- 投稿日:2020-02-20T23:37:47+09:00
言語処理100本ノック 00~09 解答
00
00.pys = "stressed" print(s[::-1])実行結果
desserts01
01.pys = "パタトクカシーー" print(s[::2])実行結果
パトカー02
02.pyret = '' s1 = 'パトカー' s2 = 'タクシー' s = ''.join([a + b for a, b in zip(s1, s2)]) print(s)実行結果
パタトクカシーー03
03.pys = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." s = s.replace(',','') s = s.replace('.', '') l = s.split() ret = [len(s) for s in l] print(ret)実行結果
[3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 9]04
04.pys = "Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can." i = 1 n = (0, 4, 5, 6, 7, 8, 14, 15, 18) d = {i: word[0:1] if i in n else word[0:2] for i, word in enumerate(s.split())} print(d)実行結果
{0: 'H', 1: 'He', 2: 'Li', 3: 'Be', 4: 'B', 5: 'C', 6: 'N', 7: 'O', 8: 'F', 9: 'Ne', 10: 'Na', 11: 'Mi', 12: 'Al', 13: 'Si', 14: 'P', 15: 'S', 16: 'Cl', 17: 'Ar', 18: 'K', 19: 'Ca'}05
05.pydef ngram(s, n): return [s[i:i+n] for i, _ in enumerate(list(s))] print(ngram("I am an NLPer", 2))実行結果
['I ', ' a', 'am', 'm ', ' a', 'an', 'n ', ' N', 'NL', 'LP', 'Pe', 'er', 'r']06
06.pydef ngram(s, n): return {s[i:i+n] for i, _ in enumerate(list(s))} s1 = "paraparaparadise" s2 = "paragraph" X = ngram(s1, 2) Y = ngram(s2, 2) print("X | Y :", X | Y) print("X & Y :", X & Y) print("X - Y :", X - Y) print("se" in X) print("se" in Y)実行結果
X | Y : {'ra', 'h', 'gr', 'pa', 'ph', 'ap', 'ar', 'ad', 'di', 'is', 'se', 'ag', 'e'} X & Y : {'pa', 'ap', 'ra', 'ar'} X - Y : {'ad', 'di', 'se', 'is', 'e'} True False07
07.pydef template(x, y, z): return str(x) + "時の" + y + "は" + str(z) print(template(x=12, y="気温", z=22.4))実行結果
'12時の気温は22.4'08
08.pydef cipher(s): return ''.join([chr(219-ord(s1)) if s1.islower() else s1 for s1 in s]) s = "Are you sure?" s_encrypted = cipher(s) print(s_encrypted)実行結果
Aiv blf hfiv?09
09.pyimport random def typoglycemia(s): return ' '.join([s1 if len(s1)<=4 else shuffle_string(s1) for s1 in s.split()]) def shuffle_string(s): return s[0] + ''.join(random.sample(s[1:-1], len(s[1:-1])))+ s[-1] s = "I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind ." print(typoglycemia(s))実行結果
I c'odulnt bievele that I colud aatcluly uasdnnertd what I was rdeaing : the poenhaenml poewr of the hamun mind .
- 投稿日:2020-02-20T22:54:42+09:00
Route53をAWS-CLIを使用してコマンドラインで操作する。
前提条件
・Windows端末(著者はwin10)
・Pythonインストール済行う事
AWS-CLIを使用してコマンドラインでRoute53にレコードをセットする
手順
pythonのバージョンの確認
pythonが入っているか確認(画像は3.8.1)
>python --version Python 3.8.1pipを使用して、AWS CLI をインストール
> pip3 install awscliパスの確認
where /R c:\ awsPathの設定
Windowsボタンを押して検索ボックスで「環境変数」と入力して検索し、上で表示されたPathを設定する
【例】表示結果:「c:[userdirectory]\Python\Python37\Scripts\aws」の場合
設定内容: c:[userdirectory]\Python\Python37\Scripts
※pythonインストール時にPATHを設定してくれるオプションもありました。AWS CLIのバージョンの確認
>aws --version aws-cli/1.18.3 Python/3.8.1 Windows/10 botocore/1.15.3IAMでユーザーを作成する
accessKeys.csvをダウンロードする。
認証情報の設定
> aws configure以下を入力する。
> AWS Access Key ID [None]:csvファイルのAccess key IDを入力 > Secret access key:csvファイルのSecret access keyを入力 > Default region name [None]: ap-northeast-1 > Default output format [None]:json実際にレコードセットしてみる
sample.jsonを作成する
{ "Comment": "CREATE/DELETE/UPSERT a record ", "Changes": [{ "Action": "CREATE", "ResourceRecordSet": { "Name": "a.example.com", "Type": "A", "TTL": 300, "ResourceRecords": [{ "Value": "4.4.4.4"}] }}] }コマンド change-resource-record-sets を使用し、ドメインのリソースレコードセットをホストゾーンに作成する。レコードを作成するための値は、sample.json ファイルで指定する。
コマンド実行
aws route53 change-resource-record-sets --hosted-zone-id ZXXXXXXXXXX --change-batch file://sample.jsonJSON ファイルにエラーがなければ、一意の ID とともにステータスとしてPENDING (保留中) が返される。
$ aws route53 change-resource-record-sets --hosted-zone-id ZXXXXXXXXXXX --change-batch file://sample.json { "ChangeInfo": { "Status": "PENDING", "Comment": "optional comment about the changes in this change batch request", "SubmittedAt": "2018-07-10T19:39:37.757Z", "Id": "/change/C3QYC83OA0KX5K" } }変更のステータスを確認するには、API コール get-change で change-resource-record-sets レスポンスの Id 値を使用します。
aws route53 get-change --id /change/C3QYC83OA0KX5K・PENDING (保留中) は、このリクエストの変更が、まだサーバーには伝播済みでないことを示す。
・INSYNC (同期中) は、変更がサーバーに伝播済みであることを示す。
- 投稿日:2020-02-20T22:47:38+09:00
einsum(アインシュタインの縮約記法)による多次元配列の掛け算
einsumを使うと多次元配列の掛け算が簡単に行えます。
記述方法には、癖がありますが、覚えてしまえば難しくありません。
einsumには、他にもいろいろな演算を行うことができますが、ここでは、多次元配列の掛け算について書きます。2次元配列
アダマール積
各要素の積
\begin{pmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ \end{pmatrix} × \begin{pmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ \end{pmatrix} = \begin{pmatrix} 1 & 4 & 9 \\ 16 & 25 & 36 \\ \end{pmatrix}x = np.array([[1.,2.,3.],[4.,5.,6.]]) y = np.array([[1.,2.,3.],[4.,5.,6.]])演算子
x*yarray([[ 1., 4., 9.], [16., 25., 36.]])ループ
要素ごとに計算すると、以下のようになります。
# 要素ごとに計算 z = np.zeros((2,3)) for i in range(2): for j in range(3): z[i,j] += x[i,j] * y[i,j] zarray([[ 1., 4., 9.], [16., 25., 36.]])einsum
for文中の計算式の以下の部分の添え字をそのまま書けば良いです。
z[i,j] += x[i,j] * y[i,j]
上の例では、以下のように書きます。
xの添え字,yの添え字->zの添え字
(添え字に利用する文字な何でも構いません。)# einsumで計算 np.einsum("ij,ij->ij", x, y)同じ結果になりました。
array([[ 1., 4., 9.], [16., 25., 36.]])内積
\begin{pmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ \end{pmatrix} \begin{pmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \\ \end{pmatrix} = \begin{pmatrix} 38 & 44 & 50 & 56 \\ 83 & 98 & 113 & 128 \\ \end{pmatrix}x = np.array([[1.,2.,3.],[4.,5.,6.]]) y = np.array([[1.,2.,3.,4.],[5.,6.,7.,8.],[9.,10.,11.,12.]])演算
2次元の配列では、np.dotまたはnp.matmulで内積を計算できます。
dot
# ドット積で計算 np.dot(x, y)array([[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]])matmul
# matmulで計算 np.matmul(x, y)array([[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]])ループ
# 要素ごとに計算 z = np.zeros((2,4)) for i in range(3): for j in range(2): for k in range(4): z[j,k] += x[j,i] * y[i,k] zarray([[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]])einsum
for文中の計算式の添え字をそのまま書けばよいのでした。
z[j,k] += x[j,i] * y[i,k]# einsumで計算 np.einsum("ji,ik->jk", x, y)array([[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]])3次元配列
2次元配列のバッチ処理を考えます。
バッチの次元が、1次元目の場合の内積
x = np.array([[[1.,2.,3.],[4.,5.,6.]],[[1.,2.,3.],[4.,5.,6.]]]) print("x.shape=", x.shape) print("x=") print(x)x.shape= (2, 2, 3) x= [[[1. 2. 3.] [4. 5. 6.]] [[1. 2. 3.] [4. 5. 6.]]]y = np.array([[[1.,2.,3.,4.],[5.,6.,7.,8.],[9.,10.,11.,12.]],[[1.,2.,3.,4.],[5.,6.,7.,8.],[9.,10.,11.,12.]]]) print("y.shape=", y.shape) print("y=") print(y)y.shape= (2, 3, 4) y= [[[ 1. 2. 3. 4.] [ 5. 6. 7. 8.] [ 9. 10. 11. 12.]] [[ 1. 2. 3. 4.] [ 5. 6. 7. 8.] [ 9. 10. 11. 12.]]]内積の結果は、以下となります。
array([[[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]], [[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]]])演算
dot
# ドット積で計算 np.dot(x, y)array([[[[ 38., 44., 50., 56.], [ 38., 44., 50., 56.]], [[ 83., 98., 113., 128.], [ 83., 98., 113., 128.]]], [[[ 38., 44., 50., 56.], [ 38., 44., 50., 56.]], [[ 83., 98., 113., 128.], [ 83., 98., 113., 128.]]]])正しく計算できませんでした。
matmul
バッチが1次元目の場合、np.matmulで計算できます。
# matmulで計算 np.matmul(x, y)array([[[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]], [[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]]])ループ
# 要素ごとに計算 z = np.zeros((2,2,4)) for i in range(2): for j in range(3): for k in range(2): for l in range(4): z[i,k,l] += x[i,k,j] * y[i,j,l] zarray([[[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]], [[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]]])einsum
3次元でも同じです。for文中の計算式の添え字をそのまま書きます。
z[i,k,l] += x[i,k,j] * y[i,j,l]# einsumで計算 np.einsum("ikj,ijl->ikl", x, y)array([[[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]], [[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]]])バッチの次元が、2次元目の場合の内積
RNNなどで、バッチの次元を2次元目としたい場合があります。
xt = x.transpose(1,0,2) print("xt.shape=", xt.shape) print("xt=") xtxt.shape= (2, 2, 3) xt= array([[[1., 2., 3.], [1., 2., 3.]], [[4., 5., 6.], [4., 5., 6.]]])yt = y.transpose(1,0,2) print("yt.shape=", yt.shape) print("yt=") ytyt.shape= (3, 2, 4) yt= array([[[ 1., 2., 3., 4.], [ 1., 2., 3., 4.]], [[ 5., 6., 7., 8.], [ 5., 6., 7., 8.]], [[ 9., 10., 11., 12.], [ 9., 10., 11., 12.]]])内積の結果は、以下となります。
array([[[ 38., 44., 50., 56.], [ 38., 44., 50., 56.]], [[ 83., 98., 113., 128.], [ 83., 98., 113., 128.]]])演算
dot
# ドット積で計算 np.dot(xt, yt)ValueError Traceback (most recent call last) <ipython-input-24-a174c5fa02ae> in <module> 1 # ドット積で計算 ----> 2 np.dot(xt, yt) <__array_function__ internals> in dot(*args, **kwargs) ValueError: shapes (2,2,3) and (3,2,4) not aligned: 3 (dim 2) != 2 (dim 1)エラーとなりました。
matmul
# matmulで計算 np.matmul(xt, yt)--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-25-281cba2a720e> in <module> 1 # matmulで計算 ----> 2 np.matmul(xt, yt) ValueError: matmul: Input operand 1 has a mismatch in its core dimension 0, with gufunc signature (n?,k),(k,m?)->(n?,m?) (size 2 is different from 3)こちらもエラーとなりました。
ループ
# 要素ごとに計算 zt = np.zeros((2,2,4)) for i in range(2): for j in range(3): for k in range(2): for l in range(4): zt[k,i,l] += xt[k,i,j] * yt[j,i,l] ztarray([[[ 38., 44., 50., 56.], [ 38., 44., 50., 56.]], [[ 83., 98., 113., 128.], [ 83., 98., 113., 128.]]])結果を転置し、バッチを1次元目とすると結果が同じとなります。
zt.transpose(1,0,2)array([[[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]], [[ 38., 44., 50., 56.], [ 83., 98., 113., 128.]]])einsum
