- 投稿日:2020-03-19T23:49:27+09:00
pyparsingを使って日本語で日本語のパーサを書いてみた。
概要
Pythonのライブラリpyparsingを使うと、階層的な定義の箇条書きで、読み易く変更し易い文法を定義できる。if文など使わず記述出来る点に目を付け、pyparsingのクラスやメソッド、変数名に日本語を使って文法を書いてみた。同じ内容の英文記述に較べて、日本語によるコードは一目見た時に把握し易いと感じた。クラスやメソッドまで日本語にしたのはやりすぎかもしれないが、Pythonで日本語を使ってここまでできるとは思っていなかった。
Python3.7, pyparsing 2.4.6を使用。(Anacondaディストリビューション)記述と実行例
組織の3種類のメンバ名簿を想定して、それを読み込むパーサの文法を日本語で定義してみた。 Pythonの予約語以外の変数名(文法名、式名)、関数名、importしたクラス名や関数名、パース対象とも漢字を使っている。
コードは、上から下に向かって文をボトムアップに積み上げた記述になる。最後に記述された以下の文の右辺式がトップレベルの文法で、組織のメンバに3種類あることがわかる。協会員 = 賛助会員 | 学生会員 | 個人会員ボトムアップに、と書いたが、記述の際はこの最後の定義をまず決め、次いで部品に相当する下位の定義を書いたら、この最後の文から細部に分解していく方法をとった。
一番重要な3種類のメンバの分岐を行うために、名簿の各行の最初のトークンに一致する式を定義する。つまりパースする文字列の最初の一致が会社名か学校名かで分岐する。個人会員はそれ以外というわけだ。(以下にコードを抜き出し)会社名 = 後方一致('会社') 賛助会員 = (会社名 + 代表者 + 会員番号)('賛助会員') 学校名 = 後方一致('大学') | 後方一致('高専') | 後方一致('大学校') 学生会員 = (学校名 + 姓名 + 姓名読み + 会員番号)('学生会員')尚、〇✖株式会社のように、区切り無の連続した文字列を想定した会社名、学校名の一致は上記のように正規表現の後方一致で行っている。 当初、以下の記述を考えていたのだが先行する式である漢字列(Word)に、例えば '株式会社' まで食われてしまういわゆる過食(greedy)問題でうまくいかなかった。最長一致も試したがうまくいかない。pyparsingではトークンを左から消費していくためで前方一致では問題が起きない。
"""後方一致は過食問題を起こす""" 会社名 = 結合(漢字列 + oneOf('株式会社 合同会社 有限会社'))('会社名') """前方一致は過食問題を起こさない""" 会社名前方 = 結合('株式会社' + 漢字列)正規表現を使って文の羅列という形式を保つために、後方一致のRegexを返す関数(lambda式)を設けている。後方一致関数には、'株式会社 合同会社' のように複数の文字列を渡せる定義とした方が効率は良いが、単一引数にして文法記述で複数記述する形態とした。
pyparsingで文法を定義する際に、先ほどの過食問題を避けるには、正規表現での回避方法の他に、入力の文字種を前後で変える、区切り文字を入れるなどで、消費を止めることが考えられる。対症療法では解決に無駄に時間をかけることになる。(実際2日間をああでもないこうでもないと無駄にした)
以下は全コードで、メイン部分でデータを与えてテストしており簡単な例外処理も入れている。但し、バックトラックによると思われるが、pe.locは正しく最初のエラー箇所を示してくれるとは限らないようだ。
文法記述に最初はとまどうが、いくつか書くとコツがわかってくる。イメージではパース対象の文字列が、文法記述したコードに注入され、どれかの式にマッチしたものだけがフィルタされて抜けてくる、というように捉えている。parse_OrgMemberRecordReg.py#by T.Hayashi #tested with Python3.7, pyparsing 2.4.6 #don't use full-width space as delimitter in this script. from pyparsing import ( Combine as 結合, Word as 列, nums as 数字, __version__ as 版数, Regex , pyparsing_unicode as uni, ParseException) #以下日本語 def 文法を定義(): 後方一致 = lambda s : Regex(r'.*'+s) 整数 = 列(数字) 漢字列 = 列(uni.Japanese.Kanji.alphas) かな列 = 列(uni.Japanese.Hiragana.alphas) 会員番号 = 整数('会員番号') 姓名 = 漢字列('姓名') 姓名読み = かな列('姓名読み') 会社名前方 = 結合('株式会社' + 漢字列) 会社名 = 会社名前方 | 後方一致('会社') 代表者 = 漢字列('代表者') 賛助会員 = (会社名 + 代表者 + 会員番号)('賛助会員') 学校名 = 後方一致('大学') | 後方一致('高専') | 後方一致('大学校') 学生会員 = (学校名 + 姓名 + 姓名読み + 会員番号)('学生会員') 個人会員 = (姓名 + 姓名読み + 会員番号)('個人会員') 協会員 = 賛助会員 | 学生会員 | 個人会員 return 協会員 def テスト(gram,instr): try: r=gram.parseString(instr) name=r.getName() print(name,r.get(name)) print() except ParseException as pe: print(f'error at {pe.loc} of {instr}') print(instr) #loc : char position. print(' '*(pe.loc-2)+'^') #print('Explain:\n',ParseException.explain(pe)) print('pyparsing 版数:',版数) 文法=文法を定義() テスト(文法,'山田太郎 やまだたろう 3456') テスト(文法,'架空東大学 川崎三郎 かわさきさぶろう 5127') テスト(文法,'株式会社架空商事 東太郎 0015') #前方一致 テスト(文法,'架空商事株式会社 海山太郎 0010') #後方一致 テスト(文法,'北北西高専 伊藤一郎 いとういちろう 900') #エラーの確認 高校は定義に無い テスト(文法,'北北東高校 鈴木三郎 すずきさぶろう 1000') #エラーの確認 会社が抜け テスト(文法,'株式架空商事 東太郎 0015') #エラーの確認 読みに漢字 テスト(文法,'山田一太郎 やまだ一太郎 3456')以下は実行結果。
pyparsing 版数: 2.4.6 個人会員 ['山田太郎', 'やまだたろう', '3456'] 学生会員 ['架空東大学', '川崎三郎', 'かわさきさぶろう', '5127'] 賛助会員 ['株式会社架空商事', '東太郎', '0015'] 賛助会員 ['架空商事株式会社', '海山太郎', '0010'] 学生会員 ['北北西高専', '伊藤一郎', 'いとういちろう', '900'] error at 6 of 北北東高校 鈴木三郎 すずきさぶろう 1000 北北東高校 鈴木三郎 すずきさぶろう 1000 ^ error at 7 of 株式架空商事 東太郎 0015 株式架空商事 東太郎 0015 ^ error at 9 of 山田一太郎 やまだ一太郎 3456 山田一太郎 やまだ一太郎 3456 ^終わりに
BNF(Backus-Naur form)風の定義の羅列で、通常のプログラムに比べ理解し易い文法を定義できた。日本語を使ったら、いろいろ予期しないことが起きるのではと思っていたが、それもなく、Pythonでここまでできるとは意外だった。気を付けたのは、過食問題を持ち込まないようにすること、コード入力時見えない全角空白が入らないようにすることであった。
より大きな規模の文法を正しく動作するように定義、デバッグするのはトレースが難しいこともあり、書き方によっては通常のPythonのプログラムより簡単ではないかもしれない。このため、作っては例外や想定外動作を見て修正することを繰り返す小生の場合は、通常のプログラムに較べて、始めからできるだけ正しいコードを書くことを強く心掛ける必要がある、と思う次第..。
注:過食問題と呼んだが一般的な用語ではなくここで仮にそう名付けた。

- 投稿日:2020-03-19T23:39:14+09:00
大量データで散布図を描いた時のオーバーラップをなんとかする(Matplotlib, Pandas, Datashader)
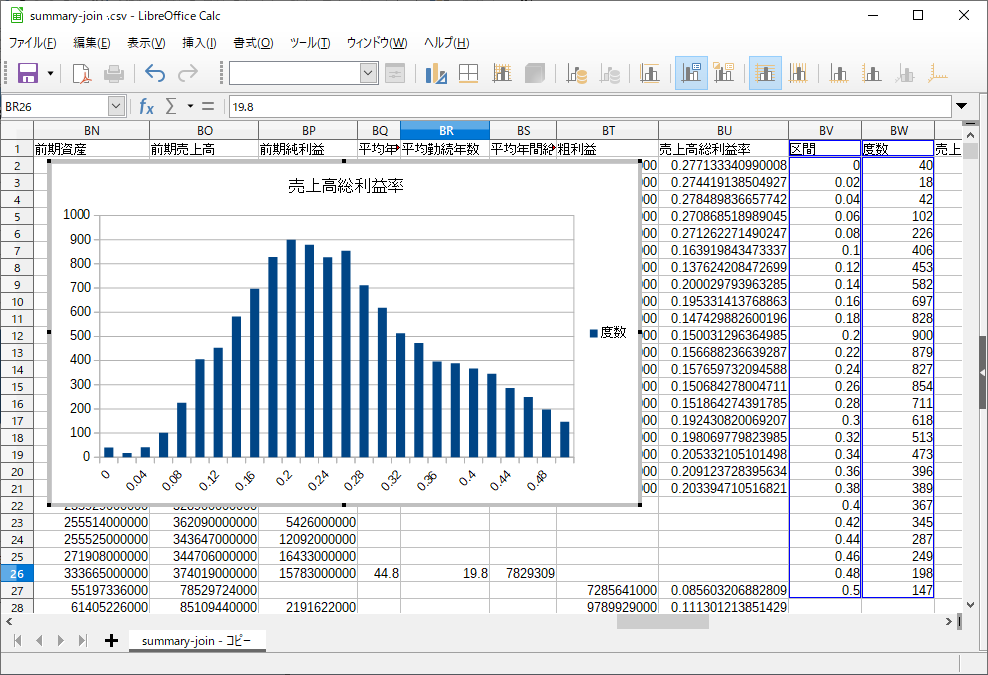
大量のデータ点で散布図を描くと、あまりに密集してしまって、ある領域にどの程度のデータが存在するのかよくわからなくなる。
例として、手書き数字画像データセット(MNIST)をUMAPで二次元に圧縮した次のようなデータを考える。
import pandas as pd df = pd.read_csv('./mnist_embedding.csv', index_col=0) display(df)
x y class 0 1.273394 1.008444 5 1 12.570375 0.472456 0 2 -2.197421 8.652475 4 3 -5.642218 -4.971571 1 4 -3.874749 5.150311 9 ... ... ... ... 69995 -0.502520 -7.309745 2 69996 3.264405 -0.887491 3 69997 -4.995078 8.153721 4 69998 -0.226225 -0.188836 5 69999 8.405535 -2.277809 6 70000 rows × 3 columns
xがX座標、yがY座標、classはそれぞれのラベル(0~9のどの数字を書いた画像か)。
普通にmatplotlibで散布図を描いてみる。ちなみに本筋ではないけど、最近追加された
legend_elements関数によって、複数カテゴリの散布図はfor文をまわさずとも簡単に凡例が作れるようになった。import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(12, 12)) sc = ax.scatter(df['x'], df['y'], c=df['class'], cmap='Paired', s=6, alpha=1.0) ax.add_artist(ax.legend(*sc.legend_elements(), loc="upper right", title="Classes")) plt.axis('off') plt.show()
7万個の点がプロットされている。それぞれの数字ごとにクラスタが別れているのはいいんだけど、これだけデータサイズが大きいと点があまりに密集して、オーバーラップして塗り潰されてしまい、それぞれのクラスの中の構造がほとんど見えない。これをなんとかしたい。
解決策1: sizeやalphaを調整してがんばる
オーバーラップを避けるために、点のサイズを小さくする、あるいは点の透明度を調整して密度をわかりやすくする。試行錯誤が必要だし、必ずしも見やすくなるとは限らない。
fig, ax = plt.subplots(figsize=(12, 12)) sc = ax.scatter(df['x'], df['y'], c=df['class'], cmap='Paired', s=3, alpha=0.1) ax.add_artist(ax.legend(*sc.legend_elements(), loc="upper right", title="Classes")) plt.axis('off') plt.show()
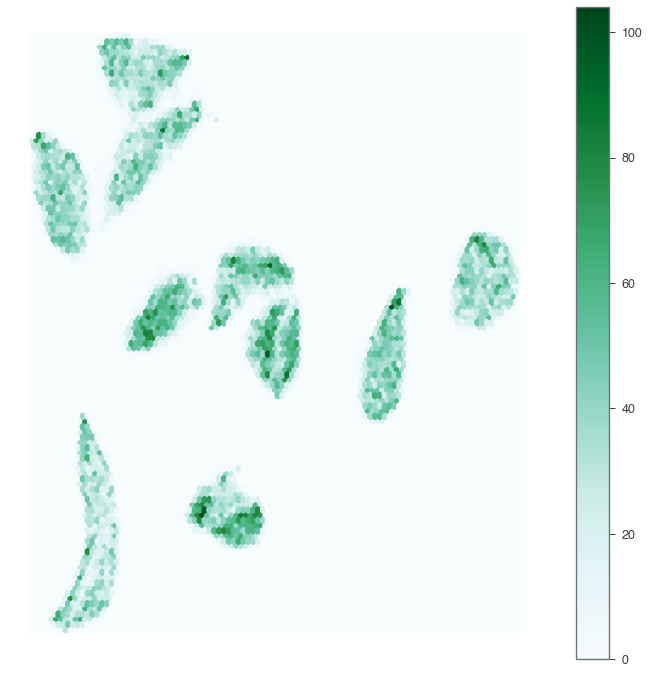
解決策2: Hexagonal Binning
これもよくやる方法。キャンバスを六角形のグリッドで敷き詰めて、それぞれの中に入るデータ点の数を集計して色の濃さで表現する。Pandasのプロット関数を使うのが簡単。
fig, ax = plt.subplots(figsize=(12, 12)) df.plot.hexbin(x='x', y='y', gridsize=100, ax=ax) plt.axis('off') plt.show()
解決策3: Datashaderを使う
応用が効いて使いやすい。使い方に慣れさえすれば。
Datashaderは大規模なデータセットについて「ラスタライズされたプロット」を高速に生成するライブラリ。
最初に出力する図の解像度(ピクセル数)を決めてしまってから、各ピクセルにデータを集計して、画像として出力する、という3つのステップで描画する。それぞれのステップで細かく調整ができるので自由度が高い。
各ステップは後述するけど、全部デフォルト設定でちぢめて書くと次のようになる。
import datashader as ds from datashader import transfer_functions as tf tf.shade(ds.Canvas().points(df,'x','y'))
各ステップの設定
Datashaderでは、
キャンバスを設定
集計関数の設定と計算
画像へ変換
の三つのステップでプロットを作る。以下、それぞれ説明。
1. キャンバスを設定
datashader.Canvasでキャンバスのもろもろを設定する。縦と横の解像度(ピクセル)、対数軸か否か、数値のレンジ(matplotlibでいうxlim, ylim)など。canvas = ds.Canvas(plot_width=600, plot_height=600, # 縦横600ピクセル x_axis_type='linear', y_axis_type='linear', # 'linear' or 'log' x_range=(-10,15), y_range=(-15,10))2. 集計関数の設定と計算
上で(600 x 600)ピクセルのキャンバスを作った。このピクセルひとつひとつについて、データをどのように集計するかをここで設定する。たとえば、ピクセルに入るデータ点のカウントに応じて色の濃さを変える、データ点がひとつでも入るか否かの二値にする、など。
たとえば上で設定したcanvas変数に対して以下のように、データフレーム、x軸座標(のカラム名)、y軸座標、集計関数を入れて計算を実行する。
datashader.reductions.count関数の場合は、ピクセルに入るデータ点の個数をカウントする。canvas.points(df, 'x', 'y', agg=ds.count())<xarray.DataArray (y: 600, x: 600)> array([[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], dtype=int32) Coordinates: * x (x) float64 -9.979 -9.938 -9.896 -9.854 ... 14.85 14.9 14.94 14.98 * y (y) float64 -14.98 -14.94 -14.9 -14.85 ... 9.854 9.896 9.938 9.979このように、(600 x 600)のサイズの行列で、データ点の個数をカウントした描画用のデータが生成された。
カウントではなくデータ点が入るか否かの二値で集計したい場合は、
datashader.reductions.any関数を使って次のようにすればいい。canvas.points(df, 'x', 'y', agg=ds.any())<xarray.DataArray (y: 600, x: 600)> array([[False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], ..., [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False]]) Coordinates: * x (x) float64 -9.979 -9.938 -9.896 -9.854 ... 14.85 14.9 14.94 14.98 * y (y) float64 -14.98 -14.94 -14.9 -14.85 ... 9.854 9.896 9.938 9.9793. 画像への変換
画像への変換は
datashader.transfer_functionsのshade関数を使う。shade関数の引数に、上で計算した集計済みの行列データを渡せばいい。また他にも様々なtransfer_functionsが用意されていて、画像出力の微調整ができる。ここではカウント集計した結果をset_background関数で白背景にして画像化してみる。tf.set_background(tf.shade(canvas.points(df,'x','y', agg=ds.count())), 'white')
データ点の密度に応じて濃淡が表現されてだいぶ構造が見やすくなった。
同じようにデータ点が入るか否かの二値で集計した場合もやってみる。
tf.set_background(tf.shade(canvas.points(df,'x','y', agg=ds.any())), 'white')
他の補助データで集計する
これまではデータの座標情報だけ使って集計をしたけど、データ点それぞれになんらかのカテゴリのラベルがついていたり、連続値が割り振られていたりすることもよくある。
単にピクセルに入るデータ点を数えるだけだとそういった情報が反映されないので、それぞれに応じた特別な集計関数が存在する。
補助データがカテゴリカル変数の場合の集計
MNISTの場合は正解クラスのラベルがついているので、それでちゃんと色分けをしてプロットしたい。そのための集計関数として、
datashader.reductions.count_catがある。この関数は、それぞれのラベルごとにピクセルに入るデータ点の個数をカウントする。つまりMNISTの場合は(600 x 600)の集計行列が10個できあがることになる。count_catを使うためには、ラベルデータがPandasのcategory型である必要があるので(int型じゃダメ)、まずはデータフレームのラベル列をcategory型に変換する。
df['class'] = df['class'].astype('category')count_catで集計する。
countやanyの集計関数と違って、データフレームのどのカラムがラベルを表しているのか、カラム名を指定する必要がある。agg = canvas.points(df, 'x', 'y', ds.count_cat('class'))それぞれのラベルの色は、ラベルをキーとした辞書で定義しておく。冒頭で描画したときの図の色と合わせるためにmatplotlibから"Paired"の色を取り出す。辞書型のリスト内包を使うと簡単。
import matplotlib color_key = {i:matplotlib.colors.rgb2hex(c[:3]) for i, c in enumerate(matplotlib.cm.get_cmap('Paired', 10).colors)} print(color_key){0: '#a6cee3', 1: '#1f78b4', 2: '#b2df8a', 3: '#fb9a99', 4: '#e31a1c', 5: '#fdbf6f', 6: '#cab2d6', 7: '#6a3d9a', 8: '#ffff99', 9: '#b15928'}画像化してみる。各ピクセルの色は、ピクセルに入るデータ点のラベルの数に応じてそれぞれの色がミックスされて描画されるらしい。
tf.set_background(tf.shade(agg, color_key=color_key), 'white')
補助データが連続値の場合の集計
データ点のひとつひとつに、なんらかの連続値が紐づいていることがある。シングルセル解析とかで、数万の細胞の次元圧縮した図に関して、細胞ごとになんらかの遺伝子発現量で色の濃さを変える場合とか。
ピクセルには複数のデータ点が入るので、なんらかの方法で代表値を決めなくてはならない。そのための集計関数として、max, mean, modeなど簡単な統計量は一通り揃えてくれている。
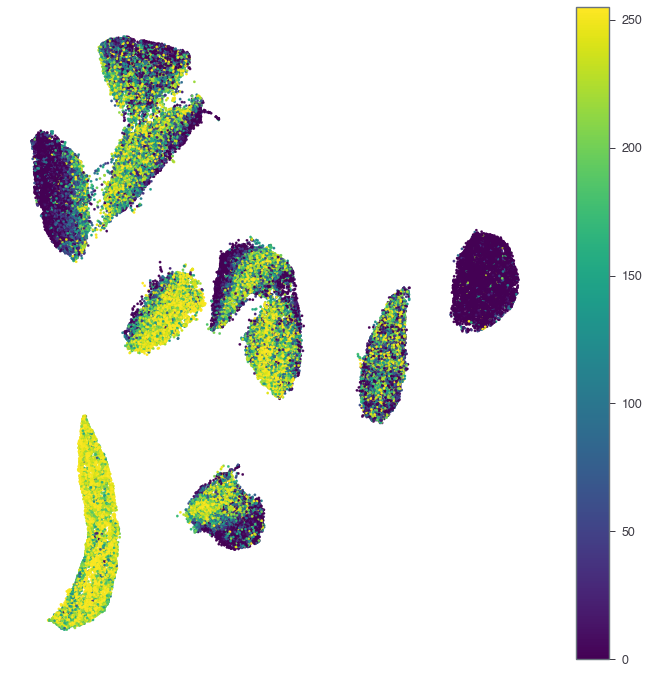
MNISTは連続値補助データがないので、適当に作ってみる。わかりやすい量として、画像の中心のエリアの平均的な輝度を計算してみる。ゼロだと(画像の真ん中を線が走ることはあまりないから)暗くなり、1だと明るくなるはず。
data = pd.read_csv('./mnist.csv').values[:, :784] data.shape(70000, 784)# 28 x 28のサイズの画像なので。 upper_left = 28 * 13 + 14 upper_right = 28 * 13 + 15 bottom_left = 28 * 14 + 14 bottom_right = 28 * 14 + 15 average_center_area = data[:, [upper_left, upper_right, bottom_left, bottom_right]].mean(axis=1)まずは普通にmatplotlibで描いてみる。
fig, ax = plt.subplots(figsize=(12, 12)) sc = ax.scatter(df['x'], df['y'], c=average_center_area, cmap='viridis', vmin=0, vmax=255, s=6, alpha=1.0) plt.colorbar(sc) plt.axis('off') plt.show()
やはりつぶれてしまってよくわからない。
Datashaderに渡して、各ピクセルに入ったデータ点の「最大値」で塗り分けてみる。
datashader.reductions.max関数で集計できる。df['value'] = average_center_area agg = canvas.points(df, 'x', 'y', agg=ds.max('value')) tf.set_background(tf.shade(agg, cmap=matplotlib.cm.get_cmap('viridis')), 'white')
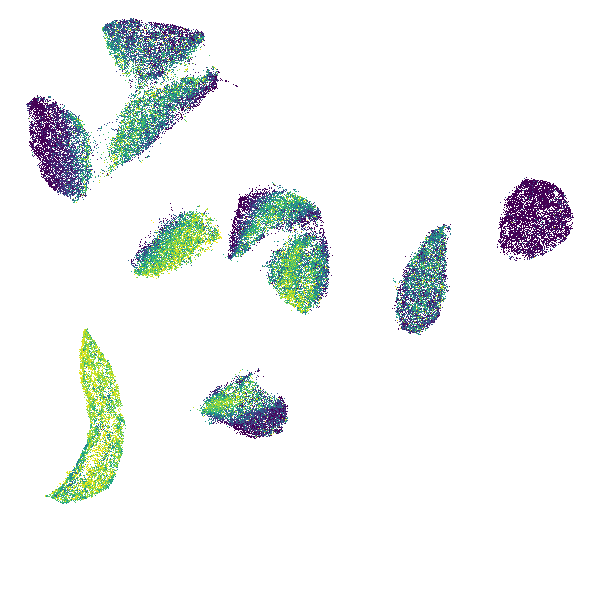
見やすくなった。matplotlibのscatterでサイズを小さく調整する場合とあまり変わらないかもしれないが、細かい試行錯誤なしでも綺麗に描画できるのが便利。
あとデータサイズが巨大でも高速なので、平均値で集計する場合はどうなるか、などいろいろと調整してみるのもストレスにならない。
agg = canvas.points(df, 'x', 'y', agg=ds.mean('value')) tf.set_background(tf.shade(agg, cmap=matplotlib.cm.get_cmap('viridis')), 'white')





- 投稿日:2020-03-19T23:17:47+09:00
PySpark DataFrameのgroupByでAUCを算出する(pandas_udfで集計関数を定義する)
はじめに
PySparkでAUCを算出する際、
BinaryClassificationEvaluatorクラスを利用すれば簡単に求めることが出来る。
ただし、そのままではモデル間の違いを把握するために、テストデータ全体ではなく、セグメントごとにAUCを算出したいというニーズに対応することが出来ない。この対処法として、
pandas_udfを使ってAUCを算出する集計関数を定義し、aggメソッドで算出することを行った。実装例
サンプルは以下の通り。
事前に正解ラベル(
true)と予測スコア(pred)を算出の上、それを参照してAUCを算出する集計関数を定義している。
aggメソッドの中で、pandas_udfで定義した集計関数は、sparkで用意された集計関数と併用することはできないので注意。
(併用しようとすると、Cannot use a mixture of aggregate function and group aggregate pandas UDFというエラーが出る)UDF定義from sklearn.metrics import roc_auc_score from pyspark.sql.types import DoubleType from pyspark.sql.functions import pandas_udf, PandasUDFType @pandas_udf(DoubleType(), functionType=PandasUDFType.GROUPED_AGG) def auc_udf(true, pred): return roc_auc_score(true, pred)算出方法data.groupBy(key).agg(auc_udf('true', 'pred').alias('auc'))参考
- 投稿日:2020-03-19T23:17:07+09:00
【Python】QRコードをインメモリに生成
QRコードを生成しAPI等で返したり、メール送信する場合、
一度ファイルにセーブし、それを読み出ししたりする処理が入ります。
この処理の場合、I/Oでの速度的問題や、並列処理時に問題が生じます。
BytesIOモジュールを使えば、一度ファイルに吐き出すことなく、インメモリに画像を生成出来ます。環境
- Python 3.7.4
- qrcode 6.1
- Pillow 7.0.0
qrcodeおよびPillowライブラリが必要です。
pip install qrcode pillow生成
from io import BytesIO import base64 import qrcode class QRImage(): @staticmethod def to_bytes(text: str) -> bytes: stream = BytesIO() img = qrcode.make(text) img.save(fp, "PNG") stream.seek(0) byte_img = stream.read() stream.close() return byte_img @classmethod def to_b64(cls, text: str) -> bytes: byte = cls.to_bytes(text) return base64.b64encode(byte).decode("utf-8") if __name__ == "__main__": binary = QRImage.to_bytes(text="some_text") base64_encoded = QRImage.to_b64(text="some_text")
BytesIO()でバイナリストリームを生成、ファイルストリームのようにmakeやread、saveを行うだけです。StringIO等も存在し、stringを格納することが出来ます。
また、with構文もサポートしています。from io import StringIO def main(): with StringIO() as fp: fp.write("Hello") print(fp.closed) # True print(fp.getvalue()) # Hello print(fp.closed) # False main()これで中間ファイルとはおさらばしましょう。
- 投稿日:2020-03-19T22:59:46+09:00
LINE BOT(オウム返し)を作る
LINEBOTで単純なオウム返しを、Heroku、Flask、line-bot-sdkで作成した。丸2日かかり詰まった点も多いのでメモも含めて共有。
・Mac
・Python(1)環境整備、ディレクトリ構成
デスクトップに、ディレクトリtest_linebotを作成。
ディレクトリ内に仮想環境を構築して起動。python3 -m venv . source bin/activate最終的なディレクトリ構成は以下の通り
test_linebot ├main.py ├runtime.txt ├Procfile └requirements.txt(2)必要なフレームワークをインストール
pip install flask pip install gunicorn pip install line-bot-sdk(3)main.pyを作成
main.pyfrom flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) import os app = Flask(__name__) #herokuの環境変数に設定された、LINE DevelopersのアクセストークンとChannelSecretを #取得するコード YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) #herokuへのデプロイが成功したかどうかを確認するためのコード @app.route("/") def hello_world(): return "hello world!" #LINE DevelopersのWebhookにURLを指定してWebhookからURLにイベントが送られるようにする @app.route("/callback", methods=['POST']) def callback(): # リクエストヘッダーから署名検証のための値を取得 signature = request.headers['X-Line-Signature'] # リクエストボディを取得 body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # 署名を検証し、問題なければhandleに定義されている関数を呼ぶ try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' #以下でWebhookから送られてきたイベントをどのように処理するかを記述する @handler.add(MessageEvent, message=TextMessage) def handle_message(event): line_bot_api.reply_message( event.reply_token, TextSendMessage(text=event.message.text)) # ポート番号の設定 if __name__ == "__main__": port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)※上記コードの補足説明
try:〜
Webhookに関する記述。Webhookとはイベント(メッセージ送信、友達追加など)が起きた時にイベントを処理するサーバーへイベントを送る処理をするもの(サーバーへ送るためにはLINE DevelopersのWebhookにURLを指定が必要)。
@handler.add(MessageEvent, message=TextMessage)
1つ目の引数にはイベントの種類を入れる(今回はメッセージが送られてきた時に返信したいので、MessageEventとした)、2つ目の引数にはメッセージの種類を入れる(今回はテキストを返したいので、message=TextMessageとした)。
def handle_message(event):
イベント処理する関数handle_messageが呼び出され、reply_messageの第2引数の値がLINEの返信として返される。lineメッセージとして返すためにはlineb_bot_apiのreply_message関数を使う。reply_messageである第一引数のevent.reply_tokenはreply_tokenが入る。これはwebhookオブジェクトから取得できるもので、どのイベントに対して返信するのか識別するもの。イベントの応答トークンを意味する。第二引数にはlinebot.modelsに定義されている返信用のTextSendMessageという関数を入れ、この関数は引数に返すメッセージを入れる。
また、event.message.textはLINEから送られてきたメッセージが格納されている。例えば”おはよう”と送られてきたら、event.message.text="おはよう"が格納されている。仮に、TextSendMessage(text='おはよう'))とすれば、返信は全て"おはよう"と返す。
ちなみに、eventの中身は以下のようになっている。{ "message": { "id": "***************", "text": "おはよう", "type": "text" }, "replyToken": "***********************", "source": { "type": "user", "userId": "************************" }, "timestamp": *********************, "type": "message" }port = int(os.getenv("PORT", 5000))
Herokuは動的にポート番号を割り当てているようなので、os.environ.get()を使用して,以下のようにする。os.environ.get('PORT', 5000)は,環境変数'PORT'を取得を試みて、取得できた場合はその取得した値が返され、取得できない場合:5000が返される。5000はローカル環境で作業する場合を想定としたもの。
# ポート番号の設定 if __name__ == "__main__": port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)(4)LINE Developersに登録
LINE Developersへアクセスして、登録後、サービス提供者を表す「プロバイダー」を作成。プロバイダー内で新規チャネルを作成。チャネルの種類はMessage APIを選択。
(5)Herokuの環境変数を設定
Herokuにログインして、アプリを作成する。今回は、testlinebot0319という名前とした。
heroku loginheroku create testlinebot0319初期化して、
git initherokuのアプリとgitを紐つけて、
heroku git:remote -a testlinebot0319herokuの環境変数に、Line developersの「アクセストークンの文字列」と「チャンネルシークレットの文字列」を設定する。
例えば、heroku config:set YOUR_CHANNEL_ACCESS_TOKEN="チャネルアクセストークンの文字列" -a (アプリ名)とする。heroku config:set YOUR_CHANNEL_ACCESS_TOKEN="チャネルアクセストークンの文字列" -a testlinebot0319 heroku config:set YOUR_CHANNEL_SECRET="チャネルシークレットの文字列" -a testlinebot0319heroku上に環境変数がちゃんとセットされたか確認。
heroku config(6)その他、必要なファイルを揃える
Procfile、runtime.txt、requirements.txtを作成する。
runtime.txtは、自身のpythonのバージョンを確認の上作成する。
runtime.txtpython-3.8.0Procfileは以下を記述。
Prockfileweb: python main.pyrequirements.txtは以下をターミナルで入力して記述。
pip freeze > requirements.txt(7)Herokuへデプロイ
gitを再度初期化、紐つけて、addして、the-firstという名前でcommitする。
最後にHerokuにプッシュ。git init heroku git:remote -a testlinebot0319 git add . git commit -m'the-first' git push heroku masterheroku openして、
heroku openブラウザに以下が出れば成功。
(8)LINE DevelopersのWebhook設定
以下のように、自分のHeroku上のアプリ名をLINE DevelopersのWebhook欄に設定する。Heroku上のアプリ名=testlinebot0319
この時、Webhookの利用をオンにしておく。
これで、LINE Developersの上記にあるQRコードを読み込み友達登録すればオウム返しのアプリの完成。
うまく、オウム返ししてくれないなどLINEBOTが機能しない場合は、Webhookの利用を、オン、オフを繰り返すとる場合がある(私の場合はそれでうまくいった)。参考にしたサイト
1時間でWikipedia検索できるLINE BOTをサクッと作ってみよう!
