- 投稿日:2020-05-18T23:50:42+09:00
railsアプリでホームのビューを指定する[root]
rootについて
railsのアプリでメイン画面を指定したい時があるかと思います。
そんな時にroutes.rbにrootを指定するだけで簡単に指定できます。config/routes.rbroot to: "コントローラー名#アクション名"これでメイン画面を指定できます。
例を書いてみます。
posts_controllerのindexアクションのビューをメイン画面に指定したいときは、config/routes.rbroot to: "posts#index"と記載します。
この場合、posts_controllerにindexアクションを書かなくても、app/views/posts/index.html.erbさえあればビューとして表示することが可能です。
最後までご覧いただきありがとうございます。
- 投稿日:2020-05-18T23:19:36+09:00
【Rails】Railsチュートリアルでの学び
- 投稿日:2020-05-18T23:00:42+09:00
コメント投稿機能の非同期通信 js.hamlバージョン
what
create.js.hamlなどのアクション名のjs.hamlファイルを利用して、
コメント投稿機能を非同期通信にします!初めに
自分は某スクールに通っていて、その時にjbuilderとjsファイルを使って
コメント投稿の非同期化を行いました。
ですが、そのやり方だとコメントの投稿はできても編集や削除を行うのが非常に難しいのと、
コードが非常に冗長になるので短くしたい。
なので、別のやり方で実装しようと考えて実行しました。注意事項
初学者のコメント機能を実装した時の備忘録として書いてます。
長々と解説してますが、まずはコピペして実践してみるのをおすすめします。
筆者が言語化して理解するためにこの記事を書いてます。
ご指摘がありましたら何なりとお申し付け下さい。この記事を読むことで得られるメリット
コメント投稿機能をjubilder形式で冗長なコードを書かずに、
可読性が高く短いコードで簡単に非同期通信が実装できる。前提条件
userテーブル、tweetテーブルは作成済みとして進みます。
全体の流れ
1,モデルを作成、マイグレーションファイルを編集
2,各テーブルとアソシエーションを組む
3,tweetsとcommentsコントローラーの編集
4,コメントのviewファイルの作成
5,js.hamlファイルを作成今回実装する機能
投稿、編集、削除機能の3つです。
まずは、commentテーブルを作成します
ターミナルrails g model commentマイグレーションファイルを編集します。
class CreateComments < ActiveRecord::Migration[5.2] def change create_table :comments do |t| t.integer :user_id, null: false t.integer :tweet_id, null: false t.text :content, null: false t.timestamps end end end終わったらrails db:migrateする。
?解説
user_idとtweet_idに外部キー制約をかけていないのは、
該当するtweet(例えばtweet_idが1のtweet)が削除された時に、
commentテーブルのtweet_idが保てなくなり
削除ができないエラーが発生するため。言い換えると、
tweet_idに外部キーをかけちゃうと、もしtweetが削除された時に
commentテーブル君が
「そのtweet_idは俺の情報を維持するために必要なんじゃ!消さないでくれ!」 と、言われてtweetの削除をしようとするとエラーが発生して削除できなくなるから。
(実際にはずらーっとMySQLエラーが出ます)
難しく言うと、情報の整合性が保てなくなるから。 って言う認識です。user_idは消えることがない(予定)なので、外部キー制約かけてもいいと思うけど、
一応なしで。問題ないと思うので
次は各モデルの編集コメントモデルのカラム
comment.rbbelongs_to :tweet belongs_to :user validates :content, presence: truetweetテーブルとuserテーブルにアソシエーションを組みます。
commentテーブルの1つのidごとににtweet_idとuser_idは1つしかないので、
belongs_toになります。tweet.rbbelongs_to :user has_many :comments, dependent: :destroyhas_many :commentsにdependent: :destroyを追加してる理由は、
tweetが削除された時にcommentの内容も削除して欲しいからです。user.rbhas_many :tweets has_many :comments次にcommentsコントローラーを実装していきます。
commentsコントローラーを作成
ターミナルrails g controller commentscommentsコントローラーを編集
comments_controller.rbclass CommentsController < ApplicationController before_action :set_tweet, only: [:create, :edit, :update, :destroy] before_action :set_comment, only: [:edit, :update, :destroy] def create @comment = @tweet.comments.create(comment_params) if @comment.save @comment = Comment.new get_all_comments end end def edit end def update if @comment.update(comment_params) get_all_comments end end def destroy if @comment.destroy get_all_comments end end private def set_tweet @tweet = Tweet.find(params[:tweet_id]) end def set_comment @comment = Comment.find(params[:id]) end def get_all_comments @comments = @tweet.comments.includes(:user).order('created_at asc') end def comment_params params.require(:comment).permit(:content).merge(user_id: current_user.id) end end上から順番に解説してきます。
before_action :set_tweet, only: [:create, :edit, :update, :destroy] before_action :set_comment, only: [:edit, :update, :destroy] private def set_tweet @tweet = Tweet.find(params[:tweet_id]) end def set_comment @comment = Comment.find(params[:id]) endbefore_actionにset_tweetメソッドとset_commentメソッドを設定しているのは、
各アクションが発火した時に、
現在操作している@tweetの情報と@commentの情報が必要だからです。
createだけはset_coomentメソッドは設定してません。
理由は新しい@commentを作成している情報が代入されているからです。例えば、editアクションが発火した時にどのtweetに紐付いた(ネストされた)commentか
情報が必要ですよね。他のアクションも同じ理由です。def create @comment = @tweet.comments.create(comment_params) if @comment.save @comment = Comment.new get_all_comments end end@comment = @tweet.comments.create(comment_params)2行目でこのように記述している理由は、どの@tweetに紐付いた(ネストされた)コメントかを分かりようにするため。だと思ってます。
createよりbuildの方が適切かも?
comment_paramsメソッドは読んで字の通りなので省略します。もし、コメント投稿が成功したら、新しいコメントとして代入されます。
def get_all_comments @comments = @tweet.comments.includes(:user).order('created_at asc') end次にget_all_commentsメソッドが発火されます。
これは、投稿が終わった時に全てのコメントの内容を取得する必要があるためです。?updateとdestroyにif文がある理由
もし、コメントが更新(編集、削除)された時に限定しないと、
後述するjs.hamlファイルの関係でget_all_commentsが正しく動作しないから。
(詳しく言うと、js.hamlファイルでcommentのviewをrenderして読み込むのですが、その時に読み込むことができない。)
と、考えてます。次はtweets_controllerのshowアクションを編集します。
def show @tweet = Tweet.find(params[:id]) @comment = Comment.new @comments = @tweet.comments.includes(:user).order('created_at asc') end@tweetでクリックしたtweet_idを取得する。
@comment = Comment.newで新しいcommentを代入する
コメントを新規投稿できるようにする。
これがないと当たり前ですが新しいコメント投稿できません。
変数が定義されてないから。
@commentsで該当する全てのcommentを取得する。N+1問題解消のためにincludes次はビューを編集します。
コメント表示部分部分のみ抜粋してます。tweets/show.html.haml= render "comments/index"renderしてcommentsページに飛ばしてます。
comments/index.html.haml.div#comment_form = render "comments/form" .div#comment_area = render "comments/comment"ここで投稿フォームとコメント一覧にrenderして分かれさせてます。
フォームを分ける理由はjs.hamlファイルのrenderする指定先の関係です。フォームの内容です
comments/_form.html.haml- if user_signed_in? = form_with(model: [@tweet, @comment]) do |form| = form.text_area :content, class: 'textarea' = form.submit value: "送信" - else コメントの投稿にはログインが必要です。いつも通りですね。form_withで入力した情報を飛ばしてcreateかupdateアクションを発火させます。
form_withはデフォルトでremote: tureなので、省略。
remote: trueに関しては次のviewで解説します。
htmlでデータを送ってほしい時はlocal: trueが必要です。次はコメント一覧です。
comments/_comment.html.haml- @comments.each do |comment| %div{id: "comment_#{comment.id}"} = comment.user.nickname = comment.content = comment.updated_at.strftime("%Y-%m-%d %H:%M") .list-inline-item - if user_signed_in? && comment.user_id == current_user.id = link_to edit_tweet_comment_path(comment.tweet_id, comment.id),remote: true do %input{type: "submit", value: "編集"} = link_to tweet_comment_path(comment.tweet_id, comment.id), method: :delete, remote: true, data: { confirm: '削除してよろしいですか?' } do %input{type: "submit", value: "削除"}ここではコメント一覧と、その編集と削除のリンクがあります。
2行目でdivクラスにcommentのidを指定している理由は最後に説明します。link_toの中で大事な点が2つあります。
1つ目はprefixのルート、2つ目はremote: trueの仕様についてです。?1つ目
prefixのパスが見慣れない形(idを2つ指定している)になってますが、
rails routesを確認していただければ分かります。edit_tweet_comment GET /tweets/:tweet_id/comments/:id/edit(.:format) comments#edit tweet_comment PATCH /tweets/:tweet_id/comments/:id(.:format) comments#update PUT /tweets/:tweet_id/comments/:id(.:format) comments#update DELETE /tweets/:tweet_id/comments/:id(.:format) comments#destroycommentはtweetにネストされているので、tweet_idの中のcommentっていう形になってます。
例)tweet_idが1に紐付いたcomment_idみたいなイメージ
なので、tweet_idとcomment_idの2つを指定する必要があります。◎余談
routes.rbでresources :tweetsに「shallow true」を追加すると
ネストされたprefixを以下のように省略できます。edit_comment GET /comments/:id/edit(.:format) comments#edit comment PATCH /comments/:id(.:format) comments#update PUT /comments/:id(.:format) comments#update DELETE //comments/:id(.:format) comments#destroy「edit_commentのcomments/:id」と、tweetが省略されます。
ですが、このprefixに変更すると上手くルートを辿ってくれません。
routing errorじゃなくてtweetが見つけられません。っていうエラーが出ました。
解決が難しそうなので、とりあえず今回はshallow trueはなしで実装しました。?2つ目
= link_toでremote: trueを書いてる理由は、js形式で送られてほしいからです。
デフォルトはhtml形式でデータが送られるけど、remote: trueを書くことで
js形式でデータが送られるようになります。すごい。
後1つ、js形式になることで、次に紹介するjs.hamlファイルの対応するアクション名の内容が発火されるようになります。remote: true有能。例えば、comments_controllerのcreateアクションが発火された場合は、命令通りcreateアクションが発火されますが、その時に同時に同じファイルにあるアクション名のjs.hamlファイルも発火されます(今回の場合はcomments/create.js.hamlファイルが発火する)
これで最後です。js.hamlファイルの解説です。
ファイルの場所はcommentsフォルダの中に作成します。?js.hamlファイルとは?
