F値が
0.3150495795155014となり、前回からさらに精度向上し、30%台に乗りました。また、適合率が0.45、再現率が0.24で、競馬の予測結果としてはまずまずかと思います。回帰係数の重みを確認
最後に説明変数のどの値が、競馬予測に強く影響しているかを回帰係数で確認します。
build.ipynbpd.options.display.max_rows = X_train_rus_std.columns.size print(pd.Series(clf.coef_[0], index=X_train_rus_std.columns).sort_values()) 騎手名_下原理 -0.092015 騎手名_左海誠二 -0.088886 騎手名_江田照男 -0.081689 騎手名_三津谷隼 -0.078886 騎手名_山本聡哉 -0.075083 騎手名_御神本訓 -0.073361 騎手名_伴啓太 -0.072113 騎手名_岩部純二 -0.070202 騎手名_武士沢友 -0.069766 騎手名_宮崎光行 -0.068009 ...(省略) 騎手名_岩田康誠 0.065899 騎手名_田辺裕信 0.072882 騎手名_モレイラ 0.073010 騎手名_武豊 0.084130 騎手名_福永祐一 0.107660 騎手名_川田将雅 0.123749 騎手名_戸崎圭太 0.127755 騎手名_M.デム 0.129514 騎手名_ルメール 0.185976 本賞金 0.443854本賞金が最も、3着以内に入ると予測するPositiveな影響を及ぼし、続いてはメジャーな騎手が影響度の上位を形成しているのが分かります。
5. モデルの運用
ここまでの作業で、モデルの構築を何とか実現することができました。次は実際の運用を考えてみましょう。競馬は毎週定期開催されていますが、毎レースの3着以内に入るであろう出走馬を予測して、あわよくばお金持ちになりたいと考えています。
では毎週、機械学習のワークフローを最初から順番に実施していきますか?1. データの取得は最新の出馬表データを取得するために毎回実施する必要がありますが、2. データの前処理と3. モデルの学習は毎回実施せずに、一度構築したモデルを再利用すればいいはずです(定期的なモデルのアップデートは必要ですが)。ということで、その運用を実施してみましょう。
build.ipynbimport pickle filename = 'model_sample.pickle' pickle.dump(clf, open(filename, 'wb'))このように、pickleというライブラリを使用することで、構築したモデルをシリアライズしてファイルに保存することができます。
そして、保存したモデルの復元方法がこちらです。
restore.ipynbimport pickle filename = 'model_sample.pickle' clf = pickle.load(open(filename, 'rb')) # 予測 y_pred = clf.predict(予測対象レースの説明変数データ)簡単にモデルを復元し、未来のレース予測に利用することができます。これでデータの前処理やモデルの学習を必要としない、効率的な運用が可能になります。
さいごに
以上で、環境構築からモデル構築まで、一連の作業を順を追って実施することができました。初心者による拙い説明にはなりますが、似たような境遇の方々の参考になれば幸いです。
次回は別のアルゴリズムを使って、今回作ったモデルとの比較検証や予測精度だけでなく、実際の収支はどうなのかという一歩踏み込んだ仕組み作りに挑戦したいと思います。


- 投稿日:2020-09-26T20:01:27+09:00
DjangoのチュートリアルをIISにデプロイする①
はじめに
Windows10上のIISでDjangoのチュートリアルを動かした手順を備忘録として残しておきます。
参考記事
はじめての Django アプリ作成、その 1
Windows7 + IIS + virtualenv + wfastcgiで、Djangoをホストする
Python(Django) をWindows+IISで動かす
IIS Web ページを開くときの HTTP エラー500.19目次
- 環境
- Pythonのインストール
- PostgreSQLのインストール
- IIS(Internet Information Services)の有効化
- Djangoのプロジェクト作成
- 開発環境の準備
- プロジェクトの作成
- IISの設定
- サイトの追加
- Pythonのハンドラーマッピングを追加
- wfastcgiの設定
- IIS用権限の付与
- 動作確認
- エラーが出た場合
環境
- Windows10 Pro
- IIS10
- Python 3.8.5
- Django 3.1.1
Pythonのインストール
公式サイトからインストーラーをダウンロードします。
インストールする際、すべてのユーザーにインストールをしてください。
個別ユーザーインストールだとIISのユーザーが利用できず動かすことが出来ません。
PostgreSQLのインストール
PostgrSQLを使っていきたいのでインストールします
公式サイトからインストーラーをダウンロードします。
今回はWindows x86-64のversion13をインストールしました。IIS(Internet Information Services)の有効化
コントロールパネル>プログラム>Windowsの機能の有効化または無効化 から
インターネットインフォメーションサービスを有効化します。
コンピュータの管理>サービスとアプリケーションに
インターネットインフォメーションサービスが追加されていたら有効化出来ています。
Djangoのプロジェクト作成
1.開発環境の準備
C:\Users\ユーザー名配下に「web」ディレクトリを作成しそこで作業することにします。
コマンドプロンプトC:\Users\ユーザー名> mkdir webvirtualenvのインストール
コマンドプロンプトC:\Users\ユーザー名\web> pip install virtualenv仮想環境(env)の作成
コマンドプロンプトC:\Users\ユーザー名\web> virtualenv env仮想環境の有効化
コマンドプロンプトC:\Users\ユーザー名\web> env\Scripts\activateDjangoのインストール
コマンドプロンプト(env) C:\Users\ユーザー名\web> pip install Djangowfastcgiのインストール
コマンドプロンプト(env) C:\Users\ユーザー名\web> pip install wfastcgipsycopg2のインストール
コマンドプロンプト(env) C:\Users\ユーザー名\web> pip install psycopg2pip listの結果は以下です。
コマンドプロンプト(env) C:\Users\ユーザー名\web>pip list Package Version ---------- ------- asgiref 3.2.10 Django 3.1.1 pip 20.2.3 psycopg2 2.8.6 pytz 2020.1 setuptools 49.6.0 sqlparse 0.3.1 wfastcgi 3.0.0 wheel 0.35.12.プロジェクトの作成
Djangoのチュートリアルに沿ってプロジェクトを作成していきます。
コマンドプロンプト(env) C:\Users\ユーザー名\web> django-admin startproject mysiteローカルで動くか確認
コマンドプロンプト(env) C:\Users\ユーザー名\web>mysite> python manage.py runserverhttp://127.0.0.1:8000/ にアクセスし、以下のページが表示されたらOKです。
IISの設定
サイトの追加
新規にサイトを追加します。
コンピュータの管理>インターネットインフォメーションサービス から
サイト>Webサイトの追加で物理パス等を設定します。物理パスは、Djangoプロジェクトのフォルダ(manage.pyなどの親フォルダ)を設定します。
Pythonのハンドラーマッピングを追加
ハンドラーマッピング>スクリプトマップの追加から設定します。
実行可能ファイルは、env環境のpython.exeを指定します。
wfastcgiの設定
wfastcgiを利用するためロックを解除
(env) C:\Users\ユーザー名\web\mysite>%windir%\system32\inetsrv\appcmd unlock config -section:system.webServer/handlers 構成パス "MACHINE/WEBROOT/APPHOST" のセクション "system.webServer/handlers" のロックを解除しました。wfastcgi enableを実行
(env) C:\Users\ユーザー名\web\mysite>wfastcgi-enable 構成変更を構成コミット パス "MACHINE/WEBROOT/APPHOST" の "MACHINE/WEBROOT/APPHOST" のセクション "system.webServer/fastCgi" に適用しました "c:\users\ユーザー名\web\env\scripts\python.exe|c:\users\ユーザー名\web\env\lib\site-packages\wfastcgi.py" can now be used as a FastCGI script processorweb.configを作成
Djangoプロジェクト配下(manage.pyと同じディレクトリ)にweb.configを作成します。
scriptProcessorの値はwfastcgi-enableで表示された値を設定します。web.config<configuration> <appSettings> <add key="WSGI_HANDLER" value="django.core.wsgi.get_wsgi_application()" /> <add key="PYTHONPATH" value="C:\Users\ユーザー名\web" /> <add key="DJANGO_SETTINGS_MODULE" value="mysite.settings" /> </appSettings> <system.webServer> <handlers> <add name="Python FastCGI" path="*" verb="*" modules="FastCgiModule" scriptProcessor="c:\users\ユーザー名\web\env\scripts\python.exe|c:\users\ユーザー名\web\env\lib\site-packages\wfastcgi.py" resourceType="Unspecified" /> </handlers> </system.webServer> </configuration>IIS用権限の付与
コンピュータの管理>インターネットインフォメーションサービス の
MySite(新規に作成したサイト)からアクセス許可の編集をします。
セキュリティタブで[コンピュータ名\IIS_IUSRS]のユーザーを追加また、ファイルエクスプローラーでC:\Users\ユーザー名\webのenvフォルダを右クリック>プロパティから
同じく[コンピュータ名\IIS_IUSRS]のユーザーを追加してください。動作確認
コンピュータの管理>インターネットインフォメーションサービスからMySiteを選択しWebサイトの参照でロケットが飛んだらDjangoサイトが動作しています。
エラーが出た場合
以下のように0x800700005エラーや0x8007010bエラーになる場合は、
ファイルアクセスの権限やハンドラーマッピングで設定したPython.exeのパスが適切か確認してみて下さい。原因 :サイトのディレクトリにコンピュータ名\IIS_IUSRSのアクセス権限がない場合に起こる
解決策:コンピュータ名\IIS_IUSRSの権限を追加する
原因 :使用しているPython.exeのディレクトリにコンピュータ名\IIS_IUSRSのアクセス権限がない場合に起こる
解決策:コンピュータ名\IIS_IUSRSの権限を追加する
次回はデータベースをPostgreSQLに変更する手順を書きます











- 投稿日:2020-09-26T19:13:09+09:00
ポケモン機械学習 N番煎じ
はじめに
機械学習をしてみたいと思って、選ばれたのが『ポケモン』でした。
ポケモンは種族値がポケモンごとに決まっているので、データの宝石箱だと考えました。しかし、今回はGoogleで『ポケモン 機械学習』で検索してトップに出てきた人のものを参考にした完全下位互換記事なので、真似したい方は是非元記事をご参照ください。
ポケモンで学ぶ機械学習環境
OS:Win10 home
IDE:VScode
言語:python 3.7.3 64bitやったこと
7世代までのポケモンのデータベースを元に、『ひこう』、『エスパー』のポケモンを抽出して、ロジスティック回帰で二値分類させてみました。
ちなみに、ポケモンにおける各タイプの数は以下(7世代まで)
タイプ 匹数 ノーマル 116匹 かくとう 63匹 どく 69匹 じめん 75匹 ひこう 113匹 むし 89匹 いわ 67匹 ゴースト 55匹 はがね 58匹 ほのお 72匹 みず 141匹 でんき 60匹 くさ 103匹 こおり 43匹 エスパー 100匹 ドラゴン 59匹 あく 59匹 フェアリー 54匹 みずが最多で、こおりが最小でしたね。フリーズドライで倍返しですね。
Codeは以下です。
lr_pokemon.pyimport pandas as pd import codecs from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt # read data by pandas with codecs.open("data/pokemon_status.csv", "r", "Shift-JIS", "ignore") as file: df = pd.read_table(file, delimiter=",") # print(df.head(15)) p_type = ["ノーマル","かくとう","どく","じめん","ひこう","むし","いわ","ゴースト","はがね","ほのお","みず","でんき","くさ","こおり","エスパー","ドラゴン","あく","フェアリー"] print(len(p_type)) # make functions def count_type(p_type): list1 = df[df['タイプ1'] == p_type] list2 = df[df['タイプ2'] == p_type] lists = pd.concat([list1, list2]) print(p_type + "のポケモン: %d匹" % len(lists)) def type_to_num(p_type): if p_type == "ひこう": return 1 else: return 0 # count number of type in pokemons for i in p_type: count_type(i) # make sky_df sky1 = df[df['タイプ1'] == "ひこう"] sky2 = df[df['タイプ2'] == "ひこう"] sky = pd.concat([sky1, sky2]) # make psycho_df psycho1 = df[df['タイプ1'] == "エスパー"] psycho2 = df[df['タイプ2'] == "エスパー"] psycho = pd.concat([psycho1, psycho2]) df_s_p = pd.concat([sky, psycho], ignore_index=True) type1 = df_s_p['タイプ1'].apply(type_to_num) type2 = df_s_p['タイプ2'].apply(type_to_num) df_s_p['type_num'] = type1 + type2 print(df_s_p) X = df_s_p.iloc[:,7:13].values y = df_s_p['type_num'].values X_train,X_test,y_train,y_test = train_test_split(X, y, test_size = 0.3, random_state = 0) lr = LogisticRegression(C = 1.0) lr.fit(X_train, y_train) # show scores print("train_score: %.3f" % lr.score(X_train, y_train)) print("test_score: %.3f" % lr.score(X_test, y_test)) i = 0 error1 = 0 success1 = 0 error2 = 0 success2 = 0 print("[ひこうタイプと判断したポケモン一覧]") print("----------------------------------------") print("") while i < len(df_s_p): y_pred = lr.predict(X[i].reshape(1, -1)) if y_pred == 1: print(df_s_p.loc[i, ["ポケモン名"]]) if df_s_p.loc[i, ["type_num"]].values == 1: success1 += 1 print("ひこうタイプですよね") print("") else: error1 += 1 print("ひこうタイプやと思ってしまいました") print("") else: print(df_s_p.loc[i, ["ポケモン名"]]) if df_s_p.loc[i, ["type_num"]].values == 0: error2 += 1 print("エスパータイプですよね") print("") else: success2 += 1 print("エスパータイプやと思ってしましました") print("") i += 1 print("----------------------------------------") print("正しくひこうタイプと判断したポケモンの数: %d匹" % success1) print("正しくエスパータイプと判断したポケモンの数: %d匹" % success2) print("誤ってひこうタイプと判断したポケモンの数: %d匹" % error1) print("誤ってエスパータイプと判断したポケモンの数: %d匹" % error2) print("")結果
結果は正答率75%でした。低いですね。機械学習では使えない数値でした。
私はもっと良い数字がでると思ったんですけどね。なぜなら『ひこう』なら物理アタッカー、『エスパー』なら特殊アタッカーと大まかに分けられるかなと思ったからです。現実はそんなに単純ではありませんね。
とはいえ、実際に誤検知されたポケモンを見ると私でも誤検知してしまうなーという理由が得られました。
例えば、ひこうなのにエスパーと間違えられた子として『サンダー』、『フリーザー』がいたのですが、とくこうが高いのでそりゃそうよな。俺でも初見なら間違えるわ、となりました。
逆に、エスパーなのにひこうと間違えられた子として『ケーシィ』、『ラルトス』がいたのですが、これは低種族値なので仕方ないかなと思いました。低種族値帯では数値に差がつきにくいので。
進化系の『フーディン』や『サーナイト』、『エルレイド』はばっこしエスパーに割り振られていたので安心です。
ん??
エルレイドはんっ!
あんたはひこうタイプに間違われても良かったんちゃいまっか!!!おわりに
やはり種族値だけでポケモンを判断するのは間違っている 完

- 投稿日:2020-09-26T18:22:54+09:00
Pythonで、ファイルの読み込みと出力
Pythonで、ファイルの操作をする。
簡単ですが、ファイルの操作のコードです。
実行したソースコード
import string with open('directly_folder/sample.html') as f: #sample.txtでも可能 t = string.Template(f.read()) contents = t.substitute(name='your nickname',contents='favorite phase?') print(contents)ディレクトリーファイルを作って、フロントエンドとバックエンドのファイルを管理する認識だと思います。
合ってますでしょうか?
