- 投稿日:2019-10-09T23:40:35+09:00
csvファイルに入っている日本語のリストをgoogle翻訳で英訳する
CSVファイルに入っている日本語リストを翻訳し、別のCSVファイルに対応させて、出力する。
まずターミナルで
pip install googletrans
と打ってpythonパッケージをインストールしてください。ja_to_english.pyimport pandas as pd from googletrans import Translator translator = Translator() data=pd.read_csv('trans.csv') english_list=[] for i in data['japanese']: dst = translator.translate(i, src='ja', dest='en') english_list.append(dst.text) data['english']=english_list data.to_csv("result.csv",encoding='utf_8_sig' ,index=False)以上のようなファイルを作り、ターミナルにて
python ja_to_english.py
で実行してください。trans.csvの例
japanese english 赤 黄色 黒 日本語 英語 アボカド 出力されるresult.csvの例
japanese english 赤 red 黄色 yellow 黒 black 日本語 japanese 英語 english アボカド avocado 参考
- 投稿日:2019-10-09T22:34:08+09:00
pythonの関数をデコレータ(@関数)で使用する
はじめに
flaskなどで@app.route()を使用していましたが、@とは何だろうと思って以前調べましたが複雑で理解を断念していました。
最近、ふと気になって調べてみると理解ができて、色々できそうでしたのでまとめました。
厳密に説明を書くとわかりにくくなってしまうので、分かりやすさ優先で書いています。
参考にするときは、説明は雰囲気を感じて具体例で正確な理解をしてください。環境
- python:3.6.5
デコレータの基本
デコレータとは
ある関数を拡張する機能で関数の開始前や終了後などに処理を付け加えることができる機能。
例えば、関数Aがあるとして、関数Aの前と後に好きな処理を追加することができます。デコレータの形式
ある関数の開始前や終了後に実行する処理を書いた関数をデコレータ用の関数として作成して、ある関数の前に@デコレータ用関数名をつけることで適用します。
具体例
具体例とその結果は次のようになります。
詳しい説明は関数のデコレータの項目でします。main.pydef my_decorator(my_func): def decorator_wrapper(*args, **kwargs): print('decorator before my_func') my_func(*args, **kwargs) print('decorator after my_func') return decorator_wrapper @my_decorator def print_hello(): print('my function hello world') print_hello()結果
# python3 main.py decorator before my_func my function hello world decorator after my_funcシンプルなデコレータ
シンプルなデコレータの例
上の具体例と同じです。
main.pydef my_decorator(my_func): def decorator_wrapper(*args, **kwargs): print('--- decorator before my_func ---') my_func(*args, **kwargs) print('--- decorator after my_func ---\n') return decorator_wrapper @my_decorator def print_hello(): print('my function hello world') print_hello()結果
# python3 main.py decorator before my_func my function hello world decorator after my_funcシンプルなデコレータの説明
具体例の上から順に説明していきます。
def my_decorator(my_func):がデコレータ用の関数です。引数のmy_funcにデコレータを適用した関数が渡されます。具体例の場合は、def print_hello()。
次のdef decorator_wrapper(*args, **kwargs):は、実際に拡張する処理を書く場所になります。今回はシンプルに標準出力の後に、my_func(*args, **kwargs)で引数で渡された関数を実行して、最後にもう一度標準出力をしています。
実際に拡張する処理を書いた関数を返却してデコレータ用の関数が作成できます。
関数(print_hello())にこのデコレータを適用する場合は、適用したい関数の前に先ほど作成した関数を@の後に記載します。
最後に適用した関数print_hello()を実行するとdecorator_wrapperの処理通り標準出力、関数の実行、標準出力されます。引数を渡す関数のデコレータ
引数を渡す関数のデコレータの例
適用した関数の引数がデコレータ内でどう扱われるかを試す例です。
main.pydef my_decorator(my_func): def decorator_wrapper(*args, **kwargs): print('--- decorator before my_func ---') print('args:{}'.format(args)) print('kwargs:{}'.format(kwargs)) my_func(*args, **kwargs) print('--- decorator after my_func ---\n') return decorator_wrapper @my_decorator def print_hello(a, b): print('my function hello world') print_hello(1, 2) print_hello(a=1, b=2)結果
# python3 main.py --- decorator before my_func --- args:(1, 2) kwargs:{} my function hello world --- decorator after my_func --- --- decorator before my_func --- args:() kwargs:{'a': 1, 'b': 2} my function hello world --- decorator after my_func ---引数を渡す関数のデコレータの説明
普通の関数と同様に適用した関数
print_hello(a, b)に引数を追加するだけでデコレータ内でも引数を使用することができます。
print_hello()の呼び方の違いでデコーダに伝わる引数も変わります。
print_hello(1, 2)のように位置で引数を与えるとdef decorator_wrapper(*args, **kwargs):のargsに与えた引数が入ります。print_hello(a=1, b=2)のようにキーワード引数で与えるとkwargsに与えた引数が入ります。
デコーダ内でmy_func(*args, **kwargs)に与える引数を変えると実際にprint_hello(a, b)のaとbに入る内容が変わります。デコレータ関数に引数を渡す
デコレータ関数に引数を渡す例
デコレータ自体に関数を渡した方法を試す例です。
main.pydef my_decorator(my_func, *args, **kwargs): print('--- my_decorator before decorator_wrapper ---') print('args:{}'.format(args)) print('kwargs:{}'.format(kwargs)) def decorator_wrapper(*args, **kwargs): print('--- decorator before my_func ---') my_func() print('--- decorator after my_func ---\n') return my_func print('--- my_decorator after decorator_wrapper ---') return decorator_wrapper def print_hello(): print('my function hello world') @my_decorator(print_hello, 1, a=2) def print_hello_2(): print('my function hello world2') print_hello_2()結果
# python3 main.py --- my_decorator before decorator_wrapper --- args:(1,) kwargs:{'a': 2} --- my_decorator after decorator_wrapper --- --- decorator before my_func --- my function hello world --- decorator after my_func --- my function hello worldデコレータ関数に引数を渡す説明
今回はデコレータ自体に引数を渡したいため、デコレータ用の関数
def my_decorator(my_func, *args, **kwargs):にargsとkwargsを追加します。
その後、デコレータを適用する際に@my_decorator(print_hello, 1, a=2)のようにデコレータに引数を与えます。これも上の例と同じで位置による引数はargsに、キーワードによる引数はkwargsに入っています。
my_funcに実行するべき関数を入れている点に注意してください。本当は自分の関数オブジェクトを渡せたらよかったのですが、やり方がわかりませんでした。色々な使い方
JSONからvalueのみ抜き出して使用する
デコレータにJSON文字列を解析して、その値を抜き出して関数に渡す処理を追加しています。
実際の関数は引数にjsonの値がそのまま入っているため、そのまま使えます。main.pyimport json def my_decorator(my_func): def decorator_wrapper(*args, **kwargs): print('--- decorator before my_func ---') json_dict = json.loads(args[0]) args = json_dict.values() my_func(*args, **kwargs) print('--- decorator after my_func ---\n') return decorator_wrapper @my_decorator def print_hello(a, b=None, c=None): print('my function hello world') print('a:{}, b:{}, c:{}'.format(a, b, c)) print_hello(json.dumps({'a':1, 'b':2, 'c':10}))結果
# python3 main.py --- decorator before my_func --- a:1, b:2, c:10 my function hello world --- decorator after my_func ---JSONからvalueのみ抜き出して使用する
必ず引数は文字列にしてほしい場合を想定して、デコレータに引数を文字列にする処理を入れました。
それによって、関数に来る引数は必ず文字列になっています。main.pydef my_decorator(my_func): def decorator_wrapper(*args, **kwargs): print('--- decorator before my_func ---') args = [str(i) for i in args] my_func(*args, **kwargs) print('--- decorator after my_func ---\n') return decorator_wrapper @my_decorator def print_hello(a, b=None, c=None): print('my function hello world') print('a:{}, b:{}, c:{}'.format(type(a), b, c)) print_hello(1, 2, 3)結果
# python3 main.py --- decorator before my_func --- my function hello world a:<class 'str'>, b:2, c:3 --- decorator after my_func ---おわりに
関数のデコレータを色々見ていきました。
ぱっと見は何をしているのか分かり難いため取っつきにくいですが、応用すれば色々なことができました。
記載した内容以外にもjsonのチェックであったり、ファイル名を与えてファイルの中身を引数として引数として与えるなど多くのことができそうです。
さらにクラスをデコレータ化することでさらに色々なことができるようになります。クラスのデコレータ化については次回まとめます。
- 投稿日:2019-10-09T21:58:21+09:00
常微分方程式を解いて未来のことを知りたい(ルンゲ-クッタ法) ~計算物理学I (朝倉書店)を参考にpythonを使って~
前置き
今回は常微分方程式の解法で有名な2次のルンゲ-クッタ法を実行するプログラムをpythonで作製しましたので紹介します。(n番煎じのような気はしますが、そこはご愛敬ということで……。)
プログラムの前に、標準形について
プログラムを作製する前に、常微分方程式を計算するプログラムに必要な「標準形」について、ニュートンの運動方程式を例にあげて説明していきます。普通、ニュートンの運動方程式は以下のように表現されます。
\frac{d^2x}{d t^2} = \frac{1}{m} F (t,x,\frac{dx}{dt})ここで$m$は物体の質量、$F$は物体に働く力で時間$t$・位置$x$・速度$dx/dt$に依存しています。
さて、こちらを計算しやすいように標準形に変換していきましょう。まずは位置$x$を従属変数$y^{(0)}$、速度$dx/dt$を$y^{(1)}$とします。このようにおくと、上記の運動方程式は以下の2本の連立1次方程式に書き改めることができます。\begin{eqnarray*} \frac{dy^{(0)}}{dt} &=& y^{(1)} \\ \frac{dy^{(1)}}{dt} &=& \frac{1}{m} F (t,y^{(0)},y^{(1)}) \\ \end{eqnarray*}ここでさらに、$f^{(0)} = y^{(1)}$、$f^{(1)} = F/m$とおけば、以下のような非常にシンプルな形に表すことができます。
\frac{dy^{(i)}}{dt} = f^{(i)}(t, y^{(j)}) (i, j = 0,1)このように、常微分方程式を連立一次常微分方程式の形で表す方法を標準形と呼びます。初めにも言いましたが、プログラムの中で使用していますので確認してください。
より一般的な常微分方程式の標準形は以下のように表されます。
\frac{dy^{(0)}}{dt} = f^{(0)}(t,y^{(i)}) \\ \frac{dy^{(1)}}{dt} = f^{(1)}(t,y^{(i)}) \\ \vdots \\ \frac{dy^{(N-1)}}{dt} = f^{(N-1)}(t,y^{(i)})ここで右辺の$f^{(j)}$は、微分係数$dy^{(i)}/dt$は含みません。また、これらは$N$次元ベクトル${\bf y}$と${\bf f}$を用いて、以下のようにも書けます。
\frac{{\bf y}(t)}{dt} = {\bf f}(t,{\it y}), \\ {\bf y} = \left( \begin{array}{c} y^{(0)}(t) \\ y^{(1)}(t) \\ \vdots \\ y^{(N-1)}(t) \end{array} \right), {\bf f} = \left( \begin{array}{c} f^{(0)}(t,{\bf y}) \\ f^{(1)}(t,{\bf y}) \\ \vdots \\ f^{(N-1)}(t,{\bf y}) \end{array} \right),プログラムの前に、ルンゲ-クッタ法について
次に、常微分方程式を解く方法で有名な2次のルンゲ-クッタ法を説明します。(より精度の高い4次のルンゲ-クッタ法もありますが今回は割愛します。)
ルンゲ-クッタ法は以下の微分方程式の積分から求めることができます。\frac{dy}{dt}=f(t,y) \Rightarrow y = \int f(t,y) dtここで、時刻$t_n$の$y_n$から次の時刻$t_{n+1}$の$y_{n+1}$を求めるとすれば、上式は、
y_{n+1} = y_n + \int^{t_{n+1}}_{t_n} f(t,y) dtと書けます。ここで、$f(t,y)$を積分区間の中点$t_{n+1/2}$のまわりでテイラー展開し、第2項まで残すと、以下となります。
f(t,y) \simeq f(t_{n+1/2}, y_{n+1/2}) + (t-t_{n+1/2})\frac{df}{dt}(t_{n+1/2}, y_{n+1/2}) + O(h^2)ここで、$h$は時間の間隔$(t_{n+1}-t_n = h)$です。積分区間$t_n \le t \le t_{n+1}$では$(t-t_{n+1/2})$は正と負の値が等価に含まれているので定積分の値が消え、上式の$(t-t_{n+1/2})$の1次の項の積分は$0$となります。したがって、$f(t,y)$の積分、および、$y_{n+1}$を求める式は、
\begin{eqnarray*} \int^{t_{n+1}}_{t_n} f(t,y) dt &\simeq& f(t_{n+1/2}, y_{n+1/2})h + O(h^3) \\ y_{n+1} &\simeq& y_n + f(t_{n+1/2}, y_{n+1/2})h + O(h^3) \end{eqnarray*}と表すことができます。さらに、時刻$t_{n+1/2} = t_n + h/2$の時の$y_{n+1/2}$をオイラー法によって近似的に求めると、
y_{n+1/2} \simeq y_n + \frac{h}{2} \frac{dy}{dt} = y_n + \frac{h}{2}f(t_n,y_n)となります。したがって、時刻$t_n$の$y_n$から$y_{n+1}$を求める式は以下のようにまとめることができます。
\begin{eqnarray*} y_{n+1} &\simeq & y_n + k_2 \\ \\ k_1 & = & hf(t_n,y_n) \\ k_2 & = & hf(t_n + \frac{h}{2}, y_n+ \frac{k_1}{2}) \end{eqnarray*}上記のような数式を用いて常微分方程式の解を求めるアルゴリズムを、2次のルンゲクッタ法と言います。
ようやくルンゲ-クッタ法のプログラム
さて、前置きが長くなりましたが、ルンゲクッタ法のプログラムは非常に簡単なものとなります。使用したパッケージはnumpyだけです。
import numpy as np #時間間隔h、時刻tn、その時のynの値のリストlist_yn、標準形の右辺funcを与えることで #時刻tn+1の値yn+1のリストを返すルンゲクッタ法のアルゴリズム def rk2(h,tn,list_yn, func): k1 = h*func(tn,list_yn) k2 = h*func(tn+h/2, list_yn+k1/2) return list_yn + k2 #初期時刻t_ini、終了時刻t_last、分割点数n、初期条件list_y_ini、 #標準形の右辺funcを与えることで #時刻のリストlist_t、ルンゲクッタ法の解のリストlist_ynを返す。 def runge_kutta2(t_ini, t_last, n, list_y_ini, func): #時間間隔hを求める h = (t_last-t_ini)/n #list_t, list_ynの入れ物を作製 list_t = np.zeros(n+1) list_yn = np.zeros([n+1,list_y_ini.shape[0]]) #初期位置の格納 list_t[0] = t_ini list_yn[0,:] = list_y_ini #ルンゲクッタ法で随時計算し結果を格納 for i in range(1,n+1): list_yn[i,:] = rk2(h, list_t[i-1] ,list_yn[i-1,:] ,func) list_t[i] = list_t[i-1] + h return list_t, list_ynルンゲ-クッタ法のプログラムのテスト
例の如く、プログラムのテストをしてみます。調和振動子の運動方程式を使って確認していきましょう。調和振動子の運動方程式の標準形は、
\begin{eqnarray*} \frac{dy^{(0)}}{dt} &=& y^{(1)} \\ \frac{dy^{(1)}}{dt} &=& - \frac{k}{m}y^{(0)} \\ \end{eqnarray*}と書けるので、プログラムにおいては、
def harmonic(list_y): return np.array([list_y[1], -4*np.pi**2*list_y[0]])のように定義します。list_yは0列に位置、1列に速度が格納された1行2列のリストです。また、$k/m = 4 \pi ^2$としていますが、これは調和振動子の厳密解が、
\begin{eqnarray*} x(t) &=& A \sin (\omega_0 t) \\ v(t) &=& \omega_0 A \cos (\omega_0 t) \\ \omega_0 &=& \sqrt{\frac{k}{m}} \end{eqnarray*}であるため、$\omega_0 = 2 \pi$とし、プログラムの確認を用意にするためです。
さて、このharmonicを使用してルンゲ-クッタ法のプログラムをテストしていきます。時刻は0~1、分割点数を100、初期位置を0、初速を1として計算しました。
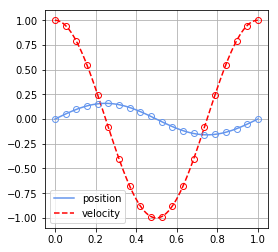
num = 100 t_ini = 0 t_last = 1 list_y_ini = np.array([0,1]) list_t2H, list_yn2H = runge_kutta2(t_ini, t_last, num, list_y_ini, harmonic)さて上記の計算結果は以下のような図になりました。青い実線が位置、赤い破線が速度の計算結果です。また、同じ色の丸はそれぞれの厳密解を表していますが、なかなかに一致していることが分かります。実際に計算を行うと1E-3程度まで一致していることが分かりました。そこそこの精度ですね。
感想
今回は、2次のルンゲ-クッタ法を実行するプログラムを作製しました。数式を以下にコンピュータで取り扱っていくかの工夫は勉強していて面白いですね。
数式やプログラムに間違いなど、ありましたらお知らせいただけると幸いです。参考書籍
R.H.Landau・他 (2018)『実践Pythonライブラリー 計算物理学I -数値計算の基礎/HPC/フーリエウェーブレット解析』 (小柳義夫・他訳) 朝倉書店
- 投稿日:2019-10-09T21:31:48+09:00
OneDriveにクソたまった写真と動画をpythonとか色々駆使して整理する物語 第一話
長年動画や写真を撮っているとどんどんたまってしまいます。子供が生まれてからさらに加速し、写真とスマホの動画だけで、ファイル数は90000を超え、300GBを超えてしまいました。動画と合わせて750GB、OneDriveの上限に近づいて来たので色々駆使して整理することにしました。
環境
- MacBook Air 2014 late
- Python 3.7
- ffmpeg
- ffprobe
- Microsoft OneDrive
このシリーズでやりたいこと
- 過去1つのフォルダに全てバックアップされてしまっているデータを年月のフォルダを作って分けたい
- バックアップや手動アップのミスなどで重複してしまったファイルを消して容量を削減したい
- 1フォルダあたりに保存する写真の数の上限を決めてスムースに表示できるようにしたい
- 表示がスムースになったら勝手にバックアップされてしまった意味なしやピンボケ画像も削除して容量を削減したい
手順
- パソコン用の同期アプリでローカルパソコンの外付けドライブに写真フォルダを同期する
- 写真のフォルダ内に自動で年月フォルダを作って写真を振り分けるPythonプログラムを作成して実行、その際、同じファイル名がかってに上書きされないようにする
- 重複検出のpythonプログラムを作ってファイル名は違うけど同じ中身のファイルを削除する。
- 類似を検出して目視で確認しつつ不要ファイルを削除する
上記手順を実行すれば、そのまま同期したOneDrive内の写真も整理され、容量も削減できるというわけです。万歳。
OneDriveのメリットとデメリット
写真のバックアップにMicrosoftのOneDriveはオススメです。何しろどうせ必要なOfficeを使うのに、昨今はOffice365を契約する人が多いと思いますが、Office365を契約すると、自動的にOneDriveの容量1TBがついてくるからです。
OneDriveが写真バックアップに便利な点
- 写真が劣化しない!
