- 投稿日:2020-03-31T23:46:23+09:00
matplotlibとscipyのフーリエ変換(FFT)を用いてパーシバルの定理を確認する方法
python でパワースペクトルを計算する方法
matplotlib と spicy で FFT を計算する方法
matplotlib と spipy のどちらもパワースペクトルを計算する方法があるが、両者でデフォルトで持っている関数と定義が違う。大概の使い分けは次の通り。
- 単純にパワースペクトルを計算する場合、mlab.psd が一番簡単。
- scipy.fftpack を使うと実部と虚部が得られる。位相の計算など細かいことが可能だか、規格化は自分で行う必要あり。
どちらでやっても、パーセバルの定理から全パワーは同じになるが、両者の規格化の違いを考えないとパワースペクトルの縦軸が完璧に同じにならない。
ここでは単純な三角関数を両方の方法でフーリエ変換して、完璧にmatplotlibとscipyのFFTで結果が同じになる例を示す。おまけで、パワースペクトルから三角波の振幅を求めて、それがもとの三角関数の振幅と同じになること、フィルターを入れるとどういう影響があるかを紹介する。
問題設定
フーリエ変換する前の関数
縦軸は特に意味はないが、電圧V(t)という信号で単一の三角関数を考える。最も簡単な表式として$$y=V(t)=\sin(t)$$を用いる。周期 $f$ の三角関数は、$$\sin(2\pi ft)$$と書けるので、周期 $$f=1/2\pi$$ という設定になる。振幅は1.0である。
これを mlab.psdとscipy.fftpackの両方でフーリエ変換してパワーを計算する。それぞれ、hanning filter をかけた場合も計算し、違いを見てみる。
時間分解能 dt は0.1秒とする。ナイキスト周波数 f_n は、その逆数の半分で、5Hzとなる。
サンプルコード
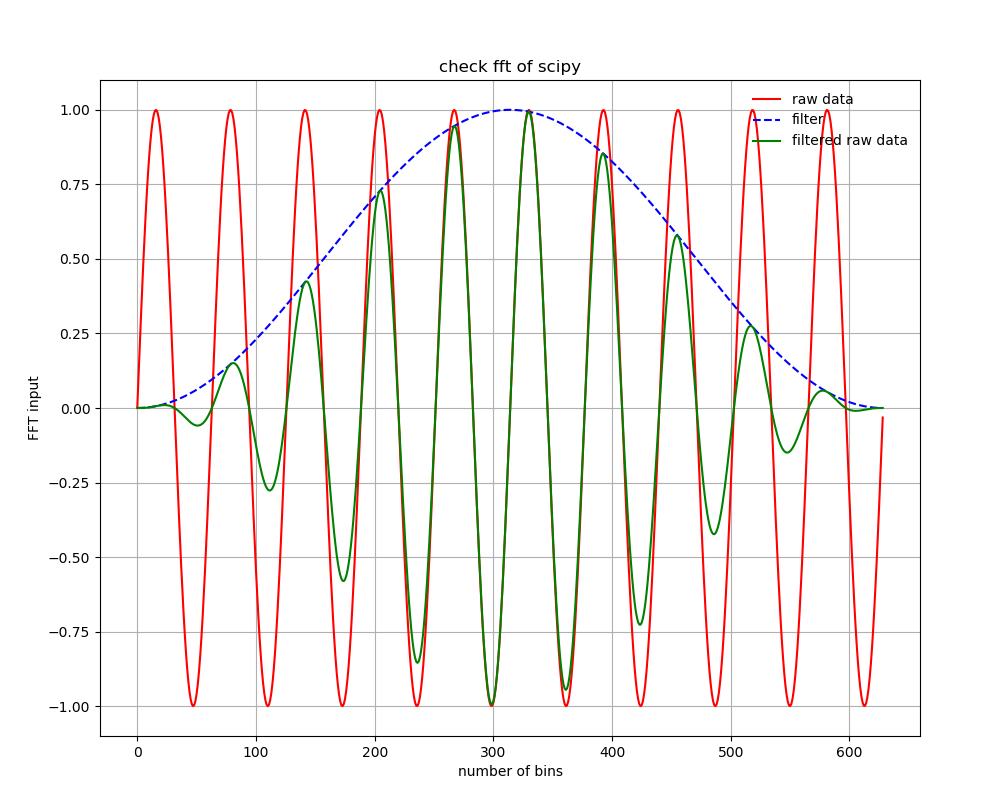
qiita_fft_matplotlib_scipy_comp.py#!/usr/bin/env python """ #2013-03-12 ; ver 1.0; First version, using Sawada-kun's code #2013-08-28 ; ver 1.1; refactoring #2020-03-31 ; ver 1.2; updated for python3 """ __version__= '1.2' import numpy as np import scipy as sp import scipy.fftpack as sf import matplotlib.mlab as mlab import matplotlib.pyplot as plt import optparse def scipy_fft(inputarray,dt,filtname=None, pltfrag=False): bin = len(inputarray) if filtname == None: filt = np.ones(len(inputarray)) elif filtname == 'hanning': # filt = sp.hanning(len(inputarray)) filt = np.hanning(len(inputarray)) else: print('No support for filtname=%s' % filtname) exit() freq = sf.fftfreq(bin,dt)[0:int(bin/2)] df = freq[1]-freq[0] fft = sf.fft(inputarray*filt,bin)[0:int(bin/2)] real = fft.real imag = fft.imag psd = np.abs(fft)/np.sqrt(df)/(bin/np.sqrt(2.)) if pltfrag: binarray = range(0,bin,1) F = plt.figure(figsize=(10,8.)) plt.subplots_adjust(wspace = 0.1, hspace = 0.3, top=0.9, bottom = 0.08, right=0.92, left = 0.1) ax = plt.subplot(1,1,1) plt.title("check fft of scipy") plt.xscale('linear') plt.grid(True) plt.xlabel(r'number of bins') plt.ylabel('FFT input') plt.errorbar(binarray, inputarray, fmt='r', label="raw data") plt.errorbar(binarray, filt, fmt='b--', label="filter") plt.errorbar(binarray, inputarray * filt, fmt='g', label="filtered raw data") plt.legend(numpoints=1, frameon=False, loc=1) plt.savefig("scipy_rawdata_beforefft.png") plt.show() return(freq,real,imag,psd) usage = u'%prog [-t 100] [-d TRUE]' version = __version__ parser = optparse.OptionParser(usage=usage, version=version) parser.add_option('-f', '--outputfilename', action='store',type='string',help='output name',metavar='OUTPUTFILENAME', default='normcheck') parser.add_option('-d', '--debug', action='store_true', help='The flag to show detailed information', metavar='DEBUG', default=False) parser.add_option('-t', '--timelength', action='store', type='float', help='Time length of input data', metavar='TIMELENGTH', default=20.) options, args = parser.parse_args() argc = len(args) outputfilename = options.outputfilename debug = options.debug timelength = options.timelength timebin = 0.1 # timing resolution # Define Sine curve inputf = 1/ (2 * np.pi) # f = 1/2pi -> sin (t) inputt = 1 / inputf # T = 1/f t = np.arange(0.0, timelength*np.pi, timebin) c = np.sin(t) fNum = len(c) Nyquist = 0.5 / timebin Fbin = Nyquist / (0.5 * fNum) fftnorm = 1. / (np.sqrt(2) * np.sqrt(Fbin)) print("................. Time domain ................................") print("timebin = " + str(timebin) + " (sec) ") print("frequency = " + str(inputf) + " (Hz) ") print("period = " + str(inputt) + " (s) ") print("Nyquist (Hz) = " + str(Nyquist) + " (Hz) ") print("Frequency bin size (Hz) = " + str(Fbin) + " (Hz) ") print("FFT norm = " + str(fftnorm) + "\n") # Do FFT. # Hanning Filtered psd2, freqlist = mlab.psd(c, fNum, 1./timebin, window=mlab.window_hanning, sides='onesided', scale_by_freq=True ) psd = np.sqrt(psd2) spfreq,spreal,spimag,sppower = scipy_fft(c,timebin,'hanning',True) # No Filter psd2_nofil, freqlist_nofil = mlab.psd(c, fNum, 1./timebin, window=mlab.window_none, sides='onesided', scale_by_freq=True ) psd_nofil = np.sqrt(psd2_nofil) spfreq_nf,spreal_nf,spimag_nf,sppower_nf = scipy_fft(c,timebin,None) # Get input norm from FFT intergral print("................. FFT results ................................") amp = np.sqrt(2) * np.sqrt(np.sum(psd * psd) * Fbin) print("Amp = " + str(amp)) peakval = amp / (np.sqrt(2) * np.sqrt(Fbin) ) print("Peakval = " + str(peakval)) # (1) Plot Time vs. Raw value F = plt.figure(figsize=(10,8.)) plt.subplots_adjust(wspace = 0.1, hspace = 0.3, top=0.9, bottom = 0.08, right=0.92, left = 0.1) ax = plt.subplot(3,1,1) plt.title("FFT Norm Check") plt.xscale('linear') plt.xlabel(r'Time (s)') plt.ylabel('FFT input (V)') plt.errorbar(t, c, fmt='r', label="raw data") plt.errorbar(t, amp * np.ones(len(c)), fmt='b--', label="Amplitude from FFT", alpha=0.5, lw=1) plt.ylim(-2,2) plt.legend(numpoints=1, frameon=True, loc="best", fontsize=8) # (2a) Plot Freq vs. Power (log-log) ax = plt.subplot(3,1,2) plt.xscale('log') plt.yscale('log') plt.xlabel(r'Frequency (Hz)') plt.ylabel(r'FFT Output (V/$\sqrt{Hz}$)') plt.errorbar(freqlist_nofil , psd_nofil, fmt='r-', label="Window None, matplotlib", alpha=0.8) plt.errorbar(freqlist, psd, fmt='b-', label="Window Hanning, matplotlib", alpha=0.8) plt.errorbar(spfreq_nf, sppower_nf, fmt='mo', label="Window None, scipy", ms = 3, alpha=0.8) plt.errorbar(spfreq, sppower, fmt='co', label="Window Hanning, scipy", ms = 3, alpha=0.8) plt.errorbar(freqlist, fftnorm * np.ones(len(freqlist)), fmt='r--', label=r"1./($\sqrt{2} \sqrt{Fbin}$)", alpha=0.5, lw=1) plt.legend(numpoints=1, frameon=True, loc="best", fontsize=8) # (2b) Plot Freq vs. Power (lin-lin) ax = plt.subplot(3,1,3) plt.xscale('linear') plt.xlim(0.1,0.2) plt.yscale('linear') plt.xlabel(r'Frequency (Hz)') plt.ylabel(r'FFT Output (V/$\sqrt{Hz}$)') plt.errorbar(freqlist_nofil , psd_nofil, fmt='r-', label="Window None, matplotlib", alpha=0.8) plt.errorbar(freqlist, psd, fmt='b-', label="Window Hanning, matplotlib", alpha=0.8) plt.errorbar(spfreq_nf, sppower_nf, fmt='mo', label="Window None, scipy", ms = 3, alpha=0.8) plt.errorbar(spfreq, sppower, fmt='co', label="Window Hanning, scipy", ms = 3, alpha=0.8) plt.errorbar(freqlist, fftnorm * np.ones(len(freqlist)), fmt='r--', label=r"1./($\sqrt{2} \sqrt{Fbin}$)", alpha=0.5, lw=1) plt.legend(numpoints=1, frameon=True, loc="best", fontsize=8) plt.savefig("fft_norm_check.png") plt.show()実行方法は、単に何も指定しないか、-t で時間幅を変えるくらい。
$ python qiita_fft_matplotlib_scipy_comp.py -h Usage: qiita_fft_matplotlib_scipy_comp.py [-t 100] [-d TRUE] Options: --version show program's version number and exit -h, --help show this help message and exit -f OUTPUTFILENAME, --outputfilename=OUTPUTFILENAME output name -d, --debug The flag to show detailed information -t TIMELENGTH, --timelength=TIMELENGTH Time length of input dataフーリエ変換する前の時系列データ
何もオプションを指定しないで実行すると、次のような時系列データのフーリエ変換を実行する。
hanningフィルタがかかる場合、元の時系列データ(赤)に対して、hanning フィルタ(青)がかかって、緑のデータをフーリエ変換することになる。フィルターを使わない場合は、赤を周期境界条件でフーリエ変換することになる。フィルターをかける場合は、オフセット(周波数=0の成分)が乗っている場合は、フィルターによる人為的な低周波ノイズがのる場合があるので、フィルターを使う場合はDC成分は引いてから使うほうがよい。
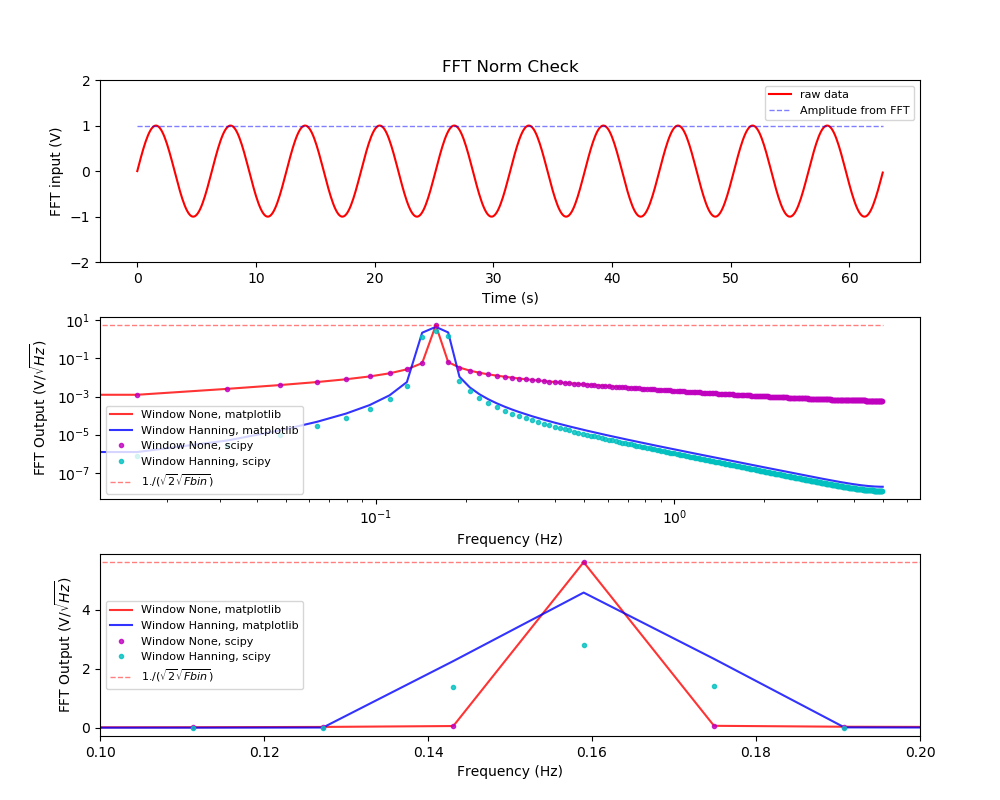
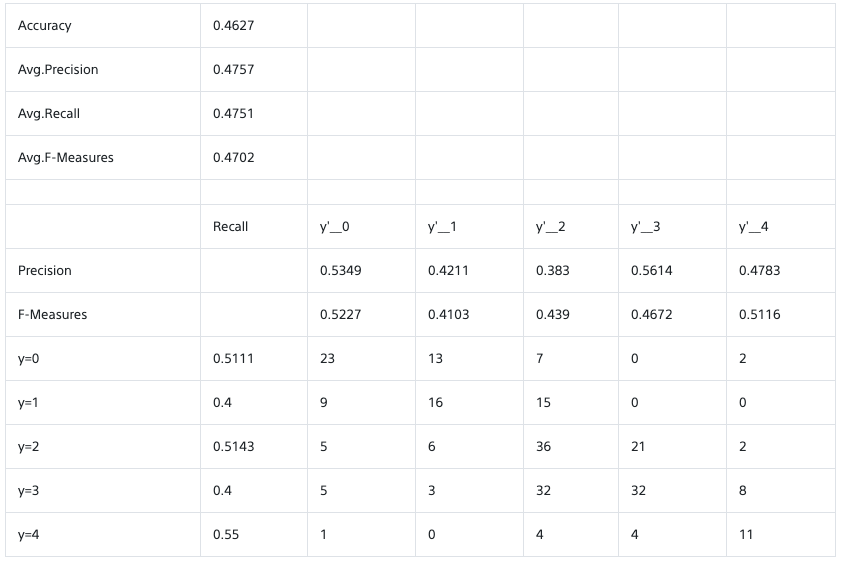
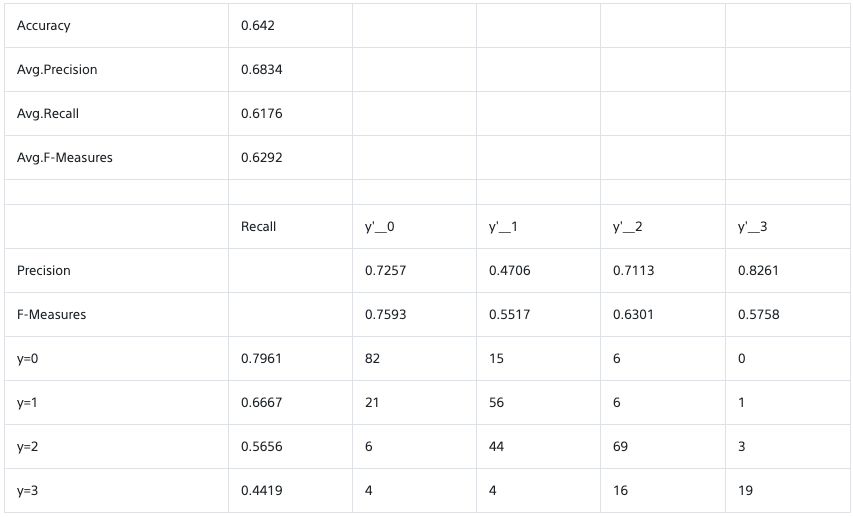
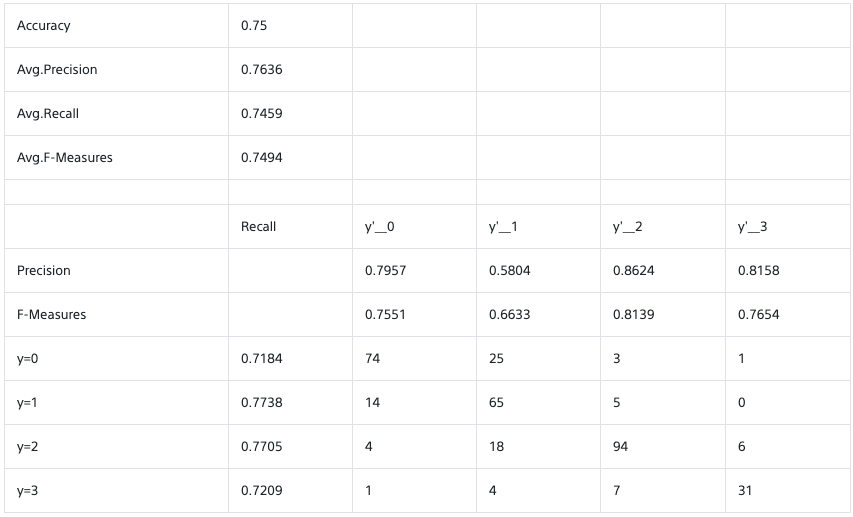
パワースペクトルの計算結果
(上段) フーリエ変換する時系列データ。パワースペクトルから計算した時系列データの振幅を重ねて表示した。(中段)赤がフィルターなしの場合、青がhanning filter ありの場合。実線がmatplotlibで計算した場合で、ドットはscipyで計算したもの。赤い薄い線は時系列データから推定したパワーの値。(下段)中段の縦軸リニアバージョン。
パーセバルの定理の確認
パーセバルの定理より、周波数空間と時空間の積分値のパワーは一致する。三角関数の場合は、変動のパワー(RMS)と振幅は$\sqrt{2}$で結ばれているので、振幅とRMSは相互に変換できる。ここでは、周波数空間を全積分したパワーから時系列データの振幅(この例では1)を計算し、それが一致することを上の絵の青点線で示した。
周波数空間で積分している箇所は、コードの、
amp = np.sqrt(2) * np.sqrt(np.sum(psd * psd) * Fbin) print("Amp = " + str(amp))に該当する。$$ amplitude = \sqrt{2} \sqrt{ \Sigma_i psd(f_i)^2 \Delta f }$$ で計算している。この値がこの例では1になっていて、
plt.errorbar(t, amp * np.ones(len(c)), fmt='b--', label="Amplitude from FFT", alpha=0.5, lw=1)で上段に青い点線でプロットしている。
hanning フィルターの効果
フィルタがなければ、mlab.psdとscipy.fftpack は完璧に一致する。hanning filterを使うとパワーはある割合で下がるのでその分を補正する必要があるのだが、matplotlibとscipyで定義が違うのか(深追いしてない)、デフォルトのまま使うと両者の結果は一致はしない。
コードの補足
mlab.psdの使い方
# Do FFT. # Hanning Filtered psd2, freqlist = mlab.psd(c, fNum, 1./timebin, window=mlab.window_hanning, sides='onesided', scale_by_freq=True ) psd = np.sqrt(psd2)ここで、c はFFTしたい同時間感覚幅で取得されたデータ。FFTはサンプルが全く同じ時間間隔でされたことを前提としている。(もし、時間間隔が変わる場合にはダイレクトに離散フーリエ変換をするが、計算時間はかかる。精密な実験などではそうする場合もある。) fNumはサンプル数、1/timebin で時間幅の逆数を指定する、window は None とすれば何もなし、mlabのオプションにいろんなフィルターがあるが、ここでは hanningの例を示した。sidesは onesided で片面(周波数が正の値)で積分したときにトータルのパワーが時系列のパワーと一致するように規格化するという意味。scale_by_freq で、周波数あたりに直す。これにより、返り値はpower^2/Hzの単位となる。ここでは最後に、psd = np.sqrt(psd2) をすることで、power/sqrt(Hz)の単位にしている。
scipy.fftpack の使い方
freq = sf.fftfreq(bin,dt)[0:int(bin/2)] df = freq[1]-freq[0] fft = sf.fft(inputarray*filt,bin)[0:int(bin/2)]fftfreq という関数を使うことで、周波数を計算してくれる。これは実はとっても大事な機能である。なぜかというと、ここscipyのfftでは複素フーリエ変換を実行するのであるが、返り値は実部と虚部の係数であり、それをどういう周波数の順番でユーザーに返すのかは自明ではないので、対応のとれた周波数を返してくれる関数が必要になる。
real = fft.real imag = fft.imag psd = np.abs(fft)/np.sqrt(df)/(bin/np.sqrt(2.))で、実部を虚部を取り出し、片側(周波数が正)で規格化して帳尻があるように規格化を行う。
- 投稿日:2020-03-31T23:38:33+09:00
iTerm2のカラースキームを時間帯によって自動的に変えよう
ずっと同じカラースキームでターミナルの画面を見ていると飽きるし、日中はライトテーマ・夕方はダークテーマにして気分をリフレッシュしたいと思いませんか? ですが、毎日いちいち手動で朝晩にテーマを切り替えるのは面倒なのでPythonにやらせます。
Python API
2019年7月にリリースされたiTerm2バージョン3.3.0からPython APIが提供されるようになりました(それ以前はAppleScriptというAPIがあったらしい?)。
pip install iterm2すればiTerm2外部からもAPIを叩けます。APIを使用するには Preferences > General > Magic にある Enable Python API にチェックを入れます。
自前のスクリプトを用意したい場合、Scripts > Manage > New Python Script を選ぶとガイドが出てきて雛形を作ってくれます。
作成したPythonのコードは~/Library/Application Support/iTerm2/Scriptsに保存するようになっていますが、アプリ立ち上げ時に自動で読み込ませたい場合は上記のScripts傘下にAutoLaunchフォルダを作り、そこに保管します。実はカラースキームの自動切り替えスクリプトはフルスクラッチする必要がなく、公式の Example Scripts にほぼ完成形が用意してあります。
元のサンプルコードだとカラースキームの切り替え時にiTerm2が起動している必要があったので、アプリ起動時にも現在の時刻を参考に切り替えてくれるよう変更してあります。以下のコードを
~/Library/Application Support/iTerm2/Scripts/AutoLaunch/change_color.pyとして保存してください。change_color.py#!/usr/bin/env python3.7 import asyncio import datetime import iterm2 # Clock time to change colors. LIGHT_TIME = (7, 0) DARK_TIME = (17, 0) # Color presets to use LIGHT_PRESET_NAME = "material" DARK_PRESET_NAME = "onedark" # Profiles to update PROFILES = ["Default"] def get_datetime(t, time): return datetime.datetime(t.year, t.month, t.day, time[0], time[1]) def datetime_after(t, time): today = get_datetime(t, time) if today > t: return today # Same time tomorrow return today + datetime.timedelta(1) def next_deadline_after(t): light_deadline = datetime_after(t, LIGHT_TIME) dark_deadline = datetime_after(t, DARK_TIME) if light_deadline < dark_deadline: return (LIGHT_PRESET_NAME, light_deadline) return (DARK_PRESET_NAME, dark_deadline) def get_duration(): now = datetime.datetime.now() preset_name, deadline = next_deadline_after(now) duration = (deadline - now).seconds print("Sleep for {} seconds until {}".format(duration, deadline)) return duration, preset_name async def set_colors(connection, preset_name): print("Change to preset {}".format(preset_name)) preset = await iterm2.ColorPreset.async_get(connection, preset_name) for partial in (await iterm2.PartialProfile.async_query(connection)): if partial.name in PROFILES: await partial.async_set_color_preset(preset) async def main(connection): now = datetime.datetime.now() begin = get_datetime(now, LIGHT_TIME) end = get_datetime(now, DARK_TIME) if (now > begin and now < end): await set_colors(connection, LIGHT_PRESET_NAME) else: await set_colors(connection, DARK_PRESET_NAME) while True: duration, preset_name = get_duration() await asyncio.sleep(duration) await set_colors(connection, preset_name) await asyncio.sleep(1) iterm2.run_forever(main)最初に定義した5つの定数
LIGHT_TIME=(7, 0): ライトテーマに切り替える時間(HH, MM)DARK_TIME=(16, 0): ダークテーマに切り替える時間(HH, MM)LIGHT_PRESET_NAME="...": ライトテーマ名(デフォルトテーマはLight Background)DARK_PRESET_NAME="...": ダークテーマ名(デフォルトテーマはDark Background)PROFILES=["..."]: テーマを変更させるプロファイル名(複数選択可)は好みに合わせて変更してください。プロファイル名は自分の作ってあるプロファイル一覧から、テーマのプリセット名は右下の Color Presets... メニューから選びます。
ちなみに
print(...)の標準出力や、存在しないプリセット名を指定してしまったときなどのエラーは Scripts > Manage > Console に吐き出されます。退屈なことPythonにやらせるのサイコ〜〜〜〜〜〜
参考
- 投稿日:2020-03-31T23:15:38+09:00
Kaggleコンペ ハンズオン:Real or Not? NLP with Disaster Tweets 〜EDA・前処理編〜
記事の全体像
この記事は2部構成になっています。
・第一部:EDA・前処理 ← いまここ
・第二部:ベクトル化・モデル作成編(LSTM、BERT) (工事中、Coming Soon!)第二部では第一部で前処理を行ったデータを用いる為、
記事の最下部に前処理を一括で実行できるコードを記載しているので、
第一部をスキップされたい方はそちらを実行して第二部に進んでください。
(※データはこの記事を参照して入手してください!)コンペティションの概要
Kaggle : Real or Not? NLP with Disaster Tweets
自然言語処理の入門コンペです。
タスクは、ツイートを「災害ツイート」or「災害以外のツイート」の2つに分類することです。最近では、災害時の救助要請などにツイッターが使われており、災害救援団体や通信社などで災害発生時のツイート自動監視の関心が高まっています。
しかし、ツイートが実際に災害を表しているかどうかを機械的に判断することは難しいです。
それは、例えば災害を明示的に表す「燃えている」という表現も、比喩表現として「空が燃えている」のように使われることがあるからです。
このコンペでは、10,000のツイートのデータセットを使用して、「災害ツイート」or「災害以外のツイート」を予測する機械学習モデルを構築します。いざハンズオン!
