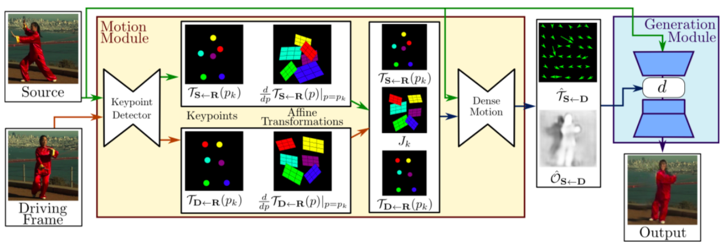
- 投稿日:2020-08-12T23:25:22+09:00
機械学習の可視化ツールTensorboardを使ってみた
はじめに
Tensorboardを初めて使いグラフを書きその便利さに感動したので、共有します。
Deep LearningのフレームワークはPyTorchを使用しました。インストール
Anacondaを使っているので以下のコマンドでTensorboardをインストールします。
conda install tensorboardコーディング
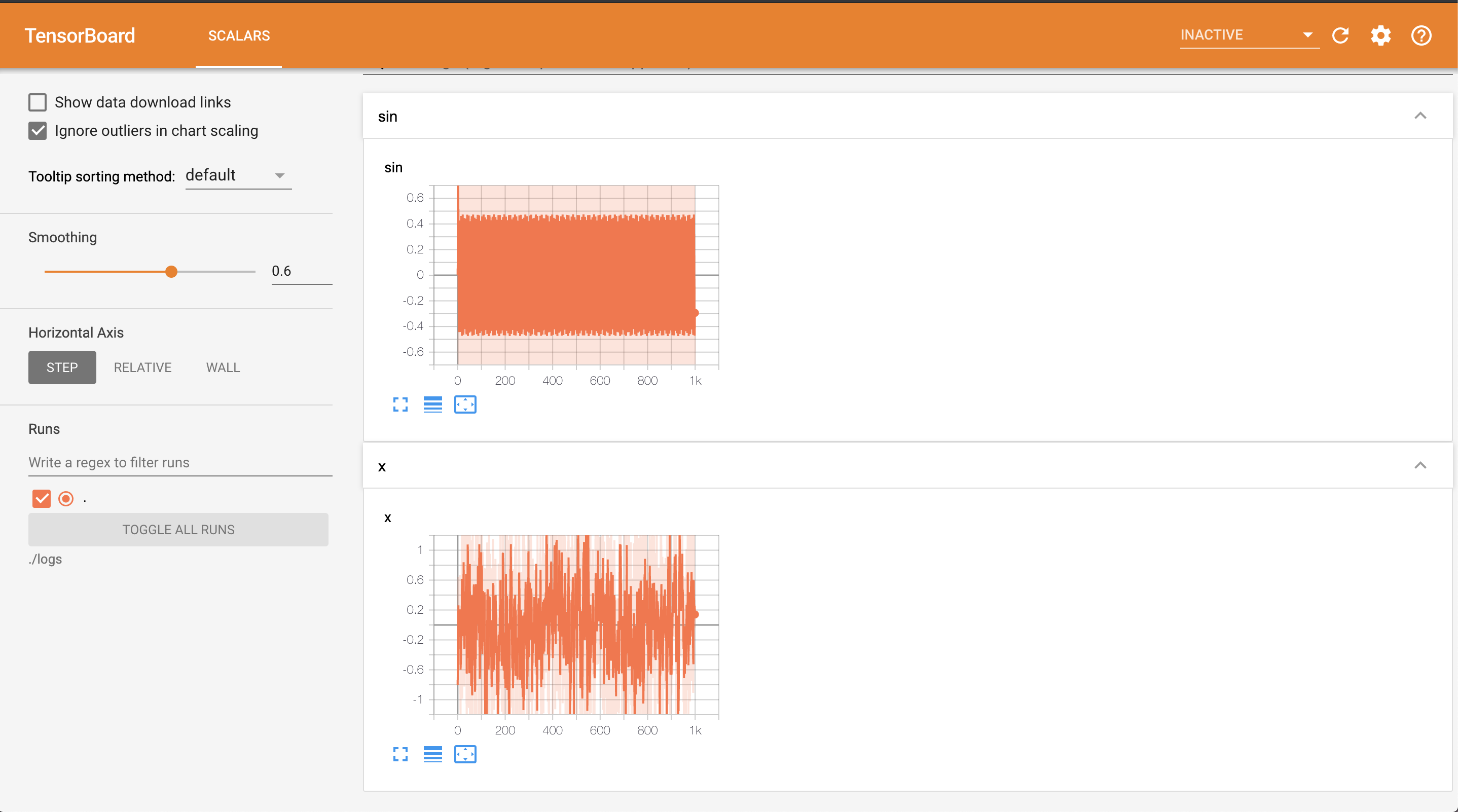
tb.pyimport numpy as np from torch.utils.tensorboard import SummaryWriter#グラフを書くSummaryWriterをimport np.random.seed(1000) x = np.random.randn(1000) writer = SummaryWriter(log_dir="./logs")#インスタンス生成 保存するディレクトリも指定 for i in range(1000): writer.add_scalar("x", x[i], i)#値を書き込む writer.add_scalar("sin", np.sin(i), i) writer.close()#閉じるファイル名をtensorboard.pyにするとmoduleと被りImportErrorになるので注意しましょう。
解説
簡単にいうと、上のコードでは、ランダムな値を持つ配列とsin関数をプロットしています。
SummaryWriterをimport
from torch.utils.tensorboard import SummaryWriter
Tensorboardでグラフの描画に必要なmoduleであるSummaryWriterをimportします。インスタンス生成
writer = SummaryWriter(log_dir="./logs")
これはカレントディレクトリにlogsディレクトリを作成し、そのlogsの中にTensorboard用のファイルが保存されます。値を代入
writer.add_scalar("x", x[i], i)で配列の値を入れます。
writer.add_scalar(tags, scalar_value, global_step)となっており、tagsでグラフの名前を指定して、scalar_valueで保存する値を代入、global_stepでグラフの横軸の間隔を指定します。閉じる
writer.close()で最後に閉じましょう。グラフをみる
tb.pyの実行
上記のコードを実行しましょう。グラフが描画されます。
python tb.pyグラフをみる
以下のコマンドを実行しましょう。
--logdir=""で保存したディレクトリを指定しましょう。
今回は./logsです。tensorboard --logdir="./logs"そうすると、以下の文がターミナルに出力されます。
TensorBoard 2.2.1 at http://localhost:8000/ (Press CTRL+C to quit)ローカルサーバーが立ち上がるので、ブラウザに
http://localhost:8000/と打ちましょう。
chromeでみると、グラフが綺麗にプロットしていることがわかります。
ssh先のグラフをみる
Deep Learningのコードは計算量が多くローカルPC(手元のPC)では莫大な時間がかかるので、
研究室にあるサーバーのGPUにsshしてサーバー上でコードを回すことがデフォルトです。
では、そういう場合はリモートサーバーで描画したグラフをローカルPCでどうやってみるのでしょうか?リモートサーバーにsshする
sshをする時に、-Lオプションを用いてクライアント(ローカルPC)のlocalhost:9000をリモートサーバーのユーザ名@サーバーのIPアドレス:8000に繋げます。
@ローカルPCssh ユーザ名@サーバーのIPアドレス -L 9000:localhost:8000リモートサーバーでtb.pyの実行
sshしたリモートサーバーでグラフを描画するコードを実行しましょう。
@リモートサーバーpython tb.pyTensorboardの実行
sshしたリモートサーバーでグラフをみるためのコマンドを実行しましょう。
sshした際にローカルPCに繋いだポートは8000なので、--portオプションで8000を指定して実行しましょう。@リモートサーバーtensorboard --logdir="./logs" --port 8000以下のような文が出力されます。
@リモートサーバーTensorBoard 2.2.1 at http://localhost:8000/ (Press CTRL+C to quit)グラフをみる
さっきは
http://localhost:8000/をブラウザに入力したら、グラフがみれましたが今回は見れません。今回はリモートサーバーのポート8000とローカルPCのポート9000を繋げたので、
ローカルPCのブラウザでhttp://localhost:9000/と入力すれば、さっきと同じグラフが見れます。
まとめ
PyTorchでTensorboardを用いてグラフを描画しました。
また、ssh先のリモートサーバーでまわしたコードのグラフをローカルPCでみる方法を紹介しました。
私もこのTensorboardとssh -Lを利用してDeep Learningに活用していきたいと思います。
- 投稿日:2020-08-12T23:14:19+09:00
【Python】PDFからコピーした改行コードだらけのテキストを上手いこと整形する
はじめに
もともとは前々回、前回の記事
【Python】英文PDF(に限らないけど)をDeepLやGoogle翻訳で自動で翻訳させてテキストファイルにしてしまおう。
続【Python】英文PDF(に限らないけど)をDeepLやGoogle翻訳で自動で翻訳させてテキストファイル、いやHTMLにしてしまおう。で使用するために書いたものですが、役に立ちそうなので別途紹介する次第です。
PDFからコピーしたテキストの問題点
PDFについての詳しい知識は持ち合わせていないのですが、
PDF内ではテキストが細かいパーツに分割されて書き込んであるようで、コピーしたテキストにもPDFでの表示の通りの位置に改行コードが含まれます。例えば、PDFで
$$ABC.\\DFE.\\GHI.$$
のような表示の場合、コピーしたテキストは、
$$ABC.{\r\n}DEF.{\r\n}GHI.$$
といった具合です。(上の例はWindows系の場合)
だったらその改行コードを消して文章を繋げればいいじゃないかということで、
$$ABC.DEF.GHI.$$
このようにすると、この例の場合、ピリオドがあるのでそれぞれの文章が混ざることなく済んでいます。
ところがこれで全て解決するかと言うと、そんなに単純な話ではないのです。以下のような場合はどうでしょう
$$1. Introduction\\ABCDEF.\\GHIJKL.\\MNOPQR.$$
単純に改行コードを消すだけだと、
$$1. IntroductionABCDEF.GHIJKL.MNOPQR.$$
となりピリオドのない1行目と2行目の区別がつかなくなってしまいました。
つまり問題となるのは、
見出しなどといったピリオドのような切れ目の目印が必ずしも付かないパーツを、
文章と改行コードしかヒントの存在しないコピーしてきたテキストから如何にして推測し、分解するか。
という点です。やったこと
- 改行コードで分割する
- 空行を消す
- 分割された 注目している文章と次の文章との文字数の差から、本文か見出し文か推測する
- 次の文章の1文字目が小文字かどうかで判断する
- すべて大文字の場合、見出し文と判断する
- 数字(アラビア数字、ローマ数字)+.(ピリオド)が頭についていたら見出し文と判断する
- 注目している文章と次の文章との文字数の差が大きかった場合でも、次の文章ののほうが短く、かつピリオド(または句点)がついていた場合、連続する文と判断する
- 括弧が閉じていない限り連続する文と判断する。
などといった方法を採用しました。
結構シンプルですが大抵の文章は・見出し
・段落
・文章のいずれかの単位で分割する事ができる関数が出来上がりました。
コード
import re import unicodedata def len_(text): cnt = 0 for t in text: if unicodedata.east_asian_width(t) in "FWA": cnt += 2 else: cnt += 1 return cnt def textParser(text, n=30, bracketDetect=True): text = text.splitlines() sentences = [] t = "" bra_cnt = ket_cnt = bra_cnt_jp = ket_cnt_jp = 0 for i in range(len(text)): if not bool(re.search("\S", text[i])): continue if bracketDetect: bra_cnt += len(re.findall("[\((]", text[i])) ket_cnt += len(re.findall("[\))]", text[i])) bra_cnt_jp += len(re.findall("[「「『]", text[i])) ket_cnt_jp += len(re.findall("[」」』]", text[i])) if i != len(text) - 1: if bool(re.fullmatch(r"[A-Z\s]+", text[i])): if t != "": sentences.append(t) t = "" sentences.append(text[i]) elif bool( re.match( "(\d{1,2}[\.,、.]\s?(\d{1,2}[\.,、.]*)*\s?|I{1,3}V{0,1}X{0,1}[\.,、.]|V{0,1}X{0,1}I{1,3}[\.,、.]|[・•●])+\s", text[i])) or re.match("\d{1,2}.\w", text[i]) or ( bool(re.match("[A-Z]", text[i][0])) and abs(len_(text[i]) - len_(text[i + 1])) > n and len_(text[i]) < n): if t != "": sentences.append(t) t = "" sentences.append(text[i]) elif ( text[i][-1] not in ("。", ".", ".") and (abs(len_(text[i]) - len_(text[i + 1])) < n or (len_(t + text[i]) > len_(text[i + 1]) and bool( re.search("[。\..]\s\d|..[。\..]|.[。\..]", text[i + 1][-3:]) or bool(re.match("[A-Z]", text[i + 1][:1])))) or bool(re.match("\s?[a-z,\)]", text[i + 1])) or bra_cnt > ket_cnt or bra_cnt_jp > ket_cnt_jp)): t += text[i] else: sentences.append(t + text[i]) t = "" else: sentences.append(t + text[i]) return sentences結果がイマイチなときは
nの値を調節してみてください(大きいほど纏まって、小さいほどばらけます)。
括弧の数が何らかの理由でズレて文章が変に固まってしまった場合はbracketDetectをFalseにしてください。使用例
Python 3.8.5 Documentation
PDF (US-Letter paper size)\tutorial.pdf ページ番号5(p.11)より原文をコピーしたもの
CHAPTER TWO USING THE PYTHON INTERPRETER 2.1 Invoking the Interpreter The Python interpreter is usually installed as /usr/local/bin/python3.8 on those machines where it is available; putting /usr/local/bin in your Unix shell’s search path makes it possible to start it by typing the command: python3.8 to the shell.1 Since the choice of the directory where the interpreter lives is an installation option, other places are possible; check with your local Python guru or system administrator. (E.g., /usr/local/python is a popular alternative location.) On Windows machines where you have installed Python from the Microsoft Store, the python3.8 command will be available. If you have the py.exe launcher installed, you can use the py command. See setting-envvars for other ways to launch Python. Typing an end-of-file character (Control-D on Unix, Control-Z on Windows) at the primary prompt causes the interpreter to exit with a zero exit status. If that doesn’t work, you can exit the interpreter by typing the following command: quit(). The interpreter’s line-editing features include interactive editing, history substitution and code completion on systems that support the GNU Readline library. Perhaps the quickest check to see whether command line editing is supported is typing Control-P to the first Python prompt you get. If it beeps, you have command line editing; see Appendix Interactive Input Editing and History Substitution for an introduction to the keys. If nothing appears to happen, or if ^P is echoed, command line editing isn’t available; you’ll only be able to use backspace to remove characters from the current line. The interpreter operates somewhat like the Unix shell: when called with standard input connected to a tty device, it reads and executes commands interactively; when called with a file name argument or with a file as standard input, it reads and executes a script from that file. A second way of starting the interpreter is python -c command [arg] ..., which executes the statement(s) in command, analogous to the shell’s -c option. Since Python statements often contain spaces or other characters that are special to the shell, it is usually advised to quote command in its entirety with single quotes. Some Python modules are also useful as scripts. These can be invoked using python -m module [arg] ..., which executes the source file for module as if you had spelled out its full name on the command line. When a script file is used, it is sometimes useful to be able to run the script and enter interactive mode afterwards. This can be done by passing -i before the script. All command line options are described in using-on-general. 1 On Unix, the Python 3.x interpreter is by default not installed with the executable named python, so that it does not conflict with a simultaneously installed Python 2.x executable.各行末に改行コードが入っています。わかりやすいように”改行コードのまま”表示すると
CHAPTER\r\nTWO\r\nUSING THE PYTHON INTERPRETER\r\n2.1 Invoking the Interpreter\r\nThe Python interpreter is usually installed as /usr/local/bin/python3.8 on those machines where it is available;\r\nputting /usr/local/bin in your Unix shell’s search path makes it possible to start it by typing the command:\r\npython3.8\r\nto the shell.1 Since the choice of the directory where the interpreter lives is an installation option, other places are possible;\r\ncheck with your local Python guru or system administrator. (E.g., /usr/local/python is a popular alternative\r\nlocation.)\r\nOn Windows machines where you have installed Python from the Microsoft Store, the python3.8 command will be\r\navailable. If you have the py.exe launcher installed, you can use the py command. See setting-envvars for other ways to\r\nlaunch Python.\r\nTyping an end-of-file character (Control-D on Unix, Control-Z on Windows) at the primary prompt causes the\r\ninterpreter to exit with a zero exit status. If that doesn’t work, you can exit the interpreter by typing the following command:\r\nquit().\r\nThe interpreter’s line-editing features include interactive editing, history substitution and code completion on systems that\r\nsupport the GNU Readline library. Perhaps the quickest check to see whether command line editing is supported is typing\r\nControl-P to the first Python prompt you get. If it beeps, you have command line editing; see Appendix Interactive\r\nInput Editing and History Substitution for an introduction to the keys. If nothing appears to happen, or if ^P is echoed,\r\ncommand line editing isn’t available; you’ll only be able to use backspace to remove characters from the current line.\r\nThe interpreter operates somewhat like the Unix shell: when called with standard input connected to a tty device, it reads\r\nand executes commands interactively; when called with a file name argument or with a file as standard input, it reads and\r\nexecutes a script from that file.\r\nA second way of starting the interpreter is python -c command [arg] ..., which executes the statement(s) in\r\ncommand, analogous to the shell’s -c option. Since Python statements often contain spaces or other characters that are\r\nspecial to the shell, it is usually advised to quote command in its entirety with single quotes.\r\nSome Python modules are also useful as scripts. These can be invoked using python -m module [arg] ...,\r\nwhich executes the source file for module as if you had spelled out its full name on the command line.\r\nWhen a script file is used, it is sometimes useful to be able to run the script and enter interactive mode afterwards. This\r\ncan be done by passing -i before the script.\r\nAll command line options are described in using-on-general.\r\n1 On Unix, the Python 3.x interpreter is by default not installed with the executable named python, so that it does not conflict with a simultaneously\r\ninstalled Python 2.x executable.このような形になっています。
今回作った関数に投げてみます。
上の文がクリップボードにコピーされている状態を想定して、from pyperclip import paste #クリップボードから値(テキスト)を取得する関数 print("\n".join(textParser(paste())))outCHAPTER TWO USING THE PYTHON INTERPRETER 2.1 Invoking the Interpreter The Python interpreter is usually installed as /usr/local/bin/python3.8 on those machines where it is available;putting /usr/local/bin in your Unix shell’s search path makes it possible to start it by typing the command:python3.8to the shell.1 Since the choice of the directory where the interpreter lives is an installation option, other places are possible;check with your local Python guru or system administrator. (E.g., /usr/local/python is a popular alternativelocation.)On Windows machines where you have installed Python from the Microsoft Store, the python3.8 command will beavailable. If you have the py.exe launcher installed, you can use the py command. See setting-envvars for other ways tolaunch Python. Typing an end-of-file character (Control-D on Unix, Control-Z on Windows) at the primary prompt causes theinterpreter to exit with a zero exit status. If that doesn’t work, you can exit the interpreter by typing the following command:quit(). The interpreter’s line-editing features include interactive editing, history substitution and code completion on systems thatsupport the GNU Readline library. Perhaps the quickest check to see whether command line editing is supported is typingControl-P to the first Python prompt you get. If it beeps, you have command line editing; see Appendix InteractiveInput Editing and History Substitution for an introduction to the keys. If nothing appears to happen, or if ^P is echoed,command line editing isn’t available; you’ll only be able to use backspace to remove characters from the current line. The interpreter operates somewhat like the Unix shell: when called with standard input connected to a tty device, it readsand executes commands interactively; when called with a file name argument or with a file as standard input, it reads andexecutes a script from that file. A second way of starting the interpreter is python -c command [arg] ..., which executes the statement(s) incommand, analogous to the shell’s -c option. Since Python statements often contain spaces or other characters that arespecial to the shell, it is usually advised to quote command in its entirety with single quotes. Some Python modules are also useful as scripts. These can be invoked using python -m module [arg] ...,which executes the source file for module as if you had spelled out its full name on the command line. When a script file is used, it is sometimes useful to be able to run the script and enter interactive mode afterwards. Thiscan be done by passing -i before the script. installed Python 2.x executable.Pretty good!
とは言ったものの、これだけきれいなPDFをきれいに分割できるのは当然で、
もっと複雑な1カラムと2カラムを行き来するようなPDFにも使えますのでお試しあれ。まとめ
あらゆるPDFに対して完璧に整えられるわけでは決してありませんが、そこそこ使える物ができました。
日本語のPDFにも対応していますが、日本語PDFはOCRでテキストが振ってあることが結構あるのでそういう場合は.replace(" ","")などしてスペースを消してやればきれいになると思います(英文が含まれてるとこの方法は使えませんが)。
前記事のようにPDFを翻訳したいときなど、何気に使い道が多いと思うので、ぜひ使ってやってください。
- 投稿日:2020-08-12T22:23:22+09:00
【データサイエンティスト入門】Pythonの基礎♬関数とクラス
昨夜の【データサイエンティスト入門】Pythonの基礎♬関数と無名関数ほかの続きで関数とクラスの話です。
【注意】
「東京大学のデータサイエンティスト育成講座」を読んで、ちょっと疑問を持ったところや有用だと感じた部分をまとめて行こうと思う。
したがって、あらすじはまんまになると思うが内容は本書とは関係ないと思って読んでいただきたい。前振り
この章では、pythonの関数呼び出しの仕組みと,クラスの記載法と関数との違いを中心にまとめます。
関数の呼び出しの仕組みについては、以下を参考にしています。
【参考】
モジュールの関数呼び出し@PyQChapter1-2 Pythonの基礎
1-2-6 クラスとインスタンス
クラスからインスタンスを生成する。
ここでは、本書を少し離れて、関数呼び出しとクラスの宣言、そしてインスタンス実行の類似性を示すこととする。関数呼び出し
関数は、一つのPG内で利用することもあるが、複雑なPGを書こうとすると、構造的なディレクトリ構成にして、Package的に関数を保存して利用する。その場合、重要な仕組みがpythonにはある。
すなわち、以下のコードを>python calc_add.pyで実行すると以下の順番に動作する。
①二つの関数定義が行われる
②__name__にcalc_addというモデュール名が代入される
③
④if文がTrueであり、以下の二つのcalc_add.pydef calc_add(a, b): return a + b def calc_multi(a, b): return a * b print('__name__:', __name__) if __name__ == '__main__': print(calc_add(5,3)) print(calc_multi(5, 3))結果
__name__: __main__ 8 15他のコード
main.pyから実行するこの場合、
>python main.pyと実行すると
①最初の宣言文により、calc_add.pyから二つの関数calc_add, calc_multiを読み込む。このとき、出力を見ると分かるように上記のcalc_add.pyが実行され、__name__: calc_addが出力される。if文はFalse(__name__ = calc_add)なので、実行されない
②次に、main.pyのprint文が実行される
③main.pyのif文はTrueなので、以下の二つの
という仕組みで、関数呼び出しして使えるようになっている。
④というわけで、if __name__ == '__main__':という記法が入れる必要があるというわけです。しかし、呼び出して使う場合は必須ではない。main.pyfrom calc_add import calc_add, calc_multi print('__name__2:', __name__) if __name__ == '__main__': print(calc_add(5,3)) print(calc_multi(5, 3))結果
__name__: calc_add __name__2: __main__ 8 15注意)
print('__name__:', __name__)は仕組み説明のために入れているものであり、通常は必要ないclass
classも見た目、関数と同じ。
ただし、classの宣言をする。
そして、クラスはif文の中を見ると分かるように、instanceを定義してから、class内で定義した関数を呼び出して利用する。
この仕組みをオブジェクト指向と呼んでいる。
すなわち、classから多くのinstanceを生成して、それを実行させる仕組みである。
クラス定義の特徴は以下の通り。
①class宣言する
②コンストラクタdef __init__(self,x,y):を定義する。selfという変数は必須で定義する(selfという変数は特別だけど、これを単なる変数の一つなんだと思えるようになるまで少し時間がかかった)。引数xやyはその時々で必要なものを定義する。
【参考】
Pythonのselfとは?使い方や注意点について解説selfについて ・selfはinstance宣言時、引数として記述しない ・selfはクラス変数である ・クラス継承の際も使える ・クラス変数にもインスタンス変数にも値がある場合は、インスタンス変数を優先して参照③コンストラクタ
def __init__(self,x,y):はクラスのinstanceを定義した時点で、最初に動くコードである。
④その他の必要な関数を定義する。
⑤instance.calc_add()のように必要な処理を実行する
⑥if __name__ == '__main__':は、関数の時と同じ理由で書くが、呼び出して使う場合は必須ではないので、多くのクラスはこのif文や実行文が無い。
注意)print('__name__:', __name__)は仕組み説明のために入れているものであり、通常は必要ないcalc_class.pyclass MyCalcClass: def __init__(self,x,y): self.x = x self.y = y def calc_add1(self, a, b): return a + b def calc_add2(self): return self.x + self.y def calc_multi(self, a, b): return a * b print('__name__:', __name__) if __name__ == '__main__': instance_1 = MyCalcClass(1,2) instance_2 = MyCalcClass(5,10) print(instance_1.calc_add1(5,3)) print(instance_1.calc_add2()) print(instance_1.calc_multi(5, 3)) instance_1.calc_print(5)
>python calc_class.py
結果
以下の通りだが、結果はinstance1の初期値に依存して計算しているのが分かる。
if文部分を削除すると__name__: __main__のみ出力される。__name__: __main__ 8 3 15 data:5: yの値2他のコード
main.pyから実行するmain_class.pyfrom calc_class import MyCalcClass print('__name__2:', __name__) if __name__ == '__main__': instance_1 = MyCalcClass(1,2) instance_2 = MyCalcClass(5,10) print(instance_1.calc_add1(5,3)) print(instance_1.calc_add2()) print(instance_1.calc_multi(5, 3)) instance_1.calc_print(5)結果
>python main_class.py
もちろん、結果は↑と同じです。ただし、関数と同じように__name__: calc_classが出力されている。
すなわち、__name__には、呼び出したファイル名が入力され、自分自身のときは、__main__が入力される。__name__: calc_class __name__2: __main__ 8 3 15 data:5: yの値2まとめ
・関数呼び出しとクラスを比較してみた
・クラス定義して呼び出して、インスタンスを実行した・一般的なpythonコードを記述する一歩手前まで来た
・本書は、この項でpythonの基礎は終わるが、不足した部分は、今後の項で補足される(ある意味、本書はこれからもpythonの各種Libを利用してのコード解説である)
- 投稿日:2020-08-12T22:04:39+09:00
【成長日記:3日目】根尾くんのプロ初ヒットを見守るプログラムを書いてみた【NEO-METER】
根尾くん、プロ初ヒットおめでとう!
