- 投稿日:2020-12-07T23:28:21+09:00
Progate Python学習
Pythonとは
Pythonとは、Webアプリ開発や機械学習、統計処理などを行うことの出来るプログラミング言語です。ProgateのPython学習は約5時間ほどかかりましたが、Pythonについて深く学ぶことが出来ます。
Pythonの基本的な使い方
文字列
'またはダブルクォーテーション"で囲みます。
行頭に#を書くことでコメントを書くことが出来ます。print("Hello World") #この行はコメントです数値
数値は文字列と違い、クォーテーションで囲む必要はありません。
+,-,*,/を用いて足し算、引き算、掛け算、割り算を行うことが出来ます。print(3) print(3 + 7) print(7 - 3)変数
「変数名 = 値」と書くことで変数を定義することが出来ます。
print(変数名)と入力することで変数の値を出力することが出来ます。この時クォーテーションは書きません。name = "John" number = 5 print(name)データ型
「文字列」や「数値」というのはデータ型と呼ばれ、それぞれ「文字列型」と「数値型」と言います。データ型の異なる文字列型と数値型を連結すると、エラーが起きてしまいます。そのため、型変換をする必要があります。数値型を文字列型に変換するには「str」を用います。文字列型を数値型に変換したい場合には「int」を用います。
price = 100 print("りんごの価格は" + str(price) + "円です") count = "3" price = 100 total_price = price * int(count) print(total_price)リスト
複数のデータをまとめて管理するにはリストというものを用います。リストの要素には、前から順に「0, 1, 2,・・・」と数字が割り振られており、これをインデックス番号といいます。リストの各要素は、
リスト[インデックス番号]とすることで取得することができます。foods = ["pasta","curry","sushi"] print("好きな食べ物は" + foods[2] + "です")条件分岐
if文
if文を用いると「もし○○ならば☓☓を行う」という条件分岐が可能になります。
ifの条件式が成立した後の処理を書く時、インテンドしないと処理が実行されないのでインテンドするようにします。
条件式の中では、2つの値を比較するための記号比較演算子がよく使われます。
==は二つの値が等しいとき、!=は二つの値が等しくないときに実行されます。
if文に「else」を組み合わせることで「もし○○ならば☓☓を行う、そうでなければ△△を行う」という条件分岐ができるようになります。if文の条件がFalseのとき、elseの処理が実行されます。
if文で、条件が成り立たなかった場合を複数定義したい場合は、「elif」を用います。score = 50 if score == 100: print("よくできました") elif score >= 60: print("もう少し頑張りましょう") else: print("もっと頑張りましょう")「条件1も条件2も成り立つ」というような場合の条件式は
andを用いて、条件1 and 条件2のように書きます。
「条件1か条件2が成り立つ」というような場合の条件式はorを用いて、条件1 or 条件2のように書きます。
notを用いると、条件の否定をすることができます。time = 14 if time > 10 and time < 18 : print("就業時間です") time = 15 if time == 10 or time == 18 : print("おやつの時間です") time = 9 if not time == 18 : print("退社時刻ではありません")while文
for文を使うと、リストの要素を順に取り出して処理を行うことができます。
for 変数名 in リスト:と書くことで、リストの要素の数だけ、処理を繰り返すことができます。foods = ["pasta","curry","sushi"] for food in foods: print("好きな食べ物は" + food + "です")while文もif文と同様に繰り返し処理を行うことが出来ます。下のようにコードを書くと、初めxの値が10で、xの値は1ずつ減り続け、xが1になるまで処理し続けます。
x = 10 while x > 1: print(x) x -= 1最後に
洗練さんでインターンの課題(Progate 学習コース PythonⅠ~Ⅳ)です。
Progate Python最後に
現在ここでインターンしています。
まだまだ駆け出しですが頑張ります!やる気は人一倍です!
洗練
- 投稿日:2020-12-07T23:02:36+09:00
深層学習: Day2
講義要約
Sec1: 勾配消失問題
ビジョン
- シグモイド関数の微分値は最大でも0.25。故に何度もシグモイドで微分を行うと勾配消失が起きやすい。
\begin{align} f(u)' &= (1 - sigmoid(u)) * sigmoid(u)\\ &= (1 - 0.5) * 0.5 \end{align}勾配消失問題の解決法
- 活性化関数の選択
- Relu関数:閾値を超えた値はそのままの値で伝わる関数。
- 重みの初期値設定
- Xavierの初期値:重みの要素を、前の層の平方根で除算した値。
network["W1"] = np.random.randn(input_layer_size, hidden_layer_size) / np.sqrt(input_layer_size) network["W2"] = np.random.randn(hidden_layer_size, output_layer_size) / np.sqrt(hidden_layer_size)
- Heの初期値:重みの要素を、前の層の平方根で除算した値に対し、$\sqrt 2$を掛け合わせた値
network["W1"] = np.random.randn(input_layer_size, hidden_layer_size) / np.sqrt(input_layer_size) * np.sqrt(2) network["W2"] = np.random.randn(hidden_layer_size, output_layer_size) / np.sqrt(hidden_layer_size) * np.sqrt(2)
- バッチ正規化
- ミニバッチ単位で、入力値のデータの偏りを抑制する手法
- 活性化関数に値を渡す前後に、バッチ正規化処理を含んだ層を加える。
- バッチ正規化層への入力値は $$ u^{(l)} = w^{(l)}z{(l-1)} + b^{(l)}$$ または $$ z $$
- $u^{(l)}$は入力値に重みが掛けられバイアスが加わった値
- $z$は、$u^{(l)}$が活性化関数を通った後の値
- バッチ正規化の数学的記述
$$
\begin{align}
&1. \mu_t = \frac{1}{N_t} \sum_{i=1}^{N_t} x_{n i} \\
&2. \sigma_t^2 = \frac{1}{N_t} \sum_{i=1}^{N_t} (x_{n i} - \mu_t)^2 \\
&3. \hat{x_{n i}} = \frac{x_{n i} - \mu_t}{\sqrt{\sigma_t^2 + \theta}} \\
&4. y_{n i} = \gamma_{ni}^x + \beta \\
\end{align}
$$\begin{align} &\mu_t: ミニバッチt全体の平均 \\\ &\sigma_t^2: ミニバッチ全体の標準偏差\\\ &N_t: ミニバッチのインデックス\\\ &\hat{x_{n i}} : 0に近づける計算(0を中心とするセンタリング)と正規化を施した値\\\ &\gamma : スケーリングパラメータ\\\ &\beta: シフトパラメータ\\\ &y_{n i}: ミニバッチのインデックス値とスケーリングの積にシフトを加算した値(バッチ正規化オペレーションの出力) \end{align}Sec2: 学習率最適化手法
- 深層学習の目的は誤差を最小化するパラメータ$w$を発見すること。
→勾配降下法を利用してパラメータを最適化 $$ w^{(t+1)} = w^{(t)} - \epsilon \nabla E $$- 勾配降下法の学習率は手動で設定する他に、学習率最適化手法がある。
モメンタム
$$ V_t = \mu V_{(t-1)} - \epsilon \nabla E $$
self.v[key] = self.momentum * self.v[key] - self.learning_rate * grad[key]$$ w^{(t+1)} = w^{(t)} + V_t $$
params[key] += self.v[key]$$慣性:\mu $$
* 誤差をパラメータで微分したものと学習率の積を減算した後、現在の重みに前回の重みを減算した値と慣性の積を加算する。
* 慣性の値:0.5~0.9程度か
* モメンタムのメリット:
+ 局所的最適化にならず大域的最適解となる。
+ 谷間に着いてから最も低い位置(最適値)に行くまでの時間が早い。AdaGrad
- 誤差をパラメータで微分したものと再定義した学習率の積を減算する
- 初期値に$\theta$(=極小の値)を与える $$ h_0 = \theta $$
self.h[key] = np.zeros_like(val)
- 誤差を二乗して加算していく $$ h_t = h_{t-1} + (\nabla E)^2 $$
self.h[key] += grad[key] * grad[key]
- $\theta$(コードでは1e-7)は分母が0にならないために与える $$ w^{(t+1)} = w^{(t)} - \epsilon \frac{1}{\sqrt{h_t} + \theta} \nabla E $$
params[key] -= self.learning_rate * grad[key] / (np.sqrt(self.h[key]) + 1e-7)
- AdaGradのメリット:
- 勾配の緩やかな斜面に対して、最適値に近づける
- 課題:
- 学習率が徐々に小さくなるので、鞍点問題(極小値でなく極大値に陥る)を引き起こすことがあった。
RMSProp
- 誤差をパラメータで微分したものと再定義した学習率の積を減算する。 $$ h_t = ah_{t-1} + (1-a)(\nabla E)^2 $$
self.h[key] *= self.decay_rate$$w^{(t+1)} = w^{(t)} - \epsilon \frac{1}{\sqrt{h_t} + \theta} \nabla E $$
params[key] -= self.learning_rate * grad[key] / (np.sqrt(h[key]) + 1e-7)
- RMSPropのメリット:
- 局所最適解にはならず、大域的最適解となる。(AdaGradの解決策として)
- ハイパーパラメータの調整が必要な場合が少ない。
Adam
- モメンタムの、過去の勾配の指数関数的減衰平均
- RMSPropの、過去の勾配の2乗の指数関数的減衰平均
- 上記をそれぞれ孕んだ最適化アルゴリズムである。
Sec3: 過学習
- 過学習:テスト誤差と訓練誤差とで学習曲線が乖離すること。
- 原因: ネットワークの自由度が高い
- パラメータの数が多い
- パラメータの値が適切でない
- ノードが多過ぎる など
- 正則化:ネットワークの自由度(層数、ノード数、パラメータの値など)を制約すること
- 荷重減衰(Weight decay)
- 過学習の原因:重みが大きい値をとることで発生
- 学習の過程で重みにばらつきが発生する。重みが大きい値は、学習において重要な値であり、重みが大きいと過学習が起こる。
- 過学習の解決策:誤差に対し正則化項を加算し重みを抑制する
- 過学習が起こりそうな重みの大きさ以下で重みをコントロールし、かつ重みの大きさにバラつきを出す必要がある。
L1正則化、L2正則化
- 誤差関数にpノルムを加える $$ E_n(W) + \frac{1}{p} \lambda \begin{Vmatrix} x \end{Vmatrix}_p $$
weight_decay += weight_decay_lambda * np.sum(np.abs(network.params['W' + str(idx)])) loss = network.loss(x_batch, d_batch) + weight_decay
- pノルムの計算 $$ \begin{Vmatrix} x \end{Vmatrix}_p = (\begin{vmatrix} x_1 \end{vmatrix}^p + \cdots + \begin{vmatrix} x_n \end{vmatrix}^p)^{\frac{1}{p}} $$
np.sum{np.abs(network.params['W' + str(idx)])}
- p = 1の場合、L1正則化と呼ぶ。
- 0の値をとる事ができる→スパース化の問題に対応できる。
- p = 2の場合、L2正則化と呼ぶ。
- 精度向上の面では積極的に採用すべきか。
ドロップアウト
- ランダムにノードを削除して学習させることで、ノード数が多い問題に対処。
- 各層ないし各ノードに閾値を設けて、閾値を超えないノードを不活性化させる。
- メリット:データ量を変化させずに、異なるモデルを学習させていると解釈できる。
Sec4: 畳み込みニューラルネットワーク
- LeNet:CNNの基本型
- 入力値 * フィルター(全結合でいう重み) → 出力値 + バイアス → 活性化関数$f(x)$ → 出力値
畳み込み層
- 三次元の空間情報も学習できるような層が畳み込み層である。
- バイアス:フィルターを掛けた値に加算する。
- パディング: 入力データ周縁に値を与え入出力データのサイズを合わせる、基本はゼロパディング。
- ストライド:フィルターをズラす幅。
- チャンネル:入力データを分解した層数・奥行き。チャンネル数はフィルターも合わせる。
- 全結合層では画像も1次元データとして処理されチャンネル間の関係性が学習されなかったが、畳み込み層ではチャンネル間の関係性が学習され3次元データに対応できるようになった。
- im2col(image to column)
- 画像のような多次元データを2次元配列にする。
- メリット:行列計算に落とし込むことで、多くのライブラリを活用できるようになる。
- col2im(column to image)
- im2colとは全く別のアルゴリズムを使っているので、im2colの出力をcol2imで復元しようとしても整合性が取れない。
プーリング層
- 入力画像の対象領域のMax値または平均値を取得し、出力として採用する。
- それぞれ MaxPooling、Average Pooling という。
Sec5: 最新のCNN
AlexNet
- 5層の畳み込み層およびプーリング層など、それに続く3層の全結合層から構成される。
- ポイント:過学習を防ぐ施策
- サイズ4096の全結合層の出力にドロップアウトを使用している。
確認テストと考察
Sec0.
- 連鎖律の原理を使い、dz/dxを求めよ。 $$z = t^2$$ $$t = x+y$$
\begin{align} \frac{dz}{dx} &= \frac{dz}{dt}\frac{dt}{dx} \\\ &= 2t * 1\\\ &= 2t\\\ &= 2(x + y) \end{align}
- シグモイド関数を微分したとき、入力値が0のときに最大値を取る。その値として正しいものを選択肢から選べ。
\begin{align} f(u)' &= (1 - sigmoid(u)) * sigmoid(u)\\\ &= (1 - 0.5) * 0.5 \end{align}\\\ \\\ (2)0.25Sec1.
- 重みの初期値に0を設定すると、どのような問題が発生するか。簡潔に説明せよ。
計算結果が0になり誤差が伝わらずパラメータチューニングが行われない。
- 一般的に考えられるバッチ正規化の効果を2つ挙げよ。
・勾配消失問題が起きづらくなる ・ニューラルネットが学習しやすくなり計算精度や速度があがるSec2.
- モメンタム・AdaGrad・RMSPropの特徴をそれぞれ簡潔に説明せよ。
・モメンタム:谷間に落ちてから収束するまでが早い ・AdaGrad: 緩やかな斜面に対しても対応できる ・RMSProp: パラメータの調整が少ないSec3.
- 機械学習で使われる線形モデルの正則化は、モデルの重みを制限することで可能となる。前述の線形モデルの正則化手法の中にリッジ回帰という手法があり、その特徴として正しいものを選択しなさい。
(a) ハイパーパラメータを大きな値に設定すると、全ての重みが限りなく0に近づく
- L1正則化を表しているのはどちらか答えよ。
右図 (Lasso推定量/スパース推定)
- 5. L2パラメータ正則化
(4) param
- 6. L1パラメータ正則化
(3) np.sign(param) ※符号関数:正の数は1、0は0、負の数は-1で返す関数。故に絶対値の微分
- 7. データ集合の拡張
(4) image [ top:bottom, left:right, : ]Sec4.
- サイズ6×6の入力画像を、サイズ2×2のフィルタで畳み込んだときの出力画像のサイズを答えよ。ストライドとパディングは1とする。
7×7演習結果と考察
2_2_1_vanishing_gradient
演習結果
http://foraistudy.s3-website-ap-northeast-1.amazonaws.com/考察
- 活性化関数をシグモイド関数からReLU関数に変えることで精度が向上し勾配消失問題が解消されたことが確認出来た。
- 初期値設定を行うことで収束速度が劇的に向上することが確認出来た。
2_2_2_vanishing_gradient_modified
考察
- 隠れ層のノード数を増やすことで多少の精度向上が見て取れたが、計算に掛かる時間は目に見えて増加した。
- 2種類の初期値についてはどちらかが常に精度・速度について優れているというわけではなく、組み合わせ次第で変化し得ることが見て取れた。
2_4_optimizer
演習結果
https://24optimizer.s3-ap-northeast-1.amazonaws.com/2_4_optimizer_2.html考察
- momentumの値を0.9→0.5に変更したところ、収束速度が著しく低下した。
- バッチ正規化がいかに効果的かが確認できた。
- AdaGradの学習率を0.1から上げても大きな変化は見られないが、下げると収束速度が目に見えて低下した。
- RMSPropのdecay_rateは0.99など極大値や0.01など極小値では収束が遅れる傾向にあるように見えたが、どの値が適切であるかは判断が難しく多くの試行を要した。
2_5_overfiting
演習結果
https://25overfiting.s3-ap-northeast-1.amazonaws.com/2_5_overfiting.html考察
正則化強度については何度か試行をして微調整する必要があると思った。
L1正則化に関して、学習精度にムラがあり実用性については疑問符が付くと感じた。
dropputを組みわせることで、L1における学習曲線のムラが抑制された。
2_6_simple_convolution_network
演習結果
https://26scn.s3-ap-northeast-1.amazonaws.com/2_6_simple_convolution_network_2.html考察
- im2colの出力をcol2imに通しても完全に元データを復元することはできないことが確認できた。

- 投稿日:2020-12-07T22:53:19+09:00
Neo4j とGraphQL でSNSを分析する
最初に
Neo4jとGraphQLを会社のプロジェクトで採用し、新しいプロダクトを開発しています。
今回はNeo4jとGraphQLを使った所感や事例などを共有したいと思います。
技術スタック:
- Neo4j : 永続用のグラフデータベース
- GraphQL: バックエンド API を提供するためのクエリ言語
- Vue.js : フロントエンド
プロジェクトについて
現在私達が取り組んでいるプロジェクトは、ファッションAIプラットフォーム mielの延長線の内容で、インスタグラムを代表とするSNSの投稿やソーシャルグラフを取得して分析を行い、ブランドや製品の影響力などを調査・評価をするプラットフォームの構築です。
今回の記事では、分析したいSNSアカウント(特にインスタグラム)やキャンペーンを登録し、キャンペーンのパフォーマンスを評価できるようにする機能に関して書きたいと思います。
GraphQL/Neo4Jを選んだ理由
私たちは、GraphQLを使うことを考えていて、Neo4jについての宣伝記事を読んで、グラフデータベースを使うことがどれほど素晴らしいかを考えていました。これらの技術の完璧なユースケースにマッチする新しいプロジェクトが出てきたとき、私たちはそれを試してみたいと思いました。
ソーシャルネットワークは、人やグループ、そしてそれらが相互に作用するものの間の直接的・間接的な関係を特定するのに役立ち、ユーザーはお互いに評価したり、レビューしたり、気になるものを発見したりすることができるようになります。誰が誰と交流しているのか、人々はどのようにつながっているのか、グループ内の代表者がグループの集合的な行動に基づいてどのような行動や選択をする可能性が高いのかを理解することで、個人の行動に影響を与える目に見えない力についての大きな洞察を得ることができます。
ソーシャルネットワークはすでにグラフ化されているので、Neo4jを使ってデータモデルを作成することで、ドメインモデルと直接一致し、データをよりよく理解することができ、無駄な作業を避けることができます。
GraphQLは、グラフデータベースで表現されるデータモデルに自然にフィットするように思われます。基礎となるデータモデルをGraphQLでモデリングすることで、データを消費するコントロールをフロントエンドアプリに転送し、永続層から必要なデータをクエリすることができます。GraphQL型のシステムは、クエリの妥当性を保証し、バックエンドとフロントエンドの間の通信オーバーヘッドを削減する開発努力を大幅に節約します。
Data Model
Neo4jについての売り文句の一つは、データモデリング、つまりデータモデルの構築がいかに簡単で直感的にできるかということでした。私たちの経験では、実際にその通りであることがわかりました。議論の間にホワイトボードに描くようなイメージをNeo4jモデルに持ってくることは、はるかに簡単でした。正規化、主キー/外部キーはなく、円と矢印だけです。
Neo4j/Neomodel
モデリングには、Neo4j用のオブジェクトグラフマッパー(OGM)であるNeomodelを使用しました。
NeomodelはNeo4jのCypherクエリ言語の複雑さをすべて隠していますが、それは最初は威圧的で、バックエンドのチームでは私たちはPythonが大好きです。Neomodelでは、クライアントとプロジェクト`のためのオブジェクトとその関係は以下のようになります。model_1.pyclass Client(StructuredNode): uid = UniqueIdProperty() name = StringProperty(required=True) # relationships instagram = RelationshipTo(InstaUser, 'HAS', cardinality=ZeroOrMore) projects = RelationshipTo('Project', 'OWNS', cardinality=ZeroOrMore) class Project(StructuredNode): uid = UniqueIdProperty() name = StringProperty(required=True) # relationships hashtags = RelationshipTo(Hashtag, 'PROMOTED_WITH', cardinality=ZeroOrMore) campaigns = RelationshipTo('Campaign', 'CONTAINS', cardinality=ZeroOrMore)各クライアントは複数のプロジェクトを持つことができる」「各プロジェクトは複数のキャンペーンを持つことができる」「プロジェクトは複数のハッシュタグでプロモーションされる」といった関係性は、カーディナリティルール
ZeroOrMoreによって強制される。
クライアントが運営するキャンペーンは、特定のハッシュタグを持つことができ、そのハッシュタグはキャンペーンに登録したインスタグラマーによってプロモーションされます。キャンペーンは、タグ付けされたり、クライアントのInstagramアカウントが言及されたり、ハッシュタグがプロモーションされたりと、複数の方法で可視性を得ています。我々はそれをリレーションシップAIDとしてモデル化しました。model_2.pyclass AidRel(StructuredRel): AID_TYPE = {'M': 'mention', 'T': 'tagged', 'H': 'hashtag', 'O': 'manual'} type = StringProperty(choices=AID_TYPE) name = StringProperty() class Campaign(StructuredNode): uid = UniqueIdProperty() name = StringProperty() start = DateTimeProperty() end = DateTimeProperty() url = StringProperty() # relationships posts = RelationshipTo(InstaPost, 'AID', cardinality=ZeroOrMore, model=AidRel) entry_users = RelationshipTo(InstaUser, 'ENTRY', cardinality=ZeroOrMore) aid_users = RelationshipTo(InstaUser, 'PROMOTE_BY', cardinality=ZeroOrMore)注:
InstaUserInstaPostのモデルは簡潔にするために図示していませんGraphQL と Ariadne
APIの実装にはAriadneのGraphQLライブラリを選択しました。これはスキーマファーストのアプローチで、まずAPIをGraphQLクエリ言語でモデル化してから、データリゾルバをスキーマ定義にバインドします。
スキーマ
GraphQL APIは、すべてのAPIエンティティに型を強制します。これにより、APIはより堅牢になり、APIの消費はエラーが発生しにくくなります。GraphQL playgroundのようなIDEは、APIスキーマを読み込んで、クエリがディスパッチされる前にクエリを検証することができるので、フロントエンド開発者にとって、GraphQL APIを使った開発は非常に快適な経験になります。
GraphQL APIの設計目標は、基礎となるデータモデルを表現し、消費者がどのように使用するかをあまり気にすることなく、異なるタイプの関係性を高めることです。最終的には、データモデルのノード型に1対1のGraphQL型をマッピングします。model_1.graphqltype Client { uid : ID name: String user: User instagram: InstaUser projects: [Project] } type Project { uid: ID name: String hashtags: [Hashtag] campaigns: [Campaign] }リレーションシップデータ(ノードの代わりにエッジに配置されたデータ)を取得するために、リレーションシップデータ(
AidRel)と対応するノードデータ(InstaPost)を集約するために、AidRelInstaPostのような新しい型を作成しました。model_2.graphqltype Campaign { uid: ID name: String start: DateTime end: DateTime url: String posts: [InstaPost] aid_users: [InstaUser] aid_rel_posts: [AidRelInstaPost] } type AidRelInstaPost { aid: AidRel # edge data post: InstaPost # node data }Resolvers
GraphQLは、reslolverと呼ばれるメカニズムを使って、型のフィールドを問い合わせるためのエレガントで柔軟な方法を提供しています。ほとんどのスカラフィールド(
ID,String,Intなど)については、リゾルバを用意する必要がありませんでした。なぜなら、AriadneはNeomodelデータオブジェクトのフィールド名と対応する GraphQL 型のフィールド名を自然にマッピングしてくれるからです。配列フィールドの場合、90%以下のような結果になることが多いです。resolver_1.py@campaign.field("posts") def reslove_campaign_posts(campaign, *_): return campaign.posts.all()エッジとノードの両方の情報を含むハイブリッド型については、データを構築するための情報を得るためにNeo4j
Cypherクエリ言語に頼らなければならなかった。resolver_2.py@campaign.field("aid_rel_posts") def reslove_campaign_aid_rel_post(campaign, *_): query = f""" MATCH (c:Campaign)-[a:AID_BY]->(p:InstaPost) WHERE c.uid = '{campaign.uid}' RETURN a, p """ results, _ = db.cypher_query(query) # Create AidRelInstaPost objects res = [{'aid': AidRel.inflate(r[0]), 'post': InstaPost.inflate(r[1])} for r in results] return resデータモデルをGraphQLで表現すると、プロジェクトに関連するあらゆるデータの問い合わせは、単純な
getProjectsクエリで行うことができます。query_1.graphqltype Query { getProjects(project: ProjectQueryInput): [Project] } input ProjectQueryInput { # project by uid uid: ID # project query by client.uid or .name and project.name client_uid: ID client_name: String project_name: String }また、グラフQLのオプションフィールドを使用することで、
QueryInputフィールドに異なる条件でクエリを実行することができます。上の例では、uidやclient_id,project_nameのペア、あるいはclient_name,project_nameのペアでプロジェクトをクエリすることができました。しかし、この場合の欠点は、クエリの検証をクエリリゾルバに押し付けてしまうことでした。データの問い合わせ
クライアントのキャンペーンを表すデータは、Neo4jデータベースでは以下のようになりますす。
rgb(86,148,128)-Client
rgb(247,195,82)-Project
rgb(235,101,102)-Campaign
rgb(141,204,147)-InstaPost
rgb(218,113,148)-InstaMedia
rgb(89,199,227)-InstaUserクエリ
getProjectsは、これらのノードに属するオブジェクトのいずれかから必要なフィールドを要求することができる。例えば、プロジェクトレポートを生成するクエリは以下のようになります。report_query{ getProjects(project: { # all projects or criteria }) { # Project attributes uid name hashtags { tag_id name } campaigns { # Campaign attributes uid name start end url posts { # Post attributes post_id shortcode media(first: 1) { # media selection: only first one display_url media_id shortcode } } entry_users { # entry user attributes ig_id username } } } }フロントエンドは任意のデータ要素を取得することができ、リゾルバは要求された要素に対してのみ実行されます。下の画像は、GraphQL Playgroundで提供されている上記のクエリを示しています。このようなツールは、フロントエンド開発者のためのクエリ構成を簡単にしてくれます。自動補完、エラー処理により開発プロセスを迅速化し、API仕様の変更にも少ない通信オーバーヘッドで対応することができます。
キャンペーンのクライアントレポートを提示するためのクエリからのデータのフロントエンドレンダリングは次のようになります。
最後に
新しいプロジェクトでのNeo4jとGraphQLの使用は、これまでのところ楽しい経験でした。プロジェクトの要件の進化に伴い、スキーマを拡張し、大きなリファクタリングなしでデータモデルに新しいエンティティとリレーションシップを追加することができました。Neomodelは、エンティティの関係を明確に記述し、クエリを構築する初期段階では不可欠でしたが、後になってより良い制御をするためにクエリ言語のCypherに頼らざるを得なくなりました。GraphQLのAPIはデータモデルを反映したものなので、APIを壊すことなく新しい機能を追加することができました。APIのリファクタリングでさえも、GraphQLスキーマのドキュメント、クエリの検証、時として、タイプミスがあった場合に正しいフィールド名を使用するための驚くほど便利な提案など、効果的にフロントエンドに伝えることができました。
このスタックを使い始めてまだ数ヶ月しか経っていません。探求すべきことはたくさんありますが、この技術スタックが私たちのプロジェクトの期待に応え続けてくれると確信しています。また、GRANstackについても言及する価値があり、これはjavascriptの開発者コミュニティとより連携しています。





