- 投稿日:2019-12-13T23:40:34+09:00
Chromeのユーザー機能によってAWSマネジメントコンソールで複数のアカウントを使い分ける方法
運用するサービスやデプロイする環境ごとにAWSアカウントを分けるのは、よくある手法かと思います。
そこで問題となるのが、AWSマネジメントコンソールで同時に複数のアカウントにログインできないことです。
この制約を回避すべく、ブラウザのシークレットモードを使ったり、別のブラウザを起動したりしている人も多いのではないでしょうか。
その問題、Chromeなら解決できます。ユーザー管理機能を使う
Chromeには、ユーザー管理機能が存在します。
ほとんどの人はGoogleアカウントと紐づけているかと思いますが、同じデバイス上で複数のユーザーを作成して使い分けることも可能です。Chromeのユーザーを作成
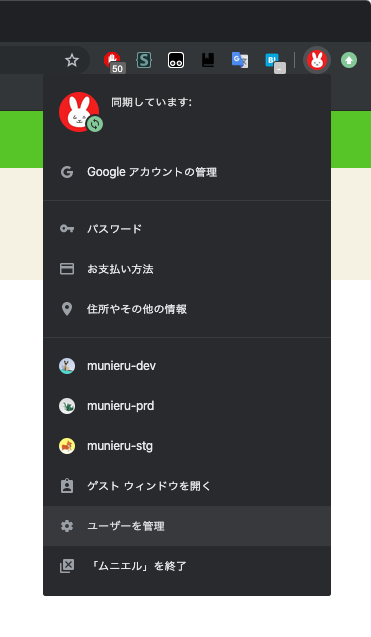
Chromeのウインドウ上部にあるユーザーのアイコンをクリックすると、次のようなメニューが表示されます。
「ユーザーを管理」をクリックすると、ユーザー管理画面が開きます。
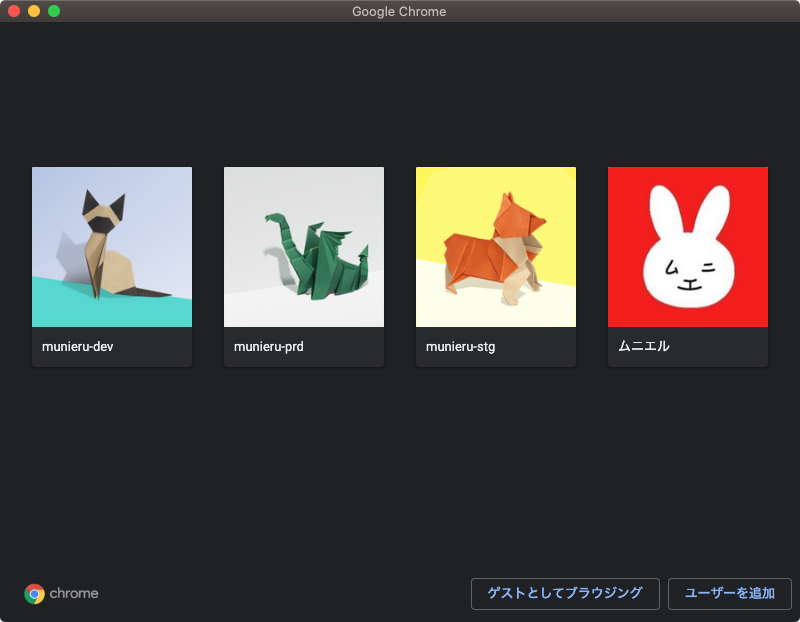
さらに「ユーザーを追加」ボタンをクリックすると、ユーザー追加画面が開きます。
ここでは、作成するユーザーの名前とアイコンを設定します。
名前には、AWSアカウントのアカウント名を入れるといいでしょう。
アイコンはデフォルトで用意されたものの中から選ぶ必要がありますが、どうしても独自の画像を使いたい場合は設定ファイルを直接書き換える方法もあるようです。1ユーザーの設定を変更
ユーザーを作成すると、そのユーザーとして新しいウインドウが開きます。
そのまま使い始めてもいいのですが、せっかくなので起動時にログイン画面を開くようにしておきましょう。
AWSマネジメントコンソールのログイン画面のURLは、次のような形式になっています(実際にアクセスするとアカウント名が入力された状態のログイン画面にリダイレクトされます)。https://<アカウント名>.signin.aws.amazon.com/consoleSSO環境を構築している場合は、よしなに置き換えてください。
参考リンク


- 投稿日:2019-12-13T23:39:06+09:00
Terraformで立てたec2インスタンスをAnsibleで管理してみる
この記事はニフティグループ Advent Calendar 2019の13日目の記事です。
昨日は@hmmrjnさんの「WebページもOSのDark Modeに対応できる」でした。
個人的にDark Modeは大好きなので、対応がしやすくなるのはとても嬉しいですね。
はじめに
近年、TerraformのようなオーケストレーションツールやChef・Ansibleといった構成管理ツールの利用により、リソースの構築・管理がより容易になってきています。
私も今更ながらAnsibleを扱い始めました。そのなかで、クラウドリソースはIPアドレスが決まっていないことが多いため、インベントリの扱いが非常に面倒なことがありました。この記事では、Terraformで立てたec2インスタンスに対して、Ansibleで用途ごとにグループ分けして構成管理することを目標としています。
これを達成する手段の一つとして、AnsibleのInventory Pluginを利用してみました。環境
- OS: macOS Catalina 10.15.1
- Ansible: 2.9.2
- Terraform: v0.12.18
ディレクトリ構成
今回は簡単化のため、以下に示す最小限のディレクトリ構成で進めていきます。
実際に利用する際は各ツールのベストプラクティスに従ってください。. ├── ansible │ ├── group_vars │ │ └── aws_ec2.yml │ ├── inventory │ │ └── aws_ec2.yml │ └── site.yml └── terraform ├── ec2.tf ├── main.tf └── vpc.tf前準備
Ansibleで管理する対象サーバーをTerraformで作成します。
tfファイル作成
今回はタグのみが異なる3つのec2インスタンスを作成するように記述します。
各ec2インスタンスに対するタグの付け方は以下のようになっています。
- タグなし
- Nameタグ: "web-ec2"、Webserverタグ: "httpd"
- Nameタグ: "web-ec2"、Webserverタグ: "nginx"
このタグの付け方がAnsibleのインベントリを作成する上で重要になってきます。
terraform/main.tfの内容
main.tfprovider "aws" { version = "~> 2.41" region = "ap-northeast-1" }
terraform/ec2.tfの内容
ec2.tfresource "aws_security_group" "web_sg" { vpc_id = aws_vpc.example.id ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } } resource "aws_instance" "example" { ami = "ami-068a6cefc24c301d2" instance_type = "t2.micro" subnet_id = aws_subnet.public.id key_name = "my-aws-key" vpc_security_group_ids = [aws_security_group.web_sg.id] } resource "aws_instance" "httpd" { ami = "ami-068a6cefc24c301d2" instance_type = "t2.micro" subnet_id = aws_subnet.public.id key_name = "my-aws-key" vpc_security_group_ids = [aws_security_group.web_sg.id] tags = { Name = "web-ec2" Webserver = "httpd" } } resource "aws_instance" "nginx" { ami = "ami-068a6cefc24c301d2" instance_type = "t2.micro" subnet_id = aws_subnet.public.id key_name = "my-aws-key" vpc_security_group_ids = [aws_security_group.web_sg.id] tags = { Name = "web-ec2" Webserver = "nginx" } }
terraform/vpc.tfの内容
terraform/vpc.tfresource "aws_vpc" "example" { cidr_block = "10.0.0.0/16" enable_dns_hostnames = true enable_dns_support = true } resource "aws_subnet" "public" { vpc_id = aws_vpc.example.id cidr_block = "10.0.0.0/24" map_public_ip_on_launch = true availability_zone = "ap-northeast-1a" } resource "aws_internet_gateway" "example" { vpc_id = aws_vpc.example.id } resource "aws_route_table" "public" { vpc_id = aws_vpc.example.id } resource "aws_route" "public" { route_table_id = aws_route_table.public.id gateway_id = aws_internet_gateway.example.id destination_cidr_block = "0.0.0.0/0" } resource "aws_route_table_association" "public" { subnet_id = aws_subnet.public.id route_table_id = aws_route_table.public.id }リソース作成
terraform planで確認後、間違えがなければterraform applyを実行します。$ cd terraform $ terraform init $ terraform plan $ terraform applyインベントリ作成
Ansibleでサーバを管理するためには、各サーバのIPアドレスを知らなければいけません。しかし、ec2インスタンスのようなクラウドリソースは作成するたびに、IPアドレスが変化します。また、WEBサーバやDBサーバといった用途ごとに使い分ける場合、グループ分けをする必要があります。これらを手動でインベントリに記述していくことは大変だと思います。
そこで、Dynamic InventoryやInventory Pluginを利用することで、取得した情報から動的にインベントリを作成することができます。今回はInventory Pluginのうち、AWS EC2用プラグインを利用します。
Inventory Plugins — Ansible Documentation
aws_ec2 – EC2 inventory sourceaws_ec2 プラグイン
aws_ec2プラグインにより、AWS上にあるec2インスタンスに対するインベントリをコンパイルできます。
以下のようにファイルを記述することで、各ec2インスタンスをタグやインスタンスタイプ等でグループ分けできます。
ここで注意が必要なのは、ファイル名のサフィックスがaws_ec2.(yml|yaml)である必要があります。
プラグインを利用したファイルは通常のインベントリファイルと同様にansible-playbookなどで扱うことができます。ansible/inventory/aws_ec2.ymlplugin: aws_ec2 regions: - ap-northeast-1 strict: no keyed_groups: # Nameタグの値により、グループを分類。グループ名のプレフィックスに"tag_Name_"を付与 - key: tags.Name prefix: tag_Name_ separator: "" # インスタンスタイプ(t2.microなど)により、グループを分類 - key: instance_type prefix: instance_type # Webserverタグの値により、グループを分類 - key: tags.Webserver separator: "" groups: # Nameタグのプレフィックスが"web-"のとき、webグループに分類 web: "tags.Name is match('^web-')" # ホストごとの変数の設定。 # ここではグローバル経由でアクセスするため、`ansible_host`変数にグローバルIPを格納する。 compose: ansible_host: global_ip_addressインベントリの確認
ansible-inventoryコマンドを利用することでプラグインから作成されたグループ構成を確認することができます。$ ansible-inventory -i inventory/aws_ec2.yml --graph @all: |--@aws_ec2: | |--ec2-13-113-228-112.ap-northeast-1.compute.amazonaws.com | |--ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com | |--ec2-52-68-129-109.ap-northeast-1.compute.amazonaws.com |--@httpd: | |--ec2-13-113-228-112.ap-northeast-1.compute.amazonaws.com |--@instance_type_t2_micro: | |--ec2-13-113-228-112.ap-northeast-1.compute.amazonaws.com | |--ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com | |--ec2-52-68-129-109.ap-northeast-1.compute.amazonaws.com |--@nginx: | |--ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com |--@tag_Name_web_ec2: | |--ec2-13-113-228-112.ap-northeast-1.compute.amazonaws.com | |--ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com |--@ungrouped: |--@web: | |--ec2-13-113-228-112.ap-northeast-1.compute.amazonaws.com | |--ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com設定したタグやインスタンスタイプごとに、グループ分けができていることがわかります。
Playbookの実行
最後に、以下のPlaybookを実行して、グループごとに構成管理できるかを確認します。
httpdグループにapache、nginxグループにnginxをインストールして起動します。(このようなグループ分けはあまりなさそうですが、例のために行います)ansible/site.yml--- - hosts: httpd gather_facts: no become: yes tasks: - yum: name: httpd state: latest - systemd: name: httpd state: started - hosts: nginx gather_facts: no become: yes tasks: - command: "amazon-linux-extras enable nginx1.12" changed_when: false - yum: name: nginx enablerepo: amzn2extra-nginx1.12 state: present - systemd: name: nginx state: started$ cd ansible $ ansible-playbook -i inventory/aws_ec2.yml site.yml PLAY [httpd] ********************************************************************************************************************************************* TASK [Install httpd] ************************************************************************************************************************************* changed: [ec2-13-113-228-112.ap-northeast-1.compute.amazonaws.com] TASK [Start httpd] *************************************************************************************************************************************** changed: [ec2-13-113-228-112.ap-northeast-1.compute.amazonaws.com] PLAY [nginx] ********************************************************************************************************************************************* TASK [command] ******************************************************************************************************************************************* ok: [ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com] TASK [yum] *********************************************************************************************************************************************** changed: [ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com] TASK [systemd] ******************************************************************************************************************************************* changed: [ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com] PLAY RECAP *********************************************************************************************************************************************** ec2-13-113-228-112.ap-northeast-1.compute.amazonaws.com : ok=2 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com : ok=3 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
curlコマンドでサーバにアクセスしてみます。
それぞれapacheとnginxがインストールできていることがわかります。$ curl -I ec2-13-113-228-112.ap-northeast-1.compute.amazonaws.com HTTP/1.1 403 Forbidden Date: Fri, 13 Dec 2019 14:30:29 GMT Server: Apache/2.4.41 () Upgrade: h2,h2c Connection: Upgrade Last-Modified: Tue, 22 Oct 2019 22:56:48 GMT ETag: "e2e-59587b710ac00" Accept-Ranges: bytes Content-Length: 3630 Content-Type: text/html; charset=UTF-8 $ curl -I ec2-52-199-119-151.ap-northeast-1.compute.amazonaws.com HTTP/1.1 200 OK Server: nginx/1.12.2 Date: Fri, 13 Dec 2019 14:31:13 GMT Content-Type: text/html Content-Length: 3520 Last-Modified: Wed, 28 Aug 2019 19:52:13 GMT Connection: keep-alive ETag: "5d66db6d-dc0" Accept-Ranges: bytesおわりに
Inventory Pluginにより、Terraformで立てたec2サーバをAnsibleで管理することができました。予めリソースに対するタグの付け方をルール化することで、より良い構成管理ができると思います。
検証機や勉強会用サーバといった同一のサーバを立てたり、クラウド間の移行など、構成管理をしておくことは非常に重要だと思います。そのため、さらにベターなリソース管理を目指して頑張っていきたいです。
参考文献
- 投稿日:2019-12-13T23:32:36+09:00
AWSでJupyterHub (HTTPS化)
概要
全体概要は, AWSでJupyterHub (概要) にあるので,参照してください.今回は,前回のHTTP接続を,HTTPS化させようと思います.
また,セキュリティ的な絡みでWAFを少しやってみようと思います.
今回も例によって,画像を使った説明を多用しましたため眺めの記事となっております.おしながき
- ACMで証明書の発行
- ALBに証明書を追加
- ALB用にWAFを作成
- ALBニWAFを追加
ACMで証明書の発行
さっそく,証明書を発行していきます.
まず,ACM(Amazon Certificate Manager)に行きます.
