- 投稿日:2019-12-15T23:59:27+09:00
Naumachiaを使ったペネトレーションテストのトレーニング環境構築
本記事は、NTTコミュニケーションズ Advent Calendar 2019 15日目の記事です。
昨日は @Mahito さんの記事、 保育園にChaos Engineeringを提案した話 でした。はじめに
先日公開されたNTTコミュニケーションズの開発者ブログの記事にもあったように、NTTコミュニケーションズグループではグループ社員を対象としたセキュリティコンテスト「ComCTF」を開催しています。
私は決勝で出題した「Pentest」という問題を作問しました。
Pentest(ペンテスト)は、ペネトレーションテストと呼ばれるセキュリティテストの略称で、明確な意図を持った攻撃者にその目的が達成されてしまうかを検証します。 1この問題は仮想の企業ネットワークに侵入し、複数のサーバの脆弱性を悪用、最終的に重要データが保存されているサーバから情報を入手できるかを問う問題で、まさに攻撃者の気持ちになって重要なデータを入手するという目的が達成可能かどうかを検証してもらう、ペネトレーションテストをしてもらう問題でした。
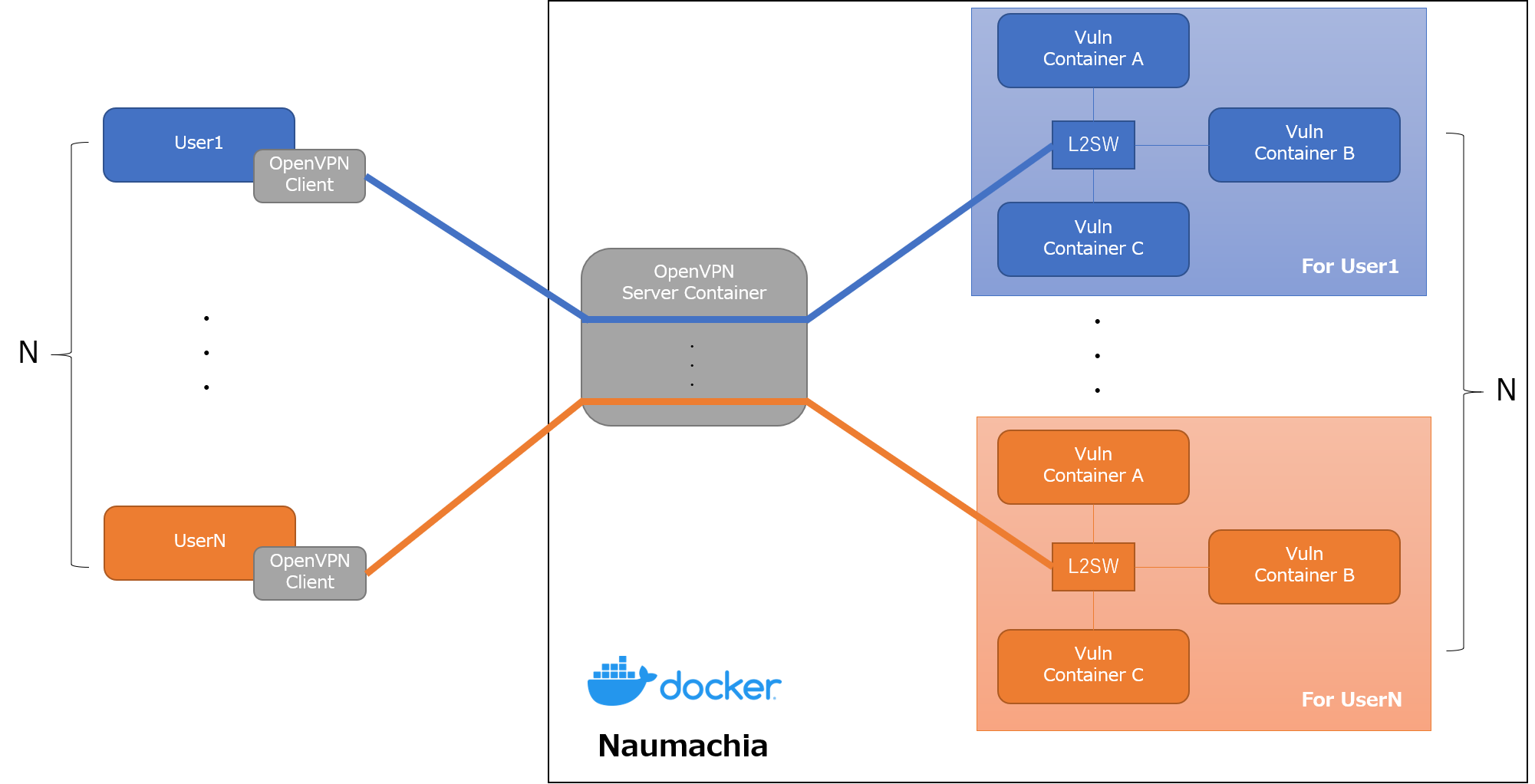
今回、この問題の基盤を作るにあたり、Dockerを使ってペネトレーションテストのトレーニング環境を構築できる Naumachia と呼ばれるOSSを使用しました。
この記事では、Naumachiaの概要と構築方法、この基盤を使ったペネトレーションテストのトレーニング環境構築について紹介します。
Naumachia とは
Naumachiaは、Dockerを使ってクローズドネットワークと脆弱なサーバを構築できるOSSです。
私がこのOSSを知ったきっかけは、Texas A&M University が主催する TAMUctf 19 と呼ばれるCTFです。
NetworkPentestというジャンルの問題の基盤にこの Naumachia が使用されています。なお、このCTFの問題はGitHubで公開されているので興味がある方は見てみてください。
https://github.com/tamuctf/TAMUctf-2019
Naumachia には、以下の機能が実装されています。
- ユーザごとにトレーニング用のDockerコンテナとネットワークを作成、管理
- トレーニング環境を他のユーザの環境と分離
- OpenVPNを使ったトレーニング環境ネットワークへのL2レベルの接続の提供
これにより、以下のようなインターネットからVPNの接続情報を持つユーザのみアクセス可能な専用のトレーニング環境を構築できます。
例えば、Drupalの任意コード実行の脆弱性(CVE-2018-7600)を使ってシステムに侵入できるか試すような問題を作ろうとした場合、インターネットからアクセスできる問題サーバを作ろうとすると、インターネット上の脆弱性のスキャンに引っかかり、最悪サーバが踏み台にされる可能性もあります。
Naumachia を使えば、インターネットからはVPNの接続情報を持つユーザのみ問題に挑戦できるので、そのようなリスクなく作問できます。また、L2レベルでのアクセスも提供してくれるので、ARPスプーフィングにような同一LAN内で行われる攻撃手法を試すような問題も作ることができます。
詳しい機能や仕組みは、Naumachia のREADME に書いてあるので、こちらを読むと良いと思います。
Naumachia の構築
ここからは Naumachia の構築手順を紹介します。
動作環境
READMEには、
Obtain a Linux server (tested on Ubuntu 16.04 and 18.04)
と書いてあるので、使うOSは Ubuntu 18.04 がベストでしょう。
しかし、今回のコンテストでは諸事情ありCentOS 7を使ったので、CentOS 7 で検証した構築手順を書いておきます。構築手順を検証したOSの情報は以下のとおりです。
# uname -a Linux localhost.localdomain 3.10.0-957.21.3.el7.x86_64 #1 SMP Tue Jun 18 16:35:19 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux # cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core)Naumachia のインストール準備
Naumachiaを構築するには、
docker,docker-compose,Python3,pip3が必要となるので、これらをまずインストールする必要がある。
その後、GitHubにあるNaumachiaのリポジトリからソースコードをCloneし、requirements.txtに書かれているPython3のライブラリをインストールする。dockerのインストール
# yum install -y yum-utils device-mapper-persistent-data lvm2 # yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # yum install -y docker-ce docker-ce-cli containerd.io # systemctl start docker # systemctl enable dockerdocker-composeのインストール
# curl -L https://github.com/docker/compose/releases/download/1.22.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose # chmod +x /usr/local/bin/docker-composePython3.6、pip3のインストール
# yum install -y https://centos7.iuscommunity.org/ius-release.rpm # yum install python36u python36u-libs python36u-devel python36u-pipGitHubからソースコードをCloneする
# git clone https://github.com/nategraf/Naumachia.gitPython3のライブラリをインストール
# cat requirements.txt jinja2==2.10.1 PyYAML==4.2b4 requests==2.21.0 nose2==0.8.0 pytest==4.5.0 hypothesis==4.23.5 # pip3 install -r requirements.txtNaumachia のセットアップ
トレーニング用のDockerコンテナとネットワークの準備
Naumachiaでユーザに対して提供するトレーニング用のDockerコンテナとネットワークは、
docker-compose.ymlで定義します。
Naumachia起動後、OpenVPNでユーザが接続してくると、このdocker-compose.ymlをもとに自動でdocker-composeが実行されトレーニングの環境が構築されます。今回の説明では、Naumachiaの問題集 (nategraf/Naumachia-challenges) から、
exampleというチャレンジを動かしてみます。問題集のGitHubのリポジトリをCloneし、Naumachiaディレクトリ内の
challengesディレクトリにexampleチャレンジに必要なファイルをコピーします。# git clone https://github.com/nategraf/Naumachia-challenges # mkdir Naumachia/challenges # cp -r Naumachia-challenges/example Naumachia/challengesちなみに、
exampleのdocker-compose.ymlは以下のとおりです。
bobとaliceという2つのコンテナと、defaultという1つのネットワークが作成されるのがわかります。docker-compose.ymlversion: '2.4' # The file defines the configuration for simple Nauachia challenge where a # sucessful man-in-the-middle (MTIM) attack (such as ARP poisoning) provides a # solution # If you are unfamiliar with docker-compose this might be helpful: # * https://docs.docker.com/compose/ # * https://docs.docker.com/compose/compose-file/ # # But the gist is that the services block below specifies two containers, which # act as parties in a vulnerable communication services: bob: build: ./bob image: naumachia/example.bob environment: - CTF_FLAG=fOOBaR restart: unless-stopped networks: default: ipv4_address: 172.30.0.2 alice: build: ./alice image: naumachia/example.alice depends_on: - bob environment: - CTF_FLAG=fOOBaR restart: unless-stopped networks: default: ipv4_address: 172.30.0.3 networks: default: driver: l2bridge ipam: driver: static config: - subnet: 172.30.0.0/28カスタマイズされたDocker libnetwork Driverのインストール・起動
上記のNaumachiaのチャレンジでは、すべてのユーザに同じ環境を提供、安全なトレーニング環境を構築するために、カスタマイズされたDocker libnetowrk driverを使用しています。
https://github.com/nategraf/l2bridge-driver
https://github.com/nategraf/static-ipam-driverこれを使うことで、デフォルトのDocker libnetowrk driverではできない以下のことが可能となります。
- 重複したIPサブネットの許可
- コンテナネットワークからインターネットへのアクセス禁止
ここでUbuntuやDebianであれば、サービスとしてDriverをインストールする方法が紹介されてますが、今回はCentOSであったため以下のようなスクリプトを作成し、無理やりDriverのプログラムを動かしました。(sysv.sh をRedHat系のOS向けに書き直す余裕はなかった…
driver_start.sh# Download the static-ipam driver to usr/local/bin if [ ! -e /usr/local/bin/l2bridge ]; then echo "[!] l2bridge driver is not installed" echo "[+] Download the l2bridge driver to usr/local/bin" curl -L https://github.com/nategraf/l2bridge-driver/releases/latest/download/l2bridge-driver.linux.amd64 -o /usr/local/bin/l2bridge chmod +x /usr/local/bin/l2bridge else echo "[*] l2bridge driver is installed" fi # Download the static-ipam driver to usr/local/bin if [ ! -e /usr/local/bin/static-ipam ]; then echo "[!] static-ipam driver is not installed" echo "[+] Download the static-ipam driver to usr/local/bin" curl -L https://github.com/nategraf/static-ipam-driver/releases/latest/download/static-ipam-driver.linux.amd64 -o /usr/local/bin/static-ipam chmod +x /usr/local/bin/static-ipam else echo "[*] static-ipam driver is installed" fi # Activate the service echo "[+] Startup the servicies" if [ ! -e /run/docker/plugins/l2bridge.sock ]; then nohup /usr/local/bin/l2bridge > /dev/null 2>&1 & echo "[*] Done: l2bridge" else echo "[!] Started l2bridge driver" fi if [ ! -e /run/docker/plugins/static.sock ]; then nohup /usr/local/bin/static-ipam > /dev/null 2>&1 & echo "[*] Done: static-ipam" else echo "[!] Started static-ipam driver" fi sleep 0.5 # Verify that it is running echo "[+] Verify that it is running" echo "" echo "[*] stat /run/docker/plugins/l2bridge.sock" stat /run/docker/plugins/l2bridge.sock # File: /run/docker/plugins/l2bridge.sock # Size: 0 Blocks: 0 IO Block: 4096 socket # ... echo "" echo "[*] stat /run/docker/plugins/static.sock" stat /run/docker/plugins/static.sock # File: /run/docker/plugins/static.sock # Size: 0 Blocks: 0 IO Block: 4096 socket # ... echo "" echo "[*] Complete!!"なお、シャットダウンするとDriverのプログラムは停止し、再起動時に立ち上がらないので、再起動時には必ずこれを実行する必要があります。
bridgeを通るパケットのフィルタリング無効
bridgeを通るパケットがフィルタ対象になっているとうまく動かないことがあるようなので、
disable-bridge-nf-iptables.shを実行します。disable-bridge-nf-iptables.shecho 0 > /proc/sys/net/bridge/bridge-nf-call-iptables echo 0 > /proc/sys/net/bridge/bridge-nf-call-ip6tablesconfig.yml の修正
config.example.ymlをconfig.ymlにコピーして一部を書き換えます。
書き換えるのは、challengesの部分。
変更する点は以下のとおり。
files:に、「トレーニング用のDockerコンテナとネットワークの準備」で作ったdocker-compose.ymlファイルの場所を書くcommonname:にサーバのアドレス(ドメイン、IPアドレス)を書く# [required] Configurations for each challenge challenges: # [required] An indiviual challenge config. The key is the challenge name # This should be a valid unix filename and preferably short example: # [default: 1194] The exposed external port for this challenges OpenVPN server port: 2000 # [default: [{challenge name}/docker-compose.yml] ] The compose files to which define this challenge # Paths should be relative to the challenges directory files: - example/docker-compose.yml # [default: {challenge name}.{domain}] The commonname used for the OpenVPN's certificates # This should be the domain name or ip that directs to this challenge commonname: 192.168.91.130 # [default: None] If set, the OpenVPN management interface will be opened on localhost and the given port openvpn_management_port: null # [default: None] If set, the OpenVPN server will inform the client what IPv4 address and mask to apply to their tap0 interface ifconfig_push: 172.30.0.14/28Naumachiaのビルド
configure.pyを実行すると、config.ymlに書かれている内容をもとにNaumachiaをbuildします。
これにより、Naumachiaのdocker-compose.ymlやOpenVPNの鍵や証明書、設定のファイルが自動で生成されます。# ./configure.py [INFO] Using config from /root/Naumachia/config.yml [INFO] Using easyrsa installation at /root/Naumachia/tools/EasyRSA-v3.0.6/easyrsa [INFO] Rendered /root/Naumachia/docker-compose.yml from /root/Naumachia/templates/docker-compose.yml.j2 [INFO] Configuring 'example' [INFO] Created new openvpn config directory /root/Naumachia/openvpn/config/example [INFO] Initializing public key infrastructure (PKI) [INFO] Building certificiate authority (CA) [INFO] Generating Diffie-Hellman (DH) parameters [INFO] Building server certificiate [INFO] Generating certificate revocation list (CRL) [INFO] Rendered /root/Naumachia/openvpn/config/example/ovpn_env.sh from /root/Naumachia/templates/ovpn_env.sh.j2 [INFO] Rendered /root/Naumachia/openvpn/config/example/openvpn.conf from /root/Naumachia/templates/openvpn.conf.j2また、競技用のコンテナもbuildしておきます。
# docker-compose -f ./challenges/example/docker-compose.yml build競技環境の実行
ここまでの作業を行うと、
docker-compose.ymlが自動で生成されているはずなので、buildしてupします。# docker-compose build # docker-compose up -dこの状態で
docker ps -aで立ち上がってるコンテナを見てみると、以下のようなコンテナが立ち上がっているはずです。# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES dd9e858277bd naumachia/manager "python -m app" 27 seconds ago Up 25 seconds build_manager_1 f80057d9dc2e naumachia/openvpn "/scripts/naumachia-…" 27 seconds ago Up 25 seconds 0.0.0.0:2000->1194/udp build_openvpn-example_1 86fc3709d4e3 redis:alpine "docker-entrypoint.s…" 27 seconds ago Up 26 seconds build_redis_1 a0f45e1f292a naumachia/registrar "gunicorn -c python:…" 27 seconds ago Up 26 seconds 0.0.0.0:3960->3960/tcp build_registrar_1 9d1ef7902351 alpine "/bin/true" 27 seconds ago Exited (0) 27 seconds ago build_bootstrapper_1ユーザへ配布するOpenVPN設定ファイルの生成
ユーザがOpenVPNサーバに接続し、トレーニング環境にアクセスするためには設定ファイルが必要です。
これもNaumachiaが自動で生成してくれます。生成する方法には、以下の2つの方法があります。
- registrar CLIのPythonスクリプトを使用する
- registrar serverのREST APIを使用する
3960/tcpで待ち受けてるコンテナがそう- 認証がないので外部に公開するときは注意
今回はregistrar CLIのPythonスクリプトを使って、設定ファイルを作成、取得します。
registrar-cliを以下のように実行すると、OpenVPNの鍵、サーバ証明書、認証局の証明書を含んだOpenVPNの設定ファイルが作成できるので、これをユーザに配ります。# ./registrar-cli example add user1 # ./registrar-cli example get user1 > user1.ovpn # cat user1.ovpn client nobind dev tap remote-cert-tls server float explicit-exit-notify remote 192.168.91.130 2000 udp <key> -----BEGIN PRIVATE KEY----- (省略) -----END PRIVATE KEY----- </key> <cert> -----BEGIN CERTIFICATE----- (省略) -----END CERTIFICATE----- </cert> <ca> -----BEGIN CERTIFICATE----- (省略) -----END CERTIFICATE----- </ca> key-direction 1 cipher AES-256-CBC auth SHA256 comp-lzo構築したトレーニング環境で遊んでみる
それでは、構築したトレーニング環境にアクセスして遊んでみましょう。
検証に使用する環境
今回はユーザ側はデフォルトでOpenVPNのクライアントとペネトレーションテスト用のツールがインストールされている
Kali Linuxを使用します。# grep VERSION /etc/os-release VERSION="2018.1" VERSION_ID="2018.1"OpenVPNでトレーニング環境へ接続
生成したOpenVPNの設定ファイルを使って、Naumachia上のトレーニング環境にアクセスします。
Initialization Sequence Completedと出れば成功です!# openvpn user1.ovpn Sun Dec 15 06:33:45 2019 OpenVPN 2.4.5 x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Mar 4 2018 Sun Dec 15 06:33:45 2019 library versions: OpenSSL 1.1.0h 27 Mar 2018, LZO 2.08 Sun Dec 15 06:33:45 2019 TCP/UDP: Preserving recently used remote address: [AF_INET]192.168.91.130:2000 Sun Dec 15 06:33:45 2019 UDP link local: (not bound) Sun Dec 15 06:33:45 2019 UDP link remote: [AF_INET]192.168.91.130:2000 Sun Dec 15 06:33:45 2019 [192.168.91.130] Peer Connection Initiated with [AF_INET]192.168.91.130:2000 Sun Dec 15 06:33:46 2019 Options error: Unrecognized option or missing or extra parameter(s) in [PUSH-OPTIONS]:1: dhcp-renew (2.4.5) Sun Dec 15 06:33:46 2019 TUN/TAP device tap0 opened Sun Dec 15 06:33:46 2019 do_ifconfig, tt->did_ifconfig_ipv6_setup=0 Sun Dec 15 06:33:46 2019 /sbin/ip link set dev tap0 up mtu 1500 Sun Dec 15 06:33:46 2019 /sbin/ip addr add dev tap0 172.30.0.14/28 broadcast 172.30.0.15 Sun Dec 15 06:33:46 2019 WARNING: this configuration may cache passwords in memory -- use the auth-nocache option to prevent this Sun Dec 15 06:33:46 2019 Initialization Sequence Completedifconfigでインターフェースの状態を見てみると、
tap0というインターフェースが作成され、172.30.0.14というIPアドレスが割り当てられていると思います。# ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.91.129 netmask 255.255.255.0 broadcast 192.168.91.255 inet6 fe80::20c:29ff:fe18:a0c8 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:18:a0:c8 txqueuelen 1000 (Ethernet) RX packets 14781 bytes 9483880 (9.0 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 6484 bytes 645921 (630.7 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 31612 bytes 10003030 (9.5 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 31612 bytes 10003030 (9.5 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 tap0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.30.0.14 netmask 255.255.255.240 broadcast 172.30.0.15 inet6 fe80::c0d8:eeff:fe38:d79b prefixlen 64 scopeid 0x20<link> ether c2:d8:ee:38:d7:9b txqueuelen 100 (Ethernet) RX packets 16 bytes 1272 (1.2 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 21 bytes 1622 (1.5 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0このとき、NaumachiaのサーバでDockerコンテナとネットワークの状態を見ると、新たに
user1_example_というプレフィックスがついたコンテナとネットワークが作成されているはずです。これがユーザ専用のトレーニング用のコンテナとネットワークです。ユーザが増えると、コンテナとネットワークも増えていきます。
# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 17c4ef2ccbb9 naumachia/example.alice "python /app/alice.py" About a minute ago Up About a minute user1_example_alice_1 ff271a01eba9 naumachia/example.bob "python /app/bob.py" About a minute ago Up About a minute user1_example_bob_1 dd9e858277bd naumachia/manager "python -m app" 32 minutes ago Up 32 minutes build_manager_1 f80057d9dc2e naumachia/openvpn "/scripts/naumachia-…" 32 minutes ago Up 32 minutes 0.0.0.0:2000->1194/udp build_openvpn-example_1 86fc3709d4e3 redis:alpine "docker-entrypoint.s…" 32 minutes ago Up 32 minutes build_redis_1 a0f45e1f292a naumachia/registrar "gunicorn -c python:…" 32 minutes ago Up 32 minutes 0.0.0.0:3960->3960/tcp build_registrar_1 9d1ef7902351 alpine "/bin/true" 32 minutes ago Exited (0) 32 minutes ago build_bootstrapper_1# docker network ls NETWORK ID NAME DRIVER SCOPE 743f747a01b3 bridge bridge local 7017ddd37ba8 build_default bridge local dce5de7a2fa2 build_internal bridge local de7c1746cc32 host host local 6dc0c89a9ccf none null local b1649b2f2e93 user1_example_default l2bridge localARPスプーフィングを試してみる
この問題は example の docker-compose.yml に書かれているとおり、ARPスプーフィングのようなMITM(中間者攻撃)を行う問題です。
The file defines the configuration for simple Nauachia challenge where a sucessful man-in-the-middle (MTIM) attack (such as ARP poisoning) provides a solution
今回は
172.30.0.2と172.30.0.3のIPアドレスを持つ2台の端末がいるので、この2台が行っている通信をARPスプーフィングして盗聴することを試みます。ARPスプーフィングの仕組みや具体的な攻撃手法についてはここでは詳しくは説明しませんが、成功すると以下のように
172.30.0.2と172.30.0.3の2つのホスト間の通信が見えてしまいます。# tcpdump -i tap0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes 06:40:47.791591 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:48.042999 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:48.696193 IP 172.30.0.3.55672 > 172.30.0.2.5005: UDP, length 30 06:40:49.792320 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:50.044301 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:51.700769 IP 172.30.0.3.55672 > 172.30.0.2.5005: UDP, length 30 06:40:51.793616 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:52.044971 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:53.794367 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:54.045958 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:54.705584 IP 172.30.0.3.55672 > 172.30.0.2.5005: UDP, length 30 06:40:55.795642 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:56.047136 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28L2で接続されている同じネットワークにいる場合、このようなリスクがあることを認識しなければいけません。
おわりに
この記事では、NaumachiaというOSSを使ったペネトレーションテストのトレーニング環境の構築について紹介しました。
明日は @nyakuo さんの担当となります。
それでは良いお年を!
ペネトレーションテストについて by 脆弱性診断士スキルマッププロジェクト ( https://github.com/ueno1000/about_PenetrationTest ) ↩
- 投稿日:2019-12-15T23:51:28+09:00
matplotlibまとめ
https://estuarine.jp/2016/09/jp-fonts-matplotlib/
yum -y install ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fonts
rm fontList.py3.cache # Python 3]
https://qiita.com/ysdyt/items/3eb9b438980409c8f3e2
/usr/share/fonts/ipa-pgothic/ipagp.ttf
import matplotlib
from matplotlib.font_manager import FontPropertiesfont_path = './TakaoPGothic.ttf' #DLしたパスを指定. /font以下でなくても良い
font_path = '/usr/share/fonts/ipa-pgothic/ipagp.ttf'
font_prop = FontProperties(fname=font_path)例
plt.text(X[i, 0], X[i, 1], hoge, fontproperties=font_prop)
他のブログでは、matplotlibの環境ファイルであるmatplotlibrcファイルのfont.familyの箇所を、DLしたフォント名で指定して、使用するフォントを書き換えているがmatplotrcファイルを書き換えることができない弱い権限のときは plotする時にいちいち引数にfontproperties=font_propを渡してあげることで解決している
(※いちいち引数に書くのはややめんどくさくはあるが、そこまで頻繁にmatplotlibで日本語表示をしない人は、環境ファイルを書き換えて何かよくわからんことになってしまうより、暫定的に変更する方がむしろ楽かもしれない)fontproperties=font_propをいちいち渡して日本語表示する際の注意点としては、
plt.legendするときだけfontproperties=font_propではなく、prop=font_propとなる点。例
plt.legend(['hoge'], prop=font_prop, loc='upper left')
(備考)MatplotlibのFontキャッシュ削除
Fontのキャッシュが残っていると、設定変更しても反映されない可能性があるのでこれを削除する$ rm ~/.cache/matplotlib/fontList.cache
- 投稿日:2019-12-15T23:50:28+09:00
Djangoまとめ
いい感じの管理画面
xadmin
https://qiita.com/Syoitu/items/11fac037759220b30cd2
いい感じのcsvパッケージ
import export
https://blog.daisukekonishi.com/post/django-import-export-csv/
- 投稿日:2019-12-15T23:43:28+09:00
マジカル交換200回やってみた【ポケモン剣盾】
はい、どうも。ポケモン剣盾にハマりすぎて研究が進みません。
Dasonと申します。よろしくお願いします。さて、私が卒業した現象数理学科には、学生発の学年間交流LTの「#MS_NCLT」というものがあります(というか、僕らが作った)。そこで私が今年発表した内容なのですが、その裏にPythonの基礎集計を学ぶ良い題材があったので、Qiitaにまとめていこうかな、と思います。
技術的な話は...
- pandasで簡単な集計
- matplotlibで横軸ラベルが斜めな棒グラフを描く
- matplotlibで日本語を利用する
になります。簡単なのしか使わないです。
ポケモン剣盾「マジカル交換」
ポケモンをやったことのある方ならお馴染みですね、マジカル交換。
(最近まで「ミラクル交換」だと思ってました。アローラ!)世界中の誰かとランダムに接続して、その人と1回だけポケモン交換をするという機能です。
相手から何が来るか分からないのが良さでもあり、怖さでもあります。
200回やってみた
マジカル交換に流れて来るポケモンは
よっぽど不要なポケモン or 孵化厳選の余りポケモン
になります。実験日は11月30日。発売から2週間しか経っておらず
いわゆる「ガチ勢」が孵化厳選をしまくっている時期で、良い個体が多く流れて来る期間でもあります。つまり、
この時期にマジカル交換に流れてくるポケモンを見れば
今作の強いor人気なポケモンが分かるのではないか?
と思ったわけです。そこで、200回。
交換しては、手元に来たポケモンをメモっていく。
〆切3日前の論文要旨執筆と〆切5日前のレポート執筆をしながら
およそ8時間。頑張りました。さぁ、集計するぞ!!!
Pythonの登場
200回交換を記録したファイルを
NCLT_pokemon.csvと名付けました。ここには、上から順に手元に来たポケモンが羅列されています。これをpythonで読み込んで、集計していきます。
まずは使うパッケージを宣言。import numpy as np import pandas as pd import collections import matplotlib.pyplot as plt %matplotlib inlineそしたら、csvを読み込む。
df = pd.read_csv('NCLT_pokemon.csv')データの中身を見てみましょう。
#データフレームdfからランダムに3つ抽出する。 df.sample(3)
ポケモンたち 21 ロゼリア 10 ベロバー 89 ワンリキー こんな感じ。
では、各ポケモンが何回手元に来たか、集計します。collectionsの中のCounterを使えば、一瞬で数えてくれます。
c = collections.Counter(np.array(df['ポケモンたち']))この
cには、集計結果がもう入っています。
ただ、このままでは非常に見辛いので、pandasで整形してあげましょう。#Counterが辞書になっているので、それをDataFrameに変換する。 num_poke = pd.DataFrame.from_dict(c, orient='index') #ついでに列名を指定する num_poke.columns = ['出現回数'] #出現回数順にソートする。 num_poke_sort = num_poke.sort_values('出現回数', ascending=False)これで整形完了です。
Top5をみてみましょう!num_poke_sort.head(5)
出現回数 ドラメシア 12 コイキング 9 ミミッキュ 6 ヒバニー 6 ガラルポニータ 5 というわけで、200回の結果
ドラメシアが12回で1位でした!
新600族で強いですもんね〜最後にプロットしてみましょう。
ポケモンの名前を日本語にしているので、matplotlibを日本語対応させるライブラリjapanize-matplotlibを使います。インストールはpip install japanize-matplotlibからできます。
では、描画しましょう。import matplotlib.pyplot as plt import japanize_matplotlib #図の画面サイズを指定 plt.figure(figsize=(30,5)) #棒グラフを描画 plt.bar(np.array(num_poke_sort.index), num_poke_sort['出現回数']) #横軸のラベルを70度回転して見やすく plt.xticks(rotation=70)できました。
まとめ
今回はただ単純にポケモンネタでした。
ドラメシア 1強ですね!!


