- 投稿日:2020-09-26T22:13:13+09:00
Oracle公開されたTribuoをさわってみた。ドキュメント Tribuo - Intro classification with Irises
※原文は Intro classification with Irises を参照してください。
分類チュートリアル
このチュートリアルでは、Fisherの有名なアヤメ(アイリス)データセットを使って、Tribuoの分類モデルを使ってアヤメ(アイリス)種を予測する方法を紹介します(今は2020年ですが、デモではまだ1936年のデータセットを使っています。次回は90年代のMNISTを使いますのでご安心ください)。ここでは、単純なロジスティック回帰に焦点を当て、Tribuoが各モデルの内部に保存しているデータの出所とメタデータを調査します。
セットアップ
アヤメ(アイリス)のデータセットのコピーを取得する必要があります。wget https://archive.ics.uci.edu/ml/machine-learning-databases/iris/bezdekIris.dataまず必要なTribuoのjarライブラリをロードします。ここでは、分類実験ジャーとjson interop jarライブラリを使って、証明情報を読み書きしています。
jars ./tribuo-classification-experiments-4.0.0-jar-with-dependencies.jar %jars ./tribuo-json-4.0.0-jar-with-dependencies.jarimport java.nio.file.Paths;基本のorg.tribuoパッケージからすべてをインポートし、シンプルなCSVローダーと分類パッケージもインポートします。ロジスティック回帰を構築しようとしているので、それも必要になります。
import org.tribuo.*; import org.tribuo.evaluation.TrainTestSplitter; import org.tribuo.data.csv.CSVLoader; import org.tribuo.classification.*; import org.tribuo.classification.evaluation.*; import org.tribuo.classification.sgd.linear.LogisticRegressionTrainer;これらのインポートは来歴システムのためのものです。
import com.fasterxml.jackson.databind.*; import com.oracle.labs.mlrg.olcut.provenance.ProvenanceUtil; import com.oracle.labs.mlrg.olcut.config.json.*;
データの読み込み
Tribuoでは、すべての予測タイプは、入力から適切なOutputサブクラスを作成することができるOutputFactoryの実装に関連付けられています。ここでは、マルチクラス分類を実行しているので、LabelFactoryを使用します。次に、labelFactoryをシンプルなCSVLoaderに渡して、DataSourceにすべての列を読み込みます。var labelFactory = new LabelFactory(); var csvLoader = new CSVLoader<>(labelFactory);アヤメ(アイリス)のコピーにはカラムヘッダがないので、ヘッダを作成し、パスとどの変数を出力するか(この場合は "species")とともにロードメソッドに供給します。アヤメ(アイリス)にはあらかじめ定義された訓練/テストの分割がないので、70%のデータを訓練に使用して、分割を作成することにします。
var irisHeaders = new String[]{"sepalLength", "sepalWidth", "petalLength", "petalWidth", "species"}; var irisesSource = csvLoader.loadDataSource(Paths.get("bezdekIris.data"),"species",irisHeaders); var irisSplitter = new TrainTestSplitter<>(irisesSource,0.7,1L);トレーニングデータソースとテストデータソースをそれぞれのデータセットに投入する。これらのデータセットは、特徴領域や出力領域など、必要なメタデータをすべて計算します。学習データセットにはMutableDatasetを使用するのがベストです。これでデータセットが揃ったので、モデルを学習する準備ができました。
var trainingDataset = new MutableDataset<>(irisSplitter.getTrain()); var testingDataset = new MutableDataset<>(irisSplitter.getTest()); System.out.println(String.format("Training data size = %d, number of features = %d, number of classes = %d",trainingDataset.size(),trainingDataset.getFeatureMap().size(),trainingDataset.getOutputInfo().size())); System.out.println(String.format("Testing data size = %d, number of features = %d, number of classes = %d",testingDataset.size(),testingDataset.getFeatureMap().size(),testingDataset.getOutputInfo().size()));Training data size = 105, number of features = 4, number of classes = 3 Testing data size = 45, number of features = 4, number of classes = 3
Training the modelそれでは、トレーナーのインスタンスを作成して、デフォルトのハイパーパラメータを見てみましょう。これらのパラメータを完全に制御するために、完全に設定可能なLinearSGDTrainerを直接使用することができます。
Trainer<Label> trainer = new LogisticRegressionTrainer(); System.out.println(trainer.toString());LinearSGDTrainer(objective=LogMulticlass,optimiser=AdaGrad(initialLearningRate=1.0,epsilon=0.1,initialValue=0.0),epochs=5,minibatchSize=1,seed=12345)これは、ロジスティック損失を用いた線形モデルで、AdaGradを用いて5エポックで学習したものです。
それでは、モデルを訓練してみましょう。他のパッケージと同様に、訓練アルゴリズムと訓練データがあれば、訓練は非常に簡単です。
Model<Label> irisModel = trainer.train(trainingDataset);
モデルの評価
モデルを学習したら、それがどれくらい学習できているのかを評価する必要があります。このために、適切な評価器が何であるかをlabelFactoryに尋ね(または直接インスタンス化し)、評価器にモデルとテストデータセットを渡します。また、dataestの代わりにデータソースを渡すこともできます。LabelEvaluator クラスは、一般的な分類メトリックをすべて実装しており、それぞれを個別に検査することができます。LabelEvaluator.toString() は、メトリクスのきれいにフォーマットされた要約を生成します。var evaluator = new LabelEvaluator(); var evaluation = evaluator.evaluate(irisModel,testingDataset); System.out.println(evaluation.toString());Class n tp fn fp recall prec f1 Iris-versicolor 16 16 0 1 1.000 0.941 0.970 Iris-virginica 15 14 1 0 0.933 1.000 0.966 Iris-setosa 14 14 0 0 1.000 1.000 1.000 Total 45 44 1 1 Accuracy 0.978 Micro Average 0.978 0.978 0.978 Macro Average 0.978 0.980 0.978 Balanced Error Rate 0.022precision(精度)、recall(リコール)、F1は、多クラス分類器を評価する際に使用される標準的な指標です。
また、混同行列を表示することもできます。
System.out.println(evaluation.getConfusionMatrix().toString());Iris-versicolor Iris-virginica Iris-setosa Iris-versicolor 16 0 0 Iris-virginica 1 14 0 Iris-setosa
モデルメタデータTribuoは、構築されたすべてのモデルの特徴領域と出力領域を追跡します。これにより、元の学習データにアクセスせずにLIMEのようなテクニックを実行したり、特定の入力が学習モデルの範囲内にあるかどうかのチェックを追加したりすることが可能になります。
Irisesモデルの特徴領域を見てみましょう。
var featureMap = irisModel.getFeatureIDMap(); for (var v : featureMap) { System.out.println(v.toString()); System.out.println(); }CategoricalFeature(name=petalLength,id=0,count=105,map={1.2=1, 6.9=1, 3.6=1, 3.0=1, 1.7=4, 4.9=4, 4.4=3, 3.5=2, 5.9=2, 5.4=1, 4.0=4, 1.4=12, 4.5=4, 5.0=2, 5.5=3, 6.7=2, 3.7=1, 1.9=1, 6.0=2, 5.2=1, 5.7=2, 4.2=2, 4.7=2, 4.8=4, 1.6=4, 5.8=2, 3.8=1, 6.3=1, 3.3=1, 1.0=1, 5.6=4, 5.1=5, 4.6=3, 4.1=2, 1.5=9, 1.3=4, 3.9=3, 6.6=1, 6.1=2}) CategoricalFeature(name=petalWidth,id=1,count=105,map={2.0=3, 0.5=1, 1.2=3, 0.3=6, 1.6=2, 0.1=3, 0.4=5, 2.5=3, 2.3=4, 1.7=2, 1.1=3, 2.1=4, 0.6=1, 1.4=6, 1.0=5, 2.4=1, 1.8=12, 0.2=20, 1.9=4, 1.5=7, 1.3=8, 2.2=2}) CategoricalFeature(name=sepalLength,id=2,count=105,map={6.9=3, 6.4=3, 7.4=1, 4.9=4, 4.4=1, 5.9=3, 5.4=5, 7.2=3, 7.7=3, 5.0=8, 6.2=2, 5.5=5, 6.7=7, 6.0=3, 5.2=2, 6.5=3, 5.7=4, 4.7=2, 4.8=3, 5.8=4, 5.3=1, 6.8=3, 6.3=5, 7.3=1, 5.6=6, 5.1=7, 4.6=4, 7.6=1, 7.1=1, 6.6=2, 6.1=5}) CategoricalFeature(name=sepalWidth,id=3,count=105,map={2.0=1, 2.8=10, 3.6=4, 2.3=3, 2.5=5, 3.1=8, 3.8=4, 3.0=19, 2.6=4, 4.4=1, 3.3=4, 3.5=4, 2.4=2, 3.2=10, 2.9=5, 3.7=3, 3.4=6, 2.2=2, 3.9=2, 4.2=1, 2.7=7})4つの特徴と、それらの値のヒストグラムを見ることができます。この情報は、各特徴からサンプリングしたり、LIMEのような局所的な説明変数の候補例を構築したり、範囲を確認したりするのに利用できます。特徴情報はモデル学習時に凍結されているので、特徴集合が疎な場合(NLP問題ではよくあることですが)には、学習集合中に特徴が何回発生したかを確認するのにも使えます。
モデル証明書最近のアプリケーションでは,多くの異なる種類のMLモデルが配備されており,アプリケーションの様々な側面を支援しています。しかし、ほとんどのMLパッケージは、モデルの追跡と再構築をサポートしていません。Tribuoでは、各モデルがその実績を追跡します。どのようにして作成されたのか、いつ作成されたのか、どのようなデータが関係しているのかを知ることができます。ここでは、アイリスモデルのデータの実績を見てみましょう。デフォルトでは、Tribuo は、各証明書オブジェクトの toString() メソッドを使用することによって、人間が読みやすい適度な形式で証明書を表示します。すべての情報はプログラムからアクセスできます。
var provenance = irisModel.getProvenance(); System.out.println(ProvenanceUtil.formattedProvenanceString(provenance.getDatasetProvenance().getSourceProvenance()));TrainTestSplitter( class-name = org.tribuo.evaluation.TrainTestSplitter source = CSVLoader( class-name = org.tribuo.data.csv.CSVLoader outputFactory = LabelFactory( class-name = org.tribuo.classification.LabelFactory ) response-name = species separator = , quote = " path = file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data file-modified-time = 1999-12-14T15:12:39-05:00 resource-hash = 0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC ) train-proportion = 0.7 seed = 1 size = 150 is-train = true )特定のランダムシードと分割率を使用して、2つに分割されたデータソース上でモデルが学習されていることがわかります。元のデータソースはCSVファイルで、ファイルの修正時刻とSHA-256ハッシュも記録されています。
同様に、訓練者の出所を調べることで、訓練アルゴリズムを知ることができます。
ここでは、予想通り、我々のモデルは勾配降下アルゴリズムとしてAdaGradを使用したLogisticRegressionTrainerを使用して訓練されていることがわかります。
別の記録を残したい場合は、モデルから実績を抽出してjsonファイルとして保存することができます(または、デプロイされたモデルから実績を取り消すこともできます)。
ObjectMapper objMapper = new ObjectMapper(); objMapper.registerModule(new JsonProvenanceModule()); objMapper = objMapper.enable(SerializationFeature.INDENT_OUTPUT);jsonの実績は冗長ですが、人間が読める別のシリアル化フォーマットを提供しています。
System.out.println(jsonProvenance);[ { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "linearsgdmodel-0", "object-class-name" : "org.tribuo.classification.sgd.linear.LinearSGDModel", "provenance-class" : "org.tribuo.provenance.ModelProvenance", "map" : { "instance-values" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.MapMarshalledProvenance", "map" : { } }, "tribuo-version" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "tribuo-version", "value" : "4.0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "trainer" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "trainer", "value" : "logisticregressiontrainer-2", "provenance-class" : "org.tribuo.provenance.impl.TrainerProvenanceImpl", "additional" : "", "is-reference" : true }, "trained-at" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "trained-at", "value" : "2020-08-31T20:24:37.854775-04:00", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DateTimeProvenance", "additional" : "", "is-reference" : false }, "dataset" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "dataset", "value" : "mutabledataset-1", "provenance-class" : "org.tribuo.provenance.DatasetProvenance", "additional" : "", "is-reference" : true }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.linear.LinearSGDModel", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "mutabledataset-1", "object-class-name" : "org.tribuo.MutableDataset", "provenance-class" : "org.tribuo.provenance.DatasetProvenance", "map" : { "num-features" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-features", "value" : "4", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "num-examples" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-examples", "value" : "105", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "num-outputs" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-outputs", "value" : "3", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "tribuo-version" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "tribuo-version", "value" : "4.0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "datasource" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "datasource", "value" : "traintestsplitter-3", "provenance-class" : "org.tribuo.evaluation.TrainTestSplitter$SplitDataSourceProvenance", "additional" : "", "is-reference" : true }, "transformations" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ListMarshalledProvenance", "list" : [ ] }, "is-sequence" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-sequence", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "is-dense" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-dense", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.MutableDataset", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "logisticregressiontrainer-2", "object-class-name" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "provenance-class" : "org.tribuo.provenance.impl.TrainerProvenanceImpl", "map" : { "seed" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "seed", "value" : "12345", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.LongProvenance", "additional" : "", "is-reference" : false }, "minibatchSize" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "minibatchSize", "value" : "1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "train-invocation-count" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "train-invocation-count", "value" : "0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "is-sequence" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-sequence", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "shuffle" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "shuffle", "value" : "true", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "epochs" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "epochs", "value" : "5", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "optimiser" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "optimiser", "value" : "adagrad-4", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "additional" : "", "is-reference" : true }, "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "Trainer", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "objective" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "objective", "value" : "logmulticlass-5", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "additional" : "", "is-reference" : true }, "loggingInterval" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "loggingInterval", "value" : "1000", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "traintestsplitter-3", "object-class-name" : "org.tribuo.evaluation.TrainTestSplitter", "provenance-class" : "org.tribuo.evaluation.TrainTestSplitter$SplitDataSourceProvenance", "map" : { "train-proportion" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "train-proportion", "value" : "0.7", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "seed" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "seed", "value" : "1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.LongProvenance", "additional" : "", "is-reference" : false }, "size" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "size", "value" : "150", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "source" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "source", "value" : "csvloader-6", "provenance-class" : "org.tribuo.data.csv.CSVLoader$CSVLoaderProvenance", "additional" : "", "is-reference" : true }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.evaluation.TrainTestSplitter", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "is-train" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-train", "value" : "true", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "adagrad-4", "object-class-name" : "org.tribuo.math.optimisers.AdaGrad", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "map" : { "epsilon" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "epsilon", "value" : "0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "initialLearningRate" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "initialLearningRate", "value" : "1.0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "initialValue" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "initialValue", "value" : "0.0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "StochasticGradientOptimiser", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.math.optimisers.AdaGrad", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "logmulticlass-5", "object-class-name" : "org.tribuo.classification.sgd.objectives.LogMulticlass", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "map" : { "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "LabelObjective", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.objectives.LogMulticlass", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "csvloader-6", "object-class-name" : "org.tribuo.data.csv.CSVLoader", "provenance-class" : "org.tribuo.data.csv.CSVLoader$CSVLoaderProvenance", "map" : { "resource-hash" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "resource-hash", "value" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.HashProvenance", "additional" : "SHA256", "is-reference" : false }, "path" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "path", "value" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.URLProvenance", "additional" : "", "is-reference" : false }, "file-modified-time" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "file-modified-time", "value" : "1999-12-14T15:12:39-05:00", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DateTimeProvenance", "additional" : "", "is-reference" : false }, "quote" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "quote", "value" : "\"", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.CharProvenance", "additional" : "", "is-reference" : false }, "response-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "response-name", "value" : "species", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "outputFactory" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "outputFactory", "value" : "labelfactory-7", "provenance-class" : "org.tribuo.classification.LabelFactory$LabelFactoryProvenance", "additional" : "", "is-reference" : true }, "separator" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "separator", "value" : ",", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.CharProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.data.csv.CSVLoader", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "labelfactory-7", "object-class-name" : "org.tribuo.classification.LabelFactory", "provenance-class" : "org.tribuo.classification.LabelFactory$LabelFactoryProvenance", "map" : { "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.LabelFactory", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } } ]別の方法として、モデルの証明書は Model.toString() の出力にも存在しますが、この形式は機械可読ではありません。
linear-sgd-model - Model(class-name=org.tribuo.classification.sgd.linear.LinearSGDModel,dataset=Dataset(class-name=org.tribuo.MutableDataset,datasource=SplitDataSourceProvenance(className=org.tribuo.evaluation.TrainTestSplitter,innerSourceProvenance=CSV(class-name=org.tribuo.data.csv.CSVLoader,outputFactory=OutputFactory(class-name=org.tribuo.classification.LabelFactory),response-name=species,separator=,,quote=",path=file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data,file-modified-time=1999-12-14T15:12:39-05:00,resource-hash=SHA-256[0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC]),trainProportion=0.7,seed=1,size=150,isTrain=true),transformations=[],is-sequence=false,is-dense=false,num-examples=105,num-features=4,num-outputs=3,tribuo-version=4.0.1),trainer=Trainer(class-name=org.tribuo.classification.sgd.linear.LogisticRegressionTrainer,seed=12345,minibatchSize=1,shuffle=true,epochs=5,optimiser=StochasticGradientOptimiser(class-name=org.tribuo.math.optimisers.AdaGrad,epsilon=0.1,initialLearningRate=1.0,initialValue=0.0,host-short-name=StochasticGradientOptimiser),objective=LabelObjective(class-name=org.tribuo.classification.sgd.objectives.LogMulticlass,host-short-name=LabelObjective),loggingInterval=1000,train-invocation-count=0,is-sequence=false,host-short-name=Trainer),trained-at=2020-08-31T20:24:37.854775-04:00,instance-values={},tribuo-version=4.0.1)評価には、テストデータの実績とともにモデルの実績を記録する実績もあります。JSON 実績の別の形式を使用しています。しかし、これは少し精度が落ます。そのかわり、読みやすくなっています。この形式は参照に適していますが、すべてを文字列に変換しているため、元の実績オブジェクトを再構築するためには使用できません。
