- 投稿日:2019-12-05T23:54:21+09:00
ナンプレをPythonで解く(前編)
※当記事は編集中です
IPFactory Advent Calender 2019 5日目
5日目も書かせていただきます。
IPFactory所属、ISC 1年のpycysです。
コード書きながら記事書いていきます。(現在12/5/1:02)
今日中に終わるかはわかりません。
終わらなそうです。(現在18時)
終わりません。(現在23時半)
諦めて前編として投稿します。プログラムが受け取るデータ
※画像の数字は添字であり、受け取るデータではありません。
0から9までのいずれかの数字81個が空白区切りで渡されるものとします。
ナンプレの左上マス(0, 0)の値は1番目に、右上マス(0, 8)の値は9番目に、
左下マス(8, 0)の値は73番目に、右下マス(8, 8)の値は81番目に記述されています。
0は空白を、1から9はその数字が設定されていることを示します。どう解いていくか
解法考えていきます。
データを受け取って先頭から9個づつに分け、ナンプレにおける横列の配列に加工。
これを横列グループと呼ぶことにします。横列グループから縦列グループを作る。
そのまま縦列グループと呼ぶ。加工した2次元配列から3×3マスのグループ(上の画像の赤字で書かれたグループ)を9個作り、これを3マスグループと呼びます。
3マスグループ内で位置が確定している数字と確定していない数字をそれぞれまとめてグループを作る。
確定したものは3マス確定グループ、未確定のものは3マス未確定グループと呼びます。縦列、横列も同様に、列ごとに確定した数字と未確定の数字をまとめてグループを作る。
それぞれ、縦確定グループ、縦未確定グループ、横確定グループ、横未確定グループと呼びます。問題受け取り
nums = [int(i) for i in input().split()] nampre = [[] for i in range(9)] for index, i in enumerate(nums): nampre[(index)//9].append(i)入力を受け取って空白で区切って整数に変換したり、2次元配列に格納したりしてます。
縦列生成
# 縦列に整形 def columns_generator(rows): columns = [[] for i in range(9)] for i in range(9): for j in range(9): columns[i].append(rows[j][i]) return columns3マスグループを作る
# 3マスグループを作る def cube_generator(rows): cubes = [[[] for j in range(3)] for i in range(9)] for i in range(9): for j in range(9): cubes[i//3*3+j//3][i%3].append(rows[i][j]) return cubes3マス確定グループを作る
# 3マス確定グループを作る def confirm_cube_generator(cubes): confirm_cubes = [[] for i in range(9)] for i in range(9): confirms = [] for j in range(9): if cubes[i][j//3][j%3]: confirms.append(cubes[i][j//3][j%3]) confirm_cubes.append(copy.deepcopy(confirms)) return confirm_cubes3マス未確定グループを作る
明日の記事に続きます。

- 投稿日:2019-12-05T23:54:14+09:00
fastTextでサクッと単語の分散表現を使ってみよう!
本稿ではfastTextを使ってサクッと単語の分散表現を獲得する方法について見ていきます。前日の記事と少しリンクするお話に出来れば良いなあと思って書きました。
fastTextとは
fastTextはFacebookが発表した単語の分散表現(単語を数値で表現したもの)を獲得する手法です。基となっているのはお馴染みWord2Vec(CBOW / skip-gram)です。Word2Vecについては今更も今更なので説明は不要でしょう。
論文:Enriching Word Vectors with Subword Information
Word2VecとfastTextの違いは、ベクトルの取り方です。サブワードという仕組みを入れることによって、活用形等の近い単語同士を汲み取っています。
Word2Vecではgoとgoesは全く別の単語でした。しかしfastTextではこれを考慮し、同じ構成要素としてgoとgoesに意味を持たせます。
当然、未知語にも強くなりますね!
詳細は論文や次の資料をお勧めします。
FastTextで遊ぼう
今回の目的は「PythonとFastTextを使ってサクッと単語の分散表現で遊ぶ」ことです。
環境構築
え?Pythonの導入すらサクッと出来ない?ではGoogle Colaboratoryを使いましょう。(以下colab)
colabはGoogleアカウントさえあれば誰でも簡単にPythonやGPUが使える最強の無料環境です。
はい、環境構築 終。
サクッとfastText
fastTextを使うには学習モデルが必要になります。これは自分でデータを収集して、学習させても良いのですが、ここでは学習済みモデルを使わせてもらいます。
学習済みモデル:fastTextの学習済みモデルを公開しました - Qiita
モデルはそのままGoogleドライブの中に放りこんでください。せっかくなのでcolabの使い方説明も含めて、ドライブから解凍してしまいましょう!
colabでドライブの中を触るにはマウントが必要です。これは以下のコードを実行すればよいのですが、「ドライブをマウント」ボタンを押せば同じコードが出てくるはずなのでそれを実行してください。
from google.colab import drive drive.mount('/content/drive')あとはURLにアクセスして、アカウントにログイン、するとauthorization codeが出てくると思うのでそれをcolabでコピペするだけです。簡単。
あとは解凍するだけ!
%cd /content/drive/My Drive/data !unzip vector_neologd.zippathはドライブに上げた学習済みモデルの場所を指定してくださいね。
それでは類似する言葉を探してみましょう。
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('model.vec', binary=False) model.most_similar(positive=['自然言語処理'])結果。
[('自然言語理解', 0.7600098848342896), ('自然言語', 0.7503659725189209), ('計算言語学', 0.7258570194244385), ('自動プログラミング', 0.6848069429397583), ('テキストマイニング', 0.6811494827270508), ('コンピュータ言語', 0.6618390083312988), ('メタプログラミング', 0.658093273639679), ('Webプログラミング', 0.6488876342773438), ('形態素解析', 0.6479052901268005), ('コーパス言語学', 0.6465639472007751)]色々遊ぶと意外と楽しい。
model.most_similar(positive=['友人'], negative=['友情'])[('知人', 0.4586910605430603), ('自宅', 0.35488438606262207), ('知り合い', 0.329221248626709), ('入り浸り', 0.3212822675704956), ('親戚', 0.31865695118904114), ('知り合っ', 0.3158203959465027), ('宅', 0.31503963470458984), ('誘わ', 0.302945077419281), ('繁く', 0.30250048637390137), ('同僚', 0.29792869091033936)]サクッと?fastText
あまりにサクッとし過ぎたので、続いてボキャブラリーを制限して同じことをしてみます。こんなやり方もあるよというオプションです。
今回扱うのは日本語のテキストですが、日本語は英語と違い各単語がスペース等で分割されていないので、初めに前処理を行わなければなりません。(分かち書き)
尚、実装は書籍「つくりながら学ぶ! PyTorchによる発展ディープラーニングを参考にしています。
ここではjanomeを使います。
!pip install janomeでは分かち書きをしましょう。
from janome.tokenizer import Tokenizer j_t = Tokenizer() def tokenizer_janome(text): return [tok for tok in j_t.tokenize(text, wakati=True)]janomeだけで分かち書きがサクッと出来ますが、加えて簡単な前処理をしましょう。
import re import unicodedata import string def format_text(text): text = unicodedata.normalize("NFKC", text) table = str.maketrans("", "", string.punctuation + "「」、。・") text = text.translate(table) return text def preprocessing(text): """ 前処理をする関数 """ text.translate(str.maketrans({chr(0xFF01 + i): chr(0x21 + i) for i in range(94)})) # 全角→半角 text = text.lower() # 大文字→小文字 text = re.sub('\r', '', text) text = re.sub('\n', '', text) text = re.sub(' ', '', text) text = re.sub(' ', '', text) text = re.sub(r'[0-9 0-9]', '', text) # 数字の除去 text = re.sub(r'[!-/:-@[-`{-~]', '', text) # 半角記号の除去 text = re.sub(r'/[!-/:-@[-`{-~、-〜”’・]', '', text) # 全角記号の除去 text = format_text(text) # 全角記号の除去 return text def tokenizer_with_preprocessing(text): text = preprocessing(text) text = tokenizer_janome(text) return textコメントに書いた通りですが、いくつかの前処理を行っています。もちろんタスクや用途によって前処理で行うべきことは変わるはずです。
では試しに適当な文章を入れてみましょう。
text = '今回は fastTextを 使って 分散表現を獲得したい!!!?' print(tokenizer_with_preprocessing(text))結果。
['今回', 'は', 'fasttext', 'を', '使っ', 'て', '分散', '表現', 'を', '獲得', 'し', 'たい']上手くいっているようですね。
続いてtorchtextを使って諸々を楽にします。torchtextについてはtorchtextで簡単にDeepな自然言語処理 - Qiitaが詳しいです。
import torchtext max_length = 25 TEXT = torchtext.data.Field(sequential=True, tokenize=tokenizer_with_preprocessing, use_vocab=True, lower=True, include_lengths=True, batch_first=True, fix_length=max_length) LABEL = torchtext.data.Field(sequential=False, use_vocab=False) train_ds, val_ds, test_ds = torchtext.data.TabularDataset.splits( path='./tsv/', train='train.tsv', validation='val.tsv', test='test.tsv', format='tsv', fields=[('Text', TEXT), ('Label', LABEL)])train.tsv / test.tsv / val.tsvを用意しました。これは本稿の「fastTextとは」の文章を適当に3分割してtsvファイルとしました。これも上記のリンクが詳しいのでそちらをお勧めします。
from torchtext.vocab import Vectors vectors = Vectors(name='model.vec') # ベクトル化したバージョンのボキャブラリーを作成します TEXT.build_vocab(train_ds, vectors=vectors, min_freq=1) # ボキャブラリーのベクトルを確認します print(TEXT.vocab.vectors.shape) # 52個の単語が300次元のベクトルで表現されている TEXT.vocab.vectors # ボキャブラリーの単語の順番を確認します TEXT.vocab.stoiこれで準備が出来たのでボキャブラリーの各単語の類似度を計算してみます。「単語」に3つの単語が類似するか見てみましょう。
import torch.nn.functional as F tensor_calc = TEXT.vocab.vectors[TEXT.vocab.stoi['単語']] # コサイン類似度 print("論文", F.cosine_similarity(tensor_calc, TEXT.vocab.vectors[TEXT.vocab.stoi['論文']], dim=0)) print("ワード", F.cosine_similarity(tensor_calc, TEXT.vocab.vectors[TEXT.vocab.stoi['ワード']], dim=0)) print("ベクトル", F.cosine_similarity(tensor_calc, TEXT.vocab.vectors[TEXT.vocab.stoi['ベクトル']], dim=0))結果。
論文 tensor(0.3089) ワード tensor(0.3704) ベクトル tensor(0.3265)もっと詳しくやりたい人は
fastTextについてはWord2Vecほどではありませんが、色んな記事がありますので、特におすすめなもの(参考文献)を紹介して締めます。
fastTextで分類
- pythonでfasttextを使って文書分類してみた - Qiita
- テキスト分類器fastTextを用いた文章の感情極性判定 - Qiita
- 【python】fastText用の学習データ作成とモデルの生成 - Qiita
- keras + fastText(学習済み)で文書のジャンル分類してみた - Qiita
- fastTextで自然言語(日本語)の学習モデルを生成する手順まとめ
fastText以外の単語埋め込み
もっと最近の単語埋め込みを知りたい方はELMoとかBERTでググって貰えれば沢山出ると思います。
次回は?
@takashi1029さんです!本稿は当日ぎりぎりに投稿しているので(申し訳ない)すぐ投稿されるかもしれません。
次回リンク:まだ
- 投稿日:2019-12-05T23:47:02+09:00
Few shot NODOGURO turningして、ノドグロを自動カウントしてみた
この記事は古川研究室 Advent_calendar4日目の記事です。
はじめに
PyTorch、Chainer、Keras、TensorFlowなど色々なフレームワークが登場し、誰でも簡単にDeep Learningが使えるようになったと言われています。
実際Deep Learningを使っている人たちからすると単に動かすだけなら簡単に思えるかもしれません。しかしDeep LearningというよりPythonをあまり使ってない人からするとメチャクチャ難しいです。
私の感覚としてはDeep Learningを動かすのは自転車に乗るのに似ていると思います。
一度、自転車に乗れた人は「自転車に乗ることなんて簡単だよ」とか「他の自転車も同じようすれば乗れるでしょ?」とか好き勝手言いますが、乗ったことない人や乗れない人からは「何言っているんだ」って感じです。さらにDeep Learningを使う場合、下図のような感じでどこまでしたいかで求められるスキルが違いますのもDeepを使うハードルを上げている一因かと思います。
この記事ではDeep Learningと言う名の自転車に乗る手助けとして、私が実際にやった2nd Stepの道のりを解説していきます。
とりあえずDeepで物体認識をやってみる
準備
今回はChainerを使います。
そのためにChainerを入れてあげましょう。$ pip install chainer $ pip install chainercv実行
以下みたいな感じで動かします。
import matplotlib.pyplot as plt import numpy as np from PIL import Image from chainercv.visualizations import vis_bbox from chainercv.datasets import voc_bbox_label_names from chainercv.links import FasterRCNNVGG16 # 使用するラベル(今回はデフォルトのやつ) label_names = voc_bbox_label_names # データの読み込み「'./fish/test.jpeg」は好きな画像ファイルにしてね test_data = Image.open('./fish/test.jpg') test_data = np.asarray(test_data).transpose(2, 0, 1).astype(np.float32) # モデルの構築、とりあえずモデルは学習済みvoc07を使用 model_frcnn = FasterRCNNVGG16(n_fg_class=len(voc_bbox_label_names), pretrained_model='voc07') # 予測 bboxes, labels, scores = model_frcnn.predict([test_data]) predict_result = [test_data, bboxes[0], labels[0], scores[0]] # 結果の描画 res = predict_result fig = plt.figure(figsize=(6, 6)) ax = fig.subplots(1, 1) line = 0.0 vis_bbox(res[0], res[1][res[3]>line], res[2][res[3]>line], res[3][res[3]>line], label_names=label_names, ax=ax) plt.show()結果
うまく認識できました!
次に、のどぐろ画像を入れてやってみました。
当然だけどデフォルトのままだとノドグロのラベルもないし、上手くいきません。
なのでノドグロ特化識別器のにするためにFine-turningをします。
Fine-turningの詳細な説明は飛ばしますが、要は学習済みのモデルに追加学習させる感じです。データの準備
追加学習するにもそもそも学習データが必要なので学習データをつくりましょう。
labelImgっていうやつがおすすめです。
入れ方や使い方は↑のgithubサイトのREADMEに書いてあるので、とりあえず簡単な簡単な流れだけ説明します。
まず、labelImgを動かすために必要なやつをいれます。$ brew install qt # Install qt-5.x.x by Homebrew $ brew install libxml2 $ pip3 install pyqt5 lxml # Install qt and lxml by pip $ make qt5py3実行します。
気をつける点とかはないと思いますが、しいて言えばクローンしたディレクトリ内で操作するところですね。No such file or directoryとか出てエラーになります$ python3 labelImg.py
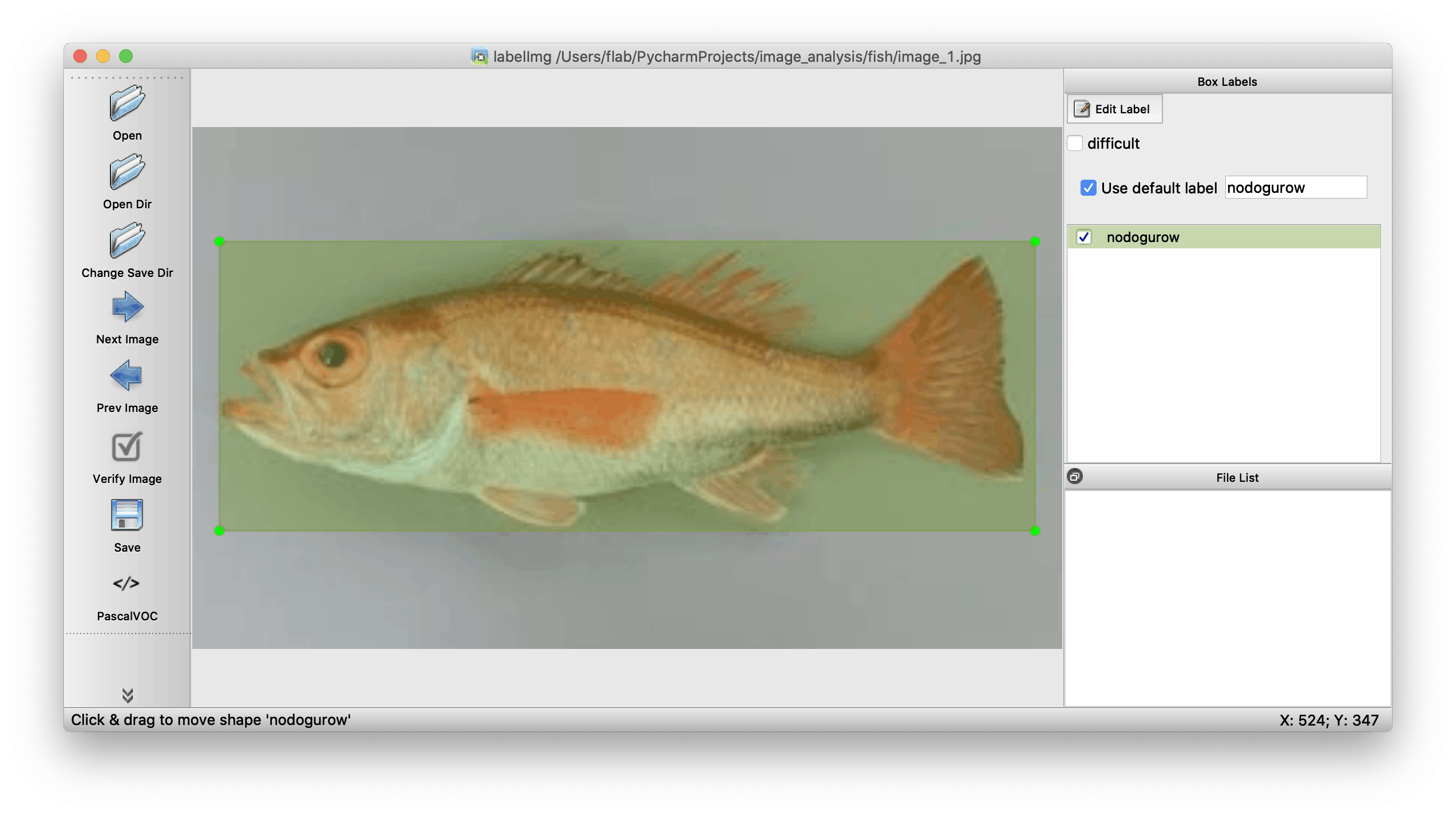
labelImg.pyを実行すると以下のような画面がでます。
openで画像を開いて、右側のlabelに「nodoguro」って入力します
wキーを押すと範囲を選択できるので、ノドグロを選択します。
すると、こんな感じでラベルをつけることができます。
こんな感じで2つ付けることもできます。
最後にsaveのボタンを押すとxmlファイルができます。このファイルにラベルとか枠線がどの座標にあるかの情報が入ってます。
あとはclasses.txtって名前のラベル名が箇条書きで書かれたファイルを作ります。classes.txtnodoguro iwashi cat学習データ作りはこれで終了です!
気をつける点としては「画像サイズを揃えること」と「ラベルを2種類以上にすること」です。
ラベルの種類が1種類だと学習の際にうまくいきませんでした。NODOGURO turning
学習データができたので実際に学習させてみましょう。学習済みモデルにはImagenetを使用しました。
今回は7枚の画像を追加学習します。またディレクトリ構造は以下の感じにしています。
sample/ ├ fish/ │ ├ res_images/ │ │ ├ images.npy │ │ ├ bounding_box_data.npy │ │ └ object_ids.npy │ ├ classes.txt │ ├ image_1.jpg │ ├ image_1.xml │ ├ ... │ ├ image_7.xml │ └ test.jpg ├ out/ ├ learn.py ├ predict.py └ xml2numpyarray.pyデータ整形
今回学習させる前にnumpyarrayの形にしておいた方が都合よかったため、以下のコードを使ってその変換をしました。
import errorが起きる場合はpipで入れてください。xml2numpyarray.pyimport matplotlib.pyplot as plt import numpy as np import glob import os import cv2 from PIL import Image import xmltodict # Global Variables classes_file = 'fish/classes.txt' data_dir = 'fish' classes = list() with open(classes_file) as fd: for one_line in fd.readlines(): cl = one_line.split('\n')[0] classes.append(cl) print(classes) def getBBoxData(anno_file, classes, data_dir): with open(anno_file) as fd: pars = xmltodict.parse(fd.read()) ann_data = pars['annotation'] print(ann_data['filename']) # read image img = Image.open(os.path.join(data_dir, ann_data['filename'])) img_arr = np.asarray(img).transpose(2, 0, 1).astype(np.float32) bbox_list = list() obj_names = list() for obj in ann_data['object']: bbox_list.append([obj['bndbox']['ymin'], obj['bndbox']['xmin'], obj['bndbox']['ymax'], obj['bndbox']['xmax']]) obj_names.append(obj['name']) bboxs = np.array(bbox_list, dtype=np.float32) obj_names = np.array(obj_names) obj_ids = np.array(list(map(lambda x:classes.index(x), obj_names)), dtype=np.int32) return {'img':img, 'img_arr':img_arr, 'bboxs':bboxs, 'obj_names':obj_names, 'obj_ids':obj_ids} def getBBoxDataSet(data_dir, classes): anno_files = glob.glob(os.path.join(data_dir, '*.xml')) img_list = list() bboxs = list() obj_ids = list() # imgs = np.zeros([4, 3, 189, 267]) # num = 0 for ann_file in anno_files: ret = getBBoxData(anno_file=ann_file, classes=classes, data_dir=data_dir) print(ret['img_arr'].shape) img_list.append(ret['img_arr']) # imgs[num] = ret['img_arr'] bboxs.append(ret['bboxs']) obj_ids.append(ret['obj_ids']) imgs = np.array(img_list) return (imgs, bboxs, obj_ids) imgs, bboxs, obj_ids = getBBoxDataSet(data_dir=data_dir, classes=classes) np.save(os.path.join(data_dir, 'images.npy'), imgs) np.save(os.path.join(data_dir, 'bounding_box_data.npy'), bboxs) np.save(os.path.join(data_dir, 'object_ids.npy'), obj_ids)学習
以下のコードで実行
learn.pyimport os import numpy as np import chainer import random from chainercv.chainer_experimental.datasets.sliceable import TupleDataset from chainercv.links import FasterRCNNVGG16 from chainercv.links.model.faster_rcnn import FasterRCNNTrainChain from chainer.datasets import TransformDataset from chainercv import transforms from chainer import training from chainer.training import extensions HOME = './' data_dir = os.path.join(HOME, './fish/res_images') file_img_set = os.path.join(data_dir, 'images.npy') file_bbox_set = os.path.join(data_dir, 'bounding_box_data.npy') file_object_ids = os.path.join(data_dir, 'object_ids.npy') file_classes = os.path.join(data_dir, 'classes.txt') # データセットの読み込み imgs = np.load(file_img_set) bboxs = np.load(file_bbox_set, allow_pickle=True) objectIDs = np.load(file_object_ids, allow_pickle=True) # ラベル情報の読み込み classes = list() with open(file_classes) as fd: for one_line in fd.readlines(): cl = one_line.split('\n')[0] classes.append(cl) dataset = TupleDataset(('img', imgs), ('bbox', bboxs), ('label', objectIDs)) N = len(dataset) N_train = (int)(N*0.9) N_test = N - N_train print('total:{}, train:{}, test:{}'.format(N, N_train, N_test)) # ネットワーク構築 faster_rcnn = FasterRCNNVGG16(n_fg_class=len(classes), pretrained_model='imagenet') faster_rcnn.use_preset('evaluate') model = FasterRCNNTrainChain(faster_rcnn) # GPUの設定(今回は使用しない) gpu_id = -1 # chainer.cuda.get_device_from_id(gpu_id).use() # model.to_gpu() # 何の手法で最適化するか設定 optimizer = chainer.optimizers.MomentumSGD(lr=0.001, momentum=0.9) optimizer.setup(model) optimizer.add_hook(chainer.optimizer_hooks.WeightDecay(rate=0.0005)) # データの用意 class Transform(object): def __init__(self, faster_rcnn): self.faster_rcnn = faster_rcnn def __call__(self, in_data): img, bbox, label = in_data _, H, W = img.shape img = self.faster_rcnn.prepare(img) _, o_H, o_W = img.shape scale = o_H / H bbox = transforms.resize_bbox(bbox, (H, W), (o_H, o_W)) # horizontally flip img, params = transforms.random_flip( img, x_random=True, return_param=True) bbox = transforms.flip_bbox( bbox, (o_H, o_W), x_flip=params['x_flip']) return img, bbox, label, scale idxs = list(np.arange(N)) random.shuffle(idxs) train_idxs = idxs[:N_train] test_idxs = idxs[N_train:] # 学習するためのいろいろな設定 train_data = TransformDataset(dataset[train_idxs], Transform(faster_rcnn)) train_iter = chainer.iterators.SerialIterator(train_data, batch_size=1) test_iter = chainer.iterators.SerialIterator(dataset[test_idxs], batch_size=1, repeat=False, shuffle=False) updater = chainer.training.updaters.StandardUpdater(train_iter, optimizer, device=gpu_id) n_epoch = 20 out_dir = './out' trainer = training.Trainer(updater, (n_epoch, 'epoch'), out=out_dir) step_size = 100 trainer.extend(extensions.snapshot_object(model.faster_rcnn, 'snapshot_model.npz'), trigger=(n_epoch, 'epoch')) trainer.extend(extensions.ExponentialShift('lr', 0.1), trigger=(step_size, 'iteration')) log_interval = 1, 'epoch' plot_interval = 1, 'epoch' print_interval = 1, 'epoch' trainer.extend(chainer.training.extensions.observe_lr(), trigger=log_interval) trainer.extend(extensions.LogReport(trigger=log_interval)) trainer.extend(extensions.PrintReport(['iteration', 'epoch', 'elapsed_time', 'lr', 'main/loss', 'main/roi_loc_loss', 'main/roi_cls_loss', 'main/rpn_loc_loss', 'main/rpn_cls_loss', 'validation/main/map', ]), trigger=print_interval) trainer.extend(extensions.PlotReport(['main/loss'], file_name='loss.png', trigger=plot_interval), trigger=plot_interval) trainer.extend(extensions.dump_graph('main/loss')) # 学習 trainer.run()こちらが設定するパラメータとしては
・gpuのところ(今回はgpuは使用していません)# chainer.cuda.get_device_from_id(gpu_id).use() # model.to_gpu()・最適化(optimizer)のところ
optimizer = chainer.optimizers.MomentumSGD(lr=0.001, momentum=0.9) optimizer.setup(model) optimizer.add_hook(chainer.optimizer_hooks.WeightDecay(rate=0.0005))・学習回数のところ
n_epoch = 20 step_size = 100になります。
他にもbatch_sizeやテストデータを何個にするか(N_train = (int)(N*0.9)N_test = N - N_train)など他にもいろいろありますが、とりあえずは上の3つぐらいです。ちなみに学習済みのネットワークは
out/snapshot_model.npzってファイルに保存されます。予測
実際にノドグロを認識してみました。
Scoreが0.9以上のやつだけ認識するようにしました。import matplotlib.pyplot as plt import numpy as np from PIL import Image from chainercv.visualizations import vis_bbox from chainercv.links import FasterRCNNVGG16 # ラベル読み込み classes = list() with open('./fish/classes.txt') as fd: for one_line in fd.readlines(): cl = one_line.split('\n')[0] classes.append(cl) # テストデータの読み込み test_data = Image.open('./fish/test.jpg') test_data = np.asarray(test_data).transpose(2, 0, 1).astype(np.float32) # 学習したモデルを読み込み pretrain_model = 'out/snapshot_model.npz' # ネットワーク構築 model_frcnn = FasterRCNNVGG16(n_fg_class=len(classes), pretrained_model=pretrain_model) # 予測 bboxes, labels, scores = model_frcnn.predict([test_data]) predict_result = [test_data, bboxes[0], labels[0], scores[0]] # スコアが0.9以下のやつを認識しないようにスレッショルド設定 line = 0.9 # 描画 res = predict_result fig = plt.figure(figsize=(6, 6)) ax = fig.subplots(1, 1) vis_bbox(res[0], res[1][res[3]>line], res[2][res[3]>line], res[3][res[3]>line], label_names=classes, ax=ax) plt.show()結果がこちらになります。
ちゃんと認識できました!
print(np.sum(labels[0] == 0))で認識した数を表示することもできます。さいごに
今回はエイヤッでfine-turningをしてノドグロ検出をしてみました。
終わってみるとけっこう簡単でしたね。次はノドグロを好きな画像に変えればいいだけなので比較的楽に実装できますね。
ただ実際高精度な検出やカウントを実現する場合は、重なりの部分をどうするかや回転をどうするかなど、そもそものネットワーク構造や問題設定から練り直したりしなくちゃいけないので大変です。
研究レベルや商品レベルにもっていくには難しいですが、今回の実装を通して「とりあえずDeepを使って遊んでみる」ってところまでは比較的簡単にできるってことは分かってもらえたんじゃないかなと思います。参考サイト
ほとんど、このサイトを参考にしてやりました。
http://chocolate-ball.hatenablog.com/entry/2018/05/23/012449







