- 投稿日:2020-07-21T22:46:55+09:00
Python からの C/C++ コード呼び出し on OSX
Boost.Python を使って、Python から C/C++ の関数を呼び出しを、OSX でトライしたときの記録です。Python3 前提です。
OSX で Boost.Python を使う方法がうまく見つけられなかったので、記録として残しておきます。どれくらい需要があるかはナゾですが、、
情報はすべて 2020/07 現在のものです。(Python3.8)
手順
1. Boost.Python のインストール
Python3 版は
boost-python3という Formula になります。brew install boost-python32. C/C++ コードのコンパイル
例えば、C++ ライブラリとして以下のようなコードを用意します。
my_sample.cpp#include <string> #include <boost/python.hpp> using namespace std; string add_hello( const string s ) { return "Hello, " + s; } // モジュールの初期化ルーチン:モジュール名=my_sample BOOST_PYTHON_MODULE( my_sample ) { // C++のadd_hello関数を、greetという名前でpython用に公開 boost::python::def( "greet", add_hello ); }コンパイルのためのコマンドは下記になります。
g++ -shared -fPIC -I/usr/local/include -L/usr/local/lib \ $(python3-config --includes --ldflags --embed) -lboost_python38 \ my_sample.cpp -o my_sample.soこれで、Python からは
my_sample.soをimport my_sampleとして呼び出すことができるようになります。3. Python からの呼び出し
import my_sample print(my_sample.greet("hoge")) # "Hello, hoge"補足
私がトライしたときは、コンパイラは brew で入る
g++-10ではうまく行かず、XCode 付属のg++でうまくいきました。C++ 標準が違う、みたいな警告が出てたので、boost_phthon38がg++でコンパイルされているから、ということでしょうか。参考資料
boost-python3Formula のテストコード。ここの処理内容をみてようやく、OSX でのコンパイル方法がわかりました。
- 投稿日:2020-07-21T21:29:55+09:00
[python] バスのGPSデータを時系列データとして処理し道路状況(渋滞)を予測してみる
はじめに
こんにちは。Qiita初登校・エンジニア転職を目指し勉強中のものです。
プログラミングに初めて触れた、深層学習の勉強をまともに始めたのが今年の一月というかなりの初心者でございます。
学習のアウトプット発信の一環として本記事を発信させていただきます。
至らぬ点等ございますでしょうが、どうか暖かくご指摘・コメントを頂ければ幸いです。環境
・Windows 10 Home 1909
・anaconda 2020.02
・python 3.7.6
・keras 2.3.1
・tslearn 0.4.1目的
本記事では、GPSと取得時間のデータを用いて、道路状況を解析・予測をすることを目的とします。
解析・予測する道路状態は、「渋滞」についてです。実施手順
1、リカレントネットワークを用いてGPS情報から次の時間の時速を予測するモデルを作成する。
作成したモデルから得られた予測値と実測値を比較し、誤差の大きい箇所を異常データ、小さい箇所を通常データとする。2、tslearnを用いて時系列データのクラスタリングをする。
通常データと異常データそれぞれに対しクラスタリングを行い、分析・要因調査を行う。3、kapler.glを用いて結果の可視化を行う。
※tslearnとはk-means法を用いて時系列クラスタリングをすることを目的としたpythonパッケージのこと
参考:https://irukanobox.blogspot.com/2019/05/python.html?m=0※kapler.glとはコードを全く使わずに位置情報データを可視化することができるウェブサービスのこと
参考:https://note.com/kazukio/n/n3407e34d2985それでは以下より、実施手順の詳細に入りたいと思います。
1. データの確認・前処理
今回はkaggle内にあるデータセット:Transjakarta Bus GPS Data( https://www.kaggle.com/rasyidstat/transjakarta-bus-gps-data )を用いて学習を行います。
2019年11月26日の14時から18時の間に走行したバスのGPSを30秒毎に取得したデータのようです。なにはともあれ、データの中身を確認していきます。
gps_data = pd.read_csv('transjakarta_gps.csv') gps_data.head()
bus_codeやtrip_idなどの位置情報に関係がなさそうな情報が多く含まれています。
他の情報はさておき、bus_codeとtrip_idが変化したタイミングではデータの連続性が危ぶまれそうです。次に欠損値の確認を行います
print(len(gps_data)) print(gps_data.isnull().sum())
経度と緯度の情報がしっかり入っているため特に問題はなさそうです。以下、numpy配列にし、時間変化・変位・時速の情報を追加していきます。
#np.arrayの配列を作成 bus_trip_gps = gps_data[["bus_code", "trip_id","gps_datetime", "longitude", "latitude"]] bus_gps = bus_trip_gps.values #距離の変位を調査する bus_gps_plus = np.vstack((np.zeros(2).reshape(1,2), bus_gps[:, 3:5])) bus_gps_minus = np.vstack((bus_gps[:, 3:5], np.zeros(2).reshape(1,2))) delta_bus_gps = bus_gps_plus - bus_gps_minus delta_bus_gps = delta_bus_gps[1:,:] #直感的に異常値に気付けるように単位をkmにする delta_bus_gps*=110.94297 #距離のデータを作成 delta_distans = (np.square(delta_bus_gps[:,0:1]) + np.square(delta_bus_gps[:, 1:2]))**0.5 #時間の変化のデータを作成 bus_time_minus = pd.to_datetime(bus_gps[:-1,2:3].reshape(-1)) bus_time_plus = pd.to_datetime(bus_gps[1:,2:3].reshape(-1)) delta_time_gps = bus_time_plus - bus_time_minus delta_time_gps = delta_time_gps/np.timedelta64(1,'s') delta_time_gps = np.array(delta_time_gps, dtype='float') delta_time_gps = np.append(delta_time_gps,0) delta_time_gps = delta_time_gps.reshape(len(delta_time_gps),1) #変化量、速度を時速になおす delta_bus_gps /= (delta_time_gps + 1e-8)/(60*60) delta_distans /= (delta_time_gps + 1e-8)/(60*60) #bus_gpsに変位と距離を追加する bus_gps = np.insert(bus_gps,[5] , delta_bus_gps, axis=1) bus_gps = np.insert(bus_gps,[7] , delta_distans, axis=1) bus_gps = np.insert(bus_gps,[3] , delta_time_gps, axis=1)では、時系列データの作成に取り掛かります。今回は、5つ連続するデータ(約150秒)で一つの時系列データとしました。
また、trip_idとbun_codeの変化が起きたときにデータの連続性が危ぶまれるため、その変化点で違う時系列データとして扱うように処理しています。#5回の測定で一回の時系列データとする #bus_codeとtrip_idで別々の時系列のデータとなるようにする。 gps_input_data=[] gps_correct_data =[] len_sequence = 5 # 時系列の長さ bus_gps[:,0:2] = bus_gps[:,0:2].astype(np.str) bus_code_list = np.unique(bus_gps[:,0:1]) for i in range(len(bus_code_list)): bus_code = bus_code_list[i] bus_code_gps = bus_gps[np.any(bus_gps==bus_code,axis=1)] trip_id_list =np.unique(bus_code_gps[:,1:2]) if i%100 == 0: print(i) for j in range(len(trip_id_list)): trip_id = trip_id_list[j] trip_id_gps = bus_code_gps[np.any(bus_code_gps[:,1:2]==str(trip_id),axis=1)] if len(trip_id_gps)>(len_sequence+2): for k in range(len(trip_id_gps)-(len_sequence+2)): gps_input_data.append(trip_id_gps[k:k+len_sequence,2:]) gps_correct_data.append(trip_id_gps[k+len_sequence:k+(len_sequence+1),2:].reshape(7)) #インプット用のデータ #axis0 データ、axis1 同一データ内の時系列位置 axis2 時間、時間変化、緯度,経度,緯度方向変位(km),経度方向変位(km),時速(km/h) gps_input_data=np.array(gps_input_data) #正解用のデータ #axis0 データ、axis1 時間、時間変化、緯度,経度,緯度方向変位(km),経度方向変位(km),時速(km/h) gps_correct_data =np.array(gps_correct_data)これでモデルにインプットする用のデータ、正解用のデータが作成できました。
2. 異常値の削除
異常値の削除を行っていきます。削除するデータは以下の三つです。
1、時速が150km/hを超えているもの
2、時系列内で移動がほとんどないもの
3、データをおおよそ30秒毎に取得できていないもの以下実行コードです。
#異常な値の削除 #正解の時速が150kmを超えているものを異常とみなす high_distans_index0 = np.where(gps_input_data[:,:,-1]>150) high_distans_index0 = high_distans_index0[0] high_distans_index1 = np.where(gps_correct_data[:,-1]>150) high_distans_index1 = high_distans_index1[0] error_data_index=np.concatenate([high_distans_index0, high_distans_index1]) error_data_index=np.unique(error_data_index) gps_input_data = np.delete(gps_input_data,error_data_index,axis=0) gps_correct_data = np.delete(gps_correct_data,error_data_index,axis=0) #データの時系列内での(1個目と5個目)移動距離が0.01km以下のものを異常とする index_destans0 = np.where(((gps_input_data[:,:,4].sum(axis=1)**2 + gps_input_data[:,:,5].sum(axis=1)**2)**0.5) < 0.01) index_destans0 = np.array(index_destans0) index_destans0 = index_destans0.reshape(-1) gps_input_data = np.delete(gps_input_data,index_destans0,axis=0) gps_correct_data = np.delete(gps_correct_data,index_destans0,axis=0) #時間の変位が25より小さい,35より大きいデータを異常とみなす index_time_short0 = np.where(gps_input_data[:,:,1]<25) index_time_short0 = index_time_short0[0] index_time_short1 = np.where(gps_correct_data[:,1]<25) index_time_short1 = index_time_short1[0] index_time_short = np.concatenate([index_time_short0, index_time_short1]) index_time_long0 = np.where(gps_input_data[:,:,1]>35) index_time_long0 = index_time_long0[0] index_time_long1 = np.where(gps_correct_data[:,1]>35) index_time_long1 = index_time_long1[0] index_time_long = np.concatenate([index_time_long0, index_time_long1]) index_time_error = np.concatenate([index_time_long, index_time_short]) index_time_error = np.unique(index_time_error) gps_input_data = np.delete(gps_input_data,index_time_error,axis=0) gps_correct_data = np.delete(gps_correct_data,index_time_error,axis=0)3. LSTM(keras)を用いた速度の予測モデルの作成
リカレントネットワークの作成に入る前に、データの分割を行います。
以下の三つにデータを分割します。・学習用:ネットワークの学習に用いる。
・評価用:ネットワークの評価に用いる。過学習していないか、表現力が足りているかどうか等の判断材料にする。
・プロット用:学習後のモデルに対し、誤差を測定するデータに用いる。各地点毎の標準的な速度をモデルに学習させるために、使用するデータは以下を用いることにしました。
・時間変化
・緯度 / 経度
・緯度経度から求めた速度#データ分割用のインデックスの準備 np.random.seed(0) all_data_number = len(gps_correct_data) data_index =np.arange(all_data_number) np.random.shuffle(data_index) #時速データの準備 X = gps_input_data[:,:,(1,2,3,6)] t = gps_correct_data[:,(1,2,3,6)] #正規化 for i in range(len(t[0,:])): Xt_min = np.min((X[:,:,i].min(), t[:,i].min())) Xt_max = np.max((X[:,:,i].max(), t[:,i].max())) X[:,:,i] = (X[:,:,i]-Xt_min)/Xt_max t[:,i] = (t[:,i]-Xt_min)/Xt_max #データの分割 train_data_number =(all_data_number*3)//5 plot_data_number = (all_data_number*1)//5 X_train = X[data_index[:train_data_number],:,:] t_train = t[data_index[:train_data_number]] X_test = X[data_index[train_data_number:(-plot_data_number)],:,:] t_test = t[data_index[train_data_number:(-plot_data_number)]] X_plot = X[data_index[(-plot_data_number):],:,:] t_plot = t[data_index[(-plot_data_number):]]それではモデルの構築に入ります。モデルの構築にはkerasを使用します。
使用するリカレント層はLSTMを使用し、リカレントドロップアウトを使用します。
誤差関数は、単純な回帰ということもあり、今回は直感的に誤差の速度を把握しやすい平均絶対誤差(mae)を使用します。input_dim = 4 # 入力データの次元数 output_dim = 1 # 出力データの次元数 num_hidden_units_1 = 64 # 隠れ層1のユニット数 num_hidden_units_2 = 32 # 隠れ層2のユニット数 batch_size = 1000 # ミニバッチサイズ num_of_training_epochs = 200 # 学習エポック数 model = Sequential() model.add(LSTM(num_hidden_units_1, input_shape=(len_sequence,input_dim), return_sequences = True, recurrent_dropout = 0.5)) model.add(LSTM(num_hidden_units_2, recurrent_dropout = 0.3)) model.add(Dense(output_dim)) model.compile(loss="mae", optimizer=RMSprop()) model.summary()
それではモデルの学習を開始しましょう。#モデルの学習 history=model.fit(X_train, t_train[:,-1], epochs=num_of_training_epochs, batch_size=batch_size, validation_data=(X_test,t_test[:,-1])) #学習結果の可視化 plt.plot(range(num_of_training_epochs),history.history["loss"], 'bo',color='red', label='Training loss',markersize=3) plt.plot(range(num_of_training_epochs),history.history["val_loss"], 'b',color='blue', label='Validation loss') plt.title('Training and Validation loss') plt.xlabel('Epochs') plt.ylabel('Loss function') plt.legend() plt.show()
残念ながら結果だけ見ても学習結果が良いかどうか検討もつきません。
そこで仮想的に常識的なベースラインを設定しモデルの優位性を証明することにしました。#時系列内で最後の一つ前から最後のデータの加速度が一定であると想定したときの平均絶対誤差(mae)を計算する #ただしデータ取得の間隔が一定であると仮定する batch_maes = [] for i in range(len(X_test)//batch_size): preds = X_test[i*batch_size:(i+1)*batch_size,-1,-1]*2 -X_test[i*batch_size:(i+1)*batch_size,-2,-1] terget = t_test[i*batch_size:(i+1)*batch_size,-1] mae = np.mean(np.abs(preds-terget)) batch_maes.append(mae) standard_mae = np.mean(batch_maes) print("平均絶対誤差(正規化):" + str(standard_mae)) #平均絶対誤差(正規化):0.083268486903678 print("平均絶対誤差 (km/h) :" + str(standard_mae * Xt_max)) #平均絶対誤差 (km/h) :11.597705343596475計算した常識的なベースラインの平均絶対誤差は0.0837となりました。
一方、モデルの損失関数の値は0.0461に収束しており、モデルの優位性を証明することができました。それではプロット用のデータをモデルに読みこみ、予測値から各地点の誤差を取得したいと思います。
その後データを正常データと異常データに分けます。plot_predict = model.predict(X_plot, batch_size=1) #予測した値とy_plotとの絶対誤差を計算する plot_predict_mae=np.abs(plot_predict[:,0]-t_plot[:,-1]) #plot用の絶対誤差と常識的な基準として作成した平均絶対誤差を比較する #plot用の絶対誤差 < 常識的な平均絶対誤差 となるデータを正常とする #plot用の絶対誤差 > 常識的な平均絶対誤差 となるデータを異常とする clustering_normaly_gps = X_plot[np.where(plot_data[:,-1]<standard_mae)[0],:,-1] clustering_anormaly_gps = X_plot[np.where(plot_data[:,-1]>standard_mae)[0],:,-1]4. tslearnを用いた時系列データのクラスタリング
では、小さいデータ(正常データ)、誤差が大きいデータ(異常データ)それぞれに対してクラスタリングをしていきます。
今回使うデータでは時間軸に対してある程度ズレがあっても同じパターンとして認識してくれるように、
距離関数にはDynamic Time Wrapping(DTW)を用いるつもりでした。
しかし、計算コストがあまりに高いためユークリッド距離を用いることにします。
データの時系列が5つしかないため、さして問題はないと判断いたしました。クラスタリングのクラスター数を確からしさを求めるために、シルエット値を利用します。
シルエット値とはクラスタリングが正しくできているかの指標です。
シルエット値は0から1の値を取り、1に近づけば同一クラスター内の距離がそれだけ近くなります。
クラスター数が2から50までのシルエット値を取得していきます。# クラスタリングに用いるデータ数 clustering_data_normalnumber = 10000 #データ分割用のインデックスの準備 np.random.seed(0) normaly_data_number = len(clustering_normaly_gps) normaly_data_index = np.arange(normaly_data_number) np.random.shuffle(normaly_data_index) anormaly_data_number = len(clustering_anormaly_gps) anormaly_data_index = np.arange(anormaly_data_number) np.random.shuffle(anormaly_data_index) #時速データの準備 normaly_ts_dataset = clustering_normaly_gps[normaly_data_index[:clustering_data_number],:] anormaly_ts_dataset = clustering_anormaly_gps[anormaly_data_index[:clustering_data_number],:] #データの保存 silhouette_normaly_data = [] km_normaly_labels = [] km_normaly_center = [] silhouette_anormaly_data = [] km_anormaly_labels = [] km_anormaly_center = [] #クラスタリングの実行 metric = 'euclidean' n_clusters = [n for n in range(2, 50)] print("正常値のクラスタリング") for n in n_clusters: km= TimeSeriesKMeans(n_clusters=n, metric=metric, verbose=False, random_state=1).fit(normaly_ts_dataset) print('クラスター数 ='+ str(n) + 'シルエット値 ='+ str(silhouette_score(normaly_ts_dataset, km.labels_, metric=metric))) silhouette_normaly_data.append(np.array([n, silhouette_score(normaly_ts_dataset, km.labels_, metric=metric)])) km_normaly_labels.append([n, km.labels_]) km_normaly_center.append([n, km.cluster_centers_]) print("異常値のクラスタリング") for n in n_clusters: km= TimeSeriesKMeans(n_clusters=n, metric=metric, verbose=False, random_state=1).fit(anormaly_ts_dataset) print('クラスター数 ='+ str(n) + 'シルエット値 ='+ str(silhouette_score(anormaly_ts_dataset, km.labels_, metric=metric))) silhouette_anormaly_data.append(np.array([n, silhouette_score(anormaly_ts_dataset, km.labels_, metric=metric)])) km_anormaly_labels.append([n, km.labels_]) km_anormaly_center.append([n, km.cluster_centers_])結果を可視化すると以下のようになりました。
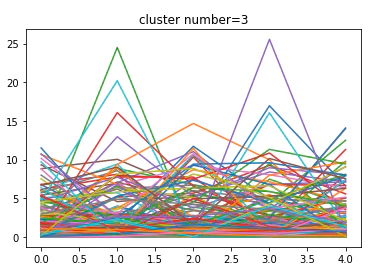
正常・異常データともにクラスター数が2の時シルエット値が最大になり、徐々に減少していきます。
異常データのシルエット値が正常データに比べ低いのは、速度の予測がしづらい=時系列内でデータに整合性がないからでしょうか。とりあえずクラスター数=2の時のクラスタリングの結果を見てみましょう。
こちらが正常のデータの中心を取ったグラフ(n=2)
こちらがクラスター毎の実データです(計100個)
・・・これはクラスタリングできているのでしょうか。
直感的に「渋滞時のデータ」と「正常時のデータ」となればうれしいのですが、そうはならない様子。ちなみにこちらが異常のデータの中心を取ったグラフ(n=2)
正常のデータと若干波形が違います。これは単なる渋滞の位置ではなく渋滞の終わりの位置とを示しているのかもしれません。n=2ではシルエット値は最大となるのですが道路状態を分割できるほどクラスタリングしていないため、
それらしくクラスタリングできているnの中で最大となる値を採用することにしました。
正常のデータではn=10、異常のデータではn=12より大きくなる際にシルエット値に解離が大きく見られたためその値を採用します。正常データ(n=10)の各データの中心
n=2 渋滞の入り口
n=3 渋滞
n=7 渋滞の出口
となっているようです。実データを見ても把握することができます。
異常データ(n=12)の各データの中心
n=2 渋滞の入り口
n=7 渋滞
n=4 渋滞の出口
となっています。
(正常データと同様に実データを見てもそうなっている、今回は割愛)これらをcsvに出力し、kepler.glに入れれる形にします。
#gps_correct_dataからプロット用のデータを作成 gps_plot_data = gps_correct_data[data_index[(-plot_data_number):],:] plot_data=np.concatenate([gps_plot_data,plot_predict_mae.reshape(len(plot_predict_mae),1)], axis=1) plot_data=plot_data[:,(0,2,3,7)] plot_normaly_gps = plot_data[np.where(plot_data[:,-1]<standard_mae)[0],:] plot_anormaly_gps = plot_data[np.where(plot_data[:,-1]>standard_mae)[0],:] #normal用データ作成 n_cluster = 10 lavel = 2 km_labels = km_normaly_labels[n_cluster-2][1]# normaly_plot_data = plot_normaly_gps[normaly_data_index[:clustering_data_number],:]# normaly_plot_data_label = normaly_plot_data[np.where(km_labels.reshape(clustering_data_number,1)==lavel)[0],:]# df_normaly_plot_lavel = pd.DataFrame(normaly_plot_data_label0, columns=['gps_datetime', 'longitude', 'latitude', 'error']) df_normaly_plot_lavel.to_csv('normaly_plot_lavel='+str(lavel)+'(渋滞の入り口).csv')5. kepler.glを用いたデータの可視化
それではデータの可視化を行います。
渋滞のデータを時間毎にプロットしたものが下になります。・水色のデータ:予測に使用した全データ
・黄色のデータ:正常・異常、入口・出口問わずクラスタリングにて渋滞と判断された全データ
少々荒いですが、時間ごとにどこで渋滞が起きているのかを把握することができます。
予測に使用した全データを同時にプロットすることにより、黄色の面積が少ない箇所は「データの取得率が単純に少ないのでは?」と指摘される心配がなくなります。
これにより、渋滞の度合いをより直感的に把握してもいい画面ということが保証されました。どうやら都市部を中心に渋滞が起きているようです。一方で都市部から少し離れれば快適な運転が可能なことがうかがえます。
では、渋滞の入り口と出口の違いを見てみましょう。
・薄い水色のデータ:正常・異常の渋滞データ
・黄色のデータ:正常・異常の渋滞入口データ
・緑色のデータ:正常・異常の渋滞出口データ
ぼんやりとデータを眺めていると、はじめは渋滞出口データが多く、渋滞がおだやかに緩和されていることが分かります。
しかし、徐々に渋滞入口データが多くなったと思ったら、あっという間に渋滞の箇所がとても多くなってしまいました。このことから、渋滞入口データと渋滞出口データは大きな範囲での道路状態を予測するのに役立つ情報になる可能性が分かります。
渋滞のまわりに渋滞の入口が発生するのではなく、渋滞の入口があつまっていつのまにか渋滞が発生しているようなので、
渋滞入口・出口の情報のみでは、ピンポイントでこの場所が渋滞になる、という予測は難しそうです。最後に正常・異常データの比較を行いましょう。
プロットデータ:正常・異常の渋滞・渋滞入口・渋滞出口のデータ
縦軸・色:モデルでの予測値との誤差
一方こちらは渋滞とそうでないところの境い目で誤差が大きくなっているようです。
誤差が大きくなっている境界で、いつも間にか渋滞に発生したり渋滞が緩和されたりしています。この情報を用いれば次に渋滞の発生・緩和される個所の場所をある程度絞ることができそうです。
結果
速度予測のモデルとクラスタリングを用いいることによって以下のことを把握できました。
現状:渋滞の位置
予測:今後渋滞が緩和されるか、渋滞が発生するか。どの場所でそれが起こりうるか
今後の課題・反省点
全体の進め方の反省
データ分析をする際に目的が不明確なまま開始してしまった。
特に、速度予測モデルに関しては「こんなことできたら面白いな」という興味本位で取り組んでしまった。データの選択について
結果的に渋滞を予測することとなったが、今回のデータではバス停で止まっているのか渋滞で遅延しておるのか判断をすることができない。
また、予測した速度もおそらく実際の速度とは解離があり、もっとデータ取得間隔の短いデータを用いるか、
地図と位置をリンクさせ、経路を予想したうえで速度を予測するべきであった。モデルについて
学習・予測の際にデータ取得位置の情報も入れるべきかの判断を正しく行えなかった。
位置を入れることで地点毎に道路状態を学習させるというと聞こえはいいが、
誤差が高くなってほしい箇所(渋滞の境い目など)を学習し、誤差が不必要に低くなるリスクがあることを考慮できなかった。クラスタリングについて
結果的にユークリッド距離を使用したため、わざわざ tslearn を使用した意味がなくなってしまった。
また、正常データ・異常データ別々にクラスタリングしたが、今回の解析ではプロットデータのクラスタリングを行うのみで十分であった。ここまでご覧くださりありがとうございました。
まだまだ学ぶことが多いことを改めて思い知らされました。
これからも日々勉強を続けていきたいと思います。以上。















- 投稿日:2020-07-21T20:20:23+09:00
PyAutoItとAutoItの違い
「PyAutoItをちょっとだけ触ってみた」では、PyAutoItについて簡単な記事を投稿しました。
今回はAutoItとPyAutoItの違いについて触れたいと思います。
はじめに
PyAutoItは以前の記事で紹介した通り、AutoItをラップしたものとなっています。
そのためAutoItとメソッドの多くはPyAutoItでも共通しています。
しかしそのまま使えるわけではないので注意してください。参考までにAutoItのメソッドについて参考リンクを貼っておきます。
Function Refarence:https://open-shelf.appspot.com/AutoIt3.3.6.1j/html/functions.htm
AutoItで使用可能な関数の一覧が見られます。AutoItとPyAutoItでの関数の違い
実際に同じ処理をそれぞれのルールに沿ってプログラミングをしてみたいと思います。
例として、下記のシナリオをそれぞれの書き方で記述してみます。
1. メモ帳を開く
2. "Hello World!"と入力する
3. 保存せずにメモ帳を閉じるAutoIt
AutoItRun("notepad.exe") 'メモ帳の起動 WinWaitActive("[CLASS:Notepad]") 'メモ帳が開くまで待機 ControlSend("[CLASS:Notepad]", "", "Edit1", "hello world!") 'hello world! と入力する WinClose ("[CLASS:Notepad]") 'メモ帳を閉じる ControlClick ( "メモ帳", "いいえ(&N)", "Button2") '保存せずに終了するPyAutoIt
PyAutoItimport autoit autoit.run("notepad.exe") #メモ帳の起動 autoit.win_wait_active("[CLASS:Notepad]", 3) #メモ帳が開くまで待機 autoit.control_send("[CLASS:Notepad]", "Edit1", "hello world{!}") #hello world! と入力する autoit.win_close("[CLASS:Notepad]") #メモ帳を閉じる autoit.control_click("[Class:#32770]", "Button2") #保存せずに終了する比較
AutoItとPyAutoItを比較してみました。
操作内容 AutoIt PyAutoIt 比較 起動 Run("notepad.exe") autoit.run("notepad.exe") 大きな違いはありませんね 表示待機 WinWaitActive("[CLASS:Notepad]") autoit.win_wait_active("[CLASS:Notepad]", 3) 引数の数が違います 文字入力 ControlSend("[CLASS:Notepad]", "", "Edit1", "hello world!") autoit.control_send("[CLASS:Notepad]", "Edit1", "hello world{!}") 内容はほぼ同じですが、ちょっと違いますね 終了 WinClose ("[CLASS:Notepad]") autoit.win_close("[CLASS:Notepad]") 内容はほぼ同じですが、ちょっと違いますね ボタン操作 ControlClick ( "メモ帳", "いいえ(&N)", "Button2") autoit.control_click("[Class:#32770]", "Button2") 引数も内容も少々違います それぞれの違いについて
比較をした表を見ると、以下のことが分かりました。
関数の記述方法が違う
pyAutoItでは、[ _ ]で関数名が分かれています。
AutoItだと「winClose」でもPyAutoItでは「Win_Close」となっているようです。引数の数が違う
WinWaitActive , Win_Wait_Active でそれぞで引数が違います。
なぜ違うのかは正直分かりません。プロパティの定義が少し違う
関数内で指定するプロパティがAutoItとPyAutoItでは異なります。
何が違うのか、その法則性が分からずにいます。終わりに
AutoIt と PyAutoIt
使える関数はほぼ共通していますが、使い方が微妙に異なるため、
AutoItの関数一覧を見ても、そのまま適用することが出来ない場合が多いです。また、PyAutoItの関数についてまとめられているサイトや記事は私が探した限り見つからず、
正直手探りで使っていくしかないのが現状です。だれかにまとめを作ってほしいのが正直な気持ちです...
