- 投稿日:2020-06-21T23:38:44+09:00
Node.jsからobnizでBME280(気温、湿度、気圧)センサーを動かす
これまでのおさらい
- Raspberry piにNode.jsをインストールする
- Node.jsでrequestモジュールを使ってHTTPリクエストを実行する
- Node.jsでIFTTTのWebhooksを使う(requestモジュール利用)
今回のお話
- Raspberry Piで、Node.jsからobnizを利用する。
- obnizでBME280センサーを動かす。
- BME280センサーで気温、湿度、気圧のデータを取得したら、IFTTTを使って、Google スプレッドシートにデータを書き込む。
順番にやっていきます。
Raspberry Piで、Node.jsからobnizを利用する
obnizをインストール
npm install obnizNode.jsからObnizを使うには
const Obniz = require("obniz");BME280センサーを動かす
コードは、このページを参考にしました。
https://karaage.hatenadiary.jp/entry/2019/10/23/07300010KΩの抵抗を2つ入れています。
Obnizと接続します。
Obnizのディスプレイにデータを表示してみます。
Obnizの番号はマスクしています。const Obniz = require("obniz"); // デバイスに接続 var obniz = new Obniz("****-****"); //Obnizの番号を指定 obniz.onconnect = async function () { var bme280 = obniz.wired("BME280", {vio:0, vcore:1, gnd:2, csb:3, sdi: 4, sck: 5, sdo:6 }); await bme280.applyCalibration(); await bme280.setIIRStrength(1); val = await bme280.getAllWait(); //obniz画面表示 obniz.display.clear(); obniz.display.print("temperature:" + val.temperature.toFixed(1)) //気温 obniz.display.print("humidity:" + val.humidity.toFixed(1)) //湿度 obniz.display.print("pressure:" + val.pressure.toFixed(1)) //気圧 }これでObnizでBME280センサーのデータ取得ができました。
Obnizの画面に、気温、湿度、気圧が表示されていると思います。BME280センサーで気温、湿度、気圧のデータを取得したら、IFTTTを使って、Google スプレッドシートにデータを書き込む。
IFTTT経由でGoogle スプレッドシートにデータを書き込みます。
コードを追加しています。
1回データを書き込んだら、Obnizの接続を切っています。// デバイスに接続 const Obniz = require("obniz"); // デバイスに接続 var obniz = new Obniz("****-****"); //Obnizの番号を指定 var webclient = require("request"); obniz.onconnect = async function () { const ifttt_event = "Record"; //イベント名 const ifttt_secret_key = "あなたのキーを書く"; //キー const IFTTT_URL_GoogleSheets = 'https://maker.ifttt.com/trigger/' + ifttt_event + '/with/key/' + ifttt_secret_key; const bme280 = obniz.wired("BME280", {vio:0, vcore:1, gnd:2, csb:3, sdi: 4, sck: 5, sdo:6 }); await bme280.applyCalibration(); await bme280.setIIRStrength(1); val = await bme280.getAllWait(); //obniz画面表示 obniz.display.clear(); obniz.display.print("temperature:" + val.temperature.toFixed(1)) //気温 obniz.display.print("humidity:" + val.humidity.toFixed(1)) //湿度 obniz.display.print("pressure:" + val.pressure.toFixed(1)) //気圧 //送信データ作成 const p1 = val.temperature.toFixed(1); const p2 = val.humidity.toFixed(1); const p3 = val.pressure.toFixed(1); //IFTTTリクエスト webclient.post({ url: IFTTT_URL_GoogleSheets, headers: { "content-type": "application/json" }, body: JSON.stringify({'value1': p1, 'value2':p2, 'value3':p3}) }, function (error, response, body){ console.log(body); }); obniz.close();//Obniz切断 }実行してみます。
pi@raspberrypi:~/myapp $ node BME280.js Congratulations! You've fired the Record eventCongratulations! の行が表示されたら、成功です。
Google スプレッドシートを確認すると、取得したデータが記録されています。
今回はここまで。


- 投稿日:2020-06-21T23:17:31+09:00
Promiseは何時呼ばれるのか?
Promiseは何時呼ばれるのか?
