- 投稿日:2020-07-07T23:51:38+09:00
質問:pythonによる多重積分がうまくいかないです
環境はpython 3. 7. 6 、windows10。
多重積分integrate.nquadがうまく作動していないようで、結果が1.000になるはず(同時確率密度関数なので)が、1.326が返ってきてしまいます。
正しく多重積分するにはどうすればよいでしょうか。
code
import numpy as np
from scipy import integratedef f_xy(x, y):
if 0 <= y <= 1 and 0 <= x-y <= 1:
return 4 * y * (x - y)
else:
return 0integrate.nquad(f_xy, [[-np.inf, np.inf],[-np.inf, np.inf]])[0]
Out: 1.326
- 投稿日:2020-07-07T23:21:26+09:00
最終成果物
最終成果物で挑戦したもの
・サッカーのPKゲーム
・あみだくじ
etc... しかし、、、
自分の能力では作ることがまだ出来ず断念。考え直し思いついたのは
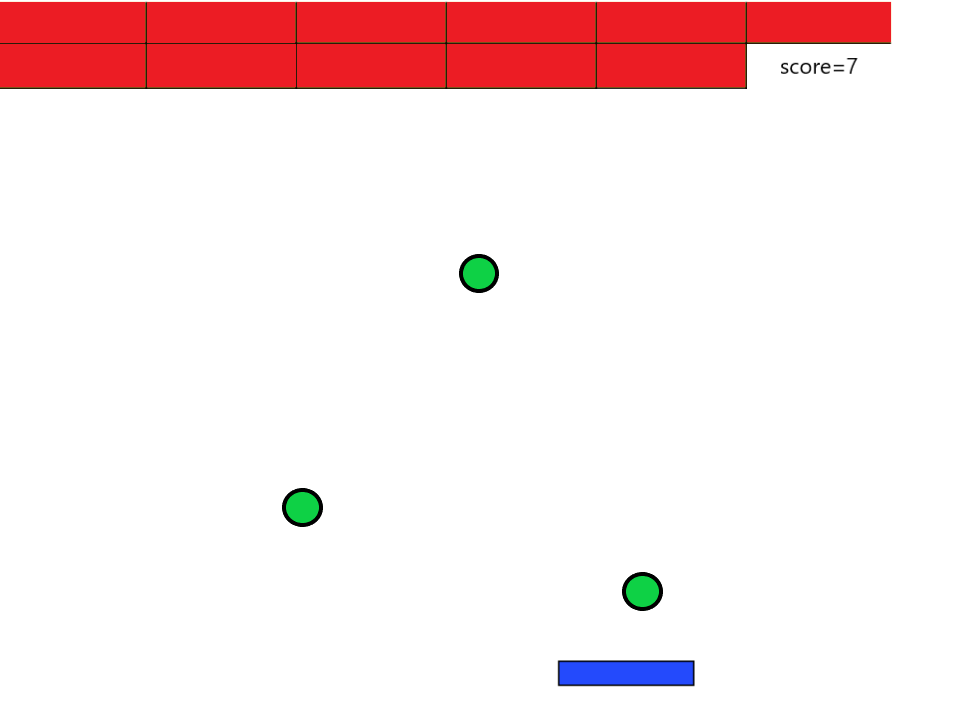
三つのボールでブロック崩し
#coding:utf-8 import tkinter as tk class Ball: def __init__(self, x, y, dx, dy, color): self.x = x self.y = y self.dx = dx self.dy = dy self.color = color def move(self, canvas): # いまの円を消す self.erase(canvas) # X座標、y座標を動かす self.x = self.x + self.dx self.y = self.y + self.dy #次の位置に円を描画する self.draw(canvas) # 端を超えていたら反対向きにする if (self.x >= canvas.winfo_width()): self.dx = -1 if (self.x <= 0): self.dx = 1 if (self.y >= canvas.winfo_height()): self.dy = -1 if (self.y <= 0): self.dy = 1 def erase(self, canvas): canvas.create_oval(self.x - 20, self.y - 20, self.x + 20,self.y + 20, fill="white", width=0) def draw(self, canvas): canvas.create_oval(self.x - 20, self.y - 20, self.x + 20,self.y + 20, fill=self.color, width=0) class Rectangle(Ball): def erase(self, canvas): canvas.create_rectangle(self.x - 20, self.y - 20, self.x + 20,self.y + 20, fill="white", width=0) def draw(self, canvas): canvas.create_rectangle(self.x - 20, self.y - 20, self.x + 20,self.y + 20, fill=self.color, width=0) class Triangle(Ball): def erase(self, canvas): canvas.create_rectangle(self.x - 20, self.y - 20, self.x + 20,self.y + 20, fill="white", width=0) def draw(self, canvas): canvas.create_polygon (self.x, self.y - 20, self.x + 20,self.y + 20, self.x -20, self.y + 20, fill=self.color, width=0) # 円3つを、まとめて用意する balls = [ Ball(400, 300, 1, 1, "red"), Ball(200, 100, -1, 1, "green"), Ball(100, 200, 1, -1, "blue") ] def loop(): #動かす for b in balls: b.move(canvas) #壊すブロック class Block: w_x = 100 #ブロックの幅(x座標) w_y = 30 #ブロックの幅(y座標) global dy, score #衝突の際にボールのクラスの移動量およびスコアを変更したいので、グローバル宣言を行う。 #ブロックのスイッチ。1がON,0がOFF block_list =[[1,1,1,1,1,1,1,1,1,1,1,1], # j = 0 , i = 0 ~ 11 [1,1,1,1,1,1,1,1,1,1,1,1], # j = 1 , i = 0 ~ 11 [1,1,1,1,1,1,1,1,1,1,1,1]] # j = 2 , i = 0 ~ 11 行・列の順番 def draw(self): for i in range(6): for j in range(3): cv.create_rectangle(i*self.w_x, j*self.w_y, (i+1)*self.w_x, (j+1)*self.w_y, fill = "orange", tag = "block"+str(j)+str(i)) def reflect(self): for i in range(12): for j in range(3): #ボールが上から反射 if (ball.y-ball.w < (j+1)*self.w_y #ボールがブロックよりも下 and i*self.w_x < ball.x < (i+1)*self.w_x #ボールがブロックの左右に挟まれている and self.block_list[j][i] == 1): #スイッチが1 ball.dy *= -1 #反射させる cv.delete("block"+str(j)+str(i)) #ブロックの描画を消す self.block_list[j][i] = 0 #スイッチを切る score.score += 1 #スコアの加点 score.delete() #スコアを更新(削除-生成) score.draw() #もう一回 root.after(10,loop) # ウィンドウを描く root = tk.Tk() root.geometry("800x600") #ゲームオーバー def gameover(): global w, dx, dy if ball.y + ball.w > win_height : cv.delete("paddle") cv.delete("ball") cv.create_text(win_center_x, win_center_y, text = "GAME OVER(T_T)", font = ('FixedSys', 40)) ball.w = 0 ball.dx = 0 ball.dy = 0 #ゲームクリア def gameclear(): global w, dx, dy if score.score == 18 : cv.delete("paddle") cv.delete("ball") cv.create_text(win_center_x, win_center_y, text = "GAME CLEAR(^0^)", font = ('FixedSys', 40)) ball.w = 0 ball.dx = 0 ball.dy = 0 # canvasを置く canvas =tk.Canvas(root, width =800, height =600, bg="#fff") canvas.place(x = 0, y = 0) # タイマーをセットする root.after(10, loop) root.mainloop()
まとめ
こうすることにより授業でしたボール、三角形、四角形をすべてボールにして、そして壊す用のブロックをプログラムすることによってブロック崩しができる。できなかったサッカーのpkゲームやあみだくじも再挑戦しようと思います。
参考
- 投稿日:2020-07-07T23:17:45+09:00
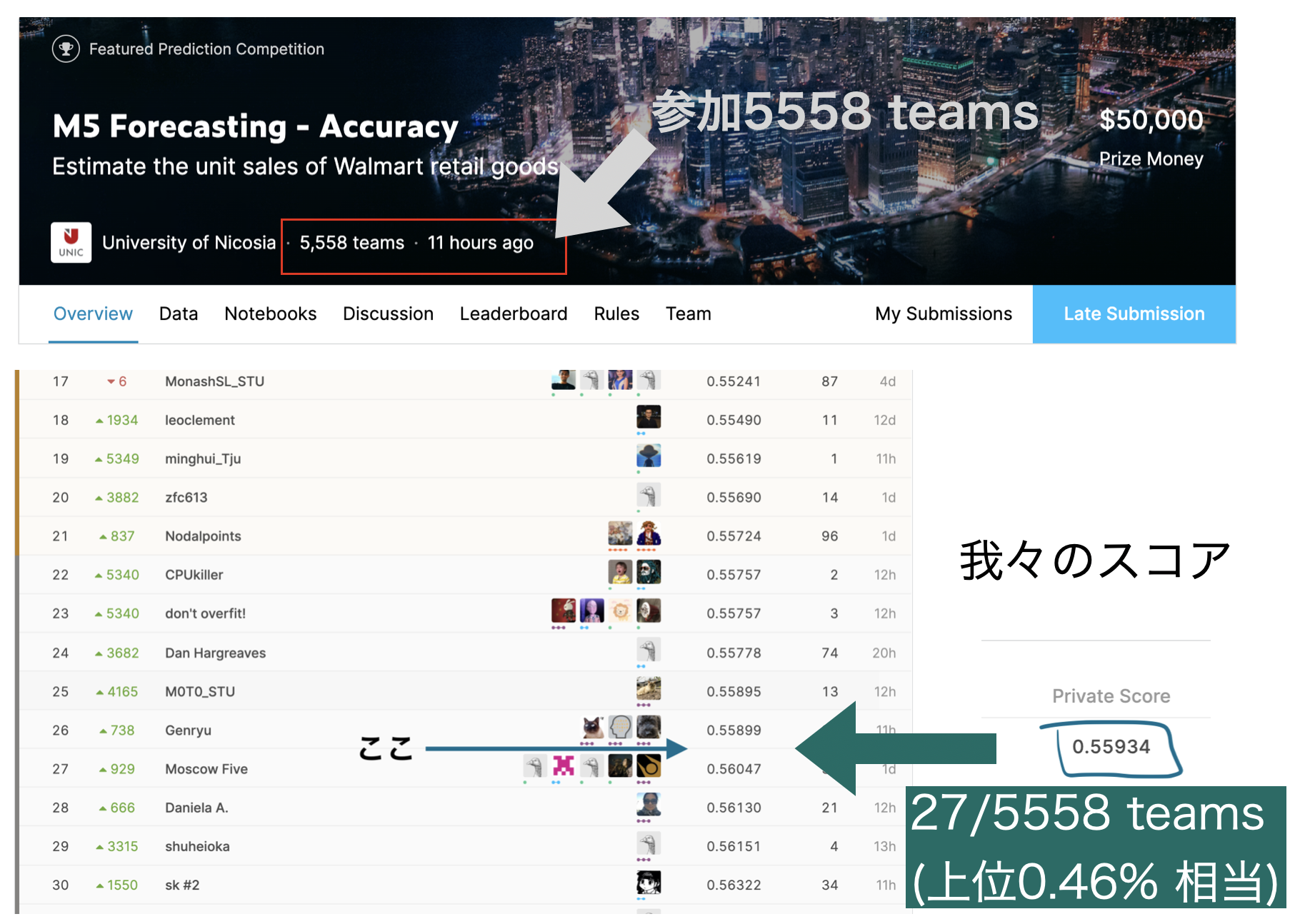
7月,某,M5 ~Kaggle初心者 時系列データコンペ失敗談~
人生,27位がとれるならM5は僕を救った.
27位なんてとれない 形式が違うんだから...
原曲 ヨルシカ/8月,某,月明かりはじめに
2020年3月から6月にかけて開催されていたコンペKaggle M5 Forecasting Accuracyに参加しました.
27位(上位0.4%)相当のモデルを提出したのですが,
形式を間違え 最下位になってしまったので解法を悼みます.
僕に知り合いの人は今度会ったら慰め代としておごってください.
さて僕らが地獄に落ちるまでの物語をお楽しみ下さい.コンペ概要
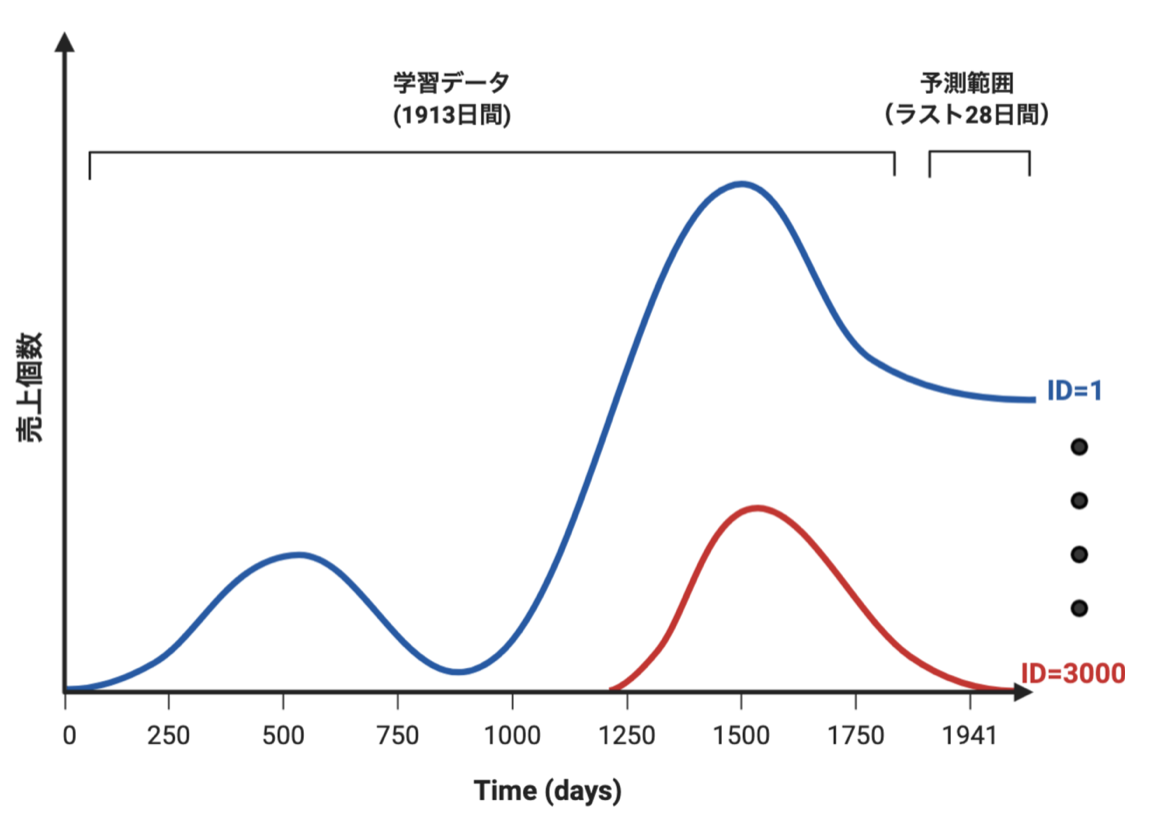
Kaggle M5 Forecasting:ウォルマート(スーパーマーケット)の売上予測コンペ
過去1913日間の売上データから未来の28日間における商品(3049種)ごとの売上(販売数量)予測.
対象店舗はカリフォルニア州、テキサス州、ウィスコンシン州にある10店舗.
与えられたデータは
-過去の売上(IDごと,ストアごと,品目ごとなど)
-価格の推移,
-カレンダー(祝日など)
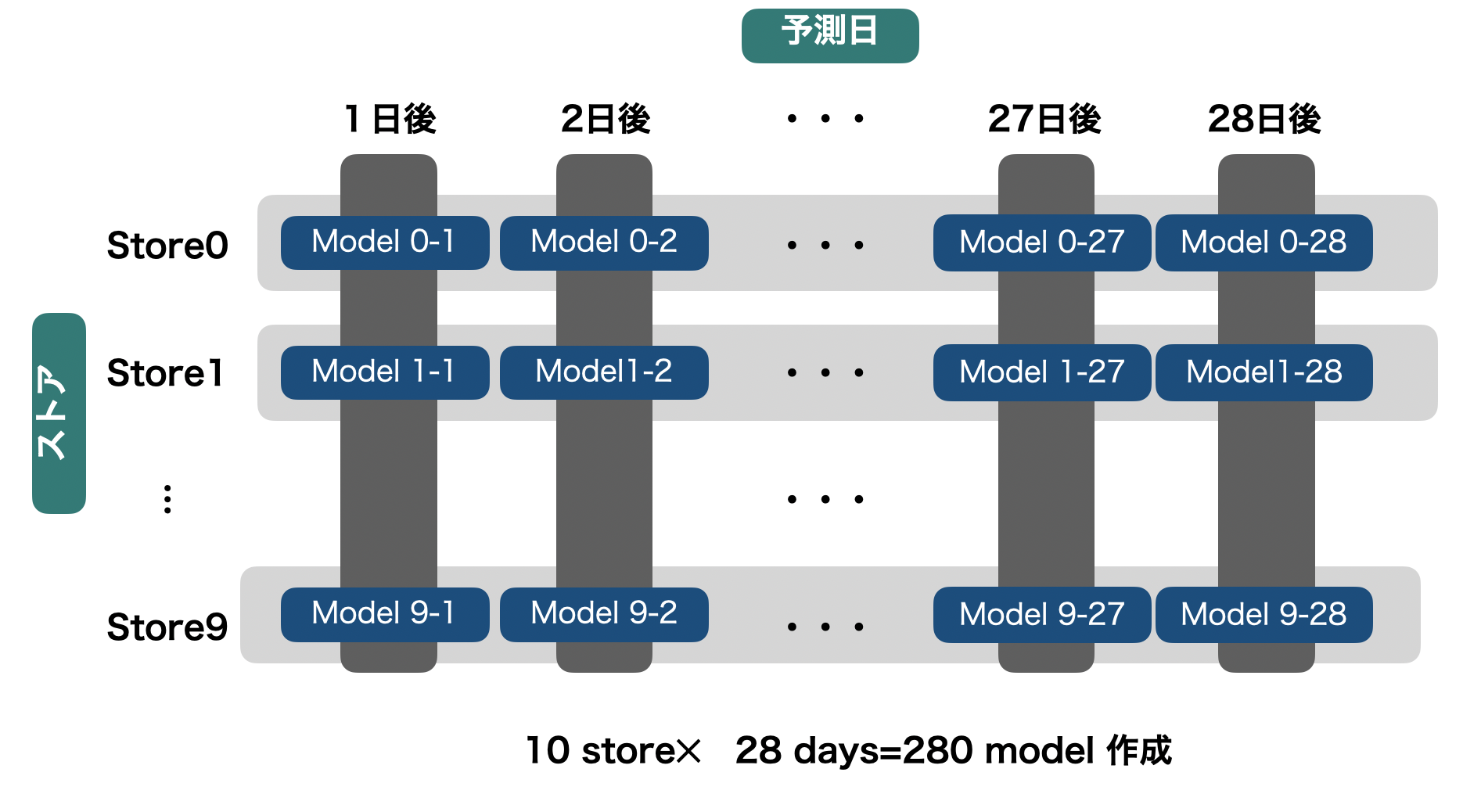
評価指標は基本的にはRMSE(ちょっとテクニカルなWRMSSEというものでしたが今回は省略)モデル
LGBMをStoreごと予測日ごとに作成(下図)
※基本的に時系列予測は非常に難易度が高いタスクである為,私のリソースはほとんどモデル作成について費やしました.チームメイトが特徴量作成やベースモデル構築などをやってくれて本当にありがたかったです.
方針
時系列データの予測は,機械学習に向いていない(参考)という話もあったので最初は統計モデルやLSTMを試しました.何故かうまく行かず.そこでできるだけデータを支配するダイナミクスが揃うように地域ごと,予測日ごとにLGBMを作成しました.
-LGBMにした理由
統計モデルやLSTMなど時系列予測のために作られたモデルは基本的に大きなダイナミクスを学習しているように思います.でも今回予測したいのは商品ごと,つまり小さなダイナミクスなのです.例えば,日本人全体の動きは予測できても個人個人の予測は難しい気がします(日本人はラーメンが好きな気がするのですが,読者のあなたがラーメンが好きか分かりません.あ,僕は担々麺が好きです).そこで表現力の高いLGBMにお願いしてみることにしました.店舗ごとにモデルを作成した理由
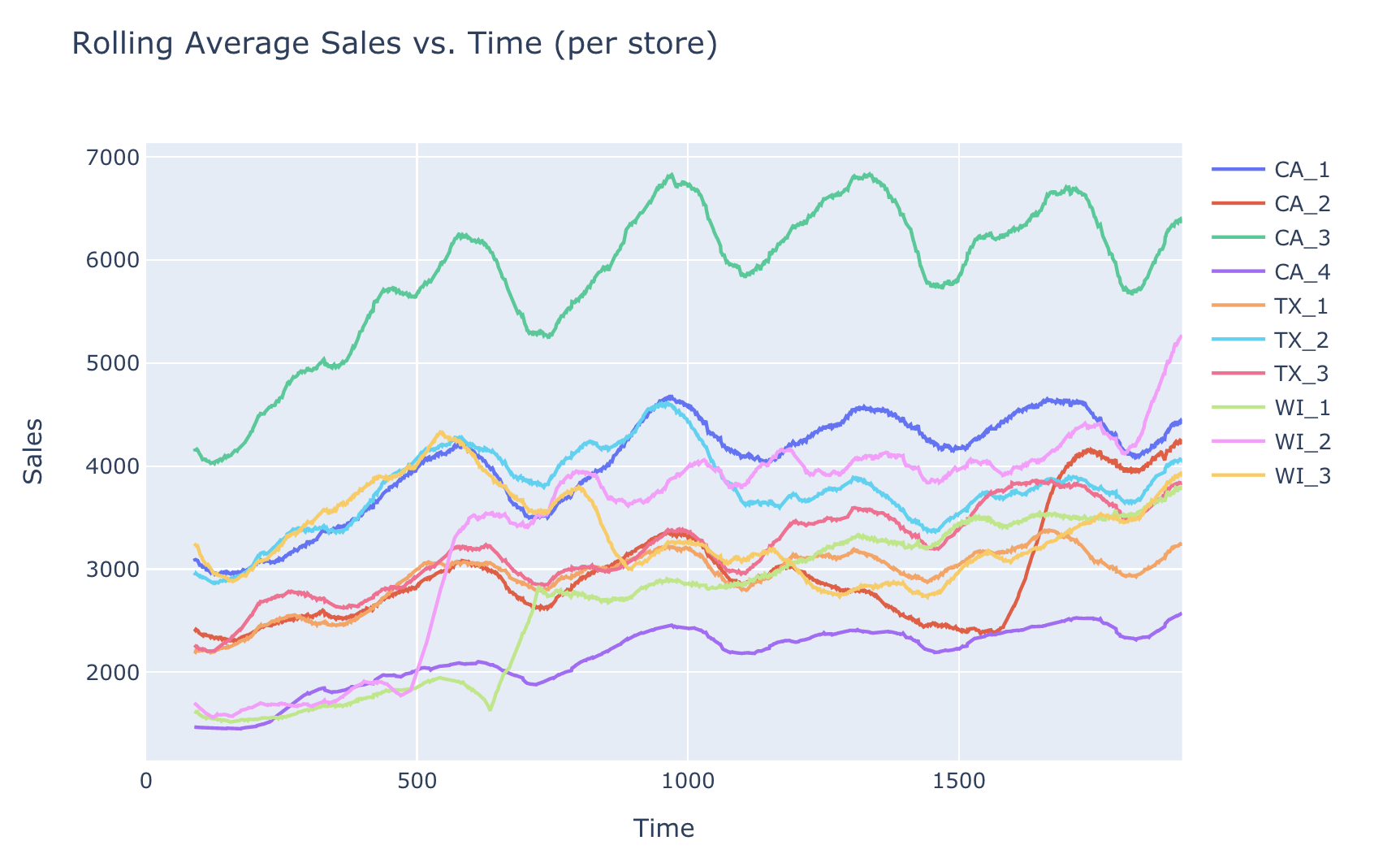
EDA notebookを参考にしてストアごとの売上推移を可視化すると,結構動きがstoreごとに異なることに気が付きました.
またUMAPを使ってクラスタリングしてみたところFOODSはだいたい同じように分布をしているのに対してHOBBBIESは地域差が顕著でした.
これらの結果から店舗ごとに売れるもの売れないものがあり,それを支配するダイナミクスは異なると考えモデルを分けることにしました.店舗のあるカリフォルニア州、テキサス州、ウィスコンシン州はそれぞれ地理的に離れており,売れ方が異なるのは妥当だと考えました.日毎に予想した理由
Discussionで行われているように再帰的なモデルがいいのか日毎に予測したほうがいいのかは今回の重要なポイントでした.私達は,単純に大きく外さない安全な道を選択しました.実際に再起的モデルにするとpermutation importanceをみるとlag1がマイナスに振り切っていました
特徴的エンジニアリング
基本的な特徴量(移動平均,ある期間のmax/minなど)
・商品の値段が上昇、減少をしてからの経過日数
・売り上げを初めて記録した日
これ以前のデータは学習に入れませんでした.
・Ordered TS
時系列データ用のリークしないTarget encodingのようなものです
・特定の期間での売り上げの最大値と、最小値を記録してからの経過日数
これは時間の概念を学習モデルに教えてあげたくて作りました.
・過去の売上における0から10の割合
その時点での売上の確率分布を表現するために作成しました.また,売上が0の場合は在庫切れ?なのか突然現れていたので0に関わる統計量を入れる必要があると考え導入しました.特徴量作成時に考えていたこと
統計的に意味のある特徴量を入れようとしました
加えて
・チームメイト:購買意欲に関わるものが分かれば売上がわかるはず
・書いてる人:LGBMが知らない情報を教えてあげようと考え時間に関わるもの
を考えて入れていました.
実際に,デノイズ処理なや波形の複雑度,フーリエ空間での特徴量など様々試しましたがなかなか有効なものは多くは存在しませんでした.CV方針
直近の3ヶ月のデータを用いました。一部特異的にCVが改善したものは採用せずひたすらにロバストに作って行くことを気をつけました.Darker magicやPublic leaderboardを当てにしなかったのは過適合を疑っていた為です.
サブミット前のslack
Iwamo 8:49 PM 頭働いてなさすぎて笑う
チームメイト 9:10 PM 一応確認頼んだ
Iwamo 9:10 PM 大丈夫そうだけどなそして死
前述の通り,提出形式の一部を間違え提出していない人と同じ順位,つまり 最下位でした...あったかもしれない世界線
未練がましく本来のモデルでのスコアを載せます.
最後に
チームメイトには申し訳ない気持ちでいっぱいです.最後に確認されてたのに...
実はkaggleを初めて半年程度なのですが,本当に多くのことを学べているように思います.
本当に悔しいですが,これからもがんばります.

- 投稿日:2020-07-07T23:09:23+09:00
Djangoで目的の日時のデータを抽出したかっただけの話
初投稿です
目的の日時のデータを抽出したかった
タイトルの通りDjangoで特定の日時のデータを取得しようとして四苦八苦した話です。
目的の処理ができるまでに丸一日費やしてしまったのでこの苦労を忘れないように備忘録として、またこの記事を見た人が同じようなことをするときの苦しみを減らせたらと思い投稿しました。・DateTimeField に filter をかけるときに month や day を指定するにはどうしたらいいんだ?
といった悩みを持っている人には少しは参考になるかもしれません。
models.pyfrom django.db import models class Article(models.Model): user_id = models.IntegerField() wirriten_date = models.DateTimeField() text = models.CharField(max_length=255) def __str__(self): return self.texturls.pyfrom django.urls import path from . import views urlpatterns = [ path('<int:user_id>/<int:date_delta>/', views.index, name=index), # ここで date_delta 今から何日前のものを取得するかを指定します。 ]このようにmodelsとurlsを定義したとき、user_idで指定したユーザーがdate_deltaで指定した日に投稿した文章をすべて取得しようとしました。
どうしたか
結論としてビューを以下のように書けばテンプレートにデータを送れることがわかりました。
views.pyfrom django.shortcuts import render from .models import Article from datetime def index(request, user_id, date_delta): date_now = datetime.datetime.now() wrriten_date = date_now - datetime.timedelta(days=date_delta) article = Article.objects.filter(user_id=user_id, menu_date__month=menu_date.month, menu_date__day=menu_date.day) context = { 'article': article[0], } return render(request, 'myapp/index.html', context)一番困ったのはArticle.objectsのfilterメソッド条件をどのように書くかでした。
menu_dateのあとの__ month と__ day はルックアップフィールドというもので、モデルの変数名につけると条件を加えることができます。ルックアップフィールドについては以下の記事を見て知りました。
・ウェブディー株式会社/サービス/BLOG/Django フィールドルックアップの使い方
https://webty.jp/staffblog/production/post-1263/データベースからデータを取り出すとQuerySetという型でデータが届くので、各要素を指定するにはリストのようにarticle[0]、article[1]などのようにする必要があります。
タイムゾーンの設定
前項のようにviewsを記述しても環境によってはうまく動作してくれません。その場合はタイムゾーンの設定を変えればうまく動作するかもしれません。
setting.pyTIME_ZONE = 'Asia/Tokyo' USE_TZ = True私の場合はsettingのタイムゾーンに関する設定を以上のように行いタイムゾーンを日本に設定したらうまく動作するようになりました。
おわりに
この記事が少しでも誰かの役に立ったら幸いです。
まだプログラミングもQiitaも初心者なので色々至らぬ点が多いかもしれませんが、今後も積極的にアウトプットを続けていきたいです。
「ここがおかしいぞ」や「もっとこうするといいよ!」といったアドバイスがございましたら、コメントしていただけると嬉しいです。参考文献
・ウェブディー株式会社 / サービス / BLOG / Django フィールドルックアップの使い方
https://webty.jp/staffblog/production/post-1263/
- 投稿日:2020-07-07T22:53:55+09:00
numpyのライブラリ関数一覧を少しずつ入れていく - c編
numpyの関数リストのc編を作りました。ググって簡単にどういうことしてるか書いて、使えそうな例のあるリンク先を貼ってるだけですが、これをやってるとだんだんnumpyでどういうことができるかわかってきます。そろそろコードの入った記事も試してみたいところです。
np.c_ 接続、中で後ろにつなげる r_はより内側につなぐ hstackと同じ
np.can_cast (a,b) でaからbにキャストできるならTrue。キャストとは別の型に変換すること
https://numpy.org/doc/stable/reference/generated/numpy.can_cast.html
np.cast 型変換する。今はastypeに取って代わられてる?
https://www.programcreek.com/python/example/61566/numpy.cast
np.cbrt 立方根
np.cdouble doubleのサイズをもった複素数の型
np.ceil 切り上げ
np.cfloat floatのサイズをもった複素数の型
np.char char型だがこれにつながる関数が多数
https://numpy.org/doc/stable/reference/routines.char.html
np.character ?
np.chararray 文字列演算のベクトル化
http://www.turbare.net/transl/scipy-lecture-notes/advanced/advanced_numpy/index.html
np.choose 2次元arrayの中から1次元arrayの値に従った番号の値を抽出
https://qiita.com/junkoda/items/2d1d82e00b29e50df90c
np.clip array内の値に上限値と下限値を与えて制限する
https://analytics-note.xyz/programming/numpy-clip/
np.clongdouble 複素数で片方が整数、片方が浮動小数点? (あとで下記をみて確認)
https://www.programcreek.com/python/example/78125/numpy.clongdouble
np.clongfloat clongdoubleに類似。浮動小数側が単精度に
np.column_stack 2つのベクトルを縦か横に結合して2次元配列を作る
https://stats.biopapyrus.jp/python/vector.html
np.common_type arrayの型を返す
https://numpy.org/doc/stable/reference/generated/numpy.common_type.html
np.compare_chararrays 2つの文字列配列の要素別比較
https://kite.com/python/docs/numpy.compare_chararrays
np.compat ?
np.complex 複素数の型
np.complex128 計128ビットの複素数
np.complex256 計256ビットの複素数
np.complex64 計64ビットの複素数
np.complex_ np.complex128と同じ
np.complexfloating ?
np.compress 条件にあうものを選択してそれの配列にする
https://numpy.org/doc/1.18/reference/generated/numpy.compress.html
https://www.youtube.com/watch?v=B0gN6Jn4QSg
np.concatenate arrayを結合する
https://note.nkmk.me/python-numpy-concatenate-stack-block/
np.conj 複素共役(虚数の符号を反転させたもの)を返す。もととかければ実数にできる
https://deepage.net/features/numpy-math.html
np.conjugate 複素共役を返す。np.conjと同じ
np.convolve 畳み込み計算を行う。CNNの畳み込み部分を1次元でやる関数
https://deepage.net/features/numpy-convolve.html
np.copy コピーする
https://qiita.com/mytk0u0/items/231807f4136b2b1681b0
np.copysign 別の配列から符号部分だけをコピーする
https://note.nkmk.me/python-numpy-sign-signbit-copysign/
np.copyto 配列をコピーする
https://www.programcreek.com/python/example/102241/numpy.copyto
np.core ?
np.corrcoef 相関係数を計算する
https://deepage.net/features/numpy-corrcoef.html
np.correlate 相互相関関数を計算する - 下記を見てあとで理解しておく
https://lambdalisue.hatenablog.com/entry/2017/01/04/194634
np.cos コサイン
np.cosh ハイパボリックコサイン
np.count_nonzero 条件を入れてTrueの数をカウントする
https://note.nkmk.me/python-numpy-count/
np.cov 共分散を計算する
https://deepage.net/features/numpy-cov.html
np.cross ベクトルの外積を計算する
https://algorithm.joho.info/programming/python-numpy-vector-cross/
np.csingle singleのサイズをもった複素数の型
np.ctypeslib C言語との連携で使う。C言語の関数の呼び出し。ここは勉強しておく
https://kyotogeopython.zawawahoge.com/html/%E5%BF%9C%E7%94%A8%E7%B7%A8/Fortran,%20C%E8%A8%80%E8%AA%9E%20%E3%81%A8%E3%81%AE%E9%80%A3%E6%90%BA.html
np.cumprod 累積積(配列内を順に掛け算していく)を計算する
http://pppurple.hatenablog.com/entry/2016/05/02/235158
np.cumproduct np.cumprodと同じ?
np.cumsum 要素を足し合わせたものを配列として入れる
https://qiita.com/Sa_qiita/items/fc61f776cef657242e69
- 投稿日:2020-07-07T22:33:20+09:00
Kaggle~住宅分析③~Part1
1. はじめに
住宅分析もかれこれ3回目になりました。
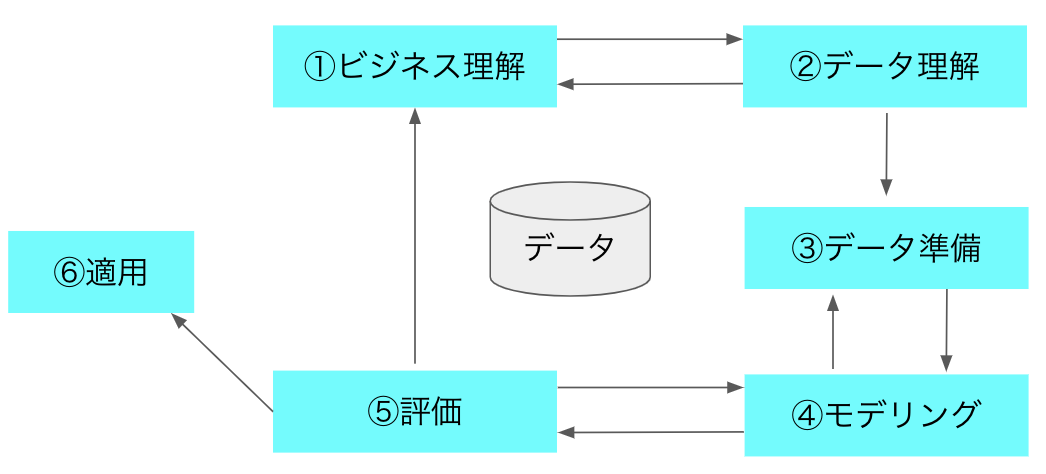
前回までスコアが0.17付近でモデルを変えてもこれ以上伸びないなーといった感じ。今回はCRISP-DMを用いた標準プロセスで実施。
※Shearerらが提唱しているCRISP-DM(CRoss Industry Standard Process for Data Mining)データ分析のプロセスには、標準プロセスとしてCRISP-DMとCRIISP-DMよりデータ分析部分にフォーカスしているKDDがあります(今回はKDDの説明は省略)
CRISP-DMのプロセスは①ビジネス理解→②データ理解→③データ準備→④モデリング→⑤評価→⑥適用というふうに進んでいく。
図1 CRISP-DMといった流れで進め、なおかつこれらについて自分の考えたこと調べたことを紹介します。
Part1ということで複数回に渡って紹介していきます。2. ビジネス理解
このコンペでは住宅の価格を予想することが課題です。
なので住宅の価格がどんな要素で左右されるのか想像してみた。====================以下想像内容====================
一般的には"場所" 都市部や駅に近い、交通の便が良い、高級住宅
”家の大きさ” 敷地面積、階数、建屋の広さ
”付属” プール付き、テニスコート付き等々
"新築"か”中古”は結構重要な気がする(築何年っていうのが大切?)
"品質"というのは素材等も重要なファクターかと思います。挙げ出せばキリがないですが予測する上では非常に重要だと思います。
3. データ理解
いよいよkaggleの中身について見ていく
# 1-1. データを読み込む df_train = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/train.csv') df_test = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/test.csv') df_train.head()出力結果
Id MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities ... PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice 0 1 60 RL 65.0 8450 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 2 2008 WD Normal 208500 1 2 20 RL 80.0 9600 Pave NaN Reg Lvl AllPub ... 0 NaN NaN NaN 0 5 2007 WD Normal 181500 2 3 60 RL 68.0 11250 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 9 2008 WD Normal 223500 3 4 70 RL 60.0 9550 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 2 2006 WD Abnorml 140000 4 5 60 RL 84.0 14260 Pave NaN IR1 Lvl AllPub ... 0 NaN NaN NaN 0 12 2008 WD Normal 250000 # 1-2. データ構造の確認 print(df_train.shape) print(df_test.shape) df_train.columns出力結果
(1460, 81)
(1459, 80)
Index(['Id', 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street',
'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig',
'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType',
'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd',
'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType',
'MasVnrArea', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual',
'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1',
'BsmtFinType2', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating',
'HeatingQC', 'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF',
'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath',
'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual',
'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType',
'GarageYrBlt', 'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual',
'GarageCond', 'PavedDrive', 'WoodDeckSF', 'OpenPorchSF',
'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC',
'Fence', 'MiscFeature', 'MiscVal', 'MoSold', 'YrSold', 'SaleType',
'SaleCondition', 'SalePrice'],
dtype='object')説明変数が80個もある。
今回はスペースの関係で以上とする。
次回はいよいよデータ前処理を実際に行っていく。
- 投稿日:2020-07-07T22:08:20+09:00
ゼロから始めるLeetCode Day79「1282. Group the People Given the Group Size They Belong To」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day78 「206. Reverse Linked List」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
1282. Group the People Given the Group Size They Belong To
難易度はMedium。問題としては、
0からn - 1までのIDを持つ人がn人存在し、それぞれはちょうど1つのグループに所属しています。各人が所属するグループのサイズを示す長さnの配列groupSizesが与えられた場合、グループの数と、各グループに含まれる人のIDを返します。任意の解を任意の順番で返すことができ、
IDについても同様です。また、少なくとも一つの解が存在することが保証されています。Example 1:
Input: groupSizes = [3,3,3,3,3,1,3]
Output: [[5],[0,1,2],[3,4,6]]
Explanation:
Other possible solutions are [[2,1,6],[5],[0,4,3]] and [[5],[0,6,2],[4,3,1]].Example 2:
Input: groupSizes = [2,1,3,3,3,2]
Output: [[1],[0,5],[2,3,4]]#解法
class Solution: def groupThePeople(self, groupSizes): ans,group,next_group = [],[],[] for i,j in enumerate(groupSizes): group.append((j,i)) group.sort() for length,index in group: next_group.append(index) if len(next_group) == length: ans.append(next_group) next_group = [] return ans # Runtime: 64 ms, faster than 75.60% of Python online submissions for Group the People Given the Group Size They Belong To. # Memory Usage: 12.7 MB, less than 59.40% of Python online submissions for Group the People Given the Group Size They Belong To.最初に
groupSizesのインデックスと値を入れ替え用意したgroupに入れ、ソートします。そしてソートした長さとインデックスを取得して長さを
next_groupに追加し、毎回groupの長さとnext_groupの長さが同値であるかをチェックし、仮に同値であれば返す予定のansに追加、終了です。その
ansに追加した後にnext_groupを初期化しておかないと以下のようになる点に注意してください。Input [3,3,3,3,3,1,3] Output [[5,0,1,2,3,4,6],[5,0,1,2,3,4,6]] Expected [[5],[0,1,2],[3,4,6]]Acceptanceが高いので何かあるのかと思いましたが、特に何もなかったですね。
では今回はここまで。お疲れ様でした。
- 投稿日:2020-07-07T21:45:40+09:00
テトリス風ゲーム作ったれ!
はじめに
今回はPythonのtkinterを利用して、テトリス風ゲームを作りました。プログラムがかなり長くなってしまったので、説明は大幅に省略させていただきますが、ポイントだけ説明させていただきます。
テトリミノの種類
参考にさせていただいたサイトのプログラムでは4種類でしたが、少し工夫を加えて7種類にしてみました。
テトリミノには以下のものがあります。
Tミノ
Zミノ
Iミノ
Lミノ
Jミノ
Oミノ
Sミノ
ゲーム画面

