- 投稿日:2020-02-18T23:58:50+09:00
COTOHAを使って「タイポグリセミア」文章を作成する
この きじ の がよいう を せめつい するよ
いきなりですが、以下の文章をざっと読んでみてください。
こんちには みさなん おんげき ですか? わしたは げんき です。
この ぶんょしう は いりぎす の ケブンッリジ だがいく の けゅきんう の けっか
にげんんは たごんを にしんき する ときにその さしいょ と さいご の もさじえ あいてっれば
じばんゅん は めくちちゃゃ でも ちんゃと よめる という けゅきんう に もづいとて
わざと もじの じんばゅん を いかれえて あまりす。
どでうす? ちんゃと よゃちめう でしょ?どうですか?意外とすんなり読めるのではないでしょうか。
この文章は(個人的には)割と有名なコピペで、正式名称をタイポグリセミアというらしいです。カラクリをざっくりと説明すると、人間は単語を認識する際に1文字ごとに理解するのではなく文字の集合として視覚的に認識しています。その際に、脳内で単語を瞬時に理解・予測しているため、単語を構成する文字が多少入れ替わっても補正されて読むことができるそうなのです。
※これらの補正は個人の知識やボキャブラリーに依存するため、個人差があります。今回はCOTOHA APIで提供されている構文解析APIを使って、入力された文章を解析してタイポグリセミア文章として出力します。
こんな かじんで しつゅりょく さるれよ
before : PythonとCOTOHAを使用して出力されたタイポグリセミア文章をQiitaに投稿 after : pothyn と choota を しよう し て しょつりゅく さ れ た たぽせいみりぐあ ぶしょんう を qiita に とこううなんともそれっぽい結果に!!
CHOOTA って いたっい どんな API なだんい?
COTOHAとはNTTコミュニケーションズが提供する自然言語処理・音声処理APIプラットフォームです。
今回の記事で紹介する構文解析以外にも固有表現抽出・照応解析・キーワード抽出・類似度算出・文タイプ判定・ユーザ属性推定・感情分析・要約などなど様々な機能が用意されています。ユーザ登録も簡単で、無料枠内でも各APIを1000コール/日使用できるため、軽く遊びで動かしてみることも可能です。
今ならQiitaとコラボしてこんな企画をやっているので是非是非参加してみてください!!ユーザの無料登録はCOTOHA API Portalからできます。
いくつかの基本項目を入力すると、APIを利用するためのユーザIDとシークレットが発行されるので、もし以降のスクリプトをお手元で試したい場合は控えておいてください。Pothyn を つっかて じそっう するよ
以下の記事を参考にさせていただきました。
どちらの記事も非常に分かりやすくまとまっているので非常にオススメです!ベースは上の記事を参考にしていますが、APIのエンドポイント部分をちょっとだけいじってあります。
元はBASE_URLにnlpまで含めてありましたが、COTOHA公式のフォーマットに合わせて省いています。
メインプログラム
cotoha_api.pyimport os import urllib.request import json import configparser import codecs import re import jaconv import random # COTOHA API操作用クラス class CotohaApi: # 初期化 def __init__(self, client_id, client_secret, developer_api_base_url, access_token_publish_url): self.client_id = client_id self.client_secret = client_secret self.developer_api_base_url = developer_api_base_url self.access_token_publish_url = access_token_publish_url self.getAccessToken() # アクセストークン取得 def getAccessToken(self): # アクセストークン取得URL指定 url = self.access_token_publish_url # ヘッダ指定 headers={ "Content-Type": "application/json;charset=UTF-8" } # リクエストボディ指定 data = { "grantType": "client_credentials", "clientId": self.client_id, "clientSecret": self.client_secret } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 res = urllib.request.urlopen(req) # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディからアクセストークンを取得 self.access_token = res_body["access_token"] # 構文解析API def parse(self, sentence): # 構文解析API URL指定 url = self.developer_api_base_url + "nlp/v1/parse" # ヘッダ指定 headers={ "Authorization": "Bearer " + self.access_token, "Content-Type": "application/json;charset=UTF-8", } # リクエストボディ指定 data = { "sentence": sentence } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 try: res = urllib.request.urlopen(req) # リクエストでエラーが発生した場合の処理 except urllib.request.HTTPError as e: # ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト if e.code == 401: print ("get access token") self.access_token = getAccessToken(self.client_id, self.client_secret) headers["Authorization"] = "Bearer " + self.access_token req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) # 401以外のエラーなら原因を表示 else: print ("<Error> " + e.reason) # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディから解析結果を取得 return res_body # 固有表現抽出API def ne(self, sentence): # 固有表現抽出API URL指定 url = self.developer_api_base_url + "nlp/v1/ne" # ヘッダ指定 headers={ "Authorization": "Bearer " + self.access_token, "Content-Type": "application/json;charset=UTF-8", } # リクエストボディ指定 data = { "sentence": sentence } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 try: res = urllib.request.urlopen(req) # リクエストでエラーが発生した場合の処理 except urllib.request.HTTPError as e: # ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト if e.code == 401: print ("get access token") self.access_token = getAccessToken(self.client_id, self.client_secret) headers["Authorization"] = "Bearer " + self.access_token req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) # 401以外のエラーなら原因を表示 else: print ("<Error> " + e.reason) # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディから解析結果を取得 return res_body # 照応解析API def coreference(self, document): # 照応解析API 取得URL指定 url = self.developer_api_base_url + "beta/coreference" # ヘッダ指定 headers={ "Authorization": "Bearer " + self.access_token, "Content-Type": "application/json;charset=UTF-8", } # リクエストボディ指定 data = { "document": document } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 try: res = urllib.request.urlopen(req) # リクエストでエラーが発生した場合の処理 except urllib.request.HTTPError as e: # ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト if e.code == 401: print ("get access token") self.access_token = getAccessToken(self.client_id, self.client_secret) headers["Authorization"] = "Bearer " + self.access_token req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) # 401以外のエラーなら原因を表示 else: print ("<Error> " + e.reason) # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディから解析結果を取得 return res_body # キーワード抽出API def keyword(self, document): # キーワード抽出API URL指定 url = self.developer_api_base_url + "nlp/v1/keyword" # ヘッダ指定 headers={ "Authorization": "Bearer " + self.access_token, "Content-Type": "application/json;charset=UTF-8", } # リクエストボディ指定 data = { "document": document } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 try: res = urllib.request.urlopen(req) # リクエストでエラーが発生した場合の処理 except urllib.request.HTTPError as e: # ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト if e.code == 401: print ("get access token") self.access_token = getAccessToken(self.client_id, self.client_secret) headers["Authorization"] = "Bearer " + self.access_token req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) # 401以外のエラーなら原因を表示 else: print ("<Error> " + e.reason) # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディから解析結果を取得 return res_body # 類似度算出API def similarity(self, s1, s2): # 類似度算出API URL指定 url = self.developer_api_base_url + "nlp/v1/similarity" # ヘッダ指定 headers={ "Authorization": "Bearer " + self.access_token, "Content-Type": "application/json;charset=UTF-8", } # リクエストボディ指定 data = { "s1": s1, "s2": s2 } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 try: res = urllib.request.urlopen(req) # リクエストでエラーが発生した場合の処理 except urllib.request.HTTPError as e: # ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト if e.code == 401: print ("get access token") self.access_token = getAccessToken(self.client_id, self.client_secret) headers["Authorization"] = "Bearer " + self.access_token req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) # 401以外のエラーなら原因を表示 else: print ("<Error> " + e.reason) # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディから解析結果を取得 return res_body # 文タイプ判定API def sentenceType(self, sentence): # 文タイプ判定API URL指定 url = self.developer_api_base_url + "nlp/v1/sentence_type" # ヘッダ指定 headers={ "Authorization": "Bearer " + self.access_token, "Content-Type": "application/json;charset=UTF-8", } # リクエストボディ指定 data = { "sentence": sentence } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 try: res = urllib.request.urlopen(req) # リクエストでエラーが発生した場合の処理 except urllib.request.HTTPError as e: # ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト if e.code == 401: print ("get access token") self.access_token = getAccessToken(self.client_id, self.client_secret) headers["Authorization"] = "Bearer " + self.access_token req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) # 401以外のエラーなら原因を表示 else: print ("<Error> " + e.reason) # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディから解析結果を取得 return res_body # ユーザ属性推定API def userAttribute(self, document): # ユーザ属性推定API URL指定 url = self.developer_api_base_url + "beta/user_attribute" # ヘッダ指定 headers={ "Authorization": "Bearer " + self.access_token, "Content-Type": "application/json;charset=UTF-8", } # リクエストボディ指定 data = { "document": document } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 try: res = urllib.request.urlopen(req) # リクエストでエラーが発生した場合の処理 except urllib.request.HTTPError as e: # ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト if e.code == 401: print ("get access token") self.access_token = getAccessToken(self.client_id, self.client_secret) headers["Authorization"] = "Bearer " + self.access_token req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) # 401以外のエラーなら原因を表示 else: print ("<Error> " + e.reason) # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディから解析結果を取得 return res_body if __name__ == '__main__': # ソースファイルの場所取得 APP_ROOT = os.path.dirname(os.path.abspath( __file__)) + "/" # 設定値取得 config = configparser.ConfigParser() config.read(APP_ROOT + "config.ini") CLIENT_ID = config.get("COTOHA API", "Developer Client id") CLIENT_SECRET = config.get("COTOHA API", "Developer Client secret") DEVELOPER_API_BASE_URL = config.get("COTOHA API", "Developer API Base URL") ACCESS_TOKEN_PUBLISH_URL = config.get("COTOHA API", "Access Token Publish URL") # COTOHA APIインスタンス生成 cotoha_api = CotohaApi(CLIENT_ID, CLIENT_SECRET, DEVELOPER_API_BASE_URL, ACCESS_TOKEN_PUBLISH_URL) # 解析対象文 sentence = "PythonとCOTOHAを使用して出力されたタイポグリセミア文章をQiitaに投稿" # 整形前を表示 print('before :') print(sentence) # 構文解析API実行 result_json = cotoha_api.parse(sentence) # 整形前の文字列リスト word_list_base = [] # 整形後の文字列リスト word_list = [] # 英数字判定用の正規表現 alnumReg = re.compile(r'^[a-zA-Z0-9 ]+$') # 解析結果をループして処理 for i in range(len(result_json['result'])): for j in range(len(result_json['result'][i]['tokens'])): # 英数字の場合は'form'の値を、日本語の場合は'kana'の値を利用する word = result_json['result'][i]['tokens'][j]['form'] kana = result_json['result'][i]['tokens'][j]['kana'] # 半角英数字か判定 if alnumReg.match(word) is not None: # 1単語かそうでないかを判定 if ' ' in word: # 複数後で構成される場合はさらに分解する word_list_base.extend(word.split(' ')) else : word_list_base.append(word) # 日本語 else : # カタカナをひらがなに変換してリストに追加 word_list_base.append(jaconv.kata2hira(kana)) # 各単語を解析し4文字以上の文字の先頭と末尾以外を入れ替える for i in range(len(word_list_base)): # 4文字以上 if len(word_list_base[i]) > 3: # まず1文字ずつのリストに分解 wl_all = list(word_list_base[i]) # 先頭文字と末尾文字を保持しておく first_word = wl_all[0] last_word = wl_all[len(wl_all) - 1] # 中の文字をリスト形式で取得 wl = wl_all[1:len(wl_all) - 1] # シャッフルする random.shuffle(wl) word_list.append(first_word + ''.join(wl) + last_word) # 4文字未満ならそのまま else : word_list.append(word_list_base[i]) # 整形結果を表示 print('after :') print(' '.join(word_list))
設定ファイル
config.ini[COTOHA API] Developer API Base URL: https://api.ce-cotoha.com/api/dev/ Developer Client id: 【クライアントID】 Developer Client secret:【シークレット】 Access Token Publish URL: https://api.ce-cotoha.com/v1/oauth/accesstokens使い方は
config.iniにクライアントIDとシークレットを入力し、cotoha_api.pyと同じ階層に置きます。
実行は下記の通りです。python cotoha_api.py実行結果before : PythonとCOTOHAを使用して出力されたタイポグリセミア文章をQiitaに投稿 after : pothyn と choota を しよう し て しょつりゅく さ れ た たぽせいみりぐあ ぶしょんう を qiita に とこううまとめ
Pythonや自然言語処理に関する知識など全く持ち合わせていないにも関わらず、流行りに乗って実装(ほぼ人様のスクリプト)まで行ってしまいました。
しかしながら、そんな状態でも個人的には満足な結果が得られたのでCOTOHAは非常に扱いやすく、入門としても最適なのではないでしょうか。この記事を読んで少しでも
COTOHAに興味を持っていただけたら幸いです。さこんぶぶうけん
- COTOHA APIリファレンス
- 自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた
- 「メントスと囲碁の思い出」をCOTOHAさんに要約してもらった結果。COTOHA最速チュートリアル付き
あがとき
余談ですが「タイポグリセミア」は、誤植を意味する"typographical error"と低血糖を意味する"Hypoglycemi"のかばん語のようです。
かばん語とは、「熱さましーと」とか「ネスプレッソ」のように複数単語を用いて作られた単語です。あれ?これはこれで
COTOHAで扱ったら面白そうな予感が・・・やるとすれば、「COTOHAを使ってナウいかばん語を生み出してみた」とかですかね(笑)
- 投稿日:2020-02-18T23:55:52+09:00
サイトの更新日を真面目に取得する
サイトの更新日を取得するのってむずくね
レスポンスヘッダーを調べることで、静的なサイトであれば最終更新日がわかることがあります。
get_lastmodified.pyimport requests res = requests.head('https://www.kantei.go.jp') print(res.headers['Last-Modified'])Mon, 17 Feb 2020 08:27:02 GMT(前回記事)【Python】ウェブサイトの最終更新日を取得
一部ニュースサイトや日本の政府関係の多くのサイトではこれで問題なく取れるのですが、大半のサイトはうまくいきません。
KeyError: 'last-modified'じゃどうしたらいいかというと、大きく2つの方法がありそうです。
方針1 URLを見る
URLの中には 2019/05/01 や 2019-05-01 のような文字列が入っていることがあります。これを抜き出すのは有力で確実な手段です。
方針2 スクレイピング
最終的に頼るのはここなんでしょう。
ということで、これらの合わせ技で、普段読んでいるニュースサイトから自動でサイト更新日を抜き出していきます。
なお、サイトによってはBOTでのクロールを禁じていますので、あくまでHTMLファイルが手元にある状態で使ってください。スクレイパーはBeautifulSoup4を用い、取得した更新日はdatetime型に変換します。文字列の抽出や整形は正規表現を使います。
get_lastmodified.pyimport bs4 import datetime import re調べたニュースサイト
CNN
Bloomberg
BBC
Reuter
Wall Street Journal
Forbes Japan
Newsweek
朝日新聞
日経新聞
産経新聞
読売新聞
毎日新聞CNN
https://edition.cnn.com/2020/02/17/tech/jetman-dubai-trnd/index.html
get_lastmodified.pyprint(html.select('.update-time')[0].getText()) #Updated 2128 GMT (0528 HKT) February 17, 2020 timestamp_temp_hm = re.search(r'Updated (\d{4}) GMT', str(html.select('.update-time')[0].getText())) timestamp_temp_bdy = re.search(r'(January|February|March|April|May|June|July|August|September|October|November|December) (\d{1,2}), (\d{4})', str(html.select('.update-time')[0].getText())) print(timestamp_temp_hm.groups()) print(timestamp_temp_bdy.groups()) #('2128',) #('February', '17', '2020') timestamp_tmp = timestamp_temp_bdy.groups()[2]+timestamp_temp_bdy.groups()[1]+timestamp_temp_bdy.groups()[0]+timestamp_temp_hm.groups()[0] news_timestamp = datetime.datetime.strptime(timestamp_tmp, "%Y%d%B%H%M") print(news_timestamp) #2020-02-17 21:28:00 # 日付だけならURLからも取れる URL = "https://edition.cnn.com/2020/02/17/tech/jetman-dubai-trnd/index.html" news_timestamp = re.search(r'\d{4}/\d{1,2}/\d{1,2}', URL) print(news_timestamp.group()) #2020/02/17 news_timestamp = datetime.datetime.strptime(news_timestamp.group(), "%Y/%m/%d") print(news_timestamp) #2020-02-17 00:00:00コメント:'Updated'の文字列が常に入っているのかは未検証。CNNの記事はまとめページを除くと日付がURLに入っているので、これを取るのが確実に見える
Bloomberg
https://www.bloomberg.co.jp/news/articles/2020-02-17/Q5V6BO6JIJV101
get_lastmodified.pyprint(html.select('time')[0].string) # # # # 2020年2月18日 7:05 JST # # timesamp_tmp = re.sub(' ','',str(html.select('time')[0].string)) timesamp_tmp = re.sub('\n','',timesamp_tmp) news_timestamp = datetime.datetime.strptime(timesamp_tmp, "%Y年%m月%d日%H:%MJST") print(news_timestamp) #2020-02-18 07:05:00 # URLでも日付までは取れる URL = "https://www.bloomberg.co.jp/news/articles/2020-02-17/Q5V6BO6JIJV101" timestamp_tmp = re.search(r'\d{4}-\d{1,2}-\d{1,2}', URL) print(news_timestamp_tmp.group()) #2020-02-17 news_timestamp = datetime.datetime.strptime(timestamp_tmp, "%Y-%m-%d") print(news_timestamp) #2020-02-17 00:00:00コメント:タグ内で改行と空白があり一手間必要。
BBC
https://www.bbc.com/news/world-asia-china-51540981
get_lastmodified.pyprint(html.select("div.date.date--v2")[0].string) #18 February 2020 news_timestamp = datetime.datetime.strptime(html.select("div.date.date--v2")[0].string, "%d %B %Y") print(news_timestamp) #2020-02-18 00:00:00コメント:細かい時間はどこ見ればいいのかわかりませんでした。
Reuter
https://jp.reuters.com/article/apple-idJPKBN20C0GP
get_lastmodified.pyprint(html.select(".ArticleHeader_date")[0].string) #February 18, 2020 / 6:11 AM / an hour ago更新 m1 = re.match(r'(January|February|March|April|May|June|July|August|September|October|November|December) \d{1,2}, \d{4}',str(html.select(".ArticleHeader_date")[0].string)) print(m1.group()) #February 18, 2020 m2 = re.search(r'\d{1,2}:\d{1,2}',str(html.select(".ArticleHeader_date")[0].string)) print(m2.group()) #6:11 news_timestamp = datetime.datetime.strptime(m1.group()+' '+m2.group(), "%B %d, %Y %H:%M") print(news_timestamp) #2020-02-18 00:00:00Wall Street Journal
