- 投稿日:2021-01-01T23:39:07+09:00
【Python】PyCharmの環境設定(インストール、インタプリタ設定、パッケージの追加)Mac環境
こんにちは、かをるです。
今回は、GUIツールである【PyCharm】をつかってPythonの環境構築を行なっていきます。
PyCharmとは、Pythonの統合開発環境です。
コマンドラインによる環境開発よりもこういったツールを使いこなすことで、より効率的に開発を進めることができます。
有償と無償とありますが、今回は無償のインストール方法を紹介していきます。
記事を書きました。
https://kaworublog.com/wp-admin/post.php?post=1065&action=edit
- 投稿日:2021-01-01T22:34:37+09:00
多次元連想配列のソート
Pythonで少し複雑な辞書オブジェクトをsortする - 午後から→オーバークロック
Perlのsortの基本的なやつ - QiitaPython
s.pydict = { 1: { 'name': 'A', 'age': 30, }, 2: { 'name': 'B', 'age': 31, }, 3: { 'name': 'C', 'age': 29, }, } for i in sorted(dict.items(), key=lambda x: x[1]['age'], reverse=True): print(i)$ python3 s.py (2, {'name': 'B', 'age': 31}) (1, {'name': 'A', 'age': 30}) (3, {'name': 'C', 'age': 29})Perl
s.pluse strict; use warnings; use Data::Dumper; my %hash = ( 1 => { name => 'A', age => 30 }, 2 => { name => 'B', age => 31 }, 3 => { name => 'C', age => 29 }, ); foreach my $key ( reverse sort { $hash{$a}{'age'} <=> $hash{$b}{'age'} } keys %hash ){ print "$key\n"; print Dumper \%{$hash{$key}}; }$ perl p.pl 2 $VAR1 = { 'name' => 'B', 'age' => 31 }; 1 $VAR1 = { 'age' => 30, 'name' => 'A' }; 3 $VAR1 = { 'age' => 29, 'name' => 'C' };
- 投稿日:2021-01-01T21:43:16+09:00
全ての点を通って最短で移動する経路を探したい
前回の続き
前回の記事ではいくつかの点をとったときに、始点から終点までの最短経路を求めるコードを読み解きました。
前回のコードでは全ての点を経由することができなかったので、その部分を少し考えてみます。
結局色々失敗してる最適化のお勉強メモですのでご了承ください。
色々まとまっている教科書はこちら。実装内容
前回の実装
ある点に注目した時に、その点に入る道とその点から出る道の本数の関係を定式化しました。
始点の場合はその点から出る道のほうが一本多く、終点の場合はその点に入る道の方が一本多い、
それ以外については双方が同数になるという実装です。
この実装だと「全ての点を通った」最短経路にはならないので、その部分をトライしてみます。for nd in g.nodes(): m += lpSum(x[k] for k, (i, j) in r if i == nd) \ == lpSum(x[k] for k, (i, j) in r if j == nd) + {source:1, sink:-1}.get(nd, 0) # 制約進歩1:ある点に出入りする本数を規定する
ある点に注目した時に、その点に入る本数と出る本数の合計が2(終点始点は1)になるようにすれば、「通らない」ということは無くなりそう。
ですが実際にやってみると、本命の経路以外で輪を作ってしまうパターンに。
難しい・・・。from pulp import * import networkx as nx g = nx.fast_gnp_random_graph(10, 0.8, 0) #第三引数を1にすると双方向の経路をg.edgesに保持 source, sink = 0, 2 # 始点, 終点 r = list(enumerate(g.edges())) m = LpProblem() # 数理モデル x = [LpVariable('x%d'%k, lowBound=0, upBound=1) for k, (i, j) in r] # 変数(路に入るかどうか) m += lpSum(x) # 目的関数 for nd in g.nodes(): m += lpSum(x[k] for k, (i, j) in r if i == nd) \ + lpSum(x[k] for k, (i, j) in r if j == nd) == {source:1, sink:1}.get(nd, 2) # 制約 m.solve() print([(i, j) for k, (i, j) in r if value(x[k]) ==1])この結果がこちら。
0から2へ行く、というはずなのに、0,5,2以外の点で円環ができてしまっています。
この2つの経路をどうつないだらいいのか・・・。
進歩2:道に距離の概念を導入
前回の実装ではすべての道を同じ長さと考えて最短経路を選択していました。
もう少し実用に近づけるべく、長さの概念を入れてみるとどうなるかやってみました。
一旦長さは「各経路の両端のノード番号を足した値」と定義してみました。
g.edges[i,j]["dist"]のようなお作法についてはこちらの記事を参考にしました。#https://qiita.com/kzm4269/items/081ff2fdb8a6b0a6112f n = 10 # ノード数 g = nx.random_graphs.fast_gnp_random_graph(n, 0.9, 8) for i,j in g.edges(): g.edges[i, j]["dist"] = i+j最適化部分のコードはたいして変更していませんが念のため再掲です。
source, sink = 0, 9 # 始点, 終点 r = list(enumerate(g.edges())) m = LpProblem() # 数理モデル x = [LpVariable('x%d'%k, lowBound=0, upBound=1) for k, (i, j) in r] # 変数(路に入るかどうか) m += lpSum(x[k] * g.edges[i,j]["dist"] for k, (i, j) in r) # 目的関数 for nd in g.nodes(): m += lpSum(x[k] for k, (i, j) in r if i == nd) \ + lpSum(x[k] for k, (i, j) in r if j == nd) == {source:1, sink:1}.get(nd, 2) # 制約 m.solve() print([(i, j) for k, (i, j) in r if value(x[k]) ==1])最適な経路に選ばれたものを取り出して図示します。
sprint_layoutについてはこちらの記事が便利でした。def draw(g): rn = g.nodes() # ノードリスト pos = nx.spring_layout(g, pos={i:(i/4, i%4) for i in rn}) # ノード位置 """描画""" nx.draw_networkx_labels(g, pos=pos) nx.draw_networkx_nodes(g, node_color='w', pos=pos) nx.draw_networkx_edges(g, pos=pos) plt.show() G = nx.DiGraph() for k,(i,j) in r: if value(x[k]) == 1: nx.add_path(G, [i, j]) draw(G)描画の結果はこちら。
今回はたまたまちゃんとした経路になったようです。
円環を作ってしまう現象はこちらでも起こりうる状態なはず。
最適解の時の総距離はこちら。
これもあってそう!value(m.objective) >>>81.0最後に
最適化楽しい!


- 投稿日:2021-01-01T20:51:13+09:00
じぶんpython環境メモ
katayamashunyuunoMacBook-Pro:~ katayamashunsuke$ which python /Users/katayamashunsuke/.pyenv/shims/python #pyenvのpythonを使っている katayamashunyuunoMacBook-Pro:~ katayamashunsuke$ which pip /Users/katayamashunsuke/.pyenv/shims/pip #pipもpyenv由来 katayamashunyuunoMacBook-Pro:~ katayamashunsuke$ which conda katayamashunyuunoMacBook-Pro:~ katayamashunsuke$ which anaconda #conda anacondaは入ってない katayamashunyuunoMacBook-Pro:~ katayamashunsuke$ pyenv versions system 3.6.5 * 3.7.4 (set by /Users/katayamashunsuke/.pyenv/version) 3.7.7 3.8.2 anaconda3-5.3.1 #anacondaでjupyter notebookを使いたい時はpyenvからlocalで使う #使い方 #適用ディレクトリに移動して pyenv local anaconda3-5.2.0 jupyter-notebookpipとcondaをconflictさせずにどっちも使うことができる
- 投稿日:2021-01-01T18:29:55+09:00
PythonでZoomのミーティングをスケジュールする
あけましておめでとうございます。
Zoomのミーティングを予約することが地味に面倒だと思うこともあり、プログラムを書いてみました。
ログインして、時間を選択して…と意外に手数が多いので。
pyzoomというライブラリを使うと簡単にできるようですが、
使いこなすのが難しい(というよりかゆいところのセッティングを変える方法がいまいち分からなかった)のと、勉強を兼ねてclassを組んでみました。APIキーとシークレットキーはZOOMのマーケットプレイスで取得ができます。
https://marketplace.zoom.us/develop/createimport requests import json from datetime import datetime import jwt import time import random from pprint import pprint class ZoomClient(object): URL = 'https://api.zoom.us/v2' def __init__(self, key: str, secret: str, user_id: str): """ :param key:Zoom Api Key :param secret: Zoom Api Secret :param user_id: Zoom ID(mail address) """ self.key = key self.secret = secret self.user_id = user_id self.token = self.generate_token() def generate_token(self): header = {"alg": "HS256", "typ": "JWT"} payload = {"iss": self.key, "exp": int(time.time() + 600)} return jwt.encode(payload, self.secret, algorithm='HS256', headers=header).decode('utf-8') def create_meeting(self, topic: str, start_time: datetime, duration_min: int, pass_code: str = None, **settings: dict): end_point = f'/users/{self.user_id}/meetings' headers = {'Authorization': f"Bearer {self.token}", 'Content-Type': 'application/json'} # パスコード:指定なしの場合は適当に作る if not pass_code: pass_code = str(random.randint(100000, 999999)) # セッティング:デフォルトで設定 default_setting = self.default_setting() # セッティング:指定有は書き換え if settings: for k, v in settings.items(): default_setting[k] = v body = { "topic": topic, 'type': 2, # scheduled meeting "start_time": start_time.isoformat(), "duration": duration_min, "timezone": "Osaka, Sapporo, Tokyo", "password": pass_code, "settings": default_setting} response = requests.request('POST', self.URL + end_point, headers=headers, data=json.dumps(body)).json() return response @staticmethod def default_setting(): return { 'host_video': True, # start video when the host joins 'participant_video': True, # start video when the participants join 'join_before_host': True, 'mute_upon_entry': True, 'approval_type': 0, # automatically approve 'cn_meeting': False, # host meeting in china 'in_meeting': False, # host meeting in india 'watermark': False, 'use_pmi': False, # personal meeting id 'registration_type': 1, 'audio': "voip", 'auto_recording': "none", 'enforce_login': False, 'waiting_room': False, 'registrants_email_notification': False, 'meeting_authentication': False, 'contact_name': "UFY", 'contact_email': "ufyit@support.com"} def invitation(self, meeting_id: int): end_point = f"/meetings/{meeting_id}/invitation" headers = {'authorization': 'Bearer ' + self.token} return requests.request("GET", self.URL + end_point, headers=headers).json()実際にミーティングをスケジュールして、招待状を表示させてみます。
def job(): api_key = 'your zoom api key' api_secret = 'your zoom api secret' user_id = 'your zoom id' # account mail address client = ZoomClient(api_key, api_secret, user_id) day = '2021/1/5' start_time = '11:30' end_time = '15:30' mtg_start_time = datetime.strptime(day + ' ' + start_time, '%Y/%m/%d %H:%M') mtg_end_time = datetime.strptime(day + ' ' + end_time, '%Y/%m/%d %H:%M') duration_min = int((mtg_end_time - mtg_start_time).seconds / 60) mtg = client.create_meeting(topic='api test', start_time=mtg_start_time, duration_min=duration_min, **{'host_video': False}) mtg_id = mtg['id'] invitation = client.invitation(mtg_id) pprint(invitation) if __name__ == '__main__': job()ミーティングを作成→
json形式で受け取る→
ミーティングidを取り出す→
ミーティングidを元に招待状を発行
という流れです。出力です
{'invitation': '〇〇さんがあなたを予約されたZoomミーティングに招待しています。\r\n' '\r\n' 'トピック: api test\r\n' '時間: 2021年1月5日 11:30 AM 大阪、札幌、東京\r\n' '\r\n' 'Zoomミーティングに参加する\r\n' 'https://invitation/url\r\n' '\r\n' 'ミーティングID: 生成されたid\r\n' 'パスコード: 生成されたpass code\r\n'}zoomには謎のセッティングも多く、まだ解明しきれていません。
色々と試してみたいと思います。
- 投稿日:2021-01-01T18:29:21+09:00
HoloViewsとBokehでぐりぐり動かせるグラフを描く
職場でのpython導入を画策中。
エクセルで出来なくてPythonで出来ることがないかなー、と模索していたら、
Bokehというライブラリを使ってインタラクティブなグラフが書けるとのこと。
こちらの記事で気になっていたHoloViewsと合わせて色々調べたのでまとめてみた。インタラクティブなグラフって?
ユーザーの操作に対して応答するグラフを指す。(インタラクティブ=双方向の~という意味)
こんな感じでマウスでぐりぐり動かしたり、ズームしたり、情報を表示させたりできる。環境
とりあえず手っ取り早く取り掛かりたかったので、GoogleColaboratoryで実装。
そのため本稿ではライブラリのインストールに関する記述は省略。
(未検証だがライブラリのインストールを行なえばJupyterNotebookでも動くはず)データ
下記のような初代ポケモンのデータをDataFrame形式で準備。
データは公式ポケモン図鑑とポケモンWikiから引用。実装
基本
基本となるグラフの書き方。今回は散布図(Scatter Graph)を書いていく。
# グラフ関連ライブラリのインポート import holoviews as hv hv.extension('bokeh') # 基本的な描画 poke_graph = hv.Scatter(poke_df,kdims=["height"],vdims=["weight"]) # 表示 poke_graph
hv.extension('bokeh')でholoviewsをbokehモードに拡張。
(セルごとに毎回上記を記述しないとグラフが表示されない)
hv.Scatter()で散布図インスタンスを生成。
Scatterの場合、引数には使用するデータセットとkdims、vdimsを指定する。
kdims:key dimensions。キーとなる要素。x軸のイメージ。
vdims:value dimensions。上記キーに対応した値の要素。y軸の他、後述のオプションの値にも適用できる。表示はpandasみたいにインスタンス名を書くだけで表示できる。
(JupyterNotebookではグラフを表示するためにoutput_notebook()というおまじないが必要とのこと)オプションの設定
holoviewsは後からグラフに関するオプションを追加できる。
hv.extension('bokeh') # タイトルの設定 poke_graph.opts(title="ポケモンデータ") # グリッドの描画 poke_graph.opts(show_grid=True) # 軸ラベルの変更 poke_graph.opts(xlabel="たかさ", ylabel="おもさ")
インスタンス.opts(…)で各種オプションを設定する。
分かりやすくするために個別に設定しているが、一度の.optsでまとめて設定することもできる。
poke_graph.opts(title="ポケモンデータ", show_grid=True, xlabel="たかさ", ylabel="おもさ")マーカーに関する設定はこんな感じ
hv.extension('bokeh') # マーカーの色の設定 poke_graph.opts(color = "red") # マーカーの縁の色の設定 poke_graph.opts(line_color = "black") # マーカーのサイズの設定 poke_graph.opts(size=7) # マーカーの透過率の設定 poke_graph.opts(alpha = 0.8)
上記だとちょっと窮屈なので、見やすさを意識して設定を追加。
hv.extension('bokeh') # 背景色の設定 poke_graph.opts(bgcolor = "whitesmoke") # グラフ領域の描画サイズの設定 poke_graph.opts(width=640, height=480) # フォントサイズの一律で大きく poke_graph.opts(fontscale=1.5) # 軸のフォーマット変更 poke_graph.opts(xformatter="%.1f m", yformatter="%.1f kg")
要素をオプションへ適用する
マーカーサイズへの適用
ここでは、バブルチャートのように種族値合計をマーカーの大きさに適用してみる。
要素をオプションに適用する場合、vdimsに要素が追加されていないと表示がおかしくなる。
なので、.add_dimension()でディメンジョンに要素を追加。poke_graph2 = poke_graph.add_dimension("種族値合計",dim_pos=2,vdim=True,dim_val = "合計")第一引数に要素名を指定。
dim_posで何番目に要素を追加(挿入)するか指定。
(vdimsの順番がどのように影響してくるか不明だが、とりあえず新しい要素が先頭にさえならなければ良さそう。なので適当に2とかにしている。)
vdim=Trueでvdimsに追加するようにする(省略するとkdimsに追加されてしまう)。
dim_val=で実際に値として使用するデータを指定する。今回の場合、すでにデータセットをDataFrame形式で渡してあるので、カラム名で指定するだけでOK。データセットで指定した以外にもdim_val=df["特殊"]やdim_val=poke_df["合計"]**2のように新しい値を指定することもできる。vdimsに追加したら、optsで引数に追加したディメンジョン名を渡すことができるようになる。
poke_graph2 = poke_graph2.opts(size="種族値合計")
おっと。
上記のようになってしまうのは、sizeに600とか大きい値が渡されているため。
これを回避するために、値を数式で変換する。その際、要素を数式に適用するにはdim()を使わないといけない。from holoviews import dim poke_graph2 = poke_graph2.opts(size=(dim("種族値合計")/poke_df["合計"].min())*5)
上記の例では、各ポケモンの種族値合計の値と種族値合計の最小値の比率に5をかけて、sizeの値としている。マーカーカラーへの適用
要素からマーカーの色を指定することも可能。