ゲーム画面は縦に20マス、横に10マスとなっている。
また右側のStartボタンを押せば、テトリミノが降ってくるようになり、ゲーム開始である。
本来のテトリスと同じように、横一列が揃えば一列消える仕組みとなっており、テトリミノが一番上まで積み上がってしまうとゲームオーバーとなる。
←ゲームオーバー時の表示
しかし、本来のテトリスと違い、テトリミノを回転させることができないという点では注意が必要である。そのため長く生き残るための難易度はかなり上がっている。ちなみに私もテストプレイを試みましたが、とても苦戦しました。
プログラムの完成例
# -*- coding:utf-8 -*- import tkinter as tk import random # 定数 BLOCK_SIZE = 25 # ブロックの縦横サイズpx FIELD_WIDTH = 10 # フィールドの幅 FIELD_HEIGHT = 20 # フィールドの高さ MOVE_LEFT = 0 # 左にブロックを移動することを示す定数 MOVE_RIGHT = 1 # 右にブロックを移動することを示す定数 MOVE_DOWN = 2 # 下にブロックを移動することを示す定数 # ブロックを構成する正方形のクラス class TetrisSquare(): def __init__(self, x=0, y=0, color="gray"): '1つの正方形を作成' self.x = x self.y = y self.color = color def set_cord(self, x, y): '正方形の座標を設定' self.x = x self.y = y def get_cord(self): '正方形の座標を取得' return int(self.x), int(self.y) def set_color(self, color): '正方形の色を設定' self.color = color def get_color(self): '正方形の色を取得' return self.color def get_moved_cord(self, direction): '移動後の正方形の座標を取得' # 移動前の正方形の座標を取得 x, y = self.get_cord() # 移動方向を考慮して移動後の座標を計算 if direction == MOVE_LEFT: return x - 1, y elif direction == MOVE_RIGHT: return x + 1, y elif direction == MOVE_DOWN: return x, y + 1 else: return x, y # テトリス画面を描画するキャンバスクラス class TetrisCanvas(tk.Canvas): def __init__(self, master, field): 'テトリスを描画するキャンバスを作成' canvas_width = field.get_width() * BLOCK_SIZE canvas_height = field.get_height() * BLOCK_SIZE # tk.Canvasクラスのinit super().__init__(master, width=canvas_width, height=canvas_height, bg="white") # キャンバスを画面上に設置 self.place(x=25, y=25) # 10x20個の正方形を描画することでテトリス画面を作成 for y in range(field.get_height()): for x in range(field.get_width()): square = field.get_square(x, y) x1 = x * BLOCK_SIZE x2 = (x + 1) * BLOCK_SIZE y1 = y * BLOCK_SIZE y2 = (y + 1) * BLOCK_SIZE self.create_rectangle( x1, y1, x2, y2, outline="white", width=1, fill=square.get_color() ) # 一つ前に描画したフィールドを設定 self.before_field = field def update(self, field, block): 'テトリス画面をアップデート' # 描画用のフィールド(フィールド+ブロック)を作成 new_field = TetrisField() for y in range(field.get_height()): for x in range(field.get_width()): square = field.get_square(x, y) color = square.get_color() new_square = new_field.get_square(x, y) new_square.set_color(color) # フィールドにブロックの正方形情報を合成 if block is not None: block_squares = block.get_squares() for block_square in block_squares: # ブロックの正方形の座標と色を取得 x, y = block_square.get_cord() color = block_square.get_color() # 取得した座標のフィールド上の正方形の色を更新 new_field_square = new_field.get_square(x, y) new_field_square.set_color(color) # 描画用のフィールドを用いてキャンバスに描画 for y in range(field.get_height()): for x in range(field.get_width()): # (x,y)座標のフィールドの色を取得 new_square = new_field.get_square(x, y) new_color = new_square.get_color() # (x,y)座標が前回描画時から変化ない場合は描画しない before_square = self.before_field.get_square(x, y) before_color = before_square.get_color() if(new_color == before_color): continue x1 = x * BLOCK_SIZE x2 = (x + 1) * BLOCK_SIZE y1 = y * BLOCK_SIZE y2 = (y + 1) * BLOCK_SIZE # フィールドの各位置の色で長方形描画 self.create_rectangle( x1, y1, x2, y2, outline="white", width=1, fill=new_color ) # 前回描画したフィールドの情報を更新 self.before_field = new_field # 積まれたブロックの情報を管理するフィールドクラス class TetrisField(): def __init__(self): self.width = FIELD_WIDTH self.height = FIELD_HEIGHT # フィールドを初期化 self.squares = [] for y in range(self.height): for x in range(self.width): # フィールドを正方形インスタンスのリストとして管理 self.squares.append(TetrisSquare(x, y, "gray")) def get_width(self): 'フィールドの正方形の数(横方向)を取得' return self.width def get_height(self): 'フィールドの正方形の数(縦方向)を取得' return self.height def get_squares(self): 'フィールドを構成する正方形のリストを取得' return self.squares def get_square(self, x, y): '指定した座標の正方形を取得' return self.squares[y * self.width + x] def judge_game_over(self, block): 'ゲームオーバーかどうかを判断' # フィールド上で既に埋まっている座標の集合作成 no_empty_cord = set(square.get_cord() for square in self.get_squares() if square.get_color() != "gray") # ブロックがある座標の集合作成 block_cord = set(square.get_cord() for square in block.get_squares()) # ブロックの座標の集合と # フィールドの既に埋まっている座標の集合の積集合を作成 collision_set = no_empty_cord & block_cord # 積集合が空であればゲームオーバーではない if len(collision_set) == 0: ret = False else: ret = True return ret def judge_can_move(self, block, direction): '指定した方向にブロックを移動できるかを判断' # フィールド上で既に埋まっている座標の集合作成 no_empty_cord = set(square.get_cord() for square in self.get_squares() if square.get_color() != "gray") # 移動後のブロックがある座標の集合作成 move_block_cord = set(square.get_moved_cord(direction) for square in block.get_squares()) # フィールドからはみ出すかどうかを判断 for x, y in move_block_cord: # はみ出す場合は移動できない if x < 0 or x >= self.width or \ y < 0 or y >= self.height: return False # 移動後のブロックの座標の集合と # フィールドの既に埋まっている座標の集合の積集合を作成 collision_set = no_empty_cord & move_block_cord # 積集合が空なら移動可能 if len(collision_set) == 0: ret = True else: ret = False return ret def fix_block(self, block): 'ブロックを固定してフィールドに追加' for square in block.get_squares(): # ブロックに含まれる正方形の座標と色を取得 x, y = square.get_cord() color = square.get_color() # その座標と色をフィールドに反映 field_square = self.get_square(x, y) field_square.set_color(color) def delete_line(self): '行の削除を行う' # 全行に対して削除可能かどうかを調べていく for y in range(self.height): for x in range(self.width): # 行内に1つでも空があると消せない square = self.get_square(x, y) if(square.get_color() == "gray"): # 次の行へ break else: # break されなかった場合はその行は空きがない # この行を削除し、この行の上側にある行を1行下に移動 for down_y in range(y, 0, -1): for x in range(self.width): src_square = self.get_square(x, down_y - 1) dst_square = self.get_square(x, down_y) dst_square.set_color(src_square.get_color()) # 一番上の行は必ず全て空きになる for x in range(self.width): square = self.get_square(x, 0) square.set_color("gray") # テトリスのブロックのクラス class TetrisBlock(): def __init__(self): 'テトリスのブロックを作成' # ブロックを構成する正方形のリスト self.squares = [] # ブロックの形をランダムに決定 block_type = random.randint(1, 7) # ブロックの形に応じて4つの正方形の座標と色を決定 if block_type == 1: color = "aqua" cords = [ [FIELD_WIDTH / 2, 0], [FIELD_WIDTH / 2, 1], [FIELD_WIDTH / 2, 2], [FIELD_WIDTH / 2, 3], ] elif block_type == 2: color = "yellow" cords = [ [FIELD_WIDTH / 2, 0], [FIELD_WIDTH / 2, 1], [FIELD_WIDTH / 2 - 1, 0], [FIELD_WIDTH / 2 - 1, 1], ] elif block_type == 3: color = "orange" cords = [ [FIELD_WIDTH / 2 - 1, 0], [FIELD_WIDTH / 2, 0], [FIELD_WIDTH / 2, 1], [FIELD_WIDTH / 2, 2], ] elif block_type == 4: color = "blue" cords = [ [FIELD_WIDTH / 2, 0], [FIELD_WIDTH / 2 - 1, 0], [FIELD_WIDTH / 2 - 1, 1], [FIELD_WIDTH / 2 - 1, 2], ] elif block_type == 5: color = "red" cords = [ [FIELD_WIDTH / 2, 0], [FIELD_WIDTH / 2, 1], [FIELD_WIDTH / 2 - 1, 1], [FIELD_WIDTH / 2 - 1, 2], ] elif block_type == 6: color = "green" cords = [ [FIELD_WIDTH / 2 - 1, 0], [FIELD_WIDTH / 2 - 1, 1], [FIELD_WIDTH / 2, 2], [FIELD_WIDTH / 2, 1], ] elif block_type == 7: color = "purple" cords = [ [FIELD_WIDTH / 2, 1], [FIELD_WIDTH / 2 - 1, 0], [FIELD_WIDTH / 2 - 1, 1], [FIELD_WIDTH / 2 - 1, 2], ] # 決定した色と座標の正方形を作成してリストに追加 for cord in cords: self.squares.append(TetrisSquare(cord[0], cord[1], color)) def get_squares(self): 'ブロックを構成する正方形を取得' # return [square for square in self.squares] return self.squares def move(self, direction): 'ブロックを移動' # ブロックを構成する正方形を移動 for square in self.squares: x, y = square.get_moved_cord(direction) square.set_cord(x, y) # テトリスゲームを制御するクラス class TetrisGame(): def __init__(self, master): 'テトリスのインスタンス作成' # ブロック管理リストを初期化 self.field = TetrisField() # 落下ブロックをセット self.block = None # テトリス画面をセット self.canvas = TetrisCanvas(master, self.field) # テトリス画面アップデート self.canvas.update(self.field, self.block) def start(self, func): 'テトリスを開始' # 終了時に呼び出す関数をセット self.end_func = func # ブロック管理リストを初期化 self.field = TetrisField() # 落下ブロックを新規追加 self.new_block() def new_block(self): 'ブロックを新規追加' # 落下中のブロックインスタンスを作成 self.block = TetrisBlock() if self.field.judge_game_over(self.block): self.end_func() print("Game Over!") # テトリス画面をアップデート self.canvas.update(self.field, self.block) def move_block(self, direction): 'ブロックを移動' # 移動できる場合だけ移動する if self.field.judge_can_move(self.block, direction): # ブロックを移動 self.block.move(direction) # 画面をアップデート self.canvas.update(self.field, self.block) else: # ブロックが下方向に移動できなかった場合 if direction == MOVE_DOWN: # ブロックを固定する self.field.fix_block(self.block) self.field.delete_line() self.new_block() # イベントを受け付けてそのイベントに応じてテトリスを制御するクラス class EventHandller(): def __init__(self, master, game): self.master = master # 制御するゲーム self.game = game # イベントを定期的に発行するタイマー self.timer = None # ゲームスタートボタンを設置 button = tk.Button(master, text='START', command=self.start_event) button.place(x=25 + BLOCK_SIZE * FIELD_WIDTH + 25, y=30) def start_event(self): 'ゲームスタートボタンを押された時の処理' # テトリス開始 self.game.start(self.end_event) self.running = True # タイマーセット self.timer_start() # キー操作入力受付開始 self.master.bind("<Left>", self.left_key_event) self.master.bind("<Right>", self.right_key_event) self.master.bind("<Down>", self.down_key_event) def end_event(self): 'ゲーム終了時の処理' self.running = False # イベント受付を停止 self.timer_end() self.master.unbind("<Left>") self.master.unbind("<Right>") self.master.unbind("<Down>") def timer_end(self): 'タイマーを終了' if self.timer is not None: self.master.after_cancel(self.timer) self.timer = None def timer_start(self): 'タイマーを開始' if self.timer is not None: # タイマーを一旦キャンセル self.master.after_cancel(self.timer) # テトリス実行中の場合のみタイマー開始 if self.running: # タイマーを開始 self.timer = self.master.after(1000, self.timer_event) def left_key_event(self, event): '左キー入力受付時の処理' # ブロックを左に動かす self.game.move_block(MOVE_LEFT) def right_key_event(self, event): '右キー入力受付時の処理' # ブロックを右に動かす self.game.move_block(MOVE_RIGHT) def down_key_event(self, event): '下キー入力受付時の処理' # ブロックを下に動かす self.game.move_block(MOVE_DOWN) # 落下タイマーを再スタート self.timer_start() def timer_event(self): 'タイマー満期になった時の処理' # 下キー入力受付時と同じ処理を実行 self.down_key_event(None) class Application(tk.Tk): def __init__(self): super().__init__() # アプリウィンドウの設定 self.geometry("400x600") self.title("テトリス") # テトリス生成 game = TetrisGame(self) # イベントハンドラー生成 EventHandller(self, game) def main(): 'main関数' # GUIアプリ生成 app = Application() app.mainloop() if __name__ == "__main__": main()最後に
テトリスの醍醐味でもある、テトリミノの回転を再現できなかったことはとても残念ですが、ゲームとしては成り立っているので誰でも楽しめるのではないかと思います。初めてPythonを使ってゲームを作ってみましたが、出来た時の達成感は素晴らしかったです。次は回転可能なテトリスを作れるよう、リベンジします!
参考サイト

- 投稿日:2020-07-07T21:31:53+09:00
PyCaret2.0 (pycaret-nightly)を試してみた
はじめに
- PyCaret2.0が、Nightlyビルド版が公開されており、試してみました。
- PyCaret自体については、以前投稿させて頂いた下記もご確認ください。
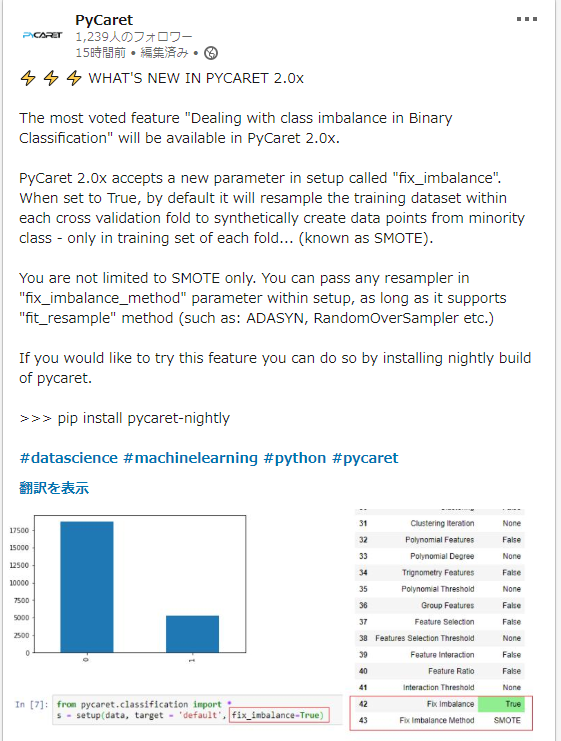
- v2では下記のように、不均衡データに対しての前処理が追加されているようなので、試してみたいと思います。
試し方
- pipしてください。
pip install pycaret-nightly
- pipすると、version 2.0.0を試すことができます。
試す
不均衡データに対する前処理
- v2では、2値分類での不均衡(正例、負例の一方がごく少数)データに対する前処理が追加されています。
- 指定方法は簡単で、setupする際の引数にて、fix_imbalance=True を指定します。
from pycaret.classification import * exp1 = setup( data, target = 'default', fix_imbalance=True # この行を追加 )
- この指定により、不均衡データに対する前処理が実施されます。
実施される前処理(SMOTE)
- 上記画像のとおり、SMOTE(Synthetic Minority Over-sampling TEchnique)がデフォルトの様です。
- SMOTEについては、Qiitaにも解説記事ありますのでリンクさせていただきます。
他の前処理
- 冒頭の記事にあったとおり、ADASYNやRandomOverSampler等にも対応しているようです。
- 内部的には、v2(ナイトリリース版)では、依存ライブラリに、imbalanced-learnが追加されています。
- docstringにも下記の記述がありますね。
fix_imbalance_method: obj, default = None When fix_imbalance is set to True and fix_imbalance_method is None, 'smote' is applied by default to oversample minority class during cross validation. This parameter accepts any module from 'imblearn' that supports 'fit_resample' method.他の前処理の指定方法
- 上記のdocStringの指示のとおり、imblearnのclassを指定してみたいと思います。
- imblearn.over_samplingから指定するover_samplingアルゴリズムをimportして指定します。
from pycaret.classification import * from imblearn.over_sampling import ADASYN, BorderlineSMOTE, KMeansSMOTE, RandomOverSampler, SMOTE, SMOTENC, SVMSMOTE exp1 = setup( data, target = 'default', fix_imbalance=True, fix_imbalance_method=ADASYN() # この行で指定 )
指定できたアルゴリズム
- 下記の通りです。
モデル評価時の表示上の工夫
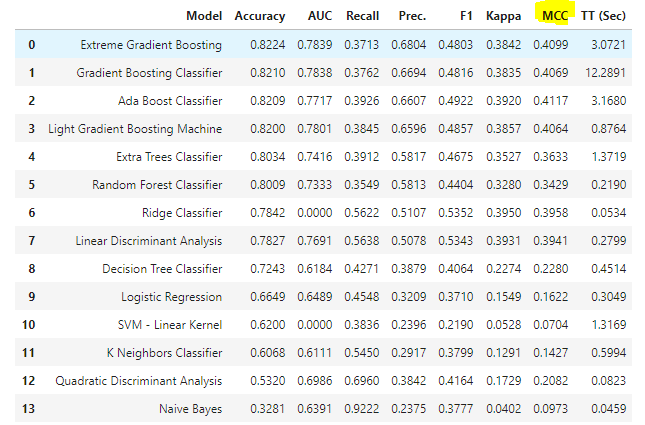
- 不均衡データに対する前処理の実装と共に、精度一覧上にMCC(Matthews相関係数)が追加されています。
- 少数(マイノリティ)クラスを正例としている場合では、F-measureでも良いのですが、そういった考慮ができていない状況でも、MCCは不均衡データに対する学習精度を正しく評価できるので良いですね。
- 不均衡データ時の、F-measureとMCCの関係性はこちらのブログが参考になるのでリンクさせていただきます。
最後に
- 今回は、v2の不均衡データに対する対応をご紹介しました。
- これ以外にも、mlflowへの対応等が計画されているようで、v2の正式リリースが楽しみです。
- 雑な記事となりましたが、最後までお付き合い頂きありがとうございます。

