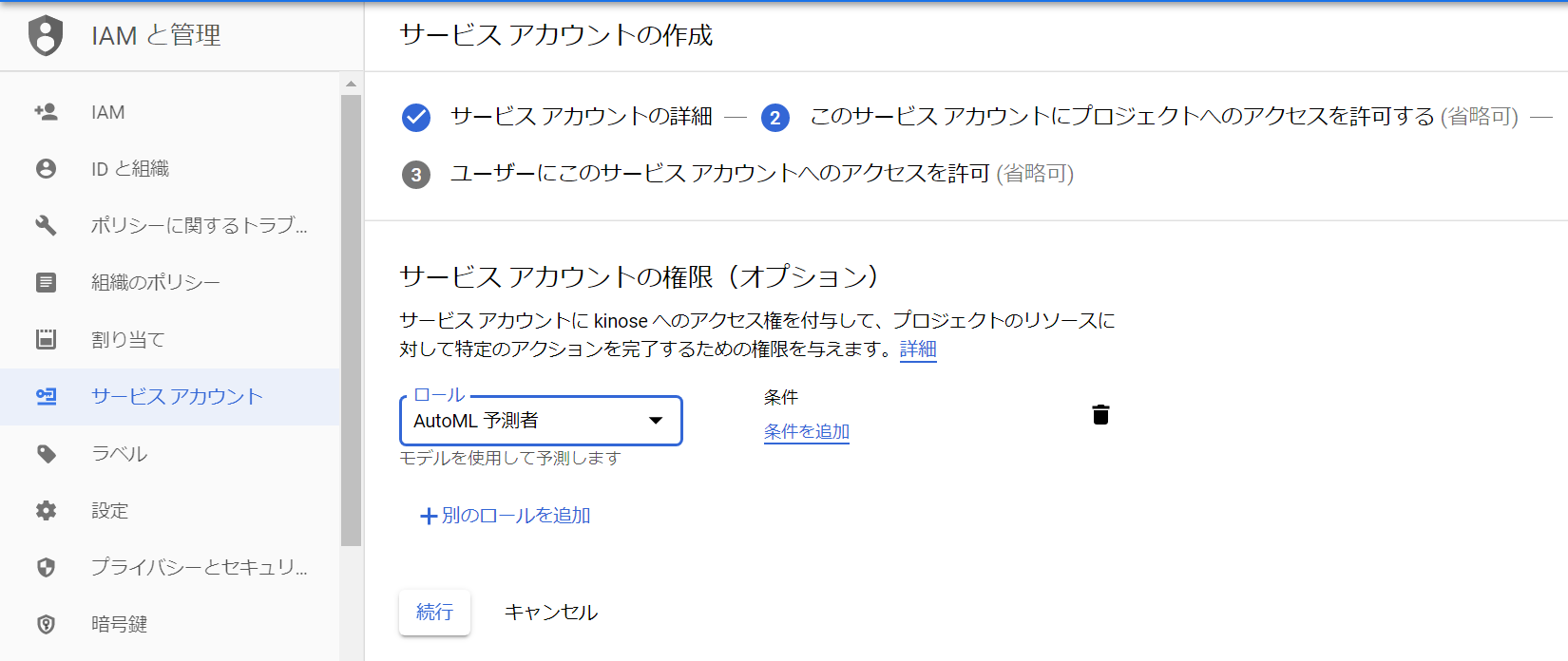
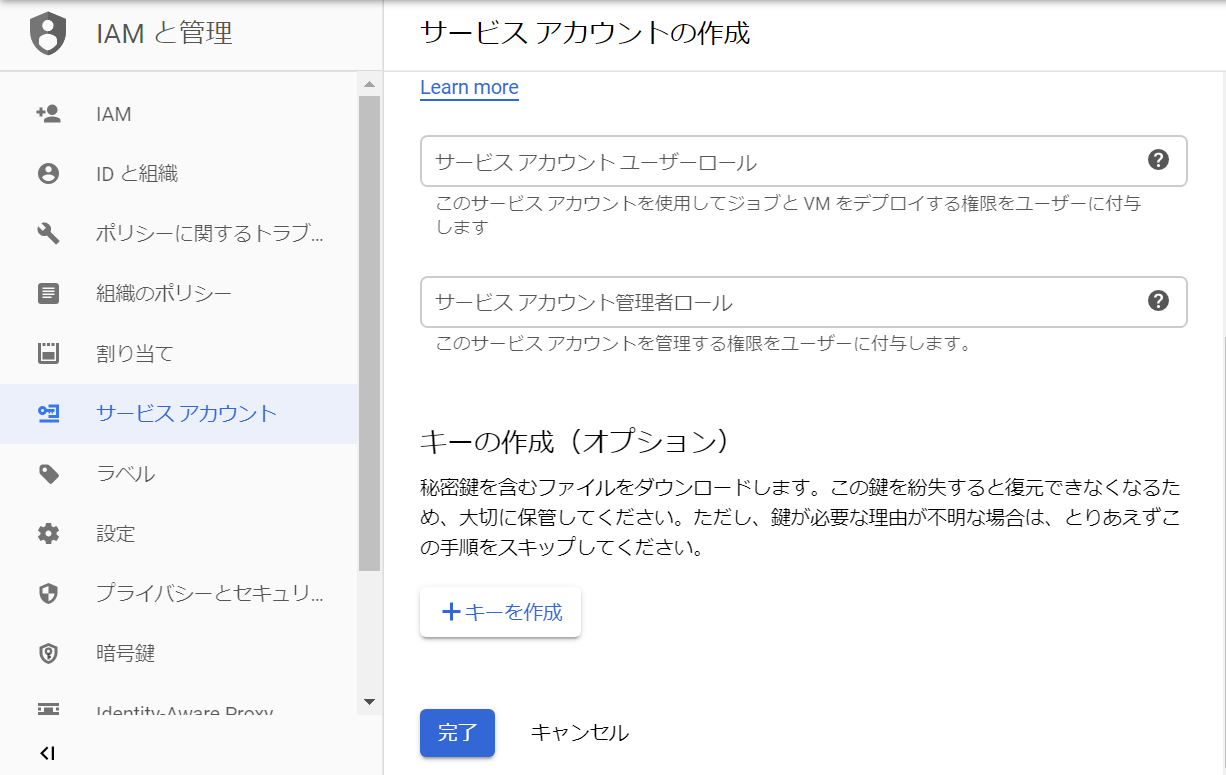
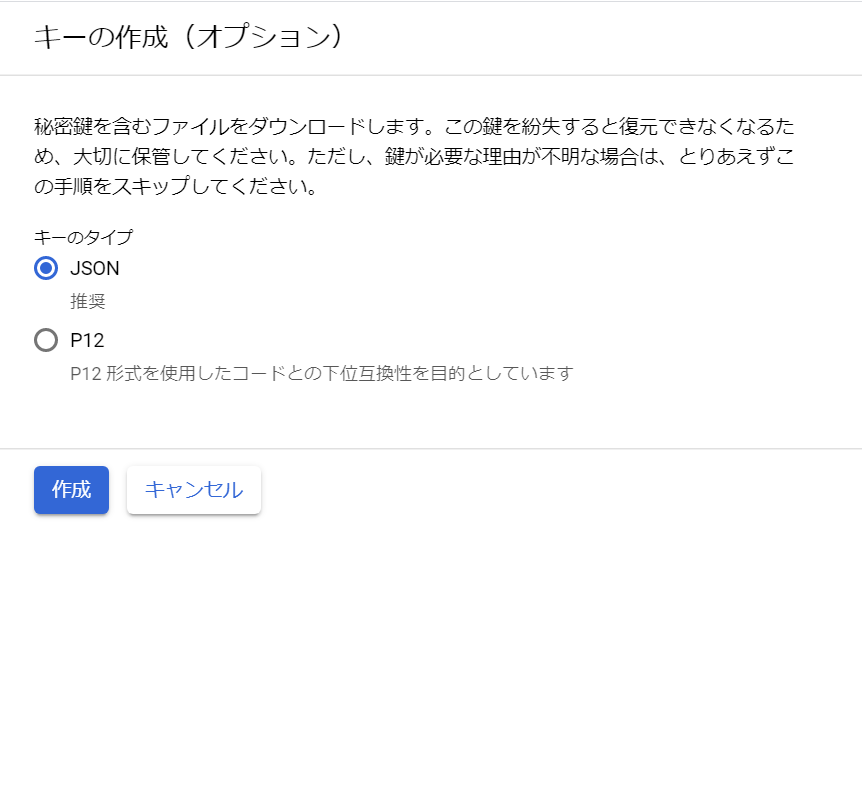
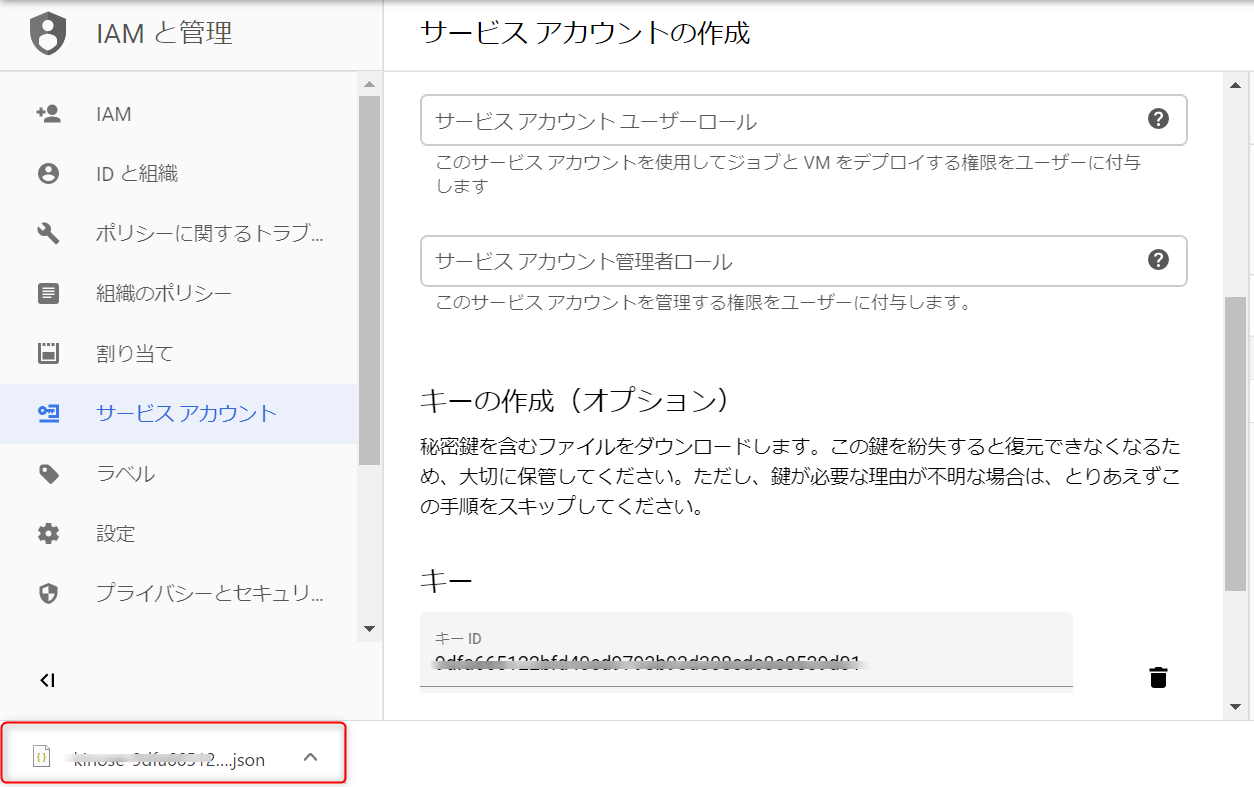
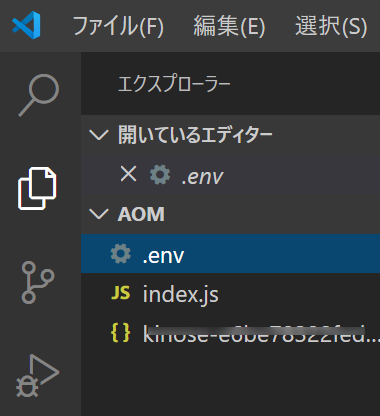
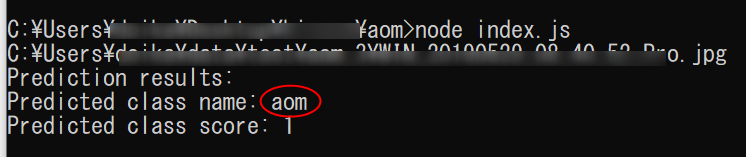
require('dotenv').config();//.envを読み込むconstautoml=require('@google-cloud/automl');constfs=require('fs');// Create client for prediction service.constclient=newautoml.PredictionServiceClient();/**
* TODO(developer): Uncomment the following line before running the sample.