サイズの時と同様、まずvdimsに要素を追加し、color=にディメンジョン名を指定する。hv.extension('bokeh') # データ要素にタイプ1を追加 poke_graph3 = poke_graph2.add_dimension("タイプ1",dim_pos=2,vdim=True,dim_val = "タイプ1") # マーカーの色を「タイプ1」に応じて設定 poke_graph3.opts(color="タイプ1") # 凡例の位置を右側に設定 poke_graph3.opts(legend_position="right") # 描画サイズの幅を再設定 poke_graph3.opts(width=800)
上記はカラーが自動で振られているが、任意の色にすることも可能。
colorに渡す要素をキー、色を値にした辞書を作成し、cmap=に渡せばOK。color_table = {"ノーマル":"cornsilk", "ほのお":"orangered", "みず":"royalblue", "でんき":"gold", "くさ":"green", "こおり":"powderblue", "かくとう":"darkorange", "どく":"mediumorchid", "じめん":"saddlebrown", "ひこう":"lightcyan", "エスパー":"khaki", "むし":"yellowgreen", "いわ":"dimgrey", "ゴースト":"mediumpurple", "ドラゴン":"lightseagreen", "あく":"indigo", "はがね":"steelblue","フェアリー":"pink", } poke_graph3.opts(color="タイプ1",cmap=color_table)
色名はmatplotlibと同じものを使用可能。多分16進数RGB指定もできる。ツールチップを使う
bokehの特徴の一つ、ツールチップを使ってみる。
hv.extension('bokeh') # データ要素にポケモン名を追加 poke_graph4 = poke_graph3.add_dimension("name",dim_pos=2,vdim=True,dim_val = "name") # ホバーツールのインポート from bokeh.models import HoverTool # ホバーツールの設定 TOOLTIPS = [("name","@name")] hover = HoverTool(tooltips=TOOLTIPS) # グラフにホバーツールの設定適用 poke_graph4 = poke_graph4.opts(plot=dict(tools=[hover]))
ホバーツールはツールチップの一種。カーソルが合った要素の情報を表示することができる。
HoverToolインスタンスを生成し、引数tooltips=に表示したい情報をタプルのリストで渡す。
タプルの中には一行に表示する情報が記述される。複数タプルを渡せば複数行表示可能。
"@~"でvdimsに追加したディメンション名を指定する。ディメンション名が日本語の場合、"@{攻撃}"みたいに{}で囲まないと認識してくれないので注意。
また、"@~"の他、"\$x"や"$index"等で要素の基本的な情報を表示することもできる。また、HTML記述でより凝ったレイアウトが可能。
<div>タグや<table>タグのほか、<img>タグも使用可能なので画像を表示することもできる。TOOLTIPS_2 = """ <div> : </div> """のようにHTML記述をした文字列を渡す。
文中で<img src="@img_path">のように@ディメンション名を文字列として渡せばその情報を表示してくれる。サンプル(コードは冗長になったのでクリックで表示)
コード
# 図鑑No.から画像アドレスを指定する関数を定義 def path_create(id): result = r"file:///C:\Users\aaa\Desktop\ずかん\pokemon_" + str(id).zfill(3) + ".png" return result # データ要素の追加 poke_graph5 = poke_graph4.add_dimension("img_path",dim_pos=2,vdim=True, dim_val = poke_df["No."].apply(path_create)) poke_graph5 = poke_graph5.add_dimension("タイプ2",dim_pos=2,vdim=True,dim_val = "タイプ2") poke_graph5 = poke_graph5.add_dimension("HP",dim_pos=2,vdim=True,dim_val = "HP") poke_graph5 = poke_graph5.add_dimension("攻撃",dim_pos=2,vdim=True,dim_val = "攻撃") poke_graph5 = poke_graph5.add_dimension("防御",dim_pos=2,vdim=True,dim_val = "防御") poke_graph5 = poke_graph5.add_dimension("特攻",dim_pos=2,vdim=True,dim_val = "特攻") poke_graph5 = poke_graph5.add_dimension("特防",dim_pos=2,vdim=True,dim_val = "特防") poke_graph5 = poke_graph5.add_dimension("素早さ",dim_pos=2,vdim=True,dim_val = "素早さ") # ツールチップの設定 TOOLTIPS_2 = """ <div style="clear:both; margin: 0px 10px 0px 10px;"> <div style="float:left ;margin: 0px 0px 0px 0px;"> <p style="margin: 5px 0px 5px 5px"><span style="font-size:12px; color:navy ;font-weight:bold">@name</span></p> <img src="@img_path" height="72" alt="" width="72"><br> <span style="font-size:10px"> たかさ:@{height}{0.f} m<br> おもさ:@{weight}{0.f} kg<br> </span> </div> <div style="float:right"> <span style="font-size:10px"> <div style="clear:both"> <p align="right">タイプ: @{タイプ1} @{タイプ2}</p> </div> <div style="clear:both"> <table align="right" style="margin: 5px 0px 0px 0px"> <tr><td align="right">HP: </td><td align="right">@HP</td></tr> <tr><td align="right">こうげき: </td><td align="right">@{攻撃}</td></tr> <tr><td align="right">ぼうぎょ: </td><td align="right">@{防御}</td></tr> <tr><td align="right">とくこう: </td><td align="right">@{特攻}</td></tr> <tr><td align="right">とくぼう: </td><td align="right">@{特防}</td></tr> <tr><td align="right">すばやさ: </td><td align="right">@{素早さ}</td></tr> </table> </div> </span> </div> </div> """ hover2 = HoverTool(tooltips=TOOLTIPS_2) # グラフにホバーツールの設定適用 poke_graph5 = poke_graph5.opts(plot=dict(tools=[hover2]))
GoogleCoboratoryではローカル画像が表示されないため、上記のようになってしまう。
HTML形式で保存(後述)し、ファイルから開けば画像が表示される。
(画像は公式ポケモンずかんから拝借したものをローカルに保存して参照)結果をファイルに保存
Holoviews(Bokeh)のグラフはHTML形式でファイル出力することができる。
ファイル出力すれば、python環境でないPCでもグラフをグリグリすることが出来るはず。# グラフをhtmlで保存 renderer = hv.renderer('bokeh') renderer.save(poke_graph5, 'output_poke_graph5')上記の例だとpoke_graph5をoutput_poke_graph5.htmlとして出力する。
出力先はカレントディレクトリ。
GoogleColaboの場合はdrive.mount("/content/gdrive")でグーグルドライブをマウントし、%cd "gdrive/My Drive/任意のフォルダ"でカレントディレクトリの変更すればよい。所感
Holoviewsは最初こそ書き方がいまいち掴めなかったが、kdimsとvdimsさえ理解すればシンプルな記述ができると感じた。
ただ、現状の理解力だと職場のエクセル作業を置き換えるにはまだハードルが高いなぁと感じてしまう。
Holoviews(Bokeh)で出来ることはまだまだありそうなので、もっと勉強してエクセルで実現できないことを探さねば。
職場のエクセル作業をPythonに置き換えられた人の体験談とかも聞いてみたい。参考
- Pythonの可視化ツールはHoloViewsが標準になるかもしれない(Qiita記事)
- HoloViews公式ユーザーガイド(外部サイト・英語)
- ポケモンずかん(公式)(外部サイト)
- ポケモンWiki(外部サイト)













- 投稿日:2021-01-01T18:21:20+09:00
[Python] 動的計画法 TDPC D
TDPC D
部分構造最適性と部分問題重複性を有するので、動的計画法を検討する。
問題内のデータをそのまま実装するのは難しいので、単純化する必要がある。
積について考えるので、サイコロの目に存在する素因数 2,3,5 の指数のみを考えれば良い。
$10^{18}<2^{60}$ なので、指数として考える値はそれぞれ 60 以下でよいです。
動的計画法の設計は次の通り。
$dp[n][c_2][c_3][c_5]$の定義:
$n$ 回振ったときに、出た目の積に含まれる素因数 2,3,5 の個数がそれぞれ$c_2,c_3,c_5$となる確率dpの漸化式:
dp[n][nc_2][nc_3][nc_5]=\sum_{i=0}^{n-1}\sum_{c_2\ge nc_2, c_3 \ge nc_3, c_5 \ge nc_5}dp[i][c_2][c_3][c_5]dp初期条件:
$dp[0][0][0][0]=1$(0 回振ったとき、目の積を 1 とするので、素因数にいかなる素数も含まれない)
$dp[0][*][*][]=0$求めるもの:
$D=2^a 3^b 5^c$のとき
\sum_{p_2\ge a, p_3 \ge b, p_5 \ge c}dp[N][p_2][p_3][p_5]実装は、ボトムアップ方式の配るDPで行う。
サンプルコードn, d = map(int, input().split()) # サイコロの目を素因数分解すると、2, 3, 5しか現れない count2 = 0 count3 = 0 count5 = 0 while d % 2 == 0: d //= 2 count2 += 1 while d % 3 == 0: d //= 3 count3 += 1 while d % 5 == 0: d //= 5 count5 += 1 # 2, 3, 5以外があったらだめ if d != 1: print(0) exit() # dp初期化 dp = [[[[0] * (count5 + 1) for i in range(count3 + 1)] for j in range(count2 + 1)] for k in range(n + 1)] dp[0][0][0][0] = 1 # サイコロの目1~6を素因数分解 d2 = [0, 1, 0, 2, 0, 1] d3 = [0, 0, 1, 0, 0, 1] d5 = [0, 0, 0, 0, 1, 0] # dp[i][c2][c3][c5] := サイコロを i 回振って、2^c2 * 3^c3 * 5^c5 になる確率 for i in range(n): # c2,c3,c5および6つの目についてi+1のdpを更新 for c2 in range(count2 + 1): for c3 in range(count3 + 1): for c5 in range(count5 + 1): for j in range(6): nc2 = min(count2, c2 + d2[j]) nc3 = min(count3, c3 + d3[j]) nc5 = min(count5, c5 + d5[j]) dp[i + 1][nc2][nc3][nc5] += dp[i][c2][c3][c5] / 6 print(dp[n][count2][count3][count5])
- 投稿日:2021-01-01T18:01:50+09:00
3. Pythonによる自然言語処理 5-3. 日本語文の感情値分析[単語感情極性値対応表]
- 感情分析でネガポジの極性値を取得する元となる感情値辞書は、日本語では次の3つが挙げられます。
- 本記事では全 55,125 語が登録された「単語感情極性値対応表」を利用させて頂きます。上記公式サイトによれば『岩波国語辞書』をリソースとして、感情極性値は語彙ネットワーク(筆者注 : 語や語句の意味的な関連性を示すネットワーク)を利用して自動的に計算された-1 から +1 の実数値となっています。
⑴ 「単語感情極性値対応表」の取得
1. 「単語感情極性値対応表」を読み込む
import pandas as pd pd.set_option('display.unicode.east_asian_width', True) # 感情値辞書の読み込み pndic = pd.read_csv(r"http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic", encoding="shift-jis", names=['word_type_score']) print(pndic)
- pandas の
set_option()は表示形式など様々なオプションを指定するもので、引数の'display.unicode.east_asian_width'は全角文字を考慮してカラム名と値の位置をそろえて表示させます。- 「単語感情極性値対応表」は、1行ずつ「語(終止形):読み:品詞:感情値[-1, +1]」の形式で登録されており、極性値は -1 に近いほどネガティブ、+1 に近いほどポジティブを表します。
2. 語と感情値のみ抽出して dict 型に変換
- カラム内を
split()で「:」を区切り文字として4分割し、語(終止形)"word"と感情値"score"を抽出して dict 型に変換します。import numpy as np # 語と感情値を抽出 pndic["split"] = pndic["word_type_score"].str.split(":") pndic["word"] = pndic["split"].str.get(0) pndic["score"] = pndic["split"].str.get(3) # dict型に変換 keys = pndic['word'].tolist() values = pndic['score'].tolist() dic = dict(zip(keys, values)) print(dic)
⑵ 分析対象となるテキスト
- 今回はリソースを NHK のニュースサイトに求め、任意に2020年12月29日付のビジネス関連記事「スパゲッティ輸入量 過去最多に」を取り上げます。
- 句点「。」を区切り文字として行単位のリストに変換します。
text = 'スパゲッティの全国の輸入量が、ことし10月までに過去最多となり、税関は新型コロナウイルスの感染拡大の影響で増えた、いわゆる『巣ごもり需要』が背景にあるでのはないかとしています。横浜税関によりますと、全国の港や空港から輸入されたスパゲッティの量はことし10月末の時点でおよそ14万2000トンでした。これは、3年前の1年間の輸入量を4000トンほど上回り、過去最多となりました。また、マカロニもことし10月までの輸入量が1万1000トン余りに上り、過去最多だった4年前の1年間の輸入量とほぼ並んでいるということです。' lines = text.split("。")
⑶ 形態素解析によるテキストのデータ化
1. MeCab による形態素解析のインスタンスを生成
- MeCab をインストールします。
!apt install aptitude !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3==0.7
- MeCab をインポートし、出力モードを
"-Ochasen"としてインスタンスを生成します。- 例として 1 行目の形態素解析結果を示します。
import MeCab mecab = MeCab.Tagger("-Ochasen") # 1行目の形態素解析結果を例示 print(mecab.parse(lines[0]))
2. 品詞を限定してデータリスト化
- 文章ごとの ポジティブ/ネガティブ の性格づけに寄与すると考えられる品詞として、名詞・形容詞・動詞・副詞の4カテゴリに絞ります。
# 形態素解析に基づいて単語を抽出 word_list = [] for l in lines: temp = [] for v in mecab.parse(l).splitlines(): if len(v.split()) >= 3: if v.split()[3][:2] in ['名詞','形容詞','動詞','副詞']: temp.append(v.split()[2]) word_list.append(temp) # 空の要素を削除 word_list = [x for x in word_list if x != []] print(word_list)
- こちら文章単位のリストを対象として「単語感情極性値対応表」から ポジティブ/ネガティブ を判定する感情極性値を取得します。
⑷ 感情極性値の取得
1. 辞書から感情極性値を取得
- 文章ごとに、単語ごとの感情極性値を取得してデータフレームに出力してみます。
result = [] # 文単位の処理 for sentence in word_list: temp = [] # 語単位の処理 for word in sentence: word_score = [] score = dic.get(word) word_score = (word, score) temp.append(word_score) result.append(temp) # 文毎にデータフレーム化して表示 for i in range(len(result)): print(lines[i], '\n', pd.DataFrame(result[i], columns=["word", "score"]), '\n')
全 4 行の結果を下表にまとめました。左から順に、各行の単語とその感情極性値となっています。
まず None は「単語感情極性値対応表」に登録されていない単語であり、いかに収録語彙数の多い辞書を以てしても必ず起きる問題といえます。
ただ、問題といえば、感情極性値に正の値をもつ単語はただ一つ「最多」しかなく、それ以外はすべて負の値となっていることです。その中には、なぜネガティブと判定されるのか実感のわかないものが少なくありません。
2. 文章ごとに感情極性値の平均値を計算
# 文単位の平均値を計算 mean_list = [] for i in result: temp = [] for j in i: if not j[1] == None: temp.append(float(j[1])) mean = (sum(temp) / len(temp)) mean_list.append(mean) # データフレーム化して表示 print(pd.DataFrame(mean_list, columns=["mean"], index=lines[0:4]))
- 全般的にほぼ負の値なので、自ずと語数が少ないほど平均値は高くなり、もっとも文章の短い3行目のネガティブの程度が小さめとなっています。
- ここで改めて「単語感情極性値対応表」を検討してみます。
⑸ 「単語感情極性値対応表」再考
1. ネガポジの構成比を確認する
- そもそも「単語感情極性値対応表」における ポジティブ/ネガティブ 及び ニュートラル の割合はどうなっているのでしょうか。
# ポジティブの語数 keys_pos = [k for k, v in dic.items() if float(v) > 0] cnt_pos = len(keys_pos) # ネガティブの語数 keys_neg = [k for k, v in dic.items() if float(v) < 0] cnt_neg = len(keys_neg) # ニュートラルの語数 keys_neu = [k for k, v in dic.items() if float(v) == 0] cnt_neu = len(keys_neu) print("ポジティブ の割合:", ('{:.3f}'.format(cnt_pos / len(dic))), "(", cnt_pos, "語)") print("ネガティブ の割合:", ('{:.3f}'.format(cnt_neg / len(dic))), "(", cnt_neg, "語)") print("ニュートラル の割合:", ('{:.3f}'.format(cnt_neu / len(dic))), "(", cnt_neu, "語)")
- ネガティブが全体の9割を占めており、著しく偏っていることがわかります。かりに10語あったとしてポジティブな語はそのうち1語あるかないかですから、文章単位の平均値は概ねネガティブとなります。
- また例えば、先に「スパゲッティ:-0.270203」「マカロニ:-0.384254」とありましたが、人それぞれの嗜好やシチュエーションによってネガポジの実感は異なるはずです。
- なお、先の結果で唯一ポジティブな語とされた「最多」ですが、昨今の「新規感染者が最多を更新」といった語用をみても、必ずしもポジティブな意味だけに使われる語でないことは明らかです。
2. 重複している語を確認する
- 登録数は 55,125 語ですが、dict 型に変換した時点でその総数は 52,671 語に減じています。
print("dict型に変換前の要素数 :", len(pndic)) print("dict型に変換後の要素数 :", len(dic), "\n") pndic_list = pndic["word"].tolist() print("dict型に変換前の一意な要素数 :", len(set(pndic_list)))
- 登録の形式は原則として
語(終止形):読み:品詞:感情値[-1, +1]となっていますが、例えば、次のように同一の語(終止形)をもつ複数のデータが散在しています。こうした重複をなくした一意な要素数をカウントすると、上記のとおり dict 型に変換後の要素数 52,671 と一致します。
- さて、感情分析には「-ない」「だが」といった否定による極性の反転や、「とても」「非常に」というような感情強度の増幅などの処理が必要です。辞書自体の問題のみならず、以上の処理では全く十分ではありません。
- 辞書作りには多大なエネルギーと莫大なコストがかかります。そうした先行投資があってのことで、既成のものの恩恵に浴しようとして、その完成度をあれこれ批評することにいささか抵抗を感じます。かつてヒューマンリソースをつかって自然言語処理をやってきた個人的な経験からいえば、当事者意識をもって日本語の感情分析を考えていきたい、ですね。











- 投稿日:2021-01-01T17:40:11+09:00
これから、AIやML・データサイエンティストのスクール講座を受講される方へ贈る言葉
初めまして、ももちゃんのパパです。
タイトルがいきなり偉そうな事言いやがってと言われそうですが、今まで某スクールで200名以上教えてきました。
Python,AI(じゃなくてMLなんだけど。。。)、DataScience、Blockchain(Solidity)と、幅広くメンターとして
教師ではなくこれから同じ業界で働いてくれる仲間を増やせるんだと意気込みを持って、最初は転職活動中でしたが、仕事が決まってからは
仕事の合間にメンターとして(講師とか教師とかではなく、敢えて言うなら新人の方に仕事が出来るようになるために
他のことも色々と相談に載ったり)活動してきました。これが、日本が遅れていると言われているところを変えられるんだ!!