- 投稿日:2020-07-07T20:48:09+09:00
[光-Hikari-のPython]09章-04クラス(メソッドのオーバーライド)
【目次リンク】へ戻る
[Python]09章-04 メソッドのオーバーライド
前節では継承について触れました。継承を行うことで、差分のみのデータ(属性)やメソッド部分を書くだけで済むといったことも説明しました。
今回も引き続き継承についてもう少し深く触れていきたいと思います。
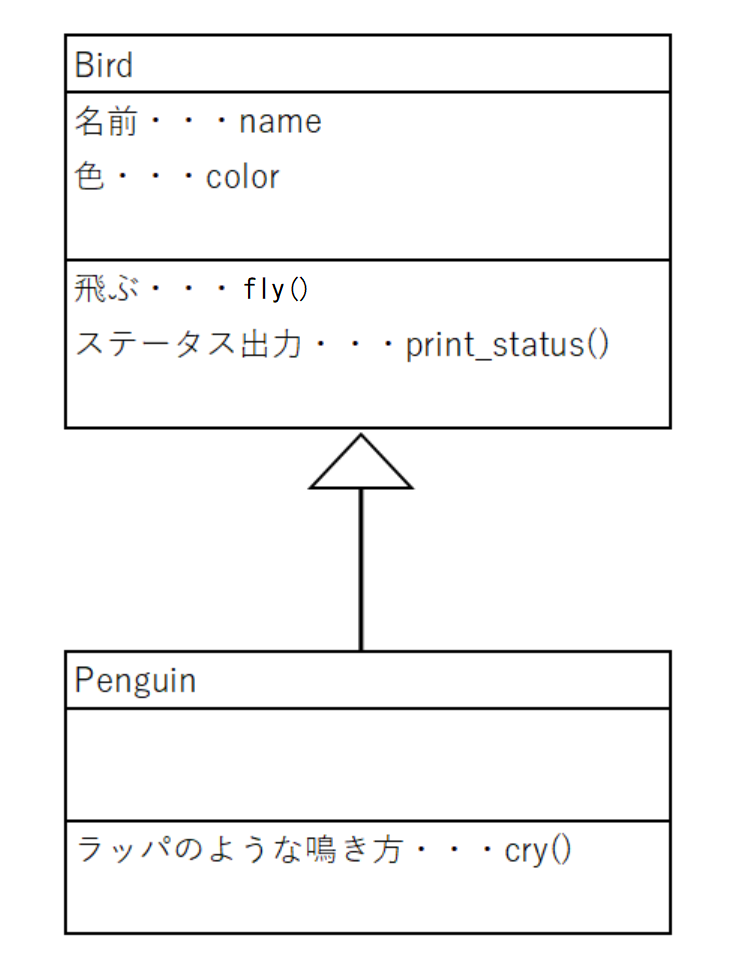
今回もBirdのスーパークラスを継承して、また別の種類の鳥のサブクラスを作成することを考えてみます。
例えば、ペンギン(Penguin)のサブクラスを作成することを考えてみましょう。
※ペンギンは調べたところ、ラッパのような鳴き方をするようですが、具体的には不明です。
前節の復習と思って、上記のクラス図を参考にプログラムを作成して実行してみましょう。chap09の中にsamp09_04_01.pyに以下のコードを書いてください。そして実行してみてください。
(ペンギンの名前や色は自由に指定してかまいません。)samp09_04_01.py#スーパークラスの記載 class Bird: def __init__(self, name, color): print('-----インスタンス化したと同時にコンストラクタを呼び出します。-----') self.name = name self.color = color #飛ぶというメソッド def fly(self, m): print('-----flyメソッドを呼び出します。-----') print(f'バサバサと{self.name}は空を飛びます。') print(f'{m}mの高さを飛んでいます。') #インスタンス化したBirdのステータスを出力するメソッド def print_status(self): print('-----print_statusメソッドを呼び出します。-----') print(f'{self.color}色の鳥です。') #サブクラスの記載 class Penguin(Bird): def cry(self): print('-----ペンギン・サブクラスにあるcryメソッドを呼び出します。-----') print('ラッパを吹くような鳴き方です。') #サブクラスのPenguinをインスタンス化する pgn = Penguin('ペン太', '白と黒') #ペンギン・サブクラスにあるcryメソッドを呼び出す pgn.cry() #スーパークラスにあるflyメソッドを呼び出す pgn.fly(0) #スーパークラスにあるprint_statusメソッドを呼び出す pgn.print_status()【実行結果】
-----インスタンス化したと同時にコンストラクタを呼び出します。-----
-----ペンギン・サブクラスにあるcryメソッドを呼び出します。-----
ラッパを吹くような鳴き方です。
-----flyメソッドを呼び出します。-----
バサバサとペン太は空を飛びます。
0mの高さを飛んでいます。
-----print_statusメソッドを呼び出します。-----
白と黒色の鳥です。さて、実行結果を見て気づいた方もいるかと思いますが、ペンギンは空を飛びません。(同様にニワトリもそうです??)
このままでは飛ばない鳥もflyメソッドで呼び出せてしまい、飛ぶことになってしまいます。こういったケースの場合、どうすればよいのでしょうか?
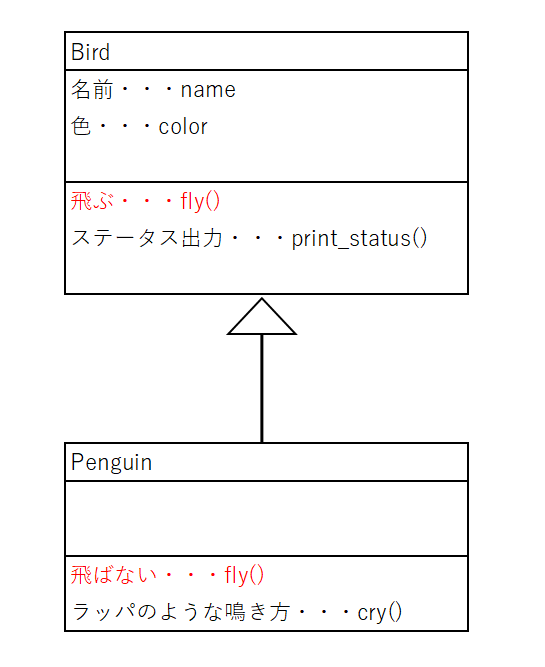
オーバーライド
先ほどのクラス図では、「鳥が空を飛ぶ」という前提でスーパークラスを作っていました。
しかし、先ほどのペンギンの例のように、空を飛ばない鳥の場合、クラスとメソッドが成り立ちません。そこで、メソッドのオーバーライド(上乗せ)を使用します。
サブクラスには、スーパークラスにあるメソッド名と同じメソッド名を指定して、オーバーライドを行います。クラス図でイメージすると以下の通りです。
クラス図を見てもわかる通り、PenguinクラスはBirdクラスを継承していますが、スーパークラスにあるfly()メソッド(「飛ぶ」と出力)はサブクラスにあるfly()メソッド(「飛ばない」と出力)を上乗せしています。
これをもとに、プログラムを作成してみましょう。chap09の中にsamp09_04_02.pyに以下のコードを書いてください。
samp09_04_02.py#スーパークラスの記載 class Bird: def __init__(self, name, color): print('-----インスタンス化したと同時にコンストラクタを呼び出します。-----') self.name = name self.color = color #飛ぶというメソッド def fly(self, m): print('-----flyメソッドを呼び出します。-----') print(f'バサバサと{self.name}は空を飛びます。') print(f'{m}mの高さを飛んでいます。') #インスタンス化したBirdのステータスを出力するメソッド def print_status(self): print('-----print_statusメソッドを呼び出します。-----') print(f'{self.color}色の鳥です。') #サブクラスの記載 class Penguin(Bird): def cry(self): print('-----ペンギン・サブクラスにあるcryメソッドを呼び出します。-----') print('ラッパを吹くような鳴き方です。') #メソッドのオーバーライドをしています def fly(self): print('-----ペンギン・サブクラスにあるflyメソッドを呼び出します。-----') print('ペンギンは空を飛びません。') print('地上を歩いています。') #サブクラスのPenguinをインスタンス化する pgn = Penguin('ペン太', '白と黒') #ペンギン・サブクラスにあるflyメソッドを呼び出す pgn.fly() #ペンギン・サブクラスにあるcryメソッドを呼び出す pgn.cry() #スーパークラスにあるprint_statusメソッドを呼び出す pgn.print_status()【実行結果】
-----インスタンス化したと同時にコンストラクタを呼び出します。-----
-----ペンギン・サブクラスにあるflyメソッドを呼び出します。-----
ペンギンは空を飛びません。
地上を歩いています。
-----ペンギン・サブクラスにあるcryメソッドを呼び出します。-----
ラッパを吹くような鳴き方です。
-----print_statusメソッドを呼び出します。-----
白と黒色の鳥です。今回注目してほしいのは、pgn.fly()の個所です。fly()メソッドは、サブクラスでオーバーライドをしているため、スーパークラスにもサブクラスにもfly()メソッドは存在していますが、どちらが呼び出されるかというと、サブクラスにあるfly()メソッドが呼び出されています。
メソッドのオーバーライドにより、メソッドが上乗せされていることが分かったかと思います。
実は、スーパークラスのfly()メソッドも呼び出すことができますが、こちらについては別の機会にお伝えします。
最後に
今回はオーバーライドについて触れましたが、今後様々なライブラリを扱っていくうえではよく出てくる概念です。
基本情報技術者試験などでも出題される可能性があるかもしれませんので、プログラムを読めるようにしておきましょう。【目次リンク】へ戻る
- 投稿日:2020-07-07T20:18:07+09:00
さ~て、おみくじでも引いてみっか>一条楽Vo.
作成動機
自分の好きな漫画「ニセコイ」を読み直していた時、主人公らがおみくじを引いていて、最近自分もおみくじを引いてないので引きたくなったが、そのためだけに神社に行くのも少し気が引けた上、簡単そうだから初心者の自分でも作れると思い、作ってみることにした。余談であるが自分はニセコイでは小野寺姉妹が大好きだ。
すべてのコード
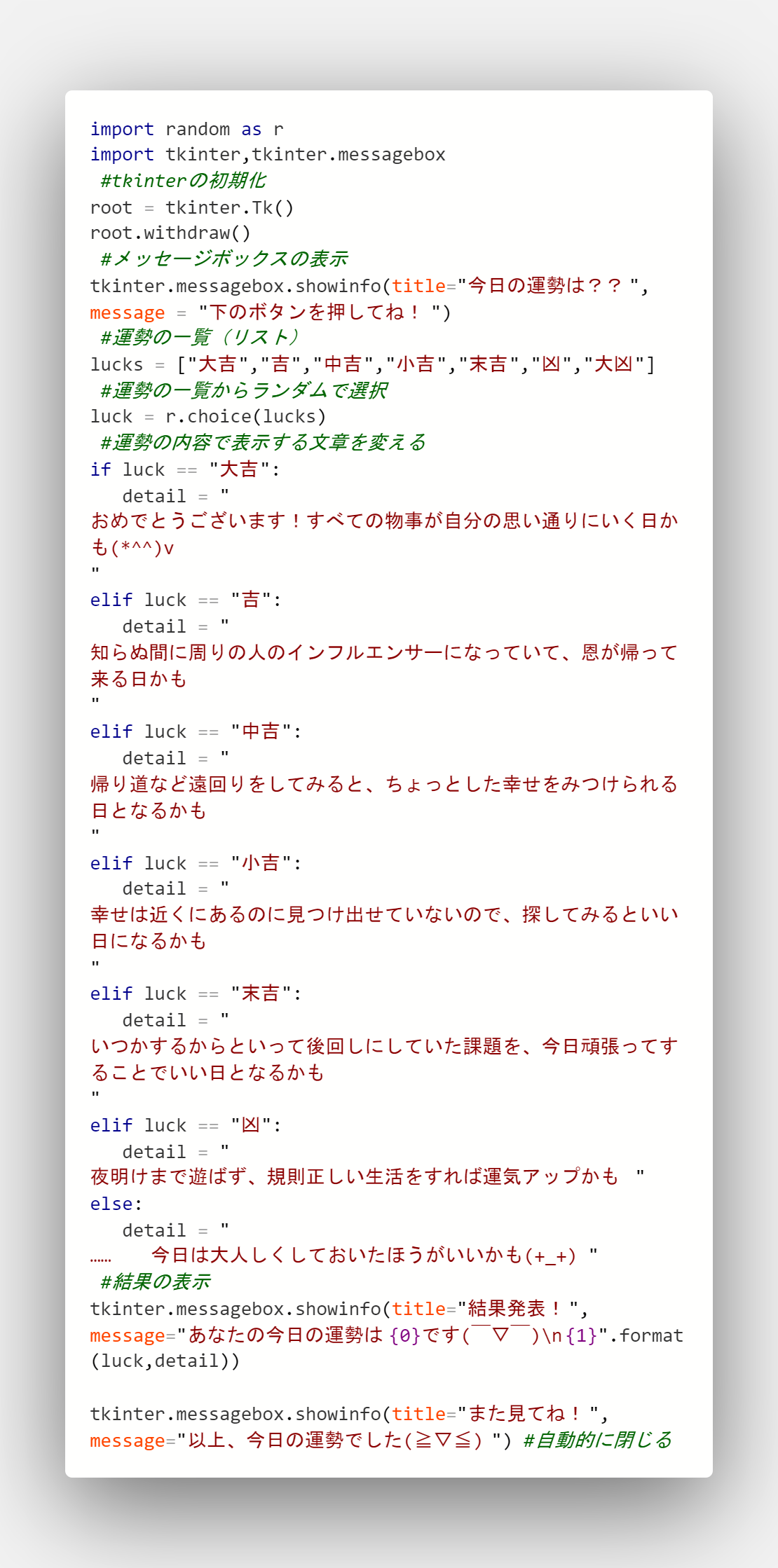
結論から言うのが好きなので結論から。
こうしてみると最初に思った通り、簡単そうに見える。。
だけである。初心者の自分にとってはこれでもとても難しく、エラーを幾度となく叩き出したため引用を用いた。
自分にはプログラムの知識と才能が圧倒的に足りないのだろう。。
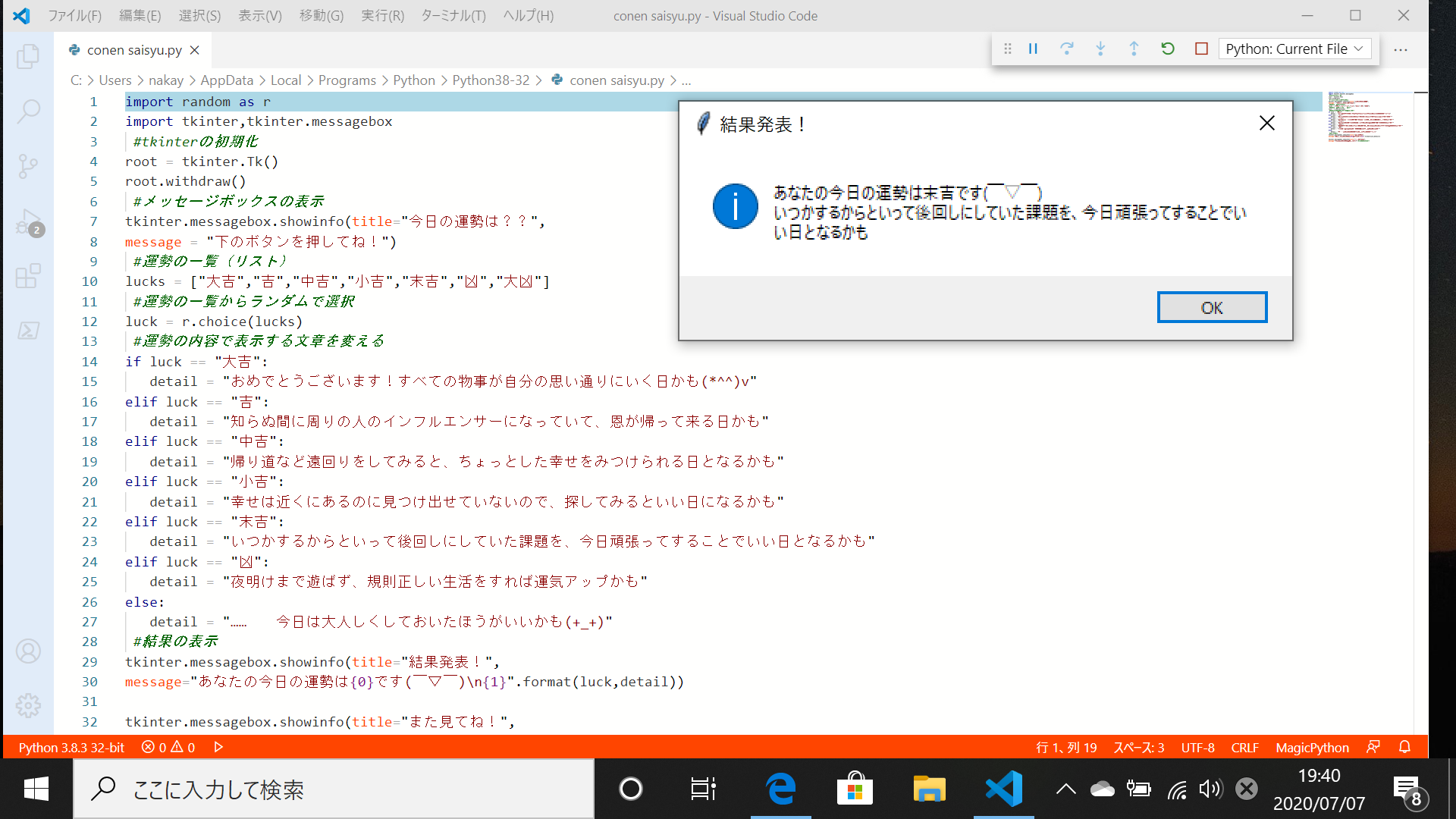
実行してみた
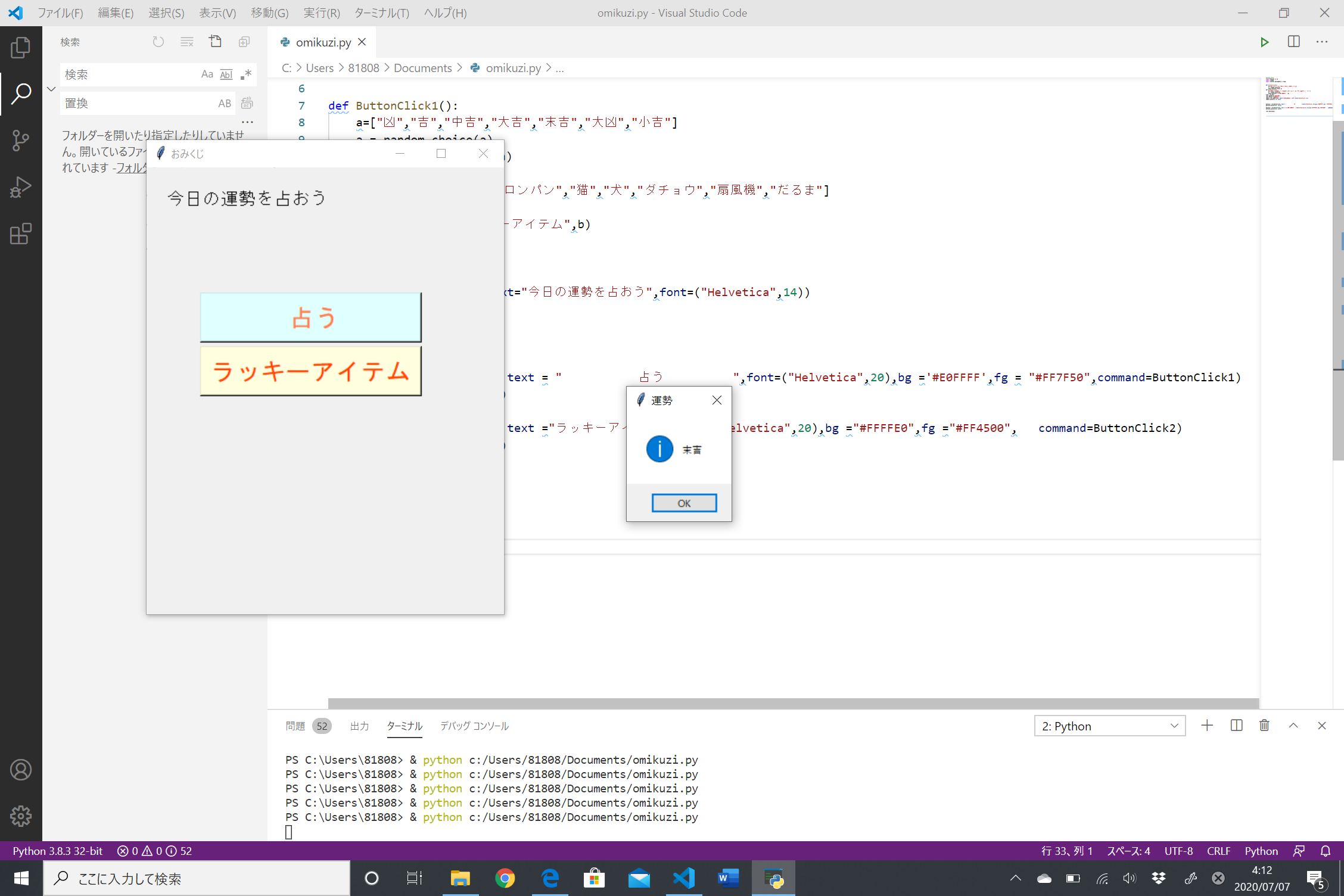
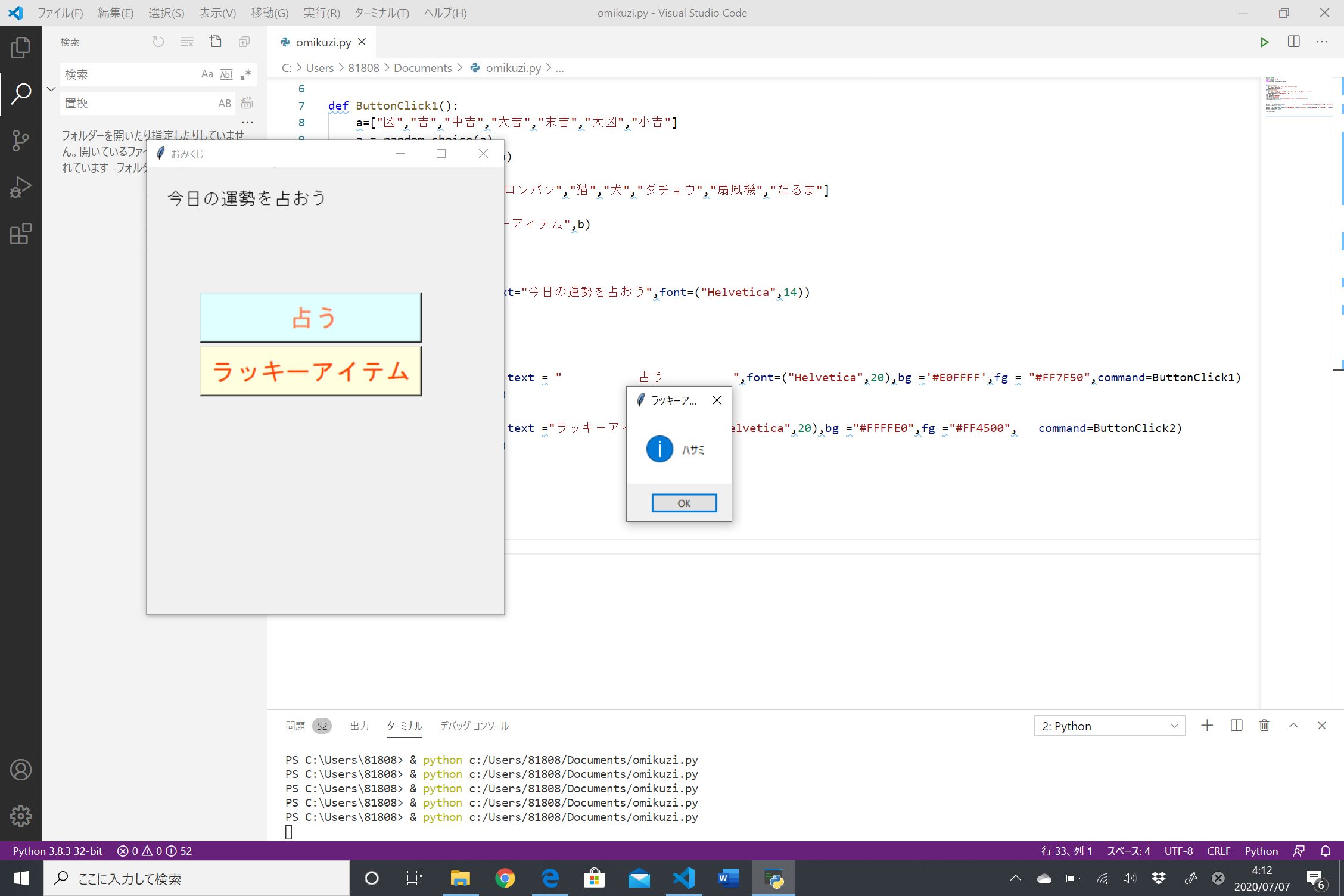
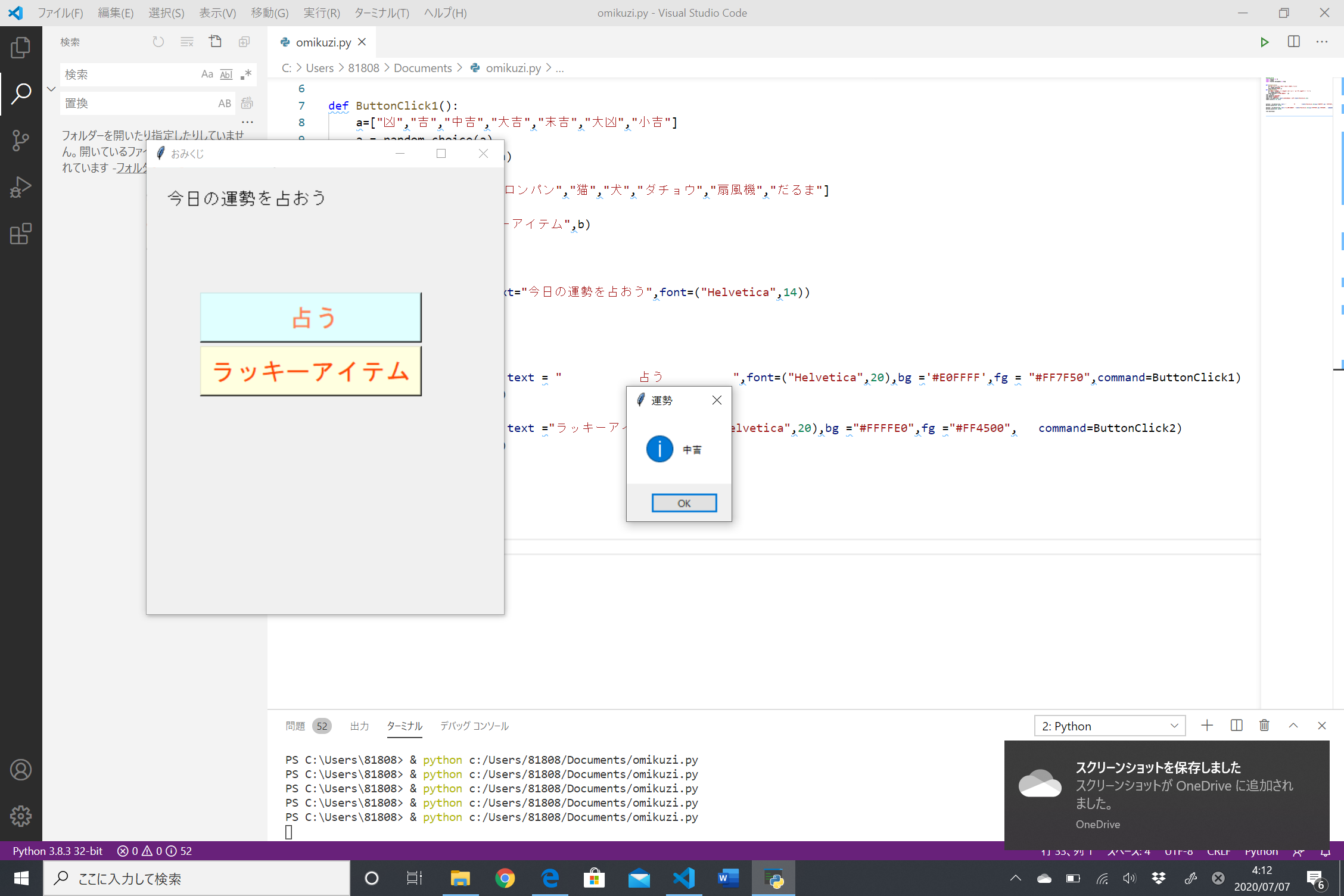
結果は!!!
…末吉でした。うーーん、微妙(´・ω・`) どちらかに振れていてほしかったような……
はい、すいません。おとなしくためていた課題します……
感想
エラーをたくさん出してしまったが、そのたびそのたびどこがダメなのかをしっかりとわかったことで、少しは成長できたのかなと感じた。今後は知識を増やして、ぜひとも一人でプログラムを作ってみたい!!
引用・参考文献
・pythonの簡単な初心者向け占いプログラム
・「いちばんやさしいPython入門教室」, 著者:大沢文孝
- 投稿日:2020-07-07T20:07:58+09:00
S3サーバーサイド暗号化SSE with Python boto3
S3に書き込むデータを暗号化するのを、boto3(Python)で行いたいと思います。
SSE サーバーサイド暗号化の種類は以下の通りです。
Default encryption (デフォルト暗号化)
- SSE with AES-256
- SSE with KMS AWS Managed Keys
- SSE with KMS CMK(Customer Managed Keys)
デフォルト暗号化以外
- SSE with AES-256
- SSE with KMS AWS Managed Keys
- SSE with KMS CMK(Customer Managed Keys)
- SSE with Customer Key(AES-256 etc.)
サンプル
前準備
ソースの中にある、BUCKET_NAME の値をご自身のS3バケット名に変更してください。
SSEKMSKeyIdをご自身のCustomer Managed Keys のKey ID に変更してください。
AES-256で暗号化できるように、SSECustomerKeyを作成してください。
私はUbuntu18.04を使用していますが、以下のコマンド実行結果を使いました。
SSE_CUSTOMER_KEY=$(cat /dev/urandom | base64 -i | fold -w 32 | head -n 1)event = { "BUCKET_NAME" : "xxxxxxxxx", "encryption_mode" : default_encryption, "SSEKMSKeyId" : "yyyyyyyy", "SSECustomerKey" : "zzzzzzzzzzzz" }デフォルト暗号化、デフォルト暗号化以外の切り替え
デフォルト暗号化
デフォルト暗号化を行うときは、S3コンソールにて、S3バケットのProperties → Default Encryptionを押して、AES-256 または AWS-KMSを選択してください。
上記event変数の encryption_mode 値を default_encryption にしてください。デフォルト暗号化でないパターン
デフォルト暗号化でないパターンで暗号化するときは、S3コンソールにて、S3バケットのProperties → Default Encryptionを押して、Noneを選択してください。
上記event変数の encryption_mode 値を non_default_encryption にしてください。#-*- encoding:utf-8 -*- from datetime import datetime,timedelta,timezone import json import os,os.path import sys #Third Party import boto3 #kms kms = boto3.client("kms") #s3 s3 = boto3.client("s3") def default_encryption(**event) -> None: """ Check the "Default encryption" on the S3 bucket Properties Automatically encrypt objects when stored in Amazon S3 Args: event Returns: None """ #SSE with AES-256 #SSE with KMS AWS Managed Keys #SSE with KMS CMK(Customer Managed Keys) response = s3.put_object( Bucket = event["BUCKET_NAME"], Key = "test", Body = "Encrypted".encode("UTF-8") ) print(f'ServerSideEncryption'.ljust(20) + f' = {response["ServerSideEncryption"]}') #just only for KMS. check the KeyManager if response["ServerSideEncryption"] == "aws:kms": KeyManager = kms.describe_key( KeyId = response["SSEKMSKeyId"] )["KeyMetadata"]["KeyManager"] print(f"KeyManager".ljust(20) + f" = {KeyManager}") #Body Body = s3.get_object( Bucket = event["BUCKET_NAME"], Key = "test" )["Body"].read().decode("UTF-8") print(f"Body".ljust(20) + f" = {Body}") def non_default_encryption(**event) -> None: """ Encrypt the data on your behalf Args: event Returns: None """ #SSE with AES-256 #SSE with KMS AWS Managed Keys #SSE with KMS CMK(Customer Managed Keys) #SSE with Client operations key. This is not the key which S3 or KMS operates l = [ {"ServerSideEncryption" : "AES256"}, {"ServerSideEncryption" : "aws:kms" }, {"ServerSideEncryption" : "aws:kms","SSEKMSKeyId" : event["SSEKMSKeyId"]}, {"SSECustomerAlgorithm" : "AES256","SSECustomerKey" : event["SSECustomerKey"]} ] for item in l: params = { "Bucket" : event["BUCKET_NAME"], "Key" : "test", "Body" : "Encrypted".encode("UTF-8") } for key in item: params[key] = item[key] response = s3.put_object(**params) if "ServerSideEncryption" in response: print(f'ServerSideEncryption'.ljust(20) + f' = {response["ServerSideEncryption"]}') #just only for KMS. check the KeyManager if response["ServerSideEncryption"] == "aws:kms": KeyManager = kms.describe_key( KeyId = response["SSEKMSKeyId"] )["KeyMetadata"]["KeyManager"] print(f"KeyManager".ljust(20) + f" = {KeyManager}") elif "SSECustomerAlgorithm" in response: print(f'SSECustomerAlgorithm'.ljust(20) + f' = {response["SSECustomerAlgorithm"]}') #Body params = { "Bucket" : event["BUCKET_NAME"], "Key" : "test" } if "SSECustomerAlgorithm" in item: params["SSECustomerAlgorithm"] = item["SSECustomerAlgorithm"] params["SSECustomerKey"] = item["SSECustomerKey"] Body = s3.get_object( **params )["Body"].read().decode("UTF-8") print(f"Body".ljust(20) + f" = {Body}") if __name__ == "__main__": event = { "BUCKET_NAME" : "xxxxxxxxx", "encryption_mode" : default_encryption, "SSEKMSKeyId" : "yyyyyyyy", "SSECustomerKey" : "zzzzzzzzzzzz" } event["encryption_mode"](**event)
- 投稿日:2020-07-07T19:53:58+09:00
Google ColabでYOLO v3動かしてみた
はじめに
今回は、Google Colaboratoryの環境でYOLO v3を動かしてみました。
Google ColaboratoryへのYOLO v3のセットアップの手順は、
YOLOのセットアップ
の章を参照下さい。YOLO v3とは
YOLOとは、リアルタイム物体検出システムです。
Darknetという、ニューラルネットワークフレームワークの一部です。
YOLOということばは、「You only look once(一度しか見ない)」の頭文字をとったものです。
YOLO v3は、YOLOのversion3のことで、現在最新版のバージョンになります。
詳細は、YOLOの公式ページを参照下さい。Google ColabでYOLO v3
環境
今回使用する環境はGoogle Colaboratoryです。
その他、バージョンは以下です。import platform import cv2 print("Python " + platform.python_version()) print("OpenCV " + cv2.__version__) # Python 3.6.9 # OpenCV 4.1.2準備
画像を表示するのに必要なライブラリをインポートしておきます。
import cv2 import matplotlib.pyplot as plt %matplotlib inline import matplotlibYOLOのセットアップ
それでは、Google ColabにYOLO v3をセットアップしていきましょう。
作業ディレクトリを作成し、その中で作業を行うことにします。
なお、このセットアップは最初の一回だけ行えば以後不要です(そのために、作業ディレクトリ配下で作業します)。import os os.mkdir(working_dir) # working_dir は作業ディレクトリ os.chdir(working_dir)darknetをクローンします。
!git clone https://github.com/pjreddie/darknetクローンができたら、darknetディレクトリ配下に移動し、makeを実行します。
os.chdir(working_dir + 'darknet') !makemakeが終わったら、学習済みモデル(のウエイト)をダウンロードします。
!wget https://pjreddie.com/media/files/yolov3.weightsこれで、Google ColabへのYOLO v3のセットアップは完了です。
YOLOを動かしてみよう
それでは、YOLOを動かして物体検出をしてみましょう。
すでに用意されているサンプル画像を使用します。
サンプル画像は、 darknet/data 配下にあります。!./darknet detect cfg/yolov3.cfg yolov3.weights 'data/dog.jpg' # layer filters size input output # 0 conv 32 3 x 3 / 1 608 x 608 x 3 -> 608 x 608 x 32 0.639 BFLOPs # 1 conv 64 3 x 3 / 2 608 x 608 x 32 -> 304 x 304 x 64 3.407 BFLOPs # 2 conv 32 1 x 1 / 1 304 x 304 x 64 -> 304 x 304 x 32 0.379 BFLOPs # 3 conv 64 3 x 3 / 1 304 x 304 x 32 -> 304 x 304 x 64 3.407 BFLOPs # 4 res 1 304 x 304 x 64 -> 304 x 304 x 64 # 5 conv 128 3 x 3 / 2 304 x 304 x 64 -> 152 x 152 x 128 3.407 BFLOPs # 6 conv 64 1 x 1 / 1 152 x 152 x 128 -> 152 x 152 x 64 0.379 BFLOPs # 7 conv 128 3 x 3 / 1 152 x 152 x 64 -> 152 x 152 x 128 3.407 BFLOPs # 8 res 5 152 x 152 x 128 -> 152 x 152 x 128 # ......... # 97 upsample 2x 38 x 38 x 128 -> 76 x 76 x 128 # 98 route 97 36 # 99 conv 128 1 x 1 / 1 76 x 76 x 384 -> 76 x 76 x 128 0.568 BFLOPs # 100 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs # 101 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs # 102 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs # 103 conv 128 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 128 0.379 BFLOPs # 104 conv 256 3 x 3 / 1 76 x 76 x 128 -> 76 x 76 x 256 3.407 BFLOPs # 105 conv 255 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 255 0.754 BFLOPs # 106 yolo # Loading weights from yolov3.weights...Done! # data/dog.jpg: Predicted in 22.825540 seconds. # dog: 100% # truck: 92% # bicycle: 99%物体検出が終わりました。
それでは画像を表示して確認してみましょう。
物体検出の結果を描画した画像は、 darknet/predictions.jpg です。img_in = cv2.imread('data/dog.jpg') img_out = cv2.imread('predictions.jpg') plt.figure(figsize=[20,10]) plt.subplot(121);plt.imshow(img_in[:,:,::-1]);plt.axis('off') plt.subplot(122);plt.imshow(img_out[:,:,::-1]);plt.axis('off')
「犬」「自転車」「車」を検出できています。
その他の画像も確認してみましょう。
!./darknet detect cfg/yolov3.cfg yolov3.weights 'data/horses.jpg'img_in = cv2.imread('data/horses.jpg') img_out = cv2.imread('predictions.jpg') plt.figure(figsize=[20,10]) plt.subplot(121);plt.imshow(img_in[:,:,::-1]);plt.axis('off') plt.subplot(122);plt.imshow(img_out[:,:,::-1]);plt.axis('off')
!./darknet detect cfg/yolov3.cfg yolov3.weights 'data/person.jpg'img_in = cv2.imread('data/person.jpg') img_out = cv2.imread('predictions.jpg') plt.figure(figsize=[20,10]) plt.subplot(121);plt.imshow(img_in[:,:,::-1]);plt.axis('off') plt.subplot(122);plt.imshow(img_out[:,:,::-1]);plt.axis('off')
!./darknet detect cfg/yolov3.cfg yolov3.weights 'data/kite.jpg'img_in = cv2.imread('data/kite.jpg') img_out = cv2.imread('predictions.jpg') plt.figure(figsize=[20,10]) plt.subplot(121);plt.imshow(img_in[:,:,::-1]);plt.axis('off') plt.subplot(122);plt.imshow(img_out[:,:,::-1]);plt.axis('off')
まとめ
今回は、Google Colaboratoryの環境でYOLO v3を動かしてみました。
すでに用意されているサンプル画像で物体検出を行いました。
色々な画像を用意して物体検出してみると面白いと思います。参考




