- 投稿日:2020-06-21T23:42:33+09:00
【Docker】3分でjupyterLab(python)環境を作る!
はじめに
docker-composeファイルを使ってjupyterLabの環境構築方法を記す。
python以外にもsql,R言語にも対応している。
JupyterLabとは、Jupyter(iPython notebook)をベースにしたインタラクティブな開発環境
必要なファイル、ディレクトリ
- docker-compose.yml
- jupyterLab環境に必要な設定などを記述するために使用する。
- docker runコマンドで起動することもできるが、コマンドが面倒なためこちらを使用。
- workディレクトリ
- ipynbファイルなどを保存するための使用する。
ディレクトリ構成
以下のような構成図になるようにファイル、ディレクトリを作成。
構成図. ├── docker-compose.yml ├── workdocker-compose.ymlの内容
jupyterLab環境を構築するために、docker-compose.ymlに必要な設定を記述する。
docker-compose.ymlversion: "3" services: notebook: # https://hub.docker.com/r/jupyter/datascience-notebookからimageをpullする image: jupyter/datascience-notebook # ポートの設定("ホスト:コンテナ") ports: - "8888:8888" # 環境変数の設定 environment: - JUPYTER_ENABLE_LAB=yes # ボリューム(データの永続化の場所)の設定(ホスト:コンテナ) # ホスト内のworkディレクトリとコンテナ内の/home/jovyan/workディレクトリが紐づいているイメージ volumes: - ./work:/home/jovyan/work # 最後にjupyterLabに接続するためのコマンドを実行する。 command: start-notebook.sh --NotebookApp.token=''起動方法
docker-compose.ymlを書き終えたら、以下のコマンドを実行
$ docker-compose up -d初回はimageのpullなどで時間がかかる。
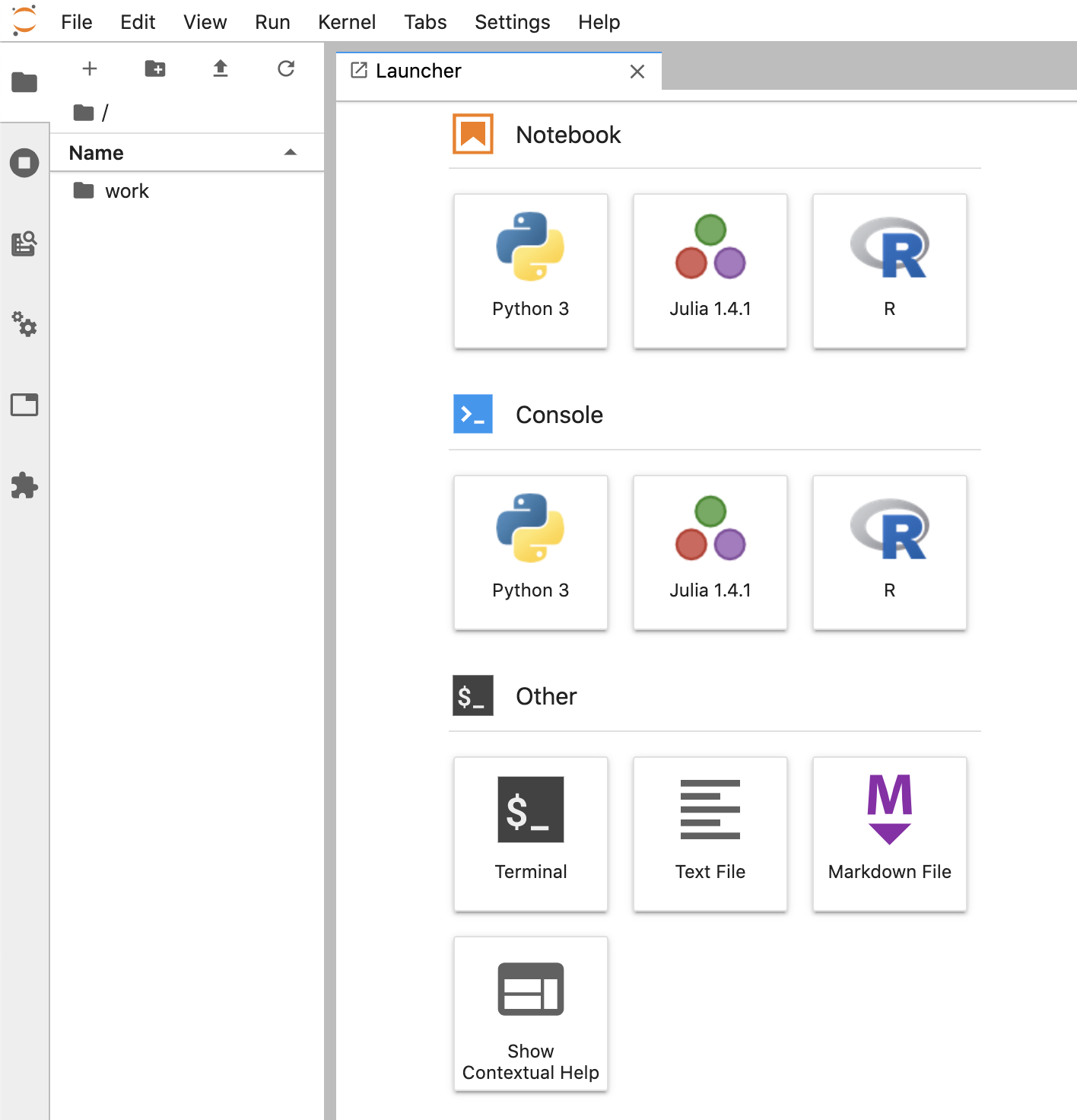
コンテナが立ち上がったら、http://localhost:8888 にアクセス。
以下のような画面が立ち上がれば成功!
補足(docker runコマンドで起動したい人向け)
個人的はdocker-composeファイルを利用して起動する方法が好みだが、docker-composeファイルを作るのが面倒な方は以下のコマンドで起動することも可能。
$ docker run --rm -p 8888:8888 -e JUPYTER_ENABLE_LAB=yes -v ./work :/home/jovyan/work jupyter/datascience-notebook起動時、コンソールに以下のようなログが出てくるので、[トークン]の部分をコピ-。
Copy/paste this URL into your browser when you connect for the first time, to login with a token: http://7dae9a493ca7:8888/?token=[トークン]http://localhost:8888 にアクセス。
すると、パスワードなどを求められるので、password欄に先ほどコピーしたtokenをペースト。
すると、jupyterLabの画面となる。
- 投稿日:2020-06-21T23:35:32+09:00
[光-Hikari-のPython]07章-01 例外処理(エラーと例外)
[Python]07章-01 エラーと例外
今までいろいろなプログラムを書いてきました。自分で記載したプログラムを実行するにはおよそ以下の手順で行います。
【1】プログラムの作成
例えば、割り算の計算を行うプログラムを例にとってみましょう。プログラムの作成は、コンピュータに何かを処理させるため、Pythonなどのプログラムの文法に従って、処理のためのコード記述する作業です。これまで何度も実施してきました。
print('割り算a÷bを求めます。') a = int(input('aの値を入力してください:')) b = int(input('bの値を入力してください:')) print(a / b)なお、上記のコードは人間には読みやすく作られていますが、このままでは実はコンピュータ上では処理はできないのです。正確にはコンピュータ内部にあるCPU(中央処理装置)で処理するのに、上記のコードを実行はできません。この状態のコードをソースコードと言ったりします。
【2】インタプリタ処理
ソースコードを実行できるようにするには、翻訳する必要があります。翻訳するにはPythonのインタプリタを指定します。インタプリタを使用することで、CPUが理解できるマシン語に翻訳ができます。
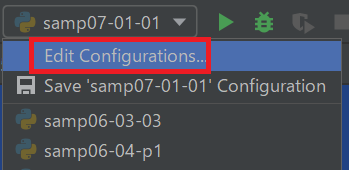
実は01章でインタプリタは指定しています。少し見てみましょう。Pycharmの右上にある[Edit Configurations...]をクリックしてください。
[Python interpreter]でインタプリタのある個所を指定していました。
【3】一行ずつ実行
インタプリタで翻訳しながらプログラム一行ずつを実行していきます。
もし、プログラムの実行中に文法ミスがあったら、構文エラーとして以下のようにエラーが表示され、インタプリタによる翻訳を中止します。。Traceback (most recent call last):
File "C:/Users/***/Desktop/python/chap07/samp07-01-01.py", line 6, in
a = inat(input('aの値を入力してください:'))
NameError: name 'inat' is not definedもし、文法ミスがなければ、そのままプログラムを実行し処理に進みます。
以上がプログラムのコードの記載から実行までの流れです。
例外(0による除算)
先ほど、プログラムを実行して文法エラーがなければプログラムの実行がされると記載しましたが、プログラムを無事に実行してもその時に問題が起こることもあります。
例えば先ほどのプログラムです。chap07を新たに作成し、その中にsamp07-05-01.pyというファイル名でファイルを作成し、以下のコードを書いてください。そして実行してみてください。
print('割り算a÷bを求めます。') a = int(input('aの値を入力してください:')) b = int(input('bの値を入力してください:')) print(a / b)【実行結果】
割り算a÷bを求めます。
aの値を入力してください:10
bの値を入力してください:4
2.5プログラムの内容は問題ないかと思います。
さて、今回はインタプリタによる翻訳も無事に成功し、実行はできていることは確認しました。では、実行後にbの値について0を入力したらどうなるでしょうか?再度実行してbに0を入力してみてください。
【実行結果】
割り算a÷bを求めます。
aの値を入力してください:10
bの値を入力してください:0
Traceback (most recent call last):
File "C:/Users/光矢(koya)/Desktop/python/chap07/samp07-01-01.py", line 5, in
print(a / b)
ZeroDivisionError: division by zero何が起こったかというと、エラーの最後に「ZeroDivisionError: division by zero」とあり、これは「0で割ろうとしてエラーとなっています」という意味です。
実際に算数や数学の世界でも値を0で割ることはできません。さて、この入力した0という値、インタプリタによる翻訳時に発生したエラーではなく、翻訳が無事に終わった後に起きたエラーです。
実際には、実行時に実行画面から人による0の入力です。こういった文法の誤りでなく実行時に発生したエラーを例外(Exception)と言います。
また、インタプリタによる翻訳時に発生する文法のエラーを構文エラーと言います。まとめると、エラーには構文エラーと例外が存在します。
さて、例外ですが、実行時に人が実行画面からbの値として0を入力しないように気を付けても、人が入力するものですから、今回のような例外はどこかで必ず発生します。例外(リストの要素を超えて指定した場合の例外)
先ほど、0による除算について触れましたが、ほかにもまだあります。例えば、リストの要素の番号を指定する際に、リストの要素数を超える要素番号を指定した際にも例外が発生します。chap07を新たに作成し、その中にsamp07-05-02.pyというファイル名でファイルを作成し、以下のコードを書いてください。
07-05-02.pyls = [1, 3, 5, 7, 9] print(ls) i = int(input('上記のリストの要素番号を指定してください:')) print(ls[i])【実行結果】
[1, 3, 5, 7, 9]
上記のリストの要素番号を指定してください:5
Traceback (most recent call last):
File "C:/Users/***/Desktop/python/chap07/samp07-01-02.py", line 5, in
print(ls[i])
IndexError: list index out of rangeエラーメッセージの最後に「IndexError: list index out of range」とあります。これは、「リストの範囲を超えてインデックスを指定指定しています」といった旨のエラーメッセージです。
今回、リストの要素はls[0]~ls[4]までしかないはずなのに、ls[5]と指定しているので、例外となります。今回も人の入力によって例外が起こっています。最後に
今回はエラーの種類として例外と構文エラーについて触れました。例外の例として、0による除算やリストの要素外の指定などを取り上げました。
このような、人的なミスによる例外はよく見られます。いくら人に対して「気を付けてください」と言っても、ミスは起きてしまいます。こういったミスを起こさないために、人にゆだねるのは危険です。さて、この例外を避けるためのエラーに強いプログラムを作成するにはどうすればよいか、それについては次回触れたいと思います。
【目次リンク】へ戻る
- 投稿日:2020-06-21T23:14:32+09:00
Windows上でシンボリックリンクを作成するツール
概要
windows環境でシンボリックリンクを作成する機会が頻繁にあったので、
右クリックメニューからシンボリックリンクを作成するツールを自作した。環境
- Windows10 Pro
- python3.6.8
- pyinstaller3.4
githubリポジトリ
https://github.com/nakashimn/win_symlink
準備
ツールをgit cloneする
- 上記githubリポジトリをgit cloneする
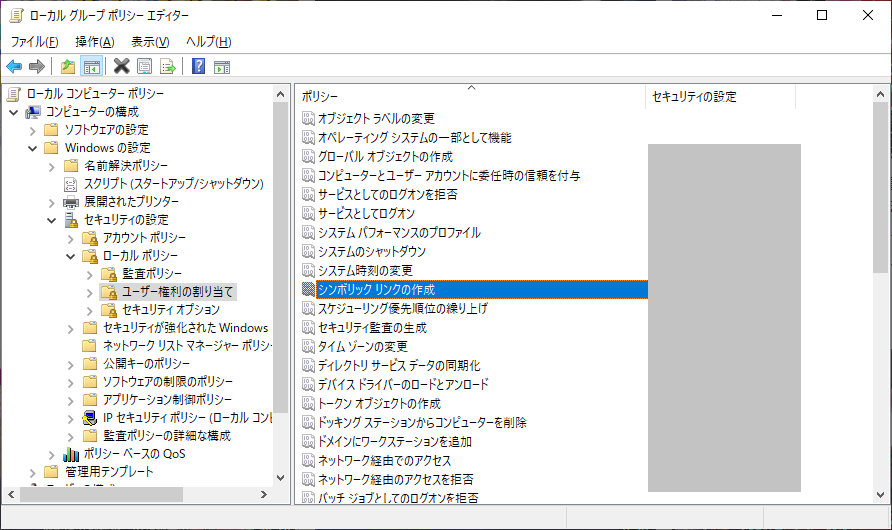
グループポリシー設定
- 「グループポリシーの設定」から下図の「シンボリックリンクの作成」を開く
- ユーザーを追加する
(参考)https://qiita.com/masinc000/items/512d0a46f53be4180852
右クリックメニューの「送る」にツールを追加
- エクスプローラーでshell:sendtoを指定して「送る」ディレクトリを開く
- git cloneしたディレクトリのsrc/dist/winsymlink.exeのショートカットを上記ディレクトリに作成
使い方
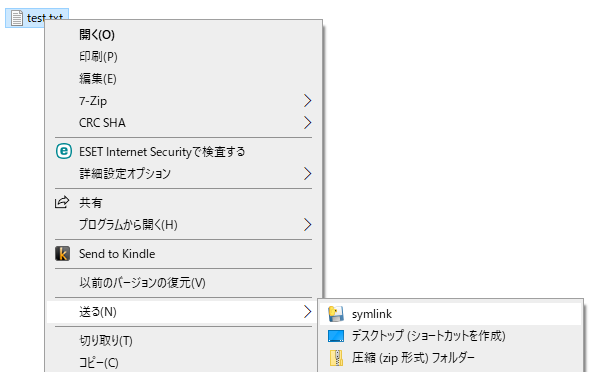
- シンボリックリンクを作成したいファイルorディレクトリで右クリック
- 「送る」メニューからsymlinkを選択
- 同ディレクトリに *_symlink の名称でシンボリックリンクが作成される

- 投稿日:2020-06-21T22:53:04+09:00
[ev3dev×Python] カラーセンサ
この記事はPythonでev3を操作してみたい人のための記事です。
今回はカラーセンサを使っていろいろな操作をしていきたいと思います。目次
0 . 用意するもの
1 . カラーセンサのプログラム0.用意するもの
◯ ev3(タンク) とカラーセンサ、タッチセンサ
◯ パソコン(VSCode)
◯ bluetooth
◯ microSD
◯ 資料(これをみながら進めていくのがオススメです。)1.カラーセンサのプログラム(資料p.33)
1-0 . カラーセンサが色を検出したら〜するプログラム
colorsensor00.py#!/usr/bin/env python3 from ev3dev2.sensor.lego import ColorSensor from ev3dev2.sound import Sound cs = ColorSensor() spkr = Sound() while True: if cs.color == 5: spkr.speak('Red is detected')Point : カラーセンサが赤に反応したら"赤が検出されました"と発声するプログラム
Point : 色はあらかじめ数字と対応する形で定義されていて、プログラム内で色は数字として扱われる。
color
Color detected by the sensor, categorized by overall value.
• 0: No color
• 1: Black
• 2: Blue
• 3: Green
• 4: Yellow
• 5: Red
• 6: White
• 7: Brown1-1 . ライントレースのプログラム①
colorsensor01.py#!/usr/bin/env python3 from ev3dev2.motor import MoveTank,OUTPUT_A,OUTPUT_B from ev3dev2.sensor.lego import ColorSensor tank_drive = MoveTank(OUTPUT_A,OUTPUT_B) cs = ColorSensor() while True: if cs.reflected_light_intensity < 15: tank_drive.on(10,0) else: tank_drive.on(0,10)Point : カラーセンサが検知した光の反射率によって場合分けして、ラインに沿って走るプログラム
Point : ライントレース
黒と白では光の反射率が異なります。
白は光をよく反射して、黒は光をあまり反射しません。
反射率が異なることを利用して、白いフィールド上で黒のラインを検出しながら走るのが一般的なライントレースです。1-2 . ライントレースのプログラム②
colorsensor02.py#!/usr/bin/env python3 from ev3dev2.motor import MoveTank,OUTPUT_A,OUTPUT_B from ev3dev2.sensor.lego import ColorSensor from ev3dev2.sensor import INPUT_1,INPUT_2 tank_drive = MoveTank(OUTPUT_A,OUTPUT_B) cs_1 = ColorSensor(INPUT_1) cs_2 = ColorSensor(INPUT_2) while True: if cs_1.reflected_light_intensity > 15: if cs_2.reflected_light_intensity > 15: tank_drive.on(10,10) else: tank_drive.on(10,0) else: if cs_2.reflected_light_intensity > 15: tank_drive.on(0,10) else: tank_drive.on(-10,10)Point : カラーセンサを2個使ったライントレースのプログラム
Point : プログラムのイメージ
cs_1 が白を検出 and cs_2 が白を検出: 直進
cs_1 が白を検出 and cs_2 が黒を検出: 右へ進む
cs_1 が黒を検出 and cs_2 が白を検出: 左へ進む
cs_1 が黒を検出 and cs_2 が黒を検出: その場で回転(ラインを探索)1-3 . ライントレースのプログラム③
colorsensor03.py#!/usr/bin/env python3 from ev3dev2.motor import OUTPUT_A, OUTPUT_B, MoveTank, SpeedPercent, follow_for_ms from ev3dev2.sensor.lego import ColorSensor tank = MoveTank(OUTPUT_A, OUTPUT_B) tank.cs = ColorSensor() try: tank.follow_line( kp=11.3, ki=0.05, kd=3.2, speed=SpeedPercent(30), follow_for=follow_for_ms, ms=4500 ) except LineFollowErrorTooFast: tank.stop() raisePoint : PID制御を利用したライントレースのプログラム
Point : PID制御
PID制御は、出力値が目標値に近づくように、入力値を制御する、フィードバック制御の一種出力値 : 光の反射率
目標値 : ライン際での光の反射率
入力値 : モーターの回転スピード
(カラーセンサ1つでライントレースする場合)Point : follow_line(kp, ki, kd, speed, target_light_intensity=None, follow_left_edge=True, white=60,off_line_count_max=20, sleep_time=0.01, follow_for=,**kwargs)
PID line follower
kp, ki, and kd are the PID constants.Point : PID制御についての参考記事
Point : pythonの例外処理についての参考記事
Pythonの例外処理(try, except, else, finally)
1-4 . リストと色を照合するプログラム
colorsensor04.py#!/usr/bin/env python3 from ev3dev2.sensor.lego import ColorSensor,TouchSensor from ev3dev2.display import Display cs = ColorSensor() ts = TouchSensor() dsp = Display() color_list = [1,2,4,5] while True: dsp.update() if ts.is_pressed: if cs.color in color_list: dsp.text_pixels(cs.color_name + ' is detected',True,0,52,font = 'helvB' + '12') else: dsp.text_pixels('No such color in the color_list',True,0,52,font = 'helvB' + '10') else: dsp.text_pixels('please set the color !!!!',True,0,52,font = 'helvB' + '12')Point : タッチセンサを押しながら色をかざす。
その時にかざした色がcolor_listに存在する色ならば
"~色が検出されました"
と表示される。
かざした色がcolor_listに存在しなければ
"その色はカラーリストに存在しません"
と表示される。Point :
if a in b:
処理要素aがb(今回はリスト)に含まれるならば、処理を実行するというプログラム
参考記事
Pythonのin演算子でリストなどに特定の要素が含まれるか判定1-5 . 色をリストに保存していくプログラム
colorsensor05.py#!/usr/bin/env python3 from ev3dev2.motor import OUTPUT_A,OUTPUT_B,MoveTank from ev3dev2.sensor.lego import ColorSensor,TouchSensor from ev3dev2.sound import Sound from time import sleep cs = ColorSensor() ts = TouchSensor() spkr = Sound() tank_drive = MoveTank(OUTPUT_A,OUTPUT_B) color_list = [] for i in range(4): ts.wait_for_bump() sleep(0.1) color_list.append(cs.color) spkr.speak(cs.color_name) for c in color_list: sleep(1) if c == 1: spkr.speak('turn left') tank_drive.on_for_rotations(0,50,2) if c == 2: spkr.speak('go forward') tank_drive.on_for_rotations(50,50,2) if c == 4: spkr.speak('turn right') tank_drive.on_for_rotations(50,0,2) if c == 5: spkr.speak('go back') tank_drive.on_for_rotations(-10,-10,2)Point : 空の
color_listに、タッチセンサを押した時にかざしていた色を追加していく。
追加し終わったらリストの先頭から順番に、色に紐づけられた処理を実行する。Point : append()
リストの末尾に要素を追加できる参考記事
Pythonでリスト(配列)に要素を追加するappend, extend, insert最後に
読んで頂きありがとうございました!!
次回は超音波センサについて書いていきたいと思います!より良い記事にしていきたいので
◯こうした方がわかりやすい
◯ここがわかりにくい
◯ここが間違っている
◯ここをもっと説明して欲しい
などの御意見、御指摘のほどよろしくお願い致します。
- 投稿日:2020-06-21T22:42:22+09:00
AtCoder Beginner Contest 171 参戦記
AtCoder Beginner Contest 171 参戦記
20分でE問題まで終わって、これは初の全完!?と思ったが、Fの問題文を見た瞬間に無理だーってなって、232位から700番台まで下がっていくのを80分眺めることになった.
ABC171A - αlphabet
1分半で突破. 書くだけ.
A = input() if A.isupper(): print('A') else: print('a')ABC171B - Mix Juice
1分半で突破. 書くだけ. B問題で sort が出てくるのは珍しいのでは?
N, K = map(int, input().split()) p = list(map(int, input().split())) p.sort() print(sum(p[:K]))ABC171C - One Quadrillion and One Dalmatians
5分半で突破. 過去にEXCEL列名と数字の双方向の変換を書いたことがあったので、それを引っ張り出してきて Python に落とした. 微妙に26進数でもない辺りがいやらしいというか.
N = int(input()) t = [] while N > 0: N -= 1 t.append(chr(N % 26 + ord('a'))) N //= 26 print(''.join(t[::-1]))ABC171D - Replacing
6分で突破. 先週の ABC170E - Count Median を思い出した. 現在値を引いて、新値を足すという操作をループするのが似てる. 合計値をループごとに計算すると O(NQ) になってしまうが、引いて足すというつじつま合わせをすることによって計算量が O(N+Q) になって解ける.
from sys import stdin readline = stdin.readline N = int(readline()) A = list(map(int, readline().split())) Q = int(readline()) t = [0] * (10 ** 5 + 1) s = sum(A) for a in A: t[a] += 1 for _ in range(Q): B, C = map(int, readline().split()) s -= B * t[B] s += C * t[B] t[C] += t[B] t[B] = 0 print(s)ABC171E - Red Scarf
5分で突破. 一目簡単すぎて、誤読かと一瞬思った. xor の特性からして、自分以外の全ての xor と自分を含めた全ての xor を xor すれば自分が出てくるのは分かる. そして、a を全て xor すれば自分を含めた全ての xor が出来るのも分かる.
N = int(input()) a = list(map(int, input().split())) t = 0 for e in a: t ^= e print(*[e ^ t for e in a])ABC171F - Strivore
全然わかりません. 本当にありがとうございました. 入力例の oof に o を一つ挿入するのでも、3つダブるのだが、このダブリをどう除去するのかが全然思いつかない.
