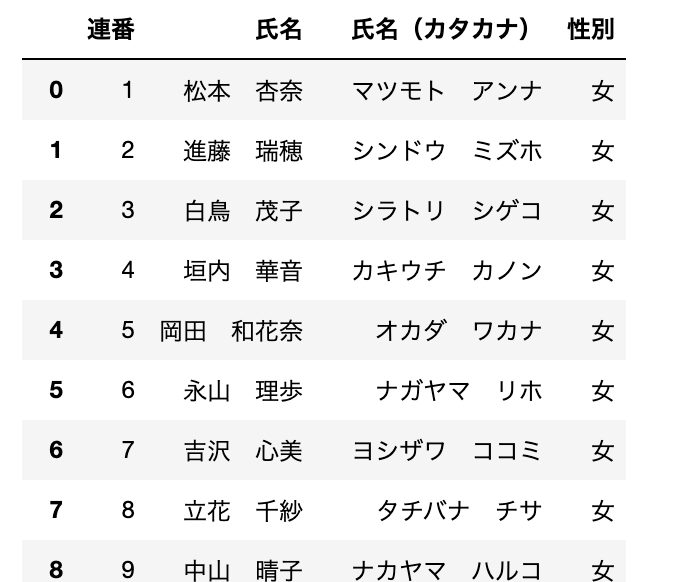
- 投稿日:2020-08-10T23:58:15+09:00
Django で Hello World(初心者)
はじめに
Python をちょっとだけ触ってみたく、最も人気である Django というフレームワークを用いてブラウザに
Hello Worldと表示させるまでやってみたので、その備忘録を投稿いたします。今回こちらの記事を参考にさせていただきました。
Djangoで初めてのHello World
https://qiita.com/Yuji_6523/items/d601ad11ad49b9e7ab0e前提として python と pip はインストール済みとします。
django コマンドのインストール
pip install djangoと実行して、 django コマンドをインストールします。$ python --version Python 3.8.2 $ pip install django # (省略) $ python -m django --version 3.1Django プロジェクトの作成
今回は
helloWorldProjectという名前のプロジェクトを作成してみた例になります。
django-admin startproject [プロジェクト名] [作成するディレクトリ先]とコマンドを実行することでプロジェクトが作成できます。$ django-admin startproject helloWorldProject . $ tree . ├── helloWorldProject │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── manage.pyアプリケーションの追加
このままだと何もない状態なので、
ドメイン/helloとブラウザでアクセスしたときに起動するようなアプリケーションを追加してみます。今回は
helloという名前のアプリケーションを追加します。
python manage.py startapp [アプリケーション名]というコマンドを実行することでアプリケーションを追加できます。$ python manage.py startapp hello $ tree . ├── hello │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── helloWorldProject │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-38.pyc │ │ └── settings.cpython-38.pyc │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── manage.pysettings.py への追記
このままだと、
helloアプリケーションは適用されていないので設定を追記します。
helloWorldProject/settings.pyにhelloというアプリケーションがあることを追記します。helloWorldProject/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', # 追加 'hello', ]ルーティング設定
helloWorldProject/urls.pyでルーティング設定を行います。helloWorldProject/urls.pyfrom django.contrib import admin from django.urls import path, include # include 追加 urlpatterns = [ path('admin/', admin.site.urls), # 追加 path('', include('hello.urls')), ]ここに
path('hello',と書くのもありですが、今回は、hello/urls.pyというファイルを作成して、ドメイン/helloとリクエストされた場合のルーティングについてはhello/urls.pyに丸投げします。そうした理由はなるべく高凝集で低結合なプログラムを目指すためです。
さらに
hello/urls.pyを新規に作成して、ドメイン/helloとアクセスされた場合hello/views.pyの index()関数を呼び出すように設定します。hello/urls.py(新規追加ファイル)from django.urls import path from . import views urlpatterns = [ path('hello', views.index), ]view の設定
hello/urls.pyで設定したようにhello/views.pyにindex()関数を作成します。今回は HTTPレスポンスで
Hello Worldと記述されたContent-Type: text/htmlのファイルを返却するようにします。hello/views.pyfrom django.http import HttpResponse def index(request): return HttpResponse('Hello World')マイグレーション
今回はあまり関係ないのですが、ここでいうマイグレーションとはアプリケーションで使うデータベースの定義を自動的に作成・管理する機能のことを指します。
以下のコマンドで実行できます。
$ python manage.py migrateマイグレーションに成功すればコマンド実行後にエラーが出ないはずです。
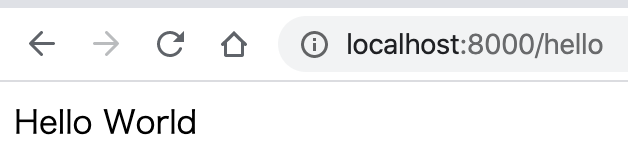
ローカルホストでの起動
以下のコマンドでローカルホストに起動することができます。
$ python manage.py runserverデフォルトではポート8000番で起動するので、
http://localhost:8000/helloにアクセスして、python:hello/views.pyで記述したHello Worldが表示されてば成功です。
以上になります。まとめ
- Django というフレームワークを用いてプロジェクトを作成できるようになった
- Django でアプリケーションを追加できるようになった
- Django でローカルホストでアプリケーションを起動して、動作が確認できるようなった
さいごに
今回作成したプロジェクトはGitHubで公開しました。
- 投稿日:2020-08-10T23:45:51+09:00
pyinstaller: error: argument --add-binary: invalid add_data_or_binary value:が出たときの対処法
Selenium WebDriverを使用しているpythonスクリプトをpyinstallerで実行ファイル(exe)に変換する場合、デフォルトだと実行ファイルにWebDriverが含まれないため、--add-binaryオプションを使用して下記の様なコマンドを実行する必要があります。
pyinstaller ./main.py --onefile --noconsole --add-binary "元ファイルパス;取込先ファイルパス"ところが、Unix環境(MacOSX含む)で上記を実行すると、下記のようなエラーメッセージが出力され、実行不可となってしまうことがあります。
pyinstaller: error: argument --add-binary: invalid add_data_or_binary value: '元ファイルパス;取込先ファイルパス'下記サイトで調べてみたところ、--add-binaryで指定するパスのセミコロン(;)になっている箇所をコロン(:)に置き換えてあげればOKらしいです。これで実行してみたらうまくいきました。
https://github.com/pyinstaller/pyinstaller/issues/3968pyinstaller ./main.py --onefile --noconsole --add-binary "元ファイルパス:取込先ファイルパス"自分はMac OS Xの環境で実行してたら今回の事象に遭遇しました。
結構解決まで手こずったので、同じ事象で悩んでいる方の助けになれば幸いです。
- 投稿日:2020-08-10T23:29:07+09:00
Django REST Frameworkでdynamodbを操作するREST APIを作成する
はじめに
django REST Frameworkとboto3でAWSのDynamoDBに対して操作を行うapiを作成する。
GET、POST、PUT、DELETEの操作ができるようにする。Dynamodbテーブル作成(事前準備)
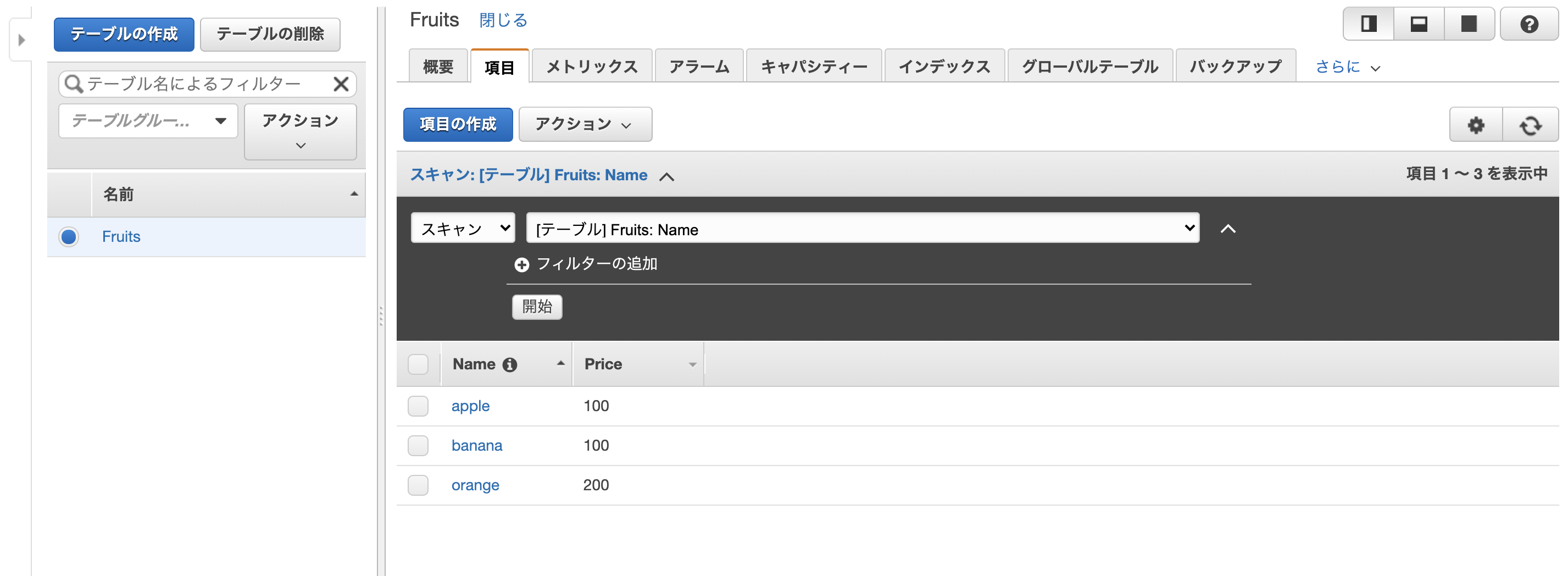
下記のようなテーブルを事前に用意し、いくつかデータを入れておく
テーブル名: Fruits
hash key: Name
djangoプロジェクトの作成
django project(dynamo_operation)とapp(api)を作成
$ django-admin startproject dynamo_operation $ cd dynamo_operation/ $ django-admin startapp apisetting.pyの編集
setting.pyにrest_frameworkと先ほど作成したappのconfigを追加する。dynamo_operation/setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework', #追加 'api.apps.ApiConfig', #追加 ]DynamoDBリクエスト用のmodelを作成
djangoではDBの作成、操作に
modelを用意する。
DynamoDBへのリクエストはboto3を使用するので特にmodelは必要ないが、今回はmodel(dynamo_model.py)を用意した。api/dynamo_model.pyclass Fruit(): def __init__(self, name): self.name = nameviews.pyの編集
api/views.pyfrom rest_framework import status from rest_framework.views import APIView from rest_framework.response import Response from api.dynamo_models import Fruit from boto3 import client dynamodb_client = client('dynamodb') class DynamoRequest(APIView): # 全体GET def get(self, request): response = [] items = dynamodb_client.scan(TableName='Fruits')['Items'] for item in items: fruit = Fruit(item['Name']['S']) fruit.price = item.get('Price',{}).get('N', '') response.append(fruit.__dict__) return Response(response) def post(self, request): request_data = request.data item = {'Name': {'S': request_data['Name']}} if 'Price' in request_data: item['Price'] = {'N': request_data['Price']} dynamodb_client.put_item( TableName = 'Fruits', Item = item ) return Response(status=status.HTTP_201_CREATED) class DynamoDetailRequest(APIView): #単体GET def get(self, request, pk): item = dynamodb_client.get_item( TableName = 'Fruits', Key = { 'Name': {'S': pk}, } )['Item'] fruit = Fruit(item['Name']['S']) fruit.price = item.get('Price',{}).get('N', '') return Response(fruit.__dict__) def put(self, request, pk): request_data = request.data item = dynamodb_client.get_item( TableName = 'Fruits', Key = { 'Name': {'S': pk}, } )['Item'] price = item.get('Price',{}).get('N', '0') if 'Price' in request_data: price = request_data['Price'] dynamodb_client.put_item( TableName = 'Fruits', Item = { 'Name': {'S': item['Name']['S']}, 'Price': {'N': price} } ) return Response(status=status.HTTP_200_OK) def delete(self, request, pk): dynamodb_client.delete_item( TableName = 'Fruits', Key = { 'Name': {'S': pk}, } ) return Response(status=status.HTTP_204_NO_CONTENT)
rest_frameworkのAPIViewを継承したclassでリクエストを処理する。
DynamoRequestがpathパラメータなしのリクエストを処理し、DynamoDetailRequestでpathパラメータ(pk)ありのリクエストの処理を行う。
APIViewを継承することにより、HTTPメソッドごとにfunctionを用意することでそれぞれのメソッドに対応する処理を追加することができる。urls.pyの編集
api/urls.pyfrom django.urls import path from api import views urlpatterns = [ path('api/', views.DynamoRequest.as_view()), path('api/<pk>/', views.DynamoDetailRequest.as_view()) ]
dynamo_oprationフォルダのurls.pyも編集するdynamo_opration/urls.pyfrom django.urls import path, include urlpatterns = [ path('', include('api.urls')), ]curlコマンドで動作確認
serverの起動
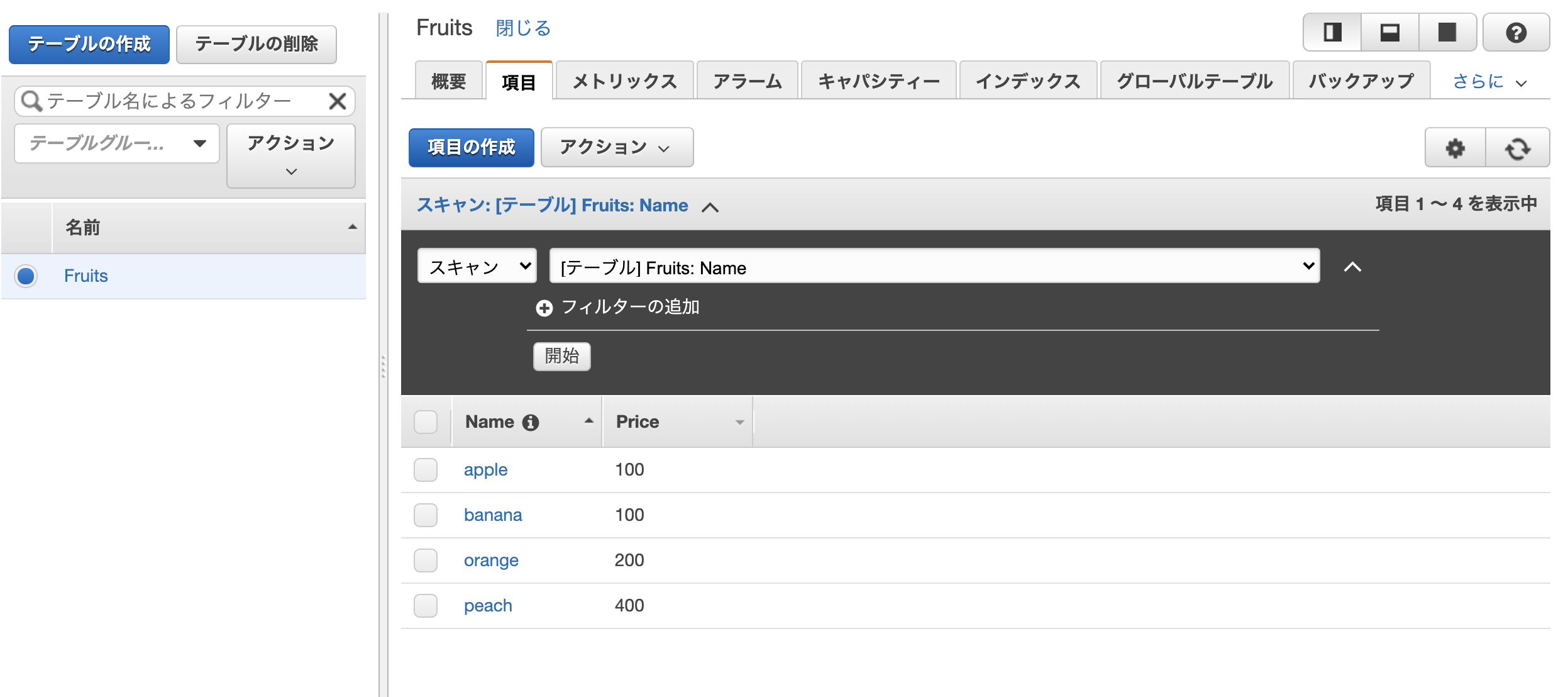
$ python manage.py runserverGET(全体検索)
$ curl http://127.0.0.1:8000/api/ # レスポンス [{"name":"orange","price":"200"},{"name":"banana","price":"100"},{"name":"apple","price":"100"}]POST
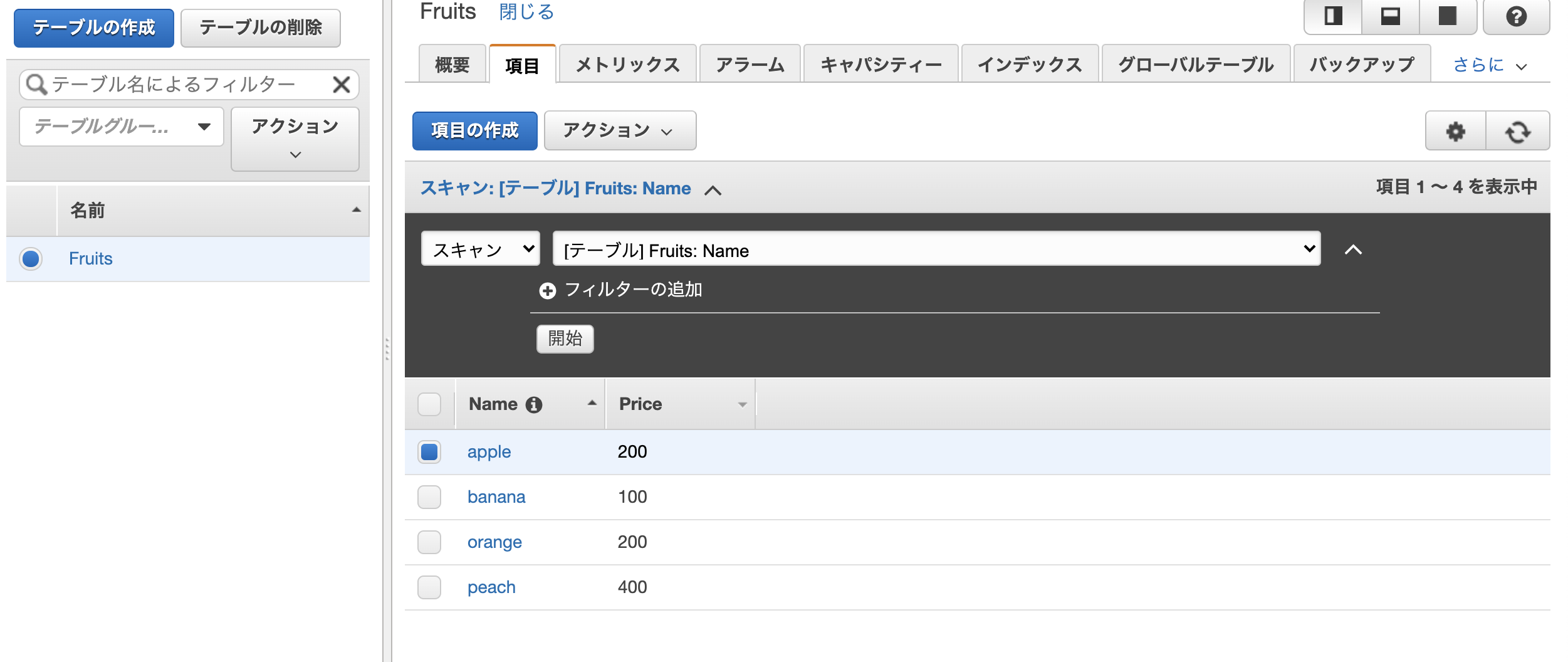
$ curl -X POST \ -H 'Content-Type:application/json' \ -d '{"Name": "peach", "Price": "400"}' \ http://127.0.0.1:8000/api/POSTリクエスト後のテーブル
peachの項目が追加されている。
GET(単体)
appleの項目を取得
$ curl http://127.0.0.1:8000/api/apple/ # レスポンス {"name":"apple","price":"100"}PUT
appleのpriceを100 -> 200へ変更する
$ curl -X PUT \ -H 'Content-Type:application/json' \ -d '{"Price": "200"}' \ http://127.0.0.1:8000/api/apple/PUTリクエスト後のテーブル
DELETE
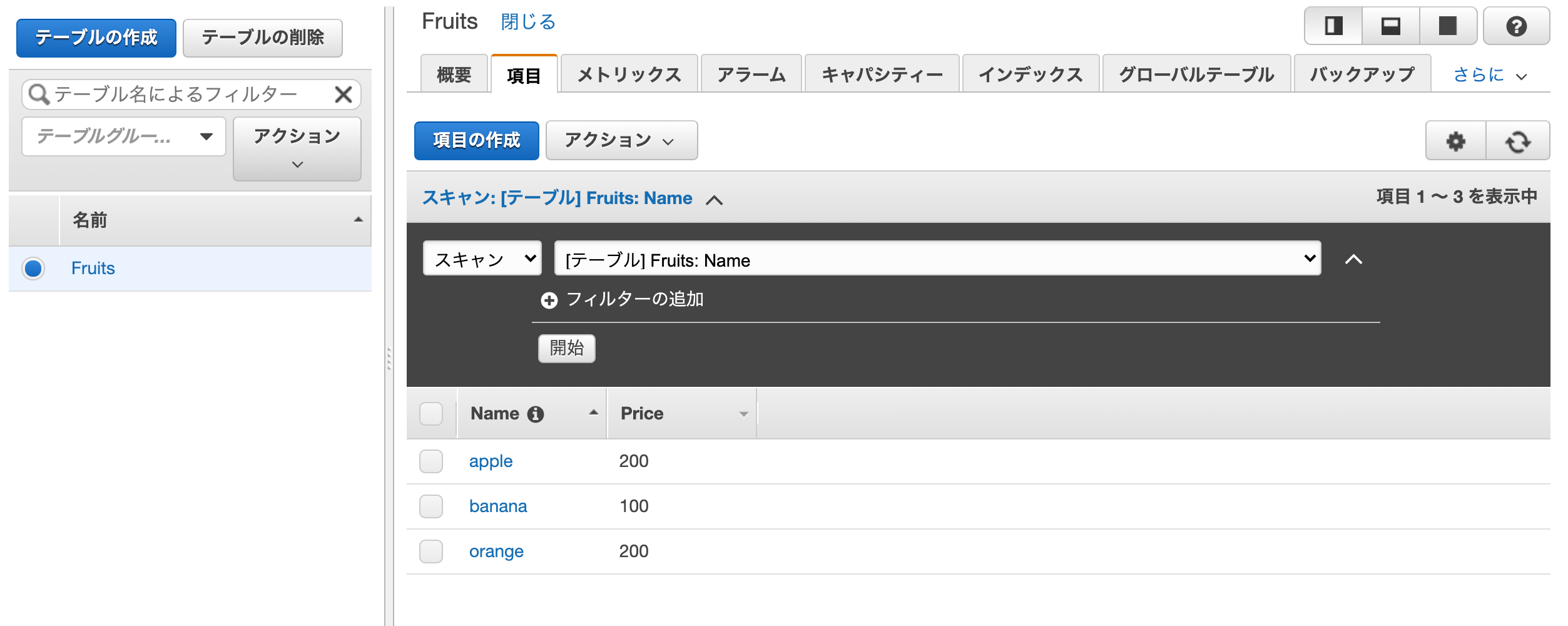
peachの項目を削除する。
$ curl -X DELETE http://127.0.0.1:8000/api/peach/DELETEリクエスト後のテーブル
おわりに
django REST Framework + boto3でDynamoDBの操作を行うREST Apiを作成した。
今回は、dynamodb_model.pyを用意してmodelを管理するようにしたが、必要なかったかもしれない(この辺の設計は今後改善していきたい)。
- 投稿日:2020-08-10T23:29:07+09:00
[DRF+boto3]Djangoでdynamodbを操作するAPIを作成する
はじめに
django REST Frameworkとboto3でAWSのDynamoDBに対して操作を行うapiを作成する。
GET、POST、PUT、DELETEの操作ができるようにする。Dynamodbテーブル作成(事前準備)
下記のようなテーブルを事前に用意し、いくつかデータを入れておく
テーブル名: Fruits
hash key: Name
djangoプロジェクトの作成
django project(dynamo_operation)とapp(api)を作成
$ django-admin startproject dynamo_operation $ cd dynamo_operation/ $ django-admin startapp apisetting.pyの編集
setting.pyにrest_frameworkと先ほど作成したappのconfigを追加する。dynamo_operation/setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework', #追加 'api.apps.ApiConfig', #追加 ]DynamoDBリクエスト用のmodelを作成
djangoではDBの作成、操作に
modelを用意する。
DynamoDBへのリクエストはboto3を使用するので特にmodelは必要ないが、今回はmodel(dynamo_model.py)を用意した。api/dynamo_model.pyclass Fruit(): def __init__(self, name): self.name = nameviews.pyの編集
api/views.pyfrom rest_framework import status from rest_framework.views import APIView from rest_framework.response import Response from api.dynamo_models import Fruit from boto3 import client dynamodb_client = client('dynamodb') class DynamoRequest(APIView): # 全体GET def get(self, request): response = [] items = dynamodb_client.scan(TableName='Fruits')['Items'] for item in items: fruit = Fruit(item['Name']['S']) fruit.price = item.get('Price',{}).get('N', '') response.append(fruit.__dict__) return Response(response) def post(self, request): request_data = request.data item = {'Name': {'S': request_data['Name']}} if 'Price' in request_data: item['Price'] = {'N': request_data['Price']} dynamodb_client.put_item( TableName = 'Fruits', Item = item ) return Response(status=status.HTTP_201_CREATED) class DynamoDetailRequest(APIView): #単体GET def get(self, request, pk): item = dynamodb_client.get_item( TableName = 'Fruits', Key = { 'Name': {'S': pk}, } )['Item'] fruit = Fruit(item['Name']['S']) fruit.price = item.get('Price',{}).get('N', '') return Response(fruit.__dict__) def put(self, request, pk): request_data = request.data item = dynamodb_client.get_item( TableName = 'Fruits', Key = { 'Name': {'S': pk}, } )['Item'] price = item.get('Price',{}).get('N', '0') if 'Price' in request_data: price = request_data['Price'] dynamodb_client.put_item( TableName = 'Fruits', Item = { 'Name': {'S': item['Name']['S']}, 'Price': {'N': price} } ) return Response(status=status.HTTP_200_OK) def delete(self, request, pk): dynamodb_client.delete_item( TableName = 'Fruits', Key = { 'Name': {'S': pk}, } ) return Response(status=status.HTTP_204_NO_CONTENT)
rest_frameworkのAPIViewを継承したclassでリクエストを処理する。
DynamoRequestがpathパラメータなしのリクエストを処理し、DynamoDetailRequestでpathパラメータ(pk)ありのリクエストの処理を行う。
APIViewを継承することにより、HTTPメソッドごとにfunctionを用意することでそれぞれのメソッドに対応する処理を追加することができる。urls.pyの編集
api/urls.pyfrom django.urls import path from api import views urlpatterns = [ path('api/', views.DynamoRequest.as_view()), path('api/<pk>/', views.DynamoDetailRequest.as_view()) ]
dynamo_oprationフォルダのurls.pyも編集するdynamo_opration/urls.pyfrom django.urls import path, include urlpatterns = [ path('', include('api.urls')), ]curlコマンドで動作確認
serverの起動
$ python manage.py runserverGET(全体検索)
$ curl http://127.0.0.1:8000/api/ # レスポンス [{"name":"orange","price":"200"},{"name":"banana","price":"100"},{"name":"apple","price":"100"}]POST
$ curl -X POST \ -H 'Content-Type:application/json' \ -d '{"Name": "peach", "Price": "400"}' \ http://127.0.0.1:8000/api/POSTリクエスト後のテーブル
peachの項目が追加されている。
GET(単体)
appleの項目を取得
$ curl http://127.0.0.1:8000/api/apple/ # レスポンス {"name":"apple","price":"100"}PUT
appleのpriceを100 -> 200へ変更する
$ curl -X PUT \ -H 'Content-Type:application/json' \ -d '{"Price": "200"}' \ http://127.0.0.1:8000/api/apple/PUTリクエスト後のテーブル
DELETE
peachの項目を削除する。
$ curl -X DELETE http://127.0.0.1:8000/api/peach/DELETEリクエスト後のテーブル
おわりに
django REST Framework + boto3でDynamoDBの操作を行うREST Apiを作成した。
今回は、dynamodb_model.pyを用意してmodelを管理するようにしたが、必要なかったかもしれない(この辺の設計は今後改善していきたい)。
- 投稿日:2020-08-10T23:29:07+09:00
[DRF+boto3] Djangoでdynamodbを操作するREST APIを作成する
はじめに
django REST Frameworkとboto3でAWSのDynamoDBに対して操作を行うapiを作成する。
GET、POST、PUT、DELETEの操作ができるようにする。Dynamodbテーブル作成(事前準備)
下記のようなテーブルを事前に用意し、いくつかデータを入れておく
テーブル名: Fruits
hash key: Name
djangoプロジェクトの作成
django project(dynamo_operation)とapp(api)を作成
$ django-admin startproject dynamo_operation $ cd dynamo_operation/ $ django-admin startapp apisetting.pyの編集
setting.pyにrest_frameworkと先ほど作成したappのconfigを追加する。dynamo_operation/setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework', #追加 'api.apps.ApiConfig', #追加 ]DynamoDBリクエスト用のmodelを作成
djangoではDBの作成、操作に
modelを用意する。
DynamoDBへのリクエストはboto3を使用するので特にmodelは必要ないが、今回はmodel(dynamo_model.py)を用意した。api/dynamo_model.pyclass Fruit(): def __init__(self, name): self.name = nameviews.pyの編集