- 投稿日:2020-12-07T22:20:13+09:00
pytorchで物体検出
概要
pytorchでゲーム画面の物体検出をします。
pytorchのfastrcnnを用いてスクリーンショットから物体検出し、物体に合わせてマウスを移動させます。学習データの準備
ゲームプレイ中に1秒毎にスクリーンショットを撮り、学習に使用する画像を150枚ほど用意します。
各画像に対してアノテーションデータを作成します。学習
学習済みモデルを用いたので30分程度で終わらせました。
推論
なかなかいい感じです。
動作確認
ゲーム画面からスクリーンショットを撮り続け、学習させたモデルに入力し物体の座標を獲得します。あとは座標に合わせてマウスの操作をさせます。
視点を故意にずらしても検出した物体に合わせてマウスが自動で移動しています。
動作が遅く実用的ではないですが、きちんと動作しました。


- 投稿日:2020-12-07T21:57:37+09:00
API Gateway + Lambda + DynamoDB サーバレスWebAPI開発まとめ
はじめに
スマホアプリのバックエンドとしてAWSの「API Gateway + Lambda + DynamoDB」でサーバレスなWebAPIを開発しました。
現在、開発環境と本番環境を運用しています。
「API Gateway + Lambda + DynamoDB」の構築手法はたくさん紹介されていますが、知識ゼロの状態から構築するのは難しく、時間がかかりました。
この記事ではAPI Gateway、Lambda、DynamoDBそれぞれの概要と、私がサーバレスWebAPIを構築する上で参考になった記事を紹介します。API Gateway + Lambda + DynamoDB
とりあえず「API Gateway + Lambda + DynamoDB」の構成でWebAPIを開発する際には以下が参考になると思います。
まずは簡単なサーバーレスアプリケーションを作成して感覚を掴むのが良いと思います。
初めてのサーバーレスアプリケーション開発 ~DynamoDBにテーブルを作成する~
初めてのサーバーレスアプリケーション開発 ~LambdaでDynamoDBの値を取得する~
初めてのサーバーレスアプリケーション開発 ~API GatewayからLambdaを呼び出す~API Gateway
スマホアプリなどのクライアントからのHTTPリクエストは、API Gatewayで受け付けてLambda関数で処理されます。API GatewayではLamba関数に渡す前のデータ形式を調整し、Lambda関数から返ってきたデータの形式を調整してクライアントにHTTPレスポンスとして返却します。
初期設定など
API Gatewayの設定、Lambdaへのパラメータの受け渡しなどについて、以下が参考になりました。
https://qiita.com/naoki_koreeda/items/c2a32198c86e8d9a5bb6統合レスポンスやヘッダーの設定
統合レスポンスやステータスコードのLambdaでのエラーの正規表現の書き方、ヘッダーのマッピングの仕方などについて、以下が参考になりました。
https://qiita.com/naoki_koreeda/items/5351f8ab803db655b0b4formでPOSTする際のマッピングテンプレート
「application/x-www-form-urlencoded」の形式でPOSTする際のマッピングテンプレートの作成に苦労しました。以下の記事を参考に作成しました。
https://dev.classmethod.jp/articles/sugano-013-api-gateway/OpenAPI、Swagger形式でエクスポート
API GatewayでREST APIを作成および設定したら、API GatewayコンソールなどからOpenAPIファイルやSwaggerファイルにエクスポートできます。
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/api-gateway-export-api.html
逆にOpenAPI、Swaggerファイルからインポートすることもできるので、ドキュメントを変更してそれを環境に反映させるのも簡単です。開発効率が向上します。API Gatewayのドメインを変更したい
API GatewayではデフォルトのURLを使用する代わりに、任意のカスタムドメイン名を使用することができます。
API Gatewayでカスタムドメインを設定し、HTTPS化する際に以下が参考になりました。
https://dev.classmethod.jp/articles/api-gateway-custom-domain-ssl/応答性を強化するためにAPIキャッシュを設定したい
APIキャッシュを有効にして、エンドポイントのレスポンスがキャッシュされるようにできます。
キャッシュを有効にすると、エンドポイントへの呼び出しの数を減らすことができ、また、APIへのリクエストのレイテンシーを短くすることもできます。
メソッド毎にのキャッシュを有効または無効にしたり、TTL期間を変更したりすることもできます。
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/api-gateway-caching.html開発環境、本番環境で使用するLambdaやDynamoDBを変更したい
2つの異なるHTTPエンドポイントが存在する場合に、API Gatewayのステージ変数を使用することで、異なるAPIデプロイステージのHTTPとLambdaバックエンドにアクセスできます。
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/amazon-api-gateway-using-stage-variables.htmlAPI Gatewayで設定したステージ変数をLambdaへパラメータとして渡すことで、ステージ変数を元にLambda内で使用するDynamoDBのテーブルを変更することができます。
Lambda
Lambdaはサーバーの準備・管理をしなくても、コードを実行できるサービスです。
今回の構成ではAPI Gatewayをトリガーにして実行されます。
Lambda関数内でサードパーティのライブラリを使いたい
Lambdaでrequestsを使いたいなど、サードパーティのライブラリを使いたいときに、以下の記事が参考になりました。
https://qiita.com/Hironsan/items/0eb5578f3321c72637b4Lambdaで環境変数を使いたい
Lambdaではキーバリュー形式で環境変数を設定することができます。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/configuration-envvars.htmlLambdaにデフォルトで設定されている環境変数は以下です。
https://qiita.com/ykarakita/items/c9b1ee133fe03bbd4f1eLambdaでHTMLを返す
LambdaでHTMLを返す方法は以下が参考になりました。
https://qiita.com/yoshidasts/items/d58c555aed2693e99ae6LambdaからLambdaを非同期で呼び出したい
Lambdaから別のLambdaを呼び出したいときは
invokeを使います。
呼び出す際に同期/非同期を設定することができます。
以下が参考になりました。
https://qiita.com/ume1126/items/8170a10fad6b21f0f54aDynamoDB
DynamoDBはフルマネージド型のNoSQLデータベースサービスです。
Lambdaとの相性が良く、サーバレスなWebAPIではDynamoDBを使用するのが最も一般的です。
DynamoDBではパーティションキーを設定する必要があります。パーティションキーのみで一意にならない場合は、ソートキーを設定します。
完全一致検索、範囲検索、前方一致検索などが可能です。以下の例ではパーティションキーに型番、ソートキーにメーカー名を設定しています。
imageURLやtypeなど、他の項目をキーにして検索したい場合は、グローバルインデックスを設定することで検索可能になります。
Amazon DynamoDB とは - Amazon DynamoDBAWSのDBには多くの選択肢が存在します。それぞれのユースケースなどは以下に記載されています。
https://aws.amazon.com/jp/products/databases/DynamoDBのデータを自動で削除したい
DynamoDBに登録したデータを自動で削除したいことがあったので調べました。
リアルタイム性が重要でない場合、DynamoDBのTTL機能で自動削除できます。
https://dev.classmethod.jp/articles/try-dynamodb-ttl/リアルタイム性が必要な場合は、AWSStepFunctionsを使って自動削除を実現できます。
https://qiita.com/se_fy/items/dfe5bccaca80deebfa1b\AWSStepFunctionsについては以下が参考になりました。
https://dev.classmethod.jp/articles/step-functions-parameters/DynamoDBのデータをインポート・エクスポートしたい
DynamoDBのデータはDataPipelineを使用してインポート・エクスポートをすることができます。
https://www.wakuwakubank.com/posts/694-aws-data-pipeline-dynamodb/DynamoDBではデータをJSON形式でエクスポートしたときに、単純なキーバリュー形式ではなく、間にデータ型が入ってしまいます。
このようなJSONからデータタイプを排除する方法は以下が参考になりました。
https://bbh.bz/2019/12/09/delete-data-type-from-dynamodb-json/CloudWatch Logs
CloudWatch Logsでは、ログの簡単な表示や特定のエラーコードまたはパターンの検索などが可能です。
Lambda関数には、CloudWatch Logsのロググループが付属しており、ログが自動で出力されます。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/python-logging.htmlログデータを分析したい
CloudWatch Logs Insightsを使用することで、ログデータを簡単に分析することができます。
ログの操作にはクエリ言語を使用します。
CloudWatch Logs Insightsについては以下の記事が参考になりました。
https://qiita.com/sakochi/items/8e60654ffe36432c5228CloudWatch Logs Insightsではクエリが保存できます。
https://hacknote.jp/archives/57401/CloudWatch Logsのエラーログ内容をメールで送信したい
CloudWatch Logsで出力しているログファイルに特定の文字列がログに存在した場合に、メールで通知することができます。以下の記事が参考になりました。
https://dev.classmethod.jp/articles/notification_cloudwatchlogs_subscriptoinfilter/メトリクスフィルターでのパターンマッチングについては以下が参考になりました。
https://dev.classmethod.jp/articles/cloudwatch-metricsfilter-filterpattern/CloudWatch Logsのエラーログ内容をSlackに通知したい
Slackで通知する方法は以下が参考になると思います。
https://qiita.com/yahagin/items/2248287c5285cd1e9201おわりに
私がサーバレスWebAPIを構築する上で参考になった記事を紹介しました。
これらの記事のおかげでサーバレスWebAPIを構築し、運用することができました。
この記事が、私のように初めてAPI Gateway、Lambda、DynamoDBに触れる方やAWSのサーバレス開発で困っている方の一助になれば幸いです。
この記事は自分用のメモでもあるので、今後運用する中で困ったことがあれば参考にした記事などを順次追加していきます。




- 投稿日:2020-12-07T21:41:35+09:00
'Python 自作スクリプト名.py'に別名(alias)を設定すると、自作スクリプトファイルをUNIXコマンドのように実行できる
以下のコマンドに、エイリアスで別名を与える!
自作したPythonスクリプトは、任意のディレクトリから、以下で実行できます。
任意のディレクトリpython 自作ファイルの格納場所の絶対パス/.XXXXX.py上記のコマンドに、エイリアス(alias)で別名を与える。
自由に設定した「別名」が、自作スクリプトファイルを実行する際に呼び出すコマンド名になります。
Terminalalias 好きなコマンド名='python 自作ファイルの格納場所の絶対パス/.XXXXX.py'すると、任意のディレクトリから、「別名」と打つだけで、自作したPythonスクリプトを実行できる。
( 解説 )
(1) pwdで、自作したPythonスクリプトファイルの絶対パスを確認
(例)スクリプトファイルから見たカレントディレクトリのパスの例/Users/ユーザ名/xxxxx/yyyyy/zzzzz/sample.py(2) echo $HOMEで、ホームディレクトリの絶対パスを確認
(例)HOMEディレクトリのパスの例/Users/ユーザ名(3) 1)で確認した絶対パスのうち、$HOMEの絶対パスと一致する部分を$HOMEに置き換える。
(例)変更前/Users/ユーザ名/xxxxx/yyyyy/zzzzz/sample.pyを、以下に変える。
変更後$HOME/xxxxx/yyyyy/zzzzz/sample.py(4) 任意のディレクトリから、 python $HOME/xxxxx/yyyyy/zzzzz/sample.pyを実行することで、sample.pyを実行できる。
(5) (4)のコマンドに、打ちやすい短い別名をつける。
変更後python $HOME/xxxxx/yyyyy/zzzzz/sample.py別名は、エイリアス(alias)でつけることができる。
Terminalalias 別名='python $HOME/xxxxx/yyyyy/zzzzz/sample.py'(7). Macbookをログアウトして、再ログインした際に、上記のエイリアスが読み込まれるように、bash_profileに上記を書き込む。
Terminalecho "alias 別名=\"python $HOME/xxxxx/yyyyy/zzzzz/sample.py\"" >> ~/.bashrc source ~/.bashrc(8). 任意のカレントディレクトリで、Terminal上で、「別名」を叩くと、自作スクリプトファイルが実行される。
任意のディレクトリで実行別名
( 実例 )
過去に作成した自作スクリプトファイルを例に、エイリアスを定義して、実行してみる。
以下で実行できる。
・ カレント・ディレクトリ; Users/ユーザ名の直下
・ 自作のPythonスクリプトファイルを、カレント・ディレクトリからの相対パスで実行(実行成功)Terminalocean@AfoguardMacBook-Pro ~ % pwd /Users/ocean ocean@AfoguardMacBook-Pro ~ % python ./Desktop/tkinter_test/tkinter_ner_svo_list_filter_by_target_word_and_case_file_dialog3.py ocean@AfoguardMacBook-Pro ~ %・ カレント・ディレクトリ; Users/ユーザ名の直下
・ 自作のPythonスクリプトファイルを、ルートからの絶対パスで実行(実行成功)Terminalocean@AfoguardMacBook-Pro ~ % python3 /Users/ocean/Desktop/tkinter_test/tkinter_ner_svo_list_filter_by_target_word_and_case_file_dialog3.py ocean@AfoguardMacBook-Pro ~ %・ スクリプトファイルの絶対パスのうち、\$HOMEで置き換えられる部分を、\$HOMEで置き換えて実行(実行成功)
Terminalocean@AfoguardMacBook-Pro ~ % echo $HOME /Users/ocean ocean@AfoguardMacBook-Pro ~ % python3 $HOME/Desktop/tkinter_test/tkinter_ner_svo_list_filter_by_target_word_and_case_file_dialog3.py ocean@AfoguardMacBook-Pro ~ %上記の実行コマンド文字列に、エイリアスで別名を定義__
'file_content'という別名を定義する。
Terminalocean@AfoguardMacBook-Pro ~ % alias file_content='python3 $HOME/Desktop/tkinter_test/tkinter_ner_svo_list_filter_by_target_word_and_case_file_dialog3.py' ocean@AfoguardMacBook-Pro ~ %Terminal上で、'file_content'と打ち込でエンターターキーを押すと、自作Pythonスクリプトファイルが実行できた。
Terminalocean@AfoguardMacBook-Pro ~ % file_content ocean@AfoguardMacBook-Pro ~ %任意のディレクトリから、実行できる
・1つ上の階層のディレクトリに移動後に、別名を実行(実行成功)
Terminalocean@AfoguardMacBook-Pro ~ % cd .. ocean@AfoguardMacBook-Pro /Users % pwd /Users ocean@AfoguardMacBook-Pro /Users % file_content ocean@AfoguardMacBook-Pro /Users %・2つ下の階層のディレクトリに移動後に、別名を実行(実行成功)
Terminalocean@AfoguardMacBook-Pro /Users % cd ocean/Desktop/files_test ocean@AfoguardMacBook-Pro files_test % ocean@AfoguardMacBook-Pro files_test % file_content ocean@AfoguardMacBook-Pro files_test %・同じ階層の別のディレクトリに移動後に、別名を実行(実行成功)
Terminalocean@AfoguardMacBook-Pro files_test % cd ../tkinter_test ocean@AfoguardMacBook-Pro tkinter_test % file_content ocean@AfoguardMacBook-Pro tkinter_testwhichコマンドで、エイリアスで設定した「別名コマンド」が呼び出す実行ファイルのパスを確認
Terminalocean@AfoguardMacBook-Pro tkinter_test % which file_content file_content: aliased to python3 $HOME/Desktop/tkinter_test/tkinter_ner_svo_list_filter_by_target_word_and_case_file_dialog3.py ocean@AfoguardMacBook-Pro tkinter_test %
- 投稿日:2020-12-07T21:37:37+09:00
LeetCodeに毎日挑戦してみた 70. Climbing Stairs(Python、Go)
はじめに
無料英単語サイトE-tanを運営中の@ishishowです。
プログラマとしての能力を上げるために毎日leetcodeに取り組み、自分なりの解き方を挙げていきたいと思います。
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
18問目(問題70)
70. Climbing Stairs
問題内容
You are climbing a staircase. It takes
nsteps to reach the top.Each time you can either climb
1or2steps. In how many distinct ways can you climb to the top?(日本語訳)
あなたは階段を上っています。
nトップに到達するためのステップが必要です。1 登ったり、2足を踏み入れたりするたびに。いくつの明確な方法でトップに登ることができますか?
Example 1:
Input: n = 2 Output: 2 Explanation: There are two ways to climb to the top. 1. 1 step + 1 step 2. 2 stepsExample 2:
Input: n = 3 Output: 3 Explanation: There are three ways to climb to the top. 1. 1 step + 1 step + 1 step 2. 1 step + 2 steps 3. 2 steps + 1 step考え方
こちら冷静に考えてみるとn番目のフィボナッチ数を求めるのと同じ意味で出題されているとわかります。
今回はループ処理で解いてみました。再帰的に説くことも可能です。
- 解答コード
class Solution: def climbStairs(self, n): a, b = 1, 1 for i in range(n): tmp = b b = a + b a = tmp return a
- Goでも書いてみます!
func climbStairs(n int) int { a := 1 b := 1 tmp := 0 for i := 0; i < n; i++ { tmp = b b = a + b a = tmp } return a }
- 投稿日:2020-12-07T21:21:57+09:00
畳み込みとプーリングについてのメモ
Pytorchを使ってDLを組んでるときに、畳込みとプーリングが曖昧な理解だった気がするので、
忘れたら見に来れるようにメモる局所受容野
視覚野のニューロンが反応する範囲のことを受容野と呼ぶらしく、
ニューロンが入力のごく一部にだけ応答する性質を局所受容野というらしい
詳しい定義はこちら局所受容野のニューロンには2種類あり「単純型細胞」と「複雑型細胞」
この2つに対応してるのが畳み込みとプーリング
単純型細胞はイメージ通りある特定の形状に反応する細胞で、その形状がずれると反応しない
ただ、いろんな形状に対応した単純型細胞が連携すれば複雑な形状の物体を認識することができる。一方の複雑型細胞は形状の空間的なズレを抜き取る。
単純型は形状が変わると別の細胞の形状になってしまう。
複雑型細胞は空間的な位置ずれを抜き取り、同一形状と見なせるように働く
そうすることで空間的な位置ずれがあっても同じ形状で認識することが可能畳み込み層
畳み込み層は単純型細胞をモデルにし、この特定の形状に対応するように構成されており、フィルターと呼ばれる
例えば、数値を認識する際の手がかりは数値の直線や曲線であり、それをフィルターとして設定する
ということは、フィルターの数が多いとそれだけ、様々な形状を持つことになるのか。なるほど。畳み込みネットワークの構造は、最初の入力層で画像の1ピクセルが1ニューロンに対応し、
次に単純型細胞に相当する畳み込み層、そして複雑型細胞に相当するプーリング層と続く。
そのあとは、全結合層と出力層につながる。
- 局所受容野
- 単純型細胞 <-> 畳み込み
- 複雑型細胞 <-> プーリング
フィルターと一部の入力画像を対応させて、そのフィルターが局所受容野に見つかれば畳み込み層のニューロンが発火する
入力層と畳み込み層の間の結合を数式で表すと、
\sigma(b+\sum_{l=0}^{2}\sum_{m=0}^{2}w_{l,m}x_{{j+l}, {k+m}})xが入力画像の各ピクセルの値、wが重み、bがバイアス、σが活性化関数
この数式のチューニング対象になるのは、wとbで、
NNと同様にCNNの出力値と正解の値との差が小さくなるようチューニングされる。このwはフィルタで、判別に必要な形状になっている。
フィルタを複数構成することで識別性能があがりやすい
なぜなら、特定の形状に対応したフィルタを複数持てるので、
より正しく識別できそうなのは感覚的にわかる。
各フィルタに対応する畳み込み層内のニューロンセットをチャネルという畳み込みの計算方法についてわかりやすかった例
引用元※プーリング層はまた次回