- 投稿日:2020-06-21T22:27:10+09:00
Google Vision APIで『免許証OCR』してみた
はじめに
活字や手書き文字を読み取って文字データに変換する、「OCR(光学文字認識)」という技術があります。
請求書やレシート、名刺や免許証といった様々なドキュメントに対してOCRのサービスが提供されています。
OCRを使用することで、データ入力の手間を少なくすることができます。
また、他のシステムと連携することで、データの有効活用も可能になります。各企業が提供するOCRには、企業向け・個人向けのサービスがあります。
個人でも使用できるOCRとして、「Google Vision API(以下、Vision APIという)」があります。
Vision APIは、Googleが提供する非常に高性能な画像分析サービスです。
(無料トライアルページはこちら)今回は、Vision APIを使用して簡単な免許証OCRをやってみました。
免許証OCR
環境
環境はGoogle Colaboratoryを使用します。
Pythonのバージョンは以下です。import platform print("python " + platform.python_version()) # python 3.6.9画像の表示
では、早速コードを書いていきましょう。
まずは、画像の表示に必要なライブラリをインポートします。import cv2 import matplotlib.pyplot as plt %matplotlib inline import matplotlib免許証のサンプル画像も用意しておきます。
それでは画像を表示してみましょう。img = cv2.imread(input_file) # input_fileは画像のパス plt.figure(figsize=[10,10]) plt.axis('off') plt.imshow(img[:,:,::-1])
Vision API セットアップ
それでは、このレシート画像をVision APIに投げてOCRをしてみましょう。
Vision APIの料金体系について
・最初の 1,000 ユニット/月は無料(2020/06/21時点)
・料金体系の詳細はこちらを参照ください。まず、Vision APIを使用するのに必要な準備を行います。
こちらを参考に、セットアップをします。
クライアントライブラリのインストールと、サービスアカウントキーの発行が必要になります。
クライアントライブラリのインストールは以下です。pip install google-cloud-vision発行したサービスアカウントキーを使用して、環境変数を設定します。
import os os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = json_path # json_pathは、サービスアカウントキーのパステキスト検出
それでは、OCRによるテキスト検出を行ってみましょう。
今回は、Vision APIのDOCUMENT_TEXT_DETECTIONというオプションを使用してテキスト検出を行います。
Vision APIのDOCUMENT_TEXT_DETECTIONの詳細については、こちらを参照下さい。APIへリクエスト送信・レスポンス取得
それでは、Vision APIへリクエストを送信し、レスポンスを取得しましょう。
import io from google.cloud import vision from google.cloud.vision import types client = vision.ImageAnnotatorClient() with io.open(input_file, 'rb') as image_file: content = image_file.read() image = types.Image(content=content) response = client.document_text_detection(image=image) # テキスト検出エラーなく実行できれば、無事にAPIへのリクエストの送信とレスポンスの取得ができています。
このresponseに、Vision APIのOCR結果が入っています。
読み取った文字、文字の座標、確信度、言語の種類など、様々な情報が入っています。
ここでは、読み取った全文テキストを確認してみましょう。
画像と並べて表示してみます。print(response.text_annotations[0].description)

氏名
日
本
花子
昭和61年5月1日生)
住所 東京都
千代田区霞2-1-2
交付 和01年05月07日 12345
12024年(今和06年)06月01日未有动
眼鏡等
免許の
条件等
見本
優良
番号| 第 012345678900 号
|-- 平成15年04月01日
庆中
他平成17年06月01日
(三種平成29年08月01日
運転免許証
種類
大型小特
中型原付
一天
天特普二
大自天持
普皇引
中二
00000
公安委員会
KA | ||
Q00
読み取り結果が確認できました。
Vision APIは、1文字ごとの座標の情報を持っています。
それぞれの座標を画像にプロットして確認してみましょう。document = response.full_text_annotation img_symbol = img.copy() for page in document.pages: for block in page.blocks: for paragraph in block.paragraphs: for word in paragraph.words: for symbol in word.symbols: bounding_box = symbol.bounding_box xmin = bounding_box.vertices[0].x ymin = bounding_box.vertices[0].y xmax = bounding_box.vertices[2].x ymax = bounding_box.vertices[2].y cv2.rectangle(img_symbol, (xmin, ymin), (xmax, ymax), (0, 255, 0), thickness=1, lineType=cv2.LINE_AA) plt.figure(figsize=[10,10]) plt.imshow(img_symbol[:,:,::-1]);plt.title("img_symbol")
テンプレート作成
免許証は、「氏名」「生年月日」「住所」など、項目ごとに記載される場所が決まっています。
どこに何が書かれるか定まっているものを、OCRの業界用語で定型と呼びます。
そして、定型のものをOCRすることを、定型OCRと言います。
一方、レシートや名刺、請求書などといった、どこに何が書かれているか定まっていないものを非定型、それらのOCRを非定型OCRと呼びます。定型OCRでは、テンプレートを作成することができます。
テンプレートで各項目ごとに領域を指定し、領域内に含まれるOCR結果を抽出することで、項目ごとの読み取り結果を出力することができます。それではテンプレートを作成してみましょう。
今回は、アノテーションツールであるlabelImgを使用します。
アノテーションとは、あるデータに対して何かしらの情報を付加することです。
ここでは、枠で囲んだ領域に対して、それが「氏名」なのか「生年月日」なのかといったラベルを付けることを表します。
labelImgによりアノテーションした結果は、xmlファイルとして保存されます。以下は、アノテーション結果のxmlファイルの例です。
<annotation> <folder>Downloads</folder> <filename>drivers_license.jpg</filename> <path>/path/to/jpg_file</path> <source> <database>Unknown</database> </source> <size> <width>681</width> <height>432</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>name</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>78</xmin> <ymin>26</ymin> <xmax>428</xmax> <ymax>58</ymax> </bndbox> </object> <object> <name>birthday</name> <pose>Unspecified</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>428</xmin> <ymin>27</ymin> <xmax>652</xmax> <ymax>58</ymax> </bndbox> </object> <!-- 中略 --> </annotation>テンプレート情報の読み込み
それでは、上記のxmlファイルを読み込んでみましょう。
確認のため、テンプレートの枠とラベルの情報を画像に描画してみます。import xml.etree.ElementTree as ET tree = ET.parse(input_xml) # input_xmlはxmlのパス root = tree.getroot() img_labeled = img.copy() for obj in root.findall("./object"): name = obj.find('name').text xmin = obj.find('bndbox').find('xmin').text ymin = obj.find('bndbox').find('ymin').text xmax = obj.find('bndbox').find('xmax').text ymax = obj.find('bndbox').find('ymax').text xmin, ymin, xmax, ymax = int(xmin), int(ymin), int(xmax), int(ymax) cv2.rectangle(img_labeled, (xmin, ymin), (xmax, ymax), (0, 255, 0), thickness=1, lineType=cv2.LINE_AA) cv2.putText(img_labeled, name, (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), thickness=1) plt.figure(figsize=[10,10]) plt.imshow(img_labeled[:,:,::-1]);plt.title("img_labeled")
テンプレート情報が適切に設定されていることが確認できました。
labelImgを使用して、氏名や生年月日など、読み取りたい項目を枠で囲んでラベル付けしています。テンプレートマッチング
それではテンプレートとOCR結果をマッチングしてみましょう。
テンプレートの枠内にある文字列を、それぞれの項目ごとの結果として分類します。
テンプレートマッチングの結果を、画像と並べて表示しています。text_infos = [] document = response.full_text_annotation for page in document.pages: for block in page.blocks: for paragraph in block.paragraphs: for word in paragraph.words: for symbol in word.symbols: bounding_box = symbol.bounding_box xmin = bounding_box.vertices[0].x ymin = bounding_box.vertices[0].y xmax = bounding_box.vertices[2].x ymax = bounding_box.vertices[2].y xcenter = (xmin+xmax)/2 ycenter = (ymin+ymax)/2 text = symbol.text text_infos.append([text, xcenter, ycenter]) result_dict = {} for obj in root.findall("./object"): name = obj.find('name').text xmin = obj.find('bndbox').find('xmin').text ymin = obj.find('bndbox').find('ymin').text xmax = obj.find('bndbox').find('xmax').text ymax = obj.find('bndbox').find('ymax').text xmin, ymin, xmax, ymax = int(xmin), int(ymin), int(xmax), int(ymax) texts = '' for text_info in text_infos: text = text_info[0] xcenter = text_info[1] ycenter = text_info[2] if xmin <= xcenter <= xmax and ymin <= ycenter <= ymax: texts += text result_dict[name] = texts for k, v in result_dict.items(): print('{} : {}'.format(k, v))

name : 日本花子
birthday : 昭和61年5月1日生
address : 東京都千代田区霞2-1-2
date of issue : 和01年05月07日12345
expiration date : 2024年(今和06年)06月01日未有动
number : 第012345678900号
drivers license : 運転免許証
Public Safety Commission : 00000公安委員会
テンプレートマッチングの結果、項目ごとにOCR結果を分類できていることが確認できました。
顔検出
以上、OCRによるテキストの検出について見てきました。
ところで、免許証などの身分証明書の画像判定では、顔写真もチェックすることが考えられます。
Vision APIは、OCR以外にも様々な画像分析の機能を持っており、顔検出もその一つです。
Vision APIの顔検出の詳細については、こちらを参照下さい。それでは、Vision APIを使用して、顔検出も行ってみましょう。
APIへリクエスト送信・レスポンス取得
それではテキスト検出同様、Vision APIへリクエストを送信し、レスポンスを取得しましょう。
import io from google.cloud import vision client = vision.ImageAnnotatorClient() with io.open(input_file, 'rb') as image_file: content = image_file.read() image = types.Image(content=content) response2 = client.face_detection(image=image) # 顔検出このresponse2に、Vision APIの顔検出の結果が入っています。
検出した顔の座標、特徴点、確信度、感情の可能性(怒っているのか、笑っているのか等)など様々な情報が入っています。それでは、検出した顔の座標を表示してみましょう。
faces = response2.face_annotations img_face = img.copy() for face in faces: bounding_poly = face.bounding_poly fd_bounding_poly = face.fd_bounding_poly xmin = bounding_poly.vertices[0].x ymin = bounding_poly.vertices[0].y xmax = bounding_poly.vertices[2].x ymax = bounding_poly.vertices[2].y cv2.rectangle(img_face, (xmin, ymin), (xmax, ymax), (0, 255, 0), thickness=1, lineType=cv2.LINE_AA) cv2.putText(img_face, 'bounding_poly', (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), thickness=1) xmin = fd_bounding_poly.vertices[0].x ymin = fd_bounding_poly.vertices[0].y xmax = fd_bounding_poly.vertices[2].x ymax = fd_bounding_poly.vertices[2].y cv2.rectangle(img_face, (xmin, ymin), (xmax, ymax), (0, 255, 0), thickness=1, lineType=cv2.LINE_AA) cv2.putText(img_face, 'fd_bounding_poly', (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), thickness=1) plt.figure(figsize=[10,10]) plt.imshow(img_face[:,:,::-1]);plt.title("img_face")
顔検出ができているのを確認できました。
それでは、顔検出の確信度も表示してみましょう。
あらかじめ閾値(しきいち)を設定し、閾値以上であれば顔検出できたと判定することも可能です。
これにより、不鮮明な画像や、顔写真と判別できないものを取り除き、信頼性に足る画像だけに絞り込むことができます。for face in faces: detection_confidence = face.detection_confidence if detection_confidence > 0.90: print('Face detected') print('detection_confidence : ' + str(detection_confidence)) # Face detected # detection_confidence : 0.953563392162323上記では、閾値を0.90として、顔写真の信頼性を判定してみました。
今回の確信度は0.95と高く、顔写真として信頼に足るものだと言えそうです。まとめ
いかがでしたか?
今回は、Vision APIを使用して、免許証OCRを行ってみました。
まず、テキスト検出を行いました。
また、labelImgを使用して別途テンプレートを作成しました。
OCR結果とテンプレートをマッチングさせることで、それぞれの項目ごとに読み取り結果を分類しました。
その際、Vision APIの結果として含まれる、1文字ごとの座標の情報を使用しました。
免許証のような定型OCRでは、テンプレートを作成して読み取りたい項目ごとに結果を出力することが可能です。また、顔検出も行いました。
今回は、検出した顔の座標のみ使用しましたが、他にも特徴点の座標や感情の可能性などもレスポンスに含まれています。
色々な表情の顔写真に対して、顔検出をしてみると面白いと思います。Vision APIは、様々な画像分析を行うことができるツールです。
今回紹介したテキスト検出や顔検出に加え、色々と試してみてはいかがでしょうか?


- 投稿日:2020-06-21T22:04:00+09:00
StyleGAN 論文紹介 & 実験
はじめに
近年急速に進化しているGANの中でも、特に有名な物の一つであるStyleGANについて改めて勉強したいと思い、今回のテーマにしました。
前半は論文紹介として、StyleGANの構造や特徴について勉強した事をまとめます。
後半は、実際に学習済みのStyleGANを使って画像生成を試してみたので、その結果を書いていきます。論文紹介
StyleGAN (v1)
StyleGANは2018年に発表されました。(論文リンク)
以下はStyleGANで生成された画像例の引用ですが、本物の写真と見分けがつかないような高品質の画像が生成されていると思います。
以下、StyleGANの特徴を説明していきます。
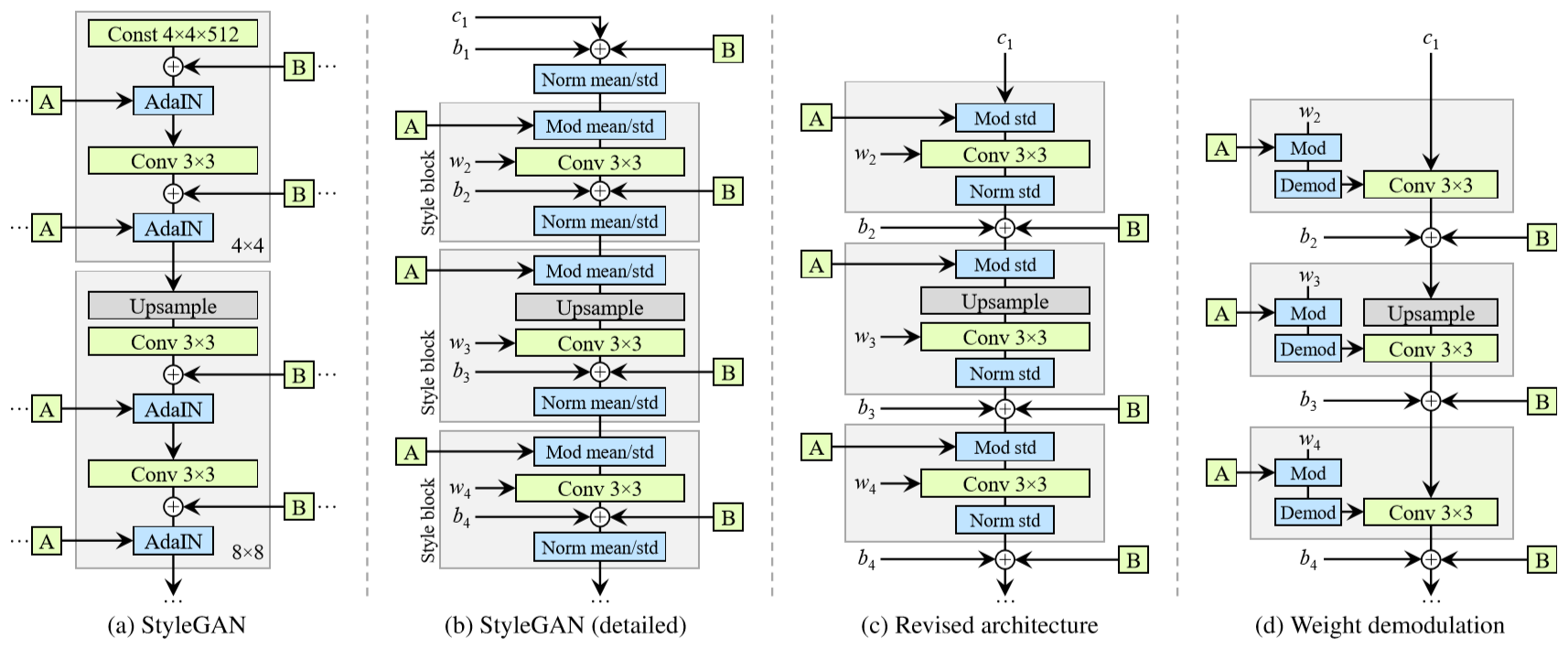
generatorの構造
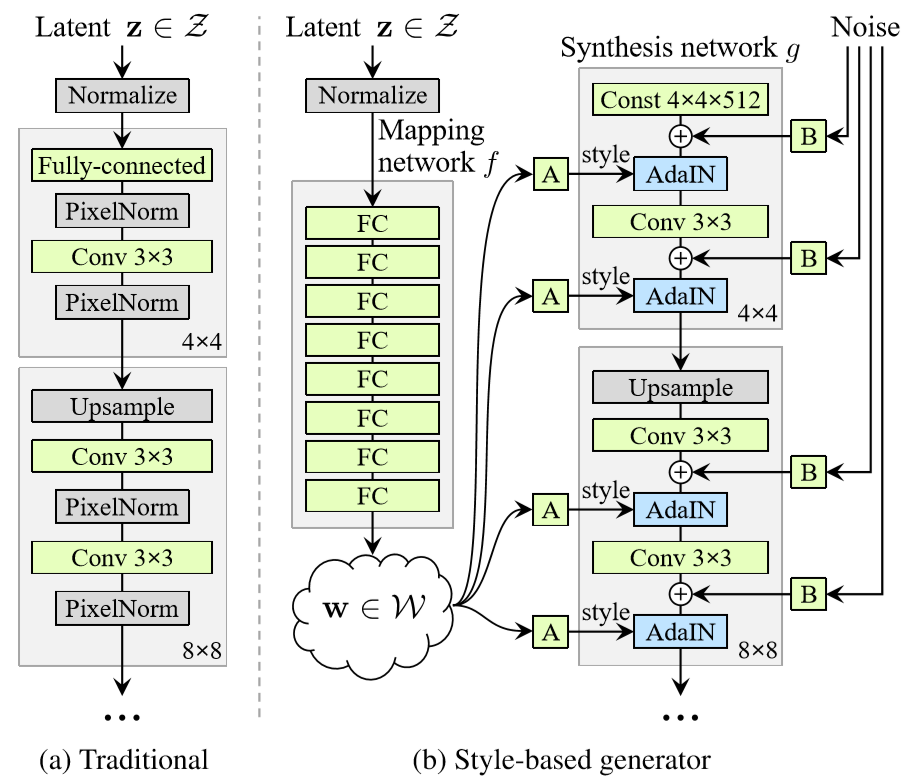
StyleGANの特徴は、主にgeneratorの構造にあると言っていいかと思います。
論文中の以下の図について、左側が従来のGAN(ここではPGGAN)のgenerator、右側がStyleGANのgeneratorの構造です。
従来のGANでは潜在変数(latent z)をランダムに生成してgeneratorの最初のレイヤから入力しています。対して、StyleGANの場合はgeneratorの最初の入力は固定値とし、latent zはまずMapping networkを通して変換された後、generator途中の各所でAdaINを使って入力されます。
さらにgenerator各層に対し、ランダムに生成したノイズも加えています。※AdaINについて
AdaIN(Adaptive Instance Normalization)は、スタイル変換の研究で提案された正規化手法です。以下式のように、変換元の特徴マップxの平均・分散を、適用するスタイル画像の特徴マップyの平均・分散に合わせる操作です。
StyleGANでは、zをMapping networkにより変換した結果がスタイルにあたります。Style Mixing
generator各層に入力するスタイル情報は全て同一である必要はなく、複数を組み合わせる事ができます。
例えば、ある画像A・Bを生成するような潜在変数z1・z2があるとして、generatorのある層まではz1由来のスタイルを、その後からz2由来のスタイルを入力することで、A・Bの特徴を混ぜたような画像を生成することができます。(Style mixing)この時、前段の方でz1→z2に切り替えるとBの大きな特徴(顔の向きや形状)が反映されますが、後段の方で切り替えると細かな特徴(髪の色など)しか反映されないことがわかっています。
※詳細と具体的な画像例は論文のFigure 3を参照してください。Progressive Growing
これはPGGAN(Progressive-Growing GAN)で提案された学習方法です。※StyleGANはPGGANをベースラインとしている。
学習時にgenerator・discriminatorの層を段階的に追加することで生成画像の解像度を上げていく方法で、1024x1024といった高解像度の画像を安定して生成できることが報告されています。ただ、Progressive Growingにはデメリットもあるようです。以下のStyleGAN2では、その辺りについても検討されています。
StyleGAN2
StyleGANの改良版として、StyleGAN2が2019年に発表されました。(論文リンク)
以下はStyleGAN2で生成された画像例です。
見た感じだとStyleGANとの品質の差はわかりにくいですが、StyleGANで発生する特徴的な水滴状パターンが解消され、画像品質の指標であるFID等のスコアも大きく向上した事が報告されています。具体的な改良点としては、主に以下の点が挙げられます。
- AdaINに相当する処理を単一のConv層で実現 (Weight demodulation)
- 正則化の改善 (Path length regularization, Lazy regularization)
- ネットワーク構造を改良し、Progressive Growingを不要に以下、各項目について記載します。
AdaINに相当する処理を単一のConv層で実現
StyleGANではAdaINの正規化処理により水滴状のパターン(water droplet-like artifacts)が引き起こされることが判明したため、StyleGAN2ではこれの改善が行われています。
以下、generatorの構造を論文中から引用します。
左側(a)(b)が元のStyleGAN、一番右(d)がAdaINを使わない形に変更された結果です。
AdaINによる正規化と同等の操作を、Weight demodulationという操作(Conv層の重みを標準偏差で割ること)で実現しています。
※論文ではより丁寧に、段階的に説明されています。ポイントは、実際の入力データの統計量を使わず、分布の仮定に基づいてWeight demodulationを行っているという点で、これにより水滴状パターンの問題が解消されたと報告されています。
正則化の改善
潜在空間が知覚的に滑らかであるかを示すPerceptual Path Lengthが生成画像の品質向上において重要ということで、これを正則化項に加えています。(Path length regularization)
この辺りの理解が曖昧ですが、潜在空間内で距離が近いzに対しては、知覚的に似ている画像が生成されるべき(そうなるよう学習させるべき)ということでしょうか。。また、メインの損失項に対して、正則化項の更新は頻度を下げてもスコアに悪影響がなかったと報告されています。(正則化項の更新頻度を下げる事を"Lazy regularization"と呼んでいます)
これにより計算コストとメモリ使用量が削減でき、学習時間の短縮にも寄与しています。ネットワーク構造を改良し、Progressive Growingを不要に
Progressive Growingは高解像度の画像生成を安定して学習できるメリットがありますが、
目や歯といった局所的な部分が、全体的な動き(顔の向き)に追従しないという問題があります。
一例としては以下の図があります。顔の向きが変わっても、歯の並びが動いていないのがわかります。
2,3年前のGANと比べれば、こんな細かい箇所について議論していること自体がすごい気がしますが…。
上記の問題は、Progressive Growingで段階的に解像度を上げる事で頻出の特徴が生成されやすくなるのが原因であるとし、これを使わずに学習を成功させられるようネットワーク構造が見直されています。
実験の結果、generatorとdiscriminator双方にスキップ構造を導入する事が有効であることが示され、Progressive Growing無しでも高品質の画像生成に成功しています。(→ 歯や目が顔の向きに追従しない件も解決)
※GとDではスキップ構造の入れ方が異なります。詳細は論文のFigure7, Table2を参照してください。...勉強は以上として、ここからはStyleGANによる画像生成を実際に試してみます。
学習済みモデルによる実験
画像生成の実験を行うにあたり、以下に公開されているStyleGAN実装を使わせて頂きました。
(GitHub) stylegans-pytorch公式のStyleGANはTensorFlowですが、上記はPyTorchで再現実装されています。環境準備から学習済み重みの変換手順まで丁寧に説明されていて、とても助かりました。
StyleGAN1,2の両方に対応されていますが、今回はStyleGAN1の方で試してみました。(使える重みの種類が多そうだったので)準備・動作確認
環境としては以下の通りです。ゲーム用PCにUbuntuとCUDA等を入れて作った環境です。
OS : Ubuntu 18.04.4 LTS
GPU : GeForce RTX 2060 SUPER x1準備はREADMEの手順に沿って特に問題なくできました。
変換した重みを使って実際に生成した画像が以下です。
本家と同じ画像が生成できていることから、重みの変換とgenerotorによる生成処理が正しくできていることが確認できました。
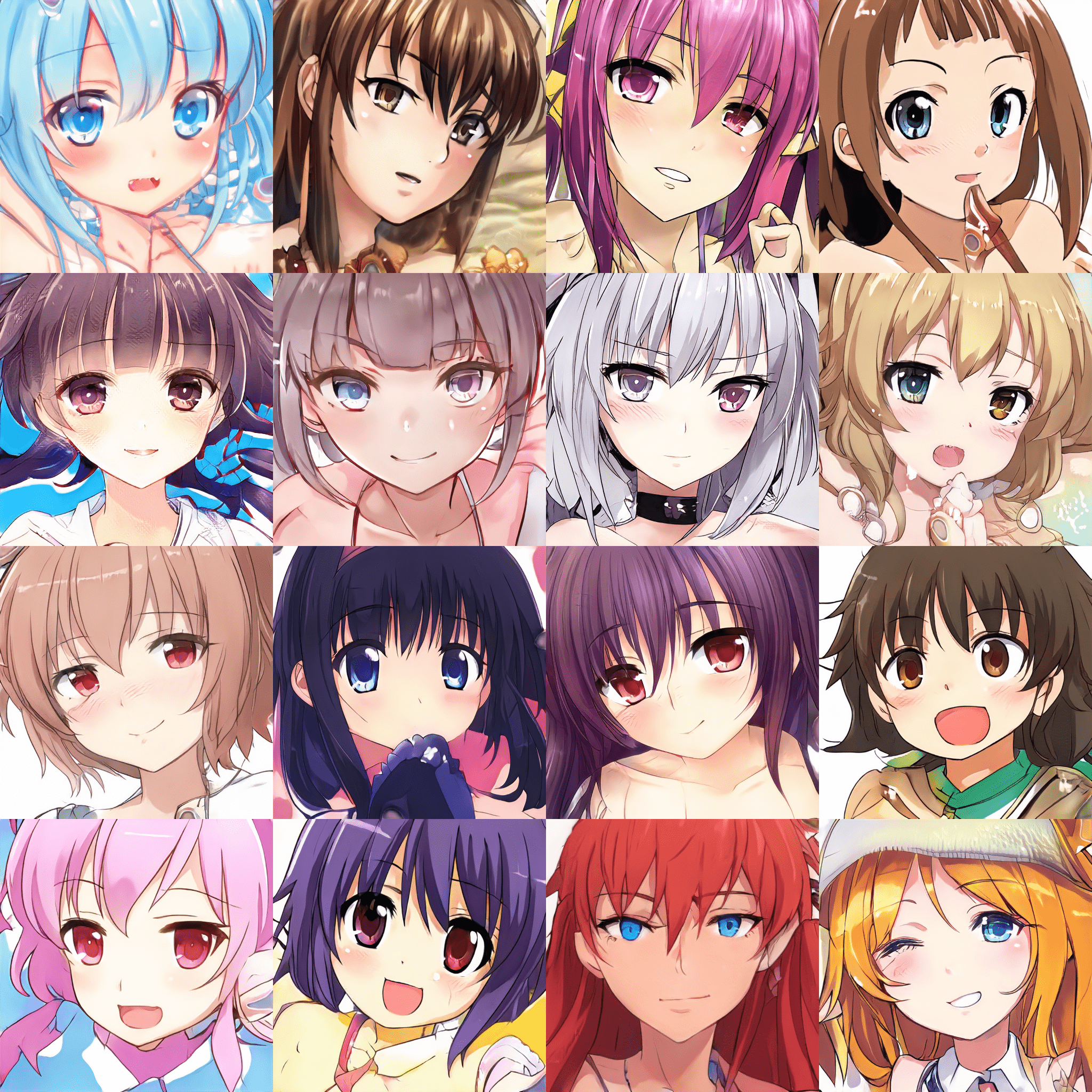
また、二次元キャラクター生成用の学習済みモデルにも対応されていたので、これも試しました。
[face_v1_1]
[portrait_v1]
interpolation実験
ここまででStyleGANによる画像生成を試すことができましたが、せっかくなのでGANの動画などでよく見る潜在変数zのinterpolationを試してみることにしました。
元のwaifu/run_pt_stylegan.pyを参考に、アニメキャラの学習済みモデルでzのinterpolationを行って結果をgifとして保存する処理を書きました。
anime_face_interpolation.pyimport argparse from pathlib import Path import pickle import numpy as np import cv2 import torch from tqdm import tqdm def parse_args(): parser = argparse.ArgumentParser() parser.add_argument('--model', type=str, default='face_v1_1', choices=['face_v1_1','face_v1_2','portrait_v1','portrait_v2']) parser.add_argument('--weight_dir', type=str, default='../../data') args = parser.parse_args() return args def prepare_generator(args): from run_pt_stylegan import ops_dict, setting if 'v1' in args.model: from stylegan1 import Generator, name_trans_dict else: from stylegan2 import Generator, name_trans_dict generator = Generator() cfg = setting[args.model] with (Path(args.weight_dir)/cfg['src_weight']).open('rb') as f: src_dict = pickle.load(f) new_dict = {k : ops_dict[v[0]](src_dict[v[1]]) \ for k,v in name_trans_dict.items() if v[1] in src_dict} generator.load_state_dict(new_dict) return generator def make_latents_seq(): n_latent_point = 3 interpolation_step = 13 n_image = 3 latent_dim = 512 #起点となるlatentsをランダムに生成 points = np.random.randn(n_latent_point, n_image, latent_dim) results = [] for i in range(n_latent_point): s = points[i] e = points[i+1] if i+1 < n_latent_point else points[0] latents_ = np.linspace(s, e, interpolation_step, endpoint=False) #線形補間 results.append(latents_) return np.concatenate(results) def generate_image(generator, latents, device): img_size = 320 latents = torch.from_numpy(latents.astype(np.float32)) with torch.no_grad(): N, _ = latents.shape generator.to(device) images = np.empty((N, img_size, img_size, 3), dtype=np.uint8) for i in range(N): z = latents[i].unsqueeze(0).to(device) img = generator(z) normalized = (img.clamp(-1, 1) + 1) / 2 * 255 np_img = normalized.permute(0, 2, 3, 1).squeeze().cpu().numpy().astype(np.uint8) images[i] = cv2.resize(np_img, (img_size, img_size), interpolation=cv2.INTER_CUBIC) def make_table(imgs): num_H, num_W = 1, 3 #並べる画像数 (縦, 横) H = W = img_size num_total = num_H * num_W canvas = np.zeros((H*num_H, W*num_W, 3), dtype=np.uint8) for i, p in enumerate(imgs[:num_total]): h, w = i//num_W, i%num_W canvas[H*h:H*-~h, W*w:W*-~w, :] = p[:, :, ::-1] return canvas return make_table(images) def save_gif(images, save_path, fps=10): from moviepy.editor import ImageSequenceClip images = [cv2.cvtColor(img, cv2.COLOR_BGR2RGB) for img in images] clip = ImageSequenceClip(images, fps=fps) clip.write_gif(save_path) if __name__ == '__main__': args = parse_args() device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') generator = prepare_generator(args).to(device) latents_seq = make_latents_seq() print('generate images ...') frames = [] for latents in tqdm(latents_seq): img = generate_image(generator, latents, device) frames.append(img) save_gif(frames, f'{args.model}_interpolation.gif')make_latents_seq()の中で、3点のlatent zを起点として線形補間を行い、シーケンスとしてのzを生成しています。
※本家論文ではSlerp(球面線形補間)が使われますが、ここでは単に線形補間しています。結果は以下の通りです。
[face_v1_1]
[portrait_v1]
期待通り、キャラの顔が連続的に変化する動画が得られました。学習時のデータによるのでしょうが、色々な作画スタイルが混在していて面白いと思います。(なんとなく見覚えがあるような顔もちらほらと...)