Python + Flask + HerokuでLINE BOT
【Python初心者! -LINE Botでオウム返し編-】

- 投稿日:2020-03-19T22:28:53+09:00
ラズパイ4B+BU-353S4でGPSトラッキング(Python)
ラズパイ4 + BU-353S4 + PythonでGPSトラッキング
ラズパイを用いて、GPS情報を取得する
Raspberry Pi 4Bを使いますが、別に3とかでも同じだと思います。用意するもの
- GLOBALSAT BU-353S4 => USB接続のGPSセンサー
- Raspberry Pi 4
手順
必要なパッケージをインストール
sudo apt-get upgrade sudo apt-get install gpsd gpsd-clients python-gps cuUSBにBU-353S4を差込み、以下のコマンドで接続を確認
lsusb # Prolific Technology, Inc. PL2303 Serial Portがあればok ls /dev/ttyUSB* # => /dev/ttyUSB0 # 使用されているポートを確認(あとで使います)USBの接続が確認できたら、以下のコマンドでgpsd設定ファイルを作成(既存の場合は下に追加)
vi /etc/default/gpsd # vim /etc/default/gpsd/etc/default/gpsd# 以下の2行を追加(DEVICESには先ほどのデバイス番号) DEVICES="/dev/ttyUSB0" GPSD_OPTIONS="-n"# 自動起動を設定して再起動 sudo systemctl enable gpsd.socket sudo systemctl start gpsd.socket sudo rebootPythonサンプルコード
gps3をインストール
pip3 install gps3gps.pyfrom gps3 import gps3 gps_socket = gps3.GPSDSocket() data_stream = gps3.DataStream() gps_socket.connect() gps_socket.watch() for new_data in gps_socket: if new_data: data_stream.unpack(new_data) print('time : ', data_stream.TPV['time']) print('lat : ', data_stream.TPV['lat']) print('lon : ', data_stream.TPV['lon'])python3 gps.py # 以下のように出力されます。 # time : 2020-03-19T13:24:08.000Z # lat : 35.633116667 # lon : 139.703893333 # alt : 17.1まとめ
意外と簡単だったけど、まともな解説記事やサンプルコードを探すのに苦労した。
参考記事
- 投稿日:2020-03-19T22:20:08+09:00
PythonでのDB接続管理の良さそうな方法の紹介
はじめに
とあるOSSのコードを眺めてて、良さそうなのがあったのでそれの紹介をば。
コード
とあるOSSというのは、Apache Airflow。
この中で、airflow/utils/session.py がいい感じでした。簡単な説明
まずは、
session.pyから。import contextlib from functools import wraps from airflow import settings # contextlib.contextmanager を指定すると with を使って close を自動でやってくれる @contextlib.contextmanager def create_session(): """ Contextmanager that will create and teardown a session. """ session = settings.Session() try: yield session session.commit() except Exception: session.rollback() raise finally: session.close() # Sessionを使いたい function で使うといい感じに Session を補完してくれる def provide_session(func): """ Function decorator that provides a session if it isn't provided. If you want to reuse a session or run the function as part of a database transaction, you pass it to the function, if not this wrapper will create one and close it for you. """ @wraps(func) def wrapper(*args, **kwargs): arg_session = 'session' func_params = func.__code__.co_varnames session_in_args = arg_session in func_params and \ func_params.index(arg_session) < len(args) session_in_kwargs = arg_session in kwargs # function の引数で session があるならそれを使い、なかったら作るという処理 if session_in_kwargs or session_in_args: return func(*args, **kwargs) else: with create_session() as session: kwargs[arg_session] = session return func(*args, **kwargs) return wrapperで、次に使う側のコード。
airflow/models/baseoperator.py の 940行目にある@provide_session def get_task_instances(self, start_date: Optional[datetime] = None, end_date: Optional[datetime] = None, session: Session = None) -> List[TaskInstance]: """ Get a set of task instance related to this task for a specific date range. """ end_date = end_date or timezone.utcnow() return session.query(TaskInstance)\ .filter(TaskInstance.dag_id == self.dag_id)\ .filter(TaskInstance.task_id == self.task_id)\ .filter(TaskInstance.execution_date >= start_date)\ .filter(TaskInstance.execution_date <= end_date)\ .order_by(TaskInstance.execution_date)\ .all()のように
sessionを使う function でデコレータとして指定すると
呼び出し元でsessionを設定していない場合は新規に作成され(且つ終了時にcloseされる)
sessionを設定している場合はそれをそのまま使うといういい感じなことが実現できる。終わりに
この方法はDB接続以外にも色々応用ができそうだなと思う。
参考
- 投稿日:2020-03-19T22:00:46+09:00
AWSマネジメントコンソールにフェデレーテッドログインしてみた。
はじめに
皆さん、業務でAWSは使われているでしょうか。
AWS、インフラの構築から運用までいろいろサポートしてくれていて、とても便利ですよね。
それこそインフラ担当だけじゃなくて、CloudWatchやセッションマネージャーのような環境に接続するすべての関係者にとってメリットがある機能なんかもよくリリースされています。ところで (問題提起)
これらの素晴らしいAWSの機能って、インフラ担当ばっかりメリットを享受していて、コンサルタントや製品開発者にはあまり届いてこないことが多いです。
何故かというと、「マネジメントコンソール」を使える人間が限られているからです。
AWSはどんどんいい機能を出してくれるのに、それを使える人間が限られているのはとてももったいないですよね。
かといって、それらをいろんな人が使えるようにインターフェースを実装するのは大変ですし、AWSが機能拡張するたびに対応する必要があるのも格好が悪いです。だったら (解決案)
AWSのあらゆる機能にアクセスできる最強のインターフェース、「マネジメントコンソール」を「AWSユーザーが割り当てられていない人」にも使えるようにしたらいいんじゃないか。
これが、本記事の本題になります。今回使うもの
1.Amazon Cognito
https://dev.classmethod.jp/cloud/aws/what-is-the-cognito/
Cognito は、2014年7月に発表された ユーザーのアイデンティティ をテーマにしたサービスです。「こぐにーと」と読みます。
簡単に言うと、AWS内のリソースをユーザーごとに分けて提供できる機能で、例えばAさん専用のファイルアップロード領域を作ったりできます。2.カスタム ID ブローカーに対する AWS コンソールへのアクセスの許可
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles_providers_enable-console-custom-url.html#STSConsoleLink_programPython
組織のネットワークにサインインするユーザーに対して AWS マネジメントコンソール への安全なアクセスを許可するには、そのための URL を生成するコードを記述して実行できます。この URL は、AWS から取得したサインイントークンを含み、それを使って AWS に対してユーザーを認証します。3.Python(boto3)
boto3というモジュールを使って、pythonでAWSのAPIを操作します。
どう使うのか (概要)
「Amazon Cognito」のIDPoolを使用することで、アクセス権限を制限したポリシーを持つAWSユーザーを払い出すことができます。
これらはアクセスキーも持っているので、それを使って「カスタム ID ブローカーに対する AWS コンソールへのアクセスの許可」で提示されているログインURLを生成することができます。
これらを行うためにはAWSアカウント上にいくつかのリソースの準備が必要であるため、それらも説明していきます。AWSリソースの準備
1.AWSリソース操作に使用するユーザーに、アクセス権限を追加
AmazonCognitoPowerUserポリシー、AmazonCognitoDeveloperAuthenticatedIdentitiesポリシーをアタッチしてください。
2.IDPoolの作成
以下のURLから、ユーザーの情報を保管しておくIDPoolという領域を作成してください。
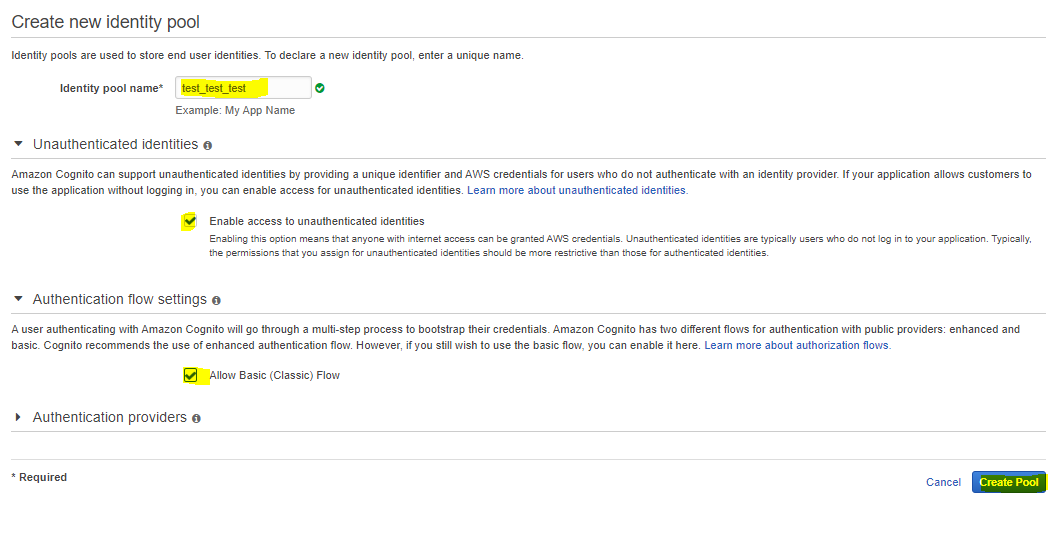
https://ap-northeast-1.console.aws.amazon.com/cognito/create/?region=ap-northeast-1#
1.Identity Pool Name = 好きな名前を付けましょう。2.Unauthenticated Identitiesで匿名IDを許可するために「Enable Access to Unauthenticated Identities」にチェックを入れてください。今回、認証ロジックについては解説しないため、未認証でアクセスキーを発行します。
3.未認証ユーザーを使用する場合、基本 (クラシック) フローを使用しないと管理コンソールの使用認可を行えないので、「基本 (クラシック) フローを許可する」にチェックを入れてください。
4.プールの作成を行ってください。
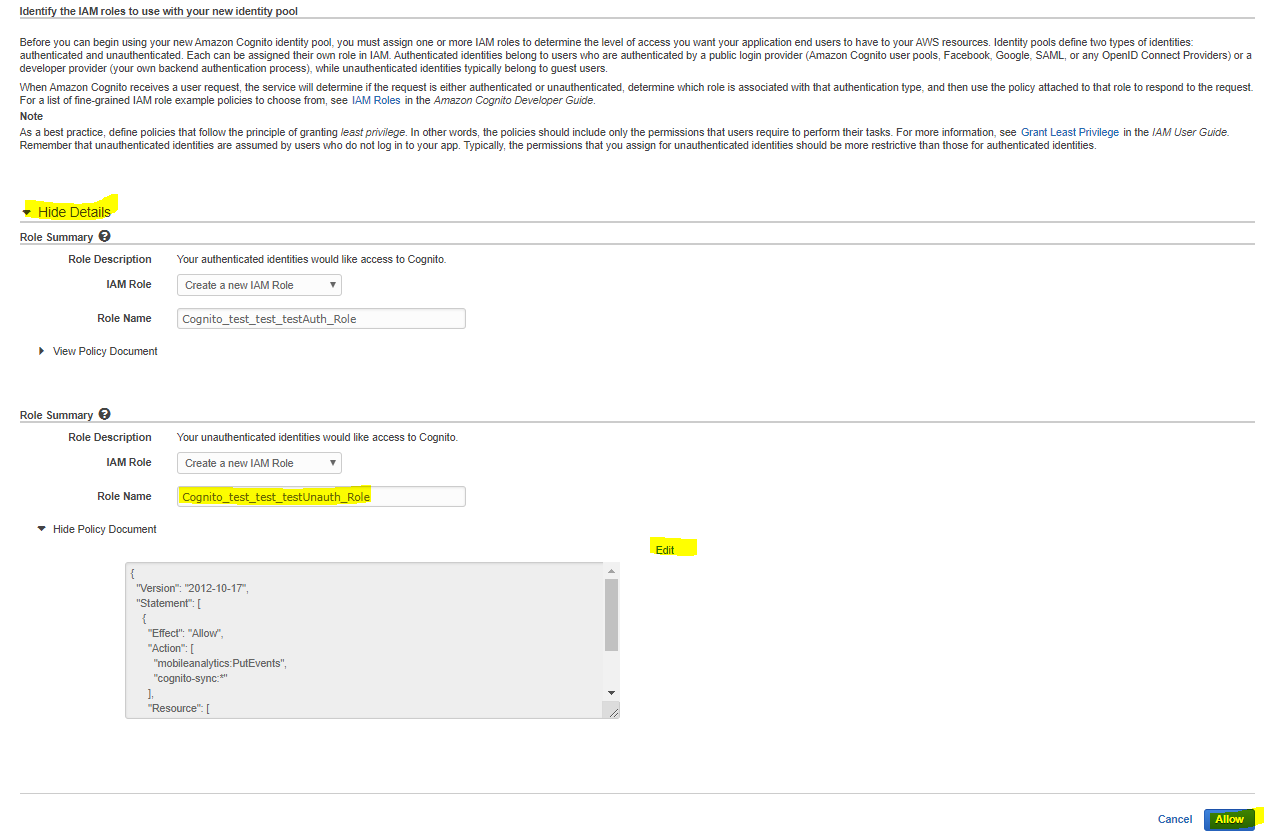
5.Identify the IAM roles to use with your new identity pool のページが表示されるので詳細の表示をしてください。(ちなみに、上が認証済みID、下がゲストIDの設定)
6.新しいロールの作成をします。認証済み、未認証それぞれで権限を変えることができるので、Unauth ・Authedそれぞれを作成しましょう。ちなみに、今回Authedは使う予定がないので中身は適当でも問題ありません。
7.Unauth にReadOnlyAccessと以下をアタッチしましょう。今回はセッションマネージャーを使用可能なゲスト用ロールにしてみます。
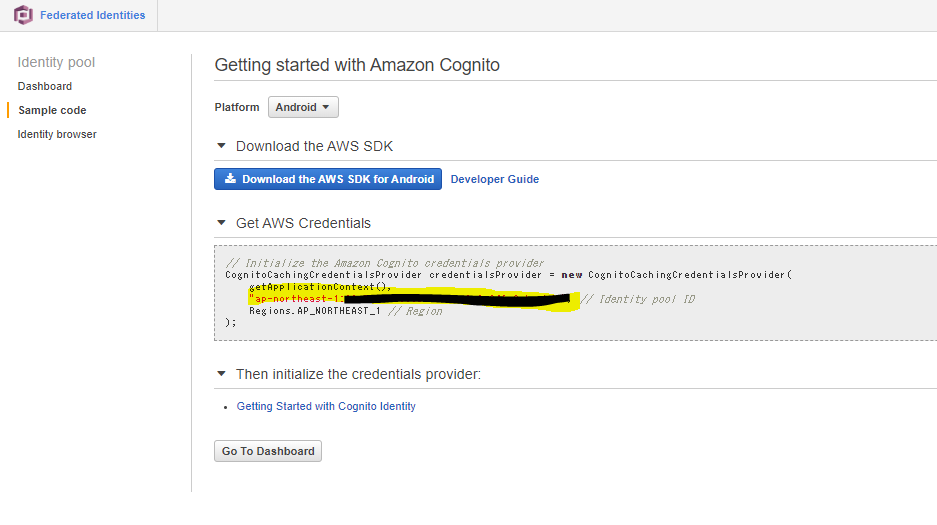
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Cognito", "Effect": "Allow", "Action": [ "mobileanalytics:PutEvents", "cognito-sync:*", "sts:GetFederationToken" ], "Resource": [ "*" ] }, { "Sid": "Ssm", "Effect": "Allow", "Action": [ "ssmmessages:CreateDataChannel", "s3:GetEncryptionConfiguration", "ssm:UpdateInstanceInformation", "ssmmessages:OpenDataChannel", "ssmmessages:OpenControlChannel", "ssmmessages:CreateControlChannel", "ssm:StartSession" ], "Resource": "*" } ] }8.サンプルコードのところに書いてあるIDプールのIDをメモしておいてください。
3.以下のpythonのコードからcredentialの設定部分をcognitoに置き換えたlogin_test.pyを実装します。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- #以下のように実行します。 #python3 login_test.py user_name import urllib, json, sys import requests import boto3 import datetime _args = sys.argv _USER = _args[1] _AWS_ACCOUNT = "123456789012" _CONV_AWS_ACCESS_KEY_ID = "ASIA*******:" _CONV_AWS_SECRET_ACCESS_KEY = "**********" _CONV_AWS_SESSION_TOKEN = "*********" _REGION_NAME = "ap-northeast-1" _ID_POOL_ID = "手順8でメモしておいたものを使用します。" _ARN = "arn:aws:cognito-identity:ap-northeast-1:123456789012:identitypool/ap-northeast-1:*******" _ROLE_ARN = "arn:aws:iam::123456789012:role/Unauth" class GetLoginUrl(): def cognito_auth(self): try: #cognitを操作するためのclient作成 cognito_client = boto3.client('cognito-identity', region_name = _REGION_NAME, aws_access_key_id = _CONV_AWS_ACCESS_KEY_ID, aws_secret_access_key = _CONV_AWS_SECRET_ACCESS_KEY, aws_session_token = _CONV_AWS_SESSION_TOKEN #MFAを使用していないなら不要 ) #ID取得 user_id = cognito_client.get_id( AccountId = _AWS_ACCOUNT, IdentityPoolId = _ID_POOL_ID )["IdentityId"] print("Cognito ID:"+user_id) except: raise Exception("get id faild.") try: #Role設定確認 roles = cognito_client.get_identity_pool_roles(IdentityPoolId=_ID_POOL_ID)["Roles"]["unauthenticated"] print("Use role:"+roles) # GetOpenIdToken + AssumeRoleWithWebIdenity token = cognito_client.get_open_id_token( IdentityId=user_id ) sts_client = boto3.client('sts', region_name = _REGION_NAME, aws_access_key_id = _CONV_AWS_ACCESS_KEY_ID, aws_secret_access_key = _CONV_AWS_SECRET_ACCESS_KEY, aws_session_token = _CONV_AWS_SESSION_TOKEN #MFAを使用していないなら不要 ) d_today = str(datetime.date.today()) credentials_for_identity = sts_client.assume_role_with_web_identity( RoleArn = _ROLE_ARN, RoleSessionName = _USER + "-" + d_today,#ログの頭に付く文字列 誰のセッションか識別できる情報を入れよう。 WebIdentityToken = token["Token"] ) AccessKeyId = credentials_for_identity["Credentials"]["AccessKeyId"] SecretKey = credentials_for_identity["Credentials"]["SecretAccessKey"] SessionToken = credentials_for_identity["Credentials"]["SessionToken"] except: #id削除 #失敗したときは無駄に作成したidは消しておこう。 del_response = cognito_client.delete_identities( IdentityIdsToDelete=[ user_id ] ) raise Exception("cognito_auth faild.","delete id :"+str(del_response["ResponseMetadata"]["RequestId"])) url_credentials = {} url_credentials['sessionId'] = AccessKeyId url_credentials['sessionKey'] = SecretKey url_credentials['sessionToken'] = SessionToken json_string_with_temp_credentials = json.dumps(url_credentials) request_parameters = "?Action=getSigninToken" request_parameters += "&SessionDuration=43200" if sys.version_info[0] < 3: def quote_plus_function(s): return urllib.quote_plus(s) else: def quote_plus_function(s): return urllib.parse.quote_plus(s) request_parameters += "&Session=" + quote_plus_function(json_string_with_temp_credentials) request_url = "https://signin.aws.amazon.com/federation" + request_parameters r = requests.get(request_url) # Returns a JSON document with a single element named SigninToken. signin_token = json.loads(r.text) # Step 5: Create URL where users can use the sign-in token to sign in to # the console. This URL must be used within 15 minutes after the # sign-in token was issued. request_parameters = "?Action=login" request_parameters += "&Issuer=Example.org" request_parameters += "&Destination=" + quote_plus_function("https://console.aws.amazon.com/") request_parameters += "&SigninToken=" + signin_token["SigninToken"] request_url = "https://signin.aws.amazon.com/federation" + request_parameters # Send final URL to stdout print (request_url) def main(self): print("success login! welcome "+_USER) self.cognito_auth() if __name__ == "__main__": GLU = GetLoginUrl() GLU.main()4.login_test.pyを実行します。
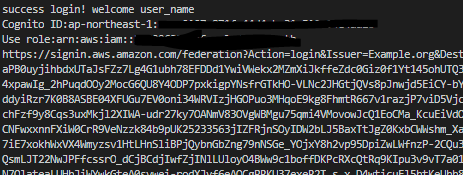
login_test.pyは、実行されるまでにユーザーが認証を通したという前提で実装されています。
なので、これ単体でたたくとそれだけでアカウントが発行され、とても長いログイン用のURLが発行されます。
そのURLにアクセスすると、マネジメントコンソールの画面にリダイレクトされ、フェデレーテッドログインに成功します。
権限はReadOnlyに加え、セッションマネージャーも許可しているので、EC2からどのインスタンスが立っているか確認したり、セッションマネージャーを使用して環境にアクセスしたりすることができます。おわりに
今回は、AWSマネジメントコンソールに対してAWSユーザーを発行されていないユーザーがログインできるようにしました。
この仕組みを使えば、IAMで個別にアカウントを管理して、退職者が出たりするたびにメンテナンスする必要もなく、お手軽にマネジメントコンソールを提供することができます。
マネジメントコンソールはAWSが勝手に強化してくれるので、我々の開発工数をかけずに業務効率化を継続して行えるようにもなります。
とても便利ですので、ぜひ一度お試しください。私もAWS初心者(クラウドプラクティショナー程度)であるため、ご指摘・ご質問・ご感想はどのようなものでもありがたくいただく所存です。
何かございましたら、ぜひコメントを頂ければと存じます。以上、お疲れ様でした。

- 投稿日:2020-03-19T21:23:00+09:00
機械学習に関する個人的なメモとリンク集③
はじめに
機械学習もデータ見える化が重要ですよね。それについても様々な先人の知恵がありました。
Python
PythonのグラフといえばMatplotlibがよく使われますが、もうちょっとカッコいいグラフにしたいというニーズで記事がまとまっています。
seaborn
-pythonでデータを可視化したいならseabornを使おう!
Yellowbrick
pandas-profiling
BI
BIと言えば、最近はTableauやLookerが有名ですが、Google Data Portalが色々とできて好きです。
DataPortal
Tableau
- 投稿日:2020-03-19T21:22:55+09:00
量子情報理論の基本:量子誤り訂正(CSS符号)
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
前回の記事で古典線形符号について理解できたので、今回はそれをベースとした量子誤り訂正のクラスである「CSS符号(Calderbank-Shor-Steane code)」について勉強します。さらに、その具体的な符号方式として「Steane符号」についても見ていきます。一通り理解できたところで、量子計算シミュレータqlazyを使って、その「Steane符号」の動作を確認してみます。
ちなみに、「CSS符号」は、より一般的な量子誤り訂正のクラスである「スタビライザー符号(Stabilizer code)」の部分クラスに相当するとのことです。今回の記事は、それへの布石という位置づけでもあります。
参考にさせていただいたのは、以下の文献です。
理論の説明
CSS符号の定義
$C_1$と$C_2$は古典線形符号$[n,k_1]$と$[n,k_2]$であり、$C_2 \subset C_1$とします。また、$C_1$と$C_{2}^{\perp}$はともに$t$個の誤りに対応可能であるとします。このとき$t$個の誤りに対応できる、$[n, k_1 - k_2]$の量子符号として、CSS符号$CSS(C_1,C_2)$を構築することができます。$x \in C_1$を符号$C_1$における任意の符号語であるとします。このとき量子状態$\ket{x + C_2}$を、
\ket{x+C_2} \equiv \frac{1}{\sqrt{|C_{2}|}} \sum_{y \in C_2} \ket{x+y} \tag{1}のように定義します。ここで、右辺の$+$は2を法とするビットごとの和を表すものとします(以下同様)。この$\ket{x+C_2}$たちの重ね合わせによって表現される符号がCSS符号です。
イキナリなんのことかわかりません。噛み砕きます。
$x$は$[n,k_1]$符号$C_1$の要素なので、$k_1$次元のすべてのバイナリ・ベクトル($0$または$1$を要素とするベクトル)から生成される$n$次元のバイナリ・ベクトルです。したがって、$x$の総数$|C_1|$は$2^{k_1}$個です。一方、$y$は$[n,k_2]$符号$C_2$の要素なので、$k_2$次元のすべてのバイナリ・ベクトルから生成される$n$次元のバイナリ・ベクトルです。したがって、$y$の総数$|C_2|$は$2^{k_2}$個です。また、$C_2 \subset C_1$ということなので、$k_2 < k_1$です。前回の記事で「古典線形符号」が理解できていれば、ここまでは全然難しくないですね。
さて、式(1)の右辺は、$C_1$の要素$x$と$C_2$の要素$y$との和を指標とする状態ベクトル$\ket{x+y}$を、すべての$y \in C_2$について足しあげる格好になっています。それを$\ket{x+C_2}$という記号で定義しています。少し別の言い方をすると、$\ket{x+C_2}$は、ある$\ket{x} \space (x \in C_1)$を種にして、それに対してすべての$y \in C_2$を総動員して行った変換(ケットの中身に$y$を加える)を全部を合わせた重ね合わせ状態です。
ここで、線形符号の要素同士を足し合わせても、その同じ線形符号の要素になるので1、右辺のすべてのケットの中身は$C_1$の要素であることに注意しておきましょう。つまり、種になる$x \in C_1$にすべての$y \in C_2 \subset C_1$を加えた結果の各々は、すべて$C_1$に属する符号になります。別の$x^{\prime} \in C_1$を種にしてすべての$y \in C_2$を加えた結果の各々も、すべて$C_1$に属する符号になります。ここで質問です。$x$と$x^{\prime}$を種にして生成された2つの符号の集まり(各々$2^{k_2}$個の集まりですが)に何か関係はありますでしょうか?実は、「全部同じ」または「全部違う」のどちらかであって、部分的に重なっているということはありません。
どういうことでしょうか?