— ゆーさん (@fukannk0423) August 11, 2020
プログラムも無事に動いてくれました
NEO-METER 1 pic.twitter.com/tl05IWZVIm2018年ドラフト会議で4球団競合の末中日ドラゴンズに入団した根尾昂選手ですが、2019年の間はなかなか1軍での出番をもらえずノーヒットでシーズンを終えました。
しかし2020年は2軍での打撃成績の向上にともなって1軍に呼ばれる機会が増え、プロ初ヒットを待ちわびるファンが根尾くんの打席に注目するようになりました。
僕もそんなファンの一人です。ということで今回は、イチメーター(ICHI-METER)になぞらえて根尾くんのプロ初ヒットの瞬間を記録するためのプログラムをPythonで書きました。よかったこと
根尾くんの初ヒットまでにプログラムを完成させないといけないという制限がある中なんとか動くプログラムの作成までこぎつけることができた
悪かったこと
プログラムの中身に関してはまだまだ納得いかない要素が多く、「動きゃなんでもいい」というような付け焼刃なプログラムになってしまった
ということで、ここで振り返りたいと思います。
NEO-METER.pyの内容
基本的には、
1分ごとにスポナビの試合速報ページから根尾くんの安打数をスクレイピングするループを回して、安打数が1になったらbreakし「プロ初ヒット」のメッセージを出す
という内容のプログラムです。単純にそれだけだと根尾くんのヒットが出るまで何日でもループを続けてしまうので、ループを抜けるための条件をいくつか追加しています。
1. 試合が行われてない時(試合終了時)
2. 根尾くんが試合に出てない時
3. 240回ループを回した時以下がスクリプトです。
NEO-METER.pyimport requests import time from bs4 import BeautifulSoup import re import pandas as pd #今回はデータ処理とかしてないので使ってない neo_meter = 0 #根尾くんの安打数 count = 0 #ループした回数 endgame = False #試合終了を判断 #1分ごとにwhileループを回す while neo_meter == 0: #試合終了を判断するためにスポナビの試合ページをスクレイピングする html_eg = requests.get('https://baseball.yahoo.co.jp/npb/game/2020081102/top') soup_eg = BeautifulSoup(html_eg.content, "html.parser") ext_eg = soup_eg.select(".bb-gameCard__state") ext_eg_2 = ext_eg[0].text if '試合終了' in ext_eg_2: print('試合は終了しました') endgame = True break print('試合継続中') #ループを240回回したらbreakする if count >= 240:break #スポナビの試合ページから選手の試合成績をスクレイピングする html = requests.get('https://baseball.yahoo.co.jp/npb/game/2020081102/stats') soup = BeautifulSoup(html.content, "html.parser") ext = soup.select("td") txt = [] for i in ext: txt_temp = i.text txt.append(re.sub('\n', '', txt_temp)) #根尾くんの試合成績の部分を抜き出し、試合に出場してなかったらbreakする kensaku = '根尾' ind = [] for i,name in enumerate(txt): if kensaku in name: ind.append(i) if len(ind) == 0 :break neo = txt[ind[0]-1:ind[0]+22] ''' スポナビのページのHTMLの仕様で、 ビジターチームの打席の結果だけ、</td>が省略されているので成績表示がバグる。 NEO-METERには直接影響しないので今回はスルー ''' #根尾くんの安打数を確認しprintする #安打数が0だったらもう一度ループ、0でなかったらbreakする neo_meter = int(neo[5]) count = count + 1 print('NEO-METER', neo_meter) if neo_meter != 0:break print('終了まであと', 240 - count, '回ループを回します') time.sleep(60) #breakの条件によってメッセージを出す if neo_meter > 0: print('根尾選手、プロ初ヒット!\nN E O - M E T E R ', neo_meter-1, '→', neo_meter) else: if len(ind) == 0: print('根尾くんは今日はまだ試合に出てないみたい') elif endgame == True: print('根尾くんプロ初ヒットならず\nまた次の試合') elif count >= 240: print('240回ループを回したのでプログラムを終了します') else: print('予期せぬエラーが起きました。') exit()反省点
- ところどころバグを起こす要素が残っている
ind[]のリストの要素が2つ以上になった場合うまく成績を抜き出せない可能性- その他、主に制御文関連に自信なし
- 最初に日付を
input()で入力することでその日の中日の試合のページをスクレイピングするという機能にしたかった
- というか今日の日付から勝手にサイトをクローリングして中日の試合に飛ぶようにしたかった
- というか今日の日付自体自動で取得できる気がする
- 「只今根尾くんは打席に立っています どきどき」とか「現在相手チームの攻撃 根尾くんはセンターの守備位置についています」とかもっと状態を逐一報告させたかった
- 根尾くんがヒットを打った日を同時に表示しておいた方がのちのち振り返るときに記念日の感があってよかった
- 厳密には今日の試合の安打数のカウントをしているだけなので、ICHI-METERのように通算安打をカウントする際は改変が必要
- ループを抜けたい時にいつでも抜けられる機能を追加したかった
- プログラムが流れ作業っぽすぎてまとまりがない
- オブジェクト指向っぽいプログラムを作成できなかった
と反省する部分はたくさんありますが、とりあえず根尾くんの記念すべきプロ初ヒットを自分なりに祝うことができたので嬉しいです。今後も野球関連でおもしろそうなプログラムを書いていきたいです。
展望
「任意の選手の通算安打数をカウントする」という内容でclass化して「XXX-METER」というモジュールを作る
- 投稿日:2020-08-12T21:48:51+09:00
暇だったのでカラオケ作ってみた(第2回 ボーカル抽出と音程推定)
内容
今回はspleeterで音楽ファイルからボーカルの分離とpyworldで分離したボーカルから音程(ピッチ)を推定するところを記述します。
spleeterによるボーカル分離
まず、分離したい音楽を用意してください。
今回は魔王魂様からシャイニングスターをお借りしました。
今回は ./music に test.mp3 に名前を変更して配置しています。from spleeter.separator import Separator def main(): sp = Separator("spleeter:2stems") sp.separate_to_file("music/test.mp3","music/spleeter") if __name__ == '__main__': main()とすると ./music/spleeter にtestフォルダが作成されその中にvocals.wavとaccompaniment.wavが作成されます。
music/
├ test.mp3
└ spleeter/
├ vocals.wav
└accompaniment.wav
のようになっていれば成功です。pyworldによる音程推定
公式のGitHubにf0(ピッチ)推定のやり方があるのでそれをもとに実行していきます。
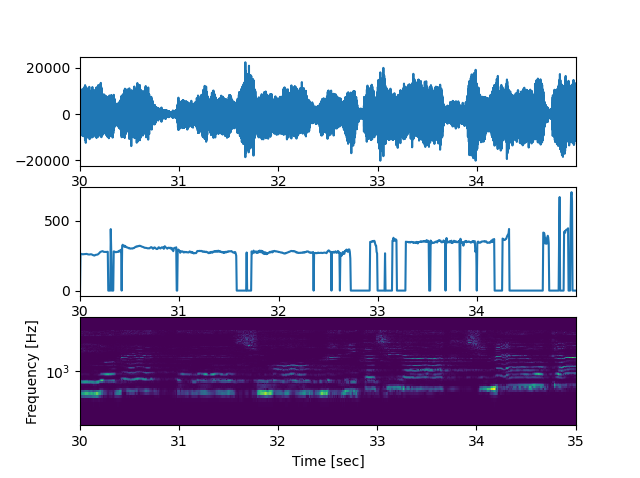
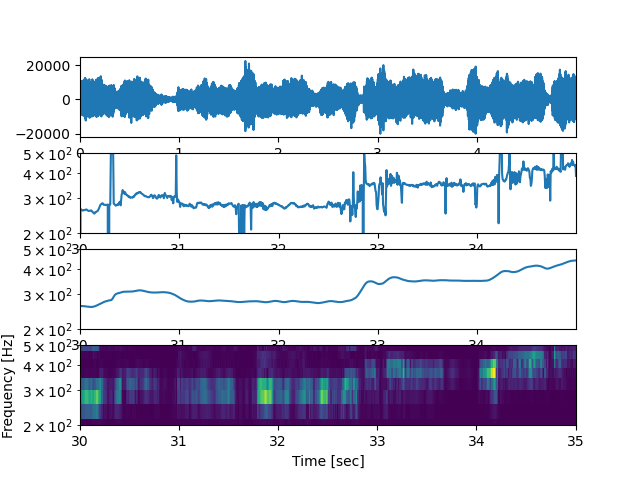
まず、波形・f0推定・スペクトログラムを見てみます。import pyworld as pw import matplotlib.pyplot as plt import numpy as np from scipy import signal from pydub import AudioSegment start = 30 #音声の抜き出し範囲 前半に無音区間があるのでそこを避けた end = 35 sound = AudioSegment.from_wav("music/spleeter/test/vocals.wav") fs = sound.frame_rate #音声はステレオなので片方を抽出する data = np.array(sound.get_array_of_samples())[start*fs*2:end*fs*2:2] data = data.astype(np.float) #音声波形の表示 t=np.arange(data.shape[0])*(data.shape[0]/fs/data.shape[0])+start plt.subplot(3,1,1) plt.plot(t,data) plt.xlim([t[0],t[-1]]) #f0推定の表示 plt.subplot(3,1,2) _f0, _time = pw.dio(data, fs) # 基本周波数の抽出 f0 = pw.stonemask(data, _f0, _time, fs) # 基本周波数の修正 t=np.arange(f0.shape[0])*(data.shape[0]/fs/f0.shape[0])+start plt.plot(t,f0) plt.xlim([t[0],t[-1]]) #スペクトログラムの表示 plt.subplot(3,1,3) f, t, Zxx = signal.stft(data, fs, nperseg=1024) plt.pcolormesh(t+start, f, np.abs(Zxx)) plt.ylim([f[1], f[-1]]) plt.ylabel('Frequency [Hz]') plt.xlabel('Time [sec]') plt.yscale('log') plt.show()これを実行すると
のような画像が作成されます。
推定はうまくいってそうですが、一部音声があるのにもかかわらず推定されていない場所がありますね。
これを改善するためにパラメータを指定してみます。
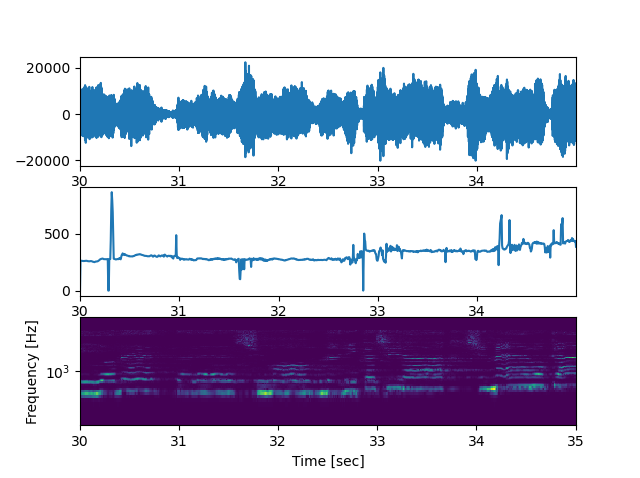
先ほどの周波数の抽出の部分を以下のように修正します。_f0, _time = pw.dio(data, fs,allowed_range=1)このように修正すると
少々外れ値がありますが、先ほどのような推定されない区間がなくなりました。
さて、次はこのグラフを外れ値を取り除いて滑らかにしたいと思います。
今回は畳み込み積分を利用して外れ値の推定と補正を行います。
こちらのサイトに詳しい畳み込み積分の説明があります。
異なる点として畳み込みする数列を以下のようにしています。
このようにすることで外れ値の時は畳み込み積分後の数列と元の数列で値の差に幅が生まれます。
また距離に応じて減衰させることで、近くの値の重みを重視するようにしました。
コードは以下の通りです。#畳み込み積分を行う関数 #useCenter=Falseのとき、weightの中央の値を0にする。 #つまり畳み込み積分を行うときにその値を使用しない。(外れ値推定に利用) def avg(f0,r,useCenter=False): ''' :param f0:畳み込み積分したい音程 :param r: 値を使用する半径 :param useCenter: もとの数列の値を使用するか(外れ値用) :return: 畳み込み積分後の音程 ''' weight = np.arange(2*r+3) weight = 1-np.abs(1-weight/(r+1))[1:-1] if not useCenter: weight[r]=0 arr = np.convolve(f0,weight,"same") arr_num = np.convolve(f0>0,weight,"same") arr_num[arr_num==0]=1 arr_avg = arr/arr_num return arr_avgこれを利用すると
このように外れ値の場合は周囲から推定を行うのでかなり滑らかになります。
以下にすべてのコードを示します。import pyworld as pw import matplotlib.pyplot as plt import numpy as np from scipy import signal from pydub import AudioSegment start=30 end=35 r=20 sound = AudioSegment.from_wav("music/spleetertest/test/vocals.wav") fs = sound.frame_rate data = np.array(sound.get_array_of_samples())[start*fs*2:end*fs*2:2] data = data.astype(np.float) _f0, _time = pw.dio(data, fs,allowed_range=1) # 基本周波数の抽出 f0 = pw.stonemask(data, _f0, _time, fs) # 基本周波数の修正 #畳み込み積分を行う関数 #useCenter=Falseのとき、weightの中央の値を0にする。 #つまり畳み込み積分を行うときにその値を使用しない。(外れ値推定に利用) def avg(f0,r,useCenter=False): ''' :param f0:畳み込み積分したい音程 :param r: 値を使用する半径 :param useCenter: もとの数列の値を使用するか(外れ値用) :return:畳み込み積分後の音程 ''' weight = np.arange(2*r+3) weight = 1-np.abs(1-weight/(r+1))[1:-1] if not useCenter: weight[r]=0 arr = np.convolve(f0,weight,"same") arr_num = np.convolve(f0>0,weight,"same") arr_num[arr_num==0]=1 arr_avg = arr/arr_num return arr_avg t=np.arange(data.shape[0])*(data.shape[0]/fs/data.shape[0]) plt.subplot(4,1,1) plt.plot(t,data) plt.xlim([t[0],t[-1]]) plt.subplot(4,1,2) index=np.arange(f0.shape[0]) t=np.arange(f0.shape[0])*(data.shape[0]/fs/f0.shape[0])+start plt.plot(t,f0) plt.yscale('log') plt.ylim([200, 500]) plt.xlim([t[0],t[-1]]) plt.subplot(4,1,3) f0_=avg(f0,r) br=np.abs(f0-f0_)>50 #推定との差が50Hz以上ある場合は外れ値として値を無視します f0[br]=0 f0=avg(f0,r,useCenter=True) t=np.arange(f0.shape[0])*(data.shape[0]/fs/f0.shape[0])+start plt.plot(t,f0) plt.yscale('log') plt.ylim([200, 500]) plt.xlim([t[0],t[-1]]) plt.subplot(4,1,4) f, t, Zxx = signal.stft(data, fs, nperseg=1024) plt.pcolormesh(t+start, f, np.abs(Zxx)) plt.ylim([200, 500]) plt.ylabel('Frequency [Hz]') plt.xlabel('Time [sec]') plt.yscale('log') plt.show()次回
次回は音の区切りを決めていきたいなと思います。
- 投稿日:2020-08-12T21:28:13+09:00
pythonでrequests使ってスクレイピングやろうとしたらSSLErrorでハマったので、対処法メモ
背景
題名の通り。結構ググっても、日本語でも英語でもなかなか解決方法見つからなかったので、再発時に参照できるようメモ
エラーが発生したコード
実際はwikipediaではないけど、
https://~のサイトをスクレイピングした際に発生した。
今触ってるPCだと、そのサイトが対象でもエラー出ずにスクレイピングできる。なぜだ・・・環境の問題?import requests url = 'https://ja.wikipedia.org/wiki/%E3%83%A1%E3%82%A4%E3%83%B3%E3%83%9A%E3%83%BC%E3%82%B8' response = requests.get(url) result = response.text print(result)そのときのエラーメッセージは控えられてないけど、
SSLErrorでbad handshakeという単語が含まれてたのは覚えてる対処法
verify=False作戦は使いたくなかったので色々調べ倒したところ、urllibとsslを使ったらエラー発生せずにスクレイピングできた。
ココさえ乗り越えれば、あとはBeaurifulSoup4使って欲しい要素だけ抜き出せばOKimport urllib.request import ssl url = 'https://ja.wikipedia.org/wiki/%E3%83%A1%E3%82%A4%E3%83%B3%E3%83%9A%E3%83%BC%E3%82%B8' context = ssl.SSLContext() req = urllib.request.Request(url=url) with urllib.request.urlopen(req, context=context) as f: result = f.read().decode() print(result)参考にしたサイト
- 投稿日:2020-08-12T20:45:08+09:00
【keras】noisy studentを実装して効果確認
概要
noisy studentはImagenetでSOTAをたたき出した手法です。
普通データを増やして再学習するときは人間が教師データを作る必要がありますが、noisy studentはとにかくデータを集めて現状のモデルに推論して仮の教師データとして再学習させることで精度を上げられますので、教師データの作成の時間がいらないということになります。厳密には元のラベルのいずれかに該当するデータを集めてこないといけないですが、人が教師をつける必要がないのはありがたいですね。詳しい説明は以下のサイトを参考にしてみてください。
解説: 画像認識の最新SoTAモデル「Noisy Student」を徹底解説!
論文:Self-training with Noisy Student improves ImageNet classificationやっている1つ1つはそこまで難しいことはやっていないので本記事ではimagenetを使って再現をしてみよう
と思いましたが私のPC能力では学習にとても時間がかかるのでresnet50とcifar10での実験をしてみました。
手順と実装のやり方の参考として読んでいただけると幸いです。前提
tensorflow 1.15.0
keras 2.3.1
Python 3.7.6
numpy 1.18.1
core i7
GTX1080tinoisy studentの手順
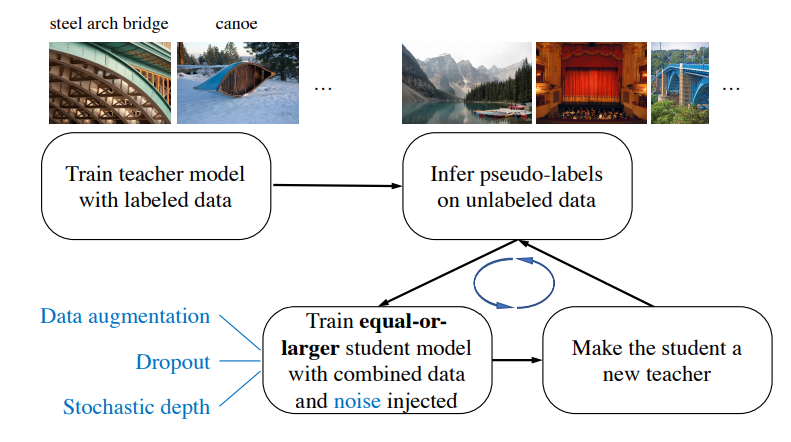
noisy studentの手順としては以下の通りになります。
引用:Self-training with Noisy Student improves ImageNet classification
日本語にしてまとめると
- 教師となるモデルをラベル有データのみで学習させる
- 教師モデルでラベルなしデータに疑似ラベルをつける
- 教師モデルと同じか大きい生徒モデルを用意する
- 生徒モデルをラベル有+疑似ラベルデータでノイズを与えて学習させる
ここでノイズとは
- Rand Augmentation→入力画像に対するノイズ
- Dropout→モデルに対するノイズ
- Stochastic depth→モデルに対するノイズ
です。
実装するにあたってそれぞれ簡単に説明しておきます。Rand Augmentation
たった2行で画像認識モデルの精度向上!?新しいDataAugmentation自動最適化手法「RandAugment」解説!
上記が解説がわかりやすいです。
要約すると、データ拡張の種類をX個準備して
- X個の中からN個取り出す
- MでAugmentationの強さを決める
以上です。簡単ですね。
noisy studentの論文ではN=2, M=27を採用しています。
今回の私の実装ではN=2, M=10としてます。
cifar10は画像サイズ小さいのであまり強くノイズをかけたら良くないかなという理由です。Dropout
これは有名なので割愛します。
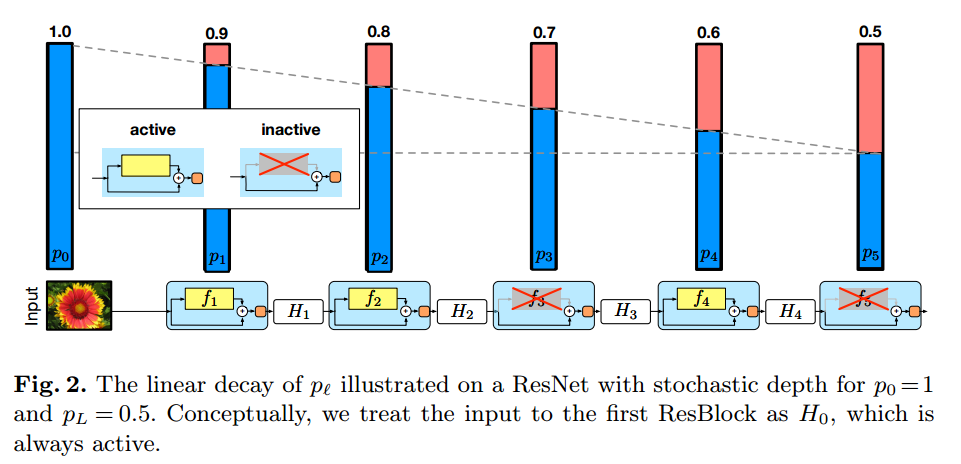
noisy studentの論文では0.5を採用しています。Stochastic depth
[Survey]Deep Networks with Stochastic Depth
詳しく知りたい方は上記の解説を参考にしてみてください。
引用:Deep Networks with Stochastic Depth上記の画像を元に簡単に説明します。
まずは基本としてはresnetの出力を確率的にスキップしている部分だけにするというものです。
そして、その確率を層が深くなるにつれて直線的に高くしていきます。
noisy studentの論文では最後の層を0.8としています。また、推論時にはその確率を各resnet blockの出力に乗算します。
実装
前段が長かったですが実装していきたいと思います。
ここで、手順をおさらいしておきます。
- 教師となるモデルをラベル有データのみで学習させる
- 教師モデルでラベルなしデータに疑似ラベルをつける
- 教師モデルと同じか大きい生徒モデルを用意する
- 生徒モデルをラベル有+疑似ラベルデータでノイズを与えて学習させる
この順番で順に実装を解説していきます。
1. 教師となるモデルをラベル有データのみで学習させる
これはよく見かけるただの分類問題です。
モデルはefficient netを準備したかったですが、実装の手間を省くためにresnet50で試しました。
注意点は基本の構造はresnet50と同じですが画像サイズが小さくなりすぎないよう
ストライドを2にする数を減らしています。データセットの準備
cifar10_resnet50.pyfrom keras.datasets import cifar10 from keras.utils.np_utils import to_categorical #cifar10のデータセットを準備 (x_train_10,y_train_10),(x_test_10,y_test_10)=cifar10.load_data() #教師データをone-hot表現に直す y_train_10 = to_categorical(y_train_10) y_test_10 = to_categorical(y_test_10)resnetのための関数準備
cifar10_resnet50.pyfrom keras.models import Model from keras.layers import Input, Activation, Dense, GlobalAveragePooling2D, Conv2D from keras import optimizers from keras.layers.normalization import BatchNormalization as BN from keras.callbacks import Callback, LearningRateScheduler, ModelCheckpoint, EarlyStopping #参考URL:https://www.pynote.info/entry/keras-resnet-implementation def shortcut_en(x, residual): '''shortcut connection を作成する。 ''' x_shape = K.int_shape(x) residual_shape = K.int_shape(residual) if x_shape == residual_shape: # x と residual の形状が同じ場合、なにもしない。 shortcut = x else: # x と residual の形状が異なる場合、線形変換を行い、形状を一致させる。 stride_w = int(round(x_shape[1] / residual_shape[1])) stride_h = int(round(x_shape[2] / residual_shape[2])) shortcut = Conv2D(filters=residual_shape[3], kernel_size=(1, 1), strides=(stride_w, stride_h), kernel_initializer='he_normal', kernel_regularizer=l2(1.e-4))(x) shortcut = BN()(shortcut) return Add()([shortcut, residual]) def normal_resblock50(data, filters, strides=1): x = Conv2D(filters=filters,kernel_size=(1,1),strides=(1,1),padding="same")(data) x = BN()(x) x = Activation("relu")(x) x = Conv2D(filters=filters,kernel_size=(3,3),strides=(1,1),padding="same")(x) x = BN()(x) x = Activation("relu")(x) x = Conv2D(filters=filters*4,kernel_size=(1,1),strides=strides,padding="same")(x) x = BN()(x) x = shortcut_en(data, x) x = Activation("relu")(x) return xresnet50実装
cifar10_resnet50.pyinputs = Input(shape = (32,32,3)) x = Conv2D(32,(5,5),padding = "SAME")(inputs) x = BN()(x) x = Activation('relu')(x) x = normal_resblock50(x, 64, 1) x = normal_resblock50(x, 64, 1) x = normal_resblock50(x, 64, 1) x = normal_resblock50(x, 128, 2) x = normal_resblock50(x, 128, 1) x = normal_resblock50(x, 128, 1) x = normal_resblock50(x, 128, 1) x = normal_resblock50(x, 256, 1) x = normal_resblock50(x, 256, 1) x = normal_resblock50(x, 256, 1) x = normal_resblock50(x, 256, 1) x = normal_resblock50(x, 256, 1) x = normal_resblock50(x, 256, 1) x = normal_resblock50(x, 512, 2) x = normal_resblock50(x, 512, 1) x = normal_resblock50(x, 512, 1) x = GlobalAveragePooling2D()(x) x = Dense(10)(x) outputs = Activation("softmax")(x) teacher_model = Model(inputs, outputs) teacher_model.summary()学習準備
cifar10_resnet50.pybatch_size = 64 steps_per_epoch = y_train_10.shape[0] // batch_size validation_steps = x_test_10.shape[0] // batch_size log_dir = 'logs/softlabel/teacher/' checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5', monitor='val_loss', save_weights_only=True, save_best_only=True, period=1) reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1) early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1) teacher_model.compile(loss = "categorical_crossentropy",optimizer = "adam", metrics = ["accuracy"]) trainj_gen = ImageDataGenerator(rescale = 1./255.).flow(x_train_10,y_train_10, batch_size) val_gen = ImageDataGenerator(rescale = 1./255.).flow(x_test_10,y_test_10, batch_size)学習
cifar10_resnet50.pyhistory = teacher_model.fit_generator(train_gen, initial_epoch=0, epochs=250, steps_per_epoch = steps_per_epoch, validation_data = val_gen, validation_steps = validation_steps, callbacks=[checkpoint]) history = teacher_model.fit_generator(trainj_gen, initial_epoch=250, epochs=300, steps_per_epoch = steps_per_epoch, validation_data = val_gen, validation_steps = validation_steps, callbacks=[checkpoint, reduce_lr, early_stopping])結果確認
cifar10_resnet50.py#参考URL:https://qiita.com/yy1003/items/c590d1a26918e4abe512 def my_eval(model,x,t): #model: 評価したいモデル, x: 予測する画像 shape = (batch,32,32,3) t:one-hot表現のlabel ev = model.evaluate(x,t) print("loss:" ,end = " ") print(ev[0]) print("acc: ", end = "") print(ev[1]) my_eval(teacher_model,x_test_10/255,y_test_10)teacher_eval10000/10000 [==============================] - 16s 2ms/step loss: 0.817680492834933 acc: 0.883899986743927結果はテストデータで88.39%の精度でした。
2. 教師モデルでラベルなしデータに疑似ラベルをつける
まずは疑似ラベルを付けるための画像を準備します。
少ないですが、ここではimagenetから10クラスそれぞれ約800枚ほど収集しました。
それを32×32にリサイズしたものをデータセットとしました。詳細の手順としては
- ラベルなし画像をnumpy配列にする
- ラベルなし画像に疑似ラベルをつける
- ある閾値以上の疑似ラベルデータのみを残す
- 各ラベルのデータ数を揃える
となります。
実装を載せますが3と4さえ守れば、決まったやり方はないと思いますので各々やりやすいように実装してみてください。ラベルなし画像をnumpy配列にする
imagenet_dummy_label.pyimg_path = r"D:\imagenet\cifar10\resize" img_list = os.listdir(img_path) x_train_imgnet = [] for i in img_list: abs_path = os.path.join(img_path, i) temp = load_img(abs_path) temp = img_to_array(temp) x_train_imgnet.append(temp) x_train_imgnet = np.array(x_train_imgnet)ラベルなし画像に疑似ラベルをつける
imagenet_dummy_label.py#バッチサイズの設定 batch_size = 1 #何ステップfor文を回すか step = int(x_train_imgnet.shape[0] / batch_size) print(step) #疑似ラベルのための空リスト y_train_imgnet_dummy = [] for i in range(step): #バッチサイズ分画像データを取り出す x_temp = x_train_imgnet[batch_size*i:batch_size*(i+1)] #正規化 x_temp = x_temp / 255. #推論 temp = teacher_model.predict(x_temp) #空リストへ追加 y_train_imgnet_dummy.extend(temp) #リストをnumpy配列へ y_train_imgnet_dummy = np.array(y_train_imgnet_dummy)ある閾値以上の疑似ラベルデータのみを残す
imagenet_dummy_label.py#閾値決め threhold = 0.75 y_train_imgnet_dummy_th = y_train_imgnet_dummy[np.max(y_train_imgnet_dummy, axis=1) > threhold] x_train_imgnet_th = x_train_imgnet[np.max(y_train_imgnet_dummy, axis=1) > threhold]各ラベルのデータ数を揃える
imagenet_dummy_label.py#onehot vectorから分類のインデックスにする y_student_all_dummy_label = np.argmax(y_train_imgnet_dummy_th, axis=1) #疑似ラベルの各クラスの数をカウント u, counts = np.unique(y_student_all_dummy_label, return_counts=True) print(u, counts) #カウント数の最大値を計算 student_label_max = max(counts) #numpy配列を各ラベル毎に分ける y_student_per_label = [] y_student_per_img_path = [] for i in range(10): temp_l = y_train_imgnet_dummy_th[y_student_all_dummy_label == i] print(i, ":", temp_l.shape) y_student_per_label.append(temp_l) temp_i = x_train_imgnet_th[y_student_all_dummy_label == i] print(i, ":", temp_i.shape) y_student_per_img_path.append(temp_i) #それぞれのラベルで最大のカウント数になるようにデータをコピー y_student_per_label_add = [] y_student_per_img_add = [] for i in range(10): num = y_student_per_label[i].shape[0] temp_l = y_student_per_label[i] temp_i = y_student_per_img_path[i] add_num = student_label_max - num q, mod = divmod(add_num, num) print(q, mod) temp_l_tile = np.tile(temp_l, (q+1, 1)) temp_i_tile = np.tile(temp_i, (q+1, 1, 1, 1)) temp_l_add = temp_l[:mod] temp_i_add = temp_i[:mod] y_student_per_label_add.append(np.concatenate([temp_l_tile, temp_l_add], axis=0)) y_student_per_img_add.append(np.concatenate([temp_i_tile, temp_i_add], axis=0)) #それぞれラベルのカウント数を確認 print([len(i) for i in y_student_per_label_add]) #ラベルごとのデータを合体させる student_train_img = np.concatenate(y_student_per_img_add, axis=0) student_train_label = np.concatenate(y_student_per_label_add, axis=0) #元のcifar10のnumpy配列と合体 x_train_student = np.concatenate([x_train_10, student_train_img], axis=0) y_train_student = np.concatenate([y_train_10, student_train_label], axis=0)3. 教師モデルと同じか大きい生徒モデルを用意する
ここでは教師モデルと同じサイズのresnet50で行こうと思います。
モデルのノイズとしては
- Dropout→モデルに対するノイズ
- Stochastic depth→モデルに対するノイズ
の2つです。
Stochastic depthの実装はgithubに上がっている下記の実装を参考にしました。
実装URL:https://github.com/transcranial/stochastic-depth/blob/master/stochastic-depth.ipynb私の実装では
先に各resblockでの確率のリストを作っておいて、モデルの定義の時に1つずつ取り出して使うという実装にしてます。
先に定義しておいて後で使う方がミスがなくていいかなと思ったのでそうしています。stochastic_resblock.py#各resblockの適用する確率を定義する関数 def get_p_survival(l, L, pl): pt = 1 - (l / L) * (1 - pl) return pt #確率で1か0を出力 #学習時:出力×1or0 #推論時:出力×確率 def stochastic_survival(y, p_survival=1.0): # binomial random variable survival = K.random_binomial((1,), p=p_survival) # during testing phase: # - scale y (see eq. (6)) # - p_survival effectively becomes 1 for all layers (no layer dropout) return K.in_test_phase(tf.constant(p_survival, dtype='float32') * y, survival * y) def stochastic_resblock(data, filters, strides, depth_num, p_list): print(p_list[depth_num]) x = Conv2D(filters=filters,kernel_size=(1,1),strides=(1,1),padding="same")(data) x = BN()(x) x = Activation("relu")(x) x = Conv2D(filters=filters,kernel_size=(3,3),strides=(1,1),padding="same")(x) x = BN()(x) x = Activation("relu")(x) x = Conv2D(filters=filters*4,kernel_size=(1,1),strides=strides,padding="same")(x) x = BN()(x) x = Lambda(stochastic_survival, arguments={'p_survival': p_list[depth_num]})(x) x = shortcut_en(data, x) x = Activation("relu")(x) #層の数をインクリメント depth_num += 1 return x, depth_num L = 16 pl = 0.8 p_list = [] for l in range(L+1): x = get_p_survival(l,L,pl) p_list.append(x) #0始まりだがinput layerを飛ばすために1で開始 depth_num = 1 inputs = Input(shape = (32,32,3)) x = Conv2D(32,(5,5),padding = "SAME")(inputs) x = BN()(x) x = Activation('relu')(x) #depth_numを関数内でインクリメントしながら次の層で使用 x, depth_num = stochastic_resblock(x, 64, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 64, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 64, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 128, 2, depth_num, p_list) x, depth_num = stochastic_resblock(x, 128, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 128, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 128, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 256, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 512, 2, depth_num, p_list) x, depth_num = stochastic_resblock(x, 512, 1, depth_num, p_list) x, depth_num = stochastic_resblock(x, 512, 1, depth_num, p_list) x = GlobalAveragePooling2D()(x) x = Dropout(0.5)(x) x = Dense(10)(x) outputs = Activation("softmax")(x) student_model = Model(inputs, outputs) student_model.summary() student_model.compile(loss = "categorical_crossentropy",optimizer = "adam", metrics = ["accuracy"])4. 生徒モデルをラベル有+疑似ラベルデータでノイズを与えて学習させる
