- 投稿日:2020-03-19T23:23:21+09:00
AWS API GatewayのAPIタイプ概要
動機
AWS API Gateway を触る機会があったので、メモする。REST API と HTTP API の機能比較を簡単にまとめる。
REST API と HTTP API の概要
よくある質問から抜粋した内容を下記に記載する。
HTTP API は次のような場合に適しています。
1. AWS Lambda または HTTP エンドポイント用のプロキシ API を構築する
2. OIDC および OAuth2 の認証を備えた最新の API を構築する
3. 非常に大規模になる可能性があるワークロード
4. レイテンシーに敏感なワークロード用の APIREST API は次のような場合に適しています。
1. API の構築、管理、公開に必要なすべての機能が含まれているセットに対して単一価格の支払いを希望されるお客様。HTTP API は REST API と比較して機能を絞っている分、低レイテンシー低コストをウリとしているらしい。レイテンシーの差異について解説しているドキュメントは見つけられなかったが、料金については Amazon API Gateway の料金に記載があり、単純計算で HTTP API の場合 REST API の約1/3のコストとなるようだ。
REST API と HTTP API の比較
基本的な機能比較はChoosing Between HTTP APIs and REST APIsに書いてある。その他、気になった点について記載する。
レスポンステンプレート
REST API
レスポンステンプレート(Gateway Response)が提供されており、レスポンス構造のカスタマイズができる。HTTP API
テンプレートが提供されていないので変更することはできない。例えば認証に失敗した場合に返すJSONオブジェクトのキーはデフォルトの値から変更できず、下記のようになる。{ "message": "Missing Authentication Token" }バックエンドに設定できるHTTPエンドポイント
REST API は VPC LinkによりVPC内にあるプライベートなHTTPエンドポイントへのリクエストを可能にする。Set up API Gateway Private Integrations
HTTP API でもつい数日前にβ版が取れ、REST API と同機能を利用できるようになったらしい。試してはいない。Working with VPC Links for HTTP APIsその他
ドキュメント内容に差分があり、多少混乱した。日本版ドキュメントは更新が遅いようなので参考程度に留めておくべき。
所感
REST API と HTTP APIの機能差分はより細かくあるはずなので、随時更新したい。
- 投稿日:2020-03-19T22:00:46+09:00
AWSマネジメントコンソールにフェデレーテッドログインしてみた。
はじめに
皆さん、業務でAWSは使われているでしょうか。
AWS、インフラの構築から運用までいろいろサポートしてくれていて、とても便利ですよね。
それこそインフラ担当だけじゃなくて、CloudWatchやセッションマネージャーのような環境に接続するすべての関係者にとってメリットがある機能なんかもよくリリースされています。ところで (問題提起)
これらの素晴らしいAWSの機能って、インフラ担当ばっかりメリットを享受していて、コンサルタントや製品開発者にはあまり届いてこないことが多いです。
何故かというと、「マネジメントコンソール」を使える人間が限られているからです。
AWSはどんどんいい機能を出してくれるのに、それを使える人間が限られているのはとてももったいないですよね。
かといって、それらをいろんな人が使えるようにインターフェースを実装するのは大変ですし、AWSが機能拡張するたびに対応する必要があるのも格好が悪いです。だったら (解決案)
AWSのあらゆる機能にアクセスできる最強のインターフェース、「マネジメントコンソール」を「AWSユーザーが割り当てられていない人」にも使えるようにしたらいいんじゃないか。
これが、本記事の本題になります。今回使うもの
1.Amazon Cognito
https://dev.classmethod.jp/cloud/aws/what-is-the-cognito/
Cognito は、2014年7月に発表された ユーザーのアイデンティティ をテーマにしたサービスです。「こぐにーと」と読みます。
簡単に言うと、AWS内のリソースをユーザーごとに分けて提供できる機能で、例えばAさん専用のファイルアップロード領域を作ったりできます。2.カスタム ID ブローカーに対する AWS コンソールへのアクセスの許可
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles_providers_enable-console-custom-url.html#STSConsoleLink_programPython
組織のネットワークにサインインするユーザーに対して AWS マネジメントコンソール への安全なアクセスを許可するには、そのための URL を生成するコードを記述して実行できます。この URL は、AWS から取得したサインイントークンを含み、それを使って AWS に対してユーザーを認証します。3.Python(boto3)
boto3というモジュールを使って、pythonでAWSのAPIを操作します。
https://aws.amazon.com/jp/sdk-for-python/どう使うのか (概要)
「Amazon Cognito」のIDPoolを使用することで、アクセス権限を制限したポリシーを持つAWSユーザーを払い出すことができます。
これらはアクセスキーも持っているので、それを使って「カスタム ID ブローカーに対する AWS コンソールへのアクセスの許可」で提示されているログインURLを生成することができます。
これらを行うためにはAWSアカウント上にいくつかのリソースの準備が必要であるため、それらも説明していきます。AWSリソースの準備
1.AWSリソース操作に使用するユーザーに、アクセス権限を追加
AmazonCognitoPowerUserポリシー、AmazonCognitoDeveloperAuthenticatedIdentitiesポリシーをアタッチしてください。
2.IDPoolの作成
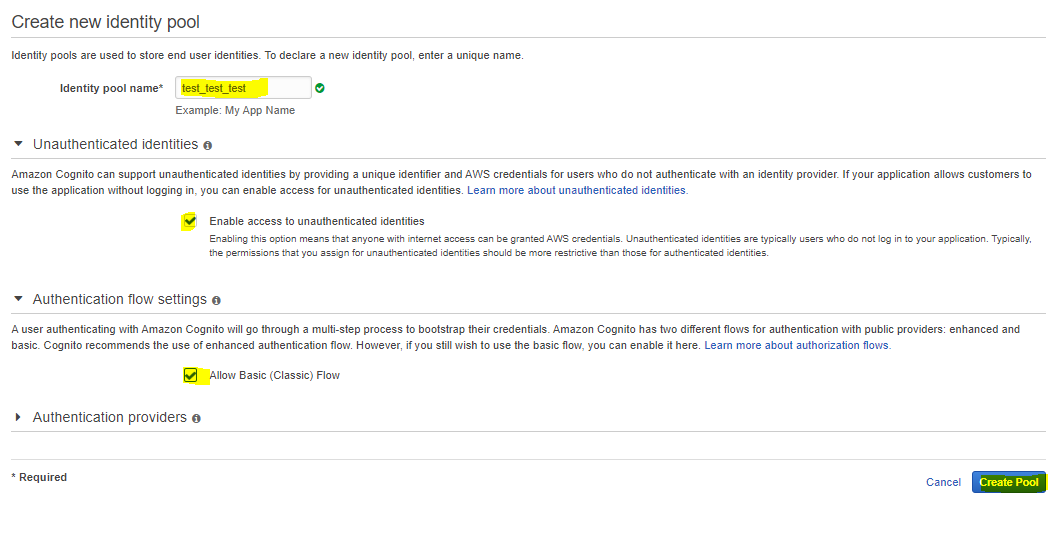
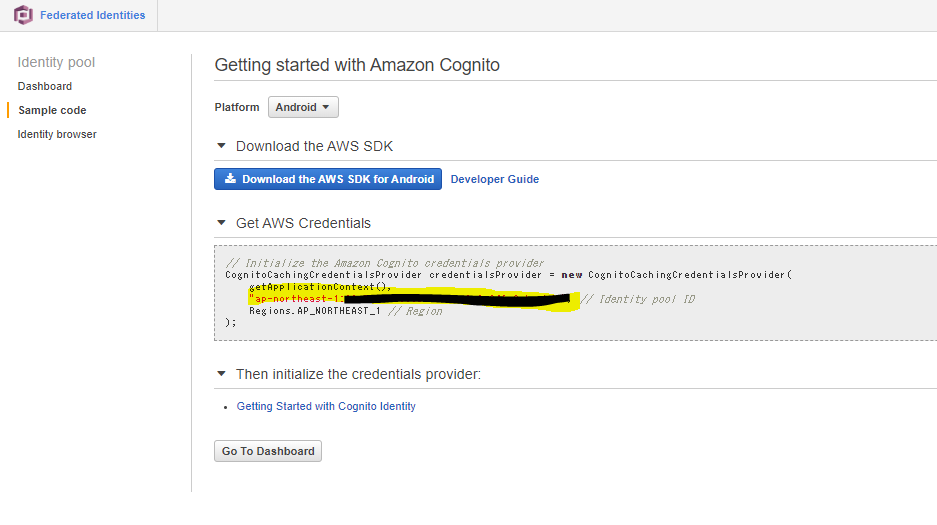
以下のURLから、ユーザーの情報を保管しておくIDPoolという領域を作成してください。
https://ap-northeast-1.console.aws.amazon.com/cognito/create/?region=ap-northeast-1#
1.Identity Pool Name = 好きな名前を付けましょう。2.Unauthenticated Identitiesで匿名IDを許可するために「Enable Access to Unauthenticated Identities」にチェックを入れてください。今回、認証ロジックについては解説しないため、未認証でアクセスキーを発行します。
3.未認証ユーザーを使用する場合、基本 (クラシック) フローを使用しないと管理コンソールの使用認可を行えないので、「基本 (クラシック) フローを許可する」にチェックを入れてください。
4.プールの作成を行ってください。
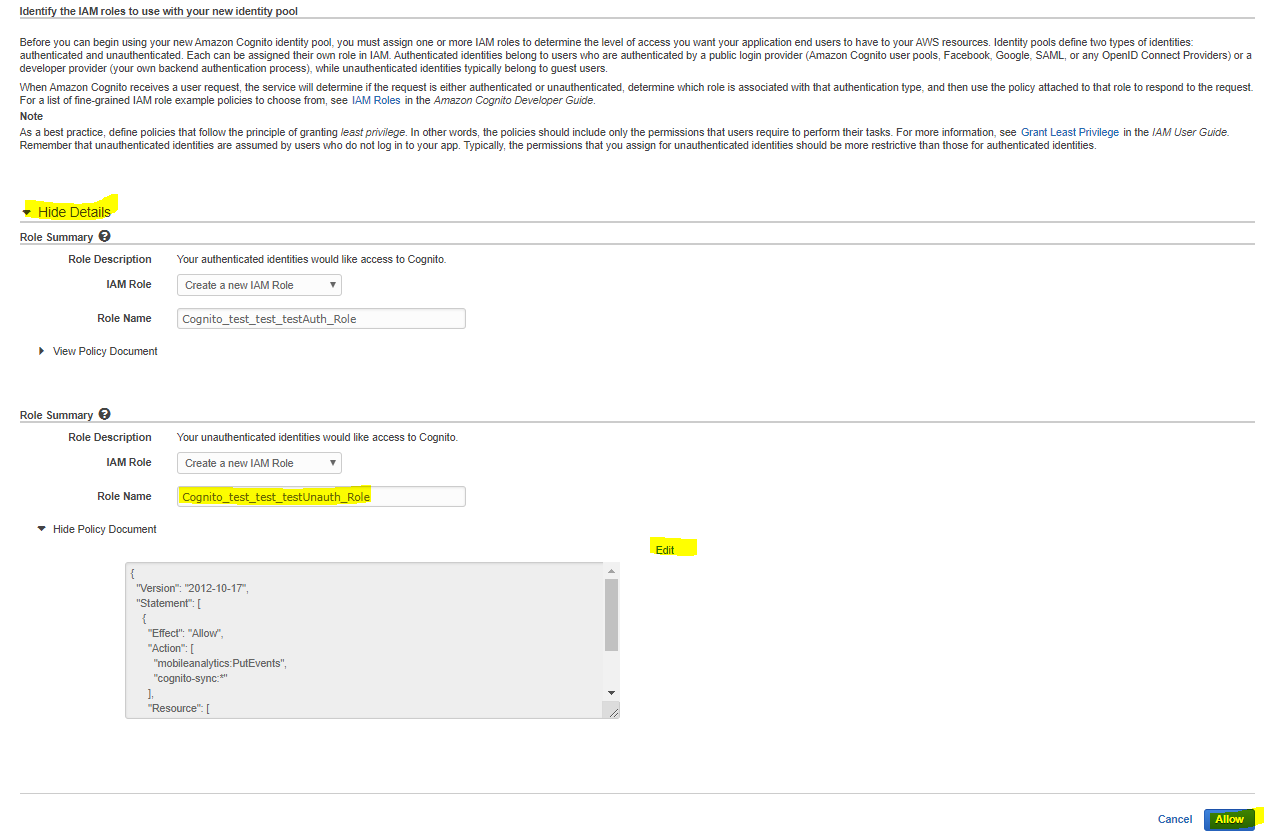
5.Identify the IAM roles to use with your new identity pool のページが表示されるので詳細の表示をしてください。(ちなみに、上が認証済みID、下がゲストIDの設定)
6.新しいロールの作成をします。認証済み、未認証それぞれで権限を変えることができるので、Unauth ・Authedそれぞれを作成しましょう。ちなみに、今回Authedは使う予定がないので中身は適当でも問題ありません。
7.Unauth にReadOnlyAccessと以下をアタッチしましょう。今回はセッションマネージャーを使用可能なゲスト用ロールにしてみます。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Cognito", "Effect": "Allow", "Action": [ "mobileanalytics:PutEvents", "cognito-sync:*", "sts:GetFederationToken" ], "Resource": [ "*" ] }, { "Sid": "Ssm", "Effect": "Allow", "Action": [ "ssmmessages:CreateDataChannel", "s3:GetEncryptionConfiguration", "ssm:UpdateInstanceInformation", "ssmmessages:OpenDataChannel", "ssmmessages:OpenControlChannel", "ssmmessages:CreateControlChannel", "ssm:StartSession" ], "Resource": "*" } ] }8.サンプルコードのところに書いてあるIDプールのIDをメモしておいてください。
Pythonの実装
1.以下のpythonのコードからcredentialの設定部分をcognitoに置き換えたlogin_test.pyを実装します。
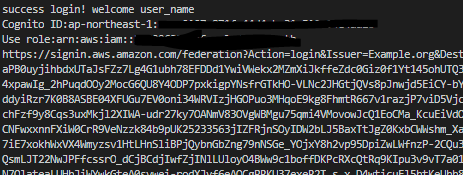
#!/usr/bin/env python3 # -*- coding: utf-8 -*- #以下のように実行します。 #python3 login_test.py user_name import urllib, json, sys import requests import boto3 import datetime _args = sys.argv _USER = _args[1] _AWS_ACCOUNT = "123456789012" _CONV_AWS_ACCESS_KEY_ID = "ASIA*******:" _CONV_AWS_SECRET_ACCESS_KEY = "**********" _CONV_AWS_SESSION_TOKEN = "*********" _REGION_NAME = "ap-northeast-1" _ID_POOL_ID = "手順8でメモしておいたものを使用します。" _ARN = "arn:aws:cognito-identity:ap-northeast-1:123456789012:identitypool/ap-northeast-1:*******" _ROLE_ARN = "arn:aws:iam::123456789012:role/Unauth" class TestClass(): def cognito_auth(self): try: #cognitを操作するためのclient作成 cognito_client = boto3.client('cognito-identity', region_name = _REGION_NAME, aws_access_key_id = _CONV_AWS_ACCESS_KEY_ID, aws_secret_access_key = _CONV_AWS_SECRET_ACCESS_KEY, aws_session_token = _CONV_AWS_SESSION_TOKEN #MFAを使用していないなら不要 ) #ID取得 user_id = cognito_client.get_id( AccountId = _AWS_ACCOUNT, IdentityPoolId = _ID_POOL_ID )["IdentityId"] print("Cognito ID:"+user_id) except: raise Exception("get id faild.") try: #Role設定確認 roles = cognito_client.get_identity_pool_roles(IdentityPoolId=_ID_POOL_ID)["Roles"]["unauthenticated"] print("Use role:"+roles) # GetOpenIdToken + AssumeRoleWithWebIdenity token = cognito_client.get_open_id_token( IdentityId=user_id ) sts_client = boto3.client('sts', region_name = _REGION_NAME, aws_access_key_id = _CONV_AWS_ACCESS_KEY_ID, aws_secret_access_key = _CONV_AWS_SECRET_ACCESS_KEY, aws_session_token = _CONV_AWS_SESSION_TOKEN #MFAを使用していないなら不要 ) d_today = str(datetime.date.today()) credentials_for_identity = sts_client.assume_role_with_web_identity( RoleArn = _ROLE_ARN, RoleSessionName = _USER + "-" + d_today,#ログの頭に付く文字列 誰のセッションか識別できる情報を入れよう。 WebIdentityToken = token["Token"] ) AccessKeyId = credentials_for_identity["Credentials"]["AccessKeyId"] SecretKey = credentials_for_identity["Credentials"]["SecretAccessKey"] SessionToken = credentials_for_identity["Credentials"]["SessionToken"] except: #id削除 #失敗したときは無駄に作成したidは消しておこう。 del_response = cognito_client.delete_identities( IdentityIdsToDelete=[ user_id ] ) raise Exception("cognito_auth faild.","delete id :"+str(del_response["ResponseMetadata"]["RequestId"])) url_credentials = {} url_credentials['sessionId'] = AccessKeyId url_credentials['sessionKey'] = SecretKey url_credentials['sessionToken'] = SessionToken json_string_with_temp_credentials = json.dumps(url_credentials) request_parameters = "?Action=getSigninToken" request_parameters += "&SessionDuration=43200" if sys.version_info[0] < 3: def quote_plus_function(s): return urllib.quote_plus(s) else: def quote_plus_function(s): return urllib.parse.quote_plus(s) request_parameters += "&Session=" + quote_plus_function(json_string_with_temp_credentials) request_url = "https://signin.aws.amazon.com/federation" + request_parameters r = requests.get(request_url) # Returns a JSON document with a single element named SigninToken. signin_token = json.loads(r.text) # Step 5: Create URL where users can use the sign-in token to sign in to # the console. This URL must be used within 15 minutes after the # sign-in token was issued. request_parameters = "?Action=login" request_parameters += "&Issuer=Example.org" request_parameters += "&Destination=" + quote_plus_function("https://console.aws.amazon.com/") request_parameters += "&SigninToken=" + signin_token["SigninToken"] request_url = "https://signin.aws.amazon.com/federation" + request_parameters # Send final URL to stdout print (request_url) def main(self): print("success login! welcome "+_USER) self.cognito_auth() if __name__ == "__main__": TC = TestClass() TC.main()2.login_test.pyを実行します。
login_test.pyは、実行されるまでにユーザーが認証を通したという前提で実装されています。
なので、これ単体でたたくとそれだけでアカウントが発行され、とても長いログイン用のURLが発行されます。
そのURLにアクセスすると、マネジメントコンソールの画面にリダイレクトされ、フェデレーテッドログインに成功します。
権限はReadOnlyに加え、セッションマネージャーも許可しているので、EC2からどのインスタンスが立っているか確認したり、セッションマネージャーを使用して環境にアクセスしたりすることができます。おわりに
今回は、AWSマネジメントコンソールに対してAWSユーザーを発行されていないユーザーがログインできるようにしました。
この仕組みを使えば、IAMで個別にアカウントを管理して、退職者が出たりするたびにメンテナンスする必要もなく、お手軽にマネジメントコンソールを提供することができます。
マネジメントコンソールはAWSが勝手に強化してくれるので、我々の開発工数をかけずに業務効率化を継続して行えるようにもなります。
とても便利ですので、ぜひ一度お試しください。私もAWS初心者(クラウドプラクティショナー程度)であるため、ご指摘・ご質問・ご感想はどのようなものでもありがたくいただく所存です。
何かございましたら、ぜひコメントを頂ければと存じます。以上、お疲れ様でした。

- 投稿日:2020-03-19T21:41:16+09:00
【AWS】CDKで出力されるテンプレートからCDKMetadataを除く方法
TL;DR
- コマンドで制御するならこれ
cdk synth {app_name} --version-reporting falsecdk synth {app_name} --no-version-reporting
- 設定ファイルで管理したい場合
- cdk.jsonに
"versionReporting": falseを加える{ "app": "...", "versionReporting": false }
- 詳しいことはここの「Opting Out from Version Reporting」見てください
なぜ除きたいか
- 社内のルールでは、AWSのリソース管理は基本的にCFNテンプレート管理
- テンプレートを出荷して商用環境に適用する
- CDKMetadataはcdkのversionなどが含まれるので、CDKのversionupをするとdiffが生まれてしまう。
- リポジトリ内のCFNテンプレートすべてが変わってしまうので、本当に見てほしいDiffが隠れる
除くとなにが消える?
