- 投稿日:2020-02-18T23:47:58+09:00
RasDashを使ってみた
RasDashは「メモリやCPU使用率、センサの値などを表示するNode.js製ダッシュボード」です。
MOON GIFTさんの「RasDash - Raspberry Pi用のダッシュボード」という記事を見て、面白そうと感じたので、使ってみました。導入
下記の手順で導入。最後の
systemctl enable RasDash.serviceは自動起動するために入力しただけなので、実行しなくても問題なし。$ git clone https://github.com/sykeben/RasDash.git ~/RasDash $ cd ~/RasDash/ $ sudo ./install_deps $ sudo ./service_manager install $ sudo ./service_manager start $ sudo systemctl enable RasDash.service表示
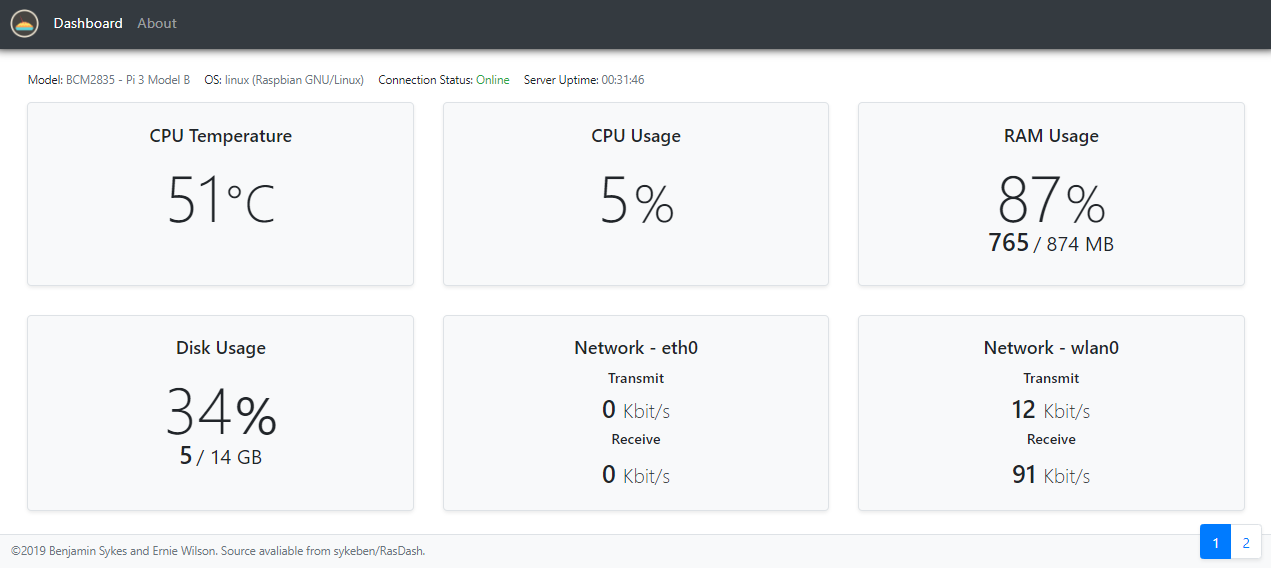
http://<Raspberry piのIPアドレス>:5808/dash/0をブラウザで表示。
各値はリアルタイムに反映される。
ポート変更
デフォルトでは、ポート番号
5808へ接続している。
~/RasDash/config.jsonに記述された数値を変更すれば、他のポート番号に変更できる。
なお、変更後すぐに動作を確認したい場合は./service_manager restartコマンドをRasDashディレクトリ上で実行する。{ "port": 5808 }表示内容変更
ダッシュボードに載せる情報は下記のファイルで変更可能。
表示するボードの順番を修正
編集対象:
~/RasDash/views/pages/dash_0.ejs通常のHTMLの編集と同様に、対象のタグ群を入れ替えるだけで順番を入れ替えられる。
ページ上部のタブに項目追加
編集対象:
~/RasDash/views/partials/navbar.ejs
<!-- Pages -->の下にページを切り替えるタブを表示するコードがあるので、ここに新しいページを記載。
<a>要素に関連付けられたidは、~/RasDash/public/javascript/navactive.jsでも利用されているため、必要に応じてこちらも変更。
下記の例ではDashboard2が追加されている。<nav class="navbar navbar-expand-lg navbar-dark bg-dark navbar-shadow"> <!-- Brand --> <div class="navbar-brand text-danger"> <img class="mr-n2" height="32px" src="/images/icon-sm.png"> </div> <!-- Pages --> <div class="navbar-nav"> <a id="nav-link-0" name="nav-link" class="nav-item nav-link" href="/dash/0">Dashboard</a> <a id="nav-link-1" name="nav-link" class="nav-item nav-link" href="/dash/1">Dashboard2</a> <a id="nav-link-2" name="nav-link" class="nav-item nav-link" href="/about">About</a> </div> <!-- Active Manager --> <script type="text/javascript" src="/javascript/navactive.js"></script> </nav>さいごに
htmlやjavascript、cssの知識はもちろん、EJSというNode.jsのテンプレートエンジンに関する知識が必要なようです。
RasDashの他の項目をいじれるよう、暇を見つけていろいろ試してみます。
- 投稿日:2020-02-18T23:10:54+09:00
Node.js QRコードを生成する

- 投稿日:2020-02-18T19:45:42+09:00
Express.jsでミニマムなローカルサーバ構成
目次
- 概要
- 環境構築
- Express.jsのみでAPIを作る方法
- Express.jsをNuxt.jsで利用してみる
- Nuxt.jsに設置したjsonファイルから結果を取得するAPI
- Nuxt.jsに設置したjsonファイルにデータを書き込むAPI