Javascriptのファイル形式だけど、hamlの記述の仕方ができる
ハイブリットのすごいやつです。
これを利用してviewを作っていきます。comments/create.js.haml$('#comment_area').html("#{ j(render 'comments/comment') }"); $('#comment_form').html("#{ j(render 'comments/form') }");?解説
comments/indexに書いてある「.div#comment_area」にcreateアクションで発火されたhtmlファイルを投げつける(formをrenderする)命令をします。j っていう文字はescape_javascriptの略です。
公式リファレンスだと「escape_javascriptはJavaScriptセグメントから改行 (CR) と一重引用符と二重引用符をエスケープします」って言ってますが意味わからないですね。
renderのformの中で生成した内容を、
上手いこと('#comment_area’)にhtml形式でformをrenderして投げつけてくれる。
っていうイメージでいます。
すごい感覚的な理解なので、違ったらごめんなさい。comments/edit.js.haml$('#comment_#{ @comment.id }').html("#{ j(render 'comments/form') }");ここも大事です。
editなのでcommentを編集したいです。
そのためには、どのcommentか見分ける必要があります。
なので、comments/commentでdivクラスにcommentのidを指定しました。
そのidのcommentを編集するよーっていうイメージです。
後はさっきと同じく、編集したいcommentのidに
html形式でformをrenderして投げつけます。comments/update.js.haml$('#comment_area').html("#{ j(render 'comments/comment') }");comment一覧フォームを再表示(更新した情報を反映)させたいので、
commentページをhtml形式でrenderしてます。comments/destroy.js.haml$('#comment_area').html("#{ j(render 'comments/comment') }");updateと全く同じです。
comment一覧フォームを再表示させたいので、commentページをhtml形式でrenderしてます。大変長くなりましたが、以上でコメント投稿機能の非同期通信が完了しました。
ここまで読んでいただいて本当にありがとうございます!最初の注意事項に書きましたが、まずはコピペして意味を考えるのがおすすめです。
自分の頭で考えるのが効率的なインプットになると思うからです。
私もそうやりました。笑では!
- 投稿日:2020-05-18T23:00:42+09:00
コメント機能の非同期通信 js.hamlバージョン
what
create.js.hamlなどのアクション名のjs.hamlファイルを利用して、
コメント投稿機能を非同期通信にします!初めに
自分は某スクールに通っていて、その時にjbuilderとjsファイルを使って
コメント投稿の非同期化を行いました。
ですが、そのやり方だとコメントの投稿はできても編集や削除を行うのが非常に難しいのと、
コードが非常に冗長になるので短くしたい。
なので、別のやり方で実装しようと考えて実行しました。注意事項
初学者のコメント機能を実装した時の備忘録として書いてます。
長々と解説してますが、まずはコピペして実践してみるのをおすすめします。
筆者が言語化して理解するためにこの記事を書いてます。
ご指摘がありましたら何なりとお申し付け下さい。この記事を読むことで得られるメリット
コメント投稿機能をjubilder形式で冗長なコードを書かずに、
可読性が高く短いコードで簡単に非同期通信が実装できる。前提条件
userテーブル、tweetテーブルは作成済みとして進みます。
全体の流れ
1,モデルを作成、マイグレーションファイルを編集
2,各テーブルとアソシエーションを組む
3,tweetsとcommentsコントローラーの編集
4,コメントのviewファイルの作成
5,js.hamlファイルを作成今回実装する機能
投稿、編集、削除機能の3つです。
まずは、commentテーブルを作成します
ターミナルrails g model commentマイグレーションファイルを編集します。
class CreateComments < ActiveRecord::Migration[5.2] def change create_table :comments do |t| t.integer :user_id, null: false t.integer :tweet_id, null: false t.text :content, null: false t.timestamps end end end終わったらrails db:migrateする。
?解説
user_idとtweet_idに外部キー制約をかけていないのは、
該当するtweet(例えばtweet_idが1のtweet)が削除された時に、
commentテーブルのtweet_idが保てなくなり
削除ができないエラーが発生するため。言い換えると、
tweet_idに外部キーをかけちゃうと、もしtweetが削除された時に
commentテーブル君が
「そのtweet_idは俺の情報を維持するために必要なんじゃ!消さないでくれ!」 と、言われてtweetの削除をしようとするとエラーが発生して削除できなくなるから。
(実際にはずらーっとMySQLエラーが出ます)
難しく言うと、情報の整合性が保てなくなるから。 って言う認識です。user_idは消えることがない(予定)なので、外部キー制約かけてもいいと思うけど、
一応なしで。問題ないと思うので
次は各モデルの編集コメントモデルのカラム
comment.rbbelongs_to :tweet belongs_to :user validates :content, presence: truetweetテーブルとuserテーブルにアソシエーションを組みます。
commentテーブルの1つのidごとににtweet_idとuser_idは1つしかないので、
belongs_toになります。tweet.rbbelongs_to :user has_many :comments, dependent: :destroyhas_many :commentsにdependent: :destroyを追加してる理由は、
tweetが削除された時にcommentの内容も削除して欲しいからです。user.rbhas_many :tweets has_many :comments次にcommentsコントローラーを実装していきます。
commentsコントローラーを作成
ターミナルrails g controller commentscommentsコントローラーを編集
comments_controller.rbclass CommentsController < ApplicationController before_action :set_tweet, only: [:create, :edit, :update, :destroy] before_action :set_comment, only: [:edit, :update, :destroy] def create @comment = @tweet.comments.create(comment_params) if @comment.save @comment = Comment.new get_all_comments end end def edit end def update if @comment.update(comment_params) get_all_comments end end def destroy if @comment.destroy get_all_comments end end private def set_tweet @tweet = Tweet.find(params[:tweet_id]) end def set_comment @comment = Comment.find(params[:id]) end def get_all_comments @comments = @tweet.comments.includes(:user).order('created_at asc') end def comment_params params.require(:comment).permit(:content).merge(user_id: current_user.id) end end上から順番に解説してきます。
before_action :set_tweet, only: [:create, :edit, :update, :destroy] before_action :set_comment, only: [:edit, :update, :destroy] private def set_tweet @tweet = Tweet.find(params[:tweet_id]) end def set_comment @comment = Comment.find(params[:id]) endbefore_actionにset_tweetメソッドとset_commentメソッドを設定しているのは、
各アクションが発火した時に、
現在操作している@tweetの情報と@commentの情報が必要だからです。
createだけはset_coomentメソッドは設定してません。
理由は新しい@commentを作成している情報が代入されているからです。例えば、editアクションが発火した時にどのtweetに紐付いた(ネストされた)commentか
情報が必要ですよね。他のアクションも同じ理由です。def create @comment = @tweet.comments.create(comment_params) if @comment.save @comment = Comment.new get_all_comments end end@comment = @tweet.comments.create(comment_params)2行目でこのように記述している理由は、どの@tweetに紐付いた(ネストされた)コメントかを分かりようにするため。だと思ってます。
createよりbuildの方が適切かも?
comment_paramsメソッドは読んで字の通りなので省略します。もし、コメント投稿が成功したら、新しいコメントとして代入されます。
def get_all_comments @comments = @tweet.comments.includes(:user).order('created_at asc') end次にget_all_commentsメソッドが発火されます。
これは、投稿が終わった時に全てのコメントの内容を取得する必要があるためです。?updateとdestroyにif文がある理由
もし、コメントが更新(編集、削除)された時に限定しないと、
後述するjs.hamlファイルの関係でget_all_commentsが正しく動作しないから。
(詳しく言うと、js.hamlファイルでcommentのviewをrenderして読み込むのですが、その時に読み込むことができない。)
と、考えてます。次はtweets_controllerのshowアクションを編集します。
def show @tweet = Tweet.find(params[:id]) @comment = Comment.new @comments = @tweet.comments.includes(:user).order('created_at asc') end@tweetでクリックしたtweet_idを取得する。
@comment = Comment.newで新しいcommentを代入する
コメントを新規投稿できるようにする。
これがないと当たり前ですが新しいコメント投稿できません。
変数が定義されてないから。
@commentsで該当する全てのcommentを取得する。N+1問題解消のためにincludes次はビューを編集します。
コメント表示部分部分のみ抜粋してます。tweets/show.html.haml= render "comments/index"renderしてcommentsページに飛ばしてます。
comments/index.html.haml.div#comment_form = render "comments/form" .div#comment_area = render "comments/comment"ここで投稿フォームとコメント一覧にrenderして分かれさせてます。
フォームを分ける理由はjs.hamlファイルのrenderする指定先の関係です。フォームの内容です
comments/_form.html.haml- if user_signed_in? = form_with(model: [@tweet, @comment]) do |form| = form.text_area :content, class: 'textarea' = form.submit value: "送信" - else コメントの投稿にはログインが必要です。いつも通りですね。form_withで入力した情報を飛ばしてcreateかupdateアクションを発火させます。
form_withはデフォルトでremote: tureなので、省略。
remote: trueに関しては次のviewで解説します。
htmlでデータを送ってほしい時はlocal: trueが必要です。次はコメント一覧です。
comments/_comment.html.haml- @comments.each do |comment| %div{id: "comment_#{comment.id}"} = comment.user.nickname = comment.content = comment.updated_at.strftime("%Y-%m-%d %H:%M") .list-inline-item - if user_signed_in? && comment.user_id == current_user.id = link_to edit_tweet_comment_path(comment.tweet_id, comment.id),remote: true do %input{type: "submit", value: "編集"} = link_to tweet_comment_path(comment.tweet_id, comment.id), method: :delete, remote: true, data: { confirm: '削除してよろしいですか?' } do %input{type: "submit", value: "削除"}ここではコメント一覧と、その編集と削除のリンクがあります。
2行目でdivクラスにcommentのidを指定している理由は最後に説明します。link_toの中で大事な点が2つあります。
1つ目はprefixのルート、2つ目はremote: trueの仕様についてです。?1つ目
prefixのパスが見慣れない形(idを2つ指定している)になってますが、
rails routesを確認していただければ分かります。edit_tweet_comment GET /tweets/:tweet_id/comments/:id/edit(.:format) comments#edit tweet_comment PATCH /tweets/:tweet_id/comments/:id(.:format) comments#update PUT /tweets/:tweet_id/comments/:id(.:format) comments#update DELETE /tweets/:tweet_id/comments/:id(.:format) comments#destroycommentはtweetにネストされているので、tweet_idの中のcommentっていう形になってます。
例)tweet_idが1に紐付いたcomment_idみたいなイメージ
なので、tweet_idとcomment_idの2つを指定する必要があります。◎余談
routes.rbでresources :tweetsに「shallow true」を追加すると
ネストされたprefixを以下のように省略できます。edit_comment GET /comments/:id/edit(.:format) comments#edit comment PATCH /comments/:id(.:format) comments#update PUT /comments/:id(.:format) comments#update DELETE //comments/:id(.:format) comments#destroy「edit_commentのcomments/:id」と、tweetが省略されます。
ですが、このprefixに変更すると上手くルートを辿ってくれません。
routing errorじゃなくてtweetが見つけられません。っていうエラーが出ました。
解決が難しそうなので、とりあえず今回はshallow trueはなしで実装しました。?2つ目
= link_toでremote: trueを書いてる理由は、js形式で送られてほしいからです。
デフォルトはhtml形式でデータが送られるけど、remote: trueを書くことで
js形式でデータが送られるようになります。すごい。
後1つ、js形式になることで、次に紹介するjs.hamlファイルの対応するアクション名の内容が発火されるようになります。remote: true有能。例えば、comments_controllerのcreateアクションが発火された場合は、命令通りcreateアクションが発火されますが、その時に同時に同じファイルにあるアクション名のjs.hamlファイルも発火されます(今回の場合はcomments/create.js.hamlファイルが発火する)
これで最後です。js.hamlファイルの解説です。
ファイルの場所はcommentsフォルダの中に作成します。?js.hamlファイルとは?
