- 投稿日:2020-02-19T23:55:49+09:00
pythonでグラフを描画
import numpy as np import matplotlib.pyplot as plt #データの作成 x=np.arange(0,12,0.1) y=np.sin(x) plt.plot(x,y) plt.show()これだけでsin関数のグラフを書くことができました
- 投稿日:2020-02-19T23:48:30+09:00
Django モデルクラスを分割する方法
モデルの数が多くなってきたときに分割する方法。
1 models.pyを削除します。
2 同じ階層にmodelsディレクトリを作成します。
3 作成したmodelsディレクトリ内に__init__.pyを作成します。
4 モデルを作成します。models/dog.pyfrom django.db import models class Dog(models.Model): name = models.CharField(max_length=10) age = models.PositiveSmallIntegerField()models/cat.pyfrom django.db import models class Cat(models.Model): name = models.CharField(max_length=10) age = models.PositiveSmallIntegerField()5 __init__.py内にモデルをインポートします。
例models/__init__.pyfrom .dog import Dog from .cat import Catモデルのインポートはfrom .models import * でもできるのですが、名前をちゃんと書くことによって、下記のメリットが得られます。
1 名前空間がシンプルになる。
2 コードが読みやすくなる。
3 コード分析ツールがより正確になります。
- 投稿日:2020-02-19T23:02:55+09:00
responder + Gunicorn + ApacheでWebサイトを公開する
はじめに
responderという、比較的新しい(2018年10月~)Python Webフレームワークがあります。
作者はrequestsなどを作った方で、いわくFlaskとFalconのいいとこどりのようなフレームワークだそうです。
Pythonで簡単なWebページを作ろうと思い立った際にresponderのことを知り、気になったので使ってみることにしました。
見た限りではApacheを用いた解説がなかったので、自分の構築方法をメモ代わりに載せておきます。(もしあればぜひ教えてください……)環境
- Ubuntu 18.04.3 LTS
- Apache 2.4.29
- Python 3.6.8
- Gunicorn 19.9.0
- responder 1.3.2
※ 現在のresponderの最新バージョンはv2.0.5ですが、v1.3.2時点で下記の設定を行ったあとに最新にバージョンアップしても使えています。
ググってみた感じではNginxの方が構築しやすそうでしたが、元々Apacheを入れていたサーバなのでそのまま作ってみることにしました。
ちなみに、Pythonの環境構築ツールについてはvenvのみ使用しています。
venvで環境を作成した上で、作業ディレクトリに以下のようなdirenv設定ファイルを適用すると、作業ディレクトリにcdすると同時にactivateされるので便利です。.envrcsource <venvのactivateファイルのフルパス>STEP0:応答を返すプログラムを書く
以下のプログラムをグローバルに公開して動かすことを目標とします。
プログラム自体に関しては公式のQuick Startに。main.pyimport responder api = responder.API() @api.route("/{who}") def greet_world(req, resp, *, who): resp.text = f"Hello, {who}!" if __name__ == '__main__': api.run()この場合、例えば
/worldにGETでアクセスするとHello, world!と表示されたり、/testtesttestにGETでアクセスするとHello, testtesttest!と表示されたりします。STEP1:responderのビルトインサーバで動かす
responderにはビルトインサーバとしてUvicornが内蔵されています。
まずはresponder(+ Uvicorn)で起動を試します。$ python main.py INFO: Started server process [693] INFO: Waiting for application startup. INFO: Uvicorn running on http://127.0.0.1:5042 (Press CTRL+C to quit)$ curl http://127.0.0.1:5042/world Hello, world!プログラムを実行するだけで自動的にサーバが立ち上がり、つなげるようになっているのが分かります。
サーバを落とすときは書いてあるとおりCtrl+Cで大丈夫です。STEP2:Gunicornを用いて動かす
Uvicorn公式ページいわく本番環境とするにはGunicornを使う方がいいそうなので、公式の設定を参考に動かしてみます。
(この記事を書こうとしてからかなり時間が経ってしまったので、タイムスタンプが数か月前ですが気にしないでください)$ pip install gunicorn $ gunicorn -k uvicorn.workers.UvicornWorker main:api [2019-10-31 09:39:11 +0900] [1227] [INFO] Starting gunicorn 19.9.0 [2019-10-31 09:39:11 +0900] [1227] [INFO] Listening at: http://127.0.0.1:8000 (1227) [2019-10-31 09:39:11 +0900] [1227] [INFO] Using worker: uvicorn.workers.UvicornWorker [2019-10-31 09:39:11 +0900] [1230] [INFO] Booting worker with pid: 1230 [2019-10-31 09:39:12 +0900] [1230] [INFO] Started server process [1230] [2019-10-31 09:39:12 +0900] [1230] [INFO] Waiting for application startup.$ curl http://127.0.0.1:8000/world Hello, world!Gunicornを立ち上げる際の引数についてはざっくり以下のような感じ。
-k uvicorn.workers.UvicornWorker: ワーカークラスにUvicornを指定するmain:api: 起動するモジュールを指定。記法は「モジュール名(プログラム名):responder.API()の変数名」Gunicornの設定ファイルを作成する
Gunicornの設定項目は設定ファイルから読み込むこともできます。設定ファイルがあった方が後々都合がいいので、作成しておきます。
上記コマンドで用いた引数は最低限のものです。ここにログファイルの保存場所などを追加する形で設定ファイルを作成します。gunicorn.pyimport multiprocessing import os name = "gunicorn" accesslog = "<アクセスログを書き込みたいファイル名>" errorlog = "<エラーログを書き込みたいファイル名>" bind = "localhost:8000" worker_class = "uvicorn.workers.UvicornWorker" workers = multiprocessing.cpu_count() * 2 + 1 worker_connections = 1024 backlog = 2048 max_requests = 5120 timeout = 120 keepalive = 2 user = "www-data" group = "www-data" debug = os.environ.get("DEBUG", "false") == "true" reload = debug preload_app = False daemon = False各項目に関しては公式Docsを参照。
設定値は、参考サイトのものを真似させてもらっています。この設定ファイルを適用してGunicornを立ち上げるには、以下のコマンドを使います。
$ gunicorn --config gunicorn.py main:apiSTEP3:Apacheをリバースプロキシサーバとして用いて動かす
最後に、Apacheを通して接続できるよう設定します。
Apacheが動いているhttp://example.com/ に接続された際、Gunicornが待ち構えている http://localhost:8000 にプロキシするように設定を行います。GunicornにプロキシするためのApache側設定
まずはリバースプロキシ用の設定ファイルを作成します。
/etc/apache2/conf-available/responder.confProxyRequests Off ProxyPass "/" "http://localhost:8000/" ProxyPassReverse "/" "http://localhost:8000/"設定ファイル&プロキシ関連モジュールの有効化を行います。
$ sudo a2enconf responder $ sudo a2enmod proxy_http proxy設定ファイルが正しく記述できているかを確認後、リロード。
$ sudo apache2ctl configtest Syntax OK $ sudo systemctl reload apache2ctlGunicornの自動起動設定
自動起動をしやすくするため、Gunicornの起動をsystemdで管理できるように設定します。
まずは設定ファイルの作成。/etc/systemd/system/webapp.service[Unit] Description=gunicorn - responder After=network.target [Service] User=www-data Group=www-data WorkingDirectory=<gunicorn.pyやmain.pyを置いているディレクトリのフルパス> ExecStart=<Gunicornのフルパス> --config <gunicorn.pyのフルパス> main:api ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s TERM $MAINPID PrivateTmp=true [Install] WantedBy=multi-user.targetこちらも分かりにくい項目について説明を入れておきます。
- ファイル名: <任意のサービス名>.serviceで大丈夫です。コマンドでの使用例は
systemctl restart <設定したサービス名>など。- [Service]-User, Group: Apacheのものを使用していますが、これで正しいのかは不明……。WorkingDirectory配下のファイルの所有者も変更しておいた方がいいかもしれません。
- [Service]-ExecStart: STEP2の「Gunicornの設定ファイルを作成する」にあるコマンドをフルパスで記述したものです。
作成後、サービスを立ち上げて自動起動をするよう設定します。
$ sudo systemctl start webapp.service $ sudo systemctl enable webapp.service念のため、きちんと動いているか確認します。
$ sudo systemctl status webapp.service ● webapp.service - gunicorn - responder Loaded: loaded (/etc/systemd/system/webapp.service; enabled; vendor preset: enable Active: active (running) (以下省略)起動、自動起動ともに成功していますね。
完成!
設定がうまくいっていれば、curlやブラウザで接続できるはずです。
$ curl http://example.com/world Hello, world!未解決?問題
何故かApacheを通すとhtmlの
Content-Typeヘッダが消失するという現象が起こっています。
(Gunicornからサーバを立ち上げた際にはきちんと付いています。謎現象)
暫定策としてレスポンスを返す際、強制的にContent-Type: text/html; charset=UTF-8を付けるコードを追加することにしています。おまけのメモ
ついでに、個人的に便利だと思った/ググって見つけにくかったresponderの文法についても書き留めておきたいと思います。
ルーティングの書き方
ルーティング(と処理部分)は、冒頭の書き方以外にもあるようです。
classを作成する+後でまとめてルーティングを設定する.pyimport responder api = responder.API() class Who: def on_get(self, req, resp, *, who): # GETのときは自動的にこっちの処理をする resp.text = f"Hello, {who}!" async def on_post(self, req, resp, *, who): # POSTのときは自動的にこっちの処理をする data = await req.media() resp.text = f"{data}" # ルーティングの設定 api.add_route("/{who}", Who) if __name__ == '__main__': api.run()冒頭の書き方がFlask風、今書いた書き方がFalcon風なんでしょうか?
自分自身は「クラスでon_getなどを用いて記述+デコレータでルーティング設定」で書いていますが、もしかすると邪道なんですかね……。Jinja2のフィルタを追加する
staticなファイルのパスを定義したり、何度も繰り返す処理をすっきりと書きたいときに使えます。
jinja_myfilter.pydef css_filter(path): return f"./static/css/{path}" def list_filter(my_list): return_text = "<ul>\n" for l in my_list: return_text += f"<li> {l} </li>\n" return_text += "</ul>" return return_textmain.pyimport responder import jinja_myfilter api = responder.API() # フィルタを追加 # 注意:v2.0以上ではこの書き方だとエラーになってしまうようです # また時間ができたら追記します api.jinja_env.filters.update( css = jinja_myfilter.css_filter, html_list = jinja_myfilter.list_filter ) @api.route("/") def greet_world(req, resp): param = ["項目1", "項目2"] resp.content = api.template("index.html", param=param) if __name__ == '__main__': api.run()index.html<link rel="stylesheet" type="text/css" href="{{ 'form.css' | css }}"> <!-- Jinja2で処理されて以下のようになる <link rel="stylesheet" type="text/css" href="./static/css/form.css"> --> {% autoescape false %} {{ param | html_list }} {% endautoescape %} <!-- Jinja2で処理されて以下のようになる <ul> <li> 項目1 </li> <li> 項目2 </li> </ul> -->なお、htmlタグを含む文字列が返される場合は
{% autoescape false %}~{% endautoescape %}で囲まないと自動エスケープが働きます。ただし渡しているパラメータがユーザ入力のものだった場合、当然パラメータもエスケープされずに出力されてしまうので気をつけてください。フィルタ内でhtml.escape()などを用いて処理しておくのが無難でしょうか。参考サイト
ResponderをUvicornやGunicornでデプロイする方法 - 技術とかボドゲとかそんな話をしたい
Python responder 入門のために… 下調べ - Qiita
Django + Nginx + Gunicorn でアプリケーションを立ち上げる | WEBカーテンコール
【第1回】ResponderとKerasを使って機械学習Webアプリケーションを作ってみる【大枠作成編】 – 株式会社ライトコード
改行をに変換するJinja2のカスタムフィルター - Google App Engine+Pythonで脱プログラミング初心者を目指す日記
- 投稿日:2020-02-19T22:27:25+09:00
嘘つき族と正直族の問題
はじめに
とあるところで、次のような「嘘つき族と正直族の問題」を見つけました。興味がわいたので自分なりにPythonでプログラムしてみました。
ある村に,Aさん,Bさん,Cさん,Dさんの4人がいました.
このうち2人は嘘つき族であり,このうち2人は正直族であることが分かっています.
嘘つき族は必ずうそをつき,正直族は必ず正直に答えます.
彼らは,論理的であり,ミスはありません.
あなたの手元には, 1,2,3,4と書かれた4枚のカードがあります.同じ数字が書かれたカードはありません.
そこからランダムに選んで,一人1枚ずつ,彼らに渡しました. 彼らは,以下のように発言しました.
Aさん:私のカードは,偶数です.
Bさん:私のカードは,3か4のどちらかです.
Cさん:Bさんは,正直族です.
Dさん:私のカードは,1です.
彼らに配られた可能性のあるカードの数字と,誰が嘘つき族/正直族かを表示するプログラムを作成します.どのように進めるか
Aさん,Bさん,Cさん,Dさんの誰が嘘つき族か正直族か分からない(これが問題だから当然)ので、各人を嘘つき族か正直族かを仮定した全パターンで、全パターンのカードを配り各人の嘘つき族か正直族を判断します。
次に仮定したパターンと判断したパターンが一致した場合に求める解とすれば良いのではないかと思ったので、そのようにプログラムを作っていきます。嘘つきか正直かの判定
以下のように、配られたカードでAさん,Bさん,Cさん,Dさんが嘘つきか正直かを判定します。ただし、CさんはBさんの嘘つき/正直により判定します。
Aさん:
配られたカード 発言内容(固定) 判定 偶数 私のカードは、偶数です. 正直 偶数でない 私のカードは、偶数です. 嘘つき Bさん:
配られたカード 発言内容(固定) 判定 3か4 私のカードは、3か4のどちらかです. 正直 3でも4でもない 私のカードは、3か4のどちらかです. 嘘つき Cさん:
Bさんが 発言内容(固定) 判定 正直 Bさんは、正直者です. 正直 嘘つき Bさんは、正直者です. 嘘つき Dさん:
配られたカード 発言内容(固定) 判定 1 私のカードは、1です. 正直 1でない 私のカードは、1です. 嘘つき 嘘つきか正直かの組合せ
嘘つきか正直かの組合せは以下の6パターンです。嘘つきは0、正直は1で現わします。
Aさん Bさん Cさん Dさん 0 0 1 1 0 1 0 1 0 1 1 0 1 0 0 1 1 0 1 0 1 1 0 0 配るカードの組合せ
配るカードの組合せは、順列のnPk(n個のものからk個選ぶ場合の数)から求めます。今回は4P4で求めます。
Pythonのitertoolsパッケージに順列を求める関数permutations()があるので、それを使います。実際のコード
Python# 嘘つき族と正直族の問題 import itertools #Aさんの判定:私のカードは,偶数です. def judge_A(card_no): if (card_no % 2) == 0: ret = 1 else: ret = 0 return ret #Bさんの判定:私のカードは,3か4のどちらかです. def judge_B(card_no): if card_no == 3 or card_no == 4: ret = 1 else: ret = 0 return ret #Cさんの判定:Bさんは,正直族です. def judge_C(judge_of_B): if judge_of_B == 1: ret = 1 else: ret = 0 return ret #Dさんの判定:私のカードは,1です. def judge_D(card_no): if card_no == 1: ret = 1 else: ret = 0 return ret # 判定 # deal_card : 配ったカード(1、2、3、4).要素数4のリスト. # [0]=Aさん、[1]=Bさん、「2」=Cさん、[3]=Dさん # return : 判定結果.要素数4のリスト. # [0]=Aさん、[1]=Bさん、「2」=Cさん、[3]=Dさん def judge(deal_card): lh_judge = [None, None, None, None] lh_judge[0] = judge_A(deal_card[0]) lh_judge[1] = judge_B(deal_card[1]) lh_judge[2] = judge_C(lh_judge[1]) lh_judge[3] = judge_D(deal_card[3]) return lh_judge def main(): # 嘘つきと正直の組合せ lh_comb = [[0, 0, 1, 1], [0, 1, 0, 1], [0, 1, 1, 0], [1, 0, 0, 1], [1, 0, 1, 0], [1, 1, 0, 0]] # 配るカード(1から4)の組合せ(順列:nPk) cards_comb = list(itertools.permutations([1, 2, 3, 4])) # 嘘つきと正直の組合せ×カードの組合せで調べる. print("\ 嘘つき(0)/正直(1) |配ったカード\n\ Aさん Bさん Cさん Dさん |Aさん Bさん Cさん Dさん\n\ ---------------------------------------------------------") for lh_assumption in lh_comb: for deal_card in cards_comb: lh_judge = judge(deal_card) if lh_assumption == lh_judge: print("{:^7d}{:^7d}{:^7d}{:^7d}|{:^7d}{:^7d}{:^7d}{:^7d}". format(lh_judge[0],lh_judge[1],lh_judge[2],lh_judge[3], deal_card[0],deal_card[1],deal_card[2],deal_card[3])) return if __name__ == '__main__': main()実行結果
以下の6ケースあることが分かりました。
嘘つき(0)/正直(1) |配ったカード Aさん Bさん Cさん Dさん |Aさん Bさん Cさん Dさん --------------------------------------------------------- 0 1 1 0 | 1 3 2 4 0 1 1 0 | 1 3 4 2 0 1 1 0 | 1 4 2 3 0 1 1 0 | 1 4 3 2 0 1 1 0 | 3 4 1 2 1 0 0 1 | 4 2 3 1おわりに
頭の体操に良い問題でした。
- 投稿日:2020-02-19T22:00:44+09:00
コンフュージョンマトリックスって、行合計に対する各要素の比率も必要なんじゃ?
はじめに
Pythonデータサイエンスハンドブックの勉強中に思ったこと。
seabornでヒートマップ作って誤分類を可視化しているけど、これって全体の中で数字が大きい値に色がつくのでは?