- 投稿日:2019-12-15T23:35:37+09:00
TwitterAPIで自分を応援する
はじめに
こちらは東京高専AdventCalendar① 16日目の記事です。プログラミング初学者であるため、お見苦しい点が多々あると思いますが、何卒ご容赦いただければ幸いです。
さて、出端から私事を挟んで申し訳ありませんが、最近私のツイートに対するフォロワーさんの反応が鈍くなってきました。これも偏に私の努力不足が原因なのですが、このままでは遠からず精神的な破綻を迎えそうなので、火急の対症療法として自分で自分のツイートにリプライを送りつけることにしました。
とりあえずは、「助けてくれ」「もう疲れた」などの私がよく使用している負のワードを含むツイートに対して、慰めと労いと励ましの言葉をありがたい画像つきでリプライしてくれる、そんなハートフルなTwitterAPIの利用を目指しました。
使用要素
- 言語: Python3
- API: TwitterAPI
- モジュール: json, random, glob, time, requests_oauthlib
- 環境: Visual Studio 2019 (Pythonアプリケーション)
前提
- Python3の開発環境が整っていること (参照: Visual StudioでのPython チュートリアル)
- 上記のモジュールが全てインストールされており、正常に動作すること
- TwitterAPIの使用申請が受理され、APIキーを既に取得していること (参照: Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ)
- Twitterをやっていること
How To Make
1. APIキーの設定
まずは、定石として、
main.pyとは別に.pyファイルを新規作成して、そちらで変数にAPIキーを代入する工程を記述していきます(ここでは、config.pyというファイル名にしています)。config.pyCONSUMER_KEY = '取得したConsumer API key' CONSUMER_SECRET = '取得したConsumer API secret key' ACCESS_TOKEN = '取得したAcccess token' ACCESS_TOKEN_SECRET = '取得したAccess token secret'これでAPIキーの設定は完了です。あとは、この
config.pyをmain.pyにインポートして変数を利用するだけです。2.
main.pyの記述
main.pyの全体は以下の通りです。main.py#ファイル(config.py)とモジュールのインポート import config import json import random, glob, time from requests_oauthlib import OAuth1Session #OAuth認証 CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET twitter = OAuth1Session(CK, CS, AT, ATS) #画像添付リプライを実行する関数 def reply(replies, id): url_media = 'https://upload.twitter.com/1.1/media/upload.json' url_text = 'https://api.twitter.com/1.1/statuses/update.json' images = glob.glob('images/*') files = {'media': open(images[random.randrange(len(images))], 'rb')} req_media = twitter.post(url_media, files = files) media_id = json.loads(req_media.text)['media_id'] params = {'status': replies[random.randrange(len(replies))], 'media_ids': [media_id], 'in_reply_to_status_id': id} req_text = twitter.post(url_text, params = params) #3秒周期の繰り返し処理 while True: #自分の最新ツイートを取得して、その中からキーワードのリスト(words)に該当する言葉が含まれているものだけを抽出する url = 'https://api.twitter.com/1.1/statuses/user_timeline.json' params ={'count': 1} req = twitter.get(url, params = params) words = ['助けてくれ', '辛い', 'キツい', 'ダメ', '無理','逃げたい', '嫌', '最悪', 'もう疲れた', '消えたい', '失敗した','線形代数落としました', '留年しました', '捕まりました'] #返信に使用されるワードのリスト(replies)に格納してある言葉をランダムに抽出してreply関数に渡す replies = ['君はよく頑張ってるよ', 'きっと大丈夫だよ', '今日はたまたま調子が悪いだけさ', '明日は絶対に上手くいくよ', 'くよくよするより元気に行こう!', '何も心配することはないよ', '神は君をお許しになるでしょう', 'さすがだぞ!人生の苦難を経験しているんだな', '甘えるな', '情けない', '人間の面汚し'] if req.status_code == 200: timeline = json.loads(req.text) for word in words: if word in timeline[0]['text']: reply(replies, timeline[0]['id_str']) print('Posted!') else: print('ERROR: %d' % req.status_code) time.sleep(3)次に、
main.pyの簡潔な解説をします。
2.1. importとOAuth認証
main.py#ファイル(config.py)とモジュールのインポート import config import json import random, glob, time from requests_oauthlib import OAuth1Session #OAuth認証 CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET twitter = OAuth1Session(CK, CS, AT, ATS)ここはほとんど一般的な雛形通りです。エンドポイントの読み込みに使用する
jsonとOAuth認証を通すためのに使用するconfig.py,requests_oauthlibの他に、random,glab,timeをインポートして後述する処理に使用しています。
2.2. リプライを実行する関数
main.py#画像添付リプライを実行する関数 def reply(replies, id): url_media = 'https://upload.twitter.com/1.1/media/upload.json' url_text = 'https://api.twitter.com/1.1/statuses/update.json' images = glob.glob('images/*') files = {'media': open(images[random.randrange(len(images))], 'rb')} req_media = twitter.post(url_media, files = files) media_id = json.loads(req_media.text)['media_id'] params = {'status': replies[random.randrange(len(replies))], 'media_ids': [media_id], 'in_reply_to_status_id': id} req_text = twitter.post(url_text, params = params)ここではコメントアウト文の通り、「画像添付リプライを実行する関数を定義」しております。画像をポストした後に、その画像の
['media_id']をmedia_idsパラメータに格納したリプライをポストすると、画像が添付されたリプライを投稿することができます。
imagesにはgrab.grab()でローカルから取得した画像群の相対座標がリスト型で代入されており、その内1つをrandom.randrange()を使用して無作為に選択して投稿する構造になっています。正直、このローカルから画像を取得する機能は勢い余って実装したので、むしろ削ったほうが煩雑さがなくなって良いかなと案じております。
2.3. 最新ツイートの定期的な取得
main.py#3秒周期の繰り返し処理 while True: #自分の最新ツイートを取得して、その中からキーワードのリスト(words)に該当する言葉が含まれているものだけを抽出する url = 'https://api.twitter.com/1.1/statuses/user_timeline.json' params ={'count': 1} req = twitter.get(url, params = params) words = ['助けてくれ', '辛い', 'キツい', 'ダメ', '無理','逃げたい', '嫌', '最悪', 'もう疲れた', '消えたい', '失敗した','線形代数落としました', '留年しました', '捕まりました'] #返信に使用されるワードのリスト(replies)に格納してある言葉をランダムに抽出してreply関数に渡す replies = ['君はよく頑張ってるよ', 'きっと大丈夫だよ', '今日はたまたま調子が悪いだけさ', '明日は絶対に上手くいくよ', 'くよくよするより元気に行こう!', '何も心配することはないよ', '神は君をお許しになるでしょう', 'さすがだぞ!人生の苦難を経験しているんだな', '甘えるな', '情けない', '人間の面汚し'] if req.status_code == 200: timeline = json.loads(req.text) for word in words: if word in timeline[0]['text']: reply(replies, timeline[0]['id_str']) print('Posted!') else: print('ERROR: %d' % req.status_code) time.sleep(3)ここでは、
urlに「自身のツイートを取得する」エンドポイントを代入して、パラメータを{'count': 1}とすることで最新のものだけを取得しています。その後、あらかじめ用意しておいたキーワードのリストに該当するか非該当かの判定を行い、該当したら先述したreply()関数に値を渡します。また、
while Trueとtime.sleep()によって、3秒周期で実行される仕組みになっています1。TwitterAPIにおけるhttps://api.twitter.com/1.1/statuses/user_timeline.jsonの取得可能回数の上限は15分で900回 = 1秒に1回ですが、不安なので余裕をもたせました。それと、やっぱりただ単にエールの言葉だけじゃつまらないので、スパイスとして軽い罵倒も混ぜました。
実行結果
無事に実行できました。これで傷は癒えるのでしょうか。
python.exePosted!結論
来世はちゃんとした人間からのリプライが欲しいです。
参照サイト
参考にさせていただいたQiita記事
公式リファレンス
正確に言えば
time.sleep()の仕様上、厳密な3秒周期にはなっていませんが、このプログラムにおいては些細な誤差であると見做して無視することにします。詳細は、Pythonで定周期で実行する方法と検証を参照してください。 ↩
- 投稿日:2019-12-15T23:33:36+09:00
学習に利用する画像のデータセットを作成する
はじめに
- 今回の、学習画像、テスト画像、水増し画像の合計サイズは、
1.4GB程度です。- これらの画像を、学習プログラム実施時に、読み込むとそれなりの時間が必要になります。
- また、別の環境で学習プログラムを実施する時も、転送時間が発生します。
- その他、画像サイズをリサイズしたり、カラーからグレーに変換する処理にも時間が必要になります。
- あらかじめ、リサイズ、グレー変換したデータセットを作成する事で、
50MB程度にすることが出来ました。- ソース一式は ここ です。
ライブラリ
- 前回と同様、
NumpyPillowを使っています。設定
- 以下の設定を追加しています。
DATASETS_PATHに、今回作成するデータセットが保存されます。IMG_ROWSIMG_COLSは、画像サイズのリサイズです。今回は、28 x 28のサイズへリサイズします。- 画像サイズは、後工程の学習モデルでも参照されます。
config.pyDATASETS_PATH = os.path.join(DATA_PATH, 'datasets') IMG_ROWS, IMG_COLS = 28, 28ファイル一覧の作成
- 学習画像、テスト画像、水増し画像のファイル一覧を作成します。
- query には、
CLASSESが順次与えられます。augment引数は、水増し画像の利用可否のフラグです。- 前回、水増し画像は、
query毎に6000作成しました。足りない場合は、エラーにしています。def make_filesets(augment): """ファイルセットの作成.""" filesets = {'train': dict(), 'test': dict(), 'augment': dict()} for query in CLASSES: train_path = os.path.join(TRAIN_PATH, query) test_path = os.path.join(TEST_PATH, query) augment_path = os.path.join(AUGMENT_PATH, query) if not os.path.isdir(train_path): print('no train path: {}'.format(train_path)) return None if not os.path.isdir(test_path): print('no test path: {}'.format(test_path)) return None if not os.path.isdir(augment_path): print('no augment path: {}'.format(augment_path)) return None train_files = glob.glob(os.path.join(train_path, '*.jpeg')) train_files.sort() filesets['train'][query] = train_files test_files = glob.glob(os.path.join(test_path, '*.jpeg')) test_files.sort() filesets['test'][query] = test_files augment_files = glob.glob(os.path.join(augment_path, '*.jpeg')) random.shuffle(augment_files) filesets['augment'][query] = augment_files if augment and len(augment_files) < AUGMENT_NUM: print('less augment num: {}, path: {}'.format(len(augment_files), augment_path)) return None return filesets画像の読み込みの関数
- ファイルのフルパスを元に画像を処理します。
- 設定ファイルに従い、リサイズされます。
- もともと、OpenCV Haar Cascades では、リサイズを行わずに保存していました。後工程でリサイズする方が、様々なサイズで試すのに便利ですね。
LANCZOSは、時間はかかるが、品質良くリサイズしてくれます。デフォルトは、NEARESTですね。品質より、速さ優先です。- その後、グレースケールに変換し、さらに
uint8に変換します。def read_image(filename): """画像の読み込み、リサイズ、グレー変換.""" image = Image.open(filename) image = image.resize((IMG_ROWS, IMG_COLS), Image.LANCZOS) image = image.convert('L') image = np.array(image, dtype=np.uint8) return imageデータセットの作成
- 学習画像、学習ラベル、テスト画像、テストラベルの配列を準備します。
def make_datasets(augment, filesets): """データセットの作成.""" train_images = [] train_labels = [] test_images = [] test_labels = []
- query には、
CLASSESが順次与えられます。- num には、ラベル が順次与えられます。
- 例えば、
CLASSESの 最初は、安倍乙ラベルは0と言う感じです。augmentで水増し画像を利用するか判断します。利用する場合は、AUGMENT_NUMに記載の数のみtrain_filesに設定します。- 各画像の読み込みには、
tqdmも合わせて利用しています。処理経過が表示され、分かりやすいですね。read_imageに画像のファイルパスを与えて、リサイズ、グレースケール化した画像を読み込みます。- 同時にラベルも付与します。
for num, query in enumerate(CLASSES): print('create dataset: {}'.format(query)) if augment: train_files = filesets['augment'][query][:AUGMENT_NUM] else: train_files = filesets['train'][query] test_files = filesets['test'][query] for train_file in tqdm.tqdm(train_files, desc='create train', leave=False): train_images.append(read_image(train_file)) train_labels.append(num) for test_file in tqdm.tqdm(test_files, desc='create test', leave=False): train_images.append(read_image(test_file)) test_labels.append(num)
- 学習画像、学習ラベル、テスト画像、テストラベルをデータセットとしてまとめます。
DATASET_PATHCLASSESIMG_ROWSIMG_COLS水増し画像の利用有無を元にデータセットのファイル名を決めます。datasets = ((np.array(train_images), (np.array(train_labels))), (np.array(test_images), (np.array(test_labels)))) datasets_path = os.path.join(DATASETS_PATH, ','.join(CLASSES)) os.makedirs(datasets_path, exist_ok=True) train_num = AUGMENT_NUM if augment else 0 datasets_file = os.path.join(datasets_path, '{}x{}-{}.pickle'.format(IMG_ROWS, IMG_COLS, train_num)) with open(datasets_file, 'wb') as fout: pickle.dump(datasets, fout) print('save datasets: {}'.format(datasets_file))
- 水増し画像の利用有無は、下記のオプションで切り替えています。
$ python save_datasets.py $ python save_datasets.py --augment
- pickle 化したデータセットは、下記の様になりました。
- オリジナルの場合は、
traintestの合計 約148MBから3.2MBの pickleファイル- 水増し画像の場合は、
augmenttestの合計 約1433MBから46MBの pickleファイル$ du -d1 -h . 115M ./train 33M ./test 51M ./datasets 1.4G ./augment $ ls 3.2M 12 15 23:22 28x28-0.pickle 46M 12 15 22:24 28x28-6000.pickleおわりに
- 学習プログラムから利用しやすい様に、画像データをリサイズ、グレースケールしたデータセットを作成しました。
- 複数のサイズ、水増し画像の数の変化などで、色々データセットを作り、ファイル名で切り替えながら利用が出来ます。
- 次回は、データセットを学習プログラムから読み込む部分を作成する予定です。

