- 投稿日:2019-04-25T23:59:51+09:00
自分用勉強メモ6日目
CpawCTF
Q17.[Recon]Who am I ?
Twitterのアカウント名とゲーム名で検索すればいい.
Q18.[Forensic]leaf in forest
fileコマンドにかけると,pcapファイルであることがわかる.
stringsコマンドで文字列を取り出すと,大量のlovelive!という文字列に混ざって,文字が3つ連なっている箇所がある.
順番に1つ1つ書き出すか,スクリプトを書いて抽出すればフラグが現れる.一応記録に残すために拙いコードを載せる.
test.pydef extract_three(string): ans = '' for i in range(len(string)-2): if string[i] == string[i+1] and string[i] == string[i+2]: ans += string[i] return ans.lower() if __name__ == '__main__': with open('//Users/katsuya2019/ctf/tmp_20190425.txt') as f: lines = f.readlines() ans = extract_three(lines[0]) print(ans)extract_threeで3つ連続している文字を取り出している.
Q19.[Misc]Image!
与えられたzipファイルをfileコマンドで調べると,
OpenDocument Drawingと出る.
Microsoft Wordで開いたら,黒い長方形の横に文字列が書いてあった.
それをcpaw{}で囲んでフラグをゲット.後で他の人のwrite-upを見たらLibreOfficeで開けばよかったらしい.
本来は長方形の下に文字列が隠れていることになっていた.Q20.[Crypto]Block Cipher
cのソースが与えられる.
中身を見ると,1つ目の引数に文字列を,2つ目の引数に整数値を取る.
見るからにシーザー暗号っぽかったので,コンパイルして,
./crypto100 暗号文 数字
で数字の部分を1から増やしていったら文章が現れてフラグ獲得.Q21.[Reversing]reversing easy!
ELFバイナリが与えられる.
Ubuntu環境で実行しても動作せず.
stringsコマンドにかけると,cpawという文字列に続いて断片的にフラグと思われる文字が出現する.
1文字ずつ繋げるとフラグになる.Q22.[Web]Baby's SQLi - Stage 1-
与えられたURLにアクセスすると,SQL文を入力してフラグを探すように要求される.
palloc_homeというテーブルにフラグがあることが書かれている.
select * from palloc_homeと入力すればフラグを得ることができる.Q28.[Network] Can you login?
pcapファイルが与えられる.
Wiresharkで開くと,FTPでやり取りしている様子が見える.
宛先URLとID,パスワードを拾って,FTPで接続を試みる.
macだとFTPコマンドが使えなかったので,Ubuntuで実行.
ログインしてディレクトリ取得,dummyというファイルを開くことまではできたが,フラグのあるファイルまでたどり着くことができず,write-upを参考にした.
パッシブモードに切り替えてls -aを実行すると隠しファイルの存在を確認できる.
ダウンロードして開くとフラグが.
- 投稿日:2019-04-25T23:31:55+09:00
ディープラーニング学習過程の数学的な部分を追う
ディープラーニングってどういう仕組みで動いているんだろうという疑問から、その学習過程を数学的な部分まで調べてみました。
私なりに理解したところまでを本記事で公開したいと思います。
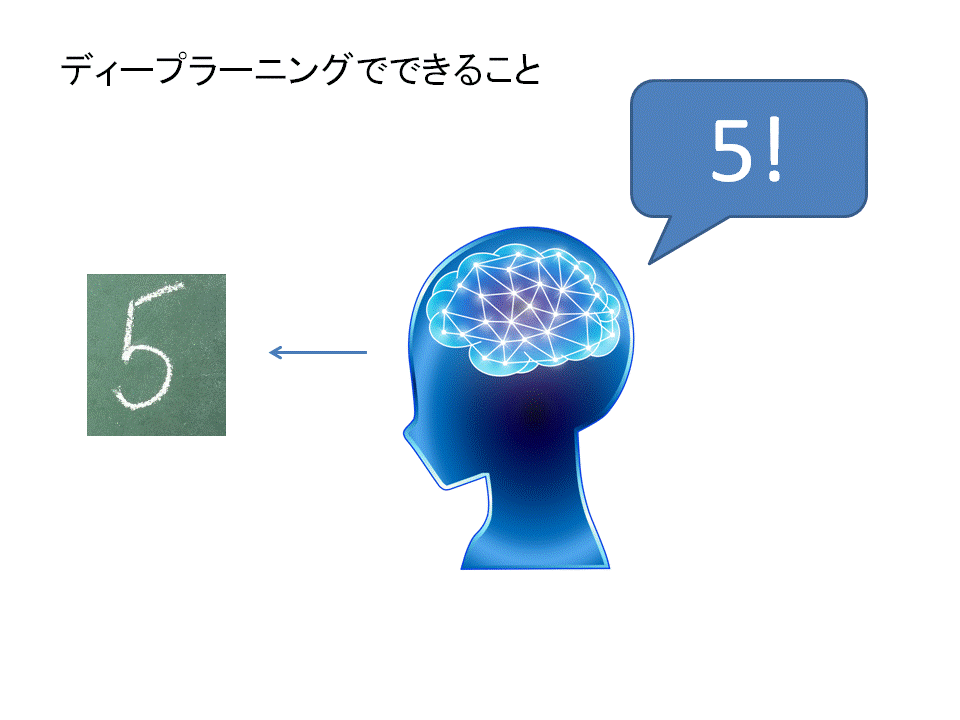
そもそもディープラーニングはどういうものかというと。
たとえば手書きの文字があったとしましょう。コンピュータに画像を読み込ませることはできますが、全く同じ画像でなければ「同じ」と認識することはできません。
手書き文字のように、表記が逐一揺らぐようなものだと途端に判定することができなくなってしまいます。
大量の画像データを学習させることで未知の画像がきても判定するようにできるのがディープラーニングです。
将来的には、レントゲン画像から人間の目視では確認できない病状を検知するなど人間の能力を超えた判定が期待されています。囲碁の世界ではすでに人工知能が人間に勝利していますよね!
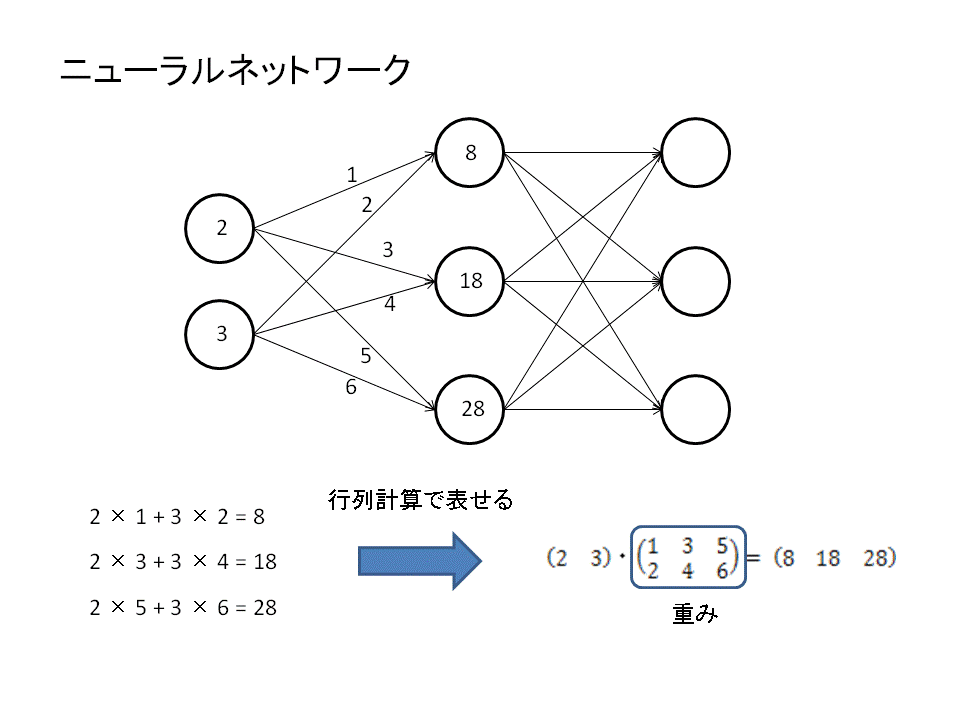
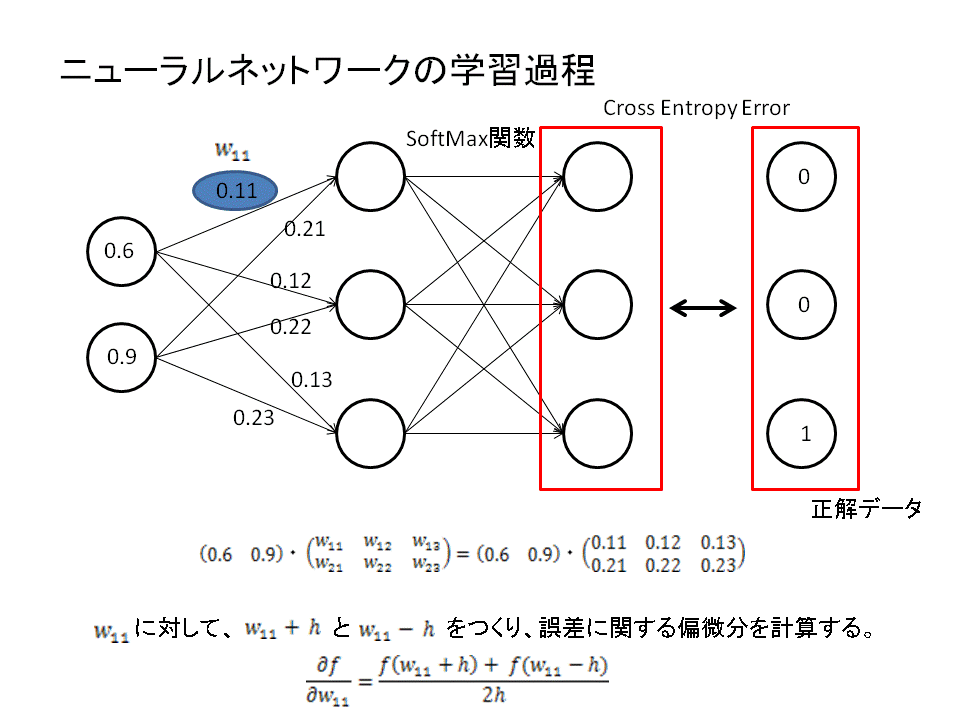
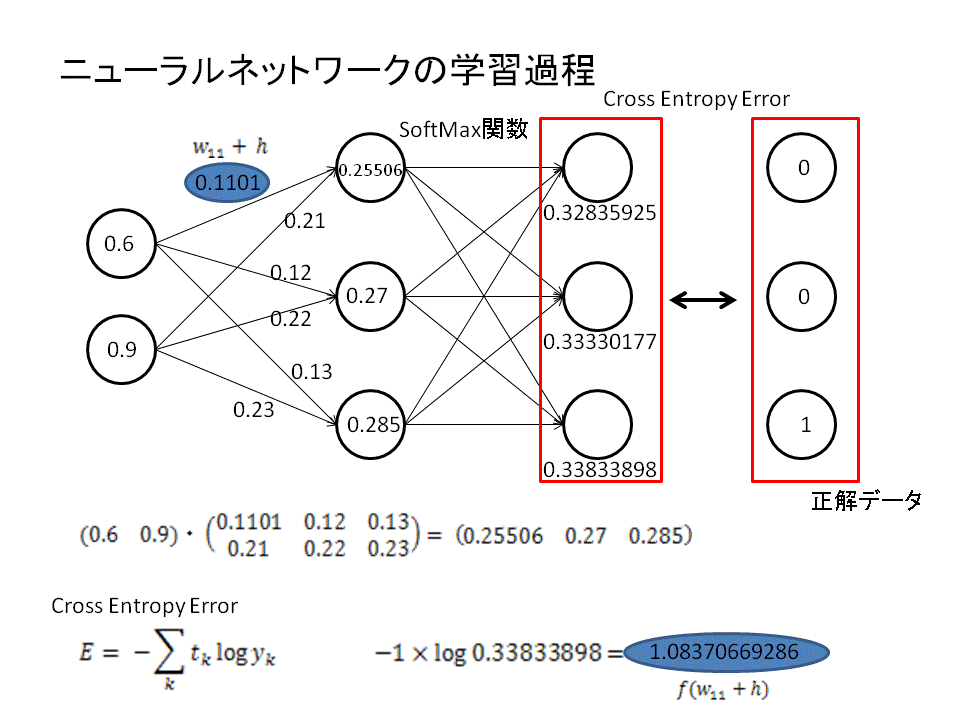
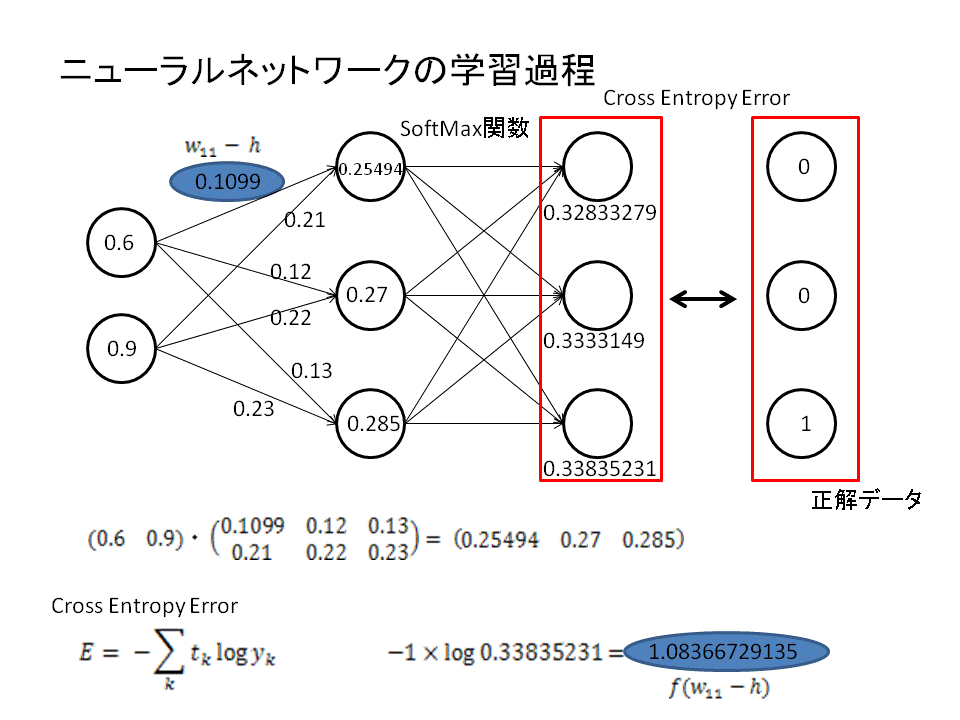
ディープラーニングはニューラルネットワークと呼ばれる計算過程を辿ります。このニューラルネットは行列計算で表すことができます。
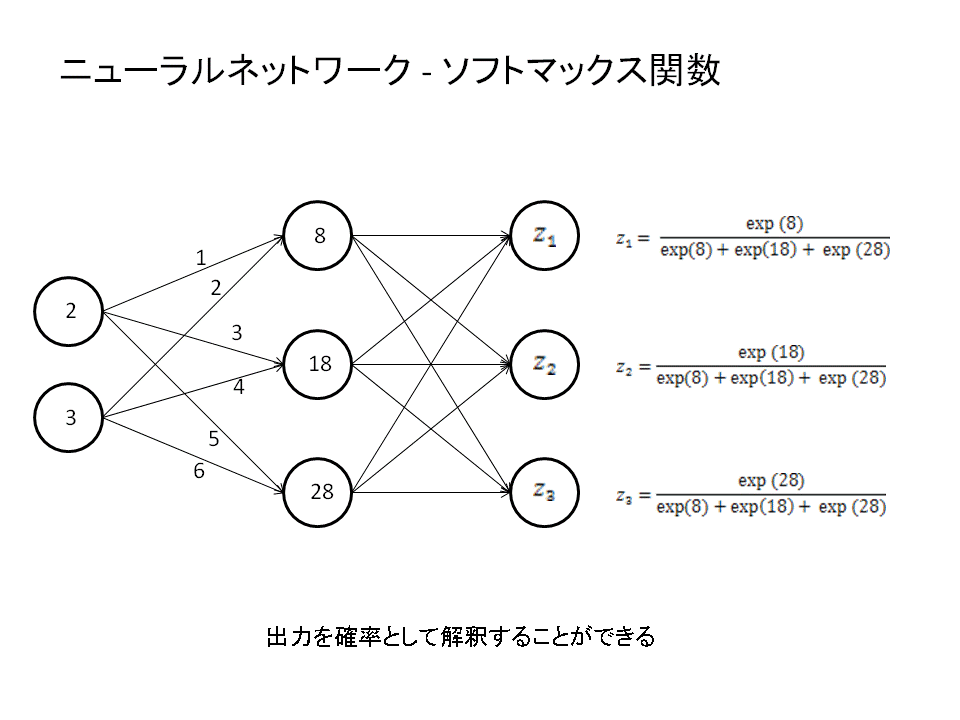
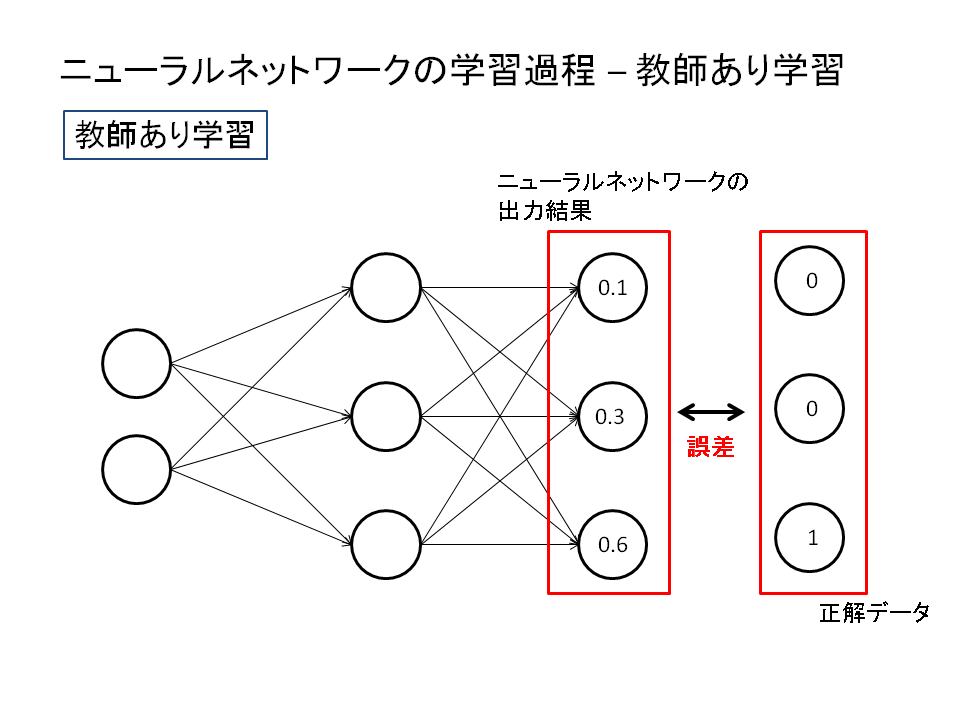
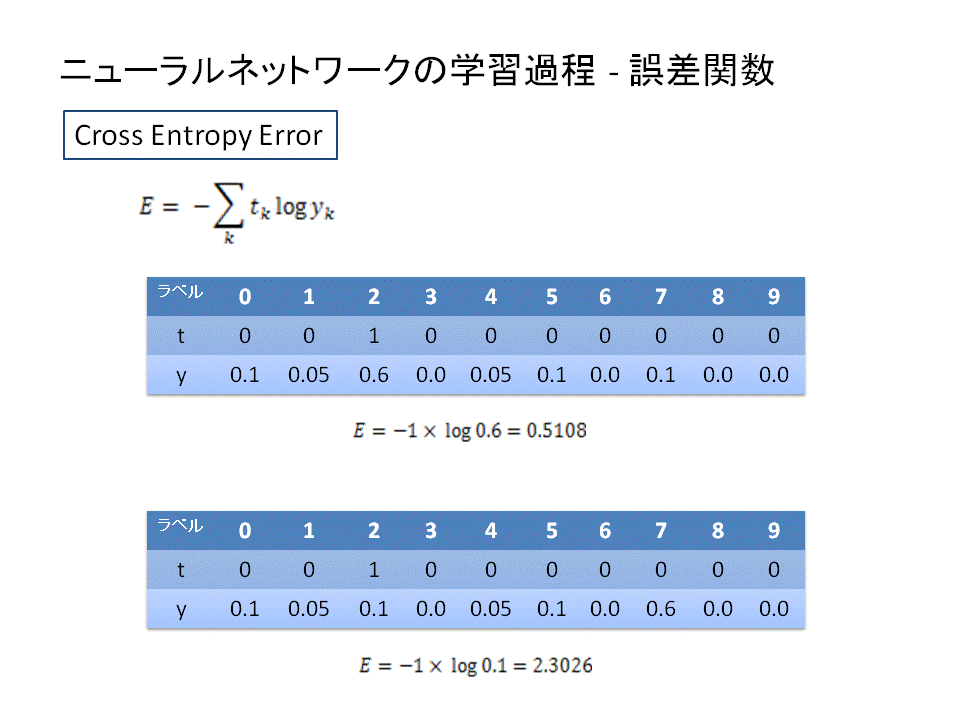
ニューラルネットワークにより出力された結果はソフトマックス関数を使うことにより確率として解釈されるように変換することができます。この出力確率を正解データと比較することで、間違いを正しながら学習していくことができるのです。
正解データとの比較は"誤差"の評価で行われます。誤差が大きければ間違い、誤差が小さければ正解に近づいているということです。
この誤差判定にもちいられるのがcross entropy errorと呼ばれる関数です。
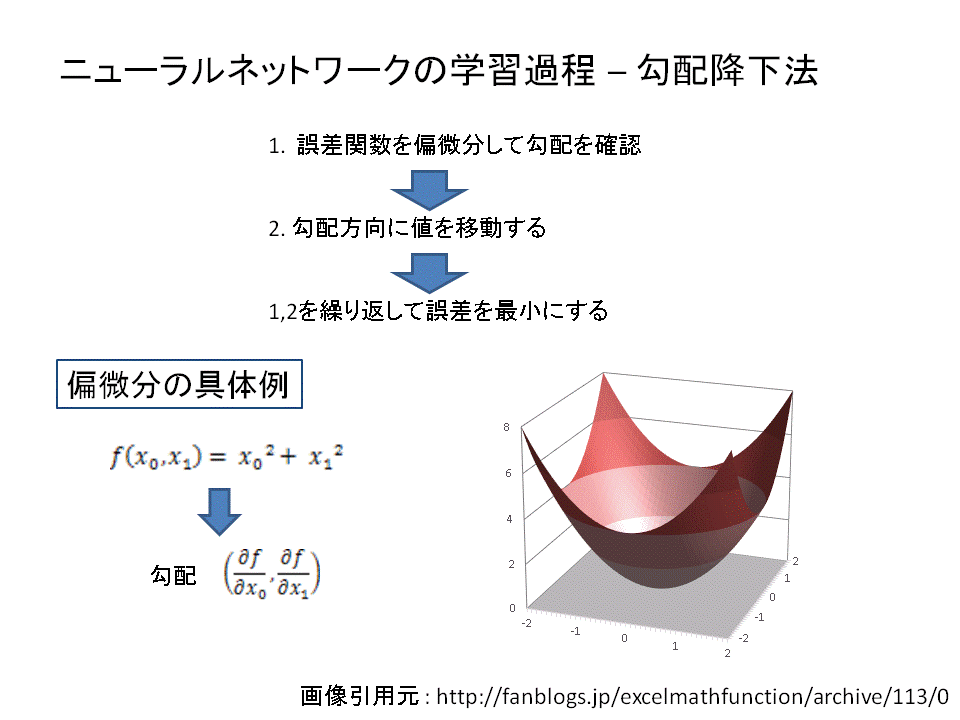
ディープラーニングの学習過程は、"誤差"を最小化することを目指して行われます。
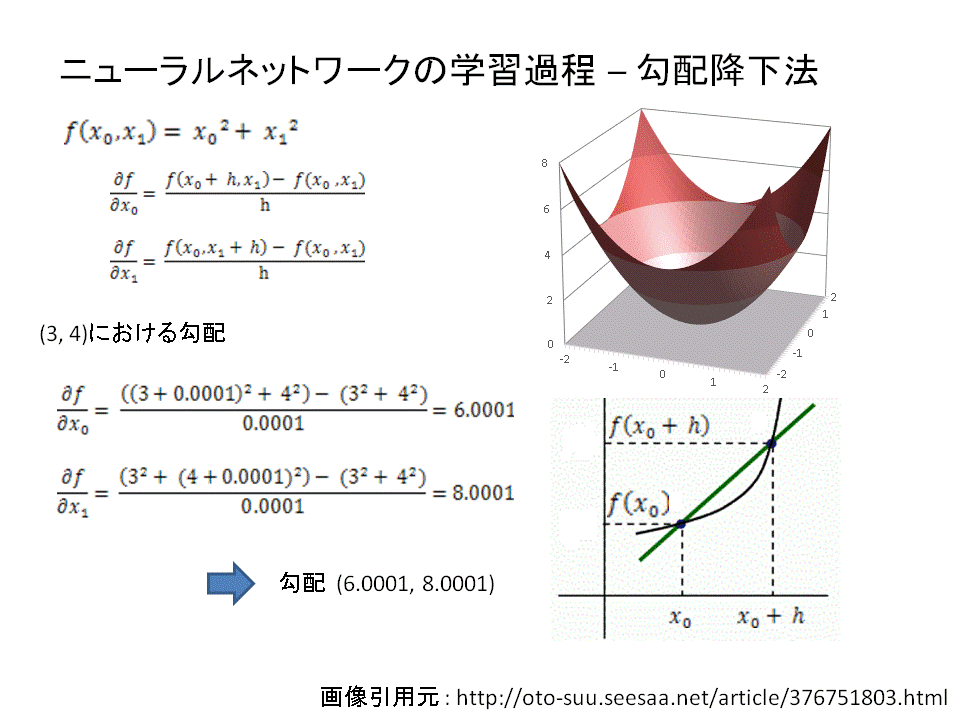
最小化を目指す際に用いられるのが「微分」です。微分をすることで勾配(傾き)を確認し、その勾配方向にパラメーターを移動させるということを繰り返すことで誤差の最小値に少しずつ近づけていくのです。
具体的には、重み係数を偏微分することでニューラルネットワークの最適化を図ります。
重み係数の偏微分により勾配を算出し、勾配の減少方向にパラメータをずらしていくという操作を繰り返していきます。
今回はニューラルネットワークの微分による学習過程を眺めてみました。
ニューラルネットワークでは、誤差逆伝播法を用いて学習していくことも可能であり、こちらの方がより効率的な計算方法として採用されることが多いです。
誤差逆伝播についても勉強していこうと思っております。
参考
「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」
斎藤 康毅(著) 出版社:オライリージャパン

- 投稿日:2019-04-25T23:21:21+09:00
機械学習ノート:ロジスティック回帰分析1(Logistic regression,参考: The elements of statistical learning)
1. Summary
本記事では,Hasitie,Tibshirani,Friedman(2009).The elements of statistical learningのchapter 4 Linear Methods for Classificationのロジスティック回帰分析について書いてある部分(や書いてない部分,自分の印象)についてまとめ,パラメータ推定のサンプルコードを添付しました.