- Office365に1TBついてくる
- iOSもAndroidもアプリで写真を自動バックアップできる
- Windows/MacOSでも自動保存用のローカルアプリケーションがある
- GoxxleやAxxzonのphotoと違って画質を劣化させないで大容量保存できる
OneDriveの写真バックアップでダメな点
- iOSもAndroidも全ての写真と動画が同じフォルダ(※1)に保存される
- 人物名のタグ付けや検索がない (Googleより不便)
- Googleほどアカウントが普及しておらず共有しづらい
※1 この仕様は数年前に改善されており今は年月ごとのフォルダに自動で保存されます。長く使い続けているユーザーならではの悩みです。
この1が非常に問題なのです。専用スマホアプリやブラウザ上で見れば、撮影日時の時系列で閲覧できる機能を備えているものの、特定の年月をピンポイントに見たい場合にとにかく表示が重いし、その上、フォルダ単位でしかローカルパソコンと同期できないため、写真があるフォルダをローカルで同期して色々したい時に、写真が何万件もたまるとファインダーやlsコマンドだけでもものすごく待たされてしまうのです。
1. OneDriveアプリケーションで外付けドライブと同期する
macのソフトは設定でそのまま外付けドライブを同期対象フォルダとして設定できません。なんか色々考えるのも面倒なのでシンボリックリンクで解決しました。
最初にOneDriveフォルダをすでに実行している場合、「基本設定」の「アカウント」タブから、「このMacのリンクを解除」をクリックして一旦同期を停止します。
次に、外付けドライブを接続したのち、外付けドライブ内にOneDriveフォルダを作ってからホームフォルダにシンボリックリンクを作成します。
cd mkdir -p /Volumes/[外付けドライブデバイス名]/OneDrive ln -s /Volumes/[外付けドライブデバイス名]/OneDrive ~/OneDrive完了したらOneDriveアプリで再度ログインし、同期フォルダ選択でホームフォルダ内のOneDriveシンボリックリンクを指定すると、無事同期させることができます万歳。
2. Pythonでフォルダ内の全ての写真や動画を読み込んで振り分けするプログラム
ポイントだけこの記事に書きますので、全ソースが欲しい方はgithubご覧ください
https://github.com/mychaelstyle/photofles_sorter
JPEGからEXIFを読み込む
pillowを使います
from PIL import Image from PIL.ExifTags import TAGS img = Image.open([file path]) exif = img._getexif() img.close()これでexifの中にEXIF項目のタグIDと値のセットの配列が読み込まれます。
ここで読み取ったタグIDは数値なので、DateTimeOriginalなどのEXIFの項目名を確認したい場合はimportしたTAGSから項目名を取得する必要があります。labeled_items = [] for id, value in exif.items(): tag_name = TAGS.get(id,id) labeled_item = ( tag_name, value ) labeled_items.append(labeled_item)これで項目のタプルの配列ができましたが、私の場合は撮影日だけわかればいいのでDateTimeOriginalだけ取り出します。
dt_origin = None for id, value in exif.items(): tag_name = TAGS.get(id,id) if tag_name == "DateTimeOriginal": dt_origin = value breakこれで無事撮影日を取得できました
取得した撮影日は文字列で"2019:10:08 12:00:00"という全てコロン区切りの見慣れないフォーマットになっていますが、(ymd, hms) = dt_origin.split()した後にymd.split(":")で年月日を別々にしてフォルダパス文字列を作ればOKですね。(ymd, hms) = dt_origin.split() (year, month, day) = ymd.split(":")Canon Rawファイル(.CR2)から撮影日を読み込む
こちらの仕様を参考にします
http://lclevy.free.fr/cr2/byte演算が必要になるのでstructを利用します。
from struct import *色々書くと長くなるので割愛しますが簡単にいうとファイルの冒頭にバイトオーダーとかCR2のバージョンとか固定の情報が入ってますよというところと、16byte目の情報は基本情報の項目数が保存されていますよというところ。項目数保存のデータ長は固定で上記URLに記載の通り。
まずバイトオーダーがリトルエンディアンなのかビッグエンディアンなのか読み取ります
structからunpack_fromを使って1byte目を数値として読み込みます。unpack_fromはbyte数が幾つだろうが有無を言わさずbyteごとの値が入ったタプルで返すので受け取り方に注意with open(path, "rb") as f: buffer = f.read(1024) (byte_order) = unpack_from('H', buffer) # Set the endian flag endian_flag = '@' if byte_order == 0x4D4D: endian_flag = '>' elif byte_order == 0x4949: endian_flag = '<'エントリーの数を取り出しループしてdateTimeの項目を表す番号0x0132を探します
(num_of_entries,) = unpack_from(endian_flag+'H', buffer, 0x10) for entry_num in range(0,num_of_entries): (tag_id, tag_type, num_of_value, value) = unpack_from(endian_flag+'HHLL', buffer, 0x10+2+entry_num*12) if tag_id == 0x0132: assert tag_type == 2 assert num_of_value == 20 datetime_offset = value break datetime_strings = unpack_from(20*'c', buffer, datetime_offset) datetime_string = "" for str in datetime_strings: datetime_string += str.decode() print(datetime_string)これで2019:10:07 12:00:00のような書式で日付を取得できました!
動画ファイル.mov/.3gp/.mp4の撮影日時を取得する
iPhoneのMOV動画とか.mp4とか、旧Androidやガラケーの3gp動画とか、デジタルビデオカメラの.mp4ファイルの撮影日を取得します。
これ、python3でいいライブラリがなかったので結局、ffmpegとffprobeをいれてsubprocessで叩くという恥ずかしいやり方をせざるをえず・・ Home brewでffmpegとffprobeをインストール
brew install ffmpeg brew install ffprobePythonからはsubprocessで叩く
import subprocess proc = subprocess.run(["/usr/local/bin/ffprobe","-show_chapters","-hide_banner",path], stdout = subprocess.PIPE, stderr = subprocess.PIPE) response = proc.stdout.decode("utf8")+"\n"+(proc.stderr.decode("utf8")) for line in response.splitlines(): if "creation_time" in line: str = line.replace(" creation_time : ","").replace("T"," ").replace("Z","") print(str) break雑なやり方ではありますが、割とあらゆる動画形式に対応できました。
U動くプログラムがそのまま欲しい方はgithubからどうぞ。https://github.com/mychaelstyle/photofles_sorter
整理手順
2019-10段階では、上記githubのプログラムは、隠しファイル、撮影日時が取得できないファイルは移動せず放置します。また、移動先に名前・ファイルサイズ・撮影日時が完全一致するファイルが既に存在していた場合も移動せず放置します。
移動やスキップの実行結果は実行フォルダ内にログとしても吐き出します。下記の手順でファイルを整理しました。
- OneDrive同期フォルダ内に画像と写真を集約するための新しいフォルダを作成します。
- 写真・動画分散しているフォルダごとに上記フォルダを出力先に指定して実行していきます。
- 移動元ごとにログを見ながら、重複ファイルは削除、必要なファイルは退避させてから移動元フォルダを削除します。
吐き出されたログは書式が決まっているので下記のようにして確認できます。ファイル名はinfo-年-月-日-時分秒.logの形式で吐き出されます。
# 隠しファイルではなく撮影日時を取得できなかったファイルのログ一覧 cat info-YYYY-MM-DD-HHmmss.log | grep "No timestamp" | grep -v "/\." # 隠しファイルではなく重複していたので移動しなかったファイルのログ一覧 cat info-YYYY-MM-DD-HHmmss.log | grep "Same file" | grep -v "/\."3. ファイル名が違うけど中身が同じファイルの検出と削除
ファイル名と撮影日時とファイルサイズが完全一致する重複ファイルはここまでの手順でなくなりました。
問題なのは、OSダウンロード時やOneDriveアップロード時、バックアップ時にこれまで量産されてしまった、ファイル名は違うけど同じ写真や動画の削除です。
上書きしない選択をした時に**(1).JPGとか、番号がついて作られてしまったファイル。写真の重複検出
第二話で進めます。まて!次号!
- 投稿日:2019-10-09T20:45:24+09:00
PycharmでGithubからSSHでcloneする
概要
Pythonの統合開発環境であるPycharmを用いてGithubからSSHでcloneする際にかなり詰まったので、備忘録。
環境
- Windows10
- Pycharm Professional 2019.2.3
状況
- 鍵ペアは作成済み
- Githubへ公開鍵は登録済み
- 秘密鍵は~/.ssh/以下に配置済み
- 鍵生成の際、区別のため 名称を初期設定のid_rsaから変更 している
この状況において、Pycharmの通常の手順に従ってcloneしようとしても
Permission denied.(Publickey)
となり、cloneに失敗する原因
デフォルトでは、SSH接続の際に読みにいく鍵のファイル名がid_rsa等、既定のものに限られていることが原因だった。
id_rsaではない名前をつけた秘密鍵は読んでもらえていない。対策
~/.ssh/config を作成する
こちらの記事 が詳しい。
~/.ssh/configHost gitHub HostName github.com IdentityFile ~/.ssh/github/(秘密鍵のファイル名) User git上記のように作成すればすればOK。
これでssh -T githubが無事に通るはず。cloneするURLを細工する
PycharmやGithubでは、デフォルトでSSHでクローンするURLが
git@github.com:domishana/dip_discord.git
のようになっている。これを上記のconfigの設定を読むために、
github:domishana/dip_discord.git
のように、":" 以前を変更する。
これで無事、独自に作成した秘密鍵を使ってSSHクローンできるようになった。
- 投稿日:2019-10-09T19:49:37+09:00
pythonで実行時間を計測する
背景・問題
time.time()の差分をとる方法で計測すると、帰ってくる値が秒数であり、hh:mm:ssの形式になっていない提案
秒数を見やすい形に変換する関数を自作しました。
def timedelta(seconds: int) -> str: """秒数が1秒未満の場合はミリ秒を、1秒以上の場合はhh:mm:ssの形式に変換する""" if seconds < 1: return f"{seconds*1000:.0f} ms" else: m, s = divmod(round(seconds), 60) h, m = divmod(m, 60) return f"{h:02d}:{m:02d}:{s:02d}"外部ライブラリを入れる以外でもっといい方法があれば教えて頂けると幸いです
使用例
import time t0 = time.time() for i in range(34): time.sleep(0.1) t1 = time.time() print(f"elapsed time: {timedelta(t1 - t0)}")elapsed time: 00:00:03
- 投稿日:2019-10-09T19:44:41+09:00
動作しているプログラムがあるディレクトリ名を取得する
vscodeでプロジェクト全体のディレクトリを開いている時に内包する個別プロジェクトのプログラムを動作させたとき、相対パスで出力を書いていると全体のディレクトリに漏れ出す
foo.py## global/local/foo.pyのプログラムを端末のpwdがglobalのところで実行したとする ## 例 `python3 blobal/local/foo.py # こう書くと実行時のpwdに漏れ出す with open("bar.txt", "w") as bar: bar.write("hello") # 変更する dir = os.path.dirname(__file__) with open(os.path.join(dir, "bar.txt") as bar: bar.write("hello")
- 投稿日:2019-10-09T18:56:00+09:00
【備忘録】it does not seem to be a scikit-learn estimator as it does not implement a 'get_params' methods【sklearn】
概要
sklearnを使ってる時、下記のようにBagging等のアンサンブルをしてる時に
from sklearn.model_selection import train_test_split from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier import numpy as np #X 何かのデータ #Y 何かのラベル Train_X,Test_X,Train_Y,Test_Y=train_test_split(X,Y,train_size=0.8,shuffle=True) B_dtree_clf = BaggingClassifier(base_estimator=DecisionTreeClassifier,n_jobs=12) B_dtree_clf.fit(Train_X,Train_Y)これを実行すると
it does not seem to be a scikit-learn estimator as it does not implement a 'get_params' methodsが出るときがある。どういうこと?って思うが、単純な話だった。以下のコードが正解
from sklearn.model_selection import train_test_split from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier import numpy as np #X 何かのデータ #Y 何かのラベル Train_X,Test_X,Train_Y,Test_Y=train_test_split(X,Y,train_size=0.8,shuffle=True) B_dtree_clf = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_jobs=12) B_dtree_clf.fit(Train_X,Train_Y)間違い探しです。どこが違うでしょうか。
...答えは()が足りなかっただけです。本当にありがとうございました(
元々どういうエラー?