- 投稿日:2019-12-15T23:31:13+09:00
jetson nano セットアップ
Jetson nano 購入から物体認識(リンゴとミカン)までの手順By カワシマ AI, Jetson, Linux, Python, 機械
sudo apt-get install git cmake
gitとコンパイルに必要なcmakeをとってきます。git clone https://github.com/dusty-nv/jetson-inference
cd jetson-inference
git submodule update --initレポジトリをcloneをします。場所はホームディレクトリで問題ないでしょう。
それから、cloneしたディレクトリに入って、依存するモジュールも全部とってきます。
次は
mkdir build
cd build
cmake ../buildというビルド用のフォルダを作って、buildディレクトリに入って、cmakeでコンパイルの準備をします。
Jetson nanoサンプルコードのコンパイル
次はcd jetson-inference/build
make
sudo make installcd jetson-inference/build
make
sudo make install
jetson-inference/buildのディレクトリにいることを確認して、makeでコンパイルします。その後、make installでインストールを完成させます。cd jetson-inference/build
make
sudo make instal実行
etson nanoサンプルコードを動かそう!
次はcd jetson-inference/build/aarch64/bin
上のディレクトリに移動します。ここにいくつかのプログラムがすでに(コンパイルとインストールで)用意されています。
まず1回目下記のコマンドを実行しましょう(Terminalで)
./imagenet-console orange_0.jpg output_0.jpg
orange_0.jpgという写真をインプットとして、認識した結果をoutput_0.jpgに書き込みます。
- 投稿日:2019-12-15T23:22:22+09:00
Python学習ノート_004
第2章のサンプルを下記のように改修しました。
- 確認するポイント
- 文字列にダブルクォーテーション「"」とシングルクォーテーション「'」の区別
- どちらも使えますが、ペアに使うことは前提です。
print( ' this is a test ") 或いは
print( ' this is a test ') 或いは
- 文字列なかにダブルクォーテーション「"」あるいは シングルクォーテーション「'」が存在する時下記の2種類の対応で実現可能です。
- input関数の出力結果は必ず文字タイプで戻る
- 演算符号の優先順位 アメリカでは PEMDAS (Parentheses, Exponents,
Multiplication, Division, Addition, Subtraction) という頭字語を使う。- print関数に出力したい文字列を複数入れると、間に半角スペースが入ります。
sample02.py#犬の名前を尋ねる dog_name = input('犬の名前はなんですか。') #犬の年齢を尋ねる dog_age = input('犬の年齢は何歳ですか。') #犬の年齢に7をかけて人間換算年齢を求める human_age = int(dog_age) * 7 #inputの戻り値のタイプは文字列(str) print('そのまま年齢×7の結果:',dog_age * 7) #print関数に出力したい文字列を複数入れると、間に半角スペースが入ります print('あなたの犬', dog_name, 'の人間換算年齢は', human_age, '歳です')
- 実行結果

- 投稿日:2019-12-15T22:17:49+09:00
GCPを使って1時間でKerasのAI予測エンジンを作る
はじめに
本記事は ぷりぷりあぷりけーしょんず Advent Calendar 2019 の13日目の記事です。
この記事ではMLエンジニアとして業務を行っている筆者が、普段利用しているGCPのAIPlatformを使って1時間でAI予測エンジンをする方法を紹介します。
AI Platformとは
最近は、AIを使ったプロダクトを作ろうという企業が増えてきたように感じます。
しかし、AIの予測エンジンを実際につくろうとすると、GPUのリソースを使えるように設定したり、それをスケールさせるようするなど、とても工数がかかると思います。
これらの問題を解決してくれるサービスがAIPlatfromです。AIPlatform とは Google Could Platform で提供されているサービスの1つです。 AIPlatform公式サイト
GPUを使った学習や予測を手軽に実装できるので、機械学習を使うプロダクトを実装するときにとても有効です。
言語としてはPythonがサポートされており、フレームワークはscikit-learn,TensorFlow,XGBoostなどを使うことができます。GCPで必要なセットアップ
この記事では以下のGCPのサービスを利用します。
- AIPlatform
- GoogleCloudStorage
それぞれのサービスを操作できるアカウントを用意してください。
Kerasのモデルをデプロイする
Kerasを使って簡単なモデルを作り、デプロイしてみます。
デプロイするには以下の手順が必要になります。
- Kerasのモデルを定義して学習させる。
- 学習したモデルを GCS(GoogleCouldStorage) へアップロードする。
- AIPlatform でモデルの名前空間を定義する。
- AIPlatform で定義したモデルの名前空間とGCSへアップロードしたモデルを紐づける。
例として
入力値xに対してx^2を回帰予測するモデルを作って、デプロイしてみます。
以下がサンプルコードです。
keras_model_deploy.pykeras_model_deploy.pyfrom tensorflow.python.keras.models import Sequential, Model from tensorflow.python.keras.layers import Dense import tensorflow as tf import numpy as np def create_data(): data_size = 1000 x = [i for i in range(data_size)] y = [i**2 for i in range(data_size)] return x, y def create_model() -> Model: model = Sequential() model.add(Dense(32, activation=tf.nn.relu, input_shape=(1,))) model.add(Dense(1)) optimizer = tf.train.RMSPropOptimizer(0.001) model.compile(loss='mse', optimizer=optimizer, metrics=['mae']) return model def run_train(x: np.ndarray, y: np.ndarray, model: Model) -> Model: history = model.fit( x, y, batch_size=1000, epochs=100, verbose=1, ) return model def save_model(model: Model) -> None: tf.keras.experimental.export_saved_model( model, "gs://your-buckets/models/sample_model", # 保存するGCSのパスを指定する serving_only=False ) if __name__ == "__main__": x, y = create_data() model = create_model() model = run_train(x, y, model) print(model.predict([2])) save_model(model)
tf.keras.experimental.export_saved_modelを使うと、モデルをGCSへ保存することができます。
ただし、これはパスの指定がgs://から始まる場合だけで、普通のパスを指定すると local へ保存されます。このコードを実行します。
output.txtEpoch 1/100 1000/1000 [==============================] - 0s 62us/sample - loss: 199351844864.0000 - mean_absolute_error: 332684.8750 Epoch 2/100 1000/1000 [==============================] - 0s 1us/sample - loss: 199338442752.0000 - mean_absolute_error: 332671.3750 Epoch 3/100 1000/1000 [==============================] - 0s 1us/sample - loss: 199328612352.0000 - mean_absolute_error: 332661.5938 Epoch 4/100 1000/1000 [==============================] - 0s 1us/sample - loss: 199320403968.0000 - mean_absolute_error: 332653.3438 Epoch 5/100 1000/1000 [==============================] - 0s 1us/sample - loss: 199313096704.0000 - mean_absolute_error: 332646.0312 Epoch 6/100 1000/1000 [==============================] - 0s 1us/sample - loss: 199306379264.0000 - mean_absolute_error: 332639.2812 Epoch 7/100 1000/1000 [==============================] - 0s 1us/sample - loss: 199300087808.0000 - mean_absolute_error: 332633.0000 Epoch 8/100 1000/1000 [==============================] - 0s 1us/sample - loss: 199294124032.0000 - mean_absolute_error: 332627.0000 Epoch 9/100 1000/1000 [==============================] - 0s 1us/sample - loss: 199288389632.0000 - mean_absolute_error: 332621.2500 ・ ・ ・ Epoch 100/100 1000/1000 [==============================] - 0s 1us/sample - loss: 198860079104.0000 - mean_absolute_error: 332191.8438 [[3.183104]]モデルの精度はお粗末ですが、きちんと予測結果を返すことが確認きました。
ここからは、GCPのコンソール上で操作してデプロイしていきます。(
gcloudコマンドを利用するとコマンド上から同じ作業ができますが、今回は紹介しません。 )まずは、 AIPlatform 上にモデルの名前空間を作りましょう。
AIPlatform のモデルのタブへ行き、
モデルの作成をクリックします。
名前とリージョンを設定します。
ログの設定はここで行います。この設定は変更することができないので、注意してください。
次に、モデルのバージョンを振ります。
ここで、GCSへアップロードしたモデルとの紐付けを行います。モデルを選択して、
新しいバージョンをクリックします。
バージョンの名前と、モデルの動作環境を指定したあと、 GCSにアップロードした SavedModelのパスを指定します。
また、使用するリソース(マシンタイプ)の設定もこちらで行います。
用途に応じて必要なリソースを選択してください。
全ての設定を指定した後、バージョンを作成するとモデルが AIPlatform 上に設置されます。
AIPlatform ではモデルを設置すると、そのモデルを使用して予測を行うAPIを提供してくれています。なので、ここまでの作業で予測のAPIを叩く準備ができました。
** 注意 **
AIPlatformでは、モデルを設置した時点で常に GPU のリソースを使い続けるようになります。
これによって、予測のリクエストを投げなくても課金が発生することになりますので、お気をつけください!!
使わないモデルは削除することをお勧めします!予測の結果を取得する
AIPlatform上にデプロイしたモデルに対して予測のリクエストを投げて結果を取得したいと思います。
pythonを利用してリクエストを投げる場合には
googleapiclientを利用してするのが簡単です。リクエストを投げる時に認証が必要になりますが、
GOOGLE_APPLICATION_CREDENTIALSという環境変数にサービスアカウントなどのクレデンシャルファイルのパスを指定すると解決します。predict.pyfrom googleapiclient import discovery project = "your-project-id" model = "model_sample" def predict(instances): service = discovery.build('ml', 'v1', cache_discovery=False) url = f"projects/{project}/models/{model}" response = service.projects().predict( name=url, body={'instances': [instances]} ).execute() return response if __name__ == "__main__": features = [2] prediction = predict(features) print(prediction)
predictの引数nameや、bodyの詳しい仕様については こちら の公式リファレンスをご確認ください。実行すると、以下のように予測結果を取得することができます。
output{'predictions': [{'dense_1': [3.183104]}]}これで予測のエンジンを構築することがきました!
(精度はお粗末ですが、、、)終わりに
記事では学習をローカル環境で行いましたが、AIPlatform上でGPUリソースを利用した学習を行うこともできます。
AIを使ったプロダクトを作る際には強力な武器になると思います。今回は簡単な Keras モデルを使った予測エンジンを1時間で作成してみました。
あなたのためになれば幸いです。




- 投稿日:2019-12-15T22:13:40+09:00
超単純なケースのk-means法のpythonのコード
k-means法の超単純なケースのpythonのコード
2019年の統計検定1級の統計応用の人文科学ではk-means法の初期値依存に関する問題が出ましたが、ここでは実際にk-meansが初期値に依存することを確認するために、超単純なケースのpythonのコードを書いてみました。
状況設定は以下の様にします。
分類する集合:(有限個の)実数を要素とする集合。
クラスターの個数:2つ。print("最初に部類する集合の要素数を入力してください。") n = int(input()) print("次に部類する集合の要素を入力してください。") a = [float(input()) for _ in range(n)] print("次に初期値を2つ入力してください。") b = [float(input()) for _ in range(2)] A = [] B = [] ''' print(A) print(B) ''' for i in range(n): if abs(b[0] - a[i]) <= abs(b[1] - a[i]): A.append(a[i]) else: B.append(a[i]) if len(A) == 0 or len(B) == 0: print("一つ目のクラスターは") print(A) print("二つ目のクラスターは") print(B) else: c = sum(A)/len(A) d = sum(B)/len(B) while c != b[0] or d != b[1]: b[0] = c b[1] = d A = [] B = [] for i in range(n): if abs(b[0] - a[i]) <= abs(b[1] - a[i]): A.append(a[i]) else: B.append(a[i]) c = sum(A)/len(A) d = sum(B)/len(B) print("一つ目のクラスターは") print(A) print("二つ目のクラスターは") print(B)このコードを初期値を変えて実行した例を2つ下に載せておきます。
ということで、実際に初期値を変えると最終的なクラスターも異なることが確認できました。∩( ・ω・)∩
k-mean法を使ってクラスター分析をするときは注意が必要ですね。


- 投稿日:2019-12-15T22:08:51+09:00
学習記録 その4(8日目)
学習記録(8日目)
勉強開始:12/7(土)〜
使用書籍:大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年)【辞書から値を取り出す(Ch.9 / p.229)】 から再開(7日目)、
【テキストファイル(Ch.13 / p.316)(一部保留)】 まで終了(8日目)ユーザ定義関数
>>>def Arnold(): return "When my muscles say "No", I say "Yes!"" >>>Arnold() "When my muscles say "No", I say "Yes!"・引数を設定することも可能
・先に定義しておく場合は、とりあえずの pass をステートメントに記載できる。
・関数定義は閉じた空間、定義内で設定した変数は外から参照できない。
・引数の前に*を付けると可変の数値に設定できる。(慣例で *args などと表す。)
・モジュールはdef関数を用いて作成されている(全てではない? ただ、円ドル換算について定義したdefファイルを、importして使えるとの記載があるので、そのように解釈)
・(今更だけど)help()で関数の説明が見れる。qを押せば戻れる。イテレータとジェネレータ
>>>muscles = ["biceps","triceps","abdominal","deltoid","gluteus"] >>>muscles_iter = iter(muscles) >>>next(muscles) "biceps" >>>next(muscles) "triceps" #中略 #取り出す要素がなくなると、最後はエラーが出る。・ジェネレータも似たような処理だが、メモリが少なくて済むというメリットがあるらしい。
よくわからないけど、使う時になったら実感できるでしょうと楽観視クラス定義
保留
テキストファイル
・open()で開き、read()で読み込み、close()で閉じる。
エラーを避けるため、読み込んだ数値を処理する前にまず閉じるのが鉄則
・with-as文であればclose()する必要はない。(with openで開いてasで定義)
・tkinterでhtml読み込んだら量が多すぎて固まった・・・ 読み進めていったら、指定数分だけ読み込めるようにもできるらしい。
・read()の引数が空欄か負の数だと全て。正の数を入れたらその文だけ。もしくはreadline()
・filedialogを用いた保存先及びファイルがあるかどうかのチェック方法
- 投稿日:2019-12-15T21:55:22+09:00
Python の通信を Fiddler で見る
az コマンドの通信を HTTPS デコードして Fiddler で見たかったけど Python は Windows の証明書ストアを見ないらしく、Fiddler のルート証明書を信頼できずに証明書エラーが発生した。
Please ensure you have network connection. Error detail: HTTPSConnectionPool(host='login.microsoftonline.com', port=443): Max retries exceeded with url: /common/oauth2/token (Caused by SSLError(SSLError("bad handshake: Error([('SSL routines', 'tls_process_server_certificate', 'certificate verify failed')],)",),))解決策
Fiddler の Root 証明書を環境変数
CURL_CA_BUNDLEにセットする。$env:CURL_CA_BUNDLE = "C:\Path\To\FiddlerRoot.cer"なお、ルート証明書は Base64 エンコードである必要がある。
証明書ストアから、Base64 でエクスポートするのが楽。
あとは環境変数に Fiddler のプロキシをセット
$env:http_proxy = "http://127.0.0.1:8888" $env:https_proxy = $env:http_proxyこれで Fiddler で通信トレースを取れる。

