- 投稿日:2021-03-21T23:58:24+09:00
PythonでHello World!!の前に
始めに
初めまして、garammsalaです。
仕事でAWSを扱うようになり、ジョブ管理ツールで制御するまで臨時でlambdaを使ったインスタンス起動をできるようにしたのですが、コードが全然理解できなくて困ったのがPythonを勉強しようと思ったきっかけです。本当はAWSで使うことが前提なのですが、AWSを個人で契約、運用するお金もないのでここではAWS CLIを使ってバリバリって訳ではなく、個人のPCにPythonをインストールしてこちょこちょいろんなことを試してみよう、というものになります。
誰かにいろんな技術を共有できたらいいな、っていうのはもっとできるようになってからでまずは備忘と知識の定着が目的となります。
仕事で悩んでGoogle先生に聞いてる!って方は速攻×ボタンで閉じたほうが良いかもです。
また、2021/03/20に始めたばかり、かつ休日にちょこちょこ思いついたことを悩みながら試してみるのがメインになるので更新は遅いです。環境
2021/03/21時点の環境です。
OS:Windows 10 Pro
Python:3.9.2 64-bit
Editor:Visual Studio Code 1.54.3
PowerShell:7.1.3
- 投稿日:2021-03-21T23:29:37+09:00
Tensorflow.kerasの事前学習済みモデルでどうしても多チャンネル入力がしたい!
はじめに
tensorflow.kerasには事前学習済みモデルがあります。
tf.keras.applications.EfficientNetB0(weights="imagenet")といった感じで、モデルが作れるので、ちょっとしたときにささっと活用できます。ですが、入力チャンネルのデフォルトはRGB3チャンネルなので、
- グレースケース1chで控えめにいきたいとき
- 多チャンネル入力でガンガンいきたいとき
に対応することができません。
inputs = Input([None,None,5])
pretrained_model = EfficientNetB0(weights="imagenet", input_tensor=inputs)
と試したところで、きっちりエラーをはいてくれます。そんなこんなでお悩みな初心者向けの記事になります。
チャンネル数を減らしたい場合
『入力1チャンネルでいいんですよ』というケース。
これは比較的簡単に解決できます。① チャンネルをコピーして増やす
同じチャンネルを3つに増やして、無理やり辻褄を合わせます。
冗長な行列になりますが、numpy やtfのtileを使うと簡単にできます。たとえば、inputs = Input([None,None,1]) x = Lambda(lambda x: tf.tile(x, [1,1,1,3]))(inputs) pretrained_model = EfficientNetB0(weights="imagenet", input_tensor=x)② 最初に畳み込みを一個かます
事前学習済みモデルの入力前に出力チャンネルを3にする畳み込みをかまします。
任意のチャンネル数の入力で使えます。inputs = Input([None,None,2]) x = Conv2D(filters=3, kernel_size=1)(inputs) pretrained_model = EfficientNetB0(weights="imagenet", input_tensor=None) outputs = pretrained_model(x) new_model = Model(inputs, outputs)チャンネル数を増やしたい場合
『私の入力は53チャンネルです』というケース。
これはちょっと厄介です。上述②の畳み込みも使えますが、チャンネル数が無駄に多いと事前学習済みモデルの入力前に情報が大幅に圧縮されてしまうのが難点です。個人的には事前学習済みモデルの中の最初に出てくる畳み込みを書き換えるぐらいの気持ちでどうにかしていただきたいところですが、私のテクニックtf.keras理解不足か、なかなかうまくいきません。
こうなったら全部レイヤーばらして再構成してやりましょう。レイヤーの入出力関係を記録しておいて、最初の畳み込みだけ再定義して繋ぎなおせばいけるはずです。
def rebuild_model(pretrained_model, inputs): name_to_num = {} for i, layer in enumerate(pretrained_model.layers): name = layer.name name_to_num[name] = i # 最初の畳み込みを書き換えるので、パラメータを保管しておく。ついでに前処理レイヤも保管。 preprocessing_layers = [] for i, layer in enumerate(pretrained_model.layers): if "preprocessing" in str(layer.__class__): preprocessing_layers.append(i) if "Conv2D" in str(layer.__class__):# rebuild first conv2d rebuild_layer_num = i rebuild_layer_params = {"filters":layer.filters, "kernel_size": layer.kernel_size, "strides": layer.strides, "activation": layer.activation, "use_bias": layer.use_bias, "name": layer.name} break # あとから再構成できるように、各レイヤーの入力を読んでおく。 # ResNetやEfficientNetは分岐があるので、複数入力になるケースがあることに注意。 in_layer_nums = [] for i, layer in enumerate(pretrained_model.layers): layer_in = layer.input if not type(layer_in)==list: in_names = layer_in.name.split("/")[0].split(":")[0] in_nums = name_to_num[in_names] else: in_names = [l_in.name.split("/")[0].split(":")[0] for l_in in layer_in] in_nums = [name_to_num[in_name] for in_name in in_names] in_layer_nums.append(in_nums) # 再構成する。最初の畳み込みだけ作り直し。 # 前処理レイヤは邪魔なので消す。(最初の0-255の変換処理でチャンネル数が違うことによるエラーが起きるので) new_layers = [inputs] for i, [layer, in_nums] in enumerate(zip(pretrained_model.layers, in_layer_nums)): if i==0: continue elif i in preprocessing_layers: print("skip preprocessing_layers: ", layer.name) x = new_layers[in_nums] elif i == rebuild_layer_num: print("rebuild conv2d layers: ", layer.name) x = Conv2D(**rebuild_layer_params)(new_layers[in_nums]) else: if type(in_nums)==list: x = layer([new_layers[num] for num in in_nums]) else: x = layer(new_layers[in_nums]) new_layers.append(x) model = Model(inputs, x) return modelという感じに作ってやれば、あとは簡単。
pretrained_model = EfficientNetB0(weights="imagenet" ,input_shape=[None,None, 3], input_tensor=None) inputs = Input([None,None,5]) new_model = rebuild_model(pretrained_model, inputs)tf.kerasの事前学習済みモデルには255除算のような正規化処理が含まれており、チャンネルが変わると怒られるのでそれを消しています。あとは畳み込みを再定義しなおしていますのでここのweightは初期化されています。ご留意のほど。
ということで、任意の入力チャンネル数にすることができました。めでたしめでたし!
- 投稿日:2021-03-21T23:29:37+09:00
Tensorflow.kerasの事前学習済みモデルで、どうしても入力チャンネル数を変えたい!
はじめに
tensorflow.kerasには事前学習済みモデルがあります。
tf.keras.applications.EfficientNetB0(weights="imagenet")といった感じで、モデルが作れるので、ちょっとしたときにささっと活用できます。ですが、入力チャンネルのデフォルトはRGB3チャンネルなので、
- グレースケース1chで控えめにいきたいとき
- 多チャンネル入力でガンガンいきたいとき
に対応することができません。
inputs = Input([None,None,5])
pretrained_model = EfficientNetB0(weights="imagenet", input_tensor=inputs)
と試したところで、きっちりエラーをはいてくれます。そんなこんなでお悩みな初心者向けの記事になります。
チャンネル数を減らしたい場合
『入力1チャンネルでいいんですよ』というケース。
これは比較的簡単に解決できます。① チャンネルをコピーして増やす
同じチャンネルを3つに増やして、無理やり辻褄を合わせます。
冗長な行列になりますが、numpy やtfのtileを使うと簡単にできます。たとえば、inputs = Input([None,None,1]) x = Lambda(lambda x: tf.tile(x, [1,1,1,3]))(inputs) pretrained_model = EfficientNetB0(weights="imagenet", input_tensor=x)② 最初に畳み込みを一個かます
事前学習済みモデルの入力前に出力チャンネルを3にする畳み込みをかまします。
任意のチャンネル数の入力で使えます。inputs = Input([None,None,2]) x = Conv2D(filters=3, kernel_size=1)(inputs) pretrained_model = EfficientNetB0(weights="imagenet", input_tensor=None) outputs = pretrained_model(x) new_model = Model(inputs, outputs)チャンネル数を増やしたい場合
『私の入力は53チャンネルです』というケース。
これはちょっと厄介です。上述②の畳み込みも使えますが、チャンネル数が無駄に多いと事前学習済みモデルの入力前に情報が大幅に圧縮されてしまうのが難点です。個人的には事前学習済みモデルの中の最初に出てくる畳み込みを書き換えるぐらいの気持ちでどうにかしていただきたいところですが、私のテクニックtf.keras理解不足か、なかなかうまくいきません。
こうなったら全部レイヤーばらして再構成してやりましょう。レイヤーの入出力関係を記録しておいて、最初の畳み込みだけ再定義して繋ぎなおせばいけるはずです。
def rebuild_model(pretrained_model, inputs): name_to_num = {} for i, layer in enumerate(pretrained_model.layers): name = layer.name name_to_num[name] = i # 最初の畳み込みを書き換えるので、パラメータを保管しておく。ついでに前処理レイヤも保管。 preprocessing_layers = [] for i, layer in enumerate(pretrained_model.layers): if "preprocessing" in str(layer.__class__): preprocessing_layers.append(i) if "Conv2D" in str(layer.__class__):# rebuild first conv2d rebuild_layer_num = i rebuild_layer_params = {"filters":layer.filters, "kernel_size": layer.kernel_size, "strides": layer.strides, "activation": layer.activation, "use_bias": layer.use_bias, "name": layer.name} break # あとから再構成できるように、各レイヤーの入力を読んでおく。 # ResNetやEfficientNetは分岐があるので、複数入力になるケースがあることに注意。 in_layer_nums = [] for i, layer in enumerate(pretrained_model.layers): layer_in = layer.input if not type(layer_in)==list: in_names = layer_in.name.split("/")[0].split(":")[0] in_nums = name_to_num[in_names] else: in_names = [l_in.name.split("/")[0].split(":")[0] for l_in in layer_in] in_nums = [name_to_num[in_name] for in_name in in_names] in_layer_nums.append(in_nums) # 再構成する。最初の畳み込みだけ作り直し。 # 前処理レイヤは邪魔なので消す。(最初の0-255の変換処理でチャンネル数が違うことによるエラーが起きるので) new_layers = [inputs] for i, [layer, in_nums] in enumerate(zip(pretrained_model.layers, in_layer_nums)): if i==0: continue elif i in preprocessing_layers: print("skip preprocessing_layers: ", layer.name) x = new_layers[in_nums] elif i == rebuild_layer_num: print("rebuild conv2d layers: ", layer.name) x = Conv2D(**rebuild_layer_params)(new_layers[in_nums]) else: if type(in_nums)==list: x = layer([new_layers[num] for num in in_nums]) else: x = layer(new_layers[in_nums]) new_layers.append(x) model = Model(inputs, x) return modelという感じに作ってやれば、あとは簡単。
pretrained_model = EfficientNetB0(weights="imagenet" ,input_shape=[None,None, 3], input_tensor=None) inputs = Input([None,None,5]) new_model = rebuild_model(pretrained_model, inputs)tf.kerasの事前学習済みモデルには255除算のような正規化処理が含まれており、チャンネルが変わると怒られるのでそれを消しています。あとは畳み込みを再定義しなおしていますのでここのweightは初期化されています。ご留意のほど。
ということで、任意の入力チャンネル数にすることができました。めでたしめでたし!
- 投稿日:2021-03-21T23:27:14+09:00
Python エモクロアTRPG基本キャラステータスランダム作成プログラム
先日発表された無料オンライン向けTRPG
エモクロアTRPGのキャラクターランダム生成プログラムをPythonで組んでみました
エモクロアTRPGのPC複雑なパラメータ持たないため下記の内容で組みました今回のコードは全ステータスをD6(6面ダイス)で値を決める動きを想定していますが
パラメータをすべて振り切るものではありません
あくまですべての値をD6を振って出目合計が25以下のパターンを設定する想定ですやってることとしてはD6を8回ふって出目の合計が25以下のパターンを出力するというシンプルなもので
25点あるステータスポイントを全部振り切るプログラムではないというのがミソ使用環境 Python3.9.1
コーディング環境 IDLE3.9randomcharacter.pyimport random bol = True while bol: sintai = random.randint(1,6) kiyou = random.randint(1,6) seisin = random.randint(1,6) gokan = random.randint(1,6) tiryoku = random.randint(1,6) miryoku = random.randint(1,6) syakai = random.randint(1,6) unsei = random.randint(1,6) goukei = sintai +kiyou +seisin +gokan +tiryoku +miryoku +syakai +unsei if goukei <= 25: bol = False print("身体"+str(sintai)) print("器用"+str(kiyou)) print("精神"+str(seisin)) print("五感"+str(gokan)) print("知力"+str(tiryoku)) print("魅力"+str(miryoku)) print("社会"+str(syakai)) print("運勢"+str(unsei)) print("HP"+str(sintai+10)) print("MP"+str(seisin+tiryoku))
- 投稿日:2021-03-21T23:01:15+09:00
cheat sheet for ysys
チートシートのリンク
チートシート以外のリンク
そのうち追加するかも
そもそもこのページは何?
