- 投稿日:2020-02-26T04:01:42+09:00
物理手書き文字認識
はじめに
初めまして。
普段は音声処理とキー配列とVimをいじっているしがない大学1回生です。
初めてのQiitaへの投稿ということで,今回は私の好きなキーボードと機械学習に関する記事です。2018/04/01,エイプリルフールにGoogleが下記の動画を公開しました。
当時高校3年生だった私はこれに衝撃を受けたのですが,知識と経験が浅かったため実装を断念しました。
大学生になった今なら出来るだろうと実装を試みたので,それについてまとめます。実行環境
- MacOS 10.15(多分Linux系でも動きます)
- Python 3.7.5
- TensorFlow 2.1.0
仕組み
ソースコードは全てGitHubで公開しています。
https://github.com/AjxLab/Tegaki# clone repo $ git clone https://github.com/AjxLab/Tegaki $ cd Tegaki/ # install python libs $ pip install -r lib/requirements.txtフローチャート
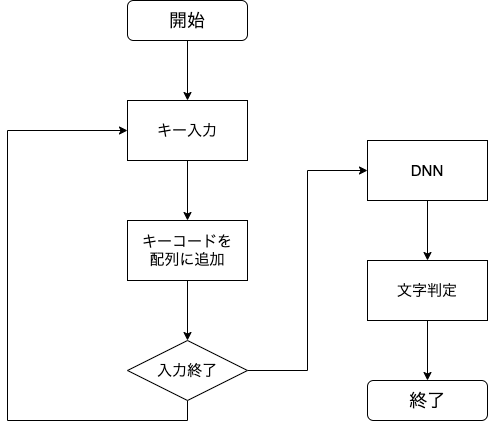
全体の大まかな流れは,下記の通りです。
キー入力
入力されたキーは,キーコード(数値)として入力することができます。
これを入力順に配列に格納することで,これをベクトルとみなしてDNNの入力とします。from getch import getch keys = [] # キーコードを格納する配列 key = getch() keys.append(int(key.encode('utf-8', 'replace').hex(), 16))これをそのまま実行しただけでは,当然うまくいきません。
ループ処理を加えて連続的に入力してあげるためには,キー入力の終了条件が必要です。今回は,下記のいずれかを満たすとき,入力終了としています。
- 入力文字が30文字を超えた
- 最後に入力してから1秒以上経過した
教師データを作成
build.pyを実行することで,教師データを作成することができます。コマンドライン引数には登録したい文字を指定します。
# 「あ」を記録する場合 $ python build.py あ 「あ」を記録(Ctrl-Cで終了) Now:0 step # キーボードに「あ」となぞるように入力してください # data/${登録する文字}/${%Y-%m-%d--%H:%M:%S:%f}.csv というファイルが生成される機械学習
今回は物理手書き文字認識を,事前に登録しておいた文字のクラスタリング問題として定式化しています。
クラスタリングにはニューラルネットを使用するのですが,ここでは安直にDNNを用いることとします。from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense, Dropout # 文字のクラス数 # 例 : 「あ, い, う, え, お」 の5文字 => 5 n_classes = 5 # モデルを定義 model = Sequential([ Dense(128, input_shape=(30,), activation='relu'), Dropout(0.5), Dense(256, activation='relu'), Dropout(0.5), Dense(256, activation='relu'), Dropout(0.5), Dense(n_classes, activation='softmax') ]) # モデルをコンパイル model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'] ) # 学習 # x : 30次元ベクトル(キーコード) # y : 正解ラベル self.__model.fit(x, y, epochs=200, batch_size=64)前述で得られた30次元ベクトル(30キー分のキーコード)をDNNの入力とし,文字のクラスタリングを行っています。
変数x,yにはそれぞれ入力ベクトルと正解ラベルを代入するのですが,今回に限って正規化などは特に行っていません。試してみよう
infer.pyを実行することで,物理手書き文字認識を試すことができます。
精度が低いようであれば,モデルを変更したり教師データを増やしたりしてみてはいかがでしょうか?さいごに
周りの友人がQiita記事を投稿しているのを指をくわえながら眺めていたのですが,そろそろ自分も...と思い立ったので筆を執りました。
今後も気が向いたら投稿していきます。参考

- 投稿日:2020-02-26T00:35:43+09:00
てんそるふろー、てんさーふろう結局どっちなん(Tensorflowの読み方)
てんそるふろー?てんさーふろー?
最後まで読むと後悔します...(たぶん?)
プログラミングをしていると読み方がわからない英単語に出会うことがよくあるのでそれについてのまとまりのない考察。
例: Tensorflow
自分の周りでも「てんさーふろー」と「てんそるふろー」の2通りの読み方をよく聞く。
「強い人」が「てんそるふろー」と読んでいたから自分もそう読むようにしたなんて言う人とかも見たことがある…そういう人の前で違った読み方をしてしまうと何か思われそうな感じがして相手に合わせようとした経験がある人も多いのではないだろうか。
1. Vectorはみんなベクトルと呼ぶ
しかし、Vectorを「ベクター」と呼ぶ人はあまり聞いたことはない。みんな「ベクトル」と呼ぶ。
テンソル積なんて言うし、やはり「てんそるふろー」が正解なのだろうか。2. 海外の人はどう発音しているのか
ここでGoogleに発音してもらったり、海外のYoutubeなどを見て確認すると「てんさーふろー」と発音している。
やはり「てんそるふろー」と決めつけるのもよくないようだ。???
1.から日本ではみんな「Vector」をベクトルと読むし、「てんそるふろー」の読みで良さそうだ。
しかし海外の方と議論する時は2.から「てんさーふろー」が良さそう。なので日本にいる人間はどう読んでもよさそうである。ただ、海外に行くと「てんそるふろー」はダメそう。日本語: 「てんそるふろー」
英語: 「てんさーふろー」
なのかな....?結論: どっちでもいい
「てんそるふろー」は間違いで、「てんさーふろー」が正しい!と言う人は
f'(x)を「エフダッシュエックス」ではなく「エフプライムエックス」と読みなさいと言う人と似たようなものなのか...?(少し違う気がするが。。)ここは日本なんだからどっちでもいいじゃんって思います。
読み方を気にしている人より凄いのは、Tensorflowを使いこなせる人で、さらに凄いのはTensorflowを作った人であるのには変わらない。結論: どっちでもいいし、どうでもいい^^
余談
自分でこの記事を書いてしまい、何かとTensorflowと言う度に意識してしまうので本当に後悔しています。
他にこの記事を読んで意識するようになってしまい、人との対話に影響が出てしまった方がいれば本当に申し訳ありませんmmコードがないと物足りないので【おまけ】
import tensorflow as tf※
読み方迷わなくていいしpytorch使えよ自分