頭の周囲や肩より下部分はかなり無秩序に変化しているようですが、顔部分については、interpolationのどの瞬間を見てもちゃんと顔になっていることがわかります。これが、潜在空間が知覚的に滑らかにつながっているという事なんでしょうか。あとgifのファイルサイズを気にしなければ、interpolation_stepをもっと上げることで更に滑らかなアニメーションになります。
おわり
StyleGANについて、論文の紹介と学習済みモデルによる実験を行いました。もし論文の解釈などで間違っている部分があったらご指摘頂けると幸いです。
自宅のマシンではだいぶ時間かかりそうですが、学習についてもいつか自分で試してみたいと思います。

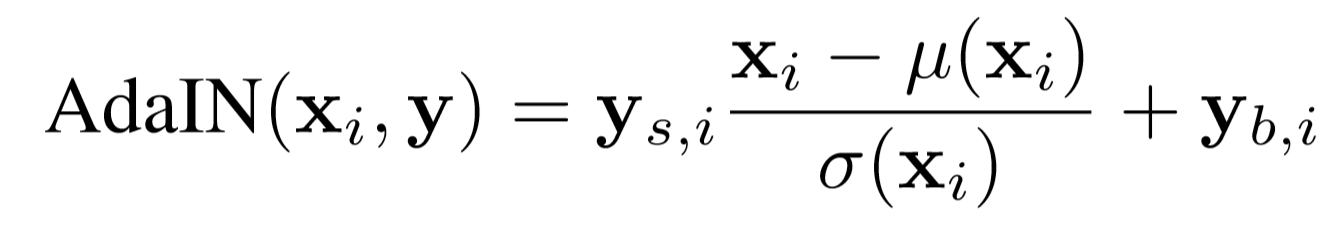




- 投稿日:2020-06-21T21:56:12+09:00
製薬企業研究者がPythonにおける正規表現についてまとめてみた
はじめに
ここでは、Pythonにおける正規表現の基本について解説します。
主な正規表現
import re m1 = re.match(r'ab*', 'a') # 直前の文字(b)の0回以上の繰り返し if m1: print(m1.group(0)) else: print('Not match') m2 = re.match(r'ab+', 'a') # 直前の文字(b)の1回以上の繰り返し if m2: print(m2.group(0)) else: print('Not match') m3 = re.match(r'ab?', 'abb') # 直前の文字(b)の0回または1回の繰り返し if m3: print(m3.group(0)) else: print('Not match') m4 = re.match(r'ab$', 'abb') # 文字列の末尾と合致するか if m4: print(m4.group(0)) else: print('Not match') m5 = re.match(r'[a-e]', 'f') # []内のいずれかの文字(a, b, c, d, e)とマッチするか if m5: print(m5.group(0)) else: print('Not match')正規表現の関数
import re # 先頭からマッチするか match = re.match(r'\d+-*\d+$', '012-3456') print(match.group(0)) # '012-3456' # 途中でマッチするか search = re.search(r'\d{3}', '012-3456') print(search.group(0)) # '012' # マッチするパターンを全て列挙 print(re.findall(r'\d{3}', '012-3456')) # ['012', '345'] # 指定したパターンの区切り文字で分割 print(re.split(r'[,、]', '1,2、さん')) # ['1', '2', 'さん'] # 指定したパターンの文字を別のパターンに変換 print(re.sub(r'(\d),(\d)', r'\2,\1', '1,2、さん')) # 2,1、さんまとめ
ここでは、Pythonにおける正規表現の基本について解説しました。
特定の文字列パターンと合致させたい場合は正規表現を利用すると便利です。参考資料・リンク
- 投稿日:2020-06-21T21:33:58+09:00
numpyのライブラリ関数一覧を少しずつ入れていく - a
初投稿です。
pythonで数値計算系で最も使いそうなライブラリであるnumpyをひととおりカバーできるようになるためにnumpyの関数が何の役割をするか書き込んでいきます。
numpyの関数一覧がこのリンク先にあったけど、かなりの数があります。https://oku.edu.mie-u.ac.jp/~okumura/python/basicstats.html
とりあえず小文字スタートで順に入れていきます。まずはaから
?のついたものは使い方をつかめなかったものnp.abs 絶対値
np.absolute 絶対値。absと同じ
np.absolute_import ?
np.add 足し算
np.add_docstring numpyに文字を追加する?ではないぽい (obj,string)
np.add_newdoc ?
np.add_newdoc_ufunc ?
np.alen 普通にlen()をつかうのと同じ
np.all すべてが()内の条件を満たすかどうかをチェック
https://note.nkmk.me/python-numpy-condition/
np.allclose ()内の2つのarrayが完全一致化かどうかを返す
https://algorithm.joho.info/programming/python/numpy-allclose/
np.alltrue ()内のarrayがすべてtrueか
np.amax 最大値を返す
np.amin 最小値を返す
np.angle ()内に複素数の値を与えて
np.any ()内の条件を一つでも満たすかどうかチェック allと関係
np.append 末尾または先頭に値や配列を追加
https://note.nkmk.me/python-numpy-append/続きは随時更新していきます
- 投稿日:2020-06-21T21:33:58+09:00
numpyのライブラリ関数一覧を少しずつ入れていく - a編
初投稿です。
pythonで数値計算系で最も使いそうなライブラリであるnumpyをひととおりカバーできるようになるためにnumpyの関数が何の役割をするか書き込んでいきます。
numpyの関数一覧がこのリンク先にあったけど、かなりの数があります。https://oku.edu.mie-u.ac.jp/~okumura/python/basicstats.html
とりあえず小文字スタートで順に入れていきます。まずはaから
?のついたものは使い方をつかめなかったものnp.abs 絶対値
np.absolute 絶対値。absと同じ
np.absolute_import ?
np.add 足し算
np.add_docstring numpyに文字を追加する?ではないぽい (obj,string)
np.add_newdoc ?
np.add_newdoc_ufunc ?
np.alen 普通にlen()をつかうのと同じ
np.all すべてが()内の条件を満たすかどうかをチェック
https://note.nkmk.me/python-numpy-condition/
np.allclose ()内の2つのarrayが完全一致化かどうかを返す
https://algorithm.joho.info/programming/python/numpy-allclose/
np.alltrue ()内のarrayがすべてtrueか
np.amax 最大値を返す
np.amin 最小値を返す
np.angle ()内に複素数の値を与えて
np.any ()内の条件を一つでも満たすかどうかチェック allと関係
np.append 末尾または先頭に値や配列を追加
https://note.nkmk.me/python-numpy-append/
np.apply_along_axis 2次元配列で軸に沿って決まった関数計算をやる(my_func, 0, b) bが2次元配列、0なのでたて方向、my_funcに関数を定義
https://qiita.com/Moby-Dick/items/f7603456260a80fd5ee3
np.apply_over_axes これも軸に沿って関数をあてはめる。along_axisと違った形で
https://numpy.org/doc/stable/reference/generated/numpy.apply_over_axes.html
np.arange 連番を作る
np.arccos アークコサイン ここからarc*は三角関数の逆関数
np.arccosh アークハイパボリックコサイン
np.arcsin アークサイン
np.arcsinh アークコサイン
np.arctan アークタンジェント
np.arctan2 アークタンジェントだがarctanよりマイナスに対応
http://nomoreretake.net/2013/10/21/arctan2/
np.arctanh アークハイパボリックタンジェント
np.argmax 最大値のある位置(インデックス)
np.argmin 最小値のある位置(インデックス)
np.argpartition 上位何件かのインデックスをとる。argsortより部分的にとる
https://biomedicalhacks.com/2020-03-20/numpy-pandas-10-tips/
np.argsort 順位を値に入れる。2次元で特定の列を基準にソートしたい時に使う
https://note.nkmk.me/python-numpy-sort-argsort/
np.argwhere () 条件を満たすインデックスをarrayにして返す
https://rennnosukesann.hatenablog.com/entry/2018/06/29/000000
np.around 四捨五入
np.array リストをnumpyに変換
np.array2string arrayを文字列に変換
np.array_equal (a,b)でaとbが全く同じかチェック np.all(a == b)と同じ
np.array_equiv array_equalと同じ
np.array_repr arrayを文字列にする。array2stringに似ているが頭にarrayがつく
np.array_split arrayを等分割する。splitと違い偶数でなくても調整してくれる。
https://note.nkmk.me/python-numpy-split/
np.array_str 文字列に変換array2stringと同じか
np.asanyarray ?
np.asarray np.arrayと同じ
np.asarray_chkfinite 基本はnp.arrayと同じだが、infやnanがあるとエラーを出す
np.ascontiguousarray ?続きは随時更新していきます
- 投稿日:2020-06-21T19:37:20+09:00
Minicondaインストール後、condaコマンド実行時に「内部コマンドまたは外部コマンド、操作可能なプログラムまたはバッチファイルとして認識されていません。」と表示されるときの対処法
Minicondaをインストールし、仮想環境を構築したうえで機械学習を勉強しようとしています。
Anacondaではサイズが大きいため、Minicondaをインストールすることにしました。Minicondaインストール後、condaコマンドを入力しても、このように表示され、その後に進むことができなくなりました。
「内部コマンドまたは外部コマンド、操作可能なプログラムまたはバッチファイルとして認識されていません。」現状、解決したので対処法を記載します。
①環境変数を設定する
コマンドプロンプトとコントロールパネルからの2通りの設定方法があるようです。
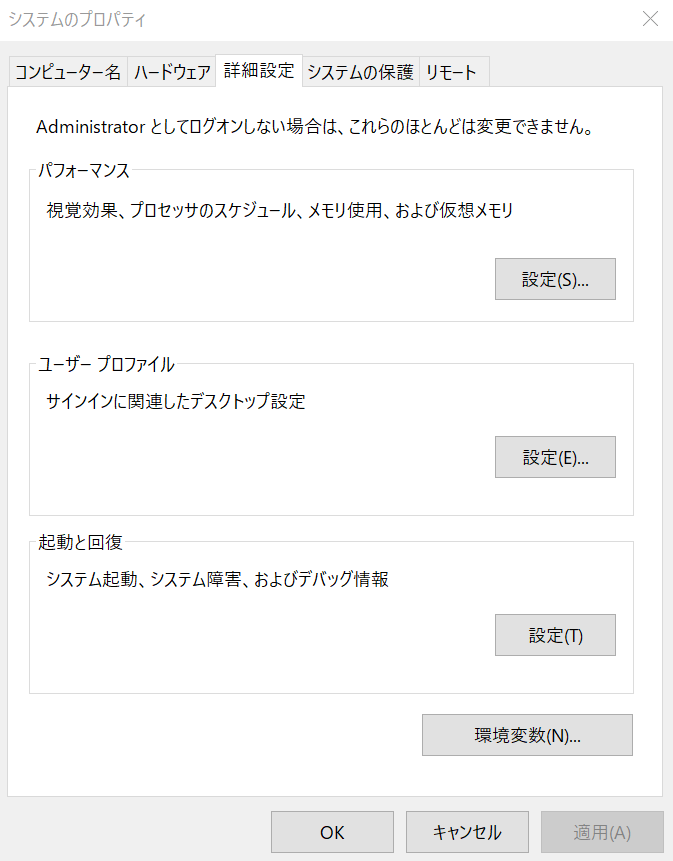
今回はコントロールパネルから設定しました。コントロールパネル>システムとセキュリティ>システム>システムの詳細設定
と進むとシステムのプロパティが表示されます。
さらに、以下の通り進みます。
詳細設定タブ>環境変数>PathPathを選択後、編集>新規と選択し、
Minicondaが保存されているディレクトリまでのファイルパスを記述しました。※Pathはシステム環境変数とユーザー環境変数の2種類があります。
試してみると、どちらでもcondaコマンドを実行できたのですが、その違いはいまいちわかっていません。②Anaconda Promptを管理者で実行
環境変数を設定できたら、Anaconda Promptを管理者として実行し、condaコマンドを入力するとうまくいきました。
- 投稿日:2020-06-21T19:10:44+09:00
【QtDesigner】PyQt5 で WebView を実装する
PyQt5 で WebView を実装してみる
QtDesignerとPyQt5を用いて、簡易的なブラウザを作成しようと思い立ったのですが、
WebView を表示するための設定方法について、日本語の記事がなかなか見つからなかったため、備忘録としてここに残しておきます。環境
OS: MacOS Catalina 10.15.3
QtDesigner: version 5.9.6
PyQt5: version 5.15.0
結論
WebView は、Qt5.6 で削除された。
代わりに、QwebEngineView を使用する必要がある。
QWebEngineView を使用するには、 QWidget を拡張して、QWebEngineView クラスを作成する必要がある。
背景
冒頭でもさらっと書いた通り、簡易的なブラウザを作成しようと思い立ちました。
色々ググってみた結果、PyQt5というライブラリを使用すればPythonでもわりと簡単に Web ページを表示する機能を実装できそうだということで、
こちらのライブラリを使用してとりあえずやってみることにしました。WebView という Widget が存在しない
PyQt5を調べていくうちに、QtDesignerという便利なレイアウトツールの存在を知りました。
せっかくですし、このツールも使用してブラウザを作成していくことにしました。しかし、Web ページを表示するために必要な WebView Widget が見当たりません。
様々なチュートリアル記事には、「WebView Widget を設置します」という感じでさらっと、Web ページを表示していました。
しかし、少なくとも私が使用している QtDesigner には、WebView Widget も、WebEngineView も見つけることができませんでした。前置きが長くなってしまいましたが、なんとか解決することができたので、その方法を以下に書いていきます。
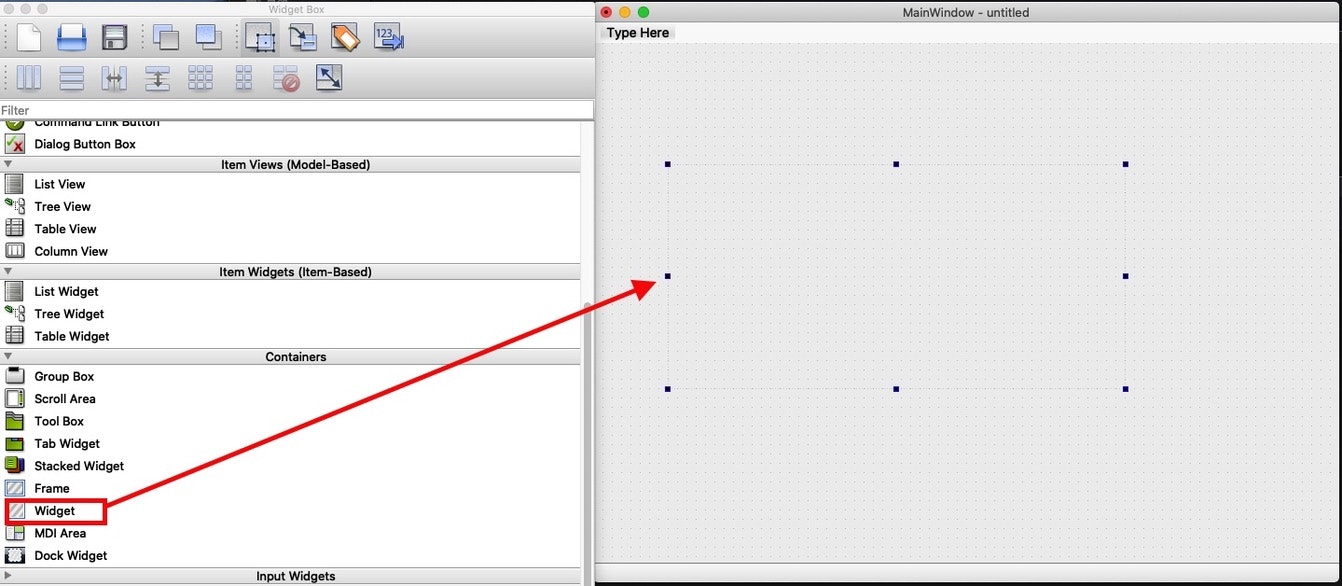
QWidget を設置する
まずは、
QtDesignerで新しいプロジェクトを作成します。
今回は、MainWindow を選択しています。
次に、作成した MainWindow に Widget を設置します。
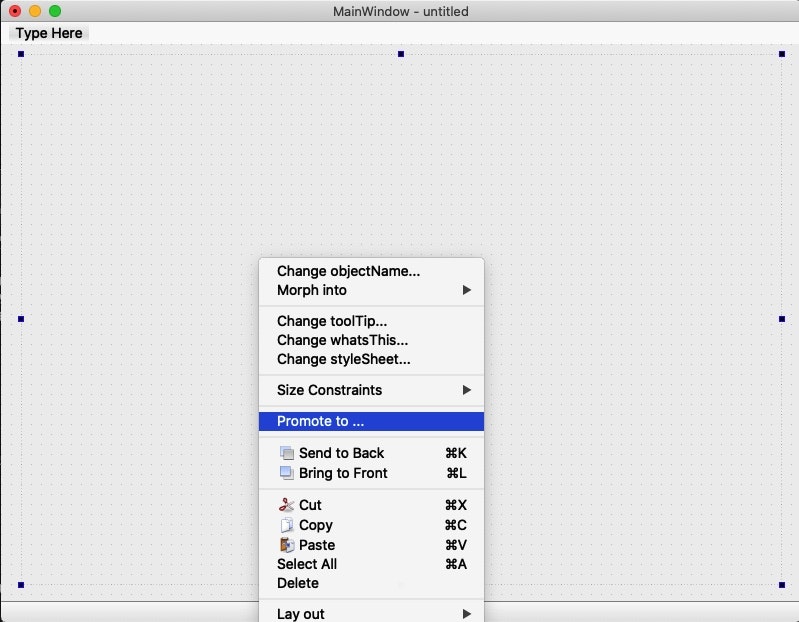
設置した Widget 上で右クリックして、「Promote to」を選択します。
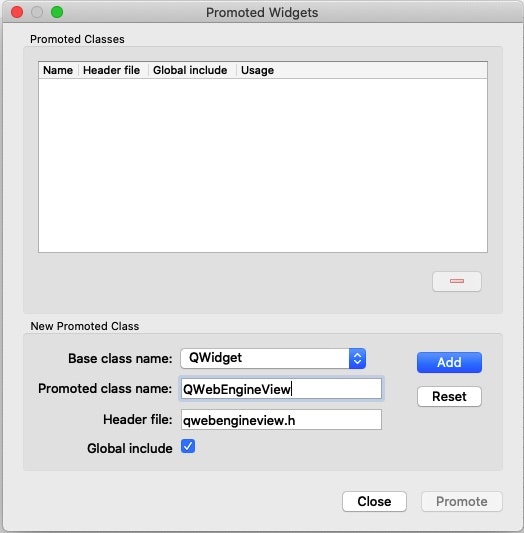
ダイアログが表示されるので、以下のように入力し、Add します。
- Base class name
- QWidget
- Promoted class name
- QWebEngineView
- Header file
- qwebengineview.h
- Global include
- チェックを入れる
QtDesignerでの操作は以上です。
作成した UI は保存します。
次は、.uiファイルを.pyファイルに変換し、コードに修正を加えていきます。pyuic5 を用いて、.ui 形式のファイルを .py 形式のファイルに変換する。
pyuic5とは、QtDesigner上で作成した.ui形式のファイルを、Python形式のファイルに変換をしてくれるツールです。
PyQt5をインストールしたときに一緒にインストールされるみたいです。pyuic5 -o WebViewSample.py WebViewSample.ui.py 形式の UI ファイルに修正を加えていく
pyuic5を用いて.ui形式のファイルを.py形式のファイルに変換を行うと、以下のようなコードが生成されます。WebViewSample.py# -*- coding: utf-8 -*- # Form implementation generated from reading ui file 'WebViewSample.ui' # # Created by: PyQt5 UI code generator 5.15.0 # # WARNING: Any manual changes made to this file will be lost when pyuic5 is # run again. Do not edit this file unless you know what you are doing. from PyQt5 import QtCore, QtGui, QtWidgets class Ui_MainWindow(object): def setupUi(self, MainWindow): MainWindow.setObjectName("MainWindow") MainWindow.resize(800, 600) self.centralwidget = QtWidgets.QWidget(MainWindow) self.centralwidget.setObjectName("centralwidget") # 以下が先ほど作成した Widget self.widget = QtWebEngineWidgets.QWebEngineView(self.centralwidget) self.widget.setGeometry(QtCore.QRect(20, 10, 761, 531)) self.widget.setObjectName("widget") # 追加ここまで MainWindow.setCentralWidget(self.centralwidget) self.menubar = QtWidgets.QMenuBar(MainWindow) self.menubar.setGeometry(QtCore.QRect(0, 0, 800, 22)) self.menubar.setObjectName("menubar") MainWindow.setMenuBar(self.menubar) self.statusbar = QtWidgets.QStatusBar(MainWindow) self.statusbar.setObjectName("statusbar") MainWindow.setStatusBar(self.statusbar) self.retranslateUi(MainWindow) QtCore.QMetaObject.connectSlotsByName(MainWindow) def retranslateUi(self, MainWindow): _translate = QtCore.QCoreApplication.translate MainWindow.setWindowTitle(_translate("MainWindow", "MainWindow")) from PyQt5 import QtWebEngineWidgets上記の
setupUiファンクションの中に以下のコードを追加します。
確認用に、起動時にアクセスする Web ページを指定します。addScipt.pyurl = "https://www.google.co.jp" self.widget.setUrl(QtCore.QUrl(url))実行用ファイルを作成する
BrowserSample.pyimport sys from PyQt5 import QtWidgets from WebViewSample import Ui_MainWindow class Browser(QtWidgets.QMainWindow): def __init__(self,parent=None): super(Browser, self).__init__(parent) self.ui = Ui_MainWindow() self.ui.setupUi(self) if __name__ == '__main__': app = QtWidgets.QApplication(sys.argv) window = Browser() window.show() sys.exit(app.exec_())上記のファイルを実行する。
とりあえず表示することができました。
ここから、色々とカスタマイズしていこうと思います。参考
QtForum: QWebEngineView in QtDesigner
living-sun.com: Qt WebEngineView is not available for creators, but qt, qt-creator, qt-designer, qwebengineview
- 投稿日:2020-06-21T18:57:06+09:00
Scikit-LearnとTensorFlowによる実践機械学習~TensorFlow編~
Scikit-LearnとTensorFlowによる実践機械学習~Scikit-Learn編~ の続きです。
前半(8章まで)は、ほぼScikit-Learnに関する話でした。
後半(9章以降)は、TensorFlowの話に移っていきます。※書籍がTensorFlow1の内容で書かれているのに対し、どうやら現在はTensorFlow2みたいだということで、TensorFlow2ではどうなってるのかよくわからない部分が多いです。
内容に入る前に、メモ程度に参考になるサイトをまとめておきます。
・サンプルコード(GitHub)
・TensorFlow公式サイト
・PFN社のChainer Tutorial
・書籍情報■ 結論
結論から言うと、TensorFlow2が現状ということを考え、TensorFlow1で学習するのはあまり効率的ではないなと感じました。
TensorFlow1と2では、まるで別物のように感じますし、TensorFlow2の方が遥かに優れているようです。初っ端に「TensorFlowは、Sessionを開始して閉じるということをするのが特徴だ。」的な雰囲気なのですが、TensorFlow2では、このSessionが廃止されているという...
TensorFlow編の初っ端からこんな感じなので、実践しようとすると、どこが変わっていてどこが変わっていないのかよく分かりませんし、もう大変です。調べていてもちょっと調べるだけで時間がみるみるうちに溶けていきます。
TensorFlow1でとりあえず勉強すればいいじゃんという意見もあると思いますが、今回の自分の目的的には、実践で使えるようにしたいのであってTensorFlowの勉強がしたいわけではないので、それはちょっと違うんですよね。書籍をTensorFlow2に対応しているものに変えるかな...(この本安くなかったんだけどなぁ)
とはいえ、バージョンが違うだけで勉強になることは多いです。実践というのを一旦置いておく段階に達したら再び読み直そうと思います。現在はまだとりあえず動いてほしいフェーズなので、しばらくは本棚を温めてもらう役割になりそうではありますが。
一応、9章(TensorFlow編の最初の章)の途中までQiitaにメモしていたので記事は下に続きますが、ぶっちゃけ内容は陳腐で読む価値があるのかは微妙です。
さてさて、Scikit-LearnとTensorFlowによる実践機械学習の全16章のうち、13章まで読んでやる気がぷつんと切れてしまったので、とりあえずDeepLearningの勉強はまたの機会に。よさげな本も増えてきましたしね、飽和するのを一旦待ちます。
※陳腐なメモは以下に続きます。
■ 9章:TensorFlowを立ち上げる。
勉強日:2020/6/21
「そもそもTensorFlowってなんだろう?Deep Learning用のライブラリ??」というところから私の知識は始まりまります。ぶっちゃけた話、このぐらいの知識から読み始めると大分つらいです。
書籍には、
① 数値計算のための強力なオープンソースソフトウェアであること
② 特に大規模な機械学習のためにチューニングされていること
③ 基本原則は、実行する計算グラフをPythonで定義すると、TensorFlowがそのグラフを読み取り、最適化されたC++コードで効率よく実行すること
④ 何より重要なのは、グラフをCPUやGPUで並列処理できること
⑤ 分散コンピューティングをサポートしていることというようなことが書かれています。
正直、ぱっと読んだ時は「なんのこっちゃ」という感じで、そもそもTensorFlowと計算グラフって何の関係があるの?という疑問を持ちました。じっくり先まで読んでみると、どうやらTensorFlowは基本的に「計算グラフの作成 → 計算の実行」という順序を踏むようです。なるほどね。
・9.1 インストール
隔離された環境というのが出てくるのですが、今まで仮想環境が必要になったことはなかったので作ったことがありませんでした。今回はいい機会だと思ったので、あれこれ調べて仮想環境も作ってみました。
書籍には、virtualenvで作ると書いてあったのですが、私はAnacondaを使って作りたかったので、以下のようなサイトを参考にしました。
・【Python】Anacondaを使った仮想環境の構築
・【Anaconda】condaコマンドで仮想環境を構築する方法TensorFlowをインストールするところで気が付いたのですが、書籍内でのTensorFlowのバージョンが1なのに対し、現在のバージョンは2になっているようです。しかも大分使い勝手が違う様子。。。
うーん、うーん、ぅ-…
まぁ、とりあえず、サンプルコードぺたぺたして分かった気になる戦法でいって、細かいところは後で調べたり別の書籍買って勉強するかな。
・9.2 最初のグラフの作成とセッション内での実行
「計算グラフは作っても何も起こらない」というのを理解できなくて何回も読み返しました。書いてあるまんまなんですけど、「なんで」がループした感じですね。
初めてTensorFlowを使った身からすると、まず変数の箱を作るというのがすごく斬新でした。
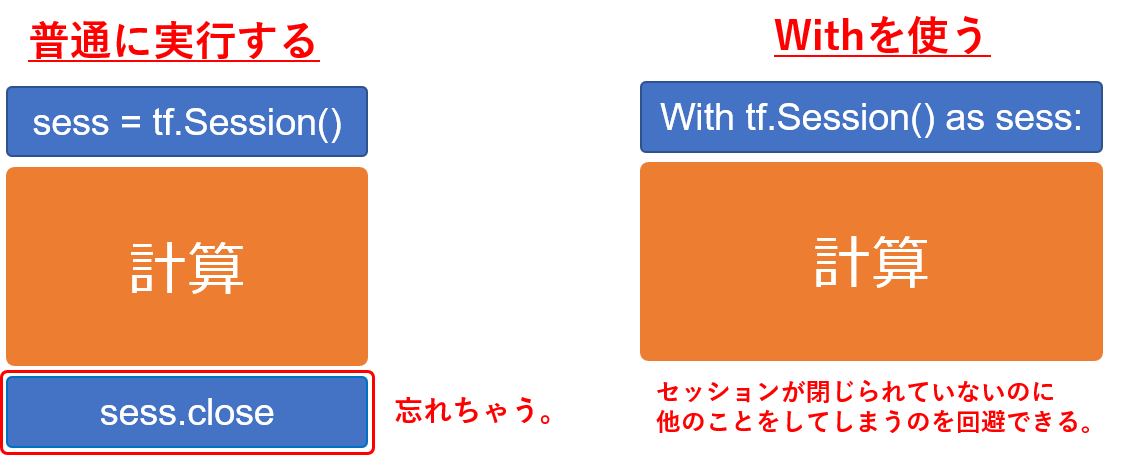
グラフを作った後は、Session()コマンドで計算実行のセッションを開始し、計算が終わったらSession.close()で終わりを明示的に宣言する。しかもセッション内は全てSession.run()で実行されるというね。
これだとセッションが閉じられていないのに、他のことをしてしまう危険性があるということで、withを使う方法が紹介されています。個人的にはこちらの方が好きですね。
※TensorFlow2では...
Sessionという概念がなくなったようです。
【参考】
・tensorflow 2.0 の紹介(日本語訳)
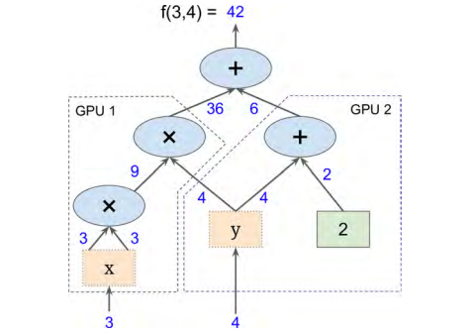
・Design Documentから見たTensorFlow 2.0の変更点例えば、$f = x^2y + y +2$ を $x=3\,,\,y=4$ として、こんな計算グラフを使って計算したいとします。
TensorFlow1では、
import tensorflow as tf # ★計算グラフの構築 x = tf.Variable(3, name = "x") y = tf.Variable(4, name = "y") f = x*x*y + y +2 # ★計算の実行 sess = tf.Session() # TensorFlowセッションを開く # 計算グラフを用いた計算をするには必ず必要 sess.run(x.initializer) # 変数の初期化 sess.run(y.initializer) result = sess.run(f) # fの評価 print(result) # 計算結果の表示 sess.close # TensorFlowを閉じる出力はもちろん
42です。TensorFlow2ではSessionの概念がなくなったのでこれが使えないのですが、基本的な概念がよくわかっていないためどうしたらいいのやら。。。
とりあえずあれこれ調べて公式にtf.functionがいいよって書いてあったのでこれを使います。import tensorflow as tf # 変数のセット x = tf.Variable(3) y = tf.Variable(4) # tf.functionで関数を作る @tf.function def f(x, y): return x*x*y + y + 2 result = f(x, y) print(result)出力はこんな感じ。たしかに分かりやすい。っていうかTensorFlow2の方がPytonぽさがありますね。
tf.Tensor(42, shape=(), dtype=int32)・9.3 グラフの管理
何言っているのかよくわからなかった。
あとで調べる。・9.4 ノードの値のライフサイクル
ほぇーという感じでした。まず、第一にTensorFlowが自動的にノード間の依存関係を拾ってくれる点に感動し、次に計算結果が再利用されない点にほぇーとなりました。
再利用されないというのは、例えば、
w = tf.constant(3) x = w + 2 y = x + 5 z = x * 3という計算があった時に、$y$ と $z$ を評価するのに
1⃣
1. $w = 3$
2. $x = w + 2$
3. $y = x + 5$2⃣
1. $w = 3$
2. $x = w + 2$
3. $z = x * 3$という処理が行われるみたいです。何かというと、$w = 3$ と $x = w + 2$ は、$y$ を求める時にも $z$ を求める時にも共通して必要なものなのに、わざわざ再計算されるということみたいです。つまり、赤字部分は同じだから人間なら1回しか計算しませんが、TensorFlowでは2回計算するということですね。
一回で処理させたい場合には、やはりwithを使います。
with tf.Session() as sess: y_val, z_val = sess.run([y, z])でもこれTensorFlow2でもあるのかな・・・
・9.5 TensorFlowによる線形回帰
なんか突然TensorFlowで、カリフォルニアの住宅価格データセットを使った線形回帰をしています。DeepLearning用のためだけのライブラリじゃないよってことかな。
・9.6 勾配降下法の実装
3種類の勾配の計算を説明してくれています。すなわち、
・マニュアルによる勾配計算
・自動微分を使う
・オプティマイザを使う
です。
マニュアルは愚直にコードを書いて計算する方法で、自動微分はTensorFlowが自動的に効率の良い方法で勾配を計算してくれるという優れもののようです。オプティマイザは、書籍の説明だと「自動微分よりも優れている」的なことしか書いていないのですが、最適化のための関数といういうことなのでしょうか?・9.7 訓練アルゴリズムへのデータの供給
プレースホルダ-の使い方が書いてあるが、TensorFlow2ではプレースホルダーは廃止になっているらしい。
TensorFlow1と2でものすごく違うものになっている気がするけど、本当にこの本で勉強を進めることが最適なのだろうかという気がしてきました。・9.8 モデルの保存と復元
モデルを使いまわしたり、他のプログラムで使ったり、他のモデルと比較したりするために、モデルを復元したいということがあります。他にも訓練を最初からやり直すのではなく、途中からやり直したい場合などにも復元する必要があります。TensorFlowでは、この復元が非常に容易らしいです。
書籍では restore() を使う方法が書いてありますが、公式では keras による方法が紹介されていました。これは確かに便利ですね。
★参考★
[1] TensorFlow 2.0 主な変更点(S-Analysis)
[2] tensorflow 2.0 の紹介(日本語訳)
[3] Design Documentから見たTensorFlow 2.0の変更点
[4] TensorFlow2.0ついにリリース!