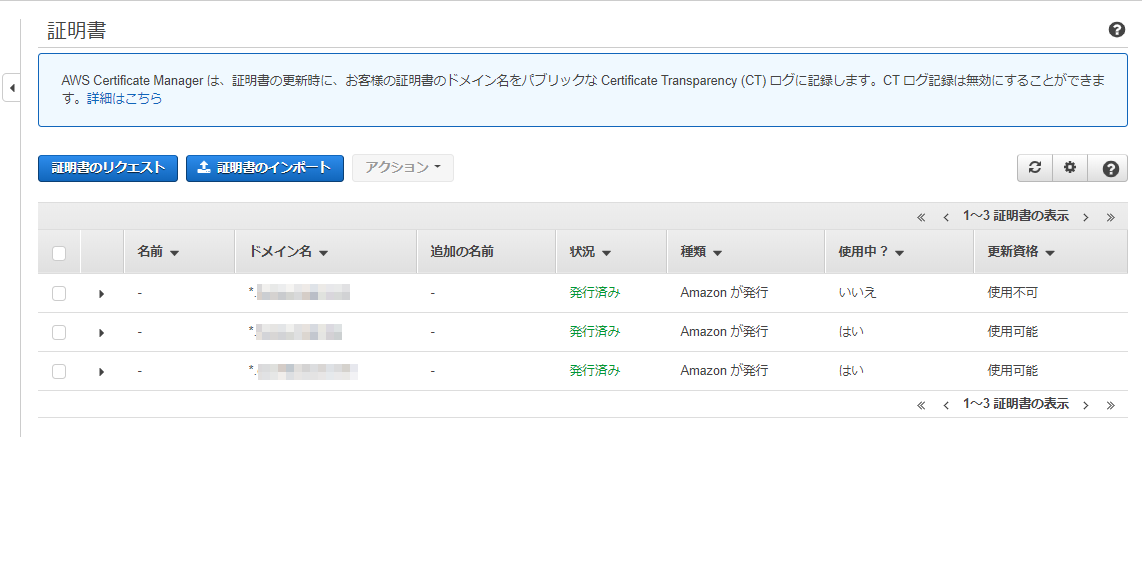
ここでは,各種証明書を一元管理できるようになっています.
パブリック証明書は無料で利用することができます.
この画像は,証明書3つある状態です.一番上は【使用中?】の項目がいいえになっているので,どこからも使われていない状態になっています.逆にほかの2つは使われているということになります.
【証明書のリクエスト】のボタンを押して,証明書を作成します.
割と簡単に作成することが出来ます.
手順は
1. 「パブリック証明書」を選択
2. 前回Route53で登録したドメインを入力
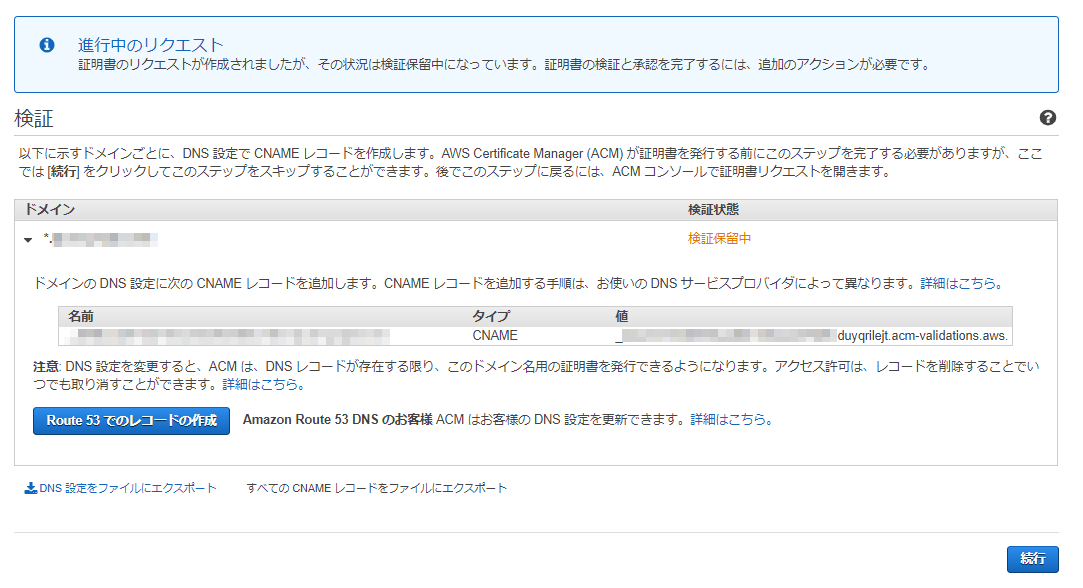
3. 「DNSの検証」を選択
4. タグは何も触らず進む
5. 確認したら【確認とリクエスト】を押す
6. 検証中にRoute53にレコード追加レコード追加は,以下の画像のように,ドメインの横にある▼を押して項目を開きます.開いた中に【Route53でのレコード作成】を押すだけです.追加先は,ドメインと同じホストゾーンになります.
ALBに証明書を追加
出来上がった証明書をALBに追加していきます.
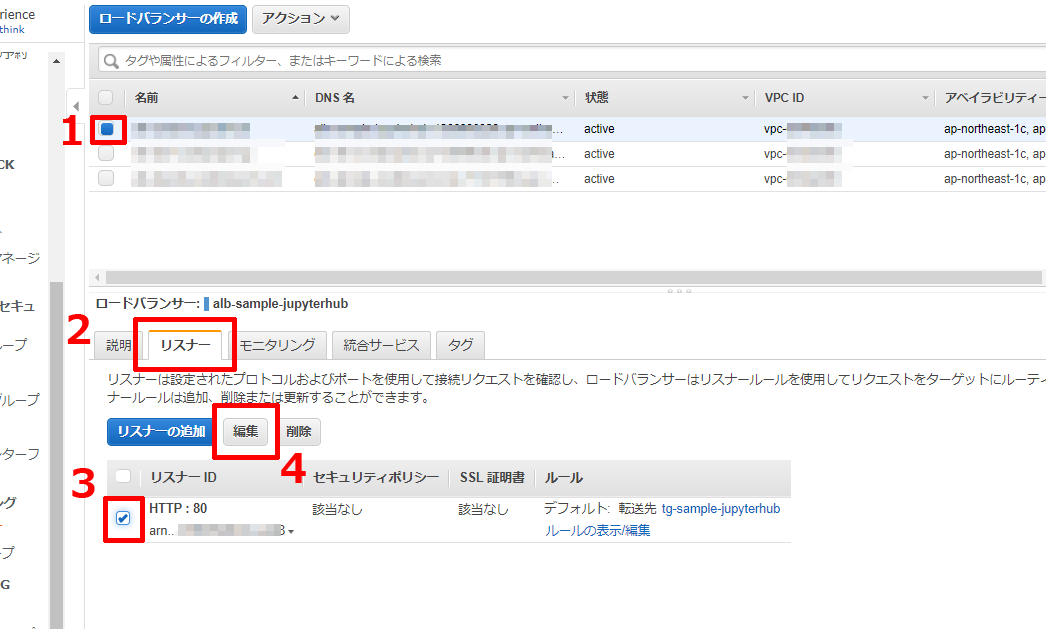
EC2のロードバランサーの画面に行き,前回作成したALBを選びます.
選んだら,以下の画像のように,リスナータブを選択し,HTTPのリスナーを選択します.
そうすると【編集】ボタンが活性化するので,押します.
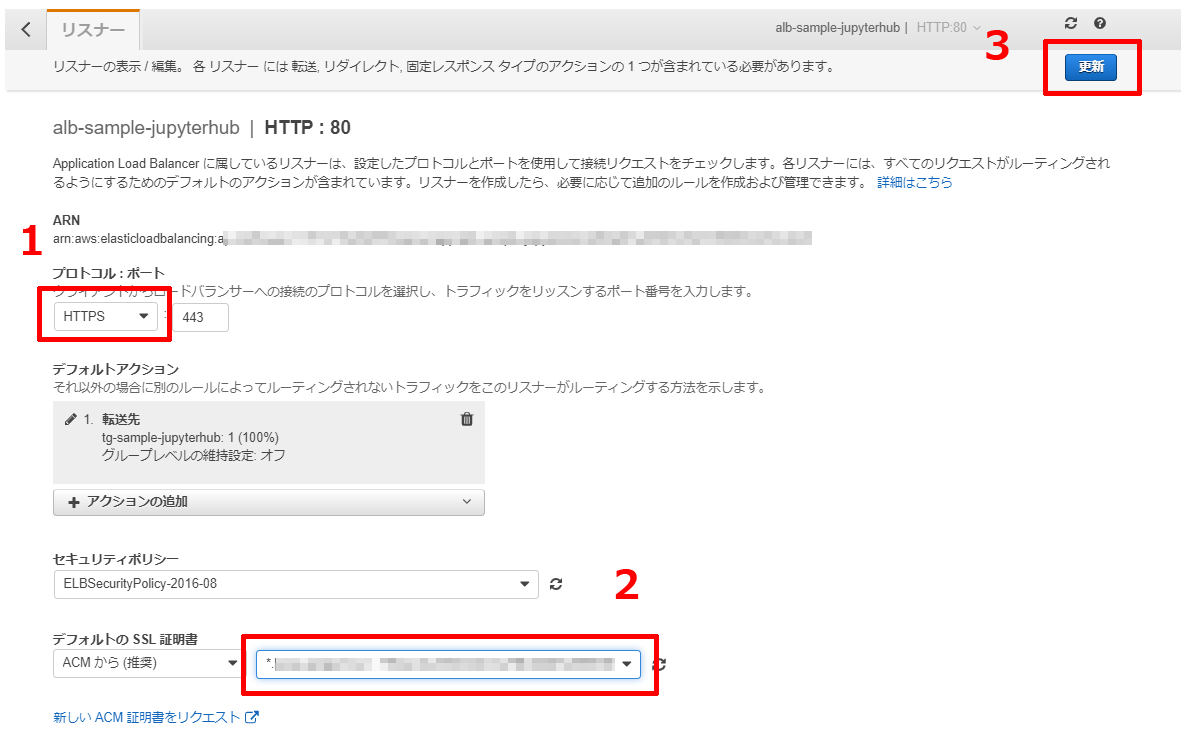
前回,HTTPプロトコルでALBを作成したため,リスナーがHTTPになっています.
以下の画像にある順番にHTTPSに変更,証明書の指定,更新,と操作していきます.
問題なく処理が出来れば,ボタンの横に「正常に変更されました」とメッセージが表示されます.
セキュリティグループの変更
このままでは,HTTPSの接続がうまくいかないです.
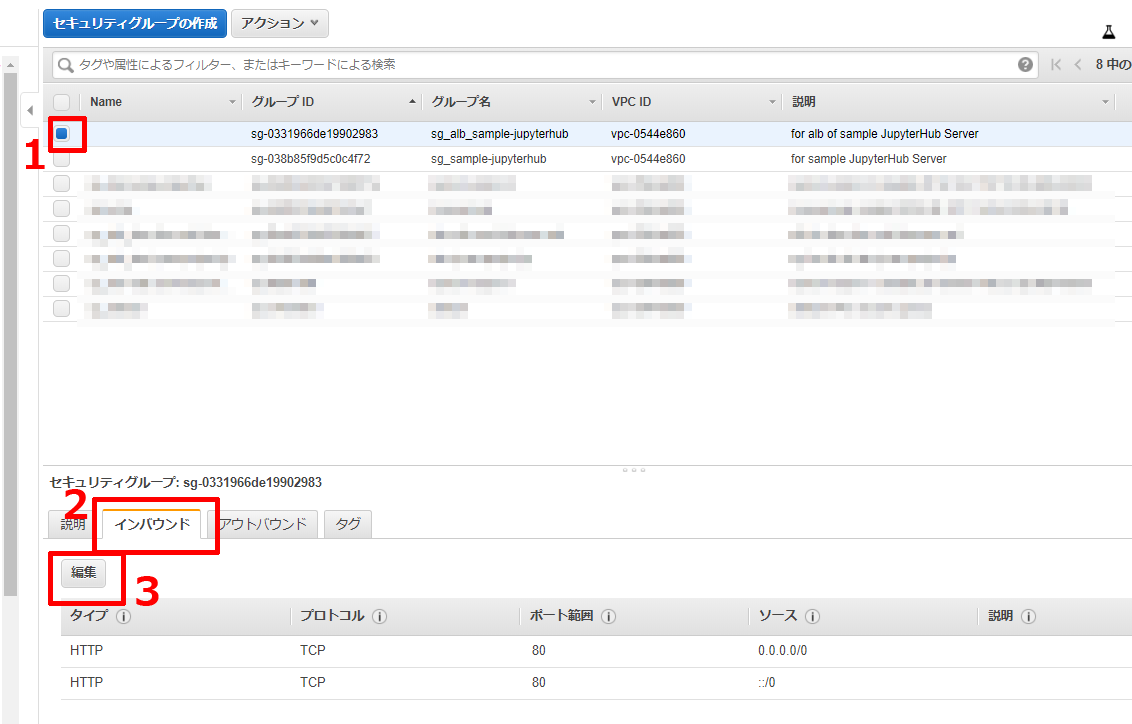
前回のALBの作成時に新規追加したセキュリティグループはHTTPのみ設定しているので,HTTPS接続は弾かれてしまいます.
なので,HTTPからHTTPSに開放プロトコルを変更します.
セキュリティグループの一覧にいき,以下の順番で編集ダイアログを表示させます.
表示されたダイアログには2つレコードが出ていて,【タイプ】がHTTPとなっています.
プルダウンメニューからHTTPSを選んで,【保存】ボタンを押します.
これで,許可される接続がHTTPからHTTPSに切り替わりました.この状態で,前回アクセスした
http://{Route53に登録したドメイン}/hub/にアクセスするとHTTPは許可していないため拒否されます.かわりに
https://{Route53に登録したドメイン}/hub/にアクセスすると以下の画像のように証明書が利いた状態でHTTPS接続が出来ていることが分かります.それまで出ていた,HTTP接続のワーニングメッセージも消えているのが分かります.
ALB用にWAFを作成
次に,簡単なWAFを作っていきます.
IPアドレスやURLをベースにしてもいいのですが,今回は地域(geometory)を指定したものにします.
許可対象は,日本ということにします.(逆に日本を拒否とかできますが...)
