- 投稿日:2020-02-19T22:25:39+09:00
API Gatewayのマッピングテンプレートがわからなすぎて色々試した記録
こちら公式ドキュメントですが、毎度のごとく何を行ってるのかさっぱりわからないし、どう書いたらいいかわからんじゃないかとキレたくなる。
ここではとりあえず各パターンを試行錯誤してみた結果を並べておく。
必要となればリクエストパラメータ・リクエストボディにはそれぞれ以下を指定する。
リクエストパラメータstr=str&num=2リクエストボディ{ "str": "str", "num": 1, "bool": true }$input 変数
$input 変数は、マッピングテンプレートによって処理されるメソッドリクエストペイロードとパラメータを示します。この変数は 4 つの関数を提供します。
$input.body
文字列として raw リクエストペイロードを返します。
メモ:リクエストボディから値を取得
マッピングテンプレート{ "val": $input.body }レスポンス本文{ "statusCode": 200, "body": { "val": { "str": "str", "num": 1, "bool": true } } }$input.json(x)
この関数は、JSONPath の式を評価し、結果を JSON 文字列で返します。
メモ:リクエストボディの値を取得。
case1
マッピングテンプレート{ "val": $input.json("str") }リクエスト本文{ "statusCode": 200, "body": { "val": "str" } }case2
マッピングテンプレート{ "val": $input.json('num') }リクエスト本文{ "statusCode": 200, "body": { "val": 1 } }case3
マッピングテンプレート{ "val": "$input.json('num')" }リクエスト本文{ "statusCode": 200, "body": { "val": "1" } }case4
マッピングテンプレート{ "val": $input.json('$') }リクエスト本文{ "statusCode": 200, "body": { "val": { "str": "str", "num": 1, "bool": true } } }case5
メモ:
'$.'っている?マッピングテンプレート{ "val": $input.json('$.num') }リクエスト本文{ "statusCode": 200, "body": { "val": 1 } }$input.json('$.pets')
pets 構造を表す JSON 文字列を返します。
メモ:謎
case1
マッピングテンプレート{ "val": $input.json('$.pets') }リクエスト本文{ "statusCode": 200, "body": { "val": "" } }case2
マッピングテンプレート{ "val": "$input.json('$.pets')" }リクエスト本文{"message": "Could not parse request body into json: Unexpected character (\'\"\' (code 34)): was expecting comma to separate Object entries\n at [Source: (byte[])\"{\n \"val\": \"\"\"\"\n}\n\"; line: 2, column: 13]"}$input.params()
すべてのリクエストパラメータのマップを返します。
メモ:リクエストパラメータから値を取得
case1
マッピングテンプレート{ "val": $input.params() }リクエスト本文{"message": "Could not parse request body into json: Unexpected character (\'p\' (code 112)): was expecting double-quote to start field name\n at [Source: (byte[])\"{\n \"val\": {path={}, querystring={str=str, num=2}, header={}}\n}\"; line: 2, column: 12]"}case2
マッピングテンプレート{ "val": "$input.params()" }リクエスト本文{ "statusCode": 200, "body": { "val": "{path={}, querystring={str=str, num=2}, header={}}" } }$input.params(x)
パラメータ名文字列 x が指定された場合に、パス、クエリ文字列、またはヘッダー値から (この順番で検索される) メソッドリクエストパラメータの値を返します。
メモ:リクエストパラメータから値を取得
case1
マッピングテンプレート{ "val": $input.params('str') }リクエスト本文{"message": "Could not parse request body into json: Unrecognized token \'str\': was expecting (\'true\', \'false\' or \'null\')\n at [Source: (byte[])\"{\n \"val\": str\n}\"; line: 2, column: 14]"}case2
マッピングテンプレート{ "val": "$input.params('str')" }リクエスト本文{ "statusCode": 200, "body": { "val": "str" } }$input.path(x)
JSONPath 式文字列 (x) を受け取り、結果の JSON オブジェクト表現を返します。
メモ:リクエストボディの値を取得。
case1
マッピングテンプレート{ "val": $input.path('str') }リクエスト本文{"message": "Could not parse request body into json: Unrecognized token \'str\': was expecting (\'true\', \'false\' or \'null\')\n at [Source: (byte[])\"{\n \"val\": str\n}\"; line: 2, column: 14]"}case2
マッピングテンプレート{ "val": "$input.path('str')" }リクエスト本文{ "statusCode": 200, "body": { "val": "str" } }#set
こいつの説明が全くない。謎。
おそらく、変数に代入しているのだろうと思ったがあってるっぽい。[参考]https://qiita.com/yoshidasts/items/ddab0ef7b983b7c5260b
#set($var = $input.json('$'))#if #elif #else #end
これはよくあるif文。わかりそうなので省略。
#foreach
#foreach($var in $foo.list) #break #endforeachもできる。
おまけ
API Gateway → stepfunctionsを繋ぐ場合の設定。
マッピングテンプレートで呼び出す先のステートマシンARNを指定する。
inputに渡した値がstatemachineに渡されるので、リクエストヘッダーやボディの情報を格納するにはここをいじってあげることでできる。{ "input": "$util.escapeJavaScript($input.json('$'))", "stateMachineArn": "arn:aws:states:us-east-1:xxxxxxxxxxxx:stateMachine:HelloWorld" }
- 投稿日:2020-02-19T21:56:45+09:00
初期EC2のTeratermログインマクロ
内容
AWSで作成したサーバへログインするTeratermマクロ(コピペで可能)
何故作ったか
AWSでサーバ作成した後に初めてSSH接続を行う際
IPアドレス⇒ユーザ(ec2-user...)⇒キーペア(鍵)選択⇒接続
上記をしているんですが、面倒になってきたので作りました。
コピペ用なので詳しい事は調べて頂くか、よければ以下を見てみてください。
Teratermマクロ初心者入門前提条件
・SSH接続可能なサーバが存在していること
・Teratermマクロとキーペア(鍵)が同ディレクトリ配下に存在していることユーザ情報
初期状態のユーザ情報を記載しておきます。
Linux インスタンスでのユーザーアカウントの管理
AMI ユーザ名 Amazon Linux 2 ec2-user Amazon Linux ec2-user CentOS centos Debian admin,root Fedora ec2-user,fedora RHEL admin,root SUSE ec2-user,root Ubuntu ubuntu IP固定してないEC2用(毎回IPだけ入力する)
;========================================================== ; <マクロ名> ; <用途> ;========================================================== ; ディレクトリ取得 getdir DIR ; IPアドレスの入力 inputbox 'IPアドレスの入力' '接続情報' ; 鍵ファイルを指定 KEY = '使用するキーペア(鍵)のファイル名' makepath KEYFILE DIR KEY ; ログディレクトリの指定 LOGSDIR = DIR strconcat LOGSDIR '\LOGS\' ; ログディレクトリの作成 foldersearch LOGSDIR if result = 0 then foldercreate LOGSDIR endif ; 接続情報 HOSTNAME = '<任意のホスト名>' HOSTADDR = inputstr USERNAME = '<接続ユーザ>' ; 接続オプション COMMAND = HOSTADDR strconcat COMMAND ':22 /ssh /2 /auth=publickey /user=' strconcat COMMAND USERNAME strconcat COMMAND ' /keyfile=' strconcat COMMAND KEYFILE ; 接続 connect COMMAND ; ログファイル情報作成 getdate LOGDATE '%Y%m%d_%H%M%S' strconcat LOGNAME LOGSDIR strconcat LOGNAME HOSTNAME strconcat LOGNAME '_' strconcat LOGNAME LOGDATE strconcat LOGNAME '.log' ; ログファイル作成 logopen LOGNAME 0 0 endIP固定しているEC2用
;========================================================== ; <マクロ名> ; <用途> ;========================================================== ; ディレクトリ取得 getdir DIR ; 鍵ファイルを指定 KEY = '使用するキーペア(鍵)のファイル名' makepath KEYFILE DIR KEY ; ログディレクトリの指定 LOGSDIR = DIR strconcat LOGSDIR '\LOGS\' ; ログディレクトリの作成 foldersearch LOGSDIR if result = 0 then foldercreate LOGSDIR endif ; 接続情報 HOSTNAME = '<任意のホスト名>' HOSTADDR = '<接続先IPアドレス>' USERNAME = '<接続ユーザ>' ; 接続オプション COMMAND = HOSTADDR strconcat COMMAND ':22 /ssh /2 /auth=publickey /user=' strconcat COMMAND USERNAME strconcat COMMAND ' /keyfile=' strconcat COMMAND KEYFILE ; 接続 connect COMMAND ; ログファイル情報作成 getdate LOGDATE '%Y%m%d_%H%M%S' strconcat LOGNAME LOGSDIR strconcat LOGNAME HOSTNAME strconcat LOGNAME '_' strconcat LOGNAME LOGDATE strconcat LOGNAME '.log' ; ログファイル作成 logopen LOGNAME 0 0 end〇ユーザにPWが設定されていて入力する必要がある場合は、
・;接続オプションのstrconcat COMMAND USERNAMEの下に以下を追記
strconcat COMMAND ' /passwd='
strconcat COMMAND PASSWORD〇認証方式が鍵ではなくPWの場合は以下を修正してください。
・; 鍵ファイルを指定を削除
・; 接続オプションの以下を削除
strconcat COMMAND ' /keyfile='
strconcat COMMAND KEYFILE
・; 接続オプションの/auth=publickeyを/auth=passwordへ変更
・;接続オプションのstrconcat COMMAND USERNAMEの下に以下を追記
strconcat COMMAND ' /passwd='
strconcat COMMAND PASSWORDこれで
最初の接続がほんのすこ~~~~~~~~~~~~しだけ楽になった気がします。
- 投稿日:2020-02-19T21:11:17+09:00
AWS試験対策(⑦ネットワーク)
自分用メモ、ネットワーク編。ポチポチ構築できるので一回やってみると意外と楽しいかもー。
但し、試験となると覚えることは多い。VPC
論理的に分割された仮想ネットワーク。
ルータとかを物理的に調達する必要がない。
VPC作成→サブネット作成→ルートテーブル作成→セキュリティ設定の流れ。まず、VPCはリージョンを跨げない。AZは跨げるよ。
CIDR(サイダー)をこのとき決める。シュワシュワして美味しそ。
サイダーってのは、ネットワークアドレスの部分を決めれる。たとえば16なら前の16ビットがネットワークアドレスになる。
10.0.0.0とかなら8ビットが、172.16.0.0とかなら16ビットが、192.168.0.0とかなら24ビットがネットワークアドレスだったのが、サイダーって技術でなくなって自分で指定できるようになったと思えばよき。その次はサブネットを作成する。
AZごとにつくる。AZを跨ぐことはできない。
サブネット作成するときに、サイダーブロックを指定する。
計算は深く考えないで、VPC側が16ビットでサブネットマスクが18なら、サブネットの数は18-16=2、2の2乗になり、IPの数は32-18=14、2の14乗になる。
一番多いのはサブネットマスクが24。第3オクテット目で区切れるからわかりやすい。
サブネットの数は24-16で2の8乗。IPの数は32-24でこちらも2の8乗になる。気をつけなきゃいけないのは、オンプレは2IP使えなかったが、AWSは5IP使えない。
また、サブネットはインターネットにルートがあるパブリックサブネットと、ルートがないプライベートサブネットがある。次に、ルートテーブルを設定することによって、サブネットを出るアウトバウンドトラフィックは送信先が指定される。
サブネットにルートテーブルを作るというよりは、ルートテーブルを作ってそれをサブネットに関連付けてるイメージ。次に、ゲートウェイを作って、VPCにアタッチする。
主要なゲートウェイは以下。
インターネットゲートウェイ
インターネットと通信するためのゲートウェイ。仮想プライベートゲートウェイ
他の拠点(オンプレとか?)とVPN接続する際の、VPC側に作るゲートウェイ。カスタマーゲートウェイ
オンプレとVCPをVPN接続する際に、クライアント側に作るゲートウェイ。NATゲートウェイ
プライベートサブネットからインターネットにアクセスする際に、プライベートIP→パブリックIPにアドレス変換してくれるゲートウェイ。インターネットからはプライベートサブネットにアクセスしないようにできる。
要するにこれをパブリックサブネットに置いて、
プライベートサブネット→パブリックサブネット→インターネットゲートウェイ→インターネットって順で繋ぐ。サブネットの種類は、ルートテーブルにインターネットゲートウェイが設定されてるかどうかで決まる。
送信先を0.0.0.0/0とするとインターネットゲートウェイを指定したことになるので、パブリックサブネットになる。逆にそうじゃないならプライベートになる。セキュリティ設定
ファイアーウォールをセキュリティグループとネットワークACLで設定する。セキュリティグループ
インスタンス単位で、許可する通信のみをインバウンドとアウトバウンドのトラフィックについて設定する。
ステートフルなので戻りのトラフィックは気にしなくていい。設定したすべてのルールが適用される。ネットワークACL
サブネット単位で、許可、拒否する通信をインバウンドとアウトバウンドのトラフィックについて設定する。
ステートレスなので戻りのトラフィックを気にしないといけない。設定した番号の順番通りにルールが適用される。エンドポイントの作成
プライベートIPで使える空間とパブリックIPで使える空間がある。パブリックIPを持つサービス(S3とか)にVPC内部からアクセスしたいときに、このエンドポイントという中継地点を使う。S3の時に書いた。略。
ピア接続
VPC同士の接続ができる。異なるAWSアカウントでも関係ない。
しかし、これで通信できるのは、直接ピア接続してるVPCのみ。友達の友達は友達じゃないのだ。その人と友好関係を築ければ別だが。ELB
ロードバランサー。3種類あるよ。ALB、NLB、CLBの3つ。アプリかネットワークかクラシックか。CLBはレガシーでもうほとんど使わないらしい。
また、作るときは2つ以上のAZを指定しないとだめだよ。
ALB NLB CLB 種類 L7 リバースプロキシ L4 NATロードバランサ L4/L7 リバースプロキシ サポートプロトコル HTTP、HTTPS(Layer7) TCP、TLS(Layer4/5) HTTP、HTTPS(Layer7) TCP、TLS(Layer4/5) セキュリティグループ 設定あり 設定なし 設定あり SSL Termination HTTPS Termination TLS Termination SSL Termination 主なユースケース 柔軟なアプリ管理とHTTP Terminationが必要な場合 高度なパフォーマンスと静的IP(固定IP)が必要な場合 昔の。 特徴は次の通り
- ALB
レイヤー7(なんのこっちゃ)をサポートする。同一インスタンスでも複数のポートに負荷分散したり、パスベース、ホストベースのルーティングサポートがあったり、ネイティブHTTP/2(なんのこっちゃ)対応してたりする。
パスベースのルーティングとは、リクエスト内のURLに基づいてリクエストを転送してくれるルーティング方式。要するに、http://hoge/app1からきたリクエストも、http://hoge/app2からきたリクエストもすべてこいつが各コンテナに振り分けてくれる。今まではhttp://hoge/app1用のロードバランサー、http://hoge/app2用のロードバランサー…と一つ一つ必要だった。
ホストベースのルーティングは、HTTPヘッダー内のホストフィールドに基づいてリクエストを転送する仕組み。要するに、http://www1.hoge/からきたリクエストも、http://www2.hoge/からきたリクエストもすべてこいつが各ホストに振り分けてくれる。今まではこっちも一つ一つ必要だった。
- NLB
レイヤー4/5をサポート(なんのこっちゃ)する。NLBは固定IPを持つことができる。
また、NATタイプのロードバランサーなので、トラフィックの宛先のIPを書き換えて転送するため、帰りのトラフィックはロードバランサー経由せずターゲットから直接クライアントへ行く。なのでパフォーマンスが高い。
要するに、クライアント→ALB→ターゲット→ALB→クライアントって戻るのが普通のところ、
クライアント→NLB→ターゲット→クライアントへ直に戻る。また、セキュリティグループが使えないため、ターゲットのインスタンスで設定する必要がある。
- CLB 古い。以上。
スケーラビリティ
負荷が増えると自動的にELBを増やしてくれるよ。負荷増えすぎて間に合わないほどやばかったら503エラーを返してくれるよ。
ただ、こうなるのを防ぐために、Pre-Warmingという暖機運転機能がある。やばくなりそうな時間帯がわかってるなら予め増やしておけばいいってわけ。しかしこれはサポートに申請する必要がある。ビジネスかエンプラじゃないと使えないってよ…ヘルスチェック
健康診断。インスタンスがちゃんと動いてるか見る。TCP/HTTP/HTTPSで応答確認する。正常ならリクエストを転送する。障害やメンテで異常になったらそこへは転送しない。検知するだけで再起動とかはしてくれない。
SSL Termination
Webサーバの場合、外部通信をSSLで暗号化するのが普通。これを使えばクライアントとELBの間をSSL通信にしてくれる。ELBとターゲット間はHTTP通信。これを使うには、証明書をロードバランサに入れる必要がある。
また、NLBではSSLアクセラレーション機能が提供されていないため、ターゲット側でSSLターミネートを行う必要がある。スティッキーセッション
ELBによってクライアントからのリクエストを毎回同一のインスタンスへ送信する方法。
同じクライアントから来たリクエストを同じインスタンスへ送信しなきゃいけない場合とかに使う。Cookieに設定した値を利用しながら動作するとき等。
株買うときとかに使われるアレかと。
- 任意の有効期限を指定する方法
任意に指定された有効期限までの間、同一インスタンスとのセッションを維持する。チケット買うときとか、10分以内に手続き済ませてくださいみたいなやつ。
有効期限指定しなかった場合はCookieをクライアント側で意図的に削除しないと永続。
- アプリケーションのCookieに従う方法
セッションの維持を行うCookie名を指定することで、そのCookie名を含むリクエストがあった場合、同一のインスタンスとのセッションを維持する。
要するに顔パス的な。最初は覚える必要あるけど二回目は前の続きからすっと入れる。Auto Scaling
需要に応じてインスタンスを増やしたり減らしたりできる機能。また、異常が起きたらそれを切り離ししたりしてくれる。
コスト最適化と高可用性。
これ自体に課金は発生しない。増えたインスタンスなどには課金される。
対象は以下。
- EC2
- EC2スポットフリート
- ECS
- DynamoDB
- Aurora
起動設定
どのようなインスタンスを起動するかの設定。自分でインスタンス作る時と同じように設定していく。設定しておけばこれが起動される、いわばAutoscalingのテンプレ。
Auto Scalingグループ
グループに対してスケーリングしてくれる。起動したインスタンスは複数のAZで均一にバランシングされる。AZ自体が逝ってしまった場合はその他のAZで起動してくれる。
しかし、リージョンをまたぐことはできない。
設定項目は以下。
- インスタンスの希望起動数(最大、最小起動数)
- VPC/サブネット
- ELB/ヘルスチェック
- スケジューリングポリシー
- スケジュールされたアクション
スケジューリングプラン
手動、動的、スケジュールの三種類がある。
手動はその名の通り、バッチ処理があるときとかに手動で設定する。
動的はCloudWatchで閾値に近づいたらインスタンス数を変更する。みたいなことができる。
Target tracking scaling
平均使用率が50%になるようにスケーリング的なStep scaling
使用率40超えたら一台追加、90超えたら二台目追加のような、ステップ(段階)を踏んで増やせる。Simple scaling
