- 投稿日:2020-09-11T22:46:38+09:00
【Java】配列とArrayListの違いについて
初心者には同じにしか見えない...
「Arrayってそもそも配列ですよね?ArrayListもArrayってあるから配列だよね!?」
これは僕だけではないと思います。
使用していく中で経験的にわかっていくとは思いますが、ちゃんと理解していないと困ることもあるかと。
自分なりの理解をメモしておきますので、初心者の方に対して少し違いがイメージできるようになる助けになればと思います。
そもそもクラスって?
- クラス
- データ(変数)
- 処理(メソッド・関数)
要はデータと処理を一まとまりにして扱うよというもの。
これが最初はわからなかったし、今でもそんなに便利なものなのかどうかもよくわかっていませんが。。。
よく車とかで説明されたりしますが、結局「言ってることはわかるけど。。。」という消化不良状態でした。
しかし、結局はテンプレだと考えればすっきりしました。
クラスはテンプレ、インスタンス化はテンプレの利用
初心者にはクラスとかインスタンス化しないと使えないとか言われてもなんのこっちゃという感じだと思います。
車でいうと
* 車種
* 排気量
* 値段とかいうものをまとめてクラスとして、インスタンス化して
* 車種:プリウス
* 排気量:1200CC
* 値段:200万円とすることで、クラスが利用できるようになるとか言われてもね。
走るという処理も、インスタンス化して、格納されている変数を下に動作するとかなんとか?書いててもよくわかりません。
しかし、そもそもテンプレだと考えればすっきりします。
車を作ろう!と思った時に、
車種:デビル
排気量:1億
燃料:原油よし作った!んじゃ売ろう!あれ、値段どうするよ?
ってなると困るやん?てか最初の段階で車作ろうぜって話をする人はその時その時で違う人のはず。その時に決め事がなければ最初に決めておくことは人によりけりってなると毎回毎回現場は困るわけです。
ということで、ここで車クラスというテンプレを作っといて
車種
排気量
燃料
値段
色
速度
走る
止まる
バックする
を最初に決めてね!ってしとけば、「これ決めてへんかった」とか「何決めなあかんかったっけ?」ということはなくなります。んでこのテンプレに沿って「じゃあ車種はデビルって奴にしようぜ!」って決めていくのがインスタンス化ですね。
厳密には違うのでしょうが、この理解でほぼ問題ないかと思います。
んで処理に関しても、走るっていう処理を設計ごとにどのくらいのスピードで動くかを決めていくんじゃなくて、速度という値を先に決めておいて、その速度の値を使って、「このくらいのスピードで前に進む」とテンプレ化しておけば毎回同じ命令の走るでちゃんと走るという感じ。
だから値だけ配列のようにまとめておくよりも、その値を使ってどうするのっていう処理もまとめておけば、記述が統一されるんですね。
テンプレだと思えば便利なものだなと思えます。
配列はクラス
クラスの中の変数を取り出す時は
クラス名.変数名
というように書くので、配列の要素数を取り出すには、配列のクラスの中にあるlengthという変数に要素数が入っているので、array.lengthのようにすれば取り出せる。
ArrayListはクラスを格納してるかつカプセル化
カプセル化してると変数に直接アクセスできません。というのも
array.lengthのように書いてもエラーになるだけということ。
じゃあどうすりゃいいのっていうとカプセル化の説明などで出てくる、getterやsetterなどのメソッドを使用して変数の値を取得したりするんですね。
メソッドを使わないといけないというところがミソ。
つまり、要素の数を取得する時に
array.size();のように最後に( )が必要になるということ。メソッドだから。
メソッドを使っているのか、変数名を指定して取得しているのかっていうところで書き方が違うので、「とりあえずこう書けば動く」と覚えるよりも「メソッドを使っているのか変数名を指定してるのか」の違いはわかっていないと( )をつけるのかどうかで迷ったりするかと思います。
あんまりまとまってないですがまとめ
とりあえず自分の頭の整理のつもりで書きました。厳密な説明ではありませんが、漠然としたイメージが少しはすっきりしたイメージに変わればと思います。
また、このあたりの話は別記事でまとめていきたいと思います。
- 投稿日:2020-09-11T20:03:56+09:00
JNIのライブラリ導入時にハマった事象
はじめに
現在参画している案件でJNIの外部ライブラリを導入する際にClassLoader問題にハマったため、備忘録として解決方法を残したいと思います。
環境
Java8
wildfly-8.1.0.FinalJNIとは
Java Native Interface (JNI) は、Javaプラットフォームにおいて、Javaで記述されたプログラムと、他のプログラミング言語(たとえばCやC++など)で書かれた、実際のCPU上で動作するコード(ネイティブコード)とを連携するためのインタフェース仕様である。
(Wikipedia:https://ja.wikipedia.org/wiki/Java_Native_Interface より引用)導入ライブラリについて
メイン処理がC++で実装された外部ライブラリで、JNIを利用してJavaに組み込もうとしていました。
ハマった点
ビルド資材を作成した際に以下のような構成にしていました。
service.ear ├ lib │ └ jni.jar ← ここにJNIのjarを配置 ├ META-INF ├ app1.jar ├ app2.jar └ webapp.warこの資材をWildFlyにデプロイして起動すると1回目は正常に動作します。
問題は2回目以降にHotDeployすると以下のエラーが発生。java.lang.UnsatisfiedLinkError: Native Library xxxx.dll already loaded in another classloader「すでに別のクラスローダーにロードされています」だと...なぜや...
WildFlyを再起動するとこの事象は解消されますが、再度HotDeployすると再発します。調査結果
ネイティブライブラリは1つのクラスローダーにしかロードできないという制限があるようです。
1回目も2回目も同じJVM上で実行されていますが、ロードするごとに異なるクラスローダーが使用されるため結果的に同じJVMで2回のロードが行われているためこの現象が発生するようです。
(と解釈しましたが、間違っていたらご指摘下さい)対応その①
ビルド資材の中からJNIのjarファイルを除去しました。
service.ear ├ lib ← ここにJNIのjarを配置しない ├ META-INF ├ app1.jar ├ app2.jar └ webapp.war対応その②
WidlFlyに静的モジュールとしてjarを配置します。
wildfly-8.1.0.Final/modules/system/layers/base配下にフォルダを作成します。
(例)wildfly-8.1.0.Final/modules/system/layers/base/xxx/yyy/main作ったフォルダにjarファイルとmodule.xmlを配置します。
base/xxx/yyy/main ├ jni.jar └ module.xml ← 新規でファイルを作成module.xmlの中身です。
maduleタグのnameに上で作成したディレクトリ構成と合わせます。<?xml version="1.0" encoding="UTF-8"?> <module name="xxx.yyy" xmlns="urn:jboss:module:1.1"> <resources> <resource-root path="jni.jar"/> </resources> </module>対応③
jboss-deployment-structure.xmlに依存関係を追加する。
<?xml version="1.0" encoding="UTF-8"?> <jboss-deployment-structure> <deployment> <dependencies> <module name="xxx.yyy" export="true" /> </dependencies> </deployment> </jboss-deployment-structure>最後に
以上の対応でHotDeploy後もClassLoaderのエラーは出なくなりました。
他にミドルウェア周りに詳しいメンバーがいなかったため必死になって調べたので備忘として残しておこうと思いました。
本当にこの対応が正しいのかは不明ですが、ひとまず事象が解決したので良しとします。参考
WildFlyのクラスローディング
https://qiita.com/tama1/items/f1556886149722b87f78
- 投稿日:2020-09-11T19:14:49+09:00
Webアプリ開発の記事まとめ
はじめに
DreamHanksの松下です。新規でWebアプリの開発を行いました。
こちらの記事は、その記事のまとめです。連載記事まとめ
【第一回】Spring-MVCフレームワークのプロジェクトの作り方
【作成予定記事】
・mybatisのインストール方法
・myBatisジェネレータでオブジェクトを作る補足記事
【作成予定記事】
・get,postの違い
・mavenでのmybatis実行方法
・maven(ビルドツール)の解説
・xmlファイルの解説
- 投稿日:2020-09-11T18:58:00+09:00
Spring-MVCフレームワークのプロジェクトの作り方
はじめに
DreamHanksの松下です。今回はSpring-MVCフレームワークのプロジェクト作成の手順を解説していきます。
今回のWebアプリ開発ではDBアクセスのフレームワークはMyBatisを使用します。
インストールするもの解説
ツール・環境関係
下記のものを用意する。
・eclipse2020
・jdk:1.8
・tomcat:8.5
・mysql:8.
・A5SQLeclipseでダウンロードするもの
下記のものはeclipse→ヘルプ→マーケットプレイスからダウンロード
・Spring4
・Spring Tools 3 Add-On for Spring Tools 4新規プロジェクトの作り方
①新規プロジェクトを選択
②Springと検索→「Springレガシー・プロジェクト」を選択→次へ
なぜ「Springレガシー・プロジェクト」を選択したのか?
確認中(2020/09/11)
③プロジェクト名を設定
④テンプレートは「Spring MVC Project」を設定→次へ
なぜテンプレートは「Spring MVC Project」を選択したのか?
