- 投稿日:2020-06-02T17:42:56+09:00
BOOTH から出力された csv ファイルをクリックポスト用に変換するプログラム作った
きっかけ
BOOTH の csv をクリックポスト用に変換するの面倒だなーと思ったので
プログラム
ソースコードと exe ファイルはここに置いてあります
https://github.com/koktoh/booth_csv_converter.Net Core 3.1 で作ってるので、マルチプラットフォームで動くはず(未検証)
使い方
BOOTH から出力した csv を
Source Pathにドラッグ&ドロップしてRunをポチるだけ雑記
- 無駄に拡張性を意識したクラス構成
(KISSの原則? なにそれ美味しいの?)- CsvHelper は偉大
- GongSolutions.WPF.DragDrop 便利
GongSolutions.WPF.DragDrop についてはこちらを参考にさせていただきました
ありがとうございますhttps://qiita.com/tomboyboy/items/cf58a1d5cbe6cd5b3155
無駄に拡張性を意識しているので、他に変換先追加したいなと思ったら追加するかもしれないし、しないかもしれません
また、リクエストがあったら対応するかもしれません
- 投稿日:2020-06-02T11:48:02+09:00
C#で個数制限付きキャッシュを作る。
前書き
C#でメモ化をしたいとき、基本は辞書を使うと思います。
ですが、すぐ手前のデータさえ残っていれば問題ないときや、長期間動かすときメモリを圧迫することがあります。
残念ながらこういった場合に使いやすいものはC#にはない気がします。
ないなら作ってしまえということで、必要になる場面はあまりない気がしますが、作ってみることにしました。要件
手軽に使えるキャッシュは以下の条件を満たすものとします。
- 一定容量のみを保持
- O(1)で取得、追加。
実装
オープンアドレッシングでの辞書構造に時系列順のリストを組み合わせて作ります。
新規に追加されたものが時系列リストの先頭に来るようにし、
要素が取得されるたびに時系列リスト内で一つ前に行くようにしています。public class FreqCache<TKey, TValue> { //時系列リストの先頭と末尾 int newest,oldest; //オープンアドレッシングでの辞書 int freelist; int[] buckets; Entry[] entries; IEqualityComparer<TKey> comparer; public int Capacity => this.entries.Length; public bool Get(TKey key, out TValue value) { var entries = this.entries; var buckets = this.buckets; var comparer = this.comparer; var