- 投稿日:2020-07-21T19:56:33+09:00
Djangoで変数を渡すときメモ
テンプレートに値を渡す方法
下記のように辞書形式で渡す。
return TemplateResponse(request, '*****.html', {"変数名": 変数})引数をhtml内で使用する方法
下記のように記載すれば変数と同様に扱える。
<h1>{{ 変数名 }}</h1>モデル等複数要素で構成されていれば、下記のように記載すれば同様に変数として扱える。
<h1>{{ 変数名.要素名 }}</h1>
- 投稿日:2020-07-21T18:33:13+09:00
Colabからyoutube-dl、最高画質・音質で
はじめに
GoogleColaboratoryからyoutube-dlを利用する方法について書きます。
動画と音声を別々でDLします。なんでColab使うの
GoogleDriveに直接保存するのが簡単だからです。
SSDを圧迫したくないPCから実行したかったんです。コード
youtube-dlインストール
Colabで新規ファイルを作成したら、まずはyoutube-dlをインストールします
"!"を先頭につけることで、コマンドプロンプトと同じコマンドが使えます。!pip install youtube-dlこのコマンドはColabを開くたびに1度だけ実行しないといけません。
どうやらそうしなくてもいい方法もあるようなのですが、私は試してもできませんでした……。Driveマウント
次にGoogleDriveをマウントします。
このノートブックに自分のDriveを使ってもいいよと許可するイメージです。ytdlbest.pyfrom google.colab import drive drive.mount('/content/drive')これを実行するとURLを提示されるので、そこにアクセスして色々許可します。
すると文字列が提示されるので、それをコピーしてColabに戻り、コードの下の入力欄に入力すればマウント完了です。動画(音声なし)のダウンロード
マイドライブ(Driveのトップのフォルダ)の下にprojectsフォルダを作成していることを前提とします。
ytdlbest.pydef videodl(url:str): vdl_opts = {'outtmpl':'/content/drive/My Drive/projects/%(title)s_video.%(ext)s','format':'bestvideo'} vdl = youtube_dl.YoutubeDL(vdl_opts) vdl.extract_info(url,download=True)youtube-dlのディレクトリ指定は、
outtmplオプションから行います。
このオプションは保存するファイルの名前を指定するものですが、保存先の指定にも使えます。更にフォーマットを
bestvideoにすることで、最も画質の高い動画をDLできます。音声のダウンロード
マイドライブ(Driveのトップのフォルダ)の下にprojectsフォルダを作成していることを前提とします。
ytdlbest.pydef audiodl(url:str): adl_opts = {'outtmpl':'/content/drive/My Drive/projects/%(title)s_audio.%(ext)s', 'format':'bestaudio/best'} adl = youtube_dl.YoutubeDL(adl_opts) adl.extract_info(url, download=True)動画の場合と同様です。
本来音声のみのDLはffmpegのインストールが必要なのですが、GoogleColaboratoryにはデフォルトで入っているようなので、このままで通ります。
Colab素晴らしいですね。実行
ytdlbest.pydef main(): url = "https://www.youtube.com/watch?v=hogehoge" videodl(url) audiodl(url) print("DL完了") if __name__ == "__main__": main()
url =以下にYoutubeのURLを貼り付けてください。
そしたら実行できます。お疲れさまでした。その他
動画と音声をくっつけたいなら、
How to get information from youtube-dl in python ??
https://stackoverflow.com/questions/23727943/how-to-get-information-from-youtube-dl-in-pythonこのあたりを参考に保存する動画/音声のファイル名を取得して、ffmpegで合成すれば出来ると思います。
- 投稿日:2020-07-21T18:33:13+09:00
GoogleColabからyoutube-dl、最高画質・音質で
はじめに
GoogleColaboratoryからyoutube-dlを利用する方法について書きます。
動画と音声を別々でDLします。なんでColab使うの
GoogleDriveに直接保存するのが簡単だからです。
SSDの小さいPCから実行したかったんです。コード
youtube-dlインストール
Colabで新規ファイルを作成したら、まずはyoutube-dlをインストールします
"!"を先頭につけることで、コマンドプロンプトと同じコマンドが使えます。!pip install youtube-dlこのコマンドはColabを開くたびに1度だけ実行しないといけません。
Driveマウント
次にGoogleDriveをマウントします。
このノートブックに自分のDriveを使ってもいいよと許可するイメージです。ytdlbest.pyfrom google.colab import drive drive.mount('/content/drive')これを実行するとURLを提示されるので、そこにアクセスして色々許可します。
すると文字列が提示されるので、それをコピーしてColabに戻り、コードの下の入力欄に入力すればマウント完了です。動画(音声なし)のダウンロード
マイドライブ(Driveのトップのフォルダ)の下にprojectsフォルダを作成していることを前提とします。
ytdlbest.pydef videodl(url:str): vdl_opts = {'outtmpl':'/content/drive/My Drive/projects/%(title)s_video.%(ext)s','format':'bestvideo'} vdl = youtube_dl.YoutubeDL(vdl_opts) vdl.extract_info(url,download=True)youtube-dlのディレクトリ指定は、
outtmplオプションから行います。
このオプションは保存するファイルの名前を指定するものですが、保存先の指定にも使えます。更にフォーマットを
bestvideoにすることで、最も画質の高い動画をDLできます。音声のダウンロード
マイドライブ(Driveのトップのフォルダ)の下にprojectsフォルダを作成していることを前提とします。
ytdlbest.pydef audiodl(url:str): adl_opts = {'outtmpl':'/content/drive/My Drive/projects/%(title)s_audio.%(ext)s', 'format':'bestaudio/best'} adl = youtube_dl.YoutubeDL(adl_opts) adl.extract_info(url, download=True)動画の場合と同様です。
本来音声のみのDLはffmpegのインストールが必要なのですが、GoogleColaboratoryにはデフォルトで入っているようなので、このままで通ります。
Colab素晴らしいですね。実行
ytdlbest.pydef main(): url = "https://www.youtube.com/watch?v=hogehoge" videodl(url) audiodl(url) print("DL完了") if __name__ == "__main__": main()
url =以下にYoutubeのURLを貼り付けてください。
そしたら実行できます。お疲れさまでした。その他
動画と音声をくっつけたいなら、
How to get information from youtube-dl in python ??
https://stackoverflow.com/questions/23727943/how-to-get-information-from-youtube-dl-in-pythonこのあたりを参考に保存する動画/音声のファイル名を取得して、ffmpegで合成すれば出来ると思います。
- 投稿日:2020-07-21T18:30:55+09:00
【Python】LINEからYoutubeの曲や動画を落としたい2/3
概要
【Python】LINEからYoutubeの曲や動画を落としたい1/3
【Python】LINEからYoutubeの曲や動画を落としたい2/3LINEへの返答、GoogleDriveへのアップロード部分の作成
前回では、youtubeやsoundcloud、ニコニコ動画に対応するダウンローダーのプログラムを作成しました。
今回はyoutube-dlを使い実際にLINEに応答を返したりGoogleDriveへアップロードする部分を作成します。まず、始める前にGoogleDriveへアップロードできるか確認しておきましょう。
GoogleDriveへのアップロードができるか確認する(手順は大きく3つ)
①GoogleDriveで共有のフォルダを一つ作成する。
GoogleDrive上で右クリック → 新しいフォルダ → 名前を入力 → 名前を付けたフォルダを右クリック →
共有可能なリンクを取得 → [制限付き▼]をクリック → リンクを知っている全員に変えておく。
※ここを変えておかないと、LINEから直接音楽を聴いたりができなくなります。
(LINEサーバ上にデータは保管されず、あくまでストリーミングとしてGoogleDrive上の音楽を取得しに行ってるからです。)②共有フォルダーのフォルダーIDを確認する。
フォルダーを作成できたらそのフォルダを開く → URLを確認 → https://drive.google.com/drive/folders/
以降のランダムな文字列がフォルダーIDになります。③GoogleDriveへのアップロードを行う部分のテストプログラムを作成して確認する
前回作成したyoutube.pyと同じディレクトリ上で作業します。・client_idとclient_secret、GoogleDriveAPIの有効化が必要です。参考
まずはsettings.yamlファイルを作成します
cd $HOME/line vim settings.yamlsettings.yamlclient_config_backend: settings client_config: client_id: "ここにGoogleClientID" client_secret: "ここにSecretID" save_credentials: True save_credentials_backend: file save_credentials_file: credentials.json get_refresh_token: True oauth_scope: - https://www.googleapis.com/auth/drive.file - https://www.googleapis.com/auth/drive.install次にyoutube-dlを使用してGoogleDriveへのアップロードまでのプログラム
vim upload.pyupload.py#!/bin/env python import youtube import os from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive #ダウンロードディレクトリ dl_dir = "youtube/" #GoogleFolderID folder_id = 'フォルダーID' #GoogleDrive認証設定 gauth = GoogleAuth() gauth.CommandLineAuth() drive = GoogleDrive(gauth) message = "/mp3 GoogleDriveへアップロードしたいyoutubeの曲" url = message.split()[1] transaction = message.split()[0] file_name = youtube.main(transaction,url,dl_dir) for i in range(len(file_name)): f = drive.CreateFile({'title': file_name[i], 'mimeType': 'audio/mpeg', 'parents': [{'kind': 'drive#fileLink', 'id':folder_id}]}) f.SetContentFile(dl_dir + f['title']) #UploadGoogleDrive f.Upload()ここまでできたら、実行してアップロードできるか確認してみましょう。
$ chmod +x upload.py $ ./upload.py問題なくアップロードできたら、次にLINE BOTアプリを作成していきます。
LINE BOTアプリを作成する
環境変数に登録する
//未登録であることを確認 export -p //登録を実施 echo 'export LINE_CHANNEL_ACCESS_TOKEN="ここにアクセストークン"' >> ~/.bash_profile echo 'export LINE_CHANNEL_SECRET="ここにチャンネルシークレット"' >> ~/.bash_profile source ~/.bash_profile //登録されていることを確認 export -pアプリの作成
vim app.pyapp.py#!/bin/env python import os import re import youtube import math from flask import Flask, request, abort from linebot import LineBotApi, WebhookHandler from linebot.exceptions import InvalidSignatureError from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, AudioSendMessage ) from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from mutagen.mp3 import MP3 #アプリケーションフレームワーク app = Flask(__name__) #LINE Channel Secret LINE_CHANNEL_SECRET = os.environ['LINE_CHANNEL_SECRET'] #LINE Access Token LINE_CHANNEL_ACCESS_TOKEN = os.environ['LINE_CHANNEL_ACCESS_TOKEN'] line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(LINE_CHANNEL_SECRET) #DownloadDirectory dl_dir = "youtube/" os.makedirs(dl_dir, exist_ok=True) #GoogleDriveAuthSettings gauth = GoogleAuth() gauth.CommandLineAuth() drive = GoogleDrive(gauth) #GoogleFolderShareID folder_id = 'GoogleDriveの共有フォルダーIDを記入' #User_Input Input_dict = { '/mp3':'/mp3', '/mov':'/mov', '/nomov':'/nomov' } @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' #Message def messagebox(event,transaction,url): transaction_dict = { '/mp3':'曲', '/mov':'本の動画', '/nomov':'本の動画' } set_transaction = transaction_dict.get(transaction) if "&list=" in url: line_bot_api.reply_message(event.reply_token, TextSendMessage(text="プレイリストの" + set_transaction + "をGoogleDriveにアップロードします。\n" + "処理に時間が掛かる場合があります。")) elif "nicovideo" in url: line_bot_api.reply_message(event.reply_token, TextSendMessage(text="ニコニコ動画は処理に時間が掛かる場合があります。")) else: line_bot_api.reply_message(event.reply_token, TextSendMessage(text="1" + set_transaction + "をGoogleDriveにアップロードします。")) #Music def music(get_id,file_name): if "ERROR" in str(file_name): line_bot_api.push_message(get_id,messages=( TextSendMessage(text="曲のダウンロード処理に失敗しました。"))) for i in range(len(file_name)): f = drive.CreateFile({'title': file_name[i], 'mimeType': 'audio/mpeg', 'parents': [{'kind': 'drive#fileLink', 'id':folder_id}]}) f.SetContentFile(dl_dir + f['title']) #UploadGoogleDrive f.Upload() file_id = drive.ListFile({'q': 'title =\"' + file_name[i] + '\"'}).GetList()[0]['id'] if len(file_name) == 1 : file_length = MP3(dl_dir + file_name[i]).info.length link = "https://drive.google.com/uc?export=view&id=" + file_id dur = math.floor(file_length * 1000) line_bot_api.push_message(get_id,messages=( TextSendMessage(text=file_name[i]), AudioSendMessage(original_content_url=link,duration=dur))) line_bot_api.push_message(get_id,messages=(TextSendMessage(text=link))) os.remove(dl_dir + file_name[i]) break os.remove(dl_dir + file_name[i]) else: line_bot_api.push_message(get_id,messages=( TextSendMessage(text=str(len(file_name)) + "曲をGoogleDriveにアップロードしました。\n" + "https://drive.google.com/drive/folders/" + folder_id))) #Video def video(get_id,file_name): video_ext_dicts = { '.mp4':'video/mp4', '.webm':'video/webm', '.mkv':'video/x-matroska' } if "ERROR" in str(file_name): line_bot_api.push_message(get_id,messages=( TextSendMessage(text="動画のダウンロード処理に失敗しました。"))) for i in range(len(file_name)): root, ext = os.path.splitext(file_name[i]) mimeType = video_ext_dicts.get(ext) f = drive.CreateFile({'title': file_name[i], 'mimeType': mimeType, 'parents': [{'kind': 'drive#fileLink', 'id':folder_id}]}) f.SetContentFile(dl_dir + f['title']) #UploadGoogleDrive f.Upload() os.remove(dl_dir + file_name[i]) line_bot_api.push_message(get_id,messages=( TextSendMessage(text=str(len(file_name)) + "本をGoogleDriveにアップロードしました。\n" + "https://drive.google.com/drive/folders/" + folder_id))) @handler.add(MessageEvent, message=(TextMessage)) def contents(event): #LINE Message message = event.message.text try: get_id = event.source.group_id except AttributeError: get_id = event.source.user_id set_input = Input_dict.get(message.split()[0]) try: if message.startswith(set_input): url = message.split()[1] messagebox(event,set_input,url) #youtube-dl file_name = youtube.main(set_input,url,dl_dir) if set_input == "/mp3": music(get_id,file_name) else: video(get_id,file_name) except TypeError: pass if __name__ == "__main__": app.run(host="127.0.0.1", port="9000")ここまでできればほぼ完成です。あとはシェルスクリプトを書いて、挙動を確認して終了です。
ではまた次回でお会いしましょう。

- 投稿日:2020-07-21T17:36:49+09:00
RNNを用いた気温の予測
とある課題でRNNを使った気温の予測をしようと思ったのですが、(詳しくは後述しますが)結果が微妙だったので没になりました。なので、ここで没供養させていただければと思います。
概要
気象庁の観測データを基にRNNを使用して平均気温の将来予測をします。
得られたデータをちょっと考察します
筆者が実行したコードは github においてありますライブラリのインポート
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.metrics import mean_squared_error from sklearn.metrics import r2_score from keras.layers.recurrent import SimpleRNN from keras.models import Sequential from keras.optimizers import Adam from keras.layers import Dense, Activation from tensorflow.keras.callbacks import EarlyStoppingここは特に言うことはないですかね
データの取得
データは 気象庁のHP からダウンロードできます。
ちなみに筆者は諸事情で別に入手しました。
ダウンロードしたデータには品質情報と均質番号があると思いますが、これは基本的に無視して大丈夫です。
あと一度にダウンロードできるデータ数に制限があるので、20年ごとに分割してダウンロードしたものをpandasで結合しました。# 読み込み tokyo1=pd.read_csv("data/tokyo_1961-1980.csv", header=2,skiprows=[4],encoding="shift-jis",parse_dates=["年月日"]) tokyo2=pd.read_csv("data/tokyo_1981-2000.csv", header=2,skiprows=[4],encoding="shift-jis",parse_dates=["年月日"]) tokyo3=pd.read_csv("data/tokyo_2001-.csv", header=2,skiprows=[4],encoding="shift-jis",parse_dates=["年月日"]) tokyo=pd.concat([tokyo1, tokyo2, tokyo3], ignore_index=True) tokyo=tokyo.sort_values("date", ignore_index=True) tokyo["year"]=tokyo["年月日"].dt.year日時情報をdatetime型にしたいので
parse_dates=["年月日"]としています。なお筆者はこのコードで実行していないのでどっか間違ってたらごめんなさいデータの整形
#整形 tem=tokyo["avtem"] timesteps = 20 x = np.empty([len(tem)-timesteps, timesteps], dtype=np.float32) y = np.empty(len(tem)-timesteps, dtype=np.float32) for i in range(len(x)): x[i] = tem[i:i+timesteps].T y[i] = tem[i+timesteps] data_len = timesteps*int(len(x)/timesteps) x = x[:data_len].reshape(data_len,timesteps,-1) y = y[:data_len].reshape(data_len,-1) x_train=x[:21164] y_train=y[:21164] x_test=x[21164:21529] y_test=y[21164:21529]データの整形は これ を参考にしました。
trainデータは2018年までのもの、testデータは2019年のものを手動で行番号を探して取り出しました(1961年1月1日からのデータを用いると同じ行数になると思います)。モデルの作成
#モデルの作成 model = Sequential() model.add(SimpleRNN(50, input_shape=(timesteps, 1), kernel_initializer='random_normal')) model.add(Dense(1)) model.add(Activation('linear')) model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.01, beta_1=0.9, beta_2=0.999)) early_stopping = EarlyStopping(monitor='val_loss', mode='auto', patience=3) model.fit(x_train, y_train, batch_size=1024, epochs=20, validation_split=0.1,callbacks=[early_stopping]) y_pred = model.predict(x_test) print("RMSE:",np.sqrt(mean_squared_error(y_test, y_pred))) print("r2 :",r2_score(y_test,y_pred),"\n")モデルの作成では これ を参考にしました。trainデータ数が2万以上あったので、バッチサイズ512と大きめに設定しています。
これを実行すると、12回ぐらいで精度が上がらくなり、スコアは、
- RMSE: 2.0795848
- r^2 : 0.9290615357147783
でした。 気象庁の予測精度 が最高気温でRMSE1.5強なので精度があまりよくないことがわかります。
特にちょっと考えてもらえばわかると思いますが平均気温は最高気温に比べてぶれにくいので平均気温でこんだけの誤差が出てしまうのではちょっと使い物にならない感がすごいです。なお、実際にこのプログラムを最高気温でやってみるとRMSE3.2程度でした。考察(というほどでもないですが)
テストデータ(2019年)の気温予測と実際の値を比較してみました。
主に上下に大きく変動しちゃったとこが予測できていないことがわかります。これは過去のデータから傾向で予測しているという都合上しょうがないと思います。
そもそも気温というか天気は気圧配置などに影響されるわけで、それに明確にパターンが決められているのかといえばそうではない気がするので、気象庁は様々な観測データから数値計算して気温を求めてるのでパターンがなくても予測することが可能であることを考えると、RNNでそこまでの精度は出ないのかなという気がします。ちなみにもっと一部分を拡大してみるとこんな感じでした。
いや、予測しているというより、前日の観測データの後追いしてるだけやん参考文献


- 投稿日:2020-07-21T16:34:54+09:00
三菱IQ-R#Socket通信
なんだか最近Socket通信に書くこと多いと気がします…まぁ、なぜかよく問い合わせきましたから。
なので今回三菱RCPUとPythonを通信すること書きます。この記事は以下のBlogにも乗っています。よろしくおねがいします。
http://soup01.com/ja/2020/07/21/mels-iqr-sockt/前書き
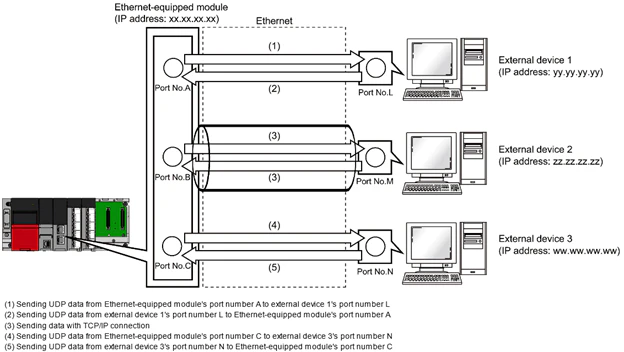
Socket通信すには、Port番号の設定によって異なる外部デバイスと通信することができます。それらのデバイスはTCP/IP・UDP/IPも使えます。
そしてTCP/IP protocolはActive openとPassive Openがあります。
簡単にいいますと、Active OpenはClientですね。
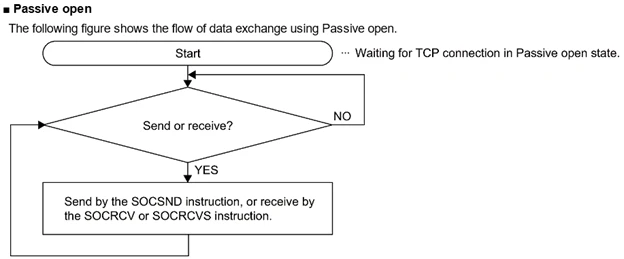
Passive OpenはServerですね。Active Open Flow
Passive Open Flow
Connectionを切断するタイミング
- Timeout
- 相手側から切断要求きたとき。そして同じのConnectionを再接続には最低限500msの間隔をあげましょう。(Manualがそういっただけですー)
TCP/IP protocolに必要なもの
- 自分のIP
- 自分のPort
- 相手のIP
- 相手のPort
Flow
使用するFunction
SP_SOCOPEN
Connectionを開くFunctionです。
- EN:Bool
- 立ち上げるとFunctionを実行する
- U:String[1]
- Dummyです。
- S1:Word