と意気込んで、仕事を後回しにして(徹夜になりますが。。。(笑))力を注いできました。2021年でスクールでの活動は辞めます
理由は、コースを受けた人が転職なり就職なり出来ていないこと=理解出来ていない、使えていない現実を知ったからです
スクール運営されている側は、「出ているじゃないか」と言い張るでしょう。でも、事実は事実。実現値は、変えられません。
同じスクール出身者が同じスクールでデータサイエンスを学んだその道のプロが面接する機会があったそうです。
(面接する側が、私の受講生だった方で、私も数学では到底及ばない方でPythonでのデータサイエンスを学びに来られていました)「それ、データサイエンティストじゃないよ」
Pythonでプログラム作れると、データサイエンスの理論(ベイズ統計とか)の課題を早々に解いても、試験問題と同じです。
現場で欲しい人は、理解している人なのです。最初は、色々あると思いますが、その姿勢がある人が欲しいのです。
「データを見て、ゴールまでの理論に関する仮説を立てて検証し、結果を理論的に説明できる人」
なのであって、1+1=2のような答えを出すだけの人なら、PCで十分です。
(現に、間違えてとってPCで計算だけさせている人も多いそうです)受講生には、お医者さんもいらっしゃいます。医療に役立てようと、凄く忙しい中、時間を取って参加されています。
お医者様に限らず、受講生の方には2つのタイプに大別されると感じています。
(1)とても、勉強熱心だけどプログラムは良くわかっていないから、課題提出も遅い
(2)早々に課題を全て終わらせて、メンター開始時には課題は全て合格(後で見ると、?なのはありますが)この2の受講生に、「機械学習の結果、600枚画像分析を86%の精度で17秒でできました。さて、お仕事に使えますか?」と質問します。
貴方ならどう答えますか?
「医療なんだから、99%精度がないと駄目ですね」→その通りです。でも、99%でないといけない根拠がありません。
「人がやった場合は17秒ではできないので、残りをどうするかを考えます」→人間がやれば、17秒で86%=516枚を正しく判別できますか?(出来たら、TVのニュースになりますね(笑))必要なのは、後者の人です。常識や業界知識、その他必要な知識を総動員して、機械学習が出した結果を検証できる人なのです。
私も、IT業界が長いので、数多くのプログラムを作ってきましたし、見てきました。
最近、単体テストレベルの不具合が、本番で発生することが多いですよね。そりゃそうですよ、目先のことしか考えてないんですから。IT業界は、魅力的かも知れません。デスマーチとか、平気でありますが(最近は、無能管理職が引き起こしているのが殆どですが)
エンジニアになりたい方は、是非プログラミングを学んで下さい。プログラムを作れる人は、普通です。色んなプログラムを合わせて
デバッグしたり機能追加したりして、期限までに目的を達成できる、そんなことを教えてくれるスクールだと良いと思います。
(どれ?と言われてもねぇ。。。行ったこと無いのでーw)・プログラムではなくプログラミングが出来る人
・数値の根拠を説明出来る人
を育成するために、チャレンジして行きたいです。
2021年の年頭に当たって、今までのモヤモヤやこれでいいのか?をスッキリさせるために記事にしてみました。※これは、私見です。色々ご意見はあるでしょうが、それはそれとして
- 投稿日:2021-01-01T17:40:11+09:00
これから、AIやML・データサイエンティストのスクール講座を受講される方へ
初めまして、ももちゃんのパパです。
タイトルがいきなり偉そうな事言いやがってと言われそうですが、今まで某スクールで200名以上教えてきました。
Python,AI(じゃなくてMLなんだけど。。。)、DataScience、Blockchain(Solidity)と、幅広くメンターとして
教師ではなくこれから同じ業界で働いてくれる仲間を増やせるんだと意気込みを持って、最初は転職活動中でしたが、仕事が決まってからは
仕事の合間にメンターとして(講師とか教師とかではなく、敢えて言うなら新人の方に仕事が出来るようになるために
他のことも色々と相談に載ったり)活動してきました。これが、日本が遅れていると言われているところを変えられるんだ!!
と意気込んで、仕事を後回しにして(徹夜になりますが。。。(笑))力を注いできました。2021年でスクールでのメンター活動は辞めます
理由は
1.コースを受けた人が転職なり就職なり出来ていないこと=理解出来ていない、使えない事実を知った
2.メンターが、環境構築すらできない(環境が壊れたから作り直せ=今までの結果は、全て消えることを平気で言う)スクール運営されている側は、「出ているじゃないか」「出来ているじゃないか」と言うでしょう。
事実は事実。実現は、変えられません。今まで、沢山の事例とヘルプも受けました。そんなことも知らないの?と
愕然としたことも何度もありました。私は、合う人とは話すタイプ(逆に、初めての方は苦手だけど、打ち解けるのは早いです。
弄られるのが仕事?(笑)みたいなものなので)で、相手の将来を思いすぎて厳しいことを言いすぎたり、
相手が適当なら適当に合わせて来ました(適当な奴に真剣にやる必要ある?)。何故知ったか。これは、皮肉にも受講生の方からのフィードバックでした(スクールも予測していなかったでしょうね)。
同じスクール出身者が同じスクールでデータサイエンスを学んだその道のプロが面接する機会があったそうです。
(面接する側が、私の受講生だった方で、私も数学では到底及ばない方でPythonでのデータサイエンスを学びに来られていました)
面接も進み、話していてペイズ統計がとか、シミュレーションとか、色々話しが出たそうです。でも、その方はこう仰ったそうです。「それ、データサイエンティストじゃないよ」
これで、面接は終わりになりました。こ
Pythonでプログラム作れるとか、データサイエンスの理論(ベイズ統計とか)の課題を早々に解いても、
試験と同じで、正解です。しかし、現場で必要な人は、データを理解している人なのです。
最初は、色々あると思いますが、その姿勢がある人が欲しいのです。
「データを見て、ゴールまでの理論に関する仮説を立てて検証し、結果を理論的に説明できる人」
なのであって、1+1=2のような答えを出すだけの人なら、PCで十分です。
(現に、間違えてとってPCで計算だけさせている人も多いそうです)理系とか文系とか分ける必要は無く、ちゃんとした教育を
受講生には、お医者さんもいらっしゃいます。医療に役立てようと、凄く忙しい中、時間を取って参加されています。
お医者様に限らず、受講生の方には2つのタイプに大別されると感じています。
(1)とても、勉強熱心だけどプログラムは良くわかっていないから、課題提出も遅い
(2)早々に課題を全て終わらせて、メンター開始時には課題は全て合格(後で見ると、?なのはありますが)この2の受講生に、「機械学習の結果、600枚画像分析を86%の精度で17秒でできました。さて、お仕事に使えますか?」と質問します。
貴方ならどう答えますか?
「医療なんだから、99%精度がないと駄目ですね」→その通りです。でも、99%でないといけない根拠がありません。
「人がやった場合は17秒ではできないので、残りをどうするかを考えます」→人間がやれば、17秒で86%=516枚を正しく判別できますか?(出来たら、TVのニュースになりますね(笑))必要なのは、後者の人です。常識や業界知識、その他必要な知識を総動員して、機械学習が出した結果を検証できる人です。
IT業界が長いので、数多くのプログラムを作ってきました。見てきました。レビューしてきました。
最近、単体テストレベルの不具合が、本番で発生することが多いですよね。そりゃそうですよ、目先のことしか考えてないんですから。
IT業界は、魅力的かも知れません。デスマーチとか、平気でありますが(最近は、無能管理職が引き起こしているのが殆どですが)
エンジニアになりたい方は、是非プログラミングを学んで下さい。プログラムを作れる人は、普通です。色んなプログラムを合わせて
デバッグしたり機能追加したりして、期限までに目的を達成できる、そんなことを教えてくれるスクールだと良いと思います。
(どれ?と言われてもねぇ。。。行ったこと無いのでーw)・プログラムではなくプログラミングが出来る人
・数値の根拠を説明出来る人
を育成するために、チャレンジして行きたいです。
2021年の年頭に当たって、今までのモヤモヤやこれでいいのか?をスッキリさせるために記事にしてみました。※これは、私見です。色々ご意見はあるでしょうが
- 投稿日:2021-01-01T17:14:00+09:00
データの数値的要約
データ解析の基本的な要約法である数値的要約について書いていきます。
一次元データの要約
import numpy as np x=np.array([1,2,3,4.5,5,6.5,7,8,9,10]) average=np.mean(x) ///平均値 mean関数/// (Out 5.6) med=np.median(x) ///中央値 median関数/// (Out 5.75) var.p=np.var(x) ///標本分散 var関数/// (Out 8.19) std=np.std(x) ///標準偏差 std関数/// (Out 2.86)各言葉の意味についてはこちらを参考にしてください。
https://note.com/karaage_love/n/n6f617d38c528二次元データの要約
import numpy as np import matplotlib.pyplot as plt array=np.loadtxt(fname='example.csv',delimiter=',',encoding="utf-8_sig") ///example.csvには二列のデータが入っています。/// array_x=array[:,0] array_y=array[:,1] ///スライス/// plt.scatter(araay_x,array_y,s=10,c='blue',alpha='0.5') ///散布図の作成 sは大きさのこと cは散布図の色のこと alphaは透明度のこと/// np.cov(array_x,array_y,bias=True) (Out [[6.72727273 3.54545455] [3.54545455 6. ]]) //共分散 結果は2×2の行列 対角成分はそれぞれx、yの分散。残りは共分散です。/// np.corrcoef(array_x,array_y) (Out [[1. 0.55805471] [0.55805471 1. ]] ///相関係数 やはり対角成分以外が相関係数です。///二次元データの要約の詳しいことをこちらを参照。
https://note.com/karaage_love/n/n992a7fdf9b1f
- 投稿日:2021-01-01T16:31:02+09:00
(Java、JavaScript、Python)文字列処理の比較
Java、JavaScript、Pythonの処理比較
最近JavaScriptとPythonの勉強を始めました。
学んだことの整理として、Java、JavaScript、Pythonの3言語の処理比較を記事にしていこうと思います。
今回は文字列処理です。文字列処理の比較一覧
処理内容 Java JavaScript Python 文字列長 length() length len(文字列) 一致比較 equals(比較文字)
equalsIgnoreCase(比較文字)==比較演算子
===比較演算子==比較演算子 検索 indexOf(検索文字列)
lastIndexOf(検索文字列)
contains(検索文字列)
startsWith(検索文字列)
endsWith(検索文字列)
indexOf(検索文字列)
lastIndexOf(検索文字列)
includes(検索文字列)
startsWith(検索文字列)
endsWith(検索文字列)find(検索文字列)
rfind(検索文字列)
in式
not in式
startswith(検索文字列)
endswith(検索文字列)単純結合 +演算子
concat(結合文字列)
StringBuilder.append(結合文字列)+演算子
concat(結合文字列,...)+演算子 空白除去 trim()
strip()trim()
trimLeft()
trimRight()strip(削除対象文字)
lstrip(削除対象文字)
rstrip(削除対象文字)大文字小文字変換 toUpperCase()
toLowerCase()toUpperCase()
toLowerCase()upper()
lower()
capitalize()
title()
swapcase()
切り出し substring(開始index,終了index)
charAt(index)substring(開始index,終了index)
charAt(index)
slice(開始index,終了index)
substr(開始index,文字数)
文字列[開始index:終了index] 繰り返し repeat(繰返し数) repeat(繰返し数) *演算子 置換 replace(前文字,後文字)
replaceFirst(前文字,後文字)
replaceAll(前文字,後文字)
replace(前文字,後文字)
replaceAll(前文字,後文字)replace(前文字,後文字)
re.sub(前文字,後文字,文字列)
re.subn(前文字,後文字,文字列)
translate(式)区切りで結合 String.join(区切り文字,結合文字列...) 結合文字配列.join(区切り文字) 区切り文字.join(結合文字配列) 区切りで分割 split(区切り文字)
split(区切り文字) split(区切り文字)
rsplit(区切り文字)
splitlines()
re.split(区切り文字)任意成型 String.format(成型式,文字列...) テンプレートリテラル→
`xxx${変数名}xxx`成型式.format(変数や式...)
f'xxx{変数や式}xxx'
形成式 % (変数や式,...)追記
- 一致比較
- JavaのequalsIgnoreCase()は大文字小文字を無視した一致比較を行います。
- ===演算子は型を含めた厳密な比較を行います。'123'===123 →false
- 検索
- 一致箇所の文字indexを返す:indexOf()、lastIndexOf()、find()、rfind()
- true/falseを返す:contains()、includes()、in式、not in式
- 先頭文字の一致判定、true/falseを返す:startsWith()
- 末尾文字の一致判定、true/falseを返す:endsWith()
- 空白除去
- いずれの言語も半角空白、タブ、改行が除去対象になります。
- Javaのstrip()は上記に加え、全角空白も除去対象になります。
- Pythonの関数は引数に削除対象文字指定可、省略時は空白・タブ・改行が除去対象になります。
- 大文字小文字変換
- Pythonは他の2つよりも細かい変換関数が存在します。capitalize()→最初の文字を大文字に他は小文字に変換、title()→単語最初の文字を大文字に他は小文字に変換、swapcase()→大文字小文字を入れ替え
- 切り出し
- substring()は終了indexを省略可能で、その場合は文字列の末尾を終了indexとします。
- JavaScriptの切り出しsubstring()とslice()は通常の使用範囲では差異はありませんが、引数がイレギュラーな場合に結果が異なります。
- 開始index>終了indexの場合、substring()は自動で開始終了を入替え、slice()は空文字を返します。
- 負数指定の場合、substring()は引数を0として扱い、slice()は「文字列長-引数」として扱います。
- Pythonは関数ではなく「文字列[start:end]」という書式のスライスを使用します。start,endいずれか省略可能、「:」省略時はcharAt()のように1文字を取得します。
- 置換
- Java:replace()はマッチした全文字置換、replaceFirst()マッチした最初の文字置換。
- JavaScript:replace()はマッチした最初の文字置換、replaceAll()はマッチした全文字置換、ただしreplace()も正規表現オプション「g」で全文字置換可能。
- Python:replace()は第3引数にsplit()のように最大置換数指定可。
- Python:translate()は複数ケースの置換が可能。ただし置換元文字は1文字であること。置換の組み合わせを「str.maketrans()」で指定します。「"abCdefghIk".translate(str.maketrans({'C':'c', 'I':'ij'}))」
- 正規表現が使用できるのは各言語で以下の通りです。
- Java:replaceFirst()、replaceAll()
- JavaScript:replace()、replaceAll()
- Python:re.sub()、re.subn()、subnは置換処理された文字列+変換した個数のリスト(正確にはタプル)を返します。
- 区切りで分割
- split()はどの言語でも第2引数に最大分割数が指定可能です。
- Java、JavaScriptのsplit()は正規表現使用可能です。JavaScriptにおいては空白区切りは正規表現で「/\s/」と指定します。
- Pythonはreモジュールのre.split()が正規表現使用可能です。
- Pythonのsplit()は引数省略可能で、省略時は空白・タブ・改行が分割対象となります。
- Pythonのrsplit()は第2引数に最大分割数指定したとき右からカウントするのがsplit()との差異になります。
- Pythonのsplitlines()は改行で分割します。OS依存の改行にも対応しています。
- 任意成型
- Pythonはいくつかの書式があります。format()は下記サンプル参照。
- 1つは%演算子:sei='山田' mei='太朗'のとき、print('名前:%s %s' % (sei,mei))
- 1つはf文字列:print(f'名前:{sei} {mei}')
サンプル
Java
public class StringSample { public static void main(String[] args) { StringSample obj = new StringSample(); obj.executeSample(); } public void executeSample() { String str = " 山田,太朗,Yamada,Taro,M,19950827,25才,東京都千代田区神田佐久間町2-XX-XX〇〇荘 "; // 空白除去 String strKuhaku1 = str.trim(); // 区切りで分割 String[] strBun1 = strKuhaku1.split(","); // 単純結合 String resName = new StringBuilder().append(strBun1[0]).append(strBun1[1]).toString(); // 大文字小文字変換 String strOoko1 = strBun1[2].toUpperCase(); String strOoko2 = strBun1[3].toUpperCase(); // 単純結合 String resAlpha = strOoko1.concat(" ").concat(strOoko2); // 一致比較 String resSex; if (strBun1[4].equals("M")) { resSex = "男性"; } else { resSex = "女性"; } // 切り出し String strKiri1 = strBun1[5].substring(0, 4); String strKiri2 = strBun1[5].substring(4, 6); String strKiri3 = strBun1[5].substring(6); // 区切りで結合 String resBirth = String.join("/", strKiri1, strKiri2, strKiri3); // 置換 String resAge = strBun1[6].replace("才", "歳"); // 文字列長 String resAddress = strBun1[7]; if (16 < strBun1[7].length()) { resAddress = strBun1[7].substring(0, 16); // 単純結合 resAddress = resAddress + "(略)"; } // 検索 String resMessage1 = ""; String resMessage2 = ""; if (strBun1[7].startsWith("東京都")) { resMessage1 = "首都です。"; } if (strBun1[7].contains("千代田区")) { resMessage2 = "東京駅があります。"; } // 任意成型 String res1 = String.format("%s(%s)様 %s %s生(%s)", resName, resAlpha, resSex, resBirth, resAge); String res2 = String.format("%s %s%s", resAddress, resMessage1, resMessage2); // 繰り返し String line = "-".repeat(64); System.out.println(line); System.out.println(res1); System.out.println(res2); System.out.println(line); } }JavaScript
<html> <head> <script> function executeSample() { let str = " 山田,太朗,Yamada,Taro,M,19950827,25才,東京都千代田区神田佐久間町2-XX-XX〇〇荘 "; // 空白除去 let strKuhaku1 = str.trim(); // 区切りで分割 let strBun1 = strKuhaku1.split(","); // 単純結合 let resName = strBun1[0] + strBun1[1]; // 大文字小文字変換 let strOoko1 = strBun1[2].toUpperCase(); let strOoko2 = strBun1[3].toUpperCase(); // 単純結合 let resAlpha = strOoko1.concat(" ", strOoko2); // 一致比較 let resSex; if (strBun1[4] == "M") { resSex = "男性"; } else { resSex = "女性"; } // 切り出し let strKiri1 = strBun1[5].substring(0, 4); let strKiri2 = strBun1[5].substring(4, 6); let strKiri3 = strBun1[5].substring(6); // 区切りで結合 let resBirth = [strKiri1, strKiri2, strKiri3].join("/"); // 置換 let resAge = strBun1[6].replace("才", "歳"); // 文字列長 let resAddress = strBun1[7]; if (16 < strBun1[7].length) { resAddress = strBun1[7].substring(0, 16); // 単純結合 resAddress = resAddress + "(略)"; } // 検索 let resMessage1 = ""; let resMessage2 = ""; if (strBun1[7].startsWith("東京都")) { resMessage1 = "首都です。"; } if (strBun1[7].includes("千代田区")) { resMessage2 = "東京駅があります。"; } // 任意成型 let res1 = `${resName}(${resAlpha})様 ${resSex} ${resBirth}生(${resAge})`; let res2 = `${resAddress} ${resMessage1}${resMessage2}`; // 繰り返し let line = "-".repeat(64); console.log(line); console.log(res1); console.log(res2); console.log(line); } </script> </head> <body onload="executeSample()"> <h1>Qiita記事</h1> <h2>文字列処理</h2> </body> </html>Python