String jsonEvaluationProvenance = objMapper.writeValueAsString(ProvenanceUtil.convertToMap(evaluation.getProvenance())); System.out.println(jsonEvaluationProvenance);{ "tribuo-version" : "4.0.1", "dataset-provenance" : { "num-features" : "4", "num-examples" : "45", "num-outputs" : "3", "tribuo-version" : "4.0.1", "datasource" : { "train-proportion" : "0.7", "seed" : "1", "size" : "150", "source" : { "resource-hash" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "path" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "file-modified-time" : "1999-12-14T15:12:39-05:00", "quote" : "\"", "response-name" : "species", "outputFactory" : { "class-name" : "org.tribuo.classification.LabelFactory" }, "separator" : ",", "class-name" : "org.tribuo.data.csv.CSVLoader" }, "class-name" : "org.tribuo.evaluation.TrainTestSplitter", "is-train" : "false" }, "transformations" : [ ], "is-sequence" : "false", "is-dense" : "false", "class-name" : "org.tribuo.MutableDataset" }, "class-name" : "org.tribuo.provenance.EvaluationProvenance", "model-provenance" : { "instance-values" : { }, "tribuo-version" : "4.0.1", "trainer" : { "seed" : "12345", "minibatchSize" : "1", "train-invocation-count" : "0", "is-sequence" : "false", "shuffle" : "true", "epochs" : "5", "optimiser" : { "epsilon" : "0.1", "initialLearningRate" : "1.0", "initialValue" : "0.0", "host-short-name" : "StochasticGradientOptimiser", "class-name" : "org.tribuo.math.optimisers.AdaGrad" }, "host-short-name" : "Trainer", "class-name" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "objective" : { "host-short-name" : "LabelObjective", "class-name" : "org.tribuo.classification.sgd.objectives.LogMulticlass" }, "loggingInterval" : "1000" }, "trained-at" : "2020-08-31T20:24:37.854775-04:00", "dataset" : { "num-features" : "4", "num-examples" : "105", "num-outputs" : "3", "tribuo-version" : "4.0.1", "datasource" : { "train-proportion" : "0.7", "seed" : "1", "size" : "150", "source" : { "resource-hash" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "path" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "file-modified-time" : "1999-12-14T15:12:39-05:00", "quote" : "\"", "response-name" : "species", "outputFactory" : { "class-name" : "org.tribuo.classification.LabelFactory" }, "separator" : ",", "class-name" : "org.tribuo.data.csv.CSVLoader" }, "class-name" : "org.tribuo.evaluation.TrainTestSplitter", "is-train" : "true" }, "transformations" : [ ], "is-sequence" : "false", "is-dense" : "false", "class-name" : "org.tribuo.MutableDataset" }, "class-name" : "org.tribuo.classification.sgd.linear.LinearSGDModel" } }この実績情報には,モデルの実績情報に含まれるすべてのフィールドと,テストデータ,分割されたデータ,CSVが含まれていることがわかります。
この実績情報は、それだけでもモデルを追跡するのに便利ですが、設定チュートリアルで説明されている設定システムと組み合わせることで、モデルや実験を再構築するための強力な方法となり、どのようなMLモデルでもほぼ完璧な再現性を実現することができます。
結論Tribuoのcsvロードのメカニズム、単純な分類器のトレーニング方法、テストデータ上での分類器の評価方法、さらにTribuoのモデルと評価オブジェクト内に保存されているメタデータと実績情報を見てみました。
- 投稿日:2020-09-26T22:13:13+09:00
Oracleから公開されたTribuoをさわってみた。ドキュメント Tribuo - Intro classification with Irises
※原文は Intro classification with Irises を参照してください。
分類チュートリアル
このチュートリアルでは、Fisherの有名なアヤメ(アイリス)データセットを使って、Tribuoの分類モデルを使ってアヤメ(アイリス)種を予測する方法を紹介します(今は2020年ですが、デモではまだ1936年のデータセットを使っています。次回は90年代のMNISTを使いますのでご安心ください)。ここでは、単純なロジスティック回帰に焦点を当て、Tribuoが各モデルの内部に保存しているデータの出所とメタデータを調査します。
セットアップ
アヤメ(アイリス)のデータセットのコピーを取得する必要があります。wget https://archive.ics.uci.edu/ml/machine-learning-databases/iris/bezdekIris.dataまず必要なTribuoのjarライブラリをロードします。ここでは、分類実験ジャーとjson interop jarライブラリを使って、証明情報を読み書きしています。
jars ./tribuo-classification-experiments-4.0.0-jar-with-dependencies.jar %jars ./tribuo-json-4.0.0-jar-with-dependencies.jarimport java.nio.file.Paths;基本のorg.tribuoパッケージからすべてをインポートし、シンプルなCSVローダーと分類パッケージもインポートします。ロジスティック回帰を構築しようとしているので、それも必要になります。
import org.tribuo.*; import org.tribuo.evaluation.TrainTestSplitter; import org.tribuo.data.csv.CSVLoader; import org.tribuo.classification.*; import org.tribuo.classification.evaluation.*; import org.tribuo.classification.sgd.linear.LogisticRegressionTrainer;これらのインポートは来歴システムのためのものです。
import com.fasterxml.jackson.databind.*; import com.oracle.labs.mlrg.olcut.provenance.ProvenanceUtil; import com.oracle.labs.mlrg.olcut.config.json.*;
データの読み込み
Tribuoでは、すべての予測タイプは、入力から適切なOutputサブクラスを作成することができるOutputFactoryの実装に関連付けられています。ここでは、マルチクラス分類を実行しているので、LabelFactoryを使用します。次に、labelFactoryをシンプルなCSVLoaderに渡して、DataSourceにすべての列を読み込みます。var labelFactory = new LabelFactory(); var csvLoader = new CSVLoader<>(labelFactory);アヤメ(アイリス)のコピーにはカラムヘッダがないので、ヘッダを作成し、パスとどの変数を出力するか(この場合は "species")とともにロードメソッドに供給します。アヤメ(アイリス)にはあらかじめ定義された訓練/テストの分割がないので、70%のデータを訓練に使用して、分割を作成することにします。
var irisHeaders = new String[]{"sepalLength", "sepalWidth", "petalLength", "petalWidth", "species"}; var irisesSource = csvLoader.loadDataSource(Paths.get("bezdekIris.data"),"species",irisHeaders); var irisSplitter = new TrainTestSplitter<>(irisesSource,0.7,1L);トレーニングデータソースとテストデータソースをそれぞれのデータセットに投入する。これらのデータセットは、特徴領域や出力領域など、必要なメタデータをすべて計算します。学習データセットにはMutableDatasetを使用するのがベストです。これでデータセットが揃ったので、モデルを学習する準備ができました。
var trainingDataset = new MutableDataset<>(irisSplitter.getTrain()); var testingDataset = new MutableDataset<>(irisSplitter.getTest()); System.out.println(String.format("Training data size = %d, number of features = %d, number of classes = %d",trainingDataset.size(),trainingDataset.getFeatureMap().size(),trainingDataset.getOutputInfo().size())); System.out.println(String.format("Testing data size = %d, number of features = %d, number of classes = %d",testingDataset.size(),testingDataset.getFeatureMap().size(),testingDataset.getOutputInfo().size()));Training data size = 105, number of features = 4, number of classes = 3 Testing data size = 45, number of features = 4, number of classes = 3
Training the modelそれでは、トレーナーのインスタンスを作成して、デフォルトのハイパーパラメータを見てみましょう。これらのパラメータを完全に制御するために、完全に設定可能なLinearSGDTrainerを直接使用することができます。
Trainer<Label> trainer = new LogisticRegressionTrainer(); System.out.println(trainer.toString());LinearSGDTrainer(objective=LogMulticlass,optimiser=AdaGrad(initialLearningRate=1.0,epsilon=0.1,initialValue=0.0),epochs=5,minibatchSize=1,seed=12345)これは、ロジスティック損失を用いた線形モデルで、AdaGradを用いて5エポックで学習したものです。
それでは、モデルを訓練してみましょう。他のパッケージと同様に、訓練アルゴリズムと訓練データがあれば、訓練は非常に簡単です。
Model<Label> irisModel = trainer.train(trainingDataset);
モデルの評価
モデルを学習したら、それがどれくらい学習できているのかを評価する必要があります。このために、適切な評価器が何であるかをlabelFactoryに尋ね(または直接インスタンス化し)、評価器にモデルとテストデータセットを渡します。また、dataestの代わりにデータソースを渡すこともできます。LabelEvaluator クラスは、一般的な分類メトリックをすべて実装しており、それぞれを個別に検査することができます。LabelEvaluator.toString() は、メトリクスのきれいにフォーマットされた要約を生成します。var evaluator = new LabelEvaluator(); var evaluation = evaluator.evaluate(irisModel,testingDataset); System.out.println(evaluation.toString());Class n tp fn fp recall prec f1 Iris-versicolor 16 16 0 1 1.000 0.941 0.970 Iris-virginica 15 14 1 0 0.933 1.000 0.966 Iris-setosa 14 14 0 0 1.000 1.000 1.000 Total 45 44 1 1 Accuracy 0.978 Micro Average 0.978 0.978 0.978 Macro Average 0.978 0.980 0.978 Balanced Error Rate 0.022precision(精度)、recall(リコール)、F1は、多クラス分類器を評価する際に使用される標準的な指標です。
また、混同行列を表示することもできます。
System.out.println(evaluation.getConfusionMatrix().toString());Iris-versicolor Iris-virginica Iris-setosa Iris-versicolor 16 0 0 Iris-virginica 1 14 0 Iris-setosa
モデルメタデータTribuoは、構築されたすべてのモデルの特徴領域と出力領域を追跡します。これにより、元の学習データにアクセスせずにLIMEのようなテクニックを実行したり、特定の入力が学習モデルの範囲内にあるかどうかのチェックを追加したりすることが可能になります。
Irisesモデルの特徴領域を見てみましょう。
var featureMap = irisModel.getFeatureIDMap(); for (var v : featureMap) { System.out.println(v.toString()); System.out.println(); }CategoricalFeature(name=petalLength,id=0,count=105,map={1.2=1, 6.9=1, 3.6=1, 3.0=1, 1.7=4, 4.9=4, 4.4=3, 3.5=2, 5.9=2, 5.4=1, 4.0=4, 1.4=12, 4.5=4, 5.0=2, 5.5=3, 6.7=2, 3.7=1, 1.9=1, 6.0=2, 5.2=1, 5.7=2, 4.2=2, 4.7=2, 4.8=4, 1.6=4, 5.8=2, 3.8=1, 6.3=1, 3.3=1, 1.0=1, 5.6=4, 5.1=5, 4.6=3, 4.1=2, 1.5=9, 1.3=4, 3.9=3, 6.6=1, 6.1=2}) CategoricalFeature(name=petalWidth,id=1,count=105,map={2.0=3, 0.5=1, 1.2=3, 0.3=6, 1.6=2, 0.1=3, 0.4=5, 2.5=3, 2.3=4, 1.7=2, 1.1=3, 2.1=4, 0.6=1, 1.4=6, 1.0=5, 2.4=1, 1.8=12, 0.2=20, 1.9=4, 1.5=7, 1.3=8, 2.2=2}) CategoricalFeature(name=sepalLength,id=2,count=105,map={6.9=3, 6.4=3, 7.4=1, 4.9=4, 4.4=1, 5.9=3, 5.4=5, 7.2=3, 7.7=3, 5.0=8, 6.2=2, 5.5=5, 6.7=7, 6.0=3, 5.2=2, 6.5=3, 5.7=4, 4.7=2, 4.8=3, 5.8=4, 5.3=1, 6.8=3, 6.3=5, 7.3=1, 5.6=6, 5.1=7, 4.6=4, 7.6=1, 7.1=1, 6.6=2, 6.1=5}) CategoricalFeature(name=sepalWidth,id=3,count=105,map={2.0=1, 2.8=10, 3.6=4, 2.3=3, 2.5=5, 3.1=8, 3.8=4, 3.0=19, 2.6=4, 4.4=1, 3.3=4, 3.5=4, 2.4=2, 3.2=10, 2.9=5, 3.7=3, 3.4=6, 2.2=2, 3.9=2, 4.2=1, 2.7=7})4つの特徴と、それらの値のヒストグラムを見ることができます。この情報は、各特徴からサンプリングしたり、LIMEのような局所的な説明変数の候補例を構築したり、範囲を確認したりするのに利用できます。特徴情報はモデル学習時に凍結されているので、特徴集合が疎な場合(NLP問題ではよくあることですが)には、学習集合中に特徴が何回発生したかを確認するのにも使えます。
モデル証明書最近のアプリケーションでは,多くの異なる種類のMLモデルが配備されており,アプリケーションの様々な側面を支援しています。しかし、ほとんどのMLパッケージは、モデルの追跡と再構築をサポートしていません。Tribuoでは、各モデルがその実績を追跡します。どのようにして作成されたのか、いつ作成されたのか、どのようなデータが関係しているのかを知ることができます。ここでは、アイリスモデルのデータの実績を見てみましょう。デフォルトでは、Tribuo は、各証明書オブジェクトの toString() メソッドを使用することによって、人間が読みやすい適度な形式で証明書を表示します。すべての情報はプログラムからアクセスできます。
var provenance = irisModel.getProvenance(); System.out.println(ProvenanceUtil.formattedProvenanceString(provenance.getDatasetProvenance().getSourceProvenance()));TrainTestSplitter( class-name = org.tribuo.evaluation.TrainTestSplitter source = CSVLoader( class-name = org.tribuo.data.csv.CSVLoader outputFactory = LabelFactory( class-name = org.tribuo.classification.LabelFactory ) response-name = species separator = , quote = " path = file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data file-modified-time = 1999-12-14T15:12:39-05:00 resource-hash = 0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC ) train-proportion = 0.7 seed = 1 size = 150 is-train = true )特定のランダムシードと分割率を使用して、2つに分割されたデータソース上でモデルが学習されていることがわかります。元のデータソースはCSVファイルで、ファイルの修正時刻とSHA-256ハッシュも記録されています。
同様に、訓練者の出所を調べることで、訓練アルゴリズムを知ることができます。
ここでは、予想通り、我々のモデルは勾配降下アルゴリズムとしてAdaGradを使用したLogisticRegressionTrainerを使用して訓練されていることがわかります。
別の記録を残したい場合は、モデルから実績を抽出してjsonファイルとして保存することができます(または、デプロイされたモデルから実績を取り消すこともできます)。
ObjectMapper objMapper = new ObjectMapper(); objMapper.registerModule(new JsonProvenanceModule()); objMapper = objMapper.enable(SerializationFeature.INDENT_OUTPUT);jsonの実績は冗長ですが、人間が読める別のシリアル化フォーマットを提供しています。
System.out.println(jsonProvenance);[ { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "linearsgdmodel-0", "object-class-name" : "org.tribuo.classification.sgd.linear.LinearSGDModel", "provenance-class" : "org.tribuo.provenance.ModelProvenance", "map" : { "instance-values" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.MapMarshalledProvenance", "map" : { } }, "tribuo-version" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "tribuo-version", "value" : "4.0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "trainer" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "trainer", "value" : "logisticregressiontrainer-2", "provenance-class" : "org.tribuo.provenance.impl.TrainerProvenanceImpl", "additional" : "", "is-reference" : true }, "trained-at" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "trained-at", "value" : "2020-08-31T20:24:37.854775-04:00", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DateTimeProvenance", "additional" : "", "is-reference" : false }, "dataset" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "dataset", "value" : "mutabledataset-1", "provenance-class" : "org.tribuo.provenance.DatasetProvenance", "additional" : "", "is-reference" : true }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.linear.LinearSGDModel", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "mutabledataset-1", "object-class-name" : "org.tribuo.MutableDataset", "provenance-class" : "org.tribuo.provenance.DatasetProvenance", "map" : { "num-features" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-features", "value" : "4", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "num-examples" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-examples", "value" : "105", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "num-outputs" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-outputs", "value" : "3", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "tribuo-version" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "tribuo-version", "value" : "4.0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "datasource" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "datasource", "value" : "traintestsplitter-3", "provenance-class" : "org.tribuo.evaluation.TrainTestSplitter$SplitDataSourceProvenance", "additional" : "", "is-reference" : true }, "transformations" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ListMarshalledProvenance", "list" : [ ] }, "is-sequence" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-sequence", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "is-dense" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-dense", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.MutableDataset", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "logisticregressiontrainer-2", "object-class-name" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "provenance-class" : "org.tribuo.provenance.impl.TrainerProvenanceImpl", "map" : { "seed" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "seed", "value" : "12345", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.LongProvenance", "additional" : "", "is-reference" : false }, "minibatchSize" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "minibatchSize", "value" : "1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "train-invocation-count" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "train-invocation-count", "value" : "0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "is-sequence" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-sequence", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "shuffle" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "shuffle", "value" : "true", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "epochs" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "epochs", "value" : "5", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "optimiser" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "optimiser", "value" : "adagrad-4", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "additional" : "", "is-reference" : true }, "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "Trainer", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "objective" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "objective", "value" : "logmulticlass-5", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "additional" : "", "is-reference" : true }, "loggingInterval" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "loggingInterval", "value" : "1000", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "traintestsplitter-3", "object-class-name" : "org.tribuo.evaluation.TrainTestSplitter", "provenance-class" : "org.tribuo.evaluation.TrainTestSplitter$SplitDataSourceProvenance", "map" : { "train-proportion" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "train-proportion", "value" : "0.7", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "seed" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "seed", "value" : "1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.LongProvenance", "additional" : "", "is-reference" : false }, "size" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "size", "value" : "150", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "source" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "source", "value" : "csvloader-6", "provenance-class" : "org.tribuo.data.csv.CSVLoader$CSVLoaderProvenance", "additional" : "", "is-reference" : true }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.evaluation.TrainTestSplitter", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "is-train" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-train", "value" : "true", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "adagrad-4", "object-class-name" : "org.tribuo.math.optimisers.AdaGrad", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "map" : { "epsilon" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "epsilon", "value" : "0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "initialLearningRate" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "initialLearningRate", "value" : "1.0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "initialValue" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "initialValue", "value" : "0.0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "StochasticGradientOptimiser", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.math.optimisers.AdaGrad", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "logmulticlass-5", "object-class-name" : "org.tribuo.classification.sgd.objectives.LogMulticlass", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "map" : { "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "LabelObjective", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.objectives.LogMulticlass", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "csvloader-6", "object-class-name" : "org.tribuo.data.csv.CSVLoader", "provenance-class" : "org.tribuo.data.csv.CSVLoader$CSVLoaderProvenance", "map" : { "resource-hash" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "resource-hash", "value" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.HashProvenance", "additional" : "SHA256", "is-reference" : false }, "path" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "path", "value" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.URLProvenance", "additional" : "", "is-reference" : false }, "file-modified-time" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "file-modified-time", "value" : "1999-12-14T15:12:39-05:00", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DateTimeProvenance", "additional" : "", "is-reference" : false }, "quote" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "quote", "value" : "\"", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.CharProvenance", "additional" : "", "is-reference" : false }, "response-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "response-name", "value" : "species", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "outputFactory" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "outputFactory", "value" : "labelfactory-7", "provenance-class" : "org.tribuo.classification.LabelFactory$LabelFactoryProvenance", "additional" : "", "is-reference" : true }, "separator" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "separator", "value" : ",", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.CharProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.data.csv.CSVLoader", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "labelfactory-7", "object-class-name" : "org.tribuo.classification.LabelFactory", "provenance-class" : "org.tribuo.classification.LabelFactory$LabelFactoryProvenance", "map" : { "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.LabelFactory", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } } ]別の方法として、モデルの証明書は Model.toString() の出力にも存在しますが、この形式は機械可読ではありません。