- Connectionの番号です。
- S2: Array [0..9] of Word
- Control Data最初から始まるメモリ番地。
- d:Array[0..1]of Bool
- Function実行後の状態、もしエラーがある場合Array[0]とArray[1]も1サイクルOnになります。
- ENO:Bool
- 実行結果。
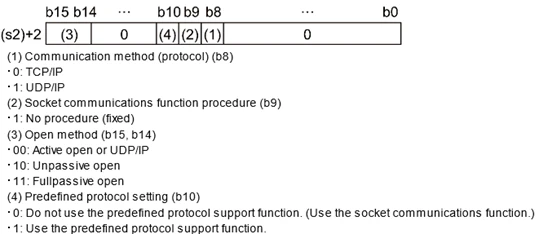
Control Word
- S2+0
- 0000H-Open setting のエンジニアツールを使う、なんらんかはしりません。
- 8000H-S2+2~+9のコントロールデータを使います。今回はこれを利用します。
- S2+1
- 実行後のStatusです。もし0でなければエラーがあります。エラーコードはここで格納します。
- S2+2
- Connectionの設定ですね。
- S2+3
- 自分のPort番号です。
- S2+4、+5
- 相手のIPアドレスです。
- S2+6
- 相手のPort番号です。
- S2+7-+9
- 使用禁止です。
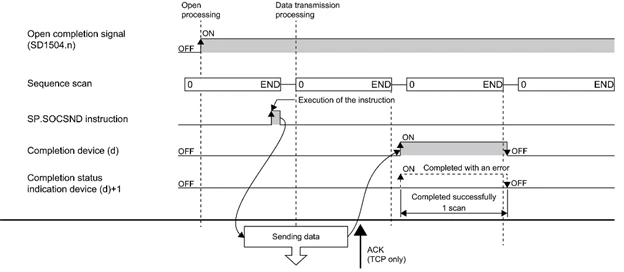
Time-Chart
SP_SOCCLOSE
Connectionを切断するFunctionです。
- EN:Bool
- 立ち上げるとFunctionを実行する
- U:String[1]
- Dummyです。
- S1:Word
- Connectionの番号です。
- S2: Array [0..1] of Word
- Control Data最初から始まるメモリ番地。
- d:Array[0..1]of Bool
- Function実行後の状態、もしエラーがある場合Array[0]とArray[1]も1サイクルOnになります。
- ENO:Bool
- 実行結果。
Time Chart
SP_SOCCINF
Connectionの設定をもらうFunctionです。
- EN:Bool
- 立ち上げるとFunctionを実行する
- U:String[1]
- Dummyです。
- S1:Word
- Connectionの番号です。
- S2::Array [0..1] of Word
- Control Data最初から始まるメモリ番地。Function実行後の状態、もしエラーがある場合Array[1]がエラーコードが格納されます。
- d:Array[0..4]of Word
- Connectionの設定格納されます。
- ENO:Bool
- 実行結果。
d
- S2+0,+1
- 相手のIPアドレス
- S2+2
- 相手のPort
- S2+3
- 自分のPort
- S2+4
- Connectionの構成Word
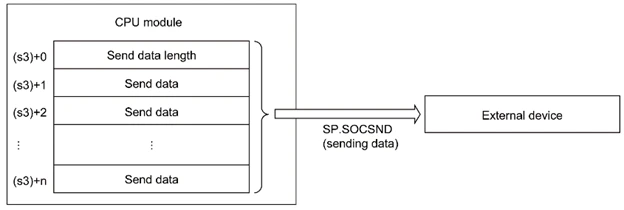
SP_SOCSND
データを送信するFunctionです。
- EN:Bool
- 立ち上げるとFunctionを実行する
- U:String[1]
- Dummyです。
- S1:Word
- Connectionの番号です。
- S2:Array[0..1] of Word
- ControlデータでもしFunction実行エラーがある場合Word[1]がエラーコードが格納されます。
- S3: Array [0..n] of Word
- 送信するデータ最初から始まるメモリ番地。Function実行後の状態、もしエラーがある場合Array[1]がエラーコードが格納されます。
- d:Array[0..4]of Word
- Connectionの設定格納されます。
- ENO
- Boolで実行結果。
S3
- S3+0
- 送るデータの長さ(Byteで計算)
- S3+1-N
- データの番地
Time Chart
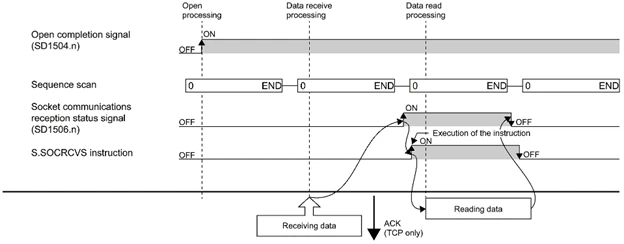
S_SOCRCVS
データ受信するFunctionです。
- EN:Bool
- ONするとFunctionを実行する
- U:String[1]
- Dummyです。
- S:Word
- Connectionの番号です。
- d: Word
- データ受信するときこの番地から始まります。Dは受信するデータの長さ・D+1からはデータの格納先です。
- ENO:Bool
- 実行結果。
d
Time Chart
実装
バージョン
CPU
Hardware設定
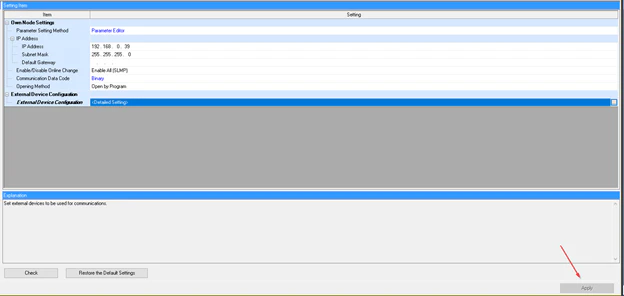
Parameter>R08CPU>Module ParameterでIPを設定します。
そしてExternal Device Configurationの隣“Detailed Setting”をクリックしConnectionの設定をします。
右のModule List>Ethernet Device(General)でActive Connection Moduleを選んでひっばります。
次はSocket Communicationを選んで、自分のPort番号設定します。今回の例は4000にします。次はちょっと右にScrollし…
こちらで相手側のIPとPortを設定し、
“Close with Reflecting the Setting”を。
最後はApply。
よし、これでConnection完了です。
プログラム
Socket設定するためにFunctionを3つ作っています。
- FC_SocketIPConfig
- IPアドレスを綺麗に一つのDWORDにまとめるFunction。
- FC_SocketConectionConfig
- Active使うか、なにないツール使うかのに設定するワードをまとめるFunction。
- FC_SocketConfig
- FC_SocketIPConfig、FC_SocketConectionConfigも含め、Port番号を全部設定するFunctionです。
FC_SocketIPConfig
Interface
Program
例え192.168.0.251はHC0A800FBです。このように百倍ずつ大きくしてプラスすれば同じの値になります。
IPConfig1:=iConfig[1]; IPConfig2:=iConfig[2]; IPConfig3:=iConfig[3]; IPConfig4:=iConfig[4]; ipConfig:=IPConfig4+int_to_Dint(IPConfig3*H100) +(IPConfig2*H10000) +(IPConfig1*H1000000); FC_SocketIPConfig:=ipConfig;Properties
FC_SocketConectionConfig
このようなワークを組みます。
Interface
- IConfig[0]はTCPを使うかどうか。
- IConfig[1]はSubFeatures、つまりPredefined Protocol Settingを使うかどうか。
- IConfig[2]はActive Open使うとき。
- IConfig[3]はFull Passive使うとき。
- IConfig[2]とIConfig[3]もONしないならUnPassiveを使う。
Program
//init ConnectionConfig:=0; TCP:=iCconfig[0]; SubFeatures:=iCconfig[1]; Active:=iCconfig[2]; FullPassive:=iCconfig[3]; //b0-b7 Always OFF ConnectionConfig.0:=FALSE; ConnectionConfig.1:=FALSE; ConnectionConfig.2:=FALSE; ConnectionConfig.3:=FALSE; ConnectionConfig.4:=FALSE; ConnectionConfig.5:=FALSE; ConnectionConfig.6:=FALSE; ConnectionConfig.7:=FALSE; IF TCP THEN ConnectionConfig.8:=FALSE; ELSE ConnectionConfig.8:=TRUE; END_IF; //b9 Always ON ConnectionConfig.9:=TRUE; IF SubFeatures THEN ConnectionConfig.a:=TRUE; ELSE ConnectionConfig.a:=FALSE; END_IF; //b11-13 Always OFF ConnectionConfig.b:=FALSE; ConnectionConfig.c:=FALSE; ConnectionConfig.d:=FALSE; IF Active THEN ConnectionConfig.e:=FALSE; ConnectionConfig.f:=FALSE; ELSIF FullPassive THEN ConnectionConfig.e:=TRUE; ConnectionConfig.f:=TRUE; ELSE ConnectionConfig.e:=FALSE; ConnectionConfig.f:=TRUE; END_IF; FC_SocketConnectionConfig:=ConnectionConfig;Properties
FC_SocketConfig
このControl Dataを組みます。
Interface
Program
Z0:=iOffset; //+0 IF iUseControlWord THEN D0Z0:=H8000; ELSE D0Z0:=H0000; END_IF; //+2 Z0:=iOffset+2; D0Z0:=FC_SocketConnectionConfig(iMyConfig); //+3 Z0:=iOffset+3; D0Z0:=iMyPort; //+4,5 Z0:=iOffset+4; _tDWord:=FC_SocketIPConfig(iParnterIP); //D0Z0:D:=_tDWord; DMOV(TRUE,_tDWord,D0Z0); //+6 Z0:=iOffset+6; D0Z0:=iParnterPort;Properties
Main Program
まずこんな感じの流れです。
STの文法などの説明ここでやめとおきます。ネット上で自分よりう前説明がたくさんあると思いますので…
Interface
Program
//Init insConNums :=1; insConnDelay :=30; insSendDelay :=2; insRetry :=3; insENO:=OUT_T( NOT insInit //Timer Trigger1 AND NOT insSOCOPENSts[1] //Timer Trigger2 ,InsT2 //Timer Register ,insConnDelay //Time Setup ); //OPEN Connection //IP Settings insMyIP[1] :=192; insMyIP[2] :=168; insMyIP[3] :=0; insMyIP[4] :=251; //Connection Configs insMyConfig[0] :=TRUE; insMyConfig[1] :=FALSE; insMyConfig[2] :=TRUE; insMyConfig[3] :=FALSE; //Config Setup Function insENO:=FC_SocketConfig( 4000 //DB Offset ,TRUE //Use Control Word Or not ,insMyConfig //[0]=Use TCP?, //[1]=SubFeatures?, //[2]=Active Connection?, //[3]=Full Passive Connection ,4000 //My Port ,4000 //Parnter Port ,insMyIP //Parnter IP ); //Connection Delay insSOCOPEN:=InsT2.S; //Function SP_SOCOPEN( insSOCOPEN //EN ,insString //Dummy ,insConNums //Connection Numbers ,D4000 //Control Word ,insSOCOPENSts//Status ); //Result IF insSOCOPENSts[0] AND NOT insSOCOPENSts[1] THEN insConnected:=TRUE; insInit:=TRUE; insSendRetry:=0; insConnRetry:=0; ELSIF insSOCOPENSts[0] AND insSOCOPENSts[1] THEN insConnected:=FALSE; END_IF; //Retry Count IF insSOCOPENSts[1] THEN insConnRetry:=insConnRetry+1; END_IF; //Get Connection Info //Config ControlWord for SP_SOCCINF D200:D:=D4004:D; //Parnter IP D202:=HFA0; //Parnter Port D203:=HFA0; //My Port D204:=D4002; //Connection Config //Function SP_SOCCINF( insSOCCINF //EN ,insString //Dummy ,insConNums //Connection Numbers ,D200 //Control Words ,D600 //Result ); //Send //Data D999:=20; //Length of bytes that need to sent D1000:=H23; //Data D1002:=H59; //Data D1004:=H99; //Data D1009:=H53; //Data //Send Trigger IF insConnected AND NOT insSOCSNDSts[0] AND NOT insSOCSNDSts[1] AND insSendRetry < insRetry THEN insSend:=TRUE; ELSE insSend:=FALSE; END_IF; //Retry Count IF insSOCSNDSts[1] THEN insSendRetry:=insSendRetry+1; END_IF; //Send Delay insENO:=OUT_T( insSend //Trigger ,insT1 //Timer Register ,insSendDelay //Time Setup ); //Send Command insSOCSND:=insT1.S; //Function SP_SOCSND( insSOCSND //EN ,insString //Dummy ,insConNums //Connection Numbers ,D400 //Control Data,if Error,+1<>0 ,D999 //Data Trasnfer ,insSOCSNDSts //Status ); //Recv //Data D1099:=10; //Function S_SOCRCVS( TRUE //EN ,insString //Dummy ,insConNums //Connection Numbers ,D1099 //Data ); //Close //Close Command insSOCCLOSE:= insSendRetry >= insRetry; //Function SP_SOCCLOSE( insSOCCLOSE //EN ,insString //Dummy ,insConNums //Connection Numbsers ,D300 //Control Data,if Error,+1<>0 ,insSOCCLOSESts //Status ); //Connect Again IF insSOCCLOSESts[0] THEN insInit:=FALSE; END_IF;Python
import socket import time DESTINATION_ADDR = '192.168.0.39' SOURCE_PORT, DESTINATION_PORT = 4000, 4000 sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind(('192.168.0.251', SOURCE_PORT)) sock.listen(1) conn, addr = sock.accept() i =0 while i<3000: if i %2 == 0: ba1 = bytearray(b"4abcdefas0") else: ba1 = bytearray(b"9kaekfyei2") response = conn.recv(1440) conn.send(ba1) # print(response) print("current:"+str(i)) i+=1 sock.close() conn.close()


























- 投稿日:2020-07-21T16:15:32+09:00
Pandasユーザーガイド「テキストデータの操作」(公式ドキュメント日本語訳)
本記事は、Pandas の公式ドキュメントのUser Guide - Working with text dataを機械翻訳した後、一部の不自然な文章を手直ししたものである。
誤訳の指摘・代訳案・質問等があればコメント欄や編集リクエストでお願いします。
テキストデータの操作
テキストデータの型
バージョン 1.0.0 から
pandasではテキストデータを保持する方法が2つあります。
objectデータ型の NumPy 配列。StringDtype拡張型。
StringDtypeを使用してテキストデータを保持することをお勧めします。pandas 1.0 以前は、
objectデータ型が唯一の方法でした。これは多くの理由で不便でした。
- 誤って文字列と非文字列を混在させて
objectデータ型配列に格納する可能性があります。専用のデータ型があるのが良いでしょう。objectデータ型は、DataFrame.select_dtypes()のようなデータ型固有の操作に適用できません。依然としてobjectデータ型の列である非テキスト列を除外しながら、テキストのみの列を選択する有効的な方法はありません。- コードを読むとき、
obejctデータ型配列の内容は'string'よりも明示的ではありません。現在、文字列を格納した
objectデータ型配列とarray.StringArrayのパフォーマンスはほぼ変わり有りません。今後の機能強化により、StringArrayのパフォーマンスが大幅に向上し、メモリオーバーヘッドが低下することが予想されます。
警告
StringArrayは現在、実験的と見なされています。実装と部分的な API は、警告なしに変更される場合があります。後方互換性のために、文字列のリストから推測する際のデフォルトの型は依然として
objectデータ型です。In [**]: pd.Series(['a', 'b', 'c']) Out[**]: 0 a 1 b 2 c dtype: object
stringデータ型を明示的に要求するには、dtypeを指定します。In [**]: pd.Series(['a', 'b', 'c'], dtype="string") Out[**]: 0 a 1 b 2 c dtype: string In [**]: pd.Series(['a', 'b', 'c'], dtype=pd.StringDtype()) Out[**]: 0 a 1 b 2 c dtype: stringまたは、既に存在する
SeriesまたはDataFrameにastypeを適用して、In [**]: s = pd.Series(['a', 'b', 'c']) In [**]: s Out[**]: 0 a 1 b 2 c dtype: object In [**]: s.astype("string") Out[**]: 0 a 1 b 2 c dtype: stringバージョン 1.1.0 から
非文字列データを文字列データ型に変換するのに
StringDtype・"string"を使用することもできます。In [**]: s = pd.Series(['a', 2, np.nan], dtype="string") In [**]: s Out[**]: 0 a 1 2 2 <NA> dtype: string In [**]: type(s[1]) Out[**]: strまたは、既に存在するpandasのデータを変換して、
In [**]: s1 = pd.Series([1, 2, np.nan], dtype="Int64") In [**]: s1 Out[**]: 0 1 1 2 2 <NA> dtype: Int64 In [**]: s2 = s1.astype("string") In [**]: s2 Out[**]: 0 1 1 2 2 <NA> dtype: string In [**]: type(s2[0]) Out[**]: str動作の違い
以下に、
StringDtypeオブジェクトの動作がobjectデータ型と異なる点を紹介します。
StringDtypeの場合、数値の出力を返す文字列アクセサメソッドは、NA 値の存在に応じて、整数または浮動小数データ型ではなく、常に欠損値許容整数データ型(Int64データ型)を返します。真偽値の出力を返すメソッドは、欠損値許容真偽値データ型(booleanデータ型)を返します。In [**]: s = pd.Series(["a", None, "b"], dtype="string") In [**]: s Out[**]: 0 a 1 <NA> 2 b dtype: string In [**]: s.str.count("a") Out[**]: 0 1 1 <NA> 2 0 dtype: Int64 In [**]: s.dropna().str.count("a") Out[**]: 0 1 2 0 dtype: Int64両方とも出力は
Int64データ型です。オブジェクトデータ型と比較してください。In [**]: s2 = pd.Series(["a", None, "b"], dtype="object") In [**]: s2.str.count("a") Out[**]: 0 1.0 1 NaN 2 0.0 dtype: float64 In [**]: s2.dropna().str.count("a") Out[**]: 0 1 2 0 dtype: int64オブジェクトデータ型では、NA 値が存在する場合、出力データ型は float64 になります。真偽値を返すメソッドの場合も同様です。
In [**]: s.str.isdigit() Out[**]: 0 False 1 <NA> 2 False dtype: boolean In [**]: s.str.match("a") Out[**]: 0 True 1 <NA> 2 False dtype: boolean
StringArrayはバイトではなく文字列のみを保持するため、Series.str.decode()などの一部の文字列メソッドはStringArrayでは使用できません。比較操作では、
array.StringArrayおよびStringArrayを基にしたSeriesは、boolデータ型オブジェクトではなくBooleanDtypeのオブジェクトを返します。StringArrayの欠損値は、numpy.nanのように常に等しくないという結果を返すのではなく、比較演算を行っても伝播します。このドキュメントの以下で紹介する、その他の関数・メソッド等は、
stringとobjectデータ型に等しく適用されます。文字列メソッド
Series および Index には、配列の各要素を簡単に操作できる一連の文字列処理メソッドが実装されています。これらのメソッドが欠損値・ NA 値を自動的に除外することは、重要なことかもしれません。これらは
str属性を介してアクセスされ、多くの場合、同等の(スカラー)組み込み文字列メソッドに一致する名前を持ちます。In [**]: s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'], ....: dtype="string") ....: In [**]: s.str.lower() Out[**]: 0 a 1 b 2 c 3 aaba 4 baca 5 <NA> 6 caba 7 dog 8 cat dtype: string In [**]: s.str.upper() Out[**]: 0 A 1 B 2 C 3 AABA 4 BACA 5 <NA> 6 CABA 7 DOG 8 CAT dtype: string In [**]: s.str.len() Out[**]: 0 1 1 1 2 1 3 4 4 4 5 <NA> 6 4 7 3 8 3 dtype: Int64In [**]: idx = pd.Index([' jack', 'jill ', ' jesse ', 'frank']) In [**]: idx.str.strip() Out[**]: Index(['jack', 'jill', 'jesse', 'frank'], dtype='object') In [**]: idx.str.lstrip() Out[**]: Index(['jack', 'jill ', 'jesse ', 'frank'], dtype='object') In [**]: idx.str.rstrip() Out[**]: Index([' jack', 'jill', ' jesse', 'frank'], dtype='object')Index における文字列メソッドは、DataFrame の列のクリーンアップまたは変換に特に役立ちます。たとえば、先頭または末尾に空白がある列がある場合を考えます。
In [**]: df = pd.DataFrame(np.random.randn(3, 2), ....: columns=[' Column A ', ' Column B '], index=range(3)) ....: In [**]: df Out[**]: Column A Column B 0 0.469112 -0.282863 1 -1.509059 -1.135632 2 1.212112 -0.173215
df.columnsは Index オブジェクトなので、.strアクセサを使用できます。In [**]: df.columns.str.strip() Out[**]: Index(['Column A', 'Column B'], dtype='object') In [**]: df.columns.str.lower() Out[**]: Index([' column a ', ' column b '], dtype='object')これらの文字列メソッドを使用して、必要に応じて列をクリーンアップできます。次の例は、先頭と末尾の空白を削除し、すべての名前を小文字にし、残りの空白をアンダースコアに置き換えています。
In [**]: df.columns = df.columns.str.strip().str.lower().str.replace(' ', '_') In [**]: df Out[**]: column_a column_b 0 0.469112 -0.282863 1 -1.509059 -1.135632 2 1.212112 -0.173215
注
多数の要素が繰り返されるSeriesがある場合(つまり、Series内の一意の要素の数がSeriesの長さよりもはるかに小さい場合)、元のSeriesをcategory型の一つに変換してから.str.<method>や.dt.<property>をそれに適用する方が高速です。このパフォーマンスの違いは、category型のSeriesの場合、文字列操作はSeriesの各要素ではなく.categoriesで実行されることに因ります。文字列の
.categoriesを持つcategory型のSeriesには、文字列型のSeriesと比較していくつかの制限があることに注意してください(例えばs + " " + sは、sがcategory型のSeriesの場合機能しません。)。また、list型の要素を操作する.strメソッドも、そのようなSeriesでは使用できません。
バージョン 0.25.0 以前は、.strアクセサは最も初歩的な型チェックのみを行いました。バージョン 0.25.0 以降、より厳密に、Series の型が推測され、許容される型(つまり文字列)が適用されます。一般的に、
.strアクセサは文字列でのみ機能するように設計されています。非常に少数の例外を除いて、他の用途はサポートされておらず、後で無効になる可能性があります。文字列の分割と置換
splitなどのメソッドは、リストからなるSeriesを返します。In [**]: s2 = pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'], dtype="string") In [**]: s2.str.split('_') Out[**]: 0 [a, b, c] 1 [c, d, e] 2 <NA> 3 [f, g, h] dtype: object分割したリストの要素には、
getまたは[]表記を使用してアクセスできます。In [**]: s2.str.split('_').str.get(1) Out[**]: 0 b 1 d 2 <NA> 3 g dtype: object In [**]: s2.str.split('_').str[1] Out[**]: 0 b 1 d 2 <NA> 3 g dtype: object
expand引数によって簡単に、これを展開してDataFrameとして返すことができます。In [**]: s2.str.split('_', expand=True) Out[**]: 0 1 2 0 a b c 1 c d e 2 <NA> <NA> <NA> 3 f g h元の
SeriesにStringDtypeがある場合、出力列もすべてStringDtypeになります。分割数を制限することもできます。
In [**]: s2.str.split('_', expand=True, n=1) Out[**]: 0 1 0 a b_c 1 c d_e 2 <NA> <NA> 3 f g_h
rsplitはsplitと似ていますが、逆方向、つまり文字列の末尾から文字列の先頭に向かって動作する点が異なります。In [**]: s2.str.rsplit('_', expand=True, n=1) Out[**]: 0 1 0 a_b c 1 c_d e 2 <NA> <NA> 3 f_g h
replaceは、デフォルトでは正規表現による置換を行います。In [**]: s3 = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', ....: '', np.nan, 'CABA', 'dog', 'cat'], ....: dtype="string") ....: In [**]: s3 Out[**]: 0 A 1 B 2 C 3 Aaba 4 Baca 5 6 <NA> 7 CABA 8 dog 9 cat dtype: string In [**]: s3.str.replace('^.a|dog', 'XX-XX ', case=False) Out[**]: 0 A 1 B 2 C 3 XX-XX ba 4 XX-XX ca 5 6 <NA> 7 XX-XX BA 8 XX-XX 9 XX-XX t dtype: string正規表現を念頭に置くには、いくつかの注意が必要です!たとえば、次のコードは $ の正規表現の意味のために問題を引き起こします。
