- 投稿日:2020-07-26T21:55:31+09:00
AWS Lambda 用の Java11 コードを docker-lambda 環境でローカル開発するメモ
Docker に慣れちゃうと、別にインストールしても問題ないものまでコンテナ上で動かしたくなりません?特に更新が激しいものはアップデートの導入が面倒なので、つい Docker image を探しがち。
というわけで、AWS Lambda で実行する Java 11 コードを、docker-lambda を用いてローカル環境で開発・テスト実行させてみました。Docker 以外はインストール不要なので、気軽に試せて良い感じです。
ググってみても python や nodejs の説明ばかりヒットする気がしたので、簡単なメモとしてまとめておきます。
docker-lambda とは
docker-lambda は AWS Lambda 開発環境を Docker ベースで提供するものです。以下、概要部分を簡単に訳しておきますね。
インストールされているソフトウェアとライブラリ、ファイル構造と権限、環境変数、コンテキストオブジェクトと動作を含む「ライブ AWS Lambda 環境」をほぼ同じように複製するサンドボックス化されたローカル環境。ユーザーと実行中のプロセスも同じです。
docker-lambda を使用することで、同じ厳密な Lambda 環境で関数を実行し、ライブでデプロイしたときに同じ動作を示せます。AWS Lambda に存在するライブラリバージョンと同様にネイティブ依存関係をコンパイルし、AWS CLI を使用してデプロイすることもできます。サンプルコードの導入
テスト用のフォルダ(ディレクトリ)を作成し、docker-lambda/examples/java/ にあるファイルを配置します。該当リポジトリ を丸ごと clone もしくは zip 形式でダウンロードして、該当部分だけをコピーすると楽でしょう。
サンプルコードのビルド
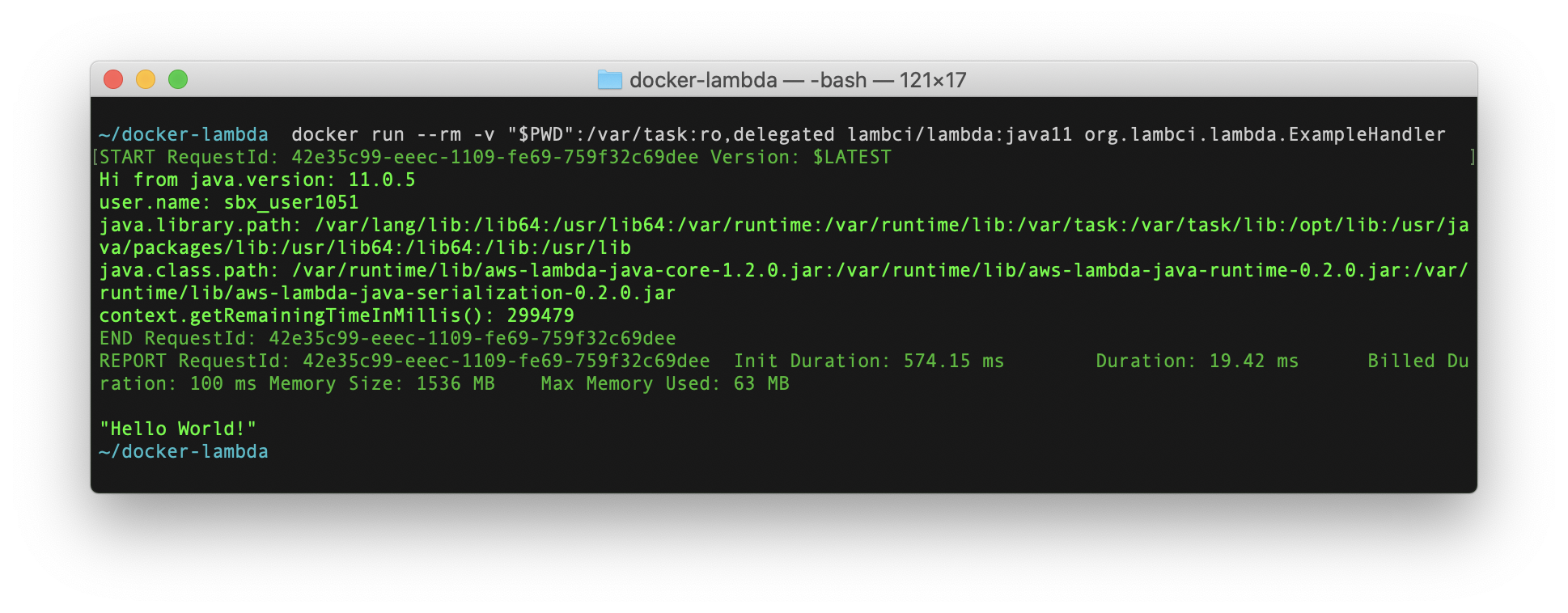
ダウンロードしたサンプルは Java のソースコード です。テスト用のフォルダに移動し、Docker コマンドでビルド(コードのコンパイル)を実施します。
docker run --rm -v $PWD:/var/task lambci/lambda:build-java11 gradle buildなお私は Windows 環境なので
$PWDが使えないため、実際のフォルダ (今回は c:/work/java/docker-lambda) を指定しました。docker run --rm -v c:/work/java/docker-lambda:/var/task lambci/lambda:build-java11 gradle build問題無く実行されれば build フォルダが作成され、その中に幾つかのフォルダが生成されるはずです。この中の docker フォルダに、コンパイルされたクラスのバイトコードと、実行に必要なライブラリが格納されています。
サンプルコードの実行
作成された実行クラスは、
build/docker/フォルダ内にあります。以下のコマンドで実行してみます。docker run --rm -v $PWD/build/docker:/var/task \ lambci/lambda:java11 org.lambci.lambda.ExampleHandler \ '{"some": "event"}'Windows 環境では改行を使わず、JSON の指定方法も修正して、実際には以下のように実施しています。
docker run --rm -v c:/work/java/docker-lambda/build/docker:/var/task lambci/lambda:java11 org.lambci.lambda.ExampleHandler "{\"some\": \"event\"}"AWS SDK API を利用してみる
サンプルの実行だけで終わるのも寂しいですので、S3 のバケット一覧を取得してみます。
サンプルコードの修正
AWSのガイド を参考に、まずは import 文を追加します。
src/main/java/org/lambci/lambda/ExampleHandler.javaimport com.amazonaws.regions.Regions; import com.amazonaws.services.s3.AmazonS3; import com.amazonaws.services.s3.AmazonS3ClientBuilder; import com.amazonaws.services.s3.model.Bucket; import java.util.List;そして
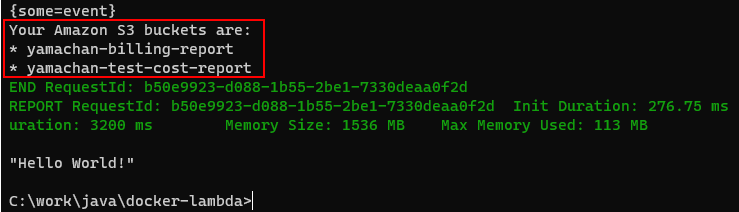
handleRequest関数の終わり (Return文の前) に以下のコードを追加します。src/main/java/org/lambci/lambda/ExampleHandler.javalogger.log("Your Amazon S3 buckets are:\n"); final AmazonS3 s3 = AmazonS3ClientBuilder.standard().withRegion(Regions.DEFAULT_REGION).build(); List<Bucket> buckets = s3.listBuckets(); for (Bucket b : buckets) { logger.log("* " + b.getName() + "\n"); }この段階でビルドを実施すると、S3 関連の SDK ライブラリが見つからずエラーになります。テスト用フォルダにある build.gradle にビルド用の設定(2行)を追加します。
build.gradledependencies { implementation platform('com.amazonaws:aws-java-sdk-bom:1.11.99') // この行を追加 implementation ( 'com.amazonaws:aws-lambda-java-core:1.2.0', 'com.amazonaws:aws-lambda-java-events:2.2.7', // カンマ追加 'com.amazonaws:aws-java-sdk-s3' // この行を追加 ) }これで先ほどと同じコマンドで、ビルドできるようになりました。
修正したサンプルコードの実行
さきほどと同様にコードを実行しようとすると、権限エラーになります。以下のように -e オプションで
AWS_ACCESS_KEYとAWS_SECRET_ACCESS_KEYの値を渡してあげましょう。docker run --rm -v $PWD/build/docker:/var/task \ -e AWS_ACCESS_KEY_ID=XXX -e AWS_SECRET_ACCESS_KEY=XXXXXX \ lambci/lambda:java11 org.lambci.lambda.ExampleHandler \ '{"some": "event"}'Windows の場合は1行にまとめて、JSON 表記など修正して以下のように実行します。
docker run --rm -v c:/work/java/docker-lambda/build/docker:/var/task -e AWS_ACCESS_KEY_ID=XXX -e AWS_SECRET_ACCESS_KEY=XXXXXX lambci/lambda:java11 org.lambci.lambda.ExampleHandler "{\"some\": \"event\"}"こんな感じで s3 バケットのリストが得られれば成功です。
AWS_ACCESS_KEYとAWS_SECRET_ACCESS_KEYは、AWS でユーザーを作成して、その「認証情報」タブから作成・取得ができます。なんの権限もない新規ユーザーを作成し、開発対象である Lambda 関数と同じアクセス権限(ロールやポリシー)を与えて利用するのが良さそうです。stay-open モードで開発する
4つのオプションを追加して、更に便利に開発していきましょう。
- 環境変数
DOCKER_LAMBDA_STAY_OPEN=1で API 待ち受けモードになる-p 9001:9001オプションで待ち受けするポートを指定する- 環境変数
DOCKER_LAMBDA_WATCH=1でファイルの変更を監視し、サービスの再スタートを実施する--restart on-failureDockerオプションでエラー時に自動的に再起動する (Java 11では必須ではない)以下のようなコマンド実行になります。
docker run -v $PWD/build/docker:/var/task \ --restart on-failure \ -e DOCKER_LAMBDA_WATCH=1 -e DOCKER_LAMBDA_STAY_OPEN=1 -p 9001:9001 \ -e AWS_ACCESS_KEY_ID=XXX -e AWS_SECRET_ACCESS_KEY=XXXXXX \ lambci/lambda:java11 org.lambci.lambda.ExampleHandler \ '{"some": "event"}'Windows の場合は以下のように実行します。
docker run -v c:/work/java/docker-lambda/build/docker:/var/task --restart on-failure -e DOCKER_LAMBDA_WATCH=1 -e DOCKER_LAMBDA_STAY_OPEN=1 -p 9001:9001 -e AWS_ACCESS_KEY_ID=XXX -e AWS_SECRET_ACCESS_KEY=XXXXXX lambci/lambda:java11 org.lambci.lambda.ExampleHandler "{\"some\": \"event\"}"別なターミナル画面を開き、以下のように curl などでアクセスしてみましょう。
curl -d "{}" http://localhost:9001/2015-03-31/functions/myfunction/invocations以下のように Return 文の内容 "Hello World!" が返ってくれば動作は成功です。ログは Docker を実行したほうのターミナルのほうに表示されています。
試しにソースコードを修正してビルドを実行すると、/build/docker フォルダの変更を感知して、サービスが自動的に再始動します。
おわりに
Docker 環境されあれば docker-lambda を用いてローカルで AWS Lambda 関数の開発を実施できます。好みのエディタでサクサク開発でき、テストも容易です。いろんなコードを書いて、試してみましょう!
それではまた。


- 投稿日:2020-07-26T21:27:26+09:00
AWS EC2でKong
AWS EC2でKongを利用してみようとしたら躓いたのでメモ。
aws market placeにあるものを使うとインスタンスの起動までしてくれる。便利。
Kongの記事で「nanoでもすごい性能を発揮したよ!」(参照:Kong、他社API管理製品の14倍の性能を実測)と出てたので、nanoでも動くと思ってインスタンスを作ってみた。
ただ、sshで入っても動いている気配がない。仕方なく、とりあえず「ベンダーおすすめ!」らしい、「c3.8xlarge」にしてみる。東京リージョンは毎時約2ドル、月で約1,440ドル、日本円で約16万円とかするので動かしっぱなしにはできない。
$ ps aux | grep -i kong ec2-user 4913 0.0 0.0 432252 14048 ? Ss 12:01 0:00 nginx: master process /usr/local/openresty/nginx/sbin/nginx -p /usr/local/kong -c nginx.confどうやらこちらは動いている。nanoのときは出てこなかった行だ。
こちらを参考にコマンドを叩いてみても、ちゃんと動いているっぽい。ささっと「c3.8xlarge」インスタンスをterminateして、安くて動くものを探す旅に出る。
結論
けっこう長い旅でした。
時間あたりの価格が安いものから試していってみた結果、「t3.medium」インスタンスならばどうやら動く、という結論に達しました。1日(24時間)あたりなら、約138円。開発時に作って使ってサッと消す、であればそこまで高額ではないですね。
表は東京リージョンのもの。ドル円相場は2020年7月26日現在で取得した値、1ドル=106.13円で換算。月の稼働時間は744時間で換算(31日×24時間)。
インスタンスタイプ ドル/毎時 RAM(GB) 月額 結果 t3.nano $0.007 0.5 553円 × t3.micro $0.014 1 1,105円 × t3.small $0.027 2 2,132円 × t3.medium $0.054 4 4,264円 ○ c4.8xlarge $2.016 60 159,185円 ○ なんで動かないのか
$ cassandra OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000cf600000, 815792128, 0) failed; error='Cannot allocate memory' (errno=12) # # There is insufficient memory for the Java Runtime Environment to continue. # Native memory allocation (mmap) failed to map 815792128 bytes for committing reserved memory.Cassandraを実行するのにメモリが足りないので。
PostgreSQLを使うんであれば、もっと下のインスタンスでも行けるかもしれない。
ワンタッチで使えるインスタンスを用意したいのであれば、t3.medium以上を選びましょう。参考
API GatewayのKongをインストールしてみた
Kongの設定コマンドがとても素敵にまとまっています?