Javascriptのファイル形式だけど、hamlの記述の仕方ができる
ハイブリットのすごいやつです。
これを利用してviewを作っていきます。comments/create.js.haml$('#comment_area').html("#{ j(render 'comments/comment') }"); $('#comment_form').html("#{ j(render 'comments/form') }");?解説
comments/indexに書いてある「.div#comment_area」にcreateアクションで発火されたhtmlファイルを投げつける(formをrenderする)命令をします。j っていう文字はescape_javascriptの略です。
公式リファレンスだと「escape_javascriptはJavaScriptセグメントから改行 (CR) と一重引用符と二重引用符をエスケープします」って言ってますが意味わからないですね。
renderのformの中で生成した内容を、
上手いこと('#comment_area’)にhtml形式でformをrenderして投げつけてくれる。
っていうイメージでいます。
すごい感覚的な理解なので、違ったらごめんなさい。comments/edit.js.haml$('#comment_#{ @comment.id }').html("#{ j(render 'comments/form') }");ここも大事です。
editなのでcommentを編集したいです。
そのためには、どのcommentか見分ける必要があります。
なので、comments/commentでdivクラスにcommentのidを指定しました。
そのidのcommentを編集するよーっていうイメージです。
後はさっきと同じく、編集したいcommentのidに
html形式でformをrenderして投げつけます。comments/update.js.haml$('#comment_area').html("#{ j(render 'comments/comment') }");comment一覧フォームを再表示(更新した情報を反映)させたいので、
commentページをhtml形式でrenderしてます。comments/destroy.js.haml$('#comment_area').html("#{ j(render 'comments/comment') }");updateと全く同じです。
comment一覧フォームを再表示させたいので、commentページをhtml形式でrenderしてます。大変長くなりましたが、以上でコメント投稿機能の非同期通信が完了しました。
ここまで読んでいただいて本当にありがとうございます!最初の注意事項に書きましたが、まずはコピペして意味を考えるのがおすすめです。
自分の頭で考えるのが効率的なインプットになると思うからです。
私もそうやりました。笑では!
- 投稿日:2020-05-18T21:31:04+09:00
Railsでgroup->order->countしたい話
> Model.group(:column_name).order(count_column_name: "DESC").count(:column_name) SELECT COUNT("model"."column_name") AS count_column_name, "model"."column_name" AS model_column_name FROM "model" GROUP BY "model"."column_name" ORDER BY "count_column_name" DESCできた。
- 投稿日:2020-05-18T19:19:23+09:00
rmagick関係でハマったときの対処法(Ubuntu18.04,rails)
1回目のエラーの状況
$ bundle install checking for brew... yes checking for Ruby version >= 2.3.0... yes checking for pkg-config... no ERROR: Can't install RMagick 4.1.2. Can't find pkg-config in対処
これで成功。
pkg-configとは何かはこちらで。
私はよくわかっていません。
https://pragma666.hatenablog.com/entry/20110623/1317812413$ sudo apt install pkg-config $ bundle install最初のエラー前にしていたこと
brew link --forceはシンボリックリンクを作成して上書きしていることを意味する。
imagemagick@6は自動的にシンボリックリンクが作成されないので、シンボリックリンクを作成している。【Homebrew】インストールしたパッケージのシンボリックリンクが作成されない場合
https://www.task-notes.com/entry/20141130/1417275206$ brew install imagemagick@6 If you need to have imagemagick@6 first in your PATH run: echo 'export PATH="/home/linuxbrew/.linuxbrew/opt/imagemagick@6/bin:$PATH"' >> ~/.bash_profile For compilers to find imagemagick@6 you may need to set: export LDFLAGS="-L/home/linuxbrew/.linuxbrew/opt/imagemagick@6/lib" export CPPFLAGS="-I/home/linuxbrew/.linuxbrew/opt/imagemagick@6/include" $ brew link --force imagemagick@62回目のエラー内容(2020.5.19追記)
$ rails g model user(controlleとconsoleも以下のエラーが出た) /home/username/.rbenv/versions/2.7.1/lib/ruby/gems/2.7.0/gems/bootsnap-1.4.6/lib/bootsnap/load_path_cache/core_ext/kernel_require.rb:23:in `require': libMagickCore-7.Q16HDRI.so.7: cannot open shared object file: No such file or directory - /home/username/.rbenv/versions/2.7.1/lib/ruby/gems/2.7.0/gems/rmagick-4.1.2/lib/RMagick2.so (LoadError)最後の
RMagick2.soは存在する。
libMagickcore-7.Q16HDRI.so.7はimagemagickの最新版をインストール後に実行したらこの表記になった。
最初のエラーはlibMagickcore-6〇〇だったが、最新版だったらエラー解消されると思ってしてみたがだめだった。
.bash_profileにPATHを書き込んだが意味がなかった(エラーが治ったあとにコメントアウトしてもエラーにならなかった。)。
その他のimagemagickのアンインストール、インストールや、rmagickのインストール、アンインストールもだめ。
gemをmini_magickに変えたら上手く行ったが、今回はrmagickができるか試したかったので、様々なネット記事のやり方でやってみたが上手く行かなかった。
kernel_require.rb:23の内容を見たりして、「$LOADED_FEATURESというものの中にPATHを入れたらいいのかな?」と考えたが、大抵ググり方を変えたら答えがダイレクトに書いてあることが多いので、もう少し粘ってみることに。.bash_profileexport PATH=/home/linuxbrew/.linuxbrew/opt/imagemagick@6/bin:$PATH export LDFLAGS="-L/home/linuxbrew/.linuxbrew/opt/imagemagick@6/lib" export CPPFLAGS="-I/home/linuxbrew/.linuxbrew/opt/imagemagick@6/include" export PKG_CONFIG_PATH="/home/linuxbrew/.linuxbrew/opt/imagemagick@6/lib/pkgconfig" export LD_LIBRARY_PATH="/home/linuxbrew/.linuxbrew/Cellar/imagemagick@6/6.9.11-13/lib"対処法
$ gem pristine rmagickこれで通常通りrailsコマンドで作成できるようになった。
最初の方でこのコマンドとちょっと違うコマンドを打ったらエラーになったことと、gemをいじっていないからしても意味がないと思ってやっていなかった。pristineコマンドは、インストールされたgemをそのキャッシュされた.gemファイルの内容と比較し、キャッシュされた.gemのコピーと一致しないファイルを復元します。
インストール済みのgemに変更を加えた場合、pristineコマンドはそれらを元に戻します。すべての拡張機能が再構築され、gemのすべてのビンスタブは、変更の確認後に再生成されます。
キャッシュされたgemが見つからない場合はダウンロードされます。
引用元:Rubygemsのガイド(https://guides.rubygems.org/command-reference/#gem-pristine)驚いたのが、エラーは出ていたが実はuserモデル自体は作成されていたこと。
userモデルが作成されていないものと思っていたので、確認しようともしなかった。$ gem pristine rmagick Restoring gems to pristine condition... Building native extensions. This could take a while... Restored rmagick-4.1.2 $ rails g model user (要約 既に同じものが作成されていますよ。) Running via Spring preloader in process 6644 invoke active_record The name 'User' is either already used in your application or reserved by Ruby on Rails. Please choose an alternative or use --force to skip this check and run this generator again. (手作業でモデルとマイグレーションファイルを削除した。) $ rails g model user Running via Spring preloader in process 6830 invoke active_record create db/migrate/20200519105406_create_users.rb create app/models/user.rb invoke test_unit identical test/models/user_test.rb identical test/fixtures/users.yml
- 投稿日:2020-05-18T19:19:23+09:00
gemのrmagickがbundle installできない(Ubuntu18.04,rails)
エラーの状況
$ bundle install checking for brew... yes checking for Ruby version >= 2.3.0... yes checking for pkg-config... no ERROR: Can't install RMagick 4.1.2. Can't find pkg-config in対処
これで成功。
pkg-configとは何かはこちらで。
私はよくわかっていません。
https://pragma666.hatenablog.com/entry/20110623/1317812413$ sudo apt install pkg-config $ bundle installその他にした無駄なこと(これらも上手く行った要因だったらいけないので)
全て
最初のエラー前にしていたことでbrew install imagemagick@6したときに表示されたものを実行しただけ。
していることは参考サイト参照。環境変数の確認とパスの追加
https://qiita.com/FJHoshi/items/c847ad51af388d2dbb4a
linuxbrewで入れるrmagickの設定
https://takkii.hatenablog.com/entry/2019/02/28/200143$ echo 'export PATH="/home/linuxbrew/.linuxbrew/opt/imagemagick@6/bin:$PATH"' >> ~/.bash_profile $ export LDFLAGS="-L/home/linuxbrew/.linuxbrew/opt/imagemagick@6/lib" $ export CPPFLAGS="-I/home/linuxbrew/.linuxbrew/opt/imagemagick@6/include"最初のエラー前にしていたこと
brew link --forceはシンボリックリンクを作成して上書きしていることを意味する。
imagemagick@6`は自動的にシンボリックリンクが作成されないので、シンボリックリンクを作成している。【Homebrew】インストールしたパッケージのシンボリックリンクが作成されない場合
https://www.task-notes.com/entry/20141130/1417275206$ brew install imagemagick@6 If you need to have imagemagick@6 first in your PATH run: echo 'export PATH="/home/linuxbrew/.linuxbrew/opt/imagemagick@6/bin:$PATH"' >> ~/.bash_profile For compilers to find imagemagick@6 you may need to set: export LDFLAGS="-L/home/linuxbrew/.linuxbrew/opt/imagemagick@6/lib" export CPPFLAGS="-I/home/linuxbrew/.linuxbrew/opt/imagemagick@6/include" $ brew link --force imagemagick@6
- 投稿日:2020-05-18T17:45:18+09:00
deviseを使ったユーザー登録
今回はdeviseを使ったユーザー登録の流れを!
忘れないように自分用です。deviseとは
ユーザー管理機能を簡単い実相するためのgem。
Gemfileに追記する
gem 'deviseを最終行に追記。
その後、プロジェクトディレクトリで
bundle installdeviseの設定ファイルを作成。
ターミナル
$ rails g devise:install
・config/initializers/devise.rb
・config/locales/devise.en.yml
上記のファイルが作成される。deviseの機能を持ったUserモデルを作成。
deviseを利用する際にはアカウントを作成するためのUserモデルを新しく作成します。通常のモデルの作成方法ではなく、devisdeのモデル作成用コマンドで作成。
①userモデルの作sでい
ターミナル
$ rails g devise user
・app/models/user.rb
・db/migrate/20XXXXXXXXXXXX_devise_create_users.rb
・test/fixtures/users.yml
・test/models/user_test.rb
上記ファイルが自動で作成され、config/routes.rbに以下の記述がされる。
Rails.application.routes.draw do
devise_for :users
この記述により、ログイン・新規登録に必要なルーティングが生成されます。②userテーブルの作成
ターミナル
$ rails db:migrate
userテーブルが作成されているのを確認できればOK!新規登録/ログインの実装
手順は以下の通り、
1.未ログイン時のボタン設定
2.未ログイン時・ログイン時でボタン表示の変更
3.devise用のビューを作成する1.未ログイン時のボタン設定については、ビューの装飾を変更するだけなので割愛。
2.未ログイン時・ログイン時でボタン表示の変更
こちらを変更できようにするのが、user_signed_in?メソッド
user_signed_in?メソッドとは
deviseでログイン機能を実相する際に使用できるメソッドで、ユーザーがサインインしているかどうかを検証するためのメソッドです。
サインインしている場合はtrueで返し、サインインしていない場合は、falseで返します。
<% if user_signed_in? %>
<%= link_to "新規投稿", [prefix], class: "" %>
<%= link_to "ログアウト", [prefix], method: :delete, class: "" %>
<% end %>
user_signed_in?が返す値は最終的に、trueかfalseになるおで、上記の例のようにif文またはunless文とともに使用します。devise用のビューを作成
deviseのコマンドを利用してビィーファイルを生成すると、簡単い新規登録画面とログイン画面が作成できます。
ターミナル
$ rails g devise:views
新規登録画面:app/views/devise/registrations/new.html.erb
ログイン画面:app/views/devise/sessions/new.html.erb
というビューファイルが対応。ユーザー名も登録できるようにする。
deviseの初期状態では、nicknameカラムは作成されないため、もし必要であれば以下のコマンドでuserテーブルにnicknameカラムを作成する。
# usersテーブルにnicknameカラムをstring型で追加するマイグレーションファイルを作成
$ rails g migration AddNicknameToUsers nickname:string
# マイグレーションファイルの実行
$ rails db:migrateconfigure_permitted_parametersメソッド
deviseの初期状態でサインアップ時にメールアドレスとパスワードのみ受け取るようにストロングパラメーターが設定してあるので、上記で追加したキー(nickname)のパラメーターは許可されていない。
追加のパラメーターを許可したい場合は、application.controller.rbにおいて以下の記述をする。
class ApplicationController < ActionController::Base
before_action :configure_permitted_parameters, if: :devise_controller?