(全分類でサンプル数が同じであればよいが、データ不均衡は往々にして発生するため)行の合計(=各分類)に対する、各要素の割合が分かるヒートマップもあった方がよいのでは。
ということで作った。データの読み込みと分類アルゴリズムの適用
load_and_modelfitting.pyimport numpy as np import matplotlib.pyplot as plt import seaborn as sns; sns.set() from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score from sklearn.metrics import confusion_matrix # サンプルとして今回は手書き文字の画像を分類タスクとしてロード digits = load_digits() X = digits.data y = digits.target # 訓練用と評価用に分割 Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, random_state=0) # 分類アルゴリズムも適当にガウシアンナイーブベイズを適用 model = GaussianNB() model.fit(Xtrain, ytrain) y_model = model.predict(Xtest) accuracy_score(ytest, y_model)ここから本題
いつもの混同行列と、行に対する比率の配列をヒートマップにする
create_confmrx.py# 普通のコンフュージョンマトリックスの2次元配列 mat = confusion_matrix(ytest, y_model) # 各行合計に対する割合を計算し、小数点第3位を四捨五入した2次元配列 mat_dec = np.round(mat / np.sum(mat, axis=1), decimals=2) fig, axes = plt.subplots(1, 2, figsize=(10, 10)) kwargs = dict(square=True, annot=True, cbar=False, cmap='RdPu') # 2つのヒートマップを描画 for i, dat in enumerate([mat, mat_dec]): sns.heatmap(dat, **kwargs, ax=axes[i]) # グラフタイトル、x軸とy軸のラベルを設定 for ax, t in zip(axes, ['Real number', 'Percentage(per row)']): plt.axes(ax) plt.title(t) plt.xlabel('predicted value') plt.ylabel('true value')
描画したヒートマップ情報の解釈案
- 全体を俯瞰する
- 左側(普通のヒートマップ)の対角線上で色が薄い要素に注目し、「全体の中でハズレが多かった行」を特定
- 分類2,9,4,0が該当
- 右側ヒートマップを見て「行単位の中でもハズレが多い要素」を確認する
- 分類2,9が該当しそうなので、サンプル数増やすとかチューニングを優先的に行う
- 逆に分類4,0は、左側だけを見ると色が薄いが、右側を見ると色が濃いのでチューニングの優先順位低
おわりに
コンフュージョンマトリックス、見方がムズい…。

- 投稿日:2020-02-19T21:54:11+09:00
UMLを使って一歩一歩作ってみる #1
はじめに
たまには何か作ってみよう…ということで、今回はUMLを利用してモデルを作成しながら何かをほそぼそ作ってみようかと思います。
どこまで続くかわかりませんが細々と続けてみます。作るもの
ではざっくり作るものを決めましょう。
せっかくなので、弊社に絡めたものにしたいと思います。
弊社では「モデリング添削講座」というサービスがあります。
上記はUMLモデリングスキルの向上を目的とした、通信添削講座です。…ふと思って今回はこれを行うためのサービスが作れないかと考えてみることにしました。
その名も…「UMLモデリング練習帳アプリ」。私自身もUMLでモデリングをするとき、そういった添削などを機械的にできないかと思うときがあります。
また、競技プログラミングも少しやるのですが、同じようにお題が出題され、モデリングスキルを競ったりする場が作れないかと思っています。
ということで、今回はそういったものを作ることを目指します。
ただし…いきなり仰々しいものは作らず、簡単なものを一歩ずつ作っていきます。まずは分析してみよう
では、今回作るべきものを分析しながら考えてみましょう。
概念
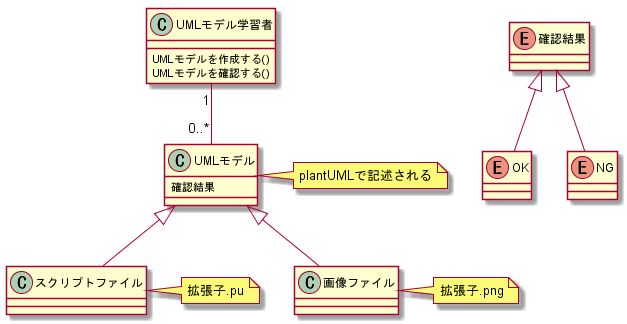
今回は、UMLモデル学習者がUMLモデルを作成し、与えられた問題に対して、作り切れたかを確認することを考えます。
背景として、UMLモデル学習者が大変お金がないので、商用のモデリングツールを使っておらずplantUMLというOSSのツールを使っていることとしました。
(ちなみに下記のファイルもplantUMLで作成したものです。)
plantUML https://plantuml.com/ja/
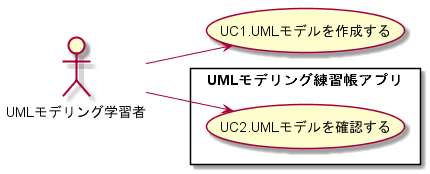
[conceptual model.pu] @startuml /' クラスの宣言 '/ class UMLモデル学習者 class UMLモデル class スクリプトファイル class 画像ファイル enum 確認結果 enum OK enum NG /' UMLモデル学習者のメソッド、フィールドの宣言 '/ UMLモデル学習者 : UMLモデルを作成する() UMLモデル学習者 : UMLモデルを確認する() UMLモデル : 確認結果 /' クラスの関係性 '/ UMLモデル学習者 "1" -- "0..*" UMLモデル UMLモデル <|-- スクリプトファイル UMLモデル <|-- 画像ファイル 確認結果 <|-- OK 確認結果 <|-- NG /' ノートの付与 '/ note right of UMLモデル plantUMLで記述される end note note right of スクリプトファイル 拡張子.pu end note note right of 画像ファイル 拡張子.png end note @endumlユースケース
それでは、そういった概念の中でどこをUMLモデリング練習帳アプリの範囲として開発していくか考えます。
まず、ユースケースを考えてみると、「UC1.UMLモデルを作成する」、「UC2.UMLモデルを確認する」の二つを考えることができました。
作成は、主にエディタであることを考えると、今回は「UC2.UMLモデルを確認する」を対象範囲とするのが良さそうです。
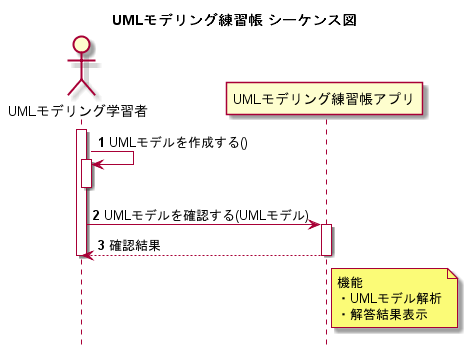
ユースケースのシナリオ(シーケンス)
続いて、ユースケースのシナリオ(シーケンス)を検討していきます。
ただし、実際にUMLモデルを解析する機能は非常に難しく、このアプリにおける重大な設計課題です。
これについては改めて設計する必要がありますが今は置いておきます。
そのため、今回は作成したUMLモデルのスクリプトが、正解となるスクリプトと一言一句一致しているかどうかを確認することにします。ユースケースと機能
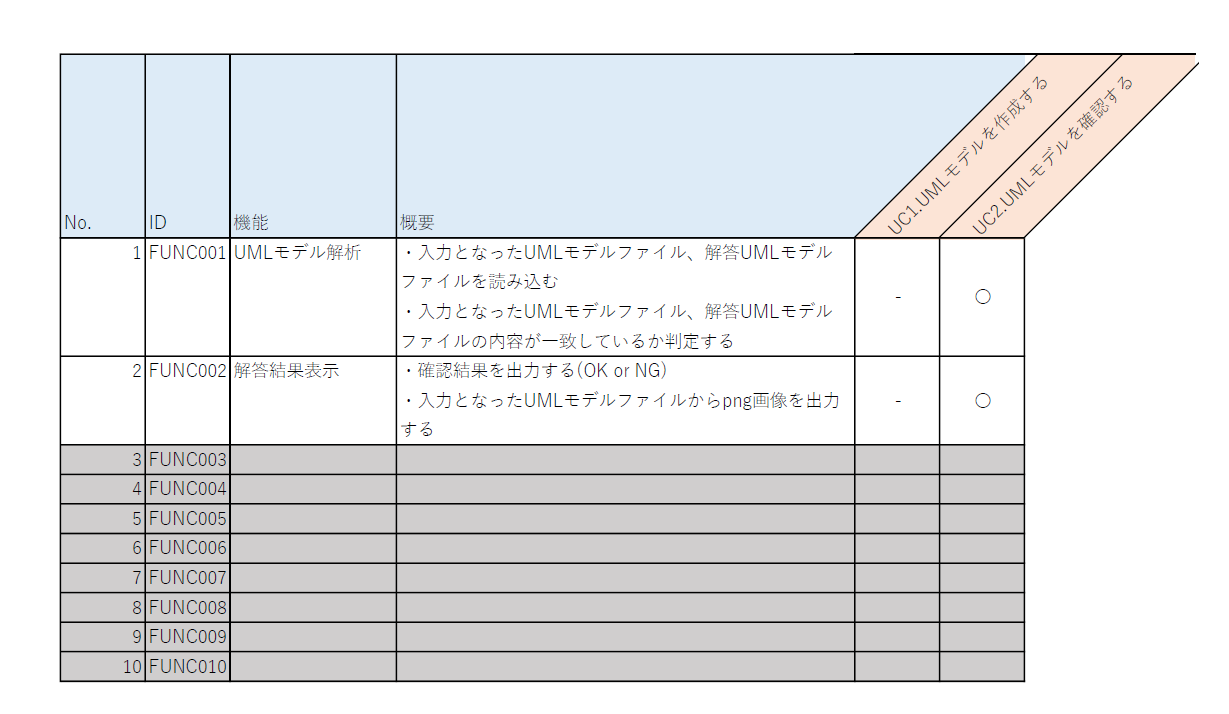
先ほどの分析結果からユースケースとアプリの機能の対応は以下となります。
作るものを決めよう
さて、作るべき機能が明確になったので作るもの決めていきましょう。
今回は、Pythonを開発言語として作ってみることにしました。
UIもこだわらず、まずはCUIで作ることにします。
ただし、UMLモデルを作成するものはplantUMLを利用することにしたため、JVMの環境が必要です。
ではどんな構成でプログラムを作成したらよいかを次に考えてみます。配置
開発する機能は下記の二つなので、main.pyを「UMLモデリング練習帳アプリ」ということにしましょう。
- UMLモデル解析
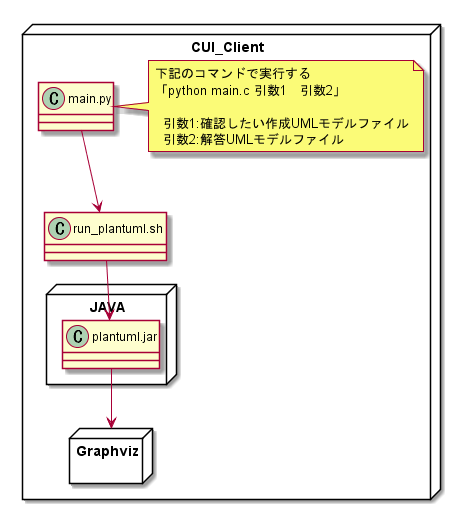
- 確認結果を表示pythonを利用することに決めましたが実際には、異なる仕組みを呼び出して利用する必要があります。
そのため、Pythonからshellスクリプトを用いてplantumlを利用するように実装します。
もちろん、plantumlはGraphvizを呼び出しているのでそれも忘れずに…。
ということで、実際には2ファイルのコードを実装することで実現できそうです。
実装
それでは実装していきます。
今回はかなりべた書き…。[main.py] #! /usr/bin/env python # -*- coding: utf-8 -*- import subprocess import sys import difflib as diff args = sys.argv # args[1] 作成UMLモデルファイル # args[2] 解答UMLモデルファイル # 1.UMLモデルを確認する # 1.1.UMLモデル解析 with open(str(args[1]),"r") as f: submit = f.readlines() with open(str(args[2]),"r") as f: answer = f.readlines() # 1.2.解答結果表示 # 1.2.1.確認結果の出力 # 差分をunified形式で取得 diffs = list(diff.unified_diff(submit, answer, fromfile=str(args[1]), tofile=str(args[2]))) # 確認結果を表示 if len(diffs) == 0 : print("確認結果:OK") else : print("確認結果:NG") # 差分をunified形式で表示 print("-差分結果を表示します-") for i in diffs: print(i, end='') # 1.2.2.画像ファイルの出力 completed_process = subprocess.Popen(["run_plantuml.sh", str(args[1])], shell=True)外部のplantumlで画像がいるを出力したいため、下記のスクリプトを実行するようにします。
[run_plantuml.sh] #!/bin/sh TARGET=$1 echo "plantuml create png image" echo plantuml file:$TARGET java -jar plantuml.jar $TARGET動きをみてみよう
実装し終えたので、今度は動作を確認しましょう。
実行結果
plantuml,Graphvizは利用できるように環境変数を登録しておきます。
登録出来たら、差異があるファイルとないファイルで出力結果を確認してみましょう。$ python main.py 作成UMLモデルファイル 解答UMLモデルファイル出力結果
確認結果がOKの場合
>python main.py usecase.pu usecase.pu 確認結果:OK確認結果がNGの場合
>python main.py usecase.pu usecase_a.pu 確認結果:NG -差分結果を表示します- --- usecase.pu +++ usecase_a.pu @@ -8,10 +8,11 @@ actor UMLモデリング学習者 +usecase UMLモデルを作成する +UMLモデリング学習者 --> (UMLモデルを作成する) + rectangle UMLモデリング練習帳アプリ { - usecase UMLモデルを作成する usecase UMLモデルを確認する - UMLモデリング学習者 --> (UMLモデルを作成する) UMLモデリング学習者 --> (UMLモデルを確認する) }以上で確認結果が出力できることが確認できました。
次回に向けて
さて、今回は一歩一歩ということでCUIベースで作成してみました。
「でもなぁ…サービスなんだから、UMLモデル作成も含めて、Webブラウザ上でやりたいよねー。」
そんな要望がやってきそうです。
ということで次回は、今回の内容をWebアプリにできるかに取り組んでいきます。以上。
- 投稿日:2020-02-19T21:54:11+09:00
UMLモデリングを通して、一歩一歩作ってみる #1
はじめに
たまには何か作ってみよう…ということで、今回はUMLを利用してモデルを作成しながら何かをほそぼそ作ってみようかと思います。
どこまで続くかわかりませんが細々と続けてみます。作るもの
ではざっくり作るものを決めましょう。
せっかくなので、弊社に絡めたものにしたいと思います。
弊社では「モデリング添削講座」というサービスがあります。
上記はUMLモデリングスキルの向上を目的とした、通信添削講座です。…ふと思って今回はこれを行うためのサービスが作れないかと考えてみることにしました。
その名も…「UMLモデリング練習帳アプリ」。私自身もUMLでモデリングをするとき、そういった添削などを機械的にできないかと思うときがあります。
また、競技プログラミングも少しやるのですが、同じようにお題が出題され、モデリングスキルを競ったりする場が作れないかと思っています。
ということで、今回はそういったものを作ることを目指します。
ただし…いきなり仰々しいものは作らず、簡単なものを一歩ずつ作っていきます。まずは分析してみよう
では、今回作るべきものを分析しながら考えてみましょう。
概念
今回は、UMLモデル学習者がUMLモデルを作成し、与えられた問題に対して、作り切れたかを確認することを考えます。
背景として、UMLモデル学習者が大変お金がないので、商用のモデリングツールを使っておらずplantUMLというOSSのツールを使っていることとしました。
(ちなみに下記のファイルもplantUMLで作成したものです。)
plantUML https://plantuml.com/ja/
[conceptual model.pu] @startuml /' クラスの宣言 '/ class UMLモデル学習者 class UMLモデル class スクリプトファイル class 画像ファイル enum 確認結果 enum OK enum NG /' UMLモデル学習者のメソッド、フィールドの宣言 '/ UMLモデル学習者 : UMLモデルを作成する() UMLモデル学習者 : UMLモデルを確認する() UMLモデル : 確認結果 /' クラスの関係性 '/ UMLモデル学習者 "1" -- "0..*" UMLモデル UMLモデル <|-- スクリプトファイル UMLモデル <|-- 画像ファイル 確認結果 <|-- OK 確認結果 <|-- NG /' ノートの付与 '/ note right of UMLモデル plantUMLで記述される end note note right of スクリプトファイル 拡張子.pu end note note right of 画像ファイル 拡張子.png end note @endumlユースケース
それでは、そういった概念の中でどこをUMLモデリング練習帳アプリの範囲として開発していくか考えます。
まず、ユースケースを考えてみると、「UC1.UMLモデルを作成する」、「UC2.UMLモデルを確認する」の二つを考えることができました。
作成は、主にエディタであることを考えると、今回は「UC2.UMLモデルを確認する」を対象範囲とするのが良さそうです。
ユースケースのシナリオ(シーケンス)
続いて、ユースケースのシナリオ(シーケンス)を検討していきます。
ただし、実際にUMLモデルを解析する機能は非常に難しく、このアプリにおける重大な設計課題です。
これについては改めて設計する必要がありますが今は置いておきます。
そのため、今回は作成したUMLモデルのスクリプトが、正解となるスクリプトと一言一句一致しているかどうかを確認することにします。ユースケースと機能
先ほどの分析結果からユースケースとアプリの機能の対応は以下となります。
作るものを決めよう
さて、作るべき機能が明確になったので作るもの決めていきましょう。
今回は、Pythonを開発言語として作ってみることにしました。
UIもこだわらず、まずはCUIで作ることにします。
ただし、UMLモデルを作成するものはplantUMLを利用することにしたため、JVMの環境が必要です。
ではどんな構成でプログラムを作成したらよいかを次に考えてみます。配置
開発する機能は下記の二つなので、main.pyを「UMLモデリング練習帳アプリ」ということにしましょう。
- UMLモデル解析
- 確認結果を表示pythonを利用することに決めましたが実際には、異なる仕組みを呼び出して利用する必要があります。
そのため、Pythonからshellスクリプトを用いてplantumlを利用するように実装します。
もちろん、plantumlはGraphvizを呼び出しているのでそれも忘れずに…。
ということで、実際には2ファイルのコードを実装することで実現できそうです。
実装
それでは実装していきます。
今回はかなりべた書き…。[main.py] #! /usr/bin/env python # -*- coding: utf-8 -*- import subprocess import sys import difflib as diff args = sys.argv # args[1] 作成UMLモデルファイル # args[2] 解答UMLモデルファイル # 1.UMLモデルを確認する # 1.1.UMLモデル解析 with open(str(args[1]),"r") as f: submit = f.readlines() with open(str(args[2]),"r") as f: answer = f.readlines() # 1.2.解答結果表示 # 1.2.1.確認結果の出力 # 差分をunified形式で取得 diffs = list(diff.unified_diff(submit, answer, fromfile=str(args[1]), tofile=str(args[2]))) # 確認結果を表示 if len(diffs) == 0 : print("確認結果:OK") else : print("確認結果:NG") # 差分をunified形式で表示 print("-差分結果を表示します-") for i in diffs: print(i, end='') # 1.2.2.画像ファイルの出力 completed_process = subprocess.Popen(["run_plantuml.sh", str(args[1])], shell=True)外部のplantumlで画像を出力したいため、下記のスクリプトを実行するようにします。
[run_plantuml.sh] #!/bin/sh TARGET=$1 echo "plantuml create png image" echo plantuml file:$TARGET java -jar plantuml.jar $TARGET動きをみてみよう
実装し終えたので、今度は動作を確認しましょう。
実行結果
plantuml,Graphvizは利用できるように環境変数を登録しておきます。
登録出来たら、差異があるファイルとないファイルで出力結果を確認してみましょう。$ python main.py 作成UMLモデルファイル 解答UMLモデルファイル出力結果
確認結果がOKの場合
>python main.py usecase.pu usecase.pu 確認結果:OK確認結果がNGの場合
>python main.py usecase.pu usecase_a.pu 確認結果:NG -差分結果を表示します- --- usecase.pu +++ usecase_a.pu @@ -8,10 +8,11 @@ actor UMLモデリング学習者 +usecase UMLモデルを作成する +UMLモデリング学習者 --> (UMLモデルを作成する) + rectangle UMLモデリング練習帳アプリ { - usecase UMLモデルを作成する usecase UMLモデルを確認する - UMLモデリング学習者 --> (UMLモデルを作成する) UMLモデリング学習者 --> (UMLモデルを確認する) }以上で確認結果が出力できることを確認できました。
次回に向けて
さて、今回は一歩一歩ということでCUIベースで作成してみました。
「でもなぁ…サービスなんだから、UMLモデル作成も含めて、Webブラウザ上でやりたいよねー。」
そんな要望がやってきそうです。
ということで次回は、今回の内容をWebアプリにできるかに取り組んでいきます。以上。
- 投稿日:2020-02-19T21:12:39+09:00
Python Data Science Handbook を和訳してみる
公開しつつ書き足し書き足し、、、
Python Data Science Handbook
Pythonデータサイエンスハンドブック
1. IPython: Beyond Normal Python
- IPython:Pythonより優れた Python
Pythonの開発環境には多くの選択肢があり、自分の仕事でどれを使うか私もよく悩む。
それに対する私の答えはときどき人々を驚かせる。
私の好む環境はIpythonとテキストエディタを併せて使うことだ。
(私の場合、EmacsとAtomを気分によって使い分けている)
Ipython(Interactive Python の略)は2001年にFernando Perezによって拡張pythonインタプリタとして開発され、「リサーチコンピューティングのライフサイクル全体のためのツール」を産み出すことに焦点をあてたプロジェクトへ成長してきた。
pythonが我々のデータサイエンスのタスクのためのエンジンであるならば、
Ipythonはインタラクティブなコントロールパネルであると捉えることができる。Ipythonは、有用なpythonのインタラクティブインターフェースであると同時に、多くの有用な(文法的)(拡張)機能をもたらしている。(そのなかでも特に有用なものが以下である。)
加えて、Ipythonは我々の開発、共同作業、共有、データサイエンスの結果の発表に役立つブラウザベースのノートブックを開発しているJupyterProjectと密接なかかわりがある。
IpythonノートブックはJuliaやRやその他のプログラミング言語用のノートブックを含む、数あるJupyter notebook群のなかでも特殊なケースである。
ノートブック形式の便利さを示す例として、
- 投稿日:2020-02-19T20:55:51+09:00
リテラルに親を殺されたPython解説
@Raclett3さんの
文字列と数値と真理値のリテラルに親を殺されたPythonプログラミング
がめっちゃ面白いなと思うと同時に、何が起きているのか理解できなかったので調べてみました。
解説というか、自分のお勉強です。おもに「小さな数値」の項目をつらつら書きます。
間違ってたらマサカリ投げてください。0
int() # 0or return 0 if no arguments are given
引数が指定されていない場合は0を返す、そうです。
これは簡単。1
len([()]) # 1これはリストがその要素にタプルを1つ持っているので、lenで長さ1が返されるだけですね。
つまり下のような例だと何が起きているか分かりやすいでしょうか。len([(), ()]) # 2 len([1, 2, 3]) # 32
len(((),())) # 2いやらしく全てタプルになっていますが、やっていることは1の外側のリストがタプルになっているだけです。
ちょっと空白を入れてやると分かりやすい。len( ( () , () ) ) # 2 len( ( () , () , () ) ) # 33
len(hex(not())) # 3not()は元記事の@Raclett3さんの解説がめっちゃ分かりやすいのでそちらを。
少しずつ変形してみます。len(hex(not())) # ↓ not() == True len(hex(True)) # ↓ True == 1 len(hex(1)) # ↓ hex()は引数を16進数の 文字列 に変換する。 len('0x1') # つまり3!!4
len(str(not())) # 4これは3が理解できると簡単ですね!
4文字のTrueをstr型にし、lenで長さを取得しています。len(str(not())) # ↓ not() == True len(str(True)) # ↓ Trueが文字列に変換される。 len('True') # 4!!5
len(str(not[()])) # 5これは4のFalse版。
len(str(not[()])) # ↓ not[()] == False len(str(False)) # ↓ Falseが文字列に変換される。 len('False') # 56
len(str(complex(not(),int()))) # 6この辺から頭痛くなりますね
complexは第一引数に実部、第二引数に虚部を取り、complex型の複素数を返します。
こちらも細かく見ていった方が分かりやすいと思います。len(str(complex(not(),int()))) # ↓ not()はTrue、int()は1 len(str(complex(True, 1))) # ↓ Trueは1 len(str(complex(1, 1))) # ↓ 実部1、虚部1のcomplex型の複素数、(1+1j)が返る。 len(str((1+1j))) # len( str( (1+1j) ) ) # ↓ (1+1j)をstr型にする。 len('(1+1j)') # ()を含んだ6文字なので6が返る。7
len(str(bytes(len(((),))))) # 7(((( ;゚Д゚)))
一瞬震えますが、よく見ると1をbytes型にしているだけ。
bytes型の文字列変換については、@Raclett3さんの記事にある通りこちらにサンプルコードもあります。len(str(bytes(len(((),))))) # bytesの中身は、len( ( (), ) ) # ↓ つまり要素数1のタプルの長さがbytesの引数になる。 len(str(bytes(1))) # ↓ 1をbytes型にする。 len(str(b'\\x00') # \\ はエスケープシーケンスなので1文字。 # ↓ b'\\x00'を文字列にしてその長さを得る。 len("b'\\x00") # 7!8
len(str(((),()))) # 8後半戦は()が多く見た目が複雑ですね...