- 投稿日:2019-12-05T23:32:40+09:00
CLIフレームワークのCliffについてとちょっとはまったよ情報
はじめに
PythonのCLIフレームワークの一つでCliffというものがあります。そこで少しハマったことをお話しようと思います。
Cliffについて
詳細はこちらを見てください。簡単にCLIツールを作れるフレームワークです。
ちょろっと書くだけで、プログラムの値の返却とか--helpとかをよしなにやってくれます。
main.pyを作ってそこからsetup.pyなどで各コマンドのクラスにマッピングするだけです。Cliffのコマンドクラスについて
一番基礎となるコマンドのクラスはCommandクラスです。
これを継承してコマンド作る感じです。sample.pyfrom cliff.command import Command class SampleCommand(Command): #~~コマンドにさせたい処理~~デフォルトでもいくつかCommandクラスを継承したクラスがあり、1つだけのオブジェクトを返却したければShowOne、オブジェクトのリストを返したければListerクラスを継承すると、クラスの関数内でkeyとvalue配列を返せば、勝手に表にしてくれたり、オプション指定でJSONやYAMLにしてくれたりします。
基本的にはコマンドは以下のように実装します。
sample.pyfrom cliff.command import Command class SampleCommand(Command): def get_parser(self, prog_name) parser = super().get_parser(prog_name) #引数を追加 parser.add_argument('something') #必須の引数 parser.add_argument('--some') #オプション引数 parser.add_argument('--so', '-s') #短縮系も追加できる return parser def take_action(self, parsed_args): #処理を実行 return something上記のtake_action内での返り値が基本的には実行時に返却されることになります。
(厳密にはrun関数でtake_actionがwrapされてるので色々やればほにゃららします)何にハマったか
上記のCommandクラスを継承したコマンドクラスのtake_action内で、JSONやdictを返そうとしたら、コマンドの出力が標準エラー出力にしか出なかったよという話です。
sample.pyimport json from cliff.command import Command class SampleCommand(Command): def get_parser(self, prog_name) parser = super().get_parser(prog_name) parser.add_argument('arg1') return parser def take_action(self, parsed_args): #処理を実行 return json.dumps(something)shell.shsamplecommand arg1 > log #なぜか出力がターミナルに出てくる! samplecommand arg1 2> log #出力がでなくなるよ理由はとしては、Commandクラスを継承しているコマンドクラスでのtake_actionの戻り値は、コマンドの終了ステータスとなっているからでした。
つまりsample.pyfrom cliff.command import Command class SampleCommand(Command): def get_parser(self, prog_name) parser = super().get_parser(prog_name) parser.add_argument('arg1') return parser def take_action(self, parsed_args): #処理を実行 return 100となっていると
shell.shsamplecommand arg1 echo $? #100が出力となります。JSONやdictやその他諸々のオブジェクトは基本的にTrueとして判定されるので、全てコマンドの戻り値が1となってしまい、終了ステータスが1だとエラー判定なので標準エラー出力に出力されちゃいます。
なんでやねん。
(元気があればプルリク投げます)
- 投稿日:2019-12-05T23:14:47+09:00
【TF2.0応用編】tf.data.DatasetでDataAugmentationをクッソ早くする
はじめに
この記事はTF2.0AdventCalendarで、
tf.data.Datasetを使うことによる副作用的な物を検証したものになります。
実際、tf.data.Datasetを使ってmodel.fit_generatorがどれくらいの速度になるのかを検証しました。CIFAR10で検証
データセットを用意しましょう。
データセットの用意import tensorflow as tf import tensorflow.keras as keras import matplotlib.pyplot as plt import sklearn import numpy as np from tqdm import tqdm (tr_x,tr_y),(te_x,te_y)=keras.datasets.cifar10.load_data() tr_x, te_x = tr_x/255.0, te_x/255.0 tr_y, te_y = tr_y.reshape(-1,1), te_y.reshape(-1,1) tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).batch(128) for img,label in tr_ds: print(img.shape,label.shape) break結果(128, 32, 32, 3) (128, 1)正常に出力されているようです。
モデルに入れる
検証用のモデルを作りましょう。
テキトーに重いモデルを作るmodel = keras.models.Sequential() model.add(keras.layers.Convolution2D(32,3,padding="same",activation="relu",input_shape=(32,32,3))) model.add(keras.layers.Convolution2D(32,3,padding="same",activation="relu")) model.add(keras.layers.Convolution2D(32,3,padding="same",activation="relu")) model.add(keras.layers.MaxPooling2D()) model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu")) model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu")) model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu")) model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu")) model.add(keras.layers.Convolution2D(128,3,padding="same",activation="relu")) model.add(keras.layers.MaxPooling2D()) model.add(keras.layers.Convolution2D(256,3,padding="same",activation="relu")) model.add(keras.layers.Convolution2D(256,3,padding="same",activation="relu")) model.add(keras.layers.Convolution2D(256,3,padding="same",activation="relu")) model.add(keras.layers.GlobalAveragePooling2D()) model.add(keras.layers.Dense(1000,activation="relu")) model.add(keras.layers.Dense(128,activation="relu")) model.add(keras.layers.Dense(10,activation="softmax")) model.compile(loss="sparse_categorical_crossentropy",metrics=["accuracy"]) model.summary()結果Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 32, 32, 32) 896 _________________________________________________________________ conv2d_1 (Conv2D) (None, 32, 32, 32) 9248 _________________________________________________________________ conv2d_2 (Conv2D) (None, 32, 32, 32) 9248 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 16, 16, 32) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 16, 16, 128) 36992 _________________________________________________________________ conv2d_4 (Conv2D) (None, 16, 16, 128) 147584 _________________________________________________________________ conv2d_5 (Conv2D) (None, 16, 16, 128) 147584 _________________________________________________________________ conv2d_6 (Conv2D) (None, 16, 16, 128) 147584 _________________________________________________________________ conv2d_7 (Conv2D) (None, 16, 16, 128) 147584 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 8, 8, 128) 0 _________________________________________________________________ conv2d_8 (Conv2D) (None, 8, 8, 256) 295168 _________________________________________________________________ conv2d_9 (Conv2D) (None, 8, 8, 256) 590080 _________________________________________________________________ conv2d_10 (Conv2D) (None, 8, 8, 256) 590080 _________________________________________________________________ global_average_pooling2d (Gl (None, 256) 0 _________________________________________________________________ dense (Dense) (None, 1000) 257000 _________________________________________________________________ dense_1 (Dense) (None, 128) 128128 _________________________________________________________________ dense_2 (Dense) (None, 10) 1290 ================================================================= Total params: 2,508,466 Trainable params: 2,508,466 Non-trainable params: 0 _________________________________________________________________いい感じに重そうですね。
データセットを入れてみる。
まずは通常の入れ方
通常の入れ方%%time model.fit(tr_x,tr_y,batch_size=128,epochs=5)timeTrain on 50000 samples Epoch 1/5 50000/50000 [==============================] - 7s 145us/sample - loss: 0.6238 - accuracy: 0.7833 Epoch 2/5 50000/50000 [==============================] - 7s 135us/sample - loss: 0.5584 - accuracy: 0.8104 Epoch 3/5 50000/50000 [==============================] - 7s 136us/sample - loss: 0.4936 - accuracy: 0.8303 Epoch 4/5 50000/50000 [==============================] - 7s 139us/sample - loss: 0.4467 - accuracy: 0.8479 Epoch 5/5 50000/50000 [==============================] - 7s 136us/sample - loss: 0.4016 - accuracy: 0.8631 CPU times: user 35.5 s, sys: 4.15 s, total: 39.6 s Wall time: 35.1 snvtopでの画像がこちら
結構いい感じにGPUを使ってるように見えます。
tf.data.Datasetで入れる次に
tf.data.Datasetでデータを入れましょう。datasetを入れる%%time model.fit_generator(tr_ds,epochs=5)結果Epoch 1/5 391/391 [==============================] - 12s 31ms/step - loss: 2.3748 - accuracy: 0.1219 Epoch 2/5 391/391 [==============================] - 12s 31ms/step - loss: 1.9375 - accuracy: 0.2519 Epoch 3/5 391/391 [==============================] - 12s 31ms/step - loss: 1.6902 - accuracy: 0.3601 Epoch 4/5 391/391 [==============================] - 12s 31ms/step - loss: 1.5300 - accuracy: 0.4300 Epoch 5/5 391/391 [==============================] - 12s 30ms/step - loss: 1.3649 - accuracy: 0.4988 CPU times: user 58.7 s, sys: 1.63 s, total: 1min Wall time: 1min 1sあら。倍かかっちゃってますね。
nvtopを見てみましょう
あまり実力を発揮できていませんね?
keras.preprocessing.image.ImageDataGenerator()でチャレンジめちゃめちゃ遅かったこいつ、
keras.preprocessing.image.ImageDataGenerator()はどうでしょうか%%time datagen = keras.preprocessing.image.ImageDataGenerator() model.fit_generator(datagen.flow(tr_x, tr_y, batch_size=128), steps_per_epoch=len(tr_x) / 128, epochs=5)結果Epoch 1/5 391/390 [==============================] - 16s 40ms/step - loss: 14.5061 - accuracy: 0.1000 Epoch 2/5 391/390 [==============================] - 16s 40ms/step - loss: 14.5057 - accuracy: 0.1000 Epoch 3/5 391/390 [==============================] - 16s 40ms/step - loss: 14.5065 - accuracy: 0.1000 Epoch 4/5 391/390 [==============================] - 16s 40ms/step - loss: 14.5067 - accuracy: 0.1000 Epoch 5/5 391/390 [==============================] - 16s 40ms/step - loss: 14.5067 - accuracy: 0.1000 CPU times: user 1min 3s, sys: 1.37 s, total: 1min 4s Wall time: 1min 18sさらに遅い・・・通常モードですらこんな重いんですね。
これは
tf.data.Datasetが重いってこと?実は
tf.data.Datasetが重いというより、Kerasのfit_gerenatorが重いっぽいんですよね。
tf.data.Datasetはフルバッチにすることもできるため、それでfitさせてみましょう。フルバッチDataset%%time tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).batch(tr_x.shape[0]).repeat(5) for x,y in tr_ds: model.fit(x,y,batch_size=128)結果Train on 50000 samples 50000/50000 [==============================] - 9s 178us/sample - loss: 2.4252 - accuracy: 0.1054 Train on 50000 samples 50000/50000 [==============================] - 7s 134us/sample - loss: 2.1042 - accuracy: 0.2025 Train on 50000 samples 50000/50000 [==============================] - 7s 137us/sample - loss: 1.7758 - accuracy: 0.3369 Train on 50000 samples 50000/50000 [==============================] - 7s 134us/sample - loss: 1.5804 - accuracy: 0.4166 Train on 50000 samples 50000/50000 [==============================] - 7s 136us/sample - loss: 1.3802 - accuracy: 0.4969 CPU times: user 38.2 s, sys: 6.05 s, total: 44.2 s Wall time: 39.6 sあら、めっちゃ早いじゃないっすか!nvtopもこの通り
それ、
tf.data.Dataset使う意味ある?意味あります。なぜって・・・それはDataAugmentationに決まってるじゃないっすか!!
通常、フルバッチデータに個々にランダムなTransformをして、それをepoch分連続して出力なんて骨が折れる作業です。
でも、先日のAdventCalendarを思い出してください。こいつはそれがフルバッチでできるんです。素敵すぎませんか?なら、速度検証だ!
やることは以下の2つです。
- random rotate
- random flip(h,v)
速度検証していきましょう。
ImageDataGeneratorでやるデータ確認
ImageDataGen%%time datagen = keras.preprocessing.image.ImageDataGenerator( horizontal_flip=True, vertical_flip=True, rotation_range=30, ) labels = np.array([ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']) plt.figure(figsize=(10,10),facecolor="white") for b_img,b_label in datagen.flow(tr_x,tr_y,batch_size=25): for i, img,label in zip(range(25),b_img,b_label): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(img) plt.xlabel(labels[label]) break plt.show()
速度検証
speedtest%%time datagen = keras.preprocessing.image.ImageDataGenerator( horizontal_flip=True, vertical_flip=True, rotation_range=30, ) model.fit_generator(datagen.flow(tr_x, tr_y, batch_size=128), steps_per_epoch=len(tr_x) / 128, epochs=5)結果Epoch 1/5 391/390 [==============================] - 18s 47ms/step - loss: 1.5626 - accuracy: 0.4296 Epoch 2/5 391/390 [==============================] - 18s 46ms/step - loss: 1.4149 - accuracy: 0.4894 Epoch 3/5 391/390 [==============================] - 18s 46ms/step - loss: 1.3278 - accuracy: 0.5236 Epoch 4/5 391/390 [==============================] - 18s 47ms/step - loss: 1.2493 - accuracy: 0.5516 Epoch 5/5 391/390 [==============================] - 18s 46ms/step - loss: 1.1884 - accuracy: 0.5787 CPU times: user 2min, sys: 4.74 s, total: 2min 5s Wall time: 1min 30sうーむ、遅いですね。
フルバッチ
tf.data.Datasetでやるまずデータ確認をしましょう
データ確認import tensorflow_addons as tfa @tf.function def rotate_tf(image,label): if image.shape.__len__() ==4: random_angles = tf.random.uniform(shape = (tf.shape(image)[0], ), minval = -30*np .pi / 180, maxval = 30*np.pi / 180) if image.shape.__len__() ==3: random_angles = tf.random.uniform(shape = (), minval = -30*np .pi / 180, maxval = 30*np.pi / 180) return tfa.image.rotate(image,random_angles),label @tf.function def flip_left_right(image,label): return tf.image.random_flip_left_right(image),label @tf.function def flip_up_down(image,label): return tf.image.random_flip_up_down(image),label tr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000) tr_ds = tr_ds.batch(25).map(flip_up_down).map(flip_left_right).map(rotate_tf) plt.figure(figsize=(10,10),facecolor="white") for b_img,b_label in tr_ds: for i, img,label in zip(range(25),b_img,b_label): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(img) plt.xlabel(labels[label]) break plt.show()
うーん、なんか荒い?
これでフルバッチでやってみましょう。
速度検証
speedtesttr_ds = tf.data.Dataset.from_tensor_slices((tr_x,tr_y)).shuffle(40000) tr_ds = tr_ds.batch(tr_x.shape[0]).map(flip_up_down).map(flip_left_right).map(rotate_tf).repeat(5) for img,label in tr_ds: model.fit(x=img,y=label,batch_size=128)結果Train on 50000 samples 50000/50000 [==============================] - 8s 153us/sample - loss: 2.3030 - accuracy: 0.1447 Train on 50000 samples 50000/50000 [==============================] - 7s 133us/sample - loss: 2.0370 - accuracy: 0.2188 Train on 50000 samples 50000/50000 [==============================] - 7s 133us/sample - loss: 1.8615 - accuracy: 0.2985 Train on 50000 samples 50000/50000 [==============================] - 7s 133us/sample - loss: 1.7357 - accuracy: 0.3570 Train on 50000 samples 50000/50000 [==============================] - 7s 133us/sample - loss: 1.6400 - accuracy: 0.3976 CPU times: user 1min 42s, sys: 15.8 s, total: 1min 58s Wall time: 42.2 sDataAugmentationしているのにも関わらず、このスピードが出てます。素晴らしい・・・
注意点
スピードの一番の要は、4Dイメージをバッチで一気に処理することによってオーバヘッドが減らせるっていうだけなので、
ImageDataGeneratorのようなバッチを排出するタイプだと遅いってことです。おわりに
まとめると
- 一気にまとめると早いのでtf.data.Datasetはおすすめ
- だけど画像は荒いし、画像処理できるtf系はかなり限られている
- Augmentationの機能は今後に期待するしかない(自分が実装してTFAにプルリクしてもいいんですが...)今後時間があれば、
tf.data.Datasetに対応した画像処理系を作ろうかと思ってます。追記
普通にこう書けばええんちゃう?
ImageDataGen%%time datagen = keras.preprocessing.image.ImageDataGenerator( horizontal_flip=True, vertical_flip=True, rotation_range=30, ) for i,(x,y) in zip(range(5),datagen.flow(tr_x, tr_y, batch_size=tr_x.shape[0])): model.fit(x,y,batch_size=128,epochs=1)確かに学習中は早いみたいです。
結果Train on 50000 samples 50000/50000 [==============================] - 7s 132us/sample - loss: 0.9494 - accuracy: 0.6730 Train on 50000 samples 50000/50000 [==============================] - 7s 140us/sample - loss: 0.9275 - accuracy: 0.6797 Train on 50000 samples 50000/50000 [==============================] - 7s 132us/sample - loss: 0.9019 - accuracy: 0.6894 Train on 50000 samples 50000/50000 [==============================] - 7s 132us/sample - loss: 0.8842 - accuracy: 0.6968 Train on 50000 samples 50000/50000 [==============================] - 7s 132us/sample - loss: 0.8769 - accuracy: 0.6957 CPU times: user 1min 20s, sys: 4.96 s, total: 1min 25s Wall time: 1min 24sでも、Wall Time(実際にかかった時間)をみると遅いんですよこれが。
毎回Batchごとに負荷が1CPUにかかってしまっていて、ボトルネックになっている関係で重いです。
同じ処理でもtf.data.Datasetの方が早かったりします。