- 投稿日:2020-12-07T21:18:13+09:00
Streamlitを使ってVAEをインタラクティブに表現する
概要
本記事は最近話題のStreamlitを使って、ディープラーニングの結果をインタラクティブに表現しようとした試みで、題材としてはVAEを用いています。
ディープラーニングの結果をweb上で公開しようと思ったら、本来ならバックエンドやJavaScriptを延々と書かいたうえに煩雑なデプロイもこなさなければなりませんが、Streamlitを使えばそれらが一瞬でできてしまいます。このStreamlitのすごさを体感してもらえればと思います。
VAEモデルの作成
題材として使うVAEモデルの作成を行います。【Python】Keras で VAE 入門 を参考にして作ってます。ここは本題ではないので、軽く流してもらって大丈夫です。
vae.pyimport matplotlib.pyplot as plt from tensorflow.keras.datasets import mnist from keras.utils import np_utils import numpy as np import keras from keras import layers from keras import backend as K from keras.models import Model K.clear_session() # MNISTを読み込み (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.astype('float32') / 255. x_train = x_train.reshape(x_train.shape + (1,)) x_test = x_test.astype('float32') / 255. x_test = x_test.reshape(x_test.shape + (1,)) # ラベルをカテゴリに y_train = np_utils.to_categorical(y_train, 10) y_test = np_utils.to_categorical(y_test, 10) img_shape = (28, 28, 1) img_shape_prod = np.prod(img_shape) epochs = 30 batch_size = 256 latent_dim = 2データセットはmnistを使っています。
モデルに関しては畳み込みを行うことにしました(パラメーターの調整が難しいので、精度だけ考えたら先例が豊富にある全結合層のみのほうがよかった泣)。
vae.py# 潜在空間に落とし込む関数 def sampling(args): z_mean, z_log_var = args epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim), mean=0., stddev=1.) return z_mean + K.exp(z_log_var) * epsilon # エンコーダー encoder_input = layers.Input(shape=img_shape) x = layers.Conv2D(32, 3, padding='same', activation='relu')(encoder_input) x = layers.Conv2D(64, 3, padding='same', activation='relu', strides=(2, 2))(x) x = layers.Conv2D(64, 3, padding='same', activation='relu')(x) x = layers.Conv2D(64, 3, padding='same', activation='relu', strides=(2, 2))(x) x = layers.Conv2D(64, 3, padding='same', activation='relu')(x) conv_shape = K.int_shape(x) x = layers.Flatten()(x) x = layers.Dense(32, activation='relu')(x) z_mean = layers.Dense(latent_dim)(x) z_log_var = layers.Dense(latent_dim)(x) z = layers.Lambda(sampling)([z_mean, z_log_var]) encoder = Model(encoder_input, [z_mean, z_log_var, z]) encoder.summary() # デコーダー decoder_input = layers.Input(shape=(latent_dim,)) x = layers.Dense(np.prod(conv_shape[1:]), activation='relu')(decoder_input) x = layers.Reshape(conv_shape[1:])(x) x = layers.Conv2DTranspose(64, 3, padding='same', activation='relu', strides=(2, 2))(x) x = layers.Conv2DTranspose(32, 3, padding='same', activation='relu')(x) x = layers.Conv2DTranspose(32, 3, padding='same', activation='relu', strides=(2, 2))(x) x = layers.Conv2D(1, 3, padding='same', activation='sigmoid')(x) decoder = Model(decoder_input, x) decoder.summary() # 結合 x = decoder(encoder(encoder_input)[2]) vae = Model(encoder_input, x)VAE特有の処理として、
z_mean, z_log_varを用いて、潜在空間(2次元)に落とし込んでいます。vae.py# 損失関数を定義 kl_loss = -0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1) encoder_input = K.reshape(encoder_input, shape=(-1, img_shape_prod)) x = K.reshape(x, shape=(-1, img_shape_prod)) xent_loss = img_shape_prod * keras.metrics.binary_crossentropy(encoder_input, x) vae_loss = K.mean(xent_loss + kl_loss) vae.add_loss(vae_loss) vae.compile(optimizer='rmsprop') vae.summary() history = vae.fit(x=x_train, y=x_train, shuffle=True, epochs=epochs, batch_size=batch_size, validation_data=(x_test, x_test)) # 保存 open("model.json", 'w').write(decoder.to_json()) decoder.save_weights('param.hdf5')損失関数は関数を作成して
vae.compile(optimizer='rmsprop', loss=loss_func)とするとうまくいかなかったですが、直接vae.add_loss(vae_loss)とするとうまくいきました。vae.pyloss = history.history['loss'] val_loss = history.history['val_loss'] plt.plot(range(1,epochs), loss[1:], marker='.', label='loss') plt.plot(range(1,epochs), val_loss[1:], marker='.', label='val_loss') plt.legend(loc='best', fontsize=10) plt.xlabel('epoch') plt.ylabel('loss') plt.show() plt.savefig("loss") from scipy.stats import norm # 潜在空間上での出力画像の分布 n = 15 digit_size = 28 figure = np.zeros((digit_size * n, digit_size * n)) grid_x = norm.ppf(np.linspace(0.05, 0.95, n)) grid_y = norm.ppf(np.linspace(0.05, 0.95, n)) for i, yi in enumerate(grid_x): for j, xi in enumerate(grid_y): z_sample = np.array([[xi, yi]]) z_sample = np.tile(z_sample, batch_size).reshape(batch_size, 2) x_decoded = decoder.predict(z_sample, batch_size=batch_size) digit = x_decoded[0].reshape(digit_size, digit_size) figure[i * digit_size: (i + 1) * digit_size, j * digit_size: (j + 1) * digit_size] = digit plt.figure(figsize=(10, 10)) plt.imshow(figure, cmap='Greys_r') plt.subplots_adjust(left=0, right=1, bottom=0, top=1) plt.axis("off") plt.savefig("change_diagram")モデルの訓練の結果はこんな感じです。
streamlitの導入
作成したモデルをstreamlitで書き下していきます。
st.pyimport numpy as np import matplotlib.pyplot as plt from PIL import Image import streamlit as st import os from scipy.stats import norm from keras.models import model_from_json st.title("Streamlitを使ってVAEをインタラクティブに表示してみる") """ ## 2次元の潜在空間上で変数を移動させることでインタラクティブに画像を生成する """まず、タイトル(h1タグ)にするものを
st.title(hogehoge)で書くことができます。
地の文は"""でコメントとして書くと反映されます。ここではマークダウンも使えます。st.pybase_dir = os.path.dirname(os.path.abspath(__file__)) # サイドバー st.sidebar.title('潜在変数を調整する') xi = norm.ppf(st.sidebar.slider('x', 0.05, 0.95)) yi = norm.ppf(st.sidebar.slider('y', 0.05, 0.95)) batch_size = 256 st.sidebar.title("訓練時の潜在空間上での出力画像の分布") img2 = Image.open(base_dir + "/change_diagram.png") st.sidebar.image(img2, width=300)折り畳み式のサイドバーも簡単に実装できます。基本的には要素を書く際に
st.sidebar.としてあげるとサイドバーに表示されます。
画像についてはpillow形式ならst.image()で書くことができます。st.py# メイン decoder = model_from_json(open(base_dir + "/model.json").read()) decoder.load_weights(base_dir + '/param.hdf5') digit_size = 28 z_sample = np.array([[xi, yi]]) z_sample = np.tile(z_sample, batch_size).reshape(batch_size, 2) x_decoded = decoder.predict(z_sample, batch_size=batch_size) digit = x_decoded[0].reshape(digit_size, digit_size) fig = plt.figure() plt.axis("off") plt.imshow(digit, cmap="Greys_r") st.write(fig)メインの部分はpillowで書くと画像として扱われてしまいぼやけた感じになってしまうので、ピクセルのような形で書けるmatplotlibで書くようにしています。
st.py# チェックボックス if st.checkbox('詳細情報を表示'): st.write(f"最大値 {digit.max():.4f}") st.write(f"最小値 {digit.min():.4f}") st.write(f"平均値 {digit.mean():.4f}") st.write(f"標準偏差{digit.std():.4f}")最後に無駄にチェックボックスなんかを使ってみました。
デプロイ
デプロイはStreamlit sharingを使うことで簡単に行えますが、2つほど準備をする必要があります。
まず、requirements.txtを作成します。requirements.txtnumpy==1.18.2 Pillow==7.1.1 matplotlib==3.2.1 Keras==2.4.3 scipy==1.4.1 streamlit==0.70.0 tensorflow-cpu==2.3.1次にstreamlit sharingのページでデプロイの申請をする必要があります。申請が通るには2,3日かかります。(https://www.streamlit.io/sharing)
申請が通ったらデプロイすることができるようになります。
このリンク(https://share.streamlit.io/deploy )で、必要事項を記入してデプロイが完成です。
リンク
プロダクト:https://share.streamlit.io/eycjur/main/VAE/st.py
github:https://github.com/eycjur/main/tree/master/VAE困った点
簡単に作れる分カスタマイズするのが難しいです。たとえばオブジェクトのマージンの設定や
st.writeで大きさを調整する方法がわかりませんでした。私の理解力不足かもしれませんが、デザインを整えようとするとできない(or調べてもわからない)ことが多いので、既存のwebフレームワークとは使い分けをする必要があると思いました。参考文献





- 投稿日:2020-12-07T20:47:14+09:00
Djangoでユニットテストを書く方法
こんにちは Masuyama です。
今回は Django でユニットテストを書く方法をお伝えしたいと思います。
Django の環境構築から丁寧に解説し、Django を使ったことがない人でもユニットテストを書けるようになるはずです。ここでは記事を投稿するようなブログアプリをベースとして、ユニットテストを書く方法をお伝えしていきます。
テスト用 Django アプリの作成
まずは土台となるアプリケーションを作成していきます。
環境構築
作業用のディレクトリを作成します。
ここでの名前はなんでもよいですが、とりあえず blog としておきます。mkdir blog cd blogpipenv のインストール
ベースとなる環境は汚さない方が他のモジュールなどの影響を排除できるため、pipenv を使って仮想環境を構築しましょう。
pip install pipenv # 環境によっては直接 pip を使えない場合もあるので、python3 -m pip install pipenv でインストールしますインストールできたら、作業用フォルダの中で下記のコマンドを実行します。
pipenv shell実行後、仮想環境に入ることが出来るとディレクトリ名に従った文字列がコマンドラインの冒頭に表示されるようになります。
(blog)bash-3.2$Django をインストール
直接 pipenv install django とでも実行して Django をインストールしてもよいですが、
後々 Docker を使うことを考えて、requirements.txt というファイルを作業用ディレクトリ直下に作成して
必要となるモジュールを記述していくことにします。いまは Django だけが必要なので、バージョン情報とともに以下のように記載します。
requirements.txtDjango==3.1.0※今回は Django 3.1.0 で作っていきますが Django 2.2 あたりでも問題なく動くとは思います
モジュールのインストール
下記のコマンドを実行することで、requirements.txt に基づきモジュールをインストールします。
ここでは Django だけがインストールされるはずです。pipenv install -r requirements.txtDjango プロジェクトの作成
blog ディレクトリ直下で実行
django-admin startproject mysite親プロジェクト直下でのファイル構成はこのようになっているかと思います。
├── Pipfile ├── Pipfile.lock ├── mysite │ ├── manage.py │ └── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── requirements.txtDjango サーバのテスト起動
開発用サーバを起動する機能がついています。
(Ruby on Rails をやったことがある人は rails -s というと分かりやすいかと思います)これを実行するには manage.py ファイルが置いてあるディレクトリに移動する方が便利なので、mysite/mysite ディレクトリに移動してから実行します
cd mysite python3 manage.py runserver正常に実行できると下記のような出力が出ます。
December 19, 2020 - 21:30:23 Django version 3.1, using settings 'mysite.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.なお、上記メッセージの前段でこのようなメッセージが表示されますが
この部分は migrate というデータベースへの統合処理が済んでいないために出力されるメッセージですが、いまのところ気にしないで大丈夫です。You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them.さて、これで Django の開発用サーバが起動したのでブラウザから確認します。
Chrome などのブラウザのアドレスバーに127.0.0.1:8000と入力して Enter を押下します。
これがすべての始まりです。この画面が出ていれば、最初のステップは完了しています!おめでとうございます。
プロジェクトの設定
さて、先ほどテストサーバへアクセスした時に英語での表記になっていましたね。
こういった設定は mysite/settings.py で設定することができ、デフォルトでは英語圏に合わせた言語表示、およびタイムゾーンになっています。mysite/settings.py(before)LANGUAGE_CODE = 'en-us' TIME_ZONE = 'UTC'これを次のように変更してあげます。
mysite/settings.py(after)LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'もう一度テストサーバへアクセスすると、日本語表記になっていることが分かるかと思います。
(また、この画面からでは確認できませんがタイムゾーンも東京設定になっています)
Django アプリの作成
先程 start-project コマンドでプロジェクトを作成しましたが、次はアプリケーションを作っていきます。
混乱しがちですが、ベースとなるプロジェクトと個別のアプリは別物です。公式ページではこのような説明です。
プロジェクトとアプリの違いは何でしょうか? アプリとは、ウェブログシステム、公的記録のデータベース、小規模な投票アプリなど、何かを行う Web アプリケーションです。プロジェクトは、特定のウェブサイトの構成とアプリのコレクションです。プロジェクトには複数のアプリを含めることができます。 アプリは複数のプロジェクトに存在できます。
では、blog アプリを作っていきましょう。mysite プロジェクトリ (manage.py ファイルがある場所) の直下で下記コマンドを実行します。
python3 manage.py startapp blog現在のディレクトリ構成はこのようになっています。
. ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── blog ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py └── views.pyblog 配下に様々なファイルが作成されていることが分かるかと思います。
ここで、このアプリが作成されたことをプロジェクトに教えてあげる必要があります。
mysite/setting.py の中に "INSTALLED_APPS" という欄がありますので、その中で blog アプリの存在を教えてあげましょう。
mysite/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'blog.apps.BlogConfig', # ここを追加 ]template, view, url の設定
まずは template を変更していきます。
template は見た目を作るための部分となっています。
mysite プロジェクト直下に templates フォルダ、その下に blogフォルダ、さらにその下に index.html を作成します。
. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates └── blog └── index.html ←ここに作成index.html の中身はとりあえず適当で大丈夫です。
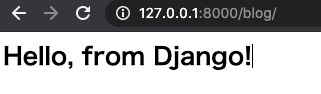
index.html<h1>Hello, from Django!</h1>また、templates フォルダをどこに作ったかをプロジェクトに教えて上げる必要があります。
INSTALLED_APPS を設定したときと同様に、settings.py に下記の記述を入れます。settings.py... import os # 追加 ... TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')], # 修正 'APP_DIRS': True,次に views.py を修正していきます。
先ほど作った template である index.html を呼び出します。blog/views.pyfrom django.views.generic import TemplateView class IndexView(TemplateView): template_name = 'blog/index.html'URL の設計
次に、blog アプリ専用のルーティング設定を作成します。
ルーティング設定は「urls.py」というファイルで設定していきます。まずはじめに説明をしますと、プロジェクト全体のルーティングを司る urls.py と、アプリ内の urls.py それぞれでルーティングを設定します。
最初に mysite 直下の urls.py から編集します。
mysite/urls.pyfrom django.contrib import admin from django.urls import include, path urlpatterns = [ path('blog/', include('blog.urls')), path('admin/', admin.site.urls), ]後に作成する blog アプリ用の urls を、urlpatterns 内で読み込むことになります。
では mysite 直下にのみ urls.py が作成されていますが、blog 直下にも自分で「urls.py」を作成します。
エディタでもよいですし、アプリの blog ディレクトリ内で下記コマンドを実行してもよいでしょう。/blogtouch urls.pyblog 配下はこのようなファイル構成です。
. ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py ├── urls.py └── views.py作成した urls.py の中身はこのように変更することで、先程 views.py で作成した関数(=index.htmlを呼び出す処理)のルーティングを設定します。
blog/urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), ]ちなみに name='index' を設定しておくことで「blog:index」という名前を使ってこの url を逆引きで呼び出すことができるようになります。
この時点で index.html を呼び出せるかの確認を行います。
manage.py が置いてあるディレクトリで runserver を実行します。
python3 manage.py runserver無事に通ったら、今度はブラウザで 127.0.0.1:8000/blog へアクセスします。
これは先程 mysite/urls.py で blog 付きのアドレスでアクセスされたときに、blog アプリ内に記述した内容を動作させるようにしているためです。アクセスし、index.html の中身が表示されれば成功です。
model の準備
実際に記事を登録するための準備をします。
ブログで記事を管理するためには model を作成します。
model はデータベースと Django の橋渡しの役割を持っており、これのおかげで我々は SQL といったデータベース構文を意識することなくデータベースにデータを登録することができます。最初に設定する models.py では、どのようなデータを登録していくのかを定義します。
Excelの表でいうと、表の各カラムのカラム名を定義したり、各カラムに入るデータがどのようなもの(文字列や数値など)を定義するところです。今回はブログアプリであり、記事 (Post) を修正していくので Post モデルを作成します。
タイトル、本文、日付が入ればとりあえず十分です。blog/models.pyfrom django.db import models from django.utils import timezone # django で日付を管理するためのモジュール class Post(models.Model): title = models.CharField('タイトル', max_length=200) text = models.TextField('本文') date = models.DateTimeField('日付', default=timezone.now) def __str__(self): # Post モデルが直接呼び出された時に返す値を定義 return self.title # 記事タイトルを返す次に、データベースに models.py で定義した情報を反映させます。
このままデータベースに対する処理を行うわけではなく、models.py の内容を反映させるためのワンクッションとなるファイルを作成します。
ファイルの作成を自動的に Django にやってもらうことができ、次のコマンドを実行することでファイルが作成されます。python3 manage.py makemigrationsすると /blog/migrations 配下に番号付きのファイルが作成されます。
. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ ├── 0001_initial.py # これが追加される │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ ├── urls.py │ └── views.py ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates └── blog └── index.htmlDjango アプリ作成の中でこのファイルを直接いじることはありませんが、中身はこのようになっており、これのおかげでカラムの作成などを Django が一気にやってくれます。
0001_initial.py# Generated by Django 3.1 on 2020-10-17 01:13 from django.db import migrations, models import django.utils.timezone class Migration(migrations.Migration): initial = True dependencies = [ ] operations = [ migrations.CreateModel( name='Post', fields=[ ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')), ('title', models.CharField(max_length=200, verbose_name='タイトル')), ('text', models.TextField(verbose_name='本文')), ('date', models.DateTimeField(default=django.utils.timezone.now, verbose_name='日付')), ], ), ]さて、この migration ファイルを使ってデータベースにテーブルを作成することになりますが
反映もコマンド一発で Django が勝手にやってくれます。
以下のコマンドを実行しましょう。(blog) bash-3.2$ python3 manage.py migrateview の準備
管理サイトで作成した記事の一覧を表示できるようにしていきます。
template 準備(ファイル作成)
最初に template を作成しましょう。
templates/blog 配下に post_list.html を作成します。└── templates └── blog ├── index.html └── post_list.htmlview ファイルの修正
Django ではクラスベース汎用ビュー という仕組みを使うと、簡単に model を引っ張ってきて記事を表示させたり、
テンプレートを表示させたりすることが出来、アプリ作成をグンと効率的に行うことができるようになります。
ちなみに前々回、views.py をいじったときに generic という表記がありました。
これもクラスベース汎用ビューを使う準備として必要な宣言です。view.pyfrom django.views.generic import TemplateView汎用クラスビューには様々な種類があり、その中でも単純に template を表示させるためだけに使われるのが
index.html の表示に使っていた TemplateView です。
index.html の表示のために、呼び出す template を views.py の中で指定していたことになります。view.pyclass IndexView(TemplateView): template_name = 'blog/index.html'また、これまではわかりやすいように generic で宣言してから使うクラスを指定して import していましたが
generic.xxxView の形で呼び出すこともできるので views.py を少し書き換えてあげましょう。views.py(書き換え後)from django.views import generic class IndexView(generic.TemplateView): template_name = 'blog/index.html'これからたくさんのクラスベース汎用ビューを呼び出すことになるので、最初の宣言をスッキリとさせました。
さて、今回は template を単純に表示させるだけでなく、データベースから記事の情報モデルも呼び出してあげる必要があります。
そのため、別の ListView というクラスベース汎用ビューを使うのですが、使い方は TemplateView のときと似ています。最初に使うモデルを宣言し、クラスを記述し、呼び出すモデルを指定してあげるだけです。
views.py(ListViewを追加)from django.views import generic from .models import Post # Postモデルをimport class IndexView(genetic.TemplateView): template_name = 'blog/index.html' class PostListView(generic.ListView): # generic の ListViewクラスを継承 model = Post # 一覧表示させたいモデルを呼び出しmodel = Post という記述を入れてあげることで、記事一覧が post_list という変数でリスト型として template に渡すことができます。
ここで TemplateView を使ったときのことを思い出して「templateを指定してあげるのでは?」と考えた方は鋭いです。
もちろん指定してもよいのですが、実は generic.ListView では template のファイル名をルールに沿った形にしてあげることで、
明示しなくても呼び出してくれる便利機能があります。
(ただし、明示した方が第三者にとって分かりやすいので、敢えて記述する場合もあるかと思います。)ルールとしては「post_list.html」のように、model名を小文字にしたものと、ListViewならば"list"という文字列をアンダースコアで区切った文字列をファイル名にすることです。
(使うクラスによって異なってくるため、後ほど説明します)これで template である post_list.html を表示させ、同時に template に記事一覧を渡すための view の準備が整いました。
template 側で記事一覧の受け取り
post_list.html に渡されたモデルを受け取るには、Django ならではの記述方法があります。
Django の template では {% %} で囲むことで Python コードを記述でき、さらに html としてブラウザに値を表示させるには {{ }} と、中括弧を重ねたもので記述します。
今回、記事一覧は post_list というリスト型で変数が template で渡されているので for ループで展開し、それぞれの記事タイトルと日付を取り出していきます。
(各カラムのデータは、変数名にドット付きでカラム名を指定する形で取り出せます)post_list.html<h1>記事一覧</h1> <table class="table"> <thead> <tr> <th>タイトル</th> <th>日付</th> </tr> </thead> <tbody> {% for post in post_list %} <tr> <td>{{ post.title }}</td> <td>{{ post.date }}</td> </tr> {% endfor %} </tbody> </table>ルーティング設定
最後に記事一覧を表示させるための URL へアクセスした時に ListView を呼び出すよう、blog/urls.py を編集します。
blog/urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('post_list', views.PostListView.as_view(), name='post_list'), # ここを追加 ]今回のように、何かを表示させるときには View, Template, URL がそれぞれ絡むことを覚えておいてください。
ユニットテスト作成
いよいよ、本記事の本題です。
Django のテストについて
どんどん機能を追加していくのは楽しいですが、普段はテストを書いているでしょうか?
各種チュートリアルなどでDjangoの簡単なアプリを作れるようになった方でも、
少し自分なりにいじった時にエラーを引き起こしてしまう場合があるかと思います。
また、Djangoをrunserver等で起動した際には特にエラーが出力されなくても
実際に画面をブラウザ経由で動かした時にエラーに気づく場合もあるかと思います。いくつかの操作を手動でテストするという方法はもちろんありますが、毎回そういったことを行うのは手間がかかりますよね。
そこで、Djangoの機能を用いてユニットテストを行うことを推奨します。
DjangoではUnitTestクラスを用いてテストを自動化することができるので、
最初にテスト用のコードだけ書いてしまえば後は何度も同じことをする必要はありません。テストの考えることは開発コードを考えるのと同じぐらい重要であり、
テストを作ってからアプリ動作のためのコードを書くという開発手法もあるぐらいです。これを機にテストを行えるようになり、あなたのテスト時間を節約してアプリ本体をより改善することに労力を費やしましょう。
フォルダ構成について
この時点では下記のようなフォルダ構成になっているはずです。
. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ ├── 0001_initial.py │ │ └── __init__.py │ ├── models.py │ ├── tests.py # 注目 │ ├── urls.py │ └── views.py ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates └── blog ├── index.html └── post_list.htmlお気づきになられた方はいるかもしれませんが、blog ディレクトリ配下に tests.py というファイルが自動的に作成されています。
この tests.py の中に直接テストケースを作成していってもよいのですが、
model のテスト、view のテストとテストごとにファイルが分かれていた方が何かと管理しやすいので
test.pyは削除してから下記のように tests ディレクトリを作成し、中にそれぞれ空ファイルを作成しておきましょう。
tests ディレクトリ内のファイルも実行されるように、中身は空の _init_.py ファイルも作成しておくのがポイントです。
※init の前後にアンダーバー2つずつ. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ ├── 0001_initial.py │ │ └── __init__.py │ ├── models.py │ ├── tests # 追加 │ │ ├── __init__.py # 追加 │ │ ├── test_models.py # 追加 │ │ ├── test_urls.py # 追加 │ │ └── test_views.py # 追加 ......なお、モジュールの名前は「test」で始めないと Django が認識してくれないので注意してください。
テストの書き方
Django では Python標準のTestCaseクラス(unittest.TestCase)を拡張した、
Django独自のTestCaseクラス(django.test.TestCase)を使います。
このクラスではアサーションというメソッドを使うことができ、返り値が期待する値であるかどうかをチェックする機能があります。また、前述の通りテストモジュールは「test」という文字列で始まっている必要があるのと、
テストメソッドも「test」という文字列で始める必要があります(詳細は後述します)。このルールを守ることで Django がテストメソッドをプロジェクト内から探し出し、自動で実行してくれるようになります。
test_models.py
それではまずは model のテストから作成していきましょう。
おさらいですが、blog/models.py に記述されている Post model はこのようになっています。models.py... class Post(models.Model): title = models.CharField('タイトル', max_length=200) text = models.TextField('本文') date = models.DateTimeField('日付', default=timezone.now) def __str__(self): # Post モデルが直接呼び出された時に返す値を定義 return self.title # 記事タイトルを返すこの model に対して、今回は次の3ケースでテストしましょう。
1.初期状態では何も登録されていないこと
2.1つレコードを適当に作成すると、レコードが1つだけカウントされること
3.内容を指定してデータを保存し、すぐに取り出した時に保存した時と同じ値が返されることではまずひとつめからです。
test_models.py を開き、必要なモジュールを宣言します。
test_models.pyfrom django.test import TestCase from blog.models import Postそしてテストクラスを作っていくのですが、必ず TestCase を継承したクラスにします。
test_models.pyfrom django.test import TestCase from blog.models import Post class PostModelTests(TestCase):さて、この PostModelTest クラスの中にテストメソッドを書いていきます。
TestCase を継承したクラスの中で「test」で始めることで、
Django がそれはテストメソッドであることを自動で認識してくれます。
そのため、def の後は必ず test で始まるメソッド名を名付けましょう。test_models.pyfrom django.test import TestCase from blog.models import Post class PostModelTests(TestCase): def test_is_empty(self): """初期状態では何も登録されていないことをチェック""" saved_posts = Post.objects.all() self.assertEqual(saved_posts.count(), 0)saved_posts に現時点の Post model を格納し、
assertEqual でカウント数(記事数)が「0」となっていることを確認しています。さて、これで一つテストを行う準備が整いました。
早速これで一回実行していきましょう。テストの実行は、manage.py が置いてあるディレクトリ (mysite内) で下記のコマンドを実行します。
実行すると、命名規則に従ったテストメソッドを Django が探し出し、実行してくれます。(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ..... ---------------------------------------------------------------------- Ran 1 tests in 0.009s OK一つのテストを実行し、エラーなく完了したことを意味しています。
ちなみに、先ほどは Post 内にデータが空 (=0) であることを確認しましたが、データが1つ存在していることを期待するようにしてみます。
test_models.py(一時的)from django.test import TestCase from blog.models import Post class PostModelTests(TestCase): def test_is_empty(self): """初期状態だけど1つはデータが存在しているかどうかをチェック (error が期待される)""" saved_posts = Post.objects.all() self.assertEqual(saved_posts.count(), 1)この時の test 実行結果は下記のようになっています。
(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). F ====================================================================== FAIL: test_is_empty (blog.tests.test_models.PostModelTests) 初期状態だけど1つはデータが存在しているかどうかをチェック (error が期待される) ---------------------------------------------------------------------- Traceback (most recent call last): File "/Users/masuyama/workspace/MyPython/MyDjango/blog/mysite/blog/tests/test_models.py", line 9, in test_is_empty self.assertEqual(saved_posts.count(), 1) AssertionError: 0 != 1 ---------------------------------------------------------------------- Ran 1 test in 0.002s FAILED (failures=1)AssertionError が出ており、期待される結果ではないためにテストは失敗していますね(実験としては成功です)。
Django のテストではデータベースへ一時的なデータの登録も create メソッドから実行できるので、
データを登録しないと確認できないような残りのテストも実行することができます。
下記に model のテストの書き方を載せておくので、参考にしてみてください。test_models.py(全文)from django.test import TestCase from blog.models import Post class PostModelTests(TestCase): def test_is_empty(self): """初期状態では何も登録されていないことをチェック""" saved_posts = Post.objects.all() self.assertEqual(saved_posts.count(), 0) def test_is_count_one(self): """1つレコードを適当に作成すると、レコードが1つだけカウントされることをテスト""" post = Post(title='test_title', text='test_text') post.save() saved_posts = Post.objects.all() self.assertEqual(saved_posts.count(), 1) def test_saving_and_retrieving_post(self): """内容を指定してデータを保存し、すぐに取り出した時に保存した時と同じ値が返されることをテスト""" post = Post() title = 'test_title_to_retrieve' text = 'test_text_to_retrieve' post.title = title post.text = text post.save() saved_posts = Post.objects.all() actual_post = saved_posts[0] self.assertEqual(actual_post.title, title) self.assertEqual(actual_post.text, text)test_urls.py
model 以外にも、urls.py に書いたルーティングがうまくいっているのかどうかを確認することもできます。
おさらいすると blog/urls.py はこのようになっていました。blog/urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('post_list', views.PostListView.as_view(), name='post_list'), ]上記のルーティングでは /blog/ 以下に入力されるアドレスに従ったルーティングを設定しているので、
/blog/ 以下が ''(空欄) と 'post_list' であった時のテストをします。
それぞれのページへ view 経由でリダイレクトされた結果が期待されるものであるかどうかを、assertEqual を用いて比較してチェックします。test_urls.pyfrom django.test import TestCase from django.urls import reverse, resolve from ..views import IndexView, PostListView class TestUrls(TestCase): """index ページへのURLでアクセスする時のリダイレクトをテスト""" def test_post_index_url(self): view = resolve('/blog/') self.assertEqual(view.func.view_class, IndexView) """Post 一覧ページへのリダイレクトをテスト""" def test_post_list_url(self): view = resolve('/blog/post_list') self.assertEqual(view.func.view_class, PostListView)ここまでで一旦テストを実行しておきましょう。
※先ほど、データベースが空である状態のテストをしたときと比べると
データを登録するテストケースが増えているため
テスト用のデータベース作成、消去の処理がメッセージに出力されていることが分かります(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ..... ---------------------------------------------------------------------- Ran 5 tests in 0.007s OK Destroying test database for alias 'default'...test_views.py
最後に view のテストも行いましょう。
views.py はこのようになっていました。
views.pyfrom django.views import generic from .models import Post # Postモデルをimport class IndexView(generic.TemplateView): template_name = 'blog/index.html' class PostListView(generic.ListView): # generic の ListViewクラスを継承 model = Post # 一覧表示させたいモデルを呼び出しIndexView のテストでは、GET メソッドでアクセスした時にステータスコード 200(=成功) が返されることを確認します。
test_views.pyfrom django.test import TestCase from django.urls import reverse from ..models import Post class IndexTests(TestCase): """IndexViewのテストクラス""" def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" response = self.client.get(reverse('blog:index')) self.assertEqual(response.status_code, 200)何か view でメソッドを追加したときは、
どんなにテストを書く時間がなくてもこれだけは最低限テストケースとして作成する癖をつけましょう。ListView の方もテストをしていきます。
同じく 200 のステータスコードが返ってくることの確認はもちろん、
ここではデータ(記事)を2つ追加した後に記事一覧を表示させ、
登録した記事のタイトルがそれぞれが一覧に含まれていることを確認するテストを作成します。なお、ここで少し特殊なメソッドを使います。
テストメソッドは「test」で始めるように前述しましたがsetUpとtearDownというメソッドが存在します。setUpメソッドではテストケース内で使うデータの登録をし、
tearDownメソッドでは setUp メソッド内で登録したデータの削除を行えます。
(どちらも、どんなデータを登録するかは明示的に記述する必要があることには注意しましょう)同じテストケースの中で何回もデータの登録をするような処理を書くのは手間&テストに時間がかかる要因になるので、
共通する処理は一箇所にまとめてしまおうというものです。これらのメソッドを使い、test_views.py を作成するとこのようになります。
test_views.pyfrom django.test import TestCase from django.urls import reverse from ..models import Post class IndexTests(TestCase): """IndexViewのテストクラス""" def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" response = self.client.get(reverse('blog:index')) self.assertEqual(response.status_code, 200) class PostListTests(TestCase): def setUp(self): """ テスト環境の準備用メソッド。名前は必ず「setUp」とすること。 同じテストクラス内で共通で使いたいデータがある場合にここで作成する。 """ post1 = Post.objects.create(title='title1', text='text1') post2 = Post.objects.create(title='title2', text='text2') def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" response = self.client.get(reverse('blog:post_list')) self.assertEqual(response.status_code, 200) def test_get_2posts_by_list(self): """GET でアクセス時に、setUp メソッドで追加した 2件追加が返されることを確認""" response = self.client.get(reverse('blog:post_list')) self.assertEqual(response.status_code, 200) self.assertQuerysetEqual( # Postモデルでは __str__ の結果としてタイトルを返す設定なので、返されるタイトルが投稿通りになっているかを確認 response.context['post_list'], ['<Post: title1>', '<Post: title2>'], ordered = False # 順序は無視するよう指定 ) self.assertContains(response, 'title1') # html 内に post1 の title が含まれていることを確認 self.assertContains(response, 'title2') # html 内に post2 の title が含まれていることを確認 def tearDown(self): """ setUp で追加したデータを消す、掃除用メソッド。 create とはなっているがメソッド名を「tearDown」とすることで setUp と逆の処理を行ってくれる=消してくれる。 """ post1 = Post.objects.create(title='title1', text='text1') post2 = Post.objects.create(title='title2', text='text2')この状態でテストを実行すると model, url, view で合計 8 つのテストが実行されます。
(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ........ ---------------------------------------------------------------------- Ran 8 tests in 0.183s OK Destroying test database for alias 'default'...これで、これまで書いたコードについてユニットテストを作成することができました。
他にも期待される template が呼び出されているかどうか等、
Django 独自のテスト方法を用いたテストで冗長的にチェックする方法もありますが
いまは使いまわしでもよいので処理を増やす時にテストを作成する癖をつけ、後々のチェックの手間を省くようにしていきましょう。