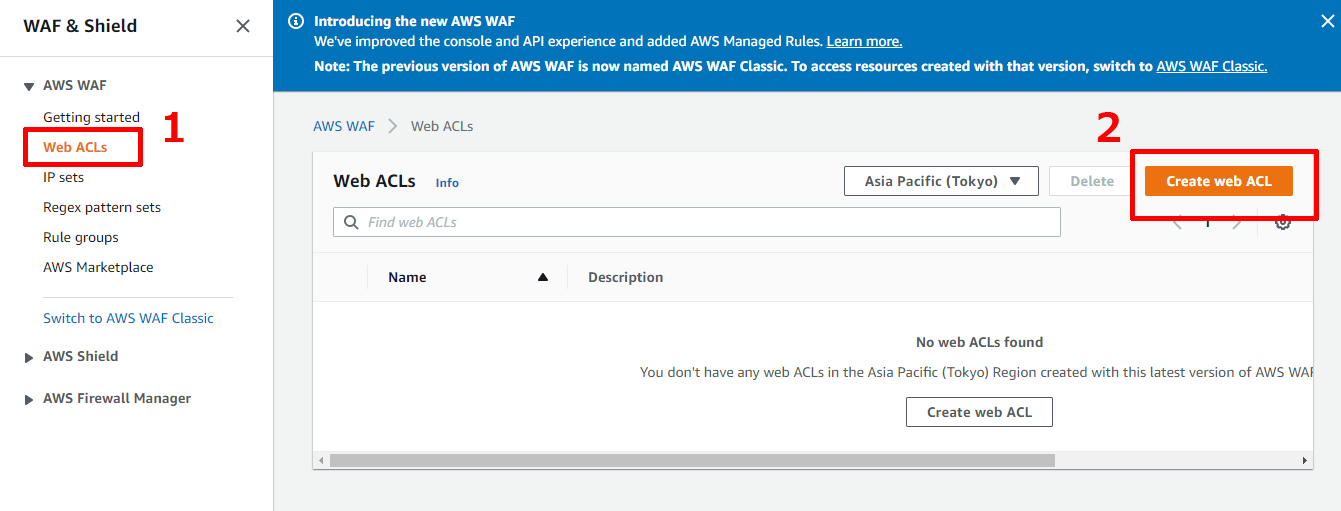
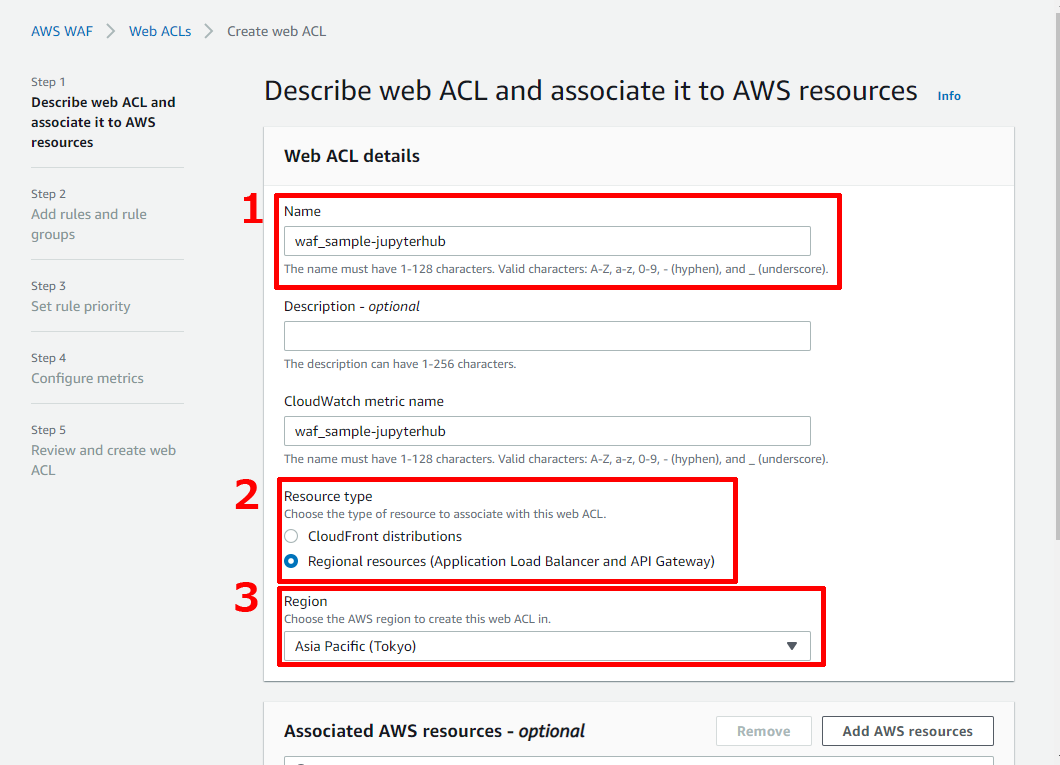
気付いたら,新しくなっていたようなので,そちらを使ってみようと思います,まず,以下の手順でweb ACL作成画面に遷移します.
まだ日本語対応していないようなので,UIがすべて英語になっています.(2019/12/13段階)
【Create web ACL】ボタンを押すと,以下のような画面が出てくるので,各項目に入力します.
NameとResource typeとRegionにそれぞれ入力します.
Nameは,管理用の名前です.わかりやすい名前を付けましょう.
CloudWatchにログを送ることが出来るため,自動的にCloudWatch用メトリクス名も入力されます.
Resource Typeは今回ALBにつけたいので,Regional resourcesを選びます.
Regionは,東京を選びます.
次に関連するリソースの指定になります.
【Add AWS resources】を選んで以下のようなダイアログを表示させます.
そしてリソースはALBなのでApplication load balancerを選択して,前回作成したALBを選択します.
入力したら【Add】ボタンを押して,Associated AWS resourcesの一覧に追加させます.
追加が確認出来たら,【Next】ボタンを押します.
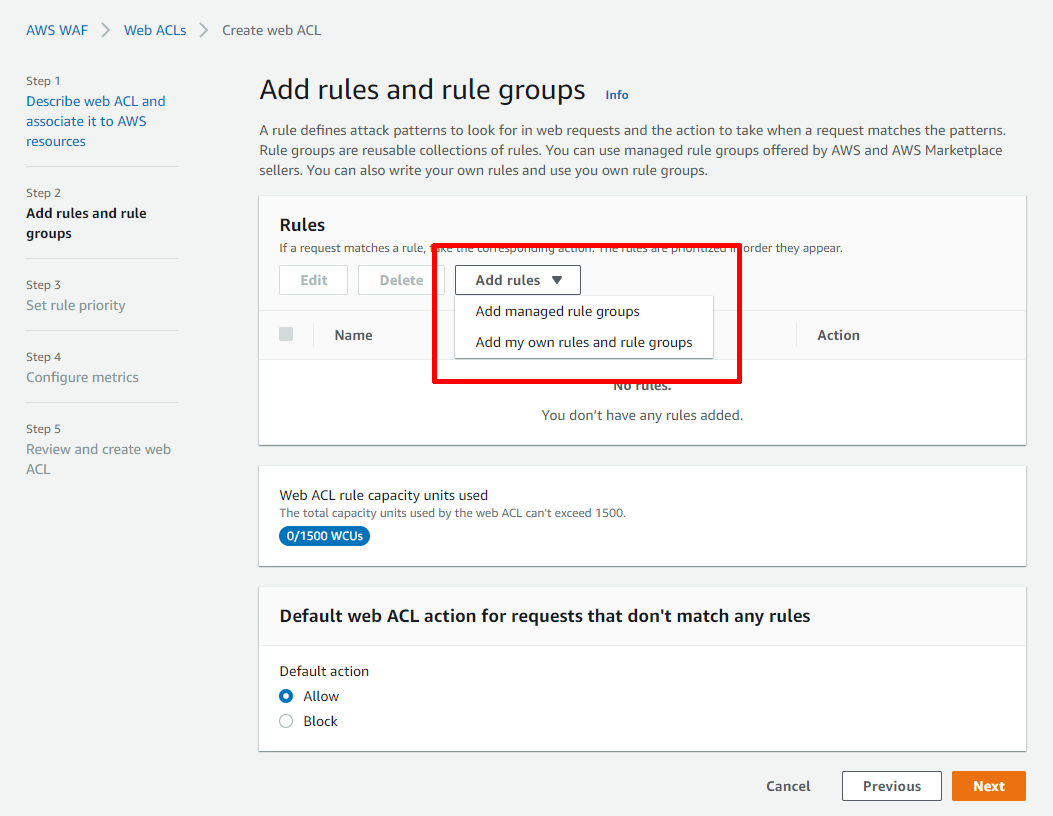
次は,アクセス時に適用させるルールを作っていきます.
「もしxxxだったら~~~する」という感じでルールを組み立てていきます.
今回は「もし日本からのアクセスだったら許可する」という感じになります.
ルールの確認できるのかというと,ちょくちょく国外からのアクセスが確認できるので,IPアドレスやヘッダなどのルールよりも個人的に感動しました.ということで,
Rulesの【Add rules】からAdd my own rules and rule groupsを選びます.
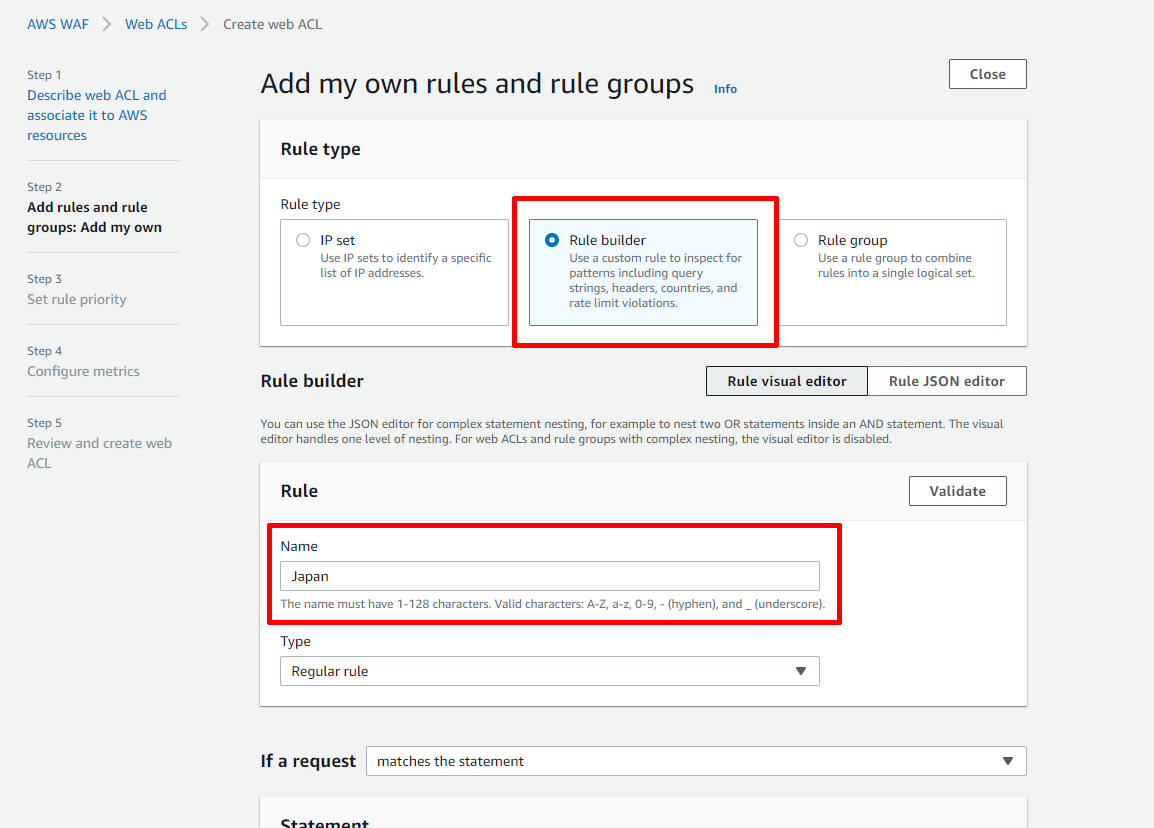
では,ルールを作っていきます.
【Rule Builder】を選んで,Nameに分かりやすく名前を決めます.今回は適当にJapanとしました.
次は,ルールを設定します.
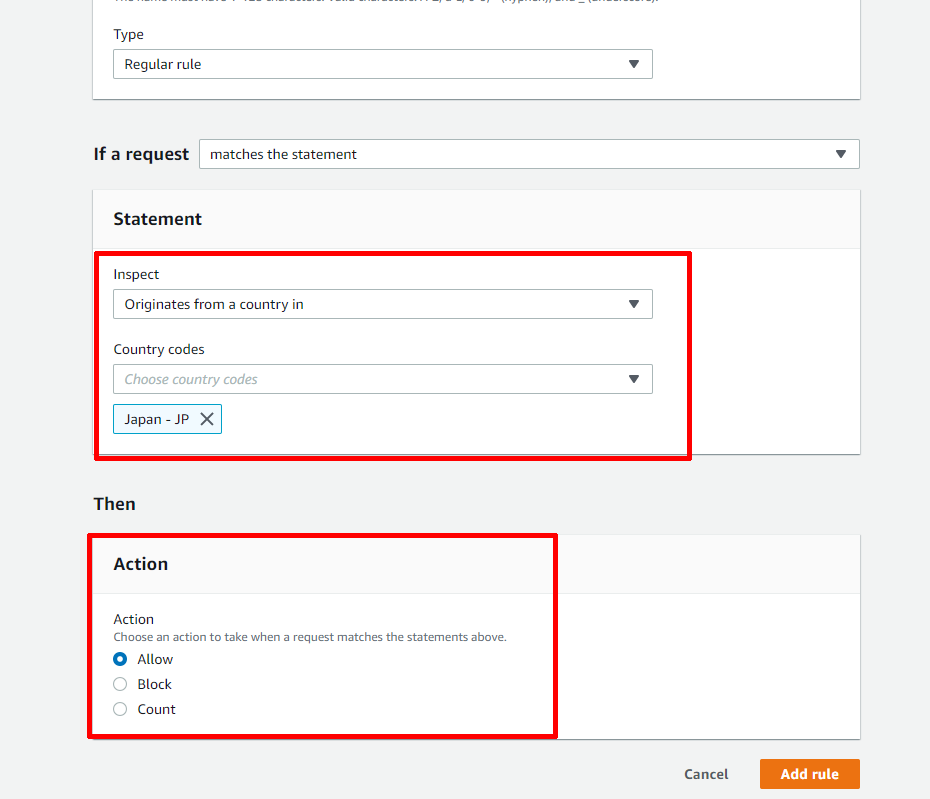
先ほどの「もし日本からのアクセスだったら許可する」という部分です.
Statementに条件を指定します.日本からのアクセスというのは地域指定となるため,InspectとCountry codesを画像のように選択します.
そして,Thenには,Statementの条件を満たしたときの動作を指定します.当然許可としたいので,Allowを選択します.
設定出来たら【Add rule】ボタンを押します.
前の画面に戻ってくるので,作り立てのルールにチェックします.
そして,下のほうにあるDefault web ACL action for requests that don't match any rulesをBlockにします.
これは,すべてのルールに該当しないリクエストの動作を決める項目になります.ルールを許可形式にすることで,ホワイトリスト形式のACLが出来上がります.
出来たら,【Next】ボタンを押します.
次の画面は,ルールの優先順なのですが,今回は1つだけのため,スルーします.
さらに次には,CloudWatchに連携するときのルールごとの名称を決められるようです.ここもルールが1つですので,そのままにしておきます.
そしたら,Review and create web ACLという画面にたどり着きます.
ここまで来たら,今までの設定を確認して問題なければ,【Create web ACL】ボタンを押します.
このボタン押すと,非活性状態になって,しばらく何も起きなくなります.(めっちゃ焦りました)そのうち,最初の
Web ACLsの画面に戻ってきて一覧にACLが追加されます.ここで作ったACLは,ロードバランサーの【総合サービス】の
AWS WAFには連動していないようです.(まだ対応してないのかな?)
でも,CloudWatchのACLログとロードバランサーのモニタリングを確認する限り連動してそうなのは確認できました.実際に,ブラウザでF5とか何かでJupyterHubに連続してリクエストを投げるとわかると思います.