- 投稿日:2019-12-05T22:56:34+09:00
Python でコマンドラインアプリを作って setup.py, argparse, GitHub Actions を理解する
setup.py, argparse, GitHub Actions あたりの技術を学ぶのに、Python でコマンドラインアプリを作ると良さそうだと思ったのでやってみました。ここでは個々の技術を詳しく解説しないので、記事中で紹介する公式ドキュメントや解説記事を参照してください。
成果物
To-Do リストアプリ を作りました。と言っても、
todo add "ほげ" todo complete "ほげ" todo remove "ほげ"などで To-Do を追加、完了、削除するだけのものです。また、
todo complete --all todo remove -aで全て完了や全て削除ができます。To-Do リストは
~/.todo.jsonに保存され、$ todo show □ ほげ ☑ ほげほげのように表示できます。
コマンドラインインターフェイスの作成
argparse を使ってコマンドライン引数の処理を定義します。
argparse は機能が多過ぎて把握しきれないですが、今回使ったのは以下です。コード全体はこちら。
parser = argparse.ArgumentParser() # git commit とか docker run などの commit や run のようなもの # をサブコマンドと名付けて追加 parser.add_argument('subcommand', help='add, complete, or remove') # サブコマンドより後ろに来る引数を content とする。 # nargs は引数の数で、1つの場合は nargs=1 # nagrgs='*' とすると0以上の可変長引数になる # nargs='+' は1以上の可変長引数 # nargs='?' は0または1個 # https://docs.python.org/ja/3/library/argparse.html#nargs parser.add_argument('content', help='Content of To-Do', nargs='?') # --all オプション (短縮形 -a) を追加 # 引数を取るオプションではなく、フラグなので、`store_true=True` を指定 parser.add_argument('-a', '--all', action='store_true', help='remove or complete all To-Dos')なお、サブコマンドが
showのときや、remove --allなどのときは引数 'content' は必要ないのですが、指定できてしまいます。指定できないように argparse で書く方法が分からなかったため、引数が指定されても内部で無視するようにしています。これを用いて、指定された引数に応じた処理を呼び出せば良いです(処理については特筆すべき知見はないのでソースコード参照)。
パッケージ化
setup.pyを書いてコマンドラインアプリを自動でインストールされるようにします。書いた
setup.pyはこちらにあります (書き方は pip や numpy のものを参考にしました) が、この中で肝心なのは以下の部分かと思います。entry_points={ "console_scripts": [ "todo=todo.main:main" ] },このようにすることで、
python3 setup.py installしたときに OS の PATH にコマンドがインストールされます。私の環境では以下のようになりました1。$ which todo /home/linuxbrew/.linuxbrew/bin/todo$ cat $(which todo) #!/home/linuxbrew/.linuxbrew/opt/python/bin/python3.7 # EASY-INSTALL-ENTRY-SCRIPT: 'todo==0.1.0','console_scripts','todo' __requires__ = 'todo==0.1.0' import re import sys from pkg_resources import load_entry_point if __name__ == '__main__': sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0]) sys.exit( load_entry_point('todo==0.1.0', 'console_scripts', 'todo')() )これで、どのディレクトリにいようとも、ターミナルで todo と叩くと todo パッケージの main モジュール内の main という関数が呼ばれて、書いた処理が実行されます。
pip でインストール
先程は
setup.pyを実行してインストールしましたが、以下のように pip を用いて Git リポジトリからもインストールできます。汎用性のあるものコマンド、パッケージであれば PyPI に登録するのも良いでしょう。pip3 install git+https://github.com/pn11/python-command-line-sampleGitHub Actions を用いた自動テスト
いつの間にか2 GitHub に追加されていた Actions というのを使ってみたいと思ったのが本記事執筆のきっかけです3。今回は無難に自動テストをしてみます。
とりあえず、ToDo リストを全部消してから追加するだけのクソみたいなテストを書きました。
import todo.main def test_add(): todo.main._remove_todo('', all_flag=True) todo.main._add_todo('foo') dic = todo.main._load_todos() assert dic['foo'] == 'Not Yet'これを GitHub Actions を使って nose で実行してみたいと思います。
Action 用 YAML 作成
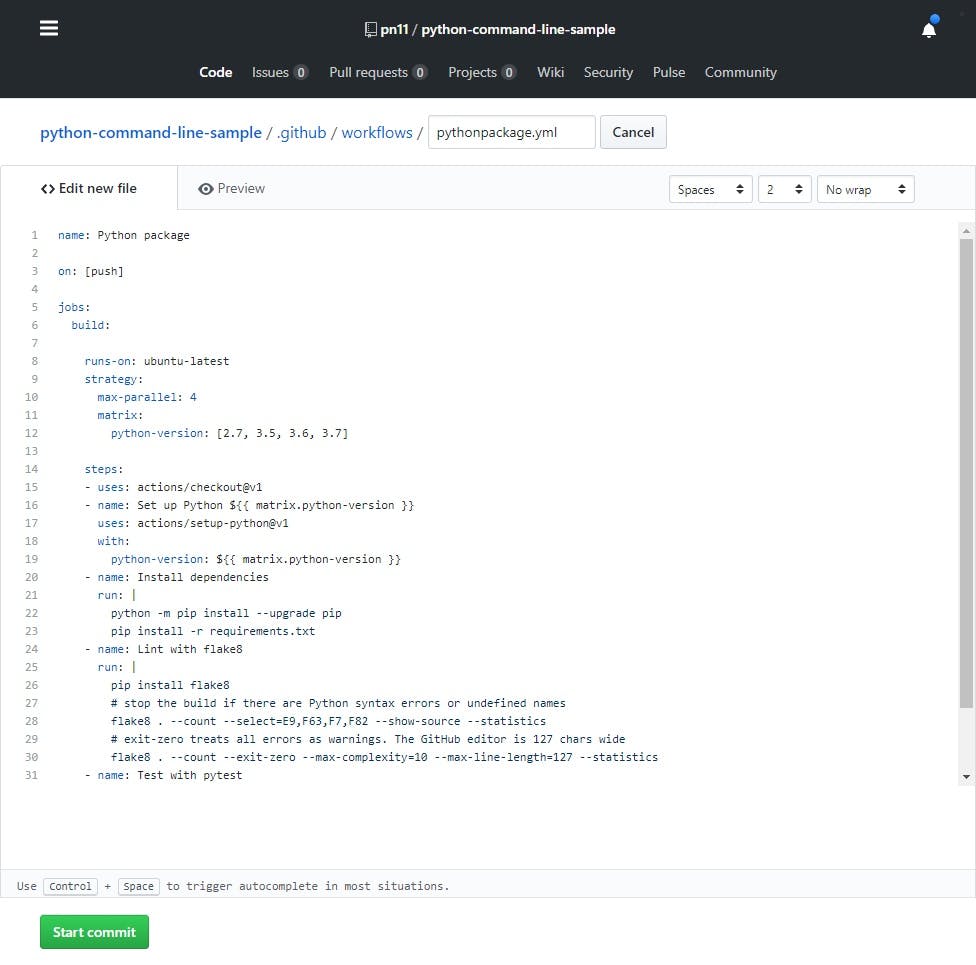
リポジトリの Actions のタブに行くと、以下のような画面になるので、とりあえず
Python packageでやってみます。
以下のような画面になるので、何も考えずとりあえず
Start Commitを押してみます。
テストに失敗します。
YAML を見てみると以下のようになっています。
name: Python package on: [push] jobs: build: runs-on: ubuntu-latest strategy: max-parallel: 4 matrix: python-version: [2.7, 3.5, 3.6, 3.7] steps: - uses: actions/checkout@v1 - name: Set up Python ${{ matrix.python-version }} uses: actions/setup-python@v1 with: python-version: ${{ matrix.python-version }} - name: Install dependencies run: | python -m pip install --upgrade pip pip install -r requirements.txt - name: Lint with flake8 run: | pip install flake8 # stop the build if there are Python syntax errors or undefined names flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics # exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics - name: Test with pytest run: | pip install pytest pytest何となく、
steps:以下の- name: やること run: | コマンド1 コマンド2みたいなところをいじれば良さそうです。ということで、以下のような処理を書きました。
- name: Install Package run: | python setup.py install - name: Test with nose run: | pip install nose nosetests
setup.pyで To-Do のパッケージをインストールした後、nose もインストールしてテストを実行します。これをコミットすると無事にテストが通りました。実行ディレクトリとかは特に意識しませんでしたが、リポジトリのルートで実行されているようです。また、何となく nose を使いましたが、特にライブラリに依存したテストではないので元のまま pytest でも動くはず?
今後はコミットする度にテストが走ります。テストに通ると
マークがついて良い感じです。
まとめ
以上、argparse でコマンド作成、setup.py でパッケージ化、GitHub Actions で自動テストをやってみました。今後はこの方法でクソコマンドを量産していきたい所存です。
その他
この記事では取り上げませんでしたが、コマンドラインツール作成の際には argparse 以外にも、click 等を使うのも良いかも知れません。
- Clickで手軽にPythonのコンソールアプリケーションを作る - Qiita
- Awesome Python:素晴らしい Python フレームワーク・ライブラリ・ソフトウェア・リソースの数々 - Qiita
Linuxbrew で入れた Python を使用しています。 ↩
[速報]GitHub Actionsが正式版に。GitHub内でビルド/テスト/デプロイなど実行、CI/CDを実現。GitHub Universe 2019 - Publickey ↩
MS に買収されてからどんどん新機能が追加されていてしゅごい。。 ↩