str1 = " 山田,太朗,Yamada,Taro,M,19950827,25才,東京都千代田区神田佐久間町2-XX-XX〇〇荘 " # 空白除去 strKuhaku1 = str1.strip() # 区切りで分割 strBun1 = strKuhaku1.split(",") # 単純結合 resName = strBun1[0] + strBun1[1] # 大文字小文字変換 strOoko1 = strBun1[2].upper() strOoko2 = strBun1[3].upper() # 単純結合 resAlpha = strOoko1 + " " + strOoko2 # 一致比較 resSex = "" if strBun1[4] == "M": resSex = "男性" else: resSex = "女性" # 切り出し strKiri1 = strBun1[5][0:4] strKiri2 = strBun1[5][4:6] strKiri3 = strBun1[5][6:] # 区切りで結合 resBirth = "/".join([strKiri1, strKiri2, strKiri3]) # 置換 resAge = strBun1[6].replace("才", "歳") # 文字列長 resAddress = strBun1[7] if 16 < len(strBun1[7]): resAddress = strBun1[7][:16] # 単純結合 + resAddress = resAddress + "(略)" # 検索 resMessage1 = "" resMessage2 = "" if strBun1[7].startswith("東京都"): resMessage1 = "首都です。" if "千代田区" in strBun1[7]: resMessage2 = "東京駅があります。" # 任意成型 res1 = "{}({})様 {} {}生({})".format(resName, resAlpha, resSex, resBirth, resAge) res2 = "{} {}{}".format(resAddress, resMessage1, resMessage2) # 繰り返し * line = "-" * 64 print(line) print(res1) print(res2) print(line)出力結果
---------------------------------------------------------------- 山田太朗(YAMADA TARO)様 男性 1995/08/27生(25歳) 東京都千代田区神田佐久間町2-X(略) 首都です。東京駅があります。 ----------------------------------------------------------------
- 投稿日:2021-01-01T16:27:25+09:00
macOSでpythonを使えるようにした
背景
macOS BigSurでpythonをつかおうとおもった。
(CuteRというコマンドを使いたかった:CuteRでQRコード画像をつくった)ところが、
pipをつかうと$ pip install dyld: Library not loaded: /System/Library/Frameworks/CoreFoundation.framework/Versions/A/CoreFoundation Referenced from: /Library/Frameworks/Python.framework/Versions/3.6/Resources/Python.app/Contents/MacOS/Python Reason: image not found Abort trap: 6
となってしまう。
$ python3でもおなじ。基本的な方向性
macOS環境のPython:https://www.python.jp/install/macos/index.html
によると
- macOSに入っている
pythonを使おうとするなHomebrewでインストールせよpip3でなくてpython3.9 -m pip xxxとせよvenvなど仮想環境で動かせということだそう。ここでは、上の3つまでやってみた。
作業ログ
$ brew updateすると、まずはgit - C ...をせよとのお達し。$ brew update Error: homebrew-core is a shallow clone. To `brew update` first run: git -C "/usr/local/Homebrew/Library/Taps/homebrew/homebrew-core" fetch --unshallowまずは
fetchして、$ brew update$ git -C "/usr/local/Homebrew/Library/Taps/homebrew/homebrew-core" fetch --unshallow remote: Enumerating objects: 690418, done. remote: Counting objects: 100% (690359/690359), done. remote: Compressing objects: 100% (233146/233146), done. remote: Total 680792 (delta 450632), reused 674814 (delta 444788), pack-reused Receiving objects: 100% (680792/680792), 271.20 MiB | 14.34 MiB/s, done. Resolving deltas: 100% (450632/450632), completed with 7510 local objects. From https://github.com/Homebrew/homebrew-core baf6aab591..b293a33dd8 master -> origin/master $ brew updatepythonのインストール。
$ brew install python Warning: python@3.9 3.9.1_3 is already installed, it's just not linked You can use `brew link python@3.9` to link this version.入っているらしい。リンクすればいいのね。
$ brew link python@3.9 Linking /usr/local/Cellar/python@3.9/3.9.1_3... Error: Could not symlink bin/2to3 Target /usr/local/bin/2to3 already exists. You may want to remove it: rm '/usr/local/bin/2to3' To force the link and overwrite all conflicting files: brew link --overwrite python@3.9 To list all files that would be deleted: brew link --overwrite --dry-run python@3.9ふむ、
rmしてbrew linkね。$ rm '/usr/local/bin/2to3' $ brew link --overwrite python@3.9 Linking /usr/local/Cellar/python@3.9/3.9.1_3... 25 symlinks createdこれをしたけど、
$ pip install $ python3とすると、また冒頭と同じエラー。そうではなくて
$ python3.9 Python 3.9.1 (default, Dec 28 2020, 11:25:16) [Clang 12.0.0 (clang-1200.0.32.28)] on darwin Type "help", "copyright", "credits" or "license" for more information.いけたー! ということで、下記サイトを参考にして
pipを試す。
https://www.python.jp/install/macos/pip.html$ python3.9 -m pip install pillow Collecting pillow Downloading Pillow-8.0.1-cp39-cp39-macosx_10_10_x86_64.whl (2.2 MB) |████████████████████████████████| 2.2 MB 3.7 MB/s Installing collected packages: pillow Successfully installed pillow-8.0.1 WARNING: You are using pip version 20.3.1; however, version 20.3.3 is available. You should consider upgrading via the '/usr/local/opt/python@3.9/bin/python3.9 -m pip install --upgrade pip' command.といわれるので、御意。
$ python3.9 -m pip install --upgrade pip Requirement already satisfied: pip in /usr/local/lib/python3.9/site-packages (20.3.1) Collecting pip Downloading pip-20.3.3-py2.py3-none-any.whl (1.5 MB) |████████████████████████████████| 1.5 MB 6.2 MB/s Installing collected packages: pip Attempting uninstall: pip Found existing installation: pip 20.3.1 Uninstalling pip-20.3.1: Successfully uninstalled pip-20.3.1 Successfully installed pip-20.3.3上記サイトに従って、いったんpillowはアンインストール
$ python3.9 -m pip uninstall pillow Found existing installation: Pillow 8.0.1 Uninstalling Pillow-8.0.1: Would remove: /usr/local/lib/python3.9/site-packages/PIL/* /usr/local/lib/python3.9/site-packages/Pillow-8.0.1.dist-info/* Proceed (y/n)? y Successfully uninstalled Pillow-8.0.1これでよいのだな。
リソース
macOS環境のPython:https://www.python.jp/install/macos/index.html
macOS環境のPython - pip :https://www.python.jp/install/macos/pip.html環境
Python 3.9.1 (Dec 28 2020, 11:25:16)
macOS BigSur バージョン 11.1
MacBook Pro (13-inch, 2020, Four Thunderbolt 3 ports)

- 投稿日:2021-01-01T15:55:55+09:00
CuteRでQRコード画像をつくった
背景
年賀状にQRコードを貼ろうとおもった。ふつうのじゃおもしろくないし、真ん中にロゴが入っているのもちょっと違うし。CuteRというpythonで書かれたコマンドがおもしろそうなので、使えるようにしてみた。
↑ こんなかんじのQRコードがつくれるらしい! ほかでも遊べそうwpythonのインストール
別記事でまとめた ⇒ macOSでpythonを使えるようにした
CuteRのインストール
作業ディレクトリを作成して移動
$ mkdir CuteR $ cd CuteRつくったディレクトリに
venvで仮想環境をつくり、アクティベート$ python3.9 -m venv .venv $ . .venv/bin/activateCuteRをつかってみる
公式サイトにある、サンプルコマンドを打ってみる。無事に動く!!
$ CuteR -c 10 -e H -o sample_output.png -v 10 sample_input.png http://www.chinuno.comいろいろ試して、コマンド調整
$ CuteR -c 10 -e H -o output.png -v 6 input.png https://scrapbox.io/HPNY2021/01-Jan使用前 ⇒ 使用後
⇒
仮想環境を抜ける
(.venv) $ deactivateリソース
CuteRのページ:https://github.com/chinuno-usami/CuteR
検討したけど使わなかったもの
QArt Codes:https://research.swtch.com/qart
オンラインサービスもあったみたいだけど、終了していた。qart.js:https://github.com/kciter/qart.js
よさそうなんだけれどSecurityError: The operation is insecure.を解消できず。呼んでいるモジュールが危ないみたい?GitHubのメンテもしばらく行われていないので、自力解決をあきらめた(CuteRのほうが最新更新が新しかった)。環境
Python 3.9.1 (Dec 28 2020, 11:25:16)
macOS BigSur バージョン 11.1
MacBook Pro (13-inch, 2020, Four Thunderbolt 3 ports)


- 投稿日:2021-01-01T15:15:32+09:00
plotlyで3次元表示
今年の年賀状の中心のなる図では、海洋予測モデルの流速を3次元地形と一緒に表示した。
plotlyで作成した。Jupyterlab上でぐりぐり動かすこともできる。
データを読み込む所は省略して、図を描く部分のコードは以下の通り。
go.Surfaceが3次元的に地形を描くところで、xがx軸、yがy軸、地形のデータがzに入っている。Ctopoは彩色のためのカラースケール。
go.Coneが流速のベクトルを3次元コーンで表現した部分。(xv,yv,zv)に3次元座標、(uv,vv,wv)に3次元ベクトルデータが入っている。
layoutでは図のアスペクト比を変えたり、座標軸を表示させなくしたりしている。import plotly.graph_objects as go Ctopo = [[0, 'rgb(0, 0, 70)'],[0.2, 'rgb(0,90,150)'], [0.4, 'rgb(150,180,230)'], [0.5, 'rgb(210,230,250)'], [0.50001, 'rgb(0,120,0)'], [0.57, 'rgb(220,180,130)'], [0.65, 'rgb(120,100,0)'], [0.75, 'rgb(80,70,0)'], [0.9, 'rgb(200,200,200)'], [1.0, 'rgb(255,255,255)']] fig = go.Figure(data=[go.Surface(z=z, x=x, y=y,showscale=False,colorscale=Ctopo,cmin=-3000,cmax=3000), go.Cone(x=xv,y=yv,z=zv,u=uv,v=vv,w=wv,sizemode="absolute",sizeref=0.05,colorscale="turbo",opacity=0.5,cmin=0,cmax=1.5,showscale=False)]) noaxis=dict(showbackground=False, showgrid=False, showline=False, showticklabels=False, ticks='', title='', zeroline=False) fig.update_layout( width=1500, height=500, margin=dict(l=0, r=0, b=0, t=0), scene_aspectmode='manual', scene_aspectratio=dict(x=2, y=1, z=0.7), scene = dict( xaxis = noaxis, yaxis = noaxis, zaxis = noaxis) ) fig.show()


- 投稿日:2021-01-01T15:05:57+09:00
macOS Big Sur にアップグレードした後にpyenv installできなくなった際の私の場合の解決方法
やろうとしたこと&遭遇したエラー
- macでpyenvで複数バージョンインストール&バージョン切り替えできる環境が機能していた (python 3.6 3.8系列)
- macOS Big sir にアップグレードした
- 3.6 3.8系列の別バージョンを
pyenv installでインストールしようとすると以下のようなエラーでインストールが完了しなくなったBUILD FAILED ... ... Last 10 log lines: ./Modules/posixmodule.c:8210:15: error: implicit declaration of function 'sendfile' is invalid in C99 [-Werror,-Wimplicit-function-declaration] ret = sendfile(in, out, offset, &sbytes, &sf, flags); ...この件多くの方が遭遇していたようで、pyenvのGitHub issueで解決策が議論されていました。このページを参照しつつ私の環境で解決できた際のオペレーションをメモします。
環境
- macOS Big Sur 11.1
- Big Sur アップグレード前にXcodeインストール済み
- pyenv 1.2.21 (python 3.6 3.8系列利用中)
- シェルはzsh
解決したオペレーション
xcodeのツールを再インストール
sudo rm -rf /Library/Developer/CommandLineTools xcode-select --installbrewで2パッケージをreinstall
brew reinstall zlib bzip2~/.zshrcに以下を追加
export PATH="$HOME/.pyenv/bin:$PATH" export PATH="/usr/local/bin:$PATH" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)" export LDFLAGS="-L/usr/local/opt/zlib/lib -L/usr/local/opt/bzip2/lib" export CPPFLAGS="-I/usr/local/opt/zlib/include -I/usr/local/opt/bzip2/include"追加した変更を有効にするために、ターミナルを開き直しました。
この時点で、自分の環境ではバージョン3.8系列はpyenv installでインストールできるようになっていました。バージョン3.6系列のインストール
これで3.6系列も入るか?と
pyenv install 3.6.12とやってみましたが、最初のエラーが出てしまいました。そこで参照ページに従って以下コマンド(1行です)を打つとバージョン3.6.0のインストールに成功しました。CFLAGS="-I$(brew --prefix openssl)/include -I$(brew --prefix bzip2)/include -I$(brew --prefix readline)/include -I$(xcrun --show-sdk-path)/usr/include" LDFLAGS="-L$(brew --prefix openssl)/lib -L$(brew --prefix readline)/lib -L$(brew --prefix zlib)/lib -L$(brew --prefix bzip2)/lib" pyenv install --patch 3.6.0 < <(curl -sSL https://github.com/python/cpython/commit/8ea6353.patch\?full_index\=1)続いてバージョン番号のみを変えて以下コマンドを打つとバージョン3.6.12のインストールにも成功しました。
CFLAGS="-I$(brew --prefix openssl)/include -I$(brew --prefix bzip2)/include -I$(brew --prefix readline)/include -I$(xcrun --show-sdk-path)/usr/include" LDFLAGS="-L$(brew --prefix openssl)/lib -L$(brew --prefix readline)/lib -L$(brew --prefix zlib)/lib -L$(brew --prefix bzip2)/lib" pyenv install --patch 3.6.12 < <(curl -sSL https://github.com/python/cpython/commit/8ea6353.patch\?full_index\=1)参照文献
- 投稿日:2021-01-01T14:56:06+09:00
pixivpyを分析する
書きかけですが公開します
時間があったら直していきます初めに
愛用しているpixivpyですが、開発が中国ということもあり、国内サイトで説明などはあまり見当たりません。
そこで自分がこれを使っているうちに学んだことなどを共有したいと思います。
pythonのpixivpyを使ってpixivから特定のユーザーの作品をすべて一括でダウンロードする(うごイラ含む)を改造したいときにどうぞ分析方法
昔はanaconda付属のspyderというソフトで、返り値の分析をすることができたのですが、
今のバージョンではできなくなってしまいました。
そのためpyscripterを使ったり、一度jsonファイルとして保存してから分析することにしました。qiita.pyfrom pixivpy3 import * import json import os from PIL import Image import glob from time import sleep #ここは各個人にやってもらう設定です #ダウンロードしたいユーザーのid(webでユーザーのページに行った際のurlの最後にある数字です) id_search = 11 #一人当たりダウンロードする作品の最大数、すべてダウンロードしたい場合はできるだけ大きくすること(一人の作者の作品数を超えること) #新しい順にダウンロードされます works=100000 #ブックマーク数によるフィルター、最小値を設定、0ならすべて score=0 #閲覧数によるフィルター、最小値を設定、0ならすべて view=0 #タグによるフィルター 書き方 target_tag = ["Fate/GrandOrder","FGO","FateGO","Fate/staynight"] target_tag = [] #target_tag内に複数書くと、そのうち少なくとも一つあればダウンロード target_tag2 = []#さらにtarget_tag2に書くとtarget_tagを満たし、かつtarget_tag2を満たすものだけダウンロード extag = ["R-18"]#extag内のタグが一つでも入っていればダウンロードしない #画像を保存するディレクトリ main_saving_direcory_path = "./img/" #事前処理 #事前に作ったアカウント情報が書かれたファイルを読み込む with open("client.json", "r") as f: client_info = json.load(f) # pixivpyのログイン処理 api = PixivAPI() api.login(client_info["pixiv_id"], client_info["password"]) aapi = AppPixivAPI() aapi.login(client_info["pixiv_id"], client_info["password"]) illustrator_id = api.users_works(id_search, per_page=works) with open("users_works.json", "w") as n: json.dump(illustrator_id, n, indent = 2) with open ("users_works.json","r") as sd: users_works = json.load(sd)api.users_works
papi.py# 用户作品列表 def users_works(self, author_id, page=1, per_page=30, image_sizes=['px_128x128', 'px_480mw', 'large'], include_stats=True, include_sanity_level=True):定義がこれです。
* self:pythonのクラス独特の因数。無視してよし
* auther_id:作者のid
* page:不明。変えたらエラーになった
* per_page:新しい順に何作品データをとってくるか
* image_sizes
* include_status
* include_sanity_level
api.users_works(11, per_page=100000)
- count:作品数
- status:情報をとってこれたかsuccessで成功
- pagination:よくわからない、あまり重要でない?
