- 投稿日:2019-11-02T23:22:13+09:00
JavaのStreamで並列化できるのは最上位のStreamだけ。
結論からいうと、Streamで並列化できるのは、最上位のStreamだけ。flatMapなどで,入れ子のStreamの処理については並行が効かない。(Javaのコードも読んだが,flatMapのStreamは内部コードでSequentialに変更されていることを確認した。)
基本的にはできるだけ上位の処理を並列化するのが,一般的には効率がよく並列化できるため,この実装は納得できるものではあるが,必ずしも万能なわけではない。
例えば,木構造を辿って処理するようなコードを書いていたりする場合に,木構造の偏りによって並列化が期待したほど効かないということがある。そもそも木構造を処理するのは別の方法のほうがよいかもしれないが。
確認のためのコードは以下。タスクを二重配列で持っていて,これをStreamで処理することを考える。
package parallel; import java.util.ArrayList; import java.util.List; import java.util.Random; import java.util.concurrent.ForkJoinPool; import java.util.stream.Collectors; import java.util.stream.IntStream; public class Test1 { static class TestTask implements Runnable { @Override public void run() { try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } } public static void main(String[] args) throws InterruptedException { List<List<TestTask>> table = new ArrayList<>(); int sum = 0; int max = 0; Random rgen = new Random(0); for (int j = 0; j < 3; ++j) { List<TestTask> list = IntStream.range(0, 5 + rgen.nextInt(10)) .mapToObj(i -> new TestTask()) .collect(Collectors.toList()); table.add(list); sum += list.size(); max = Math.max(max, list.size()); } System.out.println("table: "+ table.stream() .map(l -> Integer.toString(l.size())) .collect(Collectors.joining(", "))); System.out.printf("sum: %d, max: %d\n", sum, max); System.out.println("parallelism: "+ ForkJoinPool.commonPool().getParallelism()); System.out.println(); { // 1.base-parallel long t0 = System.currentTimeMillis(); table.stream() .parallel() .flatMap(l -> l.stream()) .forEach(task -> task.run()); System.out.printf("1.base-parallel: %,5d msec\n", (System.currentTimeMillis() - t0)); } { // 2.flat-map-parallel long t0 = System.currentTimeMillis(); table.stream() .flatMap(l -> l.parallelStream()) .forEach(task -> task.run()); System.out.printf("2.flat-map-parallel: %,5d msec\n", (System.currentTimeMillis() - t0)); } { // 3.both-parallel long t0 = System.currentTimeMillis(); table.parallelStream() .flatMap(l -> l.parallelStream() .peek(task -> task.run()) .collect(Collectors.toList()) .stream()) .forEach(task -> {}); System.out.printf("3.both-parallel: %,5d msec\n", (System.currentTimeMillis() - t0)); } } }結果は以下。
table: 5, 13, 14 sum: 32, max: 14 parallelism: 3 1.base-parallel: 1,424 msec 2.flat-map-parallel: 3,281 msec 3.both-parallel: 926 msec各結果について順にみていく。
1.base-parallelで上位の配列でのみ並列化される。そのため,タスクの二重配列の多少偏りの影響を受ける。table[3].lengthの14の影響を受けて14*100msecの時間がかかることが確認できる。
2.flat-map-parallelでは,冒頭で述べた通りparallelは効かない。そのため,すべてのタスクをsequentialに処理するため,タスクの合計の32*100msecの時間がかかっている。
3.both-parallelでは,flatMap内で無駄に終端処理collectを挟むことで,並列化させている。これによって,最も短い時間で終了できている。
ちなみに,確認した反映ではJavadocなどの記載でもこのあたりの振る舞いについての記載は見つけられなかった。どこかに記載があることをご存知の方は教えていただけると助かります。
- 投稿日:2019-11-02T17:15:54+09:00
Glide4系のDiskCacheについて
ギガを食うのを改善したいとの要望がありGlideのDiskCacheを調査したときのログ
TL;DL
- /data/data/app_dir/image_manager_disk_cacheに保存される
- キャッシュアルゴリズムはLRU(Least Recently Used)
- キャッシュ容量はデフォルトで250MB(250*1024*1024)
キャッシュの保存場所や容量について