データセットは2.で作成済なので、残りはRand Augmentationだけです。
githubに上がっている下記の実装を使わせていただきました。
実装URL:https://github.com/heartInsert/randaugment/blob/master/Rand_Augment.pygithubの実装はデータ形式がPILなのでnumpy配列に変換しながら教師データを出力するデータジェネレーターを自作しました。
Rand Augmentation定義
Rand_Augment.pyfrom PIL import Image import matplotlib.pyplot as plt import numpy as np from PIL import Image, ImageEnhance, ImageOps import numpy as np import random class Rand_Augment(): def __init__(self, Numbers=None, max_Magnitude=None): self.transforms = ['autocontrast', 'equalize', 'rotate', 'solarize', 'color', 'posterize', 'contrast', 'brightness', 'sharpness', 'shearX', 'shearY', 'translateX', 'translateY'] if Numbers is None: self.Numbers = len(self.transforms) // 2 else: self.Numbers = Numbers if max_Magnitude is None: self.max_Magnitude = 10 else: self.max_Magnitude = max_Magnitude fillcolor = 128 self.ranges = { # these Magnitude range , you must test it yourself , see what will happen after these operation , # it is no need to obey the value in autoaugment.py "shearX": np.linspace(0, 0.3, 10), "shearY": np.linspace(0, 0.3, 10), "translateX": np.linspace(0, 0.2, 10), "translateY": np.linspace(0, 0.2, 10), "rotate": np.linspace(0, 360, 10), "color": np.linspace(0.0, 0.9, 10), "posterize": np.round(np.linspace(8, 4, 10), 0).astype(np.int), "solarize": np.linspace(256, 231, 10), "contrast": np.linspace(0.0, 0.5, 10), "sharpness": np.linspace(0.0, 0.9, 10), "brightness": np.linspace(0.0, 0.3, 10), "autocontrast": [0] * 10, "equalize": [0] * 10, "invert": [0] * 10 } self.func = { "shearX": lambda img, magnitude: img.transform( img.size, Image.AFFINE, (1, magnitude * random.choice([-1, 1]), 0, 0, 1, 0), Image.BICUBIC, fill=fillcolor), "shearY": lambda img, magnitude: img.transform( img.size, Image.AFFINE, (1, 0, 0, magnitude * random.choice([-1, 1]), 1, 0), Image.BICUBIC, fill=fillcolor), "translateX": lambda img, magnitude: img.transform( img.size, Image.AFFINE, (1, 0, magnitude * img.size[0] * random.choice([-1, 1]), 0, 1, 0), fill=fillcolor), "translateY": lambda img, magnitude: img.transform( img.size, Image.AFFINE, (1, 0, 0, 0, 1, magnitude * img.size[1] * random.choice([-1, 1])), fill=fillcolor), "rotate": lambda img, magnitude: self.rotate_with_fill(img, magnitude), # "rotate": lambda img, magnitude: img.rotate(magnitude * random.choice([-1, 1])), "color": lambda img, magnitude: ImageEnhance.Color(img).enhance(1 + magnitude * random.choice([-1, 1])), "posterize": lambda img, magnitude: ImageOps.posterize(img, magnitude), "solarize": lambda img, magnitude: ImageOps.solarize(img, magnitude), "contrast": lambda img, magnitude: ImageEnhance.Contrast(img).enhance( 1 + magnitude * random.choice([-1, 1])), "sharpness": lambda img, magnitude: ImageEnhance.Sharpness(img).enhance( 1 + magnitude * random.choice([-1, 1])), "brightness": lambda img, magnitude: ImageEnhance.Brightness(img).enhance( 1 + magnitude * random.choice([-1, 1])), "autocontrast": lambda img, magnitude: ImageOps.autocontrast(img), "equalize": lambda img, magnitude: img, "invert": lambda img, magnitude: ImageOps.invert(img) } def rand_augment(self): """Generate a set of distortions. Args: N: Number of augmentation transformations to apply sequentially. N is len(transforms)/2 will be best M: Max_Magnitude for all the transformations. should be <= self.max_Magnitude """ M = np.random.randint(0, self.max_Magnitude, self.Numbers) sampled_ops = np.random.choice(self.transforms, self.Numbers) return [(op, Magnitude) for (op, Magnitude) in zip(sampled_ops, M)] def __call__(self, image): operations = self.rand_augment() for (op_name, M) in operations: operation = self.func[op_name] mag = self.ranges[op_name][M] image = operation(image, mag) return image def rotate_with_fill(self, img, magnitude): # I don't know why rotate must change to RGBA , it is copy from Autoaugment - pytorch rot = img.convert("RGBA").rotate(magnitude) return Image.composite(rot, Image.new("RGBA", rot.size, (128,) * 4), rot).convert(img.mode) def test_single_operation(self, image, op_name, M=-1): ''' :param image: image :param op_name: operation name in self.transforms :param M: -1 stands for the max Magnitude in there operation :return: ''' operation = self.func[op_name] mag = self.ranges[op_name][M] image = operation(image, mag) return imageデータジェネレーター定義
data_generator.pyimg_augment = Rand_Augment(Numbers=2, max_Magnitude=10) def get_random_data(x_train_i, y_train_i, data_aug): x = array_to_img(x_train_i) if data_aug: seed_image = img_augment(x) seed_image = img_to_array(seed_image) else: seed_image = x_train_i seed_image = seed_image / 255 return seed_image, y_train_i def data_generator(x_train, y_train, batch_size, data_aug): '''data generator for fit_generator''' n = len(x_train) i = 0 while True: image_data = [] label_data = [] for b in range(batch_size): if i==0: p = np.random.permutation(len(x_train)) x_train = x_train[p] y_train = y_train[p] image, label = get_random_data(x_train[i], y_train[i], data_aug) image_data.append(image) label_data.append(label) i = (i+1) % n image_data = np.array(image_data) label_data = np.array(label_data) yield image_data, label_dataデータジェネレーターができたので後は学習するだけです。
学習
data_generator.pylog_dir = 'logs/softlabel/student1_2/' checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5', monitor='val_loss', save_weights_only=True, save_best_only=True, period=1) reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1) early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1) batch_size = 64 steps_per_epoch = x_train_student.shape[0] // batch_size validation_steps = x_test_10.shape[0] // batch_size #0~250epochは学習率を変えずに学習 history = student_model.fit_generator(data_generator(x_train_student, y_train_student, batch_size, data_aug = True), initial_epoch=0, epochs=250, steps_per_epoch = steps_per_epoch, validation_data = data_generator_wrapper(x_test_10, y_test_10, batch_size, data_aug = False), validation_steps = validation_steps, callbacks=[checkpoint]) #250epoch~300epochは学習率を変えつつ学習の打ち止め実施 history = student_model.fit_generator(data_generator(x_train_student, y_train_student, batch_size, data_aug = True), initial_epoch=250, epochs=300, steps_per_epoch = steps_per_epoch, validation_data = data_generator_wrapper(x_test_10, y_test_10, batch_size, data_aug = False), validation_steps = validation_steps, callbacks=[checkpoint, reduce_lr, early_stopping])結果確認
eval.pymy_eval(student_model,x_test_10/255,y_test_10)student_eval10000/10000 [==============================] - 19s 2ms/step loss: 0.24697399706840514 acc: 0.9394000172615051結果はテストデータで93.94%の精度でした。
当然ですが上がっていますね。追加実験
やっていて「教師モデルの時点でノイズを有効にした場合とどちらが精度が良いか」という疑問が浮かび上がりましたので確認しました。以下の表に簡単にまとめました。
実験 教師
モデルテストデータloss/accuracy 生徒
モデルテストデータloss/accuracy 1 ノイズなし 0.8176/88.39% ノイズあり 0.2470/93.94% 2 ノイズあり 0.2492/94.14% ノイズあり 0.2289/94.28% 今回のケースだと教師からノイズを与えた方が精度が少し高くなりました。
本当はロバスト性も確認したかったのですが力尽きました。以上です。
不明点、おかしい点ありましたらコメントよろしくお願いします。
- 投稿日:2020-08-12T20:15:45+09:00
PytorchでTensorboardを使ったらエラーが出た話
はじめに
PytorchでTensorboardを使おうと思いインストールしてコードを書いて実行したらエラーに出会ったので、それの対処法を書きます。
Tensorboardのインストール
anacondaを使っているので、以下のコマンドでインストールしました。
conda install tensorboardコード
SummaryWriterでグラフを書くためにimportします。
tensorboard.pyfrom torch.utils.tensorboard import SummaryWriterエラー
下記のようなImportErrorが出ました。
ImportError: cannot import name 'SummaryWriter' from 'torch.utils.tensorboard' During handling of the above exception, another exception occurred: ImportError: TensorBoard logging requires TensorBoard with Python summary writer installed. This should be available in 1.14 or above.対処法
とりあえず、アンストして再インストール
うまくインストールができなかったのかなと思い、アンストして再びインストールしました。
同じエラーが出ました。
ここで血迷ってpipでインストールもしたりしました。(pipとcondaの混同はあまりよくない)
結局、同じエラーが出ました。Pytorchのバージョン確認
Pytorchではv1.2.0から正式にTensorboardが使えるので、とりあえずPytorchのバージョンを確認しました。
import torch print(torch.__version__)1.5.1でした。Pytorchの問題ではなさそうです。
Tensorboardのバージョン確認
エラー文には,Tensorboardのバージョンは1.14以上と書いてあるので、確認しましょう。
conda list2.2.1でした。Tensorboardの問題でもなさそうです。
ファイル名の変更
PytorchとTensorboardのバージョンを確認して大丈夫だったので、もうすることがありません。
何が原因でエラーを吐いているのかわかりません。ファイル名をみてみると、tensorboard.pyと書いてありました。
まさか、ファイル名とmoduleが衝突してimportできないことが原因なのでは?と思いました。ファイル名をtb.pyに変更しました。
そして、実行してみるとエラーが出ませんでした!!!!まとめ
PytorchでTensorboardを使おうと思いインストールしましたが、moduleとファイル名を同じにしてImportErrorが出ました。ファイル名とmoduleは別々にしましょう。
また、condaとpipの混同は避けましょう。
- 投稿日:2020-08-12T20:06:26+09:00
vscodeでpipenv使うと端末が勝手にpipenv環境内に入り込むの対処法
概要
vscodeのpython interpreterの設定がpipenv環境である場合に,vscode内の端末を開くと,勝手に
source $VENV_LOCATION/bin/activateが実行されて,pipenv環境内に入ってしまう.
それだと,.envで設定したpipenv環境内での環境変数が反映されず困る.やりたいこと
vscodeのpython interpreter設定でpipenv環境が選択されていたとしても,端末で自動的にpipenv環境がactivateされないようにする.(あとから
pipenv runなりpipenv shellを叩きたいのだ)対処法
vscodeの設定画面を開き,
python.terminal.activateEnvironmentを検索して,enableチェックを外す.
ただこれだけだったが,日本語では僕の検索能力ではヒットしなかったので,一応書いておく.
- 投稿日:2020-08-12T19:53:20+09:00
【簡単】webカメラでAI自動認識!
はじめに
webカメラでAIにより「
モノの認識」が簡単にできたら楽しいと思いませんか?
公開されているモデルを利用することで簡単にそんなことができます。
では、早速やってみましょう!具体的にどんなことをやるか
webカメラからPCに画像(映像)を取り込み、そこに写った(映った)ものは何か、AIに
リアルタイム認識させ、画面にTOP3までを表示します。今回は、学習済みモデルを利用しますので、時間のかかるAI学習などはありませんので、サクッと遊べます。
開発環境
webカメラからの画像データを取り込むために
OpenCVというライブラリとAIライブラリであるkerasを使用します。必要なライブラリのパッケージをインストールしてください。
必要なモノ 備考欄 webカメラ付きのNote PCなど PCとUSB接続によるwebカメラでもOK 開発言語 Python3.7 主な必要ライブラリ 【OpenCV】
画像や動画を処理するためのライブラリ
【keras】
Python言語のニューラルネットワークライブラリDenseNet121
簡単って言うからやっているのに、
いきなりDenseNet121と言われて、ワケワカラン!
もうやめだ!大丈夫です。落ち着いてください。これは学習済みモデルのことで、今回は
DenseNet121という学習モデルを使用しますということです。細かいこと分からなくてもできます!
- なぜ
DenseNet121モデルに選定したのか?
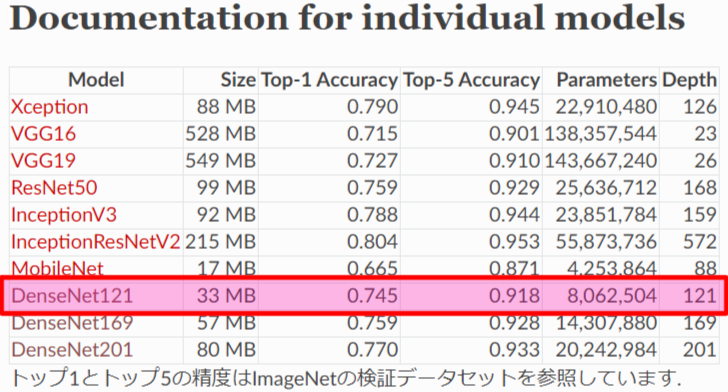
kerasライブラリからVGG16、ResNet50など様々な画像分類モデルが簡単に使えるようになっていますが、その中から今回使用する画像分類モデルは、モデルサイズが33MBと比較的小さく認識率も良いためDenseNet121を選びました。「Keras Documentation」によると、DenseNet121でモノを認識させた場合、TOP5までの認識正解率が約92%となるそうです。(TOP1だけだと約75%です)
引用元:Keras Documentation
https://keras.io/ja/applications/#documentation-for-individual-modelsAIプログラム
使用するライブラリ(keras、opencv、等)のパッケージをインストールしたら、下記AIプログラムをコピペしてください。
main.py# ------------------------------------------------------------------------------------- # カメラを画面に表示する。 # DenseNet121で画像判定 # [+]キーでCameraDevice変更 # [s]キーで画像を保存する # [ESC] or [q]キーで終了 # ------------------------------------------------------------------------------------- from keras.applications.densenet import DenseNet121 from keras.applications.densenet import preprocess_input, decode_predictions from keras.preprocessing import image import numpy as np import cv2 import datetime # ------------------------------------------------------------------------------------- # capture_device # ------------------------------------------------------------------------------------- def capture_device(capture, dev): while True: # cameraデバイスから画像をキャプチャ ret, frame = capture.read() if not ret: k = ord('+') return k # DenseNet121画像判定 resize_frame = cv2.resize(frame, (300, 224)) # 640x480(4:3) -> 300x224(4:3)に画像リサイズ trim_x, trim_y = int((300-224)/2), 0 # 判定用に224x224へトリミング trim_h, trim_w = 224, 224 trim_frame = resize_frame[trim_y : (trim_y + trim_h), trim_x : (trim_x + trim_w)] x = image.img_to_array(trim_frame) x = np.expand_dims(x, axis=0) x = preprocess_input(x) preds = model.predict(x) # 画像AI判定 # Usage disp_frame = frame txt1 = "model is DenseNet121" txt2 = "camera device No.(" + str(dev) + ")" txt3 = "[+] : Change Device" txt4 = "[s] : Image Capture" txt5 = "[ESC] or [q] : Exit" cv2.putText(disp_frame, txt1, (10, 30), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) cv2.putText(disp_frame, txt2, (10, 60), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) cv2.putText(disp_frame, txt3, (10, 90), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) cv2.putText(disp_frame, txt4, (10, 120), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) cv2.putText(disp_frame, txt5, (10, 150), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) # 画像判定文字出力 output1 = 'No.1:{0}:{1}%'.format(decode_predictions(preds, top=3)[0][0][1], int(decode_predictions(preds, top=3)[0][0][2] * 100)) output2 = 'No.2:{0}:{1}%'.format(decode_predictions(preds, top=3)[0][1][1], int(decode_predictions(preds, top=3)[0][1][2] * 100)) output3 = 'No.3:{0}:{1}%'.format(decode_predictions(preds, top=3)[0][2][1], int(decode_predictions(preds, top=3)[0][2][2] * 100)) cv2.putText(disp_frame, output1, (10, 300), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) cv2.putText(disp_frame, output2, (10, 330), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) cv2.putText(disp_frame, output3, (10, 360), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) # カメラ画面出力 cv2.imshow('camera', disp_frame) # 1msec待ってキー取得 k = cv2.waitKey(1) & 0xFF # [ESC] or [q]を押されるまで画面表示し続ける if (k == ord('q')) or (k == 27): return k # [+]でdevice変更 if k == ord('+'): txt = "Change Device. Please wait... " XX = int(disp_frame.shape[1] / 4) YY = int(disp_frame.shape[0] / 2) cv2.putText(disp_frame, txt, (XX, YY), cv2.FONT_HERSHEY_PLAIN, 1, (255, 255, 255), 1, cv2.LINE_AA) cv2.imshow('camera', disp_frame) cv2.waitKey(1) & 0xFF return k # [s]で画面に表示された画像保存 elif k == ord('s'): cv2.imwrite('camera_dsp{}.{}'.format(datetime.datetime.now().strftime('%Y%m%d_%H%M%S_%f'), "png"), disp_frame) # cv2.imwrite('camera_rsz{}.{}'.format(datetime.datetime.now().strftime('%Y%m%d_%H%M%S_%f'), "png"), resize_frame) # cv2.imwrite('camera_trm{}.{}'.format(datetime.datetime.now().strftime('%Y%m%d_%H%M%S_%f'), "png"), trim_frame) # cv2.imwrite('camera_raw{}.{}'.format(datetime.datetime.now().strftime('%Y%m%d_%H%M%S_%f'), "png"), frame) # ------------------------------------------------------------------------------------- # camera # ------------------------------------------------------------------------------------- def camera(dev): while True: capture = cv2.VideoCapture(dev) ret = capture_device(capture, dev) if (ret == ord('q')) or (ret == 27): # リソース解放 capture.release() cv2.destroyAllWindows() break if ret == ord('+'): dev += 1 if dev == 9: dev = 0 # ------------------------------------------------------------------------------------- # main # ------------------------------------------------------------------------------------- # ●DenseNet121 # https://keras.io/ja/applications/#densenet # # DenseNet121を実行することで、 # (1)DenseNet121モデル、(2)クラス分類ファイルの2つが自動的にダウンロードされます。 # そのため初回起動時は約33MBあるDenseNet121モデルとクラス分類ファイルを # ダウンロードする必要があるため起動時間は長くかかりますが、 # 2回目起動時以降はダウンロードを割愛するため起動が早くなります。 # # ダウンロードファイルは以下ディレクトリに格納されます。 # 「C:/Users/xxxx/.keras/models/」 # # (1)DenseNet121のモデル:DenseNet121_weights_tf_dim_ordering_tf_kernels.h5 # (2)クラス分類ファイル(全1000分類):imagenet_class_index.json # 画像分類モデル model = DenseNet121(weights='imagenet') # カメラ起動 camera(dev=0)AIプログラム実行
初回起動時
DenseNet121ライブラリ関数を実行することで、DenseNet121モデルとクラス分類ファイルの2つが自動的にダウンロードされます。そのため初回起動時は約33MBあるDenseNet121モデルとクラス分類ファイルをダウンロードする必要があるため起動時間は長くかかりますが、2回目起動時以降はダウンロードを割愛するため起動が早くなります。ファイル格納場所
C:/Users/xxxx/.keras/models/
- DenseNet121モデル ( DenseNet121_weights_tf_dim_ordering_tf_kernels.h5 )
- クラス分類ファイル ( imagenet_class_index.json )
モデルのDLが終わると
こんな感じにwindowが開きwebカメラの映像が出力され、AIが認識したTOP3の情報が画面に表示されれば成功です。ちなみにうちのワンコ(トイプードル)を映した結果は、下記の様にAIが76%の確率でトイプードルでしょうと言っているので、AIの認識は正しいものになります。【結果の一例】AIの認識率TOP3
1. toy_poodle : 76%
2. miniature_poodle : 20%
3. Dandie_Dinmont : 1%
※リアルタイムで認識率は変動します。AIプログラム実行ログ
下記のダウンロードログは、初回のみ表示されます。
C:\Users\xxxx\anaconda3\envs\python37\python.exe C:/Users/xxxx/PycharmProjects/OpenCV/sample09.py Using TensorFlow backend. 2020-08-12 10:38:59.579123: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2 Downloading data from https://github.com/keras-team/keras-applications/releases/download/densenet/densenet121_weights_tf_dim_ordering_tf_kernels.h5 8192/33188688 [..............................] - ETA: 12:39 16384/33188688 [..............................] - ETA: 8:26 40960/33188688 [..............................] - ETA: 5:03 106496/33188688 [..............................] - ETA: 2:59 245760/33188688 [..............................] - ETA: 1:42 ~ 省略 ~ 32743424/33188688 [============================>.] - ETA: 0s 32776192/33188688 [============================>.] - ETA: 0s 32956416/33188688 [============================>.] - ETA: 0s 33005568/33188688 [============================>.] - ETA: 0s 33193984/33188688 [==============================] - 32s 1us/step Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json 8192/35363 [=====>........................] - ETA: 0s 40960/35363 [==================================] - 0s 0us/step [ WARN:0] global C:\projects\opencv-python\opencv\modules\videoio\src\cap_msmf.cpp (436) `anonymous-namespace'::SourceReaderCB::~SourceReaderCB terminating async callback Process finished with exit code 0識別可能クラス
「
imagenet_class_index.json」ファイルを参照すると、画像が以下のNo.0~999の1000クラスに分類ができることが分かります。制限事項にもなりますが、ここに記載が無いものを認識させても、ここの中のどれかにクラス分類されてしまいます。ここに無いものを分類したい場合は、新たにモデルを作るか、転移学習、ファインチューニングなどを調べていただければと思います。imagenet_class_index.json{ "0": ["n01440764", "tench"], "1": ["n01443537", "goldfish"], "2": ["n01484850", "great_white_shark"], "3": ["n01491361", "tiger_shark"], "4": ["n01494475", "hammerhead"], "5": ["n01496331", "electric_ray"], "6": ["n01498041", "stingray"], "7": ["n01514668", "cock"], "8": ["n01514859", "hen"], "9": ["n01518878", "ostrich"], ~ 省略 ~ "990": ["n12768682", "buckeye"], "991": ["n12985857", "coral_fungus"], "992": ["n12998815", "agaric"], "993": ["n13037406", "gyromitra"], "994": ["n13040303", "stinkhorn"], "995": ["n13044778", "earthstar"], "996": ["n13052670", "hen-of-the-woods"], "997": ["n13054560", "bolete"], "998": ["n13133613", "ear"], "999": ["n15075141", "toilet_tissue"] }以上
お疲れ様でした!


- 投稿日:2020-08-12T19:06:28+09:00
Pythonでの乱数があるときのテスト
Scientific Computing with Pythonの続き
freeCodeCampでコツコツPythonを勉強しています。
前回の記事では、今回はProbability Calculatorに挑戦します。
- Python for Everybody
- Scientific Computing with Python Projects
- Arithmetic Formatter
- Time Calculator
- Budget App
- Polygon Area Calculator
- Probability Calculator(今回はここ)
5問目:Probability Calculator
今回の問題は、学生の時くらいに確率の問題で解いたことがありそうな問題。
帽子(袋)に入っている色付きボールを複数個取り出したときの確率を求める。
具体的には、
- Hatクラスの作成
- experimentメソッドの作成: 確率を求めるためのメソッド
個人的ポイント: 乱数を使ったときのテスト
今回は帽子の中からランダムにボールを取り出すという処理があります。
以下のようなテストを書きたいときにうまくいきません。1 import unittest 2 3 class UnitTests(unittest.TestCase): 4 # 赤い玉が5個、青い玉が2個入った帽子から2つボールを取り出したとき、赤い玉が1つ、青い玉が1つであること 5 def test_hat_draw(self): 6 hat = prob_calculator.Hat(red=5,blue=2) 7 actual = hat.draw(2) 8 expected = ['blue', 'red'] 9 self.assertEqual(actual, expected, 'Expected hat draw to return two random items from hat contents.') 10 actual = len(hat.contents) 11 expected = 5 12 self.assertEqual(actual, expected, 'Expected hat draw to reduce number of items in contents.')7行目で2つボールをひく時、内部の実装では乱数を使っているので、必ずしも赤い玉が1つ、青い玉が1つであるとは限らないです。
これを解決するために乱数のシードを使います。import random balls = ['red', 'red', 'red', 'red', 'red', 'blue', 'blue'] random.sample(balls, k=2) # ['red', 'red'] random.sample(balls, k=2) # ['red', 'blue'] random.seed(0) random.sample(balls, k=2) # ['blue', 'red'] random.seed(0) random.sample(balls, k=2) # ['blue', 'red']このように事前に乱数のシードを設定することによって、常に同じ挙動をさせることができます。
最後に
Scientific Computing with Pythonが一通り終わった!
次はData Analysis with Python Certificationをやり始めようと思います!