- 投稿日:2020-07-07T18:26:12+09:00
Python と selenium でAmazonの購入履歴を取得する
この記事の内容
Amazonの購入履歴から、領収書をすべてpdf化し、ファイル名を注文番号にして指定したフォルダに保存するという作業をPythonとseleniumによって実現します。
プログラミングをやり始めて3か月なので上手くないところもあるかもしれませんが、備忘を兼ねて記事を残します。目次
1.この記事を書くに至った経緯
2.実装内容の概要
3.実装
3.0.環境
3.1.コード全体
3.2.Selnium のインストール
3.3.パッケージインストール
3.4.初期設定
3.5.ログイン・注文履歴画面へ
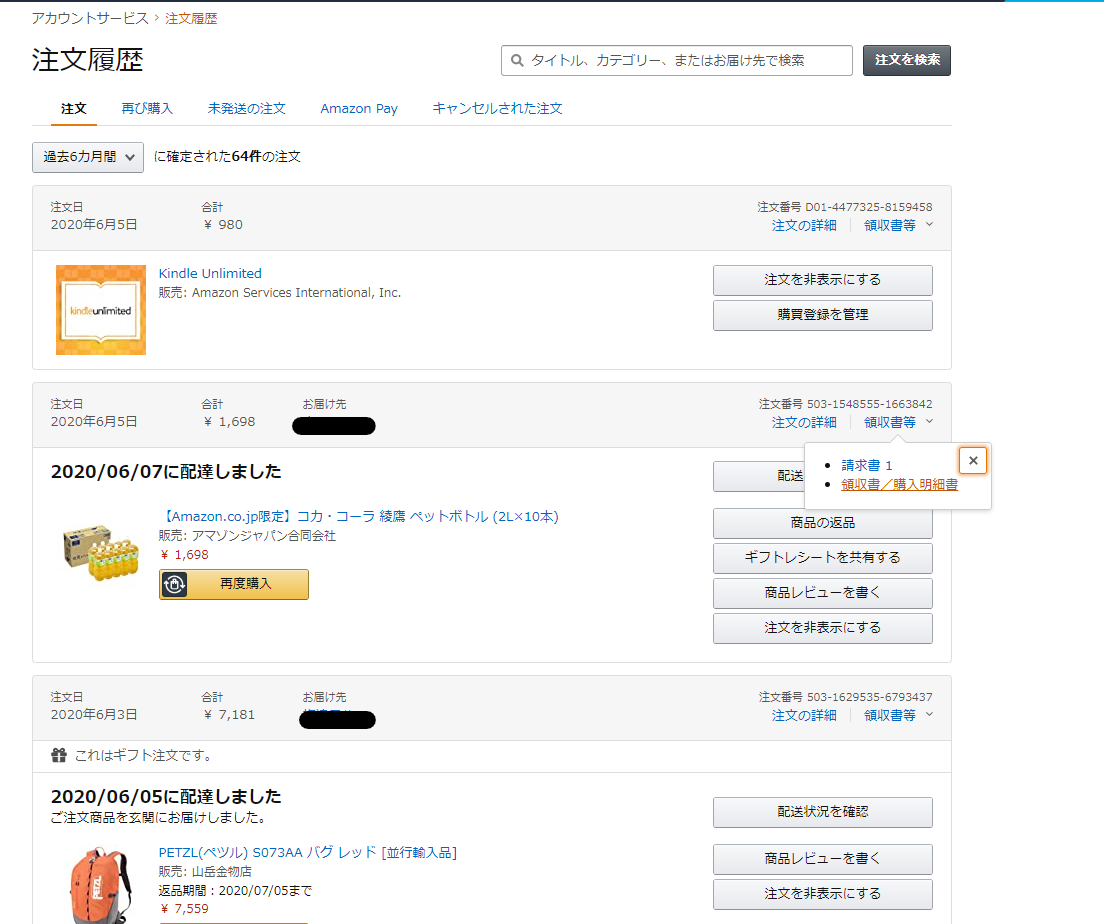
3.6.1ページ内の領収書リンクを取得、領収書内へ
3.7.領収書をpdf保存し指定のフォルダに名前を変更して保存
3.8.次のページへ
4.追加の機能追加について
5.saleceforceでの固有の論点
5.1.二段階認証の突破
5.2.画面には確かに存在する要素がdriver.find_elementsで取得できない場合->iframeを疑う
5.3.無限スクロールを読み込む
6.最後に1. この記事を書くに至った背景
先日同僚から、「saleceforceの商談一覧から各商談の内容pdfを保存するという定型業務を毎日行っているが、商談が増えてきてとても手作業では追い付かない」と相談を受けました。
聞いてみると、一日に20~50商談について、それぞれ商談画面に保存されている3~5件のpdfを保存、印刷、ファイリングしているとのこと。この業務自体いらないのではないか?、という論点はさておき、最近Pythonを学び始めた僕には格好の練習場であることから勝手に自動化に向けた学習を始めることとしました。
いきなりsaleceforceで自動化作業を試すのは危険なので、まずは自分のプライベートAmazonアカウントで練習を行うこととしました。また、自社のsaleceforceはカスタマイズがかなり入っておりあまり汎用性がないため、全体像は公開せずに末尾にポイントだけまとめておくこととしました。
2. 実装内容の概要
下記、自動化の流れを画像にて記載します。
ブラウザを立ち上げAamazon.co.jpにアクセス
ログイン
注文履歴一覧へ
個別の領収書/購入明細書へ
領収書を保存
領収書はファイル名を注文番号にして指定のフォルダに保存。これを1ページすべての注文で行う
注文履歴一覧の最後のページまで同じ操作を繰り返す
3. 実装
3.0.環境
Windows 10
Python 3.7.6
Selenium 3.141.0
エディタ: JupyterLab
ブラウザ: Chrome 83.0.4103.1163.1.コード全体
# パッケージインストール from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.support.ui import WebDriverWait import datetime import json import os import time # ユーザー情報 ID = 'XXXXXXXXXX_XXXXXX@gmail.com' PASS = 'password' PROFILE_PATH = 'Users/username/AppData/Local/Google/Chrome/User Data' # アクセスアドレス ADRESS = 'https://www.amazon.co.jp/' # ファイルの保存先 DOWNLOAD_PATH = r'C:\Users\username\Downloads' # pdfダウンロードしてデフォルトで保存される先のパス SAVE_PATH = r'C:\Users\username\Desktop\amazon_pdfs' # ファイルの保存先のパス # pdf保存のための初期設定 chrome_options = webdriver.ChromeOptions() settings = {"recentDestinations": [{"id": "Save as PDF", "origin": "local", "account": ""}], "selectedDestinationId": "Save as PDF", "version": 2} prefs = {'printing.print_preview_sticky_settings.appState': json.dumps(settings)} chrome_options.add_experimental_option('prefs', prefs) chrome_options.add_argument('--kiosk-printing') driver = webdriver.Chrome(r"chromedriver.exe", options=chrome_options) # クッキー options = webdriver.chrome.options.Options() options.add_argument('--user-data-dir=' + PROFILE_PATH) # ブラウザ立ち上げ driver.get(ADRESS) time.sleep(2) #ログイン login_btn = driver.find_element_by_id('nav-link-accountList') login_btn.click() time.sleep(1) login_email = driver.find_element_by_id('ap_email') login_email.send_keys(ID) next_btn = driver.find_element_by_id('continue') next_btn.click() time.sleep(1) login_pass = driver.find_element_by_id('ap_password') login_pass.send_keys(PASS) login_btn = driver.find_element_by_id('signInSubmit') login_btn.click() # 携帯電話登録のページがでてくる場合は後でとする try: mobile_skip = driver.find_element_by_id('ap-account-fixup-phone-skip-link') mobile_skip.click() except: pass time.sleep(1) # 注文履歴画面へ order_history = driver.find_element_by_id('nav-orders') order_history.click() time.sleep(2) #すべてのページで行う while True: main_handle = driver.current_window_handle receipt_links = driver.find_elements_by_link_text('領収書等') # 1ページないのすべての領収書で行う for receipt_link in receipt_links: receipt_link.click() time.sleep(1) receipt_purchase_link = driver.find_element_by_link_text('領収書/購入明細書') # クリック前のハンドルリスト handles_before = driver.window_handles # 新しいタブで開く actions = ActionChains(driver) actions.key_down(Keys.CONTROL) actions.click(receipt_purchase_link) actions.perform() # 新しいタブが開くまで最大30秒待機 WebDriverWait(driver, 30).until(lambda a: len(driver.window_handles) > len(handles_before)) # クリック後のハンドルリスト handles_after = driver.window_handles # ハンドルリストの差分 handle_new = list(set(handles_after) - set(handles_before)) # 新しいタブに移動 driver.switch_to.window(handle_new[0]) # pdf化 driver.execute_script('window.print();') # pdf化したものをダウンロードフォルダから指定フォルダに名前を変更して保存する new_filename = driver.find_element_by_class_name('h1').text + '.pdf'# 新しいファイル名 timestamp_now = time.time() # 現在時刻 # ダウンロードフォルダを走査 for (dirpath, dirnames, filenames) in os.walk(DOWNLOAD_PATH): for filename in filenames: if filename.lower().endswith(('.pdf')): full_path = os.path.join(DOWNLOAD_PATH, filename) timestamp_file = os.path.getmtime(full_path) # ファイルの時間 # 3秒以内に生成されたpdfを移動する if (timestamp_now - timestamp_file) < 3: full_new_path = os.path.join(SAVE_PATH, new_filename) os.rename(full_path, full_new_path) print(full_path+' is moved to '+full_new_path) time.sleep(1) driver.close() driver.switch_to.window(main_handle) # 次へのボタンが押せなくなった時点で終了 try: driver.find_element_by_class_name('a-last').find_element_by_tag_name('a') driver.find_element_by_class_name('a-last').click() driver.switch_to.window(driver.window_handles[-1]) except: break driver.quit()3.2.Selenium のインストール
まずは、SeleniumのインストールをしようとAnacondaで
conda install selenium
をしましたがうまくいかず、Anacondaではあまり推奨されていないようですがpipでインストールしました。
pip install selenium
で上手くいきました。Seleniumはこれだけではうまく動かず、別途使用するブラウザ専用のDriverをダウンロードする必要があるようです。
ダウンロードは SeleniumのHP(https://www.selenium.dev/) からダウンロードができます。
僕が使用しているChromeは83.0.4103.116だったのでここ「chromedriver_win32.zip」をダウンロードしました。
これを解凍し、exeファイルをPythonのexeファイルと同じフォルダに保存しておきました。
僕の場合は「C:\Users\username\AppData\Local\Microsoft\WindowsApps」です。
ドライバーはどこにおいても呼び出せるようですが、調べた限りここに保存するのが一番簡単そうでした。3.3.パッケージインストール
必要なPythonパッケージをインストールしておきます。
特に説明ないです。# パッケージインストール from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.support.ui import WebDriverWait import datetime import json import os import time3.4.初期設定
初期値を設定します。ここを変えれば他のアカウント、PCでも使えるはずです。
PC2台で実験しました。# ユーザー情報 ID = 'XXXXXXXXXX_XXXXXX@gmail.com' PASS = 'password' PROFILE_PATH = 'Users/username/AppData/Local/Google/Chrome/User Data' # アクセスアドレス ADRESS = 'https://www.amazon.co.jp/' # ファイルの保存先 DOWNLOAD_PATH = r'C:\Users\username\Downloads' # pdfダウンロードしてデフォルトで保存される先のパス SAVE_PATH = r'C:\Users\username\Desktop\amazon_pdfs' # ファイルの保存先のパス # pdf保存のための初期設定 chrome_options = webdriver.ChromeOptions() settings = {"recentDestinations": [{"id": "Save as PDF", "origin": "local", "account": ""}], "selectedDestinationId": "Save as PDF", "version": 2} prefs = {'printing.print_preview_sticky_settings.appState': json.dumps(settings)} chrome_options.add_experimental_option('prefs', prefs) chrome_options.add_argument('--kiosk-printing') # ドライバー作成 driver = webdriver.Chrome(r"chromedriver.exe", options=chrome_options) # クッキー options = webdriver.chrome.options.Options() options.add_argument('--user-data-dir=' + PROFILE_PATH)ユーザー情報やアクセスするアドレスは変数に入れておきます。
また、ブラウザ画面をpdfとして保存するためには、どうやらこの設定が必要のようです。中身はあまり理解できていないですがとりあえずこれで上手くいきます。本当はここでファイルの保存先も指定できれば良いのですが、どうやってもデフォルトの保存先(通常はダウンロードフォルダ)にpdfが保存されてしまい、指定した保存先にファイルを保存することができませんでした。
そこで、苦肉の策として、一度デフォルトの保存先に保存されたファイルを指定したフォルダに移動することとしました。該当コードは「3.8.領収書をpdf保存し指定のフォルダに名前を変更して保存」で記載しています。seleniumで一番重要なdriverを作成します。このあとdriverがたくさん出てきます。
クッキーについては、よくわからないんですが、多くのページで設定するほうがよいとの記載でしたのでとりあえず設定しました。これはなくても動きます。
3.5.ログインの実装
#ログイン login_btn = driver.find_element_by_id('nav-link-accountList') login_btn.click() time.sleep(1) login_email = driver.find_element_by_id('ap_email') login_email.send_keys(ID) next_btn = driver.find_element_by_id('continue') next_btn.click() time.sleep(1) login_pass = driver.find_element_by_id('ap_password') login_pass.send_keys(PASS) login_btn = driver.find_element_by_id('signInSubmit') login_btn.click() # 携帯電話登録のページがでてくる場合は後でとする try: mobile_skip = driver.find_element_by_id('ap-account-fixup-phone-skip-link') mobile_skip.click() except: pass time.sleep(1) # 注文履歴画面へ order_history = driver.find_element_by_id('nav-orders') order_history.click() time.sleep(2)Amazonのページはid名が明確でやりやすいです。ログイン、注文履歴画面まではfind_element_by_idで迷うことなく進めます。
何度かログインを繰り返す中で、「携帯電話登録」のページが出てくる場合がありました。このページをスキップするために try exceptを入れています。
3.6.1ページ内の領収書リンクを取得、領収書内へ
ここからやや汚いコードとなります。クラスや関数できれいなコードを書ければよいのですが、力及ばず。
作業の流れを淡々と書き下していきます。# すべてのページで行う while True: main_handle = driver.current_window_handle receipt_links = driver.find_elements_by_link_text('領収書等') # 1ページないのすべての領収書で行う for receipt_link in receipt_links: receipt_link.click() time.sleep(1) receipt_purchase_link = driver.find_element_by_link_text('領収書/購入明細書') # クリック前のハンドルリスト handles_before = driver.window_handles # 新しいタブで開く actions = ActionChains(driver) actions.key_down(Keys.CONTROL) actions.click(receipt_purchase_link) actions.perform() # 新しいタブが開くまで最大30秒待機 WebDriverWait(driver, 30).until(lambda a: len(driver.window_handles) > len(handles_before)) # クリック後のハンドルリスト handles_after = driver.window_handles # ハンドルリストの差分 handle_new = list(set(handles_after) - set(handles_before)) # 新しいタブに移動 driver.switch_to.window(handle_new[0])まずは、
main_handleを定義しておきます。操作するウィンドウが多くなると名前を付けておかないと、「今どのウィンドウの操作を行っているか」がわからなくなります。なのでメインとなるウィンドウについてmain_handleという名前を付けておきます。1ページには10くらいの注文履歴があるので、そのすべての注文履歴の「領収書等」のリンク先をlistに格納しておきます。
「領収書等」のリンクを取得するためにうまい具合のclass name 等の要素が見つからなかったため、直接「領収書等」のテキストを探しに行きました。「領収書等」のリストをforループで回します。
各「領収書等」をクリックした後に「領収書/購入明細書」をクリックします。これもまた、直接「領収書/購入明細書」テキストを探しに行きクリックしています。「領収書/購入明細書」を普通にクリックすると、現在のウィンドウが遷移してしまいます。なので「Ctrl + クリック」をするために下記の設定を行います。
# 新しいタブで開く actions = ActionChains(driver) actions.key_down(Keys.CONTROL) actions.click(receipt_purchase_link) actions.perform()ActionChainsのインスタンス化して、actionsとします。そのあとに、行いたい動作を記述して、perform()で実行します。ここでは「コントロールキーを押す」という動作と「領収書/購入明細書をクリックする」とう動作を記述しています。
この記述方法で、「PAGE_DOWN」を使用すればウインドウを下に移動したりできます。ほかにもいろいろできるようです。詳しくは検索すれば他のページで解説されていますので、そちらで。
新しいウィンドウを開いた後は、新しいウィンドウを選択する必要があります。ここでは最初に見つけたやり方(ハンドルリストの差分をとる)を記載していますが、この記述はやや煩雑です。もっと完結に書くのであれば
handl_new = driver.window_handles[-1]として、window_handlesリストの一番最後を取得することで、今開いたウィンドウを選択したほうがよいです。3.7.領収書をpdf保存し指定のフォルダに名前を変更して保存
# pdf化 driver.execute_script('window.print();') # pdf化したものをダウンロードフォルダから指定フォルダに名前を変更して保存する new_filename = driver.find_element_by_class_name('h1').text + '.pdf'# 新しいファイル名 timestamp_now = time.time() # 現在時刻 # ダウンロードフォルダを走査 for (dirpath, dirnames, filenames) in os.walk(DOWNLOAD_PATH): for filename in filenames: if filename.lower().endswith(('.pdf')): full_path = os.path.join(DOWNLOAD_PATH, filename) timestamp_file = os.path.getmtime(full_path) # ファイルの時間 # 3秒以内に生成されたpdfを移動する if (timestamp_now - timestamp_file) < 3: full_new_path = os.path.join(SAVE_PATH, new_filename) os.rename(full_path, full_new_path) print(full_path+' is moved to '+full_new_path) time.sleep(1) driver.close() driver.switch_to.window(main_handle)
driver.execute_script('window.print();')でプリントを実行します。初期設定でpdf化を行っているのでpdf保存されます。pdfは初期設定をどう頑張ってもデフォルトの保存先に保存されてしまうので、一度デフォルトに保存しておき、デフォルトフォルダ内で3秒以内に生成されたpdfを指定フォルダに名前を変えて保存するというコードを採用しました。
ファイル名はh1タグの注文番号を取得しています。pdfの保存が終わった段階で領収書ウィンドウを閉じ、main_handleを選択しなおします。
3.8.次のページへ
ページ内の領収書の保存が完了した後に、「次へ」ボタンを押して次のページに移ります。
# 次へのボタンが押せなくなった時点で終了 try: driver.find_element_by_class_name('a-last').find_element_by_tag_name('a') driver.find_element_by_class_name('a-last').click() driver.switch_to.window(driver.window_handles[-1]) except: break driver.quit()「次へ」ボタンは
driver.find_element_by_class_name('a-last').find_element_by_tag_name('a')で選択できます。
try exceptで「次へ」ボタンが押せなくなった段階でbreakし、driver.quit()` で作業を完了します。4.追加の機能追加について
以上が、Amazonの領収書をすべて保存するコードの説明になります。
当初の構想では商品名、購入日、金額等の情報をpandaのDataFrameにappendしていき、最後にcsvに保存しようかと考えたのですが、ややめんどくさいところがあり実装はやめました。気が向いたら実装してみます。
5.saleceforceでの固有の論点
本来の目的であったsaleceforceの自動化についてはなんとか問題なく作成することができましたが、カスタマイズしたsaleceforceのブラウザ操作をすべて載せたとしても横展が難しいと思います。
ここでは、saleceforceの自動化でややつまった箇所について備忘として記載しようと思います。
5.1.二段階認証の突破
Seleniumでsaleceforceにログインすると、必ず毎回二段階認証が行われます。二段階認証のメールを取得し、認証コードを入力するというコードを書いてもよかったのですが、saleceforceのセキュリティ設定で「組織の信頼済みIP範囲の設定」で対応が可能です。
詳細は下記をご確認ください。
(https://help.salesforce.com/articleView?id=security_networkaccess.htm&type=5)5.2.画面には確かに映っている要素がdriver.find_elementsで取得できない場合->iframeを疑う
今回一番てこずった箇所がここです。
ブラウザの画面に存在する要素を取得できないということがおきます。いろいろ調べた結果
<iframe>タグが原因ということがわかりました。
要は、<iframe>タグ内の要素については、まずdriver.switch_to_frame(iframe)で選択してから、その中の要素をfind_elementしなければならないようです。ここだけで数時間悩みました。
わかってみれば簡単です。5.3.無限スクロールを読み込む
無限スクロールの表を読み込むという実装がまだうまくできていないです。
PAGE_DOWNでウィンドウを下に移動できますが、表の読み込みとウィンドウの下の移動のタイミング?をうまく制御できていないです。
ここは現時点の課題です。6.最後に
長くなりましたが、以上となります。
思ったよりも簡単にできましたが、まだまだ課題があるので少しずつ勉強を続けたいと思います。



- 投稿日:2020-07-07T18:18:39+09:00
ストラングの線形代数を読んでみた
世界標準MIT教科書 ストラング:線形代数イントロダクション
はじめに
ベクトル
ベクトルは「運ぶ」を意味するラテン語のvehereに由来し、18世紀の天文学者によってはじめて使われた。
数理科学の分野で用いられ、それぞれの分野でそれぞれの使われ方をしている。
コンピュータの分野では、1次元の配列として表現されるデータ構造、数列としてとらえられている。コンピューターグラフィックスの世界でよく用いられている。
物理の分野でも多用されている。三次元空間または二次元空間上の問題などを扱う際にしばしば利用され、電磁気学や流体力学など広い範囲で応用される。
数学では、幾何学的空間における、大きさと向きを持った量。有向線分として捉えることができる。一般の広い意味でのベクトル。線形性を持つ、すなわち和とスカラー倍を取る事ができる量である。ある基底とそれに対する成分の組によって表わされる。
表記としては縦ベクトルと横ベクトルがある。
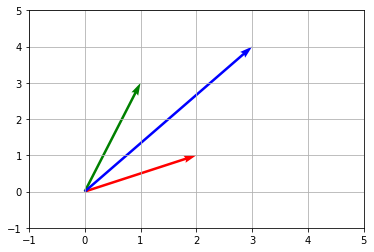
縦ベクトル\begin{bmatrix}1 \\ 20\end{bmatrix}横ベクトル\begin{bmatrix}1 &20\end{bmatrix}ベクトルを幾何学的な平面でとらえるとわかりやすい。
a= \begin{bmatrix}2 \\ 1\end{bmatrix}\\ b=\begin{bmatrix}1 \\ 3\end{bmatrix}とすると
a+b = \begin{bmatrix}2+1\\1+3\end{bmatrix} = \begin{bmatrix}3\\4\end{bmatrix}は# coding:utf-8 import numpy as np import matplotlib.pyplot as plt a = np.array([2, 1]) b = np.array([1, 3]) c = a + b origin = [0, 0, 0] # 原点(0, 0) d = np.array([a, b, c]) U = d.T[0] # 転置を取ってx成分取り出し V = d.T[1] # 転置を取ってy成分取り出し plt.quiver(origin, origin, U, V, angles='xy', scale=1, scale_units='xy', color=['r', 'g', 'b']) plt.xlim([-1, 5]) plt.ylim([-1, 5]) plt.grid() plt.show()
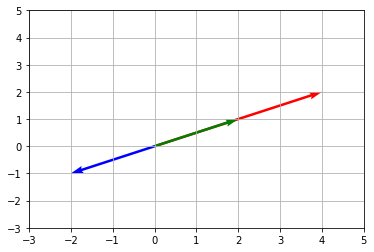
しかし、このような捉え方よりも、赤い矢印をグリーンの矢印の平行移動したほうが分かりやすい。plt.quiver(origin, origin, U, V, angles='xy', scale=1, scale_units='xy', color=['r', 'g', 'b']) b1=np.array([2,1]) origin1 = [1] # 原点(0, 0) origin2 = [3] d = np.array([b1]) U = d.T[0] # 転置を取ってx成分取り出し V = d.T[1] # 転置を取ってy成分取り出し plt.quiver(origin1, origin2, U, V, angles='xy', scale=1, scale_units='xy',color=['r']) plt.xlim([-1, 5]) plt.ylim([-1, 5]) plt.grid() plt.show()
と表される。
行列
行列は、数や記号や式などを縦と横に矩形状に配列したものである。横に並んだ数や記号や式を行、縦に並んだものを列と呼ぶ。
例えば、\begin{bmatrix}1&9&-13\\20&5&-6\end{bmatrix}は2つの行と3つの列によって構成されているため、(2,3)型または2×3型の行列と呼ばれる。
連立方程式の解法への利用
連立方程式の解法に関して、行列は長い歴史を持ち、世界最初の例は中国の書物『九章算術』(BC10世紀~BC2世紀)にある。
2 変数の連立方程式の例として
\begin{cases}x+2y=5\\2x+3y=8\end{cases}とする。この式において、2 つの線型方程式を同時に満たす (x, y) = (1, 2) が解である。
連立方程式が与えられたとき、変数の数と方程式の本数を比べれば、その解は大まかに言って
変数の数の方が多いならば、(変数の数) − (方程式の本数)の分だけ変数を自由に定めることができ、解が一つに定まらない。
変数の数と方程式の本数が一致するならば、解が存在し、一つに定まる。
方程式の本数の方が多いならば、制約が過剰なので、解が存在しない。
これを行列を用いて
\begin{bmatrix}1&2\\2&3&\end{bmatrix}\begin{bmatrix}x\\y\end{bmatrix}=\begin{bmatrix}5\\8\end{bmatrix}として、解を求めることができる。
これは
\begin{cases}x+2y=5\\2x+3y=8\end{cases}を解く場合と同じように2行目の式の$y$を消去すればよいのである。一行目の式を2で割って3を掛けて2行目の式から引けば$x$を求めることができる。
\begin{bmatrix}1&2\\2-3/2&0&\end{bmatrix}\begin{bmatrix}x\\y\end{bmatrix}=\begin{bmatrix}5\\8/3-5\cdot3/2\end{bmatrix}\begin{bmatrix}1&2\\1/2&0&\end{bmatrix}\begin{bmatrix}x\\y\end{bmatrix}=\begin{bmatrix}5\\1/2\end{bmatrix}したがって$x=1$、これを1行目の式に代入して$y=2$を得る。
同様に、
\begin{bmatrix}1&2\\2&3&\end{bmatrix}\begin{bmatrix}z\\w\end{bmatrix}=\begin{bmatrix}3\\8\end{bmatrix}を解くと、$(x,y)=(2,1)$となる。これをまとめて書くと
\begin{bmatrix}1&2\\2&3&\end{bmatrix}\begin{bmatrix}x&z\\y&w\end{bmatrix}=\begin{bmatrix}5&3\\8&8\end{bmatrix}と書ける。
行列式
\begin{bmatrix}a&b\\c&d&\end{bmatrix}\begin{bmatrix}x\\y\end{bmatrix}=\begin{bmatrix}e\\f\end{bmatrix}$d$を消去するために、$d$を掛けた一行目から$b$を掛けた2行目を引けば
\begin{bmatrix}a&b\\ad-bd &0&\end{bmatrix} \begin{bmatrix}x\\y\end{bmatrix}=\begin{bmatrix}e\\de-bf\end{bmatrix}が得られる。したがって、
x=\frac{de-bf}{ad-bd}内積
内積は、二つのベクトルに対してある数(スカラー)を定める二項演算であるためスカラー積ともいう。ドット積とは、ベクトル演算の一種で、2つの同じ長さの数列から一つの数値を返す演算である。
たとえば100円で購入したりんご1個を200円で売ったとしよう。取引の数量を$(q_1,q_2)=(-1,1)$、価格を$(p_1,p_2)=(100,200)$とするとその収益は
$$(q_1,q_2)\cdot(p_1,p_2)=q_1p_1+q_2p_2=-1\cdot100+1\cdot 200=100$$
となる。q=np.array([-1,1]) p=np.array([100,200]) np.dot(p,q) #100射影
直線のフィッティング
つぎに式の数がたくさんある場合を考えてみよう。
\begin{bmatrix}1&-2\\1&0&\\1&2\end{bmatrix}\begin{bmatrix}\alpha\\ \beta\end{bmatrix}=\begin{bmatrix}1\\2\\4\end{bmatrix}これは金融の分野でもエンジニアリングの分野でもよく見るタイプである。直線のフィッティングである。
右辺が被説明変数、左辺が説明変数と回帰係数である。$Ax=b$が解を持たないことはよくある。一般的な理由は式の数が多すぎることである。これが解けない理由として被説明変数にノイズが含まれている場合である。誤差を$e=b-Ax$とすると誤差をゼロにはできないかもしれない。$e=0$であれば解は求まる。$e$がゼロではなく最小にするとき、$\hat{x}$を最小二乗解という。この解は
$$A^TA\hat{x}=A^Tb$$
を解くことで求められる。$^T$は転置行列を表す。$Ax$は列(1,1,1)と(0,1,2)からなる平面上にある。その平面において$b$に最も近い点を探す。最も近い点は射影$p$となる。これは射影を用いた最小二乗法である。測定値を、適当なモデルから想定される1次関数、2次関数、三角関数、双曲線など特定の関数を用いて近似するときに、想定する関数が測定値に対してよい近似となるように、残差の二乗和を最小とするようにモデルを決定することができる。
固有値、固有ベクトル
線型代数学において、線型変換の特徴を表す指標として固有値や固有ベクトルがある。安定してる状態(定常状態)を議論したいときに生じる動的な問題についての解析に重要である。
$$Ax=\lambda x$$
で$A$は行列で$x$が固有ベクトル、$\lambda$が固有値である。この基本方程式をみてみると右辺と左辺に固有ベクトルがあるのが分かる。また、右辺には固有値の$\lambda$がある。固有値は1つであるとは限らない。\begin{bmatrix}4\\2\end{bmatrix}=2\cdot\begin{bmatrix}2\\1\end{bmatrix}\\ \begin{bmatrix}2\\1\end{bmatrix}=1\cdot\begin{bmatrix}2\\1\end{bmatrix} \\ \begin{bmatrix}-2\\-1\end{bmatrix}=-1\cdot \begin{bmatrix}2\\1\end{bmatrix}とすると、固有ベクトルは
\begin{bmatrix}2\\1\end{bmatrix}であり、固有値は上から2,1,-1である。平面上に表現すると
# coding:utf-8 import numpy as np import matplotlib.pyplot as plt a = np.array([4, 2]) b = np.array([2, 1]) c = np.array([-2, -1]) origin = [0, 0, 0] # 原点(0, 0) d = np.array([a, b, c]) U = d.T[0] # 転置を取ってx成分取り出し V = d.T[1] # 転置を取ってy成分取り出し plt.quiver(origin, origin, U, V, angles='xy', scale=1, scale_units='xy', color=['r', 'g', 'b']) plt.xlim([-3, 5]) plt.ylim([-3, 5]) plt.grid()
となる。たとえば
\begin{bmatrix}0.8&0.3\\0.2&0.7\end{bmatrix}x=\lambda xとする。右辺を左辺に移動して
\begin{bmatrix}0.8-\lambda&0.3\\0.2&0.7-\lambda\end{bmatrix}x=0$x \ne 0$である。
そこで\begin{cases}(0.8-\lambda)x_1+0.3x_2=0\\0.2x_1+(0.7-\lambda)x_2=0\end{cases}を解く。1式を0.3で割って、2式を$0.7-\lambda$で割ってそこから引くと
\begin{bmatrix}0.8-\lambda&0.3\\0.2/(0.7-\lambda)-(0.8-\lambda)/0.3 &0 \end{bmatrix}x=0$x \ne 0$であるから
0.2/(0.7-\lambda)-(0.8-\lambda)/0.3 =0したがって、$\lambda=1,0.5 $となる。
そうすると
$x_1=-x_2$または$1.5\cdot x_1=1\cdot x_2$となる。これは
$\lambda=1$のときx=\begin{bmatrix}0.6\\0.4\end{bmatrix}$\lambda=0.5$のとき
x=\begin{bmatrix}1\\-1\end{bmatrix}となる。
これは行列$A$をある正のベクトル$u_0$に$u_1=Au_0$,$u_2=Au_1=A^2u_0$というように何度も掛けると
$$Au_{\infty}=u_{\infty}$$
になる。ためしに$u_0=[0.9,0.1]^T$としてみよう。\begin{bmatrix}0.8&0.3\\0.2&0.7\end{bmatrix}\begin{bmatrix}0.9\\0.1\end{bmatrix}= \begin{bmatrix}0.72+0.03\\0.18+0.07\end{bmatrix}= \begin{bmatrix}0.75\\0.25\end{bmatrix}\begin{bmatrix}0.8&0.3\\0.2&0.7\end{bmatrix}\begin{bmatrix}0.75\\0.25\end{bmatrix}= \begin{bmatrix}0.6+0.075\\0.15+0.175\end{bmatrix}= \begin{bmatrix}0.675\\0.325\end{bmatrix}\begin{bmatrix}0.8&0.3\\0.2&0.7\end{bmatrix}\begin{bmatrix}0.675\\0.325\end{bmatrix}= \begin{bmatrix}0.54+0.0975\\0.135+0.2275\end{bmatrix}= \begin{bmatrix}0.6375\\0.3625\end{bmatrix}とすこしずつ
x=\begin{bmatrix}0.6\\0.4\end{bmatrix}に近づいています。
金融の例では$u$を価格として$u_1=Au_0+\epsilon_1$とするとイメージしやすい。


- 投稿日:2020-07-07T15:53:58+09:00
Pythonの文字コードの文字列のリンク集とメモ
文字コードについて
新人さんに知ってほしい「文字コードのお話」
符号化文字集合と文字符号化方式の2種類ある
符号化文字集合
文字とコードポイントのマッピング
- 例: unicode, ascii
- python3ではデフォルトunicode
>>> hex(ord("あ")) '0x3042' # unicodeの"あ"のコードポイント文字符号化方式
文字の運用方式、実装方式
- 例: utf-8, shift-jis, euc-jp
- "あ" は utf-8 と utf-16 で符号化すると異なるバイト列になる
- utf-8: 0xE3 0x81 0x82
- utf-16: 0x30, 0x42
Python3での文字の扱い
Python3で文字列を処理する際の心掛け
'あああ'のリテラルはunicodeの文字列- bytesに変換するときは
'あああ'.encode('utf-8')- bytesをunicodeに戻すときは
bytes_moji.decode('utf-8')- unicodeでファイルに書き込むときと、byteで書き込ときと読むときは関数が異なる
- Pythonでの文字コードの取り扱い
一応python2での扱いも
Python2で文字列を処理する際の心掛け
- python2ではbyte化はデフォルトasciiで行われる
- 日本語文字列をファイルに変換しようとすると、デフォルトasciiでbyteにencodeしようとしてエラーになる
- utf-8 でencodeするように指定する必要がある
- 投稿日:2020-07-07T15:27:35+09:00
PythonでScientific Programmingプチテク集
Integrator (Propagator) 作成について
Pythonでintegratorを作成する場合、scipyのsolve_ivp()関数などが便利。その際は、ODEの関数定義はnumpy可してあげるようにする。例えば、円制限三体問題の場合、
\begin{align} \ddot{x} -2\dot{y} &= x -\dfrac{1-\mu}{r_{1}^3} (x+\mu) + \dfrac{\mu}{r_{2}^3} (1-\mu-x) \\ \ddot{y} +2\dot{x} &= y -\dfrac{1-\mu}{r_{1}^3}y - \dfrac{\mu}{r_{2}^3}y \\ \ddot{z} &= -\dfrac{1-\mu}{r_{1}^3}z - \dfrac{\mu}{r_{2}^3}z \end{align}となるので、これを6つのFirst Order ODEとして表すと
\begin{align} \dfrac{d x}{d t} &= \dot{x} \\ \dfrac{d y}{d t} &= \dot{y} \\ \dfrac{d z}{d t} &= \dot{z} \\ \dfrac{d \dot{x}}{d t} &= \dfrac{d^2 x}{d t^2} = 2\dot{y} +x -\dfrac{1-\mu}{r_{1}^3} (x+\mu) + \dfrac{\mu}{r_{2}^3} (1-\mu-x) \\ \dfrac{d \dot{y}}{d t} &= \dfrac{d^2 y}{d t^2} =-2\dot{x} + y -\dfrac{1-\mu}{r_{1}^3}y - \dfrac{\mu}{r_{2}^3}y \\ \dfrac{d \dot{z}}{d t} &= \dfrac{d^2 z}{d t^2} =-\dfrac{1-\mu}{r_{1}^3}z - \dfrac{\mu}{r_{2}^3}z \end{align}関数にすると
import numpy as np from numba import jit # deifne RHS function in CR3BP @jit(nopython=True) def rhs_cr3bp(t,state,mu): """Equation of motion in CR3BP, formulated for scipy.integrate.solve=ivp(), compatible with njit Args: t (float): time state (np.array): 1D array of Cartesian state, length 6 mu (float): CR3BP parameter Returns: (np.array): 1D array of derivative of Cartesian state """ # unpack positions x = state[0] y = state[1] z = state[2] # unpack velocities vx = state[3] vy = state[4] vz = state[5] # compute radii to each primary r1 = np.sqrt( (x+mu)**2 + y**2 + z**2 ) r2 = np.sqrt( (x-1+mu)**2 + y**2 + z**2 ) # setup vector for dX/dt deriv = np.zeros((6,)) # position derivatives deriv[0] = vx deriv[1] = vy deriv[2] = vz # velocity derivatives deriv[3] = 2*vy + x - ((1-mu)/r1**3)*(mu+x) + (mu/r2**3)*(1-mu-x) deriv[4] = -2*vx + y - ((1-mu)/r1**3)*y - (mu/r2**3)*y deriv[5] = -((1-mu)/r1**3)*z - (mu/r2**3)*z return derivとなる。前期の通り、大概の場合ODEの表現はnumba化が比較的容易に可能と思われるのでおススメ。あとは、
solve_ivp()関数を呼べばいいのでfrom scipy.integrate import solve_ivp # integrate until final time tf tf = 3.05 # initial state state0 = np.array([ 9.83408400e-01, -9.42453366e-04, 1.27227988e-03, 7.03724138e-01, -1.78296421e+00, 1.13566847e+00]) # cr3bp mass parameter mu mu = 0.012150585609624 # call solve_ivp sol = solve_ivp(fun=rhs_cr3bp, t_span=(0,tf), y0=state0, args=(mu,))ここで、
argsにはODEの状態行列 (state) と時間 (t) 以外に必要になるパラメータ(上記の例ではmuを入れる。tupleなので、たとえエントリーが一つでもカンマ(,)を忘れずに。
- 投稿日:2020-07-07T15:21:54+09:00
まだプログラミングで消耗してるの?PYNQで始めるFPGA開発入門
PYNQで始めるFPGA開発入門
TL; DR
FPGAってなに?開発コストが高いんじゃないの?Pythonで開発できるってほんと?初心者でも簡単にC++とPythonだけでFPGA開発する方法を調べました!まだプログラミングで消耗している非フルスタックなエンジニアの方は、非ノイマン型エンジニアになって
もっと消耗しましょうハードも作れるフルスタックなエンジニアを目指しましょう!!はじめに
FPGAはField-Programmable Gate Arrayの略で、製造後に回路構成を変更することができます。CPUやGPUなどの汎用集積回路と違い、FPGAは用途に応じて構成を変更することができるため、ハマる用途ではCPUやGPUよりも速い処理が可能です。用途に特化した回路で処理するためオーバーヘッドが少なく、高い電力効率も実現できます。
CPUやGPUを使うには設計した計算アルゴリズムをC言語などのソフトウェアプログラムとして記述します。FPGAを使うには論理回路を設計し、Verilogなどのハードウェア記述言語(HDL)で回路を記述します。回路設計を行う必要があるためCPUやGPUのソフトウェア記述と比べて開発コストが高いとされています。
近年、高位合成(HLS)と呼ばれる回路設計手法が注目されています。従来のHDL設計ではクロックなど具体的な回路動作を設計する必要がありました。HLS設計ではC言語などを用いて計算アルゴリズムを記述することで回路を設計することができ、具体的な回路動作を設計する必要がないため短期開発を実現します。また、抽象度の高いアルゴリズムで記述できるためテストを簡単に行えます。某ゲーム会社のハードを実装したの記事1によると、HLS設計はHDL設計より30倍短い期間で開発できるそうです。
本稿では、FPGAを用いた数値計算の高速化について説明します。Xilinx社Vivado HLS2によるFPGA回路設計と、PYNQ3による制御プログラム設計について説明し、HLS設計でパフォーマンスを出すための最適化手法について解説します。本稿はソフトウェア開発の経験がある方、FPGA開発をこれから始める方、FPGA設計に興味がある方を想定しています。FPGAとは何かもっと知りたい方はXilinxが日本語で出している公式のFPGA講座4をおすすめします。
Vivado HLS
Vivado HLS2とはXilinx社が提供する高位合成ソフトを含む開発環境です。C++で記述されたプログラムをVerilogなどのHDLによる回路記述に変換するコンパイラだと思って良いでしょう。同時に付属するVivadoはFPGA回路を設計するための回路合成ソフトです。Vivado HLSによって合成されたHDLなどの回路記述はVivadoによってFPGA回路に合成されます。こちらはコンパイラと違い、論理回路の配置や配線を行う回路合成ソフトです。これらのソフトは一部無料で提供されていますが、本稿で紹介する設計法は全て無料の機能で実現できます。
環境
動作するOSはWindowsとLinuxです。特に理由がない場合はUbuntuの使用を推奨します。本稿執筆時のVivado HLSの最新バージョンは2020.1です。本稿では2020.1を元に説明していきます。インストール手順は公式ドキュメント5に詳しいですが、以下にUbuntu 18.04でのインストール手順について簡単に説明します。Ubuntu Serverへのインストールでは追加の手順が必要となります。
- PCを用意します。4コア以上の64bitCPU、16GBメモリ、空き200GB以上のストレージを推奨します。
- Ubuntu 18.04をインストールします。筆者はMacBook ProにVMWare Fusionを用いた仮想環境を用います。
- Xilinxのアカウントを用意し、ダウンロードページからVivado HLSのインストーラをダウンロードします。
- Ubuntuのターミナルから
$ sudo sh ./Xilinx-(略)64.binを実行します。
※オプションは全てデフォルトのまま続行します。
※インストールには数時間かかることがあります。
※OSのタイムゾーン設定が間違っている場合、インストールに失敗することがあります。- インストールが完了したら、ターミナルからVivado HLSとVivadoの起動を確認します。
※Vivado HLSの起動は$ /tools/Xilinx/Vivado/2020.1/bin/vivado_hlsを実行します。
※Vivadoの起動は$ /tools/Xilinx/Vivado/2020.1/bin/vivadoを実行します。PYNQ
PYNQ3とはXilinx社のFPGAを簡単に扱うPythonライブラリと、Ubuntuベースの組み込み用イメージで構成されるオープンソースのプロジェクトです。本稿において、単にPYNQという場合はPythonライブラリのことを指します。PYNQを使うことで設計したFPGA回路の制御やCPU-FPGA間のデータ転送をPythonだけで記述することが可能となります。組み込み用のFPGA SoCからサーバー用FPGAカードにまで幅広い用途で使うことができます。PYNQのダウンロードで配布されているイメージファイルをSDカードに書き込むだけで使うことができます。
環境
PYNQは組み込み用のFPGA SoCからサーバー用FPGAカード、AWS上のクラウドサービスでも使うことが可能です。本稿執筆時のPYNQの最新バージョンは2.5.1です。本稿では組み込み用のFPGA SoCボードであるPYNQ-Z16 FPGAボードを元に説明します。PYNQセットアップ方法は公式ドキュメント7に詳しいですが、以下に簡単に説明します。
- PYNQ-Z16(Z2やUltra96[^ultra96]でも可)を手元に用意します。必ず実機を用意してください。
※その他に有線LANケーブルとLANスイッチの空きポートが必要です。
※PYNQ-Z2やUltra96では一部の説明が異なりますが、大まかな開発法は同じです。
- PYNQのダウンロードから手元のFPGAボードに合うSDカードイメージをダウンロードします。
※Ultra96用のSDカードイメージはこちらで配布されています。- ダウンロードしたイメージをSDカードに書き込みます。
※Etcherというイメージ書き込みソフトがおすすめです。- SDカードを挿入し、電源ケーブルと有線LANを接続し、FPGAボードの電源を入れます。
- PCのブラウザから http://pynq:9090/ に接続して、Jupyter Notebookにアクセスできることを確認します。
※LAN環境によってはhostnameを解決できないことがあります。
※その場合は、DHCPからFPGAボードに割り当てられたIPアドレスを頑張って探します。
※http://:9090/ とすることでJupyter Notebookにアクセスできます。PYNQを用いたFPGA設計のアウトライン
1. 高速化するターゲットの決定
これが最も重要なことです。どの計算を高速化するか決定します。FPGAでの設計を開始する前に、対象の計算がFPGAによってどのくらい高速化できるのか見積もりを立てることも重要です。本稿では簡単な行列積の高速化を例に設計法を説明します。
2. Vivado HLSによるC++設計
C++を用いて高速化したい計算の動作を記述します。この記述のことを計算カーネルと呼びます。Vivado HLSでは設計される回路パフォーマンスを見積もることができます。所定のパフォーマンスを満たすかこの段階で確認し、パフォーマンスを満たさない場合は計算カーネルの再設計が必要です。
3. Vivadoでの合成
Vivado HLSで設計した計算カーネルを、Vivadoを用いてFPGA回路へと合成します。この工程では周辺回路やクロック信号の接続を設計し、動作周波数などのパラメータを設定します。大規模な回路の設計ではVivadoを用いたFPGA回路の合成には数十時間から数日かかることがあります。簡単な行列積の高速化でも、合成時間には数十分かかります。しかし、多くの場合で、この工程が一回で完了することは稀です。
4. PYNQでのホスト記述
PYNQを用いてFPGA回路を制御するホストプログラムを記述します。FPGA回路化を行なった計算カーネルを呼び出して利用するための周辺プログラムが必要です。行列積の高速化の例では、画像ファイルなど行列データの読み書き、CPUとFPGA間のデータ転送、FPGA回路の制御、計算結果の検証などが必要となります。PYNQではホストプログラムを全てPythonで記述するため、開発コストが削減され、既存のPythonライブラリとの連携が容易になります。
Vivado HLSによる計算カーネルの設計
ターゲット計算を決める
ここから、FPGA回路を設計を開始します。本稿では実装が簡単な数値計算である行列積の高速化を行います。また数値型や数値計算精度を決める必要があります。FPGAの特徴として計算精度を柔軟に変更できる点が挙げられ、端数の精度や異なる精度の演算を定義することができます。今回の実装では符号付き16bit整数(short型)とします。Pythonの数値計算ライブラリNumpyで記述すると以下となります。高速化ターゲットは最後の一行
y = np.dot(x1, x2)に該当します。import numpy as np x1 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16) x2 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16) y = np.dot(x1, x2)新規HLSプロジェクトの作成
- Vivado HLSを起動します。
Ubuntuでは、ターミナルで$ /tools/Xilinx/Vivado/2020.1/bin/vivado_hlsを実行します。
Windowsではアプリ一覧からVivado HLSを選択して起動します。- 次の画面が表示されます。Create New Projectをクリックします。