確認中(2020/09/11)
⑤packageのトップレベルのディレクトリを設定
例「com.dreamhanks.workmanager]
com.dreamhanks → トップレベルのディレクトリ名を設定すること
workmanager → 作成したいアプリ名を設定すること
xmlファイルの設定
新規でプロジェクトを作った際にデフォルトで生成される3つのxmlファイルをカスタマイズしていく。
◆pom.xmlの設定
下記のdependency(依存するライブラリ)をデフォルトで生成されたpom.xmlの<dependencies>タグの中にコピペしてください。
pom.xmlの詳しい内容は「maven(ビルドツール)の解説」という記事内で解説しています。(2020/09/11工事中)
<!-- MySQL --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.11</version> </dependency> <!-- MyBatis 3.4.1 --> <!-- https://mvnrepository.com/artifact/org.mybatis/mybatis --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.4.1</version> </dependency> <!-- MyBatis-Spring --> <!-- https://mvnrepository.com/artifact/org.mybatis/mybatis-spring --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>1.3.0</version> </dependency> <!-- Spring-jdbc --> <!-- https://mvnrepository.com/artifact/org.springframework/spring-jdbc --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-jdbc</artifactId> <version>${org.springframework-version}</version> </dependency> <!-- Spring-test --> <!-- https://mvnrepository.com/artifact/org.springframework/spring-test --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>${org.springframework-version}</version> </dependency> <!-- Mybatis log --> <!-- https://mvnrepository.com/artifact/org.bgee.log4jdbc-log4j2/log4jdbc-log4j2-jdbc4.1 --> <dependency> <groupId>org.bgee.log4jdbc-log4j2</groupId> <artifactId>log4jdbc-log4j2-jdbc4</artifactId> <version>1.16</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>2.8.8</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-annotations</artifactId> <version>2.8.8</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.8.8</version> </dependency> <!-- validation-api(入力値検証で使用) --> <dependency> <groupId>javax.validation</groupId> <artifactId>validation-api</artifactId> <version>1.1.0.Final</version> </dependency> <!-- Hibernate(入力値検証で使用) --> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-validator</artifactId> <version>5.0.1.Final</version> </dependency> <!-- https://mvnrepository.com/artifact/org.springframework.session/spring-session --> <dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session</artifactId> <version>1.0.0.RELEASE</version> </dependency> <!-- poi --> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.13</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.13</version> </dependency> <!-- https://mvnrepository.com/artifact/org.mybatis.generator/mybatis-generator --> <dependency> <groupId>org.mybatis.generator</groupId> <artifactId>mybatis-generator</artifactId> <version>1.3.5</version> <type>pom</type> </dependency>◆root-context.xmlの設定
デフォルトの状態
root-context.xml<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- Root Context: defines shared resources visible to all other web components --> </beans>設定後の状態
root-context.xml<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:context="http://www.springframework.org/schema/context" xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:mybatis-spring="http://mybatis.org/schema/mybatis-spring" xsi:schemaLocation="http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc-3.1.xsd http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring-1.2.xsd http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.1.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.1.xsd"> <!-- Root Context: defines shared resources visible to all other web components --> <context:component-scan base-package="com.dreamhanks" /> <context:component-scan base-package="com.dreamhanks.service" /> <!-- MySQL dataSource --> <bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"> <property name="driverClassName" value="net.sf.log4jdbc.sql.jdbcapi.DriverSpy"></property> <property name="url" value="jdbc:log4jdbc:mysql://localhost:3306/work_db?useSSL=false&serverTimezone=UTC"></property> <property name="username" value="root"></property> <property name="password" value="Daiki8863"></property> </bean> <!-- mybatis SqlSessionFactoryBean --> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource"></property> <property name="configLocation" value="classpath:/mybatis-config.xml"></property> <property name="mapperLocations" value="classpath:mappers/**/*Mapper.xml"></property> </bean> <!-- mybatis --> <bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate" destroy-method="clearCache"> <constructor-arg name="sqlSessionFactory" ref="sqlSessionFactory"></constructor-arg> </bean> </beans>①設定後の状態のroot-context.xmlをコピペしてください。
②<!-- MySQL dataSource -->の設定
・下記のvalue値を自分のmysqlの環境に合わせる<property name="url" value="jdbc:log4jdbc:mysql://localhost:3306/work_db?useSSL=false&serverTimezone=UTC"></property> <property name="username" value="root"></property> <property name="password" value="Daiki8863"></property>特にみるべきところ
・work_db → カレントスキーマ
・username, passwordを自分のmysqlの環境に合わせる。③パッケージ名などは自分の環境にあわせること
root-context.xmlの詳しい内容は「xmlファイルの解説」という記事内で解説しています。(2020/09/11工事中)
<context:component-scan base-package="com.dreamhanks" /> <context:component-scan base-package="com.dreamhanks.service" />◆servlet-context.xmlの設定
servlet-context.xml<?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns="http://www.springframework.org/schema/mvc" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:beans="http://www.springframework.org/schema/beans" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/mvc https://www.springframework.org/schema/mvc/spring-mvc.xsd http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"> <!-- DispatcherServlet Context: defines this servlet's request-processing infrastructure --> <!-- Enables the Spring MVC @Controller programming model --> <annotation-driven /> <!-- Handles HTTP GET requests for /resources/** by efficiently serving up static resources in the ${webappRoot}/resources directory --> <resources mapping="/resources/**" location="/resources/" /> <!-- Resolves views selected for rendering by @Controllers to .jsp resources in the /WEB-INF/views directory --> <beans:bean class="org.springframework.web.servlet.view.InternalResourceViewResolver"> <beans:property name="prefix" value="/WEB-INF/views/" /> <beans:property name="suffix" value=".jsp" /> </beans:bean> <context:component-scan base-package="com.dreamhanks.workmanager" /> </beans:beans>①特に設定すべき個所はありませんが、下記の内容が自分の環境と合っているかを確認してください
<context:component-scan base-package="com.dreamhanks.workmanager" />servlet-context.xmlの詳しい内容は「xmlファイルの解説」という記事内で解説しています。(2020/09/11工事中)
- 投稿日:2020-09-11T18:58:00+09:00
【第一回】Spring-MVCフレームワークのプロジェクトの作り方
はじめに
DreamHanksの松下です。今回はSpring-MVCフレームワークのプロジェクト作成の手順を解説していきます。
今回のWebアプリ開発ではDBアクセスのフレームワークはMyBatisを使用します。
インストールするもの解説
ツール・環境関係
下記のものを用意する。
・eclipse2020
・jdk:1.8
・tomcat:8.5
・mysql:8.
・A5SQLeclipseでダウンロードするもの
下記のものはeclipse→ヘルプ→マーケットプレイスからダウンロード
・Spring4
・Spring Tools 3 Add-On for Spring Tools 4新規プロジェクトの作り方
①新規プロジェクトを選択
②Springと検索→「Springレガシー・プロジェクト」を選択→次へ
なぜ「Springレガシー・プロジェクト」を選択したのか?
確認中(2020/09/11)
③プロジェクト名を設定
④テンプレートは「Spring MVC Project」を設定→次へ