以上で,WAF周りの設定が完了となります.
あとは同じようにルールを拡張したり,CloudWatchログからSNSなりに連携することもできます.(ワーニングを出すなど)まとめ
今回は,セキュリティ周りとして,HTTPS接続に切り替えました.やっぱり,コードを通信しているので心配しますよね.
また,セキュリティグループを絞ればいいのですが,せっかくなのでALBにWAFを追加しました.
WAF自体新しくなっていたので,そちらを使ってACLを作りALBとつなげました.総括して
今回,お題を設定して,自分なりに課題を見つけ,構成を考えて,分からないなりにもAWS上で環境を作ってみました.
dockerとかあるようなのですが,やはり最初は試行錯誤しながら自力で組み立ててみたかったので,全部自分で決めていきました.
「なんでつながらないの?」って数日考えたり,「JupyterHubでSudoSpawnerが機能しないのはなぜなのか?」で仕事が終わってからひたすら考えたり,疲れましたけど割と楽しかったですね.普段触らないような部分を直接いじることになるのでいい勉強になりました.また,別のお題を立てて,今回のような複数回に分けて記事にするのも良いかな,と思います.
初めのほうから記事を読んでいただいた方々,つたない文章だったかもしれませんが,読んでいただきありがとうございました.
すこしでも参考になっていただけたら幸いです.



- 投稿日:2019-12-13T23:09:45+09:00
AWS Lambda最小構成
Lambda最小構成
Lambdaを使うことになり色々と調べていましたが、複雑なことをしているものが多く、
まずは自分が思う最小構成を作ってみようと思いました。Lambdaでやりたいこと
S3にテキストファイルがアップロードされたことをトリガーに
テキストファイルの中身を表示するLambdaを作ります。(ランタイムはPython 3.7)
Lambdaの設定
ハンドラはデフォルトのまま「lambda_function.lambda_handler」です。
プログラムは以下のようになります。
バケット名とアップロードするテキストファイル名は自身の環境に合わせてください。def lambda_handler(event, context): # TODO implement import boto3 s3 = boto3.client('s3') data = s3.get_object(Bucket='xxxxxx-mybucket', Key='test.txt') contents = data['Body'].read() print(contents)S3へアクセスするためのポリシーをアタッチ
Lambdaを作成するときに割り当てたロールにS3へアクセスするためのポリシーをアタッチします。
とりあえず「AmazonS3FullAccess」にしておきました。実行
・まず「test.txt」をS3の指定のフォルダ配下にアップロードします。これをトリガーにLambdaが起動します。
・Lambdaの「モニタリング」タブからCloudWatchのログを表示します。
テキストファイルの中身「lambda test」が表示されました。(ログの2行目)


- 投稿日:2019-12-13T23:02:14+09:00
JAWS-UG初心者支部#16
- 投稿日:2019-12-13T21:11:59+09:00
【2020年版】AWSのEC2にPython3をインストールする方法
先日、AWSのEC2にPython3をインストールする機会がありました。
その時に「AWS EC2 Python3」でGoogle検索したのですが、検索結果の上位に表示されたページの情報がいまいちでした。
具体的には、
- pyenv
- virtualenv
を使ってPython3の仮想環境を用意する方法が紹介されていましたが、 Python3の仮想環境を用意する方法は特別な事情がない限りは
venvを使うべきです。
また、Python3をアプリ開発やデータ分析でガッツリ使う場合を除いては、そもそも仮想環境を用意する必要はないと思います。Python3の仮想環境を用意する方法として
venvを使う理由は、Pythonの公式ドキュメントで推奨されている唯一の方法だからです。
pyenvを避けるべき理由はこの記事に詳しく書かれているので、興味のある方はこちらをご覧下さい。また、AWSの公式ドキュメントでは
virtualenvを使った方法が紹介されていますが、virtualenvがvenvとしてPythonの中に正式に取り込まれたPython3.3以降においては積極的に使う理由はないと思います。ということで、改めてAWSのEC2にPython3をインストール方法を紹介したいと思います。と言っても、Pythonの公式ドキュメントで紹介されている方法に従うだけですが…。
前提
- OS
- Amazon Linux 2 AMI
- デフォルトではPython2系のみインストールされている
- インスタンスタイプ
- t2.micro
手順
OSのシステムにPython3をインストール
$ sudo yum update $ sudo yum install python3 -yPythonを使う機会は限られており、Python本体やパッケージのバージョン管理が必要ない場合はこれで十分だと思います。
一方、アプリ開発でそれ専用のバージョン管理をしたい場合や、データ分析で専用の環境を用意したい場合などは仮想環境の出番です。venvを使って仮想環境のPython3をインストール
$ python3 -m venv myenv上記のコマンドをホームディレクトリで実行すると、ホームディレクトリ配下に
myenvというディレクトリが作成されます。myenvという名前は好きなように変更して構いません。Python3の仮想環境を有効化
$ source myenv/bin/activate上記のコマンドを実行すると、Python3の仮想環境が有効化されます。
Python3の仮想環境を無効化
$ deactivatePython3の仮想環境を抜けたい場合は上記のコマンドを実行するだけです。また、環境をまるっと削除したい場合は
myenvディレクトリを削除すればOKです。最後に
AWSのEC2にPython3をインストールする方法を紹介しましたが、少なくともLinux系のOSではそのまま当てはまる話しだと思います。
Pythonをほとんど使わない人はOSのシステムにインストールしたPython3を、Pythonをガッツリ使う人はvenvを使って作成したPython3の仮想環境を使うと覚えておいて下さい。
- 投稿日:2019-12-13T20:43:59+09:00
【InfiniteWP】複数のWordpressサイトを一括管理の巻
初めに
現在弊社では複数のWordpressサイトを抱えており
その管理を如何様にするか考えた結果、こちらのツールに行き着いた次第。InfiniteWPとは
複数のWordpressサイトを1つの画面で管理・操作できるwebアプリケーション
- 基本無料
- プラグインやWordpressをワンクリックでバージョンアップ
- サイトデータのバックアップ
- サーバーステータスの監視
- 投稿の作成
- etc...
有償で機能追加も可能だが無料でも管理だけなら不足無し。
ヘルプのオペレーターも割と返事が早くて適切な回答をいただけたので
うまくいかない際も安心です。導入してみる
当方環境
PC:mac
サーバー:AWS EC2、nginx、apache1.管理画面の構築
1-1.必要ファイルのダウンロード
- https://new.infinitewp.com/install-options/
- 左側のリストから
DIY - Manual Installationを選択Download the IWP Admin Panel.リンクからダウンロード1-2.管理画面用ディレクトリ作成
# cd /var/www/html/ # mkdir -p infiniteWP/iwpdocs
- 1-3.ファイル設置、サーバー設定
- scpコマンドで先ほどダウンロードしたzipファイルをサーバーにコピー
- 解凍〜configファイル設定
# cd /var/www/html/infiniteWP/iwpdocs # unzip /home/caad_admin/IWPAdminPanel_v*.zip # mv IWPAdminPanel_v*/* ./ # rm -r IWPAdminPanel_v* //インストール用のconfigファイル作成 # touch config.php # chmod 666 config.php
- 1-4.データベース作成
mysql> create database infiniteWP; mysql> grant all privileges on infiniteWP.* to iwp_admin@'%' identified by '任意のパスワード';ローカルのhostsにサーバーIPとURLを追記後、ブラウザからアクセスする。
- 1-5.インストール〜ログイン
- ライセンス規約画面で同意ボタンをクリック
- データベース情報を入力
- メールアドレスとパスワードを入力
- インストール完了後Open my admin panelをクリック
※admin panelにアクセスできない、リダイレクトエラーになる場合、
config.phpに下記を追記define('APP_HTTPS',0); //これでエラーが出る場合は1にしてみる2.クライアントプラグイン導入〜サイト追加
- 2-1.IP制限をかけている場合は管理パネルが置いてあるサーバーのIPを許可させる
# vi /etc/nginx/conf.d/xxxx.conf allow xxx.xxx.xxx.xxx;
- 2-2.対象サイトの管理画面にログインしプラグインをインストール
- プラグイン>新規追加>
iwp-clientを検索しインストール>有効化Copy detailsをクリックし情報をコピー- 管理パネル左下の
Add Websiteをクリックし貼り付け、Add Siteで追加こうして
一時の安寧が訪れた。
クライアントプラグインのアップデートも画面に表示してくれますし
こちらもワンクリックでアップデート可能です。便利。参考サイト


- 投稿日:2019-12-13T20:39:49+09:00
bento/amazonlinux-2のVagrantBoxを使って共有フォルダとrootログインを有効にする
AWSの「Amazon Linux 2」を開発環境で使用するために、VirtualBoxとVagrantを使ってVM(仮想マシン)を構築していきます。共有フォルダとrootログインを有効にします。
検証環境
VirtualBox:6.0.14
Vagrant:2.2.6
VagrantBox:bento/amazonlinux-2 v:1.1.0手順
bento/amazonlinux-2ボックスは、デフォルトでルートによるSSHログインを許可していないため、Vagrantを一度起動してファイルを修正し、再度起動する必要があります。
1回目の起動
まずはVagrantボックスをダウンロードして追加します。
vagrant box add bento/amazonlinux-2 --box-version 1.1.0続いて、以下を実行します。
vagrant init bento/amazonlinux-2次にVagrantfileのポートとメモリを設定します(任意)。共有フォルダはデフォルトで有効になっているので指定しなくても大丈夫です。
config.vm.network "forwarded_port", guest: 80, host: 8080 vb.memory = "2048"Vagrantfileを修正したらVMを起動します。
vagrant up起動後にrootのパスワードを設定します。
sudo passwd root → 例:vagrantrootでのSSHログインを可能にする設定を行います。
vi /etc/ssh/sshd_config コメントアウトして許可 → PermitRootLogin yes設定が終えたらログアウトします。
注意点
以下のようにrootでログインするよう設定することもできますが、2回目のvagrant up時に共有フォルダが効かなくなります。
config.vm.provision "shell", inline: <<-SHELL echo "sudo su -" >> .bashrc SHELLまた、以下のように、プライベートIPを設定するとネットワークがブリッジとして設定され、vagrant up時にネットワークエラーとなります。ホストOSのブラウザからアクセスする際には上記のポートフォワーディングを利用しましょう。
config.vm.network "private_network", ip: "192.168.33.10"2回目の起動
上記の設定によりrootでのSSHログインが可能になったので、Vagrantfileに以下を追加します。
config.ssh.username = 'root' config.ssh.password = 'vagrant' config.ssh.insert_key = 'true'以下のコマンドで修正したファイルを反映させます。
vagrant provision準備が整ったのでVMを再度起動します。
vagrant uprootでSSHログインし、共有フォルダも有効になっていると思います。
以上が、rootでのSSHログインと共有フォルダを有効にする手順になります。
1回目の起動の時はrootのパスワードが設定されていないので、一度立ち上げて設定を済ませてから、2回目の起動の時にVagrantfileを修正することがポイントです。
基本的な機能ですが、はまりどころが多く注意書きもないため、正常に動作させるまでかなり時間を取られてしまいました。
公式ドキュメントにもう少し説明が欲しいところです。
- 投稿日:2019-12-13T20:27:22+09:00
Codenize警察のいる生活
この記事はくふうカンパニー Advent Calendar 2019の13日目の記事となります。
DaVinciStudioでSREをやっている横山です。
DaVinciStudioのSREは、くふうカンパニー各社のインフラ基盤の管理を行なっております。
そして、インフラ基盤の管理にはTerraformやCodenize.tools、CloudFormationを使っています。
今回はこの管理ツールの運用について一筆書きたいと思います。TerraformとCodenize.toolsとCloudFormationについて
インフラのコード管理というと、概ねこれらの3ツールを利用されている方が多いのではないでしょうか?
