- 投稿日:2019-12-03T23:15:11+09:00
django-ckeditorにコードスニペット機能を追加
django-ckeditorはリッチテキストエディター(多機能な編集機能を持った入力装置?)を提供してくれる便利なライブラリです!
インストール方法は割愛します。(時間があれば別記事で書いてみます!
今回は、ckeditorにコードスニペット(pythonやJSなどのコードをいい感じに表示してくれる機能)を実装する方法をまとめたいと思います。Step1. CKEDITOR_CONFIGにプラグインを認識させる。
django-ckeditorの設定をする際に、setting.pyの中に以下のような記述を行っていると思います。
setting.pyCKEDITOR_CONFIGS = { 'default': { 'height': 150, # defaultで高さ150pxに固定という意味 'width': '100%', # defaultで親要素の幅に固定 ー> 便利です。 }, }少し、設定をいじっていますがこんな感じになっているはずです。
ここでは自作の設定などを追加したりすることができますが、内容が本記事の趣旨と異なりますので別記事で。
続いて、以下のような自作設定に'extraPlugins'という形でコードスニペット機能を追加します。(この他にもdjango-ckeditorはプラグインという形で機能を拡張させることが可能です。
setting.pyCKEDITOR_CONFIGS = { 'custom_toolbar': { 'height': 150, 'width': '100%', 'toolbar_Custom': [ ['CodeSnippet'], # これがコードスニペットの機能 ['Bold', 'Italic', 'Underline', 'RemoveFormat', 'Blockquote'], ['TextColor', 'BGColor'], ['Link', 'Unlink'], ['NumberedList', 'BulletedList'], ['Maximize'], ['Styles', 'Format'], ], 'toolbar': 'Custom', 'extraPlugins': ','.join(['codesnippet']), # コードスニペット機能のプラグイン }, 'default': { # 'toolbar': 'Basic', 'height': 150, 'width': '100%', }, }Step2. templateでコードスニペットの表示を有効にする。
このままでは、templateにて作成した文章などを呼び出したときコードスニペットが以下のように有効になりません。
templateで有効にするためには、以下のJS/CSSファイルの読み込みが必要です。
template{# テーマに関するcssファイル #} <link rel="stylesheet" href="//cdnjs.cloudflare.com/ajax/libs/highlight.js/9.12.0/styles/default.min.css"> {# JSファイル+実行 #} <script src="//cdnjs.cloudflare.com/ajax/libs/highlight.js/9.12.0/highlight.min.js"></script> <script>hljs.initHighlightingOnLoad();</script>これでtemplateでテーマの割当が以下のように行われます。
番外編:テーマを変更する
ちゃんとテーマが割り当てられる用になりましたが、なにか物足りない。。。他のテーマを割り当てたい!というときは以下のサイトから好きなテーマを探して見てください。
各テーマのCDNを利用することができます。https://cdnjs.com/libraries/highlight.js
例えば、monokaiに変更したいときは
template{# テーマに関するcssファイル #} <link rel="stylesheet" href="//cdnjs.cloudflare.com/ajax/libs/highlight.js/9.12.0/styles/default.min.css"> -->これを変更 <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/9.15.10/styles/monokai.min.css"> --> 変更後上記のように変更したいテーマのcssファイルを指定すれば以下のように好きなテーマを割り当てることが可能です!
終わりに
多くの機能を作成して頂いてありがとうございます。。。先人に感謝です。笑



- 投稿日:2019-12-03T22:51:49+09:00
cURL API を Pythonスクリプト に変換する(IBM Cloud オブジェクトストレージを使って)
cURLでREST-APIの動作確認をしてからPythonに書き直すときの変換パターンをメモ
- IBM Cloud オブジェクトストレージを使って cURL の動作を確認する。
- 確認できたcURLをPythonスクリプトで書いて、オブジェクトストレージで検査する。
その1.認証トークンを取得する
cURLの場合
curl -X "POST" "https://iam.cloud.ibm.com/identity/token" \ -H 'Accept: application/json' \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode "apikey={api-key}" \ --data-urlencode "response_type=cloud_iam" \ --data-urlencode "grant_type=urn:ibm:params:oauth:grant-type:apikey"Pythonの場合
#!/usr/bin/env python # -*- coding: utf-8 -*- import os import requests import json # トークンを取得する headers = { 'Accept': 'application/json', 'Content-Type': 'application/x-www-form-urlencoded', } data = { 'apikey': os.environ['IBM_APIKEY'], 'response_type': 'cloud_iam', 'grant_type': 'urn:ibm:params:oauth:grant-type:apikey' } response = requests.post('https://iam.cloud.ibm.com/identity/token', headers=headers, data=data) print(response) output = response.json() #print(json.dumps(output, indent=4)) ibm_access_token = output['access_token'] print(ibm_access_token)Python実行結果
STATUS :<Response [200]> { "access_token":"eyJraWQ******************************************2Erh-Te-w", "expires_in":3600, } # すんごく長いトークンは、1時間有効(3600 = 60秒 x 60分)その2.バケットのリストを表示する
cURLの場合
curl "https://(endpoint)/" \ -H "Authorization: bearer (token)" \ -H "ibm-service-instance-id: (resource-instance-id)"Pythonの場合
# トークンの取得までは同じpythonスクリプトを書く # “#!/usr/bin/env pythonからibm_access_token = output['access_token']まで” # ここでは省略します。 # オブジェクトのリスト表示 headers = { 'Authorization': 'bearer ' + ibm_access_token } response = requests.get('https://s3.jp-tok.cloud-object-storage.appdomain.cloud/robocamera', headers=headers) print("STATUS :" + str(response)) print("HEADERS:" + str(response.headers)) print("TEXT :" + str(response.text))Python実行結果
STATUS :<Response [200]> HEADERS:{'Content-Length': '1938', 'ibm-sse-kp-enabled': <中略> 'Content-Type': 'application/xml'} TEXT :<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <中略> <Name>robocamera</Name> <Contents> <Key>ciel_face_s.png</Key><LastModified>2019-11-30T02:50:53.410Z</LastModified> <Key>ghostpicture.jpg</Key><LastModified>2019-11-30T01:46:52.413Z</LastModified> <Key>index.html</Key><LastModified>2019-11-24T14:48:55.793Z</LastModified>その3.バケットにファイルをアップロードする
cURLの場合
curl -X "PUT" "https://(endpoint)/(bucket-name)/(object-key)" \ -H "Authorization: bearer (token)" \ -H "Content-Type: (content-type)" \ -d "(object-contents)"Pythonの場合
# IBM Cloud Object Storage に、カメラ画像ファイルをアップロードする。 # この例では[/robocamera]がバケット名、[ghostpicture.jpg]がオブジェクトのキー名。 headers = { 'Authorization': 'bearer ' + ibm_access_token, 'Content-Type': 'image/jpeg', } f = open('capture_output.jpg', 'rb') img_data = f.read() f.close() response = requests.put(service_endpoint + '/robocamera/ghostpicture.jpg', headers=headers, data=img_data) # トークン取得をデバッグするときに検査したいとき print("UPLOAD STATUS:" + str(response))おっと。cURL と Pythonスクリプトを変換してくれるサイトがありました。
これは便利。
Convert curl syntax to Python https://curl.trillworks.com/
- 投稿日:2019-12-03T22:14:36+09:00
Pythonでファーストクラスコレクションを生成する
はじめに
オブジェクト指向を勉強していると、よく
「同じ型の複数のオブジェクトを扱うロジックはファーストクラスコレクションにまとめる」
というような文章を目にするかと思います。
これまで、具体的にpythonでどのように書けばいいか分からなかったのですが、
自分なりに「こう書けばすっきり分かりやすくなりそうだ」という記述ができたので記事にしました。とりあえず書いてみる
商品クラスとそのファーストクラスコレクション(以下コレクションと記載する)を考えてみます。
import dataclasses from typing import List @dataclasses.dataclass(frozen=True) class Item(object): name: str price: int @dataclasses.dataclass(frozen=True) class ItemCollection(object): # default_factoryで何の型で初期化するかを指定できます items: List[Item] = dataclasses.field(default_factory=list) def add_item(self, item): # 要素を追加する際は新しいオブジェクトを生成して返します。 # 既存のコレクションに副作用を与えずに要素を追加した新規オブジェクトを生成する方法が # これ以外に思い浮かばなかった・・・ return ItemCollection(self.items + [item])dataclassesの基本的な使い方はこちらも読んでいただければと・・・
(https://qiita.com/madogiwa_429/items/55c78fc6be7887a28df8)とりあえず、これでファーストクラスコレクションが作れます。
ファーストクラスコレクションへの疑念
これまで、コレクションに対して不便だと思っていた理由に、
「簡単に書けるはずの処理の記述が面倒になる」というのがありました。
例えば、今回の例で、「コレクションに格納されている商品の合計金額を求めたい」というとき、
どのように書けばいいでしょう。
int型でリストに入れていればsum関数で書けるものが、
Itemクラスを格納したことで簡潔に記述できなくなってしまいます。
こういうこともあり、配列を扱う場合に本当にオブジェクト指向で書くのが良いのか分からずにいました。map関数を使う
この疑念に一定の解を与えてくれるのがmap関数です。
map関数はリストなどのイテラブルオブジェクトの各要素に対して処理を行ってくれます。
map関数を使うと、コレクションに格納されている商品の合計金額を求めるメソッドは以下のように書けます。@dataclasses.dataclass(frozen=True) class ItemCollection(object): items: List[Item] = dataclasses.field(default_factory=list) def add_item(self, item): return ItemCollection(self.items + [item]) def sum_price(self): # itemsの各要素のインスタンス変数"price"の値だけのリストができる price_list = list(map(lambda item: item.price, self.items)) return sum(price_list)まとめ
map関数を使うことで、ファーストクラスコレクションのメソッドを簡潔に書けました。
Pythonでオブジェクト指向を書くときに同じ悩みを持っている方の参考になれば幸いです。ちなみに・・・
frozen=Trueとすることで、確かにインスタンス変数の再代入は防げるのですが、
リストの要素追加は防げませんでした・・・test = ItemCollection() # この処理はエラーになる test.items = ['てすと'] # この処理はエラーにならず、要素が追加されてしまう test.items.append('てすと')
- 投稿日:2019-12-03T21:54:33+09:00
【失敗】Tacotron2を用いた日本語TTSの開発~2作品目~
序
Tacotron2の後継機であるMellotronが発表され、
いよいよ音声合成業界にも追い風がでてきた昨今
私は未だにTaco2を用いたTTSの開発をするMeronはTaco2をベースにつくられているものの、
ずぶずぶの英語仕様になっている
日本語化するにはもう少し読み込んで────いや、
今のところ、移行は考えていないTaco2での開発をしていた頃、
このような文をみた「データセットのデータの量と品質が非常に重要」
概ね同意ではあるが、
あまりにも漠然としているそれ以上に答えようがないこの課題ではあるが、
クオリティがこれに左右されることは間違いないその後、
Lentoさんのブログに出会い、私は思った「 いくらノイズが多少あろうとも、
データが少なかろうとも
どうにかこうにかすれば、
TTSは作れるのでは? 」やってみることにした
結果
とりあえず、結果からいうとできなかった
いや、満足いくものにはならなかったというべきかノイズが多いので聴く方は注意
音声サンプル
(taco2: 121k, wavglw: 600k)音声再現でさえこのノイズになってしまった
Taco2
120k steps
target
inference
WaveGlow
考察
Taco2
Taco2の推論は定性評価では問題がないように見える
前回の記事でも述べた通り、
推論出力はほど綺麗なグラデーションとなり、
これはTOA-TTSでも同様の結果を得ているそれともうひとつ、
「ノイズはあってもそこまで問題にはならない」
という前回の開発を踏まえた私の(感覚による)予想は、
このグラデーションによって消されるということで
やっぱりあんまり関係ないのではという結論に至るTaco2の学習は121k stepsで打ち止めたが、
このまま続ければ、もう少し品質が上がる可能性もあるWaveGlow
こちらは見事に計算が発散してしまった
WaveGlowの学習はどれくらい必要なのか?
というイシューをみた記憶によると、100万は必要らしい120k, 600kの時点で合成を試し、
ノイズは少なくなった印象を受け、計算を続行したが
このような結果となったTOA-TTSと完全に(HP、データセット作成手順等)同条件でやってこの結果なので、
音声の質はどうやらここに影響するようだTaco2の推論に問題がないことを踏まえても、
合成にここまでノイズが入るのは、
音声波形生成のこのモデルに問題がある可能性が高い終
どうにか、音声の再生成までは上手くいくようなモデルはつくりたい
その次に音声合成の精度を上げていく方針でもう少し足掻いてみる







- 投稿日:2019-12-03T21:28:09+09:00
三項演算子で break や continue は使えない
三項演算子は『式』("expression") に対して使うもの。
break や continue は『式』ではなく『文』("statement") なので下の例のような横着はできませんよ、という話.ダメな例for i in range(100): break if i > 20 else continue
- 投稿日:2019-12-03T21:17:48+09:00
東京大学2019年数学入試第1問をpython sympyに解かせてみた
東京大学2019年数学入試第1問をpython sympyに解かせてみた。
何秒で解けるかを測定するために、時間も測ってみました。問題は、こちらを参照ください。
https://sokuho.yozemi.ac.jp/sokuho/k_mondaitokaitou/1/kaitou/kaitou/1306831_5342.html私のPCでは、23秒で計算できました。
import sympy as sym import datetime (a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z) = sym.symbols('a b c d e f g h i j k l m n o p q r s t u v w x y z') f = (x**2 + x/sqrt(1+x**2))*(1+ x/((1+x**2)*sqrt(1+x**2))) #start time start_t = datetime.datetime.now() #calc answer=sym.integrate(f,(x,0,1)) #end time end_t = datetime.datetime.now() #elapse time elapse_t = end_t - start_t print(answer) print(elapse_t,"秒かかりました")

- 投稿日:2019-12-03T21:12:45+09:00
【Blender】3Dモデルを効率よくインポートする方法
How to import 3D models efficiently in Blender.
An alternative to drag-and-drop import of 3D models in Blender.
Blenderで3Dモデルをドラッグアンドドロップインポートする代わりです。
KeyWord: obj fbx drag and drop import efficient動機
- Blenderで3Dモデルをドラッグ&ドロップでインポートできないのは不便。
- 私がPhotoshopで様々な素材(jpgやpngなど)をレイヤーを駆使して編集したのと同様に、Blenderでも複数のオブジェクトを比較しながら編集したい。
- 3Dモデルをスマートにインポートする別の方法はないかと探す旅に出た(前回)。
動作環境
macOS Mojave, Blender 2.8,
python知識0でもOK.プログラミング経験者なら何となく分かりそう.スマートな方法
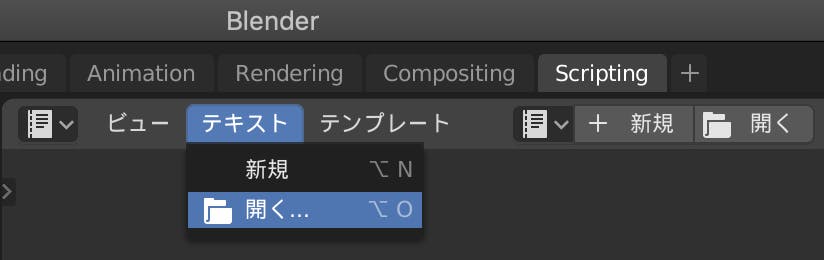
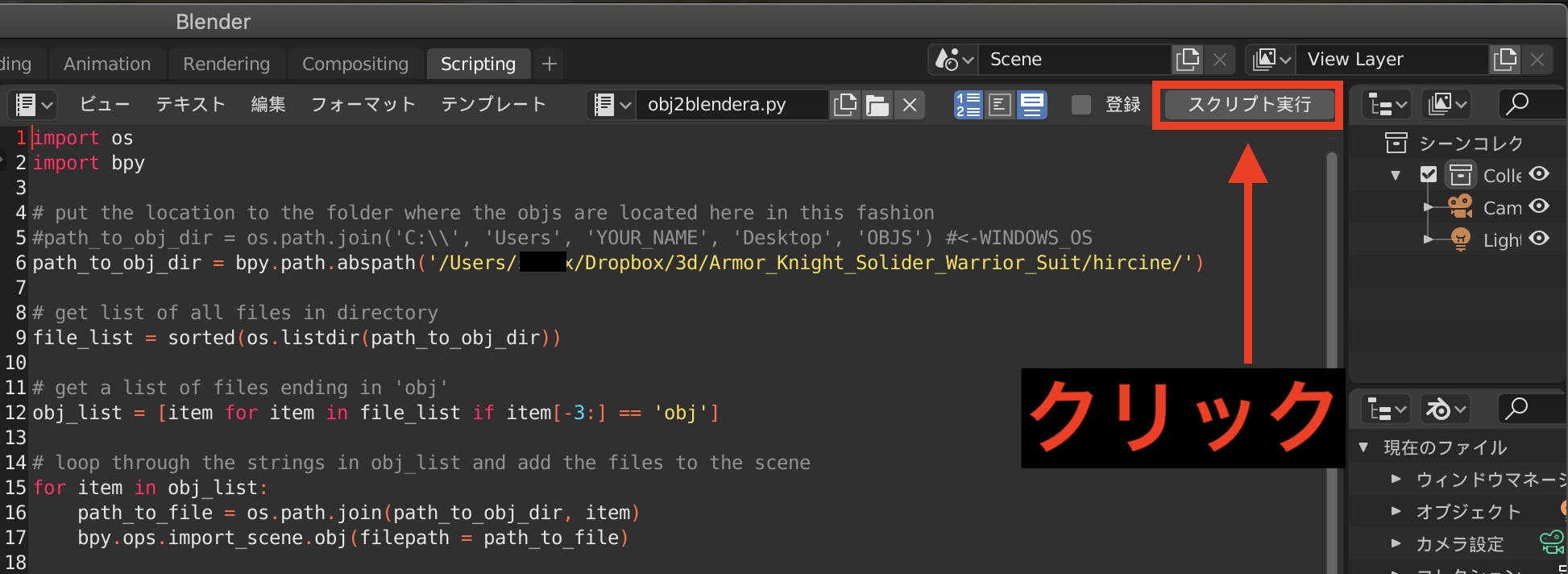
obj2blender.pyをスクリプトを実行する.