hash = key.GetHashCode(); var bucketIdx = hash % buckets.Length; for (var idx = buckets[bucketIdx]; idx > -1; idx = entries[idx].Next) { ref var entry = ref entries[idx]; if (entry.Hash != hash || !comparer.Equals(entry.Key, key)) continue; value = entry.Value; //取得された要素を一つ前に移動する。 if (entry.HasNewer) { ref var newer = ref entries[entry.Newer]; if (entry.HasOlder) entries[entry.Older].Newer = entry.Newer; else this.oldest = entry.Newer; if (newer.HasNewer) entries[newer.Newer].Older = idx; else this.newest = idx; (newer.Older, entry.Older) = (entry.Older, entry.Newer); (newer.Newer, entry.Newer) = (idx, newer.Newer); } return true; } value = default; return false; } public void Add(TKey key, TValue value) { var entries = this.entries; var buckets = this.buckets; var hash = key.GetHashCode(); var bucketIdx = hash % buckets.Length; ref var bucket = ref buckets[bucketIdx]; var nextIdx = bucket; bucket = this.freelist; if (bucket > -1) this.freelist = entries[bucket].Next; else { bucket = this.oldest; ref var oldest = ref entries[bucket]; this.oldest = oldest.Newer; //oldestを時系列のリストと辞書のリストから削除。 if (oldest.HasNewer) entries[oldest.Newer].Older = -1; if (oldest.HasPrev) entries[oldest.Prev].Next = oldest.Next; else if(bucketIdx != ~oldest.Prev) buckets[~oldest.Prev] = oldest.Next; if (oldest.HasNext) entries[oldest.Next].Prev = oldest.Prev; } //時系列リストの先頭に要素を追加。 