2. What is logistic regression?
データ分析の目的の一つにクラス判別があります.クラス判別というのは,観察や実験によって得られた個体のデータから,個体がどのグループ(=クラス)に属するかを判定することを指します.ロジスティック回帰分析では,「ある個体xが観測された場合,その個体がどのグループに属するかの確率」,つまり,$P(G=k|X=x),(k=1,\cdots,K)$という事後確率をモデル化することを目的とします.事後確率は確率なので全てを足して1にならなければなりません.個体xが観測されたとして,それぞれのグループに属する事後確率は
\begin{eqnarray} P(G=k|X=x) &=& \frac{\exp(a_{k0}+\beta_k^Tx)}{1+\sum_{l=1}^{K-1}\exp(a_{l0}+\beta_l^Tx)}\ (k=1,\cdots,K-1)\\ P(G=K|X=x) &=& \frac{1}{1+\sum_{l=1}^{K-1}\exp(a_{l0}+\beta_l^Tx)} \end{eqnarray}のように表されます.簡単な計算で$\sum_{k}P(G=k|X=x)=1$(全確率=1)であることがわかります.$K=2$(2クラス判別)の場合は単純に
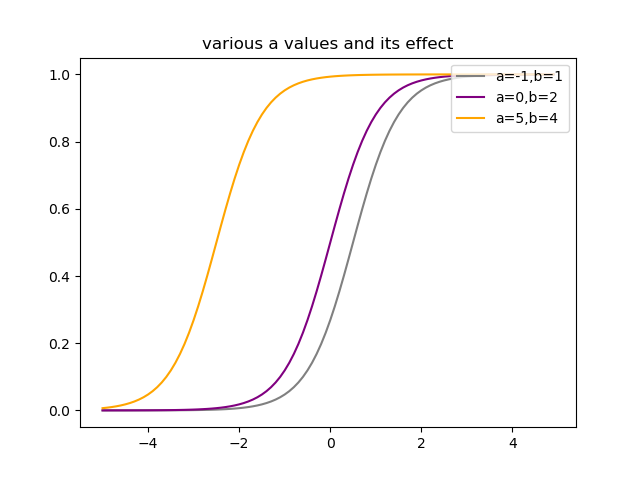
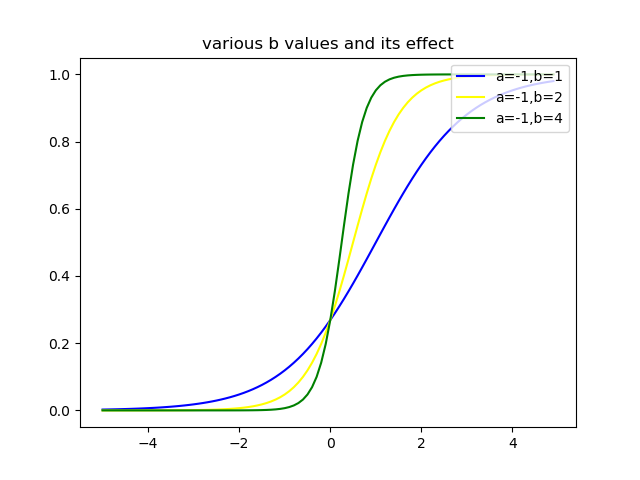
\begin{eqnarray} P(G=1|X=x) &=& \frac{\exp(a_{k0}+\beta_k^Tx)}{1+\exp(a_{10}+\beta_1^Tx)}\\ P(G=2|X=x) &=& \frac{1}{1+\exp(a_{10}+\beta_1^Tx)} \end{eqnarray}となります.以下に$K=2$として,$a,b$を変化させたロジスティック関数$P(G=1|X=x)$のグラフを示します.
$a$を変化させると,曲線の形はそのままに,左右方向にシフトしている様子がわかります.このことから,$a$はロジスティック関数の位置を決めているパラメータといえるでしょう.
次に$b$を変化させると,曲線の曲がり方が変化するということがわかります.このことから,$b$はロジスティック関数の曲率を決めるパラメータといえるでしょう.以上のグラフでは,$b,x$はスカラーとしましたが,ベクトルの場合も同様の議論ができます.項目反応理論(Item Response Theory,IRT)はこのロジスティック関数を基にした理論で,学力を測ることなどに利用されているようです(詳しくはあまり知らないので勉強します).
item response theory (IRT) (also known as latent trait theory, strong true score theory, or modern mental test theory) is a paradigm for the design, analysis, and scoring of tests, questionnaires, and similar instruments measuring abilities, attitudes, or other variables. It is a theory of testing based on the relationship between individuals' performances on a test item and the test takers' levels of performance on an overall measure of the ability that item was designed to measure. (wikipedia (Item response theory)),(日本語ver.はこちら)
(どうやらテストや質問紙の項目に対する反応から受験者の性質や,テストや質問紙の項目の難易度や識別力を測定し,デザインするための理論らしい.)
通常のロジスティック回帰によるクラス判別では,計算された$P(G=k|X=x)$のうち,最も事後確率が大きいクラスに個体xが属するというように判断します.ロジスティック回帰のパラメータ推定について考えます.3. How to estimate parameters
ロジスティック回帰のパラメータはXが与えられた下でのGの条件付き確率$P(G|X)$を用いて最尤法によって推定されます.多クラス分類の場合,事後確率が多項分布に従うと考えると,N個の個体xが観測された際の対数尤度は,$p_k(x_i;\theta)=P(G=k|X=x_i;\theta)$とすると,
\begin{eqnarray} l(\theta) &=& \log\prod_{i=1}^Np_{g_i}(x_i;\theta)\\ &=& \sum_{i=1}^N\log p_{g_i}(x_i;\theta)\ (k=1,\cdots,K) \end{eqnarray}となります.議論を単純にするため(←The elements of statistical learningにもこう書いてます!),以下では2クラス分類問題のパラメータ推定について考えます.2クラス分類では$y_i$,$p_i$を以下のように定めると便利です.
\begin{eqnarray} y_i &=& \left\{ \begin{array}{l} 1\ if\ g_i=1\\ 0\ if\ g_i=2 \end{array}\right.\\\\ p_i(x;\theta) &=& \left\{ \begin{array}{l} p(x;\theta)\ \ (if\ i=1)\\ 1-p(x;\theta)\ \ (if\ i=2) \end{array}\right. \end{eqnarray}以上のように定めた場合,事後確率は二項分布$Bin(1,p(x_i;\theta))$に従うため,対数尤度は以下のように表せます.
\begin{eqnarray} l(\beta) &=& \log\prod_{i=1}^Np(x_i;\theta)^{y_i}(1-p(x_i;\theta))^{1-y_i}\\ &=& \sum_{i=1}^N\{y_i\log p(x_i;\theta)+(1-y_i)\log (1-p(x_i;\theta))\}\\ &=& \sum_{i=1}^N\{y_i\log \frac{\exp(\beta^Tx_i)}{1+\exp(\beta^Tx_i)}+(1-y_i)\log \frac{1}{1+\exp(\beta^Tx_i)}\}\\ &=& \sum_{i=1}^N\{y_i[\log\exp(\beta^Tx_i)-\log(1+\exp(\beta^Tx_i))]+(1-y_i)[\log 1-\log(1+\exp(\beta^Tx_i))]\}\\ &=& \sum_{i=1}^N\{y_i\beta^Tx_i-\log(1+\exp(\beta^Tx_i))\}\\ \end{eqnarray}ここで$x_i$は切片項のために$x_i=(1,x_{i1},\cdots,x_{ip})^T$となっており,$\beta$も切片を含んで$\beta = (\beta_{10},\beta_1)$となっています.対数尤度を最大化するために,1次の偏微分を0とおきます.
\begin{eqnarray} \frac{\partial l(\beta)}{\partial \beta}&=&\sum_{i=1}^N(y_ix_i-\frac{\exp(\beta^Tx_i)}{1+\exp(\beta^Tx_i)}x_i)\\ &=& \sum_{i=1}^N(y_i-p(x_i;\beta))x_i = 0\\ &\Leftrightarrow&\sum_{i=1}^Ny_ix_i = \sum_{i=1}^Np(x_i;\beta)x_i\\ \end{eqnarray}以上の変形から分かるように,1次の偏微分を0とおいた解は$p+1$の$\beta$に関する非線形方程式となっています.しかし,$x_i$の第1成分が全て1であることに注意すると,最初の方程式は$\sum_{i=1}^Ny_i=\sum_{i=1}^Np(x_i;\beta)$となることがわかり,これはクラス1の期待度数が観測数と一致するということを表しています.この非線形方程式を解くために,二階の偏微分もしくは,ヘッセ行列を用いるNewton-Raphson法を利用します.この対数尤度に対する二回の偏微分は
\begin{eqnarray} \frac{\partial^2 l(\beta)}{\partial \beta\partial\beta^T} &=& \frac{\partial}{\partial\beta^T}\sum_{i=1}^N(y_i-\frac{\exp(\beta^Tx_i)}{1+\exp(\beta^Tx_i)})x_i\\ &=&-\sum_{i=1}^N[\frac{e^{\beta^Tx_i}x_ix_i^T(1+\exp(\beta^Tx_i))-e^{\beta^Tx_i}x_i\exp(\beta^Tx_i)x_i^T}{(1+\exp(\beta^Tx_i))^2}]\\ &=&-\sum_{i=1}^N[\frac{e^{\beta^Tx_i}x_ix_i^T+\exp^{2\beta^Tx_i}x_ix_i^T-e^{2\beta^Tx_i}x_ix_i^T}{(1+\exp(\beta^Tx_i))^2}]\\ &=&-\sum_{i=1}^N\frac{e^{\beta^Tx_i}}{(1+\exp(\beta^Tx_i))^2}x_ix_i^T\\ &=&-\sum_{i=1}^N\frac{e^{\beta^Tx_i}}{1+\exp(\beta^Tx_i)}\frac{1}{1+\exp(\beta^Tx_i)}x_ix_i^T\\ &=&-\sum_{i=1}^Np(x_i;\beta)(1-p(x_i;\beta))x_ix_i^T \end{eqnarray}となります.現在の係数の推定値を$\beta^{old}$とすると,Newton-Raphson法での更新式は,
\beta^{new} = \beta^{old}-\biggl(\frac{\partial^2 l(\beta)}{\partial \beta\partial\beta^T}\biggr)^{-1}\frac{\partial l(\beta)}{\partial \beta}で与えられます.これらを行列形式で書くと,
\begin{eqnarray} \frac{\partial l(\beta)}{\partial \beta}&=&X^T(y-p)\\ \frac{\partial^2 l(\beta)}{\partial \beta\partial\beta^T}&=&-X^TWX \end{eqnarray}で表されます.ここで,$y,p$は$y=(y_1,\cdots,y_N)^T$,$p=(p(x_1;\beta^{old}),\cdots,p(x_N;\beta^{old}))^T$とし,$W$は$p(x_i;\beta)(1-p(x_i;\beta))$をi番目の対角成分に持つ対角行列としています.行列表現によるNewton-Raphson法の更新式は
\begin{eqnarray} \beta^{new} &=& \beta^{old} + (X^TWX)^{-1}X^T(y-p)\\ &=& (X^TWX)^{-1}(X^TWX\beta^{old}+X^T(y-p))\\ &=& (X^TWX)^{-1}X^TW(X\beta^{old}+W^{-1}(y-p))\\ &=& (X^TWX)^{-1}X^TWz\\ &&(z:=X\beta^{old}+W^{-1}(y-p)\mbox{と置いた}) \end{eqnarray}と書き表すことができます.これは以下の重み付き交互最小二乗法(Iteratively Reweighted Least Square, IRLS)のの更新式として見なすことができます.
\begin{eqnarray} \beta_{new} \leftarrow \arg \underset{\beta}{min}(z-X\beta)^TW(z-X\beta) \end{eqnarray}次にニュートン・ラフソン法を用いて,ロジスティック回帰分析の係数を推定するサンプルコードを提示します.今回は,対数尤度が収束するまで,叛服を繰り返しました.パラメータの変化量を収束の基準として表すやり方もあるようです(どこかでみたプログラムがそうなってた.そっちの方が係数の推定精度良さそう).導出で,$y_i=0or1$としましたが,$y_i=-1or1$とした方が良さそうな気がします.大学の授業でRを用いて実装したのは後者の導出を基にしていました.
4. Sample code(python)
最初の方のグラフの描画と,ニュートンラフソン法でパラメータを求めるプログラムです.パラメータの変化量を収束の基準とするバージョンと,$y_i=-1\ or\ 1$とするバージョンもいつか書きます.
Python3, logisticRegression.pyimport numpy as np import matplotlib.pyplot as plt #ロジスティック曲線の描画 def logistic_curve(x,alpha,beta): """ f(x) = 1/(1+exp(a + bx)) """ return np.exp(alpha + beta*x)/(1+np.exp(alpha + beta*x)) x1 = np.arange(-5,5,0.1) alpha_list = [-1,0,5] beta_list = [1,2,4] plt.plot(x1,logistic_curve(x1,alpha_list[0],beta_list[0]),label="a=-1,b=1",color="blue") plt.plot(x1,logistic_curve(x1,alpha_list[0],beta_list[1]),label="a=-1,b=2",color="yellow") plt.plot(x1,logistic_curve(x1,alpha_list[0],beta_list[2]),label="a=-1,b=4",color="green") plt.legend(loc="upper right") plt.title("various b values and its effect") #plt.savefig("適当なディレクトリ") plt.show() plt.plot(x1,logistic_curve(x1,alpha_list[0],beta_list[1]),label="a=-1,b=1",color="gray") plt.plot(x1,logistic_curve(x1,alpha_list[1],beta_list[1]),label="a=0,b=2",color="purple") plt.plot(x1,logistic_curve(x1,alpha_list[2],beta_list[1]),label="a=5,b=4",color="orange") plt.legend(loc="upper right") plt.title("various a values and its effect") #plt.savefig("適当なディレクトリ") plt.show() #ロジスティック回帰のパラメータ推定 def calc_p(beta,MatX): a,b = MatX.shape pxb = np.zeros((a,1)) for i in range(a): pxb[i,0] = np.exp(MatX[i,:].dot(beta))/(1+np.exp(MatX[i,:].dot(beta))) return pxb def loglikelihood(y,beta,MatX): ll = 0 a,b = MatX.shape for i in range(a): ll += y[i,0]*beta.T.dot(MatX[i,:])-np.log(1 + np.exp(beta.T.dot(MatX[i,:]))) return ll def losgistic_estimation(y,data,tol=10**(-6),nstart=20,maxiter=50): X = data.astype("float64") n,p = X.shape X1 = np.hstack([np.ones(n).reshape(n,1),X]).reshape(n,p+1) y = y.astype("float64") beta_hat = np.zeros((p+1,1)) like_list = [] X1 = np.hstack([np.ones(n).reshape(n,1),X]) y = y.astype("float64").reshape(n,1) beta_hat = np.zeros(((p+1),1)) like_list = [] maxlike = -np.Inf for _ in range(nstart): print("---epoc:%d ---" % (_+1)) #initial beta beta = np.random.randn(p+1).reshape((p+1),1) like = -np.Inf likes = [] while True: print(" likelihood: %f" % like) #Newton-Raphson step prob = calc_p(beta,X1) #print(prob) #for check W = np.zeros((n,n)) for i in range(n): W[i,i] = prob[i,0]*(1-prob[i,0]) #print(W) # for check pd2 = -X1.T.dot(W).dot(X1) pd1 = X1.T.dot(y-prob) new_beta = beta - np.linalg.inv(pd2).dot(pd1) new_like = loglikelihood(y,new_beta,X1) likes.append(new_like) delta = new_like - like if delta > 0 and delta <= tol: print("converge") break elif delta < 0: break else: like = new_like beta = new_beta continue if delta < 0: print("ERROR:not increasing monotonely\nStop and go next epoc") continue if new_like >= maxlike: maxlike = new_like like_list = likes beta_hat = new_beta return beta_hat, like_list # データ行列の生成 N = 1000;p = 2 np.random.seed(43) X = np.random.randn(N*p).reshape(N,p) X1 = np.hstack([np.ones(N).reshape(N,1),X]) #正解ラベルの生成 y = np.zeros((N,1)) np.random.seed(67) beta = np.random.randn(p+1).reshape(p+1,1) prob = np.exp(X1.dot(beta))/(1+np.exp(X1.dot(beta))) prob # for check for i in range(N): np.random.seed(i+4) if np.random.rand(1) < prob[i]: y[i] = 1 else: y[i] = 0 y # for check res = losgistic_estimation(y,X) print(res[0]) print(beta)References
Hasitie,Tibshirani,Friedman(2009).The elements of statistical learning
- 投稿日:2019-04-25T23:06:41+09:00
オセロAIを作ってみた
オセロは初心者の壁
pythonの基礎をなんとなく理解できてきました(ライブラリはnumpyやpandasを少し使えるくらい)。自分でアプリを一から作ったほうが成長できると聞いたので、ここは新規に何か作ってみたいなと思いました。
そこで、最も初心者向けであろうオセロ(リバーシ)を作ろうと思いました。全てのゲームの基礎になるとかならないとか。挟んでひっくり返すという非常にシンプルなゲームゆえにとっつきやすいはず...
しかし、いざ作ってみると初心者はオセロすらまともに作るのに四苦八苦しました。注意
ネットに転がってるものを利用して作ってみたものです。似たようなコードは調べれば出てきます。
初心者が作っているので、かなり粗があると思います。
実行環境はgoogleドライブのcolaboratoryです。jupyterと似たような感じ。
ローカルで実行する際は2つのコードを1つにまとめるか、classの部分をimportすれば動く、のか?
ちょっと詳しくは分からないです。オセロを作るために
作ろうと思ってすぐ作れるようなスキルはないため、以下の手順で考えることにしました。
- アプリを作るためにオセロがどのような手順で進められるかを確認する。
- とりあえず、座標を入力したら石をおいてひっくり返してくれるプログラムを組んでみる。
- きちんとオセロらしく作動するように調整する。
それぞれどんなことをしたのか、記述していこうと思います。
1. アプリを作るのにどのような要素があるのか
まず、オセロはどういう感じで動くのか考えてみました。
イメージとしては
1ターンの挙動 : 石を置きたい座標を指定 → 石を置く → 挟んだ石をひっくり返す
これを繰り返す感じ。
特殊な要素として、
・パス
・石がおけないためゲーム終了
の2つが挙げられます。
これを踏まえてプログラムを組んでみます。2. 石を置いてひっくり返すコードを組んでみる
下記のコードはまず
入力座標に石を置けるか : 3つの条件
1. 入力座標が盤内であるかどうか → ①
2. 入力座標に石が置かれていないか → ②
3. 入力座標に石をおいた時にひっくり返せる石が1つでもあるかどうか → ③
の3つを考えます。
曲者は3番のひっくり返せるかどうかの判断
今回はnumpyの2次元配列を用いてます。
八方向を表すために、x方向、y方向に対して(-1,0,1)の3つをdx, dyでとりました。
ex)右上であれば方向ベクトルは(dx, dy) = (1, 1)
下方向であれば(dx, dy) = (0, -1)座標(x,y)に対して(dx,dy)方向を調べます。
まず(dx, dy) = (0, 0)はいらないので除外。 → ⑴
(x+dx, y+dy)が自分の石、もしくは空白であれば石はひっくり返せないのでFalseを返します。 → ⑵
(x+dx, y+dy)に相手の石があればその方向をさらに調べます。 → ⑶
調べた先に自分の石があればTrue、何もなければFalseを返します。 → ⑷-True,⑷-False
これで1,2,3全てを満たしていれば石をおけることがわかりました。あとは条件を満たした座標に石を置いてひっくり返します。 → ④
これらの全てを組み合わせれば挟んだ石をひっくり返すコードの完成です。
*ターンチェンジはまだ使ってないけれど一応書いてあるだけです。初期設定として
白 : white = 1
黒 : black = -1
空白 : blank = 0
盤面の大きさ : tablesize = 8osero.pyimport numpy as np white = 1 black = -1 blank = 0 tablesize = 8 class Board(object): # 初期設定 def __init__(self): self.cell = np.zeros((tablesize,tablesize)) self.cell = self.cell.astype(int) self.cell[3][3] = self.cell[4][4] = 1 self.cell[3][4] = self.cell[4][3] = -1 self.current = black self.pass_count = 0 def turnchange(self): # ターンチェンジ self.current*= -1 def rangecheck(self,x,y): # x,yが範囲内かどうか if x < 0 or tablesize <=x or y < 0 or tablesize <= y: return False return True def check_can_reverse(self,x,y): # 石を置けるかどうか if not self.rangecheck(x,y): # ① return False elif not self.cell[x][y] == blank: # ② return False elif not self.can_reverse_stone(x,y): # ③ return False else: return True def can_reverse_one(self,x,y,dx,dy): # 敵石の先に自石があるかどうか length = 0 if self.cell[x+dx][y+dy] == blank: # ⑵ return False elif self.cell[x+dx][y+dy] == self.current: # ⑵ return False else: while self.cell[x+dx][y+dy] == -self.current: # ⑶ x +=dx y +=dy length += 1 if self.cell[x+dx][y+dy] == self.current: # ⑷-True return length elif self.cell[x+dx][y+dy] == blank: # ⑷-False return False continue def can_reverse_stone(self,x,y): # ③ 入力座標ではひっくり返せる石はあるか for dx in (-1,0,1): for dy in (-1,0,1): if dx == dy == 0: continue elif self.cell[x+dx][y+dy] == blank: # ⑴ continue elif not self.can_reverse_one(x,y,dx,dy): # ⑵~⑷へ continue else: return True def reverse_stone(self,x,y): # ④ 座標に石を置いて石をひっくり返す for dx in (-1,0,1): for dy in (-1,0,1): length = self.can_reverse_one(x,y,dx,dy) if length > 0: for l in range(length): k = l+1 self.cell[x + dx*k][y + dy*k] *= -1 def display(self): # オセロ盤の表示 print('--' * 20) for y in range(tablesize): for x in range(tablesize): if self.cell[x][y] == white: print('W', end = ' ') elif self.cell[x][y] == black: print('B', end = ' ') else: print('*', end = ' ') print('\n', end = '') def put_stone(self,x,y): # 一回のターン内の行動 if self.check_can_reverse(x,y): # 入力座標に石を置ける self.pass_count = 0 # * 次の操作に必要 self.cell[x][y] = self.current self.reverse_stone(x,y) self.pass_count = 0 self.turnchange() return True else: # 入力座標に石を置けない return False if __name__ == '__main__': board = Board() board.display() board.put_stone(3,2) board.dislay実行すると以下のようになりました。
---------------------------------------- * * * * * * * * * * * * * * * * * * * * * * * * * * * W B * * * * * * B W * * * * * * * * * * * * * * * * * * * * * * * * * * * ---------------------------------------- * * * * * * * * * * * * * * * * * * * B * * * * * * * B B * * * * * * B W * * * * * * * * * * * * * * * * * * * * * * * * * * *うん、いい感じ。
3. 今度はゲームが終わるまで動かすようにする
今度は1ターンの挙動をもう少し細かく作ります。
必要なのは
1. 座標を入力するシステム → ①
2. 石を置き、挟んだ石をひっくり返す ← 上で作ったやつ
3. パスするシステム → ②
4. ゲームセット(スコア付き) → ③
5. 入力した座標に石をおけない場合再入力する → ④2の部分はパスすると相手のターンに移行するのと、二回連続でパスしたらゲーム終了、という設定にしました。 → ②' + 上記の*部分
また、ゲームが終わった時に勝敗を表示するために、両石の数、空白の数をカウントするシステムも作成しました。 → ⑤
また、あまり意味はないのですが、初期設定として各石と空白の数を設けました。
これらが書けたらあとは組み合わせるだけ。実行するときは上のプログラムの
if name == 'main':
以下を一度消してからもう一度実行しましょう(初期状態から行うため)。playgame.pyimport sys #ゲームを終わらせるsys.exit()を使うためにimport class Game(Board): def __init__(self): self.white_count = 2 self.black_scount = 2 self.blank_count = 60 # パスをする関数。一度パスするとpass_countが1増える # pass_count == 2 になるとゲームセット関数に飛ぶ def pass_system(self): # ② board.pass_count += 1 # ②' board.turnchange() if board.pass_count ==2: self.gameset() return True def gameset(self): # ③ ゲーム終了、石の数をカウント print('game set') self.count_system() print('white : ', self.white_count) print('black : ', self.black_count) if self.white_count > self.black_count: print('white WIN !!') if self.white_count < self.black_count: print('Black WIN !!') if self.white_count == self.black_count: print('Draw') sys.exit() def count_system(self): # ⑤ 盤面の状態のカウントシステム self.white_count = np.sum(board.cell == white) self.black_count = np.sum(board.cell == black) self.blank_count = np.sum(board.cell == blank) def input_point(self): # 座標を入力 print('石を置く座標を(0~7で)入力してください。(x,y)=(8,8)でpass、(9,9)で終了します。') x = input('x>>') y = input('y>>') try: # 変な入力して止まらないようにするため x = int(x) y = int(y) except: self.input_point() return x, y def one_turn_play(self): # 1ターンでの行動 (x,y) = self.input_point() # 座標を入力 board.put_stone(x,y) # 石をおいてひっ繰り返してTrueを返すか、何もせずFalseを返す print('check') if not board.put_stone(x,y): if (x,y) == (8,8): # パスするとき → ②へ self.pass_system() elif (x,y) == (9,9): # ゲームをやめる時 → ③へ self.gameset() while False: # ④ 石をおけない時は もう一度同じことをする self.one_turn_play() # 最後まで続くようにしてみる def gameplay(self): while self.blank_count >0: board.display() # 盤面を出力 self.one_turn_play() # ターンでの行動 self.count_system() # 石とblankの数を出す print('white : ', self.white_count, ', black : ', self.black_count, ', blank : ', self.blank_count) self.gameset() if __name__ == '__main__': board = Board() game = Game() game.gameplay()実行してみる
---------------------------------------- * * * * * * * * * * * * * * * * * * * * * * * * * * * W B * * * * * * B W * * * * * * * * * * * * * * * * * * * * * * * * * * * 石を置く座標を(0~7で)入力してください。(x,y)=(8,8)でpass、(9,9)で終了します。 x>>3 y>>2 check white : 1 , black : 4 , blank : 59 ---------------------------------------- * * * * * * * * * * * * * * * * * * * B * * * * * * * B B * * * * * * B W * * * * * * * * * * * * * * * * * * * * * * * * * * * 石を置く座標を(0~7で)入力してください。(x,y)=(8,8)でpass、(9,9)で終了します。 x>>4 y>>2 check white : 3 , black : 3 , blank : 58 ---------------------------------------- * * * * * * * * * * * * * * * * * * * B W * * * * * * B W * * * * * * B W * * * * * * * * * * * * * * * * * * * * * * * * * * * 石を置く座標を(0~7で)入力してください。(x,y)=(8,8)でpass、(9,9)で終了します。 x>>5 y>>2 check white : 1 , black : 6 , blank : 57 ---------------------------------------- * * * * * * * * * * * * * * * * * * * B B B * * * * * B B * * * * * * B W * * * * * * * * * * * * * * * * * * * * * * * * * * * 石を置く座標を(0~7で)入力してください。(x,y)=(8,8)でpass、(9,9)で終了します。 x>>8 y>>8 check white : 1 , black : 6 , blank : 57 ---------------------------------------- * * * * * * * * * * * * * * * * * * * B B B * * * * * B B * * * * * * B W * * * * * * * * * * * * * * * * * * * * * * * * * * * 石を置く座標を(0~7で)入力してください。(x,y)=(8,8)でpass、(9,9)で終了します。 x>>8 y>>8 check game set white : 1 black : 6 Black WIN !! An exception has occurred, use %tb to see the full traceback.これでオセロを遊べそうですね(ぼっち(セルフ)専用)。
blank = 0 になるまでは検証していませんので悪しからず。感想と今後の展望
個人的には難しかったけど、初心者としては成長したと感じました。
正直これを作る前はclassやtry, exceptなどはいまいち分からなかったのですが、多少は使えるようになったかなと...