- CDKMetadataだけでなく、CDKMetadataAvailableも消えます
- CDKMetadata: - Type: AWS::CDK::Metadata - Properties: - Modules: aws-cdk=1.24.0,@aws-cdk/aws-iam=1.24.0,@aws-cdk/core=1.24.0,@aws-cdk/cx-api=1.24.0,@aws-cdk/region-info=1.24.0,jsii-runtime=Python/3.8.1 - Condition: CDKMetadataAvailable -Conditions: - CDKMetadataAvailable: - Fn::Or: - - Fn::Or: - - Fn::Equals: - - Ref: AWS::Region - - ap-east-1 - - Fn::Equals: - - Ref: AWS::Region - - ap-northeast-1 - - Fn::Equals: - - Ref: AWS::Region - - ap-northeast-2 - - Fn::Equals: - - Ref: AWS::Region - - ap-south-1 - - Fn::Equals: - - Ref: AWS::Region - - ap-southeast-1 - - Fn::Equals: - - Ref: AWS::Region - - ap-southeast-2 - - Fn::Equals: - - Ref: AWS::Region - - ca-central-1 - - Fn::Equals: - - Ref: AWS::Region - - cn-north-1 - - Fn::Equals: - - Ref: AWS::Region - - cn-northwest-1 - - Fn::Equals: - - Ref: AWS::Region - - eu-central-1 - - Fn::Or: - - Fn::Equals: - - Ref: AWS::Region - - eu-north-1 - - Fn::Equals: - - Ref: AWS::Region - - eu-west-1 - - Fn::Equals: - - Ref: AWS::Region - - eu-west-2 - - Fn::Equals: - - Ref: AWS::Region - - eu-west-3 - - Fn::Equals: - - Ref: AWS::Region - - me-south-1 - - Fn::Equals: - - Ref: AWS::Region - - sa-east-1 - - Fn::Equals: - - Ref: AWS::Region - - us-east-1 - - Fn::Equals: - - Ref: AWS::Region - - us-east-2 - - Fn::Equals: - - Ref: AWS::Region - - us-west-1 - - Fn::Equals: - - Ref: AWS::Region - - us-west-2余談
- cdk.jsonでの制御などは意外と日本語では書かれてなかったので投稿しました。
- CDKおすすめなので、もっと広まってほしい
- 投稿日:2020-03-19T21:27:47+09:00
EC2サーバで生成した公開キーはどこからどこまでなのか
- 投稿日:2020-03-19T19:57:10+09:00
AWSが提供するサービス
IT未経験のスクール生が勉強したことをアウトプットします
AWSとは
AWSとはAmazon Web Servicesの略称で、Amazonが提供するクラウド型Webサービスの総称。
クラウドの基本的なサービスである、レンタルサーバー、データベース、ストレージを利用したデータの保存、バックアップをはじめ、ソフトウェアのオンデマンド配信、IoTシステムの構築、機会学習、画像認識といったAmazonが保有する最新の技術を利用することもできます。アプリケーションをWeb上に公開するためにはデプロイする必要があります。
AWSはデプロイするためのサーバを用意してくれます。EC2
AWSが提供するサービスの一つにEC2があります。
EC2は仮想サーバといって、LinuxやWindows 、Red Hat等様々なOSの仮想サーバをすぐに実行できる環境が用意することができます。
AWS上にデプロイするための仮想サーバを作れます。
EC2はサービス名です。自分たちで立てたサーバひとつずつのことをインスタンスと呼びますEC2のメリット
◼️低価格
Amazon EC2は新規でアカウント作成をした人には12ヶ月間の無料利用枠があります。
また料金がかかってもAmazon EC2は従量課金制のため必要以上に費用を支払うことがありません。
自分達でサーバー構築から行うオンプレミス環境に対して、圧倒的なイニシャルコストの低さがあります。経済面はもちろんのことながら、時間面も含めます。
AWSはすでに出来上がったプラットフォームを借りる形になるので、まったく真っ白な状態から自力で構築するよりも素早く、しかも低コストでスタートできます。◼️安全性・信頼性が高い
Amazon EC2はセキュリティ面の機能も充実しているため安全性・信頼性が高いです。
まずEC2インスタンスへのアクセスには鍵認証でのアクセスが必要となります。またAmazon EC2の可用性のSLAは高く99.95%になります。◼️拡張性が高い
Amazon EC2を利用していると利用しているスペックが足りなくなった時、また台数の変更をしたい時に柔軟に増減の対応をすることができます。
さらに自動的に台数の変更ができるオートスケールという機能もあるため、自分で調節をする手間も省けます。その他のサービス
Lambda
サーバーレスでプログラムを実行できる環境を提供するAWSのサービス。
通常、プログラムを開発・実行するためには、サーバーOSやアプリケーションサーバーソフトウェアを準備し、実行するためにサーバーやインスタンスを起動し続ける必要があります。こうした環境がすべてあらかじめ準備されています。Simple Storage Service (S3)
AWSが提供するオンラインストレージサービスです。
オンラインストレージなので、インターネットが接続できる環境でデータをアップロードしたり、ダウンロードしたりすることができます。
保存できるデータ容量、ファイル数に制限はありません。従量課金なので使った分だけ料金は発生しますが、容量を気にせず使用できることは大きなメリットかと思います。Relational Database Service(RDS)
データベースの機能を提供するサービスです。
通常はサーバーを準備し、データベースのライセンスをインストールして利用していきますが、RDSはサーバーの準備が不要で、構築すればすぐにデータベースを利用することができます。
- 投稿日:2020-03-19T14:48:54+09:00
AWS Lambdaのカスタムランタイムを開発する際、失敗したこと
概要
とある作業にてAWS lambdaで今度はperlを動かすことになりました。
その際、perlのライブラリ/usr/share/perl5などが見えなかったり、コマンドが実行できなかったりしたので、いろいろ調べたことをメモしておきます。
用意されているランタイム使えば余計な苦労しないのにね結論
さっさと結論だけ記載すると、以下の環境のカーネルとlibcなどの基本的なライブラリが乗っているものになります。
- Amazon Linux
- イメージ – amzn-ami-hvm-2018.03.0.20181129-x86_64-gp2
- Linux カーネル – 4.14.154-99.181.amzn1.x86_64
- ami-00a5245b4816c38e6
注意点として、このイメージは、EC2インスタンスを作るときに、クイックスタートとして表示される、Amazon Linuxのイメージとは別物ということです。
- Amazon Linux AMI 2018.03.0 (HVM), SSD Volume Type
- ami-02ddf94e5edc8e904
EC2でカスタムランタイム用のコードを作ってアップしたかった
カスタムランタイムを作成するにあたって、開発環境も含め、今回はAWS上のサービスに構築しました。
EC2でコードを開発、zipにまとめてawscliでlambdaにコードをアップロードする、まあ標準と思われる方法を使おうと思いました。自分のやった間違い
以下、公式マニュアルに記載があります。
AWS Lambda ランタイムここに、ランタイムのイメージが以下2種類あり、それぞれランタイムのバージョンごとに分かれていることがわかります。
- Amazon Linux
- Amazon Linux 2
名前 識別子 AWS SDK for Python オペレーティングシステム Python 3.8 python3.8 boto3-1.10.34 botocore-1.13.34 Amazon Linux 2 Python 3.7 python3.7 boto3-1.10.34 botocore-1.13.34 Amazon Linux さて、ここでカスタムランタイムの開発用にEC2のイメージを作るときに、クイックスタートの候補で、以下のようなものが羅列されると思います。
- Amazon Linux 2 AMI (HVM), SSD Volume Type
- Amazon Linux AMI 2018.03.0 (HVM), SSD Volume Type
カスタムランタイムのマニュアルでは、オペレーティングシステムの指定が見当たらなかったので、
Amazon Linux 2 AMI (HVM), SSD Volume Typeを選んで作ってしまいました。2だとダメなところ
そもそも、2はカーネルバージョンが違うようです。このため、libcなどのバージョンが異なり、lambdaにアップロードしたアプリケーションがそもそも起動すらしませんでした。
ここで、最初の間違いに気づき、インスタンスをAmazon Linux AMI 2018.03.0 (HVM), SSD Volume Typeに変更しますコマンドもなにも見つからない
さて、カーネルバージョンについてはこれで一致し、コンパイルしたアプリケーションが動くようにはなりました。
しかし、開発環境では実行できるコマンド、perlやawsが見つからないし、perlのコマンドをもっていってもライブラリが全く見つからなかったりしました。
そのため、足りないのを探すという作業をしつつ、最終的にはあきらめてすべてアップロードするコードの中にコピーすることとなりました。振り返りつつ、次はうまくやるために
ちゃんと指定されたイメージから開発用インスタンスを立ち上げましょう
再掲
- Amazon Linux
- イメージ – amzn-ami-hvm-2018.03.0.20181129-x86_64-gp2
- Linux カーネル – 4.14.154-99.181.amzn1.x86_64
- ami-00a5245b4816c38e6
そのうえで、perlのパッケージコントロール
cpanmやpythonのパッケージコントロールpipなどを活用し、追加したライブラリはできるだけ手元に作成したフォルダに保存し、コードとして一緒にアップロードできるように管理することが必要です。最後に要望
せめて
awsコマンドくらいlambda上で標準で使えてもいいんじゃないかなという素人考えな要望で締めたいと思います。
- 投稿日:2020-03-19T13:38:08+09:00
elasticbeanstalkにcronoを設定したので、そのconfig
Elasticbeanstalk + rails + crono
railsでcron的なものを使いたかったけど、crontabを触りたくなかったので、cronoを使うことにした.その設定ファイル(結構作るのに時間かかったので。。。)
Cronoはこちら
I would like to use something like cron with rails, but didn't want to use crontab, so I try to use crono(I know it may not be maintained, but...), here is the config which I used.環境
# rails -v Rails 6.0.2.1 # uname -a Linux ip-172-31-27-188 4.14.165-103.209.amzn1.x86_64 #1 SMP Sun Feb 9 00:23:26 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux設定ファイル
# cat .ebextensions/05_crono.config commands: create_post_dir: command: "mkdir -p /opt/elasticbeanstalk/hooks/appdeploy/post" ignoreErrors: true files: "/opt/elasticbeanstalk/hooks/appdeploy/post/50_restart_crono.sh": mode: "000755" owner: root group: root content: | #!/usr/bin/env bash EB_APP_DEPLOY_DIR=$(/opt/elasticbeanstalk/bin/get-config container -k app_deploy_dir) EB_APP_PID_DIR=$(/opt/elasticbeanstalk/bin/get-config container -k app_pid_dir) EB_APP_USER=$(/opt/elasticbeanstalk/bin/get-config container -k app_user) EB_SCRIPT_DIR=$(/opt/elasticbeanstalk/bin/get-config container -k script_dir) EB_SUPPORT_DIR=$(/opt/elasticbeanstalk/bin/get-config container -k support_dir) . $EB_SUPPORT_DIR/envvars . $EB_SCRIPT_DIR/use-app-ruby.sh PID=$EB_APP_PID_DIR/crono.pid cd $EB_APP_DEPLOY_DIR if [ -f $PID ] then su -s /bin/bash -c "kill -TERM `cat $PID`" $EB_APP_USER su -s /bin/bash -c "rm -rf $PID" $EB_APP_USER fi . $EB_SUPPORT_DIR/envvars.d/sysenv sleep 10 su -s /bin/bash -c "bundle exec crono start -P $PID " $EB_APP_USER "/opt/elasticbeanstalk/hooks/appdeploy/pre/03_mute_crono.sh": mode: "000755" owner: root group: root content: | #!/usr/bin/env bash EB_APP_USER=$(/opt/elasticbeanstalk/bin/get-config container -k app_user) EB_SCRIPT_DIR=$(/opt/elasticbeanstalk/bin/get-config container -k script_dir) EB_SUPPORT_DIR=$(/opt/elasticbeanstalk/bin/get-config container -k support_dir) . $EB_SUPPORT_DIR/envvars . $EB_SCRIPT_DIR/use-app-ruby.sh PID=$EB_APP_PID_DIR/crono.pid if [ -f $PID ] then su -s /bin/bash -c "kill -USR1 `cat $PID`" $EB_APP_USER fiテストに使ったjob
class CronoTestJob < ApplicationJob queue_as :default def logger Crono.logger.nil? ? Rails.logger : Crono.logger end def perform(*args) logger.info '*** start crono test job ***' end end
- 投稿日:2020-03-19T11:20:10+09:00
CloudFrontは同じURL+QueryStringでもキャッシュ応答しないケースがある
はじめに
あるAPIサービスが、CloudFront + API Gateway + Lambda という構成で稼働しており
CloudFrontは、URL+QueryStringごとにキャッシュし、応答速度をあげるために使用しています。事象
このAPIサービスには、Go/PHPそれぞれで実装されたプログラムがHTTPリクエストを送ります。
CloudFrontの設定は以下の通り。(関連設定のみ)
設定項目 設定値 Cache Based on Selected Request Headers None Object Caching Customize
MinTTL:0
MaxTTL: 86400
DefTTL: 86400Forward Cookies None Query String Forwarding and Caching Forward all, cache based on all Compress Objects Automatically No Go/PHPそれぞれから同じ URL+QueryString でリクエストを送信した場合は、2回目のリクエストは
キャッシュHitする想定でしたが、なぜかMissになります。(X-Cacheヘッダで確認)原因
Go実装のプログラムでは 標準のnet/httpパッケージを使ってリクエストを送信しています。
net/httpのhttpクライアントはレスポンスがgzip圧縮されていても自動的に展開してくれるため
デフォルトでAccept-Encoding: gzipヘッダが付きます。
CloudFrontは、このAccept-Encodingヘッダの有無でキャッシュが別管理になるため、
同じURL+QueryStringであっても、ヘッダ有無が異なれば再度オリジンアクセスする、という動作になります。
これは、レスポンスが圧縮されているかに関わらず上記の動作になりました。コメントで指摘あったので追記)
Vary: Accept-EncodingがレスポンスヘッダにあればAccept-Encodingヘッダ有無で
キャッシュが別になるのは理解できますが、今回使用しているオリジンは、レスポンスを圧縮しない、かつ
Varyヘッダを返さない仕様です。DefaultClientでリクエスト送信 実装例
main.gopackage main import ( "fmt" "net/http" ) func main() { url := "http://example.com/" req, err := http.NewRequest(http.MethodGet, url, nil) if err != nil { fmt.Errorf("%v", err) return } resp, err := http.DefaultClient.Do(req) if err != nil { fmt.Errorf("%v", err) return } defer resp.Body.Close() }今回CloudFront設定を素直に?以下のように解釈してたので発見が遅れました
* リクエストヘッダでキャッシュ判定しない
* URL+QueryStringごとにキャッシュする
* 自動圧縮は無効化してるのでAccept-Encodingを見ない↑このAccept-Encodingを見ないというのが勘違いで、オリジン側では通常Accept-Encodingヘッダによって
gzip圧縮するか判定しているはずで、CloudFrontも正しくキャッシュ(非圧縮を期待しているクライアントに圧縮