いま考えている集合とは正確には違うのですが、一旦感覚を掴むために、類似した例を上げてみます。$0$から$99$までの整数の集合をイメージしてください。これを集合$C_1$とします。次に、$C_1$の中から$3$の倍数を取り出します。それを$C_2$とします。いま$C_1$の中から、ある特定の整数を取り出し$x$とします。これを種にして、すべての$y \in C_2$を総動員して、その各々を$x$に加えます(ただし$100$を法とした加算にします)。得られた結果は全部$0$から$99$までの整数になるので、$C_1$の要素になっています。例えば、$x=6$としてみましょう。このとき、$y$を加えてできあがった整数は全部$3$の倍数になります。$x^{\prime}=15$を考えて、同じように$y \in C_2$を使って、整数の集合を生成してみます。簡単にわかると思いますが、これも全部$3$の倍数です。つまり、$x=6,x^{\prime}=15$を種にして生成された整数の集合は完全に一致しているということです。別の例として、$x=7,x^{\prime}=31$だとどうでしょうか。生成される整数は、どっちも$3$で割ったら余りが$1$になる集合です。ということで、この場合も両者は完全に一致します。さらに別の例として、$x=11,x^{\prime}=52$だとどうでしょうか。この場合、$x=11$から生成されるのは、$3$で割った余りが$2$の整数集合、$x^{\prime}=52$から生成されるのは、$3$で割った余りが$1$の整数集合です。ということで、両者は完全不一致です。つまり、$x \in C_1$を種に集合$C_2$を使って生成した集合を、$3$で割った余りがいくつになるかで分類することができるということです。もっと言うと、$C_2$によって$x \in C_1$を3つのグループに分類することができます。この分類のことを「剰余類」と呼びます(例えば、「$7$と$31$は同じ剰余類に属している」という言い方をします)。同じ剰余類に属しているかどうかは、いちいち全部生成してみなくても、引き算をしてみればわかります。いまの例でやってみます。$15-6$は$9$、$31-7$は$24$となり、どっちも$3$の倍数です。一方、$52-11$は$41$となり、$3$の倍数ではありません。このように同じ剰余類に属しているかどうかは、引き算をしてみて、それが$C_2$に属しているかどうかで判断できます。
さて、アナロジーはこの辺までにしておきます。前段の$C_1,C_2$の定義は忘れてください。で、改めて、式(1)の定義を見ると、これに類似したことが成り立ちそうな気がしてきます。気がするだけでなく、実際にもそうであるということを以下で示してみます。
まず、同じ剰余類に属している場合、すなわち、$x, x^{\prime} \in C_1$で、$x-x^{\prime} \in C_2$だったとすると、
\ket{x + C_2} = \ket{x^{\prime} + C_2} \tag{2}が成り立ちます。では、証明してみます。
【証明】
$\ket{x+C_2} - \ket{x^{\prime}+C_2}$が$0$になることを証明します。
\ket{x+C_2} - \ket{x^{\prime}+C_2} = \frac{1}{|C_2|} (\sum_{y \in C_2} \ket{x+y} - \sum_{y \in C_2} \ket{x^{\prime}+y}) \tag{3}$x-x^{\prime}=y^{\prime} \in C_2$とおきます。
\ket{x+C_2} - \ket{x^{\prime}+C_2} = \frac{1}{|C_2|} (\sum_{y \in C_2} \ket{x^{\prime}+y^{\prime}+y} - \sum_{y \in C_2} \ket{x^{\prime}+y}) \tag{4}$y^{\prime\prime} = y^{\prime}+y$とおきます。$y^{\prime}$と$y$は同じ符号$C_2$の要素なので$y^{\prime\prime} \in C_2$であることに注意すると、
\ket{x+C_2} - \ket{x^{\prime}+C_2} = \frac{1}{|C_2|} (\sum_{y^{\prime\prime} \in C_2} \ket{x^{\prime}+y^{\prime\prime}} - \sum_{y \in C_2} \ket{x^{\prime}+y}) = 0 \tag{5}となります。(証明終)
次に、異なる剰余類に属している場合、すなわち、$x, x^{\prime} \in C_1$で、$x-x^{\prime} \notin C_2$だったとすると、
\braket{x + C_2}{x^{\prime} + C_2} = 0 \tag{6}が成り立ちます。では、証明してみます。
【証明】
まず、いかなる2つの$y,y^{\prime} \in C_2$をもってきても、$x+y = x^{\prime}+y^{\prime}$にすることはできません。つまり、
x+y \neq x^{\prime} + y^{\prime} \tag{7}です。なぜなら、等号が成り立つとすると、$x-x^{\prime} = y^{\prime}-y \in C_2$となり2、前提を否定することになります。したがって、式(7)が成り立ちます。とすると、
\begin{align} \ket{x+C_2} &= \frac{1}{|C_2|} \sum_{y \in C_2} \ket{x+y} \\ \ket{x^{\prime}+C_2} &= \frac{1}{|C_2|} \sum_{y^{\prime} \in C_2} \ket{x^{\prime}+y^{\prime}} \tag{8} \end{align}という2つの状態は、互いに全く重なることのない状態の重ね合わせということになるので、
\braket{x+C_2}{x^{\prime}+C_2} = 0 \tag{9}が成り立ちます。(証明終)
$\ket{x+C_2}$の$x$は$C_1$の要素なので、その総数は$2^{k_1}$なのですが、上に示した性質があるので、ケットとしての総数はそれより少なくなります。簡単にわかると思いますが、$y \in C_2$の総数で割り算すれば良いです。つまり、$\ket{x+C_2}$の総数は、$|C_1|/|C_2|=2^{k_1}/2^{k_2}=2^{k_1 - k_2}$です。ということで、このCSS符号は、量子ビット長$k_1 - k_2$の状態から生成される$[n, k_1 - k_2]$符号ということになります。
ビット反転と位相反転
それでは、このように定義された量子符号で、なぜどのように誤り訂正ができるのかを見ていきます。が、まず、ビット反転と位相反転が加わった状態がどうなるかを確認しておきます。
いま、ビット反転の誤りを表すベクトルをバイナリ値を要素とする、以下のようなベクトルで表すことにします。
e_1 = (0, \cdots , 0,1,0, \cdots, 0,1,0, \cdots, 0)^T \tag{10}ここで、ベクトルの次元は$n$で、誤りが加わる量子ビット番号に相当した要素のみが$1$で、その他が$0$となっているものと思ってください。また、位相反転の誤りを表すベクトルも同様に、
e_2 = (0, \cdots , 0,1,0, \cdots, 0,1,0, \cdots, 0)^T \tag{11}と表すことにします。このような誤りによって、先程のCSS符号はどう変化するかと言うと、
\ket{x+C_2} = \frac{1}{|C_2|} \sum_{y \in C_2} (-1)^{(x+y)e_2} \ket{x+y+e_1} \tag{12}となります。ビット反転の効果が、右辺のケットの中身に$e_1$が加えられることによって表現されるのは良いですよね。ちょっとわかりにくいのは位相反転の効果が、$(-1)^{(x+y)e_2}$になっているところかと思いますので、若干説明を加えます。
$x+y$は$n$次元のバイナリ・ベクトルでした。それがケットの中に入っているということなので、
x+y = (q_1, q_2, \cdots , q_n)^{T} \tag{13}とおいてみると、$\ket{x+y}$は、
\ket{x+y} = \ket{q_1}\ket{q_2} \cdots \ket{q_n} \tag{14}と書けます。ここで、$\ket{q_i}$は$\ket{0}$か$\ket{1}$のどちらかです。位相反転は$\ket{0}$をそのままにして、$\ket{1}$を$-\ket{1}$にする変換だったので、式(11)の$n$個の成分の中で$1$となっている場所の$q_i$が$1$になっているときに、式(14)の符号が反転します。つまり、$x+y$と$e_2$の内積分だけ$-1$がかかるということなので、式(12)で示されているように、係数$(-1)^{(x+y)e_2}$が状態の前にかかることになります。
ビット反転誤りの訂正
このように誤りが入った状態をどうやって訂正していくかについて説明します。まず、ビット反転誤りの訂正についてです。式(12)の右辺の$\ket{x+y+e_1}$に注目します。$x+y \in C_1$だったので、$C_1$のパリティ検査行列を$H_1$として、それをケットの中身に適用して誤りシンドロームの計算ができれば、そこにビット反転があった量子ビット番号についての情報が入っているはずです。これを実行するためには、量子誤りシンドロームの結果を格納するためのアンシラが必要になります。すなわち、
\ket{x+y+e_1}\ket{0} \rightarrow \ket{x+y+e_1}\ket{H_1(x+y+e_1)} = \ket{x+y+e_1}\ket{H_1 e_1} \tag{15}という変換が実現できれば、右辺のアンシラ$\ket{H_1 e_1}$に、誤りビット番号に関する情報が入ることになります。
では、式(15)の変換は、どんな量子回路で実現できるでしょうか。
いきなり一般的に説明するは難しいので、簡単な例で考えてみます。$\ket{x}\ket{0} \rightarrow \ket{x}\ket{Hx}$という変換を実現したいとします。具体的には、$\ket{x}$は3量子ビットの符号語、$H$はパリティ検査行列、
H = \begin{pmatrix} 1 & 1 & 0 \\ 0 & 1 & 1 \end{pmatrix} \tag{16}とします。このとき、生成行列$G$は、
G = \begin{pmatrix} 1\\ 1\\ 1 \end{pmatrix} \tag{17}です。ということで、これは、1量子ビットを3量子ビットに冗長化する繰り返し符号に他なりません。つまり、$\ket{0} \rightarrow \ket{000}, \ket{1} \rightarrow \ket{111}$のような符号化を実現します。入力ベクトル$x=(x_1, x_2, x_3)^{T}$に$H$を演算した結果が、アンシラに転写されれば良いので、量子回路は以下のようになります。
[1行目] [2行目] |x1> --*------------- |x2> --|--*----*----- |x3> --|--|----|--*-- | | | | |0> --X--X----|--|-- |0> ----------X--X--[1行目]と書かれている箇所は$H$の1行目に対応した計算です。1列目と2列目の行列要素が1になっているので、1番目のアンシラが$\ket{x_1+x_2}$となるようにしています。[2行目]と書かれている箇所は$H$の2行目に対応した計算です。2列目と3列目の行列要素が1になっているので、今度は、2番目のアンシラが$\ket{x_2 + x_3}$となるようにしています。
任意の$\ket{x}$に対して任意の$H$が定義されたときも、この考え方は一般化できます。$H$の第$i$行の第$j$列が$1$だったとき、$j$番目の符号量子ビットを制御ビット、$i$番目のアンシラ量子ビットを標的ビットにしたCNOTゲートを配備します。これを行列要素が$1$になっている数分繰り返せば良いです。というわけで、式(15)の変換を実現する量子回路をどう作れば良いかわかったと思います3。
元の誤りありの状態は式(12)だったので、量子誤りシンドロームを通した結果は、
\begin{align} \ket{x+C_2} &= \frac{1}{|C_2|} \sum_{y \in C_2} (-1)^{(x+y)e_2} \ket{x+y+e_1} \\ & \rightarrow \frac{1}{|C_2|} \sum_{y \in C_2} (-1)^{(x+y)e_2} \ket{x+y+e_1} \ket{0} \\ & \rightarrow \frac{1}{|C_2|} \sum_{y \in C_2} (-1)^{(x+y)e_2} \ket{x+y+e_1} \ket{H_1(x+y+e_1)} \\ & \rightarrow \frac{1}{|C_2|} \sum_{y \in C_2} (-1)^{(x+y)e_2} \ket{x+y+e_1} \ket{H_1 e_1} \tag{18} \end{align}となります。誤りが1量子ビットに限定されている場合は、最後の$\ket{H_1 e_1}$の中で$\ket{0}$となっていないものは1種類しかありません。それを$\ket{z_1}$とします。アンシラが$\ket{z_1}$となっている右辺の項についてのみ、$z_1$に対応した量子ビット番号(つまり、パリティ検査行列の列ベクトルが$z_1$になっていう列番号)を反転させれば、誤り訂正ができます。2量子ビットの誤りがある場合は、$\ket{0}$以外のアンシラ状態が2種類あるということになります。それを$\ket{z_1},\ket{z_2}$とすると、アンシラが$\ket{z_1}$または$\ket{z_2}$になっている右辺の項についてのみ、$z_1$と$z_2$に対応した量子ビット番号を反転するようにすれば、誤り訂正ができます。3量子ビット以上の誤りがあった場合も同様にして誤り訂正ができます。というわけで、ビット反転誤りの訂正が完了します4。ただし、$C_1$は$t$個までの誤りを訂正できる符号だったので、対応できる量子ビット数は$t$個までです。
ビット反転誤りを訂正した結果、状態は以下のようになります。
\frac{1}{|C_2|} \sum_{y \in C_2} (-1)^{(x+y)e_2} \ket{x+y} \tag{19}位相反転誤りの訂正
次に、位相反転誤りの訂正について考えます。ヒントはアダマール変換です。
\begin{align} \ket{+} \rightarrow \ket{-} \\ \ket{-} \rightarrow \ket{+} \tag{20} \end{align}という位相反転は、アダマール変換した世界で考えると
\begin{align} \ket{0} \rightarrow \ket{1} \\ \ket{1} \rightarrow \ket{0} \tag{21} \end{align}というビット反転となります。ここから、何となくアダマール変換して、ビット反転誤りの訂正をやって、再びアダマール変換をやると、うまく行くような気がします。実際にもそれは正しくて、以下のように、きちんと数式で示すことができます。
まず、$n$量子ビット状態に対するアダマール変換$H^{\otimes n}$は、
H^{\otimes n} \ket{x} = \frac{1}{\sqrt{2^{n}}} \sum_{z} (-1)^{xz} \ket{z} \tag{22}となります5。これを使うと、式(19)に対するアダマール変換は、
\begin{align} & \frac{1}{|C_2|} \sum_{y \in C_2} (-1)^{(x+y)e_2} \ket{x+y} \\ & \rightarrow \frac{1}{|C_2|} \sum_{y \in C_2} (-1)^{(x+y)e_2} H^{\otimes n} \ket{x+y} \\ &= \frac{1}{\sqrt{|C_2| 2^{n}}} \sum_{z} \sum_{y \in C_2} (-1)^{(x+y)e_2} (-1)^{(x+y)z} \ket{z} \\ &= \frac{1}{\sqrt{|C_2| 2^{n}}} \sum_{z} \sum_{y \in C_2} (-1)^{(x+y)(e_2+z)} \ket{z} \tag{23} \end{align}$z^{\prime}=z+e_2$とおくと、上の式は、
\begin{align} & \frac{1}{\sqrt{|C2| 2^{n}}} \sum_{z^{\prime}} \sum_{y \in C_2} (-1)^{(x+y)z^{\prime}} \ket{z^{\prime} + e_2} \\ &= \frac{1}{\sqrt{|C2| 2^{n}}} \sum_{z^{\prime}} (-1)^{xz^{\prime}} \sum_{y \in C_2} (-1)^{yz^{\prime}} \ket{z^{\prime} + e_2} \tag{24} \end{align}と変形できます。ここで、$\sum_{y \in C_2} (-1)^{yz^{\prime}}$に注目して、前回の記事の式(46)のあたりで説明した双対符号の性質を使います。いまの状況に焼き直すと、その性質は、
\begin{align} & z^{\prime} \in C_{2}^{\perp} \Rightarrow \sum_{y \in C_2} (-1)^{yz^{\prime}} = |C_2| \\ & z^{\prime} \notin C_{2}^{\perp} \Rightarrow \sum_{y \in C_2} (-1)^{yz^{\prime}} = 0 \tag{25} \end{align}と表されます。これを式(24)に当てはめると、
\sqrt{\frac{|C_2|}{2^{n}}} \sum_{z^{\prime} \in C_{2}^{\perp}} (-1)^{xz^{\prime}} \ket{z^{\prime} + e_2} \tag{26}となります。つまり、アダマール変換を実行した結果、位相反転$e_2$の効果はケットの中の加算として現れることになります。こうなれば、後は先程と同様、ビット反転の誤り訂正の手続きで$e_2$の効果を消去することができます。結果、
\sqrt{\frac{|C_2|}{2^{n}}} \sum_{z^{\prime} \in C_{2}^{\perp}} (-1)^{xz^{\prime}} \ket{z^{\prime}} \tag{27}ということになります。再度アダマール変換を実行すると、完全に元に戻るはずです。やってみます。
\begin{align} & \sqrt{\frac{|C_2|}{2^{n}}} \sum_{z^{\prime} \in C_{2}^{\perp}} (-1)^{xz^{\prime}} \ket{z^{\prime}} \\ & \rightarrow \sqrt{\frac{|C_2|}{2^{n}}} \sum_{z^{\prime} \in C_{2}^{\perp}} (-1)^{xz^{\prime}} \frac{1}{\sqrt{2^{n}}} \sum_{w} (-1)^{z^{\prime} w} \ket{w} \\ &= \frac{\sqrt{|C_2|}}{2^{n}} \sum_{w} \sum_{z^{\prime} \in C_{2}^{\perp}} (-1)^{(x+w)z^{\prime}} \ket{w} \tag{28} \end{align}再び、$\sum_{z^{\prime} \in C_{2}^{\perp}} (-1)^{(x+w)z^{\prime}}$に対して、双対符号の性質を使います。$x+w \in C_2$のときのみ$|C_2|$となり、その他は$0$なので、以下のように変形できます。
\frac{\sqrt{|C_2|}}{2^{n}} \sum_{w,x+w \in C_2} |C_{2}^{\perp}| \ket{w} \tag{29}ここで、
\begin{align} & |C_2| = 2^{k_2}, |C_{2}^{\perp}| = 2^{n-k_2} \\ & |C_2| |C_{2}^{\perp}| = 2^{n} \tag{30} \end{align}が成り立つので、式(29)は、
\frac{1}{\sqrt{|C_2|}} \sum_{w,x+w \in C_2} \ket{w} \tag{31}となります。ここで、$x+w=x-w=y \in C_2$とおくと、結局、
\frac{1}{\sqrt{|C_2|}} \sum_{y \in C_2} \ket{x+y} \tag{32}とできるので、これで元の状態が完全に復元されることになります。
ビット反転や位相反転以外の連続的な誤りがあったときも、これだけで対応できることは、前々回の記事で説明していました。ということで、CSS符号がどう構築されて、どんな量子回路を通せば、誤り訂正ができるかの説明は一応完了です。
が、最後にもう一言。
CSS符号には、パラメータ$u,v$をもったバリエーションがあります。
\ket{x+C_2} \equiv \frac{1}{|C_2|} \sum_{y \in C_2} (-1)^{uy} \ket{x+y+v} \tag{33}で定義され、$CSS_{u,v}(C_1,C_2)$符号と呼ばれています。余計なパラメータが入っているのですが、先程の$CSS(C_1,C_2)$符号と同じ量子回路で誤り訂正ができます。量子鍵配送で有用になるとのことなので、ここで定義だけ掲載し、証明は省略します6。
Steane符号
CSS符号の一般論がわかったので、具体例を上げて、さらに理解を確実にしたいと思います。「Steane符号」というものがあります。これは、$C_1=C, C_2=C^{\perp}$として、$C$をHamming符号にしたCSS符号です。$C_1$のパリティ検査行列を$H_1$、生成行列を$G_1$とします。いま簡単のため、$[7,3]$Hamming符号とすると、$H_1,G_1$は各々、
H_1 = \begin{pmatrix} 0 & 1 & 1 & 1 & 1 & 0 & 0 \\ 1 & 0 & 1 & 1 & 0 & 1 & 0 \\ 1 & 1 & 0 & 1 & 0 & 0 & 1 \end{pmatrix} \tag{34}G_1 = \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 1 & 1 & 1 \\ 1 & 0 & 1 & 1 \\ 1 & 1 & 0 & 1 \end{pmatrix} \tag{35}と表せます(標準形で書きました)。一方、$C_2$は、その双対符号ですので、定義から、
H_2 = G_{1}^{T} = \begin{pmatrix} 1 & 0 & 0 & 0 & 0 & 1 & 1 \\ 0 & 1 & 0 & 0 & 1 & 0 & 1 \\ 0 & 0 & 1 & 0 & 1 & 1 & 0 \\ 0 & 0 & 0 & 1 & 1 & 1 & 1 \end{pmatrix} \tag{36}G_2 = H_{1}^{T} = \begin{pmatrix} 0 & 1 & 1 \\ 1 & 0 & 1 \\ 1 & 1 & 0 \\ 1 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix} \tag{37}と書き表せます。
ところで、このように定義した線形符号をベースにした量子符号が確かにCSS符号であるということを言うためには、$C_1$と$C_{2}^{\perp}$が同じ$t$個の誤りに対応できる、つまり符号の距離(最小距離)が等しいということと、$C_2 \subset C_1$であることが必要です。
前者は、定義より$C_1$も$C_{2}^{\perp}$もともに$C$なので自明です。後者は、前回の記事の式(45)あたりで説明したことを使えばわかります。再掲します。
G^{T} G = 0 \Leftrightarrow C \subseteq C^{\perp} \tag{38}つまり、$G_{2}^{T} G_2 = 0$が示せれば、$C_2 \subseteq C_{2}^{\perp}$、すなわち、$C_2 \subseteq C_1$が証明できたことになります。やってみます。
G_{2}^{T} G_2 = \begin{pmatrix} 0 & 1 & 1 & 1 & 1 & 0 & 0 \\ 1 & 0 & 1 & 1 & 0 & 1 & 0 \\ 1 & 1 & 0 & 1 & 0 & 0 & 1 \end{pmatrix} \begin{pmatrix} 0 & 1 & 1 \\ 1 & 0 & 1 \\ 1 & 1 & 0 \\ 1 & 1 & 1 \\ 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix} = \begin{pmatrix} 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{pmatrix} \tag{39}ということで、$C_2 \subseteq C_{2}^{\perp}$であることが確認できました7。
それでは、ベースとなる古典線形符号がわかったので、これからCSS符号を構築してみます。式(1)を改めて見てみます。
\ket{x+C_2} \equiv \frac{1}{\sqrt{|C_{2}|}} \sum_{y \in C_2} \ket{x+y} \tag{1}これに従って符号を構築すれば良いです。
いま$C_1$は[7,4]符号、$C_2$は[7,3]符号です。したがって、できあがるCSS符号は[7,1]符号です。1量子ビットを7量子ビットに冗長化する量子符号ということなので、2つの$x$を持ってきて、式(1)の右辺のようにすべての$y$を総動員して重ね合わせれば良いです。$y$の方は[7,3]符号なので、すべての3次元のバイナリ・ベクトルを持ってきて、式(35)の生成行列$G_2$を演算してやれば良いです。さて、問題はどんな$x$を持ってくれば良いかです。同じ剰余類に属する2つのの$x$を持ってきたとすると、右辺は全く同じになるので、意味がありません。違う剰余類に属する2つの$x$を持ってくる必要があります。2つの$x$の差分が$C_2$に属していないようにすれば良いので、エイヤで$x=(0,0,0,0,0,0,0)^{T}$と$x^{\prime} = (1,1,1,1,1,1,1)^{T}$という2つを持ってきます。こうすれば差分が$C_2$の要素になっていなさそうです。$x$を種にして生成される状態を$\ket{0_L}$、$x^{\prime}$を種にして生成される状態を$\ket{1_L}$とすると、
\begin{align} \ket{0_L} &= \frac{1}{\sqrt{8}} (\ket{0000000} + \ket{1101001} + \ket{1011010} + \ket{0110011} + \ket{0111100} + \ket{1010101} + \ket{1100110} + \ket{0001111}) \\ \ket{1_L} &= \frac{1}{\sqrt{8}} (\ket{1111111} + \ket{0010110} + \ket{0100101} + \ket{1001100} + \ket{1000011} + \ket{0101010} + \ket{0011001} + \ket{1110000}) \tag{40} \end{align}となり、これで量子符号ができました。実際に、$\ket{\psi} = \alpha \ket{0} + \beta \ket{1}$という1量子ビット状態を符号化する際には、
\ket{\psi} \rightarrow \ket{\psi_{L}} = \alpha \ket{0_L} + \beta \ket{1_L} \tag{41}を実現するように適当な量子回路を構築します。
次に、この状態に対して誤りが加わる想定で、先程説明したような誤りシンドロームを計算する回路を実行します。つまり、アンシラを追加して、各状態に対して、
\ket{x} \ket{0} \rightarrow \ket{x} \ket{H_1 x} \tag{42}を実現する量子回路を実行すれば、アンシラに$H_1 e_1$というビット反転誤りの効果が移るのでした。いまの場合、3量子ビット分のアンシラを用意します。先程説明したように、パリティ検査行列の各行に含まれる$1$の場所に注意しながら、CNOTゲートを並べます。
|x1> -----------*--------*-------- ... |x2> --*--------|--------|-*------ ... |x3> --|-*------|-*------|-|------ ... |x4> --|-|-*----|-|-*----|-|-*---- ... |x5> --|-|-|-*--|-|-|----|-|-|---- ... |x6> --|-|-|-|--|-|-|-*--|-|-|---- ... |x7> --|-|-|-|--|-|-|-|--|-|-|-*-- ... | | | | | | | | | | | | |0> --X-X-X-X--|-|-|-|--|-|-|-|-- ... |0> -----------X-X-X-X--|-|-|-|-- ... |0> --------------------X-X-X-X-- ...次に、アンシラの状態に応じて、ビット反転をします。アンシラの状態がパリティ検査行列$H_1$の列ベクトルの値と一致しているところに対応したビットを反転します。つまり、アンシラが$\ket{011}$なら第1量子ビット、$\ket{101}$なら第2量子ビット、$\ket{110}$なら第3量子ビット…という具合にビット反転すれば、ビット反転誤りは訂正できます。先程の回路に続けて、以下のようにします。
|x1> ... ----X--------------------------------------------- ... |x2> ... ----|------X-------------------------------------- ... |x3> ... ----|------|------X------------------------------- ... |x4> ... ----|------|------|------X------------------------ ... |x5> ... ----|------|------|------|------X----------------- ... |x6> ... ----|------|------|------|------|------X---------- ... |x7> ... ----|------|------|------|------|------|------X--- ... | | | | | | | |0> ... --X-*-X----*------*------*------*----X-*-X--X-*-X- |0> ... ----*----X-*-X----*------*----X-*-X----*----X-*-X- |0> ... ----*------*----X-*-X----*----X-*-X--X-*-X----*---これで、ビット反転誤りが訂正できたので、次に位相反転誤りに対応します。まず、アダマール変換を使います。同時に、ビット反転誤り訂正用のアンシラは役目が終わったので初期化します。上の回路に続けて、以下を実行します。
|x1> ... --H-------------*--------*-------- ... |x2> ... --H----*--------|--------|-*------ ... |x3> ... --H----|-*------|-*------|-|------ ... |x4> ... --H----|-|-*----|-|-*----|-|-*---- ... |x5> ... --H----|-|-|-*--|-|-|----|-|-|---- ... |x6> ... --H----|-|-|-|--|-|-|-*--|-|-|---- ... |x7> ... --H----|-|-|-|--|-|-|-|--|-|-|-*-- ... | | | | | | | | | | | | |0> ... -------X-X-X-X--|-|-|-|--|-|-|-|-- ... |0> ... ----------------X-X-X-X--|-|-|-|-- ... |0> ... -------------------------X-X-X-X-- ...誤りシンドロームの計算ができたので、位相反転誤りを訂正して(実際にはビット反転誤りを訂正して)、最後にアダマール変換を実行して、元に戻します。
|x1> ... ----X---------------------------------------------H-- |x2> ... ----|------X--------------------------------------H-- |x3> ... ----|------|------X-------------------------------H-- |x4> ... ----|------|------|------X------------------------H-- |x5> ... ----|------|------|------|------X-----------------H-- |x6> ... ----|------|------|------|------|------X----------H-- |x7> ... ----|------|------|------|------|------|------X---H-- | | | | | | | |0> ... --X-*-X----*------*------*------*----X-*-X--X-*-X---- |0> ... ----*----X-*-X----*------*----X-*-X----*----X-*-X---- |0> ... ----*------*----X-*-X----*----X-*-X--X-*-X----*------これで、誤り訂正は完了です8。
シミュレーション
実装
それでは、上で説明したSteane符号を実装してみます。qlazyでは、量子回路の計算は、量子状態または密度演算子に相当するクラスのインスタンスを作って、ゲート演算することで実行します。量子状態でも密度演算子でもどちらでも良いのですが、雑音付加に量子チャネル(分極解消とか、振幅ダンピングとか)を利用できる密度演算子の方でやってみます9。
全体のコードは以下です。
import numpy as np from qlazypy import QState, DensOp Hamming = np.array([[0,1,1,1,1,0,0], [1,0,1,1,0,1,0], [1,1,0,1,0,0,1]]) Hamming_T = Hamming.T Steane_0 = ['0000000', '1101001', '1011010', '0110011', '0111100', '1010101', '1100110', '0001111'] Steane_1 = ['1111111', '0010110', '0100101', '1001100', '1000011', '0101010', '0011001', '1110000'] def generate_qstate(qid_C, qid_S): a = np.random.rand() + np.random.rand() * 1.j b = np.random.rand() + np.random.rand() * 1.j print("== quantum state (a |0L> + b |1L>) ==") print("- a = {:.4f}".format(a)) print("- b = {:.4f}".format(b)) qvec = np.full(2**len(qid_C), 0.+0.j) for s in Steane_0: qvec[int(s, 2)] = a for s in Steane_1: qvec[int(s, 2)] = b norm = np.linalg.norm(qvec) qvec = qvec / norm qs_C = QState(vector=qvec) qs_S = QState(len(qid_S)) qs = qs_C.tenspro(qs_S) de_ini = DensOp(qstate=[qs]) de_fin = de_ini.clone() QState.free_all(qs_C, qs_S, qs) return de_ini, de_fin def noise(self, kind='', prob=0.0, qid=[]): print("== noise ({:}) ==".format(kind)) print("- qubit = {:}".format(qid)) print("- prob = {:}".format(prob)) qchannel = {'bit_flip':self.bit_flip, 'phase_flip':self.phase_flip, 'bit_phase_flip':self.bit_phase_flip, 'depolarize':self.depolarize, 'amp_dump':self.amp_dump, 'phase_dump':self.phase_dump} [qchannel[kind](i, prob=prob) for i in qid] return self def correct(self, kind, qid_C, qid_S): self.reset(qid=qid_S) if kind == 'phase_flip': [self.h(q) for q in qid_C] # syndrome for i, row in enumerate(Hamming): [self.cx(qid_C[j], qid_S[i]) if row[j] == 1 else False for j in range(len(row))] # correction for i, row in enumerate(Hamming_T): [self.x(qid_S[j]) if row[j] == 0 else False for j in range(len(row))] self.mcx(qid=qid_S+[qid_C[i]]) [self.x(qid_S[j]) if row[j] == 0 else False for j in range(len(row))] if kind == 'phase_flip': [self.h(q) for q in qid_C] return self if __name__ == '__main__': # add custom gates DensOp.add_method(noise) DensOp.add_method(correct) # set registers qid_C = DensOp.create_register(7) # registers for code space qid_S = DensOp.create_register(3) # registers for error syndrome DensOp.init_register(qid_C, qid_S) # generate initial quantum state (density operator) de_ini, de_fin = generate_qstate(qid_C, qid_S) # add noise de_fin.noise(kind='depolarize', qid=[qid_C[3]], prob=1.0) # error correction de_fin.correct('bit_flip', qid_C, qid_S) de_fin.correct('phase_flip', qid_C, qid_S) # print result print("== result ==") print("- fidelity = {:.6f}".format(de_fin.fidelity(de_ini, qid=qid_C))) DensOp.free_all(de_ini, de_fin)何をやっているか、簡単に説明します。基本的には、上で説明したSteane符号による誤り訂正を実行しているだけです。では、メイン処理部を見てください。
# add custom gates DensOp.add_method(noise) DensOp.add_method(correct)で、雑音付加と誤り訂正を各々一つのかたまりとしてカスタムゲートを定義して、メソッドとして設定しています。処理内容は上の方で関数定義されています。
# set registers qid_C = DensOp.create_register(7) # registers for code space qid_S = DensOp.create_register(3) # registers for error syndrome DensOp.init_register(qid_C, qid_S)で、使用する量子レジスタを定義しています。この程度であれば、こんなクラスメソッドを使わなくても手で書いてしまった方が早いかもしれません。これで、qid_Cは[0,1,2,3,4,5,6]というリストになり、qid_Sは[7,8,9]というリストになります。
# generate initial quantum state (density operator) de_ini, de_fin = generate_qstate(qid_C, qid_S)Steane符号を使った量子状態(密度演算子)をランダムに用意します。関数定義を見ていただければわかると思いますが、$a,b$という複素数をランダムに設定して、7量子ビットの量子状態$a \ket{0_L} + b \ket{1_L}$を作成し、3量子ビットのアンシラとのテンソル積を実行することによって10量子ビットの状態を作成します。それに基づき密度演算子を作成してリターンします。複製して2つ全く同じものを作っていますが、これはプログラムの最後で、初期状態と演算結果の状態を比較評価するためです。
# add noise de_fin.noise(kind='depolarize', qid=[qid_C[3]], prob=1.0)で、雑音を加えます。qlazyに標準搭載されている雑音(量子チャネル)は、「ビット反転(bit_flip)」「位相反転(phase_flip)」「ビット位相反転(bit_phasee_flip)」「分極解消(depolarize)」「振幅ダンピング(amp_dump)」「位相ダンピング(phase_dump)」の6種類であり、各々、適用する量子ビット番号リストと雑音の強度を表す確率を引数に与えるようになっています。関数(カスタムゲート)noiseは、引数にその量子チャネルの種別を表す文字列と量子ビット番号リストと確率を指定して、密度演算子に適用するものです。詳細は関数定義をご覧ください。
# error correction de_fin.correct('bit_flip', qid_C, qid_S) de_fin.correct('phase_flip', qid_C, qid_S)で、ビット反転誤り訂正と位相反転誤り訂正を実行しています。関数(カスタムゲート)correctは、引数にビット反転対応なのか位相反転対応なのかを表す文字列と、符号空間とアンシラに対応した量子ビット番号リストを指定します。correectの中身を見てみます。
self.reset(qid=qid_S)で、アンシラを初期化します。誤りシンドローム計算のために、まず初期化が必要です。
if kind == 'phase_flip': [self.h(q) for q in qid_C]位相反転に対応したい場合、アダマールをまず実行しないといけないので、ここでやっています。
# syndrome for i, row in enumerate(Hamming): [self.cx(qid_C[j], qid_S[i]) if row[j] == 1 else False for j in range(len(row))]で、誤りシンドロームの計算を実行します。上で説明した回路を実行するため、Hamming符号のパリティ検査行列の各行ごとにCNOTを適切にかけるようなループを回しています。
# correction for i, row in enumerate(Hamming_T): [self.x(qid_S[j]) if row[j] == 0 else False for j in range(len(row))] self.mcx(qid=qid_S+[qid_C[i]]) [self.x(qid_S[j]) if row[j] == 0 else False for j in range(len(row))]で、誤りシンドロームの結果に応じて、ビット反転して元に戻します。Hamming符号のパリティ検査行列の各列に応じて、マルチ制御NOT(mcxメソッド)を適切にかけるようなループを回しています。
if kind == 'phase_flip': [self.h(q) for q in qid_C]で、位相反転対応の場合、最後にアダマールをかけて、元に戻すようにします。以上で誤り訂正が完了します。
再度、メイン処理部に戻ります。
# print result print("== result ==") print("- fidelity = {:.6f}".format(de_fin.fidelity(de_ini, qid=qid_C)))で、最初の密度演算子と誤り訂正処理を実行した後の密度演算子とを比較評価するため、fidelityメソッドで両者の忠実度を計算して表示します。引数qidに関心のある量子ビット番号リストを指定することで、該当部分のみの忠実度を計算することができます。
DensOp.free_all(de_ini, de_fin)で、使用したメモリを開放します。クラスメソッドfree_allに引数として複数のDensOpインスタンスを指定すれば、1行で複数インスタンスのメモリを開放できます(引数に何個インスタンスを指定しても大丈夫です)。
動作の確認
実行結果を示します。3番目の量子ビットに対して分極解消チャネルを確率1.0で適用した結果です。
== quantum state (a |0L> + b |1L>) == - a = 0.4835+0.0654j - b = 0.2558+0.9664j == noise (depolarize) == - qubit = [3] - prob = 1.0 == result == - fidelity = 1.000000忠実度が1.0になっているので、誤り訂正は無事成功しました。量子ビット番号や量子チャンネルや確率をいろいろ変えてみましたが、どんな場合でも忠実度は1.0となり、誤り訂正できることがわかりました。
ところが、当然ですが、2つの量子ビットに雑音が入るとダメでした。以下の通りです。
== quantum state (a |0L> + b |1L>) == - a = 0.4749+0.4393j - b = 0.5424+0.6672j == noise (depolarize) == - qubit = [3, 4] - prob = 1.0 == result == - fidelity = 0.864784それから、これも当然ですが、位相反転の誤り訂正を省略した場合もダメでした。
# error correction de_fin.correct('bit_flip', qid_C, qid_S) # de_fin.correct('phase_flip', qid_C, qid_S)という具合に位相反転対応部分をコメントアウトすると、
== quantum state (a |0L> + b |1L>) == - a = 0.2903+0.1936j - b = 0.8322+0.4586j == noise (depolarize) == - qubit = [3] - prob = 1.0 == result == - fidelity = 0.707107となり、これも誤り訂正は失敗します。
というわけで、予想通りの動作が確認できました。
おわりに
ある条件を満たした古典線形符号を2つ持ってくれば、そこから量子符号を1つ必ず構築できるということがわかりました。つまり、いろんな量子符号を具体的に構築できる強力なツールの一つを手に入れたということになります。しかも、「Steane符号」は7量子ビットで実行できます。「Shorの符号」は9量子ビット必要だったので、2量子ビット削減することができました(3量子ビットのアンシラも必要でしたが)!