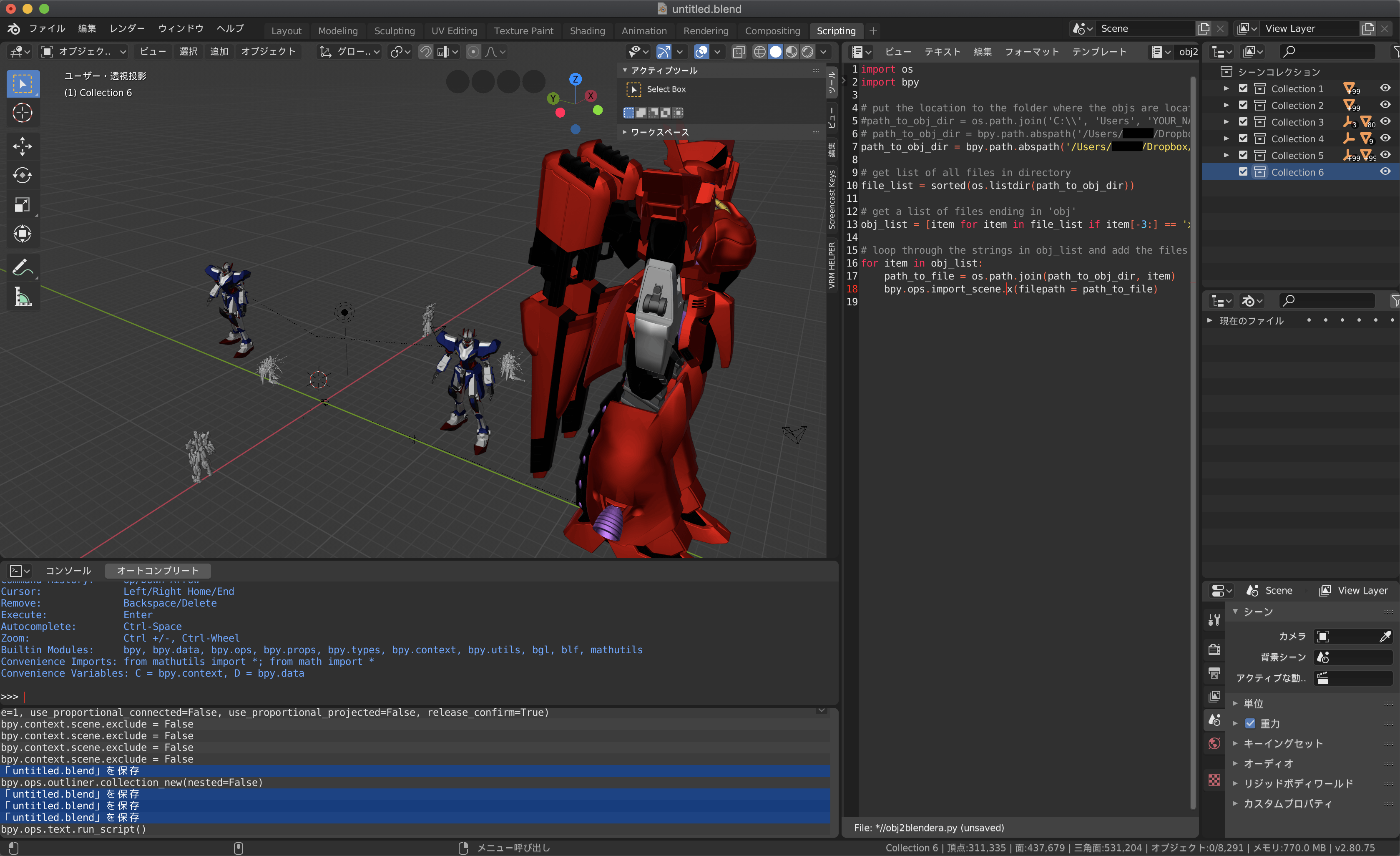
ディレクトリ内にある3Dファイルの数だけシーンにインポートされる.3Dファイルは原点に設定されていることが多いので、モデルのスケールやトランスフォームによるが度々重なる。
続けてインポートする場合は、スクリプト実行の前にモデルを原点から移動させ、シーンコレクションを新規に作成することをおすすめする。結果
楽園ができました。穏やかじゃないですね。
代償
3Dモデルのサイズに応じて、.blendのファイルサイズが大きくなる.
複数のモデルを読み込むことでBlenderの動作がだんだん重くなる.インポートサポートファイル形式
当(Mac Blender2.79 Blender2.80)環境で検証しました(現状2019/12/2)。
Blender2.79とBlender2.80で試したところどちらも同じような動作でファイルがインポートされた結果になりました。
addon(拡張機能)でImport(インポート)があると、他の3Dファイル形式をインポートできた事を確認しました。
皆さんもぜひ駄目元で試してみて下さい。
できる fbx obj vrm(addon:VRM IMPORTER) できない dae skp pmx(addon: mmd_tools) 3ds stl glTF 変化なし blend x 今後の課題
- Blenderが標準でサポートされている他3Dファイル形式への対応.(.blend .dae など)
- 座標軸の設定 位置をずらして配置
【参考】
- 投稿日:2019-12-03T20:47:32+09:00
社内chatworkにVIPチャンネルを作った話
がいよう
上記エントリが面白かったのでchatwork版を作りました。
やりたいこと
- 匿名チャンネルと、発言するbotアカウントを用意する。
- botアカウントでChatwork Webhookを使う。
- WebhookをAWS API Gatewayで受け取り、Lambdaを発火する。
- LambdaからChatwork APIを使いbotアカウントで匿名チャンネルへ発言する。
やっていきましょう
Chatworkをやる
匿名チャンネルと、発言するbotアカウントを作ります。
匿名チャンネルには一緒に遊びたいユーザーを全員追加しておきます。
botアカウントを作成したら、ChatWork画面右上のアカウント名 > API設定から
作成したbotアカウントでAPIが利用出来るよう設定しておきます。
※chatworkはAPIを利用する際管理者の許可が必要な場合があります。APIが使えるようになったらまずAPI Tokenを作成します。(後で使います)
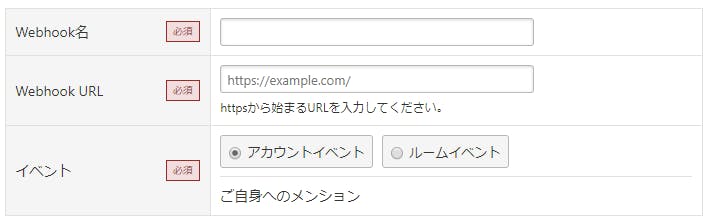
また、新規Webhookを作成しておきます。
URLは後から変えられるのでここでは適当で大丈夫です。
イベントがアカウントイベントになっていればOK。
名前は適当につけてください。AWSをやる
ChatWorkのWebhookから送信されるリクエストをLambdaで検証してみた
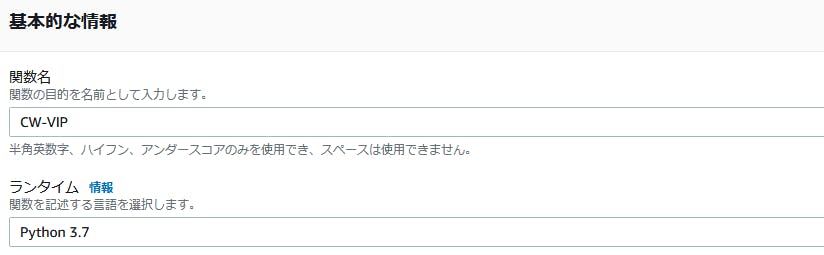
まずこれを読みます。読みました。雰囲気を掴むことができます。AWS Lambdaに新規関数を作成します。
今回はPythonを使いますので、ランタイムはPython3.7等にしておいてください。
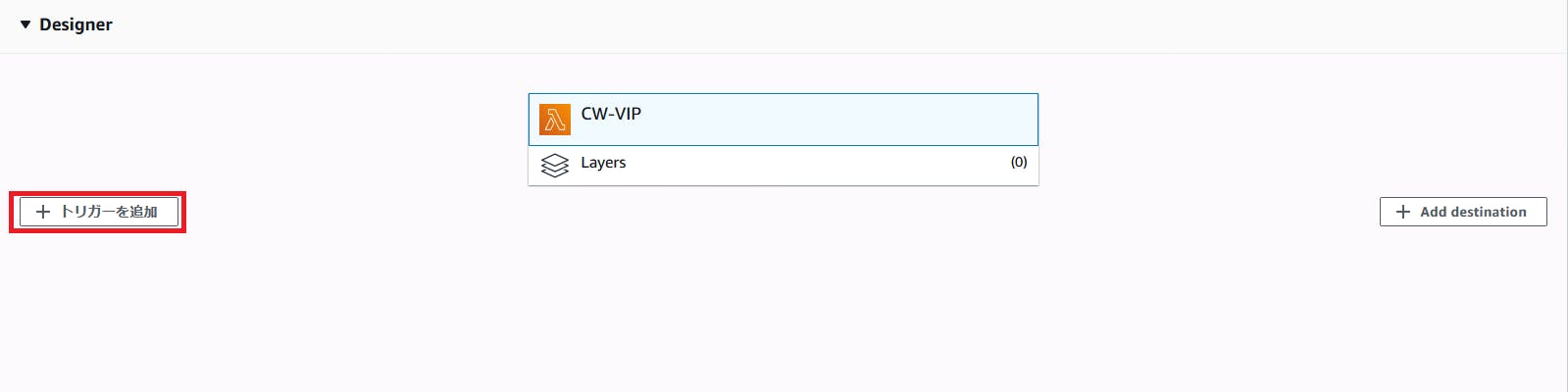
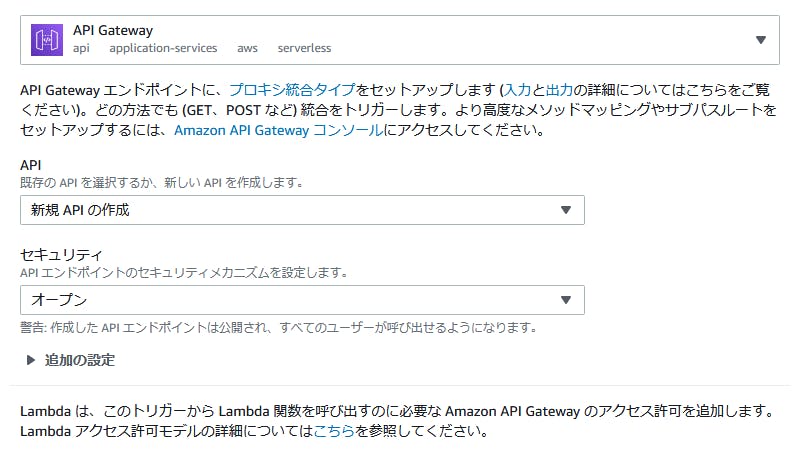
作成したら、トリガーの追加から
API Gatewayを登録します。
こんな感じに設定します。
手っ取り早く動かすためにセキュリティの設定を全て無視していますが、必要に応じて設定してください。ラムダの設定画面に戻ると
画像下部のように、少し下にAPIのエンドポイントが出てると思います。
これをchatworkのWebhook URLへ設定しておきましょう。ところで、脳がrequests以外からPOSTを送出したがらなかったため、ソースコード側の準備として
[検証]LambdaのLayer機能を早速試してみた #reinvent
上記エントリを参考にrequestsモジュールを持つLayerを追加します。
勿論、urllibの使い方を思い出す手段もあります。コストが安いと感じる方を選択してください。関数の作成
import json import os import requests def lambda_handler(event, context): url = f"https://api.chatwork.com/v2/rooms/{os.environ['ROOM_ID']}/messages" headers = {'X-ChatWorkToken': os.environ['CW_KEY']} content = json.loads(event['body']) # eventのbodyは文字列で来るようです content = content['webhook_event']['body'] # アカウントイベントにした場合、ここにメッセージ本文があります content = content.replace('[To:bot_account_id] botアカウント名さん\n', '') # Toで発言された時入ってくる文言を除去 params = {"body": f'{content}'} res = requests.post(url, data=params, headers=headers) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }最低限動作太郎です。これをLambdaのエディタ部分に書きます。
本当はWebhookに乗ってくるTOKENを使った認証を入れたり、処理の結果に応じてreturnする内容を変えたりした方がいいです。
これを書いた人はとにかく動かしたかったのでそういうのを端折りました。すみませんエディタ部分のすぐ下に環境変数の入力欄があると思いますので、匿名チャンネルのIDと匿名アカウントのAPI Tokenを設定してください。
チャンネルのIDは、ブラウザでそのチャンネルを開いた時URLに入っている数字を使っています。動かしてみる
動きます。良かったですね。
おわりに
残業の息抜きに作ったので、内容に自信がありません。
もしマサカリを投げたくなったらどんどん投げてください。
あとなんかダメなのあったら指摘して下さい。消しますので。ありがとうございました。

- 投稿日:2019-12-03T20:36:12+09:00
MySQLで大量のシンプルなクエリを高速化する
どんなに軽いクエリでも、たとえばWebサーバーとMySQLの間のRTTが5msあって20クエリを実行したらRTTだけで100msかかってしまいます。
たくさんのデータをinsertするときは bulk insert (VALUES の後に複数の行を書くクエリ) を使うテクニックは有名です。しかしこのテクニックは次のような場合に使えません。
- 複数のテーブルに1行ずつINSERTしたい
- 複数のUPDATEやSELECTをまとめたい
たとえば弊社のある案件で次のような場面がありました。
- 新規ユーザー作成時に大量のテーブルにINSERTしたい
- ログイン時に大量のテーブルにSELECTしたい
こういった場面を高速化するために multiple statements と multiple result sets を利用しました。
Multiple Statements
複数のクエリを ; で区切って一発(Pythonレベルで言えば1つの Cursor.execute() 呼び出し、プロトコルレベルで言えば1つのCOM_QUERYパケット)で送ることができます。複数のINSERT文を ; で繋ぐことで、大量のINSERT文やUPDATE文を高速化することができます。
RTTを削減できるだけでなくTCPのパケット数も削減できるので、MySQLサーバー側のクエリを受信する部分の負荷の削減も期待できます。
ただし、この ; を使ってクエリを連結する仕組みはSQLインジェクションでもよく悪用されています。そのため MySQL protocol ではハンドシェイク時に multiple statements を無効化できるようになっています。MySQLクライアントのライブラリによっては multiple statements を利用するためにオプションが必要かもしれません。
例えば Python の mysqlclient はデフォルトで multiple statements が利用できます。(fork元の昔からあるライブラリとの後方互換性のため...)
一方 Go の github.com/go-sql-driver/mysql はmultiStatements=trueを指定する必要があります。もう一つの注意点として、 MySQL の (PREPARE 文ではなくプロトコルレベルの) prepared statement を使う場合は、 placeholder を利用できません。自前でエスケープしてSQL文字列を組み立ててからクエリを投げるか、 prepared statement を使わないように設定する必要があります。
Multiple Result sets
複数のSELECT文をまとめたい場合は、複数のクエリを投げるだけでなくその結果を受け取る必要もあります。そのためには mutltiple result sets を使います。
複数の Result Set が返されたとき、Python では
Cursor.nextset()を使って次の Result Set を受け取ることができます。import MySQLdb con = MySQLdb.connect(host="127.0.0.1", port=3306, user="test", password="test") cur = con.cursor() q = """\ select 1; select 2; select 3; select 4; select 5; """ cur.execute(q) while True: print(cur.fetchall()) if not cur.nextset(): breakGo の場合は
database/sqlの Rows.NextResultSet() を使って同じように複数の Result Set を受け取ることができます。
- 投稿日:2019-12-03T20:29:31+09:00
[ゼロから作るDeep Learning]ハイパーパラメータの最適化について
はじめに
この記事はゼロから作るディープラーニング 7章学習に関するテクニックを自分なりに理解して分かりやすくアウトプットしたものです。
文系の自分でも理解することが出来たので、気持ちを楽にして読んでいただけたら幸いです。
また、本書を学習する際に参考にしていただけたらもっと嬉しいです。ハイパーパラメータとは
ハイパーパラメータとは、ニューラルネットワークの作成の時に必要となる人間の力で設定しないといけないパラメータのことを言います。例を出すと、層の数やニューロンの数などです。
このハイパーパラメータはニューラルネットワークの性能に大きく関わってきますので、ぜひ最適化したいですが、人間の力でとなるとすごく大変です。
そこで、これも機械に任せようということで、これからハイパーパラメータの最適値を自動で求める実装をしてみます。やることを簡単にいうと、ランダムな値をハイパーパラメータにして学習の結果をはかり、その結果から最適な値の範囲を絞っていきます。
# ハイパーパラメータチューニング from sklearn.model_selection import train_test_split def hayper_tyning(lr_m, lr_d, wd_m, wd_d, x_train, t_train, sanpule = 2): lr_list = [] wd_list = [] x_train = x_train[:500] t_train = t_train[:500]# 時間がものすごくかかるため (train_x, hayper_x, train_t, hayper_t) = train_test_split(x_train, t_train, test_size=0.2, random_state=0) for i in range(sanpule): train_acc_list = [] test_acc_list = [] lr = 10 ** np.random.uniform(lr_d, lr_m) weight_decay_lambda = 10 ** np.random.uniform(wd_d, wd_m) lr_list.append(lr) wd_list.append(weight_decay_lambda) network = MutiLayerNet(input_size = 784, hiden_size_list = [50], output_size = 10, weight_decay_lambda = weight_decay_lambda) for i in range(1, 101): grads = network.gradient(train_x, train_t) for p in ['W1','b1','W2','b2']: network.params[p] = network.params[p] - (lr * grads[p]) if i % 100 == 0: train_acc = network.accuracy(train_x, train_t) test_acc = network.accuracy(hayper_x, hayper_t) train_acc_list.append(train_acc) test_acc_list.append(test_acc) #後はグラフだったり絞り込んだりする
- 投稿日:2019-12-03T20:27:54+09:00
Tips: 3つの値の大小比較
ある2つの数字の間の数を取り出すには?
プログラムをやる人なら、大小比較を利用しない人はまずいない。
そのなかで、「値$c$が$a$と$b$の間にあるか?」を判定するのはよくやることだ。この、$a$と$b$の大小関係が不明なとき、上問題をどうやって解いているだろうか?