ysys(@ysys_Ba)がAtcoderのコンテスト中に参照する用のチートシートまとめページ
チートシートとしての機能性のために、ページ説明の先にリンクを列挙しています
他の人に役立つような競プロ記事を出すことはまずないと思うので、チートシート以外の競プロ関連記事もここにリンクをまとめておきます(予定)チートシートについて
自分以外の人の参照性は基本的に考慮していませんが、もしそれでも参照したいという方がいれば自由に使ってください
チートシートではありますがプログラミング初心者なので、かなり基本的なことから記載されています(♰完全に理解♰したら、その項目はページの最後に移す予定です)ysysと競プロ
Atcoderのアカウント
ゆるふわ勢なのでpythonで参加しています
かつては大学の初心者向けプログラミング授業で早々に挫折したり、エディタをメモ帳でコーディングしているのを同期にネタにされたりするレベルのプログラミング弱者でした
大学受験レベルの数学はできます
python以外に使える言語は、学科の授業でやったC(ほとんど忘れた)と、Arduino IDEで使うArduino言語(C/C++がベースらしい)ですAtcoder歴
2020/10/06 アカウント作成
2021/01/02 灰色になる(ABC187、初参加のコンテスト)
2021/02/06 茶色になる(ABC191、5回目参加のコンテスト)
2021/02/06 緑色になる(ABC194、9回目参加のコンテスト)
- 投稿日:2021-03-21T22:32:24+09:00
連続再生機能(python )
pythonで音源の連続再生機能を作ってみた
import pygame.mixer from mutagen.mp3 import MP3 as mp3 import time playlist = ['/test/test1.mp3', '/test/test2.mp3', '/test/test3.mp3'] for p in playlist: pygame.mixer.init() pygame.mixer.music.load(p) mc = mp3(p).info.length #音源の長さを取得 pygame.mixer.music.play(1) #再生 time.sleep(mc + 0.5) #誤差があるかもしれないので一応0.5足しておくmutagenとpygameは下記コマンドでインストール
$ pip install pygame mutagenランダム再生
import pygame.mixer import sys import random from mutagen.mp3 import MP3 as mp3 import time playlist = ['/test/test1.mp3', '/test/test2.mp3', '/test/test3.mp3'] num = len(playlist) - 1 try: while True: number = random.randint(0, num) p = playlist[number] pygame.mixer.init() pygame.mixer.music.load(p) mc = mp3(p).info.length pygame.mixer.music.play(1) time.sleep(mc + 0.5) except KeyboardInterrupt: sys.exit()random.randint()を使って乱数を生成してそれをリストのインデックスに代入するとランダム再生が実現出来ます(完全ランダムなので何回も同じ曲が流れる可能性があります)
またこのプログラムはKeyboardInterruptエラー、つまりCtrl+Cキーでの強制終了によって終了します。import pygame.mixer import sys import random from mutagen.mp3 import MP3 as mp3 import time playlist = ['/test/test1.mp3', '/test/test2.mp3', '/test/test3.mp3'] num = len(playlist) - 1 try: while True: numbers = random.randint(0, num) if numbers == number: continue number = numbers p = playlist[number] pygame.mixer.init() pygame.mixer.music.load(p) mc = mp3(p).info.length pygame.mixer.music.play(1) time.sleep(mc + 0.5) except KeyboardInterrupt: sys.exit()重複が嫌いな方はこちら
終わり
連続再生などは、ファイルパスをリスト化してあげると実現するのが楽です
- 投稿日:2021-03-21T22:32:23+09:00
【Django】ListViewの使い方と出来ること
はじめに
Djangoの標準ビューの一つでモデルを単純に利用した表示を行うListViewが用意されています。
1種類のモデルを利用した画面の作成に有効ですが、使い方に迷ったので、まとめてみます。環境
- Python 3.8
- Django 3.1
モデル
本記事では、画面表示するモデルとして下記を使用することにします。
models.pyclass Article(models.Model): title = models.CharField(max_length=128) content = models.TextField() is_published = models.BooleanField()使用例
シンプルに使う
ListViewを継承したビュークラスに対して、単純にモデルとテンプレート名だけ指定する状態です。
クラス変数のmodelsに表示したいモデルの名前、template_nameにレンダリングに使用するテンプレートファイルをすると、指定したモデルの全ての保存済みオブジェクトを取得して、テンプレートでレンダリングするようになります。
この時、テンプレート側にはモデルのオブジェクトはobject_listという名前で渡されます。views.pyfrom django.views.generic import ListView from .models import Article class ArticleListView(Listview): template_name = 'article_list.html' model = Articlearticle_list.html<!DOCTYPE html> <html> <head></head> <body> <!-- object_list は Article.objects.all() と同じ結果となる --> {% for article in object_list %} <li>{{ article.title }}</li> {% endfor %} </body> </html>テンプレートに渡すモデルを並び変える
orderingというクラス変数を利用して、モデルの並び替えができます。
モデル操作時にしようするorder_byに渡す並び替えに使用するキーを指定すると、そのキーで並び替えられた状態でテンプレートに渡されるようになります。views.pyfrom django.views.generic import ListView from .models import Article class ArticleListView(Listview): template_name = 'article_list.html' model = Article ordering = '-title' # order_by('-title')モデルをフィルタ・絞り込みする
QuerySetを指定する方法
modelでモデルを指定する代わりにquery_setにクエリを設定することができます。
これを利用すると、モデルのフィルタや絞り込み、並び替え等を行うことができます。views.pyfrom django.views.generic import ListView from .models import Article class ArticleListView(Listview): template_name = 'article_list.html' query_set = Article.objects.filter(is_published=True) # is_publish が Trueのものに絞るget_querysetメソッドを使う方法
query_setにQuerySetを設定する方法では、単純なワンライナー程度の設定しかできませんでしたが、get_query_setというメソッドをオーバーライドすることで、より自由度の高い実装が可能です。リクエストのGETパラメータの内容によって動作を変えたり、非表示(論理削除)のモデルを除外する等の複雑な制御が可能です。
この関数は既存のメソッドを拡張する形となるので、最初にスーパークラス(ListView)の
get_query_setを実行して元になるQuerySetを取得します。
それをもとに必要な操作を行って加工を行い、最終的なQuerySetを戻り値として返すようにします。
このとき実行するスーパークラスのget_query_setは、クラス変数のmodelやorderingを設定値を利用した結果の断面のQuerySetが返ってきます。views.pyfrom django.views.generic import ListView from .models import Article class ArticleListView(Listview): template_name = 'article_list.html' model = Article def get_queryset(self, **kwargs): queryset = super().get_queryset(**kwargs) # Article.objects.all() と同じ結果 # GETリクエストパラメータにkeywordがあれば、それでフィルタする keyword = self.request.GET.get('keyword') if keyword is not None: queryset = queryset.filter(title__contains=keyword) # is_publishedがTrueのものに絞り、titleをキーに並び変える queryset = queryset.filter(is_published=True).order_by('-title') return querysetコンテキストを加工する
get_context_dataメソッドをオーバーライドすることで、テンプレートに渡すコンテキストを加工することもできます。このメソッドも既存のListViewが持つメソッドをオーバーライドする形となりますので、最初にスーパークラスの
get_context_dataを実行して元になるコンテキストデータを取得して加工します。
スーパークラスのメソッドは、object_list(表示対象モデルのリスト)等が格納された状態のコンテキストが返ってくるため、それに対し要素の追加や変更を行いメソッドの戻り値として返します。ここで返す結果はViewで自前でコンテキストに変数を設定してレンダリングする場合と同じように、テンプレート内で使用することができます。
views.pyfrom django.views.generic import ListView from .models import Article class ArticleListView(Listview): template_name = 'article_list.html' model = Article def get_context_data(self): ctx = super().get_context_data() # page_title を追加する ctx['page_title'] = 'hoge' return ctxarticle_list.html<!DOCTYPE html> <html> <head></head> <body> <!-- 追加した変数を使用可能 --> <h1>{{ page_title }}</h1> {% for article in object_list %} <li>{{ article.title }}</li> {% endfor %} </body> </html>テンプレートに渡すモデルのオブジェクト名を変える
テンプレートに渡されるオブジェクトは
object_listという名前でしたが、クラス変数のcontext_object_nameに名前を指定することで、任意の名前に変更することもできます。views.pyfrom django.views.generic import ListView from .models import Article class ArticleListView(Listview): template_name = 'article_list.html' model = Article context_object_name = 'articles' # オブジェクト名を articles に指定article_list.html<!DOCTYPE html> <html> <body> {% for article in articles %} <!-- object_list から articles に変更 --> <li>{{ article.title }}</li> {% endfor %} </body> </html>
- 投稿日:2021-03-21T22:23:46+09:00
MySQLを利用したFlask RESTful API作成メモ
- PythonフレームワークFlaskとMySQLを利用したRESTful API(登録、取得のみ)の作成方法についてメモする。
準備
検証用MySQLコンテナ準備
- docker-composeを使用して、MySQLコンテナを起動する。
- 以下の
docker-compose.ymlファイルの配置しているフォルダでdocker-compose upコマンドを実行する。127.0.0.1:3307でMySQLコンテナが起動する。version: "3" services: db: image: mysql:5.7 container_name: db environment: MYSQL_ROOT_PASSWORD: rootpass MYSQL_DATABASE: sample_db MYSQL_USER: mysqluser MYSQL_PASSWORD: mysqlpass volumes: - ./db/data:/var/lib/mysql ports: - 3307:3307 command: --port 3307
- 以下のSQLを上記DBに実行し、テスト用テーブル
usersを作成する。CREATE TABLE `sample_db`.`users` ( `id` INT NOT NULL AUTO_INCREMENT, `name` VARCHAR(45) NOT NULL, `email_address` VARCHAR(128) NOT NULL, PRIMARY KEY (`id`), UNIQUE INDEX `id_UNIQUE` (`id` ASC), UNIQUE INDEX `name_UNIQUE` (`name` ASC)) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8mb4;モジュールインストール
pip install flask, SQLAlchemy, Flask-SQLAlchemy, marshmallow, marshmallow-sqlalchemy, flask-marshmallow, pymysqlDB接続設定
- 検証用MySQLコンテナとの接続設定
from flask import Flask, request, jsonify, make_response from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://mysqluser:mysqlpass@127.0.0.1:3307/sample_db' db = SQLAlchemy(app)モデル+コントローラー
- 検証用コード全体
app.pyfrom flask import Flask, request, jsonify, make_response from flask_sqlalchemy import SQLAlchemy from flask_marshmallow import Marshmallow from marshmallow_sqlalchemy import ModelSchema import json app = Flask(__name__) ## DB接続設定 app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://mysqluser:mysqlpass@127.0.0.1:3307/sample_db' db = SQLAlchemy(app) ma = Marshmallow() ## モデル class User(db.Model): __tablename__ = 'users' id = db.Column(db.Integer, primary_key=True, autoincrement=True) name = db.Column(db.String(45), nullable=False) email_address = db.Column(db.String(128), nullable=True) def __repr__(self): return "<User(name='%s',email_address='%s')>" % (self.name, self.email_address) # ユーザー情報登録 def registUser(user): record = User( name=user['name'], email_address=user['email_address'], ) db.session.add(record) db.session.commit() return user # ユーザー情報取得 def getUserByUserId(uid): user = User.query.get(uid) return user class UserSchema(ma.ModelSchema): class Meta: model = User fields = ('id', 'name', 'email_address') ## コントローラー # ユーザー情報登録 @app.route('/users/', methods=['POST']) def registUser(): reqData = json.dumps(request.json) userData = json.loads(reqData) user = User.registUser(userData) user_schema = UserSchema() return jsonify(user_schema.dump(user)) # ユーザー情報取得 @app.route('/users/<string:uid>/', methods=['GET']) def getUser(uid): user = User.getUserByUserId(uid) user_schema = UserSchema() if user == {}: return jsonify({}) return make_response(jsonify(user_schema.dump(user))) if __name__ == "__main__": app.run(debug=True)動作確認
- localhost:5000で起動する。
python app.pyユーザー情報登録
リクエスト
POST /users/ HTTP/1.1 Host: localhost:5000 Content-Type: application/json Content-Length: 70 { "name":"test3 user", "email_address":"test3@example.com" }レスポンス
{ "email_address": "test3@example.com", "name": "test3 user" }ユーザー情報取得
リクエスト
GET /users/3/ HTTP/1.1 Host: localhost:5000 Content-Type: application/jsonレスポンス
{ "email_address": "test3@example.com", "id": 3, "name": "test3 user" }参考情報
- 投稿日:2021-03-21T21:57:07+09:00
【FXシストレ入門】初めてのバックテストをPythonで実行してみる【超初心者向け】
概要
最近、シストレ絶賛勉強中の @kazama1209 と申します。
先日、「Pythonで為替レートを取得しチャートとして可視化するまでの手順」というめちゃくちゃ初心者向けの記事を書いたのですが、あれから色々試行錯誤した結果、簡単なバックテストを実行できるようになったので今回はその辺について書いていきたいと思います。
バックテスト: システムトレードにおいて、売買ルールの有効性を検証するために過去のデータを用いて一定期間にどの程度のパフォーマンスが得られたかをシミュレーションする事。
対象読者
- シストレに挑戦してみたい
- でも何から始めれば良いかわからない(環境構築も含めて)
- とりあえず手を動かして雰囲気を掴みたい
DockerでJupytar Notebookの環境構築をするところから始めるので、誰がやっても必ず同じ結果になる記事になっています。(ゆえに超初心者向け)
環境構築
- Docker
- Python3
- Jupytar Notebook
Jupytar Notebook: Webブラウザ上でPythonを記述・実行できる統合開発環境。
各ディレクトリ&ファイルを作成
$ mkdir fx-backtesting $ cd fx-backtesting $ mkdir work $ touch docker-compose.yml最終的に次のような構成になっていればOK。
fx-backtesting ├─ work ├─ docker-compose.ymldocker-compose.ymlを編集
./docker-compose.ymlversion: "3" services: notebook: image: jupyter/datascience-notebook ports: - "8888:8888" environment: - JUPYTER_ENABLE_LAB=yes volumes: - ./work:/home/jovyan/work command: start-notebook.sh --NotebookApp.token=''コンテナを起動
$ docker-compose up -dlocalhost:8888 にアクセスし
こんな感じの画面が表示されれば成功です。
ヒストリカルデータを取得
バックテストを行うにあたり、ある程度期間を持たせた過去のデータが必要になるので、
↑のサイトからダウンロードしておきましょう。
今回はユーロドル(EUR/USD)の2020年分のデータを使用します。
zipファイルのダウンロードが終わったら、解凍して中身のCSVファイルを「work」ディレクトリ配下に起きましょう。
fx-backtesting ├─ work ├─ DAT_ASCII_EURUSD_M1_2020.csv ├─ docker-compose.yml手動でポチポチやるのも良いですが、面倒なら下記のコマンドを叩けば一発でいけると思います。
$ unzip ~/Downloads/HISTDATA_COM_ASCII_EURUSD_M12020.zip DAT_ASCII_EURUSD_M1_2020.csv -d ./workコードを実装
大体の準備が完了したので、そろそろコードを書いていきましょう。
「work」ディレクトリへ入り、「Notebook」から「Python3」を選択。
するとこんな感じでコードを記述できるようになるので、ここに色々と書いていきます。
データフレームを作成
import pandas as pd # データ解析用ライブラリ # ヒストリカルデータが記載されているCSVファイルを読み込み df = pd.read_csv('./DAT_ASCII_EURUSD_M1_2020.csv', sep=';', names=('Time','Open','High','Low','Close', ''), index_col='Time', parse_dates=True) df
こんな感じで2020年1月1日〜12月31日までの為替レートが取得できていれば成功です。
※コードの実行は上部バーの「▶︎」を押すとできます。
タイムフレームを変更
どの時間軸でトレードをするかというのは人によって好みだとは思いますが、僕の場合は1分足でトレードをする事はまず無いので1時間足に変更したいと思います。
ちなみに、単一の時間軸に限らず複数の時間軸から分析する手法を「マルチタイムフレーム分析」と呼ぶので覚えておくと良いかもしれません。
def make_mtf_ohlc(df, tf): x = df.resample(tf).ohlc() O = x['Open']['open'] H = x['High']['high'] L = x['Low']['low'] C = x['Close']['close'] ret = pd.DataFrame({'Open': O, 'High': H, 'Low': L, 'Close': C}, columns=['Open','High','Low','Close']) return ret.dropna() ohlc_1h = make_mtf_ohlc(df, '1H') ohlc_1h
引数に渡す「tf(タイムフレーム)」の値の例としては、以下の通り。
- 'T': 分
- 'H': 時間
- 'D': 日
- 'W': 週
- 'M': 月
たとえば、1時間足のデータが欲しければ「'H'」もしくは「'1H'」と書けばOKですし、4時間足のデータが欲しければ「'4H'」と書きます。
チャートとして可視化
ここで一旦、先ほど作成したデータをチャートとして可視化してみましょう。
from matplotlib import pyplot as plt # データを可視化(チャートなどの形で表示)するためのライブラリ。 import seaborn as sns # 同上 sns.set() fig = plt.figure(figsize = (10, 8)) ax = fig.add_subplot(1, 1, 1) ax.set_title('EUR/USD') sns.lineplot(x = ohlc_1h.index, y = ohlc_1h.High, ax = ax) plt.tight_layout()
良い感じに表示されましたね。
バックテストを実行
さて、いよいよバックテストのお時間です。
バックテストを行うためには、売買ルール(どんな条件の時に売買するか)や実際の取引タイミングなど色々細かな設定をしていかなければなりません。
中にはそれらを細かに自分で一から書いていく方もいるかもしれませんが、今回の趣旨はあくまでも「入門」という事もあり、感覚を掴むというのが主な目的という意味で素直に他の方が作ってくれたライブラリに頼る事にします。
Python製のバックテスト用ライブラリとしては、
- Backtesting.py
- Backtrader
- PyAlgoTrade
- pybacktest
といった多彩なものがリリースされているようですが、今回はその中でも比較的シンプルとされている「Backtesting.py」を使ってみたいと思います。
!pip install backtesting
Backtesting.pyは標準ライブラリではないため、ここでインストールしておきます。
from backtesting import Backtest, Strategy from backtesting.lib import crossover from backtesting.test import SMA class SmaCross(Strategy): # 今回はサンプルとして良く採用される単純移動平均線(SMA)の交差を売買ルールに。 def init(self): # 初期設定(移動平均線などの値を決める) price = self.data.Close self.ma1 = self.I(SMA, price, 20) # 短期の移動平均線 self.ma2 = self.I(SMA, price, 80) # 長期の移動平均線 def next(self): # ヒストリカルデータの行ごとに呼び出される処理 if crossover(self.ma1, self.ma2): # ma1がma2を上回った時(つまりゴールデンクロス) self.buy() # 買い elif crossover(self.ma2, self.ma1): # ma1がma2を下回った時(つまりデッドクロス) self.sell() # 売り bt = Backtest(ohlc_1h, SmaCross, cash=500, commission=0, exclusive_orders=True) # バックテスト実行に渡せる引数 # class Backtest(data, strategy, *, cash=10000, commission=0.0, margin=1.0, trade_on_close=False, exclusive_orders=False) # data: ヒストリカルデータ # strategy: Strategyを継承した独自のストラテジー(今回で言えばSmaCross) # cash: 資金(今回は500ドルで試してみた) # commission: 手数料(今回は簡略化のために0) # margin: 資金に対する取引額の割合。たとえば、資金500ドルでmargin1.0なら500ドル全額で取引するし、0.5なら半分の250ドルで取引する。 # trade_on_close: 現在の足の終値で取引するかどうか(Falseなら次の足の始値で取引) # exclusive_orders: 新規注文時に前の注文をクローズするかどうか stats = bt.run() # バックテストを実行 print(stats) # バックテストの結果を表示
今回のバックテストにおける売買ルールは、最もメジャーといっても過言ではないゴールデンクロスとデッドクロスにしました。
ゴールデンクロス: 長期の移動平均線を、短期の移動平均線が下から上に突き抜ける現象。
デッドクロス: 長期の移動平均線を、短期の移動平均線が上から下に突き抜ける現象。
引用元: https://www.oanda.jp/lab-education/dictionary/goldencross/
移動平均線というのはとある一定期間における平均値を線で結んだものであるため、短期の移動平均線が長期の移動平均線と交差する瞬間というのは、トレンドの転換を表す可能性があるというわけですね。
必ずしも例のように上手く決まるわけではありませんが、多くの人が参考にしている現象という事でここでは一旦採用してみる事にします。
短期移動平均線と長期移動平均線の設定値については人それぞれ好みもあるでしょうが、僕はそれぞれ20・80を設定しました。
バックテストの結果、次のような集計値が返ってくると思います。
Start 2020-01-01 17:00:00 # 開始日時 End 2020-12-31 16:00:00 # 終了日時 Duration 364 days 23:00:00 # 期間 Exposure Time [%] 98.491172 # ポジションを持っていた期間の割合 Equity Final [$] 587.36774 # 最終的な資金 Equity Peak [$] 601.25101 # ピーク時の資金 Return [%] 17.473548 # 利益率 Buy & Hold Return [%] 8.926103 Return (Ann.) [%] 13.796855 Volatility (Ann.) [%] 7.517942 Sharpe Ratio 1.83519 Sortino Ratio 3.330257 Calmar Ratio 2.209586 Max. Drawdown [%] -6.244091 # 最大ドローダウン(最大資金からの損失率) Avg. Drawdown [%] -0.350062 # 平均ドローダウン Max. Drawdown Duration 209 days 14:00:00 Avg. Drawdown Duration 3 days 03:00:00 # Trades 76 # トレード回数 Win Rate [%] 44.736842 # 勝率 Best Trade [%] 4.640433 # 1回の取引で得た利益の最大値 Worst Trade [%] -0.911485 # 1回の取引で被った損失の最大値 Avg. Trade [%] 0.212387 # 損益の平均値 Max. Trade Duration 18 days 07:00:00 Avg. Trade Duration 4 days 18:00:00 Profit Factor 2.176097 Expectancy [%] 0.217177 SQN 1.839067 _strategy SmaCross _equity_curve ... _trades Size EntryB...重要と思われる項目にコメントをつけておきました。その他の部分はより高度な分析を行う際に必要な感じなので、気になる方は適宜調べてみてください。(ぶっちゃけ僕も良くわからない部分が多いです。)
ざっくり言うと、今回の戦略(ゴールデンクロス時に買い、デッドクロス時に売り)を採用して2020年のユーロドル相場で勝負した場合、年間で76回のトレードを行い、勝率は44%、最終的な利益率は+17%くらいが見込めたというわけですね。
なお、今回のバックテストを可視化する事も可能です。
- 1段目
- 資金の推移
- 2段目
- 損益の分布
- 3段目
- 実際にトレードが発生した場所など
これらを上手く組み合わせていく事で、より勝率の高い戦略が考えられるのではないでしょうか。
あとがき
以上、初めてのバックテストを行ってみました。採用した売買ルールはいたってシンプルなものですし、試行回数が少ない(2020年のユーロドル相場でしか試していない)ため、実際の相場で通用するかどうかと言われれば微妙だと思います。
しかしながら、バックテストがどういうものなのか、ちょっとしたコツは掴めたのでよしとしましょう。
今後はゴールデンクロス・デッドクロス以外の売買ルールも試してみたいですし、「Backtesting.py」以外のライブラリも吟味してみたいと思います。
あくまで初心者向けの記事になっているので、一読した後は各々自分なりの手法を考えてみてください。今回はFXで例えていますが、仮想通貨でも大体同じような考えでいけるはず。










- 投稿日:2021-03-21T21:34:23+09:00
M1 mac で miniforge をインストールして環境構築
目的
miniforgeをインストールして、Pythonを動かせる環境を構築する!
