- 投稿日:2020-06-02T23:41:10+09:00
PEP 612 (Parameter Specification Variables) を読んだよメモ
Microsoft の Python 向け型チェッカーの pyright の README を流し読みしていたら、初めて聞く PEP が登場したシリーズ第二弾です。
今回は PEP 612 (Parameter Specification Variables) について書きます。概要
- 汎用のデコレータを書こうとすると、型を書くのが非常に難しい
- 指定された関数と同じ引数を持つ関数 を表現する方法がほしい
アプローチ
ParameterSpecificationという引数を表す型を追加すると解決する引数を表す型として
ParameterSpecificationを追加する。
ParameterSpecificationはCallableと一緒に用いることで callable object のジェネリクスっぽく振る舞うことができる。TypeVarの引数版と考えるとわかりやすい。例
以下の例では
add_logging()の引数はCallable[Ps, R]型で、返り値も同じくCallable[Ps, R]型である。つまり、引数として指定された関数と同じインターフェースの関数を返すデコレータである。そのため、
@add_loggingでデコレートされたfoo()は(x: int, y: str) -> int型のままである。from typing import Callable, ParameterSpecification, TypeVar Ps = ParameterSpecification("Ps") R = TypeVar("R") def add_logging(f: Callable[Ps, R]) -> Callable[Ps, R]: def inner(*args: Ps.args, **kwargs: Ps.kwargs) -> R: log_to_database() return f(*args, **kwargs) return inner @add_logging def foo(x: int, y: str) -> int: return x + 7
ParameterSpecification型が導入されない場合、こういったデコレータに型をつけることは難しい。感想
- 幸いなことにこれまでデコレータに型をつけることがなかったので気づかなかったが、確かに
ParameterSpecificationがないと適切な型がつけられないParameterSpecificationという名前はちょっと長いが、特に代案は思いつかなかったの仕方ない…- 引数をいじるタイプのデコレータはこの PEP では扱わないとされているので、全てが解決ではないのが残念
- まだ Draft なので採用は決まってません
- 投稿日:2020-06-02T23:38:22+09:00
Qiskit: 任意の状態を作成する回路が作りたい!!
はじめに
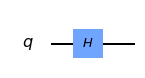
任意の状態を作成する回路を簡単に作りたい!と思うことはありませんか?
例えば...\frac{|0>+|1>}{\sqrt{2}}まあ,これは簡単ですね.以下の回路で作成できます.
しかし,Hadamard gateを知らなくてもこの状態を作成することができるツールがあるのです!
それが,StateVectorCircuitです.StateVectorCircuit
先ほどの状態を作る回路をStateVectorCircuitを用いて作成してみましょう.
まずは,使用するパッケージをimportします.
import numpy as np from qiskit.aqua.circuits import StateVectorCircuit from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, execute from qiskit import BasicAer from qiskit.visualization import plot_histogram次に今回作りたい状態を定義
state = [1 / np.sqrt(2), 1 / np.sqrt(2)]これをStateVectorCircuitに入力します.
svc = StateVectorCircuit(state)ここには二つの値が格納されています.
print(svc._num_qubits) # 1 print(svc._state_vector) # [0.70710678 0.70710678]ここではまだ回路は作成されていないので,construct_circuitを行います.
qc = svc.construct_circuit()作成された回路がこれ
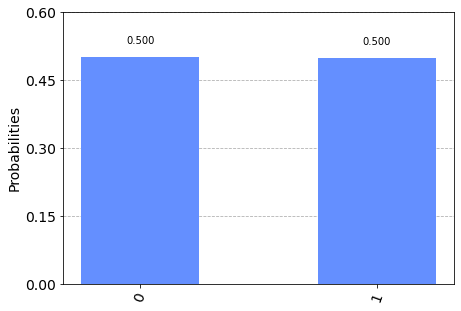
では実際に実行して結果を見てみましょう.
cr = ClassicalRegister(1) qc.add_register(cr) qc.measure([0], [0]) num_shots = 10000 backend = BasicAer.get_backend('qasm_simulator') results = execute(qc, backend, shots=num_shots).result() counts = results.get_counts(qc) plot_histogram(counts1)
ふむ.良い感じですね.
ちなみに,勝手にnormalizeしてくれるので例えば
state = [100, 100]とかでも対応してくれます.
もちろん複数qubitsでも大丈夫なのです.まとめ
今回は何かと便利そうなStateVectorCircuitを紹介しました.
ちなみに使用しているQiskitのバージョンが古いとerrorを吐くかもしれません.qiskit自体が日々進化していますからね.
- 投稿日:2020-06-02T23:30:08+09:00
djangoのadmin画面で"calendar.day_abbr"の更新に失敗する話
- 投稿日:2020-06-02T22:25:59+09:00
t-SNEを理解して可視化力を高める
はじめに
今回は次元削減のアルゴリズムt-SNE(t-Distributed Stochastic Neighbor Embedding)についてまとめました。t-SNEは高次元データを2次元又は3次元に変換して可視化するための次元削減アルゴリズムで、ディープラーニングの父とも呼ばれるヒントン教授が開発しました。(ヒントン教授凄い)今回はこのt-SNEを理解して可視化力を高めていきます。
参考
t-SNEを理解するに当たって下記を参考にさせていただきました。
- Visualizing Data using t-SNE (元論文)
- t-SNE clearly explained
- StatQuest: t-SNE, Clearly Explained
- 【次元圧縮】t-SNE (t -distributed Stochastic Neighborhood Embedding)の理論
t-SNEの概要
t-SNEの源流
t-SNEは高次元データを2次元や3次元に落とし込むための次元削減アルゴリズムです。
次元削減といえば古典的なものとしてPCAやMDSがありますが、それら線形的な次元削減にはいくつかの問題点がありました。
- 異なるデータを低次元上でも遠くに保つことに焦点を当てたアルゴリズムのため、類似しているデータを低次元上でも近くに保つことには弱い
- 特に高次元上の非線形的なデータに対しては「類似しているデータを低次元上でも近くに保つこと」は不可能に近い
これらの問題点を解決するためにデータの局所的な構造(類似しているデータを低次元上でも近くに保つこと)の維持を目的とした非線形次元削減技術が色々と生み出されました。t-SNEはその流れを汲んだアルゴリズムになります。
下記が非線形的なデータのイメージです。
※こちらのサイトより引用
t-SNEの特徴
t-SNEのポイントを記載しています。具体的な処理の中身やメリットデメリットの理由は後述のアルゴリズムの説明のところで詳細に記載したいと思います。
処理のポイント
- 高次元での距離分布が低次元での距離分布にもできるだけ合致するように変換する
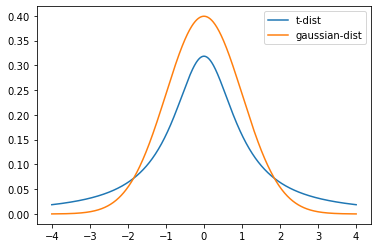
- 距離の分布をスチューデンのt-分布に従うと仮定(SNEではガウス分布を仮定していたが、そこから改良された)
メリット
- 高次元の局所的な構造を非常によく捉える
- 大局的な構造も可能な限り捉える
デメリット
- Perplexity(内部のパラメータ)を変えると全くことなるクラスターが出現してしまう
t-SNEのアルゴリズム
t-SNEのアルゴリズムを理解するに当たって、まずその前身となるSNEのアルゴリズムについて理解するところから始めます。その後SNEの問題点について整理し、問題点を解消するものして生み出されたt-SNEついてまとめます。
SNEの仕組み
1.データポイント間の距離を条件付き確率に変換
SNEはデータポイント間の距離を条件付き確率に変換するところからスタートします。
データポイント$x_{i}$ と$x_{j}$の類似度を、$x_{i}$が与えられた時に近傍として$x_{j}$を選択する条件付き確率$p_{j|i}$として表現します。さらにここでは、$x_j$は$x_{i}$を中心とした正規分布に基づいて、確率的に選択されると仮定しています。すると$p_{j|i}$は下記の数式で表現できます。
p_{j|i} = \frac{\exp(-||x_{i} - x_{j}||^2/2\sigma_{i}^2)}{\sum_{k\neq i}\exp(-||x_{i} - x_{k}||^2/2\sigma_{i}^2)}上記は正規分布の確率密度関数から求められたものです。$\frac{1}{\sqrt{2πσ^2}}$は定数のため分母分子で打ち消されています。
\frac{1}{\sqrt{2πσ^2}}\exp{(-(x-μ)^2/2σ^2)}平均$x_{i}$、分散$\sigma_{i}^2$の正規分布を仮定している訳ですが、分散$\sigma_{i}^2$の値は後述のパラメータによって調整します。分散$\sigma_{i}^2$によってどういう分布を仮定するかが変わってくるため、最終的な次元削減後のアウトプットも大きく変わります。
また今回は異なるデータ間の距離を条件付き確率で表すことを目的としているため、下記のように置きます。
p_{i|i} = 02.次元削減後のデータポイント間の距離も条件付き確率で表現
次元削減後のデータポイント$y_{i}$ と$y_{j}$の類似度も先ほどと同様に条件付き確率$q_{j|i}$として表現します。また同様に$y_j$は$y_{i}$を中心とした正規分布に基づいて確率的に選択されると仮定しますが、先ほどと異なり分散は$\frac{1}{\sqrt{2}}$で固定します。固定することで先ほどの式から分散を打ち消してシンプルにすることができます。
$q_{j|i}$は下記の数式で表現することができます。
q_{j|i} = \frac{\exp(-||y_{i} - y_{j}||^2)}{\sum_{k\neq i}\exp(-||y_{i} - y_{k}||^2)}先ほどと同様に下記のように置きます。
q_{i|i} = 03.KLダイバージェンスで損失関数設計
高次元でのデータポイント間の距離関係と次元削減後の低次元での距離関係ができるだけ一致すればよいので、$p_{i|j} = q_{i|j}$となることを目指します。今回は$p_{i|j}$と$q_{i|j}$の距離を測る指標としてKLダイバージェンス(厳密な定義での距離ではない)を使用します。KLダイバージェンスと損失関数としてその最小化を目指します。
今回の損失関数$C$は下記数式で表されます。
C = \sum_{i}KL(P_{i}||Q_{i}) = \sum_{i} \sum_{j} p_{j|i}\log\frac{p_{j|i}}{q_{j|i}}$P_{i}$は$x_{i}$が与えられた時の全ての条件付き確率を表し、$Q_{i}$は$y_{i}$が与えられた時の全ての条件付き確率を表します。
ここでKLダイバージェンスは非対称な指標なので$KL(P_{i}||Q_{i}) \neq KL(Q_{i}||P_{i})$となることがポイントです。大きな$p_{j|i}$を小さな$q_{j|i}$でモデル化する場合は損失関数は大きくなりますが、
小さな$p_{j|i}$を大きな$q_{j|i}$でモデル化する場合はそこまで損失関数は大きくなりません。これは高次元上で近くにあるデータポイントを表現するに当たって次元削減後のデータポイントの位置を遠くに配置してしまうと、非常に損失関数が大きくなるということを意味します。
これがSNEがデータの局所構造を保持すること焦点を当てていると言われる所以です。4.Perplexity
残っているパラメータとして$\sigma_{i}^2$がありました。これは高次元のデータポイント$x_{i}$を中心とした正規分布の分散です。分散$\sigma_{i}^2$によってどういう分布を仮定するかが変わってくるため非常に重要なパラメータです。
データが密であれば$\sigma_{i}^2$を小さく仮定するのが適切だし、疎では$\sigma_{i}^2$を大きく仮定するのが適切です。データをどのように仮定するのか、というところでPerplexityというパラメータが用いられます。
SNEはその使用者が指定した固定のPerplexityを持つ$P_{i}$を生成するような$\sigma_{i}^2$を二分探索します。Perplexityは下記のように定義されています。
Perp(P_{i}) = 2^{H(P_{i})}また、$H(P_{i})$は$P_{i}$のエントロピーで下記のように定義されています。
H(P_{i}) = -\sum_{j}p_{j|i}\log_{2}p_{j|i}例えばPerplexityを$40$といった値で固定して等式に合致するような$\sigma_{i}^2$を探索します。
Perplexityが大きければ当然$\sigma_{i}^2$も大きくなり、データが疎であることを仮定することになります。また、Perplexityが小さければ$\sigma_{i}^2$も小さくなり、データが密であることを仮定します。Perplexityはデータポイント$x_{i}$からどの程度の数の近傍点を考慮するか決める数であると言い換えることもできます。
5.確率的勾配降下法で損失関数を最小化する
確率的勾配降下法を使用して損失関数を最小化していきます。その勾配は損失関数を$y_{i}$で微分した値である下記を用います。
\frac{\delta C}{\delta y_{i}} = 2\sum_{j}(p_{j|i}-q_{j|i}+p_{i|j}-q_{i|j})(y_{i}-y_{j})この勾配を用いて$y_{i}$を徐々に動かしていくのですが、その更新式は下記のようになっています。
Y^{(t)} = Y^{(t-1)} + \eta \frac{\delta C}{\delta Y} + \alpha(t)(Y^{(t-1)} - Y^{(t-2)})を$Y^{(t-1)}$を勾配$\frac{\delta C}{\delta Y}$の方向だけ学習率$\eta$の分だけ動かすといったイメージです。($t$は反復回数を表す。)
最後にモメンタム項と呼ばれる$\alpha(t)(Y^{(t-1)} - Y^{(t-2)})$がついているのですが、これは勾配にを最適化から少しずらす意味合いがあります。局所的な極小値にはまらないようにできるだけ全体の中での極小値におさまるように最適化をコントールしています。これがSNEの流れになります。
SNEの問題点
上記がSNEの流れになりますが、SNEには下記2点の問題があります。
- 損失関数の最小化が難しい
- Crowding問題
損失関数はKLダイバージェンスを使用しているため、$p_{j|i}$と$q_{j|i}$を対象に扱えず損失関数の式が複雑化しています。(($p_{j|i}-q_{j|i}+p_{i|j}-q_{i|j}$)の部分)
Crowding問題多次元のものを低次元に落とし込んだ時に、お互いに等距離であれるデータポイントの数が減少するため、次元を落とす時に等距離性を保とうとして混雑化してしまうという問題です。
例えば3次元であれば次元数+1の4つのデータポイントが互いに等距離で存在できますが、2次元に落とすと次元数+1の3つしか等距離であれません。次元数を落とした時に本来発生するはずの隙間を潰してしまう可能性があります。それがCrowding問題です。
これらの解決を試みたのがt-SNEです。
t-SNEの仕組み
SNEの問題点を解決するため、t-SNEでは下記のような特徴が加えられています。
- 損失関数を対称化
- 低次元のデータポイント間の距離を考えるに当たってスチューデントのt分布を仮定
損失関数の対称化
損失関数の対称化処理として点$x_{i}$と点$x_{j}$の近さを同時確率分布$p_{ij}$で表します。(対称化するにあたって条件付き確率ではなく同時確率になっていることに注意)
p_{ij} = \frac{p_{i|j} + p_{j|i}}{2n}p_{j|i} = \frac{\exp(-||x_{i} - x_{j}||^2/2\sigma_{i}^2)}{\sum_{k\neq i}\exp(-||x_{i} - x_{k}||^2/2\sigma_{i}^2)}$p_{j|i}$に変化はないですが、平均を取るような処理$p_{ij} = \frac{p_{i|j} + p_{j|i}}{2n}$で対称化しています。
スチューデントのt分布を仮定
また低次元上の点$y_{i}$と点$y_{j}$の近さを同時確率分布$q_{ij}$で以下のように表します。
q_{ij} = \frac{(1+||y_{i} - y_{j}||^2)^{-1}}{\sum_{k\neq i}(1+||y_{i} - y_{j}||^2)^{-1}}ここで低次元上の点の距離を考えるに当たって自由度$1$のスチューデントのt分布を仮定しています。t分布は正規分布に比べて裾野が高いのが特徴です。裾野が高いt分布を使用することで高次元空間では中距離のデータポイントを、低次元空間ではより長い距離としてモデル化することができ、中距離のデータポイントについてCrowding問題を避けることができます。
損失関数の最小化
t-SNEはこの$p_{ij}$と$q_{ij}$を使って損失関数を最小化します。損失関数は下記のように表されます。
C = \sum_{i}KL(P ||Q) = \sum_{i} \sum_{j} p_{ji}\log\frac{p_{ji}}{q_{ji}}こちらもSNEと同様に確率的勾配降下法を用いて最適化していきます。
\frac{\delta C}{\delta y_{i}} = 4\sum_{j}(p_{ji}-q_{ji})(y_{i}-y_{j})(1+||y_{i} - y_{j}||^2)^{-1}更新式についてはSNEと同様です。
t-SNEの可視化例
今回はテキストデータを用いてその分布状況を可視化したいと思います。テキストデータはベクトル化すると高次元になりがちなので次元削減アルゴリズムが非常に有効です。
使用したライブラリ
scikit-learn 0.21.3
データセット
今回データセットは「livedoor ニュースコーパス」を使用してそのデータ分布状況を可視化使用と思います。データセットの詳細やその形態素解析の方法は以前投稿した記事で投稿しているの気になる方そちらをご参照いただければと思います。
日本語の場合は事前に文章を形態素単位に分解する前処理が必要となるため、全ての文章を形態素に分解した後下記のようなデータフレームに落とし込んでいます。
データ分布状況の可視化
テキストデータを一旦TF-IDFでベクトル化した後、t-SNEを使用して2次元に次元削減しています。
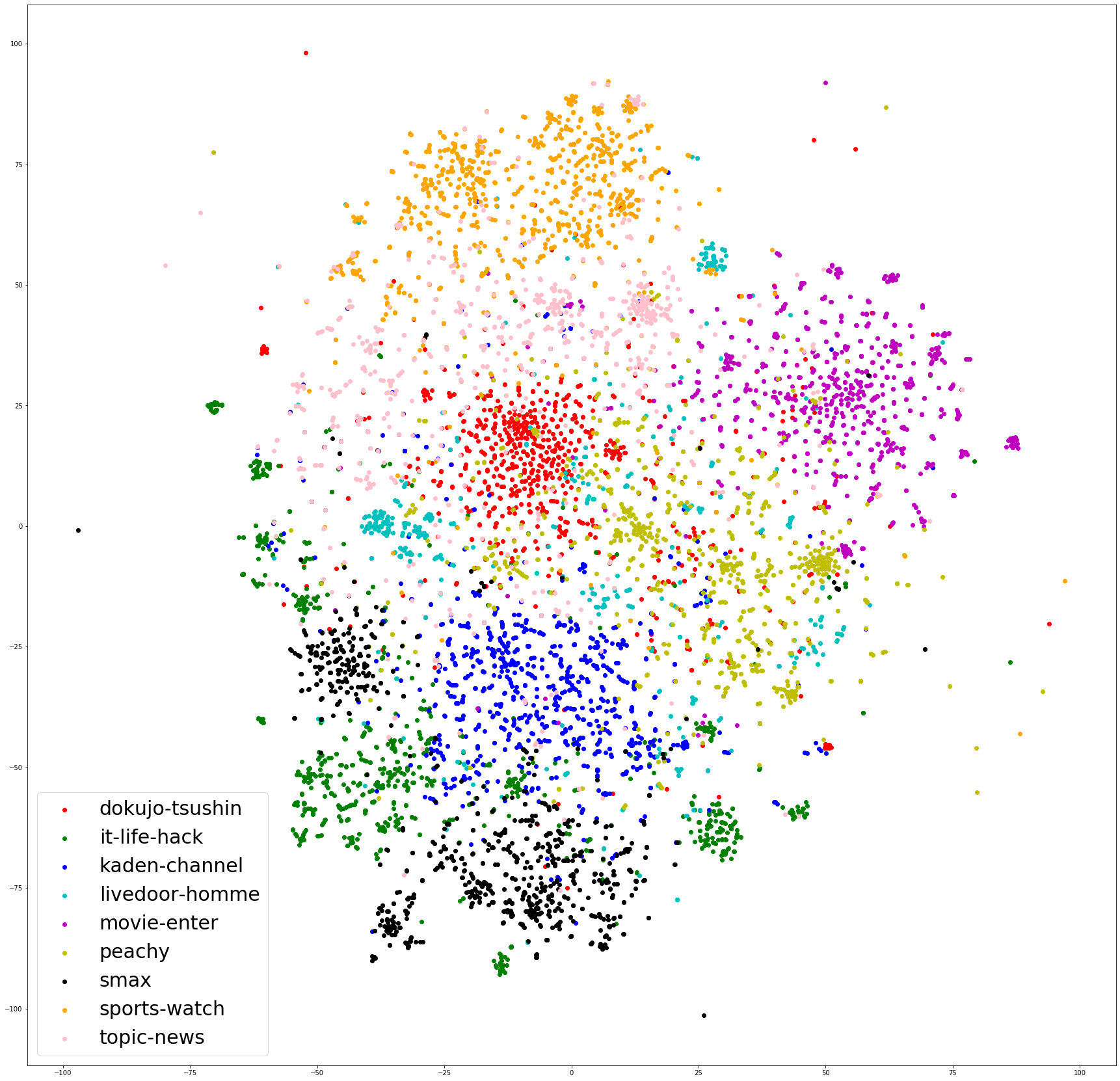
import pickle import matplotlib.pyplot as plt from sklearn.feature_extraction.text import TfidfVectorizer import pandas as pd #形態素分解した後のデータフレームはすでにpickle化して持っている状態を想定 with open('df_wakati.pickle', 'rb') as f: df = pickle.load(f) #tf-idfを用いてベクトル化 vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(df[3]) #t-SNEで次元削減 from sklearn.manifold import TSNE tsne = TSNE(n_components=2, random_state = 0, perplexity = 30, n_iter = 1000) X_embedded = tsne.fit_transform(X) ddf = pd.concat([df, pd.DataFrame(X_embedded, columns = ['col1', 'col2'])], axis = 1) article_list = ddf[1].unique() colors = ["r", "g", "b", "c", "m", "y", "k", "orange","pink"] plt.figure(figsize = (30, 30)) for i , v in enumerate(article_list): tmp_df = ddf[ddf[1] == v] plt.scatter(tmp_df['col1'], tmp_df['col2'], label = v, color = colors[i]) plt.legend(fontsize = 30)結果はこちらです。記事の媒体毎にクラスターが存在していることが可視化できています。
Next
その他の次元削減アルゴリズムについてもまとめられたいいなと思っています。最後まで読んでいただきありがとうございました。

- 投稿日:2020-06-02T22:18:06+09:00
Pandas Plotのバグ
1 この記事の説明
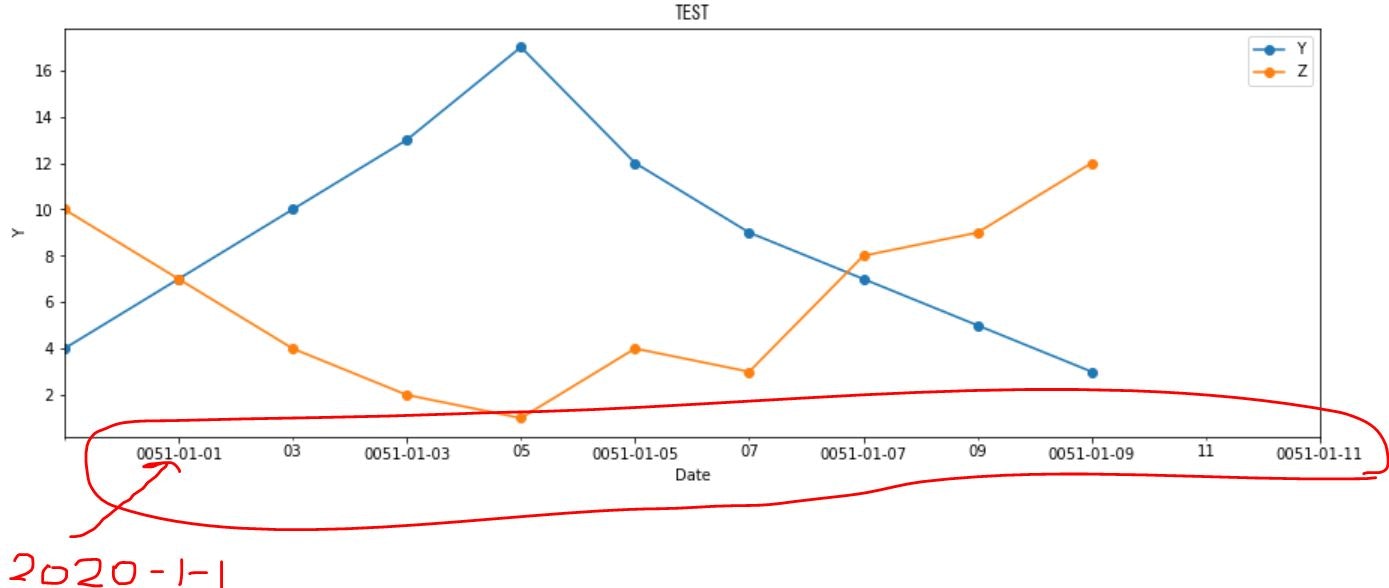
Pandasのplotを使い時系列グラフを描写したところ日付の変換が正しく動作しない。
例えば、2020-01-01が0051-01-01と誤って表示されてしまう。
2 内容
Pandasで生成したデータフレームに関して「データフレーム.plot(・・・・)」のコマンドでグラフを表示し、「mdates.DateFormatter('%Y-%m-%d')」にて「フォーマットをY-M-Dにした場合、日にちが正しく表示されないことが分かった。下記のコードを実行すると横軸日付が正しく表示されない。
/home/sampletest/sample.pyimport datetime import matplotlib.pyplot as plt import matplotlib.dates as mdates import seaborn as sns # Dataセットを定義する。(日付はdatetime.datetimeで記載する。日付型で表記する) dat = [ [datetime.datetime(2020,1,1),4,10], [datetime.datetime(2020,1,2),7,7], [datetime.datetime(2020,1,3),10,4], [datetime.datetime(2020,1,4),13,2], [datetime.datetime(2020,1,5),17,1], [datetime.datetime(2020,1,6),12,4], [datetime.datetime(2020,1,7),9,3], [datetime.datetime(2020,1,8),7,8], [datetime.datetime(2020,1,9),5,9], [datetime.datetime(2020,1,10),3,12], ] dat=pd.DataFrame(dat,columns=["DATE","Y","Z"]) dat.set_index("DATE",inplace=True) #横軸に表示する日付をDataFrameのindexにする。 print(dat) fig = sns.mpl.pyplot.figure() #グラフを描写するオブジェクトを生成する。 ax=dat.plot(marker="o",figsize=(15, 5)) #Dataframe.plotの形式でグラフを描写するとエラーになる ax.legend() #凡例を描写する # グラフのフォーマットの設定(横軸の日付の表示方法を設定する。) days = mdates.DayLocator(bymonthday=None, interval=2, tz=None) # 横軸:「毎日」を表示対象にする。(この行がないと日付が重複表示される) daysFmt = mdates.DateFormatter('%Y-%m-%d') #横軸:フォーマットをY-M-Dにする。 ax.xaxis.set_major_locator(days) #横軸に日付を表示する。 ax.xaxis.set_major_formatter(daysFmt) #横軸に日付を表示する。 fig.autofmt_xdate() #横軸の日付を見やすいように斜めにしてくれる。 # グラフに名前を付ける ax.set_xlabel('Date') #X軸のタイトルを設定する ax.set_ylabel('Y') #Y軸のタイトルを設定する plt.title(r"TEST",fontname="MS Gothic") #グラフのタイトルを設定する。日本語を指定するときは、fontnameの指定が必要 #グラフのサイズを設定する fig.set_figheight(10) fig.set_figwidth(20) #横軸の表示範囲を設定する ax.set_xlim(datetime.datetime(2020,1,1), datetime.datetime(2020,1,12))日付を正しく表示させる方法はこちら
ax.plot(df['Y'].....)の形式でグラフを表示するとよい。
- 投稿日:2020-06-02T21:21:23+09:00
「14日で作る量子コンピュータ」を読んでみる。3日目
はじめに
今回は重ね合わせの原理と、電子波束についてまとめる。
3 電子波束の観察
重ね合わせの原理
重ね合わせの原理は、シュレディンガー方程式を満たす複数の解を、足し合わせてできる関数もまたシュレディンガー方程式の解となっていると言う原理です。例えば以下のようなある分布にしたがって、$\psi_k$を重ね合わせた波動関数を用意する。
$$
\psi(x,t)=\int_{-\infty}^{\infty}a(k)\varphi_k(x)e^{-i\omega(k)t}dk=\int_{-\infty}^{\infty}a(k)e^{ikx-i\omega(k)t}dk
$$これをシュレディンガー方程式に代入してみる、この時自由空間なのでポテンシャルは0したがって
$$
i\hbar\frac{\partial}{\partial t}\int_{-\infty}^{\infty}a(k) e^{ikx-i\omega(k)t}dk=\frac{\hbar^2}{2m}\frac{\partial^2}{\partial x^2}\int_{-\infty}^{\infty}a(k)e^{ikx-i\omega(k)t}dk
$$$$