- 投稿日:2020-12-07T20:00:43+09:00
[Python]多角形の座標で内側か外側か判定
地図上の緯度経度で特定の設定領域内か、外か判定
メモ。
結果的には便利なライブラリを使ったほうが早かった
四角形、五角形などで地図上に座標でプロットしてその内側なら特定の処理をしたいという状況になったのでメモ。車輪の再発明はしない。地理空間データ分析ライブラリを使う。
$ pip install turfpypointに現在点。
polygonは多角形という意味。点を指定。領域内なら、boolean_point_in_polygonで、名前の通り、TureかFalseを返してくれる。便利。
from turfpy.measurement import boolean_point_in_polygon from geojson import Point, Polygon, Feature point = Feature(geometry=Point((0.5, 1.1))) polygon = Polygon( [ [ (0.0, 0.0), (1.0, 2.0), (3.0, 2.0), (2.0, 0.0) ] ] ) if boolean_point_in_polygon(point, polygon): print('領域内') else: print('領域外')領域外あとは、緯度経度で指定すればOK
- 投稿日:2020-12-07T19:54:55+09:00
【アンケート分析】天井効果、床効果をpythonで判定する
アンケートの分析時に出てくる、天井効果、床効果を判定する関数を作成する。
【天井効果、床効果とは?】
アンケートの分析項目において、ある項目の回答があまりにも偏っている場合はその質問項目は妥当ではないと判断される。
高いほうに偏っている場合(1~5までの5件法なら、5ばっかりな状態)ならば、「天井効果がある」という。
反対に、低いほうに偏っている状態の場合は「床効果がある」という。
【天井効果、床効果の判定】
天井効果と床効果は、その項目の平均値、標準偏差を使って判定する。
天井効果:平均値 + 標準偏差 > 最大値(5件法であれば5)ならば天井効果あり
http://www.ipc.hokusei.ac.jp/~z00105/wiki_res/wiki.cgi?%c5%b7%b0%e6%b8%fa%b2%cc床効果 :平均値 - 標準偏差 > 最小値(基本的には1)ならば床効果あり
http://www.ipc.hokusei.ac.jp/~z00105/wiki_res/wiki.cgi?%be%b2%b8%fa%b2%cc【天井効果、床効果を判定する関数】
qiita.rbdef tenjo_yuka(df): for col in df.columns: tenjo = df[col].mean() + df[col].std() yuka = df[col].mean() - df[col].std() print('-'*50) print(str(col)) if tenjo > df[col].max(): print('天井効果 あり') else: print('天井効果 なし') if yuka < df[col].min(): print('床効果 あり') else: print('床効果 なし')この関数にアンケート項目を突っ込めば天井効果、床効果の有無を判定できる
- 投稿日:2020-12-07T19:52:12+09:00
LDAの生成過程(トピックモデル)
この記事は古川研究室 Advent Calendar 7日目の記事です。
本記事は古川研究室の学生が学習の一環として書いたものです。内容が曖昧であったり表現が多少異なったりする場合があります。はじめに
トピックモデルを勉強すると必ずLDAという手法を見かけると思います。しかし、実際にLDAを勉強するとこれが意外と難しくて、LDAはいったい何をやっているのだろう???と多くの疑問が出てきて理解するのになかなか苦労します(※私は結構苦労しました汗)。そこで本記事ではLDAを初めて勉強する方の手助けになればと思い、LDAの生成過程に注目して記事を書きました。
Latent Dirichlet Allocation : LDA
潜在ディリクレ配分法(Latent Dirichlet Allocation : LDA)はトピックモデルの代表的な手法です。下図はLDAのグラフィカルモデルで、本記事ではこのグラフィカルモデルを詳しく説明していきます。
$D:文書数$
$N:単語数$
$K:トピック数$
$\alpha,\beta:ディリクレ分布のパラメーター$
$\theta_d:各文書のトピック分布$
$z_{d,n}:単語の潜在トピック$
$w_{d,n}:$ Bag of Words
$\psi_k:各トピックの単語分布$LDAの生成過程
ディリクレ分布
まずはLDA(潜在的ディリクレ配分法)の名前の元にもなっているディリクレ分布について説明します。下図はディリクレ分布から1000点サンプリングした結果であり、左図はハイパーパラメータである$\alpha$を$\alpha_i=(0.1,0.1,0.1)$とした場合であり、右は$\alpha_i=(5,5,5)$とした場合です。三角形の頂点であるa,b,cが事象を表しており、それらの事象がどのくらいの確率で発生するのかを表しています。例えば左の図では事象aに近い点の確率を表示しています(a=0.75,b=0.07,c=0.17)。LDAではこの a,b,c がトピックや単語に相当し、a,b,cをトピックとすると文書のトピックはこれらのトピックが均等に含んでいる(a=0.33,b=0.33,c=0.33)のではなく左図のように偏っていると見なします。また、LDAでは
LDAではディリクレ分布以外に多項分布も用います、以下に多項分布とディリクレ分布のinput,outputを図示しています。単語を例にすると多項分布では単語の総回数と単語の確率をinputとし、総回数の内それぞれの単語が何回でたかをoutputします。一方、ディリクレ分布では回数をinputとし、単語の確率をoutputします。
このディリクレ分布ですが各文書のトピック分布$\theta_d$と各トピックの単語分布$\psi_k$の生成に用います。そして多項分布は下図の位置で用います。LDAではまずこの2つのディリクレ分布のハイパーパラメータである$\alpha,\beta$を設定します。
以下ディリクレ分布のプログラムです、plotlyで実装しています。import plotly.express as px import numpy as np r= np.random.dirichlet([5,5,5], size=1000) r=r+0.02 fig = px.scatter_ternary(r,a=r[:,0],b=r[:,1],c=r[:,2],template="simple_white") fig.update_traces(marker=dict(size=8.5,line=dict(width=0.5),color="salmon")) fig.update_layout({ 'title': 'dirichlet', 'ternary': { 'sum':1, 'aaxis':{'title': 'a', 'min': 0.01, 'linewidth':1, 'ticks':'outside' }, 'baxis':{'title': 'b', 'min': 0.01, 'linewidth':1, 'ticks':'outside' }, 'caxis':{'title': 'c', 'min': 0.01, 'linewidth':1, 'ticks':'outside' } }, }) fig.show()各文書のトピック分布
ここから生成過程を説明します。まずはグラフィカルモデルの左側から説明します。各文書のトピック分布(一つの文書のトピック割合)はディリクレ分布から得られたと仮定しています。例えば下図の文書1はディリクレ分布のスポーツトピックに近いことから、スポーツトピックの確率が一番高くなります。一方、文書3は経済トピックに近いことから経済トピック(緑色の棒グラフ)の確率が大きくなります。このように文書ごとのトピック分布を作ります。
単語の潜在トピック
次に先ほど求めた各文書のトピック分布から単語の潜在トピックを多項分布により求めます。ここでは単語1つにトピックを1つ割り当てます。多功分布はトピックの確率と単語の総回数を入力としトピックの回数を出力します。例えば、下図の文書1ではスポーツトピックの確率が高いのでN=9とすると4つの単語にスポーツトピックが割り振られてます。次に確率が高い経済トピックは3つの単語に割り振られ、残り2単語に政治トピックが割り当てられます。
各トピックの単語分布
次にグラフィカルモデルの右側を説明します。各文書のトピック分布と同様に、各トピックの単語分布もディリクレ分布から生成されます。下図より(簡易にするため単語が3つの場合で考えます)例えばスポーツトピックに含まれる単語の確率はディリクレ分布より「野球」の確率が一番高いです。また、経済トピックではGDPと知事の確率が高くなっています。
bag of wordsの生成
最後にグラフィカルモデル中央の$w_{dn}$です。グラフィカルモデル左側で求めた単語の潜在トピックとグラフィカルモデル右側で求めた各トピックの単語分布を用いてbag of wordsを生成します。この部分は多項分布なので、確率と総回数を入力とし、回数を出力します。下図の例だと一つの文書の単語に割り振られている潜在トピックを一つ選択し、選択したトピックの単語分布から確率の高い単語が選ばれる流れになります。(スポーツトピックは4つの単語に割り振られているので、スポーツトピックの単語分布から4回単語を選択します。野球の確率が高いので今回はたまたま4回とも野球が選ばれたと仮定しています。)LDAではこのような過程を踏むことでbag of wordsが生成されているとしています。
LDAの数式
最後にLDAの数式を説明します。
LDAの数式は以下のようになっていて一見難しそうですが、部分ごとに見ていくと理解しやすいです。
$d:文書$
$n:単語$
$k:トピック$
$\alpha,\beta:ディリクレ分布のパラメーター$
$\theta_d:各文書のトピック分布$
$z_{d,n}:単語の潜在トピック$
$w_{d,n}:$ Bag of Words
$\psi_k:各トピックの単語分布$
下図は数式がグラフィカルモデルのどの部分についてなのかを図示したものです。数式それぞれの部分が各文書のトピック分布(確率)、各トピックの単語分布(確率)、単語の潜在トピック(確率)、観測データ(確率)に相当しています。ちなみに各文書のトピック分布、各トピックの単語分布がLDAのoutputになります。
参考文献
LDAの説明がとても分かりやすい動画です!
https://m.youtube.com/watch?v=T05t-SqKArYLDAの記事
https://bookdown.org/Maxine/tidy-text-mining/latent-dirichlet-allocation.htmlLDAのwikiです。
https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation











- 投稿日:2020-12-07T18:48:01+09:00
[レガシーとの闘い] SVNのsyncをpythonで半自動化してみた
はじめに
この記事の目的は私が
押し付けられた担当していた
「なんでこんな作業せなあかんねん…」的なレガシーな作業から逃れるために、
どうせなら流行りのpythonでツールを作ろうとして手探りで作成したツールをご紹介します。
明日使えるかどうかわからないムダ知識を探している方にお勧めです。(自己紹介)
2016年新卒入社の5年目社員です。
レガシーと戦う雑用係です。背景
まずこのツールの対象となるタスクについてですが、一言でいうと
「本番環境のSVNリポジトリをテスト環境のSVNリポジトリにsyncさせる」
といったようなタスクになります。SVNってなに?
SVN(Subversion)とはいわゆるバージョン管理システムの1つで、分散型のGitとは異なり、
集中型(クライアント・サーバ型)のバージョン管理システムになります。
SVNとGitの違いなどは他に詳しくまとめているページがあるので詳細は省きますが、
近年ではSVNよりもGitの方が圧倒的に主流のようで、SVNはレガシーなツールになっているようです。今回の場合は本番環境とテスト環境の2つを使用して、開発と進捗管理を行っていました。
この際リポジトリとしては2つですが、基本的に開発者がソースをコミットするのは本番環境のみで、
テスト環境の方にはsvnsyncを利用して本番環境へのコミット内容を反映させていました。ただこのsvnsyncも万能ではなく、sync時に対象ファイルに差分がある場合に失敗することが多々ありました。
従来の対応方法
このsvnsyncに失敗した場合にエラーを解消させることが課せられた使命だったのですが、
その方法が下記の通りになります。
- テスト環境のリポジトリに接続してログを表示し最新のリビジョン番号を確認
- 本番環境のリポジトリに接続してログを表示
- 1で確認したリビジョン番号+1のコミット内容を確認
- 同じコミット内容になるようにテスト環境のファイルを修正
これだけでももうめんどくさいのですが、開発過渡期にはこの対応が1日に何度も発生することになり、
なんとかこれを自動化できないだろうかと考えました。対応内容
自動化に取り掛かるにあたってまずは作業内容を大きく2つの手順に切り分け、それぞれの手順をスクリプト化しました。
- 対象ファイルの抽出
- 対象ファイルの反映
これ以外にも対応内容に従った別処理の作成とコミット完了までを通しで行うスクリプトも作成しましたが、ここでは省きます。
対象ファイルの抽出
実際のスクリプトが下記になります。
sync_target.pyimport os import subprocess # テストのリビジョン取得 os.chdir('C:\\Users\\svn\\svn_sync\\latest_test') # cmd = 'svn update' returncode = subprocess.call("svn update") cmd = 'svnversion' returncode = subprocess.Popen("svnversion", stdout=subprocess.PIPE) out = str(returncode.stdout.read().decode('cp932')) print(out) stIdx = out.find("'") + 1 edIdx = out.find("P") rev = int(out[stIdx:edIdx]) print("rev=" + str(rev)) # 更新されたファイルパス取得 os.chdir('C:\\Users\\svn\\svn_sync\\latest_main') cmd = 'svn update' returncode = subprocess.call(cmd) cmd = 'svn diff --summarize -r' + ' r' + str(rev) + ':r' + str(rev +1) print(cmd) getlst = subprocess.Popen(cmd, stdout=subprocess.PIPE) pathlst = getlst.stdout.read().decode('cp932') with open('C:\\Users\\svn\\svn_sync\\bat\\sync_path.txt', mode='w') as f: f.writelines(pathlst) # パスのリスト成形 cmd = '"C:\\Program Files (x86)\\Hidemaru\\Hidemaru.exe" /x "C:\\Users\\works\\AppData\\Roaming\\Hidemaruo\\Hidemaru\\Macro\\replace.mac" "C:\\Users\\svn\\svn_sync\\bat\\sync_path.txt"' print("cmd" + cmd) editfile = subprocess.call(cmd)ごちゃごちゃとやっているのですが、ここでやっているのは最初の手順をほぼそのまま自動でやらせたというものに近いです。
エラーとなるリビジョン取得
↓
更新されたパスをテキストに書き出し
↓
更新対象のパスを整形
最後に至ってはパスの成形のためにマクロを使っています。このスクリプト部分で躓きやすいのがパスの書き方と文字コードになっており、
これはpythonあるあるかとも思いますが、パスの区切りやファイル書き込み時の文字コード指定などが厳しいので、慣れるまでは結構迷いました。対象ファイルの反映
前述した対象ファイルの抽出を実施した後に、実際にその変更部分をチェックアウトしたリポジトリに反映させます。
sync_main.pyimport re import os import subprocess import logging import shutil import glob as gb import sync_target # 対象ファイル抽出 target:sync_target envpath = "set path=%PATH%;C:\\Users\\svn\\svn_sync\\svn_cmd_tool\\Apache-Subversion-1.9.5\\bin" os.system(envpath) # 一時チェックアウト用フォルダ指定 os.chdir('../') cd = os.getcwd() print(cd) MAIN_PATH = cd + "\\main" TEST_PATH = cd + "\\test" num = 1 os.chdir(cd + '\\bat') print(num) print(MAIN_PATH) print(TEST_PATH) # フォルダ削除&作成 os.makedirs(MAIN_PATH) os.makedirs(TEST_PATH) svn_info = "svn info http://testenv/svn/test --show-item revision" REVISION = os.system(svn_info) REVISION = REVISION + 1 print(REVISION) file = open('sync_path.txt', 'r') for fpath in file: path = fpath.rsplit('/',1)[0] name = fpath.rsplit('/',1)[1] print('path:' + path) print('name:' + name) SUB_MAIN_PATH = MAIN_PATH + '\\' + str(num) SUB_TEST_PATH = TEST_PATH + '\\' + str(num) FIN_MAIN_PATH = SUB_MAIN_PATH + '\\' + name FIN_TEST_PATH = SUB_TEST_PATH + '\\' + name os.makedirs(SUB_MAIN_PATH) os.makedirs(SUB_TEST_PATH) os.chdir(SUB_TEST_PATH) MARGE_TEST_PATH = 'http://testenv/svn/test' + path print('MERGE : ' + MARGE_TEST_PATH) print('SUB : ' + SUB_TEST_PATH) print('FIN : ' + FIN_TEST_PATH) os.system('svn co --depth=empty ' + MARGE_TEST_PATH + ' ' + SUB_TEST_PATH) os.system('svn up --set-depth=empty ' + SUB_TEST_PATH) os.system('svn up --set-depth=infinity ' + FIN_TEST_PATH) os.chdir(SUB_MAIN_PATH) MARGE_MAIN_PATH = 'http://mainenv' + path print(MARGE_MAIN_PATH) # os.system('pause') os.system('svn co --depth=empty ' + MARGE_MAIN_PATH + ' ' + SUB_MAIN_PATH) os.system('svn up --set-depth=empty ' + SUB_MAIN_PATH) os.system('svn up --set-depth=infinity ' + FIN_MAIN_PATH) num = num + 1 file.close # sync_copy sec = 1 os.chdir('C:\\Users\\svn\\svn_sync\\bat') cnt = len(open('sync_path.txt').readlines()) for i in range(cnt): files = gb.glob('C:\\Users\\svn\\svn_sync\\main\\' + str(sec) + '\\*.*') for j in range(len(files)): file = os.path.basename(files[j]) mPath = str("C:/Users/svn/svn_sync/main/" + str(sec) + "/" + file) tPath = str("C:/Users/svn/svn_sync/test/" + str(sec) + "/" + file) shutil.copyfile(mPath, tPath) sec = sec + 1最初にsync_targetを呼び出すことで更新対象のパスのリストを作成し、
コミットのファイル単位でフォルダを1つ作成し、空のままチェックアウトします。
その後フォルダ毎にアップデートをかけていくことで更新対象のパスを用意しています。これを本番とテストでそれぞれ実施し、最後はファイルの上書きという力技で対応しています。
おわりに
このタスクを通じて得た学びとしては下記2点
- pythonってすごい
- 身近なタスクをコードに起こすことから開発って始められる
歴史の長い製品ではどうしてもレガシーとの闘いになることがありますが、
それを改善していくのも楽しみの一つになると思いますので、それこそWork Funの精神を忘れずに取り組んでみるといいのではないかと思います。
- 投稿日:2020-12-07T18:46:05+09:00
Serverless/FlaskでSwagger付きサーバレスAPIを作る
はじめに
この記事は 2020 年の RevComm アドベントカレンダー 23 日目の記事です。
日目は @mpayu2 さんの「 【入門・React・TypeScript・Enzyme】Create React AppからEnzyme導入まで 」でした。こんにちは。株式会社RevCommで社内向けシステム開発・運用を担当している @zoetaka38 です。
みなさん、サーバレスシステムでサービスを開発されることはありますか?
私は今社内システムを担当しているのですが、社内システムは様々な機能が求められますが、一方で低コストで、高可用なシステムを求められることが多いです。そして、24時間ずっと使われるわけでもないことも多々あります。
そういった背景から、社内関係のシステムをサーバレスで作成しちゃうことが多いです。しかし、サーバレスでAPIを作成していくと、DBとの接続にコネクションプール気をつけないといけないとか、ドキュメントたくさん作らないといけなくてめんどくさいとか、色々問題が出てきます。
そこで、Serverless Frameworkと、Flaskを使って、サーバレスで、DBコネクションプールを気にしないですみ、かつドキュメントも勝手にできてくれるようなフレームワークを紹介したいと思います。
前提
以下のクラウド環境やモジュールバージョンで動作することは確認済みです。
- 開発環境はおそらくなんでも大丈夫ですが、macOS Big Sur と Ubuntu 20.04 desktopで動くことは確認しました
- Serverless Framework 2.11.1
- Python3.8
- インフラはAWSを使うことを前提としています。
やってみる
それでは、早速作っていきます。
環境の構築
pipenv派なので、pipenvで環境作っていきます。
$ pip install pipenv $ pipenv --python 3.8 $ pipenv install flaskローカルで開発するときは、Dockerでやりたいので、Dockerfileとdocker-compose.ymlを用意しておきましょう。
Dockerfileは、Pythonが実行できて、Pipfileからパッケージインストールされるようなものを使ってます。DockerfileFROM python:3.8.0 # set working directory RUN mkdir -p /usr/src/app WORKDIR /usr/src/app # install environment dependencies RUN apt-get update -yqq \ && apt-get install -yqq --no-install-recommends \ openssl \ && apt-get -q clean # add requirements (to leverage Docker cache) COPY Pipfile ./ COPY Pipfile.lock ./ # install requirements RUN pip install -U --no-cache-dir pipenv RUN pipenv install COPY ./api/ /usr/src/app CMD pipenv run python -B -u app.py run -h 0.0.0.0内部で開発するときにAWSのクレデンシャルが共有されるようにすることと、環境変数を
./envsフォルダ以下の.env.{環境名}ファイルから読み込むようにしていることが、工夫点です。docker-compose.ymlversion: '3.4' services: restapi: build: . volumes: - './:/usr/src/app' - $HOME/.aws/credentials:/root/.aws/credentials:ro - $HOME/.aws/config:/root/.aws/config:ro ports: - "5000:5000" env_file: - ./envs/.env.${STAGE} environment: - FLASK_DEBUG=1 - TZ=Asia/Tokyo - LC_CTYPE=C.UTF-8 - PYTHONDONTWRITEBYTECODE=1 command: pipenv run python -B -u /usr/src/app/api/app.py run -h 0.0.0.0次に、Flaskの開発ファイルと、環境変数ファイルを作成します。
# 環境変数ファイルを作成 $ mkdir ./envs $ touch ./envs/.env.dev # Flask用のファイルを作成 $ mkdir ./api $ touch ./api/app.pyここまでで、以下のようなフォルダ構造になっていると思います。
$ tree . -a . ├── Dockerfile ├── Pipfile ├── Pipfile.lock ├── api │ └── app.py ├── docker-compose.yml └── envs └── .env.devFlaskでREST APIを開発することができて、Swaggerのドキュメントを自動生成してくれるツールとして、今回はFlask-RESTXを使うことにしました。
ですので、これをインストールしておきます。
また、Flask-CORSも、CORS対策が必要なAPIとして、入れておきます。$ pipenv install flask-restx $ pipenv install flask_cors一度ここまでで、Flaskを実行してみます。
以下のように、./api/app.pyを編集します。./api/app.pyimport os from flask import Flask, make_response, jsonify from flask_cors import CORS from flask_restx import Api, Resource app = Flask(__name__) api = Api(app) CORS(app, resources={r'/*': {'origins': '*'}}) ns = api.namespace("api/v1", description="Flask Test") @ns.route('/hello') class Hello(Resource): def get(self): resp = { 'status': 'ok', 'response': "hello" } return make_response(jsonify(resp)) if __name__ == "__main__": app.run(host='0.0.0.0', debug=True)そして、Docker Composeで、コンテナを立ち上げます。
# 頭のSTAGE変数で、環境変数ファイルを切り替えます。 STAGE=dev docker-compose upそうすると、 http://localhost:5000/ にアクセスしてSwaggerドキュメントが自動生成されているのが確認できると思います。
あとは、Serverless Flameworkを導入して、APIを開発していけば良さそうです。
セキュリティ面を考えたときの壁
セキュリティ面を考えると、APIに対してはAPIキーにて、認証をかけることができるとはいえ、Swaggerドキュメントにも認証をかけたいです。
よく使われるのが、Basic認証であり、調べるとAPI Gatewayに認証をかける記事がいくつか見つかります。
これは、外部のLambdaをAPI呼び出しのときに実行するという方法ですが、本体のAPIとしては、APIキーでの認証が基本となるのでBasic認証は不要です。呼び出されたLambda側でAPIキーがある場合は無視するということも考えられますが、不要な呼び出しは実行したくありません。そうなると、ドメインか、API Gatewayで本体のAPIとSwaggerドキュメントを分けてあげる必要があります。ドメインは分けたくないので、API Gatewayレベルで分けてあげるのが良さそうです。
API Gatewayレベルで切り分けるには、Serverless Frameworkのファイルを2つ作成して、API Gatewayのベースパスマッピングを分けてあげるといけそうです。※参考
しかし、ここで1つの問題に直面しました。
なんと、Flask-RESTXには、Swaggerドキュメントを吐き出すパスを修正することができないのです!
ここで、絶対パスで指定されており、 http://localhost:5000/swagger.json となっているのを、http://localhost:5000/swaggerui/swagger.json と変更することができません。
こうなると、API Gatewayでベースパスマッピングを変えても、Swaggerドキュメントの表示ができません。。。そこで、無理やり変えてしまえばいいんじゃないか、ということで、上書きしちゃうことにしました。同じような話は、ここでもずっと議論されているみたいです。
放置されているようですし、修正の期待もなかなかできないので、なおさら無理やり変えるしかなさそうです。以下のようにFlaskのファイルを書き換えてあげると、 http://localhost:5000/swaggerui/apidocs/ からSwaggerファイルが出力されるようになります。
./api/app.pyimport os from flask import Flask, make_response, jsonify from flask_cors import CORS from flask_restx import Api, Resource from flask_restx.api import SwaggerView from flask_restx.apidoc import url_for class Custom_API(Api): def _register_specs(self, app_or_blueprint): if self._add_specs: endpoint = str("specs") self._register_view(app_or_blueprint,SwaggerView, self.default_namespace,"/swaggerui/swagger.json", endpoint=endpoint,resource_class_args=(self,), ) self.endpoints.add(endpoint) app = Flask(__name__) api = Custom_API(app, doc='/swaggerui/apidocs/', ) app.config.from_object(__name__) CORS(app, resources={r'/*': {'origins': '*'}}) ns = api.namespace("api/v1", description="Flask Test") @ns.route('/hello') class Hello(Resource): def get(self): resp = { 'status': 'ok', 'response': "hello" } return make_response(jsonify(resp)) if __name__ == "__main__": app.run(host='0.0.0.0', debug=True)Basic認証用のLambdaを用意しておく
Serverless Flameworkに進む前に、Basic認証用のLambdaを準備しておきます。Swaggerドキュメント用のAPI Gatewayからは、このLambdaを呼び出して、Basic認証をかけます。
これは、普通にAWSのコンソールからLambdaを作成して、直接コードを編集しちゃっていいと思います。serverless-basic-authorizerimport json import base64 accounts = [ # dict形式のリストで複数のUser,Passwordを設定できます。 { "user": "basic-user", "pass": "basic-path" } ] def lambda_handler(event, context): print(event) authorization_header = event['headers']['authorization'] if check_authorization_header(authorization_header): return { 'principalId': 'user', 'policyDocument': { 'Version': '2012-10-17', 'Statement': [ { 'Action': 'execute-api:Invoke', 'Effect': 'Allow', 'Resource': event['methodArn'] } ] } } else: raise ValueError('Unauthorized') def check_authorization_header(authorization_header: str) -> bool: if not authorization_header: return False for account in accounts: encoded_value = base64.b64encode(f"{account['user']}:{account['pass']}").encode('utf-8')) check_value = "Basic {}".format(encoded_value.decode(encoding='utf-8')) if authorization_header == check_value: return True return FalseServerless Frameworkの導入
ここまでできたら、API本体をデプロイするための
serverless.ymlと、Swaggerドキュメントをデプロイするようのserverless-swagger.ymlを作成して、実際にデプロイしてみるのみです。本体API用のymlです。FlaskをAPI Gateway+Lambdaで提供するための、
serverless-python-requirements、serverless-wsgiが入ってます。
また、serverless-domain-managerはドメインをServerless Frameworkで準備するために、serverless-add-api-keyはAPIキー認証を入れるためです。
serverless-dotenv-pluginは、Dockerで開発するときにも使っていた、環境変数ファイルをAWS上でも反映するために使っています。APIのエンドポイントを増やしたら、
functions > application > events配下のエンドポイントを増やします。関数そのものを分けたい場合は、functions配下のapplicationの部分から別名で分けて作成します。serverless.ymlservice: flask-serverless-api-template plugins: - serverless-python-requirements - serverless-wsgi - serverless-domain-manager - serverless-add-api-key - serverless-dotenv-plugin custom: stage: ${opt:stage, self:provider.stage} domains: dev: flask-serverless-api.test.com prod: flask-serverless-api.test.com pythonRequirements: dockerizePip: non-linux apiKeys: dev: - name: FlaskServerlessApiKey value: hogehoge prod: - name: FlaskServerlessApiKey value: fugafuga wsgi: app: api.app.app packRequirements: false customDomain: domainName: ${self:custom.domains.${self:custom.stage}} certificateName: ${self:custom.domains.${self:custom.stage}} basePath: "api" endpointType: regional stage: ${self:provider.stage} createRoute53Record: true dotenv: basePath: envs/ provider: name: aws runtime: python3.8 region: ap-northeast-1 stage: ${opt:stage, 'dev'} timeout: 60 package: exclude: - .vscode/** - envs/** - node_modules/** - notebooks/** - Dockerfile - docker-compose.yml - terraform/** functions: application: handler: wsgi_handler.handler events: - http: path: /v1/hello method: get cors: true次に、Swaggerドキュメント用のものも作成します。これはエンドポイント増やしても、中身を変える必要はありません。apidocsの認証部分に、先程作成したBasic認証用のLambdaを指定して、Basic認証を実現します。
serverless-swagger.ymlservice: flask-serverless-api-template-swagger plugins: - serverless-python-requirements - serverless-wsgi - serverless-domain-manager - serverless-dotenv-plugin custom: pythonRequirements: dockerizePip: non-linux wsgi: app: api.app.app packRequirements: false customDomain: domainName: "flask-serverless-api.test.com" certificateName: "flask-serverless-api.test.com" basePath: "swaggerui" endpointType: "regional" stage: ${self:provider.stage} createRoute53Record: false dotenv: basePath: envs/ provider: name: aws runtime: python3.8 region: ap-northeast-1 package: exclude: - .vscode/** - envs/** - node_modules/** - notebooks/** - Dockerfile - docker-compose.yml - terraform/** functions: openapidoc: handler: wsgi_handler.handler events: - http: path: /apidocs method: get authorizer: name: basic-authentication arn: arn:aws:lambda:ap-northeast-1:000000000000:function:serverless-basic-authorizer type: request - http: path: /swagger.json method: get resources: Resources: GatewayResponse: Type: 'AWS::ApiGateway::GatewayResponse' Properties: ResponseParameters: gatewayresponse.header.WWW-Authenticate: "'Basic realm=\"Enter username and password.\"'" ResponseType: UNAUTHORIZED RestApiId: Ref: 'ApiGatewayRestApi' StatusCode: '401'最終的なファイルやフォルダの構成は以下です。
sh
$ tree . -a
.
├── Dockerfile
├── Pipfile
├── Pipfile.lock
├── api
│ └── app.py
├── docker-compose.yml
├── serverless.yml
├── serverless-swagger.yml
└── envs
└── .env.dev
ここまでできたら、Serverless Frameworkの各コマンドを実行して、ドメインの作成〜Flaskのデプロイを実施します!
$ sls create_domain --stage dev --aws-profile flask-serverless $ sls deploy --config serverless.yml --stage dev --aws-profile flask-serverless $ sls deploy --config serverless-swagger.yml --stage dev --aws-profile flask-serverlessこれで、自身のカスタムドメイン配下で、APIの実行と、Swaggerドキュメントの確認ができればOKです!
- API本体 -> https://xxxx.xxxx.xxxx/api/vi/
- Swagger -> https://xxxx.xxxx.xxxx/swaggerui/apidocs
最後に
いかがでしたでしょうか?APIドキュメントをマニュアルで作成するのは非常に手間なので、自動でドキュメント生成ができると嬉しいなということで、以上のようなものを考えました。
DB周りはここには書いてませんが、PartiQLでDynamoDBを使ったり、RDS Proxyなどを使うと、Serverless Flameworkでも、安心してDB接続ができるAPI開発ができると思いますので、是非チャレンジしてみてください。
明日は @qii-purine さんの記事「 python でのアーキテクチャを考える 」です。お楽しみに!


- 投稿日:2020-12-07T18:33:56+09:00
プログラミング素人がAutoware.AIを使ったコンテストに参加した話(その3:Autoware.AIとLGSVLシミュレータを使ってみる)
まずはじめに
Autowareの機能はマップから読み取った自己位置から速度や向きを計算しているため自己位置推定ができないとなにもできません。
今回はAutowareとLGSVLシミュレータを使って自己位置推定をして自動走行するまでの過程をご紹介します。
ここではLGSVLのチュートリアルがバージョン1.14.0で構成されているため、それに合わせて1.14.0を使用します。Autowareの様々なバージョン使ってるとパラメータとか混乱してくるので
roswtf [launchファイル名]を使ってパラメータやパッケージ名を確認するといいです。・その1:Autoware.AIの環境設定
・その2:ROSの情報まとめ
・その3:Autoware.AIとLGSVLシミュレータを使ってみる←いまここ
項番 ページ内リンク 1 1. 環境設定 2 2. LGSVLシミュレータの設定 3 AutowareとLGSVLシミュレータを接続する 4 Autowareの自己位置推定 5 参考リンク 1. 必要なソフトのインストール
Git Large File Storage (LFS)のインストール
git_lfsのインストールsudo apt-get update curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash sudo apt-get install git-lfs git lfs install2. LGSVLシミュレータの設定
LGSVLのバイナリダウンロード
LGSVL Downloadから最新のバイナリをダウンロードします。
いろいろなMAPを試したい場合は最新版を使用するようにしてください。
なおシミュレータを使用するのにユーザー登録が必要です。
もし起動できない場合は実行属性がないかもしれないので[プロパティ]から[プログラムから実行可能]にチェックが入っているか確認してみてください。
下記のコマンドでも可能です。
実行属性の付与chmod a+x simulatorMapダウンロード
add newをクリックしたあとMap Nameに「Borregas Avenue」、Map URLにurlを入力します。
Borregas_AvenueのURLhttps://content.lgsvlsimulator.com/maps/borregasave/ほかのMapデータはこちらLGSVL Mapsにあります。
vehicleダウンロード
add newをクリックしたあとVehicle NameにAWF Lexus RX 2016、Vehicle URLにurlを入力します。
AWF_Lexus_RX_2016のURLhttps://content.lgsvlsimulator.com/vehicles/awflexusrx2016/ほかの車両データを使用したい場合ははこちらLGSVL Vehiclesにあります。
vehicleセンサの設定
Bridge TypeにROSを選択、サンプルにあるjsonの中身をSensorsに貼り付けます。
Complete_JSON_Configuration[ { "type": "Transform", "name": "base_link", "transform": { "x": -0.015, "y": 0.369, "z": -1.37, "pitch": 0, "yaw": 0, "roll": 0 } }, { "type": "CAN-Bus", "name": "CAN Bus", "params": { "Frequency": 10, "Topic": "/lgsvl/state_report" }, "transform": { "x": 0, "y": 0, "z": 0, "pitch": 0, "yaw": 0, "roll": 0 } }, { "type": "GPS Device", "name": "GPS", "params": { "Frequency": 12.5, "Topic": "/gnss/fix", "Frame": "gnss", "IgnoreMapOrigin": true }, "parent": "base_link", "transform": { "x": 0, "y": 0, "z": 0, "pitch": 0, "yaw": 0, "roll": 0 } }, { "type": "GPS Odometry", "name": "GPS Odometry", "params": { "Frequency": 30.0, "Topic": "/lgsvl/gnss_odom", "Frame": "odom", "ChildFrame": "base_link", "IgnoreMapOrigin": true }, "parent": "base_link", "transform": { "x": 0, "y": 0, "z": 0, "pitch": 0, "yaw": 0, "roll": 0 } }, { "type": "IMU", "name": "IMU", "params": { "Topic": "/imu/imu_raw", "Frame": "imu" }, "parent": "base_link", "transform": { "x": 0, "y": 0, "z": 0, "pitch": 0, "yaw": 0, "roll": 0 } }, { "type": "Lidar", "name": "LidarFront", "params": { "LaserCount": 16, "MinDistance": 2.0, "MaxDistance": 100, "RotationFrequency": 10, "MeasurementsPerRotation": 360, "FieldOfView": 20, "CenterAngle": 0, "Compensated": true, "PointColor": "#ff000000", "Topic": "/lidar_front/points_raw", "Frame": "lidar_front" }, "parent": "base_link", "transform": { "x": 0.022, "y": 1.49, "z": 1.498, "pitch": 0, "yaw": 0, "roll": 0 } }, { "type": "Lidar", "name": "LidarRear", "params": { "LaserCount": 16, "MinDistance": 2.0, "MaxDistance": 100, "RotationFrequency": 10, "MeasurementsPerRotation": 360, "FieldOfView": 20, "CenterAngle": 0, "Compensated": true, "PointColor": "#ff000000", "Topic": "/lidar_rear/points_raw", "Frame": "lidar_rear" }, "parent": "base_link", "transform": { "x": 0.022, "y": 1.49, "z": 0.308, "pitch": 0, "yaw": 0, "roll": 0 } }, { "type": "Vehicle Control", "name": "Autoware Car Control", "params": { "Topic": "/lgsvl/vehicle_control_cmd" } }, { "type": "Vehicle State", "name": "Autoware Auto Vehicle State", "params": { "Topic": "/lgsvl/vehicle_state_cmd" } }, { "type": "Keyboard Control", "name": "Keyboard Car Control" }, { "type": "Clock", "name": "Simulation Clock", "params": { "Topic": "/lgsvl/clock" } } ]
シミュレータの設定
Simulation Nameに適当な名前をつけたあと、Map&Vehiclesを設定する。
Mapは
Borregas Avenueを選択、VehicleはAWF Lexus RX 2016を設定して(ROSの動作するPCのIPアドレス):9090の形式でrosbridgeに対する接続設定を実施します。
(1台で完結させる場合はlocalhost:9090)
右下の赤色の三角をクリックするとシミュレーションを開始できます。
3. AutowareとLGSVLシミュレータを接続する
Autoware-dockerの起動
今回はマニュアルAutoware.AI 1.14.0 with LGSVL Simulator にそってV1.14.0をビルドしてシミュレータに接続します。
細かいところはその1を参照してください。Launch_Autoware# $WORKING_DIRECTORYは任意 cd $WORKING_DIRECTORY git clone https://github.com/Autoware-AI/docker.git cd $WORKING_DIRECTORY/docker/generic ./run.sh -t 1.14.0Autoware-dockerとの複数コンソールでの接続
--rmオプションを削除して起動するとdockerからexitしてもimageが残るようになります。
dockerからexitしてからdocker ps -aでコンテナを検索すると前回の起動していたコンテナ名がわかります。
起動していない場合はdocker start [イメージ名]で起動しましょう。
docker execコマンドでdockerに入ることができます。(コンソール1)dockerイメージへの接続docker ps -a docker start [イメージ名] docker exec -it [イメージ名] /tmp/entrypoint.sh cd $WORKING_DIRECTORY/docker/genericもう一つコンソールを開いてから
docker execコマンドを実行すると複数のコンソールでdockerに入ることができます。(コンソール2)dockerイメージへの接続docker exec -it [イメージ名] /tmp/entrypoint.sh cd $WORKING_DIRECTORY/docker/genericLGSVLシミュレータとはROSBRIDGEで接続します。
LGSVLシミュレータを立ち上げてからコンソール1でROSBRIDGEを立ち上げて接続してみましょう。(コンソール1)ROSBRIDGE# Autowareの環境ファイルの読み込み source Autoware/install/setup.bash # ROSBRIDGEを立ち上げ roslaunch rosbridge_server rosbridge_websocket.launchさきほどのコンソール2で接続を確認しましょう。
rostopic listコマンドでLGSVLシミュレータからセンサの値などのトピックを確認することができます。(コンソール2)トピックの確認# Autowareの環境ファイルの読み込み source Autoware/install/setup.bash # トピックの確認 rostopic list複数コンソールから接続するときはかならず環境ファイルの読み込みをしましょう。
4. Autowareの自己位置推定からお試し走行まで
さて、いよいよ自己位置推定です。Autoware-dockerを起動するとホームにshared_dirという共有フォルダが作られます。
shared_dirのデータはAutoware-dockerからも読み書きできるので非常に便利です。(コンソール3)Autoware-data# LGSVLのサンプルファイルの読み込み cd ~/shared_dir git clone https://github.com/lgsvl/autoware-data.gitクローンが終わったらコンソール1に戻ってruntime_managerを立ち上げます。
runtime_managerなんかパッケージに見つからないよ、というエラーが出る場合はsource Autoware/install/setup.bash
(環境ファイルの読み込み)を忘れているケースが多いです。(コンソール1)runtime_manager# runtime_managerを立ち上げ roslaunch runtime_manager runtime_manager.launchruntime_managerが立ち上がったらそれぞれlaunchファイルの設定をしていきます。
(コンソール1)runtime_managerでのlaunchファイルの設定# Map /home/autoware/shared_dir/autoware-data/BorregasAve/my_launch/my_map.launch # Sensing /home/autoware/shared_dir/autoware-data/BorregasAve/my_launch/my_sensing_simulator.launch # Localization /home/autoware/shared_dir/autoware-data/BorregasAve/my_launch/my_localization.launch # Detection /home/autoware/shared_dir/my_launch/my_detection.launch # Mission planning /home/autoware/shared_dir/my_launch/my_mission_planning.launch # Motion plannning /home/autoware/shared_dir/my_launch/my_motion_planning.launchボタンをクリックしてlaunchファイルを実行します。右下のrvizをクリックするとrvizが立ち上がります。
Autowareの自己位置推定は初期位置を指定する必要があるので2D Pose Estimateで自分の位置を指定します。
2D Pose Estimateをクリックして緑の矢印になるようにドラッグして指定します。
下記のようになればOKです。LGSVLシミュレータは十字キーで車両を操作することができるのでrvizで確認してみましょう。
Autowareで走行してみる
2D Navi Goalで目的地点をしましょう。2D Navi Goalをクリックして緑の矢印になるようにドラッグして指定します。
そうするとしばらくすると自動で走行します。経路はAutowreが道路にそって作成し走ってくれます。道路はVector_mapという形式でAutowareのパッケージが読み込んでくれます。
まとめ
年末年始にPCの入れ替えがあるのでAutowareのまとめは年明けに時間を見つけてご紹介していきたいと思います。
rvizの2D、3Dの切り替えがわかりません。誰か教えてくださるとありがたいです。5. 参考リンク
・Git Large File Storage (LFS)
・LGSVL Download
・LGSVL Maps
・LGSVL Vehicles
・Sample sensor configuration
・Autoware.AI 1.14.0 with LGSVL Simulator