なぜテンプレートは「Spring MVC Project」を選択したのか?
確認中(2020/09/11)
⑤packageのトップレベルのディレクトリを設定
例「com.dreamhanks.workmanager]
com.dreamhanks → トップレベルのディレクトリ名を設定すること
workmanager → 作成したいアプリ名を設定すること
xmlファイルの設定
新規でプロジェクトを作った際にデフォルトで生成される3つのxmlファイルをカスタマイズしていく。
◆pom.xmlの設定
下記のdependency(依存するライブラリ)をデフォルトで生成されたpom.xmlの<dependencies>タグの中にコピペしてください。
pom.xmlの詳しい内容は「maven(ビルドツール)の解説」という記事内で解説しています。(2020/09/11工事中)
<!-- MySQL --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.11</version> </dependency> <!-- MyBatis 3.4.1 --> <!-- https://mvnrepository.com/artifact/org.mybatis/mybatis --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.4.1</version> </dependency> <!-- MyBatis-Spring --> <!-- https://mvnrepository.com/artifact/org.mybatis/mybatis-spring --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>1.3.0</version> </dependency> <!-- Spring-jdbc --> <!-- https://mvnrepository.com/artifact/org.springframework/spring-jdbc --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-jdbc</artifactId> <version>${org.springframework-version}</version> </dependency> <!-- Spring-test --> <!-- https://mvnrepository.com/artifact/org.springframework/spring-test --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>${org.springframework-version}</version> </dependency> <!-- Mybatis log --> <!-- https://mvnrepository.com/artifact/org.bgee.log4jdbc-log4j2/log4jdbc-log4j2-jdbc4.1 --> <dependency> <groupId>org.bgee.log4jdbc-log4j2</groupId> <artifactId>log4jdbc-log4j2-jdbc4</artifactId> <version>1.16</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>2.8.8</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-annotations</artifactId> <version>2.8.8</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.8.8</version> </dependency> <!-- validation-api(入力値検証で使用) --> <dependency> <groupId>javax.validation</groupId> <artifactId>validation-api</artifactId> <version>1.1.0.Final</version> </dependency> <!-- Hibernate(入力値検証で使用) --> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-validator</artifactId> <version>5.0.1.Final</version> </dependency> <!-- https://mvnrepository.com/artifact/org.springframework.session/spring-session --> <dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session</artifactId> <version>1.0.0.RELEASE</version> </dependency> <!-- poi --> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.13</version> </dependency> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi-ooxml</artifactId> <version>3.13</version> </dependency> <!-- https://mvnrepository.com/artifact/org.mybatis.generator/mybatis-generator --> <dependency> <groupId>org.mybatis.generator</groupId> <artifactId>mybatis-generator</artifactId> <version>1.3.5</version> <type>pom</type> </dependency>◆root-context.xmlの設定
デフォルトの状態
root-context.xml<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- Root Context: defines shared resources visible to all other web components --> </beans>設定後の状態
root-context.xml<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:context="http://www.springframework.org/schema/context" xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:mybatis-spring="http://mybatis.org/schema/mybatis-spring" xsi:schemaLocation="http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc-3.1.xsd http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring-1.2.xsd http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.1.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.1.xsd"> <!-- Root Context: defines shared resources visible to all other web components --> <context:component-scan base-package="com.dreamhanks" /> <context:component-scan base-package="com.dreamhanks.service" /> <!-- MySQL dataSource --> <bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource"> <property name="driverClassName" value="net.sf.log4jdbc.sql.jdbcapi.DriverSpy"></property> <property name="url" value="jdbc:log4jdbc:mysql://localhost:3306/work_db?useSSL=false&serverTimezone=UTC"></property> <property name="username" value="root"></property> <property name="password" value="Daiki8863"></property> </bean> <!-- mybatis SqlSessionFactoryBean --> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource"></property> <property name="configLocation" value="classpath:/mybatis-config.xml"></property> <property name="mapperLocations" value="classpath:mappers/**/*Mapper.xml"></property> </bean> <!-- mybatis --> <bean id="sqlSession" class="org.mybatis.spring.SqlSessionTemplate" destroy-method="clearCache"> <constructor-arg name="sqlSessionFactory" ref="sqlSessionFactory"></constructor-arg> </bean> </beans>①設定後の状態のroot-context.xmlをコピペしてください。
②<!-- MySQL dataSource -->の設定
・下記のvalue値を自分のmysqlの環境に合わせる<property name="url" value="jdbc:log4jdbc:mysql://localhost:3306/work_db?useSSL=false&serverTimezone=UTC"></property> <property name="username" value="root"></property> <property name="password" value="Daiki8863"></property>特にみるべきところ
・work_db → カレントスキーマ
・username, passwordを自分のmysqlの環境に合わせる。③パッケージ名などは自分の環境にあわせること
root-context.xmlの詳しい内容は「xmlファイルの解説」という記事内で解説しています。(2020/09/11工事中)
<context:component-scan base-package="com.dreamhanks" /> <context:component-scan base-package="com.dreamhanks.service" />◆servlet-context.xmlの設定
servlet-context.xml<?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns="http://www.springframework.org/schema/mvc" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:beans="http://www.springframework.org/schema/beans" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/mvc https://www.springframework.org/schema/mvc/spring-mvc.xsd http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"> <!-- DispatcherServlet Context: defines this servlet's request-processing infrastructure --> <!-- Enables the Spring MVC @Controller programming model --> <annotation-driven /> <!-- Handles HTTP GET requests for /resources/** by efficiently serving up static resources in the ${webappRoot}/resources directory --> <resources mapping="/resources/**" location="/resources/" /> <!-- Resolves views selected for rendering by @Controllers to .jsp resources in the /WEB-INF/views directory --> <beans:bean class="org.springframework.web.servlet.view.InternalResourceViewResolver"> <beans:property name="prefix" value="/WEB-INF/views/" /> <beans:property name="suffix" value=".jsp" /> </beans:bean> <context:component-scan base-package="com.dreamhanks.workmanager" /> </beans:beans>①特に設定すべき個所はありませんが、下記の内容が自分の環境と合っているかを確認してください
<context:component-scan base-package="com.dreamhanks.workmanager" />servlet-context.xmlの詳しい内容は「xmlファイルの解説」という記事内で解説しています。(2020/09/11工事中)
おわりに
次回はmybatisのインストール方法を解説していきます。
お読みくださいまして、ありがとうございました。
- 投稿日:2020-09-11T18:22:28+09:00
【AWS x Java】DynamoDB StreamsをKinesis Client Library (KCL) で処理する
はじめに
実案件でDynamoDB StreamsをKinesis Client Library (以下KCL) で処理する機会がありましたので、KCLが実際にどういう挙動をするのか、それを踏まえてどのような実装にしたのか紹介したいと思います。
今回やりたかったこと
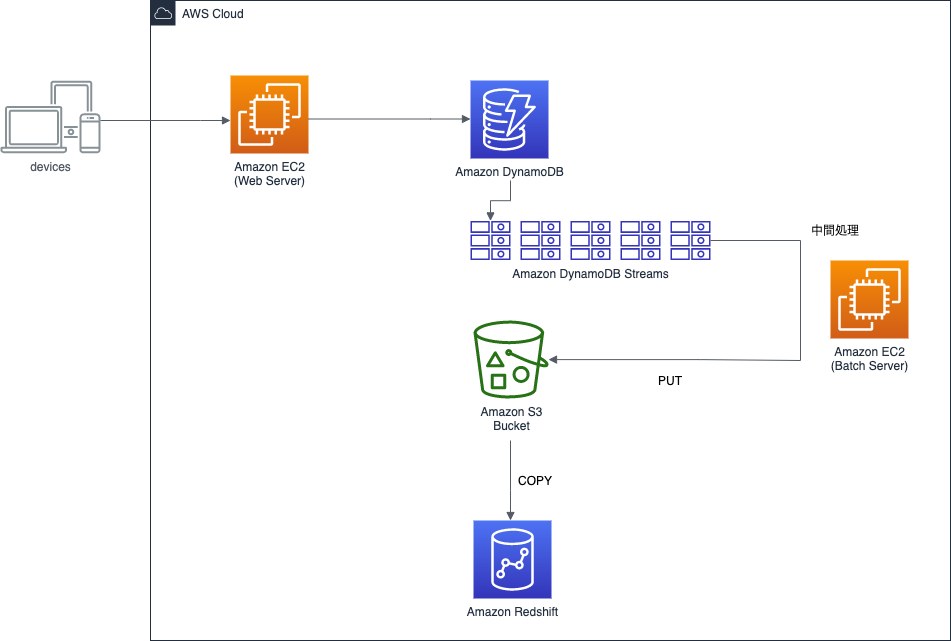
BookLive!のある機能ではDynamoDBを使用しています。
このDynamoDBのデータを、データ追加後できるだけ早いタイミングでRedshiftに転送する必要が出てきました。
