- 投稿日:2020-03-31T22:09:42+09:00
AWS SAA ななみんメモ<VPC>
経緯
AWS SAA に残念ながら落ちてしまったので改めて学習する中で
自分なりに簡単にまとめたいと思います。誰かのお役に立ててたら嬉しいです
間違いがあったらコメントでご指摘いただければと思いますVPC
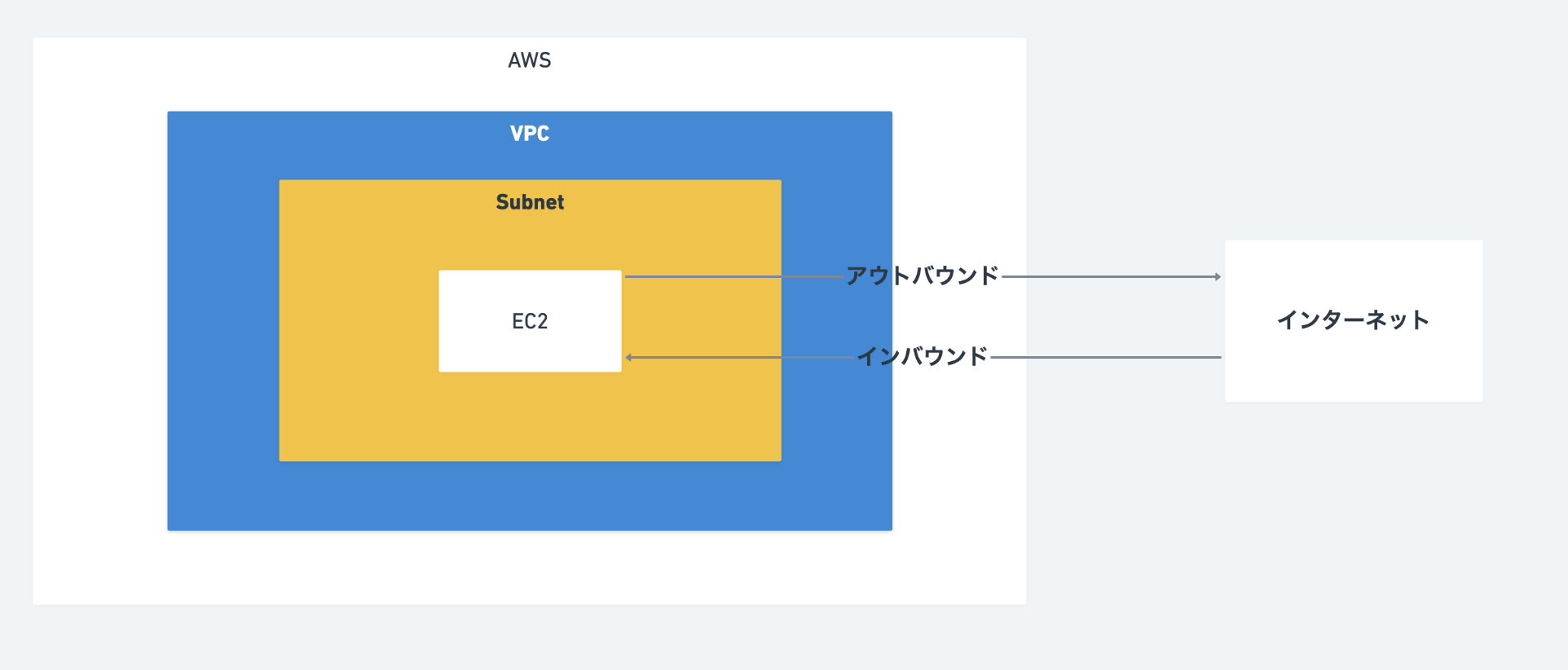
AWS環境内の仮想ネットワーク
作成直後はプライベートネットワークだが、
インターネットゲートウェイ・仮想プライベートゲートウェイをアタッチし、
ルートテーブルを設定することでインターネットやオンプレ環境と通信することが可能になるサブネット
VPCを小さいブロックに分割したもの
IPアドレス
VPCのCIDRは/16~/28まで指定することができ、サブネットについても同様
ルートテーブル
サブネットに1つルートテーブルが存在する
1つのサブネットに複数のルートテーブルは割り当てられないが、
複数のサブネットで1つのルートテーブルを使用することは可能書き方▶︎宛先アドレス ネクストホップ (例 0.0.0.0/0 igw-●●●●●●●●)
InterNetGWとNATGWの違い
InterNetGWには、GIPを持ったインスタンスからのアクセス
NATGWには、PIPしか持たないインスタンスが存在する
プライベートVPCからのアクセスNATGWは複数のPIPを1つのGIPと対応づけている
セキュリティグルーとネットワークACL
セキュリティグループは、インスタンス単位の通信制限(デフォルトは全て拒否)
ネットワークはサブネット単位の通信制限(デフォルトは全て許可)
どちらもインバウンド、アウトバウンドの2方向で制御を行う仮想プライベートゲートウェイ VGW
外部の環境(オンプレミス環境や社内ネットワークなど)に
インターネットを介さずDirectConnectやVPNを用いて通信を行う際、VPCに設置するVPCエンドポイント
インターネットの上のAWSサービスにインターネットを介さず
アクセスするための特殊なGWピアリング接続
2つのVPCをプライベートに接続する方法
クロスアカウントでもピアリング接続可能VPCフローログ
VPC内の通信を記録する
記録される情報:送信元/先アドレス、ポート、プロトコル、データ量、許可/拒否
- 投稿日:2020-03-31T21:27:46+09:00
投稿機能でS3に画像をアップロード機能(アップロード)
画像のアップロード先をS3に変更
CarrierWaveによる画像のアップロード先がアプリ内のpublicフォルダでしたが、これをS3に変更します。
以下の手順で変更していきます。
1.インターネット上にファイルをアップロードするためのGem(fog-aws)をインストールする
2.アップロードにfogを使うよう設定する
3.fogのアップロード先の情報を設定する
4.AWSのキーを安全に扱えるようにするfog-awsをインストール
fogとは画像をアップロードする際、外部のストレージを選択しアップロードするのを補助してくれるGemです。
Gemfile〜省略〜 group :development do # Access an IRB console on exception pages or by using <%= console %> in views gem 'web-console', '~> 2.0' # Spring speeds up development by keeping your application running in the background. Read more: https://github.com/rails/spring gem 'spring' end gem 'carrierwave' gem 'fog-aws' #追加開発・テスト・本番環境いずれでも使えるようにするため、group ~ end で囲まれていない部分に追記します。
ターミナルbundle installアップロードにfogを使用するための設定
今はアップロード先がpublicフォルダになっているので、これをfogを使う設定をするため、image_uploader.rbを編集します。
app/uploaders/image_uploader.rb# encoding: utf-8 class ImageUploader < CarrierWave::Uploader::Base # Include RMagick or MiniMagick support: # include CarrierWave::RMagick include CarrierWave::MiniMagick process resize_to_fit: [800, 800] # Choose what kind of storage to use for this uploader: storage :fog #編集 # Override the directory where uploaded files will be stored. # This is a sensible default for uploaders that are meant to be mounted: def store_dir "uploads/#{model.class.to_s.underscore}/#{mounted_as}/#{model.id}" end 〜省略〜storageを「:file」から「:fog」に変更することで、アップロードにfogを使う指定をします.
fogのアップロード先の設定
次に、fogが使用するアップロード先の情報を設定します。
そのため、CarrierWaveの設定ファイルを新規作成します。
アプリケーションのルートからconfig/initializers直下に、carrierwave.rbというファイルを作成してください。config/initializers/carrierwave.rbrequire 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' CarrierWave.configure do |config| config.storage = :fog config.fog_provider = 'fog/aws' config.fog_credentials = { provider: 'AWS', aws_access_key_id: Rails.application.secrets.aws_access_key_id, aws_secret_access_key: Rails.application.secrets.aws_secret_access_key, region: 'ap-northeast-1' } config.fog_directory = 'ここにバケット名を入れます' config.asset_host = 'https://s3-ap-northeast-1.amazonaws.com/ここにバケット名を入れます' endバケット名の部分は、自身で付けられた名前を入力してください。
regionで設定してある「ap-northeast-1」は、アジアパシフィック(東京)を表しています。
もしも他のリージョンを使用する場合は、インターネットで検索してください。
config.asset_hostは「https://s3-ap-northeast-1.amazonaws.com/sample-name」のような記述になっているることを確認してください。安全にAWSのキーを扱えるように設定
次に、S3で使用するキーの設定を行います。ちゃんと設定しないと、万が一漏洩すると巨額の被害を被る恐れがありますので、しっかり確認してから進めていきましょう。
アプリ名でAWSのキーを扱う際は、以下の3箇所で設定を行うことで安全性を確保します。
CarrierWave=>CarrierWaveの設定ファイル
secrets.yml=>Railsアプリケーション全体の秘密情報を管理するファイル
環境変数=>でOSが提供するデータ共有の仕組み漏洩のリスクが低い
AWSのidやパスワードそのものは「環境変数」だけに設定します。
環境変数に代入されているデータは誤操作によって漏れてしまうことがないため、安全性が高いです。
そして、環境変数の値を「secrets.yml」から読み込んで、さらにその内容を「carrierwave.rb」が読み込むという構造になっています。
環境変数の設定はS3の接続に必要な認証情報を、環境変数として設定します。
IAMユーザー設定時にダウンロードしたCSVファイル(2つ目のダウンロードファイル)を開き、その中に、Access_key_IDとSecret_access_keyというカラムがあるので、こちらに書かれた値を設定します。
この作業においては、コマンドは基本的にどこのディレクトリで入力していただいても問題ありません。特に理由がなければホームディレクトリまたはルートディレクトリで実行します。
環境変数の設定の仕方は、変数の一種なのでパソコンをシャットダウンすると消えてしまいます。それだと毎回設定しなくてはいけないので、シェルの起動時に自動で読み込まれるファイルに設定内容を記述します。
環境変数の設定方法はmacOSのバージョンによって異なります。そのため、以下の手順で確認を行います。
デスクトップの左上にあるアイコンをクリックして、「このMacについて」を選択します。
macOSのバージョンを確認することができます。MacOSがCatalina(10.15以降)の場合
ターミナル
# ローカル環境 $ vim ~/.zshrc # iを押してインサートモードに移行し、下記を追記する。既存の記述は消去しない。 export AWS_ACCESS_KEY_ID='ここにCSVファイルのAccess key IDの値をコピー' export AWS_SECRET_ACCESS_KEY='ここにCSVファイルのにSecret access keyの値をコピー' # 編集が終わったらescapeキーを押してから:wqと入力して保存して終了MacOSがMojave以前(10.14以前)の場合
ターミナル
# ローカル環境 $ vim ~/.bash_profile # iを押してインサートモードに移行し、下記を追記する。既存の記述は消去しない。 export AWS_ACCESS_KEY_ID='ここにCSVファイルのAccess key IDの値をコピー' export AWS_SECRET_ACCESS_KEY='ここにCSVファイルのにSecret access keyの値をコピー' # 編集が終わったらescapeキーを押してから:wqと入力して保存して終了※上記の設定は、現在の設定に「追加」してください。既存の設定を削除してしまうとパソコンが正常に動作しなくなる危険性があります。
次は、以下のコマンドを実行して設定を反映させます。
ターミナルローカル環境 # 編集した.zshrcを読み込み直して、追加した環境変数を使えるようにする $ source ~/.zshrcこれで環境変数が設定できました。
secrets.ymlの設定
※ここからはOSに関係なく、Mojave以前の方もCatalinaの方も同じ作業です。
次にsecrets.ymlの設定を行い、環境変数の値を読み込みます。
YAMLファイル
拡張子がymlのファイルは、YAMLと呼ばれる種類のファイルです。
設定ファイルとしてよく使われ、Rubyのハッシュのように「:(コロン)」で区切って「キー」「バリュー」を設定することができます。
secrets.ymlもYAMLファイルです。config/secrets.yml# Be sure to restart your server when you modify this file. # Your secret key is used for verifying the integrity of signed cookies. # If you change this key, all old signed cookies will become invalid! # Make sure the secret is at least 30 characters and all random, # no regular words or you'll be exposed to dictionary attacks. # You can use `rails secret` to generate a secure secret key. # Make sure the secrets in this file are kept private # if you're sharing your code publicly. development: secret_key_base: cb2965bfebd75267542611a74ab612b9754f98・・・・・ aws_access_key_id: <%= ENV["AWS_ACCESS_KEY_ID"] %> #追加 aws_secret_access_key: <%= ENV["AWS_SECRET_ACCESS_KEY"] %> #追加 test: secret_key_base: 7362cb8e960adf75f110e17bb4cd1f2d4edc3d・・・・・ # Do not keep production secrets in the repository, # instead read values from the environment. production: secret_key_base: <%= ENV["SECRET_KEY_BASE"] %>aws_access_key_id: <%= ENV["AWS_ACCESS_KEY_ID"] %>という設定を追加しています。
右側のENV[" "]という書き方は、環境変数を読み込むためのRubyのメソッドです。かっこの中には環境変数名を指定します。
つまりaws_access_key_idというキーに対して、環境変数AWS_ACCESS_KEY_IDの値をセットするという意味になります。
secrets.ymlには直接パスワードなどを記載しません。そのため、万が一このファイルが漏洩しても第三者にはパスワードはわかりません。
ここで、carrierwave.rbの設定を確認してみます。
secrets.ymlの設定まで終わりましたので、続いてCarrierWaveからこの設定を読み込めるようにする必要があります。config/initializers/carrierwave.rbrequire 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' CarrierWave.configure do |config| config.storage = :fog config.fog_provider = 'fog/aws' config.fog_credentials = { provider: 'AWS', aws_access_key_id: Rails.application.secrets.aws_access_key_id, aws_secret_access_key: Rails.application.secrets.aws_secret_access_key, region: 'ap-northeast-1' } config.fog_directory = 'ここにバケット名を入れます' config.asset_host = 'https://s3-ap-northeast-1.amazonaws.com/ここにバケット名を入れます' end値に「Rails.application.secrets.aws_access_key_id」という記述があります。
この前半の「Rails.application.secrets」という書き方によって、secrets.ymlの設定内容を呼び出すことができます。
続けて「aws_access_key_id」と書いてあるので、secrets.ymlで設定した「aws_access_key_id」の値という意味になります。
ここまでの設定を行うことで、「環境変数」→「secrets.yml」→「carrierwave.rb」の順にデータを読み込めたことになります。.gitignoreを編集
他人に知られてはいけない内容については、Gitの管理から外してアップロードされないようにします。
「.gitignore」というファイルに設定を行うことで、Gitの管理下から除外することができます。
ここまでの設定によって、secrets.ymlにはパスワードの記述はありません。そのため、今の段階でアップロードしても問題はありませんが、secrets.ymlは各種パスワードを扱うためのファイルなので、必ず以下の操作を行って、pushされないようにします。
.gitignore# ファイルの最下部に下記を追記 config/secrets.yml※.gitignoreに記載した変更は、一度gitの監視下に置かれてしまったファイルには適用されません。変更を反映させるには、アプリ名のディレクトリでコマンドを実行して、config/secrets.ymlをgitの監視から外します。
ターミナル$ cd アプリ名 $ git rm --cached config/secrets.ymlアップロードしたファイルがS3に保存されるかの確認
ローカル開発環境のアプリから、画像付きの投稿を行います。
次に、AWS内のS3のバケットを見て、ファイルがアップロードされているか確認します。
正常に投稿できていれば、バケットを選択した際に「uploads」というディレクトリができています。
さらに下の階層にたどっていくと、アップロードした画像が保存されていることが確認できます。本番環境からS3にアップロード
今まで変更したきた内容でデプロイをし直して、本番環境でもS3に画像がアップロードされるようにします。
ですが、このままだとデプロイし直しても環境変数が原因で動作しません。
環境変数とはOSが提供する変数です。ローカル環境と本番環境とでは動作している端末が別なので、環境変数も全くの別物です。
そのため、本番環境用の環境変数を別途設定します。本番環境の環境変数の設定
本番環境の設定変更をするので、sshでリモートのサーバーにログインしてから作業します。
ターミナル(ec2-user)# 本番環境 $ ssh -i [pem鍵の名前].pem ec2-user@[作成したEC2インスタンスと紐付けたElastic IP] (ダウンロードした鍵を用いて、ec2-userとしてログイン) $ sudo vim /etc/environment # iを押してインサートモードに移行し、下記を追記する。既存の記述は消去しない。 AWS_ACCESS_KEY_ID='ここにCSVファイルのAccess key IDの値をコピー' AWS_SECRET_ACCESS_KEY='ここにCSVファイルのにSecret access keyの値をコピー' # 編集が終わったらescapeキーを押してから:wqと入力して保存して終了次は、環境変数の設定を反映させます。
ターミナル(ec2-user)# 本番環境 # 編集した環境変数を適用するために一旦ログアウトします。 $ exit $ ssh -i [pem鍵の名前].pem ec2-user@[作成したEC2インスタンスと紐付けたElastic IP] # 環境変数が適用されているか確認しましょう。 $ env | grep AWS_SECRET_ACCESS_KEY $ env | grep AWS_ACCESS_KEY_IDなぜ、本番環境での環境変数を「environment」というファイルに書き込んだかについて
ローカルでは「.bash_profile」に記述することで、環境変数の設定を行いましたが、本番環境ではそれでは環境変数の設定ができません。
通常は、ユーザーがログインを行うと「.bash_profile」が読み込まれ、その内容が実行されます。
しかし、Capstranoを使用した場合はその読み込みが行われないため、別の方法で環境変数を設定する必要があります。それが「/etc/environments」に記述する、という方法になります。本番環境での環境変数読み込みの設定
ローカルは開発環境用のsecrets.ymlの設定を行いましたが、今回は本番環境用の設定を行います。
config/secrets.yml# Be sure to restart your server when you modify this file. # Your secret key is used for verifying the integrity of signed cookies. # If you change this key, all old signed cookies will become invalid! # Make sure the secret is at least 30 characters and all random, # no regular words or you'll be exposed to dictionary attacks. # You can use `rails secret` to generate a secure secret key. # Make sure the secrets in this file are kept private # if you're sharing your code publicly. development: secret_key_base: cb2965bfebd75267542611a74ab612b9754f98・・・・・ aws_access_key_id: <%= ENV["AWS_ACCESS_KEY_ID"] %> aws_secret_access_key: <%= ENV["AWS_SECRET_ACCESS_KEY"] %> test: secret_key_base: 7362cb8e960adf75f110e17bb4cd1f2d4edc3d・・・・・ # Do not keep production secrets in the repository, # instead read values from the environment. production: secret_key_base: <%= ENV["SECRET_KEY_BASE"] %> aws_access_key_id: <%= ENV["AWS_ACCESS_KEY_ID"] %> #追加 aws_secret_access_key: <%= ENV["AWS_SECRET_ACCESS_KEY"] %> #追加上記で、secrets.ymlの設定を変更しましたが、このファイルはGitで管理されないようにしています。
そのため、Capstranoで自動デプロイを行っても本番環境には送られません。
この問題を解決するために、Capistranoの設定を変更します。config/deploy.rb# secrets.yml用のシンボリックリンクを追加 set :linked_files, %w{ config/secrets.yml } # 元々記述されていた after 「'deploy:publishing', 'deploy:restart'」以下を削除して、次のように書き換え after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end desc 'upload secrets.yml' task :upload do on roles(:app) do |host| if test "[ ! -d #{shared_path}/config ]" execute "mkdir -p #{shared_path}/config" end upload!('config/secrets.yml', "#{shared_path}/config/secrets.yml") end end before :starting, 'deploy:upload' after :finishing, 'deploy:cleanup' endset :linked_filesで指定されたファイルは、元々のディレクトリを参照する代わりに、shared/元々のディレクトリ構成を参照するようになります。今回の例で言うと、config/secrets.ymlを参照する代わりに、shared/config/secrets.ymlを参照するようになります。
desc upload secrets.yml以下の記述は、ローカル環境にあるconfig/secrets.ymlを本番環境のshared/config/secrets.ymlに反映するための設定を行なっています。これで、.gitignoreに記載されているsecrets.ymlを、Githubを経由せずにデプロイすることができます。
次は、ここまでの作業を本番環境に反映させます。
変更内容をコミットしてGithubにプッシュ(publish)します。
次に、自動デプロイを実行します。
ターミナル(ローカル)$ bundle exec cap production deploy本番環境に反映の仕方は
①GitHubへのpush
②「bundle exec cap production deploy」の実行
です。正しくアップロードできるかの確認
まず、本番環境のアプリから、画像つきの投稿をしてください。
次に、最初に今の時点でS3にいくつのファイルがアップロードされているか確認してください。
次に、「本番環境」のから画像投稿を行い、もう一度S3のファイルを確認します。
今投稿したファイルがS3上で確認できれば成功です。
動作確認ができたらプルリクエストを作成します。
- 投稿日:2020-03-31T20:47:29+09:00
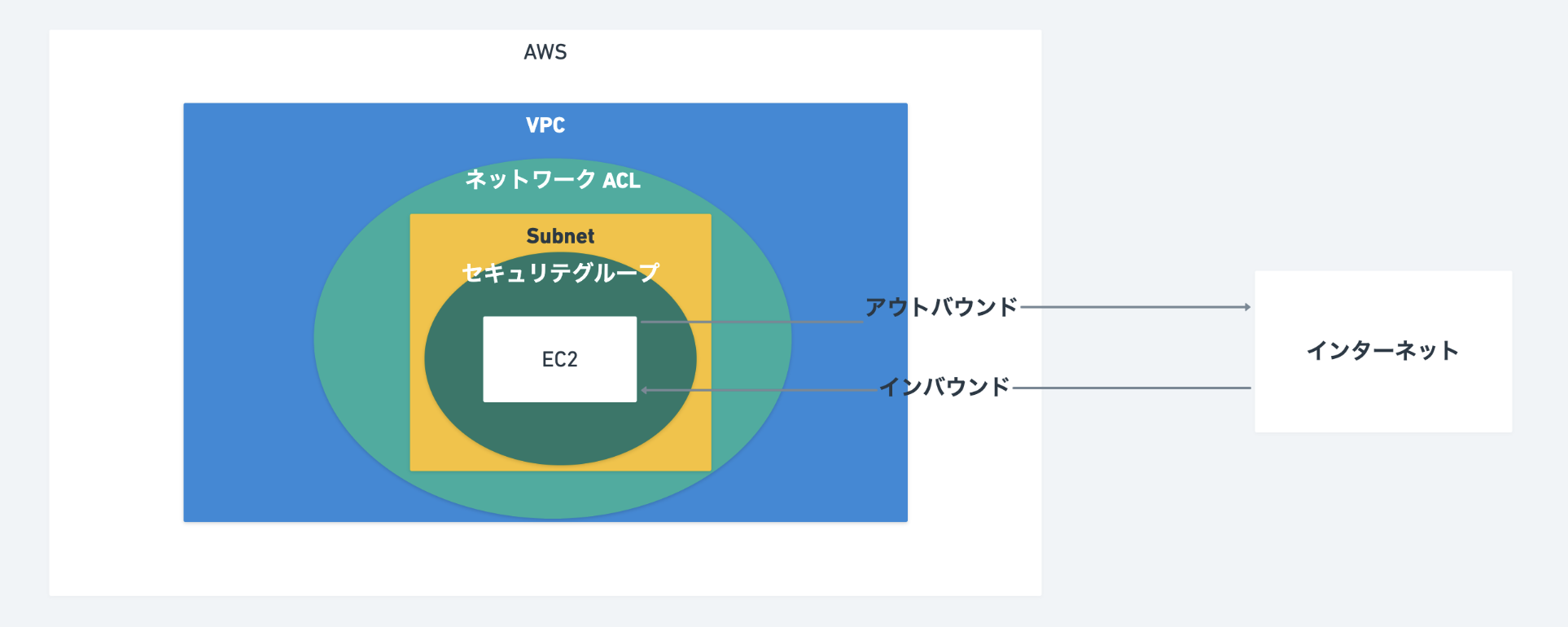
【SRE/AWS】ザーッとみるVPC
VPC
AWS内に構築することができるプライベートなネットワーク環境のことを指します。
下記は、主に参考にさせてもらった記事です。
AWS VPCについて(初心者向け) | cloudpack.media
AWS上のネットワーク構築メモ - Qiita
AWS黎明期のベストプラクティスを改めて読み返すことで、クラウドのためのアーキテクチャー大原則を再確認する | Developers.IO全体図
VPC全体の構築手順
- VPC作成
- サブネット作成
- ルートテーブル作成
- インターネットゲートウェイ作成(ここ書いてません...)