- 投稿日:2020-06-21T18:57:06+09:00
Scikit-LearnとTensorFlowによる実践機械学習~TensorFlow諦めた編~
Scikit-LearnとTensorFlowによる実践機械学習~Scikit-Learn編~ の続きです。
前半(8章まで)は、ほぼScikit-Learnに関する話でした。
後半(9章以降)は、TensorFlowの話に移っていきます。※書籍がTensorFlow1の内容で書かれているのに対し、どうやら現在はTensorFlow2みたいだということで、TensorFlow2ではどうなってるのかよくわからない部分が多いです。
内容に入る前に、メモ程度に参考になるサイトをまとめておきます。
・サンプルコード(GitHub)
・TensorFlow公式サイト
・PFN社のChainer Tutorial
・書籍情報■ 結論
結論から言うと、TensorFlow2が現状ということを考え、TensorFlow1で学習するのはあまり効率的ではないなと感じました。
TensorFlow1と2では、まるで別物のように感じますし、TensorFlow2の方が遥かに優れているようです。初っ端に「TensorFlowは、Sessionを開始して閉じるということをするのが特徴だ。」的な雰囲気なのですが、TensorFlow2では、このSessionが廃止されているという...
TensorFlow編の初っ端からこんな感じなので、実践しようとすると、どこが変わっていてどこが変わっていないのかよく分かりませんし、もう大変です。調べていてもちょっと調べるだけで時間がみるみるうちに溶けていきます。
TensorFlow1でとりあえず勉強すればいいじゃんという意見もあると思いますが、今回の自分の目的的には、実践で使えるようにしたいのであってTensorFlowの勉強がしたいわけではないので、それはちょっと違うんですよね。書籍をTensorFlow2に対応しているものに変えるかな...(この本安くなかったんだけどなぁ)
とはいえ、バージョンが違うだけで勉強になることは多いです。実践というのを一旦置いておく段階に達したら再び読み直そうと思います。現在はまだとりあえず動いてほしいフェーズなので、しばらくは本棚を温めてもらう役割になりそうではありますが。
一応、9章(TensorFlow編の最初の章)の途中までQiitaにメモしていたので記事は下に続きますが、ぶっちゃけ内容は陳腐で読む価値があるのかは微妙です。
さてさて、Scikit-LearnとTensorFlowによる実践機械学習の全16章のうち、13章まで読んでやる気がぷつんと切れてしまったので、とりあえずDeepLearningの勉強はまたの機会に。よさげな本も増えてきましたしね、飽和するのを一旦待ちます。
※陳腐なメモは以下に続きます。
■ 9章:TensorFlowを立ち上げる。
勉強日:2020/6/21
「そもそもTensorFlowってなんだろう?Deep Learning用のライブラリ??」というところから私の知識は始まりまります。ぶっちゃけた話、このぐらいの知識から読み始めると大分つらいです。
書籍には、
① 数値計算のための強力なオープンソースソフトウェアであること
② 特に大規模な機械学習のためにチューニングされていること
③ 基本原則は、実行する計算グラフをPythonで定義すると、TensorFlowがそのグラフを読み取り、最適化されたC++コードで効率よく実行すること
④ 何より重要なのは、グラフをCPUやGPUで並列処理できること
⑤ 分散コンピューティングをサポートしていることというようなことが書かれています。
正直、ぱっと読んだ時は「なんのこっちゃ」という感じで、そもそもTensorFlowと計算グラフって何の関係があるの?という疑問を持ちました。じっくり先まで読んでみると、どうやらTensorFlowは基本的に「計算グラフの作成 → 計算の実行」という順序を踏むようです。なるほどね。
・9.1 インストール
隔離された環境というのが出てくるのですが、今まで仮想環境が必要になったことはなかったので作ったことがありませんでした。今回はいい機会だと思ったので、あれこれ調べて仮想環境も作ってみました。
書籍には、virtualenvで作ると書いてあったのですが、私はAnacondaを使って作りたかったので、以下のようなサイトを参考にしました。
・【Python】Anacondaを使った仮想環境の構築
・【Anaconda】condaコマンドで仮想環境を構築する方法TensorFlowをインストールするところで気が付いたのですが、書籍内でのTensorFlowのバージョンが1なのに対し、現在のバージョンは2になっているようです。しかも大分使い勝手が違う様子。。。
うーん、うーん、ぅ-…
まぁ、とりあえず、サンプルコードぺたぺたして分かった気になる戦法でいって、細かいところは後で調べたり別の書籍買って勉強するかな。
・9.2 最初のグラフの作成とセッション内での実行
「計算グラフは作っても何も起こらない」というのを理解できなくて何回も読み返しました。書いてあるまんまなんですけど、「なんで」がループした感じですね。
初めてTensorFlowを使った身からすると、まず変数の箱を作るというのがすごく斬新でした。
グラフを作った後は、Session()コマンドで計算実行のセッションを開始し、計算が終わったらSession.close()で終わりを明示的に宣言する。しかもセッション内は全てSession.run()で実行されるというね。
これだとセッションが閉じられていないのに、他のことをしてしまう危険性があるということで、withを使う方法が紹介されています。個人的にはこちらの方が好きですね。
※TensorFlow2では...
Sessionという概念がなくなったようです。
【参考】
・tensorflow 2.0 の紹介(日本語訳)
・Design Documentから見たTensorFlow 2.0の変更点例えば、$f = x^2y + y +2$ を $x=3\,,\,y=4$ として、こんな計算グラフを使って計算したいとします。
TensorFlow1では、
import tensorflow as tf # ★計算グラフの構築 x = tf.Variable(3, name = "x") y = tf.Variable(4, name = "y") f = x*x*y + y +2 # ★計算の実行 sess = tf.Session() # TensorFlowセッションを開く # 計算グラフを用いた計算をするには必ず必要 sess.run(x.initializer) # 変数の初期化 sess.run(y.initializer) result = sess.run(f) # fの評価 print(result) # 計算結果の表示 sess.close # TensorFlowを閉じる出力はもちろん
42です。TensorFlow2ではSessionの概念がなくなったのでこれが使えないのですが、基本的な概念がよくわかっていないためどうしたらいいのやら。。。
とりあえずあれこれ調べて公式にtf.functionがいいよって書いてあったのでこれを使います。import tensorflow as tf # 変数のセット x = tf.Variable(3) y = tf.Variable(4) # tf.functionで関数を作る @tf.function def f(x, y): return x*x*y + y + 2 result = f(x, y) print(result)出力はこんな感じ。たしかに分かりやすい。っていうかTensorFlow2の方がPytonぽさがありますね。
tf.Tensor(42, shape=(), dtype=int32)・9.3 グラフの管理
何言っているのかよくわからなかった。
あとで調べる。・9.4 ノードの値のライフサイクル
ほぇーという感じでした。まず、第一にTensorFlowが自動的にノード間の依存関係を拾ってくれる点に感動し、次に計算結果が再利用されない点にほぇーとなりました。
再利用されないというのは、例えば、
w = tf.constant(3) x = w + 2 y = x + 5 z = x * 3という計算があった時に、$y$ と $z$ を評価するのに
1⃣
1. $w = 3$
2. $x = w + 2$
3. $y = x + 5$2⃣
1. $w = 3$
2. $x = w + 2$
3. $z = x * 3$という処理が行われるみたいです。何かというと、$w = 3$ と $x = w + 2$ は、$y$ を求める時にも $z$ を求める時にも共通して必要なものなのに、わざわざ再計算されるということみたいです。つまり、赤字部分は同じだから人間なら1回しか計算しませんが、TensorFlowでは2回計算するということですね。
一回で処理させたい場合には、やはりwithを使います。
with tf.Session() as sess: y_val, z_val = sess.run([y, z])でもこれTensorFlow2でもあるのかな・・・
・9.5 TensorFlowによる線形回帰
なんか突然TensorFlowで、カリフォルニアの住宅価格データセットを使った線形回帰をしています。DeepLearning用のためだけのライブラリじゃないよってことかな。
・9.6 勾配降下法の実装
3種類の勾配の計算を説明してくれています。すなわち、
・マニュアルによる勾配計算
・自動微分を使う
・オプティマイザを使う
です。
マニュアルは愚直にコードを書いて計算する方法で、自動微分はTensorFlowが自動的に効率の良い方法で勾配を計算してくれるという優れもののようです。オプティマイザは、書籍の説明だと「自動微分よりも優れている」的なことしか書いていないのですが、最適化のための関数といういうことなのでしょうか?・9.7 訓練アルゴリズムへのデータの供給
プレースホルダ-の使い方が書いてあるが、TensorFlow2ではプレースホルダーは廃止になっているらしい。
TensorFlow1と2でものすごく違うものになっている気がするけど、本当にこの本で勉強を進めることが最適なのだろうかという気がしてきました。・9.8 モデルの保存と復元
モデルを使いまわしたり、他のプログラムで使ったり、他のモデルと比較したりするために、モデルを復元したいということがあります。他にも訓練を最初からやり直すのではなく、途中からやり直したい場合などにも復元する必要があります。TensorFlowでは、この復元が非常に容易らしいです。
書籍では restore() を使う方法が書いてありますが、公式では keras による方法が紹介されていました。これは確かに便利ですね。
★参考★
[1] TensorFlow 2.0 主な変更点(S-Analysis)
[2] tensorflow 2.0 の紹介(日本語訳)
[3] Design Documentから見たTensorFlow 2.0の変更点
[4] TensorFlow2.0ついにリリース!
- 投稿日:2020-06-21T18:45:28+09:00
gunicornで立てたサーバをコード変更時にリロードする
GAE向けに flask アプリを手元で開発している時、ホットリロードどうやるんだっけと一瞬考えたわけです。
答え
gunicornの--reload起動オプションまたは設定ファイルでreload: Trueを指定しましょう。どうしてこんな記事が生まれたのか
どうも古い知識がキャッシュされていたらしく、くそー gunicorn は watchdog とか使ってリロード構成作らないといけなくて古臭いぜと思い込んでいたのですが普通に
--reloadが実装されていて衝撃を受けたからです。changelog 見ていると 2014年に追加されていたらしい。自分が python で web アプリケーションを主に書いていたのはちょうど 2014年くらいまでで、そこから ruby に転向していたのですが、自分の知識に適切に「この知識は1年以上前のものです」ってレコメンドしてくれる機能が欲しい。
- 投稿日:2020-06-21T18:02:32+09:00
[Python]Plotly Expressでカテゴリで色分けした平行座標プロットを作る
平行座標プロットをカテゴリデータで上手く色分け出来ない
神プロットライブラリ(正しくはラッパーライブラリ)と崇める
Plotly Expressはimport plotly.express as px px.parallel_categories( px.data.tips(), color="size" )な具合でカテゴリデータでの平行座標プロットを楽に書けるのですが、他のプロットとは異なり
colorパラメータにカテゴリデータのpandas.SeriesもしくはListをパスすることが出来ません。
scatterlineあたりは出来るのに、、px.parallel_categories( px.data.tips(), color="time" )と、
int型が詰まったsizeカラムからカテゴリデータのtimeカラムへ変えると、下記のエラーに、、ValueError: Invalid element(s) received for the 'color' property of parcats.line Invalid elements include: ['Dinner', 'Dinner', 'Dinner', 'Dinner', 'Dinner', 'Dinner', 'Dinner', 'Dinner', 'Dinner', 'Dinner'] The 'color' property is a color and may be specified as: - A hex string (e.g. '#ff0000') - An rgb/rgba string (e.g. 'rgb(255,0,0)') - An hsl/hsla string (e.g. 'hsl(0,100%,50%)') - An hsv/hsva string (e.g. 'hsv(0,100%,100%)') - A named CSS color: aliceblue, antiquewhite, aqua, aquamarine, azure, beige, bisque, black, blanchedalmond, blue, blueviolet, brown, burlywood, cadetblue, chartreuse, chocolate, coral, cornflowerblue, cornsilk, crimson, cyan, darkblue, darkcyan, darkgoldenrod, darkgray, darkgrey, darkgreen, darkkhaki, darkmagenta, darkolivegreen, darkorange, darkorchid, darkred, darksalmon, darkseagreen, darkslateblue, darkslategray, darkslategrey, darkturquoise, darkviolet, deeppink, deepskyblue, dimgray, dimgrey, dodgerblue, firebrick, floralwhite, forestgreen, fuchsia, gainsboro, ghostwhite, gold, goldenrod, gray, grey, green, greenyellow, honeydew, hotpink, indianred, indigo, ivory, khaki, lavender, lavenderblush, lawngreen, lemonchiffon, lightblue, lightcoral, lightcyan, lightgoldenrodyellow, lightgray, lightgrey, lightgreen, lightpink, lightsalmon, lightseagreen, lightskyblue, lightslategray, lightslategrey, lightsteelblue, lightyellow, lime, limegreen, linen, magenta, maroon, mediumaquamarine, mediumblue, mediumorchid, mediumpurple, mediumseagreen, mediumslateblue, mediumspringgreen, mediumturquoise, mediumvioletred, midnightblue, mintcream, mistyrose, moccasin, navajowhite, navy, oldlace, olive, olivedrab, orange, orangered, orchid, palegoldenrod, palegreen, paleturquoise, palevioletred, papayawhip, peachpuff, peru, pink, plum, powderblue, purple, red, rosybrown, royalblue, rebeccapurple, saddlebrown, salmon, sandybrown, seagreen, seashell, sienna, silver, skyblue, slateblue, slategray, slategrey, snow, springgreen, steelblue, tan, teal, thistle, tomato, turquoise, violet, wheat, white, whitesmoke, yellow, yellowgreen - A number that will be interpreted as a color according to parcats.line.colorscale - A list or array of any of the above
sizeではA number that will be interpreted as a color according to parcats.line.colorscaleが出来ていたものの、出来なくなってしまいました。かと言って、
time_color_map = {t: i for i, t in enumerate(px.data.tips()["time"].unique())} colors = px.data.tips()["time"].replace(time_color_map) px.parallel_categories( px.data.tips(), color=colors )とやると、
カラースケール値として設定したかっただけの
colorもグラフに表示されてしまいました。冗長で嫌だ、、
何とか、スッキリとカテゴリデータで色分けした平行座標プロットが作れないのでしょうか。
dimensionsで表示するカラムを絞るtime_color_map = {t: i for i, t in enumerate(px.data.tips()["time"].unique())} colors = px.data.tips()["time"].replace(time_color_map) px.parallel_categories( px.data.tips(), color=colors, dimensions=["sex", "smoker", "day", "time", "size"] )
dimensionsで表示するカラムを絞れるため、こちらで不要カラムを削ってしまえば出来ました!まとめ
うーん、でも、小細工無しにカテゴリデータの
pandas.Series指定でも大丈夫なインターフェースになってほしい、、


- 投稿日:2020-06-21T17:45:19+09:00
遊戯王カード名を自然言語処理する - 遊戯王データサイエンス 2. NLP編
はじめに
Pythonを使って遊戯王カードのデータをいろいろ分析する、「遊戯王DS(データサイエンス)」シリーズです。
記事は全4回を予定し、最終的には自然言語処理+機械学習でカード名から攻守属性を予測するプログラムを実装します。
尚、筆者の遊戯王知識はE・HEROあたりでギリ止まっています。カードもデータサイエンスも素人で恐縮ですが、どうかお付き合いください。
No. 記事タイトル Keyword 0 遊戯王データベースからカード情報を取得する - 遊戯王DS 0. スクレイピング編 beautifulsoup 1 遊戯王カードのデータをPythonで可視化する - 遊戯王データサイエンス1. EDA編 pandas, seaborn 2 遊戯王カード名を自然言語処理する - 遊戯王DS 2. NLP編 wordcloud, word2vec, doc2vec, t-SNE この記事! 3 遊戯王カード名から攻守属性を予測する - 遊戯王DS 3. 機械学習編 lightgbmなど 本記事の目的
1. EDA編では焦点を当てなかった「カード名」に対して更に深堀りを進めます。
遊戯王にはドラゴン・魔法使い・HERO等いろんなモンスターが登場しますが、名称によく使われるワードにはどんなものが多いのかを探っていきます。更に、属性/種別/レベル別に切り分けたとき、それぞれにどんな類似点があるかを見ていこうと思います。
本記事の技術的なテーマはMeCabによる形態素解析、WordCloudによる頻出ワード可視化、Word2Vec・Doc2Vecによる単語の分散表現、t-SNEによる次元圧縮と単語マッピングです。実装コードとともに順を追って説明します。前提事項の説明(使用環境・データ・分析方針)
使用環境
Python==3.7.4
データ
本記事で取得するデータは遊戯王OCGカードデータベースからお手製コードでスクレイピングしたものを使用しています。2020/6時点で最新です。
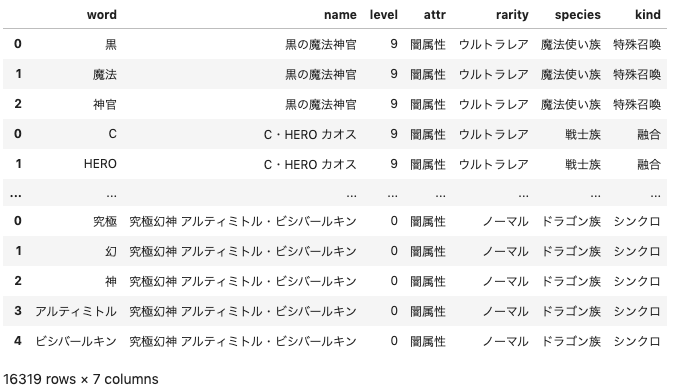
表示するグラフによって様々なデータフレームを使い分けますが、すべてのデータフレームは以下のカラムを保持します。
No. 列名 列名(日本語) サンプル 補足 1 name カード名 おジャマ・イエロー 2 kana カード名の読み おジャマ・イエロー 1 rarity レアリティ ノーマル 取得都合上、「制限」「禁止」などの情報も入る 1 attr 属性 光属性 モンスター以外の場合は、「魔法」「罠」と入る 1 effect 効果 NaN 魔法・罠カードの種類である「永続」「装備」等が入る。モンスターの場合はNaN 1 level レベル 2 ランクモンスターの場合は「ランク2」と入る 1 species 種族 獣族 1 attack 攻撃力 0 1 defence 守備力 1000 1 text カードテキスト あらゆる手段を使ってジャマをすると言われているおジャマトリオの一員。三人揃うと何かが起こると... 1 pack 収録パック名 EXPERTエキスパート EDITIONエディション Volumeボリューム 2 1 kind 種類 - モンスターカードの場合、融合、儀式などの情報が入る ※サンプルデータ
分析の方針
すべての分析は
Jupter Labなどの対話型インタープリタで実行することを想定しています。実装
1. パッケージインポート
必要なパッケージをインポートします。
MeCabやgensim、wordcloudはAnacondaでも初期から入っていないと思うので、必要に応じてpip installします。pythonimport matplotlib.pyplot as plt import MeCab import numpy as np import pandas as pd import re import seaborn as sns from gensim.models.doc2vec import Doc2Vec from gensim.models.doc2vec import TaggedDocument from gensim.models import word2vec from sklearn.decomposition import TruncatedSVD from sklearn.manifold import TSNE from PIL import Image from wordcloud import WordCloud %matplotlib inline sns.set(font="IPAexGothic") #Pythonを日本語対応2. データインポート
各データセットの取得方法は0. スクレイピング編で記載します(2020/6 時点で記事なし)。
python# 今回は使用しない # all_data = pd.read_csv("./input/all_data.csv") #全カードのデータセット(同名カードでも収録パック違いの重複あり) # print("all_data: {}rows".format(all_data.shape[0])) cardlist = pd.read_csv("./input/cardlist.csv") #全カードのデータセット(重複なし) print("cardlist: {}rows".format(cardlist.shape[0])) # 今回は使用しない # monsters = pd.read_csv("./input/monsters.csv") #モンスターカードのみ # print("monsters: {}rows".format(monsters.shape[0])) monsters_norank = pd.read_csv("./input/monsters_norank.csv") #モンスターカードからランクモンスターを除去 print("monsters_norank: {}rows".format(monsters_norank.shape[0]))cardlist: 10410rows monsters_norank: 6206rows3. MeCabの検証
※ソースは昔書いたブログ向井秀徳は結局「諸行無常」しか言ってないんじゃないか?をデータサイエンス ~自然言語処理編~から引用しています。
MeCabを使用する手順はざっくり以下の2STEPです。
- 形態素解析器を
mecabTaggerという形でインスタンス化- 形態素解析を行うメソッド
parseToNode()を実行し、結果をnodeオブジェクトに格納上記の結果、
nodeオブジェクトには2つのアトリビュートが格納されます。
- 表層形(surface): 単語そのもの。文中において文字列として出現する形式
- 素性(feature): 単語の情報のリスト
python# 1. 形態素解析器をインスタンス化し、parseToNodeメソッドでオブジェクトに処理結果を格納 text = "青眼の白竜" mecabTagger = MeCab.Tagger("-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") # 辞書:mecab-ipadic-neologdを使用 node = mecabTagger.parseToNode(text) #2. 表層形(surface)と素性(feature)を格納するデータフレームを作成 surface_and_feature = pd.DataFrame() surface = [] feature = [] #3. nodeオブジェクトのアトリビュートから表層形、素性を抽出 while node: surface.append(node.surface) feature.append(node.feature) node = node.next surface_and_feature['surface'] = surface surface_and_feature['feature'] = feature surface_and_feature
featureにはリストが入っているようなので、更にこれをデータフレーム化します。
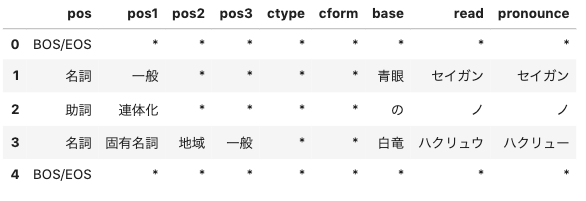
辞書mecab-ipadic-neologdを使用する場合、素性(feature)の中身には品詞(pos),品詞細分類1(pos1),品詞細分類2(pos2),品詞細分類3(pos3),活用形(ctype),活用型(cform),原形(base),読み(read),発音(pronounce)の8つがリストとして格納されます。
また、データフレームの先頭と末尾にあるBOS/EOSはnodeの先頭と末尾をそのまま表す値です。pythontext = "青眼の白竜" mecabTagger = MeCab.Tagger("-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") node = mecabTagger.parseToNode(text) # 素性(feature)のリストの中身(品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用形,活用型,原形,読み,発音)をデータフレームに格納 features = pd.DataFrame(columns=["pos","pos1","pos2","pos3","ctype","cform","base","read","pronounce"]) posses = pd.DataFrame while node: tmp = pd.Series(node.feature.split(','), index=features.columns) features = features.append(tmp, ignore_index=True) node = node.next features
4. 形態素解析
読み込んだデータをMeCabの形態素解析器にかけていきます。
4-1. 形態素解析を行う関数の実装
カード名のリストを単語に分解する関数
get_word_listを作成します。
「と」「も」等の助詞を入れるとノイズになるので、使用する品詞は名詞・動詞・形容詞のみとします。pythondef get_word_list(text_list): m = MeCab.Tagger ("-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") lines = [] for text in text_list: keitaiso = [] m.parse('') node = m.parseToNode(text) while node: #辞書に形態素を入れていく tmp = {} tmp['surface'] = node.surface tmp['base'] = node.feature.split(',')[-3] #原形(base) tmp['pos'] = node.feature.split(',')[0] #品詞(pos) tmp['pos1'] = node.feature.split(',')[1] #品詞再分類(pos1) #文頭、文末を表すBOS/EOSは省く if 'BOS/EOS' not in tmp['pos']: keitaiso.append(tmp) node = node.next lines.append(keitaiso) #名詞の場合は表層系、動詞・形容詞の場合は原形をリストに格納する word_list = [] for line in lines: for keitaiso in line: if (keitaiso['pos'] == '名詞'): word_list.append(keitaiso['surface']) elif (keitaiso['pos'] == '動詞') | (keitaiso['pos'] == '形容詞') : if not keitaiso['base'] == '*' : word_list.append(keitaiso['base']) else: word_list.append(keitaiso['surface']) # 名詞・動詞・形容詞も含める場合はコメントを解除 # else: # word_list.append(keitaiso['surface']) return word_list4-2. データフレームの作成
後続の可視化・モデリング工程で使用するデータフレームを2つ作成します。
cardlist_word_count: 全カードの重複なしデータセットcardlistを元に作成。カラムに全カードで使用された単語wordと、登場回数word_countを持つ。monsters_words: 全モンスターからランクモンスターを除いたデータセットmonsters_norankを元に作成。カラムに使用された単語wordと、単語が登場したカードの特徴name,level,attr,rarity,species,kindを持つ。行単位はカードではなく単語であることに注意。ところで遊戯王カードの名前には記号「・」による単語の分割が多く見られますが、
Mecabはこの記号を分割対象にしてくれません。なので、上記関数に実行する前に、事前に「・」で単語を分割する処理を入れます。
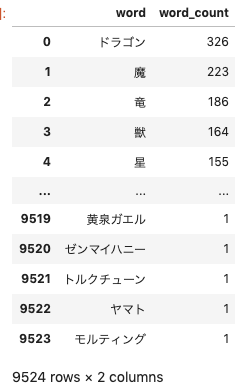
cardlist_word_countpython# 「・」は事前に区切ったリストnamelistの作成 namelist = [] for name in cardlist.name.to_list(): for name_ in name.split("・"): namelist.append(name_) # 関数get_word_listによる文字列リストword_listの生成 word_list = get_word_list(namelist) # word_listから、単語とその出現頻度をマッピングしたデータフレームwords_dfの生成 word_freq = pd.Series(word_list).value_counts() cardlist_word_count = pd.DataFrame({'word' : word_freq.index, 'word_count' : word_freq.tolist()}) cardlist_word_count
monsters_wordspythonmonsters_words= pd.DataFrame(columns=["word","name","level","attr","rarity","species","kind"]) for i, name in enumerate(monsters_norank.name.to_list()): words = get_word_list(name.split("・")) names = [monsters_norank.loc[i, "name"] for j in words] levels = [monsters_norank.loc[i, "level"] for j in words] attrs = [monsters_norank.loc[i, "attr"] for j in words] rarities = [monsters_norank.loc[i, "rarity"] for j in words] species = [monsters_norank.loc[i, "species"] for j in words] kinds = [monsters_norank.loc[i, "kind"] for j in words] tmp = pd.DataFrame({"word" : words, "name" : names, "level" : levels, "attr" : attrs, "rarity" : rarities, "species" : species, "kind" : kinds}) monsters_words = pd.concat([monsters_words, tmp]) monsters_words
5. 可視化
5-1. 使用ワードランキング
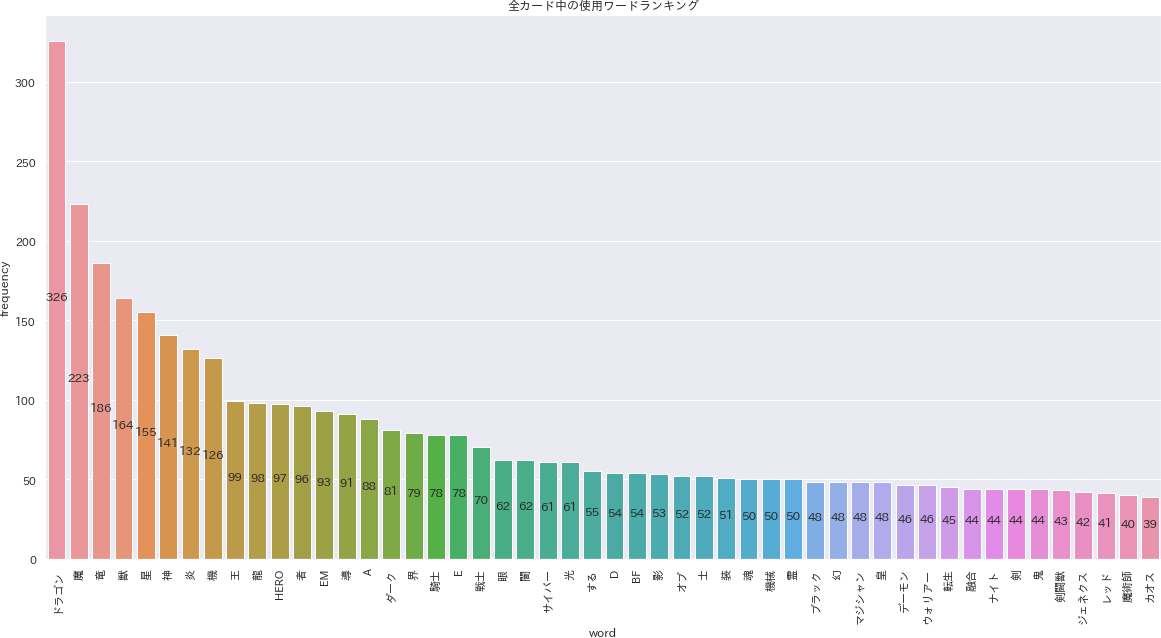
cardlist_word_countから、全カードの頻出50ワードを取り出しランキングを作ります。
「ドラゴン」が326回で圧倒的に1位です。類似ワード「竜(3位)」「龍(98位)」と合計すると610回も登場しています。
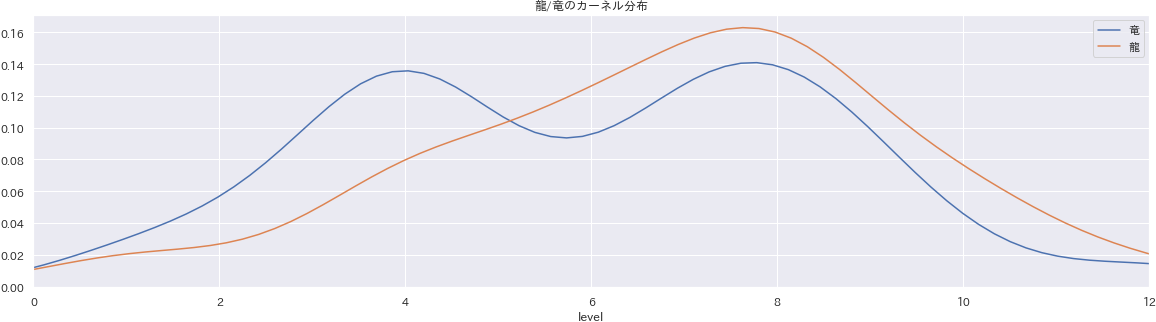
pythondf4visual = cardlist_word_count.head(50) f, ax = plt.subplots(figsize=(20, 10)) ax = sns.barplot(data=df4visual, x="word", y="word_count") ax.set_ylabel("frequency") ax.set_title("全カード中の使用ワードランキング") for i, patch in enumerate(ax.patches): ax.text(i, patch.get_height()/2, int(patch.get_height()), ha='center') plt.xticks(rotation=90) plt.savefig('./output/nlp5-1.png', bbox_inches='tight', pad_inches=0)ふとランキング中にある「龍」と「竜」の使い分けが気になったので、寄り道して探索を進めます。
x軸にレベルをとり、単語「竜」「龍」についてそれぞれカーネル密度推定の結果を描画します。各山は合計の面積が1になるように描画されていおり、山が高い部分には多くのモンスターが集まっている、と解釈できます。
龍は竜と比べてグラフの右側に山のピークがあるため、比較的レベルが高く強いカードに使用されていることが分かります。
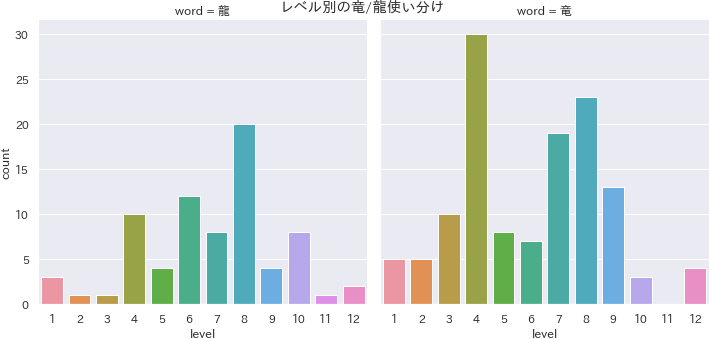
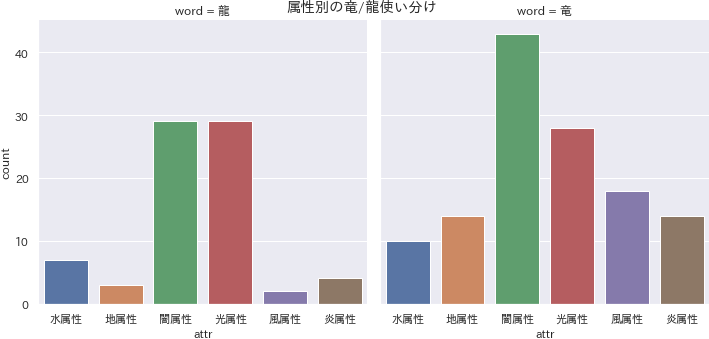
pythonmonsters_words_dragon = monsters_words.query("word == '竜' | word == '龍'") df4visual = monsters_words_dragon f, ax = plt.subplots(figsize = (20, 5)) ax = sns.kdeplot(df4visual.query("word == '竜'").level, label="竜") ax = sns.kdeplot(df4visual.query("word == '龍'").level, label="龍") ax.set_xlim([0, 12]); ax.set_title("龍/竜のカーネル分布") ax.set_xlabel("level") plt.savefig('./output/nlp5-1a.png', bbox_inches='tight', pad_inches=0)ソースコード・解釈は省略しますが、レベル・属性別の
countplot結果も載せます。
5-2. WordCloud
WordCloudは単語の可視化に使わられるライブラリです。出現頻度が多い単語を抽出して、より頻度が多いものをサイズを大きくして描画します。wordcloud.generate_from_frequencies()は単語と、その頻度の辞書をとってWordCloudオブジェクトを生成します。
図を見ると、5-1と同じように「ドラゴン」が最も大きいサイズでプロットされていることが分かります。
pythondef make_wordcloud(df,col_name_noun,col_name_quant): word_freq_dict = {} for i, v in df.iterrows(): #単語とその頻度をデータフレームから辞書化 word_freq_dict[v[col_name_noun]] = v[col_name_quant] fpath = "/System/Library/Fonts/ヒラギノ角ゴシック W3.ttc" # WordCloudをインスタンス化 wordcloud = WordCloud(background_color='white', font_path = fpath, min_font_size=10, max_font_size=200, width=2000, height=500 ) wordcloud.generate_from_frequencies(word_freq_dict) return wordcloud f, ax = plt.subplots(figsize=(20, 5)) ax.imshow(make_wordcloud(cardlist_word_count, 'word', 'word_count')) ax.axis("off") ax.set_title("全カードWordCloud") plt.savefig('./output/nlp5-2a.png', bbox_inches='tight', pad_inches=0)レベル別、属性別の抽出結果も表示します。
ちょっと縦長になってしまいますが・・興味無い方はスクロールして飛ばしてください。レベル別
レベル1~12にまんべんなく「ドラゴン」がいますが、レベル9では「竜」の方が上回っており、レベル11にはそもそもドラゴン自体がいないようです。
属性別
地属性に戦士・セイバーなどの戦士系の単語が目立ちます。闇属性に「魔」「ダーク」「デーモン」等が多いのは言わずもがなですね。
pythondef make_wordclouds(df, colname): wordclouds = [] df = df.sort_values(colname) for i in df[colname].unique(): # word_freq = df.query("{} == {}".format(colname,i))["word"].value_counts() #pandasのSeriesに変換してvalue_counts() word_freq = df[df[colname] == i]["word"].value_counts() monsters_word_count = pd.DataFrame({'word' : word_freq.index, 'word_count' : word_freq.tolist()}) wordclouds.append(make_wordcloud(monsters_word_count, 'word', 'word_count')) f, ax = plt.subplots(len(wordclouds), 1, figsize=(20, 5*int(len(wordclouds)))) for i, wordcloud in enumerate(wordclouds): ax[i].imshow(wordcloud) ax[i].set_title("{}:".format(colname) + str(df[colname].unique()[i])) ax[i].axis("off"); make_wordclouds(monsters_words, "level") plt.savefig('./output/nlp5-2b.png', bbox_inches='tight', pad_inches=0) make_wordclouds(monsters_words, "attr") plt.savefig('./output/nlp5-2c.png', bbox_inches='tight', pad_inches=0)6. モデリング(単語・文章の分散表現)
単語間の類似度や、後続の機械学習の工程に進むために、より機械が単語の意味を解釈しやすいようにするためのベクトル化を行います。単語を数次元〜数百次元のベクトルに変換することを分散表現と言います。
今回単語の分散表現を行う際にはword2vecを採用します。単語のリストを渡すことで、簡単に任意の次元数を持つベクトルに変換することが可能です。加えて、文章単位のベクトル化にはDoc2Vecを採用します。Word2Vec及びDoc2Vecの詳しい仕組み・使い方は以下のリンクをぜひ参考にしてください。
6-1. Word2Vec
事前準備として、前章で作成したデータフレーム
monsters_wordsを更に改変し、monsters_wordlistを作成します。行単位をモンスター単位に戻し、かつカラム「wordlist」に当カードが含む単語のリストや、カラム「length」として単語数を新しく加えます。pythonwordlist = monsters_words.groupby("name")["word"].apply(list).reset_index() wordlist.columns = ["name", "wordlist"] wordlist["length"] = wordlist["wordlist"].apply(len) monsters_wordlist = pd.merge(wordlist, monsters_norank, how="left") monsters_wordlist
実際にモデリングを実行するコードはこちらです。
sizeは次元数、iterは学習を繰り返す数、windwowは前後いくつの単語を見て学習するかを表すパラメータです。python%time model_w2v = word2vec.Word2Vec(monsters_wordlist["wordlist"], size=30, iter=3000, window=3) model_w2v学習が終わったら簡単に検証してみます。
wv.most_similar()メソッドによって、ある単語に対し意味が近いと判定された単語の上位n件を確認することができます。
試しに「レッド」をInputしてみると、同じく色を表す「ブラック」が1番に来ました。いい感じですね!