linear-sgd-model - Model(class-name=org.tribuo.classification.sgd.linear.LinearSGDModel,dataset=Dataset(class-name=org.tribuo.MutableDataset,datasource=SplitDataSourceProvenance(className=org.tribuo.evaluation.TrainTestSplitter,innerSourceProvenance=CSV(class-name=org.tribuo.data.csv.CSVLoader,outputFactory=OutputFactory(class-name=org.tribuo.classification.LabelFactory),response-name=species,separator=,,quote=",path=file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data,file-modified-time=1999-12-14T15:12:39-05:00,resource-hash=SHA-256[0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC]),trainProportion=0.7,seed=1,size=150,isTrain=true),transformations=[],is-sequence=false,is-dense=false,num-examples=105,num-features=4,num-outputs=3,tribuo-version=4.0.1),trainer=Trainer(class-name=org.tribuo.classification.sgd.linear.LogisticRegressionTrainer,seed=12345,minibatchSize=1,shuffle=true,epochs=5,optimiser=StochasticGradientOptimiser(class-name=org.tribuo.math.optimisers.AdaGrad,epsilon=0.1,initialLearningRate=1.0,initialValue=0.0,host-short-name=StochasticGradientOptimiser),objective=LabelObjective(class-name=org.tribuo.classification.sgd.objectives.LogMulticlass,host-short-name=LabelObjective),loggingInterval=1000,train-invocation-count=0,is-sequence=false,host-short-name=Trainer),trained-at=2020-08-31T20:24:37.854775-04:00,instance-values={},tribuo-version=4.0.1)評価には、テストデータの実績とともにモデルの実績を記録する実績もあります。JSON 実績の別の形式を使用しています。しかし、これは少し精度が落ます。そのかわり、読みやすくなっています。この形式は参照に適していますが、すべてを文字列に変換しているため、元の実績オブジェクトを再構築するためには使用できません。
String jsonEvaluationProvenance = objMapper.writeValueAsString(ProvenanceUtil.convertToMap(evaluation.getProvenance())); System.out.println(jsonEvaluationProvenance);{ "tribuo-version" : "4.0.1", "dataset-provenance" : { "num-features" : "4", "num-examples" : "45", "num-outputs" : "3", "tribuo-version" : "4.0.1", "datasource" : { "train-proportion" : "0.7", "seed" : "1", "size" : "150", "source" : { "resource-hash" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "path" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "file-modified-time" : "1999-12-14T15:12:39-05:00", "quote" : "\"", "response-name" : "species", "outputFactory" : { "class-name" : "org.tribuo.classification.LabelFactory" }, "separator" : ",", "class-name" : "org.tribuo.data.csv.CSVLoader" }, "class-name" : "org.tribuo.evaluation.TrainTestSplitter", "is-train" : "false" }, "transformations" : [ ], "is-sequence" : "false", "is-dense" : "false", "class-name" : "org.tribuo.MutableDataset" }, "class-name" : "org.tribuo.provenance.EvaluationProvenance", "model-provenance" : { "instance-values" : { }, "tribuo-version" : "4.0.1", "trainer" : { "seed" : "12345", "minibatchSize" : "1", "train-invocation-count" : "0", "is-sequence" : "false", "shuffle" : "true", "epochs" : "5", "optimiser" : { "epsilon" : "0.1", "initialLearningRate" : "1.0", "initialValue" : "0.0", "host-short-name" : "StochasticGradientOptimiser", "class-name" : "org.tribuo.math.optimisers.AdaGrad" }, "host-short-name" : "Trainer", "class-name" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "objective" : { "host-short-name" : "LabelObjective", "class-name" : "org.tribuo.classification.sgd.objectives.LogMulticlass" }, "loggingInterval" : "1000" }, "trained-at" : "2020-08-31T20:24:37.854775-04:00", "dataset" : { "num-features" : "4", "num-examples" : "105", "num-outputs" : "3", "tribuo-version" : "4.0.1", "datasource" : { "train-proportion" : "0.7", "seed" : "1", "size" : "150", "source" : { "resource-hash" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "path" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "file-modified-time" : "1999-12-14T15:12:39-05:00", "quote" : "\"", "response-name" : "species", "outputFactory" : { "class-name" : "org.tribuo.classification.LabelFactory" }, "separator" : ",", "class-name" : "org.tribuo.data.csv.CSVLoader" }, "class-name" : "org.tribuo.evaluation.TrainTestSplitter", "is-train" : "true" }, "transformations" : [ ], "is-sequence" : "false", "is-dense" : "false", "class-name" : "org.tribuo.MutableDataset" }, "class-name" : "org.tribuo.classification.sgd.linear.LinearSGDModel" } }この実績情報には、モデルの実績情報に含まれるすべてのフィールドと、テストデータ、分割されたデータ、CSVが含まれていることがわかります。
この実績情報は、それだけでもモデルを追跡するのに便利ですが、設定チュートリアルで説明されている設定システムと組み合わせることで、モデルや実験を再構築するための強力な方法となり、どのようなMLモデルでもほぼ完璧な再現性を実現することができます。
結論Tribuoのcsvロードのメカニズム、単純な分類器のトレーニング方法、テストデータ上での分類器の評価方法、さらにTribuoのモデルと評価オブジェクト内に保存されているメタデータと実績情報を見てみました。
- 投稿日:2020-09-26T22:07:44+09:00
Oracle公開されたTribuoをさわってみた。ドキュメント Tribuo - A Java prediction library (v4.0)
※ 原文は Tribuo - A Java prediction library (v4.0) を参照してください。
Introduction
Tribuoは、機械学習モデルを構築・展開するためのJavaライブラリです。中心となる開発チームはOracle Labsの機械学習研究グループであり、このライブラリはApache 2.0ライセンスのもと、Github上で公開されています。
・API は強く型付けされており、モデル、予測値、データセット、例題のためのクラスがパラメータ化されています。
・APIは高レベルで、モデルは例題を消費し、予測値を生成しますが、float配列ではありません。
・APIは統一されており、すべての予測タイプは同じ(よく型付けされた)APIを持ち、Tribuoのクラスは予測タイプによってパラメータ化されています(例:分類はLabelを使用し、回帰はRegressorを使用します)。
・APIは再利用可能で、モジュール化されており、必要なものだけを小分けにしてパッケージ化されているので、必要なものだけを導入することができます。
Tribuoは、同じAPIで幅広いMLアルゴリズムと特徴量を提供しています。
・分類:線形モデル、SVM、ツリー、アンサンブル、ディープラーニング
・回帰:線形モデル、罰則付き線形回帰、SVM、ツリー、アンサンブル、深層学習
・クラスタリング。K-Means
・異常検出。SVM
私たちは、時間の経過とともに利用可能なアルゴリズムを増やしていく予定です。
Tribuoは、データセットをロードし、モデルを訓練し、テストデータ上でモデルを評価することを簡単にします。例えば、このコードはロジスティック回帰モデルを学習し、評価します。
var trainSet = new MutableDataset<>(new LibSVMDataSource("train-data",new LabelFactory())); var model = new LogisticRegressionTrainer().train(trainSet); var eval = new LabelEvaluator().evaluate(new LibSVMDataSource("test-data",trainSet.getOutputFactory()));Getting Started
Tribuoをプロジェクトでりようするために、Mavenでは下記のように設定します。
<dependency> <groupId>org.tribuo</groupId> <artifactId>tribuo-all</artifactId> <version>4.0.0</version> <type>pom</type> </dependency>tribuo-allモジュールは、Tribuoのすべてを取り込みます。特定のユースケースのサブセットを後で選択することができます。
ここでは、分類システムを構築して評価する方法を示す簡単な例を示します。これには4つのステップがあります。1.アヤメの種を分類するためのデータセットをCSVから読み込む。
2.そのデータセットを学習用データセットとテスト用データセットに分割する。
3.異なるトレーナーを用いて2種類のモデルを学習する。
4.モデルを使ってテストセットの予測を行い、テストセット全体の性能を評価する。// ラベル付きアヤメ(アイリス)データを読み込む var irisHeaders = new String[]{"sepalLength", "sepalWidth", "petalLength", "petalWidth", "species"}; DataSource<Label> irisData = new CSVLoader<>(new LabelFactory()).loadDataSource(Paths.get("bezdekIris.data"), /* Output column */ irisHeaders[4], /* Column headers */ irisHeaders); // アヤメ(アイリス)データをトレーニングセット(70%)とテストセット(30%)に分割 var splitIrisData = new TrainTestSplitter<>(irisesSource, /* Train fraction */ 0.7, /* RNG seed */ 1L); var trainData = new MutableDataset<>(splitIrisData.getTrain()); var testData = new MutableDataset<>(splitIrisData.getTest()); // 決定木を学習する var cartTrainer = new CARTClassificationTrainer(); Model<Label> tree = cartTrainer.train(trainData); // ロジスティック回帰 var linearTrainer = new LogisticRegressionTrainer(); Model<Label> linear = linearTrainer.train(trainData); // 最終的には、目に見えないデータから予測を行う // 各予測は、出力名(ラベル)からスコア/確率へのマップ Prediction<Label> prediction = linear.predict(testData.get(0)); // 完全なテストデータセットを評価して、精度、F1などを計算してもよい。 Evaluation<Label> evaluation = new LabelEvaluation().evaluate(linear,testData); // 手動での評価を検査する。 double acc = evaluation.accuracy(); // フォーマットされた評価文字列を表示する。 System.out.println(evaluation.toString());フォーマットされた評価出力は以下のようになります。
Class n tp fn fp recall prec f1 Iris-versicolor 16 16 0 1 1.000 0.941 0.970 Iris-virginica 15 14 1 0 0.933 1.000 0.966 Iris-setosa 14 14 0 0 1.000 1.000 1.000 Total 45 44 1 1 Accuracy 0.978 Micro Average 0.978 0.978 0.978 Macro Average 0.978 0.980 0.978 Balanced Error Rate 0.022この例の詳細については、同じアヤメ(アイリス)データセットを使用した分類チュートリアルをご覧ください。
後で翻訳する。
翻訳した。Documentation Overview
機能一覧では、Tribuoでできることや、ネイティブでもサードパーティ製ライブラリへのインタフェースを介してもサポートしているアルゴリズムの概要を説明しています。Tribuoを理解するための最良の方法は、Tribuoのアーキテクチャ・ドキュメントを読むことです。基本的な定義、データフロー、ライブラリ構造、設定(オプションと実績を含む)、データロード、変換、サンプルの詳細、入力機能を隠すために利用できる難読化機能について説明しています。パッケージ構造の概要では、Tribuoのパッケージが、それぞれがサポートする機械学習タスクを中心にどのように構成されているかを説明しています。これらのパッケージはモジュールにグループ化されているので、Tribuoのユーザは実装に必要な部分だけに依存することができます。Tribuoを使用する上でのセキュリティ上の注意事項や、ユーザが期待することを必ずお読みください。その他の問題や一般的な質問については、FAQを参照してください。すべてのクラスとパッケージの詳細については、TribuoのJavaDocを参照してください。
Tutorials
分類、クラスタリング、回帰、異常検出、設定システムのチュートリアルノートを用意しています。これらはJava Jupyterノートブックカーネルを使用しており、Java 10+で動作します。varキーワードを適切な型に置き換えることで、チュートリアルのコードをJava 8のコードに戻すのは簡単なはずです。
Configuration and Provenance
Tribuoのトレーナは、OLCUT設定システムを介して完全に設定することができます。これにより、XML(またはJSONやEDN)ファイルにトレーナーを一度定義しておけば、全く同じパラメータで繰り返しモデルを構築することができます。各パッケージのconfigフォルダには、提供されているトレーナーの設定例があります。モデルは、データセット自体と同様にJavaシリアライズを使用してシリアライズ可能で、使用されたコンフィグレーションはどのモデルにも保存されます。すべてのモデルと評価には、モデルや評価がいつ作成されたか、使用されたデータは何か、データに適用された変換は何か、トレーナーのハイパーパラメータは何か、評価の場合はどのモデルが使用されたかを記録する、シリアライズ可能な証明書オブジェクトが含まれています。この情報はJSONに抽出することもできますし、Javaシリアライズを使って直接シリアライズすることもできます。本番環境では、この実績情報は、外部システムを介してモデルのトラッキングを提供するために、ハッシュに置き換えて編集することができます。設定、オプション、証明書についての詳細はこちらをご覧ください。
Platform Support & Requirements
TribuoはJava 8+で動作し、JavaのLTSバージョンと最新のリリースでテストを行っています。Tribuo自体はJavaライブラリであり、すべてのJavaプラットフォームでサポートされていますが、一部のインタフェースはネイティブコードを必要とし、ネイティブライブラリがある場所でのみサポートされます。Windows 10、macOS、Linux (RHEL/OL/CentOS 7+)上のx86_64アーキテクチャでテストしています。別のプラットフォームに興味があり、ネイティブライブラリのインターフェース(ONNXランタイム、TensorFlow、XGBoost)のいずれかを使用したい場合は、それらのライブラリの開発者に連絡することをお勧めします。
- 投稿日:2020-09-26T22:07:44+09:00
Oracleから公開されたTribuoをさわってみた。ドキュメント Tribuo - A Java prediction library (v4.0)
※ 原文は Tribuo - A Java prediction library (v4.0) を参照してください。
Introduction
Tribuoは、機械学習モデルを構築・展開するためのJavaライブラリです。中心となる開発チームはOracle Labsの機械学習研究グループであり、このライブラリはApache 2.0ライセンスのもと、Github上で公開されています。
・API は強く型付けされており、モデル、予測値、データセット、例題のためのクラスがパラメータ化されています。
・APIは高レベルで、モデルは例題を消費し、予測値を生成しますが、float配列ではありません。
・APIは統一されており、すべての予測タイプは同じ(よく型付けされた)APIを持ち、Tribuoのクラスは予測タイプによってパラメータ化されています(例:分類はLabelを使用し、回帰はRegressorを使用します)。
・APIは再利用可能で、モジュール化されており、必要なものだけを小分けにしてパッケージ化されているので、必要なものだけを導入することができます。
Tribuoは、同じAPIで幅広いMLアルゴリズムと特徴量を提供しています。
・分類:線形モデル、SVM、ツリー、アンサンブル、ディープラーニング
・回帰:線形モデル、罰則付き線形回帰、SVM、ツリー、アンサンブル、深層学習
・クラスタリング:K-Means
・異常検出:SVM
私たちは、時間の経過とともに利用可能なアルゴリズムを増やしていく予定です。
Tribuoは、データセットをロードし、モデルを訓練し、テストデータ上でモデルを評価することを簡単にします。例えば、このコードはロジスティック回帰モデルを学習し、評価します。
var trainSet = new MutableDataset<>(new LibSVMDataSource("train-data",new LabelFactory())); var model = new LogisticRegressionTrainer().train(trainSet); var eval = new LabelEvaluator().evaluate(new LibSVMDataSource("test-data",trainSet.getOutputFactory()));Getting Started
Tribuoをプロジェクトでりようするために、Mavenでは下記のように設定します。
<dependency> <groupId>org.tribuo</groupId> <artifactId>tribuo-all</artifactId> <version>4.0.0</version> <type>pom</type> </dependency>tribuo-allモジュールは、Tribuoのすべてを取り込みます。特定のユースケースのサブセットを後で選択することができます。
ここでは、分類システムを構築して評価する方法を示す簡単な例を示します。これには4つのステップがあります。1.アヤメの種を分類するためのデータセットをCSVから読み込む。
2.そのデータセットを学習用データセットとテスト用データセットに分割する。
3.異なるトレーナーを用いて2種類のモデルを学習する。
4.モデルを使ってテストセットの予測を行い、テストセット全体の性能を評価する。// ラベル付きアヤメ(アイリス)データを読み込む var irisHeaders = new String[]{"sepalLength", "sepalWidth", "petalLength", "petalWidth", "species"}; DataSource<Label> irisData = new CSVLoader<>(new LabelFactory()).loadDataSource(Paths.get("bezdekIris.data"), /* Output column */ irisHeaders[4], /* Column headers */ irisHeaders); // アヤメ(アイリス)データをトレーニングセット(70%)とテストセット(30%)に分割 var splitIrisData = new TrainTestSplitter<>(irisesSource, /* Train fraction */ 0.7, /* RNG seed */ 1L); var trainData = new MutableDataset<>(splitIrisData.getTrain()); var testData = new MutableDataset<>(splitIrisData.getTest()); // 決定木を学習する var cartTrainer = new CARTClassificationTrainer(); Model<Label> tree = cartTrainer.train(trainData); // ロジスティック回帰 var linearTrainer = new LogisticRegressionTrainer(); Model<Label> linear = linearTrainer.train(trainData); // 最終的には、目に見えないデータから予測を行う // 各予測は、出力名(ラベル)からスコア/確率へのマップ Prediction<Label> prediction = linear.predict(testData.get(0)); // 完全なテストデータセットを評価して、精度、F1などを計算してもよい。 Evaluation<Label> evaluation = new LabelEvaluation().evaluate(linear,testData); // 手動での評価を検査する。 double acc = evaluation.accuracy(); // フォーマットされた評価文字列を表示する。 System.out.println(evaluation.toString());フォーマットされた評価出力は以下のようになります。
Class n tp fn fp recall prec f1 Iris-versicolor 16 16 0 1 1.000 0.941 0.970 Iris-virginica 15 14 1 0 0.933 1.000 0.966 Iris-setosa 14 14 0 0 1.000 1.000 1.000 Total 45 44 1 1 Accuracy 0.978 Micro Average 0.978 0.978 0.978 Macro Average 0.978 0.980 0.978 Balanced Error Rate 0.022この例の詳細については、同じアヤメ(アイリス)データセットを使用した分類チュートリアルをご覧ください。
後で翻訳する。
翻訳した。Documentation Overview
機能一覧では、Tribuoでできることや、ネイティブでもサードパーティ製ライブラリへのインタフェースを介してもサポートしているアルゴリズムの概要を説明しています。Tribuoを理解するための最良の方法は、Tribuoのアーキテクチャ・ドキュメントを読むことです。基本的な定義、データフロー、ライブラリ構造、設定(オプションと実績を含む)、データロード、変換、サンプルの詳細、入力機能を隠すために利用できる難読化機能について説明しています。パッケージ構造の概要では、Tribuoのパッケージが、それぞれがサポートする機械学習タスクを中心にどのように構成されているかを説明しています。これらのパッケージはモジュールにグループ化されているので、Tribuoのユーザは実装に必要な部分だけに依存することができます。Tribuoを使用する上でのセキュリティ上の注意事項や、ユーザが期待することを必ずお読みください。その他の問題や一般的な質問については、FAQを参照してください。すべてのクラスとパッケージの詳細については、TribuoのJavaDocを参照してください。
Tutorials
分類、クラスタリング、回帰、異常検出、設定システムのチュートリアルノートを用意しています。これらはJava Jupyterノートブックカーネルを使用しており、Java 10+で動作します。varキーワードを適切な型に置き換えることで、チュートリアルのコードをJava 8のコードに戻すのは簡単なはずです。
Configuration and Provenance
Tribuoのトレーナは、OLCUT設定システムを介して完全に設定することができます。これにより、XML(またはJSONやEDN)ファイルにトレーナーを一度定義しておけば、全く同じパラメータで繰り返しモデルを構築することができます。各パッケージのconfigフォルダには、提供されているトレーナーの設定例があります。モデルは、データセット自体と同様にJavaシリアライズを使用してシリアライズ可能で、使用されたコンフィグレーションはどのモデルにも保存されます。すべてのモデルと評価には、モデルや評価がいつ作成されたか、使用されたデータは何か、データに適用された変換は何か、トレーナーのハイパーパラメータは何か、評価の場合はどのモデルが使用されたかを記録する、シリアライズ可能な証明書オブジェクトが含まれています。この情報はJSONに抽出することもできますし、Javaシリアライズを使って直接シリアライズすることもできます。本番環境では、この実績情報は、外部システムを介してモデルのトラッキングを提供するために、ハッシュに置き換えて編集することができます。設定、オプション、証明書についての詳細はこちらをご覧ください。
Platform Support & Requirements
TribuoはJava 8+で動作し、JavaのLTSバージョンと最新のリリースでテストを行っています。Tribuo自体はJavaライブラリであり、すべてのJavaプラットフォームでサポートされていますが、一部のインタフェースはネイティブコードを必要とし、ネイティブライブラリがある場所でのみサポートされます。Windows 10、macOS、Linux (RHEL/OL/CentOS 7+)上のx86_64アーキテクチャでテストしています。別のプラットフォームに興味があり、ネイティブライブラリのインターフェース(ONNXランタイム、TensorFlow、XGBoost)のいずれかを使用したい場合は、それらのライブラリの開発者に連絡することをお勧めします。
- 投稿日:2020-09-26T18:33:46+09:00
Javaに初めて触れてみた④
Javaに触れてみた
自己満の備忘録ですのでご容赦ください
いろいろ作ってみる
前回の続きです。
④4択クイズ応用
前回考えたこの機能の改善点
①[[1]明治大学, [2]法政大学, [3]早稲田大学, [4]立教大学]みたいにターミナルに配列の中身を表示させる時に[]を表示支えないようにする。
②選び直してください。の表示が出たら数字を入力できるようにする。多分繰り返し処理でできると思う。
③問題を増やす。
④問題をランダムで出題できるようにする。
⑤答えをランダム表示にできるようにする。とりあえずできそうな所から手をつけます。②を改善します。
Test4.javaimport java.util.Scanner; import java.util.ArrayList; import java.util.List; class Test4 { public static void main(String args[]) { List<String> array = new ArrayList<String>(); array.add("[1]明治大学"); array.add("[2]法政大学"); array.add("[3]早稲田大学"); array.add("[4]立教大学"); for (int i = 0; i <= 3; i++) { System.out.println("2019年ドラフト1位の森下選手の出身大学は?"); System.out.println(array); Integer number = new Scanner(System.in).nextInt(); if (number == 1) { System.out.println("正解です!"); break; } else { array.remove(number - 1); System.out.println("間違いです"); System.out.println("番号を選び直してください。"); } } } }ターミナル2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, [3]早稲田大学, [4]立教大学] 1 正解です!↑正解パターン
break;を書いたので、繰り返しが止まりました。ターミナル2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, [2]法政大学, [3]早稲田大学, [4]立教大学] 2 間違いです 番号を選び直してください。 2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, [3]早稲田大学, [4]立教大学] 1 正解です!↑1度間違えて正解のパターン
いい動きです。ターミナル2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, [2]法政大学, [3]早稲田大学, [4]立教大学] 3 間違いです 番号を選び直してください。 2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, [2]法政大学, [4]立教大学] 4 Exception in thread "main" java.lang.IndexOutOfBoundsException: Index 3 out of bounds for length 3 at java.base/jdk.internal.util.Preconditions.outOfBounds(Preconditions.java:64) at java.base/jdk.internal.util.Preconditions.outOfBoundsCheckIndex(Preconditions.java:70) at java.base/jdk.internal.util.Preconditions.checkIndex(Preconditions.java:248) at java.base/java.util.Objects.checkIndex(Objects.java:359) at java.base/java.util.ArrayList.remove(ArrayList.java:504) at Test4.main(Test4.java:23)↑問題が起きました。
間違えた後に4を選ぶと、配列上は3個目にあるので配列上の数字(2)と入力した数字(3)に齟齬ができてしまいます。
※2と3は入力した数値から1引かれるため現状の知識だとこの修正は難しいので、苦しいですがこんな感じにしました。
Test4.javaimport java.util.Scanner; import java.util.ArrayList; import java.util.List; class Test4 { public static void main(String args[]) { List<String> array = new ArrayList<String>(); array.add("[1]明治大学"); array.add("[2]法政大学"); array.add("[3]早稲田大学"); array.add("[4]立教大学"); for (int i = 0; i <= 3; i++) { System.out.println("2019年ドラフト1位の森下選手の出身大学は?"); System.out.println(array); Integer number = new Scanner(System.in).nextInt(); if (number == 1) { System.out.println("正解です!"); break; } else { array.set(number - 1, ""); System.out.println("間違いです"); System.out.println("番号を選び直してください。"); } } } }array.remove(number - 1);で要素を削除していましたが、
array.set(number - 1, "");で空欄を作ることによって要素数のズレを無くしました。ターミナル[[1]明治大学, [2]法政大学, [3]早稲田大学, [4]立教大学] 2 間違いです 番号を選び直してください。 2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, , [3]早稲田大学, [4]立教大学] 3 間違いです 番号を選び直してください。 2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, , , [4]立教大学] 4 間違いです 番号を選び直してください。 2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, , , ] 1 正解です!理想とは違いますが、まあ良しとしましょう!