使用率が40超えたら一台追加みたいな感じ。の三種類がある。維持するのか、段階を踏むのか、やばくなってきたから増やすのか。
スケジュールスケーリングは、毎日21時にアクセス多いからあらかじめ毎日21時に増やす設定しておこう!みたいな感じ。繰り返す系ならこれ。
ELB/ヘルスチェックの設定
ELB配下のインスタンスを対象にする場合、ヘルスチェックのタイプをEC2もしくはELBにする。
EC2の場合はステータスがrunning以外となった場合、また、システムステータスがimpairedとなったときに異常と判断される。
ELBの場合はEC2の場合プラス、ELBのヘルスチェックが正常とならない場合、異常と判断される。
異常になった場合、該当インスタンスは削除され、新しいインスタンスを起動することで±0する。代わりはいくらでもいるのよ。
これをAuto Healingという。
ちなみに、この管理下のインスタンスを停止すると、インスタンスはTerminate(削除)される。
これは、「EC2がrunning以外になったから異常だ!増やさなきゃ!!」ってなるのを防ぐため。
自分で停止させたのに、AutoScalingちゃんが「一台減っちゃった!増やさなきゃ!!」って増やしちゃったらまったく意味ないから。便利なようでおちゃめな子だよね。いったん区切り。次回Route53、Direct Connect、CloudFrontをやってネットワークは終わり。DBへ行く。
- 投稿日:2020-02-19T18:33:52+09:00
AWS SageMaker Studioにアクセスできなくなった
事象
ユーザを選択して、SageMaker Studioを起動しようとすると
「このページは動作していません」と先に進めなくなってしまった。解決法
AWS CLIを使います。
delete-domain コマンドでSageMaker Studioのドメインごと消して作り直す方法もありますが、
Notebookは残したいと言った要望があるかと思います。
その場合はSageMaker Studioで立ち上がっているアプリだけ立ち上げ直すことができます。list-apps で使用中のアプリを表示
aws sagemaker list-apps --domain-id-equals <domain_id> --user-profile-name-equals <profile_name> --region us-east-2{ "Apps": [ { "Status": "InService", "DomainId": "<domain_id>", "AppType": "KernelGateway", "AppName": "datascience", "CreationTime": <time>, "UserProfileName": "<profile_name>" }, { "Status": "InService", "DomainId": "<domain_id>", "AppType": "JupyterServer", "AppName": "default", "CreationTime": <time>, "UserProfileName": "<profile_name>" } ] }delete-app で、全てのアプリを削除
aws sagemaker delete-app --domain-id <domain_id> --user-profile-name <profile_name> --app-type KernelGateway --app-name datascience --region us-east-2 aws sagemaker delete-app --domain-id <domain_id> --user-profile-name <profile_name> --app-type JupyterServer --app-name default --region us-east-2後はコンソールから再度起動してみてください。
復活するはずです!まだプレビュー段階だからこういったログインできなくなるような事象が発生するんですかね。。(2020/02/19時点)
参考URL
- 投稿日:2020-02-19T18:24:42+09:00
AWS(S3)
S3
クラウド環境で使えるオブジェクトストレージ。検証しないとわからなそうなことを色々とメモ。
結果整合性
- S3は結果整合性を採用しているため、PUTリクエストが完了しても最新の状態になっていない場合がある。なぜなら複数のAZにPUT後にオブジェクトをレプリカしており、全てにレプリカが完了するまで最新の状態が反映されない。結果的に時間が経てば整合性が取れている、これが結果整合性。
- あくまでアトミックな更新になるので、PUT後に複数AZにレプリカが完了するまでは古いデータ、PUT後に複数AZにレプリカが完了したら最新のデータが参照できる形になる。
- 新規のオブジェクトに関しては例外的に、キーを直接指定して参照した場合は、PUT後にすぐ読み込みできる。(LISTの場合はこの限りではなく、結果整合性)
参考
https://dev.classmethod.jp/cloud/amazon-s3-eventually-consistent-and-consistent-read/IAMポリシー、バケットポリシー、ACL
S3へのバケット、オブジェクトに対するアクセス制御を管理する仕組みは数多くある。どれで許可・拒否・未設定の状態になっていれば結果的にオブジェクトにawscli,sdkでアクセスできるのか。基本的なポリシーは以下でシンプル。
- 最低限、対象バケット、オブジェクトにアクセスするためのIAMポリシーの明示的な許可が必要
- どれか1つでもアクセス拒否されているものがあると他でアクセス許可されていてもアクセス不可。
基本的に細かい制御が可能なIAMポリシー、バケットポリシーのいずれか、または場合によっては複数組み合わせでアクセス制御をするべきと個人的には考える。
バケットポリシー例###下記は指定したIAMロールやIAMユーザ以外のアクセスのみ許可するJSON。 ###特定のIAMユーザtestuserに対して許可する場合は、1行目のみ必要。 ###EC2に付与したIAMロールtestroleに対して許可する場合は,2,3行目両方が必要。 { "Version": "2012-10-17", "Id": "Test Bucket Policy", "Statement": [ { "Sid": "Test Policy", "Effect": "Deny", "NotPrincipal": { "AWS": [ "arn:aws:iam::<AccountId>:user/testuser", "arn:aws:iam::<AccountId>:role/testrole", "arn:aws:sts::<AccountId>:assumed-role/testrole/i-xxxxxxxxxx" ] }, "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<バケット名>", "arn:aws:s3:::<バケット名>/<対象のフォルダなど>/*" ] } ] }REST API
ライフサイクルルール
- 端的にいうと、ログ改廃または移行の仕組み
- 設定しておくと指定した期間(日)がタイムスタンプ的に経過したS3上のファイルを削除(Expiration)または他ストレージタイプへ移行(Transition)する仕組み
- 対象はバージョニングで裏で保管されているもの、または最新版いずれに対しても設定可能
- prefix単位でも指定可能
- いつの何時何分に必ず処理が発行されていつまでに終わるという明確な基準はない(ベストエフォート型)。ただ大体の目安は決まっていて毎日UTC0時頃からライフサイクルルールの対象になっているファイルの最終更新時刻をチェックして保管期限が過ぎていたら消すという仕組み https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/intro-lifecycle-rules.htmlhttps://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/intro-lifecycle-rules.html
Amazon S3 は、ルールに指定された日数をオブジェクトの次の新しいバージョンが作成された時間に加算し、得られた日時を翌日の午前 00:00 (UTC) に丸めることで、時間を算出します。たとえば、バケット内に 2014 年 1 月 1 日の午前 10 時半 (UTC) に作成されたオブジェクトの現行バージョンがあるとします。現行バージョンを置き換えるオブジェクトの新しいバージョンが 2014 年 1 月 15 日の午前 10 時半 (UTC) に作成され、3 日間の移行ルールを指定すると、オブジェクトの移行日は 2014 年 1 月 19 日の午前 0 時 (UTC) となります。
参考:現時点のライフサイクルルール対象を確認するスクリプト
タイムスタンプはデフォルトのままだとUTC時間で出てきてしまうため、JST時間で出るように手を加えている。S3バケット全体に対して指定した日数以前のファイルを出力(第一引数でバケット名、第二引数で日数を指定)#!/usr/bin/python import boto3 import sys import datetime args = sys.argv bucket_name=args[1] expired_day=int(args[2]) timestamp_now=datetime.datetime.now() s3 = boto3.resource('s3') bucket = s3.Bucket(bucket_name) for obj_summary in bucket.objects.all(): dt=obj_summary.last_modified.strftime("%Y-%m-%d %H:%M:%S") dp=datetime.datetime.strptime(dt,"%Y-%m-%d %H:%M:%S") timestamp_put=dp + datetime.timedelta(hours=9) timestamp_del=timestamp_now - datetime.timedelta(days=expired_day) if timestamp_put < timestamp_del: print (str(timestamp_put),"s3://" + bucket_name + "/" + obj_summary.key)S3バケットの特定のプレフィックスに対して指定した日数以前のファイルを出力(第一引数でバケット名、第二引数でプレフィックス名、第三引数で日数を指定)#!/usr/bin/python import boto3 import sys import datetime args = sys.argv bucket_name=args[1] prefix=args[2] expired_day=int(args[3]) timestamp_now=datetime.datetime.now() s3 = boto3.resource('s3') bucket = s3.Bucket(bucket_name) for obj_summary in bucket.objects.filter(Prefix=prefix): dt=obj_summary.last_modified.strftime("%Y-%m-%d %H:%M:%S") dp=datetime.datetime.strptime(dt,"%Y-%m-%d %H:%M:%S") timestamp_put=dp + datetime.timedelta(hours=9) timestamp_del=timestamp_now - datetime.timedelta(days=expired_day) if timestamp_put < timestamp_del: print (str(timestamp_put),"s3://" + bucket_name + "/" + obj_summary.key)署名付きURL
S3ではパブリックアクセスを禁止しているバケットでも一時的にhttp経由で対象のオブジェクトにWebアクセスできるようにする署名つきURLを発行する方法がある。それをユーザに渡せば対象のユーザのみ一時的にオブジェクトにアクセス可能。
署名付きURL発行レプリケーション
- S3バケットのオブジェクトを他のバケット(同一リージョン/他リージョン)にレプリケーションできる仕組み
- 仕組みとしては以下。レプリケーション用のIAMロールがソースBucketのオブジェクトを宛先BucketにPUTする仕組み。 https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/setting-repl-config-perm-overview.html
- レプリケーションルールはソースBucketへ設定する。ルールは複数設定可能
- 宛先Bukcetとロールは、1ソースBucketあたり1つしか選べない。
- レプリケーションは非同期で行われる。容量が大きいほど、完了時間は伸びる。RTCを使うと15分以内にレプリケーションを完了させられる、かつCloudwatchのレプリケーションメトリクスを利用できるが追加料金あり。
- 投稿日:2020-02-19T14:17:34+09:00
[やってみた]AWS EC2にCloudMapperを構築
環境
AWS EC2 Amazon Linux 2 AMI
構築手順
アクセスキーの取得
[IAM]-[ユーザ]-[ユーザ名]-[認証情報]より、アクセスキーを作成し、アクセスキーとシークレットアクセスキーを控える
CloudMapperの取得と配置
$ sudo yum install git -y $ git clone https://github.com/duo-labs/cloudmapper.git $ sudo yum install autoconf automake libtool python34-devel jq -y $ sudo yum install python3.x86_64 python3-tkinter.x86_64 python3-devel.x86_64 python3-pip.noarch -ynginxのインストール
$ sudo amazon-linux-extras install nginx1.12 -y $ sudo systemctl enable nginx $ sudo systemctl start nginxPythonモジュールのインストール
$ sudo pip3 install pyyaml $ sudo pip3 install parliament $ sudo pip3 install pyjq $ sudo pip3 install netaddr $ sudo pip3 install policyuniverse $ sudo pip3 install jinja2AWS CLIの環境設定
$ aws configure AWS Access Key ID [None]: アクセスキー AWS Secret Access Key [None]: シークレットアクセスキー Default region name [None]: リージョン名(英語) Default output format [None]: json※リージョン、アベイラビリティーゾーン、および ローカルゾーン
CloudMapperの初期設定
$ cd cloudmapper $ AWS_ID=$(aws sts get-caller-identity \ --query "Account" \ --output text) \ && echo ${AWS_ID} $ python3 cloudmapper.py configure add-account --config-file config.json --name dev.io --id ${AWS_ID} --default DEFAULT $ python3 cloudmapper.py configure add-account --config-file config.json --name demodemo --id ${AWS_ID}利用方法
構成情報の取得
$ python3 cloudmapper.py collect --config config.json --account demodemo $ python3 cloudmapper.py prepare --config config.json --account demodemoアクセス
http://ec2-xxx.xxx.xxx.xxx.ap-northeast-1.compute.amazonaws.com/
- 投稿日:2020-02-19T13:02:40+09:00
AWS Lambda@Edge で 環境変数を使う方法 (Node.js)
はじめに
Lambda ならば、環境変数という項目があり、
そこにキーと値を書けばprocess.envオブジェクトから取得できました。参考URL
AWS Lambda で環境変数を渡してみる(Node.js)
Lambda@Edge にも同じく環境変数の入力欄があるのですが、
どういうわけかまだサポートされてないらしく、
2020年2月時点では使用できません。初見殺しもいいところですね。
でも、環境変数が使いたい時はあると思います。
色々模索した結果、以下の方法に落ち着きました。結論
dotenvライブラリを使うローカル環境とかにdotenvライブラリを導入します
$ cd /path/to/project $ npm install dotenv次に、
.envファイルを用意して、そこに環境変数を色々書いておきます。$ touch .env $ vi .env私はかつてLaravel5(PHP)を使っていたので、それに習った書き方をしています。
Laravelいいよね。.envAPP_ENV=production APP_URL=https://www.example.com APP_DEBUG=falseここまで出来たら、これらをZIPファイルにまとめて、
Lambda@Edgeにアップロードします。ZIPファイルでアップロードする方法は、
ネットに腐るほど書いてますのでググってください【絶対にすること】 エディタで隠しファイルを表示する
2020.02.19 追記
下の方法よりもっと簡単な方法がありました。
プロジェクトフォルダの右の歯車をクリックした後、「Show Hidden Files」をクリックするだけです
ファイルアップロードが終わったら、
以下の手順に従い、コンソールエディタで
「.env」などの隠しファイルが表示されるようにしてください
(将来の Lambda@Edge のアップデートで表示方法が変更になる可能性があります)
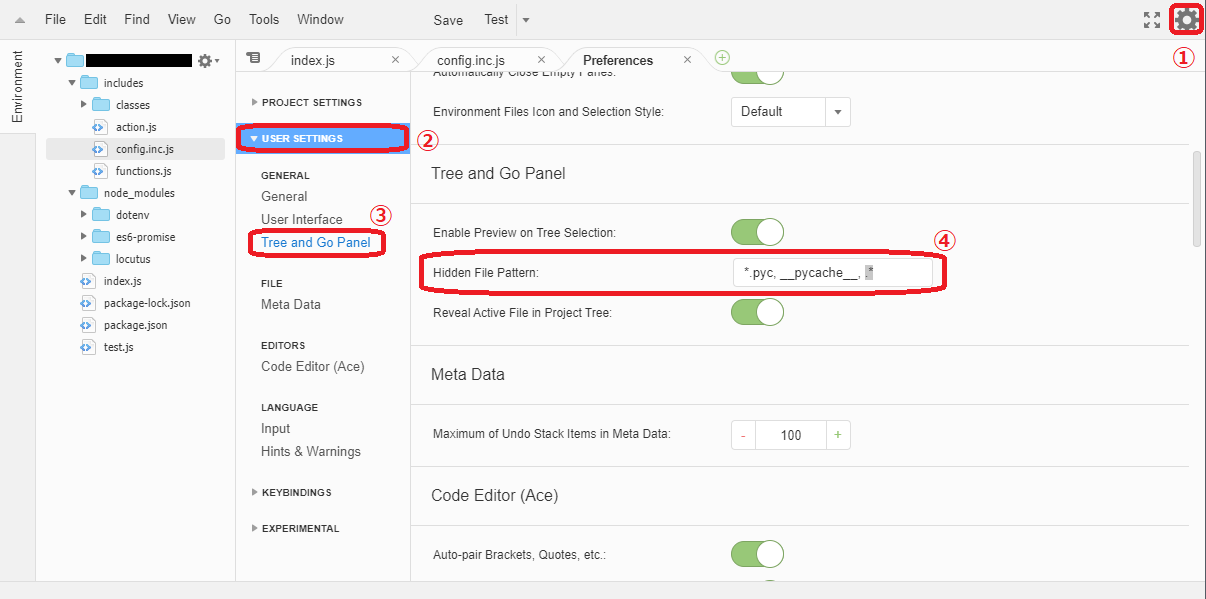
① エディタ右上の歯車マークをクリック
② User Settings をクリック
③ Tree and Go Panel をクリック
④ Hidden File Pattern: から 次のように 「, .*」 を削除*.pyc, __pycache__, .* ↓ *.pyc, __pycache__
これにより、隠しファイルが表示されるので
どこに設定ファイルがあるかがわかるようになりますね。(筆者は動作確認のために .envファイルを複数用意していますが、
必要ありません。「.env」ファイルだけが使用されます)環境変数の取得方法
Lambdaで環境変数を取得する方法と全く同じやり方で取得できます。
つまり、process.envオブジェクトから取得できます。var ENV = require('dotenv').config(); var appUrl = process.env['APP_URL']; console.log(appUrl); // e.g. "https://www.example.com"私の場合、毎回
process.envって書くのがだるいので
Laravelのenv関数みたいな感じにラッピングしてから使用していますindex.js/* ===================================================================== * Load External Modules * =================================================================== */ try { var ENV = require('dotenv').config(); // 環境変数が使えるようになったらこのモジュールは不要 } catch(ex){ // if module is not exists console.error(ex); } /** * Get Envrionment Variable * Lambda@Edgeは2020年2月時点では環境変数が使えないから * DotEnvライブラリで代用する(環境変数もDotEnvも process.env で値を取得できる) * * @param string key (should be write UPPERCASE) * @param mixed defaultValue [optional] * @return mixed */ function getEnv(key, defaultValue = null) { var myKey = key.toUpperCase(); return process.env[myKey] ? process.env[myKey] : defaultValue; } function loadProfile() { var env = new Object(); env.APP_URL = getEnv("APP_URL", "https://www.example.com"); env.APP_ENV = getEnv("APP_ENV", "development"); env.APP_DEBUG = getEnv("APP_DEBUG", true); env.S3_BUCKET_NAME = getEnv("S3_BUCKET_NAME", "my-s3-bucket-name"); env.EC2_URL = getEnv("EC2_URL", ""); return env; } exports.handler = async (event, context, callback) => { var request = event.Records[0].cf.request; var env = loadProfile(); console.log(env["APP_URL"]); // e.g. "https://www.example.com" console.log(env["APP_ENV"]); // e.g. "production" .env に定義されているので その値が使用される console.log(env["S3_BUCKET_NAME"]); // e.g. "my-s3-bucket-name" .env に定義されていないので getEnv関数の第2引数が使用される callback(null, request); };もっと良い方法をご存知の方が
いらっしゃいましたらコメントください。
- 投稿日:2020-02-19T11:20:05+09:00
scpコマンドでEC2ストレージからファイルを取り出す
備忘録的に記述
サーバー上でpwdを実行し、コピーしたいディレクトリまたはファイルを確認し、コピペ
$ pwd > /home/ubuntu/directory/to/folderローカルに戻り、scpをssh接続しながら実行する
$ pwd > ペーストしたいディレクトリの確認、今回はデスクトップにコピペ > /Users/username/desktop $ scp -i ~/.ssh/filename.pem -r ubuntu@x.xxx.xxx.x:/home/ubuntu/directory/to/folder /Users/username/desktopローカルのディレクトリと、ubuntu@以下の部分を逆にして書くと、ローカルのフォルダがサーバーにアップされてしまうため、注意!!!!