- 投稿日:2019-12-05T22:49:43+09:00
GroupbyしたGroupに関して条件抽出(条件を満たすGroupの要素を全て取得)する方法
Groupbyしたgroupに関して条件抽出したい。
Pythonでgroupbyしたgroupの中から条件を満たすgroupの要素を全て取得する方法を解説する。
例えば、以下のデータがあり、最高スコアが80以上だった場合その人のデータを全て取得するということを目指すとする。
import pandas as pd import numpy as np df = pd.DataFrame({"name":["Yamada","Yamada","Yamada","Suzuki","Suzuki","Hayashi"], "score":[60,70,80,60,70,80]}) print(df) # name score # 0 Yamada 60 # 1 Yamada 70 # 2 Yamada 80 # 3 Suzuki 60 # 4 Suzuki 70 # 5 Hayashi 80この時、groupbyをしたgroupごとに条件を満たすキーを取得して、そのキーに元々のデータフレームを左外部結合すれば良い。
具体的には、以下のコードとなる。group_df = df.groupby('name').max().reset_index() key = group_df[group_df['score'] >= 80]['name'] new_df = pd.merge(key, df, on = 'name', how = 'left') print(new_df) # name score # 0 Hayashi 80 # 1 Yamada 60 # 2 Yamada 70 # 3 Yamada 80組み込み関数で条件抽出ができない場合
場合によってはGroupに対する条件が複雑で
.max()のような組み込み関数では表現ができない場合がある。その場合はラムダ式で条件を書くこともできる。ここではgroupの長さが2以上のgroupを全て抽出することを目指す。(この操作は、組み込み関数
.count()で実現することができるが、例示のためラムダ式表記とした。)group_df = df.groupby('name').apply(lambda x: len(x)).reset_index().rename(columns = {0:'length'}) key = group_df[group_df['length'] >= 2]['name'] new_df = pd.merge(key, df, on = 'name', how = 'left') print(new_df) # name score # 0 Suzuki 60 # 1 Suzuki 70 # 2 Yamada 60 # 3 Yamada 70 # 4 Yamada 80ポイントとして、ラムダ式表記の時、ラムダ式の結果が出力される列が
0となるので、適当な名前(ここでは'length')にリネームしている。条件を満たすキーを取り出し、そこからgroupbyの操作で消してしまったスコアの情報を復元するために、左外部結合をするという一連の流れを私は頭に描けず苦戦したため、ここに残しておきます。。。
- 投稿日:2019-12-05T22:48:57+09:00
07. テンプレートによる文生成
07. テンプレートによる文生成
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y="気温", z=22.4として,実行結果を確認せよ.
Go
package main import "fmt" func template(x,y,z string) string { return fmt.Sprintf("%s時の%sは%s",x,y,z) } func main() { fmt.Println(template("12","気温","22.4")) }python
# -*- coding: utf-8 -*- def template(x,y,z): return '{0}時の{1}は{2}'.format(x,y,z) print template(12,"気温",22.4)Javascript
function template(x,y,z) { return "x時のyはz".replace("x",x).replace("y",y).replace("z",z); } console.log(template(12,"気温",22.4));まとめ
これは、こんなでいいのかしら?。
- 投稿日:2019-12-05T21:18:50+09:00
強力Jupyter Notebook
Pythonは、初めてのプログラミングではない。以前(高校生のころだから15年くらい前)少しだけVisual C#を使ったことがある。数文字打つだけでコードが補完されたりして便利だったけど、数ある機能の上澄みしか使っていないなという印象があった。
また、大学時代には数値計算の初歩の初歩を学ぶ授業でFortranを学んだこともあった。miで正しいのか正しくないのかよくわからないコードを書いて、コマンドプロンプトからコンパイルしてエラーを食らったりしていた。なんとも見通しが悪かった。PythonにはJupyter Notebookという強力なエディタがある(語弊がありそう)。起動も簡単で、コマンドプロンプトでJupyter notebookと打ち込むだけだ!前回覚えた表記を使うと↓こういうこと
$ Jupyter notebookそうするとブラウザでJupyter notebookが起動する。なんとこのエディタはブラウザ上で動く。
こんなかんじ。右上のNewからPython3をクリックすると、そこにはもうプログラムを書く枠が表示されていた。
こちょこちょとプログラムを書いて(書き方は適当に検索した)、Cellの下付近にある再生ボタン的なやつを押すと、書いたコードのすぐ下に文字列が表示された。今回はここまで。


- 投稿日:2019-12-05T21:17:09+09:00
超絶初心者がqiskitを使って1+1を実装するまで
初投稿です
自己紹介
tax_freeです。
普段はhatenaで参加した勉強会とかを書いています。
学校の期末テストと記事の日が被って苦しい
高校一年生です環境
自分の開発環境
- Mac OS Catalina 10.15.1
- Python 3.7.4
モチベーション
今は高校生なのですが、大学では量子コンピューティングの研究をしたいと考えていたら、今回のアドベントカレンダーを見つけたので参加しました。
タイトルにも書いているように超絶初心者なので、間違えていたりしたら教えてください!
量子コンピュータについての知識はネットの初心者向け記事くらいのレベルです。Qiskitとは
Qiskitは、量子コンピュータ用のオープンソースのフレームワークである。量子回路(英語版)を作成し、プロトタイプの量子デバイスやシミュレーション上で実行するためのツールを提供する。量子チューニングマシン(英語版)の量子回路(英語版)に対応しており、これに従う量子ハードウェアに使用することができる。(wikipediaより)
なぜQiskitなのか
私が知っているPythonで動く量子コンピューティング関連のライブラリは、QiskitとQgateの二つでした。最初は、Qgateを使おうと思っていた(PyConJPで聞いた)のですが、私の環境では、CUDA関係でうまく使うことができなかったので、代りにQiskitを使いました。
また、QiskitはIBMQを使えるのも選んだ理由です。
Qgateは分かりませんが、QiskitはJupyter notebookをサポートしています。準備
前置きはこれくらいにして、準備をしていきます。
まずは、Qiskitをインストールします。適当な環境を作ってpip install qiskitで、インストールできます。詳しくは公式ドキュメントを見てださい。
丸投げまた、IBMQのアカウントを作っておくと後からクラウドに接続する時に、楽です。
実装
まず、sample.pyファイルを作って
import qiskit print(2)です!!!!!!!!!!
簡単に書けますよね。
あとは、python3 sample.pyを実行すれば
2返ってきます。 1+1の結果は2なので、正解ですね。
まとめ
いかがでしたか?
量子コンピュータと聞くと難しく感じますが、簡単に書くことができましたね。ニッコリ茶番終了
盛大な茶番で、すみませんでした。
後悔はしていない本番開始
上に書いたようにQiskitをインストールします。
実装
適当な環境を作ります。今回は、Jupyter notebookを使います。ほとんど、公式チュートリアルなので、我慢できなかったら、こっちを見て癒されてください。
- 最初に必要なライブラリをimportします。
from qiskit import IBMQ #IBMQに接続するため from qiskit.tools.monitor import backend_overview from qiskit import QuantumCircuit, ClassicalRegister, QuantumRegister from qiskit import execute, Aer from qiskit.qasm import pi from qiskit.tools.visualization import plot_histogram, circuit_drawer from qiskit.providers.ibmq import least_busy import numpy as np2.IBMQアカウントを登録して、アカウントをロードします。ここでwarningが出ましたが無視します。
IBMQ.save_account('IBMQのtoken') provider = IBMQ.load_account()3.回路を登録していきます。
q = QuantumRegister(2) c = ClassicalRegister(2) qc = QuantumCircuit(q, c)これで、2個ずつ量子ビットと2個の古典ビットを登録しました。
なんで量子ビットだけじゃないのと思ったかもしれませんが、この古典ビットに量子ビットの計算結果を保存します。4.ゲートを追加します
qc.h(q[0]) qc.cx(q[0],q[1])これで、HゲートとCxゲートを回路に追加できます。
簡単に二つのゲートを説明します。
Hゲートは量子ビットを重ね合せ状態にして、
CxゲートはNOT回路みたいなもので、エンタングルさせます。qc.measure(q[0], c[0]) qc.measure(q[1], c[1])measureはとても大切で、3で書いたようにn番目の量子ビットの状態をn番目の古典ビットに保存します。
ここまで書いたら、qc.draw()を使って回路を見てみましょう。しっかり、ゲートが適用されているはずです。
5.最適なBackendを選択
ここは完全に他の人のコピペです。許してlarge_enough_devices = IBMQ.backends(filters=lambda x: x.configuration().n_qubits > 3 \ and not x.configuration().simulator) backend = least_busy(large_enough_devices) print("The best backend is " + backend.name())実際に最適なbackendが表示されるはずです。
6.実際にjobを投げる
backends = ['xxxxx','xxxx','least_busyだったbackend'] backend_q = IBMQ.get_backend(backend[1]) result = execute(qc,backend_q,shots='1024').result()backendsで複数個のbackendを設定して、backend_qのbackend[n]で要素を指定しています。
executeでjobを投げています。shotsは何回計算させるかで、数を大きくすると結構時間がかかります。最大で4096だったような。7.結果を見る
最後に結果を確認します。print(result.get_counts(qc)) plot_histogram(result.get_counts(qc))これで、確認することができます。
plot_histogramがあると視覚化できるので良い!
ここで、おもしろいのが理論的には得られない計算結果が入っていることで、これはノイズが原因なんだそう。まとめ
量子コンピュータを使うためには、もっと数学をガリガリする必要があると思っていたけど意外と簡単だった。
とりあえず、手を動かしてみることは大切だと思った。
来年のカレンダーでは数式の説明ができるように一年勉強します。
- 投稿日:2019-12-05T21:03:16+09:00
Ren’pyを使って学祭紹介ゲームを作ってみた
はじめに
近畿大学 Advent Calendar 2019の5日目担当のniyaです.
今回は, 近畿大学で毎年行われている生駒祭を紹介するゲームをRen'pyで作ったので, その時に覚えた文法等共有できたらなあと思います.成果物は以下のurlにあります.
https://drive.google.com/drive/u/2/folders/1CVx17S12MDS8VLIsH4Q2Iu4C5U93vYC_また, githubは以下です.
https://github.com/niya1123/Short-Novel/tree/devRen'pyのゲーム作りの基礎
今回はRen'py自体のDLとプロジェクトの作り方などは前回の記事で紹介しているので, そちらの方を見ていってください.
セリフの書き方
セリフの書くには以下の手順を踏めば良いでしょう.
- キャラクターのセリフなのか独白やナレーションなのかを考える.
- 前者ならキャラクターを定義する. 後者は特に定義する必要なし.
- script.pyにその定義を書き込む.
具体的には以下のようになります.
script.rpy# キャラクターの定義 define キャラ名 = Character("キャラ名", color="カラーを16進数で設定") # define直後のキャラ名は基本的には1文字やキャラ名の短縮名で定義することをお勧めする. # colorはテキストボックスに表示されるキャラ名の色. define character = Character("キャラクター", color="#c8ffc8") # ゲーム起動時はlabel startから始まる. label start: # キャラの短縮名 "セリフ"でセリフの表示 character "こんにちは!" # キャラ名を設定しないと, ナレーション. "ナレーションですこんにちは" # returnでlabelの終了. returnキャラクター画像の設定
キャラクター画像の設定は以下のように行います.
script.rpy# 略 label start: show character default with fade character "こんにちは!" returnここで注意すべきはshow以降の文字列です.ここでは任意の画像のファイル名を指定することで画像を表示します.
そして, 画像の名前には推奨される命名規則があり, 例えば
bg green.jpg (Bg Green.jpgでも可)のように"bg"がタグ, "green"が属性という風になっています.他に以下のような命名が考えられます.script.rpy# bgがタグでgreenとhouseが属性 show bg green houseまた, 同じタグの画像が同時に指定された場合一番最後に指定された画像が表示されます.
次に
with fadeとありますがこれはトランジションというものです.詳細は以下を参考にしてください(数が多いので).
https://ja.renpy.org/doc/html/quickstart.html#transitions
pythonスクリプトの使用
Ren'pyではpythonのスクリプト(python2系)が使用することができます. まだ正式に発表されていませんが今後は3系のpythonが利用できる可能性はあります.(参考: https://twitter.com/renpytom/status/1196203607252709376?s=20)
では, 使い方を説明していきます.
script.rpydefault flag = False label start: menu: "想いを伝えますか?" "はい": $ flag = True "いいえ": jump flag return label flag: if not flag: "Bad End" else: "Good End" return色々新しい要素が出てきましたね. 順番に説明します.
まず, default文がありますがこれはstartラベルの前に使いたい変数を初期化するためのものです.
なくてもいいですが, その場合label内で変数を用いるとFlaseが初期値として自動的に付与されます.次にstartラベル内のmenuというものがあります.
script.rpy略 menu: "選択肢を選んでね" "はい": jump yes "いいえ": jump no使い方はこのような感じで,ナレーション部分はなくてもいいです.
"選択肢":という風に記述していきます.その後インデントして処理を書くことができます.この辺りはpythonと同じです.jumpはjump 飛ばしたいラベル名という風に設定できてその飛びたいラベルに処理が飛び, そのラベルがreturnで終了するとまた処理が戻ってきます.次に
$ flag = Trueですが, $以降に1行のみでpythonのコードが書けます.
複数行にわたってコードを書きたい場合は次のように書けます.script.rpypython: life = 100 damage = 50 my_life = life - damage次にif文ですが, if文は$やpythonを用いずにそのまま使用することができます.
以上の基礎を押さえておけば, 皆さんもRen'pyを用いてノベルゲームが作れます!!!!
Ren'pyのゲーム作り応用
ここからはちょっとした応用です.
まずはRen'pyのデフォルトの起動画面を変更しましょう.
デフォルトの画面はこんな感じです.
右下の青文字のtestをRen'pyにして色をオレンジ色(#f59e11)にしてみましょう.
変更する点は以下です.
options.rpy(16行目あたり)define config.name = _("test") # これを以下に変更 define config.name = _("Ren'py")gui.rpy(28行目あたり)define gui.accent_color = '#0099cc' # これを以下に変更 define gui.accent_color = '#f59e11'続いてmenuの画像を変更します.
gui.rpy(96行目あたり)define gui.main_menu_background = "gui/main_menu.png" # これを以下に変更 define gui.main_menu_background = "gui/main_susuki.png"変更したらこうなります.(今回は画像サイズ合ってないけど本番は画像の方をゲームのサイズに合わせましょう)
最後に
正直色々端折ったのですが基本的にここまで理解していれば, 自分の作った成果物くらいは作れると思います.
皆さんも是非Ren'pyで何か作ってみてください!参考サイト



- 投稿日:2019-12-05T20:55:38+09:00
Kintoneをデータストアにしたときにハマること
Kintone初心者アドベントカレンダー四日目です。
ごめんなさい。昨日だったのをつい忘れてしまいました。
あぁ、やってしまった〜。
って感じです。
今日に四日目をかいてしまっています。
申し訳ございません。
よくハマりがちな罠についてかいていきたいと思います。なぜこのテーマなのか。
実はヒーローズリーグ大垣Pythonハッカソンで実はこの問題にハマりました。
それはAPIトークンとURLの場所を間違え実装してしまう。
これが一番の罠です。
Kintoneは実際言うとアプリを作るフレームワークに近いということを最初に認識していないといけません。
実際Pythonで今回は実装したのですが一番簡単なのはNode.jsです。
Python縛りがあったため自分は前職のC#の職場が実は本業はPythonなので学んでいたおかげでスイスイと組めました。
ですがここで間違えたのがAPIキーの場所です。
@RyBBさんも指摘していますが。
皆さん急ぐと間違えてしまいます。kintone_output.py#ここまでは順調です。 #ここからが問題です。 #何処を見るのでしょうか。 #APIトークンのCurlが書かれている後ろのURLです。 URL = #APIトークンもよく間違えます。 #注意が必要です。 #自分もNode.jsで教えていただいたときに間違えました。 #APIトークンの部分をコピーするのですよ。 API_TOKEN = #此処から先は通常コードで問題ないです。 #上の2つを間違えると痛い目見ます。 def get_kintone(url, api_token): "kintoneのレコードを全件取得する関数" headers = {"X-Cybozu-API-Token": api_token} resp = requests.get(url, headers=headers) return resp if __name__ == "__main__": RESP = get_kintone(URL, API_TOKEN) print(RESP.text)nodejs:kintone.jsconst kintone = require('@kintone/kintone-js-sdk'); //ここですよ。 //気をつけてください。 //自分もハマりました。 const domainName = 'SUB_DOMAIN.cybozu.com'; // Your kintone URL //ここですよ。 //気をつけてください。 const APIToken = 'YOUR_API_TOKEN'; // Your API Token const appId = ○○; // AppID const record = { text: { value: '追加したいテキスト' } }; // Connection const kintoneAuth = new kintone.Auth(); kintoneAuth.setApiToken({apiToken: APIToken}); const kintoneConnection = new kintone.Connection({domain: domainName, auth: kintoneAuth}); const kintoneRecord = new kintone.Record({connection: kintoneConnection}); // Add Record kintoneRecord.addRecord({app: appId, record: record}).then((rsp) => { console.log(rsp); }).catch((err) => { console.log(err.get()); });この二点を気をつければハッカソンでKintoneは無敵の武器になります。
下手にデータベースをいじるより楽になります。
みんなクラウドに走りがちですが自分の場合だったらハッカソンは断然Kintoneです。
ハッカソンの地図系マッシュアップにも無敵です。うーん。
来年もハッカソンではKinetone使います。
@RyBBさん。
- 投稿日:2019-12-05T20:48:30+09:00
非同期サーバー Django3.0を体験せよう
前書き
3日前に、Django3.0正式にリリースされました。
リリースノードリンク
沢山変更点がある中で、ASGIのサポートが追加されたことに非常に興味あります、
実際使ってみたいと思うます。補足:ASGIは何でしょう?
 ASGI(非同期サーバーゲートウェイインターフェイス)は、WSGIの精神的な後継者であり、非同期対応のPython Webサーバー、フレームワーク、およびアプリケーション間の標準インターフェイスを提供することを目的としています。 WSGIが同期Pythonアプリの標準を提供したのに対し、ASGIは、WSGIの下位互換性の実装と複数のサーバーとアプリケーションフレームワークを備えた非同期アプリと同期アプリの両方を提供します。
ASGI(非同期サーバーゲートウェイインターフェイス)は、WSGIの精神的な後継者であり、非同期対応のPython Webサーバー、フレームワーク、およびアプリケーション間の標準インターフェイスを提供することを目的としています。 WSGIが同期Pythonアプリの標準を提供したのに対し、ASGIは、WSGIの下位互換性の実装と複数のサーバーとアプリケーションフレームワークを備えた非同期アプリと同期アプリの両方を提供します。新規プロジェクト
テスト用の仮想環境を作ります
mkvirtualenv django3.0Djangoをインストールします
pip3 install djangoインストール終了後、Django3.0入ってることを確認します
(django3.0) ~ $ pip3 list Package Version ---------- ------- asgiref 3.2.3 Django 3.0 pip 19.3.1 pytz 2019.3 setuptools 42.0.2 sqlparse 0.3.0 wheel 0.33.6適当に新規プロジェクトを作って、サーバーを立ち上げて見ましょう
mkdir django-test && django-admin startproject newtest && cd newtest/ && python3 manage.py runserver8000番にアクセスしてみよう、馴染みのロケットが確認できます。
ここまでは ヨシッ!
公式ドキュメント見てみよう
How to deploy with ASGI¶ As well as WSGI, Django also supports deploying on ASGI, the emerging Python standard for asynchronous web servers and applications. Django’s startproject management command sets up a default ASGI configuration for you, which you can tweak as needed for your project, and direct any ASGI-compliant application server to use. Django includes getting-started documentation for the following ASGI servers: How to use Django with Daphne How to use Django with Uvicorn The application object¶ Like WSGI, ASGI has you supply an application callable which the application server uses to communicate with your code. It’s commonly provided as an object named application in a Python module accessible to the server. The startproject command creates a file <project_name>/asgi.py that contains such an application callable. It’s not used by the development server (runserver), but can be used by any ASGI server either in development or in production. ASGI servers usually take the path to the application callable as a string; for most Django projects, this will look like myproject.asgi:application. Warning While Django’s default ASGI handler will run all your code in a synchronous thread, if you choose to run your own async handler you must be aware of async-safety. Do not call blocking synchronous functions or libraries in any async code. Django prevents you from doing this with the parts of Django that are not async-safe, but the same may not be true of third-party apps or Python libraries. Configuring the settings module¶ When the ASGI server loads your application, Django needs to import the settings module — that’s where your entire application is defined. Django uses the DJANGO_SETTINGS_MODULE environment variable to locate the appropriate settings module. It must contain the dotted path to the settings module. You can use a different value for development and production; it all depends on how you organize your settings. If this variable isn’t set, the default asgi.py sets it to mysite.settings, where mysite is the name of your project. Applying ASGI middleware¶ To apply ASGI middleware, or to embed Django in another ASGI application, you can wrap Django’s application object in the asgi.py file. For example: from some_asgi_library import AmazingMiddleware application = AmazingMiddleware(application)ざっくりまとめると
python manage.py runserverでサーバー起動してはいけない、いつものwsgiのサーバー起動することになります。- サーバー起動時に
DaphneかUvicorn使用することお勧めします。
Daphneは何なのか、公式のリンク開いて見てみよう リンクHow to use Django with Daphne¶ Daphne is a pure-Python ASGI server for UNIX, maintained by members of the Django project. It acts as the reference server for ASGI. Installing Daphne¶ You can install Daphne with pip: python -m pip install daphne Running Django in Daphne¶ When Daphne is installed, a daphne command is available which starts the Daphne server process. At its simplest, Daphne needs to be called with the location of a module containing an ASGI application object, followed by what the application is called (separated by a colon). For a typical Django project, invoking Daphne would look like: daphne myproject.asgi:application This will start one process listening on 127.0.0.1:8000. It requires that your project be on the Python path; to ensure that run this command from the same directory as your manage.py file.訳すと
- pip で daphneをインストール
- daphne myproject.asgi:applicationを実行して、ASGIサーバー起動
- 127.0.0.1:8000へアクセスやってみよう
ASGIサーバー起動
daphneインストール
pip3 install daphnedaphne [プロジェクト名].asgi:application8000番アクセスしたら、またロケット見れました、文字少し変わってますが。
WebSocketテスト
ブラウザ開いて、websocketメッセージ送ってみようと思います。
500が返ってきました、エラーメッセージは以下になります。2019-12-05 11:02:09,533 ERROR Exception inside application: Django can only handle ASGI/HTTP connections, not websocket. File "/Envs/django3.0/lib/python3.7/site-packages/daphne/cli.py", line 30, in asgi await self.app(scope, receive, send) File "/Envs/django3.0/lib/python3.7/site-packages/django/core/handlers/asgi.py", line 146, in __call__ % scope['type'] Django can only handle ASGI/HTTP connections, not websocket.
asgi.pyの146行に何かありそうですね、見てみましょう。asgi.pyasync def __call__(self, scope, receive, send): """ Async entrypoint - parses the request and hands off to get_response. """ # Serve only HTTP connections. # FIXME: Allow to override this. if scope['type'] != 'http': raise ValueError( 'Django can only handle ASGI/HTTP connections, not %s.' % scope['type'] ) # Receive the HTTP request body as a stream object. try: body_file = await self.read_body(receive) except RequestAborted: return # Request is complete and can be served. set_script_prefix(self.get_script_prefix(scope))以下の二行コメントに注目してください。
# Serve only HTTP connections. # FIXME: Allow to override this.現時点でhttp通信のみを許可しています。 必要に応じてご自身で直してください!
最後
推測としては以下の原因が考えられます。
- 多分私はDjangoのことまたわかっていない
- Websocketではなくて、他の手段でASGI通信を実現している
- ASGIの完全サポートはこれから
現在のDjango3.0、もしwebsocket使用したければ、
django-channelパッケージ使用することをお勧めします。