以下のコードがファイルの場所と内容を示すコードです。copy sample.py folder/directly_folder //ターミナルでコマンドするエラーへの対処に困っています。
ファイルは、Pycharmでみれますが、エクセルシートへの出力ができません。
import 標準ライブラリーで、出力可能なものを調べてみます。
Macbook pro 13 2020を使用しています。
- 投稿日:2020-09-26T18:22:54+09:00
Pythonで、ファイルの書き出しと出力
Pythonで、ファイルの操作をする。
簡単ですが、ファイルの操作のコードです。
実行したソースコード
import string with open('directly_folder/sample.html') as f: #sample.txtでも可能 t = string.Template(f.read()) contents = t.substitute(name='your nickname',contents='favorite phase?') print(contents)ディレクトリーファイルを作って、フロントエンドとバックエンドのファイルを管理する認識だと思います。
合ってますでしょうか?
以下のコードがファイルの場所と内容を示すコードです。copy sample.py folder/directly_folder #ターミナルでコマンドするエラーへの対処に困っています。
ファイルは、Pycharmでみれますが、エクセルシートへの出力ができません。
import 標準ライブラリーまたはサードパーティーで、出力可能なものを調べてみます。
Macbook pro 13 2020を使用しています。
- 投稿日:2020-09-26T17:26:59+09:00
PythonでGmail APIを操作しメールの下書きを作成する
作成日は2020年9月26日です。
環境
Windows10 home Python 3.8.3 google-auth-oauthlib 0.4.1 google-api-python-client 1.12.2やりたいこと
ローカル環境でPythonを動かし、GmailにAPI経由で下書きを作りたい。
この記事では必要最低限だけのエラーハンドリングもクソもないコードを書きます。
悪しからず。手順
大まかな手順は以下のようになっています。
- GCPでプロジェクトの作成
- GCPで認証情報の作成
- Pythonスクリプトの作成
1. GCPでプロジェクトの作成〜 2. 認証情報の作成
1と2に関しては記事→「Python を使い、Gmail API 経由で Gmail の送受信を行う」
が大変にわかりやすいです。基本的に記事に従っていけば問題はないはずですが、自分の場合「VivaldiでGCPにアクセスをすると
client_<id>.jsonがダウンロード出来ない」というバグがありました。
これはChromeを使用することで回避出来ました。3. Pythonスクリプトの作成
流れとしては、
OAuth認証のフローに従ってアクセストークンを取得
↓
送るメールのデータを作成
↓
Gmail APIを叩いて下書きを作成という感じです。
1. アクセストークンの取得
アクセストークン取得をする必要最低限の関数は以下のような感じです。
参考→API の認証と呼び出し(Google Cloudのガイド)from google_auth_oauthlib.flow import InstalledAppFlow #APIのスコープを設定(どのAPIを使うのかの設定) SCOPES = ["https://www.googleapis.com/auth/gmail.modify"] def get_credential(): launch_browser = True flow = InstalledAppFlow.from_client_secrets_file("client_id.json", SCOPES) flow.run_local_server() cred = flow.credentials return cred
InstalledAppFlow.from_client_secrets_fileにGCPから落としてきたJSONファイルと、使用したいAPIの情報を入れFlowインスタンスを作成し、run_local_server()をするとブラウザが立ち上がりお馴染みの許可画面が出てきます。
これで許可を押すとアクセストークンが手に入ります。
因みに、このまではプログラムの実行毎に許可画面が立ち上がるので、アクセストークンをpickle化して保存するのが実用上は簡便でよさそうです。
2. メールの下書きの作成
from email.mime.text import MIMEText import base64 def create_message(sender, to, subject, message_text): enc = "utf-8" message = MIMEText(message_text.encode(enc), _charset=enc) message["to"] = to message["from"] = sender message["subject"] = subject encode_message = base64.urlsafe_b64encode(message.as_bytes()) return {"raw": encode_message.decode()}Gmail APIドキュメントのCreating draft messagesに載っているものですが、ドキュメントの場合、
create_message関数の最後の行がreturn {'raw': base64.urlsafe_b64encode(message.as_string())}となっています。
しかし、base64.urlsafe_b64encode()は入力として文字列ではなくbyteを入れる必要があるため、encode_message = base64.urlsafe_b64encode(message.as_bytes())と変更し、後の下書きに保存する過程ではstr型が求められるので
return {"raw": encode_message.decode()}とデコードします。
3. Gmail APIで作成したメールのデータを下書きに保存する
先ほど作成したメールのデータを下書きに追加します。
def create_draft(service, user_id, message_body): message = {'message':message_body} draft = service.users().drafts().create(userId=user_id, body=message).execute() return draftこの中で使われている
serviceはGmail APIを使う時の親玉みたいなやつで、Gmail APIのReferenceに載っている関数が入ったインスタンスです。
これは以下のコードで作ります。from googleapiclient.discovery import build service = build("gmail", "v1", credentials=creds, cache_discovery=False)以上をまとめて一つのプログラムにすると以下のような感じになります。
from google_auth_oauthlib.flow import InstalledAppFlow from googleapiclient.discovery import build import base64 from email.mime.text import MIMEText SCOPES = ["https://www.googleapis.com/auth/gmail.compose",] def get_credential(): launch_browser = True flow = InstalledAppFlow.from_client_secrets_file("client_id.json", SCOPES) flow.run_local_server() cred = flow.credentials return cred def create_message(sender, to, subject, message_text): enc = "utf-8" message = MIMEText(message_text.encode(enc), _charset=enc) message["to"] = to message["from"] = sender message["subject"] = subject encode_message = base64.urlsafe_b64encode(message.as_bytes()) return {"raw": encode_message.decode()} def create_draft(service, user_id, message_body): message = {'message':message_body} draft = service.users().drafts().create(userId=user_id, body=message).execute() return draft def main(sender, to, subject, message_text): creds = get_credential() service = build("gmail", "v1", credentials=creds, cache_discovery=False) message = create_message(sender, to, subject, message_text) create_draft(service, "me", message) if __name__ == "__main__": sender = "メールの送り主のアドレス" to = "送信先のアドレス" subject = "件名" message_text = "本文" main(sender=sender, to=to, subject=subject, message_text=message_text)これを実行すれば、Gmailに下書きが追加されます。
やったね!(・∀・)参考
・一番お世話になった記事
https://qiita.com/muuuuuwa/items/822c6cffedb9b3c27e21・FlowクラスやInstalledAppFlowクラスのドキュメント
google_auth_oauthlib.flow module・googleapiclient.discovery.buildのドキュメント
https://googleapis.github.io/google-api-python-client/docs/epy/googleapiclient.discovery-module.html#build・
- 投稿日:2020-09-26T17:26:59+09:00
PythonでGmailの下書きを作成する
作成日は2020年9月26日です。
環境
Windows10 home Python 3.8.3 google-auth-oauthlib 0.4.1 google-api-python-client 1.12.2やりたいこと
ローカル環境でPythonを動かし、GmailにAPI経由で下書きを作りたい。
この記事では必要最低限だけのエラーハンドリングもクソもないコードを書きます。
悪しからず。手順
大まかな手順は以下のようになっています。
- GCPでプロジェクトの作成
- GCPで認証情報の作成
- Pythonスクリプトの作成
1. GCPでプロジェクトの作成〜 2. 認証情報の作成
1と2に関しては記事→「Python を使い、Gmail API 経由で Gmail の送受信を行う」
が大変にわかりやすいです。基本的に記事に従っていけば問題はないはずですが、自分の場合「VivaldiでGCPにアクセスをすると
client_<id>.jsonがダウンロード出来ない」というバグがありました。
これはChromeを使用することで回避出来ました。3. Pythonスクリプトの作成
流れとしては、
OAuth認証のフローに従ってアクセストークンを取得
↓
送るメールのデータを作成
↓
Gmail APIを叩いて下書きを作成という感じです。
1. アクセストークンの取得
アクセストークン取得をする必要最低限の関数は以下のような感じです。
参考→API の認証と呼び出し(Google Cloudのガイド)from google_auth_oauthlib.flow import InstalledAppFlow #APIのスコープを設定(どのAPIを使うのかの設定) SCOPES = ["https://www.googleapis.com/auth/gmail.modify"] def get_credential(): launch_browser = True flow = InstalledAppFlow.from_client_secrets_file("client_id.json", SCOPES) flow.run_local_server() cred = flow.credentials return cred
InstalledAppFlow.from_client_secrets_fileにGCPから落としてきたJSONファイルと、使用したいAPIの情報を入れFlowインスタンスを作成し、run_local_server()をするとブラウザが立ち上がりお馴染みの許可画面が出てきます。
これで許可を押すとアクセストークンが手に入ります。
因みに、このまではプログラムの実行毎に許可画面が立ち上がるので、アクセストークンをpickle化して保存するのが実用上は簡便でよさそうです。
2. メールの下書きの作成
from email.mime.text import MIMEText import base64 def create_message(sender, to, subject, message_text): enc = "utf-8" message = MIMEText(message_text.encode(enc), _charset=enc) message["to"] = to message["from"] = sender message["subject"] = subject encode_message = base64.urlsafe_b64encode(message.as_bytes()) return {"raw": encode_message.decode()}Gmail APIドキュメントのCreating draft messagesに載っているものですが、ドキュメントの場合、
create_message関数の最後の行がreturn {'raw': base64.urlsafe_b64encode(message.as_string())}となっています。
しかし、base64.urlsafe_b64encode()は入力として文字列ではなくbyteを入れる必要があるため、encode_message = base64.urlsafe_b64encode(message.as_bytes())と変更し、後の下書きに保存する過程ではstr型が求められるので
return {"raw": encode_message.decode()}とデコードします。
3. Gmail APIで作成したメールのデータを下書きに保存する
先ほど作成したメールのデータを下書きに追加します。
def create_draft(service, user_id, message_body): message = {'message':message_body} draft = service.users().drafts().create(userId=user_id, body=message).execute() return draftこの中で使われている
serviceはGmail APIを使う時の親玉みたいなやつで、Gmail APIのReferenceに載っている関数が入ったインスタンスです。
これは以下のコードで作ります。from googleapiclient.discovery import build service = build("gmail", "v1", credentials=creds, cache_discovery=False)以上をまとめて一つのプログラムにすると以下のような感じになります。
from google_auth_oauthlib.flow import InstalledAppFlow from googleapiclient.discovery import build import base64 from email.mime.text import MIMEText SCOPES = ["https://www.googleapis.com/auth/gmail.compose",] def get_credential(): launch_browser = True flow = InstalledAppFlow.from_client_secrets_file("client_id.json", SCOPES) flow.run_local_server() cred = flow.credentials return cred def create_message(sender, to, subject, message_text): enc = "utf-8" message = MIMEText(message_text.encode(enc), _charset=enc) message["to"] = to message["from"] = sender message["subject"] = subject encode_message = base64.urlsafe_b64encode(message.as_bytes()) return {"raw": encode_message.decode()} def create_draft(service, user_id, message_body): message = {'message':message_body} draft = service.users().drafts().create(userId=user_id, body=message).execute() return draft def main(sender, to, subject, message_text): creds = get_credential() service = build("gmail", "v1", credentials=creds, cache_discovery=False) message = create_message(sender, to, subject, message_text) create_draft(service, "me", message) if __name__ == "__main__": sender = "メールの送り主のアドレス" to = "送信先のアドレス" subject = "件名" message_text = "本文" main(sender=sender, to=to, subject=subject, message_text=message_text)これを実行すれば、Gmailに下書きが追加されます。
やったね!(・∀・)参考
・一番お世話になった記事
https://qiita.com/muuuuuwa/items/822c6cffedb9b3c27e21・FlowクラスやInstalledAppFlowクラスのドキュメント
google_auth_oauthlib.flow module・googleapiclient.discovery.buildのドキュメント
https://googleapis.github.io/google-api-python-client/docs/epy/googleapiclient.discovery-module.html#build
- 投稿日:2020-09-26T16:55:28+09:00
pythonの環境設定(virtualenv+pipができない)
こんにちはpython初心者でdjangoでappを制作しようとしているものです。(python3系での開発)
anaconda + djangoでもできるみたいですが、情報が少ないので後々チャレンジします。まずpyenv、virtualenv、pip、anacondaの違いを確認。
https://mycodingjp.blogspot.com/2018/12/python-venv-virtualenv.html
https://oversleptabit.com/archives/2195
https://qiita.com/caad1229/items/325ca5c8ad198b0ebce7
virtualenv+pipで行くことを決意しました。公式サイトではvenvコマンドで仮想環境を作ってました。それでもできたんですが、一旦は置いておきます。
https://www.python.jp/install/macos/virtualenv.html% python -Vで自身のpcのバージョン確認。私は2系がすでに入っていました。2系はサポート終了なので、3系をインストールします。
流れとしては
xcode→homebrew→python3といくはず。
ちなみにhomebrewを使用するためにxcodeのinstallが必要みたいです。(homebrewはパッケージ管理するもの。)% xcode-select --installhomebrewのインストールはネット検索するとコマンドはすぐ出てきます
% /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"% brew install python3ここでいよいよ仮想環境を作ります。まずはvirtualenvのインストール
% sudo pip install virtualenvすると
sudo: pip: command not foundと。commandがない?ネットによるとpythonをインストールすると付随してくるような書き込みが。。pipはいないのか?
% where pip/usr/local/bin/pip私の場合はバージョンの問題かなと思ったので、バージョンをupdateします。pip3へ。。
% pip3 install --user --upgrade pippipコマンド使えない時はこちらも見るとヒントがもらえます
https://www.python.jp/install/ubuntu/pip.html
https://qiita.com/sf213471118/items/3ee4ebd5d39856345682
https://qiita.com/tom-u/items/134e2b8d4e11feea8e12再度試します
% sudo pip install virtualenv行けました!!!!