- 投稿日:2020-07-26T20:55:12+09:00
【Postfix/Dovecot】メールサーバ構築(EC2利用)
目標
AWS EC2上にPostfixとDovecotをインストールし、メールサーバ(SMTPサーバ・POP/IMAPサーバ)を構築する。
前提
・メールサーバとして利用するEC2が構築済みであること。
・ドメインを取得し、DNSに登録されていること(※1)。
・注意点として、AWSEC2はデフォルトだと、EC2⇒インターネットの25番ポート宛て通信が制限されており不可となっております(スパムメールの踏み台に利用されることを回避するためで、許可するには別途AWSへ申請を行う必要があるよう)(※2)。※1 以下記事で、ドメイン取得、及びDNS登録(AWS Route53利用)を実施致しました。
AWS Route53を利用してEC2へ独自ドメインアクセス※2 参考AWSドキュメント
EC2 インスタンスからポート 25 の制限を削除するにはどうすればよいですか?利用環境
仮想マシン: AWS EC2
OS: Red Hat Enterprise Linux 8
ミドルウェア: Postfix、Dovecot作業の流れ
項番 タイトル 1 SMTPサーバの構築 2 POP/IMAPサーバの構築 3 DNSレコード登録 4 SMTPサーバの動作チェック 5 POP/IMAPサーバの動作チェック 手順
1.SMTPサーバの構築
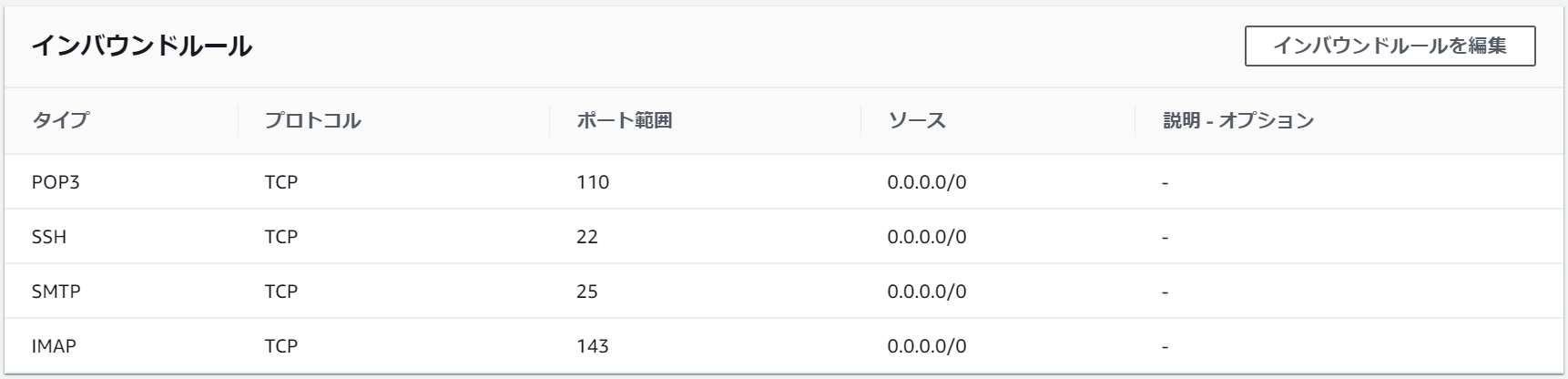
①メールサーバとして利用予定のEC2のセキュリティグループ確認
以下のように、SSHに加え、SMTP、POP3、IMAPのポートが開いていることを確認
②対象のEC2にOSログインし、postfixをインストール
ルートスイッチ
sudo su -postfixインストール実行
yum install postfix③postfixのメイン設定ファイル(main.cf)編集
設定例です。myhostname、mydomain、mynetworksに関してはホスト名やドメイン名に従って書き換えをする必要があります。vi /etc/postfix/main.cf# 自ホスト名 myhostname = mailserver.ryosukeonline.com # 自ドメイン設定 mydomain = ryosukeonline.com myorigin = $myhostname # ローカルホスト以外からも通信を受け付ける inet_interfaces = all # メールを取得するドメイン名(メールの宛先ドメインがここで指定した値にマッチした場合、自ホスト宛てとして認識する) mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain # メール中継を許可するSMTPクライアントのアドレス(VPCのネットワークアドレスとローカル通信あたりを指定すればOK) mynetworks = 172.31.0.0/16, 127.0.0.0/8 # Mairdir形式でメールを保存 home_mailbox = Maildir/③メール受信用ディレクトリ作成
本記事ではメールボックスの形式としてMaildir形式(現在の主流、各ユーザのホームディレクトリ以下に1メール1ファイルとして保存する形式)を利用しているため、ユーザ作成時、ホームディレクトリにメール受信用ディレクトリが自動的に作成されるよう設定します。mkdir -p /etc/skel/Maildir/{new,cur,tmp}chmod -R 700 /etc/skel/Maildir/④メール受信用テストユーザ作成
useradd testpasswd test# /home/test/Maildir/配下に以下のディレクトリが作成されていればOK ls -l /home/test/Maildir/ total 0 drwx------. 2 test test 6 Jul 23 10:13 cur drwx------. 2 test test 6 Jul 23 10:13 new drwx------. 2 test test 6 Jul 23 10:13 tmp⑤postfix起動
systemctl start postfix# 状態がrunnningであること systemctl status postfix25番ポートが開いていることを確認します。
# 25番ポートがLISTENであること netstat -atn自動起動も有効化しておきます。
systemctl enable postfix systemctl is-enabled postfix2.POP/IMAPサーバの構築
①Dovecotのインストール
yum install dovecot②Dovecotの設定ファイルの編集
メイン設定ファイルdovecot.conf編集
vi /etc/dovecot/dovecot.conf# IMAPとPOP3を通信プロトコルとして利用する protocols = imap pop3外部からのプレインテキスト通信を許可(IMAPとPOP3はSSL暗号化がされていないため、デフォルトの設定ですと通信が拒否されてしまうようです。その回避策として実施する必要があります。)
vi /etc/dovecot/conf.d/10-auth.confdisable_plaintext_auth = novi /etc/dovecot/conf.d/10-ssl.confssl = no③Dovecot起動
systemctl start dovecot systemctl status dovecot# 110及び143番ポートが開いていること netstat -atn自動起動の有効化
systemctl enable dovecot systemctl is-enabled dovecot3.DNSレコード登録
メールサーバのDNSレコード登録
DNSに登録済みのドメインに、メールサーバのMXレコード及びAレコードを追加(※)します。※登録方針
<ドメイン名> in MX 10 <メールサーバ名>
<メールサーバ名> in A <メールサーバのグローバルIPアドレス>
念のためコマンドプロンプトからnslookupで名前解決確認
# MXレコードの確認 nslookup -type=mx ryosukeonline.com (中略) ryosukeonline.com MX preference = 10, mail exchanger = mailserver.ryosukeonline.com # Aレコードの確認 nslookup mailserver.ryosukeonline.com (中略) 名前: mailserver.ryosukeonline.com Address: 18.183.102.1444.SMTPサーバの動作チェック
①構築したメールサーバに向けてメールを送信
Outlook等を利用します。
②メールが届いているかメールサーバ内確認
# /home/test/Maildir/new/配下にメールが追加されていればOK ls -l /home/test/Maildir/new/ total 8 -rw-------. 1 test test 7367 Jul 24 11:13 1595589209.Vca02I1000b85M204385.ip-172-31-44-212.ap-northeast-1.compute.internal5.POP/IMAPサーバの動作チェック
他のEC2からPOP及びIMAP通信(telnet利用)を試みます(※)。
※POPやIMAPのコマンドは以下を参考に致しました。
・POP
メールサーバー構築手順(Postfix / Dovecot)初心者でもできるメモ(受信メール確認)
・IMAP
IMAPをコマンド操作する①メールサーバとは別のEC2にOSログインし、telnetをインストール
sudo yum install telnet②POPサーバのチェック
POP通信でメールサーバに保存されているメールが確認できればOKです。telnet mailserver.ryosukeonline.com 110 # telnetで110番ポート(POPサーバ)接続 Trying 52.192.196.3... Connected to mailserver.ryosukeonline.com. Escape character is '^]'. +OK Dovecot ready. User test # ユーザ名の入力 +OK Pass password # testユーザのパスワードを入力 +OK Logged in. LIST # メール一覧の取得 +OK 2 messages: 1 7516 2 7517 . RETR 1 # メール番号1の内容を確認 +OK 7516 octets # 以下メール内容はほぼ省略した内容 To: "test@ryosukeonline.com" <test@ryosukeonline.com> Subject: TEST SUBJECT Thread-Topic: TEST SUBJECT Date: Sun, 26 Jul 2020 10:00:36 +0000 This is a test mail! . QUIT # 通信終了 +OK Logging out. Connection closed by foreign host.③IMAPサーバのチェック
IMAP通信でメールサーバに保存されているメールが確認できればOKです。# telnetで143番ポート(IMAP)へ通信 telnet mailserver.ryosukeonline.com 143 Trying 52.192.196.3... Connected to mailserver.ryosukeonline.com. Escape character is '^]'. * OK [CAPABILITY IMAP4rev1 SASL-IR LOGIN-REFERRALS ID ENABLE IDLE LITERAL+ AUTH=PLAIN] Dovecot ready. # <識別子> login <ユーザ名> <パスワード> //ログインする 1 login test password 1 OK [CAPABILITY IMAP4rev1 SASL-IR LOGIN-REFERRALS ID ENABLE IDLE SORT SORT=DISPLAY THREAD=REFERENCES THREAD=REFS THREAD=ORDEREDSUBJECT MULTIAPPEND URL-PARTIAL CATENATE UNSELECT CHILDREN NAMESPACE UIDPLUS LIST-EXTENDED I18NLEVEL=1 CONDSTORE QRESYNC ESEARCH ESORT SEARCHRES WITHIN CONTEXT=SEARCH LIST-STATUS BINARY MOVE SNIPPET=FUZZY PREVIEW=FUZZY LITERAL+ NOTIFY SPECIAL-USE] Logged in # <識別子> list "" * //メールボックス一覧確認 2 list "" * * LIST (\HasNoChildren) "." INBOX 2 OK List completed (0.001 + 0.000 secs). # <識別子> select INBOX //メールボックス内容確認 3 select INBOX * FLAGS (\Answered \Flagged \Deleted \Seen \Draft) * OK [PERMANENTFLAGS (\Answered \Flagged \Deleted \Seen \Draft \*)] Flags permitted. * 2 EXISTS * 0 RECENT * OK [UIDVALIDITY 1595758218] UIDs valid * OK [UIDNEXT 3] Predicted next UID 3 OK [READ-WRITE] Select completed (0.001 + 0.000 secs). # <識別子> fetch 1 body[] //メール内容確認 4 fetch 1 body[] * 1 FETCH (BODY[] {7516} To: "test@ryosukeonline.com" <test@ryosukeonline.com> Subject: TEST SUBJECT Thread-Topic: TEST SUBJECT Date: Sun, 26 Jul 2020 10:00:36 +0000 This is a test mail! 4 OK Fetch completed (0.001 + 0.000 secs). # <識別子> logout //通信終了 5 logout * BYE Logging out 5 OK Logout completed (0.001 + 0.000 secs). Connection closed by foreign host.


- 投稿日:2020-07-26T20:54:57+09:00
AWS認定 ソリューションアーキテクト プロフェッショナル(SAP-C01)に合格しました。
AWS認定のアソシエイト資格3種類合格したので
より知識の定着を図るために
AWS認定 ソリューションアーキテクト プロフェッショナル(SAP-C01)を続けて受験し合格しました。合格時のAWS歴
(業務歴的には)半年
個人学習歴的には1年程度点数推移
1回目→728点(2020-05-31)
2回目→840点(2020-07-26)難易度について
他の方もまとめている通り、難易度が高いです。
問題文と選択肢がSAAの比ではなく長文かつ、
最適なソリューションを選択肢を比較して(怪しい日本語を)咀嚼して回答しなければなりません。
試験時間(180分)はかなり長いですが、それでも厳しい時間制限です。(75問あるので、1問にかけられる時間は3分)勉強法
勉強期間は、合計で4か月程度(集中すればもっと短縮できたはず)
SAAと違ってBlackBeltで概要をつかむだけでは合格は厳しいかと思うので
可能であれば、実際にマネジメントコンソール上で操作して勉強したいのですが、
SAPはDMSなどの移行サービスも試験範囲に含まれたり、Organizationsのエンタープライズ組織前提の設計も試験範囲に含まれるので
個人利用だと難しい部分があるように思いました。
※業務で触った分野はやはり理解度が違います。書籍であればAWS認定ソリューションアーキテクト-プロフェッショナル ~試験特性から導き出した演習問題と詳細解説
が現状唯一の問題集になりますが、本番のレベル感に近いのでおすすめです。(こんなに綺麗な日本語では出ないので、英語ができる方は本番は英語で解いた方が簡単かもしれません。)ネットの問題集だとwhizlabsをグーグル翻訳しながら解きました。
問題解いて分からなかった部分を自分なりにまとめたり、検証してみるのが合格への近道かと思いました。(当然ですが)
補足:AWS SAA合格後に次に直に受験する方が特に勉強すべきと思われる部分
試験ガイド内の、
分野 1: 組織の複雑さに対応する設計
→Organizationsの実装レベルの理解(マルチアカウント前提の設計)
分野 2: 新しいソリューションの設計
→サーバレスアーキテクチャのある程度の実装レベルでの理解(概要レベルだとあやしい)
→DR設計が概要レベルで理解(パイロットライト、RTO・RPOなど)
→オンプレミスの既存サイトとの連携・設計
→Cloudformationの用語がわかること
分野 3: 移行の計画
→移行関係のマネージドサービスの理解
分野 4: コスト管理
→ワークロードに最適なインスタンスをある程度理解している(この状況なら、リザーブドインスタンスを使用すべきなど)
- 投稿日:2020-07-26T20:35:21+09:00
S3バケットポリシーでエラーが出た際の対応
S3のバケットポリシーの登録で、コピペした一見問題なさそうなコードにエラーが出て少しはまりました。
エラー内容
this policy contains invalid Json
画像コード
{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::IAMユーザーのarn情報:user/IAMユーザー名" }, "Action": "s3:*", "Resource": "arn:aws:s3:::バケット名" } ] }日本語訳は「無効なJsonデータ」とのこと。文法ミスや誤入力で起こることが多い様です。
コピペのみで、見直してもコードに誤字脱字はなさそう・・・インテンドや文法ミスも確認したのですが、問題ありませんでした。
エラー解決・原因
スマートな解決法ではないかもしれないですが、同様の記述がある違う記事をコピペしたら
エラーが出ませんでした。
コピペでも、貼り付けデータによっては無効な情報とS3側が受け取ってしまうエラーが起こることがある様です。参考元
※バケットポリシーのコードはプラグラミングスクールの教材を利用
●この記事のエラーに関わることが掲載されています
https://acloud.guru/forums/aws-certified-cloud-practitioner/discussion/-LXsAmzSKItLpOLBQe18/ERROR%20this%20policy%20contains%20invalid%20Json
- 投稿日:2020-07-26T20:35:21+09:00
S3バケットポリシーでエラーが出た際の対応【this policy contains invalid Json】
S3のバケットポリシーの登録で、一見問題なさそうなコードにエラーが出て少しはまりました。
エラー内容
this policy contains invalid Json
画像コード
{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::IAMユーザーのarn情報:user/IAMユーザー名" }, "Action": "s3:*", "Resource": "arn:aws:s3:::バケット名" } ] }日本語訳は「無効なJsonデータ」とのこと。文法ミスや誤入力で起こることが多い様です。
コピペのみで、見直してもコードに誤字脱字はなさそう・・・インテンドや文法ミスも確認したのですが、問題ありませんでした。
エラー解決・原因
スマートな解決法ではないかもしれないですが、同様の記述がある違う記事をコピペしたら
エラーが出ませんでした。