雑に比較すると以下のような感じになります。
名称 いいところ Terraform 対応するリソースが豊富(AWS,GCP,datadog,Azure,GitHub、ドミノピザ(嘘)などなど) Codenize.tools Ruby DSL,
Rubyでプログラマブルにリソース定義できるCloudFormation 公式ツールという安心感。 弊社では基本的にterraformを使い、新規で構築するものにはCloudFormationが使われることが多いです。
これはCloudFormataionでは既存のリソースのインポートができないという問題があったためです。
しかし、この問題は以下の通り、最近のアップデートで解消されました。今後は積極的に使っていこうと思っています。
https://aws.amazon.com/jp/blogs/news/new-import-existing-resources-into-a-cloudformation-stack/コード管理の辛さ
さて本題です。コード管理はこれらのツールを導入して終わりではありません。日々、運用していかなければなりません。
こんなこと、心当たりがありませんか??うーん、、この検証のためのIAMロール、いちいちプルリク作ってコード変更するのめんどいな、とりあえず手動で作るか。うまく行ったら明日ちゃんとコード化しよ。
明日なんて永遠にこないのです。そのまま忘れ去られ時が過ぎ、、
次にIAMロールに変更を加えようとした人がdry-runした時に意図しない差分に気づくのです。。
これはとても悲しい。
手動作成を禁止して、厳格に運用すべきというツッコミはおっしゃる通りだと思います。
しかし、手動で作成できるゆるい運用もこれはこれでメリットがあると思っています。
ということで、このようなゆるさを保ちつつ、悲しい思いをする人が減るようにCodenize警察を作りました。Codenize警察
Codenize警察の中身はShellスクリプトです。
たとえばhogehoge/hogehogeレポジトリにコードがある場合、以下のようになります。
GITHUB_TOKEN、SLACK_WEBHOOK_URLは環境変数として渡します。#!/bin/bash set -x function slack_notify_change_of () { payload="payload={'attachments':[{'color': '#e73613', 'text': '${1}の差分を検知しました。'}]}" curl -X POST --data-urlencode "$payload" $SLACK_WEBHOOK_URL } export AWS_REGION=ap-northeast-1 git clone --depth 1 https://$GITHUB_TOKEN@github.com/hogehoge/hogehoge.git cd /opt/hogehoge bundle install cd /opt/hogehoge/codenize-tools services=(roadwork) for service in ${services[@]}; do bundle exec ${service} -a --dry-run | grep -e Create -e Delete -e Update if [ ${?} = 0 ]; then slack_notify_change_of ${service} fi done cd /opt/hogehoge/terraform services=(cloudfront codebuild codecommit codepipeline datadog eip github iam kms lb s3 security_group vpc) for service in ${services[@]}; do cd /opt/hogehoge/terraform/${service} terraform init terraform plan -detailed-exitcode -parallelism 50 if [ ${?} = 2 ]; then slack_notify_change_of ${service} fi doneあとはこのShellスクリプトを任意の環境で動かすだけです。
弊社ではECSやEKSを導入しているため、このスクリプトを配置したDockerコンテナをECS上で1日に1回実行(巡回)させています。
こうすることで差分がある時にSlackに以下のように通知され、コードに反映されていない変更が長期間放置されることがなくなりました。
※事情によりアイコン画像はお見せできません。
まとめ
こういったちょっとしたくふうの積み重ねで暮らしを便利にしていきたいものですね。
くふうカンパニー Advent Calendar 2019、明日の14日目はmatsuhisa_h さんの「地味な話」です。

- 投稿日:2019-12-13T19:31:13+09:00
CodeBuildでECR Push&ECS Deploy
こんにちわ。Patheeの廣瀬です
ECSのデプロイ、CodePipeline+CodeBuildのパターンはよく見るのですが、
コネヒトさんのCodeBuildを使ったECSへのコンテナデプロイで、
ecs-deployを使えばCodeBuildだけで完結できるのが良さげだなと思って取り入れてみました環境
- Github
- AWS
- ECS (Fargate)
- ECR
- CodeBuild
CodeBuild設定
- イメージ:
aws/codebuild/amazonlinux2-x86_64-standard:1.0- ウェブフックイベント: PUSH
- 条件: タグ (
^refs/tags/releaseなど)buildspec.yml
version: 0.2 phases: install: runtime-versions: docker: 18 commands: ## ecs-deployのインストール - yum install -y jq which - curl -OL https://raw.githubusercontent.com/silinternational/ecs-deploy/master/ecs-deploy - chmod +x ecs-deploy - COMMIT_HASH=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | cut -c 1-7) - IMAGE_TAG=${COMMIT_HASH:=latest} pre_build: commands: ## ECRにログイン - $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION) build: commands: ## Dockerイメージのビルド - docker build -t $IMAGE_REPOSITORY_NAME:latest . - docker tag $IMAGE_REPOSITORY_NAME:latest $IMAGE_REPOSITORY_NAME:$IMAGE_TAG ## DockerイメージのECRへのプッシュ - docker push $IMAGE_REPOSITORY_NAME:latest - docker push $IMAGE_REPOSITORY_NAME:$IMAGE_TAG ## ECSへのデプロイ - ./ecs-deploy -n $ESC_SERVICE_NAME -c $ESC_CLUSTER_NAME -i $IMAGE_REPOSITORY_NAME:latest -r $AWS_DEFAULT_REGION -t 1200ポイント
- 環境変数として以下を設定
- ESC_SERVICE_NAME
- ESC_CLUSTER_NAME
- IMAGE_REPOSITORY_NAME
ecs-deployを動かすのにjq・whichが必要なのでyumでインストール
※イメージがubuntuだったりすると微妙に違ってくるかもecs-deployのタイムアウトを長めに
イメージサイズだったり設定で変わってくると思いますがPros/Cons
元の記事で
CodeBuildの良さに触れられていますが、その他の部分での良し悪しをあげてみましたPros
- CodeBuildだけで完結する
- 簡単
- メンテが1箇所だけなので見通しが良い
- タグ名をCodePiplineに渡すところでアーティファクトでつまずいたり、、、
- CodePiplineの料金がかからない
- 一つにつき固定で1$
Cons
- ECSデプロイ部分に時間がかかる場合、高頻度に実施するとCodePipline使うよりも高くなるかも
https://aws.amazon.com/jp/codebuild/pricing/- AWSコマンドで全部書けそう
- とはいえ1行で済む簡便さ
あと書き
既存プロジェクトはサクッとデプロイできるようになりましたが、
一方、新規に作る場合はGithubActionで済ませれば、CodeBuildはいらないかもです、、、
GitHub ActionsからサクッとFargateにデプロイしてみた
- 投稿日:2019-12-13T18:01:19+09:00
AWS MediaConvert で 8k エンコーディング
今日投稿しないといけないことに今日気がついた streampack 木村です。
手持ちネタが無いので、なんか無いかなと探していたところ、見つけました!
2019/11/25 に MediaConvert で 8k エンコーディングがサポートされたようなので試してみます。
AWS Elemental MediaConvert に 8K 解像度エンコードを導入
素材探し
8k エンコなら 8k 素材だろ!ってことで Web を探してみたところほとんど無し。
今日の今日なので、作る時間もない・・・
チームメンバーにお願いして、やっと見つけたものも著作権どうなの?ってことで今回は映像の写真は無しで!ffprobe
元素材情報です。
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'kartingowy-narodowy-8192x4320@crf23-h265.mp4': Metadata: major_brand : isom minor_version : 512 compatible_brands: isomiso2mp41 encoder : Lavf57.46.100 Duration: 00:01:46.11, start: 0.000000, bitrate: 17205 kb/s Stream #0:0(eng): Video: hevc (Main) (hev1 / 0x31766568), yuv420p(tv, progressive), 8192x4320, 17077 kb/s, 29.97 fps, 29.97 tbr, 30k tbn, 29.97 tbc (default) Metadata: handler_name : VideoHandler Stream #0:1(eng): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 130 kb/s (default) Metadata: handler_name : SoundHandlerこいつを S3 にアップしておきます。
MediaConvert
ややこしいことは無しで、エンコード設定で調整した点は
コーデック、解像度、ビットレートのみです。
Video Codec HEVC Resolution (w) 8192 Resolution (h) 4320 尚、8k 解像度で出力できるのは HEVC のみです (AVC の場合は最大 4k)。
Bitrate はソースに合わせて 17Mbps に。
変換
ファイルからファイルに変換してみます。(意味ないけど)
一応、通常変換と高速変換の2種類試して、どのくらい変換時間に差があるか確認してみます。通常変換
8分43秒
元が1分46秒のコンテンツですが、結構かかりますね。
高速変換
3分31秒
高速変換だと通常変換の半分以下で終わります。
できあがり
ちゃんと作成されました。
ffplay で再生可。
ffprobe
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'kartingowy-narodowy-8192x4320@crf23-h265_accelerated.mp4': Metadata: major_brand : isom minor_version : 1 compatible_brands: isom creation_time : 2019-12-13T08:00:51.000000Z Duration: 00:01:46.05, start: 0.000000, bitrate: 17223 kb/s Stream #0:0(und): Video: hevc (Main) (hev1 / 0x31766568), yuv420p(tv), 8192x4320 [SAR 1:1 DAR 256:135], 17120 kb/s, 29.97 fps, 29.97 tbr, 30k tbn, 29.97 tbc (default) Metadata: creation_time : 2019-12-13T08:00:51.000000Z handler_name : ETI ISO Video Media Handler encoder : HEVC Coding Stream #0:1(eng): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 96 kb/s (default) Metadata: creation_time : 2019-12-13T08:00:51.000000Z handler_name : ETI ISO Audio Media Handlerまとめ
8k とかまだまだ先かなと思っていましたが、AWS Elemental さん、先日の MediaLive 4k 対応といい、今回の MediaConvert 8k 対応といい、最近攻めてきていますね。





- 投稿日:2019-12-13T14:58:39+09:00
AWSCDK for TypeScript で LambdaLayer をデプロイすると前のバージョンが消し飛ぶんだが………
はじめに
この記事は、TypeScript Advent Calendar 2019 #13日目 の記事です。
13日目担当の @is_ryo です!謝辞
あまりTypeScriptの話ではありません…申し訳ございません……
はじめに(2回目)
私のいるチームではAWSの構成管理をするためにAWSCDKを使っています。
AWSCDKとは、CloudFormation(以下CFn)のテンプレートをTypeScriptやPythonといった言語で生成することができる開発キットです。
ここではAWSCDK自体の説明は省きます。詳しくは公式ページを参考にして下さい。何が起こったか…
LambdaLayer を試験的に導入していこうとなり、普段通りにCDKをTypeScriptで書いていました。
ソースコードはこんな感じstack.tsimport cdk = require("@aws-cdk/core") import { LayerVersion, AssetCode, Runtime } from "@aws-cdk/aws-lambda" export class LambdaLayerStack extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props) new LayerVersion(this, "DemoLambdaLayer", { code: AssetCode.fromAsset("lambdaSources/demo_function"), compatibleRuntimes: [Runtime.NODEJS_12_X] }) } }メンバー「よし、ソース書けたからデプロイするで!」
$ aws cdk deploy LambdaLayerStackメンバー「コンソールで確認してみるか」
コンソール「デプロイできてるで」
メンバー「ちょっとLambdaLayerのロジック変えたからデプロイしなおすか」
〜〜省略〜〜
コンソール「デプロイできてるで」
メンバー「おい…バージョン1どこにやった?」
コンソール「勘のいいガ(ry」
原因は何?
CFnが犯人。というかCFnの性質かと思われる。
スタックに定義していないリソースに関してはわざわざDeleteされる場合があります。
例えばAPIGatewayに/getと/postというresourceがあったときに、そのAPIGatewayに/getだけのスタックでUpdateをすると/postがDeleteされます。
これと同じように、スタックをUpdateしたときには前のバージョンの情報は持ってないのでDeleteされていました…対処方法
勝手に消されないようにしましょう。
CFnで生成するリソースに対してremoval policyというプロパティを設定することができます。
そのプロパティをRetainにすることで削除保護されます。
書き方はこんな感じstack.tsimport cdk = require("@aws-cdk/core") import { LayerVersion, AssetCode, Runtime } from "@aws-cdk/aws-lambda" export class LambdaLayerStack extends cdk.Stack { constructor(scope: cdk.App, id: string, props?: cdk.StackProps) { super(scope, id, props) const lambdaLayer = new LayerVersion(this, "DemoLambdaLayer", { code: AssetCode.fromAsset("lambdaSources/demo_function"), compatibleRuntimes: [Runtime.NODEJS_12_X] }) /* ここから追加 */ const lambdaLayerResource = lambdaLayer.node.findChild( "Resource" ) as cdk.CfnResource lambdaLayerResource.applyRemovalPolicy(cdk.RemovalPolicy.RETAIN) } }軽く説明する
applyRemovalPolicyという関数を使うためにはcdk.CfnResourceを変数に入れる必要があります。const lambdaLayerResource = lambdaLayer.node.findChild( "Resource" ) as cdk.CfnResource
applyRemovalPolicyという関数を使ってremoval policyを設定します。
基本的にデフォルトはDELETEになっています。lambdaLayerResource.applyRemovalPolicy(cdk.RemovalPolicy.RETAIN)試す
メンバー「デプロイや!」
コンソール「デプロイできてるで」
メンバー「前のバージョンも残ってる!」
さいごに
いかがでしょうか。
CFnを書いてる方からすると当たり前じゃんって感じなのかもしれませんが、CFnに消されて困るものがあるときはremoval policyをちゃんと付けてあげましょう。
ただ注意点として一度removal policyをRETAINでデプロイするとCFnでは削除できなくなります。コンソールから消したりする必要があります。
ではまた!



- 投稿日:2019-12-13T14:56:25+09:00
Redashの有用性をご存じでない?
Ateam cyma Advent Calendar 2019、14日目です!
14日目は 株式会社エイチーム のちょっとおちゃめな帰国子女エンジニア @NamedPython がお送りします。(母国語は忘れました)
5日目では「見える化を新卒が進めるといい感じに成長できたよ〜」というお話ともうひとつ、 「Redashは最高だよ〜」というお話もしました。そこで今日はRedashについてのお話です。
とはいってもcymaのRedashを安易には公開できないので、自前でインスタンスを用意してやりました。
Redashってなんなのよ
俗にいうBIツールというやつです。データの分析や、可視化に特化したツールで、データベース等の情報源を繋ぐことでデータの抽出やグラフ化が容易にできます。
データベースからのデータ抽出といえばSQLを書くことが必要かと思われますが、そこすらグラフィカルなUIにした非エンジニアにも扱いやすいツールも出てきています。
Redashとよく比較されるものとしては、
- metabase
- Tableau
- Google Data Portal
- Superset
等があります。
RedashのUIはこんな感じ↓↓
じゃあRedashはどんなBIツールかという特徴を簡単にまとめると
- OSS

- SQLでゴリゴリデータを引ける

- HTMLコンテンツを結果に描画できる

- SQLで引いた結果をさらにSQLで引ける(Query Results)

といった感じです。Query Resultsが極め付けに最強です。
ここからは、Redashの機能の一部とその設定方法を紹介していきます!
データを取得する
Open data等からRDSにデータを注入してやろうとも考えましたが、時間の関係でGoogle Analyticsのデータを用いて紹介していきます。
幸いなことに、自分のブログには数年前からGoogle Analyticsを導入しているおかげで多少データがたまっています。Data sourceの追加
RedashにはすでにGoogle Analyticsと連携する機能が備わっています。ここでは詳細には解説しませんが、少しステップを踏む必要があるので、挑戦する際は公式ドキュメントをご参照下さい。
Data sourceに名前をつけ、ドキュメントの手順に従い取得した認証情報のJSONをアップロードします。
すべてのData sourceには、Test connectionのボタンが必ず設置されているので、接続に成功するまでにらめっこできます。
データの取得方法
「SQLでゴリゴリデータを引ける」なんて言った矢先ですが、Google AnalyticsのData sourceはSQLを書くことができません。ここで書くのは、APIリクエストのBodyなのです。
例えば、「ページタイトル毎のUUを2年前から今日にかけて降順でみたい」というようなものを書くとします。
画面はこんな感じ。きちんと取得できていますね
スニペットもドン。
{ "ids": "ga:********", "start_date": "365daysAgo", "end_date": "today", "metrics": "ga:users", "dimensions": "ga:pageTitle", "sort": "-ga:users" }
ga:usersであったり、ga:pageTitleのようなキーワードが見て取れると思います。FAQ
Q: 「そのキーワードはどこから知るんじゃ!」
A: 「Google Analytics APIのDimensions & Metrics Explorerから探しましょう」この中から、自分の見たいメトリクス、その切り口を探します。
例えば、Google AnalyticsにAdwordsをつないでいる人はCPA(1CVあたりの広告費)を、ga:costPerConversionやga:costPerGoalConversionをメトリクスに指定することで得られます。切り口は、オーガニック, リスティングなどの流入元(
ga:medium)や日付(ga:date)など様々な切り口で分析できます。Query Results してみる
さて、データが取得できたところで続いての機能の紹介です。
どんなシチュエーションでこの機能を使うかを考えてみましょう先ほどの「ページタイトル毎のUUを2年前から今日にかけて降順でみたい」というクエリの結果をよ~く見てみると、実は似たようなものがいくつかあるんです。
記事タイトルは同じでも僕がブログタイトルを何回か変えているせいで結果が複数に分かれてしまっているんですね。じゃあこれをSQLの力で取り除くとしましょう。
Data sourceの設定
超絶簡単です。Google Analytics同様に追加できます。構成や接続を間違えていない限り作るだけで追加できます。
やっていく
さて、ここからはSQLを書きます。Query Resultsは、MySQLでもPostgreSQLでもありません!SQLiteです。少し癖はありますが調べながらやればよいでしょう。
データを加工する前に、とりあえず丸ごと引っ張ってみましょう。
Data sourceにQuery Resultsを指定するのを忘れずに
全部引っ張ってくるSQLはこれだけ。
SELECT * FROM query_3
query_3...?そんなテーブル作ってないぞ...いやまさか...?!
そう。クエリ結果は勝手にこのような名前でテーブルに保存されているのです。では
3とはなにか。それはクエリページのURLを見ればわかります。
先ほどのクエリ結果のURLが、/queries/3となっているので、テーブルの命名もquery_3となるわけです。では本題に戻ってデータ加工をやっていきます。
「タイトル(ex:
スマートフォンで撮った書類から影を取り除いてみた - 有能なフリ)から、ブログタイトル(ex:有能なフリ)を取り除き、同タイトルのUU数を合算する」、をゴールにしましょう。この記事はSQLのための記事ではないので、さっそくドーン!
