- 投稿日:2020-06-21T23:49:17+09:00
DynamoDB作成時のCloudFormation とSAM CLIの使い分け
概要
DynamoDBを使用するときにLambdaから読み書きさせるためSAM(Serverless Application Model)を使おうとしたときにうまくいかなかったのでその時の
発生した問題点
Lambdaを作成するついでにDynamoDBの定義も記載しようとしたところ
GlobalSecondaryIndexesを指定することができませんでした。
公式ドキュメントを見るとなかった・・・対応
DynamoDBで
GlobalSecondaryIndexesを使用するときはCloudFormationを使用する。
今回作成予定のDynamoDBはSAMで登録しようとしたLambda以外にも別にLambdaを作成する予定だったためほかの更新に引っ張られないようにするためにも別にするのは良かったかなと思います。
ただ、今回は検索処理の都合で PrimaryKey以外でも検索をしたかったのでGlobalSecondaryIndexesを使う予定だったのですが、本当にGlobalSecondaryIndexesを使うべきかを考える必要もありそうです。
- 投稿日:2020-06-21T23:49:02+09:00
AWS日記11 (SQS)
はじめに
今回は Amazon SQS (Simple Queue Service)を試します。
サポートされているキュータイプの 「FIFO キュー」 を試します。準備
Lambda , API Gatewayの準備をします。
SQSの準備をします。「FIFO キュー」を作成し、キューURLを確認します。[Amazon SQSの資料]
Amazon Simple Queue Service
【AWS】楽々SQS解説〜5分で理解〜WEBページ・API作成
GO言語のAWS Lambda関数ハンドラー aws-lambda-go を使用してHTMLやJSONを返す処理を作成します。
また、SQS を使用するため aws-sdk-go を利用します。[参考資料]
AWS SDK for Go API Reference
aws-sdk-goを使ってGoからAWS SQSを使うキューにメッセージを送信するには SendMessage を使う。
main.gofunc sendMessage(message string) error { t := time.Now() svc := sqs.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) params := &sqs.SendMessageInput{ MessageBody: aws.String(message), QueueUrl: aws.String(queueUrl), MessageGroupId: aws.String(messageGroupId), MessageDeduplicationId: aws.String(t.Format(layout2)), } _, err := svc.SendMessage(params) if err != nil { return err } return nil }キューのメッセージ件数を確認するには GetQueueAttributes を使う。
main.gofunc getCount()(string, error) { svc := sqs.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) params := &sqs.GetQueueAttributesInput{ AttributeNames: []*string{aws.String("ApproximateNumberOfMessages")}, QueueUrl: aws.String(queueUrl), } res, err := svc.GetQueueAttributes(params) if err != nil { return "", err } return aws.StringValue(res.Attributes["ApproximateNumberOfMessages"]), nil }キューからメッセージを受信するには ReceiveMessage を使う。
main.gofunc receiveMessage()(string, error) { svc := sqs.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) params := &sqs.ReceiveMessageInput{ QueueUrl: aws.String(queueUrl), MaxNumberOfMessages: aws.Int64(1), WaitTimeSeconds: aws.Int64(3), } res, err := svc.ReceiveMessage(params) if err != nil { return "", err } if len(res.Messages) == 0 { return "Empty.", nil } var wg sync.WaitGroup for _, m := range res.Messages { wg.Add(1) go func(msg *sqs.Message) { defer wg.Done() if err := deleteMessage(svc, msg); err != nil { log.Println(err) } }(m) } wg.Wait() return aws.StringValue(res.Messages[0].Body), nil }キューからメッセージを削除するには DeleteMessage を使う。
main.gofunc deleteMessage(svc *sqs.SQS, msg *sqs.Message) error { params := &sqs.DeleteMessageInput{ QueueUrl: aws.String(queueUrl), ReceiptHandle: aws.String(*msg.ReceiptHandle), } _, err := svc.DeleteMessage(params) if err != nil { return err } return nil }終わりに
今回はAmazon SQS の「FIFO キュー」を試しました。
- 投稿日:2020-06-21T23:41:47+09:00
Lambdaのトリガーの作成中にエラーが発生しましたの対処法
Lambdaでトリガーを指定したい
エラー内容
LambdaでS3のputをトリガーを指定しようとした時
trigger の作成中にエラー が発生しました: Configurations overlap. Configurations on the same bucket cannot share a common event type. (Service: Amazon S3; Status Code: 400; Error Code: InvalidArgument; Request ID: 8659097E5FCA60E1; S3 Extended Request ID: 2PrYTEd8BysODQscbugs/nK2CtkwOQPjw4JXuWgP6rF18PrrvTkq7cgsbs5gDDwKZdB+9qXAE1o=; Proxy: null)
というエラーが出ました。
同じバケットで同じイベントタイプでは作れませんよ的な内容です。
同じトリガーの関数を消すだけではダメ
消しても同じエラーでした。
解決策
トリガーで指定していたS3のバケット→プロパティ→イベントで該当のイベントを削除する
まとめ
覚えることいっぱいですね。
- 投稿日:2020-06-21T23:35:17+09:00
Nuxt.js で作成した静的サイトを S3 + CloudFront でホスティングするパターン
Nuxt.js で SSR を使わない静的サイトを生成(
nuxt generate)して S3 で安価にホスティングする場合、「各ページに対して index.html ファイルが生成されるが、リンクの URL では index.html は省略されるため、そのままでは Not Found になってしまう」という課題がある。通常の Web サーバーには、例えば Apache ではDocumentIndex、nginx ではindexというように、ファイル名が省略された場合にデフォルトのファイル名を配信する設定があるが、それ相当の動作が必要となる。実現方法にはいくつかパターンがあるようなので、詳細はそれぞれの解説ページに任せるとして、それらを整理してみた。
参考
構成パターン
1. S3 で Static website hosting をおこなう
- 大量のアクセスが発生しない、かつ HTTP だけで良い場合はこれが最もシンプル。
- Static website hosting の「Index document」設定に「index.html」を設定する。
- カスタムドメインで公開する場合は、バケット名を FQDN にする必要がある。
参考
2. S3 で Static website hosting をおこない、CloudFront 経由で公開する
- 1 に加えて、CloudFront から S3 で Static website hosting した URL を Origin とする。
- S3 の Static website hosting にも直接アクセスできてしまう。
- S3 への直接アクセスを制限する手段はあるが、弱い方法しかない? HTTP での直接アクセスを絶対にさせたくないといった場合は注意。
- CloudFront からのリクエストに特定のカスタムヘッダを付与し、S3 でそれをチェックするなど。
- CloudFront の Edge は多数あり変動するので IP 制限はあまり現実的ではない。
参考
- How to Deploy on AWS w/ S3 and Cloudfront? - Nuxt.js 公式
- S3+CloudFrondでNuxt.js(vue)のHTTPS静的サイトを構築・デプロイ
3. CloudFront のエラーページ設定で index.html を返す
- S3 での Static website hosting はおこなわず、CloudFront から S3 バケットを Origin とする。
- index.html が省略されて 403 となった場合に表示するエラーページとして、index.html を返すように設定する。
- 余談) CloudFront に「Default Root Object」というそれっぽい設定はあるが、これは本当にルートにしか効かないので役に立たない。
- 意味的にはエラーページとして表示することになるので、少し気持ちが悪い。(個人の感想です)
参考
- NuxtのSPAを S3+CloudFrontでホストする。デプロイはCodeBuildで自動化 - アクトインディ開発者ブログ
- Nuxt.jsで作った静的サイトをCloudFront + S3で配信するときのTips - @ryoheimorimoto
4. Lambda@Edge で index.html への書き換えをおこなう
- CloudFront へのアクセスをフックして独自の処理を加えられる Lambda@Edge を使い、index.html を付与して Origin にリクエストする。
- 設定が比較的面倒で、Lambda のぶん追加コストがかかる。
参考




- 投稿日:2020-06-21T23:15:55+09:00
【AWS】AmazonLinuxのNTP設定確認&日本語時刻設定方法
はじめに
AWS上にZabbix環境を個人的な学習で構築しようとしています。
その中でAmazonLinuxのNTP確認&日本語時刻設定を実際にやりました。
今回は、こちらの手順についてアウトプットしていきたいと思います。自宅環境
項目 説明 自宅PC Windows10 ターミナル TeraTerm クラウド環境
項目 説明 PublicCloud AWS OS Amazon Linux 2 AMI (HVM), SSD Volume Type ※自宅PC→構築したEC2に接続できるようにVPC設定済み
手順
「Amazon Time Sync Service」設定確認
①rootユーザーへ移行する。
[ec2-user@ip-192-168-8-74 ~]$ sudo su [root@ip-192-168-8-74 ec2-user]#②
chronyパッケージが存在することを確認[root@ip-192-168-8-74 ec2-user]# rpm -qa | grep chrony chrony-3.2-1.amzn2.0.5.x86_64 [root@ip-192-168-8-74 ec2-user]#③
/etc/chrony.confを確認
server 169.254.169.123 prefer iburst minpoll 4 maxpoll 4の一文が存在することを確認[root@ip-192-168-8-74 ec2-user]# cat /etc/chrony.conf | grep server server 169.254.169.123 prefer iburst minpoll 4 maxpoll 4 # Use public servers from the pool.ntp.org project. [root@ip-192-168-8-74 ec2-user]#④
chronyd起動&自動起動設定確認
chronyd起動確認
active (running)になっていること。[root@ip-192-168-8-74 ec2-user]# systemctl status chronyd ● chronyd.service - NTP client/server Loaded: loaded (/usr/lib/systemd/system/chronyd.service; enabled; vendor preset: enabled) Active: active (running) since Sun 2020-06-21 13:48:40 UTC; 9min ago Docs: man:chronyd(8) man:chrony.conf(5) Process: 2699 ExecStartPost=/usr/libexec/chrony-helper update-daemon (code=exited, status=0/SUCCESS) Process: 2680 ExecStart=/usr/sbin/chronyd $OPTIONS (code=exited, status=0/SUCCESS) Main PID: 2687 (chronyd) CGroup: /system.slice/chronyd.service mq2687 /usr/sbin/chronyd Jun 21 13:48:40 localhost systemd[1]: Starting NTP client/server... Jun 21 13:48:40 localhost chronyd[2687]: chronyd version 3.2 starting (+CMDM...) Jun 21 13:48:40 localhost systemd[1]: Started NTP client/server. Jun 21 13:48:46 ip-192-168-8-74.ap-northeast-1.compute.internal chronyd[2687]: ... Hint: Some lines were ellipsized, use -l to show in full. [root@ip-192-168-8-74 ec2-user]#
chronyd自動起動確認
enabledになっていること[root@ip-192-168-8-74 ec2-user]# systemctl is-enabled chronyd enabled [root@ip-192-168-8-74 ec2-user]#⑤時刻同期確認
chronyが169.254.169.123を使用して時刻を同期させていることを確認。
※*になっていれば、時刻同期ができている。[root@ip-192-168-8-74 ec2-user]# chronyc sources -v 210 Number of sources = 5 .-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current synced, '+' = combined , '-' = not combined, | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | \ MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* 169.254.169.123 3 4 377 1 -1396ns[-2259ns] +/- 535us ← こちらの部分 ^- x.ns.gin.ntt.net 2 6 377 40 +382us[ +388us] +/- 72ms ^- ntp-a2.nict.go.jp 1 6 377 39 +549us[ +554us] +/- 1604us ^- li1885-23.members.linode> 2 6 377 39 +615us[ +620us] +/- 28ms ^- ntp.arupaka.net 2 6 255 39 -2267us[-2262us] +/- 103ms [root@ip-192-168-8-74 ec2-user]#
※こちらでも確認可能です。[root@ip-192-168-8-74 ec2-user]# chronyc tracking Reference ID : A9FEA97B (169.254.169.123) Stratum : 4 Ref time (UTC) : Sun Jun 21 14:03:54 2020 System time : 0.000002454 seconds fast of NTP time Last offset : +0.000000805 seconds RMS offset : 0.000004196 seconds Frequency : 12.523 ppm fast Residual freq : +0.001 ppm Skew : 0.076 ppm Root delay : 0.000405045 seconds Root dispersion : 0.000289323 seconds Update interval : 16.1 seconds Leap status : Normal [root@ip-192-168-8-74 ec2-user]#日本語設定方法
①事前確認
時刻がUTC表記となっていることを確認
[root@ip-192-168-8-74 ec2-user]# date Sun Jun 21 14:05:48 UTC 2020 [root@ip-192-168-8-74 ec2-user]#②インスタンスで使用する時間帯を確認
Japanが存在することを確認[root@ip-192-168-8-74 ec2-user]# ls /usr/share/zoneinfo/ | grep Japan Japan [root@ip-192-168-8-74 ec2-user]#③clockファイルの変更
vim /etc/sysconfig/clock
- 変更前
[root@ip-192-168-8-74 ec2-user]# cat /etc/sysconfig/clock ZONE="UTC" UTC=true [root@ip-192-168-8-74 ec2-user]#
- 変更後
[root@ip-192-168-8-74 ec2-user]# cat /etc/sysconfig/clock #ZONE="UTC" ZONE="Japan" UTC=true [root@ip-192-168-8-74 ec2-user]#④時間帯ファイルにシンボリックリンクの作成
インスタンスが現地時間情報を参照する際に、時間帯ファイルを読み込むためシンボリックリンクを貼る。
[root@ip-192-168-8-74 ec2-user]# ln -sf /usr/share/zoneinfo/Japan /etc/localtime [root@ip-192-168-8-74 ec2-user]# ll /etc/localtime lrwxrwxrwx 1 root root 25 Jun 21 23:10 /etc/localtime -> /usr/share/zoneinfo/Japan [root@ip-192-168-8-74 ec2-user]#⑤OS再起動
reboot⑥日本時間になっていることを確認
[ec2-user@ip-192-168-8-74 ~]$ date Sun Jun 21 23:12:15 JST 2020 [ec2-user@ip-192-168-8-74 ~]$参考
- 投稿日:2020-06-21T22:59:28+09:00
S3 MFA Delete
S3 MFA Deleteとは
S3でオブジェクトを削除(※)する際にMFA認証を必須とする機能。
※ ここでいう削除は特定バージョンの削除。表面的なファイル削除は可能。
- 該当S3バケットのバージョニングが有効になっていることが前提条件
- マネジメントコンソール上でMFA認証は行えないため、同設定を行った場合、CLIからのみしか操作ができない
- 利用可能なMFA認証はrootアカウントのMFAデバイスのみとなる
- MFA Deleteが有効になっている際はバージョニングの無効化不可
ユーザの誤操作でバージョンが消失することを防ぎたい場合に有効か。
やってみる
注意:rootアカウントのアクセスキー/シークレットアクセスキーは作業完了次第、消す!
1.事前準備
rootアカウントのアクセスキーID/シークレットアクセスキーをIAMから発行。またMFAデバイスのARNを控えておく。
2.設定用profileの作成
rootアカウントで操作するための設定用profileを用意する(終わったら速やかに消す)
% aws configure --profile mfa-delete AWS Access Key ID [None]: [rootアカウントのアクセスキーID] AWS Secret Access Key [None]: [rootアカウントのシークレットアクセスキー] Default region name [None]: ap-northeast-1 Default output format [None]:3.MFA Delete有効化
以下コマンドでMFA Deleteを有効化する。
% aws s3api put-bucket-versioning --bucket [バケット名] --versioning-configuration Status=Enabled,MFADelete=Enabled --mfa '[MFAデバイスのARN] [MFAデバイスのトークン]' --profile mfa-delete4.結果確認
マネジメントコンソールからバージョンの削除を行ってもできない。
また、バージョニングの無効化ができない
5.後片付け
やめたいときはDisabledに戻す
% aws s3api put-bucket-versioning --bucket [バケット名] --versioning-configuration Status=Disabled,MFADelete=Enabled --mfa '[MFAデバイスのARN] [MFAデバイスのトークン]' --profile mfa-deleterootアカウントのアクセスキーとprofileも忘れずに削除!

- 投稿日:2020-06-21T21:59:31+09:00
【AWS】用語を整理しながら学ぶAWS - part2
はじめに
この記事では
AWSのあんなことやこんなことについて
まとめた記事です。
ベストプラクティスや間違いがあれば
書き直していく予定です。
今回はAmazonEC2とそれを扱う上で重要な用語について整理してみました。参考図書:さわって学ぶクラウドインフラAmazon Web Services 基礎からのネットワーク&サーバー構築
Amazon EC2とは
Amazon ECS(Amazon Elastic Container Service)で動作する
インスタンスのこと単にEC2インスタンス呼ぶことが多い。
実態はDocker
Amazon EC2という名前ですが
実際に用いられている技術はDockerです。
仮想サーバを作成するとき
Amazon EC2を使えばAWS上に
Amazon Linux 2の仮想サーバを作成できる。何がすごいってブラウザから
AWSマネジメントコンソールを開いて
ポチポチすれば数秒で仮想サーバを構築できるというところ
AmazonL Linux 2とは
Red Hat Enterprise Linux 7(RHEL7)をベースとした
Amazon Web Services用のLinux OSのこと使われているDBは「MariaDB」
実際にOSを使うときは
AmazonL Linux 2 Amazon Machine Imageを
EC2インスタンス作成時に選択する。(以下、AmazonL Linux 2 AMI)
課金
EC2インスタンスの課金タイミングは
インスタンスを「running」にしているとき※ただし、Amazon EBS(Amazon Elastic Block Store)は容量を確保しているとき
注意事項
AmazonL Linux 2 AMIをベースにして
EC2インスタンスで作成すると
Amazon EBSが消費される。(課金される)
Amazon EBS
AWS上で確保できるハードディスクのこと
Amazon EBS(Amazon Elastic Block Store)と呼ぶ。
まとめ
・AWS上でサーバを建てるときはEC2インスタンスを用いる。
・インスタンスを「running」にすると課金が始まる。
・EC2インスタンスを作成するとAmazon EBSが消費される。
・EBSは容量を確保すると課金が始まる。
おわり
- 投稿日:2020-06-21T19:20:19+09:00
AWSインスタンスをコマンドラインで起動・停止する
AWSのEC2インスタンスをシェルで起動するのをやりたかったのですが、とりあえず今回はコマンドで起動できるところまでを確認しました。ので、備忘録。
AWS-CLIをインストール
参考はこちら。
$ curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 20.7M 100 20.7M 0 0 14.6M 0 0:00:01 0:00:01 --:--:-- 14.6M$ sudo installer -pkg ./AWSCLIV2.pkg -target / Password: installer: Package name is AWS Command Line Interface installer: Installing at base path / installer: The install was successful.以下コマンドでインストールできたことを確認。
$ which aws /usr/local/bin/aws $ aws --version aws-cli/2.0.24 Python/3.7.4 Darwin/18.7.0 botocore/2.0.0dev28起動・停止にトライ
シェルを書く前に、コマンドで試してみると、、、おろ。
$ aws ec2 start-instances --instance-ids インスタンスID You must specify a region. You can also configure your region by running "aws configure".どうやら、aws configureという初期設定が必要な模様。参考はこちら。
aws-cliというユーザーを別に作り、ポリシーをアタッチし、生成したアクセスキーを使って以下のように設定。
$ aws configure AWS Access Key ID [None]: XXXXXXXXXXXXXXX AWS Secret Access Key [None]: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX Default region name [None]: ap-northeast-1 Default output format [None]: json今度こそ、、、!!