- プロジェクト名を入力します。今回は
matrix-productとし、Nextをクリックします。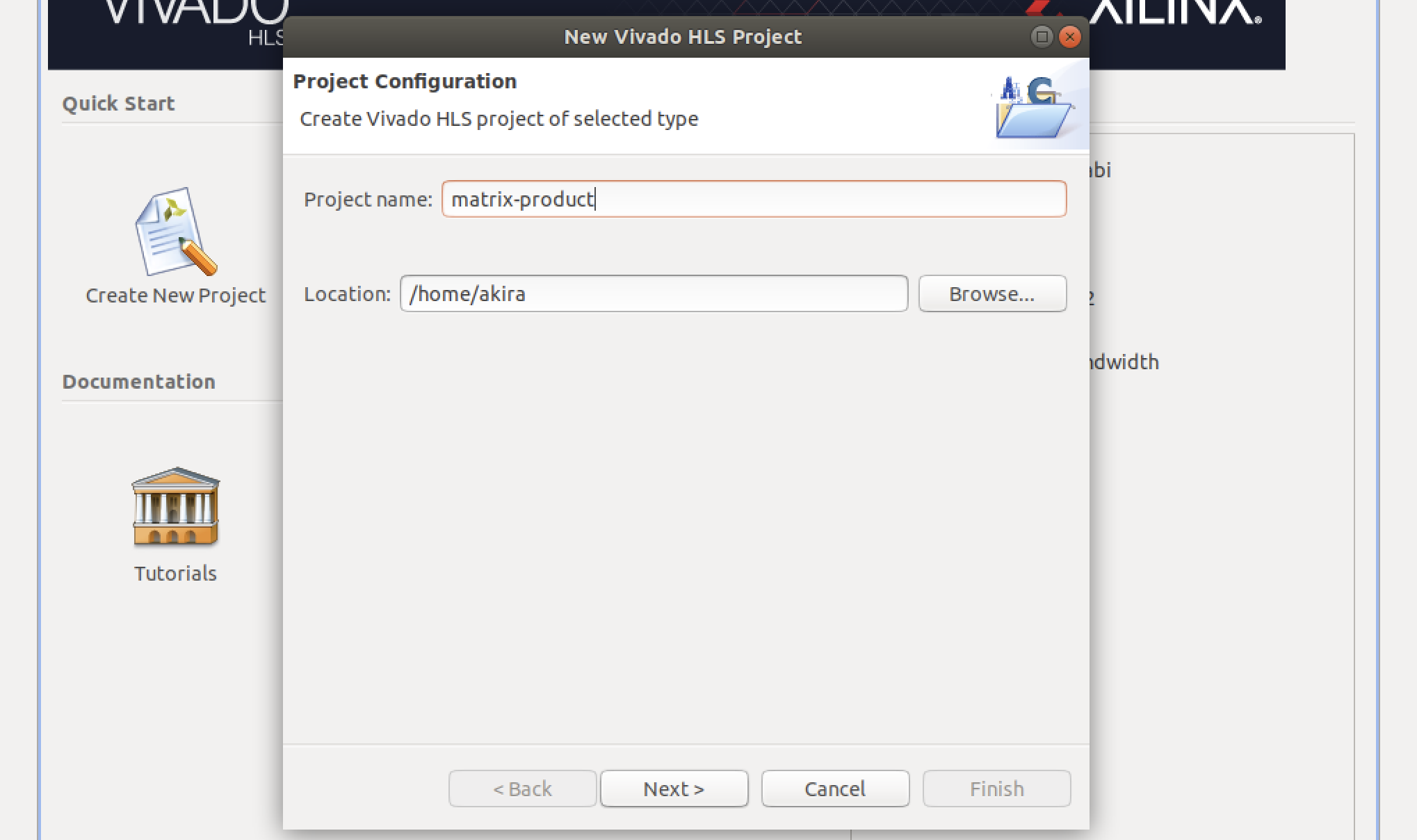
- 合成対象とするC++の関数名であるTop Functionを決めます。今回は
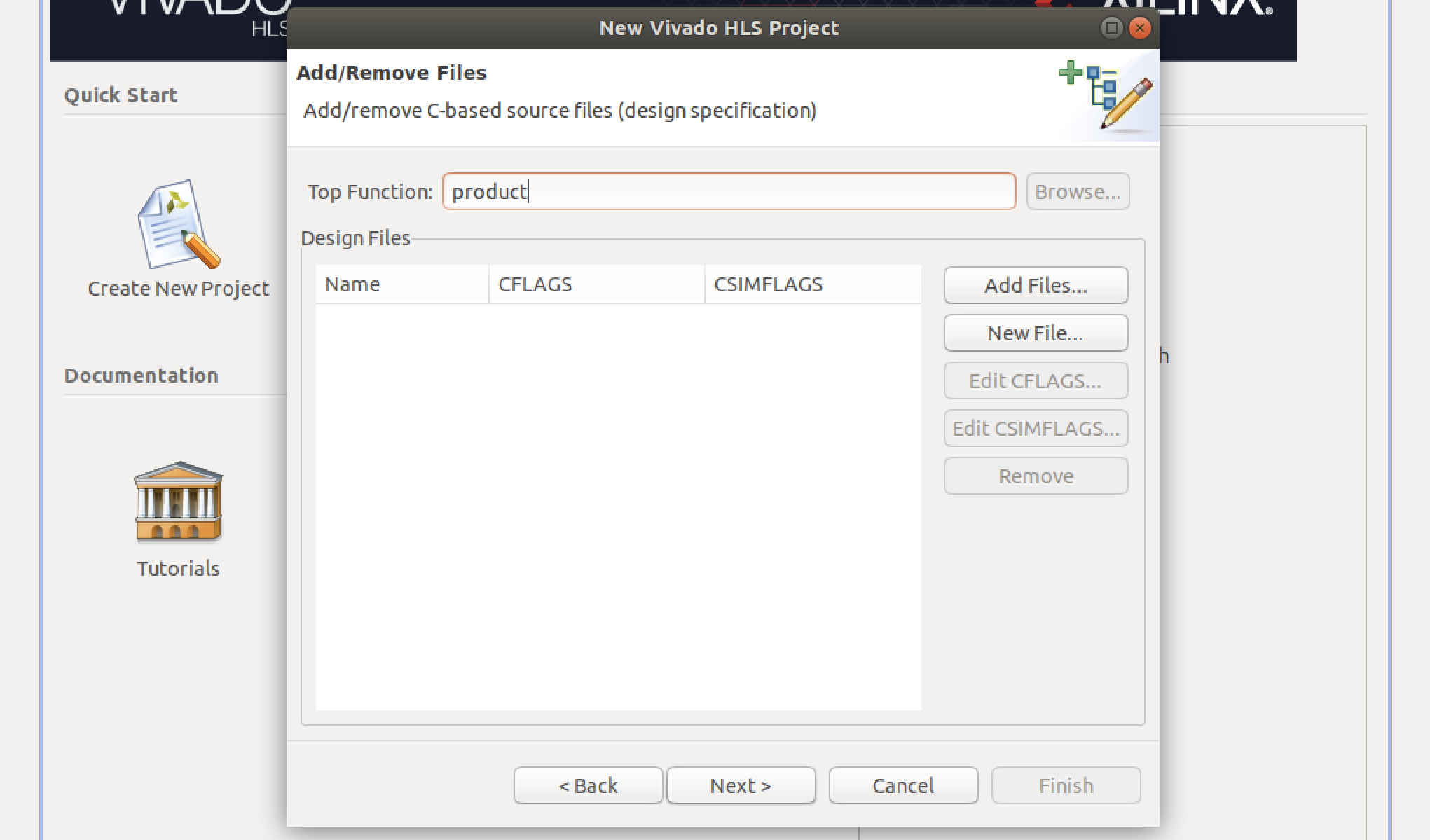
productとし、Nextをクリックします。
Top Functionに指定した文字列は、PYNQライブラリからカーネルを呼び出す際に必要となります。
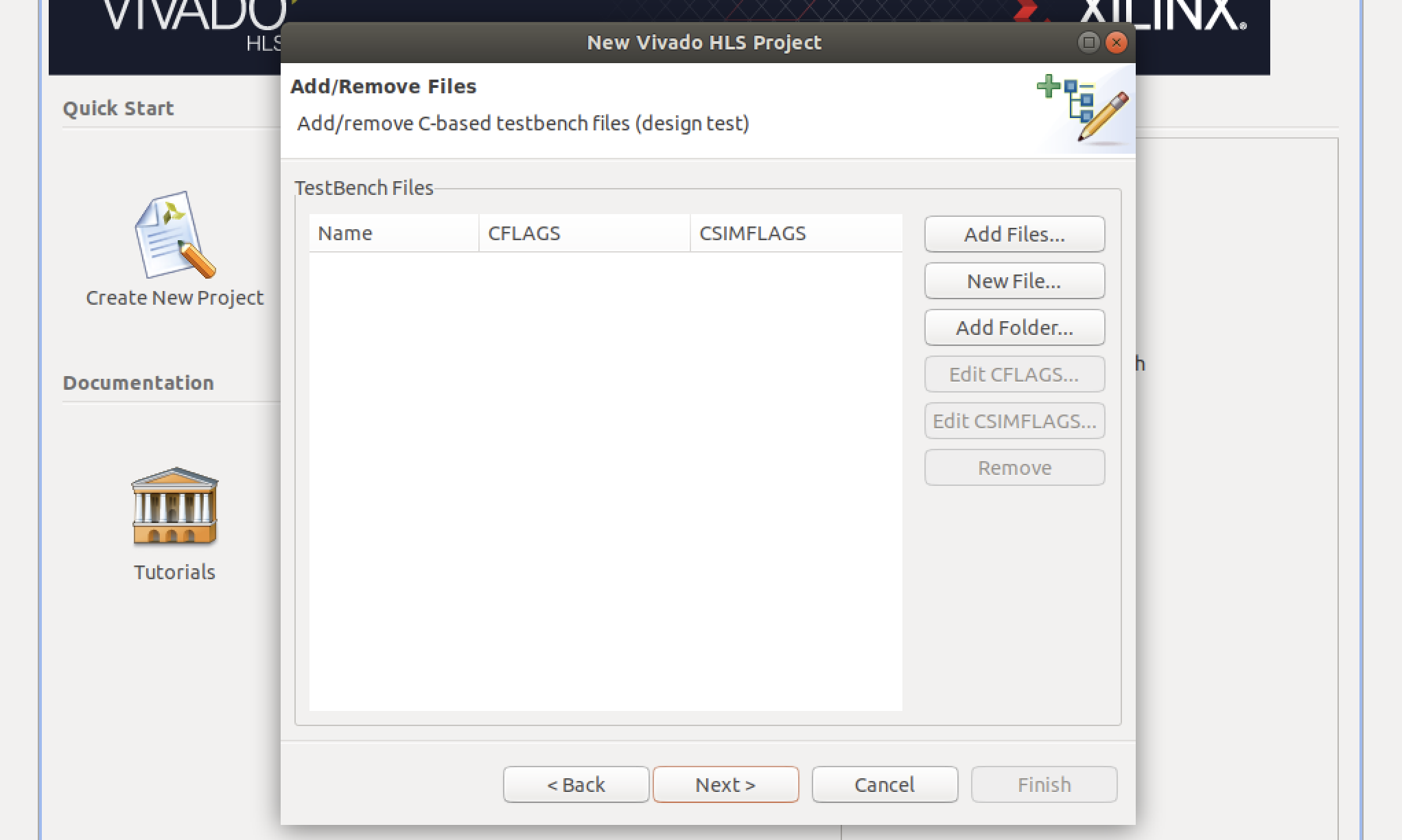
- テストベンチを追加します。今回は何も追加しません。空欄のままNextをクリックします。
- ターゲットFPGAの情報を入力します。Part Selectionの右の[...]をクリックするとデバイス選択画面が表示されます。
PYNQ-Z1 / Z2の場合は以下のようにxc7z020clg484-1を選択します。
Ultra96の場合はxczu3eg-sbva484-1-eを選択します。

- OKをクリックすると選択したデバイスが表示されています。Finishをクリックするとプロジェクトが作成されます。
その他にClockの設定がありますが初期値のまま続行します。これらの設定は後から変更することが可能です。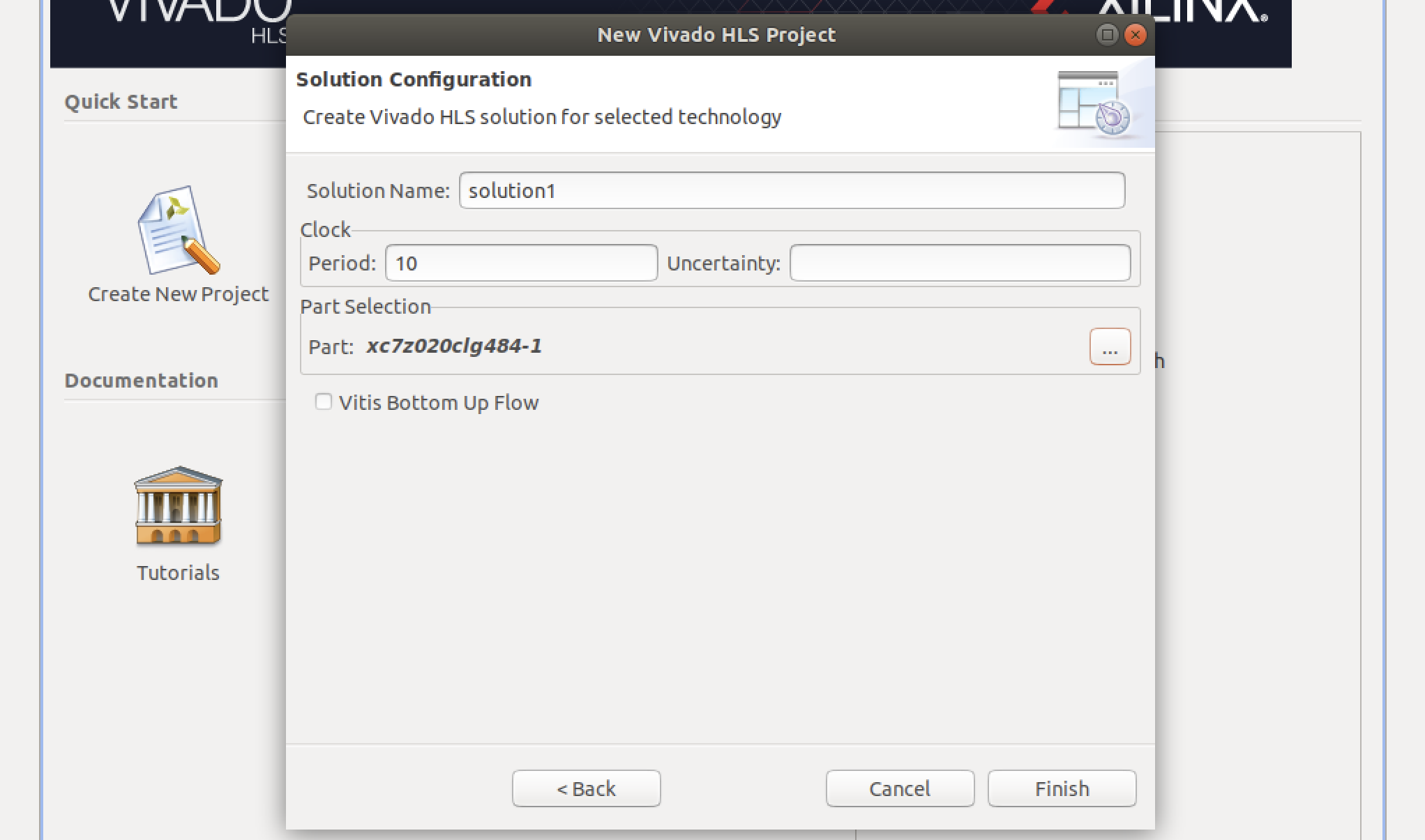
C++によるの計算カーネル作成
- カーネルを記述するC++ファイルを作成します。左側のメニューにあるSourceを右クリックし、New Fileを選択します。
- 作成するファイル名を
kernel.cppとします。ファイルの保存場所に指定はありません。OKをクリックします。
- プロジェクトに新規ファイルが追加されました。計算カーネルを記述します。以下のサンプルをコピーしてください。
プラグマ#pragma HLS XXX...によってVivado HLSのコンパイラに追加の指示を与えてます。
このサンプルでは、回路の制御方式 (port=returnの行) と、入出力引数のデータ転送方式を指示しています。
PYNQでFPGA回路を制御するためにはこれらのプラグマが必要となるため、忘れないようにしましょう。kernel-1.cppvoid product(short x1[16][16], short x2[16][16], short y[16][16]) { #pragma HLS interface s_axilite port=return #pragma HLS interface s_axilite port=x1 #pragma HLS interface s_axilite port=x2 #pragma HLS interface s_axilite port=y for (int i=0; i<16; i++) { for (int j=0; j<16; j++) { short t = 0; for (int k=0; k<16; k++) { t += x1[i][k] * x2[k][j]; } y[i][j] = t; } } }HLS合成とレポート
- HLS合成を実行します。上部アイコンの右三角ボタン [▶︎] C Synthesisをクリックします。
- 以下のような合成レポートが表示されたら合成は成功です。合成結果に関する情報を見ることができます。
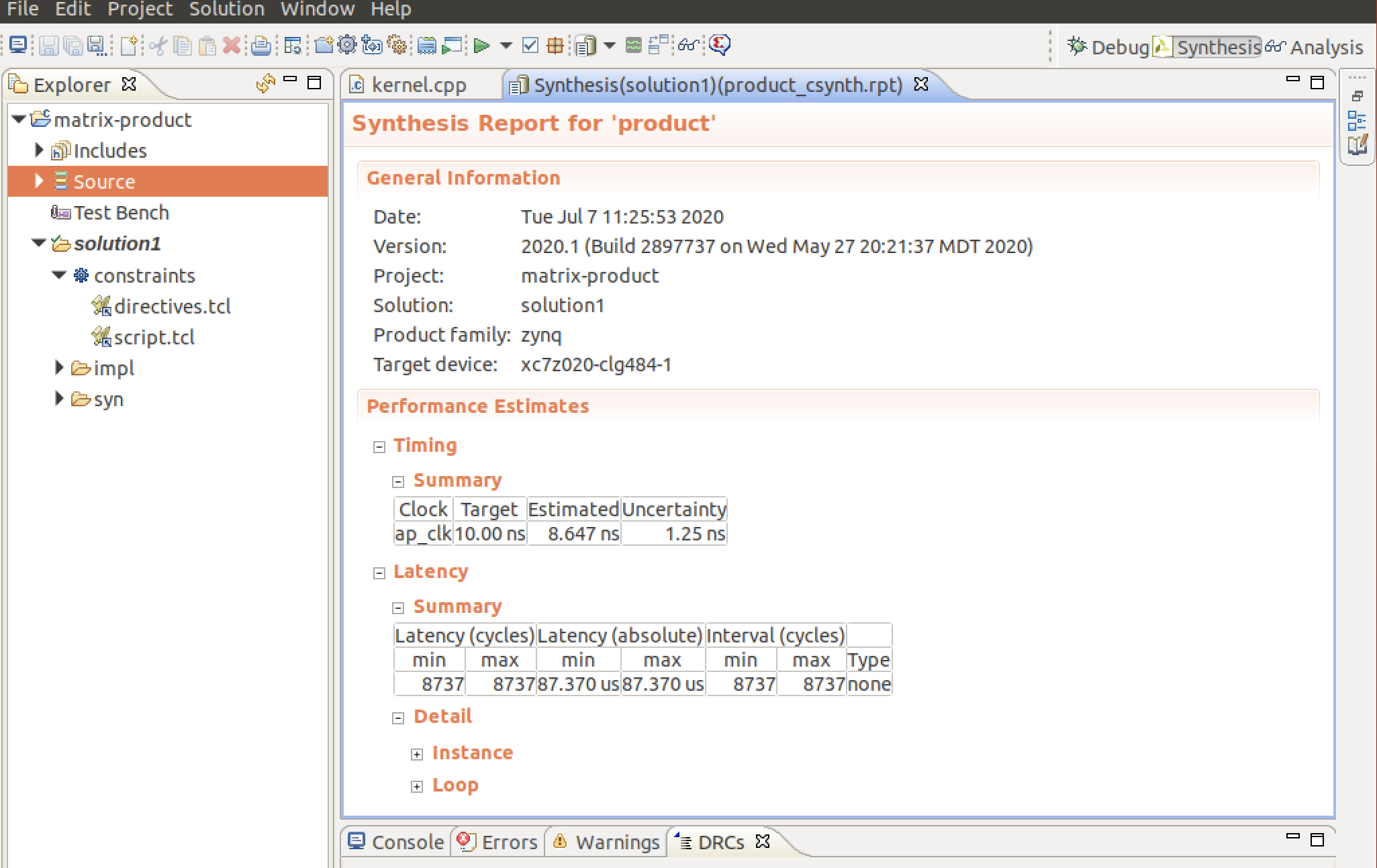
Performance Estimatesでは計算カーネルのパフォーマンスの見積もりを見ることができます。
Latencyの項目にサイクル数と実行時間の見積もりが表示されています。
今回の計算カーネルの実行には8737クロックサイクルが必要で、87.370マイクロ秒の時間がかかることがわかります。
レポートを閉じてしまった場合、上部アイコンのOpen Report (C Synthesisの3つ右) から合成レポートが開けます。
- IPコアを作成します。上部アイコンのExport RTL (C Synthesisの2つ右) をクリックします。
IPコアとはFPGA回路を合成するための回路情報と入出力データの通信方式が含まれるパッケージです。
HLS合成したカーネルをVivadoから呼び出すためにIPコアの形式を経由します。
- Export RTLの画面が表示されたら、デフォルトの設定のままOKをクリックしてIPコア(IPカタログ)を作成します。
Vivado HLSでの作業は以上になります。
Vivadoを用いた回路合成
次に、FPGA回路を合成するためのVivadoプロジェクトを作成します。
HLSによる開発では、Vivadoを用いてHLS設計したIPとベンダーに用意されている設計済みIPの配置と配線を行います。新規Vivadoプロジェクトの作成
- Vivadoを起動します。
- プロジェクトを作成します。
- 次の画面が表示されます。Nextをクリックします。
- 次のように記入してNextをクリック。
- そのままでNextをクリック。
- そのままでNextをクリック。

- そのままでNextをクリック。
- パーツにxc7z020clg484-1を選択して、Nextをクリック。
- Finishをクリックするとプロジェクトが作成されます。
IP設計
- ブロックデザインを作成します。
IP INTEGRATORのCreate Block Designをクリックします。
- OKをクリック。
- Vivado HLSで作成したIPコアを追加します。
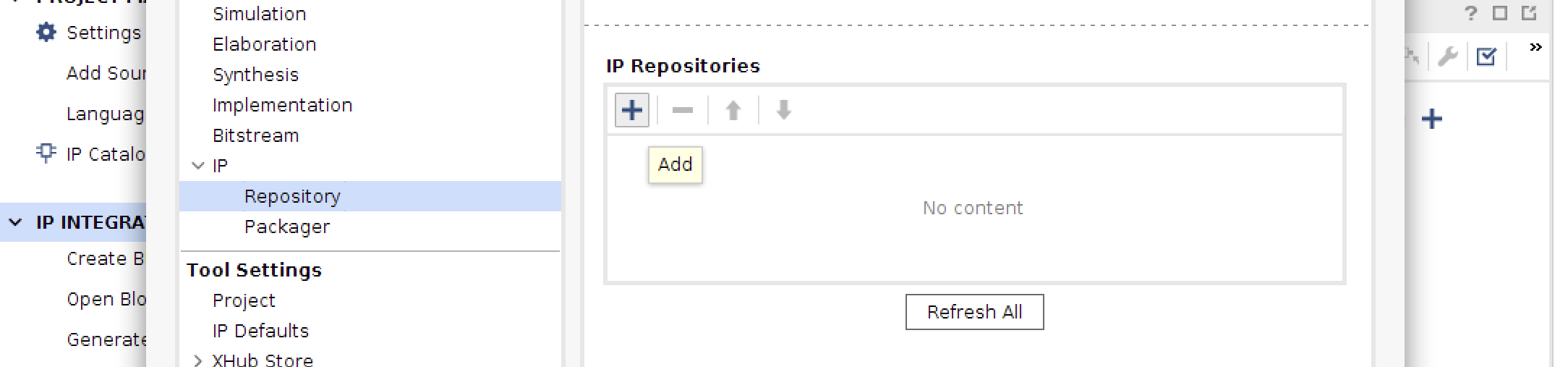
上部の歯車アイコンからSettingを開きます。
- IPのRepositoryタブを開いて、ブラスボタンをクリックします。
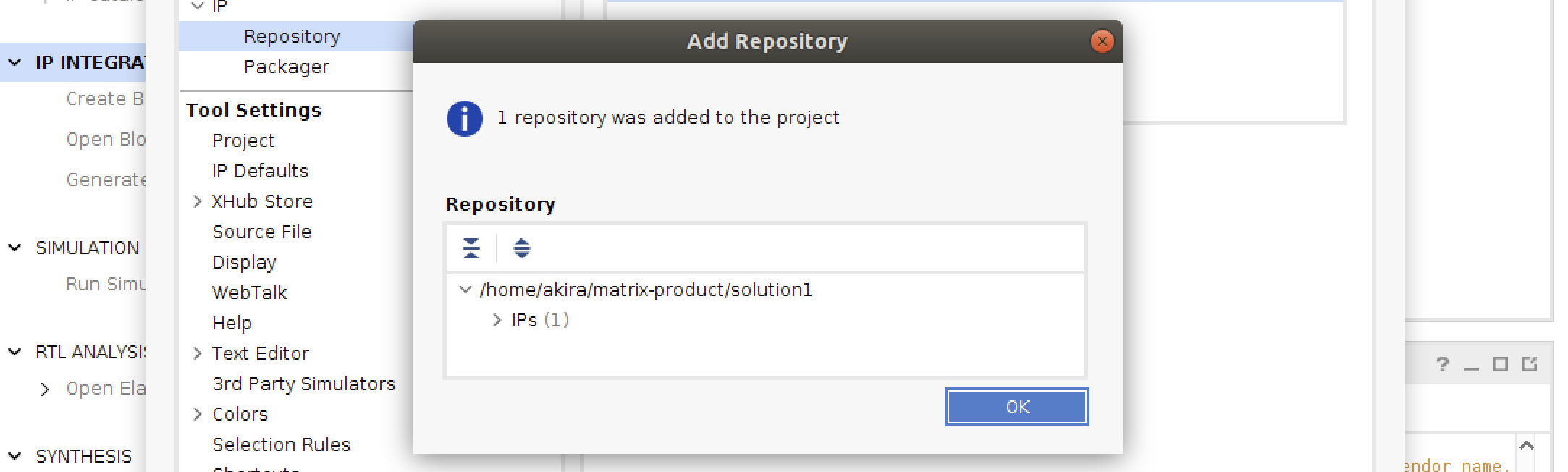
- HLS設計で作成したプロジェクトを選択します。

- IPsの右の数字が1となっていれば、HLS設計したIPが認識されています。
- OKをクリックして設定を閉じます。
- ハードコアされたARM CPUを認識するためのIPコアを追加します。
Diagramの中のプラスボタンから、図のようにZYNQを選択します。
- 同様にHLSで設計したIPを追加します。
HLSの関数名と同じ、Productとなっています。
- 二種類のAutomationを実行します。

