- 投稿日:2020-02-19T23:54:45+09:00
Tensorflow Object Detection APIで学習させたMobilenetV2のモデルをNVIDIA JetsonのDeepStream SDKで動かしてみた
はじめに
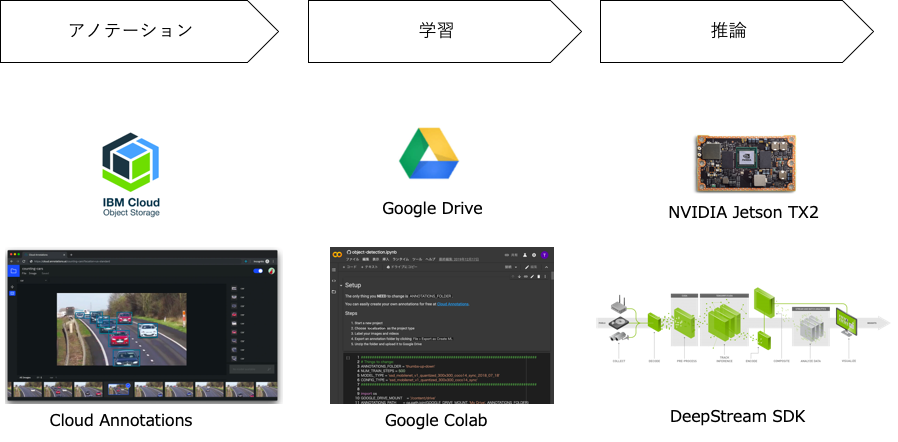
この記事では、NVIDIA JetsonのDeepStream SDKで自分で用意したデータで学習した物体検出モデルを利用する手順について記述しています。データのアノテーションと学習は以下の図にあるように、Cloud AnnotationsとGoogle colabを使って行います。どちらも無料で使えます。
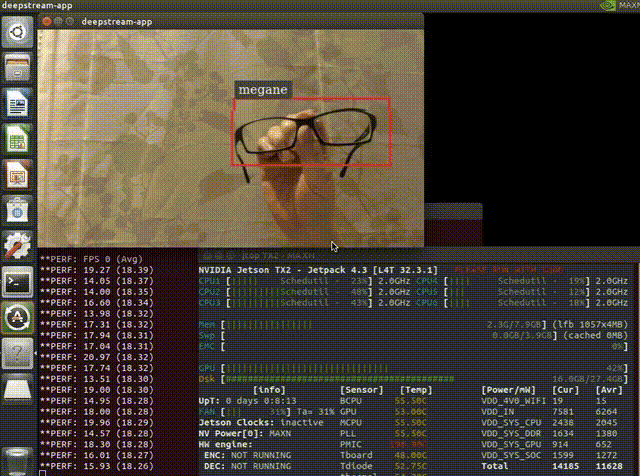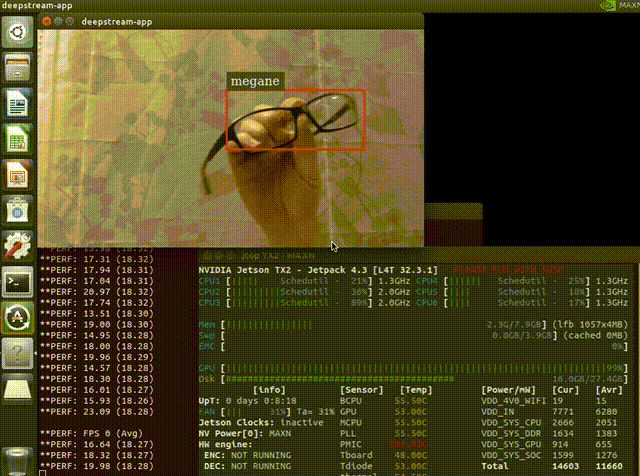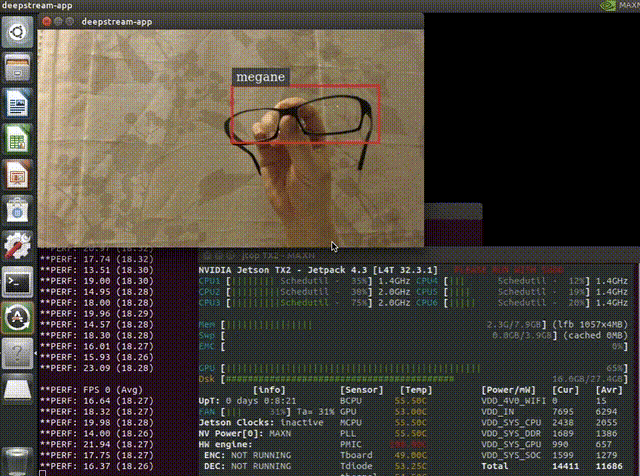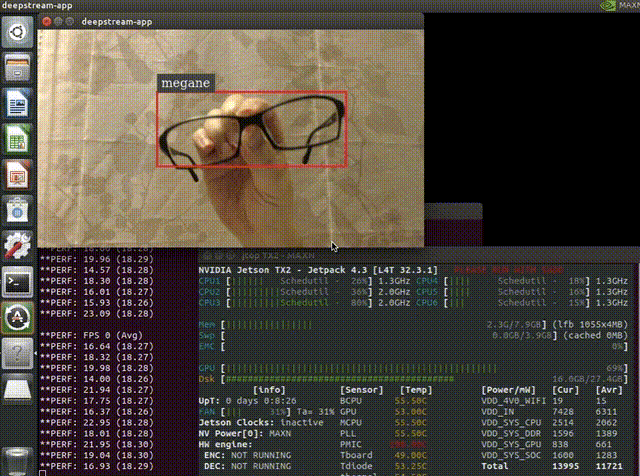
以下はメガネを検出できるように学習させたモデルをJetsonのDeepStream SDKで動かしている様子です。平均で18FPSぐらいでています。よく考えてみるとコーディングらしいコーディングをすることなく(構成ファイルやパラメーターの変更のみ)準備されたものを組み合わせて、ここまで出来てしまっています。
環境
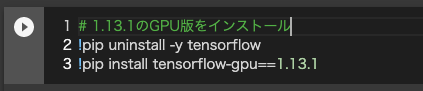
tensorflowのバージョンは、1.13.1がおすすめです。(1.15や1.14を使用すると実行時にエラーになりました)
tensorflow 1.13.1
Object Detection API tag:v1.13.0
DeepStreamSDK 4.0.2
Jetpack 4.3
Jetson TX2
カメラ:LOGICOOL HD PRO WEBCAM C920手順概要
- Cloud Annotationsでデータ・アノテーション
- Google Colabで学習
- DeepStreamで推論
1. Cloud Annotationsでデータ・アノテーション
以前の記事にCloud Annotationsでのデータ・アノテーションの方法を紹介していますので、こちらを参考にしてください。
データのアノテーションからTensorflow Object Detection APIでの学習までをクラウドで簡単に行う方法
https://qiita.com/tsota/items/123514cbfd036e6bd8082. Google Colabで学習
2-1. Notebookの修正
以下のNotebookを開き一部コードを修正します。
物体検出モデル作成のためのNotebook
https://colab.research.google.com/github/cloud-annotations/google-colab-training/blob/master/object_detection.ipynb以下の修正が必要です。
Tensorflowのバージョン1.13.1を使うために、セルを追加して、以下のようなコードを記述して実行します。
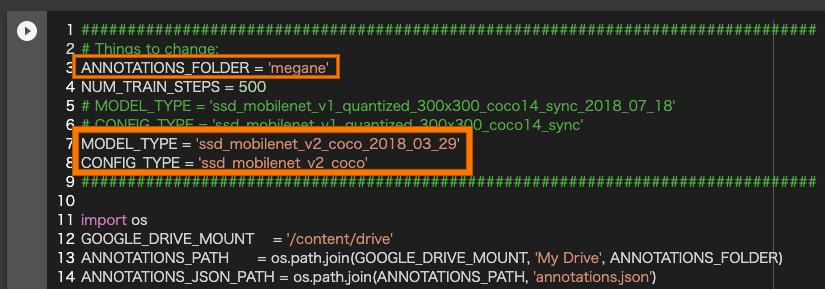
MobilenetV2を使うために「Setup」セルで以下の点を変更します。
「ANNOTATIONS_FOLDER」:Google Driveにアップロードしたフォルダ名に変更します。
「MODEL_TYPE」:ssd_mobilenet_v2_coco_2018_03_29に変更します。
「CONFIG_TYPE」:ssd_mobilenet_v2_cocoに変更します。
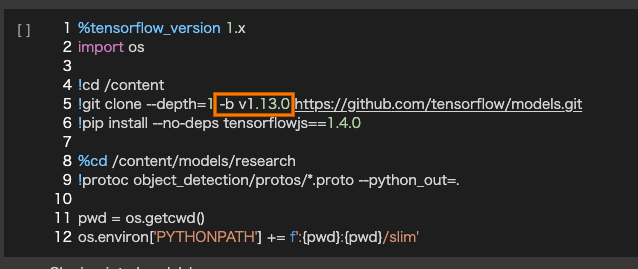