api/views.pyfrom rest_framework import status from rest_framework.views import APIView from rest_framework.response import Response from api.dynamo_models import Fruit from boto3 import client dynamodb_client = client('dynamodb') class DynamoRequest(APIView): # 全体GET def get(self, request): response = [] items = dynamodb_client.scan(TableName='Fruits')['Items'] for item in items: fruit = Fruit(item['Name']['S']) fruit.price = item.get('Price',{}).get('N', '') response.append(fruit.__dict__) return Response(response) def post(self, request): request_data = request.data item = {'Name': {'S': request_data['Name']}} if 'Price' in request_data: item['Price'] = {'N': request_data['Price']} dynamodb_client.put_item( TableName = 'Fruits', Item = item ) return Response(status=status.HTTP_201_CREATED) class DynamoDetailRequest(APIView): #単体GET def get(self, request, pk): item = dynamodb_client.get_item( TableName = 'Fruits', Key = { 'Name': {'S': pk}, } )['Item'] fruit = Fruit(item['Name']['S']) fruit.price = item.get('Price',{}).get('N', '') return Response(fruit.__dict__) def put(self, request, pk): request_data = request.data item = dynamodb_client.get_item( TableName = 'Fruits', Key = { 'Name': {'S': pk}, } )['Item'] price = item.get('Price',{}).get('N', '0') if 'Price' in request_data: price = request_data['Price'] dynamodb_client.put_item( TableName = 'Fruits', Item = { 'Name': {'S': item['Name']['S']}, 'Price': {'N': price} } ) return Response(status=status.HTTP_200_OK) def delete(self, request, pk): dynamodb_client.delete_item( TableName = 'Fruits', Key = { 'Name': {'S': pk}, } ) return Response(status=status.HTTP_204_NO_CONTENT)
rest_frameworkのAPIViewを継承したclassでリクエストを処理する。
DynamoRequestがpathパラメータなしのリクエストを処理し、DynamoDetailRequestでpathパラメータ(pk)ありのリクエストの処理を行う。
APIViewを継承することにより、HTTPメソッドごとにfunctionを用意することでそれぞれのメソッドに対応する処理を追加することができる。urls.pyの編集
api/urls.pyfrom django.urls import path from api import views urlpatterns = [ path('api/', views.DynamoRequest.as_view()), path('api/<pk>/', views.DynamoDetailRequest.as_view()) ]
dynamo_oprationフォルダのurls.pyも編集するdynamo_opration/urls.pyfrom django.urls import path, include urlpatterns = [ path('', include('api.urls')), ]curlコマンドで動作確認
serverの起動
$ python manage.py runserverGET(全体検索)
$ curl http://127.0.0.1:8000/api/ # レスポンス [{"name":"orange","price":"200"},{"name":"banana","price":"100"},{"name":"apple","price":"100"}]POST
$ curl -X POST \ -H 'Content-Type:application/json' \ -d '{"Name": "peach", "Price": "400"}' \ http://127.0.0.1:8000/api/POSTリクエスト後のテーブル
peachの項目が追加されている。
GET(単体)
appleの項目を取得
$ curl http://127.0.0.1:8000/api/apple/ # レスポンス {"name":"apple","price":"100"}PUT
appleのpriceを100 -> 200へ変更する
$ curl -X PUT \ -H 'Content-Type:application/json' \ -d '{"Price": "200"}' \ http://127.0.0.1:8000/api/apple/PUTリクエスト後のテーブル
DELETE
peachの項目を削除する。
$ curl -X DELETE http://127.0.0.1:8000/api/peach/DELETEリクエスト後のテーブル
おわりに
django REST Framework + boto3でDynamoDBの操作を行うREST Apiを作成した。
今回は、dynamodb_model.pyを用意してmodelを管理するようにしたが、必要なかったかもしれない(この辺の設計は今後改善していきたい)。
- 投稿日:2020-08-10T23:21:28+09:00
【Python】データサイエンス100本ノック(構造化データ加工編) 024 解説
Youtube
動画解説もしています。
問題
P-024: レシート明細データフレーム(df_receipt)に対し、顧客ID(customer_id)ごとに最も新しい売上日(sales_ymd)を求め、10件表示せよ。
解答
コードdf_receipt.groupby('customer_id').sales_ymd.max().reset_index().head(10)出力
customer_id sales_ymd 0 CS001113000004 20190308 1 CS001114000005 20190731 2 CS001115000010 20190405 3 CS001205000004 20190625 4 CS001205000006 20190224 5 CS001211000025 20190322 6 CS001212000027 20170127 7 CS001212000031 20180906 8 CS001212000046 20170811 9 CS001212000070 20191018 解説
・PandasのDataFrame/Seriesにて、同じ値を持つデータをまとめて処理し、同じ値を持つデータの合計や平均を確認したい時に使用します。
・'groupby'は、同じ値や文字列を持つデータをまとめて、それぞれの同じ値や文字列に対して、共通の操作を(合計や平均)行いたい時に使います。
・'.sales_ymd.max()'は、'.sales_ymd'の最大値(=最も新しい売上日)を表示させます。
・'.reset_index()'は、'groupby'によってバラバラになったインデックス番号を0始まりの連番に振り直す操作を行いたい時に使います。※以下のコードでも、同じ結果を出力します('.agg'を用いた場合)
コードdf_receipt.groupby('customer_id').agg({'sales_ymd':'max'}).reset_index().head(10)
- 投稿日:2020-08-10T23:17:44+09:00
"画像"で掲載される接触確認アプリ(COCOA)の利用状況を解析する / Tesseract
厚生労働省から”画像”で発表されるCOCOAの利用状況を解析するProgramの構築
はじめに
- 私自身、接触確認アプリ(COCOA)のダウンロード数と陽性登録数の推移をグラフでまとめている。毎日18:00頃に公式サイトを訪れデータをGoogle Sheetに書き込み、グラフ作成をするという作業をしていた。
- しかし、この手間が大変になってきたため、単純作業を自動化できないかと思ったのがきっかけである。
- 厚生労働省から掲載される情報はテキストが画像化されており、このデータを自動解析できれば全体の自動化も可能だろうと思い、試しに制作した。
厚生労働省 COCOA特設サイト(8/11現在)
今回のポイント
掲載される情報は、テキストデータで掲載されていないため、画像を取得し文字認識(OCR)をする必要があった。そこで、OCRツールの候補に挙がったのが「GCP Cloud Vision」及び「Tesseract」である。
今回は、TesseractがPythonでPyOCRのライブラリを用いることで手軽に利用できるとあったため、こちらを採用し、認識精度についても検証していく。今後はCloudVisionも利用してみて、双方の文字認識の精度についても検討したい。
実装した機能(すべてPythonで構築)
- スクレイピング機能
- OCR機能
- データ抽出機能
- Googleスプレッドシートへのデータ書き込み機能
- Googleスプレッドシートで作成されたグラフの画像取得機能(Tweet用素材)
- TwitterへCOCOAの利用状況をグラフを添付し投稿する機能(API未取得の為、動作未確認)
Tesseractとは
多様なオペレーティングシステム上で動作するオープンソースソフトウェアであり、Apache License 2.0 の下で配布されている。文字認識を行うライブラリと、それを用いたコマンドラインインターフェイスを持つ。バージョン4.0からは、従来の認識エンジンに加え、LSTMベースのニューラルネットワークによる認識エンジンが搭載されている。開発元:Google
--wikipediaより実行したOCRの結果
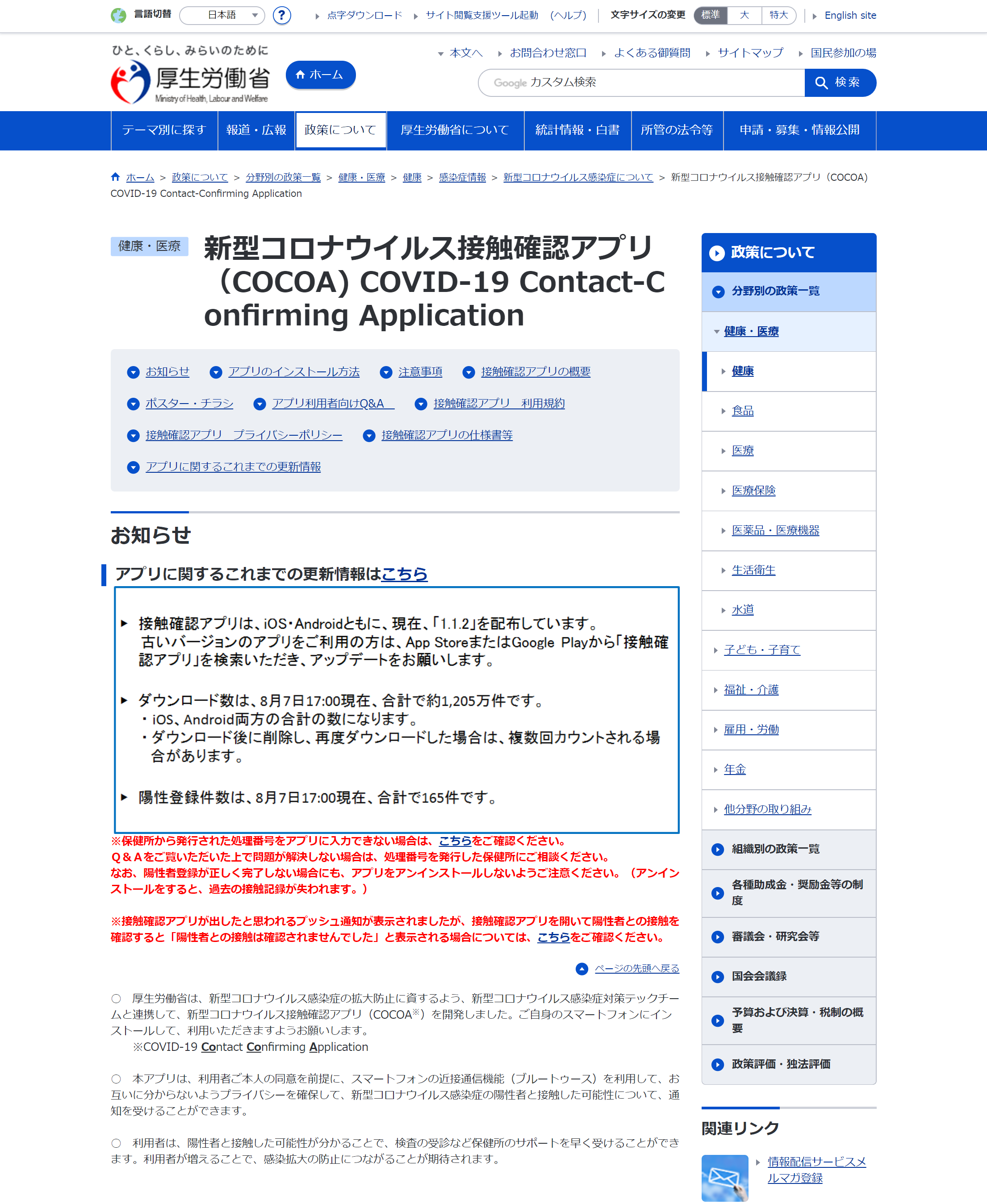
- OCR処理前(サイトから取得した画像)
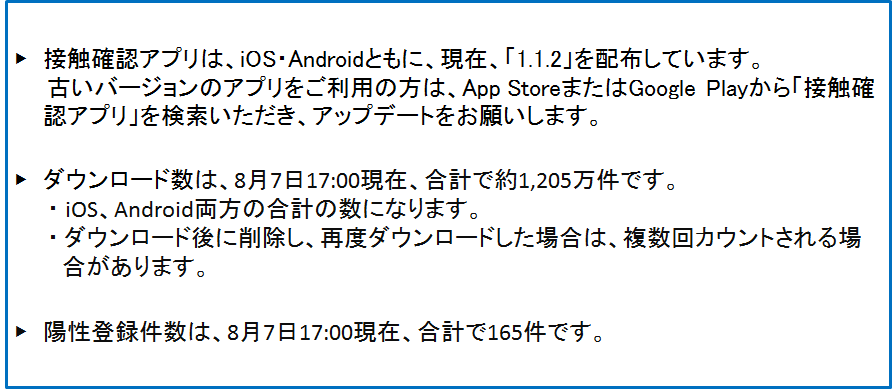
- OCR処理後
接触確認アプリは、iOS・Androidともに、現在、「1.1.2」を配布しています。 古いバージョンのアプブリをご利用の方は、App StoreまたはGoogle Playから「接触確 認アプリ」を検索いただき、 アップデートをお願いします。 ダウンロード数は、8月7日17:00現在、合計で約1.205万件です。 ・iOS、Android両方の合計の数になります。 ・ダウンロード後に削除し、再度ダウンロードした場合は、複数回カウントされる場 合があります。 陽性登録件数は、8月7日17:00現在、合計で165件です。OCRの認識精度は高く安定
誤字は、2行目の「アプリ」を「アプブリ」と認識している点のみ。そのため、データを抽出する際のダウンロード数や、陽性登録数のデータ抽出には支障がないことが分かった。複数枚のOCR処理を行ったが、かなり安定しておりデータ抽出は正確に行われていた。
まとめ
- 本システムは、Twitter投稿機能以外については正常に動作しており、データ抽出からグラフの自動作成などにより、更新作業の簡素化を実現することができた。
- 現在は、ツイートの投稿のみ手作業となっている。
- 課題として今後は、TwitterAPI交付後にツイート機能も稼働させて、解析から情報発信まで自動化させたいと考えている。
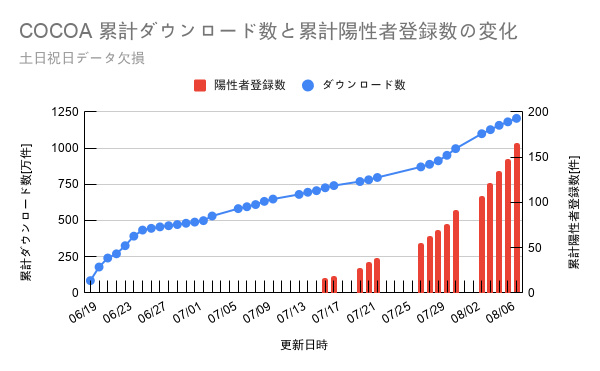
Google Sheetより自動取得した、ダウンロード数と陽性登録数の推移のグラフ
※誤った記述が存在する可能性があります。ご注意ください。
本プロジェクトの詳細について
参考リンク
- 厚生労働省特設サイト「新型コロナウイルス接触確認アプリ(COCOA) COVID-19 Contact-Confirming Application」https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/cocoa_00138.html
- Tesseractの導入や使い方について https://rightcode.co.jp/blog/information-technology/python-tesseract-image-processing-ocr
- 投稿日:2020-08-10T23:17:44+09:00
"画像"で掲載される接触確認アプリ(COCOA)の利用状況を解析する
厚生労働省から”画像”で発表されるCOCOAの利用状況を解析する / Tesseract
きっかけ
私自身、接触確認アプリ(COCOA)のダウンロード数と陽性登録数の推移をグラフでまとめている。毎日18:00頃に公式サイトを訪れデータをGoogle Sheetに書き込みグラフ作成をする作業していた。この単純作業を自動化できないかと思ったのがきっかけである。
厚生労働省から掲載される情報はテキストが画像化されており、このデータを自動解析できれば全体の自動化も可能だろうと思い、試しに制作した。今回のポイント
掲載される情報は、テキストデータで掲載されていないため、画像を取得し文字認識(OCR)をする必要があった。そこで、OCRツールの候補に挙がったのが「GCP Cloud Vision」及び「Tesseract」である。
今回は、TesseractがPythonでPyOCRのライブラリを用いて利用できるとあったためTesseractを採用し、認識精度についても検証していく。今後はCloudVisionも利用してみて、双方の文字認識の精度についても検討したい。
実装した機能(すべてPythonで構築)
- スクレイピング機能
- OCR機能
- データ抽出機能
- Googleスプレッドシートへのデータ書き込み機能
- Googleスプレッドシートで作成されたグラフの画像取得機能(Tweet用素材)
- TwitterへCOCOAの利用状況をグラフを添付し投稿する機能(API未取得の為、動作未確認)
Tesseractとは
多様なオペレーティングシステム上で動作するオープンソースソフトウェアであり、Apache License 2.0 の下で配布されている。文字認識を行うライブラリと、それを用いたコマンドラインインターフェイスを持つ。バージョン4.0からは、従来の認識エンジンに加え、LSTMベースのニューラルネットワークによる認識エンジンが搭載されている。開発元:Google
--wikipediaより実行したOCRの結果
- OCR処理前(サイトから取得した画像)
- OCR処理後
接触確認アプリは、iOS・Androidともに、現在、「1.1.2」を配布しています。 古いバージョンのアプブリをご利用の方は、App StoreまたはGoogle Playから「接触確 認アプリ」を検索いただき、 アップデートをお願いします。 ダウンロード数は、8月7日17:00現在、合計で約1.205万件です。 ・iOS、Android両方の合計の数になります。 ・ダウンロード後に削除し、再度ダウンロードした場合は、複数回カウントされる場 合があります。 陽性登録件数は、8月7日17:00現在、合計で165件です。OCRの認識精度は高く安定
誤字は、2行目の「アプリ」を「アプブリ」と認識している点のみ。そのため、データを抽出する際のダウンロード数や、陽性登録数のデータ抽出には支障がないことが分かった。複数枚のOCR処理を行ったが、かなり安定しておりデータ抽出は正確に行われていた。
進捗状況
本システムは、Twitter投稿機能以外については正常に動作しており、データ抽出からグラフの自動作成などにより、更新作業の簡素化を実現することができた。現在は、ツイートの投稿のみ手作業となっている。今後は、TwitterAPI交付後にツイート機能も稼働させて、解析から情報発信まで自動化させたいと考えている。
※誤った記述が存在する可能性があります。ご注意ください。
本プロジェクトの詳細について
参考リンク
- 厚生労働省特設サイト「新型コロナウイルス接触確認アプリ(COCOA) COVID-19 Contact-Confirming Application」https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/cocoa_00138.html
- Tesseractの導入や使い方について https://rightcode.co.jp/blog/information-technology/python-tesseract-image-processing-ocr
- 投稿日:2020-08-10T23:04:58+09:00
深層学習とかでのTensorflowエラー「ImportError: DLL load failed: 指定されたモジュールが見つかりません。 」への対処
目的
tensorflowの関連で以下のエラーが出ることがある。
ImportError: DLL load failed: 指定されたモジュールが見つかりません。もう少し手前から示すと、以下のようなエラー。
ImportError: Traceback (most recent call last): File "C:\Users\XYZZZ\AppData\Local\Programs\Python\Python37\lib\site-packages\tensorflow\python\pywrap_tensorflow.py", line 64, in <module> from tensorflow.python._pywrap_tensorflow_internal import * ImportError: DLL load failed: 指定されたモジュールが見つかりません。対処方法を示す。
対処
前提
エラーが出たときのtensorflowのバージョンは以下。
tensorflow 2.3.0個別の問題ではないので、直接は関係ないが、エラーが出たのは、
以下のgithubのコードを実行した場合(XLNET関連)。
https://github.com/zihangdai/xlnet具体的な対処
(経験的にtensorflowのバージョンの問題のような気がしたので。。。)
以下のコマンドで、tensorflowのバージョンを2より小さくした。
python -m pip install "tensorflow<2.0.0"上記のコマンドで、tensorflowのバージョンは、
tensorflow 1.15.3になった。
以下のPYPIをみると、
https://pypi.org/project/tensorflow/#history
2.0.0より小さいバージョンは、1.15.3になっているので、通常、こうなるのだろう。(引用:PYPIの上記URLの画面)
⇒ エラーは、無事消えた。
補足
- 環境を分けて、複数のバージョンをインストールすることができるのだろうけども、昔、それを実行して、嫌な感じになったので、最近は、後先考えずに、バージョンを変更している。当然、tensorflowが2以上でないと動作しないものもあるので、 それを実行する場合は、バージョンを上げる(頻繁に作業されている方は、さすがに、このやり方は、まずいかも。。。。)
- もしかすると、今回のエラーは、2.3より少しバージョンを下げるだけでも良かったのかもしれないが、この場合は、たぶん、これで正解。別途、また、確認します。
まとめ
コメントなどあればお願いします。
- 投稿日:2020-08-10T22:46:35+09:00
python jupyter notebook へのスニペット設定
スニペットとは
- 使用頻度の高いコード、定型的なクラス宣言等を、簡単に入力できるようにしたもの。
- 単純な入力や、ループ作業がごく少ない入力で済むため効率的。
- Extensionとして提携のものを導入する、自分で作成するの2パターンがある
※ ちなみに。
スニペットとは、一般的には「切れ端」「断片」という意味の英語である。 IT用語としては、プログラミング言語の中で簡単に切り貼りして再利用できる部分のこと。
ターミナルで拡張機能のDL、インストール
1. コマンドプロンプト等で拡張機能をダウンロード
pippip install jupyter_contrib_nbextensions2. 上記DLが成功したら、以下のコードで拡張機能をインストール
jupyter contrib nbextension install --user3. Jupyter notebookの起動(再起動)
jupyter notebook4.Nbextensionsタブの設定
デフォルトでは以下のチェックがついているが、これを解除する。
disable configuration for nbextensions without explicit compatibility
(they may break your notebook environment, but can be useful to show for nbextension development)Extensonの設定で以下を選択する。
- Nbextensions dashboard tab(必須;Extensionsのタブ表示)
- Snippets (オリジナルのスニペット作成・活用可能)
- Snippets Menu(スニペットを利用)
- ExecuteTime(セルごとの実行時間を表示)
参考URL
- 投稿日:2020-08-10T22:33:19+09:00
CentOS7, emacs lsp-mode で pyright を使う
CentOS7, emacs lsp-mode で pyright を使う
CentOS7, emacs の lsp-mode で pyright を使う方法です。
主な登場人物
pyright: Microsoft製の python language server
- https://github.com/microsoft/pyright
- language server, language server protocol についてはこちらの記事をどうぞ。
lsp-mode: language server protocol で language server の機能を使う emacs minor mode。lsp-ui-mode: lsp-mode の機能にポップアップ表示等のUI機能を付加する emacs minor mode。python-mode: python 用の emacs major mode。環境
- CentOS7 x64
- emacs 26.3
- ssh 経由でのvtyで使用
- node.js v14.7.0
- pyright 1.1.61
- lsp-ui 20200807.154
- lsp-mode 20200809.1551
- lsp-pyright 20200810.354
- company 20200807.48
- imenu-list 20190115.2130
- flycheck 20200610.1809
node.jsを入れる
pyrightは node.js で書かれています。ここら辺を見ていれます。
https://github.com/nodesource/distributions/blob/master/README.md#enterprise-linux-based-distributionsyum レポジトリ追加したくない人は、この辺りから、rpm ダウンロードして入れましょう。
https://rpm.nodesource.com/pub_14.x/el/7/x86_64/$ node --version v14.7.0 $ npm --version 6.14.5
pyrightを入れる$ npm -g install pyright$ pyright --version pyright 1.1.61emacs から起動されるのは
pyright-langserverです。
pyright-langserverはpyrightとともにインストールされます。emacs にパッケージを入れる
lsp-pyright, lsp-mode, lsp-ui, company, imenu-list, flycheck 全て melpa からインストールできます。
M-x package-install lsp-mode
...
lsp-modehttps://emacs-lsp.github.io/lsp-mode/
emacs で lsp の機能を使うためのパッケージです。Python用ではなく、汎用です。
Pythonで使う場合、python-modeのマイナーモードとして使用します。コード補完には、
companyが推奨されています。
http://company-mode.github.io/lsp-mode 7.0.1 で
company-lspはサポートされなくなりました。companyだけで十分です。
https://github.com/emacs-lsp/lsp-mode/blob/master/CHANGELOG.orgDropped support for company-lsp, the suggested provider is company-capf.
lsp-ui
lsp-modeを補助するパッケージです。
lsp-ui-sideline
- エラー、flycheck警告がカーソル行付近の右端に表示されるようになります。
lsp-ui-peek
- 関数定義位置へのジャンプ、関数参照箇所へのジャンプが、"peek" になります。
- "peek" は、ジャンプ前にジャンプ先をオーバーレイでプレビューできる機能です。
lsp-ui-doc
- 関数にカーソル置いたときに表示される doc-string 表示がオーバーレイでの表示になります。
- GUIだと、doc-string の WebKitレンダリングもできるっぽいです。
lsp-ui-imenu
- emacs の
imenuを使って、編集中ファイルのクラス、メソッドのツリー階層を表示してくれます。- でも2020/8時点だと、
imenu-listの方が高機能なので、そっちつかいます。