- ネットワーク ACL設定
- セキュリティグループ設定
VPCの作成
- CIDRブロック
- テナンシー
VPCの作成画面
CIDRブロック
CIDR表記
IPアドレスの後ろにスラッシュ記号(/)を書き、その後ろにネットワーク部のビット数を記述する
IPアドレスの基礎知識 - Qiitaより引用例:192.168.0.0/20
サブネット表記は、192.168.0.0/255.255.240.0のようになります。
じゃあどうやってこのCIDRを決めるかという話になりますが、色々調べてみると下記のプライベートIPから選択することが推奨されています。
10.0.0.0 - 10.255.255.255 (10.0.0.0/8)
172.16.0.0 - 172.31.255.255 (172.16.0.0/12)
192.168.0.0 - 192.168.255.255 (192.168.0.0/16)
Amazon VPC IPアドレス設計レシピ | Developers.IOより引用じゃあ仮に172.16.0.0を選択したとして、第3と第4オクテットはどのように決定するのか。
下記を参考にすると、第3と第4 両方とも0.0で選択しています。
そしてブロックサイズは16〜28から選んでいます。
AWSのCIDRってどう入力すればいい? - Qiitaを参考このブロックサイズは数値によって何が違うのかというと、利用可能のIP数が決まっています。
下記参考。/28 11ip
/27 27ip
/26 59ip
/25 123ip
/24 251ip
/23 507ip
/22 1019ip
/21 2043ip
/20 4091ip
/19 8187ip
/18 16379ip
/17 32763ip
/16 65531ip
Amazon VPC IPアドレス設計レシピ | Developers.IOより引用下記計算ツールを使用することで、ネットワークの範囲を計算することができます。
ネットワーク計算ツール・CIDR計算ツール | Softel labsまた注意することは、VPNやDirectConnectを利用する場合、サブネットとオンプレミスでCIDRの重複は許されないことです。
下記のように社内だけで使用するアプリケーションを構築する際に注意しなければいけません。サブネット
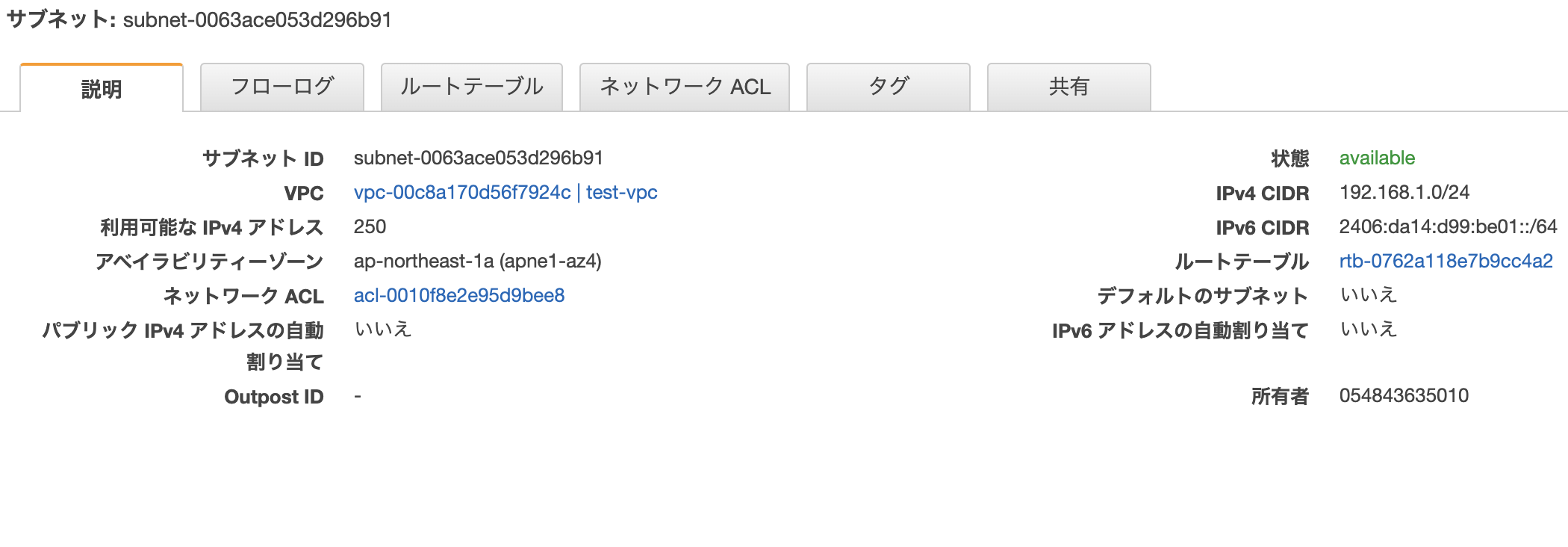
サブネット作成画面
「IPv4 CIDR ブロック」では、VPCのネットワークの範囲内でサブネットに割り振るブロックを割り当てます。
例えば、VPCのネットワークの範囲が192.168.0.0/16だったら、192.168.0.0/24などに設定します。サブネット作成後
サブネットを作成し、作成したサブネットを選択すると、下記のような画面を確認することができます。
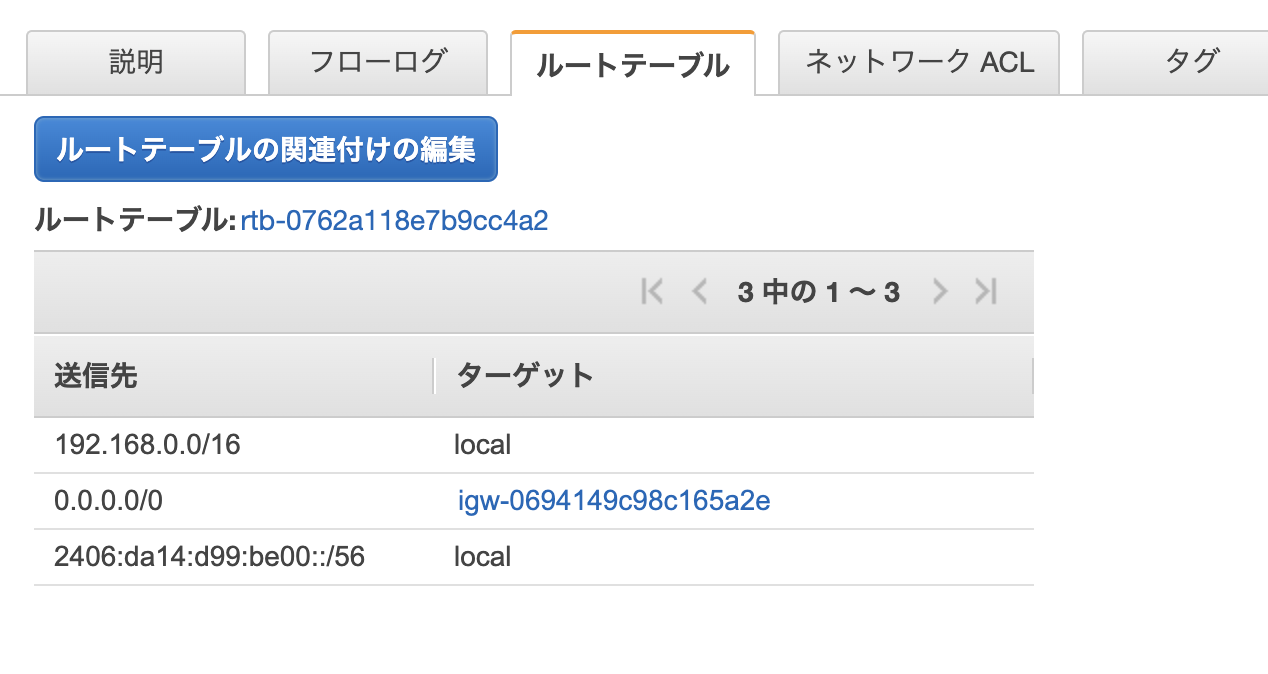
ルートテーブル
上記で作成したサブネットを選択し、ルートテーブルを選択すると、現状の設定を確認することができます。
ここで設定を追加していくことが可能です。
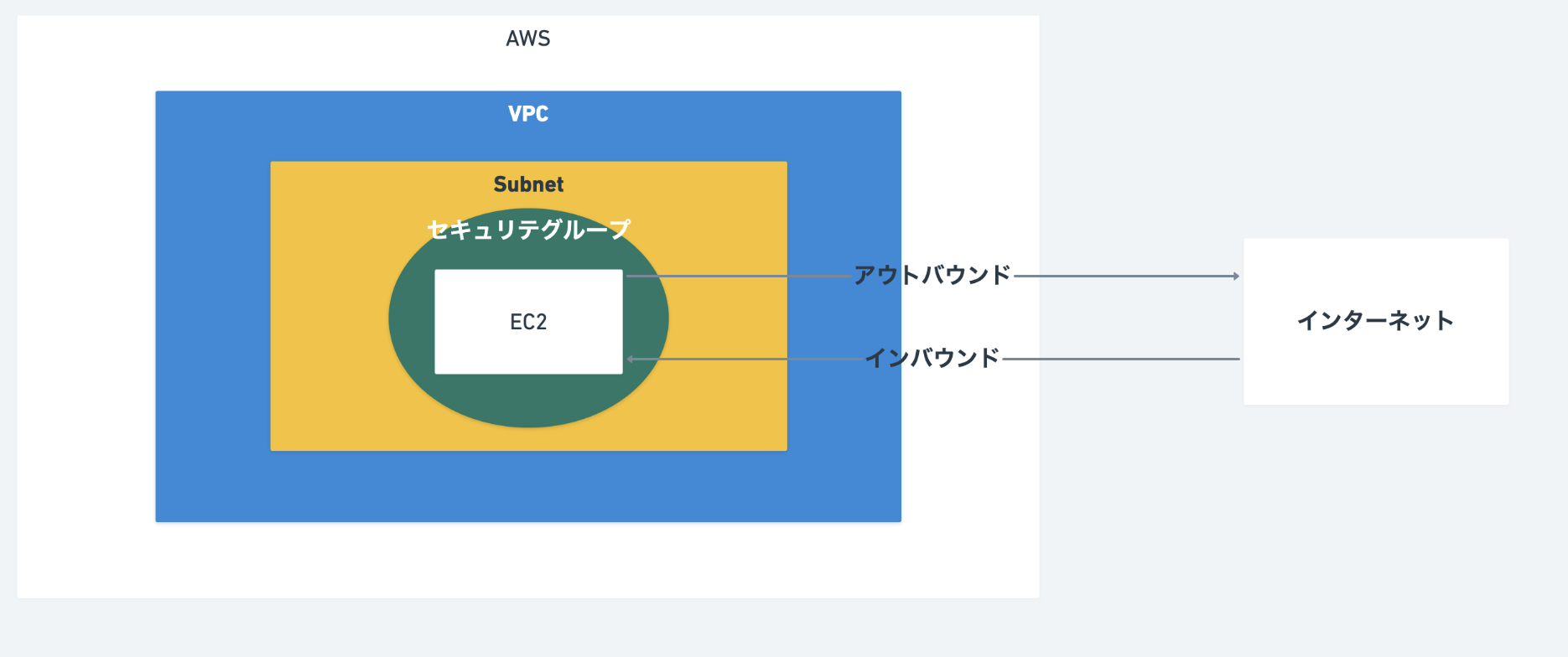
セキュリティグループ
ファイアウォールの機能を果たします。
基本的には、許可する通信を増やしていき、それ以外の通信はデフォルトでブロックされるようになっています。
トラフィック
インバウンドトラフィック
インターネットからのアクセス
80, 443, sshなどアウトバウンドトラフィック
AWS出ていくアクセス
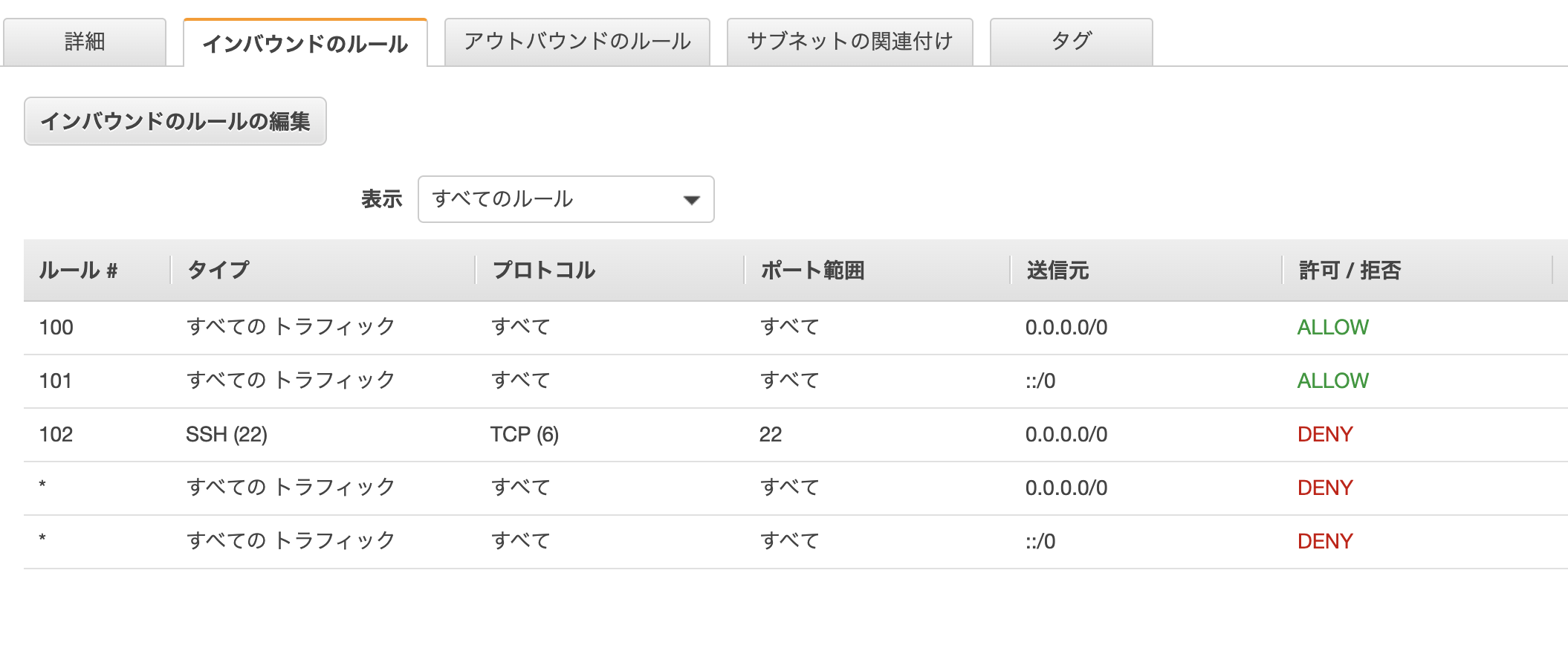
初期設定は、全て許容しているネットーワークACL(アクセスリスト)
サブネットレベルでアクセス制限したい場合に使用します。
なので、セキュリティグループよりも範囲は大きくなります。
ネットワークACL インバウンドの編集
ルールは、数値が小さい方が優先されます。
プライベートサブネット
パブリックサブネット
Apache, nginxなどに設定します。
プライベートサブネット
Rails, Djangoなどのwebアプリケーションに設定します。



- 投稿日:2020-03-31T19:44:59+09:00
Elastic BeanstalkでSpring Bootのアプリをデプロイしたときの手順と遭遇したエラー
表題の通りです。
Elastic Beanstalk(以下EB)でのデプロイ時の基本的な流れと、遭遇したエラーを紹介します。
遭遇したエラーというか、ローカル環境のソースをそのままデプロイしてみたときのエラーです。。。
設定漏れ等の参考になれば幸いです。手順
事前準備
デプロイしたいアプリケーションのjarかwarを作っておきます。
各種設定
今回は、基本的にAWSマネジメントコンソールから操作します。
まず、AWSにログインしたあとのhome画面から、Elastic Beanstalkと検索。