- 投稿日:2019-12-05T20:45:04+09:00
Blenderのデータ構造を辿り、fbxから頂点座標を抽出する
Blenderを使って、FBXデータから頂点座標のみを抜き出し配列化するスクリプトを作成したので、解説がてら紹介します。
Blenderのデータ構造
まずは見慣れたこの図(初期状態)について。
さて、Blenderの3Dビューは以下のような形で管理されています。
Pythonスクリプトで言うと
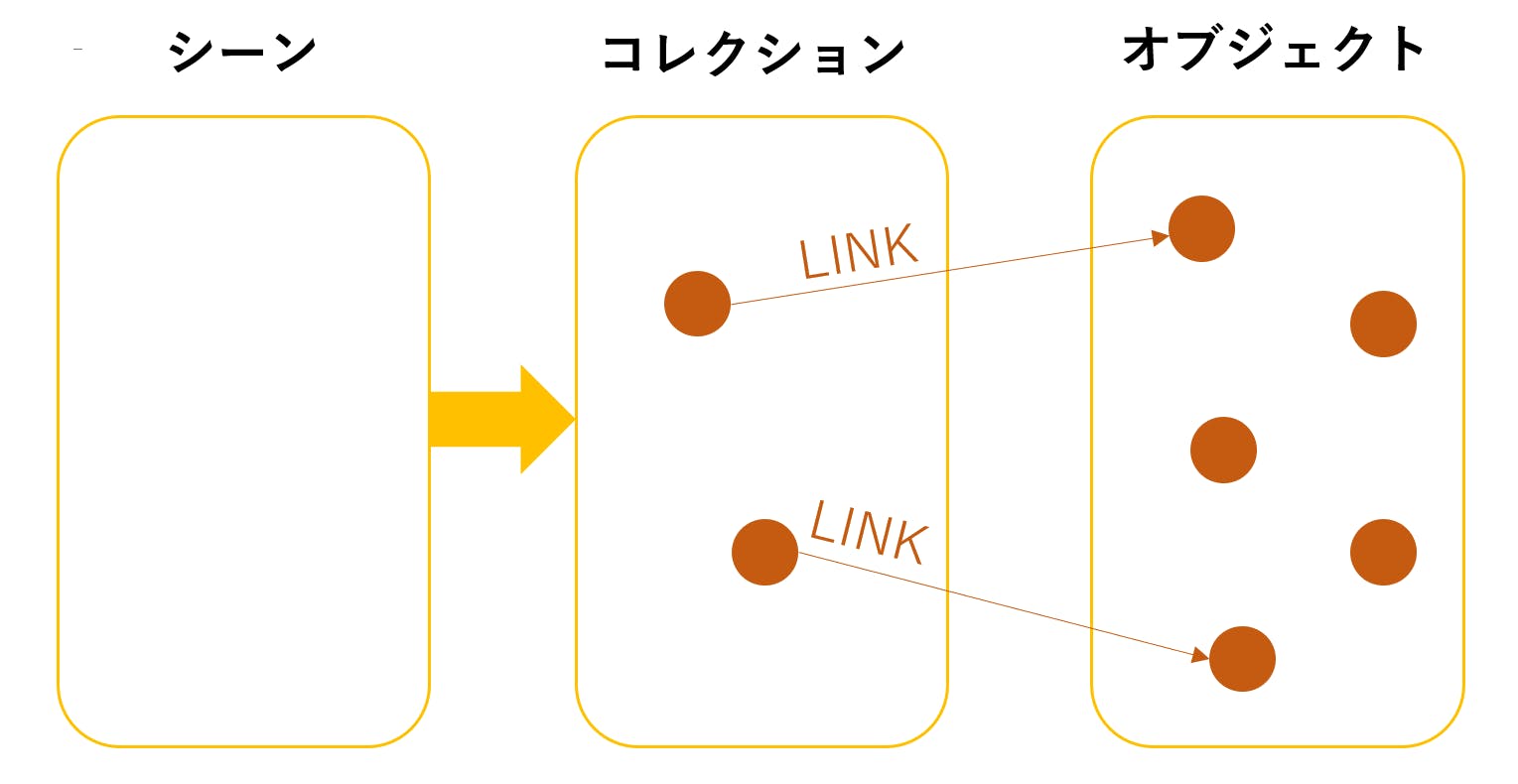
bpy.context.scene.collectionにあたるところです。
GUIでいうとここですね。
大元にシーン → コレクションがあり、コレクションの中にオブジェクトがあります。シーンとコレクションの違いはよくわかりません。ただ、オブジェクト(いわゆるキューブやカメラ等)はデータとして存在するものを、リンクという紐づけによってコレクションに呼んでいます。つまり、ビューに現れるのはリンクされたオブジェクトだけで、見えなくともデータとして存在するオブジェクトもありえる、ということです。こうすることで同じデータを使いまわせたりするようです。操作する方としてはややこしいですけど。
そしてオブジェクトと同様に、それに付随するメッシュやマテリアルにもデータリストがあって、それをリンクすることによって必要な分だけ使う、ということになります。
例えばここで、
bpy.data.objects.new("hoge", bpy.data.meshes.new("fuga"))という命令をすると、見かけ上のシーンには何も変化が起きませんが、
for i in bpy.data.objects: print(i)で、
Output<bpy_struct, Object("Camera")> <bpy_struct, Object("Cube")> <bpy_struct, Object("hoge")> <bpy_struct, Object("Light")>が返ってくるので、
hogeという謎のオブジェクトが追加されていることがわかります。また、bpy.data.objects['hoge'].to_mesh()で、
Outputbpy.data.meshes['fuga']と返ってくるので、このオブジェクトは
fugaというメッシュにリンクされていることがわかります。もちろんこれはただ名前をつけただけの空データですので、今ここでhogeをコレクションにリンクしても、何も頂点を持たない名前だけの無が召喚されます。メッシュについて詳しく見ています。メッシュの頂点情報は以下のような形で管理されています。
オブジェクトがメッシュをリンクしています。
GUIでいうとここですね。
メッシュデータが更に頂点データを格納しているので、頂点の情報が欲しい場合はそこにアクセスすることになります。今度はちゃんと形のあるキューブを対象にやっていきましょう。
bpy.data.objects['Cube'].to_mesh().verticesこれは上の絵をほぼそのままなぞったものです。
Outputbpy.data.meshes['Cube'].verticesこの中身を見ていくと、
for i in bpy.data.meshes['Cube'].vertices: print(i)Output<bpy_struct, MeshVertex at 0x0000024A9FA28038> <bpy_struct, MeshVertex at 0x0000024A9FA2804C> <bpy_struct, MeshVertex at 0x0000024A9FA28060> <bpy_struct, MeshVertex at 0x0000024A9FA28074> <bpy_struct, MeshVertex at 0x0000024A9FA28088> <bpy_struct, MeshVertex at 0x0000024A9FA2809C> <bpy_struct, MeshVertex at 0x0000024A9FA280B0> <bpy_struct, MeshVertex at 0x0000024A9FA280C4>とひたすらバイナリデータを返されます。ちゃんと8個あるのでキューブで間違いなさそうですが、できれば数値を返してほしいところです。リファレンスを見ると
coという属性で数値が得られることがわかります。for i in bpy.data.meshes['Cube'].vertices: print(i.co)Output<Vector (1.0000, 1.0000, 1.0000)> <Vector (1.0000, 1.0000, -1.0000)> <Vector (1.0000, -1.0000, 1.0000)> <Vector (1.0000, -1.0000, -1.0000)> <Vector (-1.0000, 1.0000, 1.0000)> <Vector (-1.0000, 1.0000, -1.0000)> <Vector (-1.0000, -1.0000, 1.0000)> <Vector (-1.0000, -1.0000, -1.0000)>これでやっと頂点座標の配列が得られました。
fbxに適用
インポートしたfbxについても同じことをやっていきます。
原理的には、すべてのメッシュデータに対して頂点を取り出せば上と同じ形が得られるはずです。
for i in bpy.data.meshes: print(i)Output<bpy_struct, Mesh("Cube")> <bpy_struct, Mesh("Mesh")> <bpy_struct, Mesh("Mesh.001")> <bpy_struct, Mesh("Mesh.002")> <bpy_struct, Mesh("Mesh.003")> <bpy_struct, Mesh("Mesh.004")> <bpy_struct, Mesh("Mesh.005")> <bpy_struct, Mesh("Mesh.006")> <bpy_struct, Mesh("Mesh.007")>……。謎の
Cubeがあります。
そう、Blenderを立ち上げた時に最初に存在するキューブ。あれはシーンから削除(正確にはアンリンク)しても中のデータは消えないのです。このままではキューブの頂点まで拾ってしまいます。消えてもらいましょう。bpy.data.meshes.remove(bpy.data.meshes['Cube']) for i in bpy.data.meshes: print(i)Output<bpy_struct, Mesh("Mesh")> <bpy_struct, Mesh("Mesh.001")> <bpy_struct, Mesh("Mesh.002")> <bpy_struct, Mesh("Mesh.003")> <bpy_struct, Mesh("Mesh.004")> <bpy_struct, Mesh("Mesh.005")> <bpy_struct, Mesh("Mesh.006")> <bpy_struct, Mesh("Mesh.007")>
消えました。
後はこれらのメッシュデータすべてに対し頂点座標を抽出するようなスクリプトを書きます。import bpy import numpy as np vts = [] for m in bpy.data.meshes: for v in m.vertices: vts.append(v.co) vts = np.array(vts)
coで得られる数字がVectorという型なので、扱いやすくするためnp.arrayで変換しています。ここで得られた配列が、本当に元の形を表しているのかを検証します。頂点が3次元情報を正確に保持しているなら、単に散布図にするだけで元の形を表してくれるはずです。
先ほど得られた配列
vtsをnp.savetxt(r'任意のパス\vts.txt', vts)でエクスポートします。別のPythonファイルで(Blenderの内蔵Pythonにはmatplotlibがないため……)散布図を描画します。
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D data = np.loadtxt('vts.txt') X = data[:,0] Y = data[:,1] Z = data[:,2] fig = plt.figure() ax = Axes3D(fig) ax.set_xlabel("X") ax.set_ylabel("Y") ax.set_zlabel("Z") ax.plot(X,Y,Z,marker="o",linestyle='None',ms=0.2) plt.show()
元の3Dデータの頂点を正確に配列化できていることがわかりました。