lsp-pyrighthttps://github.com/emacs-lsp/lsp-python-ms
lsp-mode で、
pyrightを使えるようにしてくれるアドオンパッケージです。
companyIntelliSense 的なコード補完を提供するパッケージです。
いろいろなバックエンドパッケージをいれることで、補完が強化されます。lsp-mode が(というか、language-serverが) company のバックエンドとして動作します。
imenu-list
imenuの内容を IDE的なサイドフレームで表示するパッケージです。
flycheck汎用 linter フレームワークです。
https://www.flycheck.org/en/latest/
emacs をコンフィグする
use-package使ってます。
自分のinit.elから切り貼りしてるので、つじつま合わないところがあるかも。(use-package python :mode ("\\.py\\'" . python-mode) ) (use-package lsp-mode :config ;; .venv, .mypy_cache を watch 対象から外す (dolist (dir '( "[/\\\\]\\.venv$" "[/\\\\]\\.mypy_cache$" "[/\\\\]__pycache__$" )) (push dir lsp-file-watch-ignored)) ;; lsp-mode の設定はここを参照してください。 ;; https://emacs-lsp.github.io/lsp-mode/page/settings/ (setq lsp-auto-configure t) (setq lsp-enable-completion-at-point t) ;; imenu-listを使うのでimenu 統合は使わない (setq lsp-enable-imenu nil) ;; クロスリファレンスとの統合を有効化する ;; xref-find-definitions ;; xref-find-references (setq lsp-enable-xref t) ;; linter framework として flycheck を使う (setq lsp-diagnostics-provider :flycheck) ;; ミニバッファでの関数情報表示 (setq lsp-eldoc-enable-hover t) ;; nii: ミニバッファでの関数情報をシグニチャだけにする ;; t: ミニバッファでの関数情報で、doc-string 本体を表示する (setq lsp-eldoc-render-all nil) ;; breadcrumb ;; パンくずリストを表示する。 (setq lsp-headerline-breadcrumb-enable t) (setq lsp-headerline-breadcrumb-segments '(project file symbols)) ;; snippet (setq lsp-enable-snippet t) ;; フック関数の定義 ;; python-mode 用、lsp-mode コンフィグ (defun lsp/python-mode-hook () (when (fboundp 'company-mode) ;; company をコンフィグする (setq ;; 1文字で completion 発動させる company-minimum-prefix-length 1 ;; default is 0.2 company-idle-delay 0.0 ) ) ) :commands (lsp lsp-deferred) :hook (python-mode . lsp) ; python-mode で lsp-mode を有効化する (python-mode . lsp/python-mode-hook) ; python-mode 用のフック関数を仕掛ける ) (use-package lsp-pyright :init (defun lsp-pyright/python-mode-hook () ;; lsp-pyright を有効化する (require 'lsp-pyright) (when (fboundp 'flycheck-mode) ;; pyright で lint するので、python-mypy は使わない。 (setq flycheck-disabled-checkers '(python-mypy)) ) ) :hook (python-mode . lsp-pyright/python-mode-hook) ) (use-package lsp-ui :after lsp-mode :config ;; ui-peek を有効化する (setq lsp-ui-peek-enable t) ;; 候補が一つでも、常にpeek表示する。 (setq lsp-ui-peek-always-show t) ;; sideline で flycheck 等の情報を表示する (setq lsp-ui-sideline-show-diagnostics t) ;; sideline で コードアクションを表示する (setq lsp-ui-sideline-show-code-actions t) ;; ホバーで表示されるものを、ホバーの変わりにsidelineで表示する ;;(setq lsp-ui-sideline-show-hover t) :bind (:map lsp-ui-mode-map ;; デフォルトの xref-find-definitions だと、ジャンプはできるが、ui-peek が使えない。 ("M-." . lsp-ui-peek-find-definitions) ;; デフォルトの xref-find-references だと、ジャンプはできるが、ui-peek が使えない。 ("M-?" . lsp-ui-peek-find-references) ) :hook (lsp-mode . lsp-ui-mode) ) (use-package imenu-list) (use-package company :init (global-company-mode t) ) (use-package flycheck :init (global-flycheck-mode) )
- 投稿日:2020-08-10T22:17:57+09:00
Flappy BirdをAIに自動プレイさせる
こんばんは。りーぜんとです。
今回はFizzBuzzのやつに引き続き、強化学習第二弾ということで、Flappy BirdをプレイするAIを作ってみます。
作成したプログラムは全てGitHubにあるので参考にしてください。目次
Flappy Birdとは
Flappy Birdというゲームを聞いたことがある人は多いんじゃないでしょうか。無料でプレイできるのでぜひ遊んでみてください。
とりあえず僕もやってみます。
いやむっず。
鳥が土管を超えるとポイントが入るのですが、結構頑張ったけど5点までいけません。今からAIを作って5点を突破できれば僕より強いってことですね。ひとまず10点を目標にしましょう。
ゲームを実装
まずは学習に使うゲーム環境を作っていきます。
今回はpygameというライブラリを使って実際に学習してる様子が見えるように作ります。
pygameについて詳しい解説はしないので、是非公式リファレンス等を読んでみてください。ライブラリのインポート
最初にライブラリをインポートしたり定数を定義します。
flappy_bird.pyimport pygame import random import sys import math from numpy import array WIN_WIDTH = 600 WIN_HEIGHT = 800 COLORS = { 'sky': (135, 206, 250), 'bird': (255, 255, 0), 'pipe': (50, 205, 50), 'ground': (160, 82, 45) } BIRD_SIZE = 50 PIPE_VEL = 4 PIPE_GAP = 200 PIPE_WIDTH = 100 PIPE_MARGIN = 100 GROUND_HEIGHT = 100鳥クラスの作成
次に鳥のクラスから作っていきます。今回もFizzBuzzの記事と同様に作っていくので、詳しくはそちらをみてください。
bird.pyclass Bird: def __init__(self, x=200, y=350): self.y = y self.vel = 0 self.rect = pygame.Rect(x, self.y, BIRD_SIZE, BIRD_SIZE) def jump(self): self.vel = -6 def move(self): self.vel += 0.4 self.y += self.vel self.rect.top = self.y def get_state(self): return [self.y, self.vel] def draw(self, win): pygame.draw.rect(win, COLORS['bird'], self.rect)y座標と、加速度、描画用のpygame.Rectオブジェクトを持たせてあります。今回はお絵かきがめんどくさかったので、全ての物体は長方形で構成されます。お許しを。
また、get_state()で現在の鳥の状態(今の位置と加速度)を取得可能にしています。これを強化学習の際に使用します。土管クラスの作成
次は土管です。
pipe.pyclass Pipe: def __init__(self, x=700): self.top = random.randrange(PIPE_MARGIN, WIN_HEIGHT - PIPE_GAP - PIPE_MARGIN - GROUND_HEIGHT) self.bottom = self.top + PIPE_GAP self.top_rect = pygame.Rect(x, 0, PIPE_WIDTH, self.top) self.bottom_rect = pygame.Rect(x, self.bottom, PIPE_WIDTH, WIN_HEIGHT - self.bottom) def move(self): self.top_rect = self.top_rect.move(-PIPE_VEL, 0) self.bottom_rect = self.bottom_rect.move(-PIPE_VEL, 0) if self.top_rect.right < 0: self.__init__() return self.top_rect.left == 200 def draw(self, win): pygame.draw.rect(win, COLORS['pipe'], self.top_rect) pygame.draw.rect(win, COLORS['pipe'], self.bottom_rect)常に二本の土管をいい感じの間隔でゲーム内に置いておき、左端まで進んだ土管を右端にテレポートさせることでずっと土管が来るようにしました。
地面クラスの作成
次の地面ですが、これに関して語ることはありません。
ground.pyclass Ground: def __init__(self): self.rect = pygame.Rect(0, WIN_HEIGHT - GROUND_HEIGHT, WIN_WIDTH, GROUND_HEIGHT) def draw(self, win): pygame.draw.rect(win, COLORS['ground'], self.rect)ゲームクラスの作成
最後にゲーム本体のクラスです。
flappy_bird.pyclass FlappyBird: def __init__(self, n_bird=1): pygame.init() self.win = pygame.display.set_mode((WIN_WIDTH, WIN_HEIGHT)) pygame.display.set_caption('Flappy Bird') self.n_bird = n_bird self.birds = [Bird() for _ in range(self.n_bird)] self.pipes = [Pipe(800), Pipe(1200)] self.ground = Ground() self.score = 0 def reset(self): self.__init__(self.n_bird) def draw(self): self.win.fill(COLORS['sky']) for bird in self.birds: bird.draw(self.win) for pipe in self.pipes: pipe.draw(self.win) self.ground.draw(self.win) pygame.display.update() def check_collide(self, bird): if bird.y <= -BIRD_SIZE: return True for pipe in self.pipes: if pipe.top_rect.colliderect(bird.rect) or pipe.bottom_rect.colliderect(bird.rect): return True if self.ground.rect.colliderect(bird.rect): return True return False def step(self, actions): passed = False for pipe in self.pipes: if pipe.move(): self.score += 1 passed = True next_birds = [] states = [] rewards = [] for action, bird in zip(actions, self.birds): if action.argmax(): bird.jump() last_y = bird.y bird.move() pipe_idx = 0 while bird.rect.x > self.pipes[pipe_idx].top_rect.left: pipe_idx += 1 rewards.append( 1 if abs( self.pipes[pipe_idx].top_rect.bottom + PIPE_GAP / 2 - last_y ) < abs( self.pipes[pipe_idx].top_rect.bottom + PIPE_GAP / 2 - bird.y ) else 0 ) pipe_state = [ self.pipes[pipe_idx].top_rect.bottom - bird.y, self.pipes[pipe_idx].top_rect.left - 200 ] states.append(bird.get_state() + pipe_state) finished = self.check_collide(bird) if not finished: next_birds.append(bird) self.birds = next_birds return array(states), array(rewards), finished def random_step(self): for pipe in self.pipes: pipe.move() state = [] for bird in self.birds: pipe_state = [ self.pipes[0].top_rect.bottom - bird.y, self.pipes[0].top_rect.left - 200 ] state.append(bird.get_state() + pipe_state) return array(state), array([0 for _ in range(self.n_bird)]), False環境を初期化するreset()、鳥が死んだかどうかを判定するcheck_collide()、次フレームに遷移するstep()、random_step()を実装しました。
step()は今の状況、それに対する報酬、ゲームが終了したかどうかを返します。DQNで挑戦
さて、前の記事同様、Deep Q Learningという手法を使って学習をしてみます。細かい解説はしないので、いろいろ調べてみてください。
エージェント、メモリ、モデルは前の記事で実装したものをそのまま使います。train.pyimport pygame from flappy_bird import FlappyBird from model import Model from memory import Memory from agent import Agent def evaluate(env, agent): env.reset() state, _, finished = env.random_step() while not finished: action = agent.get_action(state, N_EPOCHS, main_model) next_state, _, finished = env.step(action.argmax(), verbose=True) state = next_state def main(): clock = pygame.time.Clock() N_EPOCHS = 1000 GAMMA = 0.99 N_BIRD = 64 S_BATCH = 256 env = FlappyBird(N_BIRD) main_model = Model() target_model = Model() memory = Memory() agent = Agent() for epoch in range(1, N_EPOCHS + 1): print('Epoch: {}'.format(epoch)) env.reset() states, rewards, finished = env.random_step() target_model.model.set_weights(main_model.model.get_weights()) running = True while running: clock.tick(60) actions = [] for state in states: actions.append(agent.get_action(state, epoch, main_model)) next_states, rewards, finished = env.step(actions) for state, reward, action, next_state in zip(states, rewards, actions, next_states): memory.add((state, action, reward, next_state)) states = next_states if len(memory.buffer) % S_BATCH == 0: main_model.replay(memory, env.n_bird, GAMMA, target_model) target_model.model.set_weights(main_model.model.get_weights()) if not len(env.birds): running = False break env.draw() for event in pygame.event.get(): if event.type == pygame.QUIT: running = False print('\tScore: {}'.format(env.score)) pygame.quit() if __name__ == '__main__': main()さて、早速学習させてみましょう。
DQN使ったやつ
— りーぜんと (@50m_regent) August 10, 2020
全然学習が進まない pic.twitter.com/weuOJx0DmZ動画を見たらわかるように、全然成長しません。FizzBuzzのときはうまくいったのに、、、
ゲームの内容が複雑になったからかな?違うアルゴリズムに挑戦してみます。
NEATで挑戦
NEATとは
DQNでは上手くいかなかったので、NEATというアルゴリズムを使ってみます。これは遺伝的アルゴリズムといわれるものです。
簡単に説明をしてみます。
まず、DQNではエポックという単位で学習を進めましたが、NEATでは世代という考え方をします。これは人間でいう世代と同じものだと思ってください。
一世代に100羽の鳥がいるとします。各鳥は自分のニューラルネットワークを持っていて、それをもとに動きます。
一世代が全員死ぬまでゲームを動かすと、その世代の1位から100位まで順位をつけることができます。
この100羽の中で優秀な鳥から次の世代の100羽を生み出します。生み出すとは、各鳥が持ってるニューラルネットワークを少しずつ改変して新しいニューラルネットワークにするという意味です。※イメージ図
Configの設定
今回はneat-pythonというライブラリを使って学習させます。そのためにはconfigファイルを作成して設定をしておかないといけません。今回は公式サイトにあったやつを少しだけいじって使います。
neat_config.txt[NEAT] fitness_criterion = max fitness_threshold = 500 pop_size = 50 reset_on_extinction = False [DefaultGenome] activation_default = sigmoid activation_mutate_rate = 0.0 activation_options = sigmoid aggregation_default = sum aggregation_mutate_rate = 0.0 aggregation_options = sum bias_init_mean = 0.0 bias_init_stdev = 1.0 bias_max_value = 100 bias_min_value = -100 bias_mutate_power = 0.5 bias_mutate_rate = 0.7 bias_replace_rate = 0.1 compatibility_disjoint_coefficient = 1.0 compatibility_weight_coefficient = 0.5 conn_add_prob = 0.5 conn_delete_prob = 0.5 enabled_default = True enabled_mutate_rate = 0.01 feed_forward = True initial_connection = full node_add_prob = 0.2 node_delete_prob = 0.2 num_inputs = 4 num_hidden = 0 num_outputs = 1 response_init_mean = 1.0 response_init_stdev = 0.0 response_max_value = 100 response_min_value = -100 response_mutate_power = 0.0 response_mutate_rate = 0.0 response_replace_rate = 0.0 weight_init_mean = 0.0 weight_init_stdev = 1.0 weight_max_value = 100 weight_min_value = -100 weight_mutate_power = 0.5 weight_mutate_rate = 0.8 weight_replace_rate = 0.1 [DefaultSpeciesSet] compatibility_threshold = 3.0 [DefaultStagnation] species_fitness_func = max max_stagnation = 20 species_elitism = 2 [DefaultReproduction] elitism = 2 survival_threshold = 0.2学習させてみる
一世代の鳥を50羽として学習させてみます。
train.pyimport neat import pygame from flappy_bird import FlappyBird CFG_PATH = 'neat_config.txt' NUM_BIRD = 50 env = FlappyBird(NUM_BIRD) def gen(genomes, config): clock = pygame.time.Clock() env.reset() nets = [] ge = [] for _, g in genomes: nets.append(neat.nn.FeedForwardNetwork.create(g, config)) g.fitness = 0 ge.append(g) while len(env.birds) > 0: clock.tick(60) for pipe in env.pipes: if pipe.move(): env.score += 1 for g in ge: g.fitness += 3 pipe_idx = 0 while env.birds[0].rect.x > env.pipes[pipe_idx].top_rect.left: pipe_idx += 1 for i, bird in enumerate(env.birds): bird_state = bird.get_state() output = nets[i].activate(( bird_state[0], bird_state[1], env.pipes[pipe_idx].top_rect.bottom - bird.rect.y, env.pipes[pipe_idx].top_rect.left - bird.rect.x)) if output[0] > 0.5: bird.jump() bird.move() ge[i].fitness += 0.1 if env.check_collide(bird): ge[i].fitness -= 1 env.birds.pop(i) nets.pop(i) ge.pop(i) env.draw() def train(): config = neat.config.Config( neat.DefaultGenome, neat.DefaultReproduction, neat.DefaultSpeciesSet, neat.DefaultStagnation, CFG_PATH) p = neat.Population(config) p.add_reporter(neat.StdOutReporter(True)) p.add_reporter(neat.StatisticsReporter()) winner = p.run(gen, NUM_BIRD) pygame.quit() if __name__ == '__main__': train()学習の様子です。
Flappy Birdの強化学習できた!いつか記事書きたい pic.twitter.com/6G9XsPOvQ1
— りーぜんと (@50m_regent) August 10, 2020DQNのときよりもちゃんと成長してるのが分かりますね!