Object Detection APIのv1.13.0を使うために、「Install the TensorFlow Object Detection API」セルの5行目に-b v1.13.0を追加します。
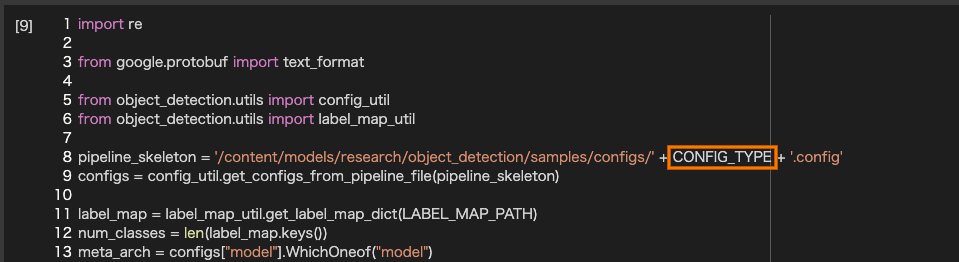
「Model config」のセルの8行目をモデルタイプが直接記述されている箇所をCONFIG_TYPEの変数名に変更します。
2-2. Notebookを実行
修正したNotebookを上から実行していきます。
2-3. モデルをダウンロード
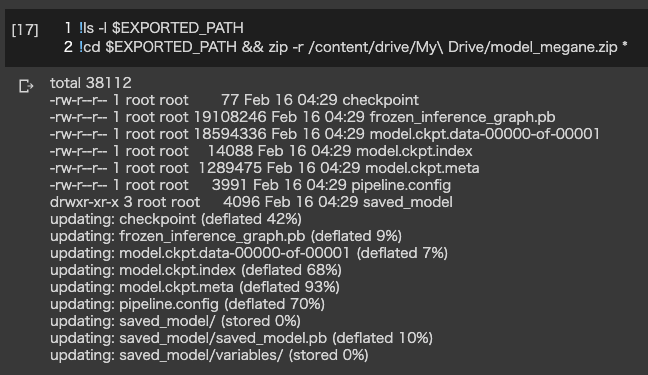
セルを追加し、以下のようなコードを記入して作成したモデルをGoogle Driveに移動します。
Google Driveからダウンロードします。
3. DeepStreamで推論
3-1. Jetsonに転送
先程DownloadしたモデルをJetsonに転送します。
3-2. サンプルコードをコピー
サンプルコードをホームディレクトリの下にコピーします。
$ mkdir ~/work $ cp -r /opt/nvidia/deepstream/deepstream-4.0/sources/ ~/work $ cp -r /opt/nvidia/deepstream/deepstream-4.0/samples/ ~/work3-3. モジュールのビルド
nvdsinfer_custom_impl_ssdモジュールをビルドします。
ビルド前にクラス数の変更をします。
ディレクトリを移動して、nvdsparsebbox_ssd.cppを編集します。$ cd ~/work/sources/objectDetector_SSD $ vi nvdsinfer_custom_impl_ssd/nvdsparsebbox_ssd.cppnvdsparsebbox_ssd.cppの52行目のNUM_CLASSES_SSDの数をクラス数+1に変更します。今回はMEGANEクラス1つなので、NUM_CLASSES_SSDは2に設定します。
nvdsparsebbox_ssd.cpp41 /* C-linkage to prevent name-mangling */ 42 extern "C" 43 bool NvDsInferParseCustomSSD (std::vector<NvDsInferLayerInfo> const &outputLayersInfo, 44 NvDsInferNetworkInfo const &networkInfo, 45 NvDsInferParseDetectionParams const &detectionParams, 46 std::vector<NvDsInferObjectDetectionInfo> &objectList) 47 { 48 static int nmsLayerIndex = -1; 49 static int nms1LayerIndex = -1; 50 static bool classMismatchWarn = false; 51 int numClassesToParse; 52 static const int NUM_CLASSES_SSD = 2; 53変更後、モジュールをビルドします。
make -C nvdsinfer_custom_impl_ssd3-4. モデルをuff形式に変換
アップロードしたモデルをuff形式に変換します。