初回利用時は以下の画面が表示されます。「今すぐ始める」ボタン押す。
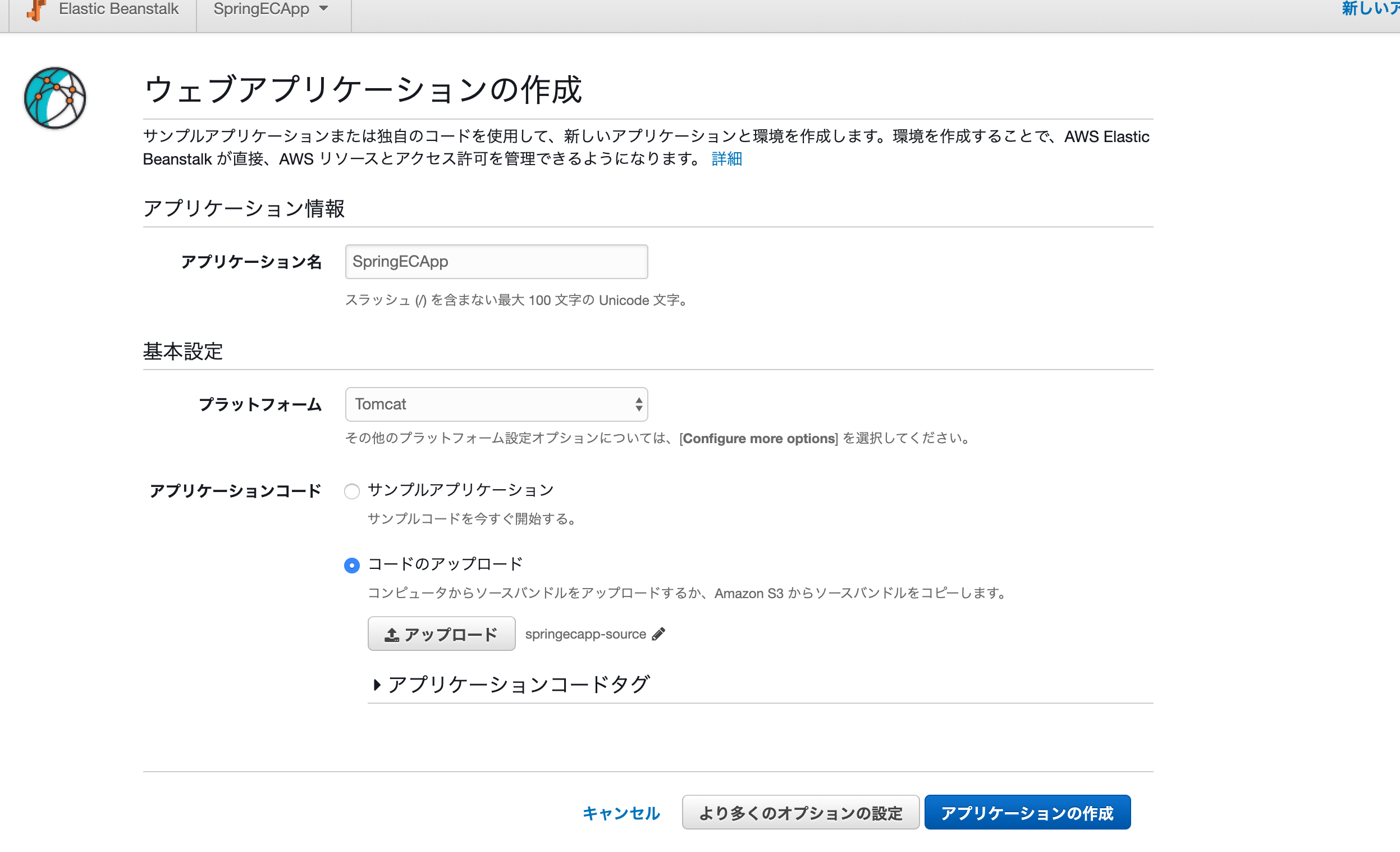
アプリケーションの基本設定です。各設定値は画像の通り。
プラットフォームの選択について、コードアップロード時のファイルが
・warの場合→Tomcat
・jarの場合→Java SE
を選択するようです。
Java SE プラットフォームを利用する場合、設定ファイルの追記が必要なので以下を参考にしてみてください。
参考:https://spring.pleiades.io/spring-boot/docs/current/reference/html/deployment.html#cloud-deployment-aws
「コードのアップロード」を押すとこんな画面になります。設定値等は画像の通り。
ソースバンドルって何だろう、と思いながらFinder内のフォルダごとアップロードしようとしたら全然できなかった、、、
要件は以下ですって。・単一の ZIP ファイルまたは WAR ファイルで構成される (WAR ファイル内に複数の ZIP ファイルを含めることが可能)
・512 MB 以下
・親フォルダまたは最上位ディレクトリを含まない(サブディレクトリを除く)
引用:https://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/using-features.managing.vpc.html
「アップロード」を押すと、基本設定の画面に戻ります。
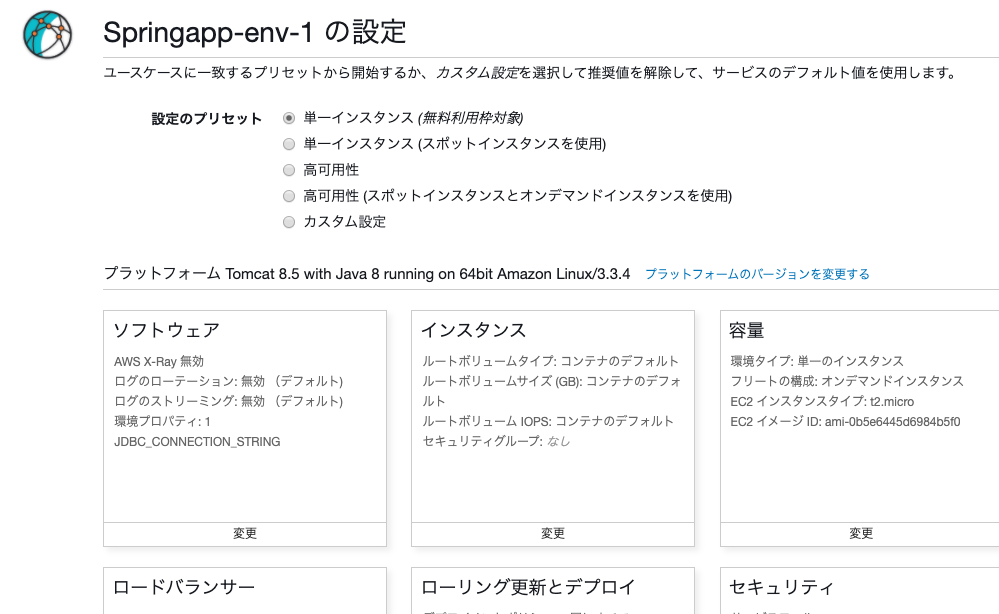
そして、「より多くの設定」を押すと、以下の画面になります。
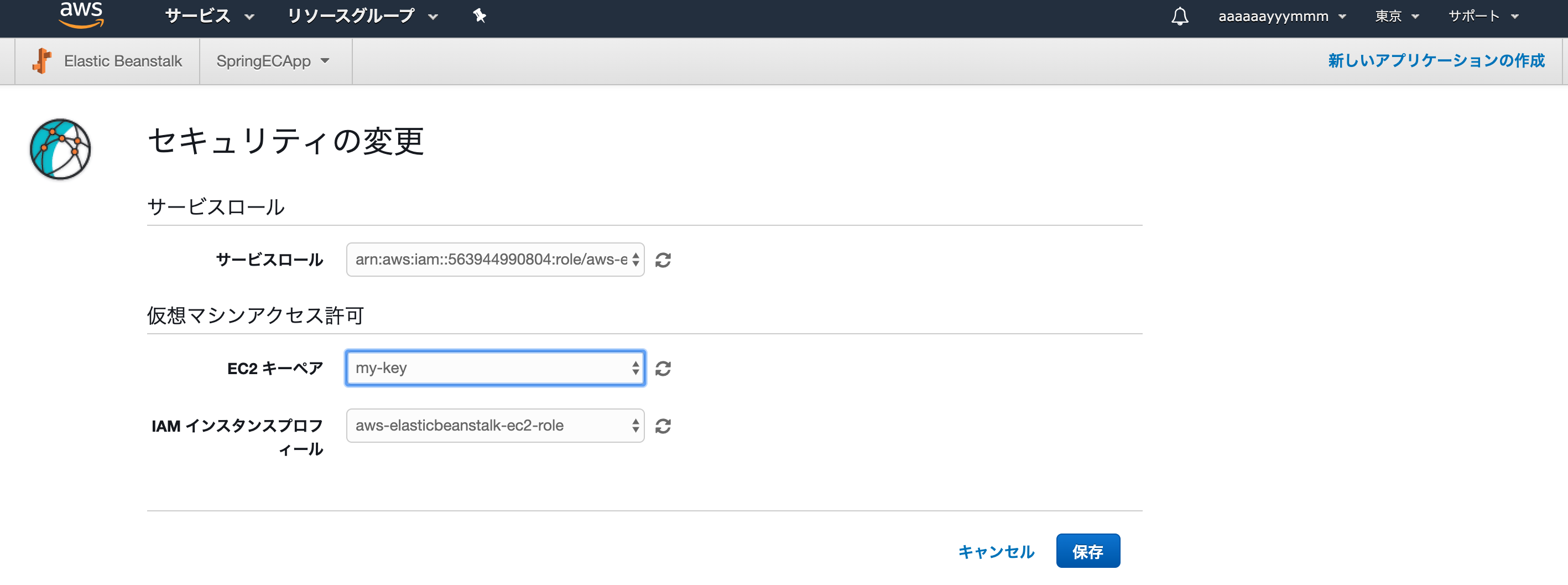
セキュリティのフィールドがあるので、「変更」押すと以下の画面に。
リモートでssh接続するためにキーペアを指定しました。
私の場合、既存のキーを利用しています。新規作成する方は、すみませんググってみてください。。。
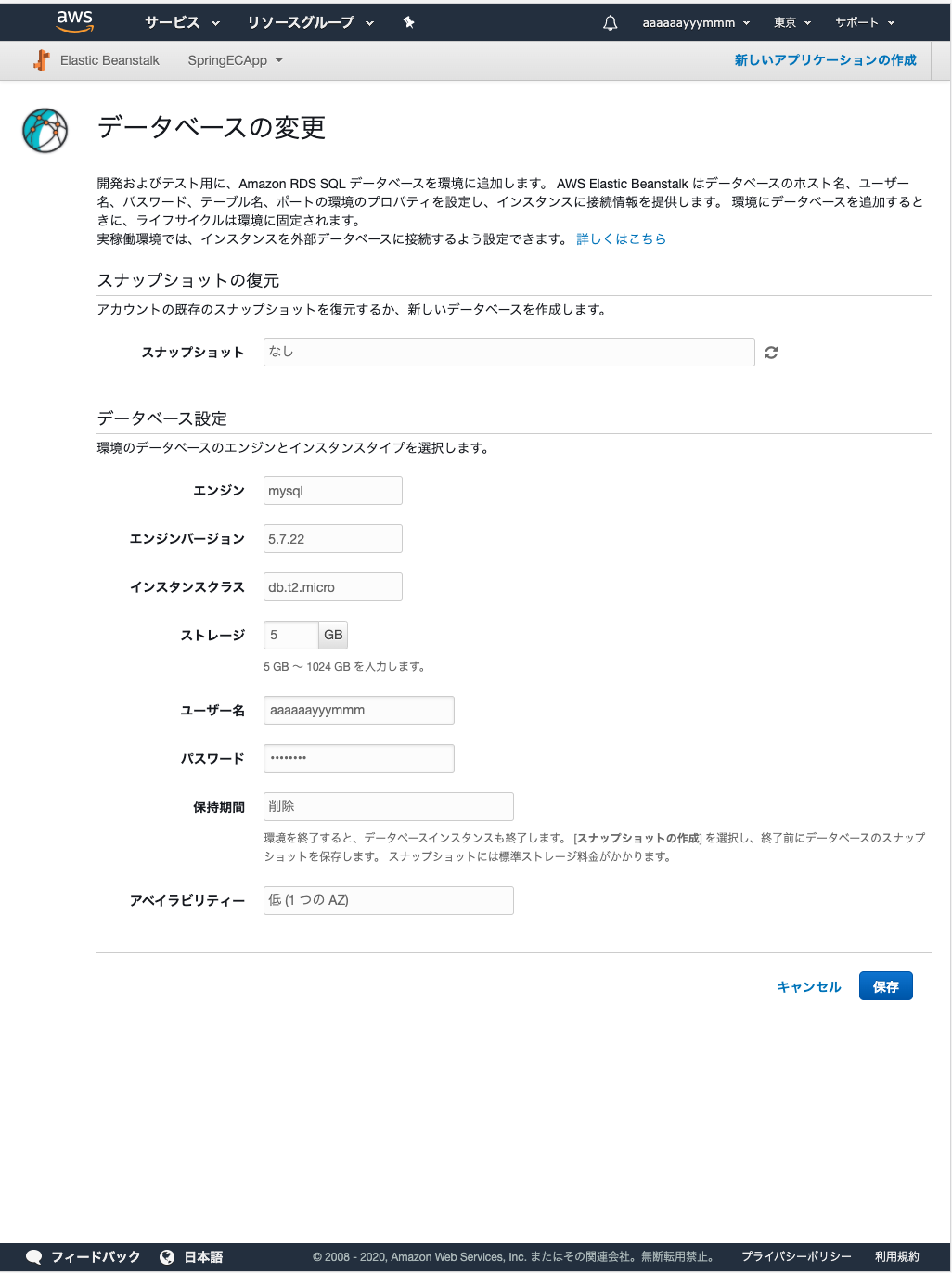
次は、データベースを利用している場合のみの設定です。
データベースフィールドの、「変更」押すと以下の画面に。設定値は画像の通り。
保持期間について、削除だとインスタンスを停止する度にDBのデータ消えてしまいます。今回は学習用なので削除を選択しました。
残しておきたい方はスナップショットの作成にする必要がありますが、課金されるようです。
「より多くの設定」画面で「環境の作成」を押すと、以下の画面になります。頑張ってくれています。
作成が終わると、以下の画面になります。
「最近のイベント」の種類にERRORがなければ、環境の設定はほぼ完成。
DBを利用している場合
データベースとテーブルを作成します。
そのために、
EC2のインスタンス一覧ページに先ほど作成した環境のインスタンスが作成されているので、パブリック DNSを確認し、ssh接続します。
ssh接続の手順は以下を参考にしてください。
https://dev.classmethod.jp/articles/aws-beginner-ec2-ssh/次に、仮想サーバー上でmysqlコマンドが打てるようにインストールします。
sudo yum install -y mysqlを実行。
そのあと、mysqlにログインし、ローカルで開発したときのように、作成したデータベースやテーブルを作成します。本当は最初にしたい準備(DB利用時のみ)
jdbcの接続先を、RDS向けに変更します。
公式によると、System.getProperty()を使って環境変数から自動的に接続先のURIを生成してくれるそうなのですが、よくわからなかったので今回は設定ファイルにベタ書きで修正します。application.propatiesの
spring.datasource.urlの値を以下のフォーマットに沿ってに変更し、warファイルを作成します。jdbc:driver://hostname:port/dbName?user=userName&password=passworddriver→mysql
port→3306
dbName→作成したDB名
userName→RDS作成時のユーザ名
password→RDS作成時のパスワード
参考:https://docs.aws.amazon.com/ja_jp/elasticbeanstalk/latest/dg/java-rds.html2回目以降のデプロイはこちらからできます。
jdbc接続先を変更したwarファイルをデプロイし直します。
この方法、不可能ではないですが良くないので、もっと良い方法が見つかり次第、記事更新します。確認
デプロイ後の画面(下の画像)、上部中央にURLが記載されているので、そこにアクセスできたら完成!