- バリデーションを実行して、エラーがないことを確かめます。
- 最後に、ラッパーRTLを作成します。
回路合成と成果物
- 回路合成を行います。合成は数十分かかります。
左部メニューのGenerate Bitstreamをクリックし、ポップアップのOKをクリックします。
- 合成結果の成果物として.bitと.hwhファイルが生成されます。
FinderからVivadoプロジェクトのディレクトリを開いてファイル名で検索すると簡単に見つかります。
分かりやすいディレクトリにコピーしておきます。
Vivado環境での作業は以上です。
PYNQでホストプログラムを書く
次に、FPGA回路を制御するホストプログラムを記述します。
実際にFPGAで数値計算を実行します。Jupyter Notebookの作成とホストプログラムの記述
- PCのブラウザからJupyter Notebookにログインします。デフォルトパスワードはxilinxです。
- 作業用ディレクトリを作成し、作成したディレクトリに移動します。
- design_1_wrapper.bitとdesign_1.hwhをアップロードします。
design_1_wrapper.bitをdesign_1.bitにリネームしておきます。
- 新しいNotebookを作成します。
- 以下のサンプルプログラム1を記述して実行する。
テキストエリアにコピペしてください。
実行にはRunをクリックするか、Shift+Enterを入力します。
JupyterNotebookでは%timeを使うことで簡単に処理速度を計測できます。
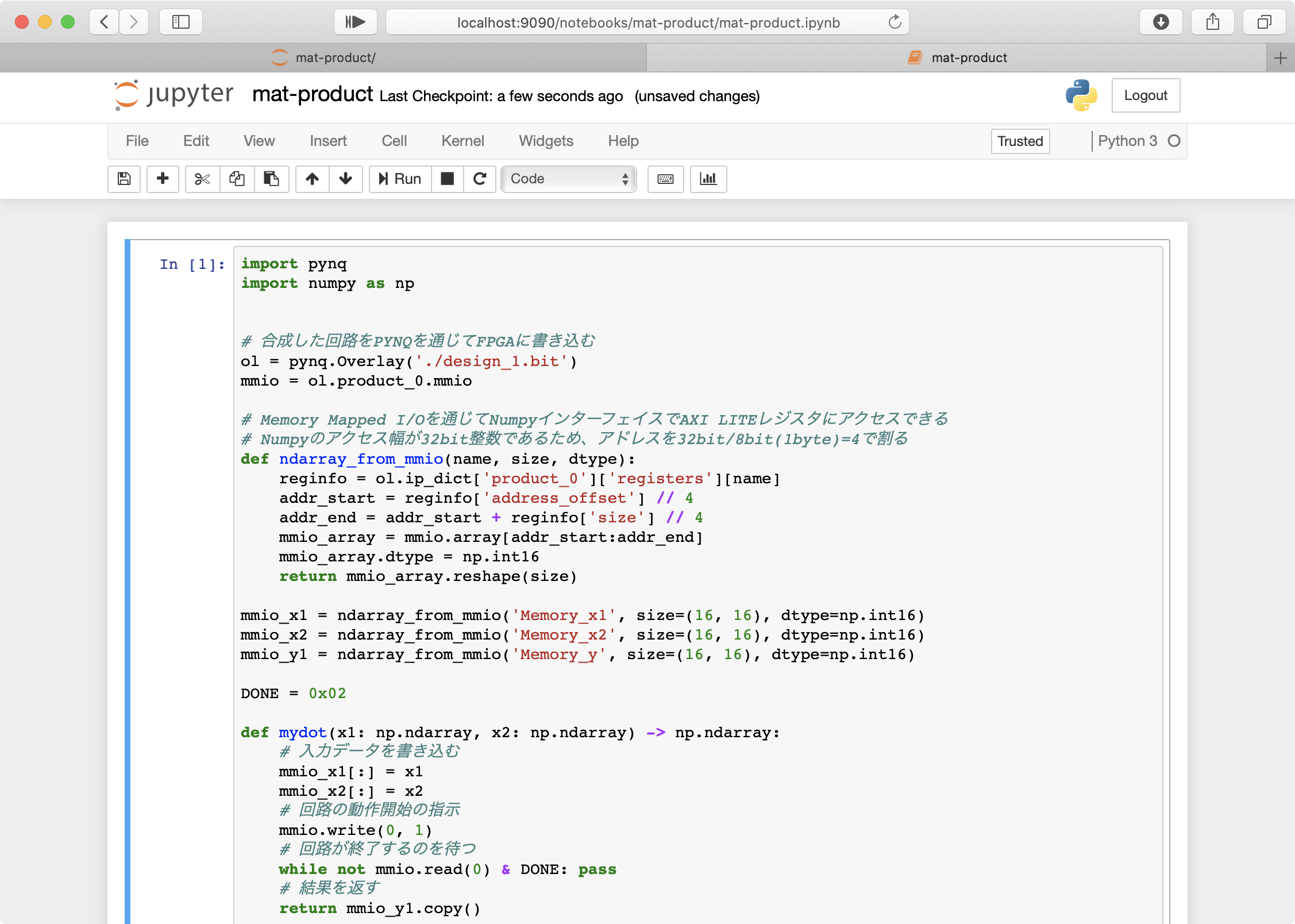
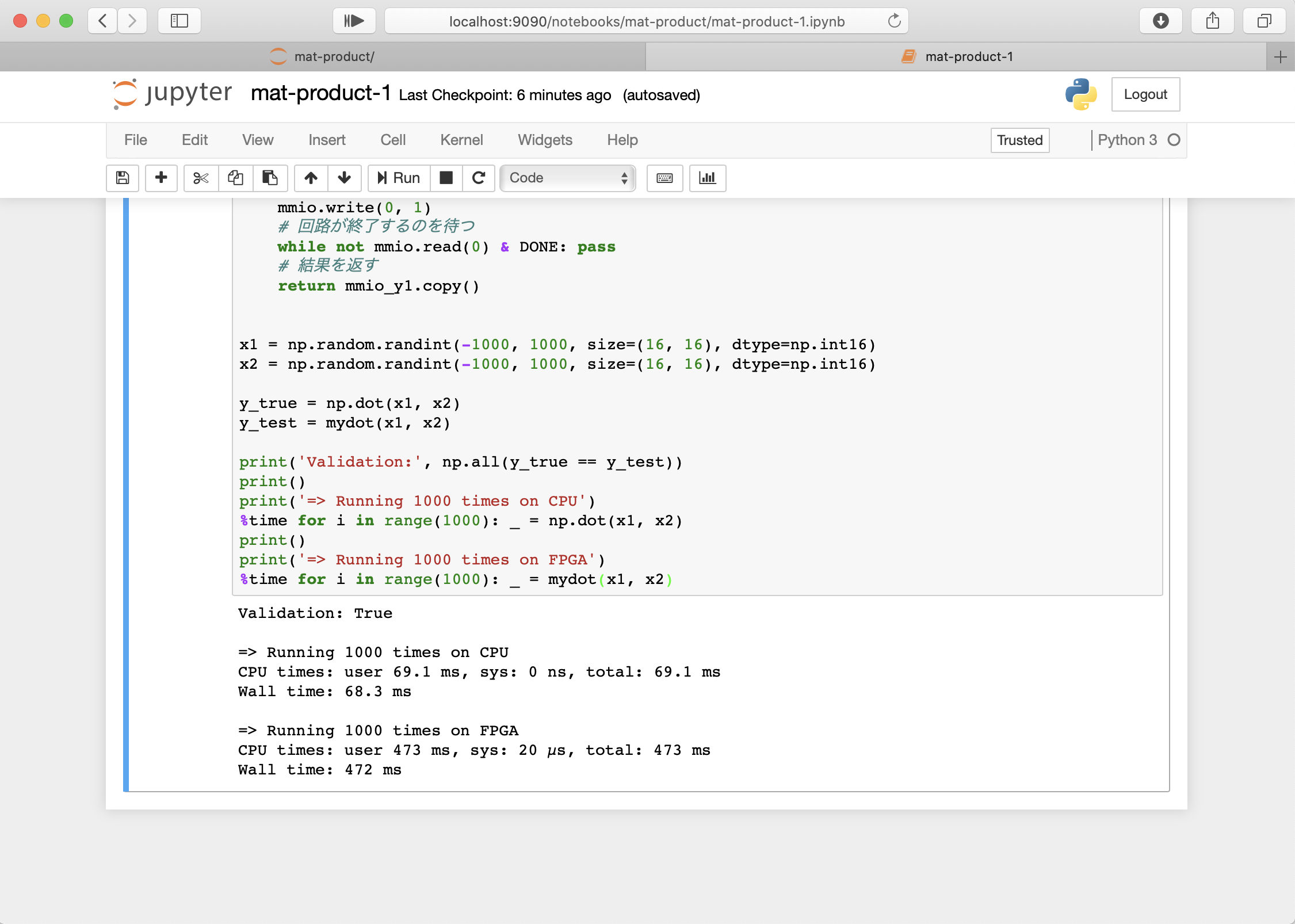 pynq-host-1.pyimport pynq import numpy as np # 合成した回路をPYNQを通じてFPGAに書き込む ol = pynq.Overlay('./design_1.bit') mmio = ol.product_0.mmio # Memory Mapped I/Oを通じてNumpyインターフェイスでAXI LITEレジスタにアクセスできる # Numpyのアクセス幅が32bit整数であるため、アドレスを32bit/8bit(1byte)=4で割る def ndarray_from_mmio(name, size, dtype): reginfo = ol.ip_dict['product_0']['registers'][name] addr_start = reginfo['address_offset'] // 4 addr_end = addr_start + reginfo['size'] // 4 mmio_array = mmio.array[addr_start:addr_end] mmio_array.dtype = np.int16 return mmio_array.reshape(size) mmio_x1 = ndarray_from_mmio('Memory_x1', size=(16, 16), dtype=np.int16) mmio_x2 = ndarray_from_mmio('Memory_x2', size=(16, 16), dtype=np.int16) mmio_y1 = ndarray_from_mmio('Memory_y', size=(16, 16), dtype=np.int16) DONE = 0x02 def mydot(x1: np.ndarray, x2: np.ndarray) -> np.ndarray: # 入力データを書き込む mmio_x1[:] = x1 mmio_x2[:] = x2 # 回路の動作開始の指示 mmio.write(0, 1) # 回路が終了するのを待つ while not mmio.read(0) & DONE: pass # 結果を返す return mmio_y1.copy() x1 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16) x2 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16) y_true = np.dot(x1, x2) y_test = mydot(x1, x2) print('Validation:', np.all(y_true == y_test)) print() print('=> Running 1000 times on CPU') %time for i in range(1000): _ = np.dot(x1, x2) print() print('=> Running 1000 times on FPGA') %time for i in range(1000): _ = mydot(x1, x2)
pynq-host-1.pyimport pynq import numpy as np # 合成した回路をPYNQを通じてFPGAに書き込む ol = pynq.Overlay('./design_1.bit') mmio = ol.product_0.mmio # Memory Mapped I/Oを通じてNumpyインターフェイスでAXI LITEレジスタにアクセスできる # Numpyのアクセス幅が32bit整数であるため、アドレスを32bit/8bit(1byte)=4で割る def ndarray_from_mmio(name, size, dtype): reginfo = ol.ip_dict['product_0']['registers'][name] addr_start = reginfo['address_offset'] // 4 addr_end = addr_start + reginfo['size'] // 4 mmio_array = mmio.array[addr_start:addr_end] mmio_array.dtype = np.int16 return mmio_array.reshape(size) mmio_x1 = ndarray_from_mmio('Memory_x1', size=(16, 16), dtype=np.int16) mmio_x2 = ndarray_from_mmio('Memory_x2', size=(16, 16), dtype=np.int16) mmio_y1 = ndarray_from_mmio('Memory_y', size=(16, 16), dtype=np.int16) DONE = 0x02 def mydot(x1: np.ndarray, x2: np.ndarray) -> np.ndarray: # 入力データを書き込む mmio_x1[:] = x1 mmio_x2[:] = x2 # 回路の動作開始の指示 mmio.write(0, 1) # 回路が終了するのを待つ while not mmio.read(0) & DONE: pass # 結果を返す return mmio_y1.copy() x1 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16) x2 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16) y_true = np.dot(x1, x2) y_test = mydot(x1, x2) print('Validation:', np.all(y_true == y_test)) print() print('=> Running 1000 times on CPU') %time for i in range(1000): _ = np.dot(x1, x2) print() print('=> Running 1000 times on FPGA') %time for i in range(1000): _ = mydot(x1, x2)考察
この時点ではCPUでの処理よりもFPGAの処理は遅くなってしまってます。
考えられる原因として次のようなものがあります。
- 転送が遅い。 入出力データの転送として、AXI LiteプロトコルをMemory Mapped IOを用いたCPU制御で実現しています。 より高速な転送方法としてAXI Streamプロトコルが挙げられます。
AXI Streamメモリ連続アクセスに対応し、FPGAからDRAMに直接アクセスアクセスできるため、高速なデータ転送を実現できます。- 制御のオーバーヘッドが大きい。
今回高速化した関数は16×16の行列積であり、そもそもそんなに計算量が多くありません。
この規模の計算では、FPGAにオフロードするための制御のオーバーヘッドが大部分を占めてしまいます。- そもそも回路が並列化されていない。
今回の設計では一切並列化を行なっていません。 100MHzで動作する並列化されていないFPGA回路より、1000MHz程度で動作するCPUの方が明らかに高速に処理できてしまいます。より高パフォーマンスな動作のために
ここまでの説明で、PYNQを用いたFPGA回路のHLS設計の基本について説明しました。
ここからは、今回の実装のさらなる高速化の方法を説明します。Vivado HLS編
以下に、並列化を施したサンプルコードを載せておきます。
高速化のために対象の計算を少し変更しました。
N×16行列と16×16行列の計算を行います。
計算の変更は、制御のオーバーヘッドの問題を解消するために行います。HLS実装では、プラグマを用いて回路の並列設計などを支持します。
#pragma HLS PIPELINE, UNROLL, ARRAY_PARTITIONなどが該当します。
ここでプラグマの詳細な動作についての説明は省略します。kernel-2.cpp#include <ap_int.h> #include <hls_stream.h> struct DataBus { ap_int<256> data; ap_uint<1> last; }; void product(short w[16][16], hls::stream<DataBus> &x, hls::stream<DataBus> &y) { #pragma HLS INTERFACE s_axilite port=return #pragma HLS INTERFACE s_axilite port=w #pragma HLS INTERFACE axis port=x #pragma HLS INTERFACE axis port=y #pragma HLS ARRAY_PARTITION variable=w dim=0 while (true) { #pragma HLS pipeline short xx[16]; #pragma HLS ARRAY_PARTITION variable=xx short yy[16]; #pragma HLS ARRAY_PARTITION variable=yy // read input data DataBus src = x.read(); for (int i=0; i<16; i++) xx[i] = short(src.data >> 16*i); // matrix product for (int j=0; j<16; j++) { #pragma HLS UNROLL short t = 0; for (int k=0; k<16; k++) t += xx[k] * w[k][j]; yy[j] = t; } // write output DataBus dst; dst.data = 0; for (int i=0; i<16; i++) dst.data |= ap_uint<256>(yy[i]) << 16*i; dst.last = src.last; y.write(dst); if (src.last) break; } }また、高速化のためにクロック周波数を変更します。
と言っても、CPUのように高速化はできず、Z1ボードでは200MHzくらいが妥当です。
以下のような手順で対象のクロック周波数を変更できます。
なお、周波数ではなく周期(200MHz => 5ns)を指定します。
最後に、三角ボタンでHLSの合成を行います。
また、IPコアのエクスポートを忘れずに。Vivado編
AXI Streamを用いた通信を実装します。
ブロックデザインでDMAを追加します。
配線はドラッグアンドドロップ
クロック周波数を200MHzに変更します。
詳しい説明は省略しますが、図のように進めるとブロックデザインが完成します。
ブロックデザインの合成が終わったら、GenerateBitstreamから合成を開始します。
先の例と同様に、成果物の.bitと.hwhファイルをコピーして、ブラウザを通してFPGAにアップロードしてください。
なお、ファイル名はそれぞれdesign_2.bitとdesign_2.hwhとしてください。PYNQホスト編
DMA転送に対応したホストプログラムです。
コピペして実行してください。
CPUよりFPGAは約3倍高速化されています。pynq-host-2.pyimport pynq import numpy as np # 合成した回路をPYNQを通じてFPGAに書き込む ol = pynq.Overlay('./design_2.bit') mmio = ol.product_0.mmio # pragma HLS array_partitionの影響でアドレス配置が変更された # プラグマの指定によって適宜変更する必要がある。 # アドレスはVivado HLSの Solution>Impl>misc>Drivers>src>xxx_hw.hで見ることができる mmio_w = mmio.array[0x010//4:0x810//4] mmio_w.dtype = np.int16 mmio_w = mmio_w.reshape(16, 16, 4)[:,:,0] # AXI DMAを使ってメモリ転送を行う dma_x = ol.axi_dma_0.sendchannel dma_y = ol.axi_dma_0.recvchannel # 大量のデータを処理 N = 30000 buff_x = pynq.allocate(shape=(N,16), dtype=np.int16) buff_y = pynq.allocate(shape=(N,16), dtype=np.int16) DONE = 0x02 def mydot(x: np.ndarray) -> np.ndarray: # 入力データを書き込む buff_x[:] = x # DMA転送を開始する dma_x.transfer(buff_x) dma_y.transfer(buff_y) # 回路の動作開始の指示 mmio.write(0, 1) # 回路が終了するのを待つ while not mmio.read(0) & DONE: pass # 結果を返す return buff_y.copy() x = np.random.randint(-1000, 1000, size=(N, 16), dtype=np.int16) w = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16) # 固定パラメータを書き込む mmio_w[:] = w # 動作周波数を設定する pynq.Clocks.fclk0_mhz = 200 y_true = np.dot(x, w) y_test = mydot(x) print('Validation:', np.all(y_true == y_test)) print() print('=> Running on CPU') %time _ = np.dot(x, w) print() print('=> Running on FPGA') %time _ = mydot(x)おわりに
以上で、PYNQを用いたFPGAのHLS設計のチュートリアルを終了します。
みなさんが、心踊る、楽しい、FPGA設計ライフを送ることを期待して。この資料は研究室内の勉強会のために作成した資料の焼き直しです。
説明の終盤が雑になってしまっています。
間違いや誤植があれば気軽に報告していただけると助かります。あなたが次にすべきこと
- この行列積プログラムをもっと高速化する
- Vivado HLSの設計方法について勉強する
- PYNQライブラリについて勉強する
- 既存のHLS実装を見て学ぶ
- いろんな計算を実装する(FIRフィルタ, テキストマイニングなど)
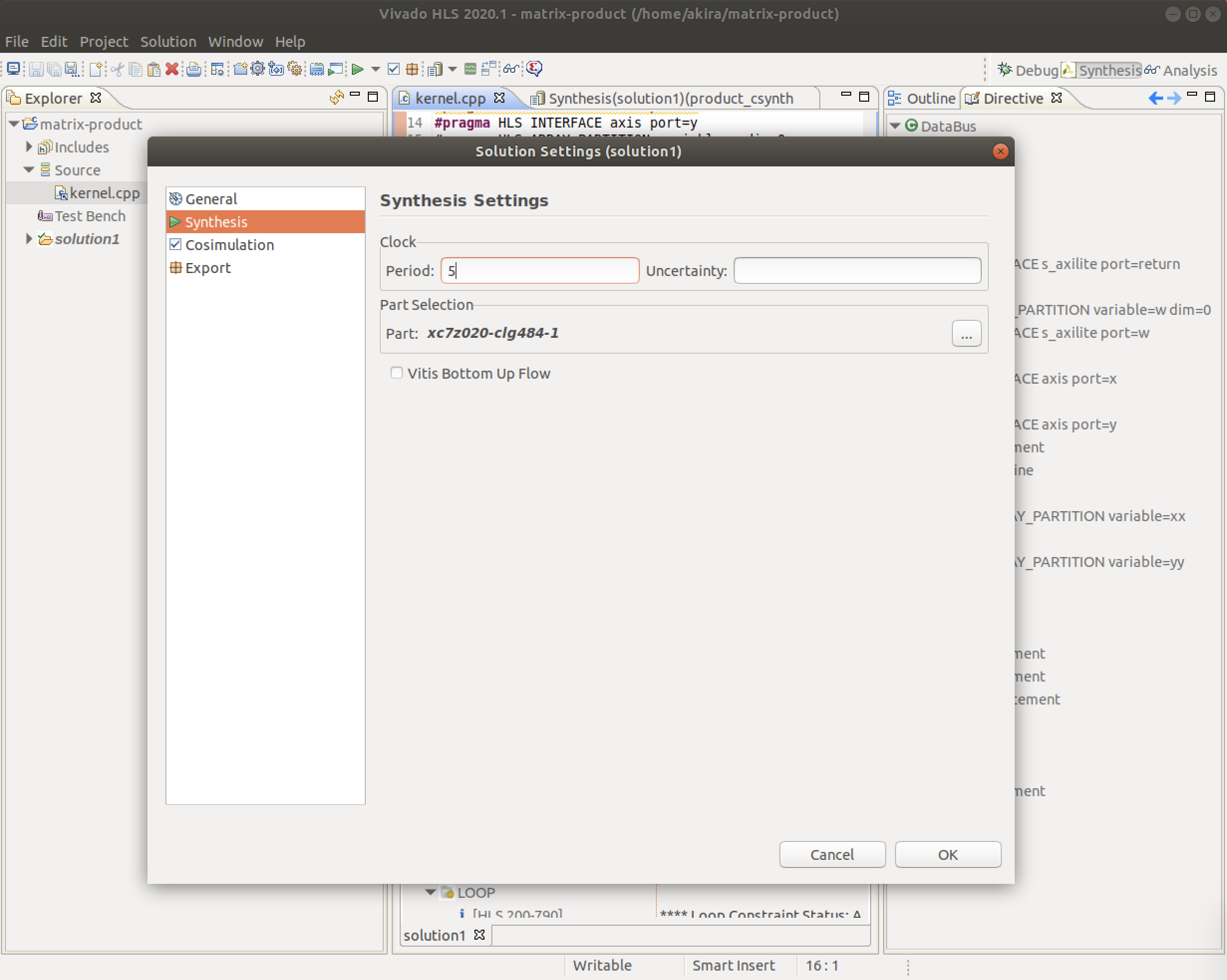
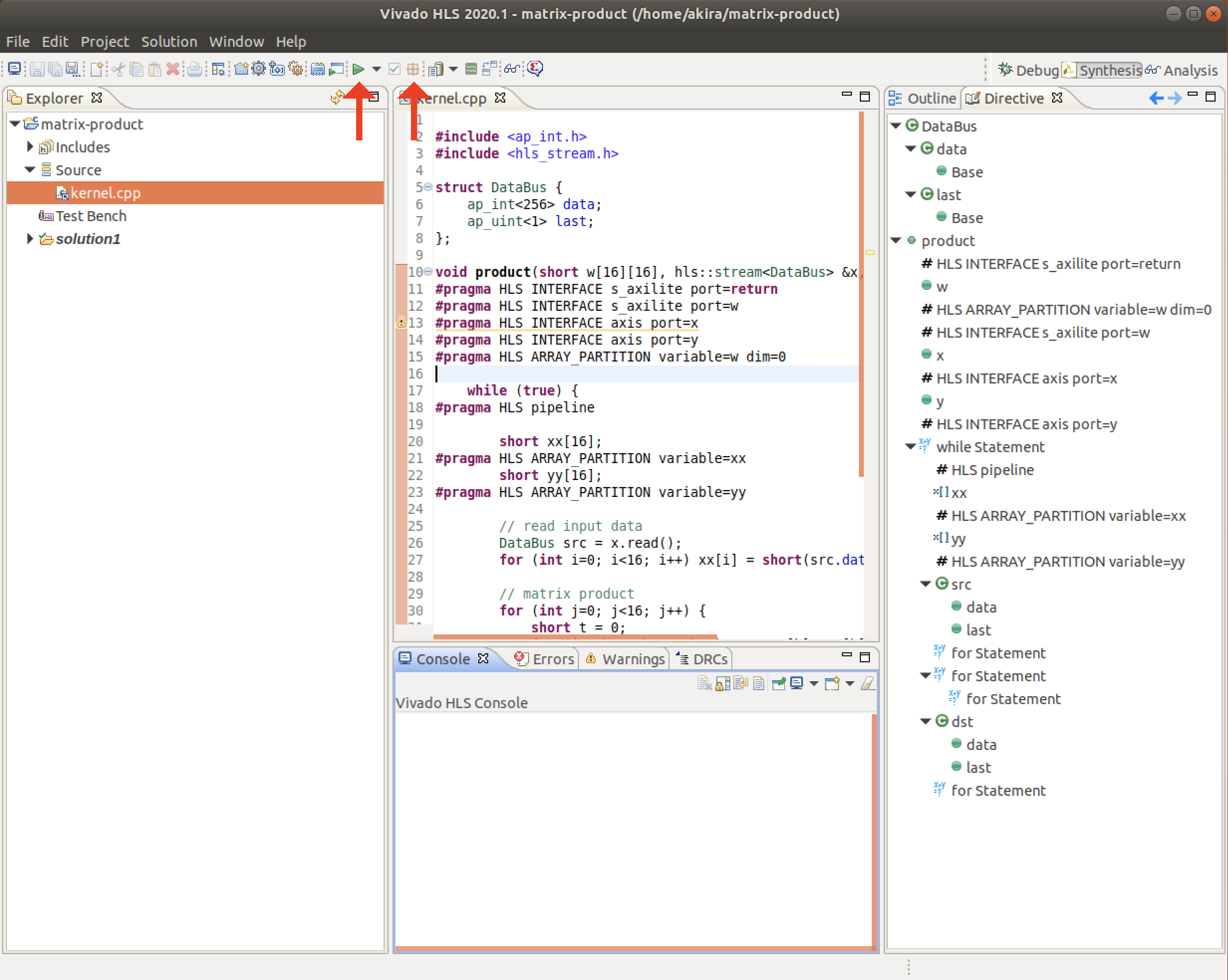
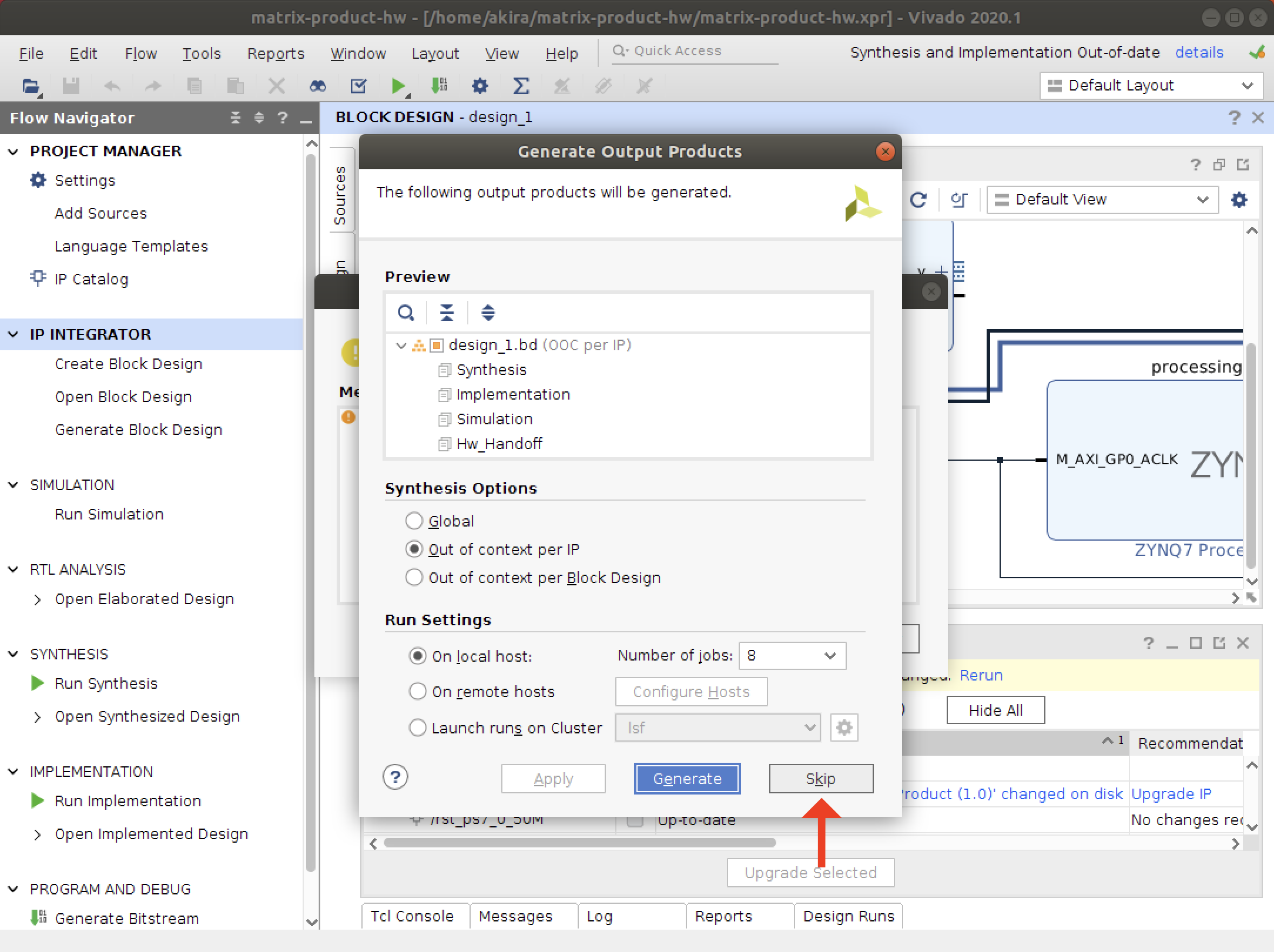
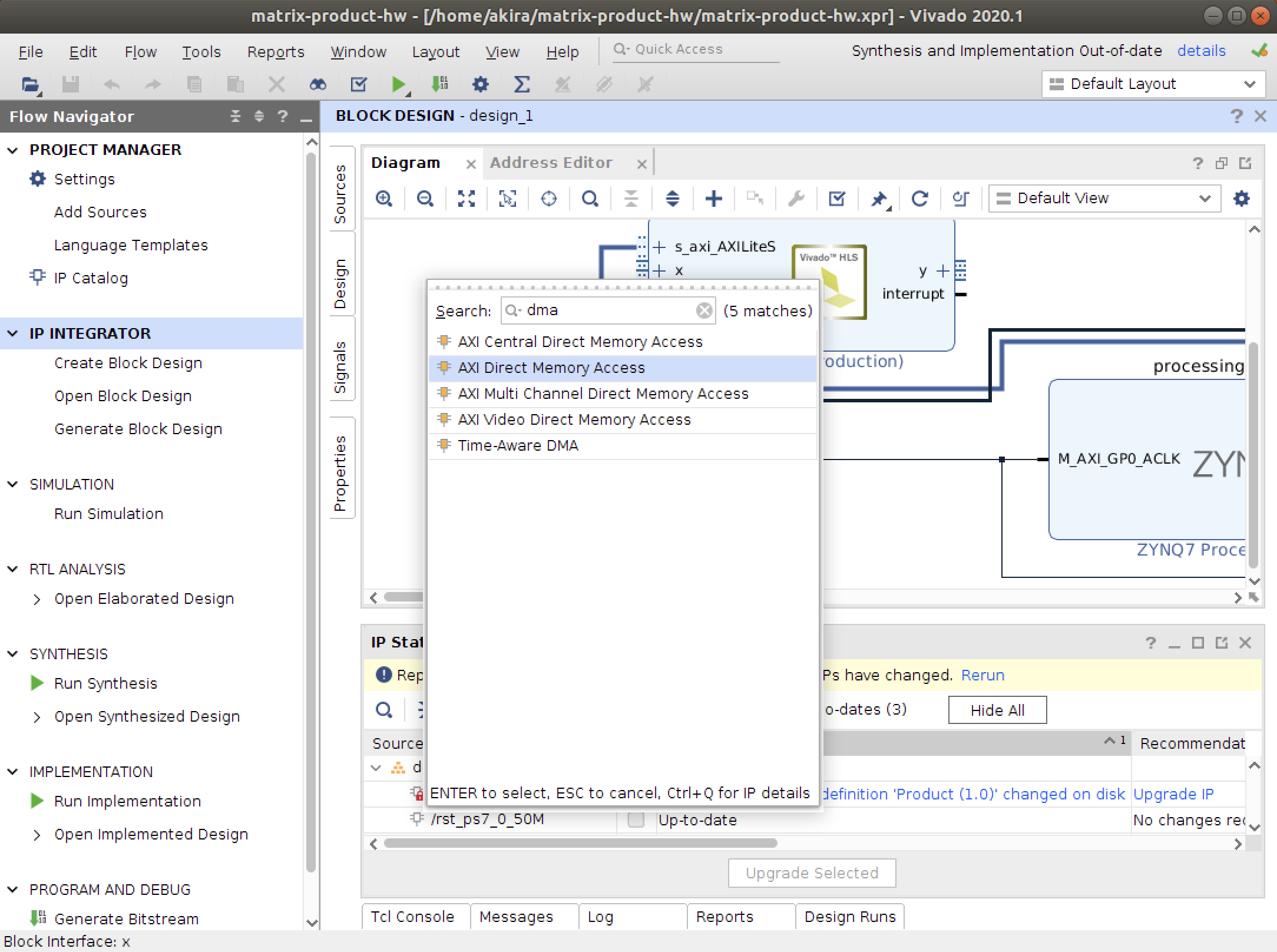
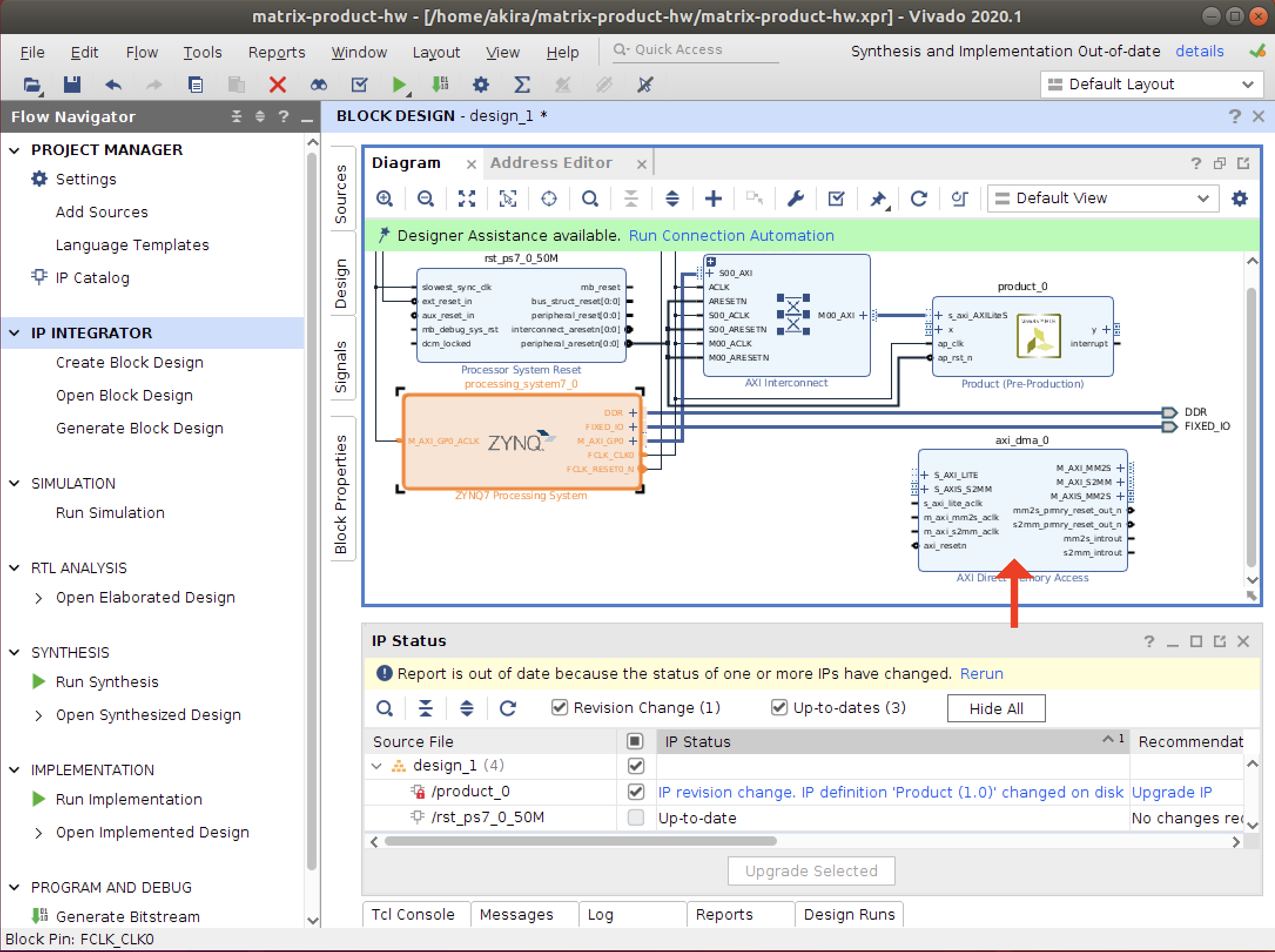
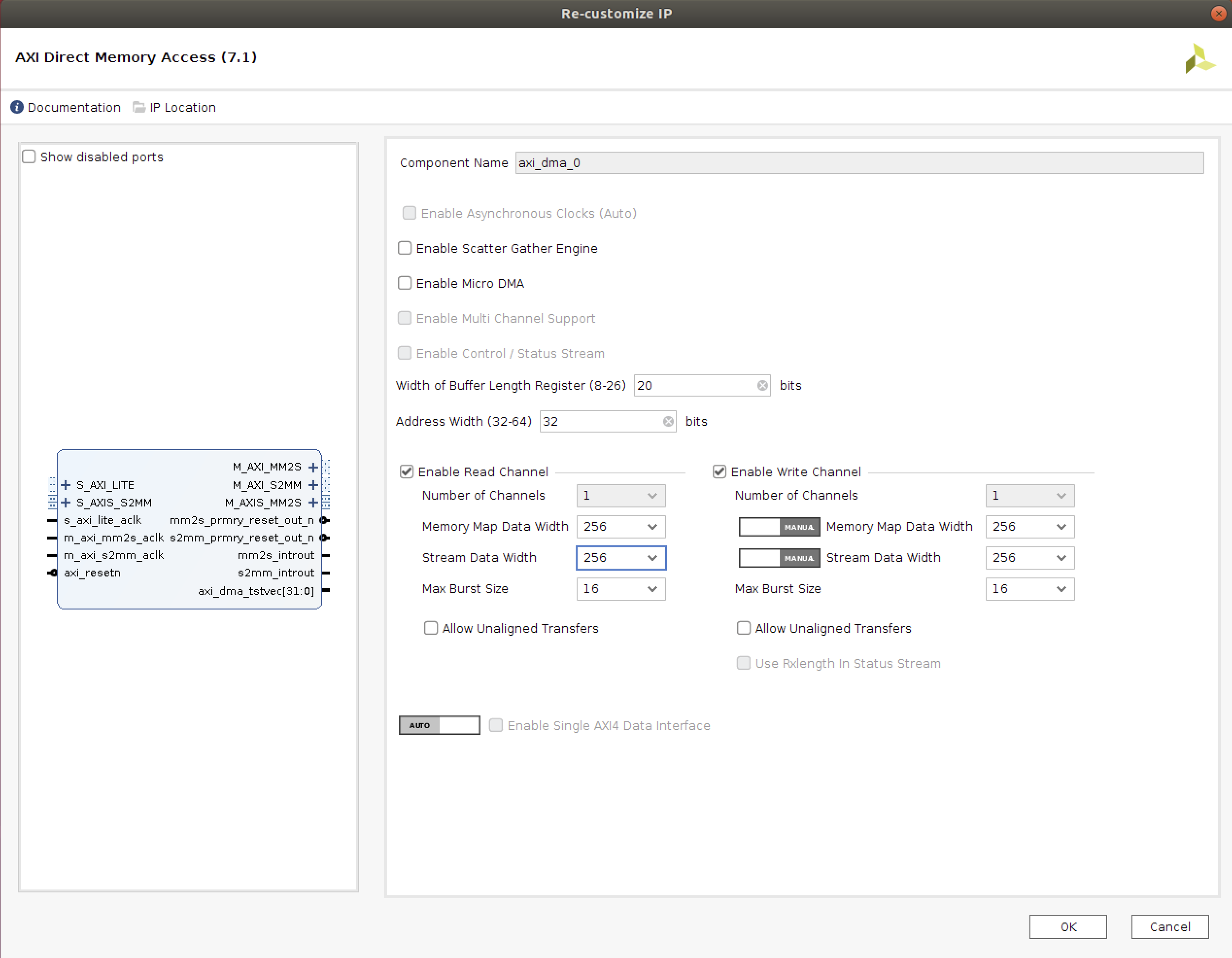