- 投稿日:2019-12-05T20:16:36+09:00
0.1 + 0.2 = 0.30000000000000004!? ②
0.1 + 0.2 = 0.30000000000000004!? ②
プロローグ: 研究動機
1
書いた日: 2019:11/21
2018/??/?? 夏? 忘れた
Pythonを習ったので、いつものように放課後にコンピュータ室で、Pythonをやっていた。
Pythonを開いて、えーと...んーと?
なんだっけ
なんかのプログラムを書いてた
なんか思った通りに動かなくて、
print()を使ってデバックしたら、誤差が出て、、、1年前のことなんて覚えてないよ!
んんんんんんん
ちょっと待って、もしかしたら...
あ、あれ???やっぱり捨てちゃったかな
あ、奇跡にあった!!!
月日: 2018/9/10 (第1章まで約1年)
その時のコードがこちら(空白含めて原文ママ)
def longmi(A): count=0 while True: A*=10 count+=1 print(A) if A % 10==0: break A/=10 count-=1 return count longmi(0.111)おそらく代入した小数の小数点の位置(?)を調べる関数と思われる
<結果>
1.11 11.100000000000001 111.00000000000001 1110.0000000000002 11100.000000000002 111000.00000000001 1110000.0000000002 11100000.000000002 111000000.00000001 1110000000.0000002 11100000000.000002 111000000000.00002 1110000000000.0002 11100000000000.002 111000000000000.02 1110000000000000.1 1.1100000000000002e+16 1.1100000000000002e+17 1.1100000000000001e+18 1.1100000000000002e+19 1.1100000000000002e+20 1.1100000000000001e+21 1.11e+22 1.1100000000000001e+23 23これがボクとFloatingPointError(海外ではそう言うらしい)との出会いである
これを先生に聞いたら仕様であること、直すのは難しいということが分かった
2
書いた日: 2019/11/24
2018/9
直すのはあきらめた
でもやっぱりもやもやする
その時は実際に自分が直せるようになるとは思っていなかったねぇ
2.5
書いた日: 2019/11/24
やっぱり1年前のことなんて忘れるよ...
なんでやろうと思ったのかとか、いつそれに思い出したとか、細かいことは忘れたので、少し繋がりがおかしかったりするかもしれません
3
書いた日: 2019/11/24
2018 冬
小数のことは諦めて
MathToolというモジュール(まだパッケージにするという考えはなかった)を作っていた3.1
書いた日: 2019/12/5
思い出せないっ...
続く
- 投稿日:2019-12-05T19:44:45+09:00
Alexaスキル「業界用語変換」でAPL部分を作りました
はじめに
今年もAlexa Developerスキルアワードに参加しました。
社内有志3人で、ハッカソンのような短期集中開発を行い、「業界用語変換」というスキルができました。_人人人人人人人人人人_
> ザギンでシースー<
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y ̄担当パートざっくり
スキル全体 @daisukeArk
形態素解析部分 @ryosukeeeee
APL部分 @sr-mtmt技術的なキャッチアップの機会にしようということで、私はAPLを触ってみることにしました。
さらに、以前Alexaスキルを作ったときはNode.js(TypeScript)で書いていたけれど、
今回はPythonで書いてみようということに。APLとは
Alexaを始めとする音声アシスタントたちにいよいよ当たり前に画面が付き始め、
視覚情報も提供できるようになりました。Alexa Presentation Language(APL)は、
アニメーション、グラフィック、画像、スライドショー、ビデオを含んだ視覚要素を
スキルのやりとりに合わせて変えていくことで様々な演出をすることができます。例としてAlexaのイベントで展示されていたりするのはPIZZA SALVATORE CUOMOのスキルですね。
体験版で実際には購入しなくてもスキルの操作だけ試すことができます。つくってみた
ちなみにNode.js版はこちらのシリーズを参考にさせていただきました。
https://qiita.com/Mount/items/72d9928ff2c0ae5de737スキル開発コンソール画面の使い方やJSONの話とかはPythonも同じなので割愛します。
# Launch Requestのhandle def handle(self, handler_input): # type: (HandlerInput) -> Response session_attr = AttributesManager.session_attributes logger.info(session_attr) speak_output = "いらっしゃいませ。\nあなたの言葉を業界人の言葉に変換します。\n「”銀座で寿司”ってなんていうの」というふうに聞いてください" builder = ( handler_input.response_builder .speak(speak_output) .ask(speak_output) ) # APL対応デバイスのときだけbuilderにAPL情報を追加 if(is_apl_supported(handler_input.request_envelope)): builder.add_directive( RenderDocumentDirective( document=GetAplJsonDocument.get_apl_json("launch"), datasources=GetAplJsonDatasources.get_apl_json("launch") ) ) return builder.response# APL情報の入ってるJSONファイルを取ってくる class GetAplJsonBase(object): _document_type = None @classmethod def get_apl_json(cls, intent_name): # このファイルの場所からの相対パスではなくLambdaから見た絶対パス指定なので注意 file_path_base = '/var/task/' with open(file_path_base + cls._document_type + '/' + intent_name + '.json', 'r', encoding="utf-8") as f: return json_load(f) class GetAplJsonDocument(GetAplJsonBase): _document_type = 'document' class GetAplJsonDatasources(GetAplJsonBase): _document_type = 'datasources' def is_apl_supported(request): apl_interface = request.context.system.device.supported_interfaces.alexa_presentation_apl return apl_interface is not NoneAPL情報のJSONはテキストファイルじゃなくて、jsで定義したほうが使い勝手が良いかも、という指摘もあったのですが
色々試していて形式が定まらなかったこともあり、今回はテキストファイルからJSONを読み込んで渡しています。jsで定義する場合の参考はこちら
function createDatasource(attributes) { return { "riddleGameData": { "properties": { "currentQuestionSsml": "<speak>" + attributes.currentRiddle.question + "<speak>", "currentLevel": attributes.currentLevel, "currentQuestionNumber": (attributes.currentIndex + 1), "numCorrect": attributes.correctCount, "currentHint": attributes.currentRiddle.hints[attributes.currentHintIndex] }, "transformers": [ { "inputPath": "currentQuestionSsml", "outputName": "currentQuestionSpeech", "transformer": "ssmlToSpeech" }, { "inputPath": "currentQuestionSsml", "outputName": "currentQuestionText", "transformer": "ssmlToText" } ] } }; }終わり
これであとはJSONを工夫すればいろいろ出せるはず
VUIの個性を活かしながら視覚情報とタッチパネルにも対応していくことを考えるのはむずかしいなと感じています。
スマホとどう使い分けていくのか、エンジニアだけでなくいろいろなひととコラボレーションして模索していきたいと思いました。スマートスピーカー Advent Calender 2019 空き枠ありますので、興味のある方ぜひご投稿ください
- 投稿日:2019-12-05T18:45:02+09:00
【初心者向け】ゼロからできる!PythonでAWS SAMによるAPI作成とOpenAPIドキュメントの出力
はじめに
以前、Swaggerツールを使ったOpenAPIドキュメント作成とAPI自動生成の流れを紹介しました。
【超初心者向け】5分で試せる!OpenAPI(Swagger3.0)ドキュメント作成〜API自動生成今回は、AWS SAM(Serverless Application Model)を使ってAPI Gateway + AWS LambdaのサーバレスなwebAPIを作成し、OpenAPIドキュメントを出力してみます。
AWS SAMを使うのは初めてです。ゼロからできるように書いてみます。AWS SAMとは
AWS サーバーレスアプリケーションモデル (SAM、Serverless Application Model) は、サーバーレスアプリケーション構築用のオープンソースフレームワークです。迅速に記述可能な構文で関数、API、データベース、イベントソースマッピングを表現できます。リソースごとにわずか数行で、任意のアプリケーションを定義して YAML を使用してモデリングできます。デプロイ中、SAM が SAM 構文を AWS CloudFormation 構文に変換および拡張することで、サーバーレスアプリケーションの構築を高速化することができます。
SAM ベースのアプリケーションの構築を開始するには、AWS SAM CLI を使用します。SAM CLI により Lambda に似た実行環境が提供され、SAM テンプレートで定義されたアプリケーションの構築、テスト、デバッグをローカルで実行できます。お使いのアプリケーションを SAM CLI を使用して AWS にデプロイすることもできます。
https://aws.amazon.com/jp/serverless/sam/
CloudFormationをサーバーレスアプリケーションで利用しやすくしたフレームワークのようです。
API Gateway , AWS Lambda , DynamoDB をひとまとめに管理できます。前提
OS:Mac
AWSアカウント作成済みやること
- 環境構築(pyenv, pipenv)
- AWS CLIを使えるようにする
- AWS SAM CLIを使えるようにする
- AWS SAMでHello Worldしてみる
- OpenAPIドキュメントを出力する
環境構築(pyenv, pipenv)
1. pyenvのインストール
$ brew install pyenvbrewコマンドが使えない場合は、以下からHomebrewをインストール
https://brew.sh/index_ja.html2. pyenvのバージョン確認
$ pyenv --version pyenv 1.2.153. pyenvでpython3.7.0をインストール
$ pyenv install 3.7.04. pyenvでインストールしたバージョンに切り替え
localの場合は今いるディレクトリに、globalの場合は全体に反映されます。
$ pyenv global 3.7.0 $ pyenv local 3.7.05. 反映されているか確認
$ pyenv versions system * 3.7.0 (set by /Users/yusaku/.pyenv/version)6. pipenvのインストール
$ brew install pipenv7. pipenvの仮想環境に入る
$ pipenv shellAWS CLIを使えるようにする
1. aws cliのインストール
$ pipenv install awscli2. aws cliのバージョン確認
$ aws --version aws-cli/1.16.294 Python/3.7.5 Darwin/19.0.0 botocore/1.13.303. アクセスキーIDとシークレットアクセスキーの確認
https://console.aws.amazon.com/iam/home?#/security_credentials
アクセスキー(アクセスキーIDとシークレットアクセスキー)の新しいアクセスキーの作成からアクセスキーを作成し、アクセスキーIDとシークレットアクセスキーを確認します。4. awscliの設定
3で確認した情報で設定します。
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-chap-welcome.html$ aws configure AWS Access Key ID [None]: XXXXXXXXXXXXXXXXXXXX AWS Secret Access Key [None]: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX Default region name [None]: ap-northeast-1 Default output format [None]: jsonAWS SAM CLIを使えるようにする
1. AWS SAM CLIのインストール
$ pipenv install aws-sam-cli2. AWS SAM CLIのバージョン確認
sam --version SAM CLI, version 0.34.0AWS SAMでHello Worldしてみる
今回はpipenv環境にインストールしたpython3.7を使います。
1. アプリケーションの初期化
$ sam init SAM CLI now collects telemetry to better understand customer needs. You can OPT OUT and disable telemetry collection by setting the environment variable SAM_CLI_TELEMETRY=0 in your shell. Thanks for your help! Learn More: https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-telemetry.html Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.5 4 - go1.x 5 - java11 6 - dotnetcore2.1 7 - nodejs10.x 8 - nodejs8.10 9 - nodejs6.10 10 - python3.7 11 - python3.6 12 - python2.7 13 - java8 14 - dotnetcore2.0 15 - dotnetcore1.0 Runtime: 10 Project name [sam-app]: AWSsam_test Allow SAM CLI to download AWS-provided quick start templates from Github [Y/n]: y ----------------------- Generating application: ----------------------- Name: AWSsam_test Runtime: python3.7 Dependency Manager: pip Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./AWSsam_test/README.md2. アプリケーションをビルドする
$ cd AWSsam_test/ $ sam build3. アプリケーションをデプロイする
$ sam deploy --guided2回目以降は
sam deployでOKです。4. 動作確認
3で出力されるエンドポイントにアクセスしてみます。
$ curl https://hoge.hoge-api.ap-northeast-1.amazonaws.com/Prod/hello/ {"message": "hello world"}hello worldが返ってきました!
AWSコンソールにログインしてLambdaを見てみると、以下のようにAPI GatewayとLambdaが起動していました。
5.Lambda関数を少し変えて実行してみる
hello_world/app.pyを以下のように変更してみます。hello_world/app.pyimport json # import requests def lambda_handler(event, context): return { "statusCode": 200, "body": json.dumps({ "message": "hello Qiita", # "location": ip.text.replace("\n", "") }), }ビルドしてデプロイします。
$ sam build $ sam deployエンドポイントにアクセスしてみます。
$ curl https://hoge.hoge-api.ap-northeast-1.amazonaws.com/Prod/hello/ {"message": "hello Qiita"}変更が反映されていることが確認できました。
OpenAPIドキュメントを出力する
AWSコンソールからAmazon API Gatewayを選択し、デプロイしたAPIを選びます。
以下の画面が表示されるので、ステージをクリックしてエクスポートを選ぶと、Swagger仕様やOpenAPI仕様のドキュメントをjson形式やyaml形式で出力できます。
おわりに
今回はAWS SAMでREST APIを作成し、OpenAPI仕様ドキュメントをエクスポートしました。
逆にOpenAPI仕様をインポートしてAWS SAMを使ったAPI作成も実施してみたいです。
以下の記事で紹介されていますが、そんなに楽ではなさそう。。
https://dev.classmethod.jp/cloud/aws/serverless-swagger-apigateway/参考
Tutorial: Deploying a Hello World Application
https://dev.classmethod.jp/cloud/aws/aws-sam-simplifies-deployment/


- 投稿日:2019-12-05T18:43:47+09:00
OCRを使ってリングフィットアドベンチャーの記録をとる
この記事はアラタナアドベントカレンダー6日目の記事になります。
みなさんリングフィットアドベンチャーしてますか?
僕はめちゃくちゃやりまくりたいけど30分もたずにダウンしちゃいます。
プレイ終了のときに今回どれだけ運動できたか記録が出るのですが、僕はそこでスマホで写真を撮ります。(Switch初心者で画面キャプチャできるの知らなかった人です)
↓こんなやつです
Switch初心者ゆえに知らないだけかもしれないのですが記録のエクスポートは出来ないっぽかったです。
どれだけ自分が努力できたか数字が欲しくなったので、今回は写真から文字起こししてくれるOCRを使って記録をとってみようと思います。準備
brew install tesseract pip install pyocr実践
オープンソースのOCRツールTesseractをラップするpyocrを使います。
ひとまず画像を読み込んでOCRかけてみます。from PIL import Image import pyocr import pyocr.builders image = Image.open("image_path") tools = pyocr.get_available_tools() tool = self.tools[0] result_ocr = self.tool.image_to_string( image, lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6)) print(result_ocr.splitlines())本 日 の 運 動 総 果 暮 ゃ す リ ン ク コ ン 挫 し こ み _ で ス ク ワ ッ ト ー バ パ ン ザ イ プ ッ シ ュ ト ニ ー ト ゥ ー チ ェ ス ト ー 椅 子 の ポ ー ズ で お な か 押 し こ み ー _ /② 団 ② 回 ⑥0 回 (eom ③⑧ 回 (③⑧ 四 ) ③① 回 G 四 ②② 回 (②② 因 ) ⑤ 回 ⑤ 四 ー ② 因 ② 回 ダ ッ シ ュ ー ジ ョ ギ ン グ モ モ あ げ ウ ォ ー キ ン グ リ ン グ コ ン 下 押 し こ み キ ー プ m ⑤ パ ー 圓 画 面 を 播 影 す る ⑥⑤⑦m(⑥⑤zm) ー m(④⑤⑧m ⑨⑨m(gom) _②m(②m) ⑯ 秋 ⑯ 功 ー ー ⑤ 程 (⑥ 功 峡0縄 と じ るひどいですね!
ひどいですがとりあえずOCR自体は成功ということで、、、文字間の空白が気になりますね、次はこの空白をどうにかします。
tesseractには空白を詰めることのできるオプションがあるようです。
-c preserve_interword_spaces=1オプションを指定する記述をpyocrのソースから見つけることができたので使ってみます。
builder = pyocr.builders.TextBuilder(tesseract_layout=6) builder.tesseract_configs.append('-c') builder.tesseract_configs.append('preserve_interword_spaces=1')本日の運動総果 暮 ゃす リンクコン挫しこみ_ で スクワット ー バパンザイプッシュ ト ニートゥーチェスト ー 椅子のポーズ で おなか押しこみ ー _ /②団②回 ⑥0回(eom ③⑧回(③⑧四) ③①回G四 ②②回(②②因) ⑤回⑤四 ー ②因②回 ダッシュ ー ジョギング モモあげ ウォーキング リングコン下押しこみキープ m ⑤パー 圓 画面を播影する ⑥⑤⑦m(⑥⑤zm) ー m(④⑤⑧m ⑨⑨m(gom) _②m(②m) ⑯秋⑯功 ー ー ⑤程(⑥功 峡0縄 とじる文字間の空白がなくなりました。
そろそろOCR自体の精度が気になります。
とりあえず前処理を追加してみます。
ついでに余計な空白がなくなったのでsplitline()からsplit()に変更しました。im_blur = cv2.GaussianBlur(image, (5, 5), 0) _, image = cv2.threshold(im_blur, 0, 255, cv2.THRESH_OTSU)ガウシアンフィルタでノイズ除去と、大津の二値化の処理を加えました。
ひとつめがsplit()する前で、ふたつめがsplit()した後のものです。
本日の逼動総果 慰 ゃす ` 画面を掘影する 。 リングコン押しこみ ⑦②回(⑦②四) ・ ダッシュ ⑥⑤⑦m(⑥⑤⑦m) “ スクワット ⑥0回(⑥ol) ・ ジョギング ④③⑧m(④③⑧m) ` バンサザイプッシュ ③⑧回(③⑧吏) * モモあけげ ⑨⑨m(⑨⑨m) ゃ ニートゥーチェスト ③①回(③①i団) ・ ウォーキング ②m(②m) ・ 椅子のポーズ ②②回(②②四) ・ リングコン下押しこみキープ ⑯秋⑯役) ゅ おなか押しこみ ⑤回(⑤四) 。 リングコン引っぱりキープブ ⑥秋(⑥君) ・ リングコン下押しこみ ②回(②回) _ カッコ内はプレイ開始からの累計価です 〔`。〈 とじる ‥* レー顕談シショコープー ー ー ・喪談e['本日の逼動総果', '慰', 'ゃす', '`', '画面を掘影する', '。', 'リングコン押しこみ', '⑦②回(⑦②四)', '・', 'ダッシュ', '⑥⑤⑦m(⑥⑤⑦m)', '“', 'スクワット', '⑥0回(⑥ol)', '・', 'ジョギング', '④③⑧m(④③⑧m)', '`', 'バンサザイプッシュ', '③⑧回(③⑧吏)', '*', 'モモあけげ', '⑨⑨m(⑨⑨m)', 'ゃ', 'ニートゥーチェスト' , '③①回(③①i団)', '・', 'ウォーキング', '②m(②m)', '・', '椅子のポーズ', '②②回(②②四)', '・', 'リング コン下押しこみキープ', '⑯秋⑯役)', 'ゅ', 'おなか押しこみ', '⑤回(⑤四)', '。', 'リングコン引っぱりキ ープブ', '⑥秋(⑥君)', '・', 'リングコン下押しこみ', '②回(②回)', '_', 'カッコ内はプレイ開始からの累 計価です', '〔`。〈', 'とじる', '‥*', 'レー顕談シショコープー', 'ー', 'ー', '・喪談e']運動の種類と回数がパット見でもわかるようになりましたね。
1が①のようになっているのはtesseractの仕様みたいなので、プログラム内でマッピング処理を書いちゃおうと思ったのですが、使えそうな関数があったので使ってみました。unicodedata.normalize()あとは運動と回数をそれぞれ雑に取り出します。
target_list = [ "スクワット", "リングコン押し込み", "ダッシュ", "ジョギング", "バンザイプッシュ", "モモあげ", "ニートゥーチェスト", "ウォーキング", "椅子のポーズ", "リングコン下押しこみキープ", "おなか押しこみ", "リングコン引っ張りキープ", "リングコン下押しこみ" ] result = [] for target in target_list: s = [] for j, line in enumerate(texts): s.append( difflib.SequenceMatcher(a=target, b=line).ratio()) result.append(texts[s.index(max(s)) + 1].split('(')[0])最後に実行するたびに追記していくようにしたものがこちらです。
{ "0": { "スクワット": "60回", "リングコン押し込み": "72回", "ダッシュ": "657m", "ジョギング": "438m", "バンザイプッシュ": "38回", "モモあげ": "99m", "ニートゥーチェスト": "31回", "ウォーキング": "2m", "椅子のポーズ": "22回", "リングコン下押しこみキープ": "16秋16役)", "おなか押しこみ": "5回", "リングコン引っ張りキープ": "6秋", "リングコン下押しこみ": "2回" }, "1": { "スクワット": "60回", "リングコン押し込み": "72回", "ダッシュ": "657m", "ジョギング": "438m", "バンザイプッシュ": "38回", "モモあげ": "99m", "ニートゥーチェスト": "31回", "ウォーキング": "2m", "椅子のポーズ": "22回", "リングコン下押しこみキープ": "16秋16役)", "おなか押しこみ": "5回", "リングコン引っ張りキープ": "6秋", "リングコン下押しこみ": "2回" } }同じ画像で実行したため2回とも同じ回数で記録されていますが、追記できました。
"リングコン下押しこみキープ": "16秋16役)",
一部きれいに取得できてなかったり”回”が認識できてないところもあるのですが一旦良しとしちゃいます。まとめ
今回はocr部分をpyocr(tesseract)に完全に乗っかったため、上記のような”回”を”秋”としてしまっているところなどどうすれば改善できるかは考えなかったのですが、次は認識精度向上もやってみたいですね。
ただ今回ocrを初めてやってみて、変な空白が入るのどうしよう…?前処理しないと精度よくならない…?など壁にぶつかるたびに対応を考えるのは楽しかったし勉強になりました。
csv出力や合計値の出力など、もう少し機能追加していきたいと思います。