Jupyter Notebookを使用してハンズオンを進めていきます。
0. データの入手
Kaggle : Real or Not? NLP with Disaster Tweets - Data
上述のページのから
・test.csv
・train.csv
の2つをダウンロードします。
以後は、分析を行うノートブックと同じ階層にこのcsvファイルを置いてください。
csvファイルの各カラムの内容は以下の通り。
ファイル名 説明 id 各ツイートの一意の識別子 text ツイートのテキスト本文 location ツイートが送信された場所(空欄有り) keyword ツイート内の特定のキーワード(空欄有り) target ツイートのラベル(災害ツイート=1、災害以外のツイート=0) 具体的な内容や欠損値の情報は次項で説明します。
コンペでは、test.csvのtargetカラムを予測します。1.ライブラリの読み込み
今回のハンズオンで使用するライブラリを事前に定義します。
# データ分析 import pandas as pd import numpy as np # 可視化 %matplotlib inline import matplotlib.pyplot as plt import seaborn as sns # 自然言語処理 import string # 記号(punctuation)の一覧を取得 import re import contractions # 文書の短縮形を from wordcloud import STOPWORDS # ストップワードのリストを取得する from collections import defaultdict # n-gram作成時に利用2.データの内容確認
早速データの内容を確認してみたいと思います。
まずは、データをデータフレームとして読み込みます。
データフレームの行数・列数を表示して、行をランダムで10個抽出してみます。# 訓練データとテストデータの読み込み df_train = pd.read_csv('train.csv', dtype={'id': np.int16, 'target': np.int8}) df_test = pd.read_csv('test.csv', dtype={'id': np.int16}) # 訓練データとテストデータの行数・列数を表示する print('Training Set Shape = {}'.format(df_train.shape)) print('Test Set Shape = {}'.format(df_test.shape)) # 訓練データの中から10行をランダムで抽出 df_train.sample(n=10, random_state=28)実行結果の一部Training Set Shape = (7613, 5) Test Set Shape = (3263, 4)以下、実行結果の続き(ランダムで抽出された行の内容)
keywordとlocationのカラムの中には欠損値NaNがある場合もありますね。欠損値について詳細に調べてみたいと思います。
# 訓練データ、テストデータの各カラムの欠損値率を算出 print("missing-value ratio of training data(%)") print(df_train.isnull().sum()/df_train.shape[0]*100) print("\nmissing-value ratio of test data(%)") print(df_test.isnull().sum()/df_test.shape[0]*100)実行結果missing-value ratio of training data(%) id 0.000000 keyword 0.801261 location 33.272035 text 0.000000 target 0.000000 dtype: float64 missing-value ratio of test data(%) id 0.000000 keyword 0.796813 location 33.864542 text 0.000000 dtype: float64欠損値は、訓練データとテストデータいずれにおいても
keywordで0.8%、locationで33~34%あることが分かります。次に、訓練データの
targetの分布を見てみましょう。# ターゲットの要素とその個数をプロット target_vals = df_train.target.value_counts() sns.barplot(target_vals.index, target_vals) plt.gca().set_ylabel('samples')
データセット中には
災害ツイート=1よりも災害以外のツイート=0の方が多いことが分かります。次に、
text、keyword、locationそれぞれのカラムのユニークな要素の個数を調べてみたいと思います。# text、keyword、locationのユニークな要素の個数を表示 print(f'Number of unique values in text = {df_train["text"].nunique()} (Training) - {df_test["text"].nunique()} (Test)') print(f'Number of unique values in keyword = {df_train["keyword"].nunique()} (Training) - {df_test["keyword"].nunique()} (Test)') print(f'Number of unique values in location = {df_train["location"].nunique()} (Training) - {df_test["location"].nunique()} (Test)')実行結果Number of unique values in text = 7503 (Training) - 3243 (Test) Number of unique values in keyword = 221 (Training) - 221 (Test) Number of unique values in location = 3342 (Training) - 1603 (Test)
textとlocationは自由入力であることが分かります。
一方でkeywordはtextの中から事前に定義された221のキーワードを自動抽出していることが分かります。3.探索的データ分析(Explanatory Data Analysis:EDA)
データの特徴を理解するための処理をいくつか行っていきたいと思います。
まずはtext内の特徴を大雑把に把握・比較したいと思います。
特徴は、単語数、ユニークな単語数、ストップワードの数、URLの数、単語文字数の平均、文字数、punctuation(※)の数、ハッシュタグ数、メンション数の9個を調べてみます。
1点補足をしておくと、ここでいうpunctuation(※)とは句読点の意味ではなく、英数字以外のアスキー文字のことを指します。
ざっくりと、string.punctuationで定義される「記号」のようなイメージを持ってもらえれば大丈夫です。
また、これらの特徴はメタ特徴量として、データフレームに結合していきます。
更に、訓練データ内で災害ツイート=1⇄災害以外のツイート=0、訓練データ⇄テストデータ
について9個の特徴の分布を比較します。
災害に関連するツイート、そうでいないツイート、訓練データ、テストデータはそれぞれデータ点数が異なるため、
分布の可視化を行う際には、カーネル密度推定を行うことによってスケールが揃えられて直感的に分布を比較することができます。
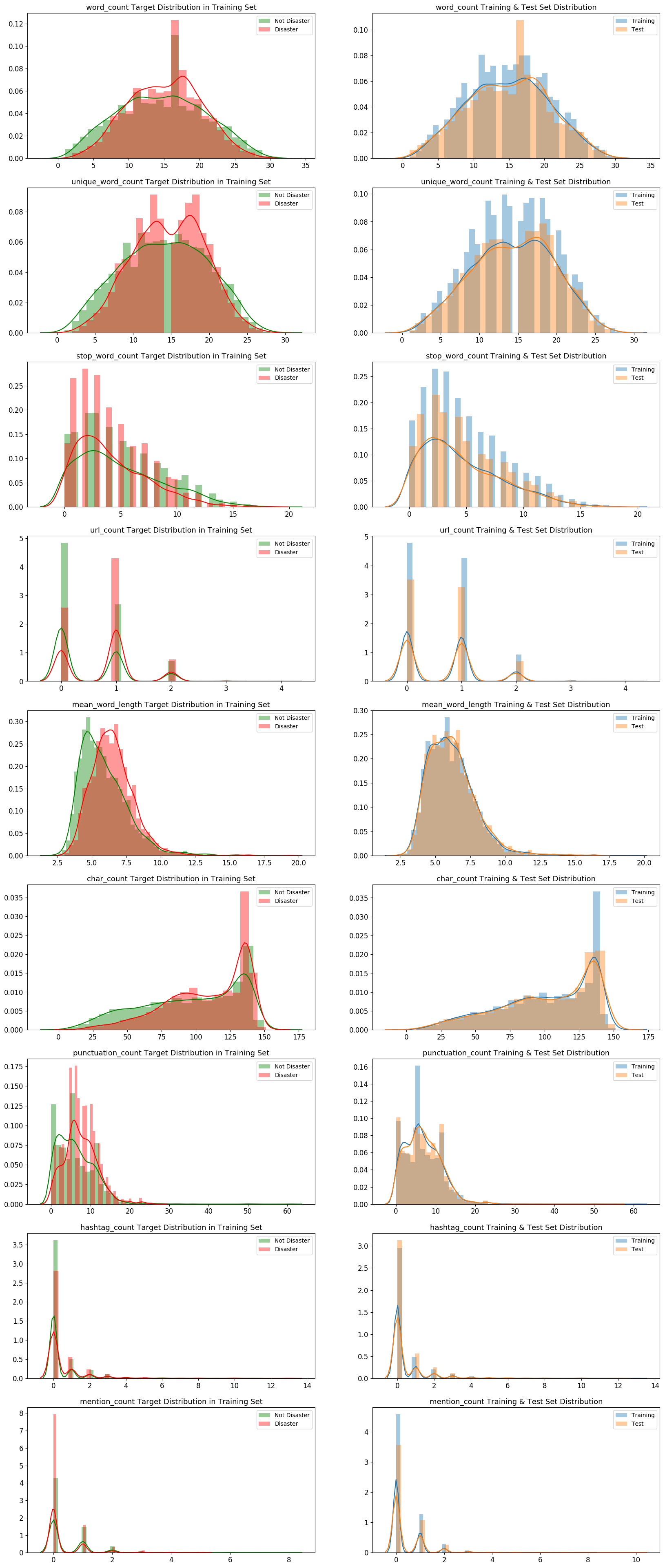
可視化のライブラリであるseabornのdistplotのデフォルト引数でkde=Trueとなっていますが、今回は明示的にkde=Trueを記載します。# 単語数 df_train['word_count'] = df_train['text'].apply(lambda x: len(str(x).split())) df_test['word_count'] = df_test['text'].apply(lambda x: len(str(x).split())) # ユニークな単語数 df_train['unique_word_count'] = df_train['text'].apply(lambda x: len(set(str(x).split()))) df_test['unique_word_count'] = df_test['text'].apply(lambda x: len(set(str(x).split()))) # ストップワードの数 df_train['stop_word_count'] = df_train['text'].apply(lambda x: len([w for w in str(x).lower().split() if w in STOPWORDS])) df_test['stop_word_count'] = df_test['text'].apply(lambda x: len([w for w in str(x).lower().split() if w in STOPWORDS])) # URLの数 df_train['url_count'] = df_train['text'].apply(lambda x: len([w for w in str(x).lower().split() if 'http' in w or 'https' in w])) df_test['url_count'] = df_test['text'].apply(lambda x: len([w for w in str(x).lower().split() if 'http' in w or 'https' in w])) # 単語文字数の平均 df_train['mean_word_length'] = df_train['text'].apply(lambda x: np.mean([len(w) for w in str(x).split()])) df_test['mean_word_length'] = df_test['text'].apply(lambda x: np.mean([len(w) for w in str(x).split()])) # 文字数 df_train['char_count'] = df_train['text'].apply(lambda x: len(str(x))) df_test['char_count'] = df_test['text'].apply(lambda x: len(str(x))) # 句読点の個数 df_train['punctuation_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c in string.punctuation])) df_test['punctuation_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c in string.punctuation])) # ハッシュタグの個数 df_train['hashtag_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c == '#'])) df_test['hashtag_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c == '#'])) # メンションの個数 df_train['mention_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c == '@'])) df_test['mention_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c == '@']))# 9つの特徴の分布を、災害ツイート=1 ⇄ 災害以外のツイート=0、訓練データ ⇄ テストデータで比較する METAFEATURES = ['word_count', 'unique_word_count', 'stop_word_count', 'url_count', 'mean_word_length', 'char_count', 'punctuation_count', 'hashtag_count', 'mention_count'] DISASTER_TWEETS = df_train['target'] == 1 fig, axes = plt.subplots(ncols=2, nrows=len(METAFEATURES), figsize=(20, 50), dpi=100) for i, feature in enumerate(METAFEATURES): # 災害ツイート=1 ⇄ 災害以外のツイート=0の分布を比較する(カーネル密度推定を行う) sns.distplot(df_train.loc[~DISASTER_TWEETS][feature], label='Not Disaster', ax=axes[i][0], color='green', kde=True) sns.distplot(df_train.loc[DISASTER_TWEETS][feature], label='Disaster', ax=axes[i][0], color='red', kde=True) # 訓練データ ⇄ テストデータの分布を比較する(カーネル密度推定を行う) sns.distplot(df_train[feature], label='Training', ax=axes[i][1], kde=True) sns.distplot(df_test[feature], label='Test', ax=axes[i][1], kde=True) for j in range(2): axes[i][j].set_xlabel('') axes[i][j].tick_params(axis='x', labelsize=12) axes[i][j].tick_params(axis='y', labelsize=12) axes[i][j].legend() axes[i][0].set_title(f'{feature} Target Distribution in Training Set', fontsize=13) axes[i][1].set_title(f'{feature} Training & Test Set Distribution', fontsize=13) plt.show()
災害ツイートと災害以外のツイート、訓練データとテストデータで分布に大きな違いが無いことがわかります。
URL、ハッシュタグ、メンションが含まれるツイートも、それらを含まないツイートと同程度かそれ以上あることが分かります。
URL、ハッシュタグ、メンション等の表記は災害ツイート、災害以外のツイートの判断に必要な情報でない可能性が高いので、前処理でクレンジングすると良いかもしれません。次に、
keywordの単語のうち、どれが災害ツイートで多く登場し、どれが災害以外ツイートで多く登場するかを調べます。
災害ツイートのtargetは整数で1、災害以外のツイートは整数で0のため、
keywordの単語毎のtargetの平均値を取り、1に近ければ災害ツイートに登場する傾向がある単語、
0に近ければ災害以外のツイートに登場する傾向がある単語であることが分かります。
pandasのgroupbyメソッドを使用して、keywordの単語毎にtargetの平均値を求めて、その値を訓練データ全体に付加します。
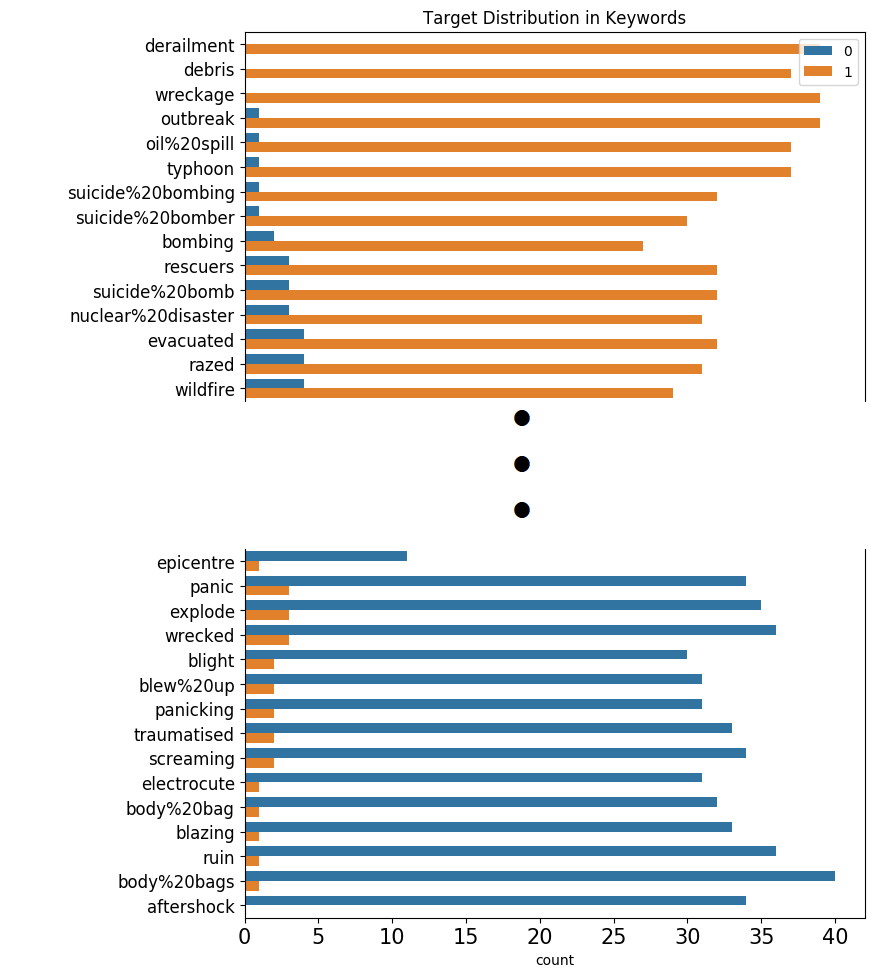
その後、災害ツイートで登場する単語から順に登場回数をプロットします。# keywordの単語毎に、targetの平均値を求めて、その値を訓練データ全体に付加する df_train['target_mean'] = df_train.groupby('keyword')['target'].transform('mean') fig = plt.figure(figsize=(8, 72), dpi=100) # keyword に含まれるラベル分布を確認 sns.countplot(y=df_train.sort_values(by='target_mean', ascending=False)['keyword'], hue=df_train.sort_values(by='target_mean', ascending=False)['target']) plt.tick_params(axis='x', labelsize=15) plt.tick_params(axis='y', labelsize=12) plt.legend(loc=1) plt.title('Target Distribution in Keywords') plt.show() # targetの値の平均値のカラムは以降使用しないので削除する df_train.drop(columns=['target_mean'], inplace=True)出力結果は以下のようになります。
221個の単語のラベル分布全てを、本記事に表示すると縦に長くなってしまうので、
災害ツイートに登場する傾向がある単語と、災害以外のツイートに登場する傾向がある単語、
それぞれ上位のみを表示します(実際は縦長のラベル分布の図が得られます)。
derailment(=脱線)、debris(=残骸)、wreckage(=残骸)といった災害に関連する具体的な状態を表す名詞は、災害ツイートで登場する傾向があります。
一方で、aftershock(=余震、余波)、body bags(=遺体袋)、ruin(=破滅(名詞)、台無しにする(動詞))などは一見災害に関連する単語ですが、
災害ツイートでは登場しない傾向があります。
これは、比喩表現としても使われる単語であるためだと考えられます。次に、n-gramによる頻出単語の確認を行います。
今回は、ユニグラム(n=1)、バイグラム(n=2)、トライグラム(n=3)で頻出単語を、災害ツイート=1⇄災害以外のツイート=0でそれぞれ確認します。
まずは、n-gramのリストを生成する関数を定義します。
n-gramのリストを生成する関数の詳しい解説記事も良かったらご覧ください。def generate_ngrams(text, n_gram=1): # ストップワードのリストにない単語のみをトークナイズ token = [token for token in text.lower().split(' ') if token != '' if token not in STOPWORDS] # n_gramのタプルの作成、zip(*)によってリストの先頭から同じインデックスの要素を取り出す。 ngrams = zip(*[token[i:] for i in range(n_gram)]) return [' '.join(ngram) for ngram in ngrams]次に、関数を用いてユニグラム(n=1)、バイグラム(n=2)、トライグラム(n=3)とその頻度を計算します。
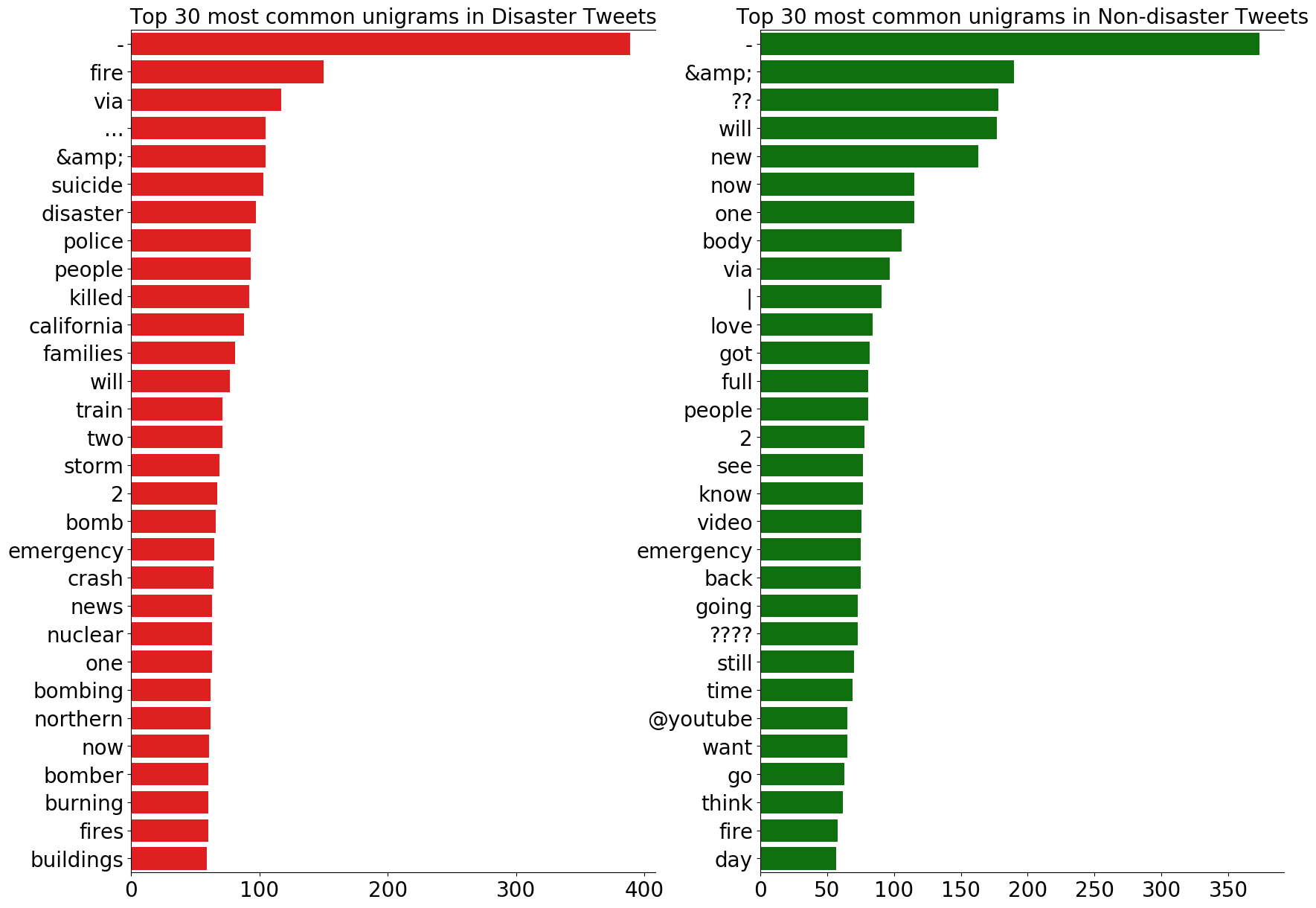
# ユニグラム disaster_unigrams = defaultdict(int) nondisaster_unigrams = defaultdict(int) # df_trainの中の災害ツイートのユニグラムを作成する for tweet in df_train[DISASTER_TWEETS]['text']: for word in generate_ngrams(tweet): disaster_unigrams[word] += 1 # df_trainの中の災害以外のツイートのユニグラムを作成する。 for tweet in df_train[~DISASTER_TWEETS]['text']: for word in generate_ngrams(tweet): nondisaster_unigrams[word] += 1 # 出現頻度でソートする df_disaster_unigrams = pd.DataFrame(sorted(disaster_unigrams.items(), key=lambda x: x[1])[::-1]) df_nondisaster_unigrams = pd.DataFrame(sorted(nondisaster_unigrams.items(), key=lambda x: x[1])[::-1]) # バイグラム disaster_bigrams = defaultdict(int) nondisaster_bigrams = defaultdict(int) for tweet in df_train[DISASTER_TWEETS]['text']: for word in generate_ngrams(tweet, n_gram=2): disaster_bigrams[word] += 1 for tweet in df_train[~DISASTER_TWEETS]['text']: for word in generate_ngrams(tweet, n_gram=2): nondisaster_bigrams[word] += 1 df_disaster_bigrams = pd.DataFrame(sorted(disaster_bigrams.items(), key=lambda x: x[1])[::-1]) df_nondisaster_bigrams = pd.DataFrame(sorted(nondisaster_bigrams.items(), key=lambda x: x[1])[::-1]) # トライグラム disaster_trigrams = defaultdict(int) nondisaster_trigrams = defaultdict(int) for tweet in df_train[DISASTER_TWEETS]['text']: for word in generate_ngrams(tweet, n_gram=3): disaster_trigrams[word] += 1 for tweet in df_train[~DISASTER_TWEETS]['text']: for word in generate_ngrams(tweet, n_gram=3): nondisaster_trigrams[word] += 1 df_disaster_trigrams = pd.DataFrame(sorted(disaster_trigrams.items(), key=lambda x: x[1])[::-1]) df_nondisaster_trigrams = pd.DataFrame(sorted(nondisaster_trigrams.items(), key=lambda x: x[1])[::-1])まずは、出現頻度の高い30のユニグラムを見てみましょう。
N = 30 # 上位30のユニグラムだけ表示する fig, axes = plt.subplots(ncols=2, figsize=(15, 15), dpi=100) plt.tight_layout() sns.barplot(y=df_disaster_unigrams[0].values[:N], x=df_disaster_unigrams[1].values[:N], ax=axes[0], color='red') sns.barplot(y=df_nondisaster_unigrams[0].values[:N], x=df_nondisaster_unigrams[1].values[:N], ax=axes[1], color='green') for i in range(2): axes[i].spines['right'].set_visible(False) axes[i].set_xlabel('') axes[i].set_ylabel('') axes[i].tick_params(axis='x', labelsize=13) axes[i].tick_params(axis='y', labelsize=13) axes[0].set_title(f'Top {N} most common unigrams in Disaster Tweets', fontsize=15) axes[1].set_title(f'Top {N} most common unigrams in Non-disaster Tweets', fontsize=15) plt.show()
災害ツイート、災害以外のツイートであっても、最頻出のユニグラムの多くが記号、取り除ききれなかったストップワード、数字であることが分かります。
これらのユニグラムはtargetの判断基準にならないので、モデリングの前に削除した方がよいでしょう。また、災害ツイートで頻出のユニグラムは、災害に関する具体的な情報を提供していることが分かります。
一方、災害以外のツイートで頻出のユニグラムの中に、動詞が多いことが分かります。
これは、災害以外のツイートでは、ユーザーが自身もしくは何かの動作についてツイートする傾向があるからだと考えられます。バイグラムとトライグラムについても見てみましょう。
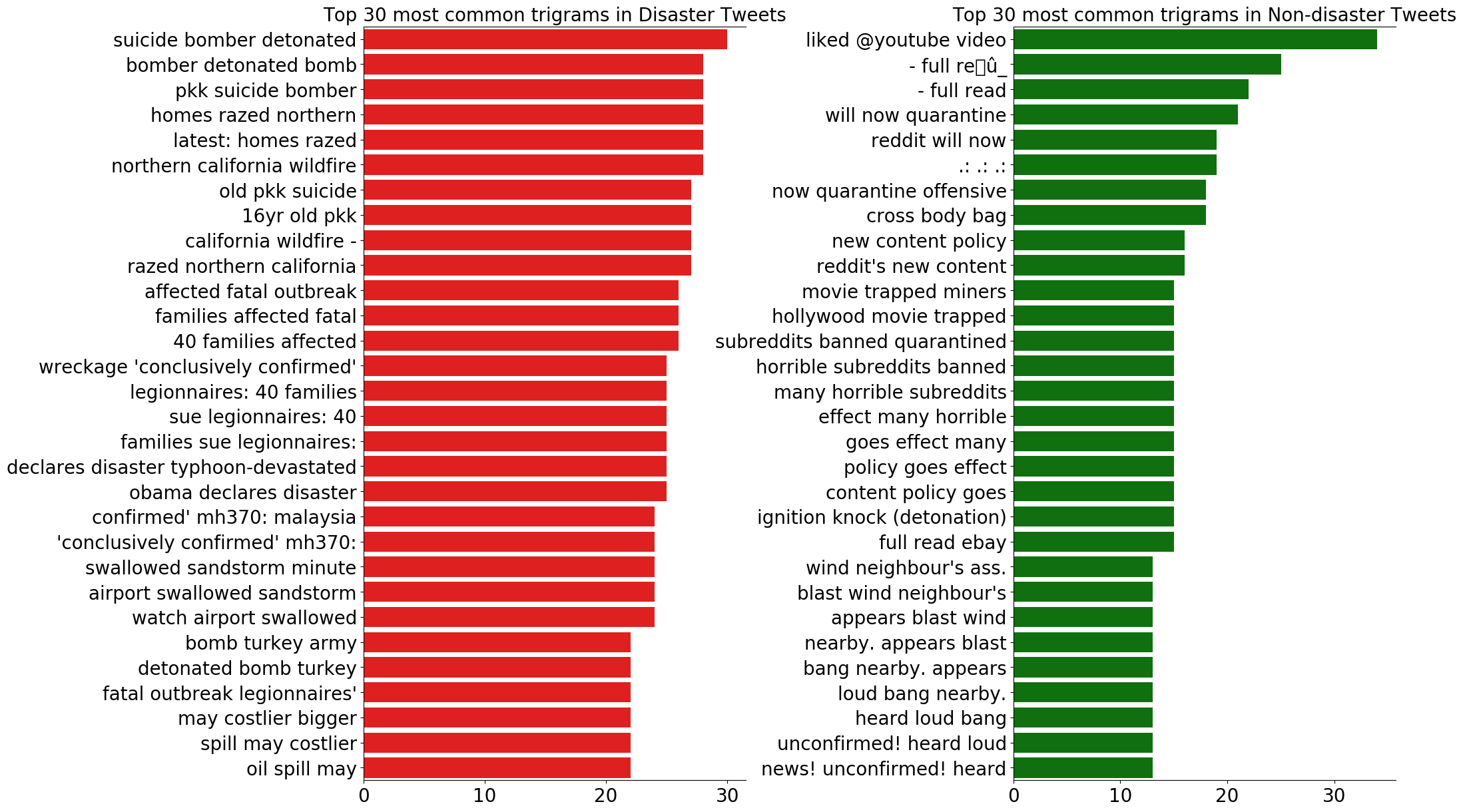