結果
さて、今回はAIにFlappy Birdを学習させてみました。ビジュアライズも可能にすると学習の様子がみれてとても可愛いですね。
数時間学習をさせたら50点に到達しました。目標の10点を軽々達成しました。
よければTwitterフォローしてください。じゃあね。

- 投稿日:2020-08-10T22:10:56+09:00
PythonによるDatetimeモジュールを使用してみた
Pythonのdatetimeモジュール使ってみた
概要
ご覧いただきありがとうございます。今回はPythonのライブラリーでDatimeを主に使っていこうと思いますのでよかったら最後までみてってください。早速なのですが、私が今回Datetimeというモジュールを勉強してQiitaに投稿した理由は、業務でDatetimeというモジュールを使ったからです。初めは全くわからなかったのですが、独習Pythonという書籍を読んで理解することができました。こちらはリンクに載せておきますのでよかったらご覧ください。
datetimeって何?
datetimeというのは日付と時刻を表すものです。モジュールというのが部品に当たるので=日付と時刻を表す部品と覚えていただければと思います。
まずdatetimeの主なモジュールを紹介します。
型 概要 datetime 日付/時刻値 date 日付値 time 時刻値 timezone タイムゾーン情報 timedelta 時間間隔(じかんかんかく・・漢字が読めなかったため) 例文を紹介します。
import datetime #モジュールのインポート #① print(datetime.datetime.today()) #出力(モジュール.日付/時刻値.今日)=つまり今日の日付/時刻を出力 print(datetime.date.today()) #出力(モジュール.日付値.今日)=つまり今日の日付を出力 #② #少し長くなります。結論=タイムゾーンを知るための出力です。 #③ print(datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=0)))) #出力(モジュール.日付/時刻値.今(モジュール.タイムゾーン情報(モジュール.時間間隔(時間=何時間)))) 出力結果================================================= #(※日付や時刻は全て一緒ではないのでこれは例えになります。) #① 2020-08-10 22:08:11.888987 #② 2020-08-10 #③ 2020-08-10 22:08:11.888987+00:00 =======================================================
- 投稿日:2020-08-10T21:53:14+09:00
Python初心者によるDjango超入門!その2 テンプレートの便利な機能を使ってみた
本記事について
UdemyでDjangoについて学習した結果のアウトプットページです。
前の記事の続きになります。
今回は、Djangoの機能の1つであるrenderを使ってみようと思います。urls.py
ulrs.pyは前回と同じです。
first\myapp\urls.pyfrom django.urls import path from . import views app_name = 'myapp' urlpatterns = [ path('', views.index, name='index'), ]views.py
views.pyを以下のように変更します。
first\myapp\views.pyfrom django.shortcuts import render def index(request): context = { 'names':['鈴木','佐藤','高橋'], 'message':'こんにちは。', } return render(request, 'myapp/index.html', context)まず
from django.shortcuts import renderでrenderをインポートします。つづいて、def indexを編集します。
def indexに、contextというdictionaryを追記します。
contextには、namesとmessageというKeyがあります。
namesには複数の値を登録しておきましょう。最後に
return render(request, 'myapp/index.html', context)でmyapp/index.htmlにcontextを渡します。
これで、myapp/index.htmlでcontextのKeyと値が利用できるようになります。テンプレートファイルの置き場所の設定
Djangoでは、テンプレートファイルの置き場所が決められています。
この辺がDjangoを学び始めだとかなり混乱するのですが、
結論から言いますと、myapp/index.htmlは以下の場所になります。
first\myapp\templates\myapp\index.html
具体的に手順を追って説明します。
1.first\myappの下に、templatesというフォルダを作成します。
2.さらにその下にアプリ名と同じフォルダ(今回はmyapp)を作成します。
3.そのmyappフォルダにindex.htmlを作成します。
4.urls.pyでmyapp/index.htmlにアクセスがあると、このindex.htmlファイルにアクセスされます。
5.↓のようなルールで保存されると覚えると良いかもしれません。
<プロジェクト名>/<アプリ名>/templates/<アプリ名>index.html
index.htmlには以下のように記述します。
first\myapp\templates\myapp\index.html<p>{{ names.0 }}さん。{{ message }}</p> <p>{{ names.1 }}さん。{{ message }}</p> <p>{{ names.2 }}さん。{{ message }}</p> <hr> {% for name in names %} <p>{{ name }}さん。{{ message }}</p> {% endfor %}DjangoのHTMLファイルに書く記述はPythonと似ているようで微妙に記法が異なります。
変数は{{ }}で囲い、forなどのプログラム命令は{% %}で囲みます。
また、HTML内にはインデントという概念が無いため、forやifの終わりに{% endfor %}などで明示的と表現してあげる必要があります。
Pythonに慣れていると、かなり面倒に感じますが、慣れるしかありません。最初の3行から解説します。
contextのnamesには、3つの値が登録されていました。
names.0とは、namesの1番目の値を引っ張ってくるという意味になります。
names.1は、namesの2番目の値です。
messageは1つしか値が無いので、添字は不要です。続いて、最後の3行について説明します。
{% for name in names %}でnamesから1つずつ値を取り出します。
この辺はPythonと表記が同じなので分かりやすいですね。
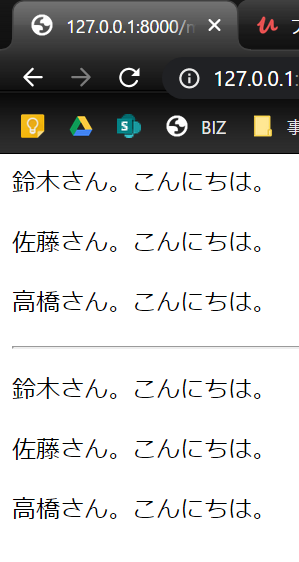
最後は{% endfor %}で閉じるのを忘れずに。動作確認
開発用サーバーを、py manage.py runserverで起動して、index.htmlにアクセスしてみましょう。以下のように表示されていれば問題ありません。
上の3行が添字での値表示で、下3行がfor分による値表示になります。
- 投稿日:2020-08-10T21:47:04+09:00
昼飯データベースを作りたい【EP1-2】はじめてのDjango勉強編
本稿は続きものです
おさらい的な
前回は
models.Modelを使ってモデルを作成したところで終わりました。
前回はよくわかってなかったのですっ飛ばしましたがsqlmigrateというコマンドでmigrateで実行したSQLの結果を確認できるようです。cmd(Django) C:\User\mysite>python manage.py sqlmigrate polls 0001 BEGIN; -- -- Create model Question -- CREATE TABLE "polls_question" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "question_text" varchar(200) NOT NULL, "pub_date" datetime NOT NULL); -- -- Create model Choice -- CREATE TABLE "polls_choice" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "choice_text" varchar(200) NOT NULL, "votes" integer NOT NULL, "question_id" integer NOT NULL REFERENCES "polls_question" ("id") DEFERRABLE INITIALLY DEFERRED); CREATE INDEX "polls_choice_question_id_c5b4b260" ON "polls_choice" ("question_id"); COMMIT;ということでSQLで実行された内容の確認ができました。
見るにこんな感じでしょうか。<Question>
polls_question id question_text pub_date : : : : <Choice>
polls_choice id choice_text votes quetion_id : : : : : Pythonの
Data Frameに似てる感じのデータベース(多分これはSQL発だから順序が逆)にデータを格納していく感じですかねー?APIをつかう
ここからAPIを扱っていきます。
APIってなーに?APIはApplication Programing Interfaceの略です。そんでApplication Programing Interfaceとは何かというと、特定のアプリ(Application)をコマンドラインなどの外部(Programing)から操作することを可能にする入口(Interface)を提供するのがAPIというのが私の理解です。
その昔、私がTwitterのAPIを使ってTweetの内容を分析用に取得したときはTwitterAPIを有効にしてサポートパッケージを入れたらプログラムの中で特定のTweetデータを取得することができたりしましたんで、外部から様々な形で機能の呼び出しができるAPIというは多様な可能性を感じさせますね。
(WebページについてたりするGoogleMapなんかもAPIを用いた技術です。)
もっといい解説⇒「API」ってつまりどんな技術?用語の意味をおさらいしよう(APIblog)
⇒公式のデータベースAPIについての解説今回はDjango Shellを使って諸々やっていきます。
このPythonのShellは対話シェルと呼ばれておりPythonが提供するAPIの一つです。cmd(Django) C:\User\mysite>python manage.py shellこのコマンドでDjangoのShellを呼び出します。
呼び出したらこの対話シェルをつかってデータベースにデータを入れていきます。cmd#クラスの呼び出し >>> from polls.models import Choice, Question #timezoneをdjangoのパッケージから使うので呼び出し >>> from django.utils import timezone #インスタンス作成 >>> q = Question(question_text="What's new?", pub_date=timezone.now())これで
Questionクラスのインスタンスの作成をしました。データベースに以下の内容で入れたということになります。<Question>
polls_question id question_text pub_date q 1 "What's next?" datetime.datetime(2020, 8, 8, 4, 8, 56, 186975, tzinfo=) 以上の内容はShell上で確認できます。
>>> q.id 1 >>> q.question_text "What's new?" >>> q.pub_date datetime.datetime(2020, 8, 8, 4, 8, 56, 186975, tzinfo=<UTC>)とにかくこれで、まずは
Questionに一つデータをセットすることができました。
ここでチュートリアルではQuestionとChoiceのモデルに__str__()メソッドの追加を行っています。
__str__()メソッドはオブジェクトを表す様々な場面で表示してくれる文字列を決めることができます。
このDjangoのチュートリアルでは
__str__()メソッドの公式のドキュメントはこちらではチュートリアルに沿ってやっていきます。
mysite/polls/models.pyclass Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published') #以下の2行を追加 def __str__(self) -> str: return self.question_text class Choice(models.Model): question = models.ForeignKey(Question, on_delete=models.CASCADE) choice_text = models.CharField(max_length=200) votes = models.IntegerField(default=0) #以下の2行を追加 def __str__(self) -> str: return self.choice_textこれで何が変わったのかを確認します。
cmd>>> from polls.models import Choice, Question >>> Question.objects.all() <QuerySet [<Question: What's new?>]>ここで先ほど設定したとおりに
question_textが表示されています。(対話シェルを開きっぱなしでmodels.pyを編集していた場合は一度対話シェルをquit()して再度開いてからでないと変更が反映されません。)
ちなみに設定していないとcmd>>> Question.objects.all() <QuerySet [<Question: Question object (1)>]>このような表示になります。
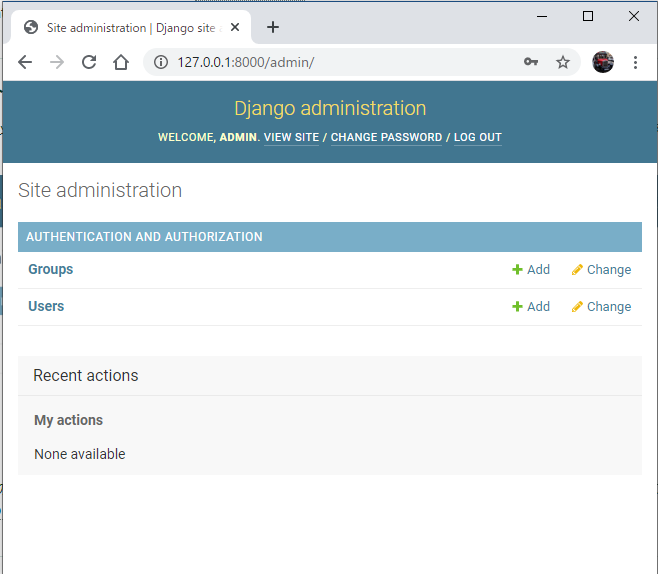
__str__()を設定しておくと見やすくなるのでいいですね。Django adminの紹介
※チュートリアルでは
__str__()メソッドの後にさらに対話シェルを用いていろいろとデータベースAPIの動作を試していますが、解説できないので割愛させていただきます。
Webサイトを作る上ではサイトの管理者というのは明確にしておく必要があります。
ということで管理者の作成をしていきます。cmd(Django) C:\User\mysite>python manage.py createsuperuser Username: <管理者ユーザー名> Email address: <管理者のメールアドレス> Password: <管理者サイトにログインするときに使用するパスワード> Password (again): <パスワードの確認> Superuser created successfully.これで管理者ユーザーの作成が終わったので、管理者サイトにはいってみましょう。(サーバーが
python manage.py runserverで立ち上がっている必要があります。)
127.0.0.1:8000/adminをブラウザに打ってみると以下のサイトが表示されます。
ここのUsernameとPasswordに先ほど設定したものを入れると以下の画面に入ります。
何にも設定を入れていなくてもすでにこれだけのGUI設定画面をDjango は提供してくれます。
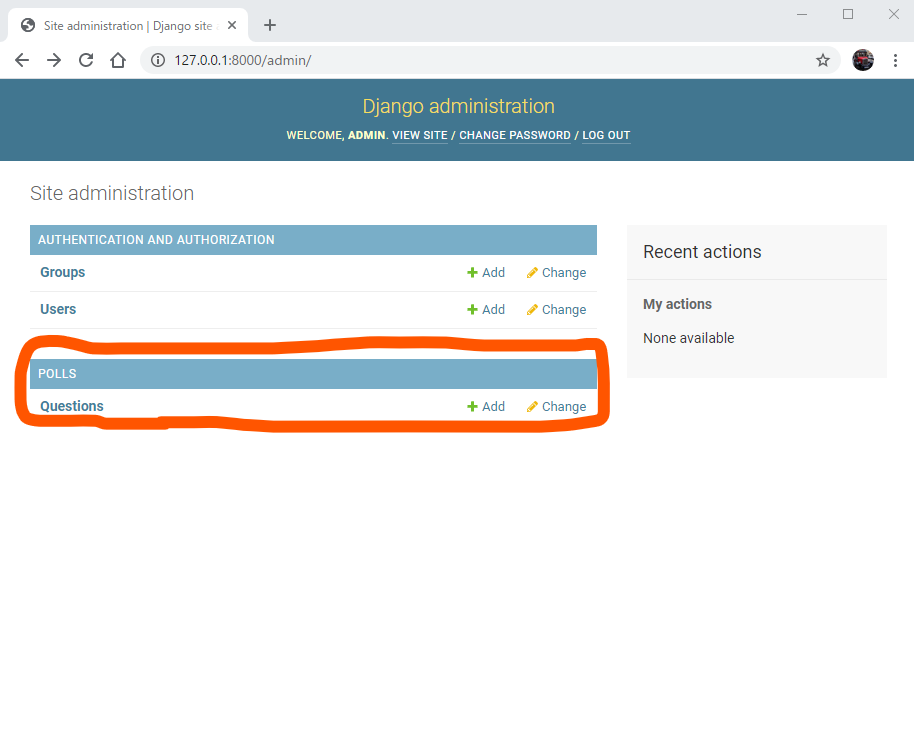
このサイト上でpollsアプリの存在を反映させるためにmysite/admin.pyをいじっていきます。mysite/polls/admin.pyfrom django.contrib import admin from .models import Question # Register your models here. admin.site.register(Question)こんな感じで書いたら再度管理者サイトにログインしてみましょう。
すると先ほどはなかったこの項目が現れました。
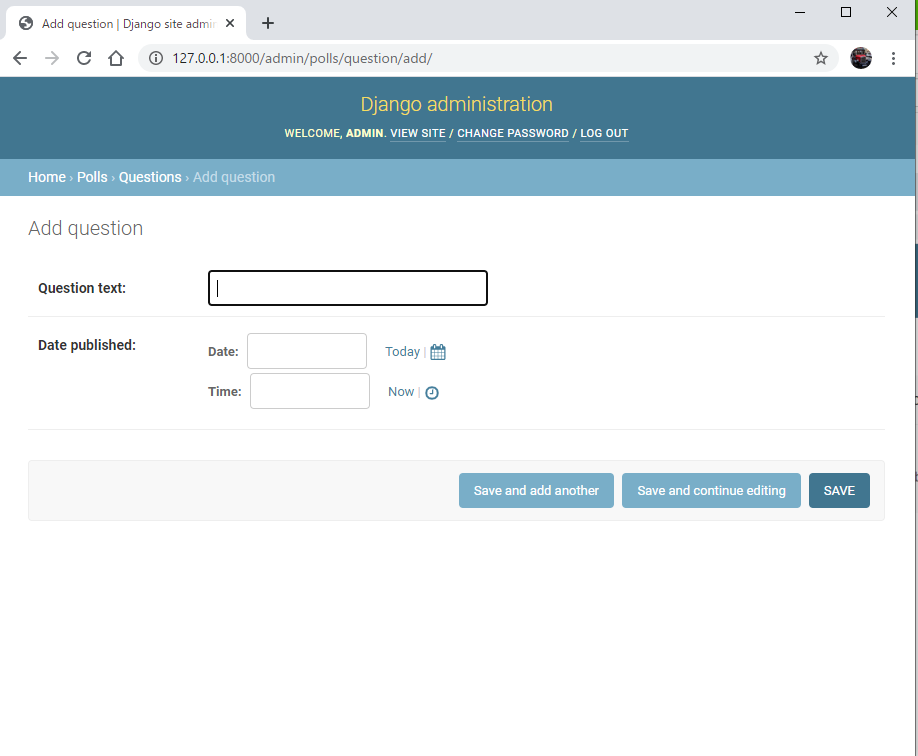
この項目のAddをクリックしてみると
こんな感じで、さっき対話シェルを使って設定したQuestionの追加がなんとブラウザ上でできるようになります。サイコー!!