\int_{-\infty}^{\infty}a(k)\hbar \omega(k) e^{ikx-i\omega(k)t}dk=\int_{-\infty}^{\infty}a(k)\frac{\hbar^2k^2}{2m}e^{ikx-i\omega(k)t}dk
$$$$
\int_{-\infty}^{\infty}a(k)\left[\hbar \omega(k)-\frac{\hbar^2 k^2}{2m}\right] e^{ikx-i\omega(k)t}dk=0
$$全ての位置と時間にかかわらず左辺はゼロになる時重ね合わせの原理は成り立つことになるので、括弧の中身がゼロになる条件について調べると
$$
\omega(k)=\frac{\hbar k^2}{2m}
$$これは$\omega$自体の定義と同じなので、常に成り立つ。つまり常に重ね合わせの原理が成り立つことが示された。
3.2 電子波束の観察
$a(k)$はどのような分布でも良いので、適当な定数$k_0$を中心とするガウス分布とするとa(k)は
$$
a(k)=e^{-(\frac{k-k_0}{2\sigma})^2}
$$この時の波動関数をプロットしてみる。
3.2.1 定数
ここで新たに必要となる定数は
# 空間の分割数 NX = 500 # 空間分割サイズ dx = 1.0e-9 # 計算区間 x_min = -10.0 * dx x_max = 10.0 * dx # 重ね合わせる数 NK = 200 # kの偏差 sigma = math.sqrt(math.log(2.0)) * 1.0e9 # kの分割 dk = 20.0 / NK # 波束の中心エネルギー E0 = 10.0 * eV # 波束の中心 k0 = math.sqrt(2.0 * me * E0 / hbar ** 2) omega0 = hbar / (2.0 * me) * k0 ** 2 # 計算時間の幅 ts = -50 te = 50 # 時間間隔 dt = 1.0e-16 # 虚数単位 I = 1.0j3.2.2 関数の定義
プロットを作るに当たって必要なのは、ある時点tにおけるグラフの配列を出力する関数が必要なので、
def dist_t(xl, t): psi_real = [] psi_imag = [] psi_abs = [] for x in xl: # スケーリング psi_c = psi(x, t) * dx * dk / 10.0 psi_real.append(psi_c.real) psi_imag.append(psi_c.imag) psi_abs.append(abs(psi_c)) return psi_real, psi_imag, psi_absそして、(x,t)が与えられた時の確率分布を出力する関数psiを定義する。
def psi(x, t): psi_sum = 0.0 + 0.0j for kn in range(NK): # 定数を取得 k = k0 + dk * (kn - NK/2) omega = hbar / (2.0 * me) * k ** 2 # 重ね合わせ psi_sum += cmath.exp(I * (k * x - omega * t)) * cmath.exp(-((k - k0) / (2.0 * sigma)) ** 2) return psi_sum3.2.3 アニメーションのプロット
これらを用いてプロットを行う。
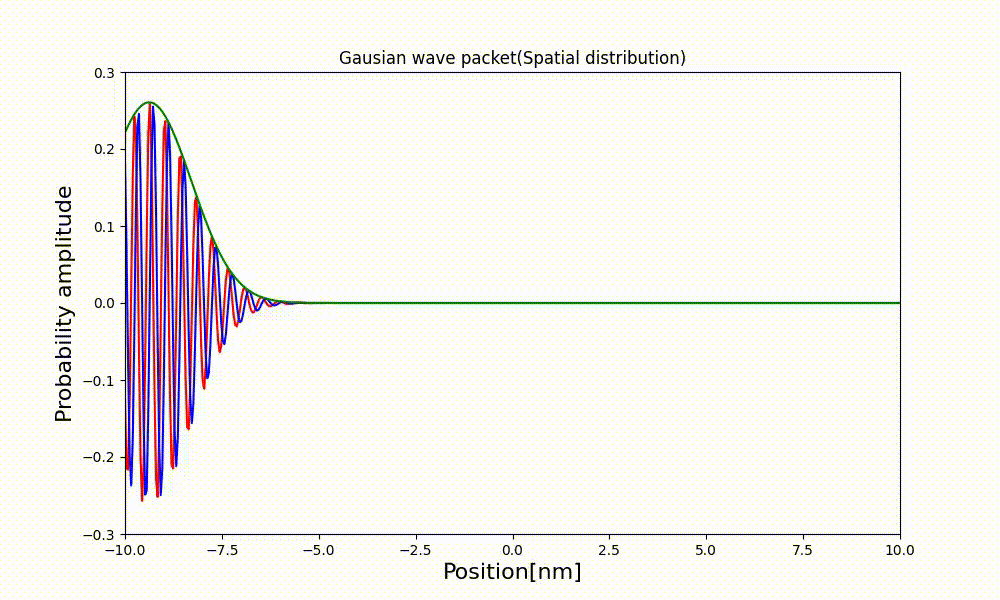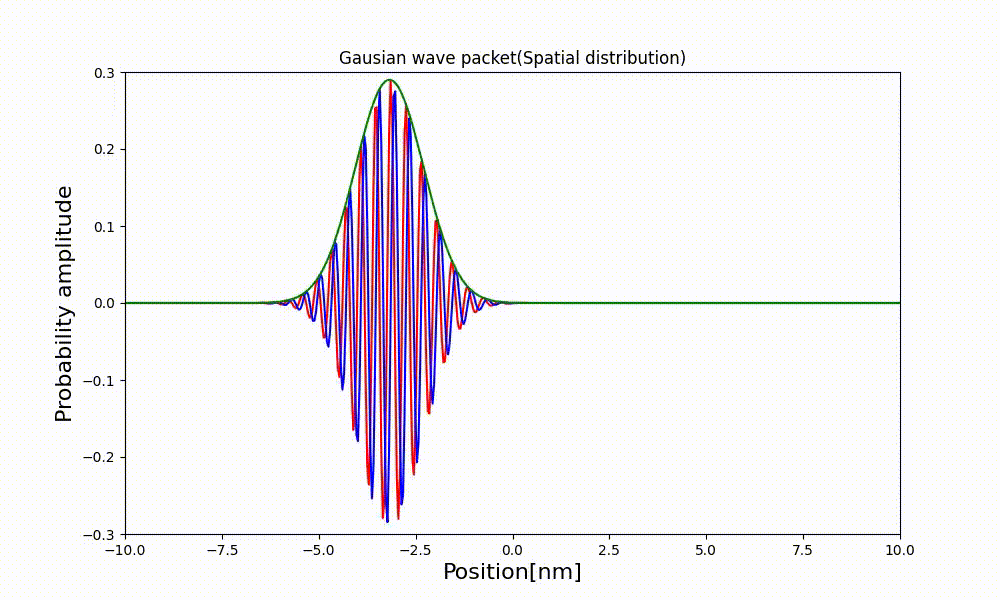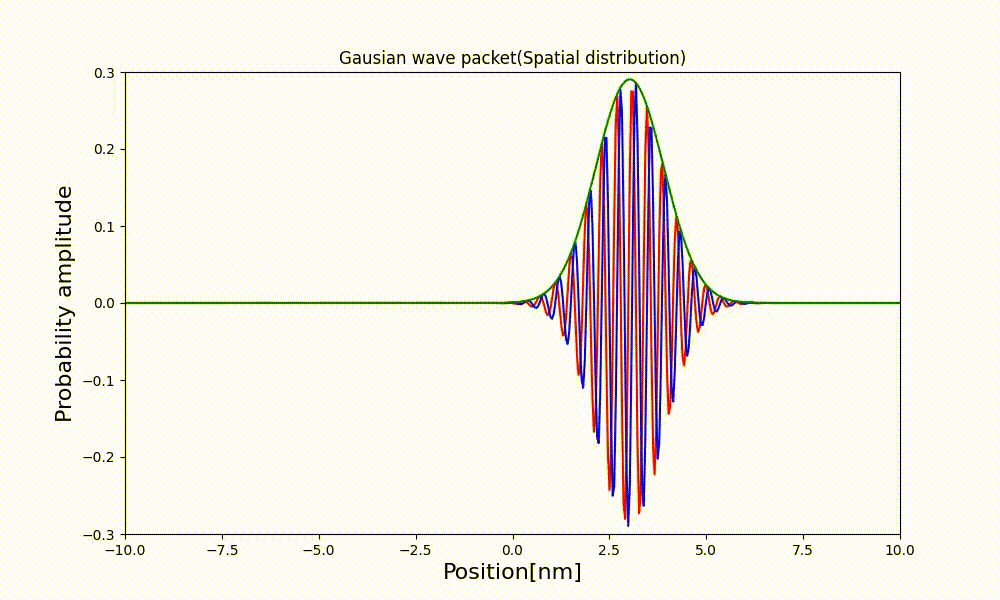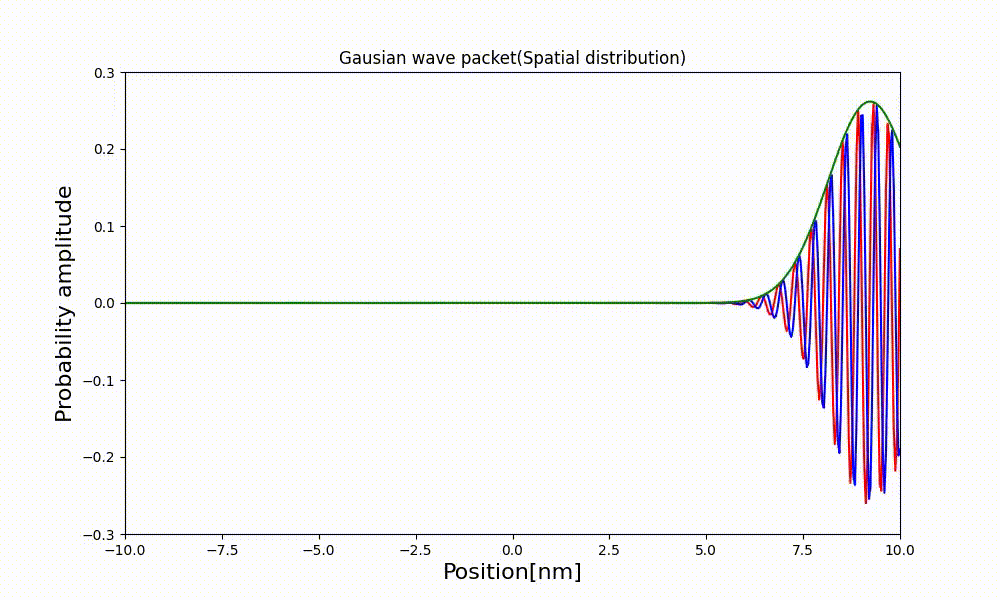
xl = np.linspace(x_min, x_max, NX) # アニメーション作成用の配列 ims = [] fig1 = plt.figure(figsize=(10, 6)) for t in range(ts, te + 1): t_real = t * dt psi_real, psi_imag, psi_abs = dist_t(xl * dx, t) # コマの描写 img = plt.plot(xl, psi_real, 'red') img += plt.plot(xl, psi_imag, 'green') img += plt.plot(xl, psi_abs, 'blue') # コマの追加 ims.append(img) # グラフの描画 plt.title("Gaussian wave packet(Spatial distribution)") plt.xlabel("Position[nm]", fontsize=16) plt.ylabel("Probability amplitude", fontsize=16) # 描画範囲 plt.xlim([-10.0, 10.0]) plt.ylim([-0.3, 0.3]) # アニメーション生成 ani = animation.ArtistAnimation(fig1, ims, fontsize=16) ani.save("g_wave_packet.html", writer=animation.HTMLWriter()) plt.show()3.3 出来上がったアニメーション
↓が出来上がった動画。時間が立つほど分布の幅が広がっているのが観察できる。
- 投稿日:2020-06-02T20:51:30+09:00
PEP 604 (Complementary syntax for Union[]) を読んだよメモ
Microsoft の Python 向け型チェッカーの pyright が最新の仕様に対応していると聞いて README を流し読みしていたら、今までウォッチしていなかった PEP 604 (Complementary syntax for Union[]) というのがリストアップされていたので目を通してみました。
ちなみに次の記事で PEP-612 についても書く予定です。概要
- 毎回
Union[int, str]って書くのうざくない?- Scala みたいに
int | strって書けるようにしようよ- 型アノテーションだけじゃなくて、
isinstance()やissubclass()でも使えるようにしようよアプローチ
- 型同士を
|でつなぐと型集合をつくれるようにする以上。
例
PEP にあるサンプルを見ると一目瞭然なので説明は省きます。
# in place of # def f(list: List[Union[int, str]], param: Optional[int]) -> Union[float, str] def f(list: List[int | str], param: int | None) -> float | str: pass f([1, "abc"], None) assert str | int == Union[str,int] assert str | int | float == Union[str, int, float] assert isinstance("", int | str) assert issubclass(bool, int | float)感想
- 正直な感想としてキモい…
- Scala で見かけるとあんまり違和感はないのに、Python として見るとなんだかゾワゾワするのは単に慣れていないだけだろうか
- Union を書くのは楽になるけど
List[int | str]を書くのにはあまりメリットないですね…- まだ Draft なので採用は決まってません
- 投稿日:2020-06-02T20:01:44+09:00
Pythonの関数入門
まえおき
- この記事は執筆中のやさしくはじめるPythonプログラミングの本の特定の章の部分抜粋です。
- 入門本なので初心者の方向けです。
- 関数の章の内容が主になります。
- Qiita記事にマッチしていない箇所(「章」や「ページ」といった単語が使っていたり、改行数が余分だったり、リンクが対応していない等)があるという点はご留意ください。
面倒なのでQiita用に調整するのやりたくない。気になる方は↑のリンクの電子書籍版をご利用ください。- コメントなどでフィードバックいただいた場合、書籍側にも活用・反映させていただく場合があります。
同じ処理のコードを使いまわす : 関数入門
この章ではPythonの関数について学んでいきます。そもそも関数ってなんだ?という感じですが、その辺りの説明を含めて説明していきます。
関数をうまく使いこなすとコードを書く量を減らせたり、同じコードを何度も書かずに済んだり、読みやすいコードにしたりとメリットがたくさんあります。
そもそも関数ってなんだろう?
まずは関数自体の説明から進めます。
関数は英語でfunctionとなります。数学でも関数と呼ばれるものがあり、そちらも英語だとfunctionとなっていますが、数学とプログラムでは関数の内容が異なります。別物なので注意してください。
Pythonのプログラムにおける関数は、主に以下のような特徴を持ちます。
- 一定の量のプログラムのまとまりである。
- 色々な場所からその関数のプログラムを実行することができる。
- 任意の受け取った内容に応じて、関数内のプログラムの挙動を変えることができる。
- 関数のプログラムの内容に応じて、任意の結果を返却することができる。
関数といったように、数とついているから数値に関連するもの?と思えるかもしれませんが、関数は数値以外の例えば文字列やリストなども様々なものを入力に受け付けてくれます。日本語だと少し紛らわしいですが、関数の英語は特に数に絡んだ単語は無く、単純にfunctionとなっている点も頭の片隅に入れておいてください。
functionは関数という意味以外に、「機能」「働き」といった意味も持ちます。プログラムの関数は、実行すると「なんらかの機能のプログラムが実行される」といったくらいに考えておくといいかもしれません。
関数の最初の一歩
Pythonの関数を作るには、
defというキーワードを使います。defの後に半角のスペースを1つ入れて、その後にその関数の名前を書き、半角の(と)の括弧を書いて行末に半角のコロンの:を付けることで関数を作ることができます。
def 関数名():といった具合です。関数名のところは基本的に半角の英数字を使います。関数のプログラムの内容は、
defで定義した関数の次の行から、インデントを1個分(半角のスペース4つ分)追加してそこに書いていきます。サンプルとして、1 + 1の内容をprintで出力するという関数のプログラム内容で、関数名を
print_one_plus_oneとしたい場合は以下のようなコードになります。def print_one_plus_one(): print(1 + 1)前章のインデント関係のセクションで、「インデントはプログラムの階層構造を表す」「右にいくほどプログラムの階層の深い」と説明しました。
関数のプログラムでも、この「右に行くほどプログラムの階層が深い」というルールは健在です。
前述のコードでインデント1つ分(半角スペース4個)が設定されている、
print(1 + 1)という部分に着目してみましょう。この部分は「関数の中のプログラム」に該当します。つまり「print_one_plus_oneという関数」の中の「
print(1 + 1)というプログラム」といったように、インデントが増えたことによってプログラムの階層が深くなっています(インデントの分、プログラムが中に入っています)。また、リストや辞書におけるインデントの説明のセクションでは、インデントを以下のように省いたコードでも一応動きはする(プログラムのエラーにはならない)と説明しました。
int_list = [ 1, 2, 3, 4, ]一方で、関数ではインデントが意味を持ちます。「インデントを含んだプログラムの開始位置」が「関数内のプログラムの開始位置」を意味し、「インデントを含まないプログラムの直前の位置」が「関数内のプログラムの終了位置」を意味します。この辺りは少々分かりづらい気もするので、プログラムを踏まえてしっかりと見ていきます。
ひとまずは正しいインデントを設定しないと関数のプログラムが動いてくれないという点を頭にぽれて置いてください。
試しに、関数の後にインデントを入れないコードを書いて実行してみましょう。
def print_one_plus_one(): print(1 + 1)File "<ipython-input-12-a31292ca450b>", line 2 print(1 + 1) ^ IndentationError: expected an indented block上記のように、関数の後にインデントが無いとエラーになってしまいます。IndentationErrorはインデントが正しくないことによって発生するエラーで、indented blockはインデントされたコードのかたまりの意味、expectedは「想定されている」といった意味合いなので、「インデントが追加されたコード部分が来ることが想定されているけれども、そうなっていない(インデントが無い)」といったようなエラーのメッセージになります。
なお、コードではない行、例えばただの空の行(プログラムの書かれていない行)であればインデントが無くても問題ありません。たとえば、以下のように
digit_value = 1 + 1の行とprint(digit_value)の間に空の行でインデントの無い行があっても問題ありません。def print_one_plus_one(): digit_value = 1 + 1 print(digit_value)関数を終わらせるには、インデントを無くしてコードを書きます。例えば、関数の内容は関数を実行(次のセクションで触れます)しないとコードの内容は実行されませんが、以下のコードでは
print(3 + 5)という部分はインデントが無い(=関数の内容が終わっている)ので、関数を呼び出さなくても即時で実行され8という結果が表示されます。def print_one_plus_one(): digit_value = 1 + 1 print(digit_value) print(3 + 5)コード実行結果の出力内容:
8
関数を実行する
作った関数を呼び出す(実行する)には、
関数名()といったように、関数名の後に半角の(と)の括弧を利用します。少し前に作った
print_one_plus_oneという関数を実行したければ、print_one_plus_one()といったように書きます。コードを実行してみると関数の中のプログラム(print(1 + 1))が実行されて、2が出力されることが分かります。def print_one_plus_one(): print(1 + 1) print_one_plus_one()コード実行結果の出力内容:
2
関数と関数の外の変数の話 : スコープ入門
関数の中で作った変数は特殊な挙動をします。
説明のためにまずは以下のコードを書いて実行してみてください。
def print_one_plus_one(): digit_value = 1 + 1 print(digit_value) print_one_plus_one() digit_value += 12 --------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-21-50561b28b02f> in <module> 5 6 print_one_plus_one() ----> 7 digit_value += 1 NameError: name 'digit_value' is not defined
print_one_plus_one関数がまずは実行され(print_one_plus_one())、そこでdigit_valueという変数が作られ(digit_value = 1 + 1)、その後関数の外でdigit_valueの変数に1をプラスする(digit_value += 1)というコードです。しかしながら実行してみると「
digit_valueという変数が定義されていないよ」というエラーメッセージ(name 'digit_value' is not defined)になってしまいました。関数内のコードで変数を作っているのに何故でしょう?
実は、関数の中で作られた変数は、基本的には関数が実行し終わると消えてしまいます。そのため、関数内で作った変数などはそのままだと関数の外のコード(インデントが無い部分)や他の関数から使ったり(参照するともよく呼ばれます)はできません。
関数という箱の中に変数が色々入っているのをイメージしてください。別の関数は別の箱となります。お互いに、変数は箱の中に入っているものしか使うことはできません。
この箱のように、参照できる変数の範囲のことをスコープと言います。英語だとscopeとなります。「範囲」や「視野」といった意味を持つ単語です。プログラミングでは「変数などのアクセスできる範囲」といった意味になります。
スコープについてもう少し見ていきます。
先ほどは関数の中の変数を関数の外でアクセスしようとしたらエラーになりました。今度は逆に関数の外で作られた変数に対して関数の中からアクセスするとどうなるでしょうか?
関数の外で作られた変数の関数内での参照は、変数の型によって挙動が変わります。
まずは例として整数(int)の変数で試してみます。
int_variable = 100 def add_one(): int_variable += 1 add_one()UnboundLocalError Traceback (most recent call last) <ipython-input-4-e73c01cb25ac> in <module> 6 7 ----> 8 add_one() <ipython-input-4-e73c01cb25ac> in add_one() 3 4 def add_one(): ----> 5 int_variable += 1 6 7 UnboundLocalError: local variable 'int_variable' referenced before assignment実行してみると上記のようなエラーになります。
Unboundは「束縛されていない」といった意味の他に、「未製本の」とか「割り当てられていない」といった意味を持ちます。また、関数の中の変数のことをローカル変数(英語でlocal variable)と言います。特定の地域だけのルールをローカルルールなどと言ったりしますが、ローカル変数も似たような感じで「特定の関数の中だけの変数」という意味になります。
referencedは参照されたという意味で、assignmentは割り振りといったような意味を持ちます。ここでは、変数が作成されていないと読み替えていただいても問題ありません。
よって
local variable 'int_variable' referenced before assignmentというエラーメッセージは、「int_variableというローカル変数が作成前に参照されているよ」というメッセージになります。ローカル変数と対になるもので、グローバル変数というものがあります。ローカル変数は特定の関数でしか参照ができない一方で、グローバル変数は設定次第で色々なところで参照することができます。
関数の外で変数を作るとそれはグローバル変数になります。実は関数の章の前に今まで色々作ってきた変数はグローバル変数に該当します。
前述のUnboundLocalErrorになったコードでは、先に
int_variable = 100というコードでグローバル変数を作っています。且つ、グローバル変数は色々な場所で参照できると説明しました。それであれば
add_one関数の中でint_variableを参照しているところでエラーになるのはおかしいのでは?という感じですし、グローバル変数なのにエラーメッセージでローカル変数云々と表示されるのはおかしくない?と感じられるかもしれません。なぜこのような挙動になっているのかというと、Pythonのプログラムからすると「これはローカル変数なの?」「グローバル変数なの?」ということが分からないためです。
グローバル変数とローカル変数には同じ名前を使うこともできます。そのため、このままだとプログラム側からするとどっちで扱うべきか判断ができず、ローカル変数で整数が扱われている形になります。整数などのグローバル変数を扱いたい場合には「これはグローバル変数だよ」と明示的にプログラムに教えてあげる必要があります。
特定の変数をグローバル変数だとプログラムに教えてあげるには関数内で
global 変数名と書きます。前述のコードのint_variableという変数をグローバル変数として扱う場合にはglobal int_variableといった形になります。エラーが起きないように書き直すと、以下のようになります。ちゃんとグローバル変数の
100の値に1プラスされて101が出力されていることを確認できます。int_variable = 100 def add_one(): global int_variable int_variable += 1 print(int_variable) add_one()コード実行結果の出力内容:
101
関数の外(グローバル変数)で事前に変数を作る前に、関数内で
globalを使ってから変数を作り、関数実行後に関数の外でその変数を参照してみるとどうなるでしょうか?コードを書いて実行してみます。
def define_global_variable(): global int_variable_2 int_variable_2 = 200 define_global_variable() print(int_variable_2)コード実行結果の出力内容:
200
今回は新しい変数名として
int_variable_2としました。define_global_variable()部分で関数が実行され、関数の中身でグローバル変数として変数が作成(global int_variable_2とint_variable_2 = 200)され、その後に関数の外でその変数を参照(出力)しています(print(int_variable_2))。
globalの記述がなかった時にはエラーになっていたものが、エラーが発生せずに変数の200という内容が出力できていることが分かります。型によってはglobalを省略してもグローバル変数にアクセスできる
先ほどのセクションで、整数などのグローバル変数を関数内でそのままアクセスしようとエラーになることを確認しました。
この挙動は整数以外の文字列(str)や浮動小数点数(float)、真偽値(bool)などの型の値でも同様の挙動になります。
一方で、リストや辞書などの値の場合は挙動が変わります。どう違うのか1つ1つ見ていきましょう。
まずは関数の外のグローバル変数を作って、関数の中で(globalの記述を省いた形で)その変数を参照してみます。
dict_variable = {'name': 'orange'} def print_dict_variable(): print(dict_variable) print_dict_variable()コード実行結果の出力内容:
{'name': 'orange'}
関数の外で辞書のグローバル変数を作成し(
dict_variable = {'name': 'orange'})、関数を実行(print_dict_variable())しています。関数の内部では辞書のグローバル変数の内容を出力(print(dict_variable))しています。前のセクションで整数の変数で試した時には、このような書き方だと
globalで変数を指定しないと(ローカル変数が未生成という判定になって)エラーになってしまいましたが、辞書のグローバル変数の場合はglobalで指定しなくてもエラーにならず、値もちゃんと出力できていることが分かります。このように、辞書やその他リストなどでもグローバル変数を関数内で参照することができます。整数などとはスコープの挙動が異なるので注意してください。
続いて、グローバル変数と同じ変数名で、関数の中でローカル変数を作った場合の挙動を確認してみます(
globalの指定は省略します)。dict_variable = {'name': 'orange'} def change_dict_variable(): dict_variable = {'name': 'apple'} change_dict_variable() print(dict_variable)コード実行結果の出力内容:
{'name': 'orange'}
まずは辞書のグローバル変数を作成(
dict_variable = {'name': 'orange'})し、その後関数を実行(change_dict_variable())しています。関数の中ではグローバル変数と同じ名前で新しい辞書の変数を作成(dict_variable = {'name': 'apple'})しています。最後に、関数の外でグローバル変数の内容を出力(print(dict_variable))しています。出力結果(
{'name': 'orange'})を見ると分かるように、関数内で設定した値({'name': 'apple'})は反映されておらず、グローバル変数を作ったときの値そのままになっています。これは、関数内で新しくリストや辞書などを作った時は、同じ名前のグローバル変数があってもローカル変数として扱われていることを意味します。つまり、関数の内容が実行され終わったらローカル変数の内容は無くなってしまうので、結果的にグローバル変数の値がそのまま残っているという形になります。
少し複雑ですね。全部は覚えられなくても、必要になった時にコードを動かして試してみるなどして、その都度思い出せれば問題はありません。条件によって色々スコープの挙動が変わるという点だけは頭の片隅に入れておいてください。
最後にもう一つ、辞書のグローバル変数を事前に作成しつつ、関数の中でglobalを使って同名の変数を指定して、新しい辞書を設定するケースでの挙動を試してみましょう。
dict_variable = {'name': 'orange'} def change_dict_variable(): global dict_variable dict_variable = {'name': 'apple'} change_dict_variable() print(dict_variable)コード実行結果の出力内容:
{'name': 'apple'}
前のコードと比べて関数内の
global dict_variableの部分が追加になっただけです。しかし、この記述によってdict_variableの変数がローカル変数扱いではなくグローバル変数扱いになったため、関数実行後の出力処理(print(dict_variable))の結果が{'name': 'orange'}(グローバル変数設定時の値)でなはく{'name': 'apple'}(関数内での設定値)に変わっています。このように値の型やglobal指定の有無で挙動が変わってきます。複雑なので、シンプルにするように以下のような工夫も役立ちます。
- グローバル変数を使わない、もしくは使っても最小限にする(後で触れる引数という機能で代替できるケースが多いので引数を主に使う)。
- グローバル変数として扱いたい場合には、数値や辞書など関係なくglobalで明示するようにする(辞書などでも省略しない)。
- 紛らわしくなりそう(支障が出そう)なときは、グローバル変数とローカル変数で同じ名前を使うのを避ける。
また、型ごとに関数内でのグローバル変数の参照でglobalが要るかどうかの判別については、厳密な定義ではありませんが指標として、
- 単一の値(整数や文字列など)はglobalの指定が必要
- 単一の値をたくさん格納するような大きな値(リストや辞書など)はglobalの指定を省略可
くらいに覚えておくと分かりやすいかもしれません。
そもそもなんで関数を使うの?