「はじめに」で述べたように「CSS符号」は、さらに、より一般的な「スタビライザー符号」の部分クラスに相当するとのことです。次回は、この「スタビライザー符号」について勉強してみたいと思います(予定です)。
以上
$[n,k]$符号$C$を考え、その生成行列を$G$とします。任意の$x_1,x_2 \in \{ 0,1 \}^{k}$に対して、$y_1 = Gx_1, y_2 = Gx_2$とすると、$y_1, y_2 \in C$です。2つの式を足すと、$y_1 + y_2 = G(x_1 + x_2)$となり、$x_1 + x_2 \in \{ 0,1 \}^{k}$なので、$y_1+y_2 \in C$が成立ちます。 ↩
2を法とするビットごとの加算は減算に等しいことにご注意。$y^{\prime}-y=y{\prime}+y$となり同じ符号に属するもの同士を足しても同じ符号に属するという線形符号の性質から$y^{\prime}-y \in C_2$が言えます。 ↩
$z_1,z_2, \cdots$の値を得るために測定して、それに応じて符号量子ビットを反転するような回路を組むことは可能です。その場合、条件つきXゲート(測定結果を古典レジスタに格納しておいて、その値が0か1かに応じてオンオフするXゲート)を使う感じになると思います。が、誤り量子ビットが1個以上ある場合は、複数$z_1,z_2, \cdots$を得るために、複数回の測定をしないといけないと思います。というわけで、あまり嬉しくないです。測定をする代わりに$\ket{z_i}$のみに反応するようにXゲートとCNOTゲートを組み合わせて、同じことを実現する回路も可能であって、その場合、量子回路を1回通すだけで、複数量子ビットの誤り訂正ができると思います。記事の後半で示すシミュレーションはこの方向で実装しました。 ↩
公式として覚えておくと良いと思います。 ↩
これについて、私は驚くべき証明を見つけたのですが、この余白はそれを書くには狭すぎます、というのは嘘です(笑、一度言ってみたかった。出典ご存知ない方はこちらをどうぞ)。ニールセン、チャンの「演習問題10.27」です。上でやったのとほぼ同じ式変形を愚直にやる感じだったので、省略しました。 ↩
[7,3]Hamming符号の場合は確認できましたが、一般のHamming符号についても成り立っているかどうかは、まだ言えてないです(多分成り立っているのだと思いますが)。一瞬、$HG=0$が使えるかと思ったのですが、勘違いでした。 ↩
もっと効率の良い回路構成はあるのかもしれませんが、とりあえず初心者コースなので、ご容赦ください。少なくとも連続しているXゲートは消去できます。それから、本当は、7量子ビットのSteane符号を1量子ビット状態から作成したかったのですが、良さげな回路を思いつかなかったので、今回の記事では、それも省略しました。もっと勉強を進めればスッキリしたカッコいい回路が書けるのだと思いますが。 ↩
10量子ビットの密度演算子の計算で、かつ、マルチ制御NOT(制御ビットが複数あるCNOT)をふんだんに使っているので、量子状態で実行するのと比べ、処理時間はかかります。 ↩
- 投稿日:2020-03-19T21:00:13+09:00
Seabornが簡単便利で感動した話
Seaborn
matplotlibで描くにはちょっと面倒なグラフでも、seabornを使えば割と簡単にかけてしまうことに感動した。
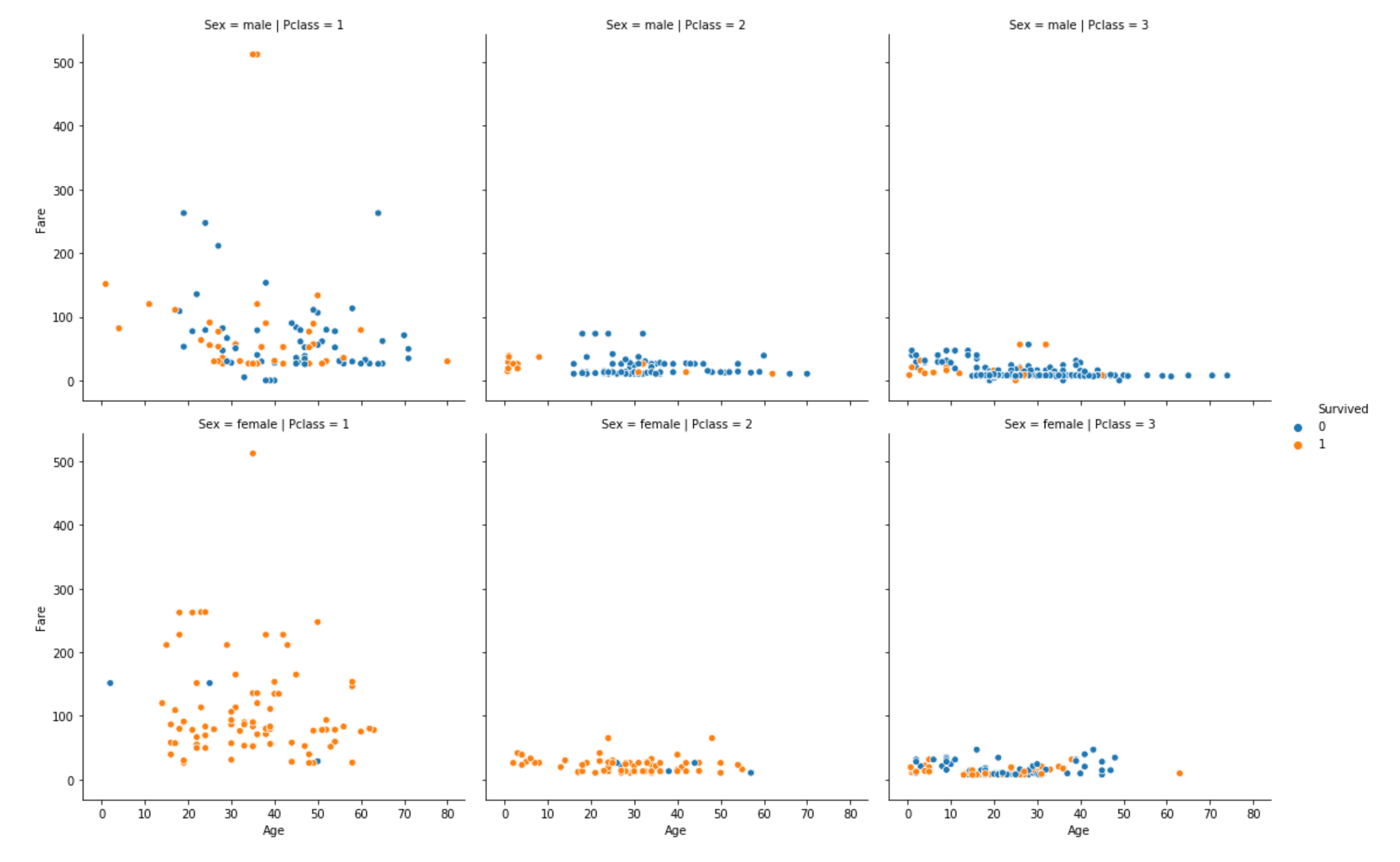
matplotlibでこれを描こうとすると、だいたいこんな感じになるとおもう。超適当だから間違ってるかもしれんが、
import itertools fig, axes = plt.subplots(2, 3) col_f = 'Pclass' col_f_domain = [1, 2, 3] row_f = 'Sex' row_f_domain = ['male', 'female'] for i, (r, c) in enumerate(itertools.product(row_f_domain, row_f_domain)): row_i = i // 3 col_i = i % 3 ax = axes[row_i][col_i] # (以下略)そうそう、forループ回すよな。
これ、seabornだと1行なんだぜ・・・sns.relplot(x='Age', y='Fare', hue='Survived', col='Pclass', row='Sex', data=train_data)最後に
EDA(Exploratory Data Analysis, 探索的データ探索)をするときは、比較対象とする特徴量や水準を変えながらたくさんグラフを書くことになるから、このように複雑なプロットもサクッとかけてしまうツールは重宝する。
逆に、matplotlibは、こう言ったハイレベルなツールでは手の届かない痒いところまでできるのが良いところ。Seabornじゃ描けなそうなプロットはmatplotlibで描こう、って感じかなと。
- 投稿日:2020-03-19T20:00:06+09:00
matplotlibでmarker="."より小さい点をプロットする
要約
タイトル通り。やろうとしたらなかなか方法が見つからなかったので。
結論だけ読みたい人は結論Axesを用いた方法 へ
調べてたらちゃんとした方法が見つかったので更新しました 2020/03/19/21:29前フリ
Pythonのグラフ描画ライブラリmatplotlibで散布図を描くとき、すごく細かい点をブワーッと並べたいときがありますよね。
plt.scatterのマーカーはmarkerパラメーターで指定でき、細かい点を打つときはmarker='.'とします。 ( ※matplotlib.pyplot.scatter )
しかしこの'.'のマーカー(ドキュメントのdescriptionでは「point」と呼ばれています)、これでもまだちょっと大きい気がします。rand = lambda n:[np.random.rand() for _ in range(n)] xy = (rand(100), rand(100)) plt.scatter(*xy, marker=".")
マーカーの枠線を消してみましょう。
plt.scatter(*xy, marker=".", linewidth=0)
若干小さくなった気がしますがこれでもまだ大きい気がします。もっとゴミみたいな点が打ちたい。
matplotlib.markers の説明を読んでみると「",":
:pixel」というのがあります。そうそう、ピクセル単位レベルの点が打ちたかったのです。
plt.scatter(*xy, marker=",")
どうしてこうなった……
どうやらサイズが規格化されているらしく、形を指定するとこのサイズいっぱいになるように拡大縮小されるようです。
結論めんどくさい例マーカーサイズの規格化を無効にするパラメーターが見つからなかったので姑息的に「規格化されても小さく見えるマーカー」を作ってみます。
(直接マーカーサイズを指定できる方法をご存知のかたは教えて下さいm(_ _)m)(Axesを使った例へ)
markerパラメーターに「2次元座標のタプルの配列」を与えることで任意の多角形を描かせることができます。
これを利用して幅ゼロの対角線を引いてサイズを確保してから中心に小さく四角を作ります。
(こんなん)
t = 0.1 plt.scatter(*xy, marker=[(0,0), (-1,-1), (1,1), (0,0), (t,t), (-t,t), (-t,-t), (t,-t), (t,t), (0,0)], linewidths=0)
ゴミみたいな点を打つことに成功しました!
マーカーオブジェクトを作って0~1倍の任意のサイズの点を打てるようにしてみました。
from matplotlib.markers import MarkerStyle dot = lambda t: MarkerStyle([(0,0), (-1,-1), (1,1), (0,0), (t,t), (-t,t), (-t,-t), (t,-t), (t,t), (0,0)]) plt.scatter(*xy, marker=dot(0.2), linewidths=0)
正直もっとまともな方法あるやろ……と思われるので、まっとうな方法で小さい点を打つ方法をご存じの方はぜひご一報ください。よろしくお願いします。Axesを用いた方法
Axes.plotではLine2Dのパラメーターを指定でき、ここにmarkersizeが存在することに気づきました。fig, ax = plt.subplots() ax.plot(*xy, linestyle='none', marker=',', markersize=1)
これが一番まともな方法だと思います。
ちょっとややこしいことをしようとするならやはりオブジェクト指向インターフェースを使うべきですね。
こちらの記事が参考になります。早く知っておきたかったmatplotlibの基礎知識、あるいは見た目の調整が捗るArtistの話 @skotaro さん※小さい点でやりたかったこと
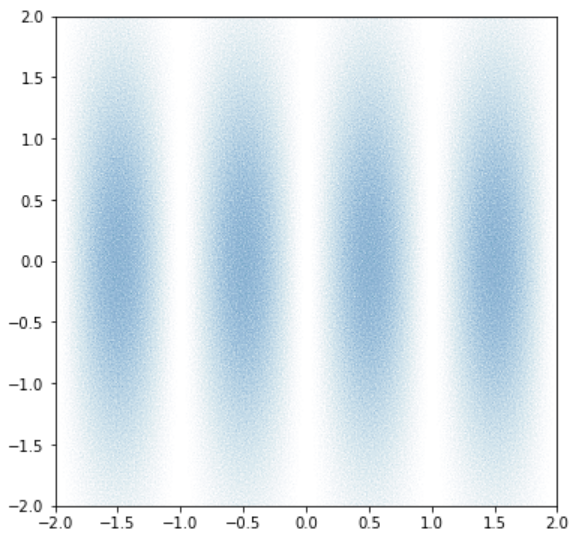
こうやって濃淡を点の密度で表現してみたかったのです。
func = lambda x,y:np.sin(x*np.pi)**2 * np.exp(-y**2/2) n = 100 dx = 0.02 xlin = np.arange(-2,2,dx) ylin = np.arange(-2,2,dx) xx, yy = np.meshgrid(xlin, ylin) pltx, plty = [], [] for x, y in zip(xx.flatten(), yy.flatten()): dense = func(x+dx/2, y+dx/2) pltx += [x+np.random.rand()*dx for _ in range(int(dense*n))] plty += [y+np.random.rand()*dx for _ in range(int(dense*n))] fig, ax = plt.subplots(figsize=(6,6)) ax.plot(pltx, plty, linestyle='none', marker='.', markersize=0.1, alpha=0.1) plt.xlim(-2,2) plt.ylim(-2,2) plt.show()
(無駄にめっちゃ重いのでカラーマップにしたほうが良いと思います。)

- 投稿日:2020-03-19T19:54:59+09:00
謎の生物
概要
ツイッターに投稿している謎の生物についてまとめました。
https://twitter.com/graph_gorilla仕組み
1.乱数を出力
謎の生物は正規乱数で作っています。全体に分布させるときは一様乱数を使っています。
謎の生物の座標を指定して生成する場合はrand_norm関数、
全体をうにょうにょさせる場合はrand_uni関数、
ランダムに動かすにはmove_random関数を使用します。2. 配列に格納
x座標用の配列dfxとy座標用の配列dfxを用意します。
出力する乱数は全てこの配列に格納します。3.seabornのkdeplotでプロット
2で格納した配列を少しずつスライドさせながらプロットしていきます。
変数sが配列の最初の位置です。s~s+1000の区間がプロットに使用するデータになります。
プロットするたびに100ずつ足すことで、配列を読み込む位置が100ずつずれていきます。4.gif画像として保存
下のリンクのやり方を参考にしました。imagemagickというパッケージが必要らしいです。test.pyimport random import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib.animation as animation import seaborn as sns #ロジスティック関数 def logi(x,a): return 1 / (1 + np.exp(-x+a)) #反転ロジスティック関数 def revlogi(x,a): return 1-(1 / (1 + np.exp(-x+a))) #壁 def wall(x,r): lx9=logi(x,90) lr9=logi(r,0) lx1=revlogi(x,10) lr1=revlogi(r,0) result=lx9*lr9+lx1*lr1 return 1-result frame_count=0 #フレームカウント用変数 colname="Blues" #ヒートマップの色 #初期設定 fig=plt.figure(figsize=(7,7)) sns.set_style({"axes.facecolor": plt.get_cmap(colname)(15)}) #乱数格納用配列 dfx = [] dfy = [] x=20 #xの位置 y=20 #yの位置 #正規乱数生成(謎の生物) def rand_norm(xx,yy,sdx,sdy,n): # (x座標, y座標 , x方向の標準偏差, y方向の標準偏差, 繰り返し数) global frame_count,x,y for i in range(n): dfx.append(random.normalvariate(x,sdx)) dfy.append(random.normalvariate(y,sdy)) x=xx y=yy frame_count+=1 #一様乱数生成(全体のうにょうにょ) def rand_uni(n): # n: 繰り返し数 global frame_count for i in range(n): dfx.append(random.uniform(0,100)) dfy.append(random.uniform(0,100)) frame_count+=1 #ランダムな動き def move_random(n,t): # (繰り返し数, 速さ) global x,y for i in range(n): rand_norm(x, y, 5, 5, t) randx = random.uniform(-10, 10) randy = random.uniform(-10, 10) randxx = wall(x, randx) * randx randyy = wall(y, randy) * randy x += randxx y += randyy #乱数生成 #--------------------------------------------------------- #rand_norm(x座標, y座標 , x方向の標準偏差, y方向の標準偏差, 繰り返し数) #rand_uni(繰り返し数) #繰り返し数1000で1秒だと思います。 #move_random(繰り返し数, 速さ) #こっちは何となくで書いているのでよくわかりません。 rand_norm(20,20,5,5,3000) rand_norm(30,30,5,5,1000) rand_norm(40,40,5,5,1000) rand_norm(40,40,10,5,1000) rand_norm(40,40,5,10,1000) move_random(50,100) rand_uni(3000) rand_norm(20,20,5,5,1000) #--------------------------------------------------------- df = pd.DataFrame({'X':dfx,'Y':dfy}) #データフレーム作成 s=0 #プロットするデータの開始位置 #プロット def plot(data): global s plt.cla() plt.xlim([0, 100]) plt.ylim([0, 100]) plt.title(str(int(s/100))+" / "+str(int(frame_count/1000-1)*10)) sns.kdeplot(df[s:s+1000].X,df[s:s+1000].Y,shade=True,cmap=colname) s+=100 print("\b"*20,s," / ",int(frame_count/1000-1)*1000+100,end="") #アニメーション ani_frame_num=int(frame_count/1000-1)*10 ani = animation.FuncAnimation(fig, plot, interval=1, frames=ani_frame_num) print("Please wait") ani.save("plot.gif", writer="imagemagick") print("\nFinished")
参考文献
matplotlib でアニメーションを作る
https://qiita.com/yubais/items/c95ba9ff1b23dd33fde2
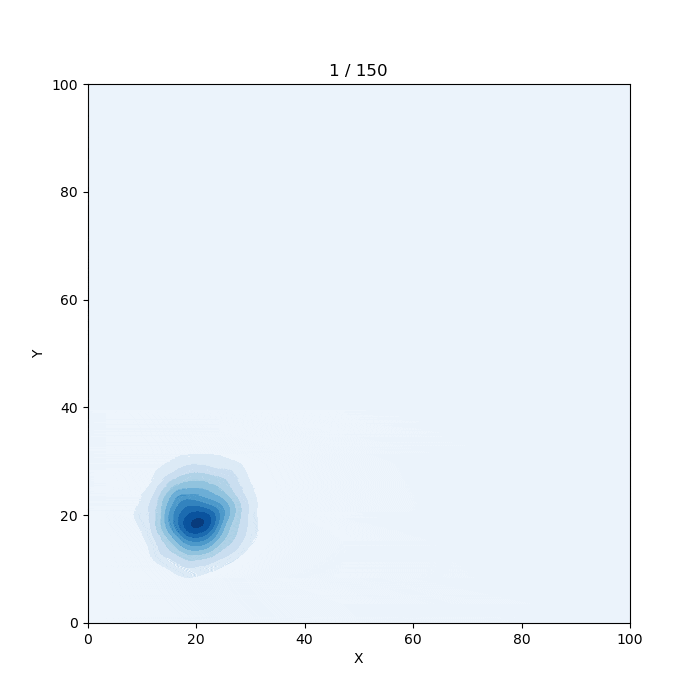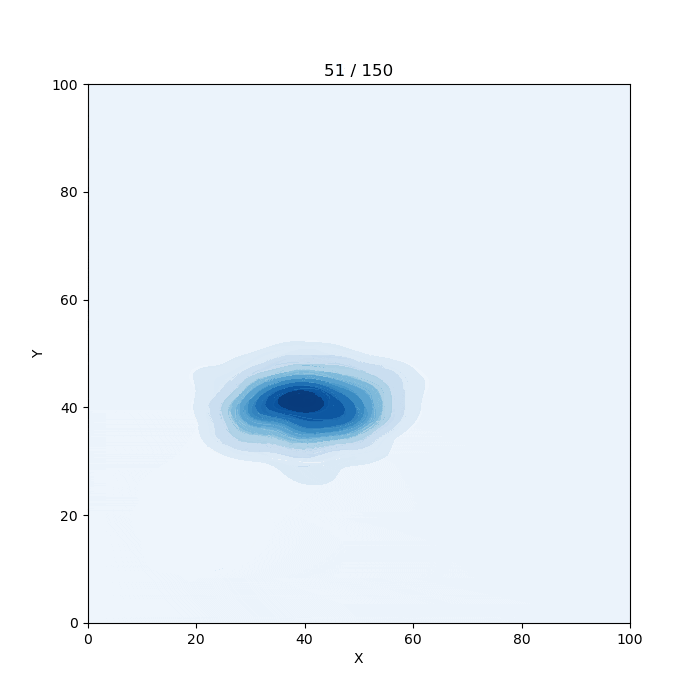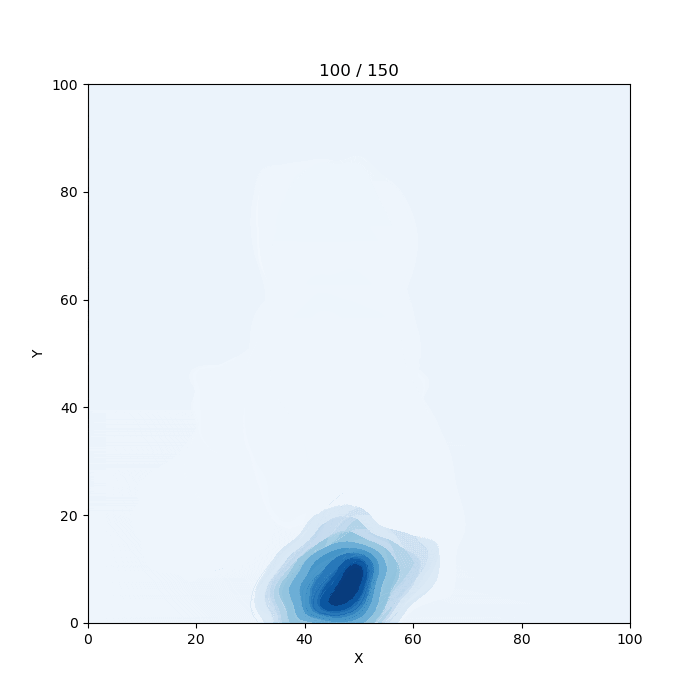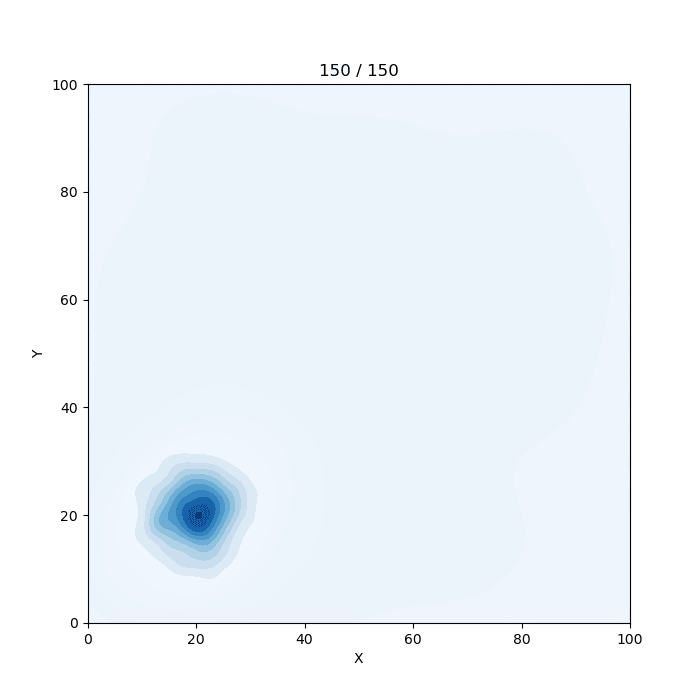
- 投稿日:2020-03-19T19:54:21+09:00
kivyを使ってGUIプログラミング ~その4 ボタンいろいろ~
はじめに
kivyでは様々なボタンがあります。普通に使えるものから、ちょっとよくわからないものまで。
そこで今回は、特に使えそうなものをピックアップして紹介したいと思います。細かいところまでは、言及しません。今までのように、kivyのuiを用いて何か作って紹介するといった感じではないです。この記事では、簡単な使い方の例だけを示します。ソースは公式のリファレンスの受け売りです。詳しい使い方はリファレンスを参照していただきたいです!※今回のボタンの定義は、押したらなんかなる奴です。細かいことは抜きにします!