変換には、config.pyファイルを作成する必要があります。# model_megane.zip: アップロードしたファイル $ mv model_megane.zip ~/work/model_megane $ cd ~/work/model_megane $ unzip model_megane.zip # config.pyファイルを作成 $ vi config.py # uff形式に変換 $ python3 /usr/lib/python3.6/dist-packages/uff/bin/convert_to_uff.py frozen_inference_graph.pb -o ssd_mobilenet_v2.uff -O NMS -p config.py # objectDetector_SSDディレクトリにコピー cp ssd_mobilenet_v2.uff ~/work/sources/objectDetector_SSD/MobilenetV2用のconfig.pyファイルは以下のQAに添付してある内容で作成します。
https://devtalk.nvidia.com/default/topic/1066088/deepstream-sdk/how-to-use-ssd_mobilenet_v2/post/5399649/#5399649config.pyの23行目のnumClassesはクラス数に合わせて変更します。ここでもクラス数+1に変更します。
config.py15 NMS = gs.create_plugin_node(name="NMS", op="NMS_TRT", 16 shareLocation=1, 17 varianceEncodedInTarget=0, 18 backgroundLabelId=0, 19 confidenceThreshold=1e-8, 20 nmsThreshold=0.6, 21 topK=100, 22 keepTopK=100, 23 numClasses=2, 24 ########################################### 25 inputOrder=[0, 2, 1], 26 # inputOrder=[1, 0, 2], 27 ########################################### 28 confSigmoid=1, 29 isNormalized=1)3-5. 各種設定ファイル修正
objectDetector_SSDディレクトリに移動して各種設定ファイルを修正します。
$ cd ~/work/sources/objectDetector_SSD/ $ vi ssd_megane_labels.txtssd_megane_labels.txtファイルは以下のような内容を記述します。
ssd_megane_labels.txtunlabeled meganedeepstream_app_config_ssd.txtファイルは以下のような内容にします。
入力をUSBカメラにしています。deepstream_app_config_ssd.txt[application] enable-perf-measurement=1 perf-measurement-interval-sec=1 gie-kitti-output-dir=streamscl [tiled-display] enable=0 rows=1 columns=1 width=640 height=360 gpu-id=0 nvbuf-memory-type=0 [source0] enable=0 #Type - 1=CameraV4L2 2=URI 3=MultiURI type=3 num-sources=1 uri=file://../../samples/streams/sample_1080p_h264.mp4 gpu-id=0 cudadec-memtype=0 [source1] enable=1 #Type - 1=CameraV4L2 2=URI 3=MultiURI type=1 camera-width=640 camera-height=360 camera-fps-n=30 camera-fps-d=1 camera-v4l2-dev-node=1 [streammux] gpu-id=0 batch-size=1 batched-push-timeout=-1 ## Set muxer output width and height