コピペでも、貼り付けデータによっては無効な情報とS3側が受け取ってしまうエラーが起こることがある様です。参考元
※バケットポリシーのコードはプラグラミングスクールの教材を利用
●この記事のエラーに関わることが掲載されています
https://acloud.guru/forums/aws-certified-cloud-practitioner/discussion/-LXsAmzSKItLpOLBQe18/ERROR%20this%20policy%20contains%20invalid%20Json
- 投稿日:2020-07-26T18:38:44+09:00
EKSのコンテナログをFluentd Bitで収集しCloudWatch Logsに集約する
はじめに
EKS上のログを収集してそれをCloudWatch Logsに集約するにはfluentd-cloudwatchをデプロイするのが定番のパターンです。
これをFluent Bitでも行えるようにAWSが公式でaws-for-fluent-bitを公開しているので試してみました。環境
macOS Mojave 10.14.6
EKS 1.16
Helm 2.14.3
Helmfile 0.122.0導入手順
EKSやHelm Tillerは既にデプロイ済みであるとします。
Fluent BitはデフォルトでCloudWatch LogsにアクセスするためのIAM Roleが付与されないので自分で設定していく必要があります。IAM Roleの用意
Fluent BitがCloudWatch Logsにログを転送させるためのIAM Roleを作成していきます。
kube2iamを利用するためAssume Roleを設定する必要があります。Node用のIAM Role
作成したWorker Node用のIAM RoleにPolicyをアタッチします。
<NODE_INSTANCE_ROLE>にはWorker Nodeのインスタンスロールが入ります。assume-role-policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "*" } ] }$ aws iam create-policy \ --policy-name assume-role-policy \ --policy-document assume-role-policy.json$ aws iam attach-role-policy \ --role-name <NODE_INSTANCE_ROLE> \ --policy-arn arn:aws:iam::XXXXXXXXXX:policy/assume-role-policyPod用のIAM Role
公式のCloudWatchLogsFullAccessのPolicyを付与したIAM Roleを作成します。
cloud-watch-logs-full-access-policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::XXXXXXXXXX:role/<NODE_INSTANCE_ROLE>" }, "Action": "sts:AssumeRole" } ] }$ aws iam create-role \ --role-name cloud-watch-logs-full-access-role \ --assume-role-policy-document cloud-watch-logs-full-access-policy.json$ aws iam attach-role-policy \ --role-name cloud-watch-logs-full-access-role \ --policy-arn arn:aws:iam::aws:policy/CloudWatchFullAccesskube2iamとFluent Bitのデプロイ
Helmでkube2iamとFluent Bitをデプロイしていきます。
Fluent Bitに関してはtemplateを修正する必要があるのでローカルにHelm Chartをダウンロードします。$ helm repo add aws https://aws.github.io/eks-charts $ helm fetch aws/aws-for-fluent-bit --version 0.1.2 $ tar xvzf aws-for-fluent-bit-0.1.2.tgz下記のようにPodのannotationsにIAM Roleを定義します。
aws-for-fluent-bit/templates/daemonset.yamlspec: template: metadata: + annotations: + iam.amazonaws.com/role: cloud-watch-logs-full-access-roleHelmfileにkube2iamとFluent Bitに関する情報を記述します。
cloudwatchの設定でリージョン名を入れます。firehoseとkinesisは今回使いません。helmfile.yamlrepositories: - name: stable url: https://kubernetes-charts.storage.googleapis.com releases: - name: kube2iam namespace: kube-system chart: stable/kube2iam version: 2.5.0 values: - host: iptables: true interface: eni+ extraArgs: auto-discover-base-arn: "" rbac: create: true - name: aws-for-fluent-bit namespace: kube-system chart: ./aws-for-fluent-bit values: - cloudWatch: region: "ap-northeast-1" firehose: enabled: false kinesis: enabled: false次のコマンドでデプロイします。
$ helmfile -f ./helmfile.yaml apply確認
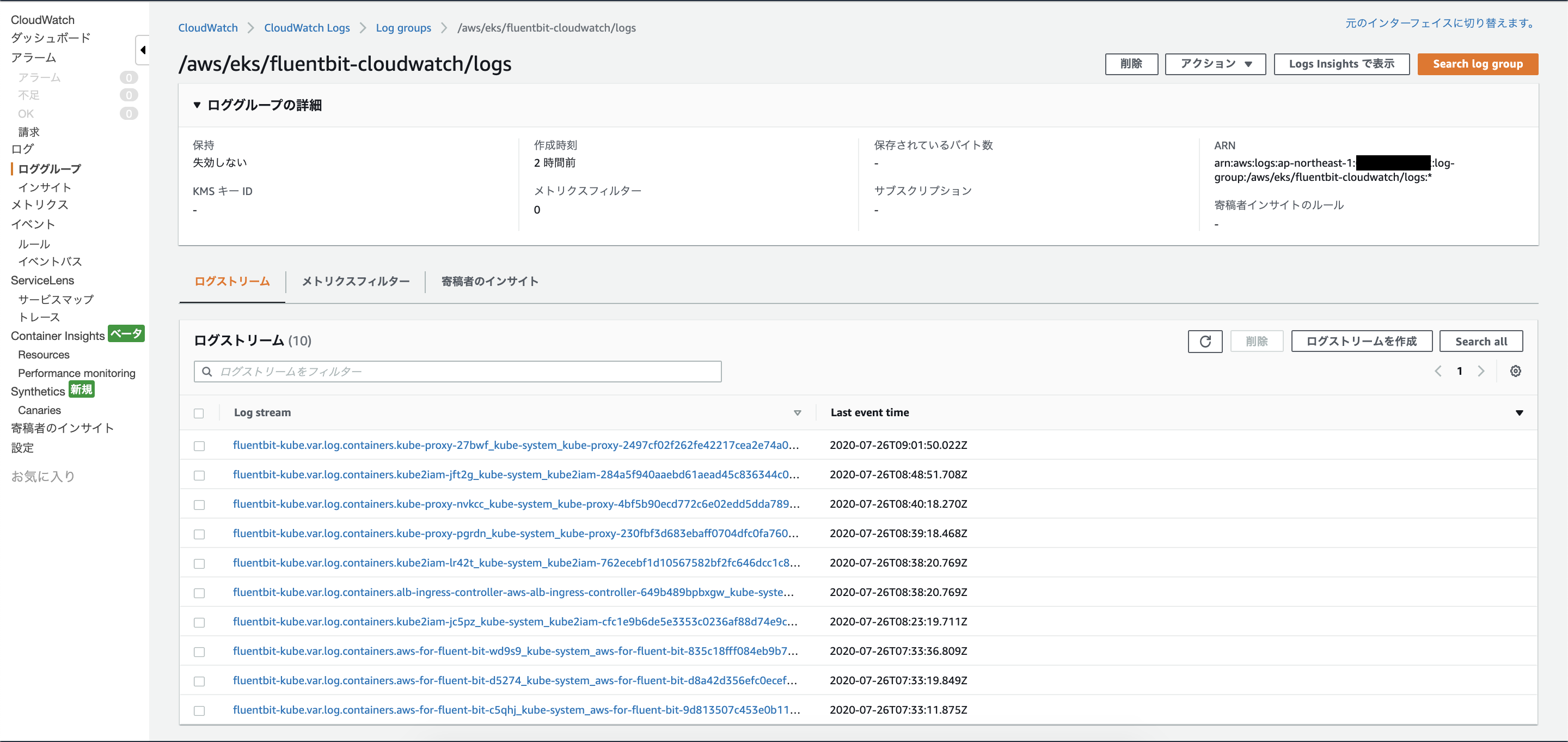
AWSコンソールで実際にログが集約されていることが確認できます。
デフォルトではロググループ名は/aws/eks/fluentbit-cloudwatch/logsとなっています。
まとめ
FluentdではなくFluent Bitでコンテナログを収集してCloudWatch Logsに集約できることを確認しました。
本来はFluent Bitを使うことでリソースの節約をしたいところですが、Helm Chartのデフォルト値は
resources.requests.cpu=500m、resources.requests.memory=500Miとなっており、Fluentd-CloudWatchがそれぞれ100m、200Miであることを考えると厳しそうです。
あくまで参考値なので、実際のリソース消費は調査しないといけないです。導入に関してはHelm Chartが存在するのでとても簡単でした。
- 投稿日:2020-07-26T18:38:44+09:00
EKSのコンテナログをFluent Bitで収集しCloudWatch Logsに集約する
はじめに
EKS上のログを収集してそれをCloudWatch Logsに集約するにはfluentd-cloudwatchをデプロイするのが定番のパターンです。
これをFluent Bitでも行えるようにAWSが公式でaws-for-fluent-bitを公開しているので試してみました。環境
macOS Mojave 10.14.6
EKS 1.16
Helm 2.14.3
Helmfile 0.122.0導入手順
EKSやHelm Tillerは既にデプロイ済みであるとします。
Fluent BitはデフォルトでCloudWatch LogsにアクセスするためのIAM Roleが付与されないので自分で設定していく必要があります。IAM Roleの用意
Fluent BitがCloudWatch Logsにログを転送させるためのIAM Roleを作成していきます。
kube2iamを利用するためAssume Roleを設定する必要があります。Node用のIAM Role
作成したWorker Node用のIAM RoleにPolicyをアタッチします。
<NODE_INSTANCE_ROLE>にはWorker Nodeのインスタンスロールが入ります。assume-role-policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "*" } ] }$ aws iam create-policy \ --policy-name assume-role-policy \ --policy-document assume-role-policy.json$ aws iam attach-role-policy \ --role-name <NODE_INSTANCE_ROLE> \ --policy-arn arn:aws:iam::XXXXXXXXXX:policy/assume-role-policyPod用のIAM Role
公式のCloudWatchLogsFullAccessのPolicyを付与したIAM Roleを作成します。
cloud-watch-logs-full-access-policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::XXXXXXXXXX:role/<NODE_INSTANCE_ROLE>" }, "Action": "sts:AssumeRole" } ] }$ aws iam create-role \ --role-name cloud-watch-logs-full-access-role \ --assume-role-policy-document cloud-watch-logs-full-access-policy.json$ aws iam attach-role-policy \ --role-name cloud-watch-logs-full-access-role \ --policy-arn arn:aws:iam::aws:policy/CloudWatchFullAccesskube2iamとFluent Bitのデプロイ
Helmでkube2iamとFluent Bitをデプロイしていきます。
Fluent Bitに関してはtemplateを修正する必要があるのでローカルにHelm Chartをダウンロードします。$ helm repo add aws https://aws.github.io/eks-charts $ helm fetch aws/aws-for-fluent-bit --version 0.1.2 $ tar xvzf aws-for-fluent-bit-0.1.2.tgz下記のようにPodのannotationsにIAM Roleを定義します。
aws-for-fluent-bit/templates/daemonset.yamlspec: template: metadata: + annotations: + iam.amazonaws.com/role: cloud-watch-logs-full-access-roleHelmfileにkube2iamとFluent Bitに関する情報を記述します。
cloudwatchの設定でリージョン名を入れます。firehoseとkinesisは今回使いません。helmfile.yamlrepositories: - name: stable url: https://kubernetes-charts.storage.googleapis.com releases: - name: kube2iam namespace: kube-system chart: stable/kube2iam version: 2.5.0 values: - host: iptables: true interface: eni+ extraArgs: auto-discover-base-arn: "" rbac: create: true - name: aws-for-fluent-bit namespace: kube-system chart: ./aws-for-fluent-bit values: - cloudWatch: region: "ap-northeast-1" firehose: enabled: false kinesis: enabled: false次のコマンドでデプロイします。
$ helmfile -f ./helmfile.yaml apply確認
AWSコンソールで実際にログが集約されていることが確認できます。
デフォルトではロググループ名は/aws/eks/fluentbit-cloudwatch/logsとなっています。
まとめ
FluentdではなくFluent Bitでコンテナログを収集してCloudWatch Logsに集約できることを確認しました。
本来はFluent Bitを使うことでリソースの節約をしたいところですが、Helm Chartのデフォルト値は
resources.requests.cpu=500m、resources.requests.memory=500Miとなっており、Fluentd-CloudWatchがそれぞれ100m、200Miであることを考えると厳しそうです。
あくまで参考値なので、実際のリソース消費は調査しないといけないです。導入に関してはHelm Chartが存在するのでとても簡単でした。
- 投稿日:2020-07-26T18:35:02+09:00
AWS Well-Architected Labsのご紹介
AWS Well-Architected Framework
「AWSのベストプラクティスに沿って設計/構築/運用したいけど、何をどうすればベストプラクティスになるのか分かってないな〜」と思っているそこのあなた。AWS Well-Architected Frameworkを使いましょう。オペレーショナルエクセレンス、セキュリティ、信頼性、パフォーマンス効率、コスト最適化の5つの柱についてAWSのベストプラクティスに沿っているかをチェックできます。AWS Well-Architected Frameworkには以下3種類があります。
1. AWS Well-Architected ホワイトペーパー
ベストプラクティスが記載されたドキュメントです。都度更新が入るので、最新のドキュメントは公式ページから確認しましょう。
2. AWSソリューションアーキテクトもしくはWell-Architected認定パートナーによるレビュ
ソリューションアーキテクトもしくはパートナーの方にレビュしてもらいます。使ったことはありませんが、お金はかかりそうです。
3. AWS Well-Architected Tool
AWSのマネジメントコンソールから質問に答えていって、ベストプラクティスに沿っているかをセルフチェックできます。
AWS Well-Architected Labs
ベストプラクティスについてドキュメント読むとか質問に答えるでも良いんだけど、実際に手を動かして理解したいと思う方は多いんじゃ無いんでしょうか。そんな方におすすめなのが、AWS Well-Architected Frameworkの内容をハンズオン形式で学べるAWS Well-Architected Labsです!
自分が実践したハンズオンの内容を別記事としてまとめるので、内容が気になる場合は以下もご覧ください(追記中)。
参考
- 投稿日:2020-07-26T17:56:05+09:00
Lambda+SAMテンプレートのBlue/Greenデプロイメントで「デプロイの再試行」した際の動作を検証する
はじめに
デプロイ運用は、Blue/Greenでシームレスにサービス移行できるのも重要だが、デプロイに失敗した際のロールバックと再デプロイをスムースに行えることも重要だ。
Canaryなデプロイにおける自動ロールバックについては、過去の記事で調査を行ったので、今回は手動ロールバックと再デプロイについての動作検証を行う。
なお、最初に断っておくと、この方法は結果的に期待した動作になっているが、途中でエラーが出たりして怪しさ満点である。もう少しちゃんとした検証が必要かもしれない。
前提条件
- Lambda+SAMテンプレートでの基本的な動作の仕様を理解している(過去の記事で紹介済み)
デプロイは以下の仕様とする
- Prodのエイリアスを使用してCanaryの向き先を制御する(SAMテンプレートで
AutoPublishAlias: Prodとしている)- API GatewayのLambda統合プロキシで、上記Prodをターゲットにしている
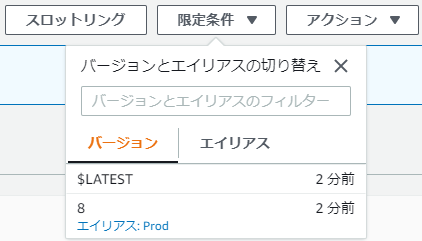
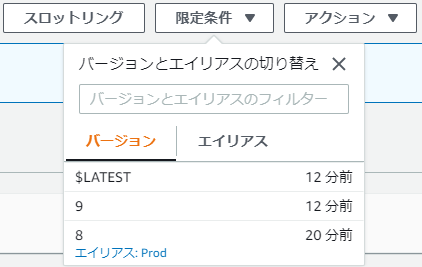
初回デプロイ直後の状態
以下のようになっている。初版と言いながらバージョン8なのは、この記事を書くにあたりいろいろ試行錯誤した結果なのであしからず。
初回の修正を行った状態
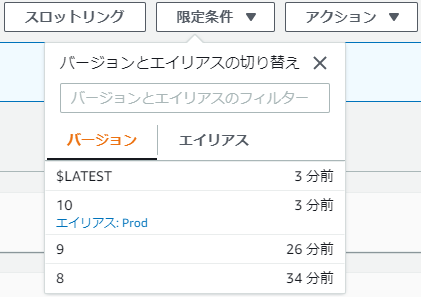
初回の修正を行い、パイプラインが走った後、以下の状態になる。
バージョン9が作られ、Prodのエイリアスが最新バージョンに向いている状態だ。
ここで、バージョン9に不具合があったことが分かったと仮定して、ロールバックをしてみよう。
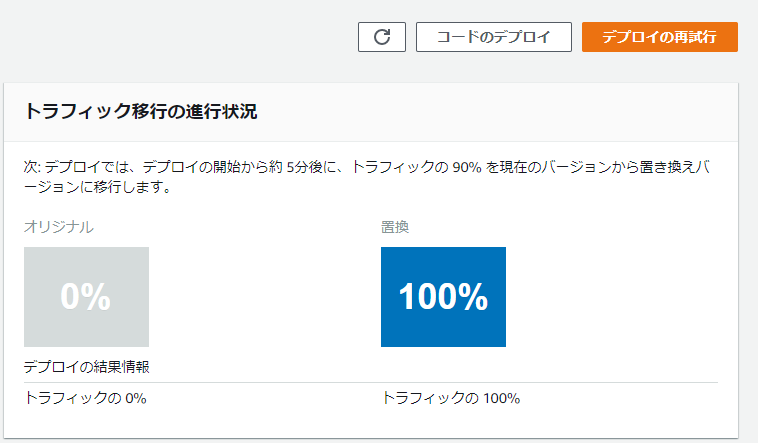
うーん、この「デプロイの再試行」ボタンなのか?日本語的には意味が違うが……
AWSはたまに翻訳が怪しいので、とりあえず押してみると…
なんかエラーが一度出た。が、結果として最後のデプロイは成功しているようなので、確認してみる。
期待した通り、Prodのエイリアスが元通り8を指している。
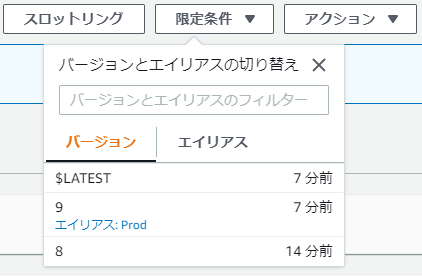
curlによる正常性確認も、しっかりバージョン8の動作をした。では、ここで再度バージョン9の不具合修正を行い、デプロイを行う。
すると、バージョン9を飛ばしてしっかりバージョン10を向くようになった。
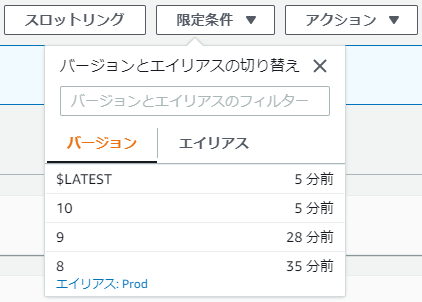
では、仮にここで、さらにバージョン10にも不具合があってロールバックしたらどうなるだろうか?