# 不適切な形式の財務データを考えます In [**]: dollars = pd.Series(['12', '-$10', '$10,000'], dtype="string") # これは単純にあなたがやりたいことが実行されます In [**]: dollars.str.replace('$', '') Out[**]: 0 12 1 -10 2 10,000 dtype: string # しかしこれは働きません In [**]: dollars.str.replace('-$', '-') Out[**]: 0 12 1 -$10 2 $10,000 dtype: string # (2文字以上のとき)特殊文字をエスケープする必要があります In [**]: dollars.str.replace(r'-\$', '-') Out[**]: 0 12 1 -10 2 $10,000 dtype: stringバージョン 0.23.0 から
(
str.replace()と同様の)文字列のリテラルな置換を行いたい場合は、各文字をエスケープするのではなく、オプションのregexパラメーターをFalseに設定します。この場合、patとreplは両方とも文字列でなければなりません。# 次の2つは同等です In [**]: dollars.str.replace(r'-\$', '-') Out[**]: 0 12 1 -10 2 $10,000 dtype: string In [**]: dollars.str.replace('-$', '-', regex=False) Out[**]: 0 12 1 -10 2 $10,000 dtype: string
replaceメソッドは、関数を呼び出して置換することもできます。re.sub()を使用して、すべてのpatに対して呼び出されます。呼び出し可能オブジェクトは、1つの位置引数(正規表現オブジェクト)を受け取り、文字列を返す必要があります。# 小文字のアルファベットをすべて逆さにします In [**]: pat = r'[a-z]+' In [**]: def repl(m): ....: return m.group(0)[::-1] ....: In [**]: pd.Series(['foo 123', 'bar baz', np.nan], ....: dtype="string").str.replace(pat, repl) ....: Out[**]: 0 oof 123 1 rab zab 2 <NA> dtype: string # 正規表現グループを使います In [**]: pat = r"(?P<one>\w+) (?P<two>\w+) (?P<three>\w+)" In [**]: def repl(m): ....: return m.group('two').swapcase() ....: In [**]: pd.Series(['Foo Bar Baz', np.nan], ....: dtype="string").str.replace(pat, repl) ....: Out[**]: 0 bAR 1 <NA> dtype: string
replaceメソッドは、パターンとしてre.compile()からコンパイルされた正規表現オブジェクトも受け入れます。すべてのフラグは、コンパイル済みの正規表現オブジェクトに含める必要があります。In [**]: import re In [**]: regex_pat = re.compile(r'^.a|dog', flags=re.IGNORECASE) In [**]: s3.str.replace(regex_pat, 'XX-XX ') Out[**]: 0 A 1 B 2 C 3 XX-XX ba 4 XX-XX ca 5 6 NaN 7 XX-XX BA 8 XX-XX 9 XX-XX t dtype: stringコンパイルされた正規表現オブジェクトで
replaceを呼び出すときにflags引数を使うと、ValueErrorが発生します。In [**]: s3.str.replace(regex_pat, 'XX-XX ', flags=re.IGNORECASE) --------------------------------------------------------------------------- ValueError: case and flags cannot be set when pat is a compiled regex結合
seriesやIndexをそれ自体ないし他と結合するには、すべてcat()またはIndex.str.catに基づいたいくつかの方法があります。単一の Series と文字列の結合
Series(またはIndex)の各要素を結合できます。In [**]: s = pd.Series(['a', 'b', 'c', 'd'], dtype="string") In [**]: s.str.cat(sep=',') Out[**]: 'a,b,c,d'区切り文字を指定する引数
sepが指定されていない場合、デフォルトとして空の文字列sep=''になります。In [**]: s.str.cat() Out[**]: 'abcd'デフォルトでは、欠損値は無視されます。
na_repを使用して、表現を指定できます。In [**]: t = pd.Series(['a', 'b', np.nan, 'd'], dtype="string") In [**]: t.str.cat(sep=',') Out[**]: 'a,b,d' In [**]: t.str.cat(sep=',', na_rep='-') Out[**]: 'a,b,-,d'Seriesにリスト等を結合
cat()の最初の引数には、呼び出し元のSeries(またはIndex)の長さと一致する、リストライクなオブジェクトを渡すことができます。In [**]: s.str.cat(['A', 'B', 'C', 'D']) Out[**]: 0 aA 1 bB 2 cC 3 dD dtype: string
na_repが指定されていない場合、どちらか一方にでも欠損値があれば、結果も欠損値になります。In [**]: s.str.cat(t) Out[**]: 0 aa 1 bb 2 <NA> 3 dd dtype: string In [**]: s.str.cat(t, na_rep='-') Out[**]: 0 aa 1 bb 2 c- 3 dd dtype: stringSeriesに配列等を結合
バージョン 0.23.0 から
othersパラメーターには2次元のデータを渡すこともできます。この場合、行数は呼び出し元のSeries(またはIndex)の長さと一致する必要があります。In [**]: d = pd.concat([t, s], axis=1) In [**]: s Out[**]: 0 a 1 b 2 c 3 d dtype: string In [**]: d Out[**]: 0 1 0 a a 1 b b 2 <NA> c 3 d d In [**]: s.str.cat(d, na_rep='-') Out[**]: 0 aaa 1 bbb 2 c-c 3 ddd dtype: stringSeries にインデックスに基づいてオブジェクトを結合
SeriesまたはDataFrameとの結合の場合、joinキーワードを設定することにより、結合する前にインデックスを調整できます。In [**]: u = pd.Series(['b', 'd', 'a', 'c'], index=[1, 3, 0, 2], ....: dtype="string") ....: In [**]: s Out[**]: 0 a 1 b 2 c 3 d dtype: string In [**]: u Out[**]: 1 b 3 d 0 a 2 c dtype: string In [**]: s.str.cat(u) Out[**]: 0 aa 1 bb 2 cc 3 dd dtype: string In [**]: s.str.cat(u, join='left') Out[**]: 0 aa 1 bb 2 cc 3 dd dtype: string
joinキーワードが渡されない場合、cat()メソッドは現在、バージョン 0.23.0 より前の動作(つまり、整列なし)にフォールバックしますが、将来のバージョンではこのデフォルトがjoin='left'に変更されるため、関連するインデックスのいずれかが異なる場合はFutureWarningが発生します。
joinには通常のオプションを使用できます('left', 'outer', 'inner', 'right'のいずれか)。ここで行われるアラインメントは、長さを一致させる必要がないことも意味します。In [**]: v = pd.Series(['z', 'a', 'b', 'd', 'e'], index=[-1, 0, 1, 3, 4], ....: dtype="string") ....: In [**]: s Out[**]: 0 a 1 b 2 c 3 d dtype: string In [**]: v Out[**]: -1 z 0 a 1 b 3 d 4 e dtype: string In [**]: s.str.cat(v, join='left', na_rep='-') Out[**]: 0 aa 1 bb 2 c- 3 dd dtype: string In [**]: s.str.cat(v, join='outer', na_rep='-') Out[**]: -1 -z 0 aa 1 bb 2 c- 3 dd 4 -e dtype: string同様に、
othersがDataFrameであっても実行可能です。In [**]: f = d.loc[[3, 2, 1, 0], :] In [**]: s Out[**]: 0 a 1 b 2 c 3 d dtype: string In [**]: f Out[**]: 0 1 3 d d 2 <NA> c 1 b b 0 a a In [**]: s.str.cat(f, join='left', na_rep='-') Out[**]: 0 aaa 1 bbb 2 c-c 3 ddd dtype: stringSeries と複数のオブジェクトの結合
複数の配列ライクのオブジェクト(具体的には、
Series・Index・および1次元のnp.ndarrayバリアント)は、リストライクなコンテナ(イテレータやdict-views などを含む)を用いて結合することができます。In [**]: s Out[**]: 0 a 1 b 2 c 3 d dtype: string In [**]: u Out[**]: 1 b 3 d 0 a 2 c dtype: string In [**]: s.str.cat([u, u.to_numpy()], join='left') Out[**]: 0 aab 1 bbd 2 cca 3 ddc dtype: string渡されたリストのうち、インデックスのない要素(例:
np.ndarray)は呼び出し元のSeries(またはIndex)と長さが一致している必要がありますが、SeriesやIndexは(join=Noneで整列が無効にされていない限り)長さは自由です。In [**]: v Out[**]: -1 z 0 a 1 b 3 d 4 e dtype: string In [**]: s.str.cat([v, u, u.to_numpy()], join='outer', na_rep='-') Out[**]: -1 -z-- 0 aaab 1 bbbd 2 c-ca 3 dddc 4 -e-- dtype: string
othersに渡したリストが異なるインデックスを含む状態でjoin='right'を指定した場合、返されるオブジェクトはこれらのインデックスの和(union)に基づいて形成されます。In [**]: u.loc[[3]] Out[**]: 3 d dtype: string In [**]: v.loc[[-1, 0]] Out[**]: -1 z 0 a dtype: string In [**]: s.str.cat([u.loc[[3]], v.loc[[-1, 0]]], join='right', na_rep='-') Out[**]: -1 --z 0 a-a 3 dd- dtype: string
.strを用いた索引
[]記法を使用して、位置の場所を指定することで直接索引できます。文字列の末尾を超えて索引すると、結果はNaNになります。In [**]: s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, ....: 'CABA', 'dog', 'cat'], ....: dtype="string") ....: In [**]: s.str[0] Out[**]: 0 A 1 B 2 C 3 A 4 B 5 <NA> 6 C 7 d 8 c dtype: string In [**]: s.str[1] Out[**]: 0 <NA> 1 <NA> 2 <NA> 3 a 4 a 5 <NA> 6 A 7 o 8 a dtype: string部分文字列の抽出
各要素の最初の一致を抽出(extract)
バージョン 0.23 より前では、extractメソッドのexpand引数のデフォルトはFalseに設定されていました。expand=Falseの場合、expandは、対象文字列と正規表現パターンに応じて、SeriesかIndexかDataFrameを返します。expand=Trueの場合、常にDataFrameを返します。これは、ユーザーの観点から見ると、より一貫性があり、混乱が少ないです。expand=Trueは、バージョン 0.23.0 以降はデフォルトになりました。
extractメソッドは、少なくとも1つのキャプチャグループを持つ正規表現を受け取ります。複数のグループを持つ正規表現を抽出すると、グループごとに1つの列を持つ DataFrame が返されます。
In [**]: pd.Series(['a1', 'b2', 'c3'], ....: dtype="string").str.extract(r'([ab])(\d)', expand=False) ....: Out[**]: 0 1 0 a 1 1 b 2 2 <NA> <NA>一致しない要素は、
NaNで満たされた行を返します。したがって、乱雑な文字列の Series は、タプルまたはre.matchオブジェクトにアクセスするのにget()を必要とせずに、クリーンアップされた、またはより有用な文字列の同様のインデックス付き Series または DataFrame に「変換」できます。一致が見つからず、結果がNaNのみであっても、データ型は常にオブジェクトです(訳注:元がstringの場合はstringになるはず)。名前付きグループ
In [**]: pd.Series(['a1', 'b2', 'c3'], ....: dtype="string").str.extract(r'(?P<letter>[ab])(?P<digit>\d)', ....: expand=False) ....: Out[**]: letter digit 0 a 1 1 b 2 2 <NA> <NA>オプションのグループ
In [**]: pd.Series(['a1', 'b2', '3'], ....: dtype="string").str.extract(r'([ab])?(\d)', expand=False) ....: Out[**]: 0 1 0 a 1 1 b 2 2 <NA> 3を使用することもできます。正規表現のキャプチャグループ名は、それぞれの列名に使用されることを覚えておいてください。キャプチャグループ名が存在しない場合は、キャプチャグループ番号が使用されます。
グループを1つだけ持つ正規表現によって抽出すると、
expand=Trueの場合、1つの列からなるDataFrameが返されます。In [**]: pd.Series(['a1', 'b2', 'c3'], ....: dtype="string").str.extract(r'[ab](\d)', expand=True) ....: Out[**]: 0 0 1 1 2 2 <NA>
expand=Falseの場合は、Seiresが返されます。In [**]: pd.Series(['a1', 'b2', 'c3'], ....: dtype="string").str.extract(r'[ab](\d)', expand=False) ....: Out[**]: 0 1 1 2 2 <NA> dtype: string
Indexに対してキャプチャグループを丁度1つだけ持つ正規表現で呼び出すと、expand=Trueの場合、1つの列からなるDataFrameが返されます。In [**]: s = pd.Series(["a1", "b2", "c3"], ["A11", "B22", "C33"], ....: dtype="string") ....: In [**]: s Out[**]: A11 a1 B22 b2 C33 c3 dtype: string In [**]: s.index.str.extract("(?P<letter>[a-zA-Z])", expand=True) Out[**]: letter 0 A 1 B 2 C
expand=Falseの場合は、Indexが返されます。In [**]: s.index.str.extract("(?P<letter>[a-zA-Z])", expand=False) Out[**]: Index(['A', 'B', 'C'], dtype='object', name='letter')
Indexに対してキャプチャグループを複数持つ正規表現で呼び出すと、expand=Trueの場合、DataFrameが返されます。In [**]: s.index.str.extract("(?P<letter>[a-zA-Z])([0-9]+)", expand=True) Out[**]: letter 1 0 A 11 1 B 22 2 C 33
expand=Falseの場合は、ValueErrorが発生します。>>> s.index.str.extract("(?P<letter>[a-zA-Z])([0-9]+)", expand=False) ValueError: only one regex group is supported with Index次の表は、
extract(expand=False)の動作をまとめたものです(1列目は入力サブジェクト、1行目は正規表現のグループ数)。
1 グループ >1 グループ Index Index ValueError Series Series DataFrame 各要素のすべての一致を抽出(extractall)
(最初の一致のみを抽出する)
extractとは異なり、In [**]: s = pd.Series(["a1a2", "b1", "c1"], index=["A", "B", "C"], ....: dtype="string") ....: In [**]: s Out[**]: A a1a2 B b1 C c1 dtype: string In [**]: two_groups = '(?P<letter>[a-z])(?P<digit>[0-9])' In [**]: s.str.extract(two_groups, expand=True) Out[**]: letter digit A a 1 B b 1 C c 1
extractallメソッドはすべての一致を返します。extractallの結果は常に、MultiIndexを行に持つDataFrameです。MultiIndexの最低レベルはmatchという名前で、要素の順序を示します。In [**]: s.str.extractall(two_groups) Out[**]: letter digit match A 0 a 1 1 a 2 B 0 b 1 C 0 c 1Series の各要素の文字列に1回だけ一致する場合、
In [**]: s = pd.Series(['a3', 'b3', 'c2'], dtype="string") In [**]: s Out[**]: 0 a3 1 b3 2 c2 dtype: string
extractall(pat).xs(0, level='match')は、extract(pat)と同じ結果になります。In [**]: extract_result = s.str.extract(two_groups, expand=True) In [**]: extract_result Out[**]: letter digit 0 a 3 1 b 3 2 c 2 In [**]: extractall_result = s.str.extractall(two_groups) In [**]: extractall_result Out[**]: letter digit match 0 0 a 3 1 0 b 3 2 0 c 2 In [**]: extractall_result.xs(0, level="match") Out[**]: letter digit 0 a 3 1 b 3 2 c 2
Indexは.str.extractallもサポートしています。デフォルトの(0から始まる)インデックスを持つSeries.str.extractallと同じ結果の、DataFrameを返します。In [**]: pd.Index(["a1a2", "b1", "c1"]).str.extractall(two_groups) Out[**]: letter digit match 0 0 a 1 1 a 2 1 0 b 1 2 0 c 1 In [**]: pd.Series(["a1a2", "b1", "c1"], dtype="string").str.extractall(two_groups) Out[**]: letter digit match 0 0 a 1 1 a 2 1 0 b 1 2 0 c 1パターンに一致する、またはパターンを含む文字列のテスト
要素にパターンが含まれているかどうかを確認できます。
In [**]: pattern = r'[0-9][a-z]' In [**]: pd.Series(['1', '2', '3a', '3b', '03c', '4dx'], ....: dtype="string").str.contains(pattern) ....: Out[**]: 0 False 1 False 2 True 3 True 4 True 5 True dtype: booleanまた、要素がパターンに一致するかどうかも確認できます。
In [**]: pd.Series(['1', '2', '3a', '3b', '03c', '4dx'], ....: dtype="string").str.match(pattern) ....: Out[**]: 0 False 1 False 2 True 3 True 4 False 5 True dtype: booleanバージョン 1.1.0 から
In [**]: pd.Series(['1', '2', '3a', '3b', '03c', '4dx'], ....: dtype="string").str.fullmatch(pattern) ....: Out[**]: 0 False 1 False 2 True 3 True 4 False 5 False dtype: boolean
match・fullmatch・containsの違いは厳密さです。fullmatchは文字列全体が正規表現にマッチするかどうかをテストし、matchは文字列の先頭を見て正規表現にマッチするかどうかをテストし、containsは文字列内の任意の位置に正規表現にマッチする部分があるかどうかをテストします。これら3つの一致モードは、
reパッケージにおけるre.fullmatch・re.match・re.searchにそれぞれ対応します。
match・fullmatch・contains・startswith・endswithなどのメソッドはオプションのna引数を受け取って、欠損値を True または False と見なすことができます。In [**]: s4 = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'], .....: dtype="string") .....: In [**]: s4.str.contains('A', na=False) Out[**]: 0 True 1 False 2 False 3 True 4 False 5 False 6 True 7 False 8 False dtype: boolean標識変数の作成
文字列の列をダミー変数化できます。たとえば、
|で区切られている場合、In [**]: s = pd.Series(['a', 'a|b', np.nan, 'a|c'], dtype="string") In [**]: s.str.get_dummies(sep='|') Out[**]: a b c 0 1 0 0 1 1 1 0 2 0 0 0 3 1 0 1文字列
Indexは、MultiIndexを返すget_dummiesもサポートしています。In [**]: idx = pd.Index(['a', 'a|b', np.nan, 'a|c']) In [**]: idx.str.get_dummies(sep='|') Out[**]: MultiIndex([(1, 0, 0), (1, 1, 0), (0, 0, 0), (1, 0, 1)], names=['a', 'b', 'c'])
get_dummies()についての説明もご覧ください。主なメソッド
メソッド 説明 cat()文字列を連結 split()区切り文字を指定して文字列を分割 rsplit()区切り文字を指定して文字列を末尾から分割 get()各要素へのインデックス(i 番目の要素を取得) join()渡された区切り文字でシリーズの各要素の文字列を結合 get_dummies()区切り文字を指定して文字列を分割し、ダミー変数化した DataFrame を返す contains()各文字列にパターン・正規表現が含まれるかどうかの、真偽値配列を返す replace()パターン・正規表現・文字列に一致する部分を、他の文字列または呼び出し可能オブジェクトの戻り値に置換 repeat()文字列を複製( s.str.repeat(3)はx * 3に等しい)pad()文字列の左・右または両側に空白を追加 center()str.centerに同じljust()str.ljustに同じrjust()str.rjustに同じzfill()str.zfillに同じwrap()長い文字列を指定した値以下の長さの行に分割 slice()Series の各文字列をスライス slice_replace()スライスした Series の各文字列を、指定した値に置換 count()パターンの出現回数をカウント startswith()各要素に対して str.startswith(pat)を適用するのと同じendswith()各要素に対して str.endswith(pat)を適用するのと同じfindall()各文字列に対して、全てのパターン・正規表現の一致リストを返す match()各要素に対して re.matchを適用し、パターン・正規表現に一致するかどうかの真偽値配列を返すextract()各要素に対して re.searchを適用し、各要素が行、各正規表現キャプチャグループが列の DataFrame を返すextractall()各要素に対して re.findallを適用し、各要素が行、各正規表現キャプチャグループが列の DataFrame を返すlen()文字列の長さ strip()str.stripに同じrstrip()str.rstripに同じlstrip()str.lstripに同じpartition()str.partitionに同じrpartition()str.rpartitionに同じlower()str.lowerに同じcasefold()str.casefoldに同じupper()str.upperに同じfind()str.findに同じrfind()str.rfindに同じindex()str.indexに同じrindex()str.rindexに同じcapitalize()str.capitalizeに同じswapcase()str.swapcaseに同じnormalize()Unicode 標準形式を返す。 unicodedata.nnormalizeに同じtranslate()str.translateに同じisalnum()str.isalnumに同じisalpha()str.isalphaに同じisdigit()str.isdigitに同じisspace()str.isspaceに同じislower()str.islowerに同じisupper()str.isupperに同じistitle()str.istitleに同じisnumeric()str.isnumericに同じisdecimal()str.isdecimalに同じ
- 投稿日:2020-07-21T15:38:27+09:00
実行中の関数名をPrint
何がしたかったか
関数には、可読性を高めるため、パッと見てどういう機能か分かる名前付けを意識しています。
となると、デバッグ等の際に、動いている関数名を取得してPrint( )すれば、「いま何をしてるか」を見える化できると思いました。
いちいち毎回、「今、こういった処理をしています」を記述せずとも、「今、{ }を動かしています」とテンプレ化してしまいたい、ということです。プログラム
inspectモジュールを使います。
import inspect def add_values(a, b): cframe = inspect.currentframe() fname = inspect.getframeinfo(cframe).function print("Running '{}' function on {} and {}".format(fname, a, b)) return a + b add_values(1, 2)出力は:
Running 'add_values' function on 1 and 2 3参考
How can get current function name inside that function in python
- 投稿日:2020-07-21T15:38:27+09:00
Pythonで、いま実行中の関数名をPrint
何がしたかったか
関数には、可読性を高めるため、パッと見てどういう機能か分かる名前付けを意識しています。
となると、デバッグ等の際に、動いている関数名を取得してPrint( )すれば、「いま何をしてるか」を見える化できると思いました。
いちいち毎回、「今、こういった処理をしています」を記述せずとも、「今、{ }を動かしています」とテンプレ化してしまいたい、ということです。プログラム
inspectモジュールを使います。
import inspect def add_values(a, b): cframe = inspect.currentframe() fname = inspect.getframeinfo(cframe).function print("Running '{}' function on {} and {}".format(fname, a, b)) return a + b add_values(1, 2)出力は:
Running 'add_values' function on 1 and 2 3参考
How can get current function name inside that function in python
- 投稿日:2020-07-21T15:26:34+09:00
Pythonにおけるクラスのメソッド定義~なぜselfがあるのか~
はじめに