にしても大した設定もしてないのにここまでのブラウザ場面を出してくれるなんて本当にDjangoは手厚いですね。ビューを書く
Adminについては一度終わり、ここからWebページの肝であるページビューの作成に入ります。
DjangoはMTVという考え方があります。MTVはModel、Template、Viewの頭文字をとったものです。
Djangoは
データベースと連携をとるModel、
htmlファイルのTemplate、
ModelとTemplateを組み合わせて画面を作るView
の以上3つが中心でで成り立っているというものです。ここまではModelを作成してきました。
ここからはViewを作っていきます。
まずはviews.pyに以下の部分を追加します。mysite/polls/views.pydef detail(request, question_id): return HttpResponse("You're looking at question %s." % question_id) def results(request, question_id): response = "You're looking at the results of question %s." return HttpResponse(response % question_id) def vote(request, question_id): return HttpResponse("You're voting on question %s." % question_id)ここでチュートリアル通りにやってるとあることに気づきます。
以下の文がすでに書かれているのです。mysite/polls/views.pydef index(request): return HttpResponse("こんにちは!")懐かしい!これは前回の最初のほうに書いたやつ!
ということは最初と同じように、この後urls.pyにルーティングを書いてなんやかんやするんだろうなーと予想がつきます。そしてそれは正解です。
urls.pyにviews.pyで作成したdetail,results,voteへのルーティングを足します。mysite/polls/urls.pyurlpatterns = [ path('', views.index, name='index'), #以下、追加分 path('<int:question_id>/', views.detail, name='detail'), path('<int:question_id>/results/', views.results, name='results'), path('<int:question_id>/vote/', views.vote, name='vote'), ]これらのルーティングは
polls/urls.pyに書いているため、開発サーバーでいえば127.0.0.1:8000/polls以下のpathになります。
pathの第一引数は.../polls/~としてつながるpathを示しています。
<int:question_id>は適当な数字を入れてよいですが、views.pyのdetailなどに渡されます。
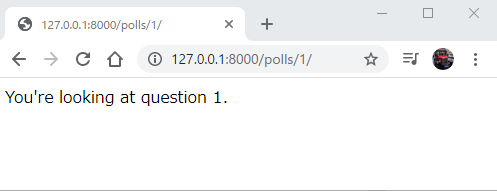
ということで127.0.0.1:8000/polls/1とすると以下のようになります。
このように...polls/1/の1がしっかりdetailに渡され反映されています。resultsとvoteも似たような感じになるので割愛。Templateづくり
続いてTemplateを作って
indexを改造していきます。
pollsファイルの下にtemplatesフォルダを作成します。そしてその下にさらにpollsフォルダを作ります。
ここでさらにpollsフォルダを作ります。このpollsフォルダは今後別のアプリを作ったときにDjangoがTemplateを区別できるようにするためです。
ファイルの階層構造としては
こんな感じです。そしてこの深いほうのpollsフォルダの下にhtmlを書きます。これを間違えるとのちの作業がすべて反映されないので注意!
それどころかエラーになります。(私はtemplatesの下にpollsフォルダ作り忘れて大変なことになりました。)mysite/polls/templates/polls/index.html{% if latest_question_list %} <ul> {% for question in latest_question_list %} <li><a href="/polls/{{ question.id }}/">{{ question.question_text }}</a></li> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %}このhtmlファイル、一般的なhtmlとちょっと違くないですか?
{%...%}?こいつです。こいつは「テンプレートタグ」と呼ばれるもので、if文・繰り返し文や変数のデータをhtmlで表現することができます。
あれ?なんかJavaScriptに似てね?それではこの
index.htmlを.../polls/で表示してくれるように`views.pyのindexにも設定を入れます。mysite/polls/views.py#追加 from .models import Question #以下差し替え def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] context = {'latest_question_list': latest_question_list} return render(request, 'polls/index.html', context)
models.pyからQuestionクラスをインポートする文の追加と既に書いてあるindex関数を以上の内容に書き換えます。
ここで登場するrenderはtemplateと使うデータを指定して画面を作ってくれます。めっちゃ有能ですこれ。
まだ使いこなすには時間がかかりそうですが、今後長い付き合いになりそうです。公式の解説はこちら以上が差分です
indexは本当にこのチュートリアルの中で何度も書き直されるので、うまくいかないときはここがおかしい時が結構ありました。エラー送出
チュートリアルでは一度
Http404を使ったエラー検知の方法を活用していますが、結果get_object_or_404を使うことになるのでここでは後者のほうのみ書きます。mysite/polls/views.py#以下追加文 from django.shortcuts import get_object_or_404 def detail(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'polls/detail.html', {'question': question})この差分を見ると
returnのところの返し方がHttpResponseからrenderに変わっています。ということでdetail.htmlが新たに書かれていますが、まだこのファイルを作っていないのでこれから作っていきます。mysite/polls/templates/polls/detail.html<h1>{{ question.question_text }}</h1> <ul> {% for choice in question.choice_set.all %} <li>{{ choice.choice_text }}</li> {% endfor %} </ul>htmlタグとDjangoのテンプレートタグ盛り盛りのコードになっていますね。
<あまりにも雑なタグ説明>
h1:タイトルタグ
ul:順序なしリスト
li:リストの項目
{{ 変数 }}:変数の展開
{% for ... %}:繰り返し文ハードコードの解消
ここもチュートリアルは寄り道しながら行っているので、ここでは最終的な差分のみ考えていこうと思います。
ここで問題となっているのは
index.htmlの以下のリンクを作っている部分mysite/polls/templates/polls/index.html<li><a href="/polls/{{ question.id }}/">{{ question.question_text }}</a></li>この
hrefのところで直接pathを打ってしまっているためコードを書き直したりするときに崩れやすくなってしまうなどのデメリットがあります。
ということで、これを{% urls 'polls:detail' question.id %}で置き換えて、urls.pyにapp_name = 'polls'を追加してうまいことやります。mysite/polls/templates/polls/index.html{% if latest_question_list %} <ul> {% for question in latest_question_list %} <li><a href="{% url 'polls:detail' question.id %}">{{ question.question_text }}</a></li> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %}
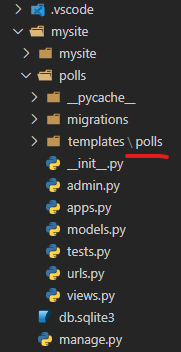
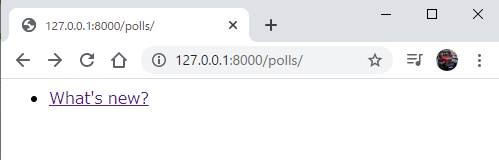
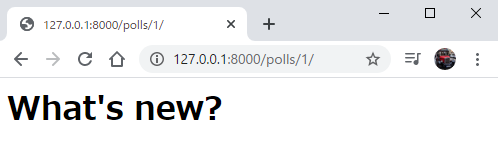
index.htmlがこのようになっていれば、大丈夫です。
127.0.0.1:8000/polls/
127.0.0.1:8000/polls/1/
まーた長くなったのでここでまた切ります。
ありがとうございます。
- 投稿日:2020-08-10T20:56:45+09:00
pipの依存関係チェックが厳しくなる
はじめに
これもPython Bytesポッドキャストを聴いていて知ったのですが、pipがモジュールインストール時に行う依存性チェックが厳しくなるみたいです。気にしないでいるとある日突然 pip をバージョンアップした途端に依存しているパッケージをインストールできなくなるかも知れないです。どう変わるのか、そしてそれに備えて何ができるのかを書いておこうかと思います。
pipの新しい依存関係チェッカー
あまり意識していませんでしが、これまでのpipでは依存関係に矛盾のあるパッケージをインストールできてしまっていました。pipの新しい依存性チェッカー (2020-resolver)ではこれを許さなくなります。
例えば、
virtualenvパッケージ(version 20.0.2)はsix>=1.12.0, <2という依存関係が設定されています。「sixのv1.12.0以上かつv2未満」ということですが、意図的にその依存関係を壊す形でのインストールを試みることができます。pip install "six<1.12" "virtualenv==20.0.2"これをpipのv20.0.1以前のバージョンで実行するとこのようになります。
$ pip install "six<1.12" "virtualenv==20.0.2" pip install "six<1.12" virtualenv==20.0.2 Collecting six<1.12 Using cached six-1.11.0-py2.py3-none-any.whl (10 kB) Collecting virtualenv==20.0.2 Using cached virtualenv-20.0.2-py2.py3-none-any.whl (4.6 MB) Collecting distlib<1,>=0.3.0 Using cached distlib-0.3.1-py2.py3-none-any.whl (335 kB) Collecting appdirs<2,>=1.4.3 Using cached appdirs-1.4.4-py2.py3-none-any.whl (9.6 kB) Collecting filelock<4,>=3.0.0 Using cached filelock-3.0.12-py3-none-any.whl (7.6 kB) ERROR: virtualenv 20.0.2 has requirement six<2,>=1.12.0, but you'll have six 1.11.0 which is incompatible. Installing collected packages: six, distlib, appdirs, filelock, virtualenv Successfully installed appdirs-1.4.4 distlib-0.3.1 filelock-3.0.12 six-1.11.0 virtualenv-20.0.2メッセージ中では ERROR と出ていますが、インストール自体はできてしまっています。見逃してしまう可能性がありますね。
これが v20.0.2からはこうなります。
pip install "six<1.12" virtualenv==20.0.2 Collecting six<1.12 Using cached six-1.11.0-py2.py3-none-any.whl (10 kB) Collecting virtualenv==20.0.2 Using cached virtualenv-20.0.2-py2.py3-none-any.whl (4.6 MB) Collecting appdirs<2,>=1.4.3 Using cached appdirs-1.4.4-py2.py3-none-any.whl (9.6 kB) Collecting distlib<1,>=0.3.0 Using cached distlib-0.3.1-py2.py3-none-any.whl (335 kB) Collecting filelock<4,>=3.0.0 Using cached filelock-3.0.12-py3-none-any.whl (7.6 kB) Installing collected packages: six, appdirs, distlib, filelock, virtualenv ERROR: After October 2020 you may experience errors when installing or updating packages. This is because pip will change the way that it resolves dependency conflicts. We recommend you use --use-feature=2020-resolver to test your packages with the new resolver before it becomes the default. virtualenv 20.0.2 requires six<2,>=1.12.0, but you'll have six 1.11.0 which is incompatible.エラーメッセージが変わっています。
- 2020年10月以降にpipの挙動が変わるのでパッケージのインストールやアップグレードのときにエラーになってしまうかも
--use-feature=2020-resolverオプション付きで実行して、新しいリゾルバーがデフォルトになる前に試してみて。ということで、そのオプション付きで実行してみます。
$ pip install --use-feature=2020-resolver "six<1.12" virtualenv==20.0.2 Collecting virtualenv==20.0.2 Using cached virtualenv-20.0.2-py2.py3-none-any.whl (4.6 MB) ERROR: Cannot install six<1.12 and virtualenv 20.0.2 because these package versions have conflicting dependencies. The conflict is caused by: The user requested six<1.12 virtualenv 20.0.2 depends on six<2 and >=1.12.0 To fix this you could try to: 1. loosen the range of package versions you've specified 2. remove package versions to allow pip attempt to solve the dependency conflict ERROR: ResolutionImpossible: for help visit https://pip.pypa.io/en/latest/user_guide/#fixing-conflicting-dependencies依存関係が満たせないのでインストールできなくなっています。これが将来のpipの動作になります。
導入のスケジュール
新しい依存関係チェッカーは以下のスケジュールで導入されます。
バージョン 導入時期 動作 20.2 導入済み デフォルトでは既存の依存関係チェッカー(リゾルバー)が使われますが、 --use-feature=2020-resolverオプションで新しいリゾルバーを使えます。20.3 2020年10月 デフォルトで新しいリゾルバーを使うようになります。 --use-deprecated=legacy-resolverオプションで以前のリゾルバーを使えます。21.0 未定 新しいリゾルバーのみを使えます(古いリゾルバーは消去) 今、何をしたら良いのか
- pipを最新の 20.2にする
--use-feature=2020-resolverオプション付きでpipを使うこれで将来のバージョンの動作を先取りできます。これで10月になって慌てなくて良くなりますが、特に
pip install -r requirements.txtあるいはinstall -c constraints.txtを使ってバージョン指定している場合に効果があります。というのも、これまでのバージョンの pipでpip freezeして作った requirements.txt あるいは constraints.txt には依存関係が矛盾した状態で書き出されているかも知れず、それを事前にチェックできるということです。一々オプション指定するのが面倒という方は、
~/.config/pip/pip.confに[install] use-feature=2020-resolverと書いておくと自動でつけてくれます。将来、バージョンが上がったときに消すのを忘れないようにしないとですが。
まとめ
pipの依存関係チェックの動作が変わるのでそれについて書いてみました。pythonのパッケージ管理は Poetryとかpipenvとかありますが、本家のpipも独自に進化しているんですね。また気になる機能追加があったら書いてみたいと思います。
- 投稿日:2020-08-10T20:47:02+09:00
Pythonのargparseで「'required' is an invalid argument for positionals」が出たら、requiredを消せばいい
ドキュメントが少し分かりづらかったのでメモ。
起動時の引数を便利に扱えるargparseモジュール
Pythonには、起動時の引数を便利に扱えるargparseモジュールがあります。
位置引数とオプション引数
argparseで扱う引数には以下の2種類があります。
- 位置引数(infile1など)
- オプション引数(-fや--barなど)(=フラグ) (公式ドキュメントのargparseの「name または flags」に書かれています)
add_argument()メソッド
どんな引数を指定できるかを
add_argument()メソッドで指定できますが、位置引数が必須だからとargument.add_argument( 'infile1', required=True, help='input file' )のように書いてしまうと、実行時に「
'required' is an invalid argument for positionals」とエラーになり実行できません。「
required」はオプション引数のみに指定できる「
required」はオプション引数に対する指定なため、位置引数に指定するとエラーになります。
もともと位置引数は必須なため、該当オプションの「required=True」を消せば、想定した動作になります。
- 投稿日:2020-08-10T20:45:12+09:00
One-Touch SearchをPython3.7.3で再現する(Windows10)
One-Touch Searchって何?
ハイライトした文字列をボタンワンクリックでgoogle検索してくれる機能です。
LogicoolのM950というマウスに搭載されている便利機能です。
今回Pythonで再現した理由は、この便利な機能が次の世代のマウスからなくなってしまったからです。余談ですが、この機能が便利すぎて離れられないためにM950を9年近く使い続けています。途中チャタリングに悩まされましたが、分解して修理して使い続けるくらい便利な機能です。
プログラムの大枠
- Pythonでスクリプトを書く。
- 1をbatファイルで起動できるようにする。
- 2のショートカットを作成し、ショートカットキーで起動させる。
1. Pythonのスクリプト
import webbrowser import pyautogui import pyperclip import time pyautogui.hotkey('alt', 'tab') time.sleep(0.03) pyautogui.hotkey('ctrl', 'c') time.sleep(0.03) clipboard = pyperclip.paste() url = 'https://www.google.co.jp/search?hl=ja&q=' + clipboard webbrowser.open(url)流れとしては、
1. pyautoguiでキーボード入力を行い、ハイライトした文字列をコピー。
2. pyperclipでクリップボードの内容を'clipboard'読み取る。
3. 'url= 'の行でgoogleでの検索用の'url'を作成。
4. webbrowserで標準ブラウザで'url'にアクセス
です。
time.sleep()の部分では、これを入れないと私の環境ではうまくコピーができなかったため入れました。
※ここで作成した.pyファイルにスペースを含めないように注意してください。2. batファイルの作成
任意の場所にbatファイルを作成します。
まずは 右クリック>新規作成>テキストドキュメント を行ってください。
テキストの内容はpython.exeへのパス(半角スペース)1で作成した.pyへのパス
です。
その後、このテキストファイルの拡張子を.txtから.batに変更してください。
その際に表示される警告は無視して構いません。3. batのショートカットを作成し、ホットキーで実行できるようにする。
- 2で作成した.batファイルを右クリックして、「ショートカットの作成」を選択して下さい。
- できたショートカットを右クリックして「プロパティ」を選択して下さい。
- 「ショートカット」のタブを選択し「ショートカットキー」を選択した後、任意のキーの組み合わせ*を押して下さい。
- 「実行時の大きさ」を「最小化」にすると見栄えが良くなります。
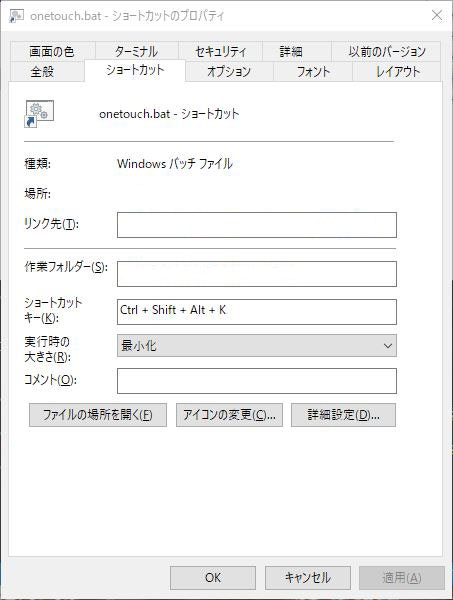
これで出来上がりです。
例ではonetouch.batというファイルを作成し、「Ctl + Shift + Alt + K」でショートカットキーを設定しました。
任意の文字列をハイライトして、3で設定したショートカットキーを押してみて下さい。うまく行けば、google検索できるはずです。
このショートカットキーをマウスのボタンに割り当てればマウスのボタンを押すだけで検索ができます。問題点
- ハイライトした文字列の始まりが「#」だとうまく検索できない。
- 純正のOne-Touch Searchより若干遅い。
- 投稿日:2020-08-10T19:32:26+09:00
4x4x4ルービックキューブを解くプログラムを書こう! 1.概要
この記事はなに?