※私の場合、Spring Securityを利用してログイン機能を実装しているためか、自動的にログイン画面にリダイレクトされるので、デフォルトページ(Springで言うとindexページ)の設定方法については後日追記します。
遭遇したエラー
振り返るとしょうもないエラーだなぁと思いますが勉強になりました。。。
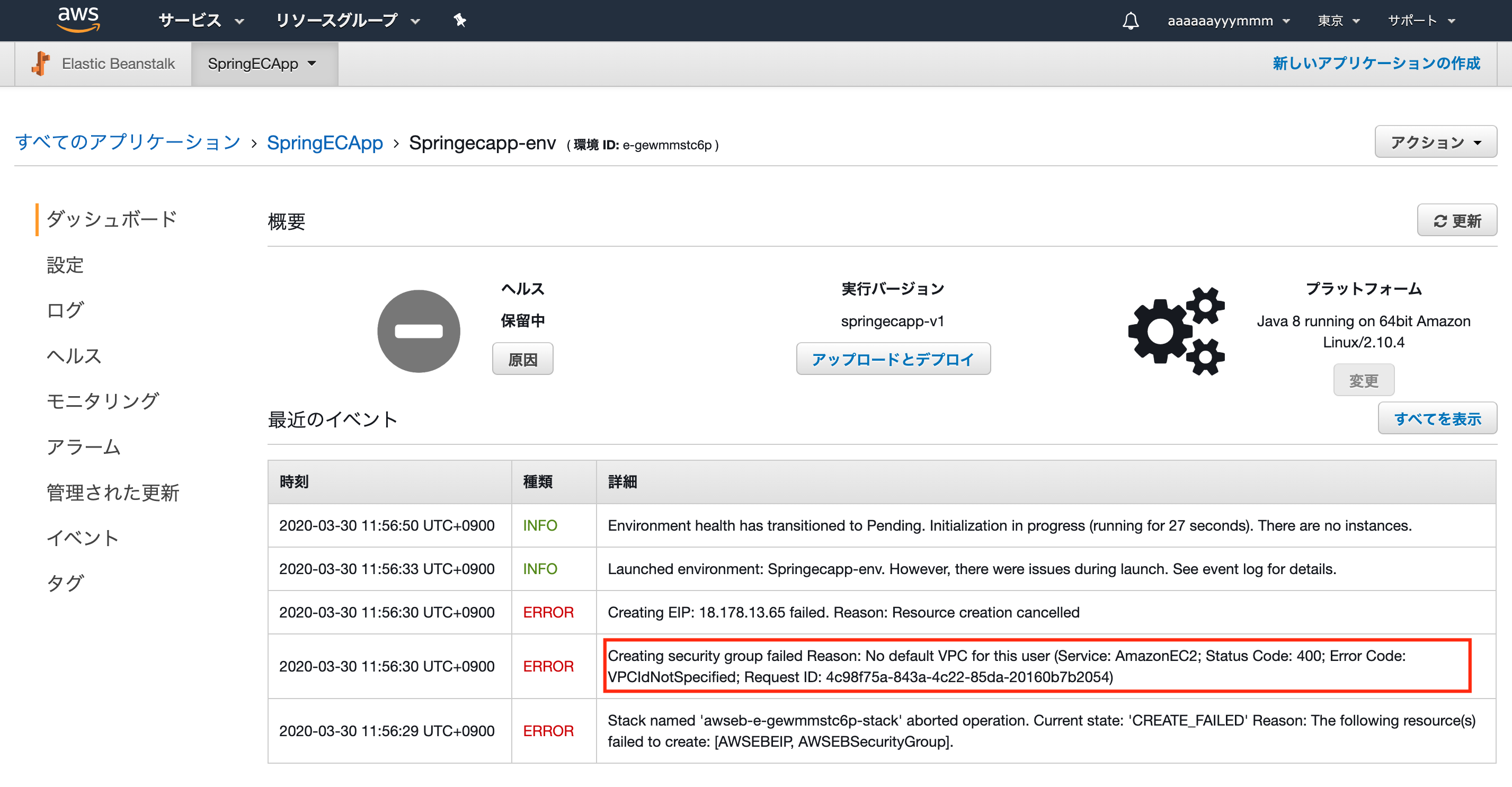
No default VPC found for this user(デフォルトVPCがない)
デプロイ時に出ました。
VPCを指定しない場合、デフォルトVPCが割り当てられます。
今回はVCP未指定かつデフォルトVPCが存在していないため、エラーが発生したようです。
以前学習したときに、デフォルトVPCを削除してたのを忘れてました。。。
ちなみに、デフォルトVPC作成したら、画像の3つのエラー全て消えました。
参考:https://aws.amazon.com/jp/premiumsupport/knowledge-center/cloudformation-cloudformer-default-vpc/500エラー(セッションテーブルがない)
There was an unexpected error (type=Internal Server Error, status=500). PreparedStatementCallback; bad SQL grammar [INSERT INTO SPRING_SESSION(SESSION_ID, CREATION_TIME, LAST_ACCESS_TIME, MAX_INACTIVE_INTERVAL, PRINCIPAL_NAME) VALUES (?, ?, ?, ?, ?)]; nested exception is java.sql.SQLSyntaxErrorExceptionデプロイ後、URLにアクセスしたら出ました。
セッション使っているのにテーブルが無いよ、とのこと。
application.propatiesにspring.session.jdbc.initialize-schema=alwaysを追記で解決。自動でセッションテーブルを作成してくれます。
以下のsqlを実行するという手もあります。
https://github.com/spring-projects/spring-session/tree/master/spring-session-jdbc/src/main/resources/org/springframework/session/jdbc
(そういえばローカルで作業してた時にこちらを実行したのを忘れてました。)おわり。



- 投稿日:2020-03-31T19:09:43+09:00
AWS EC2のインスタンスをt2からt3に変える
最初に
割と新しいインスタンスはただ単にインスタンスタイプを変えるだけで大丈夫だと思うのですが、古いとENAに対応していないということがあり得ます。
今回変更したかったのはまさにそういうものでした。
OSはCentOS7系でしたが、若干古かったのでENA対応していませんでした。
なので、ENAの対応から始まります。ENAについては
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/enhanced-networking-ena.htmlENA対応確認
modinfo ena未対応の場合
modinfo: ERROR: Module ena not found.が出ると思われる
update
CentOSならyumでアップデートしてENA対応できるので
sudo yum update今回古いインスタンスだからかupdateで失敗しました。そういう場合はrepoの情報のmirrorをコメントアウト、baseurlを有効にすればいけるはず。
インスタンス再起動
aws ec2 reboot-instances --instance-ids {InstanceID}ENA対応確認
modinfo enaさっきとは違って色々表示されるはず。
ENA有効化
ENAを有効化するためにインスタンスを止める必要があります。
# インスタンスを停止 aws ec2 stop-instances --instance-ids {InstanceID} # ENAが有効か確認 aws ec2 describe-instances --instance-ids {InstanceID} --query "Reservations[].Instances[].EnaSupport"現時点では有効化されていないので、多分[]が返ってきます。
# ENA有効化 aws ec2 modify-instance-attribute --instance-id {InstanceID} --ena-support # ENAが有効か確認 aws ec2 describe-instances --instance-ids {InstanceID} --query "Reservations[].Instances[].EnaSupport"ここの確認で
[ true ]が返ってきたらOK
t3に変更
最後にt3に変更します
# 変更して aws ec2 modify-instance-attribute --instance-id {InstanceID} --attribute instanceType --value t3.{InstanceSize} # 起動 aws ec2 start-instances --instance-ids {InstanceID}無事に変更できたようです。
- 投稿日:2020-03-31T19:06:43+09:00
AWS Command Line Interface (CLI) の出力を `--query` で制御し、パイプラインで活用する
これを
% aws organizations describe-organization { "Organization": { "MasterAccountEmail": "master-account@your-organization-example.com", "MasterAccountArn": "arn:aws:organizations::111111111111:account/o-xxxxxxxxxx/111111111111", "MasterAccountId": "111111111111", "Id": "o-xxxxxxxxxx", "AvailablePolicyTypes": [ { "Status": "ENABLED", "Type": "SERVICE_CONTROL_POLICY" } ], "FeatureSet": "ALL", "Arn": "arn:aws:organizations::111111111111:organization/o-xxxxxxxxxx" } }こう する話です
% aws organizations describe-organization --query 'Organization.MasterAccountEmail' --output text master-account@your-organization-example.comそしてたとえばこのように応用する
% aws ec2 describe-regions --query 'Regions[].{Name:RegionName}' --output text | xargs -I{} aws ec2 describe-availability-zones --region {} --query 'AvailabilityZones[].{c1:RegionName,c2:ZoneName,c3:State}' --output text eu-north-1 eu-north-1a available eu-north-1 eu-north-1b available eu-north-1 eu-north-1c available ap-south-1 ap-south-1a available ap-south-1 ap-south-1b available ...(省略)
- ※全リージョン全AZを列挙
なぜ awscli の
--queryオプションにこだわるのか。まず、 JSON 解析をわざわざ他のツールに依存したくないから です。
jq はイマイチだし、JSON なんだから JavaScript で書くのが一番自然な気はするとはいえ、Node.js で実際やってみるとこれはこれで面倒に感じてしまう。最初の
describe-organizationを JavaScript でやるとしたらこんなかんじでしょうか% aws organizations describe-organization | node -e " const data = []; process.stdin .on('readable', () => { let chunk; while ((chunk = process.stdin.read()) !== null) { data.push( chunk ); } } ) .on('end', () => { process.stdout.write( JSON.parse( data.join( '' ) ).Organization.MasterAccountEmail ); } ); "https://nodejs.org/api/process.html#process_process_stdin
readline だとこのような感じか
% aws organizations describe-organization | node -e " const data = []; require( 'readline' ) .createInterface( { input: process.stdin } ) .on( 'line', ( l ) => { data.push( l ); } ) .on( 'close', () => { process.stdout.write( JSON.parse( data.join( '' ) ).Organization.MasterAccountEmail ); } ); "やはり
--queryパラメタでやった方が楽な気がします。メリットは次のような感じでしょうか
- 他ツール非依存
- パラメタを考案する必要はあるが、比較的低負担で見通しがよい
--output textとの組み合わせで以降の処理にもパイプで繋げやすい- ※場合によっては
--filtersも有用そもそもこういった出力制御というのは、本質的に頑張りたい処理ではないので、極力最小化させたいわけです
最小化すれば、小さな処理を組み合わせた複雑なこともより書きやすくなりますaws organizations list-accounts --query 'Accounts[].{Id:Id,Name:Name}' --output text | while read a; do printf "$a\n"; aws organizations list-tags-for-resource --resource-id "`echo $a | awk '{print $1}'`" --query 'Tags[].{Key:Key,Value:Value}' --output table; done
- ※全メンバーアカウントのタグを列挙
- ※マスターアカウントで動作します
工夫次第で様々に活用できますが、リージョンやアカウントを横断した組織統制系のオペレーションなども、わざわざブラウザに行くまでもなく、このようにささっと CLI でやりますと、楽しいですよ。

- 投稿日:2020-03-31T16:51:47+09:00
AWS スイッチ先(他アカウント)のサービスを制御
目的
- ソースに認証文字列を書かない
- ローカルにセキュリティキーなどの認証文字列を置かない
- スイッチ先のRDSに接続したい、S3のデータを取りたい ...
プロフィール準備
ローカルまたは運用サーバにAWS1のUSERのプロフィールを作成
(ECSのようなサーバレスは環境変数にSSMを利用)STS(Security Token Service)を使用してスイッチ先のクレデンシャル取得
クレデンシャル取得フロー
AWS1(IAM USER) -> スイッチ先:AWS{2-N}(IAM ROLE)
IAM
AWS1 IAM USER
arn:aws:iam::012345678:user/aspnet
ポリシー{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sts:AssumeRole" ], "Resource": [ "*" ] } ] }スイッチ先 IAM Role
arn:aws:iam::123456789:role/aspnet
信頼関係{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::012345678:user/aspnet", ] }, "Action": "sts:AssumeRole" } ] }例).NET Application
app.config
<appSettings> <add key="AwsRoleArnBaseProfile" value="aspnet"/> ← IAM USER <add key="AwsRoleArnAws1" value="arn:aws:iam::123456789:role/aspnet"/> ← スイッチ先Role <add key="AwsRoleArnAws2" value="arn:aws:iam::234567891:role/aspnet"/> ... </appSettings>AmazonConfig.cs
using Amazon; using Amazon.SecurityToken; using Amazon.SecurityToken.Model; using Amazon.Runtime; using Amazon.Runtime.CredentialManagement; //スイッチ先 public enum AccountNo { AWS1 = 1, AWS2 = 2, ... } function ... (AccountNo accountNo){ var roleArn = $"AwsRoleArnAws{(byte)accountNo}"; //accountNo: 1~N var chain = new CredentialProfileStoreChain(); AWSCredentials awsCredentials; var profile = System.Configuration.ConfigurationManager.AppSettings["AwsRoleArnBaseProfile"]; if (chain.TryGetAWSCredentials(profile, out awsCredentials)) { var sts = new AmazonSecurityTokenServiceClient(awsCredentials); var arn = System.Configuration.ConfigurationManager.AppSettings[roleArn]; var stsreq = new AssumeRoleRequest { RoleArn = arn, RoleSessionName = $"{(byte)accountNo}_{region.SystemName}_{DateTime.Now.ToString("yyyyMMddHHmmsssss")}", DurationSeconds = 900 }; var stsres = sts.AssumeRole(stsreq); StsCredentials = stsres.Credentials; } }Ec2Service.cs
using Amazon; using Amazon.EC2; using Amazon.EC2.Model; ... aconf = new AmazonConfig(accountNo); IAmazonEC2 client = new AmazonEC2Client(aconf.StsCredentials, RegionEndpoint.APNortheast1); ...参考
- https://docs.aws.amazon.com/ja_jp/sdk-for-net/v3/developer-guide/net-dg-config-creds.html
https://dev.classmethod.jp/articles/sts-temporality-credential/
名前付きプロファイル