https://www.weblio.jp/content/button普通のボタンたち
kivy.uix.Button
紹介するまでもないと思いますが、普通のボタンです。
button_sample.pyfrom kivy.app import App from kivy.lang import Builder from kivy.uix.boxlayout import BoxLayout from kivy.uix.button import Button from kivy.uix.label import Label from kivy.uix.togglebutton import ToggleButton from kivy.uix.behaviors import ToggleButtonBehavior class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) # ラベルの定義 self.label = Label(text="OFF") self.add_widget(self.label) # ボタンの定義、押した時と話した時の処理 self.button = Button(on_press=self.press, on_release=self.release, text="Press!") self.add_widget(self.button) #押した時 def press(self, btn): self.label.text = "This is Button!" #話した時 def release(self, btn): self.label.text = "OFF" class Sample(App): def build(self): return Test() Sample().run()kivy.uix.togglebutton
押したらON状態、OFF状態が確認できるボタンです。
押されているかどうかは、トグルボタンのstateという変数のdownとnormalで判別できます。また、groupを設定することで、ラジオボタン的な使い方もできるようです。画像にトグルボックス的な挙動を付与できたりもするらしいです。(未検証)
https://kivy.org/doc/stable/api-kivy.uix.behaviors.togglebutton.html#kivy.uix.behaviors.togglebutton.ToggleButtonBehavior
from kivy.app import App from kivy.uix.boxlayout import BoxLayout from kivy.uix.label import Label from kivy.uix.togglebutton import ToggleButton class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) # ラベルの定義、 self.label = Label(text="OFF") self.add_widget(self.label) # トグルボタンの定義 self.toggle = ToggleButton(on_press=self.t_press, text="Press!") self.add_widget(self.toggle) # チェックボックスとして扱うトグルボタンを別で用意したボックスレイアウトに貼り付ける self.toggle_box = BoxLayout() self.t1 = ToggleButton(group="g1", on_release=self.toggle_check, text="toggle 1") self.t2 = ToggleButton(group="g1", on_release=self.toggle_check, text="toggle 2") self.t3 = ToggleButton(group="g1", on_release=self.toggle_check, text="toggle 3") self.toggle_box.add_widget(self.t1) self.toggle_box.add_widget(self.t2) self.toggle_box.add_widget(self.t3) self.add_widget(self.toggle_box) def t_press(self, btn): if btn.state == "down": self.label.text = "This is Toggle Button!" if btn.state == "normal": self.label.text = "OFF" def toggle_check(self, btn): self.label.text = btn.text class Sample(App): def build(self): return Test() Sample().run()kivy.uix.checkbox
ラジオボタンとチェックボックスです。 トグルボタンと似たような挙動をしています。
groupを設定すると、ラジオボタンになり、設定しないと、チェックボックスになります。(下記ソースのコメント部を外してもらうと確認できると思います。)
トグルボタンとは違い押されているかどうかは、activeという変数からTrue Falseで確認できます。
from kivy.app import App from kivy.uix.boxlayout import BoxLayout from kivy.uix.label import Label from kivy.uix.checkbox import CheckBox class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) self.orientation = "vertical" # ラベルの定義、スクリーンに貼り付け self.label = Label(text="OFF") self.add_widget(self.label) # チェックボックスとして扱うトグルボタンを別で用意したボックスレイアウトに貼り付ける self.checkbox_box = BoxLayout(orientation="horizontal") # チェックボックスを定義 self.t1 = CheckBox() self.t2 = CheckBox() self.t3 = CheckBox() # ラジオボタンを定義 # self.t1 = CheckBox(group="g1") # self.t2 = CheckBox(group="g1") # self.t3 = CheckBox(group="g1") self.checkbox_box.add_widget(self.t1) self.checkbox_box.add_widget(self.t2) self.checkbox_box.add_widget(self.t3) #チェックボックを押した時の処理 self.t1.bind(active=self.on_checkbox_active) self.t2.bind(active=self.on_checkbox_active) self.t3.bind(active=self.on_checkbox_active) self.add_widget(self.checkbox_box) def on_checkbox_active(self, instance, value): self.label.text = "Left : {}\n" \ "Center : {}\n" \ "Right : {}\n".format(self.t1.state, self.t2.state, self.t3.state) class Sample(App): def build(self): return Test() Sample().run()ボタンっぽいもの
上で紹介したものは、ちゃんとボタンでしたが、下記で紹介するのは、ボタンを使って何かしてるものだと認識だと思います。
kivy.uix.spinner
コンボボックスです。上下どちらかにスペースを開けてあげないと、リストが開けないことに注意してください。
from kivy.app import App from kivy.uix.boxlayout import BoxLayout from kivy.uix.button import Button from kivy.uix.label import Label from kivy.uix.dropdown import DropDown class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) self.label = Label(text="test") self.add_widget(self.label) self.dropdown = DropDown() for index in range(10): btn = Button(text='Value %d' % index, size_hint_y=None, height=44) # 定義したボタンを押した時の処理 btn.bind(on_release=lambda btn: self.dropdown.select(btn.text)) # dropdownにボタンを載せる self.dropdown.add_widget(btn) self.mainbutton = Button(text="main", size_hint=(1, 0.1), pos_hint={"y": 0.9}) self.mainbutton.bind(on_release=self.dropdown.open) self.add_widget(self.mainbutton) self.dropdown.bind(on_select=self.press) def press(self, instance, x): self.mainbutton.text = x self.label.text = "Press : {}".format(x) class Sample(App): def build(self): return Test() Sample().run()kivy.uix.dropdown
押したらドロップダウンリストが出てくるやつです。
コンボボックスと似てますが、こっちの方が開いたボタンに機能が付けることができるため、自由度が高いと思います。僕はうまく使えませんでしたが。。。
from kivy.app import App from kivy.uix.boxlayout import BoxLayout from kivy.uix.button import Button from kivy.uix.label import Label from kivy.uix.dropdown import DropDown class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) self.label = Label(text="test") self.add_widget(self.label) self.dropdown = DropDown() for index in range(10): btn = Button(text='Value %d' % index, size_hint_y=None, height=44) # 定義したボタンを押した時の処理 btn.bind(on_release=lambda btn: self.dropdown.select(btn.text)) # dropdownにボタンを載せる self.dropdown.add_widget(btn) self.mainbutton = Button(text="main", size_hint=(1, 0.1), pos_hint={"y": 0.9}) self.mainbutton.bind(on_release=self.dropdown.open) self.add_widget(self.mainbutton) self.dropdown.bind(on_select=self.press) def press(self, instance, x): self.mainbutton.text = x self.label.text = "Press : {}".format(x) class Sample(App): def build(self): return Test() Sample().run()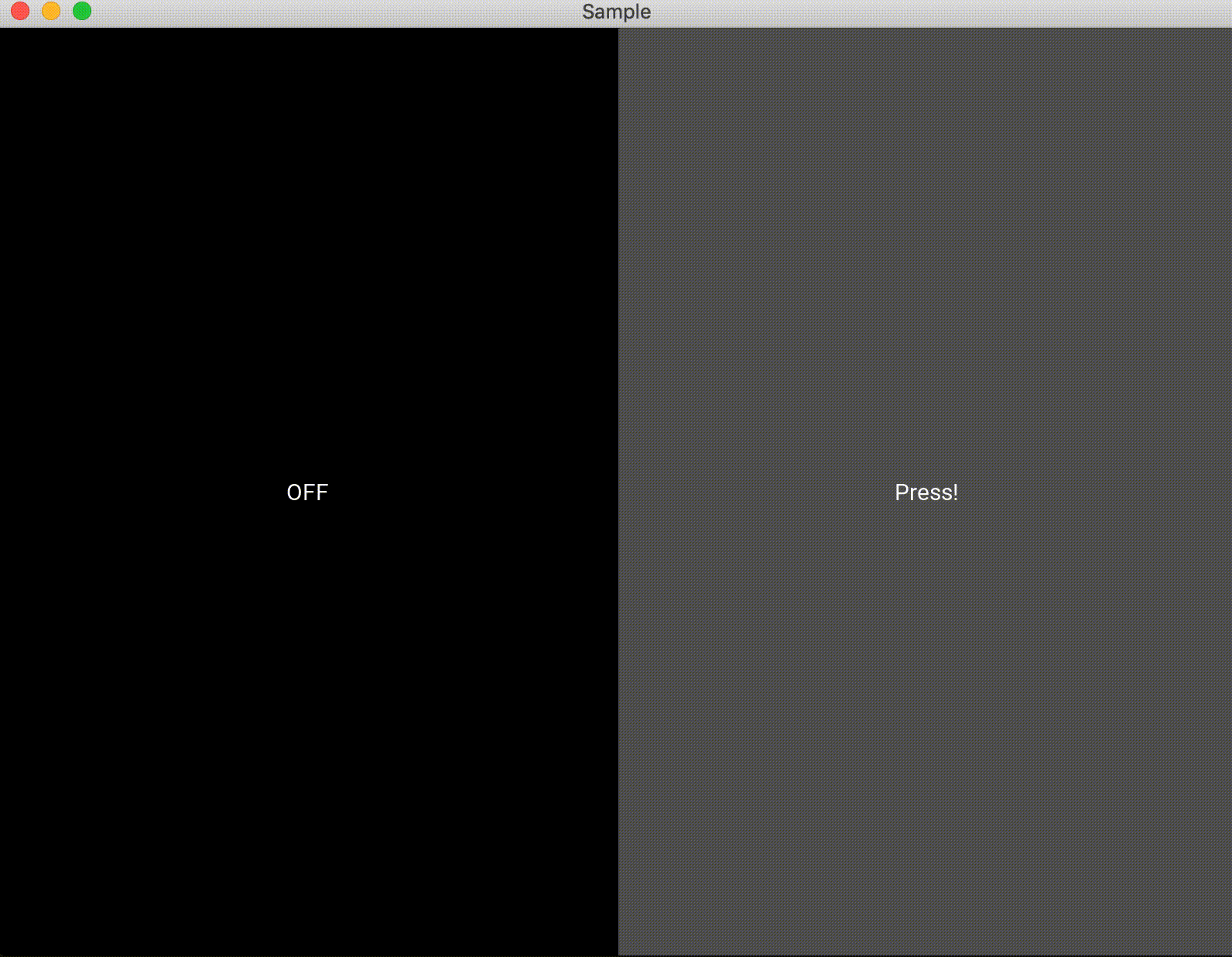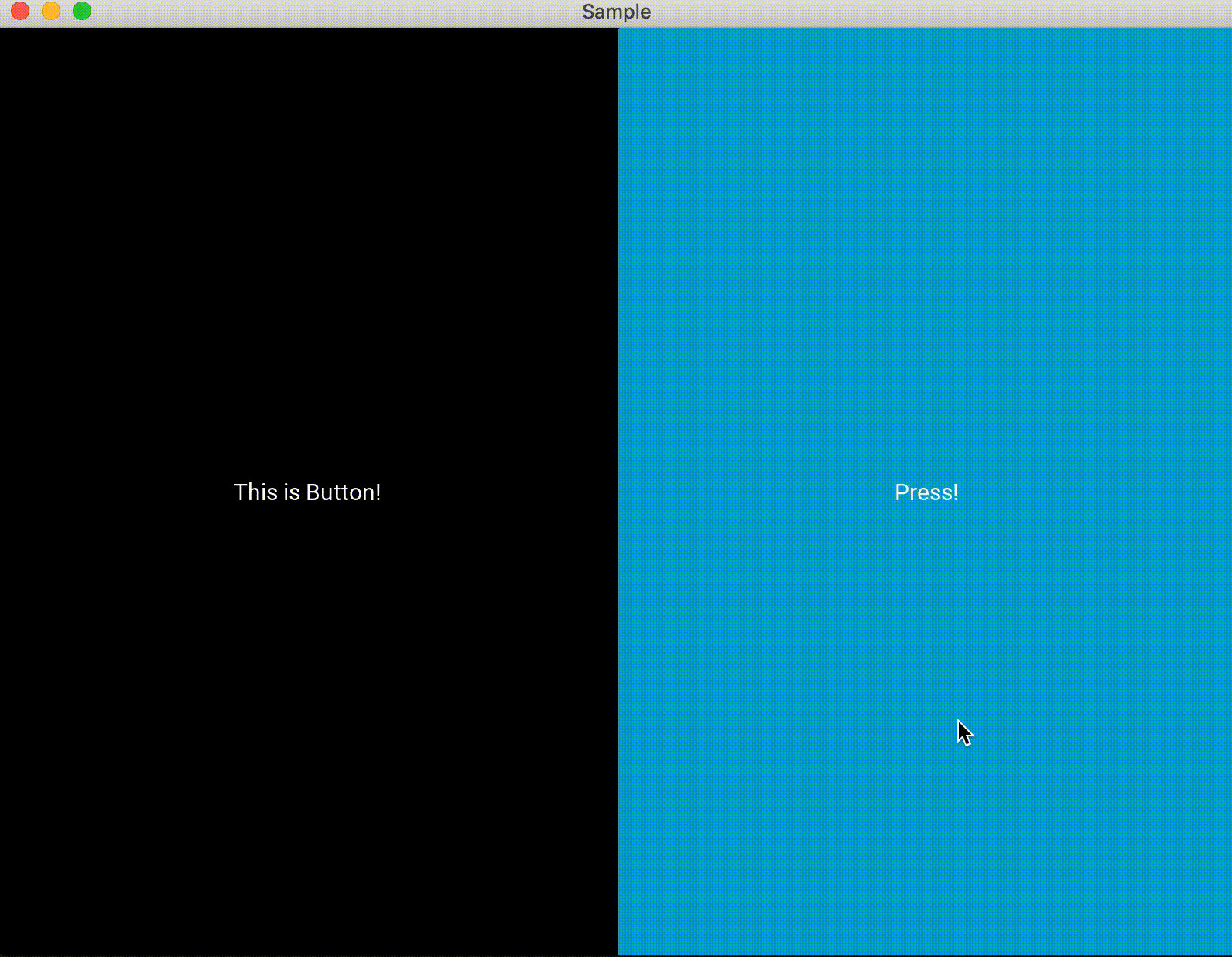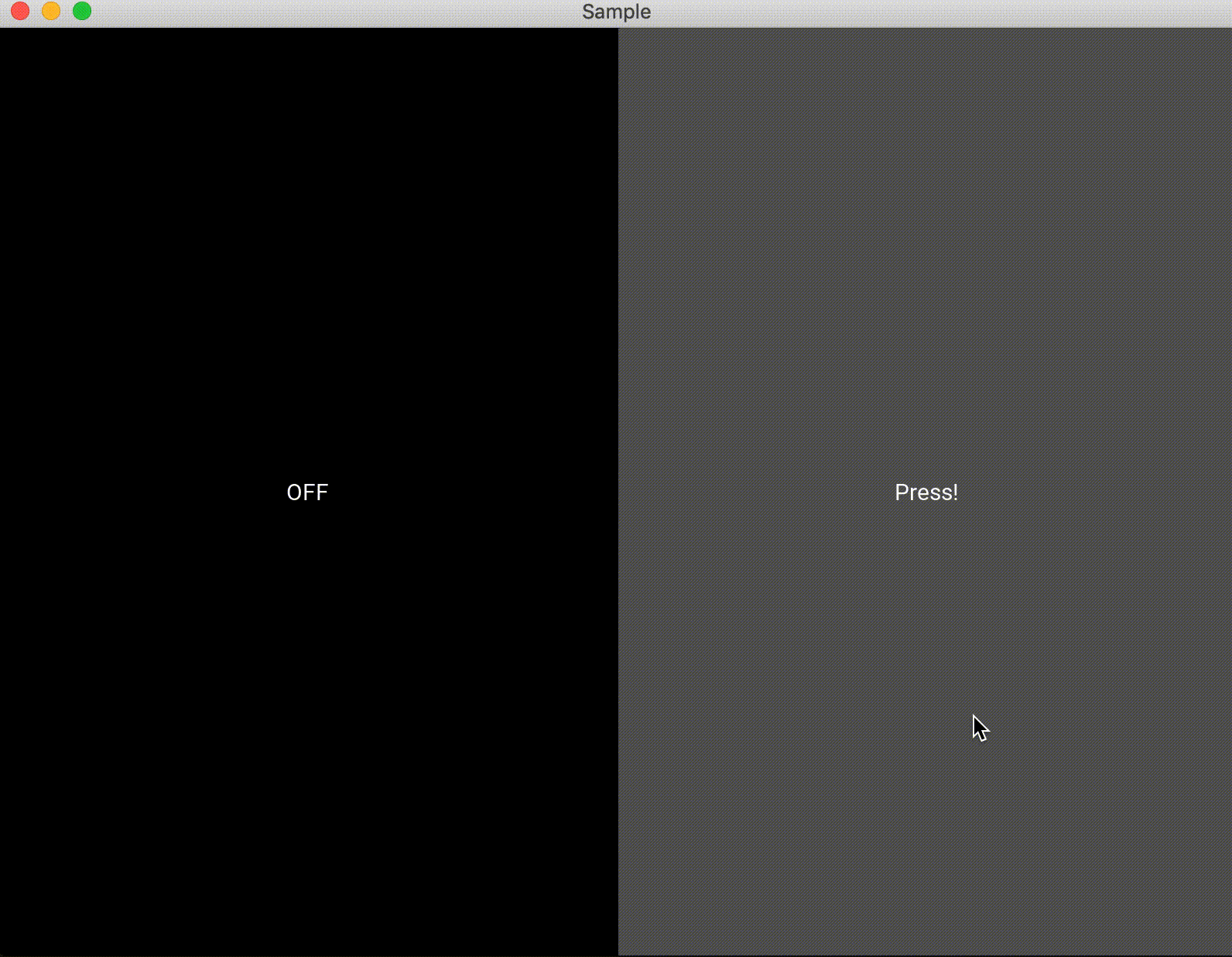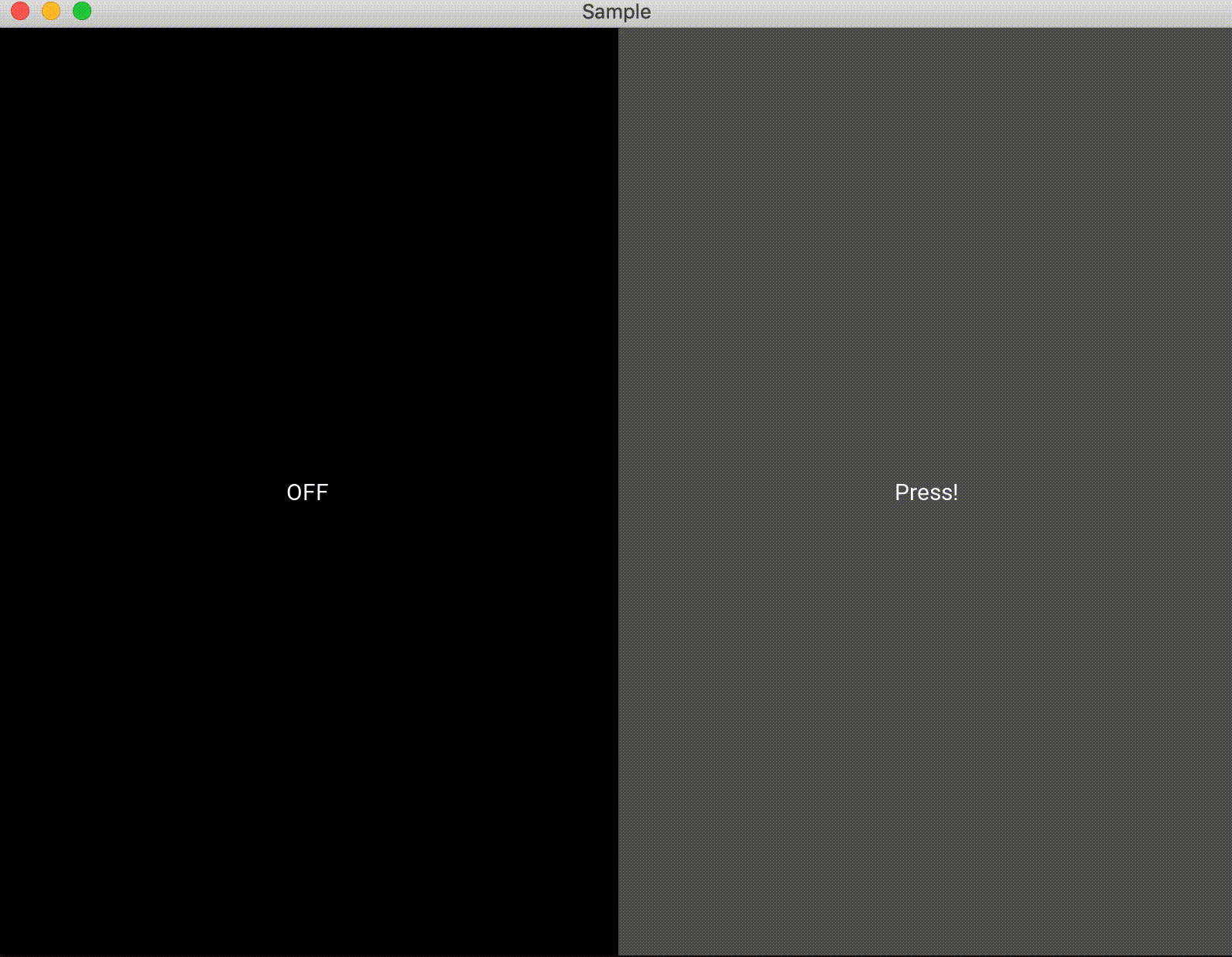kivy.uix.switch
スイッチです。使ったことはありません。
挙動自体はチェックボックスとほぼ同じだと思います。ボタンを持ってスライドさせることもできるので、ちょっと面白いと思いましたw
from kivy.app import App from kivy.uix.boxlayout import BoxLayout from kivy.uix.label import Label from kivy.uix.switch import Switch class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) self.label = Label(text="test") self.add_widget(self.label) self.switch = Switch() self.switch.bind(active=self.switch_check) self.add_widget(self.switch) def switch_check(self, instance, value): if value: self.label.text = "ON" else: self.label.text = "OFF" class Sample(App): def build(self): return Test() Sample().run()kivy.uix.accordion
ビロ〜んと出てくる、リストです。これも使ったことありません。
リストの中に何か処理とか入れたい場合には、Accordionの子要素であるAccordionImemsの宣言時にidsを入れるか、配列とかで保持しとけばできるかもしれないですね。(未検証)
from kivy.app import App from kivy.uix.boxlayout import BoxLayout from kivy.uix.label import Label from kivy.uix.accordion import Accordion, AccordionItem class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) self.label = Label(text="test") self.add_widget(self.label) self.accordion = Accordion(orientation='vertical') #Accodionの中身を定義 for x in range(5): item = AccordionItem(title='Title %d' % x) item.add_widget(Label(text='Very big content\n' * 10)) self.accordion.add_widget(item) self.add_widget(self.accordion) class Sample(App): def build(self): return Test() Sample().run()kivy.uix.tabbedpanel
タブを切り替えるボタンです。というよりもうこれボタンじゃないと思います。これはパネルですね。画面繊維を実装せずに画面の切り替えが簡単にできるので、便利なクラスだと思います。
from kivy.app import App from kivy.uix.boxlayout import BoxLayout from kivy.uix.label import Label from kivy.uix.tabbedpanel import TabbedPanel, TabbedPanelItem class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) self.tabbedPanel = TabbedPanel(do_default_tab=False) #TabbedPanelに載せるパネルの定義 self.panel1 = TabbedPanelItem(text="tab 1") self.panel1.add_widget(Label(text="This is Panel 1")) #TabbedPanelに載せるパネルの定義 self.panel2 = TabbedPanelItem(text="tab 2") self.panel2.add_widget(Label(text="This is Panel 2")) #TabbedPanelに載せる self.tabbedPanel.add_widget(self.panel1) self.tabbedPanel.add_widget(self.panel2) #Appに載せる self.add_widget(self.tabbedPanel) class Sample(App): def build(self): return Test() Sample().run()まとめ
紹介といっておきながら今まで触ったことのないボタン(?)に触れることのできる良い機会となりました。細々した内容については全く触れず簡単に紹介いたしましたが今回の紹介したボタンを別の機会で使える日が来るようもう少し勉強しておきたいと感じました。
参考文献






- 投稿日:2020-03-19T19:15:39+09:00
新型コロナの感染者数を表示するBOTを作る
今回つくるもの
アルティメット優秀な人たちが
都道府県別新型コロナウイルス感染者数マップ
https://gis.jag-japan.com/covid19jp/というサイトを作っておられますが、私はそこまでつよつよではないので、感染者数の内訳を表示するBOTを作ってみようと思いました。
同じサイトに感染者数のデータがjsonファイルで置いてあったので、そちらを使わせて頂こうと思います。
環境
- windows10
- discord.py 1.2.3
- python 3.7.3
事前準備
discord.pyを用いたDiscord BOTの作成や基本は以下のサイトがわかりやすいです。
Pythonで簡単なDiscord Botの作り方
https://qiita.com/PinappleHunter/items/af4ccdbb04727437477f
Discord Bot 最速チュートリアル【Python&Heroku&GitHub】
https://qiita.com/1ntegrale9/items/aa4b373e8895273875a8作成
まず上記のjsonファイルをダウンロードするプログラムを作ります。
urllibを使うと簡単にダウンロード出来ます。download.pyimport urllib.request def download(): url = 'https://services6.arcgis.com/5jNaHNYe2AnnqRnS/arcgis/rest/services/COVID19_Japan/FeatureServer/0/query?where=%E9%80%9A%E3%81%97%3E0&returnIdsOnly=false&returnCountOnly=false&&f=pgeojson&outFields=*&orderByFields=%E9%80%9A%E3%81%97' title = 'COVID-19_data.json' urllib.request.urlretrieve(url, "{0}".format(title))続いてBOT本体を作ります。
main.pyimport download import json from collections import defaultdict import discord TOKEN = '任意のトークン' CHANNEK_ID = '任意のチャンネルID' client = discord.Client() # 起動時に表示 @client.event async def on_ready(): print('Logged in as') print(client.user.name) print(client.user.id) print('------') # メッセージを受け取った時 @client.event async def on_message(message): # botからのメッセージは無視 if message.author.bot: return if message.content.startswith("!count"): #jsonファイルをロード download.download() json_open = open('COVID-19_data.json', 'r', encoding="utf-8_sig") json_load = json.load(json_open) jsn = json_load #居住都道府県名と数をdefaultdictで保持 properties = defaultdict(int) for f in jsn['features']: property = f['properties']['居住都道府県'] if property == '中華人民共和国' or property == '調査中' or property == '不明': continue if property not in properties: properties[property] = 0 properties[property] += 1 #一行ずつ出力すると時間がかかるので出力内容をあらかじめ保持 say = '' for p in properties: say += p + ' ' + str(properties[p]) + '\n' await message.channel.send(say) client.run(TOKEN)以上が新型コロナウイルスの各都道府県の感染者数を表示するBOTのプログラムです。
結果
デター!!!!
実はもう少し出力されているのですが、キャプチャサイズの関係で入りきりませんでした。ご了承ください。
おわりに
思いつきでざっと作ったものなので、ミスやスマートにできる場所があるかもしれません。その際はご指摘いただけると幸いです。
まだまだ新型コロナウイルスの猛威は止まりません。皆様お気をつけてお過ごしください。
https://twitter.com/hasegawa2718
- 投稿日:2020-03-19T18:52:01+09:00
Tensorflow 2.~ でCould not create cudnn handle: CUDNN_STATUS_INTERNAL_ERRORの対処
環境
バージョン
- Tensorflow: 2.1.0
- Ubuntu: 18.04
- python: 3.6.8
- CUDA: 10.0.130
- cuDNN: 7.6.5
原因
TensorflowのGPUメモリ割り当ての問題。だと思う
対処
以下のコードでメモリ割り当てを制限している場合
gpus = tf.config.experimental.list_physical_devices('GPU') if gpus: # Restrict TensorFlow to only use the first GPU try: tf.config.experimental.set_visible_devices(gpus[0], 'GPU') logical_gpus = tf.config.experimental.list_logical_devices('GPU') print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPU") except RuntimeError as e: # Visible devices must be set before GPUs have been initialized print(e)以下↓に変更することで治った。
gpus = tf.config.experimental.list_physical_devices('GPU') if gpus: try: # Currently, memory growth needs to be the same across GPUs for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True) logical_gpus = tf.config.experimental.list_logical_devices('GPU') print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs") except RuntimeError as e: # Memory growth must be set before GPUs have been initialized print(e)他
- 投稿日:2020-03-19T18:42:05+09:00
【pandas】(型に関する)条件をみたす列の列名を抽出
Pandasで型に関する条件を満たす列の列名の抽出
【方法】
#特定の条件を満たす列の列名のみ抽出 cols = df.select_dtypes('型名').columns
【例】 DataFrameのうち,str型(object型)の列の列名を抽出
import numpy as np import pandas as pd df = pd.DataFrame({'A':['a','b','c','a'], 'B':[1,2,3,4] , 'C':['apple','banana','apple','lemon']}) df.head()A B C 0 a 1 apple 1 b 2 banana 2 c 3 apple 3 a 4 lemonこの場合、列の要素がstr型(object型)の列の列名「A」と「C」を抽出したい。以下のようにして抽出可能。
#特定の条件を満たす列の列名のみ抽出 cols = df.select_dtypes('object').columns print(cols)Index(['A', 'C'], dtype='object')
【備考】
・df.select_dtypes('型名')
→ 戻り値 : DataFrame型
→ 型名で指定した型の列をもつDataFrameを返す。・df.columns
→ 戻り値 : Index型(ほぼlist型に同じ)
→ DataFrameの列名を返す。
- 投稿日:2020-03-19T18:42:05+09:00
【Pandas】(型に関する)条件をみたす列の列名を抽出
Pandasで型に関する条件を満たす列の列名の抽出
【方法】
#特定の条件を満たす列の列名のみ抽出 cols = df.select_dtypes('型名').columns
【例】 DataFrameのうち,str型(object型)の列の列名を抽出
import numpy as np import pandas as pd df = pd.DataFrame({'A':['a','b','c','a'], 'B':[1,2,3,4] , 'C':['apple','banana','apple','lemon']}) df.head()A B C 0 a 1 apple 1 b 2 banana 2 c 3 apple 3 a 4 lemonこの場合、列の要素がstr型(object型)の列の列名「A」と「C」を抽出したい。以下のようにして抽出可能。
#特定の条件を満たす列の列名のみ抽出 cols = df.select_dtypes('object').columns print(cols)Index(['A', 'C'], dtype='object')
【備考】
・df.select_dtypes('型名')
→ 戻り値 : DataFrame型
→ 型名で指定した型の列をもつDataFrameを返す。・df.columns
→ 戻り値 : Index型(ほぼlist型に同じ)
→ DataFrameの列名を返す。
- 投稿日:2020-03-19T18:28:08+09:00
スクリプト言語 KINX/ライブラリ(File/Directory)
ライブラリ(File/Directory)
はじめに
「見た目は JavaScript、頭脳(中身)は Ruby、(安定感は AC/DC)」でお届けしているスクリプト言語 Kinx。前回の記事で プレビュー・リリースしたぜ と勇み足ぎみに突っ走ったが、マニュアルが整っていないので、やはりなかなか使いづらいに違いない。現時点で参考になるのは以下しかないし、英語なので。
- Quick Reference Guide
- Kinx Specification
- 初回紹介記事 からの各種リンク
- 一応、ここは日本語。
そこでだ、若旦那。
少しだけマニュアル代わりになるように、簡易説明をここに記すことにしましたよ。今回は File と Directory。一番実用的な感じがしたので。
重要:
v0.1.0 ではファイル系のインタフェースが不完全だったので、急遽 v0.2.0 を用意しました。下記の内容は v0.2.0 のものです。v0.1.0 では動作しないものが一部あります。
また、標準入力をサポートしました。リリース内容は下記を参照してください。
* リリース・リストライブラリ
File クラス
File クラスはその名の通りファイルの読み書きをするクラスで、静的メソッドを持つ。また、
new File(filename, attr)として個別のファイル・インスタンスを作成することもできる。静的メソッド
File クラスの静的メソッドは、以下の通り。
メソッド 内容 復帰値(型) 引数 意味 File.load(path)ファイル内容をテキスト形式で一括読込み String path: String 中身を読み込むファイルパス File.mkdir(path)ディレクトリの作成 1: 成功 path: String 作成するディレクトリ・パス File.rename(oldname, newname)ファイルパスの変更 1: 成功 oldname: String 変更前のファイルパス newname: String 変更後のファイルパス File.unlink(path)ファイルの削除 1: 成功 path: String 削除するファイルパス File.exists(path)ファイルの存在確認 1: 存在する path: String 確認するファイルパス File.isDirectory(path)ディレクトリ名かどうかの確認 1: ディレクトリである path: String 確認するファイルパス File.isSymlink(path)シンボリックリンクかどうかの確認 1: シンボリックリンクである path: String 確認するファイルパス File.filesize(path)ファイルサイズの取得 Integer path: String 確認するファイルパス File.filedate(path)ファイル日付の取得 { modified, accessed, creation }path: String 確認するファイルパス File.setFiledate(path, obj)ファイル日付の設定 path: String 確認するファイルパス obj: Object { modified, accessed, creation }File インスタンス
File インスタンスは
newで作る。サンプルは以下の通り。var f = new File(filename, attr);パラメータは以下の 2 つ。
パラメータ 取りうる値 意味 filename 文字列 ファイル名 attr 以下の値の論理和 オープン属性 File.READ読込可能 File.WRITE書込可能 File.NEW新規作成モード File.TEXTテキストモード File.BINARYバイナリモード
- オープン属性は以下のような感じで指定する。
File.READ|File.WRITE... 追記モードで読み書き可能File.READ|File.WRITE|File.NEW... 新規作成モードで読み書き可能File.READ|File.TEXT... テキストモードで読み込み専用File インスタンスのメソッドは以下の通り。すみません、
peek、getch、putchは v0.1.0 に含まれていません。。。
メソッド 内容 復帰値(型) 引数 意味 f.load()ファイルの中身を一括読み込み String f.close()ファイルをクローズ f.readLine()一行読み込み String, 0: EOF f.peek(ms)入力があるか確認 1: 存在する、0: 存在しない ms: Integer タイムアウト(ミリ秒) f.getch()1 文字入力 Integer (取得文字コード) f.putch(ch)1 文字出力 ch: Integer 出力文字コード f.print(...args)改行文字なしで出力 出力文字数: Integer ...args 表示する要素(可変引数) f.println(...args)改行文字付きで出力 出力文字数: Integer ...args 表示する要素(可変引数) File.open
個別に
newした場合はcloseしなければならない(GC されたら勝手にクローズ自体はされる)が、スコープを決めて自動的にクローズさせたい場合はFile.openを使うのがオススメ。スコープを抜けるとその場で自動的にクローズされる。こんな感じ。File.open("README.md", File.READ, &(f) => { var l, n = 0; while ((l = f.readLine()).isString) { System.println("%4d: %s" % (++n) % l); } });
File.openの内容としては、意味的には次のと概ね同等。function FileOpen(filename, attr, func) { var f = new File(filename, attr); try { return func(f); } finally { f.close(); } }Directory
ディレクトリをトラバースするために使う。サブディレクトリを見つけた時に再帰的に潜っていく場合は
recursiveWalk、潜っていかない場合はwalkを使う。Directory.walk
Kinx のリポジトリ・フォルダで以下を実行してみるとなんとなくわかるかも("src" ディレクトリがあるので動作する、という意味。存在するディレクトリ名にすればどこでも OK)。
Directory.walk("src", &(name) => { System.println(name); });Directory.recursiveWalk
次のように実行すると違いがわかるはず("src" 配下にサブディレクトリがある前提)。
Directory.recursiveWalk("src", &(name) => { System.println(name); });おわりに
先日、昔のツェッペリンのインタビューを読んでみて、新しい何か、自分たちがやりたい何か、をガレージ・レベルからスタートさせてやっていく、ってのは改めて ロックだねえ、と感慨に耽っていました。ビッグになったロックスターたちも、最初は こういうのやりたいんだよ とガレージやクラブからスタートさせてる訳です。夢と希望を忍ばせて。
今あるものに満足せずに、また、今現在提供されているものに満足行かないようなら、文句を言うのではなく自分の手で実現させてしまうのが良いよね。そのアティテュードこそがまさに ロックンロール。
まだまだ転がり続けようぜ、相棒。
で、最後はいつものおねだりの時間です。
- 最初の動機は スクリプト言語 KINX(ご紹介) を参照してください(もし宜しければ「
いいねLGTM」ボタンをポチっと)。- リポジトリは ここ(https://github.com/Kray-G/kinx) です。こちらももし宜しければ★をポチっと。
- 投稿日:2020-03-19T18:20:49+09:00
[python] ERROR: Python headers are missing in /usr/include/python3.X m.