- 投稿日:2020-08-12T19:06:17+09:00
【続編】Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(実践編)〜
はじめに
- Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(入門編)〜では、Google Earth Engine (GEE)とGoogle Colabを利用した衛星画像の取得方法を紹介しました
- 本記事では、GEEで利用できる代表的な人工衛星データ(光学画像・植生指数・地表面温度)の解析方法を紹介します
- 他にも様々な衛星データセットがGEEのデータカタログには保存されており、下記コードの変数(衛星名やバンド名)を変更すれば、同様の解析が行えます
衛星データを取得するコード
- 下記のコードを利用します(コードの詳細解説は前回記事をご覧ください)
- 「衛星名」「バンド名」「データの期間」「対象エリア」「保存するフォルダ名」が変数となっており、関数を実行すると指定したフォルダ(Google Drive)に衛星画像が保存されます
関数定義
# Earth Engine Python APIのインポート import ee # GEEの認証・初期化 ee.Authenticate() ee.Initialize() # GEEのデータロード def load_data(snippet, from_date, to_date, geometry, band): # パラメータの条件にしたがってデータを抽出 dataset = ee.ImageCollection(snippet).filter( ee.Filter.date(from_date, to_date)).filter( ee.Filter.geometry(geometry)).select(band) # リスト型へ変換 data_list = dataset.toList(dataset.size().getInfo()) # 対象データ数とデータリストを出力 return dataset.size().getInfo(), data_list # 衛星画像をGoogle Driveへ保存 def save_on_gdrive(image, geometry, dir_name, file_name, scale): task = ee.batch.Export.image.toDrive(**{ 'image': image,# ロードする衛星情報 'description': file_name,# 保存するファイル名 'folder':dir_name,# 保存先のフォルダ名 'scale': scale,# 解像度 'region': geometry.getInfo()['coordinates'],# 対象エリア 'crs': 'EPSG:4326' }) # Run exporting task.start() print('Done.')変数(パラメータ)設定
## パラメーターの指定 # 衛星を指定 snippet = 'NOAA/DMSP-OLS/NIGHTTIME_LIGHTS' # バンド名を指定 band = 'avg_vis' # 期間を指定 from_date='2010-01-01' to_date='2012-12-31' # エリアを指定(日本エリアを緯度・経度を指定) geometry = ee.Geometry.Rectangle([128.60, 29.97, 148.43, 46.12]) # 保存するフォルダ名 dir_name = 'GEE_download' # ファイル名 file_name = 'file_name' # 解像度 scale = 1000処理の実行
## 処理の実行 ---------------------------------------------- num_data, data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=geometry, band=band) print('#Datasets; ', num_data) ## 全件保存(ファイル名は衛星IDを利用) for i in range(data_list.size().getInfo()): image = ee.Image(data_list.get(i)) save_on_gdrive(image, geometry, dir_name, image.getInfo()['id'].replace('/', '_'), scale)衛星データ解析① ~光学画像~
概要
- 可視光バンド(RGB)を組み合わせて表現されるカラー画像
- 一般的に利用されている「カメラ」の写真のイメージ
- RGBのそれぞれのセンサーデータをGEEから取得して、RGB合成することで可視化できる
データセット
- 衛星 = "Sentinel 2"
- バンド = TCI_R, TCI_G, TCI_B
- 解像度: 10m
- エリア: 東京(皇居を中心)
コード
- パラメータを変更して、TCI_R(可視光の赤バンド)を取得してみます
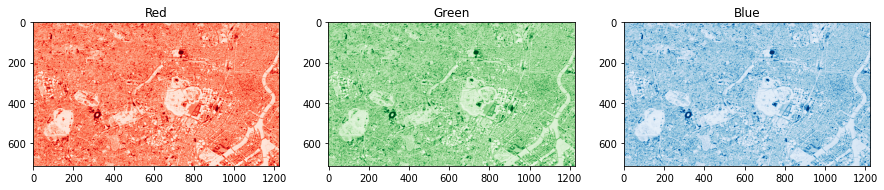
## パラメーターの指定 # 衛星を指定 snippet = 'COPERNICUS/S2_SR' # バンド名を指定 band = 'TCI_R' # 期間を指定 from_date='2020-04-01' to_date='2020-04-15' # エリアを指定(日本エリアを緯度・経度を指定) geometry = ee.Geometry.Rectangle([139.686, 35.655, 139.796, 35.719]) # 保存するフォルダ名 dir_name = 'GEE_Sentinel_Red' # ファイル名 file_name = 'file_name' # 解像度 scale = 10 ## 処理の実行 ---------------------------------------------- num_data, data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=geometry, band=band) print('#Datasets; ', num_data) ## 全件保存(ファイル名は衛星IDを利用) for i in range(data_list.size().getInfo()): image = ee.Image(data_list.get(i)) save_on_gdrive(image, geometry, dir_name, image.getInfo()['id'].replace('/', '_'), scale)- 次にダウンロードした衛星画像を可視化してみます
# パッケージのインストール&インポート !pip install rasterio import numpy as np import pandas as pd import matplotlib.pyplot as plt import rasterio import glob # データの読み込み with rasterio.open('/content/drive/My Drive/GEE_Sentinel_Red/COPERNICUS_S2_SR_20200402T012651_20200402T012651_T54SUE.tif') as src: arr = src.read() # 可視化 plt.imshow(arr[0], cmap='Reds')東京(皇居周辺)の光学画像(赤バンド)
- 中心に皇居らしきエリア、西側に代々木公園や新宿御苑が確認できます
- 次に他の緑・青バンドも取得してみます
# 緑バンドのデータ取得 ## パラメーターの指定 # バンド名を指定 band = 'TCI_G' # 保存するフォルダ名 dir_name = 'GEE_Sentinel_Green' ## 処理の実行 ---------------------------------------------- num_data, data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=geometry, band=band) print('#Datasets; ', num_data) ## 全件保存(ファイル名は衛星IDを利用) for i in range(data_list.size().getInfo()): image = ee.Image(data_list.get(i)) save_on_gdrive(image, geometry, dir_name, image.getInfo()['id'].replace('/', '_'), scale) # 青バンドのデータ取得 ## パラメーターの指定 # バンド名を指定 band = 'TCI_B' # 保存するフォルダ名 dir_name = 'GEE_Sentinel_Blue' ## 処理の実行 ---------------------------------------------- num_data, data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=geometry, band=band) print('#Datasets; ', num_data) ## 全件保存(ファイル名は衛星IDを利用) for i in range(data_list.size().getInfo()): image = ee.Image(data_list.get(i)) save_on_gdrive(image, geometry, dir_name, image.getInfo()['id'].replace('/', '_'), scale)
- 赤バンドと同様に緑バンド、青バンドも取得することができました
- 同様にデータを読み込み可視化してみます
# データの読み込み # Red with rasterio.open('/content/drive/My Drive/GEE_Sentinel_Red/COPERNICUS_S2_SR_20200402T012651_20200402T012651_T54SUE.tif') as src: red = src.read() # Green with rasterio.open('/content/drive/My Drive/GEE_Sentinel_Green/COPERNICUS_S2_SR_20200402T012651_20200402T012651_T54SUE.tif') as src: green = src.read() # Blue with rasterio.open('/content/drive/My Drive/GEE_Sentinel_Blue/COPERNICUS_S2_SR_20200402T012651_20200402T012651_T54SUE.tif') as src: blue = src.read() # 可視化 plt.figure(figsize=(15, 10)) plt.subplot(131); plt.imshow(red[0], cmap='Reds'); plt.title('Red') plt.subplot(132); plt.imshow(green[0], cmap='Greens'); plt.title('Green') plt.subplot(133); plt.imshow(blue[0], cmap='Blues'); plt.title('Blue')東京(皇居周辺)の光学画像(赤バンド・緑バンド・青バンド)
- 最後にこの3色の画像をRGB合成して、カラー画像に変換します
- RGB合成はnumpyのdstackで結合するだけです
# RGB合成 ## np.dstackで連結(Red, Green, Blueの順番に注意) rgb = np.dstack((red[0], green[0], blue[0])) # RGB合成した画像の可視化 plt.imshow(rgb); plt.title('RGB Image')東京(皇居周辺)の光学画像(RGB合成)
- RGB合成することで、衛星画像らしくなりました
- 今回は特定のエリア・タイミングだけで可視化を行いましたが、人工衛星が運用されている期間内であれば任意のタイミングでデータ取得が可能です
- 季節を変えてみたり、災害前後で比較したりすると色々なものが見えてきそうです(光学画像は雲の影響を受けやすいので、雨季や天気の悪い日は画像が不明瞭になることもあります)
衛星データ解析② ~植生指数~
概要
- 植物の分布や活性度を表す指標
- 植物に反応しやすい波長のセンサーを利用して計測
- 様々な植生指数が提案されているがNDVI(Normalized Difference Vegetation Index)が有名
- 砂漠化や森林火災の監視、都市利用分類などに利用されている
データセット
- 衛星 = "Terra(MODIS)"
- バンド = NDVI
- * 通常、NDVIは複数バンドを組み合わせた計算が必要なのですが、GEEでは計算済みのデータが保存されています(便利...!!)
- 解像度: 250m
- エリア: 東京(皇居を中心)
コード
- 各種パラメータを変更してNDVI(植生指数)を取得してみます
## パラメーターの指定 # 衛星を指定 snippet = 'MODIS/006/MOD13Q1' # バンド名を指定 band = 'NDVI' # 期間を指定 from_date='2005-01-01' to_date='2005-12-31' # エリアを指定(日本エリアを緯度・経度を指定) geometry = ee.Geometry.Rectangle([139.686, 35.655, 139.796, 35.719]) # 保存するフォルダ名 dir_name = 'GEE_NDVI' # 解像度 scale = 250 ## 処理の実行 ---------------------------------------------- num_data, data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=geometry, band=band) print('#Datasets; ', num_data) ## 全件保存(ファイル名は衛星IDを利用) for i in range(data_list.size().getInfo()): image = ee.Image(data_list.get(i)) save_on_gdrive(image, geometry, dir_name, image.getInfo()['id'].replace('/', '_'), scale) ```python ## パラメーターの指定 # 衛星を指定 snippet = 'MODIS/006/MOD13Q1' # バンド名を指定 band = 'NDVI' # 期間を指定 from_date='2005-01-01' to_date='2005-12-31' # エリアを指定(日本エリアを緯度・経度を指定) geometry = ee.Geometry.Rectangle([139.686, 35.655, 139.796, 35.719]) # 保存するフォルダ名 dir_name = 'GEE_NDVI' # 解像度 scale = 250 ## 処理の実行 ---------------------------------------------- num_data, data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=geometry, band=band) print('#Datasets; ', num_data) ## 全件保存(ファイル名は衛星IDを利用) for i in range(data_list.size().getInfo()): image = ee.Image(data_list.get(i)) save_on_gdrive(image, geometry, dir_name, image.getInfo()['id'].replace('/', '_'), scale)
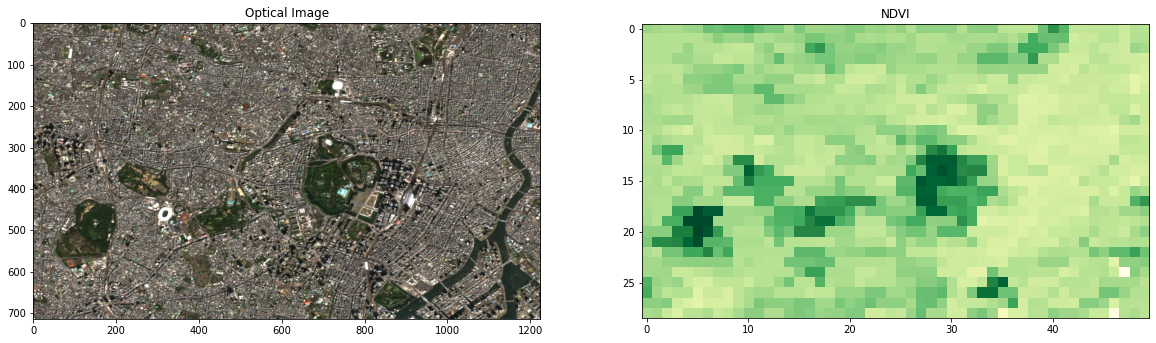
- 同様に取得したデータを読み込み、可視化してみます
# データの読み込み with rasterio.open('/content/drive/My Drive/GEE_NDVI/MODIS_006_MOD13Q1_2005_01_01.tif') as src: arr = src.read() # 可視化 plt.figure(figsize=(20, 8)) plt.subplot(121); plt.imshow(rgb); plt.title('RGB Image'); plt.title('Optical Image') plt.subplot(122); plt.imshow(arr[0], cmap='YlGn'); plt.title('NDVI')東京(皇居周辺)の光学RGB画像と植生指数
- 皇居や都内の公園は植生指数が高い値になっています
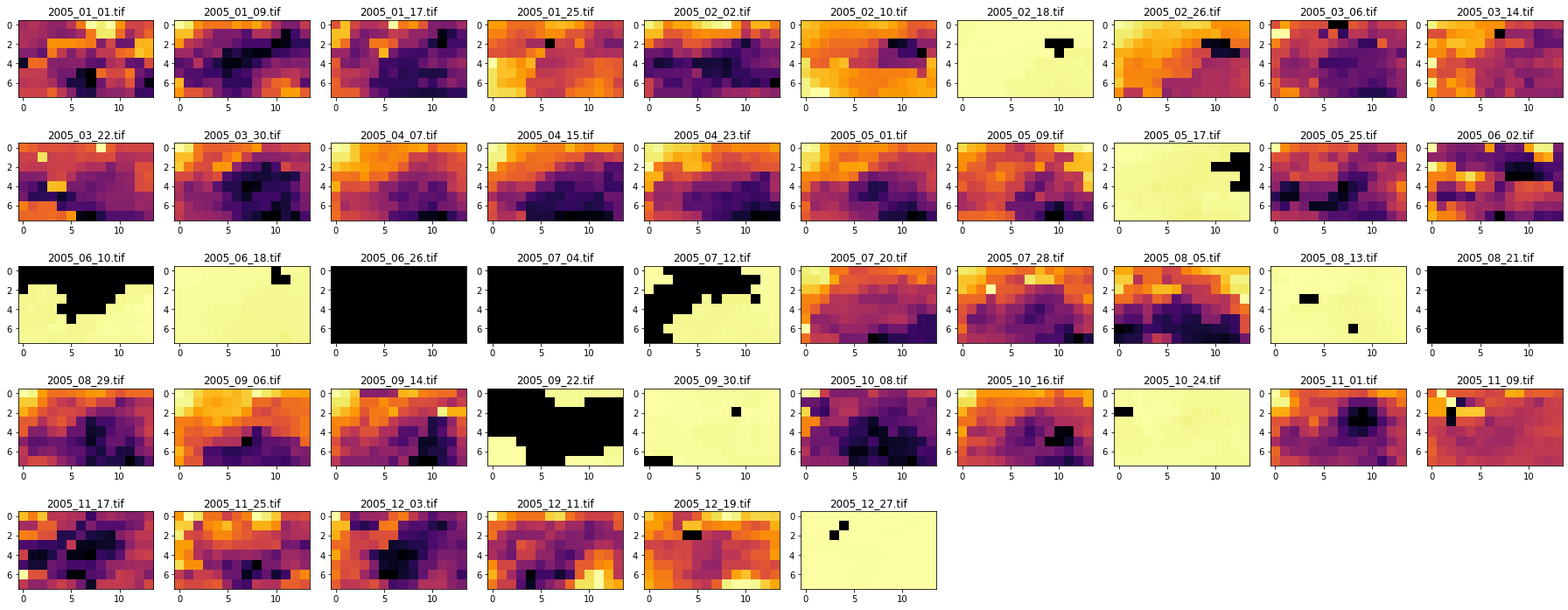
- 次に取得した期間(2005年1年間)のデータを全て可視化してみます
- 一般に植生は初夏~秋にかけて活性化し、冬には衰退するので、その様子を確認してみます
# 時系列で可視化 files = glob.glob('/content/drive/My Drive/GEE_NDVI/*tif') files.sort() plt.figure(figsize=(15, 10)) j=0 for i in range(len(files)): # 画像を1シーンずつ取得して可視化 with rasterio.open(files[i]) as src: arr = src.read() j+=1# 画像のプロット位置をシフトさせ配置 plt.subplot(5,6,j) plt.imshow(arr[0], cmap='YlGn', vmin=-2000, vmax=10000) plt.title(files[i][-14:])# ファイル名から日付を取得 plt.tight_layout()東京(皇居周辺)の植生指数の変化(1月~12月)
- 5~9月頃は植生指数が活性化している様子がみてとれます
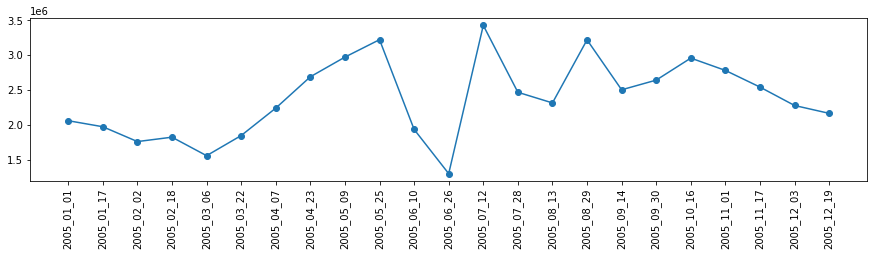
- 若干比較がしずらいので、植生指数の合計値を算出して時系列トレンドをみてみます
# 当該エリアの NDVIの数値を合計値を取得 sum_NDVI = [] label_NDVI = [] for i in range(len(files)): # 画像を1シーンずつ取得して可視化 with rasterio.open(files[i]) as src: arr = src.read() sum_NDVI.append(arr.sum()) label_NDVI.append(files[i][-14:-4]) # 可視化 fig,ax = plt.subplots(figsize=(15,3)) plt.plot(sum_NDVI, marker='o') ax.set_xticks(np.arange(0,23)) ax.set_xticklabels(label_NDVI, rotation=90) plt.show()植生指数の変化(1月~12月)
- 夏にかけて植生指数がピークを迎えている様子が確認できます
- 6月が大幅に現象しているのは雨季(雲)の影響で衛星が正しくデータ取得できない原因が考えられます
- 光学系の衛星は雲の影響を受けやすのが弱点ですが多様な情報を取得できる点に強みがあります(一方で雲の影響を受けないSARというタイプの衛星も存在します)
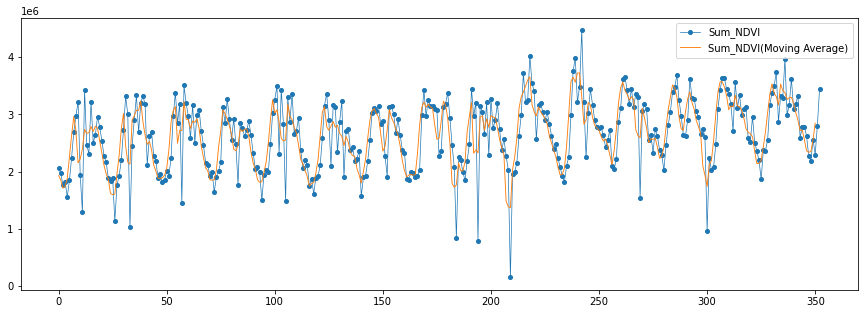
- 単年だと季節性の変化が分かりづらいので15年分のデータを取得・可視化してみました
- また移動平均も重ねて表示すると、植生指数の季節性の変化がより顕著に確認できます
植生指数の変化(15年分)
衛星データ解析③ ~地表面温度~
概要
- "気温"が空気中の温度であるのに対して、"地表面温度"は地球の表面の温度を表す
- Land Surface Temperature(LST)と呼ばれる
- 人工構造物(建物や道路)は森林や土と比べて地表面度温度が高くなる傾向にある
- ヒートアイランド現象の監視等に利用されている
データセット
- 衛星 = "Terra(MODIS)"
- バンド = LST (Land Surface Temerature)
- 解像度: 1000m
- エリア: 東京(皇居を中心)
コード
- 各種パラメータを変更してLSTを取得してみます
- 同様に取得したデータを可視化します
## パラメーターの指定 # 衛星を指定 snippet = 'MODIS/006/MOD11A2' # バンド名を指定 band = 'LST_Day_1km' # 期間を指定 from_date='2005-01-01' to_date='2005-12-31' # エリアを指定(日本エリアを緯度・経度を指定) geometry = ee.Geometry.Rectangle([139.686, 35.655, 139.796, 35.719]) # 保存するフォルダ名 dir_name = 'GEE_LST' # 解像度 scale = 1000 ## 処理の実行 ---------------------------------------------- num_data, data_list = load_data(snippet=snippet, from_date=from_date, to_date=to_date, geometry=geometry, band=band) print('#Datasets; ', num_data) ## 全件保存(ファイル名は衛星IDを利用) for i in range(data_list.size().getInfo()): image = ee.Image(data_list.get(i)) save_on_gdrive(image, geometry, dir_name, image.getInfo()['id'].replace('/', '_'), scale) # データの読み込み with rasterio.open('/content/drive/My Drive/GEE_LST/MODIS_006_MOD11A2_2005_08_05.tif') as src: arr = src.read() # 可視化 plt.figure(figsize=(20, 8)) plt.subplot(121); plt.imshow(rgb); plt.title('RGB Image'); plt.title('Optical Image') plt.subplot(122); plt.imshow(arr[0], cmap='inferno'); plt.title('Land Surface Temperature')東京(皇居周辺)の光学RGB画像と地表面温度
- 他データと比較して解像度が低いので若干分かりづらいです
- 該当期間を全て表示してみると、西側の方が温度が高くなる傾向にありそうです
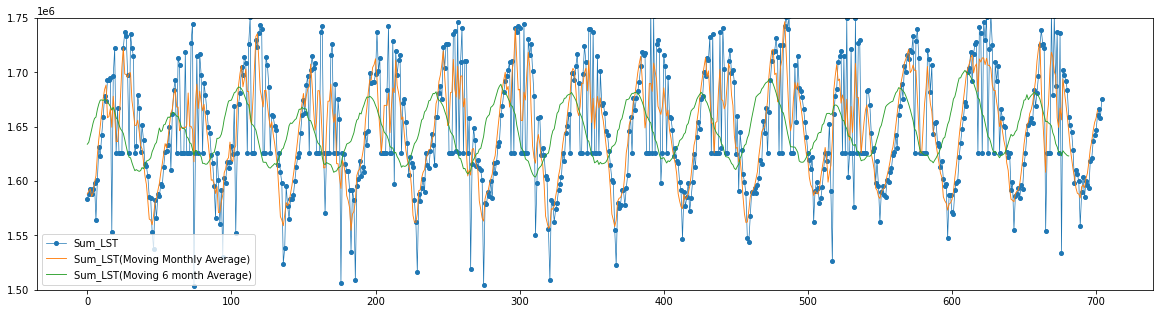
- また地表面温度は時間解像度が高い(高頻度でデータ取得している)反面、雲の影響により正しくデータが取得できていない画像が多い点も特徴の一つです東京(皇居周辺)の地表面温度の変化(1月~12月)
東京(皇居周辺)の地表面温度の変化(15年分)
- 植生指数と同様に長期間のデータも取得して、移動平均も含めて可視化をしてみました
- 植生と同様に季節性がありそうです(夏は高くなり、冬は低くなる)
- 解像度が低いので、もう少し広域で地表面温度を算出して、大局的なトレンドを分析した方が良さそうです
さいごに
- Google Earth EngineとGoogle Colabを用いて、代表的な衛星画像解析を紹介しました
- 上記の通りGEEとColabを利用することで、衛星名やバンド名の変数名を変更するだけで様々な衛星データの解析を行えることが分かるかと思います
- また衛星データ取得後、同一環境でPythonの便利な解析ライブラリを利用できる点が非常に便利です
- 実際の解析では、要件に応じて細かな前処理を追加したり、バイアスを除去するためにモデルを作ったりしますが、こういったサービスを利用するこで初期導入のステップは大幅に効率化できるかと思います
- また、手元の業務データをGoogle Driveへアップロードし、Colab上で衛星データとマージした解析も簡単に行えそうです
- 本記事をキッカケに様々な領域での人工衛星データ活用の一助になればと思います




- 投稿日:2020-08-12T19:03:56+09:00
Pythonのクラス継承の問題を解いてみる
Scientific Computing with Pythonの続き
freeCodeCampでコツコツPythonを勉強しています。
前回の記事では、今回はPolygon Area Calculatorに挑戦します。
- Python for Everybody
- Scientific Computing with Python Projects
- Arithmetic Formatter
- Time Calculator
- Budget App
- Polygon Area Calculator(今回はここ)
- Probability Calculator
4問目:Polygon Area Calculator
求められてることは以下の通り
- Rectangleクラスの作成
- Squareクラスの作成
rect = shape_calculator.Rectangle(10, 5) print(rect.get_area()) rect.set_height(3) print(rect.get_perimeter()) print(rect) print(rect.get_picture()) sq = shape_calculator.Square(9) print(sq.get_area()) sq.set_side(4) print(sq.get_diagonal()) print(sq) print(sq.get_picture()) rect.set_height(8) rect.set_width(16) print(rect.get_amount_inside(sq))50 26 Rectangle(width=10, height=3) ********** ********** ********** 81 5.656854249492381 Square(side=4) **** **** **** **** 8個人的ポイント: 特になし…
Rectangleの実装
class Rectangle: def __init__(self, width, height): self.width = width self.height = height def set_width(self, width): self.width = width def set_height(self, height): self.height = height def get_area(self): return self.width * self.height def get_perimeter(self): return 2 * self.width + 2 * self.height def get_diagonal(self): return (self.width ** 2 + self.height ** 2) ** .5 def get_picture(self): if(self.width >= 50 or self.height >= 50): return "Too big for picture." row = "*" * self.width return "\n".join([row for idx in range(self.height)]) + "\n" def get_amount_inside(self, shape): return int(self.get_area() / shape.get_area()) def __str__(self): return f"{self.__class__.__name__}(width={self.width}, height={self.height})"最後に
唯一調べたのは、クラス名を取得するのってどうだっけ?という部分だけでした。
成長しているのか?次の問題はProbability Calculatorです。
- 投稿日:2020-08-12T18:11:55+09:00
世界のアソビ大全51「ヨット」の役チョイスについてPythonを使って調べてみた
はじめに
https://youtu.be/iNAUzUEsgs4?t=8691
白雪巴さんが「世界のアソビ大全51」配信にて「ヨット」をプレイしていた時のこと.
「ここでチョイスはもったいない」
と言っていました.(その時の得点は20)
ふと疑問に思ったので, 少し調べてみました.
ヨットとは5つのサイコロを振って手を作るゲームであり, チョイスはその中の手の一つです.
チョイスは, すべての目の合計が得点となる役です.
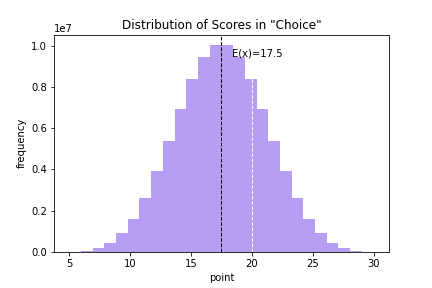
結論
20はチョイス選択「あり」
- チョイスの平均は17.5
- 20未満になる確率は 69.48%
- 21以上になる確率は 22.14%
前準備
1~6までの目がある1個のさいころを投げるとき, 出る目の数字の平均を考えます.
(※目の出方は同様に確からしいものとする)
ここで, さいころの目の合計は 21であり, それぞれの目は均等に出ることが期待できるため, もとめる平均 $E(x)$ は
$$
E(x) = \frac{1}{6} \times 21 = \frac{7}{2}
$$
と計算することが出来ます.このように求めた$E(x)$ のことを $X$ の期待値と呼び
$$
\begin{eqnarray}
E(x)
&=& x_1p_1 + x_2p_2 + \cdots + x_np_n \
&=& \sum^n_{k=1}x_kp_k\
&&(X = x_1, x_2, ..., x_n)(P=p_1, p_2, ..., p_n)
\end{eqnarray}
$$
としてもとめられる.本題
では, さいころを同時に5個投げた場合, 出た目の合計の平均を考えます.
このとき, 5個のさいころに対する確率は独立しているため, 単純に足し合わせれば求める平均を得ることが出来ます.
つまり
$$
E(x) = \frac{7}{2} \times 5 = \frac{35}{2}
$$
となります.$X$ を確率変数, $a$, $b$ を定数とするとき
$$
E(aX+b) = aE(x)+b
$$
が成り立つため, $E(X) = \frac{7}{2}$ , $a=5$, $b=0$ を代入すればもとまる実践
ここまでは数学を用いて, チョイスの平均をもとめました.
とはいえもうかなり忘れているので, 正しいかどうかわからない...ここからは Python をもちいて, もとめた平均が正しいか検証します.
なお, 以下のコードはすべて Google Colab にて動作確認しました.
平均計算
戦略は,単純.
1億回 5個のさいころを振り, その目の合計をもとめます. 次に, その平均を求めれば, もとめる平均が求まります.
つまり, 大数の法則です.
実際に試したコードが以下になります.
import numpy as np # 試行回数 N = 1 * 10**8 # チョイス実行 x = np.random.randint(1, 6+1, (N, 5)) x = x.sum(axis=1) # 平均計算 print(np.mean(x)) # 17.4996012結果は
17.4996012となり, 計算結果とほぼ一致していました.簡単に解説をば.
7行目にて, 1~6の乱数を サイズ(N, 5) で作成します.
8行目にて, 5個のさいころの合計をそれぞれ計算します.
ヒストグラム
思ったほか簡単に試せたので, おまけでヒストグラムを作成してみました.
実際に使ったコードが以下になります.
import numpy as np import matplotlib.pyplot as plt # 試行回数 N = 1 * 10**8 # チョイス実行 x = np.random.randint(1, 6+1, (N, 5)) x = x.sum(axis=1) # ヒストグラム生成 result = plt.hist(x, bins=26, alpha=0.5, color=(0.43, 0.25, 0.91)) # 補助線 ex = 17.5 min_ylim, max_ylim = plt.ylim() plt.axvline(17.5, color='k', linestyle='dashed', linewidth=1) plt.text(ex*1.05, max_ylim*0.9, f"E(x)={ex}") plt.axvline(20, color='w', linestyle='dashed', linewidth=1) # ラベル plt.title('Distribution of Scores in "Choice"') plt.xlabel("point") plt.ylabel("frequency") plt.savefig("fig.png")これにて出来たヒストグラムが以下になります.
このヒストグラムにおいて, 黒の点線が平均, 白の点線が20 となっています.
これより, 平均より超えていることが一目でわかるようになりました.
20未満の確率
さて, チョイスの得点が20未満になる確率はどれぐらいでしょうか?
これが分かれば, 説得力が増えそうです.
というわけで, Python にお願いして, 近似的に求めてみます.
import numpy as np # 試行回数 N = 1 * 10**8 # チョイス実行 x = np.random.randint(1, 6+1, (N, 5)) x = x.sum(axis=1) # 頻度計算 uni, counts = np.unique(x, return_counts=True) d = {str(u): c for u, c in zip(uni, counts)} # 20未満の発生確率 temp = [v for k, v in d.items() if int(k) < 20] print(f"{(sum(temp) / N)*100:.02f}%") # 69.48%結果は 69.48% となり, 全体の約7割が20未満となることが分かりました.
また, このプログラム 15行目にある不等号の向きを変えれば, 簡単に21以上の発生確率も調べることが出来ます.