データ加工のSQL(sqlite)SELECT substr(q.ga_pageTitle, 1, instr(q.ga_pageTitle, ' - ')) AS page_title, SUM(q.ga_users) AS uu FROM query_3 q WHERE substr(q.ga_pageTitle, 1, instr(q.ga_pageTitle, ' - ')) != "" GROUP BY 1 ORDER BY 2 DESC結果もドーン!
うまく取り除けましたね。空白になってしまう結果があったので、それは
WHERE句で取り除きました。
Google Analyticsの結果を取得しただけではできなかったことが、Query Resultsで簡単に実現できました。やったねTIPS
偉大なる先輩 @ihsiek から教えてもらったんですが、上記の方法でQuery Resultsをすると、参照しているクエリを再実行し結果を待ってからQuery Resultsをしています。
すでに実行してあるクエリなら、そのキャッシュを使ってQuery Resultsがしたいですよね?あるんです
テーブル名を
cached_query_Nにしてあげればいいだけです。実行に時間のかかるクエリを扱う際には、キャッシュされた結果をQuery Resultsすると爆速ですグラフにしてみる
さて続いての機能は、BIツールの本領、可視化です。
先ほど綺麗にしたクエリ結果を、記事タイトルごとにグラフとして描画してみましょう。Visualizationの追加
ここにボタンがありますのでポチー!
SQLを調整 & グラフを作る
UUトップ5の記事たちを並べて円グラフにしてみましょう!
トップ5なので、先ほどのSQLの最後にLIMIT 5を足してあげればいいですね。あとはカチカチっと...いじるところが多いので結果だけドーン!
ふむふむ、いいですね。
グラフもそこそこにカスタマイズが効くので何でもできそうです。検索をつけてみる
実際の業務でRedashを運用し始めると、
- この期間のこのデータが...
- この特定の自転車のこのデータが...
- こういう条件の注文データが...
というような需要がとても多くあります。Redashは、この需要をとても簡単にかなえることができます。
結果内を検索
言葉の通り、一度叩いたクエリ結果に対してかける検索です。
先ほどのクエリを、タイトルによって検索できるようなものにしてみましょう。
テーブルビューから、Edit Visualizationに行きましょう。
そして、
Use for searchにチェックを入れ、せっかくなのでついでにカラム名もいい感じにしてあげます。
そうすると何やら、テーブルビューのカラム名の下に検索欄が現れました!
そう...もう検索するだけなんです。
しかもここリアルタイム検索なので、かなりキビキビ動きます。
ただ注意点として、Use for searchはどのカラムにも付与することができますが、付与しすぎるとむしろリアルタイム検索が非常に重くなりますので、欲しい検索を使用者とすり合わせるとGoodですまとめ
Redashによるデータの取得から可視化、検索まで一通り紹介してみました。
これでもまだほ~~~~んの一部です。まだまだ紹介し足りません。この記事を書くにあたって、RedashをEC2に建てるなどしましたが、そこまで手間取らずむしろAWSの構成の勉強にもなったくらいです。
インターネットにはOpen data含めいろいろなデータが転がっているので、皆さんもぜひお手元で試してみてください!小ネタ
Redash on EC2を無料枠の中で試そうとすると
t2.microを選ぶことになるんですが、それだとまったく性能が足りないので公式アナウンスのt2.smallか、t2シリーズより安価で性能の高いt3のt3.smallか、t3とほぼ同性能だが10%ほど安価なt3aのt3a.smallあたりをお勧めします(実際に試して動きませんでした)。
t3aシリーズは、CPUにIntel XeonではなくAMD EPYCを採用しており、互換性に若干の懸念(主観)がありますが、今回のRedashインスタンス構築の際は特に問題なく、むしろサクサク動きました。おわりに
Ateam cyma Advent Calendar 2019、14日目いかがでしたか?
15日目は キャンプガチ勢デザイナーの @manooo さんが、キャリアパスやマネジメントに関する記事を書かれるそうですので、お楽しみに!株式会社エイチームでは、一緒に働けるチャレンジ精神旺盛な仲間を募集しています。
エンジニアとしての働き方に興味を持たれた方はcymaのQiita Jobsをご覧ください。
そのほかの職種は、エイチームグループ採用サイトをご覧ください。












- 投稿日:2019-12-13T10:16:22+09:00
Amazon S3
SpringBootでS3にアップロード
Clientらしきもの
UploadService.javaprivate AmazonS3 getAmazons3() { return AmazonS3ClientBuilder.standard() .withCredentials(new AWSStaticCredentialsProvider(new BasicAWSCredentials(accessKey, secretKey))) .withRegion(region) .build(); }S3にアップロード
UploadService.javapublic String putObject(MultipartFile file, String fileName) { try { InputStream inputStream = file.getInputStream(); String path = 『保存する名前、ここでランダムの名前生成など』 ObjectMetadata objectMetadata = new ObjectMetadata(); objectMetadata.setContentType(file.getContentType()); objectMetadata.setContentLength(Integer.valueOf(inputStream.available()).longValue()); getAmazons3().putObject(bucketName, path, inputStream, objectMetadata);アップロードしたものを特別取得URLを生成して返してくる
アップロードされたものを限定しないと、特別scriptなどのリンクが生成されてアクセスすると実行されてしまうので要注意!UploadService.javaGeneratePresignedUrlRequest generatePresignedUrlRequest = new GeneratePresignedUrlRequest(bucketName, path) .withMethod(HttpMethod.GET); final URL fileUrl = getAmazons3().generatePresignedUrl(generatePresignedUrlRequest); return fileUrl.toString(); }catch (Exception e) { e.printStackTrace(); throw new RuntimeException(e); } }
- 投稿日:2019-12-13T10:07:48+09:00
AWS Lambdaでbotoを使ってファイルをダウンロードするときのハマりポイント
謎の文字列がついてきてしまう問題
このように
s3 = boto3.client("s3") pdf_filepath = 'tmp/' + key.split('/')[-1] print(pdf_filepath) # => tmp/20191016101246759.pdf s3.download_file(bucket, key, pdf_filepath)S3からファイルをダウンロードするコードを動かすと
[ERROR] FileNotFoundError: [Errno 2] No such file r directory: 'tmp/20191016101246759.pdf.47cf5CFA'
このような感じで謎の文字列がついてきてしまい、エラーでダウンロードできません。Lambdaで変更できるファイルの制限
Lambdaでは、
-/tmp以下のファイルしか変更することができない
-/tmp以下でも階層構造にすることはできない(/tmp以下にディレクトリを作成することはできない)という制限があります。
なので、/tmp以外の場所にダウンロードしようとしたり/tmp/food/chocolate.jpgというようにディレクトリに区切ってダウンロードしようとするとエラーになってしまいます。解決法
今回の場合、
tmp/に保存しようとしていまっているのでs3 = boto3.client("s3") pdf_filepath = '/tmp/' + key.split('/')[-1] print(pdf_filepath) # => /tmp/20191016101246759.pdf s3.download_file(bucket, key, pdf_filepath)と
/tmp以下に直で指定することで無事にダウンロードできました。
- 投稿日:2019-12-13T09:28:56+09:00
phpMyAdminが、AWS EC2複数台構成で接続できなかった件
同じ構成のEC2インスタンスを2つ用意して、ALBで振り分ける構成の案件がありました。
それぞれにphpMyAdminが入っており、接続先は同一のRDSです。このphpMyAdminにログインしようとすると、エラーが表示されログインできない現象が起きました。
結論を先に書くと、対象のターゲットグループ設定の、維持設定を有効化にせいというアドバイスをもらい、解消しました。調べてみたら、振り分けられてセッションが上手く処理できないから、ユーザー(ブラウザ)毎に割り振りを固定するってことみたいですね。
スティッキーセッションはAWS専門用語では無く、ロードバランサー持つ一般的な機能の名称です。
セッション、インフラの知識を深めなくては
- 投稿日:2019-12-13T09:00:15+09:00
Amazon ECSでコンテナの依存関係を設定したときのエラー時の挙動が想定外でハマった
Amazon Elastic Container Service(Amazon ECS)のタスク定義で複数コンテナを追加して依存関係を設定したときにハマったのでメモ。
コンテナの依存関係については下記が参考になります。
タスク定義パラメータ - Amazon ECS
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/userguide/task_definition_parameters.htmlECSとFargateでコンテナの起動順が制御できるようになりました - Carpe Diem
https://christina04.hatenablog.com/entry/ecs-fargate-dependson-parameterなにが起こったのか
タスク定義
以下のようなコンテナをタスク定義に登録しました。
- コンテナA
- Essential(基本):
false- コンテナB
- Essential(基本):
false- DependsOn(コンテナの依存関係):
- Condition:
SUCCESS、ContainerName: コンテナA- コンテナC
- Essential(基本):
true- DependsOn(コンテナの依存関係):
- Condition:
SUCCESS、ContainerName: コンテナB正常動作時はコンテナA、コンテナB、コンテナCの順に起動してコマンドを実行して終了します。
エラー時に期待した挙動にならなかった
上記設定でコンテナAでエラーとなった場合、以下のような挙動を期待しました。連なってくれるでしょうと。
- コンテナA:
STOP(ERROR)- コンテナB:
STOP
- コンテナAが
SUCCESSを返さなかったから- コンテナC:
STOP
- コンテナBが
SUCCESSを返さなかったからところが、期待した挙動とはならずにコンテナBは
PENDINGのまま沈黙しました。
コンテナのタイムアウトを設定しなきゃダメなのかと試してみても変わらず沈黙。
- コンテナA:
STOP(ERROR)- コンテナB:
PENDING- コンテナC:
PENDINGコンテナBでエラーとなった際にはコンテナCは
STOPとなりました。
こちらは期待したどおりです。
- コンテナA:
STOP(SUCCESS)- コンテナB:
STOP(ERROR)- コンテナC:
STOP
- コンテナBが
SUCCESSを返さなかったから期待する動作をさせるには
以下のようにコンテナCの依存関係にコンテナAを追加してやると期待する動作となりました。
- コンテナA
- Essential(基本):
false- コンテナB
- Essential(基本):
false- DependsOn(コンテナの依存関係):
- Condition:
SUCCESS、ContainerName: コンテナA- コンテナC
- Essential(基本):
true- DependsOn(コンテナの依存関係):
- Condition:
SUCCESS、ContainerName: コンテナA- Condition:
SUCCESS、ContainerName: コンテナBコンテナAでエラーになるとコンテナCも
STOPしてタスクが終了します。
- コンテナA:
STOP(ERROR)- コンテナB:
STOP
- コンテナAが
SUCCESSを返さなかったから- コンテナC:
STOP
- コンテナAが
SUCCESSを返さなかったからまとめ
複数コンテナを追加して依存関係を設定したときの挙動がハマることでわかりましたが、コンテナ数が増えると大変そうなのもみえてきました・・・
参考
タスク定義パラメータ - Amazon ECS
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/userguide/task_definition_parameters.htmlECSとFargateでコンテナの起動順が制御できるようになりました - Carpe Diem
https://christina04.hatenablog.com/entry/ecs-fargate-dependson-parameter
- 投稿日:2019-12-13T06:48:26+09:00
【サーバレス時代の負荷テスト戦略】面倒な負荷テストとはおさらばしよう 〜CircleCIで実現する継続的負荷テストとチューニングTips〜
負荷テストとサーバレス
負荷テストに対する考え方は時代とともに変化してきました。従来はサーバスペックやシステムの限界性能を測るという考え方でしたが、クラウドネイティブなシステムではそれに加えて、システムの弾力性(スケールアウトのしやすさ)も考慮する必要があります。
本記事では、負荷テストによるシステムの弾力性の評価と、改善する方法についてツールの具体的な使用方法やアプリケーションのチューニング Tips を交えて説明します。システムの弾力性を評価するために、プロダクション環境でのユーザからのリクエストを想定したロードテストを検討します。
ロードテストでは以下の項目を検証します。
ドリップテスト
ドリップテストは通常、数日間にわたって行われます。通常のバックグラウンド負荷レベルをシミュレートします。遅延またはエラー率の増加が見られる処理を特定します。
スラムテスト
スラムテストは、トラフィックの突然のスパイクをシミュレートします。これにより、オートスケーリングが適切に処理するのが従来困難であったトラフィックに直面したときのシステムの動作を確認できます。
ランプテスト
ランプテストでは、キャンペーン期間中などを想定した日々トラフィックが増加する負荷をシミュレートします。システムが正常にスケールアウトすることを確認します。
負荷テストツールの選定
上記のテストが実行できるように最良の負荷テストツールを選定します。
Apache ab
Apache の ab コマンドはコマンドラインから Web リクエストの負荷をかけることができるシンプルなツールです。手軽に導入できますが、単一のサーバからしか実行できないため、大量のリクエストを送ることができません。こちらの記事が参考になります。
Apache JMeter
Apache JMeter は言わずと知れた負荷テストツールです。マスタスレーブ構成を構築し、マスタとなるサーバにはスレーブの情報(ip アドレスなど)を登録しておきます。GUI でシナリオを作り、マスタからスレーブに指示を送ることでロードテストを実行します。スレーブを増やすことで大量のリクエスト数を送ることができます。
JMeter は確かに多機能で操作性も良く、手に馴染んでいるツールですが負荷をかけるためのサーバを構築したり、GUI からシナリオを作成する手間があります。Locust
Locust は Python 製の負荷テストツールです。
JMeter 同様、GUI が提供されており、マスタスレーブ構成を取り大量リクエストを生成できます。またテストシナリオを Python で記述でき、柔軟に対応できます。Locust のシナリオの記述は容易ですが、 JMeter と同様にサーバを構築する必要があります。
アプリケーションがサーバレスで構築できるようになったのに負荷テストのためにサーバを立てなければいけないというのは残念なところです。宣言的な負荷テストツールをサーバレスで実行するという選択
最近では JAMStack な構成を採用する場合が増え、バックエンドは Web API として提供することが多くなりました。
Web API だけを対象とするならば、画面の表示を想定せずシンプルなテストシナリオを作成できます。
つまり、テストしたい API のエンドポイントと Header, Body などを宣言的に羅列しておくだけ負荷テストを実行できるようなツールがあると幸せです。Artillery
Artillery は yaml ファイルに宣言的にシナリオを記述し、シンプルなインタフェースで負荷をかけることができる Nodejs 製のツールです。
ローカル実行
npm コマンドでインストールします。
$ npm install -g artilleryab コマンドのようにワンライナーが用意されています。
以下のコマンドは、10 人の仮想ユーザーを作成し、それぞれが 20 回の HTTP GET リクエストを https://artillery.io/ に送信することを意味しています。$ artillery quick --count 10 -n 20 https://artillery.io/実際には以下のように
script.ymlにテストシナリオを記述して使用します。script.ymlconfig: target: 'https://artillery.io' phases: - duration: 60 arrivalRate: 20 defaults: headers: x-my-service-auth: '987401838271002188298567' scenarios: - flow: - get: url: "/docs"HTTP 経由で通信する https://artillery.io のエンドポイントのテストシナリオです。
phasesには、20 人の新しい仮想ユーザーで 60 秒負荷テストを実行することを記述しています。リクエストは平均で 1 秒ごとに到達します。以下のコマンドでテストシナリオを実行します。
$ artillery run script.yml以下のように結果が出力されます。
Complete report @ 2019-01-02T17:32:36.653Z Scenarios launched: 300 Scenarios completed: 300 Requests completed: 600 RPS sent: 18.86 Request latency: min: 52.1 max: 11005.7 median: 408.2 p95: 1727.4 p99: 3144 Scenario counts: 0: 300 (100%) Codes: 200: 300 302: 300
項目 説明 Scenarios launched 直前の 10 秒間に作成された仮想ユーザーの数(または合計) Scenarios completed 直前の 10 秒間(またはテスト全体)でシナリオを完了した仮想ユーザーの数 Requests completed 送信された HTTP リクエストとレスポンスまたは WebSocket メッセージの数 RPS sent 直前の 10 秒間(またはテスト全体)に完了した 1 秒あたりのリクエストの平均数 Request latency p99: 500 は 100 リクエスト中 99 リクエストが完了するまでに 500 ミリ秒以下かかったことを意味 Codes 受信した HTTP 応答コードの内訳 Lambda を使用して大量のリクエストを生み出す
Artillery だけでは単一のサーバ上から実行するため、大量のリクエストを生成できませんが、方法があります。Artillery をサーバレスな実行環境に乗せてスケールさせる serverless-artillery が公開されています。