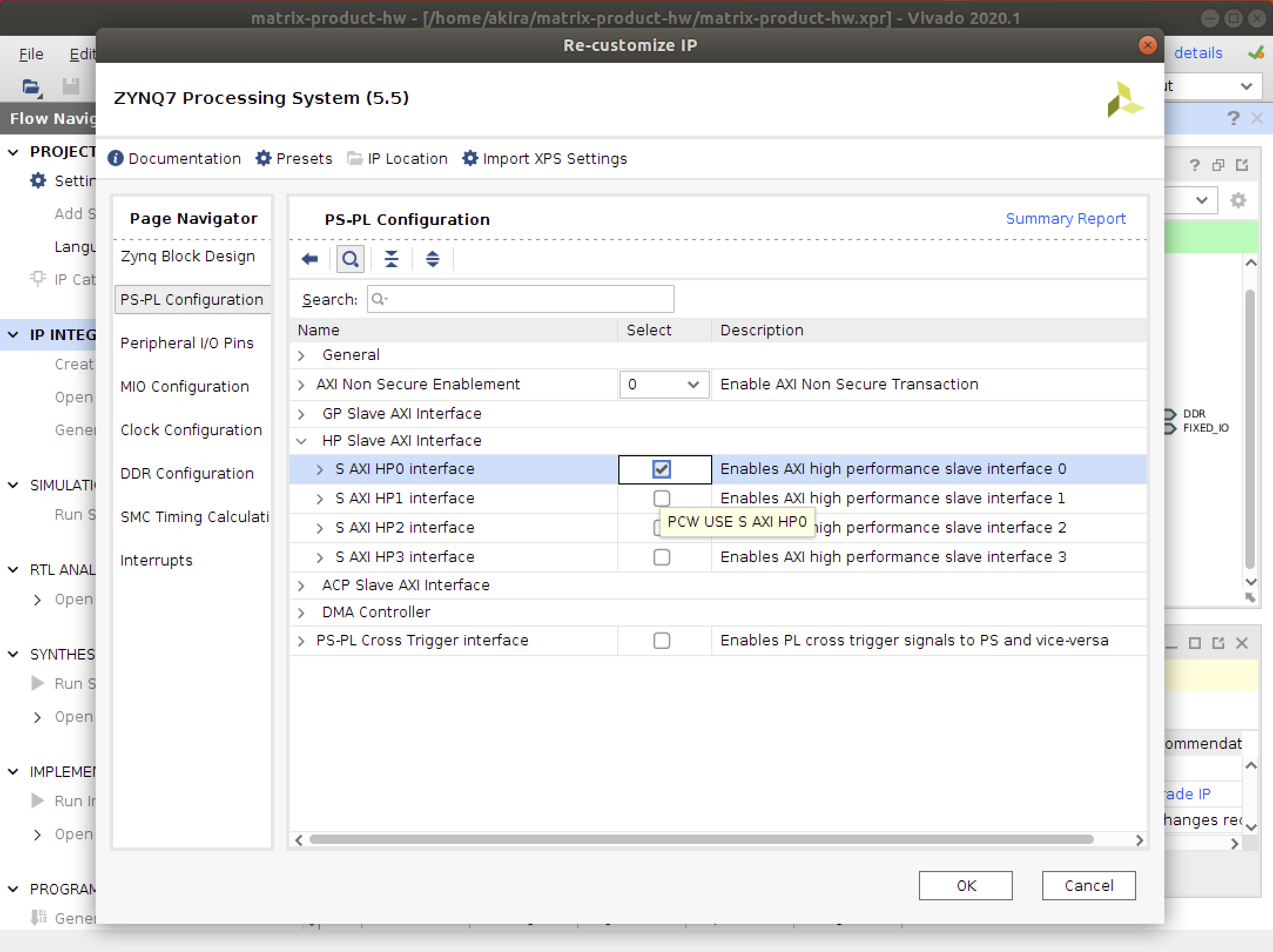
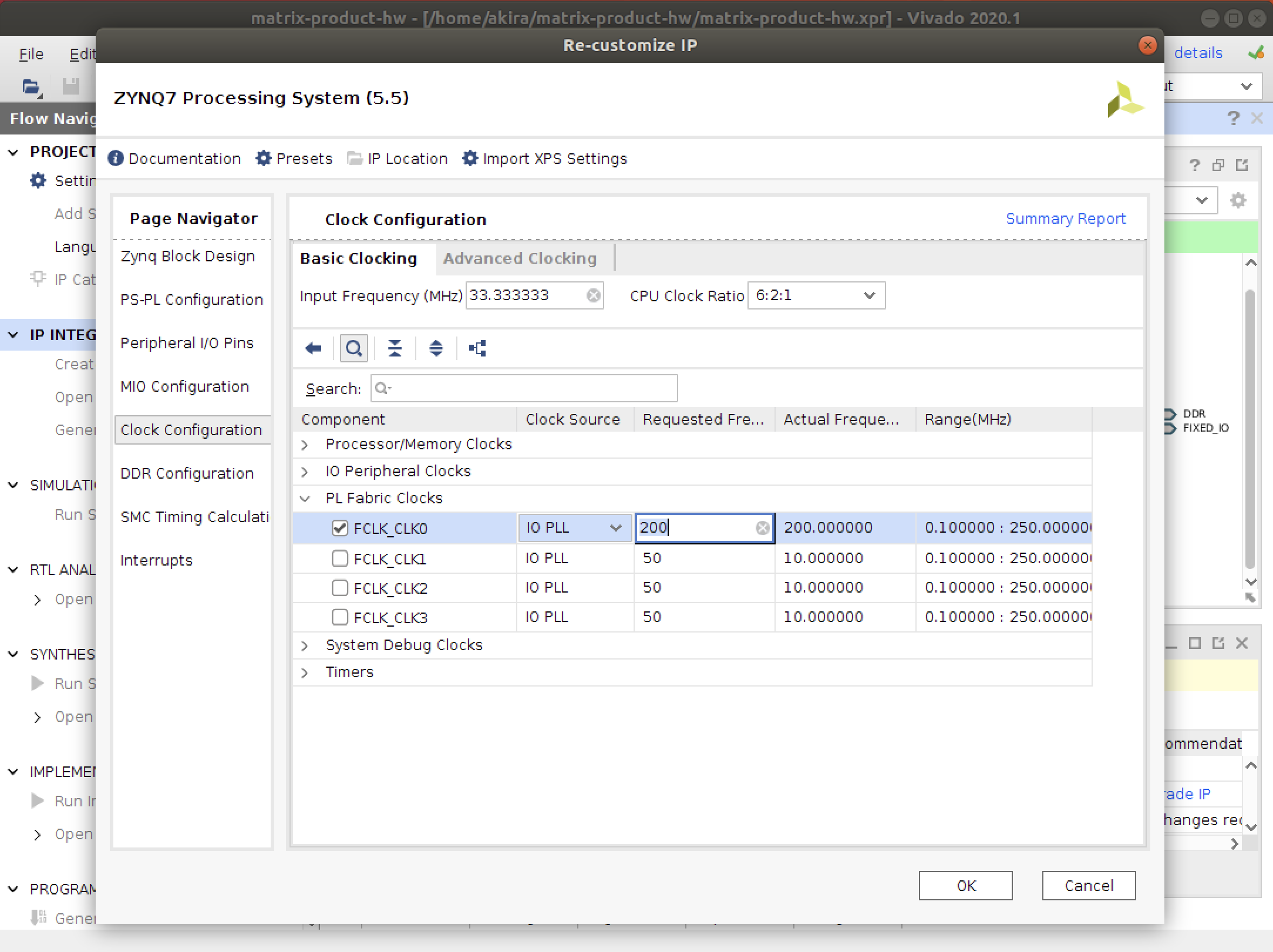
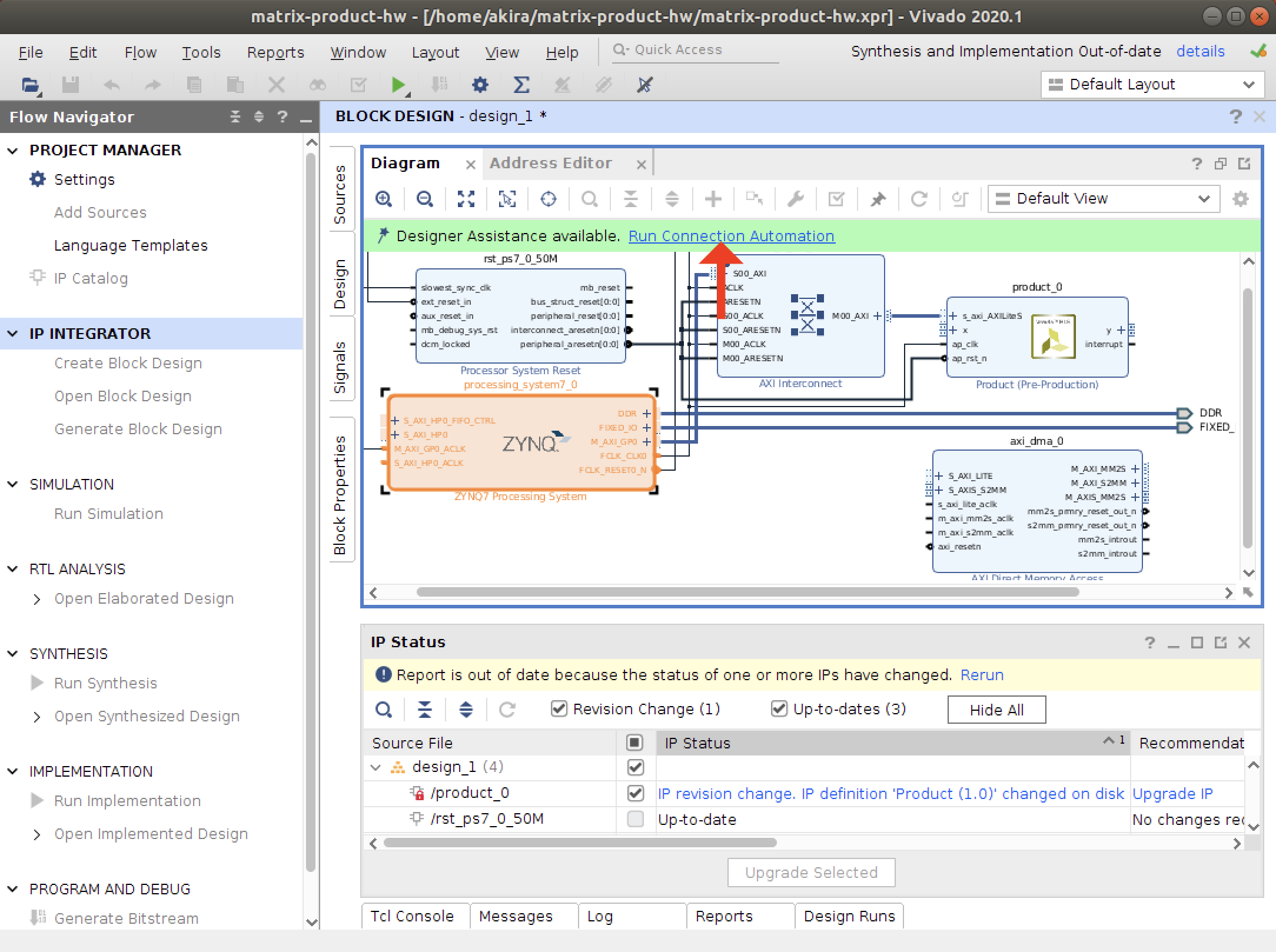
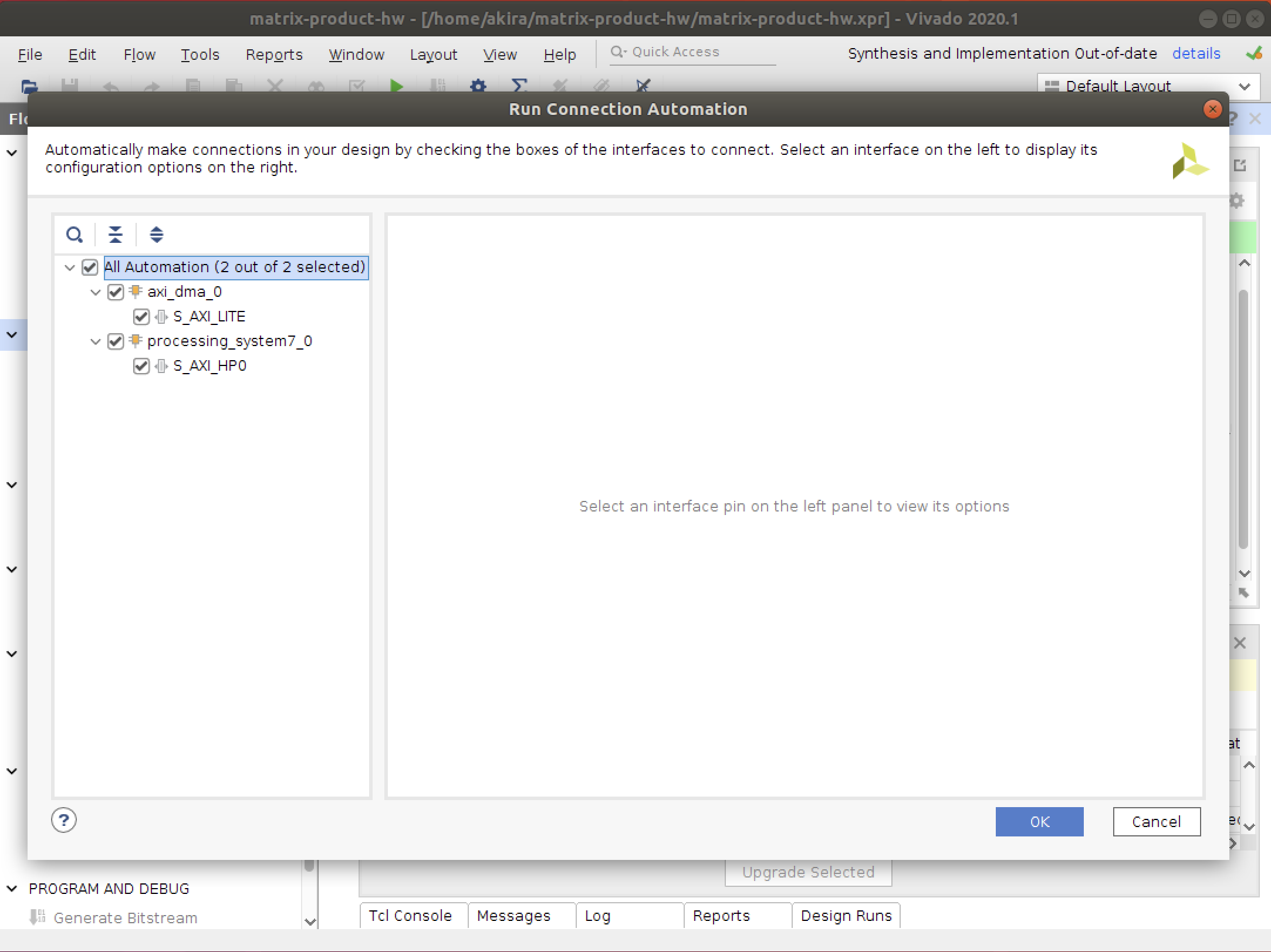
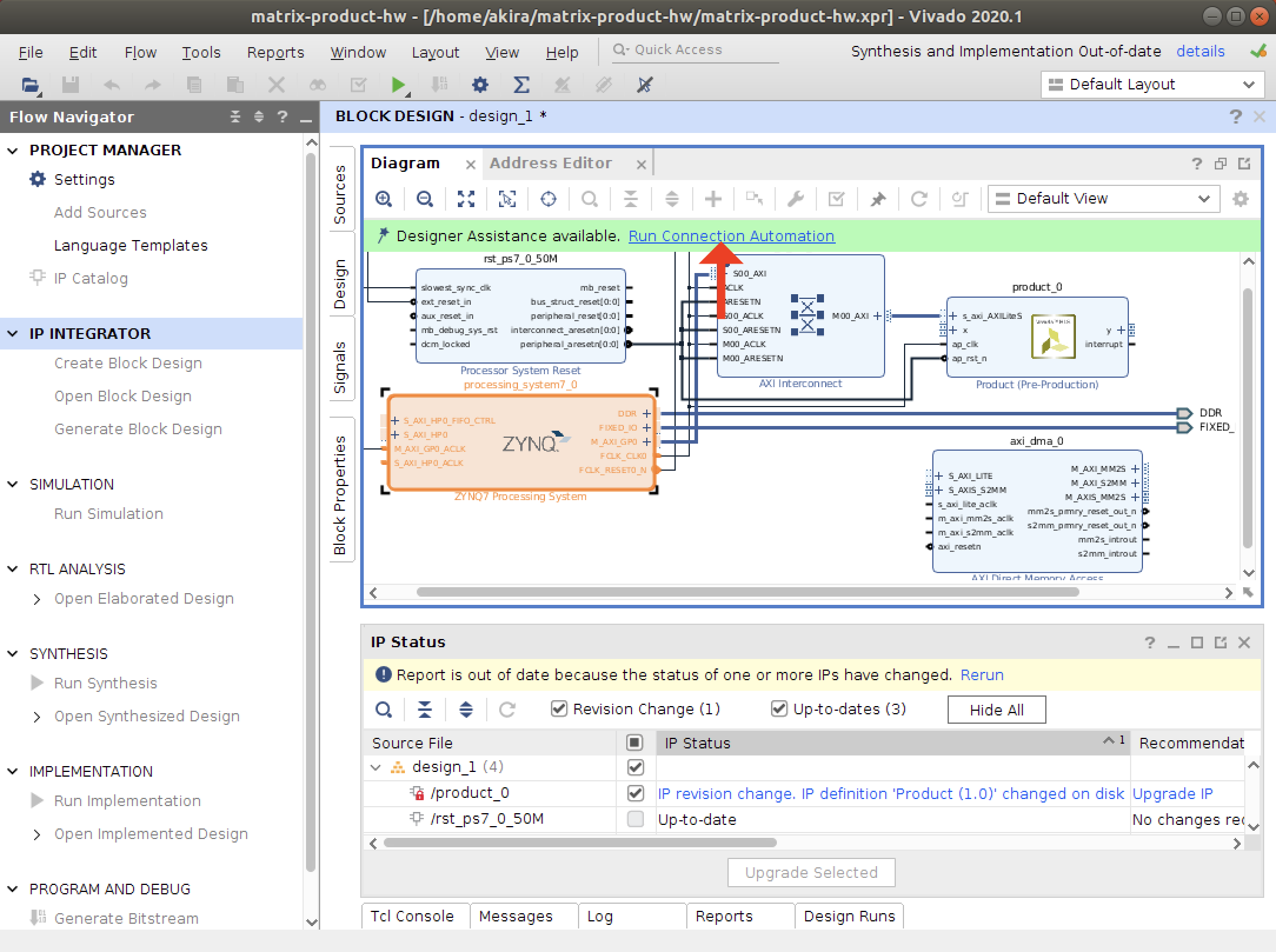
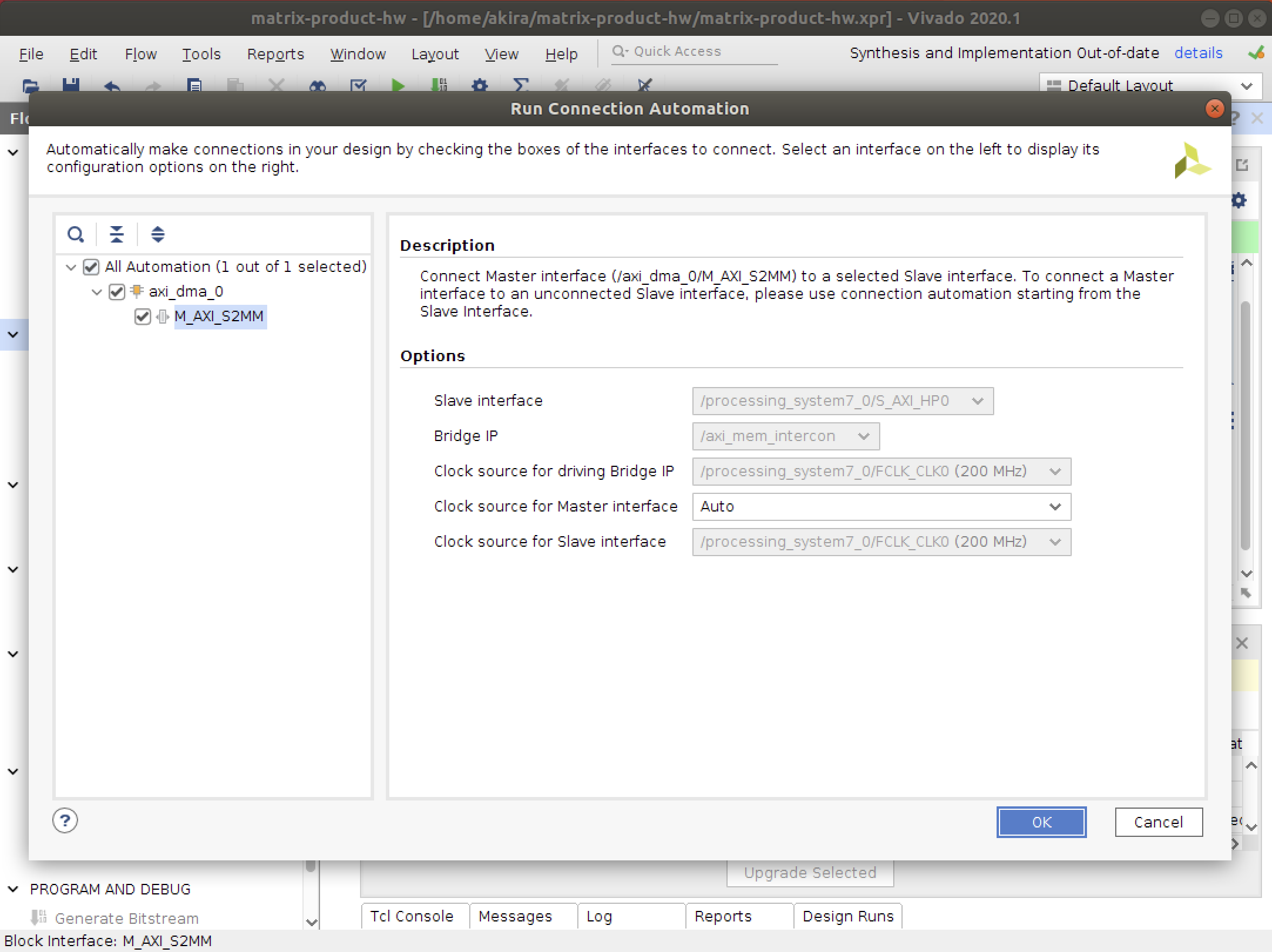
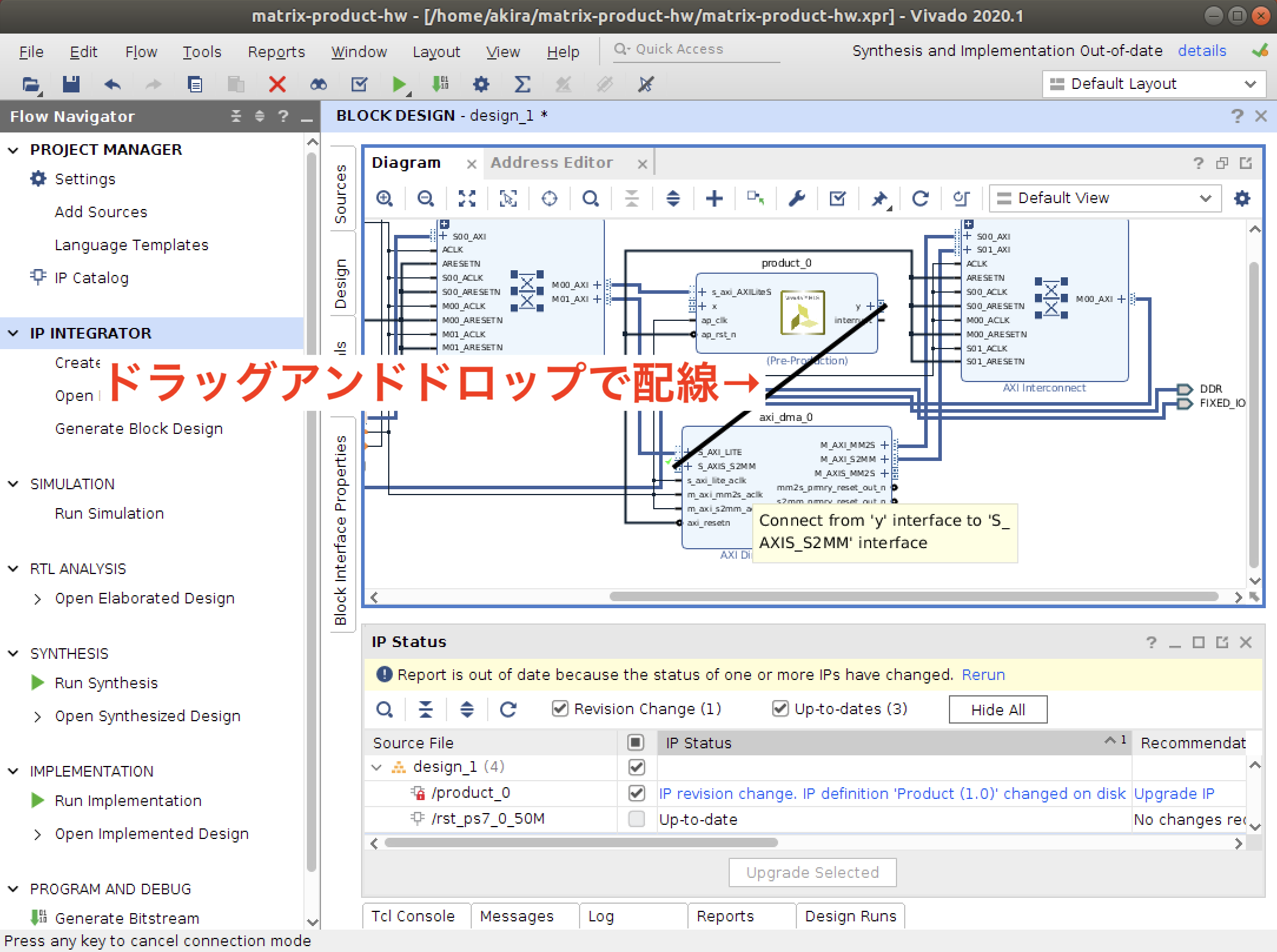
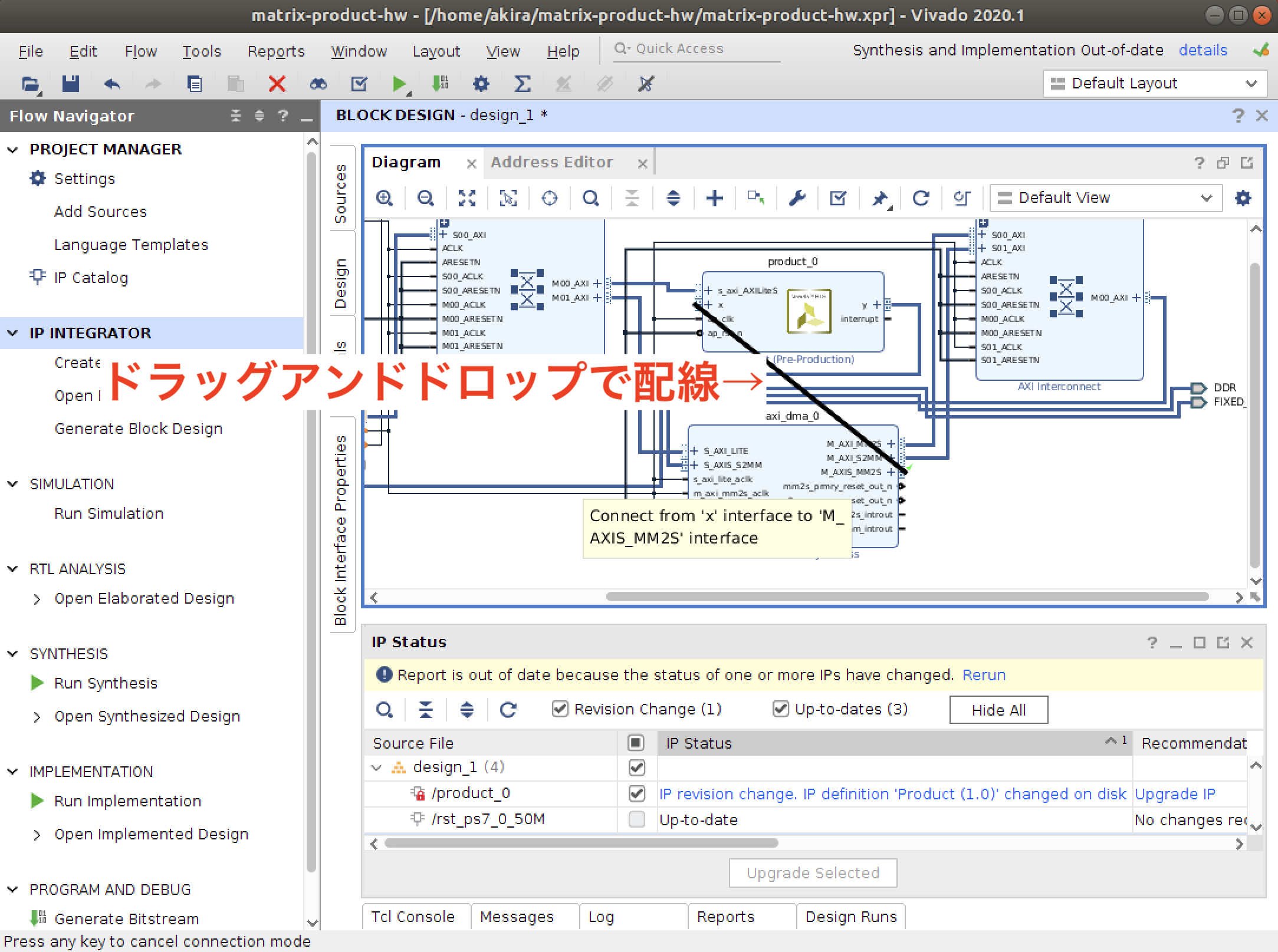
- 投稿日:2020-07-07T15:12:24+09:00
初心者のためのpandas基礎②データ概要把握
pandasとは
Pythonにて、構造化データを扱うためのデータフレームオブジェクトです。ファイルの読み込みやその後のSQL操作などを簡単に行うことができ、機械学習のようデータを加工し、計算、可視化する作業に必要となります。データ操作によく使う構文をメモ書き的にリストします。本項はデータの概要把握です。
ライブラリインポート
pandasにpdという名前をつけてimportする
import pandas as pdデータ件数の確認
「dataflame」の件数を確認します。
print(len(dataflame))データタイプの確認
dataflame.dtypes統計量(数値データ)表示
dataflame.describecount(データの個数)、mean(平均)、std(標準偏差)、min(最小)、25% etc.(四分位値)、max(最大)を集計します。
統計量(カテゴリカルデータ)表示
dataflame.describe(include='O')ゼロではなくオーです。count(データの個数)、unique(uniqueデータの数)、top(最も多く出現した要素の値)、freq(要素の数)を集計します。数値と合わせて表示したい場合は「describe(include='all')」として下さい。
欠損値の確認
初期データ読み込み後やJoinの後に正しく値を取れているかを確認します。
dataflame.isnull().sum()
- 投稿日:2020-07-07T15:09:35+09:00
初心者のためのpandas基礎①読み込み&加工
pandasとは
Pythonにて、構造化データを扱うためのデータフレームオブジェクトです。ファイルの読み込みやその後のSQL操作などを簡単に行うことができ、機械学習のようデータを加工し、計算、可視化する作業に必要となります。データ操作によく使う構文をメモ書き的にリストします。本項はデータの読み込み&加工です。
ライブラリインポート
pandasにpdという名前をつけてimportする
import pandas as pdファイルの読み込み
dataflame = pd.read_csv('file.csv')Excel等も同様の方式で読み込み可能です。Pandasの公式ドキュメント[Input/output]
データ確認
()内に必要な件数を入力します。
dataflame.head(10)最初からの表示が「head」、最後からの表示が「tail」です。
列の作成
既存の「column1」と「column2」を足して、「column3」を作ります。
dataflame['column3'] = dataflame['column1'] + dataflame['column2']Joinする
「dataflame1」と「dataflame2」をカラム「key」で「Left Outer Join」し、「join_dataflame」とします。
join_dataflame = pd.merge(dataflame1, dataflame2, on = 'key', how = 'left')カラムを制限したい場合はdataflame1[['column1','column1']]のように付け加えます。
データダンプ
csvでデータをダンプします。
dataflame.to_csv('dump_file.csv', index = false, encoding = 'utf-8', sep=",")「index」はヘッダーの有無、「encoding」はエンコード、「sep」は区切り文字を指定します。
データ件数の確認
「dataflame」の件数を確認します。
print(len(dataflame))
- 投稿日:2020-07-07T14:03:08+09:00
図解pandasの関数適用処理
DataFrameとSeries列(columns)が複数あるか否かの違い。
DataFrame["列名"]とするとSeriesを返す。
Series.map()とDataFrame.applymap()
map(),applymap()は要素ごとの適用。
Series.map()については、NaNのある表に対して適用する場合は、na_action="ignore"を指定する。また、追加機能として、関数でなく辞書型かSeriesを入力にすると、"NY"を"NewYork"に変換するといった置換ができる(DataFrame.applymap()にはなし)。
Series.apply()とDataFrame.apply()
DataFrame.apply()はアイテムごと、もしくは列ごとの処理(axisにて選択)。例えば、アイテムごとの処理の際に、複数列の要素を使用したい場合はこれを用いる。
Series.map()よりもSeries.apply()を用いる理由は特殊なケースを除けばあまりない。