次に③を改善します。
Test5.javaimport java.util.Scanner; import java.util.ArrayList; import java.util.List; class Test5 { public static void main(String args[]) { List<String> array01 = new ArrayList<String>(); array01.add("[1]明治大学"); array01.add("[2]法政大学"); array01.add("[3]早稲田大学"); array01.add("[4]立教大学"); for (int i = 0; i <= 3; i++) { System.out.println("2019年ドラフト1位の森下選手の出身大学は?"); System.out.println(array01); Integer number = new Scanner(System.in).nextInt(); if (number == 1) { System.out.println("正解です!"); break; } else { array01.set(number - 1, ""); System.out.println("間違いです"); System.out.println("番号を選び直してください。"); } } List<String> array02 = new ArrayList<String>(); array02.add("[1]明治大学"); array02.add("[2]法政大学"); array02.add("[3]東洋大学"); array02.add("[4]亜細亜大学"); for (int i = 0; i <= 3; i++) { System.out.println("2019年ドラフト2位の宇草選手の出身大学は?"); System.out.println(array02); Integer number = new Scanner(System.in).nextInt(); if (number == 2) { System.out.println("正解です!"); break; } else { array02.set(number - 1, ""); System.out.println("間違いです"); System.out.println("番号を選び直してください。"); } } List<String> array03 = new ArrayList<String>(); array03.add("[1]花咲徳栄高校"); array03.add("[2]敦賀気比高校"); array03.add("[3]霞ヶ浦高校"); array03.add("[4]大船渡高校"); for (int i = 0; i <= 3; i++) { System.out.println("2019年ドラフト3位の鈴木選手の出身高校は?"); System.out.println(array03); Integer number = new Scanner(System.in).nextInt(); if (number == 3) { System.out.println("正解です!"); break; } else { array03.set(number - 1, ""); System.out.println("間違いです"); System.out.println("番号を選び直してください。"); } } } }ターミナル2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, [2]法政大学, [3]早稲田大学, [4]立教大学] 2 間違いです 番号を選び直してください。 2019年ドラフト1位の森下選手の出身大学は? [[1]明治大学, , [3]早稲田大学, [4]立教大学] 1 正解です! 2019年ドラフト2位の宇草選手の出身大学は? [[1]明治大学, [2]法政大学, [3]東洋大学, [4]亜細亜大学] 1 間違いです 番号を選び直してください。 2019年ドラフト2位の宇草選手の出身大学は? [, [2]法政大学, [3]東洋大学, [4]亜細亜大学] 3 間違いです 番号を選び直してください。 2019年ドラフト2位の宇草選手の出身大学は? [, [2]法政大学, , [4]亜細亜大学] 2 正解です! 2019年ドラフト3位の鈴木選手の出身高校は? [[1]花咲徳栄高校, [2]敦賀気比高校, [3]霞ヶ浦高校, [4]大船渡高校] 3 正解です!とりあえず同じ機能を3つ並べてみました。
機能としては問題なしです。
ただ、もう少しコンパクトにできるとは思います。たぶん。おまけ
①ArrayListと配列は違う
これは調べていくうちに分かりました。最初は同じものだと思っていました。
【違い】
・ArrayListはサイズ(要素数)が可変
・宣言方法が違う
・ArrayListはプリミティブ型が入らない
プリミティブ型 intやbooleanなどの値型
- 投稿日:2020-09-26T14:34:23+09:00
EHRbase入門2 - REST API
はじめに
第2回目はREST APIを使ってEHRbaseとデータのやりとりを行います。EHRbaseには開発中を含めて多くのREST APIがあります。今回はそのうちでTemplate, Compositionに関係する以下のAPIを紹介します。
- POST EHR (EHRレコードの作成)
- POST EHR(外部IDつきでEHRレコードを作成)
- GET EHR (EHR IDでEHRレコードを読み出す)
- GET EHR (外部IDでEHRレコードを読み出す)
- POST Template(Tamplateの登録)
- GET Template (個別のテンプレートの読み出し)
- GET Template (テンプレート一覧の読み出し)
- POST Composition (Compositionの登録)
- GET Composition (Compositionの読み出し)
- PUT Composition (Compositionの更新)
- GET COMPOSITION (VersionごとにCompositionを読み出す)
- DELETE Composition(Compositionの論理削除)
作業環境
EHRbaseのREST APIを扱うのはEHRbaseが提供するWebのSwagger UIを利用するのがお手軽です。しかし、あとが残らないのでPostmanを利用するのが開発にはよいかと思います。
openEHRのテンプレートを作成するにはたくさんのツール類があり、Web上で作成できるものもありますが、Ocean Template Designerは歴史も古く使用者も多いです。
- Postman: https://www.postman.com/
- Ocean Template Designer: http://downloads.oceaninformatics.com/downloads/TemplateDesigner/
- このチュートリアルで使用したPostman collection: https://gist.github.com/skoba/0120873e2d31345ff86981115922300c
openEHRのREST API
openEHRの開発が始まった1990年代から2000年代のはじめのほうはRPCやSOAPでインターフェースが実装されていました。外部インターフェースとしてはAQL(Archetype Query Language)という呼び出し言語が整備されていてそれを利用して外部とのやり取りが行うというのがopenEHRでは一般的でした。しかし、2010年代に入るとREST APIが主流となり、FHIRとの連携を含めてopenEHRを実装した各社がREST APIを実装していきました。
openEHRとしては下記のようにREST APIの標準化を行い公開しています。
https://specifications.openehr.org/releases/ITS-REST/latest
しかし、簡略化したJSONフォーマットを利用したAPIがMarand社から発表され、それが便利なので他の実装も従った結果、パラメータや簡略化方法でばらつきが見られるようになりました。openEHR仕様策定委員会で協議した結果、簡略化したデータフォーマットも標準化することとなり、下記のように公開されております。
簡略化データテンプレート標準
https://specifications.openehr.org/releases/ITS-REST/latest/simplified_data_template.htmlMarand社EHRScape API
https://dev.ehrscape.com/api-explorer.htmlEHRbaseの前身の一つであるEtherCISは独自の簡略化を行っていたのですが、今は外されており新しい簡略化データテンプレート標準に基づいた実装が進められております。(2020年12月頃公開予定とのこと)
REST APIの表記
REST APIについては改めての解説は行いません。ものすごく単純化すれば、特定のURLにHTTPメソッドを使ってアクセスしてデータをやりとりすることですが、EHRbaseは各自それぞれの環境でデプロイされていると思いますので、URL表記を統一した書き方ができません。したがって、今回は下記のURLのうちhttp://からehrbase/までの部分を省略して下記のようにREST APIを表記します(良い書き方があったら教えてください)。
例: http://localhost:8080/ehrbase/rest/openehr/v1/ehr にGETメソッドを使って ehr_id に関連する情報をパラメータ付きで取り入れようとする場合
GET /rest/openehr/v1/ehr/{{ehr_id}}パラメータ
key value subject_id ins01 subject_namespace ehr_craft 実際に発行されるリクエストは下記です。URL中に出てくる{{}}は変数部分であることを示します。
curl -X GET "http://localhost:8080/ehrbase/rest/openehr/v1/ehr/f2e3ebf3-596b-4067-9f76-8f4f19c0c474?subject_id=ehr_craft&subject_namespace=ins01" -H "accept: application/xml"
EHR class
openEHRでは患者ごとにデータを管理します。患者ごとにデータを保存する単位がEHRです。EHRといってもEHRのシステムそのものではなく患者さんのデータを入れる箱を作ることをイメージしてください。したがって、REST APIを使ってEHRを作ると言っても、EHRのシステムを作るわけではありません。openEHRのアーキテクチャでは患者氏名、住所、性別などの属性情報はEHRには直接保存せず、外部の患者情報データベースからEHRクラスのIDを呼び出すことで連結します。
これはEHRを匿名データベースとして使用することを想定しての設計です。
POST EHR (EHRレコードの作成)
単に新しいEHRレコードを作成すだけであれば、パラメータ無しで下記のようにPOSTするだけです。
POST /rest/openehr/v1/ehrURLの中の localhost:8080 の部分はそれぞれの環境で読み替えください。下記のようにレスポンスがありますので、ehr_idを保存しておく必要があります。
{ "system_id": { "_type": "HIER_OBJECT_ID", "value": "b1718dd8-a45a-4ebf-a1d6-9a9fd7ca36fb" }, "ehr_id": { "_type": "HIER_OBJECT_ID", "value": "fa95a254-feb0-4b03-9fe3-193d7d485d45" }, "ehr_status": { "_type": "EHR_STATUS", "subject": { "_type": "PARTY_SELF", "external_ref": { "_type": "PARTY_REF", "namespace": "default", "id": { "_type": "HIER_OBJECT_ID", "value": "a258c07e-7b64-4062-b449-f96504e54a94" } } }, "uid": { "_type": "HIER_OBJECT_ID", "value": "1220e446-b637-4c39-a62b-1e53f479ffea" }, "is_queryable": true, "is_modifiable": true }, "time_created": "2020-09-26T02:11:21.214052" }EHRのIDは以下の部分です。
"ehr_id": { "_type": "HIER_OBJECT_ID", "value": "fa95a254-feb0-4b03-9fe3-193d7d485d45" },EHR IDはEHRデータを読み出すときに必要となりますので保存しておいてください。わからなくなるとEHRbaseにはEHR IDの一覧を取得するAPIがないので、PostgreSQLの中を見ないといけなくなります。
POST EHR (外部IDつきでEHRレコードを作成)
診察券番号のように既に患者IDが別に存在する場合は以下のようなJSONメッセージをつけて、/rest/v1/ehrにPOSTすると外部IDも保存されます。
POST /rest/openehr/v1/ehrbody
{ "_type": "EHR_STATUS", "subject": { "external_ref": { "id": { "_type": "GENERIC_ID", "value": "ins11", "scheme": "id_scheme" }, "namespace": "ehr_craft", "type": "PERSON" } }, "is_modifiable": "true", "is_queryable": "true" }EHRbaseのサンプルやSwagger UIだとITEMが空欄のother_detailsが入っていて、そこがエラーを出すので注意してください。
外部IDが重複すると下記のようなエラーが返ってきますのであまり心配せずにどんどんEHRを発行してください。
{ "error": "Specified party has already an EHR set (partyId=ce8bf586-125d-4c28-9970-465eacbaa8c4)", "status": "Conflict" }
GET EHR(EHR IDでEHRレコードを読み出す)
POSTで作ったEHRをEHR IDで呼び出してみましょう。{{EHR ID}}のところに、先ほど返ってきたehr_idを指定します。
GET /rest/openehr/v1/ehr/{{EHR ID}}作成できていれば、登録した内容と同じデータが返ってきます。デフォルトはJSONですが、以下のようにHTTP HeaderにAccept application/xmlと指定するとXML形式でデータが返ってきます。
HTTP header
key value Accept application/xml
GET EHR (外部IDでEHRレコードを読み出す)
GET /rest/openehr/v1/ehr/パラメータ
key value subject_id 0001 subject_namespace NPO openEHR Japan
Templateの作成
openEHRではEHRに登録するデータの単位はCompositionで、カルテ記録や各種レポート、検査結果などがCompositionとして記録されます。TemplateにはCompositionをベースに各種制約が記述されています。
例として体温と症状をモニタするテンプレートを作成します。使用するArchetypeは以下のとおりです。
- openEHR-EHR-COMPOSITION.health_summary.v1
- openEHR-EHR-OBSERVATION.temperature.v1
- openEHR-EHR-OBSERVATION.story.v1
- openEHR-EHR-CLUSTER.symptom_sign.v1
Ocean Template Designerを使ってテンプレートを作成したら、「利用可能なテンプレート」としてexportしておいてください。ファイル識別子がoptとして出力されたファイルを Operational Template (以下OPT)と呼びます。このファイルには扱うデータがすべて定義され、XMLで記述されています。
Tempate IDにスペースを入れると、EHRbaseでは読み出しができなかったりとトラブルが発生しましたので、現時点では避けてください。
今回使用するOPTはsymptom_screening.optとして公開しております。
POST Template(Templateの登録)
POSTでEHRbaseにTemplate(OPT)を登録しましょう。
POST /rest/openehr/v1/definition/template/adl1.4bodyに先ほど作成したoptファイルの中身を貼り付けます。Templateは以template_idとuidで識別されていますので、どちらかがかぶるとエラーが返ってきます。
<uid> <value>17bed299-2c1e-42cc-afb3-6d78002dcce3</value> </uid> <template_id> <value>symptom_screening</value> </template_id>
GET Template (個別のテンプレートの読み出し)
POSTしたTemplateがEHRbaseに登録されているかどうか、GETメソッドで確認します。先ほど登録したtemplateのtemplate_idを使って読み出しましょう。{{template_id}}のところにsymptom_screeningと入力してください。
GET /rest/openehr/v1/definition/template/adl1.4/{{template_id}}登録したOPTがresponseとして返ってきます。
GET Template (テンプレート一覧の読み出し)
現在登録されているリストを取得して確認します。
GET /rest/openehr/v1/definition/template/adl1.4/下記のようなリストが返ってきます
[ { "concept": "symptom_screening", "template_id": "symptom_screening", "archetype_id": "openEHR-EHR-COMPOSITION.health_summary.v1", "created_timestamp": "2020-09-25T03:17:54.134Z" } ]
Template対応JSONインスタンスの作成
Templateで定義された内容をもとにJSONやXMLのインスタンスを生成するのは、それほど楽ではないので自動ツールを作成しています。
EHRbaseはopenEHR-SDKを提供していて、OPTからEHRbaseにアクセスできるクラス群を生成することができます。
今回使用するJSONインスタンスのテンプレートを自動生成するツール群を開発していたのですが、そもそもJSONインスタンスがあまり公開されていませんでしたので調査に時間を要しました。ようやく、1日前に動作するインスタンスが作成できましたので今回はそれをもとにCompositionアクセスを行います。
作成した手順は下記のとおりです。
- EHRScape(Marand)のAPI経由でOPTを登録
- EHRScapeのAPI経由でJSONテンプレートを取得
- FLAT形式を最初に使用していたが通らないので、EHRbaseのコードを解析して現時点ではFLAT形式には対応していないというのを理解
- STRUCTURED形式を指定してEHRScapeよりJSONテンプレートを取得。
- インスタンスを作成しEHRbaseに登録したがcategoryでどうしてもErrorがでるのでEHRbaseの再構築やコードの解析を行いバグとして報告。
- Christian Chevalleyのコメントがかすったのでそれを元にインスタンスの調整を行い可動。
作成したインスタンスはGISTに公開しています。
https://gist.github.com/skoba/cca9f69004a229e5922a0e3e73dca53e
POST Composition(Compositionの登録)
作成したCompositionのインスタンスをREST APIを使って登録します。すでに登録しているEHR IDに紐づけます。
POST /rest/openehr/v1/ehr/{{EHR ID}}/compositionbodyにはGISTのJSONを貼り付けておきましょう。
resposeヘッダが重要です。ETagに"89b114ea-59bd-4d98-b9b8-ad8f819a5aa3::local.ehrbase.org::1"な形式のデータがかかれていますが、これはVersioned Object UIDというものです。先ほどのCompositionレコードに割り振られたUUIDとEHRに登録されている固有のURLとバージョン番号が::で区切られて書かれています。このUUIDがCompositionレコードの IDとなります。
GET Composition(Compositionの読み出し)
EHR IDとComposition IDを使って登録したデータを読み出します。
GET /rest/openehr/v1/ehr/{{EHR ID}}/composition/{{Composition ID}}{{EHR ID}}と{{Composition ID}}にはそれぞれ登録されたEHR IDとComposition IDを入れておいてください。登録したJSONと同じデータが返ってきます。
PUT Composition (Compositionの更新)
修正事項があった場合に内容を変更する場合、PUTを使います。
PUT /rest/openehr/v1/ehr/{{EHR ID}}/composition/{{Composition ID}}boodyには先ほどのJSONの一部を変更したものを使用します。
ここで重要なのは先ほどEtagにもあったCopositionのVersionObjectUIDです。HTTP request headerに以下のように指定します。
key value If-Match version_object_uid 成功するとresponse headerのETagに新しいversion object uidが返ってきます。
GET COMPOSITION (VersionごとにCompositionを読み出す)
openEHRではCOMPOSITIONはすべてバージョン管理されています。先ほどのversioned object uidを使うと先ほど更新したCompositionが変更前、変更後もデータを取り出すことができます。
GET /rest/openehr/v1/ehr/{{EHR ID}}/composition/{versioned object uid}}末尾のバージョンを変更してデータの違いを見てください。
DELETE Composition(Compositionの論理削除)
openEHRではレコードの削除は論理的な削除にとどまり、読み出しができなくなるだけでデータベースとしては保存され続けます。めったに使う機能ではありませんが、削除を行う場合は最新版のversioned oject uidを指定してDELETEを使います。
DELETE /rest/openehr/v1/ehr/{{EHR ID}}/composition/{versioned object uid}}最新版以外を指定するとそのバージョンが削除されますが、まだ他のバージョンを読み出すことはできます。最新版を削除すると旧バージョンを含めてAPIからはアクセスできなくなります。
まとめ
- openEHRのREST APIを一通り紹介しました。まだ他にもAPIはありますので、関連文書などを参照してください。
- まだ、templateからインスタンスを作成するところが難しいのですが、製品版であれば対応していますしOpen Source版でもEtherCISやCabolab EHR serverはインスタンスサンプルを提供する機能があります。
- EHRbaseを例にopenEHRのREST APIとバージョン管理にいついて解説しました。基本的にはすべてのレコードはバージョン付きで保存されていて、上書きや削除は論理的なものであってデータベースには記録されています。
- 次はデータの読み出しを行うAQLを解説します。
- 投稿日:2020-09-26T12:17:23+09:00
Oracleから Tribuo なるJava機械学習ライブラリがリリースされていたため触ってみた。① ドキュメント
Tribuo
OracleからTribuoがリリースされました。
下記は概要です。原文は Tribuo - A Java prediction library (v4.0) を参照してください。
Tribuoは、マルチクラス分類、回帰、クラスタリング、異常検出、マルチラベル分類を提供するJavaの機械学習ライブラリです。Tribuoは、一般的なMLアルゴリズムの実装を提供し、他のライブラリをラップして統一されたインタフェースを提供します。Tribuoには、データの読み込み、変換に必要なすべてのコードが含まれています。さらに、サポートされているすべての予測タイプの評価クラスも含まれています。開発はOracle Labsの機械学習研究グループが主導しています。
すべてのトレーナーは、OLCUT設定システムを使用して設定することができます。これにより、ユーザーはxmlファイルでトレーナーを定義し、繰り返しモデルを構築することができます。提供されている各トレーナーの設定例は、各パッケージのconfigフォルダにあります。これらの設定ファイルは、適切なOLCUT設定依存関係を使用して、jsonまたはednで記述することもできます。モデルとデータセットは、Javaシリアライゼーションを使用してシリアライズ可能です。
すべてのモデルと評価には、モデルや評価の作成時刻、データの同一性、それに適用された変換、トレーナーのハイパーパラメータを記録した、シリアライズ可能な証明書オブジェクトが含まれています。評価の場合、この実績情報には使用された特定のモデルも含まれます。実績情報は、JSONとして抽出することも、Javaシリアライゼーションを使用して直接シリアライズすることもできます。本番環境では、実績情報は、外部システムを介してモデルを追跡するために、ハッシュに置き換えて表示することができます。
TribuoはJava 8+で動作し、最新リリースのJavaと一緒にLTSバージョンのJavaでもテストを行っています。Tribuo自体は純粋なJavaライブラリであり、すべてのJavaプラットフォームでサポートされていますが、一部のインタフェースはネイティブコードを必要とするため、ネイティブライブラリがサポートされている場合にのみサポートされています。Windows 10、macOS、Linux (RHEL/OL/CentOS 7+)上のx86_64アーキテクチャでテストを行っています。別のプラットフォームに興味があり、ネイティブライブラリのインターフェース(ONNXランタイム、TensorFlow、XGBoost)のいずれかを使用したい場合は、それらのライブラリの開発者に連絡を取ることをお勧めします。
チュートリアルの原文は Intro classification with Irises を参照してください。
分類チュートリアル
このチュートリアルでは、Fisherの有名なIrisデータセットを使って、Tribuoの分類モデルを使ってIris種を予測する方法を紹介します(今は2020年ですが、デモではまだ1936年のデータセットを使っています。次回は90年代のMNISTを使いますのでご安心ください)。ここでは、単純なロジスティック回帰に焦点を当て、Tribuoが各モデルの内部に保存しているデータの出所とメタデータを調査します。
セットアップ
irisesのデータセットのコピーを取得する必要があります。wget https://archive.ics.uci.edu/ml/machine-learning-databases/iris/bezdekIris.dataまず必要なTribuoのjarライブラリをロードします。ここでは、分類実験ジャーとjson interop jarライブラリを使って、証明情報を読み書きしています。
jars ./tribuo-classification-experiments-4.0.0-jar-with-dependencies.jar %jars ./tribuo-json-4.0.0-jar-with-dependencies.jarimport java.nio.file.Paths;基本のorg.tribuoパッケージからすべてをインポートし、シンプルなCSVローダーと分類パッケージもインポートします。ロジスティック回帰を構築しようとしているので、それも必要になります。
import org.tribuo.*; import org.tribuo.evaluation.TrainTestSplitter; import org.tribuo.data.csv.CSVLoader; import org.tribuo.classification.*; import org.tribuo.classification.evaluation.*; import org.tribuo.classification.sgd.linear.LogisticRegressionTrainer;これらのインポートは来歴システムのためのものです。
import com.fasterxml.jackson.databind.*; import com.oracle.labs.mlrg.olcut.provenance.ProvenanceUtil; import com.oracle.labs.mlrg.olcut.config.json.*;
データの読み込み
Tribuoでは、すべての予測タイプは、入力から適切なOutputサブクラスを作成することができるOutputFactoryの実装に関連付けられています。ここでは、マルチクラス分類を実行しているので、LabelFactoryを使用します。次に、labelFactoryをシンプルなCSVLoaderに渡して、DataSourceにすべての列を読み込みます。var labelFactory = new LabelFactory(); var csvLoader = new CSVLoader<>(labelFactory);irisesのコピーにはカラムヘッダがないので、ヘッダを作成し、パスとどの変数を出力するか(この場合は "species")とともにロードメソッドに供給します。Irisesにはあらかじめ定義された訓練/テストの分割がないので、70%のデータを訓練に使用して、分割を作成することにします。
var irisHeaders = new String[]{"sepalLength", "sepalWidth", "petalLength", "petalWidth", "species"}; var irisesSource = csvLoader.loadDataSource(Paths.get("bezdekIris.data"),"species",irisHeaders); var irisSplitter = new TrainTestSplitter<>(irisesSource,0.7,1L);トレーニングデータソースとテストデータソースをそれぞれのデータセットに投入する。これらのデータセットは、特徴領域や出力領域など、必要なメタデータをすべて計算します。学習データセットにはMutableDatasetを使用するのがベストです。これでデータセットが揃ったので、モデルを学習する準備ができました。
var trainingDataset = new MutableDataset<>(irisSplitter.getTrain()); var testingDataset = new MutableDataset<>(irisSplitter.getTest()); System.out.println(String.format("Training data size = %d, number of features = %d, number of classes = %d",trainingDataset.size(),trainingDataset.getFeatureMap().size(),trainingDataset.getOutputInfo().size())); System.out.println(String.format("Testing data size = %d, number of features = %d, number of classes = %d",testingDataset.size(),testingDataset.getFeatureMap().size(),testingDataset.getOutputInfo().size()));Training data size = 105, number of features = 4, number of classes = 3 Testing data size = 45, number of features = 4, number of classes = 3
Training the modelそれでは、トレーナーのインスタンスを作成して、デフォルトのハイパーパラメータを見てみましょう。これらのパラメータを完全に制御するために、完全に設定可能なLinearSGDTrainerを直接使用することができます。
Trainer<Label> trainer = new LogisticRegressionTrainer(); System.out.println(trainer.toString());LinearSGDTrainer(objective=LogMulticlass,optimiser=AdaGrad(initialLearningRate=1.0,epsilon=0.1,initialValue=0.0),epochs=5,minibatchSize=1,seed=12345)これは、ロジスティック損失を用いた線形モデルで、AdaGradを用いて5エポックで学習したものです。
それでは、モデルを訓練してみましょう。他のパッケージと同様に、訓練アルゴリズムと訓練データがあれば、訓練は非常に簡単です。
Model<Label> irisModel = trainer.train(trainingDataset);
モデルの評価
モデルを学習したら、それがどれくらい学習できているのかを評価する必要があります。このために、適切な評価器が何であるかをlabelFactoryに尋ね(または直接インスタンス化し)、評価器にモデルとテストデータセットを渡します。また、dataestの代わりにデータソースを渡すこともできます。LabelEvaluator クラスは、一般的な分類メトリックをすべて実装しており、それぞれを個別に検査することができます。LabelEvaluator.toString() は、メトリクスのきれいにフォーマットされた要約を生成します。var evaluator = new LabelEvaluator(); var evaluation = evaluator.evaluate(irisModel,testingDataset); System.out.println(evaluation.toString());Class n tp fn fp recall prec f1 Iris-versicolor 16 16 0 1 1.000 0.941 0.970 Iris-virginica 15 14 1 0 0.933 1.000 0.966 Iris-setosa 14 14 0 0 1.000 1.000 1.000 Total 45 44 1 1 Accuracy 0.978 Micro Average 0.978 0.978 0.978 Macro Average 0.978 0.980 0.978 Balanced Error Rate 0.022precision(精度)、recall(リコール)、F1は、多クラス分類器を評価する際に使用される標準的な指標です。
また、混同行列を表示することもできます。
System.out.println(evaluation.getConfusionMatrix().toString());Iris-versicolor Iris-virginica Iris-setosa Iris-versicolor 16 0 0 Iris-virginica 1 14 0 Iris-setosa
モデルメタデータTribuoは、構築されたすべてのモデルの特徴領域と出力領域を追跡します。これにより、元の学習データにアクセスせずにLIMEのようなテクニックを実行したり、特定の入力が学習モデルの範囲内にあるかどうかのチェックを追加したりすることが可能になります。
Irisesモデルの特徴領域を見てみましょう。