私は現在4x4x4ルービックキューブ(ルービックリベンジ)を解くロボットを作り、世界記録を目指しています。ロボットを作る上で一番のハードルであったのが4x4x4キューブを現実的な時間に、なるべく少ない手数で解くアルゴリズムを実装することです。
調べてみると4x4x4については文献や先人が少ないことがわかると思います。そんな貴重な資料の一つになれば嬉しいと思い、この記事を書いています。
この記事の内容は完全ではありません。一部効率の悪いところを含んでいるかもしれません。今後改良したら随時追記していきます。↓競技用4x4x4ルービックキューブとプログラム制作のために番号を振られた競技用4x4x4ルービックキューブ
全貌
この記事集は全部で3つの記事から構成されています。
1. 概要(本記事)
2. アルゴリズム
3. 実装この記事で話すこと
この記事では4x4x4ルービックキューブを(探索アルゴリズムを使って)解くプログラムを書くために必要な知識の紹介、およびプログラムの流れを軽くお話しします。
参考になる資料
参考となる資料を私が参考になったと感じる順番に紹介します。
- https://arxiv.org/abs/1601.05744
- https://github.com/cs0x7f/TPR-4x4x4-Solver
- http://cubezzz.dyndns.org/drupal/?q=node/view/525
- http://cubezzz.dyndns.org/drupal/?q=node/view/73
最初の資料は4x4x4キューブについて私が唯一見つけられた論文です。2つ目は実際に論文と似た手法でJavaを使って実装したレポジトリです。こちらも唯一の実装例として見つかりました。3つ目は2つ目のレポジトリの持ち主による投稿です。4つ目は謎ですが一応見つかった投稿です。
この記事を読むのに必要な知識
この記事を読むのに必要な知識とその入手方法を書いておきます。
回転記号
ルービックキューブの回転を客観的に正確に表す記号です。参考資料としてこちらをおすすめします。3x3x3についての回転記号の説明ですが、4x4x4も全く同じ記号を使います。
面の名前
回転記号で出てきた
R, L, U, D, F, Bは、面の名前としても使われます。例えばF面と言えば正面の面を表します。パーツの名前
4x4x4ルービックキューブの外側に出ているパーツには3種類あります。画像の通りです。
コーナーには3つ、エッジには2つ、センターには1つのステッカーがついています。パーツの位置の表し方
パーツの位置について、またしても回転記号で出てきた
R, L, U, D, F, Bを使います。エッジとコーナーで表し方が違うので別々に紹介します。エッジ
エッジは当たり前ですが必ず2つの面にまたがっています。そこで、エッジを
R, L, U, D, F, Bのうちからまたがっている面2つを取ってきて並べて表します。例えばUFエッジと言えば、U面とF面にまたがったエッジです。コーナー
コーナーは必ず3つの面にまたがっています。そこで
R, L, U, D, F, Bのうちからまたがっている面3つを取ってきて並べて表します。例えばUFRコーナーと言えば、U面、F面、R面にまたがったコーナーです。パリティ
4x4x4ルービックキューブには特有の「パリティ」と呼ばれる状態があります。パリティには2種類ありますが、こちらの説明がわかりやすいです。なお、こちらのサイトではPLLパリティの説明が少しわかりにくいですが、要するにエッジのみの2点交換(3x3x3ルービックキューブで2点交換はありえません)の状態です。図にOLLパリティとPLLパリティの例を載せておきます。左がOLLパリティ、右がPLLパリティです。見えていない面は全部揃っています。
CP, CO, EP, EO
それぞれ
- Corner Permutation (コーナーパーツの位置)
- Corner Orientation (コーナーパーツの向き)
- Edge Permutation (エッジパーツの位置)
- Edge Orientation (エッジパーツの向き)
のことです。4x4x4キューブを構成する各パーツは、エッジとコーナーは位置と向き、センターは位置のみで一意に状態が表せます。
ベースとなるアルゴリズム
4x4x4ルービックキューブを探索で解くのはそう簡単ではありません。なにせ探索すべき木(このへんの用語や基礎知識はこちらの記事にわかりやすくまとめました)が大きすぎます。そこで、あるアルゴリズムがよく使われます。紹介した資料、および私による実装はすべてTsai's Algorithmというアルゴリズムがベースになっています。流れを説明しましょう。
なお、「使う回転」で例えばX回転を使うと書いてあったら実際に使う回転はX, X'の2種類です。そしてX2回転を使うと書いてあれば実際に使うのはX2のみです。
わからない言葉や表現があると思います。次の記事で各フェーズの詳しい解説をするときに説明しますのでここではふーんと言って流してください。
フェーズ番号 やること 使う回転 0 R面とL面のセンターパーツをすべてR面かL面に持ってくる R, R2, Rw, Rw2, L, L2, U, U2, Uw, Uw2, D, D2, F, F2, Fw, Fw2, B, B21 1. F面とB面のセンターパーツをすべてF面かB面に持ってくる 2. ハイエッジとローエッジを分離する 3. R面とL面のセンターの状態を今後処理可能な12の状態のうちの一つにする 4. OLLパリティを解消する R, R2, Rw, Rw2, L, L2, U, U2, Uw2, D, D2, F, F2, Fw2, B, B22 1. 側面( F, R, B, L面)センターに「列」を作る 2. 側面に位置するエッジのペアリングを行うR2, Rw2, L2, U, U2, Uw2, D, D2, F, F2, Fw2, B, B23 1. センターを6面完成させる 2. 残りのエッジをペアリングする 3. PLLパリティを解消する R2, Rw2, L2, U, U2, Uw2, D, D2, F2, Fw2, B24 1. U面とD面にあるべきステッカーをU面またはD面に持ってくる 2. EOを解消する R, L, U, U2, D, D2, F, B5 完成させる R2, L2, U, U2, D, D2, F2, B2まとめ
この記事では4x4x4ルービックキューブを解くプログラムを書くにあたって必要な知識の軽い解説とどのように4x4x4ルービックキューブを解くのかという概要を説明しました。



- 投稿日:2020-08-10T19:23:42+09:00
ベイズ推論用ライブラリー・・PyMC3での変数の設定
PythonのPyMC3の解説
「Pythonで体験するベイズ推論」から、
PyMC3での変数の設定の方法を解説する。第2章の2.1の
PyMC2の内容をPyMC3用に若干変更しています。変数について
PyMC3では、Modelオブジェクト内で必要なすべての変数を処理します。import pymc3 as pm with pm.Model() as model: parameter = pm.Exponential("poisson_param", 1.0) data_generator = pm.Poisson("data_generator", parameter) with model: data_plus_one = data_generator + 1 with pm.Model() as model: theta = pm.Exponential("theta", 2.0) data_generator = pm.Poisson("data_generator", theta) with pm.Model() as ab_testing: p_A = pm.Uniform("P(A)", 0, 1) p_B = pm.Uniform("P(B)", 0, 1) print("parameter.tag.test_value =", parameter.tag.test_value) print("data_generator.tag.test_value =", data_generator.tag.test_value) print("data_plus_one.tag.test_value =", data_plus_one.tag.test_value) #parameter.tag.test_value = 0.6931471824645996 #data_generator.tag.test_value = 0 #data_plus_one.tag.test_value = 1変数には親変数と子変数がある。
親変数は他の変数に影響を与える変数で、子変数は他の変数から影響を受ける変数である。この場合、
parameterは、data_generatorの親変数である。逆にdata_generatorはparameterの子変数である。
すでに作成したモデルオブジェクトの名前(model)で「with」を使用することにより、同じモデル内で変数を作ることができます。
またPyMC変数は値を持っている。もし変数が子変数であれば親変数が変われば、子変数の値も変わる。
PyMC3変数には初期値(つまり、テスト値)があります。****.tag.test_valueで初期値が得られます。test_valueは、開始位置が指定されていない場合のサンプリングの開始点として使用されます。2つの変数(確率的変数と決定的変数)
PyMC3は、確率的(stochhastic)および決定的(deterministic)という2つの変数があります。確率的変数(stochhastic)は、決定的でない変数である。つまり、この変数の親変数の値を知っていても、この変数は依然としてランダムである。このカテゴリーに属するクラスには、Poisson(ポアソン分布)、DiscreteUniform(一様分布)、およびExponential(指数分布)がある。
決定的(deterministic)変数は、親変数の値がわかっていたら、その値が決まる変数である。
一瞬紛らわしいと感じるがこのように考えましょう。「変数fooの親変数がすべてわかった時にそのfooの値が決まるか?」もし値が決まるなら、そのfooは決定的変数である。確率的変数の初期化
確率変数またはランダム変数を初期化するための第1引数は、変数の名前を表す文字列で、第2引数以降にクラス固有の追加引数を渡すことができます。
some_variable = pm.DiscreteUniform( "discrete_uni_var"、0、4)これは、DiscreteUniform(一様分布)クラスで、
discrete_uni_varが変数の名前で、0と4は、確率変数が取りえる上限と下限である。引数に渡す名前は、事後分布を作時に必要になるので、できるだけわかりやすい方がよい。
また、多くの変数を使う問題の時は、shape引数を使います。モデル化したい多くの変数$??、?= 1、...、?$が存在するという時に便利です。次のようにそれぞれに任意の名前と変数を作成する代わりにbeta_1 = pm.Uniform( "beta_1"、0、1) beta_2 = pm.Uniform( "beta_2"、0、1)次のように一つの変数で作ることができる。
betas = pm.Uniform( "betas"、0、1、shape = N)確定的変数の初期化
確率変数を作成する方法と同様に、確定変数を作成できます。
PyMC3でpm.Deterministicクラスを呼び出し、必要な引数を渡すだけです。deterministic_variable = pm.Deterministic( "deterministic variable"、some_function_of_variables)これで、決定的変数を作成することができます。
with pm.Model() as model: lambda_1 = pm.Exponential("lambda_1", 1.0) lambda_2 = pm.Exponential("lambda_2", 1.0) tau = pm.DiscreteUniform("tau", lower=0, upper=10) new_deterministic_variable = lambda_1 + lambda_2これは、ベイズ推論の考え方(3)・・pymc3による実際の計算で使ったスクリプトです。
このように加減などの演算子を使った計算をしたものは暗黙的に決定的変数になります。つまり
new_deterministic_variableは決定的変数です。\lambda = \begin{cases}\lambda_1 & \text{if } t \lt \tau \cr \lambda_2 & \text{if } t \ge \tau \end{cases}theanoとは
どうも
theanoとは、昔のディープラーニング用のライブラリーのようです。PyMC3のバックエンドで計算しています。でも、PyMC4では、tensorflowがバックエンドになったようなので、この勉強限りのお付き合いですので、あまり気にしないようにしましょう。モデルに観測を組み込む
ここまでで、変数の設定。つまり事前分布の指定が完了している。
つまりλの形とかも表すことができます。つまり、ベイズ推論の考え方(2)・・ベイズ推定と確率分布でのベイズの定理の$P(A)$を決定したことになる。これに、データ(あるいは証拠、観測等)である$X$をモデルに組み込むことを行う。
- 投稿日:2020-08-10T19:09:54+09:00
インスタから猫の画像を検出したい
1. はじめに
Aidemy研修生のATcatです。皆さんはInstagramを使うことはありますか?僕はインスタを使って猫の画像をよく眺めることがあるのですが、猫の画像を探してる最中に下の図ように猫の画像以外も混じってしまうことがよくあります。そこで猫の画像だけみたい私は、インスタ側のシステムを変更することは難しいですし、専用のアプリケーションを作成するには時間が足りないので、インスタで”猫”とされている画像を取得して猫の画像のみを抽出できるようなシステムを作ってみました。
2. 物体検出
今回猫の画像を抽出するために物体検出を用いたのですが、この物体検出という技術について簡単に説明します。
画像中の着目したい物体があるとき,画像全体における特徴から何が写っているかのみを識別する技術を画像認識といいますが、物体検出では、どこに何が写っているかまでを識別する技術です。つまり、画像中に含まれる物体について物体中注目すべき物体が何であるかということと、その物体がどこにあるのかまで特定し、バウンディングボックスという矩形によって表すものです。セマンティックセグメンテーションという技術もありますが、これはピクセルごとに分類するものでより複雑なものとなります。
今回はGoogleの事前学習済みモデルを用いての実装を行いましたが、理由として一からモデルを構築し学習するにはデータセットの用意や学習時間、適切なクラス数の設定などに膨大な時間がかかることから、業界では事前学習済みモデルを利用されることが非常に多いためです。3. 事前準備
まずは、インスタから猫の画像を集めるために#猫と#catのハッシュタグから画像収集を行うことにしました。その際、Instagram ScraperというAPIを用いて行いました。
pip install instagram-scraperとしてまずpipでインストールを行います。
Instagram Scraperでは特定のユーザーの投稿を取得することや指定したハッシュタグで投稿されている画像や動画を取得することができます。
今回は次のように実行しました。insta.sh#!/bin/sh instagram_login_user='' # あなたのユーザーネーム instagram_login_pass='' # あなたのパスワード target_tag='cat' #スクレイピング対象のタグ instagram-scraper \ --login_user $instagram_login_user \ --login_pass $instagram_login_pass \ --tag $target_tag \ --media-types image \ #取得するデータタイプの指定 --maximum 100 \ #取得するデータの最大数 --latest \ #最後にスクレイピングしたところから始める取得する数を200として設定しました。
このように画像が取得できました。4. 実装
次に取得した画像を物体検出によって猫であるかを判別します。
ここではGoogleの事前学習済みモデルであるFaster R-CNNとSSDをTensorflow Hubを通してGoogle Colaboratoryを利用して実装を行いました。今回下記のサイトを参考に実装しました。
https://qiita.com/code0327/items/3b23fd5002b373dc8ae8ここでの流れとしては、事前学習済みモデルをTensorflow Hubを通して取得して定義し、インスタで取得した猫の画像に対して物体検出を行います。その後猫を検出した場合にのみ検出結果を示す画像を出力するようにします。
まず、インポートと学習済みモデルの選択をします。
# For running inference on the TF-Hub module. import tensorflow as tf import tensorflow_hub as hub import os import glob import time import numpy as np import matplotlib.patheffects as pe import matplotlib.pyplot as plt import tempfile from six.moves.urllib.request import urlopen from six import BytesIO import numpy as np from PIL import Image from PIL import ImageColor from PIL import ImageDraw from PIL import ImageFont from PIL import ImageOps #SSDかFaster R-CNNを選択 #module_handle = 'https://tfhub.dev/google/openimages_v4/ssd/mobilenet_v2/1' module_handle = 'https://tfhub.dev/google/faster_rcnn/openimages_v4/inception_resnet_v2/1' detector = hub.load(module_handle).signatures['default']物体検出を行った結果の画像化は次のようにします。
def showImage(img, r, imgfile, min_score=0.1): fig = plt.figure(dpi=150,figsize=(8,8)) ax = plt.gca() ax.tick_params(axis='both', which='both', left=False, labelleft=False, bottom=False, labelbottom=False) ax.imshow(img) decode = np.frompyfunc( lambda p : p.decode("ascii"), 1, 1) boxes = r['detection_boxes'] scores = r['detection_scores'] class_names = decode( r['detection_class_entities'] ) n = np.count_nonzero(scores >= min_score) # class_names に対応した 色の準備 class_set = np.unique(class_names[:n]) colors = dict() cmap = plt.get_cmap('tab10') for i, v in enumerate(class_set): colors[v] =cmap(i) # 矩形を描画 スコアが低いものから描画 img_w = img.shape[1] img_h = img.shape[0] for i in reversed(range(n)): text = f'{class_names[i]} {100*scores[i]:.0f}%' color = colors[class_names[i]] y1, x1, y2, x2 = tuple(boxes[i]) y1, y2 = y1*img_h, y2*img_h x1, x2 = x1*img_w, x2*img_w # 枠 r = plt.Rectangle(xy=(x1, y1), width=(x2-x1), height=(y2-y1), fill=False, edgecolor=color, joinstyle='round', clip_on=False, zorder=8+(n-i) ) ax.add_patch( r ) # タグ:テキスト t = ax.text(x1+img_w/200, y1-img_h/300, text, va='bottom', fontsize=6, color=color,zorder=8+(n-i)) t.set_path_effects([pe.Stroke(linewidth=1.5,foreground='white'), pe.Normal()]) fig.canvas.draw() r = fig.canvas.get_renderer() coords = ax.transData.inverted().transform(t.get_window_extent(renderer=r)) tag_w = abs(coords[0,0]-coords[1,0])+img_w/100 tag_h = abs(coords[0,1]-coords[1,1])+img_h/120 # タグ:背景 r = plt.Rectangle(xy=(x1, y1-tag_h), width=tag_w, height=tag_h, edgecolor=color, facecolor=color, joinstyle='round', clip_on=False, zorder=8+(n-i)) ax.add_patch( r ) #保存 plt.savefig('/content/save/'+imgfile) plt.close()min_score以上の信頼度を出したものに対して矩形によって囲みローカライズするようにしています。
最後に検出を行う関数の定義を行います。
import time import numpy as np import PIL.Image as Image def run_detector(detector, path,img_file): # 画像を読み込んで detector に入力できる形式に変換 img = Image.open(path+img_file) # Pillow(PIL) if img.mode == 'RGBA' : img = img.convert('RGB') converted_img = img.copy() converted_img = converted_img.resize((227,227),Image.LANCZOS) # 入力サイズに縮小 converted_img = np.array(converted_img, dtype=np.float32) # np.arrayに変換 converted_img = converted_img / 255. # 0.0 ~ 1.0 に正規化 converted_img = converted_img.reshape([1,227,227,3]) converted_img = tf.constant(converted_img) t1 = time.time() result = detector(converted_img) # 一般物体検出(本体) t2 = time.time() print(f'検出時間 : {t2-t1:.3f} 秒' ) # 結果をテキスト出力するための準備 r = {key:value.numpy() for key,value in result.items()} boxes = r['detection_boxes'] scores = r['detection_scores'] decode = np.frompyfunc( lambda p : p.decode('ascii'), 1, 1) class_names = decode( r['detection_class_entities'] ) # スコアが 0.25 以上の結果(n件)についてテキスト出力 print(f'検出オブジェクト' ) n = np.count_nonzero(scores >= 0.25 ) for i in range(n): y1, x1, y2, x2 = tuple(boxes[i]) x1, x2 = int(x1*img.width), int(x2*img.width) y1, y2 = int(y1*img.height),int(y2*img.height) t = f'{class_names[i]:10} {100*scores[i]:3.0f}% ' t += f'({x1:>4},{y1:>4}) - ({x2:>4},{y2:>4})' print(t) #猫を検出したとき出力 if "Cat" in t: showImage(np.array(img), r, img_file,min_score=0.25) # 検出結果を画像にオーバーレイ return t2-t1今回は特に猫を検出した場合に出力するようにしたいので、"Cat"のクラスが検出された場合に画像が出力されるようにしました。
5. 結果
今回の結果としてFaster R-CNNで行った結果は100枚中73枚検出して出力を行っていました。両方で検知できた例がこちらになります。
この図で左側がSSDの結果,右側がFaster R-CNNの結果となります。検出にかかった時間はSSDが平均0.23秒、Faster R-CNNが平均1.30秒でした。
また、SSDの方は74枚という結果でした。枚数は近いのですが,猫と検出した画像でかぶっていないものが意外と多く検出方法による画像の得意不得意があるということがよくわかったと思います。どちらの結果もほとんど猫以外の画像が含まれていなかったので猫の画像のみを拾ってくるという点では成功したと言えるでしょう。猫ではないのに取得してしまった例として次のような画像がありました。
一覧でみたら猫かと思ったのですがよく見ると犬でした。
また、猫と検出した画像の中でも珍しいのが絵の猫を検出しているものでした。絵の猫でも検出できるというのはなかなか面白いと思いましたが、絵の猫と本物の猫の判別となるとそこでの学習が必要になるのでクラスの設定も難しそうです。
まとめ
猫の画像を検出してそれ以外の画像を拾わないようにすることができました。しかし、それぞれの検出法では漏れがあることがわかったので、今後は両方を併用しての取得や、今流行りのDETRやYOLOv5を利用しての物体検出を実装して割り出すものやセマンティックセグメンテーションで画像中の猫の部分のみ抽出できるようなシステムづくりも挑戦してみたいと思います。
最後までお付き合いいただきありがとうございました!参考にしたサイト
https://qiita.com/code0327/items/3b23fd5002b373dc8ae8
https://github.com/arc298/instagram-scraper
https://githubja.com/rarcega/instagram-scraper





- 投稿日:2020-08-10T19:04:01+09:00
Ubuntuでお手軽に機械学習(Python)の環境構築
はじめに
何番煎じかはわかりませんが、Ubuntuに新規で機械学習(Python)環境を構築した際のメモを残します。
システム(Ubuntu)にプリインストールされているPythonを用いて、最小限のインストールでお手軽に環境構築したい方向けです。
環境:Ubuntu 20.04 LTSPython, pip, venvのインストール
Ubuntu 20.04 LTSの通常ディストリビューションであれば、Python3はプリインストールされているはずです。
念のため、ターミナルに以下を入力し、確認しておきます。ターミナルpython3 -V Python 3.8.2 # インストールされていない場合 sudo apt install python3次に、各種ライブラリのインストールに必要となるpipをインストールします。
ターミナルsudo apt install python3-pip # インストールの確認 pip3 --versionシステムで使用しているPythonにライブラリを直でインストールすることは、最悪システムを壊してしまうこともあり、おすすめできません。
そこで、仮想環境を構築し、ライブラリのインストールがシステムの依存環境などに影響を与えないようにします。
UbuntuプリインストールのPythonでvenvを使用するには下記インストールが必要になります。ターミナルsudo apt install python3-venv仮想環境の作成と有効化
ライブラリをインストールする前に仮想環境を作成しておきます。
ターミナル# ホームディレクトリ内.venvフォルダにMLという仮想環境を作成 python3 -m venv .venv/ML下記を実行し、作成した仮想環境を有効化します。
ターミナルcd .venv/ML source bin/activate # 無効化する際は下記を実行 deactivateライブラリのインストール
仮想環境内にライブラリをインストールしていきます。
下記はscikit-learn, matplotlib, pandasを一括でインストールする例です。ターミナルpip3 install -U scikit-learn ,matplotlib, pandas※Matplotlibでプロットの表示
plt.show()をした際に下記のようなエラーが出る場合があります。UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure.
Python上でUIの描画に必要なTkinterがインストールされていないためです。
合わせてインストールしておくといいです。ターミナルsudo apt install python3-tk以上で環境構築は終了です。
追記
VSCodeでコーディングする場合は、先ほど作成した仮想環境をデフォルトのインタプリタに設定しておくと便利です。
Settings.jsonに下記を追加しておくと、自動的に仮想環境を有効化してプログラムを実行してくれます。Settings.json"python.defaultInterpreterPath": "/home/$USERNAME/.venv/ML/bin/python3",
- 投稿日:2020-08-10T18:50:20+09:00
Pythonで処理にかかった時間を表示する簡単な方法とそれを改良したスマートな方法
よく使うけどよく忘れるので覚えるためにアウトプット
初学者向けに易しく書いたつもりです忙しい方へ
Githubに関数の処理時間を表示するデコレータを公開しています
pipでインストールしてimportして処理時間を計測したい関数にデコレータを付けるだけ!
ぜひ使ってください本題:簡単(だが残念?)な方法
Python標準装備のtime.time()を使う
time.time()は現在のUNIXタイムを浮動小数点数で返すので処理前と処理後の時間の差分をとってやれば良いmain.pyimport time start = time.time() # 開始時刻を記録 """ 時間を計測したい処理を書く """ end = time.time() # 終了時刻を記録 proc_time = end - start # 処理時間を計算 print(f"process took {proc_time} seconds") # 処理時間を表示ただこれだと
- 計測が必要・不要になる度コードを複数行書き換える必要がある
- 計測したい処理が増えるとそれに比例してコード書き換えの手間も増える
ちょっと残念?
デコレータを使ってスマートに改良
↑のコードを関数の処理時間を計測するデコレータに作り替えてよりスマートに
mytools.pyimport time from functools import wraps def fntime(fn) : @wraps(fn) def wrapper(*args, **kwargs) : start = time.time() result = fn(*args, **kwargs) end = time.time() proc_time = end - start print(f"function:{fn.__name__} took {proc_time} seconds") return result return wrapper(´-`).。oO(今はしませんがデコレータの解説はいつかやりたい...)
main.pyfrom mytools import fntime @fntime def my_process() : """ 計測したい処理 ↓処理の例 """ sum = 0 for i in range(100000000) : sum += i my_process() # 計測したい処理を実行これら二つのファイルを同じディレクトリに置いて
main.pyを実行するとTerminal$ python main.py function:my_process took 6.954758167266846 secondsこのように表示してくれる
綺麗だ.素晴らしい.可愛い.好き.ただこれでもまだ残念な欠点がある
別のディレクトリで@fntimeを使おうとするとわざわざそのディレクトリにmytools.pyをコピペしなければならないなのでそんなことしなくてもいいようにGithubにコードを公開しました
pipでインストールしてimportして関数に@fntimeを付けるだけ!
車輪の再開発を容易に避けられるのがPythonのいいところですね.ぜひ使ってください
(´-`).。oO(Githubのコードの方は関数名と時間に色を付けたり,縦に並ぶようにしたり少しだけ見やすい工夫をしてます)twitterのフォローもお願いします!
普段は機械学習とかPythonのツイートが多め?駆け出しエンジニアなので基礎的な投稿が多いですこれからどんどんqiitaの投稿をしていきます!こういう簡単なツールとかもっと色々作っていきたい
Give me LGTM!