使う分には今まであまり意識してこなかったのですが、async/awaitを呼ぶことで処理がブロッキングされるのではないかというのを懸念していたのと、そもそもどのタイミングでPromiseのcallbackがされるのか気になったので今更ですが調べてみました。
Promiseが呼ばれる仕組みについては先にEventLoopとmicrotaskについて知る必要があります。先に結論から書くと以下の感じです。
- PromiseはEventLoop内のmicrotaskキューでFIFO実行される。
- Timer系の処理(setImmediateやsetTimeout)はmicrotaskが全て実行された後に実行される。(つまり、
setTimeout(fn, 0)はmicrotaskを全て実行した後にfnを実行するという意味)- async/awaitはPromiseの箇所でsuspendしているに過ぎない(イベントループをブロッキングするかどうかはPromise内部の処理に依存する)、ジェネレータ文法(yield)やコルーチンの概念と同じ。
- NodeJS v12以降ではasync/awaitによるパフォーマンスの劣化は改善されているので、処理の実行順序の見やすさ的に積極的に書いて問題ない。(ただし、async/await関係なしに待たなくて良い処理に関してはレスポンスを返した後に実行すべしなのとI/O系のSyncメソッドは使わないほうが良い)
- ブラウザでもPromiseはqueueMicrotaskによって実装されている(そもそもPromise、async/awaitサポートされてないブラウザもまだ生き残っているのでトランスパイル必須だが)
NodeJSの場合
NodeJSはV8エンジン(Google ChromeのChromiumでも使われている)によるJavaScriptで動く実行環境です。
元々はC10K問題(サーバーのハードウェア性能は問題ないにもかかわらず、クライアントの同時接続数が多くなるとサービスの応答が遅くなる)を解決するバックエンド環境(アプリケーションサーバ)として開発されました。
C10K問題はハードウェア性能ではなく、OSの制限によって引き起こされるクライアント同時接続数の上限です。
- プロセス数の上限
- コンテキストスイッチ(切り替え)のコスト
- ファイルディスクリプタの上限
これらの問題を解決するためにNodeJSはシングルプロセス・シングルスレッドでリクエストを捌くという設計になっています。(実際にはマルチプロセスもマルチスレッドも作れるのですが根本的な設計思想はこれです。)
シングルプロセス・シングルスレッドで全部のリクエストを処理することでプロセス数の上限にもひっかからず、大量のマルチプロセス、マルチスレッドでのコンテキストスイッチも発生しない。
DBコネクションもマルチプロセス単位で都度接続するのでなく、シングルスレッド内で使いまわしをすることでファイルディスクリプタの上限にならない。
ただ、ファイルの読み書きに関してはシングルスレッドで行うと他の処理をブロッキングするほど重たいため、非同期でのI/Oをサポート・推奨しています。
シングルスレッドで飛んでくるリクエストを管理するための仕組みがイベントキュー(イベントループ)です。
従来の1リクエストにつき1プロセス立ち上がるマルチプロセス型のアプリケーションサーバに対し、
シングルプロセス、シングルスレッド内でイベントキューにリクエストを順次詰め込み、DBやファイルからのデータ取得を非同期に取得し、レスポンスを返すことを可能にしています。
以上により、NodeJSはシングルプロセス・シングルスレッドによるイベントループでC10K問題を解決しています。
ただし、シングルスレッドならではの問題として
CPU負荷が高いループ処理などが発生するとイベントループをブロッキングしてしまい、全てのリクエストに遅延や最悪レスポンスが返って来ないほどの影響を与えてしまいます。さて、ようやくNodeJS上でPromiseがいつ呼ばれるのかという話しなのですが
setTimeout(() => console.log(1)); setImmediate(() => console.log(2)); process.nextTick(() => console.log(3)); Promise.resolve().then(() => console.log(4)); (() => console.log(5))();実行結果は次のようになります。
同期実行→nextTick→Promise(microtask)→setTimeout→setImmediate
の順番です。5 3 4 1 2
(() => console.log(5))()のみ同期タスクで他は非同期タスクです。
同期タスクが一番最初なのは理解しやすいとして、非同期タスクの順番はどのように決まっているのでしょうか?
これはなぜなのかはもう少し踏み込んでイベントループについて見てみる必要があります。
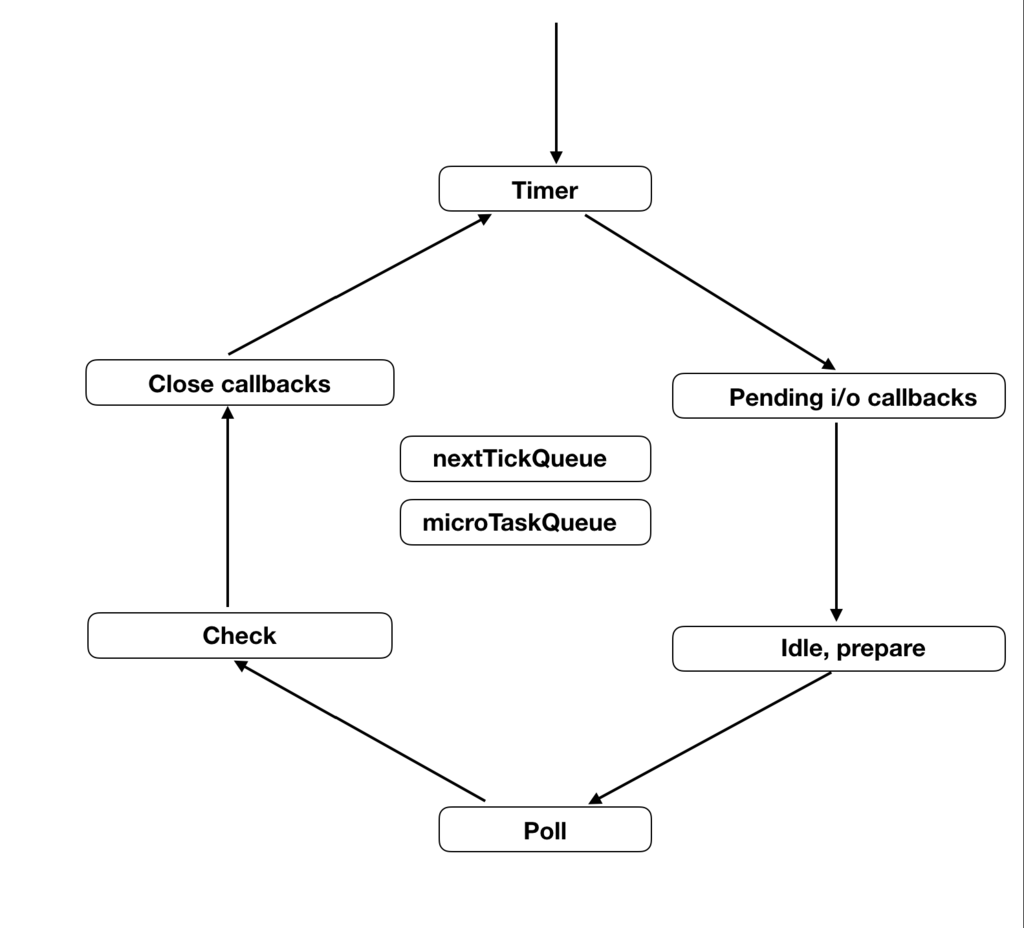
イベントループはlivuvにより実装されていて、
NodeJSが起動すると以下のイベントループが初期化されます。
(ただし、nextTickQueue、microTaskQueueはNodeJS側で実装されている)
まず、イベントループに入る前にもしくはイベントループの各フェーズの後にキューのタスクがある場合はキューが空になるまで実行されます。
(イベントループはシングルスレッドで複数のtaskを同時に処理することはできないため)
- nextTickQueueは全てのキューの中で最速に処理される→nextTickが実行される
- microTaskQueueはnextTickQueueが空になり次第、実行(Promisesオブジェクトのコールバックはここに所属)→Promiseが実行される
キューが解消されるとTimerフェーズからイベントループに入ります
- TimerフェーズでsetTimeoutが呼ばれる
- CheckフェーズでsetImmediateが必ず呼ばれる
なので
同期実行→nextTick→Promise(microtask)→setTimeout→setImmediateとなります。参考:Node.jsでのイベントループの仕組みとタイマーについて
先程シングルスレッドならではの問題点として、他の処理をブロッキングしてしまうという問題点をあげました。
次の例のようにasync functionだとしても裏側はシングルスレッドで動いているため、高負荷な処理を実行すると全てのリクエストをブロッキングしてしまいます。app.get('/compute-async', async function computeAsync(req, res) { log('computing async!'); const hash = crypto.createHash('sha256'); const asyncUpdate = async () => hash.update(randomString()); for (let i = 0; i < 10e6; i++) { await asyncUpdate(); } res.send(hash.digest('hex') + '\n'); });実は次のようにsetTimeoutを挟むことで他のリクエストをブロッキングすることなく、