今後はAIを導入してぼっちでも対戦できるようにしたいと思っています。
また、オセロから発展させてチェスや将棋なども作って行きたいと思っています。
強化学習はAIが作れてからかな...プログラムが動かないなど何か問題があれば教えてください。
以上です。参考になれば幸いです。
- 投稿日:2019-04-25T21:48:34+09:00
Kerasで「笑っている犬」と「怒っている犬」を判別する機械学習モデルを作る
半年ほど、古文書(正確には古典籍)のデータを用いた機械学習で遊んでいたが、どうにも行き詰った感じなので、気分転換にネタを変えてみることにした。
今回のテーマは「笑っている犬」と「怒っている犬」を判別すること。私は犬を飼っているわけではないので、犬の表情に詳しいわけではないが、笑っている犬と怒っている犬の写真はだいたい区別できる。
これは笑っているように見える。データ元はフリー写真素材ぱくたそ
これは怒っている。Photoangel - jp.freepik.com によって作成された background 写真ぱっと見の印象は全然違うが、それぞれの特徴を言語化してみると、口が開いている、歯が見える、目を細めているなどなど、意外と似ているのかもしれない。これをCNNでうまく判別できるのかを試してみた。
データ収集
著作権フリー画像サイトでは、笑っている犬と怒っている犬の画像が大量にあるわけではないので、画像をどこから入手するか悩んでいたところ、STORIA法律事務所のBLOGによると、ネットからダウンロードした著作権フリーではない画像を学習データに使って、機械学習のモデルを作ることは著作権違反にはならないらしい。
ということで、googleから画像を一括でダウンロードするツールgoogle_images_download を使うことにした。
まずは、Anaconda promptから、
> pip install google_images_downloadでツールをインストール。(最初はcondaで試したが、condaにはライブラリがなかった)
そのまま同じプロンプトで画像をダウンロードしようとしたら、
Evaluating... Looks like we cannot locate the path the 'chromedriver' (use the '--chromedriver' argument to specify the path to the executable.) or google chrome browser is not installed on your machine (exception: argument of type 'NoneType' is not iterable)こんなエラーが出た。要はchromedriverがないということなので、googleのchromedriverのサイトからchromedriver_win32.zipをダウンロードして適当な場所に解凍。(ダウンロードする前に、Chromeのバージョンを確認して、同じバージョンのchromedriverを選択しないとエラーになる。)
で、キーワードを指定して画像をダウンロード。
英語と日本語でキーワードを指定して、各500枚ずつの画像をダウンロードする。> googleimagesdownload --keywords "笑っている犬" --limit 500 --output_directory "C:\Users\User\Desktop\dog\down" --language Japanese --chromedriver "(chromedriverを解凍したフォルダ)\chromedriver.exe" > googleimagesdownload --keywords "怒っている犬" --limit 500 --output_directory "C:\Users\User\Desktop\dog\down" --language Japanese --chromedriver "(chromedriverを解凍したフォルダ)\chromedriver.exe" > googleimagesdownload --keywords "smile dog" --limit 500 --output_directory "C:\Users\User\Desktop\dog\down"" --language English --chromedriver "(chromedriverを解凍したフォルダ)\chromedriver.exe" > googleimagesdownload --keywords "angry dog" --limit 500 --output_directory "C:\Users\User\Desktop\dog\down"" --language English --chromedriver "(chromedriverを解凍したフォルダ)\chromedriver.exe"画像は C:\Users\User\Desktop\dog\down(入力したキーワード)
のフォルダにダウンロードされた。
フォルダの中を見てみると、Googleの画像検索で、同じキーワードで検索したときと同じ画像がダウンロードされているようだ。笑っている犬、怒っている犬の写真だけでなく、イラスト、他の動物、表情が分かりにくい犬の写真、人や他の動物や物が一緒に写っている写真もたくさんある。
そのため、私の目で見て、明らかに笑っている犬と怒っている犬の写真を各120枚ずつ選択した。
キーワードの精度(各キーワードで欲しい画像がどのぐらい入っているか)は、
「笑っている犬」>「angry dog」>「怒っている犬」>「smile dog」
だった。写真をアップする飼い主さんにも、見る人にも、怖い犬より可愛い犬のほうが好まれそうだから、笑っている犬がたくさん出てくるのは分かるのだが、英語の「smile dog」ではほとんど良いデータがなかったのは、何故だろうか? 英語ネイティブの人たちは犬にはsmileを使わないのか?それとも店の名前などによく使われるからなのか?学習データ、テストデータ作成
選んだ120枚ずつの画像を、画像形式がjpegでないものは、Windows標準の「ペイント」でjpegに変換してから、dog_smileとdog_angryという名前のフォルダに格納した。(意外とここまでの前処理の手作業が大変だった。)
笑/怒で各120枚のデータのうち、1~100枚目までを学習データ、101~120枚目までをテストデータとした。
何となく、笑=1、怒=0のほうがイメージとしてしっくり来るので、データの読み込みは怒->笑の順番にした。学習データ、テストデータ作成# 画像を読み込んで、行列に変換する関数を定義 from keras.preprocessing.image import load_img, img_to_array def img_to_traindata(file, img_rows, img_cols, rgb): if rgb == 0: img = load_img(file, color_mode = "grayscale", target_size=(img_rows,img_cols)) # grayscaleで読み込み else: img = load_img(file, color_mode = "rgb", target_size=(img_rows,img_cols)) # RGBで読み込み x = img_to_array(img) x = x.astype('float32') x /= 255 return x # 学習データ、テストデータ生成 import glob, os img_rows = 224 # 画像サイズはVGG16のデフォルトサイズとする img_cols = 224 nb_classes = 2 # 怒っている、笑っているの2クラス img_dirs = ["./dog_angry", "./dog_smile"] # 怒っている犬、笑っている犬の画像を格納したディレクトリ X_train = [] Y_train = [] X_test = [] Y_test = [] for n, img_dir in enumerate(img_dirs): img_files = glob.glob(img_dir+"/*.jpg") # ディレクトリ内の画像ファイルを全部読み込む for i, img_file in enumerate(img_files): # ディレクトリ(文字種)内の全ファイルに対して x = img_to_traindata(img_file, img_rows, img_cols, 1) # 各画像ファイルをRGBで読み込んで行列に変換 if i < 100: # 1~100枚目までを学習データ X_train.append(x) # 学習用データ(入力)に画像を変換した行列を追加 Y_train.append(n) # 学習用データ(出力)にクラス(怒=0、笑=1)を追加 else: # 101~120枚目までをテストデータ X_test.append(x) # テストデータ(入力)に画像を変換した行列を追加 Y_test.append(n) # テストデータ(出力)にクラス(怒=0、笑=1)を追加 import numpy as np # 学習、テストデータをlistからnumpy.ndarrayに変換 X_train = np.array(X_train, dtype='float') Y_train = np.array(Y_train, dtype='int') X_test = np.array(X_test, dtype='float') Y_test = np.array(Y_test, dtype='int') # カテゴリカルデータ(ベクトル)に変換 from keras.utils import np_utils Y_train = np_utils.to_categorical(Y_train, nb_classes) Y_test = np_utils.to_categorical(Y_test, nb_classes) # 作成した学習データ、テストデータをファイル保存 np.save('models/X_train_2class_120.npy', X_train) np.save('models/X_test_2class_120.npy', X_test) np.save('models/Y_train_2class_120.npy', Y_train) np.save('models/Y_test_2class_120.npy', Y_test) # 作成したデータの型を表示 print(X_train.shape) print(Y_train.shape) print(X_test.shape)出力結果は、
(200, 224, 224, 3)
(200, 2)
(40, 224, 224, 3)
となったので、意図した通り、学習データ各100個、合計200個、テストデータ各20個、合計40個となっていることが分かる。モデル定義&学習(CNN)
次に、モデルを作って学習させてみた。モデルは日本の古文書で機械学習を試す(10)で使ったのと同じ、畳み込み3層のものをベースとして、2クラス分類なので、全結合層をsoftmax->sigmoid、損失関数をcategorical_crossentropy -> binary_crossentropyに変更した。
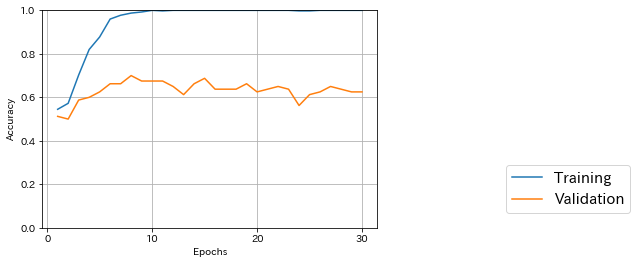
モデル定義&学習from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D # 【パラメータ設定】 batch_size = 20 epochs = 30 input_shape = (img_rows, img_cols, 3) nb_filters = 32 # size of pooling area for max pooling pool_size = (2, 2) # convolution kernel size kernel_size = (3, 3) # 【モデル定義】 model = Sequential() model.add(Conv2D(nb_filters, kernel_size, # 畳み込み層 padding='valid', activation='relu', input_shape=input_shape)) model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層 model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層 model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層 model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層 model.add(Dropout(0.25)) # ドロップアウト(過学習防止のため、入力と出力の間をランダムに切断) model.add(Flatten()) # 多次元配列を1次元配列に変換 model.add(Dense(128, activation='relu')) # 全結合層 model.add(Dropout(0.2)) # ドロップアウト model.add(Dense(nb_classes, activation='sigmoid')) # 2クラスなので全結合層をsigmoid # モデルのコンパイル model.compile(loss='binary_crossentropy', # 2クラスなのでbinary_crossentropy optimizer='adam', # 最適化関数のパラメータはデフォルトを使う metrics=['accuracy']) # 【各エポックごとの学習結果を生成するためのコールバックを定義(前回より精度が良い時だけ保存)】 from keras.callbacks import ModelCheckpoint import os model_checkpoint = ModelCheckpoint( filepath=os.path.join('models','model_2class120_{epoch:02d}_{val_acc:.3f}.h5'), monitor='val_acc', mode='max', save_best_only=True, verbose=1) # 【学習】 result = model.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test, Y_test), callbacks=[model_checkpoint])学習時間は1エポック当たり45~50秒、テストデータに対する最大精度は8/30エポック目の0.700だった。
学習経過を可視化してみると、10エポックぐらいで学習データに対する精度がほぼ1になり、その後は過学習気味となっている。
学習経過可視化# 【学習データとテストデータに対する正解率をプロット】 import matplotlib.pyplot as plt %matplotlib inline plt.plot(range(1, epochs+1), result.history['acc'], label="Training") plt.plot(range(1, epochs+1), result.history['val_acc'], label="Validation") plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.ylim([0,1])# y軸の最小値、最大値 plt.grid(True) # グリッドを表示 plt.xticks(np.arange(0, epochs+1, 10)) plt.legend(bbox_to_anchor=(1.8, 0), loc='lower right', borderaxespad=1, fontsize=15) plt.show()
ImageDataGeneratorで学習データを水増し
学習データ数が少なめなので、ImageDataGeneratorを使って、データを水増ししてみた。
まず、水増しする条件を指定してImageDataGeneratorオブジェクトを作成する。バッチサイズは先ほどと同じ20にする。generator作成from keras.preprocessing.image import ImageDataGenerator train_datagen = ImageDataGenerator( rotation_range=20, # 20°までランダムに回転 width_shift_range=0.1, # 水平方向にランダムでシフト height_shift_range=0.1, # 垂直方向にランダムでシフト shear_range=0.19, # 斜め方向(pi/16まで)にランダムに引っ張る zoom_range=0.1 # ランダムにズーム ) train_generator = train_datagen.flow(X_train, Y_train, batch_size=batch_size, seed = 16)モデルは上と同じ畳み込み3層のものを定義した。後は、ModelCheckpointで保存するモデルの名前を変更し、model.fitを以下のように変えて実行するだけ。
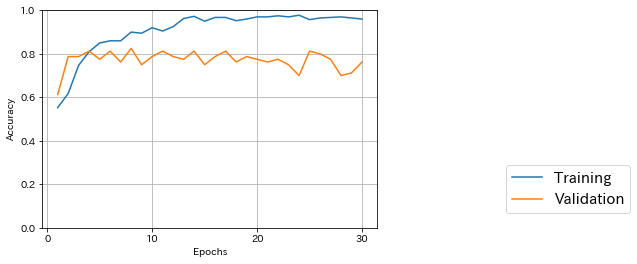
水増し、学習コードの変更部分result = model.fit_generator(train_generator, samples_per_epoch=X_train.shape[0], epochs=epochs, verbose=1, validation_data=(X_test, Y_test), callbacks=[model_checkpoint])samples_per_epoch(1エポック当たりの学習データ数)は、元の学習データ数と同じにする。実行すると、「samples_per_epochではなく、Keras 2 APIのsteps_per_epochを使うように」という警告が出たが、steps_per_epoch = samples_per_epoch / batch_size で自動変換してくれた。
テストデータに対する最大精度は29/30エポック目の0.77500だった。水増しなしのときより良くなっている。
試しに、samples_per_epochをX_train.shape[0]*2、X_train.shape[0]*4にして、学習データをさらに水増ししてみたところ
*2の最大精度 22/30エポック目の0.7250
*4の最大精度 11/30エポック目の0.7875
精度が *4 > *1 > *2 なのは謎だ。多すぎても少なすぎてもダメというなら分かるのだが、真ん中が一番低い。この後、手が滑って水増しなしの学習を最初からやり直してしまったのだが、10エポック目で0.788の精度が出た。0.700~0.788ぐらいは乱数で変わるのか?水増しなしなので、乱数の影響は各バッチで使う学習データの選び方と初期値だろうか。
転移学習
次に、日本の古文書で機械学習を試す(11)と同じようにVGG16の学習済みモデルを使って転移学習をしてみる。VGG16の最後の結合層のみを新たに定義して、再学習させる。
学習データ、テストデータは最初からVGG16の使用を念頭に置いて224x224で作ってあるので、そのまま使える。転移学習のモデル定義&学習# VGG15の学習済みモデルを読み込む from keras.applications.vgg16 import VGG16 from keras.layers import Input # 最後の全結合層を除いたモデルを読み込むのでinclude_top=False input_tensor = Input(shape=(img_rows, img_cols, 3)) base_model_v = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # 全結合層を定義(VGG15) from keras.models import Sequential, Model from keras.layers import Dense, Dropout, Activation, Flatten fc_model = Sequential() fc_model.add(Flatten(input_shape=base_model_v.output_shape[1:])) fc_model.add(Dense(256)) fc_model.add(Activation("relu")) fc_model.add(Dropout(0.5)) fc_model.add(Dense(nb_classes)) fc_model.add(Activation("sigmoid")) # 読み込んだVGG16と、定義した全結合層を連結 model_t = Model(inputs=base_model_v.input, outputs=fc_model(base_model_v.output)) # base_model_vの各層の重みを固定する(VGG16) for layer in base_model_v.layers: layer.trainable = False # モデルのコンパイル model_t.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 【各エポックごとの学習結果を生成するためのコールバックを定義(前回より精度が良い時だけ保存)】 from keras.callbacks import ModelCheckpoint import os model_checkpoint_t = ModelCheckpoint( filepath=os.path.join('models','model_2class120_transfer_{epoch:02d}_{val_acc:.3f}.h5'), monitor='val_acc', mode='max', save_best_only=True, verbose=1) # 【パラメータ設定】 batch_size = 20 epochs = 30 # 【学習】 result_t = model_t.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test, Y_test), callbacks=[model_checkpoint_t])学習時間は1エポック当たり200~260秒、テストデータに対する最大精度は18/30エポック目の0.8500だった。
モデルが複雑な分、学習に時間はかかるが、かなり精度が上がっている。(これだけ違えば乱数の影響だけではないと思う。たぶん。)
古文書(古典籍)のデータでは、VGG16の転移学習より、シンプルなCNNで最初から学習させたほうが精度が良かったが、今回は転移学習のほうが精度が高い。元データの種類や判別したい内容が近いためだろうか。転移学習 + ImageDataGenerator
ImageDataGeneratorで学習データを水増しした転移学習も試してみた。先ほどと同じように、ModelCheckpointで保存するモデルの名前を変更し、model.fitを以下のように変えて実行するだけ。
転移学習で水増し、学習コードの変更部分result = model_t.fit_generator(train_generator, samples_per_epoch=X_train.shape[0], epochs=epochs, verbose=1, validation_data=(X_test, Y_test), callbacks=[model_checkpoint])テストデータに対する最大精度は8/30エポック目の0.8250だった。水増しなしの転移学習の場合よりは下がっているが、最初のシンプルなCNNよりは良い結果となった。
こちらも学習経過を可視化してみた。15エポック前後でやめても良かったかもしれない。
画像のどこに着目しているかをGradCAMで可視化
モデルが、「笑っている犬」と「怒っている犬」をどこで区別しているのかが気になったので、GradCAMで着目箇所を可視化してみた。
GradCAMのコードはkerasでGrad-CAM 自分で作ったモデルでを参考にさせていただいた。まず、一番精度が良かった転移学習(水増しなし)の18エポック目のモデルを読み込んで、層構造を確認する。
モデル読み込みfrom keras.models import load_model model = load_model('models/model_2class120_transfer_18_0.850.h5') model.summary()出力はこうなった。
出力_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_4 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ sequential_29 (Sequential) (None, 2) 6423298 ================================================================= Total params: 21,137,986 Trainable params: 6,423,298 Non-trainable params: 14,714,688 _________________________________________________________________画像を1つ読み込んで、畳み込み層のうち、最後のもの(block5_conv3)と、モデルの最終出力の勾配から、最終出力に影響している画像の部分を可視化する。ついでに、「笑」「怒」の判別結果と、それぞれのスコアも表示してみる。
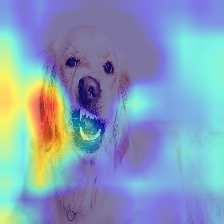
Grad-CAMimport numpy as np ## 画像読み込み filename = "freeimage/smile1.jpg" x = img_to_traindata(filename, img_rows, img_cols, 1) # img_to_traindata関数は、学習データ生成のときに定義 x = np.expand_dims(x, axis=0) ## どのクラスかを判別する preds = model.predict(x) pred_class = np.argmax(preds[0]) print("識別結果:", pred_class) print("確率:", preds[0]) from keras import backend as K import cv2 # モデルの最終出力を取り出す model_output = model.output[:, pred_class] # 最後の畳込み層を取り出す last_conv_output = model.get_layer('block5_conv3').output # 最終畳込み層の出力の、モデル最終出力に関しての勾配 grads = K.gradients(model_output, last_conv_output)[0] # model.inputを入力すると、last_conv_outputとgradsを出力する関数を定義 gradient_function = K.function([model.input], [last_conv_output, grads]) # 読み込んだ画像の勾配を求める output, grads_val = gradient_function([x]) output, grads_val = output[0], grads_val[0] # 重みを平均化して、レイヤーのアウトプットに乗じてヒートマップ作成 weights = np.mean(grads_val, axis=(0, 1)) heatmap = np.dot(output, weights) heatmap = cv2.resize(heatmap, (img_rows, img_cols), cv2.INTER_LINEAR) heatmap = np.maximum(heatmap, 0) heatmap = heatmap / heatmap.max() heatmap = cv2.applyColorMap(np.uint8(255 * heatmap), cv2.COLORMAP_JET) # ヒートマップに色をつける heatmap = cv2.cvtColor(heatmap, cv2.COLOR_BGR2RGB) # 色をRGBに変換 # 元の画像と合成 superimposed_img = (np.float32(heatmap)/4 + x[0]*255/4*3)冒頭に挙げた「笑っている犬」の画像(学習、テストには使っていない)に対する出力
識別結果: 1
確率: [0.25032192 0.7496992 ]
冒頭に挙げた「怒っている犬」の画像(学習、テストには使っていない)に対する出力
識別結果: 0
確率: [0.9978389 0.0027218]
どちらも、識別結果は正解だった。
「笑」のほうは、目のまわりと舌、「怒」のほうは口元~耳に着目しているようだ。「笑」のほうは人間の感覚と近いが、「怒」のほうは謎だ。人間が判別するときは、上の歯や牙が出ているかどうか、鼻がめくれているかどうかを見ている気がするのだが。フリー写真素材ぱくたそ からもう少し写真をダウンロードして試してみる。
元画像1。私には笑っているように見える。
識別結果: 1
確率: [0.00342841 0.9956071 ]
識別結果は正解。舌を見ているのは先ほどと同じだが、頭のリボンと首を見ているのは謎。元画像2。これもたぶん笑っている。
識別結果: 1
確率: [4.246722e-04 9.995505e-01]
これも正解。こちらは顔全体を見ているようだ。元画像3。ちょっと難易度を上げて横向きの笑っている犬。
識別結果: 1
確率: [0.0012683 0.99887735]
なぜ正解しているのか不明だが、結果は合っている。元画像4。笑っても怒っていもいない。ちょっと不満そうな顔?
識別結果: 1
確率: [0.0078612 0.989988 ]
どっちに分類されても正解ではないのだが、「笑」に分類された。目に着目しているようだ。「怒っている犬」の著作権フリー画像は最初のもの以外に見つけられなかった。著作権の関係でここには載せられないが、学習データとテストデータでもチェックしてみると、正解している画像は口周りと耳に着目しているものが多かった。耳は怒っているかどうかを判別するのに意外と重要なのだろうか?