Pythonにおけるクラスのメソッド定義は、慣習によってある種秩序が保たれています。しかし、そのままだとPythonの優秀な言語設計の力は十分に発揮されていません。人によっては、慣習とは外れた黒魔術に思えるかも知れませんが、設計上は自然であると言える定義を紹介します。
学びたての認識
ここでは、クラスの中に定義した関数をメソッド、それ以外の関数を関数と呼びます。
Pythonでメソッドを定義する際は、class定義の中に関数を定義します。
その際、第一引数にはインスタンスを指定します。慣習でselfとよく名付けられます。
以下は定義例です。
題材として二次元ベクトルを定義します。とりあえず二倍にスケールした新しい二次元ベクトルを返すメソッドを定義しました。
class Vector2D: def __init__(self, x, y): self.x = x self.y = y def twice(self): return Vector2D(self.x * 2, self.y * 2) v = Vector2D(2, 5) u = v.twice() # u => Vector(4, 10)なぜselfを指定するのか
本来はselfに当たる部分はどんな名前でもかまいません。とにかく、第一引数がクラスのインスタンスであれば良いです。
内部実装の話に近いですが、実はクラスの中に定義した関数は以下のようにも呼び出すことができます。
v = Vector2D(2, 5) u = Vector2D.twice(v) # u => Vector(2, 5) # これと一緒 # u = v.twice()クラスに定義した関数は、単純な関数として使うことができます。第一引数にインスタンスを指定する関数です。単純な関数として内部を見てみると、インスタンスのメンバ変数を利用していることがうかがえます。
このような言語設計にはいくつか利点があります。そのうち二つ紹介します。
「メソッドオブジェクト」を渡す
「メソッドオブジェクト」は「関数オブジェクト」と似たようなニュアンスの造語です。
いくつかのVector2Dインスタンスを用意しました。
a = Vector2D(2, 3) b = Vector2D(2, 40) c = Vector2D(4, 30) d = Vector2D(5, 10) e = Vector2D(20, 30)そしてそれぞれに対してtwiceメソッドを呼び出した新しいVector2Dのリストが欲しいとします。
単純に取得するなら以下のようになります。
vs = [a.twice(), b.twice(), c.twice(), d.twice(), e.twice()]内包表記で取得するなら以下のようになります。
vs = [v.twice() for v in [a, b, c, d, e]]map関数で取得するなら以下のようになります。
vs = list(map(Vector2D.twice, [a, b, c, d, e]))先ほどメソッドは第一引数にインスタンスを指定する単純な関数として使うことができると説明しました。
なので、map関数に指定することができます。これはmap関数でメソッドを呼び出すことができるという解釈ができます。
strなどもクラスですので、例えば文字列のリストに対して、両端の空白を削ったモノが欲しい場合、
str.stripメソッドを使いますがs = map(str.strip, [" a ", " g ", " e "]) print(*s, sep="\n") # a # g # eこのように記述できます。その他のstrのメソッドでも同様です。
関数。クラスベース。変幻自在なPython
関数メインで設計をするのか、クラスベースで設計をするのか、いろいろ考え方はありますが、どちらもとるという手もあります。
Pythonでは面白いメソッド定義ができます。
ドット積を定義したいとします。
まずは関数を定義します。
def dot(u, v): return u.x * v.x + u.y * v.y u = Vector2D(2, 4) v = Vector2D(5, 10) x = dot(u, v) # x => 50この動きはメソッドとしてあってもいい気はします。
def dot(u, v): return u.x * v.x + u.y * v.y class Vector2D: def __init__(self, x, y): self.x = x self.y = y def twice(self): return Vector2D(self.x * 2, self.y * 2) def dot(self, v): return self.x * v.x + self.y * v.y u = Vector2D(2, 4) v = Vector2D(5, 10) x = dot(u, v) y = u.dot(v) # x == y == 50良さそうです。しかし、同じような処理を二度定義しています。処理を変更することになった場合、どちらも修正するのは手間がかかります。
Pythonは以下のようにメソッドを定義することが可能です。
def dot(u, v): return u.x * v.x + u.y * v.y class Vector2D: def __init__(self, x, y): self.x = x self.y = y def twice(self): return Vector2D(self.x * 2, self.y * 2) dot = dot # ポイント u = Vector2D(2, 4) v = Vector2D(5, 10) x = dot(u, v) y = u.dot(v) # x == y == 50メソッドは第一引数がインスタンスの関数ですので、第一引数がインスタンスの関数はメソッドに設定することができます(進次郎構文)
このように定義した場合の
dot(u, v)とu.dot(v)は等価です。このような定義は引数を二つ持つ関数を二項演算子だと捉えると、自然なものだと言えます。
実際、足し算や掛け算は数学的にも2変数関数として定義できます。
それについて理解を深めるため、もう一つ例を挙げます。
二つのVector2Dを足し合わせる関数
vaddを定義します。def vadd(u, v): return Vector2D(u.x + v.x, u.y + v.y) u = Vector2D(2, 4) v = Vector2D(5, 10) w = vadd(u, v) # w => Vector2D(7, 14)これも
dot関数と同様メソッドとして組み込めます。def dot(u, v): return u.x * v.x + u.y * v.y def vadd(u, v): return Vector2D(u.x + v.x, u.y + v.y) class Vector2D: def __init__(self, x, y): self.x = x self.y = y def twice(self): return Vector2D(self.x * 2, self.y * 2) dot = dot add = vadd u = Vector2D(2, 4) v = Vector2D(5, 10) a = vadd(u, v) b = u.add(v) # a == b == Vector(7, 14)Pythonには、演算子を定義するための特殊メソッドがあります。
__add__や__mul__などのメソッドのことです。これらを使えば独自クラス用に演算子を定義することができます。先ほどのvadd関数は
+演算子と親和性がありそうです。つまり、以下のように定義すればよりフレンドリーな式を書くことができます。
def dot(u, v): return u.x * v.x + u.y * v.y def vadd(u, v): return Vector2D(u.x + v.x, u.y + v.y) class Vector2D: def __init__(self, x, y): self.x = x self.y = y def twice(self): return Vector2D(self.x * 2, self.y * 2) dot = dot add = vadd __add__ = vadd u = Vector2D(2, 4) v = Vector2D(5, 10) a = add(u, v) b = u.add(v) c = u + v # ポイント # a == b == c == Vector(7, 14)おわりに
Pythonのメソッド定義の仕組みについて少し詳しく説明しました。慣習とは外れているので違和感があるかもしれませんが、このような定義方法と、それが案外自然であることを知ると、Pythonのプログラミングが楽しくなるのかなと思います。
- 投稿日:2020-07-21T15:10:31+09:00
pythonでSQL使ってみた エピソードⅡ : データの横結合 left join inner join
SQLを用いたデータのハンドリング
pythonでSQLを使うシリーズ2※以下はgroup byの紹介
https://qiita.com/saspy/items/2b5aeef91e87cac503e2SAS/Rのデータの結合比較
https://qiita.com/saspy/items/43b4c368d22f45f023a2今回はleft joinなどデータの結合を紹介
準備
import pandas as pd
import dask.dataframe as dd
from pandasql import sqldf
import sqlite3Data1 <- dd.read_csv( "パス/ファイル名" )
Data2 <- dd.read_csv( "パス/ファイル名" )# Data1とData2を横結合する
pandasql sqldf
query = """
select A.変数1 , A.変数2 , B.変数1 , ...
from Data1 as A
left join Data2 as B
結合条件on A.キー変数1 = B.キー変数1 and A.キー変数2 = B.キー変数2 ...
order by A.変数1 , A.変数2 , ...;
"""
Data = sqldf( query , locals() )left joinをinner joinに変えれば、左結合から内部結合へ修正可能
right joinやfull joinにするとエラーが出た
Rのsqldfと同様、left joinとinner joinだけなのかも...SQLite3 read_sql_query
conn = sqlite3.connect( "" )
# db残したいor既存のを使用するなら"パス/db名.db"と指定# data.frameをSQL化(dbにすでに格納されているなら不要)
Data1.to_sql( "Data1_Sql" , conn )
Data2.to_sql( "Data2_Sql" , conn )query = """
select A.変数1 , A.変数2 , B.変数1 , ...
from Data1_Sql as A
left join Data2_Sql as B
結合条件on A.キー変数1 = B.キー変数1 and A.キー変数2 = B.キー変数2 ...
order by A.変数1 , A.変数2 , ...
"""
# ;なし
Data = pd.read_sql_query( sql = query , con = conn )conn.close()
left joinをinner joinに変えれば、左結合から内部結合へ修正可能
また、こっちでもright joinやfull joinを使うと以下のエラーが出た
RIGHT and FULL OUTER JOINs are not currently supportedまぁrightは使わない気もするが
Rのsqldfやpythonのsqldf、read_sql_queryではfull joinは使えないようだ
ダミーデータ作ってleft joinするか、別のパッケージ使うしかないかなdaskやpandasによるmerge
DATA = dd.merge( Data1 , Data2 , on = [ "キー変数1" , "キー変数2" , ... ] , how = "left" )
pandasならddをpdにするこちらもhow = "left"をrightやinner,outerへ変更可能
- 投稿日:2020-07-21T15:10:26+09:00
機械学習ことはじめ
はじめに
機械学習を実務で使う場合に、どのような工程を踏むのか、自分の頭の中の整理をかねて大枠を書いていければと思います。
文章ばかりで見づらいです。すみません。
今後改良更新して行きます。データサイエンスの流れ
- 分析目的の明確化
- データの準備
- 分析
- ビジネスインパクトの評価
- 5. 運用
分析目的の明確化
ビジネスゴールから分析ゴールへの翻訳
「売上向上」がビジネス課題であれば、売上について細かく分解します。
分解方法はロジックツリー、カスタマージャーニーなど、ポイント
会社が何かしら打ち手を講じる事で、影響を与えられるように分解する事。
会社にどうしようもできない分解を行っても意味がありません。例:「プラスチックストローの売上が減少している。向上させたい。」
↓
分解:社会のニーズ×購入率
↓
打ち手:「社会のニーズ向上を目指せば、売上が伸びるのではないか?」一企業で社会の環境意識を後退させようとしても、できる事が限られています。
データの準備
データを1から作成する場合
ポイント
データセットを自分で作成する場合、どんなデータを用意するかは人間が決めなくてはいけません。
データサイエンティストのビジネス課題の理解力・想像力・観察眼・仮説力が問われます。
そのためにも、ビジネス課題を分析目標に落とし込む作業が重要となります。(この過程を実務でゴリゴリ経験積んでいる人は、今後とても強いだろうなあ・・・)
データの前処理の流れ
- データの読み込み
- 欠損の確認
- 分布の理解
- 要約統計量の確認
- 特徴量の設計
2~3の工程は順不同
要約統計量とは・・・?
値の平均値・中央値・最小値・最大値など
pandasでは下記で確認pythondataset.descride()特徴量の設計
ダミー変数
Feature Engineerring(特徴量の組み合わせを自身で作成)分析
統計学と機械学習は分析ステップで用います。
統計学
- 特徴や構造を理解
- 因果関係を検証
- 影響度を推定
機械学習
- 予測(教師あり学習)・・・・・回帰問題/分類問題
- クラスタリング(教師なし学習)
教師あり学習の流れ
- 特徴量(説明変数)を用意
- 機外学習モデルに特徴量を食わせる
- 予測結果の算出(predict)
- 予測結果と(答え)目的変数の残差を計算する(残差を目的関数という)
- 目的関数が最小となるよう、モデルの更新
- 予測したい新しいデータに、最適化された機械学習モデルを食わせる
- 予測結果のアウトプット
2~5の工程を、機械学習モデルに学習させるといわれています。
予測モデルの構築プロセス
- データの準備
- データの前処理
- モデルの構築
- モデルの性能評価
ポイント
- 特徴量の選択
- 用いる機械学習アルゴリズムの選択
- 精度指標の選択
この工程を何度も繰り返し行う必要があります。
ビジネスインパクトの評価
精度を追求する場合、
外れ値に強い・弱い場合,
金額予測の場合、誤差の下振れを減らしたい場合など、
評価方法も、分析目的によって変わっていきます。主な精度指標(ほんの一部です)
- 回帰
- MSE
- RMSE
- MAE
- 分類
- AUC
- Logloss
- 混同行列
- Precision
- Recall
- F1_score
- AUC
- 投稿日:2020-07-21T15:01:57+09:00
discord.pyで管理者を判定する
discordでは、サーバを作った人が管理者になります
その管理者かどうかを判定する方法です@client.event async def on_message(message): # テキストチャンネルのみ処理 if message.channel.type != discord.ChannelType.text: return # 管理者のときのみエコーする if message.author.guild_permissions.administrator: await message.channel.send(message.contents)一応注意として、message.authorがMemberでないといけません
例えば、プライベートチャンネル(DM)だと、Memberではないので、
上の例ではテキストチャンネル限定としています
- 投稿日:2020-07-21T14:24:00+09:00
python 引数展開 リストの各要素を引数として渡す
リストやタプルの各要素を関数の引数として渡す
リスト自体ではなく、リストの要素を一つずつ関数の引数として渡したいとき、
引数の展開「*」を使えば、リストを分解したり添え字をつけたりせず扱うことができます。
(この操作はアンパックとも呼ぶようです。1)例えば、下にある数列$l$の先頭5つ分の要素を半角スペースで繋いで1行で表示したいときは
次のようにできます。l = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 期待する出力: 0 1 2 3 4 print(l[:5]) # 出力結果: [0, 1, 2, 3, 4] print(l[0], l[1], l[2], l[3], l[4]) # 出力結果: 0 1 2 3 4 print(' '.join(list(map(str, l[:5])))) # 出力結果: 0 1 2 3 4 # --- print(*l[:5]) # 出力結果: 0 1 2 3 4このように、引数のリストやタプルの先頭に「*」を付けることで、
その各要素を各引数として渡せます。その他
引数の展開「*」は可変長引数「*」と似ていますが、少し違うものです。
ちなみに、辞書型については「**」を付けることで似たようなことができます。2
- 投稿日:2020-07-21T13:33:42+09:00
だから僕はpandasを辞めた【データサイエンス100本ノック(構造化データ加工編)篇 #7】
だから僕はpandasを辞めた【データサイエンス100本ノック(構造化データ加工編)篇 #7】
データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。この問題群は、模範解答ではpandasを使ってデータ加工を行っていますが、私達は勉強がてらにNumPyを用いて処理していきます。
はじめに
NumPyの勉強として、データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。
Pythonでデータサイエンス的なことをする人の多くはpandas大好き人間かもしれませんが、実はpandasを使わなくても、NumPyで同じことができます。そしてNumPyの方がたいてい高速です。
pandas大好き人間だった僕もNumPyの操作には依然として慣れていないので、今回この『データサイエンス100本ノック』をNumPyで操作することでpandasからの卒業を試みて行きたいと思います。今回は63~74問目をやっていきます。前半は切り上げ切り捨て問題、後半は日付データを扱います。
初期データは以下のようにして読み込みました。import numpy as np import pandas as pd from numpy.lib import recfunctions as rfn # 模範解答用 df_customer = pd.read_csv('data/customer.csv', dtype={'application_date': str}) df_product = pd.read_csv( 'data/product.csv', dtype={col: 'string' for col in ['category_major_cd', 'category_medium_cd', 'category_small_cd']}) df_receipt = pd.read_csv('data/receipt.csv') # 僕たちが扱うデータ arr_customer = np.genfromtxt( 'data/customer.csv', delimiter=',', encoding='utf-8', names=True, dtype=None) arr_product = np.genfromtxt( 'data/product.csv', delimiter=',', encoding='utf-8-sig', names=True, dtype=tuple(['<U10']*4+['<f8']*2)) arr_receipt = np.genfromtxt( 'data/receipt.csv', delimiter=',', encoding='utf-8', names=True, dtype=None)最後に計算結果を構造化配列にして出力するための関数def make_array(size, **kwargs): arr = np.empty(size, dtype=[(colname, subarr.dtype) for colname, subarr in kwargs.items()]) for colname, subarr in kwargs.items(): arr[colname] = subarr return arrP_063
P-063: 商品データフレーム(df_product)の単価(unit_price)と原価(unit_cost)から、各商品の利益額を算出せよ。結果は10件表示させれば良い。
In[063]unit_profit = arr_product['unit_price'] - arr_product['unit_cost'] make_array(arr_product.size, **{col: arr_product[col] for col in arr_product.dtype.names}, unit_profit=unit_profit)[:10]Out[063]array([('P040101001', '04', '0401', '040101', 198., 149., 49.), ('P040101002', '04', '0401', '040101', 218., 164., 54.), ('P040101003', '04', '0401', '040101', 230., 173., 57.), ('P040101004', '04', '0401', '040101', 248., 186., 62.), ('P040101005', '04', '0401', '040101', 268., 201., 67.), ('P040101006', '04', '0401', '040101', 298., 224., 74.), ('P040101007', '04', '0401', '040101', 338., 254., 84.), ('P040101008', '04', '0401', '040101', 420., 315., 105.), ('P040101009', '04', '0401', '040101', 498., 374., 124.), ('P040101010', '04', '0401', '040101', 580., 435., 145.)], dtype=[('product_cd', '<U10'), ('category_major_cd', '<U10'), ('category_medium_cd', '<U10'), ('category_small_cd', '<U10'), ('unit_price', '<f8'), ('unit_cost', '<f8'), ('unit_profit', '<f8')])Time[063]# 模範解答 df_tmp = df_product.copy() df_tmp['unit_profit'] = df_tmp['unit_price'] - df_tmp['unit_cost'] df_tmp.head(10) # 2.55 ms ± 72.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) # NumPy(コード上記参照) # 1.68 ms ± 89.9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)P_064
P-064: 商品データフレーム(df_product)の単価(unit_price)と原価(unit_cost)から、各商品の利益率の全体平均を算出せよ。
ただし、単価と原価にはNULLが存在することに注意せよ。In[064]unit_profit = arr_product['unit_price'] - arr_product['unit_cost'] unit_profit_rate = unit_profit / arr_product['unit_price'] np.nanmean(unit_profit_rate)Out[064]0.24911389885177P_065
P-065: 商品データフレーム(df_product)の各商品について、利益率が30%となる新たな単価を求めよ。ただし、1円未満は切り捨てること。そして結果を10件表示させ、利益率がおよそ30%付近であることを確認せよ。ただし、単価(unit_price)と原価(unit_cost)にはNULLが存在することに注意せよ。
In[065]unit_cost = np.ascontiguousarray(arr_product['unit_cost']) new_price = unit_cost // 0.7 new_profit_rate = (new_price - unit_cost) / new_price make_array(arr_product.size, **{col: arr_product[col] for col in arr_product.dtype.names}, new_price=new_price, new_profit_rate=new_profit_rate)[:10]Out[065]array([('P040101001', '04', '0401', '040101', 198., 149., 212., 0.29716981), ('P040101002', '04', '0401', '040101', 218., 164., 234., 0.2991453 ), ('P040101003', '04', '0401', '040101', 230., 173., 247., 0.29959514), ('P040101004', '04', '0401', '040101', 248., 186., 265., 0.29811321), ('P040101005', '04', '0401', '040101', 268., 201., 287., 0.29965157), ('P040101006', '04', '0401', '040101', 298., 224., 320., 0.3 ), ('P040101007', '04', '0401', '040101', 338., 254., 362., 0.29834254), ('P040101008', '04', '0401', '040101', 420., 315., 450., 0.3 ), ('P040101009', '04', '0401', '040101', 498., 374., 534., 0.29962547), ('P040101010', '04', '0401', '040101', 580., 435., 621., 0.29951691)], dtype=[('product_cd', '<U10'), ('category_major_cd', '<U10'), ('category_medium_cd', '<U10'), ('category_small_cd', '<U10'), ('unit_price', '<f8'), ('unit_cost', '<f8'), ('new_price', '<f8'), ('new_profit_rate', '<f8')])P_066
P-066: 商品データフレーム(df_product)の各商品について、利益率が30%となる新たな単価を求めよ。今回は、1円未満を四捨五入すること(0.5については偶数方向の丸めで良い)。そして結果を10件表示させ、利益率がおよそ30%付近であることを確認せよ。ただし、単価(unit_price)と原価(unit_cost)にはNULLが存在することに注意せよ。
In[066]unit_cost = np.ascontiguousarray(arr_product['unit_cost']) new_price = np.round(unit_cost / 0.7) new_profit_rate = (new_price - unit_cost) / new_price make_array(arr_product.size, **{col: arr_product[col] for col in arr_product.dtype.names}, new_price=new_price, new_profit_rate=new_profit_rate)[:10]Out[066]array([('P040101001', '04', '0401', '040101', 198., 149., 213., 0.30046948), ('P040101002', '04', '0401', '040101', 218., 164., 234., 0.2991453 ), ('P040101003', '04', '0401', '040101', 230., 173., 247., 0.29959514), ('P040101004', '04', '0401', '040101', 248., 186., 266., 0.30075188), ('P040101005', '04', '0401', '040101', 268., 201., 287., 0.29965157), ('P040101006', '04', '0401', '040101', 298., 224., 320., 0.3 ), ('P040101007', '04', '0401', '040101', 338., 254., 363., 0.30027548), ('P040101008', '04', '0401', '040101', 420., 315., 450., 0.3 ), ('P040101009', '04', '0401', '040101', 498., 374., 534., 0.29962547), ('P040101010', '04', '0401', '040101', 580., 435., 621., 0.29951691)], dtype=[('product_cd', '<U10'), ('category_major_cd', '<U10'), ('category_medium_cd', '<U10'), ('category_small_cd', '<U10'), ('unit_price', '<f8'), ('unit_cost', '<f8'), ('new_price', '<f8'), ('new_profit_rate', '<f8')])P_067
P-067: 商品データフレーム(df_product)の各商品について、利益率が30%となる新たな単価を求めよ。今回は、1円未満を切り上げること。そして結果を10件表示させ、利益率がおよそ30%付近であることを確認せよ。ただし、単価(unit_price)と原価(unit_cost)にはNULLが存在することに注意せよ。