- 投稿日:2019-12-15T21:55:20+09:00
GPU持ってないけどDeep Learningしてみる
前書き
「複雑な環境構築をせずにディープラーニングのチュートリアルができる」をコンセプトとし、この記事のコードをコピペしていくだけで試すことができるようになっています。(と言うかGitHubからクローンしてきて実行するだけ)
環境
macOS Mojave version 10.14.6
python3.6.5
この記事の対象読者
タイトル通りGPUなど持っていないけどディープラーニングを試してみたいという方を対象としています。本格的に深層学習をしようとしたらやはりGPUが必要ですが、「何ができるのか」、「どう動くのか」を直感的に理解するには実際に動かしてみるのが良いと思います。
Python自体の環境構築はできていることを前提に進めます。ディープラーニングの定義
情報源によって定義が微妙に異なることがありますが、深層学習やディープラーニングと呼ばれるアルゴリズムはだいたい隠れ層が3層以上からそう呼ばれる事が多い気がしています。(曖昧で申し訳ありません)
この記事では隠れ層の数がそれ以下のモデルも扱いますが特に言い分けたりはしません。ただ、アルゴリズムのことをニューラルネットワーク、それが重み学習することをディープラーニングとします。
R^2スコアは簡単に言うと回帰(予測)した曲線が正解の曲線とどの程度近いかを0〜1で表す評価関数です。MSEは平均二乗和誤差と言って正解の値と予測の値の二乗和誤差の平均値です。
問題設定
2つの入力値(x1, x2)からSinCosカーブを予測する
イメージとしてはこのような感じです。
隠れ層の数や各層のユニット数で精度がどう変わるかを確認していきます。
環境構築
# 簡単のため以下の手順で僕が作業したリポジトリをクローンしてきてください。 $ git clone https://github.com/keroido/DNN-learning-Sin-Cos-wave.git $ cd DNN-learning-Sin-Cos-wave # 仮想環境を作り、仮想環境に入ります。(任意) $ pip install virtualenv $ virtualenv venv $ . venv/bin/activate # 仮想環境に必要なライブラリをまとめてインストールします。 (venv)$ pip install -r requirements.txt # 仮想環境venvから出るときは $ deactivate学習データを作る
以下の手順でデータセットを作ります。入力値x0,x1とその2つを足した時のSin,Cosの4つの列 × 1000行のデータを生成します。
このx0とx1からSinとCosを予測します。
イメージ
index x0 x1 Sin Cos 0 50.199163279521 17.5983756102216 0.925854354002364 0.377880556756848 1 127.726947420807 116.093208916234 -0.897413633456196 -0.441190174966475 2 54.2208002632216 116.589734921833 0.159699676625697 -0.987165646325705 3 156.256738791155 8.64049515860479 0.260551118156132 -0.965460053460312 : ... ... ... ... : ... ... ... ... 999 23.2978504439148 109.826906405408 0.72986697370653 -0.683589204634239 (0 <= x1, x2 <= 180)
以下のディレクトリでデータセットを生成するプログラムを実行します。またトレーニングデータセットの置き場inputと出力結果の置き場outputもここで作っておきます。
# カレントディレクトリを確認する。 $ pwd [out]: .../DNN-learning-Sin-Cos-wave/code # 入力データの置き場と出力データの置き場を作る。 $ mkdir ../input ../output # データセットを生成するプログラムを実行 $ python make_dataset.py# make_dataset.py import numpy as np import pandas as pd import math x0 = np.random.rand(1000) * 180 x1 = np.random.rand(1000) * 180 s = [math.sin(math.radians(i+s)) for i, s in zip(x0, x1)] c = [math.cos(math.radians(i+s)) for i, s in zip(x0, x1)] df = pd.DataFrame({'x0':x0, 'x1':x1, 'sin':s, 'cos':c}) df.to_csv('../input/data.csv')
するとinputディレクトリにdata.csvが生成されます。
ディープラーニングしてみる
それではいよいよディープラーニングをしてみましょう。この記事のテーマはGPUを使わずにディープラーニングすることですのでscikit-learnで実装します。
また、train.pyとありますが同時に各モデルの評価もしています。$ pwd [out]: .../DNN-learning-Sin-Cos-wave/code $ python train.py# train.py import numpy as np import pandas as pd from sklearn.model_selection import train_test_split # データを訓練セットとテストセットに分けます。 from sklearn.neural_network import MLPRegressor # sklearnで動くニューラルんネットワークの関数です。 from sklearn.metrics import mean_squared_error # MSE(平均二乗和誤差) # inputディレクトリにあるデータを読み込みます。 df = pd.read_csv('../input/data.csv') df = df.drop('Unnamed: 0', axis=1) # Xにx0とx1を、yにSinCos X = df.iloc[:, :2] y = df.iloc[:, 2:] # 訓練セットとテストセットに分けます。 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 隠れ層の数を2,3,4 ユニットの数を10,50,100,150,200 全ての組み合わせを試す。 hidden_layer_sizes = [(10, 10,), (50, 50,), (100, 100,), (150, 150,), (200, 200,), (10, 10, 10,), (50, 50, 50,), (100, 100, 100,), (150, 150, 150,), (200, 200, 200,), (10, 10, 10, 10,), (50, 50, 50, 50,), (100, 100, 100, 100,), (150, 150, 150, 150,), (200, 200, 200, 200,)] ln = list(range(len(hidden_layer_sizes))) # Sin,CosそれぞれのMSEとR^2スコアを書き込むデータフレームを作っておく score_df = pd.DataFrame(columns={'sin_mse', 'cos_mse', 'r^2_score'}) for i, hidden_layer_size in zip(ln, hidden_layer_sizes): # モデルの詳細(https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPRegressor.html) # verboseをTrueに変えて実行すると学習の進行状況がわかるようになります。 model = MLPRegressor(activation='relu', alpha=0, batch_size=100, hidden_layer_sizes=hidden_layer_size, learning_rate_init=0.03, random_state=0, verbose=False, solver='adam') # モデルに訓練データセットを食わせます。 model.fit(X_train, y_train) #テストセットのx0,x1からSin,Cosを予測します。 pred = model.predict(X_test) # ここから下は予測した結果をoutputディレクトリに出力するデータフレームの整形など pred = pd.DataFrame(pred) x = pd.DataFrame({'x':(X_test['x0'] + X_test['x1']).tolist()}) tes = y_test.rename(columns={'sin': 'sin(label)', 'cos': 'cos(label)'}).reset_index(drop=True) pre = pred.rename(columns={0: 'sin(prediction)', 1: 'cos(prediction)'}).reset_index(drop=True) ans_df = pd.concat([x, tes, pre], axis=1) ans_df = ans_df[['x', 'sin(label)', 'sin(prediction)', 'cos(label)', 'cos(prediction)']] ans_df.to_csv('../output/result_{}_{}_{}.csv'.format(str(i).zfill(2), len(hidden_layer_size), hidden_layer_size[0])) sin_mse = mean_squared_error(tes['sin(label)'].tolist(), pre['sin(prediction)'].tolist()) cos_mse = mean_squared_error(tes['cos(label)'].tolist(), pre['cos(prediction)'].tolist()) r2 = model.score(X_test, y_test) score_df.loc['{}'.format(i), 'sin_mse'] = sin_mse score_df.loc['{}'.format(i), 'cos_mse'] = cos_mse score_df.loc['{}'.format(i), 'r^2_score'] = r2 col = ['sin_mse', 'cos_mse', 'r^2_score'] score_df = score_df[col] # outputディレクトリに出力する score_df.to_csv('../output/score.csv')解説
(コードが汚くて申し訳ないのですが、、、)hidden_layer_sizesを見てください。ここでは以下のようにニューラルネットワークのレイヤー数(隠れ層数)とユニット数を色々変えてどの組み合わせが良い精度を出せるかを試行錯誤できるようにしています。
レイヤー数 \ ユニット数 10 50 100 150 200 2 精 度 が 良 く 3 な る 組 み 合 4 わ せ は 何 ? 評価、可視化してみる
可視化にはjupyter notebookが便利なので利用していきましょう。
$ pip install jupyter $ pwd [out]: .../DNN-learning-Sin-Cos-wave/code $ ls [out]: make_dataset.py train.py viewer.ipynb $ jupyter notebookブラウザでjupyter notebookが起動したらviewer.ipynbを開いてください。このノートブックは上から実行していくだけで評価とデータの可視化ができるようになっています。
https://github.com/keroido/DNN-learning-Sin-Cos-wave/blob/master/code/viewer.ipynb
以下jupyter上での実行です。(説明不要のコードは省略)outputディレクトリを見てみると'result_00_2_10.csv'などと名前のついたcsvファイルが15個存在しています。このファイルの名前は'result_00_2_10.csv'を例にとって説明すると、00は作成した順番で2はレイヤー数、10はユニット数を表しています。ですからこのcsvファイルは「0番目に作った2層10ユニットづつのニューラルネットワークで学習した結果ですよ」と言う事になります。
!ls ../output [out]: result_00_2_10.csv result_04_2_200.csv result_08_3_150.csv result_12_4_100.csv result_01_2_50.csv result_05_3_10.csv result_09_3_200.csv result_13_4_150.csv result_02_2_100.csv result_06_3_50.csv result_10_4_10.csv result_14_4_200.csv result_03_2_150.csv result_07_3_100.csv result_11_4_50.csv score.csv1, 各ニューラルネットワークのスコアを確認
score_df = pd.read_csv('../output/score.csv') score_df = score_df.drop('Unnamed: 0', axis=1) score_dfどんな条件の時にR^2スコアの値が良いかを確認してみましょう。 結果を見てみると9番目、result_09_3_200.csvの3層200ユニットのニューラルネットワークが最も良い結果を出しています。(設定によって変わるかもしれません)
単純に層が深ければ良いと言うわけではないことがわかりますね。
index sin_mse cos_mse r^2_score 0 0.118307 0.272191 0.551913 1 0.071344 0.174416 0.717997 2 0.101467 0.269444 0.574389 3 0.053282 0.022353 0.913211 4 0.374317 0.242327 0.292416 5 0.127534 0.274327 0.538875 6 0.061558 0.163282 0.742001 7 0.195692 0.262261 0.474512 8 0.034099 0.010542 0.948776 9 0.006197 0.004922 0.987241 10 0.512035 0.361053 -0.001846 11 0.116843 0.099484 0.751770 12 0.013951 0.029560 0.950072 13 0.009213 0.009595 0.978419 14 0.005862 0.006255 0.986096 2, 一番良いスコアを出したcsvファイルを確認
tmp = pd.read_csv('../output/result_09_3_200.csv') tmp = tmp.drop('Unnamed: 0', axis=1) tmp(label)が正解ラベルで、(prediction)がニューラルネットワークの予測値です。割と近い値を予測できているのがわかります。
※ここでのxはx0,x1の和です。
x sin(label) sin(prediction) cos(label) cos(prediction) 0 271.800382 -0.999506 -0.912688 0.031417 1 133.334658 0.727358 0.722477 -0.686258 2 136.451163 0.688973 0.656727 -0.724787 3 187.429195 -0.129301 -0.182335 -0.991605 4 229.748855 -0.763220 -0.801409 -0.646139 ... ... ... ... ... 3, 実際に可視化してみる
files = glob.glob('../output/result*.csv') files.sort() csvs = [] t = [] for i in range(1, 16): t.append(files[i-1]) if i%5 == 0: csvs.append(t) t = []Sin
fig, axes = plt.subplots(3, 5, figsize=(15, 10)) fig.subplots_adjust(hspace=0.3, wspace=0.3) for i in range(3): for j in range(5): tmp = pd.read_csv(csvs[i][j]) axes[i, j].scatter(tmp.loc[:, 'x'], tmp.loc[:, 'sin(label)'], c='b') axes[i, j].scatter(tmp.loc[:, 'x'], tmp.loc[:, 'sin(prediction)'], c='r', alpha=0.5) axes[i, j].set_title('layer:{}, unit:{}'.format(csvs[i][j][20], csvs[i][j][22:-4])) plt.xlim(-5, 365)
cos
fig, axes = plt.subplots(3, 5, figsize=(15, 10)) fig.subplots_adjust(hspace=0.3, wspace=0.3) for i in range(3): for j in range(5): tmp = pd.read_csv(csvs[i][j]) axes[i, j].scatter(tmp.loc[:, 'x'], tmp.loc[:, 'cos(label)'], c='b') axes[i, j].scatter(tmp.loc[:, 'x'], tmp.loc[:, 'cos(prediction)'], c='r', alpha=0.5) axes[i, j].set_title('layer:{}, unit:{}'.format(csvs[i][j][20], csvs[i][j][22:-4])) plt.xlim(-5, 365)
可視化してみるとニューラルネットワークがどう予測したかが一目でわかって楽しいですね。
以上で「GPU持ってないけどDeep Learningしてみる」終わりです。お疲れ様でした。



- 投稿日:2019-12-15T21:53:00+09:00
パーソナライズとスキル内課金を実装した(おそらく)最小のスキルを作った話
えっと、、田中みそさんのtwitterを見かけて、つい勢いでalexaのadvent calenderに参加してみましたが、とくにネタを用意しないまま直前になってしまいちょっと慌てております。。
どうしようかなー、って考えたのですが、シンプルに最近作ったスキルの解説的な記事とさせてください。
ターゲット
- パーソナライズの機能をさっくり使ってみたい
- スキル内課金のpythonでのソースが見たい
- askのcliでpython使いたい
だいたいこんな所でしょうか。
話す内容
- 「私のサンタクロース」 スキルについて
- ask-cli for python
- コードの抜粋と解説
「私のサンタクロース」 スキルについて
https://www.amazon.co.jp/dp/B081YJTLJS/
ちょっと前に「私のサンタクロース」というちょっとしたスキルをリリースしています。
このスキルの目的は・・
スキル内課金機能を実装して公開するとecho show5がもらえるキャンペーン参加のためなんでもいいからパーソナライズ機能を実装してみたかったask-cli for python使ってみたかった- サンタを信じるピュアなお子様やファミリーに幸せを届けたい
・・・こんな感じでした。シンプルですね。
ざっくりいうと、
- サンタ役がスキルに登録する
- プレゼントを欲しい側が願い事をする
- サンタ役が願いごとを確認する
というスキルです。
ポイントとしてはサンタ役の識別にパーソナライズの機能を使っているところでしょうか。
願い事をする側も、パーソナライズが有効であれば活用しています。
また、課金機能はけっこう無理やり実装しており、課金すると願い事の上限が増えるようになっています。ask-cli for python
ask-cliは使ったことあるのですがいつもnodeでやっておりました。
一度pythonも使ってみようかなと思い、今回はpython使ってます。ask-cliとは
alexa skill kitをコマンドラインで使うものです。
これを使うと開発者コンソールを開かなくてもスキルを作る事が可能です。
ask cloneで既存のスキルのコードを落としたり、チーム間でコードを共有したりする時はめちゃくちゃ便利です。
まあコンソールには何かと便利な事は多いし、申請の時なんかは結局コンソールを開く事になりますが。使い方としては下記のチュートリアルがそのまま。
クイックスタート: Alexa Skills Kitコマンドラインインターフェース(ASK CLI)
- ask init
- ask new
- ask deploy
ってやるだけ。
ask newでサンプルスキルのコードをcloneできるので、手っ取り早くなんか作る事もできる。ask-cli for python
ask newの時にpython3を選択するとpythonでalexaスキルを作れます。$ ask new ? Please select the runtime Python3 ? List of templates you can choose Hello World (using Classes) ? Please type in your skill name: skill-sample-python-helloworld-classes Skill "skill-sample-python-helloworld-classes" has been created based on the chosen template(↑なお19/12/18時点の話ですが、
.ask/configのpython3.6をpython3.7にしないとdeployでエラーになった。)ちなみに
$ ask create-hosted-skill --runtime python3.7 --skill-name ExampleSkill --auto-clone trueみたいにやるとhosted スキルが作れます。
要はalexa側でリソース(lambdaとかDynamoDbとか)をホストしてくれるスキル。ちょっとしたスキルならこれで十分。
本来はブラウザ使ってコード書かないといけないhostedスキルだけど、cli使えばローカルで開発できてしまうことになるし超便利。コードの抜粋と解説
私のサンタクロースのコードです。
(コードのお話なのにやっつけなコードですいません。)https://github.com/ikegam1/alexa-myhomesanta-ask-python37
- lambda/py/lambda_function.py スキルのバックエンド処理全般
- lambda/py/vendor/alexa/data.py スキルの発話部分のワード
- isps/subscription/my-home-santa.json 課金アイテムの設定
- models/ja-JP.json スキルのフロント部分のインテントなど
- skill.json
説明するのは
lambda_function.pyの部分です。(説明名の)流れ
こんな感じの流れに沿って解説します
- 初回起動時の流れ
- 願い事登録時の流れ
- 願い事確認の流れ
- 課金関連の流れ
関数等一覧
クラスや関数の一覧。ヘルプとか普通の処理は省いてます
項番 名称 内容 1 class LaunchRequestHandler(AbstractRequestHandler) ローンチインテント。スキル起動時に処理される 2 class WishAddInIntentHandler(AbstractRequestHandler) 願い事を登録する時のインテント。この後に確認の処理に遷移 3 class WishDeleteIntentHandler(AbstractRequestHandler) 願い事を削除するインテント。パーソナライズ必須。自身が登録したものは削除できる 4 class WishListIntentHandler(AbstractRequestHandler) 願い事を確認するインテント。パーソナライズ必須。自身が登録したものは確認できる 5 class AnswerClassIntentHandler(AbstractRequestHandler) サンタとしてユーザーを登録するためのインテント 6 class PremiumInfoIntentHandler(AbstractRequestHandler) 課金アイテムの紹介 7 class YesIntentHandler(AbstractRequestHandler) 願い事を登録時の確認が主な処理 8 class ShoppingIntentHandler(AbstractRequestHandler) 課金アイテムを購入しているかどうか 9 class BuyIntentHandler(AbstractRequestHandler) 課金アイテムを購入する際のインテント 10 class CancelSubscriptionIntentHandler(AbstractRequestHandler) 課金アイテムをキャンセルする際のインテント 11 class CancelResponseHandler(AbstractRequestHandler) 課金アイテムキャンセル処理時のレスポンスを拾う 12 class BuyResponseHandler(AbstractRequestHandler) 課金アイテム購入処理時のレスポンスを拾う 13 def is_santa(santa, person_id) 自身がサンタかどうかを判別 14 def is_skill_product(handler_input) 課金アイテムか有効かどうかを判別 15 def in_skill_product_response(handler_input) 有効か課金アイテム情報をalexa側のapiを通じて取得する 初回起動時の流れ
1.LaunchIntent
パラメータはDynamoDBに永続化されています。
persistence_attr['santa']が空だと初回起動と見なします。パーソナライズが有効かどうかチェック。チェックは
request_envelope.context.system.personにpersonIdがあるかどうかで判断できる。
If パーソナライズ無効 -> 「有効にしてね」で終了
If パーソナライズ有効 -> 「サンタとして登録しますか?」の流れ。「サンタです」と言わせて、AnswerClassIntentへ導く5. AnswerClassIntent
まずパーソナライズが有効かどうかチェック。
If パーソナライズ有効 ->
persistence_attr['santa']['id']にこのユーザーのIDを登録する。以後、このpersonIdはサンタ扱い。願い事登録の流れ
1.LaunchIntent
persistence_attr['santa']['id']にperson_idが登録されていて、それが本人の場合はサンタと判断。
そうじゃない場合は 願い事をする一般ユーザー。
なおチェックは13. def is_santa(santa, person_id)で判別する。If not サンタ -> 「願い事をする」と言わせて
WishAddInIntentに導く2.WishAddInIntent
願い事を拾うインテント。
願い事はDialogで拾うので、このインテントで処理されるタイミングでは願い事は拾えている。
ただ、確認はしたいのでリピートし、「はい」か「いいえ」を求める。「はい」であればYesIntentへ。
また、願い事は無課金時には3件がMaxとなる。persistence_attr['msg']をチェックしすでに3件登録されていたら、課金アイテムをリコメンドして終了。7.YesIntent
願い事登録時のconfirmの戻りで入ってくる。
Dialogを使いたかったが複雑になりそうなのでBuildinIntentを使った。
persistence_attr['session']['msg']に値があり、登録から1分以内であれば、WishAddInIntentからの遷移とみなす。メッセージはpersistence_attr['msg']に登録するが、もしパーソナライズが有効だった場合には、
persistence_attr['msg'][idx]['person_id']にpersonIdを登録し、本人確認に用いる。
本人確認ができた場合には自身の願い事の削除が可能願い事確認の流れ
4. WishListIntentHandler
「願い事を確認」
サンタかそうでない場合に分岐があります。If サンタ -> 登録されている願い事を順番に話します。また「○番目の願い事を削除」で願い事の削除につながる
If 一般ユーザー -> 確認するにはパーソナライズが有効である必要があり、有効であれば自身が登録した願い事を確認できる。また「削除するには四桁のパスワード1234を言ってね」みたいに削除に繋げる3. WishDeleteIntent
If サンタ -> message_numberスロットを確認。該当の願い事を削除する
If 一般ユーザー ->passwordスロットを確認。パスワードが一致した場合、自身の願い事を削除課金の流れ
「私のサンタクロースのプレミアム機能」というサブスク商品が設定されています。
9.BuyIntentHandler
「プレミアム機能を購入」から遷移。
この商品のproductIdをキーとして、alexa側に処理をぶん投げてるだけです。
return handler_input.response_builder.add_directive( SendRequestDirective( name="Buy", payload={ "InSkillProduct": { "productId": product[0].product_id } }, token="correlationToken") ).responseこれを下記のインテントが受け取る
12. BuyResponseHandler
通常のIntentではなく、
Connections.Responseというのが返ってきます。return (ask_utils.is_request_type("Connections.Response")(handler_input) and handler_input.request_envelope.request.name == "Buy")購入後の場合は"Buy"というパラメータ名で返ってきますが、ステータスとして、
PurchaseResult.ACCEPTED、PurchaseResult.DECLINED、PurchaseResult.ALREADY_PURCHASEDというような購入したか、してないか、もともと購入済みだったか、みたいな事も返ってくるのでこれに応じた発話を返しています。
キャンセルの場合の処理もBuyがCancelに変わるだけでだいたいおんなじ。おしまい
そんなわけで以上です。
ちょっとしたチュートリアルくらいのボリュームじゃないかなと個人的には思ってます。あと、正直、パーソナライズは使い所が難しく、これが必須となった時点で利用ユーザーは激減かなって思います。無効でも使えるけど、有効になっているとなお便利といった程度の利用がベストプラクティスかなぁと。今後に期待。
スキル内課金も・・日本のスキルだとまだだいぶ厳しそうですよね。生きるのはかなりニッチな領域かと思っています。
- 投稿日:2019-12-15T21:33:37+09:00
Python を触っていない Lisper のための Hy 環境構築
この記事は、Lisp Advent Calendar 2019 の 15 日目の記事です。
この記事の要旨
Hy は Python の Virtual Machine 上で動作する Clojure ライクな Lisp 方言です。
Python を触ったことがない Lisper (主にClojurian) 向けに、Hy の環境構築方法に絞って説明していきます。対象読者
- Python を触ったことがない Lisper (主にClojurian)
Hy 自体の入門ドキュメントとしては、公式チュートリアルか先人の記したものを参照していただければと思います。
環境構築
Python をインストールする
Windows 10 の場合
python.org からインストーラをダウンロードしてインストールするのが簡単です。
いきなり罠なのですが、python.org のトップページからダウンロードできる最新版インストーラは 32bit 版です(2019/12時点)。
32bit 環境でない限りはインストールしないように気を付けましょう。
MacOS の場合
Homebrew をインストールし、
brewコマンドでインストールするのが一般的なようです。
$ brew info pythonでインストール可能なバージョンを確認すると、3.7.5 でした (2019/12/13 時点)。Homebrew でインストールされる Python 3 (3.7.5) の場所
/usr/local/bin/python3site-packages の場所
/usr/local/lib/python3.7/site-packages仮想環境の構築
Python 本体の site-packages にサードパーティー製モジュールをインストールしても動作はするのですが、
プロジェクトごとに仮想環境を使い分けると元環境を汚さずに済み、他プロジェクトへの影響を回避できます。
デフォルトで付属しているvenvコマンドを使って仮想環境を作る場合、作成したいディレクトリ下で、下記のように実行すると作成されます。$ python -m venv <venv名>もし、仮想環境を使っているうちに後述するサードパーティー製モジュールの依存関係がめちゃくちゃになってしまったら、そのまま捨てて新しく作り直すだけです。
仮想環境の有効・無効を切り替えるには、
activate・deactivateコマンドを使います。
venv 内にあるactivateの場所は Shell や OS によって違うため、venv --- 仮想環境の作成 内の「仮想環境を有効化するためのコマンド」を参照ください。モジュールのインストール
Python をインストールした段階で、標準ライブラリ が一緒にインストールされており、それらを Hy から使うことができます。Python はバッテリー内蔵言語のため、標準ライブラリだけでも割といろいろなことができます。
標準ライブラリ以外のサードパーティー製モジュールを使用したい場合は、パッケージ管理ツールの pip を使って仮想環境にインストールします。
基本的に、Python のモジュールは(ほとんど)すべて Hy で動作します。
もちろん、Hy で書かれたモジュールも同じバージョンであれば動作します(ほとんど見当たりませんが…)。
Python のサードパーティー製モジュールは PyPI で探すとよいでしょう。
たまに、PyPI に登録されていない Python モジュールがありますが、それらのインストール方法も後述します(GitHub リポジトリで管理されているものに関して)。科学計算用ライブラリ Anaconda をインストールし、
condaでモジュール管理をするという手もあります。
pipと併用すると環境が壊れることがあるため、この記事ではインストールしないものとします。仮想環境を
activateし、pip install <モジュール名>でモジュールをインストールします。
一括でインストールしたい場合は、モジュール名を改行で区切った requirements.txt を書き、pip install -r requirements.txtを実行します。慣例として requirements.txt という名前にしていますが、別の名前でも構いません。requirements.txthy openpyxl PySide2特定のバージョンを指定することもできます。
requirements.txthy==0.17.0 openpyxl==3.0.2 PySide2==5.13.2モジュールが GitHub リポジトリにしかない場合は、
pip install git+https://github.com/hoge/fuga.gitのようにします。
これを requirements.txt に含めることもできます。その環境にインストールしたサードパーティー製モジュールの一覧を確認したい場合は、
pip freezeを実行します。
pip freeze > requirements.txtのように書き出しておけば、環境が壊れてしまった場合も復帰が楽になります。エディタ・IDE
Hy のプラグインがあるエディタ・IDE はまだほとんどありません。私が知る限りでは、下記の三つのみです。
パッケージの作り方
自作のアプリケーションやライブラリを階層化したいときは、パッケージを作成すると管理しやすいです。
hy ─┬─ hoge ─┬─ fuga ─┬─ __init__.hy . │ . └─ piyo │ └─ bar.hy │ ├─ __init__.hy . └─ foo.hy上図で環境変数 PYTHONPATH に
hyディレクトリを追記した場合、
hoge 以下のディレクトリにそれぞれ __init__.hy を置くことでexample_import.hy(import hoge) ;; hogeの__init__.hy がインポートされる (import hoge.foo) (import hoge.fuga) ;; hoge/fugaの__init__.hy がインポートされる (import hoge.fuga.bar)のように書くことができます。このパッケージの構造は Python と同様です。
Python チュートリアル > 6. モジュール > 6.4. パッケージ
まとめ
- Hy の環境構築は Python のそれとほとんど同じです。
- 仮想環境を作ると大元の環境が汚されずに済みます。仮想環境が壊れても、捨てて作り直すだけです。
- Hy は、Python の標準ライブラリがデフォルトで使用できます。
- 標準ライブラリになければサードパーティー製モジュールを PyPI などで探して
pipでインストールします。- requirements.txt を
pip freezeで書き出しておくと保険になります。それでは、良い Hy ライフを。