もちろん関数を設けずにそのままコードを書いても動くプログラムは実現できます。ではなぜわざわざ関数を使うのでしょうか?
理由は色々ありますが、大きなものとして「コードの重複を減らす」という目的と、「コードを読みやすくする」の2点があります。
ここまでのコードサンプルだと短いコードばかりだったため、メリットが分かりづらいかもしれません。
しかし現実の仕事などでは、長いプログラムやたくさんのファイルのプログラムを扱うことが多くなります。そういった複雑な環境では関数のメリットが生きてきます。
たとえば仕事で20行くらいのコードの処理を書いたとします。このくらいであれば何も問題にはなりません。
しかし同じような処理が将来必要になって倍の40行が必要になったり、さらに増えて60行になったり...と繰り返している間に数百行、数千行、数万行...となってきてしまいます。特に、何年も続くプロジェクトの仕事だと顕著です。
毎回毎回同じようなコードを書いていると、コードを把握するのが大変になってきます。変数なども膨大になってきますから、「この変数はどのように使われているの?」といったようにコードを追っていくのも大変になりますし、関係無い変数を操作してししまうといったようなミスも多発するようになっていきます。
また、将来必要な処理が変わって、コードを編集する必要が出てきたとします。同じようなコードが数十箇所とあったらミスせずにコードを変えるのがとても大変になります。どこか一つでも変更が漏れている箇所があったりしたら不具合(バグとも呼ばれます)やエラーになったりしてしまいます。
プログラムを書く仕事では頻繁に機能を更新したり追加したりが求められますので、これでは大分辛い感じがしますね。
一方でもし処理が関数を実行する形で、実際の処理のコードは関数内にかかれていたらどうなるでしょう?
関数内のコードだけ変更すれば済むので変更漏れを防ぐことができます。また、変更に必要な作業時間もとても少なく済みます。
このように関数をうまく使うことでコードの重複している処理の部分を関数化したりして、変更などにかかる時間やリスクなどを減らすことができます。
もう一点の大きなメリットとして、関数の使い方次第ではありますがコードが読みやすくなるという点が挙げられます。
プログラムを読んだりするときには、要素が少ない方が読みやすくなります。例えば変数が300個くらいあって、後々の章で出てくる条件分岐などもたくさんあるようなコードだと内容の正確な把握などがとても大変になりますしミスしがちになります。
一方で、関数は前のセクションのスコープで触れた通り、ローカル変数などは「その関数内でだけ使われる」「関数が終わったらローカル変数は無くなる」性質を持ちます。
この性質によって、例えば300個の変数が必要な処理をたくさんの関数に分割して1つの関数につき5個とかに細かく分割したとするとコードがとても読みやすくなります。
よく「人間が一度に覚えられる要素は3~9個くらいだ」みたいな話を聞きますが、プログラムも同様で一度にたくさんの要素があると把握や短期間の記憶などが困難になってきます。
電話番号などで3つの数字や4つの数字などでハイフンを入れて分割して、把握しやすくするといったようなことに近いかもしれません。関数で分割して、1つの関数当たりの変数や処理の数を減らすことで、電話番号を分割するようにコードを把握しやすくミスしにくいコードにすることができます。
その他にも処理の少ない関数にたくさん分割していくことで、テストが書きやすくなるといったメリットもあります。テストなどに関しては結構発展的な内容になるため、後々の章で詳しく説明します。
色々なデータに応じて振る舞いを変える : 引数設定
固定の値のみを使った関数の処理よりも、変数のように可変の値を使って関数を作った方が汎用的で使いまわしがやりやすくなります。
たとえば、「5 × 3の計算をする」という関数よりも、任意のxの値で「xを3倍する計算をする」といった方が該当の関数を使えるケースが多くなります。
前のセクションで触れたグローバル変数などを使っても任意の変数を使うこともできるのですが、こういった場合には関数の「引数」と呼ばれる機能を使うのが一般的です。引数は英語ではargumentと言います。
日本語で引数という名前になっていますが、プログラムにおける引数は数値以外も受け付けます。文字列や真偽値、リストなど色々引数に指定することができます。
英語のargumentは引数という意味の他にも、「議論する」「言い争う」という意味のargueの英単語からも予想できるように、「議論」や「主張」といった意味も持ちます。
一見引数と議論などは意味的に全然関係無さそうな感じではありますが、原義的には「論拠(議論を支持するための理由や証拠など)」から派生して、「他の量を求めるために利用される元の量」といった具合に変化してきたことに由来するそうです。
関数の処理の結果が引数の値によって変動するという性質を考えると、argumentという単語も少ししっくり来ますね。
日本語としての引数という単語は、意味的には「関数に引き渡す値」といったものに近いかもしれません。
引数を使うことで関数に任意の値を渡すことができます。
渡された引数はその関数のローカル変数として扱われます。前のセクションで「ローカル変数はその関数内でだけ使われる」「関数が終わったらローカル変数は無くなる」という性質を持つため、グローバル変数をたくさん使ってコードを書くよりも読みやすくミスしにくいコードを書くことができます。
ここまでのサンプルコードでは全て引数を使わない関数を作ってきました。
引数を受け付ける関数を作るには、関数名の後の(と)の括弧の中に引数名を指定していきます。例えば前述の「任意のxの値で、xを3倍する計算をする」という処理で、引数にxを受け付けるmultiply_threeという名前の関数を作るには
def multiply_three(x):というように書きます。関数を実行する時に引数の値を指定するには、
multiply_three()という書き方ではなく(と)の括弧の中に引数に指定したい値を設定します。例えば引数に10を指定したい場合にはmultiply_three(10)といったように書きます。実際にコードを書いて、関数を実行してみて結果を確認してみましょう。
def multiply_three(x): multiplied_value = x * 3 print(multiplied_value) multiply_three(10)コード実行結果の出力内容:
30
multiply_three(10)部分で関数を実行し、引数として10を指定しています。関数(def multiply_three(x):)の中では、引数に与えられたxの値(実行時に指定した値になるので、今回はxは10になっています)を3倍しています(multiplied_value = x * 3)。最後に3倍した値をprintで出力しています。出力結果は10の3倍で30となっています。
複数の引数を設定する
先ほどはxという引数で、xの値を3倍する関数を作りました。今度は「3倍する」方の値も引数で実行時に変えるようにしましょう。3倍部分の代わりに、yという引数を受け付けるようにします。
2つ目以降の引数を指定するには、半角のコンマを引数間に加えます。スペースを入れなくてもエラーにはなりませんが、コンマの後に半角のスペースを1つ入れるのがPythonのコーディング規約で定められているのでそのように書きます。
この場合の関数の引数部分は
(x, y)といったようなコードになります。def multiply_x_by_y(x, y): multiplied_value = x * y print(multiplied_value) multiply_x_by_y(10, 5)コード実行結果の出力内容:
50
複数の引数を持つ関数を実行する場合には、そちらも半角のコンマ区切りで値を設定します。xに10、yに5を設定したければ
multiply_x_by_y(10, 5)といったように関数実行部分を書きます。関数内の処理では、
* 3のように3倍するコードの代わりにyを掛ける形のコードにしてあります(multiplied_value = x * y)。結果として、xの10とyの5による掛け算でprintで出力される値は50になっています。
3個以上の引数を使いたい場合には、コンマを追加していくことで任意の数の引数を設定することができます。例えばx, y, zという3つの引数を取る関数を作りたい場合には以下のように書きます。
def multiply_x_y_z(x, y, z): multiplied_value = x * y * z print(multiplied_value) multiply_x_y_z(10, 5, 3)コード実行結果の出力内容:
150
引数部分が
(x, y, z)と三つの値になっており、関数実行時もmultiply_x_by_y(10, 5, 3)といったように3つの値を半角のコンマ区切りで指定しています。printによる出力結果はxyzの三つの引数の10 × 5 × 3で150となっています。
このように引数は複数の値を設定できますが、それぞれ順番に第一引数、第二引数、第三引数...といったように呼ばれます。今回の関数で言えば、
multiply_x_y_z関数の第一引数はxとなり、第二引数はy、第三引数はzとなります。渡された引数の数が一致していない場合は・・・
例えば3つの引数を受け付ける関数で、実行時に2つだけ値を指定するとどうなるのでしょうか?コードを書いて試してみましょう。
def multiply_x_y_z(x, y, z): multiplied_value = x * y * z print(multiplied_value) multiply_x_y_z(10, 5)コードの内容としては
x, y, zの3つの引数を受け付ける関数で、実行時にmultiply_x_y_z(10, 5)といったように引数に2つだけ値を渡しています(zの引数の値が指定されていません)。TypeError Traceback (most recent call last) <ipython-input-27-8cab8c50c583> in <module> 4 5 ----> 6 multiply_x_y_z(10, 5) TypeError: multiply_x_y_z() missing 1 required positional argument: 'z'実行してみるとエラーとなりました。エラーメッセージを読んでみましょう。
missingは「足りていない」、requiredは「必須の」といった意味になります。argumentは引数の英単語でしたね。
ざっくり訳すと「'z'という名前の必須の(省略できない)位置の引数が足りていないよ」というエラーメッセージになります。
このように関数を実行した時に必要な引数の指定が足りていない場合にはエラーになります。このエラーが出たときには「何の引数が足りていないのか」を確認し、実行しているコードを見て引数の数が合っているのかチェックしましょう。
指定しなくてもエラーにならない設定 : 引数のデフォルト値
先ほどのセクションのエラーで
required positional argumentと出てきて、必須の引数といったエラーメッセージになっていたことからも分かる通り、「必須ではない(省略できる)」引数設定も行うことができます。こういった省略可能な引数のことを「オプション引数(英語だとoptional arguments)」などと呼びます。
また、省略した場合に「引数がどんな値になるか」は「デフォルト値」と呼ばれるもので指定します。引数にデフォルト値を設定するには引数名の直後に半角のイコールの
=の記号と設定したいデフォルト値を設定します。例えば、xという引数に10のデフォルト値を設定したい場合にはx=10といったように書きます。変数設定を作るときなどにはイコールの前後に半角のスペースを入れていましたが、デフォルト引数ではイコールの前後にはスペースを入れないのが正しいPythonのコーディング規約です。変数設定などとは異なるので注意してください。
スペースを入れてしまってもエラーにはなりませんが、コーディング規約に準じていないコードになってしまいます。
コードを書いて試してみましょう。
def print_x(x=10): print(x)内容は引数に指定された値をprintで出力するだけのシンプルな関数です。引数もxという名前の引数1つだけです。
引数の部分が
x=10となっていることを確認してください。これは「xの引数指定を省略した場合はデフォルト値の10が設定される」という記述になります。関数を実行してみましょう。まずはxの引数を省略せずに実行してみます。xの引数には30を指定します。
print_x(30)コード実行結果の出力内容:
30
引数に指定した30の値が出力されました。
このように、デフォルト値が設定されている引数に対して値を省略せずに指定すると、指定された値が優先(今回は30)され、デフォルト値の10は無視されることが分かります。
今度は引数を省略して実行してみます。
(と)の括弧の間が何もない(引数の値を指定していない)点に注目してください。print_x()コード実行結果の出力内容:
10
結果は引数のデフォルト値として設定してある10が出力されています。
このように、デフォルト値を引数に設定した場合には、
- 引数へ値を指定した場合 -> 指定した値が設定される。
- 引数を省略した場合 -> 引数のデフォルト値が設定される
という挙動になります。
デフォルト値の使いどころですが、主に「通常はこのデフォルト値で大丈夫だけど、たまに値を変えたい」といったケースで使います。
逆に、引数に指定する値が基本的に毎回異なるようなケースではデフォルト値を設定すべきではありません。
そのようなケースでは通常の引数が必須となる形で関数を作っておくべきです。毎回引数の指定が必要なのに、指定をうっかり忘れてしまった時などにデフォルト値が設定されていると(引数を指定し忘れてしまっていても)エラーにならず、ミスに気づかないケースが発生しうるためです。
また、デフォルト値を持つ引数を設定する時には注意点として「デフォルト値が設定されている引数は必須の引数の後になっていないといけない」というルールが存在します。
たとえば以下のようにデフォルト値を持つ引数(
x=10)の後にデフォルト値を持たない必須の引数(y)を関数に設定するとエラーになります。def multiply_x_by_y(x=10, y): multiplied_value = x * y print(multiplied_value)File "<ipython-input-34-13a53a0612f1>", line 1 def multiply_x_by_y(x=10, y): ^ SyntaxError: non-default argument follows default argumentエラーメッセージを訳すと「デフォルト値を持たない引数がデフォルト値を持つ引数の後に来ているよ」といった内容になります。
これは
multiply_x_by_y(10)といったように関数を実行した際に、先にある引数が省略可能な一方で後の引数は省略不可(デフォルト値が無い)状態になっているので、(10)の値が第一引数のxに対する値なのか第二引数のyに対する値なのかがプログラム側から判断ができなくなってしまうためです。そのためデフォルト値を持つ引数は必須の引数の後に配置しないといけまぜん。以下のように、xとyの2つの引数でx側は必須の引数、y側はデフォルト値を持つ省略可能な引数を設定するケースではエラーは無く動きます。
def multiply_x_by_y(x, y=10): multiplied_value = x * y print(multiplied_value)こちらのエラーの出ないケースでは、
multiply_x_by_y(30)といったように1つの引数のみ指定して実行すれば必須の第一引数のxに対する値だと分かりますし、multiply_x_by_y(30, 20)と引数を省略せずに2つとも値を指定した場合にもxの値は30、yの値は20といったように問題なくプログラム側でコードを解釈することができます。必須の引数が複数ある場合にも、デフォルト値を持つ引数はそれらの後に来なくてはなりません。
例えば以下のように必須の引数xの後にデフォルト値を持つ引数yが来ていて、さらにその後に必須の引数zを設定するといったことはできません(エラーになります)。
def multiply_x_y_z(x, y=20, z): multiplied_value = x * y * z print(multiplied_value)File "<ipython-input-39-81a253f339fe>", line 1 def multiply_x_y_z(x, y=20, z): ^ SyntaxError: non-default argument follows default argumentこのように必須の引数は複数ある場合も、以下のようにデフォルト値を持つ引数(
z=20)はデフォルト値を持たない必須の引数の後に持ってこないといけません。def multiply_x_y_z(x, y, z=20): multiplied_value = x * y * z print(multiplied_value)デフォルト値を持つ引数を複数設定したい場合でも、必須の引数の後になっていればエラーにはなりません。たとえばyとzの引数がデフォルト値を持つ設定にしたい場合には以下のようにデフォルト値を持たない必須の引数xの後にそれぞれが続いていればエラーにはなりません。
def multiply_x_y_z(x, y=20, z=30): multiplied_value = x * y * z print(multiplied_value)関数の引数が変わっても影響を受けにくくて読みやすい : キーワード引数
例えば以下のようなたくさんの引数を持つ関数があったとします。
def calculate_cost(manufacturing_cost, labor_cost, delivery_cost, tax): sum_value = manufacturing_cost + labor_cost + delivery_cost + tax return sum_value関数を実行しようとすると以下のようになります。
calculate_cost(1000, 400, 150, 50)一応このくらいの数であれば各値がどの引数に該当するのかは一応把握できるといえば把握できます。しかし分かりづらく感じますし、うっかり順番ミスなどをしてしまいそうです。
さらに引数の数が増えたらどうなるでしょうか?例えば10個の引数が必要な関数だったり、15個の引数が必要な関数などをイメージしてみてください。
ミスせず、順番通りに引数の値を指定するのが大分難しそうですね。また、その関数が頻繁に引数の数が更新で変わってしまうようなケースを想像してみてください。途中の引数が無くなったりすることで、その後の引数の順番がずれたりしてとても混乱します。
そのようなケースの対策として、Pythonでは「キーワード引数(英語でkeyword arguments)」という機能が存在します。
キーワード引数を使うことで、引数の多い関数でも読みやすいコードを書くことができます。
実際に関数実行部分のコードを書いてみましょう。キーワード引数を使うには、関数実行箇所で
引数名=引数に指定する値という形で書くことで使えます。例えば、前述のサンプルコードの関数で言えばmanufacturing_costの引数でキーワード引数を使うにはmanufacturing_cost=1000といったように書きます。その他の複数の関数を指定するときには半角のコンマで区切るといったルールは普通に引数指定と同じです。
calculate_cost( manufacturing_cost=1000, labor_cost=400, delivery_cost=150, tax=50)キーワード引数を使うことで各引数の値がどの引数なのかすぐに分かるようになりました。例えば
delivery_costであれば150といった具合です。また、キーワード引数を使うと引数名の分コードが横に長くなって読みづらくなってしまうので、上記のコードでは引数ごとに改行を入れています。
キーワード引数には前述のように「引数が多い関数で内容が把握しやすく、ミスしにくくなる」というメリットの他にもいくつかのメリットがあります。
例えば、デフォルト値を持つ引数が多い関数で「後ろの方の一部の引数だけ特定の値を設定したい」といったケースで便利です。
以下のような関数があったとします。
def multiply_x_y_z(x=10, y=20, z=30): multiplied_value = x * y * z print(multiplied_value)この関数でx、y、zそれぞれの引数で全てにデフォルト値があります(引数が省略できる形になっています)。
この関数で、zの引数だけ100という値に変更が必要になったようなケースを想定してみます。普通の引数の指定だと順番に値を指定しないといけないので、zの値を指定しようとしたらxとyもデフォルト値と同じ値を指定しないといけません(
multiply_x_y_z(10, 20, 100)といったように)。3つくらいの引数ならまだしも、引数が多くなってくると辛くなってきます。特に、後ろの方の引数が利用頻度が多くなったケースなどは辛さが増してしまいます(コードを書いた当時は優先度順で引数が設定されていても、時間経過やアップデートなどで後ろの方の引数の方が重要度が高くなるということは起こりえます)。
また、コードがアップデートされて関数のデフォルト値が変わるとどうなるでしょう?例えば、関数のデフォルト値が
def multiply_x_y_z(x=100, y=200, z=300):といったように更新されたとします。このようなケースでは関数の実行側(
multiply_x_y_z(10, 20, 100)といったようなコード)のも漏らさずに更新しないと、「デフォルト値と同じ値を想定して指定していた」といったケースで予期せぬ挙動になってしまうかもしれません(関数の実行箇所がたくさんあると、ミス無く修正するのが手間になります)。一方でキーワード引数を使うと、特定の引数名の引数のみ直接値を指定して関数を実行することができます。
例えばzの引数のみ値を指定し、他はデフォルト値のまま設定したい場合には以下のように書くことができます。
multiply_x_y_z(100)このように書くことで余分な記述が少なくて済みますし、関数でデフォルト値が変更になった時に影響を少なくすることができます。
もう一点キーワード引数で考慮すべき点として、「デフォルト値を取る引数は基本的にキーワード引数で指定するのが好ましい」という点があります。
デフォルト値を取る引数に関しては、「設定が任意(無くてもいい)」という性質を持つ都合、日々のアップデートなどで追加になったり逆に削除されたり、もしくは引数の順番が変更されたりが発生するケースがあります。
そのためデフォルト値を持つ引数の順番が変わっても大丈夫なように、基本的にデフォルト値を持つ引数に関しては毎回キーワード引数で指定するようにしておくと影響を受けづらく堅牢なコードになります。
参照している関数を変えなければいいのでは?と思えるかもしれませんが、仕事では他の方が作ったライブラリ(便利で汎用的なコード集のようなものです)を使うケースが多く発生しますが、そういったライブラリがセキュリティ的な都合や古いバージョンでサポートが切れてしまったためにアップデートしないといけなくなるといったケースも発生してきます。
そういった場合にアップデートで動かなくなってしまったりバグの要因になったりを減らすため、適切にキーワード引数を活用していきましょう。
値渡しと参照の値渡しの話
前のセクションで触れた型ごとのグローバル変数とローカル変数の挙動の違いの件に少し似ていますが、引数にも「値渡し」と「参照の値渡し」という概念が存在します。
少々日本語の意味合いが分かりづらい単語ではありますが、それぞれ以下のような特徴を持ちます。
- 引数の値渡し -> 引数に指定した変数などの値がコピーして渡されます。そのため、関数内でその変数を更新しても関数の外の変数には影響は出ません。
- 引数の参照の値渡し -> 引数に指定された変数などの値はコピーされません。そのため、関数内でその値を更新すると関数の外の変数でも内容が変わります。
それぞれ、値の型によって値渡しと参照の値渡しに挙動が分かれます。
- 整数(int)や浮動小数点数(float)、文字列(str)や真偽値など -> 値渡し
- 辞書やリストなど -> 参照の値渡し
となります。
分かりづらいのでコードを書いて試していきましょう。
まずは値渡しとなる、整数を引数に指定するケースを試してみます。
def add_one_to_x(x): x += 1 cat_age = 10 add_one_to_x(x=cat_age) print(cat_age)コード実行結果の出力内容:
10
まずは
cat_ageという名前の変数を関数の外で作成しています。値には10を設定しています。その後
add_one_to_x(x=cat_age)部分で関数を実行し、引数の値としてcat_ageの変数を指定しています。関数の中では引数の値に1を加え、最後に
print(cat_age)で変数の値を出力しています。出力結果は関数の中で1を加えているにも関わらず10となっています(11にはなっていません)。
今回引数に指定した
cat_ageという変数は整数の値です。そのため値渡しとなり、値渡しでは関数へ値がコピーされて渡される(元の変数とは別のものとして渡される)ので関数の中でその値が更新されても元の変数には影響は発生せずに10のままとなっています。今度は参照の値渡しとなるケースをコードを書いて試していってみます。先ほどは整数の値を引数に指定しましたが今回は辞書を引数に指定します。
my_age = 25 my_age += 2 print(my_age)コード実行結果の出力内容:
27
最初に
cat_info_dictという変数にageというキーを持つ辞書を設定しています。その後関数を実行し、引数に
cat_info_dictの変数を指定しています。関数の中では引数に指定された辞書の
ageのキーの値に1を加えています。最後にprintで
cat_info_dictの変数の内容を出力しています。出力結果を見ると分かるように、関数の中で実行された辞書の値の更新が元の変数にも反映されており、辞書の
ageのキーの結果が11になっていることが分かります。このように辞書やリストなどを指定した際には参照の値渡しとなり、元の変数に対しても変更がかかります。
型によって挙動が変わるので、変数が更新されないことを想定していたのに「更新がされてしまう」ケースと、変数が更新されることを想定していたのに「更新がされない」ケース両方でうっかりミスが発生しがちなので注意しましょう。
ちなみに、何故このように型によって挙動が変わるのでしょうか?大きな理由としては2つあり、1つ目は「基本的にはローカル変数のように、関数の外に影響が出ない方がミスが少なくできる」という点があります。
ローカル変数やグローバル変数などのセクションで触れたように、ローカル変数はその関数の実行が終わると無くなります。そのため関数の外の領域に変数がたくさん出来てしまったり、他の関数からは参照できないといったように、ミスをしにくくなるという面でコードを扱う上で安全性が高まります。
整数や文字列などが値渡しで渡された時には、ローカル変数と同じような扱いになります。つまり、関数の実行が終わると引数に指定された値(元の変数などからコピーされた値)は破棄されます。
これによってローカル変数を扱うのと同じように安全性を加味した実装ができます。
では何故リストや辞書は参照の値渡しとなり、コピーされずに引数に渡されるのでしょうか?