In[067]unit_cost = np.ascontiguousarray(arr_product['unit_cost']) new_price = np.ceil(unit_cost / 0.7) new_profit_rate = (new_price - unit_cost) / new_price make_array(arr_product.size, **{col: arr_product[col] for col in arr_product.dtype.names}, new_price=new_price, new_profit_rate=new_profit_rate)[:10]Out[067]array([('P040101001', '04', '0401', '040101', 198., 149., 213., 0.30046948), ('P040101002', '04', '0401', '040101', 218., 164., 235., 0.30212766), ('P040101003', '04', '0401', '040101', 230., 173., 248., 0.30241935), ('P040101004', '04', '0401', '040101', 248., 186., 266., 0.30075188), ('P040101005', '04', '0401', '040101', 268., 201., 288., 0.30208333), ('P040101006', '04', '0401', '040101', 298., 224., 320., 0.3 ), ('P040101007', '04', '0401', '040101', 338., 254., 363., 0.30027548), ('P040101008', '04', '0401', '040101', 420., 315., 451., 0.30155211), ('P040101009', '04', '0401', '040101', 498., 374., 535., 0.30093458), ('P040101010', '04', '0401', '040101', 580., 435., 622., 0.30064309)], dtype=[('product_cd', '<U10'), ('category_major_cd', '<U10'), ('category_medium_cd', '<U10'), ('category_small_cd', '<U10'), ('unit_price', '<f8'), ('unit_cost', '<f8'), ('new_price', '<f8'), ('new_profit_rate', '<f8')])P_068
P-068: 商品データフレーム(df_product)の各商品について、消費税率10%の税込み金額を求めよ。 1円未満の端数は切り捨てとし、結果は10件表示すれば良い。ただし、単価(unit_price)にはNULLが存在することに注意せよ。
In[068]make_array(arr_product.size, **{col: arr_product[col] for col in arr_product.dtype.names}, price_tax=np.floor(arr_product['unit_price'] * 1.1))[:10]Out[068]array([('P040101001', '04', '0401', '040101', 198., 149., 217.), ('P040101002', '04', '0401', '040101', 218., 164., 239.), ('P040101003', '04', '0401', '040101', 230., 173., 253.), ('P040101004', '04', '0401', '040101', 248., 186., 272.), ('P040101005', '04', '0401', '040101', 268., 201., 294.), ('P040101006', '04', '0401', '040101', 298., 224., 327.), ('P040101007', '04', '0401', '040101', 338., 254., 371.), ('P040101008', '04', '0401', '040101', 420., 315., 462.), ('P040101009', '04', '0401', '040101', 498., 374., 547.), ('P040101010', '04', '0401', '040101', 580., 435., 638.)], dtype=[('product_cd', '<U10'), ('category_major_cd', '<U10'), ('category_medium_cd', '<U10'), ('category_small_cd', '<U10'), ('unit_price', '<f8'), ('unit_cost', '<f8'), ('price_tax', '<f8')])P_069
P-069: レシート明細データフレーム(df_receipt)と商品データフレーム(df_product)を結合し、顧客毎に全商品の売上金額合計と、カテゴリ大区分(category_major_cd)が"07"(瓶詰缶詰)の売上金額合計を計算の上、両者の比率を求めよ。抽出対象はカテゴリ大区分"07"(瓶詰缶詰)の購入実績がある顧客のみとし、結果は10件表示させればよい。
In[069]can_cd = arr_product['product_cd'][arr_product['category_major_cd'] == '07'] is_can = np.in1d(arr_receipt['product_cd'], can_cd) unq_id, inv_id = np.unique(arr_receipt['customer_id'], return_inverse=True) map_array = np.zeros((unq_id.size, 2), dtype=int) map_array[inv_id, is_can.view(np.int8)] += arr_receipt['amount'] amount_x = map_array.sum(1) amount_y = map_array[:, 1] make_array(unq_id.size, customer_id=unq_id, amount_x=amount_x, amount_y=amount_y, rete_07=amount_y/amount_x)[amount_y > 0][:10]Out[069]array([('CS001113000004', 1298., 1298., 1. ), ('CS001114000005', 626., 486., 0.77635783), ('CS001115000010', 3044., 2694., 0.88501971), ('CS001205000004', 1988., 346., 0.17404427), ('CS001205000006', 3337., 2004., 0.60053941), ('CS001212000027', 448., 200., 0.44642857), ('CS001212000031', 296., 296., 1. ), ('CS001212000046', 228., 108., 0.47368421), ('CS001212000070', 456., 308., 0.6754386 ), ('CS001213000018', 243., 145., 0.59670782)], dtype=[('customer_id', '<U14'), ('amount_x', '<f8'), ('amount_y', '<f8'), ('rete_07', '<f8')])P_070
P-070: レシート明細データフレーム(df_receipt)の売上日(sales_ymd)に対し、顧客データフレーム(df_customer)の会員申込日(application_date)からの経過日数を計算し、顧客ID(customer_id)、売上日、会員申込日とともに表示せよ。結果は10件表示させれば良い(なお、sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。
In[070]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' sales_ymd = (pd.to_datetime(arr_receipt['sales_ymd'][is_member], format='%Y%m%d') .to_numpy(dtype='datetime64[D]')) application_date = (pd.to_datetime(arr_customer['application_date'], format='%Y%m%d') .to_numpy(dtype='datetime64[D]')) unq_id, inv_id = np.unique( np.concatenate([arr_customer['customer_id'], arr_receipt['customer_id'][is_member]]), return_inverse=True) inv_cus, inv_rec = inv_id[:arr_customer.size], inv_id[arr_customer.size:] map_array = np.empty(unq_id.size, dtype='datetime64[D]') map_array[inv_cus] = application_date application_date_receipt = map_array[inv_rec] elapsed_date = sales_ymd - application_date_receipt make_array(inv_rec.size, customer_id=unq_id[inv_rec], sales_ymd=sales_ymd, application_date=application_date_receipt, elapsed_date=elapsed_date)[:10]Out[070]array([('CS006214000001', '2018-11-03', '2015-02-01', 1371), ('CS008415000097', '2018-11-18', '2015-03-22', 1337), ('CS028414000014', '2017-07-12', '2015-07-11', 732), ('CS025415000050', '2018-08-21', '2016-01-31', 933), ('CS003515000195', '2019-06-05', '2015-03-06', 1552), ('CS024514000042', '2018-12-05', '2015-10-10', 1152), ('CS040415000178', '2019-09-22', '2015-06-27', 1548), ('CS027514000015', '2019-10-10', '2015-11-01', 1439), ('CS025415000134', '2019-09-18', '2015-07-20', 1521), ('CS021515000126', '2017-10-10', '2015-05-08', 886)], dtype=[('customer_id', '<U14'), ('sales_ymd', '<M8[D]'), ('application_date', '<M8[D]'), ('elapsed_date', '<m8[D]')])P_071
P-071: レシート明細データフレーム(df_receipt)の売上日(sales_ymd)に対し、顧客データフレーム(df_customer)の会員申込日(application_date)からの経過月数を計算し、顧客ID(customer_id)、売上日、会員申込日とともに表示せよ。結果は10件表示させれば良い(なお、sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。1ヶ月未満は切り捨てること。
In[071]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' sales_ymd = (pd.to_datetime(arr_receipt['sales_ymd'][is_member], format='%Y%m%d') .to_numpy(dtype='datetime64[D]')) application_date = (pd.to_datetime(arr_customer['application_date'], format='%Y%m%d') .to_numpy(dtype='datetime64[D]')) unq_id, inv_id = np.unique( np.concatenate([arr_customer['customer_id'], arr_receipt['customer_id'][is_member]]), return_inverse=True) inv_cus, inv_rec = inv_id[:arr_customer.size], inv_id[arr_customer.size:] map_array = np.empty(unq_id.size, dtype='datetime64[D]') map_array[inv_cus] = application_date application_date_receipt = map_array[inv_rec] sales_ymd_str = np.datetime_as_string(sales_ymd) app_date_str = np.datetime_as_string(application_date_receipt) years = (sales_ymd_str.astype('<U4').astype(np.int32) - app_date_str.astype('<U4').astype(np.int32)) * 12 sales_ymd_view = sales_ymd_str.view(np.int32).reshape(inv_rec.size, -1) app_date_view = app_date_str.view(np.int32).reshape(inv_rec.size, -1) sales_ymd_month = sales_ymd_view[:, 5]*10 + sales_ymd_view[:, 6] app_date_month = app_date_view[:, 5]*10 + app_date_view[:, 6] sales_ymd_day = sales_ymd_view[:, 8]*10 + sales_ymd_view[:, 9] app_date_day = app_date_view[:, 8]*10 + app_date_view[:, 9] elapsed_date = years + sales_ymd_month - app_date_month elapsed_date[sales_ymd_day < app_date_day] -= 1 make_array(inv_rec.size, customer_id=unq_id[inv_rec], sales_ymd=sales_ymd, application_date=application_date_receipt, elapsed_date=elapsed_date)[:10]Out[071]array([('CS006214000001', '2018-11-03', '2015-02-01', 45), ('CS008415000097', '2018-11-18', '2015-03-22', 43), ('CS028414000014', '2017-07-12', '2015-07-11', 24), ('CS025415000050', '2018-08-21', '2016-01-31', 30), ('CS003515000195', '2019-06-05', '2015-03-06', 50), ('CS024514000042', '2018-12-05', '2015-10-10', 37), ('CS040415000178', '2019-09-22', '2015-06-27', 50), ('CS027514000015', '2019-10-10', '2015-11-01', 47), ('CS025415000134', '2019-09-18', '2015-07-20', 49), ('CS021515000126', '2017-10-10', '2015-05-08', 29)], dtype=[('customer_id', '<U14'), ('sales_ymd', '<M8[D]'), ('application_date', '<M8[D]'), ('elapsed_date', '<i4')])P_072
P-072: レシート明細データフレーム(df_receipt)の売上日(sales_ymd)に対し、顧客データフレーム(df_customer)の会員申込日(application_date)からの経過年数を計算し、顧客ID(customer_id)、売上日、会員申込日とともに表示せよ。結果は10件表示させれば良い。(なお、sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。1年未満は切り捨てること。
In[072]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' sales_ymd = (pd.to_datetime(arr_receipt['sales_ymd'][is_member], format='%Y%m%d') .to_numpy(dtype='datetime64[D]')) application_date = (pd.to_datetime(arr_customer['application_date'], format='%Y%m%d'). to_numpy(dtype='datetime64[D]')) unq_id, inv_id = np.unique( np.concatenate([arr_customer['customer_id'], arr_receipt['customer_id'][is_member]]), return_inverse=True) inv_cus, inv_rec = inv_id[:arr_customer.size], inv_id[arr_customer.size:] map_array = np.empty(unq_id.size, dtype='datetime64[D]') map_array[inv_cus] = application_date application_date_receipt = map_array[inv_rec] sales_ymd_str = np.datetime_as_string(sales_ymd) app_date_str = np.datetime_as_string(application_date_receipt) sales_ymd_view = sales_ymd_str.view(np.int32).reshape(inv_rec.size, -1) app_date_view = app_date_str.view(np.int32).reshape(inv_rec.size, -1) sales_ymd_month = sales_ymd_view[:, 5]*10 + sales_ymd_view[:, 6] app_date_month = app_date_view[:, 5]*10 + app_date_view[:, 6] sales_ymd_day = sales_ymd_view[:, 8]*10 + sales_ymd_view[:, 9] app_date_day = app_date_view[:, 8]*10 + app_date_view[:, 9] elapsed_date = (sales_ymd_str.astype('<U4').astype(np.int16) - app_date_str.astype('<U4').astype(np.int16)) elapsed_date[(sales_ymd_month < app_date_month) | ((sales_ymd_month == app_date_month) & (sales_ymd_day < app_date_day))] -= 1 make_array(inv_rec.size, customer_id=unq_id[inv_rec], sales_ymd=sales_ymd, application_date=application_date_receipt, elapsed_date=elapsed_date)[:10]Out[072]array([('CS006214000001', '2018-11-03', '2015-02-01', 3), ('CS008415000097', '2018-11-18', '2015-03-22', 3), ('CS028414000014', '2017-07-12', '2015-07-11', 2), ('CS025415000050', '2018-08-21', '2016-01-31', 2), ('CS003515000195', '2019-06-05', '2015-03-06', 4), ('CS024514000042', '2018-12-05', '2015-10-10', 3), ('CS040415000178', '2019-09-22', '2015-06-27', 4), ('CS027514000015', '2019-10-10', '2015-11-01', 3), ('CS025415000134', '2019-09-18', '2015-07-20', 4), ('CS021515000126', '2017-10-10', '2015-05-08', 2)], dtype=[('customer_id', '<U14'), ('sales_ymd', '<M8[D]'), ('application_date', '<M8[D]'), ('elapsed_date', '<i2')])P_073
P-073: レシート明細データフレーム(df_receipt)の売上日(sales_ymd)に対し、顧客データフレーム(df_customer)の会員申込日(application_date)からのエポック秒による経過時間を計算し、顧客ID(customer_id)、売上日、会員申込日とともに表示せよ。結果は10件表示させれば良い(なお、sales_ymdは数値、application_dateは文字列でデータを保持している点に注意)。なお、時間情報は保有していないため各日付は0時0分0秒を表すものとする。
In[073]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' sales_ymd = (pd.to_datetime(arr_receipt['sales_ymd'][is_member], format='%Y%m%d') .to_numpy(dtype='datetime64[D]')) application_date = (pd.to_datetime(arr_customer['application_date'], format='%Y%m%d') .to_numpy(dtype='datetime64[D]')) unq_id, inv_id = np.unique( np.concatenate([arr_customer['customer_id'], arr_receipt['customer_id'][is_member]]), return_inverse=True) inv_cus, inv_rec = inv_id[:arr_customer.size], inv_id[arr_customer.size:] map_array = np.empty(unq_id.size, dtype='datetime64[D]') map_array[inv_cus] = application_date application_date_receipt = map_array[inv_rec] elapsed_date = (sales_ymd - application_date_receipt) * 86400 make_array(inv_rec.size, customer_id=unq_id[inv_rec], sales_ymd=sales_ymd, application_date=application_date_receipt, elapsed_date=elapsed_date)[:10]Out[073]array([('CS006214000001', '2018-11-03', '2015-02-01', 118454400), ('CS008415000097', '2018-11-18', '2015-03-22', 115516800), ('CS028414000014', '2017-07-12', '2015-07-11', 63244800), ('CS025415000050', '2018-08-21', '2016-01-31', 80611200), ('CS003515000195', '2019-06-05', '2015-03-06', 134092800), ('CS024514000042', '2018-12-05', '2015-10-10', 99532800), ('CS040415000178', '2019-09-22', '2015-06-27', 133747200), ('CS027514000015', '2019-10-10', '2015-11-01', 124329600), ('CS025415000134', '2019-09-18', '2015-07-20', 131414400), ('CS021515000126', '2017-10-10', '2015-05-08', 76550400)], dtype=[('customer_id', '<U14'), ('sales_ymd', '<M8[D]'), ('application_date', '<M8[D]'), ('elapsed_date', '<m8[D]')])P_074
P-074: レシート明細データフレーム(df_receipt)の売上日(sales_ymd)に対し、当該週の月曜日からの経過日数を計算し、売上日、当該週の月曜日付とともに表示せよ。結果は10件表示させれば良い(なお、sales_ymdは数値でデータを保持している点に注意)。
np.busday_offset()を用います。weekmask引数を月曜日('Mon'あるいは'1000000')にセットし、roll='backward'とすれば、直前の月曜日の日付が帰ってきます。In[074]sales_ymd = (pd.to_datetime(arr_receipt['sales_ymd'], format='%Y%m%d') .to_numpy(dtype='datetime64[D]')) monday = np.busday_offset(sales_ymd, 0, roll='backward', weekmask='Mon') elapsed_weekday = sales_ymd - monday make_array(elapsed_weekday.size, customer_id=arr_receipt['customer_id'], sales_ymd=sales_ymd, monday=monday, elapsed_weekday=elapsed_weekday)[:10]Out[074]array([('CS006214000001', '2018-11-03', '2018-10-29', 5), ('CS008415000097', '2018-11-18', '2018-11-12', 6), ('CS028414000014', '2017-07-12', '2017-07-10', 2), ('ZZ000000000000', '2019-02-05', '2019-02-04', 1), ('CS025415000050', '2018-08-21', '2018-08-20', 1), ('CS003515000195', '2019-06-05', '2019-06-03', 2), ('CS024514000042', '2018-12-05', '2018-12-03', 2), ('CS040415000178', '2019-09-22', '2019-09-16', 6), ('ZZ000000000000', '2017-05-04', '2017-05-01', 3), ('CS027514000015', '2019-10-10', '2019-10-07', 3)], dtype=[('customer_id', '<U14'), ('sales_ymd', '<M8[D]'), ('monday', '<M8[D]'), ('elapsed_weekday', '<m8[D]')])
- 投稿日:2020-07-21T11:54:23+09:00
PythonではじめるAWS CDK
Pythonで始めるAWS CDK
最近までいろいろと触る機会があったのと、AWS CDK+Pythonの記事が少なかったので書いてみた。
内容はAWS CDKのインストール〜デプロイまで。ついでにLambda関係でよく使いそうなところをいくつか。実行環境
- Python 3.7.4
- OSX Catalina 10.15.5
Python、Pipが実行可能な環境であることが前提で書いています。
はじめに
AWS CDKってなに?
AWS クラウド開発キット (AWS CDK) は、使い慣れたプログラミング言語を使用してクラウドアプリケーションリソースをモデル化およびプロビジョニングするためのオープンソースのソフトウェア開発フレームワークです。
かなり大雑把にまとめると、使い慣れたプログラミング言語でAWSのリソースを定義、作成できるIaC(Infrastructure as Code)ツールですよっと。
なんでAWS CDKなの?
環境設定をコードで管理したい。けどterraformとかに手を出すほどでもないし、template.ymlは書きたくない…。何よりAWSの公式!
なんでPythonなの?
(TypeScriptやったことないから…)
LambdaをPythonで書いていたからその延長線上でPythonでやってみた使ってみた感想
- 後述するが間接的にCloudFormationを使用しているので、実務で使用する場合はAWS CloudFormation の制限は一読しておくことをお勧めする。
- リリースは頻繁にされているので日々改善されているようだが、使い込んでいくと正直、現状では痒いところに手が届かない感が否めない。少なくともクロススタック参照はなんとかして欲しい。
- 調べて出てくるのはTypeScriptがほとんどなので、わざわざPythonを使うメリットはそこまでない
AWS CDKのインストール
- Getting started with the AWS CDKを参考に進めていく。
Node.jsのインストール
前提として、Node.jsが必要なのでインストールされていない場合はまずこちらをインストールする
なぜNode.jsが必要かというと、AWS CDK自体はTypeScriptで書かれており、Pythonなど他の言語はjsiiというライブラリで自動的にTypeScriptに変換してくれているらしい。すごい。Q: AWS CDK を使用するために JavaScript ランタイムをインストールする必要があるのはなぜですか?