for文中の計算式の添え字をそのままですね。
zt[k,i,l] += xt[k,i,j] * yt[j,i,l]# einsumで計算 np.einsum("kij,jil->kil", xt, yt)array([[[ 38., 44., 50., 56.], [ 38., 44., 50., 56.]], [[ 83., 98., 113., 128.], [ 83., 98., 113., 128.]]])このようにeinsumを利用すれば、簡単に多次元配列の演算を行うことができます。
転置やtransposeにより変換を行い計算することもできますが、einsumを利用すればそのまま計算することができます。
einsumでは演算に時間がかかる場合もあるようなので、もし、性能的に問題なければ、einsumを利用すれば非常にシンプルに記述することができます。
- 投稿日:2020-02-20T22:39:20+09:00
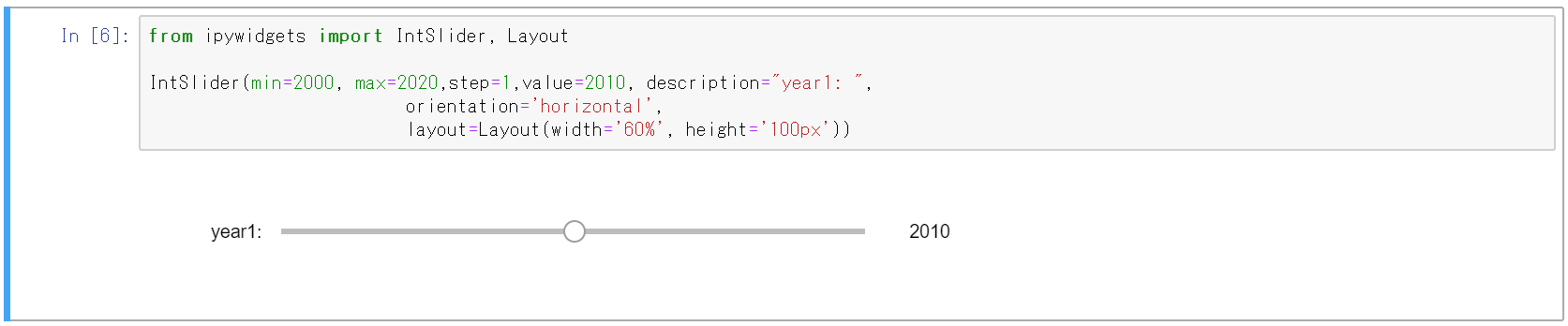
ipywidgetsでウィジェットのスタイルやレイアウトを調整する
JupyterでインタラクティブなGUI作ろうとしたけど、スライダーの幅が小さくて使いづらかったり、複数のコントロールを配置する方法が分からなかったりしたので調べてみた。
ウィジェットのスタイルの調整
CSSライクな記述でスタイルを調整できます
基本形
幅が狭く操作しづらいので、いろいろ調整したい
from ipywidgets import IntSlider IntSlider(min=2000, max=2020,step=1,value=2010, description="year1: ")
幅と高さを変えてみる
幅を60%指定、高さを100px指定にします。
from ipywidgets import IntSlider, Layout IntSlider(min=2000, max=2020,step=1,value=2010, description="year1: ", orientation='horizontal', layout=Layout(width='60%', height='100px'))
Borderもつけてみる
ついでに枠線もつけてみます。
from ipywidgets import IntSlider, Layout IntSlider(min=2000, max=2020,step=1,value=2010, description="year1: ", orientation='horizontal', layout=Layout(width='60%', height='100px', border='solid'))
その他スタイルの調整
ウィジェットごとに固有なスタイルもあります。
例えば、スライダーのハンドルに色をつけることができる。from ipywidgets import IntSlider year1 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year1: ") year1.style.handle_color = 'lightblue' year1ハンドルが薄い青色になりました。
利用可能なスタイルは以下で確認できる。
year1.style.keys
他にもいろいろなスタイルを調整できます。
公式ドキュメントに利用可能なスタイルが記載されています。
Layout and Styling of Jupyter widgets — Jupyter Widgets 7.5.1 documentationレイアウトを変える
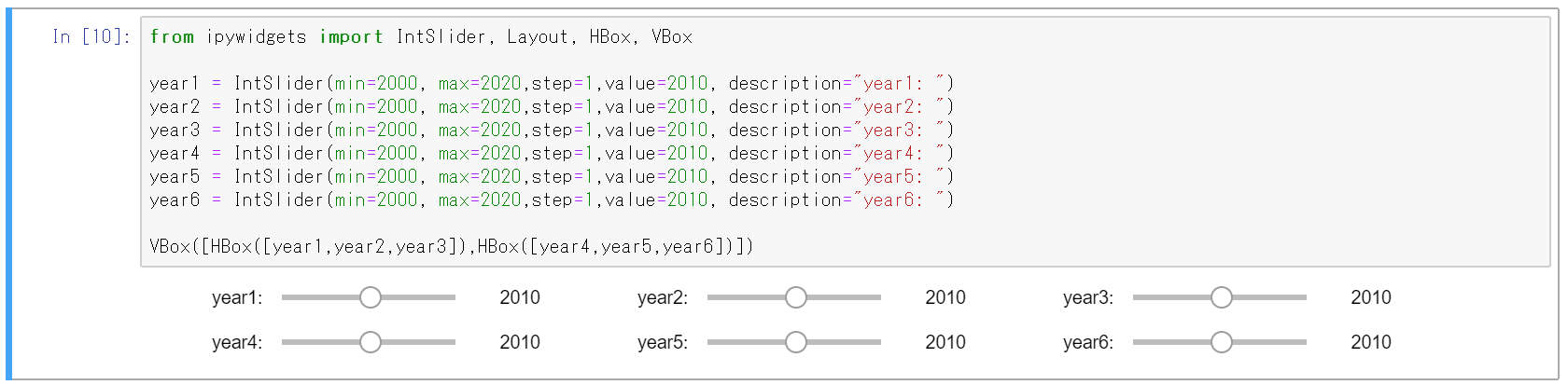
複数のウィジェットがある場合に、レイアウトにそって並べることもできます。
横と棚に並べる
横方向のコンテナ(HBox)、縦方向のコンテナ(VBox)にウィジェットを配置できる。
from ipywidgets import IntSlider, Layout, HBox, VBox year1 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year1: ") year2 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year2: ") year3 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year3: ") year4 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year4: ") year5 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year5: ") year6 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year6: ") VBox([HBox([year1,year2,year3]),HBox([year4,year5,year6])])
2×2で並べる
2×2のレイアウトでウィジェットを配置できます。
from ipywidgets import IntSlider, TwoByTwoLayout year1 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year1: ") year2 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year2: ") year3 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year3: ") year4 = IntSlider(min=2000, max=2020,step=1,value=2010, description="year4: ") TwoByTwoLayout(top_left=year1, top_right=year2, bottom_right=year3, bottom_left=year4)
グリッドに並べる
n × mの任意のサイズのグリッドにウィジェットを配置できます。
from ipywidgets import IntSlider, GridspecLayout grid = GridspecLayout(2, 3) grid[0,0] = IntSlider(min=2000, max=2020,step=1,value=2010, description="year1-1: ") grid[0,1] = IntSlider(min=2000, max=2020,step=1,value=2010, description="year1-2: ") grid[0,2] = IntSlider(min=2000, max=2020,step=1,value=2010, description="year1-3 ") grid[1,0] = IntSlider(min=2000, max=2020,step=1,value=2010, description="year2-1: ") grid[1,1] = IntSlider(min=2000, max=2020,step=1,value=2010, description="year2-2: ") grid[1,2] = IntSlider(min=2000, max=2020,step=1,value=2010, description="year2-3: ") grid
他のレイアウト
公式サイトの以下のドキュメントに記載があります。
アプリ風のApp Layoutなども使えます。
Using Layout Templates — Jupyter Widgets 7.5.1 documentationまとめ
Jupyter使う場合は、凝ったUI作りこむ必要はないけど、コントロールを使いやすくしたり、ちょっとだけ見た目よくすると、より使いやすいと思います。
そういうことやりたい方の参考になればうれしいです。




- 投稿日:2020-02-20T22:34:47+09:00
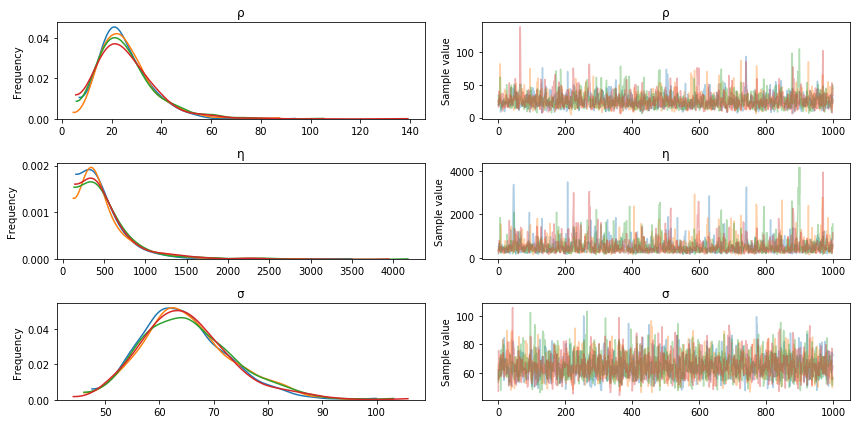
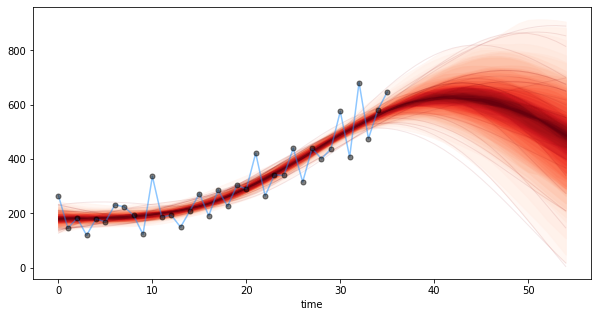
機械学習のアルゴリズム(勾配降下法)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
今回は、損失関数のパラメータ最適化の手法である勾配降下法について。数学的に解が見つかる場合はよいが、世の中そういう場合の方が少ない。最適値を探索する手法としていろんな勾配方があるが、いくつかをコードを交えてまとめてみたい。例によって参考にしたサイトは以下です。ありがとうございます。
- 確率的勾配降下法のメリットについて考えてみた
- OPTIMIZER 入門 ~線形回帰からAdamからEveまで
- 確率的勾配降下法とは何か、をPythonで動かして解説する
- 初歩からの機械学習:最急降下法による重回帰モデル~PythonとRでスクラッチから~
勾配法について
Wikipediaによると、勾配法とは
勾配法(こうばいほう、Gradient method)は、最適化問題において、関数の勾配に関する情報を解の探索に用いるアルゴリズムの総称。
と書いてある。単回帰では、$$ y = Ax+B $$という関数で近似させるために、損失関数$E$を残差の二乗和 $$ E = \sum_{i=0}^{N}(y_i - (Ax_i -B))^2 $$として、$E$を最小化するような$A$と$B$を求めた。この例では数学的に$A$と$B$を求めることができるのだが、損失関数がもっと複雑な場合であっても、最小となる(であろう)点を探すアプローチが勾配降下法である。
お題
例によってscikit-learnのdiabetes(糖尿病データ)を使います。
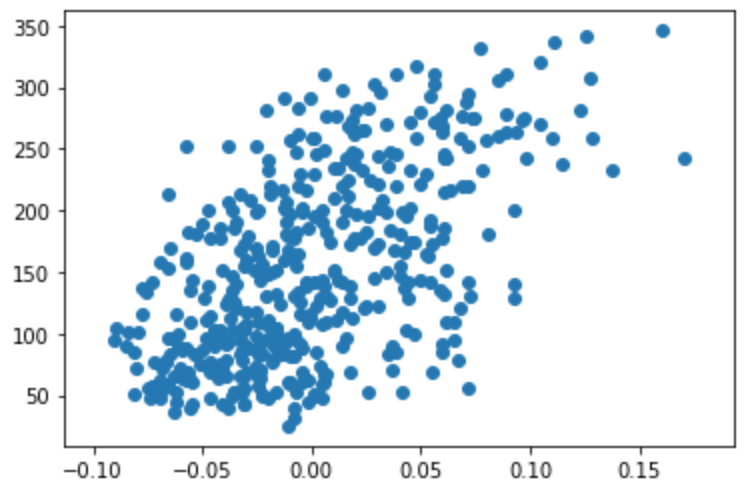
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets diabetes = datasets.load_diabetes() df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names) x = df['bmi'].values y = diabetes.target plt.scatter(x, y)
数学的に解いたときの傾きと切片はそれぞれ
傾きA: 949.43526038395 切片B: 152.1334841628967でした。
最急勾配降下法
最急降下法(Steepest Gradient Descent)は、損失関数上のある点での勾配ベクトルと逆方向に少しずつ進んでいくというアイデアです。傾きを$\nabla E$とし、$$ E_{t+1}=E_{t} - \eta\nabla E_{t} $$を計算していきます。なお、$\eta$は学習率と呼ばれ、どの程度ゆっくり進んでいくかというものです。これが大きいと解が収束せずに発散してしまいます。
損失関数$$ E = \sum_{i=0}^{N}(y_i - (Ax_i -B))^2 $$について、$A$と$B$を求めるためには、$E$を$A$と$B$それぞれについて偏微分します。($\sum$の添え字は省略)
\frac{\partial{E}}{\partial{A}}=\sum(-2x_iy_i+2Ax_i^2+2Bx_i) \\ =-2\sum(Ax_i+B-y_i)x_i \\ \frac{\partial{E}}{\partial{B}}=\sum(-2x_iy_i+2Ax_i+2B) \\ =-2\sum(Ax_i+B-y_i) \\となる。初期値を適当に決め、上の式を使って$A$と$B$を勾配方向に変化させていき、ほどよい段階で計算を打ち切ればよいことになる。
初期値の決め方、学習率の決め方、計算を打ち切る条件についてはさらなる考察が必要だが概略はこういうことだ。
pythonでの実装
最急降下法を実現するSteepestGradientDescentクラスを作成した。メソッドはなんとなくscikit-learnにあわせてみた。学習率は適当で、誤差が十分小さくなったらではなく回数で打ち切りとした。
class SteepestGradientDescent: def __init__(self, eta=0.001, n_iter=2000): self.eta = eta self.n_iter = n_iter self.grad = np.zeros((2,)) self.loss = np.array([]) def fit(self, X, Y, w0): self.w = w0 for _ in range(self.n_iter): self.loss = np.append(self.loss, np.sum((Y-self.w[0]-self.w[1]*X)**2)) self.grad[0] = np.sum(-2*(Y-self.w[0]-self.w[1]*X)) self.grad[1] = np.sum(-2*X*(Y-self.w[0]-self.w[1]*X)) self.w -= self.eta * self.grad def predict(self, x): return (self.w[0] + self.w[1]*x) @property def coef_(self): return self.w[1] @property def intercept_(self): return self.w[0] @property def loss_(self): return self.lossfitメソッドの中で全データに対して勾配を算出し、係数を更新している。損失関数の値も同時に保存して、学習がどういう風に進んでいるかわかるようにした。
このクラスを使って糖尿病データに近似させ、損失の変化をグラフにプロットしてみる。
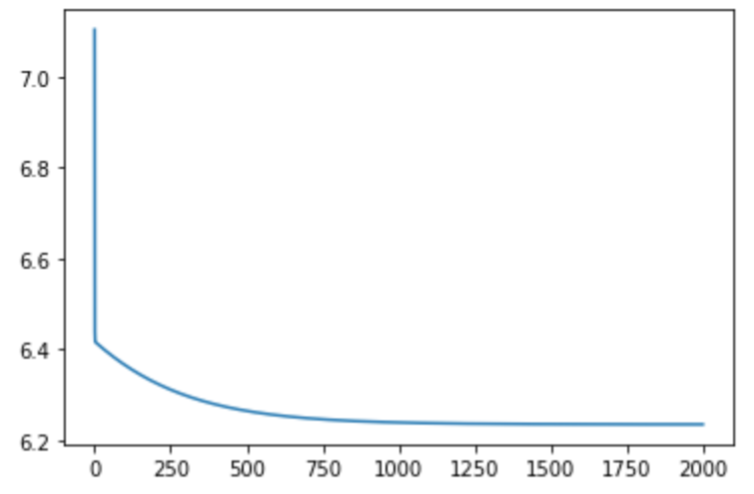
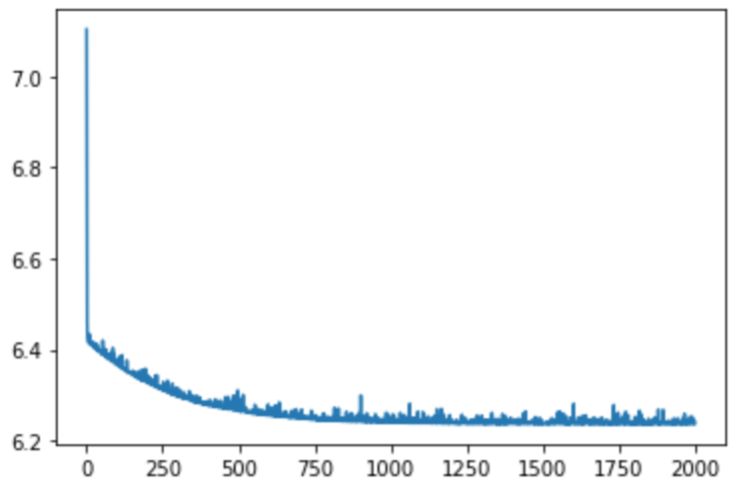
w0 = np.array([1.,1.]) model = SteepestGradientDescent() model.fit(x, y, w0) print("A: ", model.coef_) print("B: ", model.intercept_) loss = model.loss plt.plot(np.arange(len(loss)), np.log10(loss)) plt.show() A: 932.1335010668406 B: 152.13348416289668
数学的に解いた値と一緒になりました。損失が減っていく様子もみることができますね。
確率的勾配降下法
最急降下法は、サンプル全てを使って勾配を計算しました。確率的勾配降下法では、シャッフルしたデータを1つ〜複数使ってパラメータを更新します。複数使う方法をミニバッチ学習とも言います。
こうすると何がいいかという話なんですが、損失関数は形によって極小値を複数持つことがあります。地形を思い出して欲しいんですが、見えてる谷が一番低いとは限らず、山を越えたらもっと深い谷が見つかることもあります。この一見正しそうだけどそうではない谷底を局所解、もっと低い谷底のことを大域解と呼びます。
最急降下法は初期値の選び方で局所解におちいり易いのですが、確率的勾配降下法はパラメータ更新のたびに勾配計算に使うデータを選び直すので、低い山を越えて大域解にたどり着く可能性が高くなるそうです。
さらに、使うデータが決まっている必要がないのでリアルタイムの処理に向いてるとのことです。
pythonでの実装
先ほどと同じようにStochasticGradientDescentクラスを作りました。中身はパラメータの更新部分以外はほとんど最急降下法と同じです。ミニバッチのサイズは全データに対してどれくらい使うか指定できるようにしました。損失が最低だったパラメータを記憶しておき、それを返すようにしています。
class StochasticGradientDescent: def __init__(self, eta=0.01, n_iter=2000, sample_rate=0.1): self.eta = eta self.n_iter = n_iter self.sample_rate = sample_rate self.grad = np.zeros((2,)) self.loss = np.array([]) def fit(self, X, Y, w0): self.w = w0 self.min_w = w0 n_samples = int(np.ceil(len(X)*self.sample_rate)) min_loss = 10**18 for _ in range(self.n_iter): loss = np.sum((Y-self.w[0]-self.w[1]*X)**2) if min_loss>loss: min_loss = loss self.min_w = self.w self.loss = np.append(self.loss, loss) for i in range(n_samples): index = np.random.randint(0, len(X)) batch_x = X[index] batch_y = Y[index] self.grad[0] = np.sum(-2*(batch_y-self.w[0]-self.w[1]*batch_x)) self.grad[1] = np.sum(-2*batch_x*(batch_y-self.w[0]-self.w[1]*batch_x)) self.w -= self.eta * self.grad def predict(self, x): return (self.w[0] + self.w[1]*x) @property def coef_(self): return self.min_w[1] @property def intercept_(self): return self.min_w[0] @property def loss_(self): return self.lossこれを実行して、損失の変化も合わせて見てみる。
w0 = np.array([1.,1.]) model = StochasticGradientDescent() model.fit(x, y, w0) print("A: ", model.coef_) print("B: ", model.intercept_) loss = model.loss plt.plot(np.arange(len(loss)), np.log10(loss)) plt.show() A: 925.5203159922469 B: 146.8724188770836
少し厳密解とは異なるのと、少し損失が暴れる感じですね。学習率を低くするとスパイクの高さが低くなるのと、ランダムサンプリングしている関係か、もとのサンプルの相関が低いと厳密解に収束しないのかなと思いました。この辺のパラメータのチューニングは課題ですね。
まとめ
勾配降下法として、最急降下法と買う率的勾配降下法について調べてみました。scikit-learnやディープラーニングの世界ではこれ以外でも様々な勾配方があるんですが、基本は一緒です。こうして順を追って見ていくことで、パラメータのチューニングについても想像がつきやすくなるかもしれません。
次回は回帰の総まとめと過学習や正則化あたりをまとめてみたいと思います。
- 投稿日:2020-02-20T22:27:49+09:00
google images download が 100件以上の画像取れない問題の解決
以下を参考にしてサンプル画像大量ゲットできました
google image downloadが動かなかったのでその対応
よーしおじさん教師データつくっちゃうぞ、100件だと心もとないから1000件くらい画像ほしいな
ということでデバッグしました
Pythonさわったの今日がはじめてなんですけど解決できてよかった!