TensorFlowとかで作ったモデルをアンサンブルしたい時とかに、必要な機能が足りてないという意味のエラーっぽい
自作モデルをSklearnでアンサンブルする作り方はこちらのブログを参考にどうぞ。
(自分も記事書くかも)
- 投稿日:2019-10-09T18:52:06+09:00
【Python】20行で作る「数当てゲーム」
はじめに
こちらは、CUI操作のPythonで簡単に20行のコードで作れる「数当てゲーム」の記事になります。
よろしくお願いします。環境
- Windows 10 home
- Python 3.7.3
ルール
このゲームはプログラムが始まると1~5まで数字の中からランダムに、1つ目と2つ目の数字が決まるので、それぞれの数字がなんなのかを当てていくゲームになります。
片方正解すると、どちらかは合ってます!とヒントを出してくれるので、試行錯誤しながら、答えの数字を見つけていきましょう。プログラム
数当てゲーム.pyimport random as rd questionNumber = [] for i in range(2): questionNumber.append(rd.randint(1,5)) print("数当てゲームになります。\n二つの数字を当ててください。\n") num1 = input("1つ目の数字を入力してください:") num2 = input("2つ目の数字を入力してください:") while questionNumber[0] != int(num1) or questionNumber[1] != int(num2): if questionNumber[0] == int(num1) or questionNumber[1] == int(num2): print("どちらかは合ってます!") else: print("間違い! もう一度入力してください。\n") num1 = input("1つ目の数字を入力してください:") num2 = input("2つ目の数字を入力してください:") print("正解です!終了!")ぜひ、いろいろアレンジしてみてください!
ここまで読んでいただき、ありがとうございました。
- 投稿日:2019-10-09T18:32:40+09:00
[Django] restframeworkのserializerの書き下しをサボる
restframeworkを使ってシンプルなCRUDをするサーバーを建てるとき、単純にDBと一対一対応するシリアライザはこのようにすればいちいち書き下さなくて済む。
from django.db import models from rest_framework import serializers from my_app.models import Company # 開発するアプリで使うモデル def _create_vanilla_serializer( table_cls: Type[models.Model]) -> Type[serializers.ModelSerializer]: def _list_field_names(table_cls): return tuple(map(lambda f: f.name, table_cls._meta.fields)) class VanillaSerializer(serializers.ModelSerializer): class Meta: model = table_cls fields = _list_field_names(table_cls) return VanillaSerializer CompanySerializer = _create_vanilla_serializer(Company)
- 投稿日:2019-10-09T17:38:43+09:00
Python3の勉強まとめ Part.1
print関数その1
str型(文章)をprintで入力するときのオプション、注意点
・文字を囲むとき「"」と「'」はどっちでもいい
・例えばprint('I don't know.')など、文字の前後と文字の内側に同じ記号があるとエラーになる
・回避したい場合は前後と内側の記号をバラバラにするか、内側の記号の前にバックスラッシュ()を入力する
例.print('I don\'t know.') → I don't know
・\nと入力すると改行できる
例.print("Hello,World!") → Hello,World! 例.print("Hello,\nWorld!") → Hello, World!・C:\name\nameなど、フォルダの先頭がnのファイルパスをprintしたいときは、
先頭にr(raw)をつける
例.print(r'C:\name\name) → C:\name\name
・先頭にまとめて「"」を3つつけると改行して表示させることができる
例.print(""" test1 test1 test2 → test2 test3 test3 test4 test4 """)
・文章後に(半角スペース)* (数値)と入力すると繰り返し表示させることができる
例.print("Oh,Yes!" * 3) → Oh,Yes!Oh,Yes!Oh,Yes!
・文節の間に+を挟むと繋げることができる(無くてもよい)
例.print("Oh,Yes!" *3 + "Ah....") → Oh,Yes!Oh,Yes!Oh,Yes!Ah....
・通常は「+」を使わなくても文節を繋げて表示させることができるが、変数を用いた場合はできない
例.test = "Py" print(test"thon") → error! 例.test = "Py" print(test + "thon") → Python一旦ここまで!
print関数だけでめっちゃ量あるなぁ...
- 投稿日:2019-10-09T17:12:41+09:00
AzureHttpError : The specifed resource name contains invalid characters. ErrorCode: InvalidResourceNameの原因
- 投稿日:2019-10-09T16:33:41+09:00
三日坊主だけどプログラミングに挑戦してみた
Hello,World!
まずは簡単な自己紹介。
僕は今までプログラミングというものをやったことがありません。業務でプログラミングが必要になったので、
UdemyとQiitaを使ってPythonの勉強をし、記録していくことにしました。用意したもの
Windows 10搭載のノートPC
酒井 潤さんの講座
(セール中に買うと2000円以下で買えます)
やる気、元気、時間
Python 3.7.4
Anaconda3
Pycharm略歴
文系マーチ卒業(浪人して受かる程度の知能)
新卒で3年間3D CADのベンダーで技術担当として働く
某IT企業に転職した現在27歳アラサーAidemyで勉強しようと一念発起するも3日で断念
Progateに手を出すも2日で断念
2年で年収2.5倍になった方の記事を見て影響を受ける↓
(https://zine.qiita.com/products/interview_udemy_20170906/)
UdemyとQiitaの利用開始目標
- 習得してイキりたい
- 上司に自慢したい
- 副業で金を稼ぎたい
- Raspberry Piで自分でプログラムを組んで人の顔を認識すると話しかけるアプリを作りたい
学習方法
インプットはUdemy、アウトプットはQiitaで行っていきます。
とりあえずは酒井 潤さんの講座を1回見て、2回目に改めて整理しながら見るという方法でやっていきます。三日坊主にならないように頑張るぞ!
- 投稿日:2019-10-09T16:31:42+09:00
【セミナー感想】SQEX ゲーム作りをpythonで支援
会議名: SQEX ゲーム作りをpythonで支援
日付・時間・場所・出席者
- 日付: 2019年10月09日
- 時間: 14:30
- 場所: ビッグサイト 101会議室
講義内容
紹介
- SQEX
- テクノロジー推進部
- シニアAIエンジニア 太田健一郎 氏
pythonとSQEXの関係
- SQEXはゲームと映像の会社
- ゲーム → レンダリングはリアルタイムで動く必要あり
- 映像 → 時間かかっても良い
個人感想:やっぱりゲームの印象が強いし、期待するのはゲームだなぁ
pythonの歴史と特徴
- 歴史
- 10〜15年前からpythonが普及し始めた
- 以前はperlなどだった
- 特徴
- オブジェクト仕様
- 利用者の裾野が広い
- DLLと相性が良い
- 32/64bitに注意
個人感想:perlすきーだけど、もうwhile(<>){} とか、perlは使わないよね。うん。
DCCのmacro
- DCC = 2Dと3Dのツール
- 2D: Photoshopなど
- macro:JS
- 3D: MAYAなど
- macro:python
個人感想:python使いになったらデザインの方々からほめられそう?
バージョンなど
- CY2019: py2.7
- CY2020: py3.7
個人感想:しばらくは両方いれることになるよね。たしかそんな記事みたことある記憶
TA
- TA: テクニカルアーティスト
- GUI -> Qt for python
- TAのCodeの95%がpython
個人感想:TAさん大事。すごく大事。スクリプト言語だけじゃなくて、職種違いの翻訳・解釈もしてくれる。すごく大事。
SQEXのインハウスツール
- Rigging System 関節の制御
- HappySaaFace(Lipsync System)
- 字幕に合わせて口パクする→音声に合わせる
個人感想: 音声口パクできたら、ミクさんもっと最強になるね。すごいね。ワクワクしてきた。
SQEXのその他の事例
- プロトタイプをpy
- 実運用ではC++へ、ポーティング
- などなど etc...
個人感想: プロトタイプのところ、本当に昔のperlみたいな。違うのは、プロトタイプは作った側の意思や思惑とは関係なく本番にも使われてしまうのだけど。プロトのコードを1.0としてpushするとか、どんな羞恥プレイだか。
SQEXでの使用技術 QA自動化
QA自動化
- 排出率確認ツール
- キャプチャー画像からアイテムを自動分類する
- 実際にスマホの画面をキャプチャする
- Numpy
- opencv-python: 使いやすい
- AirTest
- クリッピングOpenCV
- お手本分類(自動で収集80%)、残り手動で手を加える
3Dゲームレポーティング
- バグ検出のための自動ツール
- 画像ではなく、ゲーム内の情報を利用
- 検出したバグはJenkinsもしくはRedmineに投げる
- 利用技術
- asyncio
- Tkinter
- python-Redmine
- SQLAlchemy: バグを分類するため
- venv
- 非同期処理の技術もちらほら
個人感想: 非同期処理って、作って動いてるときは楽しいけど、崩れると悲しい。スマホをキャプチャして自動化するのってやってみたい。スマホでやることに意義を感じる。
pythonが良いとおもうところ
- ライブラリが豊富
- ユースケース系
- 画像処理解析系
- 勝手に行列計算を並列実行してくれる
- REPLで試せる
使ってる開発ツール
- pytest
- Kite
- PyCharm
その他
- Qiitaなどを参考した経験
- 良くないケースも上がってたりする
- しっかりした書籍などをみましょう
個人感想: Qiitaの記事にこの下りを乗せるか、躊躇したけど、やっぱ大事なこと。自分も「やってみた」系だったりするので、しっかりと「やってみた」ダーティ状態であることを主張しよう。うん。
- 投稿日:2019-10-09T16:02:17+09:00
Pythonのbool型とNumPyのnumpy.bool_は演算結果が異なることがある
ちょっとした数値計算のコードをPythonで書いていて、なぜか計算結果が想定した結果と合わずストレスでキーボードを窓から投げ捨てそうになりましたが、どうやらこれはPythonとNumPyの真偽値の扱い方の違いに起因するということがわかりましたので、キーボードを窓から投げ捨てそうになる人が現れないよう共有しておきます。
さて、問題の計算部分では次のような計算をしておりました。
for i in range(n): for j in range(i, n): s_i, s_j = membership[i], membership[j] a[c] += weights[i,j] * ((s_i == c) + (s_j == c))ここで、
membershipは整数が入ったNumPyの1次元配列、weightsは浮動小数点数が入ったNumPyの2次元配列で、cはint型の整数です。
(s_i == c) + (s_j == c)は、s_iとs_jがcと同じ値か否かによって結果が変わります。私の想定した結果は、s_iとs_iが共にcと同じ値なら2、どちらか一方のみが同じ値なら1、それ以外なら0になるというものでした。実際、IPythonで試してみると次のような想定通りの結果になります。In [1]: (0 == 0) + (0 == 0) Out[1]: 2 In [2]: (0 == 0) + (0 == 1) Out[2]: 1 In [3]: (0 == 1) + (0 == 0) Out[3]: 1 In [4]: (0 == 1) + (0 == 1) Out[4]: 0さて、
s_iとs_jの値はmembershipというNumPyの整数配列から取り出しています。すると、ちょっと驚くべきことに、今見た想定通りの計算結果になりません。次のように0を収めたNumPyの配列xを作って、このことを確認してみましょう。xはmembershipの代わりです。In [1]: import numpy In [2]: x = numpy.array([0]) In [3]: (x[0] == 0) + (x[0] == 0) Out[3]: True In [4]: (x[0] == 0) + (x[0] == 1) Out[4]: True In [5]: (x[0] == 1) + (x[0] == 0) Out[5]: True In [6]: (x[0] == 1) + (x[0] == 1) Out[6]: False計算結果が整数でなく真偽値になってしまいましたね。実は、
x[0] == 0やx[0] == 1の結果は、Pythonのbool型ではなく、NumPy独自のnumpy.bool_というデータ型になります。面倒なことに両者は+演算の定義が違うのです。Pythonのbool型ではbool + boolはint型になりますが、NumPyのnumpy.bool_ではnumpy.bool_ + numpy.bool_がnumpy.bool_になります。このことは、次のように確認できます。In [7]: type(x[0] == 0) Out[7]: numpy.bool_ In [8]: type((x[0] == 0) + (x[0] == 0)) Out[8]: numpy.bool_さらに、Pythonの