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-configure-profiles.html
https://docs.aws.amazon.com/ja_jp/powershell/latest/userguide/specifying-your-aws-credentials.html
(Windowsはオプションでセキュリティキーが暗号化され保存される)
- 投稿日:2020-03-31T16:51:47+09:00
AWSアカウント間の認証でスイッチ先のサービスを制御
目的
- ソースに認証文字列を書かない
- ローカルにセキュリティキーなどの認証文字列を置かない
- スイッチ先のRDSに接続したい、S3のデータを取りたい ...
プロフィール準備
ローカルまたは運用サーバにAWS1のUSERのプロフィールを作成
(ECSのようなサーバレスは環境変数にSSMを利用)STS(Security Token Service)を使用してスイッチ先のクレデンシャル取得
クレデンシャル取得フロー
AWS1(IAM USER) -> スイッチ先:AWS{2-N}(IAM ROLE)
IAM
AWS1 IAM USER
arn:aws:iam::012345678:user/aspnet
ポリシー{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sts:AssumeRole" ], "Resource": [ "*" ] } ] }スイッチ先 IAM Role
arn:aws:iam::123456789:role/aspnet
信頼関係{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::012345678:user/aspnet", ] }, "Action": "sts:AssumeRole" } ] }例).Net Application
app.config
<appSettings> <add key="AwsRoleArnBaseProfile" value="aspnet"/> ← IAM USER <add key="AwsRoleArnAws1" value="arn:aws:iam::123456789:role/aspnet"/> ← スイッチ先Role <add key="AwsRoleArnAws2" value="arn:aws:iam::234567891:role/aspnet"/> ... </appSettings>AmazonConfig.cs
using Amazon; using Amazon.SecurityToken; using Amazon.SecurityToken.Model; using Amazon.Runtime; using Amazon.Runtime.CredentialManagement; function ... (accountNo スイッチ先){ var roleArn = $"AwsRoleArnAws{(byte)accountNo}"; //accountNo: 1~N var chain = new CredentialProfileStoreChain(); AWSCredentials awsCredentials; var profile = System.Configuration.ConfigurationManager.AppSettings["AwsRoleArnBaseProfile"]; if (chain.TryGetAWSCredentials(profile, out awsCredentials)) { var sts = new AmazonSecurityTokenServiceClient(awsCredentials); var arn = System.Configuration.ConfigurationManager.AppSettings[roleArn]; var stsreq = new AssumeRoleRequest { RoleArn = arn, RoleSessionName = $"{(byte)accountNo}_{region.SystemName}_{DateTime.Now.ToString("yyyyMMddHHmmsssss")}", DurationSeconds = 900 }; var stsres = sts.AssumeRole(stsreq); StsCredentials = stsres.Credentials; } }Ec2Service.cs
using Amazon; using Amazon.EC2; using Amazon.EC2.Model; ... aconf = new AmazonConfig(accountNo); IAmazonEC2 client = new AmazonEC2Client(aconf.StsCredentials, RegionEndpoint.APNortheast1); ...参考
- https://docs.aws.amazon.com/ja_jp/sdk-for-net/v3/developer-guide/net-dg-config-creds.html
https://dev.classmethod.jp/articles/sts-temporality-credential/
名前付きプロファイル
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-configure-profiles.html
https://docs.aws.amazon.com/ja_jp/powershell/latest/userguide/specifying-your-aws-credentials.html
(Windowsはオプションでセキュリティキーが暗号化され保存される)
- 投稿日:2020-03-31T14:55:32+09:00
rocket.chatをEC2上でつかう
昨今の時勢でチャットツールをちょこっと用意したいと思ったので作ってみたメモ書きです。
構成
- AmazonLinux2
- t2.microインスタンス
EC2ユーザーデータを用いてパパっと立てます。
私の要望上、使い終わったらすべてのデータを毎回削除して使いたい。というちょっと特殊な事情もあったのでdocker使ってます。
NWやSGの設定はよしなに
ALBとACM挟んでHTTPS化とかもできるのでそのへんはよしなにdocker-compose.yml
rocket.chatのページにあったものをちょこっと書き換えて使用。
volumeの部分を削除して使う&hubotいらないのでそのへんを削除して使用してます。mongovolumes: - ./data/runtime/db:/data/db - ./data/dump:/dumprocketchatvolumes: - ./uploads:/app/uploadsスクリプト
user-data#!/bin/bash amazon-linux-extras install -y docker yum install -y git systemctl enable docker systemctl start docker sudo curl -L "https://github.com/docker/compose/releases/download/1.25.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose gpasswd -a ec2-user docker systemctl restart docker # rocket.chat cat << _EOF_ > /home/ec2-user/docker-compose.yml version: '2' services: rocketchat: image: rocketchat/rocket.chat:latest command: > bash -c "for i in `seq 1 30`; do node main.js && s=$$? && break || s=$$?; echo \"Tried $$i times. Waiting 5 secs...\"; sleep 5; done; (exit $$s)" restart: unless-stopped environment: - PORT=3000 - ROOT_URL=http://localhost:3000 - MONGO_URL=mongodb://mongo:27017/rocketchat - MONGO_OPLOG_URL=mongodb://mongo:27017/local depends_on: - mongo ports: - 3000:3000 mongo: image: mongo:4.0 restart: unless-stopped command: mongod --smallfiles --oplogSize 128 --replSet rs0 --storageEngine=mmapv1 mongo-init-replica: image: mongo:4.0 command: > bash -c "for i in `seq 1 30`; do mongo mongo/rocketchat --eval \" rs.initiate({ _id: 'rs0', members: [ { _id: 0, host: 'localhost:27017' } ]})\" && s=$$? && break || s=$$?; echo \"Tried $$i times. Waiting 5 secs...\"; sleep 5; done; (exit $$s)" depends_on: - mongo _EOF_ cd /home/ec2-user docker-compose up -d起動後、
http://InstanceIP:3000/にrocket.chatのアプリがバインドされます。
使い終わったらdocker-compose downまた使う際はdocker-compose upすれば毎回初期化されて使えます。参考
https://docs.docker.com/compose/install/
https://rocket.chat/docs/installation/docker-containers/docker-compose/
- 投稿日:2020-03-31T13:56:40+09:00
AWS Aurora MySQLをLaravelプログラムと連結する方法
AWS上で展開するLaravelプログラムとAurora MySQLの連結方法について明記します。
設定は簡単です。
Laravelの
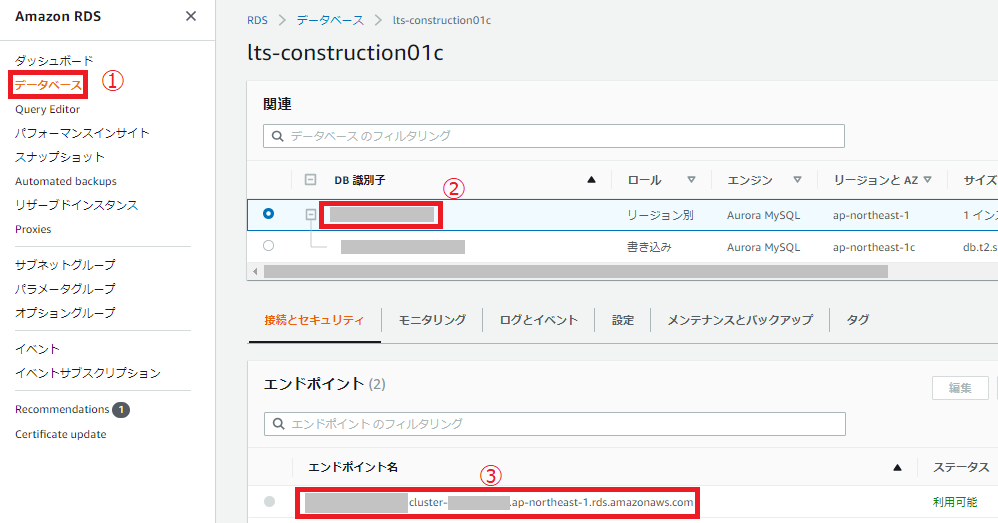
.envファイルのDB_HOSTをAmazon RDSの画面から作成済みDBのエンドポイント名をコピーして、以下の様に貼り付けるだけです。DB_HOST=xxxxxx.cluster-yyyyy.ap-northeast-1.rds.amazonaws.com具体的なAmazon RDS画面での確認場所は画像の通りです。
③のエンドポイント名をコピーしてください。
これでLaravelからのAurora MySQLへの指定はできました。
DBのユーザーやパスワード設定は.envと合わせておけばIAMロールの設定はなくても大丈夫そうです。(特に設定した覚えないまま利用してます)
- 投稿日:2020-03-31T13:32:23+09:00
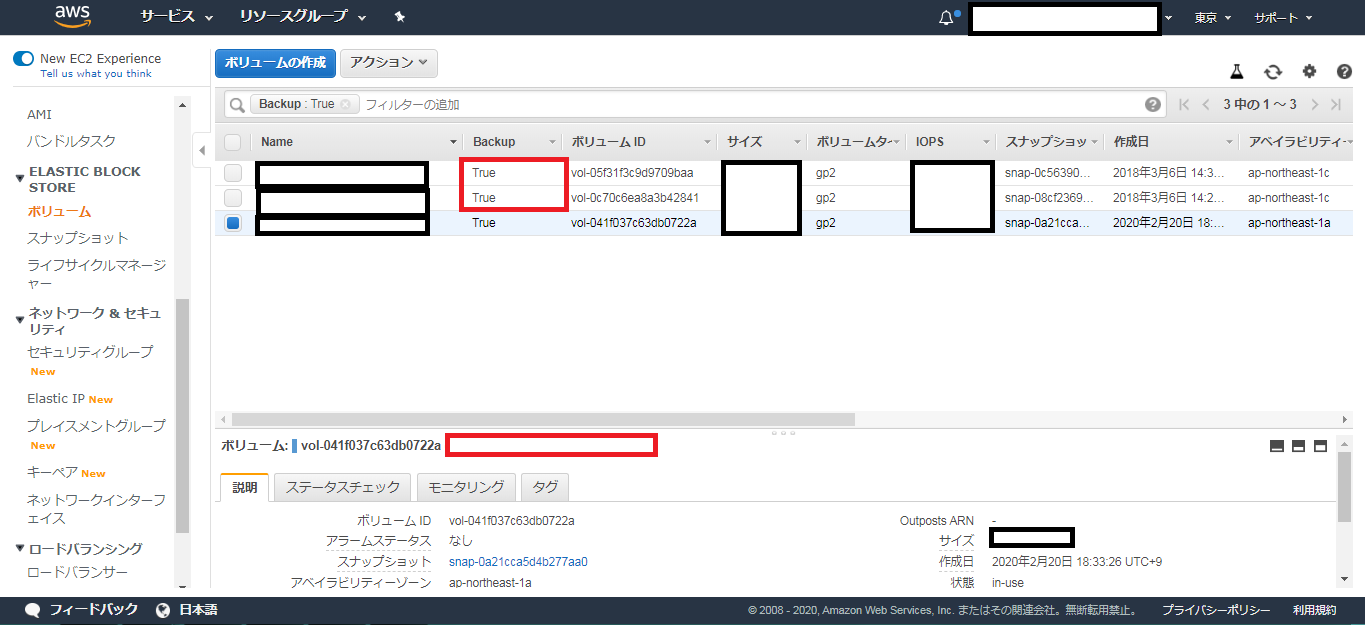
EC2のライフサイクルマネージャを使ってEBSのスナップショットを自動で作成する方法
EC2のEBSに対して、定期的にスナップショットを作成する方法
EC2のデータライフサイクルマネージャーを使用して、EBSのスナップショットを定期的に作成する方法を備忘録として残します。
大まかなフロー
1.タグエディターでスナップショットを作成したいEBSに対して共通のタグ(Name)を付与する。
2.先述の1.で設定したタグを持つEBSに対して作動するライフサイクルマネージャーポリシーを作成する。
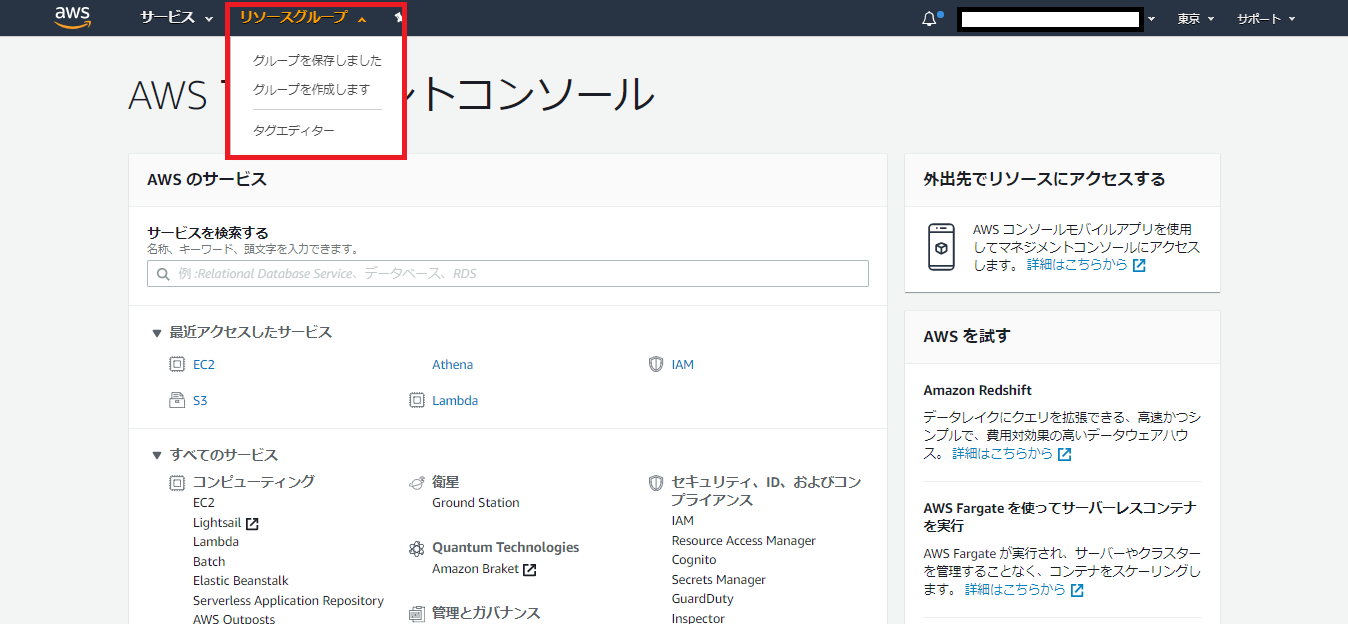
3.スナップショットが作成される。タグエディターで共通のタグを付与する
- AWSコンソール上部の「リソースグループ」から「タグエディター」を選択する。 ※どのサービスにも上部に「リソースグループ」がある。
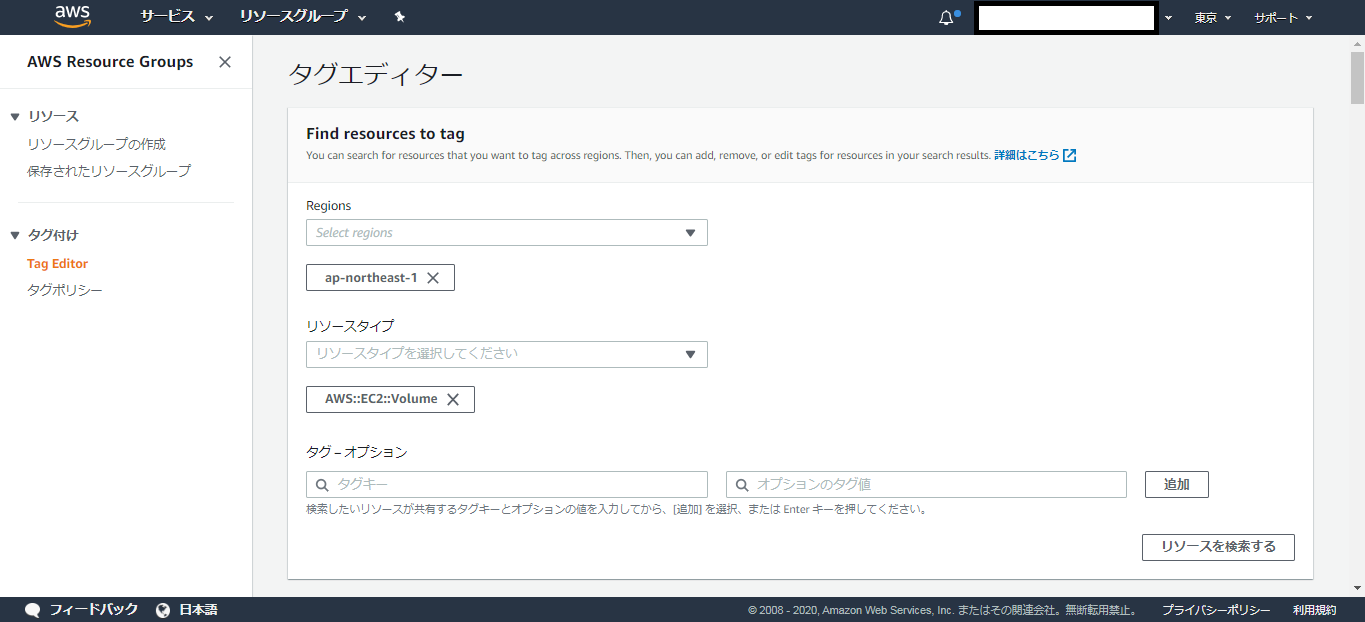
下記を参考に設定する
- リージョンはap-northeast-1(東京)を選択する
- リソースタイプ:AWS::EC2::Volume を選択する(“vol”と打てば出る)
- 「AWS::EC2::Volume」全件を表示する場合そのまま「リソースを検索する」をクリック(タグ-オプションを指定すれば条件検索できる)
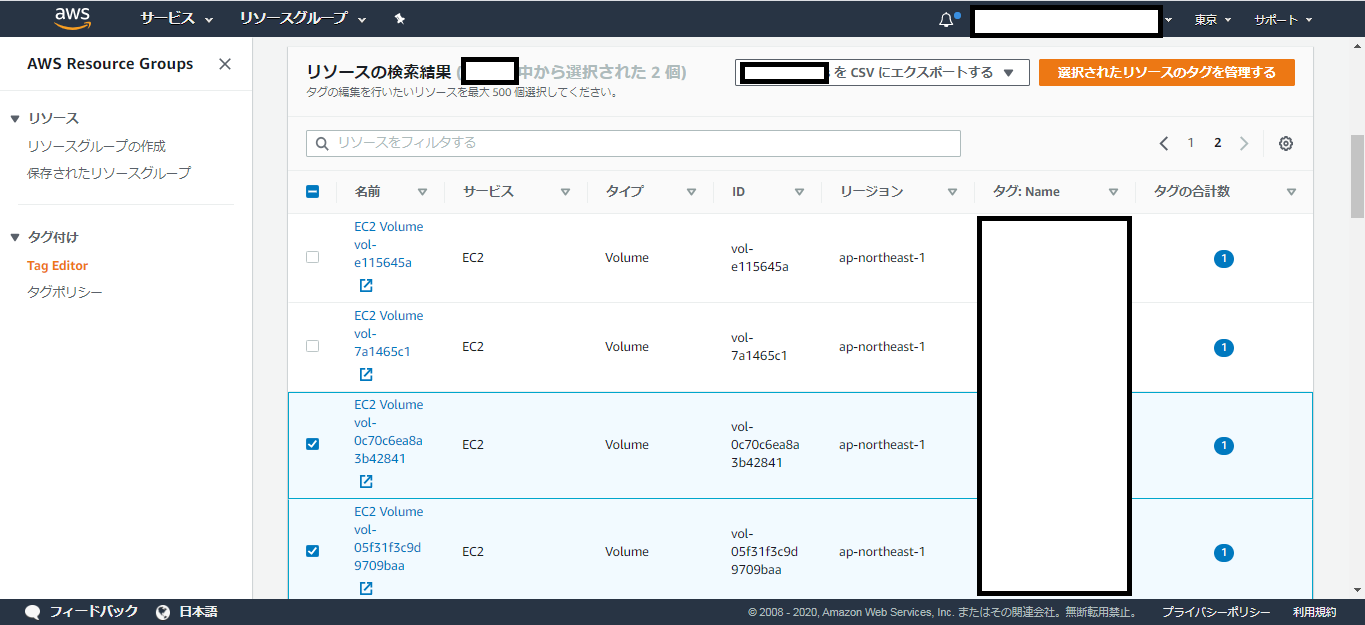
- リソースの検索結果からスナップショット作成対象にしたいボリュームを選択する
「選択されたリソースのタグを管理する」をクリックする
「タグの管理」下部の「選択されたすべてのリソースのタグの編集」にある
「タグの追加」をクリックして、先ほど選択したボリュームに対して、
共通のタグを付与する
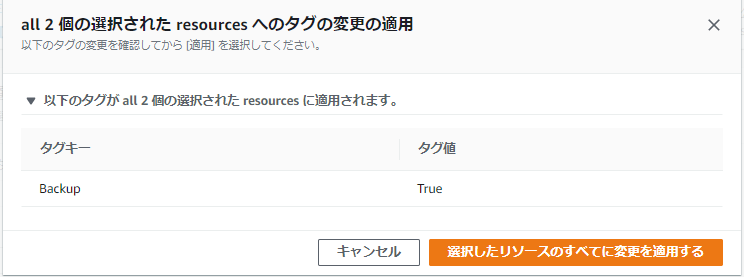
(例)”Backup : True” など同じタグであれば何でも良い「タグの変更を確認して適用する」をクリックする
タグのキーと値を確認し、「選択したリソースのすべてに変更を適用する」をクリック
EBSの中のボリュームでTagが正しく追加されているか確認できる。
以上でスナップショットの対象EBSに対しての共通タグ付け作業が完了
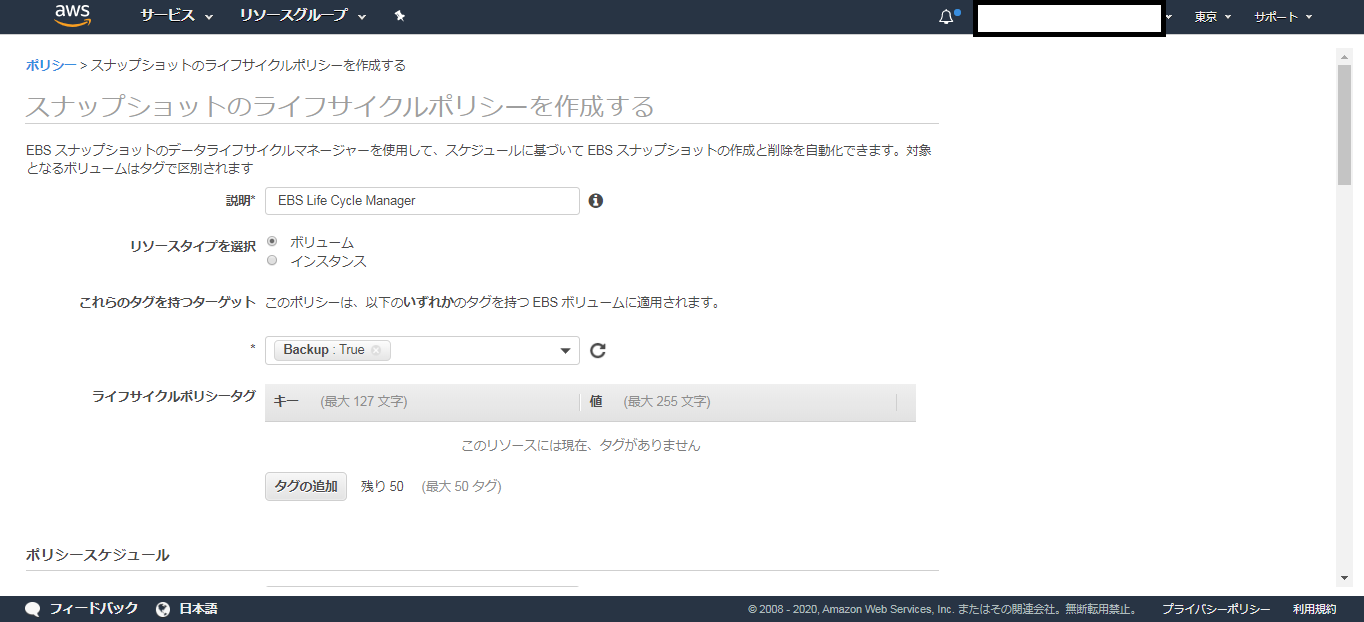
ライフサイクルマネージャーの設定
- EC2の左側「ELASTIC BLOCK STORE」から「ライフサイクルマネージャ」を選択
- スナップショットの「ライフサイクルポリシーを作成する」をクリック
以下は各メイン項目の設定テンプレです。
説明
ポリシーに説明をつける
例:EBS Life Cycle Managerリソースタイプ
EBSの場合ボリュームを選択これらのタグを持つターゲット
スナップショットの対象にしたいEBSが持つタグを選択
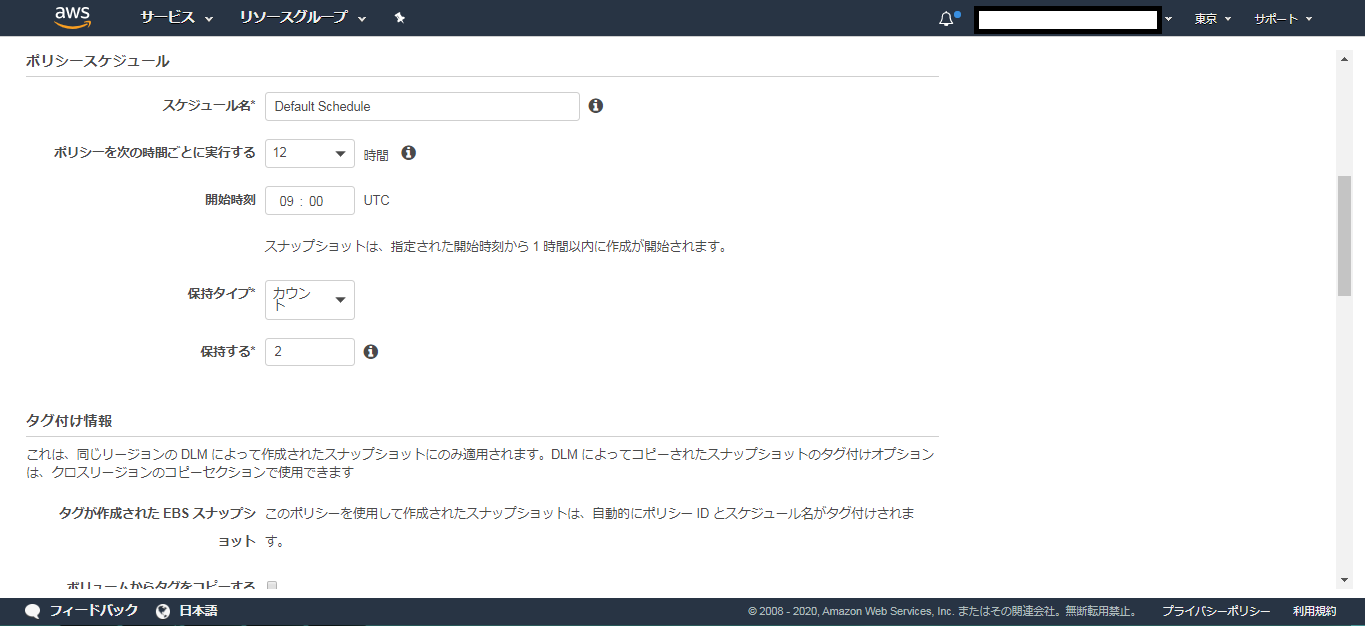
(例)Backup:Trueスケジュール名
Default Schedule(適宜変更)ポリシーを次の時間ごとに実行する
12時間 ※適宜変更開始時刻
UTC09 (JST18時) (適宜変更)保持タイプ
カウント(個数)保持する
例:2
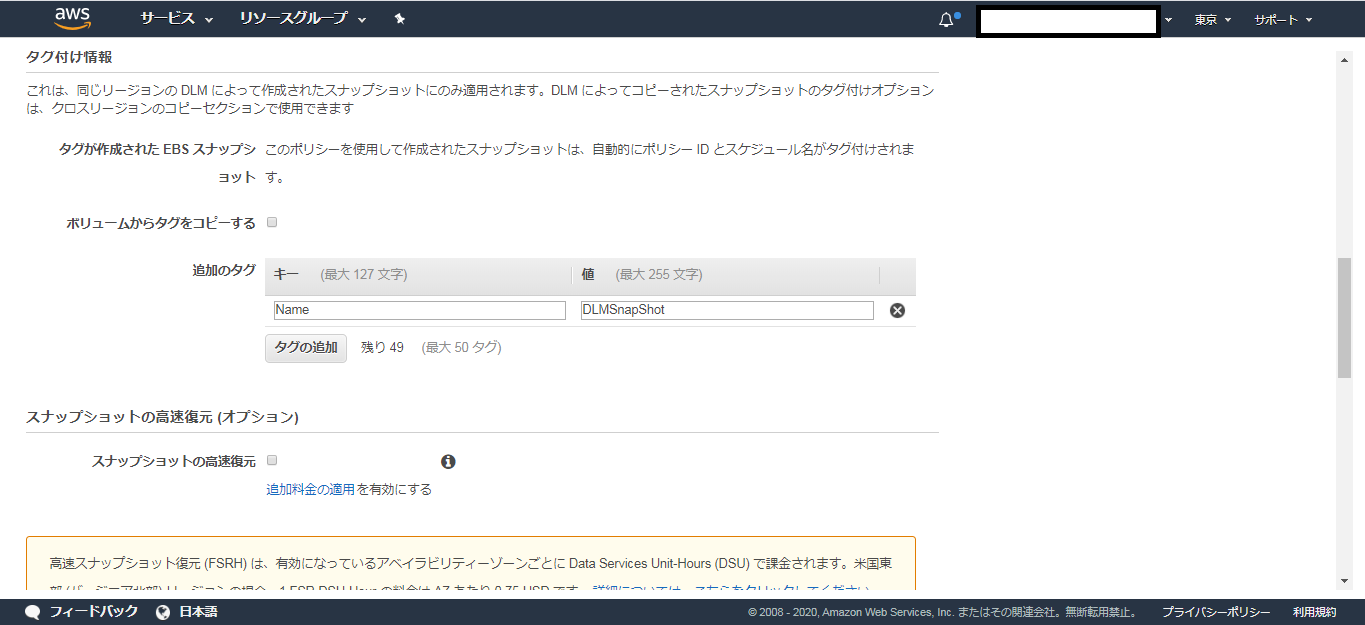
※上記設定例の場合スナップショットを直近2個保持し、古いものは勝手に消去される。ボリュームからタグをコピーする。
[チェック無し]
追加のタグ
(例)Name : DLMSnapShot
※このライフサイクルポリシーで作成されるスナップショットの名前IAM ロール
デフォルトロールポリシーステータス
ポリシーを有効にする。設定例
上記のテンプレを元に各項目を入力する。
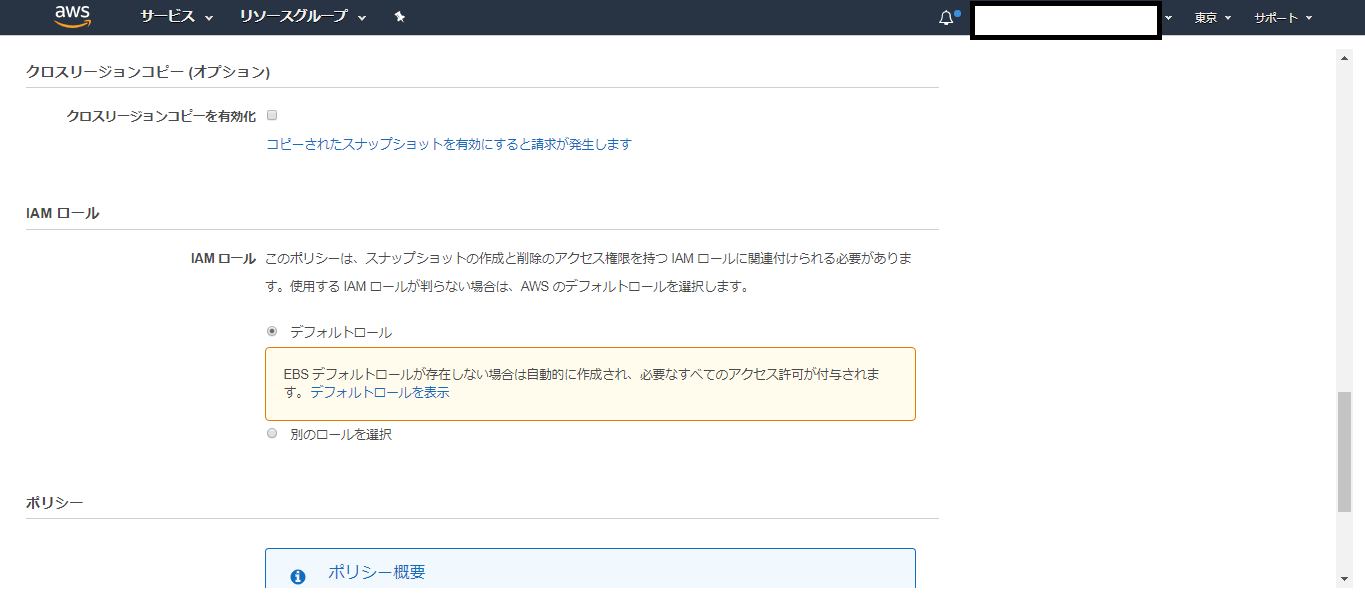
※スナップショットの高速復元は別途料金が掛かるようなので注意。
※クロスリージョンコピーを有効化も同様。
設定完了後、スナップショット一覧にて、指定した時間にスナップショット作成が行われているはずです。
参照元
https://qiita.com/quickguard/items/3e1778312b93dbe4b2a6
https://mseeeen.msen.jp/create-a-snapshot-and-manage-generations-using-amazon-dlm/
https://liberalarts.life/it/data-lifecycle-manager/


- 投稿日:2020-03-31T12:55:19+09:00
文系出身!新卒1年目の私がAWS認定クラウドプラクティショナーに合格した体験記
新卒1年目ながら、AWS認定クラウドプラクティショナーに合格しました!文系出身のIT未経験でインフラ知識がほぼない状態から、合格までの勉強方法を体験記として綴ります。「段階的に参考書を読むこと」「毎日手をつけること」という学習ポイントを踏まえつつ、点と点を繋げて広げる勉強法と初学者ならではの気づきを記していきます。
0.プロフィール
- 大学では政治学を学び、PCはwordやPowerPointをさわる程度