https://www.wsj.com/articles/solar-power-is-beginning-to-eclipse-fossil-fuels-11581964338
get_lastmodified.pyprint(html.select(".timestamp.article__timestamp")[0].string) # # Feb. 17, 2020 1:32 pm ET # news_timestamp = re.sub(' ','',str(html.select(".timestamp.article__timestamp")[0].string)) news_timestamp = re.sub('\n','',m) print(news_timestamp) #Feb.17,20201:32pmET news_timestamp = re.match(r'(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec).(\d{1,2}),(\d{4})(\d{1,2}):(\d{1,2})',str(news_timestamp)) print(news_timestamp.groups()) #('Feb', '17', '2020', '1', '32') tmp = news_timestamp.groups() timesamp_tmp = tmp[0]+' '+ tmp[1].zfill(2)+' '+tmp[2]+' '+tmp[3].zfill(2)+' '+tmp[4].zfill(2) print(timesamp_tmp) #Feb 17 2020 01 32 news_timestamp = datetime.datetime.strptime(timesamp_tmp, "%b %d %Y %H %M") print(news_timestamp) #2020-02-17 01:32:00Forbes Japan
https://forbesjapan.com/articles/detail/32418
get_lastmodified.pyprint(html.select("time")[0].string) #2020/02/18 12:00 news_timestamp = datetime.datetime.strptime(html.select("time")[0].string, "%Y/%m/%d %H:%M") print(news_timestamp) #2020-02-18 12:00:00Newsweek
get_lastmodified.pyprint(html.select('time')[0].string) # On 2/17/20 at 12:11 PM EST m = re.search(r'(\d{1,2})/(\d{1,2})/(\d{1,2}) at (\d{1,2}:\d{1,2}) ', str(html.select('time')[0].string)) print(m.groups()) #('2', '17', '20', '12:11') tmp = m.groups() timesamp_tmp = tmp[0].zfill(2)+' '+ tmp[1].zfill(2)+' '+'20'+tmp[2].zfill(2)+' '+tmp[3] print(timesamp_tmp) news_timestamp = datetime.datetime.strptime(timesamp_tmp, "%m %d %Y %H:%M") print(news_timestamp) #2020-02-17 12:11:00朝日新聞
https://www.asahi.com/articles/ASN2K7FQKN2KUHNB00R.html?iref=comtop_8_07
get_lastmodified.pyprint(html.select('time')[0].string) #2020年2月18日 12時25分 news_timestamp = datetime.datetime.strptime(html.select('time')[0].string, "%Y年%m月%d日 %H時%M分") print(news_timestamp) #2020-02-18 12:25:00コメント:静的でわかりやすい。ざっと見たところカテゴリー別でも揺らぎが無くて助かる。
日経新聞
https://r.nikkei.com/article/DGXMZO5556760013022020TL1000
get_lastmodified.pyprint(html.select('time')[1]) #2020年2月18日 11:00 news_timestamp = datetime.datetime.strptime(html.select('time')[1].string, "%Y年%m月%d日 %H:%M") print(news_timestamp) #2020-02-18 11:00:00https://www.nikkei.com/article/DGXLASFL18H2S_Y0A210C2000000
get_lastmodified.pyprint(html.select('.cmnc-publish')[0].string) #2020/2/18 7:37 news_timestamp = datetime.datetime.strptime(html.select('.cmnc-publish')[0].string, "%Y/%m/%d %H:%M") print(news_timestamp) #2020-02-18 07:37:00https://www.nikkei.com/article/DGXKZO55678940V10C20A2MM8000
get_lastmodified.pyprint(html.select('.cmnc-publish')[0].string) #2020/2/15付 news_timestamp = datetime.datetime.strptime(html.select('.cmnc-publish')[0].string, "%Y/%m/%d付") print(news_timestamp) #2020-02-15 00:00:00コメント:色々書き方がある。ざっと見で3つあったけれどもっとあるかも。
産経新聞
https://www.sankei.com/world/news/200218/wor2002180013-n1.html
get_lastmodified.pyprint(html.select('#__r_publish_date__')[0].string) #2020.2.18 13:10 news_timestamp = datetime.datetime.strptime(html.select('#__r_publish_date__')[0].string, "%Y.%m.%d %H:%M") print(news_timestamp) #2020-02-18 13:10:00コメント:よくみたらURLに時まで載ってた。
読売新聞
https://www.yomiuri.co.jp/national/20200218-OYT1T50158/
get_lastmodified.pyprint(html.select('time')[0].string) #2020/02/18 14:16 news_timestamp = datetime.datetime.strptime(html.select('time')[0].string, "%Y/%m/%d %H:%M") print(news_timestamp) #2020-02-18 14:16:00コメント:日付だけならURLから取れる。
毎日新聞
https://mainichi.jp/articles/20180803/ddm/007/030/030000c
get_lastmodified.pyprint(html.select('time')[0].string) #2018年8月3日 東京朝刊 news_timestamp = datetime.datetime.strptime(html.select('time')[0].string, "%Y年%m月%d日 東京朝刊") print(news_timestamp) #2018-08-03 00:00:00https://mainichi.jp/articles/20200218/dde/012/030/033000c
get_lastmodified.pyprint(html.select('time')[0].string) #2020年2月18日 東京夕刊 news_timestamp = datetime.datetime.strptime(html.select('time')[0].string, "%Y年%m月%d日 東京夕刊") print(news_timestamp) #2020-02-18 00:00:00https://mainichi.jp/articles/20200218/k00/00m/010/047000c
get_lastmodified.pyprint(html.select('time')[0].string) #2020年2月18日 09時57分 #最終更新はprint(html.select('time')[1].string) news_timestamp = datetime.datetime.strptime(html.select('time')[0].string, "%Y年%m月%d日 %H時%M分") print(news_timestamp) #2020-02-18 09:57:00https://mainichi.jp/premier/politics/articles/20200217/pol/00m/010/005000c
get_lastmodified.pyprint(html.select('time')[0].string) #2020年2月18日 news_timestamp = datetime.datetime.strptime(html.select('time')[0].string, "%Y年%m月%d日") print(news_timestamp) #2020-02-18 00:00:00コメント:毎日新聞では、電子版のみの記事は分単位で取得できるぽい。朝刊・夕刊からの記事と毎日プレミアについては、URLで取れるのと同じ、日付までしか取得できない。
表
ニュースサイト Rヘッダーから URLから HTML中身から CNN 年月日 年月日時分 Bloomberg 年月日 年月日時分 BBC 年月日 Reuter 年月日時分 Wall Street Journal 年月日時分 Forbes Japan 年月日時分 Newsweek 年月日時分 朝日新聞 年月日時分 年月日時分 日経新聞 年月日時分 産経新聞 年月日時分 年月日時 年月日時分 読売新聞 年月日 年月日時分 毎日新聞 年月日 年月日時分* *毎日新聞は記事によっては日付のみあるいは日付+朝/夕刊の記載
思ったこと
言語はもちろん、サイトごとに日付の表記はまちまちです。同じニュースサイト内であっても表記揺れがあり、それについては全てを確認できているわけではありません。
HTMLみても取れないけどURLを見るとわかる、というサイトは今のところ見つけられていません。合わせ技と言いましたが、スクレイピングだけで取得しても変わらないですね。
この方法は各サイトごとに地道にタグやクラス名を読んでいかなければならず、全てのサイトはもちろん、ニュースサイトのみですら対応するのはかなり難しそうです。もっと良いやり方があればぜひ教えてください。
- 投稿日:2020-02-18T23:54:56+09:00
cif2cellことはじめ
cif2cellの概要
CIF2Cell download | SourceForge.net
結晶構造のフォーマットであるcif(crystallographic Information File)から、第一原理計算コードの入力ファイル(原子配置の指定部分)を出力してくれる、pythonで書かれたアプリ。一般ユーザー権限でインストール
ものは試しで一般ユーザー権限で出来る範囲でのインストールを試みる。
例としてcif2cell-1.2.10.tar.gzを取ってきたとする。
$ tar -zxvf cif2cell-1.2.10.tar.gzで、展開し出来たcif2cell-1.2.10を/home/user/sourcesに移動。そのディレクトリに移動する。PyCiRWを一般ユーザー権限でインストール
実は、cif2cellをインストールするには、PyCiRWなるアプリが必要で、これはcif2cellのコードに同梱されている。
$ tar -zxvf PyCiRW-3.3.tar.gzで展開してできるPyCiRW-3.3に移動する。基本的には所謂
python setup.py installでインストールされる類のもの。ただ、この手続きで管理者権限がないとファイル追加できない/usr/lib64/python2.7/site-packagesにファイルを生成しようとするため、一工夫が必要。pythonで参照されるpathの確認
pythonを実行して、
import sys print(sys.path)で、現在参照できるpathの確認をしよう。この中に
home/user/.local/lib/python2.7/site-packagesのような、一般ユーザーが編集できる箇所があれば、そこに入れることができる。但し、私は極度の潔癖でインストールしたものは、それとわかるように別に置いておきたいので、明確に入れる先を作ることにする。インストール用ディレクトリを作成してインストール
インストールする先を、
/home/user/opt/PyCiRW-3.3とする。
のちに、インストールのprefixとして、このディレクトリを指定してインストールを試みると、適切なpathが設定されていないと怒られる。これは上で調べたpathの中に、これから入れるディレクトリに付随した箇所にpathが通っていないため。なので、適切にpathを追加することにする。
このpathの設定にはいくつか方法があるが、ここでは環境変数PYTHONPATHを設定することで解決することにする。export PYTHONPATH=/home/user/opt/PyCiRW-3.3/lib64/python2.7/site-packagesで、環境変数
PYTHONPATHが適切に設定される。このディレクトリはインストール前には存在していないが、これからインストールする先の下に先読みしてlib64/python2.7/site-packagesを補っておかないと、引き続くインストールのところでコケる。python setup.py install --prefix=/home/user/opt/PyCiRW-3.3で晴れてインストール終了。ソースのあるディレクトリにある
INSTALLに、import CifFileでインポートできれば、インストール成功とある。
多分だけど、これは
python setup.py installを一般ユーザー権限で行うときにいつも使える手続きのように思う。cif2cellを一般ユーザー権限でインストール
ここまでくれば、晴れてcif2cellがインストールできる。cif2cellのソースがあるディレクトリに移って、
python setup.py install --prefix=/home/user/opt/cif2cell-1.2.10でインストール完了。
cif2cellの使い方
(多分PyCiRWに
PYTHONPATHを通しておかないと実行できない気がするけれど、そのテストは後日して、ここに追記)
- 投稿日:2020-02-18T23:17:36+09:00
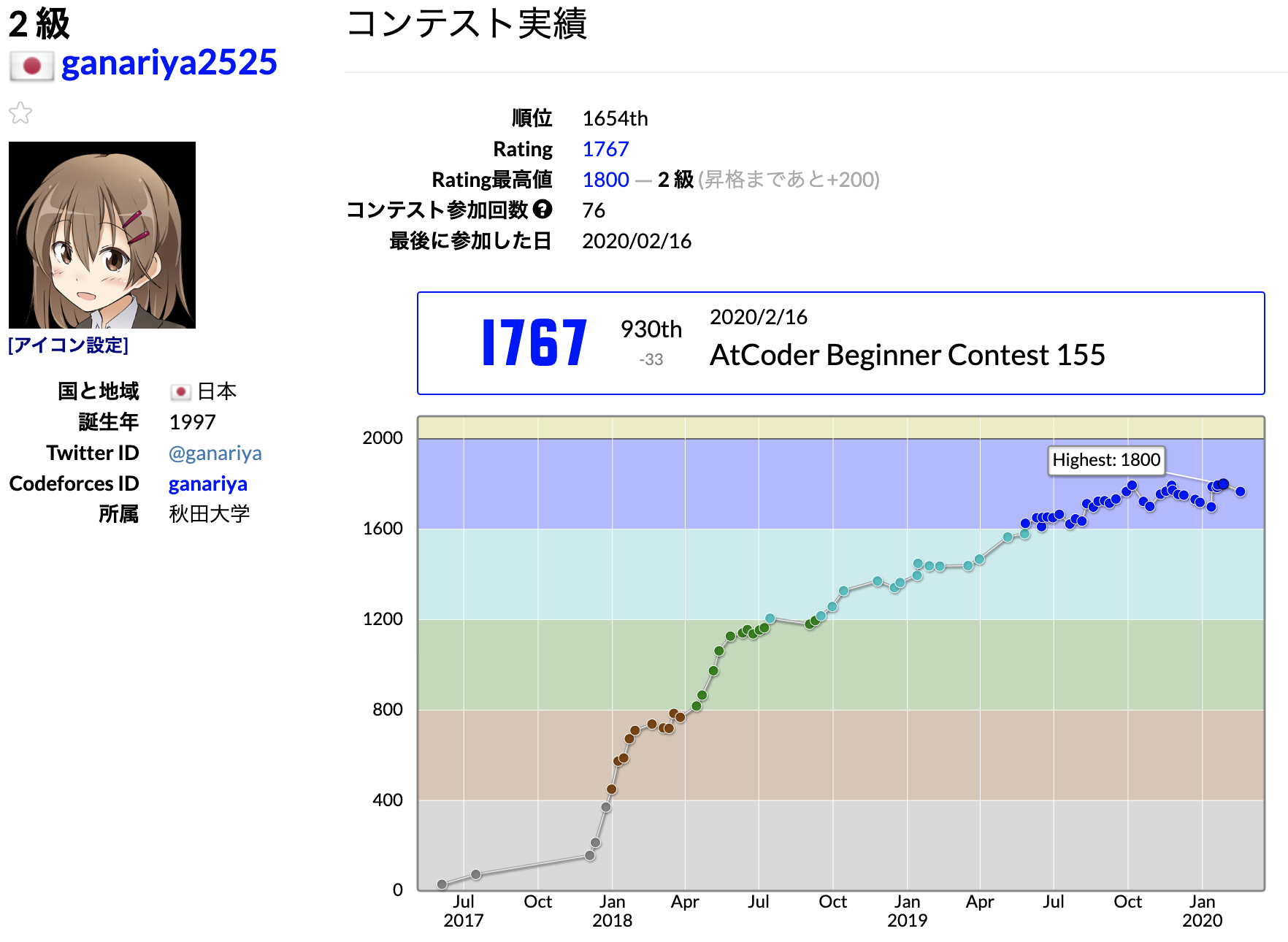
AtCoderのStreakを自分用に通知する!
この記事のまとめ
- AtCoderのStreakを続けたい!
- そのためにAtCoder APIを利用して自分宛てに通知するよ!
- Twitterやメールで通知するよ!
はじめに
AtCoderとは?
みなさんは、AtCoderって知っていますか?
AtCoderは、国内で最大の競技プログラミングサイトで、アルゴリズムやパズルの問題を世界同時に速さと正確さを競うことができます。そのうち、特に嬉しい点として
以下のようにコンテストの結果によってレートが出ます。
出れば出るほどレートは上がるというものではありません。
いい順位を取らなければ、レートは無慈悲にも下がってしまいます><
そのため、面白い問題を自分の発想で解いてレートが上がったときは、ものすごくドーパミンがドバドバ、キメるタイプの朝ココになります><Streakとは?
AtCoderの公式ではないのですが
有志で作られているもっとも有名な便利ツールにAtCoder Problemsがあります。
上記のようにこれまで解いた問題をわかりやすくビジュアライズしたり
これまでの解いてきた統計を可視化してくれる、すごすぎるサービスです><!!!!
このなかで、Streakというものが存在します。
上記の画像にCurrent Streakというものが存在しますが、これは
「何日連続で、まだ解いてない問題を新しく解いたか?」を表すものです。
つまり、このCurrent Streakが大きいほど、より熱心に毎日新規問題に取り組み、日々精進しているか?を表しています。一番大きい人だと1000弱、つまり1000日間毎日新規問題を解いていることになります。すごいです><!
発生した問題点
現在、ガナリヤは「Streakをできるだけ続けたい!」という意思を持って、毎日新規AC、つまりStreakを続けています。
しかし、自分はダメ人間なので、ニコニコ動画やYouTubeを見てるとStreakを忘れて途切れてしまうことが多々ありました。
これではStreakを大きくすることはできません。
そこで、個人用にStreakを自分宛てに通知することにしました。
AtCoder APIとStreak判定
AtCoderのStreakの判定に
AtCoder Problemsの作者(@kenkoooo)さんの非公式AtCoder APIを利用させていただきました。
ありがとうございます!今回は非常に小さいデータしか使わないため、直接APIを叩かせていただいていますが、大規模に叩く場合はドキュメントを参照してキャッシュなどの処理をしてください。
今回はこのAPIのうち
https://kenkoooo.com/atcoder/atcoder-api/results?user={user_name}を利用します。これによって、user_nameのこれまでのSubmit経歴を見ることができます。
APIをPythonで叩く
APIはpythonで叩くことにしました。
ライブラリはrequestsを用います。# coding: UTF-8 import datetime import time import os import requests user_name = "ganariya2525" user_url = f"https://kenkoooo.com/atcoder/atcoder-api/results?user={user_name}" res = requests.get(user_url).json()上記のコードで、これまでの自分のSubmit経歴を取得しましょう。
今日はStreakできているか確認する
次に、取得したデータからStreakがうまく行っているか判定しましょう。
# coding: UTF-8 import datetime import time import os import requests user_name = "ganariya2525" user_url = f"https://kenkoooo.com/atcoder/atcoder-api/results?user={user_name}" res = requests.get(user_url).json() # 今の時間(Asia) now = datetime.datetime.fromtimestamp(time.time(), datetime.timezone(datetime.timedelta(hours=9))) # 以前に解いたもの accepted = set() # 今日のAC today_accepted = [] # 各提出p を見る for p in res: # pの提出をしたときの時間 dt = datetime.datetime.fromtimestamp(p['epoch_second'], datetime.timezone(datetime.timedelta(hours=9))) # pが解いた問題のID p_id = p['problem_id'] # 正解でないなら関係ない if p['result'] != 'AC': continue # 以前に解いている if dt.date() < now.date(): accepted.add(p_id) # 今日解いて、しかもまだ解いていない問題なら if dt.date() == now.date() and p_id not in accepted: today_accepted.append(p)上記のようなソースコードにすることで、今日新しく新規ACしているか判定することができます。
多分もっと簡潔かつ丁寧なコードにできると思います。時間のあるときに、今何Streak続いているか?も判定したいですね。
あとは、today_acceptedを見て
- today_acceptedが空なら、新規ACなし!解け!
- today_acceptedが要素を持つなら、新規ACあり!好きなことしろ!
を判定できます><
通知をする
今度は実際に通知をしてみます。
今回は
- SendGrid(メール送信サービス)
- python-twitter(Twitterのサードパーティライブラリ)
を用いて、メールとTwitterで自分自身に通知しています。
以下のようなコードです。
# coding: UTF-8 import datetime import time import os import requests import twitter from sendgrid import SendGridAPIClient from sendgrid.helpers.mail import Mail api = twitter.Api( "consumer_key", "cusumer_secret", "access_token_key", "access_token_secret" ) user_url = "https://kenkoooo.com/atcoder/atcoder-api/results?user=ganariya2525" res = requests.get(user_url).json() now = datetime.datetime.fromtimestamp(time.time(), datetime.timezone(datetime.timedelta(hours=9))) accepted = set() today_accepted = [] for p in res: dt = datetime.datetime.fromtimestamp(p['epoch_second'], datetime.timezone(datetime.timedelta(hours=9))) p_id = p['problem_id'] if p['result'] != 'AC': continue if dt.date() < now.date(): accepted.add(p_id) if dt.date() == now.date() and p_id not in accepted: today_accepted.append(p) directory = os.path.dirname(__file__) dame = os.path.join(directory, 'dame.gif') happy = os.path.join(directory, 'tenor.gif') # ダメなら if len(today_accepted) == 0: text_message = "Streak (Python) " + str(now.strftime("%Y-%m-%d %H:%M:%S")) # 画像付きツイート api.PostUpdate(text_message, media=dame) # OK else: text_message = "Streakをセイキンさんも喜んでくれている (Python) " + str(now.strftime("%Y-%m-%d %H:%M:%S")) api.PostUpdate(text_message, media=happy) # メールの作成 # 普段使っている自分のメール(ganariya@ganariya.com.com)に送る message = Mail( from_email='sendgridのメアド', to_emails='ganariya@ganariya.com.com', subject='AtCoder Streak', html_content=text_message ) try: # ダメな場合のみメールを送る if len(today_accepted) == 0: sg = SendGridAPIClient('SendGridのAPIキー') response = sg.send(message) print(response.status_code) print(response.body) print(response.headers) except Exception as e: print(e.message)Sendgridでダメだったら自分宛にメールを贈っています。
また、Twitterライブラリを用いて、もしStreakを繋いでいたら嬉しいという感情のツイートを、ダメだったら焦らせるツイートをしています。Streakをセイキンさんも喜んでくれている (Python) 2020-02-18 23:00:02 pic.twitter.com/hWCsWJuLtf
— 人生さん (@ganariya) February 18, 2020上記のように自動でツイートされます。
これを用いるためにはSendgridのアカウント作成やTwitterのDeveloperアカウントの取得が必要です。
これらのプログラムは
cronを用いて
18:00, 21:00, 23:00に実行されるようになっています。
一時期cronの設定が間違っていて、毎分通知が来るようになっていて、Twitterのツイートがセイキンさんばかりになって焦りました><最後に
Streakの通知についてまとめてみました。
AtCoderのStreakは一日でも忘れると、すごく悔しいです。
みなさんも興味があればStreakの通知を行ってみてください><メールやTwitter以外にももっと色々な通知ができそうで楽しみです!
間違っている点や質問点がありましたら、ぜひコメントしていただければと思います!


- 投稿日:2020-02-18T22:25:40+09:00
【基本文法編】Ruby/Python/PHPの違い
はじめに
個人的な学習のまとめです!
3つの言語の基本文法を学習したのでまとめてみました!1. 出力
Rubyputs "Hello, world"Pythonprint("Hello, world")PHPecho "Hello, world";2. 変数
Rubyvariable = "変数”Pythonvariable = "変数”PHP$variable = "変数”;3.プロパティ値の出力
Ruby# attr_accessor :name 等でゲッターを定義する puts person.namePython# def __init__ 等でゲッターを定義する print(person.name)PHPecho $person->name();4. If文
Rubyif number % 15 == 0 puts "FizzBuzz" elsif number % 3 == 0 puts "Fizz" elsif number % 5 == 0 puts "Buzz" else puts number endPythonif number % 15 == 0: print("FizzBuzz") elif number % 3 == 0: print("Fizz") elif number % 5 == 0: print("Buzz") else: print(number)PHPif (number % 15 == 0){ echo "FizzBuzz"; } elseif (number % 3 == 0){ echo "Fizz"; } elseif (number % 5 == 0){ echo "Buzz"; } else { echo $number; }5. 配列/ハッシュ編
Ruby# 配列 array = ["赤", "青", "黄"] # ハッシュ hash = {"大阪府": "大阪", "愛知県": "名古屋", "東京都": "東京?"}Python# リスト lists = ["赤", "青", "黄"] # 辞書 dict = {"大阪府": "大阪", "愛知県": "名古屋", "東京都": "東京?"}PHP//配列 $array = ["赤", "青", "黄"]; //連想配列 $associative_array = [ "大阪府" => "大阪", "愛知県" => "名古屋", "東京都" => "東京?" ];6. 繰り返し構文
6-1.ループ処理
Rubyi = 1 while i <= 100 do # 処理 i += 1 endPythoni = 1 while i <= 100: # 処理 i += 1 for i in range(1, 101): # 処理PHPfor ($i = 1;$i <= 100;$i++){ //処理 }6-2. 反復処理(?)
Rubyarray.each do |value| #処理 end hash.each {|key, value| #処理 }Pythonfor value in lists: # 処理 for key in dict: # 処理PHPforeach($array as $value){ //処理 } foreach($associativeArray as $key => $value){ //処理 }7.関数定義
Rubydef hello # 処理 endPythondef hello(): # 処理 return # 戻り値PHPfunction hello() { // 処理 return // 戻り値 }8.クラスとインスタンス
Rubyclass Person @@number = 0 def self.classmethod # 処理 end def initialize(name) @name = name end person = Person.new("山田") endPythonclass Person: number = 0 @classmethod def classmethod: # 処理 def __init__(self, name): self.name = name end person = Person("山田") endPHPclass Person { private static $number; private $name; public function static function classmethod(){ echo self::$number; } public function __construct($name){ $this->name = $name; } $person = new Person(); }9.ゲッターとセッター
Rubydef setName(name) @name = name end def getName @name end #あるいは attr_accessor :namePythondef __init__(self, name): self._name = name @property def name(self): return self.__name @name.setter def name(self, name): self.__name = namePHPpublic function setName($name) { $this->name = $name; } public function getName() { return $this->name; }10.最後に
1ブロックをどのように(end/インデント/{})指定するかに個性がある感じですね!
ご一読頂き、ありがとうございました!