api.users_works(11, per_page=100000).paginaton
- response:投稿作品の情報が新しい順に作品ごとのリストで返される
api.users_works(11, per_page=100000).response
api.users_works(11, per_page=100000).response[0]
api.users_works(11, per_page=100000).response[0]
- age_limit:年齢制限あるか
- bookstyle:
- caption:説明文
- content_type
- created_time:公開された時間
- favorite_id
- height:画像の高さ(解像度)
- id:画像ごとに割り振られたid
- is_liked
- is_manga
- metadata
- page_count:ページ数
- pablicity
- reuploaded_time
- sanity_level
- title:作品のタイトル
- tools:作品を描くのに使った道具?ページからは確認できない
- type:作品の種類:illustration:1枚 ugoira:うごイラ manga:2枚以上
- width:画像の幅(解像度)
image_urls:画像のurlサイズごとに3つある。一番画質がいいのはlarge
api.users_works(11, per_page=100000).response[0].image_urls
tags:作品につけられたタグ
api.users_works(11, per_page=100000).response[0].tags
user:投稿者の情報
stats:作品の情報
api.users_works(11, per_page=100000).response[0].user
api.users_works(11, per_page=100000).response[0].user
- account
- id
- is_follower
- is_following
- is_friend
- is_premium
- name:ユーザー名
- profile
- profile_image_urls:ユーザーのアイコンに使われている画像
- stats
api.users_works(11, per_page=100000).response[0].stats
api.users_works(11, per_page=100000).response[0].stats
- commented_count:コメント数
- favorited_count:ブックマークの数。public:公開のブックマーク private:非公開のブックマーク
- score:いいね!の数の10倍の数。なぜ存在するかわからない
- scored_count:いいね!の数
- views_count:閲覧数
置き場
aapi.download(illustrator_id.response[0].user.profile_image_urls.px_50x50, main_saving_direcory_path)









- 投稿日:2021-01-01T13:39:37+09:00
超軽量Python「Python embeddable」の実行環境の準備方法メモ
超軽量Python「Python embeddable」。ダウンロードの圧縮ファイル.zipで、約8MB、解凍して約16MB程度の超軽量Python実行環境。実行環境の準備方法を当方でも確認できたのでメモします。
- Windows embeddable package (64-bit)をダウンロード。(python-3.9.1-embed-amd64.zip)
- 展開後、中の「python.exe」に.pyファイルを渡して、実行可。(DOSコマンド: python.exe sample.py)
- Python標準ライブラリのみしか使えないので、他のライブラリをインストールするには、まず「pip」をインストール。ダウンロード先:https://bootstrap.pypa.io/get-pip.py から「get-pip.py」をダウンロード、「get-pip.py」を「python.exe」上へドラッグ&ドロップ。
- ファイル「python39._pth」をテキストエディタで開いて、「#import site」のコメントを除去「import site」へ。
- 例えば、CPU・メモリ使用率等の情報を得るライブラリ「psutil」をインストールする場合は、「DOSコマンド: python.exe -m pip install psutil」
- OK
詳細
https://www.python.org/downloads/windows/
↓
https://www.python.org/downloads/release/python-391/
Windows embeddable package (64-bit)をダウンロード。
↓
python-3.9.1-embed-amd64.zip
↓
展開すると、フォルダ「python-3.9.1-embed-amd64」内は、
ほとんど.pyd(中身はDLL)と.dllのファイルのみで構成。
↓
中の「python.exe」を起動すると、対話式コンソールが表示されます。
import datetime datetime.datetime.now() x = 2**32 x↓
ダウンロード先:https://bootstrap.pypa.io/get-pip.py から「get-pip.py」をダウンロード、フォルダ「python-3.9.1-embed-amd64」内に保存し、「get-pip.py」を「python.exe」上へドラッグ&ドロップして(あるいは、DOSコマンド: python.exe get-pip.py)、実行。
「pip」の利用可。
↓
ファイル「python39._pth」をテキストエディタで開いて、「#import site」のコメントを除去「import site」して、
↓
例えば、CPU・メモリ使用率等の情報を得るライブラリ「psutil」をインストールすると、「DOSコマンド: python.exe -m pip install psutil」で、
↓
インストール完了。
↓
ライブラリ「psutil」を使用してみると、
CPU使用率・メモリ使用率が取得され、OK。import psutil psutil.cpu_percent() psutil.virtual_memory()↓
ライブラリ「psutil」をインストールすると、実行環境は約34MB。
参照
https://qiita.com/mm_sys/items/1fd3a50a930dac3db299
https://qiita.com/suzuki_y/items/3261ffa9b67410803443
https://pypi.org/project/psutil/















- 投稿日:2021-01-01T13:15:26+09:00
Web上でロボットを作ってみた with Python
WebでPythonを使って遊べるゲームRoPE!
最近開発しているRoPEというゲーム。Pythonの学習を目的とした教育ゲームなのだが、そのデバッグも兼ねて記事を投稿してみた。
ゲーム自体はインストール不要だ。
RoPEまずはロボットを作る
ロボットはこの画面で作っていく
手始めに以下のロボットを作っていく。モーター二つと一つのキャスターの素朴なロボットだ。
Pythonを書いていく
ここでロボット制御の要となるプログラムを書いていく
まずはただ前進&Hello Worldするだけのプログラムimport Robot from time import sleep print("Hello World") Robot.Motor("motor_0",-100) Robot.Motor("motor_1",100)動かしてみると
うん、しっかり動いてる
右下のコンソールもしっかり動いていますライントレースしてみる
Basicステージをいくつかクリアするとライントレースが解放される。
まず、ロボットにカラーセンサーを装着!
センサーの値を出力してみると...
import Robot from time import sleep Robot.Motor("motor_0",-100) Robot.Motor("motor_1",100) while True: print(Robot.CSRead("Sensor_0")) sleep(0.1)
センサー値はこんな感じのグラフになっている
おおよそ35を基準として判断すればいいみたい。まずは一本めで止まれるようにする。
import Robot from time import sleep Robot.Motor("motor_0",-100) Robot.Motor("motor_1",100) while True: blightness = Robot.CSRead("Sensor_0") print(Robot.CSRead("Sensor_0")) if blightness < 35: Robot.Motor("motor_0",0) Robot.Motor("motor_1",0) sleep(0.1)これで動くはず...しかし...
通り過ぎる..
なんでもプログラム通りに動くと思ったら間違いですよ!(これをやりたかった最後に
Pythonをハードモードで勉強したい方、このゲームで一緒にイライラしましょう!
次回はライントレースの続きをやります。








- 投稿日:2021-01-01T12:12:27+09:00
独自のデータセットをTFRecord 形式にする
TensorFlow Object Detection API で独自のデータセットをつかうには、TFRecord ファイル形式にする必要があります。
データセットからTFRecordを作る手順です。手順
個々のデータを tf_example に変換する関数を定義
個々の画像とアノテーション情報をバイトに変換して、
tf_exampleという形式に変えます。import tensorflow as tf import numpy as np from PIL import Image def create_tf_example(height, #画像の高さ width, #画像の高さ filename, #画像ファイルのパス encoded_image_data, #エンコードされた画像データ image_format, #b'jpeg' か b'png' xmins, #ボックスのxの最小 xmaxs, #ボックスのxの最大 ymins, #ボックスのyの最小 ymaxs, #ボックスのyの最大 classes_text, #クラス名 classes #クラスID番号 ): img_obj = Image.open(filename).convert("RGB") #画像を開く encoded_image_data = np.array(img_obj).tobytes() #画像をバイトに tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': tf.train.Feature(int64_list=tf.train.Int64List([height])), 'image/width': tf.train.Feature(int64_list=tf.train.Int64List([width])), 'image/filename': tf.train.Feature(bytes_list=tf.train.BytesList([filename])), 'image/source_id': tf.train.Feature(bytes_list=tf.train.BytesList([filename])), 'image/encoded': tf.train.Feature(bytes_list=tf.train.BytesList([encoded_image_data])), 'image/format': tf.train.Feature(bytes_list=tf.train.BytesList([image_format])), 'image/object/bbox/xmin': tf.train.Feature(float_list=tf.train.FloatList(xmins)), 'image/object/bbox/xmax': tf.train.Feature(float_list=tf.train.FloatList(xmaxs)), 'image/object/bbox/ymin': tf.train.Feature(float_list=tf.train.FloatList(ymins)), 'image/object/bbox/ymax': tf.train.Feature(float_list=tf.train.FloatList(ymaxs)), 'image/object/class/text': tf.train.Feature(bytes_list=tf.train.BytesList(classes_text)), 'image/object/class/label': tf.train.Feature(bytes_list=tf.train.BytesList(classes)) })) return tf_exampleデータセットをForLoop処理でtf_exampleにしてTFRecordWriterで書き込む
以下のようなアノテーションデータがあるとします。
boxは [minx, miny, maxx, maxy]{ "categories": [ { "id": 1, "name": "cat" }, { "id": 2, "name": "dog" } ], "annotations": [ { "filename": "train_000.jpg", "image_height": 3840, "image_width": 2160, "labels": [ 1, 1, 2 ], "label_texts": [ "cat", "cat", "dog" ], "boxes": [ [ 1250, 790, 1850, 1300 ], [ 920, 1230, 1310, 1550 ], [ 12, 1180, 550, 1450 ] ] }, ... } ] }データセットを1画像分ずつ tf_example にして tf_records に書き込みます。
tf_example の中身の tf.train.Feature はバイトしか受け付けないので、データをバイトにして与える必要があります。import tensorflow as tf import os import numpy as np from PIL import Image # from object_detection.utils import dataset_util output_path = './data.tfrecords' image_dir = './train_images/' writer = tf.io.TFRecordWriter(output_path) annotations = dataset['annotations'] for annotation in annotations: if annotation['boxes'] != []: height = annotation['image_height'] width = annotation['image_width'] filename = (image_dir + annotation['filename']).encode('utf-8') image_format = b'jpeg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] for box in annotation['boxes']: xmins.append(box[0] / width) # 0~1に正規化 xmaxs.append(box[2] / width) ymins.append(box[1] / height) ymaxs.append(box[3] / height) classes_text = [] for text in annotation['label_texts']: classes_text.append(text.encode('utf-8')) classes = [] for label in annotation['labels']: classes.append(bytes([label])) tf_example = create_tf_example(height,width,filename,image_format,xmins,xmaxs,ymins,ymaxs,classes_text,classes) writer.write(tf_example.SerializeToString()) writer.close()分割して書き込む
データセットが大きい場合は、TFRecordを分割してファイルにすると便利です。
公式のドキュメントによるとtf.data.Dataset APIは、入力例を並行して読み取ることができ、スループットを向上させます。
tf.data.Dataset APIは、モデルのパフォーマンスをわずかに向上させるシャードファイルを使用して例をより適切にシャッフルできます。分割するコードスニペットを使うためにobject_detectionAPI をクローンします。
import os import pathlib if "models" in pathlib.Path.cwd().parts: while "models" in pathlib.Path.cwd().parts: os.chdir('..') elif not pathlib.Path('models').exists(): !git clone --depth 1 https://github.com/tensorflow/models %%bash cd models/research/ protoc object_detection/protos/*.proto --python_out=. cp object_detection/packages/tf2/setup.py . python -m pip install .tf_example を生成し、分割して書き込みます。
import contextlib2 from object_detection.dataset_tools import tf_record_creation_util num_shards=10 output_filebase='./train_dataset.record' with contextlib2.ExitStack() as tf_record_close_stack: output_tfrecords = tf_record_creation_util.open_sharded_output_tfrecords( tf_record_close_stack, output_filebase, num_shards) annotations = dataset['annotations'] for i in range(len(annotations)): if annotations[i]['boxes'] != []: height = annotations[i]['image_height'] width = annotations[i]['image_width'] filename = (image_dir + annotations[i]['filename']).encode('utf-8') image_format = b'jpeg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] for box in annotations[i]['boxes']: xmins.append(box[0] / width) # 0~1に正規化 xmaxs.append(box[2] / width) ymins.append(box[1] / height) ymaxs.append(box[3] / height) classes_text = [] for text in annotations[i]['label_texts']: classes_text.append(text.encode('utf-8')) classes = [] for label in annotations[i]['labels']: classes.append(bytes([label])) tf_example = create_tf_example(height,width,filename,image_format,xmins,xmaxs,ymins,ymaxs,classes_text,classes) output_shard_index = i % num_shards output_tfrecords[output_shard_index].write(tf_example.SerializeToString())分割したファイルが生成されます。
./train_dataset.record-00000-00010
./train_dataset.record-00001-00010
...
./train_dataset.record-00009-00010使用するときはConfigを以下に設定します
tf_record_input_reader { input_path:" /path/to/train_dataset.record-?????-of-00010 " }?
フリーランスエンジニアです。
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。
- 投稿日:2021-01-01T12:08:15+09:00
Pythonで学ぶアルゴリズム 第13弾:ハノイの塔
#Pythonで学ぶアルゴリズム< ハノイの塔 >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第13弾としてハノイの塔を扱う.ハノイの塔
ハノイの塔はよく知られている.以下にそのルールを示す.
・端から端へ同じ形で移動させることで完成
・自分よりも小さなものの上に移動することはできない実装
ここでは,3本の軸間を移動し,扱うブロック数のみ入力することで,そのときの移動手順を示すプログラムを以下に示す.さらに可視化まで試みようとしたが,アルゴリズムを知るという意味での本質とは少しずれているため,試みた部分のみ示すこととする.
コード
hanoi.py""" 2020/12/31 @Yuya Shimizu ハノイの塔 """ #引数:ブロック数,移動元,移動先,経由 def hanoi(n, source, destination, via): if n > 1: hanoi(n-1, source, via, destination) #再帰 print(source + '->' + destination) hanoi(n-1, via, destination, source) #再帰 else: print(source + '->' + destination) n = int(input('ハノイの段数 >> ')) hanoi(n, 'a', 'c', 'b')出力
ハノイの段数 >> 3 #3と入力 a->c a->b c->b a->c b->a b->c a->cコード
hanoi_v.py""" 2020/12/31 @Yuya Shimizu ハノイの塔(可視化) """ def tower(n): result = "" for i in range(1,n+1): #偶数行 if i %2 == 0: result += f"| {' '*(n-i+1)}{'- '*(i//2)}{'- '*(i//2)}\t| " result += f"{' '*(n-i+1)}{'- '*(i//2)}{'- '*(i//2)}\t|" result += f" {' '*(n-i+1)}{'- '*(i//2)}{'- '*(i//2)}\t| " #奇数行 else: result += f"| {' '*(n-i+1)}{'- '*(i//2)}- {'- '*(i//2)}\t| " result += f"{' '*(n-i+1)}{'- '*(i//2)}- {'- '*(i//2)}\t|" result += f" {' '*(n-i+1)}{'- '*(i//2)}- {'- '*(i//2)}\t| " result += "\n" return result #引数:ブロック数,移動元,移動先,経由 def hanoi(n, source, destination, via): if n > 1: hanoi(n-1, source, via, destination) #再帰 print(source + '->' + destination) hanoi(n-1, via, destination, source) #再帰 else: print(source + '->' + destination) #n = int(input('ハノイの段数 >> ')) #hanoi(n, 'a', 'c', 'b') print(tower(4))出力
| - | - | - | | - - | - - | - - | | - - - | - - - | - - - | | - - - - | - - - - | - - - - |とりあえず,すべて並べた図だけ作ってみた.また気が向いたらやってみようと思う.
なお,コメント欄にて@shiracamusにより,可視化のプログラムが紹介されている.感想
ハノイの塔を解くアルゴリズムを知った,この時にかかる処理時間が指数関数的に増加することを知った.可視化までできると思ったが,それなりに時間が必要だということに気づき,アルゴリズムを学ぶという観点では少しずれていると思い,また気が向いたときに可視化に試みようと思う.ほかの人の記事を参考にすると,どうやら可視化までするモジュールもpythonにはあるらしく,以下のような操作で可視化というか既存のハノイの塔のプログラムが扱えるようだ.