bool型とNumPyのnumpy.bool_が通常の表示では区別できません。例えば次のように、どちらもTrueと表示されていますが、データ型が異なります。In [9]: 0 == 0 Out[9]: True In [10]: x[0] == 0 Out[10]: Trueこういう仕様になっているのは何か理由があるのでしょうが、大変ややこしいので注意が必要です。
- 投稿日:2019-10-09T15:55:11+09:00
社内勉強会 機械学習入門(8.気温予測してみよう)
今日のテーマは、「過去の気象データを使った気温予測」です。
題材
過去10年分の気象データを使って、ある日の気温を予測したいと思います。
気象データは、気象庁のサイトに公開されているので、このデータ(csvファイル)をダウンロードして使いましょう。気象庁のサイト
↑をクリックし、まずは、「拠点を選ぶ」で[埼玉]→[越谷]を選択してください。続いて「項目を選ぶ」でデータの種類:日別値、項目として日平均気温を選択してください。
続いて「期間を選ぶ」で 2009年1月1日~2018年12月31日 を指定してください。
指定した内容が正しいことを確認したうえで[CSVファイルをダウンロード]ボタンを押下してください。
ファイル名は、「data.csv」として、C:\ml-introの直下に保存してください。
データを見てみよう
「data.csv」をテキストエディタで開くと↓のようになっていますね。
邪魔なヘッダ行もあったりして、このままでは使えそうにないので、加工して使いましょう。
「data.csv」を学習に使えるデータへ加工し、「koshigaya_kion.csv」という別のファイル名で保存する。
# # ダウンロードした「data.csv」を学習に使えるデータへ加工し、「koshigaya_kion.csv」という別のファイル名で保存 # in_file = "data.csv" out_file = "koshigaya_kion.csv" # CSVファイルを読み込む with open(in_file, "rt", encoding="Shift_JIS") as fr: lines = fr.readlines() # 先頭から5レコード分を削除し、新たな行ヘッダをつける lines = ["年,月,日,気温,品質,均質\n"] + lines[5:] # / を , に置換している(年、月、日をカンマで分離するため) lines = map(lambda v: v.replace('/', ','), lines) # joinで改行付きの全レコードを結合したあと、stripメソッドで最終レコードの改行だけを取り除く result = "".join(lines).strip() # 加工された結果を out_file で指定したファイル名で出力する with open(out_file, "wt", encoding="utf-8") as fw: fw.write(result) print("saved.")加工後のファイル(ファイル名:koshigaya_kion.csv)
ゴールまでのステップ
- 「koshigaya_kion.csv」を読み込む。
- 訓練用データ(2009~2017年)とテスト用データ(2018年)を作成する。
- 訓練用データを使って学習させる。
- テスト用データを与え、2018年(1年分)の気温を予測する。
- 「予測した結果」と「2018年の正解」をグラフにプロットし、結果の精度を見てみる。
学習に使うアルゴリズムは、線形回帰を使います。
[参考情報]https://engineers.weddingpark.co.jp/?p=872ここからが本題! 機械学習プログラムを書いてみよう
## 必要なライブラリをインポート
from sklearn.linear_model import LinearRegression import pandas as pd import numpy as np import matplotlib.pyplot as plt## 1. 「koshigaya_kion.csv」を読み込む。
# 平均気温データ(越谷市 2009年1月~2018年12月までの10年分)の読み込み temper_data = pd.read_csv('koshigaya_kion.csv', encoding="utf-8")## 2. 訓練用データ(2009~2017年)とテスト用データ(2018年)を作成する。
# 元データを訓練用(9年)とテスト用(1年)に一旦分離 train_year = (temper_data["年"] <= 2017) # 2017年までを訓練用 test_year = (temper_data["年"] >= 2018) # 2018年以降をテスト用 interval = 6 # 過去6日分(説明変数) と その翌日(目的変数) をセットとした訓練用データを9年分作る def make_data(data): x = [] # 説明変数 y = [] # 目的変数 temps = list(data["気温"]) for i in range(len(temps)): if i < interval: continue y.append(temps[i]) xa = [] for p in range(interval): d = i + p - interval xa.append(temps[d]) x.append(xa) return (x, y) train_x, train_y = make_data(temper_data[train_year]) # 訓練用データ test_x, test_y = make_data(temper_data[test_year]) # テスト用データ## 3. 訓練用データを使って学習させる。
lr = LinearRegression(normalize=True) lr.fit(train_x, train_y)## 4. テスト用データを与え、2018年(1年分)の気温を予測する。
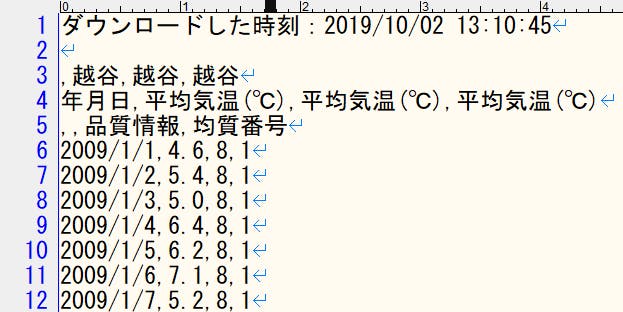
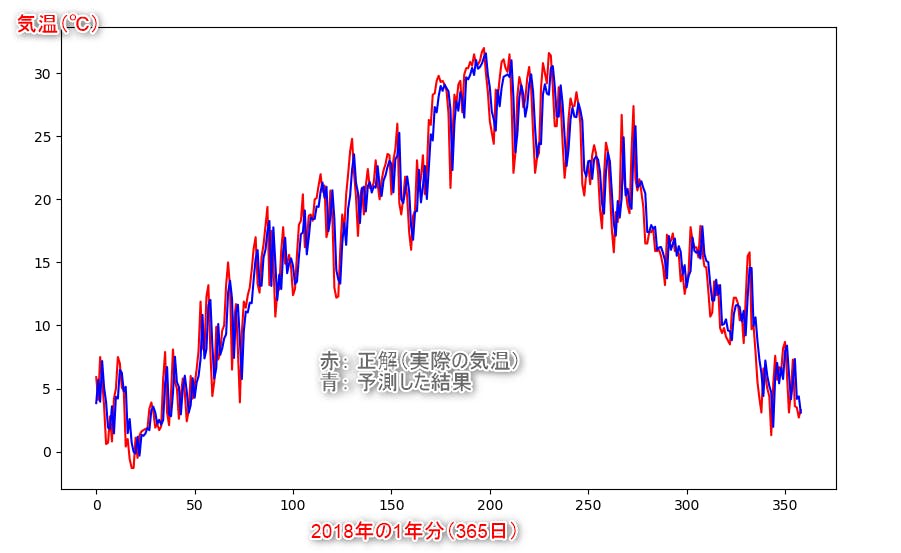
pre_y = lr.predict(test_x)## 5. 「予測した結果(青)」と「2018年の正解(赤)」をグラフにプロットし、結果の精度を見てみる。
plt.figure(figsize=(10, 6), dpi=100) plt.plot(test_y, c='r') plt.plot(pre_y, c='b') plt.savefig('tenki-kion-lr.png') plt.show()青と赤のラインがそんなに大きくは離れていないですね!
まとめ
今回は、実際の気象データをもとに「回帰分析」による未来の気温予測をしてみました。
次回は、もうちょと業務のデータを扱ってみたい、、、 検討中!
- 投稿日:2019-10-09T15:26:27+09:00
Pythonを用いた緯度経度座標系ポリゴンデータの面積計算
はじめに
以前に投稿した記事において,緯度経度座標系のグリッド面積を求めるコードを紹介した.その際,pyprojの更新によって緯度と経度の定義順序が逆転していることについて触れた.この際は手作業で緯度と経度とを逆転させた.しかし,より複雑なポリゴンデータに対する適用のためにはこの操作を自動化させる必要がある.
本記事では,geopandasパッケージで公開している世界地図ポリゴンデータを題材として,各地域の面積を算出するコードを作成した.使用モジュール
今回はpython3.7系でコードを作成した.pyprojのversionは2.2である.
import matplotlib.pyplot as plt import geopandas as gpd from functools import partial import pyproj from shapely.ops import transform世界地図データの読込
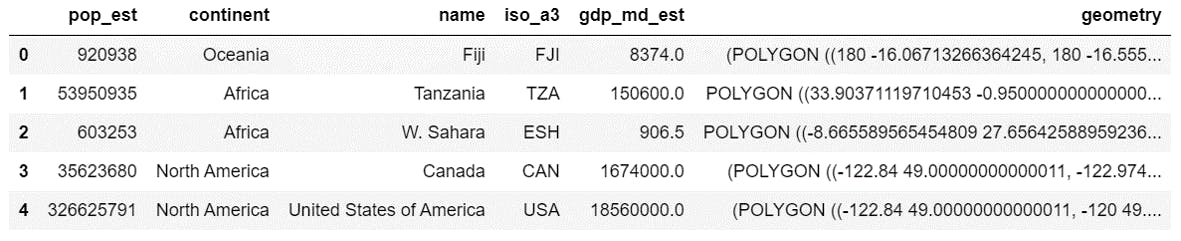
デフォルトで様々な項目(人工,GDPなど)が入っているが,本記事ではgeometryのみを用いる.
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres')) print(world.head())
ポリゴンデータから面積を算出するコード
(失敗例)緯度経度座標ポリゴンに
areaメソッド適用geometry列に並ぶshapely形式データに対し,
geom.areaを適用することで,緯度経度座標系を用いて算出された面積を計算できる.しかし,これはkm2の単位での出力ではなく,高緯度ほど相対的に面積が過大評価となる.world['geom.area'] = world['geometry'].area print(world.head())
正積図法へ投影後に面積を計算
同じコードが以前紹介した記事にも記載してある.正積図法をみたすEPSGコードを指定している.
def geom_to_area(geom, epsg=3410): # epsg=3410:正積図法 project = partial( # 関数の入力を部分的に与える. pyproj.transform, pyproj.CRS.from_epsg(4326), # WGS84 # ver 2.2.x pyproj.CRS.from_epsg(epsg)) # ver 2.2.x trans = transform(project, geom) # 座標系変換 return trans.area # 面積を返す(失敗例)緯度経度を入れ替えずに面積を計算
試しに,テーブルの2行目にあるタンザニアの面積を算出してみる.テーブル内にあるgeometryをそのまま面積計算に用いると,下記のような結果になる.
tanz = world['geometry'][1] # Polygon print(geom_to_area(tanz)
数字は計算で求められた面積を示しており,約77.4万km2となった.wikiによると,実際の値は約94.5万km2であった.境界線を簡略化しているとしても小さすぎる値である.
ここで,面積計算コード内で座標変換されたshapely形式のデータも取得してみると,上図に示すように,xyが反転してしまっていることが分かる.これが誤った面積を算出してしまう要因である.
解決策として,(やや奇妙ではあるが)事前にxy座標を反転させてから,正積図法への投影および面積計算を行うことがあげられる.xy座標の反転
この記事を参照して,PolygonもしくはMultiPolygonのxy座標を反転するコードを作成した.
def Swap_xy(geom): # (x, y) -> (y, x) def swap_xy_coords(coords): for x, y in coords: yield (y, x) # if geom.type == 'Polygon': def swap_polygon(geom): ring = geom.exterior shell = type(ring)(list(swap_xy_coords(ring.coords))) holes = list(geom.interiors) for pos, ring in enumerate(holes): holes[pos] = type(ring)(list(swap_xy_coords(ring.coords))) return type(geom)(shell, holes) # if geom.type == 'MultiPolygon': def swap_multipolygon(geom): return type(geom)([swap_polygon(part) for part in geom.geoms]) # Main if geom.type == 'Polygon': return swap_polygon(geom) elif geom.type == 'MultiPolygon': return swap_multipolygon(geom) else: raise TypeError('Unexpected geom.type:', geom.type)MultiPolygonの例として,テーブルからカナダも取得して検証を行った.wikiの数字と比較して数%程度の誤差はあるものの,ポリゴンデータから面積の計算は適切に行えていることが分かる.
tanz = world['geometry'][1] # Polygon cana = world['geometry'][3] # MultiPolygon tanz_swap = Swap_xy(tanz) cana_swap = Swap_xy(cana) tanz_area = geom_to_area(tanz_swap) # 936857756916.421 (真値:94.5万km2) cana_area = geom_to_area(cana_swap) # 9986763834110.908 (真値: 998万km2)geopandasテーブルに面積計算関数の適用
上記で定義した関数を組み合わせて,面積計算関数を作成した.これを用いて,新たな列をテーブルに追加した.
def CalcArea(geom): geom_swap = Swap_xy(geom) area = geom_to_area(geom_swap) return area * 1e-6 # m2 -> km2 world['area_km'] = world['geometry'].map(CalcArea) print(world.head())
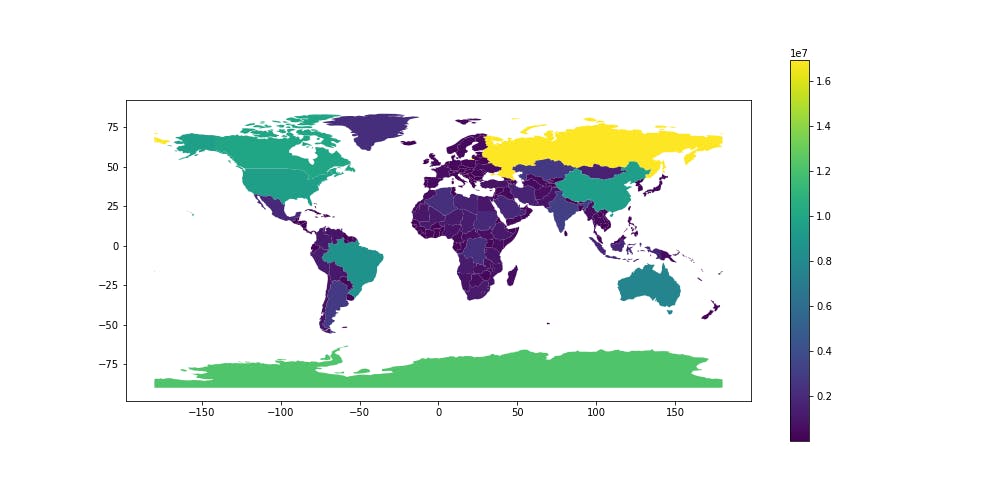
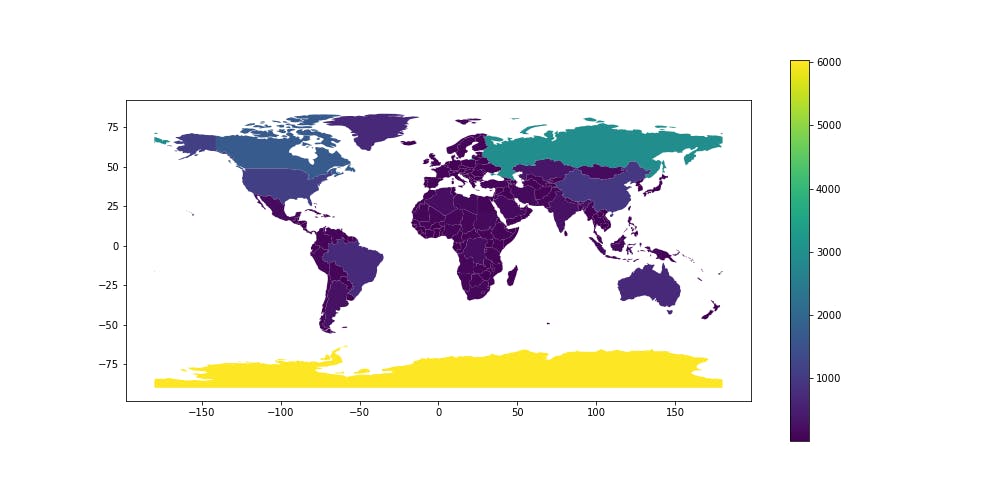
描画
新たに作成した列を用いて世界地図の描画.グリーンランドや南極大陸が,大きい国々と比較してそこまで大きくないことがわかる.
world.plot(figsize=(14, 7), column='area_km', legend=True)
重ねて,失敗例で示した,緯度経度座標系のまま計算してしまった面積も描画した.いわゆる,地図上での見た目の面積である.正しい地図とは大違いの結果となっていることが分かる.
おわりに
地域ごとの面積を簡単に比較できるサイトを紹介しておしまい.
http://thetruesize.com/



- 投稿日:2019-10-09T14:54:16+09:00
確率論のσ加法族(ほんとは有限だけど)の自動生成を Sympy で書いてみた!
はじめに
「確率空間」を学生に教えるとき,彼我ともに,最も難しく感じるのは,σ加法族(完全加法族,σ代数)のところです.
そこで,有限集合に話を限って,
- σ加法族を自分達で作らせる(本当は有限加法族だけど)
という教え方をするのですが,1つ問題がありまして,解答例を作るのが面倒なのです.