protected
def configure_permitted_parameters
devise_parameter_sanitizer.permit(:sign_up, keys: [:nickname])
end
endcurrent_userメソッド
current_userメソッドは、deviseのヘルパーメソッドで、ログイン中のユーザー情報を取得できる。
idを取得したい場合、current_user.id記述
- 投稿日:2020-05-18T17:26:17+09:00
意外と知らない「name属性について
name属性
要素の名前を指定する属性で、フォーム,フレーム,コントロール,オブジェクトなどの多数の要素で,「要素の名前」を指定する。
ユーザーがリクエストをする際に、viewの方で入力されたparameterにnameのキーをつけることができる。name属性をつけるときは、保存したいデータベースのカラム名にすること。使用例
1.JavaScript
要素にアクセスする際, この name 属性 の値を用いて,対象要素を特定することができる。
2.input 要素
フォームのデータが送信されるときに,name 属性の値が付加されており,対象とする要素のデータに簡単にアクセスできます。
また,input 要素 では, name=”charset” と name=”isindex” という指定は特別な意味を持ちます。2-1. name=”charset”
フォームデータのエンコードの種類 を送信します。
2-2. name=”isindex”
フォームデータの送信の際特別な扱いがなされ, HTML5 では廃止になっ た isindex 要素の動作がエミュレートされます。
3.iframe 要素 と object 要素
name 属性の値は, a要素のtarget属性から参照してHTML文書の表示先を指定する際に使用できます。
まとめ
簡単に言うと、上記の使用例にあるフォーム等に名前をつけることが出来て、その値を取得するために活用できると言うことです!
name属性を適当なものになっていると、JavaScriptで値がおかしかったりするので注意してください!!
- 投稿日:2020-05-18T16:25:24+09:00
【git】error: failed to push some refs to "URL"のエラー対処法
Rails で個人でアプリケーションを開発中です。
表題のエラーが出た際に、改めてgitの理解が深まりましたので備忘録として残します。状況
開発中のタイミングで普段通り、「git pusu origin ブランチ名」で、
ローカルの変更をリモートにpushしようとすると。。。terminalgit push origin develop To https:///githubのURL ! [rejected]develop -> develop (non-fast-forward)error: failed to push some refs to 'https://githubのURL' hint: Updates were rejected because the tip of your current branch is behind hint: its remote counterpart. Integrate the remote changes (e.g. hint: 'git pull ...') before pushing again. hint: See the 'Note about fast-forwards' in 'git push --help' for details.上記のエラーが出ました。
原因
このcommitを行う前に、私がリモートでgithubのREADMEの変更を行っていたことが
今回のエラーの原因でした。「リモートのファイルがローカルのファイルも最新版だから、そのファイルにpushできないですよ」ということみたいです。
対処法
いくつか対処法があるみたいです。
①git pull origin develop
git pull origin developでリモートの環境をローカルファイルにpullした後、
再度pushを行う。②git fetchした後、git mergeする
①とやっていることはほとんど変わらず、pull=fetch + mergeという意味合いなのかと思います。
③git push ––forceで矯正的にpushする
こちらは、個人開発なら自分一人しかリポジトリを操作しないので大きな影響はなさそうですが、
チーム開発の場合だと自分以外にcommitやpushする人がいる無闇に使用すべきでは無い、という記事をいくつか確認しました。①か②で対処するのが無難かもしれません・・・(私は①で対処しました)
備考
「origin」や「master」の理解については、こちらの記事が大変参考になりました!
- 投稿日:2020-05-18T15:36:02+09:00
【rails】新しいバージョンのRuby on Rails環境を用意した。
アプリケーションを作るため、新しいバージョンのRuby on Railsが必要になり、ローカル環境に用意した。
(既存アプリに影響を与えないことを条件とした)
Ruby Rails 必要なバージョン 2.7.1 6.0.3 既存のバージョン 2.5.1 5.0.7.2 参考
https://qiita.com/pharma_tech3/items/2ab578eb5b07ff0ca296
環境構築方法
rails 6.0.3の導入
terminal$ gem install rails -v 6.0.3 $ rails _6.0.3_ new linebot -d mysql ... * bin/rake: Spring inserted * bin/rails: Spring inserted rails webpacker:install sh: node: command not found sh: nodejs: command not found Node.js not installed. Please download and install Node.js https://nodejs.org/en/download/途中で
webpackage installが実行されたときに、node.jsがないとのメッセージが出ている。node.jsをインストールする。
terminal$ brew install node $ node -v v14.2.0再度
rails webpacker:installを実行する。terminal$ rails webpacker:install Yarn not installed. Please download and install Yarn from https://yarnpkg.com/lang/en/docs/install/今度は、yarnがインストールされていないからダウンロードしてインストールしてね。とのこと
terminal$ brew install yarn $ yarn -v 1.22.4
yarnがインストールされた。terminal$ rails webpacker:install ... ✨ Done in 6.92s. Webpacker successfully installed ? ?
Webpackerのインストールが成功した。terminal$ cd linebot $ rails -v Rails 6.0.3railsの新しいバージョンが使えるようになった。
新しいプロジェクトを作成する。
terminal$ rails _6.0.3_ new linebot -d mysql $ cd linebotRuby 2.7.1の導入
Ruby 2.7.1をインストールするコマンドを実行する。
terminal$ rbenv install 2.7.1 ruby-build: definition not found: 2.7.1 See all available versions with `rbenv install --list'. If the version you need is missing, try upgrading ruby-build: brew update && brew upgrade ruby-build
brew updateとbrew upgrade ruby-buildを実行してね。とのことインストール可能なリストを確認する。
terminal$ rbenv install -l ... 2.6.4 2.6.5 2.7.0-dev 2.7.0-preview1 2.7.0-preview2 2.7.0-preview3 2.7.0-rc1 2.7.0-rc2 jruby-1.5.6 jruby-1.6.3 ...インストール可能なリストの中に、2.7.1がない。
terminal$ brew update Already up-to-date.terminal$ brew upgrade ruby-build ==> Upgrading 1 outdated package: ruby-build 20191223 -> 20200401 ... ==> Caveats ==> ruby-build ruby-build installs a non-Homebrew OpenSSL for each Ruby version installed and these are never upgraded. To link Rubies to Homebrew's OpenSSL 1.1 (which is upgraded) add the following to your ~/.zshrc: export RUBY_CONFIGURE_OPTS="--with-openssl-dir=$(brew --prefix openssl@1.1)" Note: this may interfere with building old versions of Ruby (e.g <2.4) that use OpenSSL <1.1.インストール可能なリストの中に、2.7.1出現した。
terminal$ rbenv install -l ... 2.7.0-preview3 2.7.0-rc1 2.7.0-rc2 2.7.0 2.7.1 2.8.0-dev jruby-1.5.6 jruby-1.6.3 ...バージョンを指定してインストールする。
terminal$ rbenv install 2.7.1 Downloading openssl-1.1.1d.tar.gz... -> https://dqw8nmjcqpjn7.cloudfront.net/1e3a91bc1f9dfce01af26026f856e064eab4c8ee0a8f457b5ae30b40b8b711f2 Installing openssl-1.1.1d... Installed openssl-1.1.1d to /Users/Taiti/.rbenv/versions/2.7.1 Downloading ruby-2.7.1.tar.bz2... -> https://cache.ruby-lang.org/pub/ruby/2.7/ruby-2.7.1.tar.bz2 Installing ruby-2.7.1... ruby-build: using readline from homebrew Installed ruby-2.7.1 to /Users/Taiti/.rbenv/versions/2.7.1プロジェクトフォルダ内のみ、バージョン2.7.1を適用する。
$ rbenv local 2.7.1 $ rbenv rehash $ ruby -v ruby 2.7.1p83 (2020-03-31 revision a0c7c23c9c) [x86_64-darwin19]完了
- 投稿日:2020-05-18T15:19:26+09:00
railsアプリをherokuでデプロイする方法(Mysqlでも確実にデプロイできます)
本記事について
railsアプリをherokuでデプロイする方法を調べていたのですが、開発環境(developmentやtest環境)でRailsアプリに最初からついているDB(SQLite3)を使用している事を前提に書かれた記事が多く、混乱してしまったので、DBにMysqlを採用している方に向けて記事を書いていこうと思います。
※変更内容の意味を理解していればどのDBを使っていようが同じ手順だと気づくのですが、初心者の僕は混乱して躓いてしまったので、同じ様な方が少しでも楽に理解できる様に執筆しています。
環境
- Ruby 2.5.1
- Rails 5.0.7.2
- git 2.25.2
- heroku/7.41.1 darwin-x64 node-v12.16.2
事前に準備して欲しいもの
- Railsで作成したアプリ(下記二つの条件を満たしているもの)
- Gitで管理している
- ローカル環境でエラーが出ていない(デプロイ中にエラーが出た場合、デプロイ時に起こったエラーかローカル環境でのエラーが関係しているのか分からなくなってしまうので、それを防ぐ為)
- herokuのユーザー登録
- heroku-cil(herokuの機能を自分のPCに紐付けるもの→herokuのコマンドをPCで使える様にする)のインストール
今回はherokuについての記事なので、Gitについての説明は割愛させて頂きます。
デプロイ作業を始める前に
デプロイ作業を始める前に、デプロイしたいRailsアプリのコードを一部編集する必要があります。
編集するのは以下の三箇所です。
- Gemfile(各環境で使うDBの設定を変更する)
- config/datebase.yml(実際に本番環境で使うDBを接続する記述を追加する)
- config/environments/production.rb(本番環境でのプリコンパイルをオンにする)
編集する内容について一つずつ理由とともに解説していきますので、変更する場所だけ確認できたら読み進めて貰って大丈夫です。
Gemfileの設定
削除するコードが一箇所、追記するコードが二つあります。
- 削除する箇所
Gemfilegem 'mysql2'
- 追記する箇所
Gemfilegroup :development, :test do gem 'mysql2' end※group :development, :test do ~ end内に他にもgemが書いてあったと思いますが、消さないでください。
Gemfilegroup :production do gem 'pg' end何をしてんだ?
herokuではPostgreSQL(pg)というDBをデフォルトで使う様に設定されています。
普通に作っている方は、全ての環境下でmysqlを使う様に表記していると思うので、その表記を削除し、開発環境、テスト環境下のみでmysqlを使える様にgroup :development, :test do ~ end内にgem 'mysql2'の表記を追加しています。
また、本番環境でPostgreSQL(pg)が使える様にgroup :production do ~ end内にgem 'pg'を表記しています。config/datebase.ymlの設定
追記するコードが一つあります。
config/datebase.ymlproduction: <<: *default adapter: postgresql encoding: unicode pool: 5※production:内にあった元々の記述は全て削除して、上記の様に書き換えて下さい。
何をしてんだ?