var featureMap = irisModel.getFeatureIDMap(); for (var v : featureMap) { System.out.println(v.toString()); System.out.println(); }CategoricalFeature(name=petalLength,id=0,count=105,map={1.2=1, 6.9=1, 3.6=1, 3.0=1, 1.7=4, 4.9=4, 4.4=3, 3.5=2, 5.9=2, 5.4=1, 4.0=4, 1.4=12, 4.5=4, 5.0=2, 5.5=3, 6.7=2, 3.7=1, 1.9=1, 6.0=2, 5.2=1, 5.7=2, 4.2=2, 4.7=2, 4.8=4, 1.6=4, 5.8=2, 3.8=1, 6.3=1, 3.3=1, 1.0=1, 5.6=4, 5.1=5, 4.6=3, 4.1=2, 1.5=9, 1.3=4, 3.9=3, 6.6=1, 6.1=2}) CategoricalFeature(name=petalWidth,id=1,count=105,map={2.0=3, 0.5=1, 1.2=3, 0.3=6, 1.6=2, 0.1=3, 0.4=5, 2.5=3, 2.3=4, 1.7=2, 1.1=3, 2.1=4, 0.6=1, 1.4=6, 1.0=5, 2.4=1, 1.8=12, 0.2=20, 1.9=4, 1.5=7, 1.3=8, 2.2=2}) CategoricalFeature(name=sepalLength,id=2,count=105,map={6.9=3, 6.4=3, 7.4=1, 4.9=4, 4.4=1, 5.9=3, 5.4=5, 7.2=3, 7.7=3, 5.0=8, 6.2=2, 5.5=5, 6.7=7, 6.0=3, 5.2=2, 6.5=3, 5.7=4, 4.7=2, 4.8=3, 5.8=4, 5.3=1, 6.8=3, 6.3=5, 7.3=1, 5.6=6, 5.1=7, 4.6=4, 7.6=1, 7.1=1, 6.6=2, 6.1=5}) CategoricalFeature(name=sepalWidth,id=3,count=105,map={2.0=1, 2.8=10, 3.6=4, 2.3=3, 2.5=5, 3.1=8, 3.8=4, 3.0=19, 2.6=4, 4.4=1, 3.3=4, 3.5=4, 2.4=2, 3.2=10, 2.9=5, 3.7=3, 3.4=6, 2.2=2, 3.9=2, 4.2=1, 2.7=7})4つの特徴と、それらの値のヒストグラムを見ることができます。この情報は、各特徴からサンプリングしたり、LIMEのような局所的な説明変数の候補例を構築したり、範囲を確認したりするのに利用できます。特徴情報はモデル学習時に凍結されているので、特徴集合が疎な場合(NLP問題ではよくあることですが)には、学習集合中に特徴が何回発生したかを確認するのにも使えます。
モデル証明書最近のアプリケーションでは,多くの異なる種類のMLモデルが配備されており,アプリケーションの様々な側面を支援しています。しかし、ほとんどのMLパッケージは、モデルの追跡と再構築をサポートしていません。Tribuoでは、各モデルがその実績を追跡します。どのようにして作成されたのか、いつ作成されたのか、どのようなデータが関係しているのかを知ることができます。ここでは、アイリスモデルのデータの実績を見てみましょう。デフォルトでは、Tribuo は、各証明書オブジェクトの toString() メソッドを使用することによって、人間が読みやすい適度な形式で証明書を表示します。すべての情報はプログラムからアクセスできます。
var provenance = irisModel.getProvenance(); System.out.println(ProvenanceUtil.formattedProvenanceString(provenance.getDatasetProvenance().getSourceProvenance()));TrainTestSplitter( class-name = org.tribuo.evaluation.TrainTestSplitter source = CSVLoader( class-name = org.tribuo.data.csv.CSVLoader outputFactory = LabelFactory( class-name = org.tribuo.classification.LabelFactory ) response-name = species separator = , quote = " path = file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data file-modified-time = 1999-12-14T15:12:39-05:00 resource-hash = 0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC ) train-proportion = 0.7 seed = 1 size = 150 is-train = true )特定のランダムシードと分割率を使用して、2つに分割されたデータソース上でモデルが学習されていることがわかります。元のデータソースはCSVファイルで、ファイルの修正時刻とSHA-256ハッシュも記録されています。
同様に、訓練者の出所を調べることで、訓練アルゴリズムを知ることができます。
ここでは、予想通り、我々のモデルは勾配降下アルゴリズムとしてAdaGradを使用したLogisticRegressionTrainerを使用して訓練されていることがわかります。
別の記録を残したい場合は、モデルから実績を抽出してjsonファイルとして保存することができます(または、デプロイされたモデルから実績を取り消すこともできます)。
ObjectMapper objMapper = new ObjectMapper(); objMapper.registerModule(new JsonProvenanceModule()); objMapper = objMapper.enable(SerializationFeature.INDENT_OUTPUT);jsonの実績は冗長ですが、人間が読める別のシリアル化フォーマットを提供しています。
System.out.println(jsonProvenance);[ { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "linearsgdmodel-0", "object-class-name" : "org.tribuo.classification.sgd.linear.LinearSGDModel", "provenance-class" : "org.tribuo.provenance.ModelProvenance", "map" : { "instance-values" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.MapMarshalledProvenance", "map" : { } }, "tribuo-version" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "tribuo-version", "value" : "4.0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "trainer" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "trainer", "value" : "logisticregressiontrainer-2", "provenance-class" : "org.tribuo.provenance.impl.TrainerProvenanceImpl", "additional" : "", "is-reference" : true }, "trained-at" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "trained-at", "value" : "2020-08-31T20:24:37.854775-04:00", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DateTimeProvenance", "additional" : "", "is-reference" : false }, "dataset" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "dataset", "value" : "mutabledataset-1", "provenance-class" : "org.tribuo.provenance.DatasetProvenance", "additional" : "", "is-reference" : true }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.linear.LinearSGDModel", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "mutabledataset-1", "object-class-name" : "org.tribuo.MutableDataset", "provenance-class" : "org.tribuo.provenance.DatasetProvenance", "map" : { "num-features" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-features", "value" : "4", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "num-examples" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-examples", "value" : "105", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "num-outputs" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-outputs", "value" : "3", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "tribuo-version" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "tribuo-version", "value" : "4.0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "datasource" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "datasource", "value" : "traintestsplitter-3", "provenance-class" : "org.tribuo.evaluation.TrainTestSplitter$SplitDataSourceProvenance", "additional" : "", "is-reference" : true }, "transformations" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ListMarshalledProvenance", "list" : [ ] }, "is-sequence" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-sequence", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "is-dense" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-dense", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.MutableDataset", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "logisticregressiontrainer-2", "object-class-name" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "provenance-class" : "org.tribuo.provenance.impl.TrainerProvenanceImpl", "map" : { "seed" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "seed", "value" : "12345", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.LongProvenance", "additional" : "", "is-reference" : false }, "minibatchSize" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "minibatchSize", "value" : "1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "train-invocation-count" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "train-invocation-count", "value" : "0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "is-sequence" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-sequence", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "shuffle" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "shuffle", "value" : "true", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "epochs" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "epochs", "value" : "5", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "optimiser" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "optimiser", "value" : "adagrad-4", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "additional" : "", "is-reference" : true }, "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "Trainer", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "objective" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "objective", "value" : "logmulticlass-5", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "additional" : "", "is-reference" : true }, "loggingInterval" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "loggingInterval", "value" : "1000", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "traintestsplitter-3", "object-class-name" : "org.tribuo.evaluation.TrainTestSplitter", "provenance-class" : "org.tribuo.evaluation.TrainTestSplitter$SplitDataSourceProvenance", "map" : { "train-proportion" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "train-proportion", "value" : "0.7", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "seed" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "seed", "value" : "1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.LongProvenance", "additional" : "", "is-reference" : false }, "size" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "size", "value" : "150", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "source" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "source", "value" : "csvloader-6", "provenance-class" : "org.tribuo.data.csv.CSVLoader$CSVLoaderProvenance", "additional" : "", "is-reference" : true }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.evaluation.TrainTestSplitter", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "is-train" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-train", "value" : "true", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "adagrad-4", "object-class-name" : "org.tribuo.math.optimisers.AdaGrad", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "map" : { "epsilon" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "epsilon", "value" : "0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "initialLearningRate" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "initialLearningRate", "value" : "1.0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "initialValue" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "initialValue", "value" : "0.0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "StochasticGradientOptimiser", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.math.optimisers.AdaGrad", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "logmulticlass-5", "object-class-name" : "org.tribuo.classification.sgd.objectives.LogMulticlass", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "map" : { "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "LabelObjective", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.objectives.LogMulticlass", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "csvloader-6", "object-class-name" : "org.tribuo.data.csv.CSVLoader", "provenance-class" : "org.tribuo.data.csv.CSVLoader$CSVLoaderProvenance", "map" : { "resource-hash" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "resource-hash", "value" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.HashProvenance", "additional" : "SHA256", "is-reference" : false }, "path" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "path", "value" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.URLProvenance", "additional" : "", "is-reference" : false }, "file-modified-time" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "file-modified-time", "value" : "1999-12-14T15:12:39-05:00", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DateTimeProvenance", "additional" : "", "is-reference" : false }, "quote" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "quote", "value" : "\"", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.CharProvenance", "additional" : "", "is-reference" : false }, "response-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "response-name", "value" : "species", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "outputFactory" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "outputFactory", "value" : "labelfactory-7", "provenance-class" : "org.tribuo.classification.LabelFactory$LabelFactoryProvenance", "additional" : "", "is-reference" : true }, "separator" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "separator", "value" : ",", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.CharProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.data.csv.CSVLoader", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "labelfactory-7", "object-class-name" : "org.tribuo.classification.LabelFactory", "provenance-class" : "org.tribuo.classification.LabelFactory$LabelFactoryProvenance", "map" : { "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.LabelFactory", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } } ]別の方法として、モデルの証明書は Model.toString() の出力にも存在しますが、この形式は機械可読ではありません。
linear-sgd-model - Model(class-name=org.tribuo.classification.sgd.linear.LinearSGDModel,dataset=Dataset(class-name=org.tribuo.MutableDataset,datasource=SplitDataSourceProvenance(className=org.tribuo.evaluation.TrainTestSplitter,innerSourceProvenance=CSV(class-name=org.tribuo.data.csv.CSVLoader,outputFactory=OutputFactory(class-name=org.tribuo.classification.LabelFactory),response-name=species,separator=,,quote=",path=file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data,file-modified-time=1999-12-14T15:12:39-05:00,resource-hash=SHA-256[0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC]),trainProportion=0.7,seed=1,size=150,isTrain=true),transformations=[],is-sequence=false,is-dense=false,num-examples=105,num-features=4,num-outputs=3,tribuo-version=4.0.1),trainer=Trainer(class-name=org.tribuo.classification.sgd.linear.LogisticRegressionTrainer,seed=12345,minibatchSize=1,shuffle=true,epochs=5,optimiser=StochasticGradientOptimiser(class-name=org.tribuo.math.optimisers.AdaGrad,epsilon=0.1,initialLearningRate=1.0,initialValue=0.0,host-short-name=StochasticGradientOptimiser),objective=LabelObjective(class-name=org.tribuo.classification.sgd.objectives.LogMulticlass,host-short-name=LabelObjective),loggingInterval=1000,train-invocation-count=0,is-sequence=false,host-short-name=Trainer),trained-at=2020-08-31T20:24:37.854775-04:00,instance-values={},tribuo-version=4.0.1)評価には、テストデータの実績とともにモデルの実績を記録する実績もあります。JSON 実績の別の形式を使用しています。しかし、これは少し精度が落ます。そのかわり、読みやすくなっています。この形式は参照に適していますが、すべてを文字列に変換しているため、元の実績オブジェクトを再構築するためには使用できません。
String jsonEvaluationProvenance = objMapper.writeValueAsString(ProvenanceUtil.convertToMap(evaluation.getProvenance())); System.out.println(jsonEvaluationProvenance);{ "tribuo-version" : "4.0.1", "dataset-provenance" : { "num-features" : "4", "num-examples" : "45", "num-outputs" : "3", "tribuo-version" : "4.0.1", "datasource" : { "train-proportion" : "0.7", "seed" : "1", "size" : "150", "source" : { "resource-hash" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "path" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "file-modified-time" : "1999-12-14T15:12:39-05:00", "quote" : "\"", "response-name" : "species", "outputFactory" : { "class-name" : "org.tribuo.classification.LabelFactory" }, "separator" : ",", "class-name" : "org.tribuo.data.csv.CSVLoader" }, "class-name" : "org.tribuo.evaluation.TrainTestSplitter", "is-train" : "false" }, "transformations" : [ ], "is-sequence" : "false", "is-dense" : "false", "class-name" : "org.tribuo.MutableDataset" }, "class-name" : "org.tribuo.provenance.EvaluationProvenance", "model-provenance" : { "instance-values" : { }, "tribuo-version" : "4.0.1", "trainer" : { "seed" : "12345", "minibatchSize" : "1", "train-invocation-count" : "0", "is-sequence" : "false", "shuffle" : "true", "epochs" : "5", "optimiser" : { "epsilon" : "0.1", "initialLearningRate" : "1.0", "initialValue" : "0.0", "host-short-name" : "StochasticGradientOptimiser", "class-name" : "org.tribuo.math.optimisers.AdaGrad" }, "host-short-name" : "Trainer", "class-name" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "objective" : { "host-short-name" : "LabelObjective", "class-name" : "org.tribuo.classification.sgd.objectives.LogMulticlass" }, "loggingInterval" : "1000" }, "trained-at" : "2020-08-31T20:24:37.854775-04:00", "dataset" : { "num-features" : "4", "num-examples" : "105", "num-outputs" : "3", "tribuo-version" : "4.0.1", "datasource" : { "train-proportion" : "0.7", "seed" : "1", "size" : "150", "source" : { "resource-hash" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "path" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "file-modified-time" : "1999-12-14T15:12:39-05:00", "quote" : "\"", "response-name" : "species", "outputFactory" : { "class-name" : "org.tribuo.classification.LabelFactory" }, "separator" : ",", "class-name" : "org.tribuo.data.csv.CSVLoader" }, "class-name" : "org.tribuo.evaluation.TrainTestSplitter", "is-train" : "true" }, "transformations" : [ ], "is-sequence" : "false", "is-dense" : "false", "class-name" : "org.tribuo.MutableDataset" }, "class-name" : "org.tribuo.classification.sgd.linear.LinearSGDModel" } }この実績情報には,モデルの実績情報に含まれるすべてのフィールドと,テストデータ,分割されたデータ,CSVが含まれていることがわかります。
この実績情報は、それだけでもモデルを追跡するのに便利ですが、設定チュートリアルで説明されている設定システムと組み合わせることで、モデルや実験を再構築するための強力な方法となり、どのようなMLモデルでもほぼ完璧な再現性を実現することができます。
結論Tribuoのcsvロードのメカニズム、単純な分類器のトレーニング方法、テストデータ上での分類器の評価方法、さらにTribuoのモデルと評価オブジェクト内に保存されているメタデータと実績情報を見てみました。
- 投稿日:2020-09-26T12:17:23+09:00
Oracleから tribuo なるJava機械学習ライブラリがリリースされていたため触ってみた。① ドキュメント編
Tribou
Oracleからtribuoがリリースされました。
下記は概要です。原文は Tribuo - A Java prediction library (v4.0) を参照してください。
Tribuoは、マルチクラス分類、回帰、クラスタリング、異常検出、マルチラベル分類を提供するJavaの機械学習ライブラリです。Tribuoは、一般的なMLアルゴリズムの実装を提供し、他のライブラリをラップして統一されたインタフェースを提供します。Tribuoには、データの読み込み、変換に必要なすべてのコードが含まれています。さらに、サポートされているすべての予測タイプの評価クラスも含まれています。開発はOracle Labsの機械学習研究グループが主導しています。
すべてのトレーナーは、OLCUT設定システムを使用して設定することができます。これにより、ユーザーはxmlファイルでトレーナーを定義し、繰り返しモデルを構築することができます。提供されている各トレーナーの設定例は、各パッケージのconfigフォルダにあります。これらの設定ファイルは、適切なOLCUT設定依存関係を使用して、jsonまたはednで記述することもできます。モデルとデータセットは、Javaシリアライゼーションを使用してシリアライズ可能です。