- 投稿日:2020-12-07T17:59:17+09:00
生誕 11,111 日目を Twitter アカウントでカウントダウンするための Python スクリプト
最近 Tweepy で動かすオモチャの紹介ばかり書いている気がします。私が生誕してからそろそろ 11,111 日を迎えそう(2020/12/09、30歳半ぐらい)、ということで、そのことを忘れないように Twitter アカウント名を毎日更新するために作ったスクリプトの紹介をします。
(ちなみに、生誕 10,000 日記念のときにはこんなことやりました。生誕1万日記念にポッキー1万本食べようとした話 - note)
できるものはざっくりこんなイメージです。
殆どの内容は拙記事「Tweepy を使って月齢?を Twitter ユーザーネームに反映させる - Qiita」と同じです。
Pythonのdatetimeライブラリを使って生誕日から現在年月日までの日数を計算します。環境
- Python : 3.8.5
- Tweepy : 3.9.0
生誕からの日数の計算方法
やっていることはシンプルです。
- 生誕日
d_birthの設定- 現在日
d_todayの取得- 現在日と生誕日の差分
d_from_birthを計算- カウントダウンのための数字
remain_daysを計算ソースコードは以下のとおり。
# 誕生日から生誕何日か調べる # 生誕日と現在日を取得 d_birth = datetime.date(1990, 7, 9) d_today = datetime.date.today() # 日時の差を計算 d_from_birth = d_today - d_birth print(d_from_birth) # 11111 日までの残り日数 remain_days = 11111 - d_from_birth.daysTwitter アカウント更新
あらかじめ取得した API キーを使って
tweepyのupdate_profile関数を使えるようにしておき、適当な形で先程計算した日数を入れます。API の取得、設定方法は Tweepy を使って月齢?を Twitter ユーザーネームに反映させる - Qiita を参考にしてください。
API.update_profile([name][, url][, location][, description])
name – ユーザーネーム(最大 20 文字)
url – アドレス(最大 100 文字、"http://" を省略しても勝手につけられる)
location – 場所(最大 30 文字)
description – 自己紹介(最大 160 文字)# 表示名を設定 nameStr = "村橋究理基%s北大@生誕%d日目" % (moon, d_from_birth) profileStr = "名前の%sは今夜の月を表しています。仕組みの説明→https://t.co/ACE6OhPVVz 生誕11111日まで後%d日 北大理学院宇宙理学 博士3+2年 惑星気象/火星大気シミュレーション 3Dプリンタ/恵迪寮寮歌アプリ/高校専修免許(理科)/学芸員/恵迪寮第300期寮長/恵迪寮同窓会理事/愛知県立津島高校出身" % (moon, remain_days) api.update_profile(name = nameStr, description = profileStr)おわり
さあ、みなさんも任意の生誕記念日までの日数を意識してみましょう。結構たくさん記念日があるかもしれません。身近な人を適当な理由をつけて祝ってみたいときにぜひ!
ところでこの記事を書いている今日 2020/12/07 は私の生誕 11,109 日目なのですが、まだ 11,111 日記念日に何するか決まってません。結構悩んでいるので、だれか面白い案を教えてください→ https://twitter.com/mkuriki_
参考資料

- 投稿日:2020-12-07T16:57:35+09:00
Python × Elasticsearchで検索と集計をしてみよう
目次
1.はじめに
2.準備
3.検索
4.集計
5.後片付け
6.終わりに1. はじめに
この記事は 2020 年の RevComm アドベントカレンダー 13 日目の記事です。 12 日目は tomohiro86 さんの「Apollo Clientでwebsocket通信してみよう」でした。
株式会社RevCommは音声解析AI電話MiiTelの開発を行っています。
MiiTel では会話の全文文字起こしを提供しており、文字起こしした文章から単語の検索ができます。この記事では、Python(elasticsearch_dsl)とElasticsearch(AWS)を使って検索と集計をする方法をご紹介します。
2. 準備
IAM ユーザーの作成
https://console.aws.amazon.com/iam/home#users
ユーザーを追加ボタンからAWS Elasticsearch Serviceを使えるユーザーを作成します。
アクセスキー ID、シークレットアクセスキー、ARNをコピーしておいてください。Elasticsearch ドメインの作成
https://ap-northeast-1.console.aws.amazon.com/es/home
新しいドメインの作成ボタンから作成します。
1. デプロイタイプは開発およびテスト
2. Elasticsearch ドメイン名を適当につけます。
3. ネットワーク構成は今回はパブリックアクセスにします。
そして、「細かいアクセスコントロールを有効化」のチェックを外し、
アクセスポリシーに先ほどコピーしておいたARNを貼り付けます。
4. 内容を確認して確認ボタンを押したら作成が開始されます。
ドメインのステータスが「読み込み中...」から「アクティブ」に変わったら作成完了です。
少し時間がかかるのでの次に進みましょう。データ用意
日本歴代興行収入ランキングのTOP10を用意しました。
2020年11月29日時点のデータです。(鬼滅の刃はどこまで伸びるのだろうか?)
出典: http://www.kogyotsushin.com/archives/alltime/movies.json[ { "title": "千と千尋の神隠し", "company": "東宝", "type": "animation", "year": 2011, "rank": 1, "income": 308.0 }, { "title": "劇場版「鬼滅の刃」無限列車編", "company": "東宝", "type": "animation", "year": 2020, "rank": 2, "income": 275.1 }, { "title": "タイタニック", "company": "FOX", "type": "live_action", "year": 1997, "rank": 3, "income": 262.0 }, { "title": "アナと雪の女王", "company": "ディズニー", "type": "animation", "year": 2014, "rank": 4, "income": 255.0 }, { "title": "君の名は。", "company": "東宝", "type": "animation", "year": 2016, "rank": 5, "income": 250.3 }, { "title": "ハリー・ポッターと賢者の石", "company": "ワーナー", "type": "live_action", "year": 2001, "rank": 6, "income": 203.0 }, { "title": "ハウルの動く城", "company": "東宝", "type": "animation", "year": 2004, "rank": 7, "income": 196.0 }, { "title": "もののけ姫", "company": "東宝", "type": "animation", "year": 1997, "rank": 8, "income": 193.0 }, { "title": "踊る大捜査線 THE MOVIE2 レインボーブリッジを封鎖せよ!", "company": "東宝", "type": "live_action", "year": 2003, "rank": 9, "income": 173.5 }, { "title": "ハリー・ポッターと秘密の部屋", "company": "ワーナー", "type": "live_action", "year": 2002, "rank": 10, "income": 173.0 } ]ライブラリのインストール
pip install elasticsearch elasticsearch_dsl requests_aws4authデータ追加
準備したElasticsearchにPythonスクリプトでデータを追加していきましょう。
import json from elasticsearch import Elasticsearch, RequestsHttpConnection, helpers from requests_aws4auth import AWS4Auth HOST = 'search-test-foobar.ap-northeast-1.es.amazonaws.com' awsauth = AWS4Auth( 'アクセスキー ID', 'シークレットアクセスキー', 'ap-northeast-1', 'es' ) es = Elasticsearch( hosts=[{'host': HOST, 'port': 443}], http_auth=awsauth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection ) def generate(): with open('movies.json', 'r') as f: movies = json.load(f) for movie in movies: yield { "_op_movie_type": "create", "_index": "movies", "_source": movie } helpers.bulk(es, generate()) print(es.count(index="movies")["count"]) # 結果 # 10 もし10じゃなかったら少し時間を置いて試してみてください。次にtextデータのfielddataをtrueにします。
これをしないとtextデータを集計の対象にしてくれません。from pprint import pprint MAPPING = { "properties": { "company": {"fields": {"keyword": {"ignore_above": 256, "type": "keyword"}}, "type": "text", "fielddata": True}, "title": {"fields": {"keyword": {"ignore_above": 256, "type": "keyword"}}, "type": "text", "fielddata": True}, "type": {"fields": {"keyword": {"ignore_above": 256, "type": "keyword"}}, "type": "text", "fielddata": True}, } } es.indices.put_mapping(index="movies", body=MAPPING) pprint(es.indices.get_mapping()["movies"]) # 結果 # {'mappings': {'properties': {'company': {'fielddata': True, # 'fields': {'keyword': {'ignore_above': 256, # 'type': 'keyword'}}, # 'type': 'text'}, # 'income': {'type': 'float'}, # 'rank': {'type': 'long'}, # 'title': {'fielddata': True, # 'fields': {'keyword': {'ignore_above': 256, # 'type': 'keyword'}}, # 'type': 'text'}, # 'type': {'fielddata': True, # 'fields': {'keyword': {'ignore_above': 256, # 'type': 'keyword'}}, # 'type': 'text'}, # 'year': {'type': 'long'}}}}これで準備は完了です。
3. 検索
それでは検索をしてみましょう。
Elasticsearchのドキュメント
elasticsearch_dslのドキュメント会社が東宝のアニメ作品from elasticsearch_dsl import Search s = Search(using=es).sort('rank').query("match", type="animation").query("match", company="東宝") for hit in s: print(hit.title) # 結果 # 千と千尋の神隠し # 劇場版「鬼滅の刃」無限列車編 # 君の名は。 # ハウルの動く城 # もののけ姫2000年以前の作品- s = Search(using=es).sort('rank').query("match", type="animation").query("match", company="東宝") + s = Search(using=es).filter("range", year={"lte": 2000}) # 結果 # タイタニック # もののけ姫「ハリー」または「アナ」がつく作品from elasticsearch_dsl import Search, Q q = Q("multi_match", query='ハリー アナ', fields=['title']) s = Search(using=es).sort('rank').query(q) for hit in s: print(hit.title) # 結果 # アナと雪の女王 # ハリー・ポッターと賢者の石 # ハリー・ポッターと秘密の部屋会社が東宝でタイトルに「の」がつかない作品- q = Q("multi_match", query='ハリー アナ', fields=['title']) + q = Q('bool', must=[Q("match", company="東宝"), ~Q("match", title="の")]) # 結果 # 踊る大捜査線 THE MOVIE2 レインボーブリッジを封鎖せよ!4. 集計
次に集計をしてみましょう。
Elasticsearchのドキュメント
elasticsearch_dslのドキュメントまずはtermsを試してみます。
companyで集計from pprint import pprint from elasticsearch_dsl import Search, A s = Search(using=es) a = A('terms', field='company') s.aggs.bucket('results', a) resp = s.execute() pprint(resp.aggregations._d_['results']['buckets']) # 結果 # [{'doc_count': 6, 'key': '宝'}, # {'doc_count': 6, 'key': '東'}, # {'doc_count': 2, 'key': 'ワーナー'}, # {'doc_count': 1, 'key': 'fox'}, # {'doc_count': 1, 'key': 'ディズニー'}]東宝が6作品、ワーナー、FOX、ディズニーがそれぞれ1作品ということがわかりました!
typeで集計- a = A('terms', field='company') + a = A('terms', field='type') # 結果 # [{'doc_count': 6, 'key': 'animation'}, # {'doc_count': 4, 'key': 'live_action'}]アニメが6作品実写が4作品ということがわかりました!
公開年のヒストグラム- a = A('terms', field='type') + a = A('histogram', field='year', interval='5', offset='1901') # 結果 # [{'doc_count': 2, 'key': 1996.0}, # {'doc_count': 4, 'key': 2001.0}, # {'doc_count': 0, 'key': 2006.0}, # {'doc_count': 2, 'key': 2011.0}, # {'doc_count': 2, 'key': 2016.0}]2001年から2005年が4作品と最も多いことがわかりました!
他にもいろいろな集計方法がありますのでドキュメントを見てぜひ遊んでみてください。
5. 後片付け
最後に作成したIAMユーザーとElasticsearchは忘れずに削除しましょう。
IAMユーザーの削除
https://console.aws.amazon.com/iam/home?#/users
対象のユーザーにチェックを入れてユーザーの削除ボタンをクリックElasticsearchの削除
https://ap-northeast-1.console.aws.amazon.com/es/home
対象のドメインをクリックし、アクション>ドメインの削除をクリック6. 終わりに
今まで、ElasticSearchを使ったことはありませんでしたが、弊社ではやりたいと手を挙げればやらせてもらえる環境のため挑戦させてもらいました。
来年もどんどん挑戦し、どんどん成長していきたいと思います!明日は tatakahashi35 さんの「RevCommの裏側で動くアルゴリズム [二分探索編]」です。
お楽しみにー!




- 投稿日:2020-12-07T16:49:12+09:00
Alpineでバージョンを指定してPythonをいれる
Dockerでflask & vueのイメージをビルドしたかったときに詰まった.
DockerfileRUN apk update && apk add --no-cache python3 && python3 --version # 3.8.62020/12/07時点は自動的に
3.8.6がインストールされた.しかし,PipでPytorchをいれるときにエラーが出てしまったのでPythonのバージョンを指定することにまた,apkでインストールされるバージョンはこちらから確認できそう
バージョンを指定してPythonをいれる
DockerfileRUN apk update && apk add --no-chache --repository http://dl-cdn.alpinelinux.org/alpine/v3.10/main python3~=3.7リポジトリとバージョンを指定するとできた.
リポジトリのブランチとPythonのバージョンは先ほどのサイトで確認できる.上の例でいうところのv3.10とpython3~=3.7参考文献
- 投稿日:2020-12-07T16:40:39+09:00
Pythonのuuidモジュールを使う時の注意
Pythonで
import uuidする時にpip isntall uuidしてはいけないっぽい(requirements.txtに書くのも駄目)以下のようなエラーが出たので、requiremetnts.txtからuuidを消したら動いた。
[ERROR] Runtime.UserCodeSyntaxError: Syntax error in module 'hoge/app': invalid syntax (uuid.py, line 138) Traceback (most recent call last): File "/var/task/uuid.py" Line 138 if not 0 <= time_low < 1<<32L:
- 投稿日:2020-12-07T15:52:34+09:00
機械学習モデルの逆解析のススメ
都内でデータサイエンティストしている者です。はじめてのアドベントカレンダーの投稿となります。今年もはやいものですね。
よければ、暇つぶしにどうぞ。逆解析の何がウレシイの!?
皆さん、日々機械学習を用いて、データからあらゆるラベルであったり、数値であったりを予測していると思います。私も業務で、スコアリングだったり、売上だったり、様々指標を教師あり学習器を用いて、予測しています。しかし、予測値を出してプロジェクトが終わりということはなかなかありません。特に多いのは、なぜその予測値が出るのか?という説明性を求められるケースです。さらには、ほしい予測値を出すことはできるのか?といったケースもあります。この記事では後者に絞った話をします。
まず初めに、哲学的な問を投げさせてください。そもそも、モデル理解するとは何でしょう?何がどうなれば、理解したと言えるのでしょう?これにはいくつか主張はあるかと思いますが、ここでは「モデルが出す出力をコントロールできるようになること=モデルを理解していること」と考えます。例えば、あるユーザーが将来優良顧客になる確率を予測するモデルがあったとします。そのモデルはユーザーの属性や過去の行動を元に、「0.3」と予測したとします。では、このユーザーのスコアを「0.8」に上げたい場合は、どうすれば良いのでしょう?ユーザーの属性や行動には現実的に変えられないもの(性別、登録時期)と変えられるもの(1日あたりのPV数)があります。ユーザーの、変えられる特徴量を上手く変更して、0.8まで上げたいとすると、どの特徴量がどうなれば、このユーザーのスコアは0.8になるのでしょうか?
上ではスコアリングの例を挙げましたが、似たような問は例えば売上の予測のような数値の予測でも起きます。例えば、売上の予測値が100と出たとします。しかし売上目標は120となっており、このままだと未達の可能性があります(こういったプロジェクトを着地点予測といったりします)。さて、目標の120が必要な場合、何をどうすれば、120に改善できるのでしょうか?
上は、機械学習モデルの例ですが、例えば、数理最適化等で物流の効率化などに取り組んでいる例でも、適用可能です。数理最適化でトラックの配送ルートを決めたとしましょう。ですが、現実では、よりコストインパクトがほしくロジックで出した答えよりも、良い答えが欲しい場合もあります。こういった場合でも逆解析が威力を発揮します。
いかがだったでしょうか?こういったシーンは、現実のプロジェクトでは良く起きると思います。特にビジネスサイドがデータサイエンティストに意見を求めたいケースはこういったケースではないでしょうか?しかし、意外にもこのような問にダイレクトに答える方法はあまり世の中に示されていないように思います。各変数の貢献度だけでは、上のような問にダイレクトに答えることは難しいように思います。
逆解析はデータサイエンティスト的には自分が作成したモデルを理解する良い手助けにもなりますし、ビジネスサイドからしても、打ち手につながります。私は、逆解析こそが「攻めのIT」に相応しい技術かなと思ったりしています。逆解析とブラックボックス最適化について
前置きが長くなりましたが、ここからは技術的な話をします。勘の良い方は、この話は、モデルの入力と出力を逆転させたいという話だということに気づかれたのではないでしょうか?X→yを予測する機械学習モデルがあったとして、今の状況はy→Xを出したいのです。y = f(X)というモデルがあったとして、そのモデルのパラメータをいじることはせずに、欲しいyからそのyをできるだけ正しく出力するXを出したいという話です。
面白いことに、これは機械学習の世界を離れ、数理最適化問題の枠組みで定式化することができます。
左側のf^{-1}は関数fの逆関数を指しています。f(x)=x^2とかだとf^{-1}=√xですね。改めてですが、欲しい答え(y)からそれを再現するXを出したいのです。次に右側です、数理計画法として記述されています。こちらではyは固定値(定数)で\hat{y}および、Xが変数です。要するに、Xをいろいろ試して、\hat{y}をいろいろ出力し、欲しいyとの誤差が0になれば、そのときのXが逆関数の出力だと理解できます。
どうしてわざわざ、数理計画法の形式で書くのかと思った方もいるかもしれません。\min: |y - f(X)|でいいじゃん!というツッコミも来そうなところです。数理計画法として書くことでXに対する制約条件を追加することができます。↑に上げた例でいえば、ユーザーの性別、年齢といった属性値は変えることはできません。そういった変えられない変数に対しては、x_{age}=30のように変数を固定してしまえば良いのです。
さらに、f(X)の関数系は特別指定していません。fはランダムフォレストでもLightGBMでもNNでもなんでも良いのです。Xを入れたらyが出てくれば関数系は問いません。このように関数系を問わない最適化をブラックボックス最適化と呼んだりするようです(詳しいことは専門家ではないので知りません。私はあくまで実務家です。)お試し
ではでは、簡単に↑のブラックボックス最適化問題を解くコードをご紹介します。ブラックボックス最適化ができるライブラリはいくつかあるようですが、私は使い慣れているLocalsolverを使いました。ちなみに、こちらは有償ツールとなります。無料ツールであれば、hyperopt, Kurobako, といったいくつかあるようです。(これらは使ったことがないのでわかりません。)
ここでは、簡単のため、制約条件は入れずに解きます。以下のような、整数値、バイナリ値、連続値が入り混じった変数を10列用意し、連続値yを予測するモデルをランダムフォレストを用いて作成しました。4行しか表示していませんが、実際には10000行程度、用意しました。
逆解析はここからが、本番です。この学習済みのランダムフォレストを固定したまま、今度は欲しい出力の一覧を用意し、ランダムフォレストにこの出力を出させてみましょう。与えるインプットは以下のデータです。
なかなか見慣れないインプットではないでしょうか?普通は逆を思い浮かべませんか?Xが埋まっていて、yが空欄かと思いきやその逆で、yだけが埋まっています。このyを出力するXを埋めるというのがやりたきことです。入出力が逆転しているので、逆解析と呼ばれます。逆解析をしているpythonコードを簡単に紹介します。
import localsolver import numpy as np import pandas as pd import logging, os from sklearn.ensemble import RandomForestRegressor def solve_inverse_machine_learning(regressor, y_target, list_idx, list_cname, cname_map_range, cname_map_type, test_size, ls_time_limit=10): """ブラックボックス最適化を用いて、逆関数値を出力する :param regressor: 機械学習モデル :param y_target: 欲しい出力のリスト :param list_idx: Xの行のインデックス :param list_cname: Xの列のインデックス :param cname_map_range: 列ごとの取り得る値の範囲 :param cname_map_type: 列ごとの型(整数orバイナリor連続) :param test_size: y_targetの長さ :param ls_time_limit: 計算時間 """ def _predict(args): """args must be 1-d list """ X = np.array(args).reshape(test_size, len(list_cname)) res = np.abs(y_target - regressor.predict(X)) return res.sum() result = [] with localsolver.LocalSolver() as ls: model = ls.model X = [] idx_cname_map_var = {} for idx in list_idx: for cname in list_cname: type_ = cname_map_type[cname] if type_=='B': v = model.bool() elif type_=='I': v = model.int(cname_map_range[cname][0], cname_map_range[cname][1]) elif type_=='C': v = model.float(cname_map_range[cname][0], cname_map_range[cname][1]) else: raise Exception('invalid column type') v.name = cname + '_%s'%idx X.append(v) idx_cname_map_var[idx, cname] = v objective = model.double_external_function(_predict) objective.external_context.lower_bound = 0. model.minimize(objective(X)) model.close() ls.param.set_time_limit(ls_time_limit) ls.param.set_log_file('./log_%d.log'%len(list_cname)) ls.solve() sol = ls.solution for x in X: result.append(sol.get_value(x)) return result if __name__=='__main__': TIMELIMIT = 60 # * 60 NB_COLS = [10] # [10**1, 10**2, 10**3] INTEGER_COL_RATE = 0.3 BINARY_COL_RATE = 0.1 FLOAT_COL_RANGE = (0., 10.) INTEGER_COL_RANGE = (0, 5) TRAIN_SIZE = 10**4 TEST_SIZE = 10**2 Y_SCALE = 100 DATA_DIR = './data' OUTPUT_PATH = os.path.join(DATA_DIR, 'inverse_ml.xlsx') nbcols_df_map = {} np.random.seed(3655) for nb_cols in NB_COLS: logger.info('start make datamart %s'%nb_cols) integer_cols = int(nb_cols * INTEGER_COL_RATE) binary_cols = int(nb_cols * BINARY_COL_RATE) float_cols = nb_cols - integer_cols - binary_cols assert integer_cols+binary_cols+float_cols==nb_cols list_float_cname = ['x_%s'%i for i in range(1, float_cols+1)] df_float = pd.DataFrame(np.random.random_sample((TRAIN_SIZE, float_cols)) * FLOAT_COL_RANGE[1], columns=list_float_cname) list_int_cname = ['x_%s'%i for i in range(1+float_cols, 1+float_cols+integer_cols)] df_int = pd.DataFrame(np.random.randint(INTEGER_COL_RANGE[0], INTEGER_COL_RANGE[1] + 1, (TRAIN_SIZE, integer_cols)), columns=list_int_cname) list_binary_cname = ['x_%s'%i for i in range(1+float_cols+integer_cols, 1+float_cols+integer_cols+binary_cols)] df_binary = pd.DataFrame(np.random.randint(0, 2, (TRAIN_SIZE, binary_cols)), columns=list_binary_cname) list_cname = list_float_cname + list_int_cname + list_binary_cname datamart = df_float.join(df_int).join(df_binary) # datamart['y'] = np.random.randint(0, 2, TRAIN_SIZE) # set binary target datamart['y'] = np.random.random_sample(TRAIN_SIZE) * Y_SCALE # set score target logger.info('end make datamart %s'%nb_cols) cname_map_type = {} cname_map_range = {} for c in list_cname: if c in list_float_cname: v = 'C' range_ = FLOAT_COL_RANGE elif c in list_int_cname: v = 'I' range_ = INTEGER_COL_RANGE elif c in list_binary_cname: v = 'B' range_ = None else: raise Exception('invalid cname') cname_map_type[c] = v cname_map_range[c] = range_ X, y = datamart.iloc[:, :nb_cols], datamart['y'] logger.info('start fit regressor %s'%nb_cols) # regressor = LogisticRegression() regressor = RandomForestRegressor(n_estimators=10) regressor.fit(X=X, y=y) logger.info('end fit regressor %s'%nb_cols) logger.info('start optimize %s'%nb_cols) y_target = np.random.random_sample(TEST_SIZE) * Y_SCALE # set target score list_idx = list(range(1, y_target.shape[0] + 1)) res_X = solve_inverse_machine_learning( regressor=regressor, y_target=y_target, list_idx=list_idx, list_cname=list_cname, cname_map_type=cname_map_type, cname_map_range=cname_map_range, test_size=TEST_SIZE, ls_time_limit=TIMELIMIT ) logger.info('end optimize %s'%nb_cols) logger.info('start draw errors %s'%nb_cols) res_X = np.array(res_X).reshape(TEST_SIZE, nb_cols) # y_pred_array = regressor.predict_proba(res_X) y_pred_array = regressor.predict(res_X) df_result = pd.DataFrame(res_X, columns=list_cname) df_result['y_target'] = y_target df_result['y_pred'] = y_pred_array df_result['y_error'] = np.abs(y_target - y_pred_array) nbcols_df_map[nb_cols] = df_result logger.info('end draw errors %s'%nb_cols) writer = pd.ExcelWriter(OUTPUT_PATH, engine='xlsxwriter') for nb_cols, df_result in sorted(nbcols_df_map.items(), key=lambda x:x[0]): df_result.to_excel(excel_writer=writer, sheet_name='result_%d'%nb_cols, index=False) writer.save()def predict(args): となっているところが目的関数を表しています。resには、欲しい出力(y_target)とモデル出力f(X)の絶対誤差が格納されています。この絶対誤差をできるだけ小さくしようとしています。model.minimize(objective(X))で実際に目的関数に設定しています。
また、Xには連続値とバイナリと整数が入り混じっているので、その型を定義しているのが、v = model.bool()といった箇所になります。
「cnamemap_type」で、列名に対して、その列の型が返ってきます。
さてさて、このコードを実行すると、以下のように表が見事に埋まってくれました。
y_targetは元々欲しかったyで、y_predはf(X)の返り値となります。y_errorは|y_target-y_pred|です。完全一致していませんが、十分に近い値になっていることが見て取れます。これにより、めでたく、y=f(X)の逆関数値が完全ではないですが、求まったことになります。
ビジネスシーンで適用するならば、y_targetがユーザーの何かしらのスコアを表しているとし、x_iが何かしらの行動を指しているすれば、1行目のユーザーで言えば、欲しいスコア71.6点のスコアが欲しいとするならば、x_8(何かしらの回数)を4回にすればよいといった示唆が出せます。
今回は全ての値をフリーで解きましたが、x_10が性別を表しているとすれば、x_10=1と値を固定した上で解くことも可能です。(属性は変えずに、行動量を変化させた上で欲しいスコアを導き出すことができます。)まとめと注意点
この記事では、機械学習プロジェクトのビジネスシーンで求められる例を挙げ、それを解決する一つの方法として逆解析を紹介しました。逆解析は、数理計画法として自然に定式化することができ、その数理計画問題を解くことで、近似的に逆関数値を出せます。もしかすると、機械学習の専門家から、いろいろとツッコミが来るのかもしれませんが、私は論文を書いたこともなければ、学会発表もしたことがない身ですので、専門的な背景は深くは知りません。本業はあくまでクライアント業ですので、クライアント業をしていく中で、自然と、こういったのあれば良いやん!と思い立った次第です。ぜひとも、逆解析が盛り上がってほしいなと思います。
それでは、良い年末を!^^参考
以下の記事を参考にしました。
機械学習モデルを逆解析する