- 投稿日:2020-02-18T21:35:06+09:00
pythonを使った株価の自動収集
はじめに
最近、株価を予想するAIを作って欲しいということで、全くいい精度がでる期待もなかったが作ることにした。
過去にkerasやtensorflowを使ってAIを作ったことがあったが、株価を集めることはしたことがなかったのでやり方をまとめておく。
ビックデータを使いこなすにはスクレイピングやAPIの扱いになれなくてはと思ったりおもってみたり。
Quandl
流石に手動では絶命するので自動で収集する方法がないかと調べていたら、Quandlをみつけた。
銘柄コードを指定してAPIのURLにアクセスすればCSVでダウンロードできる。会員登録
まずはここから会員登録をして、API keyをもらう必要がある。
ライブラリ経由で取得
$pip3 install quandl使用方法
株価取得
データの取得は、quandl.get()でできる。引数は銘柄コードのみでOK。
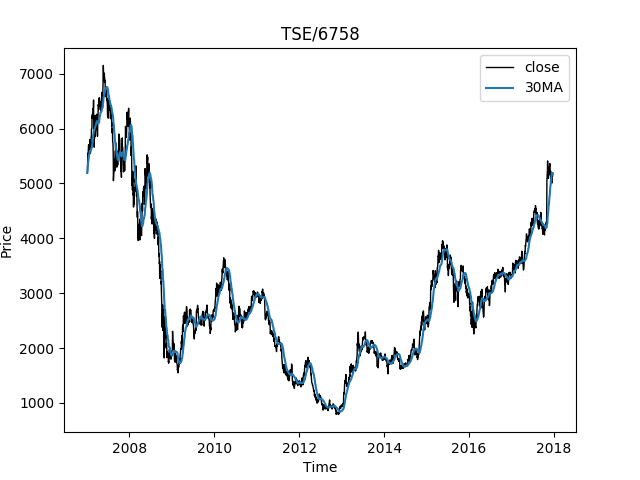
TSEは株式会社東京証券取引所らしい。import quandl import pandas as pd import matplotlib.pyplot as plt # SONYの株価を取得 brand = "TSE/6758" # quandlに登録して得られたAPI keyを指定する。 quandl.ApiConfig.api_key = 'your API key' # 株価の取得 quandl_data = quandl.get(dataset=brand, returns='pandas') # CSVへ保存 quandl_data.to_csv('stock_price_data.csv')移動平均の計算
せっかくなので終値の30日移動平均も計算。
## 移動平均を計算 quandl_data['30MA'] = quandl_data['Close'].rolling(window = 30, min_periods=0).mean()グラフに表示
fig = plt.figure() axes = fig.add_axes([0.1, 0.1, 0.8, 0.8]) axes.plot(quandl_data['Close'], 'black', lw = 1,label="close") axes.plot(quandl_data['30MA'],label="30MA") axes.set_xlabel('Time') axes.set_ylabel('Price') axes.set_title(brand) axes.legend() plt.savefig('stock_price_data.png') plt.pause(0.001)実行してみるとこんな感じ。
複数の銘柄から株価を取得
株価の学習をする上で、一つの銘柄より複数の銘柄で学習するのもいいのでは?と思いました。
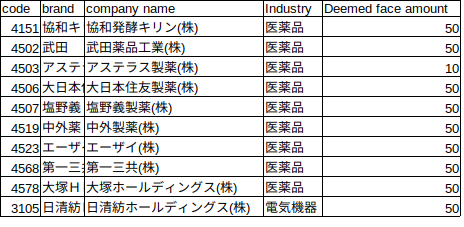
ということで、複数の銘柄を一度に取得する方法も記載。銘柄code listを作成
前もって銘柄code list(code.csv)を作成しておきます。
主要な銘柄である日経225から10件だけを対象にします。
株価取得
# get data print('Getting stock price...') import quandl import pandas as pd import matplotlib.pyplot as plt quandl.ApiConfig.api_key = 'your API key' # 銘柄codeをcsvから読み出し code = pd.read_csv('code.csv') # DataFrameからのDataをlist型かつ文字列として変換 code = ["TSE/"+str(n) for n in code['code'].values.tolist()] # 複数銘柄の株価取得 quandl_data = quandl.get(dataset=code, returns='pandas') # quandl_dataのcolumnsにあるstr(文字列)でCloseが含まれているcolumnsのみを抽出します。 quandl_data = quandl_data.loc[:,(quandl_data.columns.str.contains('Close'))] # 銘柄ごとに終値の移動平均を算出 for k in range(len(code)): quandl_data[code[k] + '_30MA'] = quandl_data.rolling(window = 30, min_periods=0).mean().iloc[:,0] quandl_data.to_csv('dataset.csv')まとめ
今回は、pythonを使って株価を自動収集した。
AIの学習には大量のデータが必要であるが手作業であつめるとなると大変。
この自動収集のやり方は、FXでも適応できますのでぜひ試してください。
AIもすでに作成して精度評価しているのでもしかしたら投稿するかも??
1銘柄のデータセットと255銘柄のデータセットどちらを使うと精度がよくなるとか、AI学習前の前処理の仕方とか、どうすれば勝率があがるかなどなど。
ちなみに、移動平均の予測値は1銘柄2007~2017年のデータセットでAccuracy84~85%、誤差16円。
工夫することで勝率96%、儲からないという検出力96%まで向上させることができた。
詳しくはAI(Deep Learning)作成編で。
- 投稿日:2020-02-18T21:26:55+09:00
【Python】Flaskチュートリアル#3 ~ DB連携編 ~
前回までのあらすじと今回実装するもの
#1ではGETリクエストに対する処理を実装しました。
#2ではPOST, PUT, DELETEリクエストに対する処理を実装しました。
#3となる今回はこれまで実装した処理を全てDB連携した処理に書き換えていきます!詳しくは以下の動画で紹介しています!
ソースコード
.envDB_USER=root DB_PASS=*********init_db.pyimport sqlalchemy import os from os.path import join, dirname from dotenv import load_dotenv load_dotenv(verbose=True) dotenv_path = join(dirname(__file__), '.env') load_dotenv(dotenv_path) DB_USER = os.environ.get('DB_USER') DB_PASS = os.environ.get('DB_PASS') url = f'mysql+mysqldb://{DB_USER}:{DB_PASS}@localhost/test?charset=utf8' engine = sqlalchemy.create_engine(url, echo=True) engine.execute(f'DROP TABLE IF EXISTS posts') engine.execute(''' CREATE TABLE posts ( id INTEGER PRIMARY KEY AUTO_INCREMENT, title CHAR(30), body TEXT ) ''')db.pyimport sqlalchemy import os from os.path import join, dirname from dotenv import load_dotenv load_dotenv(verbose=True) dotenv_path = join(dirname(__file__), '.env') load_dotenv(dotenv_path) DB_USER = os.environ.get("DB_USER") DB_PASS = os.environ.get("DB_PASS") url = f'mysql+mysqldb://{DB_USER}:{DB_PASS}@localhost/test?charset=utf8' engine = sqlalchemy.create_engine(url, echo=True)app.pyfrom flask import Flask, jsonify, request from db import engine import json app = Flask(__name__) db_data = [ {'title': 'タイトル1', 'body': '本文1'}, {'title': 'タイトル2', 'body': '本文2'}, {'title': 'タイトル3', 'body': '本文3'}, {'title': 'タイトル4', 'body': '本文4'}, {'title': 'タイトル5', 'body': '本文5'}, ] app.config['JSON_AS_ASCII'] = False @app.route('/', methods=['GET']) def index(): return 'hello world' @app.route('/posts', methods=['GET']) def get_all_posts(): if 'limit' in request.args: limit = request.args['limit'] posts = engine.execute(f''' SELECT * FROM posts LIMIT {int(limit)} ''') else: posts = engine.execute(f''' SELECT * FROM posts ''') result = [dict(row) for row in posts] return jsonify(result) @app.route('/post/<id>', methods=['GET']) def get_post(id): posts = engine.execute(f''' SELECT * FROM posts WHERE id={int(id)} ''') result = [dict(row) for row in posts] return jsonify(result) @app.route('/post/add', methods=['POST']) def create_post(): post = request.json engine.execute(f''' INSERT INTO posts (title, body) VALUES ('{post['title']}', '{post['body']}') ''') return 'success' @app.route('/post/update/<id>', methods=['PUT']) def update_post(id): post = request.json engine.execute(f''' UPDATE posts SET title='{post['title']}', body='{post['body']}' WHERE id={int(id)} ''') return 'success' @app.route('/post/delete/<id>', methods=['DELETE']) def delete_post(id): engine.execute(f''' DELETE FROM posts WHERE id={int(id)} ''') return 'success' if __name__ == '__main__': app.debug = True app.run()
- 投稿日:2020-02-18T21:26:55+09:00
Flaskチュートリアル#3 ~ DB連携編 ~
前回までのあらすじと今回実装するもの
#1ではGETリクエストに対する処理を実装しました。
#2ではPOST, PUT, DELETEリクエストに対する処理を実装しました。
#3となる今回はこれまで実装した処理を全てDB連携した処理に書き換えていきます!詳しくはこちらで紹介しています。
ソースコード
.envDB_USER=root DB_PASS=*********init_db.pyimport sqlalchemy import os from os.path import join, dirname from dotenv import load_dotenv load_dotenv(verbose=True) dotenv_path = join(dirname(__file__), '.env') load_dotenv(dotenv_path) DB_USER = os.environ.get('DB_USER') DB_PASS = os.environ.get('DB_PASS') url = f'mysql+mysqldb://{DB_USER}:{DB_PASS}@localhost/test?charset=utf8' engine = sqlalchemy.create_engine(url, echo=True) engine.execute(f'DROP TABLE IF EXISTS posts') engine.execute(''' CREATE TABLE posts ( id INTEGER PRIMARY KEY AUTO_INCREMENT, title CHAR(30), body TEXT ) ''')db.pyimport sqlalchemy import os from os.path import join, dirname from dotenv import load_dotenv load_dotenv(verbose=True) dotenv_path = join(dirname(__file__), '.env') load_dotenv(dotenv_path) DB_USER = os.environ.get("DB_USER") DB_PASS = os.environ.get("DB_PASS") url = f'mysql+mysqldb://{DB_USER}:{DB_PASS}@localhost/test?charset=utf8' engine = sqlalchemy.create_engine(url, echo=True)app.pyfrom flask import Flask, jsonify, request from db import engine import json app = Flask(__name__) db_data = [ {'title': 'タイトル1', 'body': '本文1'}, {'title': 'タイトル2', 'body': '本文2'}, {'title': 'タイトル3', 'body': '本文3'}, {'title': 'タイトル4', 'body': '本文4'}, {'title': 'タイトル5', 'body': '本文5'}, ] app.config['JSON_AS_ASCII'] = False @app.route('/', methods=['GET']) def index(): return 'hello world' @app.route('/posts', methods=['GET']) def get_all_posts(): if 'limit' in request.args: limit = request.args['limit'] posts = engine.execute(f''' SELECT * FROM posts LIMIT {int(limit)} ''') else: posts = engine.execute(f''' SELECT * FROM posts ''') result = [dict(row) for row in posts] return jsonify(result) @app.route('/post/<id>', methods=['GET']) def get_post(id): posts = engine.execute(f''' SELECT * FROM posts WHERE id={int(id)} ''') result = [dict(row) for row in posts] return jsonify(result) @app.route('/post/add', methods=['POST']) def create_post(): post = request.json engine.execute(f''' INSERT INTO posts (title, body) VALUES ('{post['title']}', '{post['body']}') ''') return 'success' @app.route('/post/update/<id>', methods=['PUT']) def update_post(id): post = request.json engine.execute(f''' UPDATE posts SET title='{post['title']}', body='{post['body']}' WHERE id={int(id)} ''') return 'success' @app.route('/post/delete/<id>', methods=['DELETE']) def delete_post(id): engine.execute(f''' DELETE FROM posts WHERE id={int(id)} ''') return 'success' if __name__ == '__main__': app.debug = True app.run()
- 投稿日:2020-02-18T20:30:12+09:00
2つの分かち書きの対応を計算する
言語処理をする際,mecabなどのトークナイザを使って分かち書きすることが多いと思います.本記事では,異なるトークナイザの出力(分かち書き)の対応を計算する方法とその実装(tokenizations)を紹介します.
例えば以下のような,sentencepieceとBERTの分かち書きの結果の対応を計算する,トークナイザの実装に依存しない方法を見ていきます.# 分かち書き (a) BERT : ['フ', '##ヘルト', '##ゥス', '##フルク', '条約', 'を', '締結'] (b) sentencepiece : ['▁', 'フ', 'ベル', 'トゥス', 'ブルク', '条約', 'を', '締結'] # 対応 a2b: [[1], [2, 3], [3], [4], [5], [6], [7]] b2a: [[], [0], [1], [1, 2], [3], [4], [5], [6]]問題
先ほどの例を見ると,分かち書きが異なると以下のような差異があることがわかります
- トークンの切り方が異なる
- 正規化が異なる (例: ブ -> フ)
- 制御文字等のノイズが入りうる (例: #, _)
差異が1.だけなら簡単に対処できそうです.二つの分かち書きについて,1文字ずつ上から比べていけば良いです.実際,以前spaCyに実装した
spacy.gold.align(link)はこの方法で分かち書きを比較します.
しかし2.や3.が入ってくると途端にややこしくなります.各トークナイザの実装に依存して良いならば,制御文字を除いたりして対応を計算することができそうですが,あらゆるトークナイザの組み合わせに対してこのやり方で実装するのは骨が折れそうです.
spacy-transformersはこの問題に対して,ascii文字以外を全部無視するという大胆な方法を採用しています.英語ならばそこそこ動いてくれそうですが,日本語ではほとんど動きません.
ということで今回解くべき問題は,上記1~3の差異を持つ分かち書きの組みの対応を計算することです.正規化
言語処理では様々な正規化が用いられます.例えば
- Unicode正規化: NFC, NFD, NFKC, NFKD
- 小文字化
- アクセント削除
などです.上記一つだけでなく,組み合わせて用いられることも多いです.例えばBERT多言語モデルは小文字化+NFKD+アクセント削除を行なっています.
対応の計算法
2つの分かち書きを
A,Bとします.例えばA = ["今日", "は", "いい", "天気", "だ"]となります.以下のようにして対応を計算することができます.
- 各トークンをNFKDで正規化し,小文字化をする
A,Bのそれぞれのトークンを結合し,2つの文字列Sa,Sbを作る. (例:Sa="今日はいい天気だ")SaとSbの編集グラフ上での最短パスを計算する- 最短パスを辿り,
SaとSbの文字の対応を取得する- 文字の対応からトークンの対応を計算する
要するに適当に正規化した後に,diffの逆を使って文字の対応を取り,トークンの対応を計算します.肝となるのは3で,これは編集距離のDPと同じ方法で計算でき,例えばMyers' algorithmを使えば低コストで計算できます.
1.でNFKDを採用したのは,Unicode正規化の中でもっとも正規化後の文字集合が小さいからです.つまりヒット率をなるべくあげることができます.例えば"ブ"と"フ"はNFKDでは部分的に対応を取れますが,NFKCでは対応を取れません.>>> a = unicodedata.normalize("NFKD", "フ") >>> b = unicodedata.normalize("NFKD", "ブ") >>> print(a in b) True >>> a = unicodedata.normalize("NFKC", "フ") >>> b = unicodedata.normalize("NFKC", "ブ") >>> print(a in b) False実装
実装はこちらに公開しています: GitHub: tamuhey/tokenizations
中身はRustですが,Pythonバインディングも提供しています.Pythonライブラリは以下のように使えます.
$ pip install pytokenizations>>> import tokenizations >>> tokens_a = ['フ', '##ヘルト', '##ゥス', '##フルク', '条約', 'を', '締結'] >>> tokens_b = ['▁', 'フ', 'ベル', 'トゥス', 'ブルク', '条約', 'を', '締結'] >>> a2b, b2a = tokenizations.get_alignments(tokens_a, tokens_b) >>> print(a2b) [[1], [2, 3], [3], [4], [5], [6], [7]] >>> print(b2a) [[], [0], [1], [1, 2], [3], [4], [5], [6]]終わりに
先日,Camphrという言語処理ライブラリを公開しましたが,このライブラリの中で
pytokenizationsを多用しています.transformersとspaCyの分かち書きの対応を計算するためです.おかげで,2つのライブラリを簡単に結合できるようになり,モデルごとのコードを書く必要がなくなりました.地味ですが実用上非常に役に立つ機能だと思います.
- 投稿日:2020-02-18T18:57:15+09:00
しきい値を自動的に決定する手法のまとめ
最近,しきい値を自動的に決定したいという話をよく相談されるので,まとめてみました.
しきい値設計とは,1次元の教師なし2グループのクラスタリングに対応し
ます.
今回は,画像の2値化を例として,5個の古典的かつ有用な手法をまとめます.注意: 分布系が未知ならば,しきい値決定には正解はありません
準備
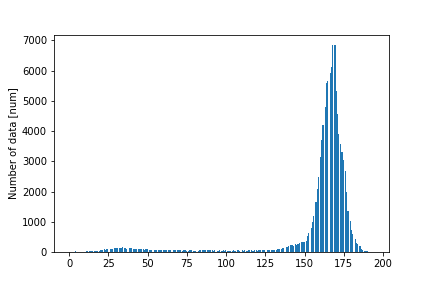
今回は適当にとったこの写真を使います.
この画像の輝度のヒストグラムは以下の様になります.
この輝度の分布から最適な閾値を設定し,バイナリー画像を作るという問題になります.
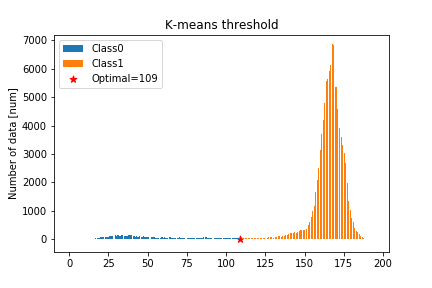
K-means [1]
教師なし学習で最も有名な手法は,K-meansです (wiki).
K-meansは以下の最適化問題の解となるそれぞれのクラスの中心点 {m1,...,mM}を探すことを目的としています.$$
{\rm minimize}_{m_1,\ldots, m_M} \quad \sum_{i=1}^N \min_j |x_i - m_j|
$$ここで{x1,...,xN}は与えられたデータになります.
クラスの中心点{m1,...,mM)}は以下の2つを繰り返すことによって求められます.
1. クラス内の平均値の計算する.
2. データをもっとも近い中心のクラスに割り当て直す.K-meansは多次元の場合でも適用できますが,閾値設計の問題ではM=2となります.
この分類の結果は次の図のようになります.
K-meansの特徴としては,以下のような特徴があります.
- 更新ごとにN×Mオーダーの距離を計算する必要がある.
- 初期値依存性が存在する.import cv2 import numpy as np import pandas as pd import matplotlib.pyplot as plt # データの読み込み img = cv2.imread('img/main.png',0) data = img.reshape(-1) # ラベルの初期化 labels = np.random.randint(0,2,data.shape[0]) # 終了条件 OPTIMIZE_EPSILON = 1 m_0_old = -np.inf m_1_old = np.inf for i in range(1000): # それぞれの平均の計算 m_0 = data[labels==0].mean() m_1 = data[labels==1].mean() # ラベルの再計算 labels[np.abs(data-m_0) < np.abs(data-m_1)] = 0 labels[np.abs(data-m_0) >= np.abs(data-m_1)] = 1 # 終了条件 if np.abs(m_0 - m_0_old) + np.abs(m_1 - m_1_old) < OPTIMIZE_EPSILON: break m_0_old = m_0 m_1_old = m_1 # 初期値によって,クラスが変化するため上界の小さい方を採用 thresh_kmeans = np.minimum(data[labels==0].max(),data[labels==1].max())大津法 [2]
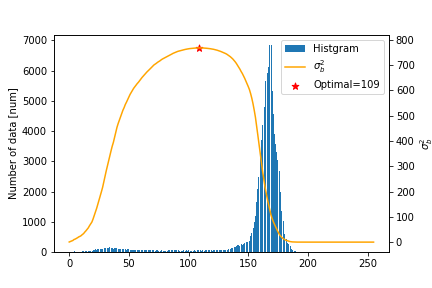
大津法は各クラスの重み付き平均値の差を最大化する方法です(wiki).
具体的には以下の最適化問題を解くしきい値Tを見つけることに対応します.$$
{\rm maximize}_T\quad \sigma_b^2 (T):= w_1 (m_1 - m)^2 +w_2 (m_2 - m)^2
$$ここで,
$$
w_1 = \frac{ | {x_1,\ldots, x_N}\leq T|}{N},\quad w_2 = \frac{ | {x_1,\ldots, x_N} > T|}{N}
$$
$$
m_1 = \frac{\sum_{x_i\leq T} x_i}{\sum x_i},\quad m_2 = \frac{\sum_{x_i>T} x_i}{\sum x_i}
$$
となります.上記のσbを最大化する問題は,各クラスの分散の重み付き和
$$
\sigma_a^2 (T) := w_1 \frac{\sum_{x_i\leq T} (x_i - m_1)^2}{N} +w_2 \frac{\sum_{x_i>T} (x_i - m_2)^2}{N}
$$
を最小化する問題と一致します.
そのため,σa最小化の問題やσa/σbを最小化する問題を解くこともあります.この分類の結果は次の図のようになります.
以下にpythonでのコードを記述します.
# Define Otsu scoring function def OtsuScore(data,thresh): w_0 = np.sum(data<=thresh)/data.shape[0] w_1 = np.sum(data>thresh)/data.shape[0] # check ideal case if (w_0 ==0) | (w_1 == 0): return 0 mean_all = data.mean() mean_0 = data[data<=thresh].mean() mean_1 = data[data>thresh].mean() sigma2_b = w_0 *((mean_0 - mean_all)**2) + w_1 *((mean_1 - mean_all)**2) return sigma2_b # Callculation of Otsu score and analyze the optimal scores_otsu = np.zeros(256) for i in range(scores_otsu.shape[0]): scores_otsu[i] = OtsuScore(data,i) thresh_otsu = np.argmax(scores_otsu)Sezanらによる方法 [3]
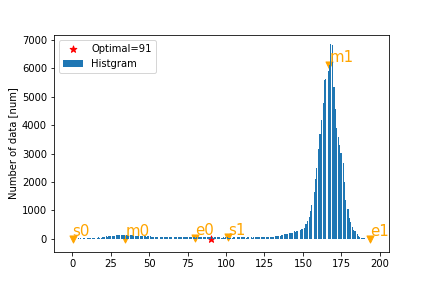
画像の輝度の分布などで,ピークが2つあるということを利用したしきい値設計手法です.
2つのピークの内側のすその値を求めることにより,しきい値を設計します.まず,平滑化したヒストグラムを極地計算により,一番左側(値が小さい)のピークと一番右側(値が大きい)のピークを検出し,それぞれ[m0,m1]とします.
同じく極地の計算によって,各ピークの左右の裾を計算し,左の裾を[s0,s1], 右の裾を[e0,e1]とします.このとき,しきい値は左側のピークの右側の裾e0と右側のピークの左側の裾s1の間にあると考えられます.
そのため,0以上1以下の設計パラメーターγを用いて,しきい値を設計します.$$
{\rm Sezan~threshold} := (1 - \gamma )e_0 + \gamma s_1
$$この分類の結果は次の図のようになります.
Sezanらによる2値のしゅほうの特徴として以下があります.
- 調整するハイパーパラメーターが多いが状況に合わせて使い分けることができる
- 多次元化が難しいpythonコードは以下のようになります.