- 投稿日:2019-12-15T21:13:49+09:00
相関行列をキレイにカスタマイズしたヒートマップで出力したい。matplotlib編
概要
Python + pandas + matplotlib で 相関行列(各変数間の相関係数を行列にしたもの)から、きれいに体裁を整えた ヒートマップ を作成していきます。
ここでは、例題として、次のような5科目成績の相関行列についてヒートマップを作成してみたいと思います。
実行環境
Google Colab.(Python 3.6.9)で実行・動作確認をしています。ほぼ Jupyter Notebook と同じです。
!pip list matplotlib 3.1.2 numpy 1.17.4 pandas 0.25.3matplotlibで日本語を使うための準備
matplotlib の出力図のなかで、日本語が使えるようにします。
!pip install japanize-matplotlib import japanize_matplotlib以上により、
japanize-matplotlib-1.0.5がインストール、インポートされて、ラベル等に日本語を使っても文字化け(豆腐化)しなくなります。相関行列を求めて、とりあえずヒートマップ化
相関行列は、pandas の機能で簡単に求めることができます。
import pandas as pd # ダミーデータ 国語 = [76, 62, 71, 85, 96, 71, 68, 52, 85, 91] 社会 = [71, 85, 64, 55, 79, 72, 73, 52, 84, 84] 数学 = [50, 78, 48, 64, 66, 62, 58, 50, 50, 60] 理科 = [37, 90, 45, 56, 59, 56, 84, 86, 51, 61] 英語 = [59, 97, 71, 85, 58, 82, 70, 61, 79, 70] df = pd.DataFrame( {'国語':国語, '社会':社会, '数学':数学, '理科':理科, '英語':英語} ) # 相関係数を計算 df2 = df.corr() display(df2)
行列の各要素は、$-1.0$ から $1.0$ の範囲の値をとります。この値が、$1.0$ に近いほど正の相関があり、$-1.0$ に近いほど負の相関があると判断します。$-0.2$ ~ $0.2$ の範囲では、相関がない(無相関)と判断します。
なお、対角要素は、同項目同士の相関係数なので $1.0$(=完全な正の相関がある)になります。
上で示したように相関係数を数値としてならべても、全体の把握が難しいので、ヒートマップを使って可視化してみます。
まずは、体裁の調整などは抜いて必要最低限のコードでヒートマップを作成してみます。
%reset -f import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.colors # ダミーデータ 国語 = [76, 62, 71, 85, 96, 71, 68, 52, 85, 91] 社会 = [71, 85, 64, 55, 79, 72, 73, 52, 84, 84] 数学 = [50, 78, 48, 64, 66, 62, 58, 50, 50, 60] 理科 = [37, 90, 45, 56, 59, 56, 84, 86, 51, 61] 英語 = [59, 97, 71, 85, 58, 82, 70, 61, 79, 70] df = pd.DataFrame( {'国語':国語, '社会':社会, '数学':数学, '理科':理科, '英語':英語} ) # 相関係数を計算 df2 = df.corr() display(df2) # 相関係数の行列をヒートマップで出力 plt.figure(dpi=120) plt.imshow(df2,interpolation='nearest',vmin=-1.0,vmax=1.0) plt.colorbar() # 軸に項目名(国語・社会・数学・理科・英語)を出力する設定 n = len(df2.columns) # 項目数 plt.gca().set_xticks(range(n)) plt.gca().set_xticklabels(df2.columns) plt.gca().set_yticks(range(n)) plt.gca().set_yticklabels(df2.columns)実行結果
次のような出力を得ることができます。右側のカラーバーをもとに、紫・青の暗めの色がついているマスのところに負の相関があり、黄・緑の明るめの色がついているところに正の相関があると読み取っていきます。
正直、デフォルト設定のままでは、分かりやすいヒートマップは作成できません。
体裁を整えて美しく出力
美しく直感的にも分かりやすいヒートマップを得るためのカスタマイズを施していきます。主なポイントは、次の通りです。
- 対角成分のマスについては白色にして斜線を引く。
- カラーマップをカスタマイズして、無相関の範囲では白色になるようにする。
- グリッドを挿入する(マスとマスの間に白色の線を引く)。
- 相関係数値をマス上に印字する。
- 背景色と重なってもきれいに見えるように縁取りをする。
コード化すると次のようになります。
%reset -f import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.patheffects as path_effects import matplotlib.ticker as ticker import matplotlib.colors # ダミーデータ 国語 = [76, 62, 71, 85, 96, 71, 68, 52, 85, 91] 社会 = [71, 85, 64, 55, 79, 72, 73, 52, 84, 84] 数学 = [50, 78, 48, 64, 66, 62, 58, 50, 50, 60] 理科 = [37, 90, 45, 56, 59, 56, 84, 86, 51, 61] 英語 = [59, 97, 71, 85, 58, 82, 70, 61, 79, 70] df = pd.DataFrame( {'国語':国語, '社会':社会, '数学':数学, '理科':理科, '英語':英語} ) # 相関係数を計算 df2 = df.corr() for i in df2.index.values : df2.at[i,i] = 0.0 # 相関係数の行列をヒートマップで出力 plt.figure(dpi=120) # カスタムカラーマップ cl = list() cl.append( ( 0.00, matplotlib.colors.hsv_to_rgb((0.6, 1. ,1))) ) cl.append( ( 0.30, matplotlib.colors.hsv_to_rgb((0.6, 0.1 ,1))) ) cl.append( ( 0.50, matplotlib.colors.hsv_to_rgb((0.3, 0. ,1))) ) cl.append( ( 0.70, matplotlib.colors.hsv_to_rgb((0.0, 0.1 ,1))) ) cl.append( ( 1.00, matplotlib.colors.hsv_to_rgb((0.0, 1. ,1))) ) ccm = matplotlib.colors.LinearSegmentedColormap.from_list('custom_cmap', cl) plt.imshow(df2,interpolation='nearest',vmin=-1.0,vmax=1.0,cmap=ccm) # 左側に表示するカラーバーの設定 fmt = lambda p, pos=None : f'${p:+.1f}$' if p!=0 else ' $0.0$' cb = plt.colorbar(format=ticker.FuncFormatter(fmt)) cb.set_label('相関係数', fontsize=11) # 項目(国語・社会・数学・理科・英語)の出力に関する設定 n = len(df2.columns) # 項目数 plt.gca().set_xticks(range(n)) plt.gca().set_xticklabels(df.columns) plt.gca().set_yticks(range(n)) plt.gca().set_yticklabels(df.columns) plt.tick_params(axis='x', which='both', direction=None, top=True, bottom=False, labeltop=True, labelbottom=False) plt.tick_params(axis='both', which='both', top=False, left=False ) # グリッドに関する設定 plt.gca().set_xticks(np.arange(-0.5, n-1), minor=True); plt.gca().set_yticks(np.arange(-0.5, n-1), minor=True); plt.grid( which='minor', color='white', linewidth=1) # 斜線 plt.plot([-0.5,n-0.5],[-0.5,n-0.5],color='black',linewidth=0.75) # 相関係数を表示(文字に縁取り付き) tp = dict(horizontalalignment='center',verticalalignment='center') ep = [path_effects.Stroke(linewidth=3, foreground='white'),path_effects.Normal()] for y,i in enumerate(df2.index.values) : for x,c in enumerate(df2.columns.values) : if x != y : t = plt.text(x, y, f'{df2.at[i,c]:.2f}',**tp) t.set_path_effects(ep)実行結果



- 投稿日:2019-12-15T20:53:14+09:00
【Python】リスト 再利用しそうなコード
空リスト
#空リストを作成 empty = [] # [] ##任意の値・要素数で初期化 n = [0] * 10 # [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] #2次元配列(リストのリスト)を初期化 n = [[0] * 4 for i in range(3)] # [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]] 【注】 data=[[list(range(1,9))]*3]*3 #この形式だと同じものを参照することになるので下記に data=[[list(range(1,9)) for i in range(3)]for i in range(3)]連番リスト
list(range(開始, 終了, 増分))
シャッフル
random.shuffle(リスト)
抽出・切り出し
#スライス #最初は+1され。最後はそのまま a = [1,2,3,4,5,6,7,8,9] print(a[1:4]) #[2, 3, 4]取出し
d=[2] print(d[0]) #2 a = [[1],[2]] print(a[0][0]) #1追加
list.append(100)list = list.append(row.split('-'))だとNG
'NoneType' object has no attribute 'append'削除
list.remove(100)結合
print([1, 2, 3] + [4, 5, 6])カウント
d=[0, 0, 5, 0, 3, 0, 6, 0, 0] print(d.count(0)) #6差分
set(リスト[i][j])-set(data[i])要素同士の掛け合わせ他
li1 = [1, 3, 5] li2 = [2, 4, 6] combine = [x * y for (x, y) in zip(li1, li2)] # [2, 12, 30]コピー
1次元の場合、「list2=list1」とすると参照渡しのせいで、list2自体を書き換えてしまうとlist1も書き換えられるので、下記のように記述する。
2次元以上の場合は、このように記述できないのでdeepcopyを使う。# 配列が1次元の場合 list2 = list1[:] # 2次元以上の場合 import copy list2 = copy.deepcopy(list1)おまけ
#for-rangeの注意 for x in range(3): =for x in [0,1,2]: for x in range(1,3+1): =for x in [1,2,3]: #0/1入れ替え a=abs(a-1)
- 投稿日:2019-12-15T20:48:28+09:00
ロケットっぽいのを作るか
1.はじめに
SpaceXとかBlue Originとか再利用型ロケットを開発して打ち上げてます。
じゃ、cursesで作ってみますか。2.こんな感じ
打ち上がり、サブのロケットが降りてきます、そしてまた打ち上がります。
Ctl-C入れると終わります。
ソースはここ
ベタがきなので、気が向いたらリファクタします。