- 渋谷に本社を置くSIerに勤める新卒1年目エンジニア
- アプリ開発の部署に所属し、Javaに奮闘する
- 1年間に、本を40冊読み映画を60本見る
1.サマリー
学習をはじめる前(2019年9月頃の状態)
- 開発系部署に本配属されるも環境構築に苦戦
- インフラの知識は新人研修で習ったのみ
- クラウドの知識・実務経験はなし
結果
AWS認定クラウドプラクティショナー 合格
2019年12月 727点学習に使ったもの
- 参考書1冊
- udemyの問題集
学習期間・時間
- 2019年9月下旬から、2019年12月下旬まで
- 平日1時間、休日は5時間程度
2.合格までに行ったこと
2.1 作戦を考える(2019年9月下旬頃)
クラウドプラクティショナー受験のきっかけは「SAAは難しいから、まずはクラウドプラクティショナーからはじめたほうがいいよ」と先輩からアドバイスを頂いたからです。会社の新卒課題としてSAAが指定されており、その基礎固めとして取り組みました。
また、基礎から学びたいと思った理由は語彙不足にあります。議事録担当としてミーティングに参加しても、全く会話を聞き取ることができませんでした。役に立っている実感がありませんでした。そして、議事録をつくる作業に時間をかけすぎて、本来のタスクに十分時間を使えず、ちょっとミス、しました。その時、「話についていける一員になりたい!」と思ったので、語彙を増やすつもりでクラウドプラクティショナーを取り組みました。
AWSについて無知の状態からスタートだったので、まず、先人の知恵に頼りながら、学習の方法を考えることからはじめました。ただ、クラウドプラクティショナーの合格体験記は、既にAWSの経験がある方のものが多く、初学者のものが少なかったです。そこで、SAAの合格体験記を参考にしました。「参考書を読んでインプットする」「問題集を解いてアウトプットする」という王道を行くものが多かったので、基本に忠実に取り組むことにしました。さらに、詳細に体験記を見比べると「参考書や問題集を『複数』取り組んでいる」という共通点を発見しました。
このような情報収集と、難易度や基礎固めという目的を踏まえて、クラウドプラクティショナーは「1つ」、SAAは「複数」の参考書や問題集を取り組むことにしました。
また、インフラ系の概念や用語を理解するのに苦戦すると思ったので、期間は長めに設定しました。「12月までにクラウドプラクティショナーを受験すること」、「2月までにSAAを受験すること」を決めました。
さらに、「毎日、AWSの何かしらに手を付ける」ということも決めました。「忙しい」「眠い」「モチベーションが下がる」など、不安要素はいつも付きまといます。一度止まると、再開するのが難しくなるので、「参考書を1行読む」など眠い時、忙しい時でもを続けられるマイルールを設定しました。続けることは知識をつけるだけではなく、自信をつけることにもつながります。試験前の精神安定のためにも、「自信」は必要です!
2.2 参考書を読んでみる(2019年9月下旬頃)
こちらの参考書を活用しました。
AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
目次
第1章 AWS認定資格
第2章 AWSクラウドの概念
第3章 AWSのセキュリティ
第4章 AWSのテクノロジー
第5章 コンピューティングサービス
第6章 ストレージサービス
第7章 ネットワークサービス
第8章 データベースサービス
第9章 管理サービス
第10章 請求と料金AWS公式のblackbeltより、取り掛かりやすかった印象です。クラウド特徴や利点の解説もあり、導入の部分から頼りになりました。各節や章のおわりにある「重要ポイント」や「本章のまとめ」がとてもありがたかったです。細かい説明をとばして、ポイントだけを追うようにも読むことができる参考書でした。
参考書は段階的に通読することを意識しました。「原理・原則をとらえるようにざっくり読む」→「データベース、ストレージなど各サービスをおおまかなイメージでつかむ」→「RDS、DynamoDBなど各特定のサービスの特徴や違いを捉える」という順番で3回は通読しました。毎日1時間程度の学習時間に読んでいました。
「原理・原則をとらえるようにざっくり読む」の段階では、先述したように細かい説明は飛ばしながら、ポイントを重点的に読みました。この時点では、「Design For Failureという考えが大事そう」、「EC2やVPCというものがあるらしい」くらいの理解でした。
次に、「データベース、ストレージなど各サービスをおおまかなイメージでつかむ」の段階では、「コンピューティングサービスにはEC2やELBなどがあって、○○ができる」ということが把握できるまで読みました。また、反対に「S3はストレージサービスである」といえるように、サービスがどの分野に含まれるのかも意識して読みました。
「RDS、DynamoDBなど各特定のサービスの特徴や違いを捉える」の段階が一番苦しかったです。AWS CloudTrailとAWS CloudWatch、Trusted Advisorなど、「概念はなんとなくわかるけど、問題に出されたら迷いそう」という状態に陥ったのです。(実際の試験で、この予想通りのことが頻繁に起きたのですが…笑)インプットだけでは定着しないと悟ったので、問題演習もはじめました。「違いを捉える読み方」と「問題演習」で、インプットとアウトプットの両方で知識の定着を図りました。
2.3 問題集を解く(11月初旬)
クラウドプラクティショナーの問題演習ではUdemyの問題をこなしました。
この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(7回分455問)
応用レベルの問題は実際の試験より、難易度は高いと思います。65問×7回の問題集で、テスト後は各分野ごとに正答率が表示されることも魅力の一つです。各問題に対する解説も充実しているので、おすすめです。問題文も本番と似た傾向であり、公式問題が少ないクラウドプラクティショナーの勉強には最適でした。
毎日1時間程度の時間を設けて、問題を10~20問解く様に心掛けました。週末には、模擬問題1回分の65問を解いていました。基本的には、7回の模擬問題を何度も解いていきました。知識を定着させるべく、まず、最初4回分を何度も解き直し、その後、後半3回以降の問題も織り交ぜていました。注意したのは、覚えてしまった正解の選択肢を安易に選ばないことです。選択肢の暗記は本番では通用しないからです。正解の選択肢を覚えてしまったときは、選ぶプロセスが正しいかということを確認してから、選ぶようにしていました。
また、問題を解くことよりも、解説を読んだり、上記の参考書で調べたりすることに注力しました。時間の割合としては、2対3くらいだったと思います。ここで役に立ったのは「段階的に読む」の2段階目でした。
また、反対に「S3はストレージサービスである」といえるように、サービスがどの分野に含まれるのかも意識して読みました。
問題を解くときに、どのカテゴリーに含まれるサービスかを知っているだけで、選択肢を消去することができました。データベースを問われている問題の選択肢に、ストレージサービスがあったらすぐに違うと判断できたのです。大枠から理解を試みる読み方のメリットだと感じました。そして、参考書で調べるときに、どこに書かれているのか見当がつきやすくなりました。このように、参考書を読んだときの知識と問題を解くときの知識が少しずつ繋がっていきました。
問題演習を始めた当初は3割くらいの正答率でした。選択肢を2つか3つまで絞ることはできるけれども、正解ができないという日々が続いたのですが、知識が繋がっていく実感があったあたりから、急に正答率があがりました。
1か月ほど続けたあとには、5割→6割と正答率は伸びていき、12月下旬には基礎レベルの問題で8~9割はとれるようになり、受験の日を迎えました。
2.4 本番に挑む(2019年12月下旬)
基礎レベルといわれるクラウドプラクティショナーでしたが、受験したときは緊張しました。一通り解いたときには時間が30分ほど余り、見直しに時間をかけることができました。ただ、知識があいまいで決めきれない問題もあり、「たくさん練習問題解いたのに~」と悔しかった問題もありました。
また、参考書や問題集で見たことのない言葉がいくつかありました。問題文に初見の言葉ができきたら前後の文章から類推する、選択肢の中にでてきたら消去法で1つに絞るように問題を解きました。知らない言葉が多数出ることも想定して逃げ方も知っていると、合格に近づけると思いました。
問題を解き終わり、アンケートに答えると合否が表示されます。「合格」と表示されたときは「ん~~~~、イェイ!!!!!」という感じでした。(伝わりますか?笑)
3.まとめ
合格まで3か月ほどかかってしまったのですが、無事に、ギリギリで、合格できました。振り返ると、クラウドの利点やAWSの基礎的な部分を一通り触ることができました。合格のポイントは「続ける」ことだったと思います。理解不足の知識はすぐ忘れます。知識を更新するには続けることが近道であり、これを学習の作戦に取り入れたこその結果だと感じています。
調べて、やってみる。
システムエンジニアとして、大事なことだと思います。ただ勉強して資格を取ったのではなく、気づきの多い3か月になりました。
12月下旬ごろには、クラウド系の会話にも少しはついていけるようになりました。業務の中で、学習の成果が感じられました。わかることが広がりました。また、「合格しました」と同じプロジェクトの方に報告した時に「よかったね!」「おめでとう!」と言ってもらえたこともうれしかったです。
この後、SAAにも挑戦し合格しました。SAAの合格体験記も準備しているので、そちらも読んで頂ければ幸いです。
最後まで読んでいただいた方、ありがとうございました。
- 投稿日:2020-03-31T12:24:17+09:00
AWS スティッキーセッションの有効化
ECSでコンテナ(EC2インスタンス)をいくつも立ち上げる場合、何らかの理由でインスタンスが停止してセッションが途切れてしまう場合があります。
そうならないように、どのコンテナ(EC2インスタンス)からでもユーザーを識別できるようにしてくれるのがスティッキーセッションです。
スティッキーセッションの有効化はとても簡単です。(1分で終わります)
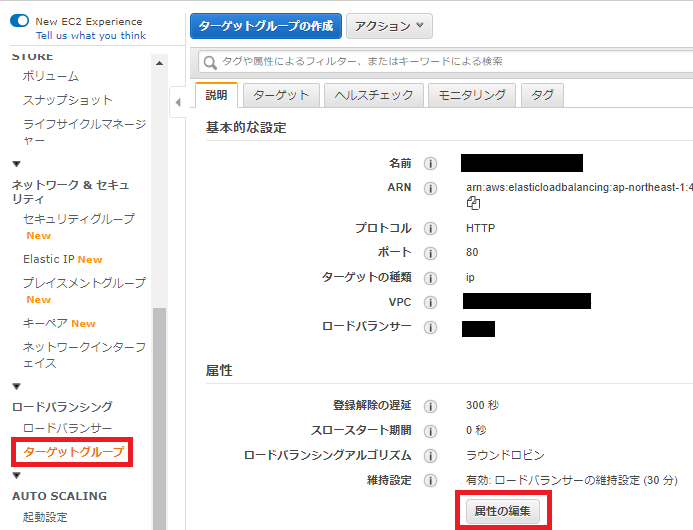
AWSマネジメントコンソールからECSの画面を開き、ターゲットグループを選んで「属性の編集」ボタンから編集可能なります。
①「維持設定」の有効化にチェックを入れて、
② 有効時間を設定して
③ 保存すれば完了です。
スティッキーセッションの仕組みは難しそうですが、ポチポチクリックするだけでうまく設定してもらえるのは非常に助かります。
難しいこともあっさりできてしまう作りになっている。
ますますAWSが好きになりました。スティッキーセッションを利用する場合とそうでない場合についても理解が必要かもしれないので、下記のページが分かりやすいかもしれません。
[参考ページ]
スティッキーセッションを使っていなければApplication Load Balancer障害に耐えれたかも??? Amazon EC2をステートレスにする為にやるべきこと

- 投稿日:2020-03-31T12:16:28+09:00
AWS EC2 https化
AWSのEC2インスタンスで起動しているWEBアプリのhttps化について
今回まずhttps化の際に一番始めに参考にさせて頂いたのがコチラ
https://qiita.com/Yuki_Nagaoka/items/3020f02d3fd74c8572a0ただ、私の場合はnignxの起動時にエラーが出てしまいました。
エラー内容としては
[emerg] no "ssl_certificate" is defined for the "listen ... ssl" directive in /etc/nginx/nginx.conf:92こんな感じでSSL証明書が定義されてないよ!と。。
じゃあ定義すればいいんだよね?
。。。。んー?AWSのACMで証明書発行したけどこれエクスポートできなくね??
AWSの一次ソースを色々漁ってみてこれかな?と思うものを幾つか試してみたりしました。
しかしうまく行かない。。。そんな時にテラテイルかな?https化の質問に対して
「せっかくAWS使ってるなら全部AWSにやらせればいいじゃない?」
と神の一言を発見。
そこからは早かった。
「ELB httpsリダイレクト」で検索してELBでhttpsレスポンスを返す設定をしてnginxの設定を初期状態に戻して(ドメイン名とかは変更ですよ?)
https化完了!
多分大丈夫、、転換点としてはnignxを使ってhttpsリダイレクト掛けようと調べていたこと。
まあそれでも設定は簡単な感じでしたけど、AWSのACMで証明書発行した場合はちょっとややこしいのかな?
自分はハマってしまいました。。そもそもAWS使うならAWSにできることは最大限AWSを使う
という考えは大事なのかなと今回思いました。
- 投稿日:2020-03-31T12:00:26+09:00
LocalStackによるインフラ構築1
Quick introduction to localstack using localstack-demo
Introduction to LocalStack
LocalStack provides an easy-to-use test/mocking framework for developing Cloud applications. It spins up a testing environment on your local machine that provides the same functionality and APIs as the real AWS cloud environment.
Setting up components
conda create -n localstack python=3.5 conda activate localstack mkdir external-master cd external-master && git clone https://github.com/good-idea/localstack-demo.git git clone https://github.com/localstack/localstack.git pip install awscliConfiguring
$aws configure --profile localstack AWS Access Key ID [None]: dummy AWS Secret Access Key [None]: dummy Default region name [None]: us-east-1 Default output format [None]: json $ tree .aws .aws ├── config └── credentials 0 directories, 2 files $ cd .aws $ ls config credentials $ vim credentials $ vim configLaunching localstack container
$ cd external-master/localstack-demo $ TMPDIR=/private$TMPDIR \ > DATA_DIR=/tmp/localstack/data \ > SERVICES=apigateway,kinesis,dynamodb,dynamodbstreams,elasticsearch,s3,\ > lambda,sns,sqs,redshift,es,ses,route53,cloudformation,cloudwatch,\ > ssm,secretsmanager,stepfunctions,logs,sts,iam,ec2 \ > docker-compose up -d Creating network "localstack-demo_default" with the default driver Creating localstack_demo ... doneCreating S3-bucket
Execute bellow commands after launching localstack.
aws --endpoint-url=http://localhost:4572 s3 mb s3://demo-bucket aws --endpoint-url=http://localhost:4572 s3api put-bucket-acl --bucket demo-bucket --acl public-readFinally, access to http://localhost:8055 and assumed result is bellow.