先ほどgemを追加し、機能をインストールするための準備は整えたのですが、実際にDBと接続する記述はまだ完了していません。どのDBに接続するのか?という設定をする箇所がconfig/database.ymlです。
※開発環境、テスト環境で使用するDBの設定もここに書かれています。追加したコードの意味は以下の様になります。
adapter: postgresql - postgreSQLのデータベースに接続。
encoding: unicode - unicodeという文字コードを使用。
pool: 5 - DBに接続できる上限の数を指定。DBに接続する為の設定をしたんだ!ってことが分かればOKです。
config/environments/production.rbの設定
追記するコードが一つあります。
config/environments/production.rb#デフォルトでfalseとなっている以下の箇所をtrueに変更 config.assets.compile = true何をしてんだ?
Railsは本番環境でのプリコンパイルがデフォルトでオフになっています。
assetsを圧縮して少しでも軽くする為だそうです。
assets以下のフォルダから動的にコンパイルしながらページを読み込む為にtrueに変更しています。
難しく書きましたが、本番環境でも画像を読み込んでくれよ~って表記にしただけです。いよいよデプロイ作業開始
これでデプロイをする前の事前準備が終わったので、いよいよデプロイ作業に移ります。
デプロイまでの流れは以下の通りです。
- herokuにログイン
- 公開されるRailsアプリのurlを決める
- pushしてデプロイ
- 本番環境でマイグレーションをする
AWSとかと比べて超絶簡単なので気負いせずにさくっと終わらせましょう!
1.herokuにログイン
ターミナル$heroku login上記コマンドでherokuにログインします。
コマンド入力に成功すると(なんか格ゲーみたい)herokuに登録したEmailとpasswordの入力を求められるので、ゆっくり正確に入力しましょう。
入力に成功すると下記の様にターミナルに表示されます。
(as ~ は自分のメールアドレスです。)ターミナルLogged in as ~~~~~@icloud.com公開されるRailsアプリのurlを決める
https://nameless-atoll-34353.herokuapp.com/
上記のURLは僕が初めて作った個人アプリなんですが、これでいうところのnameless-atoll-34353の部分を自身で決めることができます。
heroku createだけでも問題はないのですが、僕みたいになんのアプリか分からない変なURLになるのでしっかり設定しておきましょう!ターミナル$heroku create 好きな文字列pushしてデプロイ
以下のコマンドを打つだけです。楽勝です。
この時、gitのmasterで管理されているコードがpushされるので、brunch生やして作業している方は一旦masterにpushしましょう。ターミナル$git push heroku masterこんな感じで進んでいたら順調です。
ターミナルEnumerating objects: 148, done. Counting objects: 100% (148/148), done. Delta compression using up to 4 threads Compressing objects: 100% (125/125), done. Writing objects: 100% (148/148), 39.65 KiB | 2.09 MiB/s, done. Total 148 (delta 24), reused 0 (delta 0) remote: Compressing source files... done. remote: Building source: remote: remote: -----> Ruby app detected remote: -----> Installing bundler 2.0.2 remote: -----> Removing BUNDLED WITH version in the Gemfile.lock remote: -----> Compiling Ruby/Rails remote: -----> Using Ruby version: ruby-2.6.6 remote: -----> Installing dependencies using bundler 2.0.2 remote: Running: bundle install --without development:test --path vendor/bundle --binstubs vendor/bundle/bin -j4 --deployment remote: The dependency tzinfo-data (>= 0) will be unused by any of the platforms Bundler is installing for. Bundler is installing for ruby but the dependency is only for x86-mingw32, x86-mswin32, x64-mingw32, java. To add those platforms to the bundle, run `bundle lock --add-platform x86-mingw32 x86-mswin32 x64-mingw32 java`. remote: Fetching gem metadata from https://rubygems.org/............下記のコードの5行目に書かれているのが、今回デプロイしたアプリのURLです。
8行目のは全然関係ないです。僕はそれで悩んでました。ターミナルremote: -----> Compressing... remote: Done: 58.8M remote: -----> Launching... remote: Released v4 remote: https://nameless-atoll-34353.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To https://git.heroku.com/nameless-atoll-34353.git * [new branch] master -> masterこれで終わりと思いきや、、まだ本番環境にDBが作成されてないので、マイグレーションをしなきゃいけません。
それで終わりだよん。
4. 本番環境でマイグレーションをする
以下のコマンドでマイグレーションしてください。
ターミナル$heroku run rails db:migrateheroku runをつけるとrailsのコマンドをherokuを動かしているときにも使える様になります。
はい。終わりです。先ほどのURLを貼っつけて、正常に見れるか確認しましょう。
見れた方、お疲れ様でした。
見れてない方、調べても分からない方は僕のTwitterにでも相談しにきて下さい。
いつでも答えますよ?(@rurukasan0212 )
- 投稿日:2020-05-18T14:29:05+09:00
初投稿
これから書き方から学んで投稿していきます。
コードを書くときは自分のアウトプット用として、いずれ誰かの助けになるようなものまで書いていけるようになりたい。更新頻度を落とさないように習慣化を目指します!
- 投稿日:2020-05-18T11:37:28+09:00
【httpclient】でのリクエストからcontrollerまでの流れについて確認とリファクタリング
はじめに
以前、JQueryのautocomplete、ajax、そしてhttpclientを使いオートコンプリートを実装したが、内容についてぼんやりとしか把握できていなかった。リファクタリングを行いつつ、内容を確認していく。
まず、外部APIにアクセスしている部分は、クラスに切り出し、libディレクトリに入れる。
lib/api_suggest.rbrequire 'httpclient' require 'json' class ApiSuggest API_KEY = Rails.application.credentials.api[:API_KEY] API_URI = Rails.application.credentials.api[:API_URI] def self.suggest(keyword, max_num) uri = API_URI headers = { Authorization: "Bearer #{API_KEY}", } params = { keyword: keyword, max_num: max_num, } client = HTTPClient.new req = client.get(uri, body: params, header: headers) req end endリファクタリング前は、
client = HTTPClient.new req = client.get(uri, body: params, header: headers) res = JSON.parse(req.body) resと、
JSON.parse(req.body)を行っていたが、
リファクタリング後は、req = client.get(uri, body: params, header: headers)client.getした結果をである
req部分をそのままコントローラーに返し、コントローラー側では、
app/controllers/suggests_controller.rbrequire 'api_suggest' class SuggestsController < ApplicationController SUGGEST_MAX_COUNT = 5 def search @suggests = ApiSuggest.suggest(params[:keyword], SUGGEST_MAX_COUNT) render body: @suggests.body, status: @suggests.code end end7行目の、renderで、
render body: @suggests.body, status: @suggests.code各パラメータに入れる事で
JSON.parseする必要がなくなった。そして、そのパラメータが、
app/assets/javascripts/suggest.js$("#form").autocomplete ({ source: function (req, res) { $.ajax({ url: '/suggest', type: 'GET', cache: false, dataType: "json", data: { keyword: req.term }, n success: function (data) { res(data); }, error: function (xhr, ts, err) { n res(xhr, ts, err); } }); } });ajaxのsuccess以下に返されるという流れになっている。
全体の流れを確認
ajaxのオプションで指定している
url: '/suggest'にリクエストが送られ、
ルーティングでget 'suggest', to: 'suggests#search'
app/controllers/suggests_controller.rbのsearchメソッドが呼ばれ、def search @suggests = ApiSuggest.suggest(params[:keyword], SUGGEST_MAX_NUM) render body: @suggests.body, status: @suggests.code end
ApiSuggest.suggestによりhttpclientでの外部APIリクエストを介した結果、
render body: @suggests.body, status: @suggests.code
が返されて、
app/assets/javascripts/suggest.jsのajaxsuccess: function (res) { resp(res); }, error: function (xhr, ts, err) { resp(xhr, ts, err); }成功、失敗それぞれのケースに返される。
という流れ。ajax部分について詳しく
render bodyのオプションが、戻り値の本体を返していて、
statusがステータスコード(200, 404, 500など)の外部APIの結果が返される。ajax側でそれを受け取ると、
ajaxの中では、そのstatus codeを参照して、200系、300系を正常として判定して、success側を実行。それ以外のstatus codeがきたらerror側を実行、
という処理を行っている。以上。
終わりに。
最後まで読んで頂きありがとうございます
転職の為、未経験の状態からRailsを学習しております。正しい知識を着実に身に着け、実力のあるエンジニアになりたいと考えています。継続して投稿していく中で、その為のインプットも必然的に増え、成長に繋がるかと考えています。
今現在、初心者だからといって言い訳はできないですが、投稿の内容に間違っているところや、付け加えるべきところが多々あるかと思いますので、ご指摘頂けると幸いです。この記事を読んで下さりありがとうございました。
- 投稿日:2020-05-18T11:25:21+09:00
Could not find a JavaScript runtimeが出て、サーバーを起動できなくなった時の話(ターミナル)
サーバーを起動できない!