$ pip install k-peg-hanoi $ hanoi 4 4自作プログラムでの可視化についてはコメント欄にて@shiracamusにより紹介されている.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社
- 投稿日:2021-01-01T11:34:50+09:00
PythonでJリーグのデータ分析をしてみた
今回、FootyStatsというサッカーデータを扱うサイトからJリーグのデータをダウンロードしPythonで色々調べてみました。ただ2020年シーズンのcsvデータがまだダウンロードできなかったので2019年のデータを使っています。
このサイトはJリーグだけでなく世界各国のリーグの情報を扱っているので、サイトを眺めるだけでも面白いです。Jリーグ(J1、J2、J、カップ戦)のデータは、それぞれ試合データ、チームデータ、選手データがダウンロードできます。
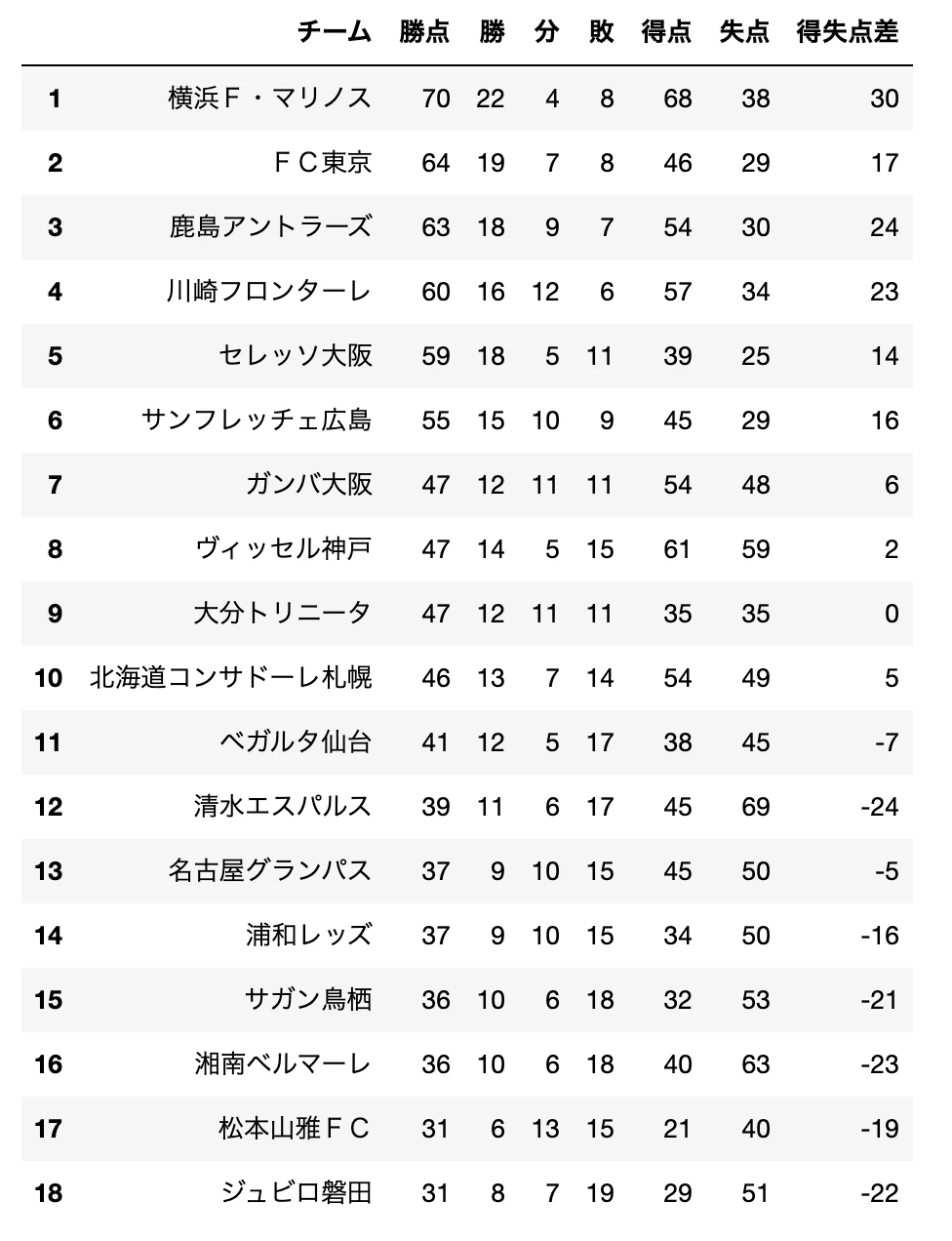
(順位表はJ.LEAGUE Data Siteから)。#各種ライブラリをインポート import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline2019年の順位
FootyStatsのデータには勝ち点カラムがなかったので、J.LEAGUE Data SiteというサイトからURLを直接取得して表示。
#データを取り込む j1_rank = 'https://data.j-league.or.jp/SFRT01/?search=search&yearId=2019&yearIdLabel=2019%E5%B9%B4&competitionId=460&competitionIdLabel=%E6%98%8E%E6%B2%BB%E5%AE%89%E7%94%B0%E7%94%9F%E5%91%BD%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&competitionSectionId=0&competitionSectionIdLabel=%E6%9C%80%E6%96%B0%E7%AF%80&homeAwayFlg=3' j1_rank = pd.read_html(j1_rank) df_rank = pd.DataFrame(j1_rank[0]) df_rank.index = df_rank.index + 1 df_rank[['チーム','勝点', '勝', '分', '敗', '得点', '失点', '得失点差']]
基本統計量をざっと見てみる
df_rank.describe()勝ち点の平均は47点、中央値46.5点なので平均と中央値がほぼ一致してます。一応順位表を確認すると勝ち点46~47が10位〜6位と真ん中か少し上に集中してます。
Footy Statsのデータを読み込む
今回の分析用のcsvデータを読み込みます。チームデータを見ると、293カラムもありました。どんな種類のデータがあるのか確認するのもなかなか大変。。。
df_team = pd.read_csv('j1_team_2019.csv') pd.set_option('display.max_columns', None) df_team.head(6)
len(df_teams.columns) #カラム数:293どんなデータがあるかざっと見てみる
df.culumns()でも表示できますが、for分で回したほうが個人的には見やすいです。
for team in df_team: print(team)
全項目は載せきれてませんが、試合の前後半の得点率などとても細かいデータも含まれていそうです。
勝率
J1チームの勝率についてまとめました。
勝利した試合のうち、どれだけホームで勝利したのか、ホームに強いクラブを見てみたかったので「勝利のうちホーム率」の列を作り、その高い順に並べています。#勝率 df_team['wins_rate'] = df_team.apply(lambda row: row['wins'] / 34, axis=1) #ホーム勝率 df_team['home_wins_rate'] = df_team.apply(lambda row: row['wins_home'] / 17, axis=1) #勝利のうちホーム df_team['wins_at_home'] = df_team.apply(lambda row: row['wins_home'] / row['wins'], axis=1) df_team = df_team[['team_name', 'wins', 'wins_home','wins_rate', 'home_wins_rate', 'wins_at_home']].sort_values('wins_at_home', ascending=False).reset_index(drop=True) df_team.index = df_team.index + 1 df_team.rename(columns={'team_name': 'クラブ名', 'wins': '勝利', 'wins_home': 'ホーム勝利', 'wins_rate': '勝率', 'home_wins_rate': 'ホーム勝率', 'wins_at_home': '勝利のうちホーム率'})
名古屋が年間9勝していますが、そのうち7試合がホーム(約78%)とホームで力を発揮してます。仙台も高いですね。下を見ると、近年優勝争いをしている川崎は意外にも低かったです。
得点数と勝利数の相関
当たり前ですが、得点を多くとれば勝つ試合も多くなると思いますが、得点数と勝利数の相関を見てみます。横軸に得点数、縦軸に勝利数をプロットしてみます。見た感じやはり正の相関が見られます。
df = df_team plt.scatter(df['goals_scored'], df['wins']) plt.xlabel('goals_scored') plt.ylabel('wins')
チーム名を表示して見てみる
for i, txt in enumerate(df.team_name): plt.annotate(txt, (df['goals_scored'].values[i], df['wins'].values[i])) print(txt) plt.scatter(df['goals_scored'], df['wins']) plt.xlabel('goals_scored') plt.ylabel('wins') plt.show()
失点数と勝利数の相関
反対に失点数と勝利数の相関を見てみます。こちらも相関(負の相関)はありそうですが、得点数と勝利数の相関ほど強くはなさそうです。
df = df_team plt.scatter(df['goals_conceded'], df['wins']) plt.xlabel('goals_conceded') plt.ylabel('wins')
for i, txt in enumerate(df.team_name): plt.annotate(txt, (df['goals_conceded'].values[i], df['wins'].values[i])) print(txt) plt.scatter(df['goals_conceded'], df['wins']) plt.xlabel('goals_conceded') plt.ylabel('wins') plt.show()チーム名を表示
相関係数
得点数と勝利数、失点数と勝利数の相関係数をそれぞれ求めてみます。
得点と勝利数の相関係数
wins = df['wins'] goals_scored = df['goals_scored'] r = np.corrcoef(wins, goals_scored) r #相関係数:0.7184946失点と勝利数の相関係数
wins = df['wins'] goals_conceded = df['goals_conceded'] r = np.corrcoef(wins, goals_conceded) r #相関係数:-0.58795491得点数と勝利数の相関係数は約0.72とやはり高めで。失点数と勝利数の相関係数は約-0.58(絶対値0.58)と相関はありそうですが、得点数ほどではありません。
他にも色々分析中なので、追記するかもしれません。
また、2020シーズンのデータがダウンロード可能になったら2020シーズンも色々見てみる予定です。
コロナの影響で過密日程になり、交代枠のルールが変わったりしているので、平年とどう変わったのか比較してみたいです。









- 投稿日:2021-01-01T11:20:02+09:00
Pythonでスクレイピングした株価をDBに格納する
0.はじめに
pythonを投資活用に使う目的で調べたまとめ記事の第3弾(最終回)です。
今までの総集編として、スクレイピングをしつつDBへ格納する一連の流れを書いていきます。
基本的に以下記事がすべてわかっている前提で記載していきます。前回までの記事
Pythonで簡単にデータベースを扱う(SQLite3)
PythonでWebスクレイピング①(スクレイピング事前知識)
PythonでWebスクレイピング②(実際に株サイトをスクレイピングする)
- 動作環境
- OS : Windows10 pro
- ブラウザ:Google Chrome
- Python : 3.8.3// Miniconda 4.9.1
- sqlite3:2.6.0
- (管理ツール:DB Browser for SQLite ※すぐに中身を見るときに便利)
1.本記事のゴール
- 株式投資メモから2020年(1/6~12/28)の全上場銘柄の4本足+出来高を取り出す
- 取り出した情報をデータベース(SQLite)へ格納する
2.個別銘柄データ(2020年の1年分)を取り出すURL,HTMLタグの確認
2-1.まずはどのURLで取得できるか?を確認
株式投資メモのTOPページから例えばトヨタ自動車を銘柄検索すれば、年間推移DBのページに飛ぶことができ、その中から「2020」を選ぶことで2020年のデータが得られる。
また、その際のURLを確認すると/stock/証券コード/確認したい年度になっていることがわかる。
つまり、この証券コードの部分を変えていくことで色々な銘柄のデータに切り替えていくことが出来る。
2-2.次にHTMLのどこのタグに取得したい情報があるか?を確認しに行く
細かい部分は前回の記事で説明済なので、詳しくはそれを確認してほしい。
対象を探していくと、table class="stock_table"以下のtheadとtbodyの部分がそうっぽいことがわかる。ただし前回の記事と異なるのは株価がtbody直下にすべて入っておらず、個々のtbody毎に格納されている点である。が、別に大したことはない。
2-3.実験としてトヨタ自動車の2020年の株価データを取得してみる
確認くん:https://www.ugtop.com/spill.shtml
import requests from bs4 import BeautifulSoup #スクレイピング対象のURLを入力 url = 'https://kabuoji3.com/stock/7203/2020/' #確認くんで調べた自分のユーザーエージェント(現在のブラウザー)をコピペ ※環境に応じて書き直す headers = {"User-Agent": "Mozilla/*** Chrome/*** Safari/***"} #Requests ライブラリを使用してWebサイトから情報(HTML)を取得する。 response = requests.get(url, headers = headers) #取得したHTMLからBeautifulSoupオブジェクト作成 soup = BeautifulSoup(response.content, "html.parser") #まずはtheadをfindメソッドでコマンドで検索し、その中のtrをfind_allメソッドですべて抽出 tag_thead_tr = soup.find('thead').find_all('tr') print(tag_thead_tr)実行結果[<tr> <th>日付</th> <th>始値</th> <th>高値</th> <th>安値</th> <th>終値</th> <th>出来高</th> <th>終値調整</th> </tr>]''' class="stock_table stock_data_table"直下の各tbody毎に株価データが格納されている よって、まずはそのテーブルクラスを取得してから中身を取得すればいい。 ''' # テーブルを指定し、findAllで検索して0番目要素(といっても1個しかないが)を取り出す table = soup.findAll("table", {"class":"stock_table stock_data_table"})[0] #その中のtrタグを取得する。ただし、最初はスレッドカラムなので省略する(1:の部分) ※tbodyでない理由は後述 tag_tbody_tr = table.findAll("tr")[1:] #例として最初だけを表示する print(tag_tbody_tr [0])実行結果[<tr> <td>2020-01-06</td> <td>7599</td> <td>7626</td> <td>7530</td> <td>7565</td> <td>6672300</td> <td>7565</td> </tr>]株価部分に関しては、実際のHTMLを確認すると下図のようになっており、
tbodyでfindAllをすると最初の<tbody>~</tbody>の2020/1/6部分しか取得できない。これはtbodyを省略できるというHTMLのルールからきている。よって、今回は前回とは違いtrを探す必要があった。
さらに、DB格納時に必要な銘柄名と証券コードも同ページから探して取得できるようにする
#ヘッダークラスのbase_box_header内のspanクラスに情報が埋め込まれているのが調べるとわかる。 name = soup.findAll("span", {"class":"jp"})[0] print(name.get_text())実行結果'7203 トヨタ自動車(株)'3.全銘柄のデータを取り出しつつ、DBへ格納していく
2までで取り出し方がわかったので、これを全銘柄に適応させつつDBに書き出していく。
3-1.DBの構成(スキーマ)を考える
どのようにデータベースとして格納するか?(これをスキーマと呼ぶ)を考えなくてはならない。
今回は単純な例なので、いきなりDBの設計図を表すER図を適当に書くと下のようになる。
※本当は「市場(東証マザーズとか)」も銘柄マスタにあった方がいいと思うが、それは各自でやってみてほしい。なお、ER図作成ツールは簡単なのでdraw.ioを使用した。
参考:ER図の作り方【簡易版】
・銘柄マスタは証券コードと銘柄名を格納する
・株価テーブルに、各銘柄のデータを全て入れ込む(codeでどの銘柄か?は識別可能)
・本記事では例としてprice(株価テーブル)の取得を記載する。name(銘柄マスタ)は簡単なので自分でやってみてほしい
・本来は更に「終値調整」に関しての処理が必要になるが、この記事ではこの部分に関して記載しない3-2.DBに格納する為に情報を取り出す関数を作成し、一旦Dataframeとして保存させる
ここからのやり方は色々あると思うが、私はpandasが使い慣れているのもあり、一旦pandasで株価テーブルを作成してからsqlに
to_sqlで変換させるのがいいと思ったので、今回はそのように記載していく。わざわざpandasにしなくても。。という方はご自身のやり方でやってほしい。なお、
time.sleep(1)の部分が、スクレイピングの負荷対策の部分になっている。もしサイトによって秒数が規定されていたら中身の数字を入れ替えて使用すればいい。import time import pandas as pd def get_brand(code): """ 証券コードからスクレイピング情報を取得し、Datafrrameにして返す関数 """ #確認くんで調べた自分のユーザーエージェント(現在のブラウザー)をコピペ ※環境に応じて書き直す headers = {"User-Agent": "Mozilla/*** Chrome/*** Safari/***"} #取得する銘柄のURLを取得 url = 'https://kabuoji3.com/stock/' + str(code) + '/2020/' #株価が存在しなければ例外処理でNoneを返す try: #取得したHTMLからBeautifulSoupオブジェクト作成 response = requests.get(url, headers = headers) soup = BeautifulSoup(response.content, "html.parser") #証券コードを取得する code_name = soup.findAll("span", {"class":"jp"})[0] #ヘッダー(カラム)情報を取得する tag_thead_tr = soup.find('thead').find_all('tr') head = [h.text for h in tag_thead_tr[0].find_all('th')] #株価データを取得し、Dataframe化する table = soup.findAll("table", {"class":"stock_table stock_data_table"})[0] tag_tbody_tr = table.findAll("tr")[1:] data = [] for i in range(len(tag_tbody_tr)): data.append([d.text for d in tag_tbody_tr[i].find_all('td')]) df = pd.DataFrame(data, columns = head) #codeカラムをassignでDataframeに新規追加する ※code_nameの最初の4桁までが証券コード df = df.assign(code=code_name.get_text()[:4]) #デバッグ用。取得できたページを出力する。※本番コードでは不要 print(url) except (ValueError, IndexError, AttributeError): return None return df def brands_generator(code_range): """ 証券コードを生成し、取得した情報を結合する関数 """ for i,code in enumerate(code_range): #初回のみデータフレーム新規作成 if i==0: cols = ['日付', '始値', '高値', '安値', '終値', '出来高', '終値調整', 'code'] df = pd.DataFrame(index=[], columns=cols) #生成した証券コードをスクレイピング関数へ渡す brand = get_brand(code) #情報が取得できていれば、情報を結合していく if brand is not None: df = pd.concat([df, brand]).reset_index(drop=True) #1秒間プログラムを停止する(スクレイピング負荷対策) time.sleep(1) return df """ ここでは例として証券コード1301~1310までを取得することにする。 本番は1301~9999まで取得すればいい(当然時間はかかる) """ df = brands_generator(range(1301,1310))実行結果https://kabuoji3.com/stock/1301/2020/ https://kabuoji3.com/stock/1305/2020/ https://kabuoji3.com/stock/1306/2020/ https://kabuoji3.com/stock/1308/2020/ https://kabuoji3.com/stock/1309/2020/取得できた証券コードのURLが出力結果として出てきていることがわかる。当然1302や1307等は存在しない証券コードなので取得できてなくて正解。これで正しくスクレイピングできていそうなことがわかる。
#最初の2行だけをサンプル表示する df.head(2)dfの結果をPandasで表示すると、以下のように日付順に取得できていることがわかる。
日付 始値 高値 安値 終値 出来高 終値調整 code 0 2020-01-06 7599 7626 7530 7565 6672300 7565 1301 1 2020-01-07 7654 7722 7619 7715 4960700 7715 1301 3-3.DBにDataframeの情報を渡して保存する
dataframe形式でデータを取得できたので、最後にDBに変換させる。
import sqlite3 #データベース名.db拡張子で設定 dbname = ('sample.db') #データベースを作成 db = sqlite3.connect(dbname, isolation_level=None) #dfをto_sqlでデータベースに変換する。DBのテーブル名はpriceとする df.to_sql('price', db, if_exists='append', index=None) #データベースにカーソルオブジェクトを定義 cursor = db.cursor() #本当にpriceテーブルが作成されたのか?を定義した関数で確認する sql = """SELECT name FROM sqlite_master WHERE TYPE='table'""" for t in cursor.execute(sql): print(t)実行結果('price',)これできちんとpriceテーブルが作成されていることがわかる。最後にこのデータベースを再度dataframeとして読み込んで、中身が同じになっているか?を確認する
# 作成したdbのpriceテーブルを再度pandasで読み出す df_db = pd.read_sql('SELECT * FROM price', db) #先ほど同様に2行だけサンプル表示 df_db.head(2)当然だが、同じ結果になっている。これでDBの中身も先ほどのpandasと同じになっていることが確認できた。
日付 始値 高値 安値 終値 出来高 終値調整 code 0 2020-01-06 7599 7626 7530 7565 6672300 7565 1301 1 2020-01-07 7654 7722 7619 7715 4960700 7715 1301 #最後に接続(connect)を閉じる db.close()4.最後に
どうだったであろうか?意外と簡単に自作DBへの保存ができたのではないか?
もちろん全証券コードを取得するのは時間がかかるが、例えば今2020年末までをとりあえず取得しておき、2021年分からは毎日DBに格納するようなバッチを作成しておけばDBは自動的に更新できるし、そこまで手間もかからないと思う。Qiitaはプログラミングの知見共有サイトなのでこれ以降の細かい解析等は控えることにする。
この記事を読んでくださった皆様自身がこれをキッカケに色々なサイトをスクレイピングすることで、皆さん独自の分析データをストックしつつ、2021年一念発起して爆益を得られるように一緒に頑張っていきましょう!また、今後も投資関連ではないものの機械学習やその他記事を毎週投稿するつもりなので、良かったらモチベ維持の為にもLGTMやストックお願いします!




- 投稿日:2021-01-01T10:01:30+09:00
【超簡単】PythonとOpenCVでリアルタイムに顔認識と表情認識を同時に実行!
準備
参照:Perception for Autonomous Systems(github)
環境:
ubuntu 20.04 lts
corei3 7th
ram 16gb
pip3を使ってTensorflow、OpenCV、NumPy、pypazをインストール
sudo pip3 install tensorflowsudo pip3 install opencv-pythonsudo pip3 install numpysudo pip3 install pypazソースコードのダウンロード
git clone https://github.com/oarriaga/paz.git実行
WEBカメラを接続しておいてください。
cd pazcd examplescd face_classificationpython3 demo.pyこれで実行できました!お疲れ様でした!