修正版は以下にあります
https://github.com/kituneponyo/google-images-download
俺としたことがgithubでforkしてプルリクまで投げてしまった、github童貞を捨ててしまった
- 投稿日:2020-02-20T22:16:43+09:00
機械学習と数理最適化
機械学習と数理最適化
「コンビニのお店×商品ごとに需要予測がしたいんです」
→ 機械学習/統計モデリングっぽい話「コンビニのお店×商品ごとに需要予測に基づいて利益の最大化をしたいんです」
→ 数理最適化っぽい話意思決定のステップとアナリティクスの到達段階
データサイエンス/AI/アナリティクスといってもレベルは様々である
意思決定のステップ
①集計(何が起きるのか)
②説明(何故起きたのか)
③予測(何が起きるのか)
④意思決定(何をすればいいのか)
⑤行動(実際の行動)アナリティクスの到達段階
①記述的アナリティクス
②診断的アナリティクス
③予測的アナリティクス
④処方的アナリティクス(AIによる意思決定支援)
⑤処方的アナリティクス(AIによる意思決定)一般的に
①集計(何が起きるのか) DWH/BIツールで行う
①記述的アナリティクス②説明(何故起きたのか)や③予測(何が起きるのか)までを機会学習/統計解析が行う
①記述的アナリティクス
②診断的アナリティクス
③予測的アナリティクス④意思決定(何をすればいいのか)や⑤行動(実際の行動)を数理最適化によって行う
①記述的アナリティクス
②診断的アナリティクス
③予測的アナリティクス
④処方的アナリティクス(AIによる意思決定支援)
⑤処方的アナリティクス(AIによる意思決定)機械学習vs数理最適化
タスク システムへの入力 システムのメカニズム システムの出力 典型的な技術 予測・推定 ⭕️ 不明→推定 ⭕️ 機械学習・統計学 最適化 最良のものは不明→探索 ⭕️ 最小化・最大化したい 数理最適化 どこまでできるか?
説明 予測 意思決定支援 意思決定 株トレード(DayTrading) ○ ○ ○ ○(HFT) スーパーの購買計画 ○ ○(需要予測) ○(最適購買) ○ 建築機材のレンタル ○ ○(需要予測) ○(支店間の機材配備の最適化) ○/?(支店間のインセンティブの対立) コモディティトレード ○ ○(価格予測) ○(売買タイミング示唆) ?(政治リスクの評価) 農業 ○ ○(収穫予想) ○(肥料最適化)/?(販売計画) ? M&A ○ ?(高い個別性) ? ? 課題・オペレーション依存になりやすい
参考
DWHとBIツール
https://it-trend.jp/bi/article/bi_dwh
- 投稿日:2020-02-20T21:51:12+09:00
基本的な機械学習の手順:②データを準備しよう
はじめに
前回、基本的な機械学習の手順:①分類モデルで、本当に基本的な分類モデルの作成手順を整理しました。
ただ、データを準備するところは、端折ってしまっていました。そこで、今回はBigQueryを使って下記のようなテーブルを作成し、Python環境に取り込むまでの手順を整理していきたいと思います。
id result product1 product2 product3 product4 product5 001 1 2500 1200 1890 530 null 002 0 750 3300 null 1250 2000 分析環境
Google BigQuery
Google Colaboratory対象とするデータ
下記の様なテーブル構造で購買データが格納されています。
id 店舗名 購入日 購入商品 購入金額 購入個数 001 〇〇店 2020-01-10 product1 2500 1 002 ☓☓店 2020-01-10 product1 750 3 002 ☓☓店 2020-01-10 product2 1000 2 テーブル名は、BQ上で次のようになっています。(日別でテーブル分け)
myproject.mydataset.transaction_年月日項目名は、残念ながら日本語ではつけられませんが、わかりやすくするためにここでは日本語にしています。
それぞれの環境に合わせて名称を変えてください。1.BigQuery上でやること
BigQuery上でやることと書いていますが、実際の操作は全てPython(Google Colaboratory)から行っています。ちゃんと、何の処理をしたかを記録に残す意味でも、Notebookは重宝しますし。
ColaboratoryからBigQueryを操作するには、次の2行で簡単に認証できます。
URLが表示されたら自身のアカウントでアクセスして、ワンタイムパスワードを発行し、Notebookに表示されたセルに貼り付けましょう。from google.colab import auth auth.authenticate_user()1-1.購買データの加工
それでは、実際に元の購買データから人別・商品別に集計する処理を進めていきましょう。
# ここでは2020年1月を対象期間とします from_day = "20200101" to_day = "20200131" query=f""" SELECT id, 購入商品, SUM(購入金額) AS 合計金額 FROM `myproject.mydataset.transaction_*` WHERE _table_suffix between `{from_day}` and `{to_day}` """ # 出力するプロジェクト・データセット・テーブル名 project = "myproject" client = bigquery.Client(project=project) dataset = "mydataset" ds = client.dataset(dataset ) table = "tmp" job_config = bigquery.QueryJobConfig() job_config.destination = ds.table(table) job_config.write_disposition="WRITE_TRUNCATE" #テーブルに上書きする場合。追加する場合は"WRITE_APPEND" job_config.allow_large_results=True #大規模な結果を許可するか。基本はTrue job_config.use_legacy_sql=False #レガシーSQLを使うか。基本はFalse job = client.query(query, job_config=job_config) result = job.result()これで、何も出ずに実行が完了したら、myproject.mydataset.tmpに実行結果が出力されています。
job_configでの設定が少々面倒ですが、最初はそれぞれが何の設定をしているのか意識しながら書いておきましょう。(慣れたらコピペでOK)ここまで実行すると、次のようなテーブルになっています。
id 購入商品 合計金額 001 product1 2500 001 product2 1200 002 product1 750 002 product2 3300 1-2.人別テーブルへ加工
次に、機械学習のモデルに読み込むために、id × 購入金額のPivotTableを作成したいと思います。
PythonでPandasを使えば、pivot_tableが使えて楽なのですが、対象の期間等によっては、データサイズが数GBや数十GBあり、データ取り込みや加工に余計な時間がかかるので、PivotTable化までをBigQueryでやっています。
new_columns=[] # 横持ちする「購入商品」の一覧を作成して、Dataframe化 new_column="購入商品" query = f'SELECT DISTINCT {new_column} FROM `{project}.{dataset}.{tmp}` ORDER BY {new_column}' df_product = client.query(query).to_dataframe() ## 購入商品のDataframeをループして、横持ちするSQLを自動生成 for index, row in df_product.iterrows(): item_frag = [] condition_frag = [] for i, v in zip(row.index, row.values): formula=f"{i}='{v}'" condition_frag.append(formula) item_frag.append(v) item=''.join(item_frag) condition=' AND '.join(condition_frag) query_frag = f'SUM(IF(({condition}),"購入金額",0)) AS {new_column}_{item}' new_columns.append(query_frag) # new_columnsというListをquery_partsという文字列に変更 query_parts = ',\n'.join(new_columns) query = f'SELECT id + query_parts + FROM `{project}.{dataset}.{tmp}` GROUP BY id' # 出力先のテーブル名 table2="pivoted_table" # BigQueryの実行は同上 job_config = bigquery.QueryJobConfig() job_config.destination = ds.table(table2) job_config.write_disposition="WRITE_TRUNCATE" #テーブルに上書きする場合。追加する場合は"WRITE_APPEND" job_config.allow_large_results=True #大規模な結果を許可するか。基本はTrue job_config.use_legacy_sql=False #レガシーSQLを使うか。基本はFalse job = client.query(query, job_config=job_config) result = job.result()Pivot TableのSQLを作るところの処理が、2重でループしていて少しややこしいですが、作りたいのは次のSQLです。
SELECT id, SUM(IF((購入商品='product1'),購入金額,0)) AS 購入商品_product1, SUM(IF((購入商品='product2'),購入金額,0)) AS 購入商品_product2, SUM(IF((購入商品='product3'),購入金額,0)) AS 購入商品_product3, ... FROM `myproject.mydataset.tmp` GROUP BY idテーブルをPivot化する定番のSQLですが、これのSUM(IF(~))部分を、商品数に応じて自動で作成するようにしています。
ここまで実行すると、次のテーブルがmyproject.mydataset.pivoted_tableとして保存されています。
id product1 product2 product3 product4 product5 001 2500 1200 1890 530 null 002 750 3300 null 1250 2000 2.Pythonの環境への取り込み
最後に、BigQueryで作成したデータをPython環境にPandas Dataframeで取り込みます。
とはいえ、Pivot化の途中で既にDataframeで取り込んでいるので、プログラムを書くのも今更ですね。。。query = f'SELECT * FROM `{project}.{dataset}.{table2}`' df = client.query(query).to_dataframe()おわりに
「基本的な機械学習の手順」と言いながら、今回はBigQueryでの操作に終始しました。
Colaboratoryからは、認証が簡単にできるため、BigQueryの操作へのハードルも低く感じますね。BigQueryは今でも十分パワフルですが、日々新たな機能がリリースされています。上手く新たな機能を使いこなしていきたいですね。
- 投稿日:2020-02-20T21:16:05+09:00
ssh先でjupyter notebookを立てる方法
- 自分用メモ
- このページに従ってやったら出来た
- AWSのEC2でjupyter notebookをたてた https://ljvmiranda921.github.io/notebook/2018/01/31/running-a-jupyter-notebook/
- 投稿日:2020-02-20T21:16:05+09:00
ssh先(AWS EC2)でjupyter notebookを立てる方法
- 自分用メモ
- このページに従ってやったら出来た
- AWSのEC2でjupyter notebookをたてた https://ljvmiranda921.github.io/notebook/2018/01/31/running-a-jupyter-notebook/
- 投稿日:2020-02-20T21:06:18+09:00
Analyzing Twitter Data | Trend Analysis編
この記事はTwitter Dataの分析のtrend分析編である。このseriesは後で深めていく。初めての記事なので、簡単にTwitter Dataの分析をしたら、詳しくこのcaseを説明します。日本語がきついから、英語にします。Git Repository
Why Analyze Twitter Data?
Twitter data analysis is used in a wide range of areas including but not restricted to analyzing the mentions of each political party in an election, detecting the reactions to the introduction of a new product, understanding the geographical scope of discussion of a news story.
How to analyze twitter data?
Twitter data can be retrieved from twitter API. Data can be wrangled and manipulated according to the purpose of analysis. For example, if we need to get insights on a certain product from twitter data, there're a few strategies we can apply:
- Collect mentions of the product and identify if people are talking about it positively. press
- Examine the size of the retweet network mentioning the product.
- Analyzing the geographical penetration of users mentioning the product. press
Collecting data via twitter API
This is a slightly complicated procedure if it's your first time to use twitter API. Here I'm going to explain how to collect data through twitter API.
- Log in your twitter account
- Apply for a developer account. Apply Here!
- Create a new application.
- Go to the application and find keys and tokens. (We'll need them later for authentication purposes.)
Authentication
from tweepy import OAuthHandler from tweepy import API import json consumer_key = ... consumer_secret = ... access_token = ... access_token_secret = ... # Consumer key authentication auth = OAuthHandler(consumer_key, consumer_secret) # Access key authentication auth.set_access_token(access_token, access_token_secret) # Set up the API with the authentication handler api = API(auth)Getting the trend
Here I'm gonna use UK as an example. Information regarding WOE ID can be found here.
UK_WOE_ID = 23424975 UK_trends = api.trends_place(UK_WOE_ID) trends = json.loads(json.dumps(UK_trends, indent=1))Local and global thought patterns
# Loading json module import json # Load WW_trends and US_trends data into the the given variables respectively WW_trends = json.loads(open('datasets/WWTrends.json').read()) US_trends = json.loads(open('datasets/USTrends.json').read()) # Inspecting data by printing out WW_trends and US_trends variables print(WW_trends) print(US_trends)Prettifying the output
# Pretty-printing the results. First WW and then US trends. print("WW trends:") print(json.dumps(WW_trends, indent=1)) print("\n", "US trends:") print(json.dumps(US_trends, indent=1))Finding common trends
# Extracting all the WW trend names from WW_trends world_trends = set([trend['name'] for trend in WW_trends[0]['trends']]) # Extracting all the US trend names from US_trends us_trends = set([trend['name'] for trend in US_trends[0]['trends']]) # Getting the intersection of the two sets of trends common_trends = world_trends.intersection(us_trends) # Inspecting the data print(world_trends, "\n") print(us_trends, "\n") print (len(common_trends), "common trends:", common_trends)Exploring the hot trend
# Loading the data tweets = json.loads(open('datasets/WeLoveTheEarth.json').read()) # Inspecting some tweets tweets[0:2]Digging deeper
# Extracting the text of all the tweets from the tweet object texts = [tweet['text'] for tweet in tweets] # Extracting screen names of users tweeting about #WeLoveTheEarth names = [user_mention['screen_name'] for tweet in tweets for user_mention in tweet['entities']['user_mentions']] # Extracting all the hashtags being used when talking about this topic hashtags = [hashtag['text'] for tweet in tweets for hashtag in tweet['entities']['hashtags']] # Inspecting the first 10 results print (json.dumps(texts[0:10], indent=1),"\n") print (json.dumps(names[0:10], indent=1),"\n") print (json.dumps(hashtags[0:10], indent=1),"\n")Frequency analysis
# Importing modules from collections import Counter # Counting occcurrences/ getting frequency dist of all names and hashtags for item in [names, hashtags]: c = Counter(item) # Inspecting the 10 most common items in c print (c.most_common(10), "\n")Activity around the trend
# Extracting useful information from retweets retweets = [(tweet['retweet_count'], tweet['retweeted_status']['favorite_count'], tweet['retweeted_status']['user']['followers_count'], tweet['retweeted_status']['user']['screen_name'], tweet['text']) for tweet in tweets if 'retweeted_status' in tweet]A table that speaks a 1000 words
# Importing modules import matplotlib.pyplot as plt import pandas as pd # Create a DataFrame and visualize the data in a pretty and insightful format df = pd.DataFrame(retweets, columns=['Retweets','Favorites', 'Followers', 'ScreenName', 'Text']) df.style.background_gradient() df = df.groupby(['ScreenName','Text','Followers']).sum().sort_values(by=['Followers'], ascending= False)Analyzing used languages
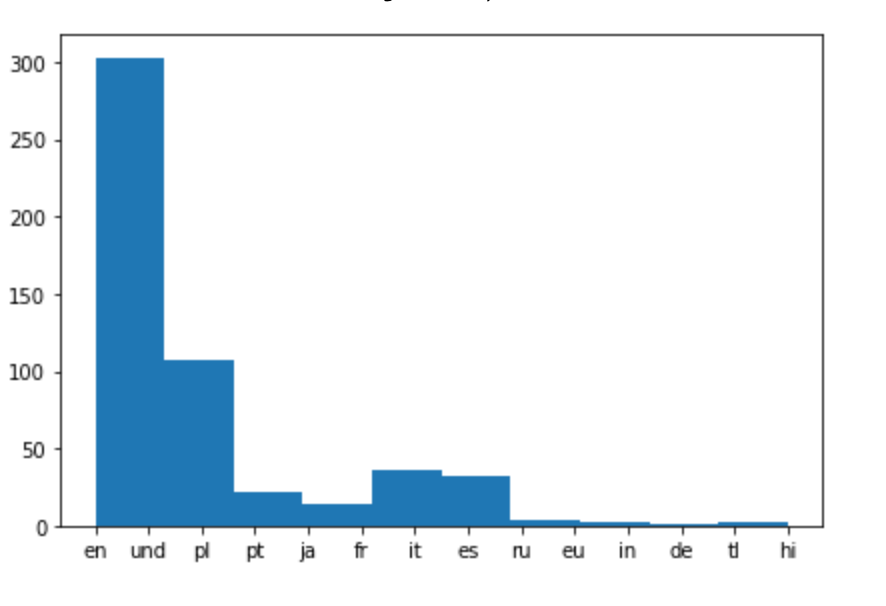
# Extracting language for each tweet and appending it to the list of languages tweets_languages = [] for tweet in tweets: tweets_languages.append(tweet['lang']) # Plotting the distribution of languages %matplotlib inline plt.hist(tweets_languages)
That's the end of our project. In the next project of this series we'll look into more complicated use of twitter API.