現状のテーブル形式を踏まえ様々な検討をした結果、DynamoDB Streamsを設定し、追加されていくデータをいわゆるストリームとして扱うことでRedshiftに持っていくことが最善策という結論に至りました。
また、DynamoDB Streamsの取得方法は公式が推奨しているKCLを使う方法で行うことにしました。
注意点
- KCLを使用するコンシューマアプリケーションは基本的にEC2インスタンスに常駐させる場合が多いと思います。しかし、今回はバッチ風(定期的な実行/クローズ)に処理するので、定石からは少し外れている部分があります。
- DynamoDBのキャパシティモードはオンデマンドに設定しているため、本記事ではキャパシティを考慮する話は出てきません。
本記事の関連技術
- JDK11 (Amazon Coretto 11)
- DynamoDB Streams
- Kinesis Client Library (KCL)
- aws-sdk-java
build.gradledependencies { implementation 'com.amazonaws:aws-java-sdk-dynamodb:1.11.833' implementation 'com.amazonaws:aws-java-sdk-kinesis:1.11.839' }build.gradledependencies { implementation 'com.amazonaws:dynamodb-streams-kinesis-adapter:1.5.2' }DynamoDB StreamsとKCL
DynamoDB Streamsについて
特徴
- DynamoDBに書き込まれた後、データは非常に低レイテンシーな間隔でストリームに追加される
- シャードは自動でスケーリングしてくれる
- また、特定のシャードが使われ続けるわけではなく、適度に新しいシャードが作られていく
- ストリームは追加後24時間保持される
- ストリームの設定はいつでも追加・削除可能
- ただし、ストリームの設定が追加された後にDynamoDBに追加されたデータのみバッファリングされる
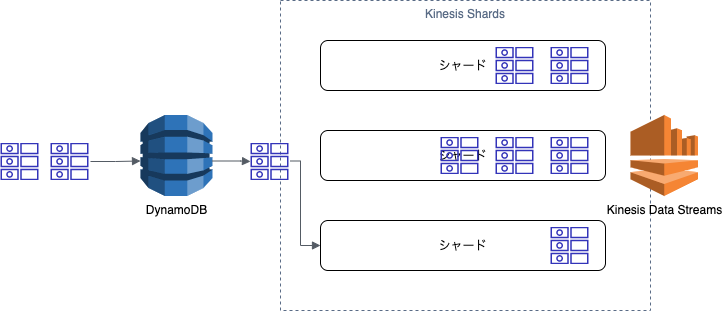
イメージ
あたかもKinesis Data Streamsのようにストリームをバッファリングしてくれます(以下の図のKinesis Shards部分をDynamoDB Streamsとして捉えることが可能です)。
KCLを直接使用することはできませんが、Kinesis Adapterを通して、Kinesis Data Streamsからストリームを取得するのと同等の方法でDynamoDB Streamsを取得することが可能です。
以下の図はあくまでも個人的なイメージであることに注意してください。
Kinesis Client Library (KCL) について
そもそもKinesisとは
ここでは触れませんが、参考記事を掲載しておきます。
特徴
- Kinesis Data Streamsを処理するためのコンシューマアプリケーション用オープンソースライブラリ
- コンシューマとはバッファリングされたストリームを取得して処理する側のこと
- 逆に追加する側はプロデューサー
- Kinesis Data Streamsを扱う上で必要な、どのシャードのどのレコードまで取得したかを記録する処理を、DynamoDBを使用して自動化してくれる
- シャードからのレコード取得もしてくれるため、開発者は基本的にレコードを取得した後の処理を実装するだけで良い
KCLの用語
以下の内容はDynamoDB Streamsを扱う場合においても同義です(Kinesis Data StreamsをDynamoDB Streamsに読み替えられます)。
- Shard(シャード)
- Kinesis Data Streamsのデータを分散バッファリングする本体
- 公式のFAQによると「シャードとは、Amazon Kinesis データストリームの基本的なスループットの単位」と記載されている
- Lease(リース)
- Kinesis Data Streamsのシャードからレコードを取得できるようになっている状態のこと
- Workerにシャードが貸し出されるという意味合いで用いられていそう(内部では、複数のWorkerから同じシャードが取得されないようになっている)
- Leaseテーブル
- Leaseの状態(Workerとシャードのマッピング)やチェックポイントを記録するDynamoDBテーブル
- 存在しなければ、KCLが自動で作ってくれる
- そのため、アプリケーションが動作するEC2インスタンスにDynamoDBテーブルを作成する権限が必要
- もしくは、Primary Keyを
leaseKey::Stringに設定したDynamoDBテーブルを自前で作っても良い
- 当社では、AWSのリソースをTerraformで管理していることもあり、この方法を採用
- この場合、テーブル名がそのままKinesisアプリケーション名となる
- LeaseKey
- Kinesis Data StreamsのシャードID
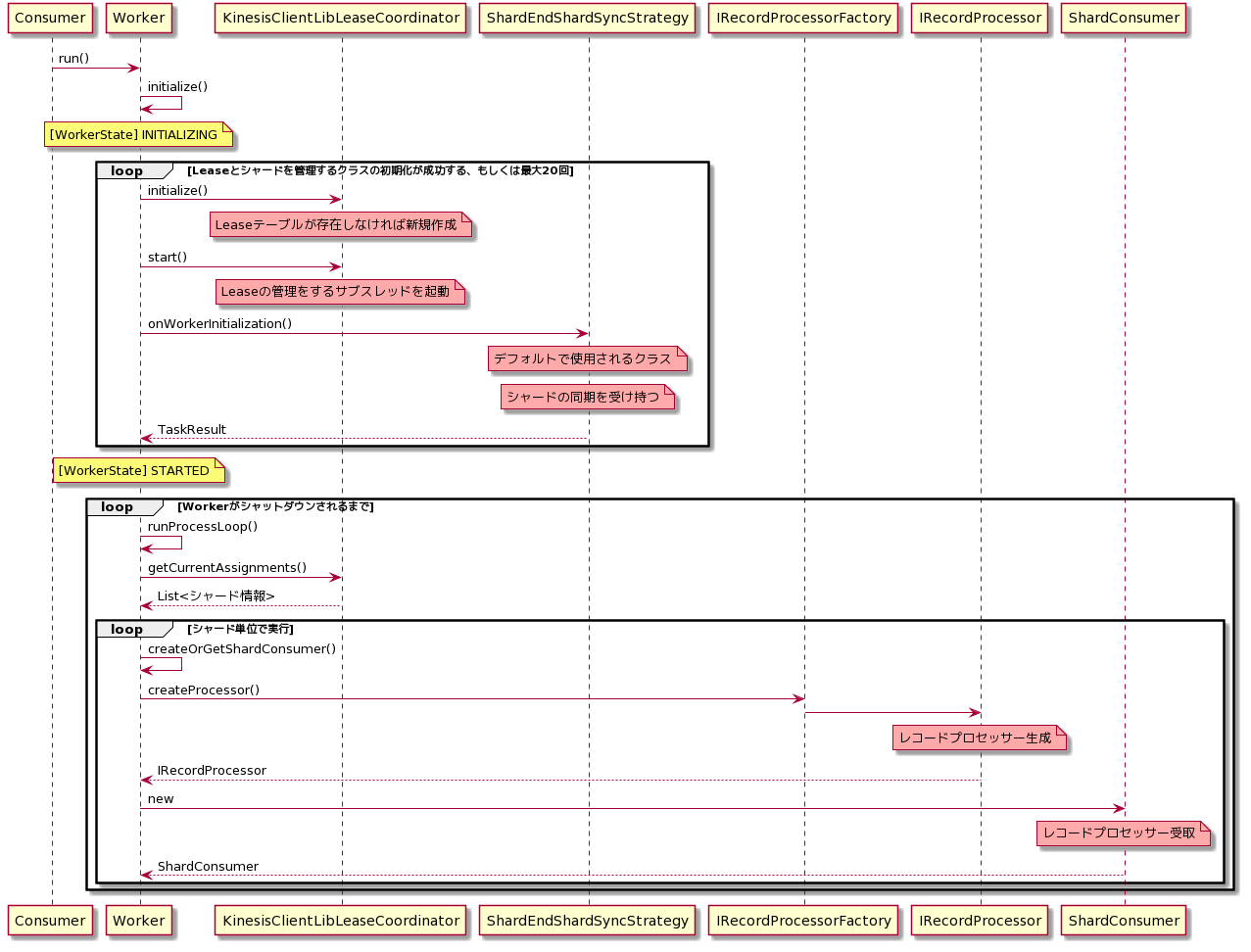
KCLのロジック(簡易版)
()がついているものはメソッドで、重要な箇所のみ抽出して記載しています。
Consumerは、Workerインスタンスを作成しrun()を呼び出す自分で実装する部分となります。■レコードプロセッサーが生成されるまで
デーモンかバッチか
runProcessLoop()が実行されるループは、実行中のWorkerインスタンスに対して、シャットダウンがリクエストされ、シャットダウンが完了するまで無限ループする作りとなっています。
つまり、
- Workerの
run()メソッドをコンシューマアプリケーションのメインスレッドで実行した場合、基本的にデーモンのように半永久的に動作し続けます- 一方で、今回目的としている定期的に開始/終了を伴うバッチ風に動作させるためには、サブスレッドを作成し、そちらにWorkerインスタンスを渡してあげる必要があります。また、一定時間後にメインスレッドからWorkerに対してシャットダウンリクエストを送ることで、Workerを終了させることができます。
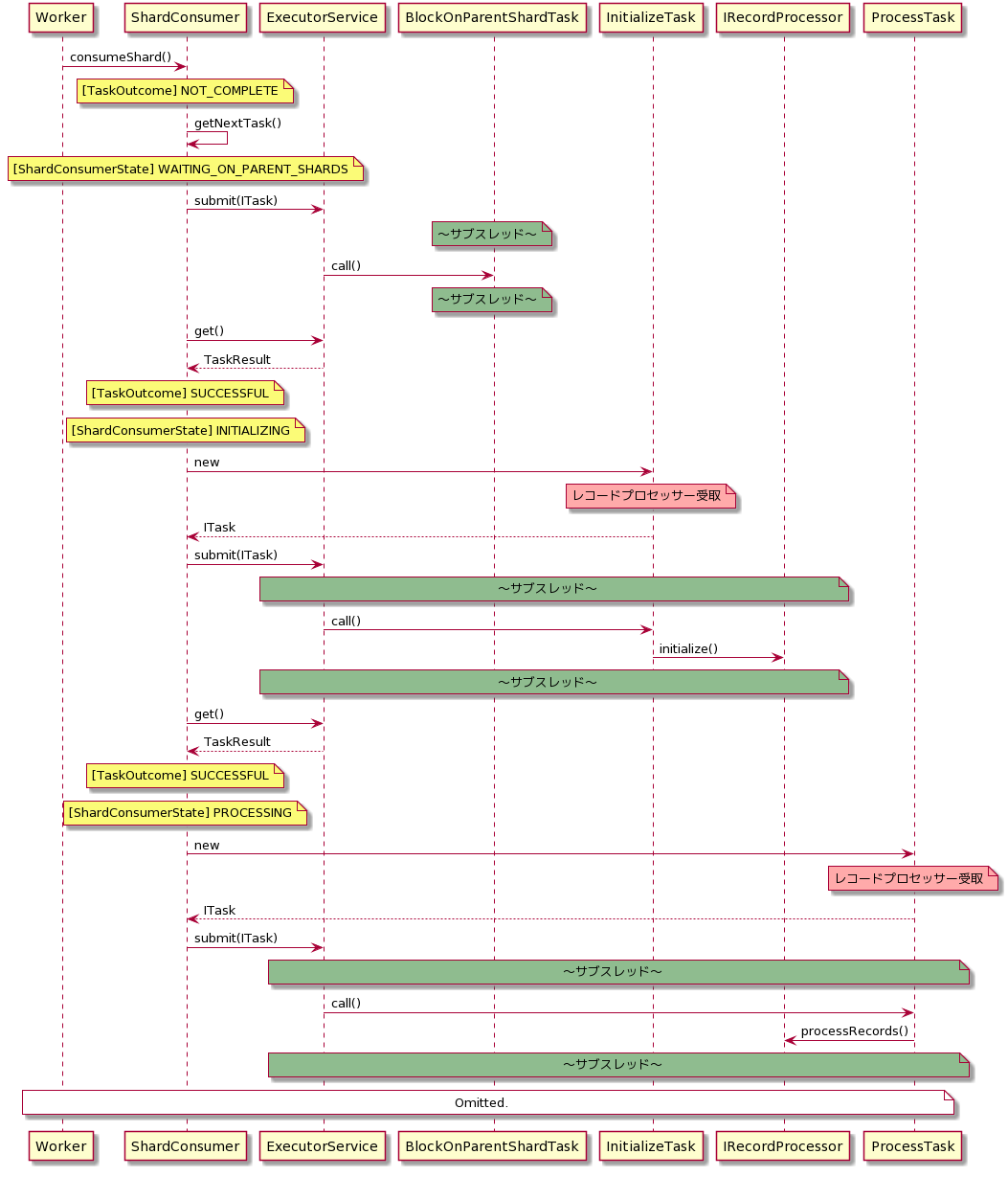
■レコードプロセッサー本体の処理
以下は、上のシーケンス図のWorkerがShardConsumerインスタンスを生成した後の処理になります。
なお、この処理は上のシーケンス図でいうところの[シャード単位で実行]のloop内で実行されます。
RuntimeExceptionを含むExceptionはKCLに握り潰される
IRecordProcessorインターフェースを実装するいわゆるレコードプロセッサー内で発生する例外は全て握り潰されます。
言い換えると、レコードプロセッサー内でどんな例外が発生してもアプリケーションは異常終了しません。
この弊害はチェックポイントの記録時に起きます。
シーケンス図を見れば分かるようにIRecordProcessorの各メソッドはそれぞれサブスレッド上で実行されます。
また、そのスレッド内で発生した例外は先に記載した通り、KCLによって無視されます。
つまり、processRecords()で例外が発生してもスレッドはあたかも正常終了したかのように扱われるということです。
ちなみに、checkpointはprocessRecords()に渡される時点で、そのシャードリースの最新シーケンスと決まっています。
このシーケンスがshutdown()時にも渡されるため、processRecords()のスレッドが異常終了したときのshutdown()時にcheckpointを記録すると、処理に失敗したはずのストリームは欠損してしまいます。KCLの仕様を踏まえたコンシューマアプリケーションの実装
実際の実装とは違いますが、ロジックの基本形だけ伝わるように書いています。
(抜き出しながら記載していったので、そのままでは実行できないかもしれません。)StreamsAdapter
- エントリーポイントのクラス
- 実行/終了を伴うバッチ処理をするため、サブスレッドでWorkerを実行しています(例では5分間有効)
- 30秒おきにShardReadWriteLockから各シャードの処理ステータスをチェックし、1つでもExceptionが発生していれば(ShardProcessStatusがFAILURE)、即座にシャットダウンを実行しています
import com.amazonaws.auth.AWSCredentialsProvider; import com.amazonaws.auth.InstanceProfileCredentialsProvider; import com.amazonaws.regions.Regions; import com.amazonaws.services.cloudwatch.AmazonCloudWatch; import com.amazonaws.services.cloudwatch.AmazonCloudWatchClientBuilder; import com.amazonaws.services.dynamodbv2.AmazonDynamoDB; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClientBuilder; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreams; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreamsClientBuilder; import com.amazonaws.services.dynamodbv2.streamsadapter.AmazonDynamoDBStreamsAdapterClient; import com.amazonaws.services.dynamodbv2.streamsadapter.StreamsWorkerFactory; import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessorFactory; import com.amazonaws.services.kinesis.clientlibrary.lib.worker.InitialPositionInStream; import com.amazonaws.services.kinesis.clientlibrary.lib.worker.KinesisClientLibConfiguration; import com.amazonaws.services.kinesis.clientlibrary.lib.worker.Worker; import software.amazon.awssdk.regions.Region; import software.amazon.awssdk.services.s3.S3Client; import java.util.Map; import java.util.concurrent.ExecutionException; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class StreamsAdapter { private static final String tableName = "tableName"; private static final String appName = "appName"; private static final String workerId = "workerId"; private static final AWSCredentialsProvider credentialsProvider = new InstanceProfileCredentialsProvider(true); public static void main(String... args) { // RecordProcessFactory S3Client s3Client = S3Client.builder().region(Region.AP_NORTHEAST_1).build(); ShardReadWriteLock shardReadWriteLock = new ShardReadWriteLock(); IRecordProcessorFactory factory = new RecordProcessorFactory(s3Client, shardReadWriteLock); // DynamoDB AmazonDynamoDB dynamoDB = AmazonDynamoDBClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_1).build(); String streamArn = dynamoDB.describeTable(tableName).getTable().getLatestStreamArn(); // DynamoDB Streams AmazonDynamoDBStreams streams = AmazonDynamoDBStreamsClientBuilder.standard() .withRegion(Regions.AP_NORTHEAST_1).build(); AmazonDynamoDBStreamsAdapterClient adapterClient = new AmazonDynamoDBStreamsAdapterClient(streams); // KCL Configuration KinesisClientLibConfiguration kclConfig = new KinesisClientLibConfiguration(appName, streamArn, credentialsProvider, workerId) .withInitialPositionInStream(InitialPositionInStream.TRIM_HORIZON); // CloudWatch AmazonCloudWatch cloudWatch = AmazonCloudWatchClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_1).build(); // KCL Worker Worker worker = StreamsWorkerFactory.createDynamoDbStreamsWorker(factory, kclConfig, adapterClient, dynamoDB, cloudWatch); System.out.println("Starting stream processing..."); ExecutorService es = Executors.newSingleThreadExecutor(); es.execute(worker); try { // Enable RecordProcessor for 5 minutes. // Check for exception every 30 seconds. boolean allSucceed = true; recordProcess: for (int i = 0; i < 10; i++) { Thread.sleep(30000); Map<String, ShardReadWriteLock.ShardProcessStatus> statusMap = shardReadWriteLock.read(); for (Map.Entry<String, ShardReadWriteLock.ShardProcessStatus> entry : statusMap.entrySet()) { ShardReadWriteLock.ShardProcessStatus status = entry.getValue(); if (status.equals(ShardReadWriteLock.ShardProcessStatus.FAILURE)) { allSucceed = false; break recordProcess; } } } worker.startGracefulShutdown().get(); if (!allSucceed) { throw new RuntimeException("Caught exception in processRecords()."); } } catch (InterruptedException | ExecutionException ex) { ex.printStackTrace(); throw new RuntimeException("Failed to process record of DynamoDB Streams via KCL."); } finally { es.shutdownNow(); } System.out.println("Completed stream processing"); } }RecordProcessorFactory