デフォルトはinternalなimage_manager_disc_cacheディレクトリに容量250MBまで保存可
これらはGlideModuleを定義すれば変更可
example.java@GlideModule public class YourAppGlideModule extends AppGlideModule { @Override public void applyOptions(Context context, GlideBuilder builder) { builder.setDiskCache(new ExternalCacheDiskCacheFactory(context)); } } @GlideModule public class YourAppGlideModule extends AppGlideModule { @Override public void applyOptions(Context context, GlideBuilder builder) { int diskCacheSizeBytes = 1024 * 1024 * 100; // 100 MB builder.setDiskCache(new InternalCacheDiskCacheFactory(context, diskCacheSizeBytes)); } } @GlideModule public class YourAppGlideModule extends AppGlideModule { @Override public void applyOptions(Context context, GlideBuilder builder) { int diskCacheSizeBytes = 1024 * 1024 * 100; // 100 MB builder.setDiskCache( new InternalCacheDiskCacheFactory(context, "cacheFolderName", diskCacheSizeBytes)); } }refs
キャッシュ戦略とアルゴリズムについて
デフォルトではAUTOMATIC
リモートデータは特に処理を加えずそのままキャッシュする。ローカルデータは必要があればリサイズ等の処理を加えた上でキャッシュする。
実装
image_manager_disc_cacheには
.0拡張子ファイルとjornalが存在する
これらはDevice File Explorerでも確認可jornalの中身は以下のような構成
libcore.io.DiskLruCache 1 100 2 CLEAN 832 21054 DIRTY 335c4c6028171cfddfbaae1a9c313c52 CLEAN 335c4c6028171cfddfbaae1a9c313c52 3934 2342 REMOVE 335c4c6028171cfddfbaae1a9c313c52 DIRTY 1ab96a171faeeee38496d8b330771a7a CLEAN 1ab96a171faeeee38496d8b330771a7a 1600 234 READ 335c4c6028171cfddfbaae1a9c313c52 READ 3400330d1dfc7f3f7f4b8d4d803dfcf6
3400330d1dfc7f3f7f4b8d4d803dfcf6→ 画像urlから生成されるハッシュ値
3934 2342→ メタデータと実レスポンスサイズ
DIRTY→ キャッシュ中
CLEAN→ キャッシュ済み
READ→ アプリによりアクセス中
REMOVE→ 削除対象これらステータスを逐一読み取りキャッシュ管理を行う
アルゴリズム
LRU(Least Recently Used)
上記実装で更新が走ったものが後列に積まれるジャーナルのリビルド
キャッシュサイズが上限に達する or
redundantOpCount(REMOVE) が2000以上かつサイズがhalveになっている場合にjournalのリビルド及びcacheの削除を行う(とコメントにあったが実装と食い違っているような気がするので詳しい人教えてください。)DiskLruCahe.java/** * We only rebuild the journal when it will halve the size of the journal * and eliminate at least 2000 ops. */ private boolean journalRebuildRequired() { final int redundantOpCompactThreshold = 2000; return redundantOpCount >= redundantOpCompactThreshold // && redundantOpCount >= lruEntries.size(); }DiskLruCahe.javaprivate void trimToSize() throws IOException { while (size > maxSize) { Map.Entry<String, Entry> toEvict = lruEntries.entrySet().iterator().next(); remove(toEvict.getKey()); } } /** This cache uses a single background thread to evict entries. */ final ThreadPoolExecutor executorService = new ThreadPoolExecutor(0, 1, 60L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(), new DiskLruCacheThreadFactory()); private final Callable<Void> cleanupCallable = new Callable<Void>() { public Void call() throws Exception { synchronized (DiskLruCache.this) { if (journalWriter == null) { return null; // Closed. } trimToSize(); if (journalRebuildRequired()) { rebuildJournal(); redundantOpCount = 0; } } return null; } };refs
https://github.com/bumptech/glide/blob/master/library/src/main/java/com/bumptech/glide/load/engine/DiskCacheStrategy.java