- 投稿日:2020-02-20T21:03:30+09:00
Djangoで画像を配信できるwebAPIを作る
概要
この記事は初心者の自分がRESTful なAPIとswiftでiPhone向けのクーポン配信サービスを開発した手順を順番に記事にしています。技術要素を1つずつ調べながら実装したため、とても遠回りな実装となっています。
前回の Django Rest Framework で JWTによるAPIの認証機能を実装 で認証機能を実装し、ある程度実用に耐えうるAPIとなりました。ただ現在のクーポンは文字情報だけでビジュアル面で弱いのが現状。
そこで今回はDjangoで画像ファイルを扱うための「Pillow」というパッケージを使い、クーポンの画像もAPIで配信出来るようにします。
Djangoで新しく画像を扱うAPIを作る場合も「Pillow」に関する部分は同じなので、参考になればと思います。
画像をwebAPIを介してクライアント側で表示する仕組み
- webAPI側のサーバで画像を保持する
- リクエストに対して画像のURLをJsonでレスポンスする
- クライアントが再度サーバにアクセスして画像を取得し画面上に表示する
参考
- はじめてのDjango (7) 画像データの管理やページへの表示,アップロードの方法などについて知ろう
- 【Django】画像をアップロードして表示する
- Django本番環境でメディアファイル公開に必要な設定
環境
- Mac OS 10.15
- pipenv 2018.11.26
- Python 3.7.4
- Django 2.2.6
- pillow 7.0.0
手順
- pillowをインストールする
- モデルを定義する
- settings.pyにMEDIA_ROOTとMEDIA_URLを定義
- urls.pyに設定を追加する
- 必要に応じてpsettings.pyに設定を追加する
- マイグレートする
- 動作確認
pillowをインストールする
自分の環境は pipenv でpythonの仮想環境を作っているので pipenvのシェルに入った後、下記の通りpillowをインストールします。インストール後に Pipfileを見てpillowがインストールされた事を確認します。
$ pipenv install pillow$ cat Pipfile [[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] [packages] django = "*" djangorestframework = "*" django-filter = "*" djangorestframework-jwt = "*" pillow = "*" ←追加されている [requires] python_version = "3.7"pipやpip3で環境構築している場合は、
$ sudo pip install pillow 又は $ sudo pip3 install pillowでインストールします。
モデルを定義する
models.pyのCouponクラスに画像を格納するモデルフィールドを追加します。pillowをインストールすると画像ファイルを扱うフィールド型
ImageFieldを使えるようになります。定義はこのようにします。
upload_to=の部分は最低限必要です。[フィールド名] = models.ImageField(upload_to=‘[画像ファイルを格納するフォルダの相対パス]’)「画像ファイルを格納するフォルダの相対パス」の起点は、settings.pyで定義する
MEDIA_ROOTで指定したパスになります。下記の通り、imageというフィールド名でImageFieldを追加しました。
なお、私のケースではnullを許容(null=True)しないとマイグレーションファイルを作成する際にエラーになりました。models.pyclass Coupon(models.Model): code = models.CharField(max_length=20) benefit = models.CharField(max_length=1000) explanation = models.CharField(max_length=2000) image = models.ImageField(upload_to='images/', null=True) #追加 store = models.CharField(max_length=1000) start = models.DateField() deadline = models.DateField() status = models.BooleanField()settings.pyにMEDIA_ROOTとMEDIA_URLを定義
前述の通り、プロジェクト名のフォルダ配下のsettings.pyに
MEDIA_ROOTには画像ファイルを相対パスで参照する際の起点のURLを指定します。
私の場合、画像ファイルを格納するフォルダをアプリのフォルダ配下に作りたかったので、アプリのフォルダのURLを指定しました。プロジェクトのフォルダまではBASE_DIRで定義されているので、下記のように記載しました。画像ファイルを格納するフォルダは初回の画像アップロード時に自動生成されるそうですが、知らなかったので
mkdir imagesで自分で作りました。ami_coupon_api/settings.pyMEDIA_ROOT = os.path.join(BASE_DIR, 'coupon')
MEDIA_URLはURLで参照する際に起点となるアドレスを指定します。
私の場合、CouponモデルのデータをGETする際のアドレスが[ip(ドメイン)]:[ポート]/api/coupons/なので、イメージに参照する際は[ip(ドメイン)]:[ポート]/api/coupons/imagesとなるように/api/coupons/を起点として設定しました。プロジェクト名のフォルダ/settings.pyMEDIA_URL = '/api/coupons/'urls.py に設定を追加する
URLで画像を参照するには urls.py に設定が必要です。
プロジェクト名のディレクトリ配下のurls.pyを開き、下記import文とurlpatternsの宣言を追加します。画像のような静的ファイルを扱うための設定で、ほとんど定型文のように扱えるようです。ami_coupon_api/urls.pyfrom django.conf import settings #画像参照のため追加 from django.contrib.staticfiles.urls import static #画像参照のため追加 from django.contrib.staticfiles.urls import staticfiles_urlpatterns #画像参照のため追加 urlpatterns += staticfiles_urlpatterns() urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)必要に応じてpsettings.pyに設定を追加する
Django Rest Framework を使っていて serializer.py にレスポンスするモデルフィールドを設定している場合は、画像ファイルのURLをレスポンスするように設定を変更をします。
下記の
fields =の部分です。’__all__’の場合は全てのモデルフィールドの値をレスポンスする設定なので変更は不要です。serializer.pyfrom rest_framework import serializers from .models import Coupon class CouponSerializer(serializers.ModelSerializer): class Meta: model = Coupon fields = '__all__'マイグレートする
モデルの定義を変更したので、DBに変更を反映するためにマイグレートをします。
マイグレーションファイルを作成→マイグレートの流れになります。(pipenvを使っている場合は仮想環境のシェルに入っている状態で実行)
$ python manage.py makemigrations [アプリ名] $ python manage.py migrate動作確認
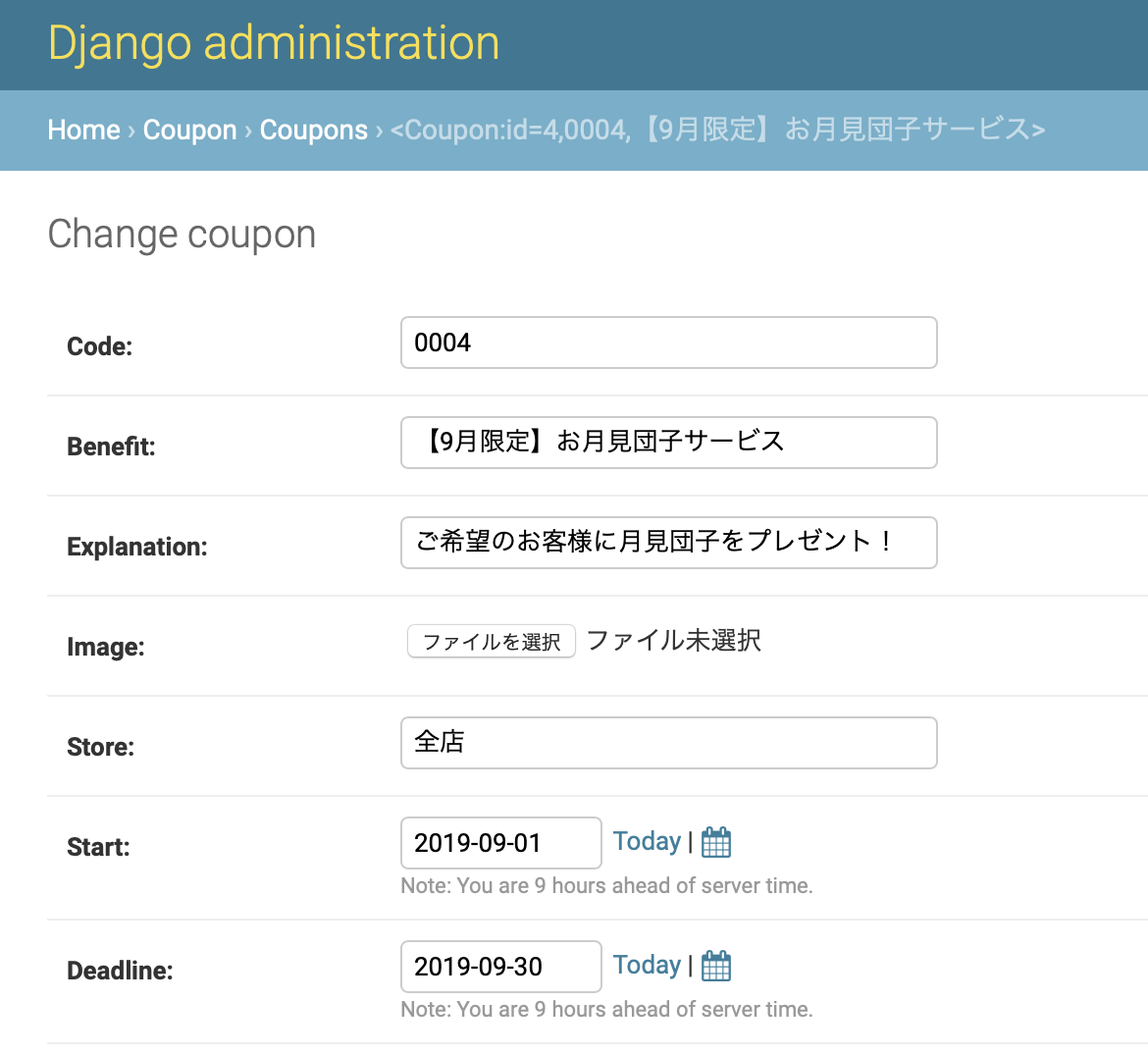
以上で画像ファイルを扱うための設定は完了となりますので、djangoのadminページを使って直接画像を投入し、実際に表示されるか確認しました。
djangoサーバを立ち上げdjangoのadminページにログインしてcouponモデルのページを開くと、画像をアップデートできるようになっています。クーポン用に作成した画像を直接アップデートします。
次にcurlコマンドでGETリクエストに対するレスポンスの json を取得します。
$ curl -X GET http://127.0.0.1:8000/api/coupons/下記の通り、画像ファイルのURLが含まれているのでコピーしてブラウザでアクセスします。
[{"id":1,"code":"0001","benefit":"お会計から1,000円割引","explanation":"5,000円以上ご利用のお客様限定。他クーポンとの併用不可。","image":"http://127.0.0.1:8000/api/coupons/images/coupon-image-001_GKrT1ju.png" ,"store":"全店","start":"2019-10-01","deadline":"2019-12-31","status":true}
ブラウザに設定したクーポンの画像が表示されたら成功です。

- 投稿日:2020-02-20T20:46:55+09:00
Anacondaにモジュールをインストール(Mac)
Anacondaにモジュールをインストール
※この記事はMacを対象にしています。
※例として、ortoolpyモジュールのインストールをとっています。他でも同じ。Anacondaにパスを通す
自分もそうでしたが、Anacondaのパスが通っていない場合、
コマンドプロンプトで"conda"と打っても反応してくれません。別記事にAnacondaへのパスの通し方があったので、こちらを参照にして下さい。
リンクはこちら:Anacondaのパスの設定
よし、condaを実行してモジュールのインストールだ!
しかしびっくり仰天
$ conda install ortoolpyとしても、
zsh: command not found: condaとなってしまう。
解決方法
$ source ~/.bash_profileを実行することで、解決しました。
$ pip install ortoolpyこれにてインストール完了です。
※condaコマンドも実行できましたが、pipでないとortoolpyはインストールできないモジュールであることが発覚しました。疑問点
最後pipでもインストールできるあたり謎です。
あと毎回$ source ~/.bash_profileとするのも面倒です。誰か良い方法を知っている方いたら教えて欲しいです、、、
- 投稿日:2020-02-20T20:28:47+09:00
【Django】 ModelSerializerにAPIで認証したユーザーインスタンスを渡す
若干詰まったのでメモ。
環境
- Python 3.7.4
- Django 3.0.3
- django-rest-framework 3.11.0
ModelSerializerについて
django-rest-framework(以降 DRF)では、ModelSerializerというオブジェクトを介して、Json - Model間の変換を行う。
APIで受け取った値を編集して登録したり、テーブルに存在しないレコードを返したり、データの加工を行ってJson化する場合、Serializerにメソッドを追加する場合が多い。またDRFではトークン認証を行った場合、requestオブジェクトにuserインスタンスが格納される。
Serializerにuserインスタンスを渡すと、リレーション先の値を自動で入れられるので、利用シーンは多い。model
前提となるVisitorモデルは以下。
import uuid from django.db import models from api.models import AppUser from web.models import AdminUser class Visitor(models.Model): class Meta: db_table = "visitor" verbose_name_plural = '訪問者' uuid = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False) parent_user = models.ForeignKey(AdminUser, on_delete=models.CASCADE, related_name='visitor') name = models.CharField(max_length=50) email = models.EmailField(max_length=255, null=True, blank=True) company = models.CharField(max_length=50, blank=True, null=True) memo = models.TextField(blank=True, null=True, max_length=300) visit_count = models.PositiveIntegerField(default=0) created_by = models.ForeignKey(AppUser, on_delete=models.SET_NULL, null=True, blank=True, related_name='visitor') created_at = models.DateTimeField(auto_now_add=True) updated_at = models.DateTimeField(auto_now=True) def __str__(self): return self.nameserializer
serializerはモデルと結び付いたfieldsを生成する。値を任意に変更するには、
SerializerMethodField()でオーバーライドする。
SerializerMethodField()で定義したfieldはget_<field名>というメソッドを呼び出し、その返り値を格納する。
get_<field名>のメソッドは引数にinstanceを持つ。
そのため、API認証を行った際ここに渡されると思っていたのだが、ここはCreate時に作成されたインスタンスそのものが渡されるようだ。
(これを利用すれば、リレーション先のデータを自動作成も出来る。)from rest_framework.serializers import ModelSerializer, SerializerMethodField class VisitorCreateSerializer(ModelSerializer): created_by = SerializerMethodField() parent_user = SerializerMethodField() class Meta: model = Visitor read_only_fields = ( 'pk', 'created_at', 'created_by', ) fields = ( 'pk', 'parent_user', 'created_at', 'name', 'email', 'company', 'memo', 'updated_at', ) def get_created_by(self, instance): """送信したユーザーがcreated_byに格納される""" return str(instance.pk) def get_parent_user(self, instance): """parent_userを自動的に格納する""" return str(instance.parent_user.pk)ViewSet
Viewにおいて、Serializerをインスタンス化する部分があるので、ここでinstanceにuserを渡せばOK.
今回はcreateだけserializerを分けたかったのでcreateメソッドをオーバーライドして、Serializerを指定している。# DRF from rest_framework import status, viewsets from rest_framework.permissions import IsAuthenticated from .serializers import VisitorSerializer, VisitorCreateSerializer from .models import Visitor from utils.auth.authentication import APIAuthentication from rest_framework.response import Response class VisitorViewSet(viewsets.ModelViewSet): serializer_class = VisitorSerializer # create以外に使用するserializer queryset = Visitor.objects.all() authentication_classes = (APIAuthentication,) permission_classes = (IsAuthenticated,) def get_queryset(self): # API認証した場合,userインスタンスはrequest.userに格納される。 admin = self.request.user.parent_user qs = Visitor.objects.filter(parent_user=admin) return qs # createメソッドをオーバーライド def create(self, request, *args, **kwargs): # Serializerにrequest.userを渡すと、get_<field名>メソッドにinstanceが渡る serializer = VisitorCreateSerializer(instance=request.user, data=request.data) # ここから下はそのまま serializer.is_valid(raise_exception=True) self.perform_create(serializer) headers = self.get_success_headers(serializer.data) return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)
- 投稿日:2020-02-20T19:34:34+09:00
画像認識にチャレンジ(ver.1.0)
1 はじめに
画像認識ができるプログラムをKerasにより作りました。
実行環境は下記になります。・python 3.5.6
・Keras 2.2.0
・tensorflow 1.5.