この推薦結果が的を得ない場合は上記パラメータをいろいろ動かして検証を繰り返します。pythonmodel_w2v.wv.most_similar(positive="レッド", topn=20)[('ブラック', 0.58682781457901), ('悪魔', 0.5581836700439453), ('アーティファクト', 0.5535239577293396), ('ファントム', 0.4850098788738251), ('れる', 0.460792601108551), ('オブ', 0.4455495774745941), ('エンシェント', 0.43780404329299927), ('ウォーター', 0.4303821623325348), ('ドラゴン', 0.4163920283317566), ('ホーリー', 0.4114375710487366), ('創世', 0.3962644040584564), ('Sin', 0.36455491185188293), ('ホワイト', 0.3636135756969452), ('巨', 0.3622574210166931), ('ロード', 0.3602677285671234), ('守護者', 0.35134968161582947), ('パワー', 0.3466736972332001), ('エルフ', 0.3355366587638855), ('ギア', 0.3334060609340668), ('ドライバー', 0.33207967877388)]次にこの結果を可視化することを考えます。今回のWord2Vecは単語を30次元のベクトルに変換しているため、グラフ化するには次元を落とす(次元削減)する必要があります。
t-SNEは次元削減を行う教師なし学習のモデルの1つで、できるだけ情報(分散)を落とさないように任意の次元にデータを集約させることが可能です。
xy軸を持つ散布図にプロットすることを考え、30次元を2次元に落とす処理を実装します。python# 頻出ワード200件を抽出 n=200 topwords = monsters_words["word"].value_counts().head(n) w2v_vecs = np.zeros((topwords.shape[0],30)) for i, word in enumerate(topwords.index): w2v_vecs[i] = model_w2v.wv[word] # t-SNEで次元削減:30次元から2次元に落とす tsne= TSNE(n_components=2, verbose=1, n_iter=500) tsne_w2v_vecs = tsne.fit_transform(w2v_vecs) w2v_x = tsne_w2v_vecs[:, 0] w2v_y = tsne_w2v_vecs[:, 1]各単語が2次元のベクトルデータをもったので、それぞれをx, y軸にとり散布図を描きます。
次元削減しても元データの情報が残っているのであれば、より近いところにある単語は意味も似通っていると解釈できるはずです。
プロット結果は一見ランダムに単語を配置したようにも見えますが、以下のように近い意味が固まっているようにも捉えられます。
- 中央左付近:「人」「レディ」「マン」等、人を表す名詞が固まっている
- 下付近:「師」「王」「神」等、神格化・目上とされる人を表す名詞が固まっている
pythondf4visual = pd.DataFrame({"word":topwords.index, "x":w2v_x, "y":w2v_y}) f, ax = plt.subplots(figsize=(20, 20)) ax = sns.regplot("x","y",data=df4visual,fit_reg=False, scatter_kws={"alpha": 0.2}) for i, text in enumerate(topwords.index): ax.text(df4visual.loc[i, 'x'], df4visual.loc[i, 'y'], text) ax.axis("off") ax.set_title("カードタイトル頻出200単語の類似度可視化") plt.savefig('./output/nlp6-1.png', bbox_inches='tight', pad_inches=0)5-2. Doc2Vec
Word2Vecは単語の分散表現を獲得するのに対し、Doc2Vecは学習時にタグ情報として単語が属する文章も加えることで、文章の分散表現を獲得することが可能です。これにより、文章(カード名)間の意味のち傘を測ることができます。下準備として、モデルのInputとする
TaggedDocumentを作成します。単語のリストに対し、その単語が構成するカード名をTagとして割り当てます。pythondocument = [TaggedDocument(words = wordlist, tags = [monsters_wordlist.name[i]]) for i, wordlist in enumerate(monsters_wordlist.wordlist)] document[0]TaggedDocument(words=['A', 'BF', '五月雨', 'ソハヤ'], tags=['A BF-五月雨のソハヤ'])学習方法は
word2vecとほぼ同じです。学習方法dmはデフォルトの0、次元数vector_sizeは30、繰り返し数epochsは200に設定します。ちなみに1epochは、データセットにおけるすべての単語を1回ずつインプットトするという意味です。python%time model_d2v = Doc2Vec(documents = document, dm = 0, vector_size=30, epochs=200)同じようにテストを実行しましょう。
docvecs.most_similar()メソッドで、カード名をインプットに、類似したカード名の上位数件を確認します。
「ブラック・マジシャン」をInputすると、1位にはブラック・マジシャン・ガールが返ってきました。同じ単語を使ったカード名が後続することから、学習はおおよそちゃんとできていそうです!pythonmodel_d2v.docvecs.most_similar("ブラック・マジシャン")[('ブラック・マジシャン・ガール', 0.9794564843177795), ('トゥーン・ブラック・マジシャン', 0.9433020949363708), ('トゥーン・ブラック・マジシャン・ガール', 0.9370808601379395), ('竜騎士ブラック・マジシャン', 0.9367024898529053), ('竜騎士ブラック・マジシャン・ガール', 0.93293297290802), ('ブラック・ブルドラゴ', 0.9305672645568848), ('マジシャン・オブ・ブラック・イリュージョン', 0.9274455904960632), ('アストログラフ・マジシャン', 0.9263750314712524), ('クロノグラフ・マジシャン', 0.9257084727287292), ('ディスク・マジシャン', 0.9256418347358704)]次元削減も
word2vecと同様に行い、カード200枚をランダムに選んで可視化を行います。
似ている単語はほぼ同じ位置に来るので、少し見づらくなってしまいますね。。しかし、同じ単語を持つカード名は近いところに散布されているのが分かります。
pythond2v_vecs = np.zeros((monsters_wordlist.name.shape[0],30)) for i, word in enumerate(monsters_wordlist.name): d2v_vecs[i] = model_d2v.docvecs[word] tsne = TSNE(n_components=2, verbose=1, n_iter=500) tsne_d2v_vecs = tsne.fit_transform(d2v_vecs) d2v_x = tsne_d2v_vecs[:, 0] d2v_y = tsne_d2v_vecs[:, 1] monsters_vec = monsters_wordlist.copy() monsters_vec["x"] = d2v_x monsters_vec["y"] = d2v_y df4visual = monsters_vec.sample(200, random_state=1).reset_index(drop=True) f, ax = plt.subplots(figsize=(20, 20)) ax = sns.regplot("x","y",data=df4visual, fit_reg=False, scatter_kws={"alpha": 0.2}) for i, text in enumerate(df4visual.name): ax.text(df4visual.loc[i, 'x'], df4visual.loc[i, 'y'], text) ax.axis("off") ax.set_title("モンスター200枚の類似度可視化") plt.savefig('./output/nlp6-2a.png', bbox_inches='tight', pad_inches=0)せっかくなので、全カードをカード名無しでプロットしてみます。下記は全カードの意味の近さ(ベクトル)を、種族で塗り分けて描画した散布図です。
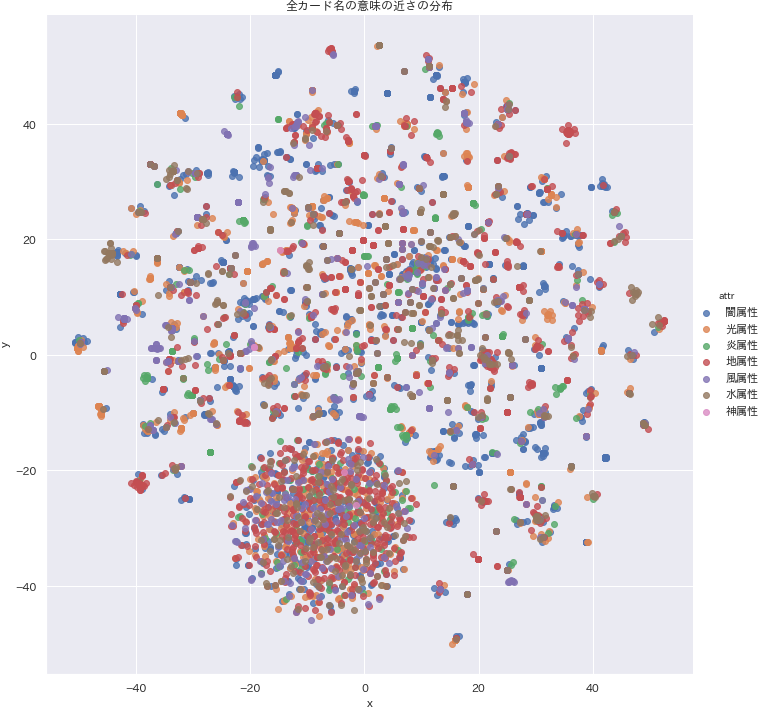
なかなか素晴らしい結果になったか思います!グラフ下部にある円状の集団は、シリーズものでないカード達がまとまっているものと推測できます。その周囲にまばらにカードが散っていますが、恐らく同一シリーズで小さな集団を形成していることが見て取れます。
pythondf4visual = monsters_vec g = sns.lmplot("x","y",data=df4visual, fit_reg=False, hue="attr", height=10) g.ax.set_title("全カード名の意味の近さの分布")例えば座標(x, y) = (-40, -20)あたりに地属性からなる集団があります。この情報をクエリで検索すると、「古代の機械」シリーズの集まりであることが分かります。いい感じです!
pythonmonsters_vec.query("-42 <= x <= -38 & -22 <= y <= -18")["name"]2740 パーフェクト機械王 3952 古代のトカゲ戦士 3953 古代の機械兵士 3954 古代の機械合成獣 3955 古代の機械合成竜 3956 古代の機械工兵 3957 古代の機械巨人 3958 古代の機械巨人-アルティメット・パウンド 3959 古代の機械巨竜 3960 古代の機械混沌巨人 3961 古代の機械熱核竜 3962 古代の機械猟犬 3963 古代の機械獣 3964 古代の機械砲台 3965 古代の機械究極巨人 3966 古代の機械箱 3967 古代の機械素体 3968 古代の機械超巨人 3969 古代の機械飛竜 3970 古代の機械騎士 3971 古代の機械魔神 3972 古代の歯車 3973 古代の歯車機械 3974 古代魔導士 4036 地球巨人 ガイア・プレート 4279 巨人ゴーグル 4491 振り子刃の拷問機械 4762 機械の兵隊 4764 機械犬マロン 4765 機械王 4766 機械王-プロトタイプ 4767 機械竜 パワー・ツール 4768 機械軍曹 4994 溶岩大巨人 5247 眠れる巨人ズシン 5597 超古代恐獣最後にカード名毎ではなく、属性・種族・レベル別の類似度も確認してみましょう。
カード毎に得たベクトルを属性・種族・レベル毎に平均し、各データの切り口毎にプロットします。属性別
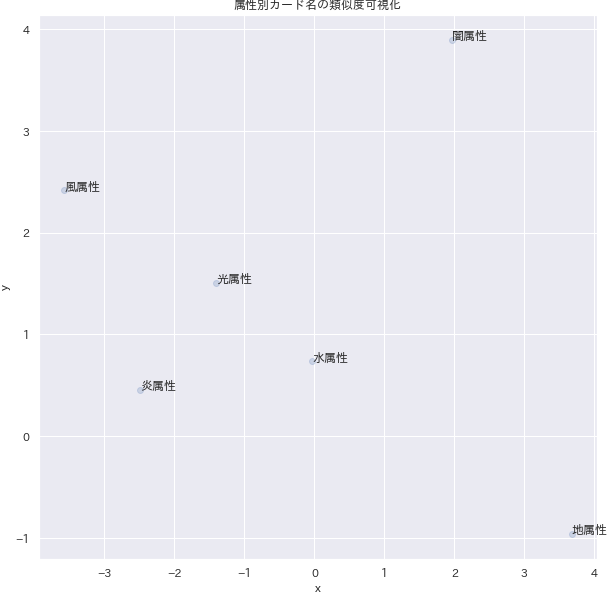
闇属性だけ気持ち外れた場所にマッピングされました。
pythondf4visual = monsters_vec.groupby("attr").mean()[["x", "y"]].reset_index().query("attr != '神属性'").reset_index(drop=True) # 神属性は外れ値になるため省略する f, ax = plt.subplots(figsize=(10, 10)) ax = sns.regplot("x","y",data=df4visual, fit_reg=False, scatter_kws={"alpha": 0.2}) for i, text in enumerate(df4visual.attr): ax.text(df4visual.loc[i, 'x'], df4visual.loc[i, 'y'], text) ax.set_title("属性別カード名の類似度可視化") plt.savefig('./output/nlp6-2c.png', bbox_inches='tight', pad_inches=0)種族別
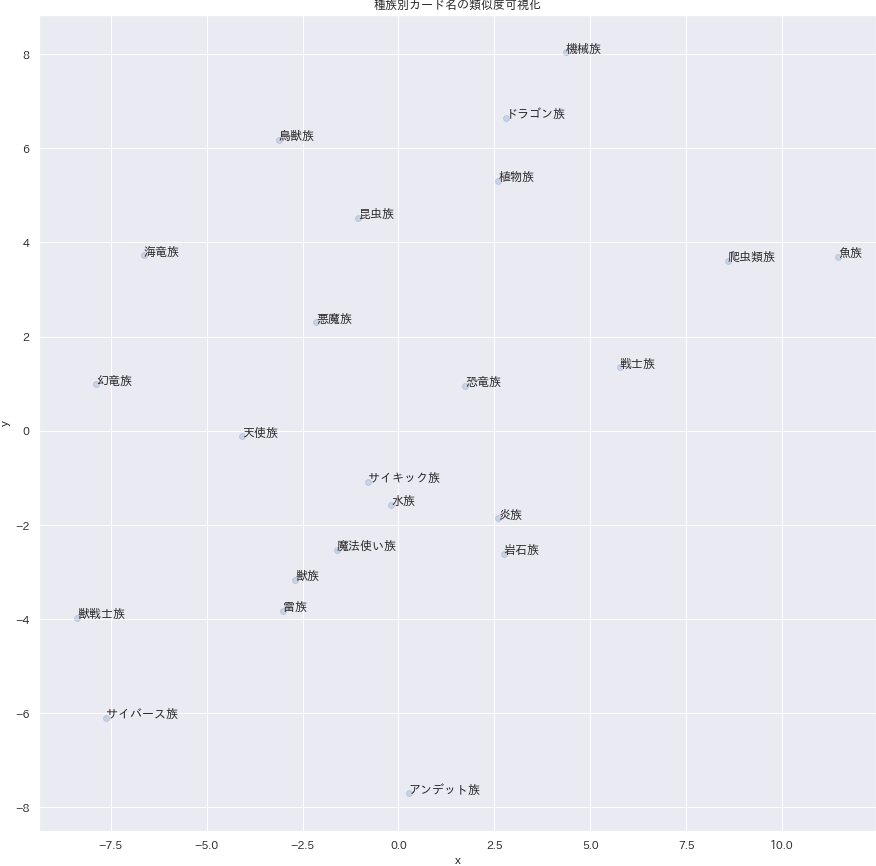
無理やり解釈しようとするなら、魚族と爬虫類族が近いところにいます。
pythondf4visual = monsters_vec.groupby("species").mean()[["x", "y"]].reset_index().query("species != '創造神族' & species != '幻神獣族'").reset_index(drop=True) # 神属性の種族は外れ値になるため省略する f, ax = plt.subplots(figsize=(15, 15)) ax = sns.regplot("x","y",data=df4visual, fit_reg=False, scatter_kws={"alpha": 0.2}) for i, text in enumerate(df4visual.species): ax.text(df4visual.loc[i, 'x'], df4visual.loc[i, 'y'], text) ax.axis("on") ax.set_title("種族別カード名の類似度可視化") plt.savefig('./output/nlp6-2d.png', bbox_inches='tight', pad_inches=0)レベル別
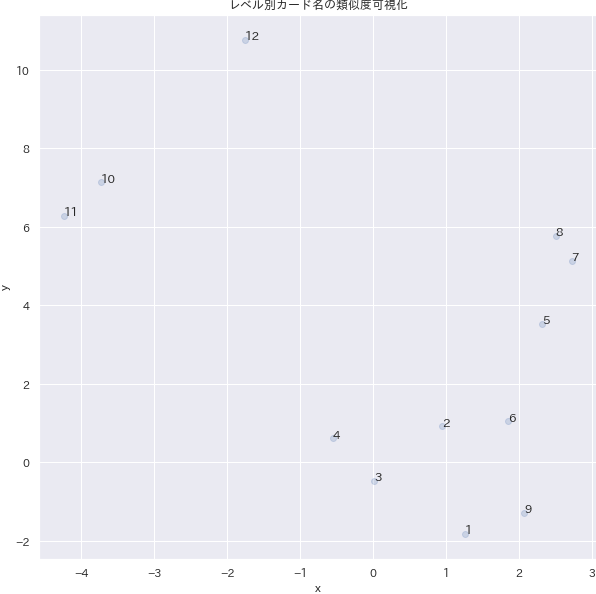
低レベル帯(1~4)は結構近くにいることが分かります。高レベル帯でも10と11は近いところにいますが、12は離れているため、別の名前の特徴を持っていることが推測できます。
pythondf4visual = monsters_vec.groupby("level").mean()[["x", "y"]].reset_index().query("level != '0'").reset_index(drop=True) # レベル0は外れ値になるため省略する f, ax = plt.subplots(figsize=(10, 10)) ax = sns.regplot("x","y",data=df4visual, fit_reg=False, scatter_kws={"alpha": 0.2}) for i, text in enumerate(df4visual.level): ax.text(df4visual.loc[i, 'x'], df4visual.loc[i, 'y'], text) ax.set_title("レベル別カード名の類似度可視化") plt.savefig('./output/nlp6-2e.png', bbox_inches='tight', pad_inches=0)まとめ
ここまで読んでいただきありがとうございました。遊戯王カード名を更に深ぼって、
Mecabによる形態素解析、WordCloudによる可視化、Word2Vec・Doc2Vecによる分散表現の獲得の一連の分析を行いました。
Doc2Vecでの全カードの散布図は我ながらいい感じになったなと思います。次工程の機械学習パートではここで得た特徴量をそのまま使用するので、精度が高い予測モデルを組めることを期待します。次回予告
いよいよ機械学習編です。まだ実装しておらずテーマも考え中ですが、概ね以下の予測モデルが組めたらいいなと考えています。乞うご期待ください。
Doc2Vec&LightGBMで任意のカード名から攻撃力・守備力・属性・種族諸々を予測するLSTMでカード名の生成を行う(こっちは時間都合上省くかも・・・)






- 投稿日:2020-06-21T16:55:25+09:00
じゃんけん
script.py
import utilsrandomモジュールを読み込んでください
import random
print('じゃんけんをはじめます')
player_name = input('名前を入力してください:')
print('何を出しますか?(0: グー, 1: チョキ, 2: パー)')
player_hand = int(input('数字で入力してください:'))if utils.validate(player_hand):
# randintを用いて0から2までの数値を取得し、変数computer_handに代入してください
computer_hand = random.randint(0,2)if player_name == '': utils.print_hand(player_hand) else: utils.print_hand(player_hand, player_name) utils.print_hand(computer_hand, 'コンピューター') result = utils.judge(player_hand, computer_hand) print('結果は' + result + 'でした')else:
print('正しい数値を入力してください')
utils.py
def validate(hand):
if hand < 0 or hand > 2:
return False
return Truedef print_hand(hand, name='ゲスト'):
hands = ['グー', 'チョキ', 'パー']
print(name + 'は' + hands[hand] + 'を出しました')def judge(player, computer):
if player == computer:
return '引き分け'
elif player == 0 and computer == 1:
return '勝ち'
elif player == 1 and computer == 2:
return '勝ち'
elif player == 2 and computer == 0:
return '勝ち'
else:
return '負け'
- 投稿日:2020-06-21T16:23:58+09:00
OR-Toolsで学ぶ最適化 Part0【導入】
このブログis何
Googleが開発したOR-Toolsを使って数理最適化を学んでいきます。
内容は殆どがこの本を参考にしたものです。
Practical Python AI Projects: Mathematical Models of Optimization Problems with Google OR-Tools (English Edition)著者によるコード一覧はこちら
本ブログに記載するコードは著者オリジナルの物と殆ど変わらず、一部日本語に直したりしている程度です。数学的な厳密さや、理論の解説は優先度低めになってます。ご勘弁を。
今回は : 導入
簡単な例題をもとに
・最適化問題ってなんやっけ?
・OR-Toolsどう使うん?
を勉強していきます場面設定
あなたはペットショップの両生類担当。同じ水槽でヒキガエル、サンショウウオ、イモリを飼うらしい。
なるべく沢山飼育したいんやけど、エサには限りがある。ちなみにエサはミミズ、コオロギ、ハエ(なんでこんな例題なんやろ)
種類によって、1日にどのエサを何匹食うかも違うわけやし、どうしたら合計で一番多く飼えるんやろか?