https://futurestud.io/tutorials/retrofit-2-analyze-cache-filesapendix
主要なクラスの関係は以下の通り
DiskLruCache.java
|
DiskLruCacheWrapper.java
|
DiskLruCacheFactory.java
|
InternalCacheDiskCacheFactory.java/InternalCacheDiskCacheFactory.java
|
GlideBuilder.java
- 投稿日:2019-11-02T17:15:54+09:00
Glide4系のDiskCacheStrategyについて
ギガを食うのを改善したいとの要望がありGlideのDiskCacheを調査したときのログ
TL;DL
- /data/data/app_dir/image_manager_disk_cacheに保存される
- キャッシュアルゴリズムはLRU(Least Recently Used)
- キャッシュ容量はデフォルトで250MB(250*1024*1024)
キャッシュの保存場所や容量について
デフォルトはinternalなimage_manager_disc_cacheディレクトリに容量250MBまで保存可
これらはGlideModuleを定義すれば変更可
example.java@GlideModule public class YourAppGlideModule extends AppGlideModule { @Override public void applyOptions(Context context, GlideBuilder builder) { builder.setDiskCache(new ExternalCacheDiskCacheFactory(context)); } } @GlideModule public class YourAppGlideModule extends AppGlideModule { @Override public void applyOptions(Context context, GlideBuilder builder) { int diskCacheSizeBytes = 1024 * 1024 * 100; // 100 MB builder.setDiskCache(new InternalCacheDiskCacheFactory(context, diskCacheSizeBytes)); } } @GlideModule public class YourAppGlideModule extends AppGlideModule { @Override public void applyOptions(Context context, GlideBuilder builder) { int diskCacheSizeBytes = 1024 * 1024 * 100; // 100 MB builder.setDiskCache( new InternalCacheDiskCacheFactory(context, "cacheFolderName", diskCacheSizeBytes)); } }refs
キャッシュ戦略とアルゴリズムについて
デフォルトではAUTOMATIC
リモートデータは特に処理を加えずそのままキャッシュする。ローカルデータは必要があればリサイズ等の処理を加えた上でキャッシュする。
実装
image_manager_disc_cacheには
.0拡張子ファイルとjornalが存在する
これらはDevice File Explorerでも確認可jornalの中身は以下のような構成
libcore.io.DiskLruCache 1 100 2 CLEAN 832 21054 DIRTY 335c4c6028171cfddfbaae1a9c313c52 CLEAN 335c4c6028171cfddfbaae1a9c313c52 3934 2342 REMOVE 335c4c6028171cfddfbaae1a9c313c52 DIRTY 1ab96a171faeeee38496d8b330771a7a CLEAN 1ab96a171faeeee38496d8b330771a7a 1600 234 READ 335c4c6028171cfddfbaae1a9c313c52 READ 3400330d1dfc7f3f7f4b8d4d803dfcf6
3400330d1dfc7f3f7f4b8d4d803dfcf6→ 画像urlから生成されるハッシュ値
3934 2342→ メタデータと実レスポンスサイズ
DIRTY→ キャッシュ中
CLEAN→ キャッシュ済み
READ→ アプリによりアクセス中
REMOVE→ 削除対象これらステータスを逐一読み取りキャッシュ管理を行う
アルゴリズム
LRU(Least Recently Used)
上記実装で更新が走ったものが後列に積まれるジャーナルのリビルド
キャッシュサイズが上限に達する or
redundantOpCount(REMOVE) が2000以上かつサイズがhalveになっている場合にjournalのリビルド及びcacheの削除を行う(とコメントにあったが実装と食い違っているような気がするので詳しい人教えてください。)DiskLruCahe.java/** * We only rebuild the journal when it will halve the size of the journal * and eliminate at least 2000 ops. */ private boolean journalRebuildRequired() { final int redundantOpCompactThreshold = 2000; return redundantOpCount >= redundantOpCompactThreshold // && redundantOpCount >= lruEntries.size(); }DiskLruCahe.javaprivate void trimToSize() throws IOException { while (size > maxSize) { Map.Entry<String, Entry> toEvict = lruEntries.entrySet().iterator().next(); remove(toEvict.getKey()); } } /** This cache uses a single background thread to evict entries. */ final ThreadPoolExecutor executorService = new ThreadPoolExecutor(0, 1, 60L, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(), new DiskLruCacheThreadFactory()); private final Callable<Void> cleanupCallable = new Callable<Void>() { public Void call() throws Exception { synchronized (DiskLruCache.this) { if (journalWriter == null) { return null; // Closed. } trimToSize(); if (journalRebuildRequired()) { rebuildJournal(); redundantOpCount = 0; } } return null; } };refs