len(str(((),()))) # len( str( ((),()) ) ) # ↓ 「空のタプルを2つ要素に持つタプル」がstr()の引数。 len('((),())') # 要素数2のタプルがそのまま文字列に変換され、文字列の長さ8が返る。9
len(str(([int()],[]))) # 9 len(str(((int()),()))) # 全部タプルにしたらやばい見辛いようやく最後です。
これは8と同じですねlen(str(([int()],[]))) # ↓ int() == 1 len(str(([1],[]))) # ↓ 8と同じくstrの引数は、([1],[])なので... len('([1],[])') # 9!!!めちゃくちゃ長くなりましたが需要あったのだろうか。
こういう基本的なやつは普段ドキュメントを読んだりすることないので勉強するいい機会になりました。
@Raclett3さんに感謝。
- 投稿日:2020-02-19T20:41:21+09:00
整形済みJSON文字列を1行JSONに変換(圧縮)する
整形済みJSON文字列を1行JSONに変換(圧縮)する際に方法を確認したのでメモ。
方法
以下の2通りの方法を紹介する。
- Python
- jqコマンド
ファイルに記載された以下のようなJSON文字列を前提にする。
file.py{ "Records": [ { "database": { "NewImage": { "eventId": { "S": "a4207f7a-5f04-471b-a338-1175182eaa6d" }, "isCompleted": { "BOOL": True } }, "OldImage": { "eventId": { "S": "a4207f7a-5f04-471b-a338-1175182eaa6d" } "isCompleted": { "BOOL": False } } } } ] }方法その1:Pythonを利用
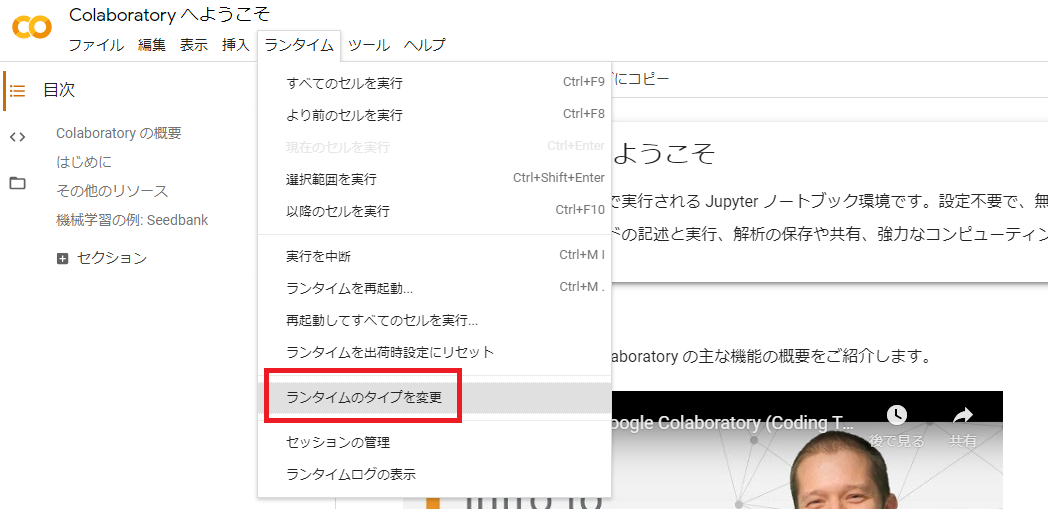
$ python >>> import json >>> f = open("file.json") >>> json.dumps(f.read()).replace("\\n","").replace("\\","").replace(" ", "") '"{"Records": [{"database": {"NewImage": {"eventId": {"S": "a4207f7a-5f04-471b-a338-1175182eaa6d"},"isCompleted": {"BOOL": True}},"OldImage": {"eventId": {"S": "a4207f7a-5f04-471b-a338-1175182eaa6d"},"isCompleted": {"BOOL": False}}}}]}"'
.replace(" ", "")ではインデント(スペース4つ)を置換して削除している。JSON文字列中で異なる文字列をインデントとしている場合は本部分の置換元を変更すれば良い。方法その2:jqコマンドを利用
基本的には
cat <ファイル名> | jq -cで対処可能である。しかし、jqは
TrueやFalseをbooleanとして扱えないため、今回のfile.jsonに対してそのまま実行しようとすると下記のようなエラーとなる。$ cat file.json | jq -c parse error: Invalid numeric literal at line 11, column 0よって、
Trueをtrueへ、Falseをfalseへ事前に変更する必要がある。事前にfile.jsonを手直しした場合は以下のように実行可能である。$ cat file.json | jq -c {"Records":[{"database":{"NewImage":{"eventId":{"S":"a4207f7a-5f04-471b-a338-1175182eaa6d"},"isCompleted":{"BOOL":true}},"OldImage":{"eventId":{"S":"a4207f7a-5f04-471b-a338-1175182eaa6d"},"isCompleted":{"BOOL":false}}}}]}以上
- 投稿日:2020-02-19T20:00:17+09:00
CodeStarでDjangoやーる(Python3.8、Django2.1.15)
プロジェクトの新規作成
CodeStarでPython(Django)を選び、プロジェクトを作成します。レポジトリはCodeCommitを使用します。
CodeStarのダッシュボードが表示され、準備ができたら、アプリケーションのエンドポイントからDjangoのページが見れます。
IAMユーザーを作成し、AWSCodeCommitFullAccessをアタッチします。
認証情報タブからAWS CodeCommit の HTTPS Git 認証情報、認証情報を生成し、ユーザー名とパスワードを保管しておきます。CodeCommitからURLクローンする際に必要になります。
CodeStarのプロジェクトチームに作成したIAMユーザーを追加してください。
プロジェクトの編集
AnacondaでPython3.8の環境を作ります。
$ conda create -n py38 python=3.8 $ conda activate py38CodeCommitからURLをコピーし、gitでクローンします。
$ git clone https://username:password@git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/gachimoto-gtfs $ cd gachimoto-gtfs必要なライブラリをインストールします。
$ pip install -r requirements.txt.gitignoreを追加します。
# Byte-compiled / optimized / DLL files __pycache__/ *.py[cod] *$py.class # C extensions *.so # Distribution / packaging .Python env/ build/ develop-eggs/ dist/ downloads/ eggs/ .eggs/ lib/ lib64/ parts/ sdist/ var/ wheels/ *.egg-info/ .installed.cfg *.egg # PyInstaller # Usually these files are written by a python script from a template # before PyInstaller builds the exe, so as to inject date/other infos into it. *.manifest *.spec # Installer logs pip-log.txt pip-delete-this-directory.txt # Unit test / coverage reports htmlcov/ .tox/ .coverage .coverage.* .cache nosetests.xml coverage.xml *.cover .hypothesis/ # Translations *.mo *.pot # Django stuff: *.log local_settings.py # Flask stuff: instance/ .webassets-cache # Scrapy stuff: .scrapy # Sphinx documentation docs/_build/ # PyBuilder target/ # Jupyter Notebook .ipynb_checkpoints # pyenv .python-version # celery beat schedule file celerybeat-schedule # SageMath parsed files *.sage.py # dotenv .env # virtualenv .venv venv/ ENV/ # Spyder project settings .spyderproject .spyproject # Rope project settings .ropeproject # mkdocs documentation /site # mypy .mypy_cache/ .idea/ db.sqlite3 migrations/buildspec.ymlの一部を編集します。
commands: # Install dependencies needed for running tests - pip install -r requirements/common.txt - python manage.py makemigrations helloworld - python manage.py migrate - python manage.py collectstatic --noinput外部ライブラリをインストールしたら(例:requests)
$ pip install requestscommon.txtも編集します。
# dependencies common to all environments Django==2.1.15 requests==2.22.0最初のページを作成
helloworld/views.py
# helloworld/views.py from django.shortcuts import render from django.views import generic from django.views.generic import TemplateView from django.views.generic import ListView class Top(generic.TemplateView): template_name = 'top.html'helloworld/urls.py
# helloworld/urls.py from django.urls import path from django.conf.urls import url from django.conf.urls.static import static from helloworld import views urlpatterns = [ # url(r'^$', views.HomePageView.as_view()), path('', views.Top.as_view(), name='top'), ]helloworld/tests.py
from django.test import TestCase, RequestFactoryhelloworld/templates/top.html
{% extends "base.html" %} {% block content %} <p> gachimoto-gtfsへようこそ </p> {% endblock %}helloworld/templates/base.html
<!doctype html> {% load staticfiles %} <html lang="ja"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.1.0/css/bootstrap.min.css" integrity="sha384-9gVQ4dYFwwWSjIDZnLEWnxCjeSWFphJiwGPXr1jddIhOegiu1FwO5qRGvFXOdJZ4" crossorigin="anonymous"> <title>gachimoto gtfs api</title> </head> <body> <!-- ナビバー --> <nav class="navbar navbar-expand-lg navbar-light bg-light"> <a class="navbar-brand" href="{% url 'top' %}">G</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav mr-auto"> </ul> </div> </nav> <!-- メインコンテント --> <div class="container mt-3"> {% block content %}{% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.0/umd/popper.min.js" integrity="sha384-cs/chFZiN24E4KMATLdqdvsezGxaGsi4hLGOzlXwp5UZB1LY//20VyM2taTB4QvJ" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.1.0/js/bootstrap.min.js" integrity="sha384-uefMccjFJAIv6A+rW+L4AHf99KvxDjWSu1z9VI8SKNVmz4sk7buKt/6v9KI65qnm" crossorigin="anonymous"></script> </body> </html>ec2django/urls.py
""" ec2django URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/2.1/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.conf.urls import url, include 2. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls')) """ from django.conf import settings from django.conf.urls.static import static from django.conf.urls import include, url from django.contrib import admin from django.contrib.staticfiles.urls import staticfiles_urlpatterns from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('helloworld.urls')), ]ec2django/settings.py
""" Django settings for ec2django project. Generated by 'django-admin startproject' using Django 2.1.14. For more information on this file, see https://docs.djangoproject.com/en/2.1/topics/settings/ For the full list of settings and their values, see https://docs.djangoproject.com/en/2.1/ref/settings/ """ import os # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # Quick-start development settings - unsuitable for production # See https://docs.djangoproject.com/en/2.1/howto/deployment/checklist/ # SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = 'CHANGE_ME' # 適当に変てね # SECURITY WARNING: don't run with debug turned on in production! DEBUG = True # bool( os.environ.get('DJANGO_DEBUG', False) ) ALLOWED_HOSTS = ['*'] # Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'helloworld.apps.HelloworldConfig', # 'helloworld', ] MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] ROOT_URLCONF = 'ec2django.urls' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [ os.path.join(BASE_DIR,'templates') ], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ] WSGI_APPLICATION = 'ec2django.wsgi.application' # Database # https://docs.djangoproject.com/en/2.1/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } # Password validation # https://docs.djangoproject.com/en/2.1/ref/settings/#auth-password-validators AUTH_PASSWORD_VALIDATORS = [ { 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', }, { 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', }, { 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', }, { 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', }, ] # Internationalization # https://docs.djangoproject.com/en/2.1/topics/i18n/ LANGUAGE_CODE = 'ja' # 'en-us' TIME_ZONE = 'Asia/Tokyo' # 'UTC' USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/2.1/howto/static-files/ STATIC_URL = '/static/' STATIC_ROOT = 'static'プロジェクトのデプロイ
ページを確認します。
$ python manage.py migrate $ python manage.py runserver
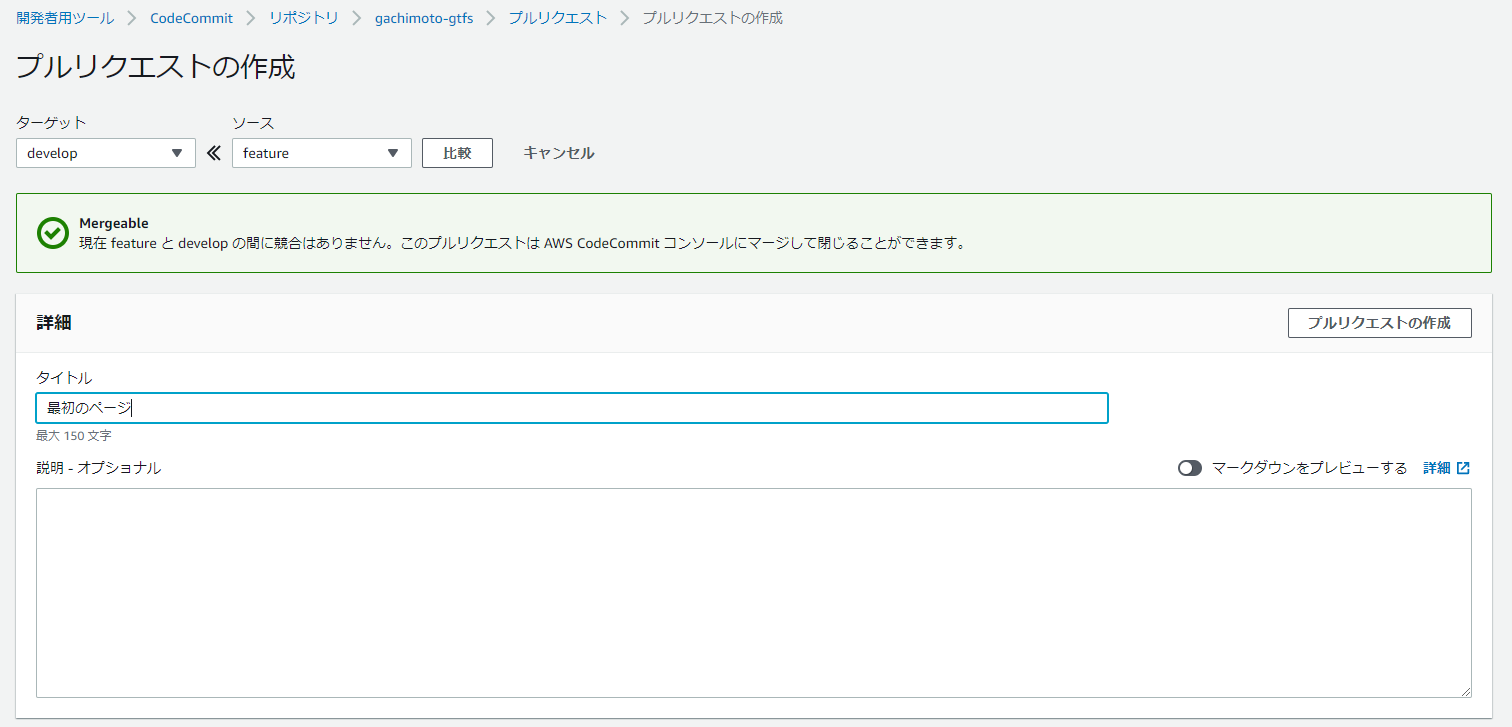
featureブランチを作成し、コミットします。
$ git branch feature $ git checkout feature $ git status $ git add . $ git commit -m "最初のページ" $ git push origin featureCodeCommitでdevelopブランチを作成します。
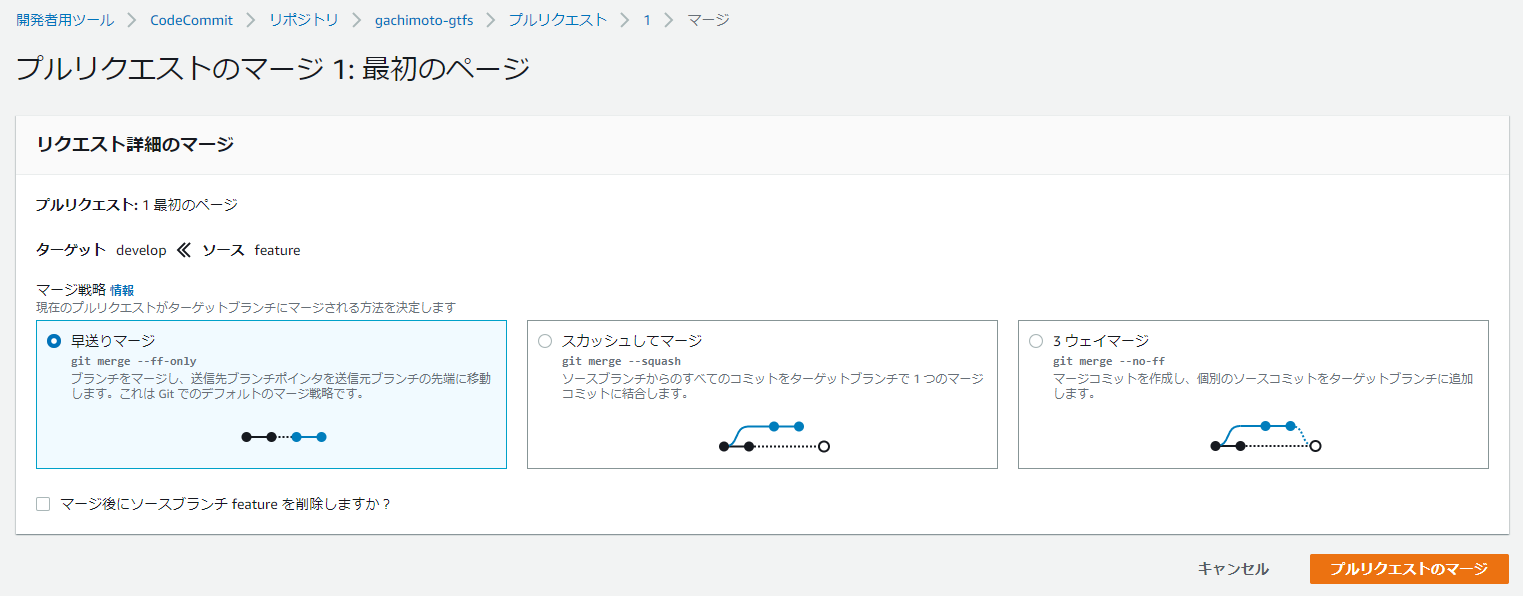
featureからdevelopへマージします。
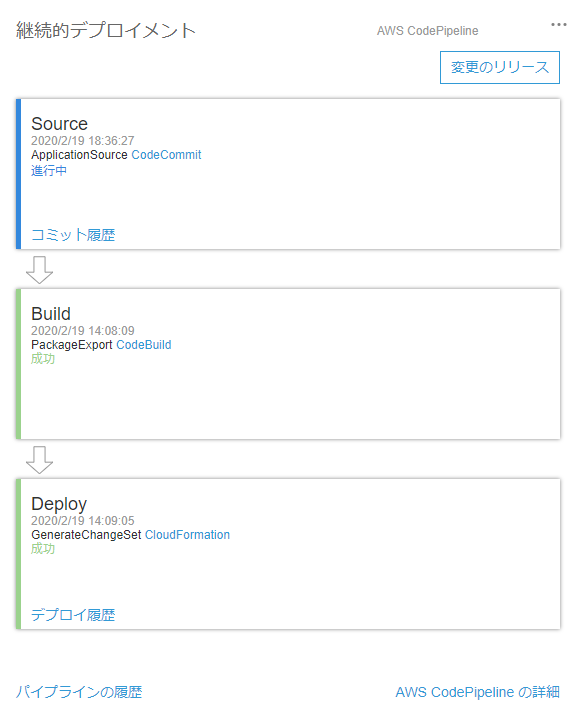
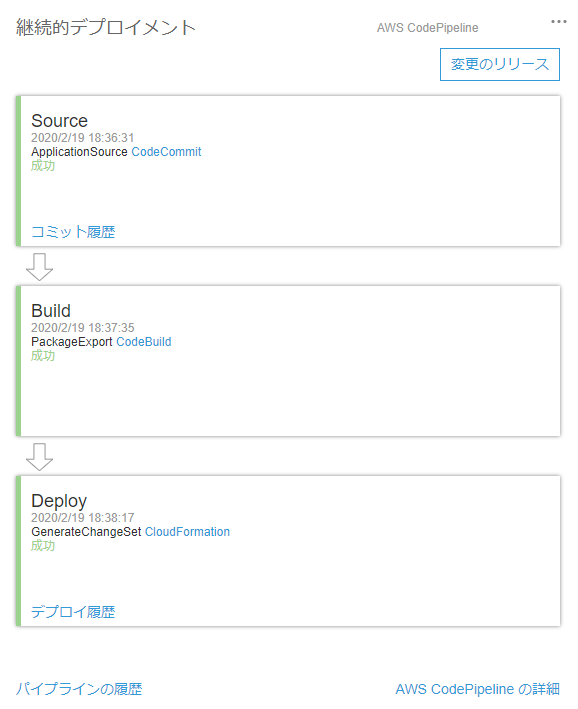
同様にdevelopからmasterへマージします。するとCodePiplineが起動し、勝手にデプロイしてくれます。
デプロイに成功しました。
デプロイに成功したらページを見てみましょう。
EC2再起動時にDjangoを起動するように設定を行います。
お疲れ様でした。これでサクッとDjangoアプリが作れますね!
追記
staticファイルの読み込みと本番設定(Debug=False)
staticファイルを集める。
$ python manage.py collectstatic --noinput $ python manage.py runserversettings.py
DEBUGモードをFalseにします。
DEBUG = Falseurls.py
staticフォルダ設定を追加します。
urlpatterns = [ path('admin/', admin.site.urls), path('', include('helloworld.urls')), ] + static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)画像追加
helloworld/static/helloworld/img/とstatic/helloworld/img/に任意の画像追加します。cssなども追加した場合、staticフォルダ以下を統一しておく必要があります。DEBUG=False時に正しく読み込めない場合があります。
画像表示例(base.html)
<a class="navbar-brand" href="{% url 'top' %}"><img src="{% static 'helloworld/img/G.svg' %}" width="11%" /></a>




- 投稿日:2020-02-19T19:49:10+09:00
【Django】ディレクトリ構成のプラクティス + 注意点
Djangoアプリケーションのディレクトリ
Djangoアプリケーションは1アプリごとにディレクトリを生成するので、
$ python manage.py startapp hogeでアプリを追加していくと、ルートディレクトリにどんどんフォルダが出来てしまう。ディレクトリごとに機能を分離できるのは良いのだが、すべての機能が並列ではないので、アプリケーションが増えるたびに見通しが悪くなっていってしまう。
自分の場合、
./app/sub_app/...とディレクトリをネストし、すっきりさせることが多い。
- 並列にアプリケーションを作っていく場合の例
機能は分離できるものの、urlと対応しておらず見通しが悪い。. ├── account/ (/account/login etc) ├── auth_api/ (/api/auth/...) ├── config │ └── settings.py ├── email/ (/account/email/...) ├── manage.py ├── password/ (/account/password/...) └── polls_api/ (/api/polls/...)