おそらく違う方法もあるのかなと公式サイトを見て思いましたが、そこはまた検討します。
あとはサクサク行けたのでよかったです。
% virtualenv -p python3 好きな名前python3を指定して仮想環境を作ります。
作った中に入ってみます% . .好きな名前/bin/activateもしくは
% source 好きな名前/bin/activate抜ける時は
% deactivateとっても時間がかかりましたが、なんとか一安心。一つapp作り終えたら、公式の方法も試そうと思います。間違いがあればお気軽に添削お願いいたします。
- 投稿日:2020-09-26T16:54:01+09:00
Jupyterで簡単な画像認識をしてみた
概要
https://qiita.com/uz29/items/ec854106355bf783e316
前回で準備が終わったのでまずは既存の学習モデルであるVGG16を使って画像判別プログラムを作った。ライブラリのインポートとモデルのインポート
初回はモデルのダウンロードが行われる。
import glob import pprint import numpy as np import tensorflow as tf from PIL import Image model = tf.keras.applications.vgg16.VGG16(weights='imagenet')予測スクリプト
フォルダに入っている画像をまとめて予測にかけたかったので、globでパス一覧を取得しそれぞれの画像の配列を作成している。
予測は一度の関数の呼び出しで複数画像を同時に処理できるらしい。#フォルダ内の写真を一括で予測 file_list = glob.glob("./images/*") pil = [] imgs = [] for path in file_list: # 画像読み込み img_pil = tf.keras.preprocessing.image.load_img(path, target_size=(224, 224)) pil.append(img_pil) # 画像を配列に変換 img = tf.keras.preprocessing.image.img_to_array(img_pil) # 4次元配列に変換 imgs.append(img) imgs = np.stack(imgs, 0) # 前処理 img_p = tf.keras.applications.vgg16.preprocess_input(imgs) # 予測 predict = model.predict(img_p) result = tf.keras.applications.vgg16.decode_predictions(predict, top=5)結果の表示
予測結果は以下で見ることができる。
pprint.pprint(result[0]) plt.imshow(pil[0])[('n02124075', 'Egyptian_cat', 0.42277277),
('n02123159', 'tiger_cat', 0.18187998),
('n02123045', 'tabby', 0.12070633),
('n02883205', 'bow_tie', 0.0892005),
('n02127052', 'lynx', 0.024664408)]
pprint.pprint(result[1]) plt.imshow(pil[1])[('n02119789', 'kit_fox', 0.6857688),
('n02119022', 'red_fox', 0.24295172),
('n02120505', 'grey_fox', 0.065218925),
('n02114855', 'coyote', 0.004371826),
('n02115913', 'dhole', 0.00046840237)]
pprint.pprint(result[2]) plt.imshow(pil[2])[('n02138441', 'meerkat', 0.9073721),
('n02137549', 'mongoose', 0.092063464),
('n02447366', 'badger', 0.00037895824),
('n02361337', 'marmot', 8.514335e-05),
('n02441942', 'weasel', 2.4436611e-05)]
動物の細かい種類はVGG16に含まれていなくて異なる場合もあるがおおむね正確な種類を返してくれている。
今後は自分で学習モデルを作って予測させてみたい。
- 投稿日:2020-09-26T15:13:42+09:00
Django a タグをつけて更新画面に遷移する
編集中のスケジュールから更新画面に遷移し、また変種画面にもどってくることを実装していきます
まずは、スケジュール表の日の時間をaタグにしてリンクをはることにします
schedule/month.html{% extends 'schedule/base.html' %} {% block header %} {% endblock header %} {% block content %} <table class="table table-striped table-bordered"> <thead> <tr align="center" class="info"> <!--日付--> <th rowspan="2"></th> {% for item in calender_object %} <th class="day_{{ item.date }}">{{ item.date | date:"d" }}</th> {% endfor %} <tr align="center" class="info"> <!--曜日--> {% for item in youbi_object %} <th class="day_{{ item.date }}">{{ item }}</th> {% endfor %} </tr> </thead> <tbody> {% for staff in user_list %} <tr align="center"> <th rowspan="1" class="staff_name" staff_id="{{ staff.staff_id }}" width="200" >{{ staff.last_name }} {{ staff.first_name }}</th> <!--staff_id要素はjsで使う--> {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> <td class="day" id="s{{ staff.id }}d{{ item.date }}"> {% if item.shift_name_1 != None %} {% if item.shift_name_1|stringformat:"s" == "有" or item.shift_name_1|stringformat:"s" == "休" %} {{ item.shift_name_1 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_1|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_1 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_2 != None %} {% if item.shift_name_2|stringformat:"s" == "有" or item.shift_name_2|stringformat:"s" == "休" %} {{ item.shift_name_2 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_2|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_2 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_3 != None %} {% if item.shift_name_3|stringformat:"s" == "有" or item.shift_name_3|stringformat:"s" == "休" %} {{ item.shift_name_3 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_3|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_3 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_4 != None %} {% if item.shift_name_4|stringformat:"s" == "有" or item.shift_name_4|stringformat:"s" == "休" %} {{ item.shift_name_4 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_4|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_4 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% endif %} {% endfor %} </td> <tr align="center"> {% for month in month_total %} {% if month.user == staff.id %}<!--usernameが同一なら--> <td><b>{{ month.month_total_worktime }}</b></td> {% endif %} {% endfor %} {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> <td class="day" id="s{{ staff.id }}d{{ item.date }}"> <a href="{% url 'schedule:update' item.pk %}">{{ item.day_total_worktime }} </a> </td> {% endif %} {% endfor %} </tr> {% endfor %} </tbody> </table> {% endblock content %}htmlは長ですが、修正したのは、さいごのforで繰り返し処理をしているところです。
aタグで、schedule:updateでitm.pkでプライマリーキー付きで時間を表示することで、対象のレコードに対して編集画面に遷移できるようになりました。
リンクになったので、水色で表示されるようになりました。
次は、更新画面から更新せずに 戻る ボタンを押下した時に戻れるようにupdate.htmlも修正しました。schedule/update.html{% extends 'schedule/base.html' %} {% block header %} {% endblock header %} {% block content %} <form action="" method="POST">{% csrf_token %} <P >社員名: {{ User_list.last_name }} {{ User_list.first_name }}</P> <p>日付: {{ Schedule_list.date }}</p> {{ form.as_p }} {% csrf_token %} <input class="btn btn-primary" type="submit" value="更新"> <a href="{% url 'schedule:monthschedule' Schedule_list.year Schedule_list.month %}" class="btn-secondary btn active">戻る</a> </form> {% endblock content %}これで編集の基礎部分はできてきましたが、まだ人が見たときに情報が少なかったり、シフト記号から合計を求めるとか、翌月作成するための機能を実装していこうと思います。
作成している中で、12月から1月に移動するときにうまくいかないことがわかりました。
そこで対応するため、relativedelta をインストールすると簡単に月の計算ができるらしいのでインストールします。terminalpip install python-dateutilschedule.Viewspyfrom django.shortcuts import render, redirect, HttpResponseRedirect from shisetsu.models import * from accounts.models import * from .models import * import calendar import datetime from datetime import timedelta from datetime import datetime as dt from django.db.models import Sum from django.contrib.auth.models import User from django.views.generic import FormView, UpdateView from django.urls import reverse_lazy from .forms import * from dateutil.relativedelta import relativedelta # Create your views here. def homeschedule(request): from datetime import datetime now = datetime.now() return HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (now.year,now.month,)) # 自動的に今月のシフト画面にリダイレクト def monthschedulefunc(request,year_num,month_num): user_list = User.objects.all() year, month = int(year_num), int(month_num) shisetsu_object = Shisetsu.objects.all() shift_object = Shift.objects.all() object_list = Schedule.objects.filter(year = year, month = month).order_by('user', 'date') month_total = Schedule.objects.select_related('User').filter(year = year, month = month).values("user").order_by("user").annotate(month_total_worktime = Sum("day_total_worktime")) #シフト範囲の日数を取得する enddate = datetime.date(year,month,20) startdate = enddate + relativedelta(months=-1) kaisu = enddate - startdate kaisu = int(kaisu.days) kikan = str(startdate) +"~"+ str(enddate) #日付と曜日のリストを作成する hiduke = str(startdate) date_format = "%Y-%m-%d" hiduke = dt.strptime(hiduke, date_format) weekdays = ["月","火","水","木","金","土","日"] calender_object = [] youbi_object = [] for i in range(kaisu): hiduke = hiduke + timedelta(days=1) calender_object.append(hiduke) youbi = weekdays[hiduke.weekday()] youbi_object.append(youbi) kaisu = str(kaisu) context = { 'year': year, 'month': month, 'kikan': kikan, 'object_list': object_list, 'user_list': user_list, 'shift_object': shift_object, 'calender_object': calender_object, 'youbi_object': youbi_object, 'kaisu': kaisu, 'shisetsu_object': shisetsu_object, 'month_total' : month_total, } return render(request,'schedule/month.html', context) def scheduleUpdatefunc(request,pk): Schedule_list = Schedule.objects.get(pk = int(pk)) User_list = User.objects.get(username = Schedule_list.user) shift_object = Shift.objects.all() if request.method == 'POST': form = ScheduleUpdateForm(data=request.POST) year = Schedule_list.year month = Schedule_list.month if form.is_valid(): Schedule_list.shift_name_1 = form.cleaned_data['shift_name_1'] Schedule_list.shisetsu_name_1 = form.cleaned_data['shisetsu_name_1'] Schedule_list.shift_name_2 = form.cleaned_data['shift_name_2'] Schedule_list.shisetsu_name_2 = form.cleaned_data['shisetsu_name_2'] Schedule_list.shift_name_3 = form.cleaned_data['shift_name_3'] Schedule_list.shisetsu_name_3 = form.cleaned_data['shisetsu_name_3'] Schedule_list.shift_name_4 = form.cleaned_data['shift_name_4'] Schedule_list.shisetsu_name_4 = form.cleaned_data['shisetsu_name_4'] Schedule_list.day_total_worktime = form.cleaned_data['day_total_worktime'] Schedule_list.save() return HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (year,month,)) else: item = { "shift_name_1":Schedule_list.shift_name_1, "shisetsu_name_1": Schedule_list.shisetsu_name_1, "shift_name_2": Schedule_list.shift_name_2, "shisetsu_name_2": Schedule_list.shisetsu_name_2, "shift_name_3": Schedule_list.shift_name_3, "shisetsu_name_3": Schedule_list.shisetsu_name_3, "shift_name_4": Schedule_list.shift_name_4, "shisetsu_name_4": Schedule_list.shisetsu_name_4, } form = ScheduleUpdateForm(initial=item) context = { 'form' : form, 'Schedule_list': Schedule_list, 'User_list': User_list, 'shift_object': shift_object, } return render(request,'schedule/update.html', context )余分なことをしたりしているところもあったので少だけ修正しました。

- 投稿日:2020-09-26T13:53:36+09:00
yukicoder contest 267 復習
結果
感想
B問題を不注意で読み違えました…。
C問題は部分列なのでDPを用いようとしたのですが、B問題の焦りで正確な考察ができませんでした。A問題
$x$時$y$秒の時に長針と短針が重なるとすれば、以下の式が成り立ちます。
$$\frac{y}{60} \times 360 \div 60=\frac{x}{12} \times 360 + \frac{y}{60} \times 30 \div 60 \leftrightarrow y=60 \times 60 \times x \div 11$$
また、$x$は12の余りで考えればよいので$x=$0~11であり、上記の式に従えば切り捨てた値として$y$が求められるので、与えられた$x$に対して与えられた$y$の値が$x$時台に重なる時刻より前かどうかを考えれば良いです。
A.pycand=[60*i*60//11 for i in range(12)] a,b=map(int,input().split()) a%=12 b*=60 if cand[a]>=b: print(int(cand[a]-b)) else: a=(a+1)%12 print(int(cand[a]+3600-b))B問題