手法1
一番脳筋な方法は、まず$a$と$b$の大小関係を把握してから、$c$と比較するというやり方だ。
if a < b: a < c < b else: b < c < aうーん、あまり美しくない。こんなことに4行も使いたくないなぁ…。
手法2
上記を見ると、$b < c < a$か$a < c < b$どちらかが成り立てば$c$は$a$と$b$の間にあるということがわかる。
つまり、次のようにかけば一行に収まる。(a < c < b) or (b < c < a)良くなってきた。
ただ、これも$a,b,c$が一回ずつ出てきてるし、少し冗長に感じる。
pythonだとこんなにきれいに書けるが、C言語だと次のように書かないといけない。((a < c) && (c < b)) || ((b < c) && (c < a))やっぱり、美しくない……。
手法3
ということで、筆者は次のように書く方法を思いついた。
(a < c) ^ (b < c)
^はあまり使わないかもしれないが、排他的論理和である。
どっちもTrue、どっちもFalseのときにFalseになり、2つがTrueとFalseならTrueになる。ただし、これには欠点がある。
上式は以下と同義である。(a < c <= b) or (b < c <= a)これは、
<を>にしたり、<=にしたりしてもa < c < bのようにすることができない。ちなみに、
(a <= c) ^ (b <= c) (a > c) ^ (b > c)のふたつは
(a <= c < b) or (b <= c < a)と同義である
手法4
なんとかして、
a < c < bやa <= c <= bをできないかなぁって思い、考えてみたのだが、以下のやり方が一番エレガントかもしれない。(a - c) * (b - c) < 0 (a - c) * (b - c) <= 0一行目が
a < c < bであり、二行目がa <= c <= bである。
値が大きいなら符号関数をとっても良いかも(といっても、計算時間はかなり遅くなりそう)。計算時間
各手法の計算時間を計測してみた。
プログラムは以下のようなものを利用した。import time import numpy as np n = 100 number1 = np.random.rand(n) number2 = np.random.rand(n) t1 = time.time() for j in range(10000): for i in range(n): if number1[i] < number2[i]: x = number1[i] < 0.5 < number2[i] else: x = number1[i] < 0.5 < number2[i] t2 = time.time() t = t2-t1 print(t) t1 = time.time() for j in range(10000): for i in range(n): x = (number1[i] < 0.5 < number2[i]) or (number1[i] < 0.5 < number2[i]) t2 = time.time() t = t2-t1 print(t) t1 = time.time() for j in range(10000): for i in range(n): x = (number1[i] < 0.5) ^ (number2[i] < 0.5) t2 = time.time() t = t2-t1 print(t) t1 = time.time() for j in range(10000): for i in range(n): x = (number1[i] - 0.5) * (number2[i] - 0.5) < 0 t2 = time.time() t = t2-t1 print(t)計算結果
手法 計算時間 手法1 0.547s 手法2 0.458s 手法3 0.370s 手法4 0.786s ……。
(a - c) * (b - c) < 0が最も遅い結果となってしまった。
手法1よりも遅いとは…。美しいだけじゃだめなのか…。何度か試してみたが、順位は変わらなかった。
うーん、やっぱり掛け算が時間かかるみたいだ。また、andやorは途中でFalse, Trueが出た時点でそれ以降の演算を無視するという特性があるからというのもある。これだけだと悔しいので、numpyの配列全体での計算でも調べてみた。
import time import numpy as np n = 100 number1 = np.random.rand(n) number2 = np.random.rand(n) t1 = time.time() for j in range(10000): x = ((number1 < 0.5) & ( 0.5 < number2)) | ((number1 < 0.5) & (0.5 < number2)) t2 = time.time() t = t2-t1 print(t) t1 = time.time() for j in range(10000): x = (number1 < 0.5) ^ (number2 < 0.5) t2 = time.time() t = t2-t1 print(t) t1 = time.time() for j in range(10000): x = ((number1 - 0.5) * (number2 < 0.5) < 0) t2 = time.time() t = t2-t1 print(t)numpyでは
a < c < bのような書き方はできない。また、and, orもないため、論理演算&や|を利用する必要がある。
計算時間は次のようになる。
手法 計算時間 手法2 0.037s 手法3 0.017s 手法4 0.031s この場合は、掛け算のほうが早いという結果になった。
なんとか面目保たれた……。まとめ
cがaとbの間にあるかどうかの判定は次の式を使おう。
1つずつの比較の場合
## a < c < b or b < c < a の場合 a < c < b or b < c < a ## a ≦ c ≦ b or b ≦ c ≦ a の場合 a <= c <= b or b <= c <= a ## a < c ≦ b or b < c ≦ a の場合 (a < c) ^ (b < c) ## a ≦ c < b or b ≦ c < a の場合 (a > c) ^ (b > c)numpy配列の場合
## a < c < b or b < c < a の場合 (a - c) * (b - c) < 0 ## a ≦ c ≦ b or b ≦ c ≦ a の場合 (a - c) * (b - c) <= 0 ## a < c ≦ b or b < c ≦ a の場合 (a < c) ^ (b < c) ## a ≦ c < b or b ≦ c < a の場合 (a > c) ^ (b > c)
- 投稿日:2019-12-03T20:20:04+09:00
[ゼロから作るDeep Learning]Dropoutについて解説してみた
はじめに
この記事はゼロから作るディープラーニング 7章学習に関するテクニックを自分なりに理解して分かりやすくアウトプットしたものです。
文系の自分でも理解することが出来たので、気持ちを楽にして読んでいただけたら幸いです。
また、本書を学習する際に参考にしていただけたらもっと嬉しいです。Dropoutとは
皆さんはアンサンブル学習というものを知っているでしょうか。
アンサンブル学習とは、複数のモデルを使って学習を行うことで、良い学習結果を生み出すことができるものです。
Dropoutでは、そのアンサンブル学習を擬似的に再現することで、学習の結果を向上させています。具体的にDropoutでは内を行なっているのでしょうか。それは、学習の際にランダムにニューロンを消去するです。
Dropoutでは、ニューロンをランダムで消去することにより、違うモデルを複数作りだしてアンサンブル学習を作り上げています。下では簡単な実装例を紹介します。
class Dropout:#活性化関数レイヤの後に生成させて、学習が行われるたびに発動させる。predictでは発動させない def __init__(self,dropout_ratio=0.5): self.dropout_ratio = dropout_ratio self.mask = None #消去されるニューロンが記された配列が入る def forward(self,x,train_flg=True): if train_flg: self.mask = np.random.rand(*x.shape) > self.dropout_ratio#ランダムで消去するニューロンを決定する return x * self.mask else: return x * (1 - self.dropout_ratio) def backward(self,dout): return dout * self.mask#Reluと同じ
- 投稿日:2019-12-03T19:39:52+09:00
Hyperoptを使って関数最適化をしてみる
はじめに
Hyperoptはハイパーパラメータの自動最適化フレームワークです。主に機械学習のハイパーパラメータチューニングのために使用されるようです。
準備
まずはライブラリをインストールしましょう。
pip install hyperoptでインストールできます。実験
今回は
x^2+y^2+z^2の最小化問題を最適化していきましょう。
目的関数の定義
はじめに目的関数を定義しましょう。
# 目的関数を設定 def objective_hyperopt(args): x, y, z = args return x ** 2 + y ** 2 + z ** 2最適化実行
最初に最適化するパラメータの探索空間を設定しましょう。
そして、fmin()を使って探索を開始します。引数のmax_evalsで探索回数を設定しましょう。# hyperoptで最適化実行 def hyperopt_exe(): space = [ hp.uniform('x', -100, 100), hp.uniform('y', -100, 100), hp.uniform('z', -100, 100) ] # 探索の様子を記録するためのオブジェクト trials = Trials() # 探索開始 best = fmin(objective_hyperopt, space, algo=tpe.suggest, max_evals=500, trials=trials)最終的に結果を知りたい場合は以下を追加しましょう。
# 結果を出力する print(best)探索中の情報はtrialsオブジェクトから取り出しましょう。以下を追加することで各試行でのパラメータや目的関数値を表示できます。
# 探索過程を調べる for i, n in zip(trials.trials, range(500)): vals = i['misc']['vals'] result = i['result']['loss'] print('vals:', vals, 'result:', result)コード
今回したコードは以下のようになります。
# -*- coding: utf-8 -*- import hyperopt from hyperopt import hp from hyperopt import fmin from hyperopt import tpe from hyperopt import Trials import matplotlib.pyplot as plt # hyperopt用の目的関数を設定 def objective_hyperopt(args): x, y, z = args return x ** 2 + y ** 2 + z ** 2 # hyperoptで最適化実行 def hyperopt_exe(): # 探索空間の設定 space = [ hp.uniform('x', -100, 100), hp.uniform('y', -100, 100), hp.uniform('z', -100, 100) ] # 探索の様子を記録するためのオブジェクト trials = Trials() # 探索開始 best = fmin(objective_hyperopt, space, algo=tpe.suggest, max_evals=500, trials=trials) # 結果を出力する print(best) epoches = [] values = [] best = 100000 # 探索過程を調べる for i, n in zip(trials.trials, range(500)): if best > i['result']['loss']: best = i['result']['loss'] epoches.append(n+1) values.append(best) vals = i['misc']['vals'] result = i['result']['loss'] print('vals:', vals, 'result:', result) # グラフを描画 plt.plot(epoches, values, color="red") plt.title("hyperopt") plt.xlabel("trial") plt.ylabel("value") plt.show() if __name__ == '__main__': hyperopt_exe()結果
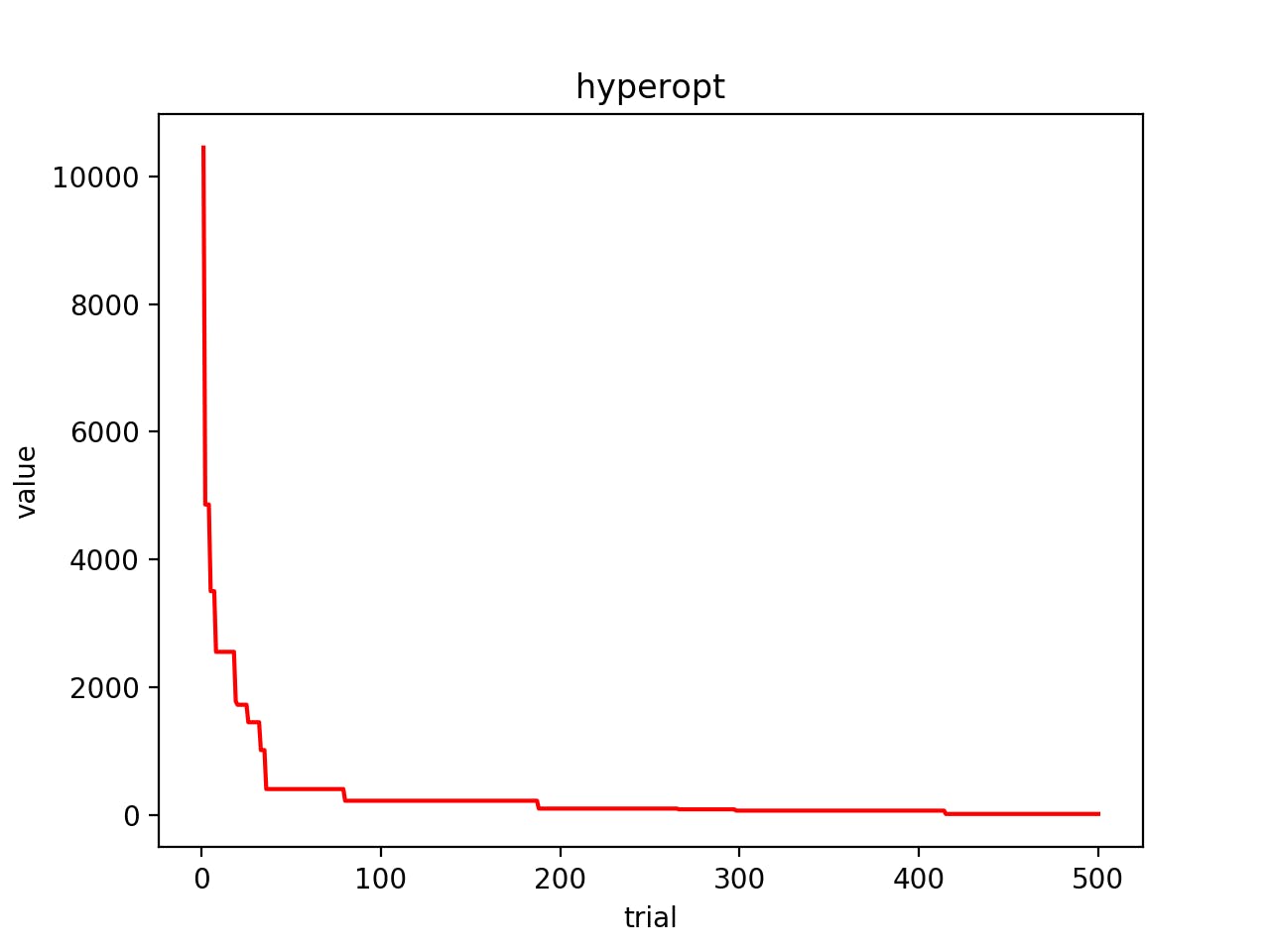
今回の実験結果の図は以下のようになりました.
早い段階で収束してきていますね。
参考サイト
- 投稿日:2019-12-03T19:27:28+09:00
pythonとdlibでお手軽に顔のランドマークを検出してみた
はじめに
私が学生の頃は顔のランドマーク検出の研究をひーひー言いながらやっていました。
今ではそれが信じられないくらい簡単になって驚きました。なので実際にやってみたいと思います。
とりあえず実装したいんじゃ、という人は「お手軽に顔のランドマーク検出をやってみた」から読んでください。顔のランドマーク検出方法について
顔のランドマーク検出の方法は主に以下の3つに分かれるようです。
各々の詳細は参考リンクに載せた論文をご参照ください。(1)Ensemble of regression treesを用いた手法
回帰ツリー分析を用いてリアルタイムで高精度なランドマーク検出を実現しています。
dlib、OpenCV(FacemarkKazemi)共に実装されています。
ただし学習モデルがデフォルトで用意されているのはdlibだけです。(2)Active appearance modelを用いた手法
物体の形状と外観から学習された統計モデルに基づき物体検出を行います。
顔に限らず高度な物体追跡として長く使われている手法です。
(学生時代に私が研究していたのもこのAAMです)
OpenCV(FacemarkAAM)に実装されていますが、学習モデルは自作する必要があります。
しかし学習モデル生成用のツールや、誰かの作った学習モデルは探せば見つかるので、敷居は低いと思います。(3)Local Binary Featuresを用いた手法
回帰学習により非常に高速なランドマーク検出が可能です。
「Ensemble of regression trees」と類似した手法のようですが細かい違いが分かりません。
OpenCV(FacemarkLBF)に実装されており、学習モデルも用意されています。お手軽に顔のランドマーク検出をやってみた
今回はpythonでお手軽に実装したいので、dlibで「(1)Ensemble of regression treesを用いた手法」を使います。
事前準備
pythonモジュールの入手
モジュールとして顔のランドマーク検出のためdlibとimutils、画像関連のためにOpenCVを追加します。
注意点としてdlibを追加するためにはAnaconda環境のpythonである必要があります。pythonモジュールのインストールpip install dlib pip install imutils pip install opencv pip install libopencv pip install py-opencv学習済みモデルの入手
学習済みモデルはdlibの公式サイトの以下から入手できます。
- dlib ~Index of /files~
http://dlib.net/files/
→「shape_predictor_68_face_landmarks.dat.bz2 」を選択余談ですが上記の学習済みモデルは以下のサイトのデータを元に生成されています。
- i・bug ~Facial point annotations~
https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/顔画像の入手
顔画像は以下から「Girl.bmp」を入手し使わさせていただきました。
- 神奈川工科大学 情報学部 情報工学科 ~標準画像/サンプルデータ~
http://www.ess.ic.kanagawa-it.ac.jp/app_images_j.html画像処理の定番の「Lenna」じゃないの? と思う方もいるかもしれません。
しかし「Lenna」は振り向き顔のせいか、思ったよりよい結果が得られなかったので外しています。
気になる方は試してください。静止画における顔のランドマーク検出
静止画から顔のランドマーク検出を実施するサンプルです。
学習済みモデル(shape_predictor_68_face_landmarks.dat)と顔画像(Girl.bmp)は面倒なので同じ階層に置いています。face_landmark_sample.py# coding:utf-8 import dlib from imutils import face_utils import cv2 # -------------------------------- # 1.顔ランドマーク検出の前準備 # -------------------------------- # 顔検出ツールの呼び出し face_detector = dlib.get_frontal_face_detector() # 顔のランドマーク検出ツールの呼び出し predictor_path = 'shape_predictor_68_face_landmarks.dat' face_predictor = dlib.shape_predictor(predictor_path) # 検出対象の画像の呼び込み img = cv2.imread('Girl.bmp') # 処理高速化のためグレースケール化(任意) img_gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # -------------------------------- # 2.顔のランドマーク検出 # -------------------------------- # 顔検出 # ※2番めの引数はupsampleの回数。基本的に1回で十分。 faces = face_detector(img_gry, 1) # 検出した全顔に対して処理 for face in faces: # 顔のランドマーク検出 landmark = face_predictor(img_gry, face) # 処理高速化のためランドマーク群をNumPy配列に変換(必須) landmark = face_utils.shape_to_np(landmark) # ランドマーク描画 for (i, (x, y)) in enumerate(landmark): cv2.circle(img, (x, y), 1, (255, 0, 0), -1) # -------------------------------- # 3.結果表示 # -------------------------------- cv2.imshow('sample', img) cv2.waitKey(0) cv2.destroyAllWindows()結果は次の通りです。
上図の通りキレイに顔のランドマークが検出されています。
ではランドマーク検出までに各コードで何をしているか解説します。顔のランドマークの番号
顔のランドマーク検出をしたあとは、当然色々な処理をしたいと思います。
その時に気になるのが、各ランドマークをどのように呼び出せばよいかです。顔のランドマークは上述したサイトのデータから学習されています。
そのためランドマークの番号も、学習元のサイトに記載されている番号通りになっています。
ランドマークの番号:https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/
上図を見れば分かる通り、番号は1~68まで割り振られています。
ただし実際に参照するときは、配列は0番から始まるため、0~67となり番号がひとつずれます。分かりにくいので図とコードを交え実際に、一部を切り取って見ます。
face_landmark_sample2.py# coding:utf-8 import dlib from imutils import face_utils import cv2 # -------------------------------- # 1.顔ランドマーク検出の前準備 # -------------------------------- # 顔検出ツールの呼び出し face_detector = dlib.get_frontal_face_detector() # 顔のランドマーク検出ツールの呼び出し predictor_path = 'shape_predictor_68_face_landmarks.dat' face_predictor = dlib.shape_predictor(predictor_path) # 検出対象の画像の呼び込み img = cv2.imread('Girl.bmp') # 処理高速化のためグレースケール化(任意) img_gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # -------------------------------- # 2.顔のランドマーク検出 # -------------------------------- # 顔検出 # ※2番めの引数はupsampleの回数 faces = face_detector(img_gry, 1) # 検出した全顔に対して処理 for face in faces: # 顔のランドマーク検出 landmark = face_predictor(img_gry, face) # 処理高速化のためランドマーク群をNumPy配列に変換(必須) landmark = face_utils.shape_to_np(landmark) # -------------------------------- # 3.ランドマークから画像を切り取り # -------------------------------- # 番号1のランドマークのX座標取得 landmark_n1_x = landmark[0][0] # 番号17のランドマークのX座標取得 landmark_n17_x = landmark[16][0] # 番号9のランドマークのY座標取得 landmark_n9_y = landmark[8][1] # 番号28のランドマークのY座標取得 landmark_n28_y = landmark[27][1] # 画像の切り出し img2 = img[landmark_n28_y:landmark_n9_y, landmark_n1_x:landmark_n17_x] # 結果表示 cv2.imshow('sample', img2) cv2.waitKey(0) cv2.destroyAllWindows()結果は次の通りです。
このようになる理由は以下の通りです。
ランドマークは1番からスタートしますが、それを格納する配列は0番からスタートします。
そのためこのようなズレが生じます。リアルタイムでの顔のランドマーク検出
おまけにカメラ画像から顔のランドマーク検出をするサンプルを載せます。
ネット上に顔を晒す勇気がないため実行結果はなしです。face_landmark_sample.py# coding:utf-8 import dlib from imutils import face_utils import cv2 # -------------------------------- # 1.顔ランドマーク検出の前準備 # -------------------------------- # 顔ランドマーク検出ツールの呼び出し face_detector = dlib.get_frontal_face_detector() predictor_path = 'shape_predictor_68_face_landmarks.dat' face_predictor = dlib.shape_predictor(predictor_path) # -------------------------------- # 2.画像から顔のランドマーク検出する関数 # -------------------------------- def face_landmark_find(img): # 顔検出 img_gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_detector(img_gry, 1) # 検出した全顔に対して処理 for face in faces: # 顔のランドマーク検出 landmark = face_predictor(img_gry, face) # 処理高速化のためランドマーク群をNumPy配列に変換(必須) landmark = face_utils.shape_to_np(landmark) # ランドマーク描画 for (x, y) in landmark: cv2.circle(img, (x, y), 1, (0, 0, 255), -1) return img # -------------------------------- # 3.カメラ画像の取得 # -------------------------------- # カメラの指定(適切な引数を渡す) cap = cv2.VideoCapture(0) # カメラ画像の表示 ('q'入力で終了) while(True): ret, img = cap.read() # 顔のランドマーク検出(2.の関数呼び出し) img = face_landmark_find(img) # 結果の表示 cv2.imshow('img', img) # 'q'が入力されるまでループ if cv2.waitKey(1) & 0xFF == ord('q'): break # 後処理 cap.release() cv2.destroyAllWindows()参考リンク