- 投稿日:2020-02-19T10:48:33+09:00
AWS セッションマネージャでSSH接続する際、認識しやすい名称で接続したい
※環境はMac前提
AWS環境のサーバ(EC2インスタンス)に接続する際
セキュリティを考慮して セッションマネージャーでトンネルしてSSHしているケースあるかと思います。Cf: AWS Systems Manager セッションマネージャーでSSH・SCPできるようになりました | Developers.IO
ただ、
ssh <インスタンスID>って、historyみたときに、あれ?このサーバなんだっけってなりますよね?いつもどおり
ssh production-serverとかしたいわけで。その方法。
~/.ssh/configを以下のように設定。Host awesome.production HostName i-0xxxxxxxxxxxxxxxx # <- ここにインスタンスID入れる # 以下、必要な数だけ 同じプリフィックスつけて HostNameを定義する Host awesome.* ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"これで
ssh awesome-productionで接続できます。ホスト名を動的に解決したい
ただ、上の方法だと、EC2インスタンスが増減したときに
~/.ssh/configを
手動でメンテしなければならず、すこぶる面倒ですよね。EC2のNameタグを利用してアクセスできるようにするには、以下のように ProxyCommand で少し頑張ってみる。
※ EC2のNameタグに設定する名前には、ピリオド「.」が入っていない前提。そうでない場合は
$(echo %h | cut -d. -f2)の箇所をよしなに修正してください
※ Mac Catalina バージョン10.15.3, シェルはzshで確認ProxyCommand $(EC2HOST=$(echo %h | cut -d. -f2);INSTANCEID=$(aws ec2 describe-instances --filters "Name=tag:Name,Values=$EC2HOST" --query "Reservations[*].Instances[*].[InstanceId]" --output text);echo aws ssm start-session --target $INSTANCEID --document-name AWS-StartSSHSession --parameters 'portNumber=%p')DBクライアントソフトの対応
MySQLWorkbenchや DataGrip など、DBクライアントソフトでSSHトンネルする場合
~/.ssh/configを考慮してくれるようなのですが(ProxyCommandも考慮してくれる)
ProxyCommand 内のコマンド展開$(echo %h | cut -d. -f2)などは考慮してくれないようです。
また、~/.ssh/configは Includeキーワードで別ファイルを読めるのですが、これも考慮してくれないようです。
なので、DBクライアントのトンネリングには、踏み台となる特定インスタンスを~/.ssh/configに定義しておくしかなさそうです。Host bastion HostName i-01xxxxxxxxxxxxxxx # <- bastionのインスタンスID ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"で、DBクライアントソフトのSSHホスト名を上で定義した「bastion」にすればOK。
※ DBクライアントによっては、session-manager-plugin をデフォルトでインストールしたときのパス
/usr/local/binが 環境変数 PATH に入って無くて読めないことがあるもよう。
その場合は、ProxyCommand にて PATHを設定するとうまくいく。ProxyCommand sh -c "env PATH=/usr/local/bin:$PATH aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"※ すべてにDBクライアントソフトを動作検証したわけではないので、これで繋がらない場合は
先に記述したDeveloper.IOの記事にあるポートフォワードを試してみてください。
- 投稿日:2020-02-19T09:23:31+09:00
Cloud Cost(AWS,OCI)
AWSとOCIを使用している時に、どっち使うか迷った時用メモ
- AWSは東京リージョン価格、OCIは全リージョン同一価格
Object Storage
ストレージ量のみ記載。リクエストやデータ転送量は公式を参照してください。
AWS
https://aws.amazon.com/jp/s3/pricing/
S3(標準) ドル 円($1=120円) 最初の50TB/月 0.025USD/GB 3 次の450TB/月 0.024USD/GB 2.88 500TB/月以上 0.023USD/GB 2.76 OCI
https://www.oracle.com/cloud/ucpricing.html
Object Storage ドル 円($1=120円) 最初の10GB無料分以降 $0.0255/GB 3.06
- 投稿日:2020-02-19T00:06:08+09:00
AWSのMulti-Attach EBS VolumesをWindows Serverで使うと、EBSの容量が実質2倍になる?
2020/2/14のAWSアップデートで、プロビジョンドIOPS (io1) のEBSボリュームに限り、複数EC2から同時アタッチできるようになりました。
つまり共有ストレージに使えるということになります。New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
https://aws.amazon.com/jp/blogs/aws/new-multi-attach-for-provisioned-iops-io1-amazon-ebs-volumes/このアップデートを聞いて、Windows Server 2019 で共有ストレージを組んでみようと思い、検証してみました。
検証の結果ですが、記事タイトルの通り、驚きの結果となりました。
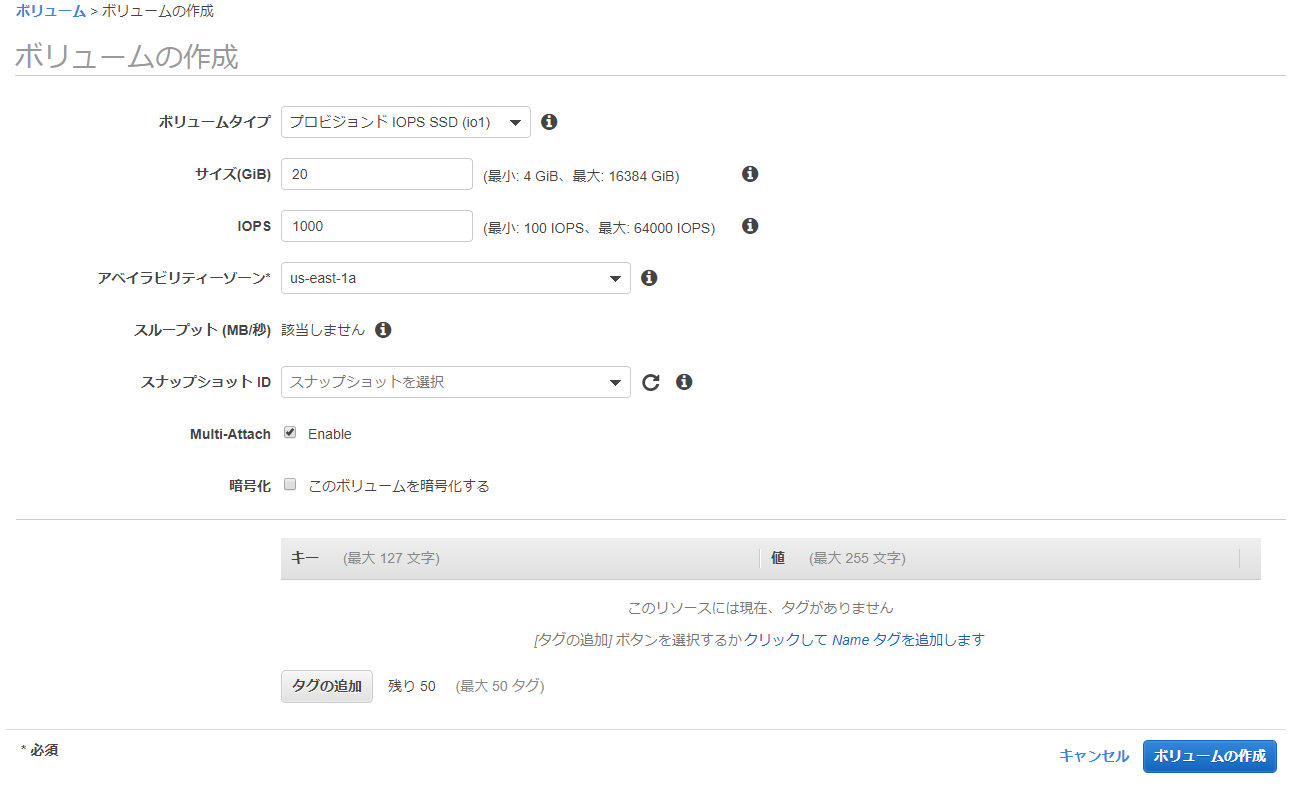
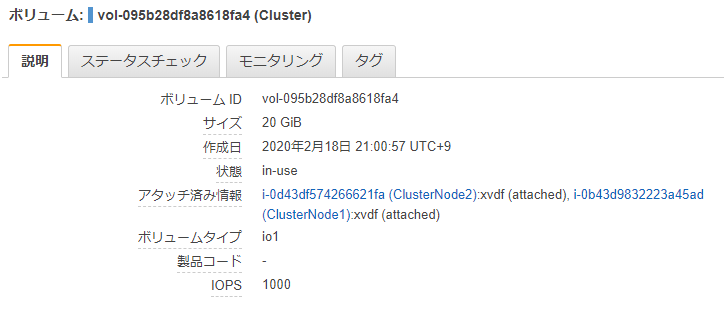
Multi-Attach EBSを作成して2台でアタッチ
プロビジョンドIOPSでEBSを作って、Multi-Attachにチェックを入れます。
2台のEC2 (Windows Server 2019) からアタッチします。
こんなふうに見えます。
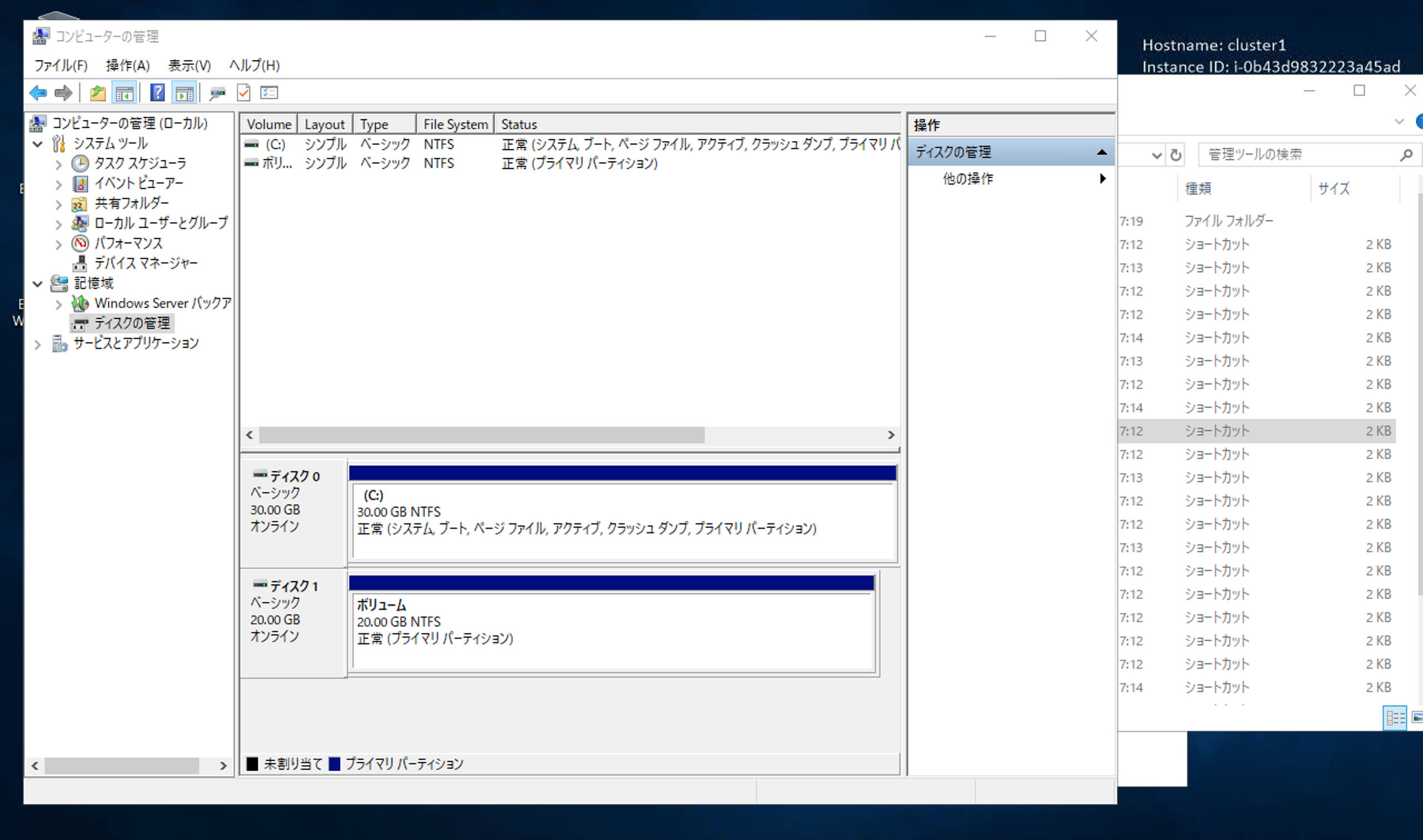
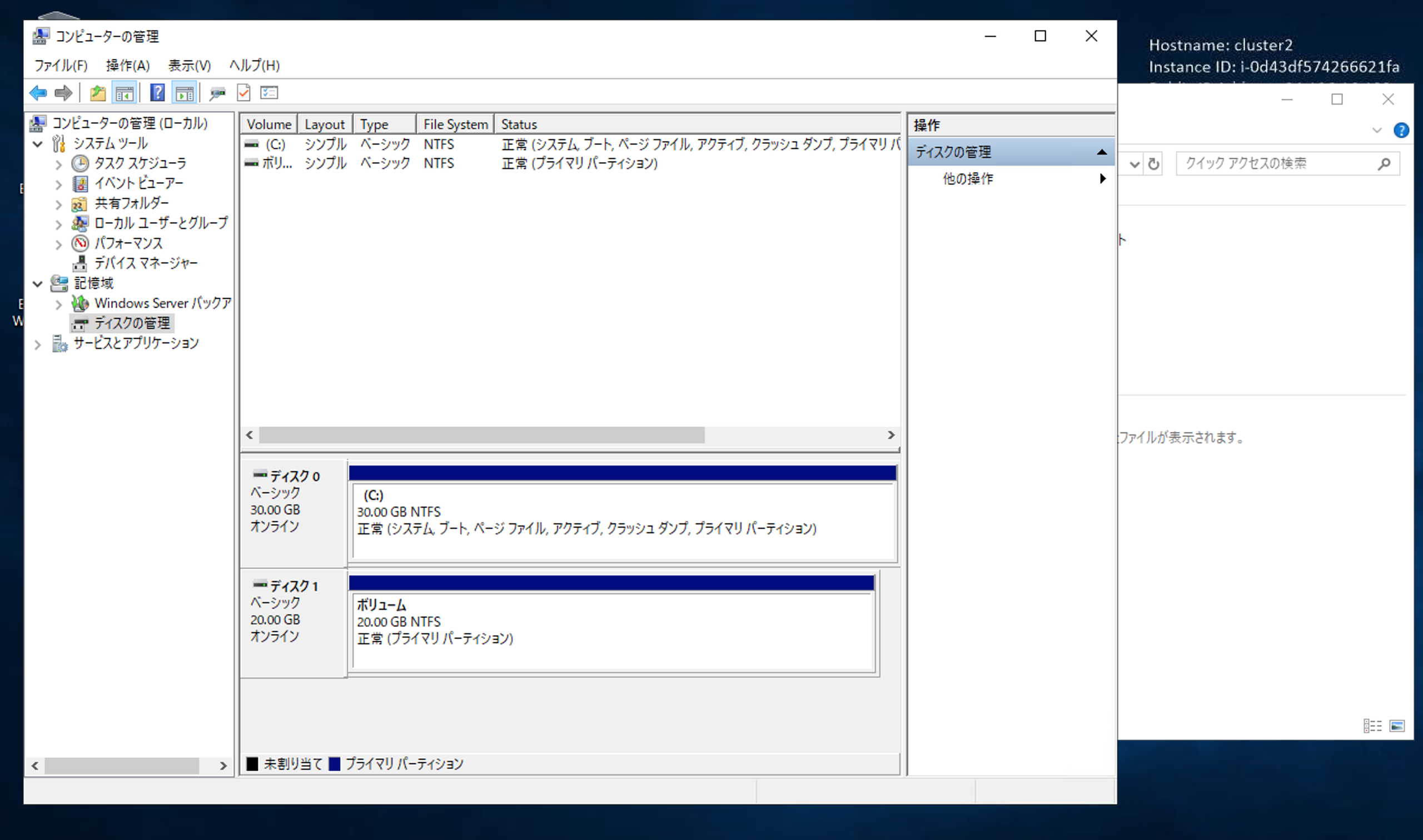
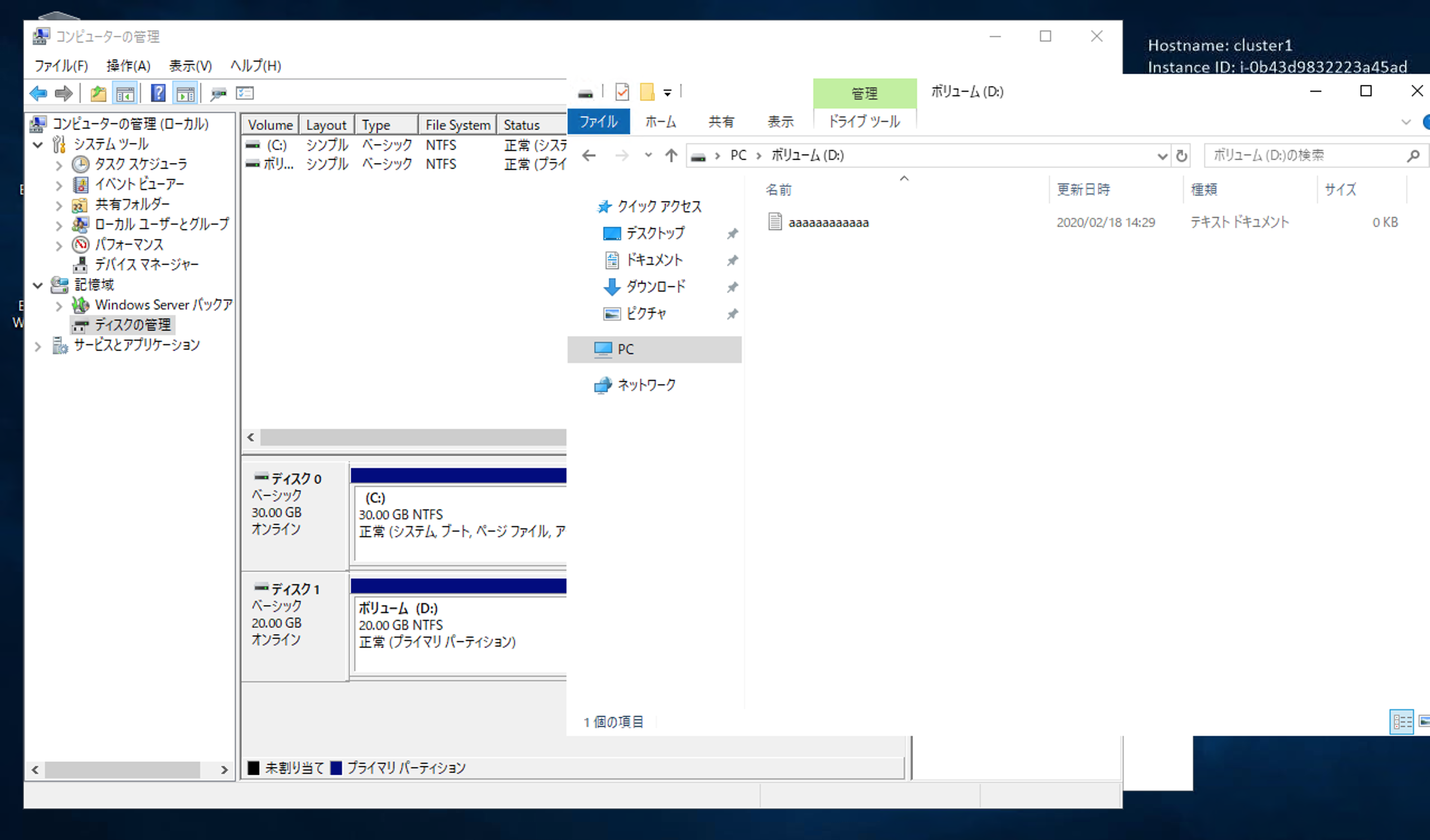
早速ローカルディスクとして使ってみる
両サーバからディスクをオンラインにして、ローカルディスクとして使うことを考えます。
記憶域での操作により、両サーバから同時にオンラインにできました。
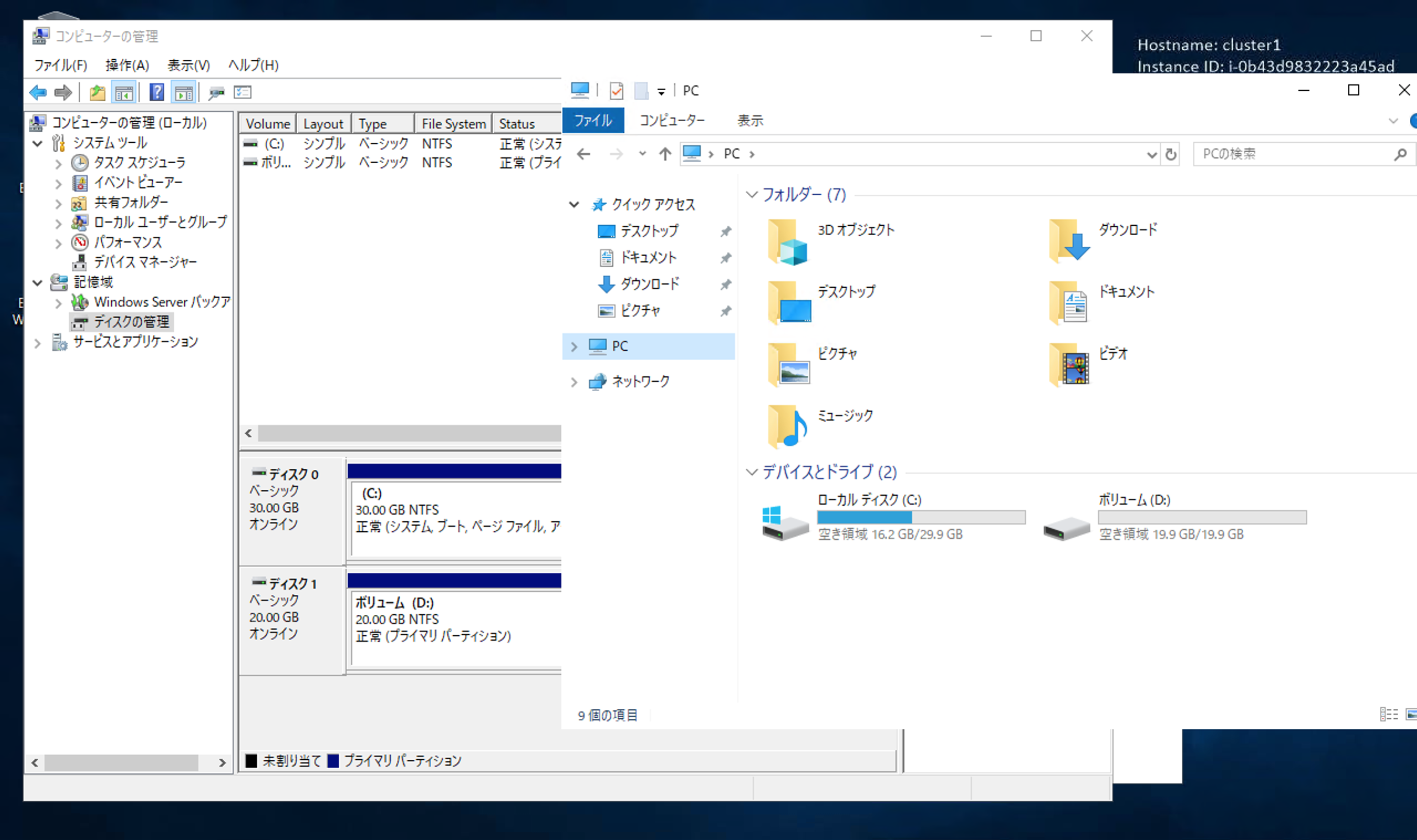
エクスプローラもご覧のとおりです。
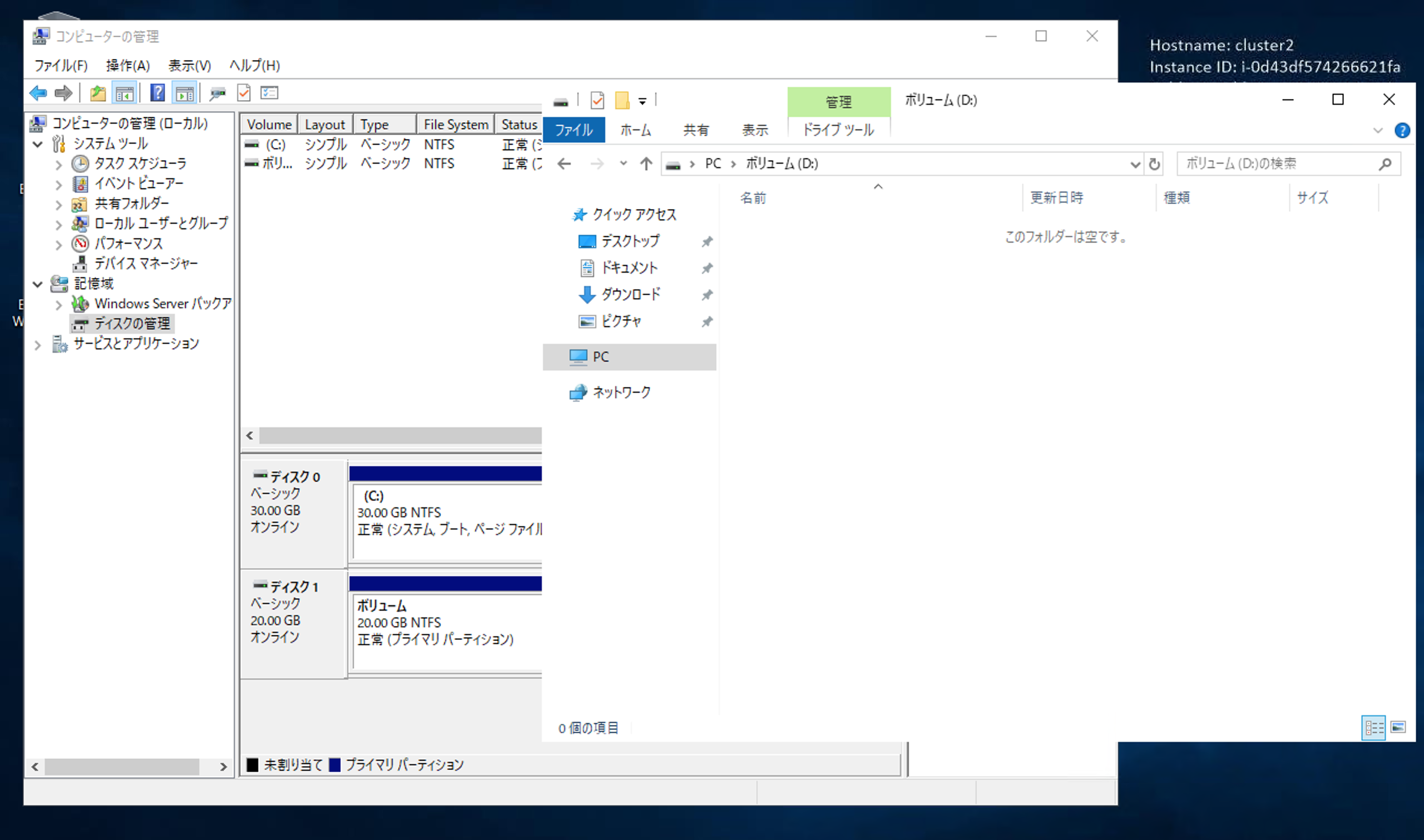
これでファイル共有できる! と思いきや
それぞれのWindows Serverの記憶域からはディスクが見えています。
なんかいい感じなので、1台目でテストファイルを置いてみます。
次に2台目で確認すると・・・
なんと、1台目で置いたテキストファイルが見えません。
これは予想外の展開です。今度は、逆のことをしてみます。
やはり、1台目では見えません。
なんと予想に反して、ファイルの共有ができませんでした。
ただ、お互いがお互いのファイルを独立して保存できているように見えます。ということは、もしかして容量が倍になる?