- 投稿日:2020-08-10T18:11:08+09:00
Flaskでエラー OSError: [Errno 98] Address already in use
現象
Flaskアプリケーションを作成中、サーバーを起動したまま何度もモジュールを修正していると、標題のエラーが発生した。
エラーメッセージ
OSError: [Errno 98] Address already in useメッセージのままだけど、「利用しようとしているアドレスはすでにほかで使ってるから今は使えないよ」ということらしい。
こういう場合はポートが埋まってるんだろうと当たりをつけてエラーメッセージを検索する。検索した結果以下の記事がでヒットした。
https://qiita.com/ringCurrent/items/2413c795372baa7b479dエラー番号が「48」と「98」で違うけど、おそらく環境差異なので気にせず解決方法を実行していく。
1.「lsof」コマンドのインストール
lsofコマンドで使用中のポートを確認するらしいが、使用しているdocker環境には入ってないみたい。(base) root@e8cf64ce12e9:/home/continuumio# lsof -i :5000 bash: lsof: command not foundさくっとインストールする。(OSがubuntuなのでaptを使用)
(base) root@e8cf64ce12e9:/home/continuumio# apt install lsof Reading package lists... Done2.重複しているポートの確認
重複して利用しているポートを確認する。対象のポートはFlaskの起動時に指定しているのでコードを確認する。main.pyif __name__ == "__main__": app.run(host='0.0.0.0', port=5000, debug=True)lsofコマンドでポート5000を使っているプロセスを確認
(-i オプションで対象を限定しないと大量に抽出されるため注意)(base) root@e8cf64ce12e9:/home/continuumio# lsof -i :5000 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME python 881 root 4u IPv4 237229 0t0 TCP *:5000 (LISTEN) python 901 root 4u IPv4 237229 0t0 TCP *:5000 (LISTEN) python 901 root 5u IPv4 237229 0t0 TCP *:5000 (LISTEN)3.抽出された一覧から不要なプロセスを終了させる。
- kill 終了コマンド。物騒な名前。
- -9 強制終了
- :xxxx ポート番号
詳細は「man コマンド」で確認
(base) root@e8cf64ce12e9:/home/continuumio# kill -9 901以上
- 投稿日:2020-08-10T17:20:30+09:00
【データサイエンティスト入門】Pythonの基礎♬関数と無名関数ほか
昨夜の続きです。
【注意】
「東京大学のデータサイエンティスト育成講座」を読んで、ちょっと疑問を持ったところや有用だと感じた部分をまとめて行こうと思う。
したがって、あらすじはまんまになると思うが内容は本書とは関係ないと思って読んでいただきたい。Chapter1-2 Pythonの基礎
1-2-5 関数
1-2-5-1 関数の基本
関数とは、以下の性質を少なくとも一つ持つ
⓪指示に従って、定められた処理をする
①一連の処理をまとめて、共通化する
②引数を渡し、返り値を取得する簡単な関数
③書式の基本は以下の通り
何もしない関数
def do_nothing(): pass do_nothing()結果
何もしないhello worldを出力する
def hello_world(): print('hello world') hello_world()結果
hello world引数により出力が変わる
def hello_world(arg='hello_world'): print(arg) hello_world('hello_world') hello_world('good morning')結果
hello_world good morning*args引数をtupleで出力する
def hello_world(*args): print(args) hello_world('hello_world','good morning')結果
関数内及び出力はtupleになる('hello_world', 'good morning')**kwargs引数を辞書で出力する
def hello_world(**kwargs): print(kwargs) hello_world(day='hello_world',morning='good morning', evening='good evening')結果
関数内及び出力は辞書になり、引数名は辞書のkey, 引数の値は、辞書の値になる。{'day': 'hello_world', 'morning': 'good morning', 'evening': 'good evening'}返り値のある関数
def calc_multi(a, b): return a * b print(calc_multi(3,5))結果
15def calc_fib(n): if n ==1 or n== 2: return 1 else: return calc_fib(n-1) + calc_fib(n-2) for n in range(1,21): print(calc_fib(n))結果
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584 4181 67651-2-5-2 無名関数lambdaとmap関数
以下のように、関数名の無い関数を無名関数lambdaという。
print((lambda a, b:a*b)(3, 5))結果
15map関数
def calc_double(x): return x * 2 for num in [1, 2, 3, 4]: print(calc_double(num))結果
2 4 6 8map関数で[1, 2, 3, 4]を一度に計算して、listで出力
print(list(map(calc_double, [1, 2, 3, 4])))結果
[2, 4, 6, 8]map関数とlambda
通常の関数をlambdaに置き換えて、一行で出力できる
print(list(map(lambda x : x*2, [1, 2, 3, 4])))結果
[2, 4, 6, 8]練習問題1-2
print((lambda x : sum(x))(i for i in range(1,51))) print( sum(i for i in range(1,51))) print( sum(range(1,51)))結果
1275filter関数とreduce関数
a = [-1, 3, -5, 7, -9] print(list(filter(lambda x: abs(x) > 5, a)))結果
[7, -9]reduce関数は要素の逐次加算した結果
from functools import reduce print(reduce(lambda x, y: x + y, a))結果
-5【参考】
Python の基本的な高階関数( map() filter() reduce() )まとめ
・関数の基本
・*argsと**kwargsの使い方
・無名関数lambda, map関数, filter関数, そしてreduce関数の使い方を並べてみた基本に立ち返って、並べてみると分かり易い。
- 投稿日:2020-08-10T17:09:00+09:00
Anaconda仮想環境を構築する
アンインストール & 再インストール
こちらの記事にしたがって、再インストール。
https://qiita.com/opankopan/items/5171116b1727c3907e86今回インストールしたのは、python3.7です。
(python-cdoはまだpython3.8に対応していないので。)
https://repo.anaconda.com/archive/Anaconda3-2020.02-Linux-x86_64.shPATHの設定をし直す。
~/.bashrcexport PATH=/home/kanon/local/anaconda3/bin:${PATH}仮想環境の構築
conda create -n [name] python=3.7.4環境の切り替えは、
conda activate [name] # 起動 conda deactivate # 終了導入したパッケージ
condaで導入したパッケージ
conda install -c conda-forgeでインストールすると、適したバージョンを探してくれる。オプション-yをつけると、一気にインストールしてくれる。
- python-cdo
- netcdf4
- xarray
- numpy
- pandas
- seaborn
- cartopy
- cmocean
- datetime
- branca
- folium
- squarify
- wordcloud
- ipython
- jupyter
- jupyterlab
- plotly
- statsmodels
- scipy
- pillow
- click
- conda
- paramiko
pipで導入したパッケージ
- datetime
- geoplotlib
- janome
- gtool3
- pip install matplotlib==3.2.2 ->新しいversionだとbasemapが動かないので注意!(参考:http://ebcrpa.jamstec.go.jp/~yyousuke/matplotlib/info.html)
- netCDF4 -> errorが出たから入れたけど、condaでinstallしたのと何が違うの??
basemapの導入
- 投稿日:2020-08-10T17:00:15+09:00
[Rust] PyO3でエラーを返す
Rust で PyO3 を用いて Python 用ライブラリを作成していたのですが, ある関数の入力に関して制約があり (例えば平方根は入力が非負でなければいけない, のような), その制約を満たさない場合にエラー (
ValueError) を返す方法がわからず手間取りました. 半年くらい後にきっとまた同じことをググる羽目になるんじゃないかと思いますが, それは面倒なのでわかったことをまとめておきます.※本記事は Rust 1.45.2, PyO3 0.11.1 を使用して2020年8月に動作確認しました.
本論
こんな感じになると思います1.
#[pyfunction] fn sqrt_rs(value: f64) -> PyResult<f64> { if value.is_sign_negative() { return Err(pyo3::exceptions::ValueError::py_err( "sqrtに負の値が入力されました. 非負の値を入力してください." ); } Ok(value.sqrt()) }他にも
pyo3::exeptionsに様々なエラー型が定義されています. 使い方はすべて同じで,py_err関数を呼べば良いです.解説
Python 側に露出する関数は Rust 側では
PyResult<T>型を返しますが, この型は何かというとPyResult<T> = Result<T, PyErr>です. ですからエラーが発生したらPyErr型のインスタンスを生成し,Errで包んでreturnすればよさそうです. それで,PyErr型ってなんでしょう?PyO3 では Python の様々なエラー型 (
ValueErrorやTypeErrorなど) をモジュールpyo3::exceptions内で定義しています. これはすべて Rust 側でも異なる型なので, そのままでは扱いがやや面倒です. そこで PyO3 では様々なエラー型とその値を保持するラッパー構造体PyErrを用意しています. 各エラー型にはPyErr型を返すpy_err関数が付随していて, これに引数としてその値を渡すことで欲しいエラー型インスタンスを包んだPyErrインスタンスが取得できます.参考文献
これは例示のためのコードなので,
NaNは? とか,if elseを使えばreturn不要, などの突っ込みを入れないでください. ↩
- 投稿日:2020-08-10T16:45:28+09:00
(たぶん)これだけで受かる、Python 3 エンジニア認定データ分析試験
はじめに
本記事は2020年6月8日から始まったPython3 エンジニア認定データ分析試験の知識を整理したものです。
プライム・ストラテジー様の模擬試験や様々なWebページからの情報を整理しています。
記事の中で「教科書」と記しているのは、主教材となっている以下の書籍のことを指します。主教材:
2018年9月19日発売(税込2,678円)
「Pythonによるあたらしいデータ分析の教科書」(翔泳社)
著者:寺田 学、辻 真吾、鈴木 たかのり、福島 真太朗(敬称略)※まだ整理途中であるため、フォーマットが汚い等のご指摘はスルーさせていただくこともございます。
※内容的な誤り、こんなことも載せたほうがよいのでは、といったご指摘は大歓迎です。出題範囲と出題配分
出題範囲 出題数 出題配分 1 データエンジニアの役割 2 5.00% 2 Pythonと環境 1 実行環境構築 1 2.50% 2 Pythonの基礎 3 7.50% 3 Jupyter Notebook 1 2.50% 3 数学の基礎 1 数式を読むための基礎知識 1 2.50% 2 線形代数 2 5.00% 3 基礎解析 1 2.50% 4 確率と統計 2 5.00% 4 ライブラリによる分析実践 1 NumPy 6 15.00% 2 pandas 7 17.50% 3 Matplotlib 6 15.00% 4 scikit-learn 8 20% 出題範囲に対応した知識の整理
大項目 小項目 概要 詳細 参考 2 Pythonと環境 pip pipコマンドは、The Python Package Index に公開されているPythonパッケージのインストールなどを行うユーティリティである。パッケージをインストールするにはpip installコマンドを使用する。 pipのUオプションについて
Ex.)
pip install -U numpy pandaspipコマンドは-Uオプションをつけることでインストールするライブラリが最新版に更新されます。
明示的に最新版をインストールするには、このようになります。PEP8 PEP8は標準のコーディング規約。同一モジュールの場合は複数インポートを許容するが、モジュールが異なる場合は改行する。 [Pythonコーディング規約]PEP8を読み解く - Qiita https://qiita.com/simonritchie/items/bb06a7521ae6560738a7 ログレベル python のロギングには、5 つのレベルがある。
1. CRITICAL
2. ERROR
3. WARNING
4. INFO
5. DEBUG便利なモジュール pickleモジュールは、Pythonのオブジェクトを直列化してファイルなどで読み書きできるようにすることができる。pickle化できるものとしてブール値や数値、文字列などがある。
ファイルのパスを扱うにはpathlibモジュールが便利である。globメソッドではファイル名をワイルドカード(*)で指定することもできる。ravelとflattenは配列を一次元化する関数。ravel()は可能な限りビューを返すが、flatten()は常にコピーを返す。reshape()もreval()と同様、可能な限りビューを返す。 配列を別の変数に代入した場合、代入された変数はもともとの配列を参照している。別オブジェクトとして生成したい場合はcopy()もしくはdeepcopy()を使う。
※numpyのravelとflattenは配列を一次元化する関数。ravel()は可能な限りビューを返すが、flatten()は常にコピーを返す。reshape()もreval()と同様、可能な限りビューを返す。データの読み書き バイナリファイルからのデータ読み込みはopenメソッドのbオプションでファイル記述子を返し、read()で読み込み、write()で書き込み stripメソッド
Ex.)
bird = ' Condor Penguin Duck '
print("befor strip: {}".format(bird))
print("after strip: {}".format(bird.strip()))両端の空白文字がさ削除されます。 正規表現
. 任意の一文字 a.c abc, acc, aac
^ 行の先頭 ^abc abcdef
$ 行の末尾 abc$ defabc
* 0回以上の繰り返し ab* a, ab, abb, abbb
+ 1回以上の繰り返し ab+ ab, abb, abbb
? 0回または1回 ab? a, ab
{m} m回の繰り返し a{3} aaa
{m,n} m〜n回の繰り返し a{2, 4} aa, aaa, aaaa
[★] ★のどれか1文字 [a-c] a, b, c
★★ ★のどれか a b a, b 正規表現 特殊シーケンス
\d 任意の数字 [0-9]
\D 任意の数字以外 [^0-9]
\s 任意の空白文字 [\t\n\r\f\v]
\S 任意の空白文字以外 [^\t\n\r\f\v]
\w 任意の英数字 [a-xA-Z0-9_]
\W 任意の英数字以外 [\a-xA-Z0-9_]
\A 文字列の先頭 ^
\Z 文字列の末尾 $正規表現
find() / findall() → それぞれ1つもしくは全てのマッチする部分文字列をリストで返す
match() → 文字列の先頭がマッチするか確認する
fullmatch() → 文字列全体がマッチするかチェック
search() → 先頭に限らずマッチするかチェックする。文字列中の一部を抜き出したい場合に使う
replace() → 文字列の置換
sub() → 文字列の置換。置換された文字列が返される。
subn() → 置換処理された文字列(sub()の返り値と同じ)と置換された部分の個数(パターンにマッチした個数)とのタプルを返す。
match/searchはマッチオブジェクトを返す。マッチオブジェクトは以下のメソッドが使える。
マッチした位置を取得: start(), end(), span()
マッチした文字列を取得: group()
各グループの文字列を取得: groups()
※正規表現パターンの文字列中の部分を括弧()で囲むと、その部分がグループとして処理される。このとき、groups()で各グループにマッチした部分の文字列がタプルとして取得できる。
subは括弧()でグルーピングした場合、置換後の文字列の中でマッチした文字列を使用することができる。
デフォルトでは\1, \2, \3...が、それぞれ1つ目の()、2つ目の()、3つ目の()...にマッチした部分に対応している。raw文字列ではない通常の文字列だと'\1'のように\をエスケープする必要があるので注意。正規表現パターンの()の先頭に?Pを記述してグループに名前をつけると、\1のような番号ではなく\gのように名前を使って指定できる。re.search("category\/(.+?)\/", "https://foo.com/category/books/murakami").group(1)
# 取得した文字列:'books'
>>> text = "123456abcedf789ghi"
>>> matchobj = re.search(r'[a-z]+', text)
>>> if matchobj:
... print(matchobj.group())
... print(matchobj.start())
... print(matchobj.end())
... print(matchobj.span())
※re.search は最初にマッチした文字列の情報しか取得できないことには注意が必要です。
replaceは対象の文字列.replace(置換される文字列, 置換する文字列 [, 置換回数])の文法。
>>> raw_abc = r"aaaaabbbbbccccc"
>>> rep_raw_abc = raw_abc.replace("c", "C")
>>> print("変更前:",raw_abc, "変更後:",rep_raw_abc)
変更前: aaaaabbbbbccccc 変更後: aaaaabbbbbCCCCC
re.sub(正規表現, 置換する文字列, 置換される文字列 [, 置換回数])とreplaceの違いに注意。【Python】とっても便利な正規表現! - Qiita https://qiita.com/hiroyuki_mrp/items/29e87bf5fe46de62983c 正規表現のフラグ
ASCII文字に限定: re.ASCII
大文字小文字を区別しない: re.IGNORECASE
各行の先頭・末尾にマッチ: re.MULTILINE
複数のフラグを指定パターンのコンパイル
p = re.compile(r'([a-z]+)@([a-z]+).com')
m = p.match(s)
result = p.sub('new-address', s)仮想環境 venvは仮想環境毎にインストールするモジュールを隔離することができる。Pythonインタプリタの切替えはpyenvやAnacondaを用いる。 https://tinyurl.com/y4ypsz9r %, %%はマジックコマンド。
!でOSのシェルコマンド実行。
Shit + Tabでdocstring表示。Jupyter Notebookのマジックコマンド(マジック関数)の使い方解説 https://miyukimedaka.com/2019/07/28/blog-0083-jupyter-notebook-magic-command-explanation/ よく使うマジックコマンド
%time:これに続くコードの実行時間を測定し、結果を表示してくれます。
%timeit:これに続くコードの実行時間を何度か測定し、その中で最速であった結果と平均を表示してくれます。
%env:環境変数を取得したり、設定したりすることができます。
%who:現在宣言されている変数を表示してくれます。
%whos:現在宣言されている変数とその型、内容を表示してくれます。
%pwd:現在のディレクトリを表示します。
%history:コードセルの実行履歴を一覧で表示してくれます。
%ls:カレントディレクトリーのファイルを一覧で表示してくれます。
%matplotlib inline:pyplotなどでグラフを描写すると結果が別ウインドーが開きそこに表示されますが、このマジックコマンドを使うとnotebook内にグラフが表示されるようになります。
%%timeit:%timeitの機能をセル内のすべてのコードに適応します。
%%html, %%HTML:htmlのコードの記述、実行を可能にします。jupyter notebookの保存形式 notebook形式 (.ipynb) はJSONファイル 3 数学の基礎 行列 「交換法則:×」,「結合法則:○」,「分配法則:○」
交換法則は必ず成立するとは限らない(成立するものもあることに注意)。
1行/1列はベクトル。
行列の列の数とベクトルのサイズが同じ場合は、これらの掛け算を定義することができ、結果は、元の行列の行数と同じサイズのベクトルになる。常用対数と自然対数 常用対数とは10を底とする対数のこと。自然対数はeを底とする。 ユークリッド距離 直線距離 マンハッタン距離 ジグザグ距離(マンハッタンの碁盤の目に由来) 関数 F(x)を微分して f(x)となったとき、F を f の原始関数、f を F の導関数と呼ぶ。 積分 積分の範囲が定められていない積分を不定積分という。任意の定数を微分すると0になるため、不定積分には積分定数「C」が通常含まれる。 微分と積分 微分は傾き、積分は面積と捉えることができる。データ分析や機械学習において、関数の傾きが0となる点は有益な情報として利用される。 偏微分 2つ以上の変数を持つ多変数関数の微分を偏微分という。偏微分ではどの変数で微分したのかを示すことが必要である。 確立 12面体のサイコロの期待値は6.5。確立変数については、離散→確立質量関数、連続→確立密度関数 0の階乗! 0!=1 であることに注意。1の対数は0であることも覚えておく。 sinとcos sin/cosはそれぞれ正弦と余弦という。tanは正接。 4 ライブラリによる分析実践 Numpy dtype属性 ndarrayの要素のデータ型を確認できる。 ndarrayの便利な生成方法
# -5~5まで0.1刻みの数値の配列を定義
x = np.arange(-5, 5, 0.1)
# 1~10までの等差数列をnumで指定した要素数分生成
np.linspace(1, 10)np.linspace(start, stop, num=50, endpoint=True)の文法で生成。numは要素数を指定する。numはデフォルトで50。 np.randomモジュール npは標準モジュールと比べ、stopに指定した値が含まれないことに注意。
random.random() / np.random.rand(size)は0~1の乱数を生成する。
import numpy as np
import random
print(random.random())
# 0.9733563537374995
print(np.random.rand(3))
# [ 0.69962497 0.61950126 0.7944733 ]
print(np.random.rand(2, 3))
# [[ 0.29315148 0.06560949 0.56110618]
# [ 0.62784039 0.19218867 0.07087768]]
np.random.randn(size)は標準正規分布に従う乱数生成。
print(np.random.randn(3, 3)) #標準正規分布の3×3配列
# [[-0.52434526 0.16597271 -2.22295048]
# [ 0.46995083 -0.64576356 -2.73155503]
# [ 1.04575168 0.05712791 -0.46522963]]
正規分布に従う乱数を生成したい場合は以下のようにする。
np.random.normal(mu, sd, 10000)
整数の乱数を生成する場合は
random.randint(low, high, size)
np.random.randint(1, 10, 2) #1以上10未満の整数2個のndarrayを生成。
np.random.randint(1, 10, (2, 3) #2行3列のndarrayを生成。
np.random.randint(2, size=8) #highを省略すると、lowの値をhigh扱い。
# array([1, 0, 0, 0, 1, 1, 1, 0])
np.random.randint(1, size=8) #1未満の整数、つまり0のみ。
# array([0, 0, 0, 0, 0, 0, 0, 0])
choichは標準モジュールと以下の違いがある。
random.choice(seq) seqから1個選択
np.random.choice(a) aから複数個選択
seq1=[0、1、2、3]
random.choice(seq1) #1回チョイス
random.choice("hello") #5文字の中から1文字チョイス
np.random.choice(seq1, 4) #重複ありで4回チョイスした配列
np.random.choice([2, 4, 6],2) #重複ありで2回チョイスした配列
np.random.choice([0, 1], (3, 3)) #size3×3の配列に0,1を埋める
np.random.choice(5, 2) #np.randint(0, 5, 2)と同義NumPyの使い方(12) 乱数、random - Remrinのpython攻略日記 http://python-remrin.hatenadiary.jp/entry/2017/04/26/233717 1次元配列への変換 2次元のNumPy配列を1次元に変換するにはravelメソッドまたはflattenメソッドを用いることができる。ravelメソッドは参照を返し、flattenメソッドはコピーを返す。 コピーと参照
a = np.array([1, 2, 3])
b = a ①
b = a.copy() ②①は参照、②はコピーになる。Python標準のリストをスライスするとコピーが渡されるが、Numpyのスライスは参照が渡されることに注意。 行列の分割
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
first1, second1 = np.vsplit(a, [2])
first2, second2 = np.hsplit(second1, [2])
print(second2)vpslit関数では行方向、hsplit関数では列方向に行列を分解します。 print文の表示について
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([7,8,9])
print(a[-1:, [1,2]], b.shape)[5 6]
aはa[-1:, [1,2]]で最後の行([4,5,6)の[1,2]なので5,6を抽出。bはカッコが1つなので1次元であることに注意。np.arangeが生成する要素数 x = np.arange(0.0, 1.5, 0.1)だとarray([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. , 1.1, 1.2, 1.3, 1.4])で15個。センターが15だとその10倍だから150。np.sin(x)は弧度法のラジアンで処理する。 pandas 日付配列
dates = pd.date_range(start="2020-01-01", end="2020-12-31")