データを応答しないこと)するためにAccept-Encodingヘッダをキャッシュ判定に使用していると思われます。Go側でリクエスト送信時にAccept-Encodingヘッダを付けないようにすればキャッシュがうまく使われるように
なります。以下Go実装の修正イメージAccept-Encodingヘッダを付加しないリクエスト送信 実装例
DisableCompressionをtrueにしたTransportを生成して、それを渡してclientを生成してclient.Doする形
main.gopackage main import ( "fmt" "net/http" ) func main() { url := "http://example.com/" req, err := http.NewRequest(http.MethodGet, url, nil) if err != nil { fmt.Errorf("%v", err) return } client := &http.Client{ Transport: &http.Transport{DisableCompression: true}, } resp, err := client.Do(req) if err != nil { fmt.Errorf("%v", err) return } defer resp.Body.Close() }おわりに
CloudFrontの公式ドキュメントに明確な記述が見つけられなかったので、今回記事にしました。
誰かの助けになれば幸いです。
- 投稿日:2020-03-19T10:39:28+09:00
AthenaでCSVファイルからParquet形式へ変換
Parquetにしたい場合
AthenaでCSVファイルを読み込んでいるとクエリによってスキャンデータ量が大きい場合があります。
例えばカラム数がかなり多いが、実際に使うカラムは少ない場合などが該当すると思います。
またCSV自体を圧縮できていなかった場合は単純にファイルサイズも減少します。Parquetに変換
変換したい際にPythonなどを使ってCSV形式からParquetへ変換を行っていたのですが、Athena上でも一応変換(指定ディレクトリに新しいParquetファイル)ができます。
convert.sqlCREATE TABLE new_table_name WITH ( format='PARQUET', external_location='path/to/new/files/directory' ) AS SELECT * FROM original_table_nameこのようにして、元々CSVを読み込んでいたテーブルから新しいテーブルを作成します。そのときに
format='PARQUET'を指定することでファイルがParquetに変換されます。
注意点としては、元ファイルのファイル数と異なるのでどのファイルに何が入っているかわからなくなる点です。
その場合は月ごとなどにテーブル・ディレクトリを作って、それをまとめて見られるテーブルを作成すると対応できます。
- 投稿日:2020-03-19T09:36:20+09:00
AWS,Azure,GCPの3大クラウドのDevOps試験に合格してみての個人的比較
以下の記事でAWS、Azure、GCPの3大クラウド(?)のアーキテクト試験について書きましたが、今度はDevOps試験も制覇したので同じ視点で書いていこうと思います。
AWS,Azure,GCPの3大クラウドのアーキテクト試験に合格してみての個人的比較
今回、取得したのは以下の3試験です。全部DevOpsというワードがついています。
- AWS Certified DevOps Engineer - Professional
- Microsoft Certified Azure DevOps Engineer Expert (※ 後述しますが試験ではなく認定名です
- Google Cloud Certified - Professional Cloud DevOps Engineer
「そもそもDevOpsって何だっけ?」と考えさせられる
私は普段の仕事でもいわゆるDevOpsという分野には良く関わります。CI/CDのパイプライン作ったり、TerraformやCloudformation作ったり、監視モニタリングの設計したり等々。名刺の肩書きがDevOpsエンジニアだった時期もあります。
そういった仕事やっている中で、漠然と「DevOps」という言葉の意味を理解している気でいました。
ただ、改めて「DevOpsって何?」と聞かれると文脈や時期によって違う気がして、「DevOpsとはこれです」とは自信を持って答えられない部分もありました。
では、DevOpsと名前のついた3試験を合格してみて結果どうだったかと言うと、「そもそもDevOpsって何だっけ?」という部分は余計に強くなったと思います。
以前記事に書いた、3大アーキテクト試験の比較はクラウドというサービス全体を見るアーキテクトという視点からか、それぞれ特色はあるものの出題範囲としては似通っていました。それに比べると、DevOps試験はDevOpsに対する各社の考えが明らかに試験内容にも反映されていました。
それでは、それぞれの試験について書いていこうと思います。
AWS DevOps Engineer Professional
試験について
この3試験では、間違いなくAWSのDevOps試験が一番有名です。Googleで検索すれば、合格者によるブログ情報が沢山見つかると思いますので、ここでは細かくは書きません。
試験で聞かれること
内容もオーソドックス(に感じる)でCodeCommit、CodeBuild、CodeDeploy、CloudFormation、SystemsManagerなどなど、これらのサービスをどう使うかが問題として出てきます。以下の試験ページに書いてあることも違和感無しです。
- 認定によって検証される能力 - AWS で継続的デリバリーのシステムと手法を実装して管理する - セキュリティコントロール、ガバナンスプロセス、コンプライアンス検証を実装し、自動化する - AWS でのモニタリング、メトリクス、ログ記録システムを定義し、デプロイする - 高可用性、スケーラビリティ、自己修復機能を備えたシステムを AWS プラットフォームで実装する - 運用プロセスを自動化するためのツールの設計、管理、維持を行う引用元: https://aws.amazon.com/jp/certification/certified-devops-engineer-professional/
実際にこれらのサービスに近いサービスはAzureでもGCPでも提供されていて、このAWSの知識を応用すると、他のクラウドでも同類のサービスの使い方を、「AWSのアレと同じね」と比較的スムーズに取得することができるのではないでしょうか。
AWSのDevOps試験内容から感じるのは、AWSのSolution Architect試験と同じ方向性で
「DevOps系のクラウドサービスの正しい使い方」なのではと感じました。クラウドのサービスを使うエンジニアの認定試験であることを考えればとても正攻法なイメージです。全部使っているけど、どのDevOps試験から取るか悩むという場合は、一番最初はAWSがオススメな気がします。
Azure DevOps Engineer Expert
試験について
Azureの認定は、複数試験の合格を前提としているものが多くあり、DevOps試験も以下の図のように複数試験の合格が必要です。
DevOpsの認定を取るには、まずは前提となっている以下の2試験のどちらか片方の合格が必要です。
- AZ-103 Azure Administrator Associate(インフラ分野の試験
- AZ-203 Azure Developer Associate(開発分野の試験
その上で、以下のDevOpsの試験に合格すると「Azure DevOps Engineer Expert」として認定されます。
- AZ-400 Azure DevOps Solutions
ちなみに、AZ-400のDevOps試験は出題範囲のドキュメントも全て英語ですし、日本語提供されてる本試験も自動翻訳レベルなので実質英語が必須の試験といえます。技術英語なのと問題数少ないので英語得意でなくても大丈夫だとは思います。
試験で聞かれること
上記の通り、複数試験の合格が必要となっている認定なので、求められているものを考えるためには前提試験も含めてみるべきかなと思いました。
私は、「AZ-203 Azure Developer Associate」を前提試験として合格してから、AZ-400 DevOpsの試験に臨みました。
AZ-203 Azure Developer Associateはコード(C#かPowerShell)の穴埋めや、順序入れ替え的な問題が3割程度出題されるような試験です。ある程度の開発の経験がある人からすれば基礎的な内容ではありましたが、私が受けた色々なクラウド試験の中では確実に一番開発スキルが問われる試験でした。出題形式が多肢選択だけでないMicrosoftの試験だからできる出題方法だと思います。(受験側は疲れますが)
他にも、サーバーレスアプリケーションの開発や、CosmosDBの話や、Azure AD絡めた認証・認可やセキュリティ周りなどサービスの使い方が出題されていて、正に盛りだくさんな試験でした。
DevOps試験は、恐らくこの試験を前提に置いていることもあってテクニカルな内容以外も多く出題されました。以下の出題分野で言うと「DevOpsストラテジーのデザイン (20-25%)」や「DevOps開発プロセスの実装 (20-25%)」という分野です。具体的にはGitのブランチ戦略とか、AgileやScrumの進め方などが出題されました。これだけで半分くらいの割合になります。
評価されるスキル - DevOpsストラテジーのデザイン (20-25%) - DevOps開発プロセスの実装 (20-25%) - 継続的インテグレーションの実装 (10-15%) - 継続的デリバリーの実装 (10-15%) - 依存性管理の実装 (5-10%) - アプリケーションインフラストラクチャの実装 (15-20%) - 継続的フィードバックの実装 (10-15%)引用元:https://azure.microsoft.com/ja-jp/services/devops/
逆にテクニカル部分はほとんどがAzure DevOpsについてでした。CI/CDの昨日だけでなく、Azure Boardsという、開発管理のアプリケーションレイヤーも含まれます。こういった、Team Foundation Serverからの流れがあり、利用のためにチーム開発の管理手法などの知識が必要になるのが、他のクラウドのDevOps試験との大きな違いの一つかなと思います。
AWSは自社サービス以外の内容はほとんど試験に出ません。GCPはGCPがオススメするOSSが良く出ます。AzureはOSSに加え、サービス内で連携する外部サービスが出ます。結果、試験対象のクラウド外の技術内容が一番出るのがAzureな気がします。
AzureのDevOps試験内容から感じるのは、前提試験で、DevかOps側で手を動かせることを担保した上で、
DevOps系のサービスの現場導入の前提知識を問われている試験に感じました。
GCP Professional Cloud DevOps Engineer
試験について
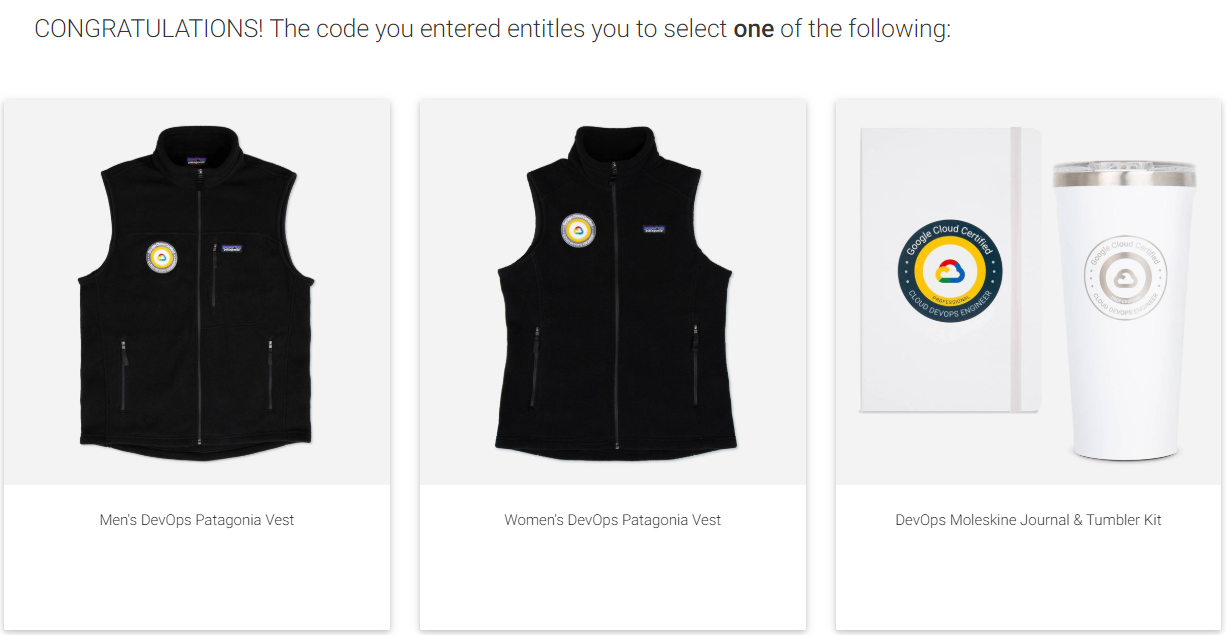
こちらの試験、確か今月(2020/3)リリースされたばかりです。受験できるようになるの待ってたので、リリースされて早速受けに行ってきました。
当然、日本語化されておらず、英語のみの試験で、かつ文章量も比較的多く、私のような英語レベルだと時間ギリギリの試験でした。
試験に合格するとプレゼントがもらえるのもGCPの試験の特徴です。5000~10000円くらいのモノが多くて結構使えるものがあります。今回はpatagoniaのベストを選びました。
試験で聞かれること
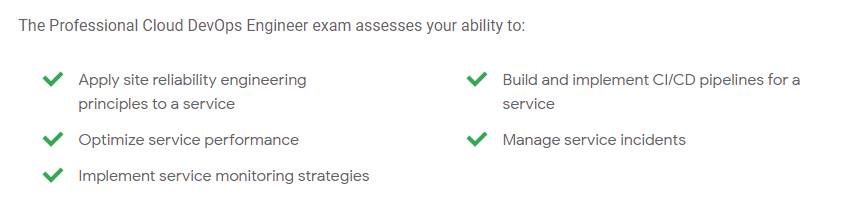
試験名はSREでも良いくらい
受けてみるとわかるのですが、「この試験ってSREの試験だっけ?」という内容です。例えばインシデントが発生した際のSREとしての行動などが出題されます。「あなたは、SREチームに属しています」とか「あなたはSRE principalsの元で動いている組織にいます」的な書き出しで、「インシデント起きたけど、次はどんな次のアクション取る」みたいな問題が1/3くらい出てきます。
試験の帰りに出題分野見てみると、確かに試験内容の一番最初にSREのことが書いてありました。
引用元: https://cloud.google.com/certification/cloud-devops-engineer家に帰ってGoogleの方が書いたOreillyのSRE本読み返してみると、こんなコラムがあります。
「DevOps?それともSRE?」
DevOpsは、SRE の中核的な方針のいくつかを、幅広い組織、管理の構造、個人に対して一般化したものと捉えることもできるでしょう。同様に、SRE をDevOps に独特の拡張を少し加えたプラクティスと捉えることもできるでしょう。
DevOps⊂SREという考え方です。恥ずかしながら、「似たような分野あるなー」くらいでSREとDevOpsの関係を見ていたので、勉強になりました。
もう少し具体的に言えば以下のような場面で、SREとして動くには?が想像できるかどうかを問われた出題に感じました。
https://cloud.google.com/blog/ja/products/gcp/incident-management-at-google-adventures-in-sre-land
CI/CDはKubernetes前提
他のクラウドの試験でもCI/CDは主な出題分野の一つなのですが、コンテナのCI/CDは一部でしかなく、どちらかと言えばVMへのソースコードのデプロイや、Azure App ServiceやElastic BeanstalkへのデプロイがCI/CDのメインシナリオだったと思います。
GCPのDevOps試験では徹頭徹尾、Kubernetesを前提としたCI/CDしか出てないと思います。(k8s以外もあったかもしれませんが忘れるくらい少ない)
GCPの他の試験でもそうですがKubernetes知らないと合格できない内容が多いなという印象です。
個人的にGCPのDevOps試験内容から感じるのは
GCPの考えるSREの仕事(DevOps含む)です。あくまで私の感想で言えば、GCPの試験に出てくるシステムは全部Kubernetes。Kubernetesシステムに対するDevOps系サービスの使い方。それを行うチームはSREの原則をもとに行動をすべし。
他のクラウドの試験で出ていた分野がGCPの別試験、Professional Cloud Developerでカバーされているという理由もあるのかもしれません。そうだとしても強いメッセージ性を感じる認定試験でした。
最後に
最後に各社のDevOpsの説明の引用を載せておきます。これを読んだ上で、もう一度試験内容見てみるとニュアンスがもう少し深まる気がして面白いです。
DevOps では、従来型のソフトウェア開発と、インフラストラクチャ管理プロセスを使用するよりも速いペースで製品の進歩と向上を達成し、企業がアプリケーションやサービスを高速で配信できるように、文化的な基本方針、プラクティス、ツールが組み合わされています。この高速化により、企業は顧客により良いサービスを提供し、市場競争力を高めることができます。
開発 (Dev) と運用 (Ops) を組み合わせたものである DevOps は、人、プロセス、テクノロジを統合したもので、お客様に継続的に価値を届けます。
DevOps とは、ソフトウェア デリバリーの速度とサービスの信頼性の向上、ソフトウェアの関係者間で共有するオーナー権限の構築を目的とする、組織的で文化的な仕組みです。
参考
AWSは書いてないですが、個別の試験の体験記は、以下の自分のブログの方に記載してます。
Google Cloud Certified Professional Cloud DevOps Engineerを取得してきました
AZ-203 Developing Solutions for Microsoft Azureを合格してきた
AZ-400 Microsoft Azure DevOps Solutions に合格してきた


- 投稿日:2020-03-19T09:00:15+09:00
Amazon CloudWatch EventsのルールでAmazon S3のキーをプレフィックス指定できた
Amazon CloudWatch EventsでS3のイベントをトリガーにすることができますが、ソースに指定できるのは完全一致するバケット名とキーだと思っていたのですが、プレフィックス指定できること知って、ふぁーっ!となったのでメモ。
イベントルールを用意する
イベントルールの作成方法は下記を参考にしました。
Amazon S3 ソースの CloudWatch イベント ルールを作成する (コンソール) - CodePipeline
https://docs.aws.amazon.com/ja_jp/codepipeline/latest/userguide/create-cloudtrail-S3-source-console.htmlイベントルールのカスタムイベントパターンは下記のように指定するのですが、
my-bucket/my-keyオブジェクトのイベントのみを検知してトリガーされます。単一のオブジェクトではなく、detail.requestParameters.key配下のオブジェクトすべて(例えばmy-key/*)を対象にしたいケースがあります。{ "source": [ "aws.s3" ], "detail-type": [ "AWS API Call via CloudTrail" ], "detail": { "eventSource": [ "s3.amazonaws.com" ], "eventName": [ "CopyObject", "CompleteMultipartUpload", "PutObject" ], "requestParameters": { "bucketName": [ "my-bucket" ], "key": [ "my-key" ] } } }アスタリスク(
*)が利用できればよいのですが、残念ながら利用できないので、これまでは諦めていたのですが、下記ドキュメントにプレフィックス指定ができるとありました。ドキュメントは2019年12月19日に追加されたみたいです。Content-based Filtering with Event Patterns - Amazon EventBridge
https://docs.aws.amazon.com/eventbridge/latest/userguide/content-filtering-with-event-patterns.html#filtering-prefix-matchingPrefix Matching
You can match on the prefix of a value in the event source. For example, the following event pattern would match on any event where the "time" field started with "2017-10-02".{ "time": [ { "prefix": "2017-10-02" } ], }素敵です。最高です。
イベントルールのカスタムイベントパターンでは下記のように利用できます。
{ "source": [ "aws.s3" ], "detail-type": [ "AWS API Call via CloudTrail" ], "detail": { "eventSource": [ "s3.amazonaws.com" ], "eventName": [ "CopyObject", "CompleteMultipartUpload", "PutObject" ], "requestParameters": { "bucketName": [ { "prefix": "my-" } ], "key": [ { "prefix": "my-key/" } ] } } }
detail.requestParameters.keyだけかなと思ってましたが、detail.requestParameters.bucketNameでも指定可能です。
detail.requestParameters.keyには/も指定できるので、指定キー配下のオブジェクトを対象にできます。素敵です。最高です。
アスタリスク!?