そこで、仮説として、共有ではなく、1台目と2台目ともに、EBSで割り当てた容量分使えるんじゃないの? と想像しました。
この仮説が正しいと、今回EBSを20GBで作りましたが、1台目と2台目を合わせて、40GB使えるということになりますが・・・
早速、検証してみました。
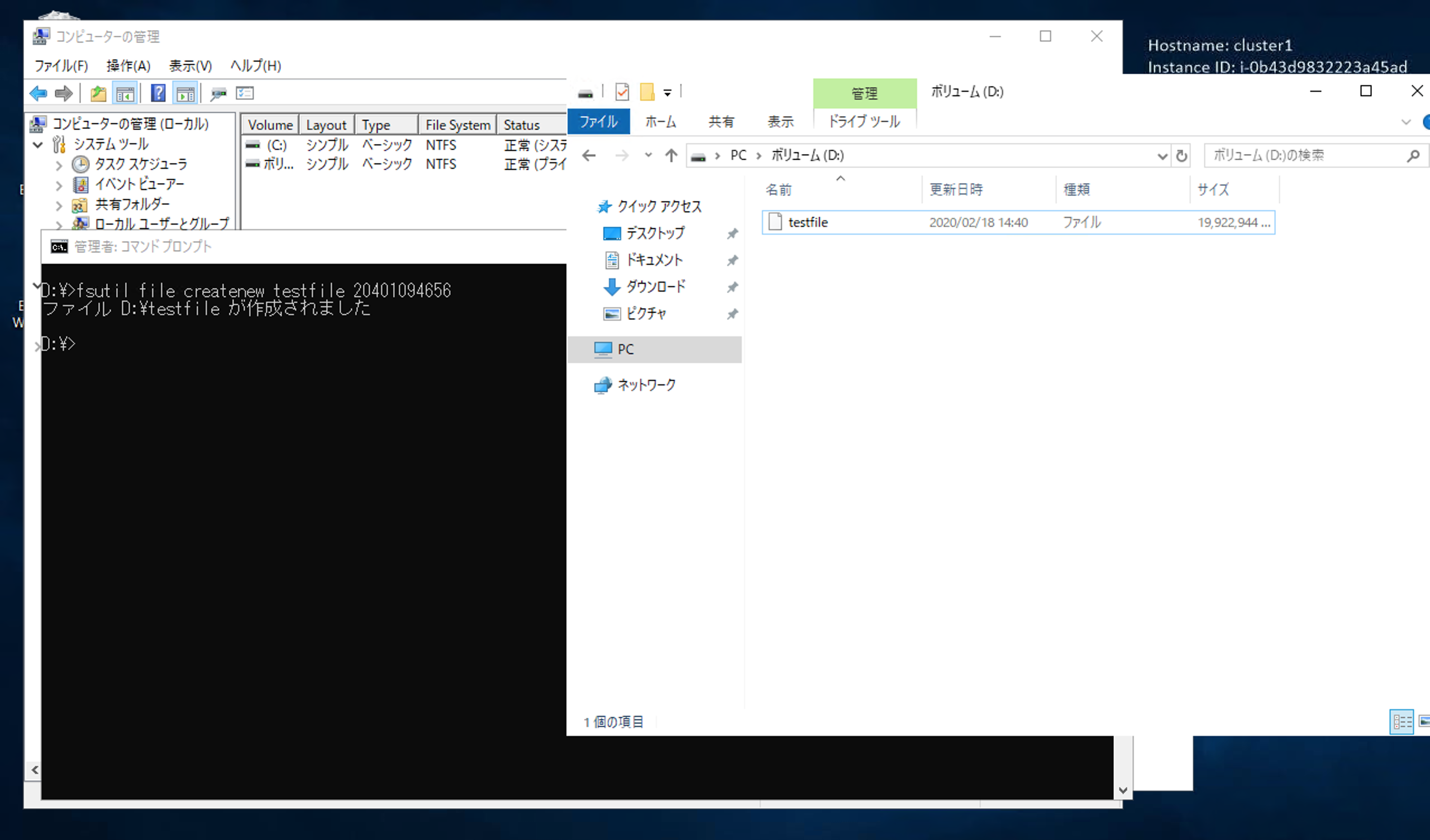
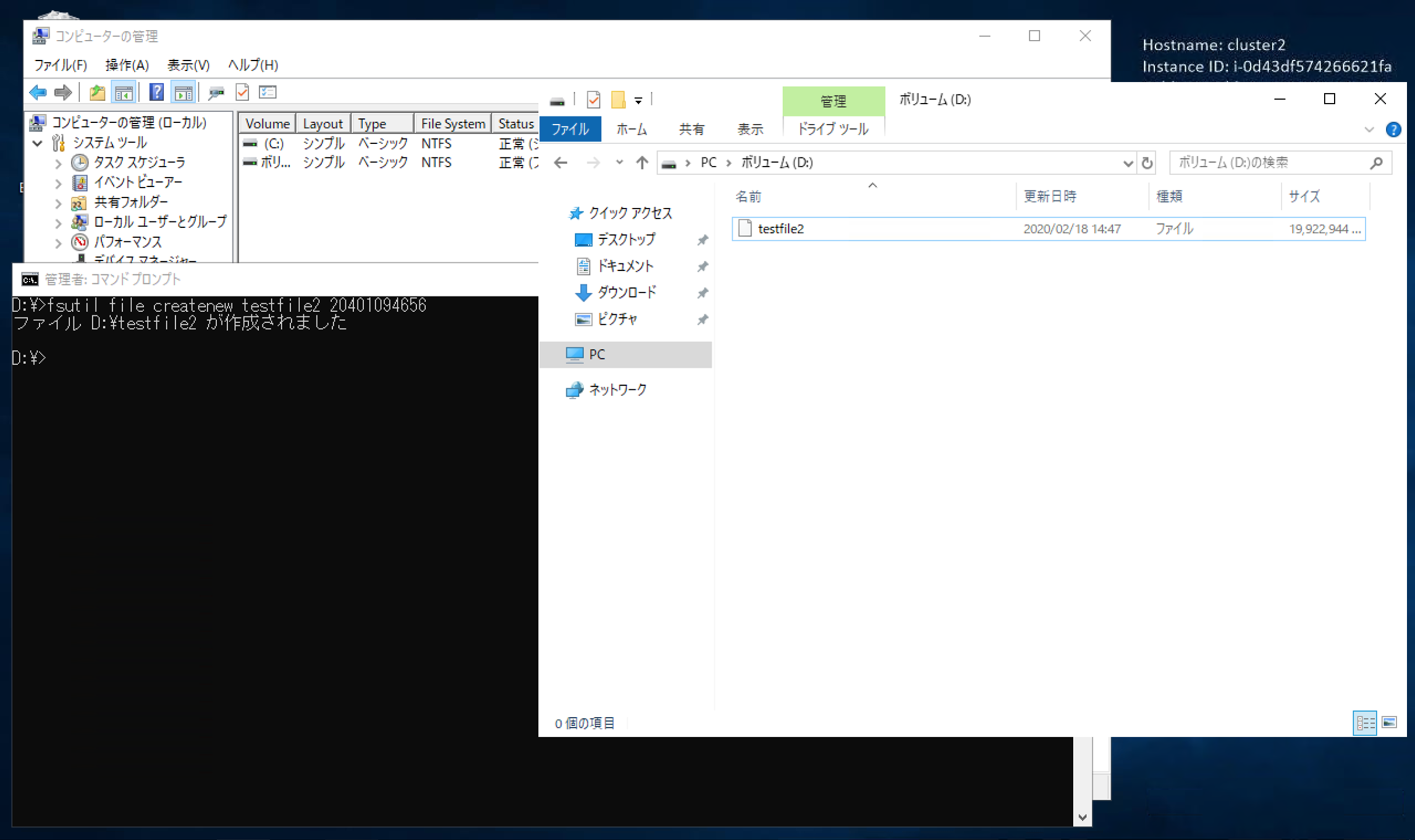
fsutilコマンドを使い、1台目で容量を埋め尽くしに行きます。
無事作成できました。この時点でEBSの20GB中、19GBは埋まっています。
先ほどの検証結果からも分かりますが、2台目では見えていません。
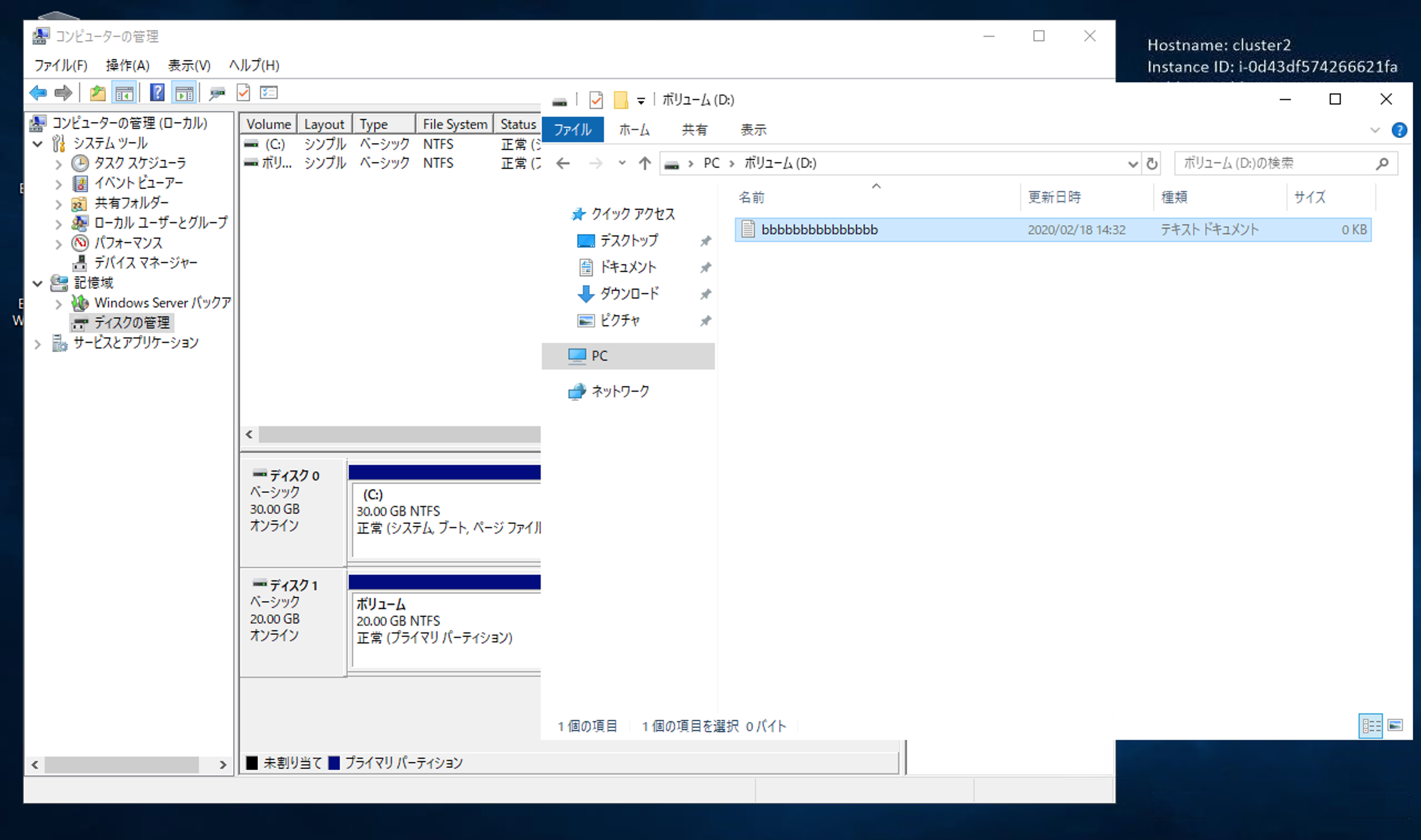
ここで、2台目からも埋め尽くしに行きます。
なんと作成できました。
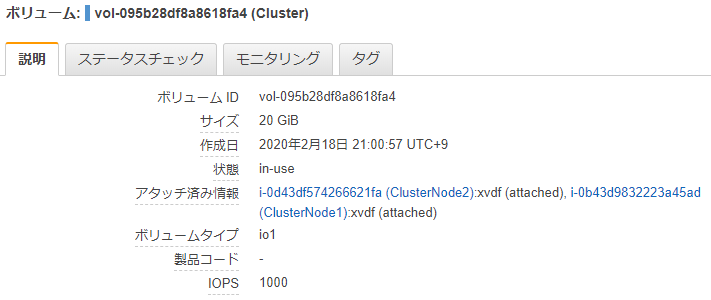
この瞬間を切り取ると、20GBのEBSに、38GBのファイルが保存されていることになります。もう一度、マネジメントコンソールでEBSを確認します。
確かに20GBしか割り当てていません。
この状態で、お互いのファイルは読み取りできました。
(追記) 片側でディスクをオフラインにして、もう一度オンラインにするとどうなるか
上記までの状態で記事をSNSで共有したところ「NTFSを両側からオンラインにするとファイルシステムが壊れるんじゃないか」「片側だけオンラインにするべき」とのメッセージをいただきました。
そこで、上記までの状態で2台目だけディスクをオフラインにしてみますと、正常にオフラインにできました。
その後、もう一度オンラインにすると、1台目と2台目でディスクの中身が同じとなりました。
(OSを再起動しても同じ事象が起こりそうです)再起動やディスクのオフラインを挟むと、その時点でディスクは共有状態となるようですが、その後の書き込み結果はやはり共有されないようです。
まとめ
見たままストレートに書いて良いのか少々疑わしいですが、Windows Server 2019でMulti-Attach EBSを使うと、共有とはならず、互いが容量をフルで使える (実質的に容量が2倍になっている) ように見え、読み書きもできました。
ただ、この状態はあくまで最初に2台をヨーイドンで使い始めて、永続的に起動し続けている間しか成り立たず、再起動等を挟むとこの状態は失われてしまうようです。公式ドキュメントや、他の方が先に書かれた記事を読みながら首をひねりましたが、なぜそうなるのかという答えは、まだ出ていません。
誠にお恥ずかしいことですが、ぜひ詳しい方から、お知恵をお借りできたらと思います。煮え切らないところですが、引き続き、調査と検証をしていきたいと思います。
続きの検証結果があれば、追記していきたいと思います。参考記事


- 投稿日:2020-02-19T00:06:08+09:00
AWSのMulti-Attach EBS Volumesは、いわゆる「共有ストレージ」としては使えなかった
2/19: 検証の結果、詳しいことが分かり、記事タイトルを改題しました。公式サイトの記事にあるIMPORTANT SAFETY TIPSがまさに記事中の事象を表していることが分かり、追記しました。
※ 旧タイトル「AWSのMulti-Attach EBS VolumesをWindows Serverで使うと、EBSの容量が実質2倍になる?」はじめに
2020/2/14のAWSアップデートで、プロビジョンドIOPS (io1) のEBSボリュームに限り、複数EC2から同時アタッチできるようになりました。
これだけを見ると、いかにも「共有ストレージ」 (後述の図のような構成) に使えそうだと思えてきます。
New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
https://aws.amazon.com/jp/blogs/aws/new-multi-attach-for-provisioned-iops-io1-amazon-ebs-volumes/このアップデートを聞いて、Windows Server 2019 で共有ストレージを組んでみようと思い、検証してみました。
検証の結果ですが、記事タイトルの通り、共有ストレージとしては使えないようです。
以下で示す検証結果は「実施してはいけない行為」の好例となります。検証の顛末を以下に記します。
大勢が想像したであろう共有ストレージの図
これと同じか、似たような絵面 (複数EC2で1ディスクを共有) だと思います。
引用: 20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS) 2018/8/9 updateこの絵面を思い浮かべて想像することは、
- 同じディスクが2台のサーバから見える
- 片方のサーバから更新したファイルは、もう片方からも見えて更新もできる
Multi-Attach EBSを作成して2台でアタッチ
プロビジョンドIOPSでEBSを作って、Multi-Attachにチェックを入れます。
2台のEC2 (Windows Server 2019) からアタッチします。
こんなふうに見えます。
早速Windowsから使おうとしてみる
両サーバからディスクをオンラインにして、ローカルディスクとして使うことを考えます。
記憶域での操作により、両サーバから同時にオンラインにできました。
エクスプローラもご覧のとおりです。
これでファイル共有できる! と思いきや
それぞれのWindows Serverの記憶域からはディスクが見えています。
なんかいい感じなので、1台目でテストファイルを置いてみます。
次に2台目で確認すると・・・
なんと、1台目で置いたテキストファイルが見えません。
これは予想外の展開です。今度は、逆のことをしてみます。
やはり、1台目では見えません。
なんと予想に反して、ファイルの共有ができませんでした。
ただ、お互いがお互いのファイルを独立して保存できているように見えます。ということは、もしかして容量が倍になる?
そこで、仮説として、共有ではなく、1台目と2台目ともに、EBSで割り当てた容量分使えるんじゃないの? と想像しました。
この仮説が正しいと、今回EBSを20GBで作りましたが、1台目と2台目を合わせて、40GB使えるということになりますが・・・
早速、検証してみました。
fsutilコマンドを使い、1台目で容量を埋め尽くしに行きます。
無事作成できました。この時点でEBSの20GB中、19GBは埋まっています。
先ほどの検証結果からも分かりますが、2台目では見えていません。
ここで、2台目からも埋め尽くしに行きます。
なんと作成できました。
この瞬間を切り取ると、20GBのEBSに、38GBのファイルが保存されていることになります。もう一度、マネジメントコンソールでEBSを確認します。
確かに20GBしか割り当てていません。
この状態で、お互いのファイルは読み取りできました。
(追記) 片側でディスクをオフラインにして、もう一度オンラインにするとどうなるか
上記までの状態で記事をSNSで共有したところ「NTFSを両側からオンラインにするとファイルシステムが壊れるんじゃないか」「片側だけオンラインにするべき」とのメッセージをいただきました。
そこで、上記までの状態で2台目だけディスクをオフラインにしてみますと、正常にオフラインにできました。
その後、もう一度オンラインにすると、1台目と2台目でディスクの中身が同じとなりました。
(OSを再起動しても同じ事象が起こりそうです)再起動やディスクのオフラインを挟むと、その時点でディスクは共有状態となるようですが、その後の書き込み結果はやはり共有されないようです。
(追記) なぜデータが2倍保存できるように見えたり、突然更新されたりするのか
調査の結果、OSの仕組み上の問題が見えてきました。
今回検証したWindows OSでは、ブロックIOのキャッシュを保持しています。
つまり、実際にストレージに対しての書き込みは、OS上の操作とは非同期に行われ、厳密に同時ではありません。
このため、今回のように同じディスクをシンプルに共有した場合、片方で既に更新操作を終えている状況にもかかわらず、もう一方のインスタンスからファイルが存在しないように見えたり、全く利用されていないように見えたり、両方のインスタンスで保存したデータのサイズが実際の物理的な容量と乖離する状況になることがあるようです。