import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessor; import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessorFactory; import software.amazon.awssdk.services.s3.S3Client; public class RecordProcessorFactory implements IRecordProcessorFactory { private S3Client s3Client; private ShardReadWriteLock shardReadWriteLock; public RecordProcessorFactory(S3Client s3Client, ShardReadWriteLock shardReadWriteLock) { this.s3Client = s3Client; this.shardReadWriteLock = shardReadWriteLock; } @Override public IRecordProcessor createProcessor() { return new RecordProcessor(s3Client, shardReadWriteLock); } }RecordProcessor
- 分かりやすさのため、processRecords()は受け取ったストリームをS3にPUTするだけの処理にしています
- processRecords()で発生したExceptionとRuntimeExceptionはKCLによって握り潰されるため、全体の処理をExceptionで囲み、例外発生時はメインスレッドから渡されてきたShardReadWriteLockにステータスFAILUREを設定しています
- 一度processRecords()が失敗しても2回目以降呼ばれる可能性があるため、対象のシャードでExceptionが一度でも発生していれば、処理をそれ以上進めないためにスレッドを即座に終了させるようにしています
- processRecords()の冒頭
- シャットダウン時は必ずcheckpointを記録する必要があるため、processRecords()で例外が発生した際に、その時点で取得しているレコード情報を全てログに吐き出すようにしています
- 仕方なく手運用でリカバリを想定していますが、もっといい方法があれば教えてください
import com.amazonaws.services.dynamodbv2.streamsadapter.model.RecordAdapter; import com.amazonaws.services.kinesis.clientlibrary.exceptions.InvalidStateException; import com.amazonaws.services.kinesis.clientlibrary.exceptions.ShutdownException; import com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessorCheckpointer; import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessor; import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IShutdownNotificationAware; import com.amazonaws.services.kinesis.clientlibrary.lib.worker.ShutdownReason; import com.amazonaws.services.kinesis.clientlibrary.types.InitializationInput; import com.amazonaws.services.kinesis.clientlibrary.types.ProcessRecordsInput; import com.amazonaws.services.kinesis.clientlibrary.types.ShutdownInput; import com.amazonaws.services.kinesis.model.Record; import software.amazon.awssdk.awscore.exception.AwsServiceException; import software.amazon.awssdk.core.exception.SdkClientException; import software.amazon.awssdk.core.sync.RequestBody; import software.amazon.awssdk.services.s3.S3Client; import software.amazon.awssdk.services.s3.model.PutObjectRequest; public class RecordProcessor implements IRecordProcessor, IShutdownNotificationAware { private final String bucket = "bucket"; private final String objectKey = "objectKey"; private S3Client s3Client; private ShardReadWriteLock shardReadWriteLock; private String shardId; public RecordProcessor(S3Client s3Client, ShardReadWriteLock shardReadWriteLock) { this.s3Client = s3Client; this.shardReadWriteLock = shardReadWriteLock; } @Override public void initialize(InitializationInput initializationInput) { shardId = initializationInput.getShardId(); } @Override public void processRecords(ProcessRecordsInput processRecordsInput) { Map<String, ShardReadWriteLock.ShardProcessStatus> statusMap = shardReadWriteLock.read(); statusMap.forEach((key, value) -> { if (key.equals(shardId) && value.equals(ShardReadWriteLock.ShardProcessStatus.FAILURE)) { throw new RuntimeException("Shard " + shardId + " have failed."); } }); shardReadWriteLock.write(shardId, ShardReadWriteLock.ShardProcessStatus.INITIALIZE); try { for (Record record : processRecordsInput.getRecords()) { if (record instanceof RecordAdapter) { com.amazonaws.services.dynamodbv2.model.Record streamRecord = ((RecordAdapter) record) .getInternalObject(); if (!streamRecord.getEventName().equals("INSERT")) { continue; } s3Client.putObject(PutObjectRequest.builder().bucket(bucket).key(objectKey).build(), RequestBody.fromString(String.valueOf(streamRecord))); } } shardReadWriteLock.write(shardId, ShardReadWriteLock.ShardProcessStatus.SUCCESS); } catch (Exception ex) { shardReadWriteLock.write(shardId, ShardReadWriteLock.ShardProcessStatus.FAILURE); processRecordsInput.getRecords().forEach(s -> System.err.println(((RecordAdapter) s).getInternalObject())); ex.printStackTrace(); throw new RuntimeException("Caught exception in process on shard " + shardId); } } @Override public void shutdown(ShutdownInput shutdownInput) { if (shutdownInput.getShutdownReason() == ShutdownReason.TERMINATE) { try { shutdownInput.getCheckpointer().checkpoint(); } catch (InvalidStateException | ShutdownException ex) { ex.printStackTrace(); } } } @Override public void shutdownRequested(IRecordProcessorCheckpointer checkpointer) { try { checkpointer.checkpoint(); } catch (InvalidStateException | ShutdownException ex) { ex.printStackTrace(); } } }ShardReadWriteLock
- マルチスレッドのデザインパターンであるReadWriteLockパターンを採用しています
- shardsProcessStatusはKeyがシャードID、ValueがShardProcessStatusのMapで、これの読み込み/書き込み時にLockをかけるように実装しています
- INITIALIZE: processRecords()の処理開始時に付与
- SUCCESS: processRecords()の処理が正常終了したときに付与
- FAILURE: processRecords()の処理で例外が発生したときに付与
import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReadWriteLock; import java.util.concurrent.locks.ReentrantReadWriteLock; public class ShardReadWriteLock { public enum ShardProcessStatus { INITIALIZE, SUCCESS, FAILURE; } private Map<String, ShardProcessStatus> shardsProcessStatus = new HashMap<>(); private final ReadWriteLock lock = new ReentrantReadWriteLock(); private final Lock readLock = lock.readLock(); private final Lock writeLock = lock.writeLock(); public Map<String, ShardProcessStatus> read() { readLock.lock(); try { return shardsProcessStatus; } finally { readLock.unlock(); } } public void write(String shardId, ShardProcessStatus status) { writeLock.lock(); shardsProcessStatus.put(shardId, status); writeLock.unlock(); } }まとめ
KCLでバッチ風に処理するのは非常に難しかったです。
外部のスレッドから各シャードの処理状況を監視することで、エラーを検知と処理中断をできるようにしました。
processRecords()がどのように呼ばれるのか、例外がどう扱われるのかを知るために、KCLの処理をシーケンス図にまとめました。
コンシューマアプリケーションをデーモンとして実行される方やKinesis Data Streamsをお使いになる方にも参考になればと思います。
課題としては、processRecords()の処理で例外が発生した際に、レコードをログに吐いて手運用するような実装になっている点です。参考

- 投稿日:2020-09-11T16:30:05+09:00
MPAndroidChart を用いて二本以上の折れ線グラフを作成する【Java】
この記事を書こうと思い当たった理由
Androidアプリ制作初心者です。
テキストやウェブ検索でなんとか形あるものを作っているのですが、考え方の基本がなかなか身につかず参考になりそうなコードをいつも探し回っています。
今回データベースと接続しそのデータを用いた二本の折れ線グラフを作成したのですが、ライン二本目の記述がわからず苦戦したのでここに記したいと思います。参考
マネーフォワードエンジニアブログ(Android:グラフ表示で表現豊かに。MPAndroidChart を使ってみよう!)