ある朝、サーバーを起動してさあ作業に取り掛かろう!ということで$rails sをしてサーバーを起動しようとすると、以下のエラーが発生しサーバーを起動することができない。
Gem Load Error is: Could not find a JavaScript runtime. See https://github.com/rails/execjs for a list of available runtimes.この時に解決するのがなかなか大変だったので、以後同じエラーが起きた時のための備忘録として書かせて頂きます。。
2つの解決法
どうやら調べてみるとエラー内容は文字通り、JavaScriptのruntimeがないよということらしい。
過去にも同様の問題に遭遇した人の記事がたくさんあり、調べてみると大まかに2つの解決法があるらしい。
Node.jsをインストールする
1つがこの方法。実際自分はこの方法で解決しました。
Node.jsをインストールするには以下の①②③のステップが必要らしい
①Homebrewをインストール
②nodebrewをインストール
③Node.jsをインストール①Homebrewをインストール
ホームディレクトリで以下を実行$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Press RETURN to continue or any other key to abort
と出たらEnterキーを押す
Password:
と出たらパスワードを入力しEnterキーを押す(入力中のパスワードは表示されないがしっかりとは入力されている)②nodebrewをインストール
brew install nodebrew③Node.jsをインストール
$ brew install nodejs最後にこれをインストールして、無事Node.jsのインストール完了
この後に再び
$ rails sをするとサーバーが起動するように!!Gemのtherubyracerを追加する
Node.jsのインストール以外に多くヒットしたもう1つがこの方法。
Gemfileに⬆️を追加して、コマンドで$bundle installするだけなので、こちらの方が簡単そうに見えるが、こちらはこちらでまたバージョン関係の別のエラーが発生してしまうことがあるらしい。(ここで発生するエラー内容については曖昧です)
最後に
今回自分がサーバーを起動できない時の対処法を自分なりに噛み砕いてメモさせて頂きました。
もし間違ってる箇所や他にも対処法が存在する場合は、ご指摘してくださると幸いです?♂️
- 投稿日:2020-05-18T11:09:42+09:00
[rails]よく使うコマンド一覧(随時追加予定)
▼Jemのインストール
ターミナル$ bundle install▼マイグレーションファイルの操作
ターミナルrails db:migrate:status rails db:migrate rails db:rollback rail db:migrate:down VERSION=●●●●▼Hmalの変換
Gemfilegem 'haml-rails' gem 'erb2haml'
- 投稿日:2020-05-18T10:42:12+09:00
Ruby 正規表現
正規表現とは
・文字列の一部分を置換
・文字列の一部分を抽出
・文字列が制約を満たしているか調べるなどの操作を行うための技術が正規表現です。
正規表現のほとんどの記述はどの言語間でも共有可能です。
メソッドと使用例
subメソッド
文字列の指定した部分を別の文字列に置き換える
irb(main):001:0> str = "リンゴを食べる" => "リンゴを食べる" irb(main):002:0> str.sub(/リンゴ/,"オレンジ") => "オレンジを食べる"変数strに文字列 "リンゴを食べる" が代入されています。
次にstrに対し、subメソッドを使用し、第一引数にリンゴ、第二引数にオレンジを指定しています。
出力すると、リンゴを食べる → オレンジを食べるになっています。
このように第一引数に置き換えたい文字列を「 / (スラッシュ)」囲み、第2引数に変換後の文字列を指定します。
matchメソッド
文字列がメソッドの左の文字列に含まれているか否かをチェックする
irb(main):001:0> str = "Hello, World" => "Hello, World" irb(main):002:0> str.match(/Hello/) => #<MatchData "Hello"> irb(main):003:0> str.match(/Good/) => nil変数strに文字列 "Hello, World" が代入されています
次にstrに対し、matchメソッドを使用し、引数にHelloを指定しています
"Hello, world" には指定した "Hello" という文字列は含まれているので、MatchDataオブジェクトの返り値として指定した文字列 "Hello" が得られます。
"Good" は含まれていないので、返り値はnilになります。
matchメソッドもsubメソッドと同じように引数を「 / (スラッシュ)」で囲みます。
gsubメソッド
文字列の指定した部分を全て別の文字列に置き換える
irb(main):001:0> tel = '080-1234-5678' => "080-1234-5678" irb(main):002:0> tel.sub(/-/,'') => "0801234-5678" irb(main):003:0> tel.gsub(/-/,'') => "08012345678"変数telには電話番号が代入されています。
次にsubメソッドでハイフンを空の文字列に置き換えることで取り除こうとしますが、最初のハイフンだけが置き換えられています。
指定した初めの文字列だけを置き換えるならsub,全て置き換えるならgsubを使います。
正規表現のメタ文字
メタ文字は、特殊な意味・機能を持った文字で、これを使用することで様々な制約が可能になります。
種類が多いので、パスワードの制約を例に挙げる中でいくつか紹介します。
irb(main):001:0> pw = 'Abcd1234' => "Abcd1234" irb(main):002:0> pw.match(/[a-z\d]{8,10}/i) => #<MatchData "Abcd1234">上記は、
・aからzの英字、数字のいずれかの文字
・8文字以上10文字以内
・文字は大小どちらでも可という制約をかけています。
引数の中身を分解し、それぞれの文字の意味を説明していきます
/[a-z\d]{8,10}/i
↓
/[a-z\d]{8,10}/ i(スッラッシュの中身の文字列は大文字小文字どちらでも可)
↓
[a-z\d] {8,10}(直前の文字が8から10文字出現するものにマッチ)
↓
[a-z] \d (数字にマッチ)
↓
[a-z] (aからzまでの文字いずれかにマッチ)
※今回はa-zに加え、数字も角括弧に囲まれているため、英数字いずれかにマッチする)
まとめ
種類 意味 [ ] 囲まれたいずれか1つの文字にマッチ \d 数字にマッチ {a,b} 直前の文字がa回以上b回以下出現するものにマッチ i (オプション) 大文字・小文字を区別しない 基本的に紹介した2つのメソッドと正規表現のパターンを組み合わせることで様々な制約が実装できます。
パターンに関してはここに記したのは一例です。他にも正規表現を用いてできることはたくさんあります。
- 投稿日:2020-05-18T09:36:47+09:00
js.erbで簡単に非同期通信画像削除
はじめ
FontAweSomeで削除アイコンを導入
qiita.rb<head> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css"> </head>xxx.html.erb<i class="fa fa-trash-o fa-lg" aria-hidden="true"></i>
Destroy一例
photos_controller.rbdef destroy @photo = Photo.find(params[:id]) room = @photo.room @photo.destroy @photos = Photo.where(room_id: room.id) respond_to :jsrespond_to :jsのファイル
photos/destroy.js.erb$('#photos').html("<%= j render 'photos_list' %>")

- 投稿日:2020-05-18T07:50:45+09:00
ActiveRecord::Migration is not supportedの時
- 投稿日:2020-05-18T05:30:02+09:00
routesの話
ルーティングの色々をまとめました
resources
resourcesはコントローラのindex、show、new、edit、create、update、destroyアクションを手軽に宣言できます。
config/routes.rbRails.application.routes.draw do resources :users endusers GET /users(.:format) users#index POST /users(.:format) users#create new_user GET /users/new(.:format) users#new edit_user GET /users/:id/edit(.:format) users#edit user GET /users/:id(.:format) users#show PATCH /users/:id(.:format) users#update PUT /users/:id(.:format) users#update DELETE /users/:id(.:format) users#destroyresourcesはネストできます。
モデル同士がリレーションを持っている場合などによく使われます。
(※resourcesのネストは扱いにくくなるので1回までにしましょう)config/routes.rbRails.application.routes.draw do resources :users do resources :schedules end endmember
memberブロックを渡すことで、パラメーター付きのアクションを追加できます。
config/routes.rbRails.application.routes.draw do resources :users do member do get :schedule end end endschedule_user GET /users/:id/schedule(.:format) users#schedule users GET /users(.:format) users#index POST /users(.:format) users#create new_user GET /users/new(.:format) users#new edit_user GET /users/:id/edit(.:format) users#edit user GET /users/:id(.:format) users#show PATCH /users/:id(.:format) users#update PUT /users/:id(.:format) users#update DELETE /users/:id(.:format) users#destroycollection
パラメーターなしのアクションはcollectionで追加できます。
config/routes.rbRails.application.routes.draw do resources :users do collection do get :schedule end end endschedule_users GET /users/schedule(.:format) users#schedule users GET /users(.:format) users#index POST /users(.:format) users#create new_user GET /users/new(.:format) users#new edit_user GET /users/:id/edit(.:format) users#edit user GET /users/:id(.:format) users#show PATCH /users/:id(.:format) users#update PUT /users/:id(.:format) users#update DELETE /users/:id(.:format) users#destroynamespace
namespaceは、コントローラを名前空間によってグループ化します。
controllerのディレクトリ構成は適宜変えましょう。config/routes.rbRails.application.routes.draw do namespace :admin do resources :users end endadmin_users GET /admin/users(.:format) admin/users#index POST /admin/users(.:format) admin/users#create new_admin_user GET /admin/users/new(.:format) admin/users#new edit_admin_user GET /admin/users/:id/edit(.:format) admin/users#edit admin_user GET /admin/users/:id(.:format) admin/users#show PATCH /admin/users/:id(.:format) admin/users#update PUT /admin/users/:id(.:format) admin/users#update DELETE /admin/users/:id(.:format) admin/users#destroymodule
moduleはcontrollerの格納フォルダが、指定パスになります。
URLは変えずにcontrollerのディレクトリ構成を変えたい場合はこちらを使いましょう。config/routes.rbRails.application.routes.draw do scope module: :admin do resources :users end endusers GET /users(.:format) admin/users#index POST /users(.:format) admin/users#create new_user GET /users/new(.:format) admin/users#new edit_user GET /users/:id/edit(.:format) admin/users#edit user GET /users/:id(.:format) admin/users#show PATCH /users/:id(.:format) admin/users#update PUT /users/:id(.:format) admin/users#update DELETE /users/:id(.:format) admin/users#destroyscope
scopeのみの場合はURLだけが指定のパスになります。
controllerの構成はそのままです。config/routes.rbRails.application.routes.draw do scope '/admin' do resources :users end endusers GET /admin/users(.:format) users#index POST /admin/users(.:format) users#create new_user GET /admin/users/new(.:format) users#new edit_user GET /admin/users/:id/edit(.:format) users#edit user GET /admin/users/:id(.:format) users#show PATCH /admin/users/:id(.:format) users#update PUT /admin/users/:id(.:format) users#update DELETE /admin/users/:id(.:format) users#destroy
- 投稿日:2020-05-18T04:45:39+09:00
趣味プロジェクトで簡単に使える双方向通信技術を模索した話
勉強を兼ねて、自分の技術スタックにマッチする範囲で利用できる双方向通信技術を一通り試し、それぞれの長所短所、向き不向きを把握しておきたくなり「いろんな技術でチャットサービスを何個か作ってみる」という活動をしておりました。
結果として、IaaS/ライブラリを変えながら4パターンでチャットサービスを構築し、各IaaS/ライブラリの特性がだいたい把握できたので記事にしたいと思います。
作ったチャットサービスはこんな感じ。
個人のサービスに導入することをメインに考えてるので、下記を重視しています。
- 双方向通信部分の実装の難易度
- 認証との連携
- インフラの制約
逆に、下記要素は気にしていません。(ゲームとか作るわけじゃないので)
- 接続数、負荷
- コスト
- リアルタイム性(遅延)
※タイトルにある「簡単に使える」というのは技術スタックによって個々人で異なると思いますので、ご参考までに。
なぜ双方向通信なのか?