すべてのモデルと評価には、モデルや評価の作成時刻、データの同一性、それに適用された変換、トレーナーのハイパーパラメータを記録した、シリアライズ可能な証明書オブジェクトが含まれています。評価の場合、この実績情報には使用された特定のモデルも含まれます。実績情報は、JSONとして抽出することも、Javaシリアライゼーションを使用して直接シリアライズすることもできます。本番環境では、実績情報は、外部システムを介してモデルを追跡するために、ハッシュに置き換えて表示することができます。
TribuoはJava 8+で動作し、最新リリースのJavaと一緒にLTSバージョンのJavaでもテストを行っています。Tribuo自体は純粋なJavaライブラリであり、すべてのJavaプラットフォームでサポートされていますが、一部のインタフェースはネイティブコードを必要とするため、ネイティブライブラリがサポートされている場合にのみサポートされています。Windows 10、macOS、Linux (RHEL/OL/CentOS 7+)上のx86_64アーキテクチャでテストを行っています。別のプラットフォームに興味があり、ネイティブライブラリのインターフェース(ONNXランタイム、TensorFlow、XGBoost)のいずれかを使用したい場合は、それらのライブラリの開発者に連絡を取ることをお勧めします。
チュートリアルの原文は Intro classification with Irises を参照してください。
分類チュートリアル
このチュートリアルでは、Fisherの有名なIrisデータセットを使って、Tribuoの分類モデルを使ってIris種を予測する方法を紹介します(今は2020年ですが、デモではまだ1936年のデータセットを使っています。次回は90年代のMNISTを使いますのでご安心ください)。ここでは、単純なロジスティック回帰に焦点を当て、Tribuoが各モデルの内部に保存しているデータの出所とメタデータを調査します。
セットアップ
irisesのデータセットのコピーを取得する必要があります。wget https://archive.ics.uci.edu/ml/machine-learning-databases/iris/bezdekIris.dataまず必要なTribuoのjarライブラリをロードします。ここでは、分類実験ジャーとjson interop jarライブラリを使って、証明情報を読み書きしています。
jars ./tribuo-classification-experiments-4.0.0-jar-with-dependencies.jar %jars ./tribuo-json-4.0.0-jar-with-dependencies.jarimport java.nio.file.Paths;基本のorg.tribuoパッケージからすべてをインポートし、シンプルなCSVローダーと分類パッケージもインポートします。ロジスティック回帰を構築しようとしているので、それも必要になります。
import org.tribuo.*; import org.tribuo.evaluation.TrainTestSplitter; import org.tribuo.data.csv.CSVLoader; import org.tribuo.classification.*; import org.tribuo.classification.evaluation.*; import org.tribuo.classification.sgd.linear.LogisticRegressionTrainer;これらのインポートは来歴システムのためのものです。
import com.fasterxml.jackson.databind.*; import com.oracle.labs.mlrg.olcut.provenance.ProvenanceUtil; import com.oracle.labs.mlrg.olcut.config.json.*;
データの読み込み
Tribuoでは、すべての予測タイプは、入力から適切なOutputサブクラスを作成することができるOutputFactoryの実装に関連付けられています。ここでは、マルチクラス分類を実行しているので、LabelFactoryを使用します。次に、labelFactoryをシンプルなCSVLoaderに渡して、DataSourceにすべての列を読み込みます。var labelFactory = new LabelFactory(); var csvLoader = new CSVLoader<>(labelFactory);irisesのコピーにはカラムヘッダがないので、ヘッダを作成し、パスとどの変数を出力するか(この場合は "species")とともにロードメソッドに供給します。Irisesにはあらかじめ定義された訓練/テストの分割がないので、70%のデータを訓練に使用して、分割を作成することにします。
var irisHeaders = new String[]{"sepalLength", "sepalWidth", "petalLength", "petalWidth", "species"}; var irisesSource = csvLoader.loadDataSource(Paths.get("bezdekIris.data"),"species",irisHeaders); var irisSplitter = new TrainTestSplitter<>(irisesSource,0.7,1L);トレーニングデータソースとテストデータソースをそれぞれのデータセットに投入する。これらのデータセットは、特徴領域や出力領域など、必要なメタデータをすべて計算します。学習データセットにはMutableDatasetを使用するのがベストです。これでデータセットが揃ったので、モデルを学習する準備ができました。
var trainingDataset = new MutableDataset<>(irisSplitter.getTrain()); var testingDataset = new MutableDataset<>(irisSplitter.getTest()); System.out.println(String.format("Training data size = %d, number of features = %d, number of classes = %d",trainingDataset.size(),trainingDataset.getFeatureMap().size(),trainingDataset.getOutputInfo().size())); System.out.println(String.format("Testing data size = %d, number of features = %d, number of classes = %d",testingDataset.size(),testingDataset.getFeatureMap().size(),testingDataset.getOutputInfo().size()));Training data size = 105, number of features = 4, number of classes = 3 Testing data size = 45, number of features = 4, number of classes = 3
Training the modelそれでは、トレーナーのインスタンスを作成して、デフォルトのハイパーパラメータを見てみましょう。これらのパラメータを完全に制御するために、完全に設定可能なLinearSGDTrainerを直接使用することができます。
Trainer<Label> trainer = new LogisticRegressionTrainer(); System.out.println(trainer.toString());LinearSGDTrainer(objective=LogMulticlass,optimiser=AdaGrad(initialLearningRate=1.0,epsilon=0.1,initialValue=0.0),epochs=5,minibatchSize=1,seed=12345)これは、ロジスティック損失を用いた線形モデルで、AdaGradを用いて5エポックで学習したものです。
それでは、モデルを訓練してみましょう。他のパッケージと同様に、訓練アルゴリズムと訓練データがあれば、訓練は非常に簡単です。
Model<Label> irisModel = trainer.train(trainingDataset);
モデルの評価
モデルを学習したら、それがどれくらい学習できているのかを評価する必要があります。このために、適切な評価器が何であるかをlabelFactoryに尋ね(または直接インスタンス化し)、評価器にモデルとテストデータセットを渡します。また、dataestの代わりにデータソースを渡すこともできます。LabelEvaluator クラスは、一般的な分類メトリックをすべて実装しており、それぞれを個別に検査することができます。LabelEvaluator.toString() は、メトリクスのきれいにフォーマットされた要約を生成します。var evaluator = new LabelEvaluator(); var evaluation = evaluator.evaluate(irisModel,testingDataset); System.out.println(evaluation.toString());Class n tp fn fp recall prec f1 Iris-versicolor 16 16 0 1 1.000 0.941 0.970 Iris-virginica 15 14 1 0 0.933 1.000 0.966 Iris-setosa 14 14 0 0 1.000 1.000 1.000 Total 45 44 1 1 Accuracy 0.978 Micro Average 0.978 0.978 0.978 Macro Average 0.978 0.980 0.978 Balanced Error Rate 0.022precision(精度)、recall(リコール)、F1は、多クラス分類器を評価する際に使用される標準的な指標です。
また、混同行列を表示することもできます。
System.out.println(evaluation.getConfusionMatrix().toString());Iris-versicolor Iris-virginica Iris-setosa Iris-versicolor 16 0 0 Iris-virginica 1 14 0 Iris-setosa
モデルメタデータTribuoは、構築されたすべてのモデルの特徴領域と出力領域を追跡します。これにより、元の学習データにアクセスせずにLIMEのようなテクニックを実行したり、特定の入力が学習モデルの範囲内にあるかどうかのチェックを追加したりすることが可能になります。
Irisesモデルの特徴領域を見てみましょう。
var featureMap = irisModel.getFeatureIDMap(); for (var v : featureMap) { System.out.println(v.toString()); System.out.println(); }CategoricalFeature(name=petalLength,id=0,count=105,map={1.2=1, 6.9=1, 3.6=1, 3.0=1, 1.7=4, 4.9=4, 4.4=3, 3.5=2, 5.9=2, 5.4=1, 4.0=4, 1.4=12, 4.5=4, 5.0=2, 5.5=3, 6.7=2, 3.7=1, 1.9=1, 6.0=2, 5.2=1, 5.7=2, 4.2=2, 4.7=2, 4.8=4, 1.6=4, 5.8=2, 3.8=1, 6.3=1, 3.3=1, 1.0=1, 5.6=4, 5.1=5, 4.6=3, 4.1=2, 1.5=9, 1.3=4, 3.9=3, 6.6=1, 6.1=2}) CategoricalFeature(name=petalWidth,id=1,count=105,map={2.0=3, 0.5=1, 1.2=3, 0.3=6, 1.6=2, 0.1=3, 0.4=5, 2.5=3, 2.3=4, 1.7=2, 1.1=3, 2.1=4, 0.6=1, 1.4=6, 1.0=5, 2.4=1, 1.8=12, 0.2=20, 1.9=4, 1.5=7, 1.3=8, 2.2=2}) CategoricalFeature(name=sepalLength,id=2,count=105,map={6.9=3, 6.4=3, 7.4=1, 4.9=4, 4.4=1, 5.9=3, 5.4=5, 7.2=3, 7.7=3, 5.0=8, 6.2=2, 5.5=5, 6.7=7, 6.0=3, 5.2=2, 6.5=3, 5.7=4, 4.7=2, 4.8=3, 5.8=4, 5.3=1, 6.8=3, 6.3=5, 7.3=1, 5.6=6, 5.1=7, 4.6=4, 7.6=1, 7.1=1, 6.6=2, 6.1=5}) CategoricalFeature(name=sepalWidth,id=3,count=105,map={2.0=1, 2.8=10, 3.6=4, 2.3=3, 2.5=5, 3.1=8, 3.8=4, 3.0=19, 2.6=4, 4.4=1, 3.3=4, 3.5=4, 2.4=2, 3.2=10, 2.9=5, 3.7=3, 3.4=6, 2.2=2, 3.9=2, 4.2=1, 2.7=7})4つの特徴と、それらの値のヒストグラムを見ることができます。この情報は、各特徴からサンプリングしたり、LIMEのような局所的な説明変数の候補例を構築したり、範囲を確認したりするのに利用できます。特徴情報はモデル学習時に凍結されているので、特徴集合が疎な場合(NLP問題ではよくあることですが)には、学習集合中に特徴が何回発生したかを確認するのにも使えます。
モデル証明書最近のアプリケーションでは,多くの異なる種類のMLモデルが配備されており,アプリケーションの様々な側面を支援しています。しかし、ほとんどのMLパッケージは、モデルの追跡と再構築をサポートしていません。Tribuoでは、各モデルがその実績を追跡します。どのようにして作成されたのか、いつ作成されたのか、どのようなデータが関係しているのかを知ることができます。ここでは、アイリスモデルのデータの実績を見てみましょう。デフォルトでは、Tribuo は、各証明書オブジェクトの toString() メソッドを使用することによって、人間が読みやすい適度な形式で証明書を表示します。すべての情報はプログラムからアクセスできます。
var provenance = irisModel.getProvenance(); System.out.println(ProvenanceUtil.formattedProvenanceString(provenance.getDatasetProvenance().getSourceProvenance()));TrainTestSplitter( class-name = org.tribuo.evaluation.TrainTestSplitter source = CSVLoader( class-name = org.tribuo.data.csv.CSVLoader outputFactory = LabelFactory( class-name = org.tribuo.classification.LabelFactory ) response-name = species separator = , quote = " path = file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data file-modified-time = 1999-12-14T15:12:39-05:00 resource-hash = 0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC ) train-proportion = 0.7 seed = 1 size = 150 is-train = true )特定のランダムシードと分割率を使用して、2つに分割されたデータソース上でモデルが学習されていることがわかります。元のデータソースはCSVファイルで、ファイルの修正時刻とSHA-256ハッシュも記録されています。
同様に、訓練者の出所を調べることで、訓練アルゴリズムを知ることができます。
ここでは、予想通り、我々のモデルは勾配降下アルゴリズムとしてAdaGradを使用したLogisticRegressionTrainerを使用して訓練されていることがわかります。
別の記録を残したい場合は、モデルから実績を抽出してjsonファイルとして保存することができます(または、デプロイされたモデルから実績を取り消すこともできます)。
ObjectMapper objMapper = new ObjectMapper(); objMapper.registerModule(new JsonProvenanceModule()); objMapper = objMapper.enable(SerializationFeature.INDENT_OUTPUT);jsonの実績は冗長ですが、人間が読める別のシリアル化フォーマットを提供しています。
System.out.println(jsonProvenance);[ { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "linearsgdmodel-0", "object-class-name" : "org.tribuo.classification.sgd.linear.LinearSGDModel", "provenance-class" : "org.tribuo.provenance.ModelProvenance", "map" : { "instance-values" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.MapMarshalledProvenance", "map" : { } }, "tribuo-version" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "tribuo-version", "value" : "4.0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "trainer" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "trainer", "value" : "logisticregressiontrainer-2", "provenance-class" : "org.tribuo.provenance.impl.TrainerProvenanceImpl", "additional" : "", "is-reference" : true }, "trained-at" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "trained-at", "value" : "2020-08-31T20:24:37.854775-04:00", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DateTimeProvenance", "additional" : "", "is-reference" : false }, "dataset" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "dataset", "value" : "mutabledataset-1", "provenance-class" : "org.tribuo.provenance.DatasetProvenance", "additional" : "", "is-reference" : true }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.linear.LinearSGDModel", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "mutabledataset-1", "object-class-name" : "org.tribuo.MutableDataset", "provenance-class" : "org.tribuo.provenance.DatasetProvenance", "map" : { "num-features" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-features", "value" : "4", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "num-examples" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-examples", "value" : "105", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "num-outputs" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "num-outputs", "value" : "3", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "tribuo-version" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "tribuo-version", "value" : "4.0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "datasource" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "datasource", "value" : "traintestsplitter-3", "provenance-class" : "org.tribuo.evaluation.TrainTestSplitter$SplitDataSourceProvenance", "additional" : "", "is-reference" : true }, "transformations" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ListMarshalledProvenance", "list" : [ ] }, "is-sequence" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-sequence", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "is-dense" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-dense", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.MutableDataset", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "logisticregressiontrainer-2", "object-class-name" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "provenance-class" : "org.tribuo.provenance.impl.TrainerProvenanceImpl", "map" : { "seed" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "seed", "value" : "12345", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.LongProvenance", "additional" : "", "is-reference" : false }, "minibatchSize" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "minibatchSize", "value" : "1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "train-invocation-count" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "train-invocation-count", "value" : "0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "is-sequence" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-sequence", "value" : "false", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "shuffle" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "shuffle", "value" : "true", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false }, "epochs" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "epochs", "value" : "5", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "optimiser" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "optimiser", "value" : "adagrad-4", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "additional" : "", "is-reference" : true }, "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "Trainer", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "objective" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "objective", "value" : "logmulticlass-5", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "additional" : "", "is-reference" : true }, "loggingInterval" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "loggingInterval", "value" : "1000", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "traintestsplitter-3", "object-class-name" : "org.tribuo.evaluation.TrainTestSplitter", "provenance-class" : "org.tribuo.evaluation.TrainTestSplitter$SplitDataSourceProvenance", "map" : { "train-proportion" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "train-proportion", "value" : "0.7", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "seed" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "seed", "value" : "1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.LongProvenance", "additional" : "", "is-reference" : false }, "size" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "size", "value" : "150", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.IntProvenance", "additional" : "", "is-reference" : false }, "source" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "source", "value" : "csvloader-6", "provenance-class" : "org.tribuo.data.csv.CSVLoader$CSVLoaderProvenance", "additional" : "", "is-reference" : true }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.evaluation.TrainTestSplitter", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "is-train" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "is-train", "value" : "true", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.BooleanProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "adagrad-4", "object-class-name" : "org.tribuo.math.optimisers.AdaGrad", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "map" : { "epsilon" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "epsilon", "value" : "0.1", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "initialLearningRate" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "initialLearningRate", "value" : "1.0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "initialValue" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "initialValue", "value" : "0.0", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DoubleProvenance", "additional" : "", "is-reference" : false }, "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "StochasticGradientOptimiser", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.math.optimisers.AdaGrad", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "logmulticlass-5", "object-class-name" : "org.tribuo.classification.sgd.objectives.LogMulticlass", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.impl.ConfiguredObjectProvenanceImpl", "map" : { "host-short-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "host-short-name", "value" : "LabelObjective", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.sgd.objectives.LogMulticlass", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "csvloader-6", "object-class-name" : "org.tribuo.data.csv.CSVLoader", "provenance-class" : "org.tribuo.data.csv.CSVLoader$CSVLoaderProvenance", "map" : { "resource-hash" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "resource-hash", "value" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.HashProvenance", "additional" : "SHA256", "is-reference" : false }, "path" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "path", "value" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.URLProvenance", "additional" : "", "is-reference" : false }, "file-modified-time" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "file-modified-time", "value" : "1999-12-14T15:12:39-05:00", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.DateTimeProvenance", "additional" : "", "is-reference" : false }, "quote" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "quote", "value" : "\"", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.CharProvenance", "additional" : "", "is-reference" : false }, "response-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "response-name", "value" : "species", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false }, "outputFactory" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "outputFactory", "value" : "labelfactory-7", "provenance-class" : "org.tribuo.classification.LabelFactory$LabelFactoryProvenance", "additional" : "", "is-reference" : true }, "separator" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "separator", "value" : ",", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.CharProvenance", "additional" : "", "is-reference" : false }, "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.data.csv.CSVLoader", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } }, { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.ObjectMarshalledProvenance", "object-name" : "labelfactory-7", "object-class-name" : "org.tribuo.classification.LabelFactory", "provenance-class" : "org.tribuo.classification.LabelFactory$LabelFactoryProvenance", "map" : { "class-name" : { "marshalled-class" : "com.oracle.labs.mlrg.olcut.provenance.io.SimpleMarshalledProvenance", "key" : "class-name", "value" : "org.tribuo.classification.LabelFactory", "provenance-class" : "com.oracle.labs.mlrg.olcut.provenance.primitives.StringProvenance", "additional" : "", "is-reference" : false } } } ]別の方法として、モデルの証明書は Model.toString() の出力にも存在しますが、この形式は機械可読ではありません。