下記に「アスタリスク使えるよ。」的なコメントがあり、期待を込めて検証しましたがアスタリスクは利用できませんでした。「2020年2月にリリースされた」とありますが、ドキュメント(英語)をみてもそれらしき記述はありません。もしかすると特定のリージョンのみで適用されていたりするのでしょうか???(2020年3月時点)
amazon s3 - Does AWS CloudWatch Events Rule supports any wildcards in S3 bucket/key names - Stack Overflow
https://stackoverflow.com/questions/49435580/does-aws-cloudwatch-events-rule-supports-any-wildcards-in-s3-bucket-key-namesI found a fancy solution for this using Content-based filtering (released in February 2020) like prefix for example.
{ "source": ["aws.s3"], "account": ["1111111xxxxx"], "detail": { "eventSource": ["s3.amazonaws.com"], "eventName": ["PutObject"], "requestParameters": { "bucketName": ["mybucket"], "key": ["myfile-*"] } } }まとめ
日々アップデートされるAWSですが、すべてが告知されるわけでなくドキュメントがひっそりと更新されるケースもあるので、利用頻度が高いサービスだけでも定期的に最新情報を確認しなきゃなと改めて感じました(まる)
参考
Amazon S3 ソースの CloudWatch イベント ルールを作成する (コンソール) - CodePipeline
https://docs.aws.amazon.com/ja_jp/codepipeline/latest/userguide/create-cloudtrail-S3-source-console.htmlContent-based Filtering with Event Patterns - Amazon EventBridge
https://docs.aws.amazon.com/eventbridge/latest/userguide/content-filtering-with-event-patterns.html#filtering-prefix-matchingamazon s3 - Does AWS CloudWatch Events Rule supports any wildcards in S3 bucket/key names - Stack Overflow
https://stackoverflow.com/questions/49435580/does-aws-cloudwatch-events-rule-supports-any-wildcards-in-s3-bucket-key-names
- 投稿日:2020-03-19T08:11:42+09:00
AWS/Azure/GCP における SQL Server の高可用性パターンまとめ
はじめに
各クラウドごとに以下のパターンを記載しています。
- マネージドサービスを利用する場合
- VM で Always On Availability Groups を構成する場合
- VM で Always On Failover Cluster Instances を構成する場合
AWS
Amazon RDS with SQL Server Always On Availability Groups
RDSのマルチAZ配置では以下のバージョンおよびエディションで Always On AG をサポート。
- SQL Server 2017:Enterprise Edition 14.00.3049.1以降
- SQL Server 2016:Enterprise Edition 13.00.5216.0以降
上記以外のSQL Server 2012 以降の Starndard Edtion および Enterprise Edtion では
データベースミラーリングによるマルチAZ構成となる。Microsoft SQL ServerのマルチAZ配置
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_SQLServerMultiAZ.htmlAmazon EC2 with SQL Server Always On Availability Groups
AWS Launch Wizard for SQL Server を使用することでマルチAZ環境で
SQL Server Always On Availability Groups を自動的にプロビジョニングすることができる。
AWS Launch Wizard を使して SQL Server Always On のデプロイを加速する
https://aws.amazon.com/jp/blogs/news/accelerate-sql-server-always-on-deployments-with-aws-launch-wizard/Amazon EC2 with SQL Server Always On Failover Cluster Instances
Amazon FSx for Windows File Server が Continuously Available File Shares をサポートした。
これにより FSx for Windows File Server を共有ディスクとして利用することで、
SMB Transparent Failover による Always On FCI 構成をデプロイをできるようになった。
また FSx for Windows File Server を最小構成の32GBで作成し、SMB ファイル共有監視として利用することで
AWS上でマネージドされたストレージを活用して以下のような構成をとることができる。
(画像は AWS Storage Blog より引用)
Simplify your Microsoft SQL Server high availability deployments using Amazon FSx for Windows File Server
https://aws.amazon.com/jp/blogs/storage/simplify-your-microsoft-sql-server-high-availability-deployments-using-amazon-fsx-for-windows-file-server/参考資料
- Best practices for advanced SQL Server storage architectures
- Design, migrate, and optimize SQL Server on AWS
- Deep dive on Amazon FSx for Windows File Server
Azure
Azure SQL Database
Basic, Standard, General Purpose サービス層では標準可用性モデルが適用される。
Premium および Business Critical サービス層ではプレミアム可用性モデルが適用される。
プレミアム可用性モデルでは Always On Availability Groups と同様のテクノロジーで
高可用性が実装されているとのこと。
Hyperscale サービス層ではアーキテクチャ自体が従来のデータベースサービスとは異なる
分散アーキテクチャで構成されている。AWS でいうところの Aurora に近い。High-availability and Azure SQL Database
https://docs.microsoft.com/ja-jp/azure/sql-database/sql-database-high-availabilityAzure VM with SQL Server Always On Availability Groups
手動で構成するか、Azure Portal のギャラリーまたは GitHub で公開されている
クイックスタートテンプレートを使用して部分的に自動プロビジョニングが可能。Use Azure quickstart templates to configure an availability group for SQL Server on an Azure VM
https://docs.microsoft.com/ja-jp/azure/virtual-machines/windows/sql/virtual-machines-windows-sql-availability-group-quickstart-templateAzure VM with SQL Server Always On Failover Cluster Instances
Windows Server 2016 以降で S2D: Storage Spaces Direct による仮想的な共有ストレージを作成するか、
Azure Files のプレミアムファイル共有を利用することで Always On FCI を構築可能。Configure a SQL Server failover cluster instance on Azure virtual machines
https://docs.microsoft.com/ja-jp/azure/virtual-machines/windows/sql/virtual-machines-windows-portal-sql-create-failover-cluster
Configure a SQL Server failover cluster instance with premium file share on Azure virtual machines