問題文をよく読めば解ける問題です。コドフォで鍛えられたと思ったのですが、注意力がなさすぎます…。
よく読めば$10^9+7$を答えで割った余りを求めるので、$A_k \geqq 4$の時に$A_k^{A_k !}>10^9+7$なので、余りは$10^9+7$になります。また、掛け算の際に$A_k=0$の場合は他の数が任意の数で答えは0になります。よって、$A_{min}=0$のときは-1を出力します($A_{min} \neq 0$のときは答えは0にはならず、割り算が行えます。)。
以上より、$A_{min}=0$のときは-1を出力、$A_{max}>3$のときは$10^9+7$を出力、それ以外の場合は愚直に計算をそれぞれ行うことで答えは以下のようになります。
B.pyn=int(input()) a=list(map(int,input().split())) #ギャグ mod=10**9+7 if min(a)==0: print(-1) exit() if max(a)>3: print(mod) exit() ans=1 for i in a: sub=1 for j in range(i): sub*=(j+1) ans*=(i**sub) if ans>10**9+7: print(mod) exit() print(mod%ans)C問題
部分列なので、$dp[i]:=$($i$番目までの集合の部分集合に対しての何か)とし遷移を含むか含まないかの2通りとするのが典型的なパターンです。今回は平均が$k$以上で平均は人数によるので、得点と人数の両方の情報を持ちながらのDPが必要そうです。しかし、計算量を考えれば両方を持つのが難しくここでは人数の情報を削ることを考えます。つまり、それぞれの人の得点を予め$-k$しておくことで部分集合に含まれる生徒の得点の合計が0以上であるかを調べることにします。よって、部分集合の点数がその集合の要素数によらない条件として情報を持つことができたので、あとは以下のようにDPをおくだけです。
$dp[i][j]:=$($i$番目までの集合の部分集合の合計の得点が$j$となる場合の数)
また、$-k$することで$j$が負になる可能性があるので、最小値になりうる10000のぶんだけ下駄を履かせれば以下のようなDPとなります。
$dp[i][j]:=$($i$番目までの集合の部分集合の合計の得点が$j-10000$となる場合の数)
そして、遷移は以下のようになります。
(1)$i$番目の要素を選ばない時
$dp[i][j]+=dp[i-1][j]$(2)$i$番目の要素を選ぶ時
$dp[i][j+a[i]]+=dp[i-1][j]$
ただし、$0 \leqq j+a[i] \leqq 20000$
また、$i$番目の要素だけの集合の場合があり、$dp[i][a[i]+10000]+=1$以上の遷移を行って、最終的に求めたいのは合計が0以上の場合の場合の数なので、$sum(dp[n-1][10000:])$となります。また、求めるのは$10^9+7$で割った余りであることにも注意が必要です。
C.pymod=10**9+7 n,k=map(int,input().split()) a=[i-k for i in list(map(int,input().split()))] dp=[[0]*20001 for i in range(n)] dp[0][a[0]+10000]=1 for i in range(1,n): for j in range(20001): dp[i][j]=dp[i-1][j] dp[i][a[i]+10000]+=1 for j in range(20001): dp[i][j]%=mod if 0<=j+a[i]<=20000: dp[i][j+a[i]]+=dp[i-1][j] #和(マイナスインデックスも) print(sum(dp[-1][10000:])%mod)D問題以降
今回は解きません。

- 投稿日:2020-09-26T12:48:49+09:00
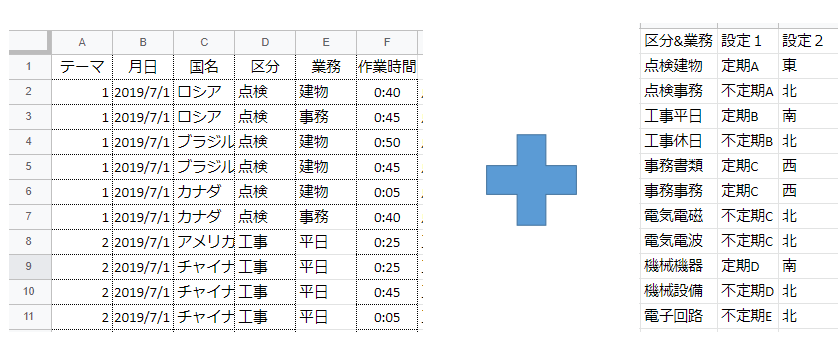
備忘録(openpyxlで①別ブックからのコピペ②対照表の参照)
概要
前回記事で第2ステップとした「表1の対照表を使って各行に設定1/設定2を付ける」がとりあえず実装できたので纏めておく。
https://qiita.com/wellwell3176/items/7dba981b479c5933bf5f成果
図1に示す生データと対照表から、図2の成果の自動生成に成功
図1 左:生データ 右:対照表
図2 成果programimport openpyxl wb1=openpyxl.load_workbook('/content/drive/My Drive/Colab Notebooks/data3.xlsx') ws1=wb1.active #対照表をマスターとして別に用意しておく。マスター側からは数式では無く数値を引っ張りたいので、data_only=trueで開く wb2=openpyxl.load_workbook('/content/drive/My Drive/Colab Notebooks/table.xlsx',data_only=True) ws2=wb2.active for i in range(12): for j in range(3): copy = ws2.cell(row = i+1, column = j+3).value ws1.cell(row = i+1, column =j+10,value=copy) #別ブックからの参照が上手く行かなかったので対照表を一度コピペ #rangeはi=0から始まるが、行と列は1から始まるので調整 min_row=2 max_row=ws1.max_row #2行目から最終行まで処理を掛けるので行数取得 ws1["H1"].value="設定1" ws1["I1"].value="設定2" #見出しは入力した方が早かった for i in range(min_row, max_row): ws1.cell(row=i, column=7).value ="=D{}&E{}".format(i,i) #7列目に区分+業務を入力 ws1.cell(row=i, column=8).value ="=INDEX($J$1:$L$12,match(G{},$J$1:$J$12,0),2)".format(i) ws1.cell(row=i, column=9).value ="=INDEX($J$1:$L$12,match(G{},$J$1:$J$12,0),3)".format(i) #INDEXを使い、参照表と7列目を照会。結果を入力 wb1.save('/content/drive/My Drive/Colab Notebooks/data4.xlsx')問題点
・図2のG列J列K列L列は後工程で不要なので消したいが、参照を使ってるので消せない。
⇨強引な解決策としてdata4をdata_only=trueで開き、不要列以外を新ファイルにコピペする手はあるが、無駄な処理な気がする。
・別ブックの参照方法が分からない
今回はtable.xlsxの中身をdata4.xlsxにコピペし、それからINDEX関数を使ったが、
どう考えても最初からtable.xlsxを参照した方が良い・・・が、記述方法を見つけられず。
次回の課題とする。

- 投稿日:2020-09-26T12:47:24+09:00
【Python】長テーブルのうなぎ屋
1.問題
円状になったテーブル(テーブル数n)に何人が座る事ができるかを求める問題。
グループの内、一人でも座れない場合そのグループは帰ってしまう。入力はm+1行から成る。
1行目にはn(座席数)とm(グループ数)が半角スペース区切りで入力される。
i+1行目(1≦i≦m)には2個の整数a_i(グループの人数)とb_i(着席開始座席番号)が半角スペース区切りで入力される。条件
全てのテストケースにおいて、入力される値は以下の条件を満たす。
1≦n≦100
1≦m≦100
1≦a_i≦n
1≦b_i≦n
2.考えた方法
(1)テーブル番号あるグループiがk人おり、b_i番テーブルから座る時
このグループはb_i,...,b_(i+k-1)
までのテーブルに座る事を想定している。
例えば、上記でテーブル数が6、(a_i,b_i)=(4,5)だった場合
座る予定のテーブル番号は(5,6,7,8)ではなく(5,6,1,2)となる事に注意する。
ここで全てのテーブル番号はb_j%n(b_jをnで割った余り)と考える事にした。
(2)あるグループが座るか座らないか:check_arr関数で判定着席しているテーブル配列:ar_table
あるグループが座る想定をしているテーブル番号の配列
(make_tblarr関数で作成):ar_chk
ar_tableにar_chkの要素が一つでも含まれる場合座れないと判定する。
(3)座っている人数の表示上記で座れる判定をされたグループは、それらのテーブル番号を着席テーブル配列に追加していく。
最終的に、着席テーブル配列のサイズを表示する。3.コード例
動作は確認済。
# coding: utf-8 # Your code here! in1=input() arr1=in1.split() n1=int(arr1[0]) n2=int(arr1[1]) in2=[] for i in range(n2): tmp=input() in2.append(tmp) #print(in2) def make_tblarr(in2,nmax): arr3=[] arr2=in2.split() nn=int(arr2[0]) st=int(arr2[1]) for i in range(nn): arr3.append((st+i)%nmax) return arr3 #ar_table:座っているテーブル番号の配列 #ar_chk:チェック対象の配列 #ar_tableにar_chkの全ての要素が含まれない時0、含まれる要素が見つかった場合1 def check_arr(ar_table,ar_chk): flg=0 for i in range(len(ar_chk)): #チェック対象の配列要素が既にar_tableに含まれる場合 if ar_table.count(ar_chk[i])>0: #flgを1にする flg=1 break return flg retar=[] for i in range(n2): ar3=make_tblarr(in2[i],n1) #print(ar3) if check_arr(retar,ar3)== 0: for j in range(len(ar3)): retar.append(ar3[j]) print(len(retar))
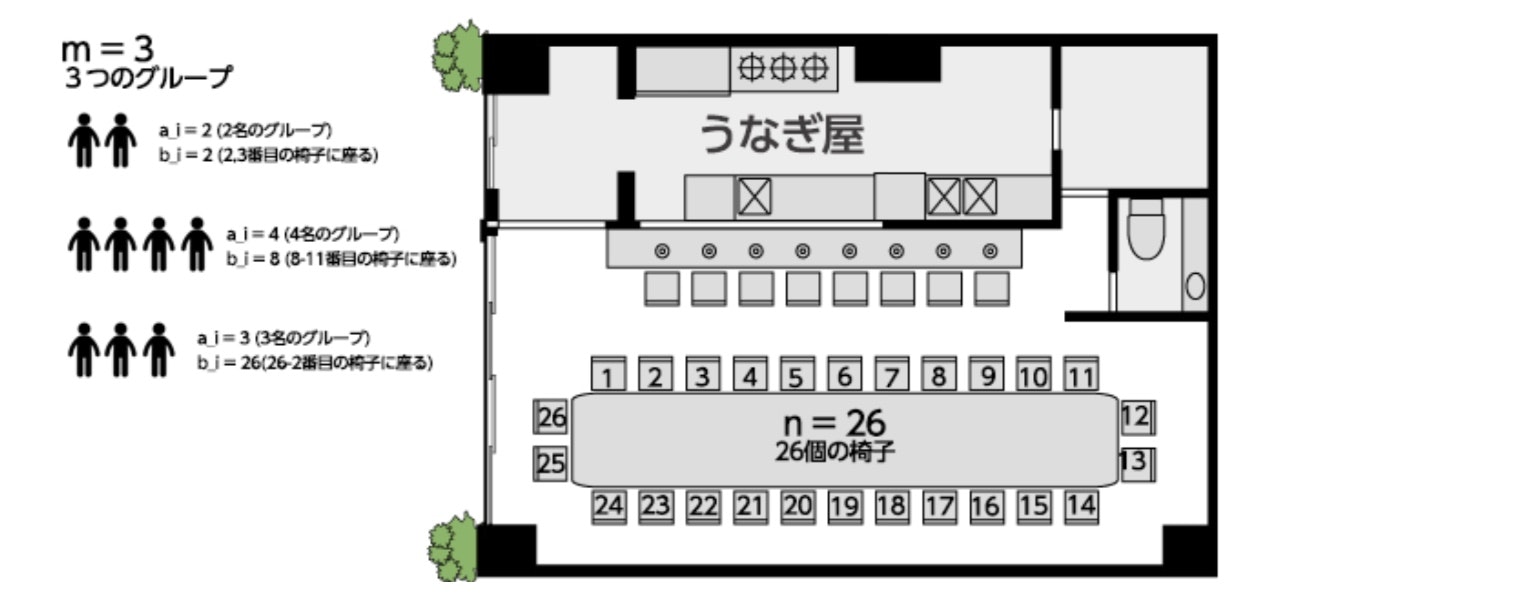
- 投稿日:2020-09-26T12:24:33+09:00
Python+Reactでレンズ検索データベースを構築した時の技術的な話
概要
この度、交換用レンズの情報について、条件を指定して検索できるツールを開発・公開しました。
自作のマイクロフォーサーズ用レンズデータベース検索Webアプリを、Firebaseでデプロイしました。
— YSR@あいミス10章クリア (@YSRKEN) August 30, 2020
追加した検索条件は、同種の条件を追加すると上書きされ、条件自体をクリックすると削除されます。
また、詳細ボタンからレンズの詳細データを確認できます。https://t.co/TRta0pX3H1 pic.twitter.com/5hQpjaOBiM【お知らせ】レンズを検索できるデータベースを更新しました。検索条件をシェアしたり、クリップボードにコピーしたりできるように!
— YSR@あいミス10章クリア (@YSRKEN) September 16, 2020
レンズデータベース(マイクロフォーサーズ, ライカL マウント向け。スマホ対応!) https://t.co/TRta0pX3H1 pic.twitter.com/l5ZA6q9XET今回は、その際に工夫したことについてのまとめです。
スクレイピング用ライブラリは適宜ラップした
今回のWebアプリでは、レンズについての情報はJSONファイルとして運用していました。
ただ、各レンズの情報を全て手打ちしたわけではありません。
PythonでWebサイトをスクレイピングし、結果をJSONファイルに保存して、フロントエンド側で読み込ませていました。……その際に使ったライブラリは、requests-HTMLです。と言っても、そのまま使うのではなく、別途クラスを作成してそちらに処理をまとめています。
from typing import List, MutableMapping, Optional from requests_html import BaseParser, Element class DomObject: """DOMオブジェクト""" def __init__(self, base_parser: BaseParser): self.base_parser = base_parser def find(self, query: str) -> Optional['DomObject']: temp = self.base_parser.find(query, first=True) if temp is None: return None return DomObject(temp) def find_all(self, query: str) -> List['DomObject']: return [DomObject(x) for x in self.base_parser.find(query)] @property def text(self) -> str: return self.base_parser.text @property def full_text(self) -> str: return self.base_parser.full_text # noinspection PyTypeChecker @property def attrs(self) -> MutableMapping: temp: Element = self.base_parser return temp.attrsなぜかと言うと、素のままだと、PyCharm上で自動型推論がちゃんと効かないことがあったからです。
また、将来的にスクレイピング用ライブラリを差し替えたくなっても、ここだけ書き換えればOKという安心もあります。さらに、Webサイトからデータを取得する部分についても、データベースと連携させてキャッシュする機構を組み込みました。
これにより、無駄なWebアクセスを避け、サーバーへの負荷を極限まで減らしています。
(IDataBaseServiceは自作クラス。詳細は書かないが、データベース操作をラップしたもの)class ScrapingService: """スクレイピング用のラッパークラス""" def __init__(self, database: IDataBaseService): self.session = HTMLSession() self.database = database self.database.query('CREATE TABLE IF NOT EXISTS page_cache (url TEXT PRIMARY KEY, text TEXT)') def get_page(self, url: str) -> DomObject: cache_data = self.database.select('SELECT text from page_cache WHERE url=?', (url,)) if len(cache_data) == 0: temp: HTML = self.session.get(url).html time.sleep(5) print(f'caching... [{url}]') self.database.query('INSERT INTO page_cache (url, text) VALUES (?, ?)', (url, temp.raw_html.decode(temp.encoding))) return DomObject(temp) else: return DomObject(HTML(html=cache_data[0]['text']))正規表現処理についてもラップした
プログラミング言語により、正規表現の有無・操作方法は様々です。Pythonについてもこの点は変わりません。
ただ、素の状態だとちょっと冗長になるなーってことがあるので、よくラップして運用しています。def regex(text: str, pattern: str) -> List[str]: """グループ入り正規表現にマッチさせて、ヒットした場合はそれぞれの文字列の配列、そうでない場合は空配列を返す""" output: List[str] = [] for m in re.finditer(pattern, text, re.MULTILINE): for x in m.groups(): output.append(x) return outputこれにより、例えば「
regex('24~70mm', r'(\d+)mm~(\d+)mm')」と書いた場合、戻り値が「['24', '70']」となって扱いやすくなります。
また、「そのパターンとマッチしない=配列の要素数が0件である」ということなので、条件分岐も効率よく記述できます。# 記述例 # ※Qiitaのソース埋め込みが壊れているので、「\d」と書くと自動色分けが正常に動作しない # ※そのため意図的に「\\d」と記している。適宜読み替えること # 35mm判換算焦点距離 result1 = regex(record['35mm判換算焦点距離'], r'(\\d+)mm~(\\d+)mm') result2 = regex(record['35mm判換算焦点距離'], r'(\\d+)mm') if len(result1) > 0: wide_focal_length = int(result1[0]) telephoto_focal_length = int(result1[1]) else: wide_focal_length = int(result2[0]) telephoto_focal_length = wide_focal_lengthdataclassesは積極的に活用した
dataclassesとは、Python3.7から登場した、データクラスを手軽に作成できる仕組みのことです。今回も次のように、レンズ情報を記録するためのクラスとして活用しました。
@dataclass class Lens: id: int = 0 maker: str = '' name: str = '' product_number: str = '' wide_focal_length: int = 0 telephoto_focal_length: int = 0 wide_f_number: float = 0 telephoto_f_number: float = 0 wide_min_focus_distance: float = 0 telephoto_min_focus_distance: float = 0 max_photographing_magnification: float = 0 filter_diameter: float = 0 is_drip_proof: bool = False has_image_stabilization: bool = False is_inner_zoom: bool = False overall_diameter: float = 0 overall_length: float = 0 weight: float = 0 price: int = 0 mount: str = ''また、dataclassesだけだとJSONデータにシリアライズする処理が面倒なので、dataclasses-jsonを追加導入して対処しています。
フィルター処理における抽象化
当Webアプリでは、検索条件を追加すると、即座に画面下のレンズ一覧が書き換わる仕組みです。
この際、レンズ情報を各種条件でフィルターする処理が挟まっているのですが、フィルター処理をどう記述しようか迷いました。例えば、真っ先に思いつくのは次のようなコードでしょう。
// サンプルのフィルター設定 const filterList = [{'type': 'MaxWideFocalLength', 'value': 24, 'type': 'MinTelephotoFocalLength', 'value': 70}]; // フィルター処理 let temp = [...lensList]; for (const filter of filterList) { // switchで種類ごとに分岐 switch (filter.type) { case 'MaxWideFocalLength': temp = temp.filter(lens => lens.wide_focal_length <= filter.value); break; case 'MinTelephotoFocalLength': temp = temp.filter(lens => lens.telephoto_focal_length >= filter.value); break; } }ただ、これだとフィルターの種類を増やすたびに、switch文がズラズラと連なることになります。可読性が悪い。
そこで、「フィルター処理を行う機構」をクラスにラップすることで解決を見ました。
また、「フィルター処理を行う機構」と「フィルターのパラメーター」を分離することで、前者の複雑度を軽減しています。※実際のコードでは、QueryType型は他にもプロパティを生やしています