コピーされてローカル変数として扱われた方が安全なのにどうしてでしょう?理由としては、リストや辞書などはたくさんの数値や文字列を格納できるので、コピーしてしまうと処理で負荷が高くなってしまうケースということが考えられます。
例えばリストに数百万件の数値が格納されていたらどうでしょう?関数を実行する度にそのリストがコピーされていたら、処理時間が長くなってしまいますし、そのような大きなリストがいくつもコピーされるとパソコンのメモリも多く必要となってしまいます(スペックの低いパソコンでコードを実行したりが難しくなります)。
そのため、関数実行時の負荷を下げるためにリストや辞書などの場合には値渡しでコピーはされずにそのまま変数の値が渡されるようになっています。このようにコピーされることなく値が引数に渡されるという点は、少ない負荷で関数が実行できるという2つ目のメリットになります。
そう考えると、数値や文字列などもコピーせずに渡された方が負荷が少なくていいのでは?という気もしてきますが、数値や文字列単体の値はコピーされても最近のパソコンであればほぼ「誤差」と言えるレベルの負荷です(あまりにも長文な文字列を指定した場合などは除きます)。
そのくらいの負荷であれば値がコピーされてローカル変数のように扱われた方が、安全面でメリットが大きいため値渡しとして値がコピーされるようになっています。
このような理由からメリット・デメリットを踏まえて型によって値渡しと参照の値渡しの挙動の違いが発生します。
混同してしまうとミスの元になるので、気を付けていきましょう。
とはいえ、慣れないうちは分かりづらい概念ではあるので、少しずつプログラミングに慣れていただく中でこれらも身に付けていけば問題ありません。コードを書き続けてさえいれば、恐らく将来値渡しや参照の値渡しによる「想定した挙動になっていない」という経験をすると思います。
そういった経験を積むことで段々と自然と覚えていくものです。焦らずにコードを書き続けることを優先してください。
関数の結果を返す : 返却値設定
前の値渡しのセクションで、引数の整数や文字列などの値はコピーされて渡され、関数内でのそれらの値の変更は関数外には反映されないと書きました。
しかし、関数の結果を受け取って、関数外の変数に設定したいようなケースも多く存在します。
そのような場合には関数の返却値(戻り値や返り値などとも呼ばれます)という機能を使うことで実現できます。返却値は英語ではreturn valueとなります。
返却値を関数で設定する場合には関数内で
return 返却する値といったように書きます。実際にコードを書いて動かしてみましょう。以下のコードでは関数内の
return added_valueの部分が返却値関係の記述となっています。def add_one(x): added_value = x + 1 return added_value returned_value = add_one(x=10) print(returned_value)コード実行結果の出力内容:
11
返却値が設定されている関数を実行すると、値が返ってくるようになります。その値を変数などに設定することで返却値の内容を取得することができます。
前述のコードでは
returned_value = add_one(x=10)の部分が該当します。add_one(x=10)部分で関数を実行し、値が返ってくるのでreturned_value =という変数へ値を設定する記述で関数で設定されている返却値の値を取得取得することができます。関数の内容はxという引数に指定された値にプラス1して、その値を返却する(
return added_value)だけです。返却値の値を出力(
print(returned_value))してみると、関数内でプラス1された結果の11が出力されることを確認できます。returnの記述は処理を停止する挙動も含まれる
returnの記述には返却値を設定する以外にも「関数の処理を停止させる」という意味も持ちます。関数内でreturn部分に遭遇した場合にはそこで関数の処理は停止して、その後の処理は実行されません。処理の停止のみを目的とした場合には、返却値の値を設定せずに
returnだけ書くこともできます。例えば以下のように関数のすぐ下に
returnの記述がある場合、その後の処理は実行されません。def add_one(x): return added_value = x + 1 return added_value returned_value = add_one(x=20) print(returned_value)コード実行結果の出力内容:
None
関数内の最初に
returnの記述があるので、その後の処理は実行されません。そのreturnの箇所の時点で処理が停止します。つまり、その後の
added_value = x + 1やreturn added_valueの処理は実行されなくなります。実際に関数を実行(
returned_value = add_one(x=20))して、その結果を出力(print(returned_value))してみても、プラス1した結果は出力されずにNoneという内容が出力されます。Noneは後の章で詳しく触れますが「何もない」といったような値です。returnだけで返却値が設定されずに処理を停止しているので、返却値がNoneとなってしまっています。計算結果などは返ってきておらず、
return added_valueなどの部分が実行されていないことが分かります。現状だとこのような関数の処理を途中で止めるという制御が何に使うのだろう?という感じではありますが、後々の章で学ぶ条件分岐などで役に立ちます。たとえば「〇〇の条件では処理を停止する」みたいな制御ができるようになります。
複数の値を返却値に設定する
返却値には複数の値を設定できます。その場合には半角のコンマ区切りで複数の値を設定します。
例えば以下のコードでは
return added_x, added_yという部分で、複数の返却値をコンマ区切りで設定しています。def add_one(x, y): added_x = x + 1 added_y = y + 1 return added_x, added_y returned_x, returned_y = add_one(x=100, y=200) print('returned_x:', returned_x, 'returned_y:', returned_y)コード実行結果の出力内容:
returned_x: 101 returned_y: 201
関数の内容としてはxとyという2つの引数を受け取り、それぞれにプラス1して2つとも返却値として返却しているという内容になります。
returned_x, returned_y = add_one(x=100, y=200)という部分を見ると分かる通り、関数を実行した後の変数に設定する値の部分もコンマ区切りで設定する必要があります。最後に返却値の内容をprintで出力しています(
print('returned_x:', returned_x, 'returned_y:', returned_y))。後々の章で詳しく触れますが、printもコンマ区切りで複数の値を同時に出力することができます(ラベルとしての文字列2つと2つの変数の値の出力のために合計四つの値をprintに指定しています)。
出力された内容を確認すると、引数のxとyに指定した値をプラス1した値がそれぞれの返却値の変数で確認できます。
複数の値の返却値設定は便利ですが、キーワード引数ではなく通常の引数でたくさんの引数を使おうとするとミスみやすくなるのと同様に、たくさんの返却値があるとミスを誘発しやすくなります。引数側と異なりキーワード返却値といった機能は無いのであまり多くならない程度に適度に使っていきましょう。
引数とアスタリスクの特殊な挙動
重要度 : ★★☆☆☆(最初は知らなくてもいいかも)
以下のコードのようにx, y, zの3つの引数を受け取る関数(
add_three_value)があったとします。また、3つの値を格納するリストの変数(argument_list)もあり、これを順番に変数に指定したいとします。def add_three_value(x, y, z): total = x + y + z return total argument_list = [10, 20, 30]引数の3つの値はそれぞれ整数で指定する必要があるため、リストをそのまま指定するだけでは引数の数が合っていない(1つしか引数が指定されておらず、残り2つの引数が足りていない)というエラーになってしまいます。
add_three_value(argument_list)TypeError: add_three_value() missing 2 required positional arguments: 'y' and 'z'このようにリストの中の値をそれぞれの引数に指定したいといったケースでは、Pythonの特殊な書き方として関数実行時の値の指定でリストの変数の直前に半角のアスタリスクの
*の記号を設定するとリストの中身を順番に引数に割り振ってくれます。以下のコードのサンプルでは
*argument_listというコード部分が該当します。returned_value = add_three_value(*argument_list) print(returned_value)コード実行結果の出力内容:
60
今度はエラー無く動作しています。また、x, y, zにそれぞれリストの中身の10, 20, 30が渡され、合計の60の値が返却されていることが出力結果を見ると分かります。
このアスタリスクを使った書き方は、リストの中身が展開されて引数に割り振られるので、引数の数とリスト内の値の数が一致していないとエラーになってしまいます。
例えば以下のように3つの引数を受け取る関数に対して、4つの値を格納したリストを指定するとエラーになってしまいます。
def add_three_value(x, y, z): total = x + y + z return total argument_list = [100, 200, 300, 400] add_three_value(*argument_list)TypeError: add_three_value() takes 3 positional arguments but 4 were givenエラーメッセージを見てみると、「add_three_value()という関数は3つの引数を必要とするけど、4つ値が指定されているよ」といったような内容になっており、関数の引数の数と実際に指定された値の数の不一致によってエラーになっていることが分かります。
ただし前のセクションで触れたデフォルト値が設定されていて省略可能な引数が含まれている場合には引数の数とリストの値の数が一致していなくても問題はありません。以下のようにx, y, zの3つの引数を持つ関数で、zにデフォルト値が設定されている(zは省略できる)場合にはリストの件数は2件でも3件でもどちらでもエラーにはなりません(2件省略したりはできないので値が1件のリストなどを指定した場合にはエラーにはなります)。
リストは一つのアスタリスクを指定することで対応ができました。ではキーワード引数に関してはどうでしょう?たとえば以下のような、前回までと同様にx, y, zの3つの引数を持つ関数に対して、キーに引数名が設定された辞書を指定したいようなケースです。
def add_three_value(x, y, z): total = x + y + z return total argument_dict = { 'x': 10, 'y': 20, 'z': 30, }このような辞書を使ってキーワード引数的に引数に値をPythonで指定したい場合には、関数実行時の引数の値の直前に半角のアスタリスクの記号を2個設定することで対応ができます。例えば、
**argument_dictといったように辞書の前にアスタリスクを2つ記述します。total = add_three_value(**argument_dict) print(total)コード実行結果の出力内容:
60
こちらの辞書によるキーワード引数の指定の仕方でも、リストの時と同様にデフォルト値が設定されている引数を除いてキーワード引数の指定が不足しているとエラーになります。たとえば前述の関数でyのキーワード引数が辞書に含まれていない形でコードを実行してみると以下のようなエラーになります。
def add_three_value(x, y, z): total = x + y + z return total argument_dict = { 'x': 10, 'z': 30, } add_three_value(**argument_dict)TypeError: add_three_value() missing 1 required positional argument: 'y'任意の個数の引数を受け付けるようにする
通常は以下のコードで2個の引数を受け付ける関数に対して3つの引数を指定したケースのように、関数に設定されてある個数を超える数の値を引数に指定するとエラーになります。
def add_two_value(x, y): total = x + y return total add_two_value(100, 200, 300)TypeError: add_two_value() takes 2 positional arguments but 3 were givenエラーメッセージを読んでみると、「add_two_value 関数は2つの引数を受け取るけれども、引数が3つ指定されているよ」といったような内容になります。このように、基本的には関数で受け付けられる引数の数は制限がされます。
一方で任意の個数の引数を受け付けるようにすると、「3つの引数の値で計算」したり「5つの引数の値で計算」したりと1つの関数で柔軟な挙動を実装することができます。
そういった関数を作るには、関数実行時と似たような形で関数の引数部分に半角のアスタリスクを使います。引数名は慣習的に「任意の関数の引数(argument)群」として
argsという名前が使われることが多めです。アスタリスクを付与して*argsという形で使われることが良くあります。
*argsの引数はタプルで設定されます(以前の章で触れた、値の変更が効かないリストのような型になります)。def print_args(*args): print(args)関数の内容は渡された
*argsの引数の内容をprintで出力するだけです。試しに3つの引数を指定して実行してみましょう。
print_args(100, 200, 300)コード実行結果の出力内容:
(100, 200, 300)
*argsの出力内容を見ると、3つの値が格納されたものがちゃんと出力されていることが分かります。また、*argsしか引数に無い関数であるのに3つの引数を指定してもエラーになっていないことが分かります。今度は5つの引数を指定して関数を実行してみましょう。
print_args(100, 200, 300, 400, 500)コード実行結果の出力内容:
(100, 200, 300, 400, 500)
こちらもエラーは発生せずに、指定した且つ5つの引数の内容が関数内で出力されていることが確認できます。
なお、
*argsといった記述で設定されるargs引数は、リストのようにインデックスで値を参照することもできます。例えば先頭の値(0のインデックス)を参照したい場合はargs[0]といったように書けば、引数の先頭の値にアクセスすることができます。以下のコードでは、関数内で先頭の引数をprintで出力しており、結果として先頭の100が表示されています(
print(args[0]))。def print_args(*args): print(args[0]) print_args(100, 200, 300)コード実行結果の出力内容:
100
任意の引数名のキーワード引数を受け付けるようにする
先ほどは任意の個数の引数を受け付けてくれる関数を作りました。今度は任意の引数名のキーワード引数を受け付けてくれる関数について説明していきます。
通常の引数同様、そのままでは関数で設定されていない引数をキーワード引数で指定すると以下のコードのようにエラーになってしまいます(関数の引数に存在しないxというキーワード引数を指定しています)。
def multiply_two(): return x * 2 multiply_two(x=100)TypeError: multiply_two() got an unexpected keyword argument 'x'エラーメッセージを読んで見ると、「multiply_two関数がxという想定外のキーワード引数を受け取りました」といったような内容になります。xという引数が定義されていないのにxという引数が指定されているためこのようなエラーメッセージになっています。
任意のキーワード引数を受け付けてくれるように関数を設定するには、引数名の直前に半角のアスタリスクを二つ連続させて関数の引数に設定します。この引数にはよく
kwargsという引数名が使われます。キーワード引数の英語のkey*word **argumentsを短縮させた引数名となります。2つのアスタリスクと共に`*kwargs`といったように書かれます。コードを書いて試してみます。
def print_kwargs(**kwargs): print(kwargs) print_kwargs(x=100, y=200)コード実行結果の出力内容:
{'x': 100, 'y': 200}
指定された各キーワード引数は
kwargsの中に格納されます。kwargsは辞書になっており、キーには引数名(今回のサンプルではxやy)が設定され、各値(今回のサンプルでは100や200)が格納されます。本章の演習問題 その1
[1]. 整数の引数を1つ受け取り、その引数の値を2倍にして返却する関数を作ってみましょう。また、その関数を実行し受け取った返却値をprintで出力してみましょう。引数名は何でも大丈夫です。
[2]. 以下のコードではエラーになってしまいました。エラーにならないように修正してみましょう。
def print_value(value): print(value)File "<ipython-input-21-def08fe6f21b>", line 2 print(value) ^ IndentationError: expected an indented block※答案例は次のページにあります。
演習問題その1の答案例
[1]. 関数を作るには
def 関数名():といったように書きます。また、問題では「整数の引数を1つ受け取り」とあるので、答案例ではxという引数を設定しています(別の名前でも構いません)。def multiply_two(x): x *= 2 return x multiplied_x = multiply_two(100) print(multiplied_x)コード実行結果の出力内容:
200
また、返却値を設定するには関数内で
return 返却値といったように書きます。上記のコードではreturn x部分が該当します。[2]. 関数の中にはインデントが1つ必要です。インデントは半角のスペース4つで設定します。スペースの数が4つ以外(2つなど)でもエラーにはなりませんが、Pythonのコーディング規約で4つと定められているため、特殊な理由などが無い場合を除いて4つのスペースを設定します。
以下のように
print(value)部分の前にインデントが加えられたコードにすればエラーは発生しません。def print_value(value): print(value)本章の演習問題 その2
[1]. 以下のように
dog_ageという変数にプラス1する処理の関数を作って実行してみたところエラーになってしまいました。エラーが出ないようにコードを編集してみましょう。dog_age = 10 def increment_dog_age(): dog_age += 1 increment_dog_age()UnboundLocalError Traceback (most recent call last) <ipython-input-23-37cd012f49bf> in <module> 6 7 ----> 8 increment_dog_age() <ipython-input-23-37cd012f49bf> in increment_dog_age() 3 4 def increment_dog_age(): ----> 5 dog_age += 1 6 7 UnboundLocalError: local variable 'dog_age' referenced before assignment[2]. 3つの引数x, y, zを受け付ける形で、それぞれの引数の合計を返却する関数を作ってみましょう。また、その関数を実行してみて結果をprintで出力してみましょう。
※答案例は次のページにあります。
演習問題その2の答案例
[1].
dog_ageという変数は整数です。整数のグローバル変数は関数内では直接参照はできません。整数のグローバル変数を関数内で参照するにはglobalと変数を指定するか、もしくは引数と返却値を使ってローカル変数として扱う必要があります。関数内で
globalと指定するケースでは以下のように書きます。エラーなく実行され、結果のdog_ageの値がプラス1されて11になっていることが確認できます。dog_age = 10 def increment_dog_age(): global dog_age dog_age += 1 increment_dog_age() print(dog_age)コード実行結果の出力内容:
11
もしくは引数と返却値を使って以下のようにも書けます。どちらを使っても同じ結果にはなりますがグローバル変数を関数内で使用することは可能であれば減らした方が好ましいので、基本的にはこのような書き方が推奨されます。
dog_age = 10 def increment_dog_age(dog_age): dog_age += 1 return dog_age dog_age = increment_dog_age(dog_age) print(dog_age)コード実行結果の出力内容:
11
[2]. 複数の引数を設定したい場合には、半角のコンマを各引数の間に設定します。コンマの後には半角のスペースを1つ入れます。
def calculate_total(x, y, z): return x + y + z total = calculate_total(100, 200, 300) print(total)コード実行結果の出力内容:
600
本章の演習問題 その3
[1]. 以下のコードを実行するとエラーになってしまいます。エラーが出ないように調整してみましょう。
def calculate_x_plus_y(x, y): total = x + y return total calculate_x_plus_y(100)4 5 ----> 6 calculate_x_plus_y(100) TypeError: calculate_x_plus_y() missing 1 required positional argument: 'y'[2]. xという名前の引数で、指定を省略できる形で、且つ指定が省略された場合に100の値が設定される引数を持った関数を作ってみましょう。関数の処理内容は何でも大丈夫です。
[3]. 以下の関数でyの引数だけ指定する形で関数を実行してください。
def calculate_total(x=100, y=200, z=300): total = x + y + z return total※答案例は次のページにあります。
演習問題その3の答案例
[1]. x, yと2つの引数を必要とする関数である一方で、関数の実行箇所が1つの引数しか指定されていません。関数の実行箇所で引数を2つにすればエラーが無くなります。
def calculate_x_plus_y(x, y): total = x + y return total total = calculate_x_plus_y(100, 200) print(total)コード実行結果の出力内容:
300
[2]. 省略が可能な引数を指定するには引数にデフォルト値を設定します。デフォルト値を設定するには
引数=デフォルト値という形で間に半角のイコールの記号を設定します。イコールの前後にスペースは入れずに記述します。今回の問題ではx=100というように書きます。def print_x(x=100): print(x) print_x()コード実行結果の出力内容:
100
[3]. 3つある引数のうち、真ん中のyだけ引数を指定したい場合にはキーワード引数を使います。キーワード引数を利用するには関数を実行するときに
引数名=値といった形で指定します。今回の問題ではy=500といった形式で指定します。total = calculate_total(y=500) print(total)コード実行結果の出力内容:
900
本章の演習問題 その4
[1]. 以下のコードの
arg_value_listのリストの変数を、calculate_total関数の引数へリストのまま指定して関数を実行してみてください。arg_value_list = [100, 200, 300] def calculate_total(x, y, z): total = x + y + z return total※補足 : 以下のようにリストの値を個別に引数に指定せずに、リストのまま指定してみてください。
calculate_total( arg_value_list[0], arg_value_list[1], arg_value_list[2], )[2]. 任意の個数の引数(3つだったり5つだったり)を受け付ける関数を作ってみてください。関数の処理内容は何でも構いません。
※答案例は次のページにあります。
演習問題その4の答案例
[1]. リストの中の各値を引数に割り振るには、リストの直前に半角のアスタリスクを指定します。今回の問題では
*arg_value_listといった書き方をします。total = calculate_total(*arg_value_list) print(total)コード実行結果の出力内容:
600
[2]. 任意の個数の引数を受け付けてくれる関数を作るには、関数の引数設定部分に
*argsといったように半角のアスタリスクを引数名の前に設定します。def print_args(*args): print(args) print_args(100, 200, 300)コード実行結果の出力内容:
(100, 200, 300)
章のまとめ
- 一連のプログラムのまとまりで、色々な場所から実行でき、引数や返却値などを使って様々な挙動を実装できる機能を関数と言います。
- 関数を使うことで、コードの重複などを減らすことができ保守性の高いコードを書くことができます。
- 関数を作るには
defというキーワードを使います。- 関数内では半角スペース4つのインデントが必要です。インデントを入れないとエラーになります。
- 関数を実行するには
関数()といったように書きます(例 :calculate_total())。- 数値や文字列のグローバル変数は関数内では直接参照できません。
globalを使って対象の変数がグローバル変数だと明示する必要があります。- 辞書やリストなどは
globalの指定をしなくても関数内で参照できます。- 引数を関数に設定することで関数に様々なパラメーターを渡すことができます。
- 省略可能な引数を設定したい場合にはデフォルト値を使います。
- キーワード引数を使うことで引数名と値を両方指定して引数の値を指定することができます。引数が多い場合などに便利です。
- 引数に数値や文字列などを指定した場合は、その値はコピーされ関数内のローカル変数として扱われます(値渡し)。
- 引数にリストや辞書などを指定した場合にはその値はコピーされません(参照の値渡し)。
- 半角のアスタリスクを引数部分に利用することで、リストや辞書を引数に展開したり、任意の個数の引数や任意の引数名のキーワード引数を受け付ける関数を作ることができます。
他にもPythonなどを中心に色々記事を書いています。そちらもどうぞ!
今までに投稿した主な記事たち参考文献・参考サイト
- 投稿日:2020-06-02T19:50:45+09:00
mglearn.plots.plot_nmf_facesで動作が止まってエラーかな?と思った話
はじめに
引き続き「Pythonではじめる機械学習」の勉強をしています。
本日はmglearnのデータセットを利用したときに異変がありましたので共有しておきます。問題
mglearn.plots.plot_nmf_faces(X_train, X_test, image_shape)
plt.show()
でコマンドプロンプトにエラー?が表示されて調べたがなかなかみつからない。
cmdには[Memory] Calling mglearn.plot_nmf.nmf_faces...
nmf_faces(array([[0.899346, ..., 0.146405],
...,
[0.09281 , ..., 0.639216]], dtype=float32),
array([[0.179085, ..., 0.420915],
...,
[0.317647, ..., 0.888889]], dtype=float32))
C:\Users\com.conda\envs\tensorflow\lib\site-packages\sklearn\decomposition_nmf.py:1077: ConvergenceWarning: Maximum number of iterations 200 reached. Increase it to improve convergence.
" improve convergence." % max_iter, ConvergenceWarning)と見たことのない表示があり、検索にかけてもよくわからず。
しかし、実行中から止まらない。解決策
しばらくそっとしておいたら終了していました。
プログラムは無事エラーなく動きました。
datasetを取得しているのでしょうか?なかなか動かなかったので焦りましたが無事動きました。[Memory] Calling mglearn.plot_nmf.nmf_faces...
nmf_faces(array([[0.899346, ..., 0.146405],
...,
[0.09281 , ..., 0.639216]], dtype=float32),
array([[0.179085, ..., 0.420915],
...,
[0.317647, ..., 0.888889]], dtype=float32))
C:\Users\com.conda\envs\tensorflow\lib\site-packages\sklearn\decomposition_nmf.py:1077: ConvergenceWarning: Maximum number of iterations 200 reached. Increase it to improve convergence.
" improve convergence." % max_iter, ConvergenceWarning)
C:\Users\com.conda\envs\tensorflow\lib\site-packages\sklearn\decomposition_nmf.py:1077: ConvergenceWarning: Maximum number of iterations 200 reached. Increase it to improve convergence.
" improve convergence." % max_iter, ConvergenceWarning)
C:\Users\com.conda\envs\tensorflow\lib\site-packages\sklearn\decomposition_nmf.py:1077: ConvergenceWarning: Maximum number of iterations 200 reached. Increase it to improve convergence.
" improve convergence." % max_iter, ConvergenceWarning)
C:\Users\com.conda\envs\tensorflow\lib\site-packages\sklearn\decomposition_nmf.py:1077: ConvergenceWarning: Maximum number of iterations 200 reached. Increase it to improve convergence.
" improve convergence." % max_iter, ConvergenceWarning)
C:\Users\co.conda\envs\tensorflow\lib\site-packages\sklearn\decomposition_nmf.py:1077: ConvergenceWarning: Maximum number of iterations 200 reached. Increase it to improve convergence.
" improve convergence." % max_iter, ConvergenceWarning)
______________________________________________________nmf_faces - 356.4s, 5.9minおわりに
みたことのないエラーやcmdの文章をみると不安になり。
おかしいなと調べる初心者の方が私以外にもいると考えメモしておきます。
- 投稿日:2020-06-02T18:50:26+09:00
ペットボトルの底のあの形状を生成する
誰しも必ず見たことがある、炭酸飲料のペットボトルの底の、あの5角形のやつ、あれをプログラミングで作ってみようと考えました。
結論から言うと、だいたい自己評価で70点くらいの出来の形状ができました。結果が気になる方は先に一番下までスクロールして完成画像を見てから、この先を読むかどうか判断してください。
炭酸飲料のペットボトルの底の形
この5角形のやつです。
この形状は一般的にペタロイドと呼ばれています。「花の形に似たもの(petal-oid)」という意味です。下から覗いたときに花弁のように見えることでそう呼ばれています。
ご自宅に炭酸のペットボトルがあれば、一度底を眺めてみてください。
なぜこの形なの?
ペットボトルにはいろいろな形がありますが、この底部形状をとっているのは基本的に炭酸飲料だけです。炭酸飲料は内部からの圧力が強いので、お茶のボトルのような形状だと底が膨らんでしまいます。そのまま転がったり破裂したりと不具合が生じるので、強度を保つためにペタロイドが用いられているという話です。
実際にお茶のペットボトルに重曹を入れて強度を試してみる実験がありましたので、ご紹介しておきます。
ペットボトルの形には、深い秘密がある - ダイヤモンド・オンライン
ペタロイドを描く
目標
この記事の目標はペタロイドの形状をプログラミングにより生成することです。クオリティはそれなりを目指します(私のそれなりは世間一般よりユルユル判定なので、あまり期待しないでください)。
ググって資料を探す
なんかこう、簡単に数式1つで表現できたりしないかなぁと、いろいろ検索してみたのですが、なんの成果も得られませんでした。圧力試験のデータとかは出てくるのだけれども……。
多分CADとかで設計しているのかなぁ。
観察する
ネットに頼れないのであれば、自分でなんとかするしかありませんね。幸いにも実物はいくらでも手元にありますからね。まずはカッターを使って、ペットボトルの底の部分だけを切り出します。
さらに、ど真ん中から縦に真っ二つにしてみます。上の画像の12時方向から6時方向にバッサリとね。
分かったこと
- 円周上に同じ形が5つ並んでいる
- 谷の部分と山の部分が交互に存在する
- 谷の部分は中心から滑らかな曲線になっている
- 中心部は特に素材が厚い
まず、パッと見て分かりますが、同じ形が5個円周上に並んでいるので、そのうち1つを再現できれば、5個コピーして並べるだけで目標達成できることが分かります。
また、形状としては、交互に山と谷があり、谷の部分はおおよそ6~7mmの幅で中心から外周に向かって平行に筋が走っているように見えます。山の形状は大分複雑ですが、真上(あるいは真下)から見ると扇状、横から見ると台形のような形をしています。正確には山と谷の間は滑らかな曲線で傾斜が作られています。
断面図をみると、谷の部分の断面は楕円形の曲線を4分の1切り取ったようなスマートな曲線をしています。一方、山の部分の断面はちょっと複雑です。
あと、これはあまり記事に関係ありませんが、底の部分はかなり分厚くて、およそ3mmもありました。最初ハサミで切れるかと思っていましたが、
刃が歯が立たなかったので、糸ノコを使う羽目になりました。方針を定める
この情報から、どのように形状を再現するかを考えます。
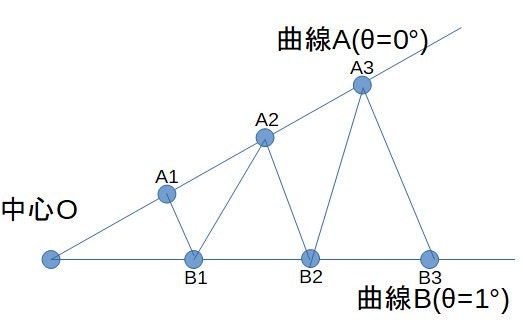
まず、基本方針として、ボトルの中心を基準にものを考えることにします。
具体的には下の図のように、中心を基準として、方位角θの方向の断面形状を都度算出し、集積することで立体を再現しようと思います。
次に断面の形状の再現ですが、以下の3種類の異なる曲線を生成する必要があります。
- 谷の部分の楕円形の円弧
- 山の部分の複雑な曲線
- 傾斜の部分の複雑な曲線
もしかすると、一つの数式でまとめることもできるかもしれませんが、私の頭では思いつかないので、今回はスプライン曲線を使う方向で行くことにしました(困った時のスプライン)。
スプラインによる曲線の再現
前述の通り3種類の異なる曲線を、方位角$θ$という変数1つに基づいて生成する方法について考えます。
まず、谷の部分の曲線をスプライン関数で表すことを考えます。観察したとおりに、この曲線はおおよそ楕円上の円弧の形をしているので、スプラインで表すのは難しくありません。
簡便のため、以降では楕円ではなく、真円として表すことにします。楕円に戻したい場合は縦方向に拡大・縮小すればいいので。
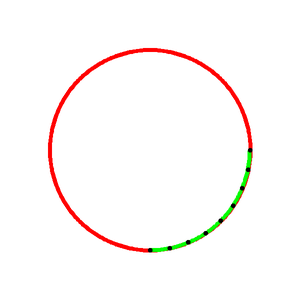
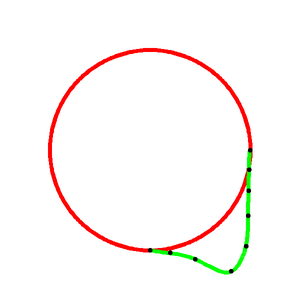
上図のように、円を描きます。第4象限(右下)部分の円弧上に$N$個の制御点を等間隔に配置し、これらをつなぐ3次スプライン曲線を描画します。この曲線は全ての制御点を通るように作られます。完璧に円弧に一致するわけではありませんが、人間の目では見分けがつかない曲線ですね。なお、$N=9$としています。
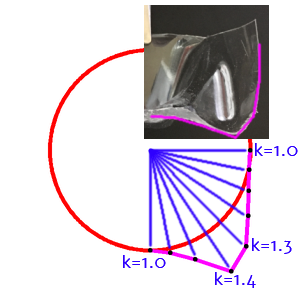
次は山の部分の曲線を作っていきます。ここでは、先ほどの谷の曲線を加工して、おおまかに観察した通りの山の曲線を模倣してみます。
具体的に言うと、円弧上の制御点$(x_i,y_i)$を円の中心$(0,0)$から$k_i$倍して延長します($1 \leq i \leq N$)。以下の図のような感じで、ざっくり概形を作ります。
x'_i = x_i * k_i \\ y'_i = y_i * k_i
撮影した画像とにらめっこしながら、大体同じような形になるように$k_i$の値を微調整していきます。最終的なパラメータは
\begin{align} K &= [k_1, k_2, k_3, ... , k_9] \\ &= [1.00, 1.05, 1.18, 1.46, 1.36, 1.18, 1.07, 1.01, 1.00] \end{align}としました。端の点(k1とk9)は1.0にしないと出来上がりがおかしくなります。
制御点の数$N$の数を多くして、より正確な曲線を再現するようにすればクオリティが上がるかもしれませんが、調整がかなり大変です。完成した後で考えると、底の部分(左から4点目)の精度を高めるために、もう1,2点追加した方が良かったかも。
この概形をスプライン補間すると以下のようになります。実物のペットボトルを真横から見ながら$k_i$を調整したので、そこそこ似てる感じ。
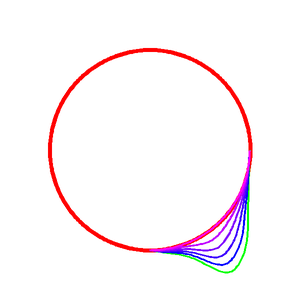
最後に、山と谷の間の傾斜部分の曲線を作ります。これは、山の曲線と谷の曲線を変形比率$D$という変数によってブレンドして求めます(やってることはただの線形補間)。
\begin{align} x''_i &= x_i * D + x'_i * (1-D) \\ &= x_i * (D + k_i - Dk_i) \\ y''_i &= y_i * D + y'_i * (1-D) \\ &= y_i * (D+k_i - Dk_i) \end{align} \quad (0 \leq D \leq 1)
上の画像はDを0.0から1.0まで0.2刻みで傾斜部の曲線を描いたものです。D=0が赤紫、D=1が黄緑の線です。等高線のような、滑らかに山と谷を間を補う曲線を作れています。
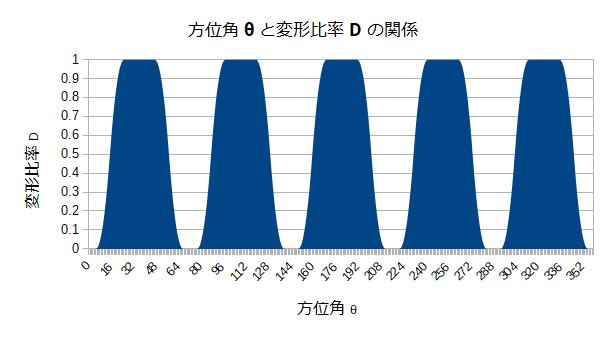
方位角θと変形比率Dの関係
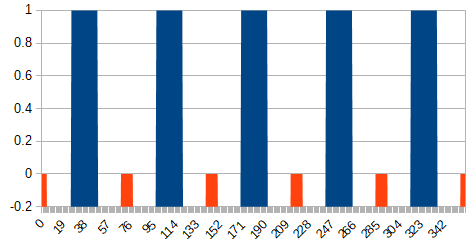
方針を決める際に、複数の方位角$θ$について、それぞれ断面の曲線を作ることにしました。また、曲線を作るために変形比率$D$という変数を導入したので、$θ$の値を元にして、$D$の値を求める必要があります。
横軸にθ(0~360度)、縦軸にD(0~1)のグラフを書いて、この関係性を明らかにすることにします。まず、山のてっぺんの部分については、$D=1$とします。てっぺんとみなす角度の範囲は目測から22度としました(ざっくり)。
また、谷の底の部分については$D=0$とします。こちらはおよそ10度としました。グラフに映らなくて分かりにくかったので、Y軸の下限を-0.2としてあります。
オレンジと青の隙間の白い部分が山と谷の間の傾斜部分になります。この部分は曲線で0と1の間を埋めることになりますが、はてさてどのように埋めましょうか。数学的にこうだよ、と言えたらかっこいいのですが、私はそこまで頭がよくありません。ここはイージング関数を使っていい感じに埋めることにします。
いろいろ試したところ、
easeInOutQuadが見た目いい感じでしたので採用しました。\begin{align} y &= easeInOutQuad(x) \\ &= \begin{cases} 2x^2 &(0 \leq x < \frac{1}{2}) \\ -2x^2 + 4x - 1 &(\frac{1}{2} \leq x \leq 1) \end{cases} \end{align}最終的なグラフは以下のようになります。縦軸の範囲は0~1に直したのに注意してください。
3Dモデル生成
ここまでで全方位における曲線が得られたので、あとはこれを使って3Dモデルを作ります。
まず方位角θを等間隔に刻んで(例えば1°毎に)、曲線を生成します。曲線はM個の点で離散化した座標を算出しておきます。2つの曲線の点について注目し、3つの点を選択して3角形ポリゴンを形成します。
完成!