- アプリケーションをネストして作っていく場合の例
urlとディレクトリが対応し、わかりやすい。. ├── account/ (/account/login etc) │ ├── email/ (/account/email/...) │ └── password/ (/account/password/...) ├── api/ │ ├── auth/ (/api/auth/...) │ └── polls/ (/api/polls/...) ├── config │ └── settings.py └── manage.pyしかし、躓く点が多いので注意点をまとめる。
環境
- CentOS 7
- Django 3.0.3
- Python 3.7.4
前提
以下は、
$ django-admin startproject config .とした後、python manage.py startapp accountとした場合のフォルダ構成。. ├── account │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── config │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py ├── poetry.lock └── pyproject.toml
- urls.pyの作成
urls.pyはよくアプリケーションディレクトリに作成するので、account/urls.pyを追加しておく。
TopViewというViewを作成したとする。account/urls.pyfrom django.urls import path, include from . import views app_name = 'account' urlpatterns = [ path("top/", views.TopView.as_view(), name="top") ]
config/urls.pyでaccount/urls.pyをincludeしておく。config/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('account/', include('account.urls')), # 追加 ]
- settings.pyに登録
最後に、accountアプリケーションをconfig/settings.pyに記入。config/settings.pyINSTALLED_APPS = [ # defaults 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', # 追加 'account' ]
- urlの参照
この場合、TopViewのurlは、
/account/topである。
template内では、以下のようにurlを指定する。<a href="{% url 'account:top'%}">トップぺージへのリンク</a>HTMLがレンダーされる際、Djangoが以下のように展開してくれる。
<a href="/account/top">トップぺージへのリンク</a>accountディレクトリ内にアプリケーションを作成
アプリを作成
accountフォルダの中に、パスワード関連機能をまとめたpasswordアプリを作成する。
python manage.py startapp password account/passwordとすると作成されそうなものだが、
残念ながらstartappで位置を指定する場合、ディレクトリを作成してくれない。$ python manage.py startapp password account/password CommandError: Destination directory '.../account/password' does not exist, please create it first.先にディレクトリを作成しろと言われるので、作成。
そうすると、account/password内にアプリが作成される。$ mkdir account/password $ python manage.py startapp password account/password現在のディレクトリ。
. ├── account │ ├── (略) │ └── password │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── config │ └── (略) ├── manage.py ├── poetry.lock └── pyproject.tomlurlを登録
今までと同じように、
account/password/urls.pyを作成する。
ViewにPassChangeViewというViewを作成した。account/password/urls.pyfrom django.urls import path, include from . import views app_name = 'password' urlpatterns = [ path('change/', views.PassChangeView.as_view(), name='change'), ]
account/urls.pyでurls.pyをincludeする。この時、
password.urlsをincludeすれば動きそうな気がするが、account.password.urlsとしなければ動かないので注意。account/urls.pyfrom django.urls import path, include from . import views app_name = 'account' urlpatterns = [ path("top/", views.TopView.as_view(), name="top"), path("password/", include('account.password.urls'), name="password") # 追加 ]このとき、PassChangeViewのurlは
/account/password/changeとなる。urlの参照
template内では、以下のようにurlを指定する。
<a href="{% url 'account:password:change'%}">トップぺージへのリンク</a>settings.pyにアプリケーションを登録
account/passwordにpasswordが作成されたが、config/settings.pyにアプリケーションを記入しなければマイグレーションができない。
INSTALLED_APPSに記入する際は、:ではなく.を使用する。config/settings.pyINSTALLED_APPS = [ # defaults 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'account', 'account.password' # 追加 ]migrate
passwordアプリケーションのmigrateを行う場合も少し挙動が違うので注意。$ python manage.py makemigrations password -> 〇 $ python manage.py makemigrations account.password -> × $ python manage.py makemigrations account:password -> × $ python manage.py makemigrations account/password -> ×まとめ
パスとある程度対応させたディレクトリ構成のほうが把握しやすいのですが、最初はいろんなところで躓いたのでまとめました。
3階層までやるとかなりごちゃごちゃしていくのですが、2階層であればすっきりするのでおすすめです。
- 投稿日:2020-02-19T18:55:12+09:00
MemSQLを使ってみようVol.13: 実践編6
今回はJupyter NotebookとMemSQLの連携に挑戦!!
前回の検証では、Mac環境上のDockerを経由して、MemSQLとRを連携してみました。今回はPython系で著名なJupyter NotebookをMemSQLと連携させてみたいと思います。Pythonの開発環境としても良く使われている様なので、分析だけではなく、機械学習やAIへのアプローチを、Python系で行われる際の参考になれば幸いです。
導入手順
今回は前回と同様に、Mac環境で作業を行います。
(1)Xcodeを導入します
まずは、お約束のXcodeを導入します。
自分の環境では、この段階でコマンドライン系も含めて全部入りましたので、関連環境の整備に移ります(既にネットに上がっている諸先輩方の投稿では、ここでコマンドライン環境を導入されているケースがありますので、念のため確認してみてください。
(3)Homebrewをインストールします
Homebrewのホームページより指示に従ってインストールします。
Homebrewが導入されたかを確認% brew update % brew upgrade % brew doctor因みに、今回の作業環境はこんな感じでした(参考まで)
pip3経由でいよいよJupyter Notebookのインストールを行います。
% pip3 install jupyterインストールが始まりますので、暫くの間心静かに完了を待ちます。
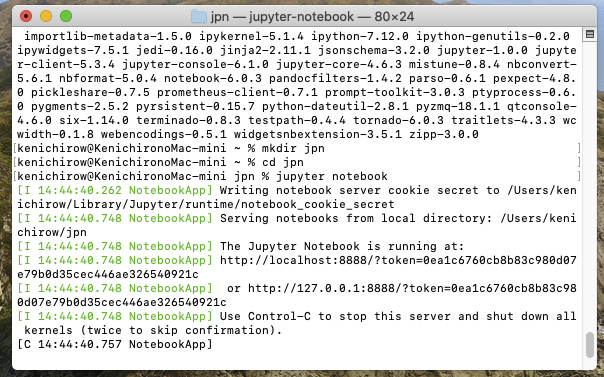
インストールが終わったら、作業用のディレクトリを作って移動します。(xxxは適宜設定してください)% mkdir xxx % cd xxxこれは、jupyter notebookを実行したディレクトリが自動的にホーム画面になるみたいなので、あちこちに散らかる事を避ける為にも、任意の場所にmkdirで作業用のディレクトリを作成して、そのディレクトリに移動してからjupyter notebookを起動するようにしましょう。
% jupyter notebook起動処理が始まりますので、暫くお待ちください。
暫くインストールが実行された後に、ブラウザへJupyter Notebookのホームページが表示されます。
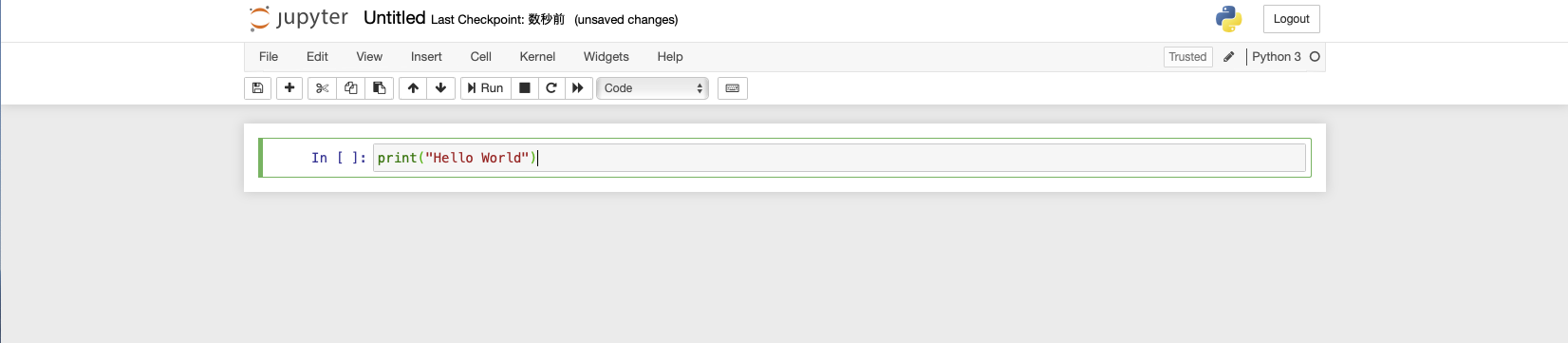
お約束の動作確認をしてみます。print("Hello World")この記述を空欄に入れてRunを選択します。
無事に動き始めた様です。
いよいよMemSQLとの連携・・・
さて、いよいよMemSQLとの連携作業に入りますが、その前にクリアしておかなければならない、ある意味非常に重要な準備作業があります。既にお気づきの方も多いかと思いますが、双方共にGUIベースのコンソールを使う場合・・・良くある8080衝突問題が顕在化してきますので、その対策を施しておく必要があります。今回はJupyter Notebook側の配信ポートを引越しさせる事にします。
作業的には以下の手順をMacのコンソールで行います。
% jupyter notebook --generate-configホームのトップディレクトリに以下のファイルが出来ると思いますので、その内容を確認してポート番号を変更します。
~/.jupyter/jupyter_notebook_config.py
viエディタ等で
#c.NotebookApp.port = 8888
を探して、行頭の#を削除してください(この場合は8888が再起動後のポートになります)
無事にMemSQLのコンソールとJupyter Notebookが共存出来る様になりました。
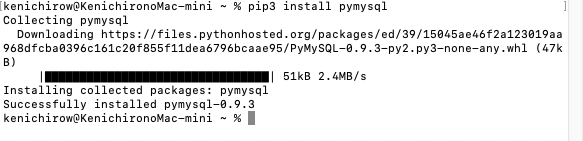
次にpymysqlをインストールします。
% pip3 install pymysqlサクッと入りました。
今回も前回同様に、Mac上のDocker環境にMemSQLを動かして、その環境と今季のJupyter Notebookを連携させる方向で作業を行います。
Docker上でMemSQLを起動します。
% docker start memsql-ciabいよいよ連携検証を実行!!
今回の連携も、得意のMySQLのフリ作戦で行きたいと思います。データベースは、以前の検証で作ったR連携時のテーブルをそのまま読み出してみます。
Jupyter Notebook上で以下のスクリプトを入力します。
import pymysql db = pymysql.connect(host='127.0.0.1', user='root', password='', db='r_db', charset='utf8', cursorclass=pymysql.cursors.DictCursor) db.commit()前段までの設定に問題が無ければ、最後のdb.commit()でMemSQLと接続されます。
次に、ターゲットのテーブルからデータを読み出してみます。
with db: cur=db.cursor() cur.execute("SELECT * FROM test99") rows=cur.fetchall() for row in rows: print (row)無事にデータを読み出せました。
今度はJupyter NotebookからMemSQLにデータを書き込んでみます・・・
基本的には、前述の方法を踏襲して行けば問題なくゴールに辿り着けると思います。
import pymysql db = pymysql.connect(host= '127.0.0.1', user='root', password='', db='r_db', charset='utf8', cursorclass=pymysql.cursors.DictCursor) db.commit() with db: cur=db.cursor() cur.execute("CREATE TABLE IF NOT EXISTS p_test(id INT auto_increment primary key, data VARCHAR(25))") cur.execute("INSERT INTO p_test(data) VALUES('aaaaaaa')") cur.execute("INSERT INTO p_test(data) VALUES('bbbbbbb')") cur.execute("INSERT INTO p_test(data) VALUES('ccccccc')")結果をMemSQLのコンソールで確認してみます。
無事に書き込みの検証も完了できました。
今回のまとめ
今回は、Python界で著名なJupyter NotebookとMemSQLの連携を簡単に検証してみました。基本環境の構築が上手く出来れば特に難しい事もなく、次の応用展開が可能になると思います。機械学習やAI,また分析等のエンジンとしてPython界で良く使われている様ですので、ぜひこの機会にMemSQLとの連携稼働を検討してみてください。
今回の環境は、Mac上にDocker版のMemSQL、通常インストールのjupyter Notebookを組み合わせています。前回のR同様パワーのあるノートブック上でも構築できる環境ですので、気軽に高速インメモリSQLを活用して頂ければ幸いです。
謝辞
本解説に転載させて頂いているスクリーンショットは、一部を除いて現在MemSQL社が公開されている公式ホームページの画像を使わせて頂いており、本内容とMemSQL社の公式ホームページで公開されている内容が異なる場合は、MemSQL社の情報が優先する事をご了解ください。



- 投稿日:2020-02-19T18:54:20+09:00
【Python & SQLite】競馬で「人気より走らせる」騎手を分析する
概要
前回【Python & SQLite】単勝1倍台の馬がいるレースの期待値分析してみた②
前々回【Python & SQLite】単勝1倍台の馬がいるレースの期待値分析してみた①
に引き続き、netkeiba-scraperで取得した過去10年データを使って競馬の妙味について分析していきます。
またSQLへ列(妙味計算用フラグ)を追加し、matplotlibで散布図を描くことも行ないます。今回のテーマは「人気より着順を上にもってくる騎手」です。
騎手で馬券を買うこと
前回までの分析では、単勝人気と競馬場コースという、「人」でも「馬」でもないファクターを使用しました。
そのため「期待値の高い買い目を探す」ことが目的となってしまい、また再現性に乏しい(分析結果を100%信じて買いづらい)分析となってしまいました。しかし「馬」にフォーカスした分析は困難な理由がいくつもあります。
・一般的に生涯1-30戦程度しか出走しないため、分析する間に引退してしまう
・走法(完歩のピッチやストライド)のデータを集めるのが非常に難しい(一頭ずつ手動計測する他ない)
・競走馬の能力は一定ではない
・レースで競う相手が毎回同じでないそこで今回は、騎手に焦点を当てて分析していこうと思いました。
得意コース、苦手コースを見極め、馬券妙味に繋げていきたいと思います。「人気より走った」フラグをSQLに追加する
「実力の割に人気しにくい馬を狙う」のが競馬ファンのセオリーの一つであります。
そこでnetkeiba-scraperで取得したテーブルに、新たに列を追加します。AddFlag# 人気と結果の差でフラグ付ける # 0が人気-結果が3以上、1が+-2以内, 2が-3以下 import mysql.connector as mydb import sqlite3 as sq conn = sq.connect('race.db') cur = conn.cursor() cur.execute("ALTER TABLE race_result ADD COLUMN umami INTEGER") cur.execute("UPDATE race_result SET umami=0 WHERE popularity - order_of_finish >= 3") cur.execute("UPDATE race_result SET umami=1 WHERE abs(popularity - order_of_finish) <3") cur.execute("UPDATE race_result SET umami=2 WHERE popularity - order_of_finish <= -3") conn.commit()umamiという名前の列を追加し、「人気 - 着順」が3以上の時は0, ±3未満の時は1, -3以下の時は2としました。
例えば12番人気で6着なら0, 2番人気で4着なら1, 1番人気で5着なら2となります。騎手別の妙味、勝率などを調べる
追加したumami列を使って、騎手別の人気-着順平均を見てみましょう。
ノイズを防ぐため、通産騎乗回数が100回未満の騎手は除いています。UmamiByJockeycur.execute("SELECT r.jockey_id, round(avg(r.umami),3), \ round(CAST(sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \ round(CAST(sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \ sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END), \ sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END), \ count(*) \ FROM race_result r INNER JOIN race_info i on r.race_id=i.id \ GROUP BY r.jockey_id HAVING count(r.umami) >= 100 ORDER BY avg(r.umami) ASC") rows = cur.fetchall() print('騎手id', 'umami', '勝率', '複勝率', '勝利数', '複勝数', '騎乗回数') for row in rows: print(row) -----結果----- 騎手id umami 勝率 複勝率 勝利数 複勝数 騎乗回数 ('01082', 0.668, 2.51, 9.55, 5, 19, 199) ('01105', 0.706, 2.39, 12.17, 10, 51, 419) ('01010', 0.713, 1.87, 8.05, 13, 56, 696) ('01177', 0.723, 0.45, 8.52, 1, 19, 223) ('01057', 0.724, 2.82, 9.32, 10, 33, 354) etc...騎手ごとのumami、勝率、複勝率をまとめることができました。
matplotlibで散布図表示する
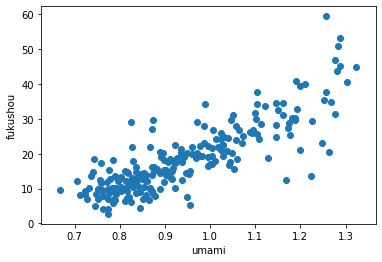
matplotlib# umamiと複勝率でグラフを描いてみる import numpy as np import matplotlib.pyplot as plt %matplotlib inline x = [] y = [] for row in rows: # xにumami, yに複勝率を入れていく x.append(row[1]) y.append(row[3]) plt.scatter(x,y) plt.xlabel("umami") plt.ylabel("fukushou") plt.show()
ここで捕捉しておきたいのは、【umamiの数値は人気のない馬ほど0に近づきやすい】ことです。
12番人気で6着であればumamiは0ですが、1番人気で1着でもumamiは1、もし4着なら2になるため、
【人気騎手ほどumamiの数値は2に近づきやすい】です。
そのためumami数値が小さい騎手は複勝率も低い結果となりがちです。こうして騎手の複勝率とumamiの相関関係を可視化することができました。
基本的にグラフ左上にいる騎手ほどオイシイ馬券をもたらし、右下にいる騎手ほど「買うべきでない」人気先行型といえます。ちなみにumamiが1未満で複勝率が30%付近にいる騎手は障害レースの金子騎手や白浜騎手、
複勝率が50%を超えている騎手はモレイラ騎手やC.ルメール騎手、
umamiが1.1以上で複勝率が20%周辺にいる騎手は藤田菜七子騎手、ミナリク騎手、ピンナ騎手などでした。騎手を深堀りしてみる
武豊騎手のコース別成績を調べる
例として、武豊騎手のデータを見てみましょう。umamiは1.267, 複勝率は35%とmatplotlibのグラフではボーダー上に位置している(人気通りの成績を残している)騎手です。
ここからは平均着順と平均人気も追加しています。TakeYutaka# 武豊を狙うべき競馬場とコースを考える # 30回以上走ったコースのみ表示する cur.execute("SELECT i.place, i.surface, i.distance, round(avg(r.umami),3), \ round(CAST(sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \ round(CAST(sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \ round(CAST(sum(r.order_of_finish) as float) / count(*), 2), \ round(CAST(sum(r.popularity) as float) / count(*), 2), \ sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END), \ sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END), \ count(*) \ FROM race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE r.jockey_id='00666' GROUP BY i.place, i.surface, i.distance HAVING count(*)>=30 ORDER BY avg(r.umami) ASC") rows0 = cur.fetchall() print('競馬場コース', '妙味', '勝率', '複勝率', '平均着順', '平均人気', '勝利数', '複勝数', '騎乗回数') for row in rows0: print(row) -----結果----- 競馬場コース 妙味 勝率 複勝率 平均着順 平均人気 勝利数 複勝数 騎乗回数 ('京都', '芝右外', 1400, 1.09, 17.72, 37.97, 5.28, 4.37, 14, 30, 79) ('阪神', '芝右', 2200, 1.1, 26.0, 52.0, 4.58, 4.04, 13, 26, 50) ('東京', '芝左', 2400, 1.106, 8.51, 19.15, 7.45, 6.26, 4, 9, 47) ('京都', '芝右', 2000, 1.121, 14.75, 39.34, 5.07, 4.11, 27, 72, 183) ('京都', '芝右外', 2400, 1.122, 22.0, 44.0, 4.32, 3.48, 11, 22, 50) etc.....傾向として、京都競馬場芝コースでは人気以上に持ってくることが多い騎手のようです。複勝率も平均以上です。
京都競馬場は武豊の庭!と言われるのも納得できますね。横山典弘騎手の「ヤラズ」を分析する
横山典弘騎手は「ポツン」「ヤラズ」など、馬の余力を残したままレースを終えることが一部で話題の騎手です。
どのような条件で「ヤラズ」になるのか? umami数値を使えば見えてきそうです。YokoyamaNorihiro# 横山典弘を狙うべき競馬場とコースを考える cur.execute("SELECT i.place, i.surface, i.distance, round(avg(r.umami),3), \ round(CAST(sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \ round(CAST(sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END) as float) / count(*) * 100, 2), \ round(CAST(sum(r.order_of_finish) as float) / count(*), 2), \ round(CAST(sum(r.popularity) as float) / count(*), 2), \ sum(CASE WHEN r.order_of_finish = 1 THEN 1 ELSE 0 END), \ sum(CASE WHEN r.order_of_finish IN (1,2,3) THEN 1 ELSE 0 END), \ count(*) \ FROM race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE r.jockey_id='00660' GROUP BY i.place, i.surface, i.distance HAVING count(*)>=30 ORDER BY avg(r.umami) DESC") rows0 = cur.fetchall() print('競馬場コース', '妙味', '勝率', '複勝率', '平均着順', '平均人気', '勝利数', '複勝数', '騎乗回数') for row in rows0: print(row) -----結果----- 競馬場コース 妙味 勝率 複勝率 平均着順 平均人気 勝利数 複勝数 騎乗回数 ('札幌', 'ダ右', 1700, 1.293, 17.24, 43.97, 5.45, 3.53, 20, 51, 116) ('福島', '芝右', 2000, 1.281, 9.38, 28.13, 7.53, 5.22, 3, 9, 32) ('新潟', 'ダ左', 1800, 1.25, 12.5, 28.13, 6.81, 5.06, 4, 9, 32) ('中山', '芝右', 2000, 1.25, 4.97, 23.2, 6.86, 5.22, 9, 42, 181) ('東京', 'ダ左', 1600, 1.24, 15.0, 31.59, 6.15, 4.56, 66, 139, 440) etc...行が多いため見せられませんが、目立つのはダートコースのumami数値の高さです。
「馬が走る気を失くしたら無理に追わない」というスタンスの騎手ですので、
馬が砂をかぶって意欲を失いやすいダートコースでは人気を裏切るケースが多いということでしょうか。武豊騎手は芝・ダート別でumami数値のバランスがよい(芝でもダートでも人気通りの着順になりやすい)のに対し、
横山典弘騎手はダートで特にumami数値が悪いなど、騎手ごとの個性も垣間見ることができました。まとめ
今回は騎手に焦点を当てて分析を行いました。
騎手のコース別成績をさらに深堀りすれば、より競馬が面白くなるかもしれませんね。ここまでご覧いただきありがとうございました。
- 投稿日:2020-02-19T18:10:01+09:00
[Pythonで遊ぼう] 文章自動生成をめざす ~文章自動生成の完成~
はじめに
文章自動生成をめざす、三回目となります。今回は文章生成のための関数を作っていきます。コードとしては長くなります。順番にやっていきましょう。
コード部分
テキストデータの準備をする
ではコードの話となります。まず使うものがこちらになります。
import re from janome.tokenizer import Tokenizer from tqdm import tqdm from collections import Counter from collections import defaultdict import random t = Tokenizer()テキストを準備して読み込ませます。さらにテキストの内容をきれいにしておきます。この辺は前回記事でやった通りです。
a = open('test.txt', 'r', encoding = "utf-8") original_text = a.read() #print(original_text) #文書を表示 first_sentence = '「Pythonの説明。」' last_sentence = 'Pythonという英単語が意味する爬虫類のニシキヘビがPython言語のマスコットやアイコンとして使われている。' #テキストデータを整理する。 _, text = original_text.split(first_sentence) text, _ = text.split(last_sentence) text = first_sentence + text + last_sentence text = text.replace('!', '。') #!や?を。に変える。全角半角に気を付ける text = text.replace('?', '。') text = text.replace('(', '').replace(')', '') #()を削除する。 text = text.replace('\r', '').replace('\n', '') # テキストデータの改行で表示される\nを削除 text = re.sub('[、「」?]', '', text) sentences = text.split('。') #。で文章を一文単位に分割 print('文字数:', len(sentences)) sentences[:10] #10文を表示文章を分解していく
一文ごとに分解します。
start = '__start__' # 文の開始マーク fin = '__fin__' # 文の終了 def get_three_words_list(sentence): #文章を3単語の組にして返す t = Tokenizer() words = t.tokenize(sentence, wakati=True) words = [start] + words + [fin] three_words_list = [] for i in range(len(words) - 2): three_words_list.append(tuple(words[i:i+3])) return three_words_list three_words_list = [] for sentence in tqdm(sentences): three_words_list += get_three_words_list(sentence) three_words_count = Counter(three_words_list) len(three_words_count)単語同士のつながりや重みを付ける
#マルコフ連鎖 def generate_markov_dict(three_words_count): markov_dict = {} for three_words, count in three_words_count.items(): two_words = three_words[:2] #前半2つの単語と次の単語に分割 next_word = three_words[2] if two_words not in markov_dict: #辞書に存在しない場合は空データを生成 markov_dict[two_words] = {'words': [], 'weights': []} markov_dict[two_words]['words'].append(next_word) #次の単語と回数を追加 markov_dict[two_words]['weights'].append(count) return markov_dict markov_dict = generate_markov_dict(three_words_count) markov_dictdef get_first_words_weights(three_words_count): first_word_count = defaultdict(int) for three_words, count in three_words_count.items(): if three_words[0] == start: next_word = three_words[1] first_word_count[next_word] += count words = [] #単語と重み(出現回数)を格納するリスト weights = [] for word, count in first_word_count.items(): words.append(word) #単語と重みをリストに追加 weights.append(count) return words, weights get_first_words_weights(three_words_count)markov_dict = generate_markov_dict(three_words_count) print(len(markov_dict)) first_words, first_weights = get_first_words_weights(three_words_count) print(len(first_words))def get_first_words_weights(three_words_count): first_word_count = defaultdict(int) for three_words, count in three_words_count.items(): if three_words[0] == start: next_word = three_words[1] first_word_count[next_word] += count words = [] #単語と重み(出現回数)を格納するリスト weights = [] for word, count in first_word_count.items(): words.append(word) #単語と重みをリストに追加 weights.append(count) return words, weights get_first_words_weights(three_words_count)def get_first_words_weights(three_words_count): first_word_count = defaultdict(int) #値がint型のdefaultdictを作成 for three_words, count in three_words_count.items(): if three_words[0] == start: #startで始まるもののみを取り出す next_word = three_words[1] first_word_count[next_word] += count # 出現回数を加算 return first_word_count get_first_words_weights(three_words_count)文章自動生成をする
def generate_text(fwords, fweights, markov_dict): first_word = random.choices(fwords, weights=fweights)[0] #最初の単語を取得 generate_words = [start, first_word] #文章生成用に単語を格納するリスト while True: pair = tuple(generate_words[-2:]) #最後の2つの単語を取得 words = markov_dict[pair]['words'] #次の単語と重みのリストを取得 weights = markov_dict[pair]['weights'] next_word = random.choices(words, weights=weights)[0] #次の単語を取得 if next_word == fin: #文章が終了した場合はループを抜ける break generate_words.append(next_word) return ''.join(generate_words[1:]) #単語から文章を作成生成開始!
for l in range(3): sentence = generate_text(first_words, first_weights, markov_dict) print(sentence)結果はこれです。
反省と注意
( ゚Д゚) 原文ママがでてしまった...