# バイグラム fig, axes = plt.subplots(ncols=2, figsize=(20, 15), dpi=100) plt.subplots_adjust(wspace=0.4, hspace=0.6) sns.barplot(y=df_disaster_bigrams[0].values[:N], x=df_disaster_bigrams[1].values[:N], ax=axes[0], color='red') sns.barplot(y=df_nondisaster_bigrams[0].values[:N], x=df_nondisaster_bigrams[1].values[:N], ax=axes[1], color='green') for i in range(2): axes[i].spines['right'].set_visible(False) axes[i].set_xlabel('') axes[i].set_ylabel('') axes[i].tick_params(axis='x', labelsize=20) axes[i].tick_params(axis='y', labelsize=20) axes[0].set_title(f'Top {N} most common bigrams in Disaster Tweets', fontsize=20) axes[1].set_title(f'Top {N} most common bigrams in Non-disaster Tweets', fontsize=20) plt.show() # トライグラム fig, axes = plt.subplots(ncols=2, figsize=(20, 15), dpi=100) plt.subplots_adjust(wspace=0.7, hspace=0.6) sns.barplot(y=df_disaster_trigrams[0].values[:N], x=df_disaster_trigrams[1].values[:N], ax=axes[0], color='red') sns.barplot(y=df_nondisaster_trigrams[0].values[:N], x=df_nondisaster_trigrams[1].values[:N], ax=axes[1], color='green') for i in range(2): axes[i].spines['right'].set_visible(False) axes[i].set_xlabel('') axes[i].set_ylabel('') axes[i].tick_params(axis='x', labelsize=20) axes[i].tick_params(axis='y', labelsize=20) axes[0].set_title(f'Top {N} most common trigrams in Disaster Tweets', fontsize=20) axes[1].set_title(f'Top {N} most common trigrams in Non-disaster Tweets', fontsize=20) plt.show()
災害ツイートは、バイグラムもトライグラムも共通して具体的な災害の内容を多く含んでいることが分かります。
また、災害ツイートではユニグラムにあったような記号やストップワード、数字があまり登場しないことも分かります。
一方、災害以外のツイートは、区切り文字やストップワードが登場し、redditやyoutubeといった単語も多く登場します。4.データの前処理
探索的データ分析によって、ツイートからモデル構築に不要な情報を取り除く必要があることが分かりました。
モデル構築の前にいくつかの前処理を訓練データ、テストデータに行います。まず、
I'mや、we'veといった短縮形の単語をI amやwe haveといった形に戻します。
pythonではcontractionsというモジュールが提供されており、contractions.fix(text)で、
短縮形を元の形に戻すことができます。def fix_contractions(text): return contractions.fix(text) # 関数適応前のツイート例 print("tweet before contractions fix : ", df_train.iloc[1055]["text"]) # 関数の適用 df_train['text']=df_train['text'].apply(lambda x : fix_contractions(x)) df_test['text']=df_test['text'].apply(lambda x : fix_contractions(x)) # 関数適用後のツイート例 print("tweet after contractions fix : ", df_train.iloc[1055]["text"])実行結果tweet before contractions fix : @asymbina @tithenai I'm hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable. http://t.co/YsFYEahpVg tweet after contractions fix : @asymbina @tithenai I am hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable. http://t.co/YsFYEahpVg次に、URLを含むツイートから、正規表現を用いてURLのみ削除します。
def remove_URL(text): url = re.compile(r'https?://\S+|www\.\S+') return url.sub(r'',text) # 関数適応前のツイート例 print("tweet before URL removal : ", df_train.iloc[1055]["text"]) # 関数の適用 df_train['text']=df_train['text'].apply(lambda x : remove_URL(x)) df_test['text']=df_test['text'].apply(lambda x : remove_URL(x)) # 関数適用後のツイート例 print("tweet after URL removal : ", df_train.iloc[1055]["text"])実行結果tweet before URL removal : @asymbina @tithenai I am hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable. http://t.co/YsFYEahpVg tweet after URL removal : @asymbina @tithenai I am hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable.次に、記号を削除したいと思います。
これによって、ハッシュタグやメンションを表す記号を含む#@!"$%&\'()*+,-./:;<=>?[\\]^_`{|}~の記号が削除されます。
削除する記号の一覧はstring.punctuationで取得可能です。def remove_punct(text): table=str.maketrans('','',string.punctuation) return text.translate(table) # 関数適応前のツイート例 print("tweet before punctuation removal : ", df_train.iloc[1055]["text"]) # 関数の適用 df_train['text']=df_train['text'].apply(lambda x : remove_punct(x)) df_test['text']=df_test['text'].apply(lambda x : remove_punct(x)) # 関数適用後のツイート例 print("tweet after punctuation removal : ", df_train.iloc[1055]["text"])実行結果tweet before punctuation removal : @asymbina @tithenai I am hampered by only liking cross-body bags. I really like Ella Vickers bags: machine washable. tweet after punctuation removal : asymbina tithenai I am hampered by only liking crossbody bags I really like Ella Vickers bags machine washable上述の3つの処理によってツイート本文が綺麗になりました。
今後は、綺麗になったテキストを用いてベクトル化、モデル化を行っていきたいと思います!ベクトル化、モデル化の記事は現在執筆中です!お待ちください!
参考にしたノートブック
本記事で参考に(or 使用)したコンペのノートブック
・https://www.kaggle.com/gunesevitan/nlp-with-disaster-tweets-eda-cleaning-and-bert
(EDA、データ前処理、ベクトル化、BERT)・https://www.kaggle.com/shahules/basic-eda-cleaning-and-glove
(EDA、データ前処理、GloVe)次章を進める前に行う前処理
以下のコードを実行した状態で次章に進んでください
# データ分析 import pandas as pd import numpy as np # 可視化 %matplotlib inline import matplotlib.pyplot as plt import seaborn as sns # 自然言語処理 import string # 記号(punctuation)の一覧を取得 import re import contractions # 文書の短縮形を from wordcloud import STOPWORDS # ストップワードのリストを取得する from collections import defaultdict # n-gram作成時に利用 # 短縮形の復元 def fix_contractions(text): return contractions.fix(text) # URLの削除 def remove_URL(text): url = re.compile(r'https?://\S+|www\.\S+') return url.sub(r'',text) # 記号の削除 def remove_punct(text): table=str.maketrans('','',string.punctuation) return text.translate(table) # 関数の適用 df_train['text']=df_train['text'].apply(lambda x : fix_contractions(x)) df_test['text']=df_test['text'].apply(lambda x : fix_contractions(x)) df_train['text']=df_train['text'].apply(lambda x : remove_URL(x)) df_test['text']=df_test['text'].apply(lambda x : remove_URL(x)) df_train['text']=df_train['text'].apply(lambda x : remove_punct(x)) df_test['text']=df_test['text'].apply(lambda x : remove_punct(x))


- 投稿日:2020-03-31T22:40:24+09:00
Pythonでいいね、RT、リプライを受けていないツイートを抽出する
自分の低クオリティツイートを抽出したかった
- Twitterには「リプライした先」のIDである
in_reply_to_status_idが存在するが「リプライを受けている」といったフラグは存在しないようだ
- ちなみにリプライではないツイートは
in_reply_to_status_idはNoneとなっていた- 最初はいいね、RTされていないツイートを抽出して、検索を行って抽出していたが、検索APIの上限にすぐに引っかかってしまった
- そこで、以下の流れにした
- いいね、RTされていないツイートを抽出
- 直近のリプライを抽出
- いいね、RTされていないツイートと直近のリプライを突合してリプライを受けるツイートを除外
- いいね、RT、リプライを受けていないツイートのIDリストが完成
コード
import tweepy consumer_key = '自分の' consumer_secret = '自分の' access_key = '自分の' access_secret = '自分の' auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_key, access_secret) api = tweepy.API(auth) noFavRtTweet = [] mentionTweet = [] noDeleteTweet = [] # No Favorite No RT Tweet for tweet in tweepy.Cursor(api.user_timeline,screen_name = "自分のID",exclude_replies = True).items(200): if tweet.favorite_count == 0 and tweet.retweet_count == 0: print(tweet.id,tweet.created_at,tweet.text) noFavRtTweet.append(tweet.id) # Reply Tweet for mentions in tweepy.Cursor(api.mentions_timeline).items(200): print(mentions.id,mentions.created_at,mentions.text) mentionTweet.append(mentions.in_reply_to_status_id) # No Favorite No RT No Reply Tweet for tweet in noFavRtTweet: for reptw in mentionTweet: if tweet == reptw: print(api.get_status(tweet).id,api.get_status(tweet).created_at,api.get_status(tweet).text) noDeleteTweet.append(tweet) # Extraction Delete Tweet perfectList = set(noFavRtTweet) ^ set(noDeleteTweet) print(list(perfectList)) # Delete Tweet for tweet in perfectList: print(api.get_status(tweet).id,api.get_status(tweet).created_at,api.get_status(tweet).text) # api.destroy_status(deltw) 自分はLambdaを使って日次で消している使い道
自分は上記スクリプトをLambdaを使って日次で消している。次はLambdaで日次バッチ的に自分の低クオリティツイートを削除するCloudFormationを投稿したい。実際無料枠で十分に消すことが可能。
- 投稿日:2020-03-31T22:39:31+09:00
【初心者向け】PythonでWebスクレイピングをやってみる
読者の想定
初心者向けとありますが、私も初心者です。
webスクレイピングの簡単なサンプルコードの理解をした後、ちょっと自身のオリジナリティを出したいなと思って、調べながらやってみたという内容です。
webスクレイピングの参考コード通りに実行したら、タイトルとかを抜きだす事ができた!がレベル1なら、今回はレベル2くらいの内容だと思います。
なので、勘違いの部分もあったりすると思うので、ご指摘あればコメントいただければと思います。はじめに
環境
python 3.7.3
私は、visual studio codeで開発しました。ライブラリのインポート
Pythonには"urlib2"というHTTPのライブラリがあるのですが、使い勝手がよくないので、"Requests"と"BeautifulSoup"のライブラリを使ってwebスクレイピングを行います。
RequestsでWebページを取得して、Beautiful SoupでそのHTMLを抽出します。やっていこう!
スクレイピング内容
日経ビジネス電子版
https://business.nikkei.com/
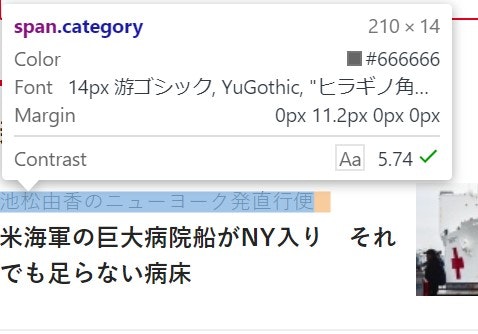
から、新着記事の見出しとURLを取得してみようと思います。Google Chromeでアクセスし、F12キーで、デベロッパーツール(検証モード)にアクセスします。
新着記事の部分が、HTMLのどの部分なのか知りたいので、Ctrl + Shift + Cで見出しにカーソルを動かします。
すると、classがcategoryという部分に、記事の連載名がある事が分かりました。
記事の見出しは、h3タグに入っています。
また、URLは、少し上のaタグの部分にある事が分かります。
この関係を図に示すと、以下のような構図になります。
あとで、プログラムと一緒に解説したいと思います。
コードの解説
code.pyimport requests from bs4 import BeautifulSoup import re urlName = "https://business.nikkei.com" url = requests.get(urlName) soup = BeautifulSoup(url.content, "html.parser")requestsのライブラリでhttp接続をして、BeautifulSoupでhtmlの解析をします。
code.pyelems = soup.find_all("span")まず、span要素を全てelemsに格納します。
code.pyfor elem in elems: try: string = elem.get("class").pop(0) if string in "category": print(elem.string) title = elem.find_next_sibling("h3") print(title.text.replace('\n','')) r = elem.find_previous('a') print(urlName + r.get('href'), '\n') except: pass次に、span要素の中から、class名を取り出して、categoryかどうかを判別します。
もし、classがcategoryであった場合には、連載名のテキストを、.stringを用いて抜き出します。そして、次は見出しの内容を取得します。
見出しは、h3タグにありました。
h3タグは、同じ深さで、すぐ下の部分にありました。
なので、find_next_sibling()を使って、要素以降の同じ深さにあるh3を検索します。
抜き出した文章には、画像もついている場合があり、改行が含まれている場合と含まれていない場合があったので、含まれている場合は削除しました。
最後に、URLを抜き出しにいきたいと思います。先ほどは、同じ深さでしたが、aタグは、ひとつ上の深さにいます。
したがって、find_previous()を使って、aタグを探しに行き、要素の指定の属性値を取得するgetメソッドを用いて、hrefのアドレスを取り出しました。
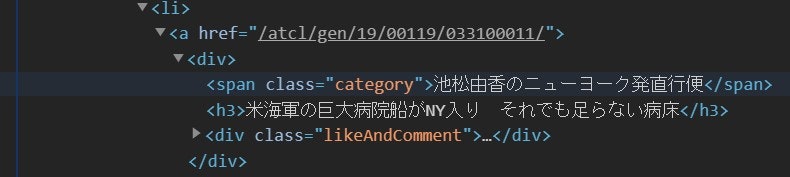
以下、実行結果の一部です。
池松由香のニューヨーク発直行便 米海軍の巨大病院船がNY入り それでも足らない病床 https://business.nikkei.com/atcl/gen/19/00119/033100011/ 市嶋洋平のシリコンバレーインサイ… 「需要2割経済」を生きる ポストコロナ考え動く米外食業界 https://business.nikkei.com/atcl/gen/19/00137/033100002/ 橋本宗明が医薬・医療の先を読む 中国平安保険と提携した塩野義・手代木社長の深謀遠慮 https://business.nikkei.com/atcl/gen/19/00110/033100012/このように、取得する事ができました。
さいごに
まだまだ勉強中なので、勘違いしている部分があったり、もっと良い方法があるかとは思います。
少しずつ理解を深めながら実践していきたいと思います。



- 投稿日:2020-03-31T22:33:34+09:00
matplotlibで画像を読み込む時に気になったこと
matplotlibで画像を表示させた時にちょっと気になった点がいくつかあったので,それをまとめておきました.
きっと気になっている人もいると思うので(特に使い始めの方),ちょっとでも検索の手間が省けたら良いなぁと思ってます.
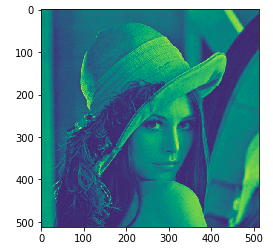
私はjupyter notebookをよく使うので,そこでの使用を前提としてます.1.あれ?グレースケールのはずなのに色が付いてるな?
百聞は一見に如かず.とりあえず画像を表示させてみます.
# いつもの色々インポート import cv2 import numpy as np from matplotlib import pyplot as plt im = np.array(cv2.imread('lena.png',0)) #画像を読み込んでnumpy形式にする
cv2.imread('lena.png',0)は"lena.png"を 0 すなわちグレースケールで読み込んでね,ということです.
ではmatplotlibで画像を表示させてみます.# matplotlibで表示させます plt.imshow(im) plt.show()するとこんな感じで表示されます.
なんだか色が付いちゃってます.
matplotlibはデフォルトでカラーマップが設定されているのでこんな感じになってしまうんですね.
これを解除するためにはplt.gray()を入れてあげるだけです.plt.gray() # カラーマップを"gray"に設定 plt.imshow(im) plt.show()
ちゃんと期待通りになりました.
実はここまではいろんなところに情報があるんですけど,私はこう思ってしまったことがあるんです.でもなんかいい感じだったから元のカラーマップに戻したいな?
案外見つからなくて,「もとに戻したいと思ってる人いないのかな…」って思ってました.
デフォルトのカラーマップが何なのかわからなかったので,元に戻すのを諦めてましたが,公式にちゃんと書いてありました.
このviridisがデフォルトのカラーマップのようです.
早速設定してみましょう.plt.viridis() plt.imshow(im) plt.show()
これで元に戻りました.めでたしめでたし.2.あれ?コントラストがおかしいな?
これに気づけたのは奇跡だと思っているんですが,なんかちょっと色がおかしいなって思ったんです.
なので,テストでこんな画像を読み込ませてみました.
まっくろです.…が,matplotlibで表示させると
どうやら色の階調が正規化されているみたいです.これを解消するためには下記のようにvminとvmaxを指定してあげないといけないようです.
plt.imshow(im, vmin = 0, vmax = 255)
目を凝らすとわずかに見えます.きっと他にも私が気づいていないデフォルト設定があるんでしょうね.
以上です.間違いなどありましたら教えて下さい.






- 投稿日:2020-03-31T22:33:34+09:00
matplotlibで画像を表示する時に気になったこと
matplotlibで画像を表示させた時にちょっと気になった点がいくつかあったので,それをまとめておきました.
きっと気になっている人もいると思うので(特に使い始めの方),ちょっとでも検索の手間が省けたら良いなぁと思ってます.
私はjupyter notebookをよく使うので,そこでの使用を前提としてます.1.あれ?グレースケールのはずなのに色が付いてるな?
百聞は一見に如かず.とりあえず画像を表示させてみます.
# いつもの色々インポート import cv2 import numpy as np from matplotlib import pyplot as plt im = np.array(cv2.imread('lena.png',0)) #画像を読み込んでnumpy形式にする
cv2.imread('lena.png',0)は"lena.png"を 0 すなわちグレースケールで読み込んでね,ということです.
ではmatplotlibで画像を表示させてみます.# matplotlibで表示させます plt.imshow(im) plt.show()するとこんな感じで表示されます.
なんだか色が付いちゃってます.
matplotlibはデフォルトでカラーマップが設定されているのでこんな感じになってしまうんですね.
これを解除するためにはplt.gray()を入れてあげるだけです.plt.gray() # カラーマップを"gray"に設定 plt.imshow(im) plt.show()
ちゃんと期待通りになりました.
実はここまではいろんなところに情報があるんですけど,私はこう思ってしまったことがあるんです.でもなんかいい感じだったから元のカラーマップに戻したいな?
案外見つからなくて,「もとに戻したいと思ってる人いないのかな…」って思ってました.