前述の通り、更新が厳密には非同期であり、どちらかのWindows OSが非同期的にディスクに書き込み操作を実行した結果、どちらかのインスタンスでファイルが存在しなくなる状況が起こりかねないと言えます。現状、このMulti-Attach EBS Volumesをマウントした時のように、見た目上各サーバのローカルディスクでありながら、物理的にディスクは共有されている構成には、Windows OSは対応していない (おそらくユースケースとして想定もされていない)と思われます。
対応策として、クラスタソフトウェアなどを導入して、ディスクへの読み書きをちゃんと制御できれば良いのですが、Multi-Attach EBS Volumesに対応しているソフトウェアはなさそうです。(追記) IMPORTANT SAFETY TIPSの追記
本件についてAWS様と会話したところ、公式ドキュメントに書かれた以下のTIPSが、まさに上記事象のようなリスクのことであるとご案内いただきました。
IMPORTANT SAFETY TIP: I mentioned above that your applications do need to provide write ordering to maintain storage consistency, as obviously if multiple instances write data at the same time there is a risk of data being overwritten and becoming inconsistent. Please ensure you fully understand what it takes to set up and run a cluster-aware file system before you attempt to use this feature. The example shown below in this post is for simplicity purposes only, does not use a cluster-aware file system, and is not suitable for production environments!
Google翻訳
重要な安全性のヒント:複数のインスタンスが同時にデータを書き込むと、データが上書きされて一貫性がなくなるリスクがあるため、アプリケーションはストレージの一貫性を維持するために書き込み順序を提供する必要があることを前述しました。この機能を使用する前に、クラスター対応ファイルシステムのセットアップと実行に必要なことを十分に理解してください。この投稿で以下に示す例は、単純化を目的としたものであり、クラスター対応ファイルシステムを使用せず、運用環境には適していません!
ここで、WindowsであればWSFCを構築することが考えられますが、Multi-Attach EBS Volumesは、ディスク単独ではiSCSIには対応しないため、それができません。
(Multi-Attach EBS VolumesをアタッチしたEC2でiSCSIサーバを立てた場合は別ですが、この場合、そもそもMulti-Attach EBS Volumesである必要性がありません。)まとめ
2台のWindows Server 2019のEC2にMulti-Attach EBS Volumesをアタッチして両側からオンラインにしても、共有とはならず、最初、互いが容量をフルで使える (実質的に容量が2倍になっている) ように見え、読み書きもできました。
ただ、この状態はあくまで最初に2台をヨーイドンで使い始めて、永続的に起動し続けている間しか成り立たず、再起動等を挟むとこの状態は失われてしまうようです。
(データロストすることになります)つまり、現在のところ、Multi-Attach EBS Volumesを、公式ドキュメント通りにアタッチして使用しても、Windows Server 2019の標準機能では共有ストレージとして活用できません。
Active-Active (本検証のようにシンプルに2サーバからマウントした状態) ではデータロスト等の不具合が生じる可能性が大きいことが分かりました。大勢が想定している共有ストレージとして使うには、どうやら、今後のアップデートを待つしかないようです。
引き続き、現時点でのユースケースを探すべく検証を続けていきますので、分かったことがあれば追記していきます。
参考記事
- New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
- Amazon EBSのマルチアタッチ機能とAzure Shared Disksを比較してみる
謝辞
本記事を執筆するにあたり、初版執筆時点から、SNS等を通じて技術的なアドバイスをいただいた全ての方に、この場を借りて、改めて感謝申し上げます。

- 投稿日:2020-02-19T00:06:08+09:00
AWSのMulti-Attach EBS Volumesを「共有ストレージ」に使えるか検証してみた
2/19: 検証の結果、詳しいことが分かり、進捗を受けて記事タイトルを改題しています。公式サイトの記事にあるIMPORTANT SAFETY TIPSがまさに記事中の事象を表していることが分かり、追記しました。
※ 旧タイトル「AWSのMulti-Attach EBS VolumesをWindows Serverで使うと、EBSの容量が実質2倍になる?」はじめに
2020/2/14のAWSアップデートで、プロビジョンドIOPS (io1) のEBSボリュームに限り、複数EC2から同時アタッチできるようになりました。
これだけを見ると、いかにも「共有ストレージ」 (後述の図のような構成) に使えそうだと思えてきます。
New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
https://aws.amazon.com/jp/blogs/aws/new-multi-attach-for-provisioned-iops-io1-amazon-ebs-volumes/このアップデートを聞いて、Windows Server 2019 で共有ストレージを組んでみようと思い、検証してみました。
検証の結果ですが、記事タイトルの通り、共有ストレージとしては使えないようです。
以下で示す検証結果は「実施してはいけない行為」の好例となります。検証の顛末を以下に記します。
大勢が想像したであろう共有ストレージの図
これと同じか、似たような絵面 (複数EC2で1ディスクを共有) だと思います。
引用: 20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS) 2018/8/9 updateこの絵面を思い浮かべて想像することは、
- 同じディスクが2台のサーバから見える
- 片方のサーバから更新したファイルは、もう片方からも見えて更新もできる
Multi-Attach EBSを作成して2台でアタッチ
プロビジョンドIOPSでEBSを作って、Multi-Attachにチェックを入れます。
2台のEC2 (Windows Server 2019) からアタッチします。
こんなふうに見えます。
早速Windowsから使おうとしてみる
両サーバからディスクをオンラインにして、ローカルディスクとして使うことを考えます。
記憶域での操作により、両サーバから同時にオンラインにできました。
エクスプローラもご覧のとおりです。
ファイル共有できる! と思いきや
それぞれのWindows Serverの記憶域からはディスクが見えています。
なんかいい感じなので、1台目でテストファイルを置いてみます。
次に2台目で確認すると・・・
なんと、1台目で置いたテキストファイルが見えません。
これは予想外の展開です。今度は、逆のことをしてみます。
やはり、1台目では見えません。
なんと予想に反して、ファイルの共有ができませんでした。
ただ、お互いがお互いのファイルを独立して保存できているように見えます。もしかして容量が倍になる?