- 投稿日:2020-03-19T18:19:00+09:00
SEIRモデルのGUIプログラム
はじめに
前回の記事に、SEIRモデルで新型コロナウイルスの挙動を予測するプログラムを掲載しました。
今回は、そのプログラムをGUI化したので、その内容を共有致します。
前回の記事:SEIRモデルで新型コロナウイルスの挙動を予測してみた。
リンク:https://qiita.com/kotai2003/items/ed28fb723a335a873061実行画面
入力パラメータ一覧
現在、新型コロナウイルスの発症事例より、SEIRのパラメータを推定する研究論文が多数発表されています。今回は、2月16日に発表された論文に掲載されたパラメータ推定値で、SEIRモデルを計算してみます。(参考文献 2)
Parameter 中国本土(湖北省除く) 湖北省(武漢除く) 武漢 人口数 N (million) 1340 45 14 感染率 [beta] 1.0 1.0 1.0 Latency period (days) 2 2 2 infectious_period (days) 6.6 7.2 7.4 E_0 696 592 318 I_0 652 515 389 実行例
ソースコード
main_routine.py
import tkinter as tk from tkinter import ttk from tkinter import Menu from tkinter import messagebox import numpy as np from scipy.integrate import odeint import matplotlib.pyplot as plt from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg from calcSEIR import SEIR_EQ class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() self.master.geometry("1000x600") self.master.title("SEIR Epidemic Model Simulator") self.create_widgets() def create_widgets(self): #Canvas Frame self.canvas_frame = tk.Frame(self) self.canvas_frame.configure(width=600, height=480) self.canvas_frame.grid(row=0, column=0) self.canvas_frame.grid(padx = 20, pady=20) #Label Frame for Input Parameters self.frame_param = tk.LabelFrame( self ) self.frame_param.configure( text=' Input Paramaters ' ) self.frame_param.grid( row=0, column=1 ) self.frame_param.grid( padx=20, pady=20 ) #1. Population #Label_population self.label_popu = tk.Label( self.frame_param) self.label_popu.configure(text ='Population (Million)') self.label_popu.grid(row =0, column = 0) #Scale population self.var_popu = tk.DoubleVar() #scale variable self.scale_popu = tk.Scale( self.frame_param) self.scale_popu.configure(orient="horizontal") self.scale_popu.configure(from_=1, to= 1350) self.scale_popu.configure(variable=self.var_popu) self.scale_popu.grid(row=0, column=1) #2. Infection Rate # Label_Infection_Rate self.label_IR = tk.Label( self.frame_param ) self.label_IR.configure( text='Infection Rate' ) self.label_IR.grid( row=1, column=0 ) # Scale Infection_Rate self.var_IR = tk.DoubleVar() # scale variable self.scale_IR = tk.Scale( self.frame_param ) self.scale_IR.configure( orient="horizontal" ) self.scale_IR.configure( from_=0.1, to=2 , resolution=0.1) self.scale_IR.configure( variable=self.var_IR ) self.scale_IR.grid( row=1, column=1 ) #3. Latency Period # Label_ self.label_LP = tk.Label( self.frame_param ) self.label_LP.configure( text='Latency Period (days)' ) self.label_LP.grid( row=2, column=0 ) # Scale self.var_LP = tk.IntVar() # scale variable self.scale_LP = tk.Scale( self.frame_param ) self.scale_LP.configure( orient="horizontal" ) self.scale_LP.configure( from_=1, to=14 , resolution=0.1) self.scale_LP.configure( variable=self.var_LP ) self.scale_LP.grid( row=2, column=1 ) # 3.5 Infection Period # Label_ self.label_IP = tk.Label( self.frame_param ) self.label_IP.configure( text='Infections Period (days)' ) self.label_IP.grid( row=3, column=0 ) # Scale self.var_IP = tk.IntVar() # scale variable self.scale_IP = tk.Scale( self.frame_param ) self.scale_IP.configure( orient="horizontal" ) self.scale_IP.configure( from_=1, to=14, resolution=0.1 ) self.scale_IP.configure( variable=self.var_IP ) self.scale_IP.grid( row=3, column=1 ) #4 E_0 self.label_E0 = tk.Label( self.frame_param ) self.label_E0.configure( text='E(t=0)' ) self.label_E0.grid( row=4, column=0 ) #Entry self.Entry_E0 = tk.Entry(self.frame_param) self.Entry_E0.grid(row=4, column=1) self.Entry_E0.insert(tk.END,"696") #5 I_0 self.label_I0 = tk.Label( self.frame_param ) self.label_I0.configure( text='I(t=0)' ) self.label_I0.grid( row=5, column=0 ) # Entry self.Entry_I0 = tk.Entry( self.frame_param ) self.Entry_I0.grid( row=5, column=1 ) self.Entry_I0.insert( tk.END, "652" ) #6 R_0 self.label_R0 = tk.Label( self.frame_param ) self.label_R0.configure( text='E(t=0)' ) self.label_R0.grid( row=6, column=0 ) # Entry self.Entry_R0 = tk.Entry( self.frame_param ) self.Entry_R0.grid( row=6, column=1 ) self.Entry_R0.insert( tk.END, "0" ) #7 Time self.label_time = tk.Label(self.frame_param) self.label_time.configure( text = 'Time [days]') self.label_time.grid(row=7, column=0) self.var_time = tk.IntVar() # scale variable self.scale_time = tk.Scale( self.frame_param ) self.scale_time.configure( orient="horizontal" ) self.scale_time.configure( from_=10, to=500, resolution=1 ) self.scale_time.configure( variable=self.var_time ) self.scale_time.grid( row=7, column=1 ) #Basic Reproduction Number # Label Frame result self.frame_basicR0 = tk.LabelFrame( self ) self.frame_basicR0.configure( text=' Basic Reproduction Number ' ) self.frame_basicR0.grid( row=2, column=1 ) self.frame_basicR0.grid( padx=20, pady=20 ) self.label_basicR0 = tk.Label(self.frame_basicR0) self.label_basicR0.grid(row = 0, column=0) self.label_basicR0.configure(text = ' R0 is ') self.msg_basicR0 = tk.Message(self.frame_basicR0) self.msg_basicR0.grid(row=0, column=1) self.msg_basicR0.configure(text ='') # Button ##Label Frame for Buttons # Label Frame for Input Parameters self.frame_button = tk.LabelFrame( self ) self.frame_button.configure( text=' Operation ' ) self.frame_button.grid( row=2, column=0 ) self.frame_param.grid( padx=20, pady=20 ) #button # Plot (Rungekutta. Plot..Canvas..) self.button_plot = tk.Button( self.frame_button ) self.button_plot.configure( text='Calculate & Plot' ) self.button_plot.grid( column=0, row=1 ) self.button_plot.configure( command=self.plotCalc ) self.button_plot.configure(width = 20, height=2) # Quit Button self.button_quit = tk.Button( self.frame_button ) self.button_quit.config( text='Quit' ) self.button_quit.grid( column=2, row=1 ) self.button_quit.configure( command=self.quit_app ) self.button_quit.configure( width = 15, height=2 ) ## Event Call Back def plotCalc(self): # parameters self.t_max = self.var_time.get() # days self.dt = 0.01 # initial_state self.N_pop = 1e6*self.var_popu.get() self.E_0 = int(self.Entry_E0.get()) self.I_0 = int(self.Entry_I0.get()) self.R_0 = int(self.Entry_R0.get()) self.S_0 = self.N_pop - (self.E_0 + self.I_0 + self.R_0) self.ini_state = [self.S_0, self.E_0, self.I_0, self.R_0] # [S[0],E,[0], I[0], R[0]] # 感染率 self.beta_const = self.var_IR.get() # 感染率 # 暴露後に感染症を得る率 self.epsilon_const = 1 / self.var_LP.get() # 回復率や隔離率 self.gamma_const = 1 / self.var_IP.get() #Basic Reproduction number in SEIR model self.basicR0 = self.beta_const/self.gamma_const +self.beta_const/self.epsilon_const self.msg_basicR0.configure( text=str(self.basicR0) ) #https://www.fields.utoronto.ca/programs/scientific/10-11/drugresistance/emergence/fred1.pdf # numerical integration self.times = np.arange( 0, self.t_max, self.dt ) self.args = (self.beta_const, self.epsilon_const, self.gamma_const, self.N_pop) # Numerical Solution using scipy.integrate # Solver SEIR model self.result = odeint(SEIR_EQ, self.ini_state, self.times, self.args ) ## Plotting # Generate Figure instance self.fig = plt.Figure() #Generate Axe instance #ax1 self.ax1 = self.fig.add_subplot(111) self.ax1.plot(self.times, self.result) self.ax1.set_title('SEIR Epidemic model') self.ax1.set_xlabel('time [days]') self.ax1.set_ylabel('population [persons]') self.ax1.legend(['Susceptible', 'Exposed', 'Infectious', 'Removed']) self.ax1.grid() #Link to Axe instance to Canvas #Then show Canvas onto canvas_Frame self.canvas = FigureCanvasTkAgg( self.fig, self.canvas_frame ) self.canvas.draw() self.canvas.get_tk_widget().grid(column=0, row=0) def quit_app(self): self.Msgbox = tk.messagebox.askquestion( "Exit Applictaion", "Are you sure?", icon="warning" ) if self.Msgbox == "yes": self.master.destroy() else: tk.messagebox.showinfo( "Return", "you will now return to application screen" ) def main(): root = tk.Tk() app = Application(master=root)#Inherit app.mainloop() if __name__ == "__main__": main()calcSEIR.py
# Define differential equation of SEIR model ''' dS/dt = -beta * S * I / N dE/dt = beta* S * I / N - epsilon * E dI/dt = epsilon * E - gamma * I dR/dt = gamma * I [v[0], v[1], v[2], v[3]]=[S, E, I, R] dv[0]/dt = -beta * v[0] * v[2] / N dv[1]/dt = beta * v[0] * v[2] / N - epsilon * v[1] dv[2]/dt = epsilon * v[1] - gamma * v[2] dv[3]/dt = gamma * v[2] ''' def SEIR_EQ(v, t, beta, epsilon, gamma, N ): return [-beta * v[0] * v[2] / N ,beta * v[0] * v[2] / N - epsilon * v[1], epsilon * v[1] - gamma * v[2],gamma * v[2]]参考資料
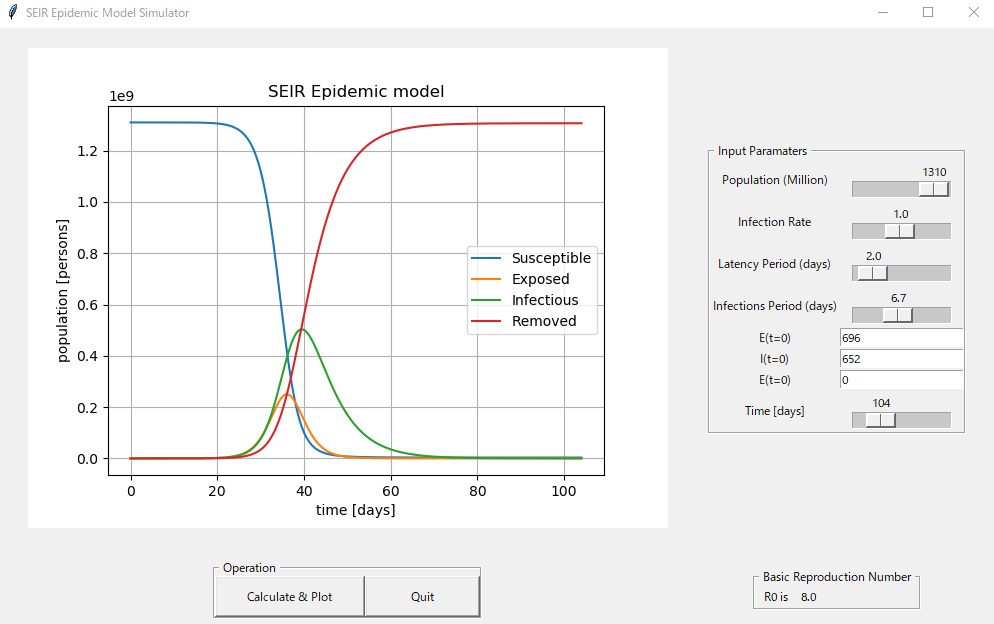
- 投稿日:2020-03-19T18:19:00+09:00
新型コロナウイルスのシミュレーション (SEIRモデル)
はじめに
前回の記事に、SEIRモデルで新型コロナウイルスの挙動を予測するプログラムを掲載しました。
今回は、そのプログラムをGUI化したので、その内容を共有致します。
前回の記事:SEIRモデルで新型コロナウイルスの挙動を予測してみた。
リンク:https://qiita.com/kotai2003/items/ed28fb723a335a873061
実行画面
入力パラメータ一覧
現在、新型コロナウイルスの発症事例より、SEIRのパラメータを推定する研究論文が多数発表されています。今回は、2月16日に発表された論文に掲載されたパラメータ推定値で、SEIRモデルを計算してみます。(参考文献 2)
Parameter 中国本土(湖北省除く) 湖北省(武漢除く) 武漢 人口数 N (million) 1340 45 14 感染率 [beta] 1.0 1.0 1.0 Latency period (days) 2 2 2 infectious_period (days) 6.6 7.2 7.4 E_0 696 592 318 I_0 652 515 389 実行例
例えば、社会距離戦略により、感染率が0.5から0.4に下がった場合、感染者のピークがどう変動するかシミュレーションで確認することが可能です。
Case 1: 感染率 0.5
Case 2: 感染率 0.4
感染者(Infections)のピークが下がり、そのタイミングが右側に移動しています。
このような計算により、政府の新型コロナウイルス感染症対策本部が2月23日に発表した「対策の目的(基本的な考え方)」の効果を確認することが可能です。
ソースコード
main_routine.py
import tkinter as tk from tkinter import ttk from tkinter import Menu from tkinter import messagebox import numpy as np from scipy.integrate import odeint import matplotlib.pyplot as plt from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg from calcSEIR import SEIR_EQ class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() self.master.geometry("1000x600") self.master.title("SEIR Epidemic Model Simulator") self.create_widgets() def create_widgets(self): #Canvas Frame self.canvas_frame = tk.Frame(self) self.canvas_frame.configure(width=600, height=480) self.canvas_frame.grid(row=0, column=0) self.canvas_frame.grid(padx = 20, pady=20) #Label Frame for Input Parameters self.frame_param = tk.LabelFrame( self ) self.frame_param.configure( text=' Input Paramaters ' ) self.frame_param.grid( row=0, column=1 ) self.frame_param.grid( padx=20, pady=20 ) #1. Population #Label_population self.label_popu = tk.Label( self.frame_param) self.label_popu.configure(text ='Population (Million)') self.label_popu.grid(row =0, column = 0) #Scale population self.var_popu = tk.DoubleVar() #scale variable self.scale_popu = tk.Scale( self.frame_param) self.scale_popu.configure(orient="horizontal") self.scale_popu.configure(from_=1, to= 1350) self.scale_popu.configure(variable=self.var_popu) self.scale_popu.grid(row=0, column=1) #2. Infection Rate # Label_Infection_Rate self.label_IR = tk.Label( self.frame_param ) self.label_IR.configure( text='Infection Rate' ) self.label_IR.grid( row=1, column=0 ) # Scale Infection_Rate self.var_IR = tk.DoubleVar() # scale variable self.scale_IR = tk.Scale( self.frame_param ) self.scale_IR.configure( orient="horizontal" ) self.scale_IR.configure( from_=0.1, to=2 , resolution=0.1) self.scale_IR.configure( variable=self.var_IR ) self.scale_IR.grid( row=1, column=1 ) #3. Latency Period # Label_ self.label_LP = tk.Label( self.frame_param ) self.label_LP.configure( text='Latency Period (days)' ) self.label_LP.grid( row=2, column=0 ) # Scale self.var_LP = tk.IntVar() # scale variable self.scale_LP = tk.Scale( self.frame_param ) self.scale_LP.configure( orient="horizontal" ) self.scale_LP.configure( from_=1, to=14 , resolution=0.1) self.scale_LP.configure( variable=self.var_LP ) self.scale_LP.grid( row=2, column=1 ) # 3.5 Infection Period # Label_ self.label_IP = tk.Label( self.frame_param ) self.label_IP.configure( text='Infections Period (days)' ) self.label_IP.grid( row=3, column=0 ) # Scale self.var_IP = tk.IntVar() # scale variable self.scale_IP = tk.Scale( self.frame_param ) self.scale_IP.configure( orient="horizontal" ) self.scale_IP.configure( from_=1, to=14, resolution=0.1 ) self.scale_IP.configure( variable=self.var_IP ) self.scale_IP.grid( row=3, column=1 ) #4 E_0 self.label_E0 = tk.Label( self.frame_param ) self.label_E0.configure( text='E(t=0)' ) self.label_E0.grid( row=4, column=0 ) #Entry self.Entry_E0 = tk.Entry(self.frame_param) self.Entry_E0.grid(row=4, column=1) self.Entry_E0.insert(tk.END,"696") #5 I_0 self.label_I0 = tk.Label( self.frame_param ) self.label_I0.configure( text='I(t=0)' ) self.label_I0.grid( row=5, column=0 ) # Entry self.Entry_I0 = tk.Entry( self.frame_param ) self.Entry_I0.grid( row=5, column=1 ) self.Entry_I0.insert( tk.END, "652" ) #6 R_0 self.label_R0 = tk.Label( self.frame_param ) self.label_R0.configure( text='E(t=0)' ) self.label_R0.grid( row=6, column=0 ) # Entry self.Entry_R0 = tk.Entry( self.frame_param ) self.Entry_R0.grid( row=6, column=1 ) self.Entry_R0.insert( tk.END, "0" ) #7 Time self.label_time = tk.Label(self.frame_param) self.label_time.configure( text = 'Time [days]') self.label_time.grid(row=7, column=0) self.var_time = tk.IntVar() # scale variable self.scale_time = tk.Scale( self.frame_param ) self.scale_time.configure( orient="horizontal" ) self.scale_time.configure( from_=10, to=500, resolution=1 ) self.scale_time.configure( variable=self.var_time ) self.scale_time.grid( row=7, column=1 ) #Basic Reproduction Number # Label Frame result self.frame_basicR0 = tk.LabelFrame( self ) self.frame_basicR0.configure( text=' Basic Reproduction Number ' ) self.frame_basicR0.grid( row=2, column=1 ) self.frame_basicR0.grid( padx=20, pady=20 ) self.label_basicR0 = tk.Label(self.frame_basicR0) self.label_basicR0.grid(row = 0, column=0) self.label_basicR0.configure(text = ' R0 is ') self.msg_basicR0 = tk.Message(self.frame_basicR0) self.msg_basicR0.grid(row=0, column=1) self.msg_basicR0.configure(text ='') # Button ##Label Frame for Buttons # Label Frame for Input Parameters self.frame_button = tk.LabelFrame( self ) self.frame_button.configure( text=' Operation ' ) self.frame_button.grid( row=2, column=0 ) self.frame_param.grid( padx=20, pady=20 ) #button # Plot (Rungekutta. Plot..Canvas..) self.button_plot = tk.Button( self.frame_button ) self.button_plot.configure( text='Calculate & Plot' ) self.button_plot.grid( column=0, row=1 ) self.button_plot.configure( command=self.plotCalc ) self.button_plot.configure(width = 20, height=2) # Quit Button self.button_quit = tk.Button( self.frame_button ) self.button_quit.config( text='Quit' ) self.button_quit.grid( column=2, row=1 ) self.button_quit.configure( command=self.quit_app ) self.button_quit.configure( width = 15, height=2 ) ## Event Call Back def plotCalc(self): # parameters self.t_max = self.var_time.get() # days self.dt = 0.01 # initial_state self.N_pop = 1e6*self.var_popu.get() self.E_0 = int(self.Entry_E0.get()) self.I_0 = int(self.Entry_I0.get()) self.R_0 = int(self.Entry_R0.get()) self.S_0 = self.N_pop - (self.E_0 + self.I_0 + self.R_0) self.ini_state = [self.S_0, self.E_0, self.I_0, self.R_0] # [S[0],E,[0], I[0], R[0]] # 感染率 self.beta_const = self.var_IR.get() # 感染率 # 暴露後に感染症を得る率 self.epsilon_const = 1 / self.var_LP.get() # 回復率や隔離率 self.gamma_const = 1 / self.var_IP.get() #Basic Reproduction number in SEIR model self.basicR0 = self.beta_const/self.gamma_const +self.beta_const/self.epsilon_const self.msg_basicR0.configure( text=str(self.basicR0) ) #https://www.fields.utoronto.ca/programs/scientific/10-11/drugresistance/emergence/fred1.pdf # numerical integration self.times = np.arange( 0, self.t_max, self.dt ) self.args = (self.beta_const, self.epsilon_const, self.gamma_const, self.N_pop) # Numerical Solution using scipy.integrate # Solver SEIR model self.result = odeint(SEIR_EQ, self.ini_state, self.times, self.args ) ## Plotting # Generate Figure instance self.fig = plt.Figure() #Generate Axe instance #ax1 self.ax1 = self.fig.add_subplot(111) self.ax1.plot(self.times, self.result) self.ax1.set_title('SEIR Epidemic model') self.ax1.set_xlabel('time [days]') self.ax1.set_ylabel('population [persons]') self.ax1.legend(['Susceptible', 'Exposed', 'Infectious', 'Removed']) self.ax1.grid() #Link to Axe instance to Canvas #Then show Canvas onto canvas_Frame self.canvas = FigureCanvasTkAgg( self.fig, self.canvas_frame ) self.canvas.draw() self.canvas.get_tk_widget().grid(column=0, row=0) def quit_app(self): self.Msgbox = tk.messagebox.askquestion( "Exit Applictaion", "Are you sure?", icon="warning" ) if self.Msgbox == "yes": self.master.destroy() else: tk.messagebox.showinfo( "Return", "you will now return to application screen" ) def main(): root = tk.Tk() app = Application(master=root)#Inherit app.mainloop() if __name__ == "__main__": main()calcSEIR.py
# Define differential equation of SEIR model ''' dS/dt = -beta * S * I / N dE/dt = beta* S * I / N - epsilon * E dI/dt = epsilon * E - gamma * I dR/dt = gamma * I [v[0], v[1], v[2], v[3]]=[S, E, I, R] dv[0]/dt = -beta * v[0] * v[2] / N dv[1]/dt = beta * v[0] * v[2] / N - epsilon * v[1] dv[2]/dt = epsilon * v[1] - gamma * v[2] dv[3]/dt = gamma * v[2] ''' def SEIR_EQ(v, t, beta, epsilon, gamma, N ): return [-beta * v[0] * v[2] / N ,beta * v[0] * v[2] / N - epsilon * v[1], epsilon * v[1] - gamma * v[2],gamma * v[2]]参考資料
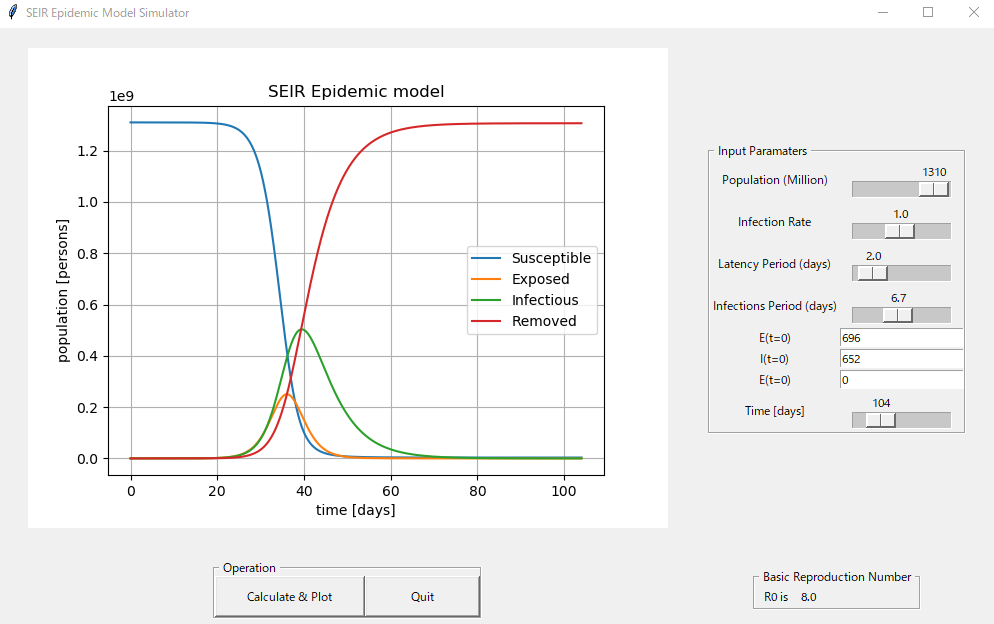
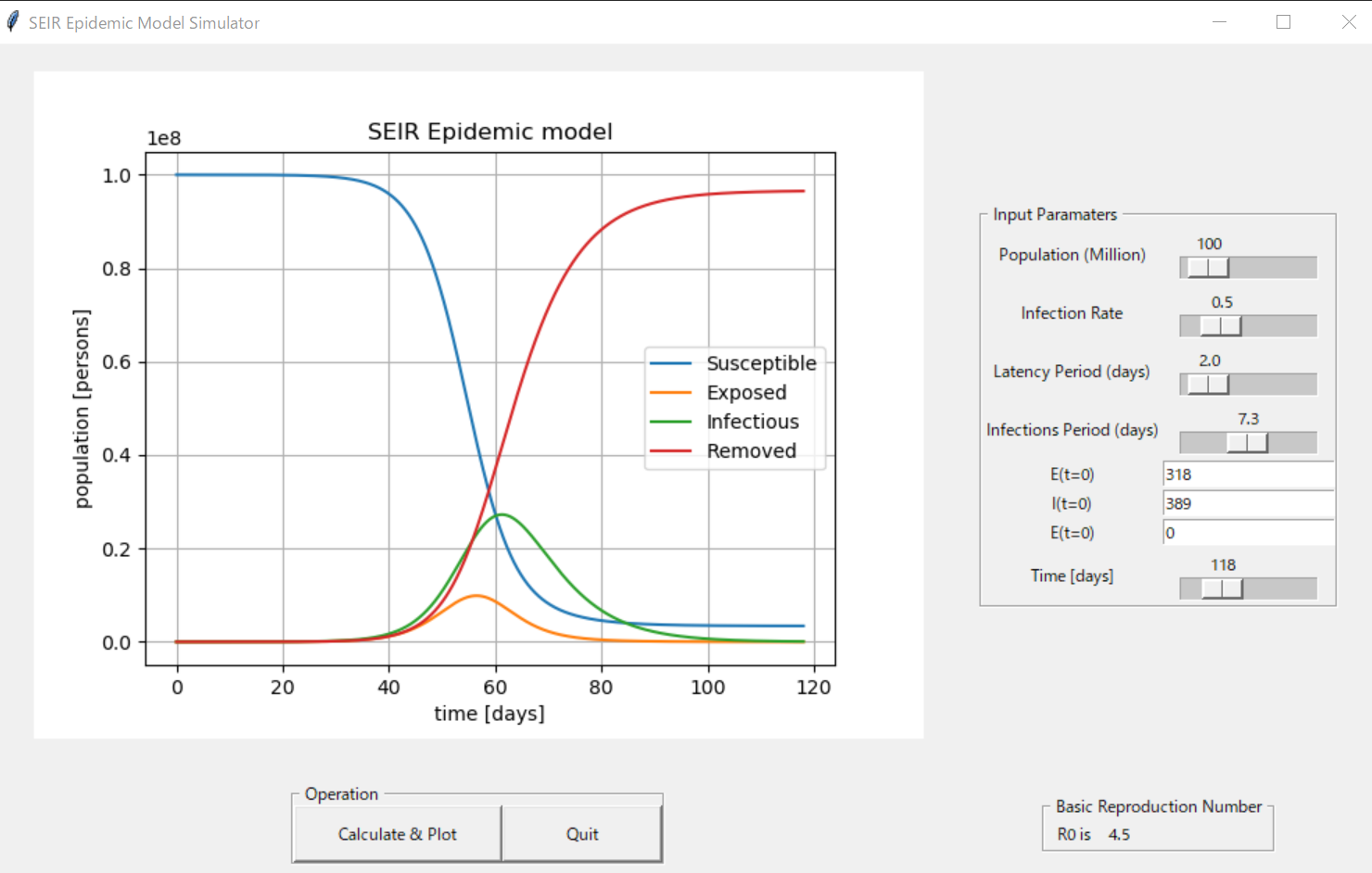
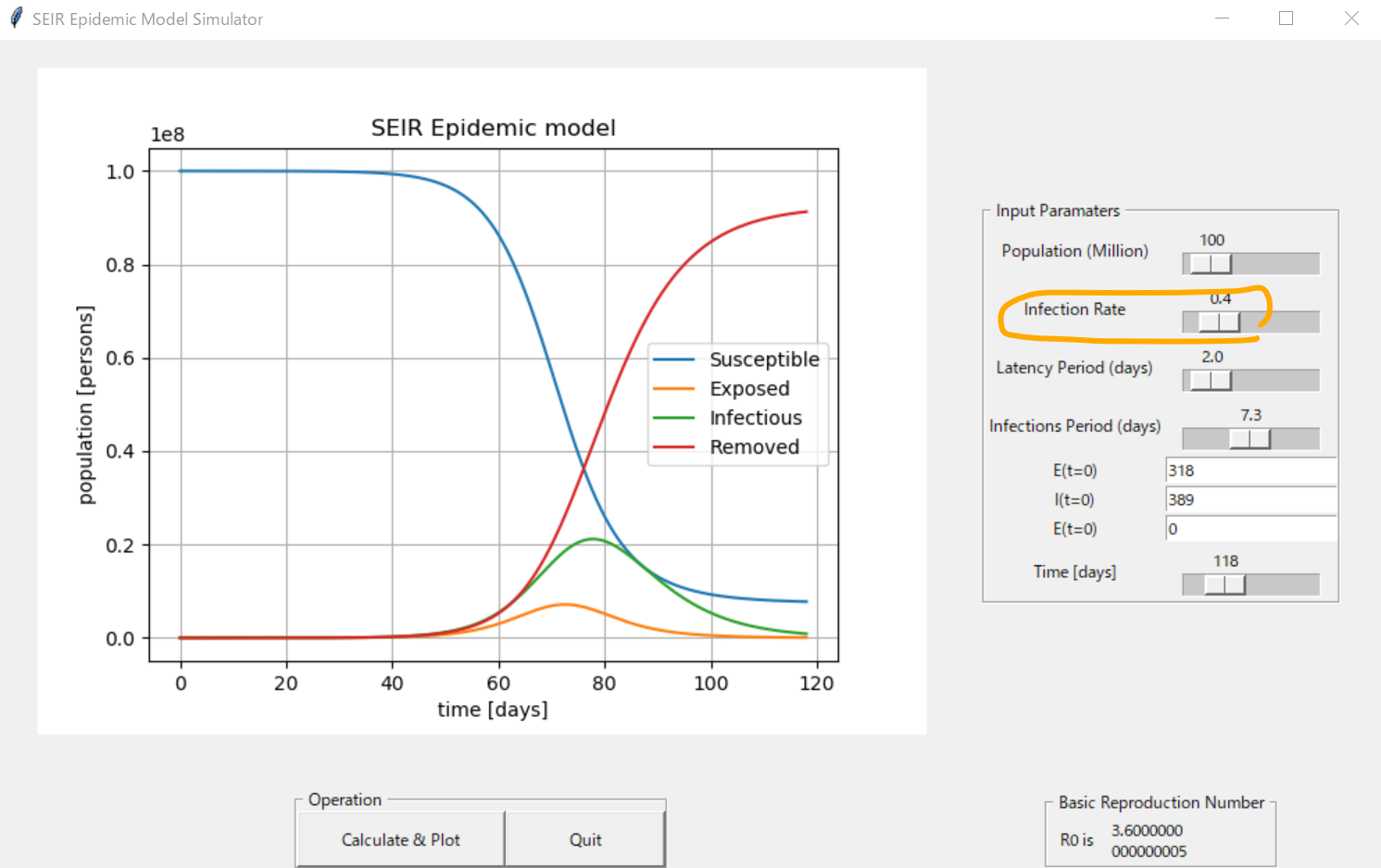
- 投稿日:2020-03-19T17:01:46+09:00
Python未経験者が東北大学言語処理100本ノックをやってみる10~13
今日から第2章。
これの続きでーす。
Python未経験者が言語処理100本ノックをやってみる07~09
https://qiita.com/earlgrey914/items/a7b6781037bc0844744b第1章で「7時間かかった」と言ったら「仕事は?」と言われました。
もちろんしてますeん。
下準備
hightemp.txtは,日本の最高気温の記録を「都道府県」「地点」「℃」「日」のタブ区切り形式で格納したファイルである.以下の処理を行うプログラムを作成し,hightemp.txtを入力ファイルとして実行せよ.さらに,同様の処理をUNIXコマンドでも実行し,プログラムの実行結果を確認せよ.