$ aws ec2 start-instances --instance-ids インスタンスID { "StartingInstances": [ { "CurrentState": { "Code": 0, "Name": "pending" }, "InstanceId": "XXXXXXXXXXXXXXXXXX", "PreviousState": { "Code": 80, "Name": "stopped" } } ] }コンソール見たら、ちゃんとrunnningになっていました。キターーーーーーーーーーーー
停止もできました。コンソールにて、stoppedになっているのを確認。
$ aws ec2 stop-instances --instance-ids インスタンスID { "StoppingInstances": [ { "CurrentState": { "Code": 64, "Name": "stopping" }, "InstanceId": "XXXXXXXXXXXXXXXXXX", "PreviousState": { "Code": 16, "Name": "running" } } ] }今回は、まだシェルを書くに至りませんでした。
次は、シェルを頑張ってみたいと思います。。
- 投稿日:2020-06-21T18:25:27+09:00
EC2のインスタンスメタデータ確認
EC2インスタンス上で実行。169.254.169.254/latest/meta-data/にアクセスする。REST形式のAPIになっているので、取得したい要素を指定する
% curl http://169.254.169.254/latest/meta-data/ ami-id ami-launch-index ami-manifest-path block-device-mapping/ events/ hibernation/ hostname iam/ identity-credentials/ instance-action instance-id instance-life-cycle instance-type local-hostname local-ipv4 mac metrics/ network/ placement/ profile public-hostname public-ipv4 public-keys/ reservation-id security-groups services/例)hostnameを取得したい場合
% curl http://169.254.169.254/latest/meta-data/hostname ip-XXX-XXX-XXX-XXX.ap-northeast-1.compute.internal
- 投稿日:2020-06-21T17:44:14+09:00
AWS PuTTYでのSSHファイル転送ではまったところ
windows上からAWSで起動しているLinux2のインスタンスのディレクトリへファイルを転送したい
[参考]
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/putty.html#Transfer_WinSCP初心者のokkumanでございます。
まあ案内にも書いている通りやればいいのですが
一応はまったので備忘録的に残していこうかと思います。自身のPCよりAWSのインスタンスマシンにファイル転送をする際
pscp -i C:\Users\user-name\(keyの名前).ppk C:\Users\user_name\requirements.txt ec2-user@DNSサーバーネイム:/home/ec2-user/requirements.txtpscp -i [ ppkファイルが格納されている場所のファイルFullパス ] 半角スペース [ 転送したいファイルのファイルFullパス] 半角スペース [ linuxユーザーネーム ] @ [ AWSのDNSのFullパス ] : [linuxの配置したいパス]
↓実行結果
requirements.txt | 0 kB | 0.3 kB/s | ETA: 00:00:00 | 100%正常な動作は上記となりますが
サーバーネイムの後に「:」がないとpscpがリモート環境と判別せず、
「Local to Local copy not supported」と表示されてエラーとなるようです。かなり前の情報ですが参考にさせていただきました。
[ 参考 ]
https://stackoverflow.com/questions/34037484/putty-pscp-error-local-to-local-copy-not-supported-when-username-contains-a-sl
- 投稿日:2020-06-21T16:33:08+09:00
AWS 最低限の料金調査とインスタンス作成、接続までのメモ
概要
数年ぶりに私的な理由でAWSを利用することになった。セットアップした際のメモ書き。
料金調査
- AWSでは特定のサービスについて無料利用枠が用意されている。
- EC2はt2.microで月750時間分が無料
- 対象サービスや無料利用枠の詳細について - AWS クラウド無料利用枠
- 今回はオンデマンド(従量課金制)を採用
- リージョン毎に1時間あたりの料金設定が異なる - オンデマンドインスタンスの料金
- 東京リージョンを選択
- 念の為、無料期間終了後に発生する月額請求を簡単に計算して把握しておく。
- EC2のタイプが 「t2.micro」 だった場合の月額費用
- $10.944/month
- EBS(ストレージ)のタイプが 「汎用 SSD (gp2) ボリューム」で30GBを割当てした場合の月額費用
- $3.6/month
- AWS公式の試算ツールで計算すると良し - AWS Pricing Calculator
- 通知設定しておくと更に安心 - 無料利用枠の使用量の追跡
EC2 インスタンス作成
- 予め各種設定に命名規則を用意しとくと良い。
- 無料利用枠の範囲(t2.micro, Amazon Linux2, SSD30GB)でインスタンスを作成
- デフォルト用意されているセキュリティグループはinboundに制限がないので注意
- 自宅IPだけ許可したセキュリティグループを新規作成
- デフォルトで用意されているサブネットを全削除して新規作成
- EC2作成時の詳細設定画面において新規作成したサブネットを指定する。
- また「自動割り当てパブリック IP」を有効設定しないと作成後のインスタンスにグローバルなIPアドレスが割当てされないので注意
- 作成後、インスタンスに接続できないオチが待っている。
- 事後に気づいて修正しようとしたけど詰まったのでインスタンスを作り直した(悲)
- Keyはダウンロードして保管
- この後、公開鍵認証で接続するのに必要になる。
EC2 インスタンス接続
- Macのターミナルからssh公開鍵認証で接続した。
- 接続前にインスタンス作成時にダウンロードした鍵ファイルの権限を変更しておく。
$ chmod 600 xxx.pem
- 所有者だけが読書きできれば良い - (参考)ssh公開鍵認証を実装する
- ダウンロードしたままの鍵ファイルは権限が緩いので、ssh接続時に警告が出て失敗する。
- 公開鍵認証でssh接続を試す。
$ ssh -i xxx.pem ec2-user@xxx.xxx.xxx.xxx
- 指定するユーザは ec2-user
- 接続先はパブリックIPもしくはパブリックDNSの値を指定
Last login: Sun Jun 21 06:35:23 2020 from xxx __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/
- 投稿日:2020-06-21T16:24:23+09:00
docker terraform実行環境を作って、仲間のterraform実行環境を尊重する
紹介する内容
- terraformの
環境別HOMEパス/.aws/credentialsからaws profileを取得する設定を利用します
- gitignoreとdockerのvolumesを利用してterraform実行環境を作ります
- 参考:https://www.terraform.io/docs/providers/aws/index.html#shared-credentials-file
- 主にMACにterraformインストールした仲間とdockerでterraform使いたい人(筆者)状況を想定しました
結論
- 同じaws profile名を設定するルールだけ守ると、MACでterraformインストールした人、dockerでterraformインストールした人はお互いの環境を気にせずにterraform運用できると思います
- dockerコンテナの中で生成したaws profileの情報をdockerのvolumesでマウントしました。
- マウントしたディレクトリを消さない限りaws profileをずっと使用できます
- gitignoreしたから、aws profile情報はgit pushされません
紹介始めます
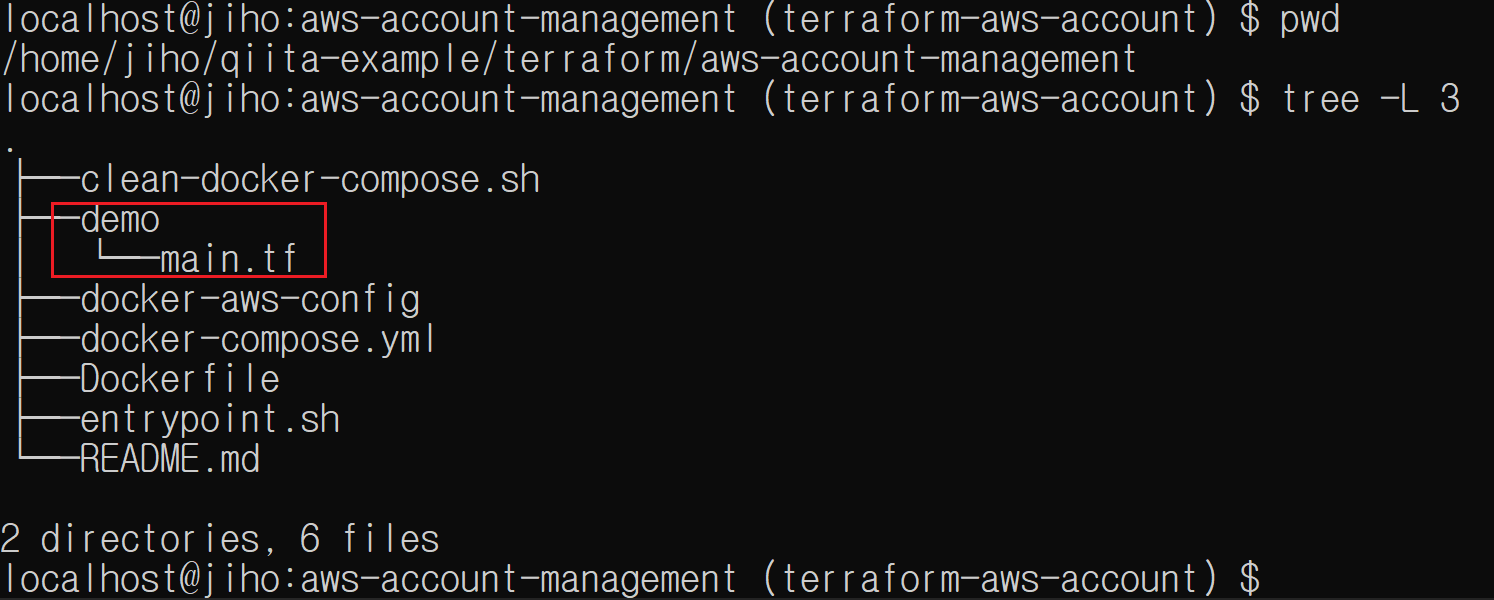
ディレクトリ構成
全体ソースコードは https://github.com/cheekykorkind/qiita-example/tree/master/terraform/aws-account-management で確認できます
全体図
aws profileの情報をマウントするディレクトリ
dockerコンテナの中で生成したaws profileの情報をマウントするところです。
terraformファイルがあるディレクトリ
aws profile名me-demoを参照して、cloudwatch logs groupを一つ作る内容が書かれてます
試し順番です
- docker composeがあるデレクトリー移動に移動します
cd qitta-example/terraform/aws-account-management- dockerコンテナをバックグラウンドで起動します
DOCKER_UID=$(id -u $USER) DOCKER_GID=$(id -g $USER) docker-compose up -d- dockerコンテナに入ります
docker exec -it aws-account-management /bin/shaws profile設定します
- 一回で十分です、HOSTマシンに影響与えません
- profile名は
my-demoにしました。terraformで参照してますaws configure --profile my-demoの実行前のイメージ
aws configure --profile my-demoの実行中のイメージ
aws configure --profile my-demoの実行後のイメージ
terraformデレクトリーに移動します
cd ~/terraform/demoterraform initします
terraform initterraformを実行します
terraform applyterraformのprofile参照名を変えてエラーになるか確認します
- main.tfを一時的に修正します
terraform apply

- 投稿日:2020-06-21T16:23:45+09:00
Cloud9をデスクトップアプリ化する(macOS 2020年版+おまけのWindows)
概要
AWS Cloud9をブラウザ(Chrome)から利用すると、Chromeにバインドされているキーボードショートカットが優先されてCloud9のキーバインドが正しく動作しません。これを回避するためにChromeをデスクトップアプリとして起動する方法です。Windowsでは簡単にできるのですが、macOSのChromeでは現状簡単にできないので、Automatorを使う方法を記述します。簡単ですが、Windowsの手順ものせますね。
用意するもの
- Mac (macOS Catalina)
- Google Chrome
- AWSアカウント(Cloud9設定済み)
MacでCloud9をデスクトップアプリ化する手順
ChromeでCloud9を開き、URLをコピーしておく
アプリケーションからAutomator.appを開く
シェルスクリプトを実行を選ぶ
シェルに/bin/bashを指定し、以下を入力して"Cloud9.app"という名前で保存する。open -n -a 'Google Chrome' --args '--app=(Cloud9のURL)'Cloud9.appの「情報を見る」
左上のアイコンを選択し、アイコンにしたい画像をそこへDrag & Dropする。
これで、
Cloud9.appを起動すると、Chromeのキーバインドが優先されなデスクトップアプリ風のCloud9コンソールが立ち上がります。Windows でCloud9をデスクトップアプリ化する手順
Windowsの場合簡単です。
- ChromeでCloud9を開く
- Chromeの設定メニュー(右上の3つの点)> その他のツール > デスクトップに追加
以上です。


- 投稿日:2020-06-21T15:57:10+09:00
ECSにdockerfileをpushしたときのメモ
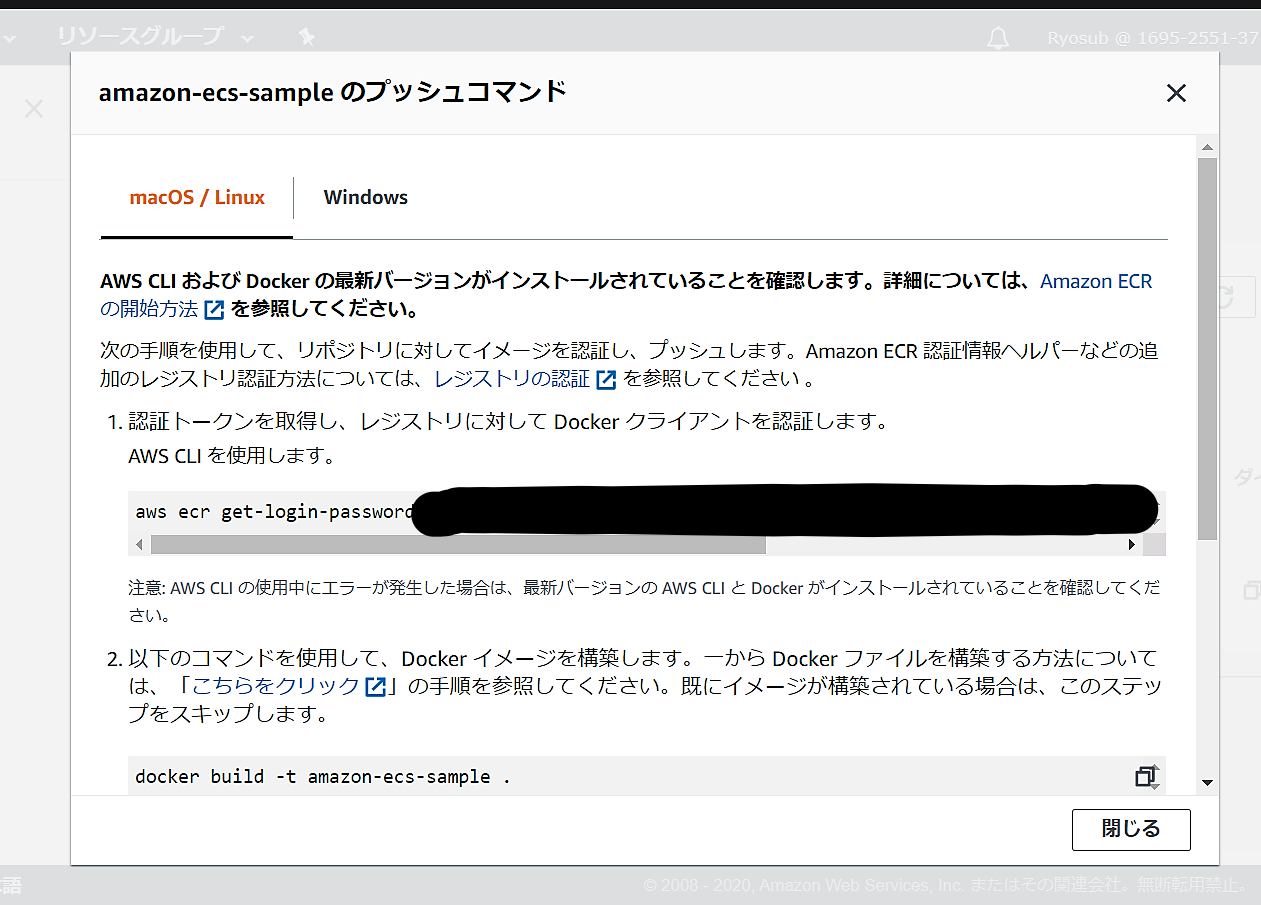
AWS ECSリポジトリの作成後「プッシュコマンドの表示」をクリックすると下記が表示される。
pushのための実行コマンドが表示され、macOS/Linux もしくは Windowsと環境に合わせて選ぶように表示される。
注意点
私はWindows環境だが、この表示される「Windows」とはホストOSを指すのではなく、使用するターミナルのことで、AWS Tools for Windows PowerShell を使用する場合という意味と思われる。
Windows環境下でもAWS Command Line Interface(AWS CTL)を使用している場合はmacOS/Linuxに表示されるコマンドを実行すること。
- 投稿日:2020-06-21T15:57:10+09:00
ECRにdockerfileをpushしたときのメモ
AWS ECRリポジトリの作成後「プッシュコマンドの表示」をクリックすると下記が表示される。
pushのための実行コマンドが表示され、macOS/Linux もしくは Windowsと環境に合わせて選ぶように表示される。
注意点
私はWindows環境だが、この表示される「Windows」とはホストOSを指すのではなく、使用するターミナルのことで、AWS Tools for Windows PowerShell を使用する場合という意味と思われる。
Windows環境下でもAWS Command Line Interface(AWS CTL)を使用している場合はmacOS/Linuxに表示されるコマンドを実行すること。
- 投稿日:2020-06-21T15:06:09+09:00
AWS SAA資格取得 ~Code3兄弟~
はじめに
構成管理サービスの
・Code Commit
・Code Build
・Code Deploy
についてメモCode Commit
AWSが提供するGitのホスティング、リモートリポジトリを提供するサービス
プライベートGitリポジトリを簡単にホストできる。
セキュアであり管理や設定の手間を省いてくれる。メリット
1:完全マネージメント型のため管理や設定が不要
2:コードを安全に保存可能
-不使用時、転送中に暗号化される。
3:バージョン管理プロジェクトをスケールする
-多数のファイルや、ブランチ、大容量のファイル、
長期間のバージョン履歴に対応してリポジトリを管理することが可能Code Build
CI(継続的インテグレーション)を行うためのサービス
アプリケーションのテストやコンパイル、デプロイなどを自動化してくれるメリット
1:アップデート、管理が不要
2:EC2 S3 CodePipeline Lambdaなど他AWSサービスと連携が容易
3:CodePipelineと連携すれば テスト⇨リリースまで自動化できるCode Deploy
デプロイ自動化サービス!