高負荷な処理を継続することができます。
先程のイベントループが理解できていれば、Promise await(microtask)の間にsetTimeoutを挟むことでmicrotaskに大量の処理を全て詰め込んでから実行するのでなく、microtask→setTimeout→microtask→setTimeoutとインターバルを挟むようになるので他の処理をブロッキングするのを防ぐことができます。
(あくまでイベントループの仕様に基づいた回避策なのでそもそも重すぎるCPU処理の実行を直接サーバ上で行うのはNodeJSは向いていません)app.get('/compute-with-set-timeout', async function computeWSetTimeout (req, res) { log('computing async with setTimeout!'); function setTimeoutPromise(delay) { return new Promise((resolve) => { setTimeout(() => resolve(), delay); }); } const hash = crypto.createHash('sha256'); for (let i = 0; i < 10e6; i++) { hash.update(randomString()); await setTimeoutPromise(0); } log('done ' + req.url); res.send(hash.digest('hex') + '\n'); });参考:Node.js: How even quick async functions can block the Event-Loop, starve I/O
このようにNodeJSでは1つの処理がボトルネックになってサーバ全体のパフォーマンスを下げてしまうという危険があります。
後は同一プロセスで実行し続けるため、メモリリークが起きるとサーバの継続実行ができなくなってしまうのでデバッグツールや計測ツールでどこに問題があるのか調査する必要があります。さて、Promiseが何時実行されるかはわかりました。
(EventLoopの合間のmicrotaskキューで実行される)
ではasync/awaitで実行した場合はどうなるでしょうか?
async/awaitの関数は次のような関数に変換されてV8上で実行されます。
suspendされて、microtaskキューの実行でsuspendの戻り値を返却し、
implicit_promiseをPromiseの結果として最終的に返します。
後は懸念すべき点のasync/awaitを使った場合のパフォーマンス低下ですがNodeJS v12以降では素のPromiseとほぼ問題ないくらいの速度は出ているのでパフォーマンスを気にすることなく積極的にasync/awaitは使って良いレベルだと思います。
つまり、async/awaitそのものでパフォーマンス低下やイベントループがブロッキングされるということはないです。
(Promise内部の実装次第ではありえますが)参考:Faster async functions and promises
ブラウザの場合
ブラウザの場合もJavaScriptの実行フローはNodeJS同様EventLoopに基づいています。
PromiseやMutationObserverはmicrotaskで実行されます。setTimeout(() => console.log("0")); Promise.resolve() .then(() => console.log("1")); console.log("2");NodeJSのときと同様に
同期処理→Promise(microtask)→setTimeout(Timer)
の順番に実行されます。2 1 0もう一つ大事な点はDOMのイベントハンドリングやレンダリングを挟む場合は
すべてのmicrotaskは他のイベントハンドリングやレンダリングやTimer系処理の前に完了します。
(つまりイベントハンドリングしている最中にPromiseのネットワーク処理でデータが書き換わるなんてことはない)
参考:イベントループ(event loop): microtask と macrotask
ChromeのWebWorkerを実装したJake氏のブログのほうがサンプル付きで実行例がわかりやすいかもしれません。
補足としてはブラウザ間の差異は解消され、FireFox、Safari、EdgeはすべてChromeと同じ挙動になっているのを確認しました。(2020/06/21現在)
元記事自体が2015年と古いため、古いブラウザでは差異があったのでしょう。参考:Tasks, microtasks, queues and schedules
ちなみに以上がわかると次記事の上級問題が解けます
参考:何問分かる?Promise に関するクイズ13問【解説付き】





- 投稿日:2020-06-21T22:40:10+09:00
【JavaScript】undefinedとnullだけfalseと判定する
値が
undefinedとnullの時だけtrueとして判定したい(0はfalse判定にしたい)タイトルの通り、こんな場合どうするか。
[JavaScript] null とか undefined とか 0 とか 空文字('') とか false とかの判定についてに全て書いてあるが、このトピックの部分だけまとめてみた。
if (!value)まず初めにこれを使っていたのだが、JSでは
0はfalse判定なので普通に間違い。勘違いして使っていたらバグの元になってしまう。
if (value === undefined && value === null)これならOKだが、どこか野暮ったい。
この書き方が最も明示的で誰にもわかりやすいと思うが、もっとシンプルに書きたい場合もあるだろう。
if (!value == null)この書き方だと
valueの値が0の時はfalse判定になる。true判定になる。厳密等価演算子ではなく等価演算子「==」を使っているため、valueの値がnullとundefinedの時は同様にtrueとして判定されるようだ。ちなみに
if (!value == undefined)でも同じ結果となるが、文字数的にはnullを使った方が良さそう。否定の時は
if (value != null)でOK。ESLintで引っかからないか気になったが、大丈夫だった(設定によっては指摘されるかも?)。
- 投稿日:2020-06-21T22:40:10+09:00
【JavaScript】値がundefined/nullの時だけtrue判定にする
値が
undefinedとnullの時だけtrueとして判定したい(0はfalse判定にしたい)タイトルの通り、こんな場合どうするか。
[JavaScript] null とか undefined とか 0 とか 空文字('') とか false とかの判定についてに全て書いてあるが、このトピックの部分だけまとめてみた。
1.