# 平滑化パラメータ sigma = 5.0 # 重要視する割合 # gamma = 1 : 黒の領域を広めに取る # gamma = 0 : 白の領域を広めに取る gamma = 0.5 # 平滑化のためのガウスカーネル def getGaus(G_size,G_sigma): G_kernel = np.zeros(G_size) G_i0 = G_size//2 for i in range(G_size): G_kernel[i] = np.exp(-(i-G_i0)**2 / (2*G_sigma**2)) # 和が1になるように調整 G_kernel = G_kernel/G_kernel.sum() return G_kernel # ガウスカーネルの作成 kernel = getGaus(55,sigma) # ヒストグラム化 num_hist, range_hist = np.histogram(data, bins= 256) mean_hist = (range_hist[1:] + range_hist[:-1]) / 2 # 平滑化 hist_bar = np.convolve(num_hist,kernel,'same') # 差分の計算 d_hist = hist_bar[:-1] - hist_bar[1:] # 端の処理 d_hist = np.r_[[0],d_hist,[0]] # ピーク検出 m = np.where((d_hist[1:] >=0) & (d_hist[:-1] <=0))[0] # 局地検出 es =np.where((d_hist[1:] <=0) & (d_hist[:-1] >=0))[0] # 最大ピークと最小ピーク m0 = m.min() m1 = m.max() # ピーク前後の局地 s0 = es[es<m0].max() e0 = es[es>m0].min() s1 = es[es<m1].max() e1 = es[es>m1].min() # 閾値決定 thresh_Sezan = (1 - gamma) * mean_hist[e0] + gamma * mean_hist[s1]カルバック・ライブラー情報量最小化 [4]
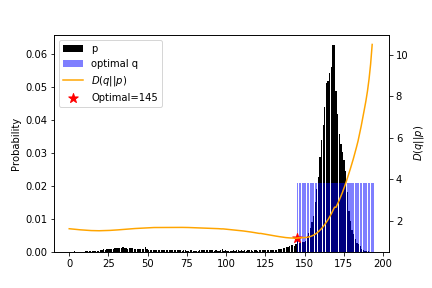
情報理論の研究者におなじみのカルバック・ライブラー(KL)情報量を使う手法です.
KL情報量以外の他の情報量基準で研究されている論文も多数あります.まず,輝度のヒストグラムを正規化した確率分布をpと定義します.
次に,しきい値Tによって定まる2値化に対応する確率関分布q(T)を以下のように定義します.
$$
q(i\leq T) = 0,\quad q(i>T) = 1/M
$$ここで,Mはしきい値より大きい要素の数です.
q(T)とpによるKL情報量D(q(T)||p)を最小化する値をしきい値とします.
つまり,以下の最適化問題を解きます.
$$
{\rm minimize}_T\quad D(q(T)||p)
$$
この結果を以下の図にしまします.
特徴としては,以下があります.
- 背景ノイズの推定に便利
- 分布が偏っていないと適用することができない.以下に,pythonコードを示します.
コード内では,「0log0」を回避するために,KL情報量を以下のような変形を行っていことに注意してください.$$
D(q(T)||p) = \sum_{i=1}^N q(T) \ln \frac{q(T)}{p}= -\ln M - \sum_{i=1}^N q(T) \ln p \
$$def InfoScore(data,thresh,bins=100): num_hist, range_hist = np.histogram(data, bins= bins) mean_hist = (range_hist[1:] + range_hist[:-1]) / 2 p = num_hist/num_hist.sum() N = p.shape[0] M = np.sum(mean_hist>thresh) if (M== 0): return np.inf q = np.zeros(N) q[mean_hist>thresh] = 1 / M Dqp = - np.log(M) - np.sum(q*np.log(p)) return Dqp # Callculation of Otsu score and analyze the optimal scores_info = np.zeros(256) for i in range(scores_info.shape[0]): scores_info[i] = InfoScore(data,i,bins = 190) thresh_info = np.argmin(scores_info)混合ガウスモデルのフィッティング
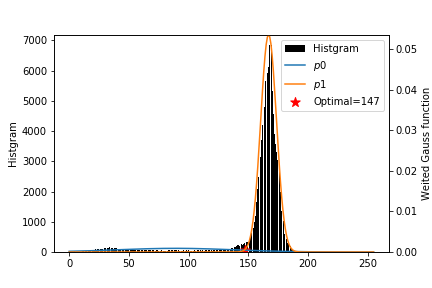
2つのクラスの分布がそれぞれガウス分布であることを仮定し,混合ガウス分布をフィッティンフする手法です.
2クラスのガウス分布であることが既知であり,データが十分にあるときのみの使用をオススメします.2つのガウス分布の交点がしきい値となります.
問題点として:
- ガウスの形状でない+long tailの場合はうまく推定できない.
- 初期値依存性があるという問題があります.
以下が結果とpythonコードになります.
pyhtonコードは勉強のためパッケージを使っていませんが,特に偏った心情がなければこちらをおつかいください.
# def gaus func def gaus(x,mu,sigma2): return 1/np.sqrt(2 * np.pi * sigma2) *np.exp(-(x-mu)**2/(2*sigma2)) # Class Number M=2 # Optimmization Condition OPTIMIZE_EPS = 0.01 # Init y = data.copy() mu = 256*np.random.rand(M) sigma2 = 100*np.random.rand(M) w = np.random.rand(M) w = w / w.sum() for cycle in range(1000): # E step gamma_tmp = np.zeros((M,y.shape[0])) for i in range(M): gamma_tmp[i] = w[i] * gaus(y,mu[i],sigma2[i]) gamma = gamma_tmp/ gamma_tmp.sum(axis = 0).reshape(1,-1) Nk = gamma.sum(axis=1) # M step mus = (gamma * y).sum(axis = 1)/Nk sigma2s = (gamma *((y.reshape(1,-1)- mu.reshape(-1,1))**2)).sum(axis = 1)/Nk ws = Nk / Nk.sum() # check break condition if (np.linalg.norm(mu-mus)<OPTIMIZE_EPS)& (np.linalg.norm(sigma2-sigma2s)<OPTIMIZE_EPS) & (np.linalg.norm(w-ws)<OPTIMIZE_EPS): break # updata mu = mus sigma2 = sigma2s w = ws print(cycle) # make distribution x = np.arange(0,256,1) p = np.zeros((M,x.shape[0])) for i in range(M): p[i] = w[i] * gaus(x,mu[i],sigma2[i]) # find threshold if m[0]<m[1]: thresh_gaus = np.where(p[0]<p[1])[0].min() else: thresh_gaus = np.where(p[0]>p[1])[0].min()まとめ
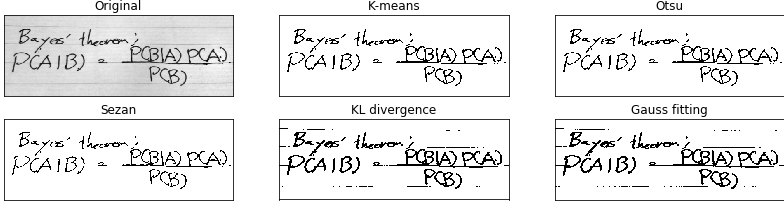
上記の4つの手法を用いたしきい値は下の表の用になりました.
K-means Otsu Sezan KL divergence Gauss Fitting Threshold 109.0 109.0 90.558594 145.0 147.0 また,2値化画像は下の図のようになります.
どれがいいとは一概に良い言えませんので,状況に合わせて使い分けましょう!
とりあえず,この記事の上からオススメします.いくつかの論文は[5]を参考にしています.
よくまとまっていていい感じです.Code詳細
https://github.com/yuji0001/Threshold_Technic
Reference
[1] H, Steinhaus,“Sur la division des corps matériels en parties” (French). Bull. Acad. Polon. Sci. 4 (12): 801–804 (1957).
[2] Nobuyuki Otsu. "A threshold selection method from gray-level histograms". IEEE Trans. Sys. Man. Cyber. 9 (1): 62–66 (1979).
[3] M. I. Sezan, ‘‘A peak detection algorithm and its application to histogram-based image data reduction,’’ Graph. Models Image Process. 29, 47–59(1985).
[4] C. H. Li and C. K. Lee, ‘‘Minimum cross-entropy thresholding,’’ Pattern Recogn. 26, 617–625 (1993).
[5] Sezgin, M. Survey over image thresholding techniques and quantitative performance evaluation. Journal of Electronic Imaging, 13(1), 220(2004).
Author
Yuji Okamoto yuji.0001@gmail.com
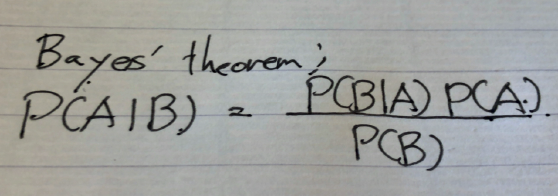
- 投稿日:2020-02-18T18:37:36+09:00
Godはなんですか?簡単なチャットボットをpythonで作る
チャットボットはよく使われてます。この記事は自分がMediumのある記事を読んで、作ったチャットボットのメモである。オリジナルの記事はここだ:
https://medium.com/analytics-vidhya/building-a-simple-chatbot-in-python-using-nltk-7c8c8215ac6e
チャットボットはなんですか?
Chatbots are used in a variety of fields for different purposes, such as i) Support bots, designed to solve customer requests related to the delivery of a service or use of a product, and ii) Financial bots, aimed to resolve inquiries about financial services. Chatbots may have some constraints regarding the requests that they can respond and the vocabulary that they can employ, which depends on the specific domain where they are serving on. Furthermore, according to the Hype Cycle for emerging technologies by Gartner [2], conversational AI platforms remain in the phases of “innovation trigger” and “peak of inflated expectations”, meaning that they are getting substantial attention from the industry.
Besides the aforementioned use cases for chatbots, cybersecurity is one of the newest where to apply this technology. Thus, there exist chatbots focused on training end-users [3] or cyber analysts [4] in security awareness and incident response. Further, there are also malicious chatbots devoted to malware distribution through a human-machine conversation [5]. In addition, there is software designed to guide the user in terms of security and privacy, such as Artemis [6], a conversational interface to perform precision-guided analytics on endpoint data. Most of these security chatbots are implemented in a question-answering context [7] using a post-reply technique. As far as we know, the use of chatbots to profile suspects in an active way of child pornography has been little investigated, existing few approaches [8, 9] employing a chatbot to emulate a victim such as a child or a teenager. Likewise, our investigation aims to emulate a vulnerable person while the suspect offers him/her illegal content.
Building the chatbot
In this section, we'll cover NLP and NLG in this project.
- NLP — Natural Language “Processing”
- NLG — Natural Language “Generation”First, we'll need to import the relevant libraries:
import io import random import string # to process standard python strings import warnings import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity import warnings warnings.filterwarnings('ignore') import nltk from nltk.corpus import gutenberg from nltk.stem import WordNetLemmatizer nltk.download('popular', quiet=True) # for downloading packagesIf this is your first time using nltk, don't forget to run the following line and use the GUI to download all the packages.
nltk.download()Preprocessing
raw = gutenberg.raw('bible-kjv.txt') #Tokenisation sent_tokens = nltk.sent_tokenize(raw)# converts to list of sentences word_tokens = nltk.word_tokenize(raw)# converts to list of words # Preprocessing lemmer = WordNetLemmatizer() def LemTokens(tokens): return [lemmer.lemmatize(token) for token in tokens] remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation) def LemNormalize(text): return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))It doesn't really matter which corpus you use. Here I use the bible from gutenberg.
Keyword Matching
GREETING_INPUTS = ("hello", "hi", "greetings", "sup", "what's up","hey") GREETING_RESPONSES = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"] def greeting(sentence): """If user's input is a greeting, return a greeting response""" for word in sentence.split(): if word.lower() in GREETING_INPUTS: return random.choice(GREETING_RESPONSES)Generating Response
TfidfVectorizer and cosine_similarity will be used to find the similarity between words entered by the user and the words in the corpus. This is the simplest possible implementation of a chatbot.
def response(user_response): robo_response='' sent_tokens.append(user_response) TfidfVec = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english') tfidf = TfidfVec.fit_transform(sent_tokens) vals = cosine_similarity(tfidf[-1], tfidf) idx=vals.argsort()[0][-2] flat = vals.flatten() flat.sort() req_tfidf = flat[-2] if(req_tfidf==0): robo_response=robo_response+"I am sorry! I don't understand you" return robo_response else: robo_response = robo_response+sent_tokens[idx] return robo_responseStart and end of the conversation
flag=True print("ROBO: My name is Robo. I will answer your queries about Chatbots. If you want to exit, type Bye!") while(flag==True): user_response = input() user_response=user_response.lower() if(user_response!='bye'): if(user_response=='thanks' or user_response=='thank you' ): flag=False print("ROBO: You are welcome..") else: if(greeting(user_response)!=None): print("ROBO: "+greeting(user_response)) else: print("ROBO: ",end="") print(response(user_response)) sent_tokens.remove(user_response) else: flag=False print("ROBO: Bye! take care..")This approach is very basic for a chatbot as the response from the bot is simply based on keywords matching.
- 投稿日:2020-02-18T18:32:47+09:00
PPLM: 指定した属性をもった文章を生成するシンプルな Deep Learning 手法
はじめに
本記事は日鉄ソリューションズ(NSSOL)様でのインターンシップで執筆したものです.
本記事は以下の構成から成ります.
- 概要
- 本記事で解説するモデルPPLMについての大まかな説明をします.
- モデル構成
- PPLMのモデル概観についての解説をします.
- PPLMの Attribute Model の設計と学習
- PPLMの「小規模モデルの接続」というメインアイデアにおける,モデルの設計・学習の解説を実際のコードを交えながら行います.
- PPLMの実行
- 学習済のモデルを実行する際の処理の流れについて,実際のコードを交えながら解説を行います.
- テスト例
- 実際に生成した文章を紹介します.
- 改善点
- 本モデルについて,改善の余地があると思われる点について解説します.
概要
本記事で解説するモデルPPLMについて,大まかな解説をします.
Plug and Play Language Model とは
Plug and Play Language Model (以下PPLM) とは, PLUG AND PLAY LANGUAGE MODELS: A SIMPLE APPROACH TO CONTROLLED TEXT GENERATION で提案されたモデルになります.著者実装もGithubに存在します.
本研究は,controlled text generation というタスクに取り組んだ研究になります.controlled text generation とは,言語生成モデルが文章を生成する際,指定した属性(positive/negative といった極性や「政治」「科学」といったトピック)に合った文章を生成させるというタスクです.
PPLMの何がすごい?
PPLMのすごいところは,既存の言語生成モデルに対して,新たに小規模なモデルを学習するだけで controlled text generation を実現するというところにあります.
このすごさは既存手法と比較することでわかります.
controlled text generation に対する既存研究のアプローチは以下のように分類できます.
- 既存の言語生成モデルを属性1つ1つに対して別々にFine-tuning
- 既存のモデルは往々にして大規模なモデルであり,その再学習を属性の数だけ行うという膨大なコストがかかる
- Decodingの際にスコアを考慮する
- 生成文の自然さが損なわれがち
- そもそもこの手法で属性をコントロールするのは難しい
前者は属性のコントロールに関して十分な性能を発揮しますが,学習コストの面で大きな問題を抱えています.新しい属性を追加したいとなったとき,大規模なモデルを再び学習する必要があります.
後者は学習コスト面では問題ありませんが,性能が前者に比べ大きく劣るようです.
PPLMで提案される手法は,前者に匹敵する性能を維持しながらも,学習コストが非常に小さいという強みを持っています.モデル構成
PPLMはTransformerをDecoderとして用いた言語生成モデルを対象としたものになります.著者実装ではGPT-2を用いているため,今後はGPT-2の利用を前提として記述します.
こちらはPPLMの原著論文 (https://openreview.net/pdf?id=H1edEyBKDS) より引用した図になります.ただし,青字($H_1, H_2, x_0, x_1, x_2$)は私が加筆したものです.
図中の黒矢印だけを見て, [Attribute Model p(a|x)] を無視すると元のTransformerのDecoderを用いたモデル(以降,オリジナルのモデルと呼称)となります.
図中のLM (Language Model) は Transformer の Decoder ブロックをl層積み上げたものです.
このl層のブロックそれぞれの中で発生する self-attention の Key, Value のペアを保持したものが$H_t$となります.つまり,$$H_t = [({K_t}^{(1)}, {V_t}^{(1)}), ... , ({K_t}^{(l)}, {V_t}^{(l)})]$$
ここで,${K_t}^{(i)}, {V_t}^{(i)}$はある時刻においてi層目のDecoderブロックによって作成された Key, Value のペアです.
オリジナルのモデルでは,前の時刻に出力した単語と共に,この$H_t$がLMに渡されます.つまり,
$$
o_{t+1}, H_{t+1} = \text{LM}(x_t, H_t)
$$
$o_{t+1}$ はLMからの出力であり,次のように行列 $W$ によって線形変換したのち,Softmax関数にかけて全単語の尤度の分布 $p_{t+1}$ が求まります. $x_{t+1}$ はこの分布に従います.
$$
x_{t+1} \sim p_{t+1} = \text{Softmax}(W o_{t+1})
$$
このようにして次々に単語を生成していくのがオリジナルのモデルになります.
ここからがPPLMの話になります.PPLMでは,接続した Attribute Model が $H_t$ を受け取り, $x_{t+1}$ が指定した属性 $a$ に対してどれだけ尤もらしいかを表す $p(a|x_{t+1})$ が大きくなるように $H_t$ を更新します.この $H_t$ を更新した $\tilde{H_t}$ をもとに新たに $\tilde{p_{t+1}}$ が計算されるため,単語の尤度の分布が変化します.図中においては,オリジナルのモデルから出力された $p_3$ では "ok" の尤度が高くなっていましたが, $\tilde{p_3}$ では "delicious" の尤度が高くなっている様子が描かれています.PPLMの Attribute Model の設計と学習
PPLMでは, Attribute Model $p(a|x)$ の構成に対して2つの手法が提唱されています.一方がBag-of-Wordsを利用するもの,もう一方が判別器によるものです.ここでは,これらについて実装コードを交えながら解説します.
Bag-of-Wordsによる Attribute Model
ここでは,事前に属性に関連するキーワードの集合を作成します.著者実装において用意されている属性には "computers", "fantasy", "kitchen", "legal", "military", "politics", "positive_words", "religion", "science", "space" があります.例えば "science" であれば, "astronomy", "atom", "biology", "cell", "chemical" など,48単語が用意されています.
ある属性 $a$ についてのキーワード集合 $\{ w_1, ... , w_k \}$ を用意したとき,オリジナルのモデルによって計算される単語の尤度の分布 $p_{t+1}$ を用いると,出力単語 $x_{t+1}$ が属性 $a$ に対してどれだけ尤もらしいかを表す $p(a|x_{t+1})$ は次のように考えることができます.
$$
p(a|x_{t+1}) = \sum_{i}^k p_{t+1}[w_i]
$$
この式の右辺が表すものは,キーワード集合に含まれる単語が出現する確率,つまり望んだ属性に関連する単語が出現する確率です.
原著論文には書いていませんが, $p(a|x_{t+1})$ (これは論文内では $p(a|x)$ と表記されています)を$p(a|p_{t+1})$ として,単語の尤度の分布がどれだけ属性 $a$ にふさわしいか,と捉えた方がわかりやすいかもしれません.
なお,後述の判別器とは違い,Bag-of-Wordsを利用した Attribute Model には学習パラメータが存在せず,学習は行いません判別器による Attribute Model
前述のBag-of-Wordsを利用した Attribute Model はシンプルな設計でしたが,問題があります.それは,属性をキーワードの集合のみで表すのが難しいケースがあるということです.そのような場合,本節で解説する判別器によるモデルが有用です.
属性の判別器は,出力単語 $x$ の属性 $a$ らしさを表す $p(a|x)$ を, self-attention の Key, Value のペア $H_t$ を利用して $p(a|H_t)$ と再解釈します.つまり, $H_t$ を入力として受け取り,属性 $a$ の尤度を返す判別器の学習を行います.
実装上ではこの判別器が返すものは,全属性に関しての尤度の分布の対数を取ったものになります.以下の実際のコードを見て行きましょう.run_pplm_discrim_train.pyclass Discriminator(torch.nn.Module): """Transformer encoder followed by a Classification Head""" def __init__( self, class_size, pretrained_model="gpt2-medium", cached_mode=False, device='cpu' ): super(Discriminator, self).__init__() self.tokenizer = GPT2Tokenizer.from_pretrained(pretrained_model) self.encoder = GPT2LMHeadModel.from_pretrained(pretrained_model) self.embed_size = self.encoder.transformer.config.hidden_size self.classifier_head = ClassificationHead( class_size=class_size, embed_size=self.embed_size ) self.cached_mode = cached_mode self.device = device def get_classifier(self): return self.classifier_head def train_custom(self): for param in self.encoder.parameters(): param.requires_grad = False self.classifier_head.train() def avg_representation(self, x): mask = x.ne(0).unsqueeze(2).repeat( 1, 1, self.embed_size ).float().to(self.device).detach() # maskはpaddingの0を無視するために利用 hidden, _ = self.encoder.transformer(x) masked_hidden = hidden * mask avg_hidden = torch.sum(masked_hidden, dim=1) / ( torch.sum(mask, dim=1).detach() + EPSILON ) return avg_hidden def forward(self, x): if self.cached_mode: avg_hidden = x.to(self.device) else: avg_hidden = self.avg_representation(x.to(self.device)) logits = self.classifier_head(avg_hidden) probs = F.log_softmax(logits, dim=-1) return probs class ClassificationHead(torch.nn.Module): """Classification Head for transformer encoders""" def __init__(self, class_size, embed_size): super(ClassificationHead, self).__init__() self.class_size = class_size self.embed_size = embed_size self.mlp = torch.nn.Linear(embed_size, class_size) def forward(self, hidden_state): logits = self.mlp(hidden_state) return logitsDiscriminator クラスは,事前学習済のモデルとこれから学習する ClassificationHead の2部から構成されます.学習済のモデルの再学習は一切行いません.なお,PPLMの実行時に $p(a|x)$ (より正確には $p(a|H_t)$)のモデルとして利用するのは ClassificationHead の部分のみになります.