指定した複数台のサーバーに同じデプロイ作業を実行することができるメリット
1:新機能を素早くリリースできる
2:デプロイ時のダウンタイムを回避できる
3:ミスが起こりやすい手動操作の必要がなくなるCode Pipeline
ソースコード管理、ソースコードビルド&テスト、デプロイを行う3つのサービスを連携させるためのサービス
(ビルド、テスト、デプロイなど一連のプロセスをまとめたもの)Code Pipelineと連携可能なAWSサービス
S3:ソースコードの配置場所
Code Deploy:デプロイプロセスを処理することができる
Elastic Beanstalk:デプロイ対象にBeanstalkアプリケーションを選択することも可能以上メモ
- 投稿日:2020-06-21T14:52:26+09:00
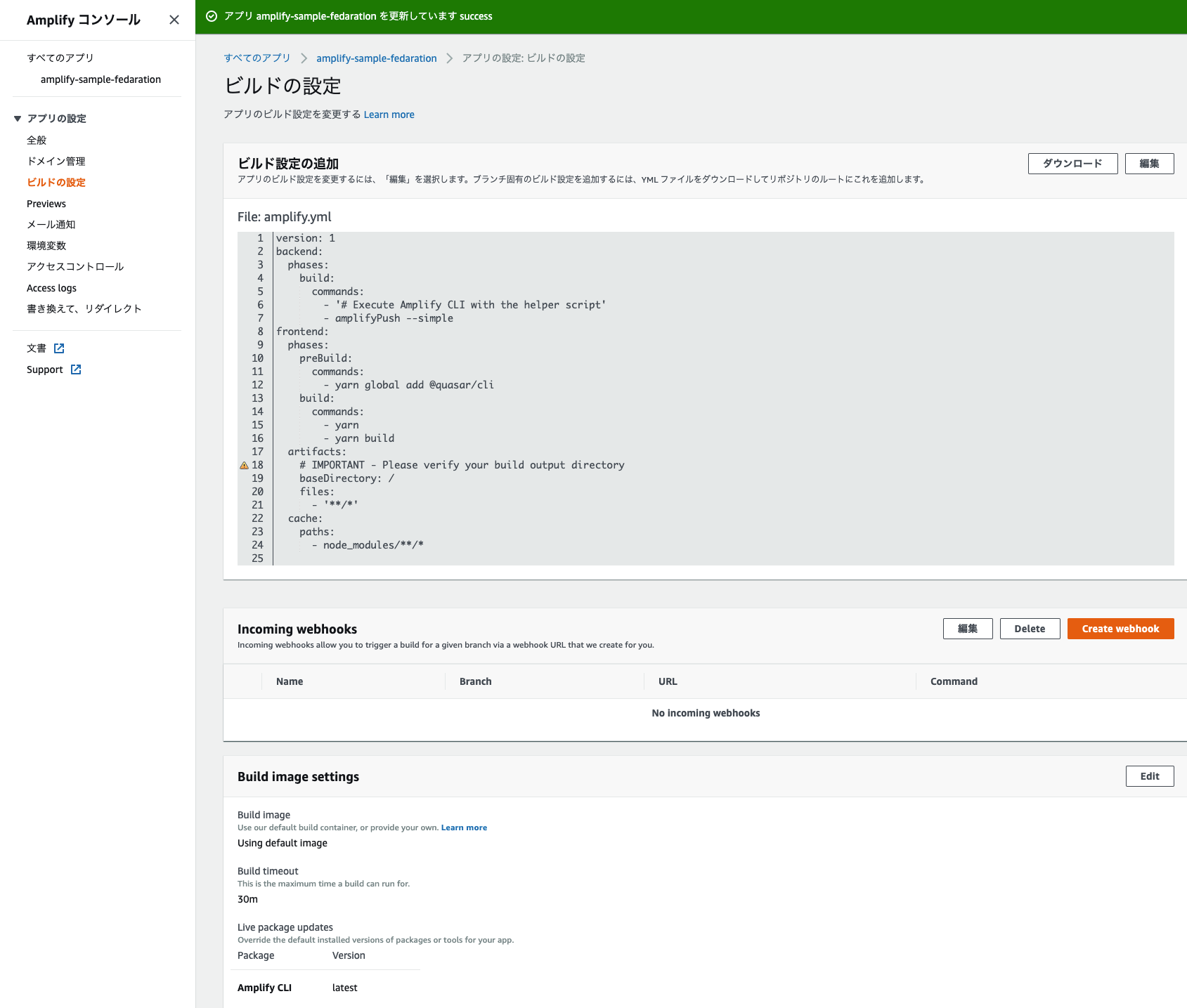
Amplify Consoleのnode、yarnをバージョンアップする(Quasarアプリをビルドする)
Amplifyは、高速でアプリを開発できる開発プラットフォームです。(AWS版のFireBase)
AmplifyでQuasar(マルチプラットフォームアプリを高速で作れるVue.jsベースのフレームワーク)で作成したアプリをデプロイ(Amplify Console利用)して少しハマったので解決方法を記載します。問題
デフォルト設定のままだと、
nodeとyarnのバージョンが古くエラーが発生します。# Starting phase: build 2020-06-20T16:01:17.980Z [INFO]: # Executing command: yarn 2020-06-20T16:01:18.130Z [INFO]: yarn install v1.16.0 2020-06-20T16:01:18.202Z [INFO]: [1/5] Validating package.json... 2020-06-20T16:01:18.204Z [WARNING]: error sample@0.0.1: The engine "node" is incompatible with this module. Expected version ">= 10.18.1". Got "10.16.0" 2020-06-20T16:01:18.205Z [WARNING]: error sample@0.0.1: The engine "yarn" is incompatible with this module. Expected version ">= 1.21.1". Got "1.16.0"対応案
解決方法を急いでいる方はこちら
- Build Imageを変更する
- ビルドコマンド
amplify.ymlで対応する- 環境変数で対応する
Build Imageを変更する
AWS Amplify- 対象のアプリ - ビルドの設定 - Build image settingsAmplify Consoleでカスタムイメージを利用する
https://docs.aws.amazon.com/amplify/latest/userguide/custom-build-image.html1-1. Amplify トップへ移動
1-2. 対象のアプリ選択
1-3. ビルドの設定を選択
1-4. ビルドイメージ変更
この方法の考察
この方法でも、
nodeやyarnのアップデートは可能ですが、aws cliとnodeが入ったイメージを探し、色々準備する必要があるため(※以下発生したエラー)、かなり面倒です。なので、2のamplify.ymlで対応する方法に切り替えました。2020-06-21T02:03:23.452Z [INFO]: aws codecommit credential-helper $@ get: 1: aws codecommit credential-helper $@ get: aws: not found 2020-06-21T02:03:23.453Z [INFO]: fatal: could not read Username for 'https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/amplify-sample-xxxxx': No such device or addressビルドコマンド
amplify.ymlで対応する
amplify.ymlで対応
preBuildフェーズで、nodeとyarnの安定版を再取得します。amplify.ymlpreBuild: commands: - nvm use stable #安定版を利用 - curl -o- -L https://yarnpkg.com/install.sh | bash #安定版を再インストール
amplify.yml全量(Quasar pwaビルド)amplify.ymlversion: 1 backend: phases: build: commands: - '# Execute Amplify CLI with the helper script' - amplifyPush --simple frontend: phases: preBuild: commands: - nvm use stable #安定版を利用 - curl -o- -L https://yarnpkg.com/install.sh | bash #安定版を再インストール - yarn global add @quasar/cli build: commands: - yarn - yarn build artifacts: # IMPORTANT - Please verify your build output directory baseDirectory: /dist/pwa #distフォルダ指定 files: - '**/*' cache: paths: - node_modules/**/*
nodeのstableを利用
Provisionフェーズを確認すると、nvmを利用していることがわかるため、nvmコマンドで安定版を利用するようにします。nvm use stable #安定版を利用
Provisionフェーズログ78 RUN curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.11/install.sh | bash
yarnのstableを利用
Provisionフェーズを確認すると、環境変数で指定したバージョンをインストールしているので、バージョン指定なしで最新の安定版をインストールします。curl -o- -L https://yarnpkg.com/install.sh | bash #安定版を再インストール
yarnのインストール(Linuxディストリビューション)
https://classic.yarnpkg.com/ja/docs/install/#alternatives-stable
ProvisionフェーズログRUN /bin/bash -c ". ~/.nvm/nvm.sh && \ nvm install $VERSION_NODE_8 && nvm use $VERSION_NODE_8 && \ nvm install $VERSION_NODE_10 && nvm use $VERSION_NODE_10 && \ npm install -g sm grunt-cli bower vuepress gatsby-cli && \ bash /usr/local/bin/yarn-install.sh --version $VERSION_YARN && \ ########## <---- ココ nvm install $VERSI_NODE_12 && nvm use $VERSION_NODE_12 && \ npm install -g sm grunt-cli bower vuepress gatsby-cli && \ bash /usr/local/bin/yarn-install.sh --version $VERSION_YARN && \ nvm alias default node && nvm cache clear"環境変数で対応する
Provisionフェーズのログからも環境変数を指定することでも課題が解決できそうでしたが、常に最新の安定版を利用してビルドしたかったため、この方法は見送りました。
ProvisionフェーズログRUN /bin/bash -c ". ~/.nvm/nvm.sh && \ nvm install $VERSION_NODE_8 && nvm use $VERSION_NODE_8 && \ nvm install $VERSION_NODE_10 && nvm use $VERSION_NODE_10 && \ npm install -g sm grunt-cli bower vuepress gatsby-cli && \ bash /usr/local/bin/yarn-install.sh --version $VERSION_YARN && \ ########## <---- ココ nvm install $VERSI_NODE_12 && nvm use $VERSION_NODE_12 && \ npm install -g sm grunt-cli bower vuepress gatsby-cli && \ bash /usr/local/bin/yarn-install.sh --version $VERSION_YARN && \ nvm alias default node && nvm cache clear"

- 投稿日:2020-06-21T12:35:15+09:00
AWS CDKでEC2 Auto Scalingをデプロイしてみる
はじめに
Auto Scalingのテスト環境の構築をAWS CDKの勉強も兼ねて行ってみました。
EC2にCPUの負荷を与えて、想定通りにEC2がスケールアウトすることを確認したかったため、作業内容を備忘録のつもりでまとめます。環境
- OS: macOS Cataline 10.15.5
- VSCode: 1.46.0
- Node.js: v14.4.0
- npm: 6.14.5
- TypeScript: 3.9.5
- CDK: 1.45.0
AWS CDKのインストール
公式の情報を参考にインストールします。
$ npm install -g aws-cdkインストールできているか、念のため確認します。
$ cdk --version 1.45.0 (build 0cfab15)プロジェクトの作成
CDKのプロジェクトを公式に沿って作成します。
$ mkdir test-asg $ cd test-asg $ cdk init app --language=typescriptコードの実装
必要なCDKのモジュールをインストールします。
$ npm install @aws-cdk/aws-autoscaling @aws-cdk/aws-ec2 @aws-cdk/aws-elasticloadbalancingv2なお、自分が検証した際にはこのエラーに遭遇したため、
package.jsonを編集して@aws-cdk/coreと@aws-cdk/assertのバージョンを合わせます。package.json{ : (省略) "devDependencies": { // 1.45.0 -> 1.46.0 "@aws-cdk/assert": "^1.46.0", "@types/jest": "^25.2.1", "@types/node": "10.17.5", "jest": "^25.5.0", "ts-jest": "^25.3.1", "aws-cdk": "1.45.0", "ts-node": "^8.1.0", "typescript": "~3.7.2" }, "dependencies": { "@aws-cdk/aws-autoscaling": "^1.46.0", "@aws-cdk/aws-ec2": "^1.46.0", "@aws-cdk/aws-elasticloadbalancingv2": "^1.46.0", // 1.45.0 -> 1.46.0 "@aws-cdk/core": "^1.46.0", "source-map-support": "^0.5.16" } }
node_modulesディレクトリを削除し、再度インストールします。これでエラーが解消され、ビルドも可能になりました。(CDKのバージョンを最初から上げていれば、このようなことはしなくても良かったかもしれません…)$ rm -rf node_modules $ npm install
lib/test-asg-stack.tsを編集します。以下の点に留意して作成しました。
- 予めAWSのコンソールで
TestAsgEnvという名前のキーペアを作成しておき、SSHでログインできるようにする。- EC2起動時に
sudo yum update -yが実行されるようにする。- CPU使用率が50%でスケールアウトするようにする。
- スタック作成完了時にALBのDNS名が表示されるようにする。