暗算しながら板書していくと,「それだと足りなくないですか」とか言われて「あっ」みたいなことになる.教室総出の人海戦術が始まり,「・・・これでいいんだっけ,まだ足んないか」みたいになって,しばし中断.そういう場面も有意義だとは思うのですが,確証ある正解は,やはり手元に欲しいものです.
というわけで,授業中の答え合わせを念頭に,
- σ加法族(ほんとは有限だけど)の自動生成を,Python3+Sympy で書いてみた!
というのが,この記事の内容です.
確率空間なんて興味ない人のほうが多い気がするので,最低限の基本事項をレビューしながら話を進めます.
基本事項 ー 確率空間と
FiniteSet確率空間というのは,$(\Omega,{\mathcal F},P)$という三つ組のことです.$\Omega$を見本空間(または標本空間),${\mathcal F}$をσ加法族(または完全加法族,σ代数)といいます.$P$は確率です(この記事では扱いません).
以下では,$\Omega$ と ${\mathcal F}$の具体例と,基本となる実装例を示していきます.
見本空間 Ω
ガチャ(カプセルおもちゃ販売機)を例にとります(講義でそうしてます).
ガチャからカプセルを取り出す試行を繰り返したところ,次のような種類のマスコットが,ランダムに出てきたとします.$$犬, 鳥, 犬, 人, 人, 鳥, 犬, · · · , 人$$このような試行結果の列を,試行列といいます.試行結果を自然言語で表すと,紙に書くのが大変なので,適当な記号や数字による,ラベリングがなされます.例えば,次のようにできます.$$1:犬,\quad 2:鳥,\quad 3:人$$個々のラベルを,見本といいます.見本を使うと,先の試行列は,次のように簡潔に書けます.$$1, 2, 1, 3, 3, 2, 1, \cdots, 3$$
次に,確率論では,試行結果の全種類を網羅した見本帳を作ります.例えば,試行結果が$1,2,3$の3種類であるとき,見本帳を次のような集合で表します.
$$\Omega :=\{1,2,3\}$$このような見本帳を表す集合を,見本空間といいます.この$\Omega$は,Sympyの
FiniteSetを使って,次のように書くことができます.python3from sympy import FiniteSet, EmptySet Om = FiniteSet(1,2,3) print('Om = ' + str(Om))実行結果Om = {1, 2, 3}事象
続いて,確率論では,見本の様々なクラス分けを導入します.
例えば,哺乳類と2足歩行(おもちゃだけど)に興味があるなら,次のようなクラス$A_1$, $A_2$が導入できます.
定義 人為的な意味付け $A_1:=\{1,3\}$ 哺乳類 $A_2:=\{2,3\}$ 2足歩行 このようなクラス分けを表す,$\Omega$の部分集合を,事象といいます.
同様に,
FiniteSetを使って次のように書けます.python3A1 = FiniteSet(1,3) A2 = FiniteSet(2,3) print('A1 = ' + str(A1)) print('A2 = ' + str(A2))実行結果A1 = {1, 3} A2 = {2, 3}以上を踏まえて,事象$A_1$, $A_2$を要素とする,族(集合を要素とする集合のこと)を考えます.$$F:=\{A_1,A_2\}=\{\{1,3\},\{2,3\}\}$$この族は,考察中の事象のリストを与えることになります.
FiniteSetの引数はFiniteSetでもよいので,次のように書けます.python3F = FiniteSet(A1,A2) print('F = ' + str(F))実行結果F = {{1, 3}, {2, 3}}σ加法族
ここからが本題です.
確率論にはルールがありまして,事象の集合演算結果もまた,事象でなければなりません.数学でよく目にするルールですね(ある集合の要素間に演算を導入したとき,演算結果がその集合から出てはいけないという).残念ながら,さきほどの事象のリスト$F$は,このルールを満たしていません.例えば,$A_1\cap A_2=\{3\}$は,$F$の要素ではありません.
そこで,不完全な$F$を拡張して,完全なる全品リストを得ることを考えます.
そのためのチェックシートが整備されています.□定義(σ加法族): $\Omega$の部分集合族$\mathcal F$で,次の3条件を満すものをσ加法族という.
- $\Omega\in{\mathcal F}$.
- $A\in {\mathcal F}\implies \overline A\in {\mathcal F}$.
- $A_1,A_2,\cdots,A_n\in {\mathcal F}\implies A_1\cup A_2\cup\cdots\cup A_n\in {\mathcal F}$. ($n$は任意の自然数)
σ加法族は集合演算で閉じる.□
この定義を満たすように,元の$F$を拡張していけば,完全なる$\mathcal F$,すなわちσ加法族が得られます.
ところが,それを手作業で,間違いなく実行するのは,案外大変なのです.
そこで,次のようなプログラムを書いてみた次第です.実装 ー σ加法族の自動生成
まず,定義(σ加法族)を満たすか,チェックする関数を作ります.
python3def is_sigma_algebra(Om,FF): is_ok = True # (条件1)のチェック is_ok = is_ok and (Om in FF) # for文で全要素を巡るためのリスト化 elm=list(FF) #リスト化 n=len(elm) #リストの要素数 # (条件2)のチェック for i in range(0,n): is_ok = is_ok and (Om-elm[i] in FF) # (条件3)の全数チェック for i in range(0,n): for j in range(i,n): is_ok = is_ok and (elm[i]+elm[j] in FF) return is_ok上述したように,さきほどの
Fは,チェックを通りません.python3print( 'F is sigma-algebra: ' + str(is_sigma_algebra(Om,F)))実行結果F is sigma-algebra: False次に,定義(σ加法族)に出てくる集合演算結果(余事象と和事象)を追加する関数を作ります.
python3#余事象を追加する関数 def append_complements(Om,F): result=F #いまある全ての事象の余事象を追加する for elm in list(F): celm = Om - elm result = result + FiniteSet(celm) return result #和事象を追加する関数 def append_unions(F): result=F Flist=list(F) Fn=len(Flist) #いまある全ての事象の組み合わせの和事象を追加する for i in range(0,Fn): for j in range(i,Fn): result = result + FiniteSet(Flist[i]+Flist[j]) return result以上を組み合わせて,σ加法族を生成する関数を作ります.
python3def generate_sigma_algebra(Om,F): cur_F = F + FiniteSet(Om) prev_F = EmptySet() #族が変化しなくなるまでループ while(prev_F != cur_F): prev_F = cur_F #余事象の追加 cur_F = append_complements(Om,cur_F) #和事象の追加 cur_F = append_unions(cur_F) return cur_Fさきほどの
Fで生成されるσ代数を求めてみます.python3FF = generate_sigma_algebra(Om,F) print('FF = ' + str(FF)) print( 'FF is sigma-algebra: ' + str(is_sigma_algebra(Om,FF)))実行結果FF = {EmptySet(), {1}, {2}, {3}, {1, 2}, {1, 3}, {2, 3}, {1, 2, 3}} FF is sigma-algebra: True$\Omega$のべき集合が出てきました.他の例も試してみます.
python3A3 = FiniteSet(2) F2 = FiniteSet(A1,A3) print('F2 = ' + str(F2)) FF2 = generate_sigma_algebra(Om,F2) print('FF2 = ' + str(FF2)) print( 'FF2 is sigma-algebra: ' + str(is_sigma_algebra(Om,FF2)))実行結果F2 = {{2}, {1, 3}} FF2 = {EmptySet(), {2}, {1, 3}, {1, 2, 3}} FF2 is sigma-algebra: True今度はもう少し小さいですね.
確率変数で生成されるσ加法族
以上の簡単な応用として,確率変数からσ加法族を生成することもできます.下記が実装例です.
おわりに
ざざっと実装してみたのですが,素人の自己流なので,もっと良い方法があるような気もします.
例えば,上述のアルゴリズムには2重ループが何度もでてくるので,事象の数が多いと厳しいですよね.
何かお気づきの点があれば,ぜひぜひご教示ください.よろしくお願いいたします.
- 投稿日:2019-10-09T13:32:15+09:00
Celery4.3.0でresult_expiresを正しく適用する
tl;dr
Celeryのドキュメントが間違っていた。
背景
DjangoでCeleryを使う際に、Result BackendにRedisを指定して動かしたとき、どうもresult_expiresの設定がうまくいかなかった。
やりたいこと
result_expiresを正しく設定する。
環境
- Celery 4.3.0
- Django 2.2.6
- Redis 5.0.1
やること
CELERY_TASK_RESULT_EXPIRESではなくCELERY_RESULT_EXPIRESで設定する。settings.py# CELERY_TASK_RESULT_EXPIRES = 3600 CELERY_RESULT_EXPIRES = 3600秒単位なので、これで期限を1時間に設定されます。
補足
PR投げるチャンスかと思いましたが、既に対応済みでした。
https://github.com/celery/celery/issues/5473
https://github.com/celery/celery/pull/54754.4.0リリース後に反映されるようで、現状(2019/10/09)のドキュメントは修正されていません。
というのもあって、この記事を書きました。
- 投稿日:2019-10-09T12:26:51+09:00
GCPで使えるデータベースそれぞれの向き不向きと料金ざっくり
GCPで使えるデータベース
- Bigtable
- BigQuery
- Datastore
- Firestore
- SQL
- Spanner
- Memorystore
Googleが提供していたディシジョンツリー(今は無い?)
Bigtable
大量データの分析や操作に適したペタバイト規模のフルマネージドNoSQLデータベースサービス。
フルマネージドとは?
オートスケーリングやバージョンなど、サーバーやサービスの運用をGCP側で管理する形態。NoSQLとは?
Not only SQLの略。SQLだけでなくドキュメントベースや列指向でクエリを発行したいデータを管理する。主な特徴
- 低レイテンシ
- スケーラブル(数十億行、数千列の規模にスケール可能)
向いてる用途
- 分析
- 時系列データ
- 購入履歴などのマーケティングデータ
- 株、為替などの金融データ
- IoTでセンサーからのデータ
- 構造化されていないデータ
向いてない用途
- トランザクション管理が必要なデータ
- 郵便番号テーブルなどの変更の少ないマスタデータ
- ユーザーと組織などのリレーショナルデータ
- そこまで大量じゃないデータ
料金
東京リージョンの3ノード(最低数)で100GBで1ヶ月の料金をざっくり計算する。(以降1ドル=108円)
- ノード料金: 198,000円
- SSDストレージ料金: 22円
- これに下りのネットワークが加算される。
だいたい最低で1ヶ月20万円。
Pythonでのサンプル(公式より)
# 接続 client = bigtable.Client(project=project_id, admin=True) instance = client.instance(instance_id) # 書込 greetings = ['Hello World!', 'Hello Cloud Bigtable!', 'Hello Python!'] rows = [] column = 'greeting'.encode() for i, value in enumerate(greetings): row_key = 'greeting{}'.format(i).encode() row = table.row(row_key) row.set_cell(column_family_id, column, value, timestamp=datetime.datetime.utcnow()) rows.append(row) table.mutate_rows(rows) # 読込 key = 'greeting0'.encode() row = table.read_row(key, row_filter) cell = row.cells[column_family_id][column][0] print(cell.value.decode('utf-8'))考察
- ノード料金が高い。
- テーブル作成などの管理にcbtコマンドツールが必要なのがちょっとダルい。
- クエリが分かりづらい。
- BigQueryとの主な違いは低レイテンシ。
- ACIDトランザクションをサポートしてないので、基本的には大量のデータをバンバン入れて加工元にするデータレイク的な使い方に限定される感じ。
BigQuery
フルマネージドエンタープライズデータウェアハウス
主な特徴
- リアルタイム分析
- 標準SQL
- ペタバイト規模のスケーリング
向いてる用途
- 分析
- リアルタイムな大規模データ
- IoT
- ログ解析
向いてない用途
- トランザクション管理が必要なデータ
- フロントエンドから操作されるような低レイテンシが求められるデータ
- 他、Bigtableと似ている
料金
BigQueryの料金計算は複雑なので、dry-run等を利用して見積もるのが良い。
Bigtableよりは概ね安いが、大量データがあるテーブルへreadが頻繁に発生するようなアプリケーションでは注意が必要。Pythonでのサンプル(公式より)
# 接続 from google.cloud import bigquery client = bigquery.Client() # 書込 # 書込みは基本的にGCSやPub/Subなどからバッチやストリーミングで実行する # Pandas等を使った書込も可能だがあまり一般的ではない # 読込 query = ( "SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` " 'WHERE state = "TX" ' "LIMIT 100" ) query_job = client.query(query) for row in query_job: print(row)考察
- BigtableとBigQueryは似ている。
- 基本的にどちらも分析用途で、低レイテンシが必要ならば料金が高くなるけどBigtableを使う。
Datastore
ウェブアプリとモバイルアプリのためのスケーラビリティの高いフルマネージドNoSQLデータベースサービス。
主な特徴
- シャーディングとレプリケーションを自動的に処理
- ACIDトランザクション
- SQLライクなクエリ
- ネイティブモードとDatastoreモードがある
- そのうちFirestoreに統合される
向いてる用途
- 大規模な構造化データ
- リアルタイムな在庫と商品の詳細を提供する商品カタログ
- レコメンデーション向けのユーザープロファイル
- トランザクション管理が必要なデータ
向いてない用途
- 構造化されていないデータ
- ユーザーと組織などのリレーショナルデータ
料金
東京リージョンで100GBで1日100万エンティティの読み書きで1ヶ月の料金をざっくり計算する。
- ストレージ料金: 1,242円
- エンティティ料金: 2,500円
だいたい最低で1ヶ月4千円弱。
Pythonでのサンプル(公式より)
# 接続 from google.cloud import datastore datastore.Client(project_id) # 書込 key = client.key('Task') task = datastore.Entity(key, exclude_from_indexes=['description']) task.update({ 'created': datetime.datetime.utcnow(), 'description': description, 'done': False }) client.put(task) # 読込 query = client.query(kind='Task') query.order = ['created'] query.fetch()考察
- Firestoreを使えとGoogleが言っているので、今からあえてDatastoreを使う理由は特に無い。
Firestore
グローバルアプリ用に構築されたNoSQLデータベース
主な特徴
- Datastoreモードをサポート
- マルチリージョンのレプリケーション
向いてる用途
- クラウドネイティブなアプリケーション
- 直接データを扱いたいモバイルアプリ
向いてない用途
- Datastoreとだいたい同じ
料金
東京リージョンで100GBで1日100万ドキュメントの読み書きで1ヶ月の料金をざっくり計算する。
- ストレージ料金: 2,000円
- ドキュメント料金: 7,700円
だいたい最低で1ヶ月1万円弱。
Pythonでのサンプル(公式より)
# 接続 from google.cloud import firestore db = firestore.Client() # 書込 doc_ref = db.collection(u'users').document(u'alovelace') doc_ref.set({ u'first': u'Ada', u'last': u'Lovelace', u'born': 1815 }) # 読込 users_ref = db.collection(u'users') docs = users_ref.stream() for doc in docs: print(u'{} => {}'.format(doc.id, doc.to_dict()))考察
- NoSQLを使うならば実質Firestore一択な感じ。
- レイテンシも悪くないので、データ構造次第ではRDBMSを使わずにこっちを使うのは十分にあり。ただし、課金がストレージ単位ではなく読み書き単位なので、大量データをものすごく頻繁に読み書きする場合は他を考慮した方が良い。
SQL
フルマネージドのリレーショナルデータベースサービス
主な特徴
- MySQL、PostgreSQL、SQL Serverが利用可能
- RDBMS
向いてる用途
- RDBMSでやりたいこと全般
向いてない用途
- すごい勢いで増えていくようなデータの管理
料金
東京リージョンの最弱1インスタンスで100GBで1ヶ月の料金をざっくり計算する。
インスタンス料金: 1,100円
ストレージ料金: 1,836円GAEスタンダード環境のPythonでのサンプル
# 接続 # ORMツールとしてSQLAlchemyを使う import sqlalchemy db = sqlalchemy.create_engine( sqlalchemy.engine.url.URL( drivername='mysql+pymysql', username=<ユーザー名>, password=<パスワード>, database=<作成したデータベース>, query={ 'unix_socket': '/cloudsql/<作成したインスタンスのインスタンス接続名>' } ) ) # 書込 # pandasを使う import pandas as pd df = pd.DataFrame([['三体', '劉慈欣'], ['なめらかな世界と、その敵', '伴名練']], columns=['book_name', 'author_name']) with db.connect() as conn: df.to_sql('books', conn, if_exists='append', index=None) # 読込 import pandas.io.sql as psql with db.connect() as conn: query = 'SELECT * FROM books' df = psql.read_sql(query, conn) print(df)考察
- Spanaerはいいお値段するので、RDBMSを使いたかったらSQL一択。
- もしくは頑張ってGCEにDBをインストールして使うのも可能だが、フルマネージドにならないしクラウドネイティブとも言えないのでおすすめしない。
Spanner
グローバルおよびリージョナルアプリケーションデータ向けのスケーラブルなフルマネージドリレーショナルデータベース サービス
主な特徴
- 大規模なSQL
- ACIDトランザクション
- 強整合性
向いてる用途
- 大規模なリレーショナルデータ
向いてない用途
- 構造化されていないデータ
料金
シングルリージョンで1ノードで100GBで1ヶ月の料金をざっくり計算する。