if (!value)まず初めにこれを使っていたのだが、JSでは
0はfalse判定なので普通に間違い。勘違いして使っていたらバグの元になってしまう。
2.
if (value === undefined || value === null)これならOKだが、どこか野暮ったい。
この書き方が最も明示的で誰にもわかりやすいと思うが、もっとシンプルに書きたい場合もあるだろう。
3.
if (!value && value !== 0)2番目の書き方よりは短くなったが、少し分かりづらくなった気がする。
4.
if (value == null)この書き方だと
valueの値が0の時はfalse判定になる。厳密等価演算子ではなく等価演算子「==」を使っているため、valueの値がnullとundefinedの時は同様にtrueとして判定されるようだ。2、3番目の書き方よりも簡潔な条件式になった。厳密には次のようなカラクリらしい。
等価演算子は、2 つのオペランドが同じ型でないならばオペランドを変換して、それから厳密な比較を行います。両方のオペランドがオブジェクトならば、 JavaScript は内部参照を比較するので、オペランドがメモリ内の同じオブジェクトを参照するときに等しくなります。
ということで、
if (value == undefined)でも同じ結果となるが、文字数的にはnullの方が簡潔になる。否定の時は
if (value != null)でOK。(valueがnullとundefined以外の時にtrue判定となる)ESLintで引っかからないか気になったが、大丈夫だった(設定によっては指摘されるかも?)。
まとめ
等価演算子「
==」を使いたくなかったり、分かりやすさを求める場合は2、3番目の書き方が良さそうです。
- 投稿日:2020-06-21T22:19:53+09:00
Promiseとは・非同期処理時にPromiseを使うメリットとは
Promiseとは
非同期処理のコードを扱いやすくするもの。
Promiseを用いると、非同期処理のコールバックの扱いがより簡単になる。Promiseを使った実装・使わない実装
・Promiseを使わずに実装
//doWorkCallback関数の定義 const doWorkCallback = (callback) => { //非同期処理。2秒後に[1,2,3]を返す setTimeOut(() => { callback(undefined, [1,2,3]) }, 2000) } //doWork関数の実行 //第一引数:エラー時の返り値、第二引数:処理成功時の返り値 doWorkCallback((error, result) => { if(error){ return console.log(error) } console.log(result) })↓
2秒後に[1,2,3]が返る
または、2秒後にerrorが返る・Promiseを使って実装
//doWorkPromise関数の定義 const doWorkPromise = new Promise((resolve, reject) => { //非同期処理。2秒後に[1,2,3]を返す setTimeOut(() => { //処理成功時の処理をresolve関数として実装 resolve([1,2,3]) //エラー時の処理をreject関数として実装 reject('Things went wrong') } },2000) //doWorkPromise関数の実行 //成功時の処理を、「.then()」をつなげることによって記述 doWorkPromise.then((result) => { console.log('success', result) //エラー時の処理を、「.catch()」をつなげることによって記述 }).catch((error) => { console.log('Error',error) })↓
2秒後に「success, [1,2,3]」が返る
または、2秒後に「Error Things went wrong」が返るPromiseを使用するメリット
Promiseを使って実装すると・・・
①成功時の処理はresolve関数、エラー時の処理はreject関数と、2つの別々の関数て処理している為、何が起こっているかわかりやすい。
Promiseを使わないと: 関数1つで成功時とエラー時の処理を行うことになる、
コールバックの全ての呼び出しを調べてから、引数errorと引数result、どちらが提供されたか判断することになる。②処理結果によって呼び出される関数はresolve関数かreject関数かのどちらか一つ。
呼び出されるとPromiseは終了する為、後から実行結果の値や状態が上書きされることがない。Promiseを使わないと: コールバックが2回呼び出され、結果が変わるリスクがある。
Promise処理中におこっている事
Promiseが作成される
↓
Pending:非同期処理実行中。Promiseの結果は保留
↓
①fulfilled:処理成功
②rejected:処理失敗Promiseをチェインさせる
複数の非同期メソッドをつなげて処理を行う時、Promiseをチェインさせて書くことができる。
・Promiseチェインを使わず実装
//add関数の定義。Promiseを使った非同期処理とし、2秒後にa+bの結果を返す const add = (a, b) => { return new Promise ((resolve, reject) => { setTimeout(() => { resolve(a + b) }, 2000) }) } add(1, 2).then((sum) => { console.log(sum) add(sum, 5).then((sum2) => { //add関数で、「add(1,2)の結果」と「5」を処理する console.log(sum2) }).catch((e) => { console.log(e) }) }).catch((e) => { //add(1,2)のエラー処理 console.log(e) })↓
2秒後に「3」、さらに2秒後に「8」が返る・Promiseチェインを使って実装
//add関数の定義。Promiseを返し、2秒後にa+bの結果を返す const add = (a, b) => { return new Promise ((resolve, reject) => { setTimeout(() => { resolve(a + b) }, 2000) }) } add(1,1).then((sum) => { console.log(sum) return add(sum, 4) //add関数で、「add(1,1)の結果」と「4」を処理する。2つ目の非同期処理を returnで返すようにしている }).then((sum2) => { //2つ目の非同期処理を「.then()」で返す console.log(sum2) }).catch((e) => { console.log(e) })↓
2秒後に「2」、さらに2秒後に「6」が返る・Promiseチェインを使うメリット
①ネストを深くせずに、複数の非同期処理を繋げて行える
②エラー時の処理コードを重複して書かなくてすむ参考文献
「The complete Node.js Developer Course」
https://www.udemy.com/share/101WGiAEIedVpTTX4D/
- 投稿日:2020-06-21T20:33:15+09:00
MongoDBで配列内の特定の値だけを更新する
やり方
Mongo公式ドキュメントの$setとarrayFiltersを利用する
実例
このようなドキュメントを持つコレクションがある時。
{ "_id" : 1, "grades" : [ { "grade" : 80, "mean" : 75, "std" : 6 }, { "grade" : 85, "mean" : 90, "std" : 4 }, { "grade" : 85, "mean" : 85, "std" : 6 } ] } { "_id" : 2, "grades" : [ { "grade" : 90, "mean" : 75, "std" : 6 }, { "grade" : 87, "mean" : 90, "std" : 3 }, { "grade" : 85, "mean" : 85, "std" : 4 } ] }idが2のドキュメント内で、「grades配列のgradeの値が90であるオブジェクト」のmeanの値を100にしたいとする。(日本語が長いな...)