miniforge構築しようと思ったキッカケ
機械学習について調べた際に、ニュートラルネットワークがとても気になり、ライブラリーを使わず再現したいと思ったのが始まりです。
ニュートラルネットワークについて記載している「ゼロから作るDeep Learning」に沿って、anacondaをインストールしようと試したが、何度やっても上手くいかず、、、。よく調べてみると、現状M1 macだと、anacondaは上手く動かないらしい。。。。(詳しくは、調べると出てきます。)
仕方ないので、M1 mac上でも動くminiforgeをインストールして環境構築するこにしました。miniforgeとは
miniforgeは コミュニティ。conda環境で必要最小限のパッケージです。
miniforge をインストール
https://github.com/conda-forge/miniforge から[Miniforge3-MacOSX-arm64]をダウンロードします。ダンロードが完了したら、ターミナル上で以下のコマンドを実行していきましょう。
# ダウンロードした[Miniforge3-MacOSX-arm64]が入ったディレクトリまで移動 cd Downloads # インストールフォルダを指定してインストール bash Miniforge3-Linux-x86_64.shあとは、時々聞かれる質問に[yes]と答えて行けば、インストールされます。
インストールされていることを確認
ターミナル上で以下を実行しましょう。
open ~/.bash_profile以下のように、condaの初期化処理が ~/.zshrc に書き込まれることが確認できれば、インストール成功です。
# >>> conda initialize >>> # !! Contents within this block are managed by 'conda init' !! __conda_setup="$('/Users/●●/miniforge3/bin/conda' 'shell.zsh' 'hook' 2> /dev/null)" if [ $? -eq 0 ]; then eval "$__conda_setup" else if [ -f "/Users/●●/miniforge3/etc/profile.d/conda.sh" ]; then . "/Users/●●/miniforge3/etc/profile.d/conda.sh" else export PATH="/Users/●●/miniforge3/bin:$PATH" fi fi unset __conda_setup # <<< conda initialize <<<インストールが完了すると、自動的にconda環境になるため、以下のコマンドをターミナルで打ち込み、自動でconda環境にならないようにしておきましょう。
conda config --set auto_activate_base falseconda環境のオン•オフは以下のとおりです。
# conda環境オン。オンになると、”(base)”がついてきます。 conda activate # conda環境オフ conda deactivate最後に、conda環境上で、以下を実行すると、pythonを実行するための環境が構築します。
conda create -n ●●(名前) python=3.9最後に、環境構築されたことを以下のコマンドで確認します。
conda listリストに名前があれば成功です!
参考資料
miniforgeをインストールする際、以下を参考にさせていただきました。
M1 MacにPythonインストールして開発環境構築してみた https://note.com/osmszk/n/n277447e8c2a4
conda 公式ドキュメント https://docs.conda.io/projects/conda/en/latest/commands.html#conda-vs-pip-vs-virtualenv-commands
AppleSilicon M1 Macにpythonをインストールする https://braveam.com/archives/1409
- 投稿日:2021-03-21T21:26:55+09:00
Python(Biopython)でGenbank形式ファイルをFASTA形式ファイルに変換する
はじめに
学生時代は主にPerl(Bioperl)を利用してバイオインフォマティクス分野の研究に携わっていましたが、最近はすっかりPythonが主流になっていますね。自分自身も業務でPythonを利用する機会が増えているので、Pythonの勉強がてらに学生時代を思い出しつつ、たまに「Python×バイオインフォマティクス」を学習してます。
今回はPython(Biopython)を利用した、Genbank形式ファイルをコーディング領域(CDS)のNucleotideまたはProteinのFASTAファイルへ変換する自作プログラムを紹介します。プログラム入出力
入力Genbank形式ファイル
バイオインフォやってる人はお馴染みの形式。
テキストをそのまま貼り付けると長くなるので、内容についてはこちらから参照してください。
ファイル(sequence.gb)のダウンロードリンクはこちら (ファイルサイズは約10kb)出力FASTA形式ファイル
上記のGenbank形式ファイルから下記のFASTA形式ファイルをそれぞれ出力可能としています。Nucleotide配列FASTAファイル(sequence.fna)>GENE00001 TCP1-beta GATCCTCCATATACAACGGTATCTCCACCTCAGGTTTAGATCTCAACAACGGAACCATTGCCGACATGAGACAGTTAGGTATCGTCGAGAGTTACAAGCTAAAACGAGCAGTAGTCAGCTCTGCATCTGAAGCCGCTGAAGTTCTACTAAGGGTGGATAACATCATCCGTGCAAGACCAAGAACCGCCAATAGACAACATATGTAA >GENE00002 Axl2p ATGACACAGCTTCAGATTTCATTATTGCTGACAGCTACTATATCACTACTCCATCTAGTAGTGGCCACGCCCTATGAGGCATATCCTATCGGAAAACAATACCCCCCAGTGGCAAGAGTCAATGAATCGTTTACATTTCAAATTTCCAATGATACCTATAAATCGTCTGTAGACAAGACAGCTCAAATAACATACAATTGCTTCGACTTACCGAGCTGGCTTTCGTTTGACTCTAGTTCTAGAACGTTCTCAGGTGAACCTTCTTCTGACTTACTATCTGATGCGAACACCACGTTGTATTTCAATGTAATACTCGAGGGTACGGACTCTGCCGACAGCACGTCTTTGAACAATACATACCAATTTGTTGTTACAAACCGTCCATCCATCTCGCTATCGTCAGATTTCAATCTATTGGCGTTGTTAAAAAACTATGGTTATACTAACGGCAAAAACGCTCTGAAACTAGATCCTAATGAAGTCTTCAACGTGACTTTTGACCGTTCAATGTTCACTAACGAAGAATCCATTGTGTCGTATTACGGACGTTCTCAGTTGTATAATGCGCCGTTACCCAATTGGCTGTTCTTCGATTCTGGCGAGTTGAAGTTTACTGGGACGGCACCGGTGATAAACTCGGCGATTGCTCCAGAAACAAGCTACAGTTTTGTCATCATCGCTACAGACATTGAAGGATTTTCTGCCGTTGAGGTAGAATTCGAATTAGTCATCGGGGCTCACCAGTTAACTACCTCTATTCAAAATAGTTTGATAATCAACGTTACTGACACAGGTAACGTTTCATATGACTTACCTCTAAACTATGTTTATCTCGATGACGATCCTATTTCTTCTGATAAATTGGGTTCTATAAACTTATTGGATGCTCCAGACTGGGTGGCATTAGATAATGCTACCATTTCCGGGTCTGTCCCAGATGAATTACTCGGTAAGAACTCCAATCCTGCCAATTTTTCTGTGTCCATTTATGATACTTATGGTGATGTGATTTATTTCAACTTCGAAGTTGTCTCCACAACGGATTTGTTTGCCATTAGTTCTCTTCCCAATATTAACGCTACAAGGGGTGAATGGTTCTCCTACTATTTTTTGCCTTCTCAGTTTACAGACTACGTGAATACAAACGTTTCATTAGAGTTTACTAATTCAAGCCAAGACCATGACTGGGTGAAATTCCAATCATCTAATTTAACATTAGCTGGAGAAGTGCCCAAGAATTTCGACAAGCTTTCATTAGGTTTGAAAGCGAACCAAGGTTCACAATCTCAAGAGCTATATTTTAACATCATTGGCATGGATTCAAAGATAACTCACTCAAACCACAGTGCGAATGCAACGTCCACAAGAAGTTCTCACCACTCCACCTCAACAAGTTCTTACACATCTTCTACTTACACTGCAAAAATTTCTTCTACCTCCGCTGCTGCTACTTCTTCTGCTCCAGCAGCGCTGCCAGCAGCCAATAAAACTTCATCTCACAATAAAAAAGCAGTAGCAATTGCGTGCGGTGTTGCTATCCCATTAGGCGTTATCCTAGTAGCTCTCATTTGCTTCCTAATATTCTGGAGACGCAGAAGGGAAAATCCAGACGATGAAAACTTACCGCATGCTATTAGTGGACCTGATTTGAATAATCCTGCAAATAAACCAAATCAAGAAAACGCTACACCTTTGAACAACCCCTTTGATGATGATGCTTCCTCGTACGATGATACTTCAATAGCAAGAAGATTGGCTGCTTTGAACACTTTGAAATTGGATAACCACTCTGCCACTGAATCTGATATTTCCAGCGTGGATGAAAAGAGAGATTCTCTATCAGGTATGAATACATACAATGATCAGTTCCAATCCCAAAGTAAAGAAGAATTATTAGCAAAACCCCCAGTACAGCCTCCAGAGAGCCCGTTCTTTGACCCACAGAATAGGTCTTCTTCTGTGTATATGGATAGTGAACCAGCAGTAAATAAATCCTGGCGATATACTGGCAACCTGTCACCAGTCTCTGATATTGTCAGAGACAGTTACGGATCACAAAAAACTGTTGATACAGAAAAACTTTTCGATTTAGAAGCACCAGAGAAGGAAAAACGTACGTCAAGGGATGTCACTATGTCTTCACTGGACCCTTGGAACAGCAATATTAGCCCTTCTCCCGTAAGAAAATCAGTAACACCATCACCATATAACGTAACGAAGCATCGTAACCGCCACTTACAAAATATTCAAGACTCTCAAAGCGGTAAAAACGGAATCACTCCCACAACAATGTCAACTTCATCTTCTGACGATTTTGTTCCGGTTAAAGATGGTGAAAATTTTTGCTGGGTCCATAGCATGGAACCAGACAGAAGACCAAGTAAGAAAAGGTTAGTAGATTTTTCAAATAAGAGTAATGTCAATGTTGGTCAAGTTAAGGACATTCACGGACGCATCCCAGAAATGCTGTGA >GENE00003 Rev7p ATGAATAGATGGGTAGAGAAGTGGCTGAGGGTATACTTAAAATGCTACATTAATTTGATTTTATTTTATAGAAATGTATACCCACCTCAGTCATTCGACTACACTACTTACCAGTCATTCAACTTGCCGCAGTTCGTTCCCATTAATAGGCATCCTGCTTTAATTGACTATATAGAAGAACTTATACTGGATGTTCTTTCTAAATTAACGCACGTTTACAGATTTTCCATCTGCATTATTAATAAAAAGAACGATTTATGCATTGAAAAATACGTTTTAGATTTTAGTGAATTACAACATGTGGATAAAGACGATCAGATCATTACGGAAACTGAAGTGTTCGACGAATTCCGATCTTCCTTAAATAGTTTGATTATGCATTTGGAGAAATTACCTAAAGTCAACGATGACACAATAACATTTGAAGCAGTTATTAATGCGATCGAATTGGAACTAGGACATAAGTTGGACAGAAACAGGAGGGTCGATAGTTTGGAGGAAAAAGCAGAAATTGAAAGGGATTCAAACTGGGTTAAATGTCAAGAAGATGAAAATTTACCAGACAATAATGGTTTTCAACCTCCTAAAATAAAACTCACTTCTTTAGTCGGTTCTGACGTGGGGCCTTTGATTATTCATCAGTTTAGTGAAAAATTAATCAGCGGTGACGACAAAATTTTGAATGGAGTGTATTCTCAATATGAAGAGGGCGAGAGCATTTTTGGATCTTTGTTTTAAProtein配列FASTAファイル(sequence.faa)>GENE00001_AAA98665.1 TCP1-beta SSIYNGISTSGLDLNNGTIADMRQLGIVESYKLKRAVVSSASEAAEVLLRVDNIIRARPRTANRQHM >GENE00002_AAA98666.1 Axl2p MTQLQISLLLTATISLLHLVVATPYEAYPIGKQYPPVARVNESFTFQISNDTYKSSVDKTAQITYNCFDLPSWLSFDSSSRTFSGEPSSDLLSDANTTLYFNVILEGTDSADSTSLNNTYQFVVTNRPSISLSSDFNLLALLKNYGYTNGKNALKLDPNEVFNVTFDRSMFTNEESIVSYYGRSQLYNAPLPNWLFFDSGELKFTGTAPVINSAIAPETSYSFVIIATDIEGFSAVEVEFELVIGAHQLTTSIQNSLIINVTDTGNVSYDLPLNYVYLDDDPISSDKLGSINLLDAPDWVALDNATISGSVPDELLGKNSNPANFSVSIYDTYGDVIYFNFEVVSTTDLFAISSLPNINATRGEWFSYYFLPSQFTDYVNTNVSLEFTNSSQDHDWVKFQSSNLTLAGEVPKNFDKLSLGLKANQGSQSQELYFNIIGMDSKITHSNHSANATSTRSSHHSTSTSSYTSSTYTAKISSTSAAATSSAPAALPAANKTSSHNKKAVAIACGVAIPLGVILVALICFLIFWRRRRENPDDENLPHAISGPDLNNPANKPNQENATPLNNPFDDDASSYDDTSIARRLAALNTLKLDNHSATESDISSVDEKRDSLSGMNTYNDQFQSQSKEELLAKPPVQPPESPFFDPQNRSSSVYMDSEPAVNKSWRYTGNLSPVSDIVRDSYGSQKTVDTEKLFDLEAPEKEKRTSRDVTMSSLDPWNSNISPSPVRKSVTPSPYNVTKHRNRHLQNIQDSQSGKNGITPTTMSTSSSDDFVPVKDGENFCWVHSMEPDRRPSKKRLVDFSNKSNVNVGQVKDIHGRIPEML >GENE00003_AAA98667.1 Rev7p MNRWVEKWLRVYLKCYINLILFYRNVYPPQSFDYTTYQSFNLPQFVPINRHPALIDYIEELILDVLSKLTHVYRFSICIINKKNDLCIEKYVLDFSELQHVDKDDQIITETEVFDEFRSSLNSLIMHLEKLPKVNDDTITFEAVINAIELELGHKLDRNRRVDSLEEKAEIERDSNWVKCQEDENLPDNNGFQPPKIKLTSLVGSDVGPLIIHQFSEKLISGDDKILNGVYSQYEEGESIFGSLF実行コマンド・ソースコード
実行コマンド
実行ソースコードへ下記3つの引数を指定してプログラムを実行
① 入力Genbank形式ファイル、② 出力FASTA形式ファイル、③ 配列タイプ出力コマンド例①:CDSのNucleotide配列FASTAファイル出力
$ python gbk2cds_fasta.py sequence.gb sequence.fna nucleotide出力コマンド例②:CDSのProtein配列FASTAファイル出力
$ python gbk2cds_fasta.py sequence.gb sequence.faa protein実行ソースコード
まずBiopythonのSeqIOでGenbank読み込み・構文解析を行い、CDSレコード情報のみを抽出しています。
その後、指定した配列タイプによりNucleotideまたはProtein配列を抜き出し、FASTA形式で書き込み実行しています。gbk2cds_fasta.pyimport sys from typing import List from Bio import SeqIO from Bio.Seq import Seq from Bio.SeqRecord import SeqRecord def main(): # 引数設定 args = sys.argv gbk_infile = args[1] cds_fasta_outfile = args[2] seqtype = args[3] # Genbank形式ファイル -> FASTA形式ファイル gbk2cds_fasta(gbk_infile, cds_fasta_outfile, seqtype) def gbk2cds_fasta( gbk_infile: str, fasta_outfile: str, seqtype: str, id_prefix: str = "GENE" ) -> None: """GenBank形式ファイル内のCDS配列情報をFasta形式で出力 Args: gbk_infile (str): 入力GenBank形式ファイル fasta_outfile (str): 出力Fasta形式ファイル seqtype (str): 出力配列タイプ("nucleotide" or "protein") id_prefix (str, optional): 出力配列連番IDのプレフィクス設定 """ gene_idx = 0 cds_seq_record_list: List[SeqRecord] = [] for record in SeqIO.parse(gbk_infile, "genbank"): # 翻訳配列レコードが存在するCDS配列を対象にFASTA出力 cds_feature_list = [f for f in record.features if f.type == "CDS"] for cds_feature in cds_feature_list: qualifiers = cds_feature.qualifiers protein_id = qualifiers.get("protein_id", ["NA"])[0] product = qualifiers.get("product", ["NA"])[0] # 翻訳配列レコードが存在しない場合は出力スキップ if qualifiers.get("translation") is None: continue gene_idx += 1 if seqtype == "nucleotide": seq_id = f"{id_prefix}{gene_idx:05d}" cds_seq = cds_feature.location.extract(record.seq) elif seqtype == "protein": seq_id = f"{id_prefix}{gene_idx:05d}_{protein_id}" cds_seq = Seq(qualifiers.get("translation")[0]) else: raise KeyError(f"seqtype '{seqtype}' is not 'nucleotide|protein'") cds_seq_record = SeqRecord(seq=cds_seq, id=seq_id, description=product) cds_seq_record_list.append(cds_seq_record) # 配列行が1行のFASTA形式で出力 SeqIO.write(cds_seq_record_list, fasta_outfile, "fasta-2line") if __name__ == "__main__": main()参考
- 投稿日:2021-03-21T20:34:06+09:00
Bashのように波括弧({},ブレース,brace)のパターン展開
波括弧の展開ライブラリの紹介
Bashで波括弧の展開にお世話になった人はいないだろうか。
Pythonのライブラリに同じことができるライブラリがあったので紹介する深いパス等指定が面倒なパスがあったとき、例えばこのファイルを退避しようとすると普通は下記のように書く
mv a/b/c/d/e/f/g/hoge.txt a/b/c/d/e/f/g/hoge_bak.txtこれをBashの波括弧の展開を使うと次のように書ける
mv a/b/c/d/e/f/g/hoge{,_bak}.txtまた、ワイルドカード(
*)やクエッション(?)だと余計なモノが含まれる場合、いちいち列挙しなければならない。例えば、下記ファイルがあったときにa1,a2,b0のファイルだけ指定したいときに
file-a0.txt file-a1.txt file-a2.txt file-b0.txt file-b1.txt file-b2.txt次のようにネストして書くこともできる。
echo file-{a{0,1},b0}.txt file-a0.txt file-a1.txt file-b0.txtそれをpythonでできるようにしたライブラリが bracex
ニッチな用途かもしれないが、使えると手間が少し減るかもしれない。
なお、もっと詳しい説明がこっちに書いてある。>>> bracex.expand("file-{a{0,1},b0}.txt") ['file-a0.txt', 'file-a1.txt', 'file-b0.txt']glob でもできればいいのにとは思うけど、globはマッチするモノを返すから混ぜるとよくないかな。。。
- 投稿日:2021-03-21T20:21:33+09:00
Steam Web APIでデータ収集