AWS は、AWS Construct ライブラリパッケージのビジネスロジックを TypeScript で構築し、サポートされている各プログラミング言語へのマッピングを提供します。これにより、AWS CDK コンストラクトの動作が異なる言語間で一貫していることを確認でき、すべての言語で利用できる包括的なコンストラクトパッケージのセットを提供できます。AWS CDK プロジェクトで作成したコードはすべてお客様ご希望のプログラミング言語でネイティブになっています。JavaScript ランタイムはお客様のプログラミング経験の実施詳細です。jsii プロジェクトは https://github.com/aws/jsii で参照できます。Node.jsのインストール自体は簡単で、Node.jsの公式からインストーラをダウンロード。あとはインストーラに従ってポチポチしていけば勝手にインストールしてくれる。
インストールが完了したらバージョンを確認
$ node -v v12.18.2 $ npm -v 6.14.5AWS認証情報の設定
AWS CLIがインストールされている場合は
aws configureコマンドを実行すればプロンプトで設定可能だが、わざわざAWS CLIインストールしたくない場合は手動で設定する。以下はmac or linuxの設定手順。Windowsの場合は
%USERPROFILE%\.aws\configと%USERPROFILE%\.aws\credentialsを作成し、認証情報、リージョンを設定する$ mkdir ~/.aws $ touch ~/.aws/config $ touch ~/.aws/credentialsエディタで
~/.aws/configを開き、以下の通りリージョンを設定し、保存する[default] region=ap-northeast-1エディタで
~/.aws/credentialsを開き、以下の通り認証情報を設定し、保存する。[default] aws_access_key_id={アクセスキーID} aws_secret_access_key={シークレットアクセスキー}AWS CDKのインストール
npmを使用してインストールする
$ sudo npm install -g aws-cdkバージョンを表示し、インストールされていることを確認。
$ cdk --version 1.52.0 (build 5263664)デプロイ用S3バケットの作成
cdk bootstrapコマンドでCloudFormationで使用するS3バケットを作成する
これはリージョンごとに実施する必要があるので注意。$ cdk bootstrap ⏳ Bootstrapping environment aws://323617333195/ap-northeast-1... CDKToolkit: creating CloudFormation changeset... ✅ Environment aws://323617333195/ap-northeast-1 bootstrapped.CDK appを作る
- Your first AWS CDK appを参考に進めていく。
- 参考までに、今回作成したコードはここに置いてあります。
プロジェクトディレクトリを作成
mkdir hello-cdk cd hello-cdk
cdk initコマンドを実行cdk init app --language python実行が終わったらvirtualenvを起動する
(pip3を使用している場合はpip3に読み替えて実行すること)source .env/bin/activate pip install -r requirements.txtpipenvを使用したい場合は、virtualenvを起動せずに
.envディレクトリを削除して代わりにpipenvを起動するS3バケットを作成してみる
pip install aws-cdk.aws-s3hello_cdk_stack.pyにs3バケットを作成するコードを追加する
(bucket_nameは既存のバケット名と重複するとデプロイ時にエラーになるため、重複しないものへ書き換えること)hello_cdk_stack.pyfrom aws_cdk import core from aws_cdk import aws_s3 as _s3 class HelloCdkStack(core.Stack): def __init__(self, scope: core.Construct, id: str, **kwargs) -> None: super().__init__(scope, id, **kwargs) # The code that defines your stack goes here bucket = _s3.Bucket(self, "MyFirstBucket", bucket_name="kimi-first-cdk-bucket")デプロイコマンドを実行
$ cdk deploy hello-cdk: deploying... hello-cdk: creating CloudFormation changeset... ✅ hello-cdk Stack ARN: arn:aws:cloudformation:ap-northeast-1:323617333195:stack/hello-cdk/3497b790-ca3f-11ea-9236-0eb7b90bbf8eデプロイ完了後にAWSマネジメントコンソールでS3バケットが作成されていることを確認できた
AWSマネジメントコンソールでCloudFormationを開くと
hello-cdkというスタックができている。
これはAWS CDKがリソースを作成するのにCloudFormationを使用しているため。
cdk synthコマンドを実行すればCloudFormationテンプレートを出力することもできる。$ cdk synthまた、作成したリソースを全て削除したい場合は
cdk destroyコマンドでスタック単位でリソースを削除することが可能。
ただし、S3バケットなど削除されないリソースが一部あるので注意が必要。$ cdk destroyLambdaをデプロイしてみる
- 参考までに、今回作成したコードはここに置いてあります。
シンプルなLambda関数をデプロイする
新しいプロジェクトを作成。
$ mkdir cdk-lambda $ cd cdk-lambda/ $ cdk init app --language pythonせっかくなのでPipenvを使ってみる。
$ rm -rf .env $ rm -rf source.bat $ rm -rf requirements.txt $ pipenv shell必要なパッケージをインストール
$ pipenv install aws_cdk.core $ pipenv install aws_cdk.aws_lambdaLambda関数を置くディレクトリを作成し、Lambda関数のPythonファイルを作成
$ mkdir function $ touch function/index.py今回はあくまでもサンプルなので、Lambdaのコードは適当
index.pyimport json print('Loading function') def lambda_handler(event, context): print("value1 = " + event['key1']) print("value2 = " + event['key2']) print("value3 = " + event['key3']) return event['key1'] # Echo back the first key value
cdk_lambda_stack.pyにLambda関数を作成するコードを追記cdk_lambda_stack.pyfrom aws_cdk import core from aws_cdk import aws_lambda as _lambda class CdkLambdaStack(core.Stack): def __init__(self, scope: core.Construct, id: str, **kwargs) -> None: super().__init__(scope, id, **kwargs) # The code that defines your stack goes here lambdaFn = _lambda.Function(self, "SampleLambdaFunction", code=_lambda.Code.from_asset('function/'), runtime=_lambda.Runtime.PYTHON_3_7, handler="index.lambda_handler", function_name="sample_lambda_function" )いざ、デプロイ!
$ cdk deployAWSマネジメントコンソールでデプロイされていることを確認。
Lambda関数に環境変数を設定する
Functionを作成する際に
environmentパラメータを指定するか、add_environmentメソッドで設定するcdk_lambda_stack.py# 環境変数を追加 lambdaFn.add_environment(key="STAGE", value="DEV")
s3トリガーを設定する
必要なライブラリをインストール
$ pipenv install aws_cdk.aws_s3 $ pipenv install aws_cdk.aws_s3_notificationsライブラリをインポート
cdk_lambda_stack.pyfrom aws_cdk import ( core, aws_lambda as _lambda, aws_s3 as _s3, aws_s3_notifications, )s3バケットを作成し、通知イベントを設定。
今のところ、この方法では既存のS3バケットには設定できない。既存のS3バケットにイベントを設定したい場合はカスタムリソースを使用する。cdk_lambda_stack.pybucket = _s3.Bucket(self, "SampleBucket", bucket_name="kimi-first-cdk-bucket") notification = aws_s3_notifications.LambdaDestination(lambdaFn) bucket.add_event_notification(_s3.EventType.OBJECT_CREATED, notification, _s3.NotificationKeyFilter(prefix="hoge", suffix=".csv"))
Cloudwatch Eventsから定期的に起動する
必要なライブラリをインストール
$ pipenv install aws_cdk.aws_events $ pipenv install aws_cdk.aws_events_targetsインストールしたライブラリをインポート
cdk_lambda_stack.pyfrom aws_cdk import ( core, aws_lambda as _lambda, aws_s3 as _s3, aws_s3_notifications, aws_events as _events, aws_events_targets as _targets )イベントルールを作成するコードを追加。
今回スケジュール文字列を使用して設定しているが、Schedule.cronやSchedule.rateなど別の方法でも指定可能。cdk_lambda_stack.pyrule = _events.Rule(self, "SampleEventRule", rule_name="schedule_trigger_event", schedule=_events.Schedule.expression("cron(10 * * * ? *)") ) rule.add_target(_targets.LambdaFunction(lambdaFn))
参考
AWS CDK Examples サンプルコード集。言語によって差はあるが、いろいろ揃っているのでかなりありがたい




- 投稿日:2020-07-21T10:28:58+09:00
Dead by Daylightのサバイバーパークの共起性を可視化する
やりたいこと
2020/07/01 ~ 2020/07/14(4周年期間中)のDead by Daylightで僕がご一緒したサバイバーのプレイヤーのパークを分析します.このゲームをプレイする上で役に立ちそうな情報を分析したくなったのがきっかけです.
Dead by Daylightについて
最近ハマっている4vs1の非対称型対戦ゲームです.殺人鬼(キラー)1名と生存者(サバイバー)4名に分かれて,箱庭と呼ばれるステージで追いかけっこをします.最近4周年を迎えたり芸人の狩野英考さんがYouTubeでゲーム実況を始めたりと,今とてもアツいと個人的に思っているゲームです.
パークとは
ゲームを有利に進めるために4つまで特殊能力を試合に持ち込むことができます.この特殊能力のことをパークといって,代表的なものには以下のような能力があります.※ PERKSより引用
- デッドハード(Dead Hard): 疲労状態でない負傷中に走っている時、Eキーを押すと効果発動.短時間だけ前方にダッシュし、その間あらゆるダメージを受けない.このパーク効果が発動すると60・50・40秒間は疲労状態となる.
- セルフケア(Self Care): 回復キット無しで自分自身を治療可能(ただし治療速度は通常の50%).自分に使う時のみ回復キット使用時の使用効率が10・15・20%上昇.
今回は生存者側のパークの共起性(同時採用率)を中心に分析したいと思います.
集めたデータ
生存者のランクと採用されたパーク4つを80名分記録しました.僕と一緒にプレイしていただいた方のみを対象にデータ収集しているため,全ユーザの統計データとはならないので一例として考えてください.ランク自体を記録したはいいものの,公式がランクシステムの廃止をアナウンスしていたため,あまり意味はなかったです.
データの形式はこんな感じです.
df = pd.read_csv("perks.csv") df
分析
パーク同士の共起性を示す指標としてJaccard係数を採用しました.Jaccard係数を利用した共起ネットワークについてはこちらの記事を参考にさせていただきました.
Jaccard係数は以下の式で表され,集合の類似度を示します.
$Jaccard = \frac{n(A \cap B)}{n(A \cup B)}$
今回はパークが採用されることを事象の単位とするため,パークAとパークBの同時採用回数とどちらか一つでも採用されている回数の比を計算することになります.$n(A \cup B)$は以下の式で簡単に計算できます.
$n(A \cup B) = n(A) + n(B) - n(A \cap B)$
今回集めたデータから簡単に計算できます.
可視化結果はこんな感じ.
中心にあるほど採用数が高く,エッジが太いほど共起性が高くなっています.デッドハード(Dead hard)・鋼の意思(Iron Will)・与えられた猶予(Borrowd Time)・決死の一撃(Decisive Strike)などはどんなパークとでも組み合わせやすいため,中心に分布しています.一方で,素早く静かに(Quick & Quiet)と真っ向勝負(Head On),ソウルガード(Soul Guard)と不滅(Unbreakable),コソ泥の本能(Plunderer's Instinct)と最後の切り札(Ace in the Hole)などの採用数が少ないものの組み合わさることによって効果を発揮するパークは外側に配置されて太い線で繋がっています.
単純な単体の採用数もこちらに載せておきます.
採用数と共起性を考えると,テンプレ構成は以下のようなものが考えられます.
- デッドハード・鋼の意思・セルフケア・決死の一撃
- デッドハード・鋼の意思・与えられた猶予・決死の一撃
- デッドハード・凍りつく背筋・与えられた猶予・決死の一撃
デッドハードはほとんどの構成に採用されていて,デッドハードの枠を全力疾走に変えている構成も頻繁に見られました.後ほどコードを公開しようと思います.



- 投稿日:2020-07-21T10:24:22+09:00
xontribを作る上で引っかかったポイント
まず
xonshと言ったらばんくしさんのブログを見ましょう。これを見れば大体できます。
https://vaaaaaanquish.hatenablog.com/archive/category/xonsh
目次
- cookiecutter-xontribが使えない!
- 関数を別モジュールに切り出したい
- -eとgitでモジュールが読めなくなる話
- テストを書きたい話
cookiecutter-xontribが使えない!
xontribの雛形を作るのに便利ですが、
https://github.com/laerus/cookiecutter-xontribがなくなってしまっています。xonsh公式が出しているのでそちらをそのまま使いましょう。 https://github.com/xonsh/xontrib-cookiecutter
作成直後の構造↓. ├── LICENSE ├── README.rst ├── setup.cfg ├── setup.py └── xontrib └── sample.xshちなみに、公式版では新しく
setup.cfgが追加されていますが、今までsetup関数に与えていた引数を別出ししているだけなので特に変わりなく使えます。関数を別モジュールに切り出したい
公式のチュートリアルにもあるように、libモジュールを作成して読み込みたい時
xontrib/ |- javert.xsh # "javert", because in xontrib |- your.py # "your", |- eyes/ |- __init__.py |- scream.xsh # "eyes.scream", because eyes is in xontrib[javert.xsh] from .eyes import scream # ○ from eyes import scream # ×xontribよりpython全般の話になってきますが、相対読み込みを使わないとこけます。半日溶かしました
xpip install -e と pip install git+ で動きが違う(動かなくなる)話
前者は動き、後者は動かなく(module not found)なりました。
結論としては、setupの書き方に問題がありました。
... package_data = {'xontrib': [ここ]}, ...xontribの先人の方々は
*.xshと書いていたため、「この部分にパッケージに含めるファイルを記述する」と推測して./**/*.pyと記述すると動きます。これも半日溶かしました。
テストを書きたい
こちらの記事(すごい!)を参考にして全てpyに置き換えている前提です。
https://qiita.com/74th/items/857e9a7aed5671e968bc
普通にunittestを走らせると、
builtins.__xonsh__.envを呼んでいるタイミングで落ちると思います。xonshがないので当然といえば当然です。
なので、mockを使います。import unittest from unittest.mock import patch, MagicMock # 別ファイルにすると見栄えがいい sample_xonsh = { "env": { # モックにしておきたい環境変数を作る }, "execer": MagicMock() } mock_xonsh = MagicMock() mock_xonsh.__getitem__.side_effect = sample_xonsh.__getitem__ mock_aliases = MagicMock() # ------------------------- class TestSample(unittest.TestCase): def setUp(self): self.patcher_xonsh = patch('builtins.__xonsh__', new=mock_xonsh, create=True) self.patcher_aliases = patch('builtins.aliases', new=mock_aliases, create=True) self.mock_xonsh = self.patcher_xonsh.start() self.mock_aliases = self.patcher_aliases.start() def tearDown(self): self.patcher_xonsh.stop() self.patcher_aliases.stop() def test_sample(self): from xontrib.hellolib import hello # テストを行う if __name__ == "__main__": unittest.main()ポイントは
create=Trueでパッチを作成すること(上書きではないので)- xontribのインポートは各テスト関数内で行うこと(patchより先にインポートしてしまうとモック化の意味がない(エラー))
- execerにMagicMockを代入しておくこと(execer.evalは関数なので引数を後から見れた方が良い感じ)
xontribのテストはモックの量がめちゃめちゃに多くなりそうで悲しくなっています。
また詰まったときは追記していきます。
- 投稿日:2020-07-21T07:11:12+09:00
ゼロから始めるLeetCode Day93 「49. Group Anagrams」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day91「153. Find Minimum in Rotated Sorted Array」Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!お知らせ
Day 100でQiitaでの投稿はひとまず区切りを付けようかと思います。
タグの記事が僕の記事ばかりになってしまうのもいかがなものかと思いましたし、他に有益な情報を提供している方の邪魔になってしまうこともあると考えたので、こうすることにしました。
至らない部分は多々ありましたが、今までお付き合い頂きありがとうございました。問題を解いて記事を書く、というのは上記の個人ブログで続けるつもりですし、興味ある方はたまにそちらを覗いていただけると嬉しいです。
Twitterの方のアカウントはほとんど更新通知用と化しているので、Leetcodeを解く記事について気になる方はそちらも合わせてフォローいただくと良いかもしれません。問題
49. Group Anagrams
難易度はMedium。
コーディング面接対策のために解きたいLeetCode 60問からの抜粋です。問題としてはアナグラムである文字列の入った配列が与えられます。
Example:
Input: ["eat", "tea", "tan", "ate", "nat", "bat"],
Output:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]解法
class Solution: def groupAnagrams(self, strs: List[str]) -> List[List[str]]: ans = collections.defaultdict(list) for s in strs: sorted_word = ''.join(sorted(s)) ans[sorted_word].append(s) return ans.values() # Runtime: 92 ms, faster than 98.06% of Python3 online submissions for Group Anagrams. # Memory Usage: 16.8 MB, less than 71.89% of Python3 online submissions for Group Anagrams.アナグラムというとハッシュマップを使うと解きやすいと思います。
2つの文字列を比較した時に、文字列を構成する要素が同じ数で揃っていれば良いので、例えば
"abc"と"cab"の場合であればどちらも
aが1回、bが1回、cが1回出現しているので、
a:0,b:0,c:0....といった風にa~zまで全ての個数をハッシュマップで管理すれば特定の文字列がアナグラムであるかを判別することができます。今回の回答は前から舐めていく過程で一旦ソートすることで、例の配列を以下のように変換しています。
aet aet ant aet ant abtそして、それぞれの要素をソートしていない元の文字列のまま
ansに追加し、そしてvalueのみを返すことできちんと分類されています。
なお、なぜきちんと分類されているか、という点についてですが、最初のdefaultdictで引数にlistを与えているため、[aet],[ant],[abt]という風にリスト化されているためです。では今回はここまで。
お疲れ様でした。
- 投稿日:2020-07-21T06:37:53+09:00
Python学習サイト備忘録
Python学習サイトこれをやる
▼めんどうなことはPythonにやらせよう
本で買うと2000円くらい。web英語版なら無料。
https://automatetheboringstuff.com/#toc▼東京大学Pythonプログラミング入門
すごい丁寧に書いてあるありがたい。
https://utokyo-ipp.github.io/toc.html
- 投稿日:2020-07-21T05:56:23+09:00
pythonで英語の音声処理をするときに使うライブラリ
英語の音声処理について
音声処理の分野の日本語用はmecabやjanomeなど数多くの有用なライブラリがpythonには存在します。その一方で英語の音声処理のライブラリもたくさんある一方でまとまってライブラリの使い方などを説明した文献はあまり多くないように感じます。
ここでは英語の音声処理をpythonで行うときに役立つライブラリをそれぞれの特徴と共に解説していきます。音声認識
GoogleSpeechRecognition
https://pypi.org/project/SpeechRecognition/
こちらはgoogleが提供する音声認識のライブラリです。googleが提供してるだけあって認識精度はかなり高いです。ただオンラインで用いること前提なので、オフラインで用いると認識精度が下がります。
pocketsphinx
https://pypi.org/project/SpeechRecognition/
こちらはgooglespeechrecognitionと比べると精度は落ちるもののオフラインでも安定した精度を発揮します。文法辞書、単語辞書と併用することで認識精度を上げることができます。
julius
こちらは京大をはじめとする大学の開発チームが開発した音声認識エンジンです。googlespeechrecognitionやpocketsphinxと違いjuliusはこれ単体では動きません。音響モデル、単語辞書、言語モデルをこちらで用意する必要があります。標準では日本語で認識されますが、英語のモデルを使えば英語の認識もできます。
自然言語処理
NLTK
シンプルで使いやすい割に機能が多いライブラリなのが特徴です。ただ公式が英語のドキュメントしかないので、英語が読めない人には厳しいかもしれません。
Polyglot
https://polyglot.readthedocs.io/en/latest/
こちらはNLTKほど機能はないものの形態素解析、分かち書き、分散表現など、自然言語処理の基本的な機能が網羅されていて使いやすいのが特徴です。
word2vec
https://pathmind.com/wiki/word2vec
word2vecは単語間の類似度比較に用いられます。単語をベクトルで表すことによって単語間の引き算ができたり中々使ってみると面白いです。ただ機械学習分野の知識が必要とされるので他のライブラリと比べるとハードルが高いかもしれません。
音声ファイル生成
gtts
https://pypi.org/project/gTTS/
gttsはGoogle Text-to-Speechの略でテキスト音声ファイルに変換できます。テスト用の音声ファイルや読み上げるのがめんどくさい時に音声ファイルをこれで作ります。
音声ファイル処理
pydub
pydubは音声ファイル処理用のライブラリです。音量を上げたり、音声ファイルの長さを変えたり色々な処理をすることができます。
- 投稿日:2020-07-21T01:47:54+09:00
Kedroで機械学習パイプライン入門
はじめに
- Kedroという機械学習向けパイプラインツールを使ってみたので備忘までに記事を書きます。
- とりあえずパイプラインを組んでみて動いたところまで、です。もう少し使い込んで、別途投稿できればと思っています。
- 公式のチュートリアルの差分は、以下くらいかなと思います。(どっちもちょっとしたことですが)
- ホストを汚さないようにDockerコンテナ内でKedroプロジェクトを作成・開発していること
- node.pyは使わず、普段慣れ親しんだディレクトリ構成で普通にスクリプトを書いていること(それらをノードとしてパイプラインでつないでいる)
パイプラインツールの必要性
- 依存関係が複雑になりがちな処理処理フローを管理できる
- データ、モデルの再現性の確保につながる
- 実装を共通化できる
- 実験環境から本番環境への移行がしやすい
- ジョブの並列実行ができる
パイプラインツールの比較
Kedroとは
* The centre of your data pipeline * Kedro is a development workflow framework that implements software engineering best-practice for data pipelines with an eye towards productionising machine learning models. We provide a standard approach so that you can: * Worry less about how to write production-ready code, * Spend more time building data pipelines that are robust, scalable, deployable, reproducible and versioned, & And, standardise the way that your team collaborates across your project.Kedroを使った理由
- Pythonにより、DAG のような形式でパイプラインを定義できる
- yamlによるデータカタログの定義ができる
- csv, pickle, feather, parquet, DB上のテーブル など様々なデータ形式に対応
- 複数のデータ形式や Pandas/Spark の切り替えなどにコードの改変が不要
- -> データカタログとパイプラインを始めに定義しておくことで、チーム開発がやりやすくなる
- データが扱いやすい
- データ・中間オブジェクトの管理が可能
- データのキャッシュ機能を活用できる
- Cookiecutterによるプロジェクトテンプレートを提供している
- Jupyter Notebook, Jupyter Labとのインテグレーションが整っている
- パラメータ管理がしやすい
- parameters.ymlに記述しておけばstringで簡単に読み出せる
- Kedro vizによるパイプラインの可視化ができる ...etc
Kedroの仕組み概要
- 1. プロジェクトのrootディレクトリでkedro runを実行すると、親パイプラインが起動される
$ kedro run
- 2. 親パイプラインが実行されて、子パイプラインが起動される
src/tutorial/pipeline.pyfrom tutorial.pipelines import data_engineering as de from tutorial.pipelines import data_science as ds def create_pipelines(**kwargs) -> Dict[str, Pipeline]: data_engineering_pipeline = de.create_pipeline() data_science_pipeline = ds.create_pipeline()
- 3. 子パイプラインが実行されて、ノード(スクリプト)が起動される
src/tutorial/pipelines/data_science/pipeline.pyfrom .nodes import report_accuracy, train_model def create_pipeline(**kwargs): return Pipeline( [ node( func=train_model, inputs=["example_train_x", "example_train_y", "example_test_x", "example_test_y", "parameters"], outputs="example_model", ), node(func=report_accuracy, inputs=["example_model", "example_test_x", "example_test_y"], outputs=None), ] )
- 4. ノード(スクリプト)が実行される
node.pydef train_model(example_train_x, example_train_y, example_test_x, example_test_y, parameters): print('test') return example_modelKedroを利用した開発手順
「はじめに」記載の通り、一部我流です。
1. 環境構築
- ベースプロジェクト作り(初回のみ)
- git clone <新リポジトリ>
- Dockerflie配置(または参考プロジェクトをごっそりcp)、コンテナビルド・起動
- kedro kedro-vizをpip installしておく
- Kedroプロジェクト作成
- kedro new
- .gitとDockerディレクトリを、上記で作成したKedroプロジェクト配下に移動
- ディレクトリ構成を変更(下記参照)
- data配下のディレクトリ構成を変更
- src配下のディレクトリ構成を変更
- notebooks配下のディレクトリ構成を変更
- README.mdを変更
- 新リポジトリにpush(コンテナの中から)
- git clone、再度コンテナビルド・起動
ディレクトリ構成例. ├── README.md ├── conf │ ├── README.md │ ├── base │ │ ├── catalog.yml │ │ ├── logging.yml │ │ └── parameters.yml │ └── local ├── data │ ├── processed │ └── raw ├── docker │ └── pytorch_1_4 │ ├── Dockerfile │ ├── requirements.txt │ └── run.sh ├── docs │ └── source │ ├── conf.py │ └── index.rst ├── kedro_cli.py ├── logs │ └── journals ├── notebooks │ └── forecast_keiba │ ├── data │ ├── features │ ├── models │ └── visualization ├── setup.cfg └── src ├── forecast_keiba │ ├── __init__.py │ ├── data │ ├── features │ ├── models │ ├── pipeline.py │ ├── pipelines │ │ └── __init__.py │ ├── run.py │ └── visualization ├── requirements.txt ├── setup.py └── tests ├── __init__.py ├── pipelines │ └── __init__.py └── test_run.py2. [option]試行錯誤
- notebooks配下で試行錯誤
- 参考にするソースとかがあれば、ディレクトリ構成を変更して動くかくらいまで何となく確認しておく+catalogとpipelineのあたりをつけておく
3. Input/Outputデータ定義
- catalog定義
- (参考)Kedroユーザーガイド
conf/base/catalog.ymltest_score: type: pandas.CSVDataSet filepath: data/raw/test_score.csv race_results_df: type: pickle.PickleDataSet filepath: data/raw/race_results_df.pickle backend: pickl4. パイプライン定義
親パイプライン定義
- 親パイラプライン定義
src/forecast_keiba/pipeline.pyfrom typing import Dict from kedro.pipeline import Pipeline from forecast_keiba.pipelines import netkeiba_base_lr def create_pipelines(**kwargs) -> Dict[str, Pipeline]: """Create the project's pipeline. Args: kwargs: Ignore any additional arguments added in the future. Returns: A mapping from a pipeline name to a ``Pipeline`` object. """ netkeiba_base_lr_pipeline = netkeiba_base_lr.create_pipeline() return { "netkeiba_base_lr": netkeiba_base_lr_pipeline, "__default__": netkeiba_base_lr_pipeline }子パイプライン定義
- パッケージとして読み込むために、init.pyの更新も忘れない
src/forecast_keiba/pipelines/__init__.pyfrom .pipeline import create_pipeline
- 子パイプライン定義
src/forecast_keiba/pipelines/pipeline.pyfrom kedro.pipeline import Pipeline, node import sys import os FILE_DIR = os.path.dirname(os.path.abspath(__file__)) sys.path.append(FILE_DIR + "/../../") from data import scraping_netkeiba from features import preprocess_race_results_base from models import train_lr from models import predict_lr def create_pipeline(**kwargs): return Pipeline( [ node( func=scraping_netkeiba.scraping_netkeiba, inputs=[], outputs="race_results_df" ), node( func=preprocess_race_results_base.preprocess_race_results_base, inputs=["race_results_df"], outputs="race_results_df_processed_base" ), node( func=train_lr.train_lr, inputs=["race_results_df_processed_base"], outputs="model_lr" ), node( func=predict_lr.predict_lr, inputs=["model_lr", "parameters"], outputs=None ), ] )4. ノード実装
- まず空で作っておく
- Inが引数で、Outがreturnで流れていくように
- -> パイプラインが通しで実行できるかどうかを確認しておく
- ノードの中身を実装していく
src/forecast_keiba/models/predict_lr.pydef predict_lr(model_lr, parameters): predict_race_id = parameters["predict_race_id"] # outputsがある場合は、returnする def main(model_lr, parameters): return predict_lr(model_lr, parameters) if __name__ == "__main__": main(model_lr, parameters)5. パイプライン実行
- パイプライン実行
$ kedro run[option]kedro-vizによる可視化
- kedro-vizの起動(デフォルトはポート4141)
$ kedro viz --host 0.0.0.0
(おまけ)触ってみて得たちょっとした知見
- リソースはDBテーブルも指定できる
- SQL発行をできる
- kedro runで実行されるrunは、kedro_cli.pyで定義されている
- ノートブックからもconfigにアクセスすることができる
- srcは、pipelineのin/outで書く(から、不要)が、jupyterは自分で最初に書く(catalogライブラリ自体のimportはいらない)
df_test_score = catalog.load("test_score") df_test_score_aggregated = df_test_score.groupby('class').mean() catalog.save("test_score_aggregated", df_test_score_aggregated)(おまけ)気になっていること
- 画像のcatalog定義
- ディレクトリ指定
- キャッシュが効く/効かない条件
- MLflowとの連携
- papermillを使ってjupyter notebookでバッチ実行
- パイプラインが落ちた地点からの再実行
- 並列実行
- confの環境ごとの使い分け
- kedro lint, kedro journal, context



- 投稿日:2020-07-21T01:20:16+09:00
「データサイエンス100本ノック(構造化データ加工編)」 Python-008 解説
Youtube
動画解説もしています。
問題
P-008: レシート明細のデータフレーム(df_receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、以下の条件を満たすデータを抽出せよ。
- 顧客ID(customer_id)が"CS018205000001"
- 商品コード(product_cd)が"P071401019"以外解答
コードdf_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \ .query('customer_id == "CS018205000001" & product_cd != "P071401019"')出力sales_ymd customer_id product_cd amount 36 20180911 CS018205000001 P071401012 2200 9843 20180414 CS018205000001 P060104007 600 21110 20170614 CS018205000001 P050206001 990 27673 20170614 CS018205000001 P060702015 108 27840 20190216 CS018205000001 P071005024 102 28757 20180414 CS018205000001 P071101002 278 39256 20190226 CS018205000001 P070902035 168 58121 20190924 CS018205000001 P060805001 495 68117 20190226 CS018205000001 P071401020 2200 72254 20180911 CS018205000001 P071401005 1100 88508 20190216 CS018205000001 P040101002 218 91525 20190924 CS018205000001 P091503001 280解説
・PandasのDataFrame/Seriesにて、列を指定しつつ、指定した行のうち、条件に当てはまる行を確認する方法です。
・列情報を絞り、かつ、行を指定して、かつ、条件に当てはまる情報を確認したい時に使用します。
・'<データ名>[['<列名A>','<列名B>','<列名C>']].guery('<列名A> == "<行情報A>" & <列名B> != <行情報B>')'で、指定した列(列名A,列名B,列名C)のうち、列名A が指定した 行情報A に該当する行で、かつ、列名B 指定した 行情報B に該当する行を表示します。※以下のコードのように「!=」を「<>」にしてしまうと、エラーになります。「<>」は、過去に「!=」と同じ意味で使用されていましたが、現在は使われていません。
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \
.query('customer_id == "CS018205000001" & product_cd <> "P071401019"')※比較演算子については、こちらの記事が参考になります
- 投稿日:2020-07-21T00:32:58+09:00
【Python】TOEFLリーディング完全対策1.0【英単語】
1. モチベーション
- TOEFLという英語の検定試験を受験しているのですが、とにかく難しい英単語が多く出てきて大変なんです。
- そこで英単語帳を買って一生懸命勉強していたのですが、ある時はっと気づいたのです。
- 英単語帳ってどうやって作っているんだ??試験に出ない単語なんか覚えても意味がない。俺は試験に出る単語だけに時間を割きたいんだ!!