以下のようなコードとなる。hoge.updateOne( { "_id": 2 }, { $set: { "grades.$[element].mean" : 100} }, { arrayFilters: [ { "element.grade": 90 } ] } )hogeはコレクション名。第一引数はドキュメントのフィルタ。(このへんは説明を割愛)
第二引数で配列(grades)と更新したいフィールド(mean)、値(100)をセットする。$[element]は識別子。
第三引数で特定の配列内の検索条件を指定。第二引数で指定した識別子を使う。結果
{ "_id" : 1, "grades" : [ { "grade" : 80, "mean" : 75, "std" : 6 }, { "grade" : 85, "mean" : 90, "std" : 4 }, { "grade" : 85, "mean" : 85, "std" : 6 } ] } { "_id" : 2, "grades" : [ { "grade" : 90, "mean" : 100, "std" : 6 }, // mean:75 -> mean:100 { "grade" : 87, "mean" : 90, "std" : 3 }, { "grade" : 85, "mean" : 85, "std" : 4 } ] }
- 投稿日:2020-06-21T13:23:38+09:00
node.js(express)でDB(Postgresql)にアクセス
背景
今日はバックエンド関連。
これまでバックエンド(主にDBアクセスまわり)は、ほぼJavaでしか書いたことがなかったので、
node.jsでDB(Postgresql)にアクセスする際には、どんな方法があるのか簡単に調べてみる。ついでに、接続先のDBがAWSのRDS(Aurora/Postgresql)だった場合に、現時点ではどういう構成が最適なのかについても調べてみようと思う。
実装
まずは、node.jsでDB(Postgresql)にアクセスする際の実装(コーディング)方法について調べて試してみる。
調査
ネットを漁って軽く調べてみた感じ、以下の2つのパターンがありそう。
- ORマッパーとしてSequelizeというライブラリを利用してDBにアクセスする
- pg(node-postgres)を直接使って、自分でSQLを書いてDBにアクセスする
参考)
https://sequelize.org/
https://node-postgres.com/ネット上の記事を見る限り、Sequelizeを使うケースのほうが多いような印象(まぁやりたいこと次第なんでしょうが)。
また、ORマッパーは他にもライブラリがあるようですが、Sequelizeが主流のようです。
検証
Sequelizeを使うパターンと、使わずに直接pg(node-postgres)を使うパターンで、それぞれシンプルな実装を試してみる。
準備
以下からPostgresqlをダウンロードしてインストール。
https://www.enterprisedb.com/downloads/postgres-postgresql-downloads今回はWindows x86-64の12.3を選択。
保存先以外はすべてデフォルトでインストールした。次にexpress環境の用意。
まずはsequelize用。
> mkdir sequelize > cd sequelize > yarn init > yarn add expressすべてデフォルトのままの設定。
プロジェクト直下に以下のように記述したシンプルなindex.jsを作成。
index.jsconst express = require("express"); const app = express(); app.get("/", function (req, res) { res.send("Hello World!"); }); app.listen(3000, () => console.log("Example app listening on port 3000!"));起動。
node index.jshttp://localhost:3000/
にアクセスして確認すると「Hello World!」が表示される。同様にpg(node-postgres)用のexpress環境も用意しておく
> mkdir node-postgres ... 省略 ...フォルダ名(プロジェクト名)以外は全部同じ設定なので省略。
sequelizeで実装
sequelizeとpgをインストールしておく。
sequelizeでpgを利用するっぽいのでpgのインストールも必要。> yarn global add sequelize-cli > yarn add sequelize > yarn add pgsequelizeコマンドが簡単に使えるようにpackage.jsonにスクリプトを追加しておく。
package.json... "scripts": { "sequelize": "sequelize" }, ...sequelize用に初期化。
> yarn sequelize init以下のようにフォルダとファイルが作成された。
|- config |- config.json |- migrations |- models |- index.js |- seedersconfig.jsonは以下のようになっており、環境ごとのDBの接続設定を記載する模様。
config.json{ "development": { "username": "root", "password": null, "database": "database_development", "host": "127.0.0.1", "dialect": "mysql", "operatorsAliases": false }, "test": { "username": "root", "password": null, "database": "database_test", "host": "127.0.0.1", "dialect": "mysql", "operatorsAliases": false }, "production": { "username": "root", "password": null, "database": "database_production", "host": "127.0.0.1", "dialect": "mysql", "operatorsAliases": false } }設定を書き換え。
config.json{ "development": { "username": "postgres", "password": "postgres", "database": "database_development", "host": "127.0.0.1", "dialect": "postgres", "operatorsAliases": false }, ... }usernameやpasswordはpostgresqlインストール時に設定したものを指定しているが、本来は別途作成したユーザー(ロール)を指定すべきなので注意。あと、postgresユーザーのpasswordもまじめに考えるように!!