lib/test-asg-stack.tsimport * as cdk from '@aws-cdk/core'; import * as autoscaling from '@aws-cdk/aws-autoscaling'; import * as ec2 from '@aws-cdk/aws-ec2'; import * as elbv2 from '@aws-cdk/aws-elasticloadbalancingv2'; export class TestAsgStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); const cidr = '10.0.0.0/16'; const vpc = new ec2.Vpc( this, 'test-asg-vpc', { cidr, natGateways: 1, subnetConfiguration: [ { cidrMask: 18, name: 'public', subnetType: ec2.SubnetType.PUBLIC, }, { cidrMask: 18, name: 'private', subnetType: ec2.SubnetType.PRIVATE, }, ], } ); const securityGroup = new ec2.SecurityGroup( this, 'test-asg-security-group', { vpc, securityGroupName: 'test-asg-security-group', allowAllOutbound: true } ); securityGroup.addIngressRule(ec2.Peer.anyIpv4(), ec2.Port.tcp(22), 'SSH from anywhere'); securityGroup.addEgressRule(ec2.Peer.anyIpv4(), ec2.Port.allTraffic()); const userData = ec2.UserData.forLinux(); userData.addCommands('sudo yum update -y'); const alb = new elbv2.ApplicationLoadBalancer(this, 'TestAsgALB', { vpc, vpcSubnets: { subnetType: ec2.SubnetType.PUBLIC }, internetFacing: true, loadBalancerName: 'test-asg-alb' }); const asg = new autoscaling.AutoScalingGroup(this, 'TestAutoScalingGroup', { vpc, instanceType: ec2.InstanceType.of(ec2.InstanceClass.T2, ec2.InstanceSize.MICRO), machineImage: new ec2.AmazonLinuxImage(), desiredCapacity: 1, maxCapacity: 3, keyName: 'TestAsgEnv', associatePublicIpAddress: true, vpcSubnets: { subnetType: ec2.SubnetType.PUBLIC }, userData, }); asg.addSecurityGroup(securityGroup); asg.scaleOnCpuUtilization('CPU50Percent', { targetUtilizationPercent: 50 }); const listener = alb.addListener('Listener', { port: 80 }); listener.addTargets('Target', { targets: [asg], port: 80 }); new cdk.CfnOutput(this, 'Application LoadBalancer DNS', { value: alb.loadBalancerDnsName }); } }デプロイ
アプリケーションをビルドします。
$ npm run buildAWS CloudFormationのスタックをデプロイします。デプロイが完了するまで待ちます。
$ cdk deployAuto Scalingのテスト
CloudWatch Alarmに2つ登録されていました。もっと細かく設定すれば、条件をカスタマイズできると思います。
Chaos EngineeringのツールであるGremlinでEC2にCPUの負荷(CPU 51%の攻撃を300秒間実行)を与えてみたところ、無事にスケールアウトできました。
(結果のスクリーンショットを取るのを忘れていました… 既に環境は削除済みで、GremlinのFreeアカウントの制約でターゲット数が限られているようなので事象の再現は控えます…)おわりに
CloudFormationのyamlファイルよりも、コードで記述できるため作りやすかったですね。
ただ、思いの外「これだ!」といえる情報を見つけられなかったので、公式の仕様のドキュメントを眺めてパラメータを推測しながら、そしてIDEの補完を駆使してゴリ押ししながら作成しました。
EKSの環境もCDKで作れるので、こういうものにもチャレンジしていきたいです。参考
AWS CDKでAutoScaling環境を作成(Single Stack / Nested Stack)
Deploy your Auto-Scaling Stack with AWS-CDK

- 投稿日:2020-06-21T11:29:14+09:00
「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート - ⑧S3バケットのサーバサイド暗号化
はじめに
AWSにはアカウントやリソースへの脅威検知に対応した、AWS IAM Access Analyzer, AWS Security Hub, Amazon Detective, Amazon Inspector, Amazon GuardDuty, AWS CloudTrail, AWS Config などのサービスが用意されています。
また、AWS Security Hub では、CIS AWS Foundations Standard , Payment Card Industry Data Security Standard , AWS Foundational Security Best Practices Standard などのセキュリティ標準が公開されており、このガイドラインは、AWSアカウントをセキュアに保つために必要なAWSのセキュリティ設定を集めたベストプラクティス集として活用できます。
本記事では、アカウントやリソースへの脅威検知が可能なAWSサービスを有効化するとともに、上記のセキュリティ標準に限りなく準拠することで、セキュアで堅牢なAWSアカウントを実現します。また、これらをお手軽に実現できるCloudFormationテンプレートを公開しています。
このCloudFormationテンプレートの実行はこちらから。

S3バケットのサーバサイド暗号化
Amazon S3には、データ保管時にオブジェクトレベルで暗号化を行う サーバサイド暗号化の機能が提供 されています。また、Payment Card Industry Data Security Standard,AWS Foundational Security Best Practices Standardの各セキュリティ標準では、各S3バケットで この サーバサイド暗号化を有効化 することを求めています。
セキュリティ標準 No. 内容 Payment Card Industry Data Security Standard PCI.S3.4 S3 バケットでは、サーバー側の暗号化を有効にする必要があります AWS Foundational Security Best Practices Standard S3.4 S3 バケットでは、サーバー側の暗号化を有効にする必要があります この規定に準拠するために、このCloudFormationテンプレートでは、以下の設定を行います。
- S3バケット が上記のポリシーに準拠しているか チェック を行う
- 非準拠であった場合には、
AWS ConfigがSSM Automationを自動起動するSSM Automationを用いて S3 バケットのサーバーサイド暗号化を有効 にするそれぞれの設定について、順を追って説明します。
1. AWS Configの有効化
AWS Configを有効化する手順については、過去の記事 をご覧ください。2. AWS Configを用いたチェック
S3 バケットの設定でサーバーサイド暗号化が有効になっているかどうかの確認には、あらかじめ
AWS Configに用意されているS3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLEDマネージドルールを使用します。なお、この
Config Ruleを設定する前にConfigurationRecorderを生成しておく必要があります。そこで、DependsOn属性にConfigurationRecorderリソースを設定しています。Resources: ConfigS3BucketServerSideEncryptionEnabled: DependsOn: - ConfigConfigurationRecorder Type: 'AWS::Config::ConfigRule' Properties: ConfigRuleName: s3-bucket-server-side-encryption-enabled Description: Amazon S3 バケットで Amazon S3 のデフォルトの暗号化が有効になっていること、または S3 バケットポリシーでサーバー側の暗号化なしの put-object リクエストを明示的に拒否することを確認します。 Source: Owner: AWS SourceIdentifier: S3_BUCKET_SERVER_SIDE_ENCRYPTION_ENABLED3. SSM Automation を用いた自動修復
Systems Manager Automationは、AWS Configで 直接指定できる、現時点で唯一の自動修復手段 となっています。そこで、S3バケットのサーバサイド暗号化を有効にするSystems Manager Automationドキュメント を作成し、AWS Configとの紐付けを行います。Systems Manager には、あらかじめ 定義済みの Automation ドキュメント が用意されており、
AWS-EnableS3BucketEncryptionという名称の 定義済みドキュメント を用いることで、 S3バケットのサーバサイド暗号化を有効にする ことができます。また、この Automation ドキュメント の実行権限を指定する必要があるため、IAM Roleもあわせて作成しています。
Resources: IAMRoleForSSM: Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: ssm.amazonaws.com Action: 'sts:AssumeRole' Description: A role required for SSM to access IAM. Policies: - PolicyName: !Sub 'DefaultSecuritySettings-AWSSystemManagerIAMRole-${AWS::Region}' PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - 's3:PutBucketEncryption' - 's3:PutEncryptionConfiguration' Resource: - '*' RoleName: !Sub 'DefaultSecuritySettings-SSM-${AWS::Region}' ConfigS3BucketServerSideEncryptionEnabledRemediationConfiguration: Condition: CreateRemediationResources Type: 'AWS::Config::RemediationConfiguration' Properties: Automatic: true ConfigRuleName: !Ref ConfigS3BucketServerSideEncryptionEnabled MaximumAutomaticAttempts: 1 Parameters: AutomationAssumeRole: StaticValue: Values: - !GetAtt IAMRoleForSSM.Arn BucketName: ResourceValue: Value: RESOURCE_ID RetryAttemptSeconds: 30 TargetId: AWS-EnableS3BucketEncryption TargetType: SSM_DOCUMENT以上で、AWSアカウントが所有する全てのS3バケットに対して 、サーバサイド暗号化を有効にすることができました。
関連リンク
- サービスの有効化 - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- パスワードポリシーの自動修復 - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- モニタリングと通知の設定 - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- アクセスキーのローテーションと削除 - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- 全てのVPCでフローログを有効化する - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- SSHとRDPのアクセスを制限する - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- デフォルトセキュリティグループを無効化する - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- S3バケットのサーバサイド暗号化 - セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート

- 投稿日:2020-06-21T10:23:06+09:00
IAM単語まとめ