結果は 22.14% つまり, これ以上高い手になる確率は 約2割となります.
ソシャゲのガチャに毒されているので高く感じますが... といった感じです.
おわりに
アソビ大全のゲーム 解析してみる楽しい
- 投稿日:2020-08-12T17:48:08+09:00
GoogleColabでdisplayにより出力されるpandasのデータフレームのデフォルトスタイル(CSS)を変更
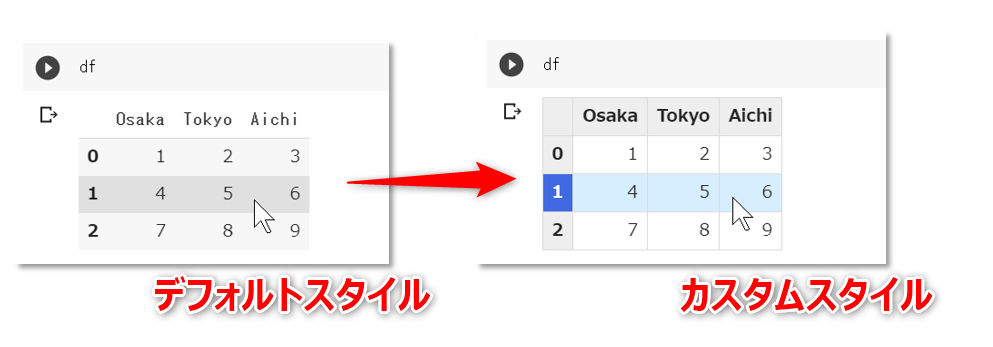
概要
GoogleColab のなかで、IPython.display モジュールで経由で出力されるデータフレーム
pandas.DataFrameのデフォルトの見た目(スタイル/CSS)を変更するための方法です。
なお、GoogelChrome で動作確認をしています。
データフレームのスタイルを変更
GoogleColab. のコードセルで下記を実行すると、
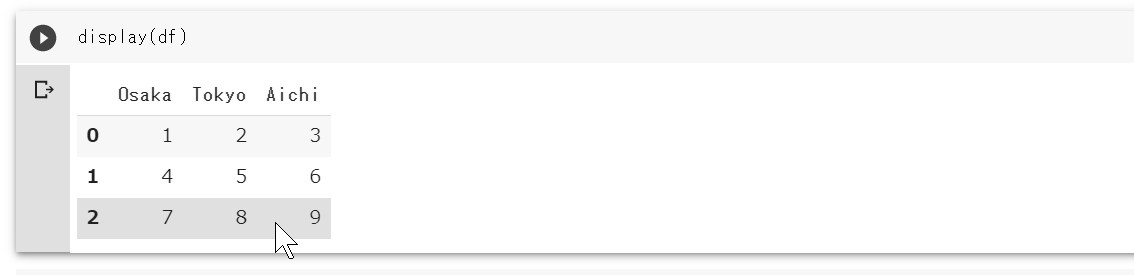
import pandas as pd df = pd.DataFrame([[1, 2, 3],[4, 5, 6],[7, 8, 9]], columns=['Osaka','Tokyo','Aichi']) display(df)次のようにHTMLのテーブル要素を使って整形されたデータフレームが出力されます。
このテーブルのスタイル(CSS)をカスタマイズしたい場合は、次のようなコードを挿入します。以降、
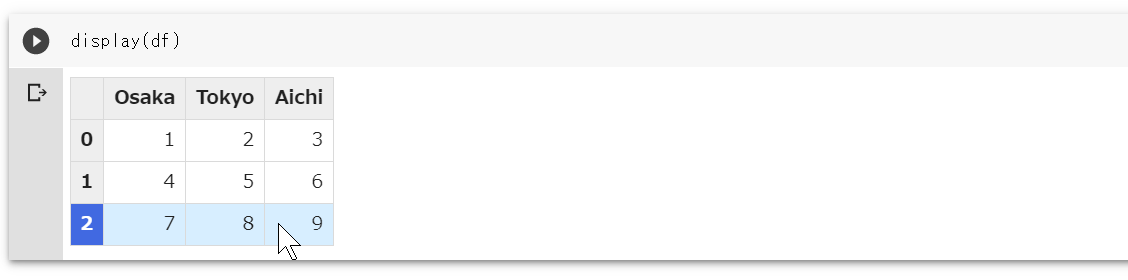
IPython.display(...)経由で出力されるデータフレーム(HTMLのテーブル要素)には、コード内で指定したCSSが適用されるようになります。データフレームの出力に適用されるCSSを変更import IPython def set_css_in_cell_output(): display(IPython.display.HTML('''<style> table.dataframe td, table.dataframe th{ border:1px solid #dadada; } table.dataframe th{ font-family: 'Roboto','Noto',sans-serif; background: #eeeeee; font-weight: bold; } table.dataframe td{ background: #ffffff; } table.dataframe tbody tr:hover th{ color: #ffffff; background-color:#4169e1; } table.dataframe tr:hover td{ background-color: #d7eeff; } </style>''')) get_ipython().events.register('pre_run_cell', set_css_in_cell_output)以降、データフレームは次のように出力されます(すべてのテーブル全体に罫線が入って、ヘッダのフォントとマウスオーバーのときの色が変わるようになりました)。
条件付き書式
セル内の数値に応じて色を変えるといった条件付き書式を適用したい場合は
DataFrame.styleを使用するようです。
- User Guide :: Styling @ pandas.pydata.org
参考資料
- How to import CSS file into Google Colab notebook (Python3) @ stackoverflow
- 投稿日:2020-08-12T17:32:04+09:00
【iOS】Pythonista3でGIFアニメ。でハマったこと。
はじめに
GIFアニメを作るアプリはたくさんありますが、せっかくPythonista3があるので、多くの先輩方の記事を参考にしながら、自分でも作ってみようと思いました。
すぐにハマる
以前にWin10上のPythonでGIFアニメを作ったことがあったので、その記憶を頼りにPILで書いたのですが、1枚目の画像しか保存されませんでした。
testGIF.pyw,h = 100,100 images = [] for c in range(0,256,8): img = Image.new('RGB',(w,h),(c,c,c)) images.append(img) images += reversed(images) SaveName = 'test.gif' images[0].save(SaveName, save_all=True, append_images=images[1:], optimize=False, duration=20, loop=0)いろいろ調べたのですが、結局win10上では動作確認ができたのでiOSのPILではうまくいかないという結論にしました。
その名も「images2gif」
調べてるうちに同様の質問があり、「images2gif」の存在を知りました。
僕のやりたかったことがそのまま名前になったようなモジュール名です。それは公式のドキュメントにも紹介されていて初めからインストールされてるものでした。
「images2gif」の使い方
基本的には次の記述でいいみたいです。
writeGif( SaveName, ImageList, duration=0.1,repeat=True)testGIF2.pyfrom PIL import Image from images2gif import writeGif w,h = 100,100 images = [] for c in range(0,256,8): img = Image.new('RGB',(w,h),(c,c,c)) images.append(img) images += reversed(images) SaveName = 'test.gif' writeGif( SaveName, images, duration=0.02,repeat=True)
PythonのGIFアート
日本語ヘルプ
最後にビックリしたのは、探してたどり着いた日本語ヘルプの記事が、「以前、僕が自分で投稿したもの」で、いよいよヤバいと思いました。

- 投稿日:2020-08-12T17:14:48+09:00
[アルゴリズム×Python] 基本統計量の計算Part2(平均値、中央値、最頻値)
アルゴリズムとPythonについて書いていきます。
今回は簡単な計算を関数を使って求めるだけでなく、関数を使わない場合にどうやって求めるかについても書いていきます。目次
0.算術演算子と比較演算子の確認
1.リスト内包表記について
2.平均値を求める
2-0.算術平均
2-1.幾何平均
2-2.二乗平均
2-3.調和平均
3.中央値を求める
4.最頻値を求める
最後に0.算術演算子と比較演算子の確認
算術演算子
◯計算を行うための記号についてです。
演算子 意味 例 結果 + 足し算 3 + 4 7 - 引き算 10 - 2 8 * かけ算 5 * -6 -30 / 浮動小数点数の割り算 5 / 2 2.5 // 整数の割り算 5 // 2 2 % 割り算のあまり 7 % 2 1 ** ~乗(指数) 2 ** 4 16 比較演算子
◯比較を行うための記号についてです。
TrueかFalseのブール値を返します。
意味 演算子 等しい == 等しくない != より小さい < 以下 <= より大きい > 等しくない >= 要素になっている in ~ リスト内包表記について
◯様々な種類のリストを効率的につくるために、リスト内包表記が使われます。
今回の記事でも色々なリストを使って行きたいと思うので、事前に書いていきます。リスト内包表記とは
リストをつくる方法の1つです。
[リストに格納する要素 for 要素 in イテラブルオブジェクト]という形で定義します。
リストに格納する要素は、要素を使用した式です。
イテラブルオブジェクトは、要素を1つずつ取り出すことのできるオブジェクトのことです。リスト内包表記の使用例
◯range()関数はイテラブルオブジェクトを返します。
ex0.py#1以上10未満の整数を1つずつ取り出して、その値をnumbersリストに格納する numbers = [number for number in range(1,10)] print(numbers)[1, 2, 3, 4, 5, 6, 7, 8, 9]ex1.py#1以上10未満の整数を1つずつ取り出して、それに2をかけた値をnumbersリストに格納する numbers = [number * 2 for number in range(1,10)] print(numbers)[2, 4, 6, 8, 10, 12, 14, 16, 18]ex2.py#1以上10未満の整数を1つずつ取り出して、偶数の値のみをnumbersリストに格納していく numbers = [number for number in range(1,10) if number % 2 == 0] print(numbers)[2, 4, 6, 8]ex3.py#文字列のリスト list_1 = ['1','2','3'] #文字列のリストlist_1から要素を1つずつ取り出して、整数にしてからリストnumbersに格納する numbers = [int(i) for i in list_1] print(numbers)[1, 2, 3]ex4.py#取り出した要素が奇数ならばそのまま格納して偶数ならば2乗してから格納する numbers = [i if i % 2 == 1 else i**2 for i in range(10)] print(numbers)[0, 1, 4, 3, 16, 5, 36, 7, 64, 9]2.平均値を求める
2-0.算術平均の求め方
◯一般的に知られている平均値です。
要素の合計値/要素の数で求めることができます。
mean()関数を使った平均値の求め方
◯標準ライブラリの
statisticsをimportしてmean()関数を使えるようにします。#モジュールをimportする import statistics numbers = [1,2,3,4,5,6] #statisticsモジュールの中にあるmean()関数を mean_of_numbers = statistics.mean(numbers) print('mean =',mean_of_numbers)mean = 3.5◯Point:モジュール
関連するPythonコードをまとめたファイルのこと。import モジュールという形で使います。◯Point:ドット(.)
ドットは、~の中に行くという意味です。
モジュールの中にある関数や変数を使うためには、statistics.mean()のように、モジュール.関数や、モジュール.変数のようにします。◯Point:
公式ドキュメント:statistics
合計値を使った平均値の求め方
◯要素の合計値/要素の数で求めます。
#リスト内包表記でリストの要素を定義してみる #定義するリストは[1,2,3,4,5,6] numbers = [number for number in range(1,7)] #平均 = 合計値 / 要素数 average = sum(numbers)/len(numbers) print('numbers = ',numbers) print('average of numbers = ', average)numbers = [1, 2, 3, 4, 5, 6] average of numbers = 3.52-1.幾何平均の求め方
◯幾何平均は、変化率で表されるデータを扱う場合に使います。
(例)
貯金が年率5%で値が大きくなったら、1.05を掛けた値になります。翌年に年率7%で値が大きくなったら、最初の貯金額に1.05を掛けたものに、さらに1.07を掛けた金額になります。
このときの変化率の年平均を求めるために、幾何平均を使います。◯幾何平均(geometric_mean)を求める公式は、xG = n√ x1*x2*x3*…*xn です。
つまり、各データ(変化率)を全て掛け合わせて、データ数の累乗根をとることで求めることができます。◯幾何平均(相乗平均)の意味と計算方法~伸び率の平均を求める~
gmean()関数を使った幾何平均の求め方
◯会社の売り上げの例について計算します。
1年目:1000万円
2年目:2500万円(前年比2.5倍)
3年目:4000万円(前年比1.6倍)売り上げの変化率の年平均を
geometric_meanとすると、#gmean()関数をimportする from scipy.stats import gmean # 2√ 2.5*1.6 を計算する #売り上げの変化率の年平均をgeometric_meanとする geometric_mean = gmean([2.5,1.6]) print(geometric_mean)2.0◯Point:Scipy
高度な科学計算を行うためのライブラリのことです。
参考記事
絶対に知っとくべきライブラリscipyの基本的な使い方◯Point:gmean()関数
参考記事
公式ドキュメント
geometric_mean()関数を使った幾何平均の求め方
◯Python3.8から、statisticsモジュールの中に、###geometric_mean()関数が導入されたようです。なのでPython3.8以上の方は使用可能です。
from statistics import geometric_mean print(geometric_mean([2.5,1.6]))2.0
root()関数を使った幾何平均の求め方
import sympy #売り上げ(sales)のリスト sales = [1000,2500,4000] #変化率(rate_of_change)のリスト #このリストは[2.5, 1.6]になる rate_of_changes = [sales[i+1]/sales[i] if i < len(sales)-1 for i in range(len(sales))] #変数mulには全ての要素の積を代入していく #まず、変化率のリストの先頭の要素を変数mulに代入する #この時点ではmul = 2.5になる mul = rate_of_changes[0] #要素を掛け合わせていく for i in range(len(rate_of_changes)): #いつまで繰り返すか if i < len(rate_of_changes)-1: #変数mulに、i+1の要素をかけて代入する mul *= rate_of_changes[i+1] else: break #root(ルートの中身,~乗根) #今回のルートの中身は全ての要素の積 geometric_mean = sympy.root(mul,len(rate_of_changes)) print('geometric_mean = ',geometric_mean)geometric_mean = 2.00000000000000Python, SymPyの使い方(因数分解、方程式、微分積分など)
2-2.二乗平均の求め方
◯二乗平均は、平均したい数値を2乗して合計し要素数nで割った値を平方根して算出します。輸送機関の時刻表に対する到着時間との差分を算出したいときなどに利用します。
◯2分の遅れも2分早く到着することも、時刻の乱れがあることに違いはありません。しかし、プラスマイナスがあるまま算術平均をするとその誤差を相殺してしまいます。
なので、2乗することでマイナスをなくして計算をおこないます。
root()関数を使った二乗平均の求め方
#root()関数を使うためにsympyをimportする import sympy #標準ライブラリのdecimalモジュールを使って最終的な値を四捨五入してみる from decimal import Decimal, ROUND_HALF_UP #誤差のリスト data_list = [-2,3,4,-5] #誤差のリストの各要素を2乗して新しいリストsquared_listをつくる squared_list = [i**2 for i in data_list] #squared_listの平均をまず求める(合計値/要素数) mean_square = sum(squared_list)/len(squared_list) #mean_squareの平方根をとる root_mean_square = sympy.root(mean_square,2) print('RMS = ',root_mean_square) #正確にその値のDecimal型として扱うためにstr()で型を変換する #Decimal('求めたい桁数')で、桁を指定する #ROUND_HALF_UPで一般的な四捨五入を行う print('Rounded RMS = ',Decimal(str(root_mean_square)).quantize(Decimal('0.1'), rounding=ROUND_HALF_UP))RMS = 3.67423461417477 Rounded RMS = 3.7◯Point:Decimal.quantize
参考記事
Pythonで小数・整数を四捨五入するroundとDecimal.quantize2-3.調和平均の求め方
◯調和平均とは、時速の平均値などを求める時に使うものです。
◯例として、車が時速80kmで往路200kmを、時速30kmで復路200kmを走行したときの平均時速を求めます。
時速は、距離/時間であり、平均時速は総距離/総時間で求められます。
総距離は200 + 200 = 400(km)
総時間(距離/速さ)は、200/80 + 200/30 = 2.5(時間) + 6.666(時間) = 9.166(時間)
時速の平均 = 総距離/総時間 = 400/9.166 = 43.636(km/時間)
harmonic_mean()関数を使った調和平均の求め方
import statistics #harmonic_mean([x1,x2,...xn]) print(statistics.harmonic_mean([80,30]))43.63636363636363
距離を使った調和平均の求め方
distance = 200 #距離を使って総距離を求める total_distance = distance* 2 #速度の値を格納したリストを用意する speed_list = [80,30] #リストの速度からそれぞれの所要時間(距離/速度)を取得してリスト化する time_list = [distance/speed for speed in speed_list] #それぞれの所要時間の合計値(総時間)を求める total_time = sum(time_list) #調和平均 = 総距離/総時間 harmonic_mean = total_distance/total_time print('harmonic_mean = ',harmonic_mean)harmonic_mean = 43.63636363636363◯Point:参考記事
調和平均の意味と計算方法3.中央値を求める
◯データを昇順、または降順に並べた時の真ん中の値を中央値といいます。データ数が偶数の時は、真ん中の数が2つになるので、それらを足して、2で割ったものが中央値になります。中央値のメリットは、外れ値(極端に他と離れた値)に左右されにくい点です。
median()関数を使った中央値の求め方
◯要素数が奇数でも偶数かで場合分けする必要はありません。
#median()関数を使う為にモジュールをimportする import statistics #リストの要素数は奇数 numbers = [1,100,4,7,3] #変数median_of_numberに中央値の値を代入する #モジュール内の関数を使うためにドットを使ってアクセスする median_of_numbers = statistics.median(numbers) print('median of numbers = ',median_of_numbers)median of numbers = 4
要素数を2分して中央値を求める
◯要素数が奇数か偶数かで場合分けして考えていきます。
奇数の場合は、要素の真ん中の数のインデックスを要素数 // 2(整数の割り算)で求めます。
偶数の場合は、要素の真ん中の数2つのインデックスを要素数 / 2と要素数/2-1で求めます。#リストの要素数は偶数 numbers = [1,100,4,7,3,8] #まずリストを昇順に並べ替える numbers.sort() #変数length_of_numbersに、numbersリストの要素数を代入する length_of_numbers = len(numbers) #もし、要素数が奇数ならば、 if(length_of_numbers % 2 == 1): #変数median_indexに、リストの要素の真ん中の値のインデックスを代入する #例えば、要素数5のリストの真ん中の値のインデックスは、5//2 = 2 median_index = length_of_numbers//2 print('median of numbers = ',numbers[median_index]) #もし、要素数が偶数ならば、 else: #リストの要素数の2分の1の値を変数median_indexに代入する median_index = length_of_numbers//2 #要素数が偶数の場合の中央値の値は、真ん中の値2つを足して、2で割ったもの #例えば要素数が6のとき、真ん中の値2つのインデックスは6/2-1 = 2と6/2 = 3 print('median of numbers = ',(numbers[median_index-1] + numbers[median_index])/2)#(4 + 7)/2 = 5.5 median of numbers = 5.54.最頻値を求める
◯リストの中から最も頻繁に現れる要素を見つけます。
Counterクラスを使った最頻値の求め方
#collectionsモジュールからCounterクラスをimportする from collections import Counter medals = ['gold','silver','gold','silver','silver','bronze'] #インスタンスの生成 medal_counter = Counter(medals) print(medal_counter)Counter({'silver': 3, 'gold': 2, 'bronze': 1})◯Point:クラスの使い方
クラスは関連のあるフィールドとメソッドをまとめたものです。
ただし、クラスそれ自体は抽象的な存在で、プログラム内で直接使うことはできません。
なので、まずクラスを具体化してオブジェクトをつくります。
今回は、Counter(medals)がそれに当たります。
これをインスタンスといいます。これをプログラム内で扱う時は、変数として扱います。
そのために、medal_counter = Counter(medals)のようにして変数medal_counterにインスタンスを代入します。◯Point:most_common()
Counterクラスのメソッドです。全ての要素を降順で返します。
引数として整数を指定すると、最上位から数えてその個数分だけを表示します。
(例)print(medal_counter.most_common(1))[('silver', 3)]
最頻値が複数存在する場合の最頻値の求め方
◯複数の最頻値が存在する場合に備えたプログラムをつくります。
最頻値のリストを返す関数を自分で定義します。#Counterクラスをimportする from collections import Counter #最頻値のリストを返す自作の関数(mode_func)を定義する def mode_func(letters): #まずletter(文字)とその出現数を取得する #letter_counter = Counter({'t': 2, 'o': 2, 'e': 1, 'x': 1, '_': 1, 'b': 1, 'k': 1}) letter_counter = Counter(letters) #次に文字とその出現数のセットを降順に並べたリストを取得して、変数letter_and_countに代入する #[('t', 2), ('o', 2), ('e', 1), ('x', 1), ('_', 1), ('b', 1), ('k', 1)] letter_and_count = letter_counter.most_common() #降順に並べたので、"一番左の要素の出現数"(ここでは2)が最頻値の1つであることは確定している #それを変数max_countに代入する max_count = letter_and_count[0][1] #最頻値を格納するリストを作って、他にも同じ出現数を持つ要素があれば随時追加していく mode_list = [] for letter in letter_and_count: #もし、要素(文字)の出現数が最頻値のそれと同じなら if letter[1] == max_count: #その文字を最頻値のリストに追加する mode_list.append(letter[0]) #最終的に最頻値のリストを返す return(mode_list) #関数を再利用しやすくするために書いておく if __name__ == '__main__': #文字列をリスト化したものを変数lettersに代入する letters = list('text_book') #mode_func()が返すリストを変数mode_listに代入する mode_list = mode_func(letters) #mode_listに、複数の最頻値があるかもしれないので、それを全て取り出して書き出す for mode in mode_list: print('Mode = ',mode)Mode = t Mode = o◯Point:
if __name__ == '__main__':
参考記事
Pythonのif __name__ == '__main__'とはなんですかへの回答最後に
読んでいただきありがとうございました。
次回は、基礎統計量の計算Part3(分散、標準平均...)について書いていきます。
間違いや改善点等のご指摘いただけると嬉しいです。
- 投稿日:2020-08-12T17:13:59+09:00
[アルゴリズム×Python] 基本統計量の計算(合計値、最大値、最小値)
アルゴリズムとPythonについて書いていきます。
今回は簡単な計算を関数を使って求めるだけでなく、関数を使わない場合どうやって求めるかについても書いていきます。目次
0.算術演算子と比較演算子の確認
1.リスト内包表記について
2.合計値を求める
3.最大値を求める
4.最小値を求める
最後に0.算術演算子と比較演算子の確認
算術演算子
◯計算を行うための記号についてです。
演算子 意味 例 結果 + 足し算 3 + 4 7 - 引き算 10 - 2 8 * かけ算 5 * -6 -30 / 浮動小数点数の割り算 5 / 2 2.5 // 整数の割り算 5 // 2 2 % 割り算のあまり 7 % 2 1 ** ~乗(指数) 2 ** 4 16 比較演算子
◯比較を行うための記号についてです。
TrueかFalseのブール値を返します。
意味 演算子 等しい == 等しくない != より小さい < 以下 <= より大きい > 等しくない >= 要素になっている in ~ リスト内包表記について
◯様々な種類のリストを効率的につくるために、リスト内包表記が使われます。
今回の記事でも色々なリストを使って行きたいと思うので、事前に書いていきます。リスト内包表記とは
リストをつくる方法の1つです。
[リストに格納する要素 for 要素 in イテラブルオブジェクト]という形で定義します。
リストに格納する要素は、要素を使用した式です。
イテラブルオブジェクトは、要素を1つずつ取り出すことのできるオブジェクトのことです。リスト内包表記の使用例
◯range()関数はイテラブルオブジェクトを返します。
ex0.py#1以上10未満の整数を1つずつ取り出して、その値をnumbersリストに格納する numbers = [number for number in range(1,10)] print(numbers)[1, 2, 3, 4, 5, 6, 7, 8, 9]ex1.py#1以上10未満の整数を1つずつ取り出して、それに2をかけた値をnumbersリストに格納する numbers = [number * 2 for number in range(1,10)] print(numbers)[2, 4, 6, 8, 10, 12, 14, 16, 18]ex2.py#1以上10未満の整数を1つずつ取り出して、偶数の値のみをnumbersリストに格納していく numbers = [number for number in range(1,10) if number % 2 == 0] print(numbers)[2, 4, 6, 8]ex3.py#文字列のリスト list_1 = ['1','2','3'] #文字列のリストlist_1から要素を1つずつ取り出して、整数にしてからリストnumbersに格納する numbers = [int(i) for i in list_1] print(numbers)[1, 2, 3]ex4.py#取り出した要素が奇数ならばそのまま格納して偶数ならば2乗してから格納する numbers = [i if i % 2 == 1 else i**2 for i in range(10)] print(numbers)[0, 1, 4, 3, 16, 5, 36, 7, 64, 9]2.合計値を求める
sum()関数を使った合計値の求め方
◯sum()関数を使うと、リストの要素の合計値を簡単に求めることができます。
#使うリストを用意する numbers = [1,2,3,4,5] #sum(リスト)というふうに使う print(sum(numbers))15
イテレータを使った合計値の求め方
numbers = [1,2,3,4,5,6] #合計値を表す変数sum_of_numbersを定義する #まだ何も足されていないので0に設定する sum_of_numbers = 0 #forループを使って、リストの要素を1つずつ取得していく #range()は'〜の間'という意味で、イテレーションの範囲を示す #len(リスト)でリストの要素数(長さ)を取得する for i in range(len(numbers)): #取得した要素を1つずつsum_of_numbersに追加していく sum_of_numbers += numbers[i] print('sum of numbers = ', sum_of_numbers)sum of numbers = 21◯Point:イテレータ
イテレーション(繰り返し)ごとにリスト、辞書などから要素を1つずつ取り出して返すものです。
リストや辞書などは、イテレータに対応しているイテラブルオブジェクトです。
イテラブルオブジェクトは、他にも文字列、タプル、集合などがあります。◯Point: +=, -=, *=, /=, //=, %=, =**
計算した値を代入するという計算過程を略して書いたものです。
(例)a = 3 #a = a * 5 a *= 5 print(a)153.最大値を求める
max()関数を使った最大値の求め方
◯max(リスト)という形で使用します
文字列を整数化してから、新しいリストに格納して、その中にある要素の最大値を求めてみます。list_1 = ['1','2','3'] #list_1の要素をint()関数を使って整数に直してからnumbersリストに格納する numbers = [int(i) for i in list_1] print('numbers = ',numbers) #リストの最大値をmax(リスト)という形で求める print('max of numbers = ',max(numbers))numbers = [1, 2, 3] max of numbers = 3
比較を使った最大値の求め方
◯暫定の最大値と要素を比較していく方法です。
#リスト内包表記でリストの要素を定義してみる #1以上11未満 かつ 2で割った余りが0 を満たす要素をリストに格納する #リストは[2, 4, 6, 8, 10]となる numbers = [number for number in range(1,11) if number % 2 == 0] #先頭の要素(今回は2)を仮の最大値に設定する max_of_numbers = numbers[0] #リストの要素を1つずつ取り出していく。 #先頭の要素は比較対象ではないので除く for i in range(1,len(numbers)): #もし、比較した要素が現在の最大値より大きければ if(max_of_numbers < numbers[i]): #最大値を更新する max_of_numbers = numbers[i] print('numbers = ',numbers) print('max of numbers = ', max_of_numbers)numbers = [2, 4, 6, 8, 10] max of numbers = 104.最小値を求める
min()関数を使った最小値の求め方
◯min(リスト)という形で使用します
#0以上10未満までの範囲のなかで、偶数の値は2乗してからリストに格納する #奇数の値はそのまま格納する #リストは[0, 1, 4, 3, 16, 5, 36, 7, 64, 9]となる numbers = [i if i % 2 == 1 else i**2 for i in range(10)] print('numbers = ',numbers) #リストの最小値をmin(リスト)という形で求める print('min of numbers = ',min(numbers))numbers = [0, 1, 4, 3, 16, 5, 36, 7, 64, 9] min of numbers = 0◯Point: if-else-
もし-なら、でなければ-という意味です。
条件に合致するかどうかを判断する比較の文です。
今回の場合は、
要素が奇数ならば(if i % 2 == 1)-する、でなければ(偶数ならば)要素を2乗する
比較を使った最小値の求め方
◯暫定の最小値と要素を比較していく方法です。
今回はランダムな整数のリストを作って、その中から最小値を選んでみます。#randomモジュールをimportする import random #0から100までの整数のリストnumbersをつくる numbers = [number for number in range(0,101)] #numbersリストからランダムに要素を10個取り出してリスト化する #このリストにある要素の最小値を求める random_numbers = random.choices(numbers,k = 10) #先頭の要素(今回は2)を仮の最小値に設定する min_of_random_numbers = random_numbers[0] #リストの要素を1つずつ取り出していく。 #先頭の要素は比較対象ではないので除く for i in range(1,len(random_numbers)): #もし、比較した要素が現在の最小値より小さければ if(min_of_random_numbers > random_numbers[i]): #最小値を更新する min_of_random_numbers = random_numbers[i] print('random_numbers = ',random_numbers) print('min of random_numbers = ', min_of_random_numbers)random_numbers = [33, 99, 33, 27, 25, 42, 19, 37, 14, 15] min of random_numbers = 14◯Point:randomモジュール
今回は、randomモジュールの中にある、choices(参照するもの,要素数)関数を使います。
choices()関数を使うと、k =で指定した数の要素のリストをつくることができます。
また、作成するリストの要素は、参照するもの(今回はnumbersリスト)からランダムに選んだ要素になります。参考記事:Pythonでリストからランダムに要素を選択するchoice, sample, choices
最後に
読んでいただきありがとうございました。
次回は基礎統計量の計算Part2(平均値、中央値、最頻値)を書いていきたいと思います。
間違いや改善点等のご指摘くださると嬉しいです。
- 投稿日:2020-08-12T17:13:46+09:00
【Python】Google Colab上でメルカリ商品ページをWebスクレイピングした結果をGoogleスプレッドシートに保存して、商品の画像も表示させてみる
この記事は以前YouTubeに公開した下記の動画の内容を元にしています。
【Python学習】メルカリ商品ページをWebスクレイピングした結果をGoogleスプレッドシートに保存して、商品の画像も表示させてみる
なお、この記事で扱っている内容はあくまで学習目的によるものとなります。
スクレイピングは場合によっては相手のサーバに対する負荷などにも繋がりますので、常識の範囲内で行うようにしてください。Google Colab上で実行するPythonコード
まずは動画内で書かれている実際のコードを下に貼っていきます。
gspreadのインストール
!pip install gspreadついつい、癖で
gspreadを明示的にコマンド打ってインストールしていましたが、これは不要でした...