ノード料金: 70,000円
ストレージ料金: 3,200円
だいたい最低で1ヶ月7万円。マルチリージョンで1ノードで100GBで1ヶ月の料金をざっくり計算する。
ノード料金: 233,000円
ストレージ料金: 5,400円
だいたい最低で1ヶ月24万円。1ノードだけというのはまずないので基本的にマルチリージョンにするとかなり高額になる。
Pythonでのサンプル(公式より)
# 接続 from google.cloud import spanner spanner_client = spanner.Client() instance_id = 'my-instance-id' instance = spanner_client.instance(instance_id) database_id = 'my-database-id' database = instance.database(database_id) # 書込 def insert_singers(transaction): row_ct = transaction.execute_update( "INSERT Singers (SingerId, FirstName, LastName) VALUES " "(12, 'Melissa', 'Garcia'), " "(13, 'Russell', 'Morales'), " "(14, 'Jacqueline', 'Long'), " "(15, 'Dylan', 'Shaw')" ) print("{} record(s) inserted.".format(row_ct)) database.run_in_transaction(insert_singers) # 読込 with database.snapshot() as snapshot: results = snapshot.execute_sql('SELECT SingerId, AlbumId, AlbumTitle FROM Albums') for row in results: print(u'SingerId: {}, AlbumId: {}, AlbumTitle: {}'.format(*row))考察
- 普通のアプリケーションではかなりオーバースペック。
- Spannerを使わないといけないような状況になったらサポートも入れた方が良い。
Memorystore
フルマネージドのRedis向けインメモリデータストアサービス
主な特徴
- インメモリデータベースであるRedisをクラウドで使える
向いてる用途
- キャッシュヒット率が高いデータ
- ゲームのリーダーボードのような頻繁に更新され共有されるデータ
向いてない用途
- バイナリデータ
- 大規模で構造化されたデータ
料金
東京リージョンで100GBで1ヶ月の料金をざっくり計算する。
料金: 1400円GAEスタンダード環境のPythonでのサンプル(公式より)
# 接続 import redis redis_host = os.environ.get('REDISHOST', 'localhost') redis_port = int(os.environ.get('REDISPORT', 6379)) redis_client = redis.StrictRedis(host=redis_host, port=redis_port) # 更新 value = redis_client.incr('counter', 1)考察
- 基本的にRedisでやるようなことに使う。
- 利用できる環境に制限があるので注意する。

- 投稿日:2019-10-09T12:26:51+09:00
GCPで使えるデータベースそれぞれの向き不向き
GCPで使えるデータベース
- Bigtable
- BigQuery
- Datastore
- Firestore
- SQL
- Spanner
- Memorystore
Googleが提供していたディシジョンツリー(今は無い?)
Bigtable
大量データの分析や操作に適したペタバイト規模のフルマネージドNoSQLデータベースサービス。
フルマネージドとは?
オートスケーリングやバージョンなど、サーバーやサービスの運用をGCP側で管理する形態。NoSQLとは?
Not only SQLの略。SQLだけでなくドキュメントベースや列指向でクエリを発行したいデータを管理する。主な特徴
- 低レイテンシ
- スケーラブル(数十億行、数千列の規模にスケール可能)
向いてる用途
- 分析
- 時系列データ
- 購入履歴などのマーケティングデータ
- 株、為替などの金融データ
- IoTでセンサーからのデータ
- 構造化されていないデータ
向いてない用途
- トランザクション管理が必要なデータ
- 郵便番号テーブルなどの変更の少ないマスタデータ
- ユーザーと組織などのリレーショナルデータ
- そこまで大量じゃないデータ
料金
東京リージョンの3ノード(最低数)で100GBで1ヶ月の料金をざっくり計算する。(以降1ドル=108円)
- ノード料金: 198,000円
- SSDストレージ料金: 22円
- これに下りのネットワークが加算される。
だいたい最低で1ヶ月20万円。
Pythonでのサンプル(公式より)
# 接続 client = bigtable.Client(project=project_id, admin=True) instance = client.instance(instance_id) # 書込 greetings = ['Hello World!', 'Hello Cloud Bigtable!', 'Hello Python!'] rows = [] column = 'greeting'.encode() for i, value in enumerate(greetings): row_key = 'greeting{}'.format(i).encode() row = table.row(row_key) row.set_cell(column_family_id, column, value, timestamp=datetime.datetime.utcnow()) rows.append(row) table.mutate_rows(rows) # 読込 key = 'greeting0'.encode() row = table.read_row(key, row_filter) cell = row.cells[column_family_id][column][0] print(cell.value.decode('utf-8'))考察
- ノード料金が高い。
- テーブル作成などの管理にcbtコマンドツールが必要なのがちょっとダルい。
- クエリが分かりづらい。
- BigQueryとの主な違いは低レイテンシ。
- ACIDトランザクションをサポートしてないので、基本的には大量のデータをバンバン入れて加工元にするデータレイク的な使い方に限定される感じ。
BigQuery
フルマネージドエンタープライズデータウェアハウス
主な特徴
- リアルタイム分析
- 標準SQL
- ペタバイト規模のスケーリング
向いてる用途
- 分析
- リアルタイムな大規模データ
- IoT
- ログ解析
向いてない用途
- トランザクション管理が必要なデータ
- フロントエンドから操作されるような低レイテンシが求められるデータ
- 他、Bigtableと似ている
料金
BigQueryの料金計算は複雑なので、dry-run等を利用して見積もるのが良い。
Bigtableよりは概ね安いが、大量データがあるテーブルへreadが頻繁に発生するようなアプリケーションでは注意が必要。Pythonでのサンプル(公式より)
# 接続 from google.cloud import bigquery client = bigquery.Client() # 書込 # 書込みは基本的にGCSやPub/Subなどからバッチやストリーミングで実行する # Pandas等を使った書込も可能だがあまり一般的ではない # 読込 query = ( "SELECT name FROM `bigquery-public-data.usa_names.usa_1910_2013` " 'WHERE state = "TX" ' "LIMIT 100" ) query_job = client.query(query) for row in query_job: print(row)考察
- BigtableとBigQueryは似ている。
- 基本的にどちらも分析用途で、低レイテンシが必要ならば料金が高くなるけどBigtableを使う。
Datastore
ウェブアプリとモバイルアプリのためのスケーラビリティの高いフルマネージドNoSQLデータベースサービス。
主な特徴
- シャーディングとレプリケーションを自動的に処理
- ACIDトランザクション
- SQLライクなクエリ
- ネイティブモードとDatastoreモードがある
- そのうちFirestoreに統合される
向いてる用途
- 大規模な構造化データ
- リアルタイムな在庫と商品の詳細を提供する商品カタログ
- レコメンデーション向けのユーザープロファイル
- トランザクション管理が必要なデータ
向いてない用途
- 構造化されていないデータ
- ユーザーと組織などのリレーショナルデータ
料金
東京リージョンで100GBで1日100万エンティティの読み書きで1ヶ月の料金をざっくり計算する。
- ストレージ料金: 1,242円
- エンティティ料金: 2,500円
だいたい最低で1ヶ月4千円弱。
Pythonでのサンプル(公式より)
# 接続 from google.cloud import datastore datastore.Client(project_id) # 書込 key = client.key('Task') task = datastore.Entity(key, exclude_from_indexes=['description']) task.update({ 'created': datetime.datetime.utcnow(), 'description': description, 'done': False }) client.put(task) # 読込 query = client.query(kind='Task') query.order = ['created'] query.fetch()考察
- Firestoreを使えとGoogleが言っているので、今からあえてDatastoreを使う理由は特に無い。
Firestore
グローバルアプリ用に構築されたNoSQLデータベース
主な特徴
- Datastoreモードをサポート
- マルチリージョンのレプリケーション
向いてる用途
- クラウドネイティブなアプリケーション
- 直接データを扱いたいモバイルアプリ
向いてない用途
- Datastoreとだいたい同じ
料金
東京リージョンで100GBで1日100万ドキュメントの読み書きで1ヶ月の料金をざっくり計算する。
- ストレージ料金: 2,000円
- ドキュメント料金: 7,700円
だいたい最低で1ヶ月1万円弱。
Pythonでのサンプル(公式より)
# 接続 from google.cloud import firestore db = firestore.Client() # 書込 doc_ref = db.collection(u'users').document(u'alovelace') doc_ref.set({ u'first': u'Ada', u'last': u'Lovelace', u'born': 1815 }) # 読込 users_ref = db.collection(u'users') docs = users_ref.stream() for doc in docs: print(u'{} => {}'.format(doc.id, doc.to_dict()))考察
- NoSQLを使うならば実質Firestore一択な感じ。
- レイテンシも悪くないので、データ構造次第ではRDBMSを使わずにこっちを使うのは十分にあり。ただし、課金がストレージ単位ではなく読み書き単位なので、大量データをものすごく頻繁に読み書きする場合は他を考慮した方が良い。
SQL
フルマネージドのリレーショナルデータベースサービス
主な特徴
- MySQL、PostgreSQL、SQL Serverが利用可能
- RDBMS
向いてる用途
- RDBMSでやりたいこと全般
向いてない用途
- すごい勢いで増えていくようなデータの管理
料金
東京リージョンの最弱1インスタンスで100GBで1ヶ月の料金をざっくり計算する。
インスタンス料金: 1,100円
ストレージ料金: 1,836円GAEスタンダード環境のPythonでのサンプル
# 接続 # ORMツールとしてSQLAlchemyを使う import sqlalchemy db = sqlalchemy.create_engine( sqlalchemy.engine.url.URL( drivername='mysql+pymysql', username=<ユーザー名>, password=<パスワード>, database=<作成したデータベース>, query={ 'unix_socket': '/cloudsql/<作成したインスタンスのインスタンス接続名>' } ) ) # 書込 # pandasを使う import pandas as pd df = pd.DataFrame([['三体', '劉慈欣'], ['なめらかな世界と、その敵', '伴名練']], columns=['book_name', 'author_name']) with db.connect() as conn: df.to_sql('books', conn, if_exists='append', index=None) # 読込 import pandas.io.sql as psql with db.connect() as conn: query = 'SELECT * FROM books' df = psql.read_sql(query, conn) print(df)考察
- Spanaerはいいお値段するので、RDBMSを使いたかったらSQL一択。
- もしくは頑張ってGCEにDBをインストールして使うのも可能だが、フルマネージドにならないしクラウドネイティブとも言えないのでおすすめしない。
Spanner
グローバルおよびリージョナルアプリケーションデータ向けのスケーラブルなフルマネージドリレーショナルデータベース サービス
主な特徴
- 大規模なSQL
- ACIDトランザクション
- 強整合性
向いてる用途
- 大規模なリレーショナルデータ
向いてない用途
- 構造化されていないデータ
料金
シングルリージョンで1ノードで100GBで1ヶ月の料金をざっくり計算する。
ノード料金: 70,000円
ストレージ料金: 3,200円
だいたい最低で1ヶ月7万円。マルチリージョンで1ノードで100GBで1ヶ月の料金をざっくり計算する。
ノード料金: 233,000円
ストレージ料金: 5,400円
だいたい最低で1ヶ月24万円。1ノードだけというのはまずないので基本的にマルチリージョンにするとかなり高額になる。
Pythonでのサンプル(公式より)
# 接続 from google.cloud import spanner spanner_client = spanner.Client() instance_id = 'my-instance-id' instance = spanner_client.instance(instance_id) database_id = 'my-database-id' database = instance.database(database_id) # 書込 def insert_singers(transaction): row_ct = transaction.execute_update( "INSERT Singers (SingerId, FirstName, LastName) VALUES " "(12, 'Melissa', 'Garcia'), " "(13, 'Russell', 'Morales'), " "(14, 'Jacqueline', 'Long'), " "(15, 'Dylan', 'Shaw')" ) print("{} record(s) inserted.".format(row_ct)) database.run_in_transaction(insert_singers) # 読込 with database.snapshot() as snapshot: results = snapshot.execute_sql('SELECT SingerId, AlbumId, AlbumTitle FROM Albums') for row in results: print(u'SingerId: {}, AlbumId: {}, AlbumTitle: {}'.format(*row))考察
- 普通のアプリケーションではかなりオーバースペック。
- Spannerを使わないといけないような状況になったらサポートも入れた方が良い。
Memorystore
フルマネージドのRedis向けインメモリデータストアサービス
主な特徴
- インメモリデータベースであるRedisをクラウドで使える
向いてる用途
- キャッシュヒット率が高いデータ
- ゲームのリーダーボードのような頻繁に更新され共有されるデータ
向いてない用途
- バイナリデータ
- 大規模で構造化されたデータ
料金
東京リージョンで100GBで1ヶ月の料金をざっくり計算する。
料金: 1400円GAEスタンダード環境のPythonでのサンプル(公式より)
# 接続 import redis redis_host = os.environ.get('REDISHOST', 'localhost') redis_port = int(os.environ.get('REDISPORT', 6379)) redis_client = redis.StrictRedis(host=redis_host, port=redis_port) # 更新 value = redis_client.incr('counter', 1)考察
- 基本的にRedisでやるようなことに使う。
- 利用できる環境に制限があるので注意する。
- 投稿日:2019-10-09T10:50:07+09:00
常磐 BATCH「お前たちの“.\venv\Scripts\activate”って、醜くないか?」
チラ裏ではありますが。
こういうバッチファイルを作って PATH を通しておくと venv をより直感的に扱えるようになるんじゃないかなあという提案です。
venv.bat@echo off IF "%~1" == "" ( set env_name=venv ) ELSE ( set env_name=%~1 ) IF NOT EXIST "./%env_name%/Scripts/activate" ( python -m venv %env_name% call ./%env_name%/Scripts/activate python -m pip install pip --upgrade pip install setuptools --upgrade ) ELSE ( call ./%env_name%/Scripts/activate )使い方
説明するまでもないですが。
作業するディレクトリで
venvと実行すると、バッチファイルが venv を呼び出して仮想環境を作成します。 一緒に pip と setuptools の更新も行ってくれます。すでに仮想環境が存在する場合単にそれに入ります。
venv envnameのように引数を与えるとその名前で仮想環境を作成します。余談
見ての通り、Python のバージョンの指定などはできないので、それを指定する必要がある場合は作成までは手作業で行う必要があるかな、と。
本体バージョンの管理は環境を分けたい理由のひとつなのにそれでいいのか?ふつうバッチファイルでは
setlocalしてpushd "%~dp0"して呼び出し元を汚染しないようにしますが、それを逆手に取ってこれらを記述しないことで呼び出し元に対する処理を記述できるってことなんでしょうかね。(バッチわからないマン)我が魔王のお言葉
「みんな瞬間瞬間を必死にコーディングしてるんだ! デコボコなのは当然だろ! それを醜いなんて言うな!」
リファクタリングしろ
- 投稿日:2019-10-09T09:52:39+09:00
isliceの紹介、具体例添え(pythonのitertoolsを使いこなすために)
Pythonの標準ライブラリであるitertoolsを(超個人的に)推している。
しかしながら、まわりで活用している人は多くない様子なので、布教紹介記事を書くことにする。この記事では isliceを紹介する。
Pythonのバージョンは3.7を使っている。はじめに:どうすれば良さが伝わるか
itertoolsを紹介するブログは日本語でもちゃんと存在する。
にも関わらず、なぜみんな使わないのか。
話を聞いていくうち、「実際に、どういうタイミングで、どう使うかわからない」という意見があることを知った。
確かに、「ここはもっとスマートに書く方法がある気がする」と思っても、今まで一度も使ったこともないitertoolsを使えばよいとは思いつかないものだ。そういう訳で、実際のコードでどう使われているのかも調べることにした。これは後半で紹介する。
isliceとは
iterable から要素を選択して返すイテレータを作成します。 start が0でない場合、iterable の要素は start に達するまでスキップされます。その後、 要素が順に返されます。
itertools.islice 公式ドキュメントよりisliceは、簡単に言えば、listの
[start:stop:step]がiterableな要素に対して実行できる関数。
下記の例では 0~999までの要素が入ったdataから最初の10個だけ出力している。islice_sample.pyfrom itertools import islice data = [ i for i in range(1000)] for line in islice(data,10): # data[:10]と等価 print(line)ファイルオブジェクトに対してisliceを使う