このまま直接OpenGLなどで描画してもいいですが、今回はDXFフォーマットでファイルを書き出し、3Dモデリングソフトで表示させてみます。
今回はPythonでコードを書いたので、PythonでDXFフォーマットを扱えるezdxfライブラリを使用しました。出力したファイルをModoというソフトで表示したのが以下の画像です。
マテリアルを割り当て、レンダリングした結果がこちら1。
こちらはBlenderで表示した結果です。AutoCAD DXF Importプラグインを有効にする必要があります。
※実は中心の部分はスプライン関数の影響で少し形がいびつだったので、コサインカーブを使って自然な感じに見えるように加工していますが、全体的な見栄えに影響しないので説明を割愛してあります。
横から見た感じはまあまあいいかな、という感じですが、底からの見た目はあんまし似ていないなーという感じですね。なんというか凹凸が足りないというか、丸みが乏しいせいかな。うーん……。
ソースコード
読む人はほとんどいないと思うので、畳んでおきます。
Pythonソースコードを見る
NumPy,SciPy,ezdxfのライブラリが必要です。
petaloid.pyfrom typing import List, Tuple import math import numpy as np from scipy.interpolate import splprep, splev import ezdxf # 型ヒントの定義 Point2D = Tuple[float, float] Point3D = Tuple[float, float, float] def mix(a: float, b: float, x: float) -> float: """線形内分 x=0のときa, x=1のときb""" return b * x + a * (1.0 - x) def easeInOutQuad(x: float) -> float: """Easing関数""" if x < 0.5: return 2.0 * x * x else: return -2 * x * x + 4 * x - 1 def calcDeformRate(t: float) -> float: """ 方位角tに対応する、曲線の変形比率Dを求める :param t: 方位角(単位は度)。72で割った余りが0のとき谷、36°のとき凸部分に対応 :return: 変形比率D(0~1) """ t = math.radians(math.fmod(t, 72.0)) M = math.radians(72.0) # 突起一つ分の角度範囲 k = math.radians(5.0) # 谷の部分の角度範囲 tL = math.radians(25.0) - k # 山の片側境界 tR = (M - k) - tL # 山の反対側境界 if t < k or t > M - k: return 0.0 # 谷の部分 elif t < k + tL: return easeInOutQuad((t-k) / tL) # 傾斜 elif t < tR: return 1.0 # 山の部分 else: return easeInOutQuad(((M-k) - t) / tL) # 傾斜(逆向き) def curve(angle: float, div_num: int) -> List[Point2D]: """ 指定された方位角に応じた外形曲線を算出する :param angle: 方位角(0~360°) :param div_num: 曲線を構成する点の数。多いほど滑らか :return: 曲線を表す点列 """ # degree -> radian angle = math.fmod(angle, 360.0 / 5) # 5角形なので360度を5等分 # 方位角に対応する変形比率Dを求める(谷でD=0、山でD=1) D = calcDeformRate(angle) # 各制御点の変形比率を求める # 谷の部分では全ての制御点が左の比率(1.0)で、円弧となる # 山の部分では全ての制御点が右の比率で、規定の曲線を描く # それ以外の部分(山の傾斜部)ではDの値に応じて補間された曲線が描かれる r_rate = [ mix(1.00, 1.00, D), mix(1.00, 1.05, D), mix(1.00, 1.18, D), mix(1.00, 1.46, D), mix(1.00, 1.36, D), mix(1.00, 1.18, D), mix(1.00, 1.07, D), mix(1.00, 1.01, D), mix(1.00, 1.00, D)] # 制御点の位置を求める xs = [] ys = [] n = len(r_rate) for i in range(n): deg = i * 90.0 / (n - 1) rad = math.radians(deg) x = r_rate[i] * math.sin(rad) y = r_rate[i] * math.cos(rad) xs.append(x) ys.append(y) # 全ての制御点を通るように、3次のスプライン曲線を引く spline = splprep([xs, ys], s=0, k=3)[0] detail = np.linspace(0, 1, num=div_num, endpoint=True) ix, iy = splev(detail, spline) points = list(zip(ix, iy)) return points def main(): # 中央底部の微小突起を作る num_bottom_point = 8 # 中央底部の微小突起の点数 bottom_width = 0.2 # 中央底部のサイズ bottom_height = 0.05 # 中央底部の高さ bottom_points = [] for i in range(num_bottom_point): n = i / num_bottom_point angle = n * math.pi x = n * bottom_width # cosを使ってY=[1.0,1.0+height]のカーブを作る y = 1.0 + (math.cos(angle) + 1) / 2 * bottom_height bottom_points.append((x, y)) # ペタロイド図形を表す3次元の頂点リストを作る num_curve: int = 180 # 方位の分割数(360なら1度毎, 180なら2度毎) num_point: int = 50 # 1方位における曲線の近似点数(中心点含む) num_point_curve = num_point - num_bottom_point # (中心点除く) aspect_adjust: float = 0.75 # 縦横比率の調整値 vertices: List[Point3D] = [] for i in range(num_curve): # 各方位毎に曲線を求める theta_deg = 360.0 / num_curve * i theta_rad = math.radians(theta_deg) points1 = curve(theta_deg, num_point_curve) # 中心部の微小突起と連結する points2: List[Point2D] = [*bottom_points] for p in points1: # 曲線を横(X)方向に少し潰して、空いた分を平面とする(何とも微妙な処理……) x = bottom_width + p[0] * (1.0 - bottom_width) y = p[1] points2.append((x, y)) # 3次元座標に変換する c = math.cos(theta_rad) s = math.sin(theta_rad) for p in points2: x2 = p[0] y2 = p[1] x3 = x2 * c y3 = y2 * aspect_adjust # 縦横比率を調整 z3 = x2 * s vertices.append((x3, y3, z3)) # 3角形分割する indices: List[Tuple[int, int, int]] = [] for angle in range(num_curve): a0 = angle a1 = (angle + 1) % num_curve for i in range(num_point - 1): i00 = a0 * num_point + i i01 = a0 * num_point + i + 1 i10 = a1 * num_point + i i11 = a1 * num_point + i + 1 if i != 0: # 中心だけは3角形なので、重複しないよう除外 indices.append((i00, i10, i11)) indices.append((i11, i01, i00)) # dxfで出力する # 折角vertexとindexに分けたが、dxfの3Dfaceでは頂点しか持たないので、 # 頂点のリストを合成する triangles: List[Tuple[Point3D, Point3D, Point3D]] = [] for i in indices: v1 = vertices[i[0]] v2 = vertices[i[1]] v3 = vertices[i[2]] triangles.append((v3, v2, v1)) doc = ezdxf.new('R2010') # MESH requires DXF R2000 or later msp = doc.modelspace() for t in triangles: msp.add_3dface(t) doc.saveas("petaloid.dxf") if __name__ == '__main__': main()残課題
私はもうこれ以上やる気はないのですが。もし、より完成度の高いペタロイドにチャレンジしたい奇特な人がいらっしゃいましたら参考にしてください。
- よりリアルなくびれの再現
- 谷の部分の両端は実物を見ているともっとこう、くびれているように見えます。特に中心側の谷はUの字にくびれが入っていますが、今回はその点を考慮すると計算が複雑になりすぎて完成にこぎつけられないと思い断念しました。具体的にどうするかは分かっていませんが、方位角だけではなく、中心からの距離あるいは天頂角に応じて変化する要素を持たせるといいかもしれませんね。
- スプラインに依存しない形状作成
- 今回はスプライン(多数の曲線のツギハギ)に頼ってしまったわけですが、実はもっと簡単な関数1つで表現できたりしないでしょうか。山の形はなんとなく4次関数っぽいなぁと思ったりするのですが、カーブフィッティングは試していません。
- メーカー毎の設計差異
- 調べた限りだと、ペットボトルには規格が存在しないようです。キャップの口径は事実上の標準が定まっていて共通化されているようですが、ボトル自体の形状はメーカーに依存しているようです。今回使ったペットボトルはウィルキンソンのものなので、皆さんの手元にあるものと比べると違いがあるかもしれません。ただ、家にあるボトルは飲料メーカーによらずみんな同じ形をしているように見えますが(同じ容器メーカーの製品なのかも。寡占市場なのだろうか……)。
終わりに
Q. なんで底だけ?胴体は?
A. やる気が尽きました _(:3」∠)_
DXFをimportした後、Mesh CleanUpを実行し、ポリゴンを結合しています。加えて、サブディビジョンサーフェスを用いて、形状を滑らかにしています ↩











- 投稿日:2020-06-02T18:44:50+09:00
100日後にエンジニアになるキミ - 74日目 - プログラミング - スクレイピングについて5
昨日までのはこちら
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回もスクレイピングの続きです。
あらかたスクレイピングの原理は前回までで終わっていますので
今日はSeleniumのお話です。Seleniumについて
SeleniumはWEBブラウザの操作を自動化するためのフレームワークソフトウェアです。
Seleniumを使うことで、Pythonrequestsライブラリ単体で行う
スクレイピングでは取得できない情報も取得できるようになります。では取得できない情報とは何でしょうか?
通常の
requestsライブラリではgetメソッドなどで取得できる情報はHTMLのソースになります。その要素の一部がJavascriptでレンダリングするように書かれている場合
Javascriptが働かないとデータとして反映されません。そのためJavascriptでで動的に生成される要素は
requestsライブラリでは
取得することはできません。
SeleniumはWEBブラウザを動かしてデータを取得しに行くため、通常のブラウザでアクセスするのと何ら変わりません。Javascriptも働きレンダリングされたデータを取得できます。Seleniumを動かすのに必要なもの
PCなどで
Seleniumを動かすのに必要なのは以下の3つです。WEBブラウザ
Chrome, Firefox, Opera などWebDriver
ブラウザを操作するためのソフトウェアSelenium
WebDriverと連携してプログラムからブラウザを操作するライブラリ各種ツールのインストール
インストール方法は以下のようになります。
WEBブラウザのインストール
各種ブラウザのダウンロードサイトからダウンロードしてインストールを行うWebDriverのダウンロード
WebDriverはインストールは必要なく、ダウンロードして配置するだけで動作します。
ダウンロード後はプログラムから見て近いディレクトリなどに配置しておきます。ドライバーはブラウザのバージョンアップとともに変更されるので、都度バージョンに合わせてダウンロードを行います。
Seleniumのインストール
Pythonでのインストール方法は下記です。pip install seleniumSeleniumを動かす
Seleniumを動かすまでの手順としては1.ブラウザのインストール
2.WebDriverのダウンロードと配置
3.Seleniumのインストール
です。ここでは
SeleniumからGoogle Chromeを操作してみましょう。from selenium import webdriver # ドライバー設定 chromedriver = "ドライバーのフルパス" driver = webdriver.Chrome(executable_path=chromedriver) driver.get('アクセス先のURL')これを実行するとブラウザが立ち上がります。
立ち上げるブラウザが
Google Chromeなのでwebdriver.Chromeを使っています。
ブラウザによって対応するメソッドが変わります。
Firefox:webdriver.Firefox
Opera:webdriver.Opera
executable_pathにはWebDriverのパスを書くのですが
フルパス(絶対パス)でないと認識しないようです。浅目の階層にwebdriverを置いておきましょう。ここまででSeleniumを使ってブラウザを起動できたのではないでしょうか?
次回はここからブラウザの操作方法に入ります。
まとめ
seleniumを使うと通常のスクレピング手法では
取得できない情報も簡単に取得できるようになるので便利です。データが取得できなくて困っている方はseleniumを試してみましょう。
君がエンジニアになるまであと26日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-06-02T18:08:39+09:00
pythonでsocketserverを使ってソケット通信を行う
目的
以下を参考に、pythonでTCP/UDPのソケット通信を手元で動かした際の備忘録です
ソケット通信について
ソケット インターネットはTCP/IPと呼ぶ通信プロトコルを利用しますが、そのTCP/IPをプログラムから利用するには、プログラムの世界とTCP/IPの世界を結ぶ特別な出入り口が必要となります。 その出入り口となるのがソケット(Socket)であり、TCP/IPのプログラミング上の大きな特徴となっています。
引用元: http://research.nii.ac.jp/~ichiro/syspro98/socket.htmlTCPのソケット通信
client側がserver側に送ったアルファベットを、server側が大文字にしてclientへ返す
receiver.pyimport socketserver class MyTCPHandler(socketserver.BaseRequestHandler): def handle(self): self.data = self.request.recv(1024).strip() print("{} wrote:".format(self.client_address[0])) print(self.data) self.request.sendall(self.data.upper()) if __name__ == "__main__": HOST, PORT = "localhost", 9999 with socketserver.TCPServer((HOST, PORT), MyTCPHandler) as server: server.serve_forever()sender.pyimport socket import sys HOST, PORT = "localhost", 9999 data = " ".join(sys.argv[1:]) with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock: sock.connect((HOST, PORT)) sock.sendall(bytes(data + "\n", "utf-8")) received = str(sock.recv(1024), "utf-8") print("Sent: {}".format(data)) print("Received: {}".format(received))実行する
$ python receive.py$ python sender.py "hello world" Sent: hello world Received: HELLO WORLDUDPのソケット通信
UDPはTCPと違い、connectionがなく、データも送りっぱなし
receiver.pyimport socketserver class MyUDPHandler(socketserver.BaseRequestHandler): def handle(self): data = self.request[0].strip() socket = self.request[1] print("{} wrote:".format(self.client_address[0])) print(data) socket.sendto(data.upper(), self.client_address) if __name__ == "__main__": HOST, PORT = "localhost", 9999 with socketserver.UDPServer((HOST, PORT), MyUDPHandler) as server: server.serve_forever()sender.pyimport socketserver class MyUDPHandler(socketserver.BaseRequestHandler): def handle(self): data = self.request[0].strip() socket = self.request[1] print("{} wrote:".format(self.client_address[0])) print(data) socket.sendto(data.upper(), self.client_address) if __name__ == "__main__": HOST, PORT = "localhost", 9999 with socketserver.UDPServer((HOST, PORT), MyUDPHandler) as server: server.serve_forever()実行する
$ python receive_udp.py$ python sender_udp.py "hello world. udp." Sent: hello world. udp. Received: HELLO WORLD. UDP.備考
通信データが大きい場合に実行時間や欠損データの扱いの面で差が出ると思うが、お試しなので省略
UDPはTCPと違いについて詳しくは以下参考
socketserver --- ネットワークサーバのフレームワーク
Pythonによる通信処理
cpython/Lib/socketserver.py
知ったかぶりをしていたソケット通信の基礎を改めて学んでみる
まつもと直伝 プログラミングのオキテ 第16回 ネットワーク・プログラミング(ソケット編)
ソケット通信
- 投稿日:2020-06-02T18:08:39+09:00
今さらpythonでsocketserverを使ってソケット通信する
目的
以下を参考に、今さら感がありつつもpythonでTCP/UDPのソケット通信した際の備忘録です
ソケット通信について
ソケット インターネットはTCP/IPと呼ぶ通信プロトコルを利用しますが、そのTCP/IPをプログラムから利用するには、プログラムの世界とTCP/IPの世界を結ぶ特別な出入り口が必要となります。 その出入り口となるのがソケット(Socket)であり、TCP/IPのプログラミング上の大きな特徴となっています。
引用元: http://research.nii.ac.jp/~ichiro/syspro98/socket.htmlTCPのソケット通信
client側がserver側に送ったアルファベットを、server側が大文字にしてclientへ返す
receiver.pyimport socketserver class MyTCPHandler(socketserver.BaseRequestHandler): def handle(self): self.data = self.request.recv(1024).strip() print("{} wrote:".format(self.client_address[0])) print(self.data) self.request.sendall(self.data.upper()) if __name__ == "__main__": HOST, PORT = "localhost", 9999 with socketserver.TCPServer((HOST, PORT), MyTCPHandler) as server: server.serve_forever()sender.pyimport socket import sys HOST, PORT = "localhost", 9999 data = " ".join(sys.argv[1:]) with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock: sock.connect((HOST, PORT)) sock.sendall(bytes(data + "\n", "utf-8")) received = str(sock.recv(1024), "utf-8") print("Sent: {}".format(data)) print("Received: {}".format(received))実行する
$ python receive.py$ python sender.py "hello world" Sent: hello world Received: HELLO WORLDUDPのソケット通信
UDPはTCPと違い、connectionがなく、データも送りっぱなし
receiver.pyimport socketserver class MyUDPHandler(socketserver.BaseRequestHandler): def handle(self): data = self.request[0].strip() socket = self.request[1] print("{} wrote:".format(self.client_address[0])) print(data) socket.sendto(data.upper(), self.client_address) if __name__ == "__main__": HOST, PORT = "localhost", 9999 with socketserver.UDPServer((HOST, PORT), MyUDPHandler) as server: server.serve_forever()sender.pyimport socketserver class MyUDPHandler(socketserver.BaseRequestHandler): def handle(self): data = self.request[0].strip() socket = self.request[1] print("{} wrote:".format(self.client_address[0])) print(data) socket.sendto(data.upper(), self.client_address) if __name__ == "__main__": HOST, PORT = "localhost", 9999 with socketserver.UDPServer((HOST, PORT), MyUDPHandler) as server: server.serve_forever()実行する
$ python receive_udp.py$ python sender_udp.py "hello world. udp." Sent: hello world. udp. Received: HELLO WORLD. UDP.備考
通信データが大きい場合に実行時間や欠損データの扱いの面で差が出ると思うが、お試しなので省略
UDPはTCPと違いについて詳しくは以下参考
socketserver --- ネットワークサーバのフレームワーク
Pythonによる通信処理
cpython/Lib/socketserver.py
知ったかぶりをしていたソケット通信の基礎を改めて学んでみる
まつもと直伝 プログラミングのオキテ 第16回 ネットワーク・プログラミング(ソケット編)
ソケット通信
- 投稿日:2020-06-02T17:19:53+09:00
DjangoでAjax(汎用クラスビューを使用)
『Django Ajax』で検索するといくつか記事がヒットするがほとんどが関数ベースビューによるものだったので、汎用ビューを使用したコードを解説。
汎用ビューよく分かってない方はまずはそちらに入門しましょう。
これは私見ですが、Djangoを採用する大きなメリットの1つがクラスベースである汎用ビューを利用することだと考えています。
したがって、たぶんこれがベストプラクティスだと思います。完成品イメージ
GitHub - skokado/django_ajax: Django + Ajax サンプル
入力した文字列を画面上に表示するというもの。
簡単に仕様を決めておく。
- ユーザは
/greetにブラウザでアクセスする- フォームに入力した値(
name)はPOSTメソッドで送信する
- ※POSTメソッドの送信先パスは画面の表示と同じ
/greetviews.pyではAjaxリクエスト(XMLHttpRequest)を識別してそれ以外の処理と切り離す- Ajaxリクエストに対して
こんにちは、[name]さん!というメッセージを<p>タグで画面内に表示する
コード解説
コンポーネントは大きく以下。
urls.py: ルーティング(URLバイディング)forms.py: ユーザがデータを入力するためのフォームを定義views.py: リクエスト処理を記述。
- 汎用ビューの
FormViewを使うRequest.is_ajax()を使用してAjaxリクエストを識別する- テンプレート(
index.html): 表示するHTML。本記事ではjQueryも同梱する。準備
DjangoプロジェクトとDjangoアプリケーションの作成を適当に済ませておく。
※プロジェクト名:django_ajax, アプリケーション名:greetingとする。
urls.pyにルーティングルールを記載。
urls.py使用するパスは
/greetのみ。django_ajax/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('greet/', views.GreetView.as_view(), name='greet'), ]
forms.py
nameを入力するだけgreeting/forms.pyfrom django import forms class GreetForm(forms.Form): name = forms.CharField(label='あなたの名前は?')