このやり方でインストールしても、元々Colabにインストールされているバージョンと変わらないので、正直意味がなかったです。こちらの詳細については、以前投稿した下記の記事を参照ください。
https://qiita.com/safa/items/bfa52430f920ac562bec#gspread%E3%81%AE%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%BC%E3%83%ABGoogleスプレッドシートにColab上からアクセスできるようにするためのおまじない
from google.colab import auth from oauth2client.client import GoogleCredentials import gspread auth.authenticate_user() gc = gspread.authorize(GoogleCredentials.get_application_default())
Google Colab上でGoogle スプレッドシートにアクセスするためのコードです。
半ば自分の中ではおなじないと化しています。こちらのコードを実行すると、URLが表示されます。
画面に従って操作していけば認証自体は問題なく完了するかと思います。
(あらかじめ自身のGoogleアカウントでログインしていると楽です)メルカリ商品ページをWebスクレイピングした結果をGoogleスプレッドシートに保存して、かつ商品の画像を表示させるためのコード
実際のPythonコードがこちらです。
保存先として指定するGoogleスプレッドシートURLを入力した上で実行してください。from bs4 import BeautifulSoup import requests workbook_url = "保存先となるGoogle SpreadsheetのURL" workbook = gc.open_by_url(workbook_url) mercari_url = "https://www.mercari.com" fetch_path = "/jp/category/967/" headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4222.0 Safari/537.36'} # fetch_url: https://www.mercari.com/jp/category/967/ fetch_url = mercari_url + fetch_path print("取得URL: " + fetch_url) r = requests.get(fetch_url, headers=headers) soup = BeautifulSoup(r.text, "lxml") title = soup.find('title').get_text() worksheet = workbook.add_worksheet(title=title, rows=100, cols=4) item_list = soup.find_all("li", class_="sc-bwzfXH") result_list = [] worksheet.append_row(["ID", "タイトル", "値段", "詳細URL", "画像"]) for i, item in enumerate(item_list): item_title = item.find("span").get_text() item_price = item.find("div", class_="style_thumbnail__N_xAi").get_text() item_url = mercari_url + item.find("a")["href"] image = "=IMAGE(\"" + item.find("img")["src"] + "\")" worksheet.append_row([i, item_title, item_price, item_url, image], value_input_option="USER_ENTERED") print("完了!")実行に成功すると、下記のようにGoogle スプレッドシート内に画像が表示された状態でデータが書き込まれます。
コードの補足説明
書いたコードに関する補足説明をいくつか行っていきます。
User-Agentの付与
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4222.0 Safari/537.36'} ・ ・ ・ r = requests.get(fetch_url, headers=headers)メルカリのページでは、
User-Agentがないアクセスに対しては403を返すようです。
requestsでは、getの第2引数にオプションとしてUser-Agentを設定することが可能なので、こちらを設定した上でアクセスを行っています。
なお、User-Agentの内容は動画作成時のGoogle Chrome Canaryのものになります。
DevtoolsのNetworkタブ内にて表示されている値をそのまま使用しています。lxmlについて
soup = BeautifulSoup(r.text, "lxml")
Google Colab上では最初からlxmlがインストールされているため、いきなりこのようなコードを書いてもエラーにはなりません。
もしローカルで同じコードを実行する場合は、lxmlも、pipインストールしておく必要があります。シートのタイトルについて
title = soup.find('title').get_text() worksheet = workbook.add_worksheet(title=title, rows=100, cols=4)Pythonスクリプトを実行した際に、取得したページのタイトルをシート名にしてシートを作成するようにしています。
add_worksheet関数内で、作成するシートの縦横を指定していますが、指定しなくとも勝手に追加はされていくようでした。
(とりあえず100行、4列で指定しています)GoogleスプレッドシートのIMAGE関数を用いて画像を表示させる
image = "=IMAGE(\"" + item.find("img")["src"] + "\")" worksheet.append_row([i, item_title, item_price, item_url, image], value_input_option="USER_ENTERED")Google スプレッドシート内に画像を表示させる場合、Googleスプレッドシート側で提供しているIMAGE関数を用います。
ドキュメントを見てみると、いくつかのオプションが提供されているようでしたが、今回は使用しませんでした。
本当は画像に合わせてセルのサイズを変更したかったのですが、残念ながらその機能は提供されていなかったので、画像URLだけを渡す形としています。画像に合わせてセルのサイズを変更するモードはありません。
上のヘルプページより引用
(この機能が使いたかった...)
gspreadのappend_row関数はそのまま画像URLを渡しても'=IMAGEとなってしまい、文字列として解釈されてしまいます。
そのためvalue_input_option="USER_ENTERED"をoptionとして指定しています。これを指定することで、Google スプレッドシート上でユーザが画面にその文字を打ち込んだときと同じ挙動をするようになります。
この場合だと=IMAGE("・・・")という値をユーザがそのまま打ち込んだとき同じように解釈されるため、スプレッドシート側は狙い通りに画像を表示してくれます。■参照ドキュメント
API Reference - gspread(append_row)
ValueInputOption | Sheet API最後に(宣伝)
これで以上となります。
YouTubeに時折Python関連の動画をアップしています。
よろしければ覗いてみてください!
- 投稿日:2020-08-12T17:10:06+09:00
【Python学習中】 ピーマン嫌いな人の強がり for/else/continue/format
子どもの頃からピーマンがあまり好きではないので。。。
ピーマンを食べずに済むコードを書きながら、Pythonの基本文法の練習です。for vegitable in ['carrot', 'green pepper', 'lettuce', 'onion', 'garlic']:
if vegitable == 'green pepper':
continue
print(f"I ate {vegitable}.")
else:
print('I love vegitables!')
- 投稿日:2020-08-12T17:10:06+09:00
【Python学習中】 ピーマン嫌いな人の強がり if/for/else/continue/format
子どもの頃からピーマンがあまり好きではないので。。。
ピーマンを食べずに済むコードを書きながら、Pythonの基本文法の練習です。green_pepper.pyfor vegitable in ['carrot', 'green pepper', 'lettuce', 'onion', 'garlic']: if vegitable == 'green pepper': continue print(f"I ate {vegitable}.") else: print('I love vegitables!')I ate carrot. I ate lettuce. I ate onion. I ate garlic. I love vegitable!
- 投稿日:2020-08-12T17:02:38+09:00
Seleniumで要素が取得できない!
※この記事は新入社員の問いにあることないことないことないこと話した備忘録です。
本日の困りごと
Seleniumを使ってのWebサイトやWebシステムの自動検証。
find_element_by_xpathを使ってもこの要素取れないんです!
この直前の要素なら取れるのに…!経緯
元々「このサイトは何故かSeleniumで検証できないんですよねー」と言われているWebサイトがあった。
えぇwまさかぁwww
作った人(もういない)の組み方が悪いんだってwwwと、メンバーに「組みなおしてみ?」と依頼する。
すると返ってきたのがこの言葉。なるほど。丸投げしてたのでHTMLでも見てみようじゃないか。
今回の解決方法
みんな、HTMLにはclass属性やid属性を付けようぜ!
…とはいえ「検証の自動化」を行うために画面を修正するのはナンセンスである。
WebサイトWebサイトと言っているが、どうせ中身はWebシステム。phpだったりJSPだったりするものだろう。今回は
sample.htmlから、記事2の本文を取得したい!
…という要件だったとして解説をしたいと思う。sample.html<html> <head><!-- 省略 --></head> <body> <div id='wrap'> <div class='article'> <article> <h1>記事1のタイトル</h1> <div> <p>記事1の本文</p> </div> </article> </div><!-- .article --> <div class='article'> <article> <h1>記事2のタイトル</h1> <div> <p>記事2の本文</p> </div> </article> </div><!-- .article --> </div><!-- #wrap --> </body> </html>「動かない」といわれた指定方法がこちら。
動かない.pypath = "/html/body/div/div[2]/article/div" elmt = driver.find_element_by_xpath(path)
htmlの中のbodyの中のdiv(id=wrap)の中のdiv(class=article)の2つ目のarticleの中のdivを指定したいらしい。ふむふむ。それって"/html/body/div[5]"なんじゃね?
動くと思う.pypath = "/html/body/div[5]" elmt = driver.find_element_by_xpath(path)xpathの指定では、画面の要素がどのようにネストしているかは関係ない。
「上から何回目に登場したdivか?」が判定の基準となる。
CSSの疑似クラス:nth-child()に似ているだろうか。2つ目の
<div class='article'>を非表示にしたくて色々消えちゃう.cssdiv#wrap div:nth-child(2) { display: none; }と指定すると、1つ目の
div#wrapの中の「2つ目のdiv」を軒並み消してしまう。
sample.htmlの場合は記事1の本文と記事2が全て非表示となる。
(サンプルなのでclass指定しろよ!…とは言ってはいけない)うーん。なんか例が悪いな。。
結論
なんせプログラマという生き物はインデントとかネストとかを気にして生きている人種なので勘違いしてしまうこともあるのだが、外部のプログラムにそのHTMLがどんな構成で書かれているかはわからない。
CSSだろうがPythonだろうがJavaだろうが、彼らは人の意思を酌んで動いてくれるものではないのだ。
今回の場合のように「記事が複数あるから同じようなブロックがある」を知っているのは、開発した人だけが知っている。find_element_by_xpathで要素を指定する時はその要素は上から数えて何回目に出現してるか?を注意してみてほしい。
- 投稿日:2020-08-12T16:21:38+09:00
Pythonでe-Stat APIを使う
総務省eStatでは、政府統計のデータを公開している。政府統計のデータを取得する方法としては
- e-Stat HPにアクセスする(or Webスクレイピング)
- e-Stat APIを利用する
がある。この記事では、主に2(e-Stat APIを利用)について説明する。PythonでAPIを扱う場合の一般的な方法と同じように、
requestやurllibを用いる。なお、eStat API (version 3.0) の詳しい仕様については、API仕様書 (ver 3.0) を参照。方法1: e-Stat HPにアクセス
e-Statのホームページでは、構造的なURLでDBからデータを提供するため、Webスクレイピングが可能である。
例として、「家計調査 / 家計収支編 二人以上の世帯 詳細結果表」に関するe-StatのURLは、それぞれの分類項目とHTTP GETのパラメータ指定(
"&<param>=<value>")は次のような対応関係をもつ。
項目 値 URL params 政府統計名 家計調査 &toukei=00200561 提供統計名 家計調査 &tstat=000000330001 提供分類1 家計収支編 tclass1=000000330001 提供分類2 二人以上の世帯(農林漁家世帯を除く結果) tclass2=000000330002 提供分類3 詳細結果表 tclass3=000000330003 提供周期 月次 &cycle=1 調査年月 2000年1月 &year=20000 &month=11010301 政府統計コード
eStatで公開されているデータは、政府統計コードや統計表IDで識別される。
たとえば、国勢調査の政府統計コードは00200521、家計調査の政府統計コードは00200561。e-Statからデータを取得するときは、まず「政府統計コード」を指定し、指定された政府統計に含まれる統計表を条件検索する。他にも都道府県コードや市区町村コードなど、総務省が定めるコードがある。条件検索する際にも参照するコードをここに記す。
- 政府統計コード一覧(例:「国勢調査2015」= "00200521")
- 統計表の作成機関コード(例:「総務省」= "00200")
- 都道府県コード、市区町村コード(例:「北海道」="01"「札幌市」= "1002 ")
- 全国地方公共団体コード(例::「北海道札幌市」= "011002")
方法2: e-Stat APIを利用する
step 1: eStat API のアプリケーションIDを取得する。
eStats APIのトップページにアクセスして、「ユーザ登録・ログイン」から手続きを行う。氏名・メールアドレス・パスワードを登録すると、メールにてアプリケーションIDが送付される。アプリケーションIDがないとAPIコールできない。
step 2: HTTP GETをコールして、APIからレスポンス(データ)を受け取る。
APIの細かい使い方は、API仕様書 (ver 3.0) を参照。基本、以下2つのコールができればほとんど困ることはない。
- 統計情報取得(getStatsList)
- 統計データ取得(getStatsData)
Pythonコード
e-Stat API (version 3.0.0)の仕様書を参考にして、指定したパラメータに対して適当なURLを生成するモジュールを作った。
import urllib import requests class EstatRestAPI_URLParser: """ This is a simple python module class for e-Stat API (ver.3.0). See more details at https://www.e-stat.go.jp/api/api-info/e-stat-manual3-0 """ def __init__(self, api_version=None, app_id=None): # base url self.base_url = "https://api.e-stat.go.jp/rest" # e-Stat REST API Version if api_version is None: self.api_version = "3.0" else: self.api_version = api_version # Application ID if app_id is None: self.app_id = "****************" # ここにアプリケーションIDをいれる else: self.app_id = app_id def getStatsListURL(self, params_dict, format="csv"): """ 2.1 統計表情報取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getStatsList?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getStatsList?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/getStatsList?{params_str}" ) elif format == "csv": url = ( f"{self.base_url}/{self.api_version}" f"/app/getSimpleStatsList?{params_str}" ) return url def getMetaInfoURL(self, params_dict, format="csv"): """ 2.2 メタ情報取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getMetaInfo?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getMetaInfo?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/getMetaInfo?{params_str}" ) elif format == "csv": url = ( f"{self.base_url}/{self.api_version}" f"/app/getSimpleMetaInfo?{params_str}" ) return url def getStatsDataURL(self, params_dict, format="csv"): """ 2.3 統計データ取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getStatsData?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getStatsData?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/getStatsData?{params_str}" ) elif format == "csv": url = ( f"{self.base_url}/{self.api_version}" f"/app/getSimpleStatsData?{params_str}" ) return url def postDatasetURL(self): """ 2.4 データセット登録 (HTTP POST) """ url = ( f"{self.base_url}/{self.api_version}" "/app/postDataset" ) return url def refDataset(self, params_dict, format="xml"): """ 2.5 データセット参照 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" + f"/app/refDataset?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/refDataset?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/refDataset?{params_str}" ) return url def getDataCatalogURL(self, params_dict, format="xml"): """ 2.6 データカタログ情報取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getDataCatalog?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getDataCatalog?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/getDataCatalog?{params_str}" ) return url def getStatsDatasURL(self, params_dict, format="xml"): """ 2.7 統計データ一括取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getStatsDatas?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getStatsDatas?{params_str}" ) elif format == "csv": url = ( f"{self.base_url}/{self.api_version}" f"/app/getSimpleStatsDatas?{params_str}" ) return urlimport csv import json import xlrd import zipfile import requests import functools import pandas as pd from concurrent.futures import ThreadPoolExecutor from tqdm import tqdm def get_json(url): """ Request a HTTP GET method to the given url (for REST API) and return its response as the dict object. Args: ==== url: string valid url for REST API """ try: print("HTTP GET", url) r = requests.get(url) json_dict = r.json() return json_dict except requests.exceptions.RequestException as error: print(error) def download_json(url, filepath): """ Request a HTTP GET method to the given url (for REST API) and save its response as the json file. Args: url: string valid url for REST API filepath: string valid path to the destination file """ try: print("HTTP GET", url) r = requests.get(url) json_dict = r.json() json_str = json.dumps(json_dict, indent=2, ensure_ascii=False) with open(filepath, "w") as f: f.write(json_str) except requests.exceptions.RequestException as error: print(error) def download_csv(url, filepath, enc="utf-8", dec="utf-8", logging=False): """ Request a HTTP GET method to the given url (for REST API) and save its response as the csv file. Args: ===== url: string valid url for REST API filepathe: string valid path to the destination file enc: string encoding type for a content in a given url dec: string decoding type for a content in a downloaded file dec = 'utf-8' for general env dec = 'sjis' for Excel on Win dec = 'cp932' for Excel with extended JP str on Win logging: True/False flag whether putting process log """ try: if logging: print("HTTP GET", url) r = requests.get(url, stream=True) with open(filepath, 'w', encoding=enc) as f: f.write(r.content.decode(dec)) except requests.exceptions.RequestException as error: print(error) def download_all_csv( urls, filepathes, max_workers=10, enc="utf-8", dec="utf-8"): """ Request some HTTP GET methods to the given urls (for REST API) and save each response as the csv file. (!! This method uses multi threading when calling HTTP GET requests and downloading files in order to improve the processing speed.) Args: ===== urls: list of strings valid urls for REST API filepathes: list of strings valid pathes to the destination file max_workers: int max number of working threads of CPUs within executing this method. enc: string encoding type for a content in a given url dec: string decoding type for a content in a downloaded file dec = 'utf-8' for general env dec = 'sjis' for Excel on Win dec = 'cp932' for Excel with extended JP str on Win logging: True/False """ func = functools.partial(download_csv, enc=enc, dec=dec) with ThreadPoolExecutor(max_workers=max_workers) as executor: results = list( tqdm(executor.map(func, urls, filepathes), total=len(urls)) ) del resultsサンプル
総務省が毎年提供している社会・人口統計体系(統計でみる市区町村のすがた)から、市区町村を地域単位として各項目をeStat API経由で集計し、ローカルファイルとして保存する。
import os from pprint import pprint from estat_api import EstatRestAPI_URLParser appId = "****************" # ここにアプリケーションIDをいれる estatapi_url_parser = EstatRestAPI_URLParser() # URL Parser def search_tables(): """ Prams (dictionary) to search eStat tables. For more details, see also https://www.e-stat.go.jp/api/api-info/e-stat-manual3-0#api_3_2 - appId: Application ID (*required) - lang: 言語(J:日本語, E:英語) - surveyYears: 調査年月 (YYYYY or YYYYMM or YYYYMM-YYYYMM) - openYears: 調査年月と同様 - statsField: 統計分野 (2桁:統計大分類, 4桁:統計小分類) - statsCode: 政府統計コード (8桁) - searchWord: 検索キーワード - searchKind: データの種別 (1:統計情報, 2:小地域・地域メッシュ) - collectArea: 集計地域区分 (1:全国, 2:都道府県, 3:市区町村) - explanationGetFlg: 解説情報有無(Y or N) - ... """ appId = "65a9e884e72959615c2c7c293ebfaeaebffb6030" # Application ID params_dict = { "appId": appId, "lang": "J", "statsCode": "00200502", "searchWord": "社会・人口統計体系", # "統計でみる市区町村のすがた", "searchKind": 1, "collectArea": 3, "explanationGetFlg": "N" } url = estatapi_url_parser.getStatsListURL(params_dict, format="json") json_dict = get_json(url) # pprint(json_dict) if json_dict['GET_STATS_LIST']['DATALIST_INF']['NUMBER'] != 0: tables = json_dict["GET_STATS_LIST"]["DATALIST_INF"]["TABLE_INF"] else: tables = [] return tables def parse_table_id(table): return table["@id"] def parse_table_raw_size(table): return table["OVERALL_TOTAL_NUMBER"] def parse_table_urls(table_id, table_raw_size, csv_raw_size=100000): urls = [] for j in range(0, int(table_raw_size / csv_raw_size) + 1): start_pos = j * csv_raw_size + 1 params_dict = { "appId": appId, # Application ID "lang": "J", # 言語 (J: 日本語, E: 英語) "statsDataId": str(table_id), # 統計表ID "startPosition": start_pos, # 開始行 "limit": csv_raw_size, # データ取得件数 "explanationGetFlg": "N", # 解説情報有無(Y or N) "annotationGetFlg": "N", # 注釈情報有無(Y or N) "metaGetFlg": "N", # メタ情報有無(Y or N) "sectionHeaderFlg": "2", # CSVのヘッダフラグ(1:取得, 2:取得無) } url = estatapi_url_parser.getStatsDataURL(params_dict, format="csv") urls.append(url) return urls if __name__ == '__main__': CSV_RAW_SIZE = 100000 # list of tables tables = search_tables() # extract all table ids if len(tables) == 0: print("No tables were found.") elif len(tables) == 1: table_ids = [parse_table_id(tables[0])] else: table_ids = list(map(parse_table_id, tables)) # list of urls table_urls = [] table_raw_size = list(map(parse_table_raw_size, tables)) for i, table_id in enumerate(table_ids): table_urls = table_urls + parse_table_urls(table_id, table_raw_size[i]) # list of filepathes filepathes = [] for i, table_id in enumerate(table_ids): table_name = tables[i]["TITLE_SPEC"]["TABLE_NAME"] table_dir = f"./downloads/tmp/{table_name}_{table_id}" os.makedirs(table_dir, exist_ok=True) for j in range(0, int(table_raw_size[i] / CSV_RAW_SIZE) + 1): filepath = f"{table_dir}/{table_name}_{table_id}_{j}.csv" filepathes.append(filepath) download_all_csv(table_urls, filepathes, max_workers=30)
- 投稿日:2020-08-12T16:21:38+09:00
e-Stat APIをPythonから使う
総務省eStatでは、政府統計のデータを公開している。政府統計のデータを取得する方法としては
- e-Stat HPにアクセスする(or Webスクレイピング)
- e-Stat APIを利用する
がある。この記事では、主に2(e-Stat APIを利用)について説明する。PythonでAPIを扱う場合の一般的な方法と同じように、
requestやurllibを使う。なお、eStat API (version 3.0) の詳しい仕様については、API仕様書 (ver 3.0) を参照。方法1: e-Stat HPにアクセス
e-Statのホームページでは、構造的なURLでDBからデータを提供するため、Webスクレイピングが可能である。
例として、「家計調査 / 家計収支編 二人以上の世帯 詳細結果表」に関するe-StatのURLは、それぞれの分類項目とHTTP GETのパラメータ指定(
"&<param>=<value>")は次のような対応関係をもつ。
項目 値 URL params 政府統計名 家計調査 &toukei=00200561 提供統計名 家計調査 &tstat=000000330001 提供分類1 家計収支編 tclass1=000000330001 提供分類2 二人以上の世帯(農林漁家世帯を除く結果) tclass2=000000330002 提供分類3 詳細結果表 tclass3=000000330003 提供周期 月次 &cycle=1 調査年月 2000年1月 &year=20000 &month=11010301 政府統計コード
eStatで公開されているデータは、政府統計コードや統計表IDで識別される。
たとえば、国勢調査の政府統計コードは00200521、家計調査の政府統計コードは00200561。e-Statからデータを取得するときは、まず「政府統計コード」を指定し、指定された政府統計に含まれる統計表を条件検索する。他にも都道府県コードや市区町村コードなど、総務省が定めるコードがある。条件検索する際にも参照するコードをここに記す。
- 政府統計コード一覧(例:「国勢調査2015」= "00200521")
- 統計表の作成機関コード(例:「総務省」= "00200")
- 都道府県コード、市区町村コード(例:「北海道」="01"「札幌市」= "1002 ")
- 全国地方公共団体コード(例::「北海道札幌市」= "011002")
方法2: e-Stat APIを利用する
step 1: eStat API のアプリケーションIDを取得する。
eStats APIのトップページにアクセスして、「ユーザ登録・ログイン」から手続きを行う。氏名・メールアドレス・パスワードを登録すると、メールにてアプリケーションIDが送付される。アプリケーションIDがないとAPIコールできない。
step 2: HTTP GETをコールして、APIからレスポンス(データ)を受け取る。
APIの細かい使い方は、API仕様書 (ver 3.0) を参照。基本、以下2つのコールができればほとんど困ることはない。
- 統計情報取得(getStatsList)
- 統計データ取得(getStatsData)
Pythonコード
e-Stat API (version 3.0.0)の仕様書を参考にして、指定したパラメータに対して適当なURLを生成するモジュールを作った。