Discriminator の処理の解説をします.入力xはミニバッチで,各単語をIDで表した文がバッチサイズ分並んだTensorになります.これが事前学習済モデルによって処理され,hiddenが出力されます.hidden, _ = self.encoder.transformer(x)この hidden は入力xの各単語を分散表現で表したようなものになっています.次に,この hidden には padding による余計な単語が Tensor のバッチ処理の関係上含まれているため,それを無視するために mask をかけます.こうすることで,padding によって追加された単語の分散表現が0になります(masked_hidden).最後に,この masked_hidden の各文中の分散表現を足し合わせることで avg_hidden が求まります.1つの文中の単語を足し合わせていると考えると,これは文を分散表現で表したものと解釈できます.この avg_hidden が ClassificationHead への入力となります.
ClassificationHead は中間層の存在しない,入力層と出力層のみのニューラルネットです.入力層のノード数はavg_hiddenの分散表現の次元数で,出力層のノード数は属性の数です.出力はロジットとなっており,これをソフトマックス関数に通してさらに対数をとります.logits = self.classifier_head(avg_hidden) probs = F.log_softmax(logits, dim=-1)このprobs (= output_t) の,正解クラス(target_t)に対応する値(負対数尤度)がlossとなり,このlossをbackpropして学習します.
loss = F.nll_loss(output_t, target_t) loss.backward(retain_graph=True) optimizer.step()PPLMの実行
前章の Attribute Model の学習を終えたら次は実際にPPLMの実行です.なお,実際には学習済の Attribute Model が用意されているため,動作を確認するだけならば改めて学習する必要はありません.また,Bag-of-Wordsによる Attribute Model を利用する場合も学習は必要ありません.
モデル構成で述べたように,PPLMではオリジナルのモデルの $H_t$ を更新した $\tilde{H_t}$ を用いることで出力単語をコントロールします.この更新は,実際には次のように行われます.\begin{align} \tilde{H_t} &= H_t + \Delta H_t \\ \Delta H_t & \leftarrow \Delta H_t + \alpha \frac{\nabla_{\Delta H_t} \log p(a | H_t + \Delta H_t)}{||\nabla_{\Delta H_t} \log p(a | H_t + \Delta H_t)||^{\gamma}} \end{align}$\alpha, \gamma$ はハイパーパラメータです.ここで行っているのは,属性 $a$ の尤度を高めるような更新 $\Delta H_t$ の計算です.この $\Delta H_t$ 自身は複数回計算して更新したのちに, $H_t$ に加算されます.この回数は3-10回だと言われています(実装コードでのデフォルト値は3).
この更新は run_pplm.py の perturb_past関数内で行われます.まず,Bag-of-Words を利用した Attribute Model による実装を見てみましょう.loss = 0.0 bow_logits = torch.mm(probs, torch.t(one_hot_bow)) bow_loss = -torch.log(torch.sum(bow_logits)) loss += bow_loss過程を省きましたが,probsは $p_{t+1}$ に相当するもので,言語モデルの知識にある全単語の尤度の分布です. one_hot_bow は属性のキーワード集合に属する各単語を,言語モデルの知識にある全単語に対する one-hot-vector で表したものです.これらを掛け合わせた bow_logits の和をとることは Bag-of-WordsによるAttribute Model に記した $\sum_{i}^k p_{t+1}[w_i]$ の計算に相当します.この和の負の対数を取ったものが bow_loss となります.この bow_loss は, $- \log p(a | H_t + \Delta H_t)$ に相当します.
次に,判別器を利用した Attribute Model による実装は以下のようになっています.
ce_loss = torch.nn.CrossEntropyLoss() prediction = classifier(new_accumulated_hidden / (curr_length + 1 + horizon_length)) label = torch.tensor(prediction.shape[0] * [class_label], device=device, dtype=torch.long) discrim_loss = ce_loss(prediction, label) loss += discrim_lossclassifier は前章で学習した,判別器の ClassificationHead の部分になります.new_accumulated_hidden の解説をします.GPT-2に対して更新した $\tilde{H_t}$ を与えて計算した,12層重ねたTransformerの最後の層から出力される隠れ状態を,判別器による Attribute Modelで解説したavg_hiddenと同様に分散表現を足し合わせたものを考えます.この計算を,未更新の $H_t$ についても同様に行い,これら2つを足し合わせたものが new_accumulated_hidden になります.このあたりは実際にコードを追いかけないとわからないかもしれませんが,隠れ状態を classifier に入力している,の認識程度でも大丈夫かもしれません.curr_length は現時点でのGPT-2に対する入力単語数, horizon_length は1がデフォルト値となっています(horizon_length 何の役割を担っているのかは本家の解説が薄くわかりません).
label に使われる class_label は run_pplm.py 実行時にユーザにより与えられるものです.例えば positive クラスに対して事前に割り当てたインデックスなどです.この label と prediction 間のクロスエントロピーロスを求めます.
このようにして計算した discrim_loss もまた,$- \log p(a | H_t + \Delta H_t)$ に相当します.
なお,Bag-of-Words と判別器による Attribute Model は併用できます.その場合は bow_loss と discrim_loss を足し合わせますloss = 0.0 loss += bow_loss loss += discrim_lossここまでで $\log p(a | H_t + \Delta H_t)$ の計算はできており( $\log p(a | H_t + \Delta H_t) = - \text{loss}$ ),あとは勾配を求めることで $\Delta H_t$ の更新が可能となりますが,これだけではうまくいきません.これまでに考えたきたことは, $p(a|x)$ (あるいは $p(a|H_t)$ )の値を大きくすることだけでした. $p(x)$ 自体については考慮していません.そのため,生成文が不自然なものになってしまう可能性が残ってしまいます.
この問題は,2つのアプローチにより解決されています.1つが, $p_{t+1}$ と $\tilde{p_{t+1}}$ 間の KL-Divergence, つまり
$$
\text{kl_loss} = \sum_i \tilde{p_{t+1}}[w_i] \log{ \frac{ \tilde{p_{t+1}}[w_i] }{ p_{t+1}[w_i] } }
$$
を小さくすることです.実装を見てみましょう.kl_loss = kl_scale * ( (corrected_probs * (corrected_probs / unpert_probs).log()).sum() ) loss += kl_lossここで, corrected_probs が $\tilde{p_{t+1}}$ ,unpert_probs が $p_{t+1}$ に当たります. kl_scale はハイパーパラメータで,基本的には0.01に設定すればいいようです.計算した kl_loss は, bow_loss や discrim_loss あるいはそれらの和にさらに加算されます. $\Delta H_t$ の更新時にすべてまとめて勾配方向に移動させる形です.
更新式の設計段階での対策は KL-Divergence のみです.もう1つのアプローチは, $\tilde{p_{t+1}}$ の計算後,実際に尤度にしたがって単語をサンプリングする際に行います.以下のようにサンプリングを行います.
$$
x_{t+1} \sim \frac{1}{\beta} \left( \tilde{p_{t+1}}^{\gamma_{gm}} {p_{t+1}}^{1-\gamma_{gm}} \right)
$$
このサンプリングが表すことは,更新した分布 $\tilde{p_{t+1}}$ だけでなく,更新前の $p_{t+1}$ も考慮したサンプリングを行うということです. $\beta$ は単なる確率分布として成立させるための正規化係数で, $\tilde{p_{t+1}}^{\gamma_{gm}} {p_{t+1}}^{1-\gamma_{gm}}$ の総和です. $\gamma_{gm}$ はハイパーパラメータで, $\gamma_{gm}$ を1に近づけると $\tilde{p_{t+1}}$ に近づき,0に近づけると $p_{t+1}$ に近づきます.実際には, $\gamma_{gm}$ は $0.8 \sim 0.95$ に設定するといいようです.つまり,更新後の分布は少し考慮するのみで,更新前の分布を重く考える,といった具合でしょうか.実装は以下のようになっています.pert_probs = ((pert_probs ** gm_scale) * (unpert_probs ** (1 - gm_scale))) pert_probs = top_k_filter(pert_probs, k=top_k, probs=True) if torch.sum(pert_probs) <= 1: pert_probs = pert_probs / torch.sum(pert_probs) if sample: last = torch.multinomial(pert_probs, num_samples=1) else: _, last = torch.topk(pert_probs, k=1, dim=-1)1行目で $\tilde{p_{t+1}}^{\gamma_{gm}} {p_{t+1}}^{1-\gamma_{gm}}$ を計算しています.2行目では,サンプリングする際に尤度の小さすぎる単語が出現しないよう,尤度上位k個の単語のみ残すようフィルタをかけています.3-4行目の操作が $\beta$ で割る操作です.6-7行目は尤度の分布にしたがってのサンプリングで,8-9行目が貪欲に最大尤度の単語をサンプリングする場合です.
以上が $H_t$ の更新およびサンプリングの工夫という,PPLMのアイデアになります.
テスト例
実際のテスト例を載せます.著者実装には2つの命令例が載せてあるため,それらを試します.
Bag-of-Words PPLMモデルの例
まず,Bag-of-Words を利用したPPLMについて.著者実装の以下の命令を試しに使います.
python run_pplm.py -B military --cond_text "The potato" --length 50 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.03 --window_length 5 --kl_scale 0.01 --gm_scale 0.99 --colorama --sample-Β military で military 属性の Bag-of-Words モデルを指定しています.結果がこちら.
Unperturbed generated text
<|endoftext|>The potato is probably the world's most widely eaten plant. But what if it's also the most dangerous?In the last two decades, there's been a dramatic decrease in potato crop damage from crop rot and disease. The decline, which started in
Perturbed generated text 1
<|endoftext|>The potato-flour soup that is the best way to start a weekend!
The following recipe is one of several that I have been working on over the past few months. I think it is the best of them. It uses all the elements of thePerturbed generated text 2
<|endoftext|>The potato bomb and the anti-Semitic attack that killed four Jewish students at a Jewish school in France are the most recent examples of bomb threats targeting Israeli facilities. The latest bomb threat targeting a U.S. nuclear facility, the bomb was sent out over thePerturbed generated text 3
<|endoftext|>The potato chip explosion has been a boon to the world's food industry since its release in late March. A handful of companies have already announced plans to produce chips using the chips, including Chipotle Mexican Grill Corp.'s parent company, Taco Bell Corp.'sPerturbed generated text 4
<|endoftext|>The potato is a very popular and delicious vegetable in many countries, but it can also cause severe health problems for people. The health of your body depends on your diet. If your diet doesn't include enough protein to get through the meal, or if you arePerturbed generated text 5
<|endoftext|>The potato plant, which is a member of the same family as wheat, can be found around the world. It's also used to make potato chips, bread, and other food products.The Plant
The plant grows as a seed and produces
Perturbed generated text 6
<|endoftext|>The potato bomb has been a controversial weapon for years. The device is packed with bomb-like devices and packed on a bomb-filled potato bomb. It's a bomb that detonates in the bomb-packed potato bomb and explodes in the potato bomb. SoPerturbed generated text 7
<|endoftext|>The potato has a lot in common with the human earworm: The first, and only, time you hear it, you'll hear the sound of the potato in your ear as well.It's the first sound you hear when your cat or dog
Perturbed generated text 8
<|endoftext|>The potato salad is coming to a restaurant near you!The new restaurant, in the heart of downtown Chicago, will be named the Potato Salad.
A photo posted by @the_mike_barnes on Aug 7, 2016 at
Perturbed generated text 9
<|endoftext|>The potato is a staple in many people's diet, and it is an easy food to make in your home.The best potato chips in the world are made by hand using only potatoes.
The potato is a staple in many people's diet
Perturbed generated text 10
<|endoftext|>The potato bomb is an improvised explosive device, typically containing one bomb and no more than 10 grams of explosive and containing no explosive material.Bombardment of an aircraft aircraft, a tank truck or explosive device
Bombardment of an aircraft aircraft
実行の際に指定した num_samples の数だけ独立に文を生成します(今回は10).赤字で強調しているのが属性に関連する語になります.これは実行時に --colorama を指定することで標準出力に赤字で表示させることができます.
生成例を見ていきましょう.まず,コントロールしていないオリジナルのモデルの生成文には military の要素は特に見られません.
コントロールした文に関しては,2, 6, 10に関しては "bomb" という単語がよく現れているのが見受けられます.ただ,他の例に関してはあまり military の文という印象は受けません.The potato から始まる military 属性の
文は少し難しかったのかもしれません.Discriminator PPLMモデルの例
属性の判別器を利用したモデルを試します.実行は著者実装の以下の文です.
python run_pplm.py -D sentiment --class_label 2 --cond_text "My dog died" --length 50 --gamma 1.0 --num_iterations 10 --num_samples 10 --stepsize 0.04 --kl_scale 0.01 --gm_scale 0.95 --sample結果がこちら.
Unperturbed generated text
<|endoftext|>My dog died in February, after suffering from severe arthritis. He had been suffering with a terrible cold that was causing his skin to break. I couldn't afford a replacement dog and couldn't afford to have him taken to the vet. I knew the vet would bePerturbed generated text 1
<|endoftext|>My dog died of a heart attack at the age of 88, his son said, and her death has shocked and brought closure to the family. (Published Wednesday, March 12, 2017)A mother who was found dead at home with a heart attack on
Perturbed generated text 2
<|endoftext|>My dog died from a rare and potentially deadly form of a rare form of sickle cell disease.A rare form of sickle cell is called hemizygaly in the families.
The family is an important part of the game and it's
Perturbed generated text 3
<|endoftext|>My dog died after being shot.A woman in the United States died after a man in his 20s opened fire at her home in North Carolina and injured several others.
On March 12 a neighbor heard a woman screaming. After she ran outside to
Perturbed generated text 4
<|endoftext|>My dog died of a heart attack, after suffering from a heart attack.The title text of this page has a a a
of
of the work and work in to be an in a way, that the idea of the idea to aPerturbed generated text 5
<|endoftext|>My dog died from a rare form of cancer that was not known before.The rare form of brain cancer called glioblastomatosis is more common in people of European descent. People of European descent are also at greater risk of glioma
Perturbed generated text 6
<|endoftext|>My dog died from anaphase and I don't know how to give birth to a child with a rare genetic condition, an important personal health gain, with health - "" " The " " " "'The'"'" The book " The wordPerturbed generated text 7
<|endoftext|>My dog died from a rare form of cancer, the Daily Mail reports.
"I have a really strong desire to help others and so I am happy to have the chance to help others to be happy and to love their loved ones and that's something I lovePerturbed generated text 8
<|endoftext|>My dog died because I didn't let him go.I have a 6-year-old, 3-year-old, 1-year-old, 2-year-old, and 2-year-old. I have a very active and
Perturbed generated text 9
<|endoftext|>My dog died of a heart attack while while while I was in the house. I had the old man's head and body, and a large one, I have my hands and feet with me. I have a good time, and the best, as I amPerturbed generated text 10
<|endoftext|>My dog died from a rare form of cancer, scientists have found.... James M. He he is is is is aA lot of a lot of a fun!! The Great Escape The Great Escape! The Great Escape! The Great Escape
Bag-of-Words のときとは違い,関連する単語の強調表示はできません.
-D sentiment で,事前に学習済の "sentiment" の判別器を指定しています.この判別器は "very_positive", "very_negative" の2つのクラスを判別する判別器で,今回指定している class_label=2 は, "very_positive" を表します.(なお, class_label=3 とすると "very_negative" を指定できます)."My dog died" というネガティブな文章しか生成されなさそうな始まりに対して,ポジティブな文を生成させようという例です.各例を見ていきましょう.
属性のコントロールをしていないオリジナルのモデルの生成文は悲観的な文章になっています.
コントロールした生成文に関しては,2, 5, 7などは比較的前向き(というよりネガティブさがない)文が生成されています.rare や love などの単語が目立ちます.1, 3, 4, 6, 8, 9, 10などはネガティブさが消えていなかったり,不自然な文になっていたりするため,文の始まりと属性が合わないと適切な生成が困難である様子が見て取れます.もう少し生成しやすそうな例を試す
上記の例は生成が難しそうな文の始まりと属性の組み合わせでした.もう少し文の始まりと属性を合わせてみましょう.始まりを The potato にして,属性を positive_words にします.
python run_pplm.py -B positive_words --cond_text "The potato" --length 50 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.03 --window_length 5 --kl_scale 0.01 --gm_scale 0.99 --colorama --sample結果がこちら.
Unperturbed generated text
<|endoftext|>The potato is probably the world's most widely eaten plant. But what if it's also the most dangerous?In the last two decades, there's been a dramatic decrease in potato crop damage from crop rot and disease. The decline, which started in
Perturbed generated text 1
<|endoftext|>The potato-like, gluten-free, low-calorie, sweet, and nutritious sweet potato pie recipe. Easy to make, and perfect for those who love to eat sweet, healthy, and filling pie!When my kids are home from school
Perturbed generated text 2
<|endoftext|>The potato has been a popular favorite since the 1980s. But with its recent popularity and rising popularity, is it time to eat your favorite potato again?The potato is still a great food to enjoy and enjoy, with its healthy benefits and delicious flavor
Perturbed generated text 3
<|endoftext|>The potato chip craze is in full swing.The popular snacks have been making the rounds in recent weeks as people seek out fresh and healthier alternatives to fried foods.
But there may have never been a better time to eat these crispy snacks than
Perturbed generated text 4
<|endoftext|>The potato is a very versatile, versatile vegetable and it is a great addition to many tasty salads, soups and stews.The potato is the star of many salads and stirfries. I love the versatility of potatoes in many recipes.
Perturbed generated text 5
<|endoftext|>The potato is a common dish, so much so in fact that it is often served with pasta. It is often served with rice, or topped with a sweet and savoury sauce.Serves 4
1 onion
2 cloves garlic
Perturbed generated text 6
<|endoftext|>The potato has become the new darling of American farmers in recent years. Its popularity is so great that it has even been featured in many successful television shows like "The Big Bang Theory".But there has never been an easier way to prepare your favorite snack
Perturbed generated text 7
<|endoftext|>The potato is a favorite among the health-conscious, so what better time to try a new way to eat them? The recipe below is easy and healthy, and you can easily freeze it, freeze it for later, reheat it for breakfast or lunch,Perturbed generated text 8
<|endoftext|>The potato salad that inspired the popular dish is one of a number of new varieties of the dish being sold at popular popular restaurants. (Photo: Thinkstock)When it comes to classic American comfort food, a popular dish that's popular around the country
Perturbed generated text 9
<|endoftext|>The potato is a staple in many people's diet, and it is not only delicious in its own right, but is also a good protein source. It is easy to eat, nutritious, and healthy.Potato, as we know it, originated
Perturbed generated text 10
<|endoftext|>The potato has been used as an ingredient in everything from salad dressing to soups for decades. However, it was once thought to be a poor performer in the kitchen. In recent years, scientists have shown potatoes to be a promising food source. The research shows最初のオリジナルの生成文は客観的な事実を述べているような文で,ポジティブな印象は特に受けません.他の文は,おおむねポジティブな文になっているのが見て取れます(2は何を言っているのかよくわからなかったり,3は better の前に never が付いてしまっていたりしますが...).
やはり,文の開始と属性の取り合わせはある程度考える必要がありそうです.これは,論文にも「属性によっては制御が難しい」と記されています.
改善点
実行時間が長い
今回の実験では,単語数50の文章を生成しました.その際,1つの文章を生成するのに,オリジナルのGPT-2による生成には2-3秒しかかかりませんが,Bag-of-Words によるモデルでは22秒ほど,判別器によるモデルでは95秒ほどかかっています.
利用タスクにも依存しますが,50単語程度の文を作成するのにこれほど時間がかかってしまうのがネックになります.学習するパラメータはオリジナルのモデルに比べると非常に少ないですが,ハイパーパラメータは $\Delta H_t$ を更新する際の $\alpha, \gamma$, KL-Divergenece kl_loss, $p_{t+1}$ と $\tilde{p_{t+1}}$ のバランスをとるための $\gamma_{gm}$ と多く,1回の実行に時間がかかりすぎるのはチューニングのコストに響いてしまうと考えられます.
この長さはおそらく, $H_t$ の更新時に偏微分の操作を何度も行っているのが原因だと私は考えています.普通のネットワークでは順方向に伝播していくだけで,そのような操作はありません.偏微分したりせずに, $H_t$ を入力すると $\tilde{H_t}$ が出力されるようなネットワークを構成・学習できればこの問題は解決できるかもしれません.Transformer 利用モデルに限定
本モデルのメインアイデアである $H_t$ の更新は, Transformer をデコーダとして利用している言語モデルに限る話になります.今後,違った構造が主流になるとこの手法は利用できない可能性があります.
まとめ
本記事では,Transformer をデコーダに用いたモデルで文を生成する際に,指定した属性に合った文章を生成する手法PPLMについて解説いたしました.
PPLMのメインアイデアは,外部接続したモデルにより,指定した属性の文を生成する方向に Transformer のself-attention の Key, Value を再帰的に更新すると言う考えです.この考えにより,オリジナルの大規模なモデルを再学習する必要なく属性の制御が可能になります.
テスト結果からは,おおむね制御できているものの,文の始まりと属性の相性が悪いと生成が困難である様子が見てとれました.また,実行時間がオリジナルのモデルに比べて長くなってしまう欠点もあります.参考文献
読んだもの
- PLUG AND PLAY LANGUAGE MODELS: A SIMPLE APPROACH TO CONTROLLED TEXT GENERATION
- 原著論文.平易な英語で書かれており,とても読みやすいため,興味があればぜひお読みください.
- Language Models are Unsupervised Multitask Learners
- GPT-2の原著論文.基本的なモデル構成についてはGPTの原著論文(後述)の方に書かれています.
- The Illustrated GPT-2 (Visualizing Transformer Language Models)
- GPT-2を懇切丁寧に図解した記事.非常にわかりやすいです.
- The Illustrated Transformer
- Transformer を懇切丁寧に図解した記事.非常にわかりやすいです.
- 作って理解する Transformer / Attention
- Transformer とその要素技術である self-attention, さらにそもそも attention とは? から始まる丁寧な記事です.上記の The Illustrated Transformer と併せて読むと理解が深まります.
他・関連文献
- Improving Language Understanding by Generative Pre-Training
- GPT-2の古いバージョン,GPTの原著論文.モデル構成についてはこちらに書かれています.
- Attention Is All You Need
- 言わずと知れた Transformer を発明した原著論文.