PCゲームのダウンロード兼販売プラットフォームであるSteamでは
Web APIが公開されており、ユーザー情報やサーバー情報など様々なデータを取得することができる。
Web APIの使用方法を学ぶついでに、データ分析の練習に使用するデータを集めることにした。
Steam Web APIの機能は、PyPIにてpython用のラッパーがいくつか公開されているが、今回は自分で機能を実装してみる。準備するもの
- steamアカウント(必須)
https://store.steampowered.com/login/
- apiキー(必須)
steamアカウントを使って発行。Web API利用時に必要。
http://steamcommunity.com/dev/apikey
api_key = "XXXXX"
- steamID(任意)
自分のでも良いし他人のでも構わない。
ただしプロフィール公開度が「公開」になっているアカウントでないとデータが取得できない。
steamidfinderで適当にアカウントを検索するのも手。
uid = "XXXXX"ユーザー情報取得関数の作成
IPlayerService インターフェースを実装する。
ドキュメントを参考に、型となるurlを作成し、json形式で受け取るよう指定。
受け取ったデータをデコードして、"response"キーに対応した値を取得。import json import requests def GetOwnedGames(api_key, uid): url = "http://api.steampowered.com/IPlayerService/GetOwnedGames/v1/?key={}&steamid={}&format=json".format( api_key, uid ) r = requests.get(url) data = json.loads(r.text) return data["response"]ownd_games = GetOwnedGames(api_key, uid) print(ownd_games["game_count"]) #所持ゲーム数 print(ownd_games["games"]) # 所持ゲームの詳細(appid, プレイ時間等)その他の機能もurlと引数を変えるだけで関数化できる。
数が多いので他の関数の実装方法は省略(jupyter notebook)。
使用例
steamレベルが非常に高いことで有名な、St4ck氏のデータを取得してみた(2021/03/21)
Steamにて、大金をかけアカウントを「レベル4000」に到達させたユーザー現る。カタールの王族であるとの噂
(補足)SteamレベルについてSteamレベルとは、Steamプロフィールの右上に表示されている数字である。レベルを上げる手順を、まずざっくりと説明しよう。Steamにてトレーディングカード対応のゲームを一定時間プレイすることで、カードをドロップ。ドロップだけではカードはコンプリートできないので、カードを購入してタイトルごとのカードを揃え、バッジが完成する。バッジを完成させれば経験値がたまっていき、指定の経験値をためるとレベルがアップするという流れだ。(https://automaton-media.com/articles/newsjp/20190118-83483/)
uid = 76561198023414915所有しているゲーム
ownd_games = GetOwnedGames(api_key, uid) ownd_games["game_count"] 4728所有ゲーム数 4728
ownd_games["games"][:5] [{'appid': 10, 'playtime_forever': 0, 'playtime_windows_forever': 0, 'playtime_mac_forever': 0, 'playtime_linux_forever': 0}, {'appid': 80, 'playtime_forever': 0, 'playtime_windows_forever': 0, 'playtime_mac_forever': 0, 'playtime_linux_forever': 0}, {'appid': 100, 'playtime_forever': 0, 'playtime_windows_forever': 0, 'playtime_mac_forever': 0, 'playtime_linux_forever': 0}, {'appid': 300, 'playtime_forever': 0, 'playtime_windows_forever': 0, 'playtime_mac_forever': 0, 'playtime_linux_forever': 0}, {'appid': 20, 'playtime_forever': 0, 'playtime_windows_forever': 0, 'playtime_mac_forever': 0, 'playtime_linux_forever': 0}]所有しているゲームのIDとプレイ時間を取得
# 最近遊んだゲーム数を表示 recently_played_games["total_count"] 3最近遊んだゲーム
# 最近遊んだゲーム recently_played_games["games"][:3] [{'appid': 433850, 'name': 'Z1 Battle Royale', 'playtime_2weeks': 4871, 'playtime_forever': 131291, 'img_icon_url': 'aee7491abfd812e2fbb4ec3326ad5f4b85c8137a', 'img_logo_url': 'b83cffe1839f3ecaec18754844b21bda9b397659', 'playtime_windows_forever': 4965, 'playtime_mac_forever': 0, 'playtime_linux_forever': 0}, {'appid': 730, 'name': 'Counter-Strike: Global Offensive', 'playtime_2weeks': 49, 'playtime_forever': 414870, 'img_icon_url': '69f7ebe2735c366c65c0b33dae00e12dc40edbe4', 'img_logo_url': 'd0595ff02f5c79fd19b06f4d6165c3fda2372820', 'playtime_windows_forever': 1200, 'playtime_mac_forever': 0, 'playtime_linux_forever': 0}, {'appid': 1238860, 'name': 'Battlefield 4™ ', 'playtime_2weeks': 31, 'playtime_forever': 13969, 'img_icon_url': 'fe0bd4bd2adde978ca411a4b2725c1b6d72717ef', 'img_logo_url': '6f4f3bf49342fcf38f9e7c63b9d9148b42c53b0b', 'playtime_windows_forever': 13969, 'playtime_mac_forever': 0, 'playtime_linux_forever': 0}]最近(おそらく2週間以内)遊んだゲームが表示される。こちらはゲーム名も明記されるらしい
Steamレベル
# レベルの表示 steam_level = GetSteamLevel(api_key, uid) steam_level 5000ニュース記事では4000超だったのが5000に増えていた。
バッジ
# バッジ情報 badges["badges"][:3] [{'badgeid': 48, 'level': 1070, 'completion_time': 1607333397, 'xp': 2070, 'scarcity': 4795}, {'badgeid': 49, 'level': 1, 'completion_time': 1616276919, 'xp': 10, 'scarcity': 3201589}, {'badgeid': 13, 'level': 4608, 'completion_time': 1615953180, 'xp': 4858, 'scarcity': 17877}]# 総経験値 badges["player_xp"] 125265813基本的にバッジ1つ作成で100 xpであることを考えると恐ろしい経験値。
コミュニティバッジ進捗
# コミュニティバッジ進捗 community_Badge_Progress [{'questid': 115, 'completed': True}, {'questid': 128, 'completed': True}, {'questid': 134, 'completed': True}, {'questid': 133, 'completed': True}, {'questid': 132, 'completed': True}, {'questid': 108, 'completed': True}, {'questid': 113, 'completed': True}, {'questid': 112, 'completed': True}, {'questid': 104, 'completed': True}, {'questid': 105, 'completed': True}, {'questid': 106, 'completed': False}, {'questid': 114, 'completed': True}, {'questid': 119, 'completed': True}, {'questid': 121, 'completed': True}, {'questid': 110, 'completed': True}, {'questid': 111, 'completed': True}, {'questid': 126, 'completed': True}, {'questid': 101, 'completed': True}, {'questid': 103, 'completed': True}, {'questid': 118, 'completed': True}, {'questid': 117, 'completed': True}, {'questid': 109, 'completed': True}, {'questid': 124, 'completed': True}, {'questid': 127, 'completed': True}, {'questid': 125, 'completed': True}, {'questid': 123, 'completed': True}, {'questid': 120, 'completed': True}, {'questid': 122, 'completed': True}]コミュニティバッジ入手のために課されたクエストの達成状況
上から順に
"Steamガードを有効化", "携帯番号の追加", "Steamモバイルアプリを利用", "ブロードキャストを表示", "ストアディスカバリーキューを使用", "ウィッシュリストにゲームを追加", "フレンドリストにフレンドを追加", "ゲームをプレイ", "ゲームのレビューを書く", "スクリーンショットを投稿", "ムービーを投稿", "ワークショップのアイテムを評価", "ワークショップのアイテムをサブスクライブ", "Steamオーバーレイからガイドを表示", "コミュニティプロフィールにアバターを設定", "コミュニティプロフィールに本名を設定", "プロフィールの背景を設定", "グループに参加", "フレンドのプロフィールにコメント", "アクティビティフィード内のコンテンツを評価", "フレンドに向けてコメントを投稿", "フレンドのスクリーンショットにコメント", "ゲームバッジを作成", "プロフィール上にバッジを張り付け", "チャット内で絵文字を使用", "掲示板を検索", "コミュニテイマーケットを利用", "トレードを利用",11番目のクエストである動画投稿は、まだやったことがないらしい。
上記のユーザー情報は、基本的にSteamのプロフィールページからも閲覧可能なものばかりだが、Web APIを使用すれば高速かつ大量のデータを得ることができる。
(細かな違いとしては、OS別でのゲームプレイ時間の閲覧や、携帯番号を追加しているかの確認はプロフィールページ上では不可能だった。APIを利用した方がより多くの情報を得られる様子)データ収集
steamidは17桁。いくつかのsteamアカウントをhttps://steamidfinder.com/ で適当に検索すると、
初めの"76561198"は全員同じだった。for i in tqdm(range(5)): # 76561198000000000 ~ 76561198999999999が格納されたジェネレータから候補ID抽出 random_numbers = (i for i in range(76561198000000000, 76561199000000000)) ids = random.sample(list(random_numbers), 100) result = GetPlayerSummaries(api_key, ids) print(len(result)) # 54, 65, 62, 71, 59。期待値62.2 # IDの先頭8桁目を変えてみる for i in tqdm(range(5)): # 76561197000000000 ~ 76561197999999999が格納されたジェネレータから候補ID抽出 random_numbers = (i for i in range(76561197000000000, 76561198000000000)) ids = random.sample(list(random_numbers), 100) result = GetPlayerSummaries(api_key, ids) print(len(result)) # 3,2,1,2,2 ほとんどヒットしない for i in tqdm(range(5)): # 76561199000000000 ~ 76561199999999999が格納されたジェネレータから候補ID抽出 random_numbers = (i for i in range(76561199000000000, 76561200000000000)) ids = random.sample(list(random_numbers), 100) result = GetPlayerSummaries(api_key, ids) print(len(result)) # 19, 14, 12, 18, 28 微妙。この部分をsteamidの識別子として利用していると仮定して、残り9桁を乱数で生成。
デタラメなidから実在するアカウントを1万件探して情報を取得。標本は10000件程度欲しいので、多めに見積もって20000個乱数を生成する。想定通りなら12000件ぐらい取れるはず。
# ID候補が入ったジェネレータ作成 random_numbers = (i for i in range(76561198000000000, 76561199000000000)) # 2万件抽出 ids = random.sample(list(random_numbers), 20000) # 100件ずつしかリクエストできないので分割 ids_list = list(np.array_split(ids, 200)) # 出力ファイル初期化 pd.DataFrame( { "steamid": [], "personaname": [], "timecreated": [], } ).to_csv("user_info.csv") for i in tqdm(ids_list): # リクエスト用のID文字列作成 ids_str = ",".join([str(j) for j in i]) # ユーザー情報取得 result = GetPlayerSummaries(api_key, ids_str) # ID, name, createtimeを取得して辞書化しリストに格納 user_info_list = [] for i in result: user_info = {} user_info["steamid"] = i["steamid"] user_info["personaname"] = i["personaname"] # 作成日がないユーザーに対しては例外処理 try: user_info["timecreated"] = i["timecreated"] except KeyError: user_info["timecreated"] = "" user_info_list.append(user_info) # 出力 # 大体60件ずつ追加されていることを確認したいのでindexは残す pd.DataFrame(user_info_list).to_csv("user_id.csv", mode="a", header=False)確認すると11508件入手できた。
入手したIDを使ってユーザー情報を取得。1件あたり1~2秒程度かかる。# ユーザー情報を取得 user_info_list = [] steam_ids = df["steamid"] for id in tqdm(steam_ids): user_info = {} user_info["steamid"] = id # 情報が取得できないユーザーがいたので例外処理 # プロフィールを非表示設定にしている場合は取得できない? # 所持ゲーム ownd_games = GetOwnedGames(api_key, id) try: user_info["game_count"] = ownd_games["game_count"] user_info["games"] = ownd_games["games"] except KeyError: user_info["game_count"] = None user_info["games"] = None # バッジ情報 badges = GetBadges(api_key, id) try: user_info["badges"] = badges["badges"] user_info["player_xp"] = badges["player_xp"] user_info["player_level"] = badges["player_level"] # コミュニティバッジ進捗 community_Badge_Progress = GetCommunityBadgeProgress(api_key, id, 2) user_info["cleard_quests"] = len( [i for i in community_Badge_Progress if i["completed"] == True] ) user_info["quests"] = community_Badge_Progress except KeyError: user_info["badges"] = None user_info["player_xp"] = None user_info["player_level"] = None user_info["cleard_quests"] = None user_info["quests"] = None user_info_list.append(user_info) # ウェイト時間を設けておく time.sleep(0.5) # DF化→jsonで出力 badge_df = pd.DataFrame(user_info_list) badge_df.to_json("user_info.json")次回は、作成したjsonファイルを使ってデータを分析してみる予定。
作成したスクリプトは以下のページで閲覧できます。
https://github.com/Chronona/FetchSteamUserInfo/blob/main/fetch_user_info.ipynb
- 投稿日:2021-03-21T20:17:46+09:00
PythonでSpotify楽曲のジャケット画像付きNowPlayingツイートをする
概要
Spotify APIとTwitter APIを利用してPythonで#NowPlayingします。
一番最後にコード全文を記載してあります。プログラミング自体超初学者なのでおかしいところは多々あると思いますがご了承ください。
APIについて
SpotifyについてもTwitterについてもまずKeyやtokenを取得する必要があります。
・Spotify API
Spotify for Developersでログインし、My Dashboardから「CREATE AN APP」→適当に情報を入力すると
上のようなページにアクセスします。「SHOW CLIENT SECRET」をクリックし、
・Client ID
・Client Secret
をメモ帳などにメモっといてください。
次に「EDIT SETTINGS」でRedirect URIsにhttps://example.com/callback/ と入力し「ADD」、下部の「SAVE」を押しときましょう。ここのURLはよくわかんねえけどとりあえずこれにしときます。これでSpotify APIの準備はOK。・Twitter API
Twitter APIを使うにはSpotifyとは異なり、申請をして審査に通らなければなりません。
Twitterでアカウントに電話番号を登録してからここで申請をしてください。詳しくは参考サイトを御覧ください。
英作文がだるい方はDeepLなんかの翻訳を使っても良いでしょう。てか使ったほうがいいです。楽だし。
各質問の回答はざっくり言うと、「Pythonの勉強をするためにTwitter APIを使って情報を収集し、分析したい」、「いいねやRTが多いツイートにはどのような単語が含まれているかなどの特徴を調べたい」などと書きました。申請をすると件名が「Verify your Twitter Developer Account」で、メールアドレスの確認をしてくれという内容のメールが届いたのでメール内のConfirm your emailを押します。参考サイトによると申請結果についてのメールが届くようですが、自分の場合先程のメアド確認だけ届き、申請結果についてのメールは届きませんでした。まあ申請直後にtokenとか取得できたから即審査通ったってことでヨシ!