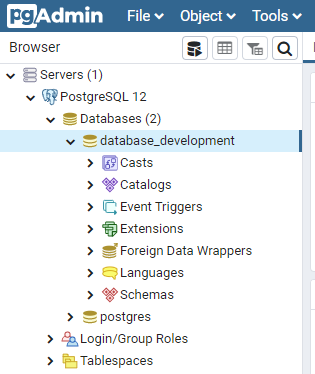
データベースの作成
> yarn sequelize db:createpgadmin4で確認してみると、config.jsonで設定した名前でデータベースが作成されている。
続いてモデルを作ってみる。
> yarn sequelize model:create --name TestClass --attributes attr1:stringこの時点でDBにテーブルが作られるわけではなく、モデル定義ファイルと、マイグレーションファイルが、それぞれmodelsフォルダとmigrationsフォルダに作成される。
models以下に自動生成されたtestclass.jsは以下。
testclass.js'use strict'; module.exports = (sequelize, DataTypes) => { const TestClass = sequelize.define('TestClass', { attr1: DataTypes.STRING }, {}); TestClass.associate = function(models) { // associations can be defined here }; return TestClass; };migrations以下に自動生成された{yyyymmddhhmmss}-create-test-class.jsは以下。
yyyymmddhhmmss-create-test-class.js'use strict'; module.exports = { up: (queryInterface, Sequelize) => { return queryInterface.createTable('TestClasses', { id: { allowNull: false, autoIncrement: true, primaryKey: true, type: Sequelize.INTEGER }, attr1: { type: Sequelize.STRING }, createdAt: { allowNull: false, type: Sequelize.DATE }, updatedAt: { allowNull: false, type: Sequelize.DATE } }); }, down: (queryInterface, Sequelize) => { return queryInterface.dropTable('TestClasses'); } };以下のコマンドでDBが更新されテーブルが作成される。
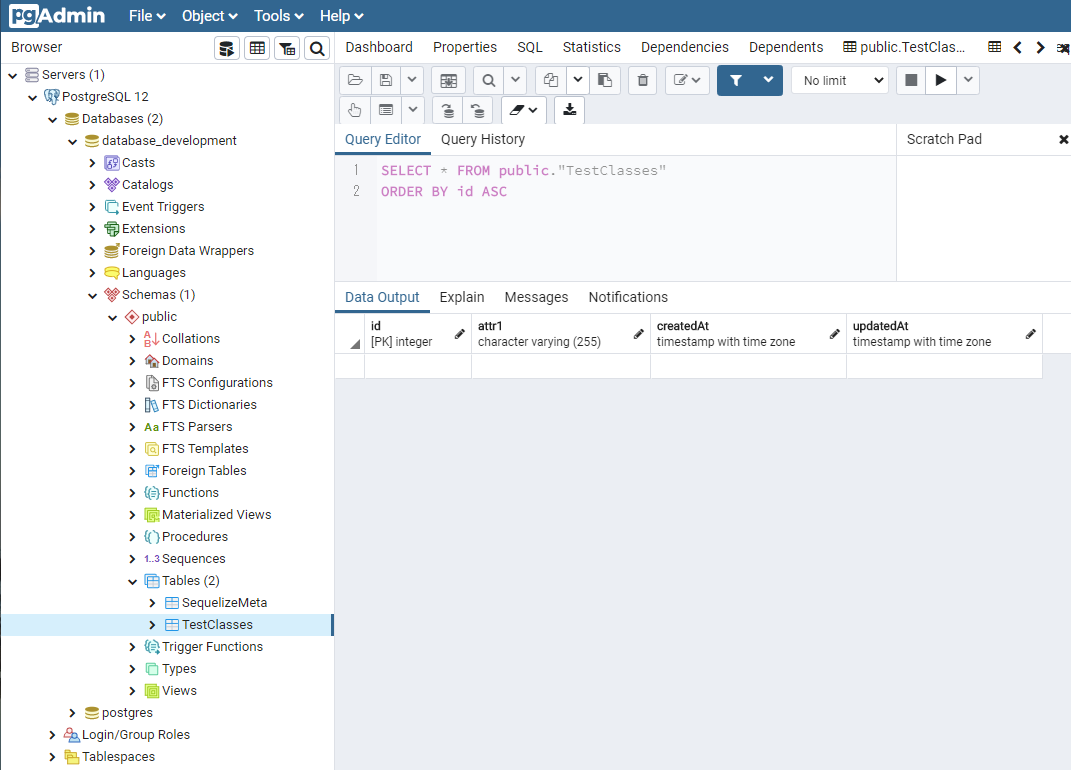
yarn sequelize db:migratepgadmin4で確認してみる。
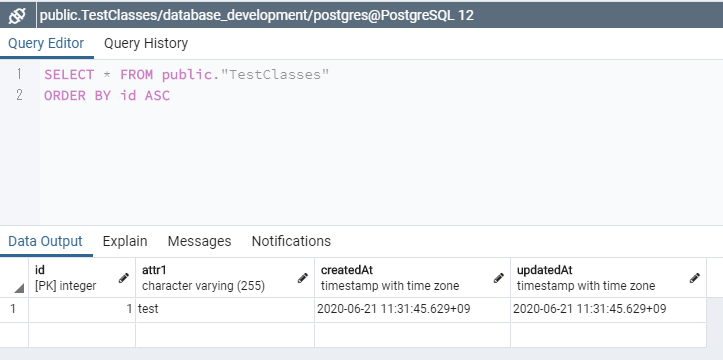
TestClassesというテーブルが追加されている。
適当に"TestClass"という名前を指定したのに、"TestClasses"となっていて、ちゃんと末尾に「es」を付けて複数形にしているのが凄い。レコードを追加してみる。
index.jsを以下のように書き換える。index.jsconst express = require("express"); const app = express(); const db = require("./models/index"); app.get("/", function (req, res) { res.send("Hello World!"); }); app.post("/create", function (req, res) { db.TestClass.create({ attr1: "test", }).then(() => { res.send("Data Created."); }); }); app.listen(3000, () => console.log("Example app listening on port 3000!"));requireの1文とapp.post部分のコードを追加しただけ。
サーバー起動
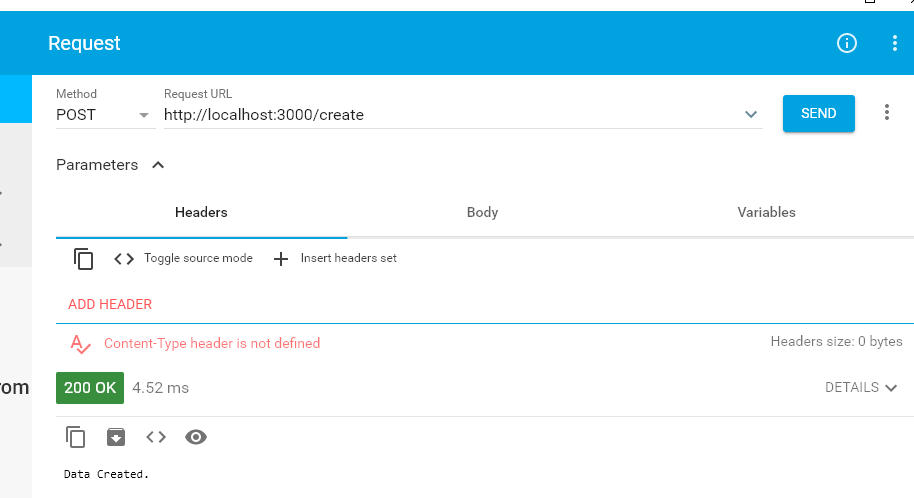
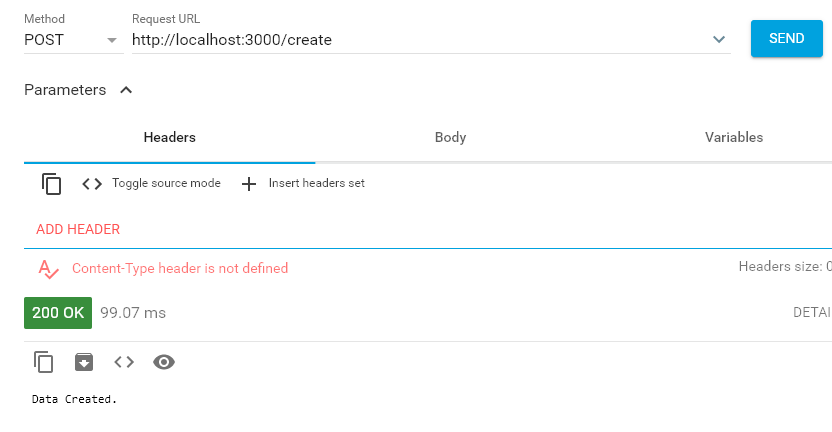
> node index.jschromeの拡張ツール「Advanced REST client」で動作確認。
http://localhost:3000/create にPOSTリクエストを送ってみる。
pgadmin4でデータを見てみる。
ちゃんとレコードが追加されていました。
簡単ですね。pg(node-postgres)で実装
続いて、pg(node-postgres)を使ってレコード追加してみようと思う。
とりあえず、準備であらかじめ作成しておいたpg(node-postgres)用のプロジェクトに移動しておく。