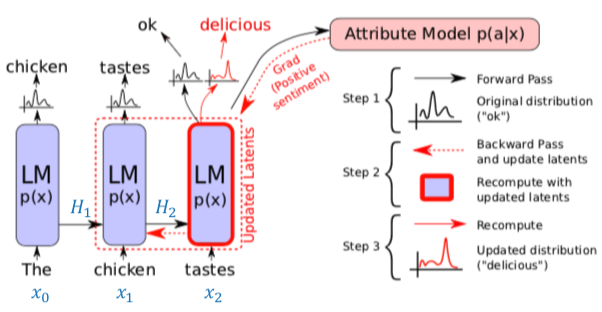
- 投稿日:2020-02-18T18:12:36+09:00
[pandas] GroupBy Tips
はじめに
KaggleのData Science Bowl 2019に参戦したときに知った、GroupByの便利なTipsをまとめてみました
動作環境
- Python 3.8.1
- pandas 0.25.3
使用するデータ
以下の架空のデータを用いる
import pandas as pd df = pd.DataFrame({ 'name' : ['Alice', 'Bob', 'Charlie', 'David', 'Eve', 'Fred', 'George'], 'state' : ['NY', 'CA', 'NY', 'CA', 'FL', 'FL', 'NY'], 'score' : [4, 3, 5, 10, 1, 0, 7] })
name state score 0 Alice NY 4 1 Bob CA 3 2 Charlie NY 5 3 David CA 10 4 Eve FL 1 5 Fred FL 0 6 George NY 7 各グループの最初の行を抽出する
first()もしくはhead(1)、nth(0)を使う
head(n)は各グループの先頭からn行を取得するので、最初の行がほしい場合はn=1を指定する
nth(n)は各グループのn行目を取得するので、最初の行がほしい場合はn=0を指定する
※Pythonのindexは0から始まる注意点として、それぞれのメソッドで欠損値がある場合の挙動が異なる
first()は各カラムごとに最初にNaNでない値を取得するので、欠損値が含まれる場合に、別々の行から継ぎはぎしたデータが返ってくるおそれがある
head()は欠損値も含めて、最初からn行を取得する
nth()はdropnaの設定値(None,any,all)によって、挙動が異なるまた、
first()とnth()は出力形式が同じだが、head()は異なるdf.groupby('state').first() # name score #state #CA Bob 3 #FL Eve 1 #NY Alice 4 df.groupby('state').head(1) # name state score #0 Alice NY 4 #1 Bob CA 3 #4 Eve FL 1 df.groupby('state').nth(0) # name score #state #CA Bob 3 #FL Eve 1 #NY Alice 4欠損値がある場合
# データの作成は省略 print(with_nan_df) # name state score #0 Alice NY NaN #1 Bob CA 3.0 #2 Charlie NY 5.0 #3 David CA 10.0 #4 Eve FL NaN #5 Fred FL 0.0 #6 George NY 7.0 with_nan_df.groupby('state').first() # name score #state #CA Bob 3.0 #FL Eve 0.0 #NY Alice 5.0 # ⇒EveとAliceのデータが別のデータと継ぎはぎになっている! with_nan_df.groupby('state').head(1) # name state score #0 Alice NY NaN #1 Bob CA 3.0 #4 Eve FL NaN # ⇒NaNはそのまま!欠損値がある場合の挙動の違いについて、詳しくは以下のページを参照
[pandas]groupbyの最初・最後の行を求めるfirst・last関数の話、headやnthとの違い各グループの最後の行を抽出する
last()もしくはtail(1)、nth(-1)を使う
tail(n)は各グループの後ろからn行を取得するので、最後の行がほしい場合はn=1を指定する
nth(n)は各グループのn行目を取得するので、最後の行がほしい場合はn=-1を指定する
※Pythonはindex=-1で最後のindexを指定できる注意点として、先ほど最初の行を抽出したとき同様に、それぞれのメソッドで欠損値がある場合の挙動が異なる
last()はfirst()と、tail()はhead()と同じ挙動をするdf.groupby('state').last() # name score #state #CA David 10 #FL Fred 0 #NY George 7 df.groupby('state').tail(1) # name state score #3 David CA 10 #5 Fred FL 0 #6 George NY 7 df.groupby('state').nth(-1) # name score #state #CA David 10 #FL Fred 0 #NY George 7各グループのサイズを取得する
size()を使う
1つのカラムだけでgroupbyする場合はvalue_counts()でも似た結果が得られるが、複数のカラムに対して各ペアのデータ数を取得する場合には便利df.groupby('state').size() #state #CA 2 #FL 2 #NY 3 #dtype: int64 df['state'].value_counts() #NY 3 #CA 2 #FL 2 #Name: state, dtype: int64複数のカラムに対して各ペアのデータ数を取得する
# データの作成は省略 print(team_df) # name state score team #0 Alice NY 4 A #1 Bob CA 3 A #2 Charlie NY 5 A #3 David CA 10 A #4 Eve FL 1 B #5 Fred FL 0 B #6 George NY 7 B team_df.groupby(['state', 'team']).size() #state team #CA A 2 #FL B 2 #NY A 2 # B 1 #dtype: int64グループごとにデータをシフトする
groupbyした結果にもshift()は使える# 結果を見やすくするため、データをstateでソート df.sort_values('state', inplace=True) print(df) # name state score #1 Bob CA 3 #3 David CA 10 #4 Eve FL 1 #5 Fred FL 0 #0 Alice NY 4 #2 Charlie NY 5 #6 George NY 7 df.groupby('state')['score'].shift() #1 NaN #3 3.0 #4 NaN #5 1.0 #0 NaN #2 4.0 #6 5.0 #Name: score, dtype: float64グループごとに累積和をとる
groupbyした結果にapplyを使ってcumsum()を適用するprint(df) # name state score #1 Bob CA 3 #3 David CA 10 #4 Eve FL 1 #5 Fred FL 0 #0 Alice NY 4 #2 Charlie NY 5 #6 George NY 7 df.groupby('state').apply(lambda tdf: tdf['score'].cumsum()) #state #CA 1 3 # 3 13 #FL 4 1 # 5 1 #NY 0 4 # 2 9 # 6 16 #Name: score, dtype: int64グループごとのカテゴリ数を取得する
例えば以下のプログラムでは、各stateごとに何種類のteamがあるかを取得する
print(team_df) # name state score team #0 Alice NY 4 A #1 Bob CA 3 A #2 Charlie NY 5 A #3 David CA 10 A #4 Eve FL 1 B #5 Fred FL 0 B #6 George NY 7 B team_df.groupby('state')['team'].agg(lambda x: len(x.unique())) #state #CA 1 #FL 1 #NY 2 #Name: team, dtype: int64さいごに
間違いや、もっと良い方法あるよ!って方は教えていただけると嬉しいです
- 投稿日:2020-02-18T17:56:07+09:00
PyEphemで宇宙がヤバい
はじめに
月の位置や月齢を取得したいなーと思って最初は安直にスクレイピングを考えていたんだけど、PyEphemというとっても便利なライブラリがあることを知った。
qiitaには1個もPyEphemのタグがついた記事がないので書いときます。PyEphemについて
- https://pypi.org/project/ephem/ (ソース)
- https://rhodesmill.org/pyephem/ (リファレンス)
詳しくはリファレンスを読むこととして、ここでは簡単な使い方を。
import ephem import datetime from math import degrees as deg # Body(天体)クラスのインスタンスを作成。 moon = ephem.Moon() # Observer(観測者)クラスのインスタンスを作成。 shinjuku = ephem.Observer() shinjuku.lat = '35.6846' shinjuku.lon = '139.7106' shinjuku.elevation = 60 shinjuku.date = datetime.datetime.utcnow() # 任意の年月日の位置を求められる # 観測者から見た天体を計算。 moon.compute(shinjuku) print(deg(moon.alt)) # 20.88288333068003(地平線からの仰角(degで度に変換)) print(deg(moon.az)) # 218.0421642706897(北を0度とした方角) print(moon.moon_phase) # 0.2820702016225599(月相) print(shinjuku.date - ephem.previous_new_moon(shinjuku.date)) # 24.138740752328886(月齢)JAXAやNASAなどの軌道情報提供サービスが提供するTLEというデータを用いて人工衛星の位置なども計算できる。
国際宇宙ステーション(ISS)のTLEは、
https://spaceflight.nasa.gov/realdata/sightings/SSapplications/Post/JavaSSOP/orbit/ISS/SVPOST.html
のTWO LINE MEAN ELEMENT SETというセクションに書かれている。(予測含めたくさんある)
値は軌道変更などにより変動するため、適宜取得する必要がある。
2020/048/17:15:00.000 (2月17日? 17時15分UTC?)時の値は、ISS 1 25544U 98067A 20048.52024880 .00016717 00000-0 10270-3 0 9000 2 25544 51.6378 225.5202 0004926 282.0303 78.0295 15.49172297 13304上記をもとに現在(shinjukuに設定した時刻)のshinjukuから見たISSの位置を計算してみる。
line1 = 'ISS' line2 = '1 25544U 98067A 20048.52024880 .00016717 00000-0 10270-3 0 9000' line3 = '2 25544 51.6378 225.5202 0004926 282.0303 78.0295 15.49172297 13304' iss = ephem.readtle(line1, line2, line3) iss.compute(shinjuku) print(deg(iss.alt)) # -19.005296771242083 print(deg(iss.az)) # 276.89649732972055西の空の地平線の下20度くらいのところにいるみたいですね。
おわりに
うちではラズパイで動かしているtwitterやLINEのbotで月の情報を表示するのに利用しています。

- 投稿日:2020-02-18T17:50:25+09:00
Lambda内でpythonを使用してCloudWatchに新規のロググループを生成する方法
概要
AWSのCloudWatchに新しいロググループをつくる。
その処理をLambdaでできないかを検証してみた。単純にロググループを生成する
makeimport boto3 logs = boto3.client('logs') response = logs.create_log_group( logGroupName = "log/group/name" )ログの保持期間を付与
makeresponse = logs.put_retention_policy( # 付与したいロググループ名 logGroupName = "log/group/name", # 保存期間(日)を設定 retentionInDays = 14 )参考にしたサイト
- 投稿日:2020-02-18T17:48:41+09:00
Courseraレッスンを完了しました
Data、R programming、Python、Google IT, および多くのレッスン、私はあなたが完了するのを手伝うことができます。 取得する証明書はあなたの名前であり、これを使用して仕事を見つけ、Linkedinに接続し、学校に申し込むことができます。 早ければ1日で完了することができます。 料金と詳細の相談は私に追加してください。財政援助(financial aid)申請パッケージが合格。Wechat:wongyikcheuk





- 投稿日:2020-02-18T17:41:24+09:00
python内でパラメータストアから値を取得する方法
概要
AWSのlambdaでパラメータストアの値を取得する方法をまとめる。
実際のコード
get# 1. boto3をインポート import boto3 ssm = boto3.client('ssm') # 2. get_parameterメソッドでパラメータを取得 response = ssm.get_parameter( # 3. パラストに登録されているキー名を設定 Name = '/add/company-codes', # 4. 値のみ取得したい場合はWithDecryption = False # 全ての情報を取得したい場合はWithDecryption = True WithDecryption=False ) value = response['Parameter']['Value']boto3で使用できるメソッドについて
ここにいくつかのメソッドが載っています↓
(上で使用しているget_parameterも)
- 投稿日:2020-02-18T17:33:21+09:00
DjangoのMarkdownx をサイトルート以外で使う
DjangoではMarkdownx というパッケージを使って、プレビューを出しながらマークダウン記法で書かれたソースのデバッグができる。
これはかなり便利なのだけど、Markdownx は、Djangoプロジェクトがサイトルート以外にデプロイされていると対応してくれない。たとえば、
apache2.confWSGIScriptAlias /prefix /django/project/project/wsgi.pyのようになっている場合、Markdownx のURLとしては
/prefix/markdownx/markdownifyのようになってくれないと困るが、Markdownxのコードでは、markdownx/settings.pyの中で固定値で書かれたものを使っているため、/markdownx/markdownifyにアクセスしようとして404になる。これを回避するには、以下のようにすればよい。
- プロジェクトの
urls.pyでmarkdownxのincludeにnamespaceを指定しておく(markdownxとする)markdownx/widgets.py内の`attrs.updateのうち、URL部分をreverse()で書き換える検索で引っかかってくるMarkdownxの解説では、
urlpatternsにnamespaceを指定してしないものもあるので、以下のようにnamespaceを指定しておく。settings.pyurlpatterns = [ path('markdownx/', include(('markdownx.urls','markdownx'))), :続いて、
markdownx/widgets.py(各環境の site-packages内にある)だが、元は以下のようになっている。(どこにあるんだよ、って時は、定番のfindで、
sudo find / -name 'widgets.py' | grep markdownx
で探しましょう。settings.pyもそこ。)widgets.py(オリジナル)attrs.update({ 'data-markdownx-editor-resizable': MARKDOWNX_EDITOR_RESIZABLE, 'data-markdownx-urls-path': MARKDOWNX_URLS_PATH, 'data-markdownx-upload-urls-path': MARKDOWNX_UPLOAD_URLS_PATH, 'data-markdownx-latency': MARKDOWNX_SERVER_CALL_LATENCY })大文字の変数は、markdownx/settings.py の中で定数として定義されていて、
widgets.pyの頭のところでimportされている。これらのうち、_URLS_PATHで終わる2つを以下のように書き換える。widgets.py(改変後)from django.urls import reverse : attrs.update({ 'data-markdownx-editor-resizable': MARKDOWNX_EDITOR_RESIZABLE, 'data-markdownx-urls-path': reverse('markdownx:markdownx_markdownify'), 'data-markdownx-upload-urls-path': reverse('markdownx:markdownx_upload'), 'data-markdownx-latency': MARKDOWNX_SERVER_CALL_LATENCY })これで、サイトルート以外にDjangoをデプロイしている場合にもMarkdownxを使うことができた。
まぁ、サイトルート以外で使う例はそれほどないのかもしれないけど、今回は既にあるPHPサイト(こいつがサイトルート)に追加でデプロイという関係からちょっとハマってしまった。
- 投稿日:2020-02-18T17:28:34+09:00
django auth.autenticateで_authenticate_with_backend functionが廃止されていた
背景
Djangoのバージョンを
1.11.1から2.2へアップデート中、
自分でカスタマイズさせといたauthenticationでエラーが出るようになった。django1.11.1のauthenticate
def authenticate(request=None, **credentials): """ If the given credentials are valid, return a User object. """ for backend, backend_path in _get_backends(return_tuples=True): try: user = _authenticate_with_backend(backend, backend_path, request, credentials) except PermissionDenied: # This backend says to stop in our tracks - this user should not be allowed in at all. break if user is None: continue # Annotate the user object with the path of the backend. user.backend = backend_path return user # The credentials supplied are invalid to all backends, fire signal user_login_failed.send(sender=__name__, credentials=_clean_credentials(credentials), request=request) def _authenticate_with_backend(backend, backend_path, request, credentials): args = (request,) # Does the backend accept a request argument? <---このコメント何。 try: inspect.getcallargs(backend.authenticate, request, **credentials) except TypeError: args = () credentials.pop('request', None) # Does the backend accept a request keyword argument? try: inspect.getcallargs(backend.authenticate, request=request, **credentials) except TypeError: # Does the backend accept credentials without request? try: inspect.getcallargs(backend.authenticate, **credentials) except TypeError: # This backend doesn't accept these credentials as arguments. Try the next one. return None else: warnings.warn( "Update %s.authenticate() to accept a positional " "`request` argument." % backend_path, RemovedInDjango21Warning ) else: credentials['request'] = request warnings.warn( "In %s.authenticate(), move the `request` keyword argument " "to the first positional argument." % backend_path, RemovedInDjango21Warning ) return backend.authenticate(*args, **credentials)↓自分で作ったauthentication
from django.contrib.auth.backends import ModelBackend from .models import UserProfile class SignedRequestBackend(ModelBackend): """認証を別途行うため、素通りの認証バックエンドを実装""" def authenticate(self, user=None, user_profile=None, **kwds): if user is None: return if not user.is_authenticated or not user.is_active: return if municipality_user_profile is None: return if not isinstance(user_profile, UserProfile): return if user.id != user_profile.user_id: return return userdjango2.2のauthenticate
def authenticate(request=None, **credentials): """ If the given credentials are valid, return a User object. """ for backend, backend_path in _get_backends(return_tuples=True): try: inspect.getcallargs(backend.authenticate, request, **credentials) except TypeError: # This backend doesn't accept these credentials as arguments. Try the next one. continue try: user = backend.authenticate(request, **credentials) except PermissionDenied: # This backend says to stop in our tracks - this user should not be allowed in at all. break if user is None: continue # Annotate the user object with the path of the backend. user.backend = backend_path return user # The credentials supplied are invalid to all backends, fire signal user_login_failed.send(sender=__name__, credentials=_clean_credentials(credentials), request=request)【結論】 _authenticate_with_backend functionが廃止されてます。
inspect.getcallargsをデバッグしてみたところ
【エラー原因】 argsに['self', 'user', 'user_profile']って代入される(ここには['self', 'request']と入ってほしい)
- あ、なんかコメントあったな...
# Does the backend accept a request argument?- 自分で作ったauthenticationの引数に
requestを設定 → エラーが解決されました。
- 投稿日:2020-02-18T17:27:45+09:00
[python] コールバック関数(引数に関数を渡す)
javascriptとpython
javascriptconst sayHello = word => console.log(word); const func = callback => { console.log('ここはsayHelloが呼ばれたあとに実行される'); return callback; } func(sayHello('hello'));実行結果hello ここはsay_somethingが呼ばれたあとに実行されるpythondef say_something(word): print(word) def func(callback): print('ここはsay_somethingが呼ばれたあとに実行される') return callback func(say_something('hello'))実行結果hello ここはsay_somethingが呼ばれたあとに実行される
- 投稿日:2020-02-18T16:30:12+09:00
なぜかpip3がpython2.7でのインストールになってしまった時用のメモ
python3にpip3を使ってパッケージをインストールしたいのになぜかpip3のpythonのバージョンがpython2.7でpython3でそのパッケージがインストールできないというエラーが起きてしまいました.
~: python3 -V Python 3.7.4 ~/program/scrape: pip3 -V pip 20.0.2 from /Users/eijikudo/Library/Python/2.7/lib/python/site-packages/pip (python 2.7)python3.7 -m pip install パッケージ名というようにpythonのバージョンを指定してinstallしたらできました。
こんな事ができるんですね。。。
- 投稿日:2020-02-18T16:25:09+09:00
基本的な機械学習の手順:①分類モデル
はじめに
最近は、AutoMLと言われるプログラミングをしないで、簡易に機械学習を実現できるサービスも増えてきました。
ただ、機械学習のプログラミングを全く知らずに、AutoMLだけで機械学習を知った気になるのは、自動運転の車でドライビングテクニックを語るようなもの(違うか)。そこで、基本的な機械学習の手順を整理しておきたいと思います。(とはいえ、scikit-learnをそのまま使いますが。。。
例として、小売で実施しているキャンペーンの反応有無を、商品の購入金額から予測するモデルをつくりましょう。分析環境
Google Colaboratory
対象とするデータ
resultをキャンペーンの反応有無、product1~を商品の購入金額として作成します。
id result product1 product2 product3 product4 product5 001 1 2500 1200 1890 530 null 002 0 750 3300 null 1250 2000 1.データ準備
元データは普段から、BigQueryに入っているのですが、それを手元にもってきて、データフレーム(df)に入れたところから、データの準備をスタートします。
1-1.欠損値補完
外れ値等は事前に除外していますが、id別の商品購入金額出すと必ず欠損が出る(その商品を買っていない)ため、欠損値を補完する必要があります。この様なケースだと、その商品を買っていないため、ゼロで補完が最適ですが、それ以外に平均値や中央値で補完するケースもあります。
#ゼロで補完 df.fillna(0, inplace=True) #平均値で補完 df.fillna(df.mean(), inplace=True) #中央値で補完 df.fillna(df.median(), inplace=True) #レコードを削除 df.dropna(inplace=True)1-2.特徴量選択
特徴量の選択は、モデルの学習時間短縮や精度向上に必須なのでぜひ実施しましょう。
個人的には、AutoMLはそのためだけに実施
特徴量の選択方法は、Filter Method, Wrapper Method, Embedded Methodの3種類があります。
それぞれの詳しい解説は、こちらが分かりやすかったです。今回は、モデル学習をしながら変数を選択するEmbedded Methodを用います。
import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectFromModel # 目的変数 label_col = "result" # 説明変数(特徴量) feature_cols = ["product1","product2","product3","product4","product5"] # numpy配列に変更 label = np.array(df.loc[0:, label_col]) features = np.array(df.loc[0:, feature_cols]) # 変数選択 ## ここでは分類を想定して、ランダムフォレスト(RandomForestClassifier)を用いる clf = RandomForestClassifier(max_depth=7) ## Embedded Methodを用いて変数を選択 feat_selector = SelectFromModel(clf) feat_selector.fit(features, label) df_feat_selected = df.loc[0:, feature_cols].loc[0:, feat_selector.get_support()]1-3.学習データ・検証データ分割
データ準備の最後として、データを学習用と検証用に分けます。
from sklearn.model_selection import train_test_split # 目的変数と説明変数を分割 state = np.random.RandomState(1) train_features, test_features, train_label, test_label = train_test_split(features, label, random_state=state)2.データ分析
さて、データの準備ができたので、購買傾向からResultを予測するモデルを作成しましょう。
分類器は、シンプルながら高い精度が期待できる、ランダムフォレストを用います。
精度向上を図るために、Grid SearchとCross Validationを実施しましょう。from sklearn.model_selection import GridSearchCV # 分類器 estimator = RandomForestClassifier() # パラメーター param = { 'n_estimators': [5, 10, 50, 100, 300], 'max_features': [10, 20], 'min_samples_split': [3, 5, 10, 20], 'max_depth': [5, 10, 20] } # 分析実行 clf = GridSearchCV( estimator, param_grid=param, cv=5 ) clf = clf.fit(train_features, train_label)3.モデル評価
できたモデルを評価します。単純に、沢山の人のresultを当てられたという正確性(Accuracy)だけではなく、resultが「1」になると予測した人のうちどこまでが正解だったのかという適合率(Precision)や、実際にresultが「1」だった人をどこまで補足できたかという再現率(Recall)も見ていきます。
それぞれの指標の意味については、こちらが詳しかったです。
from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score accuracy=accuracy_score(test_target, clf.predict(test_features)) precision=precision_score(test_target, clf.predict(test_features)) recall=recall_score(test_target, clf.predict(test_features)) print("Accuracy : "+accuracy+"%") print("Precision : "+precision+"%") print("Recall : "+recall+"%")これらの結果として、各精度が狙ったレベルを超えれば、ひとまずOKというところでしょう。
おわりに
自分の頭の整理も兼ねて、超基本的な機械学習の手順(というか、scikit-learnの手順)をまとめてみました。
今後、他の手順も整理していくとともに、新たなテクノロジー・サービスも使っていきたいと思います。
- 投稿日:2020-02-18T16:19:30+09:00
Pythonを使い、iOSアプリのレビューを取得して、Lineで知る
自身の出したアプリのレビュー件数を取って毎日Lineで知りたい時ないですか?