- 申請時と同じURLにアクセス「Create an app」をクリックして諸々を入力する。
- 「App settings」→「App permissions」→「Edit」で「Read + Write + Direct Messages」にする。
- 「Keys and tokens」タブを開き、Consumer KeysのAPI key & secretから「API keys」と「API key secret」、Authentication TokensのAccess token & secretから「Access token」と「Access token secret」を取得し、必ずメモってください。 たしかパーミッションの設定を変更するとアクセストークンが変化したと思います。上記の順番を守って各種キーを取得すれば大丈夫です。
API申請~各種キー取得までよくわからなければこのサイトにも詳しく書いてありますので参考にしてください。
APIのライブラリ
spotipyとtweepyを使います。コマンドプロンプトで
pip install spotipy
pip install tweepy
と入力してインストールしておいてください。APIの認証
Spotifyのアカウント情報からユーザー名をメモっといてください。
NowPlaying.pyimport spotipy import tweepy # Spotify APIの認証 username = 'ユーザー名' client_id = 'XXXXXXXXXX' client_secret = 'XXXXXXXXXX' redirect_uri = 'https://example.com/callback/' scope = 'user-read-currently-playing' token = spotipy.util.prompt_for_user_token(username, scope, client_id, client_secret, redirect_uri) sp = spotipy.Spotify(auth = token, language='ja') # language='ja'ついての詳細は下記 # Twitterの認証 consumer_key = 'XXXXXXXXXX' consumer_secret = 'XXXXXXXXXX' access_token = 'XXXXXXXXXX' access_token_secret = 'XXXXXXXXXX' auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth)これで各種APIが使えるようになりました。
再生中楽曲情報の取得
とりあえず書いたコードは次のようになります。
NowPlaying.pyimport requests # 再生中楽曲情報の取得 current_track = sp.current_user_playing_track() # 情報取得 playing_track = current_track['item'] # 'item'を開く artist_name = playing_track['album']['artists'][0]['name'] # アーティスト名を取得 album_name = playing_track['album']['name'] # アルバム名を取得 track_name = playing_track['name'] # 楽曲名を取得 track_url = playing_track['external_urls']['spotify'] # 楽曲URLを取得 # ジャケット画像取得 & 保存 url = playing_track['album']['images'][0]['url'] # ジャケット画像のURLを取得 file_name = 'picture.jpg' response = requests.get(url) img = response.content with open(file_name, 'wb') as art: art.write(img)詳しく
current_track = sp.current_user_playing_track()で現在Spotifyで再生している楽曲情報を取得することができます。楽曲情報
current_trackの中身はimport pprint pprint.pprint(current_track)を実行することで綺麗に表示できます。例としてみんな大好きYOASOBIの「夜に駆ける」を再生して実行し、
current_trackの中身を見てみます。(省略部分あり){'actions': {'disallows': {'resuming': True}}, 'context': {'external_urls': {'spotify': 'https://open.spotify.com/album/3GzwPyPZCyrqUTaurTaS23'}, 'href': 'https://api.spotify.com/v1/albums/3GzwPyPZCyrqUTaurTaS23', 'type': 'album', 'uri': 'spotify:album:3GzwPyPZCyrqUTaurTaS23'}, 'currently_playing_type': 'track', 'is_playing': True, 'item': {'album': {'album_type': 'single', 'artists': [{'external_urls': {'spotify': 'https://open.spotify.com/artist/64tJ2EAv1R6UaZqc4iOCyj'}, 'href': 'https://api.spotify.com/v1/artists/64tJ2EAv1R6UaZqc4iOCyj', 'id': '64tJ2EAv1R6UaZqc4iOCyj', 'name': 'YOASOBI', 'type': 'artist', 'uri': 'spotify:artist:64tJ2EAv1R6UaZqc4iOCyj'}], 'available_markets': ['AD', ..., 'ZA'], 'external_urls': {'spotify': 'https://open.spotify.com/album/3GzwPyPZCyrqUTaurTaS23'}, 'href': 'https://api.spotify.com/v1/albums/3GzwPyPZCyrqUTaurTaS23', 'id': '3GzwPyPZCyrqUTaurTaS23', 'images': [{'height': 640, 'url': 'https://i.scdn.co/image/ab67616d0000b273c5716278abba6a103ad13aa7', 'width': 640}, {'height': 300, 'url': 'https://i.scdn.co/image/ab67616d00001e02c5716278abba6a103ad13aa7', 'width': 300}, {'height': 64, 'url': 'https://i.scdn.co/image/ab67616d00004851c5716278abba6a103ad13aa7', 'width': 64}], 'name': '夜に駆ける', 'release_date': '2019-12-15', 'release_date_precision': 'day', 'total_tracks': 1, 'type': 'album', 'uri': 'spotify:album:3GzwPyPZCyrqUTaurTaS23'}, 'artists': [{'external_urls': {'spotify': 'https://open.spotify.com/artist/64tJ2EAv1R6UaZqc4iOCyj'}, 'href': 'https://api.spotify.com/v1/artists/64tJ2EAv1R6UaZqc4iOCyj', 'id': '64tJ2EAv1R6UaZqc4iOCyj', 'name': 'YOASOBI', 'type': 'artist', 'uri': 'spotify:artist:64tJ2EAv1R6UaZqc4iOCyj'}], 'available_markets': ['AD', ..., 'ZA'], 'disc_number': 1, 'duration_ms': 261013, 'explicit': False, 'external_ids': {'isrc': 'JPP301900716'}, 'external_urls': {'spotify': 'https://open.spotify.com/track/3dPtXHP0oXQ4HCWHsOA9js'}, 'href': 'https://api.spotify.com/v1/tracks/3dPtXHP0oXQ4HCWHsOA9js', 'id': '3dPtXHP0oXQ4HCWHsOA9js', 'is_local': False, 'name': '夜に駆ける', 'popularity': 79, 'preview_url': 'https://p.scdn.co/mp3-preview/11baebef4acdc0b95a329ebe195ce3c74f94fa08?cid=97222c253f5e4a9594334da03aa5f8dc', 'track_number': 1, 'type': 'track', 'uri': 'spotify:track:3dPtXHP0oXQ4HCWHsOA9js'}, 'progress_ms': 27052, 'timestamp': 1616320258470}楽曲情報
current_trackの中にはアーティスト名YOASOBI、楽曲名夜に駆ける、その他にも色々なURLや人気度なんかも入っていることが確認できます。
これらの情報は'item'の中に入っているためplaying_track = current_track['item']と置きます。
この中から#NowPlayingに必要な情報である
1. アーティスト名
2. アルバム名
3. 楽曲名
4. ジャケット画像
5. ついでにSpotifyの楽曲URL
を抽出していくと次のようになります。current_track = sp.current_user_playing_track() # 情報取得 playing_track = current_track['item'] # 'item'を開く artist_name = playing_track['album']['artists'][0]['name'] # アーティスト名を取得 album_name = playing_track['album']['name'] # アルバム名を取得 track_name = playing_track['name'] # 楽曲名を取得 track_url = playing_track['external_urls']['spotify'] # 楽曲URLを取得次にジャケット画像を取得します。
current_trackの中にはジャケット画像のURLが存在するため、そのURLから画像を保存します。import requests url = playing_track['album']['images'][0]['url'] # ジャケット画像のURLを取得 file_name = 'picture.jpg' response = requests.get(url) img = response.content with open(file_name, 'wb') as art: art.write(img)以上で、なうぷれに必要な各種情報は揃いました。
画像付き#NowPlayingツイート
最後にtweepyで画像付きツイートをします。ここではアルバム名は表記していませんが、お好みで書き足してください。
NowPlaying.pytweet = '#NowPlaying:' + track_name + ' by ' + artist_name + '\n' + track_url # ツイート文章 api.update_with_media(status=tweet, filename='./picture.jpg') # やっとツイート! print('「' + tweet + '」' + 'をツイートしました。')これでジャケット画像付きなうぷれツイが出来ます。試しに緑黄色社会のMela!で実行してみます。
「#NowPlaying:Mela! by Ryokuoushoku Shakai https://open.spotify.com/track/6IO5nn84TKArsi3cjpIqaD」をツイートしました。アーティスト名がローマ字になってしまいました...
ここで前述したlanguage='ja'が効いてくるわけです。アーティスト名を日本語表記するには
sp = spotipy.Spotify(auth = token)と書くとアーティスト名がローマ字表記になってしまうことがあります。
sp = spotipy.Spotify(auth = token, language='ja')とすることで日本語表記に出来ます。実行してみましょう。
「#NowPlaying:Mela! by 緑黄色社会 https://open.spotify.com/track/6IO5nn84TKArsi3cjpIqaD」をツイートしました。無事、アーティスト名が日本語表記になりました。
全文
NowPlaying.pyimport spotipy import tweepy import requests # Spotify APIの認証 username = 'ユーザー名' client_id = 'XXXXXXXXXX' client_secret = 'XXXXXXXXXX' redirect_uri = 'https://example.com/callback/' scope = 'user-read-currently-playing' token = spotipy.util.prompt_for_user_token(username, scope, client_id, client_secret, redirect_uri) sp = spotipy.Spotify(auth = token, language='ja') # Twitterの認証 consumer_key = 'XXXXXXXXXX' consumer_secret = 'XXXXXXXXXX' access_token = 'XXXXXXXXXX' access_token_secret = 'XXXXXXXXXX' auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth) # 再生中楽曲情報の取得 current_track = sp.current_user_playing_track() # 再生中楽曲情報の取得 playing_track = current_track['item'] # 'item'を開く artist_name = playing_track['album']['artists'][0]['name'] # アーティスト名の取得 album_name = playing_track['album']['name'] # アルバム名の取得 track_name = playing_track['name'] # 楽曲名の取得 track_url = playing_track['external_urls']['spotify'] # 楽曲URLの取得 # ジャケット画像取得 url = playing_track['album']['images'][0]['url'] # ジャケット画像のURLの取得 file_name = 'picture.jpg' # 画像のファイル名 response = requests.get(url) img = response.content with open(file_name, 'wb') as art: art.write(img) # 画像付きNowPlayingツイート tweet = '#NowPlaying:' + track_name + ' by ' + artist_name + '\n' + track_url api.update_with_media(status=tweet, filename='./picture.jpg') print('「' + tweet + '」' + 'をツイートしました。')参考サイト
NowPlayingをPythonでTweetする
Pythonを用いてSpotifyのプレイリストを作成&再生してみる
Twitter APIで遊んでみた ~1. 各種キーの申請と取得~
Twitter APIキーとトークンの取得方法
Spotify API でアーティスト名を日本語表記で取得する

- 投稿日:2021-03-21T20:11:51+09:00
python discord.py ニコニコ動画をボイスチャンネルで流す。
なぜやろうとしたか
自分のBotに入れたかったから。
知識や正式名称をしっかり覚えてなくガバガバな解説になっている可能性があります。
その時はコメントで優しく指摘してください。ニコニコ動画流すのに使用するモジュールとどういう感じにできてるか(長い)
使用するモジュールは
niconico_dl_asyncです。
pip install niconico_dl_asyncでインストール可能。niconico_dlのどういう感じに動いてるか。
ニコニコ動画の動画のページのHTMLのとあるdivにjson形式で動画の情報がある。
そこから通信に必要なのとってニコニコ動画と通信する。
(通信に必要なのはsessionというキーの中身)
この時から定期的に生きてるよーと発信しないと動画取得できない。(heartbeatとかいうやつ)
生きてるよーと発信している間にゲットした動画のリンクから動画を取得する。
っていう感じです。
なぜこんなに知っているかはniconico_dlと自分について調べれば . . .コード
コメントアウトが説明になっている。
# NicoNico import discord from niconico_dl_async import NicoNico client = discord.Client() # 起動したらメッセージ。 @client.event async def on_ready(): print("起動しました。") @client.event async def on_message(message): # もしBotだったら反応しない。 if message.author.bot: return # メッセージの内容の最初が!playなら。 if message.content.startswith("!play"): # チャンネルに入力中を送信する。 await message.channel.trigger_typing() # もしボイスチャンネルに接続していないなら、コマンド実行者のボイスチャンネルに接続する。 if not message.guild.voice_client: await message.author.voice.channel.connect() # メッセージの内容を/で分けてできたリストの最後を取得する。 # urlの最後にニコニコ動画のIDがあるはずだからそれをniconico_dlに渡す。 nico_id = message.content.split("/")[-1] niconico = NicoNico(nico_id) # 動画のURLを取得する。 url = await niconico.get_download_link() # 動画のURLからオーディオソースを作る。(ffmpegが必要) player = discord.FFmpegPCMAudio(url) # 再生する。 # playのafterという引数に終了時に実行してほしいものを入れた関数を入れることができる。 # niconico_dlはurlの使用が終わった後にclose()しなければいけない。 # なのでclose()をしてくれる関数をafterに入れる。 # 入れる関数にはエラー時のエラーメッセージをとる。 # 今回はlambdaを使って関数を作る。(lambdaについてはここを参考にしよう: https://qiita.com/nagataaaas/items/531b1fc5ce42a791c7df) after = lambda e: niconico.close() message.guild.voice_client.play(player, after=after) # 通知メッセージ。 await message.channel.send("再生します。") # 接続する。 client.run("TOKEN")最後に
特にない。
ばいばい
- 投稿日:2021-03-21T19:14:40+09:00
Python + OpenCVで顔写真のトリミング
今年も春がやってくる。生徒の顔写真をトリミングしなければいけない。
パソコンが勝手にやってくれないかなと思いつつ、色々と検索して、やってみたら出来たので、備忘録的に書いてみようと思う。環境はWindows10です。使うのは'Python'なのですが、名前を聞いたことあるぐらいの知識。'OpenCV'ってのを使って、顔認識させられるらしいという事が分かった。
そこで、環境の準備から。
まず、OpenCVをダウンロードします。
ここからWindows版のOpenCVを入手できます。ダウンロードしたアーカイブをダブルクリックすると、自動で解凍してくれますので、解凍された'opencv'フォルダを、Cドライブの直下に移動します。
そして、環境変数をいじって、pathを通します。
具体的には、コントロールパネル>システムとセキュリティ>システム>システムの詳細設定>環境変数>path>新規
で、'C:\opencv\build\x64\vc15\bin'を追加しておきます。次に、Visual Studio のインストールを行いました。
もちろん、無料のやつね。
Pythonを扱えるように、インストールします。
インストールしたら、Pythonアプリケーションを適当な名前で作成します。
作成したら、Pythonパッケージの管理で、OpenCV環境を扱えるようにします。
検索で、openと入れると、候補にopencv-python(バージョン番号)が現れると思うので、それを入れます。これで、準備はOKです。
では、コードを書いていきます。
#リソースのインポート import cv2 import glob import os #trimフォルダの作成 os.makedirs('trim', exist_ok=True) #カスケード型分類器に使用する分類器のデータ(xmlファイル)を読み込み HAAR_FILE = "C:\opencv\sources\data\haarcascades\haarcascade_frontalface_alt.xml" cascade = cv2.CascadeClassifier(HAAR_FILE) #ファイルリストの取得 files = glob.glob("*.jpg") for file in files: #取得したファイル名の表示 print(file) #画像ファイルの読み込み img = cv2.imread(file) #グレースケールに変換 img2 = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY) #カスケード型分類器を使用して画像ファイルから顔部分を検出する face = cascade.detectMultiScale(img2,minSize=(100,100)) #顔部分を切り取り、リサイズする。 for x,y,w,h in face: #横幅のエリアを1.6倍にし、縦幅のエリアを2.23倍にすることで、4:3の比率でカット face_cut = img[y-int(h*0.6):y+int(h*1.53), x-int(w*0.3):x+int(w*1.3)] #カットした画像を800*600のサイにする。 resize_img = cv2.resize(face_cut , dsize=(600, 800)) #画像の出力 cv2.imwrite('trim\\' + file , resize_img )これで、このソースと同じフォルダにある複数のjpgファイルから顔部分だけ4:3の比率でトリミングして、800*600にリサイズして、trimという名前のサブフォルダを作成して、同じ名前で保存するという作業をしてくれるようになりました。
参考になったページはたくさんあったのですが、自分が記事を書くとは思っていなかったので、追えませんでした…。
私と同じ仕事をしている方の助けになれば幸いです。





- 投稿日:2021-03-21T18:20:47+09:00
PythonでSAMLを実装
シングルサインオンの実装を理解するため、IDプロバイダの設定とサービスプロバイダをローカルで動作させるまでの手順をまとめました。
IDプロバイダにはAzureADを、サービスプロバイダにはhttps://github.com/onelogin/python3-saml というライブラリに含まれるpythonで書かれたflaskサーバーのサンプルを動作させます。
IDプロバイダ(AzureAD)の設定
- Azureポータルを開く(サブスクリプションが作成済みである必要があると思う)
- エンタープライズアプリケーションを開く
- 「新しいアプリケーション」>「独自のアプリケーションの作成」をクリックし「 Integrate any other application you don't find in the gallery (Non-gallery)」を選択してアプリを作成
- 作成したアプリに移動し、「シングルサインオン」を開く。「SAML」を選択して下記を設定。
- 識別子 (エンティティ ID):
http://localhost:8000/metadata/- 応答 URL:
http://localhost:8000/?acs- ユーザーとグループを開き、 「ユーザーまたはグループの追加」をクリックして、動作テストしたいユーザーを追加する
サービスプロバイダの設定
- サンプルコードをクローン
git clone git@github.com:onelogin/python3-saml.git
- Azureポータル > エンタープライズアプリケーション > (作成したアプリ)> シングルサインオン に表示されている内容を参考に./demo-flask/saml/settings.jsonを設定する
- sp.entityId:
http://localhost:8000/metadata/- sp.assertionConsumerService.url:
http://localhost:8000/?acs- sp.singleLogoutService.url:
http://localhost:8000/?sls- idp.entityId: XXX(アプリ名)のセットアップ > ログイン URL
- idp.singleSignOnService.url: XXX(アプリ名)のセットアップ > Azure AD 識別子
- idp.singleLogoutService.url: XXX(アプリ名)のセットアップ > ログアウト URL
- idp.x509cert: SAML 署名証明書 > 証明書 (Base64) をダウンロードした中身の文字列(改行やBEGIN CERTIFICATEなどの行は削除)
- Mac上での実行に要求されるなライブラリのインストール(必要であれば)
# 参考 https://pypi.org/project/xmlsec/ brew install libxml2 libxmlsec1 pkg-config
- パッケージのインストール
python setup.py install pip install -r demo-flask/requirements.txt
- サーバーの起動
cd demo-flask python index.py
- http://localhost:8000 にアクセスしログインすると、ユーザーの情報が取得できていることが確認できます
参考にしたリンク
- 投稿日:2021-03-21T18:19:23+09:00
【OpenCV】マウスイベントのグローバル変数を消す【Python】
OpenCVのマウスイベントの記述で「グローバル変数使わなあかんのか…」となってしまった人用
結論、マウスイベントの第三引数
paramに辞書型で渡してあげましょう。def Something(event,x,y,flags,param): global aaa,bbb,ccc aaa = 何らかの処理 if __name__=="__main__": global aaa,bbb,ccc cv2.setMouseCallback(windowName,Something)これを、
def Something(event,x,y,flags,param): param["aaa"] = 何らかの処理 if __name__=="__main__": param = {"aaa":初期値,"bbb":初期値,"ccc":初期値} cv2.setMouseCallback(windowName,Something,param)辞書型で渡してやると参照渡しになるので変数の中身が更新されるのがミソ
タプルとかでマウスイベントに渡すと値がそのまま渡されるので、「マウスイベントが実行されるたびにメインで記述した値」が渡されて値が更新されません。
なので、クリック回数の保存とかをしたいときはグローバル変数にするか辞書型で渡すのが有効だったということですね。この記事に出てくるソースコードではグローバル変数を使っていました。
↓に辞書型に書き直したコードを置いておきます。
import cv2 import numpy as np import math def draw_circle(event,x,y,flags,param): distR = math.ceil(math.sqrt((x-param["centerX"])**2 + (y-param["centerY"])**2)) if event == cv2.EVENT_LBUTTONDOWN: param["cnt"] += 1 param["isGrabbed"] = True if param["cnt"] == 1: [param["centerX"],param["centerY"]] = [x,y] if param["cnt"]>1: if param["posState"] == 0: # inside param["isInside"] = True param["isOntheLine"] = False param["distX"] = param["centerX"] - x param["distY"] = param["centerY"] - y elif param["posState"] == 1: # on the line param["isInside"] = False param["isOntheLine"] = True elif param["posState"] == 2: param["isInside"] = False param["isOntheLine"] = False if event == cv2.EVENT_LBUTTONUP: param["isGrabbed"] = False if event == cv2.EVENT_MOUSEMOVE: if param["cnt"] == 0: [param["centerX"],param["centerY"]] = [x,y] if param["cnt"] > 0: if param["isGrabbed"] == False: if distR < param["r"]-5: # inside param["posState"] = 0 param["color"] = (255,0,0) elif (distR <= param["r"]+5) & (distR >= param["r"]-5): # on the line param["posState"] = 1 param["color"] = (0,255,0) elif distR > param["r"]+5: # outside param["posState"] = 2 param["color"] = (0,0,255) else: if param["isInside"] == True: param["centerX"] = x+param["distX"] param["centerY"] = y+param["distY"] elif param["isOntheLine"] == True: param["r"] = distR img_tmp = testIm.copy() cv2.circle(img_tmp,(param["centerX"],param["centerY"]), param["r"], param["color"], 5) cv2.imshow(windowName,img_tmp) if __name__=="__main__": testIm = cv2.imread(r'C:\****\sample_pic.jpg') windowName = "Select window" param = {"centerX":0,"centerY":0,"cnt":0,"r":50,"distX":0,"distY":0,"isGrabbed":False,"isInside":False,"isOntheLine":False,"color":(0,0,255),"posState":0} cv2.namedWindow(windowName) cv2.setMouseCallback(windowName,draw_circle,param) cv2.imshow(windowName,testIm) key = cv2.waitKey()