絶対的に元のテキスト量が少ないです。
注意点) 私が実行してみたところPCのスペック不足かうまく生成されないことがありました。理由は不明。あと大量のテキストだと時間がかかる。雑談
これで文章の自動生成はできました。「文章自動生成をめざす」はこれで以上となります。改善点はいくつかありますが、やはり元となる文章量や特徴が足りていないです。そのためどうしても原文ママの文章ができあがってしまうことが多々あります。なのでこの例では面白みがない文章となってしまったのが個人的に残念な点です。多少直せたらまた記事にします。
このコードは書籍とそのサンプルコードをもとにつくっています。(本の名前は忘れてしまいました。)その際行った、太宰治.人間失格をもとにできあがった文章も載せておきます。

- 投稿日:2020-02-19T18:04:27+09:00
Dashでdcc.CheckListのチェック状態を全選択・全解除するボタンの実装
日本語と英語で検索しても全然ロクな文献がヒットしなかったので、検索ひっかかるように併記しておきます
Adding a 'Select All' and 'Remove All' Button to a dcc.CheckList.
達成したいこと
- 複数個のチェックボックスを、別に用意したボタンによって全選択・全解除する
結果だけ知りたい方は下へスクロールしてください
やったこと
dcc.CheckListのvalueをcallbackで制御する
チェックリストとボタンだけのさっぱりした環境で調査
当初のソース / at first
python {ファイル名.py} access localhost:{任意のポート}
で起動できますimport dash import dash_core_components as dcc import dash_html_components as html import dash_table from dash.dependencies import Input, Output, State from flask import Flask, request server = Flask(__name__) external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets, server=server) app.title = 'checklist-test' selected_key = None checklists = dcc.Checklist( id='checklist-states', options=[ {'label': 'New York City', 'value': 'NYC'}, {'label': 'Montréal', 'value': 'MTL'}, {'label': 'San Francisco', 'value': 'SF'} ], value=['MTL', 'SF'] ) app.layout = html.Div(id='main',children=[ html.H1(children='チェックリストのテスト'), dcc.Location(id='location', refresh=False), html.Div(className='main-block', children=[checklists]), html.Div(className='second', children=[ html.Button('全選択', id='filter-check-button', className='filter_button', n_clicks=0), html.Button('全解除', id='filter-remove-button', className='filter_button', n_clicks=0) ]) ]) @app.callback( [Output('checklist-states', 'value')], [Input('filter-check-button', 'n_clicks'), Input('filter-remove-button', 'n_clicks')] ) def remove_check(all_check, all_remove): if all_check: return ['NYC', 'MTL', 'SF'] if all_remove: return [] if __name__ == '__main__': app.run_server(host='0.0.0.0', debug=True)
CheckListのvalueへ任意のリストを返却すればいけるっしょ!と思ったが違う
全選択ボタンを押下したとき
return ['NYC', 'MTL', 'SF']dash.exceptions.InvalidCallbackReturnValue: Invalid number of output values for ..checklist-states.value... Expected 1 got 3全解除ボタンを押下したとき
return []dash.exceptions.InvalidCallbackReturnValue: Invalid number of output values for ..checklist-states.value... Expected 1 got 0どうも勝手に皮むきするっぽいので応急処置
if all_check: return [['NYC', 'MTL', 'SF']] if all_remove: return [[]]動くもののエラーは出る
どうもボタンがロードされる時?に一度実行されるっぽく、もろもろが未定義な状態で返り値を渡してしまうためのエラーっぽいdash.exceptions.InvalidCallbackReturnValue: The callback ..checklist-states.value.. is a multi-output. Expected the output type to be a list or tuple but got None.クリック以外で呼ばれたときを明示的に対処する
checklistのvalueをStateを使って読み込む
callbackにState @app.callback( [Output('checklist-states', 'value')], [Input('filter-check-button', 'n_clicks'), Input('filter-remove-button', 'n_clicks')], [State('checklist-states', 'value')] # callbackが発生したときに値を取得する ) def update_check(all_check, all_remove, value_checking):どっちもNoneなら元々valueに入ってる値を返す
皮むき対策も忘れずにif all_check: return [['NYC', 'MTL', 'SF']] if all_remove: return [[]] if all_check is None and all_remove is None: return [value_checking] # 皮むき対策ボタンを何回もクリックする
n_clicksがダメっぽい
いけた!と思ったらクリック1発目しか機能しない
調べてみるとn_clickはクリック回数をカウントするという機能らしく、クリックすると0,1,2,3,4...と値が増えていくらしいこれはこの野郎…!と思いながら撮ったSS
現在Dashには、そもそもクリックされたことだけを検知する機能は実装されていないらしい
代わりに クリックしたunixtimestamp(ミリ秒まで)を取得する n_clicks_timestampというものが用意されているので、それを使用するn_clicks_timestampを使う
イベントが発生したタイミングと今が1秒以内ならオッケーという処理にしておく
if not all_check is None: if (time.time() * 1000 - all_check) < 1000: return [['NYC', 'MTL', 'SF']] if not all_remove is None: if (time.time() * 1000 - all_remove) < 1000: return [[]] if all_check is None and all_remove is None: return [checking]結果
???????
最終的なソース / in the end
import dash import dash_core_components as dcc import dash_html_components as html import dash_table from dash.dependencies import Input, Output, State from flask import Flask, request import time server = Flask(__name__) external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets, server=server) app.title = 'checklist-test' selected_key = None checklists = dcc.Checklist( id='checklist-states', options=[ {'label': 'New York City', 'value': 'NYC'}, {'label': 'Montréal', 'value': 'MTL'}, {'label': 'San Francisco', 'value': 'SF'} ], value=['MTL', 'SF'] ) app.layout = html.Div(id='main',children=[ html.H1(children='チェックリストのテスト'), dcc.Location(id='location', refresh=False), html.Div(className='main-block', children=[checklists]), html.Div(className='second', children=[ html.Button('全選択', id='filter-check-button', className='filter_button'), html.Button('全解除', id='filter-remove-button', className='filter_button') ]) ]) @app.callback( [Output('checklist-states', 'value')], [Input('filter-check-button', 'n_clicks_timestamp'), Input('filter-remove-button', 'n_clicks_timestamp')], [State('checklist-states', 'value')] ) def update_check(all_check, all_remove, checking): if not all_check is None: if (time.time() * 1000 - all_check) < 1000: return [['NYC', 'MTL', 'SF']] if not all_remove is None: if (time.time() * 1000 - all_remove) < 1000: return [[]] if all_check is None and all_remove is None: return [checking] if __name__ == '__main__': app.run_server(host='0.0.0.0', debug=True)


- 投稿日:2020-02-19T17:54:56+09:00
軸の増やし方
pytorch
unsqueeze()を使う.a = torch.rand((3, 3)) a.size() # -> [3, 3] a = a.unsqueeze(0) a.size() # -> [1, 3, 3] a = a.unsqueeze(1) a.size() # -> [3, 1, 3]numpy
reshape,newaxis,expand_dimsを使う方法がある.
reshapeかnewaxisを使えば複数同時に増やすことも可能.
reshapeはめんどくさいからnewaxisかな〜.a = np.random.normal(size=(3,3)) a.shape # -> [3, 3] # reshape b = a.reshape(1, 3, 3) b.shape # -> [1, 3, 3] c = a.reshape(3, 1, 3) c.shape # -> [3, 1, 3] d = a.reshape(1, *a.shape) d.shape # -> [1, 3, 3] # newaxis b = a[np.newaxis] b.shape # -> [1, 3, 3] c = a[:, np.newaxis] c.shape # -> [3, 1, 3] # expand_dims b = np.expand_dims(a, 0) b.shape # -> [1, 3, 3] c = np.expand_dims(a, 1) c.shape # -> [3, 1, 3]
- 投稿日:2020-02-19T16:50:42+09:00
Python3と並列処理でチャットを作る - Part.1
前回は…
前回の記事をまだ読んでいない方は先に読むことをおすすめします。
前回は、環境構築についてと、並列処理についてちょーーーっとだけ書きました。今回はガッツリ行きます。体の弱い方はお気をつけください。(意味深)ソースコード
いきなりですが、ソースを全部載せます。
ダウンロード: GoogleドライブServer/master.pyimport socket import sys import time import concurrent.futures def init(): print("[INFO] CHAT [MASTER-SERVER] v0.10") ip = socket.gethostbyname(socket.gethostname()) port = 50000 maxListen = 100 try: global sock sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind((ip, port)) sock.listen(maxListen) except socket.error as e: print("[Err] Couldn't open the port at {}:{}".format(ip, port)) print(e) sys.exit(1) print("[INFO] SERVING AT {}:{}".format(ip, port)) main = Main() if main == 1: print("[INFO] Server will shutdown.") sock.close() sys.exit(0) def Main(): executor = concurrent.futures.ThreadPoolExecutor() time.sleep(1) while True: try: cSock, cAddr = sock.accept() except KeyboardInterrupt: break global Clients Clients.append((cSock, cAddr)) executor.submit(clientHandler, cSock, cAddr) global Quit Quit = True executor.shutdown(False) return 1 def clientHandler(cSock, cAddr): print("[INFO] Connection from {}:{}".format(cAddr[0], cAddr[1])) global Quit, Clients while not Quit: try: rcvMsg = cSock.recv(4096) except ConnectionResetError as e: print("[Err] ConnectionResetError has happened.") print("[Err] INFO: {}:{}".format(cAddr[0], cAddr[1])) print(e) break print("{}:{} -> {}".format(cAddr[0], cAddr[1], rcvMsg.decode("UTF-8"))) sndMsg = "{}:{} -> {}".format(cAddr[0], cAddr[1], rcvMsg.decode("UTF-8")) for i in Clients: if i[1][0] != cAddr[0] or i[1][1] != cAddr[1]: try: i[0].sendall(sndMsg.encode("UTF-8")) except socket.error as e: print("[Err] Socket error has happened.") print(e) if __name__ == "__main__": # Define global variable Quit = False sock = 0 Clients = [] init()Client/client.pyimport socket import sys import concurrent.futures import time def init(): print("[INFO] CHAT [CLIENT] v0.10") ip = input("[INFO] Input server IP>> ") port = 50000 try: global sock sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.connect((ip, port)) except socket.error as e: print("[Err] Couldn't connect the server-> {}:{}".format(ip, port)) print(e) sys.exit(1) print("[INFO] Connected to {}:{}".format(ip, int(port))) main = Main() if main == 1: print("[INFO] Client will shutdown.") sock.close() sys.exit(0) def Main(): executor = concurrent.futures.ThreadPoolExecutor() executor.submit(wait4Receive) time.sleep(1) while True: sndMsg = input(">> ") if sndMsg == "!q": break try: sock.sendall(sndMsg.encode("UTF-8")) except socket.error as e: print("[Err] Socket error has happened.") print(e) pass global Quit Quit = True executor.shutdown(False) return 1 def wait4Receive(): print("[INFO] ThreadStart: wait4Receive") global Quit, sock while True: try: rcvMsg = sock.recv(4096) except ConnectionResetError as e: print("\r[Err] ConnectionResetError has happened.") print(e) break print("\r" + rcvMsg.decode("UTF-8") + "\n>> ", end="") if Quit: sock.close() break if __name__ == "__main__": # Define global variable Quit = False sock = 0 init()とりあえず、これで全部です。結構短いでしょう?でも、意外とやってることがめんどくさかったり複雑だったりするんです…(泣) 僕の技術が足りなすぎるのもあるのでしょうが、なんだかんだで8時間位かかっちゃいました笑 では、解説していきましょ
今回はクライアントの解説のみ書きます。サーバー側は次回にします。クライアント
init()
初期化と準備がメインです。
try-exceptでソケットのオープンをしています。ここで一つ工夫していることがあるんです。一番最後に出てきますが、ソースコードのラストのif文(俗に言うおまじない)で、先にソケットオブジェクトを定義しておきます。そして、ソケットを開く際はglobal文でグローバルオブジェクトの使用を宣言してからsocketオブジェクトを生成しています。こうする事によってMain関数の中で終了処理を行うことができるので結構楽です。Main()
受信以外の主な処理を担当しています。
まずは、受信用のスレッドを起動します。起動待ちに1sのウェイトを入れています。その後のループでは、送信メッセージの入力、送信をしています。ここでもtry-exceptを使ってエラーを吸収しています。また、入力された文字列が"!q"の場合は終了します。そして、Quitという変数が出てきます。これは終了フラグです。ラストで書きます。wait4Receive()
受信を担当する関数です。別スレッドとして実行されます。送信と別にすることで受信待ちと送信が同時に行なえます。並列処理です。Quitとsockはそれぞれグローバルオブジェクトの使用を宣言しておきます。try-exceptで受信をして、表示します。このとき、入力プロンプトを上書きして表示するので、プロンプトも一緒に表示しておきます。end=""を指定しないと改行されてしまうので、忘れないように。そして、QuitがTrueになったらソケットをクローズしてスレッドを閉じます。そして、終了です。が、サーバー側ではエラーが出てしまう(ConnectionReset)ので、誰か解決法をコメントください…(泣)
if name == "main":
Quitとsockのグローバルオブジェクトを宣言しておきます。そして、init()を実行します。
次回予告
次回は、サーバー側の解説です。頑張ります…
やはり俺の青春ラブコメはまちがっている。所詮中3が書いたものなので他の方々に比べたら劣ると思いますが、今後も読んでいただけると嬉しいです:)
読みにくいところ、わかりにくいところ、間違っているところ等々ありましたらコメントお願いします↓↓↓
- 投稿日:2020-02-19T16:46:17+09:00
【tensorflowjs_converter】TensorflowのモデルをTensorflow.jsの形式へ変換する方法
本記事では、tensorflowで作成したモデルをTnesorflow.jsで使用できる形式へ変換する方法を示します。
python環境
pip install tensorflowjstfjs-converter
Tensorflow.js(TF.js)は、Tensorflow(TF)によって学習された既存のモデルを再利用可能。tfjs-converterは、TensorFlowモデルを変換するためのコマンドラインツールで、HDF5など様々な形式をサポートしている。
tensorflowjs_converter --help usage: TensorFlow.js model converters. [-h] [--input_format {tensorflowjs,keras,tf_hub,keras_saved_model,tf_saved_model,tfjs_layers_model}] [--output_format {tfjs_graph_model,tfjs_layers_model,tensorflowjs,keras}] [--signature_name SIGNATURE_NAME] [--saved_model_tags SAVED_MODEL_TAGS] [--quantization_bytes {1,2}] [--split_weights_by_layer] [--version] [--skip_op_check SKIP_OP_CHECK] [--strip_debug_ops STRIP_DEBUG_OPS] [--weight_shard_size_bytes WEIGHT_SHARD_SIZE_BYTES] [input_path] [output_path]TFのSavedModelを、TF.jsで読み取れるWeb形式へ以下のコマンドで変換できる。
tensorflowjs_converter \ --input_format=tf_saved_model \ /path/to/saved_model \ /path/to/web_model--input_formatは, keras, keras_saved_model, tf_hubなど、他の形式も選択可能。
portable形式
モデルが訓練される場所とは異なる場所で再利用できる。特徴は、
- 軽量: 限られたメモリ要領に格納できる
- シリアライズ: ネットワークI/Oを介して共有可能
- 互換性: 複数のプラットフォームで使用可能
Tensorflowによって生成されるファイルは、プロトコルバッファーに基づいている。そのため、多くのプログラミング言語で読み取り可能な形式です。
また、ONNXなどの形式なども、プラットフォームに依存しない形式です。(pytorchなどでも使用可能)モデルの保存
Tensorflow(Python)でモデルを保存する方法です。
mport tensorflow as tf from tensorflow import keras print(tf.__version__) #2.1 (train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data() train_labels = train_labels[:1000] test_labels = test_labels[:1000] train_images = train_images[:1000].reshape(-1, 28 * 28) / 255.0 test_images = test_images[:1000].reshape(-1, 28 * 28) / 255.0 # 短いシーケンシャルモデルを返す関数 def create_model(): model = tf.keras.models.Sequential([ keras.layers.Dense(512, activation='relu', input_shape=(784,)), keras.layers.Dropout(0.2), keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) return model # 基本的なモデルのインスタンスを作る model = create_model() model.summary() model.fit(train_images, train_labels, epochs=5) # モデル全体を1つのHDF5ファイルに保存します。 model.save('my_model.h5') tf.saved_model.save(model, "./sample/model_data") #imported = tf.saved_model.load("./sample/model_data")モデルの変換
./sample/model_dataに保存されたTFモデルをTF.js形式のモデルに変換する。
tensorflowjs_converter --input_format=tf_saved_model --output_node_names=output ./sample/model_data ./sample/model_tfjs_model #hd5データ形式 tensorflowjs_converter --input_format keras my_model.h5 ./sample/hd5_model #tf-hubのモデルを使用 tensorflowjs_converter \ --input_format=tf_hub \ 'https://tfhub.dev/google/imagenet/mobilenet_v1_100_224/classification/1' \ ./my_tfjs_modelTF-hubとは
Tensorflow Hubは、機械学習のモデルなどを再利用できるライブラリです。
モデルを読み込み、入出力の形式を合わせれば、最先端の機械学習技術を使用できます。モデルのロード
Tensorflow.jsでモデルロードする方法です。
import * as tf from '@tensorflow/tfjs'; const MODEL_URL = 'https://path/to/model.json'; const model = await tf.loadGraphModel(MODEL_URL); // Or const MODEL_PATH = 'file://path/to/model.json'; const model = await tf.loadGraphModel(MODEL_PATH);
- 投稿日:2020-02-19T16:37:11+09:00
Python astライブラリ
執筆途中
構文解析とは
ソースコードをASTに変換すること
ASTとは
抽象構文木(Abstract Syntax Tree)のこと。
抽象構文木とは
プログラムの構造を木構造で表したもの。
TLDR
Pythonの構文解析には標準ライブラリの
astを使う。参考になるのはGreen Tree Snakes - the missing Python AST docs本編
僕の環境
- Python3.8.1
- macOS Mojave
やっておくこと
pip install astorPythonコード ⇔ ASTオブジェクト
Pythonファイル -> ASTオブジェクト
import astor tree = astor.parse_file("hello.py")ASTオブジェクト -> Pythonコード
# 上記コードから続き source_code = astor.to_source(tree)
- 投稿日:2020-02-19T14:53:24+09:00
AtCoder Beginners Selection 備忘録
プログラミング初心者なので、AtCoderのBeginners Selectionで勉強します。
使用言語はpythonです。
自分の回答ans1.pya = int(input()) b,c = map(int,input().split()) s = input() print(a+b+c,s)
自分の回答ans2.pya,b = map(int, input().split()) if (a*b) % 2 == 0: print("Even") else: print("Odd") print(a+b+c,s)
自分の回答ans3.pya = input() l = [int(x) for x in list(str(a))] sum = int(l[0])+int(l[1])+int(l[2]) print(sum)このやり方は一般的ではないですね。。後に、l.count('1')というものを知りました。
自分の回答ans4.pyimport numpy as np N = input() l = list(map(int, input().split())) array = np.array(l) i = 0 while sum(array % 2) == 0: array = array/2 i = i++ print(i)
自分の回答ans5.pyA = int(input()) B = int(input()) C = int(input()) X = int(input()) count = 0 for a in range(A+1): for b in range(B+1): for c in range(C+1): if X == 500*a + 100*b + 50*c: count = count + 1 print(count)全探索?っていうのかな?