// 「フィルター処理」を表現するための抽象クラス abstract class QueryType { // フィルタ処理 abstract filter(lensList: Lens[], value: number): Lens[]; } // 個別のフィルター処理についての具象クラス class MaxWideFocalLength implements QueryType { filter(lensList: Lens[], value: number): Lens[] { return lensList.filter(lens => lens.wide_focal_length <= value); } } class MinTelephotoFocalLength implements QueryType { filter(lensList: Lens[], value: number): Lens[] { return lensList.filter(lens => lens.telephoto_focal_length >= value); } } // 「1つのフィルター」を表現するためのインターフェース interface Query { type: QueryType; value: number; } // サンプルのフィルター設定 const queryList: Query[] = [{'type': new MaxWideFocalLength(), 'value': 24, 'type': new MinTelephotoFocalLength(), 'value': 70}]; // フィルター処理 let temp = [...lensList]; for (const query of queryList) { temp = query.type.filter(temp, query.value); }抽象化の副次的作用
上記の
QueryTypeですが、実際のコードではより多くのプロパティが生えています。abstract class QueryType { // 型名 abstract readonly name: string = ''; // 数値部分の「手前」に表示するMessage abstract readonly prefixMessage: string; // 数値部分の「後」に表示するMessage abstract readonly suffixMessage: string; // フィルタ処理 abstract filter(lensList: Lens[], value: number): Lens[]; }これにより、例えば
MaxWideFocalLengthは次のような定義になっています。class MaxWideFocalLength implements QueryType { readonly name: string = 'MaxWideFocalLength'; readonly prefixMessage: string = '広角端の換算焦点距離が'; readonly suffixMessage: string = 'mm 以下'; filter(lensList: Lens[], value: number): Lens[] { return lensList.filter(lens => lens.wide_focal_length <= value); } }こうした定義なのは、このアプリの性質上、「使用できるフィルターの一覧」を表示する需要があるからです。
<select>内に<option>を並べる場合、Reactだと次のように実装される方が多いと思います。const queryTypeList = [ {type: 'MaxWideFocalLength', prefixMessage: '広角端の換算焦点距離が'}, {type: 'MaxWideFocalLength', prefixMessage: '望遠端の換算焦点距離が'}]; return ( <select> {queryTypeList.map(q => <option key={q.type} value={q.type}>{q.prefixMessage}</option>)} <select> );何も間違ってはいないのですが、このまま実装すると、
<select>された値から、MaxWideFocalLengthなどの(QueryTypeを継承した型)を生成する際にswitch文を使うことになってしまいます。これでは先ほど頑張って排除した意味がありません。そこで、型ごとに使いたいプロパティを埋め込んでおきます。
すると、<select>された値をqueryTypeとした際、queryTypeList.filter(q => q.name === queryType)[0]とするだけで、所望の(QueryTypeを継承した)型のインスタンスを取得できます。switch文なんて要らんかったんや!※この、「クエリの種類のインスタンス(フィルター処理を行う機構)を使い回せる」点が、「フィルター処理を行う機構」と「フィルターのパラメーター」を分離したご利益とも言えます
const queryTypeList = [ new MaxWideFocalLength(), new MaxWideFocalLength() ]; return ( <select> {queryTypeList.map(q => <option key={q.name} value={q.name}>{q.prefixMessage}</option>)} <select> );
- 投稿日:2020-09-26T11:47:56+09:00
SQLのAS句を、pandas(python)をrenameメソッドを使って表現して見た
はじめに
最近、プライベートでデータ分析のツールを作成している関係でpandasというpython外部ライブラリを活用している。が、いざ使って見ると、「pandas?なにそれかわいいの?」と動物のパンダ?を連想させるヤバい思考に行きつつある状況になる。
これはまずいと感じ、投稿者はpandasを探し求める旅に出る。
この記事は、pandasを飼いならすためにpandasをSQLっぽく考えるというデータサイエンス初学者に向けた記事となります。そもそもpandasとは何か
pandasとは、構造化された(表形式、多次元、潜在的に不均質)データと時系列データを簡単かつ直感的に操作できるように設計された高速で柔軟な表現力のあるデータ構造を提供するPythonパッケージで、実際的な実世界のデータ分析を行うための基本的な高レベルのビルドを行う事が可能なツールです。
要は、表データをpythonを使っていい感じに処理して目的のデータ抽出するツールです。実践
準備
今回は下記の表データ【receipt】を用いてpandas攻略を行います。(表データはCSV形式)
※データは長いので冒頭部分のみ表示参考データ:データサイエンス100本ノック
https://github.com/The-Japan-DataScientist-Society/100knocks-preprocessまた、今回はpandasを使用するため、コードは下記のように予め準備しておきます。
pythonimport pandas as pd df_receipt = pd.read_csv('receiptのCSVファイルのパス', sep=',')本題
タイトルにある通り、今回はSQLのAS句をpandasを使って再現します
問題:レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示させよ。ただし、sales_ymdはsales_dateに項目名を変更しながら抽出すること。
目的:表の特定の列の列別名を出力する事
解答
解答を記述するとこんな感じになります。
pandas(python)df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].rename(columns={'sales_ymd': 'sales_date'}).head(10)そして、図に表すとこんな感じになります。
これをSQL文で表すとこんな感じになります。
SQLSELECT sales_ymd AS sales_date,customer_id,product_cd,amount FROM receipt LIMIT 10;解説
それでは、ここから解説していきます。
- SQLのAS句を、pandasのrenameメソッドを用いて表現する
まず、pandasの二重リストを活用し、表全体から対象の列名を選択します。※補足:pandasの二重リストに関する記事は下記を参考にしてみて下さい。
https://qiita.com/syuki-read/items/9fcb06ff56b868167f85pandas(python)df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].head(10)これをSQLで考えると、こんな感じになります。
SQLSELECT sales_ymd,customer_id,product_cd,amount FROM receipt LIMIT 10;FROM句:データベース内の指定する表を選択する
SELECT文:指定した表から抽出すべき列を選択する
LIMIT句:抽出する行数を指定する図に現すとこんな感じになります。
そしてここから、pandasのrenameメソッドを用いて、(SQLのAS句のように)対象の列名(sales_ymd)を指定の列別名(sales_date)に変換を行います。
書き方は、rename(columns={'変換前の列名': '変換後の列名'})と表現します。実際に書いてみるとこんな感じになります。
pandas(python)df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].rename(columns={'sales_ymd': 'sales_date'}).head(10)これをSQLで考えるとこんな感じになります。
SQLSELECT sales_ymd AS sales_date,customer_id,product_cd,amount FROM receipt LIMIT 10;そして、図を表すとこんな感じになります。
- 全体図
全体をまとめると、こんな感じになります。
別解
pandas(python)df_receipt.rename(columns={"sales_date": "sales_ymd"}, inplace=True) df_receipt[['sales_ymd','customer_id','product_cd','amount']].head(10)こちらの場合ですと、先に対象列を指定の列別名に指定し、その後対象の列の選択を行っております。
まとめ
pandasを使って、SQLのAS句の表現を行いました。pandasはデータベース及びSQLを意識したpythonライブラリなため、普段からSQLを意識するとかなり使いやすいツールだと改めて感じます。また、特定の命令文を指示する時、SQLがいくつものパターンがあるように、pandasにも多様なパターンが存在すると、pandasを活用して日々実感を持ちます。
終わりに
今回、利活用したデータはデータサイエンス協会(DS協会)の「データサイエンス100本ノック」を参考にしております。こちらはJupyter notebookを使用しているので、より見やすいデータが抽出されます。
この記事を読んで、「実際に実装してみたい!!」という方がおりましたら、下記にその実装に関する記事を上げているので、良かったそちらの記事を参考に是非実装してみて下さい。データサイエンス初学者にむけた、データサイエンス100本ノックを実装する方法:
https://qiita.com/syuki-read/items/714fe66bf5c16b8a7407
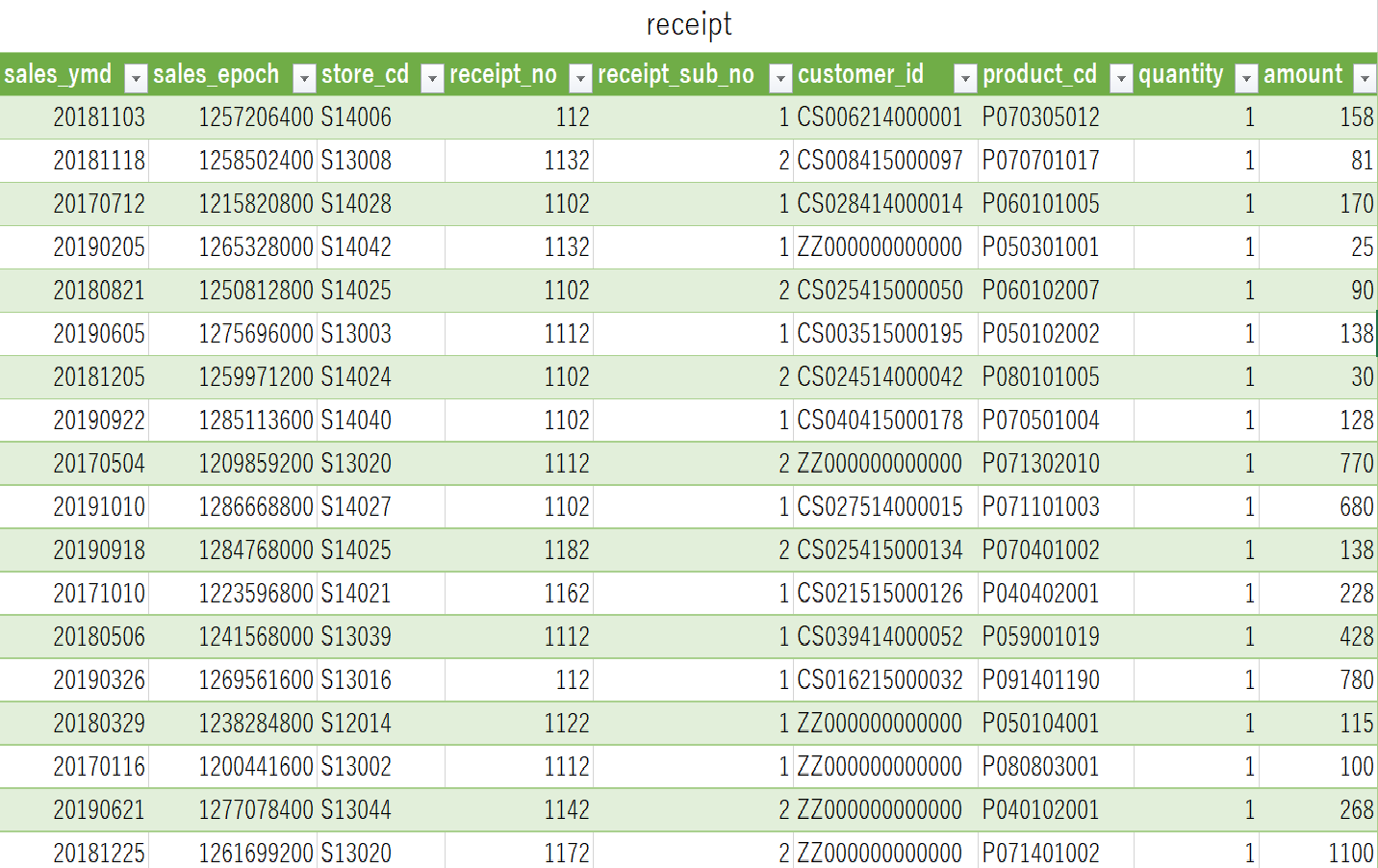
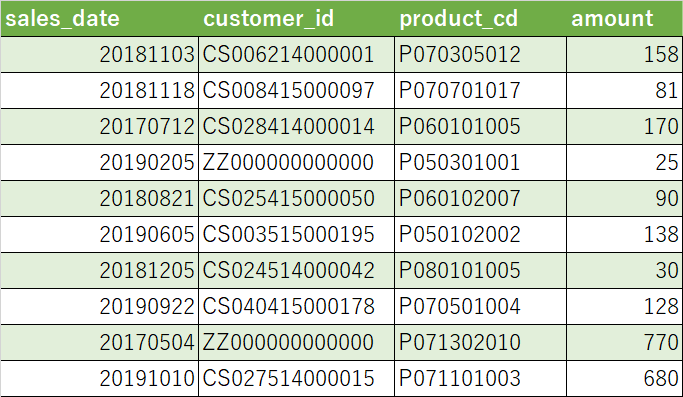
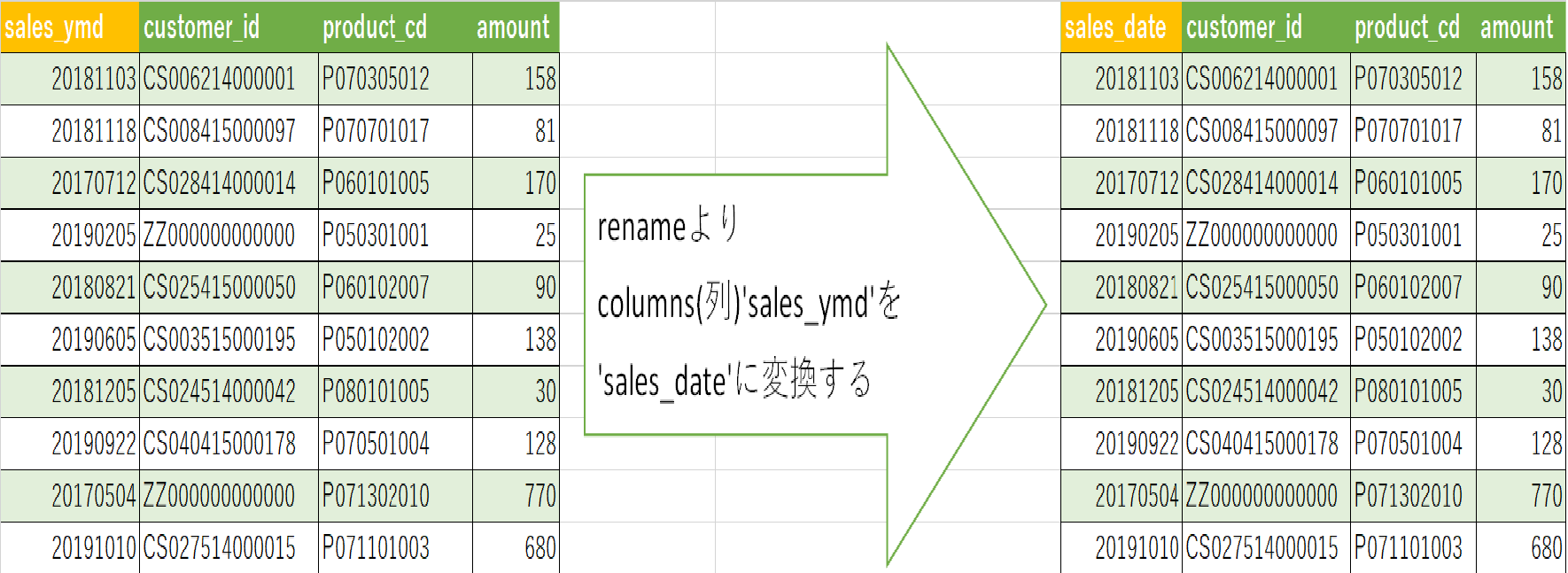
- 投稿日:2020-09-26T11:27:03+09:00
Pythonによる画像処理100本ノック#6 平均プーリング
はじめに
どうも、らむです。
今回は画像をグリッド分割する手法であるプーリング処理の中でも、領域中の平均値を代表値とする平均プーリングについき実装します。7本目:平均プーリング
プーリングとは画像を固定長の領域にグリッド分割し、その領域内の値を全てある値にする処理です。この処理を施すことで画像はモザイク状になります。
平均プーリングでは領域内の画素値の平均値で領域内を埋めます。平均プーリングは以下の式によって定義されます。
Rは領域のことで、例えば8×8ピクセルの領域であれば$|R|=8×8=64$になります。v = \frac{1}{|R|}\sum_{i \in R}v_iソースコード
avePooling.pyimport numpy as np import cv2 import matplotlib.pyplot as plt def avePooling(img,k): dst = img.copy() w,h,c = img.shape # 中心画素から両端画素までの長さ size = k // 2 for x in range(size, w, k): for y in range(size, h, k): dst[x-size:x+size,y-size:y+size,0] = np.mean(img[x-size:x+size,y-size:y+size,0]) dst[x-size:x+size,y-size:y+size,1] = np.mean(img[x-size:x+size,y-size:y+size,1]) dst[x-size:x+size,y-size:y+size,2] = np.mean(img[x-size:x+size,y-size:y+size,2]) return dst # 画像読込 img = cv2.imread('image.jpg') # 平均プーリング # kは領域サイズ img = avePooling(img,40) # 画像保存 cv2.imwrite('result.jpg', img) # 画像表示 plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.show()

画像左は入力画像、画像右は出力画像です。
上手くモザイク状の画像になっていることが分かりますね。グロそうなものに見えてしまいますが、ちゃんとお刺身です。
画像処理でよく使われるLenaさんの画像のフルバージョンも平均プーリング処理をかければQiitaにも載せることができますね。
おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。
それから、pythonは初心者なので間違っているところがあっても優しく指摘してあげてください。


- 投稿日:2020-09-26T10:00:40+09:00
初心者がPythonでウェブスクレイピング(4) - 1
今回は前回のスクレイピングプログラムをクラウドに載せて自動実行させることを目指しますが、まずはクラウドにテスト用PGMを載せて、正常稼働させるところまで持っていきます。
Pythonでのウェブスクレイピング学習のロードマップ
(1)ローカルでとりあえず目的のブツのスクレイピングに成功する。
(2)ローカルでスクレイピングした結果をGoogleスプレッドシートに連携する。
(3)ローカルでcron自動実行を行う。
(4)クラウドサーバー上での無料自動実行に挑戦する。(Google Compute Engine)
(4)-1 クラウドにテスト用PGMを載せて、CloudShell上で正常稼働させる ←いまココ
(4)-2 スクレイピングPGMをリポジトリに追加し、CloudShell上で正常稼働させる。
(4)-3 ComputeEngineのVMインスタンスを作成して、スクレイピングを自動実行させる。
(5)クラウド上で、サーバーレスでの無料自動実行に挑戦する。(たぶんCloud Functions + Cloud Scheduler)GCPに資源を持ち上げる手順
(1)gitを使って、GCPにgitリポジトリを作成(GitHubのアカウント要)
(2)ローカルにクローンを作成
(3)ローカルのリポジトリにGCPに上げたいプログラムをインデックスに追加しcommit
(4)GCP上のmasterにpush(1)gitを使って、GCPにgitリポジトリを作成
GcloudSDKを入れていない場合はインストールします。
gcloudlコマンドが、目的のプロジェクトに設定されていることを確認します。(新規プロジェクトはgcloud initコマンドでプロジェクトを設定します。)zsh16:03:04 [~] % gcloud config list [core] account = hogehoge@gmail.com disable_usage_reporting = False project = my-hoge-app Your active configuration is: [default]Cloud Source Repositoriesに新しいリポジトリを作成します。
zsh16:41:59 [~] % 16:42:00 [~] % gcloud source repos create gce-cron-test Created [gce-cron-test]. WARNING: You may be billed for this repository. See https://cloud.google.com/source-repositories/docs/pricing for details.こんな感じで対象のプロジェクトに空のリポジトリが作成されます。
(2)ローカルにクローンを作成
Cloud Source Repositoriesに作ったリポジトリのクローンをローカルに作成します。
zsh16:44:10 [~] % 16:44:10 [~] % gcloud source repos clone gce-cron-test Cloning into '/Users/hoge/gce-cron-test'... warning: You appear to have cloned an empty repository. Project [my-hoge-app] repository [gce-cron-test] was cloned to [/Users/hoge/gce-cron-test].作成されたローカルレポジトリにpyファイルを格納した状態。(gitリポジトリであることがわかります。)
zsh16:46:15 [~] % 16:46:15 [~] % cd gce-cron-test 16:46:44 [~/gce-cron-test] % ls -la total 8 drwxr-xr-x 4 hoge staff 128 9 23 16:45 . drwxr-xr-x+ 45 hoge staff 1440 9 23 16:45 .. drwxr-xr-x 9 hoge staff 288 9 23 16:45 .git -rw-r--r-- 1 hoge staff 146 9 21 15:29 cron-test.py(3)ローカルのリポジトリにGCPに上げたいプログラムをインデックスに追加しcommit
git addコマンドでファイルをインデックスに追加し、
git commitコマンドでローカルリポジトリにコミットします。zsh16:47:21 [~/gce-cron-test] % 16:47:21 [~/gce-cron-test] % git add . 16:48:03 [~/gce-cron-test] % 16:48:04 [~/gce-cron-test] % git commit -m "Add cron-test to Cloud Source Repositories" [master (root-commit) 938ea70] Add cron-test to Cloud Source Repositories 1 file changed, 5 insertions(+) create mode 100644 cron-test.py(4)GCP上のmasterにpush
master(Cloud Source Repositories)にpushします。
zsh16:50:15 [~/gce-cron-test] % 16:50:15 [~/gce-cron-test] % git push origin master Enumerating objects: 3, done. Counting objects: 100% (3/3), done. Delta compression using up to 4 threads Compressing objects: 100% (2/2), done. Writing objects: 100% (3/3), 349 bytes | 116.00 KiB/s, done. Total 3 (delta 0), reused 0 (delta 0) To https://source.developers.google.com/p/my-hoge-app/r/gce-cron-test * [new branch] master -> mastercommitのメッセージとともに、masterにpushできたことが確認できます。
CloudShellで稼働確認
GCP上のCloudShellに乗っけてテストして見ます。
目的のプロジェクトを選択してCloudShellを起動します。
ターミナル が起動します。
ローカルの時と同様、gitリポジトリをmasterからクローンします。
bashcloudshell:09/25/20 02:59:00 ~ $ gcloud source repos clone gce-cron-test Cloning into '/home/hoge/gce-cron-test'... remote: Total 3 (delta 0), reused 3 (delta 0) Unpacking objects: 100% (3/3), done. Project [my-xxx-app] repository [gce-cron-test] was cloned to [/home/hoge/gce-cron-test].クローンされました。