- 投稿日:2019-12-15T20:43:08+09:00
【LINE WORKS版Trello Bot】トークBotを含む非公開トークルームの作成方法
こんばんは、@0yanです。
LINE WORKS版のTrello Botについては、過去に以下の記事を書きました。【過去記事】
1. PythonでLINE WORKS版 Trello Botを作るまでのお話
2. LINE WORKS用Trello BotをHerokuにデプロイするまで
3. 【備忘録】PythonによるLINE WORKS版Trello Botの実装(PyPI lineworks インストールVer.)しかし、他部署からの要請でその課専用のTrello Botを作ろうとしたところ、「あれ?どうやってトークBotを含む非公開トークルーム作ればいいんだっけ・・・?」とわからなくなってしまいました(要するに忘れた)。
恐らく、上記記事をご覧になられる方は、特定のメンバーで共有しているTrelloボードの更新通知を受け取りたいはず(非公開トークルームを作りたいはず)なので、今回はその記事を書きたいと思います。
前提条件
- LINE WORKS API情報取得済(参考:API 認証の準備)
- Trello API情報取得済(参考:【備忘録】Trello Webhook関連)
環境
- Windows 10
- Python 3.7.3(Anaconda)
- GitHub
- Heroku
ライブラリ
- flask 1.1.1
- gunicorn 19.9.0
- lineworks 0.0.5
- py-trello 0.15.0
Trello Botの作成
過去記事3と同様の手順で
1. コーディング
2. GitHub経由でHerokuにデプロイ
3. Trello Webhookの作成
までを行います。トークBotの通知先が特定の個人であれば、Heroku環境変数「ACCOUNT_ID」にその個人のアカウントIDを入れればOKですが、トークBotの通知先が非公開トークルームの場合は以下の作業を行います。
トークBotの通知先が非公開トークルームの場合
①ソースコードの修正
以下のコードは上述のコーディングで書いたコードです。
create_room()の変数account_idsに代入するリスト内要素「任意のアカウントID」に、作成する非公開トークルームのメンバーとなる方のアカウントID(~@ドメイン名)を入力します。
また、create_room()の変数resに代入する関数talkbot.create_room()の引数「任意のトークルーム名」に、非公開トークルームの表示名を入力します。app.py# coding: utf-8 import os from flask import Flask, abort, request from lineworks.talkbot_api import TalkBotApi app = Flask(__name__) talkbot = TalkBotApi( api_id=os.environ.get('API_ID'), private_key=os.environ.get('PRIVATE_KEY'), server_api_consumer_key=os.environ.get('SERVER_API_CONSUMER_KEY'), server_id=os.environ.get('SERVER_ID'), bot_no=os.environ.get('BOT_NO'), account_id=os.environ.get('ACCOUNT_ID'), room_id=os.environ.get('ROOM_ID'), domain_id=os.environ.get('DOMAIN_ID') ) @app.route('/') def index(): return 'Start', 200 @app.route('/webhook', methods=['GET', 'HEAD', 'POST']) def webhook(): if request.method == 'GET': return 'Start', 200 elif request.method == 'HEAD': return '', 200 elif request.method == 'POST': action_type = request.json['action']['display']['translationKey'] if action_type == 'action_comment_on_card': card_name = request.json['action']['data']['card']['name'] user_name = request.json['action']['memberCreator']['fullName'] comment = request.json['action']['data']['text'] message = user_name + "さんがコメントしました。\n【カード】" + card_name + "\n【コメント】" + comment talkbot.send_text_message(send_text=message) return '', 200 else: pass else: abort(400) @app.route('/create_room', methods=['GET']) def create_room(): if request.method == 'GET': account_ids = [ "任意のアカウントID", "任意のアカウントID", "任意のアカウントID", "任意のアカウントID", "任意のアカウントID" ] res = talkbot.create_room(account_ids=account_ids, title="任意のトークルーム名(例:Trello Bot)") return res, 200 else: abort(400) if __name__ == '__main__': app.run()②Trello Botを含む非公開トークルームの作成及びルームIDの取得
https://{Herokuのアプリ名}.herokuapp.com/create_room
上記URLにアクセスすると、HTTPレスポンスとしてルームIDが返ってきます(ブラウザに以下のようなルームIDが表示されます)。{ "roomId": "123456" }③Herokuの環境変数にルームIDを入力
Herokuの環境変数「ROOM_ID」に、②で取得したルームIDを入力します。
なお、この時、Herokuの環境変数「ACCOUNT_ID」を削除するのを忘れないようにしてください。④テスト
Trelloのカードにコメントしてみてください。
②で指定したトークルーム名で、Trello更新通知が届きます。おわりに
ご覧頂きありがとうございました。
LINE WORKSが益々発展することを願っています!
- 投稿日:2019-12-15T20:22:08+09:00
学習画像の水増し
はじめに
- 学習画像が少ない場合のために、水増しをする手法があります。
- コントラスト、ガンマ、ブラー、ノイズ等色々あります。
- 今回は、左右反転、ランダムクロップを実施しました。
- 実は、色々実験した所、学習精度が1番良かった組み合わせでした。あくまで、今回の元画像の場合です。
- ソース一式は ここ です。
ライブラリ
NumpyPillowを使いました。$ pip install numpy==1.16.5 pillow設定
CLASSESに従い、逐次処理が繰り返されます。FACE_PATHには、顔画像が保存されています。TEST_NUMに従い、FACE_PATHからTEST_PATHへ画像が複製されます。TRAIN_PATHには、TEST_PATHへ複製されなかった画像が複製されます。AUGMENT_NUMに従い、TRAIN_PATHからAUGMENT_PATHへ水増し画像が作成されます。config.pyCLASSES = [ '安倍乙', '石原さとみ', '大原優乃', '小芝風花', '川口春奈', '森七菜', '浜辺美波', '清原果耶', '福原遥', '黒島結菜' ] BASE_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) DATA_PATH = os.path.join(BASE_PATH, 'data') FACE_PATH = os.path.join(DATA_PATH, 'face') TRAIN_PATH = os.path.join(DATA_PATH, 'train') TEST_PATH = os.path.join(DATA_PATH, 'test') AUGMENT_PATH = os.path.join(DATA_PATH, 'augment') TRAIN_NUM = 0 TEST_NUM = 100 AUGMENT_NUM = 6000顔画像を学習画像とテスト画像に複製
- 顔画像、学習画像、テスト画像のパスを確認します。
- 顔画像の一覧を作成します。
queryには、CLASSESが順次与えられます。save_train_test_from_face.pydef split(query): """顔画像の一覧の取得、学習とテストに分割しコピー.""" face_path = os.path.join(FACE_PATH, query) train_path = os.path.join(TRAIN_PATH, query) test_path = os.path.join(TEST_PATH, query) face_file_list = glob.glob(os.path.join(face_path, '*.jpeg')) face_file_list.sort()
- 顔画像の一覧をシャッフルします。
TEST_NUMに従い、顔画像のリストを学習画像とテスト画像に分割します。save_train_test_from_face.pyrandom.shuffle(face_file_list) train_file_list = face_file_list[:-TEST_NUM] test_file_list = face_file_list[len(train_file_list):]
- 学習画像とテスト画像の複製を作成します。
- 元の顔画像は、残しておく方が、やり直しの手間が省けますね。
save_train_test_from_face.pyfor face_file in train_file_list: train_file = os.path.join(train_path, os.path.basename(face_file)) shutil.copy(face_file, train_file) for face_file in test_file_list: test_file = os.path.join(test_path, os.path.basename(face_file)) shutil.copy(face_file, test_file)
- 以下の様に、顔画像が学習画像とテスト画像に分割されました。
- 学習画像は、最大
392最小269枚ですね。少ないかもな。$ python save_train_test_from_face.py query: 安倍乙, face: 415, train: 315, test: 100 query: 石原さとみ, face: 492, train: 392, test: 100 query: 大原優乃, face: 372, train: 272, test: 100 query: 小芝風花, face: 400, train: 300, test: 100 query: 川口春奈, face: 369, train: 269, test: 100 query: 森七菜, face: 389, train: 289, test: 100 query: 浜辺美波, face: 481, train: 381, test: 100 query: 清原果耶, face: 428, train: 328, test: 100 query: 福原遥, face: 420, train: 320, test: 100 query: 黒島結菜, face: 448, train: 348, test: 100学習画像の水増し
- 下記を参考にさせてもらいました。
- NumPyでの画像のData Augmentationまとめ
水平方向に反転の関数
- 最初に、
PillowからNumpyに変換します。- また、
rateで反転の確率が与えられます。0.5を設定し半々の確率にしています。Numpyに変換した上で、fliplrで水平方向に反転します。- 最後に、
NumpyからPillowに戻します。def horizontal_flip(image, rate=0.5): """水平方向に反転.""" image = np.array(image, dtype=np.float32) if np.random.rand() < rate: image = np.fliplr(image) return Image.fromarray(np.uint8(image))ランダムクロップの関数
image.shapeで、画像の高さと幅を取得します。sizeを元にクロップサイズを決めます。0.8は、80%のサイズでクロップする事を意味します。左上と右下の位置を決めます。topは、0からheight-crop_sizeの範囲のランダムな値になります。- 同様に、
leftも決めます。bottomは、topとcrop_sizeを足す事で位置を決めます。- 同様に、
rightも決めます。- 最後に、
imageからクロップします。def random_crop(image, size=0.8): """ランダムなサイズでクロップ.""" image = np.array(image, dtype=np.float32) height, width, _ = image.shape crop_size = int(min(height, width) * size) top = np.random.randint(0, height - crop_size) left = np.random.randint(0, width - crop_size) bottom = top + crop_size right = left + crop_size image = image[top:bottom, left:right, :] return Image.fromarray(np.uint8(image))水増し処理
- 学習画像と水増し画像のパスを設定します。
queryには、CLASSESが順次与えられます。def augment(query): """学習画像の読み込み、水増し、保存.""" train_path = os.path.join(TRAIN_PATH, query) augment_path = os.path.join(AUGMENT_PATH, query)
- 顔画像の一覧のリストを作成します。
train_list = glob.glob(os.path.join(train_path, '*.jpeg')) train_list.sort()
- 水増し画像の枚数から、顔画像を何枚作成するべきかを確認し、ループ処理の回数を決定します。
loop_num = math.ceil(AUGMENT_NUM / len(train_list))
- ループ処理回数と顔画像リストのループの中で以下を実施します。
- 顔画像の読み込み。
- 50% の割合で、水平方向に反転。
- 80% の画像サイズで、ランダムクロップ。
- 顔画像のファイル名に
-0001.jpegの付加し、水増し画像を保存。augment_num = 0 for num in range(1, loop_num + 1): for train_file in train_list: if augment_num == AUGMENT_NUM: break image = Image.open(train_file) image = horizontal_flip(image) image = random_crop(image) augment_file = os.path.join(AUGMENT_PATH, query, os.path.basename(train_file).split('.')[0] + '-{:04d}.jpeg'.format(num)) image.save(augment_file, optimize=True, quality=95) print('query: {}, train_file: {}, augment_file: {}'.format( query, os.path.basename(train_file), os.path.basename(augment_file))) augment_num += 1おわりに
- 学習画像の水増しを、
PilloとNumpyで行いました。- 作業の過程で、ランダムクロップ以外の、スケールクロップ、カットアプト、ランダムイレース、ランダムローテートも確認しました。今回の顔画像に場合は、精度向上に向いていなかったので、利用していません。
- 次回は、学習画像、テスト画像を扱いやすくするための、データセットを作成する予定です。
- 投稿日:2019-12-15T20:21:50+09:00
【Python】機械学習のためのWebアプリ設計
■はじめに
この記事は「DSL Advent Calendar 2019」の22日目の記事です。
もうすぐクリスマス、大晦日、お正月と、ビッグイベントを控えてこころなしか世間も
浮足立ってせわしなくなってくる季節と思われます。皆様はいかがお過ごしでしょうか?
アドベントカレンダーも終盤、少ない人数で回しているとこなんかは精神崩壊一歩手前、
今日まで書き続けられているソロプレイヤーは人間卒業間近ですね。このアドカレのメンバーはDSL関係者なのですが、私はOB枠での参加となります!
学部で卒業し、とあるITベンチャーでエンジニアをしていますが、
入社して約半年、勉強してきたことをまとめ、紹介していきたいと思います。■機械学習×Webアプリで意識すべきこと
さて、機械学習をWeb上で行うためには以下の点に気を付けなければなりません。
- 前処理、学習、予測など時間のかかる処理を動かしつつもWebサーバーを動かし続けなければならない
- 処理の開始・終了時にグラフィックメモリの操作が必要な場合がある
この点に対応するためにマルチプロセスかつ、それぞれのプロセスの開始と終了の処理を管理できるような
システムをプログラミングします。めんどくさいですね。■設計思想1:async/await
まずはノンブロッキングIOの金字塔async/awaitです。
フロントエンドに手を出したことがある方ならあたりまえのように使っているかもしれませんが
実はPythonにもあります。しかし、javascriptのasync/awaitとは違い、asyncを付けた関数は必ずコルーチンオブジェクトを
返すので、イベントループ内でしか実行できません。■設計思想2:System of Systems
具体的なシステムの設計の仕方としてSystem of Systemsという考え方があります。
本来ならばソフトウェア設計ではなく業務プロセスなどもっと別分野で
用いられるものっぽい?ですが今回はこれをうまくプロセス管理の部分に落とし込みます。>1.システムを入れ子構造に
ひとつのシステムは0個以上のシステムから構成されます。
このとき、親のシステムに対し子のシステムをサブシステムと呼び、
全てのサブシステムが起動しおえることで親のシステムが「起動した」扱いになり、
全てのサブシステムが終了することで親のシステムが「終了した」扱いになります。
>2.システムの状態
システムは以下の表の状態をとります。
各状態から遷移できる状態は決まっており、initialからいきなりrunningなどへ遷移することはできません。
状態 説明 遷移可能 initial システムが作成された直後に初期値として与えられる状態 ready, disabled ready システムを実行するための準備が完了したことを表す状態 running running システムが実行中であるときの状態 completed, intermitted, terminated completed システムが正常に実行完了したことを表す状態 - disabled システムが実行できないことを表す状態、実行不可の原因を取り除くことでreadyに遷移できる ready intermitted システムが停止中であることを表す状態、システムがrunningである間は何度でもintermittedとrunningを行ったり来たりできる(実際にそう作りこむことは困難) running terminated システムが強制終了したときの状態、disabledと違ってここから遷移することはできない - 以下の図が簡単な状態遷移図です。
途中でエラーもおきず正常に処理が進んだ場合、青いルートを通ります。
予期せぬ事態で処理を進めることができなくなった場合は赤いルートを通りdisabledやterminatedとなります。
また、緑のルートは基本的に人間による判断・操作で遷移が開始されます。
>3.システムの遷移
前項ではシステムの各状態の紹介、もとい定義を行いました。
次は状態の遷移、図でいうと矢印の定義を行います。
定義というとちょっと堅苦しいですが、しっかりしておくことでプログラムを書く際に悩まないようにしておきましょう。
先ほどと同じように表と図を用意しました。
遷移 説明 activate(活性化) 実行に必要な材料集めを行うprepare関数を実行 disable(無効化) 状態が格納された変数の値をdisabledに変更 enable(有効化) 状態が格納された変数の値をreadyに変更 start(開始) 機械学習など重い処理や無限ループを行うmain関数を実行 complete(完了) メモリの開放などを行うshutdown関数を実行 suspend(中断) 実行中のmain関数に中断シグナルを送ります resume(再開) 中断中のmain関数に再開シグナルを送ります terminate(強制終了) メモリの開放などを行うteardown関数を実行
prepare関数やらmain関数やら新たな単語が出てきましたが、
これらを用意しておくことでプログラムが書きやすくなります。具体的なイメージとしては大元となるSystemクラスを継承させて各システムを作っていくときに、
activateやstartをオーバーライドするときに必ずsuper()を挿入しなくてはいけません。
(状態変更やロギングなどは遷移のたびに行うため)
これがわずらわしいので、各システム特有の処理をprepareやmainなど別の関数に逃がすことで解決します。■プログラム例
タイトルでは機械学習を謳ってはいますが、簡単のために今回は時間のかかる処理としてsleep関数で代用します。
まずは大元のSystemクラスを作成します。class System(): def __init__(self, name): self.name = name self.state = "initial" self.kwargs = {} self.log(self.state) def log(self, msg): date = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f") line = f"{date}\t[{self.name}]\tpid:{os.getpid():05d}\t{msg}" print(line) def prepare(self, **kwargs): pass def main(self): pass def activate(self): self.prepare(**self.kwargs) self.state = "ready" self.log(self.state) def start(self): self.state = "running" self.log(self.state) self.main() def complete(self): self.state = "completed" self.log(self.state) def transit(self): self.activate() self.start() self.complete() async def run(self, **kwargs): self.kwargs = kwargs executor = ProcessPoolExecutor(max_workers=None) loop = asyncio.get_event_loop() await loop.run_in_executor(executor, self.transit)sleepを並列で実行するだけなので上で延々と紹介した状態や遷移をすべて実装していません
コンストラクタ__init__ではこのシステムの名付けと初期状態の設定を行っています。
transitでは青ルートの遷移を順番に実行しています。disableやterminateを実装する際は
この部分にtry-exceptを入れてあげると綺麗に書けると思います。最後のasync関数として定義されたrunでは、run_in_executorによってtransitをコルーチン関数として扱えるようにしています。
またprepareなどではユーザーによって引数を取る場合があるので可変長引数として
transit、さらにはactiveへと渡したいところですが、どうもこのrun_inexecutor、マルチプロセスの場合
可変長引数を渡そうとするとエラーを吐いてしまいます。しかたがないのでインスタンス変数kwargsに格納しています。次に、"sleep関数を実行するシステム"を実行するシステムを作ります。
ややこしい言い回しですが、もし複数のシステムを実行したいとなったときに、
__main__に直接書いてしまうのは避けたいのでラップシステムとしてappSystemを作ります。class appSystem(System): def prepare(self): pass def main(self): sleep1 = sleepSystem("sleepSystem1") sleep2 = sleepSystem("sleepSystem2") systems = asyncio.gather( sleep1.run(sleep=5), sleep2.run(sleep=3) ) loop = asyncio.get_event_loop() loop.run_until_complete(systems)ここでわざわざactivetとprepare、startとmainのように処理を分けた意味が出てきますね。
今回はただのsleepなのでprepareには特に書くことがありません。インスタンス格納した変数を無理やり書いてもいいが…main内で5秒間sleepするsleepSystem1と3秒間sleepするsleepSystem2を実行します。
sleepSystemは以下のような単純なシステムです。class sleepSystem(System): def prepare(self, sleep=3): self.sleep = sleep def main(self): time.sleep(self.sleep)あとはメイン関数でappSystem.run()をイベントループに追加してあげます。13
def main(): app = appSystem("appSystem") loop = asyncio.get_event_loop() loop.run_until_complete(app.run()) if __name__ == "__main__": main()それでは実行してみましょう。
2019-12-14 16:43:28.843830 [appSystem] pid:30360 initial 2019-12-14 16:43:29.196505 [appSystem] pid:21020 ready 2019-12-14 16:43:29.196505 [appSystem] pid:21020 running 2019-12-14 16:43:29.197501 [sleepSystem1] pid:21020 initial 2019-12-14 16:43:29.197501 [sleepSystem2] pid:21020 initial 2019-12-14 16:43:29.799470 [sleepSystem1] pid:29720 ready 2019-12-14 16:43:29.803496 [sleepSystem1] pid:29720 running 2019-12-14 16:43:29.872484 [sleepSystem2] pid:18868 ready 2019-12-14 16:43:29.872484 [sleepSystem2] pid:18868 running 2019-12-14 16:43:32.873678 [sleepSystem2] pid:18868 completed 2019-12-14 16:43:34.804446 [sleepSystem1] pid:29720 completed 2019-12-14 16:43:34.804446 [appSystem] pid:21020 completed左から順番に、日付、システム名、PID、状態となっています。
sleepSystem1とsleepSystem2がrunning状態になった時刻がほぼ同時刻であること、
またそれらが別プロセスとなっており同時に進行し、3、5秒後にcompleted状態遷移、
そしてappSystemのcompletedが確認できます。最後にプログラム全体を載せておきます。
import asyncio import time from datetime import datetime import os from concurrent.futures import ProcessPoolExecutor class System(): def __init__(self, name): self.name = name self.state = "initial" self.kwargs = {} self.log(self.state) def log(self, msg): date = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f") line = f"{date}\t[{self.name}]\tpid:{os.getpid():05d}\t{msg}" print(line) def prepare(self, **kwargs): pass def main(self): pass def activate(self): self.prepare(**self.kwargs) self.state = "ready" self.log(self.state) def start(self): self.state = "running" self.log(self.state) self.main() def complete(self): self.state = "completed" self.log(self.state) def transit(self): self.activate() self.start() self.complete() async def run(self, **kwargs): self.kwargs = kwargs executor = ProcessPoolExecutor(max_workers=None) loop = asyncio.get_event_loop() await loop.run_in_executor(executor, self.transit) class appSystem(System): def prepare(self): pass def main(self): sleep1 = sleepSystem("sleepSystem1") sleep2 = sleepSystem("sleepSystem2") systems = asyncio.gather( sleep1.run(sleep=5), sleep2.run(sleep=3) ) loop = asyncio.get_event_loop() loop.run_until_complete(systems) class sleepSystem(System): def prepare(self, sleep=3): self.sleep = sleep def main(self): time.sleep(self.sleep) def main(): app = appSystem("appSystem") loop = asyncio.get_event_loop() loop.run_until_complete(app.run()) if __name__ == "__main__": main()■最後に
駆け足になりましたが機械学習のためのWebアプリ設計の一例を紹介させていただきました。
プログラム例はsleepだけでwwwサーバーや機械学習の実装をしているわけではないですが
考え方自体は同じなので手間取る部分は少ないと思います。
(具体的に書きすぎると会社的にアレなのでかなり簡略化しています)また、システム間の通信は基本WebSocketで行います。
wwwSystemとは別にwebsocketSystemを作成してappSystemのサブシステムにするといいでしょう。というわけでいかがだったでしょうか?
まだ長期運用はしていないですが個人的にはきれいな設計で気に入っています。■参考
http://itdoc.hitachi.co.jp/manuals/3020/30203M8120/EM810359.HTM



- 投稿日:2019-12-15T20:18:12+09:00
M2Det で物体検出してみた!
やること
- 前々回と前回で SSD と YOLO v3 でそれぞれ物体検出を実施してみましたが、今回は M2Det で物体検出を実施してみます
- 今回は Google Colaboratory 上で実行していきます
概要
- 実行環境の準備(Google Colaboratory にて実行)
- Google Drive からモデルをダウンロード
- 画像ファイルのコピー
- モデルの実行
- 結果の表示
実行環境
- google colaboratory
- pytorch
- opencv
- tqdm
- addict
1.実行環境の準備(Google Colaboratory にて実行)
Google Colaboratory を開き、「ランタイム」タブの「ランタイムのタイプの変更」から「GPU」へ変更しておきます
その後、以下を実行していきます
- 各種パッケージをインストール
- リポジトリをクローン
- シェルを実行
実行環境の準備!pip install torch torchvision !pip install opencv-python tqdm addict !git clone https://github.com/qijiezhao/M2Det.git %cd M2Det/ !sh make.sh2. Google Drive からモデルをダウンロード
- GitHubのREADMEに学習済モデルのリンク先が記載されています(https://drive.google.com/file/d/1NM1UDdZnwHwiNDxhcP-nndaWj24m-90L/view) ので、この Google Drive のリンクからコード上でダウンロードしていきます
- ダウンロードは、こちらのコードを参考にしました
download_file_from_google_driveを実行することで、コマンドによるダウンロードが可能ですimport requests def download_file_from_google_drive(id, destination): URL = "https://docs.google.com/uc?export=download" session = requests.Session() response = session.get(URL, params = { 'id' : id }, stream = True) token = get_confirm_token(response) if token: params = { 'id' : id, 'confirm' : token } response = session.get(URL, params = params, stream = True) save_response_content(response, destination) def get_confirm_token(response): for key, value in response.cookies.items(): if key.startswith('download_warning'): return value return None def save_response_content(response, destination): CHUNK_SIZE = 32768 with open(destination, "wb") as f: for chunk in response.iter_content(CHUNK_SIZE): if chunk: # filter out keep-alive new chunks f.write(chunk) file_id = '1NM1UDdZnwHwiNDxhcP-nndaWj24m-90L' destination = './m2det512_vgg.pth' download_file_from_google_drive(file_id, destination)3. 画像ファイルのコピー
- Google Drive のマウントを実施します
- その後、画像ファイルの入ったフォルダにある jpg ファイルを、M2Det を実行する「imgs」に全てコピーします(私の環境では、My Drive > ML > work 配下に画像ファイルを格納しています)
GoogleDriveのマウントfrom google.colab import drive drive.mount('/content/drive')画像ファイルのコピー!cp /content/drive/My\ Drive/ML/work/*.jpg ./imgs4. モデルの実行
- モデルを実行します
モデルの実行!python demo.py -c=configs/m2det512_vgg.py -m=m2det512_vgg.pth5. 結果の表示
- 実行した結果を表示します
- 実行した画像ファイルは、「XXX_m2det.jpg」のように作成されます
import cv2 import matplotlib.pyplot as plt plt.figure(figsize=(5, 5), dpi=200) img = cv2.imread('imgs/herd_of_horses_m2det.jpg') show_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.imshow(show_img)
- そのほかの画像も実施しました
ソースコード
https://github.com/hiraku00/m2det_test
参考