・matplotlib 2.2.2
・numpy 1.15.2
・opencv 3.4.2参考にさせて頂いたURLは下記一覧となります。
https://qiita.com/ayumiya/items/e1e87df54c41519be6b42 画像を収集する
今回flickr APIを利用して大量の画像を収集しました。こちらに関しては、下記URLを参考にflickrの登録・API, secret KEYの発行などを行うことで画像を収集させました。
http://ykubot.com/2017/11/05/flickr-api/収集に関してもpython上で下記プログラムを実行することで自動で画像を集めることができました。300枚収集するのに必要な時間は凡そ今回のケースだと5分程度でした。
下記がプログラム全文になります。
collection.pyimport os import time import traceback import flickrapi from urllib.request import urlretrieve import sys from retry import retry flickr_api_key = "xxxx" #ここに発行されたAPI KEYを入力 secret_key = "xxxx" #ここに発行されたSECRET KEYを入力 keyword = sys.argv[1] @retry() def get_photos(url, filepath): urlretrieve(url, filepath) time.sleep(1) if __name__ == '__main__': flicker = flickrapi.FlickrAPI(flickr_api_key, secret_key, format='parsed-json') response = flicker.photos.search( text='child',#検索したいワードを入力 per_page=300,#何枚収集したいか指定 media='photos', sort='relevance', safe_search=1, extras='url_q,license' ) photos = response['photos'] try: if not os.path.exists('./image-data/' + 'child'): os.mkdir('./image-data/' +'child') for photo in photos['photo']: url_q = photo['url_q'] filepath = './image-data/' + 'child' + '/' + photo['id'] + '.jpg' get_photos(url_q, filepath) except Exception as e: traceback.print_exc()今回、「子供:child」と「老人:elder」を認識すべくそれら画像を300枚ずつ収集しました。
先にも述べますが検索ワードelderは、老人だけでなく植物、若い女性等の画像も収集されたため、それにより認識率が高くなかったものと推定しています。3 画像認識プログラムの作成
以下記事にて、画像認識プログラムについて説明します。全体像から私がつまづいてしまったところや、注意すべきポイントに絞って抜粋し、そののちにプログラム全文を記載します。
インポートしたライブラリ、モジュール等
import os import cv2 import numpy as np import matplotlib.pyplot as plt from keras.utils.np_utils import to_categorical from keras.layers import Dense, Dropout, Flatten, Input from keras.applications.vgg16 import VGG16 from keras.models import Model, Sequential from keras import optimizersモデル関数を作るうえでの注意
model = Model(input=vgg16.input, output=top_model(vgg16.output))元々、仕様環境はtensorflowをインストールしており、その中のライブラリであるkerasとして、引用していました。
例:from tensorflow.keras.utils import to_categoricalこのまま進めるていると、このModel関数を定義するうえで、
('Keyword argument not understood:', 'input')
となるエラーが発生しました。これはどうもkerasのversionが古いと起こるとのことで、
keras自体のアップデートなども行ったのですが、エラーは出続けました。
従い、keras自体を読み込む書き方をしてみたら、解決しました。本エラー概要及び、keras自体のアップデート
https://sugiyamayoshiaki.jp/%E3%80%90%E3%82%A8%E3%83%A9%E3%83%BC%E3%80%91typeerror-keyword-argument-not-understood-data_format/モデルの選定
# モデルにvggを使います input_tensor = Input(shape=(50, 50, 3)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # vggのoutputを受け取り、2クラス分類する層を定義します top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(2, activation='softmax'))今回選定したモデルはVGG16と呼ばれるモデルです。
http://cedro3.com/ai/mini-vgg-net/VGGチームが作った畳み込み13層+全結合層3層=16層のニューラルネットワークとのことです。
詳細は下記に記載されていますが、なるほど理解できていません。
https://qiita.com/MuAuan/items/86a56637a1ebf455e180子供か老人かを判別する関数を作る
def child(img): img = cv2.resize(img, (50, 50)) pred = np.argmax(model.predict(np.array([img]))) if pred == 0: return 'これは子供です' else: return 'これは老人です'全文プログラム
train.pyimport os import cv2 import numpy as np import matplotlib.pyplot as plt from keras.utils.np_utils import to_categorical from keras.layers import Dense, Dropout, Flatten, Input from keras.applications.vgg16 import VGG16 from keras.models import Model, Sequential from keras import optimizers number = 100 path_child = os.listdir('image-data/child') path_elder = os.listdir('image-data/elder') path_test = os.listdir('image-data/test') path_child_test = os.listdir('image-data/child_test') img_child = [] img_elder = [] img_test = [] img_child_test= [] input_tensor = Input(shape=(50, 50, 3)) for i in range(len(path_child)): img = cv2.imread('image-data/child/' + path_child[i]) if(type(img) != type(None)): img = cv2.resize(img ,(50,50)) img_child.append(img) for i in range(len(path_elder)): img = cv2.imread('image-data/elder/' + path_elder[i]) if(type(img) != type(None)): img = cv2.resize(img, (50,50)) img_elder.append(img) for i in range(len(path_test)): img = cv2.imread('image-data/test/' + path_test[i]) if(type(img) != type(None)): img = cv2.resize(img, (50,50)) img_test.append(img) for i in range(len(path_child_test)): img = cv2.imread('image-data/child_test/' + path_child_test[i]) if(type(img) != type(None)): img = cv2.resize(img, (50,50)) img_child_test.append(img) X = np.array(img_child + img_elder) y = np.array([0]*len(img_child) + [1]*len(img_elder)) X_t = np.array(img_child_test + img_test) y_t = np.array([0]*len(img_test) +[1]*len(img_child_test)) rand_index = np.random.permutation(np.arange(len(X))) rand_index_2 = np.random.permutation(np.arange(len(X_t))) X = X[rand_index] y = y[rand_index] X_t = X_t[rand_index_2] y_t = y_t[rand_index_2] # データの分割 X_train = X[:int(len(X)*0.8)] y_train = y[:int(len(y)*0.8)] X_test = X_t[int(len(X_t)*0.8):] y_test = y_t[int(len(y_t)*0.8):] # 正解ラベルをone-hotの形にします y_train = to_categorical(y_train) y_test = to_categorical(y_test) # モデルにvggを使います input_tensor = Input(shape=(50, 50, 3)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # vggのoutputを受け取り、2クラス分類する層を定義します top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(2, activation='softmax')) model = Model(input=vgg16.input, output=top_model(vgg16.output)) # vggの層の重みを変更不能にします for layer in model.layers[:15]: layer.trainable = False # コンパイルします model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy']) # 学習を行います model.fit(X_train, y_train, batch_size=100, epochs=20, validation_data=(X_test, y_test)) #関数定義 def child(img): img = cv2.resize(img, (50, 50)) pred = np.argmax(model.predict(np.array([img]))) if pred == 0: return 'これは子供です' else: return 'これは老人です' scores = model.evaluate(X_test, y_test, verbose=1) print('Test loss 間違い具合:', scores[0]) print('Test accuracy 正解率:', scores[1]) # cream関数に写真を渡して性別を予測します for i in range(10): img = cv2.imread('child_test/' + path_child_test[i]) if(type(img) != type(None)): b,g,r = cv2.split(img) img = cv2.merge([r,g,b]) plt.imshow(img) plt.show() print(child(img))以上になります。
Test loss 間違い具合: 2.303262777328491
Test accuracy 正解率: 0.5199999809265137となり、2択なのに正解率52%とまったく当たっていませんので、改善が必要です。
- 投稿日:2020-02-20T19:24:10+09:00
AWSを利用したAtCoderコンテスト追加通知LINE BOTの作成
LINE以外のアプリの通知を切っていますか? 僕は切っています。
AtCoderコンテストの予定が追加されたらLINEで通知してほしいなと思い、Mr JJ と共に LINE BOTを作成しました。作成したもの
毎時00分に予定されたコンテストの検索を行い、新たなコンテストが追加されている場合BOT君が通知してくれます。
一応メッセージを送ると返してくれる機能もあります。(おまけ)
作成したLINE BOTは以下のボタンから友達追加できます。
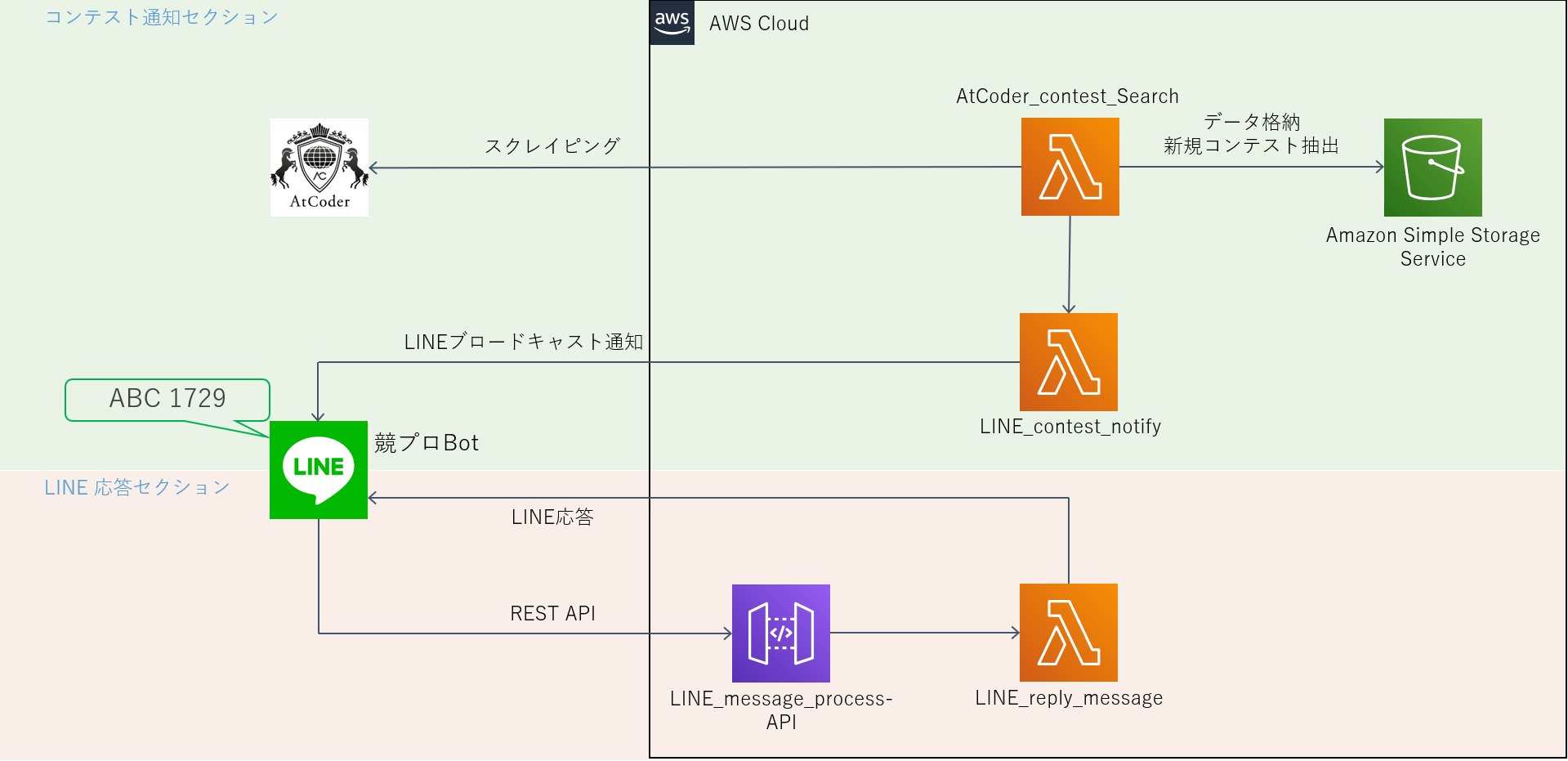
バックエンドの構成
バックエンドの処理はすべてAWS(Amazon Web Services)上で行っています。
AWS上の動作は以下の2つに分割できます。
- コンテスト通知セクション
- AtCoderコンテストの検索と新たなコンテストの通知を行う
- LINE応答セクション
- BOTに対しメッセージが送信された際に応答を行う
各セクションについて実装した機能を説明します。
コンテスト通知セクション
コンテスト通知セクションの流れ
- Lambda関数: AtCoder_contest_Search がAtCoderホームページのスクレイピングを行い、予定されたコンテストリストを取得する
- AtCoder_contest_Search が S3 から通知済みコンテスト一覧 JSON ファイルを取得する。
- 差集合を計算し、未通知コンテストを抽出する。未通知コンテストが空なら終了。
- 未通知コンテストデータをLambda関数: LINE_contest_notify に送る。
- LINE_contest_notify が送られたデータを line-bot-sdk を用いてブロードキャスト形式で通知する。
- [1] で得られたコンテストデータを S3 にアップロード
スクレイピング機能
Python3def get_contests(): # URLからデータを取ってくる url = "https://atcoder.jp/home?lang=ja" html_data = requests.get(url) # htmlパース soup = BeautifulSoup(html_data.text, "html.parser") tags = ["upcoming", "recent"] ret_dic = {} for tag in tags: div = soup.find("div", id="contest-table-"+tag) table = div.find("table") times = table.find_all("time") titles = table.find_all("a") ret_list = [] for i in range(len(times)): dic = {} dic["start"] = times[i].text dic["title"] = titles[i*2+1].text dic["url"] = "https://atcoder.jp" + titles[i*2+1].get("href") ret_list.append(dic) ret_dic[tag] = ret_list return ret_dic
データ内容 引数 null 返り値 各コンテストに対してデータ(開始時刻・タイトル・URL)を要素に持つ辞書のリスト 本BOTでは ret_dic["upcoming"] のみ使用。
S3からのファイル取得
Python3def get_data_s3(): # S3上にある通知済みコンテストjsonファイル"contests.json"の読み込み client = boto3.client("s3") try: response = client.get_object(Bucket = "bucket_name", Key = "json_file_name") except Exception as e: print(e) return json.loads(response["Body"].read().decode())
データ内容 引数 null 返り値 S3上のJSONファイルを読み込んだ辞書データ get_object メソッドの返り値は辞書であり、キー"Body"にファイルの内容が含まれる。
S3へのファイルアップロード
Python3def put_data_s3(save_dic): # 新たな通知済みコンテストjsonファイルのS3アップローダー text = json.dumps(save_dic, ensure_ascii = False) s3 = boto3.resource("s3") s3.Object("bucket_name", "json_file_name").put(Body = text)
データ内容 引数 保存対象の辞書データ 返り値 null 辞書をJSON形式のテキストにする際、ensure_ascii の値をFalseにしておくと、
JSONファイル内の日本語が読みやすくなり、ファイルサイズも小さくできる。ブロードキャスト形式のメッセージ送信
Python3def DatetimeToString(date): if not isinstance(date, datetime.datetime): date = datetime.datetime.strptime(date, "%Y-%m-%d %H:%M:%S%z") week_list = "月火水木金土日" return f"{date.strftime('%m/%d')}({week_list[date.weekday()]}){date.strftime('%H:%M')}" def MakeMessageText(event): text = DatetimeToString(event["start"]) + "\n" + event["title"] + "が開催されます!\n" + event["url"] return text def main(event, context): # ***ここでLINE BOTのチャンネルアクセストークン取得しておく*** line_bot_api = LineBotApi("channel_access_token") message = MakeMessageText(event) line_bot_api.broadcast(TextSendMessage(text=message)) # *** main関数を終える処理 ***DatetimeToString 関数でコンテスト開始時間のメッセージフォーマットを作成し、
MakeMessageText 関数で通知するメッセージのフォーマットを作成した。line-bot-sdk の LineBotApi クラス broadcast メソッドを呼び出すだけでBOTの友達全員に通知を行うことができる。
LINE応答セクション
本システムの構成図
LINE応答セクションの流れ
- LINE BOT がLINEメッセージを受け取るとWebhookを利用してAPI Gatewayへメッセージ内容をPOSTする。
- API GatewayへのPOSTがトリガーとなりLambda関数: LINE_reply_message が実行される。
- LINE_reply_message が line-bot-sdk を用いてLINEのリプライメッセージを送信する。
リプライメッセージ送信
Python3def main(event, context): # ***ここでLINE BOTのチャンネルアクセストークン・秘密鍵を取得しておく*** handler = WebhookHandler("channel_secret") line_bot_api = LineBotApi("channel_access_token") body = event["body"] # handlerにリプライ関数を追加 @handler.add(MessageEvent) def SendReply(line_event): message = MakeReplyMessage(line_event.message.text) line_bot_api.reply_message(line_event.reply_token, TextSendMessage(text=message)) try: handler.handle(body, event["headers"]["X-Line-Signature"]) except # エラー処理 # *** main関数を終える処理 ***MakeReplyMessage 関数はBOTが受け取ったメッセージ内容に応じたリプライメッセージを文字列で返す。
ここの部分に関しては特に line-bot-sdkのドキュメント を読むことをおすすめします。終わりに
作成した主な機能について紹介を行いました。
簡単にBOTの操作を行えるline-bot-sdk がとても便利です。
AWSに関する知識が少なく、かなり荒い設計になりましたが、気が向いたら今後機能追加&改善します。(たぶん)

- 投稿日:2020-02-20T19:24:10+09:00
AWSを利用したAtCoderコンテストの追加通知をするLINE BOTの作成
LINE以外のアプリの通知を切っていますか? 僕は切っています。
AtCoderコンテストの予定が追加されたらLINEで通知してほしいなと思い、Mr JJ と共に LINE BOTを作成しました。作成したもの
毎時00分に予定されたコンテストの検索を行い、新たなコンテストが追加されている場合BOT君が通知してくれます。
一応メッセージを送ると返してくれる機能もあります。(おまけ)
作成したLINE BOTは以下のボタンから友達追加できます。
バックエンドの構成
バックエンドの処理はすべてAWS(Amazon Web Services)上で行っています。
AWS上の動作は以下の2つに分割できます。
- コンテスト通知セクション
- AtCoderコンテストの検索と新たなコンテストの通知を行う
- LINE応答セクション
- BOTに対しメッセージが送信された際に応答を行う
各セクションについて実装した機能を説明します。
コンテスト通知セクション
コンテスト通知セクションの流れ
- Lambda関数: AtCoder_contest_Search がAtCoderホームページのスクレイピングを行い、予定されたコンテスト一覧を取得する
- AtCoder_contest_Search が S3 から通知済みコンテスト一覧 JSON ファイルを取得する。
- 差集合を計算し、未通知コンテストを抽出する。未通知コンテストが空なら終了。
- 未通知コンテストデータをLambda関数: LINE_contest_notify に送る。
- LINE_contest_notify が送られたデータを line-bot-sdk を用いてブロードキャスト形式で通知する。
- [1] で得られたコンテストデータを S3 にアップロード
スクレイピング機能