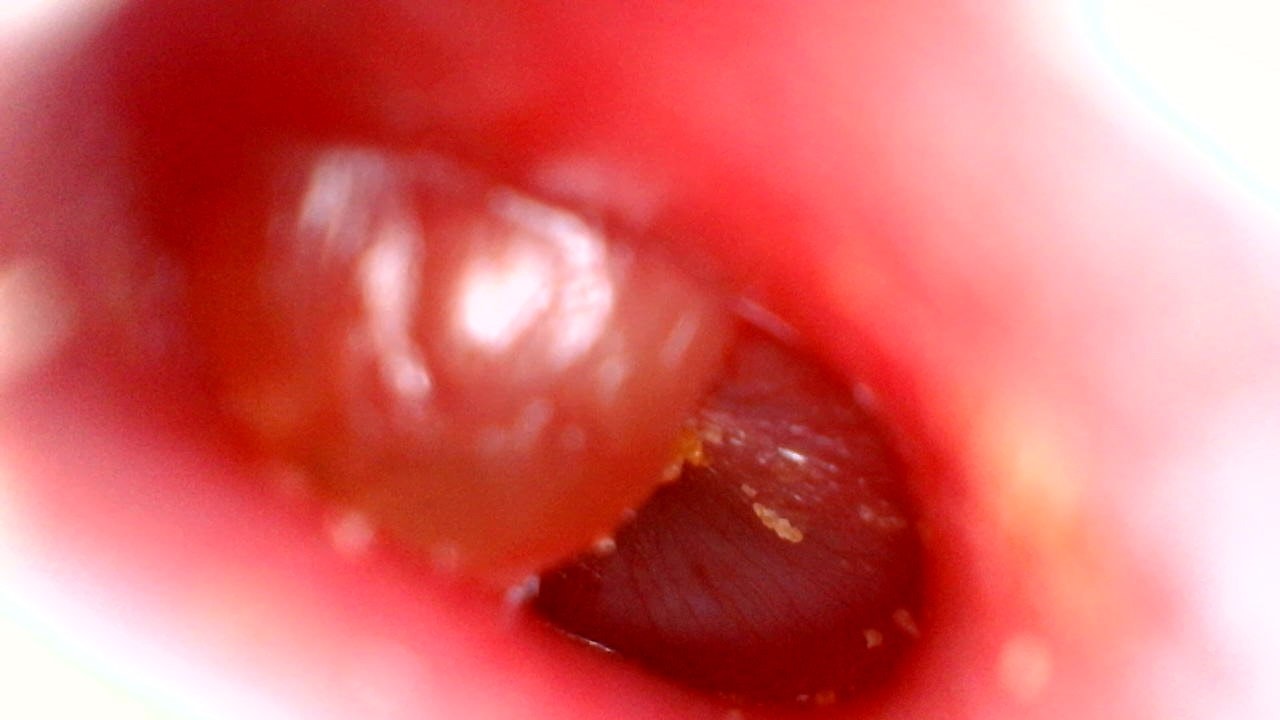
*/constprojectId=`The GCLOUD_PROJECT string, e.g. "my-gcloud-project"`;constcomputeRegion=`region-name, e.g. "us-central1"`;constmodelId=`id of the model, e.g. “ICN723541179344731436”`;constfilePath=`local text file path of content to be classified, e.g. "./resources/flower.png"`;constscoreThreshold=`value between 0.0 and 1.0, e.g. "0.5"`;// Get the full path of the model.constmodelFullId=client.modelPath(projectId,computeRegion,modelId);// Read the file content for prediction.constcontent=fs.readFileSync(filePath,'base64');constparams={};if(scoreThreshold){params.score_threshold=scoreThreshold;}// Set the payload by giving the content and type of the file.constpayload={};payload.image={imageBytes:content};asyncfunctiontest(){// params is additional domain-specific parameters.// currently there is no additional parameters supported.const[response]=awaitclient.predict({name:modelFullId,payload:payload,params:params,});console.log(`Prediction results:`);response.payload.forEach(result=>{console.log(`Predicted class name: ${result.displayName}`);console.log(`Predicted class score: ${result.classification.score}`);});}test();