簡単に言うと、ユーザー同士の操作をリアルタイムに反映するためです。
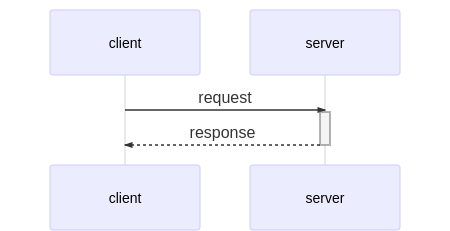
通常webサービスにおける通信は下記のように、client(ブラウザ)からリクエストをserver(サービス)に送り、そのレスポンスとしてhtmlやjsやcssが返るといった仕組みです。
※TCPコネクションまわりは省略ではチャットサービスの例を考えてみましょう。
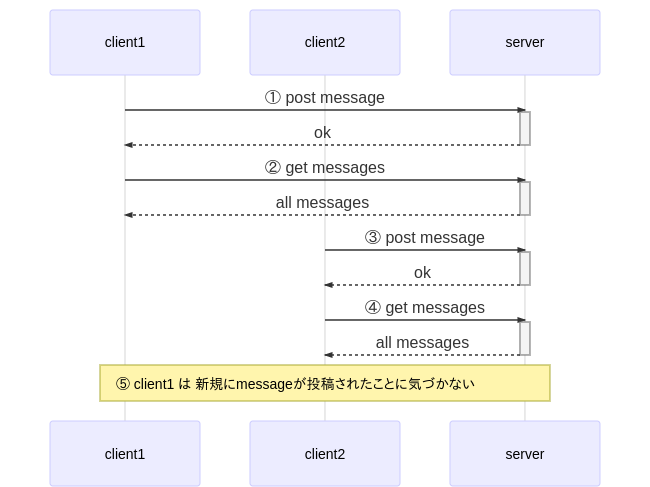
client1とclient2がチャットに参加していると仮定します。単純なREST API等のリクエストのみの場合は下記のようなシーケンスになります。
①client1が新規にメッセージを投稿し、正常に投稿できた旨のレスポンスを受け取ります。
②client1は①で正常に投稿できたので、全メッセージを取得します。これで最新のメッセージ一覧がclient1の画面に表示されます。
③今度はclient2がメッセージを新たに投稿し、正常に投稿できた旨のレスポンスを受け取ります。
④client2は③で正常に投稿できたので、全メッセージを取得します。この結果には当然client1の①での投稿も含まれるため、全メッセージを見ることができます。⑤ここで問題が発生します。
(普通のwebサービスの場合)serverからclientへはリクエストを送ることができません。
そのためclient2が新たにメッセージを投稿した瞬間に、それをclient1が知ることはできないのです。このような課題を解決する一つの方法として、双方向通信技術があげられます。
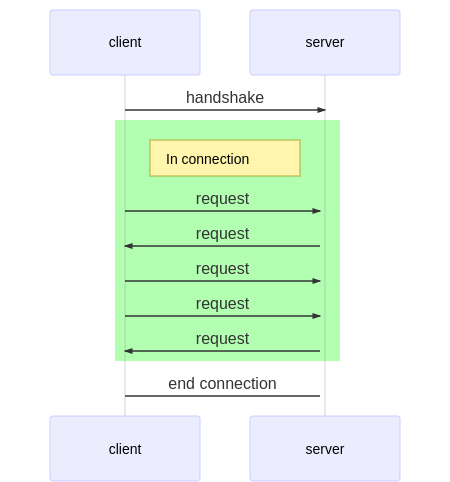
(ポーリングやPub/Subなど他にも様々な解決方法がありますが、それはまた別のお話)双方向通信でのclient-server間の通信の様子をシーケンス図で表すと下記のようになります。
コネクションを確立し、そのコネクション内でclient、serverの双方から任意のタイミングでメッセージを送信することが可能になります。
この技術により、サーバー側から任意のタイミングで確立されたコネクションを通し、クライアントにデータを送信できるようになります。
「双方から」、「任意のタイミングで」という点がキモになります。チャットサービスをWebSocketで構築した場合の通信のフローを考えてみましょう。
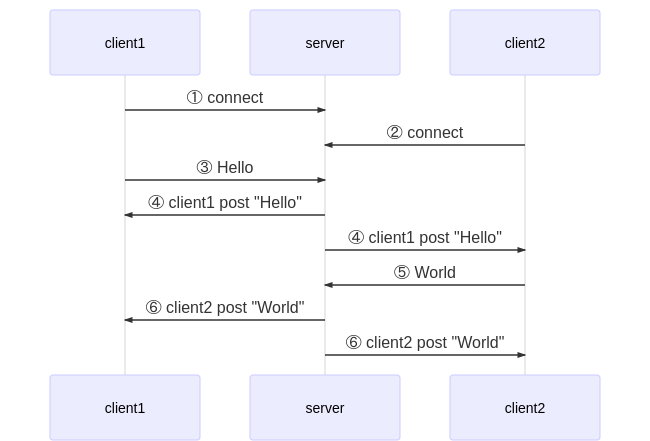
①と②でclient1とclient2がそれぞれserverへコネクションを確立します。
この時点で、client1-server間、client2-server間で双方向に通信が可能となります。③でclient1が
Helloとメッセージを投稿します。
④でserverは接続している全てのコネクションに対し、client1からHelloというメッセージが投稿されたことを送信します。
この「接続しているコネクション全てに送信する」ことをbroadcastと呼びます。
この送信により、client1、clinet2ともにHelloという新規メッセージが投稿されたことを検知でき、画面に表示することができます。⑤で今度はclient2が
Worldとメッセージを投稿します。
⑥でserverがclient2がWorldというメッセージを投稿したことをbroadcastします。
これにより、各clientが新たに投稿されたメッセージを受信します。このような仕組みでチャットサービス等でリアルタイムに別ユーザーの操作内容を伝えることができます。
チャットサービス
ということで、チャットサービスを4パターンほど実装してみました。
仕様は共通で、より現実的な課題も体験できるように下記の機能を実装しています。
- 認証機能
- チャット部屋作成/取得/削除
- チャット機能
その他UI等の実装コストを極力減らすため、下記を共通で採用しています。
- Nuxt.js(フロントエンドフレームワーク)
- Vuetify.js(マテリアルデザインコンポーネントフレームワーク)
- Auth0(認証サービス、Firebase以外で利用)
なお、チャット部分のコードを抜粋して掲載していますが、「実装イメージが湧いてくれれば幸い」程度のものになります。
(最終的な完成コードを載せると記事が長くなってしまうので)socket.io
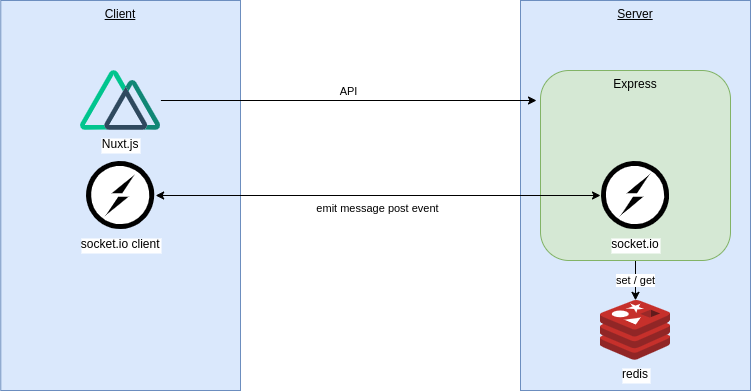
まずは最もオーソドックスな(?)Node.js用WebSocketライブラリのsocket.ioを利用した実装です。
リポジトリ
アーキテクチャ図
アーキテクチャはこのようになっています。
- Node.jsのサーバーライブラリであるExpress上でNuxt.jsを動かす
- socket.ioをExpress上で動かす
- Nuxt.js上でsocket.ioのclientを動かし、メッセージの送受信を行う
- 認証はAuth0を使う
- roomの管理等はredisを利用する(express-sessionと共通で利用して楽をしただけ)
- Herokuにデプロイ(Expressを使う都合上、サーバーが必要であるため)
チャット部分コード抜粋
socket.ioの双方向通信は極めてシンプルです。
サーバー側/クライアント側共にイベント駆動になっているので、イベントの送信とイベント種類ごとにハンドラーを定義する形になっています。サーバー側
// server/socket.js const io = socketio(http) const store = {} // コネクション確立時のハンドラーを定義 io.on('connection', (socket) => { const userId = 'express-sessionを利用して取得する' // join-roomが送信された場合のハンドラー socket.on('join-room', (data) => { store[userId] = data // socket.ioの機能でroom管理が可能 socket.join(data.roomId) }) // clientからsend-messageイベントでメッセージが送られてきた際のハンドラー socket.on('send-message', (message) => { const roomId = store[userId].roomId // roomに接続している自分以外にイベントを送信 socket.broadcast.to(roomId).emit('send-message', message) // 自分にも送信 io.to(socket.id).emit('send-message', message) // 必要であればサーバー側でメッセージを永続化 }) })クライアント側
// pages/chat.vue ※一部コードは省略 import io from 'socket.io-client' export default { created() { this.socket = io() // 現在のページに対応したroomへの参加イベントを送信 this.socket.emit('join-room', { id: this.user.id, roomId: this.$route.query.roomId, }) // serverから'send-message'イベントを受け取った場合のハンドラーを追加 this.socket.on('send-message', this.recieveMessage) }, methods: { // 新たにメッセージを受け取ったら、ローカル変数に追加し描画する recieveMessage(message) { this.messages.push(message) }, // メッセージ送信ボタンが押された際のハンドラー onPost() { if (this.text) { const message = { text: this.text, roomId: this.$route.query.roomId, } // emitすることでserver側にイベントを送る this.socket.emit('send-message', message) this.text = null } }, }, }特徴
- チャット部分のコードをシンプルに実装できる
- 部屋ごとに送信するような機能をsocket.ioが持っている
- サーバーが必要
- 認証はAuth0 + Passport + express-sessionでそこまで難しくない
- express-sessionを利用することで、WebSocket通信の認証も可能
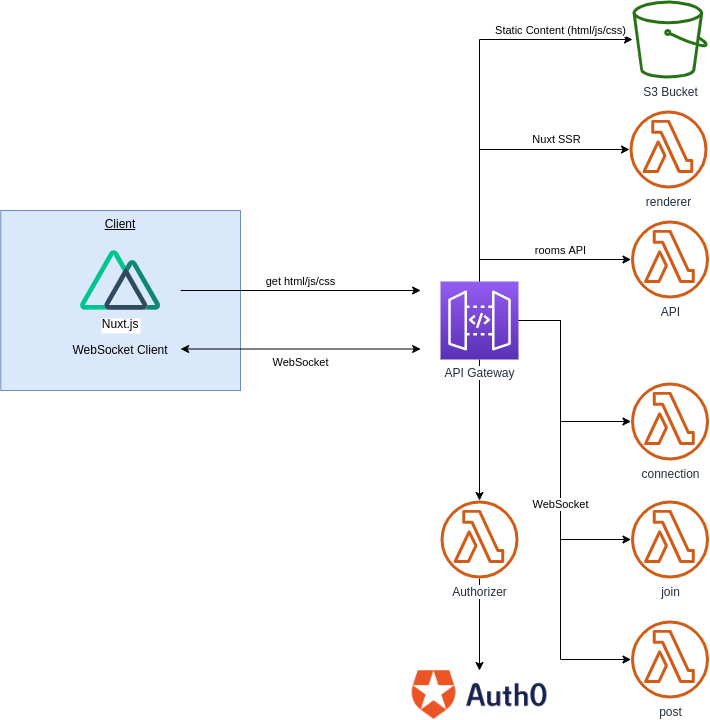
API Gateway
次はAWSのAPI Gatewayを用いた実装方法です。
API GatewayではWebSocketがサポートされており、WebSocketのbodyの指定した属性に応じて起動するLambda関数を制御できます。
Serverless Frameworkのドキュメントが参考になります。リポジトリ
アーキテクチャ図
- インフラ全体の管理にはServerless Frameworkを利用
- WebSocketはAPI Gatewayを利用し、WebSocketのイベントに合わせて実行されるLambda関数を設定
- フロント部分のコードをNuxt.jsでビルドし、API Gateway→S3というパスで配信
- Nuxt.jsのSSR部分やバックエンド(DynamoDB)と接続するAPI部分はwebpackでビルドし、それぞれLambda関数にデプロイし、API Gatewayから呼び出す形式とする
- 認証にはAPI GatewayのLambda Authorizerを利用し、Auth0で認証
チャット部分コード抜粋
サーバー側
// server/websocket.js // roomへの参加イベントのハンドラー // connectionIdとroomIdを紐付けてDynamoDBへ保存する module.exports.joinHandler = async (event, _context, callback) => { const body = JSON.parse(event.body) const params = { TableName: CONNECTIONS_TABLE, Item: { roomId: body.roomId, id: event.requestContext.connectionId, }, } await docClient.put(params).promise() callback(null, { statusCode: 200, body: 'joined', }) } // メッセージ投稿イベントのハンドラー // DynamoDBからroomに属するconnectionを全て取得し、それぞれに対してメッセージ投稿のイベントを送信する module.exports.postHandler = async (event, _context, callback) => { const body = JSON.parse(event.body) const roomId = body.roomId const params = { TableName: CONNECTIONS_TABLE, ExpressionAttributeValues: { ':room': roomId, }, ExpressionAttributeNames: { '#r': 'roomId', }, KeyConditionExpression: '#r = :room', } const data = await docClient.query(params).promise() const domain = event.requestContext.domainName const stage = event.requestContext.stage const url = `https://${domain}/${stage}` const apigatewaymanagementapi = new AWS.ApiGatewayManagementApi({ apiVersion: '2018-11-29', endpoint: url, }) for (const item of data.Items) { const apiParams = { ConnectionId: item.id, Data: JSON.stringify({ message: body.message, author: body.author, authorIcon: body.authorIcon, }), } try { await apigatewaymanagementapi.postToConnection(apiParams).promise() } catch (err) { // 切断済みのコネクションをDynamoDBから削除する if (err.statusCode === 410) { const params = { TableName: CONNECTIONS_TABLE, Key: { roomId, id: item.id, }, } await docClient.delete(params).promise() } } } callback(null, { statusCode: 200, body: 'posted', }) }クライアント側
// pages/chat/_id.vue export default { mounted() { // API GatewayのWebSocket用エンドポイントを指定して接続 // 標準APIのWebSocketクラスを利用する this.ws = new WebSocket('wss://xxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev') // イベント受信時のハンドラーを設定する this.ws.onopen = this.onOpen this.ws.onmessage = this.onMessage }, methods: { // コネクション確立後にroomへの参加イベントをsever側に送信 onOpen(event) { this.ws.send( JSON.stringify({ action: 'join', roomId: this.$nuxt.$route.params.id, }) ) }, // serverからメッセージ受信時は変数に追加し表示する onMessage(event) { const data = JSON.parse(event.data) this.messages.push({ text: data.message, author: data.author, authorIcon: data.authorIcon, }) }, // メッセージ送信ボタンが押された際のハンドラー onPost() { this.ws.send( JSON.stringify({ action: 'post', roomId: this.$nuxt.$route.params.id, message: this.text, author: this.user.sub, authorIcon: this.user.picture, }) ) this.text = '' }, }, }特徴