- 中国TPOというTOEFLの過去問があるサイトをスクレイピングして調べてみました。
2. TOEFL
- 英語の試験です。非ネイティブが留学をする際などに課せられることが多く、TOEICよりも難易度は高いです。
- リーディング・リスニング・スピーキング・ライティングの4セクションからなり、各々30点の合計120点満点の試験となります。
3. 中国TPO
- 中国語のサイトに過去に実際に使われたTOEFLの問題が公開されており、これを利用して勉強する受験生も多いと思われます。
- そのサイトへのアクセス方法についてはここでは割愛しますが、2020年7月の現時点で54回分の過去問が公開されています。
4. いざスクレイピング!
- いつもの相棒BeautifulSoupを使っていきます!
root = 'https://toefl.kmf.com' res = requests.get(root + '/read/ets/new-order/0/0') time.sleep(0.5) soup = BeautifulSoup(res.content, 'html.parser') ingr = soup.find_all('div', class_='default-list-detail js-default-list') res = requests.get(root + ingr[0].find_all('a')[0].get('href')) time.sleep(0.5) soup = BeautifulSoup(res.content, 'html.parser') doc = soup.find_all('div', class_='i-stem-stem js-translate-new') doc = doc[0].text.replace('\n','').replace('-',' ').replace('.','. ').lower()
1回目のrequestsでは↓のようなページにアクセスしています。ここで各過去問へのURLを確認しています。
2回目のrequestsで個別の問題のページにアクセスしています。過去問の文章が完全にきれいではなく、ピリオドの後にスペースがなかったりということがたまにあるため、最後の行でreplaceを使ってこの後のPoS taggingの処理がうまくいくよう少しかたちを整えます。僕はここで.replace('-',' ')をしているので、例えば"state-of-the-art"のような単語は"state","of","the","art"という4つの別々の単語として処理されていくことになります。
5. PoS tagging
- nltkというライブラリを使っていきます。理由は大きく2つ。固有名詞や前置詞、定冠詞などを除外したい。例えば動詞の過去形であれば現在形に直してから以後の処理を進めたい。
lemmatizer = WordNetLemmatizer() pos_use = ['JJ','JJR','JJS','NN','NNS','RB','RBR','RBS','VB','VBD','VBG','VBN','VBP','VBZ'] lemma_pos = ['n', 'v', 'a', 'r'] def lemma(word): for lem in lemma_pos: lem_word = lemmatizer.lemmatize(word, pos=lem) if word != lem_word: return lem_word return word tokens = nltk.word_tokenize(doc) tagged = nltk.pos_tag(tokens) corpus = {} for word, tag in tagged: if tag not in pos_use: continue lem_word = lemma(word) if lem_word not in corpus.keys(): corpus[lem_word] = 1 else: corpus[lem_word] += 1
- pos_useでこれ以降使いたい単語の品詞を指定しています。品詞についてはこちらの記事に分かりやすくまとまっており、参考にさせていただきました。
- lemmaという関数では単語を原型にする処理をしています。lemmatizer.lemmatizeの部分がそれに当たります。この処理の仕方が1番いいのかは正直そこまで自信はありません(笑) ただ、いろいろ調べて挙動を見た上でこれがいいのではないかと思ってはいます。
- 一応lemmatizeの一例を出しておきます。carsをpos='n'で名詞として渡してやると、単数形の'car'を返してくれます。pos='v'で動詞を指定するとエラーではなく、与えた単語をそのまま返します。動詞の現在進行形として'analyzing'をpos='v'で与えると原型の'analyze'を返します。
lemmatizer.lemmatize('cars', pos='n') => 'car' lemmatizer.lemmatize('cars', pos='v') => 'cars' lemmatizer.lemmatize('analyzing', pos='v') => 'analyze'
- あとはnltkのword_tokenizeとpos_tagを使ってPoS taggingは完成です。その後のforループでその単語が何回出てきたかを数えます。辞書のkeyが単語名、valueが出現回数となります。
6. Let's 分析!
- ここまできたらあとは1番楽しい部分です!
- 今回はまず、過去に出てきた単語を全てマスターした場合、次のテストの単語をどの程度カバーできるようになるのかを見ていきます。
- 例えば、過去問の1から9までの単語がどれだけ過去問10の単語をカバーできているかを見ていくわけです。
- uniqueとしたものは重複を考慮していません。その回に100語の異なる単語が使われていたとして、その100語がそれ以前の過去問で既に出てきているかを見にいっています。totalは重複を考慮しています。1回の過去問で何度も使われている単語があった場合、それが過去問でも使われているとカバー率は高くなります。
- 20回目くらいを境にどちらも頭打ちになっています。過去問の単語を覚えても毎回10%ちょっとは見たことのない単語に出くわすことを示唆しています。
- uniqueな単語数も見ておきましょう。
- 受験生には厳しい結果となりました。毎回80wordsずつ程度新しい単語が使われていっています。
- それでも一方でカーブが緩くなっていっている点からは頻出の基本的な単語が存在していることが分かりますし、これを抑えるのは必須だと考えられます。
- ざっとですがこの範囲においては、$y=-233+1087x^{1/2}$くらいの式が当てはまりがいいです。unique wordsが10,000語を超えると新しい単語は50語程度になる計算です。
- 最後に具体的な単語を見てみましょう。いかにも頻出といった感じです。
rank word frequency 1 be 3,180 2 have 839 3 water 385 4 more 384 5 not 374
- 単語の出現回数は以下のような分布になります。
7. 最後に
- 今回はここまでですが、もう少し遊べそうなので今後追加でもう少し深く触ってみようと思います。
- 単語も深追いすればキリがないですが、ある程度頻出で抑えるべき単語というのは存在することが確認できました。
- オンラインの英和辞典を使えば今回のリストをスクレイピングで簡単に単語帳にすることができます。
- これの成果があってかどうかは分かりませんが、僕は過去にリーディング満点をとることができました(笑)





- 投稿日:2020-07-21T00:10:45+09:00
icrawlerでGoogleから画像を一括ダウンロードする(2020年7月18日)
動作確認した環境
- Windows10
- WSL(Ubuntu 18.04.4 LTS)
- Python 3.7.7
- icrawler 0.6.3
どうやら、Googleの仕様変更の影響でGoogleの検索エンジンのからのクローリングが動作しなくなる問題が度々発生しているらしい
今回(2020年7月18日)、最新版でコードを一部変更したところクローリングに成功した
BingやBaiduからのクローリングは動作しているため、別にGoogleに拘る必要は無いのだが
どうしてもGoogleからクローリングしたいという人はページ下部の方法を試してみてicrawlerをインストール
https://pypi.org/project/icrawler/
を見てみるとpypi v0.6.3
Anaconda Cloud 0.6.2と書いてあり、pypiの方が新しいので、pipを使ってインストール
pip install icrawlerインストールされたことを確認
python -c 'import icrawler as ic;print(ic.__version__)'icrawlerを使ってみる
これを実行して、まずはBingの検索エンジンをクローリング
bing_sample.pyfrom icrawler.builtin import BingImageCrawler bing_crawler = BingImageCrawler(storage={'root_dir': 'download'}) bing_crawler.crawl(keyword='cat', max_num=5)$ python bing_sample.py INFO - icrawler.crawler - start crawling... INFO - icrawler.crawler - starting 1 feeder threads... INFO - feeder - thread feeder-001 exit INFO - icrawler.crawler - starting 1 parser threads... INFO - icrawler.crawler - starting 1 downloader threads... INFO - parser - parsing result page https://www.bing.com/images/async?q=cat&first=0 INFO - downloader - image #1 https://ak3.picdn.net/shutterstock/videos/3647543/thumb/12.jpg INFO - downloader - image #2 https://static.independent.co.uk/s3fs-public/thumbnails/image/2018/11/24/16/cat.jpg INFO - downloader - image #3 https://images.wagwalkingweb.com/media/articles/cat/degeneration-iris-eye/degeneration-iris-eye.jpg INFO - downloader - image #4 https://www.pethealthnetwork.com/sites/default/files/content/images/my-cat-aggressive-fb-501276867.jpg INFO - downloader - image #5 http://s1.ibtimes.com/sites/www.ibtimes.com/files/2017/11/13/cat.jpg INFO - downloader - downloaded images reach max num, thread downloader-001 is ready to exit INFO - downloader - thread downloader-001 exit INFO - icrawler.crawler - Crawling task done!カレントディレクトリを確認
$ ls download 000001.jpg 000002.jpg 000003.jpg 000004.jpg 000005.jpg指定した名前のディレクトリがカレントに作成され、
画像が指定された枚数だけ猫の画像がダウンロードされている
猫ちゃん可愛い次にGoogleの検索エンジンをクローリング
google_sample.pyfrom icrawler.builtin import GoogleImageCrawler google_crawler = GoogleImageCrawler(storage={'root_dir': 'download'}) google_crawler.crawl(keyword='cat', max_num=5)$ python google_sample.py 2020-07-18 21:59:49,783 - INFO - icrawler.crawler - start crawling... 2020-07-18 21:59:49,783 - INFO - icrawler.crawler - starting 1 feeder threads... 2020-07-18 21:59:49,785 - INFO - feeder - thread feeder-001 exit 2020-07-18 21:59:49,785 - INFO - icrawler.crawler - starting 1 parser threads... 2020-07-18 21:59:49,787 - INFO - icrawler.crawler - starting 1 downloader threads... 2020-07-18 21:59:50,646 - INFO - parser - parsing result page https://www.google.com/search?q=cat&ijn=0&start=0&tbs=&tbm=isch Exception in thread parser-001: Traceback (most recent call last): File "/home/yossy/anaconda3/envs/py37/lib/python3.7/threading.py", line 926, in _bootstrap_inner self.run() File "/home/yossy/anaconda3/envs/py37/lib/python3.7/threading.py", line 870, in run self._target(*self._args, **self._kwargs) File "/home/yossy/anaconda3/envs/py37/lib/python3.7/site-packages/icrawler/parser.py", line 104, in worker_exec for task in self.parse(response, **kwargs): File "/home/yossy/anaconda3/envs/py37/lib/python3.7/site-packages/icrawler/builtin/google.py", line 157, in parse meta = json.loads(txt) File "/home/yossy/anaconda3/envs/py37/lib/python3.7/json/__init__.py", line 348, in loads return _default_decoder.decode(s) File "/home/yossy/anaconda3/envs/py37/lib/python3.7/json/decoder.py", line 337, in decode obj, end = self.raw_decode(s, idx=_w(s, 0).end()) File "/home/yossy/anaconda3/envs/py37/lib/python3.7/json/decoder.py", line 355, in raw_decode raise JSONDecodeError("Expecting value", s, err.value) from None json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0) 2020-07-18 21:59:54,788 - INFO - downloader - no more download task for thread downloader-001 2020-07-18 21:59:54,789 - INFO - downloader - thread downloader-001 exit 2020-07-18 21:59:54,792 - INFO - icrawler.crawler - Crawling task done!アイエエエ!?エラー!?エラーナンデ!?
どうやら、Googleの仕様変更の影響でparserが上手く働いていないらしい...
類似のエラーで困っている人が居るかどうか調べてみると、解決してるっぽい人を発見!
https://github.com/hellock/icrawler/issues/65
The following code works for me. Hope it could help you.
def parse(self, response): soup = BeautifulSoup( response.content.decode('utf-8', 'ignore'), 'lxml') #image_divs = soup.find_all('script') image_divs = soup.find_all(name='script') for div in image_divs: #txt = div.text txt = str(div) #if not txt.startswith('AF_initDataCallback'): if 'AF_initDataCallback' not in txt: continue if 'ds:0' in txt or 'ds:1' not in txt: continue #txt = re.sub(r"^AF_initDataCallback\({.*key: 'ds:(\d)'.+data:function\(\){return (.+)}}\);?$", # "\\2", txt, 0, re.DOTALL) #meta = json.loads(txt) #data = meta[31][0][12][2] #uris = [img[1][3][0] for img in data if img[0] == 1] uris = re.findall(r'http.*?\.(?:jpg|png|bmp)', txt) return [{'file_url': uri} for uri in uris]この修正をライブラリに取り込んでみる
icralwerのパスを確認
$ python -c 'import icrawler as ic;print(ic.__file__)' /home/yossy/anaconda3/envs/py37/lib/python3.7/site-packages/icrawler/__init__.py該当のコードを変更
$ cd /home/yossy/anaconda3/envs/py37/lib/python3.7/site-packages/icrawler/builtin $ vi google.py変更後の差分は以下になる
change.diffdiff --git a/google.py b/google.py index bfec04c..b46798a 100644 --- a/google.py +++ b/google.py @@ -141,24 +141,27 @@ class GoogleFeeder(Feeder): class GoogleParser(Parser): - def parse(self, response): - soup = BeautifulSoup( - response.content.decode('utf-8', 'ignore'), 'lxml') - image_divs = soup.find_all('script') - for div in image_divs: - txt = div.string - if txt is None or not txt.startswith('AF_initDataCallback'): - continue - if 'ds:1' not in txt: - continue - txt = re.sub(r"^AF_initDataCallback\({.*key: 'ds:(\d)'.+data:function\(\){return (.+)}}\);?$", - "\\2", txt, 0, re.DOTALL) - - meta = json.loads(txt) - data = meta[31][0][12][2] - - uris = [img[1][3][0] for img in data if img[0] == 1] - return [{'file_url': uri} for uri in uris] + def parse(self, response): + soup = BeautifulSoup( + response.content.decode('utf-8', 'ignore'), 'lxml') + #image_divs = soup.find_all('script') + image_divs = soup.find_all(name='script') + for div in image_divs: + #txt = div.text + txt = str(div) + #if not txt.startswith('AF_initDataCallback'): + if 'AF_initDataCallback' not in txt: + continue + if 'ds:0' in txt or 'ds:1' not in txt: + continue + #txt = re.sub(r"^AF_initDataCallback\({.*key: 'ds:(\d)'.+data:function\(\){return (.+)}}\);?$", + # "\\2", txt, 0, re.DOTALL) + #meta = json.loads(txt) + #data = meta[31][0][12][2] + #uris = [img[1][3][0] for img in data if img[0] == 1] + + uris = re.findall(r'http.*?\.(?:jpg|png|bmp)', txt) + return [{'file_url': uri} for uri in uris] class GoogleImageCrawler(Crawler):手で直すのは面倒くさいよーという人は上記のコードをコピーして
~/diff/diff.txt あたりにペーストして、以下のコマンドを実行$ patch < ~/diff/change.diffpatching file google.py patch unexpectedly ends in middle of line Hunk #1 succeeded at 141 with fuzz 1.と表示されればOK
Googleの検索エンジンのクローリングを再度試す
google_sample.pyfrom icrawler.builtin import GoogleImageCrawler google_crawler = GoogleImageCrawler(storage={'root_dir': 'download'}) google_crawler.crawl(keyword='cat', max_num=5)$ python google_sample.py 2020-07-20 23:50:31,295 - INFO - icrawler.crawler - start crawling... 2020-07-20 23:50:31,296 - INFO - icrawler.crawler - starting 1 feeder threads... 2020-07-20 23:50:31,298 - INFO - feeder - thread feeder-001 exit 2020-07-20 23:50:31,299 - INFO - icrawler.crawler - starting 1 parser threads... 2020-07-20 23:50:31,302 - INFO - icrawler.crawler - starting 1 downloader threads... 2020-07-20 23:50:32,330 - INFO - parser - parsing result page https://www.google.com/search?q=cat&ijn=0&start=0&tbs=&tbm=isch 2020-07-20 23:50:32,864 - INFO - downloader - image #1 https://ichef.bbci.co.uk/news/410/cpsprodpb/12A9B/production/_111434467_gettyimages-1143489763.jpg 2020-07-20 23:50:37,042 - INFO - downloader - image #2 https://icatcare.org/app/uploads/2018/07/Thinking-of-getting-a-cat.png 2020-07-20 23:50:37,252 - INFO - downloader - image #3 https://www.humanesociety.org/sites/default/files/styles/1240x698/public/2018/08/kitten-440379.jpg 2020-07-20 23:50:40,720 - INFO - downloader - image #4 https://cdnuploads.aa.com.tr/uploads/Contents/2020/05/14/thumbs_b_c_88bedbc66bb57f0e884555e8250ae5f9.jpg 2020-07-20 23:50:41,437 - INFO - downloader - image #5 https://news.cgtn.com/news/77416a4e3145544d326b544d354d444d3355444f31457a6333566d54/img/37d598e5a04344da81c76621ba273915/37d598e5a04344da81c76621ba273915.jpg 2020-07-20 23:50:41,846 - INFO - downloader - downloaded images reach max num, thread downloader-001 is ready to exit 2020-07-20 23:50:41,847 - INFO - downloader - thread downloader-001 exit 2020-07-20 23:50:42,313 - INFO - icrawler.crawler - Crawling task done!カレントディレクトリを確認
$ ls download 000001.jpg 000002.jpg 000003.jpg 000004.jpg 000005.jpgGoogleの検索エンジンのクローリングに成功!