ここでバージョン9に戻ってしまうと、瑕疵のあるバージョンがデプロイされてしまう。
では、再び「デプロイの再試行」ボタンを押してみよう。
しっかりと、バージョン9ではなくてバージョン8に戻ってくれた。
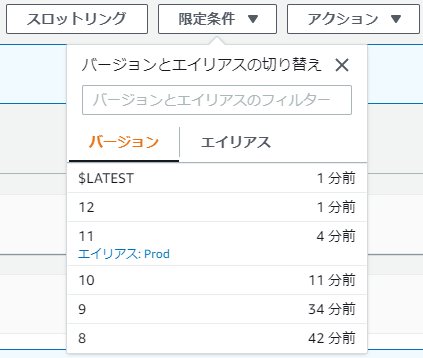
この後、バージョン11をデプロイして、これはデプロイ成功したと仮定して、さらにバージョン12をデプロイ→ロールバックとしてみた。
うむ、デプロイ成功したバージョンについてはしっかり覚えてくれて、そこまでロールバックしてくれるという仕様のようだ。
これ、エラーの謎さえ解けて、これが仕様通りの動作なのだとしたら、完璧に期待通りの動作なのだけど。
エラー内容をGoogleで確認しても分からなかったので、迷宮入りしてしまいそうである……。

- 投稿日:2020-07-26T17:51:27+09:00
Amazon EFS CSI DriverがGAした件
AmazonがEFS CSI DriverのGAをアナウンスした
参考: https://aws.amazon.com/about-aws/whats-new/2020/07/amazon-efs-csi-driver-now-generally-available/
EFSをPersistent Volumeとして使う場合の、以前までの方法
Kubernetesのincubatorリポジトリ内に、Amazon EFS用のPV Provisionerがある
これを用いることで、EFSをPVとして使用できる。
こちらは、CSIを用いていないため、CSI Driver経由でEFSが使用できることは嬉しい。CSI Driver経由でEFSを使うことの嬉しさ
KubernetesにCSI関連の機能が、追加されてきているためその恩恵を得られることと
Kubernetes側でボリューム(EFS, EBS)のバックアップを透過的に行えるのは利点特に、Kubernetes 1.17でBetaとなったVolume Snapshotや、Kubernetes 1.18でGAとなったCSI Volume Cloningが嬉しい。
GAとなったEFS CSI Driverの詳細と課題
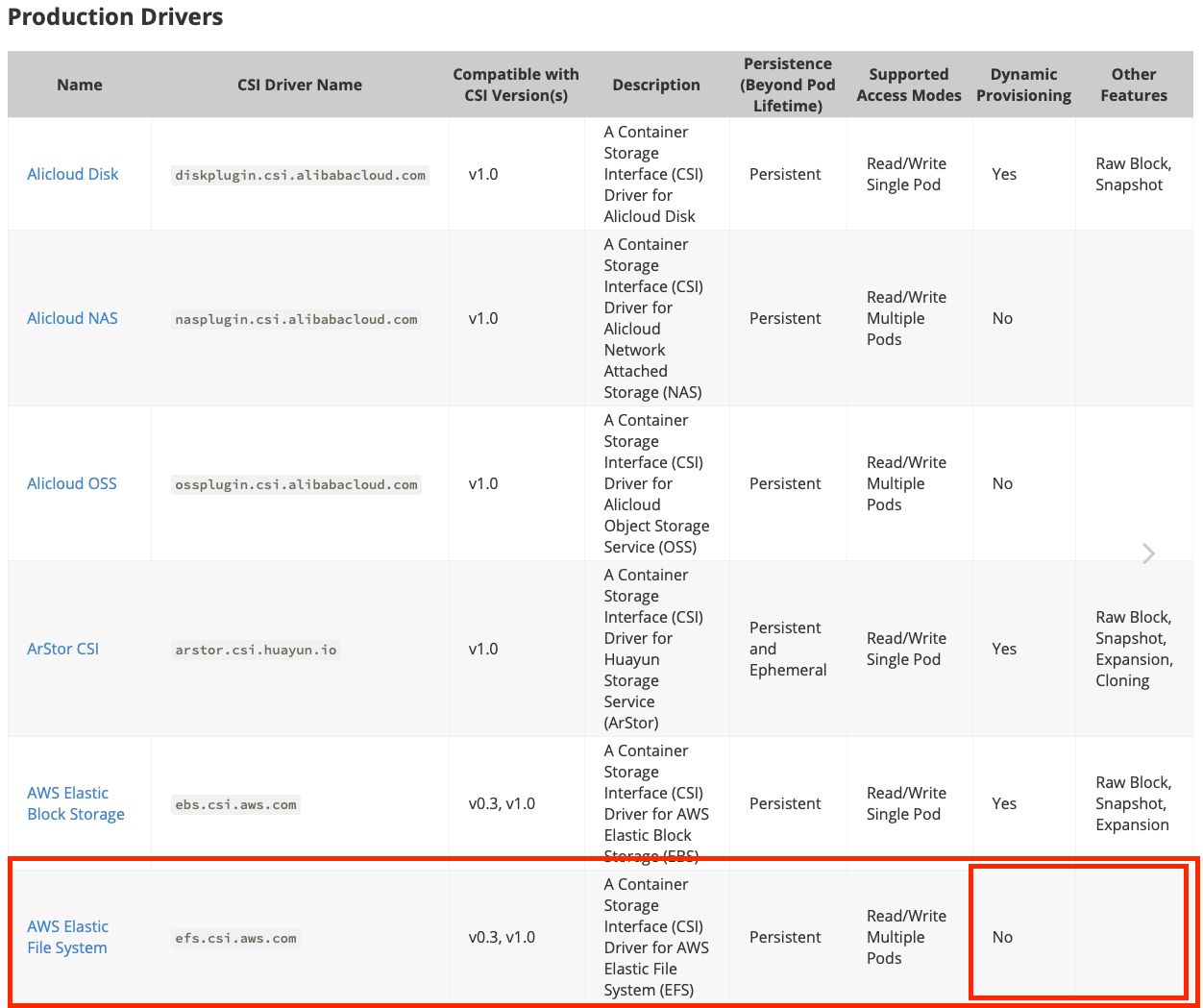
KubernetesのCSI Driverは下記のページにて一覧されており、EFS Provisionerも記載されている。
https://kubernetes-csi.github.io/docs/drivers.html下記は、CSI Driverごとの機能を示した表だが、赤枠部分に注目したい。
- Dynamic Provisioning(PVの動的確保)がまだサポートされていない(2020/07/26時点)。
- Other FeaturesにCloning, Snapshotの記載がない上記より現時点(2020/07/26時点)での導入は控えるのが無難と思われる。
特にDynamic Provisioning機能がないのは厳しい。
EFS CSI DriverのDynamic Provisioning対応状況
EFS CSI DriverのIssue"Implement dynamic provision support"にて、2019/01よりDynamic Provisioningの検討はされてきており、現在も続いている状況。
下記コメント(2020/07/07)にて、 LogMeIn社のリポジトリにてDynamic Provisioningを実装したものが提案されており、EFS CSI Driverに統合したいと申し出ている状況。
https://github.com/kubernetes-sigs/aws-efs-csi-driver/issues/6#issuecomment-654912928
まとめ
- KubernetesのCSI対応状況が進む中で、Amazon EFS CSI DriverがGAしたため詳細を確認した。
- Amazon EFS CSI DriverはDynamic ProvisioningやVolume Snapshot, Volume Cloningには対応していてない状況であり、Github上にて対応が進められている状況を確認した

- 投稿日:2020-07-26T16:18:52+09:00
AWS CDKをTypeScriptで使い始める単純な例
AWS CDKとTypeScriptのインストール
sudo npm install -g aws-cdk sudo npm install -g typescript
- macOSの人はsudoは不要
- typescriptがインストール済みの場合typescriptは不要
作業用ディレクトリ作成
mkdir my-cdk && cd my-cdkテンプレートプロジェクトの作成
cdk init app --language typescriptEC2パッケージを入れる
npm install @aws-cdk/aws-ec2サンプルのファイルを開く
ファイルは、
lib/tutorial-stack.tsにある。import * as cdk from '@aws-cdk/core'; export class TutorialStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); // The code that defines your stack goes here } }サンプルファイルを編集する
export class TutorialStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); const vpc = new ec2.Vpc(this, 'TheVPC', { cidr: "10.0.0.0/16" }) const i = new ec2.Instance(this, id, { instanceType: new ec2.InstanceType("t2.medium"), machineImage: new ec2.AmazonLinuxImage, vpc: vpc, }) } }デプロイする
cdk deploy参考
- 投稿日:2020-07-26T15:59:01+09:00
CloudFrontを使ってs3パケットを公開したらAccess Deniedになり、ハマるポイントが多いのでまとめてみた
いきなりですが、AWS基盤で独自のwebサイトを作りたいと思っています。
HTMLやCSSなどフロントのコンテンツは別のサービスを使っていい感じに作るとして、AWSを使うメリットはバックエンドがいい感じにできることです。
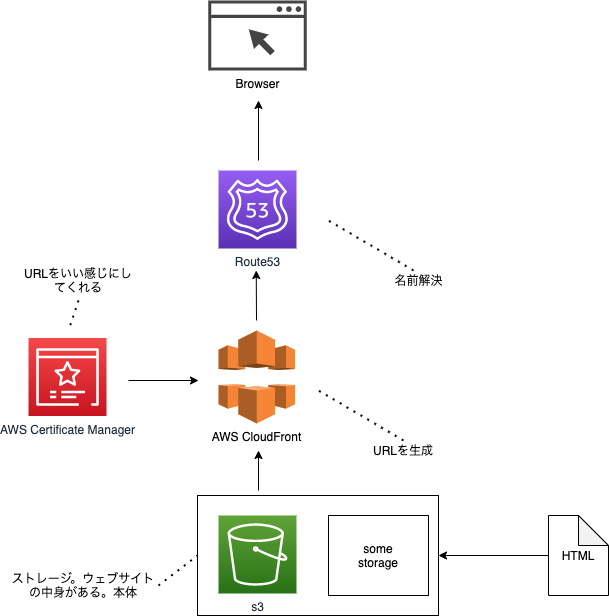
登竜門となるのが、s3といったストレージサービスに格納したファイルをいかにしてCloudFrontに乗っけるのか、という部分になると思います。
雑なイメージですが、AWSであれば以下のような構成にすることでいい感じに作れます。
詳しい作り方は、ぜひAWS公式のハンズオンなどを見てみてください。
個人的にハマリポイントがいくつかあったので、そういった点について備忘録として乗っけます。
うまく設定しないと、URLにアクセスしても「AccessDenied」のページとなってしまいます。
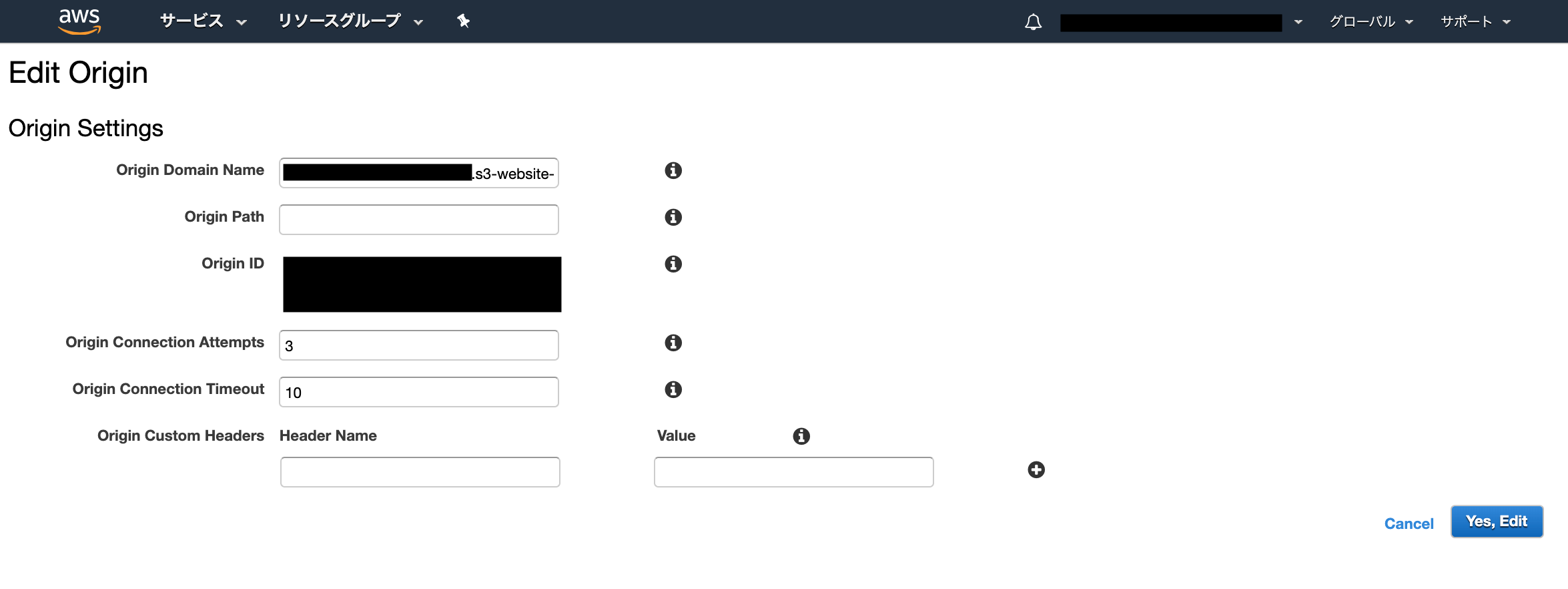
CloudFrontには、s3パケットのHTMLファイルURLをそのままコピペしてもうまくいかない
以下のように、s3にindex.htmlをインポートした後、オブジェクトURLをCloudFrontに貼り付けると思います。
そのやり方では上手く行かなくて、CloudFrontのOriginには以下の形式でDomain nameを登録する必要があります。
{your-bucket-name}.s3-website-{your-bucket-region}.amazonaws.comこの辺の書き方は、以下の記事を参考にしました。
CloudFront×S3で403 Access Deniedが出るときに確認すべきこと - Qiita
Orign Pathにも、
/index.htmlを登録する必要はありません。Origin IDは特に変える必要はありません。
s3の権限は特にいじる必要はない
公開設定がうんぬん、などありますが、特に権限周りは変えなくてもうまくいきました。
わからなければ公開設定にして、成功次第絞るやり方でよいと思われます。
- 投稿日:2020-07-26T15:48:28+09:00
AWS CodeArtifactをMavenから使ってみる
What's?
- 2020年6月に登場した、AWS CodeArtifactを使ってみたい
- そもそも、AWS CodeArtifactとはどういうものか?