このhightemp.txtを入力ファイルとして
・処理を行うPythonプログラムを書く
・UNIXコマンドでも同様の処理(コマンド実行)をしてみる
ってのが第2章の内容みたいです。hightemp.txtの中身はこんな感じ。
タブ区切りの24行4列のデータ。hightemp.txt高知県 江川崎 41 2013-08-12 埼玉県 熊谷 40.9 2007-08-16 岐阜県 多治見 40.9 2007-08-16 山形県 山形 40.8 1933-07-25 山梨県 甲府 40.7 2013-08-10 和歌山県 かつらぎ 40.6 1994-08-08 静岡県 天竜 40.6 1994-08-04 山梨県 勝沼 40.5 2013-08-10 埼玉県 越谷 40.4 2007-08-16 群馬県 館林 40.3 2007-08-16 群馬県 上里見 40.3 1998-07-04 愛知県 愛西 40.3 1994-08-05 千葉県 牛久 40.2 2004-07-20 静岡県 佐久間 40.2 2001-07-24 愛媛県 宇和島 40.2 1927-07-22 山形県 酒田 40.1 1978-08-03 岐阜県 美濃 40 2007-08-16 群馬県 前橋 40 2001-07-24 千葉県 茂原 39.9 2013-08-11 埼玉県 鳩山 39.9 1997-07-05 大阪府 豊中 39.9 1994-08-08 山梨県 大月 39.9 1990-07-19 山形県 鶴岡 39.9 1978-08-03 愛知県 名古屋 39.9 1942-08-02私はPython実行環境としてAWS Cloud9を利用していますので、
そちらに本txtファイルをアップしてから開始です。余談ですけど、Cloud9は本当に便利ですね。
Cloud9でネイティブGUIアプリの開発もできると嬉しいなぁと思ってます(おかしな事を言っている)10. 行数のカウント
行数をカウントせよ.確認にはwcコマンドを用いよ.
えーと。まずPythonでtxtファイルを読み込む方法っと。
これは知ってる。.pyと同じところに.txtを置いてるからこれで大丈夫でしょう。yomikoku.pywith open('hightemp.txt') as f: s = f.read() print(s)Traceback (most recent call last): File "/home/ec2-user/knock/02/enshu11.py", line 6, in <module> with open('hightemp.txt') as f: FileNotFoundError: [Errno 2] No such file or directory: 'hightemp.txt'あらー。ダメなのね。
~3分ほどググる~
<参考URL>
https://qiita.com/nagamee/items/b7d1b02074293fdfdfffkorede.pyimport os.path #このpyファイルのある場所を原点とする os.chdir((os.path.dirname(os.path.abspath(__file__)))) with open('hightemp.txt') as f: s = f.read() print(s)高知県 江川崎 41 2013-08-12 埼玉県 熊谷 40.9 2007-08-16 :これでOK。
このos.chdir((os.path.dirname(os.path.abspath(__file__))))のおまじない?は今後も書いていっていいものなのだろうか?
実行環境によって必要だったり不要(というか書いてはダメ)だったりしそう・・・で、ファイルを
open()したあとにどういった形で中身を読み込むかはいくつかやり方があるようだ。
今回の問題では「行数をカウントせよ」とのことなので、行単位でリストにしてくれるreadlines()を使うのがいいだろう。enshu10.pyimport os.path #このpyファイルのある場所を原点とする os.chdir((os.path.dirname(os.path.abspath(__file__)))) with open('hightemp.txt') as f: s = f.readlines() print(len(s))24簡単でござる。
UNIXコマンドでも同じことをしろとのことなので実行。[ec2-user@ip-172-31-34-215 02]$ wc -l hightemp.txt 24 hightemp.txtファイル名が邪魔だな。
catをかまそう。[ec2-user@ip-172-31-34-215 02]$ cat hightemp.txt | wc -l 2411. タブをスペースに置換
タブ1文字につきスペース1文字に置換せよ.確認にはsedコマンド,trコマンド,もしくはexpandコマンドを用いよ.
なんか1章より簡単じゃない?
eunshu11.pyimport os.path os.chdir((os.path.dirname(os.path.abspath(__file__)))) with open('hightemp.txt', mode="r") as f: s = f.read() tikango = s.replace("\t", " ") with open('hightemp.txt', mode="w") as f: f.write(tikango)hightemp.txt高知県 江川崎 41 2013-08-12 埼玉県 熊谷 40.9 2007-08-16 岐阜県 多治見 40.9 2007-08-16 山形県 山形 40.8 1933-07-25 山梨県 甲府 40.7 2013-08-10 和歌山県 かつらぎ 40.6 1994-08-08 静岡県 天竜 40.6 1994-08-04 山梨県 勝沼 40.5 2013-08-10 埼玉県 越谷 40.4 2007-08-16 群馬県 館林 40.3 2007-08-16 群馬県 上里見 40.3 1998-07-04 愛知県 愛西 40.3 1994-08-05 千葉県 牛久 40.2 2004-07-20 静岡県 佐久間 40.2 2001-07-24 愛媛県 宇和島 40.2 1927-07-22 山形県 酒田 40.1 1978-08-03 岐阜県 美濃 40 2007-08-16 群馬県 前橋 40 2001-07-24 千葉県 茂原 39.9 2013-08-11 埼玉県 鳩山 39.9 1997-07-05 大阪府 豊中 39.9 1994-08-08 山梨県 大月 39.9 1990-07-19 山形県 鶴岡 39.9 1978-08-03 愛知県 名古屋 39.9 1942-08-02ターミナルでもsedで置換してみる。
[ec2-user@ip-172-31-34-215 02]$ sed -i -e "s/\t/ /g" hightemp.txt [ec2-user@ip-172-31-34-215 02]$ cat hightemp.txt 高知県 江川崎 41 2013-08-12 埼玉県 熊谷 40.9 2007-08-16 岐阜県 多治見 40.9 2007-08-16 山形県 山形 40.8 1933-07-25 山梨県 甲府 40.7 2013-08-10 和歌山県 かつらぎ 40.6 1994-08-08 静岡県 天竜 40.6 1994-08-04 山梨県 勝沼 40.5 2013-08-10 埼玉県 越谷 40.4 2007-08-16 群馬県 館林 40.3 2007-08-16 群馬県 上里見 40.3 1998-07-04 愛知県 愛西 40.3 1994-08-05 千葉県 牛久 40.2 2004-07-20 静岡県 佐久間 40.2 2001-07-24 愛媛県 宇和島 40.2 1927-07-22 山形県 酒田 40.1 1978-08-03 岐阜県 美濃 40 2007-08-16 群馬県 前橋 40 2001-07-24 千葉県 茂原 39.9 2013-08-11 埼玉県 鳩山 39.9 1997-07-05 大阪府 豊中 39.9 1994-08-08 山梨県 大月 39.9 1990-07-19 山形県 鶴岡 39.9 1978-08-03 愛知県 名古屋 39.9 1942-08-012. 1列目をcol1.txtに,2列目をcol2.txtに保存
各行の1列目だけを抜き出したものをcol1.txtに,2列目だけを抜き出したものをcol2.txtとしてファイルに保存せよ.確認にはcutコマンドを用いよ.
なんか一気に簡単になってしまいやる気減。
enshu12.pyimport os.path os.chdir((os.path.dirname(os.path.abspath(__file__)))) with open('hightemp.txt', mode="r") as f: linedata = f.readlines() for l in linedata: with open('col1.txt', mode="a") as c1: c1.write(l.split(" ")[0] + "\r") with open('col2.txt', mode="a") as c2: c2.write(l.split(" ")[1] +"\r")col1.txt高知県 埼玉県 岐阜県 山形県 山梨県 和歌山県 静岡県 山梨県 埼玉県 群馬県 群馬県 愛知県 千葉県 静岡県 愛媛県 山形県 岐阜県 群馬県 千葉県 埼玉県 大阪府 山梨県 山形県 愛知県col2.txt江川崎 熊谷 多治見 山形 甲府 かつらぎ 天竜 勝沼 越谷 館林 上里見 愛西 牛久 佐久間 宇和島 酒田 美濃 前橋 茂原 鳩山 豊中 大月 鶴岡 名古屋cutコマンドはこうでしょ。
[ec2-user@ip-172-31-34-215 02]$ cut -f 1 -d " " hightemp.txt > col1_command.txt [ec2-user@ip-172-31-34-215 02]$ cut -f 2 -d " " hightemp.txt > col2_command.txtdiffで比較っと・・・
[ec2-user@ip-172-31-34-215 02]$ diff col1.txt col1_command.txt 1c1,24 愛知県県 \ No newline at end of file --- > 高知県 > 埼玉県 > 岐阜県 > 山形県 > 山梨県 > 和歌山県 > 静岡県 > 山梨県 > 埼玉県 > 群馬県 > 群馬県 > 愛知県 > 千葉県 > 静岡県 > 愛媛県 > 山形県 > 岐阜県 > 群馬県 > 千葉県 > 埼玉県 > 大阪府 > 山梨県 > 山形県 > 愛知県アレッ!?
cat col1.txtでも表示されないからこれは・・・
改行コードのせいだ!
ということで改行コードを\rから\nに変え、ファイル書き込み時のエンコードもUTF-8を指定しました。enshu13.pyimport os.path os.chdir((os.path.dirname(os.path.abspath(__file__)))) with open('hightemp.txt', mode="r") as f: linedata = f.readlines() for l in linedata: with open('col1.txt', mode="a", encoding="utf-8") as c1: c1.write(l.split(" ")[0] + "\n") with open('col2.txt', mode="a", encoding="utf-8") as c2: c2.write(l.split(" ")[1] +"\n")実行確認
[ec2-user@ip-172-31-34-215 02]$ python3 enshu12.py [ec2-user@ip-172-31-34-215 02]$ [ec2-user@ip-172-31-34-215 02]$ cut -f 1 -d " " hightemp.txt > col1_command.txt [ec2-user@ip-172-31-34-215 02]$ cut -f 2 -d " " hightemp.txt > col2_command.txt [ec2-user@ip-172-31-34-215 02]$ diff col1.txt col1_command.txt [ec2-user@ip-172-31-34-215 02]$ diff col2.txt col2_command.txt [ec2-user@ip-172-31-34-215 02]$おっけーでーす。
13. col1.txtとcol2.txtをマージ
12で作ったcol1.txtとcol2.txtを結合し,元のファイルの1列目と2列目をタブ区切りで並べたテキストファイルを作成せよ.確認にはpasteコマンドを用いよ.
たぶんこんな感じでいけるけど、もっといいやり方ないかしら?
tabun.pywith open col1.txt すべての行を配列1に入れる with open col2.txt すべての行を配列2に入れる for[i] 出力ファイル = write(配列1[i] + "\t" + 配列2[i])~20分後~
enshu13.pyimport os.path os.chdir((os.path.dirname(os.path.abspath(__file__)))) linedata_col1 = [] linedata_col2 = [] with open('col1.txt', mode="r") as f: linedata_col1 = f.read().splitlines() with open('col2.txt', mode="r") as f: linedata_col2 = f.read().splitlines() with open('merge.txt', mode="a", encoding="utf-8") as f: for c1, c2 in zip(linedata_col1, linedata_col2): f.write(c1 + "\t" + c2 + "\n")merge.txt高知県 江川崎 埼玉県 熊谷 岐阜県 多治見 山形県 山形 山梨県 甲府 和歌山県 かつらぎ 静岡県 天竜 山梨県 勝沼 埼玉県 越谷 群馬県 館林 群馬県 上里見 愛知県 愛西 千葉県 牛久 静岡県 佐久間 愛媛県 宇和島 山形県 酒田 岐阜県 美濃 群馬県 前橋 千葉県 茂原 埼玉県 鳩山 大阪府 豊中 山梨県 大月 山形県 鶴岡 愛知県 名古屋工夫ポイントは
linedata_col1 = f.read().splitlines()です。
f.readlines()で1行ずつ読み込むのもアリなんだけど、それだと↓のように改行コード込みのリストになってしまいます。readlinesdato.pywith open('col1.txt', mode="r") as f: linedata_col1 = f.readlines() print(linedata_col1)['高知県\n', '埼玉県\n', '岐阜県\n', '山形県\n', '山梨県\n', '和歌山県\n', '静岡県\n', '山梨県\n', '埼玉県\n', '群馬県\n', '群馬県\n', '愛知県\n', '千葉県\n', '静岡県\n', '愛媛県\n', '山形県\n', '岐阜県\n', '群馬県\n', '千葉県\n', '埼玉県\n', '大阪府\n', '山梨県\n', '山形県\n', '愛知県\n']この改行コードをわざわざ消すくらいなら、
read()で改行コード込みでブロックオブジェクトとして読み込み、改行コードでsplit()してリスト化するのがベストだと思いました。ではpasteとの比較。
[ec2-user@ip-172-31-34-215 02]$ python3 enshu13.py [ec2-user@ip-172-31-34-215 02]$ paste col1.txt col2.txt > merge_command.txt [ec2-user@ip-172-31-34-215 02]$ diff merge.txt merge_command.txt [ec2-user@ip-172-31-34-215 02]$なんだか簡単かつ、ファイルを挟むので結果検証が面倒になってきたぞ。
続きは明日にしよ~かな~
ここまで2時間かかりました!!ダラダラやってなので今回はあまり参考にならないかと。
- 投稿日:2020-03-19T16:30:16+09:00
Pythonで毎日AtCoder #10
はじめに
前回
10日目です。#10
問題
2WA
考えたこと
まず、文字列がどのように増えていくかを考えると、文字nの長さは
$n^0,n^1,n^2,...........n^{5*10^{15}}$になります。すると末項はkの最大値よりも大きくなるので、kの範囲で1以外の文字が答えになります。ですので、forで1以外の要素を探しています。s = str(input()) k = int(input()) for i in range(min(len(s),k)): if s[i] != '1': print(s[i]) quit() print('1')まとめ
次のAGCもがんばるぞい。では、また
- 投稿日:2020-03-19T16:29:59+09:00
ガウス過程を観て理解
はじめに
構成
この記事は
- 前半:観測データと推測点
- 後半:ベイズ更新と共分散行列
と分かれています。
(ゆるい)前提
一応、前記事
を読んでいること前提でお話しします。
ただ、記事の独立性はある程度あるので、
わからない単語があればそちらを見るようにする程度で(多分)結構です。前半:観測データと推測点
要するに
ガウス過程はいかに、
図1→図2へと、どのように推測の信頼度を向上させていくか?
(図でいうピンク色の、推定の信頼区間の幅を減らしていくか?)というお話です。
図1
図2
図1 図2 https://distill.pub/2019/visual-exploration-gaussian-processes/
前半では、入力データセットを一回だけ入れて、
ガウス過程がどう変化するかを観ます。
(学習の過程は後半に書きます)データ入力する前
データ入力前の、ガウス過程の出力はこうなります
図3 入力データなし出力
図3 https://distill.pub/2019/visual-exploration-gaussian-processes/
まあ……当然ですね。直線。
事前分布が多変量ガウス分布、平均0で正規化されているので。
この直線が、実際はどう生まれたのか?
どう計算されたか?について理解するため、
ガウス過程の理論的な側面に少し触れます。ベイズ的背景
そもそも、ガウス過程はベイズ系機械学習です。
ここで、ベイズ系機械学習という言葉で意味しているのは。
- 事前分布
- 尤度計算
- ベイズ更新(学習) 「事後分布 = 尤度×事前分布」
となっているもののことです。
これに、ガウス過程も属します。
ベイズ系機械学習と、ガウス過程について、絵で見て見ると
下のようになります。
(ベイズの、主観的確率、の説明に
よく赤い球と青い球が入った袋、サイコロが使われます)図4
図4 持橋『ガウス過程と機械学習』より
つまり、事前分布に従い取り出すものが、
- 赤い球や青い球
- サイコロの目
- 関数の束
になっているのが、
ガウス過程と言えます。ここでいう関数の束、の「関数」とは、
「多変量ガウス分布」、の一次元の場合。なのですが、
「多変量ガウス分布」について、
詳しくは、いずれ触れます。未来の記事への参照(予定)
今回は「観て理解」のコンセプトなので、
参考の図を貼っておきます。下図5は、二次元の場合の、多変量ガウス分布の例です。
(正確にはそれからのサンプリングですが)図5
図5 持橋『ガウス過程と機械学習』より
共分散行列(ガウス過程の文脈では、カーネルとも言います)
のΣの値によって、散布図が変わっているのがわかると思います。後半:ベイズ更新と共分散行列
さきほど、
共分散行列=カーネル
と言いました。
- その共分散行列とは何か、
- ベイズ更新に従う変化について、理解しましょう!
共分散行列(=カーネル)
ガウス過程が「関数の箱」から取り出す、
多変量ガウス分布とは。n個のガウス分布(正規分布)が、
その学習時点での共分散行列(=カーネル)
に従って相関して出てきたものを指します。
つまり、ガウス過程は
ベイズ更新するカーネル法
とも言えます。
ここが、共分散行列が、ガウス過程で「カーネル」と
呼ばれるゆえんでもあります。学習の前は、大抵RBFカーネル
(Radial Basis Function = ガウス分布 なので、ガウスカーネルともいう)
を、共分散行列の初めの値として設定することが多いです。
(ガウス過程の共分散行列がさらにガウス分布カーネル、というと「ガウス」という
言葉が出過ぎて混乱を招くので、RBFカーネルということが多いです)学習をまだしていないRBFカーネルと、その出力のガウス過程は、
図6のようになります。図6
図6 持橋『ガウス過程と機械学習』
n次共分散行列、のnの値が大きいほど、
RBFカーネルは、
滑らかな関数を出す(そこからのサンプルが取れる)ことが
観て分かると思います。(実際、RBFカーネルを共分散行列とする多変量ガウス分布は、
C_∞級です)
学習法(視覚的理解)
共分散行列の値をベイズ更新していくのが、
ガウス過程における「学習」です。いわゆるベイズ更新とは、
事後分布=尤度*事前分布
で表されるものです。
これにより、事前分布、事後分布のガウス過程が変わっていきます。
ガウス過程のもともとRBFカーネルだった共分散行列が
変化していくと、例えば次のようになります。図7
図7 (実は、そのうち紹介する「深層ベイズ学習」の一種の、学習過程動画のスクショです)https://youtu.be/Tjjq2fCY8Fc
学習法のベイズ更新については、
次回以降にまわします(今回は視覚的理解をする記事なので)さらっとだけ具体的な数式と、
学習過程のガウス過程の出力に触れると、図8
図9
図8、図9 持橋『ガウス過程と機械学習』
おわりに
記事が長くなりすぎると良くないので、
数式的な理解は次回以降に飛ばします。あと、深層ベイズについても
(最後の出力がガウス過程だったり、ガウス過程を複数段重ねたりします)
いずれ触れます。ご覧になっていただきありがとうございました。
ご意見などはコメントで。
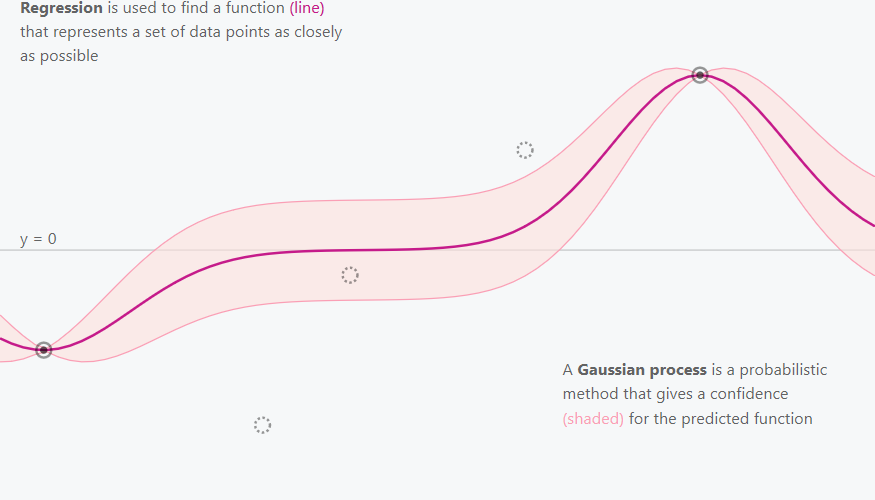
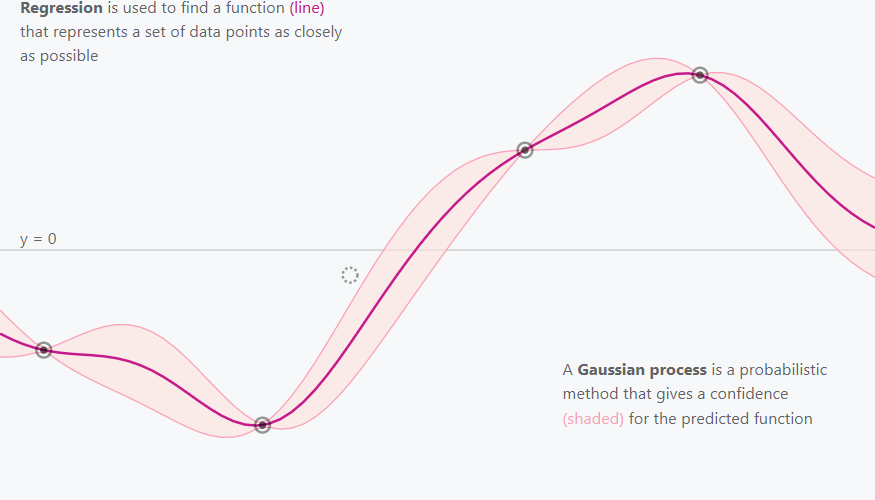
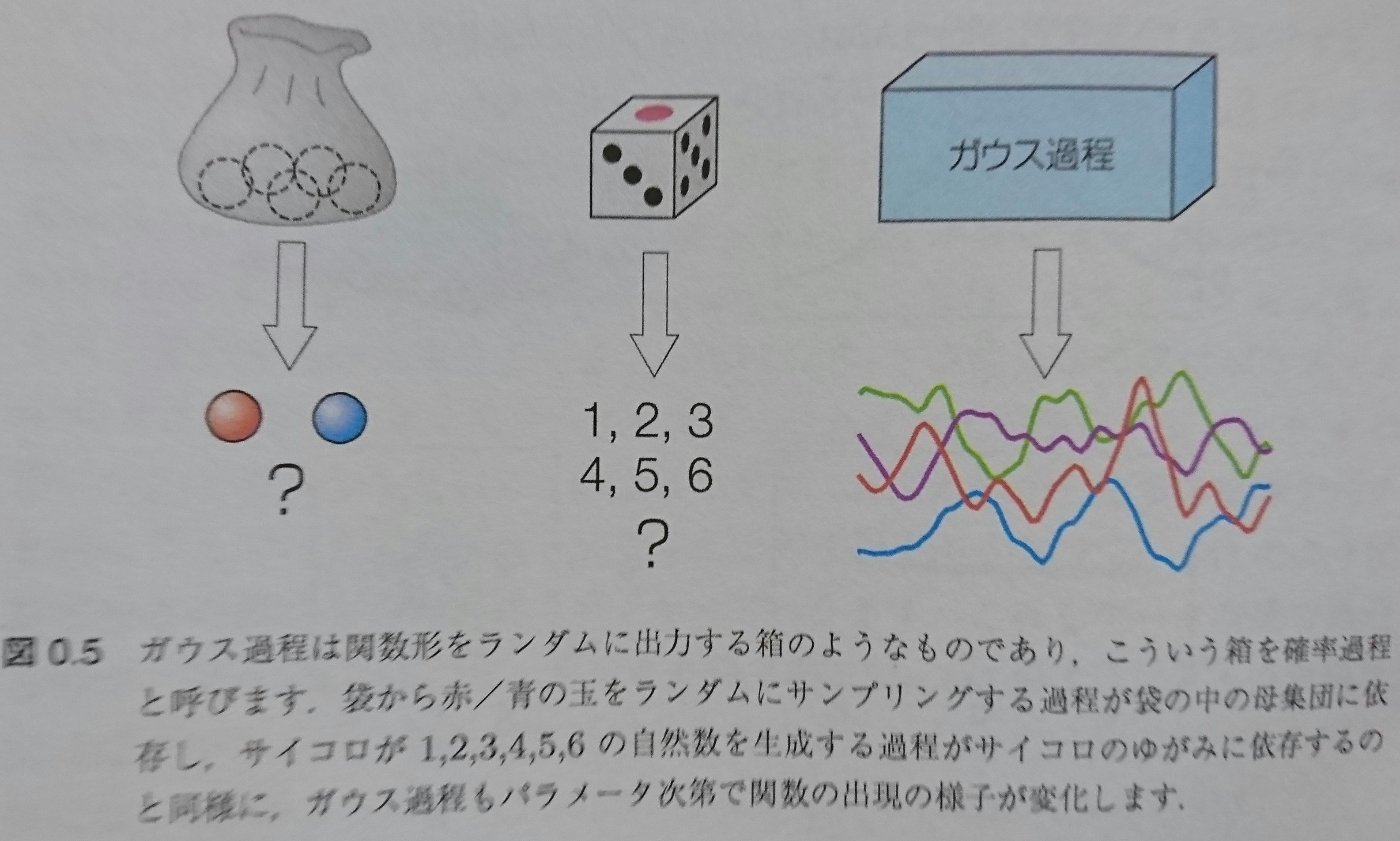
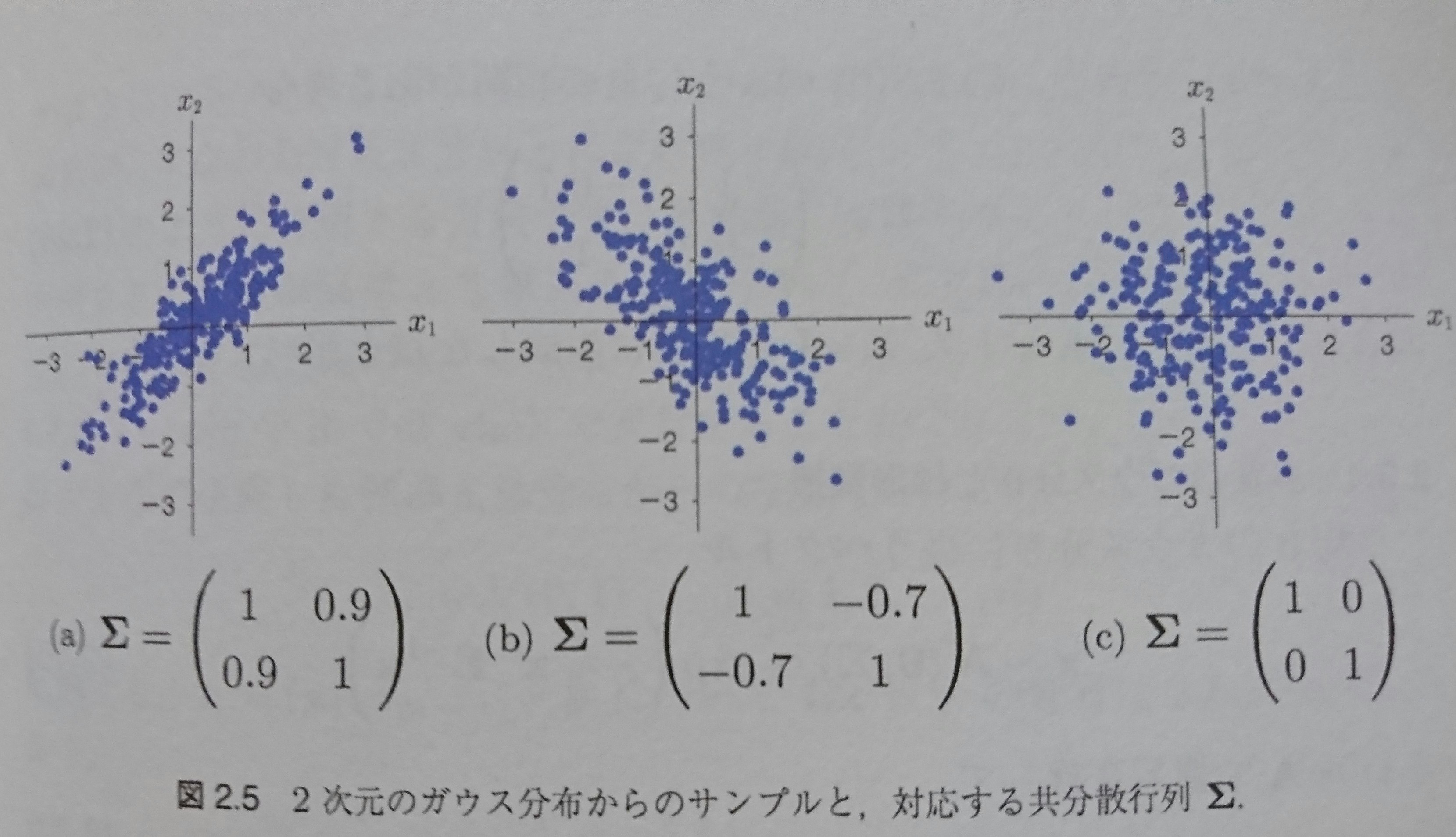
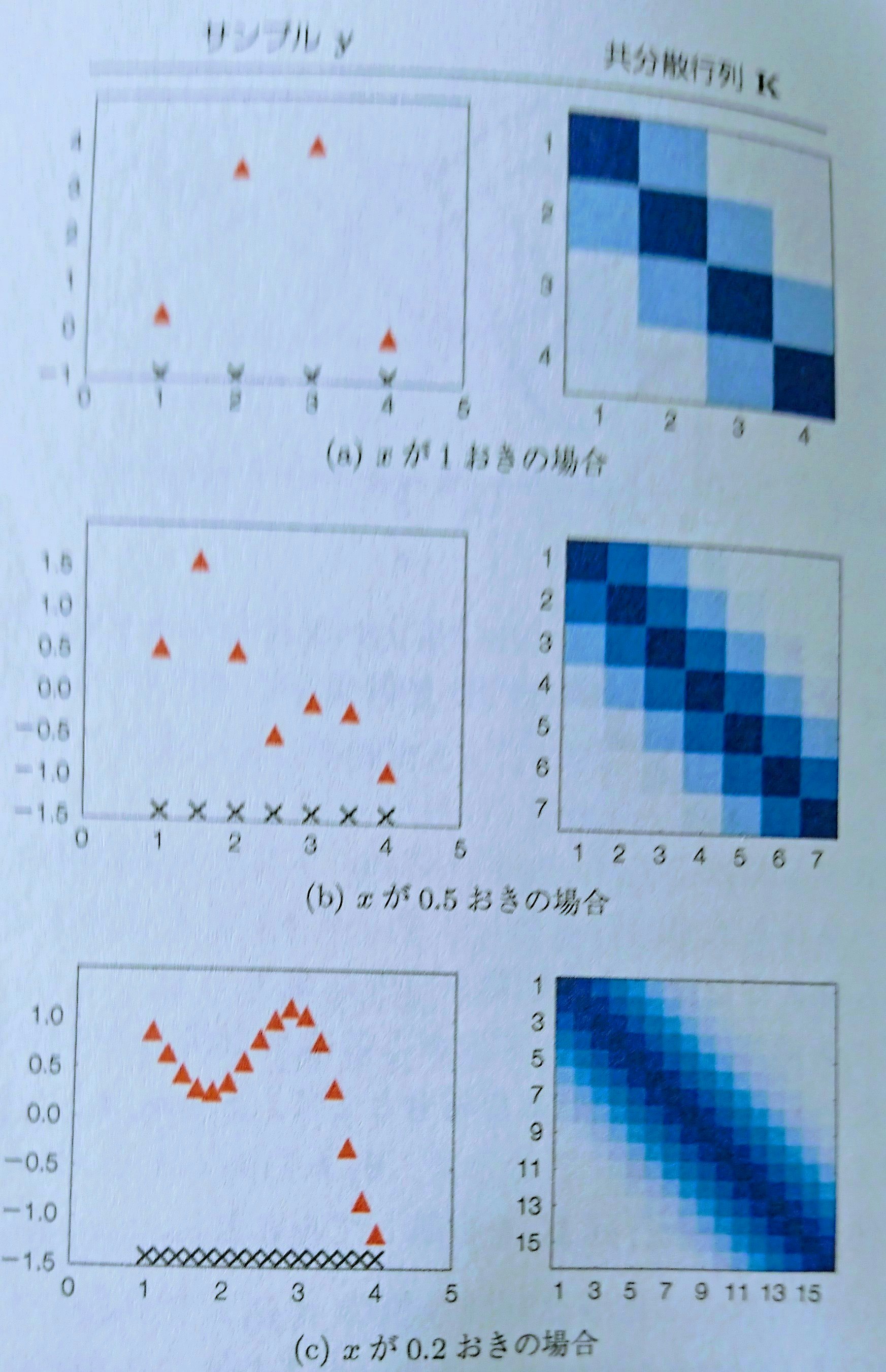

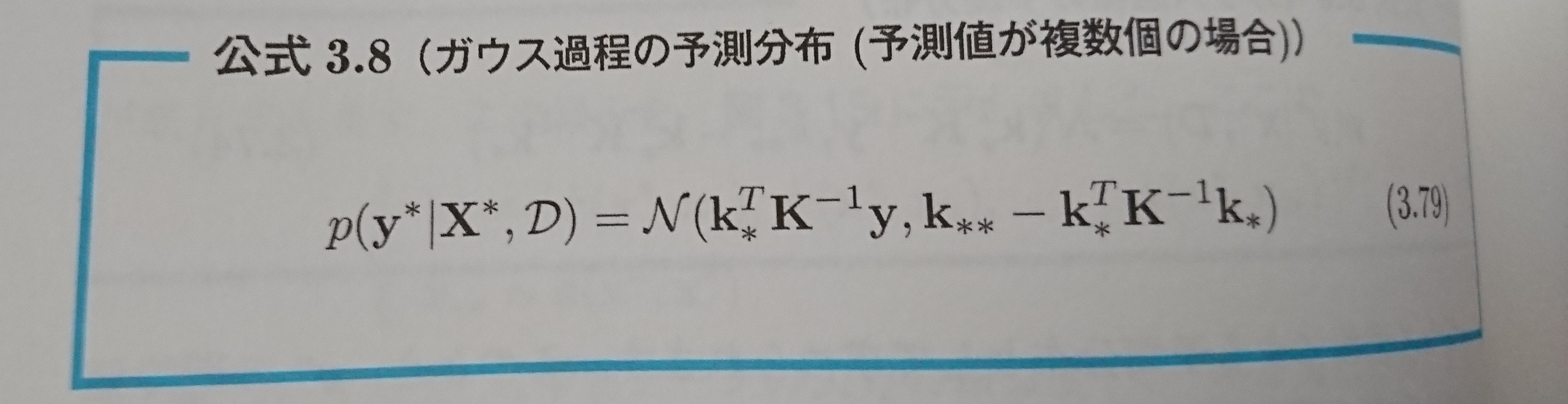

- 投稿日:2020-03-19T16:29:15+09:00
感染症流行過程の数理モデルをPythonで解く
注意!この記事はなんとなくやってみた以上の情報を含みません。
感染症数理モデル
昨今のCOVID19事情を受けて色々感染症の数理モデルの話は出ていると思うわけですが、それをPythonのodeintで解いて、そのままmatplotlibで可視化してみよう、という事です。
くどいようですがこの記事のなんかを適当に実装した結果からCOVID19に関して何かのお気持ちを表明しては駄目だぞ。で、解くのは一番簡単なSIRモデルとしまして、
\begin{align} \frac{\mathrm{d} S}{\mathrm{d} t} & = - \beta I S\\ \frac{\mathrm{d} I}{\mathrm{d} t} & = \beta I S - \gamma I\\ \frac{\mathrm{d} R}{\mathrm{d} t} & = \gamma I \end{align}としておきます。
$\beta$は感染率(/(人x時間))で、病気にかかった人間ひとりが単位時間あたりに感染す事のできるまだ伝染していない人の人数、$\gamma$は治癒率(/時間)で、治癒までにかかる時間の逆数です。
$S$はまだ感染した事がなく、かつ感染能力も無い人間の数、$I$は感染しておりかつ他人に感染させる能力をもつ人間の数、$R$は隔離・治癒・死亡などで感染しているあるいはいたが他人に感染させる能力を失った人間の数です。Python code
面倒くさいので特に解説とかは無しのコードベタ貼り。