width=640 height=360 nvbuf-memory-type=0 [sink0] enable=1 #Type - 1=FakeSink 2=EglSink 3=File type=2 sync=1 source-id=0 gpu-id=0 [osd] enable=1 gpu-id=0 border-width=3 text-size=15 text-color=1;1;1;1; text-bg-color=0.3;0.3;0.3;1 font=Serif show-clock=0 clock-x-offset=800 clock-y-offset=820 clock-text-size=12 clock-color=1;0;0;0 nvbuf-memory-type=0 [primary-gie] enable=1 gpu-id=0 batch-size=1 gie-unique-id=1 interval=0 labelfile-path=ssd_megane_labels.txt model-engine-file=ssd_mobilenet_v2.uff_b1_fp32.engine config-file=config_infer_primary_ssd.txt nvbuf-memory-type=0config_infer_primary_ssd.txtファイルを以下のような内容に変更します。
config_infer_primary_ssd.txt[property] gpu-id=0 net-scale-factor=0.0078431372 offsets=127.5;127.5;127.5 model-color-format=0 model-engine-file=ssd_mobilenet_v2.uff_b1_fp32.engine labelfile-path=ssd_megane_labels.txt uff-file=ssd_mobilenet_v2.uff uff-input-dims=3;300;300;0 uff-input-blob-name=Input batch-size=1 ## 0=FP32, 1=INT8, 2=FP16 mode network-mode=0 num-detected-classes=2 interval=0 gie-unique-id=1 is-classifier=0 # output-blob-names=MarkOutput_0 output-blob-names=NMS parse-bbox-func-name=NvDsInferParseCustomSSD custom-lib-path=nvdsinfer_custom_impl_ssd/libnvdsinfer_custom_impl_ssd.so [class-attrs-all] threshold=0.5 roi-top-offset=0 roi-bottom-offset=0 detected-min-w=0 detected-min-h=0 detected-max-w=0 detected-max-h=0 ## Per class configuration #[class-attrs-2] #threshold=0.6 #roi-top-offset=20 #roi-bottom-offset=10 #detected-min-w=40 #detected-min-h=40 #detected-max-w=400 #detected-max-h=8003-6. アプリケーションを起動
deepstream-appでdeepstream_app_config_ssd.txt構成ファイルを指定して起動します。
$ deepstream-app -c deepstream_app_config_ssd.txtアプリを起動すると以下のように検出が出来るはずです。
まとめ
Object Detection APIで学習させたMobilenetV2のモデルをNVIDIA JetsonのDeepStream SDKで動かすことが出来ました。