冒頭の画像で、シンプルCNNのモデルでも試してみた。
識別結果: 0
確率: [0.8697514 0.12745507]
これは結果が間違っているし、何を見ているのかも分からない。識別結果: 0
確率: [0.998166 0.0012412]
これは結果が正解で、歯、鼻、目を見ているのは直感とも一致する。VGG16とシンプルCNNでは着目箇所が全然違うのは意外だった。
元画像が正方形ではないので、画像を読み込んで224x224に変換するで、画像が歪んで変になっている。学習データ、テストデータは224x224に変換した後の歪んだ画像を使っていることになるので、画像を読み込む前に手動で正方形にトリミングしておくと、精度が上がるかもしれない。
やっぱり機械学習はデータ収集と前処理が大変だ。
動作環境
今回使ったマシンの環境は以下の通り。
OS Windows10
CPU Intel(R) Core(TM) i7-5500U 2.4GHz
RAM 8.00GB
数年前に買ったノートPCで、GPUなし
(pythonとライブラリのバージョン)
python3.6.6、keras2.2.4、tensorflow1.9.0、hdf51.10.2おまけ:AIがサボった話
上では各クラス100枚の学習用画像を使ったが、最初は各クラス20枚、バッチサイズ4で試してみた。そうしたら、3エポック目から、学習データの精度0.500、テストデータの精度も0.500で全く変化しなくなってしまった。バッチサイズや最適化関数の学習率(lr)を変えてみると、少しは上下に振れるようになるが、最終的には0.5で落ち着いてしまう。
何が起こっているのかと思い、次のようなコードを書いて、学習データと識別データがどちらのクラスに分類されているかをチェックしてみた。
学習結果確認for i, x in enumerate(np.concatenate([X_train, X_test], 0): x = np.expand_dims(x, axis=0) preds = model.predict_classes(x) pred = preds.tolist() prob = model.predict_proba(x) prlist = prob.tolist() print(img_file) print("No." , i, " 正解:[", np.where(Y_test[i] == 1)[0][0], "] 予測結果:" , pred , prlist)すると、何と全てのデータが高確率(スコア0.9以上)でクラス0(怒)に分類されていた。そりゃ精度50%になるわ…
昔、テストで、2択問題なら全部同じ方を選べば、確率的に100点満点の50点は取れるなどと考えていたのを思い出して笑ってしまった。
将来、AIやロボットがもっと身近なものになったら、こんな感じでおサボりしたりするのだろうか。













- 投稿日:2019-04-25T21:42:38+09:00
PythonでQt
はじめに
新しい業務をはじめるにあたり、今すぐ必要なツールは
習得済みのC++&Qtで作成してきた。
ここにきて状況が落ち着いてきたので、メンテナンスも考えて
使用言語をPythonへ切り替えようと考えている。
(既存のtoolは全てPythonのため)既存ツールはお手軽に作れることから全てCUIだが
中にはGUIのほうが相性良い処理もある。
本記事では、PythonでGUIを扱う方法を記載する。実装
Python向けのGUIライブラリはいくつかあるようだが
使用経験により学習コストを低くできそうなPyQtを使うことにした。
Anacondaをインストールすると標準で含まれているようだ。
C++&Qt時代に慣れ親しんだでUIデザインツール「Designer」も使用できるようだ。UIデザインは別途行うとして、まずは最低限のウィンドウを表示させたい。
import sys import PyQt5.QtWidgets app = PyQt5.QtWidgets.QApplication([]) widget = PyQt5.QtWidgets.QWidget() widget.show() sys.exit(app.exec())結果
思ったよりはあっけなくウインドウ表示までできた。
ちゃんとデザインしたUIの使用や、UI部品と関数のconnectなど
Pythonでの実装イメージがわかないことだらけだが
おいおい学んでいく。
- 投稿日:2019-04-25T21:00:00+09:00
pythonとフェルマーの小定理で1行FizzBuzz
FizzBuzzでフェルマーの小定理が使えるらしい
フェルマーの小定理がFizzBuzzに使えると聞いて、調べてもわかりやすいコードと記事が見つけられなかったのでpythonで自分で作ってみました。以下のコードはできあがったものです。
for n in range(1,101):print("FizzBuzz"[n**2%3*4:12-n**2%3*4-n**4%5*8] or n)これを見ても普通はよくわからないと思うので作成時の思考過程をこの記事で書いていきます。
フェルマーの小定理
まずはフェルマーの小定理の主張を確認しましょう。
n^{p-1} ≡ 1 \quad (mod \hspace{5pt} p)ただしpとnは互いに素で、pは素数。
n**(p-1)をpで割った余りが1になるということです。FizzBuzzへの応用
nがp(3または5)の倍数でないとき、nとpは互いに素だから
n^{2} ≡ 1 \quad (mod \hspace{5pt} 3)\\ n^{4} ≡ 1 \quad (mod \hspace{5pt} 5)が成り立ちます。
nがp(3または5)の倍数のとき、余りはもちろん0です。つまり3(または5)の倍数でないかどうかを1と0で表せるわけです。実装
以下の式はnが3の倍数のとき0、そうでないとき1になります。
n**2%30と1を反転させたければ以下のようにします。
1-n**2%35も同様です。
n**4%5 1-n**4%5これを利用すると次のようなFizzBuzzコードが書けます。
for n in range(1,101):print((1-n**2%3)*"Fizz"+(1-n**4%5)*"Buzz" or n)文字列"FizzBuzz"からのスライス
上記のコードはn**2%3などが数字であることを活かしきれていません。これではつまらないので"FizzBuzz"という文字列から必要に応じて必要な部分だけをスライスするプログラムを実装してみます。
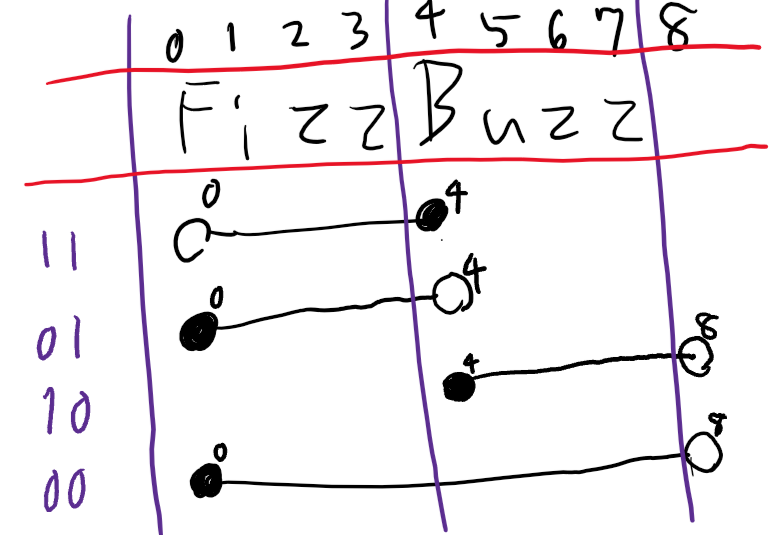
手書き失礼しました。
上の画像は"FizzBuzz"の各文字のインデックスとスライスの開始(黒丸)および終了(白丸)の対応で、上から順に数字、Fizz、Buzz、FizzBuzzの場合に相当します。紫の数字はn**2%3およびn**4%5を並べたものです。スライスに含まれるのはは開始点のインデックス以上かつ終了点のインデックス未満のインデックスを持つ要素です。また、終了点のインデックスが開始点のインデックス以下になると文字列を返しません。したがって例えば上の画像のような開始・終了の位置が考えられます。
n**2%3およびn**4%5の値をベクトル(x,y)で表し開始点と終了点を(X,Y)で表すと
X = ax + by + c\\ Y=dx+ey+fを満たすような6つのパラメータa,b,c,d,e,fを見つけます。上の図の通りだと拘束条件が8個で解は存在しない事になってしまいますが、(0,1)と(0,0)のときの開始点Xは4以下であればよく(1,0)と(0,0)のときの終了点Yは8以上であればよいので例えば(a,b,c,d,e,f)=(4,0,0,-4,-8,12)などを選びます。
X = 4x \\ Y=-4x-8y+12このX,Yで"FizzBuzz"[X:Y]のようにスライスします。これを実装したのが冒頭のコード(以下に再掲)です。
for n in range(1,101):print("FizzBuzz"[n**2%3*4:12-n**2%3*4-n**4%5*8] or n)
- 投稿日:2019-04-25T19:33:59+09:00
S3にアップロードされたJPEG画像をLambdaでWebPへ変換する
WebPとは
Googleが開発している画像フォーマットで、ウェッピーと読みます。
JPEGと比較してファイルサイズが25-34%小さくなり、採用することで表示の高速化が見込めます。
WebPに対応するプラットフォームは徐々に増加しています。参考リンク
WebサイトのWebP対応方法
まだWebPに対応できていないプラットフォームが存在するため、JPEG(またはPNG)とWebPと両フォーマットの画像を用意する必要があります。
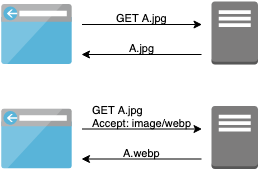
画像の使い分け方としては、HTMLタグで出し分ける方法と、HTTP RequestのAcceptヘッダの値に応じてサーバのレスポンスを変える方法があります。HTMLで出し分ける例
<picture> <source type="image/webp" src="A.webp"> <img src="A.jpg"> </picture>サーバで出し分ける例
[実践]WebP画像を用意する方法
今回WebPの対応をする画像は、Amazon S3で管理しております。
画像はブラウザからサーバサイドアプリ経由でS3にアップロードされる仕組みになっています。
既存の仕組みを変更せずWebP画像を用意したかったため、S3に画像がアップロードされるとAWS Lambdaで自動的に変換する仕組みを作ることにしました。
Lambda functionの実装
functionの作成
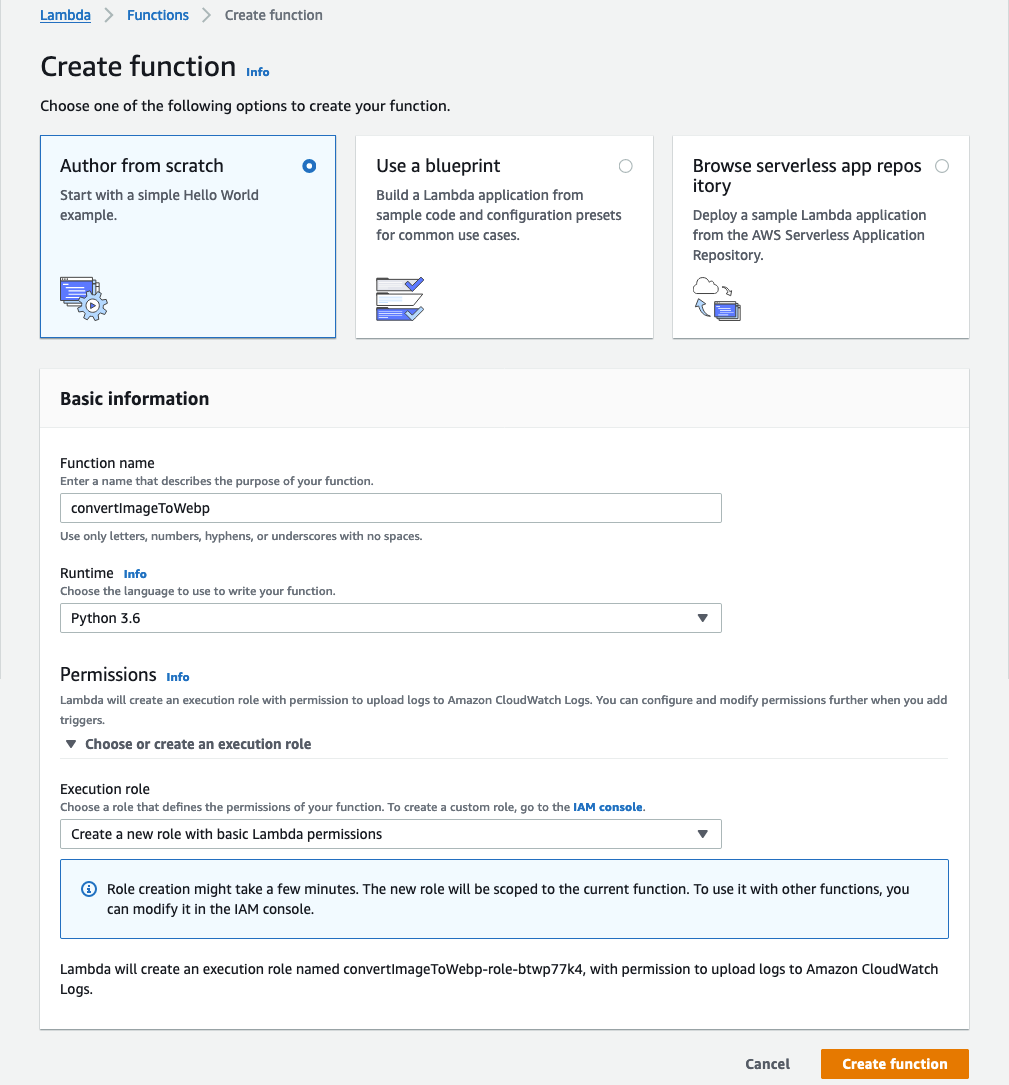
Management ConsoleでLambda functionを作成します。
Pythonで実装したかったので、RuntimeはPythonを選択しました。
IAM Roleの設定
JPEGの画像がアップロードされるバケットの読み込み、WebPの画像をアップロードするバケットへの書き込みとそのオブジェクトのパーミッション変更ができる権限を設定します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::bucketName/path-to-image/*" } ] }Codeの作成
S3のイベント情報から元画像をダウンロードし、変換したものをS3にアップロードする、という処理を記述します。
lambda_function.pyfrom PIL import Image import urllib.parse import boto3 import os s3 = boto3.client('s3') def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] source_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') destination_key = source_key + u'.webp' source_file = u'/tmp/' + os.path.basename(source_key) destination_file = source_file + u'.webp' try: s3.download_file(Bucket=bucket, Key=source_key, Filename=source_file) img = Image.open(source_file, 'r') img.save(destination_file, 'webp', quality = 80) s3.upload_file(Filename=destination_file, Bucket=bucket, Key=destination_key, ExtraArgs={"ACL":"public-read","ContentType":"image/webp"}) return source_key except Exception as e: print(e) raise eライブラリのインストールとZip化
必要なライブラリ(webp)をインストールするため、lambda_function.py を作成したディレクトリで下記のコマンドを実行します。
pip install webp -t ./ライブラリインストール後、作業中ディレクトリの内容は下記のようになります。
$ ls -1 PIL/ Pillow-6.0.0.dist-info/ _cffi_backend.cpython-36m-x86_64-linux-gnu.so* _webp.abi3.so* bin/ cffi/ cffi-1.12.3.dist-info/ lambda_function.py numpy/ numpy-1.16.3.dist-info/ pycparser/ pycparser-2.19.dist-info/ webp/ webp-0.1.0a13.dist-info/ webp_build/下記のコマンドを実行し、zipファイルを作成します。
zip -r convertJpegToWebp.zip ./*functionへの登録
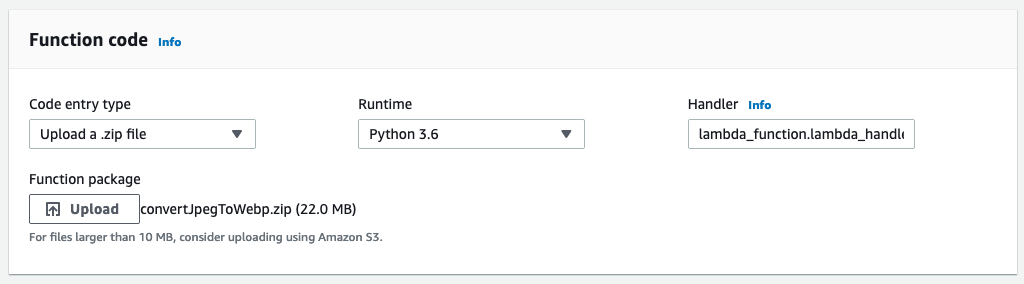
Function codeパネルにてCode entry typeを
Upload a .zip fileとし、Function packageのUploadボタンを押してzipファイルをアップロードします。
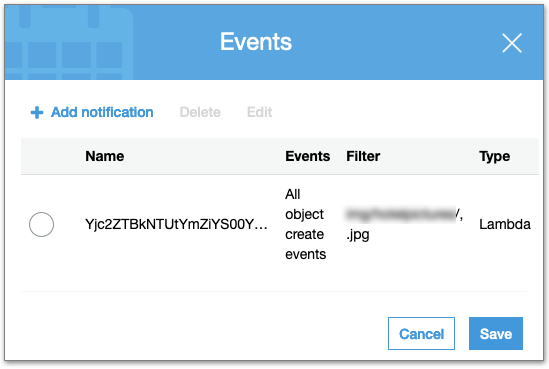
S3にEvent Notificationを登録
変換元となる画像がアップロードされるS3バケットに、Lambdaを起動するEvent Notificationを登録します。
画像の登録をトリガーとしたいため、EventsにはAll object create eventsを選択し、対象とする画像のPrefix, SuffixをFilterに設定、TypeはLambdaを選択して作成したLambda functionを設定します。
以上で実装完了です。
元画像をアップロードした数秒後に、WebPの画像が作成されていることが確認できます。
まとめ
WebP対応するにあたり、未対応環境も考慮すると、WebPとJPEG/PNGの両方を用意しておくことは必須です。手作業で画像を用意しようとしたら大変ですが、自動化する仕組みを作ってしまえば手間無く用意できます。
ファイルサイズが2〜3割程度小さくなるので、画像の多いWebサイトであれば導入のメリットは大きいと思います。



- 投稿日:2019-04-25T19:32:28+09:00
子ディレクトリにある実行ファイルから、親ディレクトリのライブラリを参照するためにsys.path.appendするコードは、pyhton-fireで解決できる
親ディレクトリにあるライブラリを使うために、実行ファイルからの相対パスを使ってimportするコードをたまに見かける。
bin/hoge.pyimport os import sys sys.path.append(os.path.join(os.path.dirname(__file__), '..')) import library def hoge(): library.echo('hoge') if __name__ == '__main__': hoge()$ python bin/hoge.py hogeこのコードは
import libraryの部分でWARNINGが出る。Python | PEP 8 coding style violation
これは、親ディレクトリに実行ファイルを作り、python-fire経由で子の関数を見るようにすると綺麗に解決できる。
run.pyimport fire import bin if __name__ == '__main__': fire.Fire(bin)bin/__init__.pyfrom .fuga import fuga from .hoge import hogebin/fuga.pyimport library def fuga(): library.echo('fuga')$ python run.py fuga fugapython-fireは、いいぞ。
- 投稿日:2019-04-25T18:57:03+09:00
ドローン操作システムを作ろう(目次)
はじめに
このページは,
Ardupilot系ドローンを,インターネット越しに遠隔操縦するシステムを作ろう!
という企画です.概要
「ドローンてのは空飛ぶ自律移動ロボットだ!」
「目視内なんてただのラジコンで十分だ!目視外飛行こそロボットの活躍の場だ!」
「ラジコンなんかDJIに任せるわ!Ardupilotはロボットのためにあるんや!」
「(DJIの)Manualを飛ばせない? へっ,それじゃ(Ardupilotの)Stabilizeは到底無理だな!!」というArdupilot愛の溢れる方向けの企画です(違
当面は「ドローン操作システムを作ろう」というタイトルですが,
ゆくゆくは操作システムじゃなくて管制システムに,変わると良いな(希望的観測段階的にページを作っていきますので,ゆっくりお待ち下さい.
準備するもの
各章によって必要な機材は異なりますが.
全体として以下が必要です.・コンパニオンPCを搭載したArdupilot系ドローン(コンパニオンはラズパイを推奨)
・プログラム練習用のUbuntu Linuxの入ったPC(Intel系)
・無線LAN,RoLa,LTEなどの無線通信装置と,インターネット接続手段
・インターネットに直結されたLinuxサーバ(できればVPS.クラウドや自宅サーバでも可能)
・Webブラウザ(PC,スマホ,タブレット)目次
現時点での目次です.たぶんコロコロ変わります...
- dronekit-python を使ってみる SITL編
- dronekit-python を使ってみる 実機編
- ドローンを動かす SITL編
- Raspberry Piでドローンを動かす 実機編
- MQTTブローカーのセットアップ
- pythonでMQTT送受信
- dronekitの情報をMQTTで送信してみる
- MQTTをWebブラウザで受信してみる
- 地図上にドローンの位置を表示してみる
- マーカーを改善する
- pythonでドローンにコマンドを送る
- MQTTでドローンにコマンドを送る
- Webブラウザからドローンにコマンドを送る
- 地図上のクリックした場所を目標地点にする
- 投稿日:2019-04-25T18:15:51+09:00
dronekit-python を使ってみる(実機編)
はじめに
このページは,
の1ページです.
全体を見たい場合は上記ページへお戻りください.概要
前回の記事で,Dronekit-Pythonを使い,
シミュレーション上のドローンとの通信・接続はできました.次は,実際にフライトコントローラを接続し,試してみます.
最初はUSBで,次はテレメトリ接続で試します.準備するもの
前回使用したLinux PC
(dronekitをインストールしたRaspberry Piでも可能です)フライトコントローラ: Pixhawk系
GPSやパワーモジュールも付けてあると,より良い一応APM2.8でも試しました.
Pixhack12やPixhawk43は試していませんが,まず大丈夫だと思います.
Navio+やNavio24はUSB接続やシリアル接続ではないので,
connection_stringsが変わります.今はLychee5を超試してみたい〜!
ファームウェア: ArduPilot系
コプター(ArduCopter)でもローバー(ArduRover)でも,どれでも良いです.
PX4系でも大丈夫だと思いますが,まだ試していません.USBケーブル: マイクロUSBのケーブル
普段,Pixhawkの設定に使っている物でかまいません.テレメトリ装置: telem1や2に接続して使う物
普段使っているテレメトリ装置でかまいません.例:
・イームズ製: ワイヤレステレメトリーユニット 2.4GHz 送受信機セット
https://store.shopping.yahoo.co.jp/elab-store/ld013.html・DJI製: Datalink 900 PRO
https://www.dji.com/jp/datalink-pro/info
※ボーレートは115200bpsに変えてください.・DIY: XBee S2Cなどで自作する
例 XBee S2C (2台購入)
https://www.switch-science.com/catalog/list/786/パソコン側基板: XBee USB アダプター rev.2
https://www.switch-science.com/catalog/3495/
ドローン側基板: XBee 5Vインターフェースアダプタ
https://www.switch-science.com/catalog/1216/・違法:Amazon等で購入できる433MHzや915MHzのテレメトリ装置
https://www.amazon.co.jp/dp/B01A8E8XWO
※海外製のPixhawkを購入すると一緒に付いてくることがありますが,
当該周波数は日本国内では違法になりますので,使用してはいけません.
3DRが作ったオリジナルの3DR Radioはともかくとして,
コピー品は,繋がらない・通信がすぐ切れるなどトラブルが多いので,
怖くて使う気になりません.テレメトリ切れるとかもう...事前準備
USB接続やテレメトリ接続では,シリアルポートを使用します.
Linuxで具体的には「/dev/ttyなんちゃら」というヤツです.例:
・/dev/ttyACM0
APMやPixhawkをUSBで接続するとACMになる.Arduinoと同じ.
・/dev/ttyUSB0
FTDIやSiLabsのUSBシリアル変換ICだとUSBになる.テレメトリはこっち.シリアルポートは,昔はモデムの接続に使われていましたから,
アクセス権はdialoutグループが持っています.(ダイヤルするんですね)そこで,Ubuntu Linuxに今ログインしているユーザを
daialoutにも参加させましょう.-aで追加ですね.dialoutのアクセス権限を追加する$sudo usermod -a -G dialout ログインユーザ名
sudo chmod a+rw /dev/ttyなんちゃらと打って,
全員にRead/Write権限を付けても良いですが,
USBデバイスを抜いてしまうと元の状態に戻ります.
chmodは一時的な処置に過ぎません.
dialoutグループを追加するほうが楽です.この作業はLinuxでArduinoの開発するときと同じですね.
USB接続で試す
では,Mission PlannerやQGroundControlを使うときと同様に,
PCにUSB接続して試してみましょう.プログラム
dronekit-sitlで使ったhello_jp.pyを少し改変しただけのプログラムです.
connection_stringが "/dev/ttyACM0,115200" になっています.
USBのときは115200bpsの高速ですね.以下をコピーするか,
あるいは ここ を右クリックして[名前を付けて保存]してください.hello_usb.py#!usr/bin/env python # -*- coding: utf-8 -*- print( "dronekitスタート" ) # 開始メッセージ # 必要なライブラリをインポート from dronekit import connect # フライトコントローラやシミュレータへ接続するのがdronekit内にあるconnect import time # ウェイト関数time.sleepを使うために必要 # 接続文字列の作成 connection_string = "/dev/ttyACM0,115200" # USB接続だとttyACM、ボーレートは115.2k # フライトコントローラ(FC)へ接続 print( "FCへ接続: %s" % (connection_string) ) # 接続設定文字列を表示 vehicle = connect(connection_string, wait_ready=True) # 接続 #Ctrl+cが押されるまでループ try: while True: # vehicleオブジェクト内のステータスを表示 print("--------------------------" ) print(" GPS: %s" % vehicle.gps_0 ) # GPSがないとゼロのまま print(" Battery: %s" % vehicle.battery ) # パワーモジュールがないとゼロのまま print(" Last Heartbeat: %s" % vehicle.last_heartbeat ) print(" Is Armable?: %s" % vehicle.is_armable ) # ARM可能か? print(" System status: %s" % vehicle.system_status.state ) print(" Mode: %s" % vehicle.mode.name ) time.sleep(1) except( KeyboardInterrupt, SystemExit): # Ctrl+cが押されたら離脱 print( "SIGINTを検知" ) # フライトコントローラとの接続を閉じる vehicle.close() print("終了.") # 終了メッセージプログラムの実行
ファイルを実行します.
$python hello_usb.py実行結果
実行結果の例は以下の表示がCtrl+cを押すまで繰り返されます.
実行結果-------------------------- GPS: GPSInfo:fix=1,num_sat=0 Battery: Battery:voltage=0.0,current=None,level=None Last Heartbeat: 0.674198211 Is Armable?: False System status: STANDBY Mode: STABILIZEGPSやパワーモジュールが有効でないと,数値はゼロになります.
また,各種キャリブレーション(加速度やコンパス)が完了していないと,
Is Armable?:も Falseのままです.GPSを必要とするフライトモードではGPSのFixもArmableの要件です.
テレメトリ接続で試す
次はフライトコントローラからUSBケーブルを外し,
テレメトリ接続で試してみましょう.フライトコントローラの電源は,パワーモジュールから供給すると良いでしょう.
USBで5V供給したい場合は,携帯電話用のモバイルバッテリー等を使います.情報を表示する(ダウンリンク側)
先程のUSB接続とは,
connection_stringが "/dev/ttyACM0,57600" になっただけの違いです.ここ を右クリックして[名前を付けて保存]してください.
テレメトリ装置の性能に依存するので,通信速度は基本的には57600bpsです.
※DJI Datalink 900 Pro を使うときは115200bpsにしてください.hello_telem.py省略 # 接続文字列の作成 connection_string = "/dev/ttyUSB0,57600" # テレメトリ接続だとttyUSB、ボーレートは57.6k 省略実行します.
$python hello_telem.pyテレメトリでdronekit接続ができました.
フライトモードの変更(アップリンク側)
データの取得だけでは面白くないので,新しいことをしてみましょう.
キーボード入力でフライトモードの変更をやってみます.キーボード入力を取る方法
まず,Pythonでキーボード入力を取る方法ですが,
通常のinput関数を使ってしまうと,プログラムが入力待ちで止まってしまいます.
(ブロッキング関数)C言語で言うところの
kbhit関数,
Arduinoで言うところのSerial.available関数
で監視する関数が欲しいですね.それができるライブラリが以下のリンク先にあるので,
kbhit.pyとして保存しましょう.
http://code.activestate.com/recipes/572182-how-to-implement-kbhit-on-linux/この
kbhit.pyを,自分で書いたプログラム(.py)があるフォルダと同じところに置けば,
機能が利用可能になります.一応,動作確認をしておきましょう.
$python kbhit.py実行すると,画面上にひたすらピリオド.が表示されます.
何かのキー(CtrlやShiftなどの機能キーはダメ)を入力すると,プログラムが終了します.kbhit.pyの使い方は割愛して説明すると以下の3つを満たすように書くことです.
(1) kbhit.pyをインポートする
from kbhit import *(2) プログラムの冒頭(インポートの後)に,この2行を書く
atexit.register(set_normal_term) set_curses_term()(3) 永久ループ内でキー入力があるかどうかチェック(C言語と同じ書き方)
if kbhit(): # 何かキーが押されるのを待つ key = getch() # 1文字取得kbhit.pyを使いこなすと,dronekitに限らず,
pythonを使ったロボットプログラミングの開発効率がUPします.例えば,
・前進・後進・旋回などの移動コマンドに使う
・パラメータ変更などのチューニングに使う
・セーブ・ロードなどのデータ管理をするなどが考えられますね.
キー入力に応じてフライトモードを変更する
それではkbhit.pyを利用してdronekitと連携させてみましょう.