https://docs.microsoft.com/ja-jp/azure/virtual-machines/windows/sql/virtual-machines-windows-portal-sql-create-failover-cluster-premium-file-shareGCP
Cloud SQL for SQL Server
2020年2月19日に一般利用可能になった。
同期レプリケーションによるHA構成をとることができるが、Always On AG ではない。
(Cloud SQL で利用できない機能の一覧に Always On Availability Groups の記載あり)General features unavailable for Cloud SQL
https://cloud.google.com/sql/docs/sqlserver/features#sqlserver-unavailableCompute Engine with SQL Server Always On Availability Groups
以下の手順で手動で構成することが可能
SQL Server AlwaysOn 可用性グループの構成
https://cloud.google.com/compute/docs/instances/sql-server/configure-availabilityCompute Engine with SQL Server Always On Failover Cluster Instances
以下の手順で、S2D を利用した Always On FCI を構成することが可能。(Windows Server 2016 以降)
SQL Server フェイルオーバー クラスタ インスタンスの構成
https://cloud.google.com/compute/docs/instances/sql-server/configure-failover-cluster-instance以上です。
参考になれば幸いです。

- 投稿日:2020-03-19T07:27:49+09:00
ハンズオンテスト
参考に設定
https://aws.amazon.com/jp/premiumsupport/knowledge-center/lambda-sns-ses-dynamodb/
dynamoDB
参考URLの通り作る。
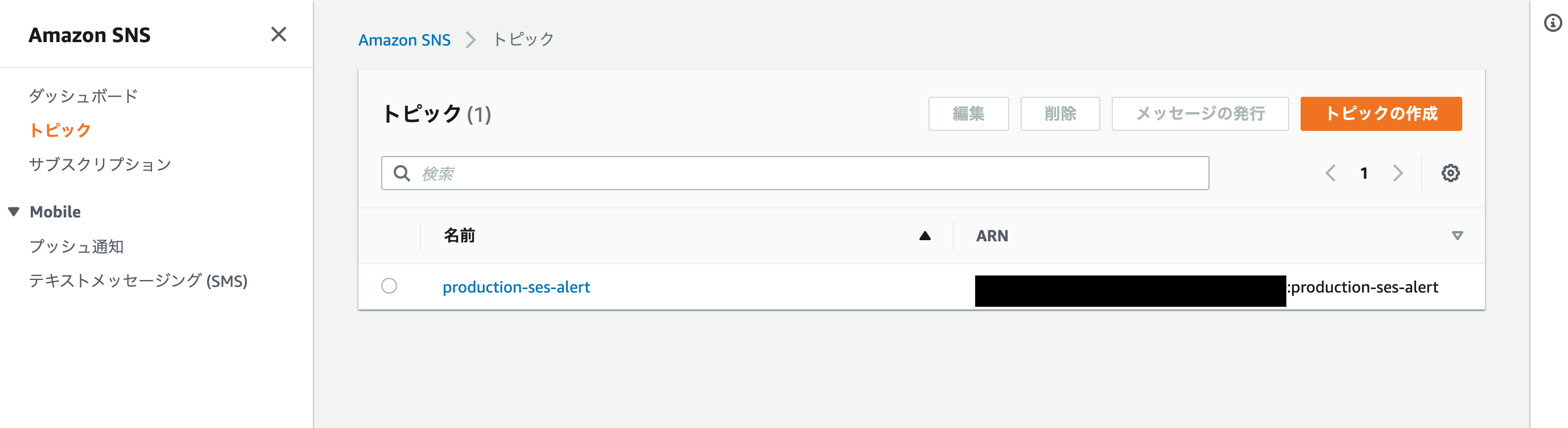
書いていないものはデフォルトトピックの設定
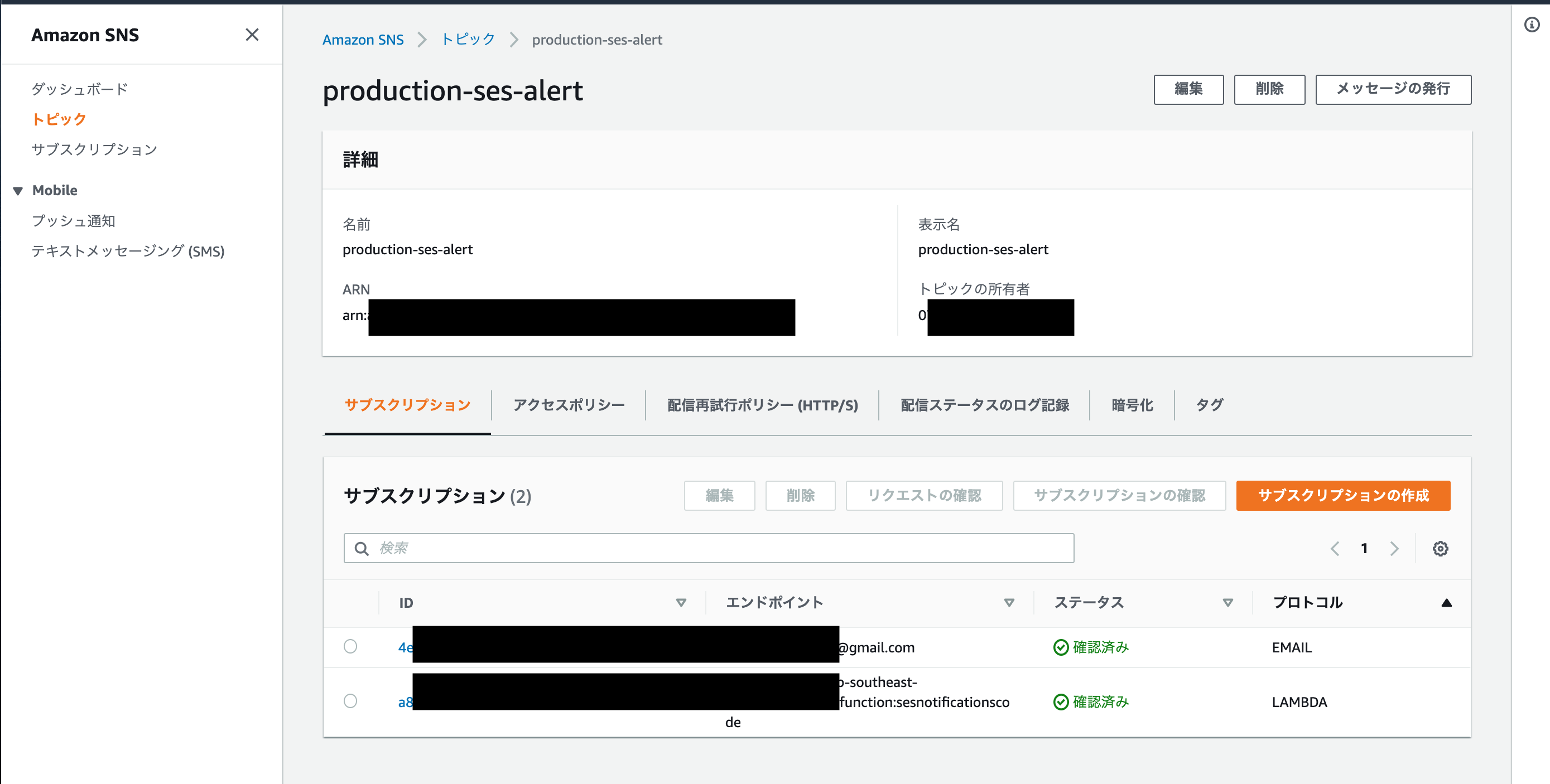
Lambdaに飛ばす用のサブスクリプションは、
プロトコルをLambdaにを選択するとエンドポイント候補に作成済みのLambdaが候補に出てくる。Lamda
トピックに紐付けるとSNSが紐づく
コードは参考URLをまるっとコピー
IAMロール作成
参考URLの通り
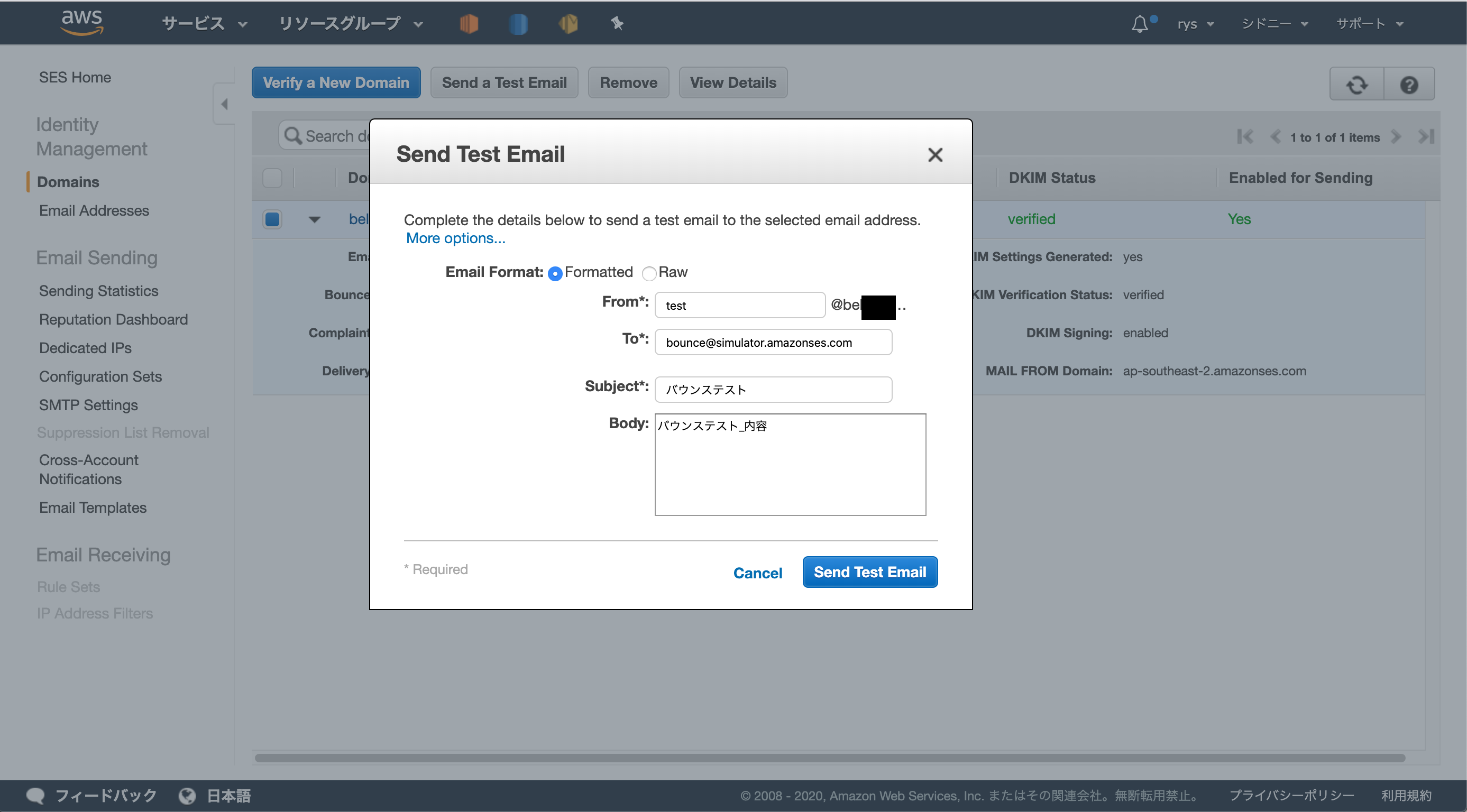
SESからテストメール
結果
- 格納


- 投稿日:2020-03-19T06:34:11+09:00
今!!流行りのSTUDIOでポートフォリオサイトをNoCodeで作り直してみた
STUDIOとは
「コードを書かずに、Webサイト制作を完結」 できるという国産デザインツール。
「デザインの後のコーディング作業や、サーバーのセットアップは必要ありません。」
「STUDIOでデザインした画面は、瞬時にコードに変換されそのまま公開が可能です。」
という素晴らしさ!!そして弊社no plan inc.の案件でもよく使うようになりとても便利に使わせてもらっていました。(no plan株式会社の技術スペック)
今回は
おかむー個人のポートフォリオサイトをSTUDIOに変更することにしました。
STUDIOを使う前
そういえばSTUDIOを使う前は、HTMLを生成してホスティングしていました。
フロント
gulp sass babelify pugサーバー
Route53 Cloudfront S3という、よく見る構成w
そろそろ別の技術使いたいなーとも思っていましたが、
ポートフォリオサイトに多くの時間をかけるのももったいないないなぁともSTUDIOを使う前で大変だったこと
- 久しぶりに触るとjsが動かないのでしんどい
- おかむー自身HTMLが苦手なので結局、うねうねするアニメーションとかかけてない
- おかむー自身HTMLが苦手なので思ったように配置できない
- レスポンシブ対応もしたくない
- 有料のbootstrap的なやつも買って編集していた
STUDIOで書き換えた
とりあえず大枠はそのままにしつつ、見にくいところだけ変更する作戦
以前の構成も、たった並べるだけ
- あれだけかかってたサイトも数時間でできた
- まじで並べるだけなので超ラク
- テンプレートも充実してて、デザインがおかしくならない
- レスポンシブ対応のテンプレートも充実
- modalや遷移、配置のガイドもわかりやすい!
HTML苦手なので、まじで最高です。
作り直したサイト
これだけの見かけのサイトを簡単に作成できてしまった!!レスポンシブも完璧(なはずw)
まじで感謝!!その他良いところ
- チュートリアルも丁寧でわかりやすい
- svg,gifもいける
- 簡単なモーダルもできる
- idが設定できるので、スムーススクロールも実現できる
- フォームまで用意されていて、指定したメールアドレスに通知される
- 独自ドメインもいける
- Googleアナリティクスもいける
- 将来CMSの導入が予定されている
気をつけたほうがいいかもしれない点
- jsのコードは入れれません
- mp4などは入れれませんのでmovieタグがありません
- 動画はYoutubeとかVimeoのiframeで埋め込みができます
- 戻ると進むが時々バグる
- もちろんgit管理できないので、定期的にページのコピーを取りながらやったりしてました
もしかしたら役に立つかもしれないTips!
ヘッダー固定もできる (no plan inc.で使用)
動画を流す (ポートフォリオで使用)
- iframeだとYoutubeのヘッダーが出てしまったり、Vimeoの有料会員にならないといけなそうだったので、gifに変換して設定
- ffmpegでとにかく綺麗なGIFを作りたい
まとめ
- みんな、とりあえず、STUDIO、さわっとこう!!!!!
- できないこともあるので、案件によっては用件を確かめたほうがいい!!!!!
- 学習コストは極めて低いです!!!!!
- 開発速度は極めて早いです!!!!!!!
最後に
- もっとTwitterとかでも発信していこうと思っています!!!(宣言駆動開発)
- Twitter: @okamu_ro

- 投稿日:2020-03-19T02:11:42+09:00
ec2をターミナルで操作するときに詰まった話(fatal: Could not read from remote repository.)
(デプロイ編①)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
を参考に、AWSにrailsアプリをあげようとしていたときの凡ミスについて。エラー箇所について
上記の記事で
[~]$ ssh mumu_key_rsaでログインした後に、
[ユーザー名|~]$ vim .gitconfigで、諸々の設定を記述するところがある。
そこで、記事通り、下記のように設定すればよかった。
[user] name = your_name (#gitに登録した自分の名前) email = hoge@hoge.com (#git登録時の自分のメアド) [alias] (#これはお好きに) a = add b = branch ch = checkout st = status [color] (#色付け) ui = true # githubの場合 [url "github:"] (#pull、pushのための設定) InsteadOf = https://github.com/ InsteadOf = git@github.com:しかしながら、筆者は
[user] name = your_name (#gitに登録した自分の名前) email = hoge@hoge.com (#git登録時の自分のメアド) [alias] (#これはお好きに) a = add b = branch ch = checkout st = status [color] (#色付け) ui = true # githubの場合 [url "github:"] (#pull、pushのための設定) InsteadOf = https://github.com/(ここに実際にcloneしたいアプリのレポジトリURLを書いていた) InsteadOf = git@github.com:(ここに実際にcloneしたいアプリのレポジトリURLを書いていた)上記を見ていただければ分かる通り、無駄にレポジトリURLを記載してしまっていた。
その結果、git cloneでfatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists.と、言われてしまったのだった。
まとめ
(デプロイ編①)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
この記事では、丁寧にコメントでここには○○を記述などと書いてくれている。
それをちゃんと読んでいなかった筆者は簡単な設定ミスで結構苦労した(3時間も使ってしまった)。
みなさんが、そして未来の自分が再びこんな凡ミスを犯さないためにも、備忘録的に書かせていただきました。
- 投稿日:2020-03-19T01:47:54+09:00
URLを気軽に「www」なしにしてトラブった話
背景
Webサイトの要件決めの時に、URLを「www」なしのZone apex(ドメイン名そのもの)で気軽に了承してしまい、環境引き渡しが遅れてしまった話。
環境(初期構築時)
- AWS
- ELB+EC2
- お名前.com
問題点
ELBのDNS登録はCNAMEレコードを使う必要があるが、Zone apexのようなサブドメインなしのドメインそのものの場合、CNAMEにマッピングすることはできません。
今回の環境では使用していませんが、CDNも同様の制約があります。