- 試しに使ってみる
ということを調べたり、やってみたりする記事です。
最後の「使ってみる」の部分には、Apache Mavenを利用します。つまり、Javaでのサンプルということになりますね。
AWS CodeArtifactとは
AWSの提供する、マネージドなアーティファクトリポジトリサービスです。
AWS CodeArtifact Documentation
AWS CodeArtifact によるソフトウェアパッケージ管理
AWSがソフトウェアパッケージのリポジトリサービス「AWS CodeArtifact」正式リリース。npmやMavenなどのパッケージを共有可能
平たく言うと、ソースコードをビルドしたりして生成された、パッケージを管理してくれるものになります。
対応しているのは、このあたりですね。
- npm
- PyPI
- Maven
AWS CodeArtifact Concepts / Package
要するに、JavaScript、Python、Java、の3つですと。
AWS CodeArtifactを使わない場合は、以下のような選択肢から環境を構築していることかと思います(GitHub Packagesは違いますが)。
この管理を、AWSに任せることができるというサービスですね。
AWS CodeArtifactにおける要素
「AWSが提供するマネージドなパッケージリポジトリだ」と書くとあっさりしていますが、いろいろと概念、要素があるようなので理解しておく必要がありそうですね。
順にちょっと見ていってみましょう。
概要自体は、こちらに書いてあります。
リポジトリ
パッケージをまとめたもので、おそらく他のパッケージマネージャーを知っていると、1番理解のしやすい概念かと。
AWS CodeArtifact Concepts / Repository
リポジトリは、各種パッケージマネージャーのクライアントツール(npm、PyPI、Mavenなど)のエンドポイントとなります。
アクセス制御を行うためのポリシーを設定することもできます。
また、リポジトリはPolyglotであり、複数の言語で利用することができます。言語ごとにリポジトリを作らなくても良い、と言っていますね。
リポジトリは、後述のドメイン内に作ることになります。ドメインなしのリポジトリは存在できません。
You cannot create a repository without a domain. When you use the CreateRepository API to create a repository, you must specify a domain name. You cannot move a repository from one domain to another.
また、アップストリームのリポジトリも持つことができたり、外部リポジトリへの接続を行うことができます。
外部接続を追加すると、AWS CodeArtifactリポジトリにパッケージがない場合に、パブリックなnpm RegistryやMaven Repositoryなどの外部リポジトリからパッケージを取得することができます。
パッケージ / パッケージバージョン / アセット
パッケージは、パッケージマネージャーを使ってソフトウェアをインストールするために必要となるメタデータです。
AWS CodeArtifact Concepts / Package
また、パッケージを構成するアセット(
.tgzファイルやJARファイルなど)を含めたものが、パッケージバージョンです。AWS CodeArtifact Concepts / Package version
AWS CodeArtifact Concepts / Asset
ドメイン
リポジトリを集約する概念のようです。
AWS CodeArtifact Concepts / Domain
パッケージのアセットとメタデータの保存先は、実はリポジトリではなくドメインです。ドメイン内にいくつリポジトリがあっても、ドメイン内に同じバージョン、アセットのパッケージは1回だけ保存されます。
また、AWS KMSを使った暗号化も行われます。
パッケージの取得は、リポジトリを介して行うことになります。
ドメインはアカウント内で複数持つことができますが、通常は単一のドメインを勧めているようです。
Although an organization can have multiple domains, we recommend a single production domain that contains all published artifacts so that teams can find and share packages across their organization.
ドメインの内容を見ると
- リポジトリのストレージ+暗号化
- リポジトリ間のメタデータのコピー(※アップストリームリポジトリに関連)
- アクセス管理(リポジトリにアクセスすることができるアカウント制限や、ポリシーの管理)
- リポジトリの名前空間の提供
といったところがドメインの主な機能なようですね。
アップストリームリポジトリ
AWS CodeArtifact Concepts / Upstream repository
アップストリームリポジトリに関しては、個別のドキュメントを見た方がわかりやすい気がします。
Working with upstream repositories in CodeArtifact
AWS CodeArtifactリポジトリが、他のAWS CodeArtifactリポジトリをアップストリーム(上流)のリポジトリにすることができる、というものです。
こういう使い方も可能みたいですね。
If an upstream repository has an external connection to a public repository, the repositories that are downstream from it can pull packages from that public repository. For example, suppose that the repository my-repo has an upstream repository named upstream, and upstream has an external connection to a public npm repository. In this case, a package manager that is connected to my-repo can pull packages from the npm public repository.
アップストリームリポジトリに対してパブリックな外部リポジトリへの接続を定義し、ダウンストリームリポジトリからアップストリームリポジトリ経由でパブリックリポジトリからパッケージを取得する、といったケースですね。
始め方(ざっくり)
AWS CodeArtifactの使う時のざっくりした流れを書きます。
まあ、ここのまとめなんですけど。
Getting started using the AWS CLI
AWS CodeArtifact側
- ドメインを作成する
- リポジトリを作成する
外部リポジトリへの接続定義は、任意でしょう。
パッケージマネージャーのクライアント側
- AWS CodeArtifactへログインする
- パッケージマネージャーのクライアントの設定に、リポジトリの情報を追加する
- 使う
最初にログインがあるのがポイントで、トークンを発行して環境変数に設定する、などの手順を踏む必要があります。
Configure pip without the login command
Using Maven / Pass an auth token using an environment variable
使ってみる
と、前置きはこれくらいにして、そろそろ使っていってみましょう。
AWS CodeArtifactでリポジトリを作って、Java(Maven)で使ってみる、というのを今回のシナリオにしてみます。
今回の環境は、こちらです。
$ aws --version aws-cli/2.0.34 Python/3.7.3 Linux/4.15.0-112-generic botocore/2.0.0dev38AWSのクレデンシャルは、環境変数で設定しているものとします。
$ export AWS_ACCESS_KEY_ID=..... $ export AWS_SECRET_ACCESS_KEY=..... $ export AWS_DEFAULT_REGION=.....AWS CodeArtifactのリポジトリを作る
こちらを参考に。
Getting started using the AWS CLI
なお、普段ならこの手のものはTerraformで構築するのですが、TerraformがまだAWS CodeArtifactには対応していないので、AWS CLIでやっていきます。
(余談)Terraformでのサポートに関するissue
Add AWS CodeArtifact service supportAWS CLIでの、AWS CodeArtifactに関するリファレンスはこちら。
最初に、AWS KMS CMKを作成します。
$ aws kms create-key $ aws kms create-alias --alias-name alias/code-artifact-key --target-key-id [作成したAWS KMS(CMK)のARN]今回は、専用のキーにしました。キーを指定しない場合は、AWSが管理するキーが使われるようです。
そして、このCMKを使ってドメインを作ります。ドメイン名は、ドキュメントのそのままですが、
my-domainにしました。$ aws codeartifact create-domain --domain my-domain --encryption-key alias/code-artifact-key次に、リポジトリを作成します。リポジトリを作成するには、ドメイン名を指定する必要があります。
$ aws codeartifact create-repository --domain my-domain --repository my-repoリポジトリ名も、ドキュメントそのまま
my-repoにしました。ドキュメントにある
-domain-ownerというオプションは完全に無視しましたが、今回はそのまま作成したAWSアカウントIDが使われます。ドキュメントでは、他にも外部リポジトリへの接続やアップストリームなどの例がありますが、今回はここまでで。
作成したドメイン、リポジトリの情報を確認してみましょう。
$ aws codeartifact describe-domain --domain my-domain { "domain": { "name": "my-domain", "owner": "[AWSアカウントID]", "arn": "arn:aws:codeartifact:ap-northeast-1:[AWSアカウントID]:domain/my-domain", "status": "Active", "createdTime": "2020-07-26T14:32:35.003000+09:00", "encryptionKey": "arn:aws:kms:ap-northeast-1:[AWSアカウントID]:key/a6529646-1a8a-4772-a28a-b62c1e82992c", "repositoryCount": 1, "assetSizeBytes": 0 } } $ aws codeartifact describe-repository --domain my-domain --repository my-repo { "repository": { "name": "my-repo", "administratorAccount": "[AWSアカウントID]", "domainName": "my-domain", "domainOwner": "[AWSアカウントID]", "arn": "arn:aws:codeartifact:ap-northeast-1:[AWSアカウントID]:repository/my-domain/my-repo", "upstreams": [], "externalConnections": [] } }これで、準備は完了です。
Mavenから使う
では、Mavenから使ってみましょう。
ドキュメントは、こちらを参考に。
今回の環境は、こちらです。
$ java --version openjdk 11.0.8 2020-07-14 OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu118.04.1) OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu118.04.1, mixed mode, sharing) $ mvn --version Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f) Maven home: $HOME/.sdkman/candidates/maven/current Java version: 11.0.8, vendor: Ubuntu, runtime: /usr/lib/jvm/java-11-openjdk-amd64 Default locale: ja_JP, platform encoding: UTF-8 OS name: "linux", version: "4.15.0-112-generic", arch: "amd64", family: "unix"こちらを見ながら、やっていってきましょう。
settings.xmlの作成と、認証トークンの取得まずは
settings.xmlを用意します。今回は、このサンプル専用に作成することにしました。
settings.xml<?xml version="1.0" encoding="UTF-8"?> <settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 https://maven.apache.org/xsd/settings-1.0.0.xsd"> <servers> <server> <id>codeartifact</id> <username>aws</username> <password>${env.CODEARTIFACT_TOKEN}</password> </server> </servers> </settings>ユーザー名は
awsみたいですね。パスワードは、環境変数として設定します。こんな感じですね。
$ export CODEARTIFACT_TOKEN=`aws codeartifact get-authorization-token --domain my-domain --query authorizationToken --output text`Pass an auth token using an environment variable
注意事項にもありますが、この認証トークンの有効期限は最大で12時間だそうです。これが切れると、都度取得する必要があります。
CodeArtifact authorization tokens are valid for a default period of 12 hours. You can change how long a token is valid using the --durationSeconds argument (max authorization period is 12 hours). When the authorization period expires, you must call get-authorization-token to get another token. The authorization period begins after get-authorization-token is called.
毎日取得してね、という感じですね。
アーティファクトをリポジトリにアップロードする
続いて、アーティファクトをリポジトリにアップロードしてみます。というわけで、簡単なライブラリを作ってみましょう。
pom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.github.charon.r13b</groupId> <artifactId>library</artifactId> <version>0.0.1</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> </properties> <repositories> <repository> <id>codeartifact</id> <name>codeartifact</name> <url>https://my-domain-[AWSアカウントID].d.codeartifact.ap-northeast-1.amazonaws.com/maven/my-repo/</url> </repository> </repositories> <distributionManagement> <repository> <id>codeartifact</id> <name>codeartifact</name> <url>https://my-domain-[AWSアカウントID].d.codeartifact.ap-northeast-1.amazonaws.com/maven/my-repo</url> </repository> </distributionManagement> <dependencies> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.11</version> </dependency> </dependencies> </project>今回の例では
repositories/repositoryは不要なのですが、なんとなく。少なくとも、distributionManagementの方のrepositoryがあればOKです。Apache Commons Langは、なんとなく依存する外部ライブラリとして使っておきました。
ドキュメントを見た時の以下のURLの解釈に迷ったのですが、
<url>https://my-domain-domain-owner-id.d.codeartifact.us-west-2.amazonaws.com/maven/my-repo/</url>こう読めばいいんですね。
<url>https://[AWS CodeArtifactのドメイン名]-[ドメインのOwner id(AWSアカウントID)].d.codeartifact.[リージョン].amazonaws.com/maven/[リポジトリ名]/</url>あとは、
mvn deployで。今回は、settings.xmlはオプションで指定しています。$ mvn deploy -s settings.xml
BUILD SUCCESSになれば、アーティファクトがアップロードされているので、確認してみましょう。$ aws codeartifact list-packages --domain my-domain --repository my-repo { "packages": [ { "format": "maven", "namespace": "com.github.charon.r13b", "package": "library" } ] }OKです。
アップロードされたアーティファクトを使ってみる
最後に、アップロードされたアーティファクトを使ってみます。
pom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.github.charon.r13b</groupId> <artifactId>app</artifactId> <version>0.0.1</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> </properties> <repositories> <repository> <id>codeartifact</id> <name>codeartifact</name> <url>https://my-domain-[AWSアカウントID].d.codeartifact.ap-northeast-1.amazonaws.com/maven/my-repo/</url> </repository> </repositories> <dependencies> <dependency> <groupId>com.github.charon.r13b</groupId> <artifactId>library</artifactId> <version>0.0.1</version> </dependency> </dependencies> </project>こちらは利用側なので、
repositories/repositoryの定義があればOKです。<repositories> <repository> <id>codeartifact</id> <name>codeartifact</name> <url>https://my-domain-[AWSアカウントID].d.codeartifact.ap-northeast-1.amazonaws.com/maven/my-repo/</url> </repository> </repositories>
depencencies/dependencyには、先ほどアップロードしたアーティファクトを含めています。<dependencies> <dependency> <groupId>com.github.charon.r13b</groupId> <artifactId>library</artifactId> <version>0.0.1</version> </dependency> </dependencies>サンプルコードは、こんな感じで。
src/main/java/com/github/charon/r13b/app/App.javapackage com.github.charon.r13b.app; import com.github.charon.r13b.library.MessageService; public class App { public static void main(String... args) { MessageService messageService = new MessageService("★★★", "★★★"); System.out.println(messageService.decorate("Hello World!!")); } }ビルドして、実行。