https://github.com/bumptech/glide/blob/master/library/src/main/java/com/bumptech/glide/load/engine/DiskCacheStrategy.java
https://futurestud.io/tutorials/retrofit-2-analyze-cache-filesapendix
主要なクラスの関係は以下の通り
DiskLruCache.java
|
DiskLruCacheWrapper.java
|
DiskLruCacheFactory.java
|
InternalCacheDiskCacheFactory.java/InternalCacheDiskCacheFactory.java
|
GlideBuilder.java
- 投稿日:2019-11-02T16:24:56+09:00
Chrome + KatalonRecorder + vscode + Katalium でUIテストの自動化を体験してみた
なんでやってみたのか
業務で、同一ファイルの複数回ダウンロードを検証する必要が発生した。
簡単な準備で検証できないかと考え、UIテスト自動化ツールが使えないかと考えた。
KatalonRecorderを以前に聞いたことがあったので、試してみた。サマリ
KatalonRecorderとVSCodeのExtensionを組み合わせることで、複数回のファイルダウンロードのテストは実現できた。
※Extensionのサンプルプロジェクトと、その中のWebDriver(Chrome)を利用。
- KatalonRecorderで1回ダウンロードをRecorde
- KatalonRecorderでRecordeしたシナリオをJavaでExport
- VSCodeの公式Extensionを利用し、ExportしたJavaをサンプルプロジェクトに取り込み
- ファイルダウンロードを待つためにSleepを追加
- 繰り返し処理を追加
動作確認環境
- macOS Catalina 10.15
- java 1.8.0_202
- nginx 1.13.10
- chrome (2019年10月上旬の最新版)
- Katalon Recorder (Selenium tests generator) 3.9.2
- vscode
- Extension: Katalium - Selenium and TestNG made easy
- Extension: Java Extension Pack
やりたいこと
下記のような画面にて、画像をクリックするとテキストファイルがダウンロードされます。
そのダウンロードを複数回(1,000回)実行して、下記の動作の確認がしたい。
- 想定回数のダンロードが完了するのか
- ダウンロードされたファイルのファイル名がどのようになるのか
テスト画面の画面イメージ
テスト画面のHTML
o310yusuke-test.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>o310yusuke-test</title> </head> <body> <h1>o310yusuke-test</h1> <div id="test0" onclick="console.log('div clicked!');"> <a href="data/test.yusuke"> <img src="img/100125-114814.jpg" height="100" onClick="console.log('img clicked!!!!');" /> </a> </div> </body> </html>やったこと・ハマったこと・脱出するためにやったこと
注意 各ツールのインストールやアクティベーションの方法は割愛させていただきます。
まずは、KatalonRecorderでRecordを。
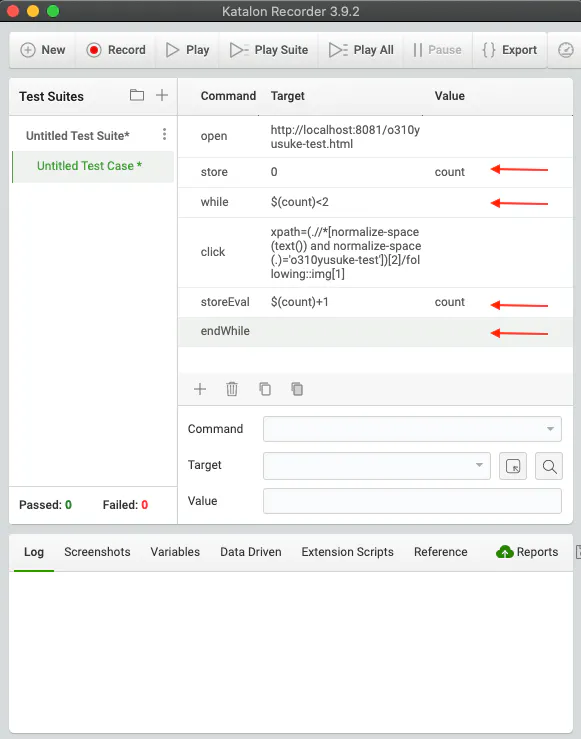
Recordした操作の中から、ダウンロードの処理をループ化する。
(赤矢印部分を追加)
- ダウンロード処理の前に変数を設定
- Command: store
- Target: 0
- Value: count
- ダウンロード処理の前でループの条件を記載
- Command: while
- Target: $(count)<2
- Value: 空欄
- カウント数を更新
- Command: storeEval
- Target: $(count)+1
- Value: count
- ループの終了を記述
- Command: endWhile
- Target: 空欄
- Value: 空欄
Play!
・・・
あれ??
・・・・・・
上記ループを追加しない状態ではダウンロードされるが、ループを追加すると動かない。。。
Chomeのダウンロード前に保存場所を確認しないようにはしている。。。
原因はなんだ?!
調べてみたが、原因の特定には至らず。。。KatalonStudioではできるのか、試してみるか。。。
KatalonStudioをMacにインストール
KatalonStudioをダウンロードして、Applicationに移動させて、さて、実行!!
・・・
あれ??
・・・・・・
起動エラーが出る。。。(内容は忘れました)うん、他の方法を探してみよう、ということで、VSCodeに公式Extensionがあるとわかったので、導入!
VSCodeに公式Extensionを導入してみる。
下記の公式サイト見ながら、サンプルプロジェクトが動作することは確認できた。
Get Started with Katalium Framework in Visual Studio Code先程RecordしたテストシナリオをVSCodeの公式Extensionを使って動くか試してみる。
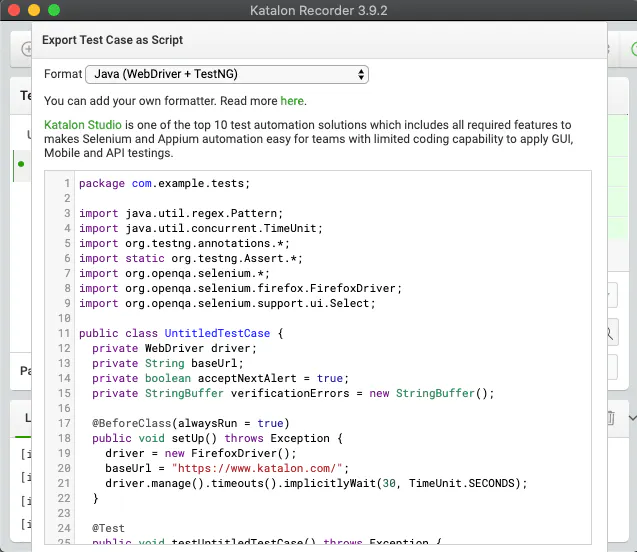
KatalonRecorderの「Export」ボタンをクリックして、フォーマットをExtensionに合わせて「Java (WebDriver + TestNG)」でExport。