IAM単語まとめ
備忘録として概要をまとめておきます。
- 責任共有モデル:セキュリティの責任をユーザーとAWSで分担している
- ユーザーの責任:物理インフラ以外
- AWSの責任:物理インフラ
- IAM:アクセス権限管理の仕組み
- ポリシー:アクセス権限
- 管理ポリシー:複数のプリンシパルエンティティに紐づけられる
- AWS管理ポリシー:AWSが作成して管理
- カスタム管理ポリシー:AWSアカウントで作成して管理
- インラインポリシー:1つのプリンシパルエンティティに紐づけられる。自分で作成して管理
- ポリシー
- ユーザーベース:ユーザーにリソースへのアクセス権限を設定
- ユーザー、グループ
- リソースベース:リソースに別のリソースへのアクセス権限を設定
- ロール
- プリンシパルエンティティ(ポリシー設定単位)
- ユーザー
- グループ
- ロール
- 投稿日:2020-06-21T10:18:30+09:00
[AWS] CloudFront + Lambda@Edge で IP 制限をかける
はじめに
こちらの記事 の 「まとめにかえて」で触れたとおり、 CloudFront へのアクセスに対して IP アドレスで制限をかける方法について触れる。
実現にあたり、本記事では CloudFront と Lambda@Edge を利用する。注意
本記事は 2020年6月21日 時点の情報です。
ご覧になられた時点で UI が変更されている可能性がありますので、その点ご注意ください。前提
- こちらの記事 の構築が完了していること
環境
サービス 概要 macOS 10.15.x Elemental MediaLive あらゆるデバイスへのブロードキャストおよびストリーミング向けにライブ動画をエンコードする Elemental MediaStore ライブストリーミングによるメディアワークフロー向けにビデオアセットを保存、配信する CloudFront 高速で安全性が高くプログラム可能なコンテンツ配信ネットワーク (CDN、content delivery network) Lambda サーバーについて検討することなくコードを実行できる Lambda@Edge ユーザーに近いロケーションでコードを実行 OBS AWS Lambda の使用開始ビデオ録画と生放送用の無料でオープンソースのソフトウェア。 想定する構成
MediaLive + MediaStore/MediaPackage のプロダクトを作る場合、CloudFront でキャッシュすると想定すると、以下の図になる。
フィルタリング
ホワイトリスト方式を採用する。指定した IP アドレスのみ許可し、リストにない IP アドレスからのアクセスはエラーとする。
制限事項
ホワイトリストの持ち方
本記事ではホワイトリストは Lambda 関数で保持する方法を示す。
ホワイトリストを DB や S3 等で保持する方法について、本記事では扱わない。(実現可能かどうかから調査が必要)トリガーとするイベント
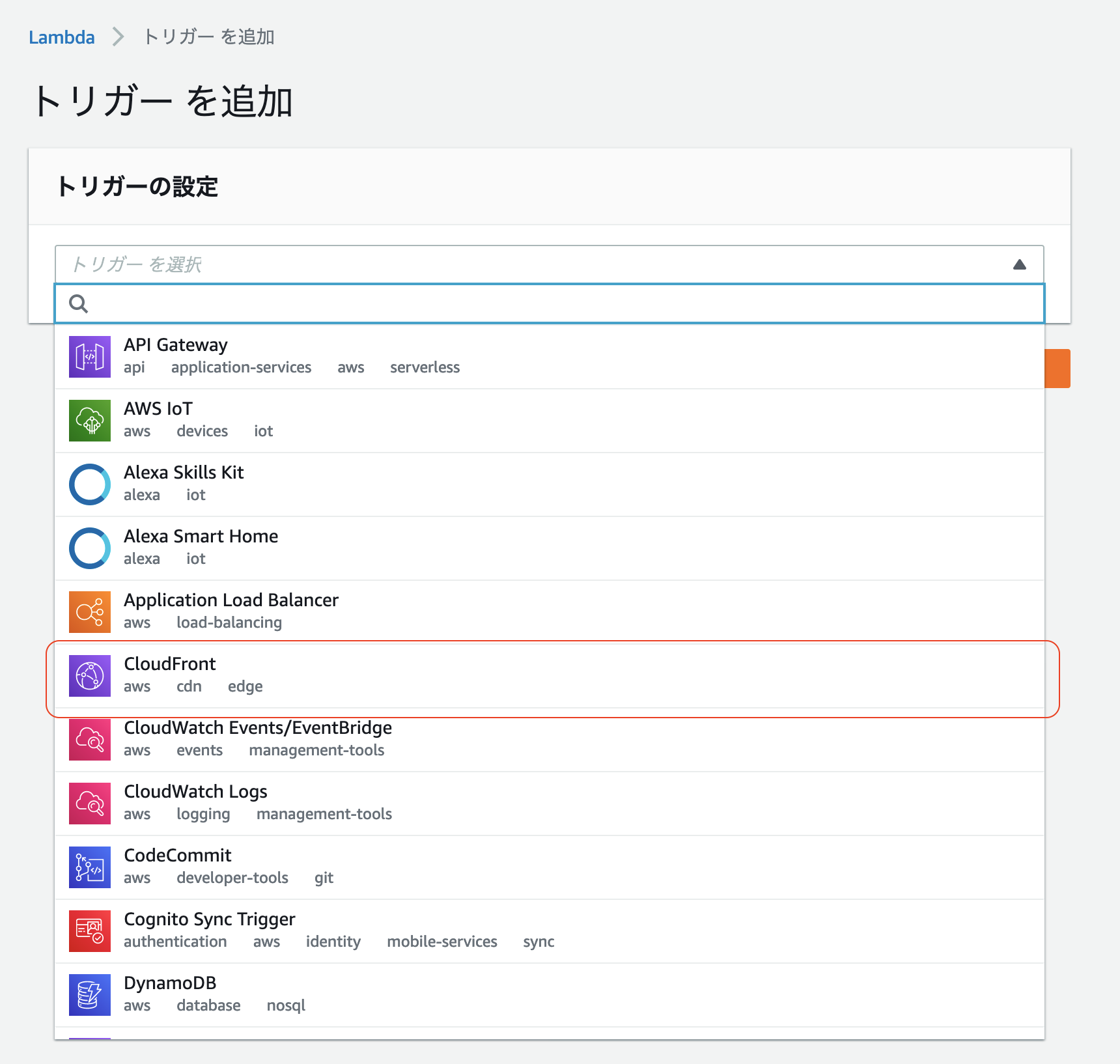
- Lambda 関数をトリガーできる CloudFront イベント には下記の4つがあり、本記事では ビューワーリクエスト をトリガーとする。
- ビューワーリクエスト
- オリジンリクエスト
- オリジンレスポンス
- ビューワーレスポンス
ビューワーリクエスト
開発ガイド から抜粋。
CloudFront がビューワーからのリクエストを受け取ると、リクエストされたオブジェクトが CloudFront キャッシュ内にあるかどうかを確認する前に、関数が実行されます。
注意事項
こちらも 開発ガイド から抜粋。
CloudFront イベントによって Lambda 関数の実行がトリガーされると、その関数が終了するまで CloudFront は続行できません。たとえば、CloudFront ビューワーリクエストイベントによって Lambda 関数がトリガーされた場合、Lambda 関数の実行が終了するまでは、CloudFront はビューワーにレスポンスを返したり、オリジンにリクエストを転送したりしません。つまり、Lambda 関数をトリガーするリクエストごとにリクエストのレイテンシーが長くなるため、関数をできるだけ速く実行する必要があります。
Lambda@Edge 関数での IP 制限
Lambda 関数を作成する
注意事項
CloudFront のリージョンは現状だとグローバルしか選択できない。それに関係してか、Lambda@Edge 用の関数は バージニア北部 のリージョンで作成する必要がある。(そうしないとトリガーに CloudFront を指定できない )
手順
リージョンに バージニア北部 を選択する
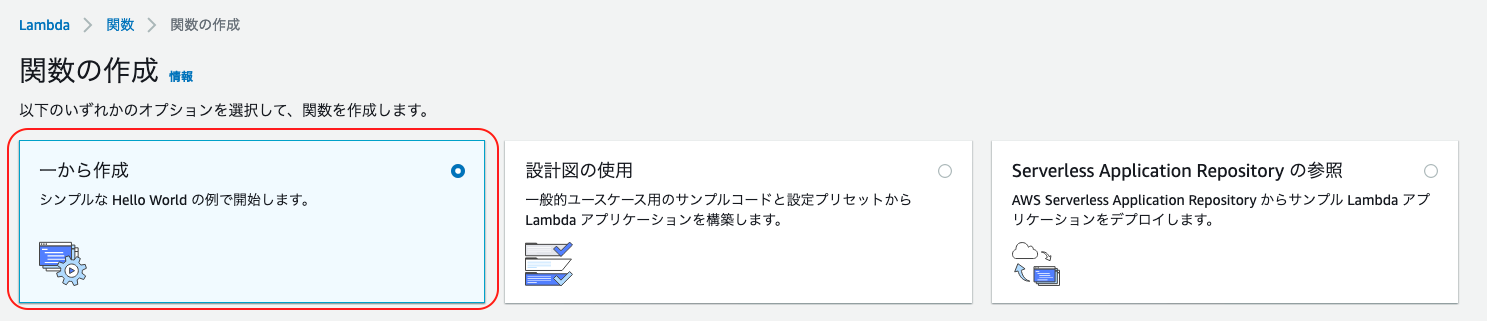
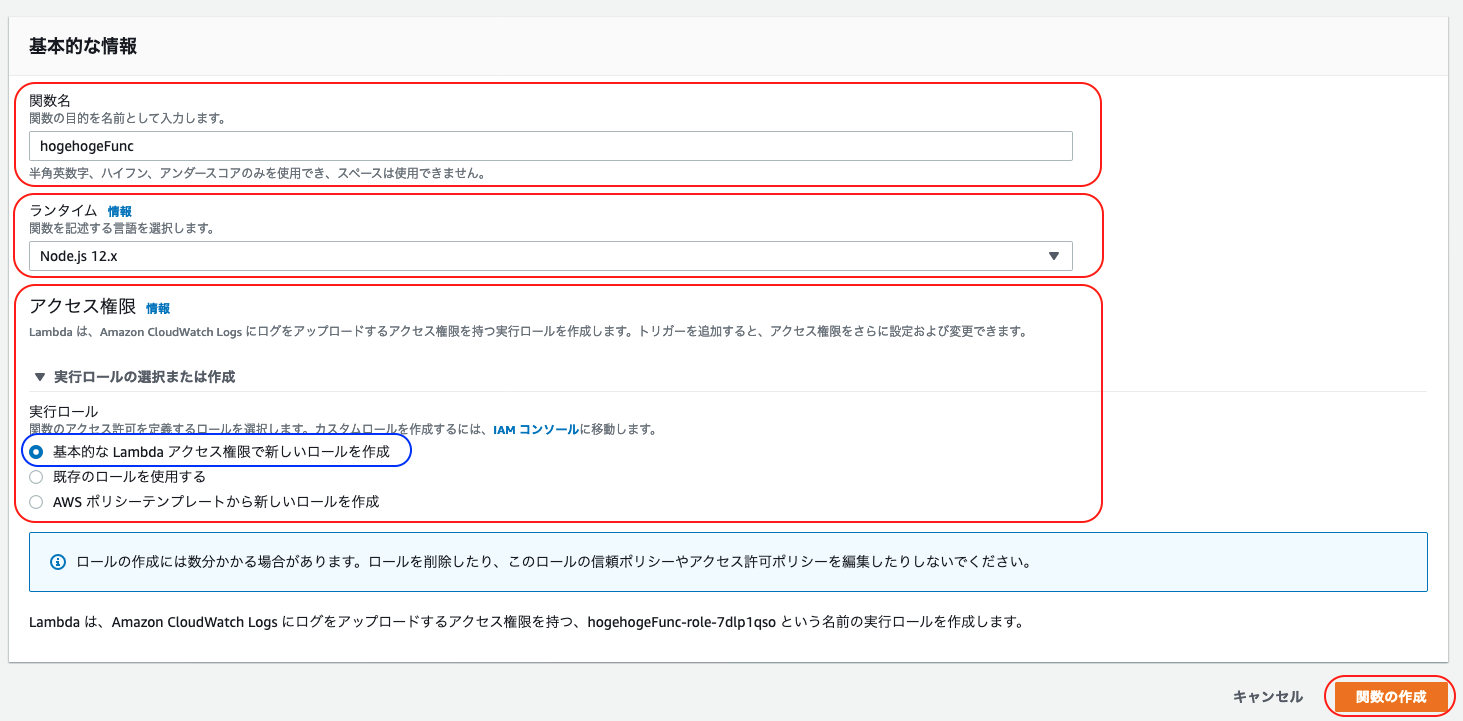
Lambda > 関数 より「関数の作成」をクリック
「一から作成」で「基本的な情報」を埋めていく
- 関数名: 実行する処理に応じた関数名を入力
- ランタイム: デフォルトのまま(今回は
Node.js 12.x)- アクセス権限
- 「実行ロールの選択または作成」で「基本的な Lambda アクセス権限で新しいロールを作成」を選択
- 「関数の作成」をクリック
Lambda 関数の設定画面が表示される(これで Lambda 関数そのものは作成できた)
一旦完了
IAM ロールの設定
CloudFront へのアクセスに対して Lambda@Edge を適用する場合、Lambda@Edge 用の IAM ロール が必要なので、作成したロールに設定を追加する。
アクセス権限の設定
IAM > ロール から「Lambda 関数を作成する」で作成したロールを選択
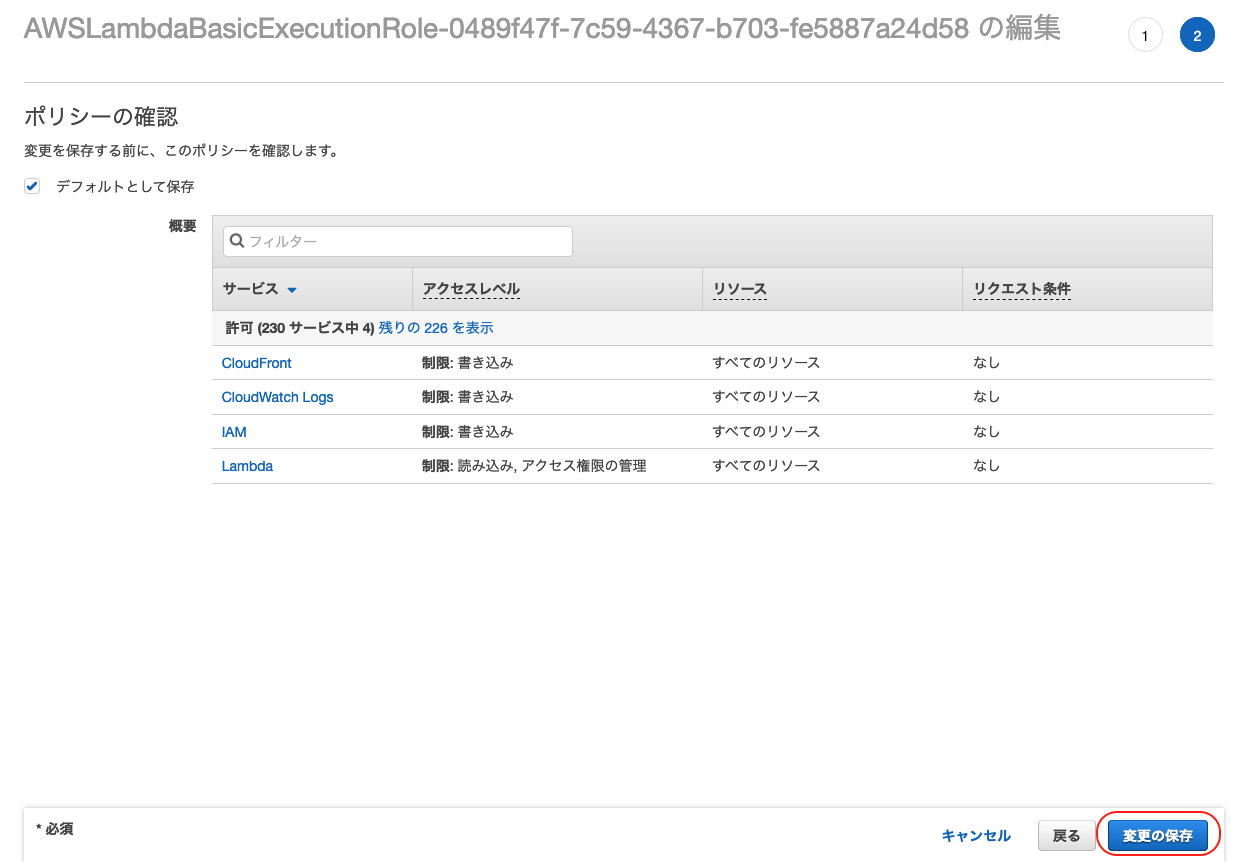
表示された概要の「アクセス権限」タブからポリシーを選択し「ポリシーの編集」をクリック
編集画面が表示されるので「JSON」タブをクリック
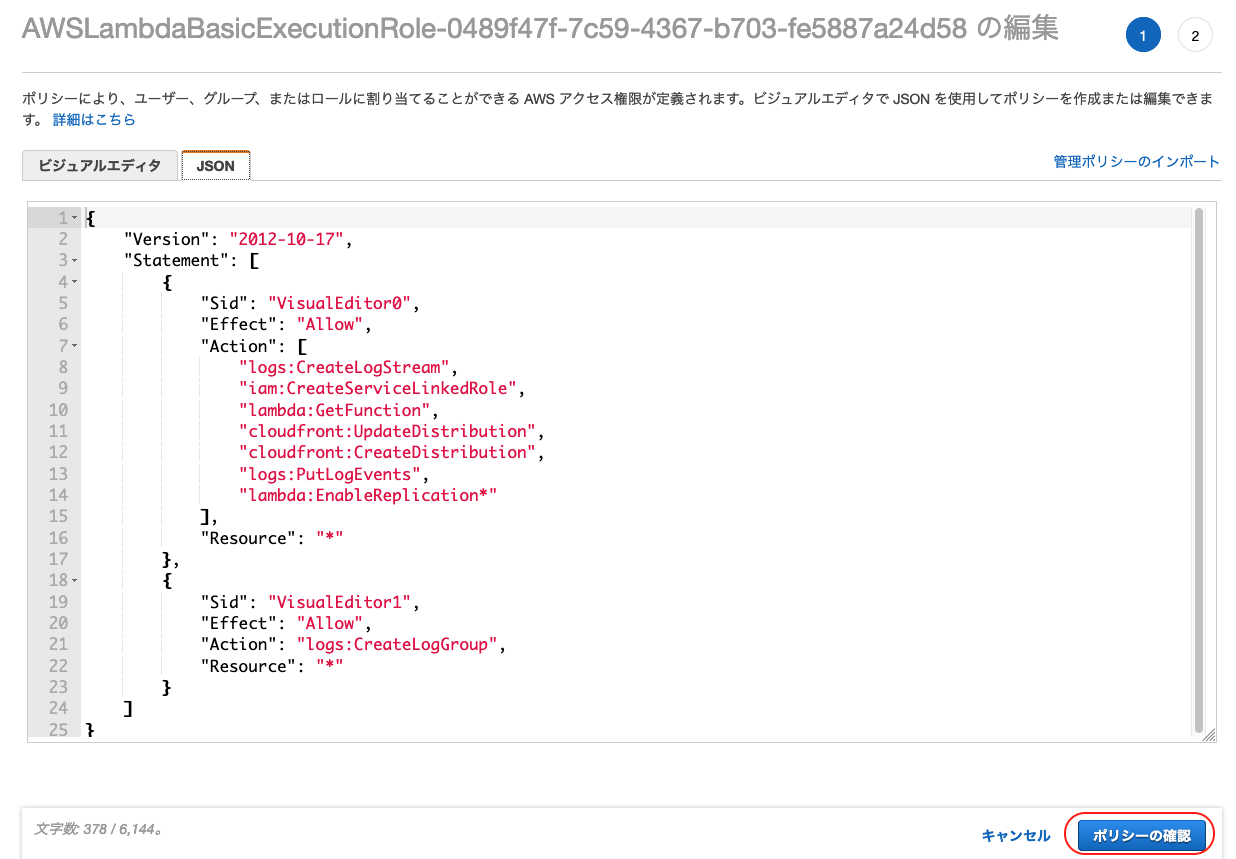
JSONを編集
次の内容を設定する。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "logs:CreateLogStream", "iam:CreateServiceLinkedRole", "lambda:GetFunction", "cloudfront:UpdateDistribution", "cloudfront:CreateDistribution", "logs:PutLogEvents", "lambda:EnableReplication*" ], "Resource": "*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "logs:CreateLogGroup", "Resource": "*" } ] }
「ポリシーの確認」をクリック
確認画面で設定した項目が追加されていることを確認し、「変更の保存」をクリック
信頼関係の設定
再度、IAM > ロール から「Lambda 関数を作成する」で作成したロールを選択
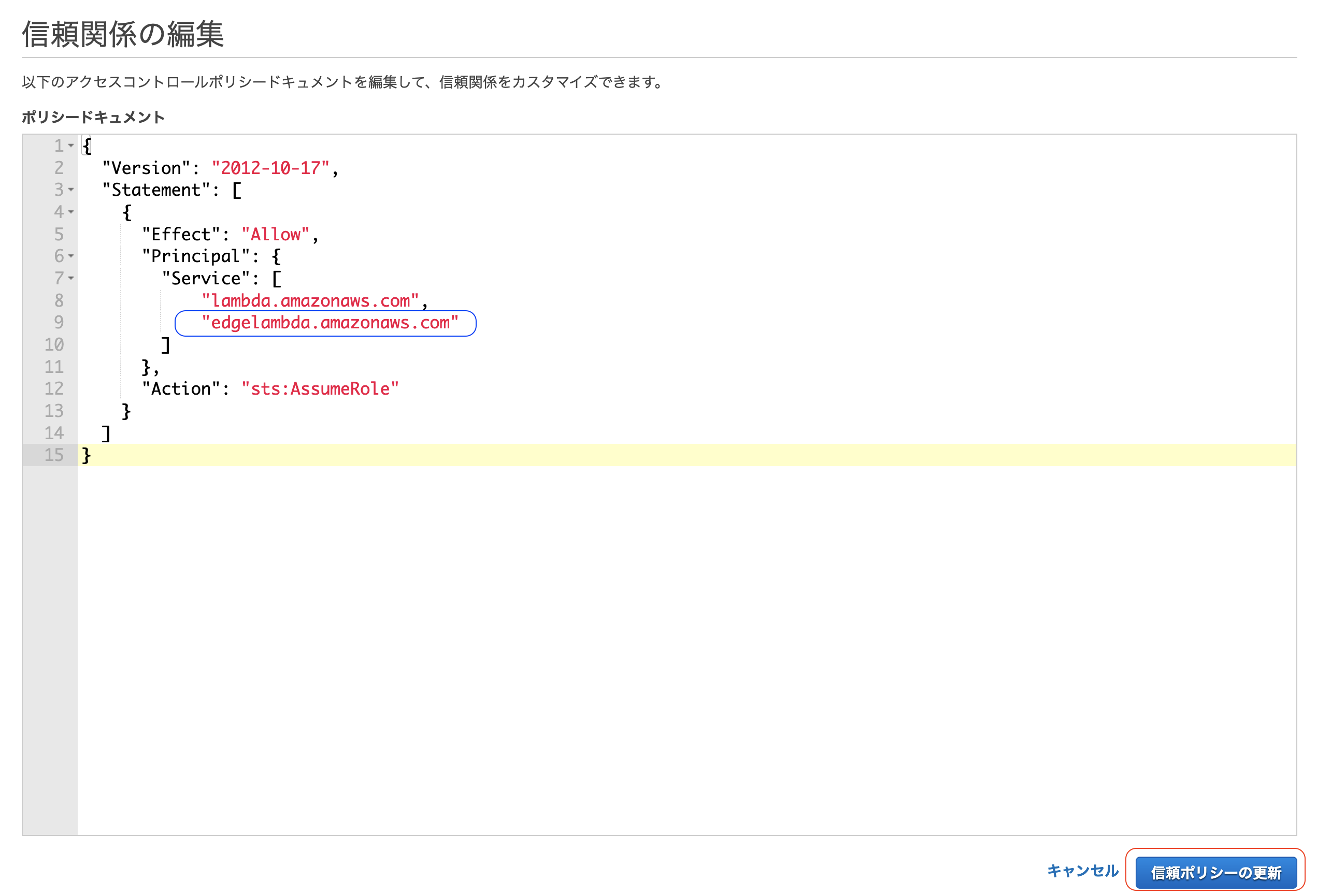
「信頼関係」のタブから「信頼関係の編集」をクリック
JSONの編集画面になるので、
Serviceプロパティに以下を追記edgelambda.amazonaws.com
Serviceプロパティの部分が配列ではない場合は配列に変更する。変更後の JSON が下記。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "lambda.amazonaws.com", "edgelambda.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }▼JSON編集後の画面
- 設定した項目が追加されていることを確認し、「信頼ポリシーの更新」をクリック

Lambda に戻って
IAM ロールの設定が完了したので、もう一度 Lambda に戻って Lambda 関数の実装を行う。
Lambda 関数の処理を実装する
- 「Lambda 関数を作成する」で作成した関数を選択〜表示し「関数コード」を編集する IPアドレスのホワイトリスト、並びにフィルタリング処理の例を以下に示す。
'use strict' // IPアドレスのホワイトリスト const IP_WHITE_LIST = [ '133.106.94.246', //IPアドレスは各自設定すること! ]; const errorResponse = (httpVersion) => { const body = '<!DOCTYPE html>\n' + '<html>\n' + '<head><title>Lambda@Edge からのエラー</title></head>\n' + '<body>\n' + '許可されていない IP アドレスです\n' + '</body>\n' + '</html>' return { status: '403', statusDescription: 'Forbidden', httpVersion: httpVersion, body: body, headers: { 'cache-control': [{ key: 'Cache-Control', value: 'max-age=100' }], 'content-type': [{ key: 'Content-Type', value: 'text/html; charset=utf-8' }], }, }; }; exports.handler = (event, context, callback) => { const request = event.Records[0].cf.request; const httpVersion = request.httpVersion; const clientIp = request.clientIp; // リクエスト情報からアクセス元のIPアドレスを取得できる const isPermittedIp = IP_WHITE_LIST.includes(clientIp); if (isPermittedIp) { // 許可されているIPアドレスなので何もしない( 通常処理へ流れる ) callback(null, request); } else { // 許可されていない IP アドレスなのでエラーを返す callback(null, errorResponse(httpVersion)); } }
- 「保存」をクリックして編集内容を保存する
Lambda関数を Lambda@Edge として CloudFront に紐付ける
Lambda 関数の実装が終わったら、次は下記の手順で Lambda@Edge として CloudFront と紐付けを行う。
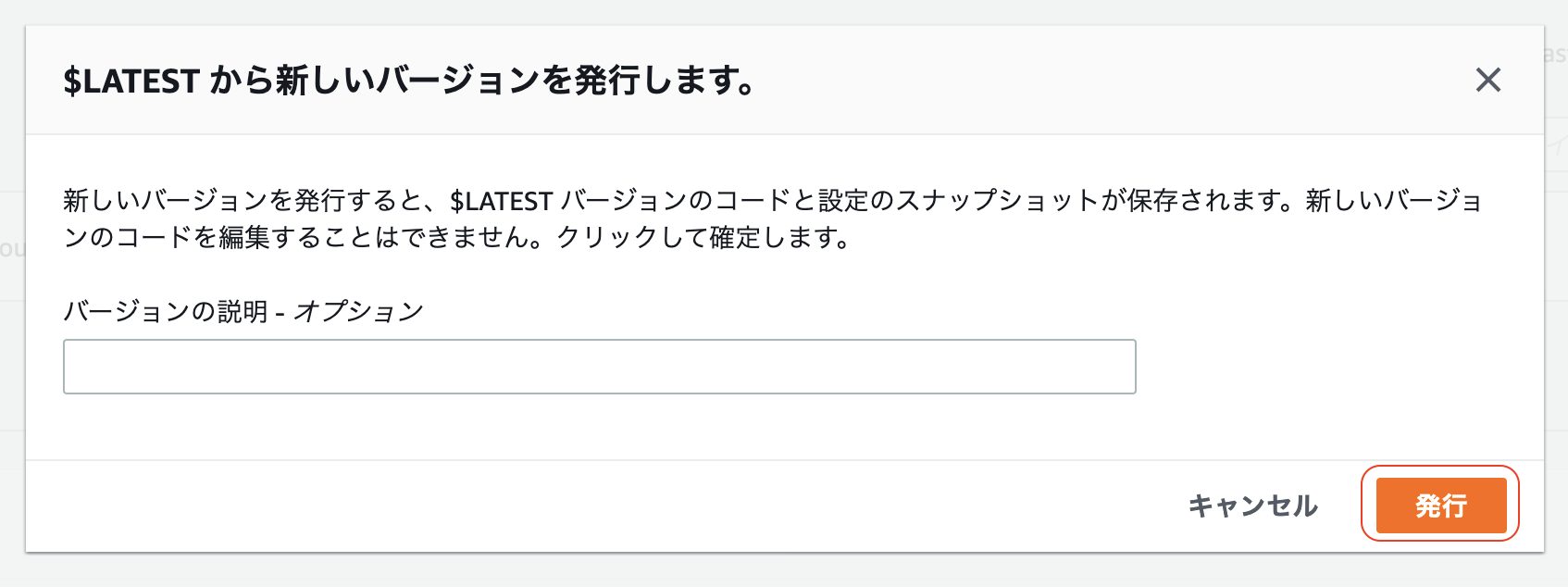
「アクション」から「新しいバージョンを発行」を選択
モーダル上で「発行」をクリック(バージョンの説明はなくてもOK)
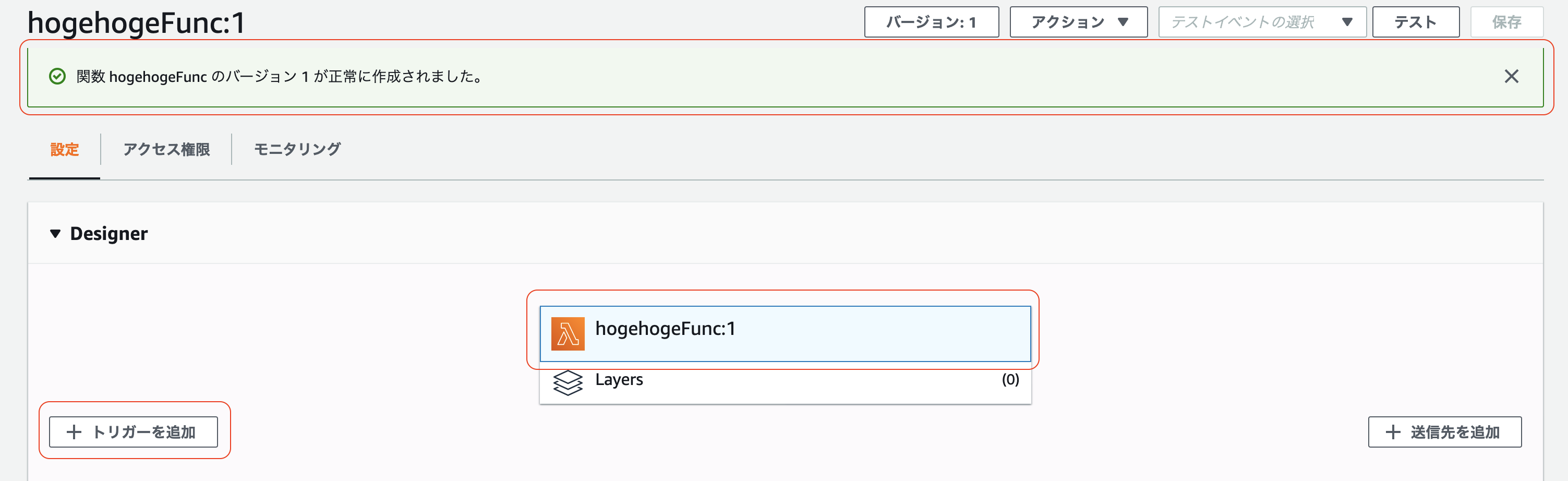
「トリガーを追加」をクリック
編集画面で「CloudFront」を選択
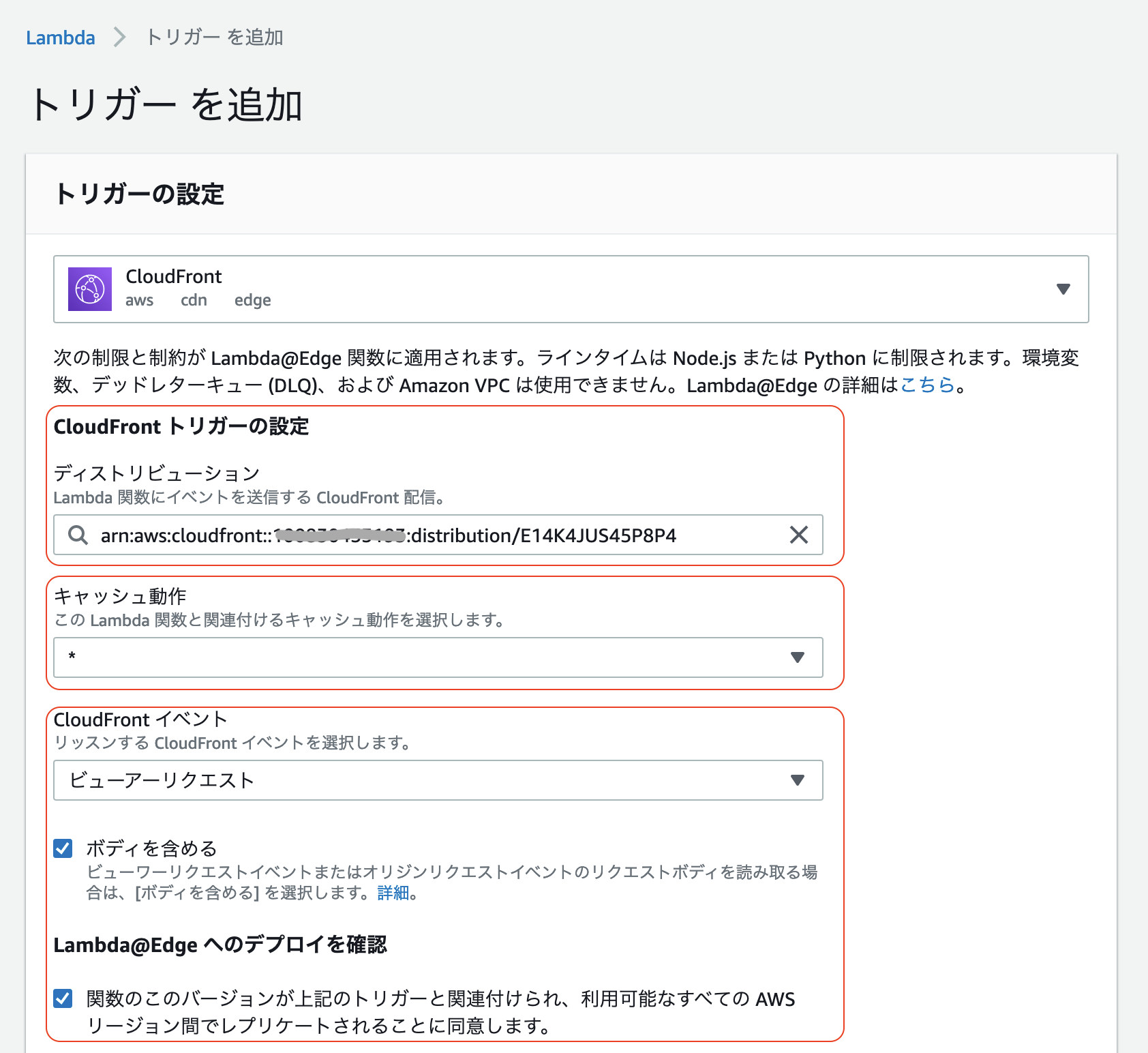
このとき Lmabda関数を バージニア北部 のリージョンで作成していないと CloudFront が選択肢に出てこないので注意。
「CloudFront トリガーの設定」を編集
- 「ディストリビューション」に紐付ける CloudFront のディストリビューションを設定
- 「キャッシュ動作」はいじらない
- 「CloudFront イベント」には「ビューアーリクエスト」を選択
- 「ボディを含める」にチェック
- 「関数のこのバージョンが〜」にチェック
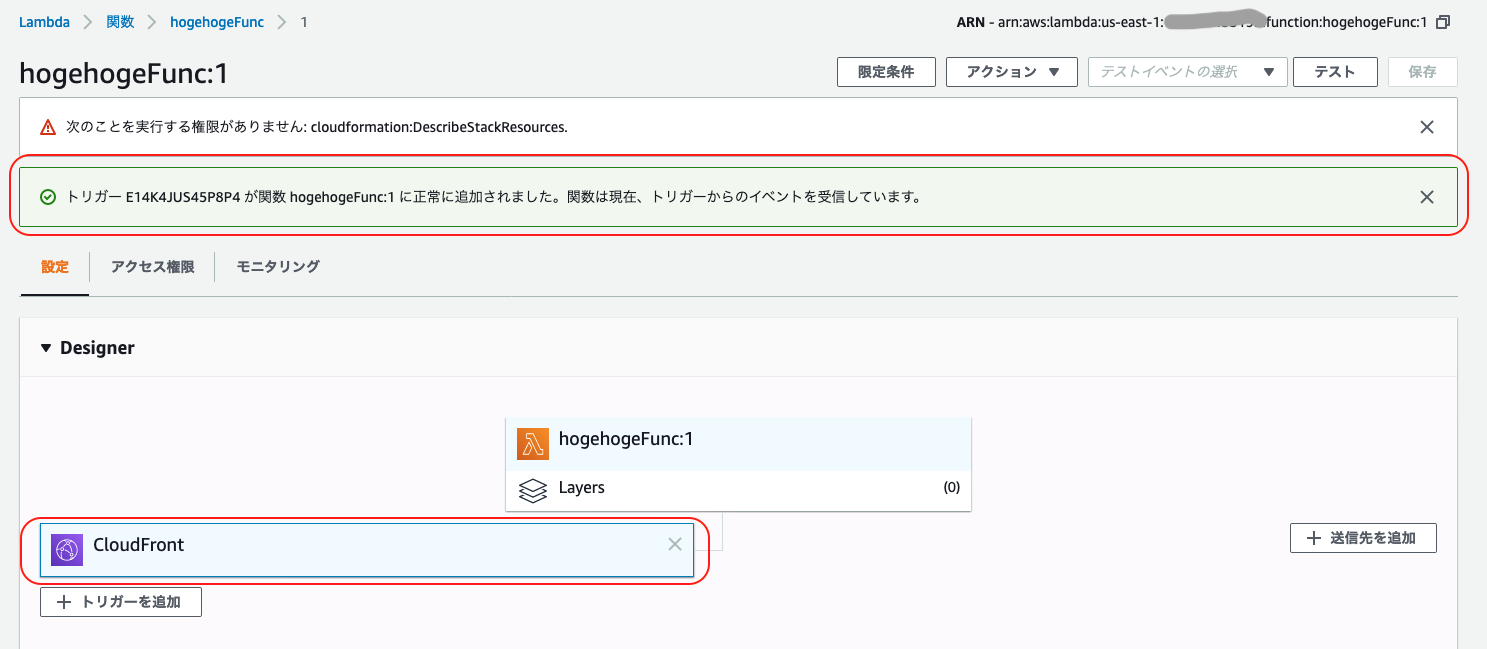
「追加」をクリック
トリガーに CloudFront が追加されていることを確認
動作確認
ホワイトリスに登録されていないIPアドレスからのアクセス
Lambda 関数で設定したエラーメッセージが表示されていることが確認できる。
まとめ
IPアドレスのフィルタリングはホワイトリスト方式とする
Lambda 関数での視聴者の IP アドレス取得方法
exports.handler = (event, context, callback) => { // 省略 const clientIp = request.clientIp; // リクエスト情報からアクセス元のIPアドレスを取得できる // 省略 }
Lambda@Edge 用の IAM ロールが必要
Lambda@Edge 用の関数は バージニア北部 のリージョンで作成する必要がある( そうしないとトリガーに CloudFront を指定できない )
CloudFront のイベントには ビューワーリクエスト を指定する
参考
Lambda@Edge関数
関数そのものの編集方法は以下を参考にした。
- Lambda コンソールで Lambda@Edge 関数を作成する
- Lambda@Edge 用の Lambda 関数の編集
- Amazon CloudFront と AWS Lambda@Edge を用いたプライベートコンテンツの提供
IP アドレスによる制限
下記を参考に IP アドレスによるホワイトリスト形式のフィルタリングを実現できた。








- 投稿日:2020-06-21T10:05:34+09:00
AWS CLI用のIAMユーザ/ロール設定
はじめに
ユーザとロールの分離とMFA設定をやった記録です。プライベートだとゆるみがちだったIAM周りを引き締めます。
やったこと
ロール作成
新規でロールを作成し、AWSのサービスを操作するのに必要十分な権限を付与します。※今回は安直にAdmin