nyanのアプリ開発([Android] MPAndroidChart ライブラリーでグラフを描画) ←沢山の記事が載ってるブログです。全体を通してお世話になりました。環境
Windows10
AndroidStudio4グラフの初期化
MPAndroidChartの導入やレイアウトは参考サイトをご覧ください。
私が使わなかったメソッドもコメントアウトしていくつか載せています。LineChartActivity.javaLineChart mChart = findViewById(R.id.lineChart); // グラフ説明テキストを表示するか mChart.getDescription().setEnabled(true); // グラフ説明テキスト(アプリ名など) mChart.getDescription().setText(getResources().getString(R.string.app_name)); // グラフ説明テキストの文字色設定 //mChart.getDescription().setTextColor(Color.BLACK); // グラフ説明テキストの文字サイズ設定 //mChart.getDescription().setTextSize(10f); // グラフ説明テキストの表示位置設定 //mChart.getDescription().setPosition(0, 0); // グラフの背景色 mChart.setBackgroundColor(Color.WHITE); // x軸の設定 XAxis xAxis = mChart.getXAxis(); // x軸を斜めに出力 xAxis.setLabelRotationAngle(45); // x軸最大値最小値 // 以下だと0~9番目が出力される(10個)書かないと、登録したデータ分表示される xAxis.setAxisMinimum(0f); xAxis.setAxisMaximum(9f); // データベースに登録した年月日をx軸に設定 xAxis.setValueFormatter(new IndexAxisValueFormatter(getDate())); // x軸を破線にする(Dashed Line) xAxis.enableGridDashedLine(10f, 10f, 0f); xAxis.setPosition(XAxis.XAxisPosition.BOTTOM); // y軸の設定 YAxis yAxis = mChart.getAxisLeft(); // Y軸最大最小設定 yAxis.setAxisMaximum(150f); yAxis.setAxisMinimum(50f); // y軸を破線にする yAxis.enableGridDashedLine(10f, 10f, 0f); yAxis.setDrawZeroLine(true); // 右側の目盛り。不要ならfalse mChart.getAxisRight().setEnabled(false);x軸の設定
x軸設定のgetDateメソッドです。
データベースに登録したデータの型を変える必要がありました。
もっとスマートに書けそうですが、今の私ではここまでです。
変数 date はデータベースのデータを保持させている ArrayList<String> です。LineChartActivity.java// String型で保存したデータをdate型に書き直して SimpleDateFormat private ArrayList<String> getDate() { ArrayList<String> dateLabels = new ArrayList<>(); for (int i = 0; i < date.size(); i++) { try { // 年月日を月日に修正 String strDate = date.get(i); DateFormat dateFormat = new SimpleDateFormat("yyyy/MM/dd"); Date entryDate = dateFormat.parse(strDate); DateFormat dt = new SimpleDateFormat("MM/dd"); String setDate = dt.format(entryDate); dateLabels.add(setDate); } catch (ParseException e) { e.printStackTrace(); } } return dateLabels; }データ表示
変数 valuesMax と valuesMin はデータベースのデータを保持させている ArrayList<String> です。
LineChartActivity.javaArrayList<Entry> valuesMax = new ArrayList<>(); ArrayList<Entry> valuesMin = new ArrayList<>(); LineDataSet max; // ライン引数 LineDataSet min; // ラインの設定メソッド max = new LineDataSet(valuesMax, "A");// ラベルの名前 max.setColor(Color.RED); // 線の色 max.setCircleColor(Color.RED); // 座標の色 max.setLineWidth(5f); // 線の太さ 1f~ max.setCircleRadius(5f); // 座標の大きさ max.setDrawCircleHole(false); // 座標を塗りつぶす→false 塗りつぶさない→true max.setValueTextSize(10f); // データの値を記す。0fで記載なし。floatだから小数点がつく max.setDrawFilled(true); // 線の下を塗りつぶすか否か max.setFillColor(Color.RED); // 塗りつぶしたフィールドの色 // もう1セット作る min = new LineDataSet(valuesMin, "B"); min.setColor(Color.BLUE); min.setCircleColor(Color.BLUE); min.setLineWidth(5f); min.setCircleHoleRadius(5f); min.setDrawCircleHole(false); min.setValueTextSize(10f); min.setDrawFilled(true); min.setFillColor(Color.BLUE); // chartにラインをset ArrayList<ILineDataSet> dataSets = new ArrayList<>(); dataSets.add(max); dataSets.add(min); LineData lineData = new LineData(dataSets); mChart.setData(lineData); // データをアニメーションで出す。ミリ秒.数値が大きいと遅い mChart.animateX(1000);ILineDateSet に追加したラインが画面に表示されます。
できあがったもの
二本のグラフが表示されました。
塗りつぶしを赤と青にしたのですが、青ラインの下は混ざって紫色になってますね◎
参考になれば幸いです。

- 投稿日:2020-09-11T16:18:23+09:00
【Java】日付の期間重複チェックサンプル
概要
日付で期間を持ってるデータを登録するときにすでに登録してある期間と重複しないようにしたい。
LocalDateを使ったJavaのサンプルがあまり見当たらなかったので公開します。環境
- Java 1.8
- SpringBoot 2.2.1.RELEASE
- thymeleaf 3.0.11.RELEASE
期間が重複するパターン
日付の期間が重複するパターンは全部で4つ。
1. 前半がかぶるパターン(①の終了日と緑の開始日が同じも含む)
2. 後半がかぶるパターン(②の開始日と緑の終了日が同じも含む)
3. 全部かぶるパターン(開始日と終了日が全く同じも含む)
4. 一部がかぶるパターン全パターンを網羅できる条件式は下記の通り。
条件式緑.開始日 <= 黒.終了日 && 緑.終了日 => 黒.開始日サンプル
画面から開始日と終了日を入力して、その入力期間が既存の期間(複数)と重複していない場合だけ登録できるサンプル。
登録する日付期間を持つModelクラス
登録する開始日と終了日、自動採番のIDを持つ画面に渡すModelクラス。
DurationModel.javapackage com.tamorieeeen.sample.model; import java.time.LocalDate; import org.springframework.format.annotation.DateTimeFormat; import lombok.Getter; import lombok.NoArgsConstructor; import lombok.Setter; /** * * @author tamorieeeen * */ @Getter @Setter @NoArgsConstructor public class DurationModel { // 保存時にauto_incrementで採番 private int id; @DateTimeFormat(pattern = "yyyy-MM-dd") private LocalDate startDate; @DateTimeFormat(pattern = "yyyy-MM-dd") private LocalDate endDate; }期間重複判定ロジックServiceクラス
Controllerから呼び出されるServiceクラス。
DurationService.javapackage com.tamorieeeen.sample.service; import java.time.LocalDate; import java.util.List; import javax.transaction.Transactional; import org.springframework.stereotype.Service; import com.tamorieeeen.sample.model.DurationModel; /** * * @author tamorieeeen * */ @Service public class DurationService { /** * すでに登録済の期間とかぶってないかチェック */ public boolean isInvalid(DurationModel model) { return this.getDurationList() .stream() .filter(u -> model.getId() != u.getId()) // ※1 .anyMatch(u -> (order.getStartDate().isBefore(u.getEndDate()) && order.getEndDate().isAfter(u.getStartDate())) || order.getStartDate().isEqual(u.getEndDate()) || order.getEndDate().isEqual(u.getStartDate())); } /** * 一覧を取得 */ private List<DurationModel> getDurationList() { // TODO すでに登録済のデータを取得 } /** * 新規登録/更新 */ @Transactional public void saveDuration(DurationModel model) { // TODO DBなどへのデータ保存処理 } }※1: 比較元(model)のIDは期間チェックを除外する
こうしないとデータ更新時にthis.getDurationList()に比較元データも含まれているため重複扱いでvalidationに引っかかってしまうため。
新規登録しか考えないのであれば、この行は不要。Controllerクラス
実際はバリデーションチェックに