以下をコピーするか,
あるいは ここ を右クリックして[名前を付けて保存]してください.change_mode.py#!usr/bin/env python # -*- coding: utf-8 -*- print( "dronekitスタート" ) # 開始メッセージ # 必要なライブラリをインポート from kbhit import * # kbhitを使うために必要(同じフォルダにkbhit.pyを置くこと) from dronekit import connect # connectを使いたいのでインポート from dronekit import VehicleMode # VehicleModeも使いたいのでインポート import time # ウェイト関数time.sleepを使うために必要 # kbhit()を使うための「おまじない」を最初に2つ書く atexit.register(set_normal_term) set_curses_term() # 接続文字列の作成 connection_string = "/dev/ttyUSB0,57600" # テレメトリ接続だとttyUSB、ボーレートは57.6k # フライトコントローラ(FC)へ接続 print( "FCへ接続: %s" % (connection_string) ) # 接続設定文字列を表示 vehicle = connect(connection_string, wait_ready=True) # 接続 #Ctrl+cが押されるまでループ try: while True: if kbhit(): # 何かキーが押されるのを待つ key = getch() # 1文字取得 # keyの中身に応じて分岐 if key=='s': # stabilize mode = 'STABILIZE' elif key=='a': # Alt Hold mode = 'ALT_HOLD' elif key=='p': # PosHold mode = 'POSHOLD' elif key=='l': # loiter mode = 'LOITER' elif key=='g': # guided mode = 'GUIDED' elif key=='t': # auto mode = 'AUTO' elif key=='r': # RTL mode = 'RTL' elif key=='d': # land mode = 'LAND' vehicle.mode = VehicleMode( mode ) # フライトモードの変更を指示 # ここはif文と同じインデントなので,キーに関係なく1秒に1回実行される # 現在のフライトモードを表示 print("--------------------------" ) print(" Mode: %s" % vehicle.mode.name ) time.sleep(1) except( KeyboardInterrupt, SystemExit): # Ctrl+cが押されたら離脱 print( "SIGINTを検知" ) # フライトコントローラとの接続を閉じる vehicle.close() print("終了.") # 終了メッセージファイルを実行します.
$python change_mode.py実行結果
キーに該当するフライトモードに変更されていることがわかります.
-------------------------- Mode: STABILIZE -------------------------- Mode: STABILIZE -------------------------- Mode: STABILIZE -------------------------- Mode: ALT_HOLD -------------------------- Mode: ALT_HOLD -------------------------- Mode: ALT_HOLD -------------------------- Mode: LOITER -------------------------- Mode: LOITER -------------------------- Mode: POSHOLD -------------------------- Mode: POSHOLDプログラム解説
key = getch()で取ったキーコードに応じて,
フライトモードの文字列を渡しているだけです.切り替えるフライトモードの文字列はプログラム通りに書いてください.
特に間違えやすいのは'ALT_HOLD'です.
AltHoldとして認知されていますが,'_'アンダーバーが必ず必要です.
(PosHoldの方はいらないのに)おわりに
今回は,実際のフライトコントローラに対してdronekitで命令を送ってみました.
正直,これだけでは全然面白くないですね.
一番おもしろいのはやはり移動させることでしょう.次回はARM/DISARMや離着陸,ウェイポイント移動などの
実際のドローンの運用を解説しようと思います.実機を移動させるのは少々危険なので,またsitlに戻ります.
CUAVのページ https://store.cuav.net/index.php ↩
CUAVのページ https://cuav.taobao.com/ ↩
Holybroのページ https://shop.holybro.com/pixhawk-4_p1089.html ↩
Emlidのページ https://emlid.com/navio/ ↩
Droneeのページ https://dronee.aero/pages/lychee ↩

- 投稿日:2019-04-25T16:58:49+09:00
【AWS習作】面白サービスRekognitionとSlackを使って画像解析アプリを作る
Rekognitionとは
画像内に存在する物体や表情、文字等をAPIを介して解析するサービス。
そんなRekognitionにも無料枠が存在するらしいので、何とか使ってみたい。無料枠期間は1 か月あたり 5,000 枚の画像分析が可能との事。
多いんだか少ないんだか…
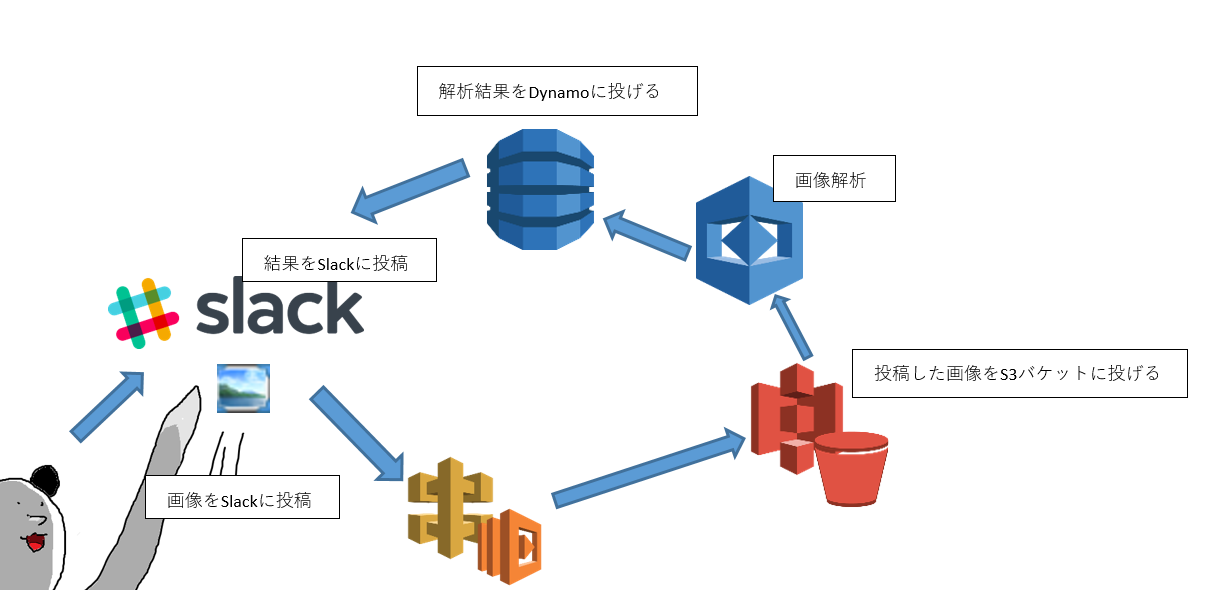
https://aws.amazon.com/jp/rekognition/pricing/雑な構成図
お仕事でこのような構成図を出したら即鉄拳が飛んできそう。
この構成図に沿ってServerlessApplicationModel、略してSAMの定義を書いていきます。
Lambdaの言語はPythonを使います。Slack側のイベントはfile sharedで発火させます。
Slackアプリのセットアップに関しては省略。SAM
template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: Slack is app Globals: Function: Runtime: python3.7 Timeout: 15 MemorySize: 256 Environment: Variables: Bucket_Name: <適切なS3バケットを指定してください> Dynamo_Table: !Ref SlackDynamo Oauth_Token: <Slack側の認証トークンを入れてください> Slack_Api_Url : https://slack.com/api/ Webhook_url : <Slack側のWebHookURLを入れてください> Resources: Slackbobobo: Type: AWS::Serverless::Function Properties: CodeUri: 'Slack_app/' Role: <"適切なIAMロールを入れてください"> Handler: slack_bobobo.lambda_handler Events: Api: Type: Api Properties: Path: /images Method: post SlackDynamo: Type: AWS::Serverless::SimpleTable Properties: PrimaryKey: Name: Imageid Type: String ProvisionedThroughput: ReadCapacityUnits: 5 WriteCapacityUnits: 5留意事項としては、まずIAMロールですがRekognition,S3,Lambda,DynamoDBに書き込んだり読み込んだりするポリシーをアタッチする必要があります。私はちまちまポリシー用のJSON作るのが面倒なので雑にFullAccess付けました。それと、Timeoutの値ですが、結構処理に時間掛かるのでデフォルトの3秒のままだと
こんなエラーが出ます。それと、今回LambdaのAPIの通信に外部ライブラリのrequestsを利用しますので、依存モジュール共々pyファイルの同階層に入れておきます。
そして、下記のコマンドでスタックをデプロイします。
deploy.bashaws cloudformation package \ --template-file template.yaml \ --s3-bucket <"パッケージ格納用S3バケット"> \ --output-template-file packaged-template.yaml aws cloudformation deploy \ --template-file packaged-template.yaml \ --stack-name <"適当なスタック名を入れてください"> \ --capabilities CAPABILITY_IAMLambda全ソース
slack_bobobo.py#coding:utf-8 import boto3 import json import os import logging import decimal import requests from botocore.exceptions import ClientError from boto3.dynamodb.conditions import Key from datetime import datetime, date, timedelta #ロギング logger = logging.getLogger() logger.setLevel(logging.INFO) dynamodb = boto3.resource('dynamodb',region_name = 'ap-northeast-1') trgt_table = dynamodb.Table(os.getenv('Dynamo_Table')) #SlackApiにイベントの種類に応じてGetを投げる def get_slack_api(base_url,token,file_id): headers = {'Authorization': 'Bearer {}'.format(token)} response = requests.get(base_url+'files.info'+'?file='+file_id,headers=headers) return json.loads(response.text) #画像ダウンロード def get_image(image_url,token): headers = {'Authorization': 'Bearer {}'.format(token)} image = requests.get(image_url,headers=headers) return image.content #S3にアップロード def image_put_s3(image,key,mimetype,bucket_name): s3 = boto3.resource('s3',region_name = 'ap-northeast-1').Bucket(bucket_name) s3_obj = s3.Object(key) s3_obj.put( Body=image, StorageClass='STANDARD', ContentType=mimetype ) return #Slackに投稿 def Slack_post(webhook_url,label,text,key): message ='S3に'+key+'をアップロードしました。\n' message +='解析結果\n' message +='\n物体検出\n' #物体検出 for lb_n in label: message +=lb_n['Name']+':'+str(round(float(lb_n['Confidence']),1))+'%\n' message +='\nテキスト検出\n' #テキスト検出 for tex_n in text: message +=tex_n['DetectedText']+':'+str(round(float(tex_n['Confidence']),1))+'%\n' item= { 'text': message } headers = {'Content-type': 'application/json'} try: requests.post(webhook_url,json=item,headers=headers) except Exception as e: logging.info("type:%s", type(e)) logging.error(e) return #rekogniton解析したやつをDynamoに投げる def rekogniton_image(bucket_name,key): rekogniton = boto3.client('rekognition',region_name ='ap-northeast-1') #boto3の公式リファレンス #https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/rekognition.html reko_label = rekogniton.detect_labels(Image={'S3Object':{'Bucket':bucket_name,'Name':key}},MinConfidence=75)['Labels'] reko_text = rekogniton.detect_text(Image={'S3Object':{'Bucket':bucket_name,'Name':key}})['TextDetections'] #DynamoDBはFloat型をサポートしていない為、Decimal型に変換する必要がある item={ 'Imageid':key, 'timestamp':int(datetime.utcnow().timestamp()), 'label':json.loads(json.dumps(reko_label),parse_float=decimal.Decimal), 'text':json.loads(json.dumps(reko_text),parse_float=decimal.Decimal) } res = trgt_table.put_item(Item=item) if(res): Slack_post(os.getenv('Webhook_url'),item['label'],item['text'],key) return def lambda_handler(event,context): #イベント設定用 body = json.loads(event['body']) if "challenge" in body: response = { 'statusCode':'200', 'body':body, 'headers':{'Content-Type':'application/json'} } return response else: try: #DynamoDB存在判定 res_get_item = trgt_table.get_item(Key={'Imageid':body['event']['file_id']}) if 'Item' not in res_get_item: file_res = get_slack_api(os.getenv('Slack_Api_Url'),os.getenv('Oauth_Token'),body['event']['file_id']) else: raise Exception("Already Exist Same Imageid!") except Exception as e: logging.info("type:%s", type(e)) logging.error(e) else: try: image = get_image(file_res['file']['url_private'],os.getenv('Oauth_Token')) except Exception as e: logging.info("type:%s", type(e)) logging.error(e) else: try: s3_key = file_res['file']['id'] + '.' + file_res['file']['mimetype'].split('/')[1] image_put_s3(image,s3_key,file_res['file']['mimetype'],os.getenv('Bucket_Name')) except ClientError as e: logging.info(e.response['Error']['Message']) logging.error(e) else: try: rekogniton_image(os.getenv('Bucket_Name'),s3_key) except ClientError as e: logging.info(e.response['Error']['Message']) logging.error(e) except Exception as e: logging.info("type:%s", type(e)) logging.error(e) else: response = { 'statusCode':'200', 'body':'OK', 'headers':{'Content-Type':'application/json'} } return responseご覧の通りS3のオブジェクトキーは、Slackにアップロードした際のfile_idをそのまま流用しています。
Botのメッセージもおかげで珍妙な感じに。実行
投稿します。
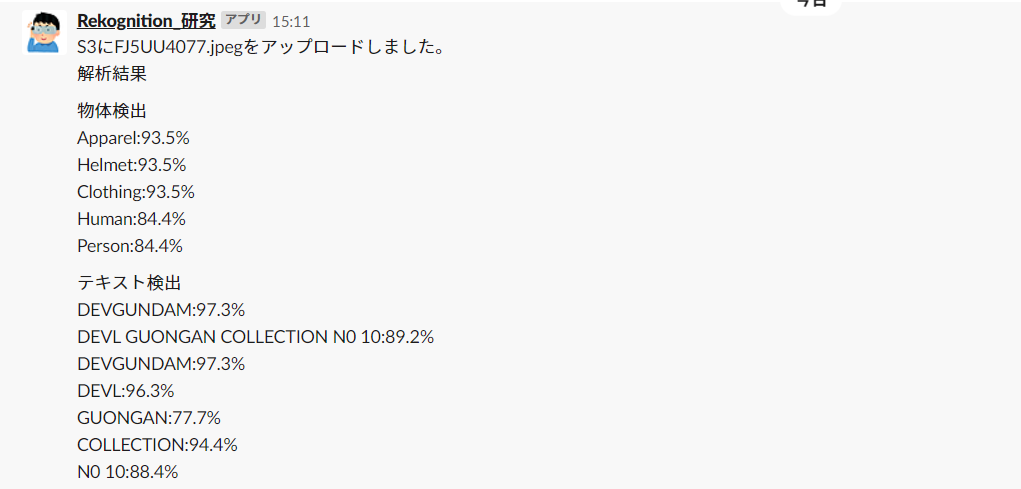
返ってきます。
単語の後ろにある謎の数字はConfidence値、つまり信頼度?です
しかし、HumanもPersonもどこにもいない筈なのに自信満々にこの結果をお出しされます。テキストの検出は及第点といったところでしょうか。DEVILのIは読み込めてませんが。
シグルイ第一巻を解析してもらいます。
紛れもなく人間が描かれているのですが、デビルガンダムより控えめな結果が返ってきました。テキストは…肝心の題名、作者名が解析されていません。日本語に対応していないという事なのでしょうか。
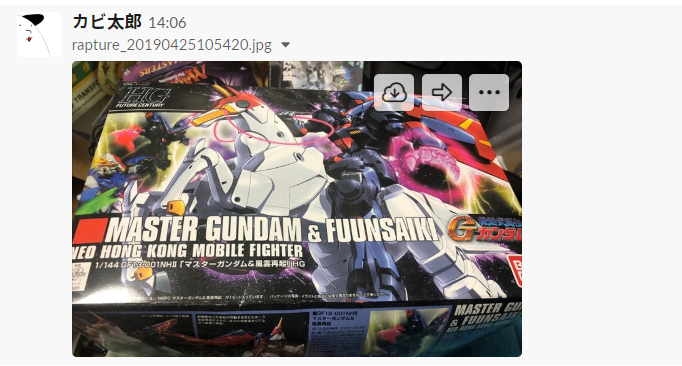
マスターガンダムを投稿します。
なんと、GundumではなくHaloが検出されます。総じてかなり微妙な感じになりました。
それと、CloudWatchのAPIログを見てみると、
画像を投稿したと同時に何故か複数のAPIが発射されている事が判明します。
つまり…
これはひどい…
S3のPutアクションの単価はかなり割高で、折角の無料枠もたちまち擦り潰されてしまいます。
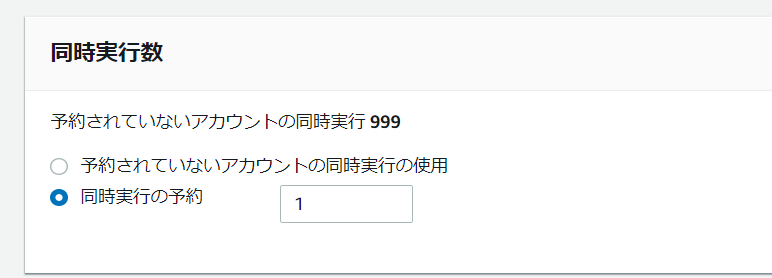
Dynamoの存在判定も同時にコンテナが起動している為、意味を成しません。そこで、
Lambdaの同時実行数を弄る事で、多少は多重解析が緩和されます。
しかし、あくまで多少であって完全に無くなる事はありませんでした。
SlackイベントApiの仕様とかなんでしょうか。総括
Rekognitionの力を引き出せませんでした。
ラズパイに音波センサーと監視カメラ取り付けて、閾値を超えたらS3に画像アップロードしてRekognitionで人間の存在判定する、みたいな使い方がいいのでしょうか。





- 投稿日:2019-04-25T16:45:19+09:00
Microsoft Graphを使ってアプリケーションからメールを送る その2
目的
前回の記事はこちら
タスクスケジューラで動かしているスクリプトの通知メールを個人Googleアカウントから会社公式メールアカウントに切り替えたい。
真の目的
Redmine用メールサーバを立てることは社内規定上禁止。
そのためチケット変更等をポーリングするスクリプトからメールを送信する。
前回上がった課題について対策が打てたのでその備忘録となります。
トークンの有効期限が1時間という問題があります。
今回手動でブラウザを使って認証コードをとってきましたが毎時間ブラウザ開くのも・・・・
スクレイピングかwebアプリを作るしかなさそうです。
何かいい方法があれば教えてください。使用する言語、技術
- Python3
- Selenium
- Selenium入門
- ブラウザの自動化テストなどに用いられるブラウザを操作するツールになります。
- BeautifulSoupではフォームへの入力やボタンクリックができないので採用しました。
- MicroSoft Edge
- トークンの取得に使用します。ブラウザであれば何でもよいと思います。
やったこと
- Seleniumの準備
- ログインページの調査
- コード実装
- トライ&エラー結果
- 対策
Seleniumの準備
SeleniumのPythonライブラリのインストール
pip install seleniumで入ります。
WebDriverのダウンロード
参考にしたのがこちらのページのため、PhantomJSを使用します。
動作環境がWin10のため、Windows用のexeをダウンロードしています。ログインページの調査
入力フォームのid確認
前回使用した認証コード取得URLにアクセスし、EdgeブラウザでF12を押してHTMLの要素を確認します。<input name="loginfmt" id="i0116" />このあたりが使えそうです。今回はidで処理を進めていきます。
「次へ」ボタンのid確認
<input class="btn btn-block btn-primary" id="idSIButton9" />ボタンはこのへんですかね、html,cssまったくわからないのですがclassは複数のオブジェクト(呼び方あってるのかな?)に設定できるはずなのでユニークなidのほうが良いと判断してid=idSIButton9で処理します。
コード実装
実際のコードは下記のとおりです。
URLへのアクセス、フォームへ入力、次へボタン押下、最後に404で表示される予定の遷移後のURLを取得しようとしています。get_authcode.py# -*- coding:utf-8 -*- from selenium import webdriver # PhantomJSのドライバーを得る browser = webdriver.PhantomJS( executable_path='C:\\path\\phantomjs.exe' ) # ドライバが読み込まれるまで待機,3秒でタイムアウトによる例外発生 browser.implicitly_wait(3) # 認証コード取得URLにアクセス url_login = "https://login.microsoftonline.com/common/oauth2/v2.0/authorize?XXXXXXXXXXXX" browser.get(url_login) print("ログインページにアクセスしました") browser.save_screenshot('./login.png') # 入力フォームのオブジェクト取得 e = browser.find_element_by_id("i0116") # ゴミが入っていた場合に備えてクリア e.clear() # フォームにアカウント名を入力 e.send_keys('xxxxxxxxxx@xxxxxxxx') browser.save_screenshot('./send_keys.png') # ボタンを押してフォームを送信 frm = browser.find_element_by_id("idSIButton9") frm.submit() print("情報を入力してログインボタンを押しました") browser.save_screenshot('./get_authcode.png') print('https://XXXXXX?XXXX=YYYY&xxxx=yyyy') print('が表示されるはず') print(browser.current_url)一回目結果
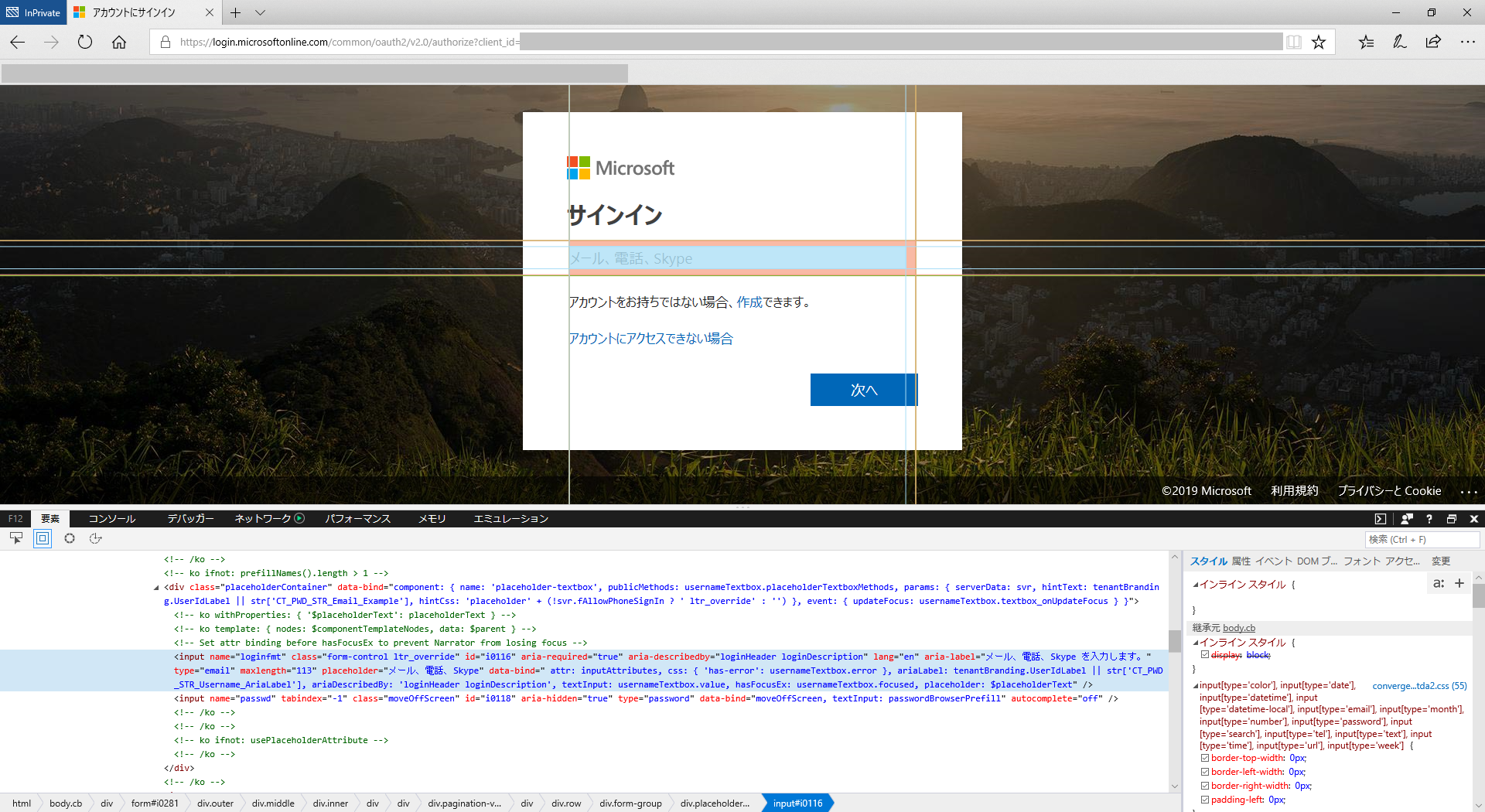
ログイン後うまくいっていないようです。
login.png
send_keys.png
get_authcode.png
InPrivateモードで手動ログインを試してみるとシステムレベル?でのダイアログが表示されました。
F12で開発者モードにもできないため、他の方法を検討します。
対策
かなり端折りますが、InPrivateモードではないEdgeならダイアログが表示されないことが分かりました。
キャッシュ、Cookieが原因だと思われますがそちらの知識にも疎いため今回はEdgeDriverとすでにEdgeに保存されているCookieを使用することで解決に至りました。↓の状態でSeleniumを実行します。
下記の課題もいつかは解決できればと思いますが今回は認証コードを取得することが目的のため、飛ばします。
* ダイアログへの入力
* OSレベル?ブラウザレベル?