パッケージ名とかクラス名は適宜修正し、Katalonのサンプルプロジェクトに取り込むと下記のような感じに。
今回は、「jp.o310yusuke.qiita.testcase.TestCase.java」とした。
このままではImportしたテストシナリオが動かないので、修正する。
- FirefoxDriverではなく、サンプルで準備しているDriverを使うようにする
- TestTemplateを継承する
- TestTemplateのWebDriverを利用するようにprivate変数のWebDriverをコメントアウトする
- 同様に、setUp()もコメントアウトする
jp.o310yusuke.qiita.testcase.TestCasepublic class TestCase extends TestTemplate { // private WebDriver driver; private String baseUrl; private boolean acceptNextAlert = true; private StringBuffer verificationErrors = new StringBuffer(); // @BeforeClass(alwaysRun = true) // public void setUp() throws Exception { // driver = new FirefoxDriver(); // baseUrl = "https://www.katalon.com/"; // driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS); // }
- インポートしたテストクラスをテスト対象に登録する
- テスト名「simple」と「parameterize」をコメントアウト
- インポートしたクラスを登録
/src/test/resources/testng.xml<?xml version = "1.0" encoding = "UTF-8"?> <!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd" > <suite name="Suite1" verbose="1" > <!-- <test name="simple" > <parameter name="kataDisableScreenshot" value="false" /> <classes> <class name="com.katalon.kata.sample.testcase.simple.MakeAppointmentTest" /> </classes> </test> <test name="parameterize" > <parameter name="kataDisableScreenshot" value="true" /> <parameter name="facility" value="Hongkong CURA Healthcare Center" /> <parameter name="visitDate" value="27/12/2016" /> <parameter name="comment" value="Please make appointment as soon as possible." /> <classes> <class name="com.katalon.kata.sample.testcase.parameterize.ParameterizedMakeAppointmentTest" /> </classes> </test> --> <test name="qiitaTest"> <classes> <class name="jp.o310yusuke.qiita.testcase.TestCase" /> </classes> </test> </suite>
- コンソールで下記を実行して、実行を確認する(繰り返し処理はコメントアウト状態)
- このままでは、ダウンロード完了前にWebDriverを閉じてしまうので、実際にはDLされず。。。
mvn clean test
- ダウンロードするようにSleepを追加
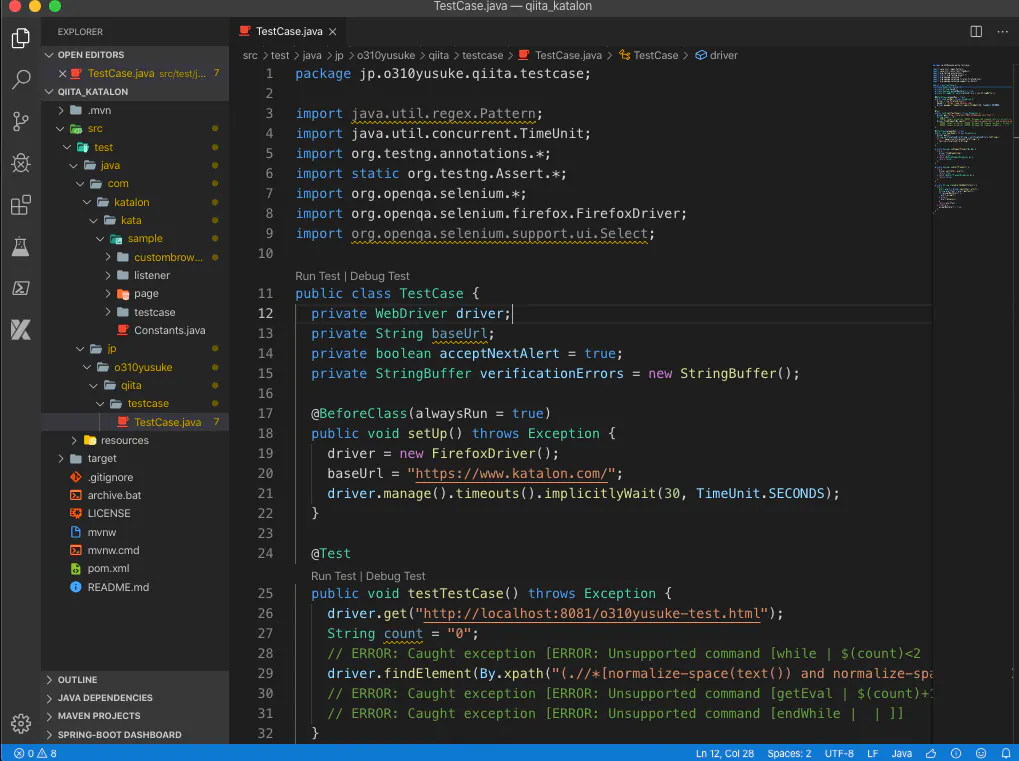
jp.o310yusuke.qiita.testcase.TestCase@Test public void testTestCase() throws Exception { driver.get("http://localhost:8081/o310yusuke-test.html"); String count = "0"; // ERROR: Caught exception [ERROR: Unsupported command [while | $(count)<2 | ]] driver.findElement(By.xpath("(.//*[normalize-space(text()) and normalize-space(.)='o310yusuke-test'])[2]/following::img[1]")).click(); // ダウンロードが完了するのを待つためにSleep try { Thread.sleep(2000); } catch (Exception e) { e.printStackTrace(); } // ERROR: Caught exception [ERROR: Unsupported command [getEval | $(count)+1 | ]] // ERROR: Caught exception [ERROR: Unsupported command [endWhile | | ]] }
- 繰り返しを実装(不要な実装は削除)
jp.o310yusuke.qiita.testcase.TestCase@Test public void testTestCase() throws Exception { driver.get("http://localhost:8081/o310yusuke-test.html"); int count = 0; while (count < 2) { driver.findElement(By.xpath("(.//*[normalize-space(text()) and normalize-space(.)='o310yusuke-test'])[2]/following::img[1]")).click(); // ダウンロードが完了するのを待つためにSleep try { Thread.sleep(2000); } catch (Exception e) { e.printStackTrace(); } count++; } }
- 完成!!!