各両生類1匹あたりの、1日に食べるエサの量
エサ ヒキガエル サンショウウオ イモリ 用意できる数 ミミズ 2 1 1 1500 コオロギ 1 3 2 3000 ハエ 1 2 3 5000 定式化
まず決定変数を設定します。
今回は「合計が最大になるような、ヒキガエル・サンショウウオ・イモリの数」を求めるので、\begin{align} &x_0 : ヒキガエル\\ &x_1 : サンショウウオ\\ &x_2 : イモリ\\ \end{align}\\ ただし、0 \leq x_i \leq 1000今回最大化したい関数は、
x_0 + x_1 + x_2やね。
これだけやと、1000匹ずつ飼えばOK!になってまうけど、エサの制約があります。
ミミズは1500匹用意できて、ヒキガエルは1日に2匹、サンショウウオは1匹、イモリは1匹食べるので、2x_0 + x_1 + x_2 \leq 1500コオロギとハエについても同様に、
x_0 + 3x_1 + 2x_2 \leq 3000\\ x_0 + 2x_1 + 3x_2 \leq 5000いざ、実装
ソルバーを定義(s)して、変数や目的関数、制約条件を加えていく(Add)って形になります。
定義する際、引数にソルバーのタイトル(今回では「両生類の共存」)と、利用するソルバー(今回はGLOP)を指定しています。GLOPは線形計画ソルバーです。coexistence.pyfrom ortools.linear_solver import pywraplp def solve_coexistence(): t = '両生類の共存' s = pywraplp.Solver(t, pywraplp.Solver.GLOP_LINEAR_PROGRAMMING) x = [s.NumVar(0, 1000, 'x[%i]' % i) for i in range(3)] # 0 <= x <= 1000 。決定変数 pop = s.NumVar(0, 3000, 'pop') # 0 <= pop <= 3000。 目的変数 s.Add(2*x[0] + x[1] + x[2] <= 1500) #ミミズ制約 s.Add(x[0] + 3*x[1] + 2*x[2] <= 3000) #コオロギ制約 s.Add(x[0] + 2*x[1] + 3*x[2] <= 4000) #ハエ制約 s.Add(pop == x[0] + x[1] + x[2]) #目的関数 s.Maximize(pop) #popを最大化したいということを指定 s.Solve() #解く ##目的関数値と、決定変数の値を返す return pop.SolutionValue(), [e.SolutionValue() for e in x]実行するコードはこちら
test_coexistence.pyfrom __future__ import print_function from coexistence import solve_coexistence pop, x = solve_coexistence() #定義した関数を呼び出し、結果を格納 T = [['種類', '数']] #結果を表示する際の列名 for i in range(3): T.append([['ヒキガエル','サンショウウオ','イモリ'][i], x[i]]) #i行に名前と個体数を追加 T.append(['合計', pop]) for e in T: print(e[0], e[1])実行結果
種類 数 ヒキガエル 100.0 サンショウウオ 300.0 イモリ 1000.0 合計 1400.0 はいこれが最適解です。イモリ多すぎて笑える
イモリはミミズやコオロギ(数少ない)をあんま食べんくて、ハエ(多い)をたくさん食うから多く入れて貰えたんやろな、知らんけど
現実やったら、サンショウウオが一番売れるからたくさん入れたいとか、イモリは高く売れないからそんなにいらんとかあるやろけど、今回は導入なのでこの辺で。OR-Toolsの使い方は次回の方が詳しく触れられそうなことに今気づきました。じゃあ今回のはなんやったん
- 投稿日:2020-06-21T16:07:48+09:00
script.py お買い物条件分岐
money = 1000
items = {'apple': 100, 'banana': 200, 'orange': 400}
for item_name in items:
print('--------------------------------------------------')
print('財布には' + str(money) + '円入っています')
print(item_name + 'は1個' + str(items[item_name]) + '円です')input_count = input('購入する' + item_name + 'の個数を入力してください:') print('購入する' + item_name + 'の個数は' + input_count + '個です') count = int(input_count) total_price = items[item_name] * count print('支払い金額は' + str(total_price) + '円です') if money >= total_price: print(item_name + 'を' + input_count + '個買いました') money -= total_price # if文を用いて、moneyの値が0のときの条件を分岐してください if money == 0: print('財布が空になりました') break else: print('お金が足りません') print(item_name + 'を買えませんでした')変数moneyと型変換を用いて、「残金は◯◯円です」となるように出力してください
print('残金は'+str(money)+'円です')
- 投稿日:2020-06-21T15:58:09+09:00
データサイエンス100本ノック(構造化データ加工編)の環境構築(Windows10)
はじめに
一般社団法人データサイエンティスト協会が、構造化データの加工を実践的に学べる無料の学習環境「データサイエンス100本ノック(構造化データ加工編)」をGitHubに公開しました。
本記事は、初学者の方でも無料の学習環境を構築できるように、導入手順の詳細を記載しました。
(構築する実行環境は下図になります。)
前提条件(Windows10)
- Docker Desktop for Windows
※起動しない場合は、Hyper-Vが「無効」になっている可能性があるので「有効」に設定変更。- Git for Windows
※インストール時のデフォルト設定である改行コード変更を「無効」に設定変更。> git config --global core.autocrlf input環境構築
学習環境用のディレクトリ(今回はdss)を作成し、100本ノックのリポジトリをクローンする。
その後、100本ノックのディレクトリ内に移動し、docker-composeコマンドを使ってコンテナを作成する。(10分前後の時間がかかる。)
※環境構築中にポップアップの警告が表示される場合、DockerのローカルPCに対するアクセス権限がない可能性があるため「Share it」を選択してアクセス権限を付与する。> mkdir dss > cd dss > git clone https://github.com/The-Japan-DataScientist-Society/100knocks-preprocess.git > cd 100knocks-preprocess > docker-compose up -d --build起動済みのコンテナを確認し、「dss-notebook」と「dss-postgres」の出力を確認できれば環境構築が成功。
> docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b35f99d4148a dss-notebook "tini -g -- start-no…" 23 seconds ago Up 22 seconds 0.0.0.0:8888->8888/tcp dss-notebook 3cb559c7f66d dss-postgres "docker-entrypoint.s…" 27 seconds ago Up 26 seconds 0.0.0.0:5432->5432/tcp dss-postgres使い方
ブラウザで下記のURLにアクセスすると、構築したJupyterの環境にアクセスできる。
http://localhost:8888
workディレクトリ配下に、構造化データ加工の演習問題の.ipynbファイルがある。
必要ライブラリのインポートや加工前のデータ取得は、最初のセルに記述済み。
演習問題に適した処理を、空欄のセルに入力して実行し、学習を進める。
演習問題の解答は、work/answerディレクトリ内に.ipynbファイルがある。
そのため、演習問題のファイルで回答した処理の正否を確認しながら作業可能。
学習環境の停止・起動
下記のコマンドで、構築した環境を停止可能。
> docker-compose stopまた、2回目以降に起動する場合は、下記のコマンドで起動可能。
> docker-compose start補足事項
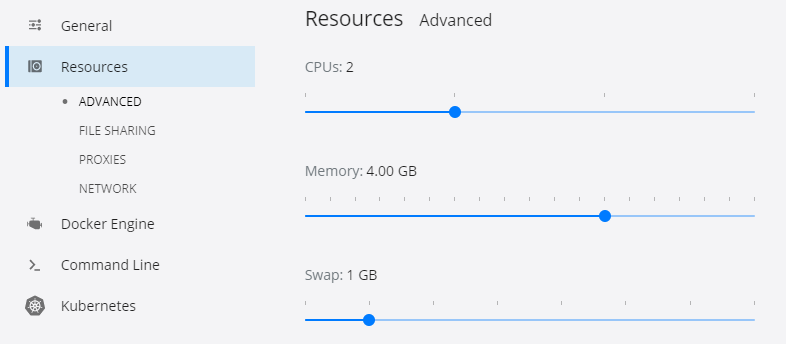
構築した環境のレスポンスが遅い場合
Docker Desktop for WindowsのSettingsでResourcesでMemoryの値を変更してください。
推奨は、4.00GB以上です。
8888ポートが使用されている場合
もし、ローカルホストの8888ポートを他の開発環境(LAMPなど)で利用している場合は、docker-compose.ymlを下記のように変更(notebookのportsの値を変更)することで対応可能。
docker-compose.ymlnotebook: ports: - "888:8888"上記の場合、下記のURLでアクセス可能になる。
http://localhost:888まとめ
Windows10環境における、データサイエンス100本ノック(構造化データ加工編)の環境構築手順を記載いたしました。
上記の手順で不明点や疑問点等がありましたら、コメントいただけますと幸いです。参考リンク
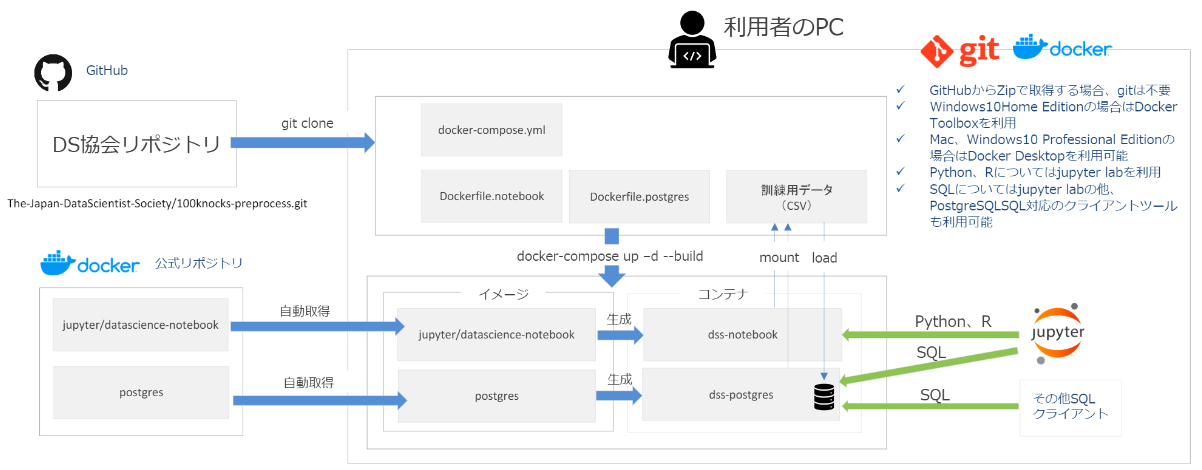
- 投稿日:2020-06-21T15:57:49+09:00
【PowerShell】 SudachiPy で形態素解析する
SudachiPy という素晴らしい形態素解析を見つけたので普段遣いの PowerShell から呼び出せるようにしてみました。
できあがったもの
文字列をパイプしてやると、
lineプロパティに入力した文字列、parsedプロパティに解析結果を持つオブジェクトを返します。コード
主な解析処理を Python で書き、 PowerShell から呼び出すという構造です。
文字列の入出力にはコマンドライン引数や
- 引数の上限
- 数百行程度が限界?
- 文字列エスケープ
- 引用符やタブ文字が含まれる場合の処理が煩雑。
- 文字コードの問題
- Windows 環境では CP932 で表現できない文字を
UnicodeEncodeErrorが発生してしまう。- 回避するには該当文字を無視するか
?に置換するしかない。Python 側での処理
Python は Scoop 経由で入手しておくとパス周りをいい感じに処理してくれて楽です。事前準備として SudachiPy と fire を
pipでインストールしておきましょう。pip install sudachipy pip install fire「テキストファイルの内容を行ごとに形態素解析して、その結果を別のテキストファイルに出力する」という処理を関数にまとめて
fire.Fire()で cli ツール化します。sudachi_tokenizer.pyimport fire import re from sudachipy import tokenizer from sudachipy import dictionary def main(input_file_path, output_file_path, ignore_paren = False): tokenizer_obj = dictionary.Dictionary().create() mode = tokenizer.Tokenizer.SplitMode.C with open(input_file_path, "r", encoding="utf_8_sig") as input_file: all_lines = input_file.read() lines = all_lines.splitlines() json_style_list = [] for line in lines: if not line: json_style_list.append({"line": "", "parsed": []}) else: if ignore_paren: target = re.sub(r"\(.+?\)|\[.+?\]|(.+?)|[.+?]", "", line) else: target = line tokens = tokenizer_obj.tokenize(target, mode) parsed = [] for t in tokens: surface = t.surface() pos = t.part_of_speech()[0] c_type = t.part_of_speech()[4] c_form = t.part_of_speech()[5] yomi = t.reading_form() parsed.append({"surface": surface, "pos": pos, "yomi": yomi, "c_type": c_type, "c_form": c_form}) json_style_list.append({"line": line, "parsed": parsed}) with open(output_file_path, mode = "w", encoding="utf_8_sig") as output_file: output_file.write(str(json_style_list)) if __name__ == "__main__": fire.Fire(main)業務上、丸パーレン
()()やブラケット[][]の中を飛ばして処理することが多いのでオプションも追加しました。入出力ファイルの文字コードを BOM つきにしているのは後述する PowerShell の仕様の関係です。
PowerShell 側の処理
上記の
sudachi_tokenizer.pyと同じディレクトリに下記の.ps1ファイルを作成し、$PROFILEから読み込むことでコンソールからコマンドレットを使えるようになります。function Invoke-SudachiTokenizer { param ( [switch]$ignoreParen ) $outputTmp = New-TemporaryFile $inputTmp = New-TemporaryFile $input | Out-File -Encoding utf8 -FilePath $inputTmp.FullName # BOMつき $sudachiPath = "{0}\sudachi_tokenizer.py" -f $PSScriptRoot $command = 'python -B "{0}" "{1}" "{2}"' -f $sudachiPath, $inputTmp.FullName, $outputTmp.FullName if ($ignoreParen) { $command += ' --ignore_paren=True' } Invoke-Expression -Command $command $parsed = Get-Content -Path $outputTmp.FullName -Encoding UTF8 @($inputTmp, $outputTmp) | Remove-Item # 一時ファイルは手動で後始末 return ($parsed | ConvertFrom-Json) }Python でリストに辞書型をまとめると json 形式の配列と同形式になるので、 PowerShellの
ConvertFrom-Jsonでオブジェクトに変換しています。コメントにも書きましたが、 PowerShell の
-encodingパラメータで UTF8 を指定すると自動的に BOM つきになるのが要注意ポイントです。
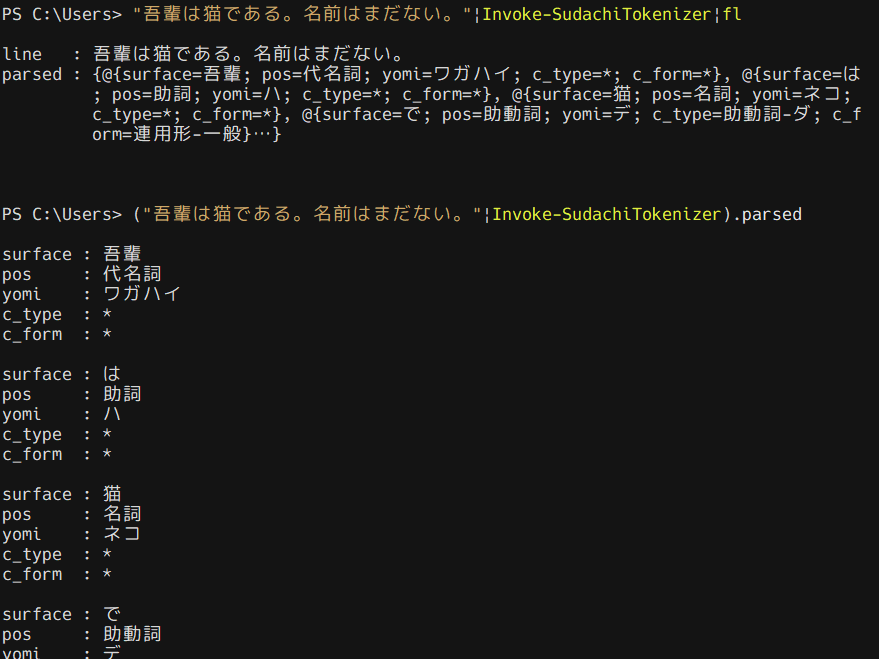
- 投稿日:2020-06-21T15:39:17+09:00
GCP:AutoML Visionで、二階堂ふみと山本舞香見分けられる?
以下の写真は誰でしょうか。
二階堂ふみさんです!
では、以下の写真は誰でしょうか。
山本舞香さんです!
髪型、表情、照明によっては、非常に似ていますね。
どちらも綺麗です。
(以下比較画像。)
今回は、Googleの機械学習を元にしたGCPのプロダクト「AutoMLVision」を
使って、二人の画像識別を行いました。Cloud AutoML
機械学習の専門知識、プログラミング知識がなくても、簡単に機械学習の
トレーニング、評価、改善、デプロイが可能。ビジネスニーズに合わせて作成することも可能。AutoMLの中には、いくつかのプロダクトがある。
プロダクト名 用途 AutoML Vision 画像分類 AutoML Video Inteligence 動画コンテンツ検出 AutoML Natural Language 自然言語処理 AutoML Translation 翻訳 AutoML Tables 構造化データ 今回使用するプロダクトは、「AutoMLVision」。
AutoML Vision
独自の画像識別の機械学習モデルを作成できる。
自分で識別したい画像をアップロードすることで、プログラムを書くことなく、
自動でアップロード画像に合わせてモデル作成される。(例: 猫の種類の識別、カレイの種類識別、不良品の識別)
注意
- GoogleCloudアカウント登録が必要。(無料枠あり)
1.準備
GCPコンソール上でCloud AutoML API
GCPメニュー Vision > ダッシュボード > AutoML Vision > 画像分類
データセット>新しいデータセット
データセット名を適当に記述。
モデルの目的を「単一ラベル分類」を選択。
2.モデル作成に必要な画像アップロード
最初に使用する画像をアップロードして、ラベリングする必要がある。
アップロード方法は、
・localから直接アップロード
・GCSからCSVファイルをアップロード
→ 今回は、直接PCからアップロード。<ポイント>
最適なモデルを作成するには、各ラベルに少なくとも 100 個の画像を含める必要があります。
より、精度を求めるには、最低1000枚必要という人もいる、、、
今回は、1000枚頑張って用意した、、、
画像の取得は、スクレイピング等を使うとある程度が取得可能。(末尾Apendixに追記)
3 ラベリング
ローカルから画像アップロードした場合、別途ラベリングする必要がある。
200枚ずつラベリング可能。
4 トレーニング
全てラベリングしたら、トレーニングを行う。
学習は、自動的に画像を3つのセットに分割されて、それぞれ
トレーニング:80%
ハイパーパラーメータ調整等:10%
モデルの評価:10%
に使用される。トレーニングタブから「新しいモデルをトレーニング」。
モデルを選択。
「Cloud hosted」を選択。
トレーニングのノード時間を設定。
今回は8時間に設定。
初回無料枠あり。請求先アカウント 1 つにつき、トレーニングとオンライン予測それぞれに 40 時間の無料ノード時間を、さらにバッチ?>予測に 1 時間の無料ノード時間を使用できます。
トレーニングを開始。(約1時間)
5 評価
以下評価結果。
適合率:84.83%
再現率:84.83%
最初にしては、いい数値かと!
6 デプロイ・テスト
モデルで実際に予測できるように、デプロイする。
APIでオンライン予測も可能。サービスに組み込むこともできる。
実際の画像をアップロードして、予測を行う。
Appendix
1000枚の画像収集が大変。以下の記事を参考に取得。
その他、Youtube動画のスクリーンショットをする。
https://qiita.com/kumakuma324/items/9e026c11838b4e94ad2dおまけ
宮崎あおいはどちらに似ているのでしょうか。



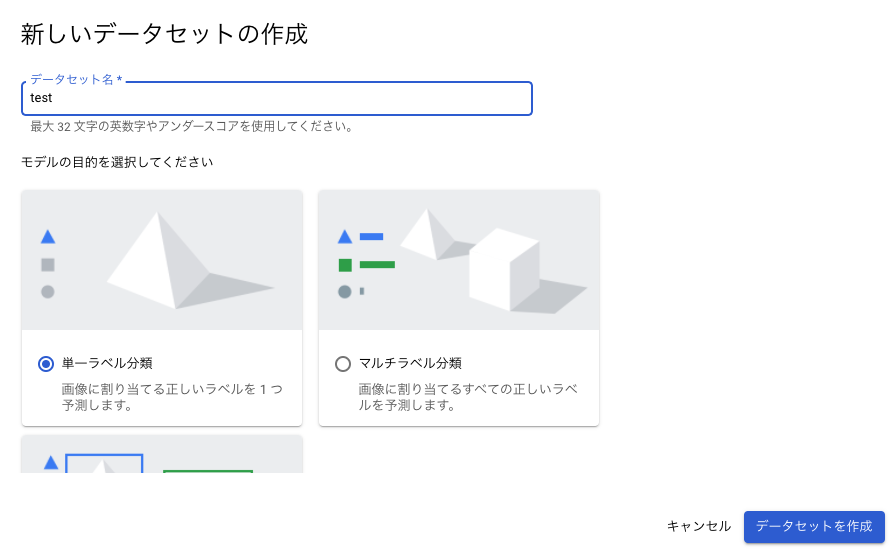
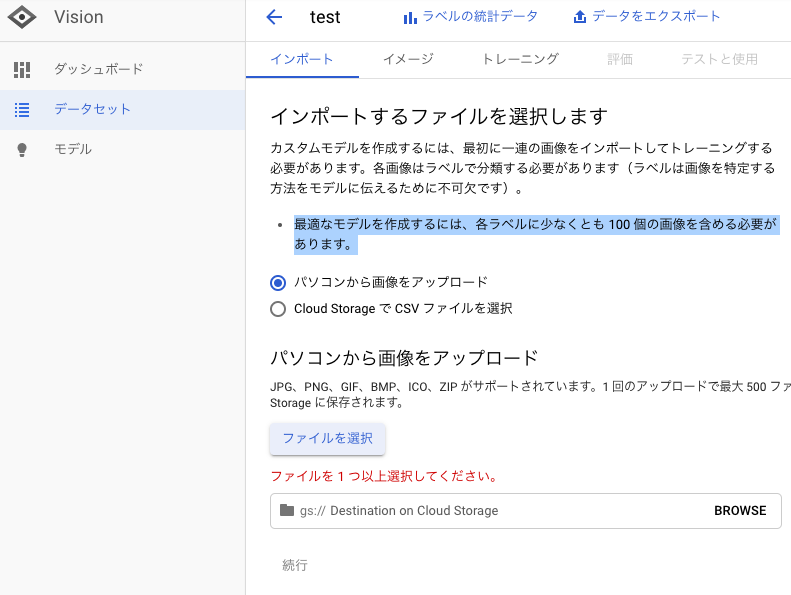
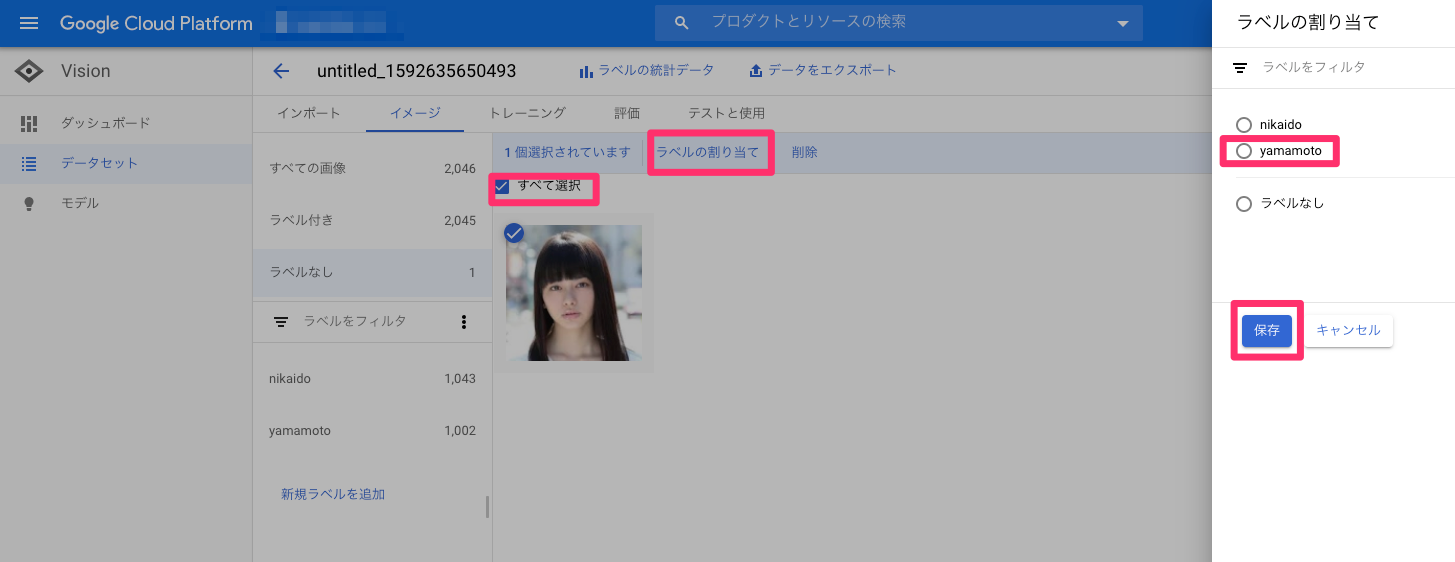
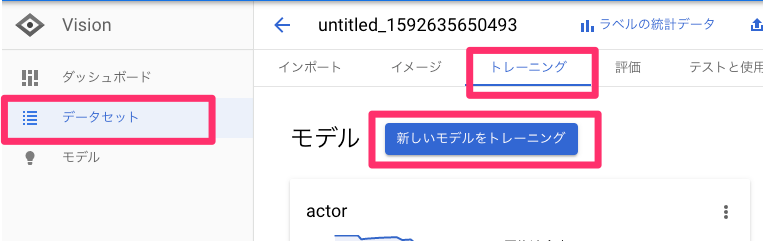
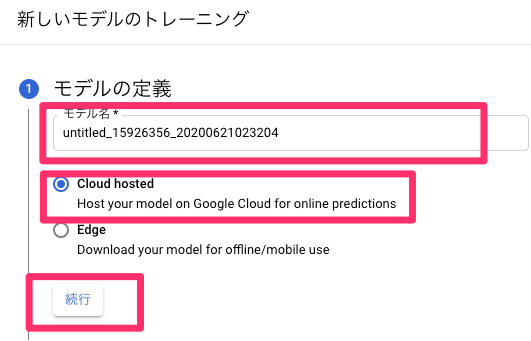
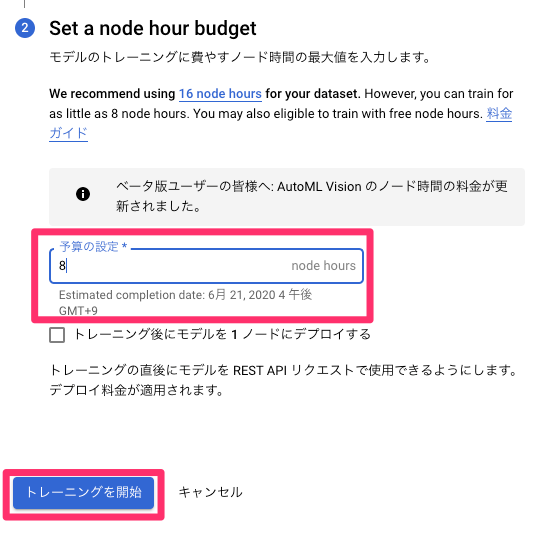
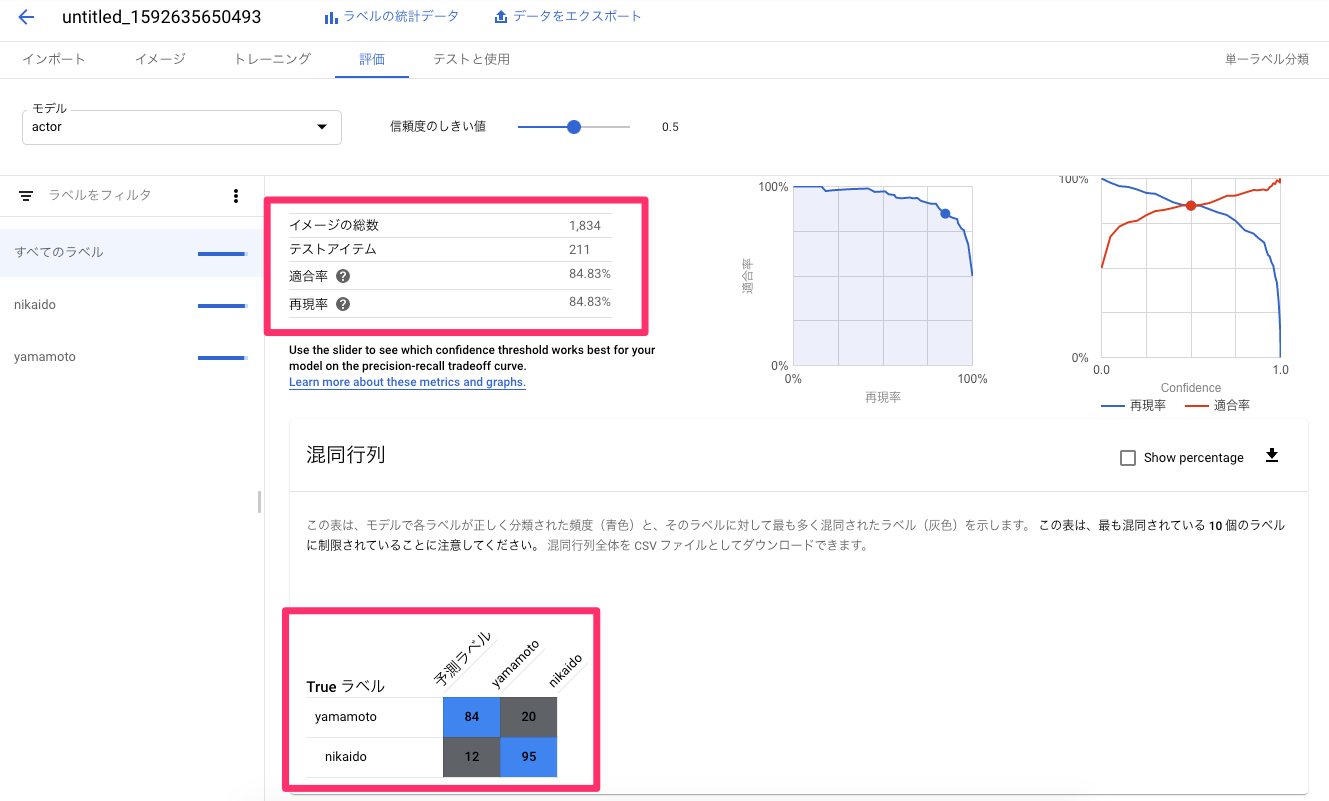
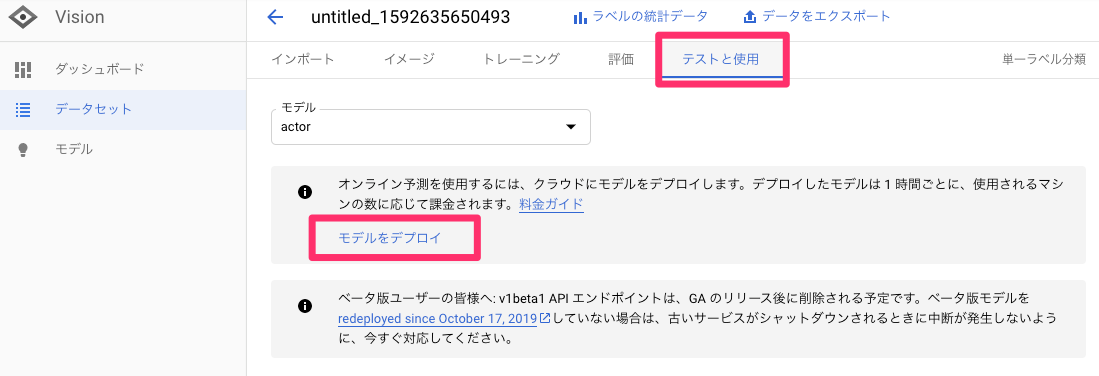
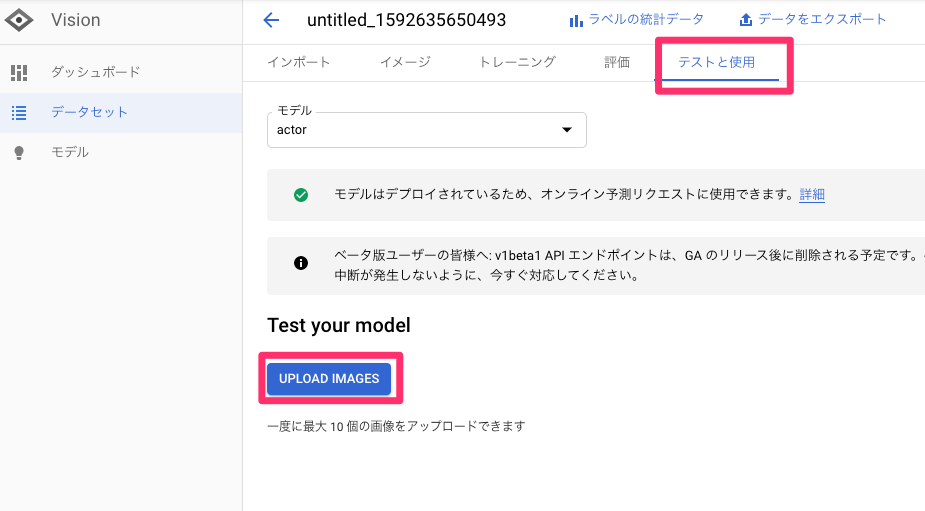


- 投稿日:2020-06-21T14:27:07+09:00
クソデカ羅生門の差分を見てみると親の仇のようにメチャメチャクソデカい文学になっていた
どこかのツイッターで知ったのですが
クソデカ羅生門
なるものが出来たということでした。羅生門
そもそもの
羅生門は、ほぼクソ少しも
読んだ覚えが無さそうなのですが
芥川龍之介なる人物がかなり昔に
書いた文学のようです。
青空文庫に乗っていたのでだいぶ昔でしょうね。参考:https://www.aozora.gr.jp/cards/000879/files/127_15260.html
クソデカ羅生門
引用:https://anond.hatelabo.jp/20200611125508
原典の
羅生門のイメージは残しつつというか
もうイヤになっちゃうくらいほぼ丸々怖いくらい
全然まったく寸分たりとも違わず完全にそのまま原典に修飾語を追加したもので有ると思われます。
という事は
差分が上手く取れるはずですね。差分を取ってみる。
差分を取る手順は以下の通りです。
1.両方の奴をファイル化する
2.不要文字(スペース)は削除
3.1行ずつ差分をとる
4.差分の所を囲むという事でこんなコードを作って差分をとりました。
# ファイルの読み込み with open('羅生門/クソでか羅生門.txt') as _f: text = _f.read() text = text.replace('。','。\n') kusodeka = text.split('\n') print(len(kusodeka)) with open('羅生門/羅生門.txt') as _f: text = _f.read() text = text.replace('。','。\n') rasyoumon = text.split('\n') print(len(rasyoumon)) # 差分チェック def check_diff(moto,kuso): res1,res2,tmp = [],[],kuso for m in moto: i = str(tmp[0:]).find(m) diff = tmp[0:i] if len(diff)>0: for d in diff: res2.append(d) res1.append(' ') res2.append(' ') res1.append(tmp[i]) tmp = tmp[i+1:] return res1,res2 template = '<table style="table-layout: fixed;"><tr>{0}</tr></table>' red = '<td><span style="color: red;">{0}</span></td>' gre = '<td><span style="color: green;">{0}</span></td>' # HTML化 def make_html(r1,r2): html = '' for i in range(len(r1)): if r1[i]==' ': html += red.format(r2[i]) else: html += gre.format(r1[i]) if r1[i]=='、': html += '</tr><tr>' return template.format(html) # 差分の囲み def make_text(r1,r2): text,flg = '',1 for i in range(len(r1)): if r1[i]==' ': if flg==1: text+='`' flg*=-1 text+=r2[i] else: if flg==-1: text+='`' flg*=-1 text+=r1[i] return text # 差分の文章化 for moto,kuso in zip(rasyoumon,kusodeka): res1,res2 = check_diff(moto,kuso) text = make_text(res1,res2) print(text) # 差分のHTML出力 html = '' for moto,kuso in zip(rasyoumon,kusodeka): res1,res2 = check_diff(moto,kuso) html += make_html(res1,res2)後程差分を文章化したものを載せさせていただきます。
どんな言葉がよく出てくるのか?