if (this.newest > -1) entries[this.newest].Newer = bucket; if (this.oldest < 0) this.oldest = bucket; if (nextIdx == bucket) nextIdx = -1; if (nextIdx > -1) entries[nextIdx].Prev = bucket; ref var newentry = ref entries[bucket]; newentry.Next = nextIdx; newentry.Prev = ~bucketIdx; newentry.Newer = -1; newentry.Older = this.newest; newentry.Hash = hash; newentry.Key = key; newentry.Value = value; this.newest = bucket; } public FreqCache(int capacity) { var entries = new Entry[capacity]; var buckets = new int[capacity]; for (var i = 0; i < capacity; ++i) { ref var entry = ref entries[i]; entry.Initialize(); entry.Next = i + 1; buckets[i] = -1; } entries[^1].Next = -1; this.buckets = buckets; this.entries = entries; this.comparer = EqualityComparer<TKey>.Default; this.freelist = 0; this.newest = this.oldest = -1; } struct Entry { public int Next, Prev, Newer, Older; public int Hash; public TValue Value; public TKey Key; public bool HasNext => this.Next > -1; public bool HasPrev => this.Prev > -1; public bool HasNewer => this.Newer > -1; public bool HasOlder => this.Older > -1; public void Initialize() { this.Next = this.Hash = this.Newer = -1; this.Value = default; this.Key = default; } } }テスト
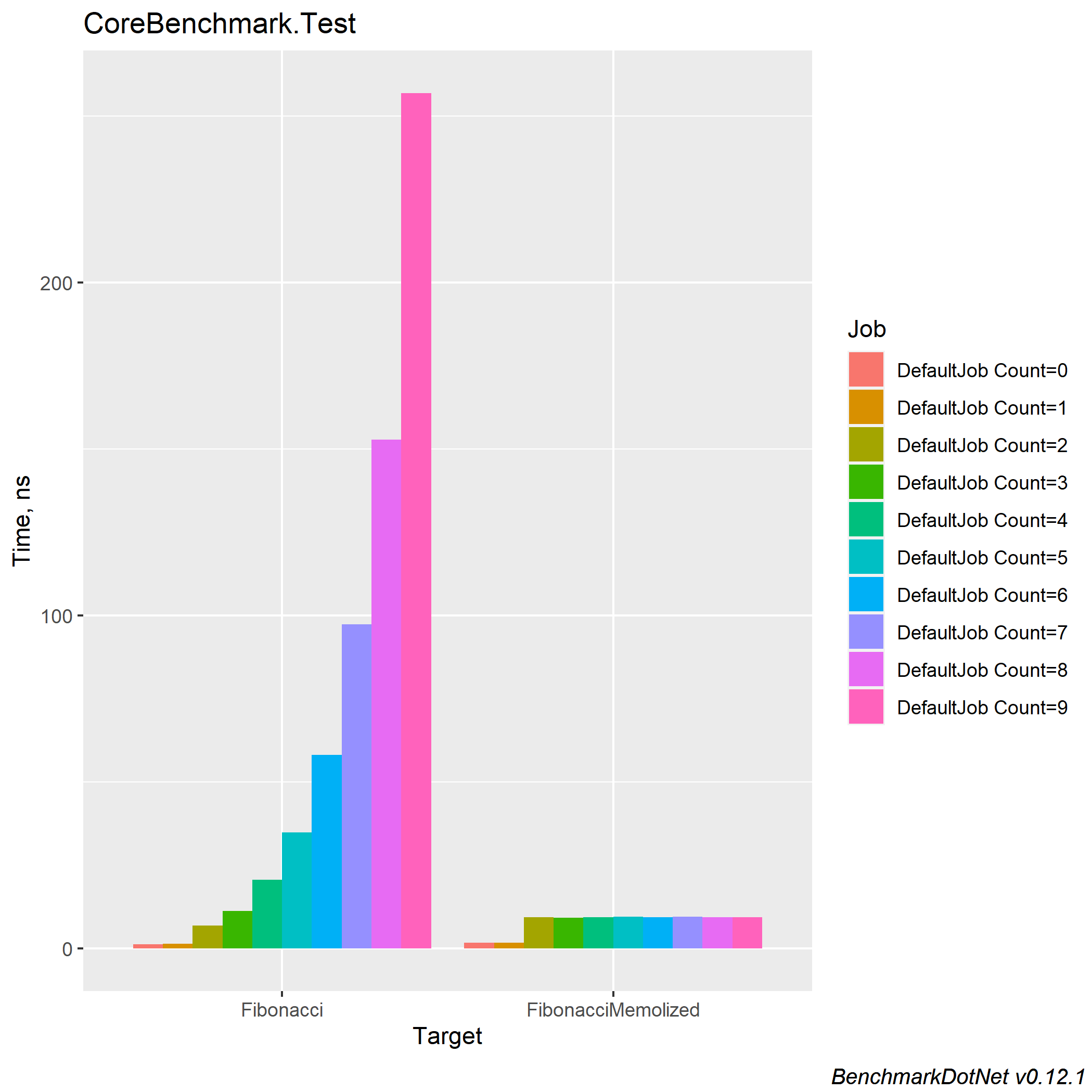