顔のランドマーク検出の論文関連
Facemark : Facial Landmark Detection using OpenCV
https://www.learnopencv.com/facemark-facial-landmark-detection-using-opencv/
各顔のランドマーク検出のアルゴリズムがどの論文から実装されているか解説されています。
またC++によるFacemakerLBFを用いた顔のランドマーク検出のサンプルも載っています。One Millisecond Face Alignment with an Ensemble of Regression Trees
http://www.csc.kth.se/~vahidk/face_ert.html
V.KazemiさんとJ. Sullivanさんによって発表された論文です。
今回使用したdlibに実装されている顔のランドマーク検出のアルゴリズムは本論文に基づいています。Optimization problems for fast AAM fitting in-the-wild
https://ibug.doc.ic.ac.uk/media/uploads/documents/tzimiro_pantic_iccv2013.pdf
G. TzimiropoulosさんとM. Panticさんによって発表された論文です。
OpenCVのFacemakerAAMは本論文に基づき実装されています。One Millisecond Face Alignment with an Ensemble of Regression Trees
http://www.csc.kth.se/~vahidk/face_ert.html
S. Renによって発表された論文です。
OpenCVのFacemakerLBFは本論文に基づき実装されています。コーディング関連
dlib C++ Library ~Face Landmark Detection~
http://dlib.net/face_landmark_detection.py.html
dlib公式サイトに紹介されている、pythonによる顔のランドマーク検出のサンプルです。顔のランドマークを検出 Python + OpenCV + dlib を使う
https://tech-blog.s-yoshiki.com/2018/10/702/
Python + OpenCV + dlibによる顔のランドマーク検出のソースコードが日本語で案内されています。
コーディングの際に参考にさせていただきました。PyImageSearch
Facial landmarks with dlib, OpenCV, and Python
https://www.pyimagesearch.com/2017/04/03/facial-landmarks-dlib-opencv-python/
(Faster) Facial landmark detector with dlib
https://www.pyimagesearch.com/2018/04/02/faster-facial-landmark-detector-with-dlib/
Python + OpenCV + dlibによる顔のランドマーク検出のソースコードが英語で案内されています。
詳しく解説されているため、各処理の理解に繋がり、大変参考になりました。




- 投稿日:2019-12-03T19:09:49+09:00
FlaskでSlack認証を完了するまでの流れ(Python)
FlaskでSlack認証を実装してみました。大体は、公式のドキュメントを見れば通るのですが、認証すると同時にユーザー情報も取得したいみたいな時にやや戸惑った部分もあるので、備忘録も兼ねて残しておきます。
前提
Slackアプリの登録については前回詳しく流れを書いています。
https://qiita.com/svfreerider/items/0e1fe74c70e2047f0ce9ほとんどは下記の公式ドキュメントのコードのまんまです。
https://slack.dev/python-slackclient/auth.htmlソースコード
auth.pyimport functools import pdb import slack from flask import ( Blueprint, flash, g, redirect, render_template, request, session, url_for ) from app.db import ( search_user, register_user, search_team, register_team, search_team_user, register_team_user ) bp = Blueprint('auth', __name__, url_prefix='/auth') client_id = 'XXXXXXXXXXXXXXX' client_secret = 'XXXXXXXXXXXXXXX' oauth_scope = 'channels:read,chat:write:bot,users:read,users:read.email'認証機能を実装していく
auth.pyを用意します。Slackアプリを登録した際に取得したclient_idとclient_secretを定義します。また、これに加えてscopeを定義します。scopeは、今回のアプリを作るにおいてユーザーに求める権限の範囲を指定します。アプリ側でも設定しておく必要があります。また、申請する際には「なぜ、このscopeが必要か」の理由を書かなければなりません。自分の場合は、ボットを作ってそこから通知を送るので、チャンネルを指定する
channels:readと、chat:write:botを加えました。それから、あとでユーザーの個人情報と、メールアドレスも欲しいので、users:readとusers:read.emailも入れておきました。auth.py@bp.route('/redirect', methods=['GET']) def authorize(): authorize_url = f"https://slack.com/oauth/authorize?scope={ oauth_scope }&client_id={ client_id }" return redirect(authorize_url)こうしておくと、
/auth/redirectへ移動することでSlackの認証画面へリダイレクトされます。auth.py@bp.route('/callback', methods=["GET", "POST"]) def callback(): auth_code = request.args['code'] client = slack.WebClient(token="") oauth_info = client.oauth_access( client_id=client_id, client_secret=client_secret, code=auth_code )
callbackした後に、URLの先についているcodeを使ってユーザーの情報を取得します。ユーザーの取得はoauth_accessで行なっています。ですが、この時はまだユーザーの名前や、メールアドレスの情報は取れていません。今度は取得した
oauth_tokenを使ってユーザーの詳細情報を別で呼んでいきます。auth.pyaccess_token = oauth_info['access_token'] client = slack.WebClient(token=access_token) user_id = oauth_info['user_id'] response = client.users_info(user=user_id)
users_infoでユーザーのメールアドレスや、名前だけでなくアイコン画像やタイムゾーンなど欲しい情報は全部取ってくることができます。これはFlaskに限らず、Pythonであればそのまま流用できるかと思います。ちょうど2週間前にFlaskを入れてみたのですが、Railsを長年やってきた身としては、全然文献が見当たらないなというのが感想です。
これから、機械学習+Flaskでアプリを作るケースは確実に増えていくと思うので、随時共有していくようにします。
- 投稿日:2019-12-03T19:09:24+09:00
Python lambda,map,listの1行のコードを解読
背景
python初心者です。
yolov3のコードを勉強しているとき、 lambda,map,listが1行で表記されていたので、頭が痛くなった。
簡単に自分のメモとしても残しておきたく、記載します。lambda,map,listの1行のコード
keras-yolov3のyolo.pyにおける85行辺りのコードである。
1_yolo_code_around_85.pyself.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))困難にしている要素とそれのザックリ解説
・(*x):可変長引数
・lambda:無名関数
・map:組み込み関数
・list:リスト化hsv_to_rgbではhsvに対応する引数が3つ必要である。
そのため以下のようにも変更できる。2_yolo_code_around_85.pyself.colors = list(map(lambda x: colorsys.hsv_to_rgb(x[0],x[1],x[2]), hsv_tuples))リストxを上記のようにするとイメージがしやすいです。
lambdaによってリストxを用いた関数を定義し、
hsv_tuplesの値を関数に代入します。
mapにより、全要素に同じ処理を行い、
リスト化する。
- 投稿日:2019-12-03T19:03:04+09:00
自分の出したプルリクがScipyに取り入れられた話
何をやった?
scipy.optimize.minimizeには、とても微妙な仕様? バグ? がありました。
バグに近いと思ったのですが、直すと既に使ってる人が困りそうな内容だったので、Issueを立てて「もし修正するならプルリク出すけどどう?」って聞いてみました。
プルリク出して、ということだったので、出しました。
つい最近、ようやくマージされました。
scipy.optimize.minimizeとは?何か関数を与えたら、パラメータをいい感じに最適化し、関数が返す値を最小化してくれます。
例えば、$z = 2x^2 + (3y - 2)^2 + xy$という式があったとしましょう。
$z$を最も小さくする$x, y$はなんですか? というのを解いてくれます。
パッと見て分かるのは$x = 0, y = 2/3$のときゼロになるなー、それより小さいのはなるのかなー、程度でしょう。def f(x, y): return 2 * x**2 + (3*y - 2)**2 + x*y print(scipy.optimize.minimize(f, [0., 0.]))と、関数と適当な初期値(
[0., 0.])を与えるといい感じの値を求めてくれます。
array([-0.16901447, 0.67605677])のとき、 -0.05633802816721355になるらしいです。何が問題だったのか
scipy.optimize.minimizeには、最小化のためのアルゴリズムは複数用意されていて、method="..."の引数を与えることで選ぶことができます。
ところで、引数がひとつだけのとき、かつ、"Powell"法を使ったときだけ、少しだけ嫌なことが起こります。import numpy as np import scipy.optimize def fun(x): return x*x res = scipy.optimize.minimize(fun, [0.1], method="Nelder-Mead") print("Nelder-Mead:") print("Optimized:", res.x, "Shape:", res.x.shape) res = scipy.optimize.minimize(fun, [0.1], method="COBYLA") print("COBYLA:") print("Optimized:", res.x, "Shape:", res.x.shape) res = scipy.optimize.minimize(fun, [0.1], method="Powell") print("Powell:") print("Optimized:", res.x, "Shape:", res.x.shape)Nelder-Mead: Optimized: [1.94289029e-16] Shape: (1,) COBYLA: Optimized: [0.00010234] Shape: (1,) Powell: Optimized: 4.163336342344337e-17 Shape: ()お分かりいただけただろうか。
返り値のshapeが違うのである。実はこれ以外にも、ヤコビアンを指定しなければいけないもの、ヘシアンを指定しなければいけないものなども含め、全14種類試したんですが、"Powell"法だけが、このようになっていました。
まぁ、バグっちゃバグなんですが。歴史あるプロジェクトです。今更直すべきかどうか、というのは判断に迷うところかもしれません。
既に、Powellはこうだと信じて使っている人に、影響出ちゃうかもしれないですし。
けど、まぁ、せっかくなので聞いてみることにしました。やったこと時系列
(2019年1月)
ということで、とりあえずフォークして、自分のリポジトリで直してみました。直せると分かったのでIssueを立てて、直したリンクも貼って「もしこれでよければPR出す」と言ってみました。
https://github.com/scipy/scipy/issues/9715(2019年8月)
そしたら「バグだから修正した方がいいが、互換性の問題から、修正を入れる関数を変えてほしい」とのことだったので、そのようにしてPRを出しました。
https://github.com/scipy/scipy/pull/10640(2019年9月)
変更内容はいいけど、付け加えたテストがやや冗長だから直してくれ、とコメントもらったので直して、などとして、
しばらく返事がないまま放置されていました。(2019年12月)
masterにマージされました。約1年かかったことになります。開発者も忙しいのと、内容が大したことないので優先度が低かったのもあると思います。
学び・感想
- Scipyにあった形式でIssueを立てたり、コミットメッセージを書いたり、PRを出したりする必要があったので「そもそもどういう風にすることになっているんだ」を調べたり、その形式に合わせたりするのが結構しんどかったです
- 普段からちゃんとコミットメッセージ書いてないのが祟ったのかもしれません
- 時間はかかりましたが、開発者たちもちゃんと対応してくれて優しかったです
- 小さなことであっても、scipyという私もみんなも利用している有名ライブラリの改善に貢献できたので、やってよかったです
- 怖がらずに、ベストを尽くして人に聞く姿勢が大切だなぁ、と改めて思いました
オープンソースは、ただ無料で使えるだけでなく、こういうチャンスにも溢れています。
すごくつまらないことでも「あれ?」と思ったら貢献チャンスかもしれません。
今後も、できそうなことがあればオープンソースに貢献したいです。
- 投稿日:2019-12-03T18:53:18+09:00
機械学習/分類モデルの性能評価を行ってみる
1.はじめに
今回は、機械学習に使われる分類モデルの性能評価を、コードを作りながら行ってみます。
2.データセット
使用するデータセットは、sklearnに付属している乳ガンのデータです。
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_breast_cancer from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.neural_network import MLPClassifier from sklearn.pipeline import Pipeline from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.metrics import accuracy_score # ----------- データセット準備 -------------- dataset = load_breast_cancer() X = pd.DataFrame(dataset.data, columns=dataset.feature_names) y = pd.Series(dataset.target, name='y') X_train,X_test,y_train,y_test=train_test_split(X, y, test_size=0.3, random_state=1) print('X_train.shape = ', X_train.shape) print('X_test.shape = ', X_test.shape) print(y_test.value_counts())
データセットを学習データ:テストデータ=7:3で分割します。テストデータは 171個、特徴量は30項目で、171個のデータの内 1:正常者が108個 、0:ガン患者が63個、です。3.分類モデル
今回使用する分類モデルは8つです。後で、使い易い様に、パイプラインの形でまとめます。ハイパーパラメータはデフォルトです。
# ---------- パイプラインの設定 ---------- pipelines = { '1.KNN': Pipeline([('scl',StandardScaler()), ('est',KNeighborsClassifier())]), '2.Logistic': Pipeline([('scl',StandardScaler()), ('est',LogisticRegression(solver='lbfgs', random_state=1))]), # solver '3.SVM': Pipeline([('scl',StandardScaler()), ('est',SVC(C=1.0, kernel='linear', class_weight='balanced', random_state=1, probability=True))]), '4.K-SVM': Pipeline([('scl',StandardScaler()), ('est',SVC(C=1.0, kernel='rbf', class_weight='balanced', random_state=1, probability=True))]), '5.Tree': Pipeline([('scl',StandardScaler()), ('est',DecisionTreeClassifier(random_state=1))]), '6.Random': Pipeline([('scl',StandardScaler()), ('est',RandomForestClassifier(random_state=1, n_estimators=100))]), ### '7.GBoost': Pipeline([('scl',StandardScaler()), ('est',GradientBoostingClassifier(random_state=1))]), '8.MLP': Pipeline([('scl',StandardScaler()), ('est',MLPClassifier(hidden_layer_sizes=(3,3), max_iter=1000, random_state=1))])1.KNN
分類したいデータに最も近いk個のサンプルを、学習データの中から見つけ出し、k個のサンプル多数決でデータを分類する、k近傍法(k-nearest neighbor)です。2.Logistic
特徴ベクトルと重みベクトルの内積結果を確率に変換し分類する、ロジスティック回帰(Logistic Regression)です。3.SVM
マージンの最大化を目的として分類する、サポートベクトルマシン(Support Vector Machine)です。4.K-SVM
射影関数を使って学習データをより高い次元の特徴空間に変換しSVMで分類する、カーネル・サポートベクトルマシン (kernel Support Vector Machine)です。5.Tree
決定木(Decision Tree)による分類モデルです。6.Random
ランダムに選んだ特徴量から複数の決定木を作成し、全ての決定木の予測を平均して出力するランダムフォレスト(Random Forest)です。7.GBoost
既存のツリー群が説明しきれない情報(残差)を後続するツリーが説明しようとする形で、予測精度を高める、勾配ブースティング(Gradinet Boosting)です。8.MLP
順伝播型ニューラルネットワークの一種である、多層パーセプトロンです。4.accuracy(精度)
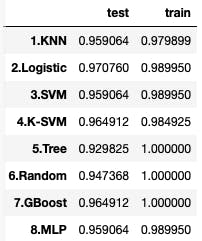
# -------- accuracy --------- scores = {} for pipe_name, pipeline in pipelines.items(): pipeline.fit(X_train, y_train) scores[(pipe_name,'train')] = accuracy_score(y_train, pipeline.predict(X_train)) scores[(pipe_name,'test')] = accuracy_score(y_test, pipeline.predict(X_test)) print(pd.Series(scores).unstack())
学習データとテストデータの精度(Accuracy)です。汎化性能を示す、テストデータの精度をみると、2.Logistic が 0.970760 と一番優れていることが分かります。5.Confusion Matrix(混同行列)
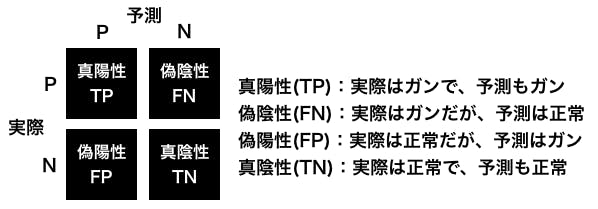
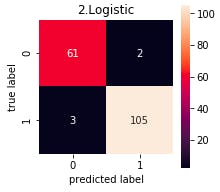
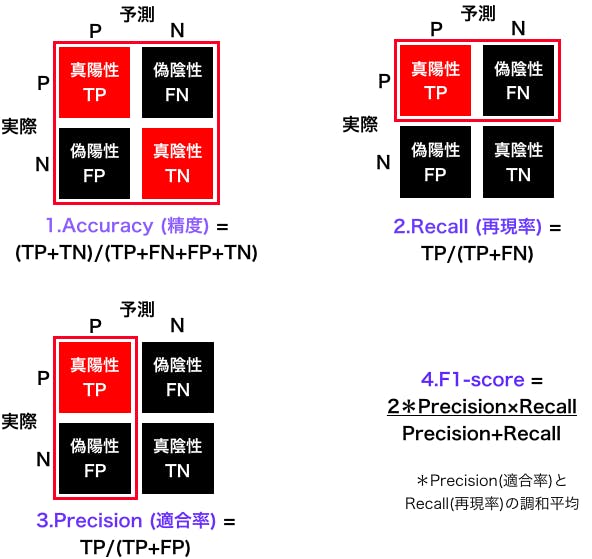
分類結果を、真陽性(true positive)、偽陰性(false negative)、偽陽性(false positive)、真陰性(true negative)の4つに分け、正方行列にしたものを、混同行列(Confusion Matrix)といいます。
下記は、ガン検診の予測結果を Confusion Matrix で表した例です。
精度は、(TP+TN)/(TP+FN+FP+TN)で表されるわけですが、ガン検診の場合、FPが増えることにはある程度目をつぶり、FNをどれだけ下げられるかも重要な視点です。# ---------- Confusion Matrix --------- from sklearn.metrics import confusion_matrix import seaborn as sns for pipe_name, pipeline in pipelines.items(): cmx_data = confusion_matrix(y_test, pipeline.predict(X_test)) df_cmx = pd.DataFrame(cmx_data) plt.figure(figsize = (3,3)) sns.heatmap(df_cmx, fmt='d', annot=True, square=True) plt.title(pipe_name) plt.xlabel('predicted label') plt.ylabel('true label') plt.show()
コードの出力は8つですが、代表として、2.Lostic の Confusion Matrix をみると、ガン患者63人の内2人は間違えて正常に分類することが分かります。6.accuracy, recall, precision, f1-score
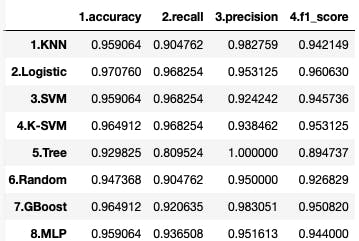
Confusion Matrix から下記の4つの指標が得られます。