自分にはありました。
そこで、作成。今回はiOS用に作成したものになります。
使用ライブラリ
- requests
- APIを叩くのに
- urllib3
- レスポンスをJSONに分解
- line-bot-sdk
- LineBOT
コマンド
pip install line-bot-sdk pip install requests pip install urllib3実際のコード
GetReview.pyfrom linebot import LineBotApi from linebot.models import TextSendMessage from linebot.exceptions import LineBotApiError import requests import json import urllib.request import urllib.parse //LINEでメッセージを送るためのキー LINE_ACSESS_KEY = "LINE_ACSESS_KEY" //送信先のLINEのID LINE_USER_KEY = "LINE_USER_KEY" def push_info(json_input, context): line_bot_api = LineBotApi(LINE_ACSESS_KEY) text_message = get_text_message() try: line_bot_api.push_message(LINE_USER_KEY, TextSendMessage(text=text_message)) except LineBotApiError as e: print(e) def get_text_message(): review_url = "https://itunes.apple.com/jp/rss/customerreviews/id=アプリID/json" headers = { "Content-Type":"application/json", } response_obj = urllib.request.Request(review_url, headers=headers) //tryでエラーハンドリング try: with urllib.request.urlopen(response_obj) as response: response_body = response.read().decode("utf-8") result_objs = json.loads(response_body) result_obj = result_objs["feed"] review_count = len(result_obj["entry"]) messages = "レビュー数は" + str(review_count) + "件です" return messages except urllib.error.HTTPError as e: if e.code >= 400: messages = e.reason return messages else: return eこれを圧縮して、AWSLambdaなどに設置してCloudWatchで定期実行すれば、レビューが全件取れます。
Lambdaにあげる時は、作業ディレクトリに移動(コマンド「cd」で)後、ライブラリのインストール時にオプションで「-t」 をつけてください。注意
その時の全件(コメントのついたレビュー)しか取れないので、差分だけ欲しいなどの時は、取得したデータをDBなどに保存して差分を出す必要があります。
github
- 投稿日:2020-02-18T16:02:42+09:00
Quantxで出来高移動平均線を実装してみた
自己紹介
某M大学理工学部2年の株式会社SmartTradeでインターンをしている益川と申します。まだまだ初心者なので拙いところもたくさんあるかと思いますが、最後までお付き合いいただけたら幸いです。
この記事でやること
当社インターン3週間目ということで、Quantx Factoryで実装したアルゴリズムを紹介したいと思います。今回は有名なテクニカル指標の一つである、出来高移動平均線による株の売買アルゴリズム実装します。
QuantX Factoryとは?
株式会社Smart Tradeが
金融の民主化
を理念に、トレードアルゴリズムを誰もが簡単に開発することのできるプラットフォーム"QuantX Factory"を開発しました。
強み
- 初心者の挫折しがちな環境構築が不要
- 各銘柄の終値や高値、出来高などの各種データが用意されていて,データセットの用意が不要
- 開発したトレードアルゴリズムは審査を通過すればQuantX Storeで販売可能
- 上級者の方にはQuantX Labといった開発環境も (引用元:公式ドキュメント)
本題
出来高移動平均線の仕組みを理解する
出来高とは
- その日売買の成立した株数のこと
- 売買の活発具合を把握できる
- 下画像下部のヒストグラムのこと
「出来高は株価に先行する」
と言われ、株価の動きよりも先に出来高に変化がみられると言われています。つまり、出来高の移動平均線を用いたらより早く買いサインや売りサインが分かるかもしれません
移動平均線とは
- 数日分の終値を合計して日数で割ることで得られる平均値をプロットした折れ線グラフのこと
- 「短期線」と「長期線」の二本を観察しながら、売買のサインを見極める
- 短期線:参照する日数の短い移動平均線(一般的に5日)
- 長期線:参照する日数の長い移動平均線(一般的に25日)
- ゴールデンクロス時に買い、デッドクロス時に売りのシグナルをそれぞれ出す
- 詳細はこちらを参考にしてください
ゴールデンクロス、デッドクロスとは
ゴールデンクロス
- 短期線が長期線を上回る瞬間のことであり、下落トレンドが上昇トレンドに転換することを示す
- 買いのサインとして使われる
デッドクロス
- 短期線が長期線を下回る瞬間のことで、上昇トレンドが下落トレンドに転換することを示す。
- 売りのサインとして使われる
出来高移動平均線とは
- 数日分の終値の代わりに、数日分の出来高の移動平均をとったもの
- 買いシグナル、売りシグナルの出し方は移動平均線と同様
短期線と長期線の状況 判断の目安 ゴールデンクロス発生 買いシグナル 短期線 > 長期線 上昇トレンド 短期線 < 長期線 下落トレンド デッドクロス発生 売りサイン コード
# Sample Algorithm # ライブラリーのimport # 必要ライブラリー import maron import maron.signalfunc as sf import maron.execfunc as ef # 追加ライブラリー # 使用可能なライブラリに関しましては右画面のノートをご覧ください① import pandas as pd import talib as ta import numpy as np # オーダ方法(目的の注文方法に合わせて以下の2つの中から一つだけコメントアウトを外してください) # オーダー方法に関しましては右画面のノートをご覧ください② #ot = maron.OrderType.MARKET_CLOSE # シグナルがでた翌日の終値のタイミングでオーダー ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー #ot = maron.OrderType.LIMIT # 指値によるオーダー # 銘柄、columnsの取得 # 銘柄の指定に関しては右画面のノートをご覧ください③ # columnsの取得に関しては右画面のノートをご覧ください④ def initialize(ctx): # 設定 ctx.logger.debug("initialize() called") ctx.high_term = 10 ctx.holding_days = 5 ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.2914", #JT(日本たばこ産業) "jp.stock.8766", #東京海上ホールディングス "jp.stock.8031", #三井物産 "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.9437", #NTTドコモ "jp.stock.4502", #武田薬品工業 "jp.stock.8058", #三菱商事 "jp.stock.9433", #KDDI "jp.stock.9432", #日本電信電話 "jp.stock.7267", #ホンダ(本田技研工業) "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.4503", #アステラス製薬 "jp.stock.4063", #信越化学工業 "jp.stock.7974", #任天堂 "jp.stock.6981", #村田製作所 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.9020", #東日本旅客鉄道 "jp.stock.8802", #三菱地所 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9984", #ソフトバンクグループ "jp.stock.6861", #キーエンス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6954", #ファナック "jp.stock.7203", #トヨタ自動車 "jp.stock.7751", #キヤノン "jp.stock.4452", #花王 "jp.stock.6098", #リクルートホールディングス ], "columns": [ "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) "volume_adj", # 出来高 #"txn_volume", # 売買代金 ] } } ) # シグナル定義 def _my_signal(data): #出来高のデータを取得 vol = data["volume_adj"].fillna(method = "ffill") syms = data.minor_axis # 銘柄リストの作成 dates = data.major_axis # 日付リストの作成 #出来高移動平均 mav5 = vol.rolling(window = 5, center = False).mean() mav25 = vol.rolling(window = 25, center = False).mean() ratio = mav5 / mav25 #出来高移動平均線のゴールデンクロス、デッドクロス vol_golden = (ratio >= 1.04) & (ratio.shift(1) < 1.0) #(mav5 > mav25) & (mav5.shift(1) < mav25.shift(1)) vol_dead = (ratio <= 0.97) & (ratio.shift(1) > 1.0) #(mav5 < mav25) & (mav5.shift(1) > mav25.shift(1)) #shiftメソッドによりDataFrameに入っているデータを一つずらし、前日の比率と比較してゴールデンクロス、デッドクロスを判断しています #売買シグナル生成部分 buy_sig = vol_golden sell_sig = vol_dead #market_sigという全て0が格納されているデータフレームを作成 market_sig = pd.DataFrame(data=0.0, columns=syms, index=dates) #buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 # ctx.logger.debug(market_sig) return { "mav5:g2": mav5, "mav25:g2": mav25, "market:sig": market_sig, } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): # 日ごとの処理部分 ''' current: pd.DataFrame ''' # initializeの_my_signalで生成したシグナルをmarket_sigに格納 market_sig = current["market:sig"] done_syms = set([]) # 利益確定及び損切りが行われた銘柄を格納するset型 none_syms = set([]) # portfolio.positionsに存在しない銘柄を格納するset型 # portfolio.positions(保有している銘柄)に対象銘柄(sym)が存在するかのチェック for (sym, val) in market_sig.items(): if sym not in ctx.portfolio.positions: none_syms.add(sym) # portfolio.positions(保有している銘柄)のそれぞれの銘柄(sym)の保有株数が0ではないかのチェック for (sym, val) in ctx.portfolio.positions.items(): if val["amount"] == 0: none_syms.add(sym) # 損切り、利益確定(利確)の設定 # 所有している銘柄を1つずつ確認する繰り返し処理 for (sym, val) in ctx.portfolio.positions.items(): # 損益率の取得 returns = val["returns"] if returns < -0.03: # 損益率が-3%未満(絶対値で3%より大きい損)の場合 # 損切りのための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) elif returns > 0.05: # 損益率が+5%より大きい場合 # 利益確定(利確)のための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) buy = market_sig[market_sig > 0.0] # 買いシグナル for (sym, val) in buy.items(): # 買いシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if sym in done_syms: continue # 処理をスキップ # 買い注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=ot, comment="SIGNAL BUY") # 買い注文のログを下に出力したい場合は以下のコメントアウトを外してください(長期間注意) #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) sell = market_sig[market_sig < 0.0] # 売りシグナル for (sym, val) in sell.items(): # 売りシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if (sym in done_syms) | (sym in none_syms): continue # 処理をスキップ # 売り注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot, comment="SIGNAL SELL")
- 完成コードはこちら
- 各行のコメントにアルゴリズムの詳細は記述してあります。
結果
評価・考察
- SharpRatio(投資効率)はそこそこ良い
- 一年間の損益率も18%と上々
- 個別の銘柄を見ると急落、急騰に弱いかも?
- 例:武田薬品工業の2019年2月18日から2020年2月18日までの値動き

終わりに
この3週間でQuantX Factoryによる基本的なアルゴリズム開発の仕方が大分身についてきました!
今後は出来高移動平均線と他のテクニカル指標を組み合わせたり、機械学習を取り入れるなどして、アルゴリズムの品質をもっと向上させたく思います。以上でこの記事を終えようと思います。拙い文章を最後まで読んでいただきありがとうございました!免責注意事項
このコード・知識を使った実際の取引で生じた損益に関しては一切の責任を負いかねますので御了承下さい。
materials
https://qiita.com/Miku_F/items/49c20fcbbbfae59cb9a6

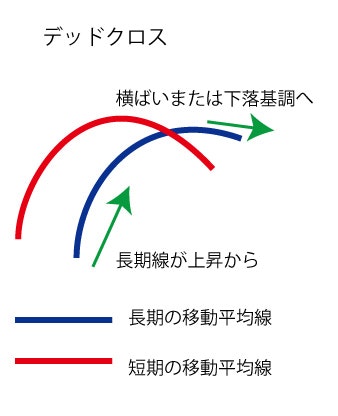

- 投稿日:2020-02-18T15:02:05+09:00
Benchmarks GameのRust vs C++をスクレイピングして決着をつける
Benchmarks GameのRust vs C++をスクレイピングして決着をつける
はじめに
注意: この記事はRust贔屓とスクレイピングの練習でできています。
Benchmarks Gameとはプログラミング言語の速度を比較するサイトです。
プログラミング言語の速さに興味がある方ならご存知でしょう。
このサイトのトップに2019年2月の現在書いている通り、現実のプログラムの動作はベンチマークとかなり異なるのですがベンチマークジャンキーには関係ないことです。
現実は置いておいてここのデータを元にRust vs C++に決着をつけましょう。この記事を書くきっかけとなったのは久しぶりにRust vs C++を見ると、ずっとちょい負けしていたRustがついにC++を超えているように見えたからです。
表の見方を説明しておきますと、secsが実行時間、memが使用メモリ、busyがCPU時間です (多分) 。gzはわかりません。
secs, mem, busyの小ささが概ね高速、省メモリ、省CPUに対応しています。
とりあえずsecsに注目してみましょう。
勝ち負けの数を比べると6勝4敗でRustの勝ち越しです。
しかし、もし辛勝6と大敗4だとしたら勝ったとは言えないでしょう。
平均を計算して決着をつけなければなりません。
ということでまずデータをスクレイピングしていきます。
スクレイピングのコードなんて興味ないという方は[データの処理][#データの処理]へ飛んでください。まとまったソースコードはリポジトリにあります。
動作はPython3.8で確認しています。スクレイピング
事前に
beautifulsoup4とlxmlをインストールしておいてください。
この表現で合っているのか自信がないですが、beautifulsoup4とlxmlはそれぞれHTMLのパースのフロントエンドとバックエンドです。インポートは次のようになります。
from urllib.request import urlopen from bs4 import BeautifulSoupそしてまずHTMLをダウンロードして
BeutifulSoupオブジェクトに変換します。rust_gpp_url = 'https://benchmarksgame-team.pages.debian.net/benchmarksgame/fastest/rust-gpp.html' with urlopen(rust_gpp_url) as f: # lxmlでないと閉じタグを省略しているbenchmarksgameのHTMLをパースできない soup = BeautifulSoup(f, 'lxml')そしてRust vs C++のソースをグッと睨むと、tbodyの中に各ベンチマークが入っていることがわかるので、頑張って数値を取り出します。
tbodies = soup.find_all('tbody') # 最後のテーブルは処理系の情報なので取り除く tbodies = tbodies[:-1] secs_table = {'Rust': [], 'C++': []} for tbody in tbodies: trs = tbody.find_all('tr') # 3, 4番目のtr要素がそれぞれRust, C++のベンチマークである rust, cpp = trs[2], trs[3] # その中のtd要素の2-5番目がそれぞれsecs, mem, gz, busyである secs = rust.find_all('td')[1].string secs_table['Rust'].append(float(secs)) secs = cpp.find_all('td')[1].string secs_table['C++'].append(float(secs)) print(secs_table)データの処理
取り出した数値から平均を計算します。
ここで秒数の平均を取るのはあまりいい方法とは言えないでしょう。
おそらく各問題のスケールが均一になっていません。
というわけで問題毎にRustの秒数とC++の秒数の比の平均や中央値を計算することになります。
しかしこの際にも注意すべきことがあり、通常の平均 (相加平均) を取るのは不自然だということです。
例えばRustが問題1, 2にそれぞれ2, 2秒かかり, C++が2, 4秒かかっている場合、Rust / C++ の平均は$$
\frac{2 / 2 + 2 / 4}{2} = \frac{3}{4}
$$ですが、C++ / Rust の平均は
$$
\frac{2 / 2 + 4 / 2}{2} = \frac{3}{2}
$$となりC++から見るとRustは3/4倍の時間で問題を解くことができるが、Rustから見るとC++は3/2倍の時間がかかるというように、変なことになっています。
比のように積や逆数を考えるのが自然な対象に関しては、相乗平均を考えるのが自然です。
定義を確認しておくと、$a_0, a_1, ..., a_{n - 1}$の通常の平均 (相加平均) は$$
\frac{a_0 + a_1 + \dots + a_{n - 1}}{n}
$$であるのに対し、相乗平均は
$$
\sqrt[n]{a_0 a_1 \dots a_{n - 1}}
$$というようにちょうど足し算をかけ算にし、$n$分の$1$を$n$乗根に変えたような形をしています。
計算するコードは次のようになります。print('C++ / Rust') for (key, rust_values), cpp_values in zip(table['Rust'].items(), table['C++'].values()): n = len(rust_values) # 中央値の計算のために収集する ratios = [] mean = 1.0 for rust_value, cpp_value in zip(rust_values, cpp_values): ratio = cpp_value / rust_value ratios.append(ratio) mean *= ratio mean **= 1 / n print(f'{key.ljust(4)} - mean: {mean:.2f}', end=', ') ratios.sort() if n % 2 == 1: median = ratios[n // 2] else: # 中央値が2つある場合はそれらの相乗平均を取る median = (ratios[n // 2 - 1] * ratios[n // 2]) ** (1 / 2) print(f'median: {median:.2f}')実行結果:
C++ / Rust secs - mean: 1.10, median: 1.02 mem - mean: 1.09, median: 1.11 gz - mean: 0.95, median: 1.02 busy - mean: 1.08, median: 1.05Rustのほうが1割近く速いです。
流石に勝ちすぎな気がするのでRustが大差をつけている問題のreverse-complementを過去のものと照らし合わせるとC++が省メモリと引き換えにかなり遅くなっているようです。(Rustがk-nucleotideで大差をつけられるのはいつもどおりのようでした)
そこでreverse-complement抜きで計算すると次のようになります。C++ / Rust secs - mean: 0.99, median: 1.02 mem - mean: 1.17, median: 1.24 gz - mean: 0.99, median: 1.10 busy - mean: 1.03, median: 1.05完全勝利とはいきませんでしたが、これならもうC++よりちょっと遅いとは言えないのではないでしょうか。
そしてもう一度確認しておきますが今はRustが明確に速いです。
せっかくだから配慮前の結果をもう一度確認しておきましょう。C++ / Rust secs - mean: 1.10, median: 1.02 mem - mean: 1.09, median: 1.11 gz - mean: 0.95, median: 1.02 busy - mean: 1.08, median: 1.05結論
Pythonの勝ち
蛇足
この記事のコードブロックの4/4がPythonなのでPythonの完勝でした。
そういえば、いつの間にかRust vs Clangというのができていて、RustとC clangを比較できるようになっていました。
同じLLVMバックエンド同士ならならC相手でも圧勝です。
まあGCCバックエンドを持たないのがRustなのですが。
- 投稿日:2020-02-18T14:40:04+09:00
【Python】誰でもできる!LINEのトーク履歴からマルコフ連鎖でチャットボット作成【markovify】
はじめに
LINEのトーク履歴からチャットボットを作成する方法を誰でもできるようになるべく丁寧に解説します。
マルコフ連鎖の詳細な解説は本記事では行わないため別の参考書等をご参照ください。実装
以下ではコードの解説を行っていきます。GitHubのレポジトリも載せておくので併せてご活用ください。
LINEのトーク履歴の抽出
まずはトーク履歴を入手しましょう。トーク画面の右上の矢印をタップし出てきた
設定を押してください。(下図参照)
次に,トーク履歴の送信(下図参照)を押します。トーク履歴がテキストファイル.txtでエクスポートされるので適当な場所に保存してください。自分は軽量なファイルはだいたいgmailの下書きに一時保存してPCからダウンロードしています。入手したデータはraw_data.txtとしてdataディレクトリ内に置いておいてください。
データ整形
入手したデータを見てみると以下のような形式になっていると思います。
sample.txt[LINE] huga子とのトーク履歴 保存日時:2020/2/14 15:15 2018/4/6(金) 22:45 hoge男 こんばんは!今日はありがとうございました! 22:58 huga子 こちらこそありがとうございました? 2018/4/7(土) 00:40 hoge男 またよろしくお願いします!名前や日付など無駄な文章が入ってしまっていますね。まずはこれを取り除きましょう。以下の作業はGoogle Colaboratory上またはJupyter Notebook上で行うと行いやすいと思います。コードの全文はGitHub上の
data_shaping.ipynbをご参照ください。使用する外部ライブラリは,
neologdn(文章の表現を正規化するライブラリ) とemoji(絵文字を除去するライブラリ) です。以下のコマンドでインストールできますが,使わなくてもまともな出力になるようなので面倒な方は使わなくても大丈夫です。
pip install neologdnpip install emojidata_shaping.pyimport neologdn import emoji for i, line in enumerate(lines): # 西暦の行を削除 if ('2018' in line) or ('2019' in line) or ('2020' in line): line = '' # 会話でないものを削除 elif ('[スタンプ]' in line) or ('[ファイル]' in line) or ('[写真]' in line) or ('[動画]' in line) or ('アルバム' in line) or ('ノートに' in line) or ('通話' in line) or ('http' in line): line = '' # 時刻を削除 if len(line) >= 4: if line[1] == ':': line = line[4:] elif line[2] == ':': line = line[5:] # 表現を正規化 line = neologdn.normalize(line) # 絵文字を除去 line = ''.join(['' if c in emoji.UNICODE_EMOJI else c for c in line]) # リストから空の文字列を削除 lines = list(filter(lambda a: a != '', lines))次に発言を自分のものと相手のものに分けます。
hoge男とhuge子は自分と相手の名前に変えてください。data_shaping.py# どちらの発言かを判定しリストに格納 my_name='hoge男' partner_name='huge子' my_remarks=[] partner_remarks=[] for line in lines: if line[0:3]==my_name[0:3]: speaker=my_name my_remarks.append(line.replace(my_name,'')) elif line[0:3]==partner_name[0:3]: speaker=partner_name partner_remarks.append(line.replace(partner_name,'')) else: if speaker==my_name: my_remarks.append(line.replace(my_name,'')) else: partner_remarks.append(line.replace(partner_name,''))最後に発言をtxtファイルに書き込みます。
data_shaping.pymy_remarks_file_path = './../data/my_remarks.txt' partner_remarks_file_path = './../data/pa_remarks.txt' # 自分の発言をtxtファイルに書き込み with open(my_remarks_file_path, mode='w') as f: f.write('\n'.join(my_remarks)) # 相手の発言をファイルに書き込み with open(partner_remarks_file_path, mode='w') as f: f.write('\n'.join(partner_remarks))以上でデータの整形は終わりです。お疲れ様でした。あと少しです。
マルコフ連鎖
いよいよ用意したデータを用いて文章を自動生成します。
使用する外部ライブラリはmarkovify(マルコフ連鎖用ライブラリ) とMeCab(分かち書き用ライブラリ) です。以下のコマンドでインストールできます。今回は必ずインストールしてください。
pip install mecab-python3pip install markovifymarkov.pyimport markovify import MeCab my_remarks_file_path = './../data/my_remarks.txt' partner_remarks_file_path = './../data/partner_remarks.txt' with open(my_remarks_file_path) as f: text = f.read() parsed_text = MeCab.Tagger('-Owakati').parse(text) text_model = markovify.Text(parsed_text, state_size=3) for _ in range(10): sentence = text_model.make_short_sentence(100, 20, tries=20).replace(' ', '') print(sentence)以下に自分が試した際の出力例を示します。一応文章っぽくなっていますね。
出力例そんなことないんですよね... ほぼ週1だと思う?って思ったけど昨日の夕飯焼き肉だった... これからどうなるんだろう嫌とかでは.......?エラー(むしろ本題)
実は自分の発言データでは正常に学習できたのですが,相手の発言データを使うと以下のエラーが出てしまっています......使用できない文字が含まれているのかと思い色々と試したのですが一向に解決しません.......