- 投稿日:2020-12-07T14:49:59+09:00
リベンジ!コロナの陽性者数を予測してみた。[Python]
概要
- コロナ陽性者数を予測したい!!!
- 前回の記事の精度を超えたい!!!リベンジしたい!!!
使ったデータ
- オープンデータ|厚生労働省の陽性者数のcsvになります。
実行結果
- 11/1から12/31までの日本のコロナ陽性者数を予測。
- 赤線は実際の陽性者数、青線は予測の陽性者数。
まとめ
- 前回との相違点はグラフの様式とSARIMAモデルのパラメータの値。精度が上がった!!
- パラメータを上手く設定できれば精度が上がる?
おまけ
- 11/1から来年の3/31までの陽性者数を予測。
- 5000人までいきそう。。。
おまけのおまけ
- 11/1から来年の12/31までの陽性者数を予測。
- マイナスの陽性者数が出てる?!?!
コード
# 基本のライブラリを読み込む import pandas as pd # グラフ描画 from matplotlib import pylab as plt # グラフを横長にする from matplotlib.pylab import rcParams rcParams['figure.figsize'] = 15, 6 import matplotlib as mpl mpl.rcParams['font.family'] = ['serif'] # データの準備 df = pd.read_csv("pcr_positive_daily.csv") corona = pd.Series(df["PCR 検査陽性者数(単日)"].values, index=pd.to_datetime(df["日付"])) # SARIMAモデル(季節自己回帰和分移動平均モデル) import statsmodels.api as sm sarima = sm.tsa.SARIMAX( corona, order=(2,1,3), seasonal_order=(0,1,1,30), enforce_stationarity = False, enforce_invertibility = False ).fit() # 予測 corona_pred = sarima.predict('2020-11-01', '2020-12-31') # 実データと予測結果の図示 plt.plot(corona, label='original', color='red') plt.plot(corona_pred, label='predicted', color='blue') plt.xlabel("date") plt.ylabel("Corona positive") plt.legend(loc='best') # # 予測値 # print(corona_pred)参考



- 投稿日:2020-12-07T14:23:09+09:00
Python-LEGO MindstormsでPIDライントレース その2
前回はev3dev環境で用意されているメソッドを利用して簡単にPID制御を用いてライントレースする内容だった。
用意されているメソッドを利用すると簡単に実装できるが、センサーなどを併用した処理ができなかったので、今回は自力でPID制御を実装していく。EV3について
本記事内での環境
PC
Windows10
Python 3.7.3
開発環境 VisualStudioCodeEV3
ev3dev
APIリファレンス環境構築やソースコードの作成、実行はこちら
今回利用するEV3のモデル
今回も前回に引き続きEV3を走行させるために
ベースロボというモデルでモーターを利用して走行を行う。
これに加え今回はタッチセンサーも利用する。
参考
ソースコード
pid-2.pyfrom ev3dev2.motor import OUTPUT_B, OUTPUT_C, LargeMotor, MoveSteering, SpeedPercent from ev3dev2.sensor.lego import ColorSensor, TouchSensor import time touch = TouchSensor() color = ColorSensor() lm_b = LargeMotor(OUTPUT_B) lm_c = LargeMotor(OUTPUT_C) stm = MoveSteering(OUTPUT_B, OUTPUT_C) #カラーセンサーによる白黒の反射光取得 def get_bw(): global black, white print('push for white') while not touch.is_pressed: pass white = color.reflected_light_intensity print('white intensity: {}'.format(white)) while touch.is_pressed: pass print('push for black') while not touch.is_pressed: pass black = color.reflected_light_intensity print('black intensity: {}'.format(black)) while touch.is_pressed: pass return black, white #PID走行をする関数 def pid_run(kp_value, ki_value, kd_value, b, w): global last_error pid_value = 0 midpoint = (b + w) / 2 last_error = 0 cs = color.reflected_light_intensity error = cs - midpoint pid_value = kp_value * error + ki_value * (error + last_error) + kd_value * (error - last_error) stm.on(pid_value, SpeedPercent(20)) last_error = error def main(): get_bw() while not touch.is_pressed: pid_run(0.5, 0.3, 0.5, black, white) lm_b.stop(stop_action='brake') lm_c.stop(stop_action='brake') if __name__ == '__main__': main()
get_bw()で走行前にライントレースコースの白部分の反射光値と黒線部分の反射光値を取得する。取得した白と黒の反射光値はpid_run()の引数b,wに入れられている。
前回の用意されているメソッドを利用したPID走行ではメソッドから処理が抜け出せなかったため、センサーなどによる割り込み判定などができなかった。今回はmain()にあるとおり、タッチセンサーが押されるまでPID走行を継続し、押されたらwhileループから抜け出し走行を終了するような処理になっている。


- 投稿日:2020-12-07T14:21:18+09:00
Tensorflow-gpu で Resource exhausted error が起きた意外な理由
概要
意外な理由で Resource exhausted error が出てどハマりしたので解決策を残しておきます.
状況
- tensorflow-gpuを使って深層学習のモデルをいくつか試していた.
- ずっと問題なく動いていた model_A が,ある日突然 Resource exhausted error を吐いて動かなくなった
- コードは動作時と全く同じ(gitHubで確認済み)
- conda の仮想環境も全く同じ
原因
model_Bを動かすために,
$HOME/.keras/keras.jsonの設定を書き換えてしまっていた.keras.json (for model_A){ "floatx": "float32", "epsilon": 1e-07, "backend": "tensorflow", "image_data_format": "channels_last" }keras.json (for model_B){ "floatx": "float32", "epsilon": 1e-07, "backend": "tensorflow", "image_data_format": "channels_first" }コメント
model_B で model_A の設定を使うと,単純に配列の型が違うというエラーが出るので簡単に気付けるのですが,逆だとメモリ不足のエラーが出るようで,原因の特定に苦労しました...
恐らくサンプル数の部分を1サンプル内のある次元の大きさとみなしてしまうことが原因かと.
- 投稿日:2020-12-07T13:55:58+09:00
Neo4j and GraphQL for evolving projects
translation
Japanese translation of this article (by courtesy of Makato Saito) can be found here.
Introduction
This is our experience with employing Neo4j graph databases and GraphQL query language in our latest project. It's been under active development for the past ~ 3 months. The technology stack we use for this project:
- Neo4j : Graph database for persistence layer
- GraphQL: query language to provide backend API
- Vue.js : For front end development
The Project
A new project to build an Instagram marketing platform came as an extension to our existing miel AI fashion platform. We have been collecting information on Instagramers who signed up for our existing platform, it seems only natural to extend that for a more comprehensive platform that could benefit marketers who want to promote their brand/products and monitor social penetration.
For the discussion purpose we limit the focus on one aspect of our platform. Among other things, one feature we want was for a customer to be able to create campaigns, sign-up Instagrammers to it and evaluate the performance of the campaign.
Technology Selection
We have been contemplating on using GraphQL and reading all the hype about Neo4j how wonderful it is to use graph databases. When the new project comes up which matches a perfect use case of these technologies we wanted to try it out.
Social networks help us identify the direct and indirect relationships between people, groups, and the things with which they interact, allowing users to rate, review, and discover each other and the things they care about. By understanding who interacts with whom, how people are connected, and what representatives within a group are likely to do or choose based on the aggregate behavior of the group, we generate tremendous insight into the unseen forces that influence individual behaviors.
The social networks are already graphs, so using Neo4j to create the data model directly matches the domain model, and helps you better understand our data, and avoid needless work. using Neo4j can improve the quality and speed, reducing the time to create data modeling.
GraphQL seems a natural fit for a data-model which will be represented with a graph database. Modeling the underlying data-model in GraphQL transfers the control of consuming data to front-end apps that can query the data it wants from the persistent layer. GraphQL type system ensures the validity of the queries and saves a lot of development effort reducing the communication overhead between back-end and front-end teams.Data Modeling
One of the hypes about the Neo4j was data-modeling i.e. how easy and intuitive it is to build a data model. In our experience it turned out to be true indeed. It was much easier to bring the mental image that we draw on a whiteboard during discussions to a Neo4j model. No normalization, primary/foreign keys, just circles and arrows.
Neo4j/Neomodel
For modeling we used Neomodel, an Object Graph Mapper(OGM) for Neo4j.
Neomodelhides all the complexity of the Neo4jCypherquery language which is intimidating at the beginning and in the back-end team we love python, thus we couldn’t think of a better way to get the project moving while we are learning the ropes with Neo4j/Cypher. InNeomodelthe objects and their relationships for ourClientandProjectslooks like below.model_1.pyclass Client(StructuredNode): uid = UniqueIdProperty() name = StringProperty(required=True) # relationships instagram = RelationshipTo(InstaUser, 'HAS', cardinality=ZeroOrMore) projects = RelationshipTo('Project', 'OWNS', cardinality=ZeroOrMore) class Project(StructuredNode): uid = UniqueIdProperty() name = StringProperty(required=True) # relationships hashtags = RelationshipTo(Hashtag, 'MONITOR', cardinality=ZeroOrMore) campaigns = RelationshipTo('Campaign', 'PROMOTE', cardinality=ZeroOrMore)The relationships like “each client can have multiple projects”, “each projects can have multiple campaigns”, "project is promoted through multiple hashtags" are enforced by cardinality rules
ZeroOrMore.
Campaign run by clients can have specific hash-tags which are promoted by Instagrammers signed up for the campaign. Campaign is getting visibility in multiple ways, getting tagged, client’s Instagram account gets mentioned, hashtag promoted etc. We modeled it as relationship AID which contains the type of the information on the relationship itself.model_2.pyclass AidRel(StructuredRel): AID_TYPE = {'M': 'mention', 'T': 'tagged', 'H': 'hashtag', 'O': 'manual'} type = StringProperty(choices=AID_TYPE) name = StringProperty() class Campaign(StructuredNode): uid = UniqueIdProperty() name = StringProperty() start = DateTimeProperty() end = DateTimeProperty() url = StringProperty() # relationships posts = RelationshipTo(InstaPost, 'AID', cardinality=ZeroOrMore, model=AidRel) entry_users = RelationshipTo(InstaUser, 'ENTRY', cardinality=ZeroOrMore) aid_users = RelationshipTo(InstaUser, 'PROMOTE_BY', cardinality=ZeroOrMore)[Note: Models of
InstaUserInstaPostare removed for brevity]GraphQL with Ariadne
We choose Ariadne GraphQL library to implement the API. It's schema-first approach makes us first model our API in GraphQL query language and then bind the data resolvers to the schema definitions.
Schema
GraphQL APIs enforces types on every API method. It makes API much more robust and consuming the API less error-prone. IDEs like GraphQL playground can read the API schema and validate the query even before it is sent, making developing against a GraphQL API a very pleasant experience for front-end developers.
Design goal of the GraphQL API is to represent the underlying data model and elevate the relationships of different types without much regard for how it will be used by the consumer. We end up mapping 1-to-1 GraphQL types for our data model's nodes types.model_1.graphqltype Client { uid : ID name: String user: User instagram: InstaUser projects: [Project] } type Project { uid: ID name: String hashtags: [Hashtag] campaigns: [Campaign] }In order to capture relationship data (ie. data placed on edges instead of nodes) we created new types like
AidRelInstaPostto aggregate relationships data (AidRel) with corresponding node data (InstaPost).model_2.graphqltype Campaign { uid: ID name: String start: DateTime end: DateTime url: String posts: [InstaPost] aid_users: [InstaUser] aid_rel_posts: [AidRelInstaPost] } type AidRelInstaPost { aid: AidRel # edge data post: InstaPost # node data }Resolvers
GraphQL provides any elegant and flexible way to query the fields of a type through a mechanism called resolvers. For most of the scalar fields (like
ID,StringIntetc.) we didn't have to provide resolvers at all, sinceAriadneprovides very natural way of mappingNeomodeldata-objects' field names to corresponding type GraphQL type's fields names. For array fields we end up with below 90% of the time.resolver_1.py@campaign.field("posts") def reslove_campaign_posts(campaign, *_): return campaign.posts.all()For hybrid-types which contain both edge and node information we had to resort to Neo4j
Cypherquery language to obtain information and construct the data.resolver_2.py@campaign.field("aid_rel_posts") def reslove_campaign_aid_rel_post(campaign, *_): query = f""" MATCH (c:Campaign)-[a:AID]->(p:InstaPost) WHERE c.uid = '{campaign.uid}' RETURN a, p """ results, _ = db.cypher_query(query) # Create AidRelInstaPost objects res = [{'aid': AidRel.inflate(r[0]), 'post': InstaPost.inflate(r[1])} for r in results] return resOnce we represented our data model in GraphQL querying any data related to projects could be done with a simple
getProjectsquery.query_1.graphqltype Query { getProjects(project: ProjectQueryInput): [Project] } input ProjectQueryInput { # project by uid uid: ID # project query by client.uid or .name and project.name client_uid: ID client_name: String project_name: String }We also had a lot of flexibility with graphQL’s optional fields which let our
QueryInputfields to come up with different criteria to query. For example above we were able to query projects byuidorclient_id,project_namepair or evenclient_name,project_name. However one drawback of this was it pushed query validation down to the query resolvers.Querying data
Data representing a client's campaign looks like below in Neo4j database.
rgb(86,148,128)-Client
rgb(247,195,82)-Project
rgb(235,101,102)-Campaign
rgb(141,204,147)-InstaPost
rgb(218,113,148)-InstaMedia
rgb(89,199,227)-InstaUserThe query
getProjectscan request required fields. from any of the objects belonging to these nodes. For example, the query to populate the project report is like below.report_query{ getProjects(project: { # all projects or criteria }) { # Project attributes uid name hashtags { tag_id name } campaigns { # Campaign attributes uid name start end url posts { # Post attributes post_id shortcode media(first: 1) { # media selection: only first one display_url media_id shortcode } } entry_users { # entry user attributes ig_id username } } } }Front end can choose to retrieve any data element and resolvers get executed only for the requested elements. Below image shows above query being served in the GraphQL Playground. Tools like this help query composition for front end developers a breeze. The auto-completion, error handling expedite the development process and can handle changes to API specification with less communication overhead.
The front end rendering of the data from the query to present the client report of the campaign looks like this.
Conclusions
Use of the Neo4j and GraphQL in the new project has been a pleasant experience so far. With evolving project requirements we were able to extend our schema and add new entities and relationships to the data model without major refactoring.
Neomodelwas indispensable in clearly describing our entity relationships and early stages of building queries, even though we had to resort toCypherquery language later on to have better control. Since the GraphQL API is a reflection of our data model it too got extended with new functionalities without breaking the API. Even some breaking API refactoring could be effectively communicated to the front-end with GraphQL schema documentation, query validation and at times, surprisingly useful suggestions to use the correct field names when typographical mistakes were made.It has been only a couple of months since we started using this stack. There is a lot to explore, we are confident that this technology stack continues to deliver our project expectations. It is also worth mentioning the GRANstack which is more aligned with javascript developer communities.
- 投稿日:2020-12-07T13:54:28+09:00
Pythonでギターのフレットから音階を求める
Pythonでギターのフレットから音階を求める
はじめに
前回の「Pythonでシンセサイザーを作って演奏する。」の記事にて音の生成については解説をしていますので、ぜひご覧ください。
ソースコード
checkChord.pyamp = 0.5 #音量 A = 440.0 #A=440Hz rate = 44100 #サンプリングレート bpm = 120 #BPM scoreWave = None fileName = "" kArray = ["C", "Cs", "D", "Ds", "E", "F", "Fs", "G", "Gs", "A", "As", "B"] #音の周波数を計算してsin波を生成する関数 def sinWave_from_key(k, o, v, s, m): """ parameters ---------- k : string key in scale o : int octave v : float volume s : int seconds t : string type Returns ---------- wave : ndarray """ t = np.arange(0, s, 1 / rate) #時間パラメータ wave = 0 * t if k in kArray: kNum = kArray.index(k) kFreq = A * (2 ** ((kNum - kArray.index("A")) / 12)) * (2 ** (o - 3)) loudness = (amp * v) param = 2 * np.pi * kFreq * t wave = loudness * np.sin(param) return wave #wav保存 def saveWav(): name = "" for s in fileName: if s is ".": break name += s if not fileName is "": wavfile.write(name + ".wav", rate, scoreWave) else: wavfile.write("untitled.wav", rate, scoreWave) #コードチェック def checkChord(): frets = [] keys = [] octave = [] for i in range(6, 0, -1): s = "" if i is 1: s = "1st" elif i is 2: s = "2nd" elif i is 3: s = "3rd" else: s = str(i) + "th" print("Please enter the number of the fret on the", s, "string.") frets.append(input()) for i, s in enumerate(frets): if s.isdecimal(): if i is 0: keys.append(kArray[(int(s) + 4) % 12]) octave.append(1 + int((int(s) + 4) / 12)) elif i is 1: keys.append(kArray[(int(s) + 9) % 12]) octave.append(1 + int((int(s) + 9) / 12)) elif i is 2: keys.append(kArray[(int(s) + 2) % 12]) octave.append(2 + int((int(s) + 2) / 12)) elif i is 3: keys.append(kArray[(int(s) + 7) % 12]) octave.append(2 + int((int(s) + 7) / 12)) elif i is 4: keys.append(kArray[(int(s) + 11) % 12]) octave.append(2 + int((int(s) + 11) / 12)) elif i is 5: keys.append(kArray[(int(s) + 4) % 12]) octave.append(3 + int((int(s) + 4) / 12)) wave = None for i in range(len(keys)): print(keys[i] + str(octave[i])) if wave is None: wave = sinWave_from_key(keys[i], octave[i], 100, 1, "default") else: wave += sinWave_from_key(keys[i], octave[i], 100, 1, "default") global scoreWave scoreWave = wave saveName = "" for i in range(len(keys)): saveName += keys[i] + str(octave[i]) global fileName fileName = saveName + "." saveWav() #main関数 def main(): checkChord() if __name__ is "__main__": main()使い方
Please enter the number of the fret on the 6th string. - Please enter the number of the fret on the 5th string. 0 Please enter the number of the fret on the 4th string. 2 Please enter the number of the fret on the 3rd string. 2 Please enter the number of the fret on the 2nd string. 1 Please enter the number of the fret on the 1st string. 0 A1 E2 A2 C3 E3 Done! A1E2A2C3E3.wav Press any key to continue . . .実行するとコンソールが立ち上がるので、テキストに沿って入力を進めていくだけです。自分もふと忘れるときがあるのですが、ギターの弦は太い方から順に6弦、5弦、4弦...となっているようです。つまり入力は、「TAB譜で下から順に」入力することです。
1弦まで入力が終わったら、コードの成分を表示し、sin波を合成して生成されたコードのwav音源が作成されます。ただしギターの和音のように綺麗な響きではありません。なんとなく音を把握する程度に使ってください。解説
発想はシンプルで、弦を開放で鳴らした音にフレットの数を加算しているだけです。ここでのギターは6弦、ノーマルチューニング(EADGBE)を仮定しています。また、フレットには上限を設けていないため「ネックが無限に長い」ギターになっています。
弦ごとのキーは単に割り算と剰余で求めることができます。
あとは前回触れたsin波から音を生成するプログラムを使って音源として保存しています。あとがき
私自身作曲をしたりカバー曲を作ったりしている過程でギターのTAB譜からピアノロールに打ち込む作業があったりして、ギターの経験が長いわけでもないので、その度に1音1音確認しながら作業していたのですが、あまりにも面倒だったため作ることにしました。
私のような人は少数だと思いますが、ギターの運指と音楽理論を同時に学習したい人や、何気なく弾いたコードがいい感じだったけどどんなコードなのかわからないって人に使ってもらえたらな~とか思ってます。
Pythonの動く環境でコピペして使ってみてください。
- 投稿日:2020-12-07T13:50:27+09:00
オフライン本番環境での機械学習実行環境構築シナリオとAnsibleによる構築自動化(後編)
初版: 2020年12月5日
著者: 株式会社 日立ソリューションズ 堤 友希
監修: 株式会社 日立製作所
はじめに
本投稿では、前編で実施したオフラインの本番環境への任意パッケージのインストールのうち、手順の多い検証サーバ上での作業を、インフラ構築自動化ツールのAnsibleを使って自動化する手順を示します。
自動化をしておくことで、定期的に本番環境の任意パッケージをアップデートする場合などに作業工数を削減できます。
*前編ではAnacondaリポジトリにアクセスしておりますが、商用でAnacondaのリポジトリを使用する場合はAnaconda Commercial Edition等のライセンスを購入する必要があります。詳細は下記リンクをご確認ください
https://www.anaconda.com/terms-of-service投稿一覧
1.オフライン本番環境での機械学習実行環境構築シナリオとAnsibleによる構築自動化(前編)
2.オフライン本番環境での機械学習実行環境構築シナリオとAnsibleによる構築自動化(後編)・・・本投稿
Ansibleの概要
はじめに、Ansibleの概要について説明します。
表1 各インフラ構築自動化ツールの特徴比較
ツール名 プログラミング知識要否 Agent要否 puppet 要(Ruby+独自) 要 chef 要(Ruby) 要 ansible 不要(YAML:データ定義) 不要 Ansibleはpuppetやchefなどの他のインフラ構築自動化ツールと比較すると、
Rubyなどのプログラミング知識が不要で、Agentlessなことが特徴となります。targetサーバに対して、 Ansibleをインストール済みのcontrollerサーバが
構築スクリプト実行リクエストを送信します。
図1 Ansible利用シーン
自動化はDockerfileでできるのでは?
コンテナを活用するのであればDockerfileで自動化できます。
ただ、今回はコンテナを活用しない場合にも対応可能なAnsibleを使った方法を紹介します。
Ansible利用環境の構築
検証環境でAnsibleを利用するために、ControllerサーバにAnsibleを導入し、Targetサーバへ疎通確認します。
下図に疎通確認のスコープやサーバ間の関係を示します。
図2 疎通確認のスコープ(赤枠)やサーバ間の関係
CentOSのコンソール画面#controllerサーバにAnsibleをインストールします。 [root@localhost ~]# yum install epel-release –y [root@localhost ~]# yum install ansible -y #続いてtargetサーバにpingモジュールで疎通確認します。 #鍵チェックする設定の場合、controller-target間で通信に鍵が必要なので、鍵生成/受け渡しをしておきます。 [root@localhost ~]# ssh-keygen -t rsa #鍵の生成 [root@localhost ~]# ssh-copy-id <targetのIPaddress>@<targetのホスト名> #鍵を渡す [root@localhost ~]# ssh <targetのIP address> #ssh接続確認 #Ansibleが利用するtargetの情報を記載したinventoryファイルを作成しておきます。 [root@localhost ~]# cat inventory.txt ansible_host=<targetのIPaddress> ansible_ssh_pass=<targetへのssh接続時パスワード> #疎通が成功すると、以下のように返答されます。 #これで、自動化スクリプト実行スクリプト実行リクエストがtargetサーバに通信可と確認できました。 [root@localhost ~]# ansible <targetのホスト名> -m ping -i inventory.txt <targetのホスト名> | SUCCESS => { "changed": false, "ping": "pong" }図3 Ansible利用環境の構築例
Rolesと自動化スコープ
Ansibleでは、playbookというyamlで記載された自動化スクリプトを実行します。
また、rolesという機能で自動化の内容を分割して整理することができます。
下記のようなrolesの構成にしており、それぞれの自動化範囲を示します。
図4 rolesと自動化スコープ
表2 各rolesとその自動化内容
roles 自動化内容 conda-install Minicondaインストール env-setting Miniconda初期化&プロキシ設定 dev-channel 仮想環境構築とカスタムチャネル開発 proenv_auto.yml(以降、メインplaybook)がconda-install→env-setting→dev-channelの順番で、各rolesのtasks直下のmain.yml(以降、サブplaybook)を実行します。
Ansibleは実行するplaybookが存在するディレクトリにあるrolesディレクトリ階層を認識します。
サブplaybookの実行順序は、メインplaybookに記載して定義します。
各rolesのfilesやvarsに存在するファイルはサブplaybookの実行時に利用するシェルスクリプトなどのファイルや変数定義です。
Minicondaインストールの自動化テンプレート
本番環境においては、多数のサーバに同様の作業をするのでなければAnsible用のControllerサーバを
用意できないので、本番環境へのパッケージインストールは自動化の範囲に含めません。その代わり、パッケージをインストールするシェルスクリプトの作成方法を記載します。
proenv_autoディレクトリ直下のメインplaybookでは全rolesで共通の変数定義やroles実行順序、targetサーバの情報を記載しています。
今回のメインplaybookであるproenv_auto.ymlの記載内容を示します。
図5 proenv_auto.yml
次にcontrollerサーバからtargetサーバへの通信に必要な情報を記載したinventory.txtの内容を示します。
図6 inventory.txt
rolesはproenv_auto.ymlでの記載に従って、conda-installから実行されます。
conda-installのtasks直下のmain.ymlの記載内容を示します。
図7 conda-installのtasks直下のmain.yml
conda-installのvars直下のmain.ymlの記載内容を示します。
ここではconda-install固有の変数名を定義しており、
Minicondaのインストーラが変更されるとき、
インストーラ名の変更に対応できます。
図8 conda-installのvars直下のmain.yml
次にenv-settingが実行されます。
env-settingのtasks直下のmain.ymlの記載内容を示します。
図9 env-settingのtasks直下のmain.yml
Minicondaのインストールをすると、Minicondaの初期化処理が行われ、CentOSやRHELのrootディレクトリに存在する.bashrcに変更が加えられます。
後述しますが、この初期化処理による.bashrcの変更部分をAnsibleで利用します。
一方、今回のAnsibleを用いて自動化されたMinicondaのインストールではインストールはバッチオプションとして行われますが、この場合Minicondaの初期化処理が行われません。
そのため、一度手動でMinicondaのインストールを実施し、その際の初期化処理で変更された.bachrcを利用します。
図10 .bashrc
任意パッケージダウンロードとカスタムチャネル化の自動化テンプレート
conda-installに続き、dev-channelが実行されます。
dev-channelのtasks直下のmain.ymlの記載内容を示します。
このmain.ymlでは任意パッケージのインストール・ダウンロード情報の取得と、カスタムチャネル化を実施します。
図11 dev-channelのtasks直下のmain.yml
main.yml内で実行されるシェルスクリプトのdev_channel.shとdev_channel2.shの記載内容を示します。
それぞれdev_channel.shは任意パッケージのインストールとダウンロード情報の取得、dev_channel2.shは任意パッケージのカスタムチャネル化を行います。
シェルスクリプトには、黄色で示したように、.bashrcにMinicondaの初期化で追記される箇所を記載しないと、playbook実行時にエラーが発生しますので、記載しておく必要があります。
図12 dev_channel.sh
図13 dev_channel2.sh
本番環境へのパッケージインストールの自動化テンプレート
本番環境では下記のシェルスクリプトで任意パッケージをインストールします。
proenv_build.sh#!/bin/sh 初期化が反映された部分。 # >>> conda initialize >>> # !! Contents within this block are managed by 'conda init’ !! __conda_setup="$('/root/miniconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)“ if [ $? -eq 0 ]; then eval "$__conda_setup“ else if [ -f "/root/miniconda3/etc/profile.d/conda.sh" ]; then . "/root/miniconda3/etc/profile.d/conda.sh“ else export PATH="/root/miniconda3/bin:$PATH“ fi fi unset __conda_setup # <<< conda initialize <<< #前提条件 #①Minicondaのインストールは手動で実施 #②/rootにカスタムチャネルが存在すること #③UnsatisfiableErrorのデバッグが完了していること conda create -n proenv -y --offline && \ conda config --add channels /root/proenv-custom-channel && \ conda config --remove channels defaults && \ conda activate proenv && \ conda install --quiet --yes 'python=3.7.6' && \ conda install --quiet --yes 'notebook=6.0.3' && \ conda install --quiet --yes 'tensorflow=2.1.0'図14 proenv_build.sh
まとめ
本投稿では、環境構築の自動化をAnsibleで実施するノウハウを示しました。
自動化により煩雑な手順を効率化できるので、本番環境の任意パッケージをアップデートする場合などの運用に活用いただければと思います。