4つの指標を表示するコードです。今回のデータセットは、0がガン患者、1を正常者なので、recall, precision, f1-score の引数に pos_label=0 を加えています。# ------- accuracy, precision, recall, f1_score for test_data------ from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score scores = {} for pipe_name, pipeline in pipelines.items(): scores[(pipe_name,'1.accuracy')] = accuracy_score(y_test, pipeline.predict(X_test)) scores[(pipe_name,'2.recall')] = recall_score(y_test, pipeline.predict(X_test), pos_label=0) scores[(pipe_name,'3.precision')] = precision_score(y_test, pipeline.predict(X_test), pos_label=0) scores[(pipe_name,'4.f1_score')] = f1_score(y_test, pipeline.predict(X_test), pos_label=0) print(pd.Series(scores).unstack())
この比較で言えば、まずなんと言ってもガン患者を正常者として間違えることが少ない(recallが高い)2〜4が候補で、その中で正常者をガン患者と間違えることも少ない(precisionが高い)、2.Logistic が最も良いと思われます。
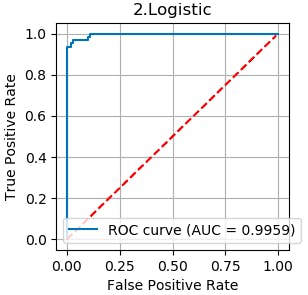
7.ROC曲線、AUC
最初に、ROC曲線とAUCについて、具体的な例を上げて説明します。
# -------- ROC曲線, AUC ----------- for pipe_name, pipeline in pipelines.items(): fpr, tpr, thresholds = metrics.roc_curve(y_test, pipeline.predict_proba(X_test)[:, 0], pos_label=0) # 0:ガン患者の分類 auc = metrics.auc(fpr, tpr) plt.figure(figsize=(3, 3), dpi=100) plt.plot(fpr, tpr, label='ROC curve (AUC = %.4f)'%auc) x = np.arange(0, 1, 0.01) plt.plot(x, x, c = 'red', linestyle = '--') plt.legend() plt.title(pipe_name) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) plt.show()
コードの出力は8つですが、代表として、2.Lostic の ROC曲線とAUC をみるとかなり理想の分類精度に近いことが分かります。


- 投稿日:2019-12-03T18:50:37+09:00
seleniumを利用するときに便利な補助ツール【selenium katalon recorder】でテスト作成
【selenium katalon recorder】でseleniumによるテストコードを自動で生成する
selenium katalon recorderを利用し、Seleniumでテストコードを作成するまでの解説
selenium katalon recorderとは
selenium katalon recorderとは
Selenium IDEと呼ばれるものの一種
Selenium IDEはブラウザの拡張機能として提供されているキャプチャ&リプレイツール
ブラウザでの操作を記録(キャプチャ)して同じ操作を再生(リプレイ)する機能を持っています。selenium katalon recorderはGoogleChromeのプラグインとして提供されておりインストールと実行が用意
だったため補助ツールとして利用クロームプラグインダウンロード先
https://chrome.google.com/webstore/detail/katalon-recorder-selenium/ljdobmomdgdljniojadhoplhkpialdid
アカウントを作れと言われるが作らなくていい
selenium katalon recorder使い方の説明
- 「Record」ボタンを押す
- https://www.google.co.jp/を開く
- 何でもいいので検索する。今回は「hogehoge」とした
- 一旦ここで「Stop」ボタンを押してシナリオを終了する
これで、ブラウザの操作内容が記録される。
コード化するためにExport
python2 webdriver +unittest
pythonのバージョンや実行環境は各自でなんとかする。
これでもうテストコードの雛形ができる。すごい
seleniumを実行するためのブラウザとパスの設定
Chromeを動かすためのドライバをインストール
クロームバージョン
https://chromedriver.chromium.org/downloads
↑ここから利用しているChromeと同じバージョンを指定使用しているブラウザのバージョンに合わせないとエラーになるよ
https://teratail.com/questions/117444パスを通す
Chromeを操作 driver = webdriver.Chrome(executable_path="D:\webDriver\chromedriver") Firefoxを操作 driver = webdriver.Firefox(executable_path="D:\webDriver\geckodriver")詳しいパスなどの設定は以下
https://qiita.com/motoki1990/items/a59a09c5966ce52128beFirefoxだとcapabilities[“marionette”] = Trueが認識できずエラーになる現象と解決方法
https://web.plus-idea.net/2017/06/selenium3-firefox-python-auto/おまけ MAC環境の構築
HomebrewのインストールからpyenvでPythonのAnaconda環境構築までメモ
https://qiita.com/aical/items/2d066801a7464a676994
mac python2系 pipのインストール
https://qiita.com/tom-u/items/134e2b8d4e11feea8e12
- curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
- python get-pip.py --user
sudo pip install selenium
- 投稿日:2019-12-03T18:06:17+09:00
seleniumでログイン用の簡単なRPAをやってみた
きっかけ
飲み会の席で、会社の同僚がRPAで勤怠の自動入力をしてくれるプログラムを作ったということを聞きました。
そこで彼の話からseleniumの存在を知り、自分も触ってみたいと思いました。導入には下記サイトを参考にさせていただきました。
【超便利】PythonとSeleniumでブラウザを自動操作する方法まとめ
https://tanuhack.com/selenium/つまづいた点として、Google Chromeとchromedriverのバージョンを合わせる必要がありました。
12/3日時点ではGoogle Chromeの最新バージョンが78なのに対し、
chromedriverの最新版はベータ版の79用のものでした。
そのため、chromedriverの最新版では動きませんでしたので改めて78用をダウンロードしました。作ったもの
ブラウザを起動し、AWSのマネジメントコンソールにログインしてくれるプログラムを作りました。
まずはモジュールのインポートです。
aws.pyfrom selenium import webdriver次に、関数を2つ作成しました。
send_idは、htmlの中の入力フォームのidを指定し、その入力フォームに対してkeyを入力します。
id_clickは、htmlの中の送信ボタンのidを指定し、そこをクリックします。aws.py#idの入力フォームにkeyを入力 def id_send(id,key): driver.find_element_by_id(id).send_keys(key) #idのボタンをクリック def id_click(id): driver.find_element_by_id(id).click()次に、ローカルにあるクローム用のドライバーを指定します。
開くブラウザはAWSのマネジメントコンソールです。aws.py#ローカルにあるクローム用のドライバーを指定 driver = webdriver.Chrome('C:\\Users\\username\\Desktop\\selenium\\chromedriver') #ブラウザを開く driver.get('https://ap-northeast-1.console.aws.amazon.com/console/home?region=ap-northeast-1#')開かれたブラウザでF12、入力フォームの情報を探します…(htmlの知識が全然ないので手探り)
id="resolved_inut"ってやつがそれっぽいですね。
では、ここにアカウントIDを入力&送信するように、作った関数を使います。
アカウントIDのところには実際には12桁の数字を入れます。aws.py#1つ目の画面の入力、送信 id_send('resolving_input','アカウントID') id_click('next_button')するとアカウントIDが入力されて…
次のページに飛びました。
ここでも同じようにユーザー名、パスワードの入力フォームのIDを探し、プログラムに落とし込みます。
aws.pyid_send('username','username') id_send('password','password') id_click('signin_button')そして無事に送信されると、ログインできました。
以上が今回のプログラムでした。
感想・今後の課題
今回はこの程度の簡単なログインでしたが、htmlやcss、javascriptについてもっと勉強すれば、
自動化の幅も広がりそうだなーと感じました。
自分でサイトを作ってみたりしながら知識を深めたいです。

- 投稿日:2019-12-03T17:45:46+09:00
Python のネストした内包表記
結論: ネストした内包表記のどちらが内側か忘れたら、for ループで書き下した時の順序と同じと思い出す。なんども忘れるのでメモしました。
一重の内包表記
まず基本的な例。
>>> [x * 2 for x in [1,2,3,4,5]] [2, 4, 6, 8, 10]
[変数を使った式 for 変数 in リスト]のようにすると、リストのそれぞれの要素に式を適用したリストを作る事が出来ます。>>> {x: x * 2 for x in [1,2,3,4,5]} {1: 2, 2: 4, 3: 6, 4: 8, 5: 10}また
{変数を使った式: 変数を使った式: for 変数 in リスト}のようにすると、リストではなく辞書を作る事が出来ます。二重の内包表記
この順番をいつも忘れる。。。
>>> [(x, y) for x in [1, 2] for y in ['a', 'b', 'c']] [(1, 'a'), (1, 'b'), (1, 'c'), (2, 'a'), (2, 'b'), (2, 'c')]このように
.. for .. in ..は二重に重ねる事が出来ます。この場合、後に書いた物が内側のループになります。この場合、後に書いたyが内側のループで、これが細かく回っている間外側のxがゆっくり回ります。覚え方としては>>> results = [] >>> for x in [1, 2]: for y in ['a', 'b', 'c']: results.append((x, y)) >>> results [(1, 'a'), (1, 'b'), (1, 'c'), (2, 'a'), (2, 'b'), (2, 'c')]のように同じ順番で
forループを書いたのと同じ動きになります。二重の内包表記を使った二重リストの展開
と、いうことは後ろのループで前の変数を使えるという事です。例えばネストしたリストを展開したい時、
>>> [item for sublist in [[1,2], [3,4], [5,6]] for item in sublist] [1, 2, 3, 4, 5, 6]のようにします。一見技巧的ですが、以下と同じです。なんとなく前の
forが内側のような気がしてしまいますが、外側です。>>> results = [] >>> for sublist in [[1,2], [3,4], [5,6]]: for item in sublist: results.append(item) >>> results [1, 2, 3, 4, 5, 6]二重の内包表記を使った二重リストの式の適用
内包表記の
forの前に内包表記を重ねると、リストの構造を変えないで内側の要素に式を適用する事が出来ます。>>> [[item * 2 for item in sublist] for sublist in [[1,2], [3,4], [5,6]]] [[2, 4], [6, 8], [10, 12]]これは単に式が書ける所に内包表記を書くだけなので直感的だと思います。念のため
forループで書くとこうなります。>>> results = [] >>> for sublist in [[1,2], [3,4], [5,6]]: subresults = [] for item in sublist: subresults.append(item * 2) results.append(subresults) >>> results [[2, 4], [6, 8], [10, 12]]参考
- 投稿日:2019-12-03T17:34:35+09:00
pandas使うときに便利だったものまとめ
この記事は古川研究室 Advent_calendar 3日目の記事です。
本記事は古川研究室の学生が学習の一環として書いたものです。内容が曖昧であったり表現が多少異なったりする場合があります。はじめに
本記事では私がデータ整形でpandasを用いた時に便利だったコマンドのまとめをしようと思います。
プログラム初心者がお送りする内容なので暖かい目で見ていただけると助かります^^本文
import pandas as pd df=pd.read_csv('ファイルパス')基本的にはこれでcsvを読む
実際にはいくつものファイルを読み込まないといけない状況もあるはずなのでそんな時に使った方法を下に示します。複数のファイルをまとめて読み込んでしまいたいとき
import glob # 同じ階層 file_pass = glob.glob('*.csv') # 階層も指定できる file_pass = glob.glob('○○/○○/*.csv')これで指定した階層にある.csvファイルのパスをとってこれます。
○○/○○ というディレクトリに
data_1.csv , data_1.txt , data_2.csv , data_2.txt
が存在している場合は[○○/○○/data_1.csv,○○/○○/data_2.csv]が返されます。
あとはfor文でcounter = -1 for i in file_pass df = pd.read_csv(i) counter = counter + 1 # なにか操作を加えて # 保存しなおし、indexなしで保存する場合はindex=Falseを付ければ良き df.to_csv('new_name_{0}.csv'.format(counter))と一気にデータ整形できます(to_csvやらcounterとかはてきとう)
os
名前つけるときとかに便利なのがこれ
import os # ()の中のパスを持ってこれる"../"でこのコード書いてる場所の一個上参照したりとか path = os.path.abspath(filepath) # パスのうちファイルネームを持ってこれる # globと合わせて使うと便利だった name = os.path.basename(filepath) # 拡張子もいらないよって時に.でsplitして分割しちゃう name = name.split(".") name = name[0]まとめ
globとosつかうと一気にcsvファイル読み込んで同じ操作加えるのが楽だよって話でした。
自分でやってる際に思ったことなんですが、pandasの操作自体は"pandas ○○"って感じでググればでてくるのですが、pandasの機能なのかpythonのライブラリなのか判断つかなくてうまく検索できないって状況が多かったです。
何ができるのか程度は知っておいて適切にググる力をつけていきたいです╭( ・ㅂ・)و
- 投稿日:2019-12-03T17:33:44+09:00
ニューラルネットワークの内部層を可視化する
今回が初の投稿となります。また、機械学習初心者です。理解が足りておらずおかしなことを言っていたり、見づらい部分も多々あるかとは思いますが、温かく見守っていただけると幸いです!
クラスの初期化
visualize.pyfrom keras.datasets import mnist from keras.utils import to_categorical from keras.models import Model, model_from_json from keras.layers import Input, Conv2D, MaxPooling2D, Dense, Flatten, Dropout import numpy as np import seaborn as sns import os class Visualize_CNN(): def __init__(self): self.conv1_filter_num = 32 self.conv1_filter_size = (3,3) self.conv1_strides = 1 self.pool1_filter_size = (2,2) self.conv2_filter_num = 64 self.conv2_filter_size = (5,5) self.conv2_strides = 1 self.pool2_filter_size = (2,2) self.dense1_output = 1024 self.dense2_output = 10 self.epochs = 1 self.batch_size = 128 self.figsize = (10,10) self.save_file_path = "../data/model"データを読み込む
visualize.pydef load_data(self): (x_train, y_train),(x_test,y_test) = mnist.load_data() x_train = x_train.astype("float32")/ 256 x_train = x_train.reshape((-1,28,28,1)) x_test = x_test.astype("float32")/ 256 x_test = x_test.reshape((-1,28,28,1)) y_train = to_categorical(y_train) y_test = to_categorical(y_test) return x_train, y_train, x_test, y_testkeras.datasetsからmnistデータを読み込んで前処理を行っています。
x_train、x_testに行ったのはタイプの指定とnormalization(正規化)です。今回行ったnormalizationはMin-Max normalizationです。数式で書くと、y = \frac{x - x_{min}}{x_{max} - x_{min}}x_{max}:与えられたデータの中の最大値, x_{min}:は与えられたデータの中の最小値となります。与えられた各データを最大値と最小値の幅で割ってやると、最大値が1、最小値が0にスケーリングすることができますよね。そのため、Min-Max normalizationというんだと思います。今回扱うデータはmnistです。そのため、グレイスケールで各ピクセルの値?は0~255だとわかっているので数式の最小値部分には0、最大値の部分には255が入ります。
y_train、y_testはone-hotラベルのデータにしています。今回はkeras.utilsの中のto_categoricalにそれぞれ引数をして与えることで自動的にデータを変換してもらっています。
モデルを構築する
build_model.pydef creat_model(self): input_model = Input(shape=(28,28,1)) conv1 = Conv2D(self.conv1_filter_num, self.conv1_filter_size, padding="same", activation="relu")(input_model) pool1 = MaxPooling2D(self.pool1_filter_size)(conv1) conv2 = Conv2D(self.conv2_filter_num, self.conv2_filter_size, padding="same", activation="relu" )(pool1) pool2 = MaxPooling2D(self.pool2_filter_size)(conv2) flat = Flatten()(pool2) dense1 = Dense(self.dense1_output, activation="relu")(flat) dropout = Dropout(0.25)(dense1) dense2 = Dense(self.dense2_output, activation="softmax")(dropout) model = Model(inputs=input_model, output=dense2) return model
今回構築したモデルは二回畳み込んで結合させるだけの簡単なものです。各レイヤーのフィルター数(カラム数?)やサイズはクラスの初期化の部分に載せています。モデルの訓練と保存
visualize.pydef train_and_save(self): x_train, y_train, x_test, y_test = self.load_data() model = self.creat_model_() model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"]) #model.summary() history = model.fit(x_train, y_train, batch_size=self.batch_size, epochs=self.epochs, verbose=2, validation_data=(x_test, y_test)) json_string = model.to_json() open(os.path.join(self.save_file_path, "model.json"),"w").write(json_string) model.save_weights(os.path.join(self.save_file_path, "model_weights.h5")) print("saving succsessful")
構築したモデルを学習させ、モデルと学習した重みを保存します。model.save(save_file_path)とかするとモデルと重みを同時に保存してくれるらしいのですが、コードを書いた当時の自分は知らなかったので別々に保存しています。中間層の可視化
visualize.pydef visualize(self): x_train,a,b,c = self.load_data() json_string = open(os.path.join(self.save_file_path, "model.json")).read() model = model_from_json(json_string) model.load_weights(os.path.join(self.save_file_path, "model_weights.hdf5")) layers = model.layers[1:5] outputs = [layer.output for layer in layers] acctivation_model = Model(inputs=model.input, output=outputs) acctivation_model.summary() image = x_train[1].reshape(-1,28,28,1)#入力画像を変更したかったらx_train[j]のjを変化させてください! plt.imshow(image.reshape(28,28)) activation = acctivation_model.predict(image) x_axis = 8 y_axis = 8 for j in range(len(activation)): cul_num = activation[j].shape[3] act = activation[j] plt.figure(figsize=(self.figsize)) for i in range(cul_num): plt.subplot(8,8,i+1) sns.heatmap(act[0,:,:,i]) plt.show()最後に保存したモデルと重みをロードして、全結合層以外の層の出力を出力するモデルを再定義し、その出力をヒートマップにして出力しています。
結果
結果は以下の通りになりました。
入力画像
畳み込み層1の出力
畳み込み層2の出力

まとめ
以上、初投稿とニューラルネットワークの中間層の可視化をやってみた!でした。
ここをこうやったら見やすくなるよ!等のアドバイス大歓迎です!