bashcloudshell:09/25/20 03:01:49 ~ $ cd gce-cron-test cloudshell:09/25/20 03:02:09 ~/gce-cron-test $ ls -la total 20 drwxr-xr-x 3 hoge hoge 4096 Sep 23 10:59 . drwxr-xr-x 13 hoge rvm 4096 Sep 23 11:18 .. -rw-r--r-- 1 hoge hoge 146 Sep 23 09:03 cron-test.py drwxr-xr-x 8 hoge hoge 4096 Sep 23 09:03 .gitpythonのパスとバージョンを確認しておきます。
この環境には予めpyenvで3.8.5を入れてあります。bashcloudshell:09/25/20 03:02:21 ~/gce-cron-test $ which python /home/hoge/.pyenv/shims/python cloudshell:09/25/20 03:02:42 ~/gce-cron-test $ python -V Python 3.8.5以下の通り、CloudShell上でも、まぁ普通に動きます。
bashcloudshell:09/25/20 03:02:50 ~/gce-cron-test $ python cron-test.py 2020/09/25 03:03:11 cronが動いた! cloudshell:09/25/20 03:03:12 ~/gce-cron-test $ただし、crontabは動きませんでした。
CloudShell環境はインタラクティブな対話型コマンドのみ受け付ける環境のようです。。。
次回は、スクレイピングPGMをリポジトリに追加し、CloudShell上で正常稼働させます。おまけ:CloudShellについて
CloudShellはgoogleのクラウド上で使えるIDE環境で、5GBのDiskを備える一種の仮想VM環境で、Theiaベースのコードエディターも使えます。
隠しファイルをエディターで編集することも、
bash$ cloudshell edit $HOME/.bashrcダウンロードもできたりします。
bash$ cloudshell download $HOME/.bashrc[CloudShell] https://cloud.google.com/shell/?hl=ja



- 投稿日:2020-09-26T08:17:39+09:00
Django Updateview で更新画面を作成
前回から、社員名と日付は編集してしまうことをできないようにしたいため、いろんなことを試していました。
forms.pyは、まだ一度も使ったことがなく(使い方を勉強していない)数時間調べていたが、うまくいかなかった。
最後に、社員名を渡すためにやったことをスケジュールと同じことをして受け渡せばどうなるのかtと思って試してみたらやっとうまくいきました。
schedule/views.pyclass ScheduleUpdate(UpdateView): template_name = 'schedule/update.html' model = Schedule fields = ('user','date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3','shift_name_4', 'shisetsu_name_4', 'day_total_worktime') success_url = reverse_lazy('schedule:homeschedule') #def get_queryset(self): # return super().get_queryset().select_related('user') # return super().get_queryset().select_related('schedule')これだけでした。最後の一行を足したらかなえれました
schedule/update.html{% extends 'schedule/base.html' %} {% block header %} {% endblock header %} {% block content %} <form action="" method="POST">{% csrf_token %} <P >社員名: {{ user.last_name }} {{ user.first_name }}</P> <p>日付: {{ schedule.date }}</p> <p>シフト1: {{ form.shift_name_1 }}</p> <p>施設名1: {{ form.shisetsu_name_1 }}</p> <p>シフト2: {{ form.shift_name_2 }}</p> <p>施設名2: {{ form.shisetsu_name_2 }}</p> <p>シフト3: {{ form.shift_name_3 }}</p> <p>施設名3: {{ form.shisetsu_name_3 }}</p> <p>シフト4: {{ form.shift_name_4 }}</p> <p>施設名4: {{ form.shisetsu_name_4 }}</p> <p>労働合計時間: {{ form.day_total_worktime }}</p> <input class="btn btn-primary" type="submit" value="更新"> <a href="{% url 'schedule:homeschedule' %}" class="btn-secondary btn active">戻る</a> </form> {% endblock content %}
これで実装できました!
やっとです!
次は、労働時間の合計を出来るようにすることに挑戦してみます…
と、やりはじめたのですが他に問題が発生しました!更新画面から編集している画面からシフト表に戻ることができない
schedule.views.pyclass ScheduleUpdate(UpdateView): template_name = 'schedule/update.html' model = Schedule fields = ('shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3','shift_name_4', 'shisetsu_name_4', 'day_total_worktime') year = Schedule.year month = Schedule.month #success_url = reverse_lazy('schedule:monthschedule', kwargs={"year": self.object.year}) #success_url = HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (Schedule.year,Schedule.month,)) success_url = reverse_lazy('/schedule/monthschedule/%s/%s/' % (year,month)) #def get_url_success(self): # url = "/schedule/monthschedulefunc/" + self.year +"/"+ self.month # return HttpResponseRedirect(url) def get_queryset(self): ###要らなかった… #return super().get_queryset().select_related('user') #return super().get_queryset().select_related('schedule') #return super().get_queryset().select_related('Shift')色々挑戦しすること、2時間ちょっと…
もう諦めましたdef関数で作り直ししようと思います!
ただ関数だからといってすぐにできるかはわたっていませんが(笑)とりあえず挑戦(⌒∇⌒)
2時間ばかりかかりましたが実現できました!
ついにforms.pyも使いました(まだ、理解には程遠い状況ですが、0 を 1 にすることが大切)まずは、views.py
schedule/views.pydef scheduleUpdatefunc(request,pk): Schedule_list = Schedule.objects.get(pk = int(pk)) User_list = User.objects.get(username = Schedule_list.user) if request.method == 'POST': form = ScheduleUpdateForm(data=request.POST) year = Schedule_list.year month = Schedule_list.month if form.is_valid(): Schedule_list.shift_name_1 = form.cleaned_data['shift_name_1'] Schedule_list.shisetsu_name_1 = form.cleaned_data['shisetsu_name_1'] Schedule_list.shift_name_2 = form.cleaned_data['shift_name_2'] Schedule_list.shisetsu_name_2 = form.cleaned_data['shisetsu_name_2'] Schedule_list.shift_name_3 = form.cleaned_data['shift_name_3'] Schedule_list.shisetsu_name_3 = form.cleaned_data['shisetsu_name_3'] Schedule_list.shift_name_4 = form.cleaned_data['shift_name_4'] Schedule_list.shisetsu_name_4 = form.cleaned_data['shisetsu_name_4'] Schedule_list.day_total_worktime = form.cleaned_data['day_total_worktime'] Schedule_list.save() return HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (year,month,)) else: item = { "shift_name_1":Schedule_list.shift_name_1, "shisetsu_name_1": Schedule_list.shisetsu_name_1, "shift_name_2": Schedule_list.shift_name_2, "shisetsu_name_2": Schedule_list.shisetsu_name_2, "shift_name_3": Schedule_list.shift_name_3, "shisetsu_name_3": Schedule_list.shisetsu_name_3, "shift_name_4": Schedule_list.shift_name_4, "shisetsu_name_4": Schedule_list.shisetsu_name_4, } form = ScheduleUpdateForm(initial=item) context = { 'form' : form, 'Schedule_list': Schedule_list, 'User_list': User_list, } return render(request,'schedule/update.html', context )コードは長いですが、ほとんどがどのフィールドとどのフィールドを結び付けているだけなので、
作り始めたらすぐにできました。次に初めてトライしたforms.py
schedule/forms.pyclass ScheduleUpdateForm(forms.ModelForm): class Meta: model = Schedule fields = ('shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3','shift_name_4', 'shisetsu_name_4', 'day_total_worktime') #shift_name_1 = forms.ForeignKey(Shift, verbose_name='1シフト名', related_name='shift_name1',on_delete=models.SET_NULL,null= True) #shisetsu_name_1 = forms.ForeignKey(Shisetsu, verbose_name='1施設', related_name='shisetsu_name1',on_delete=models.SET_NULL,blank=True, null=True) #shift_name_2 = forms.ForeignKey(Shift, verbose_name='2シフト名', related_name='shift_name2',on_delete=models.SET_NULL,blank=True, null=True) #shisetsu_name_2 = forms.ForeignKey(Shisetsu, verbose_name='2施設', related_name='shisetsu_name2',on_delete=models.SET_NULL,blank=True, null=True) #shift_name_3 = forms.ForeignKey(Shift, verbose_name='3シフト名', related_name='shift_name3',on_delete=models.SET_NULL,blank=True, null=True) #shisetsu_name_3 = forms.ForeignKey(Shisetsu, verbose_name='3施設', related_name='shisetsu_name3',on_delete=models.SET_NULL,blank=True, null=True) #shift_name_4 = forms.ForeignKey(Shift, verbose_name='4シフト名', related_name='shift_name4',on_delete=models.SET_NULL,blank=True, null=True) #shisetsu_name_4 = forms.ForeignKey(Shisetsu, verbose_name='4施設', related_name='shisetsu_name4',on_delete=models.SET_NULL,blank=True, null=True)入力制御が最初うまく連携されていなかったので、modelsから貼り付けた形跡が残っています(笑)
htmlを少し編集しました
schedule/update.html{% extends 'schedule/base.html' %} {% block header %} {% endblock header %} {% block content %} <form action="" method="POST">{% csrf_token %} <P >社員名: {{ User_list.last_name }} {{ User_list.first_name }}</P> <p>日付: {{ Schedule_list.date }}</p> {{ form.as_p }} {% csrf_token %} <input class="btn btn-primary" type="submit" value="更新"> <a href="{% url 'schedule:homeschedule' %}" class="btn-secondary btn active">戻る</a> </form> {% endblock content %}これで修正画面で更新ボタンを押下すると編集中の月に戻れるようになりました。



- 投稿日:2020-09-26T07:53:48+09:00
【python-pptx】pythonでPowerPoint のフォント情報をcsvに出力
背景
PowerPoint の資料Reviewで一部のフォントが間違っていると指摘をいただきました。
100ページ以上のスライドのどこのフォントが違っているかを、一つずつチェックして修正…。
目検でやりたくなかったですし、これから先も同様の作業をする可能性があるので効率的にできないか…と思いました。python-pptx
今の時代 python でできないことなんてないやろ!
調べてみると、python-pptx で python から PowerPoint のファイルが操作できることがわかりました。
公式ページ:python-pptxオブジェクトのイメージ
Qiitaの偉大な先駆者様達の記事を参考に、公式の Getting Start を少し触りました。
なんとなくイメージがついたので、下記にDumpします。
(間違っていたらご指摘をお願いいたします…)全体の俯瞰図
Presentation > slides[] > shapes[] > text_frame.paragraphs[] > runs[]
shapes[] とスライドの対応
slide はそのスライド内のオブジェクトを shapes[] に配列の形で持っている。
text_frame.paragraphs[] とスライドの対応
shape の中で、文字を持てるもの(?)は text_frame.paragraphs[] を持てる。
よく shapes[n].paragraphs[m] でアクセスしようとしてエラーになってました…。
runs[] とスライドの対応
1文字毎にフォントを変えられますが、どうやって持っているんだろう…と、前々から疑問でした。
run という単位で持っているようで、それぞれにフォントが設定できます。
作ったもの
全スライドの全 paragraphs と runs を csv に dump。
TARGET_FILE_PATH には対象の powerpoint ファイルへのパスを、OUTPUT_FILE_PATH には出力の csv のファイルへのパスを設定。python-pptx.pyfrom pptx import Presentation from pptx.util import Pt import csv TARGET_FILE_PATH = './targetFile/targetFile.pptx' OUTPUT_FILE_PATH = './output.csv' FONT_SIZE_DIVESER = 12700 # ["pptxFile名","slide番号","object番号","run番号","オブジェクトタイプ"," font.name"," font.size"," text"] def export_slide_fonts_and_text(): outputArray = [] outputArray.append(["pptxFile名","slide番号","object番号","paragraph番号","run番号","オブジェクトタイプ"," font.name"," font.size"," text"]) # ppt file の読み込み prs = Presentation(TARGET_FILE_PATH) slide_number = 0 # スライドの読み込み for slide in prs.slides: shape_number = 0 # shape ごとに処理 for shape in slide.shapes: if not shape.has_text_frame: shape_number = shape_number + 1 continue paragraph_number = 0 # paragraph の段階で一旦出力 for paragraph in shape.text_frame.paragraphs: if(paragraph.font.size != None): fontSize = paragraph.font.size/FONT_SIZE_DIVESER else: fontSize = None outputArray.append([TARGET_FILE_PATH, slide_number, shape_number,paragraph_number, "-","paragraph", str(paragraph.font.name), str(fontSize), paragraph.text]) run_number = 0 # runを各々出力 for run in paragraph.runs: if(run.font.size != None): fontSize = run.font.size/FONT_SIZE_DIVESER else: fontSize = None outputArray.append([TARGET_FILE_PATH, slide_number, shape_number,paragraph_number, run_number, "run", str(run.font.name), str(fontSize), run.text]) run_number = run_number + 1 paragraph_number = paragraph_number + 1 shape_number = shape_number + 1 slide_number = slide_number +1 # 書き込み with open(OUTPUT_FILE_PATH, 'w', encoding="shift-jis") as f: wirter = csv.writer(f, lineterminator='\n', quoting=csv.QUOTE_ALL) wirter.writerows(outputArray) if __name__ == "__main__": export_slide_fonts_and_text()出力されたものを少し加工
csv で出力されたものを、Excel に貼って色を付けて見たものが下記です。
大体ですが、やりたいことができていそうな感じです!