index.html
- フォーム部分
<div id="result">の要素配下にこんにちは、[name]さん!という文言が追加されていく。
(と、いう処理をjQueryに記述する)<h1>Let's Greeting!</h1> <form action="" method="post">{% csrf_token %} {{ form }} <button type="submit">送信</button> </form> <div id="result"> <!-- ここにあいさつ文の <p> タグ要素が追加されていく --> </div>
- スクリプト部分
jQuery部分についても上述の仕様通りになっていることが何となく読み取れると思う。
また、(slimでない)jQueryが必要なのでロードする。<script src="https://code.jquery.com/jquery-3.5.1.min.js" integrity="sha256-9/aliU8dGd2tb6OSsuzixeV4y/faTqgFtohetphbbj0=" crossorigin="anonymous"></script> <script> // 送信ボタンにイベントリスナーを設定。内部に Ajax 処理を記述 $("form").submit(function(event) { event.preventDefault(); var form = $(this); $.ajax({ url: form.prop("action"), method: form.prop("method"), data: form.serialize(), timeout: 10000, dataType: "text", }) .done(function(data) { $("#result").append("<p>" + data + "</p>"); }) }); </script>
上記をがっちゃんこした
index.html<h1>Let's Greeting!</h1> <form action="" method="post">{% csrf_token %} {{ form }} <button type="submit">送信</button> </form> <div id="result"> <!-- Will be replaced with inputed text by Ajax --> </div> <script src="https://code.jquery.com/jquery-3.5.1.min.js" integrity="sha256-9/aliU8dGd2tb6OSsuzixeV4y/faTqgFtohetphbbj0=" crossorigin="anonymous"></script> <script> // 送信ボタンにイベントリスナーを設定。内部に Ajax 処理を記述 $("form").submit(function(event) { event.preventDefault(); var form = $(this); $.ajax({ url: form.prop("action"), method: form.prop("method"), data: form.serialize(), timeout: 10000, dataType: "text", }) .done(function(data) { $("#result").append("<p>" + data + "</p>"); }) }); </script>
views.py
FormViewを継承したGreetView1つを定義するgreeting/views.pyfrom django.http import HttpResponse from django.views.generic import FormView from . import forms # Create your views here. class GreetView(FormView): template_name = 'index.html' # テンプレート名(htmlファイル名) form_class = forms.GreetForm success_url = '/greet' def post(self, request, *args, **kwargs): form = self.get_form(self.form_class) if form.is_valid(): if request.is_ajax(): """Ajax 処理を別メソッドに切り離す""" print('### Ajax request') return self.ajax_response(form) # Ajax 以外のPOSTメソッドの処理 return super().form_valid(form) # フォームデータが正しくない場合の処理 return super().form_invalid(form) def ajax_response(self, form): """jQuery に対してレスポンスを返すメソッド""" name = form.cleaned_data.get('name') return HttpResponse(f'こんにちは、{name}さん!')ちなみに
views.py内のif request.is_ajax():について、公式ドキュメントには以下のようにある。参照 - リクエストとレスポンスのオブジェクト | Django ドキュメント | Django
(はんなり和訳)
HttpRequest.is_ajax() HTTP_X_REQUESTED_WITHヘッダの'XMLHttpRequest'文字列で リクエストがXMLHttpRequest経由によるものかどうかをチェックし、Trueを返します。 多くのモダンなJavaScriptライブラリはこのヘッダを送信します。つまり、このメソッドはリクエストヘッダの
HTTP_X_REQUESTED_WITHにXMLHttpRequestがセットされる場合にのみ使える。
jQueryはこれをちゃんとセットしてくれるっぽい。
※jQueryを使わない(素のJavaScript)で少し試したところ上手くいきませんでした。
- 検証コード
views.pyのGreetViewを以下のように書き換えてリクエストヘッダを覗いてみる。class GreetView(FormView): template_name = 'greet.html' form_class = forms.GreetForm success_url = '/greet' def post(self, request, *args, **kwargs): # ★追加 for k, v in request.META.items(): print(k, v) # ...(以下同様)
- 結果
※デバッグモードだと大量のリクエストヘッダが全て出力されるので抜粋
... HTTP_ACCEPT text/plain, */*; q=0.01 HTTP_X_REQUESTED_WITH XMLHttpRequest # <= これ HTTP_USER_AGENT Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36 ...まとめ
以上、汎用ビューによる Django のAjax サンプルを記載した。
他の記事よりも簡潔に実装できていると思う。
他にも、StreamingHttpResponseと組み合わせるとどんなことができるか試してみたい
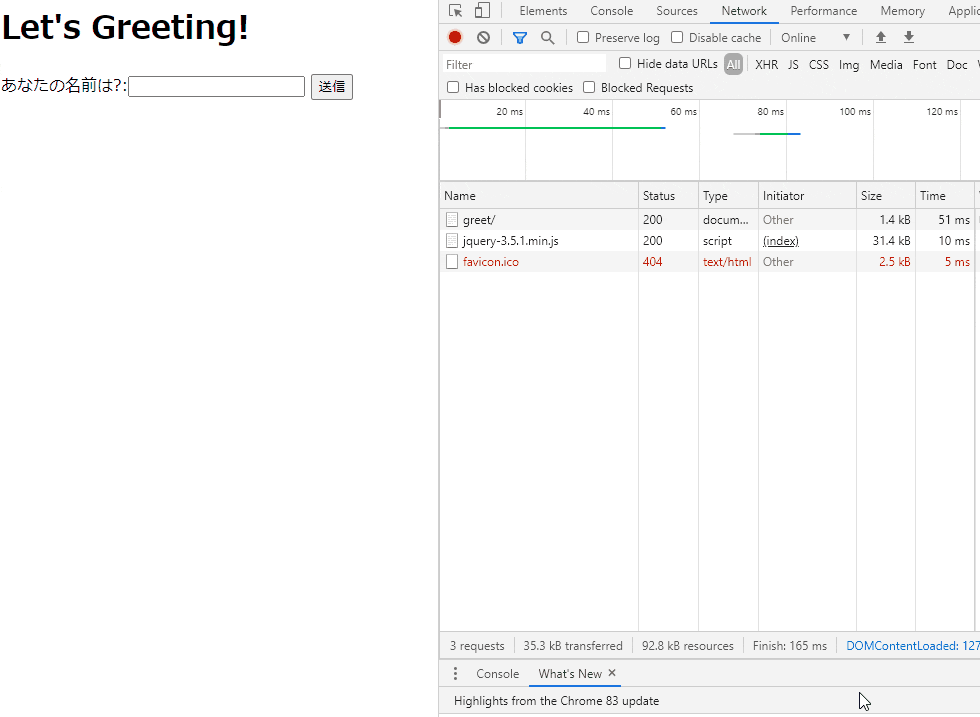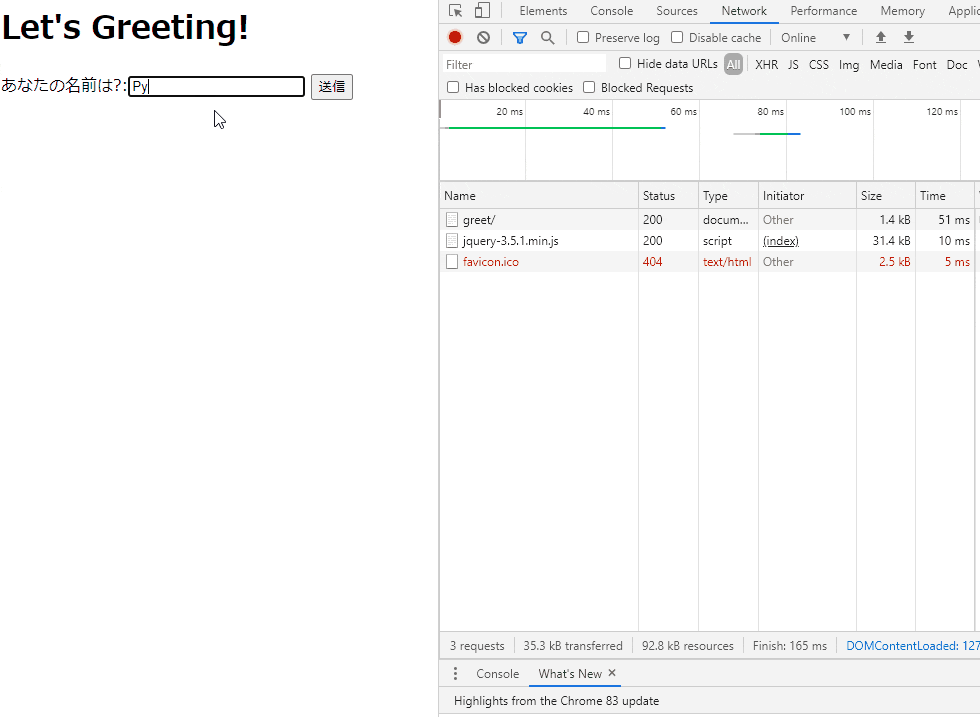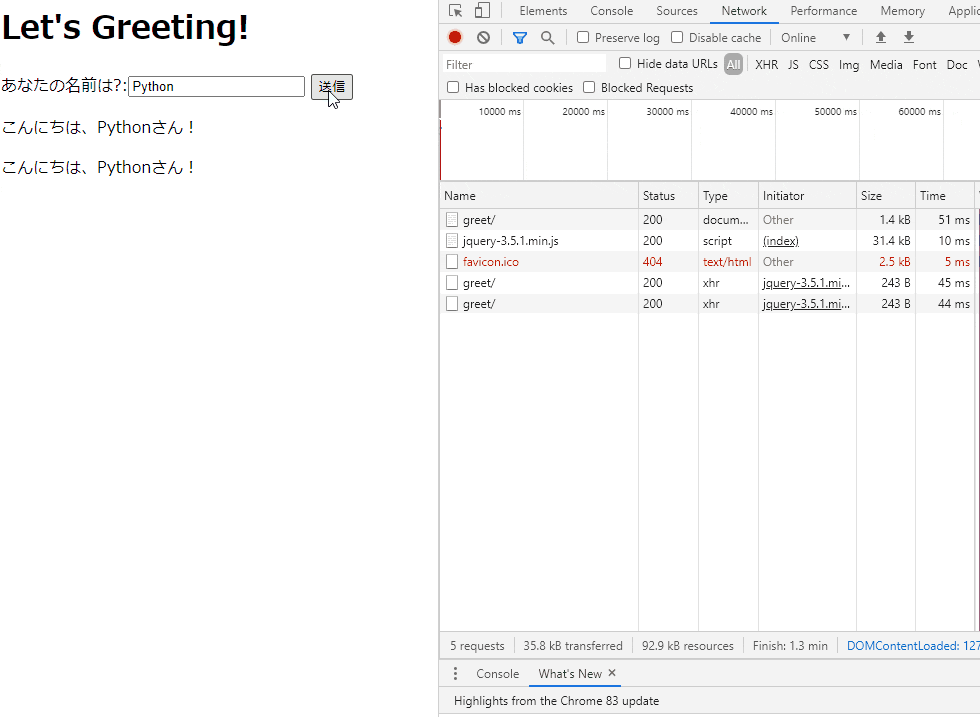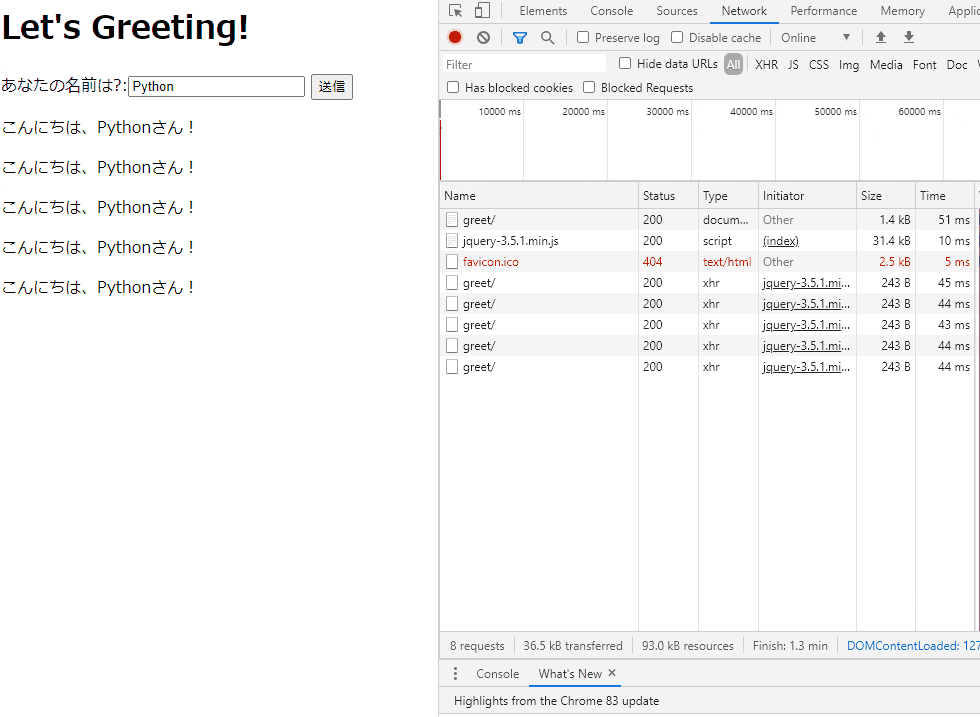
- 投稿日:2020-06-02T17:02:20+09:00
ゼロから始めるLeetCode Day44「543. Diameter of Binary Tree」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day43「5. Longest Palindromic Substring」今はTop 100 Liked QuestionsのMediumを解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
問題
難易度はeasy。
Top 100 Liked Questionsからの抜粋です。解いていたのに記事を書くのを忘れていたのを見つけたので書きます!
問題としては、二分木が与えられます。
その木の直径を調べ、二点間のノードの最も長い経路の長さを返すようなアルゴリズムを設計する、というものです。1 / \ 2 3 / \ 4 5Return 3, which is the length of the path [4,2,1,3] or [5,2,1,3].
この場合は3が返されるとなっていますね。
解説
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution: def diameterOfBinaryTree(self, root: TreeNode) -> int: self.ans = 0 def dfs(node): if not node: return 0 right = dfs(node.right) left = dfs(node.left) self.ans = max(self.ans,left+right) return max(left,right) + 1 dfs(root) return self.ans # Runtime: 40 ms, faster than 89.86% of Python3 online submissions for Diameter of Binary Tree. # Memory Usage: 16 MB, less than 34.48% of Python3 online submissions for Diameter of Binary Tree.深さ優先探索で深さを測り、直径なので最終的に親を経由するので+1をすれば解けます。
木の構造を理解できてれば比較的すんなり実装できるかと思います。
地味にてこずったとはいえない・・・今回はここまで。お疲れ様でした!
- 投稿日:2020-06-02T16:08:08+09:00
VSCodeでプロジェクト用のPython仮想環境をvenvで準備する
はじめに
前記事で環境構築と静的解析まで実施しましたが、
複数のプロジェクトを同環境で開発する場合、使うモジュールや違うバージョンのモジュールを使用したりするので、
プロジェクト毎のPython仮想環境を準備します。前記事
VisualStudioCodeでPython開発環境構築 (0からflake8による静的解析及びコード整形まで)動作確認環境
Windows 10 64bit
Python 3.8.3
VSCode 1.45.1Python仮想環境構築
プロジェクト用のディレクトリ作成
VSCodeの上部メニューのTerminalからNewTerminalを開く。
(PowershellかCmdでもOK)
任意のディレクトリにプロジェクトディレクトリを作成します。PS C:\work> mkdir TestProject PS C:\work> cd TestProject仮想環境の作成
以下のコマンドを実行し仮想環境を構築します。
PS C:\work\TestProject> python -m venv project_env仮想環境構築後は以下のようなファイル群が作成されています。
PS C:\work\TestProject\project_env> ls ディレクトリ: C:\work\TestProject\project_env Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 2020/06/02 15:00 Include d----- 2020/06/02 15:00 Lib d----- 2020/06/02 15:00 Scripts -a---- 2020/06/02 15:00 126 pyvenv.cfgPowerShellのポリシー変更
仮想環境をActivateするためには、
その機能を持つPowerShell Scriptを実行する必要があるそうですが、Windows10では標準では実行できないようです。そのため、PowerShellのポリシーを変更します。
1.管理者権限でPowerShellを開く
検索からPowerShellを見つけて管理者権限で開きます。
2.下記コマンドをPowerShellで実行
Set-ExecutionPolicy RemoteSignedPython仮想環境をVSCodeに反映
1. プロジェクトディレクトリをVSCodeで開く
VSCode上部メニューからFile⇒Open Folderをクリックし、作成したプロジェクトディレクトリを開く。
2. 確認用pythonファイル作成
プロジェクトフォルダ内にPythonファイルがないと仮想環境が読み込まれないため、任意の*.pyファイルを作成する。
3. 仮想環境の反映確認
仮想環境が正常に読み込めた場合、下記のように左下のPythonのバージョン情報の横に読み込んでいる仮想環境名が表示されます。
4. ターミナルの確認
仮想環境が反映された状態でターミナルを開くと、下記のように仮想環境がActivateされた状態で開きます。
真っ新な環境となるため、pip freezeでインストールパッケージ一覧を表示しても空の状態になります。
必要なモジュールのインストール
仮想環境では前記事で設定していた静的解析ツールもインストールされていない状態となりますので、
仮想環境にもインストールします。
※仮想環境反映時にVSCode側からinstallの指示が出ますのでそちらでインストールしても大丈夫です。pip install flake8 autopep8インストール後のパッケージ一覧
仮想環境構築は以上です。お疲れさまでした!
参考にした記事
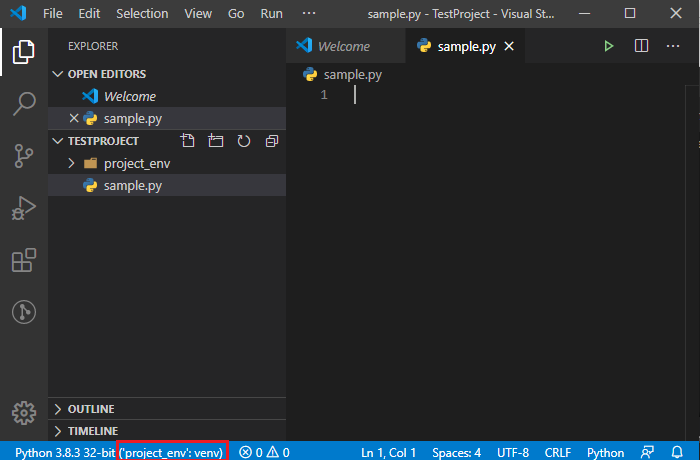
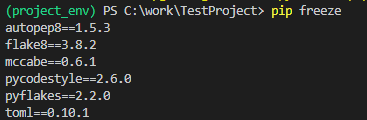
- 投稿日:2020-06-02T15:54:16+09:00
macとwinでpyInstallerを使う時経験した不具合と対処法
pyInstalllerの設定をwindowsとmacで経験した事を書き留めたいと思います。
macOSは10.13.5 Hight Sierra、windows 10 1909です。Mac:
- pyenvの問題。PyInstallerを使うと、OSErrorが発生した。対処はpyenvの再インストール。
PYTHON_CONFIGURE_OPTS="--enable-shared" pyenv install バージョン
注意:envのアンインストールは不要だった。pip listで確認できるすでにインストールしたモジュールは失われていなかった。
2.pyInstallerの再インストール必要。
上記「モジュールは失われていなかった」と書いた。pip listで確認すると存在していることが確認できた。しかしpyInstallerを実行してもまだOSErrorが発生した。pip uninstall pyInstallerとpip install pyInstallerを実行し、再インストールした。Mac環境でpython - pyenvを使う上で、インストール時--enable-sharedのオプションを使うことは重要なようです。"PYTHON_CONFIGURE_OPTS="--enable-shared" は「パイソン設定オプションでシェアを有効にする」という指定なのでしょう。
下にWindowsの問題点で書きますが、WindowsではpyInstallerインストール時、「実行ファイルがAppData下にインストールされたので、環境変数でパスを指定しなさい」と言われます。
「シェアする」(mac)という行為と「パスを通す」(win)という行為は違うようですが、macとwinを使う人々にとっては「使いやすくする」という設定、言い換えるとカスタマイズだと思います。
- 「よく読めば自分の好みにできるが、それに気づかず『使えないなぁ、もうやめる!』」と、
- 「1次情報と周辺情報などかき集めて自分の知見を積み上げ使い続ける」と、
- 「ソフトウェアは最適なUX環境が提供されるものだ」など
が混在する事を気付かされます。Win:
- pyInstallerインストール完了した時、そのメッセージには、"C:\Users\USER_NAME\AppData\Roaming\Python\Python(バージョン)\Scripts"にインストールしたから、環境変数でパス指定したほうがいいという文章がある。 2.システム環境変数のPathに"C:\Users\USER_NAME\AppData\Roaming\Python\Python(バージョン)\Scripts"を加える。 3.自分の場合そのパスを一番上の順位にする。windowsは指定した実行ファイルを上から順番に探していくので、順位を上にすることは不要だと思うが、最上位にしても問題はないと判断した。
- pyInstallerオプションで、--onedir or -p(1ディレクトリ)、--onefile or -F(1ファイル)、--noconsole or -w(コンソールを表示なし)、--clean(ビルド前に前回のキャッシュと出力ディレクトリを削除)、--icon(タイトルにアイコン表示)
- --iconオプション設定時、pythonプログラムコード内で、iconのicoファイルのある場所を指定するのだが、その書き方はフルパスで記述すること。自分の場合、pyInstallerで生成は成功したのだが、distフォルダにあるexeファイルはfata errorが発生した。フルパスで記述し直したところfatal error問題は解決した。
- 投稿日:2020-06-02T15:35:52+09:00
Ansible 自作モジュール rpm操作
背景と注意事項
Ansibleにはrpmモジュールがない。そうれはそう、
yumがあるから。構成管理ツールなので
--forceとかできるrpmはAnsibleの中では非推奨というわけだ。が、現場では過去のシステムを継ぎ接ぎで開発しているものがあって、どうしても64bitマシンに32bitの
rpmを入れたいときがあるわけだ。これをyumで実装した際に「64bitのパッケージあるから入れてやらないぞ」となったりするわけ。あるべき姿は構成管理を視野にいれた開発であって、これは非推奨モジュールである。
実現したいこと
あんまり難しいのやるつもりはなくて
rpmファイルは既にcopyなどでノードに配置されている
- これはいつか
copy相当の組み込みでファイルを配置できるようにしたいrpmコマンドのオプションを受け取ってそのまま使う
- これもいつかはフラグ管理したい
- 指定された
rpmファイルが存在することを確認- 指定された
rpmが未インストールであることを確認- 指定された
rpmをまとめて、指定されたオプションでインストールこんぐらいだろうか。
雛形を作る
過去の記事を見てね。
rpm.py#!/usr/bin/python # -*- coding: utf-8 -*- from ansible.module_utils.basic import AnsibleModule # メイン処理 #----------------------------------------------------------- def main(): # AnsibleModuleクラス: moduleを作成 module = AnsibleModule( # 引数受け取り argument_spec=dict( # ココに引数受け取り処理を書く ), # 引数チェックを有効 supports_check_mode=True ) # 指定されたファイルの存在チェック # 変更要否判定 changed = False # rpmインストール # 終了処理 if __name__ == '__main__': main()こんなところかな
引数の受け取り
今回受け付ける引数は以下のとおり
引数名 必須 デフォルト値 引数の意味 pkgs ○ - パッケージのリスト opts -Uvh rpmコマンドに与えるオプション chdir / パッケージ格納ディレクトリ ちなみに
リストの受け取り方が調べて悩んでわからず、某Q&Aに投稿したけど翌日自己解決した。
参考:Ansible with_listで渡した配列をモジュールの中でループに使用するにはrpm.py:#(省略) # 引数受け取り argument_spec=dict( # パッケージリスト(必須,list型) pkgs = dict(required = True, type = list), # オプション(str型,[-Uvh]) opts = dict(required = False, type = str, default = '-Uvh'), # パッケージ格納ディレクトリ(str型) chdir = dict(required = False, type = str, default = '/'), ), # 引数チェックを有効 supports_check_mode=True :#(省略)なお、上記のように部分的に抜粋する場合は行頭のインデントを削っています。横に長くなっちゃうから。
指定されたファイルの存在チェック
前回、
mkfifoするモジュールを作成したときは何も考えずにstatコマンドやtestコマンド使っちゃったけど、流石にそんぐらいモジュール何かあるだろうと考えた。rpm.py:#(省略) from ansible.module_utils.basic import AnsibleModule import os :#(省略) # 冗長になるので変数入れ直し pkgs = module.params['pkgs'] chdir = module.params['chdir'] # パッケージリスト毎にループ for pkg in pkgs: # 指定されたファイルの存在チェック if (os.path.isfile(chdir + '/' + pkg)): # ファイルが配置されていない module.fail_json(msg = chdir + '/' + pkg + ' is not found.') :#(省略)心配なのでココで一度動作確認しておこう。まだ
/tmp/にrpmを配置していないぞ。test.yml- name: ntp install rpm: pkgs: '{{ item }}' opts: '-ivh' chdir: '/tmp' with_list: - [ 'ntp-4.2.6p5-15.el6.centos.x86_64.rpm','ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm' ]動作確認$ ansible-playbook -i test_grp -l test_srv -u root test.yml -vvv :#(省略) ok: [192.168.56.104] => (item=[u'ntp-4.2.6p5-15.el6.centos.x86_64.rpm', u'ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm']) => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "ansible_loop_var": "item", "changed": false, "invocation": { "module_args": { "chdir": "/tmp", "opts": "-ivh", "pkgs": [ "ntp-4.2.6p5-15.el6.centos.x86_64.rpm", "ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm" ] } }, "item": [ "ntp-4.2.6p5-15.el6.centos.x86_64.rpm", "ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm" ] }あれ・・・ちょっとデバッグ。
rpm.py# 冗長になるので変数入れ直し pkgs = module.params['pkgs'] chdir = module.params['chdir'] num = 0 hog = 0 # パッケージリスト毎にループ for pkg in pkgs: num += 1 # 指定されたファイルの存在チェック if (os.path.isfile(chdir + '/' + pkg)): hog += 1 # ファイルが配置されていない module.fail_json(msg = chdir + '/' + pkg + ' is not found.') :#(省略) module.exit_json(num = num, hog = hog)実行結果ok: [192.168.56.104] => (item=[u'ntp-4.2.6p5-15.el6.centos.x86_64.rpm', u'ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm']) => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "ansible_loop_var": "item", "changed": false, "hog": 0, ★ "invocation": { "module_args": { "chdir": "/tmp", "opts": "-ivh", "pkgs": [ "ntp-4.2.6p5-15.el6.centos.x86_64.rpm", "ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm" ] } }, "item": [ "ntp-4.2.6p5-15.el6.centos.x86_64.rpm", "ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm" ], "num": 2 ★ }うーん
if (os.path.isfile(chdir + '/' + pkg)):が間違えてるのかな。いろいろ試した結果if os.path.isfile(chdir + '/' + pkg) == False:だと動いた。うーん、なぜなのか。rpm.py:#(省略) from ansible.module_utils.basic import AnsibleModule import os :#(省略) # 冗長になるので変数入れ直し pkgs = module.params['pkgs'] chdir = module.params['chdir'] # パッケージリスト毎にループ for pkg in pkgs: # 指定されたファイルの存在チェック if os.path.isfile(chdir + '/' + pkg) == False: # ファイルが配置されていない module.fail_json(msg = chdir + '/' + pkg + ' is not found.') :#(省略)変更要否判定
変更要否、つまり既にすべての
pkgがインストールされていたら作業は不要なわけだ。rpmパッケージがインストールされているかどうかは以下のコマンドでわかる。$ rpm -q ntp-4.2.6p5-15.el6.centos.x86_64 ntp-4.2.6p5-15.el6.centos.x86_64 $ echo $? 0 $ rpm -q hoge パッケージ hoge はインストールされていません。 $ echo $? 1しかし
rpmファイルは、ファイル名の末尾.rpmを抜いたものがパッケージ名とは限らない。$ ls -1 jdk-8u192-linux-x64.rpm jdk-8u192-linux-x64.rpm $ rpm -q jdk-8u192-linux-x64 パッケージ jdk-8u192-linux-x64 はインストールされていません。 $ rpm -qa | grep jdk jdk1.8-1.8.0_192-fcs.x86_64上記の例だとファイル名は
jdk-8u192-linux-x64.rpmだがパッケージ名はjdk1.8-1.8.0_192-fcs.x86_64である。これを判別するためには
rpm -qp rpmファイル名でパッケージ名を調べる必要がある。$ rpm -qp jdk-8u192-linux-x64.rpm 警告: jdk-8u192-linux-x64.rpm: ヘッダ V3 RSA/SHA256 Signature, key ID ec551f03: NOKEY jdk1.8-1.8.0_192-fcs.x86_64上記の標準出力で得られたものがパッケージ名だ。
この処理をモジュールに組み込む
rpm.py:#(省略) # 冗長になるので変数入れ直し pkgs = module.params['pkgs'] chdir = module.params['chdir'] # 変更要否判定 changed = False # インストール対象rpmファイルリスト rpms = [] # パッケージリスト毎にループ for pkg in pkgs: # ファイルのフルパスを作成 fpath = chdir + '/' + pkg # 指定されたファイルの存在チェック if os.path.exists(fpath) == False: # ファイルが配置されていない module.fail_json(msg = fpath + ' is not found.') # rpmファイルからパッケージ名を取得 rc, pkg_name, stderr = module.run_command('rpm -qp ' + fpath) # パッケージのインストール状況確認 rc, stdout, stderr = module.run_command('rpm -q ' + pkg_name) # インストール済みか if rc != 0: # インストールされていないので変更要 changed = True # インストール対象に追加 rpms.append(fpath) :#(省略)rpmインストール
インストール対象rpmリスト
rpmsが空っぽだったら終了・・・という判定はchagned != Trueに任せることにする。rpm.py:#(省略) # rpmインストール要否判定 if changed != True: # インストール対象なし module.exit_json() # rpmリスト作成 rpm_line = ' '.join(rpms) # rpmインストール rc, stdout, stderr = module.run_command('rpm ' + module.params['opts'] + ' ' + rpm_line) # rpmインストール結果判定 if rc != 0: # インストール失敗 module.fail_json(stdout = stdout, stderr = stderr) # 終了処理 module.exit_json(changed = changed) :#(省略)試運転
test.yml- name: ntp install rpm: pkgs: '{{ item }}' opts: '-ivh' chdir: '/tmp' with_list: - [ 'ntp-4.2.6p5-15.el6.centos.x86_64.rpm','ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm' ]# パッケージファイルが配置されていることを確認 $ ssh root@192.168.56.104 "ls -l /tmp/*rpm" -rw-rw-r--. 1 root root 614364 5月 11 17:01 2020 /tmp/ntp-4.2.6p5-15.el6.centos.x86_64.rpm -rw-rw-r--. 1 root root 80836 5月 11 17:00 2020 /tmp/ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm # パッケージファイルがインストールされていないことを確認 $ ssh root@192.168.56.104 "rpm -qa | grep ntp" $ # 実行! $ ansible-playbook -i test_grp -l test_srv -u root test.yml -vvv :#(省略) changed: [192.168.56.104] => (item=[u'ntp-4.2.6p5-15.el6.centos.x86_64.rpm', u'ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm']) => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "ansible_loop_var": "item", "changed": true, "invocation": { "module_args": { "chdir": "/tmp", "opts": "-ivh", "pkgs": [ "ntp-4.2.6p5-15.el6.centos.x86_64.rpm", "ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm" ] } }, "item": [ "ntp-4.2.6p5-15.el6.centos.x86_64.rpm", "ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm" ], "msg": "/tmp/ntp-4.2.6p5-15.el6.centos.x86_64.rpm /tmp/ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm" } # 冪等性確認のためもう一度実行! $ ansible-playbook -i test_grp -l test_srv -u root test.yml -vvv ok: [192.168.56.104] => (item=[u'ntp-4.2.6p5-15.el6.centos.x86_64.rpm', u'ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm']) => { "ansible_facts": { "discovered_interpreter_python": "/usr/bin/python" }, "ansible_loop_var": "item", "changed": false, "invocation": { "module_args": { "chdir": "/tmp", "opts": "-ivh", "pkgs": [ "ntp-4.2.6p5-15.el6.centos.x86_64.rpm", "ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm" ] } }, "item": [ "ntp-4.2.6p5-15.el6.centos.x86_64.rpm", "ntpdate-4.2.6p5-15.el6.centos.x86_64.rpm" ] }いいんじゃないでしょうか。
作成したモジュール
rpm.py#!/usr/bin/python # -*- coding: utf-8 -*- from ansible.module_utils.basic import AnsibleModule import os # メイン処理 #----------------------------------------------------------- def main(): # AnsibleModuleクラス: moduleを作成 module = AnsibleModule( # 引数受け取り argument_spec=dict( # パッケージリスト(必須,list型) pkgs = dict(required = True, type = list), # オプション(str型,[-Uvh]) opts = dict(required = False, type = str, default = '-Uvh'), # パッケージ格納ディレクトリ(str型) chdir = dict(required = False, type = str, default = '/'), ), # 引数チェックを有効 supports_check_mode=True ) # 冗長になるので変数入れ直し pkgs = module.params['pkgs'] chdir = module.params['chdir'] # 変更要否判定 changed = False # インストール対象rpmファイルリスト rpms = [] # パッケージリスト毎にループ for pkg in pkgs: # ファイルのフルパスを作成 fpath = chdir + '/' + pkg # 指定されたファイルの存在チェック if os.path.exists(fpath) == False: # ファイルが配置されていない module.fail_json(msg = fpath + ' is not found.') # rpmファイルからパッケージ名を取得 rc, pkg_name, stderr = module.run_command('rpm -qp ' + fpath) # パッケージのインストール状況確認 rc, stdout, stderr = module.run_command('rpm -q ' + pkg_name) # インストール済みか if rc != 0: # インストールされていないので変更要 changed = True # インストール対象に追加 rpms.append(fpath) # rpmインストール要否判定 if changed != True: # インストール対象なし module.exit_json() # rpmリスト作成 rpm_line = ' '.join(rpms) # rpmインストール rc, stdout, stderr = module.run_command('rpm ' + module.params['opts'] + ' ' + rpm_line) # rpmインストール結果判定 if rc != 0: # インストール失敗 module.fail_json(stdout = stdout, stderr = stderr) # 終了処理 module.exit_json(changed = changed) if __name__ == '__main__': main()
- 投稿日:2020-06-02T15:12:01+09:00
G検定2020#2 受験に向けて
7/4に実施される、G検定2020#2に申し込みを行いました。
自身のメモ、備忘録としての投稿です。
- 投稿日:2020-06-02T14:50:07+09:00
Djangoを一からセットアップしてみた(Vagrant, Centos, Python3)
はじめに
先日、ローカル環境でAnacondaを使ってみたのですが、「これをブラウザで表示することはできないものか…?」と思い、Djangoを使える環境を作ることにしました。
今回はVagrantのbox立ち上げから、ブラウザにDjangoの仮想サーバ画面を表示するところまで行いました。
最終的には、
ブラウザ上でフォームに入力
→送られたデータを基にサーバ側で機械学習モデルが計算
→結果をブラウザに返す
という感じのアプリが作れたらなと思っております。実行環境
ホストOS: Windows10
ゲストOS: Centos7(Vagrant)VagrantのBoxを作る
こちらはVagrant+Python3+Django環境でHelloWorldを参考にしました。
コマンドプロンプトで作業します。vagrant box add centos/7 vagrant init centos/7生成されたVagrantfileに以下の2行を追記。
config.vm.synced_folder "./", "/home/vagrant/work" config.vm.network "forwarded_port", guest: 8000, host: 18000コマンドプロンプトに戻ってvagrantを起動します。
vagrant up vagrant sshPython3をインストール
デフォルトで入っているのがpython2系のみだったので、python3を入れたい。今後のことを考えると、バージョン管理ソフトを使うのが得策かなと思ったので、pyenvを使うことにしました。非推奨らしいですが……。
pyenv を用いた Python3 インストールを参考にしています。必要な諸々を準備。ここからはTeratermで作業しています。vagrant sshでも良いかも知れません。
$ sudo yum groupinstall "Development tools" $ sudo yum install gcc zlib-devel bzip2 bzip2-devel readline readline-devel sqlite sqlite-devel openssl openssl-devel gitpyenvをインストール
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source .bash_profilepyenvを最新版に
$ pyenv --version pyenv 1.2.3-43-g35f7ef8 $ pyenv install --list # インストール可能なpythonが大量に出てきます $ pyenv install 3.8.3 # 使いたいバージョンがあることを確認し、インストール $ pyenv global 3.8.3pyenv, pythonのバージョンを確認
$ pyenv versions system * 3.8.3 (set by /home/vagrant/.pyenv/version) $ python --version Python 3.8.3Djangoをインストール
旧Djangoを削除(存在しないことが確認できれば良し)
$ python -c "import django; print(django.__path__)" Traceback (most recent call last): File "<string>", line 1, in <module> ImportError: No module named djangovirtualenv、virtualenvwrapper、djangoをインストール
$ pip install virtualenv $ pip install virtualenvwrapper $ pip install DjangoDjangoのバージョン確認
$ python -m django --version 3.0.6SQLite3のバージョンアップ
Vagrantのデフォルトで入っているSQLite3はバージョンが古いらしく、そのままサーバを立ち上げようとするとエラーが出るので、新しいものをインストールします。
Django入門 (チュートリアル) - とほほのWWW入門が参考になりました。$ yum install -y wget gcc make $ wget https://www.sqlite.org/2019/sqlite-autoconf-3290000.tar.gz $ tar zxvf ./sqlite-autoconf-3290000.tar.gz $ cd ./sqlite-autoconf-3290000 $ ./configure --prefix=/usr/local $ make $ make install $ cd .. $ rm -rf ./sqlite-autoconf-3290000 ./sqlite-autoconf-3290000.tar.gz $ mv /usr/bin/sqlite3 /usr/bin/sqlite3_old $ ln -s /usr/local/bin/sqlite3 /usr/bin/sqlite3 $ echo 'export LD_LIBRARY_PATH="/usr/local/lib"' >> ~/.bashrc $ source ~/.bashrcDjangoの仮想サーバに接続
/home/vagrant/work配下にプロジェクトを作成。
Vagrantfileで設定したので、ここに作ったファイルやアプリがローカルと仮想環境で共有されます。※確認(Vagrantfile)
config.vm.synced_folder "./", "/home/vagrant/work"Djangoプロジェクト作成
$ cd /home/vagrant/work $ django-admin startproject mysite # mysiteはお好みのプロジェクト名で $ cd mysite # プロジェクト内へ移動 $ python manage.py runserver 0:8000 # サーバ起動あとはhttp://127.0.0.1:8000 をブラウザに打ち込めばページが開けます!