そこで、仮説として、共有ではなく、1台目と2台目ともに、EBSで割り当てた容量分使えるんじゃないの? と想像しました。
この仮説が正しいと、今回EBSを20GBで作りましたが、1台目と2台目を合わせて、40GB使えるということになりますが・・・
早速、検証してみました。
fsutilコマンドを使い、1台目で容量を埋め尽くしに行きます。
無事作成できました。この時点でEBSの20GB中、19GBは埋まっています。
先ほどの検証結果からも分かりますが、2台目では見えていません。
ここで、2台目からも埋め尽くしに行きます。
なんと作成できました。
この瞬間を切り取ると、20GBのEBSに、38GBのファイルが保存されていることになります。もう一度、マネジメントコンソールでEBSを確認します。
確かに20GBしか割り当てていません。
この状態で、お互いのファイルは読み取りできました。
(追記) 片側でディスクをオフラインにして、もう一度オンラインにするとどうなるか
上記までの状態で記事をSNSで共有したところ「NTFSを両側からオンラインにするとファイルシステムが壊れるんじゃないか」「片側だけオンラインにするべき」とのメッセージをいただきました。
そこで、上記までの状態で2台目だけディスクをオフラインにしてみますと、正常にオフラインにできました。
その後、もう一度オンラインにすると、1台目と2台目でディスクの中身が同じとなりました。
(OSを再起動しても同じ事象が起こりそうです)再起動やディスクのオフラインを挟むと、その時点でディスクは共有状態となるようですが、その後の書き込み結果はやはり共有されないようです。
(追記) なぜデータが2倍保存できるように見えたり、突然更新されたりするのか
調査の結果、OSの仕組みから、上記事象の原因が見えてきました。
今回検証したWindows OSでは、ブロックIOのキャッシュを保持しています。
つまり、実際にストレージに対しての書き込みは、OS上の操作とは非同期に行われ、厳密に同時ではありません。
このため、今回のように同じディスクをシンプルに共有した場合、片方で既に更新操作を終えている状況にもかかわらず、もう一方のインスタンスからファイルが存在しないように見えたり、全く利用されていないように見えたり、両方のインスタンスで保存したデータのサイズが実際の物理的な容量と乖離する状況になることがあるようです。
前述の通り、更新が厳密には非同期であり、どちらかのWindows OSが非同期的にディスクに書き込み操作を実行した結果、どちらかのインスタンスでファイルが存在しなくなる状況が起こりかねないと言えます。現状、このMulti-Attach EBS Volumesをマウントした時のように、見た目上各サーバのローカルディスクでありながら、物理的にディスクは共有されている構成には、Windows OSは対応していない (おそらくユースケースとして想定もされていない)と思われます。
対応策として、クラスタソフトウェアなどを導入して、ディスクへの読み書きをちゃんと制御できれば良いのですが、Multi-Attach EBS Volumesに対応しているソフトウェアはなさそうです。(追記) IMPORTANT SAFETY TIPSの追記
本件についてAWS様と会話したところ、公式ドキュメントに書かれた以下のTIPSが、まさに上記事象のようなリスクのことであるとご案内いただきました。
IMPORTANT SAFETY TIP: I mentioned above that your applications do need to provide write ordering to maintain storage consistency, as obviously if multiple instances write data at the same time there is a risk of data being overwritten and becoming inconsistent. Please ensure you fully understand what it takes to set up and run a cluster-aware file system before you attempt to use this feature. The example shown below in this post is for simplicity purposes only, does not use a cluster-aware file system, and is not suitable for production environments!
Google翻訳
重要な安全性のヒント:複数のインスタンスが同時にデータを書き込むと、データが上書きされて一貫性がなくなるリスクがあるため、アプリケーションはストレージの一貫性を維持するために書き込み順序を提供する必要があることを前述しました。この機能を使用する前に、クラスター対応ファイルシステムのセットアップと実行に必要なことを十分に理解してください。この投稿で以下に示す例は、単純化を目的としたものであり、クラスター対応ファイルシステムを使用せず、運用環境には適していません!
ここで、WindowsであればWSFCを構築することが考えられますが、Multi-Attach EBS Volumesは、ディスク単独ではiSCSIには対応しないため、それができません。
(Multi-Attach EBS VolumesをアタッチしたEC2でiSCSIサーバを立てた場合は別ですが、この場合、そもそもMulti-Attach EBS Volumesである必要性がありません。)まとめ
2台のWindows Server 2019のEC2にMulti-Attach EBS Volumesをアタッチして両側からオンラインにしても、共有とはならず、最初、互いが容量をフルで使える (実質的に容量が2倍になっている) ように見え、読み書きもできました。
ただ、この状態はあくまで最初に2台をヨーイドンで使い始めて、永続的に起動し続けている間しか成り立たず、再起動等を挟むとこの状態は失われてしまうようです。
(データロストすることになります)つまり、現在のところ、Multi-Attach EBS Volumesを、公式ドキュメント通りにアタッチして使用しても、Windows Server 2019の標準機能では共有ストレージとして活用できません。
Active-Active (本検証のようにシンプルに2サーバからマウントした状態) ではデータロスト等の不具合が生じる可能性が大きいことが分かりました。大勢が想定している共有ストレージとして使うには、アプリケーションやソフトウェアで工夫するか、今後のアップデートを待つしかないようです。
引き続き、現時点でのユースケースを探すべく検証を続けていきますので、分かったことがあれば追記していきます。
(補足) 「共有ストレージ」とは
この記事を書くときに、タイトルに「共有ストレージ」と書きましたが、その背景としては、
EBSがMulti-Attachできる→複数EC2から接続できる→同時にマウントして使える?→EFSの代わりになる?
このように連想する方が少なからずおり、まさに今回実施した検証の内容ができないかと考える方が多いのではと想像しました。
(結果、タイトルの期待を裏切ることになります)思慮の上、Multi-Attachの文字列を見た人はきっとこう思うんだろうなという想像から、「共有ストレージ」というキーワードを入れています。
賛否はあるかと思いますが、どうか、ご理解いただけたらと思います。参考記事
- New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
- Amazon EBSのマルチアタッチ機能とAzure Shared Disksを比較してみる
謝辞
本記事を執筆するにあたり、初版執筆時点から、SNS等を通じて技術的なアドバイスをいただいた全ての方に、この場を借りて、改めて感謝申し上げます。
- 投稿日:2020-02-19T00:06:08+09:00
AWSのMulti-Attach EBS Volumesが「共有ストレージ」に使えるか検証してみた
2/19: 検証の結果、詳しいことが分かり、進捗を受けて記事タイトルを改題しています。公式サイトの記事にあるIMPORTANT SAFETY TIPSがまさに記事中の事象を表していることが分かり、追記しました。
※ 旧タイトル「AWSのMulti-Attach EBS VolumesをWindows Serverで使うと、EBSの容量が実質2倍になる?」はじめに
2020/2/14のAWSアップデートで、プロビジョンドIOPS (io1) のEBSボリュームに限り、複数EC2から同時アタッチできるようになりました。
これだけを見ると、いかにも「共有ストレージ」 (後述の図のような構成) に使えそうだと思えてきます。
New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
https://aws.amazon.com/jp/blogs/aws/new-multi-attach-for-provisioned-iops-io1-amazon-ebs-volumes/このアップデートを聞いて、Windows Server 2019 で共有ストレージを組んでみようと思い、検証してみました。
検証の結果ですが、Windows Server 2019の標準機能では共有ストレージとしては使えないようです。
以下で示す検証結果は「実施してはいけない行為」の好例となります。検証の顛末を以下に記します。
大勢が想像したであろう共有ストレージの図
これと同じか、似たような絵面 (複数EC2で1ディスクを共有) だと思います。
引用: 20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS) 2018/8/9 updateこの絵面を思い浮かべて想像することは、
- 同じディスクが2台のサーバから見える
- 片方のサーバから更新したファイルは、もう片方からも見えて更新もできる
Multi-Attach EBSを作成して2台でアタッチ
プロビジョンドIOPSでEBSを作って、Multi-Attachにチェックを入れます。
2台のEC2 (Windows Server 2019) からアタッチします。
こんなふうに見えます。
早速Windowsから使おうとしてみる
両サーバからディスクをオンラインにして、ローカルディスクとして使うことを考えます。
記憶域での操作により、両サーバから同時にオンラインにできました。
エクスプローラもご覧のとおりです。
ファイル共有できる! と思いきや
それぞれのWindows Serverの記憶域からはディスクが見えています。
なんかいい感じなので、1台目でテストファイルを置いてみます。
次に2台目で確認すると・・・
なんと、1台目で置いたテキストファイルが見えません。
これは予想外の展開です。今度は、逆のことをしてみます。
やはり、1台目では見えません。
なんと予想に反して、ファイルの共有ができませんでした。
ただ、お互いがお互いのファイルを独立して保存できているように見えます。もしかして容量が倍になる?
そこで、仮説として、共有ではなく、1台目と2台目ともに、EBSで割り当てた容量分使えるんじゃないの? と想像しました。
この仮説が正しいと、今回EBSを20GBで作りましたが、1台目と2台目を合わせて、40GB使えるということになりますが・・・
早速、検証してみました。
fsutilコマンドを使い、1台目で容量を埋め尽くしに行きます。
無事作成できました。この時点でEBSの20GB中、19GBは埋まっています。
先ほどの検証結果からも分かりますが、2台目では見えていません。
ここで、2台目からも埋め尽くしに行きます。
なんと作成できました。
この瞬間を切り取ると、20GBのEBSに、38GBのファイルが保存されていることになります。もう一度、マネジメントコンソールでEBSを確認します。
確かに20GBしか割り当てていません。
この状態で、お互いのファイルは読み取りできました。
(追記) 片側でディスクをオフラインにして、もう一度オンラインにするとどうなるか
上記までの状態で記事をSNSで共有したところ「NTFSを両側からオンラインにするとファイルシステムが壊れるんじゃないか」「片側だけオンラインにするべき」とのメッセージをいただきました。
そこで、上記までの状態で2台目だけディスクをオフラインにしてみますと、正常にオフラインにできました。
その後、もう一度オンラインにすると、1台目と2台目でディスクの中身が同じとなりました。
(OSを再起動しても同じ事象が起こりそうです)再起動やディスクのオフラインを挟むと、その時点でディスクは共有状態となるようですが、その後の書き込み結果はやはり共有されないようです。
(追記) なぜデータが2倍保存できるように見えたり、突然更新されたりするのか
調査の結果、OSの仕組みから、上記事象の原因が見えてきました。
今回検証したWindows OSでは、ブロックIOのキャッシュを保持しています。
つまり、実際にストレージに対しての書き込みは、OS上の操作とは非同期に行われ、厳密に同時ではありません。
このため、今回のように同じディスクをシンプルに共有した場合、片方で既に更新操作を終えている状況にもかかわらず、もう一方のインスタンスからファイルが存在しないように見えたり、全く利用されていないように見えたり、両方のインスタンスで保存したデータのサイズが実際の物理的な容量と乖離する状況になることがあるようです。
前述の通り、更新が厳密には非同期であり、どちらかのWindows OSが非同期的にディスクに書き込み操作を実行した結果、どちらかのインスタンスでファイルが存在しなくなる状況が起こりかねないと言えます。現状、このMulti-Attach EBS Volumesをマウントした時のように、見た目上各サーバのローカルディスクでありながら、物理的にディスクは共有されている構成には、Windows OSは対応していない (おそらくユースケースとして想定もされていない)と思われます。
対応策として、クラスタソフトウェアなどを導入して、ディスクへの読み書きをちゃんと制御できれば良いのですが、Multi-Attach EBS Volumesに対応しているソフトウェアはなさそうです。(追記) IMPORTANT SAFETY TIPSの追記
本件についてAWS様と会話したところ、公式ドキュメントに書かれた以下のTIPSが、まさに上記事象のようなリスクのことであるとご案内いただきました。
IMPORTANT SAFETY TIP: I mentioned above that your applications do need to provide write ordering to maintain storage consistency, as obviously if multiple instances write data at the same time there is a risk of data being overwritten and becoming inconsistent. Please ensure you fully understand what it takes to set up and run a cluster-aware file system before you attempt to use this feature. The example shown below in this post is for simplicity purposes only, does not use a cluster-aware file system, and is not suitable for production environments!
Google翻訳
重要な安全性のヒント:複数のインスタンスが同時にデータを書き込むと、データが上書きされて一貫性がなくなるリスクがあるため、アプリケーションはストレージの一貫性を維持するために書き込み順序を提供する必要があることを前述しました。この機能を使用する前に、クラスター対応ファイルシステムのセットアップと実行に必要なことを十分に理解してください。この投稿で以下に示す例は、単純化を目的としたものであり、クラスター対応ファイルシステムを使用せず、運用環境には適していません!
ここで、WindowsであればWSFCを構築することが考えられますが、Multi-Attach EBS Volumesは、ディスク単独ではiSCSIには対応しないため、それができません。
(Multi-Attach EBS VolumesをアタッチしたEC2でiSCSIサーバを立てた場合は別ですが、この場合、そもそもMulti-Attach EBS Volumesである必要性がありません。)まとめ
2台のWindows Server 2019のEC2にMulti-Attach EBS Volumesをアタッチして両側からオンラインにしても、共有とはならず、最初、互いが容量をフルで使える (実質的に容量が2倍になっている) ように見え、読み書きもできました。
ただ、この状態はあくまで最初に2台をヨーイドンで使い始めて、永続的に起動し続けている間しか成り立たず、再起動等を挟むとこの状態は失われてしまうようです。
(データロストすることになります)つまり、現在のところ、Multi-Attach EBS Volumesを、公式ドキュメント通りにアタッチして使用しても、Windows Server 2019の標準機能では共有ストレージとして活用できません。
Active-Active (本検証のようにシンプルに2サーバからマウントした状態) ではデータロスト等の不具合が生じる可能性が大きいことが分かりました。大勢が想定している共有ストレージとして使うには、アプリケーションやソフトウェアで工夫するか、今後のアップデートを待つしかないようです。
引き続き、現時点でのユースケースを探すべく検証を続けていきますので、分かったことがあれば追記していきます。
(補足) 「共有ストレージ」とは
この記事を書くときに、タイトルに「共有ストレージ」と書きましたが、その背景としては、
EBSがMulti-Attachできる→複数EC2から接続できる→同時にマウントして使える?→EFSの代わりになる?
このように連想する方が少なからずおり、まさに今回実施した検証の内容ができないかと考える方が多いのではと想像しました。
(結果、タイトルの期待を裏切ることになります)思慮の上、Multi-Attachの文字列を見た人はきっとこう思うんだろうなという想像から、「共有ストレージ」というキーワードを入れています。
賛否はあるかと思いますが、どうか、ご理解いただけたらと思います。参考記事
- New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
- Amazon EBSのマルチアタッチ機能とAzure Shared Disksを比較してみる
謝辞
本記事を執筆するにあたり、初版執筆時点から、SNS等を通じて技術的なアドバイスをいただいた全ての方に、この場を借りて、改めて感謝申し上げます。
- 投稿日:2020-02-19T00:06:08+09:00
AWSのMulti-Attach EBS VolumesをWindows Serverで使うと、EBSの容量が実質2倍になる?
2020/2/14のAWSアップデートで、プロビジョンドIOPS (io1) のEBSボリュームに限り、複数EC2から同時アタッチできるようになりました。
つまり共有ストレージに使えるということになります。New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
https://aws.amazon.com/jp/blogs/aws/new-multi-attach-for-provisioned-iops-io1-amazon-ebs-volumes/このアップデートを聞いて、Windows Server 2019 で共有ストレージを組んでみようと思い、検証してみました。
検証の結果ですが、記事タイトルの通り、驚きの結果となりました。
Multi-Attach EBSを作成して2台でアタッチ
プロビジョンドIOPSでEBSを作って、Multi-Attachにチェックを入れます。
2台のEC2 (Windows Server 2019) からアタッチします。
こんなふうに見えます。
早速ローカルディスクとして使ってみる
両サーバからディスクをオンラインにして、ローカルディスクとして使うことを考えます。
記憶域での操作により、両サーバから同時にオンラインにできました。
エクスプローラもご覧のとおりです。
これでファイル共有できる! と思いきや
それぞれのWindows Serverの記憶域からはディスクが見えています。
なんかいい感じなので、1台目でテストファイルを置いてみます。
次に2台目で確認すると・・・
なんと、1台目で置いたテキストファイルが見えません。
これは予想外の展開です。今度は、逆のことをしてみます。
やはり、1台目では見えません。
なんと予想に反して、ファイルの共有ができませんでした。
ただ、お互いがお互いのファイルを独立して保存できているように見えます。ということは、もしかして容量が倍になる?
そこで、仮説として、共有ではなく、1台目と2台目ともに、EBSで割り当てた容量分使えるんじゃないの? と想像しました。
この仮説が正しいと、今回EBSを20GBで作りましたが、1台目と2台目を合わせて、40GB使えるということになりますが・・・
早速、検証してみました。
fsutilコマンドを使い、1台目で容量を埋め尽くしに行きます。
無事作成できました。この時点でEBSの20GB中、19GBは埋まっています。
先ほどの検証結果からも分かりますが、2台目では見えていません。
ここで、2台目からも埋め尽くしに行きます。
なんと作成できました。
この瞬間を切り取ると、20GBのEBSに、38GBのファイルが保存されていることになります。もう一度、マネジメントコンソールでEBSを確認します。
確かに20GBしか割り当てていません。
この状態で、お互いのファイルは読み取りできました。
(追記) 片側でディスクをオフラインにして、もう一度オンラインにするとどうなるか
上記までの状態で記事をSNSで共有したところ「NTFSを両側からオンラインにするとファイルシステムが壊れるんじゃないか」「片側だけオンラインにするべき」とのメッセージをいただきました。
そこで、上記までの状態で2台目だけディスクをオフラインにしてみますと、正常にオフラインにできました。
その後、もう一度オンラインにすると、1台目と2台目でディスクの中身が同じとなりました。
(OSを再起動しても同じ事象が起こりそうです)再起動やディスクのオフラインを挟むと、その時点でディスクは共有状態となるようですが、その後の書き込み結果はやはり共有されないようです。
まとめ
見たままストレートに書いて良いのか少々疑わしいですが、Windows Server 2019でMulti-Attach EBSを使うと、共有とはならず、互いが容量をフルで使える (実質的に容量が2倍になっている) ように見え、読み書きもできました。
ただ、この状態はあくまで最初に2台をヨーイドンで使い始めて、永続的に起動し続けている間しか成り立たず、再起動等を挟むとこの状態は失われてしまうようです。
(つまり、データロストするということになります)現在のところ、Multi-Attach EBS VolumesをWindows Server 2019で共有ストレージとして活用するには、Active-Active (本検証のようにシンプルに2サーバからマウントした状態) ではデータロスト等の不具合が生じる可能性が大きいことが分かりました。
結果として大げさなタイトルになってしまった「2倍になる」は、かなり厳しい条件付きの場合だと分かりました。
大勢が想定している共有ストレージとして使うには、どうやら、今後のアップデートを待つしかないようです。参考記事
- 投稿日:2020-02-19T00:06:08+09:00
AWSのMulti-Attach EBS Volumesは、大勢が想像した「共有ストレージ」としては使えなかった
2/19: 検証の結果、詳しいことが分かり、記事タイトルを改題しました。
※ 旧タイトル「AWSのMulti-Attach EBS VolumesをWindows Serverで使うと、EBSの容量が実質2倍になる?」はじめに
2020/2/14のAWSアップデートで、プロビジョンドIOPS (io1) のEBSボリュームに限り、複数EC2から同時アタッチできるようになりました。
これだけを見ると、いかにも「共有ストレージ」に使えそうだと思えてきます。
New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
https://aws.amazon.com/jp/blogs/aws/new-multi-attach-for-provisioned-iops-io1-amazon-ebs-volumes/このアップデートを聞いて、Windows Server 2019 で共有ストレージを組んでみようと思い、検証してみました。
検証の結果ですが、記事タイトルの通り、共有ストレージとしては使えませんでした。
その顛末を以下に記します。大勢が想像したであろう共有ストレージの図
これと同じか、似たような絵面 (複数EC2で1ディスクを共有) だと思います。
引用: 20180704 AWS Black Belt Online Seminar Amazon Elastic File System (Amazon EFS) 2018/8/9 updateMulti-Attach EBSを作成して2台でアタッチ
プロビジョンドIOPSでEBSを作って、Multi-Attachにチェックを入れます。
2台のEC2 (Windows Server 2019) からアタッチします。
こんなふうに見えます。
早速Windowsから使おうとしてみる
両サーバからディスクをオンラインにして、ローカルディスクとして使うことを考えます。
記憶域での操作により、両サーバから同時にオンラインにできました。
エクスプローラもご覧のとおりです。
これでファイル共有できる! と思いきや
それぞれのWindows Serverの記憶域からはディスクが見えています。
なんかいい感じなので、1台目でテストファイルを置いてみます。
次に2台目で確認すると・・・
なんと、1台目で置いたテキストファイルが見えません。
これは予想外の展開です。今度は、逆のことをしてみます。
やはり、1台目では見えません。
なんと予想に反して、ファイルの共有ができませんでした。
ただ、お互いがお互いのファイルを独立して保存できているように見えます。ということは、もしかして容量が倍になる?