> cd node-postgrespg(node-postgres)をインストールする。
> yarn add pgDBやテーブルは先ほどsequelizeで作成したものをそのまま利用することにする。
index.jsを以下のように書き換え。index.jsconst express = require("express"); const app = express(); const pg = require("pg"); var pgPool = new pg.Pool({ database: "database_development", user: "postgres", password: "postgres", host: "localhost", port: 5432, }); app.get("/", function (req, res) { res.send("Hello World!"); }); app.post("/create", function (req, res) { var query = { text: 'INSERT INTO public."TestClasses" (id, attr1, "createdAt", "updatedAt") VALUES($1, $2, current_timestamp, current_timestamp)', values: [10000, "test"], }; pgPool.connect(function (err, client) { if (err) { console.log(err); } else { client .query(query) .then(() => { res.send("Data Created."); }) .catch((e) => { console.error(e.stack); }); } }); }); app.listen(3000, () => console.log("Example app listening on port 3000!"));面倒くさい処理を書いてないのでコードとしてはそんなに長くなってないが、
それでも、テーブル名の前にスキーマ名「public」を付けないとエラーになったり、
「createdAt」と「updatedAt」をダブルコートしないとエラーになったりと、いくつかハマりポイントがあった。本来ならば、さらに色々と自前で書く必要がある。
例えば、idに固定で10000を入れている部分をシーケンスから取得するような処理にしないと、2回目の実行で一意制約違反となる。
この処理はsequelizeを使えば勝手にやってくれているし、createdAtやupdatedAtも自動的に入れてくれている。とりあえず、サーバー起動して確認。
> node index.jsこちらも「Advanced REST client」で動作確認。
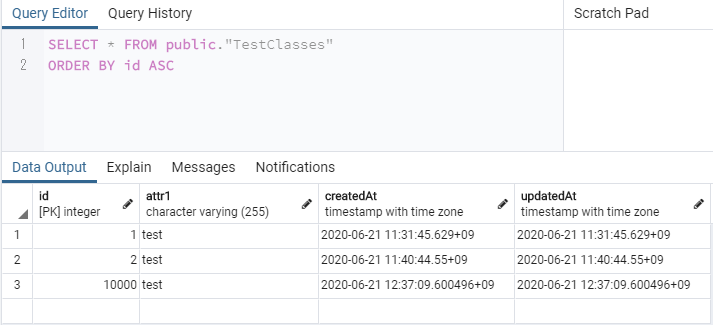
http://localhost:3000/create にPOSTリクエストを送ってみる。
pgadmin4でデータを見てみる。
一応、レコードの追加には成功した。
とりあえず、レコード追加のみ試してみたが、それだけでも結構面倒くさい。
これに加えて、sequelizeでは数コマンドの実行だけでやっていたテーブル作成等の作業も、pg(node-postgres)だけを使うのなら、手作業でやるか、自分で実装しておく必要がる。まとめ
実際に使ってみて、基本的にはsequelizeを使ってやっていくのが楽なのかなという印象。
sequelizeベースで開発して、sequelizeの機能に無いような特殊なことをやりたい場合は、直接、pg(node-postgres)を使って実装する感じかな。sequelizeは他にも色々出来そうなので、今度試してみようと思う。
システム構成 (Amazon RDS接続時)
AWS上で接続先のDBがAmazon RDS(Aurora/Postgresql)だった場合のシステム構成についての調査。
(話がガラッと変わりますが。。)調査
以下の3つのパターンが一般的かなと思う。
- EC2 → RDS
- ECS(fargate) → RDS
- Lambda → RDS
1のEC2パターンは今更感があって特に面白くもないので、個人的には選択肢としては最後かな。
2のECS(fargate)パターンは無難な選択といったイメージ。固有の問題が発生したという記事はあまり見かけない。ただ、ものすごくシンプルなサービスで利用するには大げさ過ぎる気もする。
3のLambda パターンについては、リクエスト単位でコネクションを張ってしまい、同時接続に耐えられないという問題が発生するため、これまでだったら、Lambda → RDSのパターンはそもそも"無し"だったんだけど、RDSプロキシというサービスがでてきて、この問題は最近では解決できるっぽい。