「SwitchRoleAdmin」というロールを作成した上で、下記のポリシーを付与します。
SwitchRoleAdminロールのポリシー(Admin){ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "*", "Resource": "*" } ] }このロールを想定しないユーザから使用されると困るため、特定の条件下でのみ使用できるように設定します。ここではMFA認証済みの特定ユーザのみ許可します。
IAMロール詳細画面の「信頼関係」タブから下記の設定を追加します。
信頼関係の編集(ポリシードキュメント){ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:user/nanakenashi-cli" }, "Action": "sts:AssumeRole", "Condition": { "Bool": { "aws:MultiFactorAuthPresent": "true" } } } ] }ユーザ作成
主な権限はユーザからは分離してロールに持たせるため、そのロール(SwitchRoleAdmin)を委任するための権限だけが必要です。
「nanakenashi-cli」ユーザを作成し、下記のポリシーを付与しました。
nanakenashi-cliユーザのポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::123456789012:role/SwitchRoleAdmin" } ] }加えて、コンソールで使用するときと同様にMFAデバイスを割り当てておきます。
CLI設定
ユーザ設定
※メインで使用する設定なのでprofileは使用していません
CLIの設定ファイル作成$ aws configure AWS Access Key ID [****************HOGE]: AWS Secret Access Key [****************hoge]: Default region name [ap-northeast-1]: Default output format [json]:ロール設定
ロールを使用するためのプロファイル設定を
~/.aws/configに追記します。~/.aws/config[profile default-admin] region = ap-northeast-1 output = json role_arn = arn:aws:iam::123456789012:role/SwitchRoleAdmin source_profile = default mfa_serial = arn:aws:iam::123456789012:mfa/nanakenashi-cli試用
プロファイルの指定を忘れない。
プロファイルの指定$ export AWS_DEFAULT_PROFILE=default-adminコマンドを実行してみるとMFAの入力が求められ、認証が済めば実行できます。
検証(使用しているcredentialの確認)$ aws sts get-caller-identity Enter MFA code for arn:aws:iam::123456789012:mfa/nanakenashi-cli: { "UserId": "XXXXXXXXXX", "Account": "123456789012", "Arn": "arn:aws:sts::123456789012:assumed-role/SwitchRoleAdmin/botocore-session-1234567890" }MFA認証済みをAssumeRoleの条件にしているため、mfa_serialの記述を消すと実行時にエラーになります。
エラーになった例$ aws sts get-caller-identity An error occurred (AccessDenied) when calling the AssumeRole operation: User: arn:aws:iam::123456789012:user/nanakenashi-cli is not authorized to perform: sts:AssumeRole on resource: arn:aws:iam::123456789012:role/SwitchRoleAdminむすび
セキュリティ意識は大事。
- 投稿日:2020-06-21T09:37:40+09:00
AWSアカウントのベストプラクティス(エンタープライズ向け)
はじめに
現職でHD会社のIT部門でAWS移行を担当しています。
AWSのアカウント管理の考え方について勉強したので一度整理してみます。AWSアカウントの種類
まず、AWSで扱うアカウントには以下の種類があります。
・AWSアカウント(root)
・IAMアカウント
・組織アカウントAWSアカウント
AWSを利用する際に登録するアカウントで、全ての権限を持っています。
非常に強力なアカウントのため、通常は使用しないようにします。IAMアカウント(ユーザー)
各サービスやマネージメントコンソールのログインの際に使用するユーザー。
ポリシーをアタッチすることで操作できる範囲や権限を指定します。組織アカウント(Organizations)
組織内で複数のAWSアカウントを扱う場合に、共通のポリシーなど統制を効かせるために
Organizationsというサービスがあります。
このサービスで利用する、複数のアカウントを管理するアカウントになります。なぜIAMユーザーが必要なのか
AWSアカウント(root)では権限が強すぎるため、もし乗っ取りにでもあったらそのアカウント内では全ての操作ができてしまいます。
なので基本的にはrootアカウントは使わずに、IAMユーザーを利用します。
IAMユーザーには必要最小限の権限を必要最小限のユーザーに与えて運用することが基本です。アカウント管理の考え方
アカウント管理にはいろんな考え方がありますが、
1アカウントに全てのシステムを構築し、複数のVPCを管理するやり方。
システムごとにアカウントを分けて、本番、ステージングなどの環境はVPCで分けるやり方。
1システム、環境ごとにアカウントを分けるやり方。私の結論は1システム、環境ごとに1アカウントです。
理由は後述複数のAWSアカウントを管理するには
複数AWSアカウントを作ると、管理が煩雑になってきます。
監査ログやセキュリティポリシーもアカウントごとにバラバラになってしまうと、統制が効かなくなってしまいます。
そんな時に利用できるサービスがAWS Organizationsです。Organizations専用のアカウントを登録して、配下に組織内のAWSアカウントを紐づけることで
同一のポリシー(SCP)を適用したり、請求を一括管理することも可能です。シングルアカウントとマルチアカウントどちらがいい?
「アカウント管理の考え方」の部分でも書きましたが、結局は
その組織で何を重要視するかに尽きると思います。それぞれのメリットデメリットはクラメソさんの以下の記事が参考になります。
AWSアカウントとVPC、分ける? 分けない?: 分割パターンのメリット・デメリットその上で弊社では「1システム、環境ごとに1アカウント」の方向で進めることになっています。
これは、以下の点を考慮した結果となります。
・1アカウントでは各システム担当の領域外のリソースが見えてしまう。
→ポリシーで権限管理はしんどい。。。
・環境ごとに分けることで、誤操作の影響リスクを分断する。
・利用料金を明確にする。
→弊社がHD会社なので、複数事業者でどれだけ利用しているのかコスト管理が明確になる。
・OrganizationsやTransitGatewayなどマルチアカウント運用に最適なサービスが出てきている。以上のことから、「1システム、環境ごとに1アカウント」としましたが、おそらくエンタープライズの企業であれば同じような状況で議題に上がるかと思います。
・社内に複数システムがある
・各事業部ごとにアカウントを分けたい(コスト把握、権限分離)そのようなことを実現するにはベストプラクティスとしては「1システム、環境ごとに1アカウント」が正解なのではないかと思っています。
まだまだAWS学び始めて日が浅いので、「こういう考えもある」「そこは違う」などご意見ありましたら、コメントいただけるとありがたいです。
- 投稿日:2020-06-21T09:01:34+09:00
「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート - ⑦デフォルトセキュリティグループを無効化する
はじめに
AWSにはアカウントやリソースへの脅威検知に対応した、AWS IAM Access Analyzer, AWS Security Hub, Amazon Detective, Amazon Inspector, Amazon GuardDuty, AWS CloudTrail, AWS Config などのサービスが用意されています。
また、AWS Security Hub では、CIS AWS Foundations Standard , Payment Card Industry Data Security Standard , AWS Foundational Security Best Practices Standard などのセキュリティ標準が公開されており、このガイドラインは、AWSアカウントをセキュアに保つために必要なAWSのセキュリティ設定を集めたベストプラクティス集として活用できます。
本記事では、アカウントやリソースへの脅威検知が可能なAWSサービスを有効化するとともに、上記のセキュリティ標準に限りなく準拠することで、セキュアで堅牢なAWSアカウントを実現します。また、これらをお手軽に実現できるCloudFormationテンプレートを公開しています。
このCloudFormationテンプレートの実行はこちらから。
デフォルトセキュリティグループを制限する
インスタンスの 仮想ファイアウォール として機能する VPC の セキュリティグループ には、 デフォルトセキュリティグループ と呼ばれる 特殊なセキュリティグループ が存在します。このデフォルトセキュリティグループは、 AWSアカウント作成時から存在し、明示的にセキュリティグループを指定せずにインスタンスを作成した場合は、この デフォルトセキュリティグループが自動的にインスタンスに関連付け られます。
CIS AWS Foundations Standard,Payment Card Industry Data Security Standard,AWS Foundational Security Best Practices Standardの各セキュリティ標準では、 セキュリティグループに意図した設定を適用するために、デフォルトセキュリティグループの無効化 とデフォルトセキュリティグループ以外のセキュリティグループの利用を奨励しており、 デフォルトセキュリティグループのインバウンドルールおよびアウトバウンドルールの全てを削除 することが求められています。
セキュリティ標準 No. 内容 CIS AWS Foundations Standard 4.3 すべての VPC のデフォルトセキュリティグループがすべてのトラフィックを制限するようにします Payment Card Industry Data Security Standard PCI.EC2.2 VPC のデフォルトのセキュリティグループでは、インバウンドトラフィックとアウトバウンドトラフィックが禁止されます AWS Foundational Security Best Practices Standard EC2.2 VPC のデフォルトのセキュリティグループでは、インバウンドトラフィックとアウトバウンドトラフィックが禁止されます この規定に準拠するために、このCloudFormationテンプレートでは、以下の設定を行います。
- セキュリティグループ が上記のポリシーに準拠しているか チェック を行う
- 非準拠であった場合には、
AWS ConfigがSSM Automationを自動起動するSSM Automationを用いて インバウンドルールおよびアウトバウンドルールを削除 するそれぞれの設定について、順を追って説明します。
1. AWS Configの有効化
AWS Configを有効化する手順については、過去の記事 をご覧ください。2. AWS Configを用いたチェック
インバウンドルールおよびアウトバウンドルールが存在するかどうかの確認には、あらかじめ
AWS Configに用意されているVPC_DEFAULT_SECURITY_GROUP_CLOSEDマネージドルールを使用します。これは、VPCのデフォルトのセキュリティグループでもインバウンドとアウトバウンドのいずれのトラフィックも許可しないことを確認するルール です。なお、この
Config Ruleを設定する前にConfigurationRecorderを生成しておく必要があります。そこで、DependsOn属性にConfigurationRecorderリソースを設定しています。Resources: ConfigVpcDefaultSecurityGroupClosed: DependsOn: - ConfigConfigurationRecorder Type: 'AWS::Config::ConfigRule' Properties: ConfigRuleName: vpc-default-security-group-closed Description: いずれの Amazon Virtual Private Cloud (VPC) のデフォルトのセキュリティグループでもインバウンドとアウトバウンドのいずれのトラフィックも許可しないことを確認します。 Source: Owner: AWS SourceIdentifier: VPC_DEFAULT_SECURITY_GROUP_CLOSED3. SSM Automation を用いた自動修復