import urllib import requests class EstatRestAPI_URLParser: """ This is a simple python module class for e-Stat API (ver.3.0). See more details at https://www.e-stat.go.jp/api/api-info/e-stat-manual3-0 """ def __init__(self, api_version=None, app_id=None): # base url self.base_url = "https://api.e-stat.go.jp/rest" # e-Stat REST API Version if api_version is None: self.api_version = "3.0" else: self.api_version = api_version # Application ID if app_id is None: self.app_id = "****************" # ここにアプリケーションIDをいれる else: self.app_id = app_id def getStatsListURL(self, params_dict, format="csv"): """ 2.1 統計表情報取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getStatsList?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getStatsList?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/getStatsList?{params_str}" ) elif format == "csv": url = ( f"{self.base_url}/{self.api_version}" f"/app/getSimpleStatsList?{params_str}" ) return url def getMetaInfoURL(self, params_dict, format="csv"): """ 2.2 メタ情報取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getMetaInfo?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getMetaInfo?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/getMetaInfo?{params_str}" ) elif format == "csv": url = ( f"{self.base_url}/{self.api_version}" f"/app/getSimpleMetaInfo?{params_str}" ) return url def getStatsDataURL(self, params_dict, format="csv"): """ 2.3 統計データ取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getStatsData?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getStatsData?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/getStatsData?{params_str}" ) elif format == "csv": url = ( f"{self.base_url}/{self.api_version}" f"/app/getSimpleStatsData?{params_str}" ) return url def postDatasetURL(self): """ 2.4 データセット登録 (HTTP POST) """ url = ( f"{self.base_url}/{self.api_version}" "/app/postDataset" ) return url def refDataset(self, params_dict, format="xml"): """ 2.5 データセット参照 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" + f"/app/refDataset?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/refDataset?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/refDataset?{params_str}" ) return url def getDataCatalogURL(self, params_dict, format="xml"): """ 2.6 データカタログ情報取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getDataCatalog?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getDataCatalog?{params_str}" ) elif format == "jsonp": url = ( f"{self.base_url}/{self.api_version}" f"/app/jsonp/getDataCatalog?{params_str}" ) return url def getStatsDatasURL(self, params_dict, format="xml"): """ 2.7 統計データ一括取得 (HTTP GET) """ params_str = urllib.parse.urlencode(params_dict) if format == "xml": url = ( f"{self.base_url}/{self.api_version}" f"/app/getStatsDatas?{params_str}" ) elif format == "json": url = ( f"{self.base_url}/{self.api_version}" f"/app/json/getStatsDatas?{params_str}" ) elif format == "csv": url = ( f"{self.base_url}/{self.api_version}" f"/app/getSimpleStatsDatas?{params_str}" ) return urlimport csv import json import xlrd import zipfile import requests import functools import pandas as pd from concurrent.futures import ThreadPoolExecutor from tqdm import tqdm def get_json(url): """ Request a HTTP GET method to the given url (for REST API) and return its response as the dict object. Args: ==== url: string valid url for REST API """ try: print("HTTP GET", url) r = requests.get(url) json_dict = r.json() return json_dict except requests.exceptions.RequestException as error: print(error) def download_json(url, filepath): """ Request a HTTP GET method to the given url (for REST API) and save its response as the json file. Args: url: string valid url for REST API filepath: string valid path to the destination file """ try: print("HTTP GET", url) r = requests.get(url) json_dict = r.json() json_str = json.dumps(json_dict, indent=2, ensure_ascii=False) with open(filepath, "w") as f: f.write(json_str) except requests.exceptions.RequestException as error: print(error) def download_csv(url, filepath, enc="utf-8", dec="utf-8", logging=False): """ Request a HTTP GET method to the given url (for REST API) and save its response as the csv file. Args: ===== url: string valid url for REST API filepathe: string valid path to the destination file enc: string encoding type for a content in a given url dec: string decoding type for a content in a downloaded file dec = 'utf-8' for general env dec = 'sjis' for Excel on Win dec = 'cp932' for Excel with extended JP str on Win logging: True/False flag whether putting process log """ try: if logging: print("HTTP GET", url) r = requests.get(url, stream=True) with open(filepath, 'w', encoding=enc) as f: f.write(r.content.decode(dec)) except requests.exceptions.RequestException as error: print(error) def download_all_csv( urls, filepathes, max_workers=10, enc="utf-8", dec="utf-8"): """ Request some HTTP GET methods to the given urls (for REST API) and save each response as the csv file. (!! This method uses multi threading when calling HTTP GET requests and downloading files in order to improve the processing speed.) Args: ===== urls: list of strings valid urls for REST API filepathes: list of strings valid pathes to the destination file max_workers: int max number of working threads of CPUs within executing this method. enc: string encoding type for a content in a given url dec: string decoding type for a content in a downloaded file dec = 'utf-8' for general env dec = 'sjis' for Excel on Win dec = 'cp932' for Excel with extended JP str on Win logging: True/False """ func = functools.partial(download_csv, enc=enc, dec=dec) with ThreadPoolExecutor(max_workers=max_workers) as executor: results = list( tqdm(executor.map(func, urls, filepathes), total=len(urls)) ) del resultsサンプル
総務省が毎年提供している社会・人口統計体系(統計でみる市区町村のすがた)から、市区町村を地域単位として各項目をeStat API経由で集計し、ローカルファイルとして保存する。
import os from pprint import pprint from estat_api import EstatRestAPI_URLParser appId = "****************" # ここにアプリケーションIDをいれる estatapi_url_parser = EstatRestAPI_URLParser() # URL Parser def search_tables(): """ Prams (dictionary) to search eStat tables. For more details, see also https://www.e-stat.go.jp/api/api-info/e-stat-manual3-0#api_3_2 - appId: Application ID (*required) - lang: 言語(J:日本語, E:英語) - surveyYears: 調査年月 (YYYYY or YYYYMM or YYYYMM-YYYYMM) - openYears: 調査年月と同様 - statsField: 統計分野 (2桁:統計大分類, 4桁:統計小分類) - statsCode: 政府統計コード (8桁) - searchWord: 検索キーワード - searchKind: データの種別 (1:統計情報, 2:小地域・地域メッシュ) - collectArea: 集計地域区分 (1:全国, 2:都道府県, 3:市区町村) - explanationGetFlg: 解説情報有無(Y or N) - ... """ appId = "65a9e884e72959615c2c7c293ebfaeaebffb6030" # Application ID params_dict = { "appId": appId, "lang": "J", "statsCode": "00200502", "searchWord": "社会・人口統計体系", # "統計でみる市区町村のすがた", "searchKind": 1, "collectArea": 3, "explanationGetFlg": "N" } url = estatapi_url_parser.getStatsListURL(params_dict, format="json") json_dict = get_json(url) # pprint(json_dict) if json_dict['GET_STATS_LIST']['DATALIST_INF']['NUMBER'] != 0: tables = json_dict["GET_STATS_LIST"]["DATALIST_INF"]["TABLE_INF"] else: tables = [] return tables def parse_table_id(table): return table["@id"] def parse_table_raw_size(table): return table["OVERALL_TOTAL_NUMBER"] def parse_table_urls(table_id, table_raw_size, csv_raw_size=100000): urls = [] for j in range(0, int(table_raw_size / csv_raw_size) + 1): start_pos = j * csv_raw_size + 1 params_dict = { "appId": appId, # Application ID "lang": "J", # 言語 (J: 日本語, E: 英語) "statsDataId": str(table_id), # 統計表ID "startPosition": start_pos, # 開始行 "limit": csv_raw_size, # データ取得件数 "explanationGetFlg": "N", # 解説情報有無(Y or N) "annotationGetFlg": "N", # 注釈情報有無(Y or N) "metaGetFlg": "N", # メタ情報有無(Y or N) "sectionHeaderFlg": "2", # CSVのヘッダフラグ(1:取得, 2:取得無) } url = estatapi_url_parser.getStatsDataURL(params_dict, format="csv") urls.append(url) return urls if __name__ == '__main__': CSV_RAW_SIZE = 100000 # list of tables tables = search_tables() # extract all table ids if len(tables) == 0: print("No tables were found.") elif len(tables) == 1: table_ids = [parse_table_id(tables[0])] else: table_ids = list(map(parse_table_id, tables)) # list of urls table_urls = [] table_raw_size = list(map(parse_table_raw_size, tables)) for i, table_id in enumerate(table_ids): table_urls = table_urls + parse_table_urls(table_id, table_raw_size[i]) # list of filepathes filepathes = [] for i, table_id in enumerate(table_ids): table_name = tables[i]["TITLE_SPEC"]["TABLE_NAME"] table_dir = f"./downloads/tmp/{table_name}_{table_id}" os.makedirs(table_dir, exist_ok=True) for j in range(0, int(table_raw_size[i] / CSV_RAW_SIZE) + 1): filepath = f"{table_dir}/{table_name}_{table_id}_{j}.csv" filepathes.append(filepath) download_all_csv(table_urls, filepathes, max_workers=30)
- 投稿日:2020-08-12T16:19:01+09:00
【Python】マウスがインターフェースのテルミン
背景
私は、Kensingtonのトラックボールを愛用しています。「トラックボール使いやすいですか?」と聞かれた時に「慣れたら楽だけど、テルミンみたいな感じかなぁ」と返答することがありました。本当にテルミンか?!ということを検証するために、マウス位置で音高と音量が変化するようなプログラムを作ってみました。
環境設定
以下の5つのモジュールを使用します。
import pyaudio import numpy as np import pyautogui import keyboard from scipy import arange, cumsum, sin, linspace from scipy import pi as mpipyautoguiは、今回はマウスの位置情報を取得するために使用します。pipのバージョンが20.2.1の場合、インストールエラーとなるようです(2020.8.11現在)。
一緒にインストールされるpymsgboxをダウングレードして手動でインストールして回避しました。ちなみに、サブ機はpip自体が前のバージョンだったのですが、その場合、エラーを出さずにインストールできました。
(前回記事 https://qiita.com/Lemon2Lemonade/items/0a24a4b65c9031536f6e)pyaudioは、pythonで音を鳴らすモジュール、keyboardはキーボードの入力値を得ます。
入力値
RATEはいわゆるサンプリング周波数で、今回はCDと同じ44.1kHzにしてみました。
minfreqは最低音の振動数。442HzのAから1オクターブ下がって短3度上がったCです(平均律では、振動数に2の12乗根を掛けると半音上がります)。
tonerangeはテルミンの再生範囲。本文中ではminfreq*tonerangeのように周波数を定数倍するようにしていますので、2倍ということは1オクターブを意味します。
periodは、音の持続時間です。カーソルの位置検出を0.01秒ごとに行います。
minampは音量の最小値、amprangeは音量幅です。RATE = 44100 #サンプリング周波数 CHUNK = 1024 #バッファー PITCH = 442 #ピッチ minfreq = PITCH/2*2**(3/12) tonerange = 2 period = 0.01 minamp = 0.1 amprange = 0.5位置検出
まず、ウインドウサイズを得ます。
def get_window_size(): window_size = pyautogui.size() return window_sizeカーソル縦方向の移動で音高、横方向の移動で音量が変わる設定にします。画面の相対位置を計算します。音高は画面一番下が最低音、画面一番上が最高音とします。一方、音量は画面中央が最小、両端が最大になるようにします。カーソルがx軸(横方向)、y軸(縦方向)のどの位置にいるかを相対位置で取得します。
def distance(): window_size = get_window_size() x, y = pyautogui.position() x_dist = np.sqrt((x-window_size.width/2)**2) y_dist = abs(y-window_size.height) x_max = np.sqrt((window_size.width/2)**2) y_max = window_size.height x_ratio = x_dist/x_max y_ratio = y_dist/y_max return x_ratio, y_ratio画面位置と音高、音量を対応させます。
def tonemapping(): ratio = distance() freq = minfreq*2**(tonerange*ratio[1]) return freq def ampmapping(): ratio = distance() amp = minamp+amprange*ratio[0] return ampsin波(音源)の調整と再生
以外に苦労したのがここの部分。位置に対して、ある音を一定期間鳴らすだけだと、音がぶつぶつ切れてノイズが乗ってしまいます。なので、ループのひとつ前の条件(音高とsin波の振動数、位相、振幅)を記憶しておいて、滑らかにつながるようにします。
次のサイトを参考に作りました。
http://yukara-13.hatenablog.com/entry/2013/12/23/053957位相も合わせておかないと(一つのつながったsin波にしないと)「ブツッ」っというようなノイズになりますを。再生期間を0.01秒で計算するとsin波よりノイズのほうが目立ってしまいます。
def make_time_varying_sine(start_freq, end_freq, start_A, end_A, fs, sec, phaze_start): freqs = linspace(start_freq, end_freq, num = int(round(fs * sec))) A = linspace(start_A, end_A, num = int(round(fs * sec))) phazes_diff = 2. * mpi * freqs / fs # 角周波数の変化量 phazes = cumsum(phazes_diff) + phaze_start # 位相 phaze_last = phazes[-1] ret = A * sin(phazes) # サイン波合成 return ret, phaze_last def play_wave(stream, samples): stream.write(samples.astype(np.float32).tostring()) def play_audio(): p = pyaudio.PyAudio() stream = p.open(format=pyaudio.paFloat32, channels=1, rate=RATE, frames_per_buffer=CHUNK, output=True) freq_old = minfreq amp_old = minamp phaze = 0 while True: try: if keyboard.is_pressed('q'): stream.close() break # finishing the loop else: freq_new = tonemapping() amp_new = ampmapping() tone = make_time_varying_sine(freq_old, freq_new, amp_old, amp_new, RATE, period, phaze) play_wave(stream, tone[0]) freq_old = freq_new amp_old = amp_new phaze = tone[1] except: continue if __name__ == '__main__': play_audio()
- 投稿日:2020-08-12T16:06:51+09:00
PyCaretのsetup関数の引数について
Pycaretのsetup関数の引数
PyCaret公式:Home - PyCaret
PyCaretガイド:PyCaret Guide - PyCaret
PyCaret Github:pycaret/pycaret: An open source, low-code machine learning library in Python
- 目的
- setup関数の引数が多いので、調べて、翻訳(DeepL翻訳)した。
- setup関数で何ができるのか確認を促す。
分類 classification PyCaret2.0
パラメータ 説明 詳細 data {array-like, sparse matrix} Shape (n_samples, n_features) ここで、n_samplesはサンプル数、n_featuresは特徴量の数です。 target string 文字列として渡す対象のカラム名。ターゲット変数はバイナリでもマルチクラスでもよい。マルチクラス・ターゲットの場合、すべての推定量はOneVsRest分類器でラップされます。 train_size float, default = 0.7 トレーニングセットのサイズ。デフォルトでは、データの70%がトレーニングと検証に使用されます。残りのデータはテスト/ホールドアウトセットに使用されます。 sampling bool, default = True サンプルサイズが25,000サンプルを超えると、pycaretは、元のデータセットからさまざまなサンプルサイズのベース推定器を構築します。これは、モデリングに適したサンプルサイズを決定するのに役立つ、さまざまなサンプルレベルでのAUC、Accuracy、Recall、Precision、Kappa、F1値の性能プロットを返します。その後、パイカレット環境での訓練と検証のために、希望するサンプル・サイズを入力しなければなりません。入力されたsample_sizeが1よりも小さい場合、finalize_model()が呼び出されたときにのみ、残りのデータセット(1 - サンプル)がモデルを適合させるために使用されます。 sample_estimator object, default = None Noneの場合、デフォルトではロジスティック回帰が使用されます。 categorical_features string, default = None 推論されたデータ型が正しくない場合、categorical_featuresを使用して推論された型を上書きすることができます。セットアップを実行する際に、'column1'の型がategoricalではなくnumericであると推測される場合、このパラメータを使用してcategorical_features = ['column1']を渡すことで、その型を上書きすることができます。 categorical_imputation string, default = 'constant' カテゴリ特徴量の中に欠損値が見つかった場合は,一定の「not_available」値で入力されます.もう1つの利用可能なオプションは'mode'で、学習データセットの中で最も頻度の高い値を用いて欠落値を入力します。 ordinal_features dictionary, default = None データに序列特徴が含まれる場合、 ordinal_features パラメータを用いて異なる符号化を行わなければなりません。データが'low'、'medium'、'high'の値を持つカテゴリ変数を持ち、low < medium < highであることがわかっている場合、 ordinal_features = { 'column_name' : ['low', 'medium', 'high'] }として渡すことができます。リストの順序は、低い順から高い順に増えていくものでなければなりません。 high_cardinality_features string, default = None カーディナリティの高い特徴量が含まれている場合には,カーディナリティの高いカラム名のリストとして渡すことで,より少ないレベルに圧縮することができます. high_cardinality_method string, default = 'frequency' 周波数を'frequency'に設定すると、特徴量の元の値を度数分布に置き換えて数値化します。他の利用可能な方法としては、データの統計的属性に対してクラスタリングを行い、特徴量の元の値をクラスタラベルに置き換える「クラスタリング」という方法があります。 numeric_features string, default = None 推論されたデータ型が正しくない場合、numeric_featuresを使用して推論された型を上書きすることができます。セットアップを実行する際に、'column1'の型が数値ではなくカテゴリとして推論されている場合、このパラメータを使用して、numeric_features = ['column1']を渡すことで上書きすることができます。 numeric_imputation string, default = 'mean' 数値特徴量の中に欠損値が見つかった場合、その特徴量の平均値を用いて入力されます。もう1つの利用可能なオプションは'median'で、訓練データセットの中央値を使用して値を入力します。 date_features string, default = None データに、セットアップ実行時に自動検出されないDateTimeカラムがある場合、date_features = 'date_column_name'を渡すことで、このパラメータを使用することができます。複数の日付カラムで動作させることができます。日付カラムはモデリングでは使用されません。代わりに、特徴抽出が実行され、データセットから日付列が削除されます。日付列にタイムスタンプが含まれている場合、時間に関連する特徴も抽出されます。 ignore_features string, default = None モデリングのために無視すべき特徴がある場合は、param ignore_featuresに渡すことができます。推論されたときのIDとDateTimeの列は、モデリングのために無視するように自動的に設定されます。 normalize bool, default = False True に設定されている場合、パラメータ normalized_method を用いて特徴空間が変換されます。一般的に,線形アルゴリズムは正規化されたデータの方が優れたパフォーマンスを発揮しますが,結果は異なる場合があります. normalize_method string, default = 'zscore' 正規化に使用するメソッドを定義します。デフォルトでは、正規化方法は 'zscore' に設定されています。標準の zscore は z = (x - u) / s として計算されます。 minmax 0 - 1の範囲内にあるように、各特徴量を個別にスケーリングして変換します。 maxabs 各特徴量の絶対値の最大値が1.0になるように,各特徴量を個別にスケーリングし,変換します.これは,データのシフト/センタリングを行わないので,スパリティを破壊しません. robust 各特徴量をクォークタイル間の範囲に従ってスケーリングし,変換します.データセットに外れ値が含まれている場合,ロバストスケーラーの方が良い結果が得られることが多い. transformation bool, default = False Trueに設定すると、データがより正規のガウス風になるように電力変換が適用されます。これは,異種混合性に関連する問題や,正規性が望まれるその他の状況をモデル化するのに便利です.分散を安定させ、歪度を最小化するための最適なパラメータは、最尤法によって推定されます。 transformation_method string, default = 'yeo-johnson' 変換の方法を定義します。デフォルトでは、変換方法は 'yeo-johnson' に設定されています。他のオプションとして, 'quantile' 変換があります.どちらの変換も,特徴セットをガウス分布または正規分布に従うように変換します.分位変換は非線形であり、同じ尺度で測定された変数間の線形相関を歪める可能性があることに注意してください。 handle_unknown_categorical bool, default = True Trueに設定されている場合、新規/未見のデータの未知のカテゴリレベルは、学習データで学習された最も頻度の高いレベルまたは最も頻度の低いレベルに置き換えられます。このメソッドは unknown_categorical_method パラメーターで定義されます。 unknown_categorical_method string, default = 'least_frequent' 不可視データの未知のカテゴリカル・レベルを置き換えるために使用されるメソッド。メソッドは、'least_frequent'または'most_frequent'に設定できます。 pca bool, default = False True に設定されている場合,pca_method パラメータで定義されている方法を用いて,データを低次元空間に投影するために次元削減が適用されます.教師あり学習では,一般的に,高い特徴空間を扱う場合やメモリが制約となる場合に pca が実行されます.すべてのデータセットが線形PCA手法を用いて効率的に分解できるわけではなく,PCAを適用すると情報が失われる可能性があることに注意してください.そのため、その影響を評価するために、異なるpca_methodsを用いて複数の実験を行うことをお勧めします。 pca_method string, default = 'linear' 線形メソッドは,特異値分解を使用して線形次元削減を行います.その他の利用可能なオプションは以下の通りです. kernel RVFカーネルを用いた次元削減。 incremental 分解するデータセットが大きすぎてメモリに収まらない場合に,'linear' pca を置き換える. pca_components int/float, default = 0.99 pca_components が float の場合は,情報を保持するための目標パーセンテージとして扱われる.pca_components が整数の場合は,保持する特徴量の数として扱われます. pca_components は,データセットの元の特徴量よりも厳密には少なくなければなりません. ignore_low_variance bool, default = False Trueに設定すると、統計的に重要でない分散を持つすべてのカテゴリ特徴がデータセットから削除されます。分散は,サンプル数に対する一意の値の比率,および,2番目に多い値の頻度に対する最も一般的な値の比率を用いて計算される. combine_rare_levels bool, default = False Trueに設定されている場合、param rare_level_thresholdで定義された閾値以下のカテゴリ特徴量のすべてのレベルが、1つのレベルとして結合されます。これを有効にするためには,閾値以下に少なくとも2つのレベルが存在しなければなりません. rare_level_threshold は,レベル頻度のパーセンタイル分布を表します.一般的に,この手法は,カテゴリカル特徴量の中でレベル数が多いことによる疎な行列を制限するために適用されます. rare_level_threshold float, default = 0.1 まれなカテゴリが結合されるパーセンタイル分布。combine_rare_levelsがTrueに設定されている場合のみ有効になります。 bin_numeric_features list, default = None 数値特徴量のリストが渡されると,それらはKMeansを用いてカテゴリ特徴量に変換されます.クラスターの数は,'sturges'法に基づいて決定される.これはガウスデータにのみ最適であり、大規模な非ガウスデータセットではビン数を過小評価します。 remove_outliers bool, default = False Trueに設定すると、特異値分解技術を使用したPCA線形次元削減を使用して、トレーニングデータから外れ値が除去されます。 outliers_threshold float, default = 0.05 データセットにおける外れ値の割合/割合は,パラメータ outliers_threshold を用いて定義することができます.デフォルトでは,0.05が用いられます.これは,分布の尾部の各辺の値の0.025が学習データから削除されることを意味します. remove_multicollinearity bool, default = False Trueに設定すると、multicollinearity_thresholdパラメータで定義された閾値よりも高い相互相関を持つ変数が削除されます。2つの特徴量が互いに高い相関を持つ場合,対象変数との相関が低い方の特徴量が削除されます. multicollinearity_threshold float, default = 0.9 相関した特徴量を削除するために使用される閾値。remove_multicollinearityがTrueに設定されている場合のみ有効になります。 remove_perfect_collinearity bool, default = False Trueに設定すると、完全な共線性(相関=1の特徴量)がデータセットから削除され、2つの特徴量が100%相関している場合、そのうちの1つがランダムにデータセットから削除されます。 create_clusters bool, default = False Trueに設定すると、各インスタンスがクラスタに割り当てられる追加フィーチャが作成されます。クラスターの数は、Calinski-HarabaszとSilhouette基準の組み合わせを使用して決定されます。 cluster_iter int, default = 20 クラスタの作成に使用される反復回数。各反復はクラスタのサイズを表します。create_clusters パラメータが True に設定されている場合のみ有効です。 polynomial_features bool, default = False Trueに設定すると、データセット内の数値特徴量の中に存在する、polynomial_degree paramで定義された次数までのすべての多項式の組み合わせに基づいて、新しい特徴量が作成されます。 polynomial_degree int, default = 2 多項式特徴量の次数。例えば,入力サンプルが2次元で[a, b]の形式の場合,次数=2の多項式特徴量は次のようになります.1, a, b, a^2, ab, b^2] となります. trigonometry_features bool, default = False Trueに設定されている場合,データセット内の数値特徴量の中に存在する, polynomial_degree パラメーターで定義された次数までのすべての三角関数の組み合わせに基づいて,新しい特徴量が作成されます. polynomial_threshold float, default = 0.1 ランダムフォレスト、AdaBoost、線形相関の組み合わせに基づく特徴の重要度が定義された閾値のパーセンタイル内に収まる多項式特徴と三角法特徴をデータセットに保持します。残った特徴量は,さらに処理を進める前に削除される. group_features list or list of list, default = None データセットに関連する特徴を持つ特徴が含まれている場合, group_features パラメータを統計的特徴抽出に利用することができます.例えば,データセットが互いに関連した数値特徴量('Col1', 'Col2', 'Col3')を持つ場合, group_features の下に列名を含むリストを渡すことで,平均値,中央値,モード,標準偏差などの統計情報を抽出することができます. group_names list, default = None group_featuresが渡されると、文字列を含むリストとしてgroup_namesパラメータにグループ名を渡すことができます。group_namesのリストの長さは、group_featuresの長さと等しくなければなりません。長さが一致しない場合や名前が渡されなかった場合は、 group_1, group_2 などのように新しい機能が順に命名されます。 feature_selection bool, default = False Trueに設定すると、ランダムフォレスト、Adaboost、ターゲット変数との線形相関など、さまざまな並べ替え重要度技術の組み合わせを使用して、特徴のサブセットが選択されます。サブセットのサイズは、 feature_selection_paramに依存します。一般的に、これはモデリングの効率を向上させるために特徴空間を制約するために使用されます。polynomial_featuresやfeature_interactionを使用する場合は、feature_selection_thresholdパラメータをより低い値で定義することを強く推奨します。 feature_selection_threshold float, default = 0.8 特徴選択に使用されるしきい値(新しく作成された多項式特徴を含む)。値が大きいほど、より大きな特徴空間が得られます。特に多項式特徴と特徴間相互作用が使用される場合には、異なる値のfeature_selection_thresholdを用いて複数回の試行を行うことが推奨されます。非常に低い値を設定することは効率的かもしれませんが、結果的にアンダーフィッティングになる可能性があります。 feature_interaction bool, default = False Trueに設定すると、データセット内のすべての数値変数(多項式および三角関数特徴(作成された場合)を含む)に対して相互作用(a * b)することで、新しい特徴を作成します。この機能はスケーラブルではなく、大きな特徴空間を持つデータセットでは期待通りには動作しないかもしれません。 feature_ratio bool, default = False Trueに設定すると、データセット内のすべての数値変数の比率(a / b)を計算して新しい特徴量を作成します。この機能はスケーラブルではなく,特徴空間が大きいデータセットでは期待通りに動作しないかもしれない. interaction_threshold bool, default = 0.01 polynomial_threshold と同様に,新たに作成された特徴量の疎な行列を相互作用によって圧縮するために使用される.ランダムフォレスト、AdaBoost、線形相関の組み合わせに基づく重要度が、定義された閾値のパーセンタイル内に収まる特徴量は、データセットに保存されます。残った特徴は,さらなる処理の前に削除される. fix_imbalance bool, default = False データセットに対象クラスの不均等な分布がある場合、fix_imbalanceパラメータを使用して修正することができます。Trueに設定すると、デフォルトでSMOTE (Synthetic Minority Over-sampling Technique)が適用され、マイノリティクラスの合成データポイントが作成されます。 fix_imbalance_method obj, default = None fix_imbalanceをTrueに設定し、fix_imbalance_methodをNoneに設定した場合、クロスバリデーションの際にマイノリティクラスをオーバーサンプルするために、デフォルトでは'smote'が適用されます。このパラメータは、'fit_resample' メソッドをサポートしている 'imblearn' のモジュールであれば何でも受け付けることができます。 data_split_shuffle bool, default = True Falseに設定すると、データを分割する際に行がシャッフルされるのを防ぎます。 folds_shuffle bool, default = False Falseに設定すると、クロスバリデーションを使用しているときに行がシャッフルされるのを防ぎます。 n_jobs int, default = -1 並列に実行するジョブの数を指定します(並列処理をサポートしている関数の場合)-1は全てのプロセッサを使用することを意味します。すべての関数を単一のプロセッサで実行するには、n_jobs を None に設定します。 html bool, default = True Falseに設定すると、モニターの実行時表示を禁止します。HTMLに対応していない環境を使用している場合は、Falseに設定する必要があります。 session_id int, default = None Noneの場合、ランダムなシードが生成され、Informationグリッドに返されます。その後、実験中に使用されたすべての関数で、一意の番号がシードとして配布されます。これは、実験全体の後の再現性のために使用することができます。 log_experiment bool, default = False True に設定すると、すべてのメトリクスとパラメータが MLFlow サーバに記録されます。 experiment_name str, default = None ログを記録する実験の名前。Noneに設定されている場合、デフォルトでは'clf'が実験名のエイリアスとして使用されます。 log_plots bool, default = False True に設定すると、特定のプロットを png ファイルとして MLflow に記録します。デフォルトでは False に設定されています。 log_profile bool, default = False True に設定すると、データプロファイルも html ファイルとして MLflow に記録されます。デフォルトでは False に設定されています。 log_data bool, default = False Trueに設定すると、訓練データとテストデータがcsvとして記録されます。 silent bool, default = False Trueに設定すると、データ型の確認は不要です。すべての前処理は、自動的に推測されるデータ型を想定して実行されます。確立されたパイプライン以外での直接使用は推奨されません。 verbose Boolean, default = True verbose が False に設定されている場合、情報グリッドは印刷されません。 profile bool, default = False true に設定すると、探索的データ分析のデータ プロファイルがインタラクティブな HTML レポートに表示されます。 回帰 regression PyCaret2.0