実際にやってみるといろいろハマり動かすまでに時間がかかってしまいました。以下の点に注意してください。
・tensorflowのバージョンは1.13.1を使用する
・Object Detection APIもtensorflowのバージョンに合わせてtag:v1.13.0を使用する
・deepstreamの構成ファイル等でのクラス数は学習させたクラス数+1(背景)を指定する参考
High Performance Real time object detection on Nvidia Jetson TX2.
https://techcommunity.microsoft.com/t5/educator-developer-blog/high-performance-real-time-object-detection-on-nvidia-jetson-tx2/ba-p/917067How to use ssd_mobilenet_v2
https://devtalk.nvidia.com/default/topic/1066088/deepstream-sdk/how-to-use-ssd_mobilenet_v2/post/5399649/#5399649How do I replace it with my own SSD target detection model?
https://devtalk.nvidia.com/default/topic/1069133/deepstream-sdk/how-do-i-replace-it-with-my-own-ssd-target-detection-model-/post/5415755/#5415755
- 投稿日:2020-02-19T17:42:18+09:00
GCPのGPU付きのCompute Engine上で、Dockerの中で、Tensorflowを動かす方法。
GCPのGPU付きのCompute Engine上で、Dockerの中で、Tensorflowを動かす方法。作業メモ的な感じです。
実現できること
- GPU + TensorflowでDeep Learning
- 環境構築がかんたんで、いつでもゼロからやりなおしができる
やり方
Compute EngineでGPUとGPU Driver付きのインスタンスを作る
https://cloud.google.com/compute/docs/gpus/add-gpus?hl=ja
これに従うとできます。Ubuntu 18.04で試してうまくいきました。
Dockerインストール
https://qiita.com/myyasuda/items/cb8e076f4dba5c41afbc
Tensorflowが動くdocker imageを動かす
docker run -it --rm tensorflow/tensorflow bash参考 https://www.tensorflow.org/install/docker#gpu_support
参考資料
GCPでGPU付きのインスタンスを作る方法
https://cloud.google.com/compute/docs/gpus/add-gpus?hl=jacompute engineのContainer optimizedイメージにnvidea driverを入れる方法。
https://github.com/GoogleCloudPlatform/cos-gpu-installerdockerでtensorflowを使う方法
ホスト側にgpu driverさえ入っていれば動くらしい。
https://www.tensorflow.org/install/docker#gpu_support
- 投稿日:2020-02-19T17:21:46+09:00
Tensorflowで指定したインデックスのテンソルを抜き出す
どういうことをしたいか