差分が取れるという事は、原典に対して
どんな言葉がついていたのかを知ることができます。
修飾されている言葉が何回出てくるのかを調べてみました。calc = {} for moto,kuso in zip(rasyoumon,kusodeka): res1,res2 = check_diff(moto,kuso) tmp = '' for r in res2: if r==' ': if tmp in calc: calc[tmp]+=1 else: calc[tmp] =1 tmp='' else: tmp+=r calc.pop('') print('種類数 : ',len(calc)) for k,v in sorted(calc.items(),reverse=True,key=lambda x:x[1]): print(v,'\t',k)種類数 : 341 26 大 13 まくっ 12 超 10 真 10 メチャメチャ 10 Godsに影響した 9 巨大 8 糞 7 クソデカ 7 倒し 7 完全に 7 巨大な 6 超巨大 6 巨 5 クソ 5 マジで 4 クソデカい 4 全然 4 マジで全然 4 豪 4 超苦しい 4 死ぬほど 4 大量に 3 千 3 世界最強の 3 に影響した 3 バカ 3 極 3 最強 3 王 3 まくり 3 本当に 3 まったく 3 めちゃくちゃ 2 (ほぼ夜) 2 百 2 毎日 2 りまく 2 完全 2 きったない 2 ハチャメチャに 2 びっくりするほど 2 炎 2 最高級 2 〇〇 2 続け 2 剛 2 〇〇〇〇 2 絶対に 2 雑魚 2 瞬間的に 2 極悪 2 まぶた 2 さかっ 2 いまく 2 巨大怪 1 完全な真 1 気持ち悪いほどずっと ・・・一回しか出てこないやつがげに誠、めっちゃ多い!!!!
数えたら285個もありました。これだけの表現を付け加えるというのは信じられません。
同じものが使われるケースもありますが、表現の幅を広げているのは
作者様の語彙力に他ならないと思います。どんな長い言葉が加えられているか?
これも集計で、文字数の多い修飾語でどんだけ長いかをみてみます。
上記の集計結果を使って、ソートのキーを文字数にします。for k,v in sorted(calc.items(),reverse=True,key=lambda x:len(x[0])): print(len(k),'\t',k)23 Ultimet-Sentimentalisme 20 ただでさえ最低最悪のゴミの掃き溜めである 17 ほとんど聞き取れないほどの超早口で 16 マジで悲しくなっちゃうくらい全然 16 of the Godsに影響した 15 ブッサイクで気持ちの悪い巨大な 14 クソ治安がいいことで知られる 14 三千里(約一万二千メートル) 13 もうイヤになっちゃうくらい 13 親の仇のようにメチャメチャ 13 のちに剣聖と呼ばれる最強の 13 地の果てまで広がるがごとき 13 自殺したくなるくらい本当に 13 強烈な殺意を内包した本気の 12 正気を疑うレベルでデカい 12 マジでビックリするくらい 12 本当に惨めな感じになって 12 寸分たりとも違わず完全に 12 物理的にありえない動きで 12 本当にめちゃめちゃ苦しい 12 世界最高の名刀と謳われる 12 テレパシーのごとく完全に 11 怖いくらい全然まったく 11 鼓膜破壊レベルの音量で 11 頭おかしいくらいデカい 11 トチ狂ったクソデカさの 11 意味わからんくらいクソ 11 信じられないほどデカい 11 構造的にありえない形で 10 気持ち悪いほどずっと 10 思わず目を疑うくらい 10 Godsに影響した 10 本当にマジでまったく 10 メチャメチャくっせえ 10 芸術品のように美しい 10 超メチャメチャ剣呑な 10 頬が落ちるほど本当に 10 まったく一瞬たりとも 10 目にも止まらないほど 10 えげつないスピードで10文字以上の表現が
40個も出てきました。
1つ2つ考えるのも結構な時間を要するかと
思われるのにも関わらずこの量です。もう完全に羅生門に登場してきた
傾国の美女のごとく脱毛です。修飾語の種類数で
341も有るので
長く、しかも量もあるというところが
このクソでか純文学の面白身というところでありましょう。最後に差分を含め載せさせていただきます。
差分
ある日の
超暮方(ほぼ夜)の事である。
一人の下人が、クソデカい羅生門の完全な真下で雨やみを気持ち悪いほどずっと待ちまくっていた。
馬鹿みたいに広い門の真下には、この大男のほかに全然誰もいない。
ただ、所々丹塗のびっくりするくらい剥げた、信じられないほど大きな円柱に、象くらいある蟋蟀が一匹とまっている。
クソデカ羅生門が、大河のように広い朱雀大路にある以上は、この狂った男のほかにも、激・雨やみをする巨大市女笠や爆裂揉烏帽子が、もう二三百人はありそうなものである。
それが、この珍妙男のほかには全然誰もマジで全くいない。何故かと云うと、この二三
千年、京都には、超巨大地震とか破壊的辻風とか最強大火事とか極限饑饉とか云うエグすぎる災が毎日つづいて起こった。
そこでクソ広い洛中のさびれ方はマジでもう一通りとかそういうレベルではない。
旧記によると、クソデカい仏像や文化財クラスの仏具をものすごいパワーで打砕いて、その丹がベッチャベチャについたり、金銀の箔がもうイヤになっちゃうくらいついたりした木を、路ばたに親の仇のようにメチャメチャつみ重ねて、薪の料に売りまくっていたと云う事である。
クソ治安がいいことで知られる洛中がその始末であるから、正気を疑うレベルでデカい羅生門の完全修理などは、元より誰も捨てて顧る者がマジで全然なかった。
するとそのドン引きするくらい荒れ果てたのをよい事にして、クソヤバい狐狸がドンドン棲む。
世界最強の盗人が6万人棲む。
とうとうしまいには、マジで悲しくなっちゃうくらい全然引取り手のないきったない死人を、この門へ猛ダッシュで持って来て、超スピードで棄てて行くと云う習慣さえ出来た。
そこで、日の目が怖いくらい全然まったく見えなくなると、誰でもメチャメチャ気味を悪るがって、この門の近所へはマジでビックリするくらい足ぶみをしない事になってしまったのである。その代りまた
超凶悪な鴉がどこからか、億単位でたくさん集って来た。
昼間見ると、その鴉が何万羽となく輪を描いて、クソ高い鴟尾のまわりを鼓膜破壊レベルの音量で啼きながら、亜音速で飛びまわっている。
ことに門の上の空が、夕焼けで思わず目を疑うくらいあかくなる時には、それが胡麻をえげつない量まいたようにはっきり見えた。
鴉は、勿論、頭おかしいくらいデカい門の上にメチャクチャ大量にある死人の肉を、気が狂ったように啄みに来るのである。
――もっとも今日は、刻限がハチャメチャに遅い(ほぼ夜)せいか、マジで一羽も見えない。
ただ、所々、ほぼ崩れかかった、そうしてその崩れ目にメチャメチャ長い草の森のごとくはえ倒したクソ長い石段の上に、鴉のえげつなく臭い糞が、点々と白くこびりついているのが見える。
下人は七千万段ある石段の一番上の段に、洗いざらしてほぼ透明になった紺の襖の尻を据えて、右の頬に出来まくった、クッソ大きな面皰を気にしながら、メチャメチャぼんやり、とんでもない豪雨のふりしきるのを眺めていた。作者はさっき、「下人が雨やみを
メチャメチャ待っていた」と書いた。
しかし、下人は激烈豪雨がやんでも、格別どうしようと云う当てはマジで全然ない。
ふだんなら、勿論、クソ強い主人のえげつなくデカい家へ帰る可き筈である。
所がその糞主人からは、四五日前に暇を出し倒された。
前にも書いたように、当時ただでさえ最低最悪のゴミの掃き溜めである京都の町は一通りならず衰微しまくって本当に惨めな感じになっていた。
今この最強にヤバい下人が、永年、犬のごとくこき使われていた主人から、暇を出されたのも、実はこの大衰微のクソしょぼい小さな小さな余波にほかならない。
だから「下人が雨やみをメチャメチャ待っていた」と云うよりも「クソヤバい豪雨にふりこめられた下人が、マジで全然行き所がなくて、超途方にくれていた」と云う方が、完全に適当である。
その上、今日の空模様も少からず、この平安朝のヤバい下人のUltimet-Sentimentalismeof the Godsに影響した。of theGodsに影響した。Godsに影響した。Godsに影響した。Godsに影響した。Godsに影響した。Godsに影響した。Godsに影響した。Godsに影響した。Godsに影響した。Godsに影響した。Godsに影響した。に影響した。に影響した。に影響した。
申の刻下りからふり出した大雨は、いまだに上るけしきが全然かけらもない。
そこで、のちに剣聖と呼ばれる最強の下人は、何をおいても差当り明日の暮しをメチャメチャどうにかしようとして――云わば絶望的にどうにもならない事を、どうにかしようとして、悲しくなるくらいとりとめもない考えをたどりながら、さっきからアホみたいに広い朱雀大路にふる豪雨の音を、聞くともなく聞いていたのである。
豪雨は、トチ狂ったクソデカさの羅生門をつつんで、メチャメチャ遠くから、ざあっと云う轟音をあつめて来る。
夕闇は次第に空をびっくりするほど低くして、見上げると、超巨大門の超巨大屋根が、斜につき出した超巨大甍の先に、ドチャクソ重たくうす暗い雲を嫌になるくらい支えまくっている。どうにもならない事を、どうにかするためには、手段を選んでいる遑は
本当にマジでまったくない。
選んでいれば、築土の真下か、道ばたの土の真上で、超苦しい饑死をするばかりである。
そうして、このガチで世界一デカい門の上へ猛スピードで持って来て、きったない犬のように超速で棄てられてしまうばかりである。
選ばないとすれば――巨大下人の考えは、何度も寸分たりとも違わず完全に同じ道を低徊した揚句に、やっとこの局所へ逢着した。
しかしこの「すれば」は、マジでいつまでたっても、結局「すれば」であった。
クソザコ下人は、手段を選ばないという事をエグ肯定しながらも、この「すれば」のかたをつけるために、当然、その後に来る可き「世界最強の盗人になるよりほかに仕方がない」と云う事を、積極的に肯定するだけの、莫大な勇気が出ずにいたのである。下人は、
意味わからんくらいクソ大きな嚔をして、それから、死ぬほど大儀そうに立上った。
南極かってくらいに夕冷えのする世界最悪の罪の都京都は、もう火桶が8億個欲しいほどのガチえげつない寒さである。
暴風は信じられないほどデカい門の巨柱と巨柱との間を、クソヤバい濃さの夕闇と共にマジで全然遠慮なく、吹きぬけまくる。
丹塗の超巨大柱にとまっていた象サイズの蟋蟀も、もうどこかへ行ってしまった。下人は、頸を
人間の限界を超えてちぢめながら、山吹の汗袗に無理やり重ね倒した、紺の襖の肩を物理的にありえない動きで高くしてクソデカ門のまわりを見まわした。
雨風の患のない、人目にかかる惧のない、一晩メチャメチャ楽にねられそうな所があれば、そこでともかくも、クッソ長い夜を明かそうと思ったからである。
すると、幸い超巨大門の上の宮殿並みにデカい楼へ上る、幅のバカ広い、これも丹をキチガイみたいに塗りたくった梯子が眼についた。
上なら、人がいたにしても、どうせ臭くてきったない死人ばかりである。
下人はそこで、腰にさげた巨大な聖柄の大太刀が鞘走らないように気をつけ倒しながら、藁草履をはいた巨大な足を、そのバカでかい梯子の一番下の段へ渾身の力でふみかけた。それから、何
百分かの後である。
クソデカ羅生門の楼の上へ出る、幅のアホみたいに広い梯子の中段に、一人の巨大な男が、猫のように身をちぢめまくって、ヤバいくらい息を殺しながら、上の容子を窺っていた。
楼の上からさす大火炎の目を灼く光が、かすかに、その男の右の頬をぬらしている。
えげつなく短い鬚の中に、とんでもなく赤く膿を持った巨大な面皰の大量にある頬である。
巨下人は、始めから、この上にいる者は、臭死人ばかりだと高を括っていた。
それが、梯子を二三千段上って見ると、上では誰か燃え盛る大火をとぼして、しかもその大火をそこここと疾風のごとき速さで動かしているらしい。
これは、そのドブのように濁った、この世の理を超えて黄いろい光が、すべての隅々に巨大人食い蜘蛛の巣をかけた天井裏に、激しく揺れながら映ったので、メチャすぐにそれと知れたのである。
この豪雨の夜に、このクソデカ羅生門の上で、世界すら灼く業火をともしているからは、どうせただの者ではない。下人は、
巨大な守宮のように足音をぬすんで、やっとクソ急な梯子を、一番上の段まで這うようにして上りつめた。
そうして体を出来るだけ、紙のように平にしながら、頸を出来るだけ、ろくろっ首のごとく前へ出して、恐る恐る、巨大な楼の内を覗いて見た。見ると、
地の果てまで広がるがごとき楼の内には、噂に聞いた通り、幾つかの山のように巨大な死骸が、無造作に棄ててあるが、業火の極光の及ぶ範囲が、思ったよりクソ狭いので、数は幾つともわからない。
ただ、おぼろげながら、知れるのは、その中に完全に全裸の死骸と、メチャクチャ高級な着物を着まくった死骸とがあるという事である。
勿論、中には女も男もまじっているらしい。
そうして、その死骸は皆、それが、かつて、生きていた人間だと云う事実さえ疑われるほど、土を捏ね倒して造った人形のように、口をヤバイくらい開いたり手をキロ単位で延ばしたりして、ごろごろ床の上にころがっていた。
しかも、肩とか胸とかの山くらい高くなっている部分に、ぼんやりした猛火の光をうけて、クソ低くなっている部分の影を一層超死ぬほど暗くしながら、永久に唖の如く黙っていた。下人は、それらの
超ビッグ死骸のメチャメチャくっせえ腐爛した最悪の臭気に思わず、鼻を掩って掩って掩いまくった。
しかし、その手は、次の瞬間には、もう鼻を掩う事を完全に忘れ尽くしていた。
あるハチャメチャに強いクソデカ感情が、ほとんどことごとくこの最強男の嗅覚を奪ってしまったからだ。下人の
巨眼は、その時、生まれてはじめてその激臭死骸の中に蹲っている最低最悪醜悪人間を見た。
檜皮色のきったねえ着物を着た、ノミのように背の低い、ナナフシのように痩せこけた、白銀髪頭の、豆猿のような老婆である。
その老婆は、右の手に大火炎をともした最高級松の巨大木片を持って、その大死骸の一つの巨顔を覗きこむように眺め倒していた。
髪の毛のクソ長い所を見ると、多分傾国の美女の死骸であろう。下人は、六
〇〇分の恐怖と四〇〇分の知的好奇心とにつき動かされ続けて、暫時(七十二時間)は呼吸をするのさえ忘れていた。
旧記の記者の語を全て丸々借りれば、「頭身の剛毛も一生太り続ける」ように感じまくったのである。
すると糞老婆は、高級松の大木片を、床板の間に狂ったように挿して挿して挿し倒して、それから、今まで眺め続けていた大死骸の首に両手をかけると、丁度、大猿の親が大猿の子の虱を全部とるように、そのバカ長い髪の毛を一〇〇〇〇本ずつ抜きはじめた。
髪は手に奴隷のように従って抜けるらしい。その髪の毛が、一
〇〇〇〇本ずつ抜けるのに従って、下人の腐りきった心からは、恐怖が少しずつ完全に消えて行った。
そうして、それと完全にピッタリ同時に、この老婆に対する想像を絶するはげしい憎悪が、少しずつ動いて来た。
――いや、この糞老婆に対すると云っては、語弊がありすぎるかも知れない。
むしろ、この世に存在しうるありとあらゆる悪に対する巨大な反感が、一分毎に強さを等比級数的に増して来たのである。
この時、誰かがこの最強正義の体現たる下人に、さっき門の真下でこの性根の腐ったドブ男が考えていた、超苦しい饑死をするか世界最強の盗人王になるかと云う世紀の大問題を、改めて持出したら、恐らく清廉潔白超高潔下人は、マジで何の未練のカケラもなく、本当にめちゃめちゃ苦しい饑死を選んだ事であろう。
それほど、この男の中の男のあらゆる悪を世界一憎む心は、老婆の床に挿しまくった最高級松の大木片のように、超勢いよく燃え上り出していたのである。
大馬鹿で学のない下人には、勿論、何故糞老婆が死人の髪の毛を抜くか本当に一切わからなかった。
従って、合理的には、それを善悪のいずれに片づけてよいかマジでまったく全然知らなかった。
しかし馬鹿下人にとっては、この豪雨の聖夜に、このクソデカ羅生門の真上で、大死人のぬばたまの髪の毛を抜くと云う事が、それだけで既に絶対に許すべからざる世界最低の悪の中の悪であった。
勿論、クソアホ下人は、さっきまで自分が、世界一の大盗人王になる気でいた事なぞは、とうの昔に忘れきっていたのである。そこで、下人は、両足に
剛力を入れまくって、超いきなり、大梯子から三千里(約一万二千メートル)上へ飛び上った。
そうして世界最高の名刀と謳われる聖柄の大太刀に手をかけながら、超大股に老婆のど真ん前へ歩みよった。
老婆が死ぬほど驚いたのは云うまでもない。老婆は、一目下人を見ると、まるで
攻城弩にでも弾かれたように、天高く飛び上った。「おのれ、どこへ行く。
」
最強下人は、雑魚老婆が大死骸全てに無様につまずきまくりながら、可哀想なくらい慌てふためいて逃げようとする行手を完全に塞いで、こう罵りまくった。
糞老婆は、それでも神速で巨大下人をつきのけて行こうとする。
剛力下人はまた、それを絶対に行かすまいとして、ものすごい力で押しもどす。
二人は巨大死骸のまん真ん中で、しばらく、完全に無言のまま、つかみ合った。
しかし勝敗は、宇宙のはじめから誰にでも完全にわかっている。
下人はとうとう、老婆の腕を馬鹿力でつかんで、無理にそこへ叩きつけるようにねじ倒した。
丁度、軍鶏の脚のような、本当に骨と皮ばかりの細腕である。「何をしていた。
云え。
云わぬと、これだぞよ。
」
下人は、老婆を全力でどつき放すと、いきなり、大太刀の鞘を瞬間的に払って、白いミスリル鋼の芸術品のように美しい色をその眼の前へつきつけた。
けれども、極悪老婆は完全におし黙っている。
両手をわなわな高速でふるわせて、強肩で息を切りながら、眼を、眼球がまぶたの外へ完全に飛び出そうになるほど、ありえないくらい見開いて、唖のように執拗く黙っている。
これを見ると、最強下人は始めて明白にこの糞老婆の生死が、全然、自分の完全なる自由意志にまったく支配されていると云う事をめちゃくちゃ意識しまくった。
そうしてこの超意識は、今までけわしく燃えさかっていた巨大憎悪の心を、いつの間にか絶対零度まで冷ましてしまった。
後に残ったのは、ただ、ある大仕事をして、それが超円満にめちゃくちゃうまく成就した時の、人生最高の安らかな得意と大満足とがあるばかりである。
そこで、有能下人は、老婆をはるか高みから見下しながら、少し声を柔らげてほとんど聞き取れないほどの超早口でこう云った。「己は検非違使の庁の役人などでは
断じてない。
今し方この巨門の真下を通りかかった旅の者だ。
だからお前に縄をかけまくって、どうしようと云うような事は神仏に誓って絶対にない。
ただ、今時分この巨大門の真上で、何をして居たのだか、それを己に話しまくりさえすれば最高にいいのだ。
」
すると、糞老婆は、超見開いていた眼を、構造的にありえない形で一層大きくして、じっとその下人のブッサイクで気持ちの悪い巨大な顔を見守った。
まぶたの超赤くなった、凶暴肉食最恐鳥のような、めちゃくちゃ鋭い眼で見まくったのである。
それから、本当に醜い皺で、ほとんど、鼻と一つになったタラコ唇を、何か金剛石のごとく硬い物でも噛んでいるように動かした。
極細い喉で、針のように尖った喉仏の動いているのが見える。
その時、その喉から、凶鴉の啼くような汚い声が、喘ぎ喘ぎ、下人の大耳へ伝わって来た。「この髪を抜いてな、この髪を抜いてな、
巨大鬘にしようと思うたのじゃ。
」
天下無双の無敵下人は、老婆の答が存外、めちゃくちゃ平凡なのに自殺したくなるくらい本当に失望した。
そうして極限まで失望すると同時に、また前の強烈な殺意を内包した本気の憎悪が、氷のように冷やかな侮蔑と一しょに、心の中へ大量にはいって来まくった。
すると、その超メチャメチャ剣呑な気色が、先方へもテレパシーのごとく完全に通じ倒したのであろう。
雑魚老婆は、片手に、まだ大死骸の頭から奪いまくったバカ長い抜け毛を大量に持ったなり、蟇のつぶやくようなクソ小声で、口ごもりながら、こんな事を云った。「成程な、死人の髪の毛を抜くと云う事は、何ぼう
滅茶苦茶に悪い最低の事かも知れぬ。
じゃが、ここにいる死人どもは、皆、そのくらいな事を、されてもいい人間ばかりだぞよ。
現在、わしが今、髪を抜いた女などはな、八岐大蛇を四寸ばかりずつに切って干したのを、干巨大怪魚だと云うて、太刀帯の陣へ売りに往んだわ。
大疫病に五回かかって死ななんだら、今でも毎日売りに往んでいた事であろ。
それもよ、この女の売る干巨大怪魚は、味が頬が落ちるほど本当によいと云うて、太刀帯どもが、絶対に毎日欠かさず菜料に買いまくっていたそうな。
わしは、この女のした事が人類史に残るほどに悪いとはまったく思うていぬ。
せねば、とてつもなく苦しい饑死をするのじゃて、仕方がなくした事であろ。
されば、今また、わしのしていた事も超悪い事とは全然思わぬぞよ。
これとてもやはりせねば、超苦しい饑死をするじゃて、マジ仕方がなくする事じゃわいの。
じゃて、その本当に仕方がない事を、よく知っていたこの極悪女は、大方わしのする事も大目に見まくってくれるであろ。
」
老婆は、大体こんな意味の事を超早口で云った。
巨大下人は、大太刀を瞬きの間に鞘におさめて、その大太刀の美しい柄を左の手でおさえながら、死ぬほど冷然として、この話を聞いていた。
勿論、右の手では、メチャメチャ赤く頬に膿を大量に持った超大きな面皰を気にしまくりながら、聞いているのである。
しかし、これを聞いている中に、下人の史上空前に邪悪な心には、あるクソデカい勇気が生まれて来た。
それは、さっきクソデカい門の真下で、この腑抜けカス男には全く欠けていた勇気である。
そうして、またさっきこの馬鹿でかい門の真上へ瞬間的に上って、この老婆を人間離れした動きで捕えた時の勇気とは、全然、完全に反対な方向に動こうとするデカ勇気である。
下人は、超苦しい饑死をするか大盗人王になるかに、まったく一瞬たりとも迷わなかったばかりではない。
その時のこの最低男の心もちから云えば、苦しい苦しい饑死などと云う事は、ほとんど、考える事さえ出来ないほど、意識の完全な外に追い出され倒していた。「きっと、そうか。
」
老婆の話が完ると、下人はメチャメチャ嘲るような声で念を押しに押した。
そうして、一〇〇〇足前へ出ると、不意に右の手を面皰から七尺離して、老婆の襟上を神速でつかみながら、噛みつくようにクソデカい声でこう云った。「では、己が
完全引剥をしようとまったく恨むまいな。
己もそうしなければ、二時間後に饑死をする体なのだ。
」
韋駄天の異名をとる下人は、目にも止まらないほどすばやく、老婆の着物を完全に剥ぎとった。
それから、丸太のように太い足にしがみつこうとする老婆を、超手荒く死骸の上へ蹴飛ばし倒した。
梯子の口までは、僅に五千歩を数えるばかりである。
下人は、剥ぎとった檜皮色の着物をわきにかかえて、マジでまたたく間に死ぬほど急な梯子を夜のドン底へかけ下りた。しばらく、
まさしく死んだように倒れていた糞老婆が、巨大死骸の中から、その全裸のあまりに醜すぎる体を起したのは、それから本当に間もなくの事である。
老婆はつぶやくような、うめくようなクソうるさい声を立てながら、まだ太陽のように燃えさかっている火のまばゆい光をたよりに、梯子の口まで、えげつないスピードで這って行った。
そうして、そこから、びっくりするほど短い白髪を倒にして、クソデカ門の真下を覗きこんだ。
外宇宙には、ただ、黒洞々たる極夜があるばかりである。下人の行方は、
マジで誰も全然知らない。動画のリンク
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-06-21T13:54:33+09:00
PEP 584 (Add Union Operators To dict) を読んだよメモ
先日、PEP 584 (Add Union Operators To dict) が Final になったというコミットを見かけました。
そこで、今回は PEP 584 を読んでみようと思います。概要
- ふたつの辞書を結合するいい感じの方法がほしい
d1.update(d2)は d1 を書き換えてしまうため、一時変数を用意する場面があるし、式ではないのでパラメータにしていできない{**d1, **d2}ってキモいcollections.ChainMapはマイナーな上に、 d1 を書き換える問題があるdict(d1, **d2)はキーが文字列以外の場合にエラーになる- 辞書の結合に
|演算子を使えるようにする- Python 3.9 から利用できます
アプローチ
d1 | d2でふたつの辞書を結合します。同じキーを持つ場合、右の辞書の内容で上書きするので、可換ではありません(新しい辞書のキーの順序も変わります)。>>> d = {'spam': 1, 'eggs': 2, 'cheese': 3} >>> e = {'cheese': 'cheddar', 'aardvark': 'Ethel'} >>> d | e {'spam': 1, 'eggs': 2, 'cheese': 'cheddar', 'aardvark': 'Ethel'} >>> e | d {'aardvark': 'Ethel', 'spam': 1, 'eggs': 2, 'cheese': 3}一緒に
|=演算子にも対応しました。>>> d |= e >>> d {'spam': 1, 'eggs': 2, 'cheese': 'cheddar', 'aardvark': 'Ethel'}感想
- 違和感はあるのだけど、しばらくしたら慣れてくるはず。たぶん…
d = dict(d1); d.update(d2)は何度も書いたことがあるので、嬉しさはわかる- スッキリ書けるのはいいですね
- 投稿日:2020-06-21T13:40:38+09:00
pythonの2.x, 3.x系の文字コード
簡単な備忘録
2.x系: ASCII(win環境ではcp932(SHIFT-JISの亜種が必要)
3.x系: UTF-8
- 投稿日:2020-06-21T13:28:25+09:00
PEP 614 (Relaxing Grammar Restrictions On Decorators) を読んだよメモ
先日、PEP 614 (Relaxing Grammar Restrictions On Decorators) が Final になったというコミットを見かけました。
そこで、今回は PEP 614 を読んでみようと思います。概要
- これまでデコレータに利用できるのは
dotted_nameと呼ばれる、.つきの名前のみだった- そのため、配列アクセスや辞書アクセスといった「式」の類はデコレータには使えなかった
buttons = [QPushButton(f'Button {i}') for i in range(10)] @buttons[0].clicked.connect # => NG def spam(): ...