linear-sgd-model - Model(class-name=org.tribuo.classification.sgd.linear.LinearSGDModel,dataset=Dataset(class-name=org.tribuo.MutableDataset,datasource=SplitDataSourceProvenance(className=org.tribuo.evaluation.TrainTestSplitter,innerSourceProvenance=CSV(class-name=org.tribuo.data.csv.CSVLoader,outputFactory=OutputFactory(class-name=org.tribuo.classification.LabelFactory),response-name=species,separator=,,quote=",path=file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data,file-modified-time=1999-12-14T15:12:39-05:00,resource-hash=SHA-256[0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC]),trainProportion=0.7,seed=1,size=150,isTrain=true),transformations=[],is-sequence=false,is-dense=false,num-examples=105,num-features=4,num-outputs=3,tribuo-version=4.0.1),trainer=Trainer(class-name=org.tribuo.classification.sgd.linear.LogisticRegressionTrainer,seed=12345,minibatchSize=1,shuffle=true,epochs=5,optimiser=StochasticGradientOptimiser(class-name=org.tribuo.math.optimisers.AdaGrad,epsilon=0.1,initialLearningRate=1.0,initialValue=0.0,host-short-name=StochasticGradientOptimiser),objective=LabelObjective(class-name=org.tribuo.classification.sgd.objectives.LogMulticlass,host-short-name=LabelObjective),loggingInterval=1000,train-invocation-count=0,is-sequence=false,host-short-name=Trainer),trained-at=2020-08-31T20:24:37.854775-04:00,instance-values={},tribuo-version=4.0.1)評価には、テストデータの実績とともにモデルの実績を記録する実績もあります。JSON 実績の別の形式を使用しています。しかし、これは少し精度が落ます。そのかわり、読みやすくなっています。この形式は参照に適していますが、すべてを文字列に変換しているため、元の実績オブジェクトを再構築するためには使用できません。
String jsonEvaluationProvenance = objMapper.writeValueAsString(ProvenanceUtil.convertToMap(evaluation.getProvenance())); System.out.println(jsonEvaluationProvenance);{ "tribuo-version" : "4.0.1", "dataset-provenance" : { "num-features" : "4", "num-examples" : "45", "num-outputs" : "3", "tribuo-version" : "4.0.1", "datasource" : { "train-proportion" : "0.7", "seed" : "1", "size" : "150", "source" : { "resource-hash" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "path" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "file-modified-time" : "1999-12-14T15:12:39-05:00", "quote" : "\"", "response-name" : "species", "outputFactory" : { "class-name" : "org.tribuo.classification.LabelFactory" }, "separator" : ",", "class-name" : "org.tribuo.data.csv.CSVLoader" }, "class-name" : "org.tribuo.evaluation.TrainTestSplitter", "is-train" : "false" }, "transformations" : [ ], "is-sequence" : "false", "is-dense" : "false", "class-name" : "org.tribuo.MutableDataset" }, "class-name" : "org.tribuo.provenance.EvaluationProvenance", "model-provenance" : { "instance-values" : { }, "tribuo-version" : "4.0.1", "trainer" : { "seed" : "12345", "minibatchSize" : "1", "train-invocation-count" : "0", "is-sequence" : "false", "shuffle" : "true", "epochs" : "5", "optimiser" : { "epsilon" : "0.1", "initialLearningRate" : "1.0", "initialValue" : "0.0", "host-short-name" : "StochasticGradientOptimiser", "class-name" : "org.tribuo.math.optimisers.AdaGrad" }, "host-short-name" : "Trainer", "class-name" : "org.tribuo.classification.sgd.linear.LogisticRegressionTrainer", "objective" : { "host-short-name" : "LabelObjective", "class-name" : "org.tribuo.classification.sgd.objectives.LogMulticlass" }, "loggingInterval" : "1000" }, "trained-at" : "2020-08-31T20:24:37.854775-04:00", "dataset" : { "num-features" : "4", "num-examples" : "105", "num-outputs" : "3", "tribuo-version" : "4.0.1", "datasource" : { "train-proportion" : "0.7", "seed" : "1", "size" : "150", "source" : { "resource-hash" : "0FED2A99DB77EC533A62DC66894D3EC6DF3B58B6A8F3CF4A6B47E4086B7F97DC", "path" : "file:/Users/apocock/Development/Tribuo/tutorials/bezdekIris.data", "file-modified-time" : "1999-12-14T15:12:39-05:00", "quote" : "\"", "response-name" : "species", "outputFactory" : { "class-name" : "org.tribuo.classification.LabelFactory" }, "separator" : ",", "class-name" : "org.tribuo.data.csv.CSVLoader" }, "class-name" : "org.tribuo.evaluation.TrainTestSplitter", "is-train" : "true" }, "transformations" : [ ], "is-sequence" : "false", "is-dense" : "false", "class-name" : "org.tribuo.MutableDataset" }, "class-name" : "org.tribuo.classification.sgd.linear.LinearSGDModel" } }この実績情報には,モデルの実績情報に含まれるすべてのフィールドと,テストデータ,分割されたデータ,CSVが含まれていることがわかります。
この実績情報は、それだけでもモデルを追跡するのに便利ですが、設定チュートリアルで説明されている設定システムと組み合わせることで、モデルや実験を再構築するための強力な方法となり、どのようなMLモデルでもほぼ完璧な再現性を実現することができます。
結論Tribuoのcsvロードのメカニズム、単純な分類器のトレーニング方法、テストデータ上での分類器の評価方法、さらにTribuoのモデルと評価オブジェクト内に保存されているメタデータと実績情報を見てみました。
- 投稿日:2020-09-26T10:09:17+09:00
Javaで制約プログラミング
はじめに
制約プログラミング(Constraint Programming)はプログラミングパラダイムの一つです。 制約プログラミングにおいては、変数間の関係を制約という形で記述することによりプログラムを記述します。
現在ではAIと言えばディープラーニングと同義のように言われたりしますが、かつてはこの制約プログラミングや数式処理などもAIと呼ばれていました。
Javaで制約プログラミングのライブラリを実装し、エイト・クイーン、覆面算、数独などの問題を解いてみます。対象とする問題
最も単純な問題を対象とします。具体的には以下のような問題です。
- 変数の定義域は整数のみとします。
- 変数の定義域は有限で、その範囲は問題の中で定義されているものとします。
簡単な例題
説明のために簡単な例題を考えてみます。
- 式 a + b = c を満たす変数a, b, cの値を求めてください。
- ただし a < b とします。
- 変数a, b, cの定義域は{1, 2, 3}とします。
アプローチ
各変数の定義域の値ごとに制約を満たす組み合わせを見つければよいので、単純な3重ループのプログラムを考えてみます。Javaで表現するとこんな感じです。
for (int a : List.of(1, 2, 3)) for (int b : List.of(1, 2, 3)) for (int c : List.of(1, 2, 3)) if (a < b) if (a + b == c) answer(a, b, c);
answerは解が見つかった時点で呼び出されるコールバック関数です。
このプログラムでは入れ子になったforループの最内部は 3 x 3 x 3 = 27回実行されます。
処理効率を考えるとこれを少し改善することができます。制約a < bは変数aおよびbの値が確定した時点でチェックすることができるので、以下のように書き換えることができます。for (int a : List.of(1, 2, 3)) for (int b : List.of(1, 2, 3)) if (a < b) for (int c : List.of(1, 2, 3)) if (a + b == c) answer(a, b, c);
a < bを満たす(a, b)の組み合わせは(1, 2), (1, 3), (2, 3)の3通りしかありません。この3通りに対してfor (int c : List.of(1, 2, 3))がそれぞれ実行されるので、入れ子になったforループの最内部は 3 x 3 = 9回で済むことになります。前述のコードと比べると約3倍の処理性能が期待できます。制約のチェック回数も減るのでもっと速くなるかもしれません。
このアプローチでプログラムを構成してみましょう。
まとめるとこうなります。
- 各変数に定義域の値を順次代入するループを入れ子にします。
- 制約はなるべく外側のループ内でチェックすることにより効率を上げます。
- 解が見つかった時点でコールバック関数を呼び出します。
モデル
クラスの候補としては以下が考えられます。
- 問題 (Problem)
解くべき問題のクラスです。- 変数 (Variable)
問題に表れる変数です。- 定義域 (Domain)
各変数の定義域です。- 制約 (Constraint)
変数が満たすべき制約式です。- 制約式(Predicate)
制約式をラムダ式で表現するための関数型インタフェースです。- 問題解決 (Solver)
問題を解きます。- 解 (Answer)
解が見つかったときに呼び出されるコールバックです。UMLのクラス図として表現するとこのようになります。
コード
Domain(定義域)は不変な整数のリストです。
Domain.javapublic class Domain extends AbstractList<Integer> { private final int[] elements; private Domain(int... elements) { this.elements = elements; } public static Domain of(int... elements) { return new Domain(Arrays.copyOf(elements, elements.length)); } public static Domain range(int startInclusive, int endExclusive) { return new Domain(IntStream.range(startInclusive, endExclusive).toArray()); } public static Domain rangeClosed(int startInclusive, int endInclusive) { return range(startInclusive, endInclusive + 1); } @Override public Integer get(int index) { return elements[index]; } @Override public int size() { return elements.length; } }変数(Variable)は名称(name)と定義域(Domain)を持つクラスです。
その変数に係るすべての制約(Constraint)への参照を保持しています。
インスタンスの生成は問題(Problem)のファクトリメソッドで行うため、コンストラクタはパッケージスコープとします。Variable.javapublic class Variable { public final String name; public final Domain domain; private final List<Constraint> _constraints = new ArrayList<Constraint>(); public final List<Constraint> constraints = Collections.unmodifiableList(_constraints); Variable(String name, Domain domain) { this.name = name; this.domain = domain; } void add(Constraint constraint) { this._constraints.add(constraint); } @Override public String toString() { return name; } }制約式(Predicate)は制約を式で表現するための関数インタフェースです。
制約に係るすべての変数の値が束縛されたときに各変数の値を引数として呼び出されるtest(int...)メソッドのみが定義されています。
これを使用することで制約式をラムダ式で表現することができます。Predicate.java@FunctionalInterface public interface Predicate { boolean test(int... values); }制約(Predicate)は制約式(Predicate)と制約に係る変数への参照を持つ不変のクラスです。
インスタンスの生成は問題(Problem)のファクトリメソッドで行うので、コンストラクタはパッケージスコープとします。Constraint.javapublic class Constraint { public final Predicate predicate; public final List<Variable> variables; Constraint(Predicate predicate, Variable... variables) { this.predicate = predicate; this.variables = List.of(variables); } @Override public String toString() { return "制約" + variables; } }問題(Problem)は関連するすべての変数と制約を持つクラスです。
変数の定義はvariable(String, Domain)で行います。
制約の定義はconstraint(Predicate, Variable...)で行います。
複数の変数について、どの二つの変数も値が異なるという制約を簡易に表現するためのメソッドallDifferent(Variable...)があります。Problem.javapublic class Problem { private List<Variable> _variables = new ArrayList<>(); public List<Variable> variables = Collections.unmodifiableList(_variables); private Map<String, Variable> variableMap = new HashMap<>(); private List<Constraint> _constraints = new ArrayList<>(); public List<Constraint> constraints = Collections.unmodifiableList(_constraints); public Variable variable(String name, Domain domain) { if (variableMap.containsKey(name)) throw new IllegalArgumentException("変数名が重複: " + name); Variable v = new Variable(name, domain); this._variables.add(v); this.variableMap.put(name, v); return v; } public Variable variable(String name) { return variableMap.get(name); } public Constraint constraint(Predicate predicate, Variable... variables) { Constraint c = new Constraint(predicate, variables); for (Variable v : variables) v.add(c); this._constraints.add(c); return c; } public void allDifferent(Variable... variables) { for (int i = 0, size = variables.length; i < size; ++i) for (int j = i + 1; j < size; ++j) constraint(a -> a[0] != a[1], variables[i], variables[j]); } }解(Answer)は見つかった解を受け取るためのコールバック関数です。
変数と値の対をMapとして受け取ります。
実質的に関数インタフェースなのでラムダ式でコールバック関数を記述することができます。Answer.javapublic interface Answer { void answer(Map<Variable, Integer> result); }問題解決(Solver)は問題(Problem)から解を見つける
solve(Problem, Answer)メソッドを持っています。
変数の数は可変なので冒頭に記述したようなfor文のネストで束縛を実現することはできないので、再起呼び出しによって束縛を行います。
オーバーロードされたsolve(Problem, List<Variable>, Answer)メソッドは問題を解く時に変数を束縛する順序をList<Variable>で指定することができます。
内部staticメソッドconstraintOrder(List<Variable>, List<Constraint>)は変数の束縛順序から適用可能な制約(Constraint)の順序を求めます。Solver.javapublic class Solver { static final Logger logger = Logger.getLogger(Solver.class.getName()); static List<List<Constraint>> constraintOrder(List<Variable> bindingOrder, List<Constraint> constraints) { int variableSize = bindingOrder.size(); int constraintSize = constraints.size(); List<List<Constraint>> result = new ArrayList<>(variableSize); Set<Constraint> done = new HashSet<>(constraintSize); Set<Variable> bound = new HashSet<>(variableSize); for (Variable v : bindingOrder) { bound.add(v); List<Constraint> list = new ArrayList<>(); result.add(list); for (Constraint c : constraints) if (!done.contains(c) && bound.containsAll(c.variables)) { list.add(c); done.add(c); } } return result; } public void solve(Problem problem, List<Variable> bindingOrder, Answer answer) { int variableSize = problem.variables.size(); List<List<Constraint>> constraintOrder = constraintOrder(bindingOrder, problem.constraints); int[] arguments = new int[variableSize]; Map<Variable, Integer> result = new LinkedHashMap<>(variableSize); new Object() { boolean test(int i) { for (Constraint c : constraintOrder.get(i)) { int p = 0; for (Variable v : c.variables) arguments[p++] = result.get(v); if (!c.predicate.test(arguments)) return false; } return true; } void solve(int i) { if (i >= variableSize) answer.answer(result); else { Variable v = bindingOrder.get(i); Domain d = v.domain; for (int value : d) { result.put(v, value); if (test(i)) solve(i + 1); } } } }.solve(0); } public void solve(Problem problem, Answer answer) { solve(problem, problem.variables, answer); } }テスト
冒頭の簡単な例を実際に解いてみます。
Problem problem = new Problem(); Domain domain = Domain.of(0, 1, 2, 3); Variable A = problem.variable("A", domain); Variable B = problem.variable("B", domain); Variable C = problem.variable("C", domain); Constraint X = problem.constraint(a -> a[0] + a[1] == a[2], A, B, C); Constraint Y = problem.constraint(a -> a[0] < a[1], A, B); Solver solver = new Solver(); solver.solve(problem, result -> System.out.println(result));結果はこうなりました。
{A=1, B=2, C=3}変数の束縛順と制約の適用順は以下のようになっています。
0: A []
1: B [制約[A, B]]
2: C [制約[A, B, C]]エイト・クイーン
エイト・クイーン - Wikipediaはチェスの盤上に、8個のクイーンを配置する問題です。このとき、どの駒も他の駒に取られるような位置においてはいけません。
クイーンの動きは、上下左右斜めの8方向に、遮る物がない限り進めます。将棋の飛車と角行を合わせた動きです。一辺のマスをnとした変形版を「n-クイーン」パズルといいます。
定義域が$\{1..n\}$であるような変数をn個用意して、それぞれが互いに異なり、斜めにも重ならないようにする問題として解きます。
ここでは$n ∊ \{1, 2, 3, 4, 5, 6, 7, 8, 9, 10\}$について、それぞれの解の個数を求めてみます。class TestNQueens { static Logger logger = Logger.getLogger(TestNQueens.class.getName()); static int nQueens(final int n) { long start = System.currentTimeMillis(); Problem problem = new Problem(); Domain domain = Domain.range(0, n); Variable[] rows = IntStream.range(0, n) .mapToObj(i -> problem.variable("R" + i, domain)) .toArray(Variable[]::new); for (int i = 0; i < n; ++i) for (int j = i + 1; j < n; ++j) { int distance = j - i; problem.constraint( (x, y) -> x != y && Math.abs(x - y) != distance, rows[i], rows[j]); } Solver solver = new Solver(); int[] answers = {0}; solver.solve(problem, m -> ++answers[0]); logger.info("n=" + n + " : answers=" + answers[0] + " : elapse=" + (System.currentTimeMillis() - start) + "ms."); return answers[0]; } @Test void test() { assertEquals(1, nQueens(1)); assertEquals(0, nQueens(2)); assertEquals(0, nQueens(3)); assertEquals(2, nQueens(4)); assertEquals(10, nQueens(5)); assertEquals(4, nQueens(6)); assertEquals(40, nQueens(7)); assertEquals(92, nQueens(8)); assertEquals(352, nQueens(9)); assertEquals(724, nQueens(10)); } }結果はこんな感じです。Wikipediaの記述と一致しました。
2020-05-19T16:31:06.863 情報 n=1 : answers=1 : elapse=27ms. 2020-05-19T16:31:06.941 情報 n=2 : answers=0 : elapse=3ms. 2020-05-19T16:31:06.942 情報 n=3 : answers=0 : elapse=0ms. 2020-05-19T16:31:06.944 情報 n=4 : answers=2 : elapse=0ms. 2020-05-19T16:31:06.947 情報 n=5 : answers=10 : elapse=2ms. 2020-05-19T16:31:06.953 情報 n=6 : answers=4 : elapse=5ms. 2020-05-19T16:31:06.963 情報 n=7 : answers=40 : elapse=10ms. 2020-05-19T16:31:06.984 情報 n=8 : answers=92 : elapse=20ms. 2020-05-19T16:31:07.031 情報 n=9 : answers=352 : elapse=45ms. 2020-05-19T16:31:07.118 情報 n=10 : answers=724 : elapse=87ms.覆面算
次に覆面算を解いてみます。有名なSEND MORE MONEYです。各英字に1桁の数字を割り当てて式が成立するようにします。同じ英字は同じ数字、異なった英字は異なった数字、先頭の数字はゼロ以外とします。
SEND + MORE ------ MONEYstatic Logger logger = Logger.getLogger(TestSendMoreMoney.class.getName()); static int number(int... digits) { return IntStream.of(digits).reduce(0, (t, d) -> t * 10 + d); } @Test public void test単一制約() { Problem problem = new Problem(); Domain first = Domain.of(1, 2, 3, 4, 5, 6, 7, 8, 9); Domain rest = Domain.of(0, 1, 2, 3, 4, 5, 6, 7, 8, 9); Variable S = problem.variable("S", first); Variable E = problem.variable("E", rest); Variable N = problem.variable("N", rest); Variable D = problem.variable("D", rest); Variable M = problem.variable("M", first); Variable O = problem.variable("O", rest); Variable R = problem.variable("R", rest); Variable Y = problem.variable("Y", rest); Variable[] variables = {S, E, N, D, M, O, R, Y}; problem.allDifferent(variables); problem.constraint(a -> number(a[0], a[1], a[2], a[3]) + number(a[4], a[5], a[6], a[1]) == number(a[4], a[5], a[2], a[1], a[7]), variables); Solver solver = new Solver(); solver.solve(problem, m -> logger.info(m.toString())); }結果はこうなりました。
{S=9, E=5, N=6, D=7, M=1, O=0, R=8, Y=2}この解き方は制約が一つしかなく、すべての変数が束縛された後にチェックされます。つまり最も内側のループ内で制約のチェックが行われるのであまり効率がよくありません。私の環境では2秒弱かかりました。
桁上がりの変数を追加して、各桁ごとに制約を定義するようにすると少し速くなります。@Test public void test桁ごとの制約() { Domain zero = Domain.of(0); Domain first = Domain.of(1, 2, 3, 4, 5, 6, 7, 8, 9); Domain rest = Domain.of(0, 1, 2, 3, 4, 5, 6, 7, 8, 9); Domain carry = Domain.of(0, 1); Problem problem = new Problem(); Variable Z = problem.variable("Z", zero); Variable C1 = problem.variable("C1", carry); Variable C2 = problem.variable("C2", carry); Variable C3 = problem.variable("C3", carry); Variable C4 = problem.variable("C4", carry); Variable S = problem.variable("S", first); Variable E = problem.variable("E", rest); Variable N = problem.variable("N", rest); Variable D = problem.variable("D", rest); Variable M = problem.variable("M", first); Variable O = problem.variable("O", rest); Variable R = problem.variable("R", rest); Variable Y = problem.variable("Y", rest); Variable[] variables = {S, E, N, D, M, O, R, Y}; problem.allDifferent(variables); // C4 C3 C2 C1 Z // Z S E N D // + Z M O R E // --------------- // M O N E Y Predicate digitPredicate = a -> a[0] + a[1] + a[2] == a[3] + a[4] * 10; problem.constraint(digitPredicate, Z, D, E, Y, C1); problem.constraint(digitPredicate, C1, N, R, E, C2); problem.constraint(digitPredicate, C2, E, O, N, C3); problem.constraint(digitPredicate, C3, S, M, O, C4); problem.constraint(digitPredicate, C4, Z, Z, M, Z); Solver solver = new Solver(); solver.solve(problem, m -> logger.info(m.toString())); }0.3秒くらいで解けるようになりました。