- 投稿日:2021-03-21T18:13:16+09:00
Windows10で、ウインドウを最前面に設定/解除する方法
Pythonで、Windows10のアプリケーションを最前面に表示/解除させる方法です。
以下のパッケージが必要です。
pip install pywin32importするのはpywin32ではなく、win32guiとなります。
import win32gui # ウインドウのハンドルを取得する hwnd = win32gui.FindWindow(None, title) # windowのハンドルを取得 # 最前面表示の設定 win32gui.SetWindowPos(hwnd, win32con.HWND_TOPMOST, 0, 0, 0, 0, win32con.SWP_NOMOVE | win32con.SWP_NOSIZE) # 最前面表示の解除 win32gui.SetWindowPos(self.hwnd, win32con.HWND_NOTOPMOST, 0, 0, 0, 0, win32con.SWP_NOMOVE | win32con.SWP_NOSIZE)titleにはウインドウタイトルを入れてることで、それをキーにウインドウハンドルが取得できます。
(参考)
https://office54.net/python/app/windows-foreground-active
https://blog.goo.ne.jp/masaki_goo_2006/e/6ddf4977ba01dd11d6be256c17cc2ccf
- 投稿日:2021-03-21T18:01:39+09:00
C++で .npy(NumPy Arrays) ファイルを読み書きする
はじめに
機械学習など Python 上でデータをロードするときに、.csv ファイルで数値を文字列として入力するとサイズが大きく読み込み時に重くなったり、C++ で自分フォーマットとして出力すると、Pythonで読み込むのが大変といった経験はないだろうか?また、逆にPython上で得られた機械学習で結果をC++で読み込みたい。でも、HDF5フォーマットを使うのはオーバースペック...。そんなときは .npy(NumPy Arrays) ファイルで読み書きすると便利なときがある。C++での NumPy Arrays の入出力を実装したので参考にしていただきたい。
詳しいファイルフォーマットはこちらに記載されているので参考に。
https://numpy.org/doc/1.13/neps/npy-format.html#format-specification-version-1-0試しにPythonで .npy データを作る
まず1次元配列を出力する。Jupyter などで貼り付けて実行してみよう。
float と double のデータを出力してみる。import numpy as np outputDirectory = './' data = [1] * (5) npData = np.array(data, dtype=np.float32).reshape(5) np.save(outputDirectory + 'data_float_1d.npy', npData, allow_pickle=False) npData = np.array(data, dtype=np.float64).reshape(5) np.save(outputDirectory + 'data_double_1d.npy', npData, allow_pickle=False)バイナリエディタで確認
0x93NUMPY の後に 'shape':() で配列のサイズを指定している。その後にデータが続いている。
1次元配列の読み込み
C++で読み込む。
#include <fstream> #include <iostream> bool LoadNpy(const std::string& filePath, std::vector<float>& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f4'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d,)", &axis1); if (axis1 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); fs.read((char*)&data[0], sizeof(float) * axis1); } delete header; fs.close(); return true; } bool LoadNpy(const std::string& filePath, std::vector<std::vector<double> >& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f8'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1, axis2 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d, %d)", &axis1, &axis2); if (axis1 > 0 && axis2 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); for (int i = 0; i < axis1; i++) { data[i].resize(axis2); } for (int i = 0; i < axis1; i++) { fs.read((char*)&data[i][0], sizeof(double) * axis2); } } delete header; fs.close(); return true; }1次元配列の書き込み
書き込みも同様に実装。
#include <string> #include <cstdio> #include <vector> namespace { template <typename ... Args> std::string FormatString(const std::string& fmt, Args ... args) { size_t len = std::snprintf(nullptr, 0, fmt.c_str(), args ...); std::vector<char> buf(len + 1); std::snprintf(&buf[0], len + 1, fmt.c_str(), args ...); return std::string(&buf[0], &buf[0] + len); } } bool SaveNpy(const std::string& filePath, const std::vector<float>& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const std::string headerString = FormatString("{'descr': '<f4', 'fortran_order': False, 'shape': (%d,), }", axis1); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } fs.write((char*)&data[0], sizeof(float) * axis1); return true; } bool SaveNpy(const std::string& filePath, const std::vector<double>& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const std::string headerString = FormatString("{'descr': '<f8', 'fortran_order': False, 'shape': (%d,), }", axis1); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } fs.write((char*)&data[0], sizeof(double) * axis1); return true; }4次元配列までの読み書き
機械学習で用いられる配列は4次元までなので、すべて実装すると以下。ほとんどコピペ、、、マクロを使えばもう少し見やすくなるかもしれないが、もっといい方法はないものか・・・。
#include <fstream> #include <iostream> #include <string> #include <cstdio> #include <vector> namespace { template <typename ... Args> std::string FormatString(const std::string& fmt, Args ... args) { size_t len = std::snprintf(nullptr, 0, fmt.c_str(), args ...); std::vector<char> buf(len + 1); std::snprintf(&buf[0], len + 1, fmt.c_str(), args ...); return std::string(&buf[0], &buf[0] + len); } } bool LoadNpy(const std::string& filePath, std::vector<float>& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f4'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d,)", &axis1); if (axis1 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); fs.read((char*)&data[0], sizeof(float) * axis1); } delete header; fs.close(); return true; } bool LoadNpy(const std::string& filePath, std::vector<std::vector<float> >& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f4'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1, axis2 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d, %d)", &axis1, &axis2); if (axis1 > 0 && axis2 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); for (int i = 0; i < axis1; i++) { data[i].resize(axis2); } for (int i = 0; i < axis1; i++) { fs.read((char*)&data[i][0], sizeof(float) * axis2); } } delete header; fs.close(); return true; } bool LoadNpy(const std::string& filePath, std::vector<std::vector<std::vector<float> > >& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f4'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1, axis2 = -1, axis3 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d, %d, %d)", &axis1, &axis2, &axis3); if (axis1 > 0 && axis2 > 0 && axis3 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); for (int i = 0; i < axis1; i++) { data[i].resize(axis2); for (int j = 0; j < axis2; j++) { data[i][j].resize(axis3); } } for (int i = 0; i < axis1; i++) { for (int j = 0; j < axis2; j++) { fs.read((char*)&data[i][j][0], sizeof(float) * axis3); } } } delete header; fs.close(); return true; } bool LoadNpy(const std::string& filePath, std::vector<std::vector<std::vector<std::vector<float> > > >& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f4'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1, axis2 = -1, axis3 = -1, axis4 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d, %d, %d, %d)", &axis1, &axis2, &axis3, &axis4); if (axis1 > 0 && axis2 > 0 && axis3 > 0 && axis4 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); for (int i = 0; i < axis1; i++) { data[i].resize(axis2); for (int j = 0; j < axis2; j++) { data[i][j].resize(axis3); for (int k = 0; k < axis3; k++) { data[i][j][k].resize(axis4); } } } for (int i = 0; i < axis1; i++) { for (int j = 0; j < axis2; j++) { for (int k = 0; k < axis3; k++) { fs.read((char*)&data[i][j][k][0], sizeof(float) * axis4); } } } } delete header; fs.close(); return true; } bool LoadNpy(const std::string& filePath, std::vector<double>& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f8'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d,)", &axis1); if (axis1 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); fs.read((char*)&data[0], sizeof(double) * axis1); } delete header; fs.close(); return true; } bool LoadNpy(const std::string& filePath, std::vector<std::vector<double> >& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f8'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1, axis2 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d, %d)", &axis1, &axis2); if (axis1 > 0 && axis2 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); for (int i = 0; i < axis1; i++) { data[i].resize(axis2); } for (int i = 0; i < axis1; i++) { fs.read((char*)&data[i][0], sizeof(double) * axis2); } } delete header; fs.close(); return true; } bool LoadNpy(const std::string& filePath, std::vector<std::vector<std::vector<double> > >& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f8'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1, axis2 = -1, axis3 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d, %d, %d)", &axis1, &axis2, &axis3); if (axis1 > 0 && axis2 > 0 && axis3 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); for (int i = 0; i < axis1; i++) { data[i].resize(axis2); for (int j = 0; j < axis2; j++) { data[i][j].resize(axis3); } } for (int i = 0; i < axis1; i++) { for (int j = 0; j < axis2; j++) { fs.read((char*)&data[i][j][0], sizeof(double) * axis3); } } } delete header; fs.close(); return true; } bool LoadNpy(const std::string& filePath, std::vector<std::vector<std::vector<std::vector<double> > > >& data) { std::ifstream fs(filePath.c_str(), std::ios::in | std::ios::binary); if (fs.fail()) { return false; } // header 6 byte = 0x93NUMPY unsigned char magicString[6]; fs.read((char*)&magicString, sizeof(unsigned char) * 6); if ((unsigned char)(magicString[0]) != (unsigned char)0x93 || magicString[1] != 'N' || magicString[2] != 'U' || magicString[3] != 'M' || magicString[4] != 'P' || magicString[5] != 'Y') { std::cout << "[ERROR] Not NPY file" << std::endl; return false; } unsigned char major, minor; fs.read((char*)&major, sizeof(char) * 1); fs.read((char*)&minor, sizeof(char) * 1); unsigned short headerLength; fs.read((char*)&headerLength, sizeof(unsigned short)); char* header = new char[headerLength]; fs.read((char*)header, sizeof(char) * headerLength); const std::string headerString(header); bool checkType = false; { const size_t pos = headerString.find("'descr': "); if (pos != std::string::npos) { const size_t typePos = headerString.find("'<f8'", pos); if (typePos != std::string::npos) { checkType = true; } else { std::cout << "[ERROR] Type Error." << std::endl; } } } bool checkAxis = false; int axis1 = -1, axis2 = -1, axis3 = -1, axis4 = -1; { const size_t pos = headerString.find("'shape': "); if (pos != std::string::npos) { const size_t shapeStartPos = headerString.find("(", pos); const size_t shapeEndPos = headerString.find(")", pos); if (shapeStartPos != std::string::npos && shapeEndPos != std::string::npos) { const std::string shapeString = headerString.substr(shapeStartPos, (shapeEndPos - shapeStartPos) + 1); ::sscanf_s(shapeString.c_str(), "(%d, %d, %d, %d)", &axis1, &axis2, &axis3, &axis4); if (axis1 > 0 && axis2 > 0 && axis3 > 0 && axis4 > 0) { checkAxis = true; } else { std::cout << "[ERROR] Axis Error." << std::endl; } } } } if (checkType && checkAxis) { data.resize(axis1); for (int i = 0; i < axis1; i++) { data[i].resize(axis2); for (int j = 0; j < axis2; j++) { data[i][j].resize(axis3); for (int k = 0; k < axis3; k++) { data[i][j][k].resize(axis4); } } } for (int i = 0; i < axis1; i++) { for (int j = 0; j < axis2; j++) { for (int k = 0; k < axis3; k++) { fs.read((char*)&data[i][j][k][0], sizeof(double) * axis4); } } } } delete header; fs.close(); return true; } bool SaveNpy(const std::string& filePath, const std::vector<float>& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const std::string headerString = FormatString("{'descr': '<f4', 'fortran_order': False, 'shape': (%d,), }", axis1); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } fs.write((char*)&data[0], sizeof(float) * axis1); return true; } bool SaveNpy(const std::string& filePath, const std::vector<std::vector<float> >& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const int axis2 = (int)data[0].size(); const std::string headerString = FormatString("{'descr': '<f4', 'fortran_order': False, 'shape': (%d, %d), }", axis1, axis2); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } for (int i = 0; i < axis1; i++) { fs.write((char*)&data[i][0], sizeof(float) * axis2); } return true; } bool SaveNpy(const std::string& filePath, const std::vector<std::vector<std::vector<float> > >& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const int axis2 = (int)data[0].size(); const int axis3 = (int)data[0][0].size(); const std::string headerString = FormatString("{'descr': '<f4', 'fortran_order': False, 'shape': (%d, %d, %d), }", axis1, axis2, axis3); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } for (int i = 0; i < axis1; i++) { for (int j = 0; j < axis2; j++) { fs.write((char*)&data[i][j][0], sizeof(float) * axis3); } } return true; } bool SaveNpy(const std::string& filePath, const std::vector<std::vector<std::vector<std::vector<float> > > >& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const int axis2 = (int)data[0].size(); const int axis3 = (int)data[0][0].size(); const int axis4 = (int)data[0][0][0].size(); const std::string headerString = FormatString("{'descr': '<f4', 'fortran_order': False, 'shape': (%d, %d, %d, %d), }", axis1, axis2, axis3, axis4); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } for (int i = 0; i < axis1; i++) { for (int j = 0; j < axis2; j++) { for (int k = 0; k < axis3; k++) { fs.write((char*)&data[i][j][k][0], sizeof(float) * axis4); } } } return true; } bool SaveNpy(const std::string& filePath, const std::vector<double>& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const std::string headerString = FormatString("{'descr': '<f8', 'fortran_order': False, 'shape': (%d,), }", axis1); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } fs.write((char*)&data[0], sizeof(double) * axis1); return true; } bool SaveNpy(const std::string& filePath, const std::vector<std::vector<double> >& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const int axis2 = (int)data[0].size(); const std::string headerString = FormatString("{'descr': '<f8', 'fortran_order': False, 'shape': (%d, %d), }", axis1, axis2); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } for (int i = 0; i < axis1; i++) { fs.write((char*)&data[i][0], sizeof(double) * axis2); } return true; } bool SaveNpy(const std::string& filePath, const std::vector<std::vector<std::vector<double> > >& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const int axis2 = (int)data[0].size(); const int axis3 = (int)data[0][0].size(); const std::string headerString = FormatString("{'descr': '<f8', 'fortran_order': False, 'shape': (%d, %d, %d), }", axis1, axis2, axis3); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } for (int i = 0; i < axis1; i++) { for (int j = 0; j < axis2; j++) { fs.write((char*)&data[i][j][0], sizeof(double) * axis3); } } return true; } bool SaveNpy(const std::string& filePath, const std::vector<std::vector<std::vector<std::vector<double> > > >& data) { std::ofstream fs(filePath.c_str(), std::ios::binary); const unsigned char magicString[6] = { 0x93, 'N', 'U', 'M', 'P', 'Y' }; fs.write((char*)magicString, sizeof(magicString)); const unsigned char major = 1, minor = 0; fs.write((char*)&major, sizeof(char)); fs.write((char*)&minor, sizeof(char)); unsigned short headerLength = 118; fs.write((char*)&headerLength, sizeof(unsigned short)); const int axis1 = (int)data.size(); const int axis2 = (int)data[0].size(); const int axis3 = (int)data[0][0].size(); const int axis4 = (int)data[0][0][0].size(); const std::string headerString = FormatString("{'descr': '<f8', 'fortran_order': False, 'shape': (%d, %d, %d, %d), }", axis1, axis2, axis3, axis4); fs.write((const char*)headerString.c_str(), sizeof(char) * headerString.size()); const int headerSpaceLength = headerLength - (int)headerString.size() - 1; if (headerSpaceLength > 0) { const std::string headerTailString = std::string(headerSpaceLength, ' '); fs.write((const char*)headerTailString.c_str(), sizeof(char) * headerTailString.size()); const char lineFeed = 0x0A; fs.write((char*)&lineFeed, sizeof(char)); } for (int i = 0; i < axis1; i++) { for (int j = 0; j < axis2; j++) { for (int k = 0; k < axis3; k++) { fs.write((char*)&data[i][j][k][0], sizeof(double) * axis4); } } } return true; }