同様のコンセプトを持ったツールにGoadがあります。Goad は、Go で構築された AWS Lambda 搭載の高度に分散された負荷テストツールです。ここでは名前だけの紹介に留めます。
serverless-artillery は Artillery を serverless framework を使用して AWS Lambda にデプロイします。低コストかつ短時間で大量リクエストを生成する負荷テスト環境を構築できます。
デプロイ
デプロイすると CloudFormation にスタックが作成されます。—stage オプションを使用することで複数の環境に対応させることができます。
$ slsart deploy --stage dev
実行
script.yml に記述されたシナリオを実行します。script.yml 以外の名前のファイルを実行したい場合は -o オプションをつけてシナリオファイルを指定します。
$ slsart invoke --stage devCloudWatch にダッシュボードを作成しておくことをおすすめします。
片付け
デプロイされた AWS Lambda と関連するリソースおよびスタックを削除します。
$ slsart removeプラグインの追加
Artillery には様々なプラグインが用意されています。
artillery-plugin-cloudwatch
artillery-plugin-cloudwatch を追加することで、テスト結果を AWS CloudWatch に記録できます。
他にも DataDog 用のプラグインなどが用意されています。
$ npm install --save artillery-plugin-cloudwatch以下に serverless.yml の一部を抜粋します。
service: serverless-artillery provider: name: aws runtime: nodejs8.10 region: ap-northeast-1 iamRoleStatements: - Effect: "Allow" Action: - "lambda:InvokeFunction" Resource: "Fn::Join": - ":" - - "arn:aws:lambda" - Ref: "AWS::Region" - Ref: "AWS::AccountId" - "function" - "${self:service}-${opt:stage, self:provider.stage}-loadGenerator*" # must match function name - Effect: "Allow" Action: - "sns:Publish" Resource: Ref: monitoringAlerts - Effect: "Allow" Action: - "cloudwatch:PutMetricData" Resource: - "*"継続的に負荷テストをするという考え方
従来の開発プロセスでは、アプリケーションを開発し、決められたサーバスペックの VM にデプロイ、最終的に負荷テストを実施することでサーバスペックを決定していました。
クラウド、さらにはサーバレスなアプリケーションの開発プロセスにこの方法は最適でしょうか。
仮想マシン(VM)のスペックの決定、ワークロードに応じた VM 数の調整、障害や災害に備えた可用性の確保などの作業さえもクラウドに任せ、開発者はアプリケーションの開発に専念できるサーバレス。サーバレスはクラウドのあるべき姿を体現しています。素晴らしい技術です。
しかし、その一方で制限がある条件下でのアプリケーション開発は決して容易ではありません。
例えばサーバレスを代表とする Lambda が Web API としてユーザリクエストを受けるアーキテクチャを考えます。この構成がプロダクション環境での性能に耐えうるか、開発プロセスの早い段階で判断したいものです。もし仮にどうしてもプロダクション環境での性能を満たせなかった場合は Fargate に移植するなどの選択肢をとるべきです。開発プロセスのなるべく早い段階で性能検証をするために CI のプロセスに負荷テストを組み込むアプローチをとります。
CircleCI から負荷テストを実行する
Artillery の宣言的なシナリオとシンプルな実行インタフェースにより、容易に CI に組み込むことができます。以下のようなフローを想定しています。
- アプリケーションのソースコードを master ブランチにマージする
- アプリケーションが AWS 上にデプロイされる
- 構築済みの serverless-artillery を使用して負荷テストが実行される
- CloudWatch のダッシュボードを確認する
.circleci/config.ymlは以下のようになります。説明の簡単化のためにキャッシュやユニットテストなどは割愛しましたがより詳細なソースはこちらに保管しています。.circleci/config.ymlversion: 2 jobs: build: docker: - image: circleci/node:7.10 working_directory: ~/repo steps: - checkout - run: npm install - run: npm run deploy:stg loadtest: docker: - image: circleci/node:7.10 working_directory: ~/repo steps: - checkout - run: npm --prefix ./loadtester install - run: npm --prefix ./loadtester run loadtest workflows: version: 2 workflow: jobs: - build - loadtest: requires: - build負荷にランダム性を持たせる
CircleCI から継続的に負荷テストを実行できるようになったので開発フェーズにおいて、常にある程度の負荷をかけ続けることができるようになりました。通常のバックグラウンド負荷レベルをシミュレートするドリップテストが継続的に実行できています。さらに、ある程度ユーザリクエストにゆらぎ(ランダム性)を持たせておくとより多くのケースをテストできます。
phasesの項目を動的に変更してみましょう。script.ymlconfig: target: https://gatjk9gwc4.execute-api.ap-northeast-1.amazonaws.com/dev/ phases: - duration: 10 # この部分を arrivalRate: 1000000 # ランダムに変化させる scenarios: - flow: - get: url: "/"シナリオをランダムに変更する簡単なツールを作成します。
generateSenario.jsfunction rand(min, max) { min = Math.ceil(min); max = Math.floor(max); return Math.floor(Math.random() * (max - min)) + min; //The maximum is exclusive and the minimum is inclusive } function generatePhases(phases, duration, arrivalRate) { const generatedPhases = []; for (let i = 0; i < rand(phases.min, phases.max); i++) { generatedPhases.push({ duration: rand(duration.min, duration.max), arrivalRate: rand(arrivalRate.min, arrivalRate.max) }); } return generatedPhases; } function generateScript() { fs = require("fs"); yaml = require("js-yaml"); const script = yaml.safeLoad(fs.readFileSync("./script.yml", "utf-8")); const phases = { min: 1, max: 50 }; const duration = { min: 10, max: 100 }; const arrivalRate = { min: 10, max: 10000 }; script.config.phases = generatePhases(phases, duration, arrivalRate); fs.writeFileSync("./converted.yml", yaml.safeDump(script)); } generateScript();シンプルに node コマンドで実行しても良いですが、以下のように npm スクリプトで実行できるようにしておくと CircleCI の設定を記述する際に見通しがよくなります。
$ node generateSenario.js.circleci/config.ymlversion: 2 jobs: build: docker: - image: circleci/node:7.10 working_directory: ~/repo steps: - checkout - run: npm install - run: npm run deploy:stg loadtest: docker: - image: circleci/node:7.10 working_directory: ~/repo steps: - checkout - run: npm --prefix ./loadtester install - run: npm --prefix ./loadtester run generate:senario # <--- これを追加してランダム性を持たせる - run: npm --prefix ./loadtester run loadtest workflows: version: 2 workflow: jobs: - build - loadtest: requires: - build実行結果は以下のようになります。このようにしてランダムに生成された
script.ymlを CI から実行します。今回のサンプルソースではスパイクがかかるようなケースを生成しませんでした。ランダムに生成する値をうまく調整することで、通常時の負荷を想定したドリップテストとスパイクアクセスを想定したスラムテストを同時に継続的に実行できます。script.ymlconfig: target: 'https://gatjk9gwc4.execute-api.ap-northeast-1.amazonaws.com/dev/' phases: - duration: 78 arrivalRate: 6184 - duration: 94 arrivalRate: 4583 - duration: 73 arrivalRate: 6991 - duration: 82 arrivalRate: 2664 - duration: 92 arrivalRate: 5239 - duration: 33 arrivalRate: 1596 - duration: 51 arrivalRate: 9621 - duration: 94 arrivalRate: 4155 - duration: 51 arrivalRate: 3145 - duration: 36 arrivalRate: 802 - duration: 90 arrivalRate: 6286 - duration: 46 arrivalRate: 5219 - duration: 29 arrivalRate: 8020 scenarios: - flow: - get: url: /負荷テスト CI の環境下でアプリケーションを開発する
想定するアプリケーション
シンプルな CRUD 操作ができる API を開発します。
TODO リストアプリケーションです。ユーザからのリクエストを受け、TODO タスクを登録、更新、一覧表示、削除します。リクエストは APIGateway 経由で Lambda が処理します。データベースには DynamoDB を選択します。アプリケーションのソースコードはこちらに保管しています。
テストシナリオ
- タスクを登録 取得したデータの 1 番目の id を保持する
- 全件表示
- 1件表示
- タスクを更新(id 指定)
- タスクを削除(id 指定)
- タスクを登録 データが増大し続けることを想定してさらに登録するシナリオを入れておく
シナリオを作成して CircleCI から実行する
テストシナリオを作成してローカルでテスト実行します。
Artillary の設定では、 capture に引き受ける変数を指定することでレスポンスの値を次のシナリオに引き継ぐことができます。
script.ymlconfig: target: https://35vbyy1dxd.execute-api.ap-northeast-1.amazonaws.com/dev phases: - duration: 10 arrivalRate: 10 scenarios: - flow: - post: url: /todos json: text: "my todo" capture: json: "$.id" as: "id" - get: url: /todos - get: url: /todos/{{ id }} - put: url: /todos/{{ id }} json: text: "my todo finished" checked: true - delete: url: /todos/{{ id }} json: id: { { id } }$ artillary run script.yml All virtual users finished Summary report @ 04:14:49(+0900) 2019-12-12 Scenarios launched: 100 Scenarios completed: 100 Requests completed: 500 RPS sent: 46 Request latency: min: 71.7 max: 1580.8 median: 123.4 p95: 687.9 p99: 870.6 Scenario counts: 0: 100 (100%) Codes: 200: 500 # <-- 正常にシナリオが実行できていることを確認問題がすぐに検知できる
GitHub にソースをマージして CircleCI を動かしましょう。負荷テストが実行されます。
以下は、負荷テスト実施時の APIGateway のメトリクスです。
リクエスト数、レイテンシー、4xxError, 5xxError を表示しています。
CI によって自動的に負荷がかけられるようになり、開発プロセスの早い段階からパフォーマンスの問題が検知できるようになりました。まず初めに以下のプログラムの問題を特定しました。TODO タスクの一覧を取得する処理ですが DynamoDB のスキャンを使用しており、全件検索になってしまっています。APIGateway の制限 29 秒以上かかってしまうため 5xx エラーが多発しています。とても使い物になりません。
list.js'use strict'; const dynamodb = require('./dynamodb'); module.exports.list = (event, context, callback) => { const params = { TableName: process.env.DYNAMODB_TABLE, Limit: 10 // <-- まずは取得する件数を制限してみる }; // fetch all todos from the database dynamodb.scan(params, (error, result) => { // handle potential errors if (error) { console.error(error); callback(null, { statusCode: error.statusCode || 501, headers: { 'Content-Type': 'text/plain' }, body: 'Couldn\'t fetch the todo item.', }); return; } // create a response const response = { statusCode: 200, body: JSON.stringify(result.Items), }; callback(null, response); }); };また、DynamoDB のキャパシティユニットが圧倒的に足りません。デフォルト値のままでしたから、当然といえば当然ですが。これも解消しましょう。オートスケーリングの設定をします。
分散トレーシング
複数の Lambda Function や DynamoDB を使用したアプリケーションでは、分散トレーシングを有効活用することで、そのシステムの振る舞いを可視化できます。
AWS の分散トレーシングサービスである x-ray を使用します。必要なライブラリをインストールします。$ npm install --save-dev serverless-plugin-tracing $ npm install --save aws-xray-sdkserverless.yml に必要な情報を追加します。
serverless.ymlprovider: name: aws runtime: nodejs8.10 region: ap-northeast-1 environment: DYNAMODB_TABLE: ${self:service}-${opt:stage, self:provider.stage} tracing: apiGateway: true lambda: true iamRoleStatements: - Effect: Allow Action: - dynamodb:Query - dynamodb:Scan - dynamodb:GetItem - dynamodb:PutItem - dynamodb:UpdateItem - dynamodb:DeleteItem Resource: "arn:aws:dynamodb:${opt:region, self:provider.region}:*:table/${self:provider.environment.DYNAMODB_TABLE}" - Effect: Allow Action: - xray:PutTraceSegments # <-- 追加 - xray:PutTelemetryRecords # <-- 追加 Resource: "*"アプリケーションに aws-xray-sdk を追加し、トレース可能にします。
dynamodb.js"use strict"; + const awsXRay = require("aws-xray-sdk"); + const AWS = require('aws-sdk'); - const AWS = awsXRay.captureAWS(require("aws-sdk")); let options = {}; // connect to local DB if running offline if (process.env.IS_OFFLINE) { options = { region: "localhost", endpoint: "http://localhost:8000" }; } const client = new AWS.DynamoDB.DocumentClient(options); module.exports = client;この変更をコミットし、GitHub に PUSH します。負荷テストが始まると AWS の X-Ray コンソールに以下のようにマップやトレーシング情報が作成され始めます。
随分と性能改善ができました。
まとめ
serverless-artillery を使用することで低コストかつ短時間で負荷テストの実行環境を用意できました。さらに、CircleCIと組み合わせることで継続的に負荷を与え続けながら開発を進めることも可能です。AWS X-Rayなどの分散トレーシングのサービスを使用することで、高度に分散したアーキテクチャのボトルネックを特定することができました。
サーバレスがクラウドの未来だと信じています。全てがサーバレスになる時代はもうすぐ手の届くところにあります。この先もこの技術領域を開拓して、最良の開発ができるように務めていきたいです。













- 投稿日:2019-12-13T04:05:52+09:00
Serverless Frameworkを使用して、AWS上のLambdaにデプロイするまで【開発環境構築含む】
概要
タイトルの通り、Serverless Frameworkを使用して、AWS上のLambdaにデプロイするまでの開発環境構築手順