行列から各行から異なる列の値を取り出したい(パターンA)
A = (a_{ij}) \in \mathbb{R}^{N\times M} \\ index = b_i \in \{1,\cdots,M\}^N \\ A[index] = a_{ib_i}もしくは逆に各列から異なる行の値を取り出したい(パターンB)
A = (a_{ij}) \in \mathbb{R}^{N\times M} \\ index = b_j \in \{1,\cdots,N\}^M \\ A[index] = a_{b_j j}具体例(パターンA)
A=\left(\begin{matrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{matrix}\right) \\ index=\left(\begin{matrix} 2 & 1 & 0 \end{matrix}\right) \\ A[index] = \left(\begin{matrix} 3 & 5 & 7 \end{matrix}\right)TensorFlowでの実装
以下のコードで行列AからIDXで指定された値を抜き出せる。
パターンA用
# A : 行列 # IDX : index (dtype=tf.int32, int32でない場合はキャストが必要になることがある) _IDX = tf.concat([tf.range(A.shape[0])[:,tf.newaxis], IDX[:,tf.newaxis]], axis=1) subA = tf.gather_nd(A, _IDX)パターンB用
# A : 行列 # IDX : index _IDX = tf.concat(IDX[:,tf.newaxis], [tf.range(A.shape[1])[:,tf.newaxis]], axis=1) subA = tf.gather_nd(A, _IDX)簡単な解説
gather_ndは第一引数のテンソルから第二引数で指定された座標の値を抜き出して返す関数。
tf.rangeで生成したテンソルとindexをconcatすることで、抜き出したい座標を生成し、それをgather_ndに渡すことで各行(or 列)からindexで指定された値を抜き出すことを実現している。
- 投稿日:2020-02-19T14:39:40+09:00
TensorFlowとEdge TPUによる犬の訓練
GoogleのTensorFlowLite(およびEdgeTPU)を使用すると、イヌを自律的に訓練して、座ったり、横になったり、固定したり、呼び出したりするなど、さまざまな行動に応答させることができます。 これにより、すべての犬が低コストで訓練され、犬の生活が豊かになり、経済的にストレスの多い救助ステーションと低い採用率にプラスの影響がもたらされると考えています。 Google EdgeTPUを使用すると、犬がデバイスとやり取りするときの動作を理解し、学習できます。
TensorFlowで動物を理解する
同様に、犬の訓練は、犬が放つ信号と行動をよく理解することに焦点を当てています。
TPUが知覚問題の解決にどのように役立つかを理解するには、犬のハンドラーが犬の行動を理解する上で重要だと考える情報を理解する必要があります。以下は、犬の訓練中に犬の飼い主が尋ねる質問です。
犬はおやつを食べていますか?
犬は「座る」アクションを実行していますか?
犬はすでに「横になっている」コマンドを知っていますか?
犬は以前に訓練されたことがありますか?
環境の犬は一般的にどこに滞在することを選択しますか?
犬は私からどのくらい離れていますか?
犬は私を追いかけていますか?これらの質問に答えるために、機械学習、より具体的にはディープラーニングの使用を選択しました。 ディープラーニングは、これらの人間の知覚に関連する問題を解決するのに優れており、時間の経過とともに関連する行動パターンを探します。 したがって、ディープラーニングはコンピュータービジョンや自然言語処理の分野でも広く使用されています。