この制約は何処でドメインを購入しても同様です。その辺りの詳細な話は、以下の記事で簡潔にわかりやすくまとめてありました。
https://qiita.com/haruyosh/items/95b20bef7beb63d200ab解決方法
Route53のAliasレコードならZone apexをマッピングすることは可能です。
幸いなことにネームサーバをお名前.comからRoute53に変更するのは、お名前.comのドメインNaviネームサーバー設定で、ネームサーバ情報をRoute53のものに変更で切り替えることができます。注意しなければいけないのが、ドメインを使用していた場合はTTLの有効期限切れまで2日間程待たなければいけません。
https://docs.aws.amazon.com/ja_jp/Route53/latest/DeveloperGuide/migrate-dns-domain-in-use.html#migrate-dns-wait-for-ttl補足
ネームサーバを変えてもレジストラは変わらないため、ドメインの更新通知は購入元のレジストラから連絡がきます。
まとめ
URLの「www」なしはCNAMEが使えないため、特に要件が無いのであれば「www」ありにする方がオススメです。
- 投稿日:2020-03-19T01:06:58+09:00
Python(boto3)でDynamoDB上のデータを更新しようとすると「ExpressionAttributeNames contains invalid key: Syntax error; key: <キー名>」となる
事象
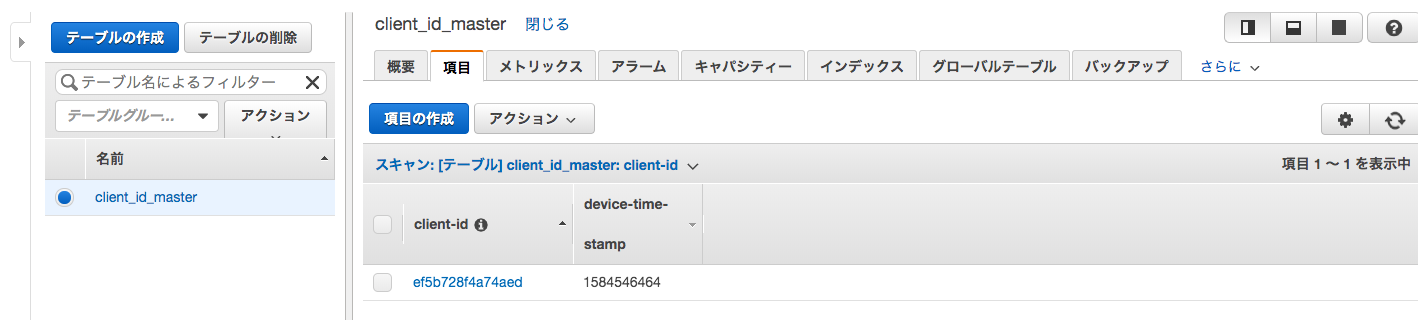
AWS上に以下のようなDynamoDBテーブルがある。
- テーブル名:
client_id_master- パーティションキー:
client-id(str)- アトリビュート:
device-time-stamp(int)今回、このテーブル上のデータの
device-time-stamp列の値を、Python(boto3)からupdate_item()メソッドにより更新する以下のようなコードを作成した。from datetime import datetime import boto3 dynamodb = boto3.resource('dynamodb') now_unix_time = datetime.now().strftime('%s') clientId = 'ef5b728f4a74aed' option = { 'Key': {'client-id': clientId}, 'UpdateExpression': 'set #device-time-stamp = :timeStamp', 'ExpressionAttributeNames': { '#device-time-stamp': 'device-time-stamp' }, 'ExpressionAttributeValues': { ':timeStamp': now_unix_time } } table = dynamodb.Table('client_id_master') table.update_item(**option)しかし、このコードを実行したところ以下のエラーとなった。
An error occurred (ValidationException) when calling the UpdateItem operation: ExpressionAttributeNames contains invalid key: Syntax error; key: \"#device-time-stamp\""原因・解決
原因としては、
update_item()のUpdateExpressionで指定する変数名に使える文字には制限があり、今回は#device-time-stampに含まれる-が利用不可文字に該当したためSyntax errorとなっていた。よって、以下のように変数名を
#device_time_stampとすることにより正常にコードが実行できるようになった。from datetime import datetime import boto3 dynamodb = boto3.resource('dynamodb') now_unix_time = datetime.now().strftime('%s') clientId = 'ef5b728f4a74aed' option = { 'Key': {'client-id': clientId}, 'UpdateExpression': 'set #device_time_stamp = :timeStamp', 'ExpressionAttributeNames': { '#device_time_stamp': 'device-time-stamp' }, 'ExpressionAttributeValues': { ':timeStamp': now_unix_time } } table = dynamodb.Table('client_id_master') table.update_item(**option)
以上
- 投稿日:2020-03-19T00:46:23+09:00
awsで大容量zipファイルをBasic認証かけてダウンロードさせる仕組みを組んだ
記事内容を三行で
- EC2とフレームワークを利用してやろう
- サーバレスでは組めない(組めるけど容量制限でNG)
- API Gateway便利(難しい)
概要
容量が大きいファイルを共有するとき、メールではだいたい8MBを超えるとメールサーバなのでブロックされたりします。ブロックされてなくてもそもそも大容量のファイルをメールで送るにはサーバへ負荷を与えたりなど結構迷惑かなと思ったりします。なので、ストレージサービスを利用したいですが、Gigaファイル便だとセキュリティ規約で怒られそうだし(過去よく使ってましたが)、GoogleDriveはGoogleアカウントがないと共有に不安(URLを知っていないとアクセスできないとはいえ、全員がアクセスできる状態は厳しい)があります。
ほしいのは、一時的にID&パスをかけて、大容量ファイルをシェアできるURLがほしいだけなのに...(おわったら削除 or タイムリミット過ぎたら非公開になるとか)
そこで、最近awsのSAAに受かったことだし、復習もかねてawsで楽にファイル共有する仕組みできないかなとチャレンジしたのがこの記事が生まれたきっかけになります。
個人的にはサーバーのon/offであったり、監視もしたくなかったので、サーバーレスで組めないかなと進めました。
ちなみに、共有したいファイルの容量は約100MBのzipファイルです。
API GatewayとLambdaとS3で組む
各サービスのそれぞれの役割
API Gateway
Lambdaを公開するためと、公開するURLにBasic認証をかけたいため。調べたらAPI Gatewayにはアクセスキーで認証させる方法と、Lambdaを用意しそれを使ってAPIのアクセスを制御することができる「API Gateway Lambda オーソライザー」という機能があります。
Lambda
「API Gateway Lambda オーソライザー」を使用するためにBasic認証をかけるLambda関数の用意と、Basic認証後にzipファイルをダウンロードさせるためのページ2つをLambda関数で用意。
1つはHTMLを表示して、ダウンロードするファイルを選択してもらう。最初はURL踏んだらダウンロードで良いと考えていたが、複数ファイルがあった場合どうすべ?ってなったのでHTMLページを用意することにした。(今考えるとquery parameterでよかったっすね。はい。。。 → って思ったけど、やっぱだめだったわ。後述。)
もうひとつはS3からファイルダウンロード & zipファイル(バイナリ)を返すLambda関数を用意。
S3
ダウンロードしたいzipファイル置き場、またHTMLテンプレート置き場として利用。
構成図
TODO: 図を作って貼る
実装・設定
Lambda
関数名:
download___authbasic認証を行うlambda
import json import os import base64 def lambda_handler(event, context): policy = { 'principalId': 'user', 'policyDocument': { 'Version': '2012-10-17', 'Statement': [ { 'Action': 'execute-api:Invoke', 'Effect': 'Deny', 'Resource': event['methodArn'] } ] } } if not basic_auth(event): print('Auth Error!!!') return policy policy['policyDocument']['Statement'][0]['Effect'] = 'Allow' return policy def basic_auth(event): if 'headers' in event.keys() and 'authorization' in event['headers'].keys(): auth_header = event['headers']['authorization'] # lambdaの環境変数から情報を取得. user = os.environ['USER'] password = os.environ['PASSWORD'] print(os.environ) _b64 = base64.b64encode('{}:{}'.format(user, password).encode('utf-8')) auth_str = 'Basic {}'.format(_b64.decode('utf-8')) return auth_header == auth_str raise Exception('Auth Error!!!')関数名:
download___indexダウンロードできるファイルをHTMLで表示するlambda。HTMLのテンプレートはS3から取得。テンプレートエンジンはjinja。