デフォルトのカラーマップが何なのかわからなかったので,元に戻すのを諦めてましたが,公式にちゃんと書いてありました.
このviridisがデフォルトのカラーマップのようです.
早速設定してみましょう.plt.viridis() plt.imshow(im) plt.show()
これで元に戻りました.めでたしめでたし.2.あれ?コントラストがおかしいな?
これに気づけたのは奇跡だと思っているんですが,なんかちょっと色がおかしいなって思ったんです.
なので,テストでこんな画像を読み込ませてみました.
まっくろです.…が,matplotlibで表示させると
どうやら色の階調が正規化されているみたいです.これを解消するためには下記のようにvminとvmaxを指定してあげないといけないようです.
plt.imshow(im, vmin = 0, vmax = 255)
目を凝らすとわずかに見えます.きっと他にも私が気づいていないデフォルト設定があるんでしょうね.
以上です.間違いなどありましたら教えて下さい.
- 投稿日:2020-03-31T22:29:56+09:00
Python&機械学習 勉強メモ②
https://qiita.com/yohiro/items/04984927d0b455700cd1
の続きmatplotlibとnumpy
matplotlibは、グラフ描画ライブラリ。pyplotをよく使うっぽい。
numpyは、数値計算ライブラリ。
この二つを組み合わせて数学グラフの描画ができるようになる。インポートの仕方
import matplotlib.pyplot as plt import numpy as npグラフ描画の仕方
$y = 2x + 1$であれば、
x = np.arange(0, 10, 0.1) # 0から10まで0.1刻みのリストxを作成 y = 2*x + 1 # x各要素の2x+1の写像としてyを作成 plt.plot(x, y) # (x, y)のグラフを描画 plt.show() # グラフ表示と書くことで以下のグラフを描ける
シグモイド関数
以下のような曲線を描く関数のこと。
式は$y=\frac{1}{1 + e^x}$で表される。
ニューロンの「入力が閾値を超えたら発火する」という性質と親和性が高く、活性化関数としてよく使われる(と思われる)。
Pythonによる実装例は下記の通り。import math def sigmoid(a): return (1.0 / (1.0 + math.exp(-a)))

- 投稿日:2020-03-31T21:55:27+09:00
【SIRモデル入門】感染数データから各国終息時期を予測する♬
今回は、対数プロットすることにより各国の感染ピークの時期を予測することとする。
やったこと
・ちょっと理論
・各国の予測
・コード解説
・追加の理論
・各国の予測II・ちょっと理論
前回、以下の式を導出した。
I = I_0\exp(\gamma (\frac{\beta}{\gamma} \frac{S}{N} - 1)t)\\この両辺を対数取ると、
\ln I = \ln I_0+\gamma (\frac{\beta}{\gamma} \frac{S}{N} - 1)t\\が得られる。すなわち、縦軸に$\ln I$横軸に時間$t$を取ったグラフを描くと、傾きが
\gamma (\frac{\beta}{\gamma} \frac{S}{N} - 1)\\の直線が描ける。ここで、この傾きは$S$に依存しており時間と共に減少する未感染者数である。
そして、この傾きは前回導入した実効再生産数$R$を使うと以下のように書き換えられる。\gamma (R - 1)\\ R = R_0 \frac{S}{N}\\ R_0 = \frac{\beta}{\gamma}\\したがって、この傾きはR=1で0になり、すなわち再生産数=0となり、これ以上感染者が増えないので感染ピークとなる。
今回は、この理論を根拠に各国のデータを$\log I\ vs\ t$でプロットし、それぞれの国の感染ピークの時期を見たいと思う。また、あわよくば立ち上がりの傾きから、$S\fallingdotseq N$であり、$\gamma (R_0 -1)$が得られる。
これを初期値にして得られたグラフをフィッティングすると、$\gamma$,$\beta$,$R_0$が求められそうである。・各国の予測
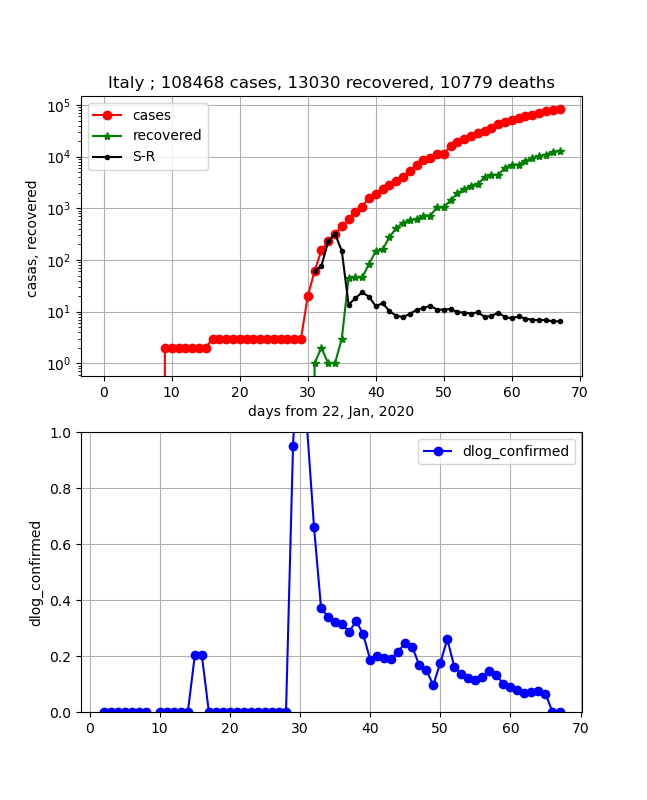
・Korea, South, Diamond Princess, Italyの状況
Italyが入っているのが不信に思われるかもしれませんが、結果は以下のとおりです。
この3つの国を並べてみると、割と様になっているのが分かります。
すなわち、適当にx,y軸を平行移動すると重なりそうです。つまり、傾きが同一な領域があることが分かります。
どのグラフも、ほぼ10日で10倍になる区間が見えます。
そうです、DPが最初に感染数曲線が飽和し、次に韓国、そしてこれからイタリアがまさしく飽和しそうな状況です。下のグラフは傾きをプロットしています。すなわち、0になると飽和したことを表します。
ということで、このグラフからも上記のことが分かります。
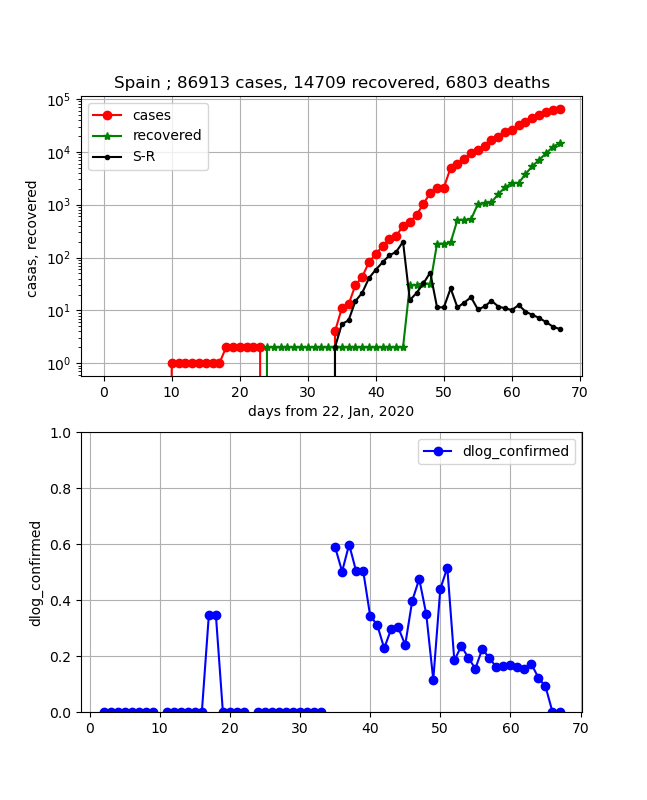
イタリアに関して言及すると、いろいろ言われてきましたがあと10日程度でピークに達すると思われます。・ヨーロッパ各国の状況
イタリア以外の、Spain,Germany,Switzerland,United Kingdom, Netherlandsについて、同一のグラフで表示します。
重ねて書いてみると、イギリスが少し遅れていますが、その他はよく似ている曲線を描いています。
縦軸はそれぞれの事情に依存して(人口など)異なりますが、ほぼ同様な傾きの変化をしています。
そして、傾きの図を見ると2週間程度内にはまとめて飽和してきそうです。・ちょっと残念な国
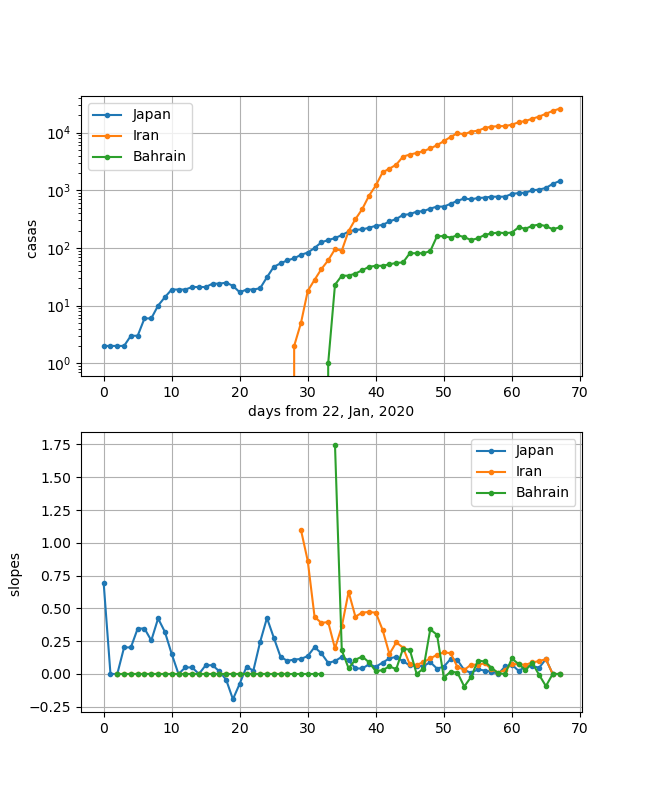
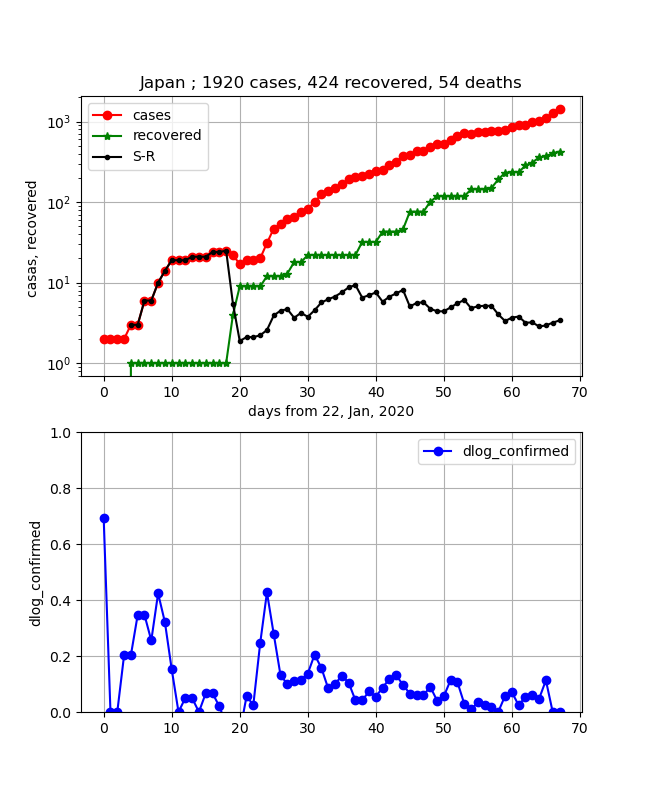
Japan, Iran, Bahrainの3つの国もある意味曲線が酷似しています。
立ち上がりの状況が異なるので、y軸が全く違うので医療体制の状況は異なると思います。
しかし、一旦立ち上がってしまったあとの傾きが割と似ており、しかもこの何日間でほぼ飽和しているにも関わらず、イランと日本は再度スーと増加してしまっています。バーレーンも傾きが負になっているのですが、再度正に戻ってしまっています。
これら3国の勾配は、安定してからの勾配として10倍/30日程度のいつでも飽和しそうな緩い勾配になっています。
これらの国はまだまだ感染が継続しており、緊張を持って社会全体で封じ込めて行く必要があります。・噂のアメリカの状況
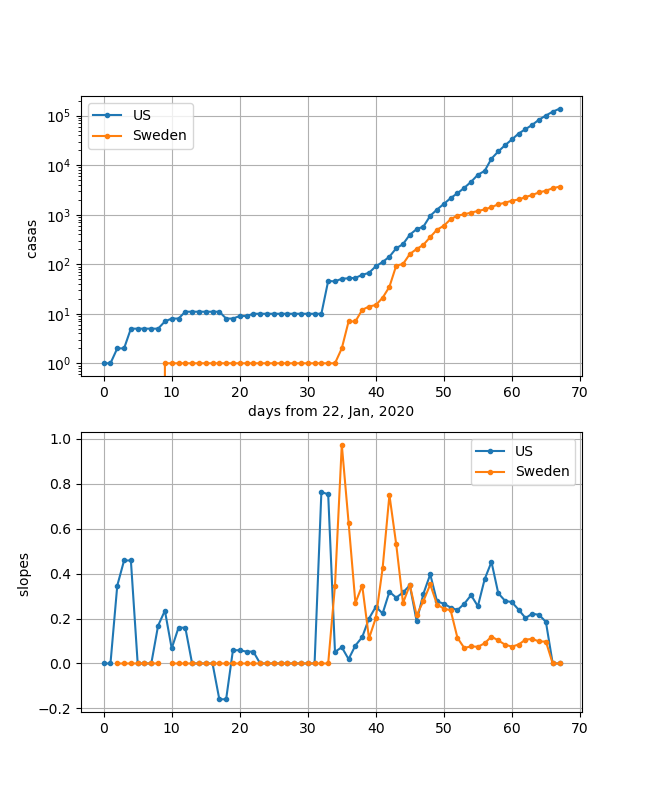
SwedenとUSを同一プロットしてみました。
一目瞭然ですが、立ち上がりは似ています。しかし、スウェーデンは途中から傾きが小さくなっています。しかし、下の傾きのグラフを見るとこのところほぼx軸に平行になっていて、0に向かっているようには見えません。つまり、近日中に飽和はしないように見えます。
ただし、58日から65日のデータがそろってきていて、傾きが0に向かって急激に近づいているようにも見えます。これを伸ばすとあと10日程度で感染ピークになる可能性もあることが分かります。
なお、両国の最大勾配は25倍/20日程度で先ほどの勾配より大きいのが分かります。・コード解説
利用するLibとデータ読み込みは前回と同一です。
死亡数データも処理していますが、以下では使わないので削除しています。import numpy as np from scipy.integrate import odeint from scipy.optimize import minimize import matplotlib.pyplot as plt import pandas as pd #pandasでCSVデータ読む。 data = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv') data_r = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')以下、データ加工関数で、処理した感染数データと勾配データを返します。
def data_city(city): #データを加工する t_cases = 0 t_recover = 0 t_deaths = 0 for i in range(0, len(data_r), 1): if (data_r.iloc[i][1] == city): #for country/region #if (data_r.iloc[i][0] == city): #for province:/state print(str(data_r.iloc[i][0]) + " of " + data_r.iloc[i][1]) for day in range(4, len(data.columns), 1): confirmed_r[day - 4] += data_r.iloc[i][day] t_recover += data_r.iloc[i][day] for i in range(0, len(data), 1): if (data.iloc[i][1] == city): #for country/region #if (data.iloc[i][0] == city): #for province:/state print(str(data.iloc[i][0]) + " of " + data.iloc[i][1]) for day in range(4, len(data.columns), 1): confirmed[day - 4] += data.iloc[i][day] - confirmed_r[day - 4] diff_confirmed[day - 4] += confirmed[day-4] / confirmed_r[day - 4] tl_confirmed = 0 dlog_confirmed = [0] * (len(data.columns) - 4) dlog_confirmed[0]=np.log(confirmed[0]) dlog_confirmed[1]=np.log(confirmed[1])-np.log(confirmed[0]) for i in range(2, len(confirmed)-2, 1): if confirmed[i] > 0: dlog_confirmed[i]=(np.log(confirmed[i+1])-np.log(confirmed[i-1]))/2 else: continue tl_confirmed = confirmed[len(confirmed)-1] + confirmed_r[len(confirmed)-1] + confirmed_d[len(confirmed)-1] t_cases = tl_confirmed return confirmed, dlog_confirmed複数の国を同一図上にプロットするために以下のようにしています。
city_listに描きたい国を入れます。
上記のデータ処理関数で感染数データとその片対数の傾きを取得します。
これを描画します。
そのためにfig, (ax1,ax2) = ...の定義をfor文外で定義しました。
最後にまとめて、表示します。
colorはあえて定義せず、自動で選んでもらっています。city_list={ "Spain","Germany","Switzerland","United Kingdom", "Netherlands" } fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 4, 4*2)) for city in city_list: confirmed = [0] * (len(data.columns) - 4) confirmed_r = [0] * (len(data_r.columns) - 4) confirmed_d = [0] * (len(data_d.columns) - 4) diff_confirmed = [0] * (len(data.columns) - 4) days_from_22_Jan_20 = np.arange(0, len(data.columns) - 4, 1) days_from_22_Jan_20_ = np.arange(0, len(data.columns) - 4, 1) recovered_rate = [0] * (len(data_r.columns) - 4) deaths_rate = [0] * (len(data_d.columns) - 4) confirmed, dlog_confirmed = data_city(city) #matplotlib描画 lns1=ax1.semilogy(days_from_22_Jan_20, confirmed, ".-", label = str(city)) lns4=ax2.plot(days_from_22_Jan_20_, dlog_confirmed, ".-",label = str(city)) ax1.set_xlabel("days from 22, Jan, 2020") ax1.set_ylabel("casas ") ax2.set_ylabel("slopes ") ax1.legend(loc=0) ax2.legend(loc=0) ax1.grid() ax2.grid() plt.pause(1) plt.savefig('./fig/logmulti_{}_.png'.format(city)) plt.close()・追加の理論
実は、治癒数曲線の推移は回復に遅れはあるが、感染数曲線と類似しているだろうという想像ができる。
ということで、以下その話を眉唾だがやってみた。
まず、SIRモデルの第三方程式に$I$を代入すると以下のとおりとなる。
※再生産数のRと回復数のRが被るのでここでは回復数を小文字にした\frac{dr}{dt} = \gamma I_0\exp(\gamma (R - 1)t) \\従って、両辺の対数を取ると
\ln (\frac{dr}{dt}) = \ln \gamma + \ln I_0 + \gamma (R - 1)t \\となる。すなわち、回復率の時間微分(傾き)は上式と傾きが同じ曲線になることが期待でき、y切片が$\ln \gamma$だけ異なるものが得られる。
しかし、これだと誤差も大きく扱い難そうなので、ちょっと変更します。すなわち、(解析的には正しくないが)Rがコンスタントとして積分すると以下の式を得る。
r = \frac{I_0}{(R-1)}\exp(\gamma (R - 1)t) + r_0\\したがって、両辺対数取ると
\ln r = \ln I_0 -\ln (R-1) + \gamma (R - 1)t +\ln r_0と書ける。ということで上記の$\ln I$の式と比較するとほぼ平行でy切片が$-ln (R-1)+\ln r_0$異なる曲線が得られることが期待できる。
・各国の予測II
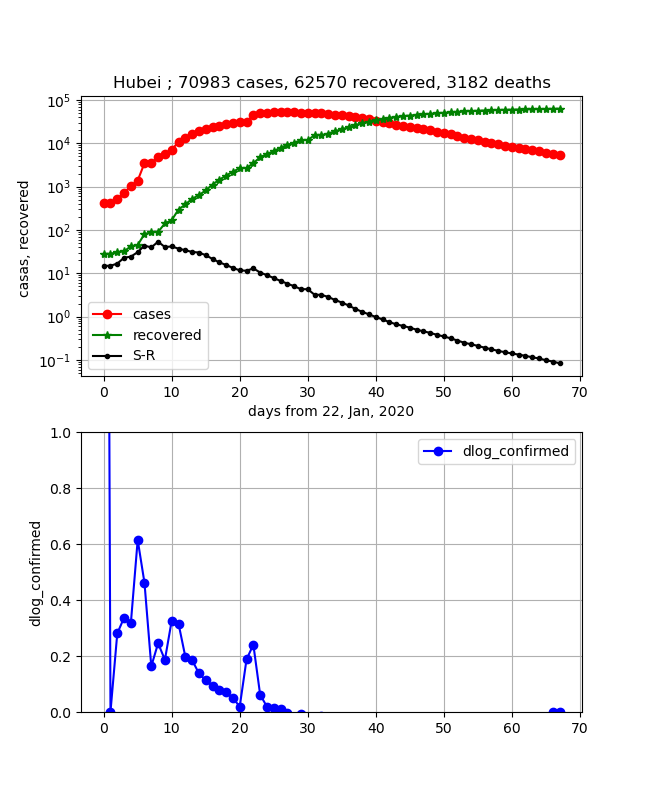
・武漢の状況
以下のように綺麗な曲線が得られました。予想どおり感染数曲線と治癒数曲線は平行に始まり感染数ピークを過ぎたところで交差します。
それに合わせて、二つの曲線の差分($\log (A/B)=\log A-\log B$)は直線的に$10^0$を通過します。
・イタリアの状況
両曲線が平行になっており、上では10日程度で感染数ピークになりそうという結論を出しましたが、そのあと、なかなか交差しないように見えます。
このあと、きっと近づいてきて交差するものと考察されますが、治癒数データが怪しいかもしれません。
・ヨーロッパを代表してスペインの状況
着実に両曲線が近づきつつあり、感染数ピークのあと交差し終息が見えてくる状況です。
・日本の状況
日本はだんだん二つの曲線が近づいて来て、差は0に向かっていましたが、このところの感染数増加で差が広がってしまいました。ということで上記と同様、感染拡大は継続しているので抑え込みが必要という結論になります。
まとめ
・各国の感染数データを対数プロットして分類し、それぞれの感染数ピークの時期を予測した
・感染数と治癒数データを同時にプロットすることにより、終息時期を予測した・日々変わる状況を追尾したいと思う
・追加部分の理論が怪しいのでもう少し整理し、パラメータ決定につなげようと思う


- 投稿日:2020-03-31T21:55:27+09:00
【対数グラフ入門】感染数データの対数グラフから各国終息時期を予測する♬
今回は、対数プロットすることにより各国の感染ピークの時期を予測することとする。
やったこと
・ちょっと理論
・各国の予測
・コード解説
・追加の理論
・各国の予測II・ちょっと理論
前回、以下の式を導出した。
I = I_0\exp(\gamma (\frac{\beta}{\gamma} \frac{S}{N} - 1)t)\\この両辺を対数取ると、
\ln I = \ln I_0+\gamma (\frac{\beta}{\gamma} \frac{S}{N} - 1)t\\が得られる。すなわち、縦軸に$\ln I$横軸に時間$t$を取ったグラフを描くと、傾きが
\gamma (\frac{\beta}{\gamma} \frac{S}{N} - 1)\\の直線が描ける。ここで、この傾きは$S$に依存しており時間と共に減少する未感染者数である。
そして、この傾きは前回導入した実効再生産数$R$を使うと以下のように書き換えられる。\gamma (R - 1)\\ R = R_0 \frac{S}{N}\\ R_0 = \frac{\beta}{\gamma}\\したがって、この傾きはR=1で0になり、すなわち再生産数=0となり、これ以上感染者が増えないので感染ピークとなる。
今回は、この理論を根拠に各国のデータを$\log I\ vs\ t$でプロットし、それぞれの国の感染ピークの時期を見たいと思う。また、あわよくば立ち上がりの傾きから、$S\fallingdotseq N$であり、$\gamma (R_0 -1)$が得られる。
これを初期値にして得られたグラフをフィッティングすると、$\gamma$,$\beta$,$R_0$が求められそうである。・各国の予測
・Korea, South, Diamond Princess, Italyの状況
Italyが入っているのが不信に思われるかもしれませんが、結果は以下のとおりです。
この3つの国を並べてみると、割と様になっているのが分かります。
すなわち、適当にx,y軸を平行移動すると重なりそうです。つまり、傾きが同一な領域があることが分かります。
どのグラフも、ほぼ10日で10倍になる区間が見えます。
そうです、DPが最初に感染数曲線が飽和し、次に韓国、そしてこれからイタリアがまさしく飽和しそうな状況です。下のグラフは傾きをプロットしています。すなわち、0になると飽和したことを表します。
ということで、このグラフからも上記のことが分かります。
イタリアに関して言及すると、いろいろ言われてきましたがあと10日程度でピークに達すると思われます。・ヨーロッパ各国の状況
イタリア以外の、Spain,Germany,Switzerland,United Kingdom, Netherlandsについて、同一のグラフで表示します。
重ねて書いてみると、イギリスが少し遅れていますが、その他はよく似ている曲線を描いています。
縦軸はそれぞれの事情に依存して(人口など)異なりますが、ほぼ同様な傾きの変化をしています。
そして、傾きの図を見ると2週間程度内にはまとめて飽和してきそうです。・ちょっと残念な国
Japan, Iran, Bahrainの3つの国もある意味曲線が酷似しています。
立ち上がりの状況が異なるので、y軸が全く違うので医療体制の状況は異なると思います。
しかし、一旦立ち上がってしまったあとの傾きが割と似ており、しかもこの何日間でほぼ飽和しているにも関わらず、イランと日本は再度スーと増加してしまっています。バーレーンも傾きが負になっているのですが、再度正に戻ってしまっています。
これら3国の勾配は、安定してからの勾配として10倍/30日程度のいつでも飽和しそうな緩い勾配になっています。
これらの国はまだまだ感染が継続しており、緊張を持って社会全体で封じ込めて行く必要があります。・噂のアメリカの状況
SwedenとUSを同一プロットしてみました。
一目瞭然ですが、立ち上がりは似ています。しかし、スウェーデンは途中から傾きが小さくなっています。しかし、下の傾きのグラフを見るとこのところほぼx軸に平行になっていて、0に向かっているようには見えません。つまり、近日中に飽和はしないように見えます。
ただしアメリカは、58日から65日のデータがそろってきていて、傾きが0に向かって急激に近づいているようにも見えます。これを伸ばすとあと10日程度で感染ピークになる可能性もあることが分かります。
なお、両国の最大勾配は25倍/20日程度で先ほどの勾配より大きいのが分かります。・コード解説
利用するLibとデータ読み込みは前回と同一です。
死亡数データも処理していますが、以下では使わないので削除しています。import numpy as np from scipy.integrate import odeint from scipy.optimize import minimize import matplotlib.pyplot as plt import pandas as pd #pandasでCSVデータ読む。 data = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv') data_r = pd.read_csv('COVID-19/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')以下、データ加工関数で、処理した感染数データと勾配データを返します。