自分の回答ans6.pyimport numpy as np N,A,B = map(int,input().split()) count = 0 l2 = [] for i in range(1,N+1): l = np.array([int(x) for x in list(str(i))]) if A <= np.sum(l) & np.sum(l) <= B: l2.append(i) l3 = np.array(l2) print(l3.sum())変数名テキトーすぎますね。。
自分の回答ans6.pyimport numpy as np N = int(input()) a = np.array(list(map(int,input().split()))) sort = np.sort(a)[::-1] alice = sort[::2] Bob = sort[1::2] print(alice.sum() - Bob.sum())
自分の回答ans7.pyimport numpy as np N = int(input()) l = [] count = 1 for i in range(N): l.append(int(input())) array = np.sort(np.array(l)) for i in range(len(array)-1): if array[i] != array[i+1]: count = count + 1 print(count)

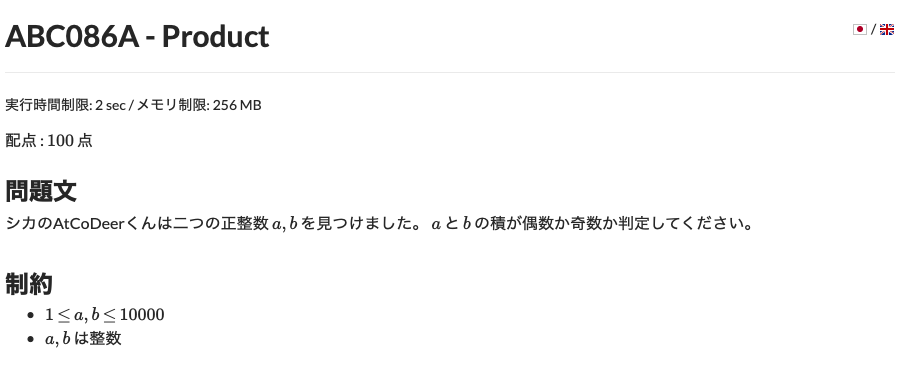



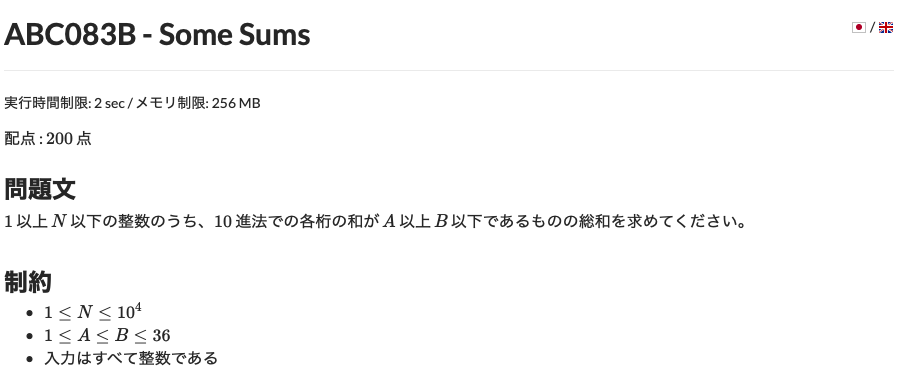


- 投稿日:2020-02-19T14:14:40+09:00
美形会議をgoogle-homeに演じてもらった
作成の動機
google-homeをpythonでしゃべらせることができるが、ただ単語を1つしゃべっても面白くないので、会話っぽくしゃべらせてみたかった
美形会議って?
ここの[NEOGEO会議室]を参照
ソース
talk.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import time import datetime import pychromecast from gtts import gTTS from mutagen.mp3 import MP3 #IPアドレスでgoogle-homeを指定 googleHome = pychromecast.Chromecast('192.168.0.xx') if not googleHome.is_idle: googleHome.quit_app() time.sleep(5) f = open('./script.txt', 'r') #会話を書いたテキストを用意 line = f.readline() while line: #1行づつしゃべらせる print(line.strip()) savefile = "voice-%s.mp3" % datetime.datetime.now().strftime('%Y%m%d-%H%M%S') savepath = "/tts/%s" % savefile try: #google speech to textで音声データへ変換して保存 tts = gTTS(text=line.strip(), lang='ja') tts.save(savepath) except: continue finally: line = f.readline() #mp3ファイルの情報を取得 audio = MP3(savepath) #上記のsavepathがwebからアクセス可能な場所として公開 mp3url = "https://(domainname)/tts/%s" % savefile; #google homeにmp3をしゃべらせる googleHome.wait() googleHome.media_controller.play_media(mp3url, 'audio/mp3') googleHome.media_controller.block_until_active() #しゃべている間に次の会話が始まると途中でストップするので、 #会話データの秒数だけ待つ time.sleep(audio.info.length) f.close()script.txtのサンプル
やぁ!餓狼伝説の美形キャラ、~ わざわざ説明せんでもええやろうけど~ サムライスピリッツの美形キャラ、橘~コマンド
docker run -v /script:/data -v /tts/:/tts toru2220/google-home-python python talk.py
- 投稿日:2020-02-19T13:56:51+09:00
【Python】流体シミュレーション:移流方程式を実装する
はじめに
空気や水といった流体のシミュレーションに関する学問である数値流体力学(CFD)の勉強も兼ねて、水の数値流体解析コードの構築に必要な知識などを(複数の記事で)まとめていきたいと思います。
初心者にもわかりやすいように書いていきたいと思います。間違い等多々含まれていると思われますので、発見された際にはご連絡していただいけると幸いでございます。また、どこがわかりにくいとかをコメントして頂けたらありがたいです。随時更新していきます。
対象読者
- Pythonを使える人
- 数値計算に興味がある人
- 流体力学に興味がある人
- 基本的な大学物理や数学を理解している人(微分方程式くらい?)
本記事の大まかな内容
水のシミュレーションで必要な流体の基礎方程式を扱う前段階として、移流方程式について簡単にまとめて、実装も行います。
移流方程式(物質の移動を表す式)
一次元の移流方程式を有限差分法で解いていきます。
移流方程式(Advection equation)
$$
\frac{\partial u}{\partial t} + c \frac{\partial u}{\partial x} = 0
$$この式が意味することは、ある関数uが速度cで移動していくということである。要するに、速度cという流れに沿って物理量が移動していくことを表す方程式である。
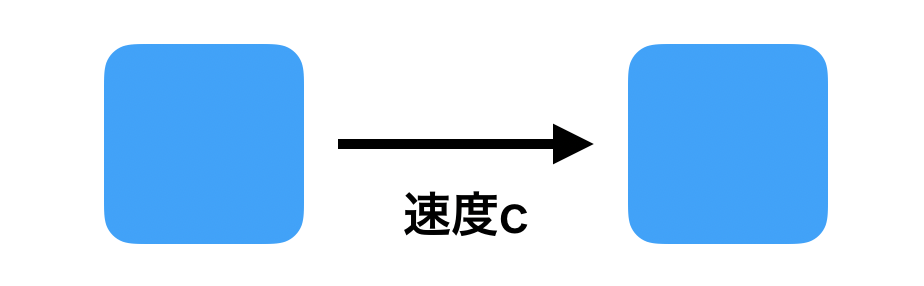
これを離散化して、方程式を解いていく。今回は陽解法と呼ばれる方法で解いていく。陽解法は簡単に言えば、現在の時間の値のみを用いて、未来の値を求める方法です。陽解法の他に陰解法と呼ばれる手法もあり、現在の値と未来の値を元に計算していく方法です。
今回実装する陽解法は以下の通り。以下の4つは気の赴くままに選びました。
- FTCS(Forward in Time and Central Difference in Space)
- 一次風上差分(Upwind differencing)
- Lax-Wendroff scheme
- CIP(Constrained Interpolation Profile scheme) method
それぞれについて、離散化した式を書き下していきます。式では、添え字jは場所を意味し、nは時刻を意味することとします。そのため、$f_j^n$は時刻$n$に場所$x_j$に位置する関数fの値を意味します。
FTCS(Forward in Time and Central Difference in Space)
- $$ u_j^{n+1} = u_j^{n} - \frac{c}{2} \left( \frac{\Delta t}{\Delta x} \right) \left(u_{j+1}^n - u_{j-1}^n \right) $$
Upwind differencing
- $$ u_j^{n+1} = u_j^{n} - c \left( \frac{\Delta t}{\Delta x} \right) \left(u_{j}^n - u_{j-1}^n \right) $$
Lax-Wendroff scheme
- $$ u_j^{n+1} = u_j^{n} - \frac{c}{2} \left( \frac{\Delta t}{\Delta x} \right) \left(u_{j+1}^n - u_{j-1}^n \right) + \frac{c^2}{2} \left( \frac{\Delta t}{\Delta x} \right)^2 \left(u_{j+1}^n - 2 u_j^n+ u_{j-1}^n \right) $$
CIP(Constrained Interpolation Profile scheme) method
詳細は後述。または、CIP法入門を参照してください。
陽解法の安定条件
陽解法を用いる際に重要な安定条件について簡単に述べておきます。数値的に情報伝播速度$\frac{\Delta t}{\Delta x}$(格子幅を時間で割ることにより求まる速度)は、物理的な信号速度$c$以上でなければならない。そうでなければ、物理現象の方が数値計算より速い速度で移動することになり、物理現象を数値的に表せれなくなるからです。その考えをもとに
$$
c \leq \frac{\Delta x}{\Delta t}
$$
という条件が導き出されます。これを変形した
$$
\nu = c \frac{\Delta t}{\Delta x} \leq 1
$$
がCFL条件と呼ばれ、数値的に安定する条件として使用されます。また、左辺はクーラン数とも呼ばれます。要は、時間刻み幅$ \Delta t$が$\frac{\Delta x}{c}$以下であれば良い。なお、こうしたCFL条件は陰解法を用いる際には関係がなくなるため、陰解法は陽解法より時間刻み大きくできるメリットがあります。ただ、その分計算が複雑になります。実装
使用言語はPython。計算式がわかりやすいよう、Numpyの関数を多用せずに書いていきます。
計算対象
矩形波の移流を計算する。格子幅$\Delta x$、物理的な信号速度$c$、時間刻み幅$\Delta t$は全て定数として計算する。今回は参考文献に合わせて、$\Delta x=1$、$c=1$、$\Delta t=0.2$として計算する。なので、$CFL=0.2$で固定されCFL条件は満たしている状態。
# Creat square wave Num_stencil_x = 101 x_array = np.arange(Num_stencil_x) u_array = np.where(((x_array >= 30) |(x_array < 10)), 0.0, 1.0) u_lower_boundary = 0.0 u_upper_boundary = 0.0 Time_step = 200 Delta_x = max(x_array) / (Num_stencil_x-1) C = 1 Delta_t = 0.2 CFL = C * Delta_t / Delta_x total_movement = C * Delta_t * (Time_step+1) exact_u_array = np.where(((x_array >= 30 + total_movement) |(x_array < 10 + total_movement)), 0.0, 1.0) plt.plot(x_array, u_array, label="Initial condition") plt.plot(x_array, exact_u_array, label="Answer") plt.legend(loc="upper right") plt.xlabel("x") plt.ylabel("u") plt.xlim(0, max(x_array)) plt.ylim(-0.5,1.5)1. FTCS(Forward in Time and Central Difference in Space)
$$
u_j^{n+1} = u_j^{n} - \frac{c}{2} \left( \frac{\Delta t}{\Delta x} \right) \left(u_{j+1}^n - u_{j-1}^n \right)
$$
解が振動します。
u_ftcs = u_array.copy() # タイムステップを設定 for n in range(Time_step): u_ftcs[0] = u_ftcs[0] - CFL / 2 * (u_ftcs[1] - u_lower_boundary) u_ftcs[-1] = u_ftcs[-1] - CFL / 2 * (u_upper_boundary - u_ftcs[-1]) for j in range(1,Num_stencil_x-1, 1): u_ftcs[j] = u_ftcs[j] - CFL / 2 * (u_ftcs[j+1] - u_ftcs[j-1]) plt.plot(x_array, exact_u_array, label="Answer") plt.plot(x_array, u_ftcs, label="FTCS") plt.legend(loc="upper right") plt.xlabel("x") plt.ylabel("u(FTCS)") plt.xlim(0, max(x_array)) plt.ylim(-0.5,1.5)2. 一次精度風上差分(Upwind differencing)
$$
u_j^{n+1} = u_j^{n} - c \left( \frac{\Delta t}{\Delta x} \right) \left(u_{j}^n - u_{j-1}^n \right)
$$
数値拡散が大きく解が滑らかになる。
u_upwind = u_array.copy() # タイムステップを設定 for n in range(Time_step): u_upwind[0:1] = u_upwind[0] - CFL * (u_upwind[1] - u_lower_boundary) for j in range(1,Num_stencil_x): u_upwind[j:j+1] = u_upwind[j] - CFL * (u_upwind[j] - u_upwind[j-1]) plt.plot(x_array, exact_u_array, label="Answer") plt.plot(x_array, u_upwind, label="Upwind differencing") plt.legend(loc="upper right") plt.xlabel("x") plt.ylabel("u(Upwind differencing)") plt.xlim(0, max(x_array)) plt.ylim(-0.5,1.5)3. Lax-Wendroff scheme
$$
u_j^{n+1} = u_j^{n} - \frac{c}{2} \left( \frac{\Delta t}{\Delta x} \right) \left(u_{j+1}^n - u_{j-1}^n \right) + \frac{c^2}{2} \left( \frac{\Delta t}{\Delta x} \right)^2 \left(u_{j+1}^n - 2 u_j^n+ u_{j-1}^n \right)
$$
数値振動は大きめ。
u_lw= u_array.copy() # タイムステップを設定 for n in range(Time_step): u_lw[0:1] = u_lw[0] - CFL / 2 * (u_lw[1] - u_lower_boundary) \ + CFL**2 / 2 * (u_lw[1] - 2 * u_lw[0] + u_lower_boundary) u_lw[-1:0] = u_lw[-1] - CFL / 2 * (u_upper_boundary - u_lw[-1]) \ + CFL**2 / 2 * (u_upper_boundary - 2 * u_lw[-1] + u_lw[-2]) for j in range(1,Num_stencil_x-1, 1): u_lw[j:j+1] = u_lw[j] - CFL / 2 * (u_lw[j+1] - u_lw[j-1]) \ + CFL**2 / 2 * (u_lw[j+1] - 2 * u_lw[j] + u_lw[j-1]) plt.plot(x_array, exact_u_array, label="Answer") plt.plot(x_array, u_ftcs, label="Lax-Wendroff scheme") plt.legend(loc="upper right") plt.xlabel("x") plt.ylabel("u(Lax-Wendroff scheme)") plt.xlim(0, max(x_array)) plt.ylim(-0.5,1.5)4. CIP(Constrained Interpolation Profile scheme) method
CIP法の基本的な考え方としては、まずある関数fについて離散化した際、ある点$x_j$とその隣の点$x_{j-1}$の物理量は滑らかに繋がっていると考えます。こうすることにより、それぞれの物理量$f_j$と$f_{j-1}$の微分値を用いて、格子間の傾きを発散させずに時間発展させることができるようになります。
つまり、関数の値と微分値が格子点上で連続という条件のもと、3次補完関数$F(x)$により格子2点間の関係を表すことができるようになる。
$x_{j-1}<= x < x_j$の領域において、
$$
F(x) = a X^3 + b X^2 +c X + d \quad ,where \quad X = x - x_j
$$
のように$F(x)$を3次補完で定義すると、関数の値と微分値が格子点上で連続という条件から、$$
F(0) = f_j^n, \quad F(\Delta x) = f_{j+1}^n, \quad \frac{\partial F(0)}{\partial x} = \frac{\partial f_j^n}{\partial x}, \quad \frac{\partial F(\Delta x)}{\partial x} = \frac{\partial f_{j+1}^n}{\partial x} \ , where \quad \Delta x = x_{j+1} - x_j
$$
が成立するので、これを$F(x)$の式に代入して、$a, b, c, d$を求めると、
$$
a = \frac{\partial f_j^n / \partial x + \partial f_{j-1}^n / \partial x }{\Delta x^2} + \frac{2 (f_j^n - f_{j-1}^n)}{\Delta x^3} \
b = \frac{3 (f_{j-1}^n - f_j^n)}{\Delta x^2} + \frac{(2 \partial f_j^n / \partial x + \partial f_{j+1}^n / \partial x )}{\Delta x} \
c = \frac{\partial f_j^n}{\partial x}\
d = f_j^n
$$以上より、速度cが一定の場合、$\frac{\partial u}{\partial t} + c \frac{\partial u}{\partial x} = 0$は微分値も満たすので、時間刻み幅$\Delta t(n+1ステップ目)$秒後における値と微分値は、
$$
u_j^{n+1} = F(x_j - c \Delta t)= a \xi^3 + b \xi^2 + c\xi + d \
\frac{\partial u_j^{n+1}}{\partial x} = \frac{d F(x_j - c \Delta t)}{d x} = 3 a \xi^2 + 2 b \xi + c \
, where \quad \xi = - c \Delta t
$$
他の三つの手法より数値拡散や振動が圧倒的に小さい。しかし、参考文献ほどうまく移流できなかった。
u_cip= u_array.copy() partial_u_cip = ((np.append(u_cip[1:], u_upper_boundary) + u_cip)/2 - (np.append(u_lower_boundary, u_cip[:-1]) + u_cip)/2)/ Delta_x # 時間発展させる for n in range(Time_step): u_cip[0] = 0 partial_u_cip[0] = 0 for j in range(1, Num_stencil_x): a = (partial_u_cip[j] + partial_u_cip[j-1]) / Delta_x**2 - 2.0 * (u_cip[j] - u_cip[j-1]) / Delta_x**3 b = 3 * (u_cip[j-1] - u_cip[j]) / Delta_x**2 + (2.0*partial_u_cip[j] + partial_u_cip[j-1]) / Delta_x c = partial_u_cip[j] d = u_cip[j] xi = - C * Delta_t # C > 0 u_cip[j:j+1] = a * xi**3 + b * xi**2 + c * xi + d partial_u_cip[j:j+1] = 3 * a * xi**2 + 2 * b * xi + c plt.plot(x_array, exact_u_array, label="Answer") plt.plot(x_array, u_cip, label="CIP method") plt.legend(loc="upper right") plt.xlabel("x") plt.ylabel("u(CIP)") plt.xlim(0, max(x_array)) plt.ylim(-0.5,1.5)まとめ
流体方程式を構成する移流方程式の基礎について簡単に実装とともにまとめました。
実装したのは以下の4つです。
- FTCS(Forward in Time and Central Difference in Space)
- 一次風上差分(Upwind differencing)
- Lax-Wendroff scheme
- CIP(Constrained Interpolation Profile scheme) method
次回は、拡散方程式について記事を書きたいと思います。
参考文献
- http://zellij.hatenablog.com/entry/20140805/p1
- https://www.cradle.co.jp/media/column/a233
- http://www.slis.tsukuba.ac.jp/~fujisawa.makoto.fu/cgi-bin/wiki/index.php?%B0%DC%CE%AE%CB%A1
- http://www.astro.phys.s.chiba-u.ac.jp/netlab/mhd_summer2001/cip-intro.pdf
- http://www.astro.phys.s.chiba-u.ac.jp/netlab/summer-school_2004/TEXTBOOK/text3-1.pdf
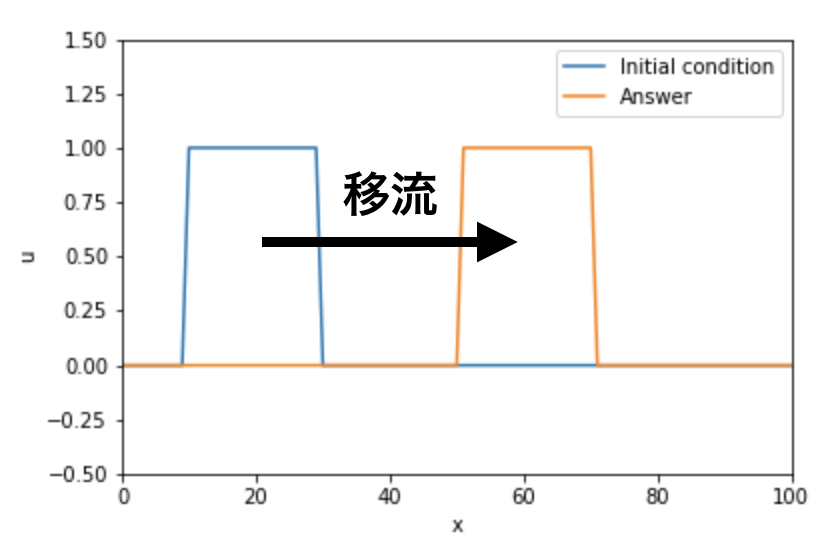
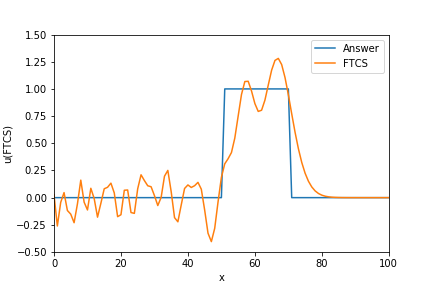
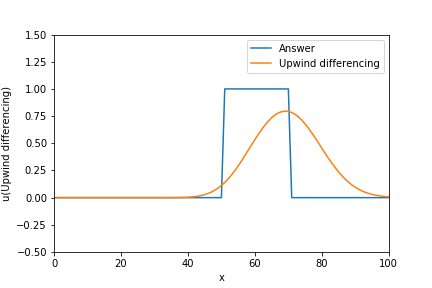

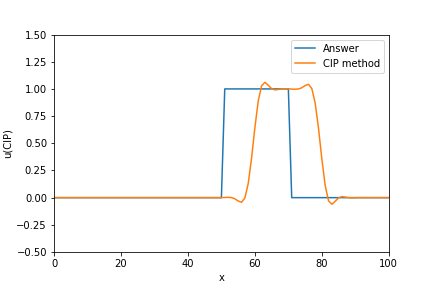
- 投稿日:2020-02-19T13:35:24+09:00
感情分析でサボテンは踊るのをやめてしまうか
やりたいこと
COTOHA APIの感情分析で文章を読み込んでいって、ネガティブな値が一定値を超えたらサボテンが踊るのをやめる
流行りのネタに乗るなとか言わないで元ネタ
突如としてツイッターにて流行り始めたこのサボテン
「みんながインターネットで争ってばかりいる」のくだりと前使ったCOTOHA APIでちょっと思いついたため記事にした。https://twitter.com/_rotaren_/status/1229235440441417728?s=20
ㅤㅤ
— 川崎 (@_rotaren_) February 17, 2020
₍₍⁽⁽?₎₎⁾⁾
見て!サボテンが踊っているよ
かわいいね
ㅤ
?