ToBe
デフォルトの値を取ってくる
上記のExcelにある通り、フォント名やフォントサイズが「None」となっているところが多くあります。
値が設定されていない場合デフォルトの値を参照するそうです。
placeholder にアクセスすることで取得できそうなのですが…もう少し調べてみたいと思います。参考にさせていただいた先駆者様
ありがとうございます…。
圧倒的感謝…!
python-pptxまとめ
python-pptxでレポーティングを自動化する
[Python]爆速で報告パワポを生成する!
Pythonを使ったレポートの自動作成【PowerPoint】【python-pptx】
https://qiita.com/code_440/items/22e8539da465686496d3
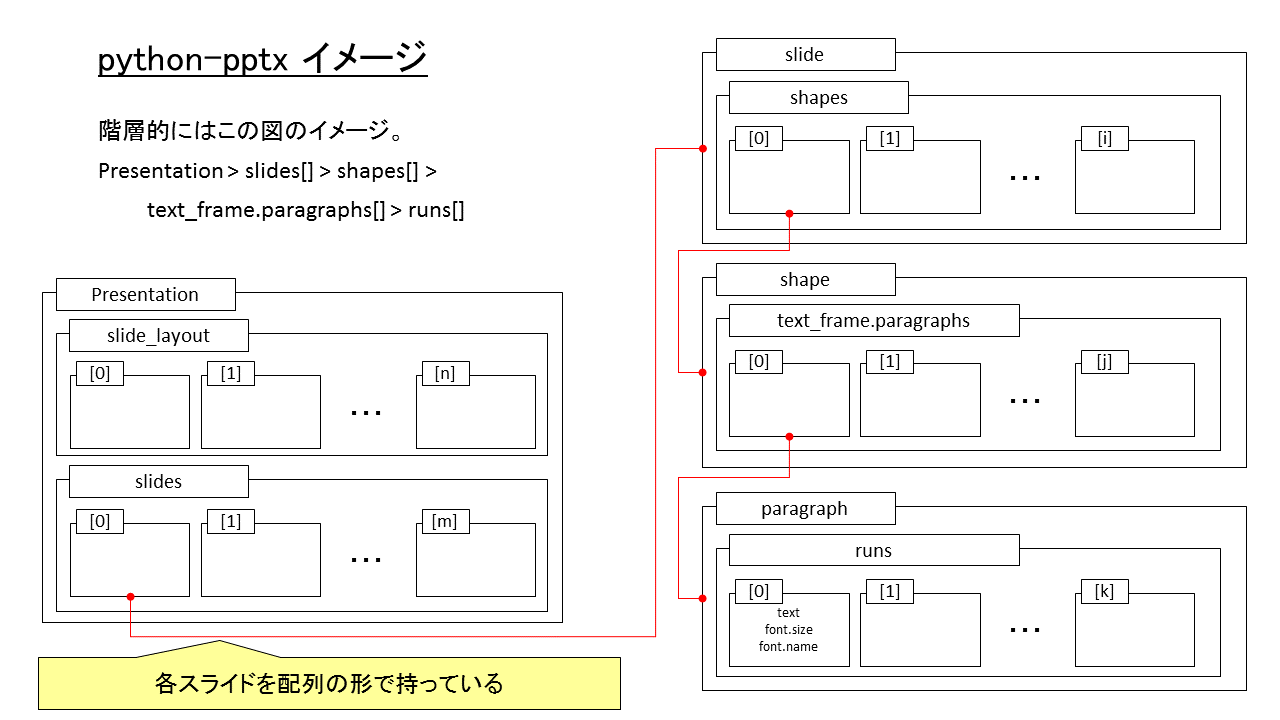
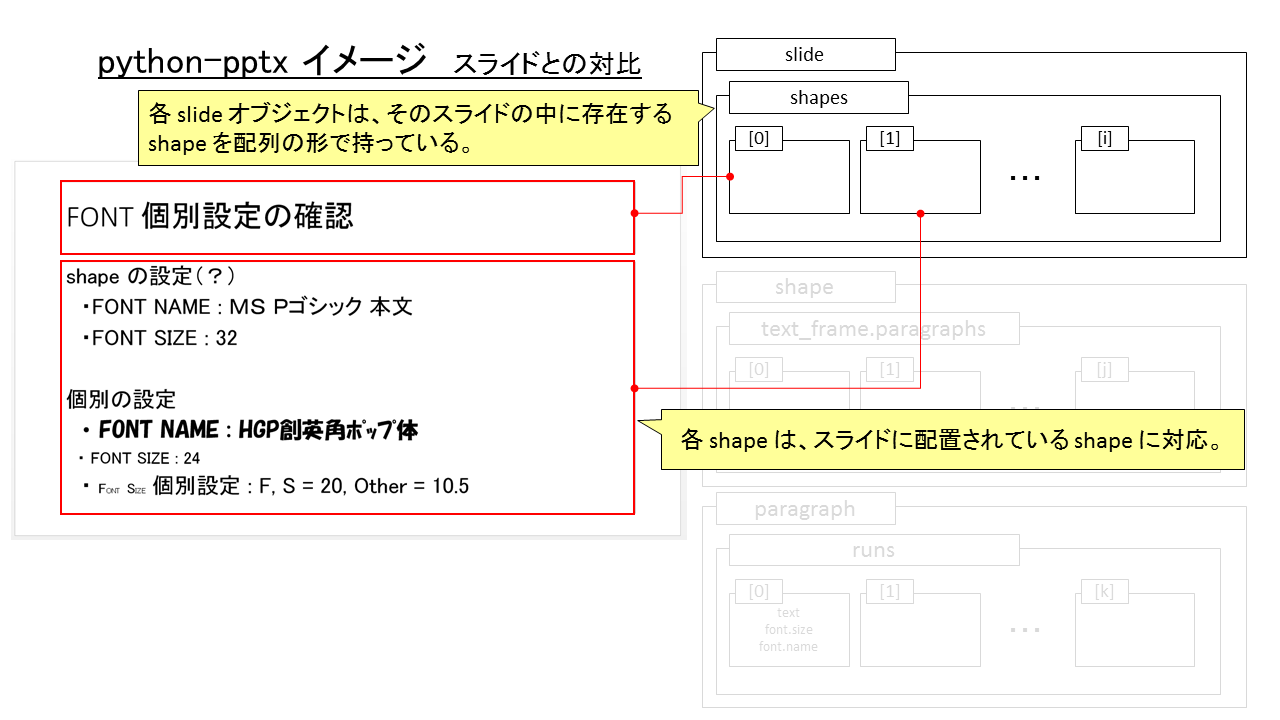
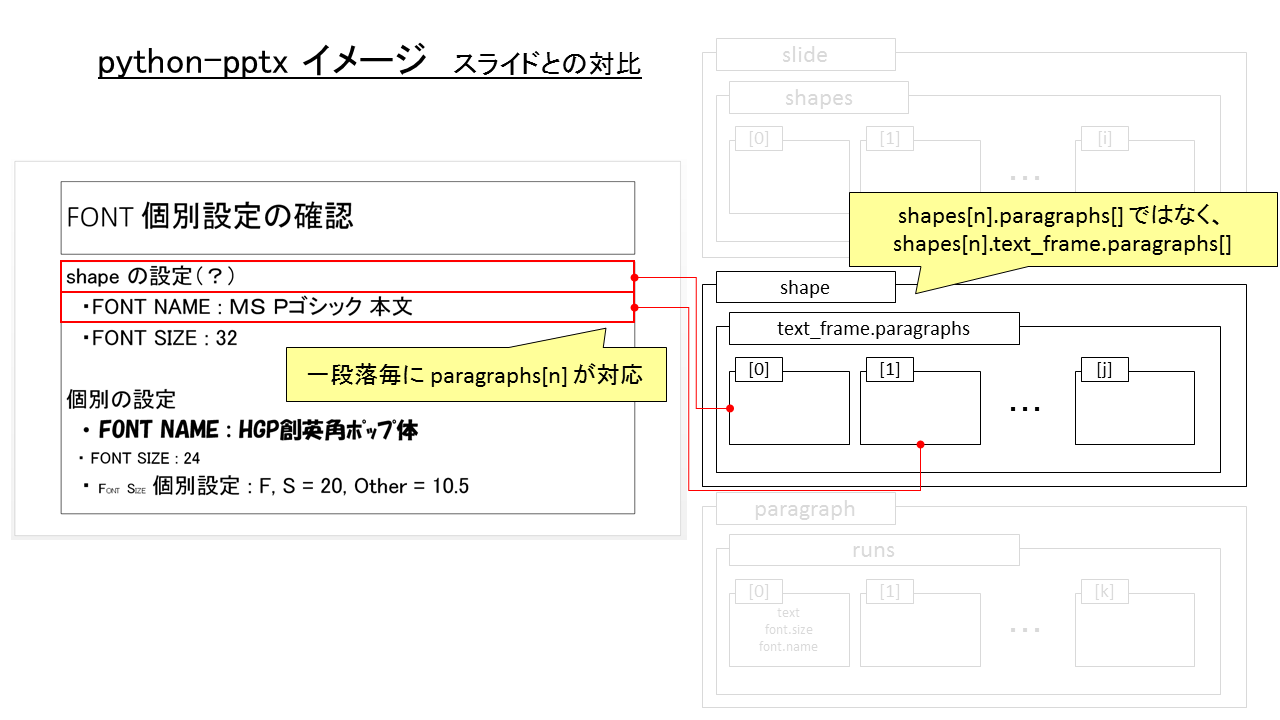
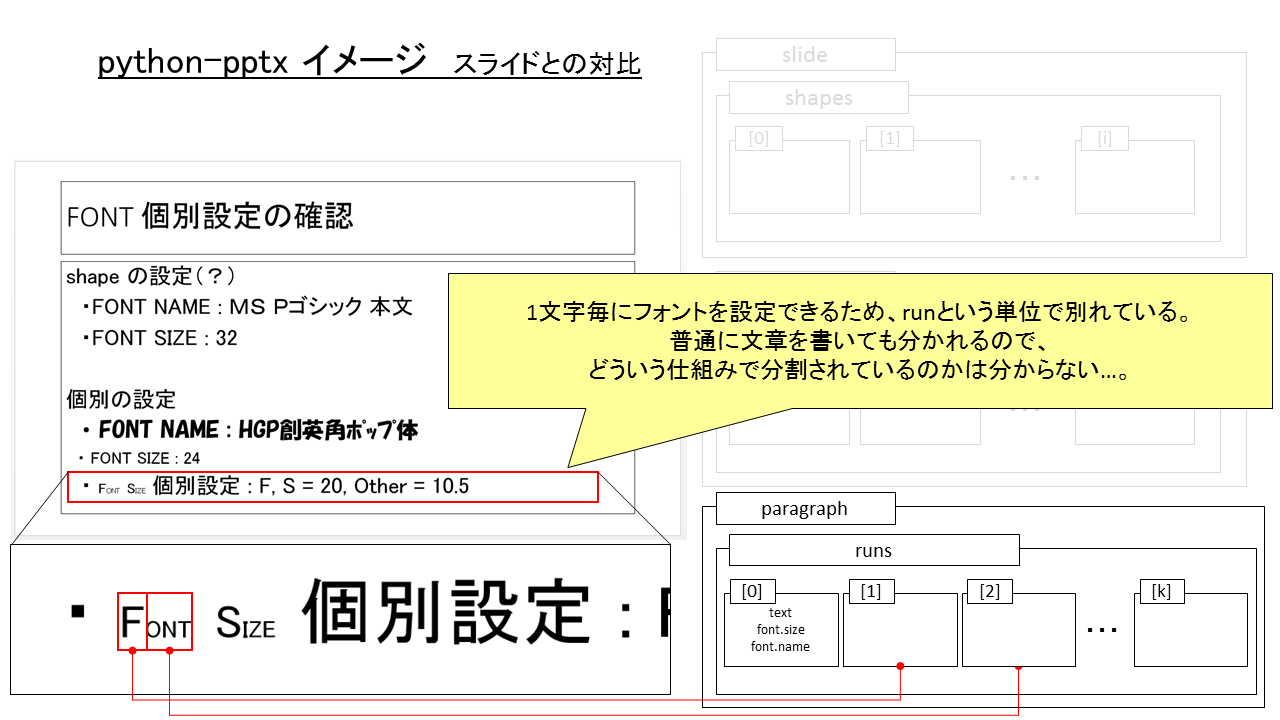
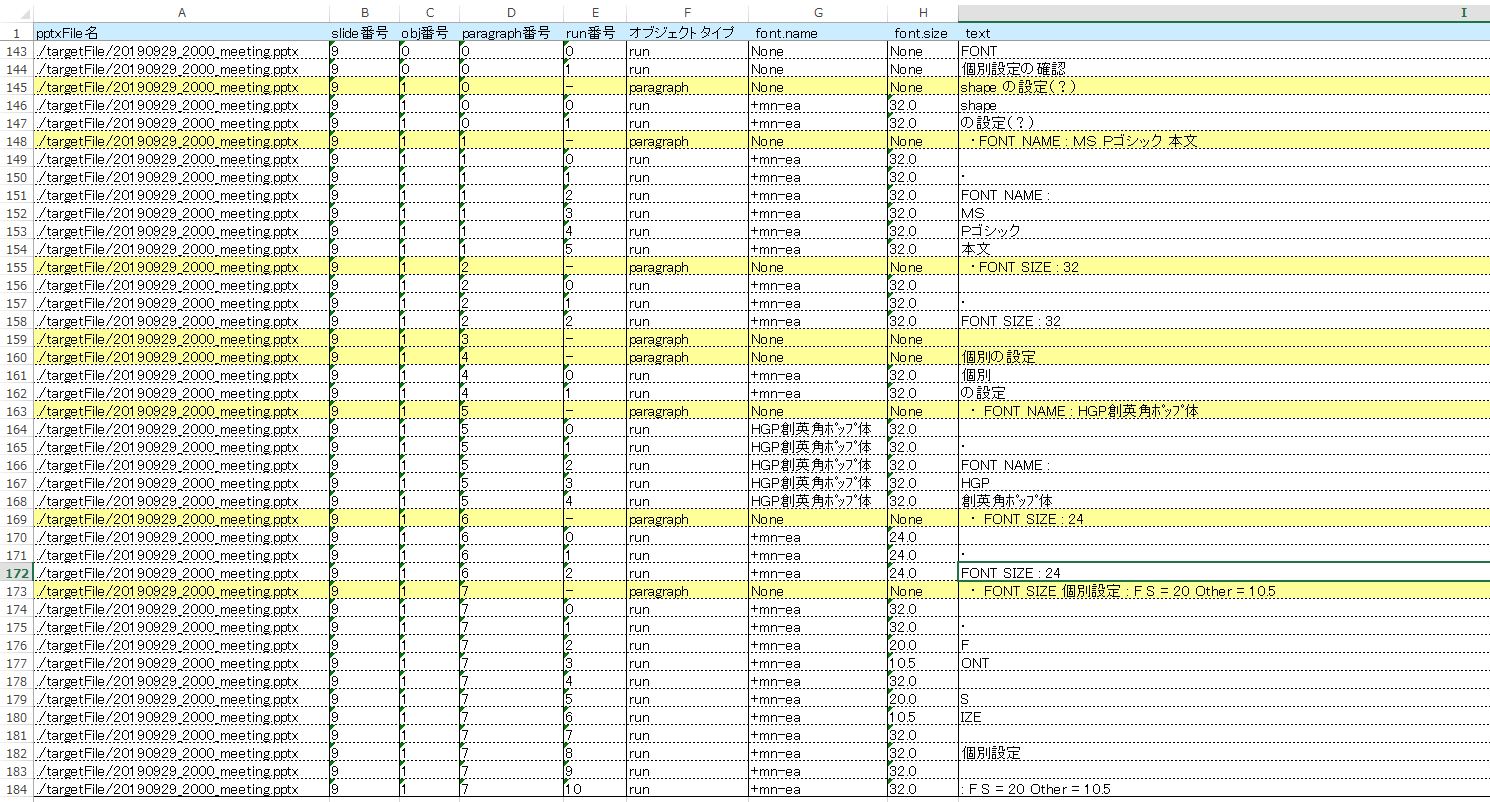
- 投稿日:2020-09-26T02:58:50+09:00
ISO-8601文字列を日本時間に変換したい
ISO-8601文字列を日本時間に変換したい
2020-09-25T18:00:00Z→2020-09-26 03:00:00Pythonでのプログラム
どう考えてもこんなに長いプログラムが必要ではないはずなんだが……
# coding: utf-8 from datetime import datetime, timezone, timedelta import dateutil.parser def time_jst(date_str: str): date_str.replace('Z', '+00:00') t = dateutil.parser.parse(date_str) JST = timezone(timedelta(hours=+9)) t_jst = t.astimezone(JST) ret = t_jst.strftime("%Y-%m-%d %H:%M:%S") return ret s = '2020-09-25T18:00:00Z' print (time_jst(s))
- 投稿日:2020-09-26T02:41:01+09:00
PythonのDataset(SQLAlchemyのラッパー)のclose系処理を調べる
概要
結論
結論からまず先に。。
コネクションプールを残したい時は、closeする必要なし。
DB切断までやりたい時は、条件5の、
con.executable.invalidate() con.executable.engine.dispose()調査内容
↓が実行されていることを前提とする。
con = dataset.connect( 'mysql://root:password@172.17.0.1:3306/hoge', engine_kwargs={ 'pool_size': 10, # 'max_overflow': 0, } ) for record in con['table1']: print(record)select実行後の状態は一律↓の通り。
con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -9 Current Checked out connections: 1※備考
close処理のcon.executable.xxxx()はSQLAlchemyの関数を実行している。条件0(close処理を実行しない)
closeを実行しない。
検証1
select実行 ↓ conを使いまわしてもう一回、select ↓ 接続が使い回される(Poolが効いてる)検証2
10スレッド同時にSQLを流す ↓ 全部終わった後、conを使いまわしてもう一回、10スレッド同時にSQLを流す ↓ 接続が使い回される(Poolが効いてる) ※`max_overflow`を`0`にしないと、デフォルト値で`10`は`pool_size`超えてくるので注意まとめ
多分、これが正解な気がする。。
条件1(con.close())
con.close()DB接続が切断されるかどうか
切断されない。
close実行後
con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : 実行できないclose後、同じconを使ってselectするとどうなるか
実行できるし、結果もとれる(接続は使いまわされている)。
が、2回目のcon.close()で↓のエラーがでる。'NoneType' object has no attribute 'dispose'まとめ
プールに接続を返し、プールが接続を1つ持っている状態。
DBとの接続自体は切れていないので注意。
conの中のengineが削除される。(つまり、どういう事なのかは分からん。。)そもそもclose()しなくていい説ある。
条件2(con.close(); con.executable.engine.dispose())
con.close() con.executable.engine.dispose()DB接続が切断されるかどうか
切断されない。
close実行後
con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : 実行できないclose後、同じconを使ってselectするとどうなるか
実行できるし、結果もとれる(接続は使いまわされている)。
が、2回目のcon.close()で↓のエラーがでる。'NoneType' object has no attribute 'dispose'まとめ
条件1と状態はかわらない。
条件3(con.executable.close())
con.executable.close()DB接続が切断されるかどうか
切断されない。
close実行後
con.executable.closed : True con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 1 Current Overflow: -9 Current Checked out connections: 0close後、同じconを使ってselectするとどうなるか
↓が出て実行できない。
(sqlalchemy.exc.ResourceClosedError) This Connection is closedまとめ
プールに接続を返し、プールが接続を1つ持っている状態。
con.executable.closedがTrueになるが、何を意味しているのかは分からん。。条件4(con.executable.close(); con.executable.engine.dispose())
con.executable.close() con.executable.engine.dispose()DB接続が切断されるかどうか
切断される。
close実行後
con.executable.closed : True con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -10 Current Checked out connections: 0close後、同じconを使ってselectするとどうなるか
↓が出て実行できない。
(sqlalchemy.exc.ResourceClosedError) This Connection is closedまとめ
DBとの接続が切断される(プールされている接続が無くなる))
条件5(con.executable.invalidate())
con.executable.invalidate()DB接続が切断されるかどうか
切断される。
close実行後
con.executable.closed : False con.executable.invalidated: True con.engine.pool.status() : Pool size: 10 Connections in pool: 1 Current Overflow: -9 Current Checked out connections: 0close後、同じconを使ってselectするとどうなるか
普通に実行できた。
# select実行後の状態 con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -9 Current Checked out connections: 1 # close実行後の状態 con.executable.closed : False con.executable.invalidated: True con.engine.pool.status() : Pool size: 10 Connections in pool: 1 Current Overflow: -9 Current Checked out connections: 0まとめ
DBとの接続が切断される(プールされている接続が無くなる)。
Connections in pool: 0ではなく、Connections in pool: 1になるが、それによる違いは分からん。。条件6(con.executable.invalidate(); con.executable.engine.dispose())
con.executable.invalidate() con.executable.engine.dispose()DB接続が切断されるかどうか
切断される。
close実行後
con.executable.closed : False con.executable.invalidated: True con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -10 Current Checked out connections: 0close後、同じconを使ってselectするとどうなるか
普通に実行できた。
# select実行後の状態 con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -9 Current Checked out connections: 1 # close実行後の状態 con.executable.closed : False con.executable.invalidated: True con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -10 Current Checked out connections: 0まとめ
DBとの接続が切断される(プールされている接続が無くなる)。
Connections in pool: 1ではなく、Connections in pool: 0になるが、それによる違いは分からん。。close後のselect再実行まで含めると、一番健全っぽく見える。
- 投稿日:2020-09-26T02:41:01+09:00
Pythonのdataset(SQLAlchemyのラッパー)のclose系処理を調べる
概要
datasetでクローズ処理した時の挙動がいまいちよく分からないので色々試して整理する。
環境
4.14.193-149.317.amzn2.x86_64 #1 SMP Thu Sep 3 19:04:44 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
Python 3.8.5
下記がpip installされている状態。
dataset 1.3.2
SQLAlchemy 1.3.19
mysqlclient 1.4.6結論
結論からまず先に。。
コネクションプールを残したい時は、closeする必要なし(条件0参照)。
DB切断までやりたい時は、条件6の、
con.executable.invalidate() con.executable.engine.dispose()ちなみに、、検証結果の
pool.status()の数字の意味は雰囲気的に↓かなぁ、、Pool size: そのまま Connections in pool: プールとして使用可能なDB接続している本数 Current Overflow: 最大で、あと何接続までできるか(max_overflowのデフォが10なので、-10からっぽい) Current Checked out connections: スレッドが掴んでるDB接続数調査内容
下記の流れ。
select実行
↓
close処理
↓
状態を見る
↓
同じconを使って再度、select実行
↓
close処理
↓
状態を見る前提
↓が実行されていることを前提とする。
con = dataset.connect( 'mysql://root:password@172.17.0.1:3306/hoge', engine_kwargs={ 'pool_size': 10, # 'max_overflow': 0, } ) for record in con['table1']: print(record)最初の"select実行"時点での状態は一律↓の通り。