メモ化の代表例であるフィボナッチ数列を使ってテストします。
BenchmarkDotNetを利用しました。テストに使った関数は以下の実装です。
static FreqCache<int,int> Cache = new FreqCache<int,int>(16); static int Fibonacchi(int num) { if (num < 0) return ((2 * (-num & 1)) - 1) * Fibonacchi(-num); if (num < 2) return num; return Fibonacchi(num - 2) + Fibonacchi(num - 1); } static int FibonacchiMemolized(int num) { if (num < 0) return ((2 * (-num & 1)) - 1) * FibonacchiMemolized(-num); if (num < 2) return num; if (Cache.Get(num, out var value)) return value; value = FibonacchiMemolized(num - 2) + FibonacchiMemolized(num - 1); Cache.Add(num, value); return value; }
歴然とした違いが表れてますね。
素直な実装では指数的に計算量が増えるので当たり前かもしれませんが。
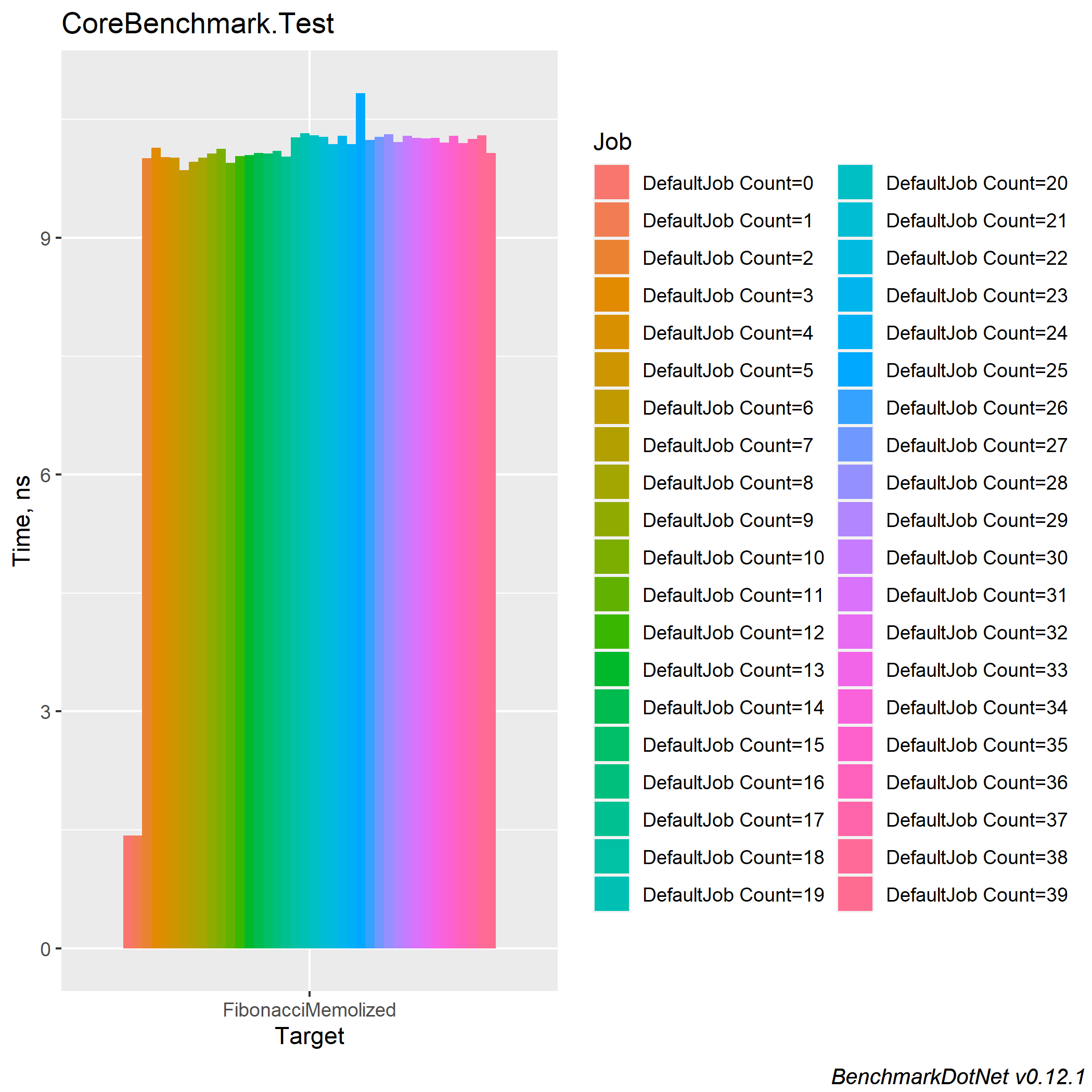
メモ化してある方のみの結果です。
メモ化が関係ないCount=1,2の時を除いて、すべて一定の時間で求められていますね。あとがき
これでメモリを圧迫せず、定数時間で追加、取得ができるキャッシュが完成しました。
こういったものはC#にもとからあると嬉しいですけどね。プログラムの不備や誤植等の指摘はコメントに頂けるとありがたいです。
ありがとうございました。
- 投稿日:2020-06-02T02:58:38+09:00
マルチストリーム GZIP 対応のストリームクラス (C#)
マルチストリーム GZIP 対応のストリームクラス (C#)
# 以下の記事が書かれた時の版数は .NET Core 3.1 (3.1.300) となります.
あるシステムで複数回追記しないといけない CSV(中間ファイル)が大きくて困っていて、サイズ・データのチャンクの連続にするか、データ・サイズのチャンクの連続にするか悩んでいたのだが(※1)、.NET Frameworkのbzip2ライブラリを調査 の記事で世の中にマルチストリーム bzip2 というものがあることに気づいた. bzip2 だと外部ライブラリが必要でちょっと嫌なので、世の中にマルチストリーム GZIP は存在しないのかを調査した. Go 言語のビルトインの GZIP パッケージはマルチストリーム対応していた. また gzip コマンドも普通に対応していた.