from jinja2 import Template import boto3 from botocore.exceptions import ClientError import os import logging logger = logging.getLogger() S3 = boto3.resource('s3') TEMPLATE_AWS_S3_BUCKET_NAME = 'hogehoge-downloader' BUCKET = S3.Bucket(TEMPLATE_AWS_S3_BUCKET_NAME) def get_object(bucket, object_name): """Retrieve an object from an Amazon S3 bucket :param bucket_name: string :param object_name: string :return: botocore.response.StreamingBody object. If error, return None. """ try: response = bucket.Object(object_name).get() except ClientError as e: # AllAccessDisabled error == bucket or object not found logging.error(e) return None # Return an open StreamingBody object return response['Body'].read() def main(): index_html = get_object(BUCKET, os.path.join('template', 'index.html')) \ .decode('utf8') li_html = get_object(BUCKET, os.path.join('template', 'file_li.html')) \ .decode('utf8') index_t = Template(index_html) insert_list = [] objs = BUCKET.meta.client.list_objects_v2(Bucket=BUCKET.name, Prefix='files') for obj in objs.get('Contents'): k = obj.get('Key') ks = k.split('/') if ks[1] == '': continue file_name = ks[1] print(obj.get('Key')) li_t = Template(li_html) insert_list.append(li_t.render( file_url='#', file_name=file_name )) output_html = index_t.render(file_li=''.join(insert_list)) return output_html def lambda_handler(event, context): output_html = main() return { "statusCode": 200, "headers": { "Content-Type": 'text/html' }, "isBase64Encoded": False, "body": output_html }関数名:
download___downloads3からファイルをダウンロードするlambda
import boto3 from botocore.exceptions import ClientError import os import logging import base64 logger = logging.getLogger() S3 = boto3.resource('s3') TEMPLATE_AWS_S3_BUCKET_NAME = 'hogehoge-downloader' TEMPLATE_BUCKET = S3.Bucket(TEMPLATE_AWS_S3_BUCKET_NAME) def get_object(bucket, object_name): """Retrieve an object from an Amazon S3 bucket :param bucket_name: string :param object_name: string :return: botocore.response.StreamingBody object. If error, return None. """ try: response = bucket.Object(object_name).get() except ClientError as e: # AllAccessDisabled error == bucket or object not found logging.error(e) return None # Return an open StreamingBody object return response['Body'].read() def lambda_handler(event, context): file_name = event['queryStringParameters']['fileName'] body = get_object(TEMPLATE_BUCKET, os.path.join('files', file_name)) return { "statusCode": 200, "headers": { "Content-Disposition": 'attachment;filename="{}"'.format(file_name), "Content-Type": 'application/zip' }, "isBase64Encoded": True, "body": base64.b64encode(body).decode('utf-8') }API Gateway
初期構築
- APIタイプはREST APIを選択
こんな感じで構築。
オーソライザーの設定
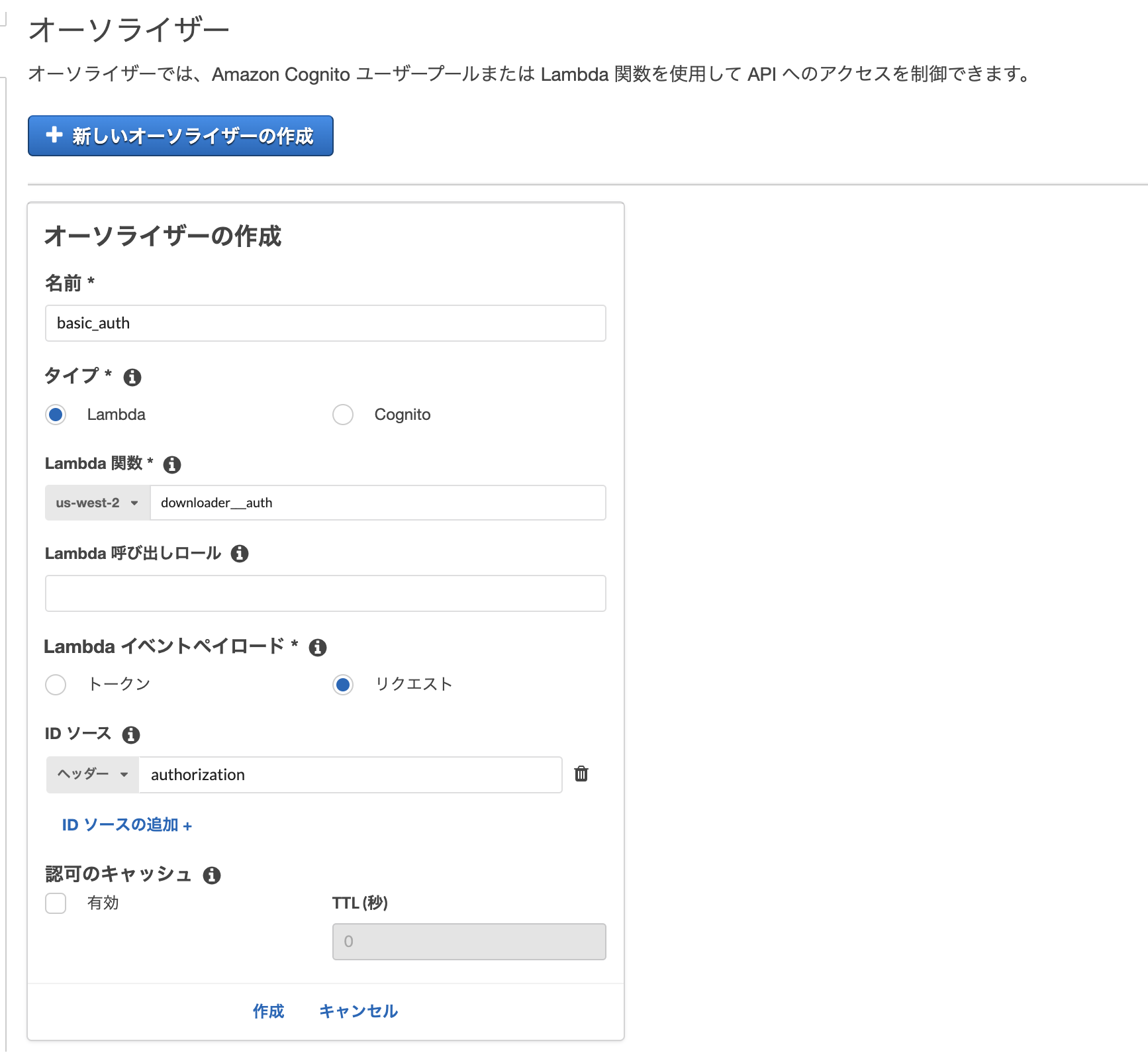
Basic認証を行うlambda関数と連携するよう設定する。
下記のように設定する。認可のキャッシュのチェックを外すのに注意。(チェック入れたままだと複数リソースを設定した場合、変な動き方をする)
authの設定はこれで完了です。あとは各メソッドで設定すればおkです。
リソース・メソッドの作成
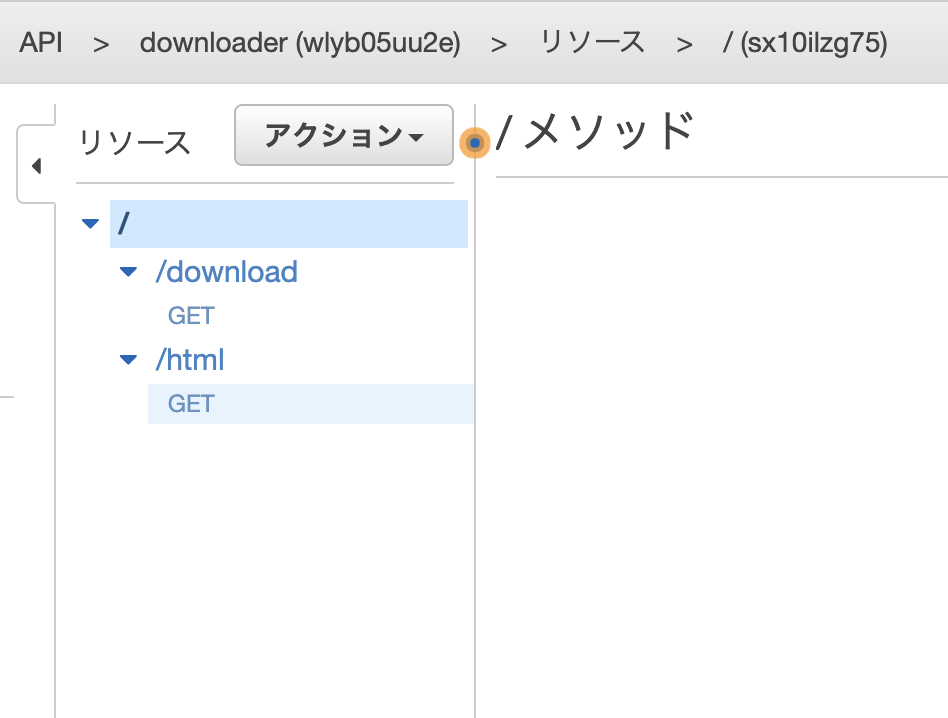
下記のようにリソース・メソッドを用意する。
それぞれの詳細の設定についてはこれから説明する。
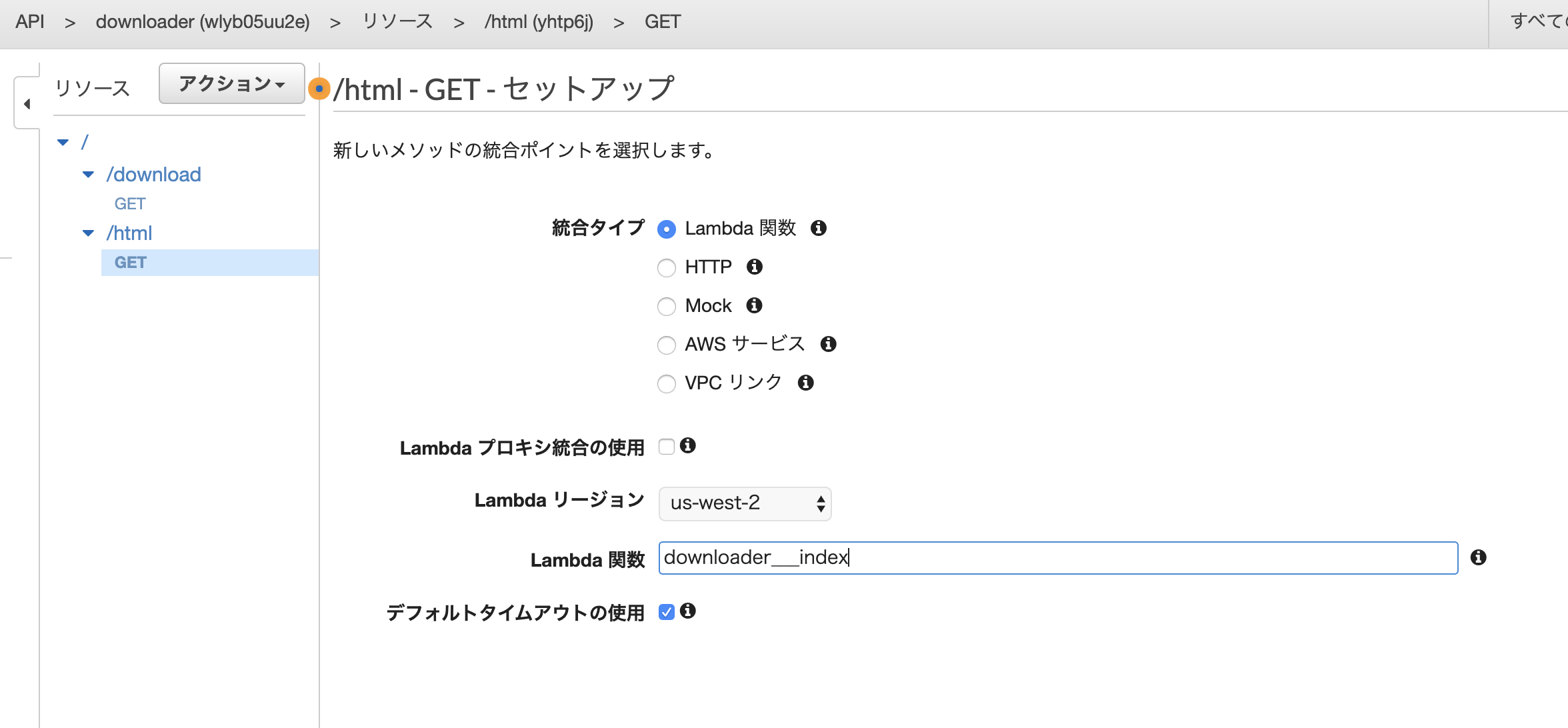
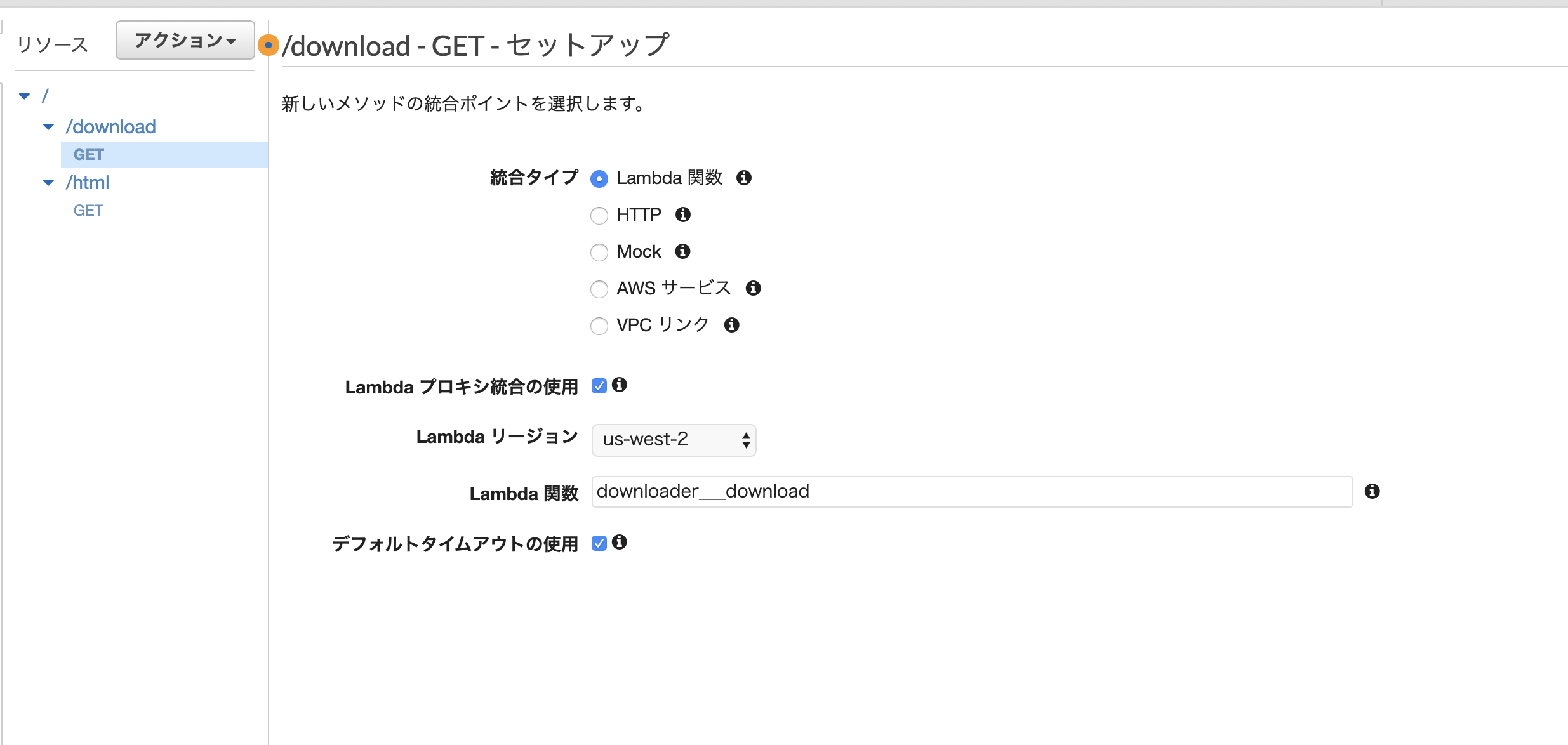
/htmllambdaプロキシ統合の使用にチェックをいれる。これをいれることで、lambda側でheaderなどを定義できるようにする。
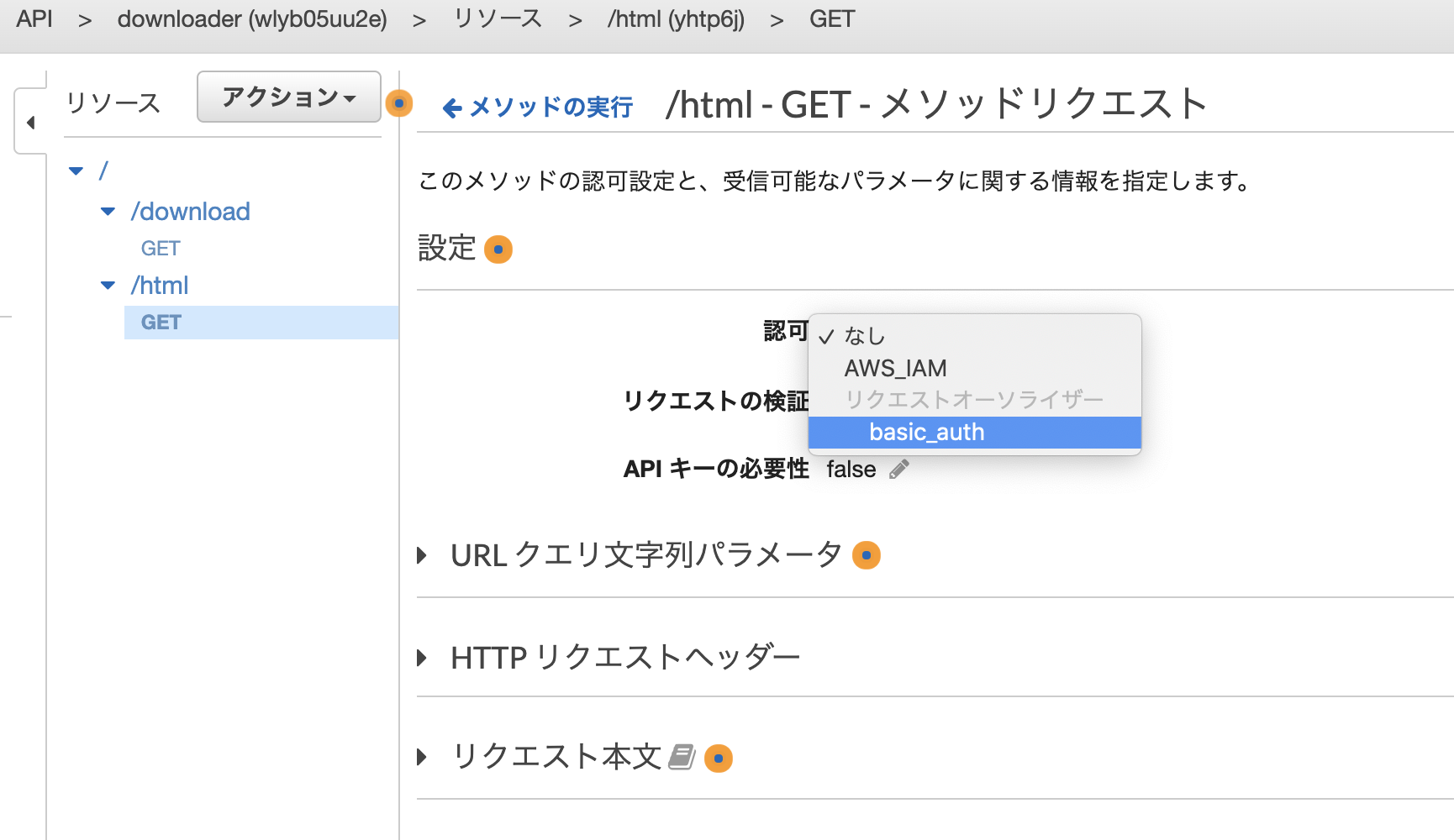
メソッドリクエストにBasic認証で認証するように設定。
メソッドレスポンスにて、htmlを認識できるように修正。レスポンス本文のコンテンツタイプを
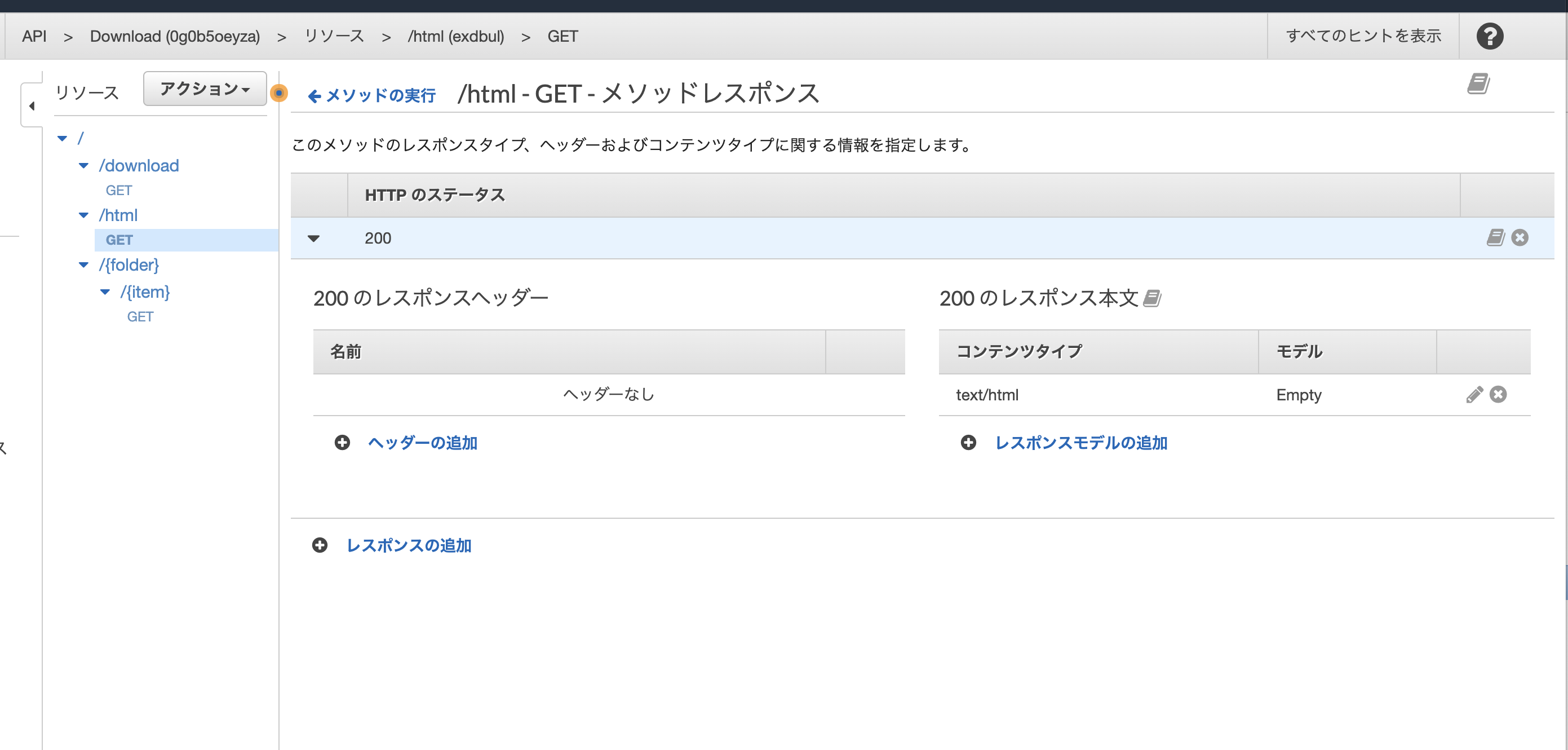
text/htmlに修正する。
これで設定完了。
/downloadHTML側と同様に、lambdaプロキシ統合の使用にチェックをいれる。
ここも同様にBasic認証を設定。
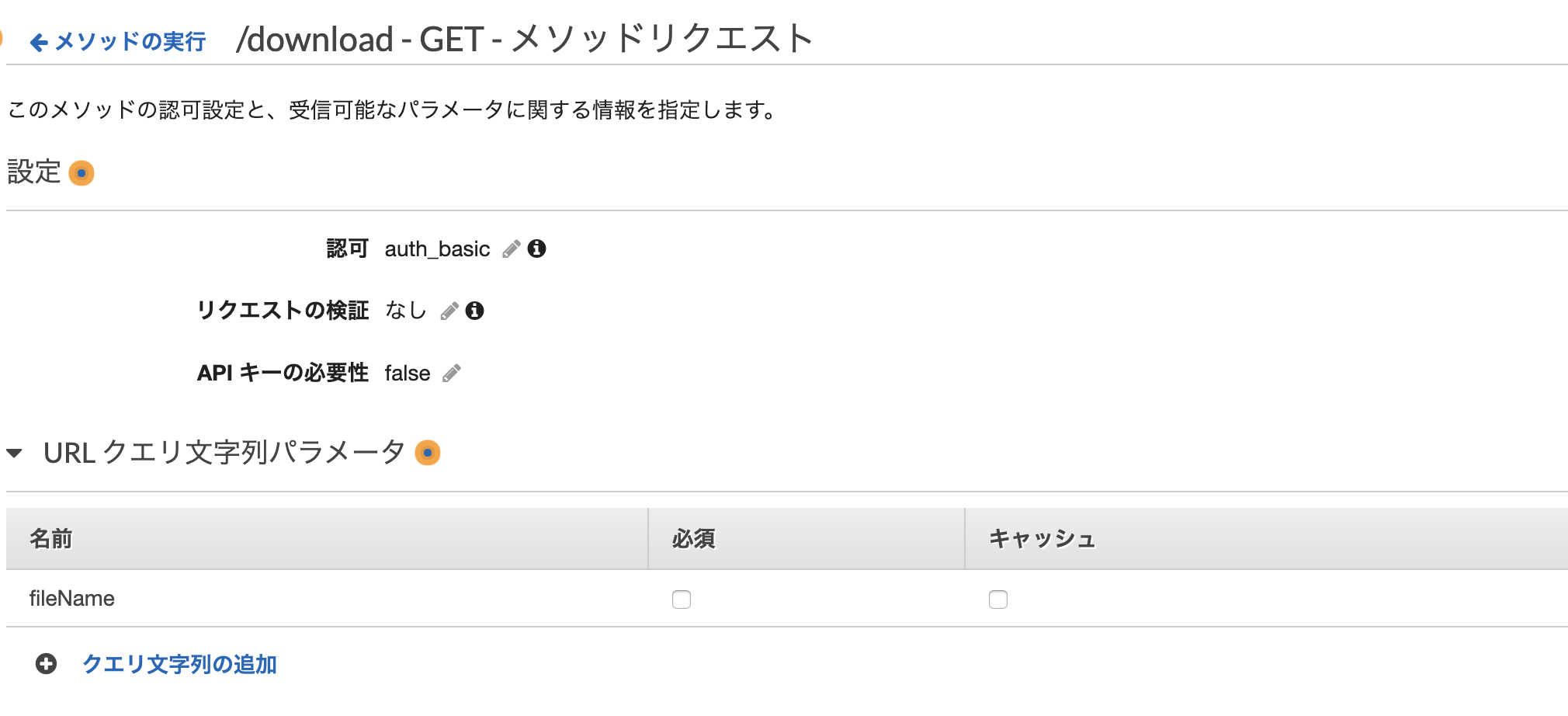
また、ダウンロードするファイル名をパラメータで受け取りたいため、URLクエリ文字列パラメータに
fileNameという名前のパラメータを設定。(必須にしたい場合はチェックを入れればよい)
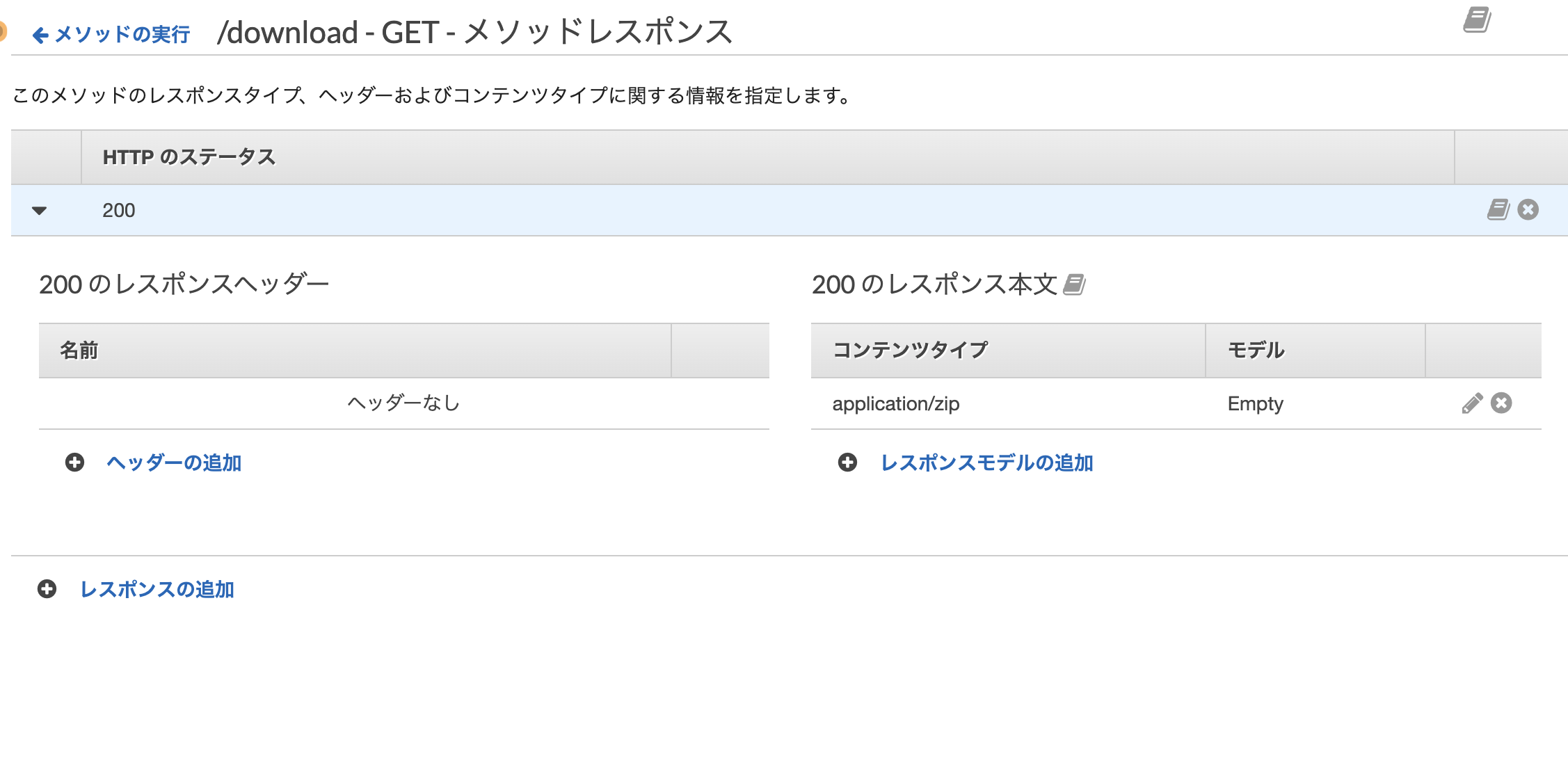
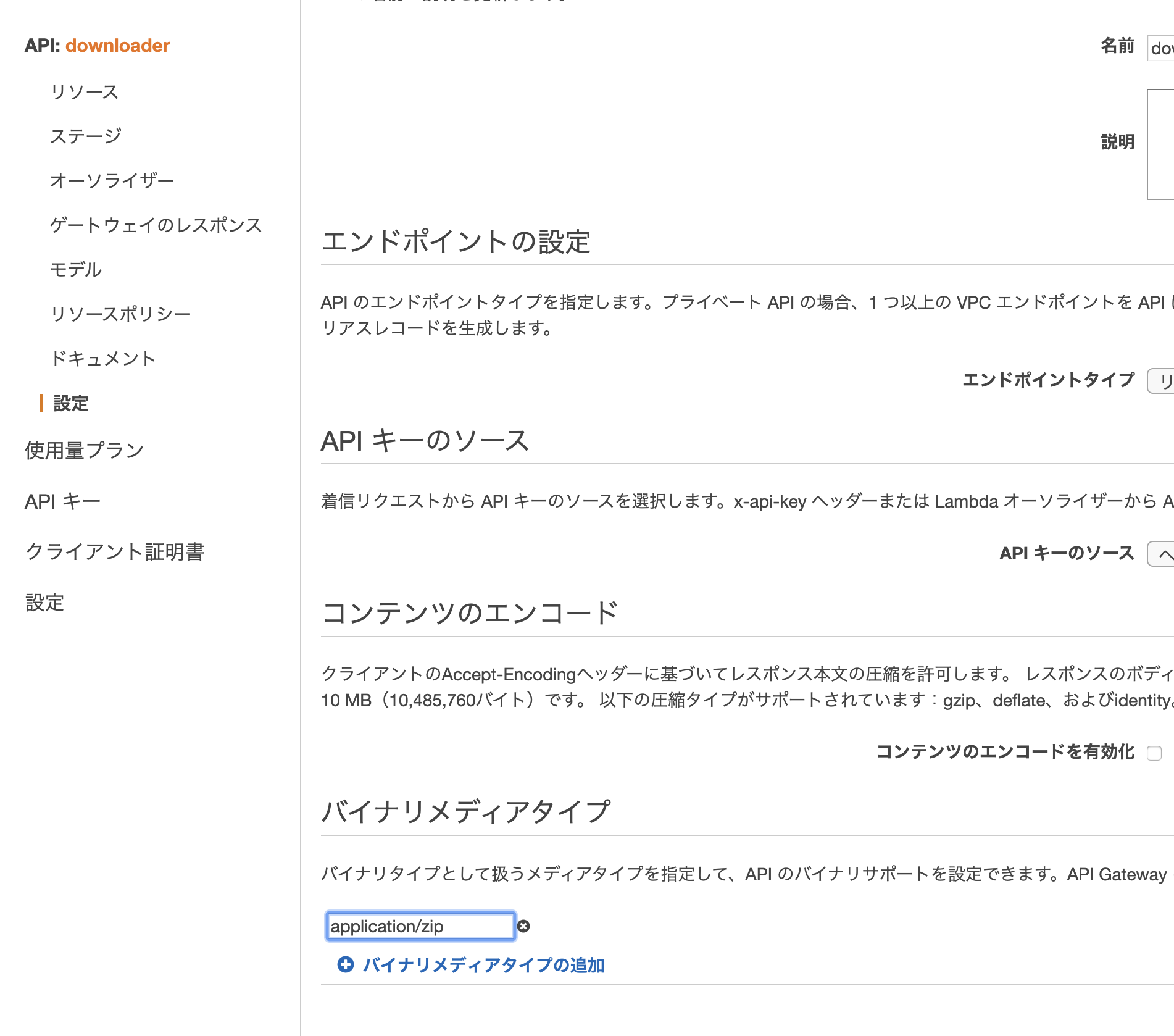
zipファイルをダウンロードさせたいため、メソッドレスポンスのコンテンツタイプを変更。
最後に、左メニューにある設定からバイナリメディアタイプを追加。ここに対象のコンテンツタイプを設定することで、lambdaからの返却値(base64)がバイナリに変換されるようになる。(ただし、リクエストヘッダーにContent-type、またはAcceptに
application/zipを追加してあげないといけない)
S3
bucket名:
hogehoge-downloaderを作成し、下記ディレクトリを作成.
files: zipファイルを格納template: HTMLテンプレートファイルを用意HTMLテンプレートは適当に作った下記。
index.html<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>ダウンローダー</title> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/bulma@0.8.0/css/bulma.min.css"> <script defer src="https://use.fontawesome.com/releases/v5.3.1/js/all.js"></script> </head> <body> <section class="section"> <div class="container"> <div class="container"> <ul>{{ file_li }}</ul> </div> </div> </section> </body> <script src="https://unpkg.com/axios/dist/axios.min.js"></script> <script> function download(e) { const zipUrl = 'https://xxx.aws.com/prod/download?fileName=' + this.filename; const blob = axios.get(zipUrl, { responseType: 'blob', headers: { Accept: 'application/zip' }, }).then(response => { window.URL = window.URL || window.webkitURL; const uri = window.URL.createObjectURL(response.data); const link = document.createElement('a'); link.download = this.filename; link.href = uri; link.click() }).catch(error => { console.log(error); }); } var links = Array.from(document.getElementsByClassName('downloadLink')); links.map(l => l.addEventListener('click', {filename: l.dataset.filename, handleEvent: download})); </script> </html>