概要
簡易的なREST APIをサクッと作りたい・・・。
しかし、その為にバックエンドエンジニアの方にお願いしたり、PHPを調べながら書いたりしたくない!
自分でちゃちゃっとJSで書きたい!!
Express.jsは、そんな人向けのNode.js(サーバサイドJS)のフレームワークです。環境構築
npm i express もしくは、 Nuxt.jsの環境構築時にExpress選択 ← おすすめExpress.jsのみでAPIを作る方法
Express.jsの基本的な使い方は下記の通り。
1. モジュールをロードしてインスタンス化
2. ポート番号を指定して待受開始
3. アプリケーションの処理を記述ブラウザから /api/list/ にアクセスし、結果を表示する様なapiを作りたい場合、下記のようになる。
// 1.expressモジュールをロードし、インスタンス化後、変数appに代入 const express = require('express') const app = express() // 2.listen()メソッドを実行し、3000番ポートで待ち受け const server = app.listen(3000, () => { console.log(`node port:${server.address().port}`) }) // ---------- ↑ここまでが基本 ---------- // 仮の配列を作成 const list = [ {id: 1, keyword: 'test1'}, {id: 2, keyword: 'test2'} ] // 3.urlに応じた処理を記述 // app.getとした場合は、getリクエスト。 // app.postとした場合は、postリクエストの時に動作する。 app.get('/api/list/', (req, res, next) => { // 定義したデータを返す res.json(list) })Express.jsをNuxt.jsで利用してみる
Nuxt.jsの環境作成時に Express を選択した場合は、server/index.js に Express.js を記述するためのファイルが作成される。
※npm run dev実行時は、このserver/index.jsが読み込まれる。Nuxt.jsからExpress.jsを利用する場合は、APIを作る方法で記述した1,2は記述済み(^^)
早速、URLをブラウザに入力し、HelloWorldを表示するAPIを作ってみる。Nuxt.js + Express.js = ?
上記を踏まえ、簡単♪簡単♪と思って、以下のようにserver/index.jsに書き、
ブラウザでアクセスすると・・・app.get('/api/', (req, res, next) => { res.json({'api': 'test'}) })404エラー
Why!!!???
LIGの記事を読んでみると、
Nuxtに「serverMiddleware」を設定して、API サーバ的な動きをさせてみた公式を読んでみると、
API: serverMiddleware プロパティ
どうやらserverMiddlewareを利用すれば、理想としている簡易APIが作れそうだ!
早速手順にそって、簡易APIを作ってみる!Nuxt.js + Express.js + serverMiddleware = ?
api記述用ファイルを準備
- apiディレクトリをNuxtプロジェクト直下に作成
- api/index.jsを作成
- api/index.jsに以下を記述
const express = require('express') const app = express() app.get('/', function(req, res) { res.send('HelloWorld'); }); module.exports = { path: '/api/', handler: app };※この時点で、npm run devでローカルサーバを立ち上げ、
http://localhost:3000/api/ にアクセスしてもPage Not Foundと表示される。serverMiddleWareを設定
nuxt.config.jsに、上記で作成したapi/index.jsを読み込む様に追記する。
module.exports = { serverMiddleware: ["~/api/"], }npm run dev でサーバ再起動後、ブラウザで下記にアクセス。
http://localhost:3000/api/HelloWorld と表示された!!?
