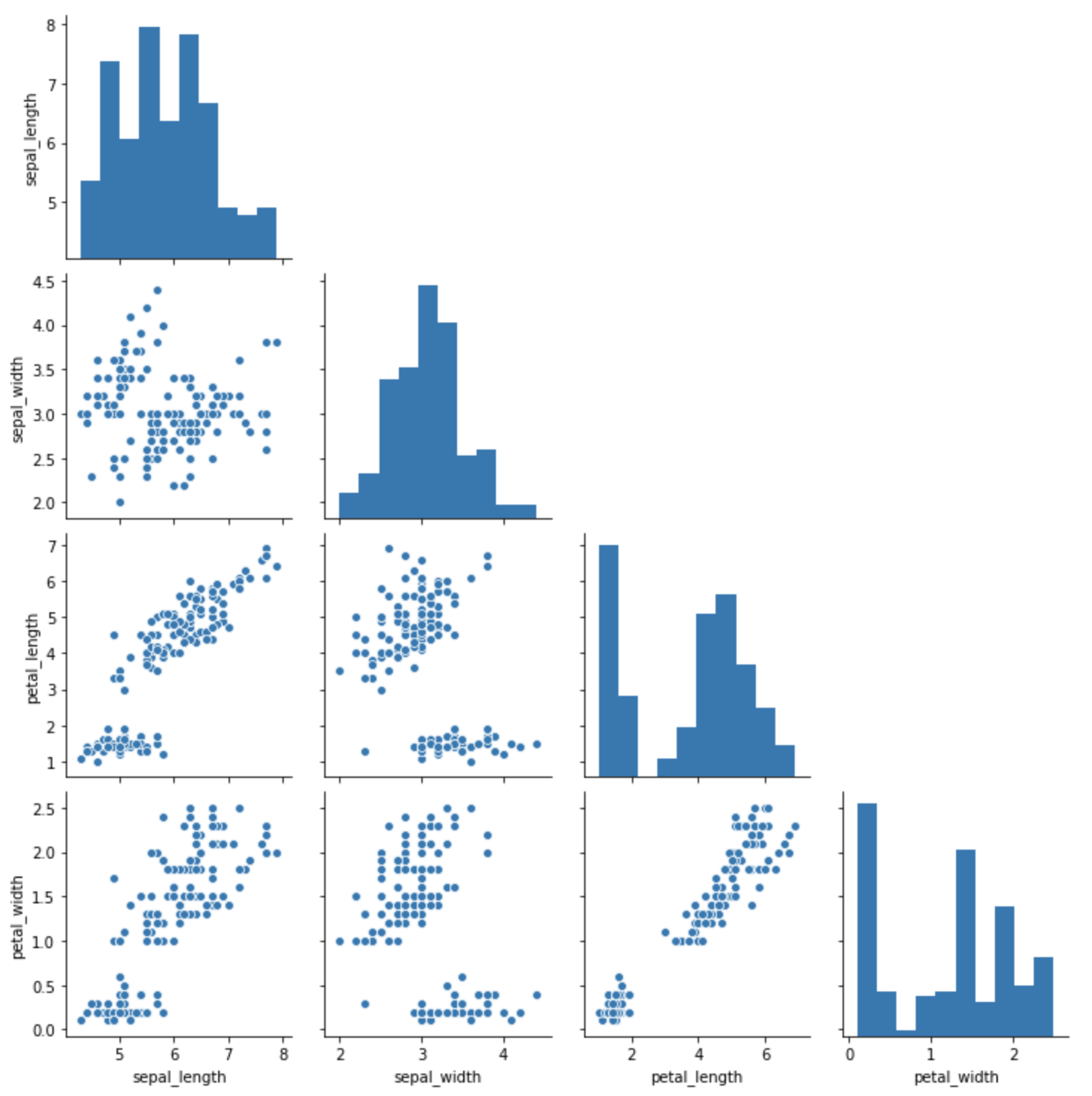
importosprint('Process (%s) start...'%os.getpid())# Only works on Unix/Linux/Mac:
pid=os.fork()ifpid==0:print('I am child process (%s) and my parent is %s.'%(os.getpid(),os.getppid()))else:print('I (%s) just created a child process (%s).'%(os.getpid(),pid))
実行結果:
Process (19148) start...