Python3def get_contests(): # URLからデータを取ってくる url = "https://atcoder.jp/home?lang=ja" html_data = requests.get(url) # htmlパース soup = BeautifulSoup(html_data.text, "html.parser") tags = ["upcoming", "recent"] ret_dic = {} for tag in tags: div = soup.find("div", id="contest-table-"+tag) table = div.find("table") times = table.find_all("time") titles = table.find_all("a") ret_list = [] for i in range(len(times)): dic = {} dic["start"] = times[i].text dic["title"] = titles[i*2+1].text dic["url"] = "https://atcoder.jp" + titles[i*2+1].get("href") ret_list.append(dic) ret_dic[tag] = ret_list return ret_dic
データ内容 引数 null 返り値 各コンテストに対してデータ(開始時刻・タイトル・URL)を要素に持つ辞書のリスト 本BOTでは ret_dic["upcoming"] のみ使用。
S3からのファイル取得
Python3def get_data_s3(): # S3上にある通知済みコンテストjsonファイル"contests.json"の読み込み client = boto3.client("s3") try: response = client.get_object(Bucket = "bucket_name", Key = "json_file_name") except Exception as e: print(e) return json.loads(response["Body"].read().decode())
データ内容 引数 null 返り値 S3上のJSONファイルを読み込んだ辞書データ get_object メソッドの返り値は辞書であり、キー"Body"にファイルの内容が含まれる。
S3へのファイルアップロード
Python3def put_data_s3(save_dic): # 新たな通知済みコンテストjsonファイルのS3アップローダー text = json.dumps(save_dic, ensure_ascii = False) s3 = boto3.resource("s3") s3.Object("bucket_name", "json_file_name").put(Body = text)
データ内容 引数 保存対象の辞書データ 返り値 null 辞書をJSON形式のテキストにする際、ensure_ascii の値をFalseにしておくと、
JSONファイル内の日本語が読みやすくなり、ファイルサイズも小さくできる。ブロードキャスト形式のメッセージ送信
Python3def DatetimeToString(date): if not isinstance(date, datetime.datetime): date = datetime.datetime.strptime(date, "%Y-%m-%d %H:%M:%S%z") week_list = "月火水木金土日" return f"{date.strftime('%m/%d')}({week_list[date.weekday()]}){date.strftime('%H:%M')}" def MakeMessageText(event): text = DatetimeToString(event["start"]) + "\n" + event["title"] + "が開催されます!\n" + event["url"] return text def main(event, context): line_bot_api = LineBotApi("channel_access_token") message = MakeMessageText(event) line_bot_api.broadcast(TextSendMessage(text=message)) # *** main関数を終える処理 ***DatetimeToString 関数でコンテスト開始時間のメッセージフォーマットを作成し、
MakeMessageText 関数で通知するメッセージのフォーマットを作成した。line-bot-sdk の LineBotApi クラス broadcast メソッドを呼び出すだけでBOTの友達全員に通知を行うことができる。
LINE応答セクション
本システムの構成図
LINE応答セクションの流れ
- LINE BOT がLINEメッセージを受け取るとWebhookを利用してAPI Gatewayへメッセージ内容をPOSTする。
- API GatewayへのPOSTがトリガーとなりLambda関数: LINE_reply_message が実行される。
- LINE_reply_message が line-bot-sdk を用いてLINEのリプライメッセージを送信する。
リプライメッセージ送信
Python3def main(event, context): handler = WebhookHandler("channel_secret") line_bot_api = LineBotApi("channel_access_token") body = event["body"] # handlerにリプライ関数を追加 @handler.add(MessageEvent) def SendReply(line_event): message = MakeReplyMessage(line_event.message.text) line_bot_api.reply_message(line_event.reply_token, TextSendMessage(text=message)) try: handler.handle(body, event["headers"]["X-Line-Signature"]) except # エラー処理 # *** main関数を終える処理 ***MakeReplyMessage 関数はBOTが受け取ったメッセージ内容に応じたリプライメッセージを文字列で返す。
ここの部分に関しては特に line-bot-sdkのドキュメント を読むことをおすすめします。終わりに
作成した主な機能について紹介を行いました。
簡単にBOTの操作を行えるline-bot-sdk がとても便利です。
AWSに関する知識が少なく、かなり荒い設計になりましたが、気が向いたら今後機能追加&改善します。(たぶん)
- 投稿日:2020-02-20T19:24:02+09:00
[python] htmlファイルを読み込んでスクレイピング練習
- 投稿日:2020-02-20T18:57:12+09:00
Python: htmlデータからタグを除外する
- 投稿日:2020-02-20T18:44:29+09:00
Python:嘘つき族と正直族をやってみた
嘘つき族と正直族の問題
何番煎じか知れませんが、おもしろそうなのでやってみました。import itertools # プレーヤーとカードデッキと言い分から、矛盾のない答を返す consistents = ( lambda players: lambda card_deck: lambda statements: ( (hands, is_each_honest) for hands in handss(card_deck) for is_each_honest in is_each_honests if statements(hands) == is_each_honest ) ) # それぞれのカードの手のタプルを返すジェネレータ handss = lambda card_deck: itertools.permutations(card_deck) # それぞれのプレーヤーが正直かどうか のタプルのタプル (決め打ち2) is_each_honests = ( (True, False, False, True) ,(False, True, True, False) ) # データ players = (0, 1, 2, 3) card_deck = (1, 2, 3, 4) statements = lambda hands: ( hands[0] % 2 == 0 , hands[1] in (3, 4) , hands[1] in (3, 4) # (決め打ち1) , hands[3] == 1 ) # 関数適用と表示 for e in consistents(players)(card_deck)(statements): print(e)# 結果: ((1, 3, 2, 4), (False, True, True, False)) ((1, 3, 4, 2), (False, True, True, False)) ((1, 4, 2, 3), (False, True, True, False)) ((1, 4, 3, 2), (False, True, True, False)) ((3, 4, 1, 2), (False, True, True, False)) ((4, 2, 3, 1), (True, False, False, True))決め打ちしてるところがあります。
決め打ち1:「Bは正直者」=>「Bの言ってることは正しい」=>Bの言ってること=>「Bのカードは3か4」 に変換
カードの手が決まればそれぞれの言い分の真偽が決まるので、問題がシンプルになります。
決め打ち2:嘘つき/正直は二人づつ=>BとCは同じ言い分=>BとCは同族=>AとDは逆の方の同族
制約がなければ全部で 6 通りですが、BとCが同族となると、バリエーションは 2 通りまで減少します。
>>> players = 0, 1, 2, 3 # 制約なし >>> tuple( tuple( not e in liars for e in players ) for liars in itertools.combinations(players, 2)) ((False, False, True, True), (False, True, False, True), (False, True, True, False), (True, False, False, True), (True, False, True, False), (True, True, False, False)) # 6 通り # 制約あり 嘘つきは ADか、でなければBC >>> tuple( tuple( not e in liars for e in players ) for liars in itertools.combinations(players, 2) if liars in ((0,3),(1,2))) ((False, True, True, False), (True, False, False, True)) # 2 通り計算してもいいけど、どうせふたつしかないんで、そこは直書きでいいかな、と。
あとは、ほぼ似たようなことをしていると思います。見た目は違いますが。
結果も同じ。当然か。
- 投稿日:2020-02-20T18:37:40+09:00
ゼロから作るDeep Learning ② をANACONDAのspyderで利用する時の「上位ディレクトリの取得ができない」エラー対策
ANACONDAのSpyderでPythonを扱う際、特に、『ゼロから作るDeep Learning ② 』で、
以下のコードでエラーが発生する際には、この様に対策すればエラーが解決しました。sys.path.append('..') # 親ディレクトリのファイルをインポートするための設定
この場合、ANACONDAのSpyderの左上のpythonタブからPYTHONPATH managerをクリックします。
その後、上位ディレクトリを入力することで解決できました。
こんな、簡単にできるなんて、素晴らしいです。
- 投稿日:2020-02-20T18:21:30+09:00
Jenkins Pipelineのpipeline {...}の"pipeline"と"{...}"は何か(Groovy初心者向け、他言語経験者向け)
背景
お仕事でJenkins Pipelineを書くことになりました。早速サンプルをコピーし、Hello Worldが表示されてうれしい一方、こんな疑問が。
この、
pipelineと{...}とは何なのか?どういう文法規則なのか?Jenkinsfilepipeline { agent any stages { stage('Build') { steps { sh 'echo "Hello World"' } } } }Jenkinsfile自体は単なるデータ構造(JSONやYAMLの仲間)に見えます。ということは何か規則があるはずです。しかしそれが書かれているページが見つからない。
職場のつよつよエンジニアに聞いたところ、JenkinsfileはGroovyのプログラムということが分かりました。その後自分で調べたことと、他の言語との対比を書いておきます。
"pipeline"と"{...}"は何かの答え
pipelineはメソッド名
{...}はクロージャ
pipeline {...}は、pipelineメソッドに、{...}というクロージャを引数として渡す、という構文です。
pipelineはメソッドなので、Jenkinsfileの実行時にdef pipeline(Closure c) { // 前処理 // クロージャを呼び出す c(); // 後処理 }のように定義されたメソッドが(どこかから)読み込まれています。
もっと詳しく
groovyのメソッド呼び出し
上記の
pipelineの呼び出しを冗長に書くと、pipeline({ -> // 処理 })です。
groovyのクロージャは{x, y -> x + y}のように、{引数 -> 処理}のように書きます。引数がない場合は、引数 ->の部分は省略可能です1。引数を省略すると、pipeline({ // 処理 })の形になります。
また、メソッド呼び出しのカッコは、引数がある場合は省略可能なので、pipeline { // 処理 }になります。Jenkinsfileと同じ形になりました。
クロージャ
クロージャとは、メソッドの呼び出し側で動いているような振る舞いをする無名関数です。
こちらの説明が分かりやすいです。
クロージャ - Apache Groovyチュートリアル他の言語で書いてみると
Groovyのクロージャを他の言語と対比します。(ここに書ききれない言語につきましてはコメントで補足お願いします)
Ruby
Groovyの
pipeline { // 処理 }という記法は、Rubyの
pipeline { # 処理 }という記法と対応します。見た目は同じですね。GroovyはRubyに強い影響を受けていることがわかります。
Rubyのブロックを、Groovyではクロージャと言います。ブロックとクロージャの違いは、こちらのページが分かりやすいです。
Rubyist のための他言語探訪 【第 5 回】 GroovyJavaScript
Groovyの
pipeline { // 処理 }という記法は、JavaScriptの
pipeline(() => { // 処理 })という記法に対応します。JavaScriptではメソッド呼び出しのカッコは省略できず、引数がない場合も引数を囲むカッコを省略できないですが、Groovyでは省略が可能です。
Java
Groovyの
pipeline { // 処理 }という記法は、Javaの
pipeline(() -> { // 処理 })に対応します。JavaScriptと同様Javaでもメソッド呼び出しのカッコと、引数がない場合は引数を囲むカッコを省略できません。Groovyではこの2つは省略可能です。
Python
Groovyの
pipeline { // 処理 }という記法は、Pythonで対応する記法がないのですが、あえて書くとしたら
pipeline(lambda: 処理)です。Pythonの場合、lambda式は複数行にまたがることができませんが、Groovyでは可能です。
参考資料
あとがき
Jenkinsfileを作成している最中、「コピペで動いてはいる、ただ、なんで動いているのか分からない」という状態でしたが、Groovyのプログラムということを理解し、実態がつかめました。
Jenkins Pipelineの記事がまだまだ少ないので、分かったことを今後も書けたらと思います。
正確に言うと、
{-> 処理}と{ 処理 }では挙動が変わります。 ↩
- 投稿日:2020-02-20T18:05:28+09:00
GAN : DCGAN Part3 - Understanding Wasserstein GAN
目標
Microsoft Cognitive Toolkit (CNTK) を用いた DCGAN の続きです。
Part3 では、Part1 で準備した画像データを用いて CNTK による DCGAN の訓練を行います。
CNTK と NVIDIA GPU CUDA がインストールされていることを前提としています。導入
GAN : DCGAN Part2 - Training DCGAN model では、Deep Convolutional Generative Adversarial Network (DCGAN) による顔生成モデルを扱ったので、Part3 では Wasserstein GAN を作成して訓練します。
Wasserstein GAN
今回実装した Wasserstein GAN [1] のネットワーク構造は Part2 と同じです。
ただし、Wasserstein GAN では Discriminator の出力層で sigmoid 関数を使用しないため Discriminator は Critic と呼ばれます。また今回の実装では、Critic の Batch Normalization をすべて Layer Normalization [2] に置き換えています。
オリジナルの GAN [3](Vanilla GAN (VGAN) と呼ぶことにします)と Wasserstein GAN (WGAN) の違いについては後ほど説明します。
訓練における諸設定
転置畳み込み・畳み込み層のパラメータの初期値は分散 0.02 の正規分布 [4] に設定しました。
今回実装した損失関数を下式に示します。[5]
\max_{C} \mathbb{E}_{x \sim p_{r}(x)}[C(x)] - \mathbb{E}_{z \sim p_z(z)}[C(G(z))] + \lambda \mathbb{E}_{x' \sim p_{x'}(x')}(||\nabla_{x'} C(x')||_2 - 1)^2 \\ \min_{G} -\mathbb{E}_{z \sim p_z(z)}[C(G(z))] \\ x' = \epsilon x + (1 - \epsilon) G(z), \epsilon \sim U[0, 1]ここで、$C$, $G$ はそれぞれ Critic と Generator を表し、$x$ は入力画像、$z$ は潜在変数、$p_r$ は本物の画像データの分布、$p_z$ は偽物の画像データを生成する事前分布、$U$ は一様分布を表しています。今回は gradient penalty [5] を用いた Wasserstein GAN を実装し、$\lambda$ は 10 に設定しました。
Generator, Discriminator ともに最適化アルゴリズムは Adam [6] を採用しました。学習率は 1e-4、Adam のハイパーパラメータ $β_1$ は 0.0、$β_2$ は CNTK のデフォルト値に設定しました。
モデルの訓練はミニバッチサイズ 16 のミニバッチ学習によって 50,000 Iteration を実行しました。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-6700K 4.00GHz
・GPU NVIDIA GeForce GTX 1060 6GBソフトウェア
・Windows 10 Pro 1909
・CUDA 10.0
・cuDNN 7.6
・Python 3.6.6
・cntk-gpu 2.7
・opencv-contrib-python 4.1.1.26
・numpy 1.17.3
・pandas 0.25.0実行するプログラム
訓練用のプログラムは GitHub で公開しています。
wgan_training.py解説
ところどころ証明や厳密性は欠けていますが、GAN の数理について理解を深めたいと思います。
そのために、まず確率分布の尺度である Kullback-Leibler divergence と Jensen-Shannon divergence から始めます。
Kullback-Leibler divergence and Jensen-Shannon divergence
2つの確率分布 $P(x), Q(x)$ の尺度として、Kullback-Leibler divergence が挙げられます。$H$ はエントロピーを表します。
\begin{align} D_{KL} (P || Q) &= \sum_x P(x) \log \frac{P(x)}{Q(x)} \\ &= H(P, Q) - H(P) \end{align}ただし KL divergence には対称性がない、つまり $D_{KL} (P || Q) \neq D_{KL} (Q || P)$ です。
また、エントロピー $H$ は以下の式で表されます。
H(P, Q) = \mathbb{E}_{x \sim P(x)} [- \log Q(x)] \\ H(P) = \mathbb{E}_{x \sim P(x)} [- \log P(x)]これを用いて表記を少し変形すると以下のように表せます。
\begin{align} D_{KL} (P || Q) &= H(P, Q) - H(P) \\ &= \mathbb{E}_{x \sim P(x)} [- \log Q(x)] - \mathbb{E}_{x \sim P(x)} [- \log P(x)] \\ &= \mathbb{E}_{x \sim P(x)} [- \log Q(x) - (- \log P(x))] \\ &= \mathbb{E}_{x \sim P(x)} [\log P(x) - \log Q(x)] \\ \end{align}一方、KL divergence の派生版である Jensen-Shannon divergence は以下のように定義されます。
D_{JS} (P || Q) = \frac{1}{2} D_{KL} (P || M) + \frac{1}{2} D_{KL} (Q || M) \\ M = \frac{P + Q}{2}JS divergence は対称性をもち、$0 \leq D_{JS} \leq 1$ となります。したがって、JS divergence が大きいと 2つの分布が似ておらず、逆に JS divergence が小さいと 2つの分布が似ていることになります。
Vanilla GAN
GAN を含む生成モデルは、現実に観測されるデータは何らかの生成モデルをもつという仮説に基づき、そのような生成モデルを獲得することを目指します。
まず、$D, G$ を Discriminator, Generator とし、$p_r$ は本物のデータの分布、$p_z$ は偽物のデータを生成する事前分布とします。また、Discriminator, Generator の評価関数を $V_D, V_G$ とします。
ここで、Discriminator は本物のデータと偽物のデータを識別する問題と考えると、Discriminator の評価関数は以下の式で表せます。
V_D = \mathbb{E}_{x \sim p_r(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))]さらに、Discriminator と Generator の評価関数の利得の和が 0 になる zero-sum game を導入すると、Generator の評価関数は次式のように定義するのが自然です。
V_G = - V_Dここで、zero-sum game のナッシュ均衡($V_D$ に関して局所最小かつ $V_G$ に関して局所最小となる解)は minimax 解となることが知られているので、VGAN の損失関数が定義されます。
\min_G \max_D V(G, D) = \mathbb{E}_{x \sim p_r(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))]ここで、上式の最適化問題がユニークな解 $G^*$ をもち、この解が $p_g = p_r$ となることを示す必要があります。その際、以下の式を用います。
\mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))] = \mathbb{E}_{x \sim p_g(x)}[\log (1 - D(x))]VGAN の損失関数を連続関数で考えると、
\begin{align} V(G, D) &= \int_x p_r(x) \log(D(x))dx + \int_z p_z(z) \log(1 - D(G(z)))dz \\ &= \int_x p_r(x) \log(D(x))dx + p_g(x) \log(1 - D(x))dx \end{align}ここで、関数 $f(y) = a\log y + b\log(1 - y)$ の臨界点を考えると、微分して 0 になるので、