パラメータ 説明 詳細 data {array-like, sparse matrix} Shape (n_samples, n_features) ここで、n_samplesはサンプル数、n_featuresは特徴量の数です。 target string 文字列として渡す対象のカラム名。 train_size float, default = 0.7 トレーニングセットのサイズ。デフォルトでは、データの70%がトレーニングと検証に使用されます。残りのデータはテスト/ホールドアウトセットに使用されます。 sampling bool, default = True サンプル・サイズが25,000サンプルを超えると、pycaretは、元のデータセットからさまざまなサンプル・サイズのベース推定器を構築します。これにより、さまざまなサンプルレベルでのR2値の性能プロットが返され、モデリングに適したサンプルサイズを決定するのに役立ちます。 次に、pycaret環境でのトレーニングと検証のために、希望するサンプルサイズを入力する必要があります。入力されたsample_sizeが1よりも小さい場合、finalize_model()が呼ばれたときにのみ、残りのデータセット(1 - sample)がモデルの適合に使用されます。 sample_estimator object, default = None なしの場合、デフォルトでは線形回帰が使用されます。 categorical_features string, default = None 推論されたデータ型が正しくない場合、categorical_featuresを使用して推論された型を上書きすることができます。セットアップを実行する際に、'column1'の型がategoricalではなくnumericであると推測される場合、このパラメータを使用してcategorical_features = ['column1']を渡すことで、その型を上書きすることができます。 categorical_imputation string, default = 'constant' カテゴリ特徴量の中に欠損値が見つかった場合は,一定の「not_available」値で入力されます.もう1つの利用可能なオプションは'mode'で、学習データセットの中で最も頻度の高い値を用いて欠落値を入力します。 ordinal_features dictionary, default = None データに序列特徴が含まれる場合、 ordinal_features パラメータを用いて異なる符号化を行わなければなりません。データが'low'、'medium'、'high'の値を持つカテゴリ変数を持ち、low < medium < highであることがわかっている場合、 ordinal_features = { 'column_name' : ['low', 'medium', 'high'] }として渡すことができます。リストの順序は、低い順から高い順に増えていくものでなければなりません。 high_cardinality_features string, default = None データに高カルディナリティの特徴量が含まれている場合,高カルディナリティのカラム名のリストとして渡すことで,より少ないレベルに圧縮することができます.特徴量の圧縮は,param high_cardinality_method で定義されている方法で行います. high_cardinality_method string, default = 'frequency' 周波数を'frequency'に設定すると、特徴量の元の値を度数分布に置き換えて数値化します。他の利用可能な方法としては、データの統計的属性に対してクラスタリングを行い、特徴量の元の値をクラスタラベルに置き換える「クラスタリング」という方法があります。 numeric_features string, default = None 推論されたデータ型が正しくない場合、numeric_featuresを使用して推論された型を上書きすることができます。セットアップを実行する際に、'column1'の型が数値ではなくカテゴリとして推論されている場合、このパラメータを使用して、numeric_features = ['column1']を渡すことで上書きすることができます。 numeric_imputation string, default = 'mean' 数値特徴量の中に欠損値が見つかった場合、その特徴量の平均値を用いて入力されます。もう1つの利用可能なオプションは'median'で、訓練データセットの中央値を使用して値を入力します。 date_features string, default = None データに、セットアップ実行時に自動検出されないDateTimeカラムがある場合、date_features = 'date_column_name'を渡すことで、このパラメータを使用することができます。複数の日付カラムで動作させることができます。日付カラムはモデリングでは使用されません。代わりに、特徴抽出が実行され、データセットから日付列が削除されます。日付列にタイムスタンプが含まれている場合、時間に関連する特徴も抽出されます。 ignore_features string, default = None モデリングのために無視すべき特徴がある場合は、param ignore_featuresに渡すことができます。推論されたときのIDとDateTimeの列は、モデリングのために無視するように自動的に設定されます。 normalize bool, default = False True に設定されている場合、パラメータ normalized_method を用いて特徴空間が変換されます。一般的に,線形アルゴリズムは正規化されたデータの方が優れたパフォーマンスを発揮しますが,結果は異なる場合があります. normalize_method string, default = 'zscore' 正規化に使用するメソッドを定義します。デフォルトでは、正規化方法は 'zscore' に設定されています。標準の zscore は z = (x - u) / s として計算されます。 minmax minmax' : 0 - 1の範囲内にあるように、各特徴量を個別にスケーリングして変換します。 maxabs maxabs': 各特徴量の絶対値の最大値が1.0になるように,各特徴量を個別にスケーリングし,変換します.これは,データのシフト/センタリングを行わないので,スパリティを破壊しません. robust robust': 各特徴量をクォークタイル間の範囲に従ってスケーリングし,変換します.データセットに外れ値が含まれている場合,ロバストスケーラーの方が良い結果が得られることが多い. transformation bool, default = False Trueに設定すると、データをより正規化/ガウス風にするために乗数変換が適用されます。これは,異種混合性に関連する問題や,正規性が望まれるその他の状況をモデル化するのに便利です.分散を安定させ、歪度を最小化するための最適なパラメータは、最尤法によって推定されます。 transformation_method string, default = 'yeo-johnson' 変換の方法を定義します。デフォルトでは、変換方法は 'yeo-johnson' に設定されています。他のオプションとして,'quantile' 変換があります.どちらの変換も,特徴セットをガウス分布または正規分布に従うように変換します.分位変換は非線形であり、同じ尺度で測定された変数間の線形相関を歪める可能性があることに注意してください。 handle_unknown_categorical bool, default = True Trueに設定されている場合、新規/未見のデータの未知のカテゴリレベルは、学習データで学習された最も頻度の高いレベルまたは最も頻度の低いレベルに置き換えられます。このメソッドは unknown_categorical_method パラメーターで定義されます。 unknown_categorical_method string, default = 'least_frequent' 不可視データの未知のカテゴリカル・レベルを置き換えるために使用されるメソッド。メソッドには 'least_frequent' または 'most_frequent' を設定することができます。 pca bool, default = False True に設定されている場合,pca_method パラメータで定義されている方法を用いて,データを低次元空間に投影するために次元削減が適用されます.教師あり学習では,一般的に,高い特徴空間を扱う場合やメモリが制約となる場合に pca が実行されます.すべてのデータセットが線形PCA手法を用いて効率的に分解できるわけではなく,PCAを適用すると情報が失われる可能性があることに注意してください.そのため、その影響を評価するために、異なるpca_methodsを用いて複数の実験を行うことをお勧めします。 pca_method string, default = 'linear' 線形メソッドは,特異値分解を使用して線形次元削減を行います.その他の利用可能なオプションは以下の通りです. kernel RVFカーネルを用いた次元削減。 incremental 分解するデータセットが大きすぎてメモリに収まらない場合に,'linear' pca を置き換える. pca_components int/float, default = 0.99 pca_components が float の場合は,情報を保持するための目標パーセンテージとして扱われる.pca_components が整数の場合は,保持する特徴量の数として扱われます. pca_components は,データセットの元の特徴量よりも厳密には少なくなければなりません. ignore_low_variance bool, default = False Trueに設定すると、統計的に重要でない分散を持つすべてのカテゴリ特徴がデータセットから削除されます。分散は,サンプル数に対する一意の値の比率,および,2番目に多い値の頻度に対する最も一般的な値の比率を用いて計算される. combine_rare_levels bool, default = False Trueに設定されている場合、param rare_level_thresholdで定義された閾値以下のカテゴリ特徴量のすべてのレベルが、1つのレベルとして結合されます。これを有効にするためには,閾値以下に少なくとも2つのレベルが存在しなければなりません. rare_level_threshold は,レベル頻度のパーセンタイル分布を表します.一般的に,この手法は,カテゴリカル特徴量の中でレベル数が多いことによる疎な行列を制限するために適用されます. rare_level_threshold float, default = 0.1 まれなカテゴリが結合されるパーセンタイル分布。combine_rare_levelsがTrueに設定されている場合のみ有効になります。 bin_numeric_features list, default = None 数値特徴量のリストが渡されると,それらはKMeansを用いてカテゴリ特徴量に変換されます.クラスターの数は,'sturges'法に基づいて決定される.これはガウスデータにのみ最適であり、大規模な非ガウスデータセットではビン数を過小評価します。 remove_outliers bool, default = False Trueに設定すると、特異値分解技術を使用したPCA線形次元削減を使用して、トレーニングデータから外れ値が除去されます。 outliers_threshold float, default = 0.05 データセットにおける外れ値の割合/割合は,パラメータ outliers_threshold を用いて定義することができます.デフォルトでは,0.05が用いられます.これは,分布の尾部の各辺の値の0.025が学習データから削除されることを意味します. remove_multicollinearity bool, default = False Trueに設定すると、multicollinearity_thresholdパラメータで定義された閾値よりも高い相互相関を持つ変数が削除されます。2つの特徴量が互いに高い相関を持つ場合,対象変数との相関が低い方の特徴量が削除されます. multicollinearity_threshold float, default = 0.9 相関した特徴量を削除するために使用される閾値。remove_multicollinearityがTrueに設定されている場合のみ有効になります。 remove_perfect_collinearity bool, default = False Trueに設定すると、完全な共線性(相関=1の特徴量)がデータセットから削除され、2つの特徴量が100%相関している場合、そのうちの1つがランダムにデータセットから削除されます。 create_clusters bool, default = False Trueに設定すると、各インスタンスがクラスタに割り当てられる追加フィーチャが作成されます。クラスターの数は、Calinski-HarabaszとSilhouette基準の組み合わせを使用して決定されます。 cluster_iter int, default = 20 クラスタの作成に使用される反復回数。各反復はクラスタのサイズを表します。create_clusters パラメータが True に設定されている場合のみ有効です。 polynomial_features bool, default = False Trueに設定すると、データセット内の数値特徴量の中に存在する、polynomial_degree paramで定義された次数までのすべての多項式の組み合わせに基づいて、新しい特徴量が作成されます。 polynomial_degree int, default = 2 多項式特徴量の次数。例えば,入力サンプルが2次元で[a, b]の形式の場合,次数=2の多項式特徴量は次のようになります.1, a, b, a^2, ab, b^2] となります. trigonometry_features bool, default = False Trueに設定されている場合,データセット内の数値特徴量の中に存在する, polynomial_degree パラメーターで定義された次数までのすべての三角関数の組み合わせに基づいて,新しい特徴量が作成されます. polynomial_threshold float, default = 0.1 これは,多項式特徴量と三角関数特徴量の疎な行列を圧縮するために使用される.ランダムフォレスト,AdaBoost,線形相関の組み合わせに基づく特徴の重要度が,定義されたしきい値のパーセンタイル内に収まる多項式特徴と三角関数特徴は,データセットに保持される.残った特徴は,さらなる処理の前に削除される. group_features list or list of list, default = None データセットに関連する特徴を持つ特徴が含まれている場合, group_featuresparam を統計的特徴抽出に用いることができる.例えば,データセットが互いに関連した数値特徴量('Col1', 'Col2', 'Col3')を持つ場合, group_featuresの下に列名を含むリストを渡すことで,平均値,中央値,モード,標準偏差などの統計情報を抽出することができます. group_names list, default = None group_featuresが渡されると、文字列を含むリストとしてgroup_namesパラメータにグループ名を渡すことができます。group_namesのリストの長さは、group_featuresの長さと等しくなければなりません。長さが一致しない場合や名前が渡されなかった場合は、 group_1, group_2 などのように新しい機能が順に命名されます。 feature_selection bool, default = False Trueに設定すると、ランダムフォレスト、Adaboost、ターゲット変数との線形相関など、さまざまな並べ替え重要度技術の組み合わせを使用して、特徴のサブセットが選択されます。サブセットのサイズは、 feature_selection_paramに依存します。一般的に、これはモデリングの効率を向上させるために特徴空間を制約するために使用されます。polynomial_featuresやfeature_interactionを使用する場合は、feature_selection_thresholdパラメータをより低い値で定義することを強く推奨します。 feature_selection_threshold float, default = 0.8 特徴選択に使用されるしきい値(新しく作成された多項式特徴を含む)。値が大きいほど特徴量が多くなります。特に多項式特徴と特徴間相互作用を利用する場合には、異なる値のfeature_selection_thresholdを用いて複数回の試行を行うことを推奨します。非常に低い値を設定すると効率的ですが、結果的にアンダーフィッティングになる可能性があります。 feature_interaction bool, default = False Trueに設定すると、データセット内のすべての数値変数(多項式および三角関数特徴(作成された場合)を含む)に対して相互作用(a * b)することで、新しい特徴を作成します。この機能はスケーラブルではなく、大きな特徴空間を持つデータセットでは期待通りには動作しないかもしれません。 feature_ratio bool, default = False Trueに設定すると、データセット内のすべての数値変数の比率(a / b)を計算して新しい特徴量を作成します。この機能はスケーラブルではなく、大きな特徴空間を持つデータセットでは期待通りには動作しないかもしれません。 interaction_threshold bool, default = 0.01 polynomial_threshold と同様に,新たに作成された特徴量の疎な行列を相互作用によって圧縮するために使用される.ランダムフォレスト、AdaBoost、線形相関の組み合わせに基づく重要度が、定義された閾値のパーセンタイル内に収まる特徴量は、データセットに保存されます。残った特徴は,さらなる処理の前に削除される. transform_target bool, default = False True に設定すると、transform_target_method パラメーターで定義されている方法でターゲット変数を変換します。ターゲット変換は、特徴量変換とは別に適用されます。 transform_target_method string, default = 'box-cox' Box-cox' および 'yeo-johnson' 法がサポートされています。Box-Cox は入力データが厳密に正の値である必要がありますが、Yeo-Johnson は正または負のデータの両方をサポートしています。transform_target_method が 'box-cox' で、ターゲット変数に負の値が含まれている場合、例外を避けるためにメソッドは内部的に 'yeo-johnson' に強制されます。 data_split_shuffle bool, default = True Falseに設定すると、データを分割する際に行がシャッフルされるのを防ぎます。 folds_shuffle bool, default = True Falseに設定すると、クロスバリデーションを使用しているときに行がシャッフルされるのを防ぎます。 n_jobs int, default = -1 並列に実行するジョブの数を指定します(並列処理をサポートしている関数の場合)-1は全てのプロセッサを使用することを意味します。すべての関数を単一のプロセッサで実行するには、n_jobs を None に設定します。 html bool, default = True Falseに設定すると、モニターの実行時表示を禁止します。HTMLに対応していない環境を使用している場合は、Falseに設定する必要があります。 session_id int, default = None Noneの場合、ランダムなシードが生成され、Informationグリッドに返されます。その後、実験中に使用されたすべての関数で、一意の番号がシードとして配布されます。これは、実験全体の後の再現性のために使用することができます。 log_experiment bool, default = False True に設定すると、すべてのメトリクスとパラメータが MLFlow サーバに記録されます。 experiment_name str, default = None ログを記録する実験の名前。Noneに設定されている場合、デフォルトでは'reg'が実験名のエイリアスとして使用されます。 log_plots bool, default = False True に設定すると、特定のプロットを png ファイルとして MLflow に記録します。デフォルトでは False に設定されています。 log_profile bool, default = False True に設定すると、データプロファイルも html ファイルとして MLflow に記録されます。デフォルトでは False に設定されています。 log_data bool, default = False Trueに設定すると、訓練データとテストデータがcsvとして記録されます。 silent bool, default = False Trueに設定すると、データ型の確認は不要です。すべての前処理は、自動的に推測されるデータ型を想定して実行されます。確立されたパイプライン以外での直接使用は推奨されません。 verbose Boolean, default = True verbose が False に設定されている場合、情報グリッドは印刷されません。 profile bool, default = False true に設定すると、探索的データ分析のデータ プロファイルがインタラクティブな HTML レポートに表示されます。
- 投稿日:2020-08-12T15:28:45+09:00
MPEG2のDICOMってどうすりゃいいの
LinacのEPIDで取得した動画をdicom形式でexportした。いつも通りにpydicomで解析してみる。
import pydicom dicom_data = pydicom.dcmread(file_name)すると、
(0002, 0010) Transfer Syntax UID UI: MPEG2 Main Profile / Main Levelなるほど、動画なんですね。
いつもの通り、array = dicom_data.pixel_arrayでpixel arrayを取得しようとすると、
NotImplementedError: Unable to decode pixel data with a transfer syntax UID of '1.2.840.10008.1.2.4.100' (MPEG2 Main Profile / Main Level) as there are no pixel data handlers available that support it. Please see the pydicom documentation for information on supported transfer syntaxesあれ、うまくいかない。
dicom_data.PixelDataから解析するかと思いながら、めんどいな、もしかして普通に動画ファイルとして解析できちゃったりしないかな、なんて思って、import cv2 cap = cv2.VideoCapture(file_name)あれ、エラーでない。いけるのか?
frames = [] while True: ret, frame = cap.read() if ret == True: frame=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) #Gray scaleにしてあるよ frames.append(frame) else: breakとかしてみたら無事に
framesのリストができてる。
これをnp.array(frames).shapeとかすれば(143, 576, 720)なるほど、576 x 720 の画像が143枚入っているのがわかる。
あとはplt.imshow(np.array(frames)[0,:,:])として最初の画像が表示できた。dicomファイルだからと身構えず普通に動画ファイルとしてopencvを使って解析できることがわかった。
- 投稿日:2020-08-12T15:25:39+09:00
コンマや△の入った数値を数値型に変換する。
1 この記事は
有価証券報報告書に記載されている△や,の入った数値をpythonが扱える数値型に変換するコードを掲載します
2 コード作成例
パターン1
'△45,931'の場合
test.pymoji='△45,931' def conv(moji): moji=moji.replace('△', '-') moji=moji.split(' ')[-1] moji=moji.replace(',', '') moji=int(moji) return moji moji=conv(moji) print(type(moji)) ##<class 'int'> print(moji) ##-45931パターン2
'※1 889,341'の場合
test.pymoji='※1 889,341' def conv(moji): moji=moji.replace('△', '-') moji=moji.split(' ')[-1] moji=moji.replace(',', '') moji=int(moji) return moji moji=conv(moji) print(type(moji)) #<class 'int'> print(moji) #889341
- 投稿日:2020-08-12T15:23:50+09:00
n以下の素数の個数を調べる
素数とは何か(序盤は雑談です)
素数とは2以上で約数が自明なものしか持たない整数のことを言います。
ここでいう自明なものとは1と自分自身を指します。
言い方を変えると、整数nに対してn÷mが整数となるmが1とnしかないとき、nを素数といいます.なぜ素数が大切なのか
それは正整数の集合に積という演算を与えたとき基底となるのが素数だからです.
数学を勉強した人なら基底がいかに大事か理解していることでしょう.
ちなみに演算が和であれば基底は1つで十分です(1のみですべての正整数を作れる)(ちなみに基底の概念が整備されていなかった昔は素数というのはそこまで重要視されていなかったららしいです.こんな数あるよねーぐらいの認識だったとか)
素数の個数は?
素数の個数は無限個であるとユークリッド大先生が相当昔に証明されています。
無限という概念がなかった時代に「素数の個数がある数であるとするとそれよりも多く素数が存在する」という言葉で書き記していらっしゃいます。今では無限大という便利な概念が整備されていますが、それがなかった時代にここまで正確に無限大の概念を直感的に理解していたユークリッド先生って何者なんでしょうね。素数の分布について
素数の全体の個数は無限個であるということは分かりました。
しかし1~nまでの数に素数はどのくらいあるんだろう?という疑問は相当難しい問題で解決したのは1896年です。(いまでは初等的な照明が存在しますがあくまで初等的なだけであって理解は相当難しいです)
しかもあくまで「割合」であり厳密に「いくつあるのか」という式はいまだにわかっていません(多分)
ただ具体的にnを与えたら人間でも、なんなら理解力がとてつもない犬でも数えることができます。
なぜならn以下のすべての数で実際に割って約数が自明なものしか存在しないことを確認すればいいのですから。頑張ればできます。
そして1800年代には素数表のようなものがあったらしいです。乗っている素数の上限がいくつか知りませんが。
しかし、間違いも結構あったらしくオイラー先生が1797年に1000009は素数ではないという定理?を証明しておられます。
つまり「nが素数であるかどうかは頑張れば理論上計算できるがまあ間違える」わけですよ。
ならどうすればよいのかコンピュータで代わりに計算すればええんです。今回はnが素数か判定するプログラムではなく1~nの間に素数がいくつあるのかを求めるプログラムを目標とします
案1.1 とにかく割ってみよう
nが素数であるとは2からn-1までの整数で割り切るものが存在しないという定義でしたね。
ならそれをプログラムで実装しますdef number1(n): cnt=1 for i in range(2,n+1): for j in range(2,i): if i%j==0: break elif i%j!=0 and j==i-1: cnt+=1 return cnt2の処理がうまくいかなかったのであらかじめcnt=1としましたが素直に実装するとこのような感じになると思います。
これでも人間よりは圧倒的に早いのですが、せめてオイラー先生の1000009までを爆速でやりたいわけですよ。これでは遅すぎます。
改善案を考えましょう案1.2 奇数だけ考えよう
素数かどうかを考える際、2を除く偶数は明らかに素数ではないですよね?ならそれを除きましょう.
def number2(n): cnt=1 for i in range(3,n+1,2):#←ここが変わっただけ for j in range(2,i): if i%j==0: break elif i%j!=0 and j==i-1: cnt+=1 return cntこれで奇数だけを考えればいいことになりました!単純に計算の数が半分になりましたね!
ただここでもう一つ......
割られる数が奇数だけなら割る数も奇数だけでええんじゃね?......案1.3 さらに奇数を
def number3(n): cnt=2#変更点 for i in range(3,n+1,2): for j in range(3,i,2):#変更点 if i%j==0: break elif i%j!=0 and j==i-2:#変更点 cnt+=1 return cntこれで2を除いて割る数、割られる数をすべて奇数にできました!単純に計算回数が0.25倍です!
ただ、まだ遅い。DI〇様に怒られます。
無駄がないのか考えてみましょう案2.1 素数で割ろう!
例えばnが5で割れなかったのに25で割れるのでしょうか?答えはNoです。
n÷25=整数なら
n÷5=5*整数になるでしょう。
つまり3で割れなかったのに9で割ったり3と5で割れなかったのに15で割るとか無駄の極みなんですね。
つまり割る数は素数のみで良いのです
しかし素数を求めたいのに素数のリストを使ったりしたら意味がないので、自分で素数のリストを作りましょう
まず定義の再確認
nが素数とは2~n-1までの数で割って整数になるのが存在しないと考えていましたが
nが素数とはn未満の素数のどれでも割れないと考えましょう!
定義としてはどっちも同じですがプログラムで書くと大きく変わりますね!
さっきの割られる数は奇数だけでよいという考えも混ぜてプログラムを書くとdef number4(n): li=[2] for i in range(3,n+1,2): for j in li: if i%j==0: break elif i%j!=0 and j==li[-1]: li.append(i) return len(li)とでもなると思います!最初に比べると相当相当早くなりました!
ただまだ明らかな無駄があります。案2.2 範囲で分けよう
n÷素数が整数かどうかのチェックを今行っているわけですね。
この「整数」の最小値って何でしょう?......
2ですよね?
つまりnが100とかだとすると53とかで割る必要ないですよね……?
だって明らかに100÷53は2より小さいので。
ならこれを使えばさらに無駄を省けますねdef number5(n): li=[2] for i in range(3,n+1,2): for j in li: if i%j==0: break elif i%j!=0 and 2*j>i:#変更点 li.append(i) break #変更点 return len(li)でもまだ範囲を減らせます!
案2.3 数の性質を考えよう
nが√n以下のすべての素数で割れなかったとします(このすべてって仮定はとても大事です)
この時nが√nより大きい素数で割れますか?実はありえません。
n÷m(√nより大きい素数)=k(整数)だったとすると
n÷k=mが成立しますね?
でも√の性質考えると
m>kです
(なぜならm<kだとするとk=m+aと書くことができ
n=m*(m+a)=m^2+m*aとなりイコールがバグるから)
先ほど√n未満の素数すべてで割れないと仮定したのにそのようなkで割れてしますことになるんですよ。
案2.2は1~n÷2までの素数という範囲で考えればよいとしましたが
実は1~√n未満の素数で良かったんですね!
ならこれを実装しましょうdef number6(n): li=[2,3] cnt=2 for i in range(5,n+1,2): for j in li: if i%j==0: break elif i%j!=0 and j**2>=i:#変更点 cnt+=1 li.append(i) break return cntこれは相当早いです。
遊び程度であればこれで十分でしょうし、これさえあれば素数の個数という知識だけはオイラー先生に勝つこともできます(多分)ではあとちょっとだけ高速化を狙いましょう
案3.1 篩にかける
僕の中学の時の数学の教科書には載っていたのですがエラトステネスの篩という素数を求める方法があります
まず2,3,4,5,6,...,nと数字を書きます
1.先頭にあるものに〇をつける
②,3,4,5,6,...,n
2.今〇をつけた数字の倍数を全部消す
②, 3,5,7,9,11,...,n
3.〇を無視して先頭の数字に〇をつける
②,③,5,7,9,11,...,n
4.今〇をつけた数字の倍数を消す
......というのを繰り返すと〇がついている数字がn以下の素数であるというアルゴリズムですね!これをプログラムで実装しよう!という考えです
素直に書いたら大体以下のようになるのかなあと思います
def number7(n): li=[int(x) for x in range(2,n+1)] pri=[] for i in range(n): pri.append(li[0]) li=[int(x) for x in li if x%pri[-1]!=0] if len(li)==0: break return len(pri)しかし、これは結構遅いです。
ただ上で考えたことがそのまま活きてきます!
まず数字を書くという部分に該当するli=[int(x) for x in range(2,n+1)]の部分。偶数は最初に消えることわかっているんだから最初から書かなくていいですね。
こうしましょうdef number8(n): li=[int(x) for x in range(3,n+1,2)]#変更点 pri=[2]#変更点 for i in range(n): pri.append(li[0]) li=[int(x) for x in li if x%pri[-1]!=0] if len(li)==0: break return len(pri)ただこれでも結構遅いんです。
なぜなら
後半になると篩がすでに終わっているんですよ。
n=100で考えますね
3,5,7の倍数を消していきます。
実はこの時点で100以下の素数がすべて出ています
さっきの話と一緒ですね.√n未満の素数で十分なんです
なのにコンピュータは最後の素数97まで篩のチェックをして、リストにあるすべての数字が11の倍数かな,13の倍数かな,17の倍数かな,...,97の倍数かな?と確かめるんですよ。
この無駄な処理で遅くなっています。
だから√n未満で十分という処理を追加してあげましょうdef number9(n): li=[int(x) for x in range(3,n+1,2)] pri=[2] for i in range(n): if pri[-1]**2>n: #ここら辺が変更点 pri+=li break else: pri.append(li[0]) li=[int(x) for x in li if x%pri[-1]!=0] if len(li)==0: break return len(pri)これで結構早くなりました!前のプログラムと競ってみましょう!
速度チェック
今回は number6とnumber9のみで速さを計測していきます!
オイラー先生の1000009をリスペクトしてn=1,000,000として10回計算をし平均を出してみますnumber6 :平均タイム5.729981923103333 number9 :平均タイム3.960706377029419篩が速いですね(タイムはpcスペックなどで変動するのであくまで参考程度に)
終わり
基本的な素数の個数の求め方をまとめてみました。
参考になると嬉しいです><また別件ですが、最近プログラムの勉強がテスト勉強という大学の一大行事()のためできていませんでした。
その分この夏休みの期間にスキルアップできるよう精進したいと考えているのでご指導ご鞭撻よろしくお願いします!
- 投稿日:2020-08-12T14:55:26+09:00
モナリザがトランプ大統領のように動き出すFirst Order Motion Modelを試してみる
1.はじめに
2019年に First Order Motion Model for Image Animation という論文が発表されました。内容は、同じカテゴリの静止画と動画を使って、静止画を動画のように動かすというものです。
百聞は一見にしかず、こんなことが簡単に出来ます。
左が有村架純さんの静止画、中央がトランプ大統領の動画、そして右が生成した有村架純さんがトランプ大統領のように動く動画です。
2.First-Order-Motion-Modelとは?
これは、モデルの概要図で、大きく分けて Motion Module と Generation Module の2つで構成されています。入力は、静止画 source と、動画 Driving Frame です。Motion Module は、静止画と動画の各フレームそれぞれに対して、キーポイント位置(顔の場合なら目、鼻、口、顔の輪郭など)、キーポイントにおける勾配を、Refarence画像(図ではRと表示)を基準として計算します。
そして、そのキーポイント計算とヤコビアン$J_k$(静止画と動画フレームの大きさの比率)から、動画の各フレームの画素を静止画のどの画素から作れば良いかを示すマッピング関数を計算します。
この様に静止画と動画の各フレームの差を計算するのではなく、Refarence画像という概念的な基準画像との差を計算することで静止画と動画の各フレームが独立に計算出来、両者の画像の差が大きくても上手く変換ができます。
また、静止画を動かすとそもそも静止画に含まれていない部分が発生しますが、それを上手く処理するオクルージョン(Oで表示)という処理を行っています。
Generation Module は、それらの結果と静止画から、画像を出力します。損失関数は、静止画と出力画像の誤差+正則化項(マッピング関数が単純な変換に近くなるような拘束条件)です。
学習時は、静止画と動画は同一の動画から任意のフレームを選択して行います。推論時は、学習時と同じカテゴリーであれば静止画と動画とも任意のもので行えます(これがこのモデルの素晴らしいところです)。
3.学習済みの重みを使って試してみる
学習済みの重みが提供されていますので、それを使って静止画と動画から動画を生成してみましょう。事前に、コードとサンプルデータ(重み、画像、動画)をダウンロードします。
まず、google colab 上で静止画や動画を表示する関数display()を定義します。
import imageio import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation from skimage.transform import resize from IPython.display import HTML import warnings warnings.filterwarnings("ignore") def display(source, driving, generated=None): fig = plt.figure(figsize=(8 + 4 * (generated is not None), 6)) ims = [] for i in range(len(driving)): cols = [source] cols.append(driving[i]) if generated is not None: cols.append(generated[i]) im = plt.imshow(np.concatenate(cols, axis=1), animated=True) plt.axis('off') ims.append([im]) ani = animation.ArtistAnimation(fig, ims, interval=50, repeat_delay=1000) plt.close() return ani引数は、静止画、動画、生成動画で、動画と生成動画は ndarray 形式です。静止画、動画、生成動画をフレーム毎に concatenate し、matplotlib の animation でアニメーション形式にしたものを返します。
4.顔のカテゴリーで試してみる
それでは顔のカテゴリーの動画を生成します。静止画・動画は、顔のキーポイント位置(目、鼻、口、顔の輪郭など)が検出できれば絵でも人形でもアニメでも構わないので、ここでは静止画はモナリザ、動画はトランプ大統領を使ってみます。
from demo import load_checkpoints from demo import make_animation from skimage import img_as_ubyte source_image = imageio.imread('./sample/05.png') driving_video = imageio.mimread('./sample/04.mp4') #Resize image and video to 256x256 source_image = resize(source_image, (256, 256))[..., :3] driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video] generator, kp_detector = load_checkpoints(config_path='config/vox-256.yaml', checkpoint_path='./sample/vox-cpk.pth.tar') predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=True) HTML(display(source_image, driving_video, predictions).to_html5_video())
凄い! モナリザがトランプ大統領のように動き出しました。正に、何でもありの世界です。このモデルには、生成動画の顔のキーポイント位置を動画の方に合わせる(つまり顔を動画の方に合わせる)というモードがあるので、そちらを試してみると、
predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=False, adapt_movement_scale=True) HTML(display(source_image, driving_video, predictions).to_html5_video())
生成された動画は、基本的にモナリザなのですが、キーポイント位置をトランプ大統領にしているので、「トランプ大統領似のモナリザ」という訳がわからない世界に突入しています(笑)。
5.オリジナルの動画を作成するには
使用する動画は顔の位置が大体合っていれば何でもOKです。なので、自分で入手した動画から顔だけクロップした動画を作れば、それが使用できます。
!ffmpeg -i ./sample/07.mkv -ss 00:08:57.50 -t 00:00:08 -filter:v "crop=600:600:760:50" -async 1 hinton.mp4ffmpeg をこのように使えば、1行でクロップ動画が作れます。引数を簡単に説明すると、
-i: 動画パス (コードは.mkvになっていますが、mp4でもOKです)
-ss: 動画のクロップスタート時刻(時間:分:秒:1/100秒)
-t: クロップ動画の長さ(時間:分:秒)
-filter:v "crop=XX:XX:XX:XX":(クロップ画像の横サイズ:クロップ画像の縦サイズ:クロップ画像の左上角の横位置:クロップ画像の左上角の縦位置)
*クロップ画像の左上角の横位置・縦位置は、動画の左上角を(0,0)として計算した位置です。
-async 1:クロップ画像保存パス簡単に使えますので、ぜひお試しを。
6.全身のカテゴリーで試してみる
キーポイント位置が検出できれば、カテゴリーは何でもOKですので、今度は全身のカテゴリーでやってみましょう。
Fashion video dataset というファッションモデルの動きを集めたデータセットを用いて体のキーポイント位置(頭、顔、各関節など)を学習した重みを使います。
波瑠さんの静止画をファッションモデルの動画のように動かしてみます。
from demo import load_checkpoints from demo import make_animation from skimage import img_as_ubyte source_image = imageio.imread('./sample/fashion003.png') driving_video = imageio.mimread('./sample/fashion01.mp4', memtest=False) #Resize image and video to 256x256 source_image = resize(source_image, (256, 256))[..., :3] driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video] generator, kp_detector = load_checkpoints(config_path='config/fashion-256.yaml', checkpoint_path='./sample/fashion.pth.tar') predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=True) HTML(display(source_image, driving_video, predictions).to_html5_video())
左が波瑠さんの静止画、中央がファッションモデルの動画、そして右が生成した波瑠さんがファッションモデルのように動く動画です。動きがスムーズですね。
ここまでにご紹介した内容を試せるコードを Google Colab で作成しましたので、やってみたい方はこの「リンク」をクリックして動かしてみて下さい。
(参考)
・AliaksandrSiarohin/first-order-model
・【論文読解】First Order Motion Model for Image Animation