Systems Manager Automationは、AWS Configで 直接指定できる、現時点で唯一の自動修復手段 となっています。そこで、インバウンドルールおよびアウトバウンドルールを削除するSystems Manager Automationドキュメント を作成し、AWS Configとの紐付けを行います。下の
Systems Manager Automationドキュメントは、EC2のRevokeSecurityGroupIngressおよびRevokeSecurityGroupEgressを実行して、デフォルトセキュリティグループのインバウンドルールおよびアウトバウンドルールを削除します。Resources: SSMAutomationRevokeDefaultSecurityGroup: Type: 'AWS::SSM::Document' Properties: Content: schemaVersion: "0.3" assumeRole: "{{ AutomationAssumeRole }}" description: Revoke Default Security Group. mainSteps: - name: DescribeSecurityGroups action: aws:executeAwsApi onFailure: Abort inputs: Service: ec2 Api: DescribeSecurityGroups GroupIds: ["{{ GroupId }}"] outputs: - Name: IpPermissionsIngress Selector: $.SecurityGroups[0].IpPermissions Type: MapList - Name: IpPermissionsEgress Selector: $.SecurityGroups[0].IpPermissionsEgress Type: MapList - name: RevokeSecurityGroupIngress action: aws:executeAwsApi onFailure: Continue inputs: Service: ec2 Api: RevokeSecurityGroupIngress GroupId: "{{ GroupId }}" IpPermissions: "{{ DescribeSecurityGroups.IpPermissionsIngress }}" - name: RevokeSecurityGroupEgress action: aws:executeAwsApi onFailure: Continue inputs: Service: ec2 Api: RevokeSecurityGroupEgress GroupId: "{{ GroupId }}" IpPermissions: "{{ DescribeSecurityGroups.IpPermissionsEgress }}" parameters: AutomationAssumeRole: type: String description: Automation Assume Role Arn GroupId: type: String description: Group Id DocumentType: Automation4. AWS Config と SSM Automation の紐付け
Systems Manager Automationドキュメントは、上述の通りEC2のRevokeSecurityGroupIngressおよびRevokeSecurityGroupEgress(およびDescribeSecurityGroups)を実行する必要があるため、このAWS API アクションをSystems Manager Automationから呼び出すことを可能とする IAM Role を作成します。Resources: IAMRoleForSSM: Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: ssm.amazonaws.com Action: 'sts:AssumeRole' Description: A role required for SSM to access IAM. Policies: - PolicyName: !Sub 'DefaultSecuritySettings-AWSSystemManagerIAMRole-${AWS::Region}' PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: - 'ec2:RevokeSecurityGroupIngress' - 'ec2:RevokeSecurityGroupEgress' - 'ec2:DescribeSecurityGroups' Resource: - '*' RoleName: !Sub 'DefaultSecuritySettings-SSM-${AWS::Region}'このIAM RoleのARNは、
AWS ConfigからSystems Manager Automationへ渡されるパラメータの1つとして規定されます。AWS::Config::RemediationConfigurationは、非準拠(NON_COMPLIANT)と判定された場合の自動修復方法を規定し、Config RuleとSystems Manager Automationとの紐付けや、受け渡されるパラメータの規定を行います。自動修復を行う場合は、AutomationAssumeRole, MaximumAutomaticAttempts, RetryAttemptSeconds の各パラメータの入力が必須です。Resources: ConfigVpcDefaultSecurityGroupClosedRemediationConfiguration: Type: 'AWS::Config::RemediationConfiguration' Properties: Automatic: true ConfigRuleName: !Ref ConfigVpcDefaultSecurityGroupClosed MaximumAutomaticAttempts: 1 Parameters: AutomationAssumeRole: StaticValue: Values: - !GetAtt IAMRoleForSSM.Arn GroupId: ResourceValue: Value: RESOURCE_ID RetryAttemptSeconds: 30 TargetId: !Ref SSMAutomationRevokeDefaultSecurityGroup TargetType: SSM_DOCUMENT以上で、デフォルトセキュリティグループのインバウンドルールおよびアウトバウンドルールの全てを削除することができました。
関連リンク
- サービスの有効化 - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- パスワードポリシーの自動修復 - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- モニタリングと通知の設定 - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- アクセスキーのローテーションと削除 - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- 全てのVPCでフローログを有効化する - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- SSHとRDPのアクセスを制限する - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- デフォルトセキュリティグループを無効化する - 「セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- S3バケットのサーバサイド暗号化 - セキュアで堅牢なAWSアカウント」を実現する CloudFormationテンプレート
- 投稿日:2020-06-21T03:30:23+09:00
SQS → Lambdaのリトライ処理について整理してみた
2018年の6月より、AWS LambdaのイベントソースとしてSQSが選択できるようになりました。
今回はLambdaのイベントソースでSQSを選択し、Lambda側で処理が失敗した場合、どのようにリトライ処理が行われるのかについて整理してみました。
リソースの作成
今回は、SNS → SQS → Lambda の構成で検証していきたいので、それぞれのリソースを作成いたします。
SQS
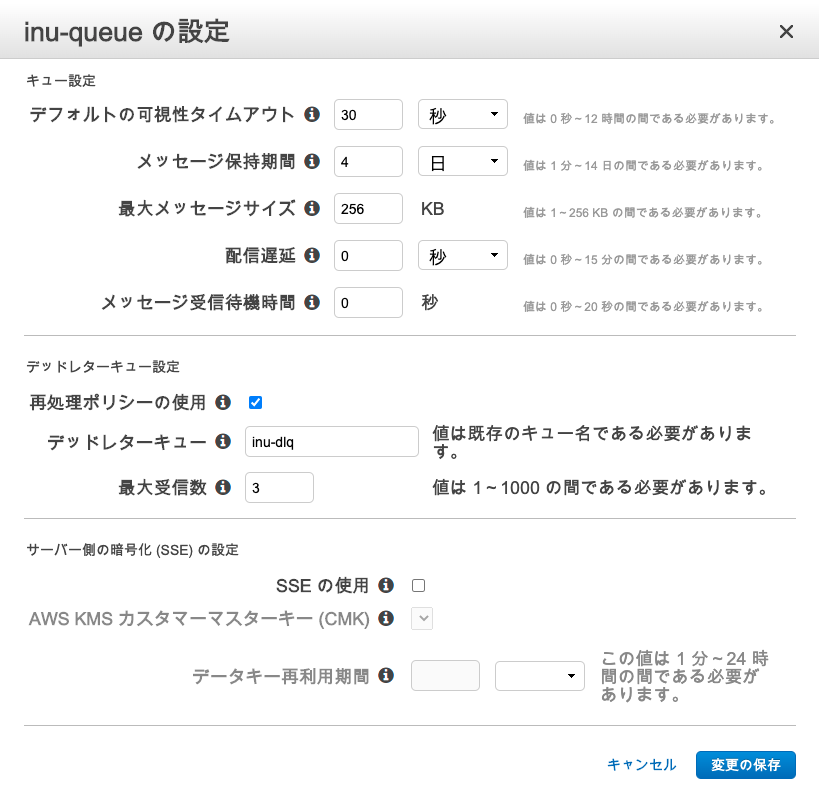
"inu-queue"というキュー名でキューを作成いたします。キューの種類は標準で各設定値はデフォルトです。
そして、"inu-dlq"というキュー名でDLQ(デッドレターキュー)用のキューも作成します。こちらもキューの種類は標準で各設定値はデフォルトになります。
2つのキューを作成したら"inu-queue"のDLQの設定を行います。
DLQの設定方法は、AWSコンソール画面だと以下の手順で設定することになります。
inu-queueのキューにチェックをつける → [キューの操作]をクリック → [キューの設定]をクリック → デッドレターキューの設定で[再処理ポリシーの使用] をチェック → デッドレターキューの記入箇所に"inu-dlq"と入力 → 最大受信回数を3に設定します。
SQSでは再処理ポリシーを設定した場合、あるメッセージに対して後段の処理(今回はLambda)が失敗した際にはそのメッセージはキュー内から削除されません。
したがって、可視性タイムアウトの時間が経過したら再びそのメッセージを処理することが可能になります。設定した最大受信回数よりも多く後段の処理が失敗した場合、そのメッセージは設定したDLQに移動します。このあたりについては後ほど具体例をもとに説明いたします。
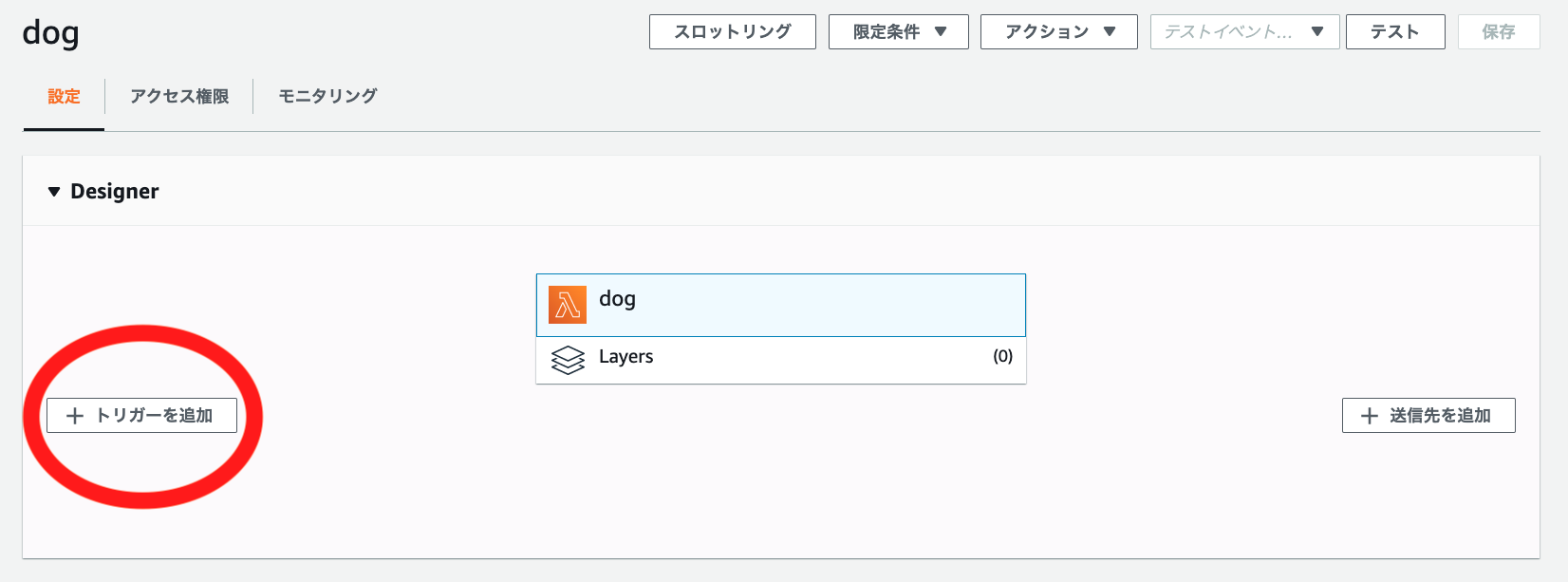
Lambda
AWSコンソールの画面でAWS Lambdaの画面に遷移して[関数] → [関数を作成]で
"dog"という名前のLambda関数を作成します。
今回はロールは[基本的な Lambda アクセス権限で新しいロールを作成] で作成しインラインポリシーで以下の権限を追加しました。
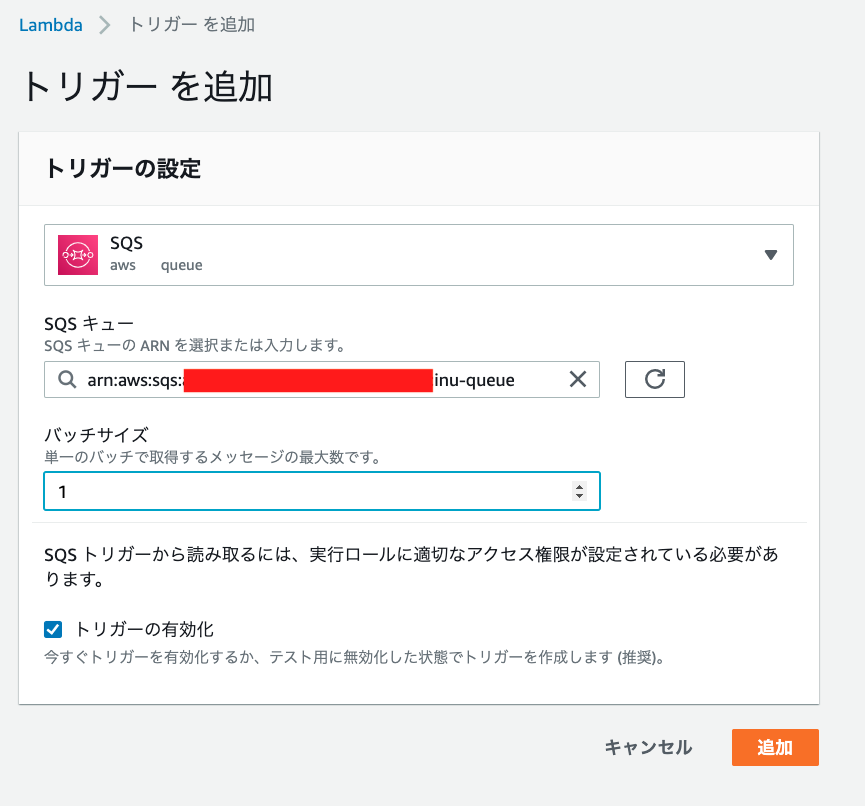
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sqs:DeleteMessage", "sqs:GetQueueAttributes", "sqs:ReceiveMessage" ], "Resource": "arn:aws:sqs:[region]:[accountID]:inu-queue" } ] }そして[トリガーの追加]から先ほど作成したSQSのキュー"inu-queue"を選択しトリガーを有効にします。
これでリソースの作成は以上になります。
ちなみにSQSのイベントトリガーを有効にする際にバッジサイズを1よりも多くすると、同時に複数のメッセージを取得できますが、冪等性の担保する必要があります。
処理の時系列の整理
具体的な数値で考えると理解しやすくなると思うのでここでは以下とします。
- 配信遅延時間:10秒
- 可視性タイムアウト:20秒
- 最大受信回数:2回
処理が成功する場合
SQSに新規メッセージAが入力される
→ 10秒(配信遅延時間)が経過した後、メッセージAを処理できる状態になる
→ LambdaがメッセージAを処理開始(1回目)
→ SQS内のメッセージAは20秒の間、どのLambdaからも処理されなくなる。
→ LambdaがメッセージAの処理を成功
→ SQS内のメッセージAが削除される処理が失敗する場合
キューに新規メッセージAが入力される
→ 10秒(配信遅延時間)が経過した後、メッセージAを処理できる状態になる
→ LambdaがメッセージAを処理開始(1回目)
→ キュー内のメッセージAは20秒(可視性タイムアウト)の間、どのLambdaからも処理されなくなる。
→ LambdaがメッセージAの処理を失敗
→ キュー内のメッセージAが削除されない
→ LambdaがメッセージAの処理を開始してから20秒経過(可視性タイムアウト)
→ キュー内のメッセージAが処理可能になる
→ LambdaがメッセージAを処理開始(2回目)
→ キュー内のメッセージAは20秒(可視性タイムアウト)の間、どのLambdaからも処理されなくなる。
→ LambdaがメッセージAの処理を失敗
→ キュー内のメッセージがDLQ(デッドレターキュー)へ移動するという流れになります。
設定した最大受信数分だけLambdaが実行し、それでも失敗した場合メッセージがDLQへ移動する点がポイントになります。検証
本当に最大受信回数分だけLambdaが実行されるのか検証してみました。
Lambda "dog"のコードを以下とし、必ずエラーとなるように設定します。
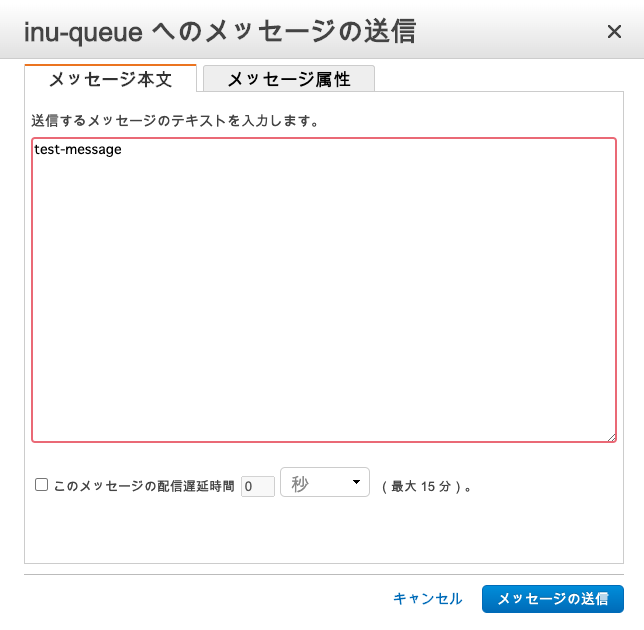
import json def lambda_handler(event, context): msg = event['Records'][0]['body'] print(msg) try: a = 1 / 0 except: raise Exception('ERROR!!') return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }そしてDLQの最大受信数を3に設定し、AWSコンソールのSQSの画面から
"inu-queue"を選択 → [キューの操作] → [メッセージの送信]でメッセージを送信します。
数分待ってからLambdaのログを確認すると...