def data_city(city): #データを加工する t_cases = 0 t_recover = 0 t_deaths = 0 for i in range(0, len(data_r), 1): if (data_r.iloc[i][1] == city): #for country/region #if (data_r.iloc[i][0] == city): #for province:/state print(str(data_r.iloc[i][0]) + " of " + data_r.iloc[i][1]) for day in range(4, len(data.columns), 1): confirmed_r[day - 4] += data_r.iloc[i][day] t_recover += data_r.iloc[i][day] for i in range(0, len(data), 1): if (data.iloc[i][1] == city): #for country/region #if (data.iloc[i][0] == city): #for province:/state print(str(data.iloc[i][0]) + " of " + data.iloc[i][1]) for day in range(4, len(data.columns), 1): confirmed[day - 4] += data.iloc[i][day] - confirmed_r[day - 4] diff_confirmed[day - 4] += confirmed[day-4] / confirmed_r[day - 4] tl_confirmed = 0 dlog_confirmed = [0] * (len(data.columns) - 4) dlog_confirmed[0]=np.log(confirmed[0]) dlog_confirmed[1]=np.log(confirmed[1])-np.log(confirmed[0]) for i in range(2, len(confirmed)-2, 1): if confirmed[i] > 0: dlog_confirmed[i]=(np.log(confirmed[i+1])-np.log(confirmed[i-1]))/2 else: continue tl_confirmed = confirmed[len(confirmed)-1] + confirmed_r[len(confirmed)-1] + confirmed_d[len(confirmed)-1] t_cases = tl_confirmed return confirmed, dlog_confirmed複数の国を同一図上にプロットするために以下のようにしています。
city_listに描きたい国を入れます。
上記のデータ処理関数で感染数データとその片対数の傾きを取得します。
これを描画します。
そのためにfig, (ax1,ax2) = ...の定義をfor文外で定義しました。
最後にまとめて、表示します。
colorはあえて定義せず、自動で選んでもらっています。city_list={ "Spain","Germany","Switzerland","United Kingdom", "Netherlands" } fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 4, 4*2)) for city in city_list: confirmed = [0] * (len(data.columns) - 4) confirmed_r = [0] * (len(data_r.columns) - 4) confirmed_d = [0] * (len(data_d.columns) - 4) diff_confirmed = [0] * (len(data.columns) - 4) days_from_22_Jan_20 = np.arange(0, len(data.columns) - 4, 1) days_from_22_Jan_20_ = np.arange(0, len(data.columns) - 4, 1) recovered_rate = [0] * (len(data_r.columns) - 4) deaths_rate = [0] * (len(data_d.columns) - 4) confirmed, dlog_confirmed = data_city(city) #matplotlib描画 lns1=ax1.semilogy(days_from_22_Jan_20, confirmed, ".-", label = str(city)) lns4=ax2.plot(days_from_22_Jan_20_, dlog_confirmed, ".-",label = str(city)) ax1.set_xlabel("days from 22, Jan, 2020") ax1.set_ylabel("casas ") ax2.set_ylabel("slopes ") ax1.legend(loc=0) ax2.legend(loc=0) ax1.grid() ax2.grid() plt.pause(1) plt.savefig('./fig/logmulti_{}_.png'.format(city)) plt.close()・追加の理論
実は、治癒数曲線の推移は回復に遅れはあるが、感染数曲線と類似しているだろうという想像ができる。
ということで、以下その話を眉唾だがやってみた。
まず、SIRモデルの第三方程式に$I$を代入すると以下のとおりとなる。
※再生産数のRと回復数のRが被るのでここでは回復数を小文字にした\frac{dr}{dt} = \gamma I_0\exp(\gamma (R - 1)t) \\従って、両辺の対数を取ると
\ln (\frac{dr}{dt}) = \ln \gamma + \ln I_0 + \gamma (R - 1)t \\となる。すなわち、回復率の時間微分(傾き)は上式と傾きが同じ曲線になることが期待でき、y切片が$\ln \gamma$だけ異なるものが得られる。
しかし、これだと誤差も大きく扱い難そうなので、ちょっと変更します。すなわち、(解析的には正しくないが)Rがコンスタントとして積分すると以下の式を得る。
r = \frac{I_0}{(R-1)}\exp(\gamma (R - 1)t) + r_0\\したがって、両辺対数取ると
\ln r = \ln I_0 -\ln (R-1) + \gamma (R - 1)t +\ln r_0と書ける。ということで上記の$\ln I$の式と比較するとほぼ平行でy切片が$-ln (R-1)+\ln r_0$異なる曲線が得られることが期待できる。
・各国の予測II
・武漢の状況
以下のように綺麗な曲線が得られました。予想どおり感染数曲線と治癒数曲線は平行に始まり感染数ピークを過ぎたところで交差します。
それに合わせて、二つの曲線の差分($\log (A/B)=\log A-\log B$)は直線的に$10^0$を通過します。
・イタリアの状況
両曲線が平行になっており、上では10日程度で感染数ピークになりそうという結論を出しましたが、そのあと、なかなか交差しないように見えます。
このあと、きっと近づいてきて交差するものと考察されますが、治癒数データが怪しいかもしれません。
・ヨーロッパを代表してスペインの状況
着実に両曲線が近づきつつあり、感染数ピークのあと交差し終息が見えてくる状況です。
・日本の状況
日本はだんだん二つの曲線が近づいて来て、差は0に向かっていましたが、このところの感染数増加で差が広がってしまいました。ということで上記と同様、感染拡大は継続しているので抑え込みが必要という結論になります。
まとめ
・各国の感染数データを対数プロットして分類し、それぞれの感染数ピークの時期を予測した
・感染数と治癒数データを同時にプロットすることにより、終息時期を予測した・日々変わる状況を追尾したいと思う
・追加部分の理論が怪しいのでもう少し整理し、パラメータ決定につなげようと思う
- 投稿日:2020-03-31T21:44:36+09:00
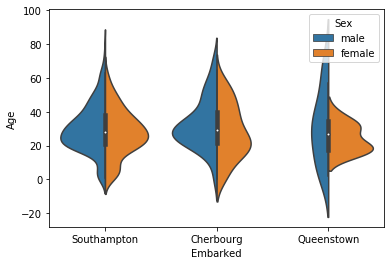
「箱ひげ図」に「ひと味」加えて可視化する(boxen / swarm / violin)
概要
- kaggleのtitanicのデータ可視化で思ったことのメモです。
- 「乗船した港」毎に「乗客の年齢」分布をうまく可視化したい。
- そういったときに、箱ひげ(seabornで言えばboxplot)を使うのがよくある手段
- 一方で、他の 可視化手段を使うと「ひと味」加える事ができるので、まとめてみました。
- 今回は、seabornの箱ひげ図(boxplot)の代替として下記あたりを検討してみたいと思います。
- 誰かの役に立つと嬉しいですが、あくまでも作業メモ&私見です。
モチベーション
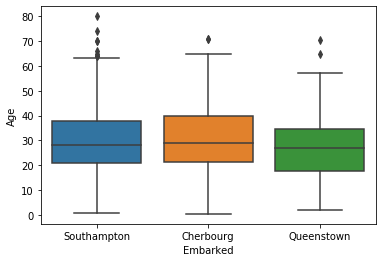
箱ひげ
- タイタニックで、乗船港毎の乗客の年齢はこんな感じ。(まずは、箱ひげ)
- 一応、下記程度は読み取れます。
- どの港から乗ったとしても、年齢の中央値は25~30歳くらい
- 中央値や第1、3分位値にも大きく差はない。(Queenstownがちょっと若め?)
- Southamptonから乗った乗客に、外れ値(高齢の方のデータ)が目立つ
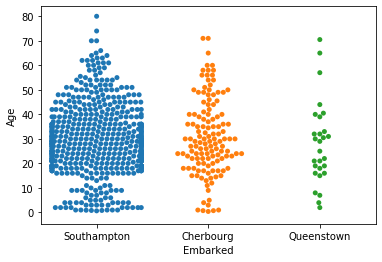
Swarmplotにしてみると
- これをSwarmplotにしてみると、四分位値は見づらくなる代わりに、ひと味加わり良い感じ。
- 系列毎のデータの個数を意識できるようになる。(実は、Queenstownは少数)
- 箱やひげの意味を知らない人にも読みやすい
- データの密な部分、疎な部分を読み取りやすい
箱ひげにひと味加える
関数やオプションを変えてみる
- 関数をかえる
- オプションをかえる
- hue、splitの指定
等々やると、ひと味加える事ができます
まとめてみると(チートシート)
- boxenplotには、splitオプションがない
- swarmplotとviolinplotでは、splitオプションの意味が、ちょっと違うので注意
オプション boxenplot swarmplot violinplot 指定無し hue="Sex" hue="Sex"
split=Trueなし 「どれ」を「いつ」使うべきか?
- 「この用途では、これ!」と言い切るのは難しいのですが、、
- それぞれ比較してみると特性が見えてきます。
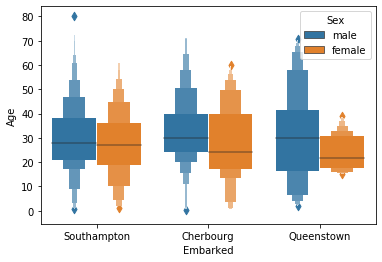
箱ひげ(boxplot) vs boxenplot
- アルファベット的にも2文字(en)しか変わらないのでそこまで差はありません
- 四分位で見せたいか、もっと細かい分位値で見せたいか? 外れ値 を意識させたいか?がポイント
箱ひげ(boxplot) boxenplot 表示 特徴 四分位、最大、最小が分かる
外れ値の状況も見えるより細かい分位値が見える
外れ値として見えづらい箱ひげ(boxplot) vs swarmplot
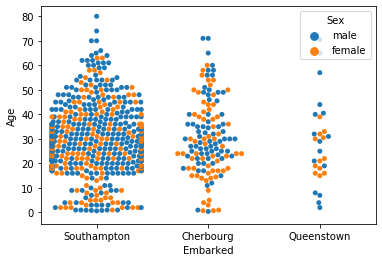
- 箱ひげに比べて、データの個々を意識し、連続的に捉えるswarmplot
- データの個数、密度、差も見えるようになるが、プロットコストが高く、大量データだと厳しい。
箱ひげ(boxplot) swarmplot 表示 特徴 区間(分位値)として捉える
プロットコストが低い個々を意識し連続的にデータを捉える
データ個数や系列毎の差も理解可
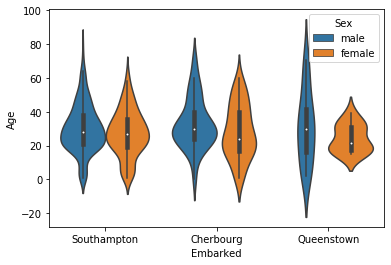
しかし、プロットコストが高いswarmplot vs violinplot
- swarmplotのように、連続的にデータを扱い、プロットコストも抑えられるのがviolinplot
- その代わり、データの個数や系列毎の差は意識できなくなる。
swarmplot violinplot 表示 特徴 個々を意識し連続的にデータを捉える
データ個数や系列毎の差も理解可
しかし、プロットコストが高い個々を意識せず、データの個数が見えないが、
全体傾向を連続的に理解可能
プロットコストも抑える事ができる。まとめ
- 一長一短あり、用途に応じて選択すべきですが、まとめると下記といったところでしょうか。
区間 vs 連続 ひと味の加え方 選ぶべき可視化手法は? データを区間
(分位)で扱い、外れ値も意識させたければ、 箱ひげ(boxplot) 四分位より細かい表示では、 boxenplot 
データを連続的に扱い、 その個数や密度を見せたければ、 swarmplot プロットコストを抑えて全体傾向を見せたければ violinplot 

- 投稿日:2020-03-31T21:29:20+09:00
Pythonで毎日AtCoder #22
はじめに
前回
今日は最近のCをやります#22
考えたこと
ABC160-C
コテンスト中は$N!*N$の全てを考えようとしていましたが、それではTLEしてしまいます。N個全て訪問するので1つ通らない区間があります。$A_i$から時計周り、反時計周りすると考えると左右どちらかは通りません。ですので$A_i$と左右の距離の最大値が答えになります。注意点は$A_N$→$A_1$の場合はそのままでは計算できないので、別で計算しました。k, n = map(int,input().split()) a = list(map(int,input().split())) cost = max(a[0]+k-a[-1],a[-1]-a[-2]) for i in range(1,n-1): cost = max(a[i]-a[i-1],a[i+1]-a[i],cost) print(k-cost)ABC159-C
直方体の時に体積が最大になるので3で割って三乗するだけprint((int(input())/3)**3)ABC158-C
計算するだけ。前回解いた時にもっと余裕持ってfor回せると言われたので10000まで計算しています。//1で切り捨て処理しています。a, b = map(int,input().split()) for i in range(10000): if (i * 0.08)//1 == a and (i * 0.1)//1 == b: print(i) quit() print(-1)ABC157-C
問題見た時は簡単だと思ったけどできなかった。strにして桁ごとに比較してもできなかった。結果を見る限りうまく場合分けでできてない。リベンジするABC156-C
$N$が小さいので$N$以下の全ての整数でコストを計算します。中央値付近で最小になる?n = int(input()) x = list(map(int,input().split())) ans = 10**9 for i in range(101): cost = 0 for j in range(n): cost += (x[j]-i)**2 ans = min(ans,cost) print(ans)ABC155-C
$S$をcollections.Counterに入れて、most_commonして最頻値を求めています。あとは出力するだけimport collections n = int(input()) s = [str(input()) for _ in range(n)] s = collections.Counter(s) s = s.most_common() c = s[0][1] ans = [] for i in range(len(s)): if s[i][1] == c: ans.append(s[i][0]) ans.sort() for i in ans: print(i)まとめ
Cは楽しい。では、また
- 投稿日:2020-03-31T21:26:17+09:00
全然エンジニアじゃないけど機械学習で顔を分類した
はじめに
IT企業でseleniumをマクロとかPythonで動かす程度の、カスタマーサポート担当やってますー。
たまたま見つけたAI開発コンテスト「Neural Network Console Challenge」に参加してみたので、投稿しますー。「Neural Network Console Challenge」とは
ソニーネットワークコミュニケーションズ株式会社がノンプログラミングでAI開発できるGUIツールである「Neural Network Console(以下NNC)」を、
ピクスタ株式会社が普段扱うことのできない10,000点もの人物画像データを提供することで、初心者にも優しいAI開発チャレンジになっているみたいです。テーマ決め
このチャレンジでは画像分類のテーマを各自が決めて、NNCで学習。学習結果をプロセスとともに提出するというもの。
画像を見渡す中で人物が写った画像がやはり多そうだったので、まずは顔を抽出。
OpenCVの分類器でPIXTA画像から大量の顔を切り抜く。画像の前処理?については下記記事を参考にさせていただきました。初心者にもわかりやすい投稿者様に感謝。
ディープラーニングでザッカーバーグの顔を識別するAIを作る
TensorFlowによるももクロメンバー顔認識顔の抽出
# -*- coding:utf-8 -*- import cv2 import numpy as np from PIL import Image # PIXTA画像を保存したフォルダ input_data_path = './pixta_images/' # 切り抜いた画像の保存先ディレクトリ save_path = './cutted_face_images/' # OpenCVのデフォルトの分類器のpath cascade_path = './opencv/data/haarcascades/haarcascade_frontalface_default.xml' faceCascade = cv2.CascadeClassifier(cascade_path) # 顔検知に成功した数 face_detect_count = 0 # 集めた画像データから顔が検知されたら、切り取り、保存する。 types = ['*.jpg'] paths = [] for t in types: paths.extend(glob.glob(os.path.join(input_data_path, t))) for p in paths: img = cv2.imread(p, cv2.IMREAD_COLOR) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) face = faceCascade.detectMultiScale(gray, 1.1, 3) if len(face) > 0: for rect in face: x = rect[0] y = rect[1] w = rect[2] h = rect[3] cv2.imwrite(save_path + 'cutted_face' + str(face_detect_count) + '.jpg', img[y:y+h, x:x+w]) face_detect_count = face_detect_count + 11500枚の画像から約2500くらいの顔が検出されました。検出した顔の中には、顔っぽく見える影やドット柄も含まれており、手作業で削除します。
1000枚程度を削除して、残ったのは1500の顔。
学習用データ提供:PIXTA運営事務局からのテーマ例には嬉しい/悲しい/恥ずかしいなど、感情によって分類するというものがあったが、顔写真をみていると、笑顔ばっかり。
そこで、笑顔を何種類かに分類することに決めました。データセットの作成
NNCにアップロードできる形にするため、1500の顔を笑顔の程度で分別していきます。
まず手始めに笑っているか笑っていないかの2つに分類し、それぞれフォルダにまとめました。さらに、ファイル名とラベルを定義したcsvを準備してNNCにアップロード。
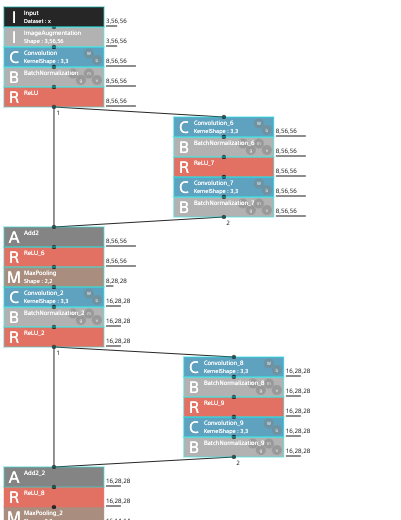
学習のモデルはSONYさんがYouTubeで配信しているNNCに関する説明動画を元に、以下のような物を作ってみました。
学習結果はというと、、、
うーん、ラベルそれぞれで画像データの数にばらつきもあったし、こんなものなのかな。
よくわかりませんが、2つの分類では面白くないので、次は分類を増やしていきます。
- アハハ(声が出てる)
- ニコニコ(顔全体の笑顔)
- にこり(口もしくは目が笑う)
- フフフ(微笑み)
- 真顔
追加での顔抽出も行い、それぞれ200枚程度準備して学習データとテストデータに分けてアップロード。
見事にグダグダな結果ですね。横に一つずれてるものも含めれば、なんとなく合ってるくらい。
原因は、私が分別する中でそもそも自分の中で定義できてないからかもしれません。抽出した笑顔をずっと見てると、何がなんだかわからなくなってしまい笑分類を一つ減らし、4つでデータを作り直しました。
- アハハ(声が出てる)
- ニコニコ(口を開けてる)
- フフフ(口を閉じてる)
- 真顔
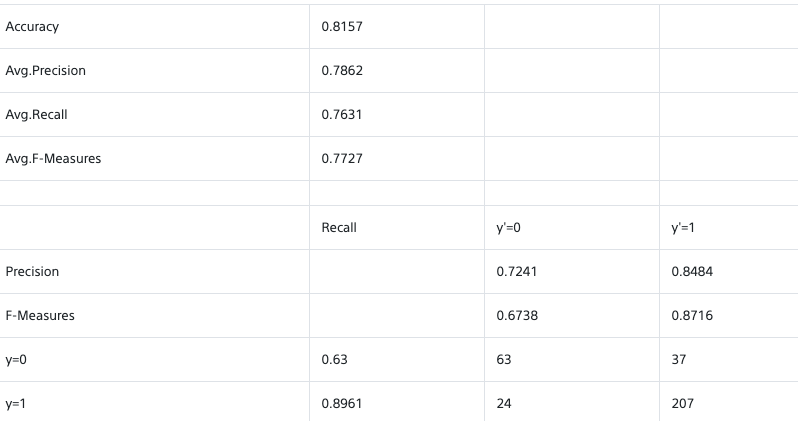
さっきより随分改善しました。が70%にも届かず。
その後は以下の動画塔を参考に、過学習を防ぐためにImage Augmentationやcutout、Dropoutなど試してみるものの、なかなか精度は向上せず。
期限ということもあり、結局中間層を減らし、以下の結果を出してタイムアップのようです。
学習用データ提供:PIXTA75%程度となかなか満足のいく結果とはなりませんでしたが、時間があれば、自分で準備した画像などで改めてチャレンジしてみたいと思いますー。知識ないながらも楽しく取り組めました!