- 投稿日:2020-12-07T13:44:59+09:00
【KDD2020 Workshop採択論文紹介】GCNで時系列予測!?
明示的にグラフ構造でないデータに対してもGraph Convolution Network(GCN)が使える!?
ドコモの久保田です。この記事では、データマイニングの国際会議であるKDD2020で開催されたThe Second International Workshop on Deep Learning on Graphs: Methods and Applications (DLG-KDD’20)に採択された私たちの論文"Time-aware GCN: Representation Learning for Mobile App Usage Time-series Data"を紹介します。論文はKDDのリンクのページからダウンロードできます。
KDD2020の投稿傾向
KDD2020のOpening1でResearch Trackのトピックごとの投稿論文数が報告されていましたが、上位2つが以下のトピックに関するものでした。
- Graph Mining 260本
- Representation Learning 168本
Research Trackの採択論文数217本から見ても多くのグラフ関連の論文や表現学習に関する論文が投稿されていたようです。
私たちの論文が採択されたのはKDD Workshopですが、Graph×Representation Learningというトレンドに乗った内容になっています。どんなもの
時系列データをグラフデータとして捉えることでGCNを適用し時系列データのよりよい表現を獲得するというものです。
今回は、アプリログを用いて、アプリログのデータの特性を考慮した手法を提案しています。普段スマホでアプリを利用しているとき、このようなことがありませんか?
- 通勤中に普段はTwitterを見てTikTokを見るが、なんとなくの気分で今日はTikTokから見始めた
- NewsPicksのアプリで気になった記事をEvernoteにメモするようにしているが、今日はNewsPicksを見ているときに友人からLINE通知が来てLINEを開いた
これらの例のように、通勤中にSNSを見るやNewsPicksを見た後にEvernoteにメモするというユーザの習慣に基づく長期的なアプリ利用のパターンは、あまり変化しないと考えられるが、短期的な利用はユーザの気分や通知等により変化する可能性があります。
よりよい表現を獲得するうえで、正確に時系列のパターンを学習するlong-short-term memory(LSTM)などの手法では対処できない可能性があります。
このような状況において、短期的なアプリ利用の変化による影響を軽減しつつアプリ利用に関するよりよい表現を獲得するために、GCNを用いた手法を提案しています。
提案手法
GCNを適用するためのグラフ構築
GCNを適用するには、グラフ構造のデータが必要であり、より良い表現を獲得するためにはアプリログから時系列情報を保持したグラフを構築する必要があります。これを実現するために、以下の手順でアプリ利用に関するグラフを構築します。
- アプリログからスライディングウィンドウを用いて$n$個のアプリを抽出(これをアプリ利用系列と定義)
- あるアプリ利用系列$S$に注目して、アプリをノード、アプリ間の利用時間間隔が$\Delta t_{\text{th}}$であれば、アプリ間にエッジを張ることでアプリ利用グラフを構築
よりよい表現を獲得できたかを評価
アプリログのより良い表現を獲得できたかを、次のアプリを予測するタスクとして定義します。また、次のアプリを予測するタスクをGCNで実現するためにグラフ分類問題として捉えることで実現します。
提案手法のT-GCNのアーキテクチャを下図に示します。
実験
実際のアプリログのデータセットを用いて評価を実施します。
ベースラインはLSTMと既存研究から時間差$\Delta t_{\text{th}}$以内の直前のアプリのみからエッジを張る手法(T-GCN-SEと定義)として実験を行いました。時系列情報をどのように考慮してグラフを構築するかが精度に影響を与えると考え、アプリ間でエッジを張る時間差$\Delta t_{\text{th}}$を変化させて実験を行いました。
結果としては、ある程度の長さの時間差内のアプリ簡にエッジを張ることが有効であることが分かりました。
最後に、ベースライン手法との比較を示します。
提案手法であるT-GCNがベースライン手法よりも精度が向上することを明らかにしました。
特に、accuracy@10では、LSTMと比較して3.6%の精度向上を確認しました。実装
実装に関しては、Deep Graph Library(DGL)2を利用しました。Pytorchから使える点と、tutorialに事例が豊富に記載されていおり参考にしながら実装できたので、実装コストが低くかった点が魅力的でした。
最後に
KDD2020のTutorialや本会議にも参加していましたが、オンライン開催だったこともあり発表動画が好きなだけ見れたので良い部分もあったなと思いました。こういった学会発表などに関しても全面的に支援してくれる環境はとても恵まれているなと思います。これからも事業的に貢献し、学術的にも貢献があるような研究開発を実施していきたいですね(来年は本会議へ!)。
最後まで読んでいただきありがとうございました。
KDD2020のOpeningは以下のリンクから閲覧できます。 ↩




- 投稿日:2020-12-07T13:42:14+09:00
Djangoで TypeError: argument of type 'PosixPath' is not iterable
Django学習中に表題のエラーに遭遇しました。
その忘備録として投稿します。1.エラー内容
File "manage.py", line 22, in <module> main() File "manage.py", line 18, in main execute_from_command_line(sys.argv) File "/Users/usr/.pyenv/versions/3.8.5/lib/python3.8/site-packages/django/core/management/__init__.py", line 401, in execute_from_command_line utility.execute() File "/Users/usr/.pyenv/versions/3.8.5/lib/python3.8/site-packages/django/core/management/__init__.py", line 395, in execute self.fetch_command(subcommand).run_from_argv(self.argv) File "/Users/usr/.pyenv/versions/3.8.5/lib/python3.8/site-packages/django/core/management/base.py", line 341, in run_from_argv connections.close_all() File "/Users/usr/.pyenv/versions/3.8.5/lib/python3.8/site-packages/django/db/utils.py", line 230, in close_all connection.close() File "/Users/usr/.pyenv/versions/3.8.5/lib/python3.8/site-packages/django/utils/asyncio.py", line 26, in inner return func(*args, **kwargs) File "/Users/usr/.pyenv/versions/3.8.5/lib/python3.8/site-packages/django/db/backends/sqlite3/base.py", line 261, in close if not self.is_in_memory_db(): File "/Users/usr/.pyenv/versions/3.8.5/lib/python3.8/site-packages/django/db/backends/sqlite3/base.py", line 380, in is_in_memory_db return self.creation.is_in_memory_db(self.settings_dict['NAME']) File "/Users/usr/.pyenv/versions/3.8.5/lib/python3.8/site-packages/django/db/backends/sqlite3/creation.py", line 12, in is_in_memory_db return database_name == ':memory:' or 'mode=memory' in database_name TypeError: argument of type 'PosixPath' is not iterable(私はすぐstackorverflowに助けを求めた。)
2.解決方法
プロジェクトファイル内のsettings.pyを以下のように修正。
修正前
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': BASE_DIR / 'db.sqlite3', } }修正後
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': str(BASE_DIR / 'db.sqlite3'), #修正 } }3.まとめ
dbのパス関連をstrに変換するとエラーがなくなるっぽい?
今の所Djangoのバージョン3.1以上で発生しているようなので気になる方はバージョンの引き下げを検討してみたほうがいいかもしれない4.参考
Stackoverflow
Django TypeError: argument of type 'PosixPath' is not iterable
- 投稿日:2020-12-07T13:41:28+09:00
グラフ生成アルゴリズム
これは上智大学エレクトロニクスラボのAdvent Calendar7日目の記事です.
まえがき
交通網やwebページなどの様々なグラフが世の中にはありますが,そのような実データの中には共通する構造を持つものも多いです.例えば人間関係のネットワークは,ある程度小さな直径を持つことが知られています.一般にスモールワールド性と言われ,電力網なども同じ性質を持つそうです.このような世の中に存在するグラフの特性を守りつつ,好きなサイズのグラフを生成する方法をいくつか紹介します.
用語
- 次数
- あるノードが持つエッジの数のこと
- 次数分布
- 次数$k$を持つノードの割合を表した分布$p(k)$
- クラスター係数
- どの程度グラフが三角形を持つか表す指標$C$1 .
- スケールフリー・ネットワーク
- 次数$k$を持つノード数$p(k)$は$p(k) \propto k^{-\gamma}$が成り立つグラフ(ネットワーク)
- スモールワールド・ネットワーク
- 直径が小さくクラスター係数が大きいグラフ(ネットワーク)
モデル
ランダムグラフ
アルゴリズム
かなり単純なアルゴリズムによって生成することができます.ただし下のアルゴリズムは参考文献1で紹介されているものです.定義とアルゴリズムは文献によって異なるようで,networkxでも複数のメソッドを提供しています2.
from random import random import networkx as nx # 実装した場合 def randomGraph(n,p): # 無向グラフを生成する graph = Graph() graph.add_nodes_from(range(n)) # 確率pで任意のノード間をつなぐ for i in range(n): for j in range(i + 1,n): if random() < p: graph.add_edge(i,j) return graph性質
全てのエッジを一様に選択しているため,次数分布は二項分布となります.実際にノード数を$1000$,$p=0.5$として次数分布をプロットしました.
紹介したアルゴリズムでは無向グラフとして生成していますが,文献によっては有向グラフとして生成される場合もあります.
WSモデル(Watts-Strogatz)
WatsとStrogatzによって発表されたものです.次数を大きくせずに,大きなクラスター係数と小さな直径からなるグラフを生成することができます.ここでも参考文献1で紹介されているアルゴリズムに従って実装しました.
アルゴリズム
import networkx as nx from random import randint,random def ws(n,k,p): # n ノード数 # k 平均次数.ただし偶数に限る graph = nx.Graph() graph.add_nodes_from(range(n)) if k%2 == 0: raise ValueError('kは偶数に限られます') if p < 0 or 1 < p: raise ValueError('pは割合です') for i in range(n): for j in range(k // 2): graph.add_edge(i,(i + j)%n) # ランダムに選択した辺から,片方の頂点を繋ぎ変える # 自己辺や多重辺を避け,u == w あるいは v == wを避ける処理を追加することもある for u,v in graph.edges: if random() > p: continue graph.remove_edge(u,v) w = randint(0,n - 1) if random() < 0.5: graph.add_edge(u,w) else: graph.add_edge(v,w) return graph今回は簡潔に最小限の要件だけ満たした実装としました.networkxでは同様のWSモデル3や連結なWSモデル4のグラフを生成するためのメソッドを提供しています.
性質
直径とクラスター係数の大きさは $p$ によって決定され,スモールワールド・ネットワークの要件を満たします.ただしスケールフリー・ネットワークの要件は満たしません.また直径とクラスター係数は $p$ が大きくなるにつれて小さくなります.厳密な関係については以下で述べます.
クラスター係数
確率 $p$ で既にあるエッジを張り替える以前の状態(拡張サイクル)のクラスター係数を考えると,$\frac{3(k/2) - 3}{4(k/2) - 2}$ となります.1つの三角形を構成する3つのエッジが張り替えられずに残る確率は $(1-p)^3$ ですから,1つのクラスターに対して,エッジを張り替えた際に残るクラスターの数の期待値は $(1-p)^3$ となります.したがって,単純にクラスター係数 $C = \frac{3k-6}{4k-4}(1-p)^3$ と表すことができます.これはエッジを張り替えたのちにできるクラスターを無視したもので当然厳密ではありませんが,実測値と経験的に一致することが知られているようです.
直径
参考文献1で求め方が紹介されていますが,やや複雑であるためここでは言及を避けます.
BAモデル(Barabási-Albert)
アルゴリズム
優先的選択に基づいて,既にあるグラフに1つずつノードを追加し,既存のノード $m$ 個に対してエッジを繋げることでグラフを生成します.初期値であるグラフは連結であること以外の条件を課されません.ノード $i$ の次数を $k_i$ と表記し,既に存在するノード数を $N'$ とすると,新しいノードを追加した際にノード $i$ にエッジを繋げる確率は $\frac{k_i}{\sum^{N'}_{j = 1} k_j }$ となります.
import networkx as nx from random import sample def ba(n,m): # 初期値とするグラフは連結であればよい # 今回は初期値を頂点数mの完全グラフとする graph = nx.complete_graph(m) # 確率を管理する用のリスト source = [i for i in range(m) for _ in range(m - 1)] for i in range( len(graph) , n + len(graph) ): # 新たなノードiを追加する graph.add_node(i) # 前述の確率に従って繋げるノードを選択する targets = sample(source,m) for target in targets: graph.add_edge(i,target) # 確率の管理 source.append(target) source.append(i) return graph同一のアルゴリズムがnetworkxのメソッドとして実装されています.5
性質
スケールフリー・ネットワークの要件を満たし,直径の点ではスモールワールド・ネットワークの要件を満たします.また $p(k) \propto k^{-3} $ であることが知られています.
実際に次数分布がべき乗則を満たしているか確認します.その際なだらかにプロットするために,縦軸には次数分布の累積をとることにします.
両対数のプロットで直線になっているので,べき乗則に従っていることが分かります.また任意のノードにおいて,少なくとも $m$ 個のエッジを持つように設定しているので次数 $0$ に近い部分では縦軸の値が $0$ に留まっています.
有向スケールフリー・ネットワーク
ここまで主に無向グラフを生成していましたが,最後に有向なスケールフリー・ネットワークを生成する方法を紹介します.これはnetworkxに
directed.scale_free_graphとして実装されているアルゴリズムです.アルゴリズム
基本的にはBAと同じように既存のグラフにノードを順次追加していく形を取ります.ただし無向グラフではないので,接続するエッジの向きに留意しなければなりません.
以下のいずれかを繰り返すことでノード数が $n$ になった時点で終了です.
- 確率 $\alpha$ で実行.新しいノード -> 既存のノード
- 確率 $\beta$ で実行.既存のノード -> 既存のノード
- 確率 $\gamma$ で実行.既存のノード -> 新しいノード
この時の既存のノードの選び方を説明するために,いくつか記法を整理します.
- $N_t$
- ステップ $t$ におけるグラフのノード数
- $E_t$
- ステップ $t$ におけるグラフのエッジ数
- $\delta_{in}$
- 既に入次数の高いノードの優先度を決定するバイアス
- $\delta_{out}$
- 既に出次数の高いノードの優先度を決定するバイアス
ノード $i$ が選ばれる確率は $ \frac{k_i + \delta_{in,out}}{E_t + \delta_{in,out} \cdot N_t} $ となります.
性質
入次数と出次数の両方でべき乗則に従います.また自己辺や多重辺を容認するアルゴリズムになっていますが,$n$ が十分大きければ最終的に削除しても次数分布に大きな影響はありません.$n = 10^4,
\alpha=0.3,\beta=0.4,\gamma=0.3$ として自己辺と多重辺を削除したグラフの次数分布を下にプロットします.
次数分布
入次数分布
出次数分布
参考文献
- 増田直紀 and 今野紀雄, 2010. 複雑ネットワーク: 基礎から応用まで. 近代科学社
- B. Bollobás, C. Borgs, J. Chayes, and O. Riordan, Directed scale-free graphs, Proceedings of the fourteenth annual ACM-SIAM Symposium on Discrete Algorithms, 132–139, 2003.
こちらの定義を参考にしてください.http://syrinx.q.t.u-tokyo.ac.jp/tori/lecture/complex/network2.pdf ↩
https://networkx.org/documentation/stable/reference/generators.html#module-networkx.generators.random_graphs ↩
https://networkx.org/documentation/stable/reference/generated/networkx.generators.random_graphs.watts_strogatz_graph.html#networkx.generators.random_graphs.watts_strogatz_graph ↩
https://networkx.org/documentation/stable/reference/generated/networkx.generators.random_graphs.connected_watts_strogatz_graph.html#networkx.generators.random_graphs.connected_watts_strogatz_graph ↩
https://networkx.org/documentation/stable/reference/generated/networkx.generators.random_graphs.barabasi_albert_graph.html#networkx.generators.random_graphs.barabasi_albert_graph ↩