file_li.html<li> <a href="{{ file_url }}" class="downloadLink" data-filename="{{ file_name }}">{{ file_name }}</a> </li>ハマったこと
- オーソライザーのキャッシュ許可するとなぜかリソースごとに認証おk・NGがでてくる → キャッシュしないようにすると回避できる
- 設定の バイナリメディアタイプ はレスポンスにはフィルタ(?)されない。リクエストヘッダーのContent-typeとAcceptで処理される
- content-dispositionを使用する場合、lambdaでheaderを用意&Lambda プロキシ統合の使用にチェックいれると良い
問題点
しかし、この構成ではだめである。組むまで僕は気づかなかった。。。
実際組んでエラーを確認するまで気づかなかった。
このページを確認してほしい。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/limits.html
呼び出しペイロード (リクエストとレスポンス) 6 MB (同期)
ファッ!!???!!6MB???!!???
Dead end.
〜完〜
EC2で組む
はい
構成図
EC2だけです。Ubuntu18.04で用意しました。
実装・設定
Dockerで用意したPythonコンテナにBottleのAPIを用意しました。Basic認証、zipファイルダウンロードの工程はすべてBottleに任せています。
カレントディレクトリに配置したzipファイルをダウンロードします。
app.py
import bottle # BASIC認証のユーザ名とパスワード USERNAME = "user" PASSWORD = "pass" def check(username, password): u""" BASIC認証のユーザ名とパスワードをチェック @bottle.auth_basic(check)で適用 """ return username == USERNAME and password == PASSWORD @bottle.route("/zip") @bottle.auth_basic(check) def zip(): zip_filename = 'files.zip' with open(zip_filename, 'rb') as f: body = f.read() response.content_type = 'application/zip' response.set_header('Content-Disposition', 'attachment; filename="{}"'.format(zip_filename)) response.set_header('Content-Length', len(body)) response.body = body return response if __name__ == '__main__': bottle.run(host='0.0.0.0', port=80, debug=True)$ docker run -p 80:80 -v $(pwd):/app -it docker-image-hogehoge python3 /app/app.pyこれで大容量(時間かかるけど)でもダウンロードするURLができました!!!!!!!
雑感想
勉強のため!サーバーレスだ!って意気込んでやったけど、最初からEC2でやればよかった。。。。。。。
- 投稿日:2020-03-19T00:31:00+09:00
AWS CDKに触れてみる
はじめに
CDKを使ってLambdaを作成してみるところまでを目標とします。
環境
今回はCloud9を使用します。
$ python --version Python 3.6.10 $ cdk --version 1.27.0 (build a98c0b3)CDKが入っていなければ以下のコマンドでインストールします。
$ npm install -g aws-cdkやってみる
CDKを使う準備
まずCDKを使うために色々準備します
プロジェクトフォルダを作成
$ mkdir hogehoge $ cd hogehogeCDKの初期設定
初期設定をします
cdk init --language python source .env/bin/activate pip install -r requirements.txtAWSユーザーデータの利用設定も行う
$ cdk bootstrap Bootstrapping environment aws://999.../ap-northeast-1... Environment aws://999.../ap-northeast-1 bootstrapped (no changes).これで準備完了です
CDKを使ってみる
Lambdaを作成していきます
pythonファイルの準備
Lambdaで使用するpythonファイルを準備します
$ mkdir lambda $ touch lambda/index.py内容はあまり気にしないので適当に
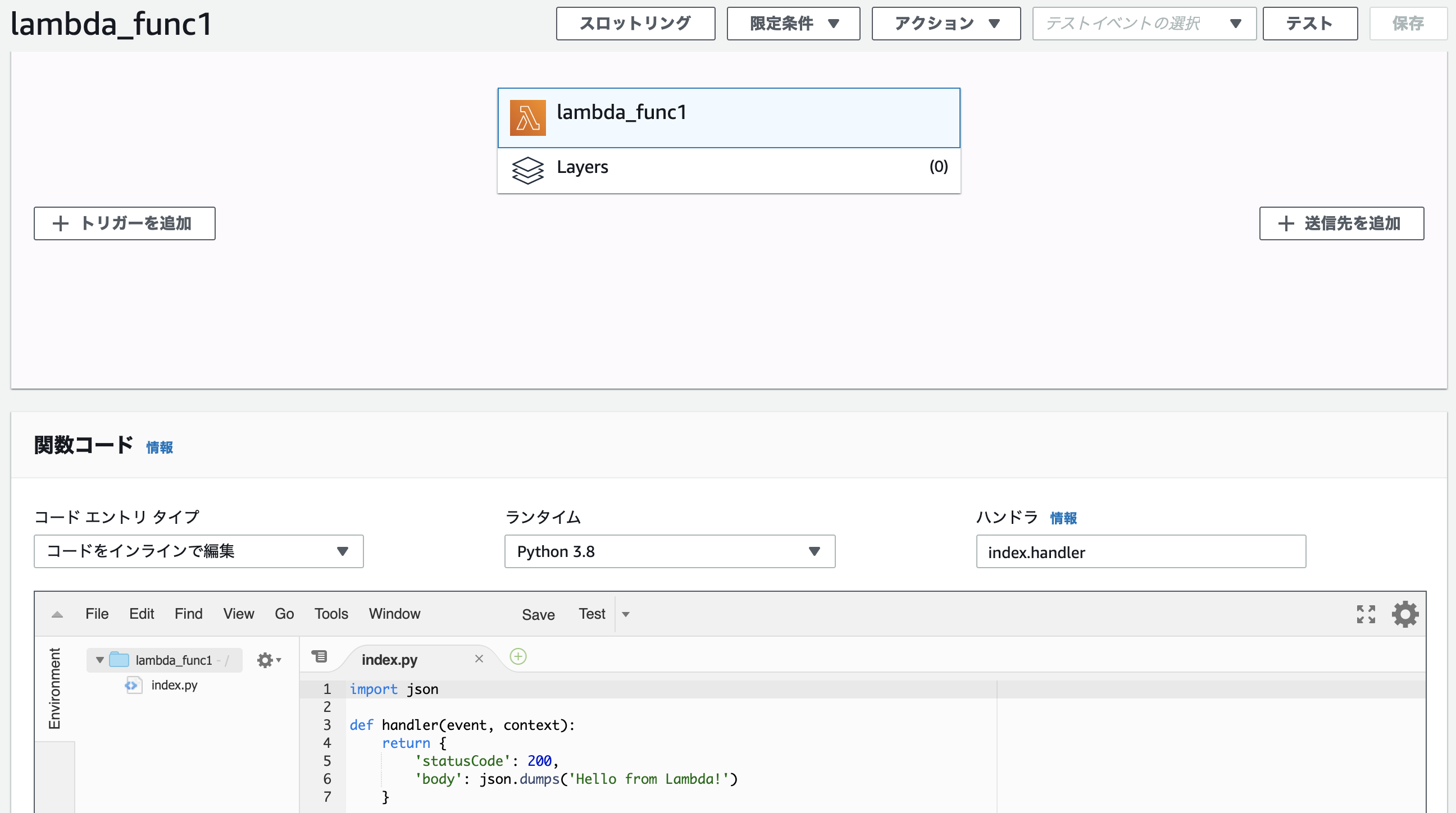
index.pyimport json def handler(event, context): return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }スタックを作成
最初に作成した
hogehogeディレクトリ下にhogehoge/hogehoge_stack.pyがあるので、ここにリソースを作成するためのコーディングをしていく。
公式が丁寧でわかりやすい。hogehoge_stack.pyimport aws_cdk.core as core import aws_cdk.aws_lambda as aws_lambda class HogehogeStack(core.Stack): def __init__(self, scope: core.Construct, id: str, **kwargs) -> None: super().__init__(scope, id, **kwargs) lambda_func = aws_lambda.Function( self, 'lambda_func1', function_name = "lambda_func1", runtime = aws_lambda.Runtime.PYTHON_3_8, code = aws_lambda.Code.asset('lambda'), handler = 'index.handler' )$ echo "aws-cdk.aws-lambda" >> requirements.txt $ pip install -r requirements.txtAWSリソースの作成
$ cdk diff $ cdk deploy作成完了!
$ cdk destroy消えた!
後処理
pushするならしちゃいましょう
$ git add . $ git remote add origin [作成済みのリポジトリを使用] $ git push -u origin masterまとめ
色々設定しなきゃいけないのかな、と思っていましたが結構簡単に作れちゃうのがいいですね。
他の環境作成ができるサービスとの住み分けはどんな感じなんでしょうかねー補足
複数のstackを作成するには
app.pyを編集する必要がありますapp.pyHogehogeStack(app, "stack_hogehoge") FugafugaStack(app, "stack_fugafuga") # こんな感じ複数のstackを作成した場合には
cdk deployだと怒られるので以下のように書く$ cdk list stack_hogehoge stack_fugafuga $ cdk deploy stack_*

- 投稿日:2020-03-19T00:07:05+09:00
EC2インスタンスからAWS CLIを実行する際には
個人的メモになります
インターネットアクセスかエンドポイントが必要
対応策
- EC2インスタンスにパブリックIPを付与する
- NATゲートウェイを使用する
- エンドポイントを使用する
EC2インスタンスにパブリックIPを付与する
- 自動割り当てパブリック IPを利用
- ElasticIPを付与パブリックサブネット上に踏み台サーバを配置する構成は、最近は少ないのではないだろうか
NATゲートウェイを使用する
プライベートサブネット上のEC2インスタンスではこちらの構成
ただ、アウトバウンドを絞りたい為、簡単にインターネットに出れない場合もエンドポイントを使用する
CLIで実行するサービスのエンドポイントが必要
EC2の場合
インターフェースエンドポイント
com.amazonaws.ap-northeast-1.ec2S3の場合
ゲートウェイエンドポイント
com.amazonaws.ap-northeast-1.s3参考