- 投稿日:2020-03-31T20:55:03+09:00
Python で Fizz Buzz の問題にチャレンジ(今だけ398までの数字)
Fizz Buzz の問題にチャレンジ
1~398までの数字で、
3で割り切れれば、「Fizz!」を表示する
5で割り切れれば、「Buzz!」を表示する
3と5で割り切れれば、「Fizz Buzz!」を表示する
上記以外の場合は、そのままの数字を表示する
ヒント:for 文と if 文を組み合わせるシンプルにforとifしか使わない例
sample1.pyfor x in range(398): fb = "" x = x + 1 if x % 5 == 0: fb = "Buzz!" if x % 3 == 0: fb = "Fizz" if x % 5 == 0: fb = fb + " Buzz!" if x % 5 != 0: fb = fb + "!" if x % 3 != 0: if x % 5 != 0: fb = x print(fb)andとかorとかelifとかいうものを使う例
sample2.pyfor x in range(398): fb = "" x = x + 1 if x % 3 == 0 and x % 5 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fuzz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x print(fb)関数を使った例
sample3.pydef fb(x): if x % 3 == 0 and x % 5 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fuzz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x return(fb) for x in range(398): x = x + 1 y = fb(x) print(y)出力結果
1 2 Fuzz! 4 Buzz! Fuzz! 7 8 Fuzz! Buzz! 11 Fuzz! 13 14 Fizz Buzz! 16 17 Fuzz! 19 Buzz! Fuzz! 22 23 Fuzz! Buzz! 26 Fuzz! 28 29 Fizz Buzz! 31 32 Fuzz! 34 Buzz! Fuzz! 37 38 Fuzz! Buzz! 41 Fuzz! 43 44 Fizz Buzz! 46 47 Fuzz! 49 Buzz! Fuzz! 52 53 Fuzz! Buzz! 56 Fuzz! 58 59 Fizz Buzz! 61 62 Fuzz! 64 Buzz! Fuzz! 67 68 Fuzz! Buzz! 71 Fuzz! 73 74 Fizz Buzz! 76 77 Fuzz! 79 Buzz! Fuzz! 82 83 Fuzz! Buzz! 86 Fuzz! 88 89 Fizz Buzz! 91 92 Fuzz! 94 Buzz! Fuzz! 97 98 Fuzz! Buzz! 101 Fuzz! 103 104 Fizz Buzz! 106 107 Fuzz! 109 Buzz! Fuzz! 112 113 Fuzz! Buzz! 116 Fuzz! 118 119 Fizz Buzz! 121 122 Fuzz! 124 Buzz! Fuzz! 127 128 Fuzz! Buzz! 131 Fuzz! 133 134 Fizz Buzz! 136 137 Fuzz! 139 Buzz! Fuzz! 142 143 Fuzz! Buzz! 146 Fuzz! 148 149 Fizz Buzz! 151 152 Fuzz! 154 Buzz! Fuzz! 157 158 Fuzz! Buzz! 161 Fuzz! 163 164 Fizz Buzz! 166 167 Fuzz! 169 Buzz! Fuzz! 172 173 Fuzz! Buzz! 176 Fuzz! 178 179 Fizz Buzz! 181 182 Fuzz! 184 Buzz! Fuzz! 187 188 Fuzz! Buzz! 191 Fuzz! 193 194 Fizz Buzz! 196 197 Fuzz! 199 Buzz! Fuzz! 202 203 Fuzz! Buzz! 206 Fuzz! 208 209 Fizz Buzz! 211 212 Fuzz! 214 Buzz! Fuzz! 217 218 Fuzz! Buzz! 221 Fuzz! 223 224 Fizz Buzz! 226 227 Fuzz! 229 Buzz! Fuzz! 232 233 Fuzz! Buzz! 236 Fuzz! 238 239 Fizz Buzz! 241 242 Fuzz! 244 Buzz! Fuzz! 247 248 Fuzz! Buzz! 251 Fuzz! 253 254 Fizz Buzz! 256 257 Fuzz! 259 Buzz! Fuzz! 262 263 Fuzz! Buzz! 266 Fuzz! 268 269 Fizz Buzz! 271 272 Fuzz! 274 Buzz! Fuzz! 277 278 Fuzz! Buzz! 281 Fuzz! 283 284 Fizz Buzz! 286 287 Fuzz! 289 Buzz! Fuzz! 292 293 Fuzz! Buzz! 296 Fuzz! 298 299 Fizz Buzz! 301 302 Fuzz! 304 Buzz! Fuzz! 307 308 Fuzz! Buzz! 311 Fuzz! 313 314 Fizz Buzz! 316 317 Fuzz! 319 Buzz! Fuzz! 322 323 Fuzz! Buzz! 326 Fuzz! 328 329 Fizz Buzz! 331 332 Fuzz! 334 Buzz! Fuzz! 337 338 Fuzz! Buzz! 341 Fuzz! 343 344 Fizz Buzz! 346 347 Fuzz! 349 Buzz! Fuzz! 352 353 Fuzz! Buzz! 356 Fuzz! 358 359 Fizz Buzz! 361 362 Fuzz! 364 Buzz! Fuzz! 367 368 Fuzz! Buzz! 371 Fuzz! 373 374 Fizz Buzz! 376 377 Fuzz! 379 Buzz! Fuzz! 382 383 Fuzz! Buzz! 386 Fuzz! 388 389 Fizz Buzz! 391 392 Fuzz! 394 Buzz! Fuzz! 397 398問題出典元
たまたまお題が出されたのでやったのですが、下記のURLの問題が大元かと思います。
https://qiita.com/Sekky0905/items/7e2b13f2a001384c7fc4
- 投稿日:2020-03-31T20:55:03+09:00
Python で Fizz Buzz! の問題にチャレンジ(今だけ398までの数字)
Fizz Buzz の問題にチャレンジ
1~398までの数字で、
3で割り切れれば、「Fizz!」を表示する
5で割り切れれば、「Buzz!」を表示する
3と5で割り切れれば、「Fizz Buzz!」を表示する
上記以外の場合は、そのままの数字を表示する
ヒント:for 文と if 文を組み合わせるシンプルにforとifしか使わない例
sample1.pyfor x in range(398): fb = "" x = x + 1 if x % 5 == 0: fb = "Buzz!" if x % 3 == 0: fb = "Fizz" if x % 5 == 0: fb = fb + " Buzz!" if x % 5 != 0: fb = fb + "!" if x % 3 != 0: if x % 5 != 0: fb = x print(fb)andとかorとかelifとかいうものを使う例
sample2.pyfor x in range(398): fb = "" x = x + 1 if x % 3 == 0 and x % 5 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fuzz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x print(fb)関数を使った例
sample3.pydef fb(x): if x % 3 == 0 and x % 5 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fuzz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x print(fb) for x in range(398): x = x + 1 fb(x)for文などの繰り返し処理を使わない例
sample4.pydef count(x): if x >= 1: count(x - 1) fb(x) def fb(x): if x % 15 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fizz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x print(fb) count(398)クラスを使った例
sample5.pyclass FizzBuzz: def __init__(self, x): self.count(x) def count(self, x): if x >= 1: self.count(x - 1) self.fb(x) def fb(self, x): if x % 15 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fizz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x print(fb) FizzBuzz(398)出力結果
1 2 Fuzz! 4 Buzz! Fuzz! 7 8 Fuzz! Buzz! 11 Fuzz! 13 14 Fizz Buzz! 16 17 Fuzz! 19 Buzz! Fuzz! 22 23 Fuzz! Buzz! 26 Fuzz! 28 29 Fizz Buzz! 31 32 Fuzz! 34 Buzz! Fuzz! 37 38 Fuzz! Buzz! 41 Fuzz! 43 44 Fizz Buzz! 46 47 Fuzz! 49 Buzz! Fuzz! ... ... ... 386 Fuzz! 388 389 Fizz Buzz! 391 392 Fuzz! 394 Buzz! Fuzz! 397 398問題出典元
たまたまお題が出されたのでやったのですが、下記のURLの問題が大元かと思います。
https://qiita.com/Sekky0905/items/7e2b13f2a001384c7fc4
- 投稿日:2020-03-31T20:55:03+09:00
Python で Fizz Buzz! の問題に5パターン挑戦(今だけ398までの数字)
Python限定のもくもく会で、個人的にFizz Buzz! の問題に取り組んだので、そこでの成果報告です!
Fizz Buzz の問題にチャレンジ
1~398までの数字で、
3で割り切れれば、「Fizz!」を表示する
5で割り切れれば、「Buzz!」を表示する
3と5で割り切れれば、「Fizz Buzz!」を表示する
上記以外の場合は、そのままの数字を表示する
ヒント:for 文と if 文を組み合わせるシンプルにforとifしか使わない例
sample1.pyfor x in range(398): fb = "" x = x + 1 if x % 5 == 0: fb = "Buzz!" if x % 3 == 0: fb = "Fizz" if x % 5 == 0: fb = fb + " Buzz!" if x % 5 != 0: fb = fb + "!" if x % 3 != 0: if x % 5 != 0: fb = x print(fb)andとかorとかelifとかいうものを使う例
sample2.pyfor x in range(398): fb = "" x = x + 1 if x % 3 == 0 and x % 5 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fuzz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x print(fb)関数を使った例
sample3.pydef fb(x): if x % 3 == 0 and x % 5 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fuzz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x print(fb) for x in range(398): x = x + 1 fb(x)for文などの繰り返し処理を使わない例
sample4.pydef count(x): if x >= 1: count(x - 1) fb(x) def fb(x): if x % 15 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fizz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x print(fb) count(398)クラスを使った例
sample5.pyclass FizzBuzz: def __init__(self, x): self.count(x) def count(self, x): if x >= 1: self.count(x - 1) self.fb(x) def fb(self, x): if x % 15 == 0: fb = "Fizz Buzz!" elif x % 3 == 0: fb = "Fizz!" elif x % 5 == 0: fb = "Buzz!" else: fb = x print(fb) FizzBuzz(398)出力結果
1 2 Fuzz! 4 Buzz! Fuzz! 7 8 Fuzz! Buzz! 11 Fuzz! 13 14 Fizz Buzz! 16 17 Fuzz! 19 Buzz! Fuzz! 22 23 Fuzz! Buzz! 26 Fuzz! 28 29 Fizz Buzz! 31 32 Fuzz! 34 Buzz! Fuzz! 37 38 Fuzz! Buzz! 41 Fuzz! 43 44 Fizz Buzz! 46 47 Fuzz! 49 Buzz! Fuzz! ... ... ... 386 Fuzz! 388 389 Fizz Buzz! 391 392 Fuzz! 394 Buzz! Fuzz! 397 398問題出典元
たまたまお題が出されたのでやったのですが、下記のURLの問題が大元かと思います。
https://qiita.com/Sekky0905/items/7e2b13f2a001384c7fc4
- 投稿日:2020-03-31T20:44:28+09:00
PyTorch model を libtorch で C++ 実行するための, Python スクリプトへの型付けメモ
背景
pytorch モデル(特に音声処理系)を trace(TensorFlow でいう freezed model, tflite model)したい.
pytorch 自体がある程度は型推論してはくれますが, 限界があります.
特に音声処理系だと, neural 部分以外にもいろいろとコードがあります. また, 動的配列とか再帰などがあるため, 適切に型付けが必要になります.JIT モデル
https://pytorch.org/docs/stable/jit.html
- TorchScript : Python のサブセットでスクリプト的. 型は必要
- 入力のテンソルが動的に変わる(特に音声系など時系列データやテキストデータなど)ときに使う
- 実行時にコンパイルが必要になりのかしら?(その場合, 起動にいくらか時間かかるかも)
- Traced model : TensorFlow で言う freezed model, tflite model に近い?
- 入力テンソルのサイズが固定のときに使える.
- 推論が早くなる... かも?
- 構文には制限があるかも
traced model が理想で, 次点で TorchScript でしょうか.
一応両方組み合わせることもできるようです.
環境
- Python 3.6 or later(Python で型付けする
typingmodule と, 型アノテーション構文が使える)型を調べる
現在の Python スクリプトの型をステップ実行して調べる手があります.
Python デバッガや ipython を使うといいのでしょうか...
Juyter lab とかでも表示してくれるのかな?筆者は基本 vim + コマンドライン実行しか知らないなので, それぞれ型が欲しいところに print(type(x)) などを挿入して調べています...
型付けする
https://pytorch.org/docs/stable/jit.html
python2 などや 3.5 用に,
torch.jit.annotateを使ったり, コメントに型を記述する手もありますが,typingモジュールを使い, python 構文内に型アノテーションするのが推奨です.サンプル
def forward(self, x: List[torch.Tensor]) -> Tuple[torch.Tensor]: my_list: List[Tuple[int, float]] = []という感じでいけます.
Optional
C++ でいう std::optional のように, None or なにか型を持つ, は
Optional[T]でいけます.Optional[int]@torch.jit.export
通常は
forward()メソッドと, forward から呼ばれる関数しか JIT compile しませんが,@torch.jit.exportデコレータを使うことで, 明示的にメソッドをエクスポート(JIT compile させる)できます
(forwardは暗に@torch.jit.exportがデコレートされている)JIT でスクリプトが実行されているか
scripting で実行されている場合に, 処理を一部省きたかったり, None が想定されるが non None のときは型は任意になるので
Optional[T]で型付けができないなどで, 処理を分けたいケースがあります.
torch.jit.is_scripting()で, scripting で python スクリプトが実行されているかどうかを判定できます. ただ, どうもうまく動いていない模様...?(v1.4.0)nn.RNN での _flatten_parameters()
内部で使っている GeneratorExp が TorchScript に対応していません.
GPU 用にメモリレイアウトを調整する用なので, 無視(コード削除)しても大丈夫でしょう.ほか
@torch.jit.unuseddecorator@torch.jit.ignoredecoratorunused や ignore は,
forwardが定義されているが, これは学習用のためなどで, TorchScript では無視したいときに使える.unused と ignore の違いは, unused ではメソッドを呼ぶと例外を出すが, ignore はメソッドを呼んでもなにもしない. 基本は unused を使ったほうがよさそう.
- 定数
T.B.W.
TODO
def myfun(x, activation = None): if activation: x = activation(x) return x myfun(activation=torch.relu)のように, 任意の関数 or None みたいなのを扱いたいときどうすればいいか?
class Mod: def forward(self, x, alpha=1.0): ... class Model: def __init__(self): self.mod = Mod() def forward(self, x): self.mod.forward(x) ...のように, 内部で呼んでいる class の forward に optional 引数がある.
実際のところ使っていなければ削除すればよい?
- 投稿日:2020-03-31T19:32:00+09:00
【Python】組込み型のlistとdequeで実行時間に差が出るケース
※誤った記載ありましたら是非マサカリください(編集リクエストでもぜひ)。
list 型と deque 型
Python の組込み型である list 型と deque 型の挙動を見ていく。
以下は一定長のリストおよびキューを生成し、その要素をで取り出していくコード。
順に1万件、10万件、100万件の長さで実行する。import time from collections import deque for count in [10000, 100000, 1000000]: # オブジェクトの初期化 l = ['a'] * count q = deque(l) # list 型の操作 time1 = time.time() while len(l) > 0: l.pop(0) # deque 型 の操作 time2 = time.time() while len(q) > 0: q.popleft() time3 = time.time() print('count:', count) print(f'list finished: {time2 - time1} sec.') print(f'deque finished: {time3 - time2} sec.') print()なお 第1要素と末尾要素を取り出す操作は list 型と deque 型でそれぞれ以下の関数。
from collections import deque # 初期化 l = [1, 2, 3] q = deque(l) # 第1要素を取り出す操作 l.pop(0) # => 1 d.popleft() # => 1 # 末尾要素を取り出す操作 l.pop(-1) # => 3 d.pop() # => 3実行結果
手元の実行環境では以下の結果となった。
count: 10000 list finished: 0.006018161773681641 sec. deque finished: 0.0003972053527832031 sec. count: 100000 list finished: 0.9306132793426514 sec. deque finished: 0.003919839859008789 sec. count: 1000000 list finished: 133.8608682155609 sec. deque finished: 0.04343390464782715 sec.件数が100万件のケースでは list 型の操作は2分以上かかった。
なぜこうなるのか
list 型はすなわちLinked Listであり、各要素は前後要素への参照先を保存している。
操作
list.pop(0)はリストの第一要素を取り除いた後、以降の要素を1つずつ詰めていく必要があり、リストの長さ n に対して常にO(n)の計算コストとなる。常に第1要素を取り出すような処理はLIFO(後入れ先出し)やスタックと呼ばれるものである。
まとめ
データ長が頻繁に変化するデータ構造としてリストは不向き。
ちなみに 上述の LIFO ではなく FIFO (先入れ先出し)を行うコードは以下。
この場合は リストの長さに拠らないO(1)の処理時間で済むため、実行時間の差はほとんど生じない。※上記との差分箇所に
# hereを記載import time from collections import deque for count in [10000, 100000, 1000000]: # オブジェクトの初期化 l = ['a'] * count q = deque(l) # list 型の操作 time1 = time.time() while len(l) > 0: l.pop(-1) # here1 # deque 型 の操作 time2 = time.time() while len(q) > 0: q.pop() # here2 time3 = time.time() print('count:', count) print(f'list finished: {time2 - time1} sec.') print(f'deque finished: {time3 - time2} sec.') print()↓実行結果
count: 10000 list finished: 0.0006232261657714844 sec. deque finished: 0.0005576610565185547 sec. count: 100000 list finished: 0.005739688873291016 sec. deque finished: 0.004764080047607422 sec. count: 1000000 list finished: 0.05780482292175293 sec. deque finished: 0.05013251304626465 sec.

- 投稿日:2020-03-31T18:42:59+09:00
アンドロイドで線形回帰モデルを使って推論してみる[PyTorch Mobile]
今回やること
python で線形回帰モデルを作ってそのモデルを使ってアンドロイド上で推論する。(アンドロイド上で学習させるわけではありません。)
今回のコードはgithubに載せているので適宜参照してください。(最下部にURL掲載)
今回作るやつ↓
・PyTorch Mobileを使う
モデルの作成
まずはアンドロイドで動かすための線形モデルを作っていく。
python環境がなくアンドロイドの方だけ読みたい方はアンドロイドで推論という見出しまで読み飛ばして、完成したモデルをダウンロードしてください。なお今回掲載するコードはjupyter notebook上で動かしたものです。
データセット
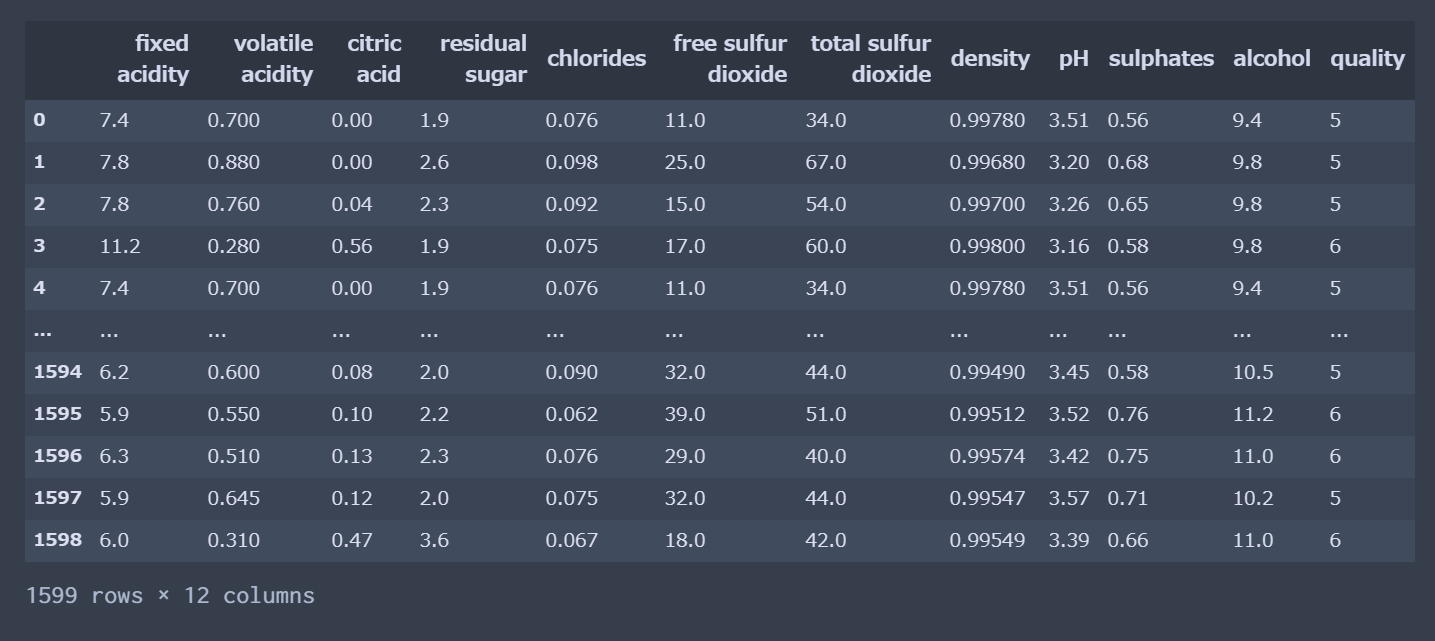
今回使うデータセットはkaggleに載ってた Red Wine Qualityを使ってみる。
酸味、ph、度数などのワインの成分データからワインの10段階の品質を予測する感じ。
今回は単に線形モデルをアンドロイドで動かしてみたいだけなのでシンプルな線形重回帰で10段階クオリティを連続値とみて線形モデルでフィッティングしていく。11カラムあるけど特にL1正則化とかは無しで。(うーん、精度悪くなりそう...)
データ整理
データを眺めたり、データの欠損地チェックや、データの整理を行う。
kaggle からダウンロードしたデータのインポート
import torch from matplotlib import pyplot as plt import pandas as pd import seaborn as sns wineQualityData = pd.read_csv('datas/winequality-red.csv')一応相関をプロットしたり、欠損チェックしたり..
sns.pairplot(wineQualityData) #欠損データのチェック wineQualityData.isnull().sum()
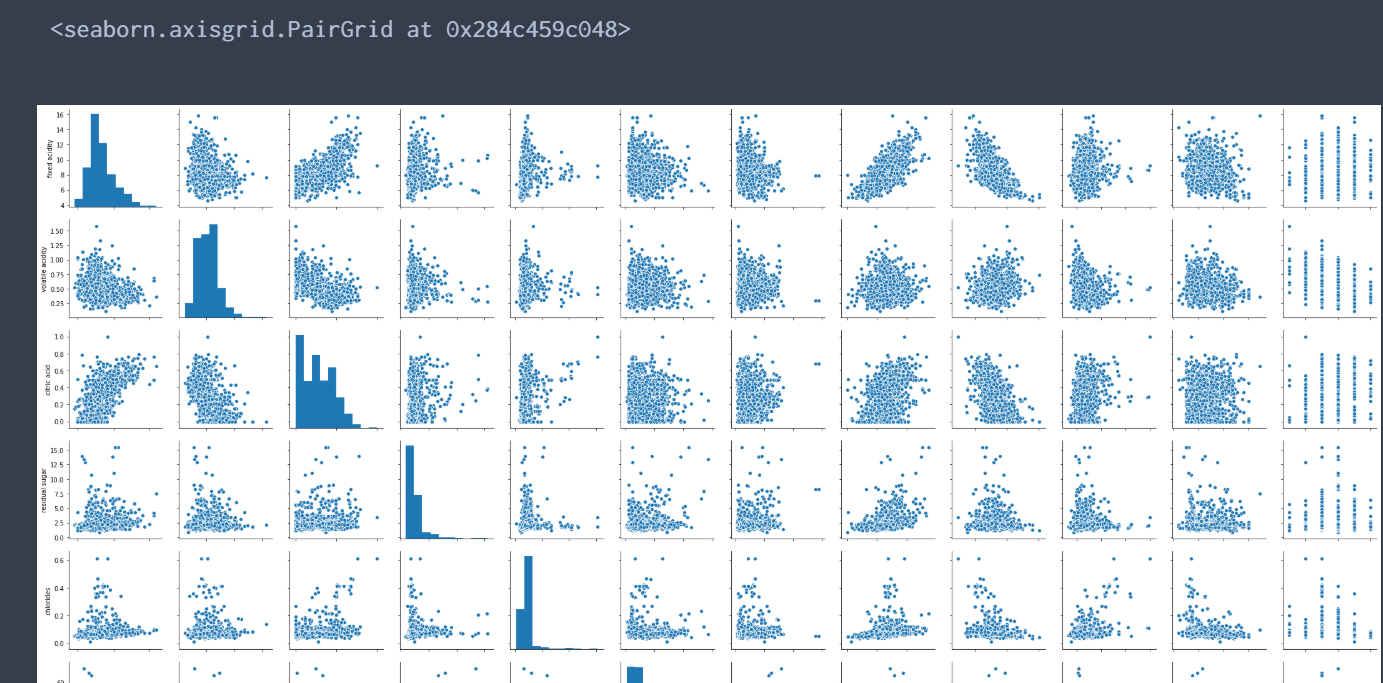
特に欠損値とかもないので次にデータローダーを作っていく
データローダーの作成
#入力と正解ラベル X = wineQualityData.drop(['quality'], 1) y = wineQualityData['quality'] #8:2で分ける X_train = torch.tensor(X.values[0:int(len(X)*0.8)], dtype=torch.float32) X_test = torch.tensor(X.values[int(len(X)*0.8):len(X)], dtype=torch.float32) #8:2で分ける y_train = torch.tensor(y.values[0:int(len(y)*0.8)], dtype=torch.float32) y_test = torch.tensor(y.values[int(len(y)*0.8):len(y)], dtype=torch.float32) #データローダー作成 train = torch.utils.data.TensorDataset(X_train, y_train) train_loader = torch.utils.data.DataLoader(train, batch_size=100, shuffle=True) test = torch.utils.data.TensorDataset(X_test, y_test) test_loader = torch.utils.data.DataLoader(test, batch_size=50, shuffle=False)pytorchにデータローダーを簡単に作れるメソッドが用意されてて楽。
今回一応テスト用データも作ってますが今回は使いません。モデルの作成
続いて線形モデルを作っていく。
from torch import nn, optim #モデル model = nn.Linear(in_features = 11, out_features=1, bias=True) #学習率 lr = 0.01 #2乗誤差 loss_fn=nn.MSELoss() #損失関数のログ losses_train= [] #最適化関数 optimizer = optim.Adam(model.parameters(), lr=lr)モデルの学習
作成したモデルを学習させる
from tqdm import tqdm for epoch in tqdm(range(100)): print("epoch:", epoch) for x,y in train_loader: # 前回の勾配をゼロに optimizer.zero_grad() # 予測 y_pred = model(x) # MSE loss とwによる微分を計算 loss = loss_fn(y_pred, y) if(epoch != 0): #誤差が小さくなったら終了 if abs(losses_train[-1] - loss.item()) < 1e-1: break loss.backward() optimizer.step() losses_train.append(loss.item()) print("train_loss", loss.item())学習結果
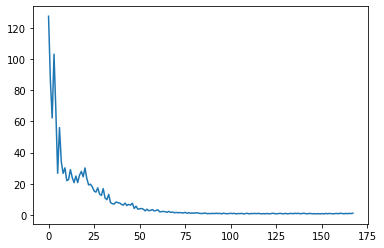
損失関数の推移
plt.plot(losses_train)
一応収束はしてるっぽい。ちょっとできたモデルを試してみる
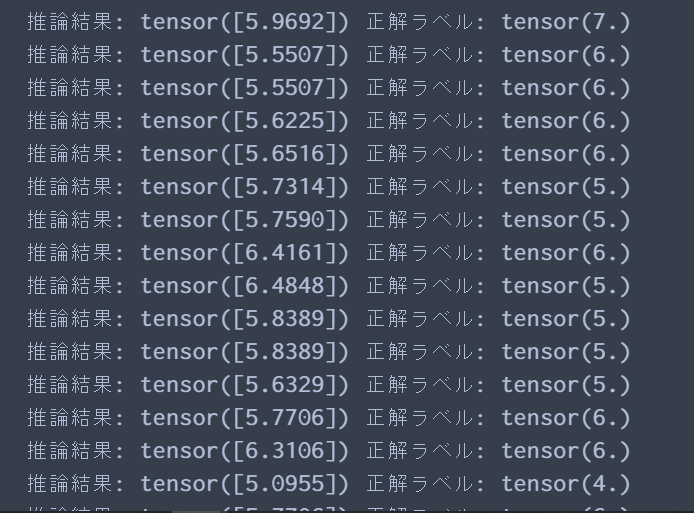
for i in range(len(X_test)): print("推論結果:",model(X_test[i]).data, "正解ラベル:", y_test[i].data)
んん?全然合ってないな。確かにただの線形重回帰だけどこんなに合わないのかなー。
データをもう一回見てみるとクオリティの56%が5だった。つまり、損失を少なくするようにほとんど5の値に収束してしまったのかな。そもそもこういうデータを連続値ラベルとみて線形重回帰するのは厳しかったのか。分類でやった方がよかったかも。ただ、今回はモデルの精度を求めるのがメインではないので、とりあえずはこれでモデル完成ということにしておく。
もし、今回の精度が悪かった原因がコードのここが悪いよとかわかる方いましたら、コメントで教えてください。
モデルの保存
アンドロイドにモデルを入れるためにモデルを保存する
import torchvision model.eval() #入力テンソルのサイズ example = torch.rand(1,11) traced_script_module = torch.jit.trace(model, example) traced_script_module.save("wineModel.pt")うまく実行できると同じフォルダないにptファイルが生成されるはず。
アンドロイドで推論
読み飛ばした方はgithubから学習済みモデルをダウンロードしてください。
ここから、アンドロイドスタジオを使っていきます。
依存関係
2020年3月時点
build.gradledependencies { implementation 'org.pytorch:pytorch_android:1.4.0' implementation 'org.pytorch:pytorch_android_torchvision:1.4.0' }モデルを入れる
アンドロイドスタジオに先ほどダウンロードまたは作成した学習済みモデル(wineModel.pt)を入れる。
まずはassetフォルダを作る(「resフォルダとか適当な場所を右クリック->新規->フォルダ->assetフォルダ」で作れる)
そこに学習済みモデルをコピペする。
レイアウト
推論結果を表示するレイアウトをつくる。といってもtextView3個並べただけ。
activity_main.xml<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <TextView android:id="@+id/result" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Hello World!" android:textSize="24sp" app:layout_constraintBottom_toBottomOf="parent" app:layout_constraintHorizontal_bias="0.5" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/label" /> <TextView android:id="@+id/label" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="TextView" android:textSize="30sp" app:layout_constraintBottom_toTopOf="@+id/result" app:layout_constraintEnd_toEndOf="@+id/result" app:layout_constraintHorizontal_bias="0.5" app:layout_constraintStart_toStartOf="@+id/result" app:layout_constraintTop_toTopOf="parent" /> <TextView android:id="@+id/textView2" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="赤ワイン品質予測" android:textSize="30sp" app:layout_constraintBottom_toTopOf="@+id/label" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toTopOf="parent" /> </androidx.constraintlayout.widget.ConstraintLayout>推論
モデルをロードして、テンソルを入れて推論
MainActivity.ktclass MainActivity : AppCompatActivity() { override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) //ワインのテスト用データ val inputArray = floatArrayOf(7.1f, 0.46f, 0.2f, 1.9f, 0.077f, 28f, 54f, 0.9956f, 3.37f, 0.64f, 10.4f) //テンソルの生成: 引数(floatArray, テンソルのサイズ) val inputTensor = Tensor.fromBlob(inputArray, longArrayOf(1,11)) //モデルのロード val module = Module.load(assetFilePath(this, "wineModel.pt")) //推論 val outputTensor = module.forward(IValue.from(inputTensor)).toTensor() val scores = outputTensor.dataAsFloatArray //結果の表示 result.text ="予測値: ${scores[0]}" label.text = "正解ラベル:6" } //assetフォルダからパスを取得する関数 fun assetFilePath(context: Context, assetName: String): String { val file = File(context.filesDir, assetName) if (file.exists() && file.length() > 0) { return file.absolutePath } context.assets.open(assetName).use { inputStream -> FileOutputStream(file).use { outputStream -> val buffer = ByteArray(4 * 1024) var read: Int while (inputStream.read(buffer).also { read = it } != -1) { outputStream.write(buffer, 0, read) } outputStream.flush() } return file.absolutePath } } }完成!!