最後まで見てくださってありがとうございましたm(_ _)m


- 投稿日:2019-12-03T17:24:11+09:00
Pythonでブラックジャック作った。
はじめに
アドベントカレンダーが空いていたのでまたまた書いていこうと思います。今回は題名の通りブラックジャックを作りました。
前回の記事はこちら→ Pythonでおみくじ作った。
環境
Ubuntu18.04LTS
Python3.6.9コード
play_bj.pyfrom random import shuffle class Deck: """ 山札を表すクラス """ def __init__(self): """ 山札を初期化して、シャッフルする。 """ suits = ['スペード', 'クラブ', 'ダイヤモンド', 'ハート'] values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K'] self.deck = [] for i in suits: for j in values: self.deck.append((i, j)) shuffle(self.deck) def draw(self): """ 山札から1枚引き、引いたカードを返す。 """ return self.deck.pop(0) class Person: """ プレイヤーを表すクラス """ def __init__(self): """ 手札を初期化する。 """ self.hands = [] self.point = 0 def add(self, card): """ 手札にカードを1枚加える。 """ self.hands.append(card) def point_sum(self): """ トランプの合計点数を求める。 """ self.point = 0 for i in self.hands: if i[1] in ['J', 'Q', 'K']: self.point += 10 else: self.point += i[1] return self.point def BJ(): """ メインの処理 """ print('ブラックジャックへようこそ!') d = Deck() p = Person() c = Person() drawing(d, p, 'あなた') drawing(d, p, 'あなた') drawing(d, c, 'CPU') card = d.draw() c.add(card) player_point = p.point_sum() cpu_point = c.point_sum() if player_point == cpu_point == 21: print('引き分けです。') return elif player_point == 21: print('あなたの勝ちです!') return elif cpu_point == 21: print('あなたの負けです。') return # ここではAは11にならないので上の条件分岐は本当はいらない。 while True: choice = input('"Hit"または"Stand"を入力してください。: ') while True: if choice.lower() == 'hit' or choice.lower() == 'stand': break else: choice = input('"Hit"または"Stand"を入力してください。: ') if choice.lower() == 'hit': drawing(d, p, 'あなた') player_point = p.point_sum() if player_point >= 22: print('あなたの負けです。') return elif choice.lower() == 'stand': break else: print('error') return print('CPUのもう1つのカードは{}の{}です。'.format(c.hands[1][0], c.hands[1][1])) while True: cpu_point = c.point_sum() if cpu_point < 17: drawing(d, c, 'CPU') cpu_point = c.point_sum() if cpu_point >= 22: print('あなたの勝ちです!') return else: break if player_point == cpu_point: print('引き分けです。') return elif player_point > cpu_point: print('あなたの勝ちです!') return elif player_point < cpu_point: print('あなたの負けです。') return def drawing(class1, class2, name): """ 山札からカードを1枚引き手札に加える。 その後、加えたカードの情報を表示する。 """ card = class1.draw() class2.add(card) print('{}の引いたカードは{}の{}です。'.format(name, card[0], card[1])) if __name__ == '__main__': BJ()おわりに
関数とクラスのいい勉強になりました。次は、Aに11も対応できるようにしようかな。もっと良いものができ次第、追記していきます。
- 投稿日:2019-12-03T17:18:30+09:00
これからのデータ分析担当者に求められる能力と勉強方法
記事の対象者と内容
記事の対象者は、これから企業のユーザー行動や売上のデータ分析をしようとする方、Excelでやるにはちょっと面倒なデータ分析をしなければなくなった研究者などを対象としています。
「デキる」データ分析者が求められる背景
近年、IT企業ではデータ分析をして、UIやUXの細かな向上やグロースハック施策の実施につなげることが非常に重要になってきました。
大学等の研究でも、高度なデータ分析を駆使していかなければ他の研究者と差別化できないようになってきています。そこで、本記事では、データ分析をこれから行いたいと考えているデータ分析/プログラミング初心者に向けて、今後の時代に求められるデータ分析能力と勉強法について書きたいと思います。
データ分析者に求められる能力とは
- データを正しく見る論理的思考力
- 統計や機械学習などの高度な分析手法
- データの整形や集計ができるプログラミング力
- データ分析まで見越したプロダクト開発や実験を計画をできる設計力
※注:面倒なのでSQLもプログラミング的なものとしてひとくくりに語ります。
価値の出せる一流の分析者には、上記すべての能力が必要であり、
上記の中でも最も重要なのは、4の「データ分析まで見越したプロダクト開発や実験を計画をできる設計力」であるというのが、本記事の趣旨です。1. データを正しく見る論理的思考力とその勉強法
データを正しく見る論理的思考力とは
これが地味に結構難しい。
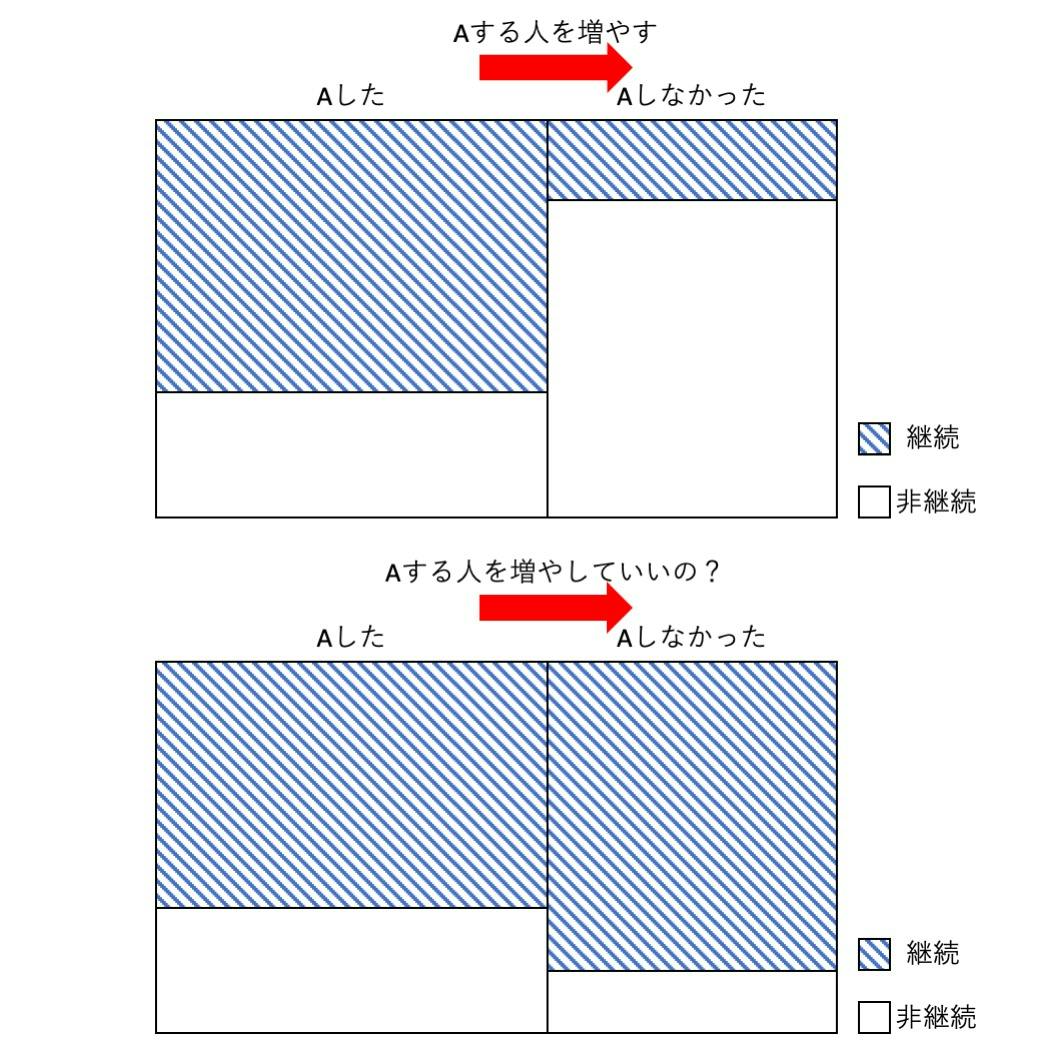
そして、自分ではできているつもりでいて、意外にできていない人が多い印象です。例えば、アプリ内でAという行動を取るかどうかが継続率に寄与するかを分析する際、
1. 「Aという行動を取った人のうち継続した人」と「しなかった人」の割合
2. 「継続した人のうちAという行動を取った人」と「取らなかった人」の割合
3. 「Aという行動を取らなかった人のうち継続した人」と「しなかった人」の割合これらの意味は当然違うものですが、あなたの分析において大事なのはどの指標でしょうか?
これらがどういう値だった場合にどういう分析を行い、次にどのような施策を打つのでしょうか。
下図のような例では、
1の「Aという行動を取った人のうち継続した人の割合」は十分に大きく、
2の「継続した人のうちAという行動を取った人」と「取らなかった人」の割合はほぼ同じであるにも関わらず、
3の「Aという行動を取らなかった人のうち継続した割合」が大きいために、
Aという行動を取らせない方がむしろ良い可能性があります。Aという1つの行動だけならまだ単純ですが、同時にBという行動もしたかどうかで分析するとなると急に複雑になってしまいますね。
頭がこんがらがらずに、きちんと状況を理解し、改善策まで考えることができますか?データを正しく見る論理的思考力の身につけ方
これは、いろんなパターンを見て考え、誰かと議論をしていくことでしか身につきません。
日頃から、ニュースやいろんな数字を見る際に、「本当なのか」と自分の頭で考えることも重要です。ちょっと前に、
「数字は嘘をつかないが嘘つきは数字を使う」
なんていう言葉も話題になっていましたね……データや論理から真実を読み取る能力は現代人には必須の能力と呼べるのではないでしょうか。
3番目のような本を読み、日本語力を鍛えることも重要です。
人間は言葉で数値を操り、人を騙すのですから。
数字と論理的言葉の扱いを徹底的に身につけ、これからのビッグデータ時代をサバイブしましょう。2. 統計や機械学習などの高度な分析手法とその勉強法
統計や機械学習などを使いこなせる数学力とは
こういった数学的な能力や知識がどの程度必要なのかは、あなたがいらっしゃる現場次第でしょう。
簡単なABテスト、コホート分析やファネル分析を行うだけなら必要ないかと思います。
これらの分析手法を駆使すれば、下記のようなグロースハック施策を考えることは十分可能です。ですが、今あるデータ数で十分な判断が可能か?
十分に正しい判断ができるようなデータのとり方がきちんとできているか。
というような、少し深い問いを考えるだけで、多少の統計的な知識と数字への理解が必要になってきます。USJや丸亀製麺のV字回復でしられるマーケターの森岡毅氏は、
著書『確率思考の戦略論 USJでも実証された数学マーケティングの力』の中で、
「数学的思考」で消費者の行動を深く洞察しようと説いています。さらにいえば、現代でビジネスを行う以上、AIやDeep Learningといったものへの深い理解は必須です。
残念ながら多くの人が、AIを漠然としか捉えておらず、話すことのほとんどが的はずれです。あなたは、競合他社が「AIを使って顧客データを〜」と言ってきた時に、どのようなことをしているのか想像がつくでしょうか。
「そんなことうちだってできる」「うちならもっと価値のあることにデータを使える」と堂々と言えるでしょうか。実は、AIを理解するのそこまで高度な数学的能力は必要とされません。
高校数学をなんとなく覚えている人であれば十分に理解可能です。
別の記事で「AI入門」も書きたいと思います。
統計や機械学習などの高度な分析手法の勉強法
これも手を動かして勉強するしかありません。
手を動かして統計や機械学習を勉強するには、簡単なプログラミングができた方が効率がいいと思います。
3ともかぶりますが、これが、分析者もプログラミングを身につけた方がいいと、ぼくが思う一つの理由です。
データをいじって体感した方が結局理解が早いですからね。繰り返になりますが、ExcelでもできるようなことをBIツールでできるようしたいだけであれば不要かもしれません。
(まずはそういった当たり前のことができるようになりましょう。)でも、そんなものは誰でも訓練すればできるようになります。
そういった分析者たちの一歩先をいく、ちょっと高度な分析手法を勉強するなら、プログラミングを使って手を動かしながら勉強するのがいいと思います。
- Pythonで理解する統計解析の基礎
- Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
- ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
3. データの整形や集計ができるプログラミング力
データの整形や集計ができるプログラミング力は必要か
分析担当者がプログラミング力を身につけるべきかは最も意見の分かれるところだと思いますし、実際いろんなことを言う人がいます。
(正確に言うと、SQLはプログラミング言語ではありません。ですが、細かい区別は無視します 笑)両者のおっしゃっていることはどちらも正しく、理解できます。
(前提にしていることもそれぞれの記事で異なりますし。)冒頭でも述べたように、ぼくは、必要派です。
4でも詳しく説明しますが、より正確に言えば、「周囲より一歩先にいき、本当に価値のあるプロダクトや実験をつくれる分析者」になるためには必要だと考えています。簡単に説明すると、以下のような理由があります。
BIツールは決して万能ではない
世に便利なBIツールはたくさんあります。
それら製品は素晴らしく、データの民主化を進めてくれるものとして、非常に価値のあるものです。
日本の全企業がBIツールを使いこなし、PDCAを回しまくれば、日本経済は爆速で成長するでしょう。ですが、プログラミングやSQLを使わずにできることには現状限られています。
多くのBIツールでは、データ集計や統合のところのSQLのクエリは自分たちで書かなければなりません。
実際、高度なことができるとうたっているBIツールも、その実は、「内部でPythonコードを書いて実行できますよ」ということだったりします。メルカリのデータサイエンスチームと分析エコシステムのはなし
この記事によると、メルカリでは非アナリスト職でもSQLを書いて、簡易な分析は自分で出来る人が多いですね。
最近は財務部、経理部、法務部、デザイナーまで勉強中という噂もあります。(事実です)とのこと。
分析するためにもSQLを実行する必要があるから、みんながんばって勉強しているのですね。そして、さらに重要なことは、
データは口を開けて待っていても降ってこない
ということです。
データを分析をするには、当然データを集めなければなりません。
超データドリブンで完璧な分析基盤が整っているハイパーつよつよ企業で働かれている分析者はいざしらず、
まだ分析基盤の整っていないスタートアップや、分析という概念すらままならない中小企業の分析者はデータを自分たちで集めるしかありません。自分で集めたデータの分析とスマートな施策案、そして、施策を実施した後チェック方法とネクストアクションまでを計画しましょう。
そして、結果を出す。
これが、「データで語ること」の重要性を示す一番簡単な方法です。さらにい、データ分析基盤を作る上でも分析者の役割は非常に重要です。
データ分析にまで明るいインフラエンジニア、データベースエンジニアが社内にいるとは限りません。他人任せで勝手に作られたデータ分析基盤で本当にあなたが欲しいデータは集まりますか?
データ分析基盤を外注して、本当にしたかった分析ができなかった時どうしますか?そして、次の4でも詳しくお話しますが、これからの分析者には、こういった上流の設計や実験計画までを経営層やエンジニアと議論できることが求められると思います。
簡単な分析はどんどん自動化されたり、便利なツールが出てきて、人間は不要になっていきますから。データの整形や集計ができるプログラミングの勉強方法
こちらも実際に手を動かしましょう。
- Pythonによるデータ分析入門 第2版 ―NumPy、pandasを使ったデータ処理
- SQLデータ分析・活用入門 データサイエンスの扉を開くための技術 MySQL/PostgreSQL 両対応
- いちばんやさしいグロースハックの教本 人気講師が教える急成長マーケティング戦略
上記のような本を読みながら、いまExcelでされていることをpythonなどのプログラミング言語で置き換えていくことが一番手っ取り早い勉強方法でしょう。
そして、本を見てテキトーなデータを準備して、無料のBIツールやSQLをいじってみることをオススメします。
(プログラミングの勉強法なのにITの知識がまったくない方はできないことを要求していますね………泣笑)4. データ分析まで見越したプロダクト開発や実験を計画をできる設計力
本当に大切なのは、データ分析までを見越したプロダクト開発や実験計画を行うことです。
これが本記事の「結論」です。
データ分析まで見越したプロダクト開発や実験計画の重要性
今後、BIツールはどんどん便利になり、できないことはほとんどなくなってくるでしょう。
現に、機械学習などの高度な分析も、誰もができるようになってきています。さらに言えば、基本的なデータ分析は自動化され、重要な指標はツールが見つけてくれるようになるでしょう。
ですが、本当に重要かつ難しいのは、プロダクトの設計や実験の計画段階で、どのような仮説を持って分析をし、そこからどのような示唆を得て、どのような施策につなげるのかを考えておくことです。
プロダクトのリリース前から新ダッシュボード「Looker」の導入に踏み切ったわけ
この記事では、メルペイが、プロダクトのリリース前からデータ分析基盤を整えていたことが書かれています。プロダクトの設計や実験の計画段階でそれらを考えておかなければ、欲しいデータが取れなかったり、分析した結果が信頼できないものだったりすることが起こってしまいます。
例えば、欲しいデータ分析をするためには、どういったログが必要なのか。ABテストなどをするにしても、どれくらいの期間、何人に対してどのような方法で実施するのが妥当かなどを考える必要があります。ここまで自動化されるにはもう少し時間がかかるでしょう。
だからこそ、データが民主化される現代において、データ分析とビジネスの基礎体力だけではなく、データの収集やプロダクト開発まで知っている「分析者」 兼 「設計者」が真に必要になると考えています。
データ分析まで見越したプロダクト開発や実験計画の勉強法
結局は、これも実践ありきですね 笑
徐々にデータ分析基盤の整ってきたものの、上位レイヤーのデータ分析者が不足してるスタートアップは、たくさんあります。逆に言うと、徐々に実績が出てきていて、これから急拡大していこうというスタートアップのほとんどが、「1人でデータの整形・収集から分析、分析結果に基づく施策出しとPDCA計画を組める」分析者を求めています。
そういう企業で自分一人でガンガン結果をだす。
いろんな人を巻き込んでPDCAサイクルを回す。
こういった分析者になることができれば、どこにいっても価値を出すことがデキるでしょう。マーケティングやグロースハック的な簡単なデータ分析をしていた人が、この記事に書かれているような方法で、エンジニアリング力をつけるのも一つの道です。
現在PMをつとめている人が、データ分析までガンガンやっていくというのもいいですね。つよつよデータ分析マンになり、周囲のデータ分析デビューを助け、データで殴り合うパーリナイをしましょう!!