Nuxt.jsに設置したjsonファイルから結果を取得するAPI
やりたいこと
- Nuxt.jsディレクトリ内に、jsonファイルを設置
- ブラウザでapiのURLにアクセスするとjsonの内容が表示される
準備
※serverMiddleWareは設定済み
1. Nuxt.jsプロジェクト直下に、databaseというディレクトリを作成
2. database/list.json というjsonファイルを作成
3. list.jsonに仮データとして、下記を記述[ { "key": "A1", "name": "test" } ]api/index.jsの設定
以下を記述
const fs = require('fs') app.get('/list/', (req, res) => { fs.readFile('${__dirname}/../database/list.json', 'utf-8', (err, data) => { if(err) { res.status(500).send(err) } else { console.log('data',data) res.status(200).send(data) } }) })↓元々のソースのこの部分は間違い!!
requireは、最新の状態ではなく、ソース読み込み時の状態のため、
常に最新を読みたい場合のファイル読み込みは、 fs.readFile で!
const list = require('../database/list.json')
res.send(list)npm run devでローカルサーバを立ち上げ、 http://localhost:3000/api/list/ にアクセス。
表示された!?
[ { key: "A1", name: "test" } ]/api/list/◯◯ の様なurlで動的に処理する場合
パス部分に*、コールバック関数のreq.paramsを利用すれば、urlの
/list/◯◯の◯◯の部分を取得可能。app.get('/list/*', (req, res) => { console.log(req.params) })/list/1は、
{ '0': '1' }と出力される。もう少し厳密に、◯◯部分を取得したい場合は、
:を利用する。app.get('/list/:id/:operation?', (req, res) => { console.log(req.params) })
?は未指定でもokという意味。?を記述しない場合、
/list/aaa/bbb はokだが、 /list/aaa といったurlは404扱いになる。/list/1は、
{ id: '1', operation: undefined }と出力される。
/list/aaa/bbbは、{ id: 'aaa', operation: 'bbb' }と出力される。Nuxt.jsに設置したjsonファイルにデータを書き込むAPI
やりたいこと(一旦、通信部分は省く)
指定のファイルに、オブジェクト形式のデータを追加する。
→ ファイル書き込みが出来ないといけない。api/index.jsに記述
ファイル読み込みと同じくファイル操作系は、 fsモジュール を利用し、下記の様な処理手順を踏む。
1. fs.readFileでjsonの内容を読み込む
2. 読み込んだ内容をjsonオブジェクト化
3. 追加処理(本来は、postで受け取った値を追加する)
4. 最新の内容を fs.writeFileSync で書き込むソースの内容を抜粋すると以下の様になる。
const express = require('express') const app = express() const fs = require('fs') // fsモジュールをロード app.get('/create/', (req, res) => { // fs.readFileでjsonの内容を読み込む fs.readFile(`${__dirname}/../database/list.json`, 'utf-8', (err, data) => { if(err) { res.status(500).send(null) } else { // 読み込んだ内容をjsonオブジェクト化 const jsonObject = JSON.parse(data) // 追加処理(本来は、postで受け取った値を追加する) jsonObject['A3'] = { 'key': 'A3' } try { // 最新の内容を fs.writeFileSync で書き込む fs.writeFileSync( `${__dirname}/../database/list.json`, JSON.stringify(jsonObject, undefined, ' ') ) res.status(200).send('ok') } catch(e) { res.status(500).send(null) } } }) })fsモジュールを利用して、ファイル操作を行う際、
ファイル読み込みには、 readFile , readFileSync があり、
ファイル書き込みには、 writeFile , writeFileSync がある。それぞれの違いは、同期か非同期かというところ。
Sync系は処理がシンプルに書けるが、Node.js特有のノンブロッキングIOが利用できない。
非同期系は、ノンブロッキングIOが利用出来るが、複雑な処理になると、コールバック地獄になりがち。
なので、同期か非同期かはそれぞれ利用するタイミングを考える必要がある。
- 投稿日:2020-02-18T19:37:25+09:00
Node.jsで画像変換処理
目次
sharp
sharp - 概要
Node.jsをサーバとして利用した時に、画像リサイズ処理の最適な方法は何かを調査する。
有名どころでは、ImageMagick。ただ、調べると sharp というNodeモジュールが、ImageMagickよりも速くリサイズ可能とのことなので、これを調べてみる。参考