How to reproduce(Fastest)
Using pre-setup docker container, we can reproduce environment easily.
docker pull yoshinobusekiyu4docker/localstack-learn:1.0.0 TMPDIR=/private$TMPDIR DATA_DIR=/tmp/localstack/data SERVICES=apigateway,kinesis,dynamodb,dynamodbstreams,elasticsearch,s3,lambda,sns,sqs,redshift,es,ses,route53,cloudformation,cloudwatch,ssm,secretsmanager,stepfunctions,logs,sts,iam,ec2 docker run -it -p '4563-4599:4563-4599' -p 8055:8080 yoshinobusekiyu4docker/localstack-learn:1.0.0 /bin/bash -c "localstack start" aws --endpoint-url=http://localhost:4572 s3 mb s3://demo-bucket aws --endpoint-url=http://localhost:4572 s3api put-bucket-acl --bucket demo-bucket --acl public-readReferences

- 投稿日:2020-03-31T11:48:24+09:00
aws-cliでCognitoのユーザステータスをFORCE_CHANGE_PASSWORDからCONFIRMEDへ変更する
- 投稿日:2020-03-31T11:44:50+09:00
AWS Organizations に属していない AWS アカウントからのリソース利用を検知できるようになったので、さっそく試してみました。
IAM Access Analyzer が AWS Organizations 管理外のアカウントからのアクセスを検出できるようになったので試してみました。
IAM Access Analyzer とは
セキュリティチームと管理者が、リソースへの意図したアクセスのみがポリシーで提供されているかを簡単に確認できるようにします。リソースポリシーにより、お客様は特定のリソースにアクセスできるユーザーと、クラウド環境全体でそのリソースを使用する方法を細かく制御できます。
対象の AWS カウント(今回の追加で AWS Organizations 管理下の AWS アカウント)外からのアクセスが意図しているものなのかを検出するための機能です。
例えば、S3 へのアクセス権を与えているが、意図していないアクセスがないかを検出してくれます。IAM Access Analyzer の設定
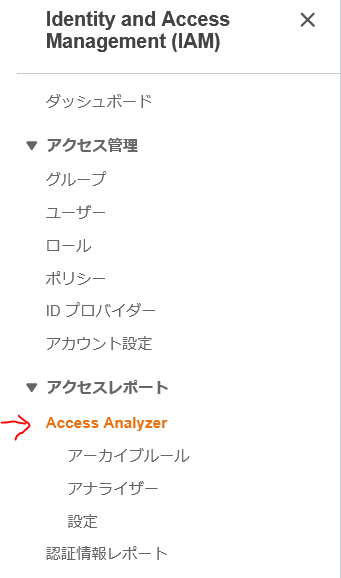
AWS Organizations のマスターアカウント(Payerアカウント)でマネージメントコンソールにログインし、 IAM の画面を表示します。そして、 Access Analyzer の箇所をクリックします。
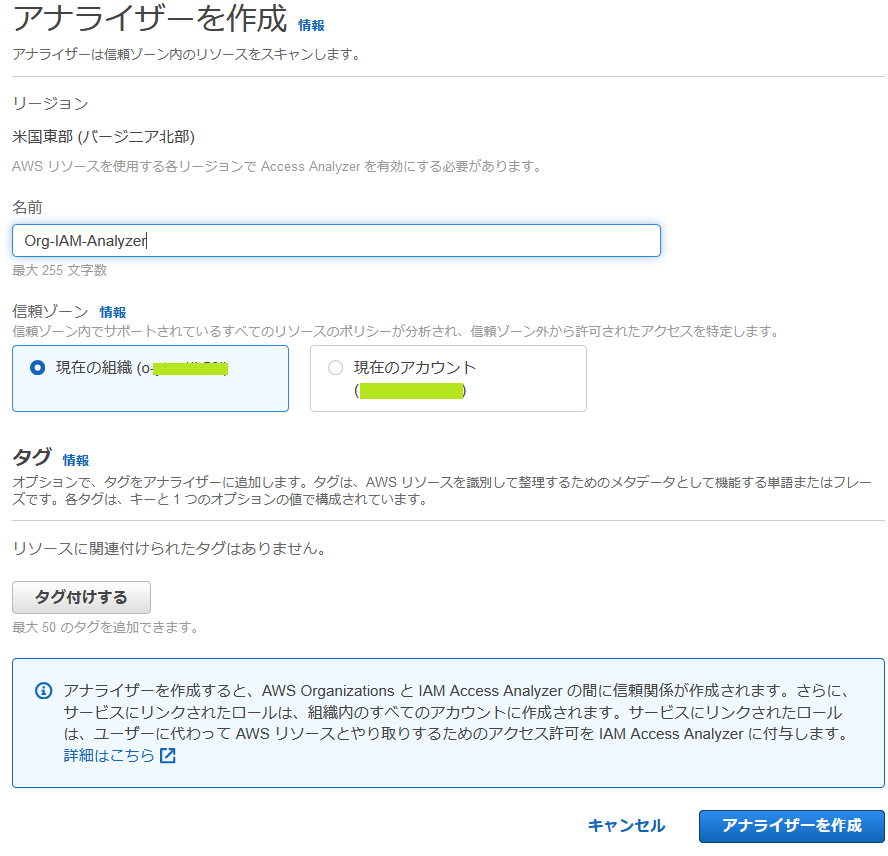
アナライザーを作成のボタンをクリックします。
アナライザーの名前を指定し、信頼ゾーンとして、現在の組織を選択。「アナライザーを作成」ボタンをクリックします。必要に応じてタグ付けをしてください。
また、この設定は、リージョンごとに実施する必要があります。
動作検証
AWS Organizations 内の操作
動作確認のため、AWS CLI をつかって、一時的なセキュリティ認証情報を取得します。これで、 IAM Role に対する検出が行えます。
aws sts assume-role --role-arn arn:aws:iam::account:role/role-name --role-session-name <セッション名>コマンドを実行したら、 IAM Access Analyzer の画面を表示します。
今までは、AWS アカウント外からのアクセスは検出されましたが、信頼ゾーンとして「現在の組織」を選んでいますので、 AWS Organizations 内のアカウントからのアクセスとなり、特になにもありません。
AWS Organizations 外からの操作
AWS Organizations 内の操作と同様に AWS CLI をつかって、一時的なセキュリティ認証情報を取得します。
aws sts assume-role --role-arn arn:aws:iam::account:role/role-name --role-session-name <セッション名>コマンドを実行したら、同様に IAM Access Analyzer の画面を表示します。
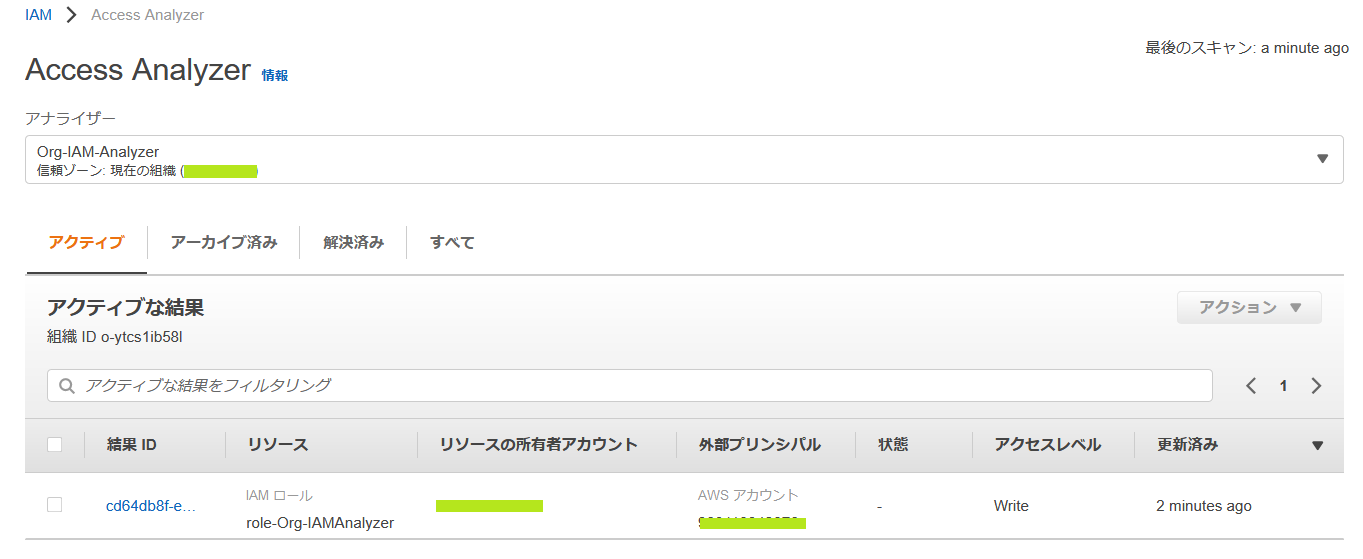
すると、このように検出結果が表示されます。
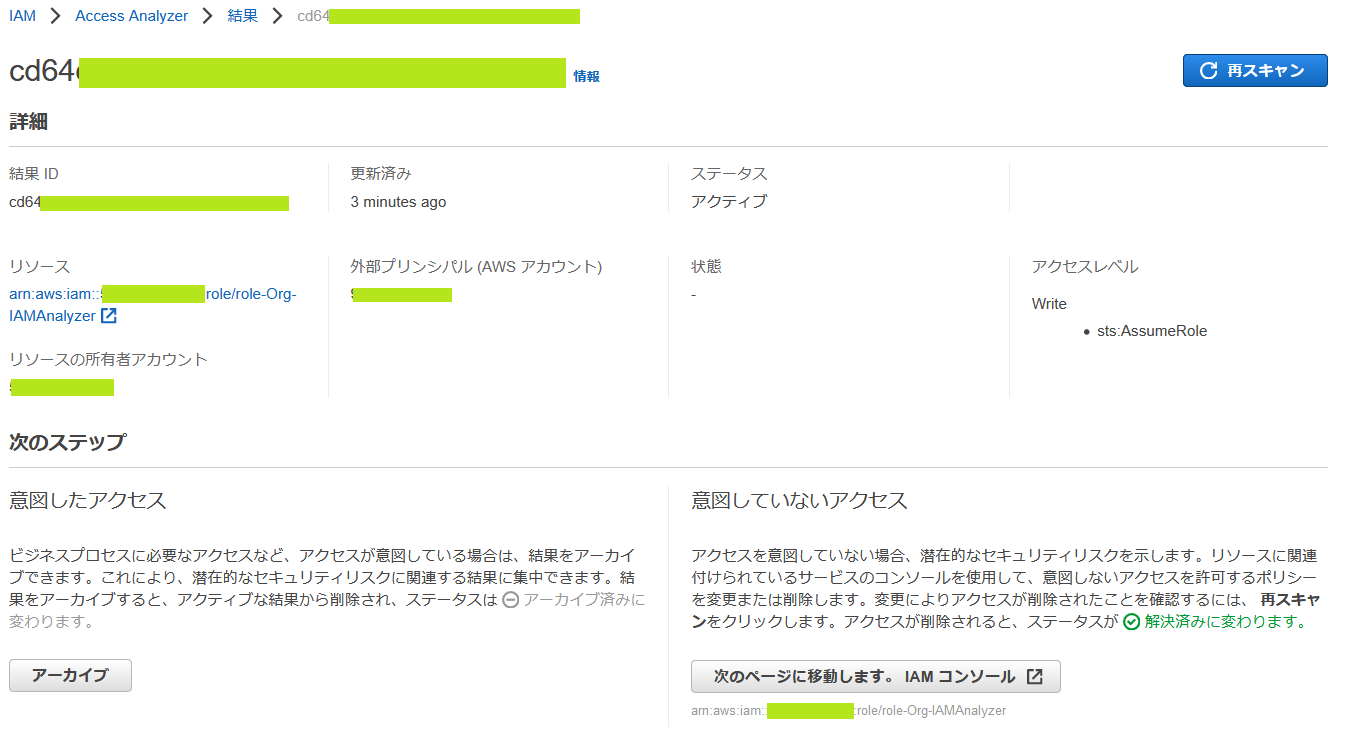
結果ID をクリックすると詳細が表示されます。
内容を確認して、意図したアクセスならば「アーカイブ」をクリック。そうでなければ、右下の「次のページに移動します。IAMコンソール」のボタンをクリックします。
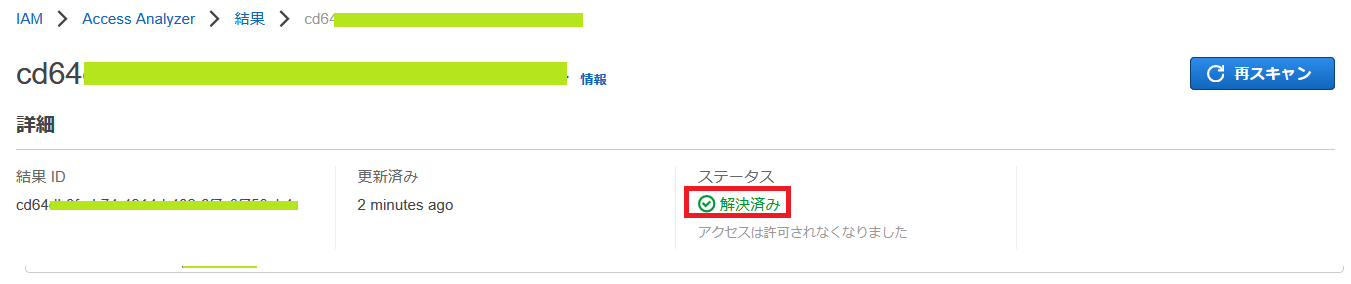
では、意図していないアクセスとして、「次のページに移動します。IAMコンソール」のボタンをクリックして、設定を変更後、改めて、前述の AWS CLI を実行します。そして、「再スキャン」のボタンをクリックします。
すると、以下のように「ステータス」が解決済みになりました。
また、アーカイブの表示についても、表記が切り替わります。
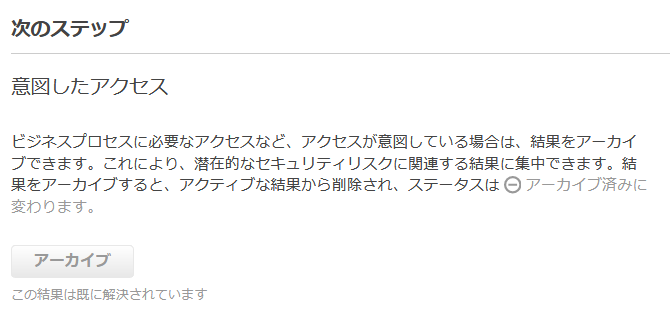
では、これが意図したアクセスだった場合はどうなるのでしょうか。
(実際にはアーカイブルールで意図したものは自動的にアーカイブに入れておくと思いますが、それが漏れていた場合などに検出されます)
改めて、設定を施したうえでアクセスし、「アーカイブ」ボタンをクリックしてみました。
すると、ステータスが「アーカイブ済み」になりました。
まとめ
マルチアカウントを AWS Organizations で管理している環境で、 IAM Access Analyzer でのアクセス管理がしやすくなりました。これまではアカウントごとでの管理だったので、煩雑な面もありました。
しかし、管理下すべてを問題なしとするのもよろしくない場面もあるので、要件に応じた設定をしていきましょう。



- 投稿日:2020-03-31T10:25:17+09:00
【AWS】EKS on Fargateでゲームをデプロイしてみたので解説してみる(with Ingress Controller, 2048)vol.2
はじめに
以前に前編の記事を書きました。
【AWS】EKS on Fargateでゲームをデプロイしてみたので解説してみる(with Ingress Controller, 2048)vol.1本当は1つの記事にまとめる予定でしたが、
記事が長くなってしまったことと、作成に時間がかかってしまったこと(主に検証)から、やむなく2部制とさせていただいておりました。前編の記事では、EKSクラスターとFargateプロファイルを作成するところまでを解説しました。
後編では、kubectlコマンドでサービスをデプロイするところを解説していきます。よろしくお願いします!
当記事でのゴール(再掲)
EKS on Fargateを使って、
2048ゲームをデプロイして遊べるようにしたいと思います。2048とはこのようなゲームです。
きっと皆さん見たこと、遊んだことのあるゲームだと思います。
前提条件(再掲)
- AWSのアカウントを所持している
- macOS
eksctlコマンドではなく、マネジメントコンソールを使用して構築する
- サービスの理解を深めるため
実際には
eksctlコマンドで一発でクラスターを作成できたりします。$ eksctl create clusterそれでは何もわからないまま終わってしまうので、
一つ一つ解説を入れながらマネジメントコンソールで作っていきたいと思います。全体の流れ(再掲)
- クラスターの作成
- Fargateプロファイルの作成
kubectlコマンドでサービスをデプロイ3.
kubectlコマンドでサービスをデプロイ作成したクラスターに向けてサービスをデプロイしていきます。
ここからはAWSマネジメントコンソールではなく、kubectlコマンドを中心に使っていきます。3.1.
kubectl、awscli、eksctlのインストール以下のサイトを参照してインストールしてください。
kubectlのインストールおよびセットアップ
macOS での AWS CLI バージョン 2 のインストール
eksctl の開始方法3.2.