- 文法を拡張して、デコレータに「式」を受け付けるようにした
- Python 3.9 から利用できます。
アプローチ
いままでの文法が
decorator: '@' dotted_name [ '(' [arglist] ')' ] NEWLINEだったのを
decorator: '@' namedexpr_test NEWLINEに変更しました。以上。
って、それだと分かりづらいですね。
namedexpr_testは Python の式(expression)を指す文法要素です。
式に該当するのは以下のものです (6. 式 (expression) — Python 3.8.3 ドキュメント より)。
- 6.1. 算術変換 (arithmetic conversion)
- 6.2. アトム、原子的要素 (atom)
- 6.2.1. 識別子 (identifier、または名前 (name))
- 6.2.2. リテラル
- 6.2.3. 丸括弧形式 (parenthesized form)
- 6.2.4. リスト、集合、辞書の表示
- 6.2.5. リスト表示
- 6.2.6. 集合表示
- 6.2.7. 辞書表示
- 6.2.8. ジェネレータ式
- 6.2.9. Yield 式
- 6.2.9.1. ジェネレータ-イテレータメソッド
- 6.2.9.2. 使用例
- 6.2.9.3. 非同期ジェネレータ関数 (asynchronous generator function)
- 6.2.9.4. 非同期ジェネレータイテレータメソッド
- 6.3. プライマリ
- 6.3.1. 属性参照
- 6.3.2. 添字表記 (subscription)
- 6.3.3. スライス表記 (slicing)
- 6.3.4. 呼び出し (call)
- 6.4. Await 式
- 6.5. べき乗演算 (power operator)
- 6.6. 単項算術演算とビット単位演算 (unary arithmetic and bitwise operation)
- 6.7. 二項算術演算 (binary arithmetic operation)
- 6.8. シフト演算 (shifting operation)
- 6.9. ビット単位演算の二項演算 (binary bitwise operation)
- 6.10. 比較
- 6.10.1. 値の比較
- 6.10.2. 所属検査演算
- 6.10.3. 同一性の比較
- 6.11. ブール演算 (boolean operation)
- 6.12. 代入式
- 6.13. 条件式 (Conditional Expressions)
- 6.14. ラムダ (lambda)
- 6.15. 式のリスト
いろいろありますね。これらがデコレータに利用できるようになったというわけです。
定義場所によっては使えないものもある(await とか)ことには注意してください。例
デコレータに lambda 式を使ってみたり...
>>> @lambda f: f ... def foo(): pass ...三項演算子的な if else を使ってみたり...
>>> x = lambda f: f >>> y = lambda f: f >>> @x if True else y ... def foo(): pass ...もちろん、配列も使えます。
>>> deco = [lambda f: f] >>> @deco[0] ... def foo(): pass ...感想
- いままで dotted_name で困っていなかったので、嬉しさがあまりピンとこない
- デコレータの配列や辞書で嬉しいことがあるのかも…?
- すごく気持ち悪いコードが書けてしまうので、容量用法には注意が必要です。
>>> @x := staticmethod # 代入式 (3.9 より) ... def foo(): pass ...
- 投稿日:2020-06-21T12:56:33+09:00
ECSとLambdaでTwitter botを作ってみた(自動RTとInstagramから自動投稿)
この記事について
この春、緊急事態宣言下で全国の動物園、水族館は休園を余儀なくされていました。
そんな中、各園が少しでもお客さんに楽しんでもらおうとSNS上で動物たちの様子を発信していました。それが「#休園中の動物園水族館」というタグです。
このタグの投稿が少しでも広まるようにという思いから、
このタグ付きのTwitter及びInstagramの投稿を自動でリツイート及びツイートするbotを作りました。
ハッシュタグ #休園中の動物園水族館 を自動でRTするbotです。
— 休園中の動物園水族館bot (@cheer_zoo_aqua) May 9, 2020
とりあえず試運転させてます。ここではその中身を共有します。
githubはこちら概要
このbotのメイン機能は以下です。
- Twitterの「#休園中の動物園水族館」というタグ付きの投稿を自動RTする。
- Instagramの「#休園中の動物園水族館」というタグ付きの投稿をTwitterに自動投稿する。
それぞれ実装はPython3系で行い、インフラにはAWSのECSとLambdaを使用しています。
Twitter投稿の自動リツイート
このbotのメインとなる機能です。
全体コード
./function.pyimport tweepy import json import os import traceback # Twitter APIで使用する各種キーをセット # API Key consumer_key = os.environ['CON_KEY'] # API secret key consumer_secret = os.environ['CON_KEY_SEC'] # アクセストークン Access_token = os.environ['ACC_KEY'] # アクセストークンシークレット Access_token_secret = os.environ['ACC_KEY_SEC'] auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(Access_token, Access_token_secret) api = tweepy.API(auth) me = api.me() class Listener(tweepy.StreamListener): """ Handles tweets received from the stream. """ def on_status(self, status): """ Prints tweet and hashtags """ if "RT" not in status.text: """ 引用RTならファボ、そうでないならRT """ if status.is_quote_status: try: api.create_favorite(status.id) except: print('------------------------------') print("@" + status.user.screen_name) print(status.text) print("") print(traceback.format_exc()) else: try: if status.user.screen_name != me.screen_name: api.retweet(status.id) except: print('------------------------------') print("@" + status.user.screen_name) print(status.text) print("") print(traceback.format_exc()) return True def on_error(self, status_code): print('Got an error with status code: ' + str(status_code)) return True def on_timeout(self): print('Timeout...') return True listener = Listener() stream = tweepy.Stream(auth, listener) stream.filter(track=[os.environ['QUERY']], is_async=True)実装
このbotはPythonのライブラリ、tweepyを使用しています。
tweepyTwitterのAPI登録を事前に実施し、
参考:Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ ※2019年8月時点の情報
- Consumer key
- Consumer Secret
- Acccess Key
- Access Secret
の4つを取得した上で、このtweepyを使用していきます。
./function.py# Twitter APIで使用する各種キーをセット # API Key consumer_key = os.environ['CON_KEY'] # API secret key consumer_secret = os.environ['CON_KEY_SEC'] # アクセストークン Access_token = os.environ['ACC_KEY'] # アクセストークンシークレット Access_token_secret = os.environ['ACC_KEY_SEC'] auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(Access_token, Access_token_secret) api = tweepy.API(auth) me = api.me()上記部分にてtweepyのオブジェクトを作成しています。
(Key類は環境変数に格納しています)
各認証情報をtweepyに渡して生成した「api」というオブジェクトに対し、
各関数を使用すれば、投稿やお気に入り、RTなどができるようになります。
参考:【Python】 Tweepyで、ツイート・フォロー・リムーブ・検索・画像投稿する方法をまとめてみた例えば、最下部のme()という関数は、tweepyにて認証したユーザの各種情報を取得できる関数です。
./function.pyclass Listener(tweepy.StreamListener): """ Handles tweets received from the stream. """ def on_status(self, status): """ Prints tweet and hashtags """ if "RT" not in status.text: """ 引用RTならファボ、そうでないならRT """ if status.is_quote_status: try: api.create_favorite(status.id) except: print('------------------------------') print("@" + status.user.screen_name) print(status.text) print("") print(traceback.format_exc()) else: try: if status.user.screen_name != me.screen_name: api.retweet(status.id) except: print('------------------------------') print("@" + status.user.screen_name) print(status.text) print("") print(traceback.format_exc()) return True def on_error(self, status_code): print('Got an error with status code: ' + str(status_code)) return True def on_timeout(self): print('Timeout...') return True listener = Listener() stream = tweepy.Stream(auth, listener) stream.filter(track=[os.environ['QUERY']], is_async=True)一方で、こちらはTwitterのタイムラインをリアルタイムに検索できるようにする部分です。
参考:tweepyでリアルタイムハッシュタグ検索
tweepy側で定義されているクラス StreamListener 及びその中のメソッドを上書きすることで、
リアルタイム検索とそれに対する処理を定義していきます。./function.pylistener = Listener() stream = tweepy.Stream(auth, listener) stream.filter(track=[os.environ['QUERY']], is_async=True)実際に関数が動作しているのは上記部分で、
Streamオブジェクトに上書きしたStreamListenerオブジェクトと認証情報(auth)を渡して、
リアルタイムにTwitterのタイムラインを受信できるようにします。
さらにfilter(track=["hoge"])で、タイムライン上にてhogeを含むツイートをリアルタイム抽出できます。
(ここも環境変数にしてますが、検索ワードは "#休園中の動物園水族館" です)./function.pydef on_status(self, status): """ Prints tweet and hashtags """ if "RT" not in status.text: """ 引用RTならファボ、そうでないならRT """ if status.is_quote_status: try: api.create_favorite(status.id) except: print('------------------------------') print("@" + status.user.screen_name) print(status.text) print("") print(traceback.format_exc()) else: try: if status.user.screen_name != me.screen_name: api.retweet(status.id) except: print('------------------------------') print("@" + status.user.screen_name) print(status.text) print("") print(traceback.format_exc()) return True通常処理はon_statusの部分で、このメソッドの引数statusに抽出されたツイートの情報が含まれています。
これをそのままRTさせるようにすればよいっちゃよいのですが、
誰かのRTや、タグを含む引用RTもRTしてしまうようで、ツイート数が増えるため処理を分岐させました。
- 誰かのRTはRTしない
- 引用RTはお気に入り登録のみする
- 上記にあてはまらないものはRTする
RTかどうかはstatusの属性textに「RT」という文字があるかどうかで判別します。
引用かどうかはis_quote_statusにbooleanで入ってるのでこれを利用します。
参考:Tweepyのstatusリストで何が取れるのかわからなかったので、取り出してみたcreate_favorite()、retweet()がそれぞれお気に入りとリツイートの関数です。
引数にstatus.idを渡して実行します。
idはツイートの投稿そのものについているIDです。./function.pytry: if status.user.screen_name != me.screen_name: api.retweet(status.id)ちなみに上記のような分岐をいれているのは、これまで書いたロジックだと自分で該当タグの投稿をした時に、
自分自身をRTしてしまうためで、これを避けるために実装してます。
(後述のInstagramの投稿をするときにあたりがあるため)user.screen_nameで@始まりのTwitter IDが取得できるため、これを自分自身(me)と比較し、
一致しないときのみリツイートするようにしています。デプロイ
AWS ECSへはgithubとCircle CIの連携によりデプロイしています。
docker-composeで使用できる書式のymlファイルを利用してタスク定義を定義し、
ECS上でサービスとして起動します。githubにプッシュ
↓
Circle CI起動
↓
CI上でdockerfileをビルド + ECRにimageをデプロイ
↓
ECS上で上記デプロイしたimageを指定してサービスを起動でデプロイ完了になります。
(本来はここにテストを入れるべきなのですが、シンプル + 個人コードなので割愛しました。。。)参考:ローカルで使用したdocker-compose.ymlを使ってECS上でコンテナを起動する
参考:CircleCI+ECS+ECR環境でDockerコンテナのCD(継続的デプロイ)環境を構築する
参考:Rails × CircleCI × ECSのインフラ構築./.circleci/config.ymlversion: 2.1 executors: default: machine: true orbs: aws-ecr: circleci/aws-ecr@6.0.0 jobs: deploy: executor: name: default steps: - checkout - aws-ecr/build-and-push-image: region: AWS_REGION account-url: AWS_ECR_REPOSITORY_URL repo: 'zooaqua' dockerfile: ./dockerfile - run: name: Install ECS-CLI command: | sudo curl -o /usr/local/bin/ecs-cli https://amazon-ecs-cli.s3.amazonaws.com/ecs-cli-linux-amd64-latest sudo chmod +x /usr/local/bin/ecs-cli - run: name: ECS Config command: | ecs-cli configure \ --cluster zooaqua \ --region ${AWS_REGION} \ --default-launch-type EC2 - run: name: Deploy command: | ecs-cli compose \ --file docker-compose_deploy.yml \ --ecs-params ./ecs-params.yml \ -p zooaqua \ service up \ --timeout 10 \ workflows: build_and_deploy: jobs: - deploy: name: deploy上記でCircle CI上で動く流れを定義しています。
必要最小限しか実装していませんが、、
環境変数系はCircle CI側にて指定しています。./ecs-params.ymlversion: 1 task_definition: task_execution_role: ecsTaskExecutionRole上記ファイルでECS上でタスクに割り当てるロールを指定しています。
(この辺のAWS周りの話は本記事では割愛します)./docker-compose_deploy.ymlversion: '3' services: web: image: ${AWS_ECR_REPOSITORY_URL_FULL} command: python function.py environment: # 本体のAPIのKEY - CON_KEY - CON_KEY_SEC - ACC_KEY - ACC_KEY_SEC - QUERY=#休園中の動物園水族館 - AWS_ECR_REPOSITORY_URL_FULL logging: driver: awslogs options: awslogs-region: ap-northeast-1 awslogs-group: zoo_aqua awslogs-stream-prefix: zoo_aquaタスク定義です。
pullするimageは、Ciercle CIにてbuildとpushしているECR上の物を指定しています。
ここでpython function.pyを起動時コマンドとして指定することで、
ECSのコンテナ上でPythonのコードが実行され、bot機能を動かすことができます。
なんらかの理由でこのプロセスが死んでも、ECSによって再起動され機能を維持できるのです。ここも環境変数系はCircle CI側に持たせています。
コード上のTwitter APIのkey等もここを経由して渡しています。
(QUERYだけべた書きなのは特に意味はないです。ここで指定した単語でリアルタイム検索を仕掛けます)またログはAWSのCloud watchにて収集できるようにしています。
参考:Amazon CloudWatch Logs logging driver./dockerfile# ベースイメージを指定 FROM python:3.6-stretch ENV PYTHONUNBUFFERED 1 RUN mkdir /code # ディレクトリを移動する WORKDIR /code # pipでrequirements.txtに記載のパッケージをインストール COPY requirements.txt /code/ RUN pip install --upgrade pip RUN pip3 install -r requirements.txt COPY function.py /code/./requirements.txttweepyここはコンテナの定義です。
tweepyをpipでインストールするように指定しています。
dockerfile内にてビルド時にfunction.pyをコンテナ内にコピーしておくことで、
このimageをpullするだけで定義したPython関数をコンテナ内で使えるようになります。Twitter側の自動RT機能については、ここまでが大枠です。
Instagremの投稿の自動Twitter投稿
ここから後半部分になります。
ここの機能はInstagramのGraph APIというのをTwitter APIに合わせて利用しています。
参考:Instagram Graph APIを使おう!1時間に1回Instagramの投稿を検索しにいき、
過去1時間以内に投稿された「#休園中の動物園水族館」を含む投稿を画像とともにTwitterに投稿します。全体コード
./insta_lamda/lambda_function.pyimport requests import json import tweepy import os import datetime import base64 import io import traceback import time # Twitter APIで使用する各種キーをセット # API Key consumer_key = os.environ['CON_KEY'] # API secret key consumer_secret = os.environ['CON_KEY_SEC'] # アクセストークン Access_token = os.environ['ACC_KEY'] Access_token_secret = os.environ['ACC_KEY_SEC'] #インスタURL url = os.environ['URL'] def lambda_handler(event, context): # インスタAPIの結果を取得 response = requests.get(url) data = response.json()["data"] #twitter auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(Access_token, Access_token_secret) api = tweepy.API(auth) for i in data: try: # 投稿日時の確認 datestr = json.dumps(i['timestamp'], ensure_ascii=False).replace('"',"") realdate = datetime.datetime.strptime(datestr, '%Y-%m-%dT%H:%M:%S%z') diff = datetime.datetime.now(datetime.timezone.utc) - realdate # 現在から1時間以内の投稿なら処理 if diff.seconds < 3600: # Tweet文を作成 # 130文字に調整 text = json.dumps(i["caption"], ensure_ascii=False)[1:130].replace(r'\n',"\r\n") + "... #休園中の動物園水族館 " link = json.dumps(i["permalink"], ensure_ascii=False).replace('"',"") # 投稿種別をチェックして画像URLを取得 img_url = "" if i["media_type"] == "CAROUSEL_ALBUM": for j in i["children"]["data"]: if "scontent" in j['media_url']: img_url = j['media_url'] break elif i["media_type"] == "IMAGE": img_url = i['media_url'] else: continue if img_url is "": continue f=io.BytesIO(requests.get(img_url).content) f.mode = 'rb' # 読み込み専用のバイナリモードであるというように擬態する f.name = 'hoge.jpg' # 拡張子さえ合っていれば問題ないと思います # 画像付き投稿 img= api.media_upload(filename="hoge.jpg",file=f) api.update_status(status=text + link, media_ids=[img.media_id_string,"","",""]) # ←4枚投稿想定らしい。残り3枚を空値に time.sleep(30) except: print(traceback.format_exc())実装
前半と異なり、上記コードはLambda上にて動きます。
環境変数系もLambda上にて指定しています。
Lambdaではイベントを契機にlambda_handlerの中に記載した処理が実行されます。./insta_lamda/lambda_function.py# Twitter APIで使用する各種キーをセット # API Key consumer_key = os.environ['CON_KEY'] # API secret key consumer_secret = os.environ['CON_KEY_SEC'] # アクセストークン Access_token = os.environ['ACC_KEY'] Access_token_secret = os.environ['ACC_KEY_SEC'] #インスタURL url = os.environ['URL']Twitter部分は前半と同じです。
urlはInstagram Graph APIにGETするためのURLを環境変数から取得しています。
詳細は下記記事を参照いただきたいですが、「#休園中の動物園水族館」というタグを含む投稿一覧を取得できるようなエンドポイントを指定しています。
参考:グラフAPIを使って任意のハッシュタグを持つ投稿をインスタグラムから取得する./insta_lamda/lambda_function.pydef lambda_handler(event, context): # インスタAPIの結果を取得 response = requests.get(url) data = response.json()["data"] #twitter auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(Access_token, Access_token_secret) api = tweepy.API(auth)上記のrequests.getにてInstagram Graph APIを叩きに行き、返り値をdataに格納します。
Twitter部分は前半と同じです。./insta_lamda/lambda_function.pyfor i in data: try: # 投稿日時の確認 datestr = json.dumps(i['timestamp'], ensure_ascii=False).replace('"',"") realdate = datetime.datetime.strptime(datestr, '%Y-%m-%dT%H:%M:%S%z') diff = datetime.datetime.now(datetime.timezone.utc) - realdate # 現在から1時間以内の投稿なら処理 if diff.seconds < 3600: # Tweet文を作成 # 130文字に調整 text = json.dumps(i["caption"], ensure_ascii=False)[1:130].replace(r'\n',"\r\n") + "... #休園中の動物園水族館 " link = json.dumps(i["permalink"], ensure_ascii=False).replace('"',"")dataには投稿件数分のデータが格納されているので、for文にて取り出します。
まず投稿の日時をチェックし、現在時刻から1時間以内の投稿かを見ます。
投稿日時はtimestampに格納されています。
参考:IG Media1時間以内なら次の処理に進めます。
Twitterには文字数制限があるため、Instagramのキャプションを途中省略して投稿できるようにし、変数に格納しています。
またInstagramの投稿そのもののリンクをpermalinkから取得しています。./insta_lamda/lambda_function.py# 投稿種別をチェックして画像URLを取得 img_url = "" if i["media_type"] == "CAROUSEL_ALBUM": for j in i["children"]["data"]: if "scontent" in j['media_url']: img_url = j['media_url'] break elif i["media_type"] == "IMAGE": img_url = i['media_url'] else: continue if img_url is "": continueInstagramの投稿種別には、画像と動画があり、またそれぞれ単独の時と複数同時投稿されているときがあります。
投稿種別には下記があり、media_typeに格納されているので、これを見て処理分岐させます。
- CAROUSEL_ALBUM:1つの投稿に複数の画像or動画が含まれる投稿(いわゆるアルバム)
- IMAGE:画像1枚の投稿
- VIDEO:動画1つの投稿
今回はTwitterへの投稿は画像1枚のみとしたいため、上記それぞれに対応できるようなコードを書き、
画像を1枚に絞った後、変数img_urlにそれを格納します。CAROUSEL_ALBUMの場合、それぞれの投稿はchildrenの中にネストされますので、さらにfor文で処理を続けています。
media_url(投稿された画像のURL)に、画像ならscontent、動画ならvideoが含まれるためここで判別し、
最初にヒットした画像に対し、img_urlにmedia_urlを格納します。一方でmedia_typeがIMAGEの場合は、そのままimg_urlにmedia_urlを格納します。
VIDEOならcontinueでスキップさせます。上記処理にて、Twitterに投稿する画像を1枚に絞ります。
./insta_lamda/lambda_function.pyf=io.BytesIO(requests.get(img_url).content) f.mode = 'rb' # 読み込み専用のバイナリモードであるというように擬態する f.name = 'hoge.jpg' # 拡張子さえ合っていれば問題ないと思います # 画像付き投稿 img= api.media_upload(filename="hoge.jpg",file=f) api.update_status(status=text + link, media_ids=[img.media_id_string,"","",""]) # ←4枚投稿想定らしい。残り3枚を空値に time.sleep(30) except: print(traceback.format_exc())取得した画像URLをGETしてデータを取得し、これをBytesIOを経由させてtweepyから画像投稿させます。
参考:python-twitter で BASE64 形式の画像をツイートするちなみにTwitter APIの画像投稿はmedia_uploadとupdate_statusの2段階のようです。
(media_uploadにて画像を先にアップロードし、update_statusでそのIDを指定して本文とともに投稿)デプロイ
こちら側はデプロイといっても、Lambdaにzipファイルにて手動でアップロードしています(工夫不足)。
Lambda上ではpipで入れるようなライブラリは使えないため、あらかじめローカルに落としたものをzipで一緒にLambdaにアップする必要があります。
(今回でいうとtweepy)
lambda_function.pyという名前の関数をLambdaは実際に読みに行きます。
lambda_function.pyでtweepyをimportするには、上記のように同じディレクトリにpipでダウンロードしたtweepyのファイル一式を配置します。このLambda関数をCloudWatch Eventsから指定して、cron式により1時間に1回の定期処理をさせます。
参考:【AWS】lambdaファンクションを定期的に実行する
参考:Rate または Cron を使用したスケジュール式ちなみにInstagramからの情報取得から実際のTwitterへの処理を、タグに該当する投稿分繰り返すので、
処理時間を考慮してLambdaのタイムアウト設定を10分に伸ばしています。Instagramの投稿をTwitterに自動投稿する部分についてはここまでが大枠になります。
終わりに
「#休園中の動物園水族館」というタグの投稿が好きで、これを集めたbotがあればよいなという構想からスタートしましたが、
APIとAWSを駆使すると意外と簡単に実装できてしまうんだな、というのが率直な感想です。特にLambdaはかなり便利だったのですが、常時プロセスを起動させておくような使い方ができなかったので、
ECSと組み合わせる方法を選択しました。早くコロナが収束してこのbotが不要になることを望むばかりです。
- 投稿日:2020-06-21T12:53:47+09:00
PEP 618 (Add Optional Length-Checking To zip) を読んだよメモ
先日、PEP 618 (Add Optional Length-Checking To zip) が Accept されたというコミットを見かけました。
そこで、今回は PEP 618 を読んでみようと思います。概要
zip()関数を使うとき、暗黙的に各要素の長さが同じであることを期待していることがある (ことが多い)- 長さの異なる要素を誤って与えてしまうと、意図せずデータを欠損してしまうことになる
>>> list(zip([1,2,3], [4])) # 2, 3 は失われてしまう [(1, 4)]
- 次のような関数があるときに、リストを渡すと意図通りに動くが、イテレータを渡すとうまく動かない (イテレータが先に進んでしまうので)。
def apply_calculations(items): transformed = transform(items) for i, t in zip(items, transformed): yield calculate(i, t)
zip()にオプションを追加し、各要素が同じ長さであることをチェックするアプローチ
Python 3.10 に
zip()関数にstrictというパラメータが追加されました。
strictに正の値を指定した場合、各要素の長さが等しくないときにValueErrorが発生します。>>> for item in zip([1, 2, 3], [4], strict=True): ... print(item) ... (1, 4) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: zip() argument 2 is shorter than argument 1
zip()の第2引数が第1引数より短い、というエラーが出ています。
ちなみに、長さが一致しないというのを検知するまでループが回っている点には注意が必要です。なお、デフォルトではいままでの挙動のままのままです(
strict=False相当、つまり長さが異なる場合はデータを捨てる)。>>> for item in zip([1, 2, 3], [4]): ... print(item) ... (1, 4) >>>感想
- 言われてみるとうっかりミスでデータ欠損を起こしそうな予感があるので、これは嬉しい
- でも、明示的に
strict=Trueと指定しないといけないので、指定しわすれてトラブルになりそう- イテレータの例はやらかしそうな気がした (すぐに気づくとは思うけど…)
- 3.10 が楽しみですね
- 投稿日:2020-06-21T12:53:08+09:00
[Python]スクレイピング初心者がJリーグの順位表をCSVファイルに保存するまで
スクレイピングの復習
スクレイピングが気になってひとまず何かのデータを取りたかったので、以下のサイトを参考にしつつ、スクレイピングをしてみました。
https://www.atmarkit.co.jp/ait/articles/1910/18/news015_2.html
復習がてらに書くので、スクレイピングを初めてする方の参考になればと思います!
Pythonを使ってGoogleColabで書きました。
そのため、ローカルでの記述とは異なるところがあるかもしれません。スクレイピングの基礎
requestとBeautiful soupでスクレイピングを行いました。
requestでは、指定したウェブkらファイルを取得して、Beautiful soupで取得したファイルから欲しい情報を抜き出します。
サイトにある通り、Jリーグの順位表を取得するプログラムを書いています。
また、追加でCSVに保存するところまで書いています。
以下に今回使ったコードを記します。qiita.rbfrom bs4 import BeautifulSoup from urllib import request url = 'https://www.jleague.jp/standings/j1/' response = request.urlopen(url) content = response.read() response.close() charset = response.headers.get_content_charset() html = content.decode(charset, 'ignore') soup = BeautifulSoup(html) table = soup.find_all('tr') standing = [] for row in table: tmp = [] for item in row.find_all('td'): if item.a: tmp.append(item.text[0:len(item.text) // 2]) else: tmp.append(item.text) del tmp[0] del tmp[-1] standing.append(tmp) for item in standing: print(item) import pandas as pd from google.colab import files del standing[0] df = pd.DataFrame(standing,columns = ['順位', 'クラブ名', '勝点', '試合数', '勝', '分', '負', '得点', '失点', '得失点']) from google.colab import drive filename = 'j1league.csv' path = '/content/drive/My Drive/' + filename with open(path, 'w', encoding = 'utf-8-sig') as f: df.to_csv(f,index=False)途中細かく確認しながら実装したので、間にprint()を挟んでいましたが、ここでは、一気にファイルに保存するところまで実装しています。