そこで、仮説として、共有ではなく、1台目と2台目ともに、EBSで割り当てた容量分使えるんじゃないの? と想像しました。
この仮説が正しいと、今回EBSを20GBで作りましたが、1台目と2台目を合わせて、40GB使えるということになりますが・・・
早速、検証してみました。
fsutilコマンドを使い、1台目で容量を埋め尽くしに行きます。
無事作成できました。この時点でEBSの20GB中、19GBは埋まっています。
先ほどの検証結果からも分かりますが、2台目では見えていません。
ここで、2台目からも埋め尽くしに行きます。
なんと作成できました。
この瞬間を切り取ると、20GBのEBSに、38GBのファイルが保存されていることになります。もう一度、マネジメントコンソールでEBSを確認します。
確かに20GBしか割り当てていません。
この状態で、お互いのファイルは読み取りできました。
(追記) 片側でディスクをオフラインにして、もう一度オンラインにするとどうなるか
上記までの状態で記事をSNSで共有したところ「NTFSを両側からオンラインにするとファイルシステムが壊れるんじゃないか」「片側だけオンラインにするべき」とのメッセージをいただきました。
そこで、上記までの状態で2台目だけディスクをオフラインにしてみますと、正常にオフラインにできました。
その後、もう一度オンラインにすると、1台目と2台目でディスクの中身が同じとなりました。
(OSを再起動しても同じ事象が起こりそうです)再起動やディスクのオフラインを挟むと、その時点でディスクは共有状態となるようですが、その後の書き込み結果はやはり共有されないようです。
(追記) なぜデータが2倍保存できるように見えたり、突然更新されたりするのか
調査の結果、OSの仕組み上の問題が見えてきました。
今回検証したWindows OSでは、ブロックIOのキャッシュを保持しています。
つまり、実際にストレージに対しての書き込みは、OS上の操作とは非同期に行われ、厳密に同時ではありません。
このため、今回のように同じディスクをシンプルに共有した場合、片方で既に更新操作を終えている状況にもかかわらず、もう一方のインスタンスからファイルが存在しないように見えたり、全く利用されていないように見えたり、両方のインスタンスで保存したデータのサイズが実際の物理的な容量と乖離する状況になることがあるようです。
前述の通り、更新が厳密には非同期であり、どちらかのWindows OSが非同期的にEBSに書き込み操作を実行した結果、どちらかのインスタンスでファイルが存在しなくなる状況が起こりかねないと言えます。現状、このMulti-Attach EBS Volumesをマウントした時のように、見た目上各サーバのローカルディスクでありながら、物理的にディスクは共有されている構成には、Windows OSは対応していない (おそらくユースケースとして想定もされていない)と思われます。
対応策として、クラスタソフトウェアなどを導入して、ディスクへの読み書きをちゃんと制御できれば良いのですが、Multi-Attach EBS Volumesに対応しているソフトウェアはなさそうです。まとめ