次に、すべてのシグナルを収集し、興味のあるものを見つけます。 私たちの動物行動チームは、犬の訓練に対する準備を理解するために収集したいすべての体のポーズと音をリストしました。
強力なコンピュータービジョンニューラルネットワークをトレーニングするために、TensorFlowを深層学習プラットフォームとして使用することにしました。 同じタスクで、GoogleのクラウドTPUを使用してネットワークをトレーニングする方が、複数のGPUを使用するよりも速くて安価です。 次に、デスクトップデバイスを使用してGPUでトレーニング済みモデルをローカルで実行し、犬のリアルタイムの動作を判断してトレーニングできます。 私たちのモデルは、犬のボディーランゲージと音を分析することにより、犬の現在の状態を理解し、相互作用します。
犬の行動をリアルタイムで理解して対応するために、ニューラルネットワークをサポートするのに必要な計算能力を備えた適切なモバイルプラットフォームを探しています。 いくつかのモバイルプラットフォームを評価した後、TensorFlowのモバイル製品TensorFlow Liteを実行できるGoogleのEdgeTPUを選択しました。 モバイルコンピュータビジョンモデルはGoogle EdgeTPUでも利用可能であり、以前のシステムよりも4倍高速に動作することがわかりました。
記事の全文を参照してください: https://blog.tensorflow.org/2020/01/autonomous-dog-training-with-companion.html
Google Edge TPU 海外代理店:https://store.gravitylink.com/global
Gravitylinkで任意の製品を購入すると、50以上のMLモデルを取得し、学習ツールを無料で移行できます


- 投稿日:2020-02-19T10:55:48+09:00
無料Python実行環境Google Colaboratoryメモ
Google Colaboratoryとは
Googleのクラウドで実行される Jupyter ノートブック環境。
https://colab.research.google.com/notebooks/welcome.ipynb無料で利用可能、環境構築不要であるため、Pythonの勉強などに便利です。
また、GPUやTPUの利用も可能で機械学習の実行時間も削減できます。
利用制限
無料で利用可能ですが、連続利用時間に12時間の制限があります。
12時間を過ぎると仮想マシンが切断されるため、機械学習で長時間利用する場合は注意が必要です。
また、アイドルタイムアウト時間放置した場合も仮想マシンが切断されます。
※アイドルタイムアウトの時間はFAQに記載されていませんが、現在は90分のようです
https://research.google.com/colaboratory/faq.htmlメモ
以下、利用メモ。
GPU/TPUの利用
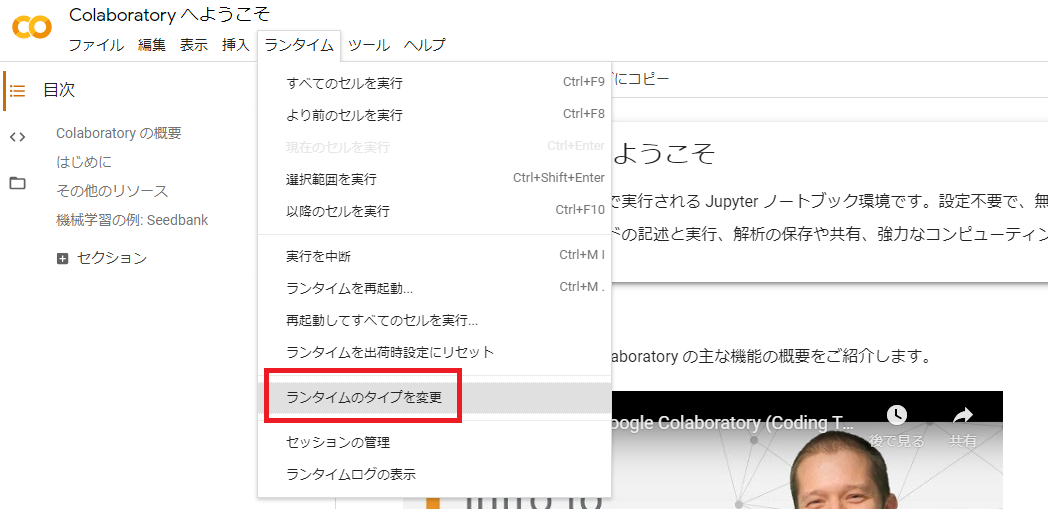
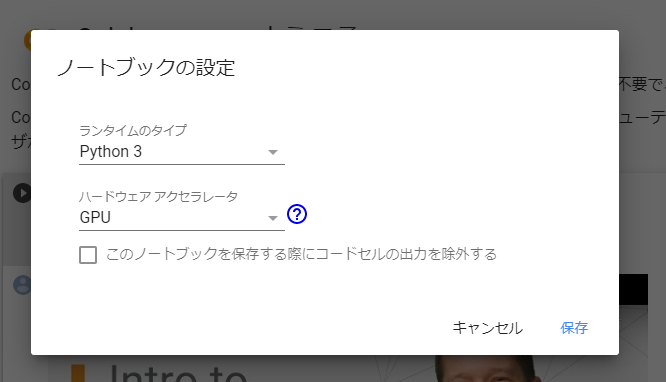
ランタイム > ランタイムのタイプを変更 から選択。
Googole Driveのマウント
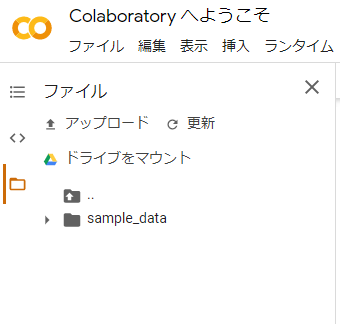
サイドメニューの「ドライブをマウント」を選択すると、マウントするためのコードが自動で生成されるので実行。
TensorFlowのバージョン変更
現在デフォルトは1.x系。以下を実行すると2.x系に変更できる。
%tensorflow_version 2.x※試す際はTensorFlowのチュートリアル( https://www.tensorflow.org/tutorials )の各ページにある「Run in Google Colab」を開くと、2.x系に変更して動かすコードで記載されています。
以上