数独
数独 - Wikipediaの最初にある問題を解いてみます。
static Logger logger = Logger.getLogger(Test数独.class.toString()); static int 辺の長さ = 9; static int 小四角形の辺の長さ = 3; static Domain 定義域 = Domain.rangeClosed(1, 9); static String 名前(int r, int c) { return r + "@" + c; } static Variable[][] 変数定義(Problem 問題, int[][] 入力) { Variable[][] 変数 = new Variable[辺の長さ][辺の長さ]; for (int r = 0; r < 辺の長さ; ++r) for (int c = 0; c < 辺の長さ; ++c) 変数[r][c] = 問題.variable(名前(r, c), 入力[r][c] == 0 ? 定義域 : Domain.of(入力[r][c])); return 変数; } static List<Variable[]> 制約定義(Problem 問題, Variable[][] 変数) { List<Variable[]> 制約変数 = new ArrayList<>(); for (int r = 0; r < 辺の長さ; ++r) 制約変数.add(変数[r]); for (int c = 0; c < 辺の長さ; ++c) { Variable[] va = new Variable[辺の長さ]; 制約変数.add(va); for (int r = 0; r < 辺の長さ; ++r) va[r] = 変数[r][c]; } for (int r = 0; r < 辺の長さ; r += 小四角形の辺の長さ) for (int c = 0; c < 辺の長さ; c += 小四角形の辺の長さ) { Variable[] va = new Variable[辺の長さ]; 制約変数.add(va); for (int i = 0, p = 0; i < 小四角形の辺の長さ; ++i) for (int j = 0; j < 小四角形の辺の長さ; ++j, ++p) va[p] = 変数[r + i][c + j]; } for (Variable[] va : 制約変数) 問題.allDifferent(va); return 制約変数; } static void 答(Variable[][] 変数, Map<Variable, Integer> 解答) { for (int r = 0; r < 辺の長さ; ++r) { StringBuilder sb = new StringBuilder(); for (int c = 0; c < 辺の長さ; ++c) sb.append(String.format("%2d", 解答.get(変数[r][c]))); logger.info(sb.toString()); } } static void 数独束縛順序指定なし(int[][] 入力) { Problem 問題 = new Problem(); Variable[][] 変数 = 変数定義(問題, 入力); 制約定義(問題, 変数); Solver 解決 = new Solver(); 解決.solve(問題, m -> 答(変数, m)); } @Test void testWikipedia束縛順序指定なし() { // Wikipedia 数独 の例題 // https://ja.wikipedia.org/wiki/%E6%95%B0%E7%8B%AC int[][] 入力 = { { 5, 3, 0, 0, 7, 0, 0, 0, 0 }, { 6, 0, 0, 1, 9, 5, 0, 0, 0 }, { 0, 9, 8, 0, 0, 0, 0, 6, 0 }, { 8, 0, 0, 0, 6, 0, 0, 0, 3 }, { 4, 0, 0, 8, 0, 3, 0, 0, 1 }, { 7, 0, 0, 0, 2, 0, 0, 0, 6 }, { 0, 6, 0, 0, 0, 0, 2, 8, 0 }, { 0, 0, 0, 4, 1, 9, 0, 0, 5 }, { 0, 0, 0, 0, 8, 0, 0, 7, 9 }, }; logger.info("test wikipedia"); 数独束縛順序指定なし(入力); }とりあえず解けましたが、20秒以上かかりました。
2020-05-16T21:01:31.789 情報 test wikipedia 2020-05-16T21:01:52.360 情報 5 3 4 6 7 8 9 1 2 2020-05-16T21:01:52.361 情報 6 7 2 1 9 5 3 4 8 2020-05-16T21:01:52.361 情報 1 9 8 3 4 2 5 6 7 2020-05-16T21:01:52.362 情報 8 5 9 7 6 1 4 2 3 2020-05-16T21:01:52.363 情報 4 2 6 8 5 3 7 9 1 2020-05-16T21:01:52.363 情報 7 1 3 9 2 4 8 5 6 2020-05-16T21:01:52.363 情報 9 6 1 5 3 7 2 8 4 2020-05-16T21:01:52.364 情報 2 8 7 4 1 9 6 3 5 2020-05-16T21:01:52.365 情報 3 4 5 2 8 6 1 7 9変数の束縛順は単純に上から下、左から右なので、少し工夫してみます。
以下の方針で束縛順を定義します。
- 数字の決定しているマス目は先に束縛します。これらのマス目は値が決定しているの後戻りがありません。
- 行、列、3x3の領域ごとにみて、なるべく数字の決定しているマス目が多い所から順に束縛します。以下の図に示すように、青で示した領域は6個の値が確定しています。赤で示した4つの領域は5個の値が確定しています。青の領域に含まれる変数→赤の領域に含まれる変数→...の順に束縛します。
この方針に従って変数の束縛順を変えたものが以下のコードです。
static List<Variable> 束縛順序定義(List<Variable> 変数, List<Variable[]> 制約変数) { Set<Variable> 束縛順序 = new LinkedHashSet<>(); for (Variable v : 変数) if (v.domain.size() == 1) 束縛順序.add(v); Collections.sort(制約変数, Comparator.comparingInt(a -> Arrays.stream(a).mapToInt(v -> v.domain.size()).sum())); for (Variable[] a : 制約変数) for (Variable v : a) 束縛順序.add(v); return new ArrayList<>(束縛順序); } static void 数独束縛順序指定あり(int[][] 入力) { Problem 問題 = new Problem(); Variable[][] 変数 = 変数定義(問題, 入力); List<Variable[]> 制約変数 = 制約定義(問題, 変数); List<Variable> 束縛順序 = 束縛順序定義(問題.variables, 制約変数); Solver 解決 = new Solver(); 解決.solve(問題, 束縛順序, m -> 答(変数, m)); }結果としては0.02秒程度で解けるようになりました。この例題は単純すぎるのでもっと難しい問題にチャレンジしてみました。Wikipediaによれば、数独の解が唯一になるためには数字の決まっているマス目が17個以上必要だそうです。
ネットで検索して数字の決まっているマス目が丁度17個の難しそうな問題を拾ってみました。
@Test void testGood_at_Sudoku_Heres_some_youll_never_complete() { // http://theconversation.com/good-at-sudoku-heres-some-youll-never-complete-5234 int[][] 入力 = { { 0, 0, 0, 7, 0, 0, 0, 0, 0 }, { 1, 0, 0, 0, 0, 0, 0, 0, 0 }, { 0, 0, 0, 4, 3, 0, 2, 0, 0 }, { 0, 0, 0, 0, 0, 0, 0, 0, 6 }, { 0, 0, 0, 5, 0, 9, 0, 0, 0 }, { 0, 0, 0, 0, 0, 0, 4, 1, 8 }, { 0, 0, 0, 0, 8, 1, 0, 0, 0 }, { 0, 0, 2, 0, 0, 0, 0, 5, 0 }, { 0, 4, 0, 0, 0, 0, 3, 0, 0 }, }; logger.info("Good at Sudoku Heres some youll never complete"); 数独束縛順序指定あり(入力); }1秒以内に解くことができました。
2020-05-16T21:22:26.176 情報 Good at Sudoku Heres some youll never complete 2020-05-16T21:22:26.310 情報 2 6 4 7 1 5 8 3 9 2020-05-16T21:22:26.311 情報 1 3 7 8 9 2 6 4 5 2020-05-16T21:22:26.312 情報 5 9 8 4 3 6 2 7 1 2020-05-16T21:22:26.313 情報 4 2 3 1 7 8 5 9 6 2020-05-16T21:22:26.315 情報 8 1 6 5 4 9 7 2 3 2020-05-16T21:22:26.316 情報 7 5 9 6 2 3 4 1 8 2020-05-16T21:22:26.317 情報 3 7 5 2 8 1 9 6 4 2020-05-16T21:22:26.318 情報 9 8 2 3 6 4 1 5 7 2020-05-16T21:22:26.320 情報 6 4 1 9 5 7 3 8 2変数の束縛順序を指定しない場合は10分経っても解けませんでした。
制約表現の改善
制約を定義するときはラムダ式と関連する変数を指定します。制約の対象となる変数の数は可変なので、このような書き方になります。
problem.constraint(a -> number(a[0], a[1], a[2], a[3]) + number(a[4], a[5], a[6], a[1]) == number(a[4], a[5], a[2], a[1], a[7]), S, E, N, D, M, O, R, Y);
a[0]がSに、a[1]がEに、...という対応関係にあるのですが、分かりにくい表現になっています。これを改善するために固定長引数のメソッドを追加します。まず最初に、以下のインタフェースを追加します。@FunctionalInterface public interface Predicate1 extends Predicate { default boolean test(int... values) { return test(values[0]); } boolean test(int a); } @FunctionalInterface public interface Predicate2 extends Predicate { default boolean test(int... values) { return test(values[0], values[1]); } boolean test(int a, int b); } .....次にProblemクラスにこれを使用した制約のファクトリメソッドを追加します。
Problem.javapublic Constraint constraint(Predicate1 predicate, Variable a) { return constraint((Predicate)predicate, a); } public Constraint constraint(Predicate2 predicate, Variable a, Variable b) { return constraint((Predicate)predicate, a, b); } .....そうすると、このような書き方ができるようになります。
constraint()メソッドに渡すVariableの数とラムダ式の引数の数が一致しないとコンパイルエラーになります。problem.constraint((s, e, n, d, m, o, r, y) -> number(s, e, n, d) + number(m, o, r, e) == number(m, o, n, e, y), S, E, N, D, M, O, R, Y);まとめ
性能に影響するのは以下の点であることがわかりました。
- 制約の与え方
制約を細かくして変数束縛の早い段階でチェックできるようにすると、選択肢が絞られるので速くなります。- 変数束縛の順序
選択肢の少ない変数を先に束縛すると速くなります。
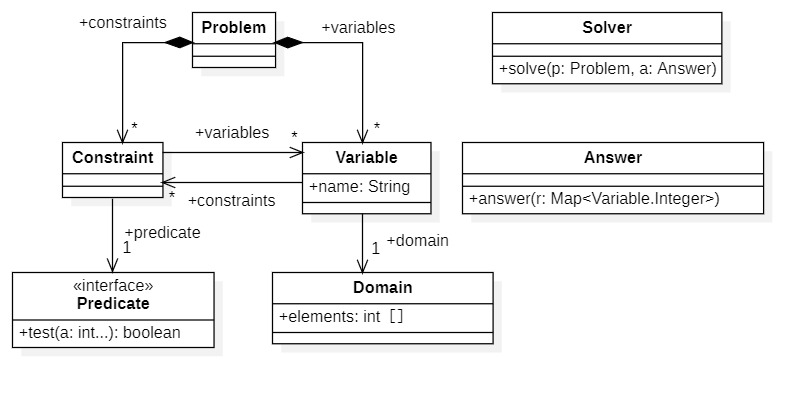
- 投稿日:2020-09-26T08:31:25+09:00
【忘備録】Java : 等価判定のequalsのオーバーライドは必要か
はじめに
先の記事でも述べているように現在参考書(スッキリわかるJava入門 実践編)を進めながらJavaを勉強し直しています。(実は既に読み終わっています
)
上記参考書の中でクラスを作成する際には既に備えられているメソッドをオーバーライドして意図しない不具合を引き起こさないようにするように注意喚起をしています。
その一つの例がequalsメソッドです。
equalsメソッドは等値ではなく等価であるかどうかを判定してくれるメソッドです。しかし参考書によると、元々備えられているObjectクラスのequalsメソッドは等価であるかどうかを等値であるかどうかで判定しています。
つまりequals を呼び出したオブジェクトと equals の引数として渡すオブジェクトが等値であれば2つのオブジェクトは等価だよね?と当たり前の事を判定している訳です。実装
上記の判定方法を裏付ける下記のコードをご覧下さい
Personクラスのインスタンスを作成後、ArrayListに追加して、追加したインスタンスのメンバと等価のメンバを持つ新しいインスタンスで削除対象を指定しています。instance.javaimport java.util.ArrayList; import java.util.List; class Person { public String name; Person(String name){ this.name = name; } } public class instance { public static void main(String[] args) { List<Person> personList = new ArrayList<Person>(); personList.add(new Person("太郎")); System.out.println("追加後(person) : " + personList.size()); personList.remove(new Person("太郎")); System.out.println("削除後(person) : " + personList.size()); } }一見、うまくいきそうですが結果は
ArrayListの要素は削除されません。結果.java追加後(person) : 1 削除後(person) : 1確かにインスタンスのメンバは等価関係ですがインスタンスのメモリの番地が違えばメンバのメモリの番地も違う筈なので
等値で無いので等価では無いと判断されたそうです。故に元々備わっているオブジェクトクラスのequalsメソッドはfalse判定となっているようです。そこで冒頭でも言及しているように
equalsメソッドをオーバーライドして上記の不具合を修正していきます。instance.javaclass Man { public String name; Man(String name){ this.name = name; } public boolean equals(Object o){ if(o == this) return true; if(o == null) return false; if(!(o instanceof Man)) return false; Man man = (Man) o ; if(!(this.name.equals(man.name))) return false; return true; } } public class instance { public static void main(String[] args) { List<Man> manList = new ArrayList<Man>(); manList.add(new Man("太郎")); System.out.println("追加後(man) : " + manList.size()); manList.remove(new Man("太郎")); System.out.println("削除後(man) : " + manList.size()); } }今度は
Manクラスの中にequalsメソッドを予め、定義しています。
具体的には比較元と比較対象のオブジェクトの型が同一でメンバ(name)が等価ならtrueを返すようにしています。結果.java追加後(man) : 1 削除後(man) : 0はい、上記のように意図するように動いてくれるようになりました。
しかし、上記のようにいちいちオーバーライドするのもかなり面倒です。
別にオーバーライドしなくとも下記のようにforで回しながら該当要素を取り除いてしまえば十分なのでは?と考えてしまいますinstancce.javaimport java.util.ArrayList; import java.util.List; class Person { public String name; Person(String name){ this.name = name; } } public class instance { public static void main(String[] args) { List<Person> personList = new ArrayList<Person>(); personList.add(new Person("太郎")); System.out.println("for文削除前(person) : " + personList.size()); for(int i=0; i<personList.size(); i++){ Person person = personList.get(i); String name = person.name; if(name.equals("太郎")){ personList.remove(person); } } System.out.println("for文削除後(person) : " + personList.size()); } }結果.javafor文削除前(person) : 1 for文削除後(person) : 0あとは
equalsメソッドの記述が冗長でいちいち書くのが面倒臭いと言う人には、commons-langと言うライブラリのEqualsBuilderを使えば全てのメンバが等価ならインスタンスも等価とみなす判定をしてくれます。
今回は試していませんが記述方法は下記です。equalsBuilder.javaimport org.apache.commons.lang3.builder.*; class Man { public String name; Man(String name){ this.name = name; } public boolean equals(Object o){ return EqualsBuilder.reflectionEquals(this,o); } }おまけ
今回、
for文で要素を指定して削除した方法を載せましたがこれを拡張for文で回すとConcurrentModificationExceptionと言うエラーが発生します。
このエラーはiteratorが作成された際に作成対象のコレクションなどがaddやremove等によって操作されると返されます。詳細は下記リンクたちを参考に。。。(書くのが面倒。。。)
https://qiita.com/sig_Left/items/eebea3f88a16dcfa2983
https://teratail.com/questions/16901
- 投稿日:2020-09-26T07:33:54+09:00
Fabric-loaderによるmod開発の手引
対象
- Fabricでmod開発をしたい
- Forgeの最新バージョンがないから仕方なくFabricを使いたい
- Javaが分かる
Fabric-loaderができた経緯
1. 既存モッドローダーの問題点
既存のForgeといったモッドローダーでは直接マインクラフトをデコンパイルしてソースコードを入手し、そのデコンパイルされたマインクラフトに簡単にアイテムなどが追加できるような仕組みが搭載されています。この方法ではモッドローダーがマインクラフトのソースコード全体を弄ることができるという(モッドローダー開発者にとっての)利点もありましたが、一つ大きな問題がありました。マインクラフトのデコンパイルは複雑で、デコンパイルされたものを再コンパイルしようとしてもできないのです。これはデコンパイラ自身によるバグのせいもありますが、コンパイル時に失われる情報(Genericsなど)もあるため仕方のない部分ではあります。この問題がモッドローダーの開発の遅れの原因となっていました。
2. SpongePowered/Mixin(Mixinフレームワーク)の誕生
Mixinフレームワークを単純にいうと、「デコンパイルをしなくてもソースコードを弄る機能群」です。classファイルにはJavaのクラスに関する全ての情報が入っていますが、その中でも特にメソッド内部の処理をデコンパイルするのが難しいのです。逆に言えば、メソッド内部の処理をデコンパイルせずにソースコードを弄ることができれば問題ないわけです。Mixinフレームワークは以下の手順でこれを可能にします。
- クラスファイルの情報を解析する(クラス・メンバ変数・メソッド)
- 解析されたクラスのラッパークラスを作成する。
- 解析されたクラスに関して、新しく作成されるオブジェクトが全てサブクラスのものになるように置き換える。
public class Player { public void kill() { ... } }public class Main { public static void main(String[] args) { Player player = new Player(); player.kill(); } }上のように(killメソッドの処理が不明な)プレイヤークラスとそれを使用するメインクラスがあると仮定します。あなたはkillメソッドの処理を消せばプレイヤーが不死身になることを確信しており、Mixinフレームワークを利用してkillメソッドの処理を消したいと思っています。
このときあなたはまずPlayerクラスを「Mixinする」ことになります。「Mixinする」事によって以下のクラスが作成されます。public class Player$1 extends Player { private final Player player; public Player$1(Player player) { this.player = player; } public void kill() { player.kill(); } }また「Mixinした」事によってメインクラスは次のように書き換えられます。
public class Main { public static void main(String[] args) { Player$1 player = new Player$1(new Player()); player.kill(); } }PlayerクラスをラップしたPlayer$1クラスが作成され、またメインクラスにおけるnewが書き換わったことがわかりますね。では、killメソッドの処理を消すにはどうしたらいいでしょうか?答えは簡単です。
public class Player$1 extends Player { private final Player player; public Player$1(Player player) { this.player = player; } public void kill() { //player.kill(); } }一行コメントアウトしただけでkillメソッドの処理を消すことができてしまいました。簡単ですね!確かにこの方法なら、メソッドの処理を消したり、メソッドの前後で処理を付け足したりするのは簡単そうです。
Fabric-loaderとは
Fabricローダーは以下の2つにより構成されます。
- マインクラフトを実行する機能
- モッドをロードしマインクラフトのロード前に「Mixinする」機能
「Mixinする」ことにより簡単にメソッドの処理を変更できると言いましたが、実際にはいくつかの制約があります。最も大きな制約の一つは、ロード済みのクラスは変更することができないということです。なのでFabric-loaderは、マインクラフトの設定ファイル(バージョン.json)に手を加えて、ランチャーからマインクラフトを起動した際に直接マインクラフトが実行されるのではなく、Fabric-loaderを介してモッドがロードされ「Mixinされた」後にマインクラフトが実行されるよう調整します。
Fabric APIとは
Fabric APIはブロック追加やアイテム追加などといった多くのmodで使われる共通部分をまとめたものです。Fabric APIもFabric-loaderを使用して動作しています。また別にFabric APIがmod作成に必ず必要かというとそういうことはなく、Sodium、Phospher、Lithiumなどといった有名どころのmodは大体Fabric APIなしでも動作します(逆にFabric APIがあると干渉しあって動作しなくなるmodもある)。
Fabric-loader & Fabric APIを使用したmodを実際に作成する
では早速Fabric-loaderを使用したmodを作成してみましょう!まずここからexample-mod(雛形となるmod)のソースコードをダウンロードします( https://github.com/FabricMC/fabric-example-mod )。
次にダウンロードしたもののうちgradle.propertiesを編集します。# Done to increase the memory available to gradle. org.gradle.jvmargs=-Xmx1G # Fabric Properties # check these on https://fabricmc.net/use minecraft_version=1.16.3 yarn_mappings=1.16.3+build.1 loader_version=0.9.3+build.207 # Mod Properties mod_version = 1.0.0 maven_group = net.fabricmc archives_base_name = fabric-example-mod # Dependencies # currently not on the main fabric site, check on the maven: https://maven.fabricmc.net/net/fabricmc/fabric-api/fabric-api fabric_version=0.20.2+build.402-1.16よくわからないと思います(もしかしたら中身が違うかもしれません)が、この部分で注目すべきなのは以下の部分です。
minecraft_version=1.16.3 yarn_mappings=1.16.3+build.1mod_version = 1.0.0 maven_group = net.fabricmc archives_base_name = fabric-example-modminecraft_versionはマインクラフトのバージョン、yarn_mappingsはマッピングのバージョン(後述します)です。またmod_versionはモッドのバージョン、maven_groupはモッドのグループ名(製作者固有のIDみたいなものです)、achives_base_nameはmodのファイル名を表します。この部分はいじらなくてもmodの動作には問題ありません。
yarn_mappingsが何かについて説明します。マインクラフトは難読化されていて、クラス名・フィールド名・メソッド名が「a」や「b」などいった意味の無いものに置き換えられています。しかしこれではmod製作者がmodを制作するのは大変な手間になりますから、こういった難読化されたクラスを意味のあるものに直してあげなければならないのです。このときに使うのがyarn_mappingsで、これは「a」や「b」といったクラス名・フィールド名・メソッド名を「RenderSystem」や「MinecraftClient」などいった意味のわかりやすい文字列と結びつけたものです(これらの「意味の分かりやすい文字列」は、処理内容から推測したものです)。マインクラフトのバージョンが上がることにクラスが増えたりフィールドが変わったりしますから、バージョンに合わせたマッピングを使用しなければなりません。マッピングデータはこのURLから見ることができます( https://github.com/FabricMC/yarn )。一通り編集が終わったら、コマンドで以下のように実行します(プロジェクトのディレクトリでコマンドを実行してください)。
./gradlew.bat buildこれによってmodがbuild/libsに作成されます。実際に導入してみてロードされているか確認しましょう。ロードされているmod一覧の確認にはこのmodがおすすめです( https://www.curseforge.com/minecraft/mc-mods/modmenu )
残念ながら今回はここまでです。次回はMixinを使用したマインクラフトのソースコード編集方法をお伝えします(たぶんこっちの記事を編集する
)。
- 投稿日:2020-09-26T07:33:54+09:00
Fabric-loaderができた経緯と仕組み
対象
- Fabricでmod開発をしたい
- Forgeの最新バージョンがないから仕方なくFabricを使いたい
- Javaが分かる
Fabric-loaderができた経緯
1. 既存モッドローダーの問題点
既存のForgeといったモッドローダーでは直接マインクラフトをデコンパイルしてソースコードを入手し、そのデコンパイルされたマインクラフトに簡単にアイテムなどが追加できるような仕組みが搭載されています。この方法ではモッドローダーがマインクラフトのソースコード全体を弄ることができるという(モッドローダー開発者にとっての)利点もありましたが、一つ大きな問題がありました。マインクラフトのデコンパイルは複雑で、デコンパイルされたものを再コンパイルしようとしてもできないのです。これはデコンパイラ自身によるバグのせいもありますが、コンパイル時に失われる情報(Genericsなど)もあるため仕方のない部分ではあります。この問題がモッドローダーの開発の遅れの原因となっていました。
2. SpongePowered/Mixin(Mixinフレームワーク)の誕生
Mixinフレームワークを単純にいうと、「デコンパイルをしなくてもソースコードを弄る機能群」です。classファイルにはJavaのクラスに関する全ての情報が入っていますが、その中でも特にメソッド内部の処理をデコンパイルするのが難しいのです。逆に言えば、メソッド内部の処理をデコンパイルせずにソースコードを弄ることができれば問題ないわけです。Mixinフレームワークは以下の手順でこれを可能にします。
- クラスファイルの情報を解析する(クラス・メンバ変数・メソッド)
- 解析されたクラスのラッパークラスを作成する。
- 解析されたクラスに関して、新しく作成されるオブジェクトが全てサブクラスのものになるように置き換える。
public class Player { public void kill() { ... } }public class Main { public static void main(String[] args) { Player player = new Player(); player.kill(); } }上のように(killメソッドの処理が不明な)プレイヤークラスとそれを使用するメインクラスがあると仮定します。あなたはkillメソッドの処理を消せばプレイヤーが不死身になることを確信しており、Mixinフレームワークを利用してkillメソッドの処理を消したいと思っています。
このときあなたはまずPlayerクラスを「Mixinする」ことになります。「Mixinする」事によって以下のクラスが作成されます。public class Player$1 extends Player { private final Player player; public Player$1(Player player) { this.player = player; } public void kill() { player.kill(); } }また「Mixinした」事によってメインクラスは次のように書き換えられます。
public class Main { public static void main(String[] args) { Player$1 player = new Player$1(new Player()); player.kill(); } }PlayerクラスをラップしたPlayer$1クラスが作成され、またメインクラスにおけるnewが書き換わったことがわかりますね。では、killメソッドの処理を消すにはどうしたらいいでしょうか?答えは簡単です。
public class Player$1 extends Player { private final Player player; public Player$1(Player player) { this.player = player; } public void kill() { //player.kill(); } }一行コメントアウトしただけでkillメソッドの処理を消すことができてしまいました。簡単ですね!確かにこの方法なら、メソッドの処理を消したり、メソッドの前後で処理を付け足したりするのは簡単そうです。
Fabric-loaderとは
Fabricローダーは以下の2つにより構成されます。
- マインクラフトを実行する機能
- モッドをロードしマインクラフトのロード前に「Mixinする」機能
「Mixinする」ことにより簡単にメソッドの処理を変更できると言いましたが、実際にはいくつかの制約があります。最も大きな制約の一つは、ロード済みのクラスは変更することができないということです。なのでFabric-loaderは、マインクラフトの設定ファイル(バージョン.json)に手を加えて、ランチャーからマインクラフトを起動した際に直接マインクラフトが実行されるのではなく、Fabric-loaderを介してモッドがロードされ「Mixinされた」後にマインクラフトが実行されるよう調整します。
Fabric APIとは
Fabric APIはブロック追加やアイテム追加などといった多くのmodで使われる共通部分をまとめたものです。Fabric APIもFabric-loaderを使用して動作しています。また別にFabric APIがmod作成に必ず必要かというとそういうことはなく、Sodium、Phospher、Lithiumなどといった有名どころのmodはFabric APIなしでも動作します(逆にFabric APIがあると干渉しあって動作しなくなるmodもある)。