Node.js の画像変換モジュール sharp の使い方 基本的な使い方はこれ一つでok
https://r17n.page/2019/08/15/nodejs-sharp-image-converter-how-to-resize/Node.jsのライブラリsharpでリサイズを試してみる 読みやすい上の記事のライト版
https://blog.kozakana.net/2019/04/sharp-resize/Node.jsのライブラリsharpの出力形式について 出力形式についてのまとめ
https://blog.kozakana.net/2019/04/sharp-output-format/sharp - 環境構築
npm i sharpsharp - 使い方
sharp(`画像ファイルパス or 画像ファイルバイナリ`) .resize(1080, 1080) .toFile(`出力パス`)
node-imagemagick
node-imagemagick - 概要
sharpは直感的ですごく使いやすいが、heic形式(iPhoneで撮った写真の形式)については対応していないとのこと。
※公式のQ&Aのやり取りを見ると、対応する方法があるみたいだが、少し複雑。その為、heic形式も対応するとなると、imagemagickを利用する必要があり、
imagemagickをNodeから実行する方法として、node-imagemagickというnodeモジュールがある。node-imagemagick - 環境構築
// imagemagickのインストール brew install imagemagick // node-imagemagickのインストール npm i imagemagick※ windowsでは、下記からstaticバージョンをインストール。
http://www.imagemagick.org/script/download.phpC:\Program Files(インストールしたimagemagick)\magick.exeにある実行ファイルを複製し convert.exe に変更。(npmパッケージから参照するため)
↓こちらの記事を参考にさせていただきました。
Windows10環境でNode.jsを使って画像処理を行うnode-imagemagick - 使い方
convertの例。imagemagickはコマンドが多すぎるので、都度調査する。
const im = require('imagemagick') // imagemagickのコマンドを配列形式で指定する im.convert(['/path/image/image.png' '/path/image/image.jpg'], (err)=> { console.log('image magick convert finish') }) // コマンド文字列を半スペでsplitするほうが使いやすい const cmd1 = `/path/image/image.png /path/image/image.jpg` im.convert(cmd1.split(' '), (err)=> { console.log('image magick convert finish') }) // 一つの画像から複数種類の画像を書き出す場合のコマンド文字列例 const cmd2 = `${file.path} `+ `-resize 3840x1080 -write ${filePath}image.jpg ` + `-resize 1080x1080 -write ${filePath}imageProFile.jpg ` + `-resize 150x150 -write ${filePath}thumbnail.jpg` im.convert(cmd2.split(' '), (err)=> { console.log('image magick convert finish') })
GraphicksMagick
GraphicksMagick - 概要
おまけ。
node-imagemagickのgithubリポジトリのReadMeを確認すると、長い間メンテナンスされていない為、GraphicksMagickを利用推奨とのこと。
使い方もsharpの用にメソッドチェーン方式なので、使いやすそうなので良き。
※ただ、heicの書き出しがうまくいかなかったので不採用。GraphicksMagick - 環境構築
// imagemagickとgraphicsmagickのインストール brew install imagemagick brew install graphicsmagick // WebPに対応する場合 brew install imagemagick --with-webp // gmモジュールのインストール npm i gmGraphicksMagick - 使い方
const gm = require('gm') gm('/path/to/my/img.jpg') .resize(240, 240) .noProfile() .write('/path/to/resize.png', function (err) { // 書き出し完了後の処理 });
- 投稿日:2020-02-18T15:41:56+09:00
Firebase FunctionsでRealtime databaseにdataを送信する
恒例
https://firebase.google.com/docs/functions ドキュメントを読んでください
Firebase CLI をインストールする
npm install -g firebase-toolsCoding