@ValidatedとBindingResultを使ってるけどその部分は省略。DurationController.java/** * * @author tamorieeeen * */ @Controller public class DurationController { @Autowired private DurationService durationService; /** * 新規登録 */ @GetMapping("/duration/register") public String register(Model model) { model.addAttribute("duration", new DurationModel()); return "duration/register"; } /** * 新規登録処理 */ @PostMapping("/duration/register") public String registerComplete(Model model, @ModelAttribute("duration") DurationModel duration, RedirectAttributes redirect) { // バリデーションチェック if (durationService.isInvalid(duration)) { model.addAttribute("invalid", true); return "duration/register"; } durationService.saveDuration(duration); redirect.addFlashAttribute("complete", true); return "redirect:/duration/register"; } }画面側html(thymeleaf)
htmlヘッダーは共通化しているが今回は関係ないので省略。
register.html<!DOCTYPE html> <html xmlns:th="http://www.thymeleaf.org"> <head th:replace="common :: meta_header('sample',~{::link},~{::script},~{::meta})"> </head> <body> <div th:if="${complete}"> <p>期間を登録しました。</p> </div> <div th:if="${invalid}"> <p>期間が重複しているため、登録できません。</p> </div> <form th:action="@{/duration/register}" method="post" th:object="${duration}"> <table> <tr><td>開始日</td><td> <input type="date" th:field="*{startDate}" th:value="*{startDate}" /> </td></tr> <tr><td>終了日</td><td> <input type="date" th:field="*{endDate}" th:value="*{endDate}" /> </td></tr> </table> <input type="button" th:value="登録する" onclick="submit();" /> </form> </body> </html>参考

- 投稿日:2020-09-11T15:16:53+09:00
@Slf4j など外部ロギングAPIを用いている時にログの出力のロガーの挙動をテストする
背景
@Slf4j など外部ロギングAPIを用いている時にログの出力のログをテスト時に確認したい。
目的
ログをモック化してログの出力をテストコードで制御できるようにする
コードをざっと確認したい人は"サンプルコード"の章で確認できます。
アプローチ
手順の流れ
1. ArgmentCaptor の定義
2. 対象のクラスのLoggerを定義し、モックのアペンダーをいれる
3. ロガーモックインスタンス指定のコールをキャッチする。1. ArgmentCaptor の定義
@Captor private ArgumentCaptor<LoggingEvent> captorLoggingEvent;ArgmentCaptor はmockito のクラスでスタブ化したメソッドがちゃんと呼ばれたか、あるいはそのメソッドに対して適切な引数が渡されたか検証したい場合に用いる。
今回ではログ出力の型であるLoggingEvent の引数をキャプチャする。2. 対象のクラスのLoggerを定義し、モックのアペンダーをいれる
@Mock private Appender mockAppender; final Logger logger = (Logger) LoggerFactory.getLogger([テスト対象のクラス名].class); logger.addAppender(mockAppender);@Slf4j を用いずに独自にlogger 変数を定義し、logger にモックしたAppender を加える。
Appender はログの出力先の設定を行うために使用されるインターフェイス。
Appender はaddAppender()メソッドでLogger にセットすることができる。
ここでは、モックAppender を用意して、それをaddAppender()することでlogger のログ出力先をモックにすることができる。3. ロガーモックインスタンス指定のコールをキャッチする
verify(mockAppender).doAppend(captorLoggingEvent.capture()); assertEquals("INFO", captorLoggingEvent.getValue().getLevel().toString());
doAppendはイベントオブジェクトを引数に持つ。
append されたAppender がロギングする役割上記の方法では最後のログしかキャッチできない。すべてのログをキャッチするためにはリストに代入する。
// アプリケーションログのみを抽出 List<LoggingEvent> events = captorLoggingEvent.getAllValues().stream() .collect(Collectors.toList());サンプルコード
メインクラス
package com.zozo.tech.search.personalize.api.logic; import lombok.extern.slf4j.Slf4j; import org.springframework.stereotype.Component; @Component @Slf4j public class Sample { public void doLogging() { log.info("sample"); log.info("sample access_log."); log.info("sample access_log 2."); } }テストクラス
package com.zozo.tech.search.personalize.api.logic; import static org.junit.Assert.assertEquals; import static org.mockito.Mockito.verify; import ch.qos.logback.classic.Logger; import ch.qos.logback.classic.spi.LoggingEvent; import ch.qos.logback.core.Appender; import java.util.List; import java.util.stream.Collectors; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import org.junit.jupiter.api.extension.ExtendWith; import org.mockito.ArgumentCaptor; import org.mockito.Captor; import org.mockito.InjectMocks; import org.mockito.Mock; import org.mockito.MockitoAnnotations; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit.jupiter.SpringExtension; @ExtendWith(SpringExtension.class) @SpringBootTest public class SampleTest { @Captor private ArgumentCaptor<LoggingEvent> captorLoggingEvent; @Mock private Appender mockAppender; @InjectMocks @Autowired Sample sample; @BeforeEach void setUp() { MockitoAnnotations.initMocks(this); } @Test void test() throws Exception { Logger logger = (Logger) LoggerFactory.getLogger(Sample.class); logger.addAppender(mockAppender); sample.doLogging(); verify(mockAppender).doAppend(captorLoggingEvent.capture()); // INFO レベルのログが出力されているか確認 assertEquals("INFO", captorLoggingEvent.getValue().getLevel().toString()); // アプリケーションログのみを抽出 List<LoggingEvent> events = captorLoggingEvent.getAllValues().stream() .filter(e -> e.getMessage().contains("access_log")) .collect(Collectors.toList()); assertEquals(2, events.size()); } }参考資料
- 投稿日:2020-09-11T12:52:03+09:00
Mapメソッド 練習
package map_renshuu; //MapクラスとHashMapクラスをインポート import java.util.HashMap; import java.util.Map; public class Map1 { public static void main(String[] args) { //Mapインスタンスを生成、キーはString型、値(要素)はint型を指定 //左辺は”ざっくり”多態性をつかうためにMapクラス Map<String,Integer> bankList=new HashMap<String,Integer>(); //<bankList>にキーと値をいれる bankList.put("福岡銀行",541); bankList.put("西日本シティ銀行",312); bankList.put("みずほ銀行",653); bankList.put("ゆうちょ銀行",685); bankList.put("三井住友銀行",797); //<bankList>に入っている値をとりだすには、一度変数に代入が必要。getメゾットを使う int sumitomo=bankList.get("三井住友銀行"); System.out.println("三井住友の銀行コードは"+sumitomo+"です"); /*---------------------------------------------- removeメゾット(ここは実行するとちゃんと出力されるので、なぜremoveされないのか謎、確認中) bankList.remove("sumitomo"); System.out.println(sumitomo); ------------------------------------------------*/ //for文で回して出力 //for文の右辺は順番にキーが返ってくる for(String nini:bankList.keySet()) { int value=bankList.get(nini); System.out.println(nini+"銀行のコードは"+value+"です"); } //bamkListを単体で出力 System.out.println(bankList); } } /*実行結果---------------------------- 三井住友の銀行コードは797です 797 福岡銀行銀行のコードは541です ゆうちょ銀行銀行のコードは685です 西日本シティ銀行銀行のコードは312です みずほ銀行銀行のコードは653です 三井住友銀行銀行のコードは797です {福岡銀行=541, ゆうちょ銀行=685, 西日本シティ銀行=312, みずほ銀行=653, 三井住友銀行=797} --------------------------------*/
- 投稿日:2020-09-11T10:47:17+09:00
JavaにおけるfinalとImmutableの違い
JavaにおけるfinalとImmutableの違いって?