- 投稿日:2021-03-21T17:58:57+09:00
FlaskのCookieをつかって「みる」~最小構成のテンプレートCookie~
はじめに
Flaskで、ログインプログラムを作ろうと思った。でも、Cookieの使い方がよくわからなかった。調べてみても「最小限」の使い方は載っていなかった。だから最低限のCookieの使い方を書いてみた。
内容
cookieを使って「みたい」人のための最小のcookieの使い方
対象
cookieをFlaskで使ってみたいと思ったけど、理解できなかった人
Flaskの使い方がある程度わかる人
よくあるサンプルコードから使い方を知る
sample.pyfrom flask import Flask, render_template, make_response, request import json import datetime app = Flask(__name__) @app.route('/resp') def resp(): max_age = 30 expires = int(datetime.datetime.now().timestamp()) + max_age response = make_response(render_template("cookie.html")) user_info = {'id':'123', 'password':'user_password'} response.set_cookie("hoge", value=json.dumps(user_info), expires=expires) return response @app.route('/view') def view(): user_info = request.cookies.get('hoge') if user_info is not None: user_info = json.loads(user_info) return render_template('view.html', user_info = user_info) app.run(debug=True)cookie.html<!DOCTYPE html> <html lang="ja"> <body> <p>cookieに値が格納されました。</p> <form action='/view'> <input type="submit" value="戻る"> </form> </body> </html>view.html<!DOCTYPE html> <html lang="ja"> <body> <form> <input type="submit" value="cookieを設定" formaction="/resp"> <input type="submit" value="更新" formaction="/view"> </form> {% if user_info == None %} <p>cookieが設定されていません。</p> {% else %} <p>id:{{user_info.id}}</p> <p>password:{{user_info.password}}</p> {% endif %} </body> </html>全体の動き
「/view」の動き
cookieが設定されているときには、idとpasswordが、されていなければ「cookieが設定されていません。」が表示される。
「/view」のform
formの「cookieを設定」を押すと、「/resp」にジャンプする。
formの「更新」を押すと、ページがリロードされる。「/resp」
cookieが設定される。そして「/view」へのボタンが表示される。
プログラムの解説
ここではプログラムを解説していこうと思う。
cookieの保存
max_age = 30 expires = int(datetime.datetime.now().timestamp()) + max_ageここの部分でcookieをいつまで保持するかを設定する。。max_ageを変えることで、時間を変更できる。
(単位は秒。この場合だと30秒になる。したがって、30秒後にページをリロードすると、「設定されていません」が表示される。)
response = make_response(render_template("cookie.html"))レスポンスを作成する。。cookie.htmlで作成する。
user_info = {'id':'123', 'password':'user_password'} response.set_cookie("hoge", value=json.dumps(user_info), expires=expires)辞書型で保存するデータを作成する。
そしてそれを、以下のようにしてレスポンスを編集(?)する。
Cookieの名前:
hoge内容:
{'id':'123', 'password':'user_password'}有効期限:
30秒return responseresponseを返す。htmlが表示され、cookieも保存される。
cookieの読み込み
user_info = request.cookies.get('hoge')user_infoのhogeという名前のcookieを読み込んで代入する。
if user_info is not None: user_info = json.loads(user_info) return render_template('view.html', user_info = user_info)色々してからrender_templateをずる。。htmlを見ると、
{% if user_info == None %} <p>cookieが設定されていません。</p> {% else %} <p>id:{{user_info.id}}</p> <p>password:{{user_info.password}}</p> {% endif %}もしuser_infoがカラなら
<p>cookieが設定されていません。</p>入っているなら
<p>id:{{user_info.id}}</p> <p>password:{{user_info.password}}</p>辞書型のuser_infoのidとpasswordを表示するようになっている。
最小構成のテンプレートcookie(書き込み)
特に何も考えずに使えるようなテンプレを書いてみた。
import json import datetime max_time = 「1」 expires = int(datetime.datetime.now().timestamp()) + max_time * 60 response = make_response(render_template(「2」)) user_info = 「3」 response.set_cookie(「4」, value=json.dumps(user_info), expires=expires) return response「1」の内容
保持する時間を「分」で書く。
「2」の内容
表示させるhtmlのファイル名を指定する。
「3」の内容
保存する内容を辞書型で記入する。
「4」の内容
保存するcookieの名前を記入する。
最小構成のテンプレートcookie(読み込み)
同じように特に何も考えずに使えるようなテンプレを書いた。
user_info = request.cookies.get(「1」) if user_info is not None: user_info = json.loads(user_info)「1」の内容
取り出したいcookieの名前を書く。
出力
user_infoの中に辞書型でcookieの内容が入っている。
終わりに
「とりあえず」の部分を書いた。10分ほどで学習できると思う。
どんなことでも少しでも知っていると「できる!」とも思うし、「もっと勉強しよう!」とも思う。だから、本当に本当に最小の部分だけを書いた。もっと調べて、広い知識をつけるのに役立ったら嬉しいと思う。
- 投稿日:2021-03-21T16:55:05+09:00
非情報系大学院生が一から機械学習を勉強してみた #7:畳み込みニューラルネットワーク
はじめに
非情報系大学院生が一から機械学習を勉強してみました。勉強したことを記録として残すために記事に書きます。
進め方はやりながら決めますがとりあえずは有名な「ゼロから作るDeep-Learning」をなぞりながら基礎から徐々にステップアップしていこうと思います。環境はGoogle Colabで動かしていきます。第7回はこれまで取り組んできたニューラルネットワークを元に畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)を実装します。目次
- 畳み込みニューラルネットワークとは
- 畳み込み層
- プーリング層
- CNNの実装
1. 畳み込みニューラルネットワーク(CNN)とは
畳み込みニューラルネットワーク(CNN)とは脳の視覚野をモデルとして後述する畳み込み演算とプーリング演算を用いたニューラルネットワークのことです。
これまでの全結合ニューラルネットワークと同様ブロック図で以下のように表すことができます。
なぜ畳み込みニューラルネットワークが良いのか
CNNは画像の認識に特に優れています。例としてこれまで見てきたMNIST手書き数字認識問題を考えます。これまでの全結合のニューラルネットワークでは28ピクセル×28ピクセルだった元の画像データを1×784のベクトルに変形して学習していました。しかしながら、本来画像のピクセルデータの並び方には意味があるはずです。例えば隣接ピクセル同士は徐々に濃度が変化しているはずです。これを表現するためには列ベクトルに変換せずに元の28×28の状態で学習を行わなくてはいけません。CNNではこのような入力を得意としているので、データをうまく理解できる可能性が高くなります。
2. 畳み込み層
畳み込み演算とは
まず畳み込み層の動作である畳み込み演算について以下の例を見ていくことにします。真ん中の記号は畳み込み演算を表します。
畳み込み演算では入力データに対してフィルタのウインドウを一定の間隔でスライドさせながら適用していきます。このスライドさせていく一定の幅をストライドと呼びます。上の図はストライドが1のときの例です。まず青の領域で畳み込みを行い
$$
1×2+2×0+3×1+0×0+1×1+2×2+3×1+0×0+1×2=15
$$
というように計算していきます。ウインドウをスライドさせながら赤、黄、緑の領域も同様に計算していきます。あとはすべての結果にバイアスを加算して畳み込み演算の出力になります。パディング
今の例で見たように畳み込み演算を行うと出力のサイズが小さくなってしまいます。そうではなく出力も同じサイズで行いたいときがあります。その場合入力データの周囲に固定のデータ(例えば0)を埋めることがあります。これをパディングといい、畳み込み演算ではよく行われます。こうすることで出力データを元のサイズと同じにすることができます。下の図は周囲に0をパディングしたときの例です。
3次元の畳み込み
これまではMNIST問題のようにグレースケール2次元画像を念頭に行ってきました。一般に画像データはR,G,Bの3色の要素があります。このように複数チャネルのデータがあるときもチャネルを3次元目として同様に畳み込み演算を行うことができます。3次元の畳み込みでは、まずチャネルごとに入力データとフィルタの畳み込み演算を行い、最後にそれらの結果を加算して1つの出力を得ます。
3. プーリング層
プーリングは縦・横方向の空間を小さくする演算です。例えば下図のように2×2の領域を1つの要素に集約するような処理を行い、空間サイズを小さくします。
図では2×2の領域から最大値を取る演算をしています。この処理をMax-Poolingといいます。最大値をとるのではなく平均値をとるものもあり、こちらはAverage-Poolingと呼びますが、画像認識では主にMax-Poolingが使われるため、以降では単にプーリングというとMax-Poolingを指すものとします。プーリング演算では通常ウインドウサイズとストライドは同じ値に設定します。
プーリング層は対象領域から最大値を取るだけなので学習パラメータが存在しない、演算はチャネルごとに行われるためチャネル数は変化しない、といった特徴があります。
また、プーリング演算は入力データの小さなズレ(ウインドウ内で多少値の変動があっても)に対してロバストという性質もあります。これは入力データの小さなズレを吸収してくれることになります。4. CNNの実装
CNNの理論を簡単にまとめたところで実装を行っていきます。今回は以下のような構造のネットワークをChainerを用いてGPUを使った実装をしていきます。
モジュールのインストールimport numpy as np import matplotlib.pyplot as plt import chainer from chainer import Variable from chainer import functions as F from chainer import links as L
- chainer: chainerメインモジュール
- chainer.Variable: 誤差逆伝播法による勾配計算の対象となる変数クラス
- chainer.functions: 誤差逆伝播法と関係のない関数群
- chainer.links: 誤差逆伝播法と関係のある関数群
です。CNNモデルの定義class CNN(chainer.Chain): # Constructor def __init__(self, initializer = None): super().__init__( Conv1 = L.Convolution2D(1, 30, ksize=(5, 5), stride=1, pad=0), Affine2 = L.Linear(4320, 100, nobias=False, initialW=initializer), Affine3 = L.Linear(100, 10, initialW = initializer), ) # Forward operation def __call__(self, x, t = None): z1 = F.relu(self.Conv1(x)) # Conv1 - ReLU1 pool1 = F.max_pooling_2d(z1, ksize=(2, 2)) #Max-Pooling1 z2 = F.relu(self.Affine2(pool1)) # Affine2 - ReLU2 a3 = self.Affine3(z2) # Affine3 if chainer.config.train: return F.softmax_cross_entropy(a3, t) # Softmax3 with cross entropy error, training else: return F.softmax(a3) # Softmax3, evaluation return a3ここでニューラルネットワークのモデルを定義し学習を行います。上の図の通りの層順で計算していきます。学習パラメータを持つConvolution層、Affine層をコンストラクタで定義し、それ以外のReLU層、Max-pooling層、Softmax層をcallメゾットとして定義します。
L.Convolution2Dの主なパラメータは
chainer.links.Convolution2D(入力チャネル数, 出力チャネル数, フィルタサイズ(カーネル), ストライド数, パディング数, バイアスの有無, 初期重み, 初期バイアス)
です。
L.Linearの主なパラメータは
chainer.links.Linear(入力ベクトル数, 出力ベクトル数, バイアスの有無, 初期重み, 初期バイアス)
です。学習環境の設定# Load datasets train, test = chainer.datasets.get_mnist(ndim = 3) x_train = train._datasets[0] # (60000, 1, 28, 28) t_train = train._datasets[1] # (60000,) x_test = test._datasets[0] # (10000, 1, 28, 28) t_test = test._datasets[1] # (10000,) # Set GPU gpu_device = 0 # 使用するGPUの指定 chainer.cuda.get_device(gpu_device).use() # Model transfer to GPU model = CNN(initializer = chainer.initializers.HeNormal()) model.to_gpu(gpu_device) # Set optimizer engine optimizer = chainer.optimizers.Adam() optimizer.use_cleargrads() optimizer.setup(model)GPUが使えるように設定していきます。
gpu_deviceで使用するGPUを指定します。
続いて先ほど定義したCNNモデルをGPUへ転送します。ここでinitializerで初期重みとして前回説明したHeの初期値を用います。
次にoptimizersで最適化エンジンを指定します。こちらも前回整理した最適化手法から今回はAdamを選択しました。これで学習を行う準備が整いました。パラメータ設定&初期化iters_num = 10000 # 最大イタレーション数 train_size = x_train.shape[0] # 訓練データ数 test_size = x_test.shape[0] #テストデータ数 batch_size = 100 # バッチサイズ iter_per_epoch = max(train_size / batch_size, 1) #1エポックに要するイテレーション数 train_acc_list = [] test_acc_list = []ここからは学習を行います。まずパラメータを設定、初期化します。
学習for i in range(iters_num): # Set mini-batch batch_mask = np.random.choice(train_size, batch_size) x_batch = chainer.cuda.to_gpu(x_train[batch_mask], device = gpu_device) t_batch = chainer.cuda.to_gpu(t_train[batch_mask], device = gpu_device) # Forward operation loss = model(x_batch, t_batch) # Backward operation model.cleargrads() loss.backward() # Update parameters optimizer.update()
batch_size個のデータをランダムに抽出しミニバッチを作成します。ミニバッチごとにデータを転送します。
続いて順伝播演算を行い損失関数を計算、逆伝播演算を行い勾配を計算します。
その結果に基づきCNNの重み、バイアスバラメータを更新します。評価# Evaluation if i % iter_per_epoch == 0 or i == iters_num - 1: # Turn training flag off chainer.config.train = False # Evaluate training set y_train = [] for s in range(0, train_size, batch_size): x_batch = chainer.cuda.to_gpu(x_train[s:s + batch_size]) y_train.extend(chainer.cuda.to_cpu(model(x_batch).data).tolist()) # Evaluate test set y_test = [] for s in range(0, test_size, batch_size): x_batch = chainer.cuda.to_gpu(x_test[s:s + batch_size]) y_test.extend(chainer.cuda.to_cpu(model(x_batch).data).tolist()) # Compute accuracy train_acc = F.accuracy(np.array(y_train), t_train).data test_acc = F.accuracy(np.array(y_test), t_test).data train_acc_list.append(train_acc) test_acc_list.append(test_acc) print(i, train_acc, test_acc) # 9999 0.9995166666666667 0.9899 # Turn training flag on chainer.config.train = True # Plot figure markers = {'train': 'o', 'test': 's'} x = np.arange(len(train_acc_list)) plt.plot(x, train_acc_list, label='train acc') plt.plot(x, test_acc_list, label='test acc', linestyle='--') plt.xlabel("epochs") plt.ylabel("accuracy") plt.ylim(0, 1.0) plt.legend(loc='lower right') plt.show()はじめに
chainer.config.trainをFalseにしてCNNモデルの定義の学習モードと評価モードを切り替えます。
訓練データについて、
x_batchとしてバッチサイズごとに入力データをGPUに転送する。model(x_batch)で訓練データに対するラベルを予測する。- 予測した結果を
chainer.cuda.to_cpuでCPUに転送する。- リスト型に変換し、その予測結果を
extend()でリストに追加する。テストデータに対しても同様に行います。
chainer.functions.accuracy関数を用いて精度を計算します。これまでべた書きしていたものを関数を使っただけです。
最後に結果をプロットします。
参考文献
ゼロから作るDeep-Learning
ゼロから作るDeep-Learning GitHub
深層学習 (機械学習プロフェッショナルシリーズ)









- 投稿日:2021-03-21T16:21:32+09:00
Haxe 4.2.1 で python コードを出力した結果
概要
Python を最近触り始めたところコードブロックがインデント基準というのが個人的に気に入らず、スーパーセットを探したところ Haxe "ハックス(Youtube調べ)" (https://haxe.org/) を見つけた。
バイトコードを吐くのではなく、Python のソースにトランスパイルできるので、既存の Python コードとキメラ合体できるのでは?と思い触ってみた。
- Python へのトランスパイル方法はこちら https://haxe.org/manual/target-python-getting-started.html
環境
Haxe: 4.2.1
コード1
Haxe
Main.hxclass Main { static public function main():Void { trace("Hello World"); } }ファイル名はクラス名と一緒じゃないといかんのかな?
Python
トランスパイルコマンド:
haxe --python main.py --main Mainmain.py# Generated by Haxe 4.2.1+bf9ff69 # coding: utf-8 import sys class Main: __slots__ = () @staticmethod def main(): print("Hello World") class haxe_iterators_ArrayIterator: __slots__ = ("array", "current") def __init__(self,array): self.current = 0 self.array = array def hasNext(self): return (self.current < len(self.array)) def next(self): def _hx_local_3(): def _hx_local_2(): _hx_local_0 = self _hx_local_1 = _hx_local_0.current _hx_local_0.current = (_hx_local_1 + 1) return _hx_local_1 return python_internal_ArrayImpl._get(self.array, _hx_local_2()) return _hx_local_3() class python_internal_ArrayImpl: __slots__ = () @staticmethod def _get(x,idx): if ((idx > -1) and ((idx < len(x)))): return x[idx] else: return None class python_internal_MethodClosure: __slots__ = ("obj", "func") def __init__(self,obj,func): self.obj = obj self.func = func def __call__(self,*args): return self.func(self.obj,*args) Main.main()でかい。
コード2
Haxe
Main.hxclass Main { static public function main():Void { trace("Hello World"); var items = ["a", "b", "c"]; for (index in 0...items.length) { trace('$index : ${items[index]}'); } if (items.length == 3) { trace('length is '); trace('3'); } else { trace('length is '); trace('not 3'); } trace('end'); } }肝心のコードブロックを作ってみた。
Python
トランスパイルコマンド:
haxe --python main.py --main Mainmain.py# Generated by Haxe 4.2.1+bf9ff69 # coding: utf-8 import sys class Main: __slots__ = () @staticmethod def main(): print("Hello World") items = ["a", "b", "c"] _g = 0 _g1 = len(items) while (_g < _g1): index = _g _g = (_g + 1) print(str(((("" + str(index)) + " : ") + HxOverrides.stringOrNull((items[index] if index >= 0 and index < len(items) else None))))) if (len(items) == 3): print("length is ") print("3") else: print("length is ") print("not 3") print("end") class haxe_iterators_ArrayIterator: __slots__ = ("array", "current") def __init__(self,array): self.current = 0 self.array = array def hasNext(self): return (self.current < len(self.array)) def next(self): def _hx_local_3(): def _hx_local_2(): _hx_local_0 = self _hx_local_1 = _hx_local_0.current _hx_local_0.current = (_hx_local_1 + 1) return _hx_local_1 return python_internal_ArrayImpl._get(self.array, _hx_local_2()) return _hx_local_3() class python_internal_ArrayImpl: __slots__ = () @staticmethod def _get(x,idx): if ((idx > -1) and ((idx < len(x)))): return x[idx] else: return None class HxOverrides: __slots__ = () @staticmethod def stringOrNull(s): if (s is None): return "null" else: return s class python_internal_MethodClosure: __slots__ = ("obj", "func") def __init__(self,obj,func): self.obj = obj self.func = func def __call__(self,*args): return self.func(self.obj,*args) Main.main()
forじゃない!…のはindex in ...でイテレートしてるからかな?まぁコードブロックはよしなにしてくれるのでありがたい。あと
HxOverridesというのが増えてる。気づき
- 互換性のためのイテレータコードとか入ってるけど、ロジックでは使ってない。そこは Tree-shaking されないっぽい。でもまぁイテレータなんて実際のコード書いたら100%出てくるから無駄ではないか。
- python の package manager (pyenv とか poetry とか) で Haxe を Virtualenv スコープにできたら、つよいと思う。
他の気になるポイント
- python の 3rd party library の使い方
- IDE補完力(上記ありきだと思うけど)
- 投稿日:2021-03-21T15:47:11+09:00
初心者がAidemyにてPythonを学んでみた
【はじめに】
私は基盤系SEです。
日々業務の過程でプログラミングに興味を持ち、今後のスキルアップを目標としAidemyにてPythonを学びました。その経緯と結末をまとめます。
プログラミングに興味を持っているが、オンライン学習が高くて迷っているという方はぜひ参考にしてください。【経緯】
Pythonは独学にて勉強をしていましたが、限界を感じていました。
ネットを参照しても何を言ってるかよくわかりませんでした(笑)
その時たまたまAidemyを見つけましたが、とにかく受講料が高い!!