mkdir test cd test mkdir functions cd functions vi package.json{ "name": "mytest", "description": "mytest", "dependencies": { "firebase-admin": "~7.1.1", "firebase-functions": "^2.2.1" }, "devDependencies": { "chai": "^3.5.0", "chai-as-promised": "^6.0.0", "firebase-functions-test": "0.1.6", "mocha": "^5.0.5", "sinon": "^4.1.3" }, "scripts": { "ci-test": "npm install && npm run test", "serve": "firebase serve --only functions", "shell": "firebase experimental:functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "8" }, "private": true }vi index.js'use strict'; const functions = require('firebase-functions'); const admin = require('firebase-admin'); admin.initializeApp(); exports.send_data = functions.https.onRequest(async (req, res) => { const time = req.query.time; const text = req.query.temp; const snapshot = await admin.database().ref('/test').push({time:time,text:text}); res.redirect(303, snapshot.ref.toString()); }); exports.read_data = functions.https.onRequest((req, res) => { var ref = admin.database().ref("test"); return ref.orderByChild("time").limitToLast(10).once('value').then(function(snapshot) { res.send(snapshot.val()); }); });Deploy
cd functions && npm install && cd .. firebase deploy送信方法
https://us-central1-[MY_PROJECT].cloudfunctions.net/send_data?time=20200218&text=uppercaseme をアクセスする
DATAを読み取る方法
https://us-central1-[MY_PROJECT].cloudfunctions.net/read_data をアクセスする
- 投稿日:2020-02-18T02:35:00+09:00
pupetterを使ってAmazonの欲しいものリストの情報を取得する
概要
pupetterを使ってAmazon.co.jpから欲しい物リストをスクレイピングする手法のメモです。
下記のように欲しいものリストのIDを指定する事で、商品名と価格、商品IDを取得できる形にします。
実装// 欲しい物リストのIDを指定 const itemList = await amazonWishScraper.getProductInfo('hogehoge'); console.log('itemList', JSON.stringify(itemList));itemListの中身[ { "title" : "ProductA", "price": 3278, "productID": "429711111X" }, { "title" : "ProductB", "price": 1234, "productID": "429711112X" }, ]背景
Amazonの欲しいものリストをスクレイピングで取得する例は、何点か見つかりましたが、紹介されているものの多くは、現在は使えないものでした。
というのも以前は、一定数商品が存在する場合にはページの切り替え行なっていましたが、現在はAjaxで同じページ内で画面をスクロールする事で非同期に読み込む方法に変更されたためです。
こうなると、GETリクエストを投げてHTMLの解析だけではなく、ブラウザの操作をエミュレートして、スクロールを行うようなヘッドレスブラウザが必要になります。
今回は、puppeteerというヘッドレスブラウザを使用して実現します。前提
MacOS 10.15.3(19D76)
VS Code 1.42.1
node.js v12.14.1
puppeteer 2.1.0実装
実装方法の検討
画面スクロール
前述の通り、一定数以上の商品が登録されている場合にはページのスクロールを行いデータを読み出す必要があります。
puppeteerにはブラウザ内で任意のjsが実行可能なので、画面をスクロールさせる処理を実行します。スクロールの停止(全商品読み込み完了の検知)
スクロールを続けた後に、全ての商品が読み込み終わった事を検知する必要があります。
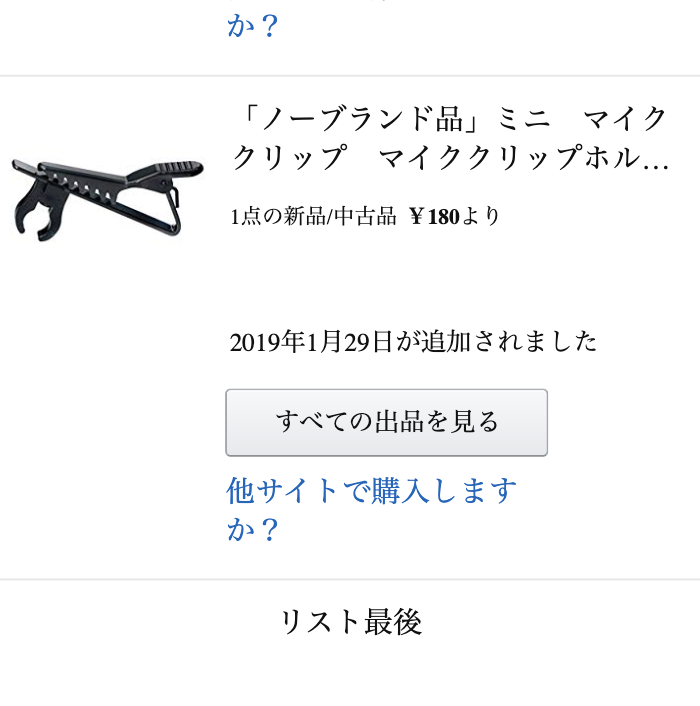
欲しい物リストの末尾には、下図のようなリストの末尾を示す情報が表示されます。
この部分のタグが検知されたら、全ての商品の読み込みが終わったと判断します。
該当箇所のタグ<div class="a-row center-align-text full-width-element"> <div id="no-items-section-anywhere" class="a-section a-spacing-none"> リスト最後 </div> </div>商品情報の取得
全ての情報が画面に描画されたのならば、後は通常のスクレイピングと同様にHTMLタグを解析するだけです。
実装コード
欲しいものリストサイトへのアクセス
puppeteerを初期化して、欲しいものリストのIDからURLを特定してアクセスします。