おわりに
当初、サーバは起動しているのにブラウザでは何も表示できず、かなり手間取りました。何とか自力で解決できて良かったです。
でも、やりきったぞ感はあるけどこれはあくまで準備段階。アプリケーションを完成させるまで道のりは遠そうです。参考
VagrantからDjangoインストールまで全般:
Vagrant+Python3+Django環境でHelloWorldSQLite3のバージョンアップ:
Django入門 (チュートリアル) - とほほのWWW入門pythonのインストール・管理:
pyenv を用いた Python3 インストール
- 投稿日:2020-06-02T14:32:16+09:00
深層学習入門 ~順伝播編~
対象者
深層学習シリーズの記事です。
前回の記事はこちらです。
ここでは順伝播について、まずはスカラでの理論を説明して、それから行列に拡張します。
前回記事で紹介したコードに追加していったり修正していく形となるので、まずは前回記事からコードを取ってきておいてくださいね〜目次
スカラでの順伝播
ここでは、スカラ(実数)での順伝播の理論と実装を説明します。といっても、だいたい基礎編で既に述べている通りです。
スカラでの順伝播理論
まずは理論ですね。
このニューロンモデルから見ていきます。
これを定式化すると$f(x) = \sigma(wx + b)$となることはここで述べている通りです。活性化関数$\sigma(•)$を通すことで非線形化し、層を重ねる意味を持たせています。
では、この操作を計算グラフで表すとどのようになるでしょうか?
こんな感じになります。今までは入力を$x$だけとしており他の要素は略していましたが、計算グラフでは重み$w$とバイアス(閾値)$b$もきちんと記述し、活性化関数を通し出力する、というように書き換えられます。
この変数たち$x, w, b, y$は諸々ニューロンオブジェクトが持つべき変数になります。
また活性化関数についても、Pythonは関数やクラスをオブジェクトとして変数に格納することが可能なので、ニューロンオブジェクトに持たせると実装がカプセル化できて良さそうですね。
スカラでの順伝播の理論は以上です。シンプルでいいですね〜。スカラでの順伝播実装
では実装してみます。実装するコードはbaselayer.pyです。
baselayer.py
baselayer.pydef forward(self, x): """ 順伝播の実装 """ # 入力を記憶しておく self.x = x.copy() # 順伝播 y = self.w * x + self.b self.y = self.act.forward(y) return self.y
入力を保持しているのは逆伝播の時に必要になるからです。
また活性化関数はまだ実装に触れませんが、上記みたいに使えるように実装しようと考えています。あと持っているメソッドは微分を計算するbackwardです。物によってはupdateメソッドを持たせる必要もあるかもしれません。順伝播自体は至極簡単ですね。数式通りです。
スカラでの実装は以上となります。続いてベクトル(というより行列)での実装を考えます。行列での順伝播
続いて行列での順伝播を考えます。
行列は線形代数の行列積の概念を知っていないと厳しいので、もしご存知でない方がいらっしゃいましたらここで簡単に説明しています。行列での順伝播理論
まずは先ほどのニューロンオブジェクトを2つ重ねたようなレイヤーオブジェクトを考えましょう。
図のうまい表現が思いつかなかったのでちょっと解説します。
まず黒の矢印たちは先ほどのニューロンオブジェクトという理解でOKです。他のカラーの矢印たちのことですね。
水色の矢印は上側のニューロンから下側のニューロンへとつながるシナプスを表しています。
真ん中の掛け算のノードを通る際に水色の重み$w_{1, 2}$を乗算して、下側の足し算のノードへ合流します。
赤色の矢印も同様ですね。
真ん中の掛け算のノードを通る際に赤色の重み$w_{2, 2}$を乗算して、上側の足し算のノードへ合流します。
足し算のノードの入力が3つになってしまっていますが、複数の足し算のノードを用いることで2入力に分解できますので、それを省略したとお考えください。
それでは、これを数式で追いかけてみましょう。まずは書き下しからです。y_1 = w_{1, 1}x_1 + w_{2, 1}x_2 + b_1 \\ y_2 = w_{1, 2}x_1 + w_{2, 2}x_2 + b_2これ自体は図を見ていただければ明白だと思います。
では、これを行列表現で表しましょう。\left( \begin{array}{c} y_1 \\ y_2 \end{array} \right) = \left( \begin{array}{cc} w_{1, 1} & w_{2, 1} \\ w_{1, 2} & w_{2, 2} \end{array} \right) \left( \begin{array}{c} x_1 \\ x_2 \end{array} \right) + \left( \begin{array}{c} b_1 \\ b_2 \end{array} \right)こんな感じになります。行列積を理解していれば等価な式になることがわかると思います。
ところで$w_{i, j}$についてですが、添字に注目してください。
ふつう添字は$i$行$j$列のように読みますよね?ですが、上の数式では$j$行$i$列のようになっていますね。このままでは理論的にも実装的にも扱いづらいため転置しましょう。\left( \begin{array}{c} y_1 \\ y_2 \end{array} \right) = \left( \begin{array}{cc} w_{1, 1} & w_{1, 2} \\ w_{2, 1} & w_{2, 2} \end{array} \right)^{\top} \left( \begin{array}{c} x_1 \\ x_2 \end{array} \right) + \left( \begin{array}{c} b_1 \\ b_2 \end{array} \right) \\ \Leftrightarrow \boldsymbol{Y} = \boldsymbol{W}^{\top}\boldsymbol{X} + \boldsymbol{B}転置についてもここで触れています。
とりあえずこれで2入力2出力のレイヤーオブジェクトの数式表現が完成です。簡単ですね。
ではこれを一般化します。と言っても特に変わりありません。数式的には\boldsymbol{Y} = \boldsymbol{W}^{\top}\boldsymbol{X} + \boldsymbol{B}のままです。これを詳しく見ていきます。
$M$入力$N$出力のレイヤーを考えると\underbrace{\boldsymbol{Y}}_{N \times 1} = \underbrace{\boldsymbol{W}^{\top}}_{N \times M}\underbrace{\boldsymbol{X}}_{M \times 1} + \underbrace{\boldsymbol{B}}_{N \times 1}のようになります。$\boldsymbol{W}^{\top}$は転置後の形状を示しています。転置前は$\underbrace{\boldsymbol{W}}_{M \times N}$ですね。
理論は以上となります。では実装に移りましょう。行列での順伝播実装
実装場所はスカラでの実装と同じくbaselayer.pyです。
スカラでの実装を書き換えます。
baselayer.py
baselayer.pydef forward(self): """ 順伝播の実装 """ # 入力を記憶しておく self.x = x.copy() # 順伝播 y = self.w.T @ x + self.b self.y = self.act.forward(y) return self.y
変わったのはわずか1行ですね。baselayer.pyy = self.w * x + self.bが
baselayer.pyy = self.w.T @ x + self.bとなっています。
numpy配列では転置をndarray.Tで行うことができます。
@演算子はあまり馴染みがない方もいらっしゃるかもしれませんが、np.dotと同じ処理になっています。
Numpyのバージョン1.10以上で利用できますので、それ以下のバージョンをお使いの場合は注意してください。
@演算子の説明test_at.pyx = np.array([1, 2]) w = np.array([[1, 0], [0, 1]]) b = np.array([1, 1]) y = w.T @ x + b print(y) print(y == np.dot(w.T, x) + b) #---------- # 出力は # [2 3] # [ True True] # となります。ここでは実は
@演算子の行列とベクトルとの演算機能を暗に用いています。きちんと行列として演算させたい場合はnp.arrayの代わりにnp.matrixとして、さらにreshapeしてやる必要があったりします。test_at.pyx = np.matrix([1, 2]).reshape(2, -1) w = np.matrix([[1, 0], [0, 1]]) b = np.matrix([1, 1]).reshape(2, -1) y = w.T @ x + b print(y) print(y == np.dot(w.T, x) + b) #---------- # 出力は # [[2] # [3]] # [[ True] # [ True]] # となります。まあめんどくさいですよね。
np.arrayでいいでしょう。
これでもう順伝播の実装は終了です。これ以上変更することはないでしょう(多分)。
__init__メソッドの実装さて、ここまででレイヤーオブジェクトが持つべきメンバがいくつか出てきましたね。これを実装しておきましょう。
あとついでにいくつかメンバを持たせておきます。
__init__の実装baselayer.pydef __init__(self, *, prev=1, n=1, name="", wb_width=1, act="ReLU", **kwds): self.prev = prev # 一つ前の層の出力数 = この層への入力数 self.n = n # この層の出力数 = 次の層への入力数 self.name = name # この層の名前 # 重みとバイアスを設定 self.w = wb_width*np.random.randn(prev, n) self.b = wb_width*np.random.randn(n) # 活性化関数(クラス)を取得 self.act = get_act(act)
それぞれ書いている通りですね。重みとバイアスはnumpy.random.randnメソッドで標準分布に従った乱数を設定しています。またそれにwb_widthを乗算し大きさを調整できるようにしています。
活性化関数はactivations.pyからget_actメソッドをインポートして取得する形にしています。いずれここのコードを調整して持ってくる予定です。行列演算について
ここでは簡単に行列演算について紹介します。こんなふうに計算するんだな〜ということだけで、数学的なことは一切説明しません(ていうかできません)のでご注意ください。
行列和
まずは行列和です。
\left( \begin{array}{cc} a & b \\ c & d \end{array} \right) + \left( \begin{array}{cc} A & B \\ C & D \end{array} \right) = \left( \begin{array}{cc} a + A & b + B \\ c + C & d + D \end{array} \right)まあ当然の結果ですね。要素ごとに足し算します。足し算はもちろん行列の形状が完全に一致している必要があります。
行列の要素積
本記事では全く出てきていない要素積についても触れておきます。
要素積のことはアダマール積とも言いますね。\left( \begin{array}{cc} a & b \\ c & d \end{array} \right) \otimes \left( \begin{array}{cc} A & B \\ C & D \end{array} \right) = \left( \begin{array}{cc} aA & bB \\ cC & dD \end{array} \right)ちなみにアダマール積の記号は
\otimesで書けます。他にもこちらに記号関連が色々乗っていますね。行列積
こちらは要素積ではなく行列積です。形状の制約とか、可換ではないとかが要素積との大きな違いですね。
\left( \begin{array}{cc} a & b \\ c & d \end{array} \right) \left( \begin{array}{cc} A & B \\ C & D \end{array} \right) = \left( \begin{array}{cc} aA + bC & aB + bD \\ cA + dC & cB + dD \end{array} \right)計算方法としては、横$\times$縦をしまくる感じですね。
こんな感じです。
このように計算できるためには、横の要素数と縦の要素数が一致している必要がありますね。
つまり一つ目の行列の列と二つ目の行列の行が一致している必要があります。
一般化すると、$L \times M$行列と$M \times N$行列の行列積の結果できる行列は$L \times N$となります。転置
転置とは行列の行と列を交換する操作のことです。
\left( \begin{array}{cc} a & b & c \\ d & e & f \end{array} \right)^{\top} = \left( \begin{array}{cc} a & d \\ b & e \\ c & f \end{array} \right)転置の記号は\topで書いています。
この操作はこれくらいの説明だけでいいでしょう。おわりに
これで順伝播の実装は終了です。特に中間層と出力層で違う処理を行う必要とかもないのでmiddlelayer.pyやoutputlayer.pyではオーバーライドする必要もありません。順伝播は簡単でいいですね。
参考
深層学習シリーズ



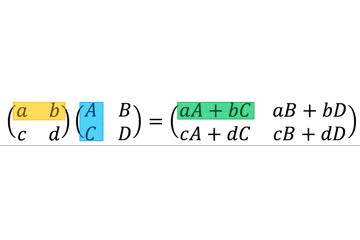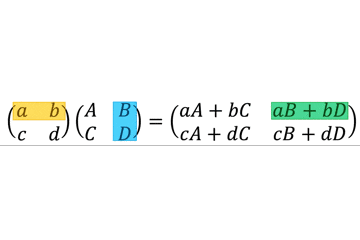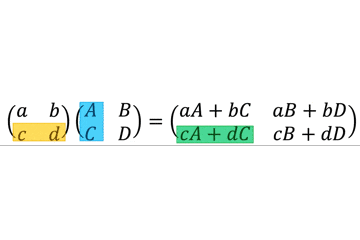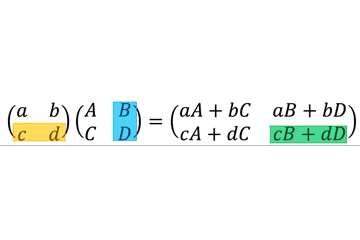
- 投稿日:2020-06-02T13:21:47+09:00
PEP 613 (Explicit Type Aliases) を読んだよメモ
最近 python/peps をフォローして PEP の更新を追いかけるようにしているのだが、GvR が PEP 613 (Explicit Type Aliases) は (3.9 ではなく) 3.10 に入れよう的なことを言っていたのでちょっと読んでみた。
I think it’s too late to add to 3.9, but it can be added to typing_extensions, and of course 3.10 is open (the master branch is now 3.10).
https://github.com/python/peps/issues/1412#issuecomment-633641359概要
- PEP-484 (Type Hints) では型エイリアスの存在については言及しているが、どう定義するのかを詳しく決めていなかった
- 今のところ グローバル変数 でなおかつ 型ヒントの付いていない変数 を型エイリアスとみなしている
- Forward Reference 問題やスコープなどで問題が起きがち
- そこで明示的に型エイリアスを定義できるようにするよ
- これまで通り暗黙的な型エイリアスの定義もしてもいいよ
- ステータスは Accepted なのでいずれ実装される (たぶん 3.10)
アプローチ
- 新たに
typing.TypeAliasを追加する- 型エイリアスを定義するときは
T: TypeAlias = intのように型エイリアス型の変数を記述する- グローバルレベルで定義された変数を型エイリアスとみなす
- ForwardReference するときは
T: TypeAlias = "int"と書いてもよい例
明示的な文法では以下のように扱われる。
# 単なるグローバル変数 x = 1 x: int = 1 # 単なるグローバル変数 x = int x: Type[int] = int # 型エイリアス x: TypeAlias = int x: TypeAlias = “MyClass”感想
- Forward Refernece を考えると単なる文字列文字列定数も 型を指している可能性がある と扱う必要があったのが、explicit syntax だとセマンティックに書けるようになった
- とはいえ、これまでの implicit syntax がなくなるわけではないので、なにかが変わるわけでもない
- 利用する側としてはとりあえず
TypeAlias型を付けておけば安心
- なのだけど、その実装は(はやくても) 3.10 からなので使えるのは来年秋以降ですよ…
- 理由もわかるし、反対する理由もないのだけど、出るのがおそすぎて使われない予感しかしない
- 動作確認してないけど pyre ではすでに実装されてるっぽい?