ここまで来て実行すると冒頭の画面が出てくるはず。おわり
画像系はチュートリアルでもあるけど、普通の線形とかはあまり載ってなかったのでこの記事を書いてみた。
モデルの精度がイマイチだったのが引っかかる所だけど、一応線形モデルを動かすことができた。
今度は分類をやってみようかな。今回のコードはこちら
pythonコード
android studio コード


- 投稿日:2020-03-31T18:31:25+09:00
VSCodeを使ったPythonパッケージの作り方
動機
プログラミングをしているとプログラムを使い回したいであったり、そのプログラムを他のメンバーに使ってもらうという場面が出てくると思います。
そんなときは、コードを機能ごとにモジュール化、パッケージ化し、きちんとドキュメントを整備しておくと、他の人が使いやすくなるとなると思います。
またPythonのパッケージを作る際はVSCodeが強力なツールとなります。そこでVSCodeを使ったPythonパッケージの作り方について説明します。
またデータ分析プログラムをパッケージ化する時に役立つ情報も載せておきます。
環境
備考 OS Windows10 conda 4.8.3 Anaconda Promptで conda -VAnaconda 2020.02 Anaconda Promptで conda list anacondaPython 3.8.2 VSCode 1.43.2 環境のセットアップ
この記事を参考にVSCodeでのPython実行環境を整えてください。
VSCodeでのPython、Jupyter実行環境の構築方法ディレクトリ構成
VSCodeでの実行環境ができたら、そこにPythonパッケージを開発するためのフォルダやファイルを作っていきます。
. ├── 好きなパッケージ名 │ ├── __init__.py │ └── 好きなファイル名.py ├── setup.py └── script.py
好きなパッケージ名フォルダ以下がパッケージ本体となります。
例として、VSCode上で上図のように作ってみました。例としてパッケージ名を
mypackageとしてみます。setup.pyを書く
setup.pyはパッケージにはこれから作るパッケージの依存情報、バージョン情報、パッケージ名を設定するファイルです。
setup.pyfrom setuptools import setup, find_packages setup( name='mypackage', install_requires=['pandas','scikit-learn'], packages=find_packages() )
setupという関数の引数に設定を書いていきます。
例えば、install_requiresにはパッケージに必要なモジュールを書きます。ほかにも様々な項目があるので、公式ドキュメント(setup スクリプトを書く)などで適宜調べてください。
プログラムを書く
早速プログラムを書いて行きましょう。例として今回はKaggleのタイタニック号のデータを分析するパッケージを作ろうと思います。
パッケージ内のファイル、
preprocessing.pyに次のようなプログラムを書いたとします。
これはデータを前処理するプログラムです。
preprocessing.pyclass Preprocesser: """ 前処理をするクラス """ def process(self,data): """ 前処理をするメソッド """ processed_data=data.copy() # Ageの欠損値を中央値に age_m=processed_data['Age'].median() processed_data['Age']=processed_data['Age'].fillna(age_m) #-----省略----- # 前処理を書いていく return processed_dataプログラムを実行する
プログラムを実行してみましょう。パッケージ
mypackageフォルダ直下にscript.pyというプログラム実行用の.pyスクリプトを作ります。例として、訓練データを前処理し、表示するプログラムを書きます。
script.pydef main(): from mypackage import preprocessing import pandas as pd train=pd.read_csv('train.csv') # 前処理インスタンスを初期化し、前処理をする preprocesser=preprocessing.Preprocesser() train_processed=preprocesser.process(train) print(train_processed.head()) if __name__=='__main__': main()自作パッケージのインポート方法についてですが、自作パッケージのフォルダ直下であれば、
from mypackage import preprocessingのように
from 自作パッケージ名 import 個々のpythonコードのファイル名でパッケージをインポートできます。
この
script.pyを開いた状態で、VSCode上でF5キーを押すと上図のようにプログラムが実行でき、実行結果がTerminal上に表示されます。パッケージをデバッグする
VSCodeでのPython、Jupyter実行環境の構築方法 #デバッグの活用
と同様にパッケージのプログラミングでもVSCodeのデバッグ機能が使えます。
例えば、上図のようにパッケージ内のコード
preprocessing.pyの7行目でF9キーを押します。そうすると、この行の左端に赤い点が表示されます。これをブレークポイントといいます。そしてこの状態でscript.pyに戻り、F5キーを押して実行すると、
上図のようにパッケージ内の7行目で実行が一時停止し、その時宣言されている変数(ここでは
preprocessing.py内の変数)が左のサイドバーに表示されています。このようにブレークポイントを用いることで、プログラムのバグ取り(=デバッグ)が捗ると思います。パッケージをインストールする
この自作パッケージを別環境にインストールしてみます。そしてその別環境でも動くかどうか試してみます。
Anaconda Promptを開き、新しく環境を作ります。
conda create -n 好きな環境名 python=Pythonバージョン
今回は例として
setup_testという環境を作りました。そしてこの環境を起動します。
conda activate setup_testそして上で編集した
setup.pyがあるフォルダまで移動します。cd setup.pyのあるディレクトリそしてこの自作パッケージをインストールします。
python setup.py installインストールできたら、この状態で上の
script.pyを実行してみます。script.pyとtrain.csvを適当な別のフォルダにコピーし、そこで実行してみます。
python script.py
上図のように実行でき、前処理された訓練データが表示されました。このフォルダにはスクリプトとデータがあるだけで、自作パッケージのフォルダはありません。つまり、このフォルダで
script.pyで実行できたということは、この自作パッケージがこの環境にインストールできたということになります。自作パッケージにデモ用データを用意する
自作パッケージを作る際に、ソースコード以外のデータファイルを含めたくなる場合があると思います。
例えばデータ分析用のパッケージを作って配布したとします。そして、他のメンバーがそのパッケージを使いたいと思った時に、データはすぐに用意できないけど分析の挙動を知りたい、というニーズがあると思います。そんなときに、あなたがデモ用のデータをパッケージの中に用意しておけば、その人にスムーズに説明できます。
例として、タイタニック号の訓練データをパッケージ内に用意する場合を説明します。ディレクトリにいくつかフォルダとファイルを加えます。
. ├── mymodule │ ├── __init__.py │ ├── preprocessing.py │ ├── load_date.py * │ └── resources * │ └── train.csv * ├── setup.py └── script.py *:新しく追加したファイル・フォルダまず、自作パッケージ内にデータ用のフォルダを作ります。ここでは
resourcesとします。そしてその中に訓練データ(train.csv)を入れます。パッケージ内のデータを読み込む
次のようなデモデータを読み込むコードを書き、パッケージに加えます。
load_date.pyimport pkgutil,io import pandas as pd class DataLoader: def load_demo(self): train_b=pkgutil.get_data('mypackage','resources/train.csv') train_f=io.BytesIO(train_b) train=pd.read_csv(train_f) return trainここで
pkgutilというPythonに標準で含まれているモジュールを使います。pkgutil.get_data()という関数は、パッケージ名とファイル名を指定するとその内容がバイナリで取得できます。また
ioは読み込んだバイナリデータをファイルっぽく(file-like object)扱えるようにするために使っています。デモデータが読み込めるかテストします。
script.pyのmain()を次のように書き換え、VSCode上でF5で実行します。
script.pydef main(): from mypackage import load_data data_loader=load_data.DataLoader() train=data_loader.load_demo() print(train.head())
上図のようにデモデータが読み込めました。
パッケージインストール時にデータも同時にインストールされるようにする
ただ、これだけだとこのパッケージをインストールしてもデータも一緒にはインストールされません。パッケージをインストールした際にデータも同時にインストールされるようにするために、
setup.pyに一行加えます。
setup.pyfrom setuptools import setup, find_packages setup( name='mypackage', install_requires=['pandas','scikit-learn'], packages=find_packages(), package_data={'mypackage': ['resources/*']}, )
package_dataにパッケージ名、フォルダ名を指定することで、パッケージインストールと同時にインストールするデータを指定することができます。詳しくは公式ドキュメント(2.6. パッケージデータをインストールする)などを参考にしてください。
そうして上で説明したように、また新しく環境を作って、
setup.pyを使って自作パッケージをインストールすると、インストールした環境でデモデータが使えるようになってることが確認できると思います。おわりに
自分の作ったプログラムを他のメンバーに説明しやすいように、そして使いやすいようにするにはまだまだこれだけでは不十分で、本来であれば、
unittestやpytestでテストを書いたり、docstringでプログラムの入出力について説明したりと、すべきことは他にもあります。ただ、パッケージ化することはそうしたことの第一歩だと思います。
ここまで来た人はぜひ、テストを書いたり、
docstringを書いたり、docstringを下のようなプログラムの仕様書に変換したりと自分のプログラムをわかりやすいものにしてください。
追加情報
Pythonコードのパッケージングについてはこの記事が大いに参考になりました。
またunittestを使ったテストの書き方についても書いてあるので参考にしてください。
(インターン向けに書いた)Pythonパッケージを作る方法ただ、テストについては
pytestの方が使いやすいです。unittestに慣れた人は是非pytestを使ってみてください。
pytest(公式ドキュメント)また自分のプログラムについて説明するドキュメントについてです。
docstringを仕様書としてドキュメント化する事ができます。
Sphinxの使い方.docstringを読み込んで仕様書を生成また、プログラムの使い方や理論を説明するのに図や式を用いて説明したい場合もあると思います。
そんなときは
mkdocsというmarkdown 形式でドキュメントが作成できるモジュールを使うといいでしょう。
MkDocsによるドキュメント作成この
sphinxとmkdocsでドキュメントを作成し、AWSのS3などでホスティングすれば、メンバーからこのプログラムどうやって使うんだ?と聞かれた場合、忙しいときはそのURLを送ればいいので非常に便利です。タイタニック号のデータ分析についてはここを参考にしました。
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
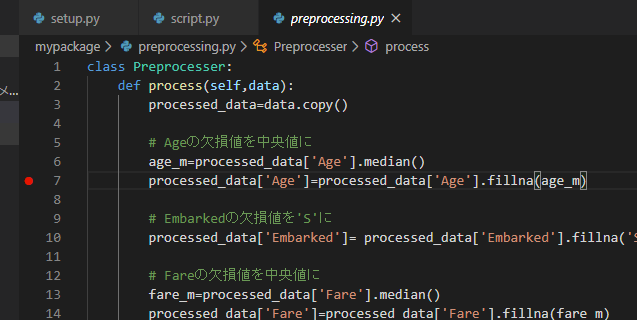
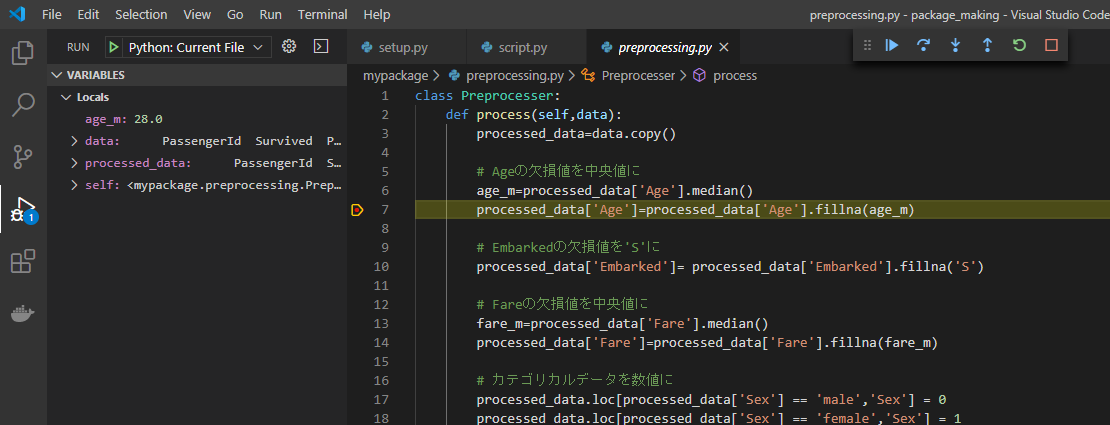

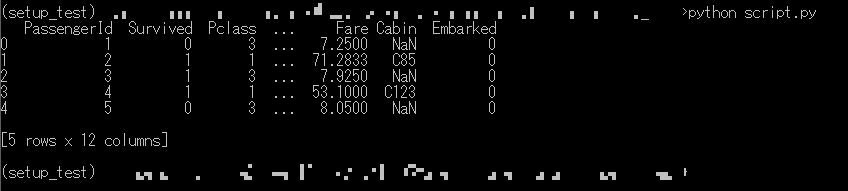

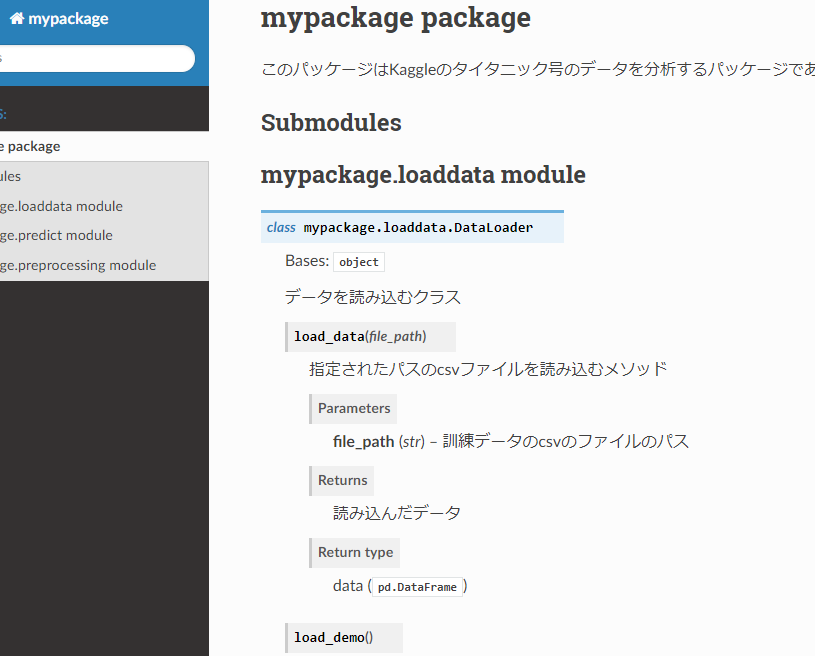
- 投稿日:2020-03-31T18:28:52+09:00
Pythonで マルケトの REST API 使ってLEADデータを取得する
背景
Marketoのデータを取得したい。
Leadsのデータをバルクで取得するサンプルをメモしておく。
他のデータリソースにも使える。始める前に
Getting Started をやっておくとREST APIの雰囲気が掴める
REST APIBulk取得の説明ページをやっておくと雰囲気掴める
Bulk ExtractBulk取得のサンプルコード
import requests import json import time import os import pendulum from google.cloud import bigquery # ↓管理画面から取得できる # https://developers.marketo.com/rest-api/ ENDPOINT = 'YOUR_ENDPOINT' CLIENT_ID = 'YOUR_CLIENT_ID' CLIENT_SECRET = 'YOUR_CLIENT_SECRET' class MarketoAPI: def __init__(self, target_date): self.target_date = target_date self.token = self.get_token() self.header = { 'Authorization': 'Bearer {}'.format(self.token), 'content-type': 'application/json' } self.export_id = None # job作成時にセットされる # CLIENT_IDとCLIENT_SECRETからtokenを発行する # 管理画面から発行したtokenはすぐexpireされるので注意 def get_token(self): URL = '{}/identity/oauth/token?client_id={}&client_secret={}&grant_type=client_credentials'.format( ENDPOINT, CLIENT_ID, CLIENT_SECRET ) headers = {'content-type': 'application/json'} r = requests.get(URL, headers=headers) if r.status_code != requests.codes.ok: r.raise_for_status() return r.json()['access_token'] # 今回はBulkExtractのAPIを使う # まずはLEADを取得するジョブの作成 # https://developers.marketo.com/rest-api/bulk-extract/bulk-lead-extract/ def create(self): URL = '{}/bulk/v1/leads/export/create.json'.format(ENDPOINT) payload = { # 取得したいfieldを指定する # 指定可能なfieldsは `GET /rest/v1/leads/describe.json` のAPIで確認できる "fields": [ "id", "email", "createdAt", "updatedAt" ], "format": "CSV", # フィルターを指定する # 指定可能なfileterは↓docに書いてある # https://developers.marketo.com/rest-api/bulk-extract/bulk-lead-extract/ "filter": { "createdAt": { "startAt": self.target_date.isoformat(), "endAt": self.target_date.end_of('day').isoformat() } } } r = requests.post(URL, data=json.dumps(payload), headers=self.header) if r.status_code != requests.codes.ok: r.raise_for_status() export_id = r.json()['result'][0]['exportId'] self.export_id = export_id return export_id # create()で作成しただけではジョブは処理されない # ここでジョブをenqueueすることによって実行待ちにできる def enqueue(self): URL = '{}/bulk/v1/leads/export/{}/enqueue.json'.format( ENDPOINT, self.export_id ) r = requests.post(URL, headers=self.header) if r.status_code != requests.codes.ok: r.raise_for_status() # enqueueさせたjobの処理終わるまでstatuspを pollingするメソッド def check_until_done(self): URL = '{}/bulk/v1/leads/export/{}/status.json'.format( ENDPOINT, self.export_id ) # 3分待ってからリクエスト # Completedになるまで3回実行する for i in range(3): time.sleep(60 * 3) r = requests.get(URL, headers=self.header) if r.status_code == requests.codes.ok: if r.json()['result'][0]['status'] == 'Completed': return True if r.status_code != requests.codes.ok: r.raise_for_status() else: raise('job status is: ' + r.json()['result'][0]['status']) # jobが完了したらfileをDownloadするメソッド def dl_file(self): URL = '{}/bulk/v1/leads/export/{}/file.json'.format( ENDPOINT, self.export_id ) r = requests.get(URL, headers=self.header) if r.status_code != requests.codes.ok: r.raise_for_status() with open('./marketo_lead_file_{}.csv'.format(self.target_date.strftime('%Y%m%d')), mode='w') as f: f.write(r.text)今回のcreateの条件だと以下のようなfileがDLされる
id,email,createdAt,updatedAt 111111,xxxxx@gmail.com,2020-01-02T15:35:37Z,2020-01-02T15:35:36Z 222222,xxxxx@gmail.com,2030-01-02T22:58:07Z,2020-01-02T22:58:07Z※BulkのAPIは1日500MBまでデータをロードできないので注意
- 投稿日:2020-03-31T17:51:16+09:00
Houdiniにグラデーションピッカーを実装する方法
はじめに
先日、PySide勉強会であんどうさんが発表したSubstance DesignerのようなグラデーションピッカーをHoudiniに実装する方法を紹介します。
あんどうさんのグラデーションピッカーの紹介、解説記事実際に使うと下図のようにランプパラメータにピッカーで拾ったグラデーションが適用されます。
下図はネットワークエディタに画像を読み込んでますが、画面内であればどこでも色を取得出来ます。
実装方法
- 下記URLからコードをダウンロードします。
https://snippets.cacher.io/snippet/2c7496d1dbbdc093033c- ダウンロードしたgradationPicker.pyをHoudiniがPythonを読み込めるフォルダに移します。
分からない場合は%HOMEDRIVE%%HOMEPATH%\Documents\houdiniバージョン\scripts\pythonにコピーすると自動で認識されます(フォルダが無い場合は作成します)。- ここからHDAに実装する場合とすでに存在してるノードのパラメータに実装する場合で少し異なります。
HDAに実装する場合
HDAのType Properties > Scriptsタブにアクセスし、Event HandlerをPython Moduleに変更します。
そうすると右側のPythonコード欄がアクティブになるので、そこに下記のランプパラメータにグラデーションを適用するコードを入力します。存在してるノードのパラメータに実装する場合
HoudiniメニューのWindows > Python Source Editorをクリックし、Python Source Editorを起動し、コード入力欄に下記のランプパラメータにグラデーションを適用するコードを入力します。ランプパラメータにグラデーションを適用するコード
# -*- coding: utf-8 -*- import hou from PySide2.QtCore import Qt from gradationPicker import ColorPick class _GCProtector(object): widgets = [] def rampColorPicker(parm, threshold=0.05): def setRampColor(colors): # 引数のcolorsは[グラデーションの位置, 色]が入ったリスト curveKeys = [] curveValues = [] # 二次元のリストをcurveKeys、curveValuesの二つに分ける for pos, color in colors: curveKeys.append(pos) # PySideの色空間がsRGBで、Houdiniはリニアなので、2.2乗して変換 curveValues.append([(ch / 255.0) ** 2.2 for ch in color]) linears = [hou.rampBasis.Linear] * len(colors) ramp = hou.Ramp(linears, curveKeys, curveValues) parm.set(ramp) picker = ColorPick() # フォーカスが移らないように最前面に表示 picker.setWindowFlags(Qt.WindowStaysOnTopHint) # どれぐらい色の差を識別するかのしきい値を設定 picker.threshold = threshold # ピッカーのメインウィンドウをスクリーン全体に表示する picker.showFullScreen() # マウスを離した時に関数を実行する picker.getGradation.connect(setRampColor) # 普通に表示するとメモリを開放してすぐに消えてしまうのを回避する処理 _GCProtector.widgets.append(picker)4. 最後にこのコードを実行する用のボタンを作成します。
5. 作成したボタンのCallback Script欄に下記コードを入力します。
HDAの場合
hou.phm().rampColorPicker(kwargs['node'].parm('ramp'), threshold=0.05)すでに存在するノードの場合
hou.session.rampColorPicker(kwargs['node'].parm('ramp'), threshold=0.05)
※parm('ramp')の箇所は対象とするランプパラメータの名前に変更して下さい。
thresholdの値は数値が低いほど、精度が上がりますが、その分キーが増えます。ボタンにアイコンを設定したい場合はButton Icon欄にBUTTONS_secondary_colorsと入力するとそれっぽいアイコンが付きます。
これでボタンを押すとグラデーションピッカーモードになるので、ドラッグして色をピックしてみて下さい。
最後に
以上グラデーションピッカーをHoudiniに実装する方法でした。
PySideは色んな事が出来て、楽しいですね。
ちなみにグラデーションピッカーを改変する事で下記のようなランプパラメータのカーブを手書きで書く機能を作ることも出来ます。


- 投稿日:2020-03-31T17:24:39+09:00
リストを特定の長さごとに分割し余った要素も含めてサブリスト化する方法
やりたいこと
["a", "b", ... ,"z"]↑の様なリストがある時、aからe、fからjのように5文字ごとに分割したい。また、最後に余るzに関しても、リストに含めたい。
つまり、
["aからe", "fからj", ..., "z"]のようなサブリストに分割したいと考えています。
方法
文字列をすべてキューに入れ、5個ごとに取り出します。また、空でないキューのみを取り出すことで、最後に余った要素以降は無視します。
コード
split.pyimport queue #aからzの文字リストを作成 chars = [chr(ord('a') + i) for i in range(26)] #キューを作成 q = queue.Queue() #キューに文字リストを挿入 for s in chars: q.put(s) #分割した文字を格納する用のリスト subList = [] #文字リストを分割 while not q.empty(): #分割したリストを一時保存 splittedList = [] #5個ごとに区切る for i in range(5): if not q.empty(): splittedList.append(q.get()) #サブリストに格納 subList.append(splittedList) #出力 print(subList)結果
>python split.py [['a', 'b', 'c', 'd', 'e'], ['f', 'g', 'h', 'i', 'j'], ['k', 'l', 'm', 'n', 'o'], ['p', 'q', 'r', 's', 't'], ['u', 'v', 'w', 'x', 'y'], ['z']]追記(2020/03/31)
@shiracamusさんからリファクタリングのコメントを頂きました。
- 投稿日:2020-03-31T16:28:59+09:00
TeamsやZoomでカメラ画像を加工する方法
本記事はこちらでも紹介しております。
https://cloud.flect.co.jp/entry/2020/03/31/162537みなさんこんにちは。
現在うちの会社では、都知事の要請を受け、新型コロナウイルス感染予防対策および拡散防止のため原則在宅勤務となっています。
同じような対応を取られている方も多く様々な困難があるかと思いますが、ぜひ力を合わせてこの難曲を乗り越えていきたいと考えています。さて、原則在宅勤務が長引いてくると、日頃行われていた何気ない会話ができないなど、ストレスも溜まってくることも考えられます。
そんな状況で一つでもクスっと笑えて息抜きができる状況が作れればよいないった思いで、一つ小ネタをご紹介します。内容は、マイクロソフトのTeamsやZoomなどのビデオ会議において、ウェブカメラをフックして加工して配信する方法です。
私がLinux使いのため、今回はLinuxでのご紹介となります。他のプラットフォームも何れ何処かで紹介されると思います。なお、「一つでもクスっと笑えて息抜きができる状況」を作るのも時と場合を選びますので、そこは自己責任でお願いします(^_^)/。
前提
大抵のLinuxシステムで問題なく動くと思いますが、私が作業した環境はDebianのBusterです。
$ cat /etc/debian_version 10.3また、python3が入っていないようでしたら、導入しておいてください。
$ python3 --version Python 3.7.3関連ソフトウェアのインストール
仮想ウェブカメラデバイス
今回はv4l2loopbackという仮想ウェブカメラデバイスを用います。
https://github.com/umlaeute/v4l2loopback仮想ウェブカメラデバイスと、実際のウェブカメラを識別する必要があるので、まずは実際のウェブカメラのデバイスファイルを確認しておきます。
下記の例だと、video0とvideo1が実際のウェブカメラに割り当てられているようです。$ ls /dev/video* /dev/video0 /dev/video1それでは、v4l2loopbackを導入しましょう。
まずはgit cloneしてmakeしてインストールしてください。$ git clone https://github.com/umlaeute/v4l2loopback.git $ cd v4l2loopback $ make $ sudo make install次に、モジュールをロードします。このとき、特にchromeで認識させるためには、exclusive_caps=1をつけてあげる必要があるようです。[https://github.com/umlaeute/v4l2loopback/issues/78]
sudo modprobe v4l2loopback exclusive_caps=1これでモジュールがロードされたと思いますので、デバイスファイルを確認しておきましょう。下記の例だとvideo2が追加されていますね。
$ ls /dev/video* /dev/video0 /dev/video1 /dev/video2ffmpeg
仮想ウェブカメラデバイスにデータを送り込むにはffmpegを用いるのが一番簡単です。
apt-getなどでさくっと導入しておいてください。Webカメラのフックと映像の配信
今回は、笑顔を検出したら画像加工を施してみようと思います。
笑顔を検出したら、映像上に笑顔マークを表示します。まず、次のリポジトリのファイルをcloneしてモジュールをインストールしてください。
$ git clone https://github.com/dannadori/WebCamHooker.git $ cd WebCamHooker/ $ pip3 install -r requirements.txtここからcascadeファイルを入手します。cascadeファイルの詳細はopencvの公式でご確認ください。
https://github.com/opencv/opencv/tree/master/data/haarcascades$ wget https://raw.githubusercontent.com/opencv/opencv/master/data/haarcascades/haarcascade_frontalface_default.xml $ wget https://raw.githubusercontent.com/opencv/opencv/master/data/haarcascades/haarcascade_smile.xml笑顔マークをいらすとやさんからお借りしましょう。
$ wget https://4.bp.blogspot.com/-QeM2lPMumuo/UNQrby-TEPI/AAAAAAAAI7E/cZIpq3TTyas/s160/mark_face_laugh.pngこんな感じのフォルダ構成になってるといいです。
$ ls -1 haarcascade_frontalface_default.xml haarcascade_smile.xml mark_face_laugh.png webcamhooker.py実行は次のように行います。
--input_video_num には実際のウェブカメラのデバイス番号を入れてください。/dev/video0なら末尾の0を入力します。
--output_video_dev には仮想ウェブカメラデバイスのデバイスファイルを指定してください。
なお、終了のさせ方はctrl+cでお願いします。$ python3 webcamhooker.py --input_video_num 1 --output_video_dev /dev/video0上のコマンドを実行するとffmpegが動き、仮想カメラデバイスに映像が配信されはじめます。
ビデオチャットをしてみよう!