みんながインターネットで争ってばかりいるので、サボテンは踊るのをやめてしまいました
お前のせいです
あ〜あイメージ
イメージとしてはターミナルで一文ずつ(ツイッターの140文字程度が目安)入力したら踊っているサボテンが返ってくる
感情値が一定ラインを越えたらサボテンは踊るのをやめる
本気で実装しようとしたら都度DBに入れてカウントすることになるが今回はそこまでしないコード
とりあえず感情値がネガティブで0.5を超えたらサボテンが止まるようにした
環境:Python 3.8.1
コードおりたたみ
top/ ├ file/ │ ├ infile.txt (分析する文章置き場) │ └ outfile.json (出力結果) ├ config.ini └ cotoha_saboten.pycotoha_saboten.py# -*- coding:utf-8 -*- import os import urllib.request import json import configparser import codecs class CotohaApi: def __init__(self, client_id, client_secret, developer_api_base_url, access_token_publish_url): self.client_id = client_id self.client_secret = client_secret self.developer_api_base_url = developer_api_base_url self.access_token_publish_url = access_token_publish_url self.getAccessToken() def getAccessToken(self): url = self.access_token_publish_url headers={ "Content-Type": "application/json;charset=UTF-8" } data = { "grantType": "client_credentials", "clientId": self.client_id, "clientSecret": self.client_secret } data = json.dumps(data).encode() req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) res_body = res.read() res_body = json.loads(res_body) self.access_token = res_body["access_token"] # 感情分析API def sentiment(self, sentence): url = self.developer_api_base_url + "v1/sentiment" headers={ "Authorization": "Bearer " + self.access_token, "Content-Type": "application/json;charset=UTF-8", } data = { "sentence": sentence } data = json.dumps(data).encode() req = urllib.request.Request(url, data, headers) try: res = urllib.request.urlopen(req) except urllib.request.HTTPError as e: print ("<Error> " + e.reason) res_body = res.read() res_body = json.loads(res_body) return res_body if __name__ == '__main__': APP_ROOT = os.path.dirname(os.path.abspath( __file__)) + "/" # config.iniの値を取得 config = configparser.ConfigParser() config.read(APP_ROOT + "config.ini") CLIENT_ID = config.get("COTOHA API", "Developer Client id") CLIENT_SECRET = config.get("COTOHA API", "Developer Client secret") DEVELOPER_API_BASE_URL = config.get("COTOHA API", "Developer API Base URL") ACCESS_TOKEN_PUBLISH_URL = config.get("COTOHA API", "Access Token Publish URL") cotoha_api = CotohaApi(CLIENT_ID, CLIENT_SECRET, DEVELOPER_API_BASE_URL, ACCESS_TOKEN_PUBLISH_URL) # 踊れサボテン saboten_dancing = 1 print ("見て!サボテンが踊っているよ") print ("かわいいね") print ("何かつぶやいてみよう") while saboten_dancing == 1: saboten_listen = input(">> ") # ファイルに入力 new_dir_path = 'file' new_filename = 'infile.txt' os.makedirs(new_dir_path, exist_ok=True) with open(os.path.join(new_dir_path, new_filename), mode='a', encoding='utf-8') as f: f.write(saboten_listen + "\n" ) # file/infile.txtから解析対象文取得 checkpath = 'file/infile.txt' test_data = open(checkpath, "r", encoding='utf-8') sentence = test_data.read() test_data.close() # API実行 result = cotoha_api.sentiment(sentence) # 確認用に出力結果をファイル出力 new_dir_path = 'file' new_filename = 'outfile.json' result_formated = json.dumps(result, indent=4, separators=(',', ': ')) new_file_content = codecs.decode(result_formated, 'unicode-escape') os.makedirs(new_dir_path, exist_ok=True) with open(os.path.join(new_dir_path, new_filename), 'w', encoding='utf-8') as f: f.write(new_file_content) # 踊るのをやめる if result['result']['sentiment'] == "Negative" and result['result']['score'] > 0.5: print ("みんながインターネットで争ってばかりいるので、サボテンは踊るのをやめてしまいました") print ("お前のせいです") print ("あ~あ") saboten_dancing = 0 else: print ("サボテンは踊り続けています")やってみた
- とりあえず無難に
$ py .\cotoha_saboten.py 見て!サボテンが踊っているよ かわいいね 何かつぶやいてみよう >> こんにちは。 サボテンは踊り続けています(感情値:Neutral、0.3162340660855847)
- 続けて攻撃的に
>> 使えないやつだな。 みんながインターネットで争ってばかりいるので、サボテンは踊るのをやめてしまいました お前のせいです あ~あ(感情値:Negative、0.6537253556009858)
- 少し優しく
>> 嘘だよ、いい子だよ サボテンは踊り続けています(感情値:Neutral、0.28391280932941443)
最初から「嘘だよ、いい子だよ」と入力すると感情値:Positive、0.5477461521779882だったのでとりあえず前の結果が影響するようにできてる。
ひとまずネガティブな話をしていると踊るのをやめるサボテンになった。争ってみた
沸点低いなこのサボテン。
文章が少ないとすぐ閾値を超えそう。見て!サボテンが踊っているよ かわいいね 何かつぶやいてみよう >> 何々って小説面白いね。 サボテンは踊り続けています >> 何々はつまらん。読んでいる奴はバカ。 みんながインターネットで争ってばかりいるので、サボテンは踊るのをやめてしまいました お前のせいです あ~あ争ってみた(長文)
適当に作った例文
A: 何々って漫画面白いね
B: わかる、特に誰誰が子猫をかばって倒れるシーンがいい
A: は?一番は強敵誰誰との死闘だろ?わかってないな、にわかか?
B: そんなの人それぞれだろ、うるさいな
A: ちゃんと読んでないだろ、クズが。
B: お前みたいなつまらない奴に読まれた漫画がかわいそうだな!
A: 黙れバカの分際で
B: お前こそ黙れ
A: お前と話してると不幸になる
- 意外とサボテンが踊り続けている
- 「バカ」「クズ」などの罵倒や煽りを検知できないから思ったよりネガティブになっていない
- 閾値を0.5にしていたが、ネガティブになった段階で止めてもよさそう。
見て!サボテンが踊っているよ かわいいね 何かつぶやいてみよう >> 何々って漫画面白いね サボテンは踊り続けています >> わかる、特に誰誰が子猫をかばって倒れるシーンがいい サボテンは踊り続けています >> は?一番は強敵誰誰との死闘だろ?わかってないな、にわかか? サボテンは踊り続けています >> そんなの人それぞれだろ、うるさいな サボテンは踊り続けています >> ちゃんと読んでないだろ、クズが。 サボテンは踊り続けています >> お前みたいなつまらない奴に読まれた漫画がかわいそうだな! サボテンは踊り続けています >> 黙れバカの分際で サボテンは踊り続けています >> お前こそ黙れ サボテンは踊り続けています >> お前と話してると不幸になる サボテンは踊り続けています
API側からの出力
{ "result": { "sentiment": "Negative", "score": 0.11156484777896825, "emotional_phrase": [ { "form": "うるさいな", "emotion": "N" }, { "form": "面白いね", "emotion": "P" }, { "form": "かわいそうだな", "emotion": "N" }, { "form": "つまらない", "emotion": "N" }, { "form": "不幸", "emotion": "N" }, { "form": "わかってないな", "emotion": "N" }, { "form": "いい", "emotion": "P" } ] }, "status": 0, "message": "OK" }改良版
サボテンが止まる条件をネガティブのみに
見て!サボテンが踊っているよ かわいいね 何かつぶやいてみよう >> 何々って漫画面白いね サボテンは踊り続けています >> わかる、特に誰誰が子猫をかばって倒れるシーンがいい サボテンは踊り続けています >> は?一番は強敵誰誰との死闘だろ?わかってないな、にわかか? サボテンは踊り続けています >> そんなの人それぞれだろ、うるさいな サボテンは踊り続けています >> ちゃんと読んでないだろ、クズが。 サボテンは踊り続けています >> お前みたいなつまらない奴に読まれた漫画がかわいそうだな! みんながインターネットで争ってばかりいるので、サボテンは踊るのをやめてしまいました お前のせいです あ~あこれで争いが始まったら踊りをやめるサボテンが爆誕しました。
5chのスレに常駐させたい
めでたしめでたし。参考
- 投稿日:2020-02-19T13:12:19+09:00
MeCab: ユーザー定義辞書に新しい単語を追加する(Windows)
SAMPLE
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ の 助詞,連体化,*,*,*,*,の,ノ,ノ 姉 名詞,一般,*,*,*,*,姉,アネ,アネ は 助詞,係助詞,*,*,*,*,は,ハ,ワ 芥川龍之介 名詞,固有名詞,作家,*,*,*,芥川龍之介,あくたがわりゅうのすけ,アクタガワリュウノスケ の 助詞,連体化,*,*,*,*,の,ノ,ノ 本 名詞,一般,*,*,*,*,本,ホン,ホン を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ よく 副詞,一般,*,*,*,*,よく,ヨク,ヨク 読ん 動詞,自立,*,*,五段・マ行,連用タ接続,読む,ヨン,ヨン で 助詞,接続助詞,*,*,*,*,で,デ,デ いる 動詞,非自立,*,*,一段,基本形,いる,イル,イル 。 記号,句点,*,*,*,*,。,。,。 BOS/EOS,*,*,*,*,*,*,*,*REFERENCE
MeCabの辞書への語彙追加方法【Windows 10, Ubuntu 18.04】
ユーザー定義辞書に新しい単語を追加する
辞書を用意する
csvファイルでutf-8として辞書を用意します。
ディレクトリ:C:\Users\ユーザー名\Desktop\MeCabUserDic
ファイル名:test_dic.csv芥川龍之介,,,5543,名詞,固有名詞,作家,*,*,*,芥川龍之介,あくたがわりゅうのすけ,アクタガワリュウノスケ 太宰治,,,5543,名詞,固有名詞,作家,*,*,*,太宰治,だざいおさむ,ダザイオサム表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音
左文脈IDおよび右文脈IDは、該当する単語をそれぞれ左・右から数えた時の内部ID
自動的に付与されるので空の状態で大丈夫だそうですが、私はエラー(しかも文字化け)してしまったので適当な値を振りました。コストには似たような頻度で出現する単語と同じスコアを振ります。
コストが小さい程検出されやすくなります。ユーザー辞書をコンパイル
MeCab\dic\ipadic\mecab-dict-indexを実行します。
通常のコマンドプロンプトで実行するとpermission deniedになってしまってしまったので
下記コマンドで管理者権限のあるコマンドプロンプトを立ち上げます。powershell start-process cmd -verb runas下記のコマンドで用意したcsvファイルに基づいてdicファイルを新しく作成します。
mecab-dict-index -t utf-8 -t utf-8 -d "<MeCab辞書ディレクトリのパス>" -u <新しくdicファイルを作成するディレクトリのパス> <定義した辞書csvファイルのパス>上記のコマンド例は下記。
mecab-dict-index -f utf-8 -t utf-8 -d "C:\Program Files\MeCab\dic\ipadic" -u C:\Users\yuri.kinoshita\Desktop\MeCabUserDic\test.dic C:\Users\yuri.kinoshita\Desktop\test_dic.csv実行結果です。
done!reading C:\Users\yuri.kinoshita\Desktop\MeCabUserDic\test_dic.csv ... 2 emitting double-array: 100% |###########################################| done!HOW TO USE
import MeCab mecab = MeCab.Tagger (r"-Ochasen -u C:\Users\yuri.kinoshita\Desktop\MeCabUserDic\test.dic") text = "私の姉は芥川龍之介の本をよく読んでいる。" node = mecab.parseToNode(text) while True: node = node.next if not node: break print(node.surface,node.feature)実行例。
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ の 助詞,連体化,*,*,*,*,の,ノ,ノ 姉 名詞,一般,*,*,*,*,姉,アネ,アネ は 助詞,係助詞,*,*,*,*,は,ハ,ワ 芥川龍之介 名詞,固有名詞,作家,*,*,*,芥川龍之介,あくたがわりゅうのすけ,アクタガワリュウノスケ の 助詞,連体化,*,*,*,*,の,ノ,ノ 本 名詞,一般,*,*,*,*,本,ホン,ホン を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ よく 副詞,一般,*,*,*,*,よく,ヨク,ヨク 読ん 動詞,自立,*,*,五段・マ行,連用タ接続,読む,ヨン,ヨン で 助詞,接続助詞,*,*,*,*,で,デ,デ いる 動詞,非自立,*,*,一段,基本形,いる,イル,イル 。 記号,句点,*,*,*,*,。,。,。 BOS/EOS,*,*,*,*,*,*,*,*
- 投稿日:2020-02-19T12:41:22+09:00
Cloud Run × Flaskでお手軽にマイクロサービスを実現する
はじめに
個人開発でアプリ作成中なんですが、バックエンドをrailsで作っていました。
そんなある日。。。 こんな記事を見ました。
Firebaseでバックエンドエンジニア不在のアプリ開発 クックパッドが体感した、メリットと課題Firebaseならバックエンドエンジニアを必要としない開発ができる
( ゚д゚) ... マジカ
これに感化されてCloud Functionでバックエンドを作ってました。
が
ある理由でそれは辞めました。
なぜ、Cloud Functionを採用しなかったか
今回マイクロサービスをアーキテクチャとして採用し、さらに各機能を自分が作るのは嫌なので、BaaSをサービスと定義して自分はBFFだけ作ってやろうという腹でした。
それだったら、BaaS単位で共通のライブラリファイル作ったほうが、他のプロジェクトを立ち上げる時に楽だよね?となり、クラウドファンクションにそういう共通化する機能があることを知り採用しようとしました。
しかし。。
めんどくさい(;´Д`)
そもそもローカルでファンクション単位でしか実行出来ないのも嫌気が差して
これ、ローカル実行出来るフレームワークをクラウドファンクションみたいにサーバレスで動かせばよいのでは?
と発想。cloud runというDockerでサーバレスに構築、しかもリクエスト単位の稼働で課金(データの永続化は出来ない)
という、正にクラウドファンクションの上位?互換のサービスがあることを知り今回採用しました。結局、何が言いたいの?
- マイクロサービス
- サーバレス
- リクエスト単位課金
- 低料金
- 自分で機能を作りたくない
- 環境構築したくない
これらを実現したい人向けにサンプル(土台)を作ったから、使ってね!
と言いたいです。作ったもの
以下です。
https://github.com/taiseiotsuka/Flask-On-CloudRun
readmeに全部構築手順書いたので、よければ使ってみてください。
※ DockerリポジトリはGoogle Container Registryを使うことを想定としています。
※ デプロイはGCPのマネコンから行うことを想定としています。
※ BaaSに当たる部分は今回サンプルとしてGoogle Firestore(Nosql DB)を使用しています。使い方わからなかったら質問してね!
Bye
- 投稿日:2020-02-19T12:28:17+09:00
感染病の数学予測モデルの紹介 (SIRモデル)
1.初めに
2019年12月に中国武漢で発生した新型コロナ肺炎(Convid-19)が、日本にも感染者数が増加している。インフルエンザ, AIDS, SARS,などの感染病がどのプロセスで人間集団の中で拡大していくことを理解することは、予防接種の設定、感染者の隔離などの保健政策の効果を確認するためにも重要である。
ここで、感染病数学予測モデルの基本であるSIRモデルを紹介し、このモデルをPythonで計算する過程を紹介する。2.伝染病の数学予測モデル(SIRモデル)
SIRモデルは、伝染病の流行プロセスを説明するモデルである。モデルの名称は、モデルの変数名のSusceptible, Infectious, Recoveredの頭文字に起因する。1927年 W.O. KermackとA.G. McKendrickの論文で初めて紹介された。
SIRモデルでは、全体人口を次の集団に分類し、時間に関する各集団の人口増減を微分方程式で表す。
- S(Susceptible) : 伝染病に対する免疫がない。感染可能者
- I Infectious):感染により発病し、感染可能者(S)への伝染可能な者。感染者
- R (Removed) : 発病から回復し、免疫を獲得したもの。あるいは発病から回復できず死亡した者。(このモデルのシステムから排除されるため、Removedと言う。)
各集団の人口増減を次の微分方程式で表す。
このSIRモデルの前提条件
- 一度免疫を獲得した者は2度と感染することなく、免疫を失うこともない。
- 全体人口で外部からの流入及び流出はない。なお出生者及び感染以外の原因で死亡する者もいない。3. SIRモデルの計算
SIRモデルは、数値積分を用いて解く。ここでは、PythonのScipyモジュールのRunge-Kutta方程式を解くodeint関数を利用する。
import numpy as np from scipy.integrate import odeint from scipy.optimize import minimize import matplotlib.pyplot as plt %matplotlib inline次に、SIRモデルの微分方程式をodeintで計算できる形に記述する。ここで、v[0], v[1], v[2]がそれぞれS,I,Rに対応する。
#Define differential equation of SIR model ''' dS/dt = -beta * S * I dI/dt = beta * S * I - gamma * I dR/dt = gamma * I [v[0], v[1], v[2]]=[S, I, R] dv[0]/dt = -beta * v[0] * v[1] dv[1]/dt = beta * v[0] * v[1] - gamma * v[1] dv[2]/dt = gamma * v[1] ''' def SIR_EQ(v, t, beta, gamma): return [-beta*v[0]*v[1], beta * v[0] * v[1] - gamma * v[1], gamma * v[1]]そして、数値積分に必要な各パラメータ及び初期条件を定義する。ここでは、人口1,000名の集団に対し、初期に感染者が1名がいたと仮定する。
感染率を0.2/1000に、除去率を0.1と設定する。
最後にBasic Reproduction NumberのR0を計算する。R0>1の場合、この伝染病が収束せずに、拡大することを意味する。#parameters t_max = 160 dt = 0.01 beta_const = 0.2/1000 gamma_const = 0.1 #initial_state S_0=999 I_0=1 R_0=0 ini_state = [S_0,I_0,R_0] #[S[0], I[0], R[0]] #numerical integration times =np.arange(0,t_max, dt) args =(beta_const, gamma_const) #R0 N_total = S_0+I_0+R_0 R0 = N_total*beta_const *(1/gamma_const) print(R0)数値積分結果をresultに格納し、この結果を時間軸に対しプロットする。
#Numerical Solution using scipy.integrate #Solver SIR model result = odeint(SIR_EQ, ini_state, times, args) #plot plt.plot(times,result) plt.legend(['Susceptible','Infectious', 'Removed'])
このグラフから言えることは、1,000名の集団に1名の感染者(Infectious(0))が発生することで、最終的に800名程度(Removed(160))が感染を経験することである。そして、感染者(Infectious)のピークは約70日辺りで発生し、その後は感染が収束することがわかる。
このように感染病に関するパラメータをもって、感染病が人口集団に及ぼす影響を評価することが可能である。4. 参考資料
-Coronavirus COVID-19 Global Cases
https://gisanddata.maps.arcgis.com/apps/opsdashboard/index.html?fbclid=IwAR2FwOf4Cjm4okosqFt0Ddr4k0dUgswM28oAqYkkVY6QT6BBCZQ1NlfPDXk#/bda7594740fd40299423467b48e9ecf6https://qiita.com/Student-M/items/4e3e286bf08b7320b665
https://scipython.com/book/chapter-8-scipy/additional-examples/the-sir-epidemic-model/

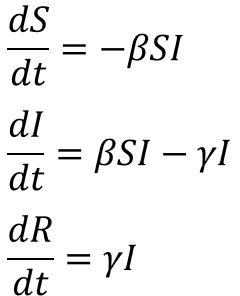

- 投稿日:2020-02-19T11:41:46+09:00
HJvanVeenの『特徴量エンジニアリング』註解
概要
一昨年くらいに書いて社内サイトに放置していましたがせっかくなので公開します.
ほぼ以下のスライドの訳です (構成を結構変えているので翻訳というより翻案?)
HJvanVeen の "Feature Engineering"
https://www.slideshare.net/HJvanVeen/feature-engineering-72376750このスライドは網羅性ならばちょっとした書籍よりも充実していると思います. しかしスライドなのでかなり簡素な記述でわかりにくい箇所も多いです. そこで補足説明を適宜補ったり, おかしいと思った点にはツッコミを入れたりしていますが, もとの発表を聞いていないため意図を誤解している可能性もあります. 1つ1つのトピックの詳細については, ググってすぐわかるレベルのことは基本的に書いていませんし補足もしません. あまり情報がないものやわかりにくいものだけに補足説明を入れています.
また, このスライドはいろんなトピックを挙げていますが具体的な活用場面やメリットデメリットについてはあまり書かれていません. 今回はそのままにしてますが, そのうちなんとかしたいです.
編注: 実装に関して
以下で紹介される特徴量エンジニアリングをPythonでやる場合は以下のモジュールが使える.
注: 書いたのが昔なのでモジュールの情報が少し古いかもしれません
pandas
表形式のデータの加工全般に使える. しかし,
get_dummies()は one-hot encoder に使えそうだが, 欠損値に対応できないので, scikit-learn のtransformer クラスラッパーを書いたほうが良いと思いますOneHotEncoderのほうが使いやすい.scikit-learn
preprocessingの各種transoformer.
基本的に全てfit(),transform()メソッドで変換できるのでソースコードが読みやすくなる
Pipeline でまとめることも可能です. 理想はこの Pipeline でまとめることですが, 実装されてるクラスはあまり多くないです.
http://scikit-learn.org/stable/modules/preprocessing.html
たとえば,
カテゴリカル変数は直接扱えない (one-hot encoder は label-encoder を噛ませる必要)最新版では改善された- 正規化処理は標準化, max-min-abs スケーリングなどがある.
- quantile transforemr, function-transformer, power transformer などの変換器もサポート
- 欠損値補完は単純平均で置き換えるなど簡単なものだけしかない.
この辺は私が以前書いた話も関連します.
Category Encoders
https://contrib.scikit-learn.org/categorical-encoding/
scikit-learn に連携できるような各種追加クラスが用意されている.
pandas.Seriesにも対応しているが、一方で速度を考慮した実装でないため, サイズの大きなデータに対する処理が効率化されていない (むっちゃ遅い)追記: 最近の更新でscikit-learn-contribでありながらパイプラインに使いづらい仕様になっています. scikit-learnネイティブのtransformerを使うか自分で実装したほうが簡単だと思います.
- Ordinal
- One-Hot
- Binary
- Helmert Contrast
- Sum Contrast
- Polynomial Contrast
- Backward Difference Contrast
- Hashing
- BaseN
- LeaveOneOut
- Target Encoding
Mlxtend
scikit-learn に連携できるように作られた、より発展的なモジュール
https://rasbt.github.io/mlxtend/
- 特徴量抽出のための前処理クラスも多い (ただしscikit-learnのパイプラインとの連携はあまり考慮されていない)
- stacking のscikit-learn準拠クラスが用意されている
- 相関ルールに基づく簡単な特徴量選択クラスも用意されている
- むしろ実装よりUser Guideでの解説が細かく有用. 今回紹介するスライドより詳しい.