I (19148) just created a child process (19149).
I am child process (19149) and my parent is 19148.
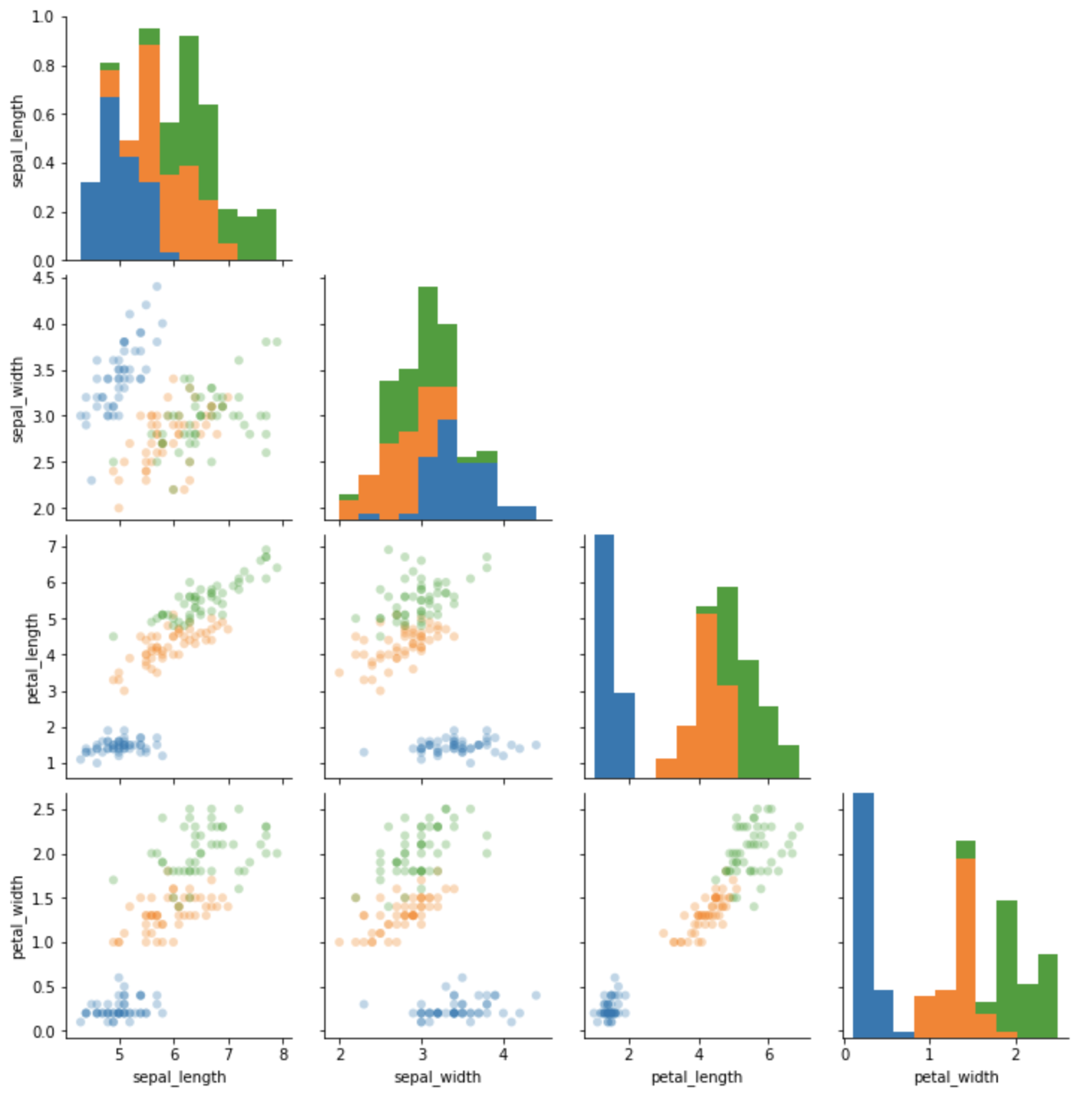
frommultiprocessingimportProcessimportos# 子プロセスが実行する処理
defrun_proc(name):print('Run child process {} ({})...'.format(name,os.getpid()))print('Parent process {}.'.format(os.getpid()))p=Process(target=run_proc,args=('test',))print('Child process will start.')p.start()p.join()print('Child process end.')