f'(y) = 0 \Rightarrow \frac{a}{y} - \frac{b}{1 - y} = 0 \Rightarrow y = \frac{a}{a + b}また、$\frac{a}{a + b}$ における 2回微分を考えると、
f''(\frac{a}{a + b}) = - \frac{a}{(\frac{a}{a + b})^2} - \frac{b}{(1 - \frac{a}{a + b})^2} < 0となり、$a, b \in (0, 1)$ なので上に凸だと分かります。したがって、$\frac{a}{a + b}$ で最大となります。よって、
\begin{align} V(G, D) &= \int_x p_r(x) \log(D(x))dx + \int_z p_z(z) \log(1 - D(G(z)))dz \\ &\leq \int_x \max_y p_r(x) \log(D(x))dx + p_g(x) \log(1 - D(x))dx \end{align}となり、$D_{G} (x) = \frac{p_r}{p_r + p_g}$ のとき最大値であり、十分にユニークな解であることが分かりました。しかし実際に $D$ の最適解を求めることはできません。なぜなら、真の本物のデータの分布 $p_r$ を知る術はないので、訓練中に使うことができないからです。ですが、$p_r$ は $G$ の最適解の存在を示すものであり、訓練において $D$ を近似することに専念すればよいことが分かりました。
次に Generator の最適解を考えるにあたって、GAN の最終到達目標は $p_g = p_r$ になることを再び提示しておきます。このとき $D_{G}^{*}$ は
D_{G}^{*} = \frac{p_r}{p_r + p_g} = \frac{1}{2}となります。$D_{G}^{*}$ が得られたとき、Generator の最小化問題を考えると、
\begin{align} \max_D V(G, D_{G}^{*}) &= \mathbb{E}_{x \sim p_r(x)}[\log D_{G}^{*}(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D_{G}^{*}(G(z)))] \\ &= \mathbb{E}_{x \sim p_r(x)}[\log D_{G}^{*}(x)] + \mathbb{E}_{x \sim p_g(x)}[\log (1 - D_{G}^{*}(x))] \\ &= \mathbb{E}_{x \sim p_r(x)} \left[\log \frac{p_r}{p_r + p_g} \right] + \mathbb{E}_{x \sim p_g(x)} \left[\log \frac{p_g}{p_r + p_g} \right] \\ &= \mathbb{E}_{x \sim p_r(x)} [\log p_r - \log (p_r + p_g)] + \mathbb{E}_{x \sim p_g(x)} [\log p_g - \log (p_r + p_g)] \\ &= \mathbb{E}_{x \sim p_r(x)} \left[\log p_r - \log \left(\frac{p_r + p_g}{2} \cdot 2 \right) \right] + \mathbb{E}_{x \sim p_g(x)} \left[\log p_g - \log \left(\frac{p_r + p_g}{2} \cdot 2 \right) \right] \\ &= \mathbb{E}_{x \sim p_r(x)} \left[\log p_r - \log \left(\frac{p_r + p_g}{2} \right) - \log 2 \right] + \mathbb{E}_{x \sim p_g(x)} \left[\log p_g - \log \left(\frac{p_r + p_g}{2} \right) - \log 2 \right] \\ &= \mathbb{E}_{x \sim p_r(x)} \left[\log p_r - \log \left(\frac{p_r + p_g}{2} \right) \right] + \mathbb{E}_{x \sim p_r(x)} [- \log 2] + \mathbb{E}_{x \sim p_g(x)} \left[\log p_g - \log \left(\frac{p_r + p_g}{2} \right) \right] + \mathbb{E}_{x \sim p_g(x)} [ - \log 2] \\ \end{align}ここで、KL divergence を用いると、
\begin{align} \max_D V(G, D_{G}^{*}) = D_{KL} \left(p_r \middle| \middle| \frac{p_r + p_g}{2} \right) + D_{KL} \left(p_g \middle| \middle| \frac{p_r + p_g}{2} \right) - \log 4 \end{align}さらに、$\frac{p_r + p_g}{2} = M$ とすると、JS divergence より、
\max_D V(G, D_{G}^{*}) = 2 \cdot D_{JS} (p_r || p_g) - \log 4したがって、$p_g = p_r$ のとき、大域的最小値の候補として $- \log 4$ をもつことが分かり、同時に Generator の最小化問題は JS divergence を最小化していると考えることができます。
以上のような理論的背景から、十分な表現力と本物のデータがあれば生成モデルを学習することができますが、依然として GAN の訓練は難しいです。
Wasserstein GAN
GAN を解析した論文 [7] では VGAN の訓練が困難な理由が明らかにされており、同論文の著者らがその解決策として提案したのが WGAN [1] です。
VGAN では Generator は結果的に JS divergence を尺度としていましたが、WGAN では Wasserstein distance を尺度とします。
Wasserstein distance は Earth-Mover(EM) distance とも呼ばれ、輸送最適化問題に基づいた尺度で、ここではある確率分布を別の確率分布に近づけるためのコストを表します。
W(p_r, p_g) = \inf_{\gamma \in \Pi(p_r, p_g)} \mathbb{E}_{(x, y) \sim \gamma} [||x - y||]Wasserstein distance は KL divergence や JS divergence にはない有益な性質があります。2つの確率分布に重なりがない場合、KL divergence は発散してしまい、JS divergence は $\log 2$ となって微分不可能になってしまいますが、Wasserstein distance は滑らかな値をとるため、勾配法での最適化が安定します。
そして、Wasserstein distance は Kantorovich-Rubinstein 双対性に基づいた変換により、下の式のような損失関数が得られます。ここで、$C, G$ は Critic, Generator を表します。
\min_G \max_{||C||_L \leq K} \mathbb{E}_{x \sim p_r(x)}[C(x)] - \mathbb{E}_{z \sim p_z(z)}[C(G(z))]ただし、Wasserstein distance には Lipshitz 連続性と呼ばれる制約が課されるため、これを保証するための方法として重みパラメータを clip する方法を用いています。
しかし weight clipping は強引な方法であるため訓練に失敗する場合があり、その改善策として gradient penalty [5] が提案されました。
Gradient penalty では、最適化された Critic において、本物のデータと生成データの間の任意の点に対する勾配の L2ノルムが 1 になるという事実を利用し、損失関数に勾配の L2ノルムが 1 以外のときにペナルティを課す方法です。
\lambda \mathbb{E}_{x' \sim p_{x'}(x')}(||\nabla_{x'} C(x')||_2 - 1)^2本物のデータと生成データの間の任意の点 $x'$ は、本物の画像データと Generator が生成した画像データをランダムな割合でブレンドした画像で表現します。
x' = \epsilon x + (1 - \epsilon) G(z), \epsilon \sim U[0, 1]また、weight clipping と gradient penalty は制約が強すぎて Generator の表現力が低くなってしまうので、本物のデータの近傍における勾配の L2ノルムを 1 に近づける正則化項を用いる DRAGAN [8] も提案されています。
結果
訓練時の各損失関数を可視化したものが下図です。横軸は繰り返し回数、縦軸は損失関数の値を表しています。Critic, Generator ともに値が非常に大きくなっています。
訓練した Generator で生成した顔画像を下図に示します。損失関数が大きな値になっているにもかかわらず、失敗している画像もありますが、Part2 よりも見栄えの良い顔画像を生成しているように見えます。
訓練時の画像生成の変遷をアニメーションで示したのが下図です。
Part2 と同様に Inception-v3 [9] で Inception Score [10] を測ってみると以下のような結果になりました。
Inception Score 2.14参考
CNTK 206 Part C: Wasserstein and Loss Sensitive GAN with CIFAR Data
GAN : DCGAN Part1 - Scraping Web images
GAN : DCGAN Part2 - Training DCGAN model
- Martin Arjovsky, Soumith Chintala, and Leon Bottou, "Wasserstein GAN", arXiv preprint arXiv:1701.07875 (2017).
- Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. "Layer Normalization", arXiv preprint arXiv:1607.06450 (2016).
- Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mira, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. "Generative Adversarial Nets", Advances in neural information processing systems. 2014, pp 2672-2680.
- Alec Radford, Luke Metz, and Soumith Chintal. "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks", arXiv preprint arXiv:1511.06434 (2015).
- Ishaan Gulrahani, Faruk Ahmed, Martin Arjovsky, Vincent DuMoulin, and Aron Courville. "Improved Training of Wasserstein GANs", Neural Information Processing Systems (NIPS). 2017, pp 5767-5777.
- Diederik P. Kingma and Jimmy Lei Ba. "Adam: A method for stochastic optimization", arXiv preprint arXiv:1412.6980 (2014).
- Martin Arjovsky and Leon Bottou, "Towards Princiled Methods for Training Generative Adversarial Networks", International Conference on Learning Representations (ICLR). 2017.
- Naveen Kodali, Hacob Avernethy, James Hays, and Zsolt Kira, "On Covergence and Stability of GANs", arXiv preprint arXiv:1705.07215.
- Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. "Rethinking the Inception Architecture for Computer Vision", The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016, pp 2818-2826.
- Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen, "Improved Techniques for Training GANs", Neural Information Processing Systems. 2016. pp 2234-2242.



- 投稿日:2020-02-20T17:04:26+09:00
【django version up】TestFiledの保存の仕方が変わった
背景
Djangoのバージョンを
1.11.1から2.2へあげると、バイト文字列で保存したTextFieldsの値が取り出した時に、
b'...'と皮まで保存されるようになっていた。結論
- decodeを使ってstring型に変換していたのがstr()を使ってstring型へ変更するようになっていた。
- str()を使うと改行文字がエスケープされたり、b''まで文字列に含まれたりする。
参考
version 1.11.1
- s = s.decode(encoding, errors)
- https://docs.djangoproject.com/ja/1.11/_modules/django/db/models/fields/
django.db.models.fields.pyfrom django.utils.encoding import ( force_bytes, force_text, python_2_unicode_compatible, smart_text, ) class TextField(Field): description = _("Text") def to_python(self, value): if isinstance(value, six.string_types) or value is None: return value return force_text(value)django.utils.encoding.pydef force_text(s, encoding='utf-8', strings_only=False, errors='strict'): """ Similar to smart_text, except that lazy instances are resolved to strings, rather than kept as lazy objects. If strings_only is True, don't convert (some) non-string-like objects. """ # Handle the common case first for performance reasons. if issubclass(type(s), six.text_type): return s if strings_only and is_protected_type(s): return s try: if not issubclass(type(s), six.string_types): if six.PY3: if isinstance(s, bytes): s = six.text_type(s, encoding, errors) else: s = six.text_type(s) elif hasattr(s, '__unicode__'): s = six.text_type(s) else: s = six.text_type(bytes(s), encoding, errors) else: # Note: We use .decode() here, instead of six.text_type(s, encoding, # errors), so that if s is a SafeBytes, it ends up being a # SafeText at the end. s = s.decode(encoding, errors) except UnicodeDecodeError as e: if not isinstance(s, Exception): raise DjangoUnicodeDecodeError(s, *e.args) else: # If we get to here, the caller has passed in an Exception # subclass populated with non-ASCII bytestring data without a # working unicode method. Try to handle this without raising a # further exception by individually forcing the exception args # to unicode. s = ' '.join(force_text(arg, encoding, strings_only, errors) for arg in s) return sversion 2.2
django.db.models.fields.pyclass TextField(Field): description = _("Text") def to_python(self, value): if isinstance(value, str) or value is None: return value return str(value)
- 投稿日:2020-02-20T17:04:26+09:00
【django version up】TextFiledを保存するときのstringへの変換の仕方が変わった
背景
Djangoのバージョンを
1.11.1から2.2へあげると、バイト文字列で保存したTextFieldsの値が取り出した時に、
b'...'と皮まで保存されるようになっていた。結論
- decodeを使ってstring型に変換していたのがstr()を使ってstring型へ変更するようになっていた。
- str()を使うと改行文字がエスケープされたり、b''まで文字列に含まれたりする。
参考
version 1.11.1
- s = s.decode(encoding, errors)
- https://docs.djangoproject.com/ja/1.11/_modules/django/db/models/fields/
django.db.models.fields.pyfrom django.utils.encoding import ( force_bytes, force_text, python_2_unicode_compatible, smart_text, ) class TextField(Field): description = _("Text") def to_python(self, value): if isinstance(value, six.string_types) or value is None: return value return force_text(value)django.utils.encoding.pydef force_text(s, encoding='utf-8', strings_only=False, errors='strict'): """ Similar to smart_text, except that lazy instances are resolved to strings, rather than kept as lazy objects. If strings_only is True, don't convert (some) non-string-like objects. """ # Handle the common case first for performance reasons. if issubclass(type(s), six.text_type): return s if strings_only and is_protected_type(s): return s try: if not issubclass(type(s), six.string_types): if six.PY3: if isinstance(s, bytes): s = six.text_type(s, encoding, errors) else: s = six.text_type(s) elif hasattr(s, '__unicode__'): s = six.text_type(s) else: s = six.text_type(bytes(s), encoding, errors) else: # Note: We use .decode() here, instead of six.text_type(s, encoding, # errors), so that if s is a SafeBytes, it ends up being a # SafeText at the end. s = s.decode(encoding, errors) except UnicodeDecodeError as e: if not isinstance(s, Exception): raise DjangoUnicodeDecodeError(s, *e.args) else: # If we get to here, the caller has passed in an Exception # subclass populated with non-ASCII bytestring data without a # working unicode method. Try to handle this without raising a # further exception by individually forcing the exception args # to unicode. s = ' '.join(force_text(arg, encoding, strings_only, errors) for arg in s) return sversion 2.2
django.db.models.fields.pyclass TextField(Field): description = _("Text") def to_python(self, value): if isinstance(value, str) or value is None: return value return str(value)
- 投稿日:2020-02-20T17:04:19+09:00
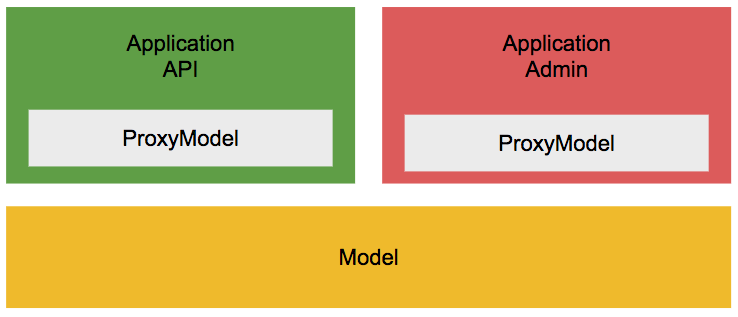
Django の ProxyModelについて
Django には ProxyModel というのがある。これはどうに使うと便利で、どういう時に活躍するものなのか?
プロキシモデル
https://docs.djangoproject.com/en/3.0/topics/db/models/#proxy-models単に説明だけみるとこういう事です。
モデルのPythonの動作のみを変更したい場合があります。
デフォルトのマネージャーを変更したり、新しいメソッドを追加したりする場合があります。しかし、色々と痒いところがあるようですし、便利に使うにはどうしたら良いのかは悩みどころです。あくまでも目的があっての手段ですから、無理やり使いたいわけではありませんし。
Right way to return proxy model instance from a base model instance in Django?とりあえず、こういう時はどうでしょうか?