ビデオチャットをするときにビデオデバイスの一覧にdummy〜〜というものが現れると思うのでそれを選択してください。 これはTeamsの例。左右がそれぞれの参加者の画面だと思ってください。 左側が今回の仮想カメラデバイスを使っているユーザです。右側が受信側です。 ニッコリすると笑顔マークが出ますね。大成功(^_^)/。
最後に
対面のコミュニケーションが難しい今、ビデオチャットを使ってもっと楽しめたらいいですね。
今回は笑顔を検出して画像を加工する例で示しましたが、opencvやその他のツールを使って工夫次第でいろんな加工ができると思います。
ぜひいろいろ試してみてください!参考
opencvでの笑顔検出はこちらを参考にさせていただきました。
https://qiita.com/fujino-fpu/items/99ce52950f4554fbc17dopencvでの画像貼り付けはこちらを参考にさせていただきました。
https://qiita.com/a2kiti/items/9672fae8e90c2da6f352
- 投稿日:2020-03-31T15:42:32+09:00
WindowsのPythonで、Cannot load mkl_intel_thread.dll に詰まったら
何番煎じかわからないけれど、Windows上のPython (Anaconda/Miniconda) で
Intel MKL Fatal ERROR: Cannot load mkl_intel_thread.dllで自分も詰まって、色々調査して解決したので、自分の思うベストソリューションをまとめてみる。1. まず、どのdllが読み込まれているかを確認する
Anaconda PromptやPowershellなどで、
where.exe mkl_intel_thread.dllを実行するとどのdllが読み込まれているかがわかる。> where.exe mkl_intel_thread.dll C:\Miniconda3\envs\mkl_test\Library\bin\mkl_intel_thread.dll # メモ: Powershellで実行する場合は、where じゃなくて必ず where.exe !ここでAnacondaやMinicondaでインストールされている以外のdllが表示されているときは、間違いなくバージョンのミスマッチでうまくいかないので、削除するか別のフォルダに移動する。(ちなみに手動でIntelのサイトから最新バージョンのMKLを入れている場合も、一旦Pathのフォルダから消したほうが良い。自分はここでハマッた。)
なお、
conda activate xxxを行うとwhere.exeの表示も変わるので、condaで独自環境を作っている場合は先にactivateしてから実行すべき。2. dllを整理してもうまく行かなかったら、新規に環境を作る
1.の手順で、余計なdllを削除して再度実行してもうまく行かない場合は、新規環境を作るのが良い。例えばPython3.6.5で環境を新規に作る場合は以下。
mkl_testのところは好きな名前でOK。conda create -n mkl_test python=3.6.5 conda activate mkl_test # NOTE: Anaconda PromptではなくPowershellで最初にactivateを行うときは、 # `conda init powershell` してPowershellの再起動が必要。ただしこの
createのとき、いつものように最後にanacondaを入れると、デフォルトのnumpyとかscipyとかが入ってしまうので、入れるべきではない。あくまでMKLから先にインストールして、そこから自分の必要なライブラリをどんどん追加していく。MKLのバージョンについては、自分は2019.4ではうまく行かず、2019.1や2018.0.3ではうまくいった。
conda install mkl=2019.1ここから、必要なライブラリを追加していく。
conda install numpy scipy conda install -c pytorch pytorch=0.4.1 # などなどそして最終的に
where.exe mkl_intel_thread.dllでdllを確認して、今回作った環境のenvs以下のdllのみが表示されているのが正しい。> where.exe mkl_intel_thread.dll C:\Miniconda3\envs\mkl_test\Library\bin\mkl_intel_thread.dllこの状態でもう一度
import numpyなどを実行すれば、多分うまくいく。
- 投稿日:2020-03-31T15:34:39+09:00
Pillowで画像をいじってみた
Pillowとは?
Pythonの画像処理ライブラリです。
https://pillow.readthedocs.io/en/stable/今回の環境
- Jupyter Notebook 5.7.8
- Pillow 5.4.1
- Matplotlib 3.0.3
準備
パッケージをインポートします。
from PIL import Image import matplotlib.pyplot as plt %matplotlib inlineとりあえず画像を表示させる
lena = Image.open("./lena.png") type(lena)出力PIL.PngImagePlugin.PngImageFilefig, ax = plt.subplots() ax.imshow(lena) plt.title("Lena Color") plt.show()
グレースケール化してみる
lena_gray = lena.convert("L") type(lena_gray)出力PIL.Image.Imagefig, ax = plt.subplots() ax.imshow(lena_gray) plt.title("Lena Gray") plt.show()
変な色になりますが、これはMatplotlibの仕様です。
カラーマップをデフォルト値から変更する必要があります。
グレースケールの画像を表示する場合はcmap="gray"を指定します。For actually displaying a grayscale image set up the color mapping using the parameters
https://matplotlib.org/3.2.1/api/_as_gen/matplotlib.pyplot.imshow.html
fig, ax = plt.subplots() ax.imshow(lena_gray, cmap="gray") plt.title("Lena Gray") plt.show()
保存する
lena_gray.save("./lena_gray.png")リサイズする
lena_resize = lena.resize((150,150)) fig, ax = plt.subplots() ax.imshow(lena_resize) plt.title("Lena Resize") plt.show()
画像の目盛に注目するとサイズが変更されていることが分かります。
回転させる
今回は画像を75度回転させます。
lena_rotate = lena.rotate(75) fig, ax = plt.subplots() ax.imshow(lena_rotate) plt.title("Lena rotate 75") plt.show()
見切れてしまいました。
元の画像のサイズから変更されていないようです。
Image.rotateにexpand=Trueを追記して見切れないようにします。Optional expansion flag. If true, expands the output image to make it large enough to hold the entire rotated image. If false or omitted, make the output image the same size as the input image.
https://pillow.readthedocs.io/en/3.1.x/reference/Image.html#PIL.Image.Image.rotate
lena_rotate_expand = lena.rotate(75, expand=True) fig, ax = plt.subplots() ax.imshow(lena_rotate_expand) plt.title("Lena rotate 75 expand") plt.show()






- 投稿日:2020-03-31T15:13:04+09:00
Pytorchを使った最適化のメモ
関数ベースになったtensorflow2が使いづらいので,Pytorchに移行中.
この記事は,パッケージをそのまま使う現代っ子ではなく,loss関数や最適化手法は自分で作りたいという懐古主義向けです.
「勾配は手計算するものだ」という,化石は対象ではないです.データ生成
適当に生成
import numpy as np import matplotlib.pyplot as plt import torch from torch.autograd import Variable import torch.optim as optim N = 100 a_data = - 1 b_data = 1 sigma_data = 0.1 x_data = 2 * np.random.rand(N) y_data = a_data * x_data + b_data + sigma_data * np.random.randn(N)
最適化パッケージを使った場合
Loss関数を自分で作りたい,ひねくれた人向け.
# 変数の定義 a = Variable(torch.randn(1), requires_grad=True) b = Variable(torch.randn(1), requires_grad=True) #データの変換 x_train = torch.tensor(x_data) y_train = torch.tensor(y_data) # 最適化関数の設定 optimizer = optim.Adam([a, b]) # 繰り返し回数 epoch = 4000 loss_epoch = np.zeros(epoch) for i in range(epoch): #optimizerに使われていた勾配の初期化 optimizer.zero_grad() #線形モデル y_hat = a * x_train + b #loss関数の計算 loss = (y_train - y_hat).norm() loss_epoch[i] = loss.item() #勾配の設定 loss.backward() #最適化の実行 optimizer.step()
勾配のみ使う場合
Optimizerを使いたくない,もっとひねくれた人向け.
勾配法をつかって最適化.# パラメーターの準備 a = torch.randn(1,requires_grad=True) b = torch.randn(1,requires_grad=True) #データの変換 x_train = torch.tensor(x_data) y_train = torch.tensor(y_data) # 学習率 eta = 0.001 # 繰り返し回数 epoch = 4000 loss_epoch = np.zeros(epoch) for i in range(epoch): #勾配の記録開始 a.requires_grad_(True) b.requires_grad_(True) #予測とloss関数の計算 y_hat = a * x_train + b loss = (y_train - y_hat).norm() loss_epoch[i] = loss.item() #勾配の設定 loss.backward() #勾配の記録停止 a.requires_grad_(False) b.requires_grad_(False) #勾配を用いた更新 a = a - eta * a.grad b = b - eta * b.grad
まとめ
勾配の記録と停止の部分を慣れたら使いやすそうですね.
Code詳細
https://github.com/yuji0001/2020Introduction_of_Pytorch
Reference
Pytorchのチュートリアルとか(ここ).
Author
Yuji Okamoto yuji.0001@gmail.com
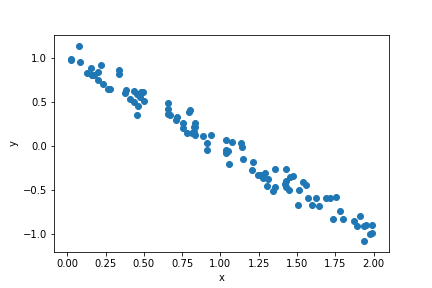
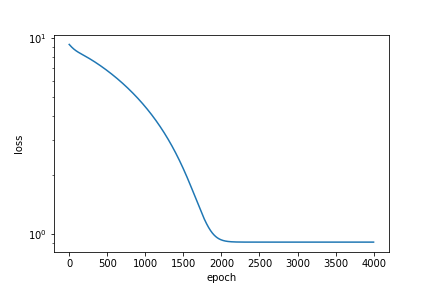
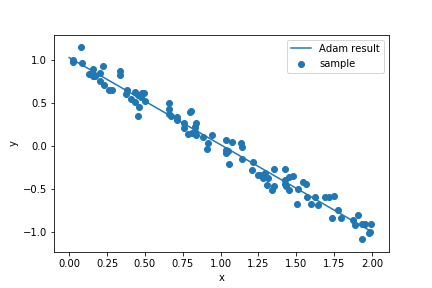
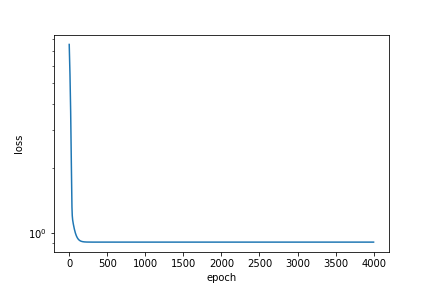
- 投稿日:2020-03-31T14:59:52+09:00
AtCoder Beginner Contest 087 過去問復習
所要時間
感想
ABC085と連続で087も解きました。
D問題が解けずに一時間過ごしていましたが、おそらくありがちなミスに気づきませんでした。D問題の章で述べたいと思います。A問題
まず一個ケーキを買い、残りをドーナツで買うだけです、
answerA1.pyx,a,b=int(input()),int(input()),int(input()) print(x-a-((x-a)//b)*b)answerA2.pys=list(input()) s[3]="8" print("".join(s))B問題
xは50の倍数なので全て50で割って考えればよく、10i+2j+k=x(0<=i,j,k<=n,i+j+k=n)という方程式を考えます。このi,j,kの組で異なるものを考えれば良いのでそれを数え上げて答えになります。
answerB.pya,b,c,x=int(input()),int(input()),int(input()),int(input()) x//=50 ans=0 for i in range(x//10+1): k=x-i*10 for j in range(k//2+1): l=k-j*2 ans+=(0<=i<=a and 0<=j<=b and 0<=l<=c) print(ans)C問題
縦が2マスぶんしかないので、どこで下に行くかを考えれば良いだけ、O(n)。
answerC.pyn=int(input()) a=[list(map(int,input().split())) for i in range(2)] ans=0 for i in range(n): ans=max(ans,sum(a[0][:(i+1)])+sum(a[1][i:])) print(ans)D問題
それぞれの人の位置関係が重要になります。
従って、その位置関係を表すのにグラフを用いるとうまく考察を進めることができます。
まず、この問題では人の位置関係が相対的なので始点となる人の位置を0として定めます。そして、その人と位置関係のある人から順に定めていけば良いです。そのために、まず最初にそれぞれの人がどの人と位置関係があるかとその距離を保存する配列を用意し、(Li,Ri,Di)という情報を入力で受け取ったらLiとRiに相当する配列の要素にその情報をそれぞれ入れておきます。
そして、一つ以上の要素と連結な要素から初めて順に他の要素を辿ってそれぞれの人の位置を決めていきますが、この際に配列に格納した情報が矛盾する可能性があるのでその場合はNoを出力します。また、この際にグラフが非連結な場合に注意が必要です。まず、辿る初めの要素を決めますが、どの要素とも非連結であるような要素の場合は情報が矛盾する可能性がないので飛ばします(次文で用意するチェックの配列にはチェックを入れておきます。)。また、それぞれの要素をチェックしたかどうかを判定する配列も用意しておき、その配列中で未チェックのものから順に上記の操作をBFSを用いて行うことで全ての情報について矛盾するかどうかを確認することができます。
僕が解いた際にはこの非連結である要素をうまく判定できていませんでした。グラフの問題は非連結の場合があることを忘れずにこれからは解いていきたいと思います。✳︎以下に二つのコードがありますが、一つ目のコードは矛盾した瞬間にNoを出力してexitしプログラムを終了させるコード、二つ目のコードは全ての要素を全てチェックした後にそれぞれの情報が矛盾しないかチェックしていくコードになります(もちろん前者の方が早いです。)。
answerD.pyimport sys sys.setrecursionlimit(400000000) inf=1000000000000000000 n,m=map(int,input().split()) x=[inf]*n check=[True]*n lrd=[[] for i in range(n)] for i in range(m): l,r,d=map(int,input().split()) l-=1 r-=1 lrd[l].append((r,d)) lrd[r].append((l,-d)) def bfs(z): global lrd,check,x for i in range(len(lrd[z])): k=lrd[z][i] if check[k[0]]: x[k[0]]=x[z]+k[1] check[k[0]]=False bfs(k[0]) else: if x[k[0]]!=x[z]+k[1]: print("No") sys.exit() st=0 while any(check): for i in range(st,n): if len(lrd[i])!=0 and check[i]: st=i break else: check[i]=False else: break x[st]=0 check[st]=False bfs(st) print("Yes")answerD2.pyimport sys sys.setrecursionlimit(100000000) inf=1000000000000000000 n,m=map(int,input().split()) x=[inf]*n check=[True]*n lrd=[[] for i in range(n)] for i in range(m): l,r,d=map(int,input().split()) l-=1 r-=1 lrd[l].append((r,d)) lrd[r].append((l,-d)) st=-1 for i in range(n): if len(lrd[i])>=1: st=i break def bfs(z): global lrd,check,x for i in range(len(lrd[z])): k=lrd[z][i] if check[k[0]]: x[k[0]]=x[z]+k[1] check[k[0]]=False bfs(k[0]) st=0 while any(check): for i in range(st,n): if len(lrd[i])!=0 and check[i]: st=i break else: check[i]=False else: break x[st]=0 check[st]=False bfs(st) for i in range(n): l=len(lrd[i]) for j in range(l): k=lrd[i][j] if x[k[0]]!=x[i]+k[1]: print("No") sys.exit() print("Yes")

- 投稿日:2020-03-31T14:58:17+09:00
[python] 商と剰余の取得
商と剰余を同時に取得してみる
ポイント
divmodを使うn = 3 cnt = 10 quot, mod = divmod(cnt, n) #商 print(quot) #剰余 print(mod)>>> #商 >>> >>> print(quot) 3 >>> #剰余 >>> >>> print(mod) 1 >>>商と剰余を別々にとってみる
ポイント
- 商
//- 剰余
%n = 3 cnt = 10 #商 print(cnt // n) #剰余 print(cnt % n)>>> #商 >>> >>> print(cnt // n) 3 >>> #剰余 >>> >>> print(cnt % n) 1 >>>
- 投稿日:2020-03-31T14:37:29+09:00
flaskによるslackのOAuth認証をやってみる(Slack API V2)
OAuth認証の必要性
スラックアプリを作るときに、一つのワークスペースにだけインストールするならば、アプリの設定ページから手動インストールすることができます。
しかしアプリを個人的にインストールしたり、最終的にSlackディレクトリで公開する場合は、OAuth認証でのインストールをする必要があります。slackのOAuth認証の仕組みは一般的なものと同じだと思います。
flaskによる実装
必要な情報
- client_id
- client_secret
コード
import os import slack from flask import Flask, request client_id = os.environ["SLACK_CLIENT_ID"] client_secret = os.environ["SLACK_CLIENT_SECRET"] #ここにアプリが要求するスコープを追加します。 oauth_scope = ",".join([ "channels:history", "groups:history", "im:history", "mpim:history", "chat:write" ]) #os.environ["SLACK_BOT_SCOPE"] uuids = [] app = Flask(__name__) @app.route("/begin_auth", methods=["GET"]) def pre_install(): """slackのOAuth認証ページに飛ばすリンクを作成し、表示させます。""" from uuid import uuid4 state_string = str(uuid4()) uuids.append(state_string) return f'<a href="https://slack.com/oauth/v2/authorize?scope={ oauth_scope }&client_id={ client_id }&state={ state_string}">Add to Slack</a>' @app.route("/finish_auth", methods=["GET", "POST"]) def post_install(): """認証が終わった後、リダイレクトされたアクセスの処理です""" auth_code = request.args['code'] state_code = request.args['state'] #state_codeが一致しなければ401 if not state_code in uuids: return make_response("", 401) else: uuids.remove(state_code) #認証をするには空白のトークンでクライアントを作成します。 client = slack.WebClient(token="") #認証トークンを要求します。 response = client.oauth_v2_access( client_id=client_id, client_secret=client_secret, code=auth_code ) #スラックボットトークンをDBなどに保存します。 SLACK_BOT_TOKEN = response['access_token'] #ユーザーに成功を伝えるのを忘れないでください! return make_response("認証成功!!", 200) app.run()リダイレクトURLの設定
App > Basic Information > OAuth & Permissions > Redirect URLsにhttp://localhost:500/finish_authを登録。
Save URLsで保存
アクセス
これで準備は完了
flaskを起動して、http://localhost:5000/begin_authにアクセスします。
リンクをクリックするとslackの認証を求められます。
Allowを押しますと、次の画面に遷移し、そのときにtokenを生成します。
確認のためのUUID4が一致すれば、リストから消去し、slackClientを使ってアクセストークンを取得します。
今回のコードでは書いてませんが、得られたアクセストークンは次に利用するために保存しましょう。
参考