* Cookieの操作など実装(修正後)
get_authcode2.py# -*- coding:utf-8 -*- import requests import time from bs4 import BeautifulSoup from selenium import webdriver # EdgeDriverはEdgeがすでに起動中の場合エラーになるので # 終了後必ずbqowser.quit()でEdgeを閉じる try: browser = webdriver.Edge( executable_path='C:\\path\\edgedriver.exe' ) browser.implicitly_wait(3) url_login = "https://login.microsoftonline.com/common/oauth2/v2.0/authorize?client_id=XXXX" browser.get(url_login) print("ログインページにアクセスしました") # 「Windowsに接続済み」のオブジェクトclass名は"table-row" frm = browser.find_element_by_class_name("table-row") frm.click() print("情報を入力してログインボタンを押しました") # コールバックの画面に切り替わるまでループ while 1: time.sleep(3) url = browser.current_url print('------------URLを確認する------------') print(url) # 前回コールバックURLをlocalhostにしたので判定条件を"http://localhost"に if 'http://localhost:10101' in url: break print('終了') except e: print('Error') browser.quit()二回目結果
実行後のログになります。
codeを取得することが出来ました!ログインページにアクセスしました 情報を入力してログインボタンを押しました ------------URLを確認する------------ https://login.microsoftonline.com/hogehoge/この時点ではまだ変わっていません ------------URLを確認する------------ ms-appx-web://microsoft.microsoftedge/assets/errorpages/dnserror.html?ErrorStatus=0x800C0005&DNSError=0#http://localhost:10101/authorized?code="とれました!!!"&state=1234&session_state="XXXXX" 終了さいごに
これで個人メールを使わない&メールサーバを立てずにRedmineのデータをフルオートでメール送信することが出来ます。
メールだけでなくOffice365の機能であればどれにでも有効だと思うので社内システムがOffice365でかゆいところに手が届かないって問題があれば今回の記事を参考にしていただければと思います。言い忘れてましたがRestAPIでメール送るだけならFlowでノンコーディングでできます。

- 投稿日:2019-04-25T16:27:14+09:00
Openstackで立てたVMのフレーバー情報を確認するコマンド
概要
払い出したVMのフレーバーを確認するために1つ1つのVMをGUIなどで確認するのは手間がかかるため、novaコマンドを利用してコマンド一発で全VMのフレーバーを確認するスクリプトを作成してみました。
使うこと
- python2
- VMの一覧を確認するために
nova list --fieldsを使います。このとき、VMのidは数字および小文字の羅列が8文字以上存在することを想定しています。- フレーバーの一覧を確認するために
nova flavor-listを使います。このとき、Is_Public列のTrueとFalseで必要な行を取得します。- テナントIDを引数として渡します。(テナントIDを調べるのもぶっちゃけ面倒なので、テナント名に命名規則があるなら、それを特定するようなコードを挟むと良いです。)
# -*- coding: utf-8 -*- import sys import commands # nova listの結果からVM名、flavorIDだけ取り出してリスト化します。 def flavorCount(tenant): dic = flavorDict() novaResult = commands.getoutput("export OS_TENANT_ID=" + tenant + " ; nova list --fields name,flavor | grep '[0-9a-z]\{8\}' | awk -F '|' '{print $3 $4}' | sed -e 's/[ ]^*//'") for column in novaResult.splitlines(): vm = column.split() if len(vm) == 2: vm[1] = dic[vm[1]] print(vm) # nova flavor-listの結果からflavorID, Nameを取り出して辞書化します。 def flavorDict(): fravorDictionary = {} flavorListResult = commands.getoutput("nova flavor-list | grep -e 'True' -e 'False' | awk -F '|' '{print $2 $3}' | sed -e 's/[ ]^*//'") for column in flavorListResult.splitlines(): vm = column.split() if len(vm) == 2: fravorDictionary[vm[0]] = vm[1] return fravorDictionary if __name__ == '__main__': args = sys.argv if len(args) < 2 or len(args) > 2: print('usage: thiscode.py tenant_id') sys.exit() tenant = args[1] flavorCount(tenant.decode()) print('Completed.')実行例
$ python thiscode.py 5wfd9ab3109aee53bbb8e91ad6a4523d ['vm1', 'm1-large'] ['vm2', 'm1-small'] ['vm3', 'm2-small'] ['vm4', 'm1-medium'] Completed.今後
VMごとの起動時間・課金情報とかと組み合わせると、VMのフレーバー別の使用状況も見れたりしてよさそうです。
- 投稿日:2019-04-25T15:17:41+09:00
Cognitive Service: Anomaly Detector APIを試す
はじめに
2019/04/18、Cognitive Servicesに新しくAnomaly Detector APIが追加されました。
Anomaly Detector APIは、読んで字のごとく「異常検知」に特化したAPIで、時系列数値データに含まれる異常な挙動の検出を簡単なREST APIで利用できるようです。
せっかくなので、適当なサンプルデータを使ってAnomaly Detector APIの異常検知を試してみます。Anomaly Detector APIの仕様等々
※以下、執筆時点(2019/04/25)での情報となります。
APIメソッド
Anomaly Detector APIでは
- Detect anomaly status of the latest point in time series.
- Find anomalies for the entire series in batch.
の2つのメソッドが使用できます。
これらの違いは、最終データポイントの判定結果を返すか、すべてのデータポイントの判定結果を返すか、というものでリクエスト形式はともに同じものとなっています。
実利用においては、「Find anomalies for the entire series in batch.」でパラメータ調整を行い、リアルタイムでの異常検知に「Detect anomaly status of the latest point in time series.」を使用するという形になると思われます。リクエスト形式
APIのリクエスト本文は、JSON形式でデータの粒度を示す「granularity」と時系列データ「series」が含まれる必要があります。
「granularity」は時系列の間隔を指定するパラメータで「daily」、「minutely」、「hourly」、「weekly」、「monthly」、「yearly」の6パターンが指定できます。
「series」は「timestamp」と「value」をペアにしたオブジェクトの配列を指定し、データ数は最小で12、最大で8640とし、時系列でソートされている必要があります。また、「timestamp」はISO 8601のUTCタイムスタンプ、「value」は数値型とし、1つでも型の異なる値が入るとリクエストエラーとなります。
そのほか、パラメータとして「sensitivity」、「period」、「maxAnomalyRatio」、「customInterval」が使用できるようです。
四半期ごとの時系列データを使用する場合は、以下のようなリクエスト本文とすればよさそうです。{ "series": [ { "timestamp": "1972-01-01T00:00:00Z", "value": 826 }, { "timestamp": "1972-04-01T00:00:00Z", "value": 902 }, ... ], "granularity": "monthly", "customInterval": 3, "maxAnomalyRatio": 0.25, "sensitivity": 95, "period": 4 }データ欠損
データ欠損は期間全体の10%まで許容されるようです。10%を超える欠損が含まれる場合はリクエストエラーが発生します。
レスポンス
Anomaly Detector APIの成功時のレスポンスは、以下のようなJSON形式となります。
「expectedValues」は学習モデルから得られる予測値で、異常判定のマージン「upperMargins」、「lowerMargins」と組み合わせて閾値を求めることができます。
「isAnomaly」、「isNegativeAnomaly」、「isPositiveAnomaly」はそれぞれ異常判定の真偽値で、異常判定閾値から外れた場合は「true」となりますが、「isNegativeAnomaly」は下限閾値、「isPositiveAnomaly」は上限閾値から外れた場合のみの判定となっています。
「period」はデータの周期性を示す値で、特定のパターンが何データポイントごとに現れるかの判定結果となります。リージョン
「西ヨーロッパ」、「米国西部2」の2リージョンで利用可能です
利用料金
利用料金は以下の通りです。パブリックプレビューのため、Standardは一般公開時の価格の50%となっています。
インスタンス 料金 (プレビュー) Free (F0) 20000 無料トランザクション/月 Standard (S0) ¥17.584 / 1,000トランザクション 検証データ
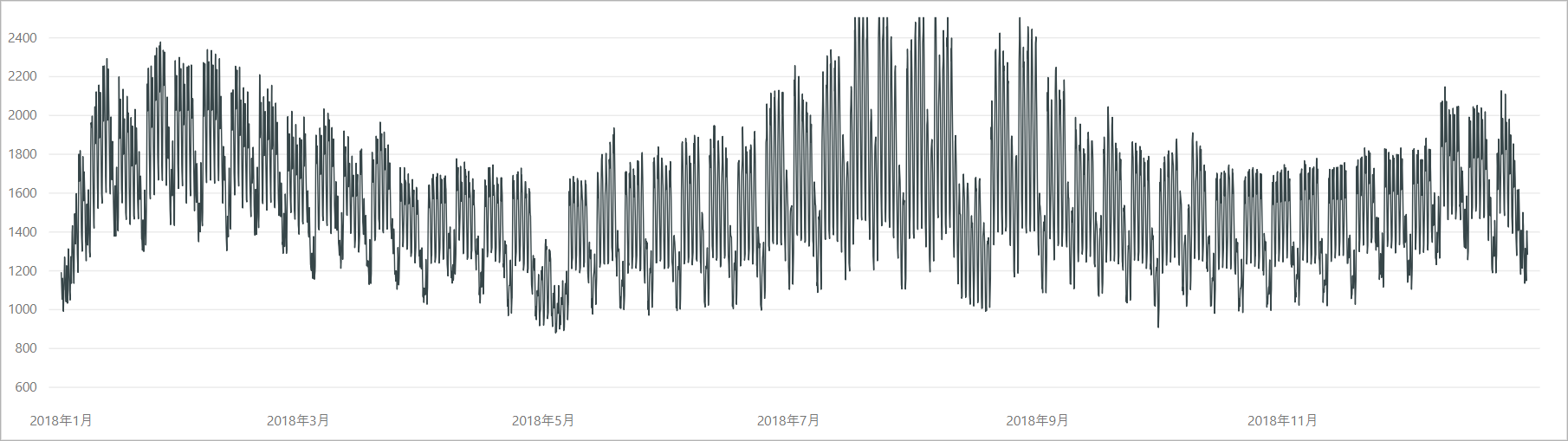
適当なサンプルデータといっても都合のいいセンサーデータを持っているわけではないので、検証データには、中部電力ホームページの「電力需給状況のお知らせ」にある「過去実績データ」を使ってみます。
試しに2018年データを可視化すると、電力データは気象条件に大きく影響を受け、夏季、冬季は特に冷暖房の使用等に伴って電力需要が増大することがわかります。
また、電力需要は1日、1週間単位で周期的なパターンを示すことがわかります。人や業務機器が稼働する平日日中帯は電力需要が大きく、土日等の休日は相対的に電力需要が小さくなります。
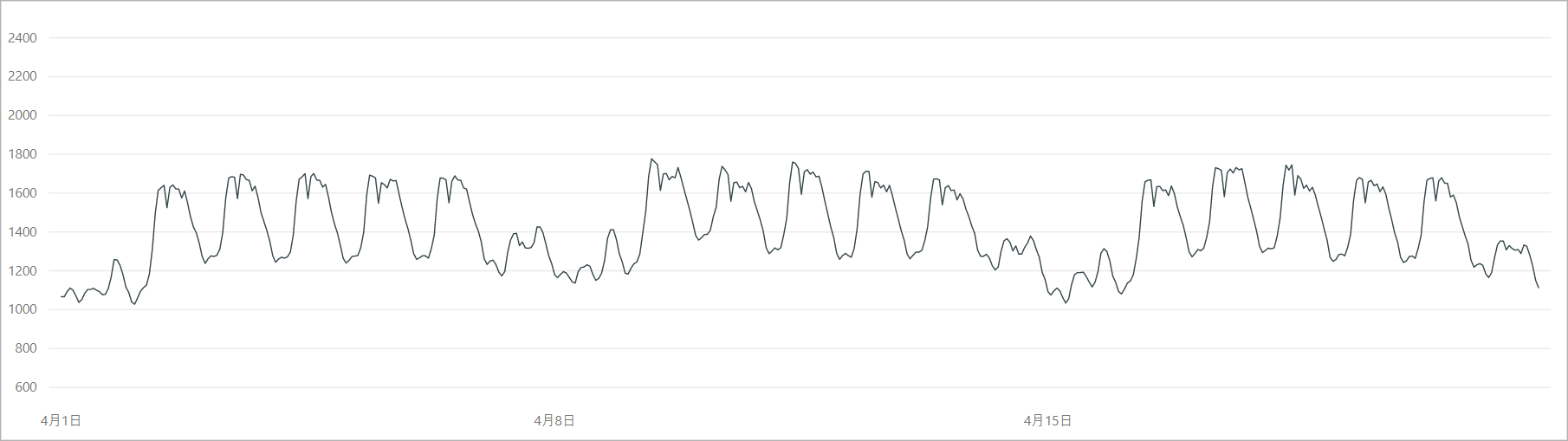
今回の検証には、電力需要データのうちの2018年4月~5月を使用します。
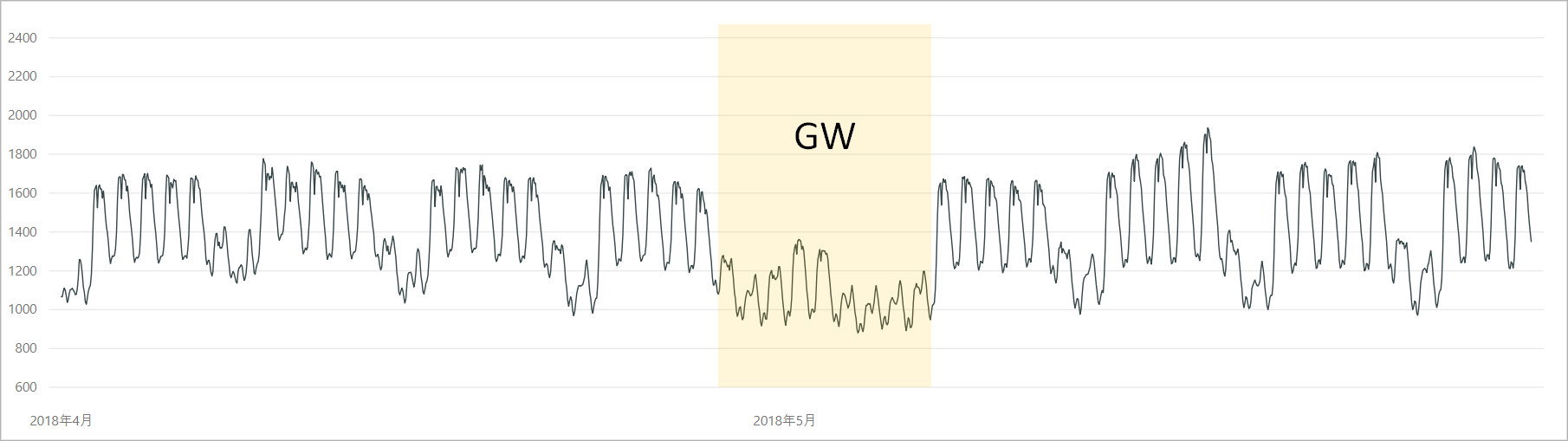
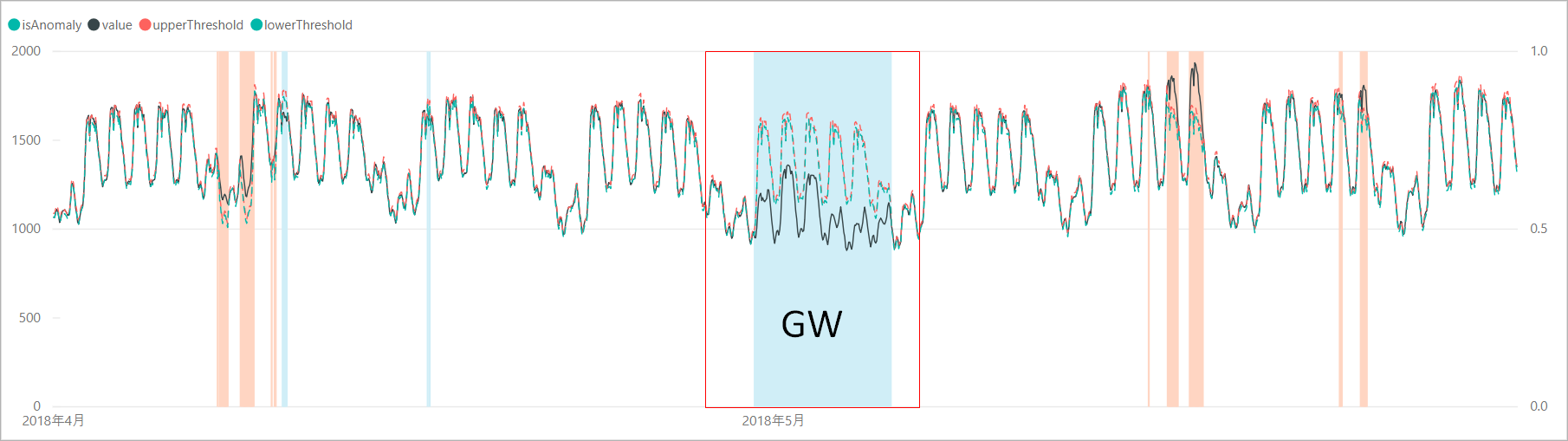
この時期は冷暖房の使用が少なく電力需要は比較的安定しますが、期間にゴールデンウィークがあり、前後の週と比較して電力需要の落ち込みが発生します。
もちろんこれを「異常」とは言えませんが、「通常とは異なる」という点から異常検知のサンプルとして使ってみます。
Anomaly Detectorの作成
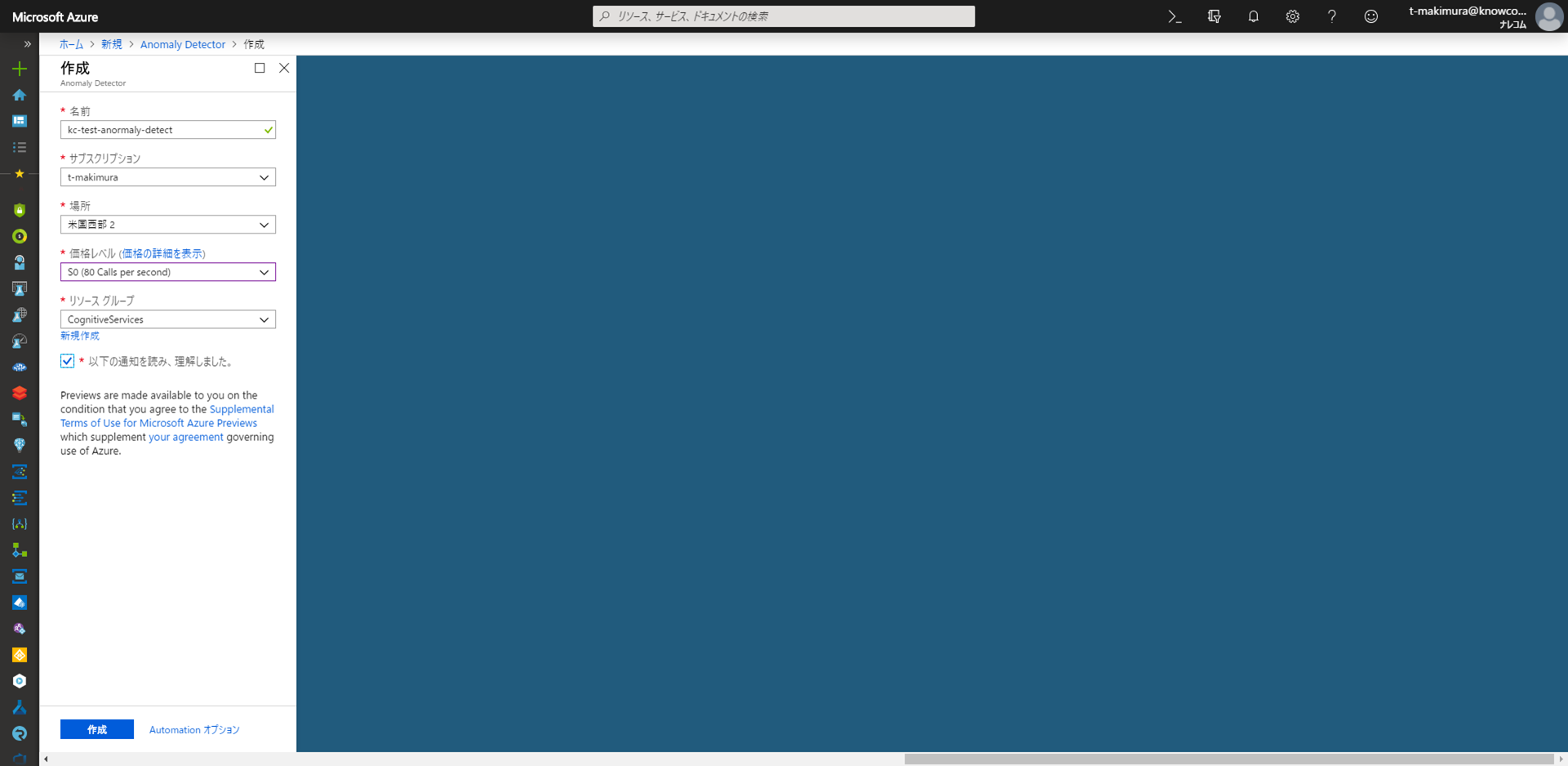
Azureポータルの「リソースの作成」から「Anomaly Detector」を選択して作成を開始します。
必要な内容を入力して、作成を行います。
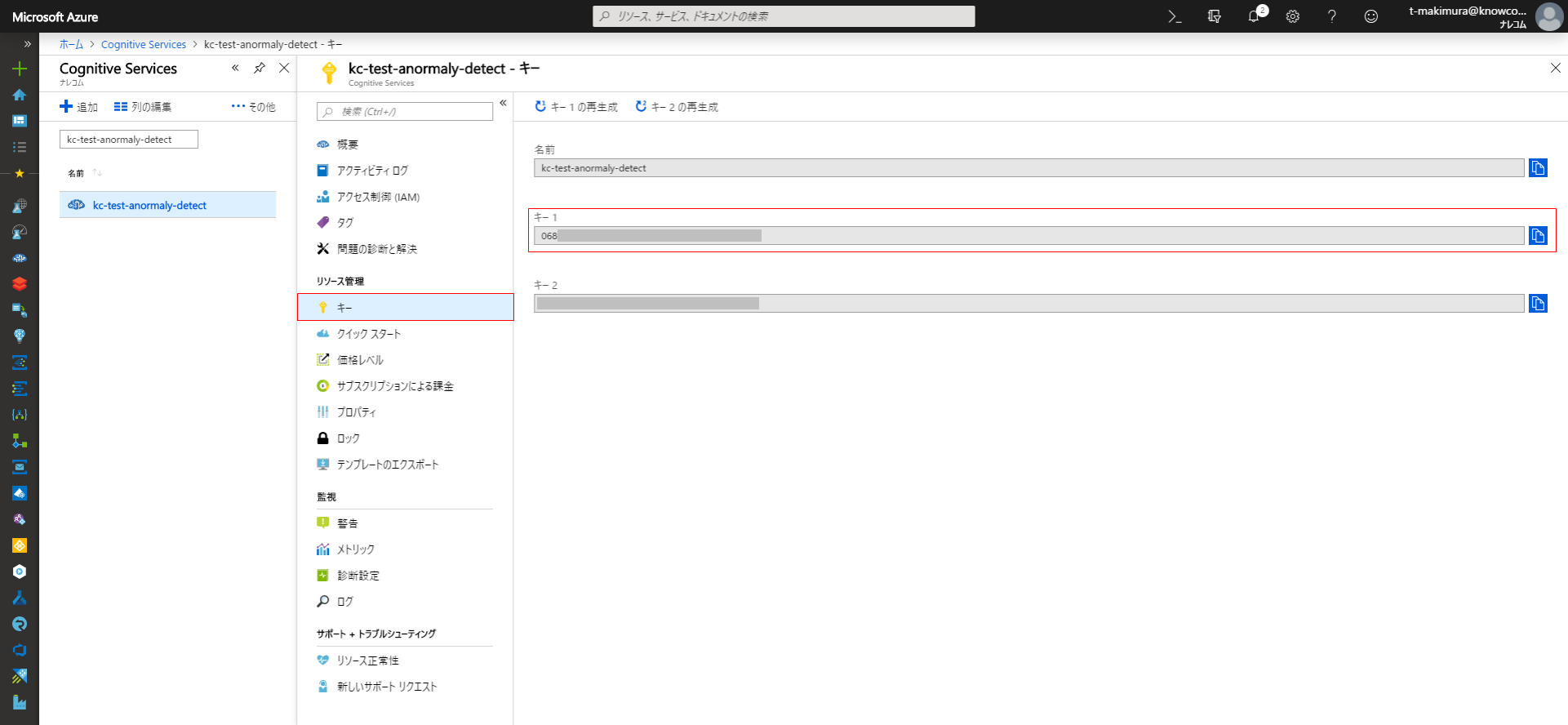
作成が完了したらAPIキーを取得します。リソースに移動し、メニューの「キー」からAPIキーをコピーして控えておきます。
スクリプト
今回は、PythonでAnomaly Detector APIにリクエストしています。
Anomaly Detector APIは、Face APIといったCognitive ServicesのAPIとリクエスト方法が変わらないため、簡単に利用できます。detect-anomaly.py# coding: utf-8 import pandas as pd import json import requests def main(): # 対象期間 begin = '2018-04-01 00:00:00' end = '2018-06-01 00:00:00' # 電力需要データの読み込み df = pd.read_csv("./areajuyo_current.csv", encoding="shift-jis") # データ加工 df["timestamp"] = df["DATE"] + " " + df["TIME"] df.loc[:, ["timestamp"]] = pd.to_datetime(df["timestamp"], format="%Y/%m/%d %H:%M") df = df[["timestamp", "実績(万kW)"]] df = df.rename(columns={"実績(万kW)": "value"}) # 検出対象データの抽出 df_req = df[(df.timestamp >= begin) & (df.timestamp < end)].reset_index() df_req # リクエスト用時系列データに変換 df_req.loc[:, ["timestamp"]] = df_req["timestamp"].dt.strftime("%Y-%m-%dT%H:%M:%SZ") series = json.loads(df_req.to_json(orient="records")) # リクエスト設定 api_key = "{APIキー}" # 取得したAPIキー endpoint = "https://westus2.api.cognitive.microsoft.com/anomalydetector/v1.0/timeseries/entire/detect" headers = { "Ocp-Apim-Subscription-Key": api_key, "Content-Type": "application/json" } body = { "series": series[:8640], "granularity": "hourly" } # Anomaly Detector APIにリクエスト res = requests.post(endpoint, headers=headers, json=body) results = res.json() # レスポンスの保存 json.dump(results, open("./response.json", "w"), indent=4) # 判定結果の統合、保存 del results["period"] df_res = pd.concat([df_req, pd.DataFrame(results)], axis=1) df_res.loc[:, ["timestamp"]] = pd.to_datetime(df_res["timestamp"], format="%Y-%m-%dT%H:%M:%SZ") df_res.to_csv("./detect_results.csv") if __name__ == "__main__": main()実行結果
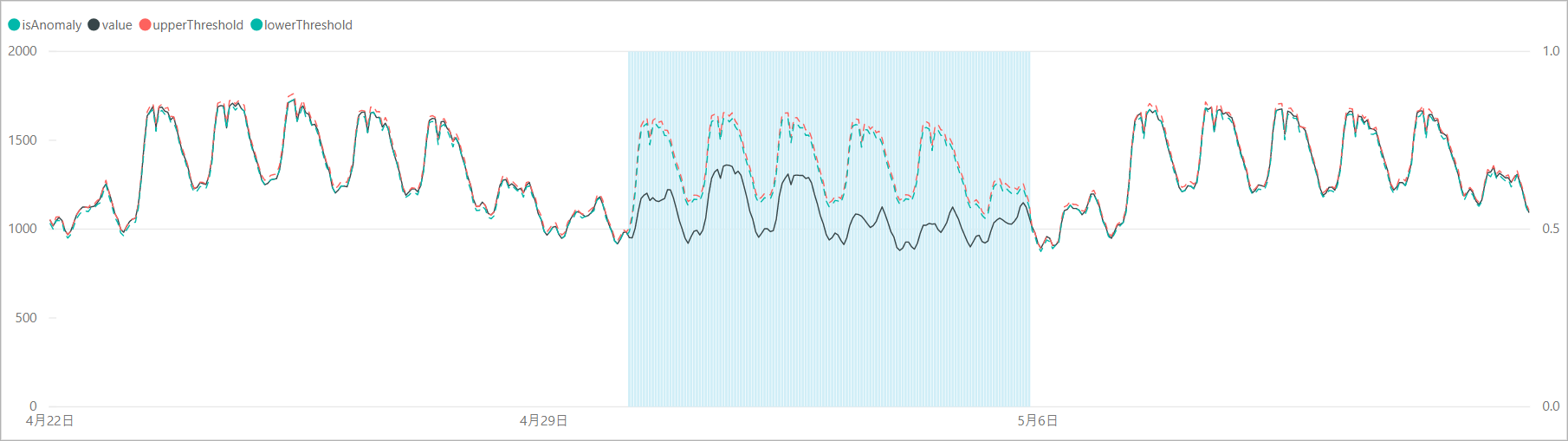
スクリプトを実行して得られた結果を可視化してみると、ゴールデンウィーク期間の平日の電力需要を「異常」として検知できていました。
ゴールデンウィーク期間の閾値のカーブを見ると、前後の週と似たような電力需要カーブを示しており、1週間のパターンに基づいて需要の予測をしていることがわかります。
レスポンスの「period」を見ると168 (= 7×24)となっており、電力需要のパターンが1週間単位で現れることを判定できていました。{ "expectedValues": [ 1077.67, ... ], "isAnomaly": [ false, ... ], "isNegativeAnomaly": [ false, ... ], "isPositiveAnomaly": [ false, ... ], "lowerMargins": [ 10.7767, ... ], "period": 168, "upperMargins": [ 10.7767, ... ] }異常判定の調整
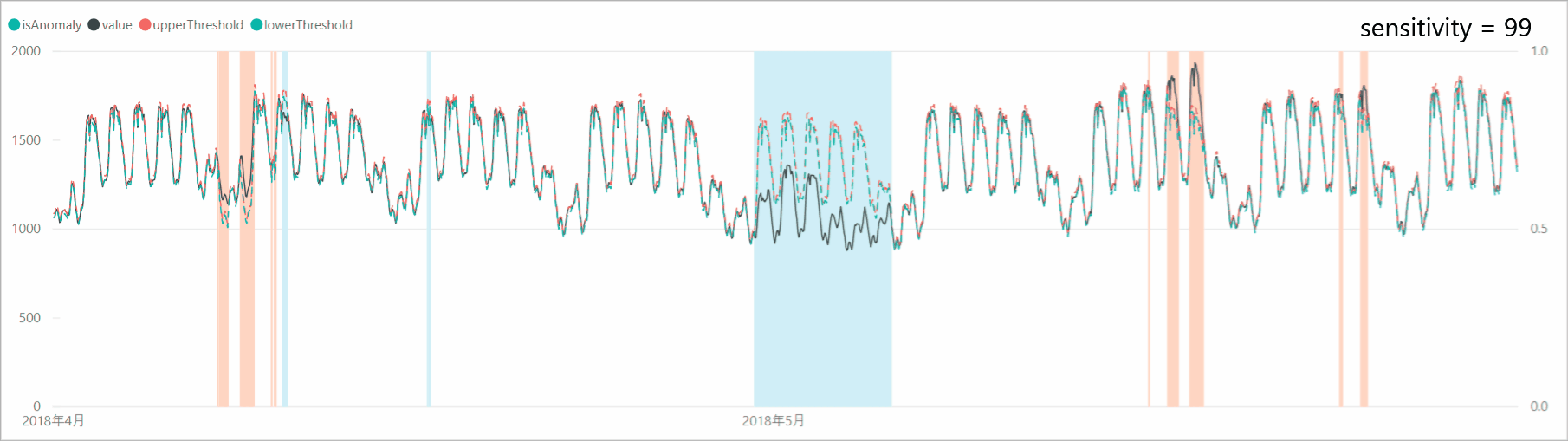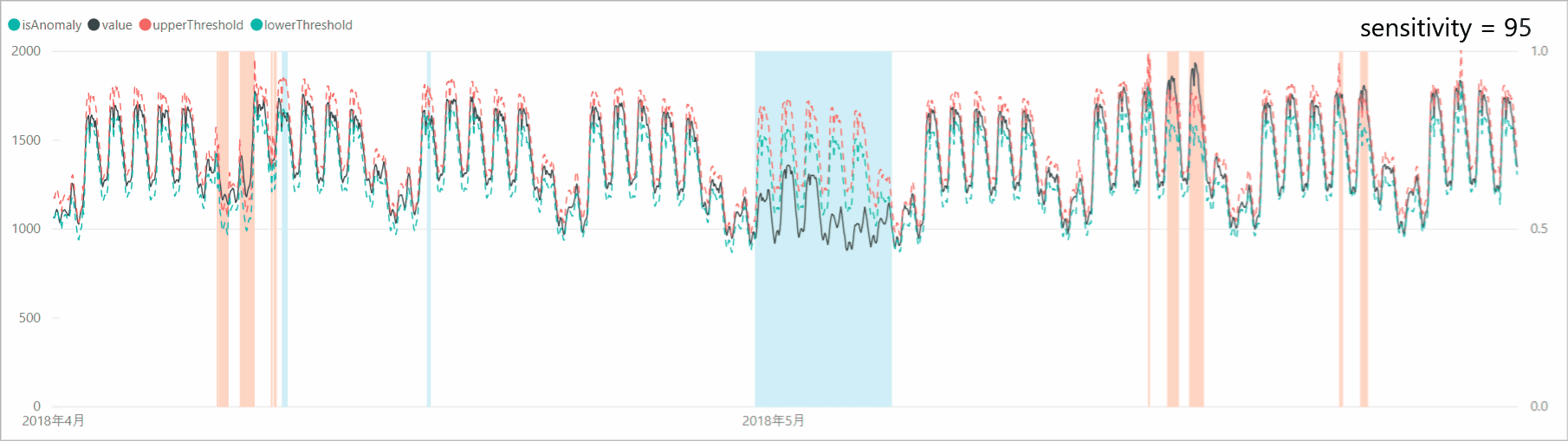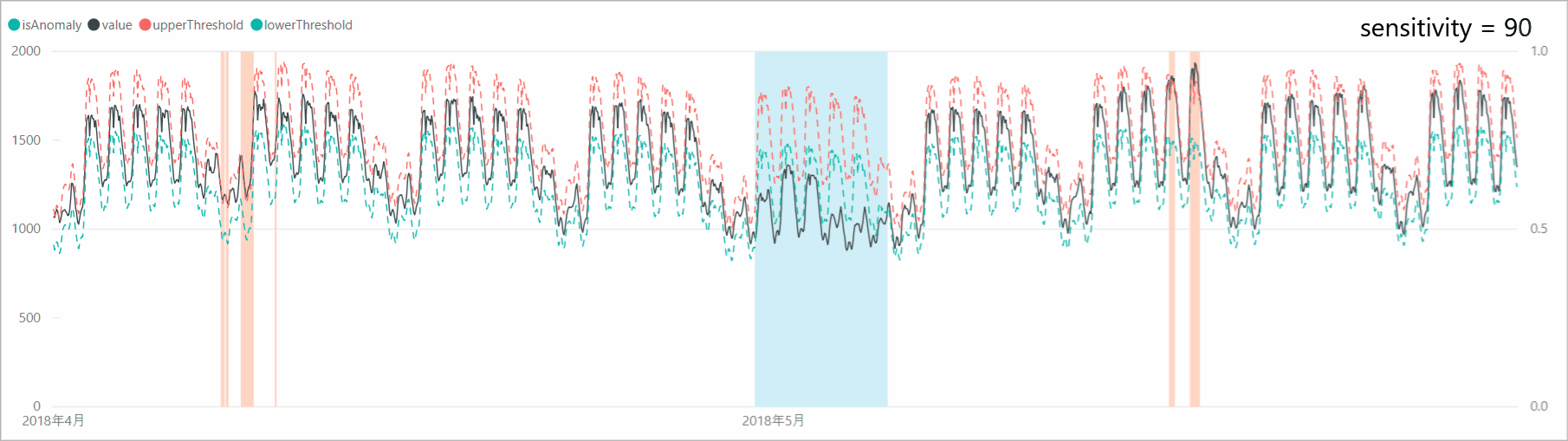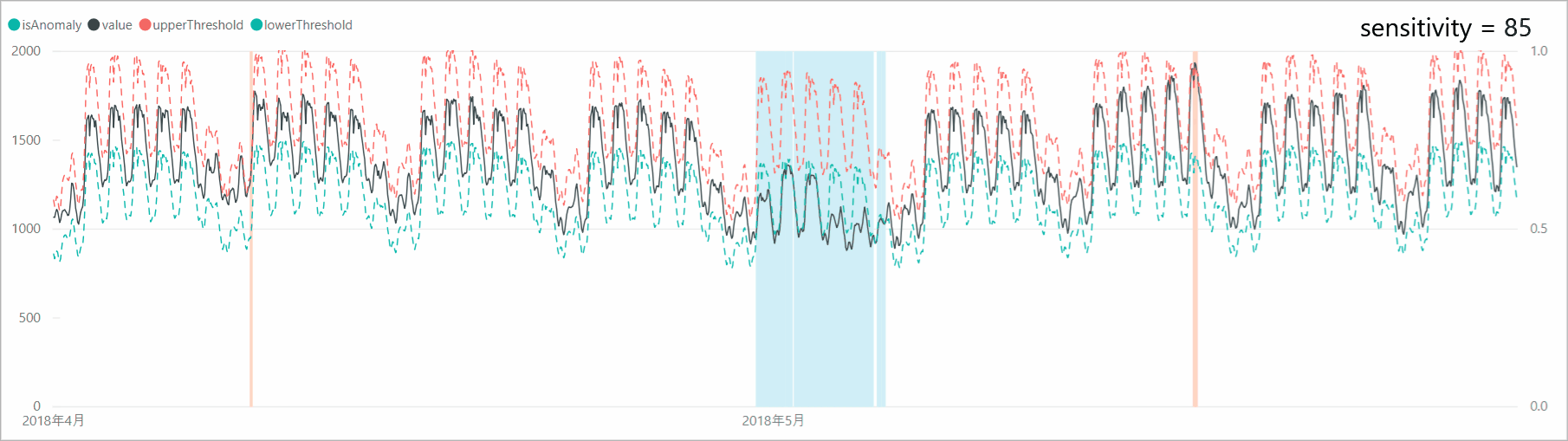
リクエスト本文に「sensitivity」オプションを付加すると、異常検知の感度調整をすることができます。感度が高すぎると判定マージンが狭くなり、誤検知も増えるため、「sensitivity」で本当の異常値のみを検知するよう調整します。
とはいえ、今回のデータは「異常」があるわけではないので「sensitivity」の調整による閾値、異常判定の変化を確認します。スクリプトでは、リクエスト本文の設定を以下のように変更します。body = { "series": series[:8640], "granularity": "hourly", "sensitivity": 99 # => 95, 90, 85 }「sensitivity」を99、95、90、85と下げていくと、判定マージンが広がり、異常と判定されるポイントが減少していくことがわかります。なお、「sensitivity」が99の場合は、設定しない場合と結果が同じであり、「sensitivity」のデフォルト値は99となっているようです。
まとめ
Anomaly Detector APIは、非常に簡単なリクエストでデータの時系列パターンを判定し、異常を検知できることがわかりました。今回は単純なパターンでの検証でしたが、決まったパターンを持つ時系列データに対しては、モデル作成といった面倒な作業無しに異常検知の仕組みを導入できそうです。
まだ公開されたばかりということもあって、使用できるメソッドは少なく、実行のたびに過去データを送信する必要があるなど、やや使い勝手の悪い面もありますが、Face APIのようにカスタマイズができるように変更が加えられ、より使いやすいAPIになっていくことに期待したいところです。
- 投稿日:2019-04-25T14:29:23+09:00
Python 重回帰分析(自作とscikit-learn)
はじめに
機械学習というのがはやっているようだが、私の仕事上では今のところ特に必要性はない。とは言いながら10連休中に何か新しいことをやってみようと思い、scikit-learnをいじってみようと思い立った。TensorFlowも触ってみたいのだが、いまだにPython3.7へのインストールはうまくいかないようなので、Python3.7に問題なくインストールできるscikit-learnにしたわけである。
手始めに行ってみたのが、重回帰分析。まずはnumpyを用いて自作し、同じ処理をscikit-learnで行ってみた。使用したサンプルデータは、scikit-learnに付属のボストン土地価格である。
参考にしたサイトは以下の通り。
scikit-learnのデータセット
Pairplot
https://note.nkmk.me/python-seaborn-pandas-pairplot/
相関係数のheatmap
https://note.nkmk.me/python-pandas-corr/
今回紹介する内容は以下の通り。
前処理
サンプルデータとしてscikit-learn付属のデータベースを利用するため、以下の前処理を実行。
- データセットの解説を表示し目的変数名を確認
- データセットの内容を、メインプログラムで読み込むため、一度csvファイルとして保存。