import numpy as np from scipy.integrate import odeint import matplotlib.pyplot as plt from matplotlib.widgets import Slider, Button def solve(value, t, foi, rr): # fio = force of infection (beta) # rr = recovery rate S, I, R = value dSdt = - foi * I * S dIdt = foi * I * S - rr * I dRdt = rr * I return [dSdt, dIdt, dRdt] span = 100 t = np.linspace(0, span, 256) initial_value = [0.9, 0.1, 0] # initial values for S, I, R solution = odeint(solve, initial_value, t, args = (0.5, 0.5)) fig, ax = plt.subplots(figsize=(12, 6)) plt.xlim(0, span) plt.ylim(0, 1) plt.subplots_adjust(bottom = 0.2) data_S, = plt.plot(t, solution[:, 0], "blue", label = "Susceptible") data_I, = plt.plot(t, solution[:, 1], "red", label = "Infectious") data_R, = plt.plot(t, solution[:, 2], "orange", label = "Removed") plt.legend(loc = "best") rr_slider = Slider(plt.axes([0.2, 0.02, 0.65, 0.02]), "recovery rate", 0, 1, valinit = 0.5, valstep = 0.1) foi_slider = Slider(plt.axes([0.2, 0.05, 0.65, 0.02]), "force of inf.", 0, 1, valinit = 0.5, valstep = 0.1) def update(val): rr = rr_slider.val foi = foi_slider.val solution = odeint(solve, initial_value, t, args=(foi, rr)) data_S.set_ydata(solution[:, 0]) data_I.set_ydata(solution[:, 1]) data_R.set_ydata(solution[:, 2]) fig.canvas.draw_idle() rr_slider.on_changed(update) foi_slider.on_changed(update) plt.show()実行結果
こんなのが出てくるんじゃないかなと思います。
ちなみに感染率と治癒率はどの程度の値が正しいのかよくわからなかったので、適当につまみを作って値をいじれるようにしておいたので、遊んでみてください。で
まあ遊んでみてください。
あなたもパラメーターをうねうねさせながら微分方程式を解きたくなったらぜひパクってください。
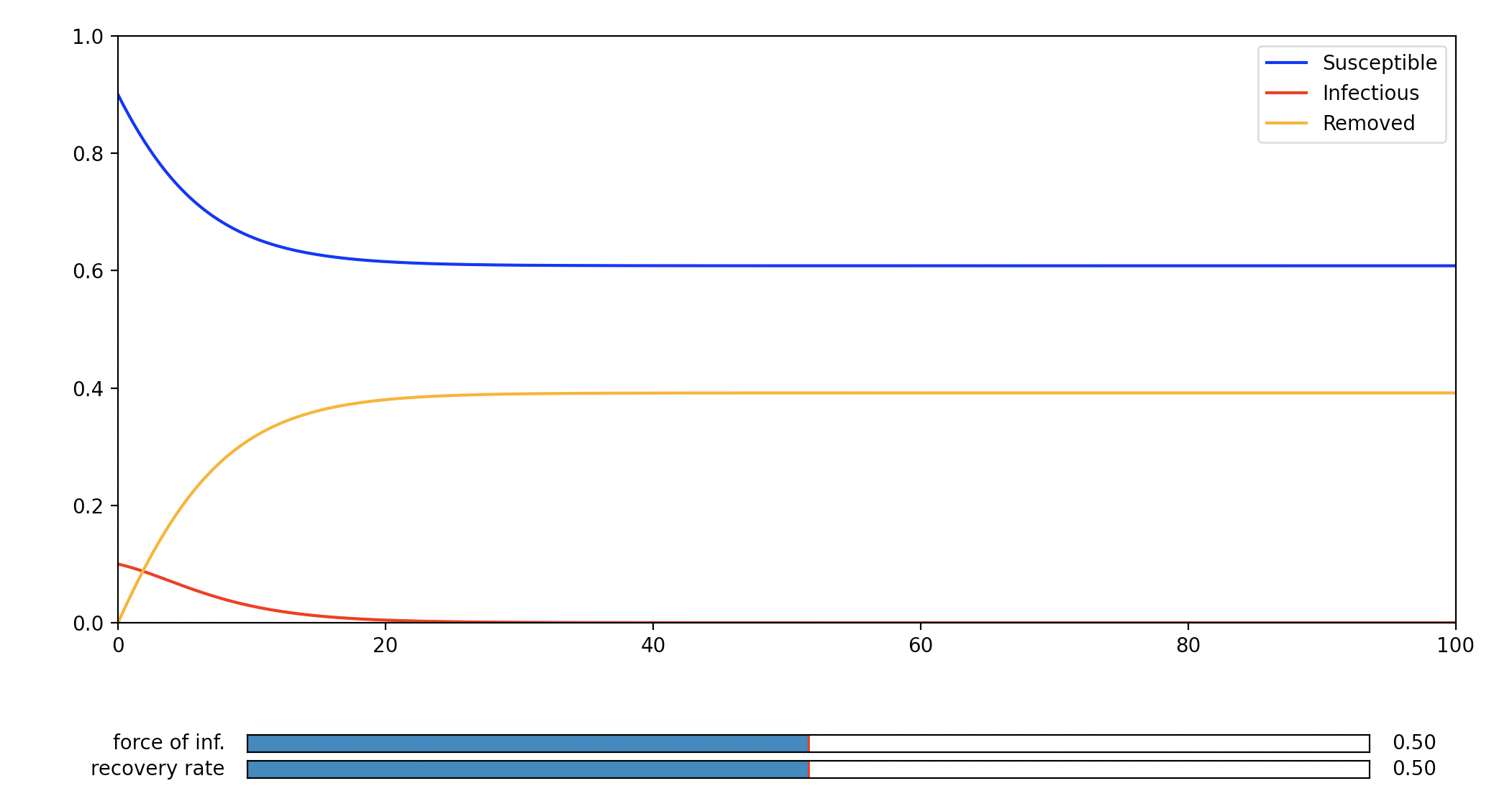
- 投稿日:2020-03-19T15:35:00+09:00
Pythonを用いた最小2乗法の実装
あらまし
最小2乗法の理論を理解したので、数式を用いて理論を説明し、標準偏差0.3のノイズが入ったデータから理論値を予想するプログラムを実装する。
最小2乗法
最小2乗法は、回帰分析の基礎となるアルゴリズムである。ここで、回帰分析は、与えられたデータがどのような関数から生み出されているかという関数関係を推測することを目標とする操作である。とある多項式の関数関係があるものと仮定して、多項式から得られる予測値と実際の観測値の誤差を最小にするようにすることで、多項式の係数を決定する。
理論
特徴変数を$x$、目的変数を$t$とする。$x$を入力すると、何らかの関数によって$t$が出力されると考える。
ここでは、データのペア$(x, t)$が$N$個あるとする。この$N$個のデータから、関数関係を推定したい。
仮定する多項式を、
$$
\begin{align}
f(x) &= w_{0} + w_{1}x + w_{2}x^{2} + \cdots + w_{M}x^{M} \\
&=\sum_{m=0}^{M}w_{m}x^{m} \qquad(1)
\end{align}
$$
とする。
ここで、$M$は次数であり、決まった値を取るものとすると、係数${w_{m}}$が未知のパラメーターとして残る。このパラメーターをうまく決定することで、与えられたデータを正確に再現する多項式を推定したい。
推定した多項式と実際の観測値との誤差$E$を、以下の式で定義する。
$$
E = \{f(x_1) - t_1\}^2 + \{f(x_2) - t_2\}^2 + \cdots + \{f(x_N) - t_N\}^2 \qquad \tag{2}
$$
計算の都合上、(2)式を1/2倍した式を$E_d$とする。$E_d$は、以下の式で表せる。
$$
E_d = \frac{1}{2}\sum_{n=0}^{N}\{f(x_n) - t_n\}^2 \qquad \tag{3}
$$
(2)式を最小にする条件と(3)式を最小にする条件は等しいので、どちらで計算を進めても結果は不変である。(1)式を(3)式へ代入する。
$$
E_d = \frac{1}{2}\sum_{n=0}^{N}\Bigr(\sum_{m=0}^{M}w_{m}x_{n}^{m} - t_n\Bigr)^2 \tag{4}
$$
となる。この$E_d$が最小となるようなパラメーターを求める。この手法を最小2乗法という。以降、(4)式を最小にするような$\{w_m\}^M_{m=0}$を決定する。これは、(4)式を$\{w_m\}^M_{m=0}$の関数といなした際の偏微分係数が0となるという条件を考えれば良い。
$$\frac{\partial E_d}{\partial w_m} = 0 (m = 0, ..., M) \tag{5}
$$
(5)式に(4)式を代入して偏微分を計算すると以下のようになる。ここで、添え字$m$が被らないよう、(4)式の$m$を$m'$へ変更する。
$$\sum_{n=1}^{N}(\sum_{m'=0}^{M}w_{m'}x_n^{m'}-t_n)x_n^m = 0 \tag{6}
$$
これを、次のように変形する。
$$\sum_{m'=0}^{M}w_{m'}\sum_{n=1}^{N}x_n^{m'}x_n^m - \sum_{n=1}^{N}t_{n}x_{n}^{m} = 0 \tag{7}
$$ここで、$x_n^m$を$(n, m)$成分とする$N \times (M+1)$行列$\Phi$を用いると、これは、行列形式で書き直すことが可能である。
$$ \boldsymbol{w}^T\Phi^T - \boldsymbol{t}^T\Phi = 0 \tag{8}
$$
$\boldsymbol{w}$は、$\boldsymbol{w} = (w_0, w_1, ..., w_M)^T$であり、求めたい係数を並べたベクトルである。(8)式を$\boldsymbol{w}$について解けば良い。すなわち、$E_d$を最小にする求めるべき係数は以下の通り。
$$\boldsymbol{w} = (\Phi^T\Phi)^{-1}\Phi^Tt \tag{9}
$$実践
予想したい理論式
今回は、最小二乗法を用いて、高校数学でお馴染みの$y = cos(x)$を予想する。ノイズとして、[-0.3, 0.3]の偏差を含めた$y = cos(x)$の値100個をデータセットとする。
ソースコード
main.py#!/usr/bin/env python # coding: utf-8 import math import numpy as np import matplotlib.pyplot as plt def cos_f(x): '''理論値の計算''' return np.cos(2*np.pi*x) def return_weight(M): '''指定された次元の重みベクトルを出力''' #データセットを並べた行列Φの準備 phi = np.zeros([N+1, M+1]) #N行M列の配列を用意 for i in range(0, N+1): for j in range(0, M+1): phi[i][j] = math.pow(x[i], j) #観測値x_iのj乗をphi[i][j]に格納 #行列Φを用いて、重みベクトルwを計算 w = np.matmul(np.dot(np.linalg.inv((np.dot(np.transpose(phi), phi))), np.transpose(phi)), y) #matmul 行列積の計算 #linalg.inv 逆行列の計算 #transpose 転置行列の計算 return w def f(x, w): '''多項式f(x)の値を出力''' #xはベクトルではない #wはベクトル result = 0.0 for i in range(0, len(w)): result += pow(x,i) * w[i] return result def calc_E(x, w): '''二乗誤差を出力''' result = 0.0 for i in range(0, N+1): result += ((f(x[i], w) - y[i])**2)/2 result = math.sqrt((2*result)/N) return result if __name__ == '__main__': N = 100 #データの個数 M = [1, 2, 3, 4, 7, 10] #次元 #データセットを用意 x = np.linspace(0, 1, N+1) y = [] for i in range(N+1): y.append(np.cos(2*np.pi*x[i]) + np.random.normal(-0.3,0.3)) i=1 plt.figure(figsize=(15,12)) for m in M: # 多項式の次数 w = return_weight(m) e = calc_E(x, w) plt.subplot(2,3,i) plt.scatter(x, y, color="orange", s=5) plt.plot(x,cos_f(x), label=("theoretical value"), color="blue") plt.plot(x,f(x, w), label="predicted value", color="red") plt.title("dimension:" + str(m) + "\nE_rms = %.4f" % e) plt.subplots_adjust(hspace=0.6) plt.legend(loc=4) i+=1 plt.show()実行結果
左上から順に次元を1, 2, 3, 4, 7, 9に制限した場合の実行結果を示している。それぞれ青色のグラフは理論値、赤色のグラフは最小二乗法から予想された値、そして橙色の点はデータセットを示している。結果を観察してみる。1次元の場合は、予想したグラフは直線になっている。これは、多項式が$y = w_0+w_1x$という一次式からなるためである。次数が上がれば上がるほど、グラフの形は複雑になっている。このうち、予想式が元の理論式である$y = cos(x)$に最も近いのは、4次元の時である。次数をそれ以上に上げると、過剰適合が発生しグラフの形がいびつになった。まとめ
最小二乗法の勉強をしたので、理論と実践に用いたソースコード、及び実行結果を記した。
参考文献
『ITエンジニアのための機械学習理論入門』中井悦司, 技術評論社(2015).

- 投稿日:2020-03-19T14:59:06+09:00
【Django】pollsアプリに新規質問作成機能を追加
Djangoの公式ドキュメントで投票アプリを作成した後に機能を追加したい
Djangoの公式ドキュメントに沿って一通りフレームワークの仕組みを学んだ後、機能を追加してみたいと思い、実装してみることにした。
はじめに
・Djangoの公式ドキュメントでは、簡単な投票アプリを1から作成しながらDjangoに触れ、学ぶことができる。
・Djangoの公式ドキュメントで初めてDjangoに触れてみたが、初学者にとっては解説が丁寧ではないと感じ、アプリ作成の途中で本チュートリアルで学ぶことを停止し、UdemyのDjango 教材(Djangoで検索して一番売れていたもの)で基礎の基礎を学ぶことにした。
・Udemyの教材でDjangoの基礎の基礎を学んだ後、公式ドキュメントに立ち返り投票アプリを作成完了させた。
環境
・Python 3.8.2
・django 3.0.3
・OSはWindows10とmacOSの両方追加機能作成(質問&選択肢の新規作成)
公式ドキュメントで作成した投票アプリは、質問と選択肢を追加するために管理ユーザー画面を使わなければならない。
一般ユーザー画面でも新規作成画面を追加しようと思う。実装方法
・CreateViewを用いた実装を行う
・質問一覧ページに質問作成ページへのリンクを作成する
・最初にQuestionテーブルに新規質問を作成する
・その後に、質問に紐づいた新規選択肢を作成する完成イメージ
コード
[views.py]
polls/views.py#importは省略 #省略 class QuestionCreate(CreateView): #template_name = 'polls/createquestion.html' model = Question fields = ('question_text',) success_url = reverse_lazy('polls:index') class ChoiceCreate(CreateView): model = Choice fields = ('choice_text',) success_url = reverse_lazy('polls:index') def dispatch(self, request, *args, **kwargs): self.question = get_object_or_404(Question, pk=kwargs['question_id']) return super().dispatch(request, *args, **kwargs) def form_valid(self, form): form.instance.question = self.question return super().form_valid(form)①テンプレートの名前を「 template_name = (任意の画面名).html 」 と記述しなかった(コメントアウトしている)のは、
画面名を「 モデル名_form.html 」とすればCreateViewと画面が自動的に紐づくから。
※画面名を任意の名前にしたい場合は、template_nameを指定する必要がある。②fieldsの中に指定するカラムが1つの場合、カラム名の後にカンマ( , )が必要
③一番厄介なのは
ChoiceCreate
dispatchは何をしているのかというと、、
既存のViewクラスのメソッドであるdispatchをオーバーライドしている。choiceはquestionと紐づけなければならないため、
dispatchでquestion_idを指定している。基本的に汎用ビュー(CreateViewなど)の中で
def XXXX():といった形はオーバーライドしているケースが多いと考えられる。(異論は認めます。。。)気になる方は、汎用ビューの定義を参照してみるといい。
※VScodeの場合は気になるメソッドやクラスを右クリックで「定義へ移動」をクリックすると上位クラスの中身が見られる。[urls.py]
polls/urls.py#importは省略 app_name = 'polls' urlpatterns = [ #公式ドキュメントと同様のため省略 path('question_create/', views.QuestionCreate.as_view(), name='questioncreate'), path('<int:question_id>/choice_create/', views.ChoiceCreate.as_view(), name='choicecreate'), ][models.py]
polls/models.pyclass Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published', auto_now_add=True) def __str__(self): return self.question_textpub_dateの第二引数に
auto_now_add=Trueを追加する。[templates]
polls/templates/polls/index.html{% if latest_question_list %} <ul> {% for question in latest_question_list %} <li><a href="{% url 'polls:detail' question.id %}">{{ question.question_text }}</a> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %} <a href="{% url 'polls:questioncreate' %}">New Question</a>最後の行に、新規質問作成画面へのリンクを追加する。
polls/templates/polls/question_form.html<form method="post">{% csrf_token %} {{ form.as_p }} <input type="submit" value="Save"> </form>polls/templates/polls/choice_form.html<form method="post">{% csrf_token %} {{ form.as_p }} <input type="submit" value="Save"> </form>最後に
最後までご覧いただきありがとうございました!
本記事は私のQiita初投稿のため、つたない部分も大いにあったと思いますが、同じような機能追加に困っている方の一助になればと思います。
私はこの実装に結構時間がかかったので。。。基本的に汎用ビューは1つのモデルに対応しています。
今回のアプリは2つのテーブルに新規の内容を追加しなければならないため、質問作成と選択肢作成を別々で実装しました。本当は1つの画面で質問とそれに紐づく選択肢を作成したかったのですが、私のいまの技術では実装することができませんでした。
QuestionとChoiceのテーブルを結合してしまえばできたのかもしれませんが、、、今回は新規作成機能を追加してみましたが、他にも編集・削除機能の追加も検討中です。
余裕があればQiitaに投稿しようと思います。ご指摘・ご質問等ございましたらお気軽に@hiyoku0918へご連絡ください!
- 投稿日:2020-03-19T11:23:56+09:00
Python上でShellファイルを呼び出した後、CSVをParquetに変換する。
全体的にやりたいこと
大量のCSVファイルをParquetに直す必要があるが、
そもそもCSVファイルのヘッダーにカラム名行が存在しないため、
・CSVファイルにヘッダー追加
・CSVをParquetに変換
この2ステップを行うツールを作成する必要がありました。<<前提>>
CSVのヘッダーに追加するカラム名がParquetファイルの値に対するタイトルとなります。
もし、ヘッダー行が存在せず、いきなりデータが存在する場合、
出力したParquetファイルの各タイトルは、1行目のデータとなってしまいます。PythonからShellを呼び出す
CSVのヘッダー行を追加する処理はPythonでも書くことができましたが、
Shellで比較的簡単に追加可能だったので、
Shellで作成し、そのファイルをPythonから呼び出すようにしました。qiita.pyimport subprocess # comment cmd = './add_header.sh' subprocess.call(cmd, shell=True)subprocessでShellを指定することで、
外部のShellファイルを呼び出すことができます。add_header.sh##!/usr/bin/env bash for file in `\find from_dir -maxdepth 1 -type f`; do gsed -i '1iheader1,header2' $file donegsed呼び出し時の「1i」が必要になります。
gsed・・・gnu-sedのインストールをお願いします。
■実行結果CSVファイルのヘッダー
header1,header2CSVをParquetに変換
S3上に存在する大量のCSVファイルをParquetに変換する必要がありました。
ファイルは全てローカルにダウンロードしている状態です。qiita2.pyimport pyarrow as pa import pyarrow.parquet as pq import pandas as pd import glob from_dir = './from_dir/' to_dir = './to_dir/' #from_dir内のCSVを全て読み込む files = glob.glob(from_dir + "*", recursive=True) #1ファイルずつ変換し、to_dirに格納する for file in files: path_name = file.split('/') df = pd.read_csv(file) table = pa.Table.from_pandas(df) pq.write_table(table, to_dir + path_name[2] + '.pq')csvファイルの読み込み、出力はpandas
Parquetへの変換はpyarrowで簡単に可能です
- 投稿日:2020-03-19T10:39:10+09:00
全上場企業の過去5年間の決算情報をCSVファイルに変換
はじめに
前回の記事では金融庁のEDINETというサイトから得たXBRL形式のデータから決算書の情報を得る方法について書きました。
その後EDINETでは EDINET API というWebAPIが公開され自動でXBRLファイルをダウンロードできるようになりました。
今回は全上場企業の過去5年間のXBRLファイルをダウンロードして、CSVファイルに変換するプログラムを作ってみました。
処理結果のCSVファイルは以下にあります。
http://lkzf.info/xbrl/data/summary-join.csv
以下のように1行ごとに決算情報が書かれています。
決算の数値は連結決算の値です。
簡単な応用例
表計算ソフト(LibreOffice Calc)を使ってCSVファイルから売上総利益率(粗利率)の度数分布表を作ってみました。
ほかにもいろんな使い方があると思います。
CSVファイルの作成手順
アプリのソースは前回の記事と同じGitHubに入っています。
https://github.com/teatime77/xbrl-reader
Wikiに簡単な説明があります。
* データのダウンロードとCSVファイルへの変換
* コンテキストとCSVファイル財務分析のサンプルアプリ
CSVファイルのデータを使って財務分析をするウェブアプリも作ってみました。
以下のURLからアプリにアクセスできます。
http://lkzf.info/xbrl/chart/
ChromeとFireFoxで動作を確認しています。
グラフの描画にPlotly.jsを使いました。
ソースはGitHubにあります。
https://github.com/teatime77/xbrl-chartおわりに
アプリを作ったばかりなので、今はYahoo!ファイナンス などを見ながら数値が合ってるか調べているところです
まちがいなどがあれば、コメント欄に書くかTwitterまでご連絡をお願いします。
teatime77
今後はこのソースコードが多くの人に使ってもらえるようにソースやドキュメントの整理をしていきたいと思います。ここまで読んでいただき、ありがとうございました。