- 投稿日:2019-12-05T18:40:28+09:00
量子性を活かしたゲームの開発
こんにちはQuemixの須郷です。
現在IPAの未踏事業で行なっているプロジェクトについて概要を紹介いたします。
量子の性質を含んだゲームを作るということで、期間内に2つ作るということになっています。今回はそのうち1つ目のゲームについてのご紹介です。おことわり
ゲームができるまでの経緯やルールの詳細、量子についての説明等あらゆることを初めて見る人にわかるように説明しようとするとあまりにも分量が多くなりすぎてしまうため、かなり端折った紹介になっていることをご了承ください。どんなことをやっているのかの雰囲気だけ感じとってもらえればと思います。
また、技術的に優れたことをやっているわけではないのでコードは載せていません。qiskit等量子コンピューティング用のプログラムも今回は利用していません(利用するほど複雑なことを行なっていないから)。
本記事の内容
- プロジェクトの概要
- 題材にした量子の性質について
- ゲームのルールの概略
- 気づき
プロジェクトの概要
量子の性質を面白さに結びつけた新規なゲームを開発する
できる限り繰り返し遊べるものを目指します。単に重ね合わせを用いましたというだけでは面白くなりません。量子のことを知らなくてもゲームのルールを理解でき、遊びを通して量子についての感覚等が身につくようなものを目指します(努力目標)。
とった戦略
全く新規なゲームを1から考えるというのはかなりハードルが高いため、既存のゲームに量子の要素をくっつけて新しいゲームをつくろうと思いました。また、元のゲームに対する知識があれば最初にルールを理解する際の役に立つと考えました。
ここまでの成果(EPRペア発見ゲーム)
EPRペア発見ゲームを制作しました。プロジェクトはまだ途中ですが、前述の通り2つゲームを作ることになっていて、今回紹介するゲームに関しては一通り全て終わっています。pygameで実装し、私の手元では遊べる状態になっています。このゲームは「神経衰弱+量子もつれ」をテーマとしています。EPRペアと呼ばれる量子的な性質を持ったペアを神経衰弱の要領で見つけていくというゲームです。最終的なルールは神経衰弱と離れてしまっている部分も多々ありますが、発想はここからスタートしています。
題材にした量子の性質について
EPRペア発見ゲームにはQカードと呼ばれる量子の性質を含んだカードギミックが登場します。本作の量子要素はこのQカードの中にしかでてこないため、ここを理解してしまえばあとは普通のゲームです。
Qカード
通常のトランプには表に数字とマーク(スート)が書かれていて、裏向けたトランプを表に向けるとその両方が見える状態になります。そのトランプの数字とマークは何度みても変わることはありませんが、Qカードは以下のような違いがあります。
- 数字は0と1の2種類あり、マークは+と-の2種類ある
- Qカードの表には数字とマーク両方が書いてあるが、数字とマークは一度に片方しか見れない
- 数字とマークは見るたびに結果がランダムに変わることがある
そしてQカードは以下の5種類があります。
- 0カード : 数字は必ず0が出るが、マークは+と-が半々の確率で出る
- 1カード : 数字は必ず1が出るが、マークは+と-が半々の確率で出る
- +カード : マークは必ず+が出るが、数字は0と1が半々の確率で出る
- -カード : マークは必ず-が出るが、数字は0と1が半々の確率で出る
- EPRカード : 数字もマークも半々の確率で出る。常に2枚で1セットになっており、数字もマークも必ず結果が一致する。
(突然Z測定とかX測定とかいう言葉が出ていますが、スライドの流用なので許してください)
詳しい説明は省略しますが、この数字とマークのどちらを見ても結果が一致するという性質が今回採用した量子的な性質(量子相関)となります。
Qカードは実際に作れるの?
完全に余談ですが、このQカードという量子トランプのようなものは、普通の紙で作ることはできませんが、プログラム可能な電子ペーパーのようなものを使えば手で触れる実物を作れるだろうという議論が先日の中間報告会でありました。誰か一緒に作りましょう。
ゲームのルールの概略
ここからゲームのルールを簡単に解説します(一部細かい点は省略)。ゲームはルールを文章で伝えて面白さが伝わるものではないので、本来は何らかの形でデモをお見せできるのがベストですが、今回はルール紹介のみとなります。
場の状態
場には4~8枚のQカードを置きます。この中には1~4組のEPRペア(カードとしては2~8枚)があります。EPRペア以外のカードは上述した5種類のカードのうちEPRカードではない4種類のカードがランダムに配置されます。例えばQカードが8枚でEPRペアが2組の場合、残りの4枚はランダムなQカード(EPRカードを除く)が配置されます。どの種類のQカードが配置されているかはプレイヤーにはわかりません。場のQカードが全てEPRペアのカードである場合、ランダムに置かれるカードはありません。
プレイヤーのとれる行動
このゲームは次の3つの行動で成り立っています。通常の神経衰弱では「見る」と「回答する」という区別はありませんが、本作では明確に役割がわかれています。
見る
- 選んだQカードの数字またはマークのいずれかを確認します

回答する
- 選んだQカードがEPRペアであると宣言し、正解であればそのペアを取得できます。

追加回答する
- 後述
勝利条件
場にある最後のEPRペアを取ったプレイヤーの勝利です。
ゲームの流れ
- プレイヤーの数(2~4)、Qカードの数(4~8)、EPRペアの数(1~4)、を決める
- 各プレイヤーがひとりずつ順に以下の行動を行う(勝敗が決まるまで)
- 場のQカードから2枚を選び、数字かマークを見ます
- 1ターンに2回まで見れます(1回目と2回目で見る2枚のカードを変更することはできません)
- 上で選んだ2枚に対して回答するかどうかを選びます
- 回答しない場合はターン終了で次のプレイヤーに移ります
- 回答し、正解だった場合はそのプレイヤーが追加回答できます
- 回答し、不正解だった場合は次のターンプレイヤーが追加回答できます
追加回答
誰かが回答した場合、その結果に応じて追加回答の権利が発生します。この追加回答はこのゲームで唯一プレイヤー間に情報の格差を生み出す仕組みです。基本ルールは通常の回答と同じですが、以下の点で異なります。
- 追加回答の結果を見ることができるのは追加回答をしているプレイヤーのみです。
- 追加回答以外のプレイ結果は全てのプレイヤーが平等に共有しています。元の神経衰弱と同じですね。もちろん追加回答で正解した場合は場のカードが減るので全員に結果が共有されますが、失敗した場合は追加回答したプレイヤーのみが結果を知れます。
- 追加回答で不正解でも次のプレイヤーに追加回答されることはありません。つまりノーリスクです。
- 追加回答で正解した場合、さらに追加回答を行うことができます。

追加回答の仕様について
この追加回答の仕様は正直あてずっぽうでペアを取れてしまうという点で少し微妙な仕様となってしまっています。この点については先日の中間報告会で個人的にアドバイスを下さった方がいたので、そちらのより量子を活かしたルールへの変更を検討した方がよいかもしれませんが、未踏期間内にはおそらくできそうにないです。
狙っているゲーム性
- カードを見た結果を覚える記憶ゲーム本来のゲーム性
- このゲームでは出た数字やマークそのものではなく、同じ数字、マークが出たかどうかを覚えることになる
- 回答をするかどうかの選択による駆け引きのゲーム性
- 回答し、成功すれば自分だけ追加の情報を得られる
- 回答し、失敗すれば相手に追加の情報を与えてしまう
気づき
ゲームを作る中で考え、気づいたことをいくつかリストアップしてみます。
確率について
これは一番最初にぶつかる問題ですが、量子を入れるとどうやっても確率の要素が入ってきます。確率ゲー( = 運ゲー)は基本的にクソゲーになりがちなので、何も考えずに量子要素を加えるとオリジナルのゲームが面白くてもクソゲーになってしまう確率が高いです。確率の要素があっても面白いゲームはいくらでもありますが、私の考えではプレイヤーの意思決定がゲームの勝ち負けにしっかり反映される必要があると思います。その辺りをしっかりデザインしなければいけません。
また、もともと確率の要素がないゲーム(オセロ等の完全情報ゲーム)は組み合わせるゲームとしてあまり相性が良くないと思われます。これらのゲームは運の要素がないことで相手の行動を予測し先を読む面白さが成立していますが、確率の要素が入ってしまうとその先読みがそもそもできなくなってしまいます。
ルールが複雑になる
(ここは多少量子論の知識を前提としたことを書いています)
ゲームに量子の要素を入れるにあたって、「エンタングルした量子状態を作って測定する」ということをまじめにやると、
- 重ね合わせを作る
- エンタングルさせる
- 測定する
のように3ステップかかってしまうことがわかります。これらに対応するプレイヤーの行動をそれぞれ追加するとルールが複雑化し過ぎると思います。つまり古典的な状態からプレイヤーの手によって量子的な状態を作っていくという流れにするのは意外と大変です。神経衰弱でいうともともとがカードをめくるという”シンプルな”操作のみであるのに対してこれらの行動をプラスしようとするとシンプルさが一気に損なわれる可能性が高いです。これはオセロ等プレイヤーの行動がそもそもシンプルであるようなゲーム全般に言えると思いました。もちろん複雑なルールになっても理解しやすくデザインされていれば問題はありません。
今回私がこの問題に対してとった解決策は、エンタングルした量子状態が最初から実現していて、プレイヤーは測定のみを行うといったものでした。測定した後はシステム側がまたエンタングルした初期状態に自動的に戻してくれるので、プレイヤーの行動はシンプルさを保てます。
神経衰弱との相性
従来の神経衰弱は一度見たカードの情報は確定情報(♠️が次に見たら♣️とかはない)であるのに対して、今回のEPRペアは何度測定してもこの2枚がEPRペアであると「確定」することはできません(たまたま結果が一致しているだけかもしれない)。また、Qカードの種類をでた数字やマークを覚えることで特定することは一応可能ですが、Qカード1枚につき4つの情報(0,1,+,-が出たか否か)を覚えないといけないのですぐに限界がきます。やってみるとわかりますが、真面目に覚えようとするととにかく覚えることが急激に多くなります。よって自分でやっておいてなんですが、記憶ゲームとの親和性は低いかもしれないです。
また、これは記憶ゲームに限ったことではないですが、重ね合わせによって膨れ上がった場の状態それぞれに対して何かしら判断・記憶をしなければいけないようなルールは全く現実的ではないでしょう。これはおそらく完全なログが見れる仕様のゲームだったとしてもそうだと思います。プレイヤーが意識しなければならない情報量を少なくする工夫が必須です。
どう考えて作るか
今回作っている途中で、既存のゲームのルールに量子を入れるという考えから、量子のギミック(今回の場合はQカード)を作るという感覚に変わりました。この利点は量子性をそのギミックの中に制限できることです(量子の守備範囲が明確になる)。また、量子ギミック以外の部分には極力ランダム要素を入れない様にすることで、プレイヤーの意思決定でゲームの勝敗を十分左右できる様にバランスをとることもできます。つまり量子としての面白さとゲームとしての面白さを別々に考える方がよいと思いました。今回の場合でいうと、
- 量子としての面白さ
- Qカードというギミック
- 神経衰弱の面白さ
- 出た情報を忘れずに覚えていられたことの達成感
- 連続でペアを取れた時の爽快感
神経衰弱の面白さを残しながら量子のギミックを足し、ルールとして成立させ、オリジナルにはなかった駆け引きの要素を足した、ということになります。
最後に
で、面白いの?
めちゃくちゃ面白いというものではないと思いますが、神経衰弱が面白いと思えるならそれなりに遊べると思います。一応何度も遊んでますが、目標であった繰り返しプレイに耐えうるものではあると思います、
2つ目のゲームは?
製作中です。ギミックのアイデアがある、という段階です。
どうやって遊ぶの?今後は?
現状私のところに来てもらう(もしくは私が出向く)他ありません。すみません。ですが、先日未踏の中間報告会でも刺激をいただいて、遊びたいという声も多少いただいたので、いずれ何らかの形で遊んでいただけるようにはしたいと思います。
見た目やUI等々まだまだ遊びにくいですが(誰かまともなUIで作ってくれないかな(小声))、公開されたあかつきには感想をいただけるとありがたいです。何かしら質問等興味をもっていただけた方はお気軽にお問い合わせ(ssugo@quemix.com)ください。




- 投稿日:2019-12-05T18:35:37+09:00
エラー:pyenv: no such command `sh-activate'
- 投稿日:2019-12-05T18:23:59+09:00
PyQt5で画像ファイルをクリップボードにコピー
コマンドラインで画像をクリップボードにコピーしたい
コマンドラインでテキストファイルをクリップボードにコピーしたいとき、Macでは
$ cat textfile | pbcopyと
pbcopyが使えます。これと同じようなコマンドを作ろうと思って、PyQt5を利用したら簡単にできちゃいました。#!/usr/bin/env python # -*- coding:utf-8 -*- from PyQt5.QtWidgets import QApplication from PyQt5.QtGui import QPixmap def copy_image(imageFile): app = QApplication([]) clip = QApplication.clipboard() clip.setPixmap(QPixmap(imageFile)) if __name__ == "__main__": import sys from pathlib import Path if len(sys.argv) != 2: print("usage: copy_image imagefile") elif Path(sys.argv[1]).exists(): copy_image(sys.argv[1]) print(f"{sys.argv[1]} is copied")使い方はソースを見ればわかると思います。
QApplicaitonはcopy_imageメソッド内でインスタンス作成してください。メソッドから抜けたときに自動的にデストラクタ処理されます。
- 投稿日:2019-12-05T17:34:03+09:00
使う:Django-MySQL
この記事はDjango Advent Calendar 2019 5日目の記事です。
はじめに
DjangoのORMではselect_related, prefetch_related, Preftch, Qオブジェクト、などを駆使することによって開発するにあたって十二分なクエリを発行することができる。
しかし、できないこともいくつかあり、生SQLを書かなければならない、というケースもあったりする。例えば、複数のインデックスを貼っている場合、使いたいインデックスを指定する、
USE_IDNEXや、使いたくないインデックスを指定するIGNORE_INDEXなど。その場合、生SQLを書く必要がある。Django-MySQL
しかし、こちらのDjango-MySQLを使うことによって、生SQLを書かずにDjangoのORMを拡張し、
USE_IDNEXやIGNORE_INDEXといったクエリを発行できる。セットアップ
インストール
pip install django-mysqlsettings.pyの編集
INSTALLED_APPSにdjango-mysqlを追加する
INSTALLED_APPS = ( "django.contrib.admin", "django.contrib.auth", ... ... "django_mysql", )DJANGO_MYSQL_REWRITE_QUERIESを有効にする
DJANGO_MYSQL_REWRITE_QUERIES = Truesql_modeとinnodb_strict_modeの設定
DATABASES = { "default": { "ENGINE": "django.db.backends.mysql", "HOST": "127.0.0.1", "NAME": "hogehoge", "USER": "fugafuga", "OPTIONS": { "charset": "utf8mb4", "init_command": "SET sql_mode='STRICT_TRANS_TABLES', innodb_strict_mode=1", }, } }この変更による注意点として、STRICTモードを有効にすると、max_lengthを超えたデータをinsert/updateしようとするとエラーが発生する。
STRICTモードを有効にしていない場合、max_lengthを超えたデータをinsert/updateすると、超えた分を切り捨てて、エラーが発生せずに処理されるので、そこらへんのバリデーションをちゃんとやっていなかったりする場合は注意が必要。なお、この変更はDjangoからMySQLに接続するときの設定なので、新たにmigrateをしなおすとかそういうことは必要ない。
使ってみよう
modelの設定
usersアプリケーションにhogeというモデルを作ってみる。
フィールドのfuga,piyo両方にindexを貼る。users/hoge.pyfrom django.db import models from django_mysql.models import QuerySet class Hoge(models.Model): fuga = models.IntegerField(db_index=True) piyo = models.IntegerField(db_index=True) objects = QuerySet.as_manager()通常と違う点は
from django_mysql.models import QuerySetをして、ORMのマネージャに使用するという点。
これをやることによって、Django-MySQLで拡張したクエリを発行することができる。作られたテーブルの情報
mysql> show index from users_hoge; +------------+------------+--------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +------------+------------+--------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | users_hoge | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | | users_hoge | 1 | users_hoge_fuga_8a4fba19 | 1 | fuga | A | 0 | NULL | NULL | | BTREE | | | | users_hoge | 1 | users_hoge_piyo_4539c423 | 1 | piyo | A | 0 | NULL | NULL | | BTREE | | | +------------+------------+--------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+こんな感じです。
IGNORE INDEXしてみる
fugaのindexを使わないでクエリ発行する、というケースの場合は、以下のようにやっていく。
Hoge.objects.all().ignore_index("users_hoge_fuga_8a4fba19")これによって発行されるSQLはこの通り
SELECT `users_hoge`.`id`, `users_hoge`.`fuga`, `users_hoge`.`piyo` FROM `users_hoge` IGNORE INDEX(`users_hoge_fuga_8a4fba19`);ちゃんとignore indexが発行されている。
なお、これをDjango-MySQLを使わずにやろうとすると
AttributeError: 'QuerySet' object has no attribute 'ignore_index'このようにエラーが出る。
おわり
今の所、IGNORE INDEXしか使ったことがないけれど他にも force indexが使えたり、その他便利機能があるので、詳細はドキュメントを読んでみてください。
通常のORMでは実現できずに、苦肉の策でSQLを書かなければ、というケースが発生したときに一度、Djnago-MySQLの導入を検討してみるといいかもしれません。余談
いつ見ても、ロゴ?というかキャラクターがやばい。