おまけ
ウィンドウサイズを大きくする
sudo nano demo.pyこの行を
player = VideoPlayer((640, 480), pipeline, camera)以下のように変更
player = VideoPlayer((1152, 864), pipeline, camera)これでウィンドウサイズが大きくなり見やすくなりました!
最後に
最後まで読んでいただきありがとうございました!
他にもプログラムがexamplesファイルの中にあるので試してみてください!

- 投稿日:2021-01-01T07:37:59+09:00
RoPEをやってみた
RoPEとは
今日(2021年1月1日)リリースしたRoPEなるものがあるらしい。
自分でロボットを組み立て、取り付けたセンサーやモーターをPythonスクリプトで制御する。
いくつかのミッションが用意されており、それを順番にこなしていく、というものだ。
2021年1月1日現在 早期アクセス
リンク: RoPE
RoPEのいいところ
このコンテンツはネットとGoogleアカウントがあればすぐに始められるところだ。
煩わしい設定やインストールは何もいらない。また、ロボット制御を始めるにはパソコンだけでなく、マイコンやモーターなど、揃えると結構なお金がかかってしまう。しかし、RoPEならパソコンだけでロボット制御ができてしまう。
やってみた感覚
現実世界とはかなり異なるので、実際にロボット制御で役に立つとは思えない。
が、即座に実行できたり実際に動いているものがわかりやすく、
「プログラミング練習」や「おもちゃ」にするには良いのではないかと思った。


- 投稿日:2021-01-01T01:26:07+09:00
Wagtailのすすめ(2) ページを定義し,編集し,表示してみよう
はじめに
今回から数回に分けて,実際にWagtailで簡単なCMSを構築していってみようと思う.ゴールとしては,複数の研究プロジェクトや研究グループのページをホストするサイトをイメージしてみた.
各研究プロジェクトや研究グループのトップページを
TopPageと名付けよう.その下には,プロジェクトの概要説明,メンバー紹介などのページなどを置くことになりそうだが,それらのために使うページをPlainPageと呼ぶことにする.さらに,ブログポスト的なページPostPageと,関連するブログポストをまとめてリスト表示するページListPageを用意することにしよう.ひとまず,デフォルトで用意されている
HomePageはそのままにしておいて,その下に複数のTopPageをぶら下げられるようにする.そして,TopPageの下にはPlainPage,もしくはListPageをぶら下げられるようにし,ListPageの下にはさらに別のListPage,あるいはPostPageをぶら下げられるようにする.今回は,
TopPageを題材にして,実際にページを定義し,編集し,それを表示させるまでの大まかな流れをみていこう.ページの定義
上で導入した
HomePage,TopPage,PlainPage,ListPage,PostPageなどはCMSで管理するページの種類を表している.Wagtailでは,これらのページを,Pageクラスを継承したサブクラスとして定義していく.デフォルトで用意されている
HomePageの定義はhome/models.pyに下記のように記述されている.from wagtail.core.models import Page class HomePage(Page): passすなわち,
HomePageは,デフォルトではPageクラスに何も追加されていない.スーパーユーザでWagtailの管理サイトにログインすると,"Welcome to your new Wagtail site!"というタイトルのページが1つだけ登録済みになっているはずである.これは,
HomePageクラスのインスタンスに対応している.このページの編集画面を開いてみると,CONTENT,PROMOTE,SETTINGSという3つのタブがあり,各タブからそれぞれいくつかの情報を追加できるようになっている.これらの情報は,Pageクラスが保持できる情報の例である.自作のページを定義していく際には,
Pageクラスを継承することによって,Pageクラスにもともと用意されている以外の情報(フィールドやメソッド)を追加していくことになる.この際に検討すべきことは次の2つである.
- そのページのために編集者が管理サイトから投入すべき情報はなにか?
- そのページを表示する(レンダリングする)ためにテンプレートに渡すべき情報はなにか?
これらの項目への答えは必ずしも一致しない.後者の項目の一部は,編集者が投入しなくとも,別の方法で自動的に取得できる可能性があるからである.ここではまずは,前者の項目に対応する情報をフィールドとして
Pageクラスに追加した上で,管理サイトからそれらを投入できるように編集画面を拡張していこう.自作ページの定義は,前回追加したcmsアプリケーションの中のmodelモジュール,すなわちcms/models.pyの中に記述していく.ここでは,下のように
TopPageクラスを定義した.from django.db import models from wagtail.core.models import Page from wagtail.core.fields import RichTextField from wagtail.admin.edit_handlers import FieldPanel from wagtail.images.edit_handlers import ImageChooserPanel class TopPage(Page): cover_image = models.ForeignKey( 'wagtailimages.Image', null=True, blank=True, on_delete=models.SET_NULL, related_name='+' ) intro = models.CharField(max_length=255) main_body = RichTextField(blank=True) side_image = models.ForeignKey( 'wagtailimages.Image', null=True, blank=True, on_delete=models.SET_NULL, related_name='+' ) side_title = models.CharField(blank=True, max_length=255) side_body = RichTextField(blank=True) content_panels = Page.content_panels + [ ImageChooserPanel('cover_image'), FieldPanel('intro'), FieldPanel('main_body', classname="full"), ImageChooserPanel('side_image'), FieldPanel('side_title'), FieldPanel('side_body', classname="full"), ]
intro(ページの紹介文の情報),side_title(サイドバーのタイトル)の2つがDjangoのmodels.CharFieldとして追加されていることがわかる.また,Wagtail独自のフィールドであるRichTextFIeldを用いて,main_body(ページの本文)とside_body(サイドバーの本文)の2つが追加されている.RichTextFIeldは,リッチテキスト形式で編集画面から投入した文書を,適切なhtmlタグ付きでテンプレートに渡すためのものであり,CMSには欠かせないフィールドであると言える.また,
cover_imageやside_imageを見ると,画像の情報を追加する方法もわかるだろう.具体的には,Djangoのmodels.ForeignKeyを利用してwagtailimages.Imageクラスと紐付けすればよい.最後に
content_panelsのリストに,新たに追加したフィールドに関するパネルの情報が追加されていることも見て取れる.これは,管理サイトのページ編集画面のCONTENTタブから,それらのフィールドに関する情報を投入するための入力フォームの形式を指定するものである.画像についてはImageChooserPanel,それ以外にはFieldPanelが指定されている(ひとまず,画像以外はFieldPanelを指定しておけば,フィールドのタイプに応じて適切な入力フォームが用意されると考えておけばいいだろう).ページの編集
続いて,上で定義したページを管理サイトのページ編集画面で編集してみよう.そうすることで,
content_panelsに追加した指定が編集画面にどのように反映されたのかもわかる(例えば,classname="full"の指定を外すと編集画面がどう変わるかなどを確めてみるといいだろう).具体的には,ページ一覧から先ほどの"Welcome to your new Wagtail site!"を選択し,EDITではなく,ADD CHILD PAGEをクリックし,
TopPageを選択すれば,新しいTopPageインスタンスの編集画面が開く.編集自体は直感的に行えるので説明は不要と思う.自由に情報を追加してサンプルとなるインスタンスを作成してみよう.なお,PROMOTEタブのSlugには自動生成された文字列が入るが,これを変更すれば,このページが公開される際のURL(の末尾)を変更することができる.
ページの表示
以上で,自作の
TopPageクラスを定義し,そのインスタンスを生成するところまで進んだ.次に,これをブラウザで表示させてみることにしよう.ページのURLは上のSlagの文字列に基づいて決まる.通常のDjangoアプリケーションの場合,所定のアドレスにアクセスするとurls.pyでそれに紐付けられたview関数が呼ばれる.そして,view関数が適切なcontextを生成しそれをテンプレートに組み込むことによってページがレンダリングされるという流れが一般的である.したがって,ページを表示できるようにするためには,urls.pyにルーティングの指定を追加し,view関数とテンプレートを用意する必要があった.
これに対して,Wagtailでは,ルーティングは自動的に行われるためurls.pyの編集は不要であり,標準的な使い方では,view関数のようなものも用意する必要はない.テンプレートだけ準備しておけば,自動的にそれに従ってインスタンスの情報を元にページのレンダリングが行われる仕組みになっている.
ということで,まずはテンプレートを用意しよう.cms/models.pyに定義された
TopPageクラスのページが利用するテンプレートは,デフォルトではtemplates/cms/top_page.htmlという名称になる(クラス名称のパスカルケースがテンプレートではスネークケースになる点に注意しよう).通常はそのままデフォルトの名称を利用すればいいだろう.templates/cms/top_page.htmlをゼロから作成するのは大変なので,Wagtailがデフォルトで用意してくれているtemplates/base.htmlから継承していくことにする.templates/base.htmlには,スタイルファイルを追加するためのextra_css,コンテンツを追加するためのcontent,javaScriptを追加するためのexstra_jsというブロックが含まれているので,それらのブロックを利用する.
テンプレートの継承関係の見通しをよくするために,まずtemplates/cms/base.htmlを次のように作成した.
{% extends 'base.html' %} {% load static %} {% block extra_css %} <link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css" integrity="sha384-9aIt2nRpC12Uk9gS9baDl411NQApFmC26EwAOH8WgZl5MYYxFfc+NcPb1dKGj7Sk" crossorigin="anonymous" /> <link rel="stylesheet" type="text/css" href="{% static 'css/cms/base.css' %}"> {% endblock %} {% block content %} <div id="nav_bar">{% block nav_bar %}{% endblock %}</div> <div id="header">{% block header %}{% endblock %}</div> <div id="main">{% block main %}{% endblock %}</div> <div id="footer">{% block footer %}{% endblock %}</div> {% endblock %} {% block extra_js %} <script src="https://unpkg.com/react@17/umd/react.production.min.js" crossorigin></script> <script src="https://unpkg.com/react-dom@17/umd/react-dom.production.min.js" crossorigin></script> <script src="https://unpkg.com/react-bootstrap@next/dist/react-bootstrap.min.js" crossorigin></script> {% endblock %}extra_cssのブロックでは,Bootstarapのためのcssと,自作のcss/cms/base.cssを読み込んでいる.contentブロックでは,
<body>タグの中身をさらにnav_bar,header,main,footerというidの4つの<div>に細分している.また,extra_jsのブロックでは,ReactとReact Bootstrapのためのスクリプトを読み込んでいる(React Bootstrapを使うのは,他の箇所でReactを利用したいからである.単に,Bootstrapを使うだけなら,普通にjQueryを取り込めばよいだろう).なお,自作のcssの記述は最小限に抑えた.css/cms/base.cssの中身は下記の通りである.
body { font-family: 'Avenir', Helvetica, Arial, sans-serif; padding: 50px 0 50px 0; } .jumbotron { height: 400px; color: #ffffff; background-size: cover; background-position: center center; background-color: rgba(0, 0, 0, 0.5); background-blend-mode: multiply; } #main > .container { max-width: 992px; } #footer { font-size: 90%; } /* これ以下の記述は,埋込みメディアをレスポンシブルにするための指定 */ .rich-text img { max-width: 100%; height: auto; } .responsive-object { position: relative; } .responsive-object iframe, .responsive-object object, .responsive-object embed { position: absolute; top: 0; left: 0; width: 100%; height: 100%; }後半の記述は画像やその他の埋込みメディアをレスポンシブルにするための指定である(詳しくはここを参照).あわせて,config/settings/base.pyに以下の記述を追加しておく.
WAGTAILEMBEDS_RESPONSIVE_HTML = True続いて,これらを元に,templates/cms/top_page.htmlを下のように作成した.
{% extends 'cms/base.html' %} {% load static wagtailcore_tags wagtailimages_tags %} {% block nav_bar %} <nav class="navbar fixed-top navbar-dark bg-dark mb-0"> <span class="navbar-text mx-auto"> Say something at the begining. </span> </nav> {% endblock %} {% block header %} {% image page.cover_image fill-1000x400 as my_image %} <div class="jumbotron jumbotron-fluid" style="background-image: url('{{ my_image.url }}');"> <div class="container"> <h1 class="display-4">{{ page.title }}</h1> <p class="lead">{{ page.intro }}</p> </div> </div> {% endblock %} {% block main %} <div class="container"> <div class="row"> <div class="col-md-8"> {% block main_body %} <div class="rich-text"> {{ page.main_body|richtext }} </div> {% endblock %} </div> <div class="col-md-4"> {% block side_bar %} <div class="card my-4"> <h4 class="card-header">{{ page.side_title}}</h4> <div class="card-body"> {% image page.side_image fill-200x200 class="img-fluid rounded-circle d-block mx-auto" alt="" %} </div> <div class="card-body"> <div class="rich-text"> {{ page.side_body|richtext }} </div> </div> </div> {% endblock %} </div> </div> </div> {% endblock %} {% block footer %} <nav class="navbar navbar-dark bg-dark fixed-bottom"> <span class="navbar-text mx-auto py-0"> Say something at the end. </span> </nav> {% endblock %} {% block extra_js %} {{ block.super }} {% endblock %}wagtailcore_tagsとwagtailimages_tagsをloadすることで,Wagtailが用意しているテンプレートタグが使えるようになる(上の例では,imageタグやrichtextフィルタ).また,ページインスタンスのフィールド情報には
page.フィールド名でアクセスできていることがわかる.RichTextフィールドに格納された文書ではhtmlタグがエスケープされているので,richtextフィルタを通して元に戻している.また,その部分を<div class="rich-text">で囲むことによって,css/cms/base.cssに記述した下記の指定が効くようにしてある(詳しくはここを参照)..rich-text img { max-width: 100%; height: auto; }ここでは,imageタグを用いた画像の扱い方には立ち入らない(が,詳しくはここを参照してほしい).nav_barブロックとfooterブロックはダミーである.headerブロックには,cover_imageで指定した画像を背景にしたジャンボトロンを表示させるようにした.サイドバーにはBootstrapのcardを利用している.
おわりに
今回は,Wagtailでのページの定義,編集,表示までの流れをざっと紹介した.素のDjangoで同様のページを作成するよりはかなり簡単だと思う.また,個人的には,管理サイトの使い勝手も気に入っている.見栄えの調整は少し面倒かもしれないが,公開されているBootstrapのテンプレートを利用する手もある(その方法はこのチュートリアルが詳しい).
次回以降は,少しずつ細かな話題に触れていきたいと思う.