- seabor のPairplotと相関行列のHeatmapでデータの関連線をざっくりと把握。
重回帰分析
重回帰分析プログラム本体での処理内容は以下の通り。今回の紹介事例では、オリジナルデータのままの回帰と、オリジナルデータを標準化(平均値:0、標準偏差:1)したものの回帰を行っている。
- csvファイルよりデータ読み込み
- 正規方程式を作成し、
np.linalg.solveで解く- 目的変数と回帰推定値の重相関係数を算出
- 目的変数(観測値)と回帰推定値の関係をプロット
ここでは練習なので、説明変数の吟味・選択は行わず、全変数を使った計算をしている。
データセットの解説を見る
import pandas as pd from sklearn import datasets dataset = datasets.load_boston() print(dataset.DESCR)これにより、
MEDVという変数が目的変数(下記説明では target)であることがわかる。.. _boston_dataset: Boston house prices dataset --------------------------- **Data Set Characteristics:** :Number of Instances: 506 :Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target. :Attribute Information (in order): - CRIM per capita crime rate by town - ZN proportion of residential land zoned for lots over 25,000 sq.ft. - INDUS proportion of non-retail business acres per town - CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise) - NOX nitric oxides concentration (parts per 10 million) - RM average number of rooms per dwelling - AGE proportion of owner-occupied units built prior to 1940 - DIS weighted distances to five Boston employment centres - RAD index of accessibility to radial highways - TAX full-value property-tax rate per $10,000 - PTRATIO pupil-teacher ratio by town - B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town - LSTAT % lower status of the population - MEDV Median value of owner-occupied homes in $1000's :Missing Attribute Values: None :Creator: Harrison, D. and Rubinfeld, D.L. This is a copy of UCI ML housing dataset. https://archive.ics.uci.edu/ml/machine-learning-databases/housing/ This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University. The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic prices and the demand for clean air', J. Environ. Economics & Management, vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics ...', Wiley, 1980. N.B. Various transformations are used in the table on pages 244-261 of the latter. The Boston house-price data has been used in many machine learning papers that address regression problems. .. topic:: References - Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261. - Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.データのファイル化
一般的なデータ処理を考え、scikit-learn付属のデータセットをcsvファイルに書き込み保存する。
import pandas as pd from sklearn import datasets dataset = datasets.load_boston() df = pd.DataFrame(dataset.data,columns=dataset.feature_names) df['MEDV'] = dataset.target pd.options.display.float_format = '{:10.4f}'.format print(df.head()) df.to_csv('boston.csv', index=False)作成したデータフレームの表示結果(先頭付近)は以下の通り。
CRIM ZN INDUS CHAS NOX RM \ 0 0.0063 18.0000 2.3100 0.0000 0.5380 6.5750 1 0.0273 0.0000 7.0700 0.0000 0.4690 6.4210 2 0.0273 0.0000 7.0700 0.0000 0.4690 7.1850 3 0.0324 0.0000 2.1800 0.0000 0.4580 6.9980 4 0.0691 0.0000 2.1800 0.0000 0.4580 7.1470 AGE DIS RAD TAX PTRATIO B \ 0 65.2000 4.0900 1.0000 296.0000 15.3000 396.9000 1 78.9000 4.9671 2.0000 242.0000 17.8000 396.9000 2 61.1000 4.9671 2.0000 242.0000 17.8000 392.8300 3 45.8000 6.0622 3.0000 222.0000 18.7000 394.6300 4 54.2000 6.0622 3.0000 222.0000 18.7000 396.9000 LSTAT MEDV 0 4.9800 24.0000 1 9.1400 21.6000 2 4.0300 34.7000 3 2.9400 33.4000 4 5.3300 36.2000ざっくりとデータを眺める
ざっくりとデータを眺めるため、seaborn の pairplot と、相関行列の heatmap を描いてみた。
これらにより、目的変数の説明に必要な変数が、直感的にわかる。
seaborn を使うのは初めてだが、簡単な操作で作図が実現でき、とても便利。
Heatmap の色は、相関係数の表示なので、最小0、最大1、中央0としているところがミソです。でもなんとなくパッとしない感じなので、もっといい感じにしたい。import pandas as pd import matplotlib.pyplot as plt import seaborn as sns fnameR='boston.csv' # input file name df = pd.read_csv(fnameR, sep=',') # data input as a DataFrame sns.pairplot(df) fnameF='fig_mra1.jpg' plt.savefig(fnameF, dpi=200, bbox_inches="tight", pad_inches=0.1) plt.show() cm=np.corrcoef(df.transpose()) plt.figure(figsize=(12, 10)) cmap = sns.color_palette("RdBu_r", 100) sns.heatmap(cm, annot=True,vmax=1,vmin=-1,center=0,cmap=cmap,xticklabels=df.columns,yticklabels=df.columns) fnameF='fig_mra2.jpg' plt.savefig(fnameF, dpi=200, bbox_inches="tight", pad_inches=0.1) plt.show()Pairplot
相関行列のHeatmap
numpyを用いた自作
import numpy as np import pandas as pd import matplotlib.pyplot as plt def drawfig(yd,ye,ystr): fsz=12 xmin=0;xmax=60 ymin=0;ymax=60 plt.figure(figsize=(6,6),facecolor='w') plt.rcParams['font.size']=fsz plt.rcParams['font.family']='sans-serif' plt.xlim([xmin,xmax]) plt.ylim([ymin,ymax]) plt.xlabel(ystr+' (Observed)') plt.ylabel(ystr+' (Predicted)') plt.grid(color='#999999',linestyle='dashed') plt.gca().set_aspect('equal',adjustable='box') plt.scatter(yd,ye) plt.plot([xmin,xmax],[ymin,ymax],'-') fnameF='fig_mra.jpg' plt.savefig(fnameF, dpi=200, bbox_inches="tight", pad_inches=0.1) plt.show() def calc(df,ystr): x1=df.drop(ystr, axis=1).values # create numpy array of data without objective variable x2=np.ones((len(df),1),dtype=np.float64) # create column vector with values of one xd=np.hstack([x1,x2]) # create data matrix with conjunction of numpy arrays yd=df[ystr].values # create column vector of objective variable aa=np.dot(xd.T,xd) # normal equation (1) bb=np.dot(yd,xd) # normal equation (2) cc=np.linalg.solve(aa,bb) # splve normal equation ye=np.dot(xd,cc) # estimate predicted values rr=np.corrcoef(yd,ye)[0][1] # multiple correlation coefficient coef=np.append(cc,rr) # partial regression coefficients + r return yd,ye,coef def main(): fnameR='boston.csv' # input file name ystr='MEDV' # name of objective variable df = pd.read_csv(fnameR, sep=',') # data input as a DataFrame cname=[] cname.extend(df.columns.values) # add column names in the list cname.remove(ystr) # remove objective variable name from list cname.extend(['constant','r']) # add names of 'constant' and 'r' in the list yd1,ye1,coef1=calc(df,ystr) # calculation for multiple regression analysis drawfig(yd1,ye1,ystr) # draw a relationship between observed data and predicted data y_mean=np.mean(df,axis=0) # mean of each column y_std=np.std(df,axis=0,ddof=1) # standard deviation of each column by N-doff df=(df-y_mean)/y_std # standardization yd2,ye2,coef2=calc(df,ystr) # calculation for multiple regression analysis pd.options.display.float_format = '{:15.4f}'.format dfr=pd.DataFrame({'Name':cname,'Original':coef1,'STD':coef2}) print(dfr.to_string(index=False)) if __name__ == '__main__': main()scikit-learnを用いた実装
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import linear_model def drawfig(yd,ye,ystr): fsz=12 xmin=0;xmax=60 ymin=0;ymax=60 plt.figure(figsize=(6,6),facecolor='w') plt.rcParams['font.size']=fsz plt.rcParams['font.family']='sans-serif' plt.xlim([xmin,xmax]) plt.ylim([ymin,ymax]) plt.xlabel(ystr+' (Observed)') plt.ylabel(ystr+' (Predicted)') plt.grid(color='#999999',linestyle='dashed') plt.gca().set_aspect('equal',adjustable='box') plt.scatter(yd,ye) plt.plot([xmin,xmax],[ymin,ymax],'-') plt.show() def calc(df,ystr): clf = linear_model.LinearRegression() xd = df.drop(ystr, axis=1).values # create data matrix without objective variable yd = df[ystr].values # create column vector of objective variable clf.fit(xd,yd) ye = clf.predict(xd) # estimate predicted values const=clf.intercept_ # constant term rr=np.sqrt(clf.score(xd, yd)) # multiple correlation coefficient coef=np.append(clf.coef_,const) # conjunction of partial regression coefficients and constant term coef=np.append(coef,rr) # append correlation coefficient to regression coefficient vector return yd,ye,coef def main(): fnameR='boston.csv' # input file name ystr='MEDV' # name of objective variable df = pd.read_csv(fnameR, sep=',') # data unput cname=[] cname.extend(df.columns.values) # add column names in the list cname.remove(ystr) # remove objective variable name from list cname.extend(['constant','r']) # add names of 'constant' and 'r' in the list yd1,ye1,coef1=calc(df,ystr) # calculation for multiple regression analysis drawfig(yd1,ye1,ystr) # draw a relationship between observed data and predicted data y_mean=np.mean(df,axis=0) # mean of each column y_std=np.std(df,axis=0,ddof=1) # standard deviation of each column by N-doff df=(df-y_mean)/y_std # standardization yd2,ye2,coef2=calc(df,ystr) pd.options.display.float_format = '{:15.4f}'.format dfr=pd.DataFrame({'Name':cname,'Original':coef1,'STD':coef2}) print(dfr.to_string(index=False)) if __name__ == '__main__': main()出力事例
下記は画面出力事例。
Nameは変数名、Originalは生データのまま、STDは生データを標準化処理(平均値:0、標準偏差:1)したものの処理結果。Name Original STD CRIM -0.1080 -0.1010 ZN 0.0464 0.1177 INDUS 0.0206 0.0153 CHAS 2.6867 0.0742 NOX -17.7666 -0.2238 RM 3.8099 0.2911 AGE 0.0007 0.0021 DIS -1.4756 -0.3378 RAD 0.3060 0.2897 TAX -0.0123 -0.2260 PTRATIO -0.9527 -0.2243 B 0.0093 0.0924 LSTAT -0.5248 -0.4074 constant 36.4595 -0.0000 r 0.8606 0.8606感想
- データをざっくり見るため、seabornでPairplotと相関行列のHeatmapを作ってみたが、とても簡単にでき、便利である。
- 回帰分析だけのコーディング量は、自作でもscukit-learn利用でもそれほど変わらない。
- 画面出力、csv出力するなら、pandasのDetaFrameとして書き出すのが便利である。
- 最近の仕事で統計分析をすることはないのだが、勉強がてらいろいろやってみようと思う。
以 上
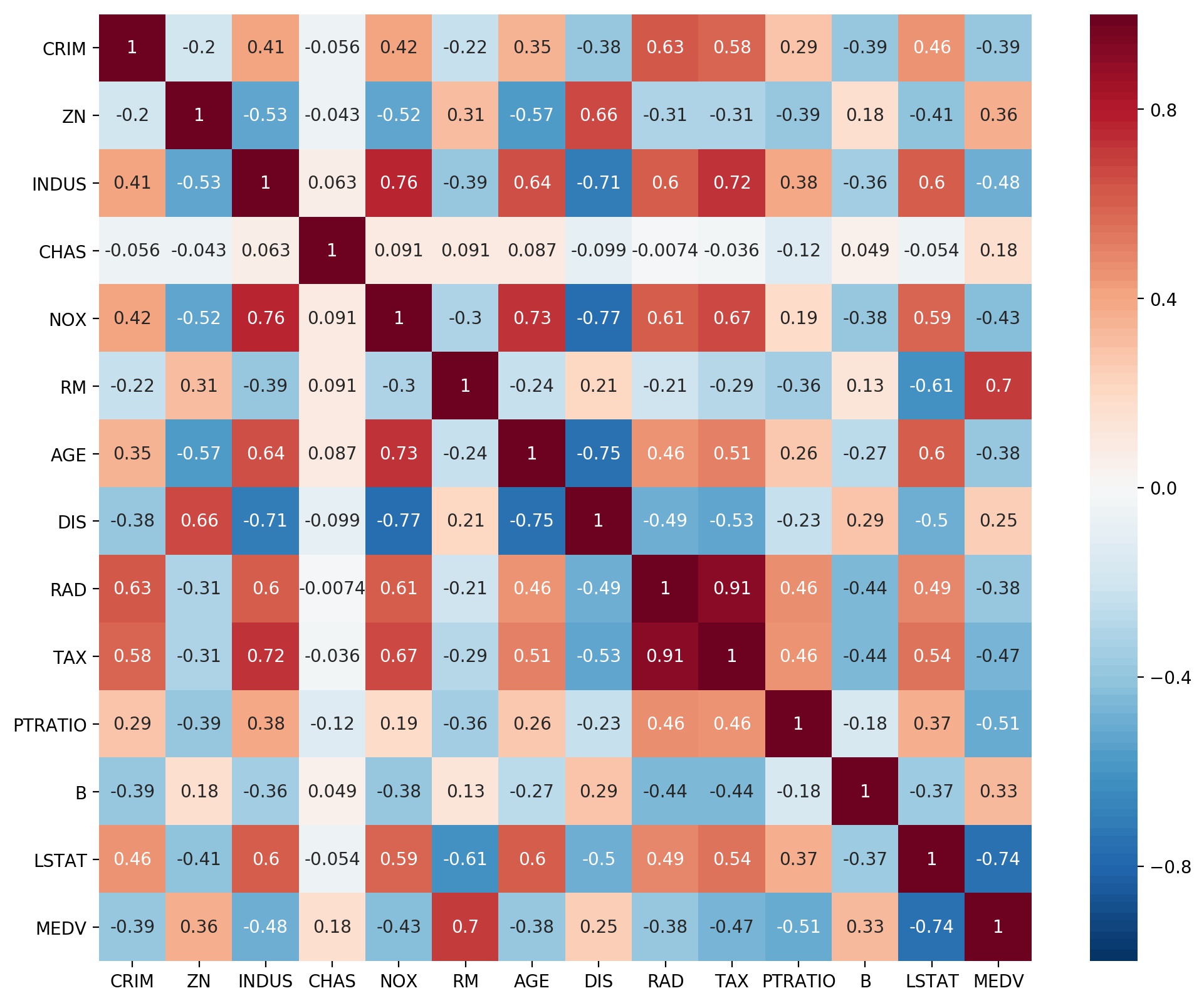

- 投稿日:2019-04-25T12:53:10+09:00
Djangoの開発サーバーをプロダクション環境で使わないように、という話
TL;DR
- Djangoの開発サーバーはあくまで開発用、プロダクション環境では使わないこと
- プロダクション環境では、GunicornやuWSGIなどのWSGIサーバーを使うこと
Djangoの開発サーバー
Djangoには、
runserverで起動できるWebサーバーが付属しています。この開発サーバーはPythonで書かれており、またアプリケーションを変更しても(ある程度)リロードしてくれる、開発中に便利なツールになっています。
開発サーバーをプロダクション環境では使わないこと
この開発サーバーをプロダクション環境で利用することは、推奨されていません。というか、禁止されています。絶対に使うな、という感じです。
ここでちょっと注意しておきましょう。このサーバは開発中の利用だけを考えて作られています。絶対に運用環境では 使わないでください (筆者たちの専門は Web フレームワークであって、Web サーバではありません)。
Now’s a good time to note: don’t use this server in anything resembling a production environment. It’s intended only for use while developing. (We’re in the business of making Web frameworks, not Web servers.)