test-messageのメッセージが3回処理されエラーが発生していることが確認できました。
次にDLQにメッセージが移動しているのか確認します。
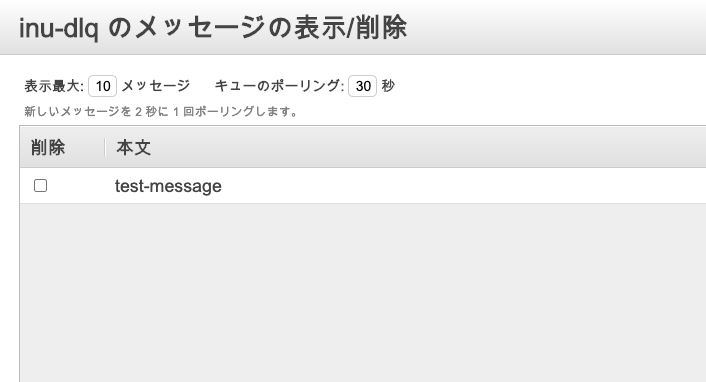
そしてDLQの最大受信数を3に設定し、AWSコンソールのSQSの画面から
"inu-dlq"を選択 → [キューの操作] → [メッセージの表示/削除]でメッセージを確認します。
test-messageのメッセージが追加されていることが確認できました。同様に"inu-queue"内のメッセージを確認するとtest-messageが削除されていました。
これでメッセージがDLQへ移動していることが確認できました。
DLQに蓄えられたメッセージは再度元のキューに戻したり、デバッグ用にログとしてアーカイブすることができます。
最後に
今回は、LambdaのイベントソースにSQSを選択した際のリトライ処理について整理させていただきました。
SQS と Lambdaの組み合わせはサーバーレスな組み合わせでも強力なものですのでこれからも知見を深めていきたい次第です。

- 投稿日:2020-06-21T00:50:32+09:00
AWS基礎
前提
AWS(ブログシステム構築)について学んだことを書いていきます。
本題
DBを用いたブログシステムの構築
NATゲートウェイ構築後、プライベートサブネットに配置されたDBサーバーに、各種ソフトウェアをインストールできるようになった。
MariaDBをインストールし、データベースを構成したり、WebサーバーにWordPressをインストールしたりし、ブログシステム構築を行う。内容
WebサーバーにWordPressをインストールし、ブログシステムを構築する。
ブログのデータはDBサーバー上のMariaDBに保存する。1、DBサーバーの構成
DBサーバーにMariaDBをインストールし、WordPressからデータを保存できるようデータベースを作成。2、WebサーバーにWordPressをインストール
3、WordPressを初期設定
※MySQLとMariaDB
WordPressで利用できるデータベースサーバーは、MySQLかMariaDB。
MariaDBはMySQLの開発者が枝分かれし開発し始めたオープンソースの互換データベース。
AmazonLinux2には、MySQLではなくMariaDBがパッケージとして含まれている。DBサーバーにMariaDBをインストール
まずは、DBサーバーにMariaDBをインストールし、データベースサーバーとして使えるように設定。
MariaDBインストール
yumコマンドを使ってインストールする。
Webサーバーを踏み台にDBサーバーにログインした状態で下記のコマンドを入力。$ sudo yum -y install mariaDB-serverNATゲートウェイを経由し、ダウンロードが始まりMariaDBがインストールできる。
MariaDBの起動と初期設定
インストール後、MariaDBを起動する。
下記のコマンドを入力。$ sudo systemctl start mariadb次にMariaDBの管理者パスワードを設定。
管理者は「root」というユーザー。
次のようにmysqladminコマンドを実行すると管理者であるrootユーザーのパスワードを変更できる。
設定したパスワードは以降、rootユーザーで操作する際に尋ねられるため忘れないようにする。
※MariaDBのrootユーザーとLinuxシステムのrootユーザーは、異なるユーザー。
MariaDBは、Linuxシステムのユーザーアカウントではなく、独自のユーザーアカウントを用いる。$ mysqladmin -u root passwordWordPress用のデータベースを作成
WordPressで利用するデータベースを作成。
下記のようにmysqlコマンドを実行し、rootユーザーでMariaDBに接続する。
この時、先に設定したパスワードが求められる。$ mysql -u root -pすると、ウェルカムメッセージが表示された後
MariaDB[none]>のようにMariaDBのコマンドプロンプトが表示される。
ここでSQLを実行することで、データベースの各種操作ができる。
まずは、データベースを作成するため、下記のように入力。
- 投稿日:2020-06-21T00:17:34+09:00
AWS X-Ray+Goを使ってSQSでのメッセージングを観測する
概要
タイトルの遠り、AWS X-Rayを使って、SQSでのメッセージングを観測します。X-Rayを使えば、複数のアプリケーション間で「どこからどこにメッセージが送られているか」が図示されるため、アプリ間通信の仕様や障害発生箇所の把握がしやすくなります。今回は、Go言語を使って実装します。
結論(ソース)はページ下部にあります。
環境
- Go言語 1.14.3
- aws-sdk-go
- aws-xray-sdk-go
- Mac OS X 10.15.4
前提として、aws-sdk-go, aws-xray-sdk-goは
go getコマンドでインストール済みとします。この記事の対象読者
- AWSの有名どころサービスなら開発したことがある。AWS CLIも設定済み。
- SQSは知識があるがX-Rayはあまり知らない。X-Rayの概要や実装方法を知りたい
- (実装部分については)Go言語はそれなりに読める
X-Rayの概要
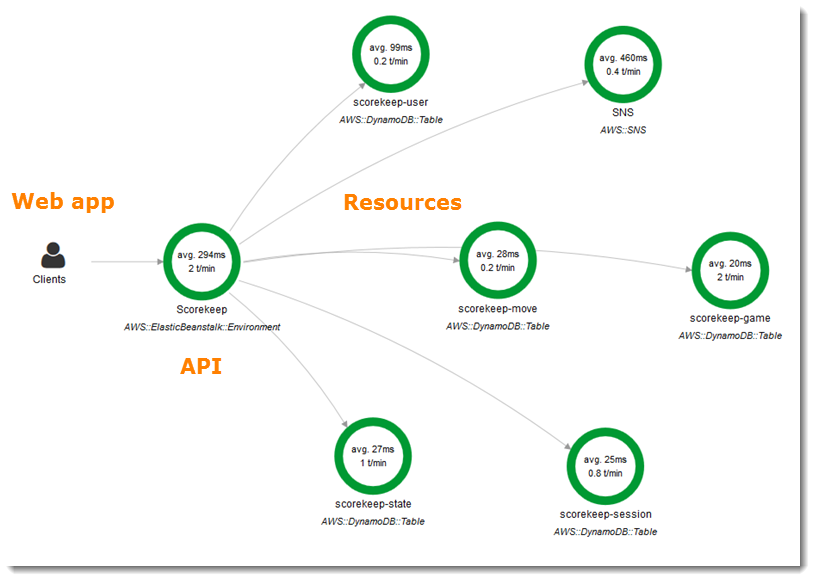
アプリから情報を収集して、以下のようなサービスグラフを作成したり、リクエストの実行時間を計測することができます。アプリのパフォーマンス可視化や障害発生箇所の特定など、可観測性の向上に役立てることができます。また様々なAWSサービスと統合することができます。
出典:https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/aws-xray.htmlデータ収集の仕組み
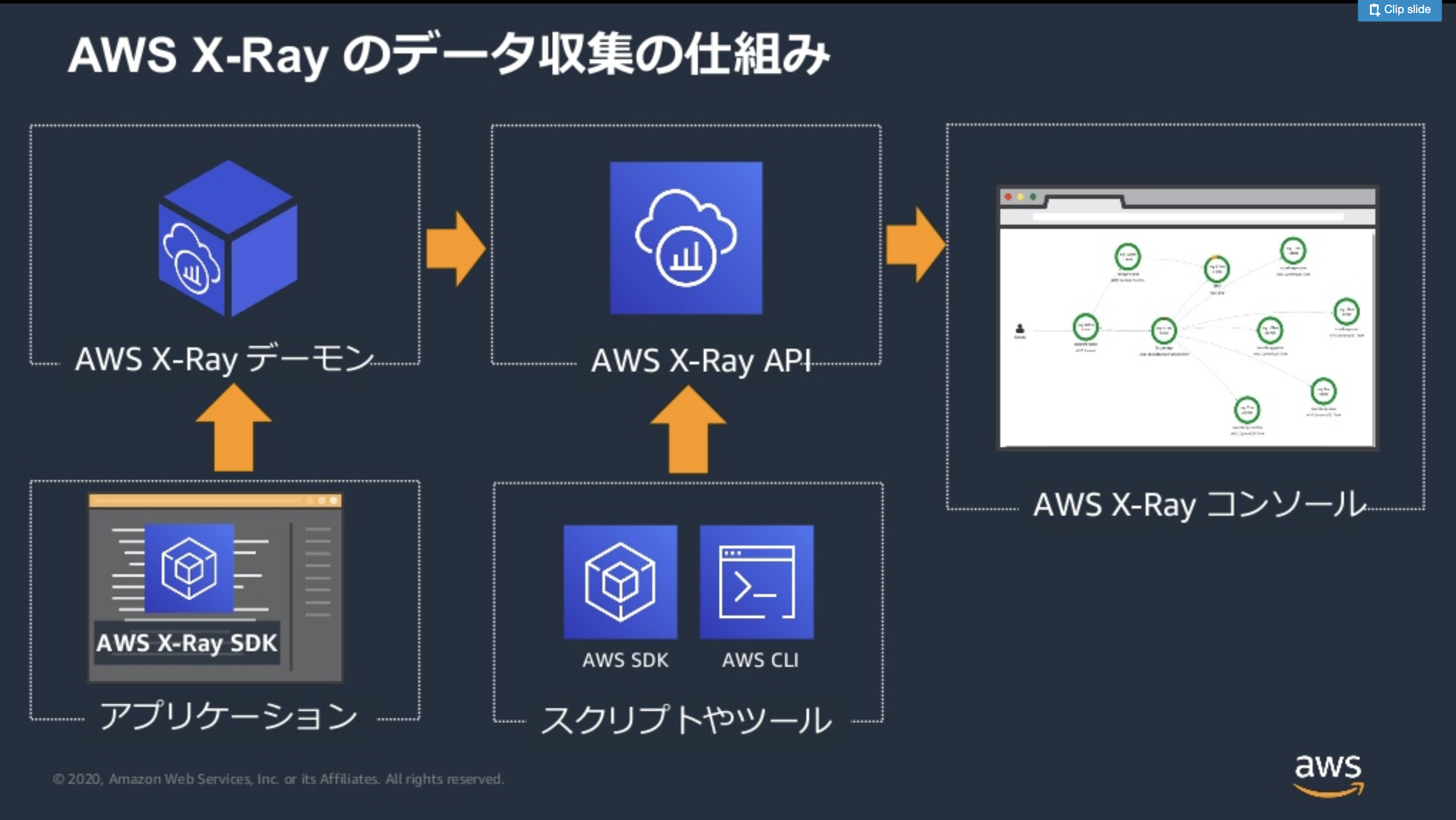
X-Rayは、アプリに組み込まれたSDKが情報を収集し、X-Rayデーモンを経由してコンソールに情報を表示します。以下のイメージがわかりやすいです。左下のアプリケーションからの流れになります。
※スクリプトやツールから直接X-RayのAPIへデータを送る流れはこの記事では扱いません。
出典:20200526 AWS Black Belt Online Seminar AWS X-Rayそのため、以下2つの準備が必要になります。
- SQSを実行するアプリにxray-sdkを組み込む
- X-Rayデーモンの起動
X-Rayの主要な要素
今回の実装に関係する部分のみ記載します。
セグメント/サブセグメント
セグメントは、X-Ray上で処理を分割する単位です。アプリやリソース、ホスト名などがイメージしやすいです。
一方、サブセグメントはセグメントを分割した細かな処理の単位です。HTTPのリクエスト、SQSのキューなどを定義できます。
基本的には、設定した名前がX-Rayのサービスグラフ上で表示される名前となります。トレースヘッダー
X-Rayでは、アプリケーション間の通信をトレースするためにトレースIDが発行されます。これがHTTP通信ヘッダーに
X-Amzn-Trace-Idとして設定されることで、通信のトレースが可能となります。これをトレースヘッダーと呼びます。今回のSQSとX-Rayの統合では、SQSのメッセージ送受信元のアプリをセグメントに設定し、メッセージングにトレースヘッダーを設定することでトレースを可視化します。
その他の概要やより詳細な説明は、公式のドキュメントやBlack Belt資料がわかりやすいです。
AWS X-Ray の概念
20200526 AWS Black Belt Online Seminar AWS X-RaySQSとX-Rayの統合
先述の「データ収集の仕組み」に沿って、2つの準備をします。
SQSを実行するアプリにxray-sdkを組み込む
aws-xray-sdk-goの基本的な使い方として、コンテキスト(context)を用います。Go言語のコンテキストは、HTTPリクエスト等に引数として渡すことでタイムアウトやキャンセルを可能とする仕組みですが、X-Rayではトレースのためにコンテキストを利用しているわけです。
contextの設定ctx, seg := xray.BeginSegment(context.Background(), "service-name") // service-nameがセグメント名 subCtx, subSeg := xray.BeginSubsegment(ctx, "subsegment-name") // subsegment-nameがサブセグメント名 // ...略... // 終了時にはcontectのクローズを行う subSeg.Close(nil) seg.Close(nil)通常、SQSでメッセージを送信するには
SendMessageを用いますが、これにはコンテキストを渡すことができません。そのため、コンテキストを渡すせるようWithContextを付加した関数が用意されています。SQSへのメッセージ送信の場合だとSendMessageWithContextとなります。この関数にcontextを追加で渡すことでトレースヘッダーが設定されます。受信側でそれを受け取ることにより、トレースが可能となるわけです。SQSへのメッセージ送信処理resp, err := svc.SendMessage(params) // 通常のメッセージ送信 resp, err := svc.SendMessageWithContext(ctx, params) // X-Rayを使う場合のメッセージ送信コンテキストを追加で渡すだけで、それ以外は元の関数と差異はありません。
X-Rayデーモンの起動
X-Rayデーモンは、実行可能ファイルがAWS公式から提供されています。ここから環境に合わせた実行可能ファイルをダウンロードして実行します。
AWS X-Ray デーモンなお、MacOSの場合、「開発元を確認できないため開けません」というメッセージが表示されることがありますが、以下などを参考に回避可能でした。
Macで「開発元を確認できないため、開けません」と表示された時の対処法ソース
実際にX-RaySDKを組み込んだGoのソースです。
- メッセージ送信処理(sqs-sender)
sqs-send-sample.gopackage main import ( "context" "fmt" "log" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/sqs" "github.com/aws/aws-xray-sdk-go/xray" ) var ( QueURL = "https://sqs.<リージョン>.amazonaws.com/<アカウントID>/<キューの名前>" AwsRegion = "<リージョン>" ) var svc *sqs.SQS func SendMessage() error { // SQSクライアントをxrayでラップ xray.AWS(svc.Client) // キューに送るメッセージと送信時に渡す構造体を設定 message := "hello" params := &sqs.SendMessageInput{ QueueUrl: aws.String(QueURL), MessageBody: aws.String(message), } // セグメントの宣言、contextの生成 ctx, seg := xray.BeginSegment(context.Background(), "sqs-sender") subctx, subseg := xray.BeginSubsegment(ctx, "sqs-sender-sub") // メッセージ送信処理 resp, err := svc.SendMessageWithContext(subctx, params) if err != nil { return err } fmt.Println(resp) // セグメントのクローズ subseg.Close(nil) seg.Close(nil) return nil } func main() { sampleSession := session.Must(session.NewSession()) svc = sqs.New(sampleSession, aws.NewConfig().WithRegion(AwsRegion)) if err := SendMessage(); err != nil { log.Fatal(err) } }
- メッセージ受信処理(sqs-reciever)
sqs-recieve-sample.gopackage main import ( "context" "fmt" "log" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/sqs" "github.com/aws/aws-xray-sdk-go/xray" ) var ( AwsRegion = "<リージョン>" QueURL = "https://sqs.<リージョン>.amazonaws.com/<アカウントID>/<キューの名前>" // エンドポイント ) var svc *sqs.SQS func GetMessage() error { xray.AWS(svc.Client) // SQSから受け取る際に渡す構造体 params := &sqs.ReceiveMessageInput{ AttributeNames: aws.StringSlice([]string{"AWSTraceHeader"}), // トレースヘッダーを受け取る QueueUrl: aws.String(QueURL), MaxNumberOfMessages: aws.Int64(10), // 一度に取得するメッセージの最大数 WaitTimeSeconds: aws.Int64(20), // ロングポーリングの時間 } // セグメントの宣言、contextの生成 ctx, seg := xray.BeginSegment(context.Background(), "sqs-reciever") subctx, subseg := xray.BeginSubsegment(ctx, "sqs-reciever-sub") // メッセージ受信の実行 resp, err := svc.ReceiveMessageWithContext(subctx, params) if err != nil { return err } } for _, msg := range resp.Messages { fmt.Println(*msg.Body) // トレースヘッダーも取得&表示してみる msgAtr := msg.Attributes traceHeaderStr := msgAtr["AWSTraceHeader"] fmt.Println("AWSTraceHeader: ", traceHeaderStr) // メッセージ削除関数にもcontextを渡す if err := DeleteMessage(subctx, msg); err != nil { fmt.Println(err) } } // セグメントのクローズ subseg.Close(nil) seg.Close(nil) return nil } func DeleteMessage(ctx context.Context, msg *sqs.Message) error { params := &sqs.DeleteMessageInput{ QueueUrl: aws.String(QueURL), ReceiptHandle: aws.String(*msg.ReceiptHandle), } // メッセージの削除を実行。このときもcontextを渡す _, err := svc.DeleteMessageWithContext(ctx, params) if err != nil { return err } return nil } func main() { sampleSession := session.Must(session.NewSession()) svc = sqs.New(sampleSession, aws.NewConfig().WithRegion(AwsRegion)) // ポーリング for { if err := GetMessage(); err != nil { log.Fatal(err) } } }実行結果
事前にX-Rayデーモンを動かしておきます。
X-Rayデーモンの実行(東京リージョンの場合)$ ./xray_mac -o -n ap-northeast-1 2020-06-19T22:29:57+09:00 [Info] Initializing AWS X-Ray daemon 3.2.0 2020-06-19T22:29:57+09:00 [Debug] Listening on UDP 127.0.0.1:2000 2020-06-19T22:29:57+09:00 [Info] Using buffer memory limit of 163 MB 2020-06-19T22:29:57+09:00 [Info] 2608 segment buffers allocated 2020-06-19T22:29:57+09:00 [Debug] Using Endpoint read from Config file: xray.ap-northeast-1.amazonaws.com 2020-06-19T22:29:57+09:00 [Debug] Using proxy address: ... # 以下省略その後、メッセージの送受信処理を動かします。一応マスクしていますが、こんな感じの実行結果が出力されます。
メッセージ送信処理$ go run sqs-send-sample.go 2020-06-20T20:33:00+09:00 [INFO] X-Ray proxy using address : 127.0.0.1:2000 { MD5OfMessageBody: "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX", MessageId: "XXXXXX-XXXXX-XXXX-XXXX-XXXXXXXXXXXXXXX" } 2020-06-20T20:33:00+09:00 [INFO] Emitter using address: 127.0.0.1:2000メッセージ受信処理$ go run sqs-recieve-sample.go 2020-06-20T20:32:54+09:00 [INFO] X-Ray proxy using address : 127.0.0.1:2000 hello # メッセージ本文 AWSTraceHeader: XXXXXXXXXXX # 16進数の値が出力される 2020-06-20T20:33:00+09:00 [INFO] Emitter using address: 127.0.0.1:2000 ... # ポーリングのため中断されるまで続きますX-Rayのコンソール
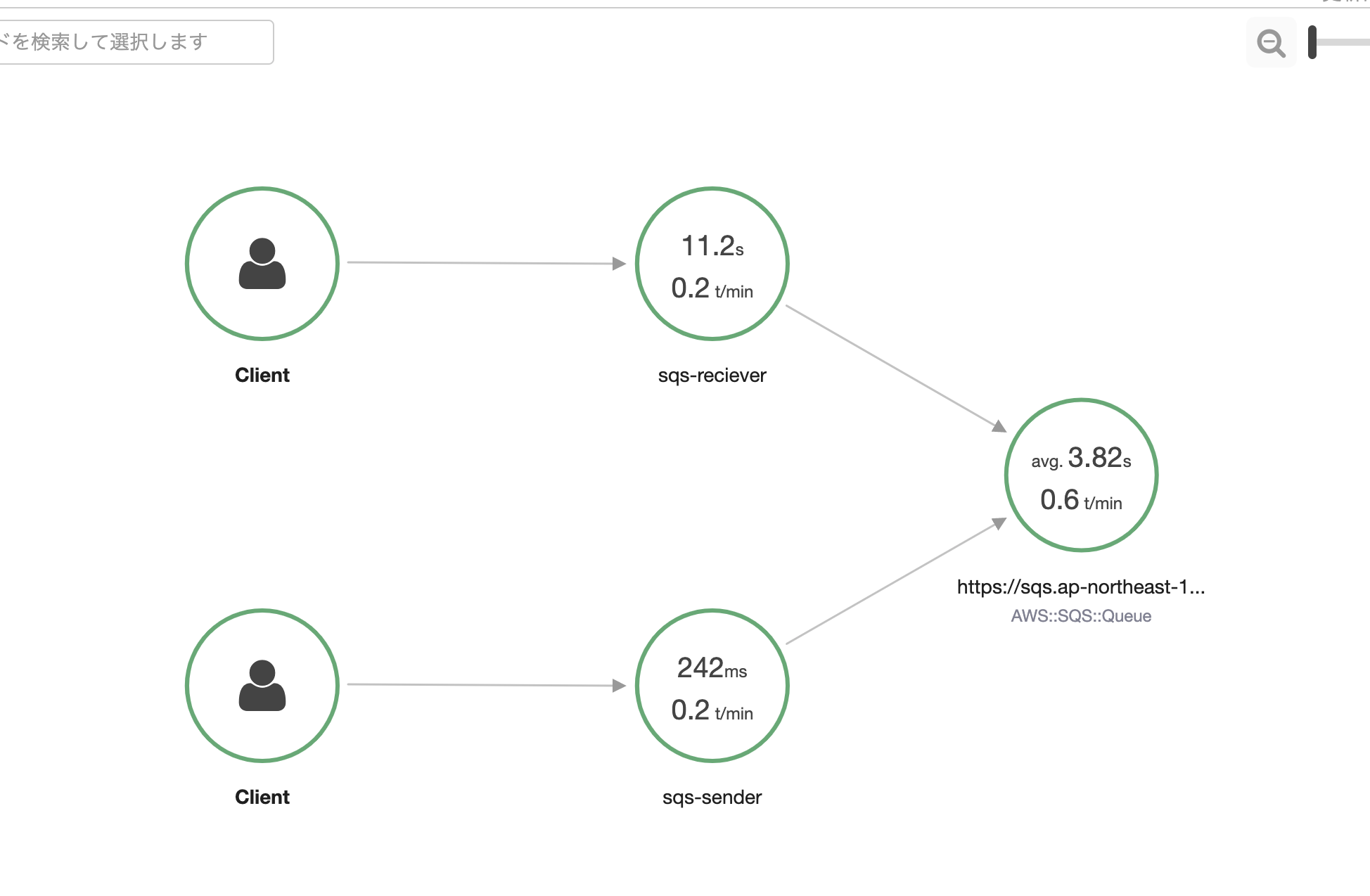
以下の通り、サービスマップが表示されました。下のsqs-senderからキューにメッセージが送られ、sqs-recieverがそれをポーリングしている状態です。
終わりに
X-RayをGo言語で使っているサンプルが少なく色々苦労しましたが、なんとか良い感じのグラフを描くことができました。X-Rayは使いこなせれば面白いサービスだと思うので、他のAWSサービスとも統合させてみたいと思います。
余談
SQSは、SNSと統合して用いることが多々あると思います。X-RayはSNSとの統合もサポートしているのですが、SNSのサブスクライバーとしてトレースがサポートされているのは、2020/6時点でHTTP/HTTPSとAWS Lambdaの2つです。つまり、残念ながらSNS+SQSの統合は、SQSがサブスクライバーとして統合されていないため、まとめてサービスグラフを描くことができません。今後のアップデートに期待したいと思います。
その他参考