- 投稿日:2019-12-03T17:18:30+09:00
これからのデータ分析担当者に求められる知識と勉強方法
記事の対象者と内容
記事の対象者は、これから企業のユーザー行動や売上のデータ分析をしようとする方、Excelでやるにはちょっと面倒なデータ分析をしなければなくなった研究者などを対象としています。
「デキる」データ分析者が求められる背景
近年、IT企業ではデータ分析をして、UIやUXの細かな向上やグロースハック施策の実施につなげることが、非常に重要になってきました。
大学等の研究でも、高度なデータ分析を駆使していかなければ、他の研究者と差別化できないようになってきています。そこで、本記事では、データ分析をこれから行いたいと考えているデータ分析/プログラミング初心者に向けて、今後の時代に求められるデータ分析能力と勉強法について書きたいと思います。
データ分析者に求められる能力とは
- データを正しく見る論理的思考力
- 統計や機械学習などの高度な分析手法
- データの整形や集計ができるプログラミング力
- データ分析まで見越したプロダクト開発や実験を計画をできる設計力
※注:面倒なのでSQLもプログラミング的なものとしてひとくくりに語ります。
価値の出せる一流の分析者になるには、上記すべての能力が必要であり、
上記の中でも最も重要なのは、4の「データ分析まで見越したプロダクト開発や実験を計画をできる設計力」であるというのが、本記事の趣旨です。1. データを正しく見る論理的思考力とその勉強法
データを正しく見る論理的思考力とは
これが地味に結構難しい。
そして、自分ではできているつもりでいて、意外にできていない人が多い印象です。例えば、アプリ内でAという行動を取るかどうかが継続率に寄与するかを分析する際、
1. 「Aという行動を取った人のうち継続した人」と「しなかった人」の割合
2. 「継続した人のうちAという行動を取った人」と「取らなかった人」の割合
3. 「Aという行動を取らなかった人のうち継続した人」と「しなかった人」の割合これらの意味は当然違うものですが、あなたの分析において大事なのはどの指標でしょうか?
これらがどういう値だった場合にどういう分析を行い、次にどのような施策を打つのでしょうか。
下図のような例では、
1の「Aという行動を取った人のうち継続した人の割合」は十分に大きく、
2の「継続した人のうちAという行動を取った人」と「取らなかった人」の割合はほぼ同じであるにも関わらず、
3の「Aという行動を取らなかった人のうち継続した割合」が大きいために、
Aという行動を取らせない方がむしろ良い可能性があります。Aという1つの行動だけならまだ単純ですが、同時にBという行動もしたかどうかで分析するとなると急に複雑になってしまいますね。
頭がこんがらがらずに、きちんと状況を理解し、改善策まで考えることができますか?データを正しく見る論理的思考力の身につけ方
これは、いろんなパターンを見て考え、誰かと議論をしていくことでしか身につきません。
日頃から、ニュースやいろんな数字を見る際に、「本当なのか」と自分の頭で考えることも重要です。ちょっと前に、
「数字は嘘をつかないが嘘つきは数字を使う」
なんていう言葉も話題になっていましたね……データや論理から真実を読み取る能力は現代人には必須の能力と呼べるのではないでしょうか。
3番目のような本を読み、日本語力を鍛えることも重要です。
人間は言葉で数値を操り、人を騙すのですから。
数字と論理的言葉の扱いを徹底的に身につけ、これからのビッグデータ時代をサバイブしましょう。2. 統計や機械学習などの高度な分析手法とその勉強法
統計や機械学習などを使いこなせる数学力とは
こういった数学的な能力や知識がどの程度必要なのかは、あなたがいらっしゃる現場次第でしょう。
簡単なABテスト、コホート分析やファネル分析を行うだけなら必要ないかと思います。
これらの分析手法を駆使すれば、下記のようなグロースハック施策を考えることは十分可能です。ですが、今あるデータ数で十分な判断が可能か?
十分に正しい判断ができるようなデータのとり方がきちんとできているか。
というような、少し深い問いを考えるだけで、多少の統計的な知識と数字への理解が必要になってきます。USJや丸亀製麺のV字回復でしられるマーケターの森岡毅氏は、
著書『確率思考の戦略論 USJでも実証された数学マーケティングの力』の中で、
「数学的思考」で消費者の行動を深く洞察しようと説いています。さらにいえば、現代でビジネスを行う以上、AIやDeep Learningといったものへの深い理解は必須です。
残念ながら多くの人が、AIを漠然としか捉えておらず、話すことのほとんどが的はずれです。あなたは、競合他社が「AIを使って顧客データを〜」と言ってきた時に、どのようなことをしているのか想像がつくでしょうか。
「そんなことうちだってできる」「うちならもっと価値のあることにデータを使える」と堂々と言えるでしょうか。実は、AIを理解するのそこまで高度な数学的能力は必要とされません。
高校数学をなんとなく覚えている人であれば十分に理解可能です。
別の記事で「AI入門」も書きたいと思います。
統計や機械学習などの高度な分析手法の勉強法
これも手を動かして勉強するしかありません。
手を動かして統計や機械学習を勉強するには、簡単なプログラミングができた方が効率がいいと思います。
3ともかぶりますが、これが、分析者もプログラミングを身につけた方がいいと、ぼくが思う一つの理由です。
データをいじって体感した方が、結局理解が早いですからね。繰り返しになりますが、ExcelでもできるようなことをBIツールでできるようしたいだけであれば不要かもしれません。
(まずはそういった当たり前のことができるようになりましょう。)でも、そんなものは誰でも訓練すれば、できるようになります。
そういった分析者たちの一歩先をいく、ちょっと高度な分析手法を勉強するなら、プログラミングを使って手を動かしながら勉強するのがいいと思います。
- Pythonで理解する統計解析の基礎
- Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
- ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
3. データの整形や集計ができるプログラミング力
データの整形や集計ができるプログラミング力は必要か
分析担当者がプログラミング力を身につけるべきかは最も意見の分かれるところだと思いますし、実際いろんなことを言う人がいます。
(正確に言うと、SQLはプログラミング言語ではありません。ですが、細かい区別は無視します 笑)両者のおっしゃっていることはどちらも正しく、理解できます。
(前提にしていることもそれぞれの記事で異なりますし。)冒頭でも述べたように、ぼくは、必要派です。
4でも詳しく説明しますが、より正確に言えば、「周囲より一歩先にいき、本当に価値のあるプロダクトや実験をつくれる分析者」になるためには必要だと考えています。簡単に説明すると、以下のような理由があります。
BIツールは決して万能ではない
世に便利なBIツールはたくさんあります。
それら製品は素晴らしく、データの民主化を進めてくれるものとして、非常に価値のあるものです。
日本の全企業がBIツールを使いこなし、PDCAを回しまくれば、日本経済は爆速で成長するでしょう。ですが、プログラミングやSQLを使わずにできることには現状限られています。
多くのBIツールでは、データ集計や統合のところのSQLのクエリは自分たちで書かなければなりません。
実際、高度なことができるとうたっているBIツールも、その実は、「内部でPythonコードを書いて実行できますよ」ということだったりします。メルカリのデータサイエンスチームと分析エコシステムのはなし
この記事によると、メルカリでは非アナリスト職でもSQLを書いて、簡易な分析は自分で出来る人が多いですね。
最近は財務部、経理部、法務部、デザイナーまで勉強中という噂もあります。(事実です)とのこと。
分析するためにSQLを実行する必要があるから、みんながんばって勉強しているのですね。そして、さらに重要なことは、
データは口を開けて待っていても降ってこない
ということです。
データを分析をするには、当然データを集めなければなりません。
超データドリブンで完璧な分析基盤が整っているハイパーつよつよ企業で働かれている分析者はいざしらず、
まだ分析基盤の整っていないスタートアップや、分析という概念すらままならない中小企業の分析者はデータを自分たちで集めるしかありません。自分で集めたデータの分析とスマートな施策案、そして、施策を実施した後のチェック方法とネクストアクションまでを計画しましょう。
そして、結果を出す。
これが、「データで語ること」の重要性を示す一番簡単な方法です。さらに、データ分析基盤を作る上でも分析者の役割は非常に重要です。
データ分析にまで明るいインフラエンジニア、データベースエンジニアが社内にいるとは限りません。他人任せで、勝手に作られたデータ分析基盤で、本当にあなたが欲しいデータは集まりますか?
データ分析基盤を外注して、本当にしたかった分析ができなかった時どうしますか?そして、次の4でも詳しくお話しますが、「これからの」分析者には、プロダクト開発や実験計画などの上流の設計までを経営層やエンジニアと議論できることが求められると思います。
簡単な分析はどんどん自動化されたり、便利なツールが出てきて、人間は不要になっていきますからね。
データの整形や集計ができるプログラミングの勉強方法
こちらも実際に手を動かしましょう。
- Pythonによるデータ分析入門 第2版 ―NumPy、pandasを使ったデータ処理
- SQLデータ分析・活用入門 データサイエンスの扉を開くための技術 MySQL/PostgreSQL 両対応
- いちばんやさしいグロースハックの教本 人気講師が教える急成長マーケティング戦略
上記のような本を読みながら、いまExcelでされていることをPythonなどのプログラミング言語で置き換えていくことが、一番手っ取り早い勉強方法でしょう。
そして、本を見てテキトーなデータを準備して、無料のBIツールやSQLをいじってみることをオススメします。
(プログラミングの勉強法なのに、ITの知識がまったくない方には難しいことを要求していますね………泣笑)4. データ分析まで見越したプロダクト開発や実験を計画をできる設計力
本当に大切なのは、データ分析までを見越したプロダクト開発や実験計画を行うことです。
これが本記事の「結論」です。
データ分析まで見越したプロダクト開発や実験計画の重要性
今後、BIツールはどんどん便利になり、できないことはほとんどなくなってくるでしょう。
現に、機械学習などの高度な分析も、誰もができるようになってきています。さらに言えば、基本的なデータ分析は自動化され、重要な指標はツールが見つけてくれるようになるでしょう。
ですが、本当に「重要」かつ難しいのは、今後どのような仮説を持って分析をし、そこからどのような示唆を得て、どのような施策につなげるのか、をプロダクトの設計や実験の計画段階で考えておくことです。
プロダクトのリリース前から新ダッシュボード「Looker」の導入に踏み切ったわけ
この記事では、メルペイが、プロダクトのリリース前からデータ分析基盤を整えていたことが書かれています。実際、プロダクトの設計や実験の計画段階で、データ分析のことを考えておかなければ、欲しいデータが取れなかったり、分析した結果が信頼できないものだったりすることが起こってしまいます。
例えば、欲しいデータ分析をするためには、どういったログが必要なのか。ABテストなどをするにしても、どれくらいの期間、何人に対してどのような方法で実施するのが妥当かなどを考える必要があります。ここまで自動化されるには、もう少し時間がかかるでしょう。
だからこそ、データが民主化される現代において、データ分析とビジネスの基礎体力だけではなく、データの収集やプロダクト開発まで知っている「分析者」 兼 「設計者」が真に必要になると考えています。
データ分析まで見越したプロダクト開発や実験計画の勉強法
結局は、これも実践ありきですね 笑
徐々にデータ分析基盤の整ってきたものの、上位レイヤーのデータ分析者が不足してるスタートアップは、たくさんあります。逆に言うと、実績が出てきていて、これから急拡大していこうというスタートアップのほとんどが、「1人でデータの整形・収集から分析、分析結果に基づく施策出しとPDCA計画を組める」分析者を求めています。
そういう企業で自分一人でガンガン結果をだす。
いろんな人を巻き込んでPDCAサイクルをブン回す。
こういった分析者になることができれば、どこにいっても価値を出すことがデキるでしょう。マーケティングやグロースハック的な簡単なデータ分析をしていた人が、この記事に書かれているような方法で、エンジニアリング力をつけるのも一つの道です。
現在PMをつとめている人が、データ分析までガンガンやっていくというのもいいですね。つよつよデータ分析マンになり、周囲のデータ分析デビューを助け、データで殴り合うパーリナイをしましょう!!
- 投稿日:2019-12-03T17:10:05+09:00
OpenCV で'美顏'してみた
お久しぶりです.
そろそろ投稿しないとマズイかなと思って,約9ヵ月を投稿した.
今回は,pythonのOpenCVを使って'美顏'のコードを書いて試しました.
ぜひ試して画像'美顏'する前後を比較してください.コード
import cv2 image = cv2.imread('photo.jpg') value = 20 image_dst = cv2.bilateralFilter(image,value,value * 2,value / 2) cv2.imwrite('new_photo.png',image_dst) cv2.namedWindow('image') cv2.imshow('image',image_dst) cv2.waitKey(0) cv2.destroyAllWindows()コード説明
OpenCVをインポート
import cv2画像を読み込む
image = cv2.imread('photo.jpg')画像を美顏 value値が大きいほど美顏効果が強い,小さいほど美顔効果が弱い
value = 20 image_dst = cv2.bilateralFilter(image,value,value * 2,value / 2)新規画像をファイルに保存する
cv2.imwrite('new_photo.png',image_dst)windowを作る
あらかじめウィンドウを作成しておき,後から読み込んだ画像を表示させたい場合
cv2.namedWindow(window_name, flag) を用いるcv2.namedWindow('image')windowを開く
cv2.imshow('image',image_dst)windowを待機
入力待ち時間でミリ秒単位
cv2.waitKey(0)windowを閉じる
現在までに作られた全てのウィンドウを閉じる関数です.
特定のウィンドウのみを閉じる場合は cv2.destroyWindow() 関数に閉じたいウィンドウ名を指定してくださいcv2.destroyAllWindows()以上で,今回の「OpenCV で'美顏'してみた」が終わります.
読んでいただいてありがとうございます.
- 投稿日:2019-12-03T16:57:49+09:00
Oracle VM VirutualBoxとCent OS 7で作った環境を別のパソコンに移す
どんな人向けの記事か
新年に向けてのカウントダウンが迫ってきました。来年から新しい世界に飛び出していくという方もたくさんいらっしゃると思います。
そういった方の中でCent OSで作った環境を作り直すのが面倒くさいと考える方がいれば、別のパソコンに引き継ぎたいと思う方に向けての記事です。記事を書いた理由
先日、PythonでCartopyという地図用のモジュールをインストールしようとしたところ、長文のエラーが出てしまい、ほとほと困り果てていました。原因はqiitaで質問して教えていただいたのですがhttps://qiita.com/Daisuke__/items/99de0098ec5668070f75 にあるようにcondaとpipという二種類のモジュール導入のコマンドを使うと環境が壊れてしまうことがあるようです。私もモジュールが必要な時にはGoogle先生に「~のインストール」のような形で検索し、記事が新しいものを見ながら導入するということを行っていたため、知らないうちにこのタブーに触れていたようです。そこで、これを機に新しい環境を作ろうと思ったのですが、マウスの統合や画面サイズの設定がうまくいかないという問題に直面しました。Linuxを使い始めた初期のころにネット記事を見ながら設定したのですが、どこのサイトを見たかさっぱり思い出せません。こういうことがよくあるので最近はログをきちんととるようにしているのですが、この件についてログがとられていませんでした。みなさんもきちんとログをとることをお勧めします。幸いpipとcondaを混ぜる前のクローンを残していたので、それを使ってモジュールの導入には成功したのですが、気が付いたのが、あれ?パソコン変わったら詰みじゃね?ということです。もちろん、マウスの統合や画面サイズの変更のやり方を知りたいのですが、私生活がバタバタしてきたのでそれどころではなさそうです。そこで、この環境引き継げたらとりあえず解決するじゃんと思い、作った仮想環境を別のパソコンに移すということができないか試してみて、初学者の私は若干てこずったのでログを兼ねて、記事を書きました。というのは建前で
誰かCent OS 7でマウスの統合とゲストOSの画面を自動リサイズする方法を教えてくださいお願いします!!ということを言いたかっただけです。環境
元々Cent OSが入っている方のデスクトップが
Windows10でVirtualBoxの方がhttps://www.virtualbox.orgからダウンロードした**VirtualBox 6.0.14*を使いました。
環境を移す方のノートパソコンも
**Windows10とVirtualBox 6.0.14*を使いました。
Windows→MacOSのように異なるOSをまたがっても大丈夫なのかは確かめていないのでやった方がいたら報告してくださるとうれしいです。(個人的にMacに買い替える予定があるため)何をやったのか
元のパソコンでの操作
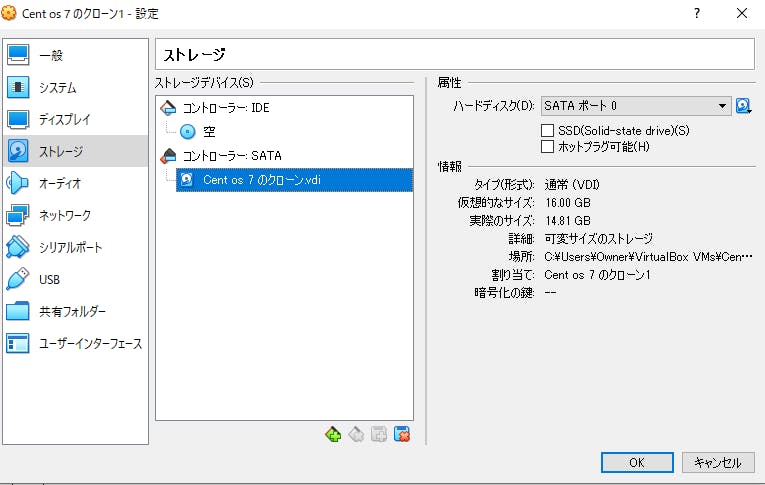
まず、現在使っているゲストOSがどこに保存されているのか調べました。C:\Users\Owner\VirtualBox VMs\"名前"\"名前".vdiに保存されているようです。Virtual Boxを開いて設定>ストレージ>コントローラー:SATAをクリックし、情報の中にある場所にファイルパスから確認できます。
注意
16GBぐらいあるのでかなり重いです。SSDやUSBなどを使って私はファイルの移動を行いました。これを保存し、操作はノートパソコンに移ります。
移す方のパソコンでの操作
まず、https://www.virtualbox.org からVirtualboxをダウンロードします。
次にCent OSをダウンロードします。Get CensOS Nowをクリックし、Older Version(下へスクロール)then click hereを押してバーションを7を選びます。最新のCent OSについては試していません。
Cent OSはダウンロードしなくても保存したファイルの方に含まれているのかもしれないのでダウンロードの必要はないのかもしれませんが、念のためにダウンロードしておきます。
仮想マシンの追加
VisualBoxの「ツール」をクリックし、「追加(A)」を選択し、先ほど
先ほど保存したクローンを選択し、無事起動させると起動できした。追記
私のノートパソコンの容量が100 GB中90 GB程度使っていたので外部SSDにクローンファイルを保存して起動させてみましたがサクサク起動したしました。パソコンやその他の環境にもよりますが、外部ハードディスクだと読み込みが遅くエラーが発生したのでSSDを使っています。終わりに
マウスの統合とゲストOSの画面を自動リサイズする方法がわからないという根本的な問題が解決していないので、解決できたら記事を追加しようと思います。コメントなどで教えていただけると幸いです。

- 投稿日:2019-12-03T16:50:02+09:00
GoogleColaboratoryにAppleWatchデータを取り込んで分析してみた
はじめに
溜め込んだAppleWatchのデータをColab上でpandasとmatplotlibでいい感じに可視化したい
パパこんなにガンバッたんだよって、、娘に褒められたいんです。。
娘に尊敬されたい一心で、ガンバッてみました。先に結論です。
作業自体は難しくないけど、データがとにかく重い。。
1年間コツコツ記録したおかげで、データ容量(xml)が643MB!