$ echo -n "hello " | gzip > /tmp/hello.gz $ echo -n "world" | gzip >> /tmp/hello.gz $ gzip -dc /tmp/hello.gz hello worldなのでこれ採用って気分になったが、.NET の GZipStream はマルチストリームに対応してなさげだったので、読み込み用に
GZipMultiStreamを作成した.using System; using System.IO; using System.IO.Compression; namespace MyCSharpLibrary { public class GZipMultiStream : Stream { private readonly Stream BaseStream; private GZipStream BaseGzipStream; private bool Disposed; public GZipMultiStream(Stream stream) { BaseStream = stream; BaseGzipStream = new GZipStream(stream, CompressionMode.Decompress, true); } public override bool CanRead => true; public override bool CanSeek => false; public override bool CanWrite => false; public override long Length => throw new NotImplementedException(); public override long Position { get => throw new NotImplementedException(); set => throw new NotImplementedException(); } public override void Flush() { throw new NotImplementedException(); } public override int Read(byte[] buffer, int offset, int count) { var result = BaseGzipStream.Read(buffer, offset, count); if (result == 0) { BaseGzipStream.Close(); BaseGzipStream = new GZipStream(BaseStream, CompressionMode.Decompress, true); result = BaseGzipStream.Read(buffer, offset, count); } return result; } public override long Seek(long offset, SeekOrigin origin) { throw new NotImplementedException(); } public override void SetLength(long value) { throw new NotImplementedException(); } public override void Write(byte[] buffer, int offset, int count) { throw new NotImplementedException(); } protected override void Dispose(bool disposing) { if (Disposed) return; BaseGzipStream.Close(); BaseStream.Close(); Disposed = true; } } }あまりテストしていないが、以下のテストは通っている. マルチストリームだと、BOM 付き UTF-8 めんどくさいっすね…….
[TestMethod] public void GZipMultiStreamTest() { var text1 = "Hello "; var text2 = "World!"; var expected = text1 + text2; var ms = new MemoryStream(); using (var writer = new StreamWriter(new GZipStream(ms, CompressionLevel.Optimal, true), Encoding.UTF8)) { writer.Write(text1); } using (var writer = new StreamWriter(new GZipStream(ms, CompressionLevel.Optimal), new UTF8Encoding(false))) { writer.Write(text2); } ms = new MemoryStream(ms.ToArray()); using (var reader = new StreamReader(new GZipMultiStream(ms), Encoding.UTF8)) { Assert.AreEqual(expected, reader.ReadToEnd()); } }※1: xxx.001.csv.gz, xxx.002.csv.gz みたいな連番ファイルにすることや、xxx.csv.zip の中に 001.csv, 002.csv みたいな連番データを入れることも考えたが、002 以降に CSV ヘッダを入れても入れなくても微妙だなあと思いボツに. 前者はファイル数が多いことも微妙.
- 投稿日:2020-06-02T02:58:38+09:00
マルチストリーム GZIP は GZipStream でそのまま読み込める (C#)
マルチストリーム GZIP は GZipStream でそのまま読み込める (C#)
# 以下の記事が書かれた時の版数は .NET Core 3.1 (3.1.300) となります.
あるシステムで複数回追記しないといけない CSV(中間ファイル)が大きくて困っていて、サイズ・データのチャンクの連続にするか、データ・サイズのチャンクの連続にするか悩んでいたのだが(※1)、.NET Frameworkのbzip2ライブラリを調査 の記事で世の中にマルチストリーム bzip2 というものがあることに気づいた. bzip2 だと外部ライブラリが必要でちょっと嫌なので、世の中にマルチストリーム GZIP は存在しないのかを調査した. Go 言語のビルトインの GZIP パッケージはマルチストリーム対応していた. また gzip コマンドも普通に対応していた.