- 投稿日:2020-06-02T13:03:09+09:00
Pythonのインポートディレクトリの順番
Pythonのインポート順
EC2(amazonlinux2)上にanacondaを入れています。
環境にもよるみたいですがインポート順は下記。(base) [ec2-user@ip-172-31-42-102 wk]$ echo $PYTHONPATH /home/ec2-user/wk/lib (base) [ec2-user@ip-172-31-42-102 wk]$ pwd /home/ec2-user/wk (base) [ec2-user@ip-172-31-42-102 wk]$ ls path.py lib (base) [ec2-user@ip-172-31-42-102 wk]$ cd ../ (base) [ec2-user@ip-172-31-42-102 ~]$ pwd /home/ec2-user (base) [ec2-user@ip-172-31-42-102 ~]$ python3 ./wk/path.py ['/home/ec2-user/wk', '/home/ec2-user/wk/lib', '/home/ec2-user', '/home/ec2-user/anaconda3/lib/python37.zip', '/home/ec2-user/anaconda3/lib/python3.7', '/home/ec2-user/anaconda3/lib/python3.7/lib-dynload', '/home/ec2-user/anaconda3/lib/python3.7/site-packages']①pyファイルがあるディレクトリ
②PYTHONPATHに設定しているディレクトリ
③カレントディレクトリ
④anacondaの標準、サードパーティディレクトリ下記でインポート順を調べれるため、気になったときは試してみる。
path.pyimport sys import pprint pprint.pprint(sys.path)
- 投稿日:2020-06-02T12:16:00+09:00
NOMURAプログラミングコンテスト2020 復習
所要時間
感想
今回はC問題で詰まってそれ以降の問題にチャレンジすることすらできませんでした…。
焦ると適当な実験を繰り返してしまうので、方針を明確化するのが大事だと思いました。
次に解いたことのないパターンの問題がきたらしっかり上記を忘れないように考察したいと思います。A問題
Hの差とMの差に注目すれば難しくありません。
answerA.pyh1,m1,h2,m2,k=map(int,input().split()) print((h2-h1)*60+(m2-m1)-k)B問題
DPを一瞬疑いましたが、結局?をPに変えるかDに変えるかで「博士・PD指数」がどれだけ増加するかを考えれば良いです。Pに変える場合は直後の文字がDの時のみ1だけ増えますが、Dに変える場合はその文字自身が変わることで1増えその直前の文字がPのときはさらに1増えるので全ての?はDに変えるのが最適であることがわかります。
answerB.pyt=input() t=t.replace("?","D") print(t)C問題
考えてるときは難しいと感じましたが解答をみると当然の答えが書いてあったので、一旦落ち着いて方針を順序立てる余裕が必要であると思いました。
まず、方針として真っ先に立てるべきなのはそれぞれの深さでの頂点の数を記録するということです。これを立てないとスタートラインにすら立てませんが、問題で深さごとに葉の個数の条件が与えられているので難しくはないと思います。
このもとで根に近いところから順に頂点の個数を決めると、二分木であることからそれぞれの深さ$d$での最大の頂点数は深さ$d-1$での頂点数から葉の数を引いた数の2倍になることはわかると思います。しかし、この方法で増やすと最終的に多くなりすぎて葉が余ってしまうというパターンが発生することが二つ目のサンプルでわかると思います。…①
したがって、多すぎないように調整しようと考えましたが、この調整を言語化して行おうとせず適当にやったので解くことができませんでした。
また、考察中に逆から決める方針は立てることができたのですが、これを突き詰めることができませんでした。二つ目のサンプル(下図)を見ればわかるように、深さ$d$の頂点数は深さ$d$以下にある葉の合計以下でなければならないことがわかります。下図のように深さ$d$で葉でない頂点について深さ$d+1$以上の頂点を辿れば必ずどこかの深さで葉が存在し異なるパスが同じ頂点を指すことがないので、上記のように言えます。…②
①,②の考察さえ行うことができれば、深さd以下の頂点数を保存するような配列を累積和で求めたもとで、根に近いから順に②の上限内で①にしたがってできるだけ頂点数を増やせば良いです。
また、②の考察については、できるだけ増やしたいのに増やせないという気持ちをもてば上限が何かということにのみ注目して考察を行うことができるので難しくないと思います。(やはり整理しながら考察するのは大事ですね、ABCに慣れていると考察が簡単な問題が多いので忘れてしまいますが…)
コンテスト中に解けず悔しい思いをしましたが、冷静になれば順序立てて考察のできる良問であると感じました。
answerC.pyfrom itertools import accumulate n=int(input()) a=list(map(int,input().split())) c=list(accumulate(a)) b=[0]*(n+1) def f(): global n,a,b for i in range(n+1): if i==0: b[0]=min(c[n]-c[0],1) else: b[i]=min(2*(b[i-1]-a[i-1]),c[n]-c[i-1]) if n==0: if a[0]!=1: print(-1) else: print(1) elif b[n]!=a[n]: print(-1) else: print(sum(b)) f()answerC_shortest.pyp=print;n,*a=map(int,open(0).read().split());t=sum(a);p(sum([w:=1]+[exit(p(-1))if(w:=min(2*(w-q),t:=t-q))<0 else w for q in a]))D問題以降
ARCであることもあり実力不足なので、優先順位が低いと判断しこの記事では解説しません。

- 投稿日:2020-06-02T12:00:15+09:00
データ分析初心者のSEがデータサイエンス部隊と一緒に学ぶ vol.1
はじめに
こんにちは!(株) 日立製作所 Lumada Data Science Lab. の中川です。
Lumada Data Science Lab. では、お客様へのご提案品質の向上を目的として、社内の SE を積極的に実習生として受け入れて、データサイエンティストを育成しています。実習では定期的にデータ分析のお題に挑戦して、データ分析業務に従事する研究所のメンバと、お題で生じた疑問点をディスカッションしています。この記事では、そのデータ分析やディスカッションの内容をご紹介したいと思います。
データ分析を始めたばかりの方がつまづきやすい問題の解決策を共有したり、データ分析を既に業務としている方にも有効なテクニックを共有したりする事で、データ分析とは何かをみんなで考える機会となれば良いなと考えています。
実習生のプロフィール
- 松下さん (入社9年目の男性)
- 公共システム事業部で社会保障関連の SE 業務に従事
- Java や C 言語での開発経験はあるがデータ分析は未経験
- 海外旅行やお酒が大好きなアクティブ系中堅 SE
演習の内容
ここでは演習について、松下さんが具体的にまとめた内容をご紹介します。
お題
- Python と scikit-learn を用いて重回帰分析をします。 (開発環境は Python を使ったデータ分析で便利な Jupyter Notebook)
- scikit-learn には、データ分析・機械学習をすぐに試せるように、いくつかの 付属データセットがあります。
- 今回は付属データセットのうち、ボストン住宅価格問題 (Boston house prices dataset) に取り組みます。
- データ分析は CRISP-DM のプロセスを参考にして行います。
0. CRISP-DM
データ分析を進める上で有効な考え方がCRISP-DM (CRoss-Industry Standard Process for Data Mining) です。以下のプロセスに分かれており、お客様のビジネス課題の理解から、実際のモデリング、その評価とビジネスへの展開 (業務改善) まで、PDCAサイクルを回しながらデータ分析を行うデータマイニングの方法論及びプロセスモデルです。
- ビジネスの理解
- データの理解
- データの準備
- モデリング
- 評価
- 展開
今回のお題についても、この順番に沿って取り組みました。
1. ビジネスの理解
ビジネス上の課題を明確化し、データ分析を行う上での目標を設定します。今回はすでに解くべき課題が明確になっているので以下とします。
目標:ボストン住宅価格の数値予測モデルの作成と評価
2. データの理解
データ分析の対象となるデータを確認し、そのまま使用可能か、データの加工が必要か方針を決定します。具体的には、欠損や外れ値が多くてそのままデータ分析に使えないデータがないかを確認し、使えないデータがあれば削除や補完などのデータ加工の方針を決めます。
データの読み込み
使用するライブラリをインポートし、データ分析の対象データを読み込みます。
# ライブラリのインポート import numpy as np import pandas as pd import seaborn as sns from matplotlib import pyplot as plt %matplotlib inline # データセットの読み込み from sklearn import datasets boston_data = datasets.load_boston() # 説明変数の格納 boston = pd.DataFrame(boston_data.data, columns=boston_data.feature_names) # 目的変数 (住宅価格) の格納 boston_medv = pd.DataFrame(boston_data.target) # データの確認 boston.info()今回のデータ分析の対象となるBoston house prices datasetの変数は以下の通りです。
カラム名 内容 CRIM 町ごとの1人当たりの犯罪率 ZN 25,000平方フィートを超える区画に分けられた住宅地の割合 INDUS 町当たりの非小売業の面積の割合 CHAS チャールズリバーのダミー変数 (=河川の境界にある場合は1、それ以外の場合は0) NOX 一酸化窒素濃度 (1000万分の1) RM 住居ごとの部屋の平均数 AGE 1940年より前に建てられた住居の割合 DIS 5つのボストンの雇用センターまでの距離 (重み付き) RAD 放射状高速道路へのアクセシビリティの指標 TAX 10,000ドルあたりの固定資産税率 PTRATIO 町ごとの生徒-教師の比率 B 「1000(Bk - 0.63)^2」で算出した居住割合の指標 ※Bkは町ごとのアフリカ系アメリカ人の割合 LSTAT 人口当たりの低所得者の割合 MEDV 1000ドル単位での住宅価格の中央値 ※目的変数 欠損値の確認
Boston house prices dataset に欠損値がないか確認します。
# 欠損値の確認 boston.isnull().sum()出力結果
# 欠損値の数 CRIM 0 ZN 0 INDUS 0 CHAS 0 NOX 0 RM 0 AGE 0 DIS 0 RAD 0 TAX 0 PTRATIO 0 B 0 LSTAT 0 dtype: int64今回のデータには欠損値がないことが確認できました。
外れ値・異常値の確認
外れ値・異常値についてはそもそも何を外れ値・異常値として扱うかを考える必要があります。このためにはデータ分析の対象となるビジネス・事象の背景や、測定方法等のデータの背景を理解する必要があります。背景を理解した上で、例えば以下のような観点で外れ値・異常値を判断します。
- 変数の性質上、明らかにありえない値ではないか (例:年齢がマイナスや文字列などの値の場合)
- ビジネスや事象の性質上、ありえない値ではないか (例:ローンの申込可能年齢に制限があるが、制限を満たさない値の場合)
- 変数の確率分布が想定できる場合、大きく異なる分布となっていないか (例:正規分布の想定に対して、両極端な値が頻出している場合)
まずは値のばらつきを箱ひげ図を用いて確認します。
# 箱ひげ図で外れ値を確認 (タイル状に可視化) fig, axs = plt.subplots(ncols=5, nrows=3, figsize=(13, 8)) for i, col in enumerate(boston.columns): sns.boxplot(boston[col], ax=axs[i//5, i%5]) # グラフ間隔の調整 fig.subplots_adjust(wspace=0.2, hspace=0.5) # 余白の削除 fig.delaxes(axs[2, 4]) fig.delaxes(axs[2, 3])出力結果
箱ひげ図を確認すると CRIM, ZN, CHAS, RM, DIS, PTRATIO, B, LSTAT の値のばらつきが多く、外れ値を含む可能性がありそうです。さらに、ヒストグラムを用いて具体的な変数の値と分布を確認します。
# ヒストグラムで分布を確認 (タイル状に可視化) fig, axs = plt.subplots(ncols=5, nrows=3, figsize=(13, 8)) for i, col in enumerate(boston.columns): sns.distplot(boston[col], bins=20, kde_kws={'bw':1}, ax=axs[i//5, i%5]) #グラフ間隔の調整 fig.subplots_adjust(wspace=0.2, hspace=0.5) #余白の削除 fig.delaxes(axs[2, 4]) fig.delaxes(axs[2, 3])出力結果
変数の性質を想像しながらヒストグラムを確認したところ、取り得る値であると見受けられるため、ここでは外れ値・異常値として扱わないこととします。"CHAS" は箱ひげ図・ヒストグラムとも特殊な形となりますが、これは川沿いかどうかを 0, 1 でフラグ化したダミー変数であるためです。
3. データの準備
「データの理解」で決定した方針に従い、次のモデリングに投入可能な状態にデータを加工します。例えば、以下のような処理を行います。
- 欠損値・外れ値・異常値を平均値や最頻値で補完または除外
- 数値データを意味のある単位で区切り、カテゴリデータに変換
- ラベルデータを数値として取り扱うためにフラグ化
「データの理解」で確認した通り、欠損値・外れ値・異常値はないものとして次フェーズへ進みます。
4. モデリング
データ分析の条件に適した手法でモデリングを行います。モデルに投入する変数を選択し、データをモデルの学習用とテスト用に分けてデータ分析に用います。今回はモデル化のアルゴリズムとして、線形回帰分析 (重回帰) を選択します。ちなみに、scikit-learnではどのアルゴリズム・モデリング手法を使用すると良いかの選択指標がcheat sheet にまとめられています。
変数の選択
モデルに投入する変数を選択します。実際に使用する変数の数を減らしつつ、有効な組み合わせを探索するプロセスです。使用する変数を減らすことには、下記のようなメリットがあります。
- 計算コストを下げて、処理時間を短縮する
- 過学習 (オーバーフィッティング) を避けて汎化性 (未知のデータへの予測性能) を向上させる
変数の選択方法には以下のような手法があります。
- Filter Method: 評価指標に基づいて変数をランク付けし、上位の変数を選択する手法
- Wrapper Method: 複数の変数の組み合わせで実際にモデリングを行い、 最も結果の良い変数の組み合わせを選択する手法
- Embedded Method: 機械学習アルゴリズムの中で同時に変数も選択する手法
今回はFilter Method の方法論に則り、変数間の相関の強さを確認する方法を例として記載します。pairplotを用いると各変数のヒストグラムと、全ての2変数の組合せの相関を可視化してくれるので便利です。
# seaborn の heatmap を用いて量的変数の相関を数値化 boston["MEDV"] = boston_medv plt.figure(figsize=(11, 11)) sns.heatmap(boston.corr(), cmap="summer", annot=True, fmt='.2f', square=True, linewidths=.5) plt.ylim(0, boston.corr().shape[0]) plt.show() # seabornのpairplotを用いて量的変数の相関をグラフで可視化 sns.pairplot(boston) plt.show()出力結果
heatmapを確認するとRADとTAXの間に強い正の相関があるため、ここでは2変数のうちMEDVとの負の相関がより強いTAXを選択します。
学習用・テスト用データの分割
データのうち一部をモデル学習に用い、残りを作成したモデルの予測能力の検証に用いる方法が一般的です。今回は学習用とテスト用で 50% ずつのデータを用いることとします。
# 説明変数、目的変数を Xm, Ym にそれぞれ格納 Xm = boston.drop(['MEDV', 'RAD'], axis=1) Ym = boston.MEDV # trainデータとtestデータの分割を行うライブラリを import from sklearn.model_selection import train_test_split # X_train, X_test に振り分けられるデータはランダムに決まる # test_size=0.5で 50% をtestに振り分け X_train, X_test = train_test_split(Xm, test_size=0.5, random_state=1234) Y_train, Y_test = train_test_split(Ym, test_size=0.5, random_state=1234)モデルフィッティング
実際にデータを与えて線形回帰モデル (重回帰モデル) にフィッティングします。
# sklearnの線形回帰モデルをimportし、trainデータでフィッティング from sklearn import linear_model model_lr = linear_model.LinearRegression() model_lr.fit(X_train, Y_train) # 生成されたモデルを用いて、testデータの説明変数に対する予測値を取得 predict_lr = model_lr.predict(X_test) # 回帰係数 print(model_lr.coef_) # 切片 print(model_lr.intercept_)出力結果
# 回帰係数 [-2.79020004e-02 5.37476665e-02 -1.78835462e-01 3.58752530e+00 -2.01893649e+01 2.15895260e+00 1.95781711e-02 -1.66948371e+00 6.47894480e-03 -9.66999954e-01 3.62212576e-03 -6.65471265e-01] # 切片 48.68643686655955
5. 評価
作成したモデルの精度・性能等を評価し、目標を達成可能か判断します。また、評価結果をもとに必要に応じてモデルのチューニングを行います。
モデルの評価
モデルの精度評価では、以下の指標を用いて作成したモデルの予測値と正解値の誤差や相関の強さを評価します。
- MAE (Mean Absolute Error): 誤差の絶対値の平均
- MSE (Mean Squared Error): 誤差の二乗の平均
- RMSE (Root Mean Squared Error): MSE の平方根
- 決定係数: 相関の強さの2乗
# 評価 # MAE from sklearn.metrics import mean_absolute_error mae = mean_absolute_error(Y_test, predict_lr) print("MAE:{}".format(mae)) # MSE from sklearn.metrics import mean_squared_error mse = mean_squared_error(Y_test, predict_lr) print("MSE:{}".format(mse)) # RMSE rmse = np.sqrt(mse) print("RMSE:{}".format(rmse)) # 決定係数 print("R^2:{}".format(model_lr.score(X_test, Y_test)))#評価結果 MAE:3.544918694530246 MSE:23.394317851152568 RMSE:4.83676729346705 R^2:0.7279094372333412決定係数が約 0.73 のモデルを作成できました。
6. 展開
ビジネス課題を解決するためにデータ分析の評価結果をビジネスに適用します。今回はモデルを作成・評価するところまでが目標ですが、実際のビジネスでは作成したモデルを用いて業務改善につなげたり、システム開発を行ったりします。
ディスカッション
実習生が実際にデータ分析を体験してみて感じた率直な疑問に対し、Lumada Data Science Lab. のメンバがお答えします。
何を外れ値として除去するか悩んだのですがどう判断すれば良いでしょうか?
箱ひげ図とヒストグラムを見てもよくわかりませんでした。明らかにあり得ない値や、条件が特殊なレコードを除くことが目的です。これらのデータは、モデリングの結果を不用意に歪めてしまうためです。まずはデータを良く眺めることが重要です。松下さんが行ったように、箱ひげ図やヒストグラムをプロットするのも気づきを得るためによく用いられる方法です。例えば変数の値に異常な偏りがある場合、プロットすれば容易に気づくことができます。また、そのような値を取っているレコードの傾向にさらに踏み込んでみることで、背景に潜む現象や値の意味づけに気づくこともあります。
変数間の相関が強いと判断するのは、相関係数がいくつ以上の場合ですか?
もしくは別の方法で確認できますか?判断基準がよくわかりません。相関係数が 0.7 以上で一般に相関が強いと考えられることが多いようですが、実際にはドメインによります。そのため、お客様と判断基準を議論することが非常に大切です。今回の場合は、説明変数間で相関係数が 0.9 以上の組合せに着目しましたが、相関係数だけを見るのではなく、散布図でばらつきの傾向もよく確認することが大切です。
k-fold 交差検証の
cross_val_scoreで算出しているのは決定係数 $R^2$ ですか?ライブラリの実装に関する情報は、API リファレンスにまとめられているので、それを参照すると良いです。質問の
cross_val_scoreの算出指標については、引数のscoringで指定します。名前や関数で算出するスコアを指定することできます。無指定の場合には、モデリングのアルゴリズムで実装されているscore関数を利用します。LinearRegressionでは $R^2$ が実装されています。k-fold 交差検証って毎回やるべきものですか?
交差検証をしない場合もあるのでしょうか。k-fold 交差検証は一つの手段で、一般論として検証を行うことが大事です。データ量やばらつきなどの条件に応じて、hold-out 検証や k-fold 交差検証、leave-one-out 交差検証などが行われます。検証の目的は、モデルが学習に用いたデータへ過剰に適合する現象 (過学習) を検出し、未知のデータへの予測性能 (汎化性) を高めることです。母集団の統計的なふるまいを知っており、分布が明らかである場合には分布のパラメータ推定にすべてのデータを活用しても良いでしょう。
主要要因 (目的変数にもっとも影響を与える説明変数) は何を確認するべきですか?
回帰係数?相関係数?やり方は色々ありそうだけれど、何で選べきぶかよくわかりません。重回帰モデルであれば説明変数の独立性 (多重共線性がないこと) に注意したうえで、変数の大きさや単位の違いを考慮するため、標準化した回帰係数を比較すれば良いです。多重共線性は多変数の関係を慎重に確認する必要があり、VIF (分散拡大係数) のように、ある変数を他の変数で実際に回帰して影響を評価するアプローチや、主成分回帰のように、予め相関のない変数を合成してから回帰するアプローチなどがとられます。
データ分析を一通り記述した他の方の実装を参考にしたいのです。
何か良い方法はありますか?Qiitaを熟読するというのは言わずもがなですが、Kaggle というデータサイエンスのコンペティションを実施しているサイトがあり、Boston housingを含む様々な問題に対する Notebook (データ分析プログラム) の公開や議論が活発に行われています。他のデータ分析者がどんな方法を用いているのか、これを読むだけでもとても勉強になります。また、前提となる統計の基礎知識をつけるために、入門書を読むのも良いでしょう。
演習の感想
sklearnではデータ分析メソッドが沢山用意されているので、想像以上に順調にモデルの実装ができました。ただ、今回のように整ったサンプルデータでも、データ分析の方針では悩むことが多かったので、実際のビジネスにおけるデータ分析では、もっと試行錯誤が必要なんだろうなと想像しました。「データ分析はモデリングまでの前処理が9割」なんて言われるのも、少し分かった気がします。今回はメソッドの使いこなしがメインでしたが、演習を通じて何故その方法なのか本質まで理解して、お客様に納得感のあるデータ分析に基づいたご提案が出来るようになると良いなと考えています。
おわりに
今回は実習生の松下さんにボストン住宅価格問題 (Boston house prices dataset) に取り組んで頂きました。ディスカッションでは、外れ値や相関や検証に関する考え方など有意義な議論ができたかと思います。Lumada Data Science Lab.では、これからも様々な実習記事を投稿していきたいと考えていますので、次回の投稿をどうぞご期待下さい。ここまで読んで頂き、ありがとうございました。
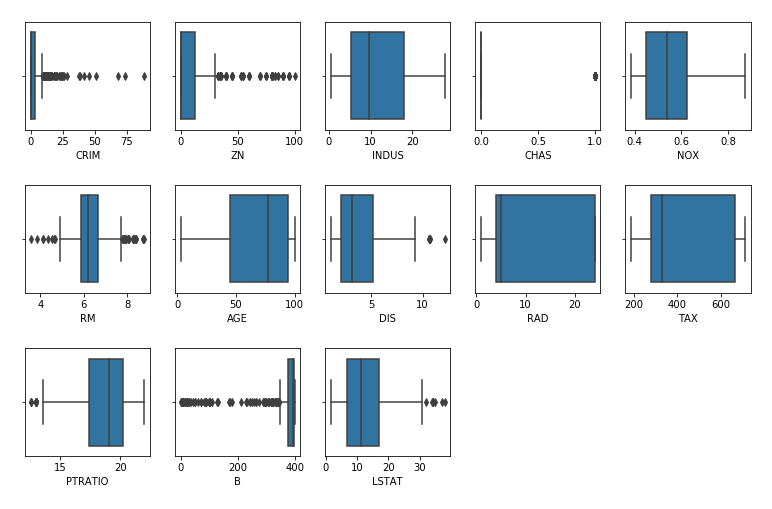
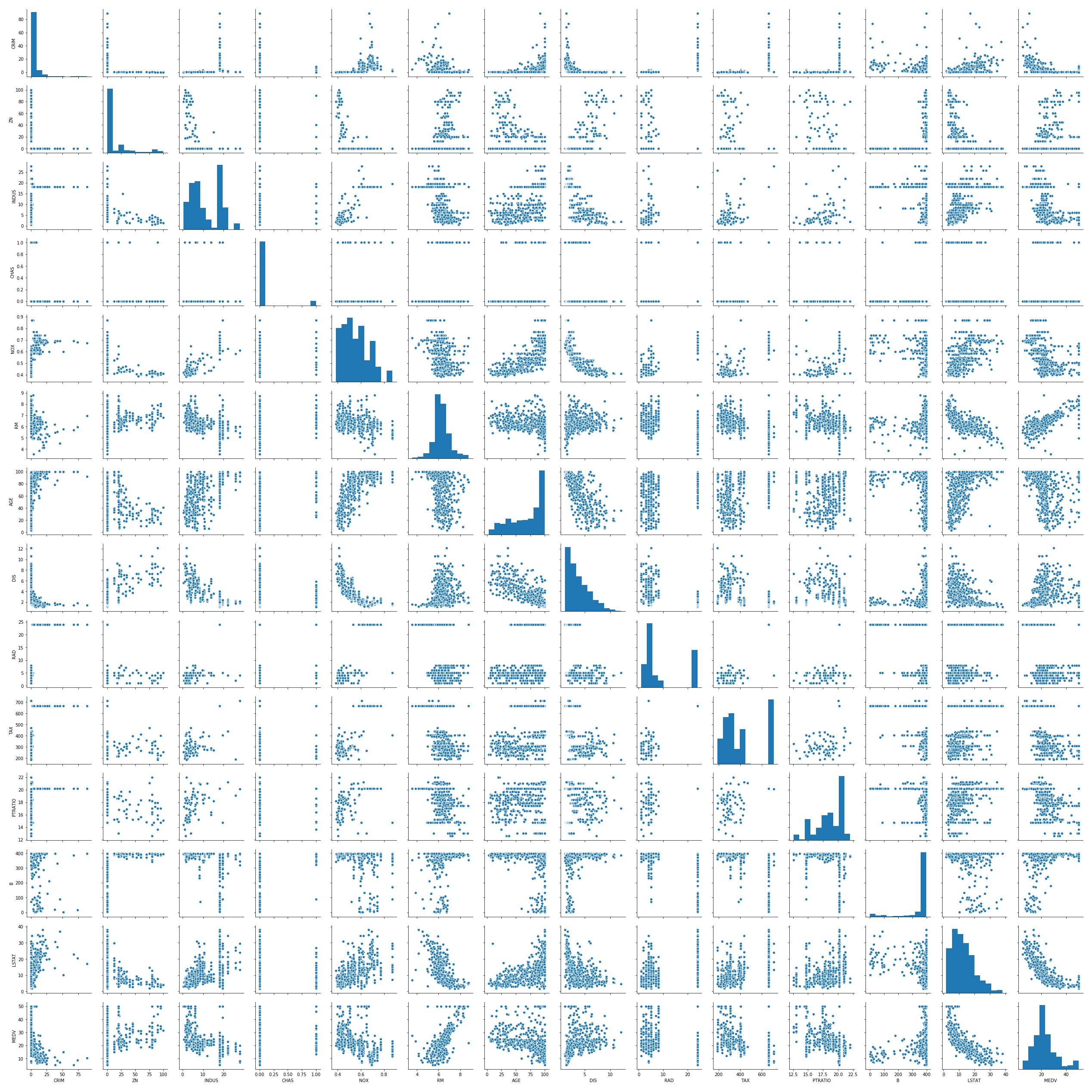
- 投稿日:2020-06-02T11:10:44+09:00
toio(nodejs)のwebsocketと、python/websocketがつながらない。
課題
toio(nodejs)のwebsocketと、python/websocket,socketが接続できない。
toioとUnity/websocketは接続できる。検証コード
x項目も、同言語ではserver-client接続できている。
検索するとjavascriptはHTML絡みの記事が多いので良くわからない。

- 投稿日:2020-06-02T11:03:48+09:00
コードテストで力を付ける②
- 投稿日:2020-06-02T11:01:35+09:00
【Python】『涼宮ハルヒの消失』の改変された世界から戻るための世界から戻るための緊急脱出プログラムを再現してみた
しょーもないものを作ってしまったので供養します。作ったもの
映画『涼宮ハルヒの消失』に出てくる緊急脱出プログラムを再現してみました。
作中と同様、1文字ずつ順番に文字が出力されます。
コードの最後は「input()」で終わっているので、エンターキーを押すとプロンプトが消えるようになっています。
作中ではキョンがエンターキーを押した瞬間に改変された世界から戻り、部室にいたはずの面々がいなくなり、PCの画面に写っていたはずのプロンプトが消えていました。さすがに周囲の人間を消すプログラムは書けませんでしたが、エンターキーでプロンプトが消せるようにしたので、ひとりで遊ぶ分には改変された世界から移動した気分になれます。
ソースコード
from time import sleep #引数に与えられた文字をYUKI.Nっぽく表示する def yuki_n(*message, speed=0.15): count = 0 #何行目を出力し終わったあとかを代入する変数 name = "YUKI. N>" #1行目の出力に対して行う処理 msg = message[0] #名前を表示 for s in range(len(name)): print(name[0:s+1]+"\r",end="") sleep(speed) for i in range(len(msg)): #行の最後の文字の場合、文末に_をつけない if i == len(msg)-1: print(name + msg) sleep(speed) count += 1 else: print(name + msg[0:i+1],end="") print("_"+"\r",end="") sleep(speed) #2行目以降の出力があれば行う処理 if len(message) > 1: for msg in message[1:]: for i in range(len(msg)): #行の最後の文字の場合、文末に_をつけない if i == len(msg)-1: print(" " + msg) sleep(speed) count += 1 else: print(" " + msg[0:i+1],end="") print("_"+"\r",end="") sleep(speed) #最後の行を出力し終わったあとに改行する if count == len(message): print("") #「Ready?」を表示する def ready(speed=0.5): ready = "Ready?" #「_」を点滅させる for _ in range(2): print(" " + "_"+"\r",end="") sleep(speed) print(" " + " "+"\r",end="") sleep(speed) print(" " + "_"+"\r",end="") sleep(speed) for s in range(len(ready)): print(" " + ready[0:s] + "_" + "\r",end="") sleep(0.15) print(" " + ready,end="") #改行する時は複数の引数としてyuki_n関数ににわたす yuki_n("これをあなたが読んでいる時、","わたしはわたしではないだろう。") yuki_n("このメッセージが表示されたということは、","そこにはあなた、わたし、涼宮ハルヒ、朝比奈みくる、","小泉一樹が存在しているはずである。") yuki_n("それが鍵。","あなたは回答を見つけ出した。") yuki_n("これは緊急脱出プログラムである。"," ","起動させる場合はエンターキーを、","そうでない場合はそれ以外のキーを選択せよ。"," ","起動させた場合、"\ ,"あなたは時空修正の機会を得る。","ただし成功は保証できない。","また帰還の保証もできない。") yuki_n("このプログラムが起動するのは一度きりである。","実行ののち、消去される。"," ","非実行が選択された場合は起動せずに削除される。"," ") ready() input()キャリッジリターンを使っただけの簡単なプログラムです。キャリッジリターンの使い方に関しては、『Pythonでprint関数のターミナル出力を上書きで1行表示する方法』が参考になりました。
その他
文字の出力は「yuki_n」という関数にしてあるため、引数に渡す文字次第では、
というようなこともできます。「Ready?」じゃないよ。怖いですね。
- 投稿日:2020-06-02T10:12:31+09:00
気象庁のAtomフィールド(XML電文)をラズパイで取得してツイートさせた話
何をしたいか
特務機関NE〇VみたいなTwitterアカウントを完全自己満足で作りたかった
とりあえず地図の自動作成とかは置いておいて気象注意報・警報・地震情報を取得、ツイートさせたい。どこから情報を取得するか
「気象庁防災情報XMLフォーマット形式電文」とやらが気象庁HPで公開されていたのでありがたく使わせてもらうことに。
取得できるAtomフィードは
・定時:気象に関する情報のうち、天気概況など定時に発表されるもの
・随時:気象に関する情報のうち、警報・注意報など随時発表されるもの
・地震火山:地震、火山に関する情報
・その他:上記3種類のいずれにも属さないもの
のいずれかを選べるので各自好きなのを選んで以下コードの変数「Atom_URL」を置き換えてください。
なお、この記事は「随時:気象に関する情報のうち、警報・注意報など随時発表されるもの」で進めています。
ファイルを複製して変数「Atom_URL」が異なるファイルを作れば複数の情報を取得することも可能です。最終的に何ができるか
こういうのができます
当方の環境とか
Raspberry Pi 3 Model B+、Python 2.7.16[GCC 8.3.0] on linux2。
TwitterAPIの取得
まずはここから。このあたりを参考にしてTwitterAPIを取得しておいてください。
https://qiita.com/kazupen2018/items/ff9828cc853ab9c3357efeedparserのインストール
$ pip install feedparser情報を取得する
test.py# coding: utf-8 from twython import Twython, TwythonError import feedparser Atom_URL = "http://www.data.jma.go.jp/developer/xml/feed/extra.xml" news_dic = feedparser.parse(Atom_URL) latest_entry = news_dic['entries'][0] rss1 = latest_entry.title + latest_entry.author rss2 = latest_entry.content print (rss1) print rss2[0]["value"]実行してみる
$ python test.py実行結果
気象警報・注意報函館地方気象台 【渡島・檜山地方気象警報・注意報】注意報を解除します。こんな感じのが出力されることを確認したら次の段階へ。
取得した情報をツイートする
Twythonのインストール
$ pip install twythonコードを書いてみる
JMA_XML.py# coding: utf-8 from twython import Twython, TwythonError # 気象庁Atomフィールド import feedparser APP_KEY = "ここに取得したAPP KEYを入力" APP_SECRET = "ここに取得したAPP SECRETを入力" OAUTH_TOKEN = "ここに取得したOAUTH TOKENを入力" OAUTH_TOKEN_SECRET = "ここに取得したOAUTH TOKEN SECRETを入力" # 気象に関する情報のうち、警報・注意報など随時発表されるもの Atom_URL = "http://www.data.jma.go.jp/developer/xml/feed/extra.xml" news_dic = feedparser.parse(Atom_URL) latest_entry = news_dic['entries'][0] rss1 = latest_entry.content rss2 = rss1[0]["value"] twitter = Twython(APP_KEY, APP_SECRET, OAUTH_TOKEN, OAUTH_TOKEN_SECRET) try: twitter.update_status(status=rss2) except TwythonError as e: print e(APP_KEY、APP_SECRET、OAUTH_TOKEN、OAUTH_TOKEN_SECRETは各自置き換えてください)
(取得したいAtomフィールドを変えたい場合は変数「Atom_URL」を置き換えてください)実行してみる
$ python JMA_XML.pyTwitterを確認
このようにツイートされていたら成功です。