kube.configにEKSクラスターを登録する
kubectlコマンドの向き先を、ローカルではなく前手順で作成したEKSクラスターに変更します。$ aws eks --region ap-northeast-1 update-kubeconfig --name eks_handsonこのようなメッセージが出力されたら成功です。
Added new context arn:aws:eks:ap-northeast-1:xxxxxx:cluster/eks_handson to ~/.kube/config
~/.kube/configというファイル作成されます。
ファイルの中身
apiVersion: v1 clusters: - cluster: certificate-authority-data: xxxxxx server: https://xxxxxx.gr7.ap-northeast-1.eks.amazonaws.com name: arn:aws:eks:ap-northeast-1:xxxxxx:cluster/eks_handson contexts: - context: cluster: arn:aws:eks:ap-northeast-1:xxxxxx:cluster/eks_handson user: arn:aws:eks:ap-northeast-1:xxxxxx:cluster/eks_handson name: arn:aws:eks:ap-northeast-1:xxxxxx:cluster/eks_handson current-context: arn:aws:eks:ap-northeast-1:xxxxxx:cluster/eks_handson kind: Config preferences: {} users: - name: arn:aws:eks:ap-northeast-1:xxxxxx:cluster/eks_handson user: exec: apiVersion: client.authentication.k8s.io/v1alpha1 args: - --region - ap-northeast-1 - eks - get-token - --cluster-name - eks_handson command: aws認証が通っているか確認します。
$ kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 4m27s3.3. デプロイするアプリのマニュフェストを入手する
Kubernetesでは、マニュフェスト(設計書)を使用してコンテナをデプロイしていきます。
どんなserviceに対して、どのようなdeploymentを行うのかというのがマニュフェストには定義されています。
docker-compose.ymlのようなものです。実際に、
Komposeというdocker-compose.ymlをKubernetesマニュフェストに変換するサービスも存在します。
次回の記事ではその紹介したいですね。そのマニュフェストをダウンロードしてきます。
$ mkdir 2048 $ cd 2048 $ curl -OL https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-deployment.yaml $ curl -OL https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-service.yaml $ curl -OL https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-ingress.yamlダウンロードしてきたマニュフェストを少し編集します。
# Namespace(名前空間)の変更 $ sed -i -e "s/namespace: \"2048-game\"/namespace: \"handson\"/" ./*.yaml
2048-ingress.yamlにも1行追加します。
target-typeにはinstanceおよびipの2つのモードがあるのですが、
EKS on Fargateではipのみでしか動かないようです。
詳細はIngress annotationsannotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing # 以下の1行を追加 alb.ingress.kubernetes.io/target-type: ipNamespaceには、手順
2.3で設定したものを設定します。Serviceの公開(タイプ)については、下記URLに説明がされています。
Service - Kubernetesデフォルトでは静的なポートで公開する設定がされていたので、
ロードバランサーを使用してサービスが公開されるように設定しています。3.4. Ingress Controllerのための設定
ロードバランサーとして、
ALB Ingress Controllerなるものを使用します。
Amazon EKS の ALB Ingress Controller基本的に上記URLの手順で設定を行なっていきます。
サブネットにタグを追加
- パブリックサブネットに、
kubernetes.io/role/elb:1- プライベートサブネットに、
kubernetes.io/role/internal-elb:1を設定していきます。
また、kubernetes.io/cluster/eks_handsonタグが設定されていることを確認していください。
EKSクラスター作成時に自動でタグが付けられているはずです。IAMにOIDCプロバイダーを登録
OIDCとはOpenID Connectの略です。
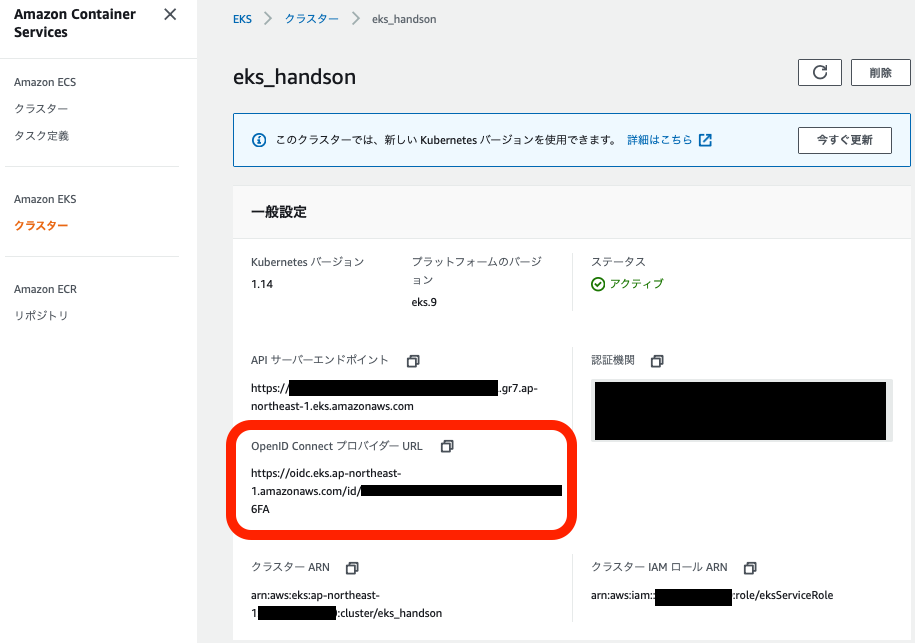
EKSクラスターの認証に使用するIDになります。EKSクラスター作成時に「OpenID Connect プロバイダー URL」は付与されています。
これを、以下のコマンドを実行することによってIAMに登録します。
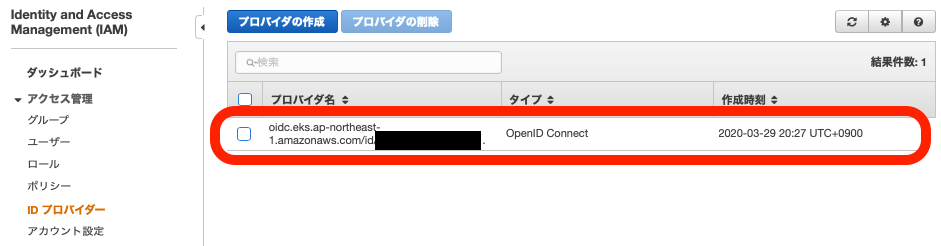
eksctl utils associate-iam-oidc-provider \ --region ap-northeast-1 \ --cluster eks_handson \ --approveマネジメントコンソールのIAMのページを確認すると、IDプロバイダーが作成されています。
マネジメントコンソールから作成する場合には、
- プロバイダーのタイプ:OpenID Connect
- プロバイダーのURL:EKSクラスターのページからコピペ
- 対象者:sts.amazonaws.com
を設定することで同様のものを作成できます。
Ingress ControllerのためのIAMポリシー作成
以下のコマンドを実行することでIAMポリシーが作成されます。
aws iam create-policy \ --policy-name ALBIngressControllerIAMPolicy \ --policy-document https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/iam-policy.json作成したIAMポリシーを持つIAMロールをマネジメントコンソールで作成します。
IAMロールの作成方法
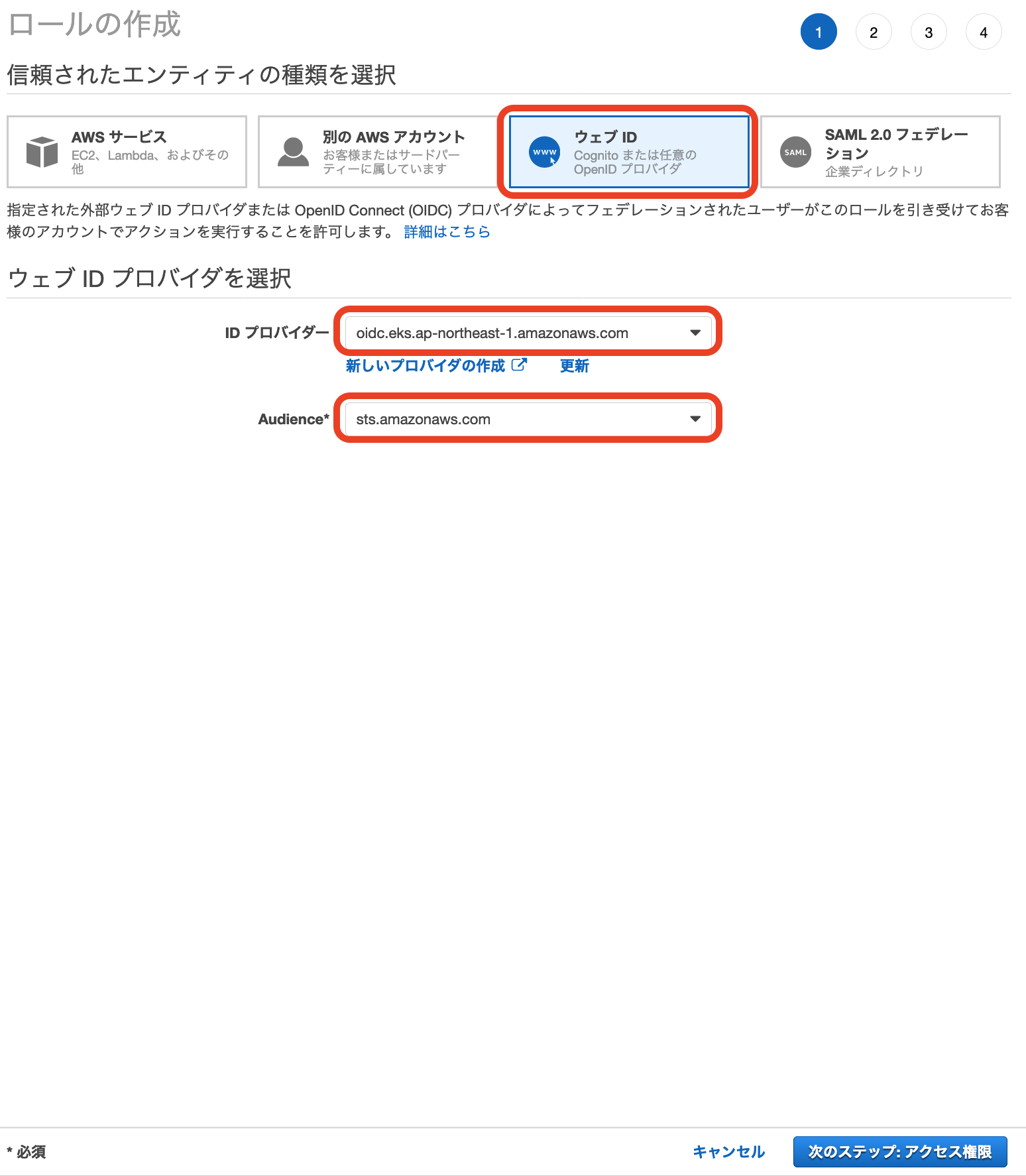
IAMロール作成画面の信頼されたエンティティから「ウェブID」を選択し、
IDプロバイダーにEKSクラスターを、Audienceにstsを選択します。
ポリシーに先ほど作成した
ALBIngressControllerIAMPolicyを選択します。
ロール名を
eks-alb-ingress-controllerとして、作成します。次に信頼関係の編集を行います。
Principal > Federated の箇所にはEKSクラスターのページに記載されている
OpenID Connect プロバイダー URLをコピペします。Condition > StringEquals の箇所にも編集を加えます。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { # 以下の行を編集する。 "Federated": "arn:aws:iam::xxxxxx:oidc-provider/oidc.eks.ap-northeast-1.amazonaws.com/id/xxxxxx" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { # 以下の行を編集する。 # aud -> sub # sts.amazonaws.com -> system:serviceaccount:kube-system:alb-ingress-controller "oidc.eks.ap-northeast-1.amazonaws.com/id/xxxxxx:sub": "system:serviceaccount:kube-system:alb-ingress-controller" } } } ] }この信頼関係によって、
alb-ingress-controllerというKubernetesのサービスロールから、
指定のOIDCを持つリソースに対してのみ、
このIAMロールが付与されます。
Kubernetesのサービスアカウント追加
以下コマンドによって、
alb-ingress-controllerのサービスアカウントを作成します。kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/rbac-role.yaml追加したサービスアカウントに、IAMロール
eks-alb-ingress-controllerを適用させます。kubectl annotate serviceaccount -n kube-system alb-ingress-controller \ eks.amazonaws.com/role-arn=arn:aws:iam::xxxxxxxx:role/eks-alb-ingress-controllerALB Ingress Controllerのマニュフェスト入手
ALB Ingress Controllerのマニュフェストをダウンロードしてきます。
$ cd .. $ mkdir ingress $ cd ingress $ curl -OL https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/alb-ingress-controller.yamlマニュフェストを編集し、下記の箇所を変更します。
- クラスター名
- VPCのID
- リージョン
変更箇所詳細
apiVersion: apps/v1 kind: Deployment metadata: labels: app.kubernetes.io/name: alb-ingress-controller name: alb-ingress-controller namespace: kube-system spec: selector: matchLabels: app.kubernetes.io/name: alb-ingress-controller template: metadata: labels: app.kubernetes.io/name: alb-ingress-controller spec: containers: - name: alb-ingress-controller args: - --ingress-class=alb # クラスター名を変更 - --cluster-name=eks_handson # VPCのIDを変更 - --aws-vpc-id=vpc-xxxxxx # リージョンを変更 - --aws-region=ap-northeast-13.5. CoreDNSのFargate適用
現時点ではデフォルトで作成されるPod、CoreDNSは常にPendingになっていると思います。
これを適用します。kubectl patch deployment coredns -n kube-system --type json \ -p='[{"op": "remove", "path": "/spec/template/metadata/annotations/eks.amazonaws.com~1compute-type"}]'少し待つと立ち上がるはずです。
NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-9c47646f9-nbc6k 1/1 Running 0 26h kube-system coredns-9c47646f9-vmm42 1/1 Running 0 26h3.6. サービスをデプロイする
お待たせしました!
ついにサービスをデプロイしていきます。
その際、Namespaceを先に作成しています。# Namespaceの作成 $ kubectl create namespace handson # デプロイ $ cd .. $ kubectl apply -f ingress/ $ kubectl apply -f 2048/デプロイまで少し時間がかかりますので、コーヒーでもすすりながら待ちます。
$ kubectl get pods -n handsonNAME READY STATUS RESTARTS AGE 2048-deployment-7f77b47f7-8hqsw 1/1 Running 0 83s 2048-deployment-7f77b47f7-b9chm 1/1 Running 0 83s 2048-deployment-7f77b47f7-hhvt7 1/1 Running 0 83s 2048-deployment-7f77b47f7-k8m2x 1/1 Running 0 83s 2048-deployment-7f77b47f7-km4d6 1/1 Running 0 83sSTATUSがRunningになっていたらデプロイ成功です。
現在は5つのコンテナにスケールされてデプロイされています。続いて、
$ kubectl get nodes -n handsonNAME STATUS ROLES AGE VERSION fargate-ip-172-31-48-253.ap-northeast-1.compute.internal Ready <none> 114s v1.14.8-eks fargate-ip-172-31-49-226.ap-northeast-1.compute.internal Ready <none> 107s v1.14.8-eks fargate-ip-172-31-59-36.ap-northeast-1.compute.internal Ready <none> 106s v1.14.8-eks fargate-ip-172-31-62-48.ap-northeast-1.compute.internal Ready <none> 114s v1.14.8-eks fargate-ip-172-31-63-145.ap-northeast-1.compute.internal Ready <none> 103s v1.14.8-eksノードが5つ立ち上がっていることと、Fargateで立ち上がっていることがわかります。
ノードの名前は自動で作成されるので、そこでFargateなのかEC2なのか判別することができます。次にサービスが公開されているURLを調べます。
Ingress$ kubectl get ingress -n handsonNAMESPACE NAME HOSTS ADDRESS PORTS AGE handson 2048-ingress * xxxxxx.ap-northeast-1.elb.amazonaws.com 80 2m40sADDRESSに記載されているURLにアクセスすると、、、
出ました!!
画面にアクセスできるまで少し時間がかかるケースもあります。少し待ってからアクセスしてみましょう。ロードバランサーについて
マネジメントコンソールのEC2のページからロードバランサーを選択すると、
Ingress Controllerによって作成されたロードバランサーを確認できます。DNS名を確認すると、先ほどアクセスしたURLと同じものになっていると思います。
このロードバランサーに設定されたセキュリティグループも、Ingress Controllerによって作成されたものです。このセキュリティグループの設定を変えてあげることで、アクセスできるIPアドレスを限定したり、ポートを増やしてあげたりすることができます。
(おまけ)HTTPSを実装する
今のままだとHTTPのみでセキュリティ的によろしくありません。
HTTPSでもアクセスできるようにする方法も紹介します。
ついてに、HTTPでアクセスしたらHTTPSの方にリダイレクトする設定も行なっていきます。1. 証明書の作成
少し面倒ですが、AWS Certificate Manager上に証明書を作成しなければなりません。
手段は2通りで、
- マネジメントコンソールから作成(CA作成→証明書作成)
- オレオレ証明書をCertificate Managerにインポート
前者は若干お金がかかります。
後者の場合、おあつらえのQiita記事があります。
AWS Certificate Managerでオレオレ証明書をインポートする2. Ingressの設定変更
2048-ingress.yamlを編集します。
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: "2048-ingress" namespace: "handson" annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: ip # 以下のannotationを追加。1番上は証明書のARNを記載します。 alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-1:xxxxxx:certificate/xxxxxxxxxx alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS": 443}]' alb.ingress.kubernetes.io/actions.ssl-redirect: '{ "Type": "redirect", "RedirectConfig": { "Protocol": "HTTPS", "Port": "443", "StatusCode": "HTTP_301" } }' labels: app: 2048-ingress spec: rules: - http: paths: # pathを一つ追加。annotationに追加したactionに紐付けます。 - path: /* backend: serviceName: ssl-redirect servicePort: use-annotation - path: /* backend: serviceName: "service-2048" servicePort: 80修正したらデプロイしましょう。
$ kubectl apply -f 2048再びIngressの情報を取得し、ADDRESSにアクセスすると自動的にHTTPSにリダイレクトされているはずです。
どうぞお試しください。まとめ
想像以上に長くなってしまいました。
Ingress Controllerの設定周りでだいぶ苦戦しました。。KubernetesやEKSを初見で触った時には、
数時間で完全理解!わりとゴツいKubernetesハンズオン!!
の記事に本当にお世話になりました。図解付きで説明されていて、非常にわかりやすいと感じました。
こちらもぜひ、参考にしてみてください。ご覧いただき、ありがとうございました。
参考
AWS公式
その他記事



- 投稿日:2020-03-31T00:45:20+09:00
AWSソリューションアーキテクトプロフェッショナル資格(SAP)に合格しました
はじめに
先日(3/29)、かねてからの目標だったAWS Certified Solutions Architect - Professional(SAP)を取得しましたので、いつものように勉強した内容や試験の所感を残しておこうと思います。
(今回に限って言うと、試験自体よりもそもそも試験会場が営業しているかが一番の心配事でした……)※過去の記事
AWS SAAに受かった話
AWS SOAに受かった話
AWS DVA(とCLP)に受かった話勉強期間
前回DVAを受けたのが3/1なので、SAPとして確保したのは約1ヶ月ぐらいです。
とはいえ、AWSの資格試験は重なる部分も多いので、DVAとその前のSOAも合算すると3.5ヶ月になります。
(そういう理由もあるので、AWSの資格を取る時はあまり間を開けずに次へ次へと目指した方が良いです)獲得スコア
受験日 スコア/合格点/満点 結果 2020/3/29 756/750/1000 合格 問題を解きながら全く手応えが無かったので「今回はアカンかも」と思っていましたが、結果は(ぎりぎりながら)合格。
試験を受けての所感は後述しますが、とにかく問題文の分量が多く、長い試験時間(190分)が足りなくなるほどの大変な試験でした。
(最後の問題を解き終えた時の残り時間は10秒)SAP試験の勉強方法
SAPは(上位資格の中では)比較的情報が揃っている方だと思いますが、この試験の難しさは、
- とにかく試験範囲が広い
これに尽きると思います。
(他に挙げるとすれば、「全体的に問題文が長い」でしょうか)さすがに開発者専用みたいなCode系までは網羅されていませんが、それ以外のOpsworkやAPI Gatewayなどは当たり前のように出ますし、普段の業務ではあまり触らないStorage Gatewayや DMS、SMSみたいなややマイナーのサービスも出てきます。
しかも、それが様々なサービスの複合問題として出題されるため、それぞれがどのような用途で使われるサービスで、どういう構成がベストプラクティスかを問われます。
選択肢が4つあったらその内1つぐらいは明らかに違うものが混じっているのですが、それ以外は「ケースによっては有用」という微妙な選択肢になっていることが多いので、AWSの知識と合わせて国語力(読解力)も試されます。そういう試験の特性を踏まえた上で、自分がやった勉強は前回のDVAと同じく、
- サンプルや模擬試験、Whizlabsの問題を解く
- わからなかった部分や、理解が曖昧だと思ったサービスについて公式ドキュメントで調べたり、チュートリアルをやったりする
という流れ(繰り返し)でした。
あとはAWSの知識ではなく、基本的なインフラの知識(IPSecやVPNなど)もあると問題が解きやすいと思います。
AWSのマネージドサービスは「煩わしい構築や管理の手間を省いて簡単に使える」というのを売りにしていて、一般のユーザー(企業)は気にせず使って良いと思いますが、AWSのソリューションを提供する側はその裏側で何が行われているかをちゃんと理解しないといけないと思いました。学習で使った教材
AWS公式
今回は基本的にWhizlabsの問題ばかりやっていましたが、その問題をやる中でわからない機能やサービスが出てきたらBlackbeltオンラインセミナーの資料を見て補足する、というのを繰り返していました。
もちろんわからないサービスの資料を端から端まで見ていたら時間がいくらあっても足りませんが、メジャーではないサービスはそこまで出題の範囲も頻度も広く(高く)ないので、早送りでスライドを流して大事なところ、または試験で間違えた部分だけをおさらいするだけでも十分だと思います。
(最低でもOrganizationsとCognito、Cloudfrontは見ておいた方が良いです)あとは模擬試験も受けましたが、その問題は(記憶にある限りでは)一つも出題されませんでした。
ただ、問題を解く際に使ったサービスの知識(機能やベストプラクティスなど)は実際の試験でも活かされたと思っているので、やはり受けて損はないです。
(これは前も書きましたが、模擬試験を受ける際は合格特典の無料バウチャーを使うのを忘れずに)それ以外だとAWSトレーニングのSAP試験講座の動画も観ました。こちらは英語(日本語字幕)ですが、AWS Innovate Onlineセミナー2020に登録していれば日本人のソリューションアーキテクトによる解説が聞けます(※4/10ぐらいまで)
この中で紹介されるサービスはあくまで「最低限」ですが、その代わり「必ず出る」と思って良いです。問題集
「WHIZLABS」(https://www.whizlabs.com/)
毎度お馴染みの試験問題を販売している海外のサイト。
会員登録すると頻繁に割引バウチャーがもらえるので有料版も2000円ぐらいで購入でき、80問×6セット解けるのでかなりコストパフォーマンスは良いです。これも前回同様、問題と答えを丸暗記するというよりは、自分が何をわかっていないのかを洗い出して何度も復習する、というのを意識しました。
模擬試験とはいえ、真面目に解くと一回につき3時間ぐらいかかるので、かなりタフでした。
(そしてそれだけ苦労して終わった後に「Failed(不合格)」と表示されると心が折れそうになります)試験を受けての所感
- 問題数が多く(75問)、加えて全体的に問題文が長いため、時間配分は大事 (自分は半分解いた時点で遅れていると気付いた後ペースを上げて最後はぎりぎりだったので、最初に10問を何分で解くと決めておくと良いかも)
- ユーザーの権限問題はよく出る(OrganizationsのOU階層で違う権限が設定されていた場合、どの権限が有効になるか、等)
- Storage Gatewayの「cache volume」と「stored volume」の違いは説明できるように
- AWSのバックグラウンドの知識(DNSや暗号化など)もわかっていると一つか二つ拾える問題があった(気がする)
- 聞いたことがないサービスの問題は間違いなく解けないので、概要程度でも理解しておくように
- サービスの使い分け問題が多かった(たとえばkinesisとSQSはどう使い分ける?)
- Cloudfrontはよく出る
- 一目でわかる問題はほぼ無かったが、ちゃんと読めば二択ぐらいまでは絞れるので、諦めないように(その意味でも時間配分は大事)
- ECSだかEKSだかの(中身の)問題が出て、あまり準備していなくて「アカン」ってなった(DVAの時から繰り返される過ち)
今後の予定
AWS系だと次はDevOps ProfessionalかSecurityだと思っていますが、そろそろ仕事で本格的にAzureを使うことになりそうなのでAzure Administrator Associate(AZ-103)を受けようと思っていました。
過去形になっているのは、どうもAZ-103試験が3月一杯で終了し、新しい試験(AZ-104)に更新されるということを今日知りました。https://blog.trainocate.co.jp/blog/415_018
とりあえずはAZ-103の問題で頑張ろうと思いますが、受けるのは少なくとも日本語版の試験が配信されてからかなと思っています。
2020/3/31追記
AZ-103廃止の件、よくよく内容を読んだら「3月で英語版のベータ試験が公開される」と言っているだけで、3月末で無くなるわけではないんですね。
また、試験のアウトライン(試験範囲)を見ると、4月に新試験が始まった後90日間は受けれられるようです。https://query.prod.cms.rt.microsoft.com/cms/api/am/binary/RE3VwUR
別に新しい試験でも良いのですが、差し当たりAZ-103の受験を目指したいと思います(できれば4月中)