$ echo -n "hello " | gzip > /tmp/hello.gz $ echo -n "world" | gzip >> /tmp/hello.gz $ gzip -dc /tmp/hello.gz hello world.NET の
GZipStreamを試したところ、マルチストリームでもそのまま読み込めた. マルチストリームで BOM 付き UTF-8 を書き出すのめんどくさいっすね…….[TestMethod] public void GZipMultiStreamTest() { var text1 = "Hello "; var text2 = "World!"; var expected = text1 + text2; var ms = new MemoryStream(); using (var writer = new StreamWriter(new GZipStream(ms, CompressionLevel.Optimal, true), Encoding.UTF8)) { writer.Write(text1); } using (var writer = new StreamWriter(new GZipStream(ms, CompressionLevel.Optimal), new UTF8Encoding(false))) { writer.Write(text2); } ms = new MemoryStream(ms.ToArray()); using (var reader = new StreamReader(new GZipStream(ms, CompressionMode.Decompress), Encoding.UTF8)) { Assert.AreEqual(expected, reader.ReadToEnd()); } }※1: xxx.001.csv.gz, xxx.002.csv.gz みたいな連番ファイルにすることや、xxx.csv.zip の中に 001.csv, 002.csv みたいな連番データを入れることも考えたが、002 以降に CSV ヘッダを入れても入れなくても微妙だなあと思いボツに. 前者はファイル数が多いことも微妙.
- 投稿日:2020-06-02T00:31:13+09:00
C#でHEAD HTTPリクエストを送信する
HEADメソッドでインターネット上のファイルのプロパティのようなものを取得できます。C#でも使えます。
まえがき
URLからデータをダウンロードするとき、サーバーの負荷等を考えてデータが新しい場合だけダウンロードしたいことがあります。HTTPプロトコルではHEADメソッドのリクエストに対するレスポンスヘッダーが日付やETagといった情報を持ち、これらを利用して前述の目的を達成できます。
これらの情報はGETメソッドのリクエストに対するレスポンスヘッダーにも含まれますが、GETメソッドはデータそのものを取得するのでサーバーの負荷等は軽減できません。
C#における実装
C#では
System.Net.Http名前空間のHttpClientクラスを使用してURLにHEADメソッドのリクエストを送信できます。以下にサンプルコードを示します。using System; using System.Net.Http; namespace ConsoleApp1 { class Program { // HttpClientのインスタンスは再利用すべきです。 // https://docs.microsoft.com/ja-jp/dotnet/api/system.net.http.httpclient?view=netcore-3.1#remarks private static readonly HttpClient httpClient = new HttpClient(); static void Main() { // HTTPリクエストを送信するURL // ここではQiitaのURLをお借りしています。 var url = "https://qiita.com/"; // URLに対するHTTP HEADリクエストメッセージを作成して送信 // ここではResultを呼び出して同期処理にしています。 var headMessage = new HttpRequestMessage(HttpMethod.Head, url); var response = httpClient.SendAsync(headMessage).Result; // ETagを出力する // nullの可能性があります。 var headers = response.Headers; Console.WriteLine($"ETag:{headers.ETag?.Tag}"); } } }参考
HTTPヘッダーやETagについてはMDNを参照ください。
- 投稿日:2020-06-02T00:09:04+09:00
コード書く際にみんなが考えていることを知りたい
初めに
初投稿
人に何かを伝える能力が皆無なもので・・・
お遊び感覚でアウトプットの練習していきます。社内若手勉強会にて
ネットで見つけたプログラミング問題に関して、
勉強会メンバー全員で同じ問題を解いた。問題のボリュームは、
社内の若手が平均1時間30分くらいで解くくらい解いた結果、1人(Kさん)を除き、大体似たようなソースになった。
コードの違い
その問題は、オセロのように「盤面」や「駒」があるのだが、
「盤面」をKさん以外は「2次元配列」、KさんはListで定義した。上記の違いにより、その後の駒の各種判定に関して、
ソースコードの内容に大きく違いが生じた。ちなみに読解力のない自分にはKさんのコードが読みづらくて仕方なかった。
学んだこと
同じ問題を解くにしても
やはり人によって、モノの考え方、見えているものが異なるんだなぁと思った。みんなプログラム作るとき、処理の流れとかクラス設計とかってどうやって決めてるんだろう。
なんか参考になる良いサイトないかなぁ。