上記例(
islice_sample.py)だと、「data[:10]でいいじゃん」と思うかもしれない。
しかし、isliceは、listではないiterableに対しても使えることがキモだ。具体的には、ファイルを特定の行数だけ読み込む時に便利だ。
- テキストファイルを読み込んだ時のオブジェクト TextIOWrapper はiterableなため1、以下の例(
islice_sample2.py)のように、ファイルの最初のn行だけ読み込むことができる。
- 例えば、巨大なファイルを扱う時、とりあえず最初の10行だけ受け取り、関数の動作を確認できる。
islice_sample2.py# isliceで10行だけ読み込み with open("./sample.txt", "r")as f: for line in islice(f, 10): print(line.strip()) # 20~30行目だけdataに読み込み with open("./sample.txt", "r")as f: for line in islice(f, 20, 30): print(line.strip())具体例
テキストファイルの他にも活用方法はないか、普段使っているレポジトリでisliceが使われている箇所を調べてみた。
ざっとみたところ、やはりファイル読み込みに使われることが多く、クラスの__iter__()に活用されているようだ。
ファイル読み込みの例を含め、利用しているコードを紹介する。ファイル読み込み(gensim)
word2vec.pyfor line in itertools.islice(self.source, self.limit): line = utils.to_unicode(line).split()
sourceファイルからlimitだけ読み込む。
- one line one sentence のファイルからsentence(文)を読み込むクラスの、
__iter__()内で使われている。limitのデフォルトはNoneなので、基本的にはファイル全てのsentenceを読み込んでいるミニバッチ生成(spacy)
util.pywhile True: batch_size = next(size_) batch = list(itertools.islice(items, int(batch_size))) if len(batch) == 0: break yield list(batch)
minibatch関数における実装。
batch_sizeの数だけitemsを受け取り、ミニバッチをyieldで返す
size_のデフォルトはitertools.repeat(size)で定義されるため、itemsの中身がなくなるまで返し続けるラベルの色指定(scikit-learn)
plot_linkage_comparison.pycolors = np.array(list(islice(cycle(['#377eb8', '#ff7f00', '#4daf4a', '#f781bf', '#a65628', '#984ea3', '#999999', '#e41a1c', '#dede00']), int(max(y_pred) + 1))))引用元 scikit-learn/examples/cluster/plot_linkage_comparison.py
- scikit-learnにある
examplesのクラスタリングの結果をプロットする例cycleによって色情報のlistが無限ループしているので、そのうちint(max(y_pred) + 1(=予測クラス数) だけ読み込む
- クラス数が1~9ならば
cycleなし(islice(['#377eb8', '#ff7f00', '#4daf4a', ..., '#dede00']), int(max(y_pred) + 1))))と等価- プロットに使う色数がわからないとき、使う色数を制限したいときに便利かもしれない
ちなみに、実際にプロットした結果はscikit-learnのサイトにある→該当ページ
まとめ
- isliceはテキストファイルから特定の行数のみ取得したいときに便利
repeatやcycleのような Infinite iteratorsと組み合わせて、ループを止めるカウンターのように扱うときにも便利
- zip_longest でも、以下のように書いてある。
iterables の1つが無限になりうる場合 zip_longest() は呼び出し回数を制限するような何かでラップしなければいけません(例えば islice() or takewhile())。
https://docs.python.org/ja/3/library/itertools.html#itertools.zip_longest
もう少し詳しく書くと、TextIOWrapperはIOBaseを継承しているため(参考: 【Python】open関数で返されたtext objectがiterableなわけ) ↩
- 投稿日:2019-10-09T05:00:30+09:00
Discord botがエラーを吐いたときにエラーIDを発行して通知する
作ろうと思ったきっかけ
私のBotはHerokuで運営しているのですが、エラーを吐いたときにいちいち確認するのが面倒なのと、ログが多いのでその中から発掘するのが大変なので作りました。
https://qiita.com/Taku_427_T/items/9caaf59a5fad011b6841
もともとはこれが便利そうなので作ろうと思っただけですが。
ソースの流用は一切してないです。環境
ソフトウェア バージョン 開発OS Ubuntu 18.04.3 LTS 実行OS Ubuntu 18.04.3 LTS(Heroku) Python Python3.7 Discord.py 1.2.3 インストールは割愛します。
エラーIDをどうするか
エラーIDは絶対に重複させてはいけません。
どれかわからなくなるからですね。
では何を使うか。絶対重複しないIDといえばUUIDですね。
しかし、
- UUIDを使うのは大袈裟すぎる
- いちいちimportするまでもない
- もっと別のいい方法がある
と言う理由により別の方法に。
ではどうするか。別のチャンネルに転送するのだからそのメッセージIDを使えばいいじゃないか、と。
URLも生成できますし。ソースコード
というわけでソースコードです
bot.py@bot.event async def on_command_error(ctx, error): ch = int型のチャンネルID embed = discord.Embed(title="エラー情報", description="", color=0xf00) embed.add_field(name="エラー発生サーバー名", value=ctx.guild.name, inline=False) embed.add_field(name="エラー発生サーバーID", value=ctx.guild.id, inline=False) embed.add_field(name="エラー発生ユーザー名", value=ctx.author.name, inline=False) embed.add_field(name="エラー発生ユーザーID", value=ctx.author.id, inline=False) embed.add_field(name="エラー発生コマンド", value=ctx.message.content, inline=False) embed.add_field(name="発生エラー", value=error, inline=False) m = await bot.get_channel(ch).send(embed=embed) await ctx.send(f"何らかのエラーが発生しました。ごめんなさい。\nこのエラーについて問い合わせるときはこのコードも一緒にお知らせください:{m.id}")解説
on_command_errorでエラーを受信(?)します。
次にembedを生成します。
- サーバー名
- サーバーID
- ユーザー名
- ユーザーID
- 実行コマンド
- 発生したエラーの内容
ですね。
これをch変数で指定したチャンネルに送信します。
エラーが発生したチャンネルにその送信したメッセージIDと一緒にメッセージを送信する、といった感じですね。
エラーIDからエラー情報へ行くにはhttps://discordapp.com/serverID/channelID/messageIDでできます。
- 投稿日:2019-10-09T00:54:24+09:00
画像っぽい素数をつくる
経緯
「2が現れる素数」という記事がありました。
http://integers.hatenablog.com/entry/2017/11/29/082604こちらでは
700000000000000007 000000222222000000 000022222222220000 000222000002222000 000000000022220000 000000000222200000 000000002222000000 000000222200000000 000022220000000000 000222222222222000 000222222222222000 700000000000000003という素数を紹介していました。
同様に、マリオが現れる素数というのも紹介されています。
https://akiyah.hatenablog.com/entry/2017/12/05/144440一方で、2が現れる素数が奇跡だという人に物申す
https://qiita.com/elzup/items/1d882f3af040506aec8b
という記事にもあるように、桁数の多い数字でも素数の確率は意外と大きく、コメント欄では $\pi(x)/x \sim 1/\ln(x)$ だと見積もられています。さて、マリオ素数だと多いときは10色を10個の数字に割り当てるのですが、その場合の数は $10! = 3628800$ 通りです。左上は0を使えないとか、右下は5以外の奇数だとしても相当の場合の数があります。この場合の数だと相当大きい画像を素数化しない限り、素数はほぼ必ず見つかるのではと考え、やってみました。
僕は数学はあまり詳しくないので、愚直に画像を10色以下に減色、数字を全パターン当てはめ、素数になるまで繰り返すこととしました。
ということで、この記事の個人的なポイントは、
1. 減色のアルゴリズム
2. 素数判定のコマンドssl prime
です。処理の方針
- 画像のリサイズ
- 画像の減色
- 数字のあてはめ、素数判定
- 素数が見つかれば終了、結果表示
画像のリサイズ
特に難しいことは無いです。
ただ普通は縮小処理だと思いますが、ごくまれに拡大することがあるかもしれません。このとき、線形補間ではなく最近傍を用いた方が補間時に色が増えず、素数画像の見た目が良くなるかと思います。ここで縦横ともにピクセル数を素数 $p$、$q$ にすると、$pq$ 桁の素数を渡されたときに$p$ × $q$ に並べてみるという発想に自然に行き着くかなと思います。$p = q$ だとさらに都合がいいです。
トリミングは考えてなかった。前もって適当なレタッチソフトで余白を削っている前提とします。
画像の減色処理
ピクセルごとに0~9の数字しかあてはめられないので、最大でも10色しか使っていない画像にする必要があります。
ここでは2通りの方法を紹介します。
- グレースケールののちLook up tableを用いる
def quantize_img_LUT(img, ncolor): img_p = None img_g = img if len(img.shape) == 3: img_g = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) max_bin = img_g.max() min_bin = img_g.min() n = min(ncolor, max_bin - min_bin + 1) bins = np.linspace(min_bin, max_bin + 1, n + 1) y = np.array([bins[i - 1] for i in np.digitize(np.arange(256), bins)]).astype(int) img_p = np.array(cv2.LUT(img_g, y), dtype=np.uint8) return img_p画像をグレースケールにし、一番暗い画素値と一番明るい画素値を取ってきて
ncolor分割、あとはdigitizeで代表値を設定してcv2.LUTで画像を減色します。ただし、カラーだと違う色でもグレースケール観点では同じ色になってしまうことがあり、そうなると同じ数字を当てはめてしまうので、今回は違う方法を考えます。
- k-means法による色のクラスタ
画像中の各ピクセルは $(b, g, r)$ の値を持っていますが、これを $(b, g, r)$ 空間中にピクセルが散らばっているとして、クラスタ分けするという発想です。$x$、 $y$ 座標といった空間的な情報は今回は捨てています。
参考:https://docs.opencv.org/4.0.0/d1/d5c/tutorial_py_kmeans_opencv.html
def quantize_img_kmeans(img, ncolor): h, w, c = img.shape Z = np.float32(img.reshape((-1, 3))) crit = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.1) ret, label, center = cv2.kmeans(Z, ncolor, None, crit, 10, cv2.KMEANS_RANDOM_CENTERS) center = np.uint8(center) result = center[label.flatten()] img_p = result.reshape(img.shape) return img_pこれでこの関数は
ncolor色に減色した画像を返します。
コードの解説を少し。k-means法の実装は
cv2.kmeansを使います。OpenCV、ほんとにいろいろあるな。
center = np.uint8(center)は各クラスタの重心座標を表していて、ここでは各点が $(r, g, b)$ の3次元なので、center.shapeは[ncolor, 3]です。
laeblはサンプルの各点がどのクラスタに属するかのラベルが並んでいて、全ピクセル数をnpixelとして、成分がnpixelあります。 なんか 1 の成分があるかもしれないので、 shapeはちょっと断言できません。
以上を合わせるとresult = center[label.flatten()]はnumpyのインデクシングにより、各点の $(r, g, b)$ 値が並んだ配列になります。result.shapeは[npixel, 3]となります。
あとはimg_p = result.reshape(img.shape)として画像としてのサイズの情報を持たせ、完成です。たとえばWindowsのサンプルピクチャにあるペンギンの写真を6色に落としてみました。
元画像:
減色:
黄色の部分を残すのに6色必要でした。
ただ、今回の話は数字を当てはめるという関係上ピクセルごとの色のラベルがあればいいので、
centerから画像を作ることをせず、途中で関数から抜けます。def quantize_img_kmeans(img, ncolor): h, w, c = img.shape Z = np.float32(img.reshape((-1, 3))) crit = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.1) ret, label, center = cv2.kmeans(Z, ncolor, None, crit, 10, cv2.KMEANS_RANDOM_CENTERS) return label.reshape((h, w))これでこの関数はピクセルごとのラベルを返します。同じラベルなら同じ色(数字)。
減色画像が得られたら
さて、ラベルが得られたら各ラベルが元の画像ではどんな色かを調べないといけません。
# img_ico: 入力画像をリサイズした画像 img = quantize_img_kmeans(img_ico, ncolor) pixels = list(set(img.flatten())) avgcolor = {} for ipix, pix in enumerate(pixels): avgcolor[ipix] = np.array(np.mean(img_ico[img == pix].reshape(-1, 3), axis=0), dtype=np.uint8)なにか配列などiterableなもの
hogeがあったとき、set(hoge)とすれば重複したものが取り除けます。もともとはsetは集合をあらわすものですが、その性質をうまく使ったかんじですね。
これで画像中にある画素値のリストpixelsが得られます。k-means法で作っていればcenterに当たる変数です。
avgcolorというdictに、ipix番目の色が実際どんな色を持っているかを保存します。
img_ico[img == pix].reshape(-1, 3)は減色画像中で画素値pixをもつ画素を抽出する処理になります。元はカラー画像だからreshapeに 3 が入っています。また、そのため平均するのも画素間であって同じ画素中の $(r, g, b)$ までは平均しないように、np.meanの引数にaxis=0を指定しています。k-means法だと
centerなど途中に出てきた変数を使えば必要なかった処理ですが、一応k-means法以外の方法で減色処理をするかもしれないので、二度手間でもこの処理を書いておきます。素数判定
素数判定アルゴリズム
Pythonでこういうアルゴリズムを実装するとすごい重そうなので、おとなしくLinuxコマンドにあるものを使うことにしました。
RSA暗号では巨大な桁数の素数を使います。その一環でopensslには素数かどうかを判定するコマンドopenssl primeがありますので、これを用います。まず画像のピクセルに0-9の数字が割り当てられていて、それを並べた2次元行列があったとして、これを数字にします。といっても2次元のndarrayを単純に1行の文字列にするだけです。
numpyにちょうどいい関数がありますので、それを使います。def array_to_str(arr): # arr: array of 0-9 integers ret = np.array2string(arr.flatten(), max_line_width=arr.size+2, threshold=arr.size, separator="")[1:-1] return retそしてその文字列が素数かどうかのチェック関数です。
$ openssl prime xxxxとした時、このコマンドは
xxxxが素数だとxxxx is prime、 合成数だとxxxx is not primeと標準出力に出力します。なのでsubprocessあたりで実行して標準出力をとり、is primeという文字列があるかどうかを確かめる関数とします。def check_prime(string): cmdret = subprocess.run(["openssl", "prime", string], stdout=subprocess.PIPE) return "is prime" in cmdret.stdout.decode()
subprocess.runのcapture_output引数はpython 3.7からです。確認してないこと
factorコマンドは因数分解ですが、openssl primeは判定だけするコマンドかなと思い、opensslを使ってみました。factorコマンドを使うとどれくらい実行時間が変わるかは確認してません。ただちょっと確かめた感じでは、
openssl primeだと1秒程度だった素数に対し、それから1/3程度切り出した数字にたいしてfactorを使ってみると数時間たっても終わりませんでした。また、
openssl primeはミラーラビン法を使っているかもしれません。この場合、素数でないものを素数だと判定する可能性があります。対策としては、-checksオプションでより厳しくする、素数と判定されたものに対しては別の判定プログラムと組み合わせるなどが考えられます。ちょうどいい数字割りあてのサーチ
単純なループです。
npix = len(pixels) idx_mat = np.zeros_like(img) for i, px in enumerate(pixels): idx_mat[img == px] = i lefttop = idx_mat[0, 0] rightbottom = idx_mat[-1, -1] last_img = np.array(idx_mat) for newpx in itertools.permutations(range(10), npix): if newpx[lefttop] == 0: continue if newpx[rightbottom] in (0, 2, 4, 5, 6, 8): continue for i in range(npix): last_img[idx_mat == i] = newpx[i] numstring = array_to_str(last_img) if check_prime(numstring): # 適当な出力 break
new_pxは色ラベル番号と数字の対応をもちます。例えばnew_px[i]が3だったら、色ラベルiには3を当てはめるという事になります。
idx_matが色ラベル番号を保持する行列です。あるピクセル[y,x]が元の画像でどんな色に対応しているかを知りたい時、idx_mat[y, x]の値を取り出し、これがkだったらこのピクセルはavgcolor[k]だという事になります。
last_imgは実際に置かれる数字を並べた画像です。last_img[y, x]がkだった場合、このピクセルには数字kが置かれます。その他の処理