settings.xmlは、アーティファクトをアップロードした時に使ったものと、同じものを使用しています。$ mvn compile exec:java -s settings.xml -Dexec.mainClass=com.github.charon.r13b.app.App実行できました、と。
[INFO] --- exec-maven-plugin:1.6.0:java (default-cli) @ app --- ★★★Hello World!!★★★なお、認証トークンがない状態だと、
401になるのでアーティファクトを使うのにも認証が必要ですよ、と。[ERROR] Failed to execute goal on project app: Could not resolve dependencies for project com.github.charon.r13b:app:jar:0.0.1: Failed to collect dependencies at com.github.charon.r13b:library:jar:0.0.1: Failed to read artifact descriptor for com.github.charon.r13b:library:jar:0.0.1: Could not transfer artifact com.github.charon.r13b:library:pom:0.0.1 from/to codeartifact (https://my-domain-[AWSアカウントID].d.codeartifact.ap-northeast-1.amazonaws.com/maven/my-repo/): Authentication failed for https://my-domain-[AWSアカウントID].d.codeartifact.ap-northeast-1.amazonaws.com/maven/my-repo/com/github/charon/r13b/library/0.0.1/library-0.0.1.pom 401 Unauthorized ## ココ 401 Unauthorizedこれで、確認ができました。
ポリシーについて
今回、利用したIAMユーザーが
AdministratorAccessポリシーを持っていたのでなんでもやれているのですが、実際にはIAMユーザーでアーティファクトのアップロードの可否、参照の可否などを設定していくことになると思います。ドメイン、リポジトリにそれぞれ設定できるので、見ておきましょう。
後片付け
最後に作成したリソースの後片付けをしておきます。
リポジトリとドメインの削除。
$ aws codeartifact delete-repository --domain my-domain --repository my-repo $ aws codeartifact delete-domain --domain my-domainAWS KMSのCMKの削除。
$ aws kms delete-alias --alias-name alias/code-artifact-key $ aws kms schedule-key-deletion --key-id [AWS KMS(CMK)のキーID]
- 投稿日:2020-07-26T14:41:29+09:00
AWS WAFv2 を Terraform で扱うときの注意点
概要
- マネジメントコンソール(手動)で CloudFront 用に作成した AWS WAFv2 を terraform import したときにハマったこと。
- 最初から terraform で AWS WAFv2 を作成するときも同様にハマったと思う。
ハマったこと
AWS provider のバージョンが古かった
- エラー
- AWS provider 2.48.0 で terraform import すると、次のようなエラーが出る
Error: unknown resource type: aws_wafv2_web_acl
原因
- aws_wafv2_web_acl は、AWS provider 2.67.0 から使えるようになった
https://github.com/terraform-providers/terraform-provider-aws/pull/12688対処
- AWS provider を 2.67.0 へ上げた
- AWS provider を上げた後は、terrafrom init を実行
terraform import を実行するリージョンが違っていた
- エラー
- 東京リージョンから terraform import すると、次のようなエラーが出る
Error: WAFInvalidParameterException: Error reason: The scope is not valid., field: SCOPE_VALUE, parameter: CLOUDFRONT { RespMetadata: { StatusCode: 400, RequestID: "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" }, Field: "SCOPE_VALUE", Message_: "Error reason: The scope is not valid., field: SCOPE_VALUE, parameter: CLOUDFRONT", Parameter: "CLOUDFRONT", 1 resource "aws_wafv2_web_acl" "example" { Reason: "The scope is not valid." }
原因
- AWS WAFv2 の terraform 実行は、us-east-1 (バージニア北部)で実行する必要があるらしい。
- ここが参考になった
https://dev.classmethod.jp/articles/cloudformation-webacl-cloudfront-error/対処
- us-east-1 から terraform import を実行する
$ terraform import -provider="aws.virginia" aws_wafv2_web_acl.example xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/example/CLOUDFRONTterraform 設定例
構成
└── wafv2 ├── backend.tf ├── example.tf └── provider.tfprovider.tf 抜粋
provider "aws" { version = "2.67.0" shared_credentials_file = "credentials" profile = "terraform" region = "ap-northeast-1" } provider "aws" { version = "2.67.0" shared_credentials_file = "credentials" profile = "terraform" alias = "virginia" region = "us-east-1" }
- 投稿日:2020-07-26T13:37:13+09:00
AWS CDKで配布可能なサーバレスアプリを作る
これまでAWSのSAM (Serverless Application Model) などを使ってサーバレスアプリを作成することが多かったのですが、サーバレスの構成情報とそこに必要となるパラーメタなどが密に結合してしまいがちで、どこでも使えるようなアプリが作りづらいという問題がありました。定義ファイルに後から値を埋め込めるParameterなどの機能はあったものの、YAMLやJSON上で無理くりやっている感があってわりと消耗が多かったです。
これに対してAWS CDK (Cloud Development Kit) では定義ファイルに相当する Constrcut をコードで記述することができ、かなり柔軟性高く利用できます。配布可能な形でいくつかのサーバレスアプリを作成してみたので、その際の知見を記事にまとめてみます。
CDKそのものの解説はこちら https://docs.aws.amazon.com/cdk/latest/guide/home.html
CDKのプロジェクトを作成する
今回は
onigiriという名前のモジュールを作成するとします。まず普通のCDKプロジェクトを作成します。% mkdir onigiri % cd onigiri % cdk init --language typescriptCDK Constructを作る
Construct は最終的にCloudFormationでデプロイされるStackのテンプレートです。
onigiriという名前でinitすると、lib/onigiri-stack.tsというファイルが生成されるのでそこに記述します。以下の例は、一定時間ごとに起動されるLambdaが何かをクエリして、その結果をDynamoDBに書き込む、という想定のConstructです。Lambda Functionを1つ、DynamoDBを1つデプロイします。import * as cdk from "@aws-cdk/core"; import * as dynamodb from "@aws-cdk/aws-dynamodb"; import * as lambda from "@aws-cdk/aws-lambda"; import * as events from "@aws-cdk/aws-events"; import * as eventsTargets from "@aws-cdk/aws-events-targets"; import { NodejsFunction } from "@aws-cdk/aws-lambda-nodejs"; import * as path from "path"; export interface properties extends cdk.StackProps { someParameter: string; } export class OnigiriStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props: properties) { super(scope, id, props); const cacheTable = new dynamodb.Table(this, "cacheTable", { partitionKey: { name: "pk", type: dynamodb.AttributeType.STRING }, billingMode: dynamodb.BillingMode.PAY_PER_REQUEST, }); const lambdaQuery = new NodejsFunction(this, "query", { entry: path.join(__dirname, "lambda/query.js"), handler: "main", environment: { TABLE_NAME: cacheTable.tableName, SOME_PARAM: props.someParameter, }, }); cacheTable.grantReadWriteData(lambdaQuery); new events.Rule(this, "periodicQuery", { schedule: events.Schedule.rate(cdk.Duration.minutes(10)), targets: [new eventsTargets.LambdaFunction(lambdaQuery)], }); } }Constructを書く上でのコツは以下の通りです。
- 今回はLambda functionもTypeScriptで作成しするため、
./node_modules以下のモジュールも同時にデプロイするために@aws-cdk/aws-lambda-nodejsパッケージにあるNodejsFunctionを利用します。他にも別レイヤーに./node_modulesを格納する方法などがあるようですが、今回は割愛。
- 本来
NodejsFunctionのpathパラメータはこのファイルからの相対パスが使えますが、モジュールとして配布した際に相対パスの基準が変わってしまうため、__dirnameをjoinして絶対パス指定にしています。- pathを指定する際には
.jsファイルにします。これはモジュール配布後にNodejsFunction経由でトランスコンパイルしようとするとうまくいかない場合があるからです@aws-cdk/aws-lambdaなどCDKのモジュールを追加する場合は、必ずinit時に追加されたaws-cdk/coreとバージョンを揃えてインストールします。わずかでもずれるとtscでエラーになります。- 単体のCDKプロジェクトとして使う場合、
@aws-cdk/aws-lambdaなどCDKのモジュールを追加はdevDependenciesになるようnpm i --save-dev @aws-cdk/aws-lambdaなどとしますが、今回はモジュール配布先で利用する必要があるため、npm i @aws-cdk/aws-lambdaでインストールします。また、配布用のconstructではパラメータを可変にしておくのが良いので、もともと
OnigiriStackの引数であるcdk.StackPropsを拡張してpropertiesというinterfaceを作っています。これによってなんらかの環境変数を渡したり、外部リソースを参照したりしたい場合に、情報を引数として渡すことが出来ます。同時にLambda Functionを作成します。今回は
./onigiri/lib/lambda/query.tsにLambda Functionのファイルがある想定です。package.json を編集する
package.jsonに以下の変更を加えます。
files: ["lib"]を追加:lib以下にトランスコンパイル済みのコードを配置するため"main": "./lib/onigiri-stack.js"を追加:配布先のプロジェクトからconstructのコードが読み込めるように"type": "./lib/onigiri-stack.d.ts"を追加:同上scripts内に"prepare": "tsc"を追加:パッケージ公開時やgithubからのインストール時にトランスコンパイルを実行させるためトランスコンパイルの出力先を
distにするというやりかたもありますが、そのあたりはお好みで調整して下さい。出来上がりのサンプルは https://github.com/m-mizutani/dnstrack/blob/master/package.json などをご参照下さい。デプロイ
この記事の目的は作成したCDK constructをモジュールとして配布することですが、作成途中でテストとしてデプロイしたい場合があるかと思います。そのための1つの方法として、
bin/onigiri.tsは環境変数でデプロイできるようになっていると、小回りがきいて便利です。例として、bin/onigiri.tsを以下のようにします。#!/usr/bin/env node import "source-map-support/register"; import * as cdk from "@aws-cdk/core"; import { OnigiriStack } from "../lib/onigiri-stack"; const stackName = process.env.ONIGIRI_STACK_NAME || "onigiri"; const app = new cdk.App(); new OnigiriStack(app, stackName, { someParameter: process.env.ONIGIRI_PARAM!, });こうしておくことで、環境変数で指定して開発中のレポジトリからそのままデプロイ出来つつ、開発環境のパラメータを埋め込むのを防ぐことができます。
% env ONIGIRI_STACK_NAME=onigiri-1 ONIGIRI_PARAM=nanika cdk deployパッケージ公開&配布
ここまでの設定ができていればあとは
npm publishでパッケージ公開、あるいはプッシュされたgithubからインストールすることで、作成したCDK constructを外部プロジェクトで再利用することができるようになります。npm i dareka/onigiriなどでインストールし、配布先の./bin/nanika.tsなどで以下のように記述して利用できます。#!/usr/bin/env node import "source-map-support/register"; import * as cdk from "@aws-cdk/core"; import { OnigiriStack } from "onigiri"; const app = new cdk.App(); new OnigiriStack(app, "wagaya-no-onigiri", { someParameter: "nanika-sugoi-guzai", });サンプル
上記の手法にそって作成したconstructが以下になりますので、ご参考までに。
- DNS track: https://github.com/m-mizutani/dnstrack
- 投稿日:2020-07-26T13:34:49+09:00
Lambdaを使ってTwitter定期投稿botを作ろう
1.基本構成
- ツイートデータはAmazon S3に格納
- Lambda→S3へのアクセス権限はIAMで設定
- Cloud Watch Eventsで1時間ごとにLambda Functionを発火
- Lambdaを使ってS3のテキストを検索し、内容をTwitter REST APIへ連携
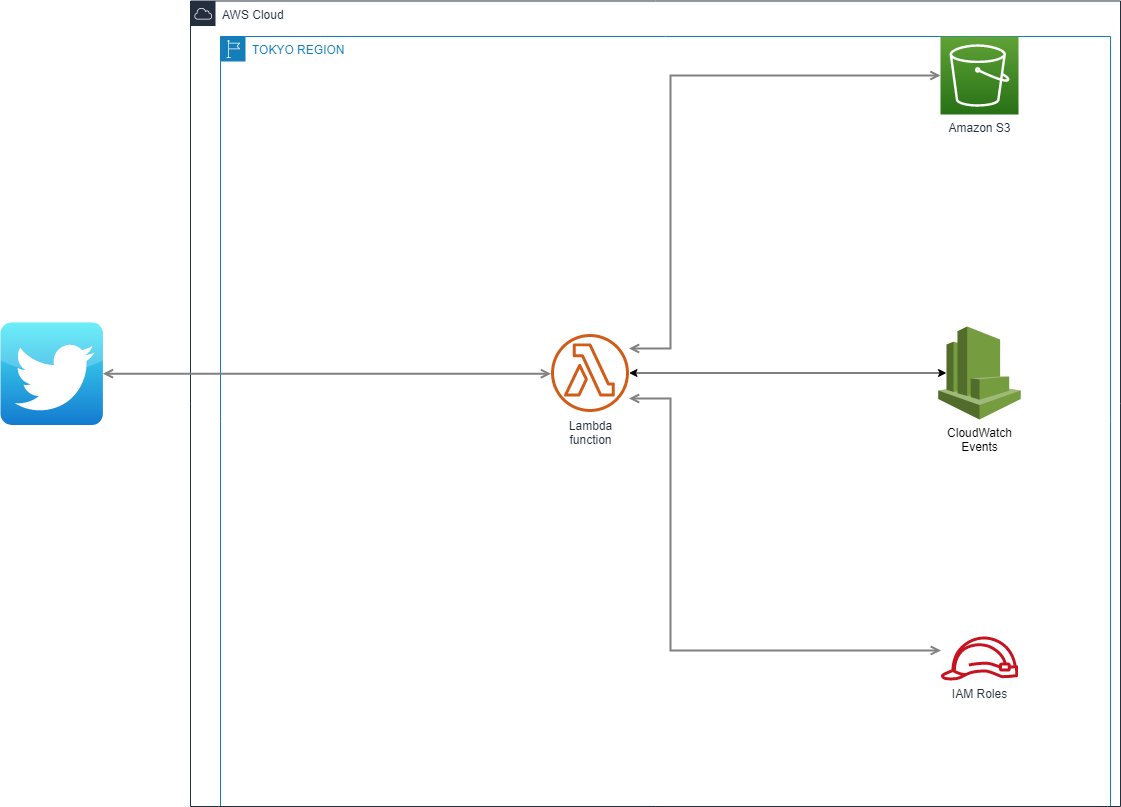
2.S3に格納するデータ様式
csv形式でツイートする時間とツイート内容を記載する。
即席なのでテキストファイル使ったけど、ここはNoSQL使ったりしてもよいかも……。
Example)
[ツイート時間],[ツイート内容]3.IAM Roleの設定
下記の通りに,S3アクセスを許可するIAMポリシーを作成し、IAM Roleにアタッチする。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:*", "Resource": "*" } ] }4.Lambda Function の作成
Lambda Functionを作成し、トリガー(一時間ごとにテキストファイルを検索)は
Cloud Watchを使用する。
作成するLambda関数のプログラムは下記の通り。
仕組みとしては、「テキストファイルに記載されている時間」と「現在時刻」が合致したら
Twitter REST APIにツイート情報を連携するというもの。import json import boto3 import re import datetime from requests_oauthlib import OAuth1Session S3 = boto3.client('s3') def lambda_handler(event, context): # TODO implement #バケットファイルからテキスト一覧を取得 BUCKET = S3.list_objects_v2(Bucket="daily-tweets",Prefix="DAILY_TWEETS") for content in BUCKET['Contents']: #~~.txtファイルを検索 if re.match(r'^[^\.]+\.txt',content['Key']): obj=S3.get_object(Bucket="daily-tweets",Key=content['Key']) l=obj['Body'].read().decode('utf-8').split(",") time=datetime.datetime.utcnow() + datetime.timedelta(hours=9) print (time.strftime("%H") ) #時間データと照合して合致したらツイート if time.strftime("%H") == l[0]: print (l[1]) CK = '****' # * enter your Consumer Key * CS = '****' # * enter your Consumer Secret * AT = '****' # * enter your Access Token * AS = '****' # * enter your Accesss Token Secert * UPDATE_URL = 'https://api.twitter.com/1.1/statuses/update.json' twitter = OAuth1Session(CK, CS, AT, AS) req = twitter.post(UPDATE_URL,params={"status":l[1]}) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }これだけでは、「一回だけ」起動するプログラムなので、定期実行のためにCloud Watch Eventsにcronを設定する。
設定値は下記にすると、1時間ごとにツイートされる。(cronを変えれば10分毎・この曜日だけ、とかも可能です。)
cron(0 * * * ? *)注)
from requests_oauthlib import OAuth1Session →こちらはAWSの標準では使えないのでlayerを作る必要があります。詳しくは
下記記事が参考になります。
https://www.yamamanx.com/aws-lambdapython-twitter-post/5.イカしてないところ
- APIのキーを直接書くな! →secret managerとかで何とかできるかも…
- S3である必要なくない? →簡単さを重視してS3使ったけどNoSQLとか使えるかもね…?