- この4つのサンプルサービスの実装の中で最も難易度が高く時間がかかった
- API GatewayのLambda Authorizer + Auth0による認証
- API GatewayのWebSocketでLambda Authorizerを使う方法
- DynamoDBを利用した自前でのWebSocketコネクション管理
- Nuxt.jsをSSR on Lambdaで動かす部分
- スケーラビリティはかなり高く、AWSとの連携も柔軟にできるので拡張性は最も高いといえる
- すくなくとも趣味で軽く作る範囲ではないなという印象
Action Cable
続いてはRuby on RailsのAction Cableでの実装です。
Railsガイドでは「WebSocketとRailsのその他の部分をシームレスに統合するためのもの」と紹介されています。リポジトリ
アーキテクチャ図
Railsの場合、アーキテクチャはとてもシンプルになります。
- フロントエンドは既存の実装を使いまわすために、WebPacker + Vue.jsで実装
- 認証はAuth0 + omniouthで実装
- Herokuへデプロイ
- DBはHerokuのPostgreSQLを利用
チャット部分コード抜粋
サーバー側
app/controllers/api/v1/messages_controller.rbclass Api::V1::MessagesController < Api::ApplicationController include Secured def create # ActionCableを通し、全clientへメッセージをbroadcastする ActionCable.server.broadcast "rooms:#{params[:room_id]}:messages", message render json: {} end private def message { text: params[:text], user: current_user } end endその他のファイルはRailsガイドのこのへんを参照
クライアント側
app/javascript/components/pages/rooms/Show.vueimport consumer from '../../../channels/consumer' // ※もろもろ省略 created() { // イベント受信時のハンドラーを定義 consumer.subscriptions.create( { channel: 'ChatChannel', room_id: this.roomId }, { received: (data) => { this.messages.push({ text: data.text, author: data.user.uid, authorIcon: data.user.image, }) } } ) }, methods: { // client→serverではWebSocketを利用せずに普通にAPIでメッセージをPOST async onPost() { if (this.text) { await axios.post(`/api/v1/rooms/${this.roomId}/messages`, { text: this.text, }) this.text = null } }, }特徴
- なんと言っても「Railsが使える」というのが最大の利点
- 全てWebSocketで通信するというよりも、一部をWebSocketでbroadcast配信するような用途での利用が多く見られた
- 「サーバー側の何かの通知をクライアントにリアルタイムに送る」のみであれば比較的簡単に実装が可能である
Firebase
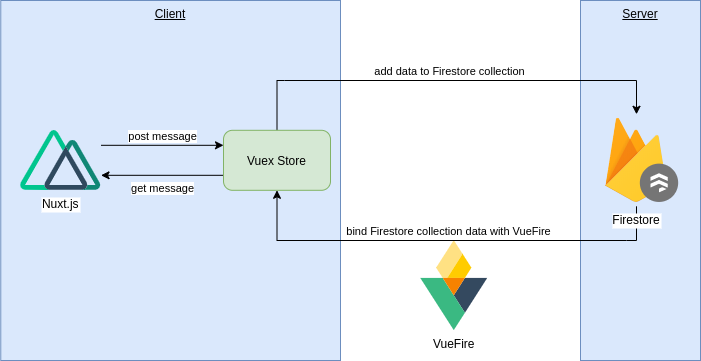
最後はみんな大好き(?)Firebaseでの実装です。
FirebaseにはFirestoreという強力なNoSQLデータベースがあります。
このFirestoreの特徴の一つとして、更新をクライアント側からwatchできるというものがあるので、これを利用して実装します。
ちなみに、FirestoreのwatchはgRPCのBidirectional Streamingを利用して実装されています。リポジトリ
アーキテクチャ図
おそらくFirestore + Vue.jsの鉄板の構成になっていると思います。
- チャット部分はFirestoreのデータをvuexfireを利用してVuexのstoreに同期
- メッセージ投稿はNuxt.jsからFirestoreのclientで登録
- 認証はFirebase Authentication + firebaseui-webを利用
- Nuxt.jsで静的サイトとしてgenerateしFirebase Hostingへデプロイ
チャット部分コード抜粋
サーバー側:なし
クライアント側
// store/index.js import { firestoreAction } from 'vuexfire' import firebase from '@/plugins/firebase' export const actions = { // vuexfireを利用して、Firestore上のcollectionをstateへbindする bindMessages: firestoreAction(({ bindFirestoreRef }, payload) => { return bindFirestoreRef( 'messages', db .collection('rooms') .doc(payload.id) .collection('messages') .orderBy('createdAt', 'asc') ) }), // Firestoreにごく普通の方法でレコードを追加する addMessage(_, payload) { const message = { author: payload.uid, authorIcon: payload.authorIcon, text: payload.text, createdAt: firebase.firestore.FieldValue.serverTimestamp(), } db.collection('rooms') .doc(payload.roomId) .collection('messages') .add(message) }, } // pages/chat.vue import { mapActions, mapGetters } from 'vuex' import moment from 'moment' export default { data() { return { text: null, } }, computed: { ...mapGetters(['user', 'messages']), }, created() { // ページ描画時にFirestore上のmessagesをlocalのstoreにbindする // これにより、computedのmessagesでFirestore上のレコードが取得できる this.bindMessages({ id: this.$route.query.roomId }) }, methods: { onPost() { if (this.text) { // storeのaddMessageをmapActions経由で呼び出す this.addMessage({ uid: this.user.uid, authorIcon: this.user.photoURL, text: this.text, roomId: this.$route.query.roomId, }) this.text = null } }, ...mapActions(['bindMessages', 'addMessage']), }, }特徴
- 認証、データストア、リアルタイムが組み合わさったFiresotreはかなり便利で洗練されているということを再認識した
- とくに認証とデータ永続化がお手軽に実装できる点は他にはない強みである
- 逆に永続化しないで良いデータの送信であればsocket.io等のほうがシンプルでインフラも柔軟である
- Authentication(認証), Functions(FaaS)、Hosting(静的サイトホスティング)、Messaging(push通知)等一通りの機能がそろっているのでインフラの柔軟性という点でも十分である
- Firebaseで不足している場合はGCPとも連携が容易なので問題ない
- Firebase固有の知識がけっこう必要になる
- Firestoreの設計や認証まわりのコード等
所感
どの実装方法も他と異なる点がいくつかあり、とても勉強になりました。
socket.ioが思っていた以上にシンプルだったことや、いくつかの方法において認証の連携がとても手間であること等様々な発見がありました。Firebaseが実装難易度、インフラ管理コスト、認証/DBとの連携などかなりの面で優れていることを再認識できたので、今後の個人サービス開発は相変わらずFirebaseを利用していくことになりそうです。


- 投稿日:2020-05-18T02:05:29+09:00
Rubyの基礎2~わかりにくいところ復習~
メソッド
メソッドは使えるオブジェクトが決まっている。
eachメソッドの場合は配列オブジェクトや範囲オブジェクトにしか使えません。
また、eachメソッドを配列オブジェクトに使った場合の返り値は配列オブジェクトそのものです。クラス
クラスとは、とあるオブジェクトの共通の属性とメソッドをまとめておく型のようなもの。
"Hello"と"こんにちは"はそれぞれ別のオブジェクトですが、文字を持つと言う点においては共通です。
この性質は予めクラスの性質として定義されているものなのです。
この型を予め用意しておけば、その肩に沿って効率的にオブジェクトを生成できます。インスタンス
クラスから生まれたオブジェクトのことをインスタンスと言います。
オブジェクトから先に生まれることはなく、クラスからインスタンスというオブジェクトが生まれます。
属性と属性値とメソッドが入った状態でインスタンスが生成されます。
つまり、クラスで属性が定義されていて、具体的な属性値を持った状態でインスタンスが生成されます。例えば文字列オブジェクトの "Hello" は Stringクラスで定義された属性=文字に、属性値="Hello"が入った状態、かつlengthメソッドやto_iメソッドなどのメソッドを持った状態でインスタンスが生成されます。
Rubyに予め定義されているクラス
Rubyには予め定義されたクラスがある。
文字列オブジェクトのStringクラス
配列オブジェクトのArrayクラス
数値オブジェクトのIntegerクラス
ハッシュオブジェクトのHashクラスnewメソッド
newメソッドは全てのクラスで定義しなくても使うことができます。
newメソッドを使うことによってインスタンスを生成できます。
返り値として利用したクラスのインスタンスを返します。
クラスメソッドである。なぜならインスタンスを生成するのはクラスが行うべきだから。クラスメソッド
クラスメソッドはクラスメソッドを定義したクラス自身が利用できるものでクラスで共通の情報を使った処理に使います。
メソッド名の前にselfをつけます。インスタンスメソッド
インスタンスメソッドは、インスタンスが利用できるメソッドです。インスタンスメソッドを定義したクラスのインスタンスに使用できる。インスタンスごとの個別の情報を使った処理に使えます。
クラスメソッドとインスタンスメソッドの違い
特徴 インスタンスメソッド クラスメソッド 定義方法 メソッド名の前に selfを付けない メソッド名の前にselfを付ける 用途 インスタンスごとの属性を用いるとき 属性が関係のない共通の処理をするとき 呼び出せるオブジェクト クラスのインスタンス クラス自身 呼び出し方 インスタンス名.メソッド名(引数) クラス名.メソッド名(引数) クラスの変数
クラスでは共通の属性は変数を使って定義します。
その変数に代入した値が属性値です。
クラスに定義できる変数は、クラス変数とインスタンス変数があります。クラス変数
クラス変数はクラス全体で使用できる変数です。つまり、クラスメソッド内でもインスタンスメソッド内でも使用することができます。クラスを通して値が共通の情報に使用する変数。
インスタンス変数
インスタンス変数は、共通の属性としてインスタンスに定義できる変数です。
値はそれぞれのインスタンスごとに設定できます。
各インスタンスでのみ使用ができます。
定義場所はインスタンスメソッド内で行います。
インスタンスメソッド内で定義されたインスタンス変数の値は、そのインスタンスメソッドを利用したインスタンスが持つインスタンス変数の値になる。initializeメソッド
initializeメソッドはインスタンスを生成したと同時に実行したい処理を自動で実行できます。
クラスの継承
あるクラスに定義されたメソッドを別のクラスで利用できるようにすることを継承と言います。
継承したいクラスのことを親クラスといい継承する側のクラスのことを子クラスと言います
class 子クラス名 < 親クラス名 で親クラスを継承できます。pメソッド
pメソッドはpの右側に書かれたオブジェクトやインスタンスを出力するものです。putsメソッドと似ていますがputsメソッドが返り値nilを返すのに対しpメソッドはそのオブジェクトやインスタンス自体を返り値として返します。
for文
while文と同じ繰り返しを行う文法です。
for num in 1..10 do puts num end 変数numに1〜10を代入して出力しています。 inの後ろにあるオブジェクト順番に変数numに代入しています。 1..10は1~10という意味です。