実行結果:
Parent process 19218.
Child process will start.
Run child process test (19219)...
Child process end.
frommultiprocessingimportProcess,Queueimportosimporttimeimportrandom# Queueにデータを書き込む
defwrite(q):print('Process to write: {}'.format(os.getpid()))forvaluein['A','B','C']:print('Put {} to queue...'.format(value))q.put(value)time.sleep(random.random())# Queueからデータを読み取り
defread(q):print('Process to read: {}'.format(os.getpid()))whileTrue:value=q.get(True)print('Get {} from queue.'.format(value))# 親プロセスがQueueを作って、子プロセスに渡す
q=Queue()pw=Process(target=write,args=(q,))pr=Process(target=read,args=(q,))# pwを起動し、書き込み開始
pw.start()# prを起動し、読み取り開始
pr.start()# pwが終了するのを待つ
pw.join()# prは無限ループなので、強制終了
pr.terminate()
実行結果:
Process to write: 19489
Put A to queue...
Process to read: 19490
Get A from queue.
Put B to queue...
Get B from queue.
Put C to queue...
Get C from queue.
Put task 7710...
Put task 6743...
Put task 8458...
Put task 2439...
Put task 1351...
Put task 9885...
Put task 5532...
Put task 4181...
Put task 6093...
Put task 3815...
Try get results...
Connect to server 127.0.0.1...
run task 7710 * 7710...
run task 6743 * 6743...
run task 8458 * 8458...
run task 2439 * 2439...
run task 1351 * 1351...
run task 9885 * 9885...
run task 5532 * 5532...
run task 4181 * 4181...
run task 6093 * 6093...
run task 3815 * 3815...
worker exit.
result_queueの中に結果が入ってきたら、サーバープロセスは順に出力します。
task_master.py
Put task 7710...
Put task 6743...
Put task 8458...
Put task 2439...
Put task 1351...
Put task 9885...
Put task 5532...
Put task 4181...
Put task 6093...
Put task 3815...
Try get results...
Result: 7710 * 7710 = 59444100
Result: 6743 * 6743 = 45468049
Result: 8458 * 8458 = 71537764
Result: 2439 * 2439 = 5948721
Result: 1351 * 1351 = 1825201
Result: 9885 * 9885 = 97713225
Result: 5532 * 5532 = 30603024
Result: 4181 * 4181 = 17480761
Result: 6093 * 6093 = 37124649
Result: 3815 * 3815 = 14554225
master exit.
Traceback (most recent call last):
File "sumple_ws.py", line 10, in <module>
from websocket import create_connection
ImportError: cannot import name 'create_connection' from 'websocket' (unknown location)
Traceback (most recent call last):
File "sumple_ws.py", line 10, in <module>
from websocket import create_connection
ImportError: cannot import name 'create_connection' from 'websocket' (unknown location)
col,row=map(int,input().split())map_list=[[0]*(col+2)]for_inrange(row):map_list.append([0]+list(map(int,input().split()))+[0])map_list.append(map_list[0])defcheck(x,y):lands=[[x,y]]whilelands:x,y=lands.pop()map_list[y][x]=0# down
ifmap_list[y+1][x]==1:lands.append([x,y+1])# right
ifmap_list[y][x+1]==1:lands.append([x+1,y])# up
ifmap_list[y-1][x]==1:lands.append([x,y-1])# left
ifmap_list[y][x-1]==1:lands.append([x-1,y])count=0forrinrange(1,row+1):forcinrange(1,col+1):ifmap_list[r][c]==1:check(c,r)count+=1print(count)