- API Gateway使ってtweet登録できるようにしたほうよいかも…(ただWEBに晒すサービスとなるとセキュリティ面少し心配…)
6.おわりに
ものすごくザックリ、作成したツイートボットの解説していきました。なので「こっちの構成の方がいいよ!」とか
あったらどしどしツッコミ入れてください。
- 投稿日:2020-07-26T13:32:35+09:00
AWS Amplify Libraryで取得した認証をAWS SDKで利用する
AWS Amplifyのライブラリが提供する機能群は便利ですが、S3を操作する一部の機能についてはAWS SDKと比べると少ない部分があります。そういったケースのために、Amplify側で取得した認証をAWS SDK側へ引き渡して使います。
サンプル S3のリストを実行する
Amplify ライブラリのStorageが提供するS3のListには、Delimiterなどによる柔軟な問い合わせ機能が用意されておらず、S3のListについてはAWS SDKを利用したいという場合を想定したサンプルです。
わかりやすくするために一つの関数へまとめていますが、
AWS.S3クラスは流用させるため、他で作成して再利用させる形が良さそうです。import AWS from 'aws-sdk'; import { Auth } from '@aws-amplify/auth'; const listFiles = async () => { const credentials = await Auth.currentCredentials(); const s3 = new AWS.S3({ credentials: credentials, region: '対象のリージョンの名前', }); const req = s3.listObjectsV2({ Bucket: '対象のバケットの名前', }); req.promise().then((result) => { // 処理結果が返却されるので、あとは好きな処理をする console.log(result); }).catch(err => { // エラーハンドリングする console.error(err); }); }認証情報の取得
下記の部分についてです。
const credentials = await Auth.currentCredentials();事前にAuthにより、Cognitoによる認証が通っていることが前提です。
Auth.currentCredentials()は、現在の認証情報をPromise<ICredentials>として返却します。ここでは await することで中身のICredentialsを取り出しています。
Promise<ICredentials>はAWS Amplify ライブラリのAuthクラスに所属するインターフェイスであり、下記のように定義されています。export interface ICredentials { accessKeyId: string; sessionToken: string; secretAccessKey: string; identityId: string; authenticated: boolean; }認証の取れたユーザのキー情報などが入っているものであることがわかります。
認証情報の引き渡し
下記の部分についてです。
const s3 = new AWS.S3({ credentials: credentials, region: '対象のリージョンの名前', });AWS Amplifyの
Auth.currentCredentials()から取得できた認証情報を、そのままAWS SDKのAWS.S3クラスのコンストラクタのcredentials変数へ代入しています。credentialsは下記のように定義されています。credentials?: Credentials|CredentialsOptions|null
credentialsの実装をAuth.currentCredentials()で取れた値が満たすため、そのまま代入することができます。処理の実行
あとは下記のように任意の処理を実行できます。
const req = s3.listObjectsV2({ Bucket: '対象のバケットの名前', }); req.promise().then((result) => { // 処理結果が返却されるので、あとは好きな処理をする console.log(result); }).catch(err => { // エラーハンドリングする console.error(err); });
- 投稿日:2020-07-26T11:49:57+09:00
【AWS】aws configure コマンド実行で、.aws配下に設定ファイルが作成される
aws configure コマンド
aws configure
このコマンドを実行すると、認証情報、リージョン、出力形式をすばやく設定および表示できます。$ aws configure AWS Access Key ID [None]: AKI*************PLE AWS Secret Access Key [None]: wJa***********************************KEY Default region name [None]: ap-northeast-1 Default output format [None]: jsonこの設定の保存先
bundle installでオプション(例えば
--path vendor/bundle)を追加すると.bundle/configに設定が保存されるのと同じ要領で、
aws configure コマンド実行後、ホームディレクトリーに.awsというディレクトリーが作成され、設定ファイルが格納されます。[root@vanilla ~]# ls -a . .. .bash_logout .bash_profile .bashrc .cshrc .ssh .tcshrc ### ###↑.awsディレクトリーは存在しない [root@vanilla ~]# [root@vanilla ~]# [root@vanilla ~]# aws configure AWS Access Key ID [None]: AKI*************PLE AWS Secret Access Key [None]: wJa***********************************KEY Default region name [None]: ap-northeast-1 Default output format [None]: json [root@vanilla ~]# [root@vanilla ~]# [root@vanilla ~]# ls -a . .. .aws .bash_logout .bash_profile .bashrc .cshrc .ssh .tcshrc ### ###↑.awsディレクトリーが作成された [root@vanilla ~]# [root@vanilla ~]# cat .aws/credentials [default] aws_access_key_id = AKI*************PLE aws_secret_access_key = wJa***********************************KEY [root@vanilla ~]# [root@vanilla ~]# cat .aws/config [default] output = json region = ap-northeast-1AWS CLIは設定ファイルから認証情報を読み取るので、
aws configureをしなくても、そのまま.awsディレクトリーと設定ファイルを作成すれば事足ります。例えばChefなどのIaCツールで自動的にEC2インスタンスを立ち上げたい場合は、
「.awsディレクトリー配下に設定ファイルを作成する」という記述でOK。
- 投稿日:2020-07-26T11:14:15+09:00
ドメイン駆動設計をキングクリムゾンで実装する
今回の記事では、ドメイン駆動設計を簡単に設計する方法について解説します。
ドメイン駆動設計が簡単に導入できない理由として、チーム間で共通したドメインの認識を持つためのドメインモデルの設計に苦労しているからだと思います。
今回はドメインモデルなしで簡単にドメイン駆動設計を行える方法を紹介します。ドメイン駆動設計は要素還元主義
還元主義とは、欠陥のある方法論、どんな複雑な現象でも単純な要素に還元し、そこから元の現象を復元できれば、その現象が理解されたと考える。
ドメイン駆動設計は、全てのビジネスロジックをドメイン層の各要素に分解し、そこからビジネスロジックを組み立てれば全てのビジネスロジックを実現できると考えます。
しかし、ビジネスロジックが変更されたり、ドメイン層のモデルが誤っている場合、ビジネスロジックの組み立てに失敗します。
アジャイル手法などを用いて認識のずれを素早く修正するという方法もありますが、ドメイン駆動設計が要素還元主義という誤った思考方法で行われている以上、問題の根本的な解決にはなりません。西洋式の因果律型モデル
西洋式の基本的な思考パターンとして、目的 -> 方法 -> 手段 -> 結果の順番で物事を考えます。
この思考パターンはギリシャのアリストテレスによって確立されました。
アリストテレスは著書「形而上学」で「質料因」「形相因」「作用因」「目的因」の要素が相互作用して結果が発生する「四原因説」を説きました。
このように西洋式の思考パターンの伝統として要素還元主義の傾向を持っています。
この思考パターンは、原因と結果のプロセスを明らかにするという面で有効な手法なのですが、長期的計画に因果律型モデルを適用すると大きな弊害が発生します。
現実の世界では確定した事象よりも不確定な要素のほうが多く、カオス化する傾向を持っています。
予め作成した計画は絶えず修正が行わるため、因果律モデルによって作成された大規模なスケジュールやウォーターフォール型の計画は崩壊する傾向を持っています。中国式の状況帰結モデル
西洋型の因果律型モデルを長期的計画に適用した際に生じる弊害を回避するには、中国式の思考パターンである状況帰結モデルを用います。
中国の基本的な思考パターンとして、重要なのは個人の技量や技能ではなく、予め計画、設定された配置によって生じる勢いが最も大事だと考えます。
中国式の基本的な思考パターンは孫子によって確立されました。以下の孫子の文言に中国の状況帰結モデルが集約されています。「古くから兵法家が考える優れた者とは、容易に勝てる相手に勝つ者である。
それ故、優れた者が戦って勝利しても、智将だとの名声もなく、勇敢であると称えられることもない。
それは、その戦いの勝利が間違いのない、当たり前のものだからだ。
間違いなく勝つと思われるのは、その勝つための段取りが、すでに戦う前から負けが確定
しているような敵に勝つように仕向けられているからである。」中国の基本的な思考パターンは、目的 -> 結果 -> 方法-> 手段 の順番で物事を考えます。
予め目的と結果を設定し、設定された流れに合うように方法や手段を行使します。
そのため、上流から水が流れ、下流に行き着くように物事は設定された結果に辿り着くため、計画にずれは発生しません。
しかし、状況は常に変化するため、実行する方法や手段やは柔軟に変更する必要があります。
以下の孫子の文言に手段を変更する必要性について説明しています。
水が地形に応じて流れを決めるように、軍も敵の動きや態勢に応じて動いて勝利する。したがって、軍には一定の勢いというものもないし、常に固定の形というものもない。西洋型の因果律型モデルと中国式の状況帰結モデルを組み合わせる
西洋式の因果律型モデルと中国式の状況帰結モデルは以下のように長所と短所が分かれています。
因果律型モデル
長所:プロセスを明らかにすることができる。
短所:要素還元主義になるため、計画にずれが発生する長期的な計画には向かない。状況帰結モデル
長所:想定した結果に辿り着くように手段が設定されるため、計画にずれが発生しない。
短所:プロセスの内部構造が不明なので、問題点を発見、修正することができない。
西洋型の因果律型モデルと中国式の状況帰結モデルは補完関係にあります。2つの思考モデルはセットで運用することが重要です。中国式の状況帰結モデルをドメイン駆動設計に組み込むには
中国式の状況帰結モデルをドメイン駆動設計に組み込むには、従来のドメイン駆動設計の4層モデルでは実装することはできません。
そのため、ドメイン駆動設計の4層モデルを拡張した以下の5層モデルを使用します。
・コントロール層・・・RestApiなどでアプリへの接続窓口を担当
・ユースケース層・・・ミッション層を呼び出し、実現したいユースケースを作成
・ドメイン層・・・共通処理を記述する層。ユースケース層で呼び出す
・インフラ層・・・メール、FTP接続、など外部ライブラリに依存した技術的なロジックを担当。インフラ層以外の層から呼び出される。
ミッション層・・・アプリのビジネスロジックを担当。ドメイン層のメソッドをここに集約する
5層モデルに関する詳しい説明は以下のURL参照
https://qiita.com/aLtrh3IpQEnXKN7/items/b7fe2014ccefcbb9e4585層モデルのユースケース層で実現したい最終的な結果に辿り着くための中間目標をミッション層に設定し、
実現する手段に関してはドメイン層に任せることによって、目的と手段を分離し、組み合わせることが可能になります。
ミッション層で設定された結果に辿り着くようドメイン層は呼び出されるため、ビジネスロジックにずれが発生しません。まとめ
ドメイン駆動設計の実装が計画通りいかないのは、手段であるはずのドメインモデルに固執して結果を想定していないのが大きな問題だと思われます。
結果を先に設定した後にドメインモデルを作成すれば、ドメインモデルを作成する理由や結果と一致しないドメインモデルが誤りだと判断することができます。
結果を想定してからドメインモデルを作成するようにしましょう。

- 投稿日:2020-07-26T11:10:44+09:00
AWS認定Alexaスキルビルダー専門知識(AXS)を、ツンデレメイドスキルを作りながら取得したやったことまとめ
はじめに
AWS認定Alexaスキルビルダー専門知識(AXS)について、受験者数の絶対数が少ないのか試験対策に関する参考記事の投稿が少なく情報収集に苦労しました。
今回実際に EchoShow8で動作するAlexaスキルを作りつつ、取得できた試験準備のコツなどについてまとめてみました。Alexaスキルビルダー専門知識に関わるAWS関連サービスのイメージを掴んでいただければ幸いです。
本記事の主な対象者
- AWS認定の他の試験区分は取得済みで、Alexaスキルビルダー専門知識の受験を検討している方
- 取得に向けて有効な学習方法などの情報収集したい方
筆者のAWS認定履歴
AWS認定 取得日 ソリューションアーキテクト - アソシエイト 2018-05-13 デベロッパー - アソシエイト 2018-06-03 SysOpsアドミニストレーター - アソシエイト 2018-06-10 ソリューションアーキテクト - プロフェッショナル 2018-07-29 DevOpsエンジニア - プロフェッショナル 2018-08-26 ビッグデータ専門知識 2019-08-25 セキュリティ専門知識 2019-12-08 機械学習専門知識 2020-02-23 高度なネットワーキング専門知識 2020-06-20 データベース専門知識 2020-07-04 Alexaスキルビルダー専門知識 2020-07-24 さて、今回の受験モチベーションは、率直に、自身の最後の専門知識区分にチャレンジしてみたくなったのがきっかけです。
今回のスコア(2020-07-24受験)
総合スコア: 884/1000 (ボーダー750)AWS認定Alexaスキルビルダー専門知識(AXS)について
ここからが本題となります。
まずは、以下の公式ページから試験概要の把握を行いました。具体的な試験準備で効果があったと思えること
実際に受験をしてみて、試験対策として効果があったと思う内容について、主観的な効果度合いで順に記載します。
- 公式のトレーニングコースの受講
Alexaスキル開発自体が初めての経験だったため、公式のトレーニングコースで、Alexaスキル開発のエッセンス及び、認定に関わる出題範囲の確認を行いました。こちらのコースは、AWS認定の申し込みの際に使用するアカウントをお持ちの方であれば、無料で受講することができます。
上記の公式のトレーニングコースでは、Alexa Skills Kit 開発者ドキュメントから引用されている部分がありました。ドキュメント量は膨大なのですが、このドキュメントから引用される設問が多い感じがしましたので、軽く一読することをオススメします。
- 実際にAlexaスキルを作ってみる