どなたか原因が分かる方がいらっしゃれば教えていただければと思います。error--------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-6-776ef0b0de18> in <module>() 10 11 parsed_text = MeCab.Tagger('-Owakati').parse(text) ---> 12 text_model = markovify.Text(parsed_text, state_size=3) 13 /usr/local/lib/python3.6/dist-packages/markovify/text.py in __init__(self, input_text, state_size, chain, parsed_sentences, retain_original, well_formed, reject_reg) 48 # Rejoined text lets us assess the novelty of generated sentences 49 self.rejoined_text = self.sentence_join(map(self.word_join, self.parsed_sentences)) ---> 50 self.chain = chain or Chain(self.parsed_sentences, state_size) 51 else: 52 if not chain: /usr/local/lib/python3.6/dist-packages/markovify/chain.py in __init__(self, corpus, state_size, model) 51 self.compiled = (len(self.model) > 0) and (type(self.model[tuple([BEGIN]*state_size)]) == list) 52 if not self.compiled: ---> 53 self.precompute_begin_state() 54 55 def compile(self, inplace = False): /usr/local/lib/python3.6/dist-packages/markovify/chain.py in precompute_begin_state(self) 97 begin_state = tuple([ BEGIN ] * self.state_size) ---> 98 choices, cumdist = compile_next(self.model[begin_state]) 99 self.begin_cumdist = cumdist 100 self.begin_choices = choices KeyError: ('___BEGIN__', '___BEGIN__', '___BEGIN__')おわりに
読んで頂きありがとうございました。
次はLSTM等を用いた対話型チャットボットを作成したいと考えていますが,自前の1対1の対話型のデータセットを作成するのは大変そうですね...自然言語処理は素人なので何か良いアイデアがあったら教えていただけたらと思います。

- 投稿日:2020-02-18T14:37:41+09:00
Raspberry+am2302温湿度センサーで温湿度を計測する
GPIOに繋がる
https://github.com/adrianlois/RaspberryPi-sensor-dht22-am2302-thingspeak を参考して
am2302温湿度センサーをraspberry piのGPIOに繋がる。Pythonの設置
pip install --upgrade pip setuptools wheel
pip install Adafruit_DHTAdafruit_DHTはpython2とpython3両方対応しています
python code
AdafruitDHT.py
import sys import Adafruit_DHT sensor_args = { '11': Adafruit_DHT.DHT11, '22': Adafruit_DHT.DHT22, '2302': Adafruit_DHT.AM2302 } if len(sys.argv) == 3 and sys.argv[1] in sensor_args: sensor = sensor_args[sys.argv[1]] #センサーのタイプー pin = sys.argv[2] #GPIOのpinナンバー else: print('Usage: sudo ./Adafruit_DHT.py [11|22|2302] <GPIO pin number>') print('Example: sudo ./Adafruit_DHT.py 2302 4 - Read from an AM2302 connected to GPIO pin #4') sys.exit(1) humidity, temperature = Adafruit_DHT.read_retry(sensor, pin) if humidity is not None and temperature is not None: print('Temp={0:0.1f}* Humidity={1:0.1f}%'.format(temperature, humidity)) else: print('Failed to get reading. Try again!') sys.exit(1)実行
python AdafruitDHT.py 2302 4
- 投稿日:2020-02-18T13:21:02+09:00
THORLABSのカメラCS2100M-USBをPythonで動かす【研究用】
はじめに
THORLABS(ソーラボ)のカメラCS2100M-USBをPythonで動かす方法についてシェアしたいと思います。前回の記事THORLABS自動ステージをPythonで動かす【研究用】に使用したカメラと同じカメラです。
サンプルプログラムの実行結果
開発環境
- Windows10 (x64)
- Python3.6
- Anaconda3
使用する機材
インストール
使用できる言語は以下の通りです。充実していますね。
C、C++、C#、Python、Visual Basic .NET API
LabVIEW、MATLABならびにµManagerサードパーティーソフトウェアSDK(Software Development kits)はWindows®7、10用のThorCam™ソフトウェアをダウンロードすると一緒についてきます。
さっそくダウンロードしていきましょう。1. ThorCam™ソフトウェアのダウンロード
まず、ThorCam™ソフトウェアをダウンロードします。
ThorCam™ Software for Scientific and Compact USB Cameras
赤枠の①をクリック
ダウンロード画面
てきとうにポチポチして完了。
2. ディレクトリの確認
以下の名前のフォルダが生成されていることを確認してください。
このフォルダ内で作業します。
C:\Program Files\Thorlabs\Scientific Imaging3. あれやこれや
Scientific_Camera_Interfaces.zipを解凍します。
解凍できない場合は、管理者権限で解凍を選択するとうまくいきます。
C:\Program Files\Thorlabs\Scientific Imaging\Scientific Camera Support\Scientific_Camera_Interfaces\Scientific Camera Interfaces
にSDKが入っています。
Python README.txtに従ってあれやこれやしましょう。(これが面倒)
以下のディレクトリにあるファイルを全選択し、
C:\Program Files\Thorlabs\Scientific Imaging\Scientific Camera Support\Scientific_Camera_Interfaces\Scientific Camera Interfaces\SDK\Native Compact Scientific Camera Toolkit\dlls\Native_64_lib以下のディレクトリにコピーします(写真参照)。
C:\Program Files\Thorlabs\Scientific Imaging\Scientific Camera Support\Scientific_Camera_Interfaces\Scientific Camera Interfaces\SDK\Python Compact Scientific Camera Toolkit\dlls\64_lib
続いて、以下のディレクトリにある
thorlabs_tsi_camera_python_sdk_package.zipを管理者権限で解凍します。
C:\Program Files\Thorlabs\Scientific Imaging\Scientific Camera Support\Scientific_Camera_Interfaces\Scientific Camera Interfaces\SDK\Python Compact Scientific Camera Toolkit解凍したフォルダの中に入っている
thorlabs_tsi_sdkフォルダをコピーして
C:\Program Files\Thorlabs\Scientific Imaging\Scientific Camera Support\Scientific Camera Interfaces\SDK\Python Compact Scientific Camera Toolkit\examplesに貼り付けます。
4. 必要なモジュールのインストール
以下のモジュールをpipまたはcondaコマンドでインストールします。
- pillow >= 5.4.1
- tifffile >= 2019.3.8
- numpy
準備完了です。
ここまで出来たらいったん休憩しましょう。サンプルプログラムの動作確認
exampleフォルダに格納されている、
tkinter_camera_live_view.py
を実行してみましょう。
以下の写真のようにウィンドウが1つ出現し、動画が表示されます。
今回はテストチャートを観察しています。
カスタムするためには
サンプルプログラムをカスタムするためのクラスの説明書が用意されています。
以下のファイルを参照してください。
C:\Program Files\Thorlabs\Scientific Imaging\Documentation\Scientific Camera Documents\Thorlabs_Camera_Python_API_Reference.pdf
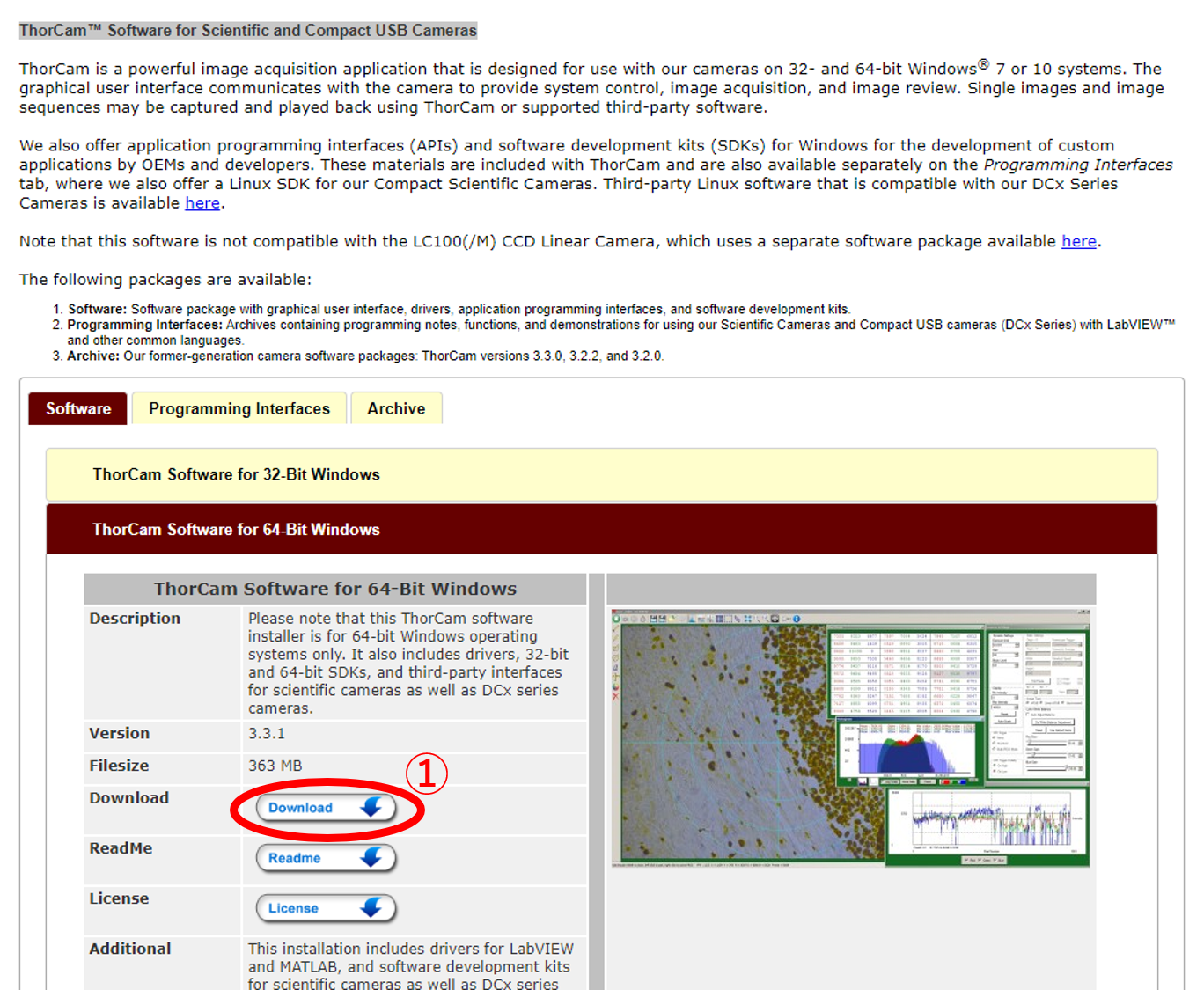
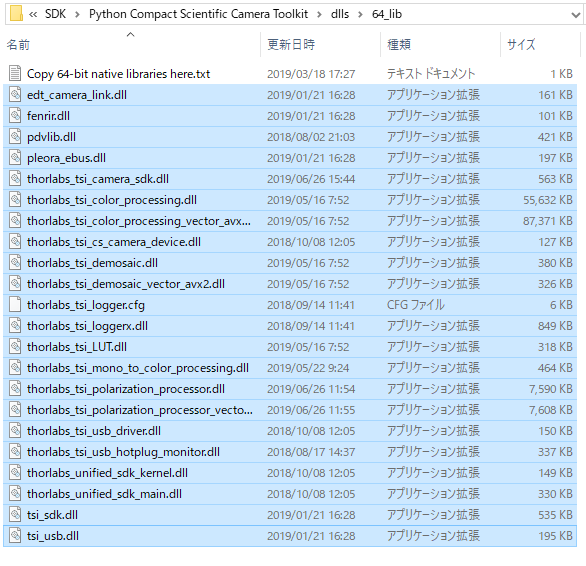
- 投稿日:2020-02-18T12:28:33+09:00
[Python] Pythonとセキュリティ - ②Pythonで作るポートスキャニングツール
はじめに
前回([Python] Pythonとセキュリティ - ②Pythonで作るポートスキャニングツール)でPythonの概要や特徴について調べてみた。
今回はPythonを利用した簡単なポートスキャニングツールを作ってみよう。
また、ツールを利用することで不用意に動作しているサービスを確認して対応することが出来る。情報を収集する行為である「Banner Grabbing」になるため、許可を得ていない対象に実施するのは犯罪です。当該の記事で問題が発生した場合、弊社では一切責任を負い兼ねますのでご了承ください。
Port Scan(ポートスキャン)とは?
ポートスキャンは対象のサーバーもしくはネットワーク機器などに対してオープンしているポートを検索し、識別することである。オープンしているポートを確認することで、対象から起動しているサービスの確認ができ、攻撃者にとってはポートスキャンが攻撃のための事前準備とも言える。
Port Scanの種類は以下のものがある
- UDP Port Scan
- TCP Port Scan
- Connect Scan
- Half-open(SYN) Scan
- FIN / NULL / Xmas Scan
Port Scan種類別特徴
UDP Port Scan
UDP Scanの場合は、UDPプロトコルを利用してポートをスキャンする。ポートがオープンされている場合、対象からは応答はないが、クローズされている場合は、ICMPメッセージ(Destination Unreachable, Port Unreachable)の応答がある。但し、UDP Scanはルータやファイアウォールからパケットが損失される可能性が高いため、信頼性は低い。
TCP Connect Scan(TCP Open Scan)
connect()関数を利用して、対象と3 Way-Handshakingを結び、オープンされているポートを確認するスキャン。信頼性が高くて、rootと権限がなくてもスキャンを行えるが、スキャンの速度が遅く、ログが残る。
TCP Half-Open Scan(SYN Stealth Scan)
SYNスキャンとも呼ばれるHalf-Open Scanは、TCP Connect Scanとは違って、3 Way-Handshakingで完全なセッションは結ばず、SYNパケットのみ利用してポートを確認する。ログは残らないが、実施のため、root権限が必要である。
root権限が必要な理由?
TCPプロトコルのヘッダーの制御ビットの設定が必要なため、root権限じゃないとSYNスキャンは実行できない。
ログが残らない理由?
対象からSYN/ACKの応答を受信したら、応答としてACKではなく、RSTに設定したパケットを送信する。
RSTのパケットのため、通信が強制に終了されてしまい、通信設定が最後まで(セッションを結ぶ)行わなかったため、システムにログが残らない可能性が高い。FIN/NULL/Xmas Scan
三つのスキャンはFlagをFINに設定するTCP FIN Scan, 何も設定しないNULL Scan, FIN, PSH, HUGを同時に設定するXmas Scanがある。
それぞれ正常な通信ではないため、ログが残らない、対象がUNIX/Linux環境のみ使える、また、Open/Filter/エラーの結果が不明である特徴を持っている。FIN Scan
NULL Scan
Xmas Scan
socketモジュールを利用してPythonでScanningツールを作ってみよう
socketモジュールをインポート後、connect()関数を利用し、IPとPort番号を指定したら、TCP通信を行う。send(), recv()関数を利用してデータの送信、受信が可能である。
port_scanning.pyimport socket s = socket.socket() s.connect(('IPアドレス', ポート番号)) s.close()「結果」port_scanning.py#portがオープンされている場合 >> #portがオープンされていない場合 Traceback (most recent call last): File "C:/~", line 3, in <module> s.connect(('127.0.0.1', 23)) ConnectionRefusedError: [WinError 10061] 対象のコンピューターによって拒否されたため、接続できませんでした。エラーを解決するために、簡単な方法で「try」と「except」文を利用して成功と失敗に対してそれぞれ区別する。
port_scanning.pyimport socket try: s = socket.socket() s.connect(('IPアドレス', ポート番号)) print('success') s.close() except: print('fail')「結果」port_scanning.py#portがオープンされている場合 >> success #portがオープンされていない場合 >> failroop文を利用して範囲内のポート番号を自動で確認するように作る。
port_scanning.pyimport socket for port in range(1,101): try: s = socket.socket() s.connect(('IPアドレス', port)) print('オープンされているポート:%d' % port) s.close() except: pass「結果」port_scanning.py>> オープンされているポート:22 >> オープンされているポート:801から100までのポートを確認するのは、時間がかかるので、Pythonのリストデータ型を利用して、主に使用されているポートのみスキャンしてみよう。
良く使用されるポート
20, 21(FTP) / 22(SSH) / 23(Telnet) / 25(SMTP) / 53(DNS) / 80(HTTP) / 110(POP3) / 123(NTP) / 443(HTTPS) / 1433(MSSQL) / 3306(MYSQL) / 1521(ORACLE) / 8080(ORACLE, TOMCAT) / 3389(RDP)port_scanning.pyimport socket ports = [20, 21, 22, 23, 25, 53, 80, 110, 123, 443, 1433, 3306, 1521, 8080, 3389] for port in ports: try: s = socket.socket() s.connect(('IPアドレス', port)) print('オープンされているポート:%d' % port) s.close() except: pass「結果」port_scanning.py>> オープンされているポート:80 >> オープンされているポート:443 >> オープンされているポート:3306 >> オープンされているポート:8080input()関数を利用して、ホストアドレスを入力し、ポートスキャニングを実施するコードを作ってみよう。
port_scanning.pyimport socket ports = [20, 21, 22, 23, 25, 53, 80, 110, 123, 443, 1433, 3306, 1521, 8080, 3389] host = input('IPアドレス:') for port in ports: try: s = socket.socket() s.connect((host, port)) print('オープンされているポート:%d' % port) s.close() except: pass「結果」port_scanning.py>> IPアドレス:127.0.0.1 >> オープンされているポート:80 >> オープンされているポート:443 >> オープンされているポート:3306 >> オープンされているポート:8080まとめ
今回はPythonのsokectライブラリを利用して簡単なポートスキャニングツールを作ってみたが、これを実務的に使うためには色々修正が必要である。
但し、ポートスキャンの原理、またPythonで基本的なポートスキャンのツールが作れるので、担当者及び管理者はこの投稿を参考して、より安全なネットワーク環境の構築に役に立てればと思っている。記事まとめ
2020年02月14日 -
[Python] Pythonとセキュリティ - ①Pythonとは
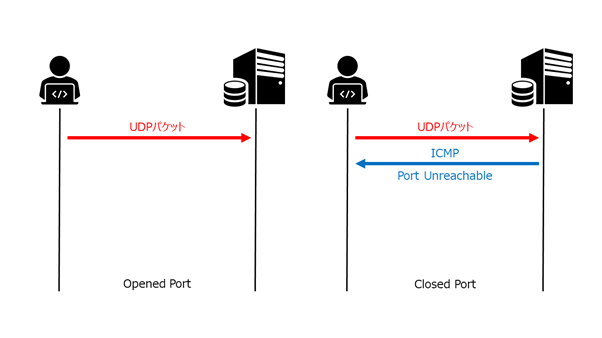
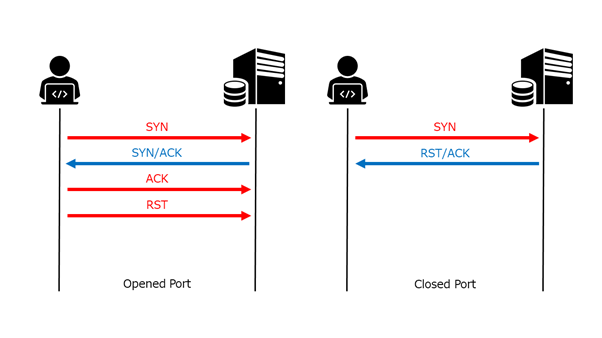
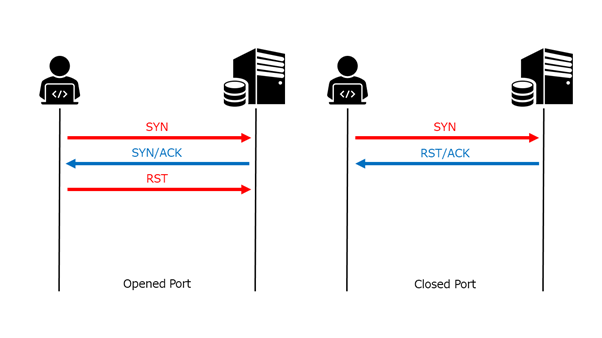
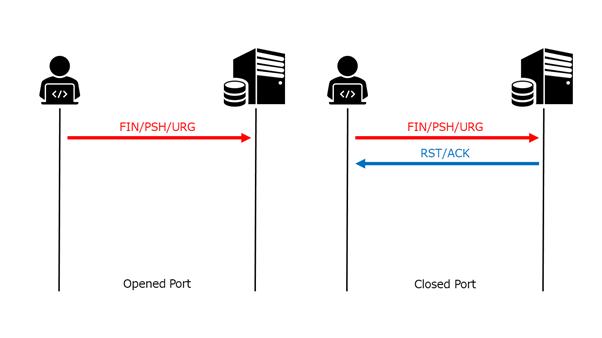
- 投稿日:2020-02-18T12:23:05+09:00
Django rest framework decorators `action decorator replaces list_route and detail_route`
背景
Django1.11.1のサポートが4月とかで切れるので、Django2.2にupdateを行っている。
Djangoのアップデートに伴って、restframeworkのバージョンも3.6.3から3.8.2にアップ。
するとPyCharmのapi.pyにこんな横棒が。from rest_framework.decorators import
detail_route,list_routeしかしroutingは正常に行えている。
確認
以下のページでアナウンスされていた。
https://www.django-rest-framework.org/community/3.8-announcement/Both list_route and detail_route are now pending deprecation. They will be deprecated in 3.9 and removed entirely in 3.10.なるほど、バージョン
3.8.2ではまだ完全には廃止されていない。