Djangoはプロジェクト内にいくつもアプリケーションを持てる構造です。よくあるパターンとしては、Djangoで管理画面(Django Adminではなく中の人用の管理ツール)、DRFでAPIを作るケースでしょうか? こういう時に、この2つのアプリではDBは共通で使いたいことが多いはずです。例えば規模が大きいサービスではマイクロサービス化され、そういう分け方(管理の仕方)ではないかもしれませんが、何よりも先に成果がほしいスタートアップでは、こういう構成は結構多いと思います。
こういう構成を取る時に、Django,DRFではモデルを共通して使う方法を取る必要がありますが、これは検索すれば結構簡単に見つかりますし、システムの出来上がりも実装もこれだけで基本的には何も問題がありません。
modelにたくさんメソッド書きますか?
DjangoのORMは優秀で、ほぼ生のSQLを書く機会はありませんが、viewにORMの命令を書いて良いとは思っていません。こういうのですが。
class MyViewSet(mixins.ListModelMixin, viewsets.GenericViewSet): queryset = schema.MyObject.objects.all().order_by('id') serializer_class = MyObjectSerializerこれって昔からよく言われる
ControllerにSQLを書くんじゃねーってのと何が違うのでしょうか?
こんな感じにするともっとその駄目さがわかるでしょうか?class MyViewSet(mixins.ListModelMixin, viewsets.GenericViewSet): queryset = schema.MyObject.objects.filter(type=schema.MyObject.TYPE.OPEN).order_by('id') serializer_class = MyObjectSerializerということで、modelにメソッドを書くことが良いと思っています。
class MyViewSet(mixins.ListModelMixin, viewsets.GenericViewSet): queryset = schema.MyObject.filter_of_open_object() serializer_class = MyObjectSerializer class MyObject(models.Model): @classmethod def filter_of_open_object(cls): return cls..objects.filter(type=schema.MyObject.TYPE.OPEN).order_by('id')こんな感じ。
別のアプリに関係ないメソッドを共通で利用するモデルに書くのってどうなの??
例で言えばAdminアプリに必要な論理削除されたデータすらも含めて一覧するLIST系のQUERYはAPI側には不要です。不要というより間違えて叩かれると(実装ミスですが)、見せてはならないデータが外に出てしまうことになります。
こういう時にProxyModelが使えます。
こういう感じです。
Modelメソッドと、ProxyModelの注意点
ProxyModelの書き方例
class Article(XModel): TYPE = Choices( ('DRAFT', '下書き'), ('PUBLISH', '公開中'), ) type = StatusField( choices_name='TYPE', blank=False, default=TYPE.DRAFT, help_text="記事の状態", ) text = models.TextField( null=False, blank=False, default="", help_text="記事の内容", ) writer = models.ForeignKey( to="Account", related_name="articles", null=False, on_delete=models.DO_NOTHING, help_text="記事の記入者", ) class ArticleProxy(ProxyModel, schema.Article): @classmethod def list_of_draft(cls): return cls.objects.filter(type=cls.TYPE.DRAFT)こんな形で書いてください。ポイントは
cls.objects.filterです。意味合いは同じでもschema.Article.objects.filterだと、戻り値はArticleの配列になります(厳密にはQuerySetであり配列じゃないですが)Model(Proxy)にメソッドを書く注意点
class ArticleProxy(ProxyModel, schema.Article): @classmethod def list_of_future(cls): return cls.objects.filter(resavation_at=now()) class MyViewSet(mixins.ListModelMixin, viewsets.GenericViewSet): queryset = ArticleProxy.list_of_future() serializer_class = ArticleSerializerこれ、バグってるの分かりますか? now()は一度しか評価されず、リクエストのある度に計算されないです。
この問題の本質は、本来メソッド(古い言い方だと関数)はブラックボックスであり中身を知らなくても呼べるべきことところです。この例だとViewの実装者は普通に「便利なメソッドがあるな、使おう!」ってなりますよね。なぜ、こういうこだわりをするのか?
爆速で事業を立ち上げるスタートアップでは、コミュニケーションすらも無駄だという考え方が存在しています(僕の中には)。ホウレンソウからザッソウに変わりながらも 1on1が推奨されたり、マネジメントを重要視したりしている時代な気がしていますが、XTechではマネジメントが必要な組織は古い、それぞれがプロではないから、そういうのが必要なんだと考えています。(僕のキャリアで一番長いのはマネジメントですがw)
要するに実装をするときにでも、コミュニケーションを取らなくても分かる、普通に作っていれば変なバグやセキュリティホールを作らないというフレームワークは生産性を上げるために大事だと考えています。
ProxyModelのススメ
各アプリケーションを実装する人は、ProxyModel上にメソッドを追加したり、それを利用したりする。普通に利用していれば管理者しかアクセスしないデータにはアクセスできない(そういうメソッドを書かない限り)
最後に
上の例であげたModelにメソッドを書いて、それがブラックボックス的に利用されてバグを踏むケースも回避策があります。これは皆さんが勝手に想像するか、次のコンテンツにでもしようかなと思ってます。
走り書きなので誤字脱字、変なところがあると思いますので、コメント頂ければ時間作って見直します!
- 投稿日:2020-02-20T16:35:01+09:00
Pythonのtry/exceptメモ
webアプリのソースコードをいじっている際、以下のような状況に出会した。
- とある関数を実行した際、特定の処理によるエラーのみスルーさせて処理を続行したい
- 成功の場合も失敗の場合も必ず実行させたい処理がある
- フロントには処理中に一部エラーが発生したことを通知したい
pythonのtry/catchでこんな感じの書き方をしたら動いたので備忘録として書き留めておく。
サンプルコード
class SampleException(Exception): pass def specific_func(raise_error: bool): if raise_error: raise Exception("error from specific_func") else: print("[INFO] success specific_func") def error_sample(raise_error: bool): try: specific_func(raise_error=raise_error) except Exception as e: print("[ERROR] ",e) raise SampleException("一部の処理に失敗しました") finally: print("[INFO] 必ず実行したい処理")main.pyprint("=== 異常系 =====================") try: error_sample(raise_error=True) print("(通知) 処理に成功しました") except SampleException as e: print("(通知)", e) print("=== 正常系 =====================") try: error_sample(raise_error=False) print("(通知) 処理に成功しました") except SampleException as e: print("(通知)", e)実行結果
=== 異常系 ===================== [ERROR] error from specific_func [INFO] 必ず実行したい処理 (通知) 一部の処理に失敗しました === 正常系 ===================== [INFO] success specific_func [INFO] 必ず実行したい処理 (通知) 処理に成功しました
- 投稿日:2020-02-20T16:28:04+09:00
wxListCtrlのカラムクリックのソート
wxListCtrlでカラムクリックしたときに、降順昇順方法をぐぐっていたら下記の記事を見つけたら動作しなかったので
自分でちょっと修正してみました。https://bty.sakura.ne.jp/wp/archives/42
wxListCtrl.py#!/usr/bin/env python #coding:utf-8 import wx caption = (u"No",u"都道府県",u"男女計",u"男",u"女") data = [ (1,u"北海道",5570,2638,2933), (2,u"青森県",1407,663,744), (3,u"岩手県",1364,652,712), (4,u"宮城県",2347,1140,1208), (5,u"秋田県",1121,527,593), (6,u"山形県",1198,575,623), (7,u"福島県",2067,1004,1063), (8,u"茨城県",2969,1477,1492), (9,u"栃木県",2014,1001,1013), (10,u"群馬県",2016,993,1024), (11,u"埼玉県",7090,3570,3520), (12,u"千葉県",6098,3047,3051), (13,u"東京都",12758,6354,6405), (14,u"神奈川県",8880,4484,4396), ] class MyTable(wx.ListCtrl): def __init__(self,parent): wx.ListCtrl.__init__(self,parent,-1,style = wx.LC_REPORT | wx.LC_VIRTUAL) self.InsertColumn(0,caption[0],wx.LIST_FORMAT_CENTER) self.InsertColumn(1,caption[1]) self.InsertColumn(2,caption[2],wx.LIST_FORMAT_RIGHT) self.InsertColumn(3,caption[3],wx.LIST_FORMAT_RIGHT) self.InsertColumn(4,caption[4],wx.LIST_FORMAT_RIGHT) self.items=data self.SetItemCount(len(self.items)) self.Bind(wx.EVT_LIST_COL_CLICK,self.Sort) self.prevColumn = None self.sortAcend = True def OnGetItemText(self,line,col): return str(self.items[line][col]) def Sort(self,event): global data col=event.GetColumn() if col != self.prevColumn: self.sortAcend = True else: if self.sortAcend: self.sortAcend = False else: self.sortAcend = True if self.sortAcend: data = sorted(data, key=lambda x: x[col]) else: data = sorted(data, key=lambda x: x[col], reverse=True) self.prevColumn = col self.DeleteAllItems() self.items=data self.SetItemCount(len(self.items)) class MyWindow(wx.Frame): def __init__(self,parent,id): wx.Frame.__init__(self,parent,id,"MyTitle",size=(450,300)) MyTable(self) if __name__=='__main__': app=wx.App(False) frame=MyWindow(parent=None,id=-1) frame.Show() app.MainLoop()
- 投稿日:2020-02-20T16:26:49+09:00
Djangoを使って将棋棋譜管理アプリを作る3 ~Djangoデフォルトの管理サイトの設定~
はじめに
Djangoを使って将棋の棋譜管理アプリを作っていくなかでの備忘録、第3回です。
作業環境
今回の作業環境は以下の通りです
- Windows 10 Pro
- Anaconda
- version1.7.2
- python 3.7
- django 2.2.5
- git
- version 2.25.0.windows.1
- mysql
- ver 8.0.15 for Win64 on x86_64
また、Djangoのディレクトリ構造は次のようになります。
- kifu_app_project/ - kifu_app_project/ - setting.py - urls.py - wsgi.py - __init__.py - manage.py - kifu_app - admin.py - apps.py - migrations - models.py - tests.py - views.py - __init__.py本稿の内容
- Djangoデフォルトの管理サイトの設定
Djangoデフォルトの管理サイトの設定
Djangoには、DBのデータを閲覧・管理するための管理サイトが、標準で備わっています。
今回はこの管理サイトを使うための設定を行っていきます。admin.pyの編集
kifu_appの中にあるadmin.pyを編集します。
admin.pyfrom django.contrib import admin # Register your models here. # 以下追加 from .models import LargeClass, MiddleClass, SmallClass, Information, Kifu admin.site.register(LargeClass) admin.site.register(MiddleClass) admin.site.register(SmallClass) admin.site.register(Information) admin.site.register(Kifu)前回作成した、models.pyに作成したクラスを全てimportします。
そして、importしたクラスを全てadmin.site.register()の引数に渡します。ログインのためのユーザー作成
次に、manege.pyが見えるところまで、移動し、以下のコマンドを打ちます。
$ python manage.py createsuperuser Username: <ユーザー名> Email address: <Eメール> Password: <パスワード>設定に必要な情報を入力します。
Eメールは入力しなくても大丈夫です。ローカルサーバーを立ち上げる
連載もようやく3回目ですが、ようやくサーバーを立ち上げます。
manage.pyが見えるディレクトリで、次のコマンドを打ってください$ python manage.py runserver
Starting development server at ~に書いてあるアドレスにアクセスしてみてください。通常はlocalhost:8000のはずです。
下の写真のような画面が表れれば、OKです!
管理サイトにログイン
次に今のURLから、
/admin/にアクセスしてください。(通常はlocalhost:8000/admin/)
そこで、先程設定したユーザー名とパスワードを入力して、ログインします。恐らく、下の写真のような画面に遷移すると思います。
管理サイトをカスタマイズ
管理サイトはCSSなどを変更して、自分オリジナルのものに変更できるようです。
ここでは、より使いやすい設定にしていきます。
新規データの挿入
まずはデータをいくつか入れてみて下さい。
addボタンを押せば、簡単に挿入できます。データ内容を返すように、models.pyを変更
しかし、挿入したデータを一覧から見てみると、Objectであることしか分からず、いちいち詳細を確認しなくてはいけません。
そこで、models.pyの各クラスに、
__str__メソッドを追加します。models.pyfrom django.db import models from django.core.validators import MaxValueValidator, MinValueValidator # Create your models here. class LargeClass(models.Model): name = models.CharField(max_length=10) def __str__(self): # 追加 return self.name class MiddleClass(models.Model): large_class = models.ForeignKey(LargeClass, on_delete=models.CASCADE) name = models.CharField(max_length=10) def __str__(self): # 追加 return self.name class SmallClass(models.Model): middle_class = models.ForeignKey(MiddleClass, on_delete=models.CASCADE) name = models.CharField(max_length=10) def __str__(self): # 追加 return self.name class Information(models.Model): date = models.DateTimeField() sente = models.CharField(max_length=50) gote = models.CharField(max_length=50) result = models.IntegerField(validators=[MinValueValidator(0), MaxValueValidator(3)]) my_result = models.IntegerField(validators=[MinValueValidator(0), MaxValueValidator(3)]) small_class = models.ForeignKey(SmallClass, on_delete=models.CASCADE) create_at = models.DateTimeField(auto_now_add=True) update_at = models.DateTimeField(auto_now=True) def __str__(self): # 追加 return self.date class Kifu(models.Model): information = models.ForeignKey(Information, on_delete=models.CASCADE) number = models.IntegerField(validators=[MinValueValidator(0)]) te = models.CharField(max_length=20) def __str__(self): # 追加 return self.te
__str__()メソッドで、表示させたいカラムの変数をreturnさせるようにします。
これでブラウザを更新すると、無事情報が表示されるようになりました。
他にも様々にカスタマイズできるので、以下のサイトを参考にしてみてください。
Python Django チュートリアル(2)
はじめての Django アプリ作成、その 7次回予告
Viewの作成
- 投稿日:2020-02-20T16:25:25+09:00
pymc3でガウス過程
こちらのサイトで見つけたシャンプーの売上に関するデータを用いてGaussian Processによって推定してみようと思います。
https://machinelearningmastery.com/time-series-datasets-for-machine-learning/
ガウス過程はノンパラメトリックの代表的な回帰モデルです。
非線形性のあるデータに強かったり、推定の不確実性を確認できるといったメリットがあります。import os import pandas as pd shampoo_df = pd.read_csv('../data/shampoo.csv') shampoo_df shampoo_df.plot.line(x='Month', y='Sales',c="k");
以下では、適切な尤度と事前分布のペアを得るために、周辺尤度を算出しています。
with pm.Model() as shampoo_model: ρ=pm.HalfCauchy('ρ', 1) # これらはLength scale 大きい値ほど、近い動きに見える <=自己相関的な η = pm.HalfCauchy('η', 1) # これらはLength scale 大きい値ほど、近い動きに見える <=自己相関的な M = pm.gp.mean.Linear(coeffs=(shampoo_df.index/shampoo_df.Sales).mean()) # 初期値 K= (η**2) * pm.gp.cov.ExpQuad(1, ρ) σ = pm.HalfCauchy('σ', 1) gp = pm.gp.Marginal(mean_func=M, cov_func=K) gp.marginal_likelihood("recruits", X=shampoo_df.index.values.reshape(-1,1), y=shampoo_df.Sales.values, noise=σ) trace = pm.sample(1000) pm.traceplot(trace);
最尤推定は、尤度関数p(X|θ)をパラメータθに関して最大化することで当てはまりの良いモデルを作って行くのですが、事前分布p(θ)を使いません。一方、事前分布がある場合を最大事後確率推定というらしいです。
詳しくは以下の本を参照ください。
須山敦志. 機械学習スタートアップシリーズ ベイズ推論による機械学習入門 (Japanese Edition) (Kindle Locations 2154-2156). Kindle Edition.最大事後確率推定によって最適なパラメータを得る。
with shampoo_model: marginal_post = pm.find_MAP(){'ρlog': array(2.88298779),
'η_log': array(5.63830367),
'σ_log_': array(4.13876033),
'ρ': array(17.86757799),
'η': array(280.98567051),
'σ': array(62.72501496)}X_pred=np.array([r for r in range(X_pred.max()+10)]).reshape(-1,1) with shampoo_model: shampoo_pred = gp.conditional("shampoo_", X_pred) samples=pm.sample_ppc([marginal_post], vars=[shampoo_pred] ,samples=100) fig = plt.figure(figsize=(10,5)); ax = fig.gca() from pymc3.gp.util import plot_gp_dist plot_gp_dist(ax, samples["shampoo_"], X_pred); ax.plot(shampoo_df.index, shampoo_df.Sales, 'dodgerblue', ms=5, alpha=0.5); ax.plot(shampoo_df.index, shampoo_df.Sales, 'ok', ms=5, alpha=0.5); plt.show()pm.sample_ppcではmarginal_post内のパラメータに基づく事後予測分布からサンプリングしています。