それと、
一部のデータがiphone・AppleWatchと値がなぜだか合わないです。
私のある1日の活動代謝は8972kcalでした。
あれっ?この日は、椅子に座ってコーディングだけだったのですが、、
ちなみに、ガチのトライアスロンと同じぐらいの消費カロリーだそうです。
(スイム:3.8km +バイク:180km +ラン:42.195km)出力ミスなのか、それともPandasの操作ミスなのか、謎が深まります。。
それ以外は、おおむね使えそうなデータでしたので、歩数データを取り出して色々とゴニョってみることにしました。
Applewatchデータのエキスポート
兎にも角にも、まずはデータのエキスポートしないと始まらないです。
AppleWatchのデータは同期しているiphoneに貯められています。
AppleWatchに限らずに「ヘルスケア」アプリに紐付けられたデバイス、サードパーティアプリのログも1つのデータに統合されます。それでは、iphoneの「ヘルスケア」アプリからエキスポートします。
今の所は、このアプリからのエキスポート以外の方法は無さそうです。「ヘルスケア」アプリから書き出す
- iphoneの「ヘルスケア」を起動
- 右上の自分のアイコンを選択
- 「ヘルスケアデータを書き出す」を選択
- 案内に沿って、出力方法を選択し書き出す。
iphoneでの書き出しに10分程かかりました。
ファイルはzip圧縮されて、出力先はiCloud、メールなど選べます。
私の場合は、結構大きなファイルだったため、AirDropで直接macbookに転送しました。zipを解凍すると、export.xmlを取り出せます。これがAppleWatchのログデータとなります。
xmlだとデータの取り回しが悪いので、csvに変換していきます。データをCSVに変換
GitHubGistにステキな変換プログラムが公開されているのでそちらをダウンロード
ConvertAppleHealthXMLtoCSV.py
https://gist.github.com/xiantail/12784626d1c82411e0b986f71d1171ee#file-convertapplehealthxmltocsv-pyいくつか修正
ConvertAppleHealthXMLtoCSV.py#以下:33行ー39行目をコメントアウト #valueをkeyとする値が無くそのままではエラーになってしまったので try: float(att_values['value']) except ValueError: #att_values['value_c'] = att_values['value'] #att_values['value'] = 0 continue #以下:56行目 #自分の環境に合わせて任意にpathを変更 if __name__ == '__main__': convert_xml_to_csv('export.xml')日付付きファイル名のcsvが生成されます。
export20191021214259.csv
(以降、面倒なのでexport.csvとします)GoogleColab
正式名は、「Google Colaboratory」です。
Googleが提供するサービスで、一言でいうと「jupyter notebook」のクラウド版です。
こちらにデータを持ち込んでゴニョゴニョやっていきます。Colabへのデータ取り込みにはいくつか方法があるようですが、私が行ったのは以下の方法です。
- export.csvをGoogleDriveにアップ
- GoogleColabからGoogleDriveのファイルを読み込む
GoogleDriveにアップは割愛させていただきます。
GoogleDriveからファイルを読み込む
Clob上から、GoogleDriveにアップしたデータを読み込みます。
from google.colab import drive drive.mount('/content/drive')実行すると、リンク先の表示と
authorization codeの入力を求められます。
リンクを辿って、自分のGoogleアカウントの権限コードをコピーして入力すると、
サイドバー > ドライブにgoogleDriveのファイルが表示されます。余談ですがGoogleColabは英語ではありますが、痒い所に手が届く親切サービスです。
何か分からない、きっとそんな機能がありそうだなーと感じたら、
コードスニペットから検索することができます。
driveって打つだけでGoogleDriveの接続方法を教えてくれます。
さらに、「挿入」ボタンクリックするだけでコードをペーストしてくれます、便利ですね。前処理
まずはお決まりのモジュールの読み込み。
import pandas as pd import matplotlib.pyplot as plt続いて、export.csvを読み込みます。
読み込みPathは、先程取り込んだサイドバー >ドライバーで該当のファイルを右クリックすると
パスをコピーが出てくるのでそちらを使ってコピペが便利です。
ファイルが大きすぎて読み込みに何度か失敗する場合は、low_memory=Falseのオプションを使ってみてください。取り込み
df = pd.read_csv('/content/drive/My Drive/ColabNotebooks/export20191021214259.csv', low_memory=False) df.head(3)
AppleHealthCareデータのフォーマットは以下となります。
- type: AppleHealthCare内でのデータ区分
- sourceName: データの取得元(この場合、「わたしの水」という連動アプリから取得されたデータ)
- sourceVersion: データ取得元のバージョンナンバー
- unit: 単位
- creationDate: データ作成日時
- startDate: データの取得の開始日時
- endDate: データの取得の終了日時
- value: 値 ほしいのはコレ
- device: 取得デバイス(センサー機器)
データ整理
データも重いし、見ずらいのでDataframeを少し整理します。
# デバイスはNaNか、appleWatchしか無いので削除、versionも特に必要無いので削除 df_apple = df.drop(["sourceVersion","device"], axis=1) df_apple = df_apple.loc[:,['type','sourceName','value','unit', 'creationDate', 'startDate', 'endDate']] #作成日をIndexに設定、日付はただの文字列なのでdatetimeに型変換 df_apple = df_apple.set_index('creationDate') df_apple.index = pd.to_datetime(df_apple.index, utc=True).tz_convert('Asia/Tokyo') #値を整える。NaNのデータを削除、数値では無いものも削除、浮動小数点に型変換 df_apple = df_apple.dropna(subset=['value']) df_apple.drop(df_apple.index[df_apple['value'].str.match('[^0-9]')], inplace=True) df_apple['value'] = df_apple['value'].astype(float) #タイプが長ったらしいので、共通の余分な箇所を削除 df_apple['type'] = df_apple['type'].str.replace('HKQuantityTypeIdentifier','') #後で、月ごとや曜日ごとなどでソートしたり分析したいので、Indexに年、月、日、時間、曜日を追加 df_apple = df_apple.set_index([df_apple.index.year, df_apple.index.month, df_apple.index.day, df_apple.index.hour, df_apple.index.weekday, df_apple.index]) df_apple.index.names = ['year', 'month', 'day', 'hour', 'weekday', 'date'] df_apple.head()
だいぶスッキリしました。
df_apple.info()
NaNなど掃除しましたが、データ数は153万以上ありますね。
日付はIndexに変換、valueがfloat型にしてあります。
xmlから変換して、データ整理してもまだ87MB以上ありますね。。重いです。区分を見てみる
データの内訳はどうなってるか見てみます。
print(df_apple['type'].drop_duplicates().to_string(index=False, header=False)) print(df_apple['sourceName'].drop_duplicates().to_string(index=False, header=False))

- type
データの取得元なので、アプリ名だったりデバイス名が入ります(akinkoは私のニックネーム)- sourceName
データの項目名だったり、種類が入っています。例えば体重とか、歩行距離とかです(余分な接頭辞は消去済みです)基本的にはsourceNameでデータを絞り込んでいきます。
複数のアプリや端末で、ひとつのsourceNameを共用している場合もあり、個別で調べたい場合はtypeを利用してデータを絞り込むと良いでしょう。
(例:appleWatchとiphone両方でstepcount(歩数)を取っているけど、applewatchで計測したデータだけを利用したい場合など)分析
ここまでで、データの整頓と、ザックリと内容の確認ができました。
実際にデータの中身を見ていきます。歩数
まずは、歩数データだけを絞り込んだDataFrameを作成
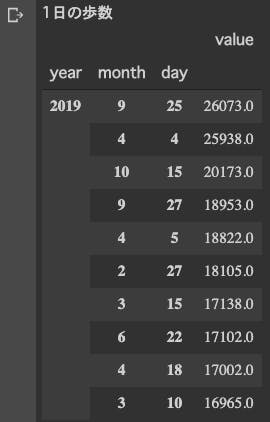
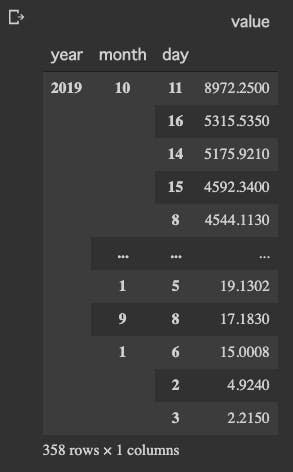
# 歩数:StepCount #アプリで2重に取得している箇所があったため一方を削除 df_step = df_apple[(df_apple['type'] == 'StepCount') & ~(df_apple['sourceName'] == 'ヘルスケア')] #理由は不明だが、2018年が誤差が多く、2019年のみに絞る df_step = df_step.query("year == '2019'")1日の歩数ランキングTOP10
#日毎の歩数合計 daily_step = df_step.sum(level=['year', 'month', 'day']).sort_values('value', ascending=False) print('1日の歩数') daily_step.head(10)
すごい歩いてますね、1位の9/25。
iphoneのデータとも整合取れているので、エラーではなさそうです。
調べてみると、有給休暇使ってお台場のチームラボ展に行って歩き回った日でした、なるほど♪曜日ごと
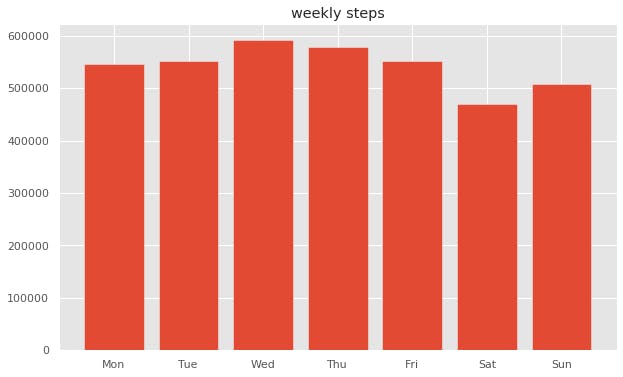
何曜日が1番歩いているのか調べてみました。
#曜日毎の歩数合計 #0月曜ー6日曜 weekly_step = df_step.sum(level=['weekday']).sort_values('weekday') weekly_stepplt.figure(figsize=(10,6)) plt.style.use('ggplot') plt.title("weekly steps") label = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"] # plt.xlabel("week") # plt.ylabel("steps") # plt.ylim(450000, 600000) plt.bar(weekly_step.index, weekly_step.value, tick_label=label, label="steps", align="center") plt.show()
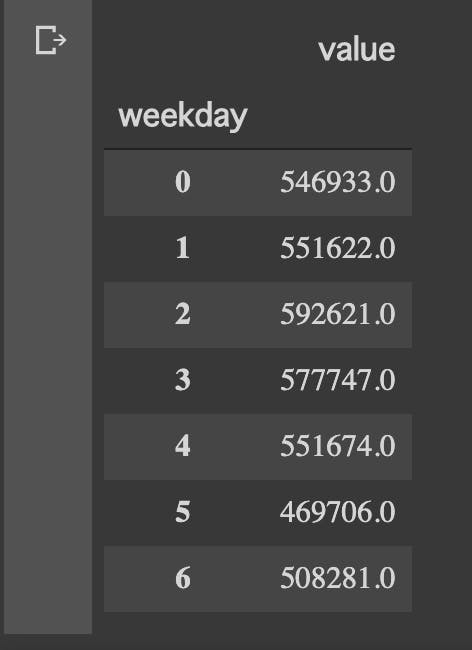
ふむふむ、
出勤が無いので土日が少なめだが、比較的に日曜は家族で出かけることが多い。
水曜は会社帰りにジムでランニングマシーンで少し走るから1番多いのか。
土曜ももう少し体を動かすことにします。月ごと
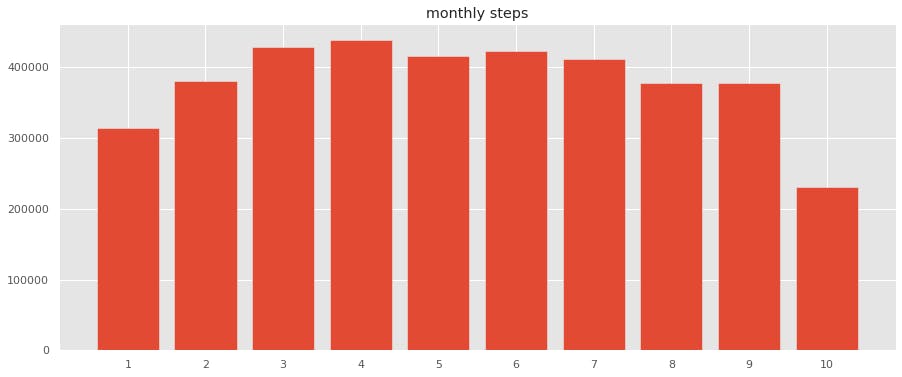
月ごとの歩数量も見てみます。
#月ごとの歩数合計 monthly_step = df_step.sum(level=['month']).sort_values('month') monthly_stepplt.figure(figsize=(15,6)) plt.style.use('ggplot') plt.title("monthly steps") label = list(range(1, 11)) # plt.xlabel("month") # plt.ylabel("steps") plt.bar(monthly_step.index, monthly_step.value, tick_label=label, label="steps", align="center") plt.show()
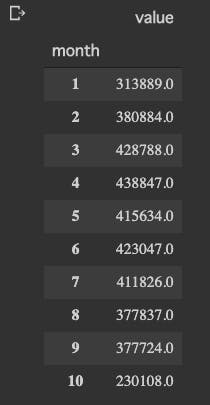
10月の途中でデータエクスポートしたので、10月は少ないです。
1月はインフルエンザと、寝正月で運動してないですね、、
今年の8月、9月は暑かったのであまり外に出なかった。
来年はインドアでも運動できるように工夫しよう。週の歩数と合わせると
けっこう自分の行動パターンがわかって面白いです。消費カロリー
最後に、消費カロリーについて触れておきます。
- 基礎代謝:basalEnergyBurned
何もしていなくても、生命維持のため消費されるカロリー- 活動代謝:activeEnergyBurned
運動により、消費されるカロリー冒頭でも触れたとおり、とんでもない値が出てしまっています。
そのためか、iphone,applewatchとの合計値が整合取れてないです。
xmlからcsvへの変換でミスをしているのか、
それともログ計測1年間の間でAppleHealthCareで仕様が変更されたのかもしれません。いちおう、活動代謝を計算して1日の消費TOP10を出してみました。
明らかにおかしい・・w
椅子に座ってコーディングしてただけなのに、8972kcal!!(トライアスロンのアイアンマン)
米国の特殊部隊でもこんなにカロリー消費しないのでは(´゚д゚`)この記事を書き終わる直前ですが、連動させている体重計やサードパーティアプリの値も被って入っている可能性に気づきました。
機会があれば検証してみたいと思います。Appleさん、csv変換プログラムさん疑ってすいませんでしたおわりに
後々、気付いてしまったのですが、
11月のiOSアップデートで「ヘルスケア」アプリが結構優秀になっていました。
アプリ内だけでも、分かりやすく表示してくれるようになりました。AppleWatchの活動データだけでなく、体重計や、睡眠時間、筋トレログなどと連動して分析してみるのも面白そうですね。
ここまでお読み頂きありがとうございました、皆様のヘルシープログラマーライフをお祈りしております。





- 投稿日:2019-12-03T16:41:55+09:00
スプラトゥーン2の戦績データを取得する+おまけ
これはCAMPHOR- Advent Calendar 2019の7日目の記事です。6日目は@watamboさんの「中目黒のコミュニティスペースCAMPHOR- BASEにみんなおいでヨ!」でした
こんにちは。@asamasです。あさますと読みます。
みんなが「リングフィットアドベンチャー」や「ポケモンソード」などを楽しんでいる中、僕は相も変わらずスプラトゥーン2をプレイしてます。今回は、スプラトゥーン戦績管理アプリである「ikaWidget2」に記録されているデータを引っこ抜いて、簡単な分析などをしてみようと思います。
.ikax -> .zip
ikaWidget2にはバックアップ機能があり、そこからファイルを出力すると、
asamas-20191204-1011.ikaxのようなファイルが作成されます。このファイルは拡張子を変えれば、そのままzipファイルとして読み込めます。
解凍すると、下の写真のように、info.jsonとstats.realmが見つかると思います。戦績データは、stats.realmの中に入っています。
realmファイルの内容をjsonに書き出す
realm studioをインストールします。stats.realmファイルを開いた後、File > Save Data > Jsonで書き出せます。
この機能に気づかずに、realm (nodejs) 使おうとしてめちゃくちゃ時間とかしました戦績データの解析
このデータを使って、自分の苦手ステージを調べてみました。
まずはjsonファイルを取り込みましょう# -*- coding: utf-8 -*- import json with open("results.json","r",encoding="utf-8") as f: result_json=json.load(f)ルールごとの違いを調べます。下の例ではガチエリア(
splat_zonesgachi)を調べています。ガチホコを調べたいときはrainmakergachi、ガチヤグラはtower_controlgachi、ガチアサリはclam_blitzgachiに変更してください。area_result={} for item in result_json["Result"]: if item["udemae"]<9 and item["game"]!="splat_zonesgachi": #S以上の戦績に限定&ガチエリア以外のルールを排除 continue for i in result_json["Stage"]: if i["ID"]==item["stage"]: stage_name=i["name"] if not stage_name in area_result.keys(): area_result[stage_name]={"win":0,"lose":0} if item["win"]: area_result[stage_name]["win"]+=1 else: area_result[stage_name]["lose"]+=1 for key in sorted(area_result.keys(),key = lambda x:area_result[x]["win"]/(area_result[x]["win"] +area_result[x]["lose"]),reverse=True): print(key,area_result[key]["win"]/(area_result[key]["win"] +area_result[key]["lose"]))結果はこのようになりました。
ガチエリア
ガチヤグラ
ガチホコ
モズク農園やニューオートロがどのルールでも上位に来ています。僕の持ちブキのクーゲルシュライバーで、得意とされているルールですね。一方でザトウ・チョウザメ・ムツゴロウなどの勝率は30~40%ぐらいなので、相性が悪いステージだとわかります。
今後
今回は時間がなくて中途半端な記事になってしまいましたが、ikaWidget2からデータを引っこ抜く方法はわかりましたので、LightGbmなどを使って、より詳しい分析ができたらと思います