今回は表示される情報量を減らし、スクレイピングの効率を上げるためにデスクトップPCではなく、iPhone(スマホ)をシミュレートします。この部分の処理は、puppeteerの基本的な動作方法ですので詳細は割愛します。
const puppeteer = require('puppeteer'); const devices = require('puppeteer/DeviceDescriptors'); const iPhone = devices['iPhone 8']; const urlbase = 'https://www.amazon.co.jp/hz/wishlist/ls/'; async function getProductInfo(wishListId) { const browser = await puppeteer.launch({ headless: true, args: ['--no-sandbox', '--disable-setuid-sandbox'] }); try { const page = await initPage(browser); // 欲しいものリストのURLを開く await page.goto(urlbase + wishListId); // スクレイピング(中身は後述) return await scrapePage(page); } catch (err) { console.error(err); throw err; } finally { browser.close(); } } async function initPage(browser) { const page = await browser.newPage(); await page.emulate(iPhone); return page; }欲しいものリストサイトへのアクセス
実装方法の検討で説明した通り、
- リストの末尾が見つかるまで画面をスクロールする
- HTMLをquerySelectorで解析する
といったことを実施します。
querySelectorでのデータの切り出しは、生のHTMLを確認しながら商品ブロック単位で情報を取得するように対応しています。async function scrapePage(page) { return await page.evaluate(async () => { // スクロールでの移動距離と待機間隔ms const distance = 500; const delay = 100; // リストの末尾が検知されない限りループする while (!document.querySelector('#no-items-section-anywhere')) { // 500pxずつスクロール移動して、100ミリ秒待機する document.scrollingElement.scrollBy(0, distance); await new Promise(resolve => { setTimeout(resolve, delay); }); } // 全ての商品の表示が終わったらスクレイピングを実施 const itemList = []; // 商品の情報のBOX単位でデータを切り出す [...document.querySelectorAll('a[href^="/dp/"].a-touch-link')].forEach( el => { const productID = el .getAttribute('href') .split('/?coliid')[0] .replace('/dp/', ''); const title = el.querySelector('[id^="item_title_"]').textContent; let price = -1; const priceEle = el.querySelector('[id^="itemPrice_"] > span'); if (priceEle && priceEle.textContent) { price = Number(priceEle.textContent.replace('¥', '').replace(',', '')); } itemList.push({ price: price, title: title, productID: productID }); } ); return itemList; }); }まとめ
簡単にはですが、puppeteerを使ってAmazonの欲しいものリストから情報を一覧取得する法法を紹介しました。
スクロールをシミュレートし、非同期で読み込まれるデータの取得を実現しています。
こういったユーザの操作が必要となる処理に関しても、puppeteerを使う事で簡単に実現ができました。

- 投稿日:2020-02-18T01:27:12+09:00
nodemailer で 複数宛メール作成時の注意
nodemailer を使って宛先が複数ある時の設定メモ。
envelopeを設定していてはまりました。
ヘッダーがどうなってるとかきちんとした確認はとってません。
- nodemailer v6.3
send-mail.jsvar mailer = require('nodemailer'); ︙ const transporter = mailer.createTransport({ sendmail: true, newline: 'windows', logger: false }) transporter.sendMail({ from: 'me@example.com', to: 'to@example.com', cc: 'cc@example.com', envelope : { from: 'me@example.com', // ここのtoは実際に送信する宛先。 // 複数宛先がある場合はすべて含める必要がある。 // ✖ to: 'to@example.com', to: ['to@example.com', 'cc@example.com'], }, subject: 'THIS IS A TEST MAIL.', text: 'HELLO! nodemailer!!' })