- 投稿日:2019-12-15T19:26:32+09:00
MTGをハックする技術
みなさんこんにちは。LAPRASでデータベースエンジニアをしている@denzowillです。
突然ですが、社会人のスケジュールで最も多くの時間を占める予定はなんでしょうか?そうです。"MTG"です。
社会人のスケージュルには多くのMTGが入っています。私も、LAPRASで勤務する中では業務時間中はもちろん、時にはランチMTG、業務時間終了後の残業MTGをすることもあります。
パフォーマンスチューニングでは、最も大きなボトルネックから着手するのが定石です。そのため、予定の多くを占めるMTGをハックすることは、労働効率を上げる上で効果的と言えます。
私はエンジニアなのでハックするなら精神論ではなくシステムを使うなり作るなりして対処したいです。そこで今回はMTGをハックするための技術を見ていきます。
MTGの定義
まずはハック対象であるMTGの定義を確認します。今回対象としているMTGは
- 集会
- 会合
- 報告会
などではなく、Magic: The Gatheringです。ということで、ミィーティングの効率化を知りたい方はこれ以降有用な情報は一切書かれていないことをお伝えしておきます。
MTG関連のAPI等
MTGは歴史が長いだけあって、色々データが整っています。利用できるメジャー所のサービスも色々特徴がありますのでそれぞれ紹介していきます。
Magic: The Gathering API(
api.magicthegathering.io)MTGのカードやフォーマット等の情報を取得することが出来るAPIが提供されています。Qiitaでもいくつか記事で紹介されています。
こちらは
https://api.magicthegathering.io/<version>/<resource>と言った形式のREST APIを提供している上、各種主要言語に対応したSDKを提供しています。
ちなみにドキュメント外ではありますが、直接GitHubを見に行くと
ElixirやRust等のSDKも提供されています。ちなみにこの手のSDKは単にAPIのラッパーなだけなことが多いのですが、こいつは
QueryBuilderを持っていておしゃれに使えます。例えば、以下はカード名のオーコを日本語表記内で含み、カードタイプがPlainswalkerを含むカードを探し出します。samplecards = Card.where(name='オーコ').where(language='japanese').where(types='Planeswalker').all() for card in cards: original_name = card.name japanese_name = [f for f in card.foreign_names if f['language'] == 'Japanese'][0]['name'] print(f'English: {original_name}, Japanese: {japanese_name}')実行例English: Oko, Thief of Crowns, Japanese: 王冠泥棒、オーコ English: Oko, the Trickster, Japanese: トリックスター、オーコこのAPIのRate limitは 5000 request/1時間 で特に引き上げる方法もなさそうなのでおとなしめに使いましょう。また、検索系のパフォーマンスはかなり悪いです。おそらく全文検索エンジン等を使用しない素直なRDBMSをバックエンドに持っているのでしょう。先のサンプルコードでも5秒くらいかかります。
なお、このAPIは決して公式(ウィザーズオブザコースト)が提供しているものではありません。有志の方が管理しているAPIのようです。
MTGJSON
先のAPIのデータとして利用されているのがmtgjsonです。
mtgjsonは、有志によってMTGに存在するカード等の全てを取り回しの効くフォーマットとしてメンテナンス・提供をするプロジェクトです。これらのデータはJSONやSQLファイル、sqliteのデータベースファイルとして誰でもダウンロード可能になっています。
https://mtgjson.com/downloads/all-files/
これらを利用して、先のAPIのように独自のMTG関連のサービスを提供することが出来ます。逆に、カード情報に関するサービスを自作するのであれば先のAPIを使うのではなくこちらのデータベースを直接利用する方が楽です。
なお、mtgjsonはGitHubリポジトリもあります。
https://github.com/mtgjson/mtgjson
これは、mtgjsonが提供しているデータをビルドするためのコードが提供されています。そのため、このリポジトリをローカルで動かすことで同様のデータを手に入れることが出来ます。じゃあその元データは何処?と思って見てましたが https://scryfall.com/ から取得しているようです。
mtgjson4/provider/scryfall.pySCRYFALL_API_SETS: str = "https://api.scryfall.com/sets/" SCRYFALL_API_CARD: str = "https://api.scryfall.com/cards/" SCRYFALL_API_CATALOG: str = "https://api.scryfall.com/catalog/{0}-types" SCRYFALL_VARIATIONS: str = "https://api.scryfall.com/cards/search?q=is%3Avariation%20set%3A{0}&unique=prints" SCRYFALL_SET_SIZE: str = "https://api.scryfall.com/cards/search?order=set&q=set:{0}%20is:booster%20unique:prints" SCRYFALL_API_SEARCH: str = "https://api.scryfall.com/cards/search?q=(o:deck%20o:any%20o:number%20o:cards%20o:named)"scryfall
MTGのカードの検索を提供している https://scryfall.com/ にもREST APIが提供されています。
こちらも
api.magicthegathering.io同様にカードの検索等が提供されており、更にapi.magicthegathering.ioよりも高速に動作します。残念ながら公式に提供されているSDKはありませんが、REST APIなのでラップしたSDKを作ることはそれほど難しくないでしょう。気になるRateLimitは明確な値は書かれていませんが、10 request/秒程度とのことですので
api.magicthegathering.ioより少し厳し目ですが、APIとしてのスペック的にはこちらのほうが良さそうです。まとめ
結局何使えばいいのかという点でいうと以下の様な形になります。
- とにかくSDKがほしい
api.magicthegathering.io- 高性能な検索APIがほしい
- scryfall
- データベースごとほしい
- mtgjson
自身でデータベースを持たない場合はscryfall, データベースを持った上で何か作るのであればmtgjsonを利用するのが良さそうです。MTGが好きなエンジニアさんが自分でなにか面白いことをする時のデータの取得先として参考になれば幸いです。



- 投稿日:2019-12-15T19:15:22+09:00
TwitterでAPIを使って自分のアカウントに投稿する
久しぶりにTwitter触って、自分のアカウントに自動でツイートをPOSTする処理作ろうとしたら思いがけずはまりポイントが多かったので備忘録です。
手順1:Twitterアカウント作成する
普通のユーザのアカウント作成手順でOK。
電話番号で登録できるようになっていたりと色々昔と変わっていて、多少ドキドキする。
手順2:APIの使用申請をする
去年あたりから使用するために申請が必要になったそうで…
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ
を参照させていただいてクリア。
申請ではねられないために、真面目な人に見えるよう使用目的を多少盛り気味に頑張って書いたんですが(文字数のボーダーライン超えるためにわざわざ迂遠な言い回し使うとか姑息な手段まで駆使)、申請した次の瞬間承認メールが飛んできて拍子抜け。
内容をチェックしているとしても多分絶対人力じゃなさそう。手順3:アプリを作成し、認証キーを発行
べつにアプリを作るわけじゃないんだが…と不安になるのですが、認証キーの発行のためには必要なのでおそるおそる
Create New Appボタンをクリックしてアプリを作成し認証キーを発行。
以下のページが参考になるかと。※上記ページで、アクセストークンについて「プログラミングなしで取得する」の手順が実行できればOK。
手順4:投稿用のAPIを呼ぶ(Python使用)
公式ドキュメントのサンプルコードを参考に、最終的にはこんな感じ。
tweet.pydef tweet(text): url = "https://api.twitter.com/1.1/statuses/update.json?status={}".format(text) consumer = oauth2.Consumer(key='手順3で取得できるConsumer API keys の API key', secret='手順3で取得できるConsumer API keys の API secret key') token = oauth2.Token(key='手順3で取得できるAccess token', secret='手順3で取得できるAccess token secret') client = oauth2.Client(consumer, token) resp, content = client.request( url, method="POST") return content tweet("test")実はここが最大のハマりポイントでした。できあがったものはとても簡単だったのですが、簡単なのにというかそれゆえにというか、これについてさくっと解説しているようなページというのがなかなか見つかりませんでした。
そもそも、ツイートの投稿が「statuses/update」というパスなのがちょっと意外でそこにもしばらくはまっていたのですが、なによりもTwitterが公開している公式ドキュメントでも検索してヒットするページも 「第三者に認証させてそのユーザのアカウントに投稿する」サービスが前提という感じで、シングルユーザで使いたいだけ、というのは、あまりに簡単すぎて逆にないがしろにされている感(※)すらありました。(被害妄想中)
ともあれこれにてツイート成功です。
以上、お役に立ちましたら幸いです。
※余談
なおシングルユーザでのAPI使用がどれくらいないがしろにされているかといえば、Twitterが公開している公式ドキュメントのサンプルコードにシンタックスエラーが混入しているレベルです。
以下は上記ページの
Using Python-OAuth2 libraryからコピペしたコードですが、引数post_bodyあたりに注目してください。def oauth_req(url, key, secret, http_method="GET", post_body=””, http_headers=None): consumer = oauth2.Consumer(key=CONSUMER_KEY, secret=CONSUMER_SECRET) token = oauth2.Token(key=key, secret=secret) client = oauth2.Client(consumer, token) resp, content = client.request( url, method=http_method, body=post_body, headers=http_headers ) return content home_timeline = oauth_req( 'https://api.twitter.com/1.1/statuses/home_timeline.json', 'abcdefg', 'hijklmnop' )もう泣いちゃうだろこんなの。
- 投稿日:2019-12-15T19:07:43+09:00
Python学習ノート_003
本の第一章のサンプルコードを理解した上で練習のために下記のように修正しました。
- ポイント:
- バックスラッシュ(\)を使う(Macには「option + ¥」で入力する)
- 文字列中にバックスラッシュを使うと改行後のスペースもそのまま出力される
- 2つ改行した文字列の間にバックスラッシュを使うとスペースなしで連結できる
sample_01.pyimport random #リストを定義する subjects = ['私\ は','あな\ たは'] verbs = ['好き'\ 'です', '嫌い'\ 'です'] nouns = ['夏が','秋が'] #リストから1つ要素を選ぶ subject = random.choice(subjects) verb = random.choice(verbs) noun = random.choice(nouns) #単語を連結してフレーズを作る phrase = subject + ' ' + noun + ' ' + verb #フレーズを出力する print(phrase) #出力結果の1つ #あな たは 秋が 好きです
- 投稿日:2019-12-15T18:34:44+09:00
Nginx + uWSGI + Python(Django)の環境をdockerで作成する
この記事はウェブクルー Advent Calendar 2019の16日目の記事です。
昨日は@Hideto-Kiyoshima-wcさんのScalaのOption/Either/Try超入門でした。はじめに
株式会社ウェブクルーに新卒で入社して、2年目の@yagiyuuuuです。
現在、Nginx + uWSGI + Python(Django)のアプリ環境をDockerで作成して、開発をしています。
これから、Djangoでアプリ開発をする人の助けになればと思い、この記事を書きました。Docker for Windowsのインストール
コントロールパネルを開いて、
「プログラムと機能」→「Windowsの機能を有効化または無効化」→「Hyper-V」にチェックが入っているか確認します。
チェックが入っていなかった場合は、チェックを入れてPCを再起動させて有効化させます。
次に「Docker Desktop for Windows」のインストールをする。
インストールはここからできます。Djangoを動かす環境構築
ディレクトリ構成
以下、構成でDjangoアプリを動かします。
Infrastrcuture作成
Alpineにpython + uWSGI、Nginxをインストールします。
docker-compose.yml作成
Nginxとpython + uWSGIのコンテナを作成します。
今回はログをdjango-sample配下に出力するようにしていますが、お好きなところにログを吐き出すように設定してください。django-sample/docker-compose.ymlversion: '2' services: nginx: build: "./Infrastructure/nginx/" volumes: - ./logs/nginx:/var/log/nginx ports: - "80:80" networks: django-sample-network: ipv4_address: 172.23.0.4 python: build: "./Infrastructure/python/" volumes: - ./Application/django-sample:/home/work/django-sample - ./logs/django:/home/work/django - ./logs/uwsgi:/home/work/uwsgi ports: - "8000:8000" networks: django-sample-network: ipv4_address: 172.23.0.5 networks: django-sample-network: driver: bridge ipam: driver: default config: - subnet: 172.23.0.0/24Dockerfile作成
Nginx
django-sample/Infrastructure/nginx/DockerfileFROM nginx:1.13.1-alpine COPY work/nginx.conf /etc/nginx RUN apk --no-cache add tzdata && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \ apk del tzdata CMD ["nginx", "-g", "daemon off;"]uWSGI
django-sample/Infrastructure/python/DockerfileFROM python:3.7 ENV LANG C.UTF-8 ENV TZ Asia/Tokyo RUN mkdir /home/work RUN mkdir /home/work/django RUN mkdir /home/work/uwsgi COPY work/ /home/work WORKDIR /home/work RUN pip install --upgrade pip RUN pip install -r requirements.txt CMD ["uwsgi", "--ini", "/home/work/uwsgi.ini"]Nginxの設定
django-sample/Infrastructure/nginx/work/nginx.confworker_processes auto; error_log /var/log/nginx/error_app.log; events { worker_connections 1024; } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access_app.log main; sendfile on; tcp_nopush on; keepalive_timeout 120; proxy_read_timeout 120; proxy_send_timeout 120; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; server { listen 80 default_server; server_name _; fastcgi_read_timeout 60s; client_max_body_size 1m; location ~ ^/app/ { add_header Cache-Control no-cache; include uwsgi_params; uwsgi_pass 172.23.0.5:8000; uwsgi_read_timeout 60s; } } }uWSGI + Djangoの設定
django-sample/Infrastructure/python/work/uwsgi.ini[uwsgi] chdir=/home/work/django-sample module=django-sample.wsgi master=True vacuum=True max-requests=5000 socket=:8000 py-autoreload=1 logto=/home/work/uwsgi/django-app.log buffer-size=10240 log-format=%(addr) - %(user) [%(ltime)] "%(method) %(uri) %(proto)" %(status) %(size)`` "%(referer)" "%(uagent)"django-sample/Infrastructure/python/work/requirements.txtdjango==2.2 uwsgi==2.0.17.1
requirements.txtにインストールしたいモジュールを記載します。.envファイル作成
django-sample/.envCOMPOSE_FILE=docker-compose.ymlApplication作成
ここではアプリを作成することに焦点を当てていますので、
Djangoアプリの詳細に関しては、公式サイトなどをみていただきたいです。
また、__init__.pyと__pycache__にはコードを書きませんが、作成をしてください。
作成されていないとアプリが動かなくなってしまいます。プロジェクト作成
django-sample/Application/django-sample/manage.py#!/usr/bin/env python import os import sys if __name__ == "__main__": os.environ.setdefault("DJANGO_SETTINGS_MODULE", "django-sample.settings") try: from django.core.management import execute_from_command_line except ImportError as exc: raise ImportError( "Couldn't import Django. Are you sure it's installed and " "available on your PYTHONPATH environment variable? Did you " "forget to activate a virtual environment?" ) from exc execute_from_command_line(sys.argv)django-sample/Application/django-sample/django-sample/settings.py""" Django settings for django-sample project. Generated by 'django-admin startproject' using Django 2.0.3. For more information on this file, see https://docs.djangoproject.com/en/2.0/topics/settings/ For the full list of settings and their values, see https://docs.djangoproject.com/en/2.0/ref/settings/ """ import os import json import traceback # ログ出力で仕様するハンドラを指定する LOG_HANDLER = ["app"] # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # Quick-start development settings - unsuitable for production # See https://docs.djangoproject.com/en/2.0/howto/deployment/checklist/ # SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = 'ekf!&30u3&idt-qr3250(t+j#%@(vyxr02c-7fj!a81$!)#q=(' # SECURITY WARNING: don't run with debug turned on in production! DEBUG = True # 接続を許可するサーバのIPやドメインを設定する # 何も設定していない場合は、ローカルホスト(localhost)からの接続のみ可能な状態 ALLOWED_HOSTS = ["localhost"] # Application definition # 「app」を追加。これを追加しないとtemplatetagsに定義したカスタムタグが認識されない INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'app', ] ROOT_URLCONF = 'django-sample.urls' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [ os.path.join(BASE_DIR, 'templates'), ], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ] WSGI_APPLICATION = 'django-sample.wsgi.application' # Database # https://docs.djangoproject.com/en/2.0/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } # Password validation # https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators AUTH_PASSWORD_VALIDATORS = [ { 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', }, { 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', }, { 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', }, { 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', }, ] # Internationalization # https://docs.djangoproject.com/en/2.0/topics/i18n/ #LANGUAGE_CODE = 'en-us' LANGUAGE_CODE = 'ja' #TIME_ZONE = 'UTC' TIME_ZONE = 'Asia/Tokyo' USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/2.0/howto/static-files/ STATIC_URL = '' LOGGING = { 'version': 1, 'formatters': { 'app': { 'format': '%(asctime)s [%(levelname)s] %(pathname)s:%(lineno)d %(message)s' } }, 'handlers': { 'app': { 'level': 'DEBUG', 'class': 'logging.handlers.TimedRotatingFileHandler', 'filename': '/home/work/django/app.log', 'formatter': 'app', 'when': 'D', # 単位 Dは日 'interval': 1, # 何日おきか指定 'backupCount': 30, # バックアップ世代数 } }, 'loggers': { 'django': { 'handlers': ['app'], 'level': 'DEBUG', 'propagate': True, }, 'django.server': { 'handlers': ['app'], 'level': 'DEBUG', 'propagate': True, }, 'app': { 'handlers': LOG_HANDLER, 'level': 'DEBUG', 'propagate': True, }, }, } # セッションエンジンの設定 # cookieを用いたセッションを使用する SESSION_ENGINE = 'django.contrib.sessions.backends.signed_cookies' # ログイン状態の有効期限(秒) # ここに指定した有効期限(秒)を超えるまでログイン状態を保つ事ができる # セッション自体の有効期限はSESSION_COOKIE_AGE # 8h * 60m * 60s LOGIN_LIMIT = 28800 # セッションの有効期間(秒) # 利用者毎にセッション有効期間を変えたい場合は、request.session.set_expiry(value)を用いる SESSION_COOKIE_AGE = 1800django-sample/Application/django-sample/django-sample/urls.py"""django-sample URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/2.0/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: path('', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.urls import include, path 2. Add a URL to urlpatterns: path('blog/', include('blog.urls')) """ from django.urls import path, include urlpatterns = [ path('app/', include("app.urls")), ]django-sample/Application/django-sample/django-sample/wsgi.py""" WSGI config for django-sample project. It exposes the WSGI callable as a module-level variable named ``application``. For more information on this file, see https://docs.djangoproject.com/en/2.0/howto/deployment/wsgi/ """ import os from django.core.wsgi import get_wsgi_application os.environ.setdefault("DJANGO_SETTINGS_MODULE", "django-sample.settings") application = get_wsgi_application()アプリ作成
djnago-sampleプロジェクト内にアプリを作成します。django-sample/Application/django-sample/app/urls.pyfrom django.urls import path from app.views.login import view as login_view urlpatterns = [ path("", login_view.top, name="login_top") ]django-sample/Application/django-sample/app/views/login/view.pyfrom django.http import HttpResponse from django.http.request import HttpRequest from django.template import loader def top(request: HttpRequest): template = loader.get_template("login/index.html") return HttpResponse(template.render({}, request))画面表示させるテンプレート作成
django-sample/Application/django-sample/templates/login/index.htmlHello Django!!コンテナを立ち上げる
docker-compose.ymlがある階層で以下コマンドを叩くコンテナのビルド、起動
$ docker-compose up --build -d
-dをつけることでバックグラウンドで起動できるコンテナを確認する
$ docker-compose psコンテナを削除する
$ docker-compose down作成したアプリにアクセスする
コンテナを起動したら、
http://localhost/app/にアクセスすると
Hello Django!!が表示される終わりに
Djangoアプリを作成していく上で、自分好みの環境にしていってください!!
明日の記事は@yuko-tsutsuiさんです。
よろしくお願いします。