リンク
- 投稿日:2021-01-01T01:12:51+09:00
【備忘録】Python logging 動作確認用コード
概要
はじめ公式ドキュメントを見ても何がなんだか分からなかったので、
logging.__init__.pyなどを見ながら、適当に簡単なコードを作成してみました。logging が意味分からない…という人向けです。まずは動かすことが重要だと思うので、適当に動かして動作の理解をする時だけ使用することを推奨します。
因みに、このコードを脳死ロガーと名付けます!(どう、でも、いい)この記事を書いたもう一つの目的
はじめ公式ドキュメントを見ても分からなかったと書きましたが、それを踏まえ、わざと公式ドキュメントをきちんと読む前の状態を書き残し、読んだ後の状態と比較することも個人的な目的としています(クックブックは少し読んだ)。
実行環境
- Chromebook (88.0.4324.47 Official Build beta 64bit)
- Debian GNU/Linux 10 (buster)
- VS Code
- Pyenv 1.2.21
- Python 3.8.6
確認用コードについて
早速ですが、以下が確認用のコードです。
使い方は次の項で説明しています。※ 一応、脳死状態から少しスキルアップした際にも、
brain_dead_logger関数を使用せずにハンドラーの追加タイミングや設定などを変更する事も容易にできるように関数を作っています。create_logger.pyfrom logging import ( Logger, # 型の明示にのみ使用 getLogger, Formatter, StreamHandler, FileHandler, NOTSET, DEBUG, INFO, WARNING, ERROR, CRITICAL # 必要に応じてインポート ) def create_logger( logger_name: str, log_level: int = DEBUG ) -> Logger: """ RootLogger に接続する Logger オブジェクトの新規作成に使用 (同名の Logger オブジェクトが存在する場合は getLogger を使用) 別途、必要に応じてハンドラーを追加 Args: logger_name (str): Logger の名前 log_level (int, optional): Logger のログレベル. Defaults to DEBUG. Returns: Logger: 指定した名前空間を持つ Logger オブジェクト """ logger = getLogger(logger_name) # create logger logger.setLevel(log_level) # set the logger log level return logger def set_console_handler( logger: Logger, log_level: int = NOTSET, is_formatter: bool = True ) -> None: """ コンソールハンドラーの追加 logger 取得後に任意で追加 Args: logger (Logger): 追加したい logger を指定 log_level (int, optional): コンソールハンドラーのログレベル. NOTSET の場合、logger のログレベルに従う. Defaults to NOTSET. is_formatter (bool, optional): コンソールハンドラーのログフォーマットを独自に設定するかどうか. Defaults to True. """ ch = StreamHandler() # ハンドラーオブジェクトの作成 ch.setLevel(log_level) # コンソールハンドラーのログレベルを設定 if is_formatter: formatter = Formatter('%(asctime)s %(name)s %(levelname)s - %(message)s') # フォーマッターオブジェクトの生成 ch.setFormatter(formatter) # フォーマッターをコンソールハンドラーに追加 logger.addHandler(ch) def set_file_handler( logger: Logger, log_file_path: str = "./", log_file_name: str = "sample.log", log_file_encoding: str = "utf-8", log_level: int = DEBUG, is_formatter: bool = True ) -> None: """ ファイルハンドラーの追加 logger 取得後に任意で追加 Args: logger_ (Logger): 追加したい logger を指定 log_file_path (str, optional): ログファイルのディレクトリ. Defaults to "./". log_file_name (str, optional): ログファイルの名前. Defaults to "sample.log". log_level (int, optional): ファイルハンドラーのログレベル. NOTSET の場合、logger のログレベルに従う. Defaults to NOTSET. is_formatter (bool, optional): ファイルハンドラーのログフォーマットを独自に設定するかどうか. Defaults to True. """ fh = FileHandler(f'{log_file_path}{log_file_name}', encoding=log_file_encoding) # ファイルハンドラーオブジェクトの作成 fh.setLevel(log_level) # ファイルハンドラーのログレベルを設定 if is_formatter: formatter = Formatter('%(asctime)s %(name)s %(levelname)s - %(message)s') # フォーマッターオブジェクトの生成 fh.setFormatter(formatter) # フォーマッターをファイルハンドラーに追加 logger.addHandler(fh) def brain_dead_logger( logger_name: str, logger_log_level: int = DEBUG ) -> None: """ 脳死ロガー """ logger = create_logger(logger_name, log_level=logger_log_level) # ロガーを生成 if not logger.handlers: # ハンドラーの重複追加を避けるため set_console_handler(logger) # 標準出力のハンドラーをロガーに追加 set_file_handler(logger) # ファイルハンドラーをロガーに追加 return logger if __name__ == "__main__": logger = brain_dead_logger("test_logger") logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}')確認用コードの使い方
基本的な使い方
基本的な使い方は
create_logger.pyのif __name__ == "__main__":以下と同じですが、とりあえずロガーがよく分からないけれどもログを入れたい!ログファイルを吐き出したい!という場合は、作成したcreate_loggerモジュールからbrain_dead_loggerをインポートしてロガー名を引数として渡すだけでOK。まさに、脳死ロガー。
test_logger.pyfrom logging import Logger # 型の明示にのみ使用 from create_logger import brain_dead_logger # 同じディレクトリに `create_logger.py` がある場合 logger_name: str = __name__ # モジュール名をロガー名とする場合 logger: Logger = brain_dead_logger(logger_name) if __name__ == "__main__": logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}')別モジュールで定義されたロガーを使用するなどの場合は、ロガーインスタンスを直接インポートせずに、ロガー名を指定して使用します。この場合は基本的に
getLogger関数で十分です。
getLoggerを使用して別モジュールからtest_loggerロガーを使用する場合は以下のようになります。main.pyfrom logging import ( Logger, # 型の明示にのみ使用 getLogger ) logger = getLogger("test_logger") # test_logger.py で __name__ で定義したロガーを使用する場合 if __name__ == "__main__": logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}')なお、重複してハンドラーを追加しないようになっているので、
brain_dead_logger関数を使用してもOKです。
確認のために、ハンドラー重複を回避している文を削除しても良いかもしれません。main.pyfrom create_logger import brain_dead_logger # 同じディレクトリに `create_logger.py` がある場合 logger = brain_dead_logger("test_logger") # test_logger.py で __name__ で定義したロガーを使用する場合 if __name__ == "__main__": logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}')サブルートを作成し、接続する使い方
いろいろな分岐の方法はあるかもしれませんが、サブルートを作成し、そこから分岐させる方法を例として挙げます。因みに自作ライブラリを作成し、アプリケーションと別にロガーレベルを管理したかったため、こういう方法も試しています。
また、サブルート(ルートとして定義するロガー)でハンドラーを追加してしまうと融通がきかない場合がありそうなので悩みましたが、小規模であればむしろサブルートで追加してしまったほうが楽だろうと思い、そうしています。
なお、以下コードではクラスにもロガーを定義していますが、基本的にはモジュール単位でロギングするらしい?です。そのためクラス内にもロガーを生成するかどうかは場合によりけりかもしれませんが、こういう事もできるという参考です。以下の
Testクラス内ではgetLoggerという予め用意された関数を使用し、自分で定義したsubrootロガーを取得しています。そして、subrootへの子ロガーの追加は、.getChild()という予め用意されたメソッドを利用しています(subroot.childのようにピリオドでセパレートして、親にしたいロガー名を指定してもOK。コード内のコメントにも参考に入れてあります)。因みに、名前は
subrootではなくても、自作ライブラリの名前でも、何でもOKです。test_subroot_logger.pyfrom logging import Logger # 型の明示にのみ使用 from create_logger import brain_dead_logger logger_name: str = "subroot" # サブルートであることを明示するために subroot という名前を付けています logger: Logger = brain_dead_logger(logger_name) class Test(): # logger: Logger = None # クラス内に logger インスタンスを保持しているという明示をしても良いかもしれません @classmethod def get_logger(cls): from logging import getLogger class_name = cls.__name__ cls.logger = getLogger(logger_name).getChild(class_name) # サブルートに接続し、クラス名をロガー名として登録 # cls.logger = getLogger(f'{logger_name}.{class_name}') # 上の文と同義 def __init__(self): Test.get_logger() # クラスメソッドで定義しているのでクラス名を指定して logger を取得 Test.logger.debug(f'logger name: {Test.logger.name}') Test.logger.debug(f'logger parant: {Test.logger.parent}') if __name__ == "__main__": logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}') test = Test()階層イメージroot (RootLogger:logging) └─ subroot (モジュール内で生成した logger) <- ここに追加していく └─ Test (クラス内で生成した self.logger)ロガーの基本的な使い方
ログレベルに応じて以下のようにしてメッセージを表示できるそうです。
基本的にはデバッグ時に追いたい箇所にprint("message")と同じような感覚でlogger.debug("message")を入れる感じで良いのかな、と思っています。この辺は追々調べたり、実際に使っていく中で掴んでいきたいですね。
logger.debug("message")logger.info("message")logger.warning("message")logger.error("message")logger.critical("message")以下は詳細を表示したい場合に使用。意外と言及されている事が少ないですが、とても便利です。
logger.warn("message"):警告メッセージとして詳細の表示ができる(warningと同レベル扱い)logger.exception("message"):トレースバックが表示できる(errorと同レベル扱い)その他 要点・注意点
- 今どこに接続されているのか、
logger.parentで確認すると分かりやすい。RootLoggerはloggingをインポートして使用した場合に呼び出される大本のロガー。- 上記も踏まえ、ログレベルや、生成するロガーの位置を把握することが重要。
getLogger関数について
getLogger関数は、ロガーの作成と取得を兼ねているが、使う際は作成と取得を意識せずに使える。- 存在しない名前が指定された場合は
RootLoggerの子ロガーが生成される。- 以下は
RootLoggerを呼び出してしまうので注意。
getLogger()getLogger("root")(RootLoggerの名前はrootなので)ハンドラーについて
- 恐らく親のログには、子のログも通されるので、親でハンドラーを登録した後、子にも同じ出力先のハンドラーを登録すると、重複して表示されることになる。
ログレベルについて
- ログレベルは、各ハンドラーとロガーのログレベルを比較し、よりレベルの高いほうが適用される。
- 一括でログレベルを変更したい場合は、自分で作成した
subrootロガーのログレベルを変更するのが個人的なベストプラクティス。まだやったことはないが、恐らく最終的なプロダクトとしては、RootLoggerで全体を一括して変更するのが良いと現段階では考えている。最後に
Logger は名前空間によって管理されていて、インポートしたりしなくても名前だけわかっていれば、
getLoggerで名前を指定して、どこでも作成も呼び出しもできるようになっている、というのが一番の要点なのかなと感じました。とても考えられているんだなぁ!と感心しました。偶に、Logger インスタンスをインポートして使用している方がいるようですが(自分)、そこさえ分かってしまえば、重複してハンドラーを追加してしまったりすることもないのかな?(自分)、と思いました。
ロギングの使い方、そしてログに関してとても奥が深いことも分かり、追々勉強していきたいと思いました。
参考
以下、主に参考にさせて頂いた記事等です。
logging.__init__.pyの DocString など- Logging クックブック
- Python の logging について
- 初心者のためのPythonにおけるlogging入門
- Windows10 + python3 + logger でログファイルの出力にUTF-8を使うよう指定する
- 投稿日:2021-01-01T01:12:51+09:00
【備忘録】Python 脳死logging
概要
はじめ公式ドキュメントを見ても何がなんだか分からなかったので、
logging.__init__.pyなどを見ながら、適当に簡単なコードを作成してみました。あくまで備忘録なので良いコードかどうかは保証しませんが、可能な限り何も考えずに使用できるコードを共有できる形で備忘録として残すことを主な目的としています。この記事を書いたもう一つの目的
はじめ公式ドキュメントを見ても分からなかったと書きましたが、それを踏まえ、わざと公式ドキュメントをきちんと読む前の状態を書き残し、読んだ後の状態と比較することを個人的な目的としています(クックブックは少し読んだ)。
実行環境
- Chromebook (88.0.4324.47 Official Build beta 64bit)
- Debian GNU/Linux 10 (buster)
- VS Code
- Pyenv 1.2.21
- Python 3.8.6
脳死ロガーのコード
早速ですが、以下が脳死ロガーの定義でメインになるコードです。
使い方は次の項で説明しています。※ 一応、脳死状態から少しスキルアップした際にも、
brain_dead_logger関数を使用せずにハンドラーの追加タイミングや設定などを変更する事も容易にできるように関数を作ったつもりです。create_logger.pyfrom logging import ( Logger, # 型の明示にのみ使用 getLogger, Formatter, StreamHandler, FileHandler, NOTSET, DEBUG, INFO, WARNING, ERROR, CRITICAL # 必要に応じてインポート ) def create_logger( logger_name: str, log_level: int = DEBUG ) -> Logger: """ RootLogger に接続する Logger オブジェクトの新規作成に使用 (同名の Logger オブジェクトが存在する場合は getLogger を使用) 別途、必要に応じてハンドラーを追加 Args: logger_name (str): Logger の名前 log_level (int, optional): Logger のログレベル. Defaults to DEBUG. Returns: Logger: 指定した名前空間を持つ Logger オブジェクト """ logger = getLogger(logger_name) # create logger logger.setLevel(log_level) # set the logger log level return logger def set_console_handler( logger: Logger, log_level: int = NOTSET, is_formatter: bool = True ) -> None: """ コンソールハンドラーの追加 logger 取得後に任意で追加 Args: logger (Logger): 追加したい logger を指定 log_level (int, optional): コンソールハンドラーのログレベル. NOTSET の場合、logger のログレベルに従う. Defaults to NOTSET. is_formatter (bool, optional): コンソールハンドラーのログフォーマットを独自に設定するかどうか. Defaults to True. """ ch = StreamHandler() # ハンドラーオブジェクトの作成 ch.setLevel(log_level) # コンソールハンドラーのログレベルを設定 if is_formatter: formatter = Formatter('%(asctime)s %(name)s %(levelname)s - %(message)s') # フォーマッターオブジェクトの生成 ch.setFormatter(formatter) # フォーマッターをコンソールハンドラーに追加 logger.addHandler(ch) def set_file_handler( logger: Logger, log_file_path: str = "./", log_file_name: str = "sample.log", log_file_encoding: str = "utf-8", log_level: int = DEBUG, is_formatter: bool = True ) -> None: """ ファイルハンドラーの追加 logger 取得後に任意で追加 Args: logger_ (Logger): 追加したい logger を指定 log_file_path (str, optional): ログファイルのディレクトリ. Defaults to "./". log_file_name (str, optional): ログファイルの名前. Defaults to "sample.log". log_level (int, optional): ファイルハンドラーのログレベル. NOTSET の場合、logger のログレベルに従う. Defaults to NOTSET. is_formatter (bool, optional): ファイルハンドラーのログフォーマットを独自に設定するかどうか. Defaults to True. """ fh = FileHandler(f'{log_file_path}{log_file_name}', encoding=log_file_encoding) # ファイルハンドラーオブジェクトの作成 fh.setLevel(log_level) # ファイルハンドラーのログレベルを設定 if is_formatter: formatter = Formatter('%(asctime)s %(name)s %(levelname)s - %(message)s') # フォーマッターオブジェクトの生成 fh.setFormatter(formatter) # フォーマッターをファイルハンドラーに追加 logger.addHandler(fh) def brain_dead_logger( logger_name: str, logger_log_level: int = DEBUG ) -> None: """ 脳死ロガー """ logger = create_logger(logger_name, log_level=logger_log_level) # ロガーを生成 if not logger.handlers: # ハンドラーの重複追加を避けるため set_console_handler(logger) # 標準出力のハンドラーをロガーに追加 set_file_handler(logger) # ファイルハンドラーをロガーに追加 return logger if __name__ == "__main__": logger = brain_dead_logger("test_logger") logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}')脳死ロガーの使い方
基本的な使い方
基本的な使い方は
create_logger.pyのif __name__ == "__main__":以下と同じですが、とりあえずロガーがよく分からないけれどもログを入れたい!ログファイルを吐き出したい!という場合は、作成したcreate_loggerモジュールからbrain_dead_loggerをインポートしてロガー名を引数として渡すだけでOK。まさに、脳死ロガー。
test_logger.pyfrom logging import Logger # 型の明示にのみ使用 from create_logger import brain_dead_logger # 同じディレクトリに `create_logger.py` がある場合 logger_name: str = __name__ # モジュール名をロガー名とする場合 logger: Logger = brain_dead_logger(logger_name) if __name__ == "__main__": logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}')別モジュールで定義されたロガーを使用するなどの場合は、ロガーインスタンスを直接インポートせずに、ロガー名を指定して使用します。この場合は基本的に
getLogger関数で十分です。
getLoggerを使用して別モジュールからtest_loggerロガーを使用する場合は以下のようになります。main.pyfrom logging import ( Logger, # 型の明示にのみ使用 getLogger ) logger = getLogger("test_logger") # test_logger.py で __name__ で定義したロガーを使用する場合 if __name__ == "__main__": logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}')なお、重複してハンドラーを追加しないようになっているので、
brain_dead_logger関数を使用してもOKです。main.pyfrom create_logger import brain_dead_logger # 同じディレクトリに `create_logger.py` がある場合 logger = brain_dead_logger("test_logger") # test_logger.py で __name__ で定義したロガーを使用する場合 if __name__ == "__main__": logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}')サブルートを作成し、接続する方法
いろいろな分岐の方法はあるかもしれませんが、サブルートを作成し、そこから分岐させる方法を例として挙げます。因みに自作ライブラリを作成し、アプリケーションと別にロガーレベルを管理したかったため、こういう方法にしています。
また、サブルート(ルートとして定義するロガー)でハンドラーを追加してしまうと融通がきかない場合がありそうなので悩みましたが、小規模であればむしろサブルートで追加してしまったほうが楽だろうと思い、そうしています。
なお、以下コードではクラスにもロガーを定義していますが、基本的にはモジュール単位でロギングするらしい?です。そのためクラス内にもロガーを生成するかどうかは場合によりけりかもしれませんが、こういう事もできるという参考です。以下の
Testクラス内ではgetLoggerという予め用意された関数を使用し、自分で定義したsubrootロガーを取得しています。そして、subrootへの子ロガーの追加は、.getChild()という予め用意されたメソッドを利用しています(subroot.childのようにピリオドでセパレートして、親にしたいロガー名を指定してもOK。コード内のコメントにも参考に入れてあります)。因みに、名前は
subrootではなくても、自作ライブラリの名前でも、何でもOKです。test_subroot_logger.pyfrom logging import Logger # 型の明示にのみ使用 from create_logger import brain_dead_logger logger_name: str = "subroot" # サブルートであることを明示するために subroot という名前を付けています logger: Logger = brain_dead_logger(logger_name) class Test(): # logger: Logger = None # クラス内に logger インスタンスを保持しているという明示をしても良いかもしれません @classmethod def get_logger(cls): from logging import getLogger class_name = cls.__name__ cls.logger = getLogger(logger_name).getChild(class_name) # サブルートに接続し、クラス名をロガー名として登録 # cls.logger = getLogger(f'{logger_name}.{class_name}') # 上の文と同義 def __init__(self): Test.get_logger() # クラスメソッドで定義しているのでクラス名を指定して logger を取得 Test.logger.debug(f'logger name: {Test.logger.name}') Test.logger.debug(f'logger parant: {Test.logger.parent}') if __name__ == "__main__": logger.debug(f'logger name: {logger.name}') logger.debug(f'logger parant: {logger.parent}') test = Test()階層イメージ(Logging) └─ root (RootLogger) └─ subroot (モジュール内で生成した logger) <- ここに追加していく └─ Test (クラス内で生成した self.logger)ロガーの基本的な使い方
ログレベルに応じて以下のようにしてメッセージを表示できるそうです。
基本的にはデバッグ時に追いたい箇所にprint("message")と同じような感覚でlogger.debug("message")を入れる感じで良いのかな、と思っています。この辺は追々調べたり、実際に使っていく中で掴んでいきたいですね。
logger.debug("message")logger.info("message")logger.warning("message")logger.error("message")logger.critical("message")以下は詳細を表示したい場合に使用。意外と言及されている事が少ないですが、とても便利です。
logger.warn("message"):警告メッセージとして詳細の表示ができる(warningと同レベル扱い)logger.exception("message"):トレースバックが表示できる(errorと同レベル扱い)その他 要点・注意点
- 今どこに接続されているのか、
logger.parentで確認すると分かりやすい。loggingはRootLoggerより上位階層に位置するため、loggingをインポートして使用する場合は注意が必要。- 上記も踏まえ、ログレベルや、生成するロガーの位置を把握することが重要。
ハンドラーについて
- 恐らく親のログには、子のログも通されるので、親でハンドラーを登録した後、子にも同じ出力先のハンドラーを登録すると、重複して表示されることになる。
ログレベルについて
- ログレベルは、各ハンドラーとロガーのログレベルを比較し、よりレベルの高いほうが適用される。
- 一括でログレベルを変更したい場合は、
RootLogger、もしくは自分で作成したsubrootロガーのログレベルを変更するのが個人的なベストプラクティス。まだやったことはないが、恐らく最終的なプロダクトとしては、loggingで全体を一括して変更するのが良いと現段階では考えている。
getLogger関数について
getLogger関数は、ロガーの作成と取得を兼ねているが、使う際は作成と取得を意識せずに使える。- 存在しない名前が指定された場合は
RootLoggerの子ロガーが生成される。- 以下は
RootLoggerを呼び出してしまうので注意。
getLogger()getLogger("root")(RootLoggerの名前はrootなので)最後に
Logger は名前空間によって管理されていて、インポートしたりしなくても名前だけわかっていれば、
getLoggerで名前を指定して、どこでも作成も呼び出しもできるようになっている、というのが一番の要点なのかなと感じました。とても考えられているんだなぁ!と感心しました。偶に、Logger インスタンスをインポートして使用している方がいるようですが(自分)、そこさえ分かってしまえば、重複してハンドラーを追加してしまったりすることもないのかな?(自分)、と思いました。
ロギングの使い方、そしてログに関してとても奥が深いことも分かり、追々勉強していきたいと思いました。
参考
以下、主に参考にさせて頂いた記事等です。
logging.__init__.pyの DocString など- Logging クックブック
- Python の logging について
- 初心者のためのPythonにおけるlogging入門
- Windows10 + python3 + logger でログファイルの出力にUTF-8を使うよう指定する