あとは途中経過だったり結果画像を作って表示・保存するコードを足してやってひとまずは動きます。
コマンドライン引数を一通り整備したスクリプトをgithubに上げました。
https://github.com/sage-git/prime_image_maker実行例
次の画像を使ってみます。
これを縦横サイズを37ピクセルに縮小し、数字を当てはめて画像になる素数を作ってみたく思います。
checking (1, 3) checking (1, 7) checking (1, 9) checking (2, 1) checking (2, 3) checking (2, 7) checking (2, 9) checking (3, 1) found good permutation ---- 3333333333111111113333333333331111111333333311111111111111333333333111111133333311111111111111113333333331111113333311111111111111111113333333311111333311111111111111111111333333331111133311111111111111111111113333333311113311111111111111111111111133333331111331111111111111111111111111333333111131111111111111111111111111133333331113111111111111111111111111113333333111111111111111111111111111111133333311111111111111111111111111111113333331111111111111111111111111111111333333111111111111111111111111111111133333311111111111111111111111111111113333331111111111111111111111111111111333333111111111111111111111111111111133333311111111111111111111111111111113333331113111111111111111111111111113333333111311111111111111111111111111333333311133111111111111111111111111333333311113311111111111111111111111133333331111333111111111111111111111133333333111133331111111111111111111133333333111113333311111111111111111133333333311111333333111111111111111133333333311111133333333111111111111333333333331111113333333333311111133333333333333311111333333333333333333333333333333333111113333333333333333333333333333333331111133333333333333333333333333333333311111333333333333333333333311333333333111111333333333333333333111113333333331111111133333333333311111111133333331111111111111111111111111111111333331111111111111111111111111111111113331111111111111111111111111111111111131111 ---- 3333333333111111113333333333331111111 3333333111111111111113333333331111111 3333331111111111111111333333333111111 3333311111111111111111113333333311111 3333111111111111111111113333333311111 3331111111111111111111111333333331111 3311111111111111111111111133333331111 3311111111111111111111111113333331111 3111111111111111111111111113333333111 3111111111111111111111111113333333111 1111111111111111111111111111333333111 1111111111111111111111111111333333111 1111111111111111111111111111333333111 1111111111111111111111111111333333111 1111111111111111111111111111333333111 1111111111111111111111111111333333111 1111111111111111111111111111333333111 1111111111111111111111111111333333111 3111111111111111111111111113333333111 3111111111111111111111111113333333111 3311111111111111111111111133333331111 3311111111111111111111111133333331111 3331111111111111111111111333333331111 3333111111111111111111113333333311111 3333311111111111111111133333333311111 3333331111111111111111333333333111111 3333333311111111111133333333333111111 3333333333311111133333333333333311111 3333333333333333333333333333333331111 1333333333333333333333333333333333111 1133333333333333333333333333333333311 1113333333333333333333333113333333331 1111133333333333333333311111333333333 1111111133333333333311111111133333331 1111111111111111111111111111113333311 1111111111111111111111111111111333111 1111111111111111111111111111111131111 Avg color: 3 (253, 254, 253) 1 (13, 187, 89)以下の画像のようなのが得られます。
無事Qiita素数が得られました。
その他
7777777777777730000669999994606000097777777777777777777777777777777900666699999946660600477777777777777777777777777777774006666999999966660000377777777777777777777777777777700066669999999666660009777777777777777777777777777777006666699999996666000097777777777777777777777777777770006666999999906666000977777777777777777777777777777700666669999999066666669777777777777777777777777777777906666619999919666666097777777777777777777777777777779006399999999999166660177777777777777777777777777777790599992999299999996006777777777777777777777777777777619999229929299999981907777777777777777777777777777773999992922392999999998937777777777777777777777777777099999999229932999999999997777777777777777777777777779999918999999999999999911997777777777777777777777777999999899999999999999999999997777777777777777777777709999918989999999919999999989997777777777777777777777999999189899999999439199999899937777777777777777777779999191898747699894499849999999977777777777777777777799991811889979998144198999991999977777777777777777773999811318899999984444988999999999577777777777777777799998334918899999344449889999999999777777777777777777999885144881999995444498888999999995777777777777777759988141444488999944444158889999999997777777777777777999881434222418981222445588899999999977777777777777779998884427622488807722444888899999999177777777777777681988854772264188722223441888999999999777777777777771899884147222345847222274418881999988997777777777777788918853471385445472891744188189999819977777777777777189988154729874444628917448811899998199777777777777773899918447722644444722664485488999981997777777777777788999985444444444444444444348889998819977777777777777889999884444444444444444444888899988999777777777777778189999844444444444444444888888999889997777777777777738889998844444411154444418888899988898677777777777777788889988814444444444458888888999887987777777777777777987589188815444444438888873889988779777777777777777777577777788891144434311187778188677777777777777777777777777777788199453499199777788777777777777777777777777777777777999899119999997777777777777777777777777777777777777779999989999919977777777777777777777777777777777777777199441899986664643777777777777777777777777777777777754666153995636665444777777777777777777777777777777777446663666366566614444777777777777777777777777777777744466666660666666044447777777777777777777777777777777444666666606666666444457777777777777777777777777777764446666666066666664444477777777777777777777777777777544566666660666666344444577777777777777777777777777774440666666666666666344444767777777777777777777777773344406666666066666661444366977777777777777777777777763444666666663666666634366669777777777777777777777777666046666666636666666666666647777777777777777777777776666666666666366666666666666677777777777777777777777766666666666666666666663666666777777777777





- 投稿日:2019-10-09T00:11:37+09:00
PoWにおけるマイニングのプログラムを作ってみた
はじめに
こんにちは。ブロックチェーン技術関連の記事になります。
この記事では、コンセンサスアルゴリズムであるPoWにおけるマイニングのプログラムについて書いていきます。
ブロックチェーン技術の詳しい内容についてはこちらの「ブロックチェーン技術及び関連技術(ブロックチェーン実装あり)」の記事を参照してください。よろしくお願いします。
環境
- Windows 10 home
- Python 3.7.3
プログラム
mining.pyimport hashlib import random import string class Mining(): def __init__(self,difficulty): self.data = self.calcRandomText(10) #データ self.difficulty = difficulty #求める規定のハッシュ値の難易度(何文字か) self.nonce = 0 #ナンス self.answerText = self.calcRandomHexDigitsText(self.difficulty) #求める規定のハッシュ値を算出 self.nonceDataText = self.calcNonceDataText() #データとナンス値を合わせる self.hashText = self.calcHash(self.nonceDataText) #ハッシュ値を算出する self.miningLoop() #マイニング開始 def calcRandomText(self,num): #ランダムな文字列を返す _randTextList = [random.choice(string.ascii_letters + string.digits) for i in range(num)] return "".join(_randTextList) def calcRandomHexDigitsText(self,num): #16進数のランダムな文字列を返す _randHexDigitsTextList = [random.choice(string.hexdigits) for i in range(num)] return "".join(_randHexDigitsTextList) def calcNonceDataText(self): #データのナンス値を合わせる return self.data + str(self.nonce) def calcHash(self,text): #ハッシュ値を算出する return hashlib.sha256(text.encode("utf-8")).hexdigest() def miningLoop(self): #マイニングのメソッド while self.hashText[-1*self.difficulty:] != self.answerText.lower(): print("マイニング中 試行回数:" + str(self.nonce+1) + " 求める規定のハッシュ値:"+ self.answerText.lower() + " 算出ハッシュ値:" + self.hashText[-1*self.difficulty:]) self.nonce += 1 #ナンス値に1を加算していく self.nonceDataText = self.calcNonceDataText() #データとナンス値を合わせる self.hashText = self.calcHash(self.nonceDataText) #ハッシュ値を算出する print("マイニング中 試行回数:" + str(self.nonce+1) + " 求める規定のハッシュ値:"+ self.answerText.lower() + " 算出ハッシュ値:" + self.hashText[-1*self.difficulty:] + "\n") print("マイニング成功!" + " データ:" + self.data + " ナンス値:" + str(self.nonce)) print("マイニングに成功したハッシュ値:" + self.calcHash(self.data + str(self.nonce))) def main(): difficulty = 3 #求める規定のハッシュ値の難易度(何文字か) mining = Mining(difficulty) #インスタンスの生成 if __name__ == "__main__": main()マイニングを成功させるには、規定のハッシュ値を算出するためにナンスの計算をし続けます。
このプログラムでは、既定のハッシュ値というのはメイン関数にある
difficultyの値によって決まる特定の値と算出されたハッシュ値の末の値が一致しているハッシュ値のことです。ハッシュ値から入力データを予測することは困難なので、規定のハッシュ値を算出できるまで、ハッシュ関数にいろんなデータを突っ込みます。そこでいろんなデータにするために使うものがナンスです。
ナンスの使い方としては、ナンスに1を加算しては、ナンスをデータに足して、ハッシュ関数に突っ込むといった感じです。
これを繰り返し、規定のハッシュ値を算出していきます。ぜひ
difficultyの値を変えてみて、マイニングの試行がどのくらいの間隔を生み出すのか試してみてください。これがプルーフオブワーク!仕事量の証明です!
ここまで読んでいただき、ありがとうございました。
- 投稿日:2019-10-09T00:03:06+09:00
Python3 とりあえず理解する例外処理
例外処理について
いまいち理解できなかったので、ざっくり覚えて使ってたらなんとなくわかってきた
try:
try: r = x + y print(r) z = Trueここには処理したい内容を記入
この場合 r に x + y を代入した後rを出力する
後々の判定で分かり易くするため最後にz に True を代入except:
ここにはエラーが起きた場合の処理を書く
TypeErrorと書いてあるのはエラーの種類
エラーの種類とエラーが出た時にコンソールに出てくる英文の左端の方にかいてあるやつ
エラーが起きたら z に False を代入except TypeError: z = Falsefinally:
finally: if z: print("エラー起きてないよ") else: print("エラー起きたよ")ここにはエラーが起きようが起きまいが最後に処理する項目を書く
この場合zの中身を判定して文字を出力どうなるか
エラーにならない場合x = 1 y = 2 try: r = x + y print(r) z = True except TypeError: z = False finally: if z: print("エラー起きてないよ") else: print("エラー起きたよ") # 結果 >>> 3 >>> エラー起きてないよr = 1 + 2
print(r)
見て分かるようにエラーになる処理がないので
最後の z に True が代入され try: 内の処理は無事成功
エラーがー起きようが起きまいが処理するfinally:に飛んで
ifで z を判定、z は True なので print("エラー起きてないよ") が実行されるエラーにならない場合x = 1 y = "文字" try: r = x + y print(r) z = True except TypeError: z = False finally: if z: print("エラー起きてないよ") else: print("エラー起きたよ") # 結果 >>> エラー起きたよx は数値で y は文字列
文字列型と整数型を + する、加算は出来ないので所謂くっつける場合はstr(整数型)としないとTypeErrorが発生します
なので、ここでエラーが発生して r に代入どころか次の行の print(r) にも行けず
except TypeError: に飛んで z = False の代入をします
おなじみfinally:はエラーが起きようが起きまいが処理するので
z を判定すると False なっているので print("エラー起きたよ") が実行されるという本来は
TypeError: unsupported operand type(s) for +: 'int' and 'str'このようなエラーが出て処理がプログラムが停止するけども
例外処理をすることによって、エラーが発生しても停止せずに処理を続けることができるコードを臨機応変にさせよう