- 投稿日:2019-12-05T16:59:39+09:00
ImportError: 'tests' module incorrectly imported from '/home/circleci/repo/project/foo/tests'. Expected '/home/circleci/repo/project/foo'. Is this module globally installed?
備忘。
テスト書いてPush後にCircle-ciから言われたのが上のエラー。/project/ └-foo/ ├ test.py └-test/ test_views.py test_models.pyこうしてた。もともとあったtest.pyを放置したままtestディレクトリを掘ったのが敗因。
ずぼらは良くないというのが本日の教訓です。
- 投稿日:2019-12-05T16:43:05+09:00
Chaotic PSOでベンチマーク関数を評価する
この記事は「群知能と最適化2019 Advent Calender」7日目の記事です。
カオスとかAIWFとかかっこよくね?ということで調べて実装してみました。概要
カオス粒子群最適化 (CPSO: Chaotic Particle Swarm Optimization) とは、メタヒューリスティックアルゴリズムの一つであるPSOにカオスを組み込んだ最適化アルゴリズムです。
他のPSOアルゴリズムと同様、多くの変形モデルがありますが、基となる論文は2005年に発表されました。
この記事ではCPSOをPythonで実装した上で、ベンチマーク関数で評価を行ったのでまとめます。アルゴリズムと実装
CPSOは大まかに以下のような手順で実装していきます。
1. PSOの実行(重みにおいてAIWF*を使用)
2. 上位1/5のParticleを抽出
3. 抽出したParticleに対してCLS*を行い、位置を更新
4. CLSを行ったParticleの位置情報を基に探索範囲を削減
5. 新しい探索範囲内で下位4/5のParticleをランダムに再生成
6. 各Particleの評価を行い、停止条件を満たしていれば終了、満たしていなければ1.に戻る*AIWF (Adaptive Inertia Weight Factor): 適応慣性荷重係数。PSOにおけるパラメータの一つである慣性係数に対する提案手法。
*CLS (Chaotic Local Search): カオス的局所探索。PSO実行後、局所探索のために用いる提案手法。記事内では主要な部分だけコードを載せています。
全体のコードはGitHubで公開しています。
https://github.com/TatsukiSerizawa/Meta-heuristic/blob/master/cpso.py1. PSOの実行
まず、PSOを実行します。
PSOは各粒子が現在の位置$x$と速度$v$を持ち、それらを更新していくことで最適解を探索します。移動にかかる各粒子の速度と位置は以下の式で更新されます。
$$
v_{id}(t+1) = w_{id}(t) + c_p × r_p × (pBest_{id} - x_{id}(t)) + c_g × r_g × (gBest_{id} - x_{id}(t))
$$
$$
x_{id}(t+1) = x_{id}(t) + v_{id}(t+1)
$$
ここで、それぞれが見つけた最良の位置をパーソナルベスト(pBest)、群全体の最良の位置をグローバルベスト(gBest)と呼びます。
また、$v_{id}$はd次元のi番目の粒子の速度、$x_{id}$はd次元のi番目の粒子の位置、$w$は慣性係数、$c_p$、$c_g$は加速係数と呼ばれる定数、$r_p$、$r_g$は0~1の乱数です。
パラメータである慣性係数にはAIWFを使い、加速係数には一般に多く用いられている2.0の定数を指定しています。
特に慣性係数は結果に大きく影響を与えると言われており、値を大きくするほど大域探索に有効ですが、局所探索には向かないという課題があります。
そこで、AIWFではParticleごとに毎回値を変えることで課題に対応しています。
AIWFにおける慣性係数wは以下の式で求めることができます。$$
w=
\left\{
\begin{array}{}
\frac{(w_{max} - w_{min})(f-f_{min})}{(f_{avg}-f_{min})}, ( f \leq f_{avg}) \\
w_{max}, ( f > f_{avg})
\end{array}
\right.
$$AIWFのコード
def aiwf(scores, W): for s in range(SWARM_SIZE): if scores[s] <= np.mean(scores): W[s] = (np.min(W) + (((np.max(W) - np.min(W)) * (scores[s] - np.min(scores))) / (np.mean(scores) - np.min(scores)))) else: W[s] = np.max(W) return W2. 上位1/5のParticleを抽出
CLSを行うParticleを決めるため、PSOの結果Scoreの良かった上位1/5を抽出します。
3. 抽出したParticleに対してCLSを行い、位置を更新
CLSによって局所探索を行います。$x$を各粒子の位置としたとき、CLSは以下の手順で行います。
$cx_{i}^{(k)}$を求める
$$
\displaystyle cx_i^{(k)}=
\frac{x_{i}-x_{max,i}}{x_{max,i}-x_{min,i}}
$$$cx_{i}^{(k)}$を基に$cx_{i}^{(k+1)}$を求める
$$
cx_{i}^{(k+1)}=
4cx_{i}^{(k)}(1-4cx_{i}^{(k)})
$$$cx_{i}^{(k+1)}$を基に位置$x_{i}^{(k+1)}$を求め、評価する
$$
x_{i}^{(k+1)}=
x_{min,i}+cx_{i}^{(k+1)}(x_{max,i}-x_{min,i})
$$新しい評価結果が$X^{(0)}=[x_{1}^{0},...,x_{n}^{0}]$より良い場合、または最大反復数に達した場合、結果を出力。それ以外の場合は2.に戻る
CLSのコード
def cls(top_scores, top_positions): cx, cy = [], [] min_x, min_y = min(top["x"] for top in top_positions), min(top["y"] for top in top_positions) max_x, max_y = max(top["x"] for top in top_positions), max(top["y"] for top in top_positions) for i in range(len(top_scores)): cx.append((top_positions[i]["x"] - min_x) / (max_x - min_x)) cy.append((top_positions[i]["y"] - min_y) / (max_y - min_y)) for i in range(K): logistic_x = [] logistic_y = [] chaotic_scores = [] chaotic_positions = [] for j in range(len(top_scores)): logistic_x.append(4 * cx[j] * (1 - cx[j])) logistic_y.append(4 * cy[j] * (1 - cy[j])) # 位置の更新 chaotic_x, chaotic_y = chaotic_update_position(logistic_x[j], logistic_y[j], min_x, min_y, max_x, max_y) chaotic_positions.append({"x": chaotic_x, "y": chaotic_y}) # score評価 chaotic_scores.append(evaluation(chaotic_x, chaotic_y)) # 新しいscoreが前より優れていれば値を返し,それ以外はcx, cyを更新して繰り返す if min(chaotic_scores) < min(top_scores): print("Better Chaotic Particle found") return chaotic_scores, chaotic_positions cx = logistic_x cy = logistic_y return chaotic_scores, chaotic_positions # Chaotic position更新 def chaotic_update_position(x, y, min_x, min_y, max_x, max_y): new_x = min_x + x * (max_x - min_x) new_y = min_y + y * (max_y - min_y) return new_x, new_y4. CLSを行ったParticleの位置情報を基に探索範囲を削減
CLSの結果を基に次の探索範囲を削減します。
CLSを用いたParticleの位置情報を基に、以下の式を用いて探索範囲を再指定します。
ただし、論文の通り実装したとき、最小値に対して複数の最小値の中の最大値を用い、最大値に対して複数の最小値の中の最小値を用いると、最小値と最大値が逆転してしまったため、実装では最小値には最小値、最大値には最大値を用いて探索範囲を広く取りました。探索範囲削減のコード
def search_space_reduction(top_positions): min_x, min_y, max_x, max_y = [], [], [], [] min_x.append(min(top["x"] for top in top_positions)) min_y.append(min(top["y"] for top in top_positions)) max_x.append(max(top["x"] for top in top_positions)) max_y.append(max(top["y"] for top in top_positions)) x = [top.get("x") for top in top_positions] y = [top.get("y") for top in top_positions] for i in range(len(top_positions)): min_x.append(x[i] - R * (max_x[0] - min_x[0])) min_y.append(y[i] - R * (max_y[0] - min_y[0])) max_x.append(x[i] + R * (max_x[0] - min_x[0])) max_y.append(y[i] + R * (max_y[0] - min_y[0])) # 論文通り new_min_x = max(min_x) などにすると最小値と最大値が逆転してしまうので,修正 new_min_x, new_min_y = min(min_x), min(min_y) new_max_x, new_max_y = max(max_x), max(max_y) search_space_x = {"min": new_min_x, "max": new_max_x} search_space_y = {"min": new_min_y, "max": new_max_y} return search_space_x, search_space_y5. 新しい探索範囲内で下位4/5のParticleをランダムに再生成
削減した新しい探索範囲内には下位4/5のParticleが入らないので、範囲内に収まるように新しく生成します。
Particleの生成に関しては初期設定と同様ランダムに生成しています。6. 各Particleの評価を行い、停止条件を満たしていれば終了、満たしていなければ1.に戻る
各Particleに対して評価を行います。
この時、事前に閾値として設定したScoreより良かった場合、または最大探索回数に達した場合は探索を終了し、結果を出力します。
条件を満たしていない場合は1.に戻り、またPSOから実行して探索を継続します。ベンチマーク関数での評価結果
最適化アルゴリズムを評価するための関数として、多くのベンチマーク関数が存在します。
ベンチマーク関数が詳しく紹介されているものとしてtomitomi3さんの記事があります。
今回はこの中でも紹介されているSphere functionを用いました.この関数の最適解は$f_{min}(0,...,0)=0$となっています。今回はScore < 1.000e-15または反復回数10回を終了条件としました。
結果として、図のように収束していく様子が観測できました。
また、画像の描画無しで実行した場合及びシンプルなPSOを実行した場合の結果は以下のようになりました。
CLSによって精度が向上した場合はScoreも更新され、精度が向上しなかった場合はCLS前のScoreが引き継がれています。
探索範囲は毎回削減され、Scoreも向上していることが確認できます。
また、下のPSOのみを実行した結果と比較すると、精度が向上している反面,時間が掛かっていることが分かります。CPSO log and result
Lap: 1 CLS: before: 1.856166459555566e-09 after: 1.7476630375799616e-07 Search Area: before x: {'min': -5.0, 'max': 5.0} y: {'min': -5.0, 'max': 5.0} after x: {'min': -0.0010838869646188037, 'max': 0.0013954791030881871} y: {'min': -0.001201690486501598, 'max': 0.0016078160576153975} Score: 1.856166459555566e-09 Lap: 2 CLS: before: 2.0926627088682597e-13 Better Chaotic Particle found after: 7.821496571701076e-14 Search Area: before x: {'min': -0.0010838869646188037, 'max': 0.0013954791030881871} y: {'min': -0.001201690486501598, 'max': 0.0016078160576153975} after x: {'min': -7.880347663659637e-06, 'max': 1.5561134225910913e-05} y: {'min': -1.83517959693168e-05, 'max': 1.853229861175588e-05} Score: 7.821496571701076e-14 Lap: 3 CLS: before: 6.562680339774457e-17 Better Chaotic Particle found after: 5.0984844476716916e-17 Search Area: before x: {'min': -7.880347663659637e-06, 'max': 1.5561134225910913e-05} y: {'min': -1.83517959693168e-05, 'max': 1.853229861175588e-05} after x: {'min': -3.794413350751951e-07, 'max': 1.6057623588141383e-07} y: {'min': -2.7039514283878003e-07, 'max': 8.373690854089289e-08} Score: 5.0984844476716916e-17 Best Position: {'x': 6.92085226884776e-09, 'y': 1.7568859807915068e-09} Score: 5.0984844476716916e-17 time: 0.7126889228820801PSO result
Best Position: {'x': -0.23085945825227583, 'y': -0.13733679597570791} Score: 4.218973135139706e-06 time: 0.006306886672973633まとめ
今回実験してみて,CPSOの精度のと実行時間について知ることができました.今回は最適解が一つ(単峰性)のシンプルな関数で評価しましたが,多峰性の関数などで評価した場合などについても機会があれば調べたいと思います.

- 投稿日:2019-12-05T16:01:56+09:00
【Python用】Lambda Layerへのアップロードファイルをササッと作る
前提
Dockerを利用して、Lambdaで使うPythonライブラリのLayerアップロード用zipを作る。
手順はrequestsをzipにする場合のサンプル。手順
ホストOSで、ライブラリを使うバージョンのPythonコンテナにアタッチする。
$ docker pull python:3.8 $ docker images $ docker run -itd ImageID bash $ docker attach ContainerIDコンテナ側では、pipでライブラリを取得し、zipにまとめる。
$ apt-get update & apt-get install zip $ mkdir python & pip install requests -t ./python $ zip -r upload.zip python「Ctrl + p, Ctrl + q」でコンテナから抜け、コンテナからホストにzipをコピーし、コンテナを終了させる。
$ docker cp ContainerID:/root/upload.zip upload.zip $ docker stop ContainerID後はアップロードしておしまい。
- 投稿日:2019-12-05T16:01:56+09:00
【Python用】AWS Lambda Layerへのアップロードファイルをササッと作る
前提
Dockerを利用して、Lambdaで使うPythonライブラリのLayerアップロード用zipを作る。
手順はrequestsをzipにする場合のサンプル。手順
ホストOSで、ライブラリを使うバージョンのPythonコンテナにアタッチする。
$ docker pull python:3.8 $ docker images $ docker run -itd ImageID bash $ docker attach ContainerIDコンテナ側では、pipでライブラリを取得し、zipにまとめる。
$ apt-get update & apt-get install zip $ mkdir python & pip install requests -t ./python $ zip -r upload.zip python「Ctrl + p, Ctrl + q」でコンテナから抜け、コンテナからホストにzipをコピーし、コンテナを終了させる。
$ docker cp ContainerID:/root/upload.zip upload.zip $ docker stop ContainerID後はアップロードしておしまい。
- 投稿日:2019-12-05T15:58:32+09:00
ROS MultiArray を Python で扱う際の注意
ROS で配列を Publish したかったときに詰まったので共有します
最初はC++ の書き方を真似てこうすればいけるやろ!
ってやると...import rospy from std_msgs.msg import Float32MultiArray def talker(): pub = rospy.Publisher('/hoge', Float32MultiArray, queue_size=10) array=Float32MultiArray() array.data.resize(5) i=0 for p in range(5): array.data[i]=p i+=1 pub.publish(array)AttributeError: 'list' object has no attribute 'resize'と怒られました
正解の文は以下
import rospy from std_msgs.msg import Float32MultiArray def talker(): pub = rospy.Publisher('/hoge', Float32MultiArray, queue_size=10) array=[] for p in range(5): array.append(p) array_forPublish = Float32MultiArray(data=array) pub.publish(array_forPublish)一度List型にぶちこんでから MultiArray に変換するといけます
- 投稿日:2019-12-05T15:58:32+09:00
ROS MultiArray型 を Python で扱う際の注意
ROS で配列を Publish したかったときに詰まったので共有します
最初はC++ の書き方を真似てこうすればいけるやろ!
ってやると...import rospy from std_msgs.msg import Float32MultiArray def talker(): pub = rospy.Publisher('/hoge', Float32MultiArray, queue_size=10) array=Float32MultiArray() array.data.resize(5) i=0 for p in range(5): array.data[i]=p i+=1 pub.publish(array)AttributeError: 'list' object has no attribute 'resize'と怒られました
正解の文は以下
import rospy from std_msgs.msg import Float32MultiArray def talker(): pub = rospy.Publisher('/hoge', Float32MultiArray, queue_size=10) array=[] for p in range(5): array.append(p) array_forPublish = Float32MultiArray(data=array) pub.publish(array_forPublish)一度List型にぶちこんでから MultiArray に変換するといけます
- 投稿日:2019-12-05T15:49:58+09:00
A2019 Community EditionでPythonコードを動かす
A2019の目玉機能として、PythonやVBScriptを呼び出したり、インラインで書き込める。というものがあります。
今回はその中で、データ分析や機械学習、画像解析などなど、さまざまな扱いやすいライブラリが用意されている、
PythonをA2019から実行してみる方法をご紹介します。Pythonのコード自体は今回は非常にシンプルな、メッセージボックスで任意のメッセージを表示する。というものですが、うまく動いたら色々と試してみてください。
準備するもの
Automation Anywhere A2019 Community EditionのセットアップされたPC
大まかな流れ
色々ごちゃごちゃーっと書いてますが、シンプルにまとめると、やる事はこれだけです。
設定
Pythonをセットアップする
Windows側の設定をする(Python.exeにPathを通す)A2019
Botを作る
実行する手順(設定編)
1. Python公式ページのDownloadセクションからPythonをダウンロード。
ver2系、3系どちらでも大丈夫です。(私はver 3.8を落としました。)
Welcome to Python.org
https://www.python.org/2. Pythonをインストール。
実行ファイルを起動して案内に従って入れるだけです。
3. A2019でPythonを呼び出せるようにするための設定。
コマンドプロンプトで"Python"と打っただけでPythonが起動できるように設定します。
I. コントロールパネルを開く。(Win+PauseBreakで一発で開きます)
II.左側のメニューの「システムの詳細設定」をクリック。
III.「詳細設定」のタブを開く。
IV.「環境変数」をクリック。
V. 環境変数の設定-1
上下に似たようなリストが並んでいますが、現在ログインしているユーザにのみ適用するなら上側、
PCに登録された全ユーザに適用するなら下側のリストで、「Path」という項目を探し、開きます。VI. 環境変数の設定-2
環境変数「Path」の設定ダイアログが開きますので、右側のメニューの「New」をクリック。
Python.exeのインストールされているフォルダのパスを記入。
私の環境では以下のようなパスにインストールされていました。
C:\Users\ユーザ名\AppData\Local\Programs\Python\Python38-324. Python.exeにパスが通っているかを確認する
コマンドプロンプトを開きます。(Win+r -> cmdと打ってEnter。という方法が早いです。)
コマンドプロンプトが開いたら、「Python」と打ってEnterキーを押します。
以下のような表示が出ていれば成功です。
手順(A2019編)
準備が出来たら、A2019で実際にPythonのコードを実行してみましょう。
1. まず、新しいBotを作成します。
2. Python scriptのアクションを挿入
左側のメニューからPython Scriptを探し、ツリーを開きます。(検索しても良いです。)
Python Script: Open
Python Script: Execute script
Python Script: Close
という順にアクションをドラッグして配置してください。こんな感じになります。
Python Script: Openのみ以下のように設定してみてください。他のアクションは今回はそのままで大丈夫です。
Pythonのコードは以下の通りです。
SimpleMessageBox.pyfrom tkinter import messagebox messagebox.showinfo('PythonのGUI', 'メッセージ')今回はManual inputを選択して、直接Pythonのコードを書き込んでいますが、
Import existing fileという方を選ぶと、.pyという拡張子のPythonのソースファイルを呼び出すことも出来ます。Python runtime versionは、見たままなのですが、Pythonのバージョンが2系なら2、3系なら3を選択します。
今回、ver 3.8.0を使用していますので、「3」を選んでいます。設定が終わったら保存ボタンを押しましょう。(各ノードの「適用」ボタンを押すのをお忘れなく。)
3. 実行してみる
実行ボタンを押して、以下のようなメッセージボックスが表示されれば、成功です☆彡
元々Python使いの方はもちろん、今回が初めてという方も、Pythonを使えば様々な事が可能になりますので、
これを機会にぜひ色々と試してみてください。






- 投稿日:2019-12-05T15:29:40+09:00
【ネタ】O(1)のソートアルゴリズム
はじめに
ある日、こんな記事を見つけた。
スターリンソートよりも速いO(1)のソート「真実を握りつぶしあらかじめ決められた情報を流す」
といったことから大本営発表ソートと名付けられたこのソート、なんか面白そう。他にもないのか調べたら、色々見つけたのでまとめる。
実装してみる
大本営発表ソート
Propaganda.pydef propaganda_sort(list): return [1, 2, 3]入力
[3, 4, 6, 1, 2, 5, 9, 8, 10, 7]
出力
[1, 2, 3]
まあそうなるなって感じのアルゴリズムですね。オートクラシーソート
オートクラシーソートを発見。
Autocracy.pydef autocracy_sort(list): return [list[0]]入力
[3, 4, 6, 1, 2, 5, 9, 8, 10, 7]
出力
[3]大本営発表ソートと比べて、一応元の配列の考慮をしている。当然計算量も$O(1)$。
スピリチュアルソート
このソートはKuina-Chanのサイトに上がっていた。
「スピリチュアルソート」というアルゴリズムを思いつきました。 順番に並んでいないデータ列に対して、「順番に並んでいるんだ…」と深く信じることで、なんと順番に並んでいるかのように思えてしまうO(1)の奇跡のアルゴリズムなのです。
実装してみる。Spiritual.pydef spiritual_sort(list): return list入力
[3, 4, 6, 1, 2, 5, 9, 8, 10, 7]
出力
[3, 4, 6, 1, 2, 5, 9, 8, 10, 7]
このソートアルゴリズムすごいですね。順番に並んでいるのがよくわかります。
え?順番に並んでない?
何を言ってるんですか?よく見てくださいよ。しっかり並んでいるじゃないですか。わかりませんか?このままでは新規性がない
このまま終わるとただ他人の褌で相撲を取っているだけなのでよろしくない。
というわけでなんか考える。要件は以下の一つだけ!
$O(1)$であること。正直無理ゲーすぎるのでは?
頑張って一つだけ思いついた。名付けて検閲ソートです。
検閲ソート
正直、大本営発表ソートの発表する内容が変わっただけなので新規性としては微妙なのですが、これしか思い浮かばなかったです。
内容は以下。
1. 入力を受け取ると、手始めにすべて握り潰す。
2. 握りつぶした後で、検閲したことと空になったリストを表示する。これを実装するとこんな感じになる。
Censorship.pydef censorship_sort(list): print("WARNING: This input array was deleted for legal reasons.") return []入力
[3, 4, 6, 1, 2, 5, 9, 8, 10, 7]
出力
WARNING: This input array was deleted for legal reasons.
[]
要素を全部消し飛ばしたので当然ソートできてるし、無限長の長さの配列を持ってこられたところで出力は同じなので$O(1)$です。参考
スターリンソートよりも速いO(1)のソート
「スターリンソート」を改善したオートクラシーソート
Kuina-Chan:くいなちゃんノート