最近GuavaのImmutable Listを使う機会があったのですが、ふとImmutableとfinalの違いってなんだ?と疑問になって調べてみました。
Immutableの特徴
・オブジェクトの値そのものを変更することを禁止
・参照先を変更することは可能finalの特長
・参照先の変更をすることを禁止
・変数の値そのものを変更することは可能では、JavaではImmutableで代表的なStringとMutableなStringBuilderを使って検証してみます。
class Main { public static void main (String[] args) throws java.lang.Exception { final String str = "apple"; final StringBuilder sb= new StringBuilder("ringo"); str = str + "ringo"; //コンパイルエラー。Stringの+は参照先変更を伴う。 String s = "ringo"; str = s; //コンパイルエラー sb.append("apple"); sb = new StringBuilder("ringo"); ///コンパイルエラー。参照先変更。 System.out.println(str); System.out.println(sb); } }こうやって比較してみると割と単純ですが、finalは値が不変であることと勘違いしていたのと、意外と日本語記事がなかったので書いてみました。
- 投稿日:2020-09-11T10:01:05+09:00
Java開発リンクまとめ
Java
Java sample
http://java2s.com/
https://devlights.hatenablog.com/entry/20061030/p1
http://www.tohoho-web.com/socket
http://manabu.quu.cc/up/6/e62tcpjava.htmListener
https://docs.oracle.com/javase/tutorial/essential/io/notification.html#try
https://www.javaworld.com/article/2077351/java-se/events-and-listeners.html
http://www.vogella.com/tutorials/DesignPatternObserver/article.htmlJNI
https://blog.goo.ne.jp/xmldtp/e/75720fd5daebcfd6d6b77292048f6345DB
https://ts0818.hatenablog.com/entry/2017/07/10/223553web service Axis
https://www.eclipse.org/webtools/community/tutorials/BottomUpAxis2WebService/bu_tutorial.html
https://crunchify.com/create-and-deploy-simple-web-service-and-web-service-client-in-eclipse/Java thread safe
https://www.journaldev.com/1061/thread-safety-in-java
https://www.baeldung.com/java-thread-safetySLMP (Binary)
https://qiita.com/hidehito108/items/e8eca75a46ee7d59feed
https://qiita.com/nwtgck/items/c53db76e19ef80296a71
https://itsakura.com/java-socket
https://weblabo.oscasierra.net/java-hex-convert-1/
http://commons.apache.org/proper/commons-codec/download_codec.cgiSLMP (ASCII)
http://rabbitfoot141.hatenablog.com/entry/2015/11/28/215745
https://chakouro.exblog.jp/1894935/
*ASCIIの伝文は大文字・小文字で変わるから注意java taskschedule
http://www.sauronsoftware.it/projects/cron4j/manual.php
http://netbuffalo.doorblog.jp/archives/4525514.htmljava スレッドスケジューラ
https://qiita.com/yacchi1123/items/958c908d8c9018c1eba4
https://techbooster.org/android/application/934/サーブレット
https://itsakura.com/eclipse_tomcat
http://ashitawa-harerukana.hatenablog.com/entry/2014/01/26/000335
https://www25.atwiki.jp/dotcom/pages/46.htmljava Multithreading
https://www.tutorialspoint.com/java/java_multithreading.htmjava excel read
https://www.callicoder.com/java-read-excel-file-apache-poi/
(必要なjar↓↓)
poi-4.0.1.jar
poi-ooxml-4.0.1.jar
poi-ooxml-schemas-4.0.1.jar
xmlbeans-3.0.2.jar
commons-compress-1.18.jar
commons-collections4-4.3.jar
https://www.javadrive.jp/poi/cell/java serial
http://www.java2s.com/Code/JavaAPI/javax.comm/SerialPortEventDATAAVAILABLE.htm
https://qiita.com/kota344@github/items/35e0e1746d889d0365a3
https://github.com/damellis/A4S/issues/12
http://5bai.jugem.jp/?eid=332
http://jlog.org/rxtx-win.html
rxtxSerial.dllは64を使う、デフォルトは32virtual com port(CPDE&VSPE)
https://stackoverflow.com/questions/1059451/how-can-i-emulate-a-com-port-write-data-to-it-and-read-data-from-it
https://www.aggsoft.com/com-port-emulator/download.htm
http://icas.to/sdrplay/vspe/index.htm
http://www.eterlogic.com/Products.VSPE.htmljava xml passer
http://daisuke-m.hatenablog.com/entry/20090113/1231853050java DOM
https://www.mlab.im.dendai.ac.jp/~yamada/web/xml/dom/
read
https://code-examples-ja.hateblo.jp/entry/2014/08/08/Java_XML%E3%82%92DOM%E3%81%A7%E8%AA%AD%E3%81%BF%E8%BE%BC%E3%82%93%E3%81%A7%E5%86%85%E5%AE%B9%E3%82%92%E5%8F%96%E5%BE%97%E3%81%99%E3%82%8B
write
https://www.mkyong.com/java/how-to-create-xml-file-in-java-dom/java StAX
http://www.java2s.com/Tutorials/Java/Java_XML/0300__Java_StAX_Intro.htmjava arraylist next
https://java-reference.com/java_collection_arraylist.htmljava encryption
https://www.ssl2buy.com/wiki/symmetric-vs-asymmetric-encryption-what-are-differencesjava Asymmetric
https://www.mkyong.com/java/java-asymmetric-cryptography-example/
http://commons.apache.org/proper/commons-codec/download_codec.cgijava Symmetric
https://gist.github.com/twuni/5668121junit
https://konbu13.hatenablog.com/entry/2014/01/18/230415
https://blog.codebook-10000.com/entry/20141020/1413810704
http://summer-wars.hatenadiary.jp/entry/2017/06/27/144626#1EclEmma%E3%81%AE%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%BC%E3%83%AB
https://javaworld.helpfulness.jp/post-66/java Singleton
https://techacademy.jp/magazine/18939java Map
https://qiita.com/yoshi389111/items/7ea0f9b9483b0138ecdf
https://stackoverflow.com/questions/2889777/difference-between-hashmap-linkedhashmap-and-treemap
https://crunchify.com/hashmap-vs-concurrenthashmap-vs-synchronizedmap-how-a-hashmap-can-be-synchronized-in-java/
- 投稿日:2020-09-11T03:42:16+09:00
メソッドを解説してみた
初めに
- この記事を開いてくれてありがとうございます.
- 教え方が下手な自分がなんとかまとめたものなので,多めに見てください.
- 要望,指摘あればどんどん書いてください.
- それでは,長らくのお付き合いお願いします.
そもそもメソッドとは
10人のテストの平均点、最高点、最低点を表示してください。
java=Question_11.javapackage Question_04; public class Question_11 { public static void main(String[] args) { int[] english = {98,80,78,85,65,86,90,94,70,92}; int high = english[0]; int low = english[0]; int avg = 0; for(int i = 0;i < english.length;i++) { if(high <= english[i]) { high = english[i]; }else if(low >= english[i]){ low = english[i]; } avg+=english[i]; } avg/=english.length; System.out.println("平均点:"+avg+"点"); System.out.println("最高点:"+high+"点"); System.out.println("最低点:"+low+"点"); } }
- 上記のブログラムは以下のようなmainメソッド1つのメソッド構成になっています.
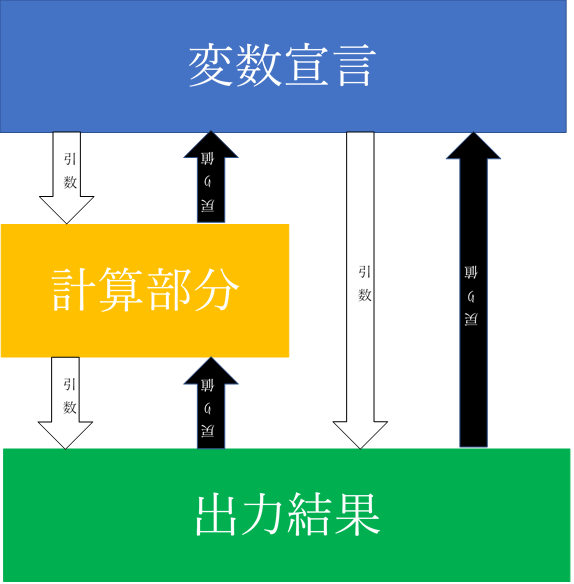
- このプログラムではmainのメソッドに 「変数宣言」,「計算部分」,「結果出力」 の動作すべてが書き込まれているということになります.
- 変数宣言(mainメソッド):テストの点数を格納
- 計算部分:テストの点数を比較
- 結果出力:テストの点数を表示
- mainメソッド1つでもいいのですが,もし,大きなプログラムを書く場合に,数千行という行数になってしまい管理がとても大変です.
- そこで,「変数宣言」,「計算部分」,「結果出力」 を分けようということで,メソッドという考え方を使用します.
どのような基準でメソッドを分けるのか.
- 「行数が増えると大変だからメソッドを分けるのか」という漠然とした理解を得られたところで,どのように分けていくか解説します.
- まず,プログラムを大きく分けると以下のように分けられます.
変数宣言部分
- 変数宣言部分では,使用する変数に値を格納している動作です.
java=Question_11.javaint[] english = {98,80,78,85,65,86,90,94,70,92};//englishに10人分の点数を格納 int high = english[0];//最高点を比較するための変数を宣言 int low = english[0];//最低点を比較するための変数を宣言 int avg = 0;//平均点を算出するための変数を宣言計算部分
- 計算部分では,点数の比較を行い,最高点,最低点,平均点を算出します.
java=Question_11.javafor(int i = 0;i < english.length;i++) {//10人分の点数を比較するために10回(人数分)ループ if(high <= english[i]) {//最高点を選別 high = english[i]; }else if(low >= english[i]){//最低点を選別 low = english[i]; } avg+=english[i];//平均点を算出するために点数の合計を格納 }結果出力部分
- 結果出力部分では,問題文であるように,「表示してください」の動作を行っています.
java=Question_11.javaSystem.out.println("平均点:"+avg+"点"); System.out.println("最高点:"+high+"点"); System.out.println("最低点:"+low+"点");実際どのようなプログラムになるのか
java=Question_11.javapackage Question_05; public class Test { public static void main(String[] args) { int[] english = {98,80,78,85,65,86,90,94,70,92}; int highscore = english[0]; int lowscore = english[0]; int avgscore = 0; int highend = high(english,highscore); int lowend = low(english,lowscore); int avgend = avg(english,avgscore); display(highend,lowend,avgend); } public static int high(int[] english,int highscore) { for(int i = 0;i < english.length;i++) { if(highscore <= english[i]) { highscore = english[i]; } } return highscore; } public static int low(int[] english,int lowscore) { for(int i = 0;i < english.length;i++) { if(lowscore >= english[i]){ lowscore = english[i]; } } return lowscore; } public static int avg(int[] english,int avgscore) { for(int i = 0;i < english.length;i++) { avgscore+=english[i]; } avgscore/=english.length; return avgscore; } public static void display(int highend,int lowend,int avgend) { System.out.println("平均点:"+avgend+"点"); System.out.println("最高点:"+highend+"点"); System.out.println("最低点:"+lowend+"点"); } }
- このように分けることができます.メソッドを分けることができるのは分かったが,引数や,戻り値って何?
- メソッドを分けたことによって変数宣言したものは,メソッド内でしか,呼び出すことができません.
- 例:mainメソッドで
int x = 0;とコードを書いても,highメソッドでSystem.out.println(x);のように使用してもxの値を表示することはできません.- つまり,変数宣言してもメソッド内でしか使用することができない.
- なので,引数や,戻り値を使って値を呼び出します.
引数や,戻り値を使う理由
- 変数宣言(mainメソッド)で宣言した点数格納用のenglishや,点数を比較するためのhighscoreなどの変数は計算部分で使用するために宣言したものです.
- なので,引数として,これらの変数を参照します.そして,計算結果を戻り値として,変数宣言に戻します.こうすることで,mainメソッドで計算結果を扱うことができます.
- 同様に,出力結果を出力するためには,計算結果が必要です.
- なので,引数として,計算結果を先ほど戻り値として返した変数宣言から参照します.
- これらの動作によって出力結果を出力することができます.
最後に
- お付き合いいただきありがとうございました.
- 質問や要望があればどんどん書いてください.