最終的には、NestJSのアプリケーションをLambdaにデプロイして「Hello World」を表示させたいと思います。1. Serverless Frameworkをインストールする前に
事前に開発環境を整えます。本記事の開発端末はMacです。
基本的なインストールが完了している方は、Serverless Frameworkをインストールするところから読んでいただければと思います。Homebrewのインストール
ホームページにあるスクリプトを実行する
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"nodebrewのインストール
「Homebrew」が使えるようになったので、次に「nodebrew」をインストールします。
nodebrewはNode.jsのインストールから複数のバージョンを管理・切り替えできるツールになります。$ brew install nodebrewNode.jsのインストール
必要なバージョンを指定してインストールします。
$ nodebrew install-binary latestインストール直後は
current: noneとなっているため、必要なバージョンを有効化します。nodebrew use v x.x.x参考記事:https://qiita.com/kyosuke5_20/items/c5f68fc9d89b84c0df09
AWSCLIのインストール
Macの場合、pipが初めからインストールされているため、pipを使用してAWSCLIをインストールしたいと思います。
sudo pip install awscliGitのインストール
GitはHomebrewを使用してインストールします。
参考:https://qiita.com/micheleno13/items/133aee005ae37c28960e
Gitをインストールしても
xcode-selectがインストールされていないと使用できない場合があります。xcode-select --install参考:https://qiita.com/royroy/items/338362362de73a94fc0c
必要アカウントの用意(登録)
awsアカウント
- アカウントの作成
https://aws.amazon.com/jp/register-flow/- IAMユーザの作成
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_users_create.html- IAM アクセスキーの発行
作成したIAMユーザを選択し、「認証情報」から「アクセスキーの作成」を選択し、アクセスキーとシークレットキーを取得します。(後ほど使用するのでどこかに保管してください)GitHub(コード管理する場合のみ)
GitHub(アカウント)登録:https://github.co.jp/
Gitについて参考(全般):https://employment.en-japan.com/engineerhub/entry/2017/01/31/1100002. Serverless Frameworkのインストール
参考:https://dev.classmethod.jp/cloud/aws/easy-deploy-of-lambda-with-serverless-framework/
npmからServerless Frameworkをインストールします。
$ npm install -g serverless完了したら動作確認します。(バージョン確認)
$ serverless -v Framework Core: 1.59.3 Plugin: 3.2.5 SDK: 2.2.1 Components Core: 1.1.2 Components CLI: 1.4.0AWSアカウントの設定
Serverless FrameworkからLambdaなどAWSのリソースにデプロイする際にアクセス権限が必要なための設定です。
先ほどAWSアカウントを登録した際のIAMアクセスキーの情報をServerless Frameworksに設定します。sls config credentials --provider aws --key XXXXXXXXXXXXEXAMPLE --secret XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXEXAMPLEKEY3. NestJS を Lambda にデプロイする
基本的な開発環境が整ったので、実際にServerless Frameworkを使用してデプロイを行いたいと思います。
以下リポジトリをそのまま引用します。
https://github.com/rdlabo/serverless-nestjsNestJSのインストール
今回はNestJSのアプリケーションを使用するためインストールします。
$ npm install @nestjs/cli serverless -gソースをローカルにコピー
Git Cloneでローカルにソースをコピーします。
git clone https://github.com/rdlabo/serverless-nestjs.gitデプロイ時に必要なパッケージをインストール
$ npm installローカルで「Hello World」が表示されるか確認
$ npm startブラウザで確認します。
http://localhost:3000/
Lambdaデプロイ
$ sls deploy Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Creating Stack... ~~~~~~~~~~~~~~~~~~~~~~~~~~ 省略 ~~~~~~~~~~~~~~~~~~~~~~~~~~ endpoints: ANY - https://jpvi3b5i8a.execute-api.us-east-1.amazonaws.com/dev/ ANY - https://jpvi3b5i8a.execute-api.us-east-1.amazonaws.com/dev/{proxy+} functions: index: serverless-nestjs-dev-index layers: None Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.生成されたエンドポイントで確認します。
※デプロイしたサーバによってエンドポイントは異なります。
https://jpvi3b5i8a.execute-api.us-east-1.amazonaws.com/dev/
AWSコンソール上でリソースが作成されたことを確認します。
リージョンはバージニア北部(us-east-1)に作成されています。
確認したらリソースは削除してください。
- 投稿日:2019-12-13T02:21:03+09:00
AWS Python(Boto3)の例外ハンドリングとテスト時のraise方法
Lambdaなど、AWSリソースを使用した開発をしているとboto3のエラーハンドリングをする機会が必ず出てきます。
また、Pytestなどテスト自動化を導入している際にraiseさせたい場面もよくあります。
そこで、エラーハンドリングをする際の手順を簡単にまとめました。ハンドリング方法
- DynamoDBへレコード追加
- ID重複時に重複している旨を出力する
という想定で行っていきます。
エラーハンドリングimport boto3 from botocore.exceptions import ClientError # boto3のエラーを司るClientErrorをimportしておく dynamodb_client = boto3.client('dynamodb') def main(table_name, id_): param = { "TableName": table_name, "Item": { "id": {"S": id_} }, "Expected": { "id": { "Exists": False } } } try: dynamodb_client.put_item(**param) except ClientError as e: # ClientErrorをキャッチするようにする # エラー内容からCodeを抜き取り比較する。重複時にはConditionalCheckFailedExceptionが返ってくる。 if e.response['Error']['Code'] == 'ConditionalCheckFailedException': print("IDが重複しています。") return # 重複以外はエラー raise e if __name__ == "__main__": main('hogehoge', 'fugafuga')一回目は正常に動きますが、2回目は
IDが重複しています。とメッセージが出ます。ClientErrorのエラー内容を確認
VSCodeのデバッガを使用して中身を確認してみました。
御覧の通り、response内にErrorのキーがあり、さらにCodeのキーがあるのが確認できると思います。
エラーコード自体はAWSの公式リファレンスに載っていますので、事前に確認しておくのが良いと思います。
AWS Dynamodb | エラー処理raise方法
ここまでは他にもたくさんqiitaの記事がありますが、raiseさせる方法を記述している記事はなかなか無かったのでメモがてら。
結論から言うとraiseするClientErrorに引数を渡してあげます。
try内でraiseさせる# 先ほどのコードのtry,except部分のみ抜粋です try: # "Error"キーと"Code"キーの辞書型を用意 # "Code"にはハンドリングさせたいエラーコードを入力 error_response = { "Error": { "Code": "ConditionalCheckFailedException" } } # 文字列です。関数名などを格納する? operation_name = "put_item" raise ClientError(error_response, operation_name) dynamodb_client.put_item(**param) except ClientError as e: # ClientErrorをキャッチするようにする # エラー内容からCodeを抜き取り比較する。重複時にはConditionalCheckFailedExceptionが返ってくる。 if e.response["Error"]["Code"] == "ConditionalCheckFailedException": print("IDが重複しています。") returnこれで
raiseできます。raise ClientErrorのエラー内容を確認
若干メンバが足りないようですが、動作確認などには十分ですね。
ClientErrorの実態
ClientErrorはどのような構成になっているのか見てみました。
ClientErrorclass ClientError(Exception): MSG_TEMPLATE = ( 'An error occurred ({error_code}) when calling the {operation_name} ' 'operation{retry_info}: {error_message}') def __init__(self, error_response, operation_name): retry_info = self._get_retry_info(error_response) error = error_response.get('Error', {}) msg = self.MSG_TEMPLATE.format( error_code=error.get('Code', 'Unknown'), error_message=error.get('Message', 'Unknown'), operation_name=operation_name, retry_info=retry_info, ) super(ClientError, self).__init__(msg) self.response = error_response self.operation_name = operation_name (続く)...こちらがClientErrorの中身です。
__init__で2つの引数を受け取ることができるのが読み取れます。
第1引数のerror_responseは辞書型であり、Errorがありその下にCodeが存在していればいいみたいです。


- 投稿日:2019-12-13T02:14:18+09:00
AWS Lambda関数の呼び出し方を改めて確認する(1)
はじめに
AWS Lambdaを皆さんどのようにお使いですか?
数msで終わるような軽量の処理から、900秒まで(2019年12月12日現在)の処理までプログラムを実装して簡易な設定をすればすぐ動作させることができて非常に便利なサービスだと思います。そのAWS Lambda関数の呼び出し方(起動方法)について改めて確認したいと思い、記事を書いてみました。なお、当記事ではWebアプリケーションのバックエンドとして動作するLambdaを例にLambda関数がどう呼び出されるのか説明し、別の記事(2019/12/18公開予定)、もう少し踏み込んで呼び出されるケースについて確認したいと思います。
サマリ
- 様々な方法でLambda関数を起動することが可能だが、リクエスターにはIAMポリシーまたは、Lambda関数のアクセス許可ポリシーによる許可が必要
- 同期で応答を受け取る方式と非同期で受付のみをし別プロセスで受け取る方式がある
- 呼び出す際には、AWS Lambdaのエンドポイントにアクセスする必要がある
Lambda関数を起動する方法
Lambda関数を呼び出す方法としては様々な方法がサポートされています。
シェルやプログラム等で呼び出したければ以下の方法を使うことが多いでしょう。
- AWS CLI
AWS SDK
また、既に登録済みの関数を試しに起動したいという場合にはAWSマネジメントコンソール経由でボタンクリックで起動することもあるでしょう。
それ以外に以下に一部記載しましたが様々なAWSサービスと連携してLambda関数を起動することができます。Amazon API Gatewayのバックエンド
Amazon API Gatewayの認可機構であるCustom Authorizer
Amazon SQS, Amazon Kinesis Data StreamsやAmazon DynamoDB Streamsのバックエンド
CloudWatch Eventsによるタイマー起動先
Amazon Alexaのバックエンド
同期と非同期
Lambda 関数を前述の方法で呼び出すことができますがその際に抑えておくべきこととして同期呼び出しと非同期呼び出しがあります。なお、非同期呼び出しの内容についてはこちらの記事にまとめてみたので見てください。それぞれ、応答方法、エラー時の挙動が異なりますので未確認というかたは是非ご確認ください。例えば、AWS CLI で以下のコマンドを実行した場合は同期呼び出しとなり、関数の処理応答を待ち次に進みます。一方、非同期呼び出しは受付のみをし、関数の実行は別のプロセスで行う呼び出し方になりますので当然、関数の処理結果は戻ってきません。
aws lambda invoke --function-name QiitaSample --payload '{"key1":"test"}' result.txtちなみにCLIでは
--debugをつけて実行するとAWS CLIがAWSのエンドポイントとどのように通信しているかログを表示してくれます。試しに実行した結果の一部を抜粋しています。以下をご覧いただくとわかとおり、CLIはAWS Lambdaのエンドポイント(lambda.us-east-1.amazonaws.com)にPOSTで通信していることがわかります。AWS Lambda関数を起動した場合は上記エンドポイントにアクセスしてLambdaを起動する形となります。2019-12-12 17:07:36,780 - MainThread - botocore.auth - DEBUG - CanonicalRequest: POST /2015-03-31/functions/QiitaSample/invocations host:lambda.us-east-1.amazonaws.com x-amz-date:20191212T170736Z x-amz-security-token:IQoJb3JpZアクセス制御
Lambda関数の呼び出しは誰でも成功できるわけではありません。許可がないと呼び出しは失敗します。AWS CLIのバックエンドで呼び出される場合にも、CloudWatch Eventsのタイマー起動で呼び出される場合にも、Alexaのバックエンドとして呼び出される場合にも、許可を明示的にする必要があります。許可を与える方法としては以下の二種類があります。
- AWS IAM(User/Role/Group)へ適用する許可ポリシー
- 各Lambda関数のアクセス許可ポリシー
クロスアカウントあるいは、各種AWSサービスからの呼び出しを許可したい場合には、自身のアカウントのIAMユーザー、ロール、グループが使えないので(別アカウントだから)、各Lambda関数にリソースベースのアクセス許可ポリシーで許可を与える方式となります。
では、許可設定について間違いやすいので、実際にコンソールでみてみましょう。
図ではQiitaSampleを真ん中に左側と右側にそれぞれAPI GatewayとAmazon SQSが配置されています。左側、つまり、この例ではAPI Gatewayは、このLambda関数(QiitaSample)のアクセス許可ポリシによってQiitaSample関数を呼び出す許可を与えられていることを意味します。
右側のAmazon SQSは、このLambda関数(QiitaSample)からアクセスできるサービスを表しています。これは、各Lambda関数ごとに指定可能な「実行ロール」でに指定されたロールがアクセス許可されているサービスが表示されています。さらに細かい内容は「アクセス権限」タブを開くと確認ができるようになっています。なお、Lambda関数内から出力するログについては、CloudWatch Logsへの書き込み権限を関数に与える必要があり、各関数の実行ロールで指定する形となります。重要なことは、以下の3つを理解することです。
1. Lambda関数を呼び出すには、リクエスターに「許可」が与えられている必要があること
2. 許可はIAMで設定するか各関数でアクセス許可設定をすること
3. Lambda関数がAWSサービスを呼び出したい場合は、Lambda関数の実行ロールに許可設定をするか、呼び出すサービスのリソースベースポリシーでLambda関数に許可を与えること呼び出し経路
さて、ここからはAWS Lambdaを呼び出す方法をもう少し深掘りしていきたいと思います。今回は、WebアプリケーションをAWSLambda等で実装する場合を題材にパターンを上げて整理したいと思います。
No. ケース 説明 1 直接呼び出し モバイルやPC上のアプリやSPA(Single Page Application)からAWS Lambda関数を直接呼び出す方式 2 API Gateway 経由呼び出し モバイルやPC上のアプリからAPI Gateway経由で呼び出す方式
実は、私自身、初めてAWS Lambdaを勉強した際に、上記の1,2両方呼び出し方があるけど、どう違うの?という疑問を持ちました。違いとしては、以下があるかなと思います。
No. 観点 直接呼出し API Gateway経由 1 Lambda起動のための認可 アプリ自身が直接呼び出すため、Credentialを事前にアプリ側で取得し(例;CognitoのIDプールの利用)、それを利用して呼び出す必要がある。 Lambda関数がAPI Gatewayの呼び出し許可をアクセス許可ポリシーで指定するか、API Gatewayの実行ロールでLambda関数の呼び出しを許可する必要がある。必ずしもアプリでCredentialを取る必要はない(API Gatewayの構成次第 2 Web API向け機能 直接Lambda APIを実行するため追加機能はつけられない スロットリング、課金、JWT/OIDCによる認可等の機能を組み込めることや、バックエンドの隠蔽が可能 3 クロスリージョン ユーザーのロケーションに関係なく呼び出し可能 Lambda関数がAPI Gatewayと異なるリージョンにいても呼び出しは可能 4 クロスアカウント アプリ自身が直接呼び出すため各アカウントのCredentialが必要、かつ、Lambda関数側にもアクセス許可ポリシーで許可設定が必要 Lambda関数がAPI Gatewayの呼び出し許可をアクセス許可ポリシーで指定することで、API Gatewayが異なるアカウントでも呼び出し可能 もちろん API Gatewayを挟むことでAWSサービル利用料金に違いがでます。ただ、API Gatewayを挟むことでAPIの機能(課金・ログ・認可等)をより実装しやすくなるというところがメリットかなと考えています。
さて、Webアプリケーションを題材に、Lambda関数の呼び出し方についてはここまでとし、次回はLambda関数が別のサービス等を呼び出す部分にも光を当ててみます。