print(dates)date_range()で日付配列を生成する。startとendで開始、終了日時を指定できる。 DataFrameの結合
連結: データの中身をある方向にそのままつなげる。pd.concat, DataFrame.append
結合: データの中身を何かのキーの値で紐付けてつなげる。pd.merge, DataFrame.joinpd.concat([df1, df2])は縦方向の結合、横方向に結合したい場合はaxis=1をつける。何も指定しないと完全外部結合になるため、内部結合にしたいならjoin=innerをつける。join_axes=[df1.index]のように結合行/列を指定することも可能。
縦方向にはシンプルにdf1.append(df2)として連結することもできる。df2の箇所をSeriesにすると行追加。ignore_index=Trueを指定しないとindexはそのままに連携されることに注意。
結合はmergeによっておこなう。文法はpd.merge(left, right, on='key', how='inner')。howはinner/left/right/outerを指定可能。複数のkeyで結合する際はonにリストを渡す。indexをキーとして結合したい場合はDataFrame.joinが便利。規定は左外部結合となるがhowで変更可能(left.join(right, how='inner'))。Python pandas 図でみる データ連結 / 結合処理 - StatsFragments http://sinhrks.hatenablog.com/entry/2015/01/28/073327 read_html() tableが複数ある場合はDataFrameのリストとして取得する 欠損値処理 fillna()は、引数をmethod = 'ffill', method = 'bfill'と指定することで、欠損した要素に同じ列内の別の値を格納することができます。method = 'ffill'とした場合は、添え字が小さい要素に格納されていた値で、method = 'bfill'とした場合は、添え字が大きい要素に格納されていた値で欠損値を穴埋めします。
data['Age'].fillna(20) # 列Ageの欠損値を20で穴埋め
data['Age'].fillna(data['Age'].mean()) # 列Ageの欠損値をAgeの平均値で穴埋め
data['Age'].fillna(data['Age'].median()) # 列Ageの欠損値をAgeの中央値で穴埋め
data['Age'].fillna(data['Age'].mode()) # 列Ageの欠損値をAgeの最頻値で穴埋めPandasで欠損値処理 - Qiita https://qiita.com/0NE_shoT_/items/8db6d909e8b48adcb203 NumpyとPandasの相互変換 pandas→numpy変換はDataFrameのvalues属性で、逆はndarrayをpd.DataFrame()の引数とすることで変換できる。
numpyに変換する際はインデックス名、カラム名は保持されない。pd.describe() describeは各列毎に平均や標準偏差、最大/最小、最頻値を取得できる。 stdは標準偏差。topは最頻値。 https://tinyurl.com/y3gn3dz4 groupbyとGrouperの使い方
import numpy as np
import pandas as pd
np.random.seed(123)
dates = pd.date_range(start="2017-04-01", periods=365)
df = pd.DataFrame(np.random.randint(1, 31, 365), index=dates, columns=["rand"])
df_year = pd.DataFrame(df.groupby(pd.Grouper(freq='W-SAT')).sum(), columns=["rand"])Grouperはfreqで頻度を指定するなどして柔軟にグルーピングができる。
※5行目は、日付をインデックスとするDataFrameを作成している。rand列の各値は、1から30までのランダムな整数となる。Matplotlib MATLABスタイルとOOP(オブジェクト指向)スタイル 前者の方がコードは短いが細かい指定はできない。基本、後者を使うべき。
単体のグラフを作成する場合、ユーザーは Figure や Axes を準備する必要はありません。これらのオブジェクトは自動生成されます。描画オブジェクト、サブプロットオブジェクトの生成
fig, axes = plt.subplots(2)左記のとおり、一括でfigとaxesを生成できる。fig.add_subplot()でfigに対して個別にサブプロットを生成していくことも可能。
■fig,axを個別に作る場合
# Axesを配置する領域を作成
fig = plt.figure(facecolor = "lightgray")
# FigureにAxesを追加
ax = fig.add_subplot(111)
subplots(2)とするとサブプロットは2行、ncol=2のようにすると2列となる。複数のサブプロットの配置方法
ax_1 = fig.add_subplot(221)
ax_2 = fig.add_subplot(222)
ax_3 = fig.add_subplot(223)
# 3行2列目にあるAxesにデータをプロット
ax[2, 1].plot(x, y)pyplot.subplots() を使うと、複数の Axes オブジェクトを一度に生成できます。第 1 引数 nrows と 第 2 引数 ncols には、それぞれ Axes の行方向の数と列方向の数を渡します。 [Matplotlib] OOP と MATLAB スタイル https://python.atelierkobato.com/matplotlib/ 軸の設定
# Axesの設定
ax.grid() # グリッドを表示
ax.set_title("Axes sample", fontsize=14) # タイトルを表示
ax.set_xlim([-5, 5]) # x軸の範囲
ax.set_ylim([-5, 5]) # y軸の範囲Figureオブジェクトの書式設定
# Figureオブジェクトの作成と書式設定
fig = plt.figure(
# サイズ
figsize = (5, 5),
# 塗り潰しの色
facecolor = "lightgray",
# 枠線の表示
frameon = True,
# 枠線の色
edgecolor = "black",
# 枠線の太さ
linewidth = 4)# FigureにAxes(サブプロット)を追加
ax = fig.add_subplot(
#行数と列数、Axes番号
111,
# 塗り潰しの色
facecolor = "lightgreen",
# x軸とy軸の範囲
xlim = [-4,4], ylim = [0,40])グラフの表示
plt.show()showメソッドでグラフを表示する。 import matplotlib.pyplot as plt
fig, ax = plt.subplots()
x = [1, 2, 3]
y1 = [10, 2, 3]
y2 = [5, 3, 6]
labels = ['Setosa', 'Versicolor', 'Virginica']
ax.bar(x, y_total, tick_label=labels, label='y1')
ax.bar(x, y2, label='y2')
ax.legend()
plt.show()y1は変数として使われていない点に注意 import numpy as np
import matplotlib.pyplot as plt
np.random.seed(123)
mu = 100
sigma = 15
x = np.random.normal(mu, sigma, 1000)
fig, ax = plt.subplots()
n, bins, patches = ax.hist(x, bins=25, orientation='horizontal')
for i, num in enumerate(n):
print('{:.2f} - {:.2f} {}'.format(bins[i], bins[i + 1], num))
plt.show()binsのデフォルト値は10。教科書P192参照。返り値としてのbinsは境界の値で、bin数+1となる。
変数muは平均値、変数sigmaは標準偏差を意味する。
ヒストグラムは横向きに描画される。
histメソッドの返り値が格納される「n, bins, patches」のうち「bins」にはビンの境界の値が入っており、その個数は26である。
このスクリプトを実行するとヒストグラムに加えて度数分布表が出力される。
左記のprint文の箇所が度数分布表の表示になっている。
51.53 - 55.62 2.0
55.62 - 59.70 3.0
59.70 - 63.78 6.0
63.78 - 67.86 7.0
67.86 - 71.94 16.0
71.94 - 76.02 29.0
76.02 - 80.11 37.0円グラフ表示 教科書P198参照。アス比を保持するには、ax.axis('equal')とする。autopctは各値を%表示できる。強調表示はexplode。
例:plt.pie(x, labels=label, counterclock=False, startangle=90)で真上から時計回りに描くhttps://tinyurl.com/yyl8yml6 Scikit-learn DBSCAN 教師なし学習の1つであるDBSCAN法は密度準拠クラスタリングアルゴリズムであり、特徴量ベクトル間の距離に着眼した手法である。 分類の評価尺度
Precision(適合率)
Recall(再現率)
F1 Score
Accuracy(正解率)PrecisionとRecallはトレードオフの関係にある。そのため、F1 Score指標も併せて見るとよい。
よくあるがん診断の例でいうと、
Precision → 誤診を少なくしたい場合に重視
Recall → 正例の見逃しを避けたい場合に重視
Accuracy → 分類の精度を確認するための一般的な指標機械学習 実践(教師あり学習:分類) - KIKAGAKU https://www.kikagaku.ai/tutorial/basic_of_machine_learning/learn/machine_learning_classification 回帰モデルの評価尺度 MSE(Mean Squared Error:平均二乗誤差)、RMSE(Root Mean Sqaured Error:平均平方二乗誤差)、MAE(Mean Absolute Error:平均絶対誤差)が有名。 https://tinyurl.com/y2xc9c58
https://tinyurl.com/y5k8gc9a
いろいろな誤差の意味(RMSE、MAEなど) - 具体例で学ぶ数学 https://mathwords.net/rmsemae#:~:text=MAE%EF%BC%88Mean%20Absolute%20Error%EF%BC%89,-%E3%83%BB%E5%AE%9A%E7%BE%A9%E5%BC%8F%E3%81%AF&text=%E3%83%BB%E5%B9%B3%E5%9D%87%E7%B5%B6%E5%AF%BE%E8%AA%A4%E5%B7%AE%E3%81%A8%E3%82%82%E8%A8%80%E3%81%84,%E3%81%A8%E3%81%97%E3%81%A6%E6%89%B1%E3%81%86%E5%82%BE%E5%90%91%E3%81%8C%E3%81%82%E3%82%8A%E3%81%BE%E3%81%99%E3%80%82Scikit-learnに付属のデータセット
load_iris
load_bostonirisは150枚のアヤメの「がく」や「花びら」の長さと幅、そして花の種類が記録されている。説明変数4、目的変数1。bostonは米国ボストン市郊外の地域別に、人口一人当たりの犯罪件数や住居の部屋数の平均などを含む14個の特徴量と住宅価格を記録したデータセットである。 決定木
回帰・分類を行うアルゴリズム。解釈が容易で前処理が少なくてすむという強みがある。教科書P235。情報利得=親ノードの不純度-子ノードの不純度の合計 で表され、正であれば子ノードに分割すべき、負であれば分割すべきでないとなる。 木構造 (データ構造) - Wikipedia https://ja.wikipedia.org/wiki/%E6%9C%A8%E6%A7%8B%E9%80%A0_(%E3%83%87%E3%83%BC%E3%82%BF%E6%A7%8B%E9%80%A0)#%E7%94%A8%E8%AA%9E SVM
マージンが最大となるように決定境界を引く。線形分離不可能なデータを線形分離可能にする手法をカーネルトリックという。from sklearn.svm import SVC
svc = SVC()
Cはコストパラメータで誤った予測に対するペナルティを意味する。大きすぎると過学習を起こす。gammaはモデルの複雑さを決定する。値が大きくなるほど複雑になり過学習を起こす。シグモイド関数
y = 1 / 1 + exp(x) の形をとる。(0, 0.5)をとおり、0 < y < 1となる。シグモイドは二値分類を行うモデル。3クラス分類であれば、二値分類をクラス数だけ行うことで対応できる。 正規化 正規化は、平均0分散1にする標準化[StandardScaler]と最大1、最小0にする正規化[MinMaxScaler]が有名。 訓練データとテストデータの分割 from sklearn.model_selection import train_test_split 線形モデル 線形モデル(LinearRegression)は説明変数が1つの単回帰と複数の重回帰に分かれる。 主成分分析 分散が大きくなる方向を探して、元の次元と同じかそれよりも低い次元にデータを圧縮する手法である。
主成分分析(principal component analysis)は、scikit-learnのdecompositonモジュールのPCAクラスを用いて実行することができる。グリッドサーチ
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
clf = DecisionTreeClassifier()
param_grid = {'max_depth': [3, 4, 5]}
cv = GridSearchCV(clf, param_grid=param_grid, cv=10)
cv.fit(X_train, y_train)
y_pred = cv.predict(X_test)左記のコードでは、実行するたびに決定木の深さの最適値が変わる可能性がある。再現性をもたせる場合は、以下のようにする。
clf = DecisionTreeClassifier(random_state=0)決定木分析のパラメータ解説 – S-Analysis http://data-analysis-stats.jp/2019/01/14/%E6%B1%BA%E5%AE%9A%E6%9C%A8%E5%88%86%E6%9E%90%E3%81%AE%E3%83%91%E3%83%A9%E3%83%A1%E3%83%BC%E3%82%BF%E8%A7%A3%E8%AA%AC/ クラスタリング k-meansは、最初にランダムにクラスタ中心を割り当て、クラスタ中心を各データとの距離を計算しながら修正し、最終的なクラスタ中心が収束するまで再計算を行いクラスタリングする手法である。
クラスタリングには大きく分けて、分割最適型クラスタリングと階層型クラスタリングがあります。分割最適型クラスタリングは、事前にクラスタの良さを測る関数を準備しておいて、その関数の値を最小化するようなクラスタリングを求める手法です。一方で、階層型クラスタリングはクラスタを分割したり併合したりすることによってクラスタを階層的に構築する手法です。
また階層型クラスタリングには、さらに凝集型と分割型があります。凝集型はデータポイント1つ1つをクラスターと考えた状態から始め、類似しているクラスターを逐次的に凝集していく手法です。分割型はデータポイント全体で1つのクラスターと考えた状態から始め、類似していないデータポイント群を逐次的に分割していく手法です。
分割型は凝集型に比べ、計算が多くなる傾向があります。https://tinyurl.com/y6cgp24f
https://tinyurl.com/y2df2w4c
- 投稿日:2020-08-10T15:48:00+09:00
Pythonプログラミング:Qiita記事のタグから3D散布図を描画してみた
はじめに
過去の記事(ウィキペディアのデータを使ってword2vecをしてみる{4. モデル応用編})では、word2vecモデルの多次元ベクトルを用いて単語の非階層型クラスタリングをしました。
今回は、非階層型クラスタリングの結果を見せ方を変えて、3D散布図を描画します。最終的に、以下のようなモノを作ります。
本稿で紹介すること
- 3D散布図の描画
Plotly Python Graphing Library | Python | Plotly
本稿で紹介しないこと
- Pythonライブラリの使い方
- scikit-learn
- pandas
- matplotlib
- plotly ※グラフ描画用のPythonライブラリ
サンプルコード
非階層型クラスタリングを実行するところまでは、過去の記事を参考されたし。
クラスタリングの結果から、可視化しいてゆくCodeに焦点を絞ってCodeを紹介
まずは、PCAで次元圧縮をする部分です。
次元数の指定を変えて、実行するだけです。analyzeWiki_Word2Vec1from sklearn.decomposition import PCA import pandas as pd import matplotlib.pyplot as plt #PCAで3次元に圧縮 pca = PCA(n_components=3) pca.fit(df.iloc[:, :-2]) feature = pca.transform(df.iloc[:, :-2]) #日本語フォントの指定 plt.rcParams["font.family"] = 'Yu Gothic' #散布図プロット color = {0:"green", 1:"red", 2:"yellow", 3:"blue"} colors = [color[x] for x in cluster_labels] plt.figure(figsize=(20, 20)) for x, y, name in zip(feature[:, 0], feature[:, 1], df.iloc[:, -2]): plt.text(x, y, name) plt.scatter(feature[:, 0], feature[:, 1], color=colors) plt.savefig("../result/word_clustering_scatter2.png") plt.show()当たり前ですが、2D散布図だと、結果は同じです。
次に、3D散布図のための、データ加工です。
analyzeWiki_Word2Vec2feature_df = pd.DataFrame(feature) #feature_df.head() feature_df["word"] = words feature_df["cluster"] = cluster_labels #feature_dfそして、本稿の本題、3D散布図を描画します。
analyzeWiki_Word2Vec3import plotly import plotly.express as px plotly.offline.init_notebook_mode(connected=False) fig = px.scatter_3d(feature_df, x=0, y=1, z=2, text="word", color='cluster', symbol='cluster', opacity=0.7) fig.update_layout(margin=dict(l=0, r=0, b=0, t=0)) plotly.offline.plot(fig, filename='../result/word_clustering_scatter2.html', auto_open=True)すると、冒頭で示した画面が表示されます。
Plotlyを利用した理由が、ここから発揮されます。
Plotlyで描画した3D散布図は、画面上で拡大・縮小はもちろん、回転もできてしまいます!早速、回転をしてみると、matplotlibで描画した2D散布図と似たような断面が現れました。
もう少し回転してみて、”東京”と”日本”、そして3都市(”神奈川”、”千葉”、”埼玉”)との位置関係を探ってみます。
まず、国(”日本”、”アメリカ”、”ドイツ”)は概ね同じ平面上に存在していました。
画像からは分かりにくいかもしれませんが、東京も3都市も、国の平面とは異なる場所に位置しています。
そして、異なるアングルから。
3都市は概ね同じ平面に存在していました。が、同じ平面状に”東京”は存在していませんでした。
”東京”は、国の平面とも、都市の平面とも、異なる場所に位置しています。
Plotly、非常に強力ですね。
3D散布図を取り上げましたが、それ以外の利用にも対応した、汎用的なグラフ化ツールです!!!ちなみに
word2vecモデルでも単語の類似度はどうなっているかと言うと、、、以下の通りでした。
多次元ベクトル空間上でも、”東京”は3都市に比べて、”日本”の方が類似度が高くなっていました。analyzeWiki_Word2Vec4$ model.wv.similarity('東京', '日本') 0.329558 $ model.wv.similarity('東京', '神奈川') 0.2497174 $ model.wv.similarity('東京', '千葉') 0.25432715 $ model.wv.similarity('東京', '埼玉') 0.21400008まとめ
word2vecモデル(多次元ベクトル)のクラスタリング結果を可視化する手法、3次元空間上に散布図を描画する方法を紹介。

- 投稿日:2020-08-10T15:43:32+09:00
PythonでGenderAPIとPykakasiを使って氏名から性別を予測する
はじめに
氏名から性別を予測したい利用シーンがあるかと思います。
例えば、会員制のサービスで登録フォームで性別を聞くとCVRが下がってしまう、だったら予測で補おう!などと言ったシーンでしょうか。氏名から性別を予測する方法は、機械学習で分類器を生成し予測する方法や外部APIを用いて予測を行う方法などいくつかあります。
今回はPythonで名前からGenderAPIを用いて性別を予測するアプローチとなります。GenderAPIはアメリカの企業で、膨大な氏名データから性別予測をこれまで行ってきたようです。
類似するサービスはいくつかありますが、今回はこのGenderAPIを用いて性別予測を行います。前準備
Gender API
まずは、GenderAPIのアカウントを作成しましょう。
作成後、API_KEYを取得します。
無料で使用したい方は、500の氏名までなら無料で使用することができます擬似個人情報取得
PersonalGeneratorを使って、擬似的に個人情報を生成します。
自由に表示する項目を選択できますが、今回は、正解判定も行いたいので、連番,氏名,氏名(カタカナ),性別を取得します。
今回は30人程度の氏名から性別を予測してみます。
Pykakasi
予測対象の氏名はFirst_nameになり、名前を漢字、カタカナ、ひらがな、ローマ字のいづれで予測させるかは精度に大きく影響します。
結論、海外のサービスだからか、ローマ字に変換し、予測させた方が精度が最も高かったです。(検証過程は割愛します。)ですので、下の名前からローマ字変換を行う必要があります。
使い方については、開発者のドキュメントが参考になります。pykakasiの使い方
以下の2点のパッケージをインストールします。pip install six semidbm pip install pykakasi性別予測
pythonで性別予測
実際に対象者30人の性別を予測していきます。
大まかな手順は以下の通りです。
1. 対象者のdataframeを用意、全角スペースで分割し名前列を生成
2. Pykakasiインスタンスを生成し、ローマ字変換する設定をし、名前を変換しローマ字列を生成
3. ローマ字リストをGenderAPIに渡し、予測結果を取得
4. 予測結果と元のdataframeをマージgender_estimation.pyimport sys import json from urllib import request, parse from urllib.request import urlopen import pandas as pd import pykakasi class GenderEstimation: """ ローマ字変換した氏名から性別を予測 """ __GENDER_API_BASE_URL = 'https://gender-api.com/get?' __API_KEY = "your api_key" def create_estimated_genders_date_frame(self): df = pd.DataFrame(self._estimate_gender()) print('\n{}人の性別予測を完了しました。'.format((len(df)))) df.columns = [ 'estimated_gender', 'accuracy', 'samples', 'duration' ] df1 = self._create_member_data_frame() estimated_genders_df = pd.merge(df1, df, left_index=True, right_index=True) return estimated_genders_df def _estimate_gender(self): unique_names = self._convert_first_name_to_romaji() genders = [] print(u'{}人の性別予測を行います'.format(len(unique_names))) for name in unique_names: res = request.urlopen(self._gender_api_endpoint(params={ 'name': name, 'country': 'JP', 'key': self.__API_KEY })) decoded = res.read().decode('utf-8') data = json.loads(decoded) genders.append( [data['gender'], data['accuracy'], data['samples'], data['duration']]) return genders def _gender_api_endpoint(self, params): return '{base_url}{param_str}'.format( base_url=self.__GENDER_API_BASE_URL, param_str=parse.urlencode(params)) def _convert_first_name_to_romaji(self): df = self._create_member_data_frame() df['first_name_roma'] = df['first_name'].apply( lambda x: self._set_kakasi(x)) return df['first_name_roma'] def _set_kakasi(self, x): kakasi = pykakasi.kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') kakasi.setMode('r', 'Hepburn') kakasi.setMode('s', False) kakasi.setMode('C', False) return kakasi.getConverter().do(x) def _create_member_data_frame(self): df = pd.read_csv('personal_infomation.csv').rename(columns={ '連番':'row_num', '氏名':'name', '氏名(カタカナ)':'name_katakana', '性別':'gender' }) df['first_name']=df.name_katakana.str.split().str[1] print(u"{}人の予測対象者を抽出します。".format(len(df))) return df性別予測結果
予測結果のdataframeは以下のようになりました。
GenderAPIの予測に関するレスポンスは以下のような定義になります。
estimated_gender accuracy samples duration 性別予測結果 予測の正しさ 予測に用いたサンプルサイズ 1callまでの経過時間
性別予測精度検証
最後に、性別予測結果の精度について検証しましょう。
以下の表の用に、正解と予測結果とその数をプロットし、マトリックスを生成します
正解率はほぼほぼ100%となりました。
今回の場合、1件だけ本当は女性なのに、男性と予測してしまいました。
やはり「イオリ」など男性とも女性とも取れる名前の予測は困難なようです。
正解 予測 num male male 11 male female 0 male unknown 0 female male 1 female female 18 female unknown 0 unknown male 0 unknown female 0 unknown unknown 0
予測/正解 male female unknown 正解率 male 11 0 0 100.00% female 1 18 0 94.74% unknown 0 0 0 0%