- 投稿日:2019-11-02T14:48:47+09:00
Java 1 1 support from Google App Engine
Google’s App Engine cloud has added official support for Java 11, the latest long-term support (LTS) version of the Java language platform, as a production release.
The App Engine Standard Environment Java 11 runtime is generally available for running any Java 11 application, web framework, or service in a managed serverless environment. Java 11 had been offered on App Engine in a beta release since June.
The Java 11 runtime on App Engine offers twice the amount of memory as the earlier Java 8 runtime, providing better support for applications that run under a heavy workload with large amounts of data. Developers can use frameworks including Spring Boot, Ktor, Vert.x, or Micronaut.In the Google App Engine managed the environment, the runtime is automatically updated with the latest security patches to the operating system and minor revisions to the Java Development Kit (JDK). App Engine also provides services including request tracing, traffic splitting, centralized logging, and production debugging.
Java 11, or JDK 11, was made available by Oracle in September 2018. As an LTS version, Java 11 is slated to receive support from Oracle well into the next decade. This contrasts with six months of Oracle support for other releases, such as the current JDK 13 release or the prior JDK 12 release.
How to access Google App Engine’s Java 11 runtime;
You can access the Google App Engine Java 11 Standard Environment documentation from the Google Cloud website. Google also is offering guidance on migrating App Engine Java 8 applications to App Engine Java 11. You can learn directly from the java training in Chennai. for references google cloud website.
- 投稿日:2019-11-02T09:38:50+09:00
forの書き換えなんだろと理解しているStreamAPIを少し深堀する。
JavaのStreamAPIを書きながら、そういえばこれってどういことなんだと
自分が疑問に思っていたことについて少しまとめてみました。
StreamAPIのtips集ではないので、そういうの期待されて記事を覗いた方は申し訳ありません。この記事の概要
この記事を読めばこの要素について、ちょっと理解できる。
- 関数型インターフェース
- 中間処理と終端処理この記事の目指すところ
なんとなく理解しているStreamAPIの文法的な要素を覚える。
そもそもStreamAPIの書き方って、どんなのだっけ。
1~10の偶数のみを表示するといった処理の場合のStreamAPIの書き方は下記のような形です。
Arrays.stream(new int[]{1,2,3,4,5,6,7,8,9,10}) .filter( i -> (i % 2) == 0 ) .forEach( i -> System.out.println(i));(IntStream.rangeを使ったカッコいい形もありますが、そこは置いといて、、、)
ちなみに、従来通りのfor文とif文の書き方は下記のような形です。for(int i : new int[]{1,2,3,4,5,6,7,8,10}) { if((i % 2) == 0) { System.out.println(i); } }これぐらいの短い処理なら、行数的には同じだし変わりなく見えてしまいますよね。
しかし、複雑な処理になった場合、StreamAPIのfilterとかforEachだとかいうメソッドをしっかり覚えれば、
どこで何をやっているかが明確なので、見やすく理解しやすくなると個人的に思っています。
だけど、いきなり見るとこの引数ってなに?とかfilterとforEachの違いって?となるので、
少しまとめてみました。関数型インターフェース
上のソースで見た引数の部分は、初めてだと見慣れないですよね。
filter( i -> (i % 2) == 0 )実はこれは、関数型インターフェースを引数にもらう書き方で、ラムダ式というものに省略した書き方になっています。
java7以前を中心に業務をしている方は初めて見ると思います。
java8以降では関数型インターフェースの条件を満たしているものは関数の処理を引数に直接設定するラムダ式と
いう書き方ができます。関数型インターフェースの定義とは?