Windows Server 2019でMulti-Attach EBS Volumesを使うと、共有とはならず、最初、互いが容量をフルで使える (実質的に容量が2倍になっている) ように見え、読み書きもできました。
ただ、この状態はあくまで最初に2台をヨーイドンで使い始めて、永続的に起動し続けている間しか成り立たず、再起動等を挟むとこの状態は失われてしまうようです。
(データロストすることになります)つまり、現在のところ、Multi-Attach EBS Volumesを、公式ドキュメント通りにアタッチして使用しても、Windows Server 2019では共有ストレージとして活用できません。
Active-Active (本検証のようにシンプルに2サーバからマウントした状態) ではデータロスト等の不具合が生じる可能性が大きいことが分かりました。大勢が想定している共有ストレージとして使うには、どうやら、今後のアップデートを待つしかないようです。
参考記事
- New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
- Amazon EBSのマルチアタッチ機能とAzure Shared Disksを比較してみる
謝辞
本記事を執筆するにあたり、SNS等を通じて技術的なアドバイスをいただいた全ての方に、この場を借りて、改めて感謝申し上げます。
- 投稿日:2020-02-19T00:02:30+09:00
S3の静的ホスティングサービスを利用する
S3にはサーバーサイドの処理をする機能がないため、リクエストされたものをただレスポンスするだけの静的ファイルを外部公開にしたいときなどに今回の機能を利用する。
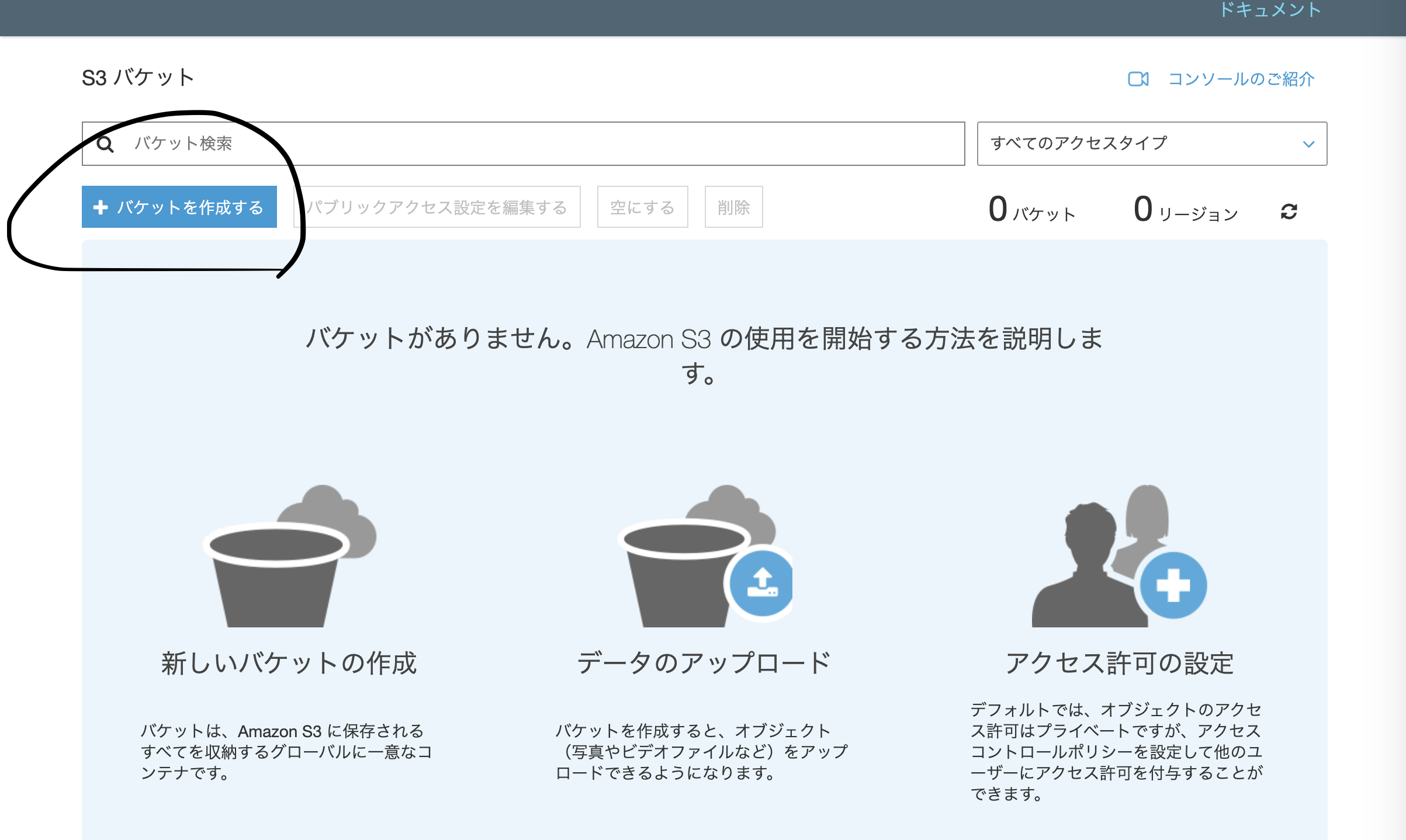
S3の画面へ行き、バケットを作成を押下。
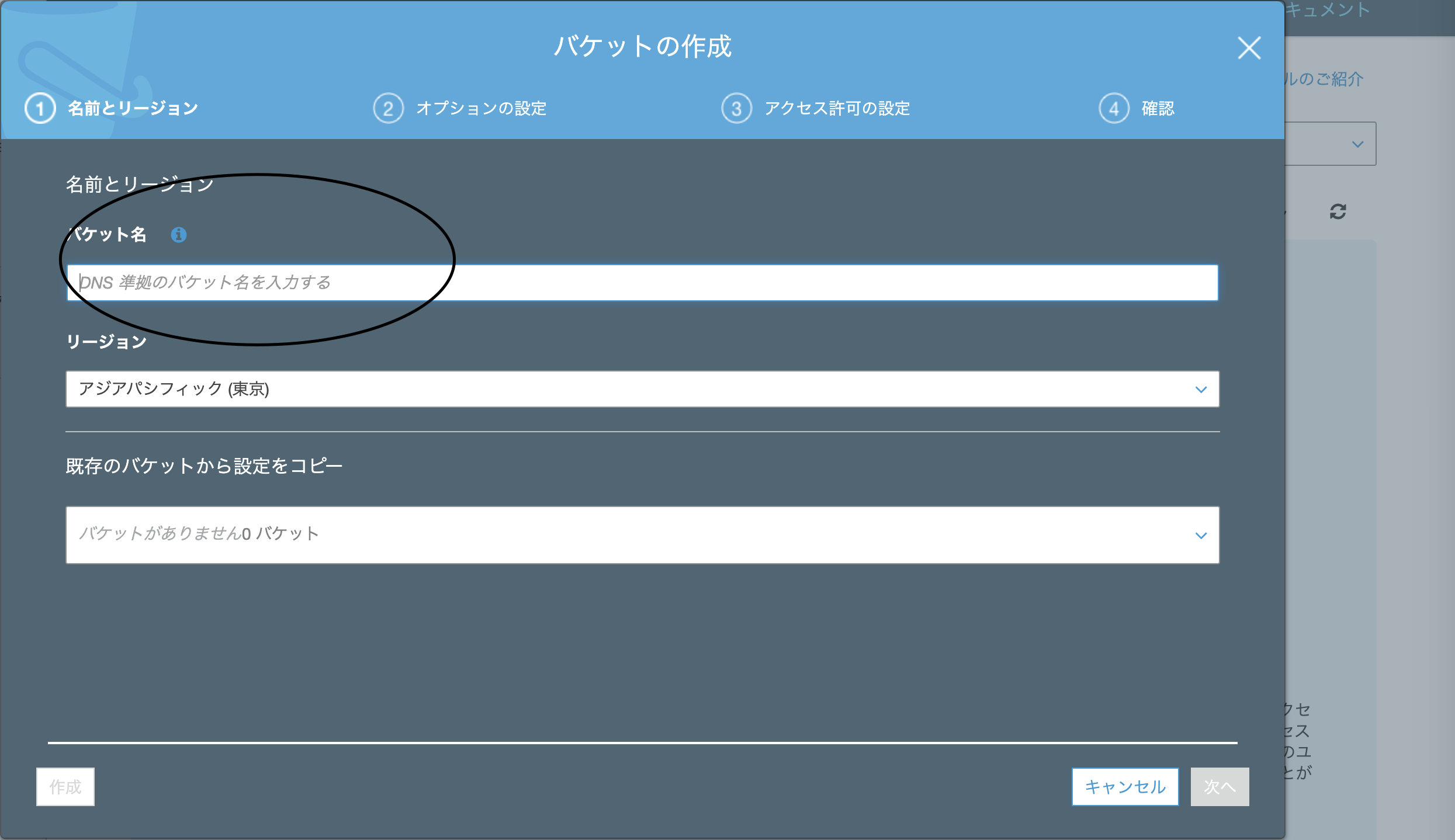
バケット名を入力
次の画面はデフォルトのまま次へ
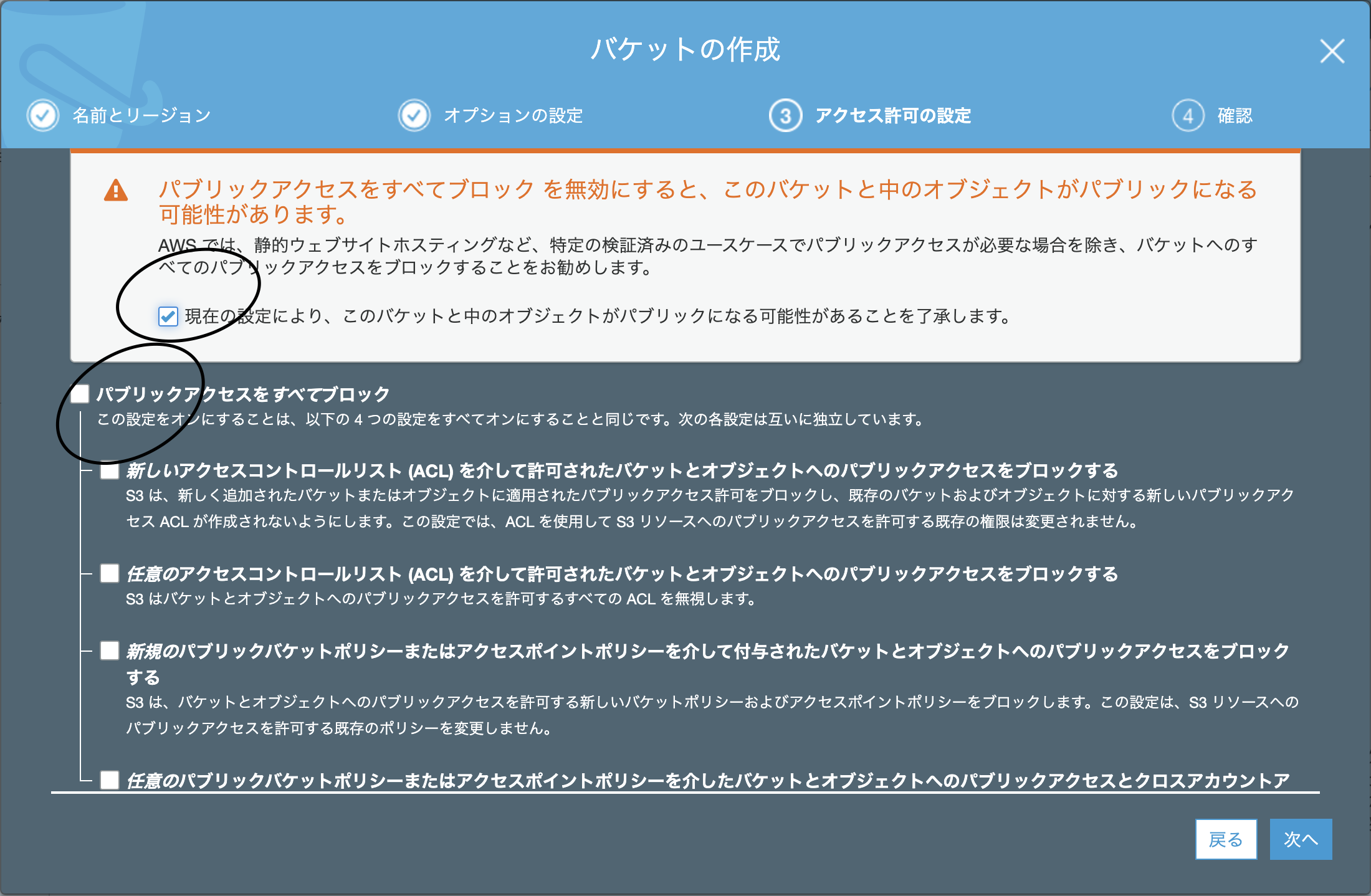
パブリックアクセスをすべてブロック
アラートの「現在の設定により、〜」をチェック
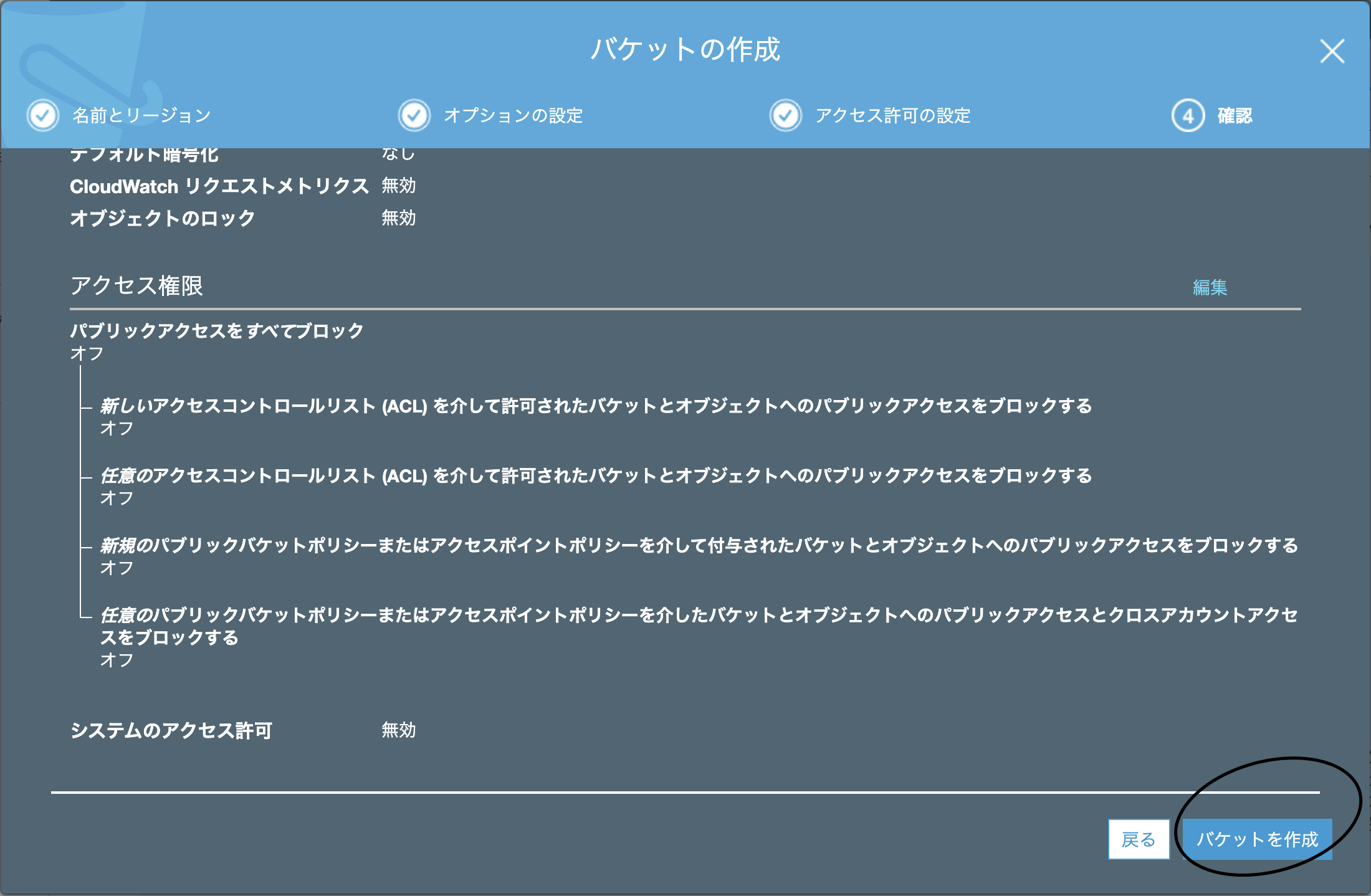
次の画面はデフォルトのままバケットを作成
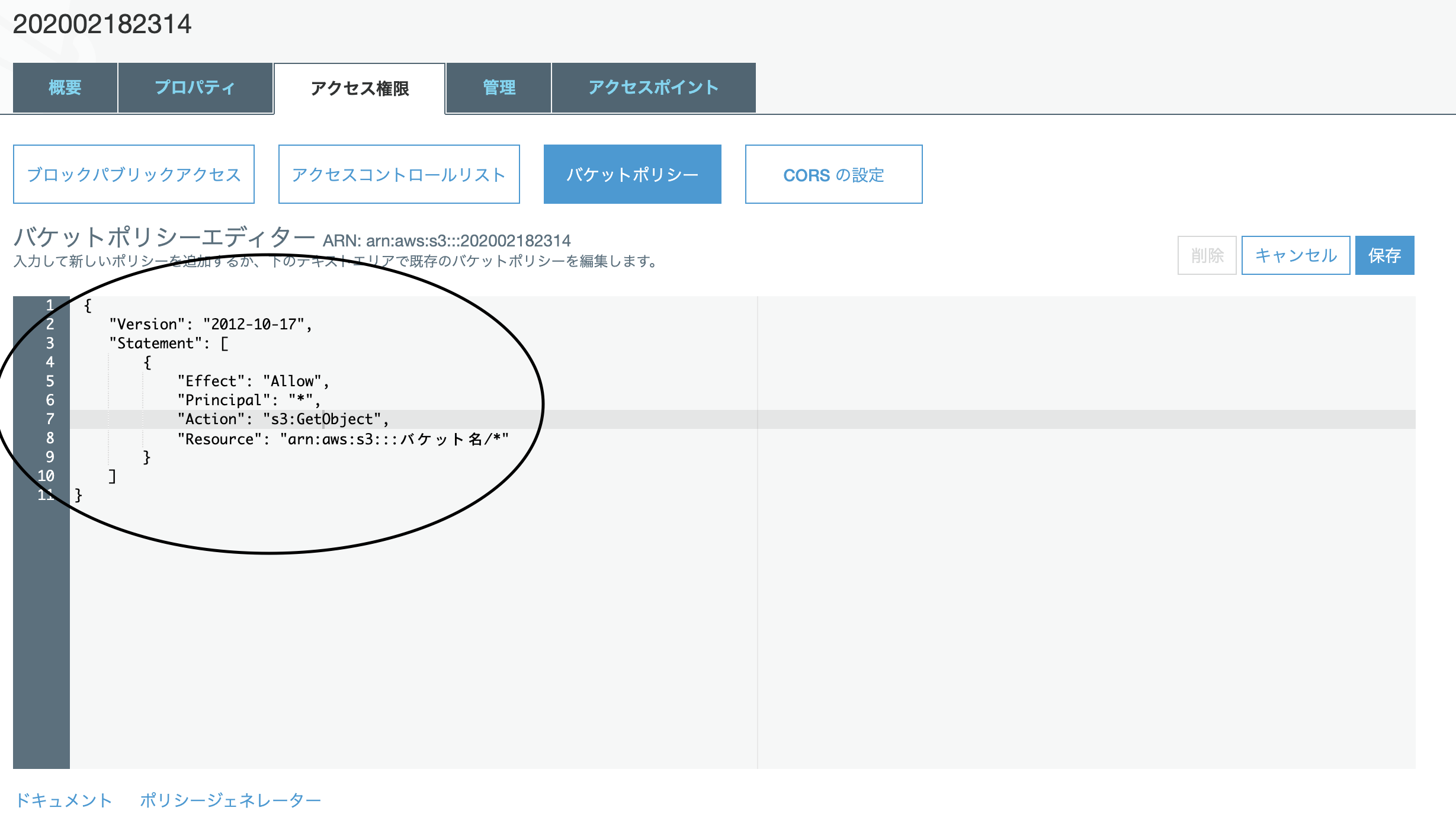
作成したバケットのアクセス権限タブのバケットポリシーに、「バケットの下のファイルは全て読み取り専用であること」を示すJSONを記述
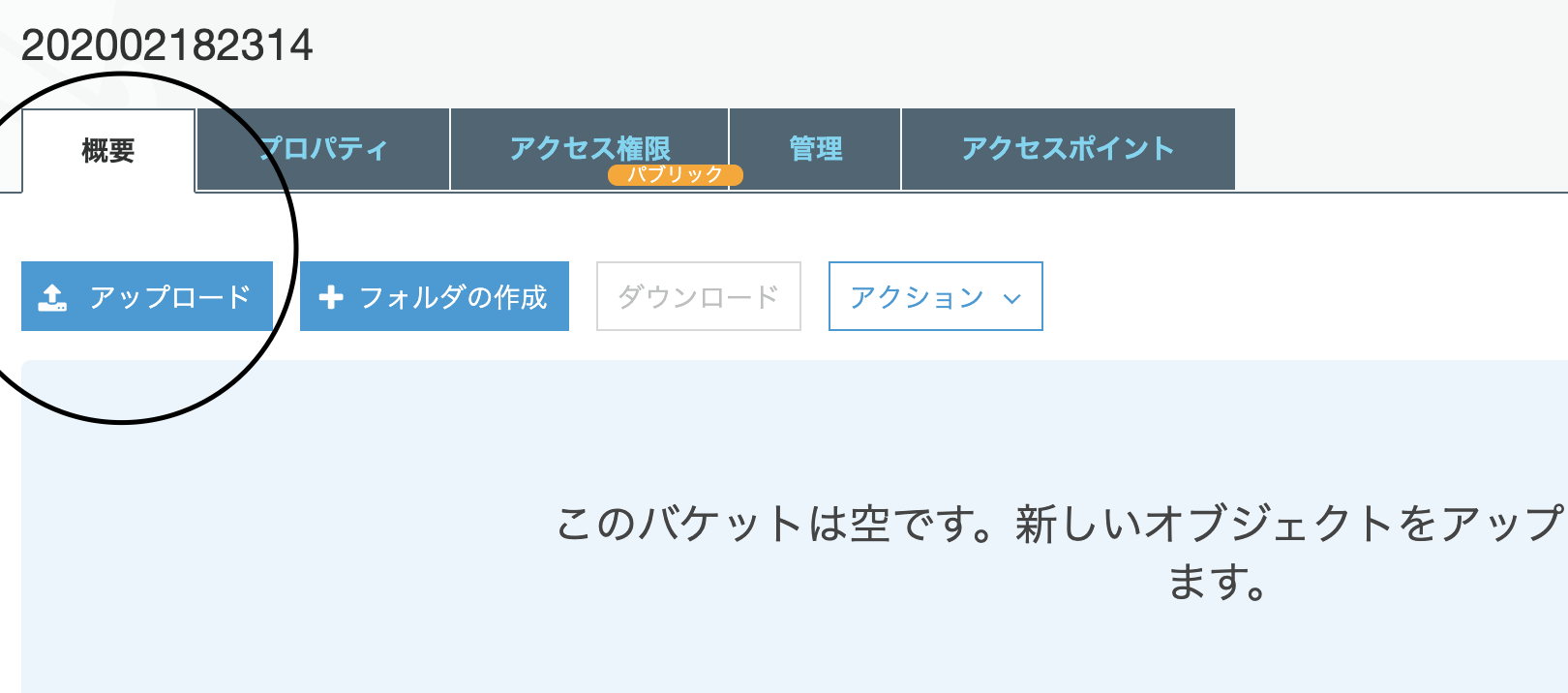
概要タブからホスティング対象のファイルをアップロード
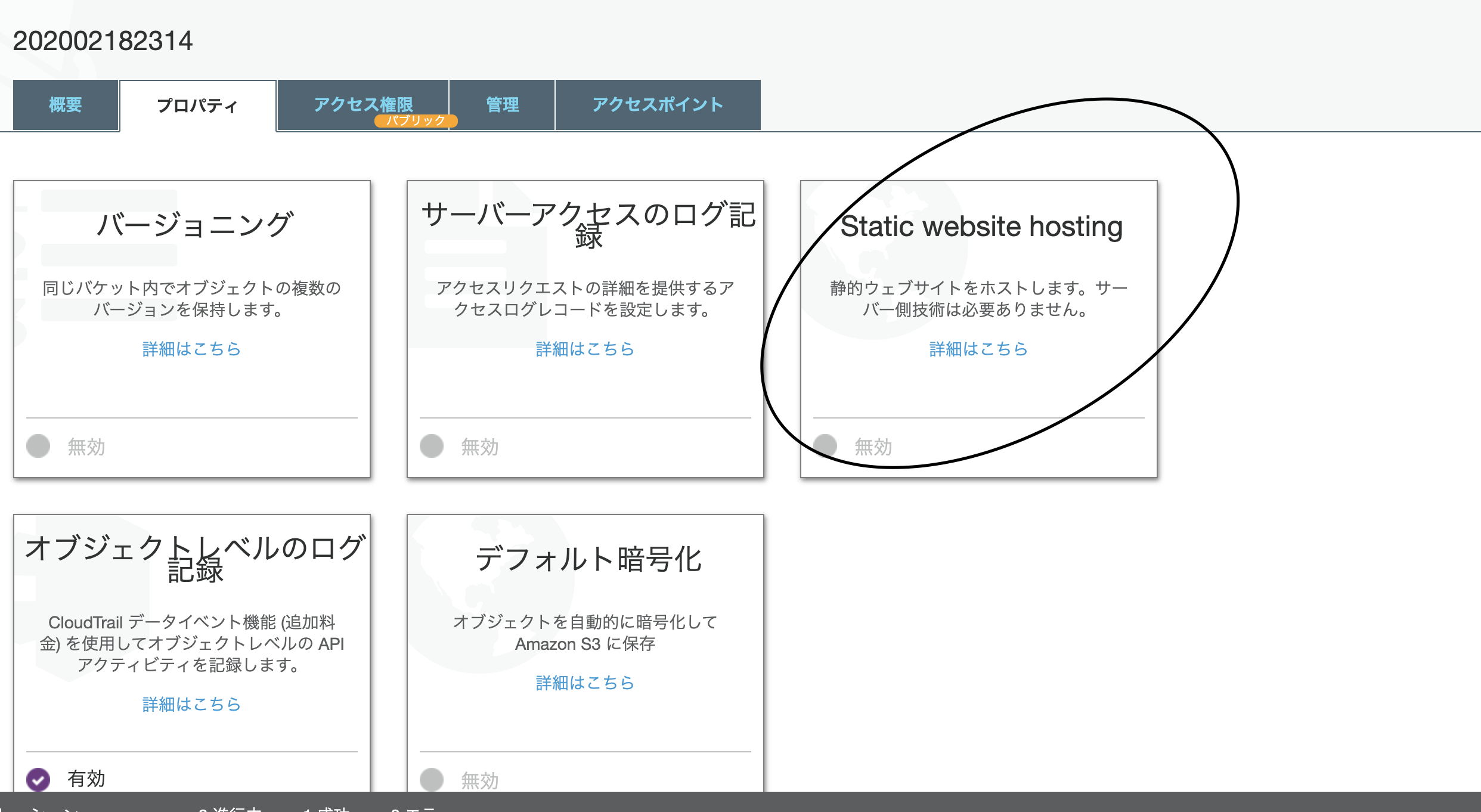
プロパティタブからStatic website hostingを押下
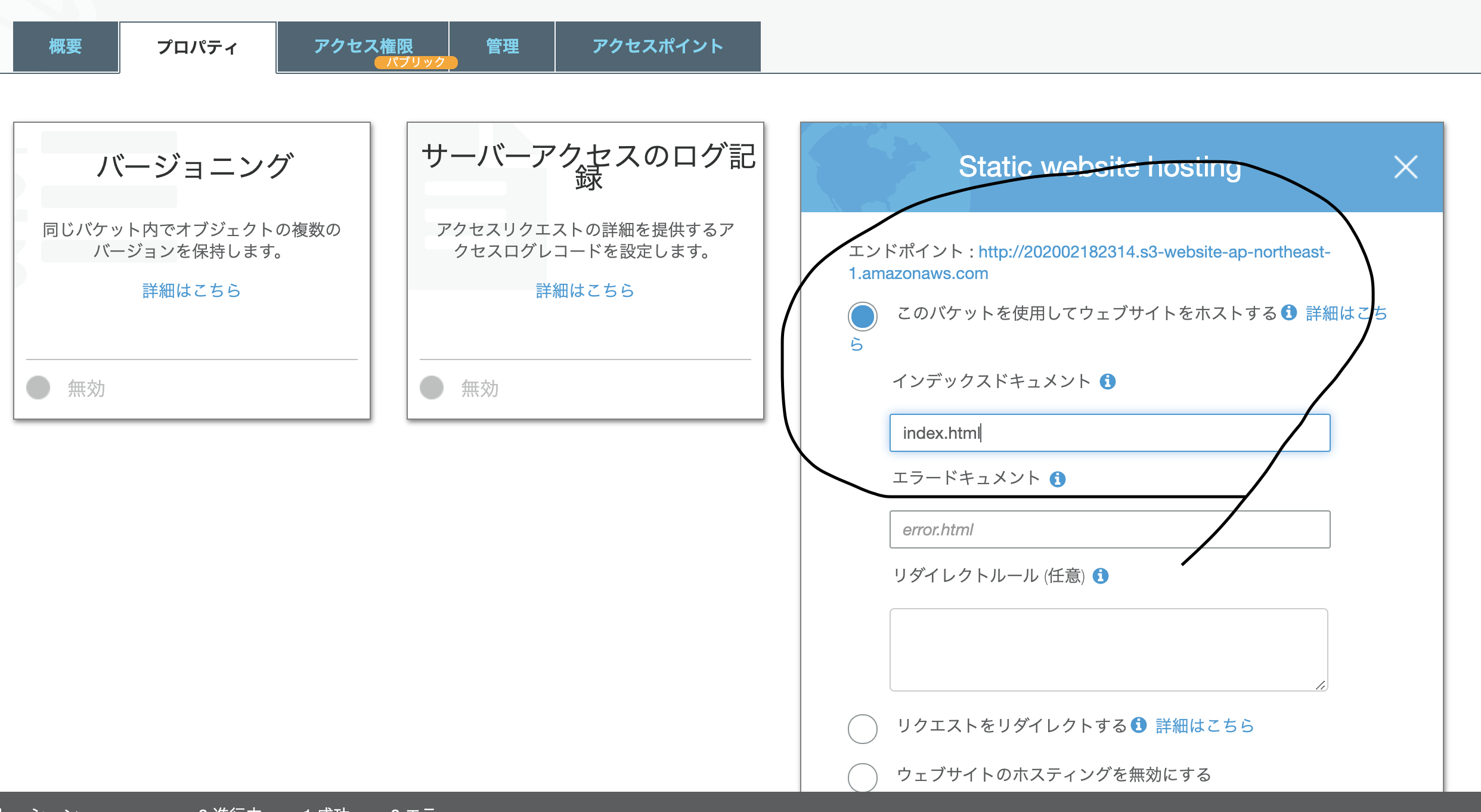
「このバケットを使用してウェブサイトをホストする」にチェック
インデックスドキュメントにファイル名を記述
エンドポイントのURLを叩くとサイトを閲覧できる。