con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -9 Current Checked out connections: 1"DB接続が切断されるかどうか"の項目に関して
MySQLに対し、1秒ごとに
show processlist \gを実行して、DBとの接続がされているかどうか見てる。備考
close処理の
con.executable.xxxx()はSQLAlchemyの関数を実行している。調査結果
条件0(close処理を実行しない)
closeを実行しない。
検証1
select実行 ↓ conを使いまわしてもう一回、select ↓ 接続が使い回される(Poolが効いてる)初回実行後 con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -9 Current Checked out connections: 1 ↓ 2回目実行後 con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -9 Current Checked out connections: 1検証2
10スレッド同時にSQLを流す ↓ スレッドが全部終わった後、conを使いまわしてもう一回、10スレッド同時にSQLを流す ↓ 接続が使い回される(Poolが効いてる) ※`max_overflow`を`0`にしないと、デフォルト値で`10`は`pool_size`超えてくるので注意 ※DB接続はスレッドが終了するタイミングで勝手に開放してる(Pythonのスレッドってどうなんだっけ。。)初回実行後 con.engine.pool.status() : Pool size: 10 Connections in pool: 9 Current Overflow: 0 Current Checked out connections: 1 ↓ 2回目実行後 con.engine.pool.status() : Pool size: 10 Connections in pool: 10 Current Overflow: 1 Current Checked out connections: 1 ※overflowが発動してしまっているけど。。接続の使いまわしの確認方法
最初に流したSQLのMySQL側のプロセスIDと2回目のプロセスIDが一致することで確認している。
※show processlist \gのIDカラムの値が最初と2回目で一致するスレッドで実行している場合も同様。
10スレッド同時実行時は初回でIDが 1,2,3,4,5,6,7,8,9,10 になっていたら、2回目でもIDが 1,2,3,4,5,6,7,8,9,10 になっていることを確認している。余談
pool_size:10, max_overflow: 0で、20スレッド実行とかした場合、ちゃんとpoo_sizeを超えないように制限される。
※上記設定の場合、同時に処理されるのが10接続分までになり、空いた接続が再利用されるまとめ
多分、これが正解な気がする。。
条件1(con.close())
con.close()DB接続が切断されるかどうか
切断されない。
close実行後
con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : 実行できないclose後、同じconを使ってselectするとどうなるか
実行できるし、結果もとれる(接続は使いまわされている)。
が、2回目のcon.close()で↓のエラーがでる。'NoneType' object has no attribute 'dispose'まとめ
プールに接続を返し、プールで接続を1つ持っている状態(と思われる)。
pool.status()が見れなくなるのでプール管理がどうなっているのかの詳細が分からない。DBとの接続自体は切れていないので注意。
conの中のengineが削除される。(つまり、どういう事なのかは分からん。。)あと
close()2回目でエラーが出てしまうので使いどころはない印象。そもそも
close()しなくていい説ある。条件2(con.close(); con.executable.engine.dispose())
con.close() con.executable.engine.dispose()DB接続が切断されるかどうか
切断されない。
close実行後
con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : 実行できないclose後、同じconを使ってselectするとどうなるか
実行できるし、結果もとれる(接続は使いまわされている)。
が、2回目のcon.close()で↓のエラーがでる。'NoneType' object has no attribute 'dispose'まとめ
条件1と状態はかわらない。
条件3(con.executable.close())
con.executable.close()DB接続が切断されるかどうか
切断されない。
close実行後
con.executable.closed : True con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 1 Current Overflow: -9 Current Checked out connections: 0close後、同じconを使ってselectするとどうなるか
↓が出て実行できない。
(sqlalchemy.exc.ResourceClosedError) This Connection is closedまとめ
プールに接続を返し、プールが接続を1つ持っている状態。
con.executable.closedがTrueになるが、何を意味しているのかは分からん。。
selectの再実行ができないし、DB切断もされないので使いどころがない感じ。条件4(con.executable.close(); con.executable.engine.dispose())
con.executable.close() con.executable.engine.dispose()DB接続が切断されるかどうか
切断される。
close実行後
con.executable.closed : True con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -10 Current Checked out connections: 0close後、同じconを使ってselectするとどうなるか
↓が出て実行できない。
(sqlalchemy.exc.ResourceClosedError) This Connection is closedまとめ
DBとの接続が切断される(プールされている接続が無くなる))
selectの再実行ができなくなるので、最終処理用な気がする。条件5(con.executable.invalidate())
con.executable.invalidate()DB接続が切断されるかどうか
切断される。
close実行後
DB接続は切れているのにプールに接続が残っていることになっている。
con.executable.closed : False con.executable.invalidated: True con.engine.pool.status() : Pool size: 10 Connections in pool: 1 Current Overflow: -9 Current Checked out connections: 0close後、同じconを使ってselectするとどうなるか
普通に実行できた。
一度切断しているので再接続している(MySQL側でSQLを実行しているプロセスのIDが変わる)。# select実行後の状態 con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -9 Current Checked out connections: 1 # close実行後の状態 con.executable.closed : False con.executable.invalidated: True con.engine.pool.status() : Pool size: 10 Connections in pool: 1 Current Overflow: -9 Current Checked out connections: 0まとめ
DBとの接続が切断される(プールされている接続が無くなる)。
実際のDB接続は切れているが、プール管理的には接続している体になっているのであまり良い状態ではない気がする。
※実際には切れているのに、Connections in pool: 1になっている条件6(con.executable.invalidate(); con.executable.engine.dispose())
con.executable.invalidate() con.executable.engine.dispose()DB接続が切断されるかどうか
切断される。
close実行後
con.executable.closed : False con.executable.invalidated: True con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -10 Current Checked out connections: 0close後、同じconを使ってselectするとどうなるか
普通に実行できた。
一度切断しているので再接続している(MySQL側でSQLを実行しているプロセスのIDが変わる)。# select実行後の状態 con.executable.closed : False con.executable.invalidated: False con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -9 Current Checked out connections: 1 # close実行後の状態 con.executable.closed : False con.executable.invalidated: True con.engine.pool.status() : Pool size: 10 Connections in pool: 0 Current Overflow: -10 Current Checked out connections: 0まとめ
DBとの接続が切断される(プールされている接続が無くなる)。
実際のDB接続状態とプール管理状態が一致しており、close後のselect再実行まで含めると、一番健全っぽく見える。
- 投稿日:2020-09-26T00:21:11+09:00
Pythonによる画像処理100本ノック#6 減色処理
はじめに
どうも、らむです。
今回は画像中の色の数を減らす減色処理を実装します。
ちなみに、前回から一本飛んでいるのはどうしても5本目のHSV変換が実装できなかったからです。6本目:減色処理
減色処理はその名の通り、色の数を減らす処理のことです。
通常の画像ではBGRでそれぞれ[0:255]の256色が存在し、1つの画素値で$256^3 = 16,777,216$色の組み合わせがあります。
今回の処理ではBGRそれぞれに[32,96,160,224]の4色、1つの画素値で$4^3 = 64$色に減色します。今回、減色は以下の式に従って行います。
pix = { 32 ( 0 <= pix < 64) 96 ( 64 <= pix < 128) 160 (128 <= pix < 192) 224 (192 <= pix < 256)ソースコード
decreaseColor.pyimport numpy as np import cv2 import matplotlib.pyplot as plt def decreaseColor(img): dst = img.copy() idx = np.where((0<=img) & (64>img)) dst[idx] = 32 idx = np.where((64<=img) & (128>img)) dst[idx] = 96 idx = np.where((128<=img) & (192>img)) dst[idx] = 160 idx = np.where((192<=img) & (256>img)) dst[idx] = 224 return dst # 画像読込 img = cv2.imread('../assets/imori.jpg') # 減色処理 img = decreaseColor(img) # 画像表示 plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.show()
画像左は入力画像、画像右は出力画像です。
上手く色が減っていることが分かりますね。似たような色の箇所をベタ塗りしたような出力結果になりました。おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。
それから、pythonは初心者なので間違っているところがあっても優しく指摘してあげてください。