ですが、教育訓練給付金制度を知り、「この機会しかない!」と思い即決で申し込みました。【学習の振り返り】(3ヵ月コース)
・1ヶ月目
なにもできませんでした(笑)
他のことが忙しく、環境を構築したぐらいでした。
・2ヶ月目
月末になってから本格的に勉強しました。
内容は基礎~様々なモジュールの使用方法です。(Numpy等)
・3ヶ月目
ここからはモジュールの使用方法~ディープラーニングを使用したAIまで一気に勉強しました。
・振り返って
少し触っていた他にVBA等他の言語でプログラミング自体は触っていたので、最初のほうは苦ではなかったです。ただ、応用を用いた課題と直面した時、アルゴリズムは思い浮かぶけどコードがきちんと書けない場面が多々ありました。(おそらく期限的に焦っていたのもあります)
そんな時にエラーの意味、改善点等をわかりやすく・かつ詳細に説明していただき、理解することに繋がりました。
何とか一通り期間内に理解して終了することが出来ました。【成果物】
以下は住宅価格データセットを用いた価格予測のためのプログラムです。
よろしければ参考にしてください。(必要モジュールをインポート)
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, Dropout, Input, BatchNormalization
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
%matplotlib inline(データセットの読み込み)
boston=load_boston()
X = boston.data
Y = boston.target(テストデータとトレーニングデータに分割)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.25, random_state=42)
model = Sequential()(ディープラーニングによるモデルの構築)
model.add(Dense(256, input_dim=13))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation("sigmoid"))
model.add(Dropout(rate=0.5))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
(モデルによるテストデータの学習)
history = model.fit(X_train, y_train, epochs=64 , batch_size=32 , verbose=1, validation_data=(X_test, y_test) )(予測値を算出)
y_pred = model.predict(X_test)(二乗誤差を使用した性能評価)
mse= mean_squared_error(y_test, y_pred)
print("REG RMSE : %.2f" % (mse** 0.5))【まとめ】
結論としてとても有意義でした。
反省点としては、時期を見誤って時間に追われた学習だったため、サービスを十分に活用できなかったと思います。
ただ、一人では苦戦していたものがこんな短時間で理解できるようになるとは思いませんでした。
もしオンライン学習に迷っている方がいる方はぜひ一度お試しください。
- 投稿日:2021-03-21T15:43:05+09:00
pymysql.err.OperationalError: (1193, "Unknown system variable 'tx_isolation'")
- 投稿日:2021-03-21T15:17:55+09:00
SudachiPyでユーザ辞書をビルドするときに遭遇するかもしれないエラー一覧
日本語形態素解析エンジンSudachiのPython実装であるSudachiPyでは、
sudachipy ubuildコマンドを使って、ユーザ辞書をビルドすることができます。$ sudachipy ubuild -h usage: sudachipy ubuild [-h] [-d string] [-o file] [-s file] file [file ...] Build User Dictionary positional arguments: file source files with CSV format (one or more) optional arguments: -h, --help show this help message and exit -d string description comment to be embedded on dictionary -o file output file (default: user.dic) -s file system dictionary (default: linked system_dic, see link -h)ビルド時に遭遇するかもしれないエラーをリスト化しておきます。
ValueError: invalid format
reading the source file...中に発生。reading the source file...Traceback (most recent call last): (トレースバック省略) ValueError: invalid format列が足りていない
Sudachiのユーザ辞書は、各エントリ18列のフィールドがあるはずだが、列が足りていないエントリが存在するために発生。
余分な空行
ソースCSVファイルに余分な空行が存在したために発生。とくに、最後のエントリの行のあとは、改行させないか、改行しても1回までにさせておく。
ValueError: invalid literal for int() with base 10: 'なんちゃら'
reading the source file...中に発生。なんちゃらの部分は空文字の場合もある。reading the source file...Traceback (most recent call last): (トレースバック省略) ValueError: invalid literal for int() with base 10: 'なんちゃら'左連接ID または 右連接ID の未指定
左連接ID(CSVの左から2列目)または右連接ID(CSVの左から3列目)が未指定、または文字列になっているエントリが存在するために発生。
余分な列
Sudachiのユーザ辞書は、各エントリ18列のフィールドがあるはずだが、余分な列が存在し、そこになにか文字列を入力しているエントリが存在するために発生。(ちなみに、余分な列が存在しても、その値が数値や
*(アスタリスク)であればエラーとはなりませんでした。)ValueError: headword is empty
reading the source file...中に発生。reading the source file...Traceback (most recent call last): (トレースバック省略) ValueError: headword is empty見出し語が空
見出し語(CSVの左から1列目)の値が空であるエントリが存在するために発生。
OverflowError: int too big to convert
writing the word parameters...中に発生。reading the source file...64 words writing the POS table...24 bytes writing the connection matrix...4 bytes building the trie...done writing the trie...3076 bytes writing the word-ID table...324 bytes writing the word parameters...Traceback (most recent call last): (トレースバック省略) OverflowError: int too big to convert左連接ID・右連接ID・コスト値の不正
左連接ID・右連接ID・コスト値(CSVの左から2~4列目の値)のいずれかの値が、「
-32768または-32767~32767」以外範囲の値を指定しているエントリが存在するために発生。私は、コスト値で-32768と指定しているつもりが、マイナスが取れて32768になっていることがありました。ValueError: too few columns
writing the word_infos...中に発生。reading the source file...64 words writing the POS table...24 bytes writing the connection matrix...4 bytes building the trie...done writing the trie...3076 bytes writing the word-ID table...324 bytes writing the word parameters...388 bytes writing the word_infos...Traceback (most recent call last): (トレースバック省略) ValueError: too few columns不正な列
エントリの一番最後の列(未使用フィールド)には、
*(アスタリスク)を入力しておかなければならないが、それ以外の値が入っているために発生。未使用だから、適当なメモ書きでも入れておこうと思ったのですが、許してくれませんでした。
- 投稿日:2021-03-21T15:00:16+09:00
pyyamlを使ったyamlの読み込み書き込み
はじめに
pythonでyamlファイルの読み込みと書き込みを必ず忘れるので、メモ代わりにまとめています。
環境
win10
python 3.9.1
pyyaml 5.4.1pyyamlのインストール
pip install pyyaml使用例
自分がよく使うためのテンプレートの意味もあるので、ここ違うんじゃねって思ったらコメントで指摘してくれるとありがたいです。
ここで使うyamlファイル
example.yamlkey1: value key2: value読み込み
read_yaml.pyimport yaml with open('example.yaml')as f: example = yaml.safe_load(f) print(example) #{'key1': 'value', 'key2': 'value'}書き込み
write.pyimport yaml example = {'key1': 'value', 'key2': 'value'} with open('example.yaml','w')as f: yaml.dump(example, f, default_flow_style=False, allow_unicode=True)
default_flow_style=Falseはyamlをfllowスタイル(上のexample.yamlの形)に出力するため
allow_unicode=Trueは日本語などをエンコードしないで、読めるように出力するため書き込みが必要で実際にコード内で使うとき
主に自分が使うとき用
example.pyimport yaml with open('example.yaml')as f: example = yaml.safe_load(f) def close_example(): with open('example.yaml','w')as f: yaml.dump(example, f, default_flow_style=False, allow_unicode=True)こうしておくことで、内部で変更したりして保存するときに、関数を呼び出すだけで済む。
- 投稿日:2021-03-21T14:53:25+09:00
THE文系の俺が機械学習コース無職転生 ~Part2 CNNの分からなさが凄い~
またまた、題目の通りそんな私がCNNをほんのちょっっとだけわかるようになったきっかけを記載します。(相当短いよ)
分からない場合のアプローチ方法は人それぞれ
元も子もないことを言いますが(元も子もないって初めて文字にしたな・・・)、勉強のアプローチ方法は人それぞれだと思うんです。
例えば・・・①動画で学ぶ
②人に聞く
③ググってわかりやすそうなのを探す
④本読む
⑤渚のエトセトラおそらくその人の脳みその作りとか、生きてきた経験値に、その学びの習熟度によって、どういう学び方をしたほうがいいのかは、それぞれかと。
ですので、今回は③に絞ってのみお伝えしようと思います。(どこらへんが’ですので’なのかはスルーして下さい。)
分からないとはっきり伝える
正直ニューラルネットワークに入ってからほぼほぼ内容が分からず、DNN,CNNと進んでしまい、沼にはまっていました。自己嫌悪に陥り、自分には機械学習は向いていないんじゃないか・・・とか思ったり、思わなかったり。
そんな私でも色んなこと、色んな方に協力いただき少しずつ分かってきたのですが、最近あることに気がついたんです。もっと端的に調べてみたら分かりやすく学べる方法が見つかるんじゃないか・・・(´ω`)
こんな感じです。
当たり前のことなのかもしれないのですが、この検索ワードに辿り着くまで2ヶ月半かかりました笑
難しいことを没頭して勉強したり、それを調べたりという経験もなく、こんなことにも気が付きませんでした。
おかげさまで、1ページ目で3件ほど、理解がぬるぬる進む記事がありまして、CNNが身近になってきております。(記事を書いた人の優しさを感じながら学べています)
結論
CNNだけの問題ではないですね!折角なので、参考にさせていただいたサイトのURLを貼らせていただきます!

- 投稿日:2021-03-21T14:34:41+09:00
LIMEを用いて機械学習(回帰モデル)の予測結果を解釈してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はLIMEを用いて機械学習(回帰モデル)の予測結果を解釈してみました。
はじめに
前回、機械学習の予測モデルをscikit-learnを活用して実装してみました。また、構築したモデルは評価指標を用いてモデルを評価します。
しかし、評価指標だけでモデルの良し悪しを判断するのは危険であり、構築したモデルが実態と乖離している場合があります。つまり、汎化能力が低いモデルである可能性があるということです。汎化能力を高める方法は多々ありますが、製造現場では構築したモデルの解釈性を求められることが多いです。実際は、回帰モデル系であれば各説明変数の回帰係数の正負や標準偏回帰係数で変数間の影響度を見て固有技術と合致しているかを見極めたりします。また、決定木系のモデルであれば変数重要度を見て判断をします。
しかし、決定木系のモデル(RandomForest、GBDT、等)は各変数が目的変数へ与える影響の正負を判断することができません。また、SVRではカーネルをlinear以外を選択すると回帰係数も変数重要度も算出することができません(※scikit-learnのライブラリーに限った話です)。
そこで、今回は上記のような課題を解決する手段の一つとして、LIMEを用いて、予測した値に対して、「各変数がどのような影響を与えたのか?」を可視化する技術を整理しました。
ちなみに過去に他の手法としてSHAPについても整理しております。
LIMEの実装
今回はUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて予測モデルを構築します。
項目 概要 データセット ・boston house-price サンプル数 ・506個 カラム数 ・14個 pythonのコードは下記の通りです。
# ライブラリーのインポート import pandas as pd import numpy as np from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor from lime.lime_tabular import LimeTabularExplainer # データセットの読込み boston = load_boston() # データフレームの作成 # 説明変数の格納 df = pd.DataFrame(boston.data, columns = boston.feature_names) # 目的変数の追加 df['MEDV'] = boston.target # カラム名 feature_names = np.array(df.drop('MEDV', axis=1).columns) # データの中身を確認 df.head()
各カラム名の説明は省略します。
・説明変数:13個
・目的変数:1個(MEDV)次に、予測モデルを構築します。今回は、RandomForest回帰を活用します。
# ライブラリーのインポート from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor # 学習データと評価データを作成 x_train, x_test, y_train, y_test = train_test_split(df.iloc[:, 0:13], df.iloc[:, 13], test_size=0.2, random_state=1) # モデルの学習 RF = RandomForestRegressor() RF.fit(x_train, y_train)LIMEで結果を解釈する
今回は、線形モデルを使用して局所的な解釈を得ます。
# 学習データやタスクの内容といった情報を渡してインスタンスを作成 explainer = LimeTabularExplainer(training_data=np.array(x_train), feature_names=feature_names, training_labels=np.array(y_train), discretize_continuous=True, mode='regression', verbose=True, ) # 予測値を返す関数の作成 predict_proba = lambda x: np.array(list(zip(1-RF.predict(x), RF.predict(x)))) # 線形モデルを使って近似させたときの切片と予測値、本来のモデルの予測値が出力 exp = explainer.explain_instance( x_train.iloc[0], predict_proba, num_features=x_train.columns.shape[0] )下記のように線形モデルを使って近似させたときの切片と予測値、そして本来のモデルの予測値が出力されます。
Intercept -20.775610936690455 Prediction_local [-26.36992196] Right: -24.018000000000008最後に結果をJupyter Notebook上で確認します。
# Notebook 上で視覚的に確認 exp.show_in_notebook(show_all=False)
さいごに
最後まで読んで頂き、ありがとうございました。
今回は機械モデルの結果を解釈する手法としてLIMEを実装してみました。
使い勝手的には過去に紹介したSHAPの方が使いやすそうです。訂正要望がありましたら、ご連絡頂けますと幸いです。
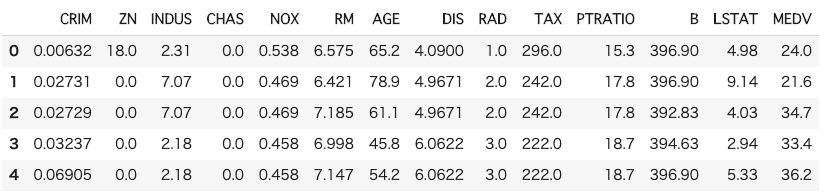

- 投稿日:2021-03-21T14:17:39+09:00
Djangoのリクエストを非同期で処理
[Views.py] import time import json import logging import requests import queue from rest_framework import generics from rest_framework.views import APIView from rest_framework.response import Response import api.myutils as myutils from books.models import Book SLEEP_TIME = 10 class BookApiView(APIView): def get(self, request): resp = {'API': ''} return Response(resp, status = '200', content_type='application/json') class BooksView(APIView): def get(self, request): resp_books = [] resp = {} for book in Book.objects.all(): resp_book = {'isbn': book.isbn, 'title': book.title, 'subtitle': book.subtitle, 'author': book.author} resp_books.append(resp_book) resp['Books'] = resp_books return Response(resp, status = '200', content_type='application/json') def post(self, request): try: data = json.loads(request.body) new_isbn = data["isbn"] new_title = data["title"] new_subtitle = data["subtitle"] new_author = data["author"] except KeyError: return Response(None, status = '400') if Book.objects.filter(isbn = new_isbn): return Response(None, status = '400') book = Book(isbn=new_isbn, title=new_title, subtitle=new_subtitle, author=new_author) if myutils.submit_task(new_isbn, BooksView.post_task, book): resp = {'id': new_isbn} return Response(resp, status = '200', content_type='application/json') else: resp = {'code': '409'} return Response(resp, status = '409', content_type='application/json') def post_task(book:Book): print('[post_task] start: ' + str(book)) time.sleep(SLEEP_TIME) book.save() print('[post_task] end ' + str(book)) return True def delete(self, request): Book.objects.all().delete() resp = {} return Response(resp, status = '200', content_type='application/json') class BookView(APIView): def get(self, request, isbn): if not Book.objects.filter(isbn = isbn): return Response(None, status = '404') book = Book.objects.get(isbn = isbn) resp = {'isbn': book.isbn, 'title': book.title, 'subtitle': book.subtitle, 'author': book.author} return Response(resp, status = '200', content_type='application/json') def delete(self, request, isbn): if not Book.objects.filter(isbn = isbn): return Response(None, status = '404') Book.objects.get(isbn = isbn).delete() resp = {} return Response(resp, status = '200', content_type='application/json')[myutils.py] import json import time import datetime import logging import queue from queue import Queue from threading import Thread from datetime import datetime THREAD_MAX_SIZE = 2 task_queue = Queue(maxsize = THREAD_MAX_SIZE) worker_threads = [] logger = None class TaskEvent: def __init__(self, task_id, task, task_args): self.id = task_id self.task = task self.args = task_args class WorkerThread(Thread): def __init__(self, tq:Queue, logger:logging.Logger): super().__init__() self.tq = tq self.logger = logger self.working = True def run(self): while self.working: task_event = self.tq.get() self.logger.info('task[' + task_event.id + '] start') result = task_event.task(task_event.args) self.logger.info('task[' + task_event.id + '] end: result = %s', result) def initialize(): formatter = '%(levelname)s : %(asctime)s : %(message)s' logging.basicConfig(level=logging.DEBUG, format = formatter) logger = logging.getLogger(__name__) for i in range(THREAD_MAX_SIZE): wt = WorkerThread(task_queue, logger) worker_threads.append(wt) wt.start() def submit_task(task_id, task, task_args): try: task_event = TaskEvent(task_id, task, task_args) task_queue.put_nowait(task_event) return True except queue.Full: return False