思い立ったが吉日、ということでお試しでAlexaスキルを作成してみました。基本的な流れは、開発者コンソールでスキルの環境設定を行い、Lambdaでコードを書くという流れになります。今回は、役に立つスキルというものよりかは、頭の中の物を形にすることに重点をおいたため、安直ながらツンデレメイドのAlexaちゃんと非日常的なマルチターン会話を楽しめるスキルを作成してみました。馴染みのあるNode.jsでハンドラー部分のコードを実装しながら、開発のお作法を確認していきました。
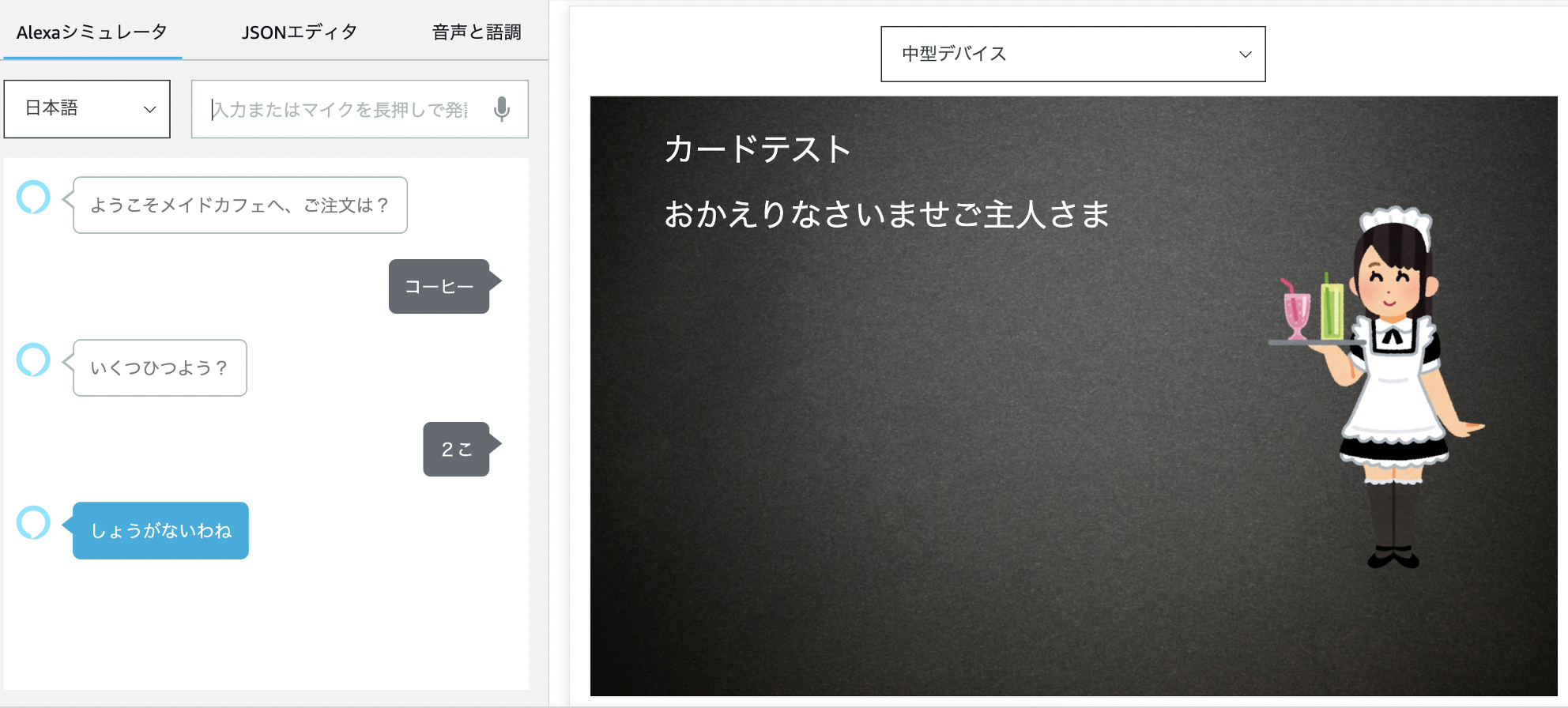
また、動作検証用にEchoShow8を準備していたため、認定の重要ポイントである実機でのベータテストまでを行いました。なお、今回の認定準備の話題とは若干離れる内容とはなりますが、一般公開レベルのAlexaスキルを作成するにあたっては、Lambdaでコードを書くということよりも、ユーザーエクスペリエンスを意識したVUIのデザインの方が、重要かつ難しいポイントだなと感じました。
以下、スキルのイメージになります。ダイアログをデリゲートしつつ、来店回数(スキル起動回数)を永続値としてDynamoDBに保存し、来店回数が一定以上になるとランクアップし、接客のデレ度が上がっていくという仕様としました。
抑えるべき3つのポイント
実際に認定試験を受けてみて、試験ガイドとは別軸で大きく3つのカテゴリーがあるのかなと感じました。
1. 公式のトレーニングコースの内容の理解
- 先にご紹介した、トレーニングコースですが、Alexaスキルビルダー専門知識の取得に特化した公式のトレーニングコースになります。即ち、出題される可能性のある分野に絞っての解説となりますので、こちらを開発から公開までの流れを通しで理解することがとても重要です。
2. JSONインターフェースの仕様の理解
実際にAlexaスキルを開発してみると腹落ちしてくる部分があるのですが、開発者コンソールでのスキルの環境設定内容を含めて、リクエスト及びレスポンスは、エンドポイントLambdaとやりとりするためのJSONインターフェースに全て集約されます。この部分は設問にも直結しており、JSON例示から回答を導くという内容も散見されましたので十分な理解が必要です。以下、Alexa Skills Kit 開発者ドキュメントの関連ページをご紹介します。
3. Alexaスキルに関連するAWSリソース
- AWSリソースについては、カスタムスキルを実装する Lambda、 Lambdaのデバッグに使用する CloudWatch、 永続的なデータを保存する際に使用する DynamoDB、 アセットを配置する S3、 CDNとしての CloudFront について抑えておく必要があります。なお、AWSリソースについての設問は比較的素直な内容が多く、アソシエイトレベルの知識があれば十分かと思いました。
おわりに
Alexaスキルビルダー専門知識については、必要な知識範囲も他の専門知識区分と比べ狭く、日頃から開発者のロールで業務に携わっている方であれば、相対的に取組みやすいほうの認定区分かなと思いました。
今後受験を検討される方の一助になれば幸いです。著者関連リンク
- 投稿日:2020-07-26T11:07:28+09:00
【AWS】アカウント削除
アカウント使用の流れ
- 開始前知っておくべきポイント
- アカウント申請
- ログイン
- IAM設定
- MFA多要素認証
- アカウント削除
参考資料
請求については「Youtube」の「Amazon Web Services」を参照
https://www.youtube.com/watch?v=oauevo1zf28手順については「Youtube」の「AEM and Devops Tutorial」を参照
https://www.youtube.com/watch?v=1Np5U98vUtQアカウント削除
削除する前の確認リスト
- 大切なものをロカールにバックアップしておく
- EC2のインスタンスを削除
- S3のバケットを削除
- 使用していたIPの削除を確認(VPC)
- 今までの請求書を払う
1.AWSマネジメントコンソール
2.アカウント設定
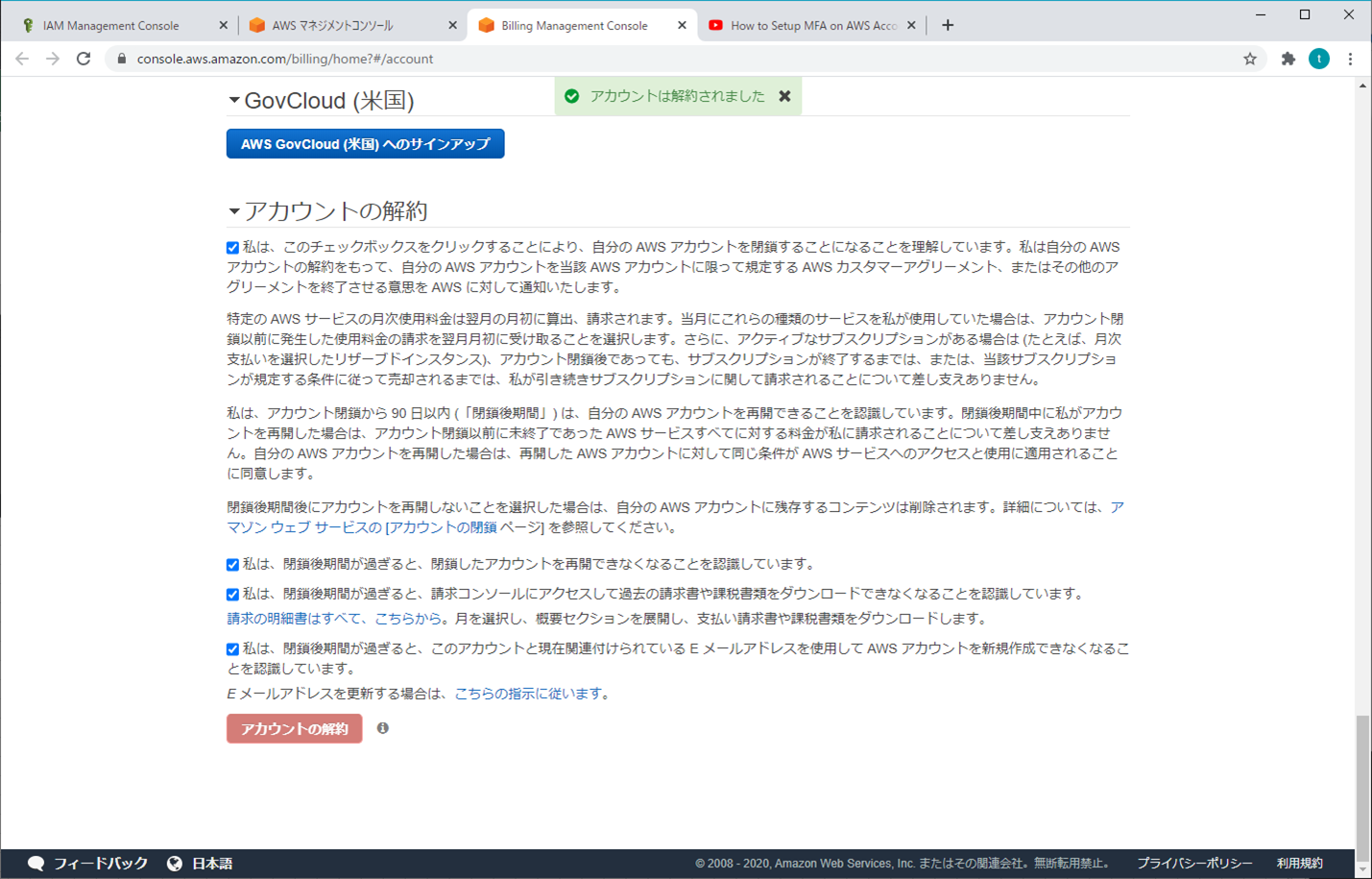
3.アカウントの解約
4.解約終了
(90日間は閉鎖期間 → 再開できる)
5.ログアウト





- 投稿日:2020-07-26T10:54:51+09:00
MSP32にFreeRTOSを入れてAWSにつないでみました
はじめに
IoT機器を触ってみようと思い、ESP32-DevKitCを入手して少しずつ試してます。
ボードは秋月電子通商にて以下を入手。
ESP32-DevKitC-32DESP32の入門的な部分はこちらの本で勉強させていただきました。
IoT開発スタートブック今回はESP32にFreeRTOSを入れてAWSへ接続してみたので、その記録です。
AWSから提供されている手順に沿って進めます。あらかじめ用意されているデモプログラムが、MQTTでAWS IoTへ
Hello worldを送ってくれます。
Espressif ESP32-DevKitC と ESP-WROVER-KIT の開始方法PCやAWSの環境設定
PC側の環境はCentOS 7.7を使いました。
前提条件
AWSコンソールのIAMの設定にて、以下の権限ポリシーをAWSのアカウントに割り当てます。
- AmazonFreeRTOSFullAccess
- AWSIoTFullAccess
Espressif ハードウェアの設定
ESP32-DevKitCは既に使っていたので省略。
開発環境をセットアップする
AWSの手順に記載の通り、Espressif社のToolchain設定手順に沿って進めます。CentOSなので手順はこちら。
Standard Setup of Toolchain for LinuxInstall Prerequisites
CentOS 7用として記載されている以下を実行。
sudo yum install git wget ncurses-devel flex bison gperf python pyserial cmake ninja-build ccacheついでに後でpipも必要になるので入れておきます。
sudo yum install python3-pipまた、CentOS 7.7の標準ではpython2が使われる設定になっていましたが、python3とpip3の組み合わせで使えるようにシンボリックリンクを付け替えておきます。
cd /bin sudo rm python sudo ln -s python3 python sudo ln -s pip3 pipツールチェーンの設定
wgetでファイルをダウンロードして、展開。
cd ~/IoT wget https://dl.espressif.com/dl/xtensa-esp32-elf-linux64-1.22.0-80-g6c4433a-5.2.0.tar.gz mkdir -p ~/IoT/esp cd ~/IoT/esp tar -xzf ../xtensa-esp32-elf-linux64-1.22.0-80-g6c4433a-5.2.0.tar.gz
~/.bash_profileを開いてPATHの先頭に$HOME/IoT/esp/xtensa-esp32-elf/binを追加。これでEspressif社のToolchain設定手順は終了。AWSの手順に戻ります。
CMake をインストールする
CentOS 7.7標準のcmake (v2.8.12.2)が古かったので、最新のcmakeをダウンロードして使えるようにします。
wget https://github.com/Kitware/CMake/releases/download/v3.18.0/cmake-3.18.0-Linux-x86_64.sh chmod +x cmake-3.18.0-Linux-x86_64.sh ./cmake-3.18.0-Linux-x86_64.sh
~/.bash_profileを開いてPATHの先頭に$HOME/IoT/cmake-3.18.0-Linux-x86_64/binを追加。シリアル接続の確立
ここのページを参考に進めます。
Establish Serial Connection with ESP32まず、Silicon LabsのページからVirtual COM Port (VCP) driversをダウンロード(要ユーザ登録)。
CP210x USB - UART ブリッジ VCP ドライバzipを解凍し、中に含まれているtxtファイルのRedHat向け手順を参考に、cp210x.koをビルドして所定の位置にセット。
make sudo cp cp210x.ko to /lib/modules/<kernel-version>/kernel/drivers/usb/serial insmod cp210x.ko sudo chmod 666 /dev/ttyUSB0なお、Redhat向け手順にある
usbserial.koについては、CentOSの場合はKernelに含まれているので考慮不要だそう。AWSCLIのインストールと設定
以下を参考にインストール。
Linux での AWS CLI バージョン 2 のインストールcd ~/IoT/ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install以下を参考にAWSCLIへクレデンシャルを設定。
設定の基本aws configureAWS SDK for Python (boto3) をインストール。
pip install tornado nose --user pip install boto3 --userFreeRTOSの設定
これで環境設定はほぼ終了したので、FreeRTOSの設定に移ります。
FreeRTOS をダウンロードして設定する
まずGitHubからFreeRTOSをダウンロード。
cd ~/IoT git clone https://github.com/aws/amazon-freertos.git --recurse-submodules次に以下のファイルをviで開いてWIFI等の情報を設定。
~/IoT/amazon-freertos/tools/aws_config_quick_start/configure.jsonそして設定スクリプトを実行します。
cd ~/IoT/amazon-freertos/tools/aws_config_quick_start python3 SetupAWS.py setup設定スクリプトを実行すると、機器に対するクレデンシャルを生成し、AWS IoTへ登録してくれます。
$ python SetupAWS.py setup Creating a Thing in AWS IoT Core. Acquiring a certificate and private key from AWS IoT Core. Writing certificate ID to: ESP32-DevKitC_cert_id_file Writing certificate PEM to: ESP32-DevKitC_cert_pem_file Writing private key PEM to: ESP32-DevKitC_private_key_pem_file Creating a policy on AWS IoT Core. Completed prereq operation! Updated aws_clientcredential.h Updated aws_clientcredential_keys.h Completed update operation! $FreeRTOS デモプロジェクトをビルド、フラッシュ、実行する
手順にはないですが、FreeRTOSをビルドする際に怒られるので、以下を実行しておきます。
python -m pip install --user -r /home/hisashij/IoT/amazon-freertos/vendors/espressif/esp-idf/requirements.txt続いて、以下を実行してビルドファイルを作成。
cd ~/IoT/amazon-freertos/ mkdir ../FreeRTOS/ cmake -DVENDOR=espressif -DBOARD=esp32_wrover_kit -DCOMPILER=xtensa-esp32 -S . -B ../FreeRTOS/そして、ビルドディレクトリに移り、以下を実行してビルド。
cd ../FreeRTOS/ make all -j4FreeRTOS をフラッシュおよび実行する
まず以下を実行してメモリ内を消去します。
cd ~/IoT/amazon-freertos/ ./vendors/espressif/esp-idf/tools/idf.py erase_flash -B ../FreeRTOS/最初は以下のエラーが出ましたが、何度かリトライしているうちに成功。
A fatal error occurred: Failed to connect to Espressif device: Invalid head of packet (0x2E)削除が終わったら、ビルドしたFreeRTOSを書き込んで実行します。
./vendors/espressif/esp-idf/tools/idf.py flash -B ../FreeRTOS/以下で実行状況を確認できます。
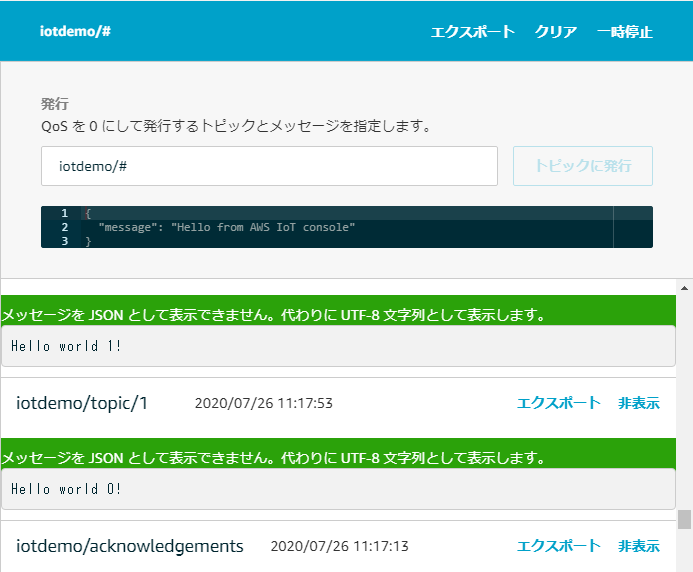
./vendors/espressif/esp-idf/tools/idf.py monitor -p /dev/ttyUSB0 -B ../FreeRTOS/また、AWSコンソールでは、MQTTでHello worldが送られていることが確認できます。
ひとまずデモプログラムはこれで終了。
(おまけ)Windowsでの環境構築の挫折の記録
最初は、CygwinでFreeRTOSのビルドを試みました。が、環境設定を終え、いよいよFreeRTOSのビルドのところで頓挫。Cygwin上で動くNinjaが参照するパスと、Windows上で動くEspressif Toolchainが参照するパスが食い違っていることが原因と思われます。
$ ninja [0/2] Re-checking globbed directories... (snip) xtensa-esp32-elf-gcc.exe: error: /home/hisas/hisas/Downloads/amazon-freertos/vendors/espressif/boards/esp32/components/mbedtls/port/esp_sha256.c: No such file or directory xtensa-esp32-elf-gcc.exe: fatal error: no input files compilation terminated.次に、AWSのWindows向け手順に沿ってMSYS2を入れてMinGW32上での環境構築を試みましたが、AWS CLIを入れようと
pip install awscliを実行したところエラーが発生。復旧方法がわからず、あきらめました。
- 投稿日:2020-07-26T05:13:57+09:00
GoでEC2describeinstanceをする
- リージョンを指定しないとだめだった(awsのdefaultのcredentialにセットされていても)
- DescribeInstancesは
errにあたる部分のエラーハンドリング用の引数を指定しないと怒られた(そういうものなんですか)
./describe.go:32:33: multiple-value svc.DescribeInstances() in single-value contextpackage main import ( "fmt" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/awserr" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/ec2" ) func main() { svc := ec2.New( session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) input := &ec2.DescribeInstancesInput{ InstanceIds: []*string{ aws.String("i-xxxxxxxxxxxxxxxx"), }, } result, err := svc.DescribeInstances(input) if err != nil { if aerr, ok := err.(awserr.Error); ok { switch aerr.Code() { default: fmt.Println(aerr.Error()) } } else { // Print the error, cast err to awserr.Error to get the Code and // Message from an error. fmt.Println(err.Error()) } return } fmt.Println(result) }