大まかにいうと抽象メソッドが一つだけ定義されたインターフェースのことです。
実例だとこのようなものです。@FunctionalInterface public interface Predicate<T> { boolean test(T t); }見ての通り、単なるインターフェースですよね。
抽象メソッドが一つだけということが重要で、この形の時のみ処理のみを記述するラムダ式という書き方ができます。
(defaultメソッドは書いてあっても問題ないです。)
ちなみに、FunctionalInterfaceは関数型インターフェースで使用可能と明示しているだけで
処理的に意味のあるものではありません。関数型インターフェースをラムダ式で引数に設定する
filterメソッドを参考にしていくと、filterはPredicateインターフェースを引数に受け取ります。
Stream<T> filter(Predicate<? super T> predicate);上のソースコードだと、こんな書き方をしていました。
filter( i -> (i % 2) == 0 )Predicateの抽象メソッドはtestメソッドになります。
ので、引数を一つ受け取り、booleanを戻り値で返す処理をラムダ式で引数に指定してあげるだけです。
(実際に上の例がそれです。)
といっても、いきなり上の書き方がラムダ式ですと言われても、ラムダ式とは???ってなりますよね
軽く文法を見ていきましょう。ラムダ式
ラムダ式の基本的な文法はこのような形です。
(引数) -> {処理}アローの左側に引数を設定して、右側に処理を書くといった感じです。
つまり、今回書いたfilterのラムダ式を省略せずに見るとこのような形です。filter( (int i) -> {return (i % 2) == 0;} )この書き方なら初めて見る方でも、なんとなく判断がつくのではないでしょうか。
一番上のサンプルでは、引数の型とかを省略できるものを、全て省略しただけです。
(ラムダ式は省略のルールはまた今度、記事に起こそうかなと思います。)簡単に言うと、引数の型と()を省略して、更にreturnステートメントと{}を省略しています。
全て条件付きですが、省略すると見通しが良くなりますよね。
文法さえ勉強すればわかるので、省略できる箇所は省略していくといいとおもいます。関数型インターフェースの種類
関数型インターフェースは標準で様々なものが定義されています。
(ちなみに、EffectiveJavaでは自作の関数型インターフェース作ることを推奨していないので、
使用するときは、標準なものを使用することを心がけましょう。)
しかし、大別すると4つの系統にわけられます。
あとは、intとかlongとかプリミティブなもの専用だったり、引数が二つになったりとするものです。
基本となるものを覚えて、ケースバイケースで調べてみるのがおすすめです。
(数が多いので、私の頭では無理でした、、、)とりあえず、基本となるSupplier、Consumer、Predicate、Functionの存在とメソッドを覚えていきましょう。
// Supplierインターフェース // 引数を受け取らず、値を返却するgetメソッドを定義しています。 @FunctionalInterface public interface Supplier<T> { T get(); } // Consumerインターフェース // 引数を受け取り、戻り値を返さないacceptメソッドを定義しています。 @FunctionalInterface public interface Consumer<T> { void accept(T t); } // Predicateインターフェース // 引数を受け取り、booleanを返却するtestメソッドを定義しています。 @FunctionalInterface public interface Predicate<T> { boolean test(T t); }; // Functionインターフェース // 任意の型の引数を受け取り、任意の型の戻り値を返却するapplyメソッドを定義しています。 @FunctionalInterface public interface Function<T, R> { R apply(T t); }ちなみに、全ての種類を見たい人は「java.util.function」パッケージを調べて見るのがおススメです。
関数型インターフェースのまとめ
- 関数型インターフェースはラムダ式でかけて、スマートな見た目。
- 標準な関数型インテーフェースを覚えるのが重要。
中間処理と終端処理
StreamAPIの処理の流れは主に3つの流れに区分されます。
1. streamの生成
今回もArrays.stream()でstreamを生成しています。streamを生成するだけなので、特に詳しく説明しません。
2. 中間処理
今回の場合、filterが該当します。中間処理は一つのStreamの中で何回もすることができます。
3. 終端処理
今回の場合、forEachが該当します。終端処理は一つのStreamで一回しか呼び出すことができません。StreamAPIの処理の流れは生成→中間処理→終端処理になります。
しかし、なぜ、中間処理が複数回の実行ができて、終端メソッドは一回だけなのでしょうか。
よくある説明のこれだけの情報だと混乱してしまいます。中間処理と終端処理を区物していく
正直言うと、中間処理と終端処理のメソッドだけ覚えて区別していくと大変です。
(何個覚えればいいんだ、、、、、)
メソッドを覚えるよりも、中間処理と終端処理の流れを理解するのが重要です。何回も、登場しますが、また同じソースコードを。
Arrays.stream(new int[]{1,2,3,4,5,6,7,8,9,10}) .filter( i -> (i % 2) == 0 ) .forEach( i -> System.out.println(i));ここで重要なのが、filterメソッドの後にforEachメソッドを呼び出せているということです。
ちなみに、こんな書き方しても動きません。// ダメな例(というか、コンパイルエラー) Arrays.stream(new int[]{1,2,3,4,5,6,7,8,9,10}) .forEach( i -> System.out.println(i)); .filter( i -> (i % 2) == 0 )実はfilterメソッドの後にforEachメソッドが呼び出せる理由は、Streamインターフェースを見れば直に理解できます。
Streamインターフェースで理解する中間処理と終端処理
下のソースコードはStreamインターフェースの抽象メソッドを抜き出したものです。