追記: 最近の更新でscikit-learnも簡単なヘテロアンサンブル学習用のクラスがサポートされるようになりました.
使い勝手の比較は未調査imbalance-learn
scikit-learn との連携を前提に作られたモジュール
不均衡データの処理
http://contrib.scikit-learn.org/imbalanced-learn/stable/
- たとえば, SMOTE が実装されている
- パイプラインにも対応している (scikit-learnのではなく
imblearn.pipeline.Pipelineで置き換える)- 一方で, 事後確率の較正機能がない1
fancyimpute
欠損値補完用のモジュール
https://github.com/iskandr/fancyimpute(使ったことはないです)
本編
本編の前に少しだけ補足しておきます
- encoding
- 変換のこと、特に1対1になるようなもの?
- collision
- 変換後の値が1対1にならない (衝突する) こと
カテゴリカル特徴量に対する変換
one-hot変換 one-hot encoding
- カテゴリカル変数のラベル1つ1つをダミー変数1つに変換する
- メモリを多く占有してしまう
- sparse-format ならましになる2
ハッシュ変換 hash encoding
hashing trick, feature hashingともいいます3.
- カテゴリ変数を指定した大きさのハッシュへ変換して、さらに one-hot encoding
- one-hot と違い列の増加を抑制する
- テストデータの新しいラベルにも対応しうる
ラベル変換 label encoding
- 各ラベルに対して、一意な数値で置き換える
- 当然、次元は増えない
- (非線形の) 決定木型のアルゴリズムを使うときに有効
- (線形) 回帰には不適当 (であることが多い)
カウント変換 count encoding
- 各ラベルを、訓練データ内でのそのラベルの発生頻度に置き換える
- 次元は増えない
- 線形・非線形どちらでも有効4
- 外れ値に敏感すぎるかもしれない
- (上記の問題は)対数変換すれば感度を弱められることもある
- 一度も現れないラベルは
"1"にする- 異なるラベルでも変換後に同じ値になる可能性がある
ラベルカウント変換 label-count encoding
- count encoding をさらに、頻度の大きさの順位に変換する
- 線形・非線形どちらでも有効5
- 外れ値に敏感ではない
- コリジョンしない6
- (元の変数が異なっても衝突しやすいので)異なる変数を複数変換するときは注意
- (そのような場合はそれぞれの変数の)いいとこどりをしよう
ターゲット変換 target encoding
- count encoding のようにカテゴリごとに頻度にする代わりに、目的変数の相対頻度 (割合) を計算する
- オーバーフィットを回避するのが重要!
- オーバーフィット回避には交差検証などを使おう
- ゼロが多い場合は平滑化で補間することも検討
- オーバーフィットを防ぐためにノイズを加えることもある
- うまく使いさえすれば線形・非線形どちらでも有効
カテゴリ埋め込み category embedding
- dense embedding をニューラルネットで
- カテゴリカル変数を任意の次元のユークリッド空間上の近似関数に写す
- 学習が速い
- メモリのオーバーヘッドが少ない
- one-hot よりもパフォーマンスがよい7
NaN 変換 NaN encoding
- NaN という値じたいにも情報はある
- NaN値がある場合、その情報を保持したダミー変数を作る
- オーバーフィットしやすいので注意!
- 訓練データ・テストデータ両方に (CVで分割するならその中にも) NaN が現れるような場面でのみ使うように
多項式変換 Polynomial encoding
- カテゴリカル変数どうしの交互作用項を変換する方法
- 線形モデルで相互作用項がないと、XOR を表現できない
- 多項式カーネルなら XOR 問題を解決できる
- 特徴空間が爆発するので FS8, ハッシュ化、VW9などを併用する
訳注: 多項式変換とはカテゴリカル変数どうしの組み合わせを特徴量として使うことを意味しています. それは2つ以上の組でもいいですし, 3つ以上の組み合わせも考えられます. カテゴリカル変数をone-hot変換すれば次元が非常に大きくなることが多いので, さらにそれらの組み合わせも追加した場合「組み合わせ爆発」が起こります. カテゴリカル変数が多い場合はむしろ多項式変換を内包した学習アルゴリズムである Factorlization Machine (10.1109/ICDM.2010.127) を使えば良いでしょう
展開変換 expansion endoding
- 1つのカテゴリカル変数を複数のラベルに分解
- ブラウザのユーザーエージェント情報, OSのバージョン情報など、整頓されていない変数
連結変換 consolidation encoding
- むしろ1対1に変換せずに丸めてしまう
- スペルミスや表記のゆらぎ, 正式名称と略称の混在するテキストデータを扱うときに有効
- 現実のデータ, 自由記入欄は特に乱雑である
数値特徴量に対する変換
カテゴリカル変数よりはアルゴリズムにとって認識しやすい, 連続変数, カウントなどの数字情報の変換.
丸め rounding/ビンニング binning
- 特性をよりはっきり表現したいときのための不可逆な変換
- 桁数の多すぎる数字は, 時として単なるノイズかもしれない
- 丸めた変数はカテゴリカル変数として扱うこともできる
- 丸める前に対数変換という手もある
- 最適なビン幅を実用的なやりかたで決める必要がある. 例えば分位点とか
- ビンニングは訓練データに現れない範囲の値もうまく変換できることがある
スケーリング Scaling
数値変数を特定のレンジにおさまるように変換すること.
- Z-scaling (標準化)
- Min-Max scaling10
- root scaling
- log scaling
欠損値補間 Imputation
訳注: そもそも欠損値を扱えないアルゴリズムならば動くようになるだけましかもしれませんが, 上から3つのやり方が一般に有効かというと全くそういうことはないです. 4番目の「モデルで推定」では「推定値のバイアスが加わることに注意」と書いていますが, 平均値や中央値で補間するという方法にも特徴量の分布に恣意的なモデルを課していることも明らかで, これらの方法が有効だというのならば例えば欠損値を一律ゼロに変換するようなやり方も有効だと言えてしまいます.
交互作用 Interactions
- ためそう: 加減算、乗算、除算
- つかおう: feature importance などで選別する
- やめよう: 人間の勘13. 思いもよらない組み合わせが意味を成すこともある
線形に落とし込むための非線形アルゴリズム
非線形変換することで線形モデルへの当てはまりを良くする方法14.
- 多項式カーネル
- leafcoding
- 遺伝的アルゴリズム
- 局所線形埋め込み, スペクトル埋め込み, t-SNE
訳注: leafcoding について具体的な説明がないですが, おそらくランダムフォレストなど決定木系のアルゴリズムを当てはめ, その予測値を使う代わりにどのリーフノードに落ちたかの情報を特徴量として使う方法のことを指しています. ランダムフォレストは複雑な構造も学習できるため, リーフノードの情報は非線形な関数を線形の情報に変換できているかもしれないとされています. 最初に提案したのが誰なのか私は知りませんが, 例えば 10.1145/2648584.2648589 で使用例があります.
行ごとの統計量を特徴量に
- 欠損値の数
- ゼロの数
- 負値の数
- 平均最大最小歪度その他
時間変数 Temporal Variables
日付などを表す変数, しばしば確認が必要なもの. 間違いを犯しやすい箇所で, しかし大きく改善できる可能性もしばしば
- 循環的な変換: 週、月の日付のように循環する数値を, 円の座標のように循環する2つの変数に置き換える
- トレンドを取り出す: 例えば購入額の総計を, 週末の値, 月末の値などにすると, 総額が同じでも購入額が増えていく顧客と減っていく顧客を区別できる
- 大きなイベントからの距離
- 祝日の何日前/後かを表す特徴量を作る
訳注: 著者は触れていませんが, 「循環的な変換」について, 周期関数の近似に使われる有限フーリエ級数(三角多項式展開)を使うという古典的なやり方があります. 例えばprophetはこの方法で周期性を表現しています(prophetを知らない方は私の書いたものとそのリンク先を見てください). prophetはそれ以外にも簡単に自前で実装できるテクニックが多く, 時間変数を扱う際の参考になります. もちろんもっと単純に曜日, 1月の何日目か, 1年の何日目かといった情報をカテゴリカル変数としてone-hot変換しても表現できる場合もあるでしょう.
空間変数 Spatical Variables
空間上の位置: GPS座標、都市、国や地域、住所など
- クリギング15
- K-平均法でクラスタリング
- 経緯度の生データをそのまま使う
- 都市の位置を経緯度に変換する
- 郵便番号を住所のテキストに
- ハブ都市との距離
- 小さな町は近くの大都市の文化の影響下にある
- 電話番号は地理的な距離に関係があることも
- 位置情報のなかには疑わしいものもある
- ありえない移動速度
- 自宅や移動経路と異なる位置に滞在
- 同じ場所に二度と滞在していない
探索 Exploration
データの精査のこと. データの品質, 外れ値, ノイズ, 特徴量抽出のアイディアを見つける.
- コンソールなり Notebook なり pandas で操作
- 単純な記述統計を取って確認
- 目的変数との相関関係を見る
反復とデバッグ Iteration/Debugging
特徴量エンジニアリングは何度も繰り返す作業なので、すばやく繰り返せるような作業フローにする
* 「おおむね一直線のデバッグ」中間情報を擬似的なログとして、処理の中間で出力して確認
* より速い調査ができるようにツールを使う
* うまくいくアイディアよりも失敗するアイディアのほうが多いと心得よラベルエンジニアリング
ラベル/ターゲット/目的変数自体を特徴量として使用できる. 逆も然り
- 対数/指数変換
- 2乗変換
- Box-Cox 変換
- 2値変数を回帰問題にするためにスコアリングする
- テストデータでは使えない未来の特徴量を予測するために目的変数で訓練する
訳注: この項目は記述が曖昧すぎてわかりにくいですが, 大きく分けて3つのテクニックに言及していると私は考えています.
第1のテクニックは, 目的変数を変換することで当てはまりを良くする方法です. 例えば単純な線形回帰モデルでは分布が非対称で歪んでいる場合当てはまりが悪い傾向があります. しかし対数変換や2乗変換などで目的変数を変換して対称になるよう調整すれば, 線形回帰モデルでも当てはまりがよくなることがあります. 典型例に一般化線形モデル(GLM)があります.
第2は, さらにそのようなモデルに対して別の方法で変換した目的変数を特徴量として加えるとさらに当てはまりがよくなる可能性に言及しています. 目的変数を特徴量に使っているため, もちろん実際の予測には使えませんが, これで当てはまりの悪さの原因がどこにあるのか, 言い換えるなら現在試しているモデルで捉えきれていない目的変数の傾向がどうなっているか, の確認には使うことができます. つまり, このようなモデルを残差ヒストグラムやq-qプロットで確認することで, 第1のテクニックで挙げた目的変数の変換方法をより改善できるヒントが得られます. 著者は統計学で残差診断 residual diagnosis と呼ばれる方法について言及しているのだと思います.
第3は, 最後から2つ「2値変数を~」「テストデータでは使えない~」で言及されている内容です. 2値変数は名前どおり2つしか値がないため情報が少ないです. しかし, この2値変数がどちらの値になるかが未知の変数によって決まるという潜在変数モデルのように, 背後には見えない確率が存在すると考えられます. スコアリングとは2値変数の値に対応する確率を表す変数を作り, 分類問題をスコア変数に対する回帰問題に置き換えよう, という意味です. このスコア変数は何も考えずに作れるものではない(いつもどおりにデータに一番当てはまるモデルだけを選んでいては通常の分類問題を解いているのと変わらない)ため, 確率がどう決まるのかという情報をデータの外から得る, いわゆる「ドメイン知識」から導く必要があるでしょう. 「テストデータでは使えない~」は, 未来の特徴量の値を予測するために, 他の特徴量や目的変数を特徴量としてもう1つの予測モデルを作成するという意味です. これらは広義の欠損値補完とも考えられます. この2つのテクニックは予測モデルをもう1つ作る手間はありますが, もちろんこのような方法も有効な場合があります.
自然言語処理の場合
訳注: このセクションはごく初歩的な話の羅列で具体的な説明がないのでちゃんとした教科書(例えばコロナ社の自然言語処理シリーズなど)を読んだほうがいいかもしれません.
- カテゴリカルな特徴量と同じアイディアが使える
- 深層学習(オートエンコーダ/自己符号化器) がこの分野を浸食しつつあるが, よくエンジニアリングされた特徴量による浅い学習にも未だに競争力がある
- データの高いスパース性によっていわゆる「次元の呪い」が引き起こされる
- 特徴量エンジニアリングの機会は多い (以下は英文の話であることに注意)
- クリーニング:
- lowercasing 小文字化
- unidecode アクセント記号つき文字を ASCII 文字に置換
- removing non-alphanumeric 英数字の除去 (あるいは約物などを除去する)
- repairing エンコード上の問題修正: 全角文字を半角に, 字間の変なスペースを除去する、など
- tokenizing トークナイズ
- encoding punctuation marks 約物の変換
- token-grams
- skip-grams
- char-grams 文字単位で n-gram を作成すること
- affixes char-grams の冒頭末尾だけを残すやつ
- 除去
- removing stopwords ストップワード除去
- removing rare/very common workds 希少語・頻出語の除去
- 語幹
- Chopping 単語の冒頭n文字だけを残す
- Speling correction 表記ゆれ補正
- Stemming 語幹だけを残す
- Lemmannization 意味上の語幹を見つける?
- 情報の付与
- Document features スペース/tabの数、行数、文字数、など文書全体の情報
- Entity insersion 単語補完 テキストの意味を明確にするために語を補う
- Parse trees 文の論理構造を付与: 主語、目的語、動詞...
- Reading level 文書の読解レベル(?)
- 類似度
- word2vec, glove/doc2vec
- token smilarity 文字列の類似度
- Levenstein?Hamming/Jaccard dist.
- nearest neighbor 最近傍法
- TF-IDF
- term frequency 全ての文書に対してある文書内に登場するトークンの頻度 文書の長さの違いによるバイアスを削減できる
- inverse document frequency 逆文書頻度: 文書ごとのトークン出現頻度の逆数。頻出トークンのバイアスを削減
- TF-IDF 重要なトークンを特定し、重要度の低いものを除外できる。
- 次元削減
- 主成分分析 (PCA)・特異値分解 (SVD): 50-100次元程度なら16
- 潜在ディリクレ配分法 (LDA): TF-IDFにSVD
- 潜在意味解析法 (LSA): トピックベクトルの作成
- 外部モデルに頼る
- 意味分析: 感情分析 テキストのポジティブ/ネガティブ情報
- トピックモデル
ニューラルネットワーク & 深層学習
- ニューラルネットは特徴量エンジニアリングをゆりかごから墓場まで全部自動でやってくれると主張する人がいる17
- では特徴量抽出はもう無意味?
- いいえ! アーキテクチャエンジニアリングへ視点を変えましょう18
- ニューラルネットの有無と無関係である証拠: 画像認識分野ではHOG, SIFT, ホワイトニング、摂動、イメージピラミッド、回転、z変換、対数変換、frame-grams, 外部の意味情報などなどを使って特徴量抽出している. (明らかに深層学習だけでこなせるタスクではないとわかる)
Leakage/Golden Features
- 特徴量抽出はleakageの活用の助けになる19
- リバースエンジニアリングをする
- rainbow table で MD5 ハッシュを復号
- TF-IDF から単語頻度を復元
- 標本データセットの並びを符号化
- ファイル作成日を符号化
- ルールマイニングをする
- 特徴量の単純なエンコーディングルールを見つけ出す
エピグラフ
各所に挿入されていますがここにまとめておきます.
Andrew Ng「『特徴量を捉えるのは難しく、時間を浪費し、専門知識もいる』機械学習の応用の本は特徴量エンジニアリングにあり。」
Domingos 「機械学習は成功例も失敗例もある。違いは何か? 単純に言えば、最も重要な要因は使用した特徴量」
Locklin: 「特徴量エンジニアリングは査読論文や教科書に載せるほどではない、何か別のものであるが、機械学習を成功させるに絶対不可欠だ。(中略) 機械学習の成功例の多くは実際特徴量エンジニアリングに帰する」
Miel: 「入力データをアルゴリズムが理解できるものにしよう」
Hal Daume III 「大抵の論文に書いてあること: 特徴量エンジニアリングは大変で時間がかかります。しかし我々が発見した、同様のことができるニューラルネットワークの新規的な方法はこのたった8ページの論文に書いてあります」
Francois Chollet 「良いモデルを開発するには当初のアイディアを締め切り近くまで何度も繰り返すことが要求される。モデルを改善する可能性は常にある。最終的なモデルはたいてい、問題に最初に取り組んだときの見通しとほとんど違っている。なぜならアプリオリな予定は原理的に実験による現実との対立に生き残れないからだ」
不均衡データのリサンプリングは事後確率を歪めるため, (当たり前だが)そのまま分類に使うと予測にバイアスを引き起こす. この問題と解決方法は理論的に示されている(10.1109/SSCI.2015.33)が, この論文のアイディアはそれ以前からも何度もあちこちで言及されている. 北澤拓也氏の個人ページではこの辺のアイディアがまとめられていて参考になる. ↩
訳注:
pandas.get_dummiesやsklearn.preprocessing.OneHotEncoderなどの実装がある. いずれもscipyのスパース行列として返すことができる.: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.get_dummies.html, http://contrib.scikit-learn.org/categorical-encoding/onehot.html, http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.htmlただし sklearn は numpy 準拠なので入力データは数値型のみ現在はobject型にも対応してかなり使いやすくなった. ↩訳注: もともとの論文(DOI: 10.1145/1553374.1553516)では hash trick はハッシュ変換とカーネルトリックをあわせた手法のことを指している. 最近では単なるハッシュ変換までこう呼ぶ人が多い. ↩
訳注: 線形モデルの場合は目的変数とカウントがある程度線形相関していないと有効でないことに注意 ↩
訳注: 例によって「有効(な場合もある)」という意味 ↩
訳注: 順位タイの場合はどうするのか ↩
訳注: 例によって普遍的な性質ではなく, そういうケースがあるという話 (arXiv: 1604.06737). これによれば, 「次元よりも複雑な構造」の場合に有効とのこと. いわゆるスイスロール問題のような状況. ↩
訳注: feature selection(特徴量選択)と言いたいのでしょうか? ↩
訳注: これはよくわかりません. VowpalWabbitの特徴量選択アルゴリズムのこと? ↩
訳注: normalizeとも呼ばれる. レンジが0-1になる. ↩
訳注: ペアワイズ除去のこと? ↩
訳注: Tobitモデルとか多重代入法とか? ↩
勘というか「思い込み」みたいな ↩
ここで挙げられている方法はほとんどが計算量が多かったり, 次元に対して爆発的に計算量が増えたりします. よって変数が多い場合は実用的でないものが多いです. この辺の話は,例えば赤穂『カーネル多変量解析』などが参考になります. ↩
訳注: そこまでやるか? バリオグラムを特徴量に入れるとかから試すくらいで良さそうな気がする ↩
訳注: この数字の根拠は不明 ↩
訳注: HAHAHA 今日はエイプリルフールじゃないですぜ! ↩
訳注: そもそも特徴量抽出の一側面は悪条件問題を改善して最適化計算を安定させるための処理ではないか? ↩
訳注: leakageは本来学習時点に得られない情報を使ってテストデータの当てはまりを良くする上げる手法のこと. kaggleで出題者のミスでときどき発生するらしい. よって実用性はないが, 以下リバースエンジニアリング, ルールマイニングで挙げられるテクニックはどの場面でも使う機会があるだろう. ↩
- 投稿日:2020-02-19T11:37:44+09:00
【Windows】AnacondaのPATHの設定で躓く初学者の話。
きっかけ
Rで解析してたら、Pythonも学習しようと声をかけられたので、いざPythonの環境を構築しようと頑張っていたら躓きました。
bashにもパスを通したいのに通ってくれない。。
なんでだー。ってなったお話です。解決方法
ここを参考にすればだいたいおっけーのはずなのですが。。。
なぜか通らない。
$ conda -V conda: command not foundを何回も見る羽目に笑
まず最初の課題はこれ。
bash: export PATH=~/anaconda3/bin : No such file or directoryなんか見つからない。なんでだー。
よくわからんが、
""でパスをくくってみる。export PATH="/Users/user_name/anaconda3/bin:$PATH"そしたら、エラーしなくなりました。
vimのことよくわからないので誰かコメントで教えて下さい;
それからもう一回
sourceコマンドを実行して追加したパスを反映させてみる。$ conda -V conda: command not foundなんでだーー。
解決方法 -> 深く悩む。
---終---
なんでやねん笑
もうちょっと調べると
解決した方法 # 4
場合によっては、anacondaもインストールした後に端末を再起動しないと、このエラーが発生します。
ターミナルウィンドウを閉じて再起動します。
それは今私のために働いた!とありました。
おかしいなーターミナル再起動したはずなんだけどなぁと思いながら、とりあえずPCを再起動笑
その結果、
$ conda -V conda 4.7.12感激。
詳しい原因は正直わかりませんが、一つの解決方法としてメモ残しておきます。
- 投稿日:2020-02-19T10:55:48+09:00
無料Python実行環境Google Colaboratoryメモ
Google Colaboratoryとは
Googleのクラウドで実行される Jupyter ノートブック環境。
https://colab.research.google.com/notebooks/welcome.ipynb無料で利用可能、環境構築不要であるため、Pythonの勉強などに便利です。
また、GPUやTPUの利用も可能で機械学習の実行時間も削減できます。
利用制限
無料で利用可能ですが、連続利用時間に12時間の制限があります。
12時間を過ぎると仮想マシンが切断されるため、機械学習で長時間利用する場合は注意が必要です。
また、アイドルタイムアウト時間放置した場合も仮想マシンが切断されます。
※アイドルタイムアウトの時間はFAQに記載されていませんが、現在は90分のようです
https://research.google.com/colaboratory/faq.htmlメモ
以下、利用メモ。
GPU/TPUの利用
ランタイム > ランタイムのタイプを変更 から選択。
Googole Driveのマウント
サイドメニューの「ドライブをマウント」を選択すると、マウントするためのコードが自動で生成されるので実行。
TensorFlowのバージョン変更
現在デフォルトは1.x系。以下を実行すると2.x系に変更できる。
%tensorflow_version 2.x※試す際はTensorFlowのチュートリアル( https://www.tensorflow.org/tutorials )の各ページにある「Run in Google Colab」を開くと、2.x系に変更して動かすコードで記載されています。
以上