- 投稿日:2019-12-15T18:03:56+09:00
素人がpython(kivy)でブロック崩しを作ってみた話①
前置き1 kivy始めるまで
本格的にプログラミングを始めて多分半年くらいなのですが、なんとなくアプリっぽいものを作ってみたいなと思っていたところ、ツイッターで知り合った鳩からkivyを勧められたので勢いで始めてみました。製作過程・内容の説明を通して、他の人がkivyでのアプリ開発に入門しやすくなるといいなと思います。
前置き2 そもそもkivyとは
kivyとはマルチタップアプリを開発することのできる、Pythonの
オープンソースライブラリのことで、kivyで作製したアプリは、macOS、Windows、LinuxなどのPC環境を始めとして、iOS・Androidデバイス上で動作させることができます。また、kivyではPythonと合わせてKV言語と呼ばれる独自の言語を使用することもでき、プログラムを多層的なものにできることが特徴です。このKV言語の理解がなかなか難しいのと、日本語対応があまりよくないのが難点といったところのようです。まずはとりあえずチュートリアルをやってみようとしたが、さっぱり分からん……。
さて、概要だけ読んでいても、とりあえずやってみないことにはよく分かりません!というわけで、早速kivyをインストールし、チュートリアルのPong Gameの作製を通して、いっちょkivyを始めてみるか~~~~。と気楽な気持ちで初めてみたものの、コピペでそれっぽいものは作れはしましたが、プログラミングどこがどうなっているのかさっぱり分からない。ずぶの素人だからWidgetが何なのかよく分からないし、詳細説明に行ってみても、そこも知らない言葉ばかりで頭に入ってきません。また、先述のKV言語のためにプログラムの構造が非常に読み取りづらく感じてしまいます。どうも画面に表示するものの位置や大きさを決めているようではありますが……。
よく分からん。何かいい資料はないものか……。あるじゃん。
それで、何かいい資料はないものかと調べていたら、いつもお世話になっている朝倉書店から、kivyプログラミングの本が出ているじゃありませんか。これ幸いとばかりに購入してみましたが、とても分かりやすく、ようやくスタート地点に立つことができました。今回もまた、大いに参考にさせていただきながら話を進めていこうと思っております。
ロード トゥ ブロック崩し- GUIプログラミングの基本構造(Widget)を学ぶ…… -
さて、ようやくkivyプログラミングでブロック崩しを作るまでの話です。難解に思えるKV言語に入る前に、そもそものGUIのプログラムの構造とWidgetについて知る必要がありました。
Widget、ウィキペディアに載ってるほどの有名な単語だった……。GUIプログラムはWidgetの組み合わせによって作られているそうですが、kivyプログラムも同様、様々な機能を持つWidgetが組み合わされることでできていますが、これらのWidgetに親子関係を持たせる(Widget treeを構成する)ことでプログラムを管理しているとのことです。言い換えれば、ボタンやラベルなどのパーツ(Widget)それぞれに上下関係があるということで、各パーツがどこの階層にあるかを理解しておくのが大切でした。複雑化したプログラムでは関係性が分かりやすいように図を描いた方がよさそうですね。ロード トゥ ブロック崩し- kivyでWidget treeを構成してみよう -
やるべきことは何となく分かってきましたので、まずはWidget treeを構成してみよう!というわけで、参考文献を片手に以下のようなものを作ってみました。配置を定めるBoxlayoutに、add_widget()メソッドを使用することで、子WidgetとしてLabel(文字列の記載)とButton(ボタン)を追加するプログラムです。
main.py#使用するwidgetをimportする。今回はLabelとButtonとBoxLayout。 from kivy.app import App from kivy.uix.label import Label from kivy.uix.button import Button from kivy.uix.boxlayout import BoxLayout #アプリの内容を記述するAppクラスのサブクラス class testApp(App): #メインループが開始されると実行されるbuildメソッドの定義 def build(self): #Boxlayoutオブジェクト、Buttonオブジェクトの生成 layout1 = BoxLayout(orientation='vertical') button1 = Button(text='children') label1 = Label(text='children') #layout1の子Widgetとしてbutton1とlabel1を追加 layout1.add_widget(button1) layout1.add_widget(label1) return layout1 #メインループの開始 testApp().run()上記を実行すると、以下のような画面が表示されます。親WidgetであるBoxlayoutにorientation='vertical'と指示しているため、子Widgetとして追加されたButtonとLabelが縦に並んでいます。verticalをhorizontalに変更すれば横並びに変えることも可能です。
また、以下のような多岐にわたるWidget treeも作れます。Boxlayoutが子Widget(children1)としてButtonとBoxlayoutを持ち、かつ、子Widget(children1)のBoxlayoutが子Widget(children2)としてButtonとLabelを持つ構造です。
main.pyfrom kivy.app import App from kivy.uix.label import Label from kivy.uix.button import Button from kivy.uix.boxlayout import BoxLayout class testApp(App): def build(self): #Boxlayoutオブジェクト、Buttonオブジェクトの生成 layout1 = BoxLayout(orientation='vertical') button1 = Button(text='children1') layout2 = BoxLayout(orientation='horizontal') label2 = Label(text='children2') button2 = Button(text='children2') #layout2の子Widgetとしてbutton2とlabel2を追加 layout2.add_widget(button2) layout2.add_widget(label2) #layout1の子Widgetとしてbutton1とlayout2を追加 layout1.add_widget(button1) layout1.add_widget(layout2) return layout1 testApp().run()実行結果は以下のようになります。少し複雑な構造を作ることができました。ようやくGUI作製の入り口に立てた気がしますネ。
まとめと今後
今回は画面にパーツを表示するための基本構造Widget treeを理解するために、簡単なプログラムを作製しました。次回はWidget treeに配置されたButtonやLabelにどのように関連性を持たせていくかを説明しようと思います。
参考文献・web
原口和也 (2018)『実践Pythonライブラリー Kivyプログラミング -Pythonでつくるマルチタップアプリ―』久保幹雄,朝倉書店
https://kivy.org/#home


- 投稿日:2019-12-15T17:46:27+09:00
東京大学大学院情報理工学系研究科 創造情報学専攻 2014年度冬 プログラミング試験
2014年度冬の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。出題テーマ
- 数値計算
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。
(1)
def solve1(x): if (x <= 2): return 1 else: return solve1(x - 1) + solve1(x - 2)(2)
memo = [0] * 100 memo[0], memo[1] = 0, 1 def init(): for i in range(2, 99): memo[i] = memo[i - 1] + memo[i - 2] def solve2(x): init() return memo[x](3)
def solve3(s1, s2): carry = 0 ret = '' for i in range(32): ch1 = s1[31 - i] ch2 = s2[31 - i] n1 = int(ch1) n2 = int(ch2) a = n1 + n2 + carry if (a >= 10): carry = 1 else: carry = 0 b = a % 10 ret += str(b) return ret[::-1](4)
memo = [0] * 141 memo[0], memo[1] = 0, 1 def init(): for i in range(2, len(memo)): memo[i] = memo[i - 1] + memo[i - 2] def solve4(x): init() return memo[x](5)
def solve5(s1, s2): n1 = int(s1) n2 = int(s2) return n1 / (10**(31 - n2))(6)
def root(x): x = float(x) right = x left = 0.0 esp = 1e-7 while (abs(right - left) > esp): mid = (right + left) / 2 if (mid * mid > x): right = mid else: left = mid return right def solve6(): return (1 + root(5)) / 2(7)
# (a + b * root(5) / 2)** 2のa, b def func1(a, b): new_a = int((a ** 2 + (b**2)*5) / 2) new_b = int(a * b) return new_a, new_b # (a + b * root(5) / 2) * (c + d * root(5) / 2) def func2(a, b, c, d): new_a = int((a * c + b * d * 5) / 2) new_b = int((a * d + b * c) / 2) return new_a, new_b root5 = root(5) class obj: def __init__(self, a, b): self.a = a self.b = b def __repr__(self): return '({0} + {1} * root5) / 2'.format(self.a, self.b) def cal(self): return (self.a + self.b * root5) / 2 def f1(self): new_a, new_b = func1(self.a, self.b) return obj(new_a, new_b) # (1+roo5/2)の2のindex-1乗のobjを格納 memo1 = [obj(0, 0)] * 9 memo1[1] = obj(1, 1) def init_memo1(): # 128 (2^7)まで計算 for i in range(2, len(memo1)): memo1[i] = memo1[i - 1].f1() init_memo1() # ex) 139 = 128(2^7) + 8(2^3) + 2(2^1) + 1(2^0) = [1, 1, 0, 1, 0, 0, 0, 1] def func3(x): ret = [0] * 8 if (x >= 128): ret[7] = 1 x -= 128 if (x >= 64): ret[6] = 1 x -= 64 if (x >= 32): ret[5] = 1 x -= 32 if (x >= 16): ret[4] = 1 x -= 16 if (x >= 8): ret[3] = 1 x -= 8 if (x >= 4): ret[2] = 1 x -= 4 if (x >= 2): ret[1] = 1 x -= 2 if (x >= 1): ret[0] = 1 x -= 1 return ret def obj_mul(obj1, obj2): a = obj1.a b = obj1.b c = obj2.a d = obj2.b new_a, new_b = func2(a, b, c, d) return obj(new_a, new_b) # (1+roo5/2)index乗のobjを格納 memo2 = [obj(0, 0)] * 141 memo2[1] = obj(1, 1) for i in range(2, len(memo2)): digit2 = func3(i) obj_array = [] for (index, j) in enumerate(digit2): if (j == 1): obj_array.append(memo1[index+1]) tmp = obj_array[0] for k in range(1, len(obj_array)): tmp = obj_mul(tmp, obj_array[k]) memo2[i] = tmp def g(x): return memo2[x].cal() / root5(8)
def f(x): return solve4(x) def solve8(): Max = 0.0 for i in range(1, 141): Max = max(abs(f(i) - g(i)), Max) return Max感想
- pythonがデフォルトで(3)みたいなことできるから(4), (5)が...
こういうのはやはりpythonのいいところ笑- (8)はxが整数前提で解いたが、区間の場合どちらも指数的に単調増加するから多分x=140のとき差が最大になるとなんとなく予想。
- 区間の場合はそれこそf(x)とg(x)を求め、f(x) - g(x)を微分してnewton法でやるしかないかなぁ
- pythonの仕様にだいぶ助けられたから1時間くらいで終わったちゃった。(8)が区間指定なら数学になるなぁ


- 投稿日:2019-12-15T17:11:19+09:00
Redisとredis-pyを使って、緯度経度での位置情報検索を実装する
レコメンドのプロジェクトで「緯度経度で最寄りの市区町村を検索し、その市区町村に紐づくアイテム(物件)を提案する(それを機械学習アルゴリズムで再ソートする)」ような実装が必要なことがありました。
ちなみに、元々はもっと複雑な特徴量を使って近似最近傍探索のようなロジックを考えていたそうなのですが、上記のような比較的シンプルな方法で早く試そうという方針に決まりました。(レコメンドアルゴリズムは別のメンバーが検証し、私は実装担当として関わっています)
その際に「最寄りの市区町村を検索する」アルゴリズム部分で、Redisの位置情報系の機能を使うと簡単に実装できたのでメモしておきます。…ここまでの情報で、あとはredis-pyのドキュメントを読めば実装できると思いますが、他メンバーの類似プロジェクトでも利用検討することがありそうなので、共有のために書いておきます。
Redisのクライアントライブラリ
Pythonではredis-pyというライブラリが用意されています。
https://github.com/andymccurdy/redis-py
import redis client = redis.Redis(host='{Redisのエンドポイント}', port="6379", decode_responses=True)ここで
decode_responses=Trueのオプションをつけていないと、レスポンスが全てbytes型で返ってしまい、それを.decode("utf-8")し続けるので大変になります。アイテムの追加
このように追加します。第一引数(name)で登録先のkeyを指定します。
client.geoadd("restaurants", 139.741072, 35.684266, "LIFULL TABLE")※LIFULL Tableは弊社半蔵門オフィスにあるカフェです。弊社にいらっしゃった時はぜひいらっしゃってください。
緯度経度による検索
近い順で1件取得します。
response = client.georadius("restaurants", 139.741072, 35.684266, 10, "km", "ASC", count=1) print(response) # => [['LIFULL TABLE', 0.0002]]同じ点なのに距離が出てしまっているのは、おそらく浮動小数点かなにかの誤差なんじゃないかと思います。
アイテムの削除
client.zrem("restaurants", "LIFULL TABLE")また
geodelコマンドじゃないのは、緯度経度の実態がSorted setで、そちらで用意されているzremコマンドで十分だからのようです。公式ドキュメントでは次のように説明されています。Note: there is no GEODEL command because you can use ZREM in order to remove elements. The Geo index structure is just a sorted set.
ちなみにSorted setを使えばリアルタイムのランキングの実装も簡単だそうです。
制限
Sorted setで、valueとして入れられる値は文字列のみに制限されているようです。そのため緯度経度で近い「レストラン名」は管理できても、これ単体でそれ以上(例えばレストランのメニューも入れてupdateさせるとか)はできないようでした。
実は「緯度経度で指定し、その最寄りのランドマーク周辺の
jsonオブジェクト(最新の物件情報)をレスポンスとして返す」という実装をしたかったのですが、valueの値が物件情報が変わるたびに毎回変わり、挿入するたびに過去の値が消えずに残っていきます。そのため実は別の方法で実装しています。また、極地付近のデータは利用できないようです。
The command takes arguments in the standard format x,y so the longitude must be specified before the latitude. There are limits to the coordinates that can be indexed: areas very near to the poles are not indexable.
参考
- 投稿日:2019-12-15T17:09:53+09:00
2020 年の Python パッケージ管理ベストプラクティス
この記事は Python Advent Calendar 2019 の 19 日目の記事です。
? あらすじ
Python のパッケージ管理。特にここ数年で新しいツールが多く出たこともあり、一体何を使うべきなのか、少し調べただけでは分からないと思います。本記事では、新しめの管理ツールを独断と偏見で比較します。著者は Poetry 信者なのでバイアスが掛かっているので悪しからず。
- 本記事で書いていること
- Pipenv、Poetry、Pyflow の違いと使い方
- 本記事で書いていないこと
- Pyenv、Venv、Virtualenv などの既存ツールの説明
著者の環境は以下の通り。
Ubuntu 18.04Python 3.8.0Pipenv 2018.11.26Poetry 1.0.0Pyflow 0.2.1特に Poetry と Pyflow は開発途中なので、本記事の内容と違う可能性があるのでご了承ください。
ちなみに 2019/12/15 時点での GitHub の Star の推移はこんな感じ。少しタイミングが悪いのは、Poetry 1.0.0 のリリースがつい 3 日前だってこと。
? 紹介
まずはツールごとに簡単に紹介します。
Pipenv
かなりの期間、
requirements.txtでパッケージの記述していた Python のパッケージ管理 (というかライブラリ一覧を記述するだけ) の風潮を、Node.js の npm や yarn、Ruby の gem のように、依存関係も扱えるようにしたことで話題になったツールです。Pipfileというパッケージを管理するファイルとPipfile.lockという依存関係が記述されるファイルを使います。依存関係を扱えるということは、例えば内部で numpy を使う pandas をインストールした環境で pandas をアンインストールすると、Pip では pandas のみが削除されるのに対して、Pipenv では numpy も同時に削除できます (他に依存しているライブラリが無ければ)。Pipfile[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] black = "*" [packages] numpy = "*" [requires] python_version = "3.8" [pipenv] allow_prereleases = truePoetry
Pipenv が流行ると思われたのもつかの間、PEP 518 で提案された
pyproject.tomlによるパッケージ管理を導入した Poetry が開発されました。Pipenv が alt-requirements.txt に過ぎないのに対し、Poetry はこれまでパッケージングする際に記述していたsetup.pyやsetup.cfg、MANIFEST.inなどのファイルもコンパクトにpyproject.tomlに記述できる点で優れています。他にも、linter や formatter の設定を同じファイルに記述できます。pyproject.toml[tool.poetry] name = "sample-ploject" version = "1.0.0" description = "" authors = ["Your Name <you@example.com>"] license = "MIT" [tool.poetry.dependencies] python = "^3.8" numpy = "^1.17.4" [tool.poetry.dev-dependencies] black = {version = "^19.10b0", allows-prereleases = true} [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api"Pyflow
Pyflow はおそらく一番新参のパッケージ管理ツールです。Rust で書かれており、Poetey で導入された PEP 518 に加え、PEP 582 で提案された、プロジェクト内で扱える仮想環境を複数の Python バージョンに対応させることができます。Pyenv + venv で 1 つの Python のパージョンの 1 つの仮想環境を扱う Pipenv/Poetry に対して、Pyflow は単体で Python のバージョンを複数管理して任意のバージョンで仮想環境を作ることができます。現環境で大きな恩恵は無い気もしますが、今後 Python にメジャーアップデートがあった場合などに重宝されるかもしれません。個人的な懸念は Rust で書かれていることで、速度等で恩恵がありそうな一方で、Rust にある程度の理解がないとエラーメッセージに対応しづらい点と、開発コミュニティが伸びにくいということです。
pyproject.toml[tool.pyflow] name = "sample-project" py_version = "3.8" version = "1.0.0" authors = ["Your Name <you@example.com>"] [tool.pyflow.scripts] [tool.pyflow.dependencies] numpy = "^1.17.4" [tool.pyflow.dev-dependencies] black = "^19.10.0b0"✏️ 使い方
インストールはそれぞれのリンクを読んでいただきたいですが、基本的に Pip でユーザディレクトリにインストールするのがいいかと思います。ただ Pyflow は今のところ Pip を推奨しておらず、Mac では非対応らしいので Rust を入れてインストールするといいかもしれません。
全てのツールが CLI を内蔵しており、プロジェクトの作成、パッケージの追加や削除、実行などが可能です。それぞれコマンドが微妙に違うので、よく使うものだけ表にして比較してみます。
動作 Pip Pipenv Poetry Pyflow プロジェクトの作成 - - poetry new samplepyflow new sampleプロジェクトの初期化 - pipenv --python 3.8poetry initpyflow initパッケージの追加 pip install numpypipenv install numpypoetry add numpypyflow install numpyパッケージの削除 pip uninstall numpypipenv uninstall numpypoetry remove numpypyflow uninstall numpy依存環境のインストール pip install -r requirements.txtpipenv syncpoetry installpyflow sync仮想環境内で実行 - pipenv run python main.pypoetry run python main.pypyflow main.pyパッケージのビルド python setup.py bdist_wheel- poetry buildpyflow packageパッケージのアップロード (PyPI) twine upload --repository pypi dist/*- poetry publishpyflow publishどれもコマンドは直感的ですが、Pyflow は Pipenv を意識しているみたいです。パッケージング周りで Poetry と Pyflow の良さが分かると思います。
Pyflow のプロジェクトページでは特徴を比較した表が載っていますので合わせて参考に。
それぞれの初期化後のディレクトリ構造は以下の通り (.lock ファイル生成のために numpy をインストールした後)。
pipenv-tree./ ├── .venv/ ├── Pipfile └── Pipfile.lockpoetry-tree./ ├── .venv/ ├── poetry.lock ├── pyproject.toml ├── README.rst ├── sample/ └── tests/pyflow-tree./ ├── .git/ ├── .gitignore ├── __pypackages__/ ├── LICENSE ├── pyflow.lock ├── pyproject.toml ├── README.md └── sample/? 独断と偏見による評価
頑張って褒めます。
Pipenv
最近使っていないので著者の勘違いだったら教えてください。
? 1. Python パッケージ管理の歴史を変えたパイオニア
ずっと
requirements.txtや conda1 で曖昧に管理されていた歴史を変えてくれたことは非常に大きな功績だと思います。最近記事に取り上げられることも増え、使い方も多く紹介されています。? 2. 移行が楽
requirements.txtから引き継ぎが出来るように実装されているので、既存プロジェクトへの導入は比較的簡単です。? 1.
--preがライブラリごとに設定できないalpha や beta 段階でしか公開されていないパッケージをインストールする際に、Pipenv では
--preオプションをつけるのですが、一度--preすると次回以降どのパッケージでも最近版を取ってきます。blackをフォーマッタにしている場合、まだ正式版がリリースされていないので多分ハマります。? 2. パッケージのインストールが遅い
体感ですが、Pipenv はインストールがかなりと遅いときがあります。
torchとか重た目のフレームワーク入れようとすると結構時間がかかる印象。計測するのが面倒なので誰か実験してみてください。Poetry
? 1. 安定感がある
ここ半年はほぼ Poetry しか使っていませんが、エラーで困ることも機能で不足を感じることもありませんでした。パッケージングが楽な点、インタラクティブな CLI でプロジェクトを作成できる点など、npm と同じ感覚で使えています。
Pyflow
? 1. PEP 582 への対応
先日リリースされた
Python 3.8から導入された PEP 582 にいち早く対応した点で評価できます。バージョンのスイッチや選択もコマンドラインでインタラクティブに行うことが出来ます。? 2. 仮想環境内での実行が楽
仮想環境内で実行する際に、
pyflow main.pyやpyflow blackのようにrun pythonなどをつけなくても引数から判定してくれるのでコマンドが短く済むのはいいと思いました。? 3. 移行が楽
requirements.txtだけでなく、Pipfileからの移植にも対応している点は評価できます。? 1. Rust への理解が必要
著者が今回 Pyflow を触ってみた感じですが、そこそこの頻度でエラーが出てよく分からなくなりました。現状では、Rust について最低限知っておく必要があるかもしれません。
? 2. プロジェクト生成時のモジュール名
細かいことですが、Poetry は
poetry newでハイフン付きのプロジェクトを作成した際に、ハイフンをアンダースコアに置換してモジュールディレクトリを生成してくれますが、Pyflow はpyflow newでは同じ名前のモジュールディレクトリが生成されます。命名規則として PEP では短い単語を推奨していますが、アンダースコアの使用は認められています。現状 Pyflow ではこのような場合はディレクトリ名を手動で変える必要があります。? オススメの使い方
これまで色々比較をして来ましたが、冒頭に述べたように今の所 Poetry を推しています。Poetry を普段使っている私がオススメする使い方を紹介します。
Pyenv + Poetry
Poetry で仮想環境の管理を行うことが出来ますが、様々な Python プロジェクトを扱うと、様々な Python のバージョンが必要になると思います。Pyenv は任意のバージョンの Python をインストールすることが出来るのでオススメです。ホームディレクトリにインストールするので root がいらない点でも扱いやすいです。
プロジェクト内に venv を作成
Pipenv と Poetry では、初期設定では venv がホームディレクトリ内に作られます。
Pipenv の場合は
export PIPENV_VENV_IN_PROJECT=1を Poetry の場合はpoetry config virtualenvs.in-project trueを行うことで、プロジェクト内に仮想環境を作成できます。プロジェクト外にあると管理が不便なのでこれをオススメします。オススメの alias
.zshrcalias po='poetry run' alias pp='poetry run python' function pdev () { poetry add -D --allow-prereleases black poetry add -D flake8 mypy pylint }Pipenv にしろ Poetry にしろ、venv のように
source .venv/bin/activateする必要はありません (一応pipenv shellのように環境に入るコマンドも存在)。理由としては、別のプロジェクトにターミナルの同じセッションで移動したときにdeactivateし忘れて環境を変えてしまうことへの対処です。? まとめ
Pyflow はさておいて、ところどころで比較されるようになった Pipenv vs. Poetry は少なくとも現状の機能面では Poetry に軍配が上がるでしょう。まだ
requirements.txtやsetup.pyが使われているプロジェクトがほとんどですが、今後pyproject.tomlによる管理がどんどん広まってくれたらと思います。是非小さなプロジェクトから導入してみてください。
著者は宗教上の理由で Anaconda を使うことが出来ません。 ↩