public interface Stream<T> extends BaseStream<T, Stream<T>> { // 戻り値がStream Stream<T> filter(Predicate<? super T> predicate); <R> Stream<R> map(Function<? super T, ? extends R> mapper); IntStream mapToInt(ToIntFunction<? super T> mapper); LongStream mapToLong(ToLongFunction<? super T> mapper); DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper); <R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper); IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper); LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper); DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper); Stream<T> distinct(); Stream<T> sorted(); Stream<T> sorted(Comparator<? super T> comparator); Stream<T> peek(Consumer<? super T> consumer); Stream<T> limit(long maxSize); Stream<T> substream(long startInclusive); Stream<T> substream(long startInclusive, long endExclusive); // 戻り値がいろいろ void forEach(Consumer<? super T> action); void forEachOrdered(Consumer<? super T> action); Object[] toArray(); <A> A[] toArray(IntFunction<A[]> generator); T reduce(T identity, BinaryOperator<T> accumulator); Optional<T> reduce(BinaryOperator<T> accumulator); <U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner); <R> R collect(Supplier<R> resultFactory, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner); <R> R collect(Collector<? super T, R> collector); Optional<T> min(Comparator<? super T> comparator); Optional<T> max(Comparator<? super T> comparator); long count(); boolean anyMatch(Predicate<? super T> predicate); boolean allMatch(Predicate<? super T> predicate); boolean noneMatch(Predicate<? super T> predicate); Optional<T> findFirst(); Optional<T> findAny(); }よく見るとfilterメソッドって、Streamを戻り値にしています。
そして、forEachは戻り値がないですよね。これです!(どれだよ)
これはインターフェースですけど、実装クラス「ReferencePipeline」とか見てみると
filterメソッドなど中間メソッドたちは、メソッド内でStreamを新しく作って、戻り値に設定しています。
Streamを戻り値に設定しているから、連続してStreamメソッドを呼び出せるのです。
逆に、メソッドの戻り値を見てわかる通り、forEachなどの終端メソッドは戻り値にStreamを設定していないので、
連続してStreamメソッドを呼び出せないのです。これを理解すると中間メソッドと終端メソッドってすごく簡単ですよね。
Streamを戻り値にしているメソッドが中間処理で
Streamを戻り値にしていないのが終端処理と大雑把に理解することができます。中間処理と終端処理のまとめ
- 中間処理はStreamを戻り値にしているから何回も呼び出せる。
- 終端処理はStream以外を戻り値にしているから一回しか呼び出せない。
まとめ
- 関数型インターフェースを理解してラムダの文法を覚えれば引数が怖くない。
- 中間処理と終端処理って大層な名前だけど戻り値が違うだけ
理解すればStreamAPIって怖くない。
TODO
- メソッド参照で引数設定できるって聞いたけど。
- なんかいろんな実例が欲しい。
- 投稿日:2019-11-02T02:48:08+09:00
ArrayList配列でwhileによる繰り返し処理でIteratorで全部表示する
ArraylistをIteratorで全件表示する方法
//Listの宣言 List<String> fruits =new ArrayList<>(); fruits.add("リンゴ"); fruits.add("スイカ"); fruits.add("ナシ"); fruits.add("バナナ"); //Iterator<Stromg>の宣言 Iterator<String> it2= fruits.iterator(); //hasNextを使用して値がある場合はループを継続する while(it2.hasNext()){ //nextを使用して値を取得する String nation = it2.next(); System.out.println(nation); }
- 投稿日:2019-11-02T00:39:20+09:00
Spring Boot でテーブルのデータをビューに出力するまでの流れ
事前に必要なこと
・DBへの接続設定を行う
大まかな流れ
Usersテーブルからデータを取得し、表示するという設定です。
- エンティティを作成する
- リポジトリを作成する
- コントローラを作成する
- ビューを作成する
エンティティを作成する
Usersテーブルのデータを取得した値を保存するのに利用する。
com.example.entities.UsersEntity.java@Entity @table(name="Users") public class UsersEntity{ @Id private Integer id; private String name; public Integer getId(){ return id; } public String getName(){ return name; } }リポジトリを作成する
リポジトリはDBとデータのやり取りを行う。
com.example.repositories.UsersRepository.javaimport com.example.entities.UsersEntity; import org.springframework.data.jpa.repository.JpaRepository; public interface UsersRepository extends JpaRepository<UsersEntity, Integer>{ }コントローラを作成する
com.example.controller.UserController.java@Controller public class UserController{ @Autowired // 変数に代入 private UsersRepository usersRepository; // このURLにアクセスした際の動作 @RequestMapping("/index") public String index(Model model){ List<UsersEntity> users = usersRepository.findAll(); model.addAttribute("userlist", users); return "view/user/index"; } }ビューを作成する
/view/user/index.html<table> <tr th:each="users : ${userlist}"> <td th:text="${users.id}"></td> <td th:text="${users.name}"></td> </tr> </table>