- 投稿日:2020-07-07T11:04:10+09:00
LightGBMのObjectiveをpythonで再現する
kaggleで人気のライブラリのLightGBMは最小化したい目的関数の勾配を与えることでいい感じに最適化してくれるのが特徴の一つです。
この目的関数を適切に選ぶことは良いモデルを作るためのコツの一つで、デフォルトでもたくさんのobjectiveが実装されていますが、LightGBMではpythonで勾配を計算する関数を渡すことができます。この記事ではLightGBMの公式実装を参考にしながらpythonで同等のobjectiveを作ることでどのような実装がされているか紹介していきたいと思います。前提条件
この記事では回帰/二クラス分類で、lgb.trainにlgb.Datasetを渡して学習を行う場合を想定しています。多クラス分類のobjectiveを作る際は俵さんの記事(LightGBM で強引に Multi-Task(は???) Regression を行う)あたりを読むと分かりやすいと思います。また、gradとhessを求める理由はよく分かっていないのでその辺りは他の資料をあたってください。
公式の挙動を真似する
objective = "l2" の時
本題に入ります。lightGBMはコア部分は高速化のためC++で実装されているのでObjectiveの部分もC++で書かれています。objective="l2"の時の挙動について該当箇所のコード(https://github.com/microsoft/LightGBM/blob/master/src/objective/regression_objective.hpp) を読んでみましょう。勾配を計算する部分はGetGradients()で実装されています。
github.com/microsoft/LightGBM/blob/master/src/objective/regression_objective.hppvoid GetGradients(const double* score, score_t* gradients, score_t* hessians) const override { if (weights_ == nullptr) { #pragma omp parallel for schedule(static) for (data_size_t i = 0; i < num_data_; ++i) { gradients[i] = static_cast<score_t>(score[i] - label_[i]); hessians[i] = 1.0f; } } else { #pragma omp parallel for schedule(static) for (data_size_t i = 0; i < num_data_; ++i) { gradients[i] = static_cast<score_t>((score[i] - label_[i]) * weights_[i]); hessians[i] = static_cast<score_t>(weights_[i]); } } }遅くなるので実用性はありませんが、これをpythonで再現するとこうなります。
def l2_loss(pred, data): true = data.get_label() grad = pred - true hess = np.ones(len(grad)) return grad, hessobjective = "poisson" の時
このobjectiveはpoisson lossを最小化します。poisson lossについてmetricを読んでみると以下のようになっています。
github.com/microsoft/LightGBM/blob/master/src/metric/regression_metric.hppclass PoissonMetric: public RegressionMetric<PoissonMetric> { public: explicit PoissonMetric(const Config& config) :RegressionMetric<PoissonMetric>(config) { } inline static double LossOnPoint(label_t label, double score, const Config&) { const double eps = 1e-10f; if (score < eps) { score = eps; } return score - label * std::log(score); } inline static const char* Name() { return "poisson"; } };そして、objectiveを読んでみると、以下の様な実装になっています。
github.com/microsoft/LightGBM/blob/master/src/objective/regression_objective.hppvoid GetGradients(const double* score, score_t* gradients, score_t* hessians) const override { if (weights_ == nullptr) { #pragma omp parallel for schedule(static) for (data_size_t i = 0; i < num_data_; ++i) { gradients[i] = static_cast<score_t>(std::exp(score[i]) - label_[i]); hessians[i] = static_cast<score_t>(std::exp(score[i] + max_delta_step_)); } } else { #pragma omp parallel for schedule(static) for (data_size_t i = 0; i < num_data_; ++i) { gradients[i] = static_cast<score_t>((std::exp(score[i]) - label_[i]) * weights_[i]); hessians[i] = static_cast<score_t>(std::exp(score[i] + max_delta_step_) * weights_[i]); } } }...お気づきになられましたか?実はこのobjectiveのscoreは予測値そのままではなく、score = e^x で表した際のeの指数部xの値が入っているのです。WolframAlphaで実際に数式を入力してみる とわかるでしょう。そのため、objectiveでpoisson系のobjective(他にはgammaやtweedie等)を作った際は、metricも予測値 = e^(pred) で計算しないといけません。
def poisson_metric(pred, data): true = data.get_label() loss = np.exp(pred) - true*pred return "poisson", np.mean(loss), False def poisson_object(pred, data): poisson_max_delta_step = 0.7 true = data.get_label() grad = np.exp(pred) - true hess = exp(pred + poisson_max_delta_step) return grad, hessobjective = "binary" の時
ダメ押しでニクラス分類の時のobjectiveも見たいと思います。binaryの時のmetricは以下のようになっています。
github.com/microsoft/LightGBM/blob/master/src/metric/binary_metric.hppclass BinaryLoglossMetric: public BinaryMetric<BinaryLoglossMetric> { public: explicit BinaryLoglossMetric(const Config& config) :BinaryMetric<BinaryLoglossMetric>(config) {} inline static double LossOnPoint(label_t label, double prob) { if (label <= 0) { if (1.0f - prob > kEpsilon) { return -std::log(1.0f - prob); } } else { if (prob > kEpsilon) { return -std::log(prob); } } return -std::log(kEpsilon); } inline static const char* Name() { return "binary_logloss"; } };objectiveはis_unbalance=Falseのときsigmoid = 1, label_val = [-1, 1], label_weights = [1, 1]であることを気を付けてください。
github.com/microsoft/LightGBM/blob/master/src/objective/binary_objective.hppvoid GetGradients(const double* score, score_t* gradients, score_t* hessians) const override { if (!need_train_) { return; } if (weights_ == nullptr) { #pragma omp parallel for schedule(static) for (data_size_t i = 0; i < num_data_; ++i) { // get label and label weights const int is_pos = is_pos_(label_[i]); const int label = label_val_[is_pos]; const double label_weight = label_weights_[is_pos]; // calculate gradients and hessians const double response = -label * sigmoid_ / (1.0f + std::exp(label * sigmoid_ * score[i])); const double abs_response = fabs(response); gradients[i] = static_cast<score_t>(response * label_weight); hessians[i] = static_cast<score_t>(abs_response * (sigmoid_ - abs_response) * label_weight); } } else { #pragma omp parallel for schedule(static) for (data_size_t i = 0; i < num_data_; ++i) { // get label and label weights const int is_pos = is_pos_(label_[i]); const int label = label_val_[is_pos]; const double label_weight = label_weights_[is_pos]; // calculate gradients and hessians const double response = -label * sigmoid_ / (1.0f + std::exp(label * sigmoid_ * score[i])); const double abs_response = fabs(response); gradients[i] = static_cast<score_t>(response * label_weight * weights_[i]); hessians[i] = static_cast<score_t>(abs_response * (sigmoid_ - abs_response) * label_weight * weights_[i]); } } }poissonの時と同様に、scoreが予測値 = sigmoid(score) になっているからこのような勾配になっています。先ほどと同様にWolframAlphaで確認するとlabel=0のとき、label=1のときになるので、pythonでobjectiveを書くと以下のようになります。
def binary_metric(pred, data): true = data.get_label() loss = -(true * np.log(1/(1+np.exp(-pred))) + (1 - true) * np.log(1 - 1/(1+np.exp(-pred)))) return "binary", np.mean(loss), False def binary_objective(pred, data): true = data.get_label() label = 2*true - 1 response = -label / (1 + np.exp(label * pred)) abs_response = np.abs(response) grad = response hess = abs_response * (1 - abs_response) return grad, hessおわりに
今回はlightGBMの公式実装をpythonで再現しました。今回紹介した基本を理解するとcustom objectiveを自作しやすくなります。いずれ別の記事で私がコンペで実装したobjectiveを紹介したいと思っているのでその際はよろしくお願いします。
- 投稿日:2020-07-07T10:44:18+09:00
REST APIベースwebアプリ開発時のHTTPキャッシュについて【GCP使用】
概要
自分はサーバサイドをCloud runにてPython(Flask)、クライアントサイドはFirebaseにてJavascript(Vue.js)で開発しています。pythonではFirestoreのデータの読み書きを主に行っています。このとき、以下の二つの課題に当たってしまいました。
- GETリクエストしているのに、OPTIONSリクエストしている(ブラウザにて確認)
- GETリクエストがCloud runに届いていないが、レスポンスが返ってくる。このとき、PUTなどでFirestoreの内容を変更していても、GETリクエストのレスポンスが以前のFirestoreの内容になっている。
本記事は、これらの原因と対策について示します。
「1.」について
1については、OPTIONSリクエストはプレフライトリクエストと言い、単純リクエストではない場合、CORS プロトコルが理解されているかどうかを確認する CORS リクエストであるらしいです。これはクライアント側のリクエスト設定を見直すと飛ばなくすることが出来ます(REST APIの時、Authrizationヘッダがある場合があるため、飛んでしまうことが多いかもしれない)。プレフライトリクエストについては、以下のサイトを参考にしてください。結局これは特に問題ではなかったので、ここまで。
- オリジン間リソース共有 (CORS):https://developer.mozilla.org/ja/docs/Web/HTTP/CORS
「2.」について
こちらは、HTTPキャッシュが原因となっています。サーバサイドでレスポンス生成した際、自分はHTTPキャッシュに係る「Cache-controlヘッダ」を設定していなかったことが原因でした。これにより、本来Cloud run側にリクエストがいかず、FirebaseにあるHTTPキャッシュがクライアントサイドにレスポンスされていました。deploy後の1回目のGET通信は問題ないですが、その後はFirestoreの内容を変更しても、2回以降のGET通信は1回目の内容と同じものとなってしまいます。
- HTTP キャッシュ:https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/http-caching?hl=ja
- HTTP キャッシュ(MDN web docs):https://developer.mozilla.org/ja/docs/Web/HTTP/Caching
おわりに
もしかしたらweb屋さんの常識過ぎるためか、あまりそれっぽい記事はありませんでしたので、備忘録として記述しました。
- 投稿日:2020-07-07T09:54:53+09:00
麦わら海賊団のメンバーのだれにどのくらい似ているのか調べるアプリを作ってみた
麦わら海賊団のメンバーのだれにどのくらい似ているのか調べるアプリを作ってみた
今回は機械学習の画像認識を使ったアプリを作りました。
題名にある通り、自分の顔がワンピースの麦わら海賊団のメンバーのだれにどのくらい似ているのかを調べることができます。git hubはこちら
↓↓↓
https://github.com/Sho-cmyk/shiny-winnerまずは完成形を見てください。
撮影ボタンを押すと、、
自分の顔が麦わら海賊団のメンバーのだれにどのくらい似ているのかを示してくれます。
似ているキャラクター上位2つが表示されます。
私はジンベエに38%ルフィに20%似ていることがわかりました。アプリが気になる方はこちらのURLから試してみてください。
↓↓↓
https://one-piece-camera.herokuapp.com/アプリを作る手順
次にアプリを作る手順を紹介していきます。
手順は大きく分けて以下の通りです。1.学習用の画像を集める
2.画像の前処理
3.学習
4.推定
5. html/css/jsで出力画面を整える1.学習用の画像を集める
私はYahooの画像検索で、麦わら海賊団のメンバーそれぞれの画像をスクレイピングします。
それぞれ200枚スクレイピングしました。
詳しいスクレイピング方法は、以下を参照しました。
引用:https://www.youtube.com/watch?v=BrCaYYJtC4w2.画像の前処理
次に使える画像だけを残していきます。
目的のキャラクターが単体で移っていない写真は消していきます。
その画像を今度は訓練データとテストデータに分けます。訓練データはImageDataGeneratorを使って水増しします。
from PIL import Image import os,glob import numpy as np from sklearn.model_selection import train_test_split from keras.preprocessing.image import ImageDataGenerator classes=["ウソップ","サンジ","ジンベエ","ゾロ","チョッパー","ナミ","ビビ","フランキー","ブルック","ルフィ","ロビン"] num_classes=len(classes) image_size=50 num_testdata=30 #画像の読み込み X_train=[] X_test=[] Y_train=[] Y_test=[] for index,classlabel in enumerate(classes): photos_dir="./"+classlabel files=glob.glob(photos_dir+"/*.jpg") for i,file in enumerate(files): if i >=200:break image= Image.open(file) image=image.convert("RGB") image=image.resize((image_size,image_size)) data=np.asarray(image) X_train.append(data) #リストの最後尾に追加する Y_train.append(index) #ラベルを追加する #標準化 datagen=ImageDataGenerator(samplewise_center=True,samplewise_std_normalization=True) g=datagen.flow(X_train,Y_train,shuffle=False) X_batch,y_batch=g.next() #rgb値の比率を保ったまま0-255に近づけて見やすくする X_batch *=127.0/max(abs(X_batch.min()),X_batch.max()) X_batch +=127.0 X_batch =X_batch.astype('unit8') #配列にしてテストとトレーニングデータに分けて入れる X_train=np.array(X_train) X_test=np.array(X_test) y_train=np.array(Y_train) y_test=np.array(Y_test) #X_train,X_test,y_train,y_test=train_test_split(X,Y) xy=(X_train,X_test,y_train,y_test) np.save("./one-piece_aug.npy",xy)#コードを保存3.学習
学習モデルはCNNを利用します。
コードは以下のとおりです。from keras.models import Sequential from keras.layers import Conv2D,MaxPooling2D from keras.layers import Activation,Dropout,Flatten,Dense from keras.utils import np_utils import keras import numpy as np from tensorflow.keras.optimizers import RMSprop classes=["ウソップ","サンジ","ジンベエ","ゾロ","チョッパー","ナミ","ビビ","フランキー","ブルック","ルフィ","ロビン"] num_classes=len(classes) image_size=50 #トレーニングを実行するメインの関数を定義する def main(): X_train,X_test,y_train,y_test=np.load("./one-piece.npy",allow_pickle=True) #テキストファイルからデータを読み込む X_train=X_train.astype("float")/256 #正規化してRGBの値を0~1に収束させ、ニューラルネットワークが学習しやすくする X_test=X_test.astype("float")/256 #同じく y_train=np_utils.to_categorical(y_train,num_classes) #one-hot-vector:正解値は1,ほかは0。第一引数がベクトルに変換したいラベル、第二引数がベクトルに変換できるラベル。 y_test=np_utils.to_categorical(y_test,num_classes) #同じく model=model_train(X_train,y_train) #学習を行う model_eval(model,X_test,y_test) #評価を行う #CNNのモデルを定義 def model_train(X,y): model=Sequential() #ニューラルネットワークの各層を順番につなげたSequentialモデルをつくる #特徴量を取り出す model.add(Conv2D(32,(3,3),padding='same',input_shape=X.shape[1:])) #畳み込み層3×3の32層 model.add(Activation('relu')) #活性化関数relu,負→0、正→そのまま model.add(Conv2D(32,(3,3))) #2層目の畳み込み層 model.add(Activation('relu')) #活性化関数relu model.add(MaxPooling2D(pool_size=(2,2))) #プーリング層でより特徴を際立たせて取り出す model.add(Dropout(0.25)) #データの偏りを減らすために25%のデータを捨てる model.add(Conv2D(64,(3,3),padding='same')) #次は64個のカーネル層 model.add(Activation('relu')) #relu活性化関数 model.add(Conv2D(64,(3,3))) #また畳み込み層 model.add(Activation('relu')) #relu活性化関数 model.add(MaxPooling2D(pool_size=(2,2))) #マックスプーリング #全結合する。特徴に基づく分類を行う model.add(Flatten()) #まずデータを一列に並べる model.add(Dense(512)) #全結合する model.add(Activation('relu')) #relu活性化関数 model.add(Dropout(0.5)) #半分捨てる model.add(Dense(11)) #出力層のノードは11個 model.add(Activation('softmax')) #合計が1になるソフトマックス関数を使う opt=RMSprop(lr=0.0001,decay=1e-6) #最適化手法の定義。トレーニング時の更新アルゴリズム。 model.compile(loss='categorical_crossentropy', optimizer=opt,metrics=['accuracy']) #評価関数。loss:損失関数で正解と推定値の誤差。opt:最適化手法。metrics:評価の値 model.fit(X,y,batch_size=32,epochs=100) #パラメータの最適化。batch_size:一回に使うデータの数。epoch:学習回数。 #モデルの保存 model.save('./one-piece_cnn.h5') return model #モデルを使えるようにする def model_eval(model,X,y): scores=model.evaluate(X,y,verbose=1) #verbose:経過を表示する,scoreに学習結果を入れる print('Test Loss:',scores[0]) #損失 print('Test Accuracy:',scores[1]) #正確さ #このプログラムがほかのファイルから呼ばれるようにする if __name__=="__main__": main()学習結果は以下のようになりました。
Epoch 100/100 7888/7888 [==============================] - 64s 8ms/step - loss: 0.0200 - acc: 0.9962 330/330 [==============================] - 1s 4ms/step4.推定
import PIL import io import base64 import re from io import StringIO from PIL import Image import os from flask import Flask, request, redirect, url_for, render_template, flash,jsonify from werkzeug.utils import secure_filename from keras.models import Sequential, load_model from keras.preprocessing import image import tensorflow as tf import numpy as np from datetime import datetime classes=["ウソップ","サンジ","ジンベエ","ゾロ","チョッパー","ナミ","ビビ","フランキー","ブルック","ルフィ","ロビン"] classes_img=["static/img/usoppu.jpg","static/img/sanji.jpg","static/img/jinbe.jpg","static/img/zoro.jpg","static/img/chopper.jpg","static/img/nami.jpg","static/img/bibi.jpg","static/img/franky.jpg","static/img/bruck.jpg","static/img/rufi.jpg","static/img/robin.jpg"] num_classes=len(classes) image_size=50 UPLOAD_FOLDER = "./static/image/" ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif']) app = Flask(__name__) def allowed_file(filename): return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS model = load_model('./one-piece_cnn_aug.h5')#学習済みモデルをロードする graph = tf.get_default_graph() app = Flask(__name__) @app.route('/', methods=['GET', 'POST']) def upload_file(): global graph with graph.as_default(): if request.method == 'POST': myfile= request.form['snapShot'].split(',') imgdata = base64.b64decode(myfile[1]) image = Image.open(io.BytesIO(imgdata)) #保存 basename = datetime.now().strftime("%Y%m%d-%H%M%S") image.save(os.path.join(UPLOAD_FOLDER, basename+".png")) filepath = os.path.join(UPLOAD_FOLDER, basename+".png") image=image.convert('RGB') image=image.resize((image_size,image_size)) data=np.asarray(image) X=[] X.append(data) X=np.array(X).astype('float32') X /=256 result=model.predict([X])[0] result_proba = model.predict_proba(X, verbose=1)[0] percentage=(result_proba*100).astype(float) array_sort =sorted(list(zip(percentage,classes,classes_img)),reverse=True) percentage,array_class,array_img = zip(*array_sort) pred_answer1="ラベル:"+str(array_class[0])+ ",確率:"+str(percentage[0])+"%" pred_answer2="ラベル:"+str(array_class[1])+ ",確率:"+str(percentage[1])+"%" pred_answer3="ラベル:"+str(array_class[2])+ ",確率:"+str(percentage[2])+"%" img_src1=array_img[0] img_src2=array_img[1] img_src3=array_img[2] basename = datetime.now().strftime("%Y%m%d-%H%M%S") filepath3 = UPLOAD_FOLDER + basename+".png" return render_template("index.html",answer1=pred_answer1,img_data1=img_src1,answer2=pred_answer2,img_data2=img_src2,answer3=pred_answer3,img_data3=img_src3) return render_template("index.html",answer="") if __name__ == '__main__': app.run(debug = True)5.出力画面を整える

- 投稿日:2020-07-07T09:33:41+09:00
Jupyterプロセスの管理
課題
起動済みのJupyterにブラウザでアクセスするためには、そのJupyterがつながっているポート番号と、アクセストークンが必要になる。これらは、Jupyterプロセスの標準エラーに出力されるログに記載されている。Jupyterにアクセスする度に、この情報を端末やログファイルから探し出すのが面倒なので、これらを管理するコマンド
jmanagerを作成した。インストール
pip install jmanager使い方
jupyterを使いたいディレクトリで
$ jmanagerを実行する。この時、既にカレントディレクトリから起動済みのjupyterサーバーがあれば、それに接続し、なければ新しいjupyterサーバーを立ち上げる。
仕組み
初回実行時に、ポート・トークン・プロセスIDをローカルの
jupyter.pidファイルに保存する。この時、単純にjupyterサーバーを立ち上げるだけではなく、サーバープロセスの終了を待つプロセスも同時に作成し、サーバープロセス終了時にjupyter.pidファイルを削除する。ソース
https://github.com/hotoku/jmanager
コマンドラインオプション
COMMANDを省略すると、
runが選ばれる。$ jmanager --help Usage: jmanager [OPTIONS] COMMAND [ARGS]... Options: --help Show this message and exit. Commands: ignore Print lines for .gitignore kill Terminate jupyter process run Launch new jupyter or connect to existing one.
- 投稿日:2020-07-07T08:46:00+09:00
「データサイエンス100本ノック(構造化データ加工編)」を試す準備
あらまし
データサイエンティスト協会https://www.datascientist.or.jp/が「データサイエンス100本ノック(構造化データ加工編)」を公開している。Windows 10 Home Edition、Anaconda(2020.02)インストール済のPCで、Dockerをインストールせずに、Jupyter NotebookのPython版を試すための作業を記録する。
「データサイエンス100本ノック(構造化データ加工編)」とは
下で紹介されているデータ付きの問題集(言語は3通り、解答付き)になる。
https://digitalpr.jp/r/39499Dockerがあるが
私の環境
・PCはWindows 10 Home。DockerToolboxで対応はされているが。
・メモリは8GB。
・Anacondaをインストール完了しているのでPythonとJupyter Notebookは動作する。
まずは、Dockerをインストールしないとどうなるのか試してみようと考えた。GitHubからZipファイルをダウンロードする
プロジェクトのトップページに行く。例えば今回の「データサイエンス100本ノック」のトップページは下になる。
https://github.com/The-Japan-DataScientist-Society/100knocks-preprocessここで右にある「緑色のCode」をクリックする。
次にDownload ZIPをクリックする。
PCのダウンロードフロルダに100knocks-preprocess-master.zipがダウンロードされる。
zipを展開すると中身は次の通り。
私が必要なのは問題が書かれたコードとデータ一式、かつ解答コードになる。
例えばJupyterNotebookのコードは下にある。
例えばデータは下にある。
MyPython(Pythonコードを入れているフォルダ)の下にフォルダごと移動する。
JupyterNotebookを起動する
フォルダを
MyPython → 100knocks-preprocess-master → docker → work と進む。
preprocess_knock_Python.ipynbをクリックして開く。
最初のInboxをクリックしてRunを実行する。
importを確認すると
psycopg2でひっかかる。よく見るとインストールしていないライブラリがある。ここで考える。
①これらをインストールするのか(二度と使わないかもしれないのに?という疑問あり)。
②自分でdataframeを定義するのか(csvのデータから操作できないと後々自分が困るよね、という気持ちあり)。dataframeを自分で定義することにした。
importはそのまま流用(インストールしていないライブラリはひとまず除いた)、geocode.csvは空白になっているデータがあるので型を定義した。
import os import pandas as pd import numpy as np from datetime import datetime, date from dateutil.relativedelta import relativedelta import math from sklearn import preprocessing from sklearn.model_selection import train_test_split df_customer = pd.read_csv('data/customer.csv') df_category = pd.read_csv('data/category.csv') df_product = pd.read_csv('data/product.csv') df_receipt = pd.read_csv('data/receipt.csv') df_store = pd.read_csv('data/store.csv') df_geocode = pd.read_csv('data/geocode.csv',\ converters={'prefecture':str,'city':str,'town':str,'street':str,'address':str})演習問題はそれなりに実行できる。
参考にしたサイト
データサイエンス初学者のための実践的な学習環境 「データサイエンス100本ノック(構造化データ加工編)」をGitHubに無料公開:https://digitalpr.jp/r/39499

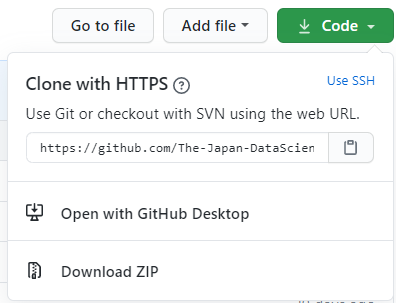

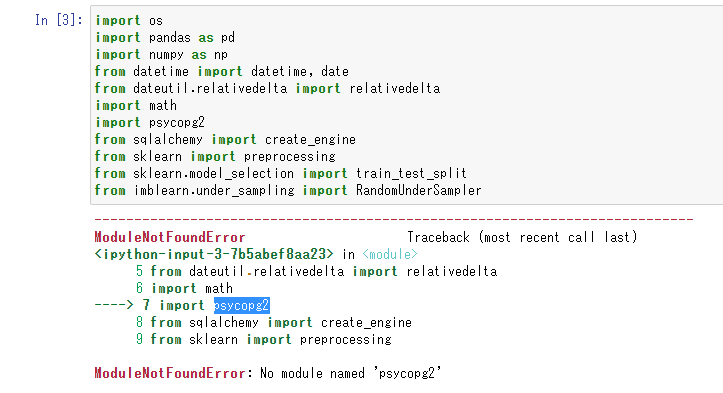
- 投稿日:2020-07-07T05:52:02+09:00
Pythonを触りたい!
Pythonを勉強することになったきっかけ
前々から話題になっており触りたいと思っていたまま、時が過ぎてました...
つい最近、Python触れる子が周りにいたり、企業の人にも他の言語にも触れてみたらとアドバイスをもらったりしたので勉強するモチベが高くなっったって感じです。余談
この画像はちょまどさんが描かれたものです。Pythonちゃん可愛いですよね!
この記事を読む前に
投稿主はC/C++、Java、C#をすでに触っているため、そういったC系の言語と比較した視点で記事を書いていくので予めご了承ください。
お〇ぱいそんを触りたい
ド下ネタな見出しですみません。ただ言いたいだけです。
ここから具体的なPythonの基本文法についてまとめてます。参考記事の内容を自分なりに省略しているので詳細は参考記事をご覧ください。セミコロンが要らない
タイトルの通り過ぎてこれ以上書くことがないですが、文末にセミコロン付けなくていいらしので1タイプ手間が減りますね!!
個人的には普段C系の言語を触っているので違和感しか感じませんが笑型の指定が要らない
C/C++などでは変数を宣言する際に型を明示しなければなりません。
C++int num = 100;これがPythonだとこうなります。
Pythonnum = 100C++やC#でいうautoやvar(型推論)的なことをPythonはデフォルトでやってるみたいですね。(動的型付け)
ただ、明示した方が良いこともあるので一長一短ですね。
ちなみに関数の引数や戻り値っも同様に型指定がありません。中括弧が要らない(ifやforに括弧が要らない)
ないないだらけですね笑
Pythonnum = 77 if num % 2 == 0: print("偶数です") else: print("奇数です")中括弧がない代わりに:(コロン)で条件と処理を分けてるみたいですね。インデントをすることで階層を判断するみたいです
またifやfor、whileなどの条件に括弧をつけないそうです。
これなら中括弧の位置で戦争することが無いので平和だぁ...switch~case、do~whileが無い
タイトルの通りありません。do~whileについてはほぼ使わないんですけどね。
switchの代わりにif~elif~elseで代用するみたいです。else ifではなくてelifみたいなので注意。(なぜ省略したんだろ...)リストに型の制約がない
Cでいう配列なのですが、配列と違いPythonのリストは型の制約がないので数値型や文字列が混在していても大丈夫なようです。
Pythonのforは拡張for(C#でいうforeach)
PythonarrayList = ["cat",100,25.25,"Python"] #リスト内をぶん回します for array in arrayList: print(array) #indexで指定してforを回したい場合 for index in range(0,10): print(index)上のコードのコメントの通りです。rangeを使うことで0から9の配列を用意しています。
ちなみにコメントは// の代わりが # で /~/ の代わりが ''' ~ '''です。演算子系
- インクリメント・デクリメント演算子が存在しない(+=や-=では使える)
- //(小数点以下を切り捨て、整数値を低い方に合わせる)や**(べき乗)がある
- 論理演算の&& や || 、! が and、 or、 notという予約語として扱われる。
関数
Pythonの関数は関数オブジェクトとして扱われています。
Pythondef Add(x,y): return x + y前述したとおり型指定が要らないのでこういう風に描けます。手前にdefを付けたら関数です。物凄くシンプルで好き。
しかもこれの凄いところが型指定が無いのでこんなこともできます。Pythonprint(Add(2,5)) print(Add(1.6,4.8)) print(Add("Hello","World"))C++やC#でいうテンプレート関数として扱えます。(<>で型指定しないのが便利すぎる)
ただ関数のオーバーロードが出来ないそうです。似たようなことをしようと思ったらデフォルト引数を用いればできるみたい。pass文
pass文っていう処理書かなくてエラー出ずに通るっていう分があります。
Pythondef AddPosition(): #TODO:後で実装 passこんな感じで後で実装したいときとかにpass文を使うそうです。なるほどーって感じです。
その他
- import が Cでいう #include
- 連想配列(dict)、タプルが標準で使える
- const や readonly、finelなどの定数のキーワードが無い。(慣習で大文字の変数は定数と扱っているみたい)
- public や private などのアクセス指定子がない。(慣習でprivateなものには _を 1つ付けるとかなんとか)
- virtualやoverrideがない。(継承して同名のメソッドを定義すれば可能)
- 多重継承が可能。(その代わりjavaでいうインターフェースがない)
まとめ
ぱーっと基本的な文法についてはこんなものかなと思います。C++やC#でもあるような機能は省いています。詳細は参考記事をご覧ください。
軽く勉強してみて感じたのは可読性の高いコードを書きやすいなと思いました。
今後はPythonを用いて自動化やAIについての勉強もできたらなと思います。またPythonについてご意見やアドバイスがありましたら気軽にコメントくださると嬉しいです!
参考記事
C言語系プログラマのためのPython入門
https://qiita.com/shiracamus/items/fd35c685e9679323471fC#エンジニアが初めてpythonを学習して感じた違い
https://qiita.com/CEML/items/29944cbeb8e38171a630C#からPythonに乗りかえるための両者の比較
https://qiita.com/kent-u/items/e6b210d38ca39b4cd107C#erがPythonを勉強したので、違いについて比較しながら述べてみる その1 構文
https://hiroronn.hatenablog.jp/entry/20170717/1500281854Python入門
https://python.keicode.com/

- 投稿日:2020-07-07T05:52:02+09:00
C系プログラマが始めるPython
Pythonを勉強することになったきっかけ
前々から話題になっており触りたいと思っていたまま、時が過ぎてました...
つい最近、Python触れる子が周りにいたり、企業の人にも他の言語にも触れてみたらとアドバイスをもらったりしたので勉強するモチベが高くなったって感じです。余談
この画像はちょまどさんが描かれたものです。Pythonちゃん可愛いですよね!
この記事を読む前に
投稿主はC/C++、Java、C#をすでに触っているため、そういったC系の言語と比較した視点で記事を書いていくので予めご了承ください。
お〇ぱいそんを触りたい
ド下ネタな見出しですみません。ただ言いたいだけです。
ここから具体的なPythonの基本文法についてまとめてます。参考記事の内容を自分なりに省略しているので詳細は参考記事をご覧ください。セミコロンが要らない
タイトルの通り過ぎてこれ以上書くことがないですが、文末にセミコロン付けなくていいらしので1タイプ手間が減りますね!!
個人的には普段C系の言語を触っているので違和感しか感じませんが笑型の指定が要らない
C/C++などでは変数を宣言する際に型を明示しなければなりません。
C++int num = 100;これがPythonだとこうなります。
Pythonnum = 100C++やC#でいうautoやvar(型推論)的なことをPythonはデフォルトでやってるみたいですね。(動的型付け)
ただ、明示した方が良いこともあるので一長一短ですね。
ちなみに関数の引数や戻り値っも同様に型指定がありません。中括弧が要らない(ifやforに括弧が要らない)
ないないだらけですね笑
Pythonnum = 77 if num % 2 == 0: print("偶数です") else: print("奇数です")中括弧がない代わりに:(コロン)で条件と処理を分けてるみたいですね。インデントをすることで階層を判断するみたいです
またifやfor、whileなどの条件に括弧をつけないそうです。
これなら中括弧の位置で戦争することが無いので平和だぁ...switch~case、do~whileが無い
タイトルの通りありません。do~whileについてはほぼ使わないんですけどね。
switchの代わりにif~elif~elseで代用するみたいです。else ifではなくてelifみたいなので注意。(なぜ省略したんだろ...)リストに型の制約がない
Cでいう配列なのですが、配列と違いPythonのリストは型の制約がないので数値型や文字列が混在していても大丈夫なようです。
Pythonのforは拡張for(C#でいうforeach)
PythonarrayList = ["cat",100,25.25,"Python"] #リスト内をぶん回します for array in arrayList: print(array) #indexで指定してforを回したい場合 for index in range(0,10): print(index)上のコードのコメントの通りです。rangeを使うことで0から9の配列を用意しています。
ちなみにコメントは// の代わりが # で /*~*/ の代わりが ''' ~ '''です。演算子系
- インクリメント・デクリメント演算子が存在しない(+=や-=では使える)
- //(小数点以下を切り捨て、整数値を低い方に合わせる)や**(べき乗)がある
- 論理演算の&& や || 、! が and、 or、 notという予約語として扱われる。
関数
Pythonの関数は関数オブジェクトとして扱われています。
Pythondef Add(x,y): return x + y前述したとおり型指定が要らないのでこういう風に描けます。手前にdefを付けたら関数です。物凄くシンプルで好き。
しかもこれの凄いところが型指定が無いのでこんなこともできます。Pythonprint(Add(2,5)) print(Add(1.6,4.8)) print(Add("Hello","World"))C++やC#でいうテンプレート関数として扱えます。(<>で型指定しないのが便利すぎる)
ただ関数のオーバーロードが出来ないそうです。似たようなことをしようと思ったらデフォルト引数を用いればできるみたい。pass文
pass文っていう処理書かなくてエラー出ずに通るっていう文があります。
Pythondef AddPosition(): #TODO:後で実装 passこんな感じで後で実装したいときとかにpass文を使うそうです。なるほどーって感じです。
その他
- import が Cでいう #include
- 連想配列(dict)、タプルが標準で使える
- const や readonly、finalなどの定数のキーワードが無い。(慣習で大文字の変数は定数と扱っているみたい)
- public や private などのアクセス指定子がない。(慣習でprivateなものには _を 1つ付けるとかなんとか)
- virtualやoverrideがない。(継承して同名のメソッドを定義すれば可能)
- 多重継承が可能。(その代わりjavaでいうインターフェースがない)
まとめ
ぱーっと基本的な文法についてはこんなものかなと思います。C++やC#でもあるような機能は省いています。詳細は参考記事をご覧ください。
軽く勉強してみて感じたのは可読性の高いコードを書きやすいなと思いました。
今後はPythonを用いて自動化やAIについての勉強もできたらなと思います。またPythonについてご意見やアドバイスがありましたら気軽にコメントくださると嬉しいです!
参考記事
C言語系プログラマのためのPython入門
https://qiita.com/shiracamus/items/fd35c685e9679323471fC#エンジニアが初めてpythonを学習して感じた違い
https://qiita.com/CEML/items/29944cbeb8e38171a630C#からPythonに乗りかえるための両者の比較
https://qiita.com/kent-u/items/e6b210d38ca39b4cd107C#erがPythonを勉強したので、違いについて比較しながら述べてみる その1 構文
https://hiroronn.hatenablog.jp/entry/20170717/1500281854Python入門
https://python.keicode.com/
- 投稿日:2020-07-07T05:25:11+09:00
VSCodeのunresolved importエラーを解決する
- 投稿日:2020-07-07T04:18:36+09:00
おみくじ
導入
今回大学の課題でpythonで何か動くものを作れという課題が出たのでこれを作った。プログラミング初心者なので、習った範囲のもので作った。たいそうなものではないが、頑張りだけは認めてほしい。
参考資料
いちばんやさしいPython入門教室で勉強し、このテキストの6章を参考にしながら作った。
内容
tkinterを使用し、ウィンドウを作り、ボタンを押せばpythonのrandomモジュールを使ってランダムに、吉や、大吉、ランダムにあらかじめ入力しておいたアイテムがウィンドウに出るようにした。
ソースコード
omikuzi.py#coding:utf-8 import tkinter as tk import random import tkinter.messagebox as tmsg def ButtonClick1(): a=["凶","吉","中吉","大吉","末吉","大凶","小吉"] a = random.choice(a) tmsg.showinfo("運勢",a) def ButtonClick2(): b=["時計","ハサミ","メロンパン","猫","犬","ダチョウ","扇風機","だるま"] b = random.choice(b) tmsg.showinfo("ラッキーアイテム",b) root = tk.Tk() root.geometry("400x500") root.title("おみくじ") label1 =tk.Label(root, text="今日の運勢を占おう",font=("Helvetica",14)) label1.place(x= 20, y=20) button1 = tk.Button(root, text = " 占う ",font=("Helvetica",20),bg ='#E0FFFF',fg = "#FF7F50",command=ButtonClick1) button1.place(x=60, y=140) button2 = tk.Button(root, text ="ラッキーアイテム",font=("Helvetica",20),bg ="#FFFFE0",fg ="#FF4500", command=ButtonClick2) button2.place(x=60, y=200) root.mainloop()
実行様子
感想
1から何かを作るのは大変だった。でもその分楽しかったし、作り終わった後の達成感が気持ちよかった。