(とはいえ、RDSプロキシは「プレビューである事に起因した変更が発生する可能性があるため、本番ワークロードにはこのサービスを使用しないでください」と公式に書いてあるので、現時点(2020/6)では検証でしか使えない。)さらに、Aurora ServerlessのData APIによっても最大同時接続数の問題に対応できるらしい。
(ただ、こちらもAurora Serverless自体にいくつか制約があるので使用には注意が必要。)
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-serverless.html#aurora-serverless.limitationsということで、現在では、単純に、アンチパターンだからLambda → RDSは無し、というような感じでは無くなってきていることが分かった。
もう少し具体的な要件で選択していく必要がありそう。ECSとLambdaを比較した記事だと、小粒のサービスはLambdaで中規模以上はECSといった記述をよく見かける。
Lambdaで大規模なサービスを実現しようとした場合に問題となりそうな制約がいくつかあるので、その辺りだろう。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/gettingstarted-limits.html上記公式サイトに書いてあるLambdaの制約のうち、同時実行数(1000)やストレージ(75 GB)、VPCのENIの数(250)は、サポートに拡張してもらうことができるが、関数のタイムアウト(15分)やデプロイパッケージサイズ(50MB)、tmpの容量(512MB)などは変更できないので、サービスによっては問題になりそう。
500MB以上のコンテンツを処理する可能性があるとか、そこそこ時間のかかるバッチ処理などを実行する必要がある場合などはLambdaの選択は危険そう。
まとめ
結局、どれを選択するかは要件次第という感じだけど、中規模以上のサービスで、後々、制約で苦労したくないなら、ECS(Fargate)を選択しておくのが無難といったところでしょうか。
(RDS接続というより、単純なLambdaとECSの比較になってしまいましたが。)
- 投稿日:2020-06-21T07:10:28+09:00
ESLint v7.3.0
前 v7.2.0 | 次 (2020-07-04 JST)
ESLint v7.3.0 has been released: https://t.co/cGcdAuYc9s
— ESLint (@geteslint) June 19, 2020ESLint
7.3.0がリリースされました。小さな機能追加とバグ修正が含まれています。質問やバグ報告等ありましたら、お気軽にこちらまでお寄せください。
? 日本語 Issue 管理リポジトリ
? 日本語サポート チャット (招待リンク)
? 本家リポジトリ
? 本家サポート チャット (招待リンク)
[PR] ESLint は開発リソースを確保するための寄付を募っています。
応援してくださると嬉しいです。
✨ 本体への機能追加
特になし
? 新しいルール
no-promise-executor-return
? #12648
Promiseコンストラクタに渡す関数にて値を返すreturn文を書くとエラーにするルールが追加されました。値を返すのではなくresolve()を呼ぶ必要があります。例/* eslint no-promise-executor-return: error */ //✘ BAD new Promise((resolve, reject) => { if (someCondition) { return defaultResult; } getSomething((err, result) => { if (err) { reject(err); } else { resolve(result); } }); }); //✔ GOOD new Promise((resolve, reject) => { if (someCondition) { resolve(defaultResult); return; } getSomething((err, result) => { if (err) { reject(err); } else { resolve(result); } }); });no-unreachable-loop
? #12660
ループしないループ構文をエラーにするルールが追加されました。
例/* eslint no-unreachable-loop: error */ //✘ BAD for (let i = 0; i < arr.length; i++) { if (arr[i].name === myName) { doSomething(arr[i]); // break was supposed to be here } break; }? オプションが追加されたルール
特になし