なのですが、この開発サーバーをプロダクション環境で使ってはいけないの?他のサーバーとなにが違うんですか?という質問はややあるようです。
Why should I use nginx server or apache on production vps but not just manage.py runserver?
Is it OK to use "python manage.py runserver" in production?
別にミドルウェアなどを用意する手間が嫌だ、みたいな話なんでしょうかね。
でも、パフォーマンス出ませんよ、と。
WSGIサーバーを使おう
では、開発サーバーを使わない場合はどうするの?という話ですが、GunicornやuWSGIなどのWSGIサーバーを使い、こちらにアプリケーションをデプロイします。
さらに言うと、これらのWSGIサーバーの前段にリバースプロキシとしてnginxなどのWebサーバーを配置することが推奨されています。
自身で困ったこと
で、なんでこういう記事を書いたかというと、身の回りに割とCPUを使うアプリケーションがDjangoで書かれていて、複数リクエストを全然さばけない状態のものがあったのですが、これがこそっとDjangonの開発サーバーで動いていました。
CPUバウンドな処理なので複数CPUを使ってくれないと困るのですが、これをやるにはGunicornやuWSGIを使って複数プロセスでアプリケーションを動作させる必要があります。
※PythonはGILの制約があるので、ひとつのプロセス中で同時に動かせるスレッドはひとつだけですこれをなんとかするために、この環境ではuWSGIでアプリケーションを動かすことにしました。
もちろん、サーバーを変更して動作するかという確認は必要になるのですが…。
結果、無事に複数CPUを使ってある程度リクエストをさばけるようになりました、と。
開発中の構成と、プロダクション向けの構成は、ちゃんと考えましょうね、という話でした。
- 投稿日:2019-04-25T12:40:01+09:00
numpy.arraysの和集合・差集合まとめ
概要
numpyのarrayを使った和集合と差集合のまとめです。
nunique・appendなどのメソッドや、set型を組み合わせれば、工夫次第で実現できますが、用意された関数が既にあるようなので、それを使ってしまいましょう!準備
In [1]: import numpy as np In [2]: array_a = np.array([1, 2, 3, 4, 5]) In [3]: array_b = np.array([1, 3, 5, 7, 9])和集合(Union)
np.union1d(A, B)は、np.array型の新しい集合
A∪B = {x|x∈A 又は x∈B}を返します。In [4]: np.union1d(array_a, array_b) Out[4]: array([1, 2, 3, 4, 5, 7, 9])差集合(Difference set)
np.setdiff1d(A, B)は、np.array型の新しい集合
A\B = {x|x∈A かつ x∉B}を返します。In [5]: np.setdiff1d(array_a, array_b) Out[5]: array([2, 4])
- 投稿日:2019-04-25T12:13:22+09:00
pandasについて
pandas
pandasは、Pythonにおいて、データ解析を支援する機能を提供するライブラリである。
pandasのimport
pandasにpdという名前をつけてimportする
import pandas as pdcsvファイルの読み込み
URIAGE.csvという名前のcsvファイルを読み込む
df = pd.read_csv('./data/URIAGE.csv')データの確認
dfというデータの最初の10行を表示する
df.head(10)dfというデータの最後の10行を表示する
df.tail(10)任意の列だけ取り出す
TANKAという列とSURYOという列だけ取り出し、上から5行を表示
df[['TANKA', 'SURYO']].head()どんなデータが入っているか表示
unique()により重複しないようにデータを表示できる
HIN_NMという列のデータを表示(重複なし)df.HIN_NM.unique()
- 投稿日:2019-04-25T11:45:02+09:00
Pythonのopen関数はencoding引数を指定しよう
結論
WindowsでPythonのopen関数を使うなら、encoding引数を指定しよう(血涙
何があったのさ
WindowsにてPythonを用いて、テキストファイルの書き出しと読み込みをしようとしたんです。
そうしたら憎きアイツが出てきたわけです。
出たよ、
UnicodeDecodeError・・・。環境
- Windows 10
- Python 3.6
- Visual Studio Code
コード
s = '\x85' print(s) with open('C:/app/hoge.txt', mode='w', encoding='utf-8') as f: f.write(s) with open('C:/app/hoge.txt', mode='r') as g: print(g.read()) # UnicodeDecodeError`でエラー※問題の部分だけ抜粋しています。本来のソースは入力の文字列がもっとごちゃごちゃしてました。
原因
つまるところ、読み込み時の
openで引数のencodingを指定していなかったからでした_:(´ཀ`」 ∠):_書き出しの際には下記のように
encodingを指定していました。with open('C:/app/hoge.json', mode='w', encoding='utf-8') as f:ただ、書き出したファイルを読み込む際に、
encodingの指定を失念していました。with open('C:/app/hoge.json', mode='r') as g:
encodingの指定がない場合については、オフィシャルだと下記のように説明されています。encoding が指定されていない場合に使われるエンコーディングはプラットフォームに依存します
Windowsだと利用されるエンコーディングはCP932です。Pythonから入出力する際、CP932に変換できない文字が存在したため、「変換できないよ!」とエラーになったわけです。
ちなみに
Python内部では文字列型はUnicodeで保持されています。そして、入出力の際はPythonがシステムのエンコーディングに自動で変換してくれます。この場合、もともとUTF-8で保持されていたものをCP932に変換します。
この変換をユーザーが意識する必要はありません。逆に言えば、知らない間に勝手に変換されます。そして、この自動変換の際に何かしらの「変換できない文字」があるとエラーになる、というわけです。
解消方法
エラーを解消するには、書き出し時と同様に読み込み時にも
encodingを指定する必要があります。with open('C:/app/hoge.json', mode='r', encoding="utf-8) as f: j = json.load(g)ちなみに、書き出しの際に
encodingを指定しなかった場合も、読み込みと同様にエラーになります。当然っちゃ当然ですね。
とりあえず今回は、両方に
encodingを指定する方法を取りました。おわりに
encodingを指定は、手癖にしておくべきだと思いました(小並感参考文献
追記
コメントでのご指摘に基づき、PEP8で非推奨のエンコーディング宣言を削除しました。
ASCII (Python 2) や UTF-8 (Python 3) を使用しているファイルにはエンコーディング宣言を入れるべきではありません。
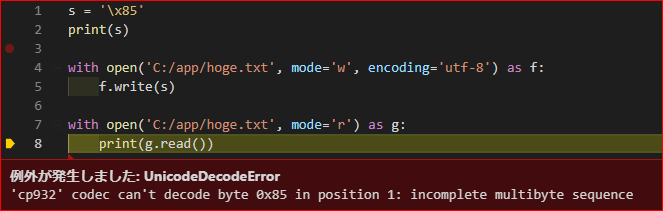
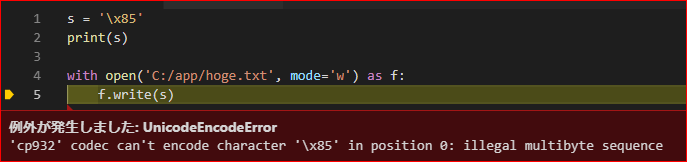
- 投稿日:2019-04-25T10:49:23+09:00
一般化線形回帰の拡張
SAS Viyaで一般線形回帰モデルの拡張を行う方法を紹介します。プログラミング言語はPythonになります。
モデルの生成
モデルは Genmod メソッドを使います。
cars = conn.CASTable('cars') genmodModel1 = cars.Genmod()モデルに対してパラメータの設定
genmodModel1.modelに対してパラメータを設定します。今回はリンク関数にlogを指定しています。genmodModel1.model.depvars = 'MSRP' genmodModel1.model.effects = ['MPG_City'] genmodModel1.model.dist = 'gamma' genmodModel1.model.link = 'log' genmodModel1.model.depvars = 'Cylinders' genmodModel1.model.dist = 'multinomial' genmodModel1.model.link = 'logit' genmodModel1.model.effects = ['MPG_City'] genmodModel1.display.names = ['ModelInfo', 'ParameterEstimates']アウトプットの設定を行う
そして結果の出力用テーブルを用意します。
genmodResult = conn.CASTable('CylinderPredicted', replace=True) genmodModel1.output.casout = genmodResult genmodModel1.output.copyVars = 'ALL'; genmodModel1.output.pred = 'Prob_Cylinders' genmodModel1() genmodResult[['Prob_Cylinders','_level_','Cylinders','MPG_City']].head(24)結果は次のように出力されます。
Selected Rows from Table CYLINDERPREDICTED
Prob_Cylinders _LEVEL_ Cylinders MPG_City 0 1.928842e-19 3.0 6.0 17.0 1 1.442488e-02 4.0 6.0 17.0 … 22 9.999077e-01 8.0 6.0 20.0 23 9.999530e-01 10.0 6.0 20.0 まとめ
SAS Viyaでは簡単に一般化線形回帰が使えますが、よりカスタマイズしたい時にも簡単にできます。ぜひデータ分析に役立ててください。
- 投稿日:2019-04-25T10:48:56+09:00
SAS Viyaで分析するためのSAS言語を取得する
SAS ViyaはAIプラットフォームです。SAS言語の他、RやJava、Pythonに対応しています。Pythonであれば機械学習に慣れたエンジニアであれはすぐに使いこなせるでしょう。
今回はこのPythonから、同内容をSAS言語にして取得する方法を紹介します。
テーブルを開く
まずテーブルを作成、または開きます。
organics = conn.upload('organics.csv').casTablelogisticを実行する
例えばlogisticプロシージャを実行する際に、同時にcodeオプションを指定します。中身は空のDictです。
result = organics.logistic( target = 'TargetBuy', inputs = ['DemAge', 'Purchase_3mon', 'Purchase_6mon'], code = {}, ) result['_code_']コードを確認する
結果の
result['_code_']にコードが入っています。SASCode /*----------------------------------------- Generated SAS Scoring Code Date: 11Apr2019:22:53:31 -----------------------------------------*/ drop _badval_ _linp_ _temp_ _i_ _j_; _badval_ = 0; _linp_ = 0; :まとめ
このコードを使うことで、同じ分析結果がSAS言語でも得られるようになります。Pythonは分かるけれどSAS言語に詳しくない方は、このcodeオプションを使いこなしてください。
- 投稿日:2019-04-25T10:48:18+09:00
SAS Viyaでグルーピングした結果を別テーブルに保存する
SAS ViyaはAIプラットフォームです。大量のデータを素早く分析したり、機械学習を用いて新しいデータの分類や判別をすることができます。開発者であればJupyter Notebookを使ってデモ環境で試すことができます。
今回はデータの簡易的な分類分けを行い、その結果をテーブルに保存する方法を紹介します。
元データについて
元データはGitHubにて公開しているcars.csvです。
まずデータをグルーピングします。
cars = conn.CASTable('cars') cars.groupby=['Origin'] cars.where = 'MSRP < 100000 and MPG_City < 40' nomList = ['Type','DriveTrain'] contList = ['MPG_City','Weight','Length']そして、そのデータの一般線形化モデル(GLM)を取得します。
linear4 = cars.glm出力先の定義と設定
そして、この線形モデルの出力先を設定します。
linear4.output.casout = conn.CASTable('MSRPPredictionGroupBy')後はデータを設定し、最後にlinear4を実行して終了です。
linear4.target = 'MSRP' linear4.inputs = nomList + contList linear4.nominals = nomList linear4.display.names = ['FitStatistics','ParameterEstimates'] linear4.output.copyVars = 'ALL'; linear4.output.pred = 'Predicted_MSRP' linear4.output.resid = 'Residual_MSRP' linear4.output.lcl = 'LCL_MSRP' linear4.output.ucl = 'UCL_MSRP' linear4()出力
結果は以下のように出てきます。
§ ByGroupInfoBY Groups
Origin Origin_f _key_ 0 Asia Asia Asia 1 Europe Europe Europe 2 USA USA USA
§ ByGroup1.FitStatistics
Fit Statistics
RowId
Description
Value
Origin
Asia
RMSE
Root MSE
7.023321e+03
Asia
RSQUARE
R-Square
6.432711e-01
Asia
ADJRSQ
Adj R-Sq
6.211293e-01
Asia
AIC
AIC
2.912330e+03
Asia
AICC
AICC
2.914176e+03
Asia
SBC
SBC
2.785764e+03
Asia
TRAIN_ASE
ASE
4.614465e+07
§ ByGroup1.ParameterEstimates
Parameter Estimates
Effect
Type
DriveTrain
Parameter
DF
Estimate
StdErr
tValue
Probt
Origin
Asia
Intercept
Intercept
1
-7800.227372
19135.597840
-0.407629
6.841472e-01
Asia
Type
SUV
Type SUV
1
-968.795973
2805.772482
-0.345287
7.303792e-01
Asia
Type
Sedan
Type Sedan
1
3766.422921
2436.960318
1.545541
1.243951e-01
Asia
Type
Sports
Type Sports
1
9154.062848
2929.463572
3.124826
2.149295e-03
Asia
Type
Truck
Type Truck
1
-11550.233853
3982.945107
-2.899923
4.313916e-03
Asia
Type
Wagon
Type Wagon
0
0.000000
NaN
NaN
NaN
Asia
DriveTrain
All
DriveTrain All
1
-8003.325899
2150.711618
-3.721245
2.828697e-04
Asia
DriveTrain
Front
DriveTrain Front
1
-12340.999993
1974.140868
-6.251327
4.295785e-09
Asia
DriveTrain
Rear
DriveTrain Rear
0
0.000000
NaN
NaN
NaN
Asia
MPG_City
MPG_City
1
17.219012
250.187094
0.068825
9.452241e-01
Asia
Weight
Weight
1
10.934945
2.354866
4.643552
7.607689e-06
Asia
Length
Length
1
14.517900
114.818053
0.126443
8.995567e-01
§ ByGroup2.FitStatistics
Fit Statistics
RowId
Description
Value
Origin
Europe
RMSE
Root MSE
8.984900e+03
Europe
RSQUARE
R-Square
7.682232e-01
Europe
ADJRSQ
Adj R-Sq
7.513667e-01
Europe
AIC
AIC
2.296227e+03
Europe
AICC
AICC
2.298264e+03
Europe
SBC
SBC
2.200239e+03
Europe
TRAIN_ASE
ASE
7.462291e+07
§ ByGroup2.ParameterEstimates
Parameter Estimates
Effect
Type
DriveTrain
Parameter
DF
Estimate
StdErr
tValue
Probt
Origin
Europe
Intercept
Intercept
1
-97268.426796
23984.147398
-4.055530
9.371452e-05
Europe
Type
SUV
Type SUV
1
-8680.048584
4832.887423
-1.796038
7.523358e-02
Europe
Type
Sedan
Type Sedan
1
3983.432570
2826.381315
1.409375
1.615450e-01
Europe
Type
Sports
Type Sports
1
28690.137970
3766.149186
7.617897
9.639114e-12
Europe
Type
Wagon
Type Wagon
0
0.000000
NaN
NaN
NaN
Europe
DriveTrain
All
DriveTrain All
1
-5872.661455
2354.280432
-2.494461
1.410149e-02
Europe
DriveTrain
Front
DriveTrain Front
1
-5977.536993
2282.743859
-2.618575
1.007440e-02
Europe
DriveTrain
Rear
DriveTrain Rear
0
0.000000
NaN
NaN
NaN
Europe
MPG_City
MPG_City
1
-572.454386
438.201671
-1.306372
1.941510e-01
Europe
Weight
Weight
1
15.461755
3.107484
4.975652
2.418969e-06
Europe
Length
Length
1
514.342947
125.888841
4.085691
8.374752e-05
§ ByGroup3.FitStatistics
Fit Statistics
RowId
Description
Value
Origin
USA
RMSE
Root MSE
7.336632e+03
USA
RSQUARE
R-Square
6.317860e-01
USA
ADJRSQ
Adj R-Sq
6.075967e-01
USA
AIC
AIC
2.775430e+03
USA
AICC
AICC
2.777386e+03
USA
SBC
SBC
2.656335e+03
USA
TRAIN_ASE
ASE
5.016452e+07
§ ByGroup3.ParameterEstimates
Parameter Estimates
Effect
Type
DriveTrain
Parameter
DF
Estimate
StdErr
tValue
Probt
Origin
USA
Intercept
Intercept
1
27189.194732
17038.936722
1.595710
0.112858
USA
Type
SUV
Type SUV
1
-2642.099747
3692.428467
-0.715545
0.475490
USA
Type
Sedan
Type Sedan
1
1143.294987
2930.398473
0.390150
0.697032
USA
Type
Sports
Type Sports
1
16249.501038
4286.648839
3.790724
0.000224
USA
Type
Truck
Type Truck
1
-8503.479255
3650.165897
-2.329614
0.021288
USA
Type
Wagon
Type Wagon
0
0.000000
NaN
NaN
NaN
USA
DriveTrain
All
DriveTrain All
1
-2882.556364
2448.067975
-1.177482
0.241045
USA
DriveTrain
Front
DriveTrain Front
1
-660.205840
1827.536082
-0.361255
0.718466
USA
DriveTrain
Rear
DriveTrain Rear
0
0.000000
NaN
NaN
NaN
USA
MPG_City
MPG_City
1
-1069.867684
340.679897
-3.140390
0.002067
USA
Weight
Weight
1
6.966966
1.889464
3.687271
0.000326
USA
Length
Length
1
-21.416004
71.698994
-0.298693
0.765627
elapsed 0.00926s · user 0.008s · sys 0.006s · mem 24.9MB
まとめ
出力先を指定しておくことで、重たい分析処理であってもすぐに結果を何度も確認できます。SQLで書くこともできますが、大抵行わないでしょう。Pythonでのプログラミングであれば出力先のテーブル名を指定するだけなので簡単です。ぜひお試しください。
- 投稿日:2019-04-25T10:47:37+09:00
SAS Viya The Python Perspectiveで利用されている元データについて
SAS Viyaを使ったPythonによる開発手法についてはSAS Viya The Python Perspectiveを読んでいただくことで前処理であったり、データの簡易分析について理解してもらえます。
本書籍では幾つかデータを用意した上でコードを書いていますが、そのデータの場所を紹介します。
organic.sashdat
organic.sashdatという名前自体のファイルは公開していませんが、元データになるCSVについてはGitHubにて公開しています。なお、このファイルはZipで52.7MP、解凍すると
252.9MBあります。本番環境であれば問題ありませんが、デモ環境では25MB以上のファイルがアップロードできないため、一部だけを取り出す必要があります。例えばRubyの場合は以下のようなスクリプトでデータの一部だけをピックアップできます。
f = File.open(ARGV[0]) s = ARGV[1].to_i f.each_line.with_index do |l, i| next if i % s != 0 puts l end以下はサイズを30分の1にします。
$ ruby csv.rb ./organics.csv 30 > organics_mini.csv読み込むと構造が分かりやすくなります。
from swat import * cashost='localhost' casport=5570 useremail='dev@sas.com' userpassword='password' casauth='~/.authinfo' conn = CAS(cashost, casport, useremail, userpassword, caslib="casuser") cars = conn.upload('organics2.csv').casTable cars.columninfo()
Column ID Type RawLength FormattedLength NFL NFD 0 ID 1 double 8 12 0 1 DemAffl 2 double 8 12 0 2 DemAge 3 double 8 12 0 3 DemGender 4 varchar 1 1 0 4 DemHomeowner 5 varchar 3 3 0 5 DemAgeGroup 6 varchar 7 7 0 6 DemCluster 7 double 8 12 0 7 DemReg 8 varchar 10 10 0 8 DemTVReg 9 varchar 12 12 0 9 DemFlag1 10 double 8 12 0 10 DemFlag2 11 double 8 12 0 11 DemFlag3 12 double 8 12 0 12 DemFlag4 13 double 8 12 0 13 DemFlag5 14 double 8 12 0 14 DemFlag6 15 double 8 12 0 15 DemFlag7 16 double 8 12 0 16 DemFlag8 17 double 8 12 0 17 PromClass 18 varchar 8 8 0 18 PromTime 19 double 8 12 0 19 TargetBuy 20 varchar 6 6 0 20 Bought_Beverages 21 varchar 3 3 0 21 Bought_Bakery 22 varchar 3 3 0 22 Bought_Canned 23 varchar 3 3 0 23 Bought_Dairy 24 varchar 3 3 0 24 Bought_Baking 25 varchar 3 3 0 25 Bought_Frozen 26 varchar 3 3 0 26 Bought_Meat 27 varchar 3 3 0 27 Bought_Fruits 28 varchar 3 3 0 28 Bought_Vegetables 29 varchar 3 3 0 29 Bought_Cleaners 30 varchar 3 3 0 30 Bought_PaperGoods 31 varchar 3 3 0 31 Bought_Others 32 varchar 3 3 0 32 purchase_3mon 33 double 8 12 0 33 purchase_6mon 34 double 8 12 0 34 purchase_9mon 35 double 8 12 0 35 purchase_12mon 36 double 8 12 0 cars.csv
cars.csvはGitHubにて公開しています。リポジトリがorganic.csvとは異なるので注意してください。こちらはサイズが小さいので、デモ環境でもアップロードして利用できます。
構造は次の通りです。
Column ID Type RawLength FormattedLength NFL NFD 0 Make 1 varchar 13 13 0 1 Model 2 varchar 39 39 0 2 Type 3 varchar 6 6 0 3 Origin 4 varchar 6 6 0 4 DriveTrain 5 varchar 5 5 0 5 MSRP 6 double 8 12 0 6 Invoice 7 double 8 12 0 7 EngineSize 8 double 8 12 0 8 Cylinders 9 double 8 12 0 9 Horsepower 10 double 8 12 0 10 MPG_City 11 double 8 12 0 11 MPG_Highway 12 double 8 12 0 12 Weight 13 double 8 12 0 13 Wheelbase 14 double 8 12 0 14 Length 15 double 8 12 0 まとめ
この他、デモ用のデータであったり、GitHubリポジトリ内にもファイルがアップロードしてあります。SAS Viyaを体験する際にご利用ください。
- 投稿日:2019-04-25T10:20:50+09:00
AWS Lambdaをローカル環境で動作確認しよう!
前提条件
環境はMacOSを想定しています。
Linux環境であれば問題ないとは思いますが、
Windows環境の方はパスなどを適宜読み替えてください。また、Dockerの事前導入が必須です。
各環境へのDocker導入については他に素晴らしい記事があるので割愛します。概要
ローカル環境で
Lambda用に作成したスクリプトを動かします。経緯
私は今まで、AWSマネジメントコンソールから、
WebIDEを用いて、もしくはzip形式でアップロードし
実機のLambdaにデータを送信することでテストを行っていました。しかし、開発中何度もコードを修正すると
いちいちコンソールを開いたりzipに固めてアップするのがかなり億劫になってきます。?また、Lambdaは動作分だけ料金が発生してしまうので、
重たい処理をバシバシ叩いているとコストが嵩んだりも?そこで、今回紹介する方法でローカル開発環境を用意し、
課金を発生させず、開発効率をガンガン上げていきましょう!環境構築
Dockerの導入
各環境へのDocker導入については、
公式ドキュメント他、Web上に素晴らしい記事がたくさんあるので割愛します。Dockerがインストールされた状態を用意してください。
インストールされていれば、以下のコマンドを実行できるハズです。# Dockerが動作していることを確認 $ docker --version Docker version 18.09.2, build 6247962動作確認用スクリプト
ファイル構成
今回作成するのは
Lambdaのスクリプト、スクリプトが使用するLayerモジュール、環境変数ファイル
の3ファイルです。AWS Lambda レイヤーについてはこちらを参照してください。
簡単に言うとLambda内のスクリプトに対して割り当てられるモジュール(ライブラリ)です。
今回の方法ではこのレイヤー機能を使用している場合でも動作させることができます。something_dir ├── src │ └── lambda_function.py ├── layer │ └── layer_module.py └── .envファイル内容は以下のとおりです。
lambda_function.py"""メイン関数ファイル """ import os import json from layer_module import return_prefix def lambda_handler(event, context): """環境名+eventの内容を標準出力に出す """ env = os.environ.get("ENV", "no_env") # [環境名]: eventの中身 return return_prefix(env) + json.dumps(event)layer_module.py"""Layerモジュール """ def return_prefix(env_name): """ "[環境変数名]: "を返す """ return "[" + env_name + "]: ".envENV=LOCALローカル環境で動かしてみる
早速スクリプトを動かしてみましょう。
Lambda環境を模倣するのに、Dockerを使用します。
既にOSSでLambCIという、Lambdaの環境を用意したイメージがありますので、これをお借りします。このイメージの使い方はRun Examplesにてほぼ全て網羅されています。
docker run [--rm] -v <code_dir>:/var/task [-v <layer_dir>:/opt] lambci/lambda:<runtime> [<handler>] [<event>]では以下のように指定し、Lambdaを動かしてみましょう。
cd something_dir docker run --rm -v "$PWD"/src:/var/task -v "$PWD"/layer:/opt/python --env-file .env lambci/lambda:python3.6 lambda_function.lambda_handler '{"foo":"bar"}'すると、以下のようなメッセージが現れるはずです。
START RequestId: 67154e64-2a74-4ce5-80ca-be4f9f158850 Version: $LATEST END RequestId: 67154e64-2a74-4ce5-80ca-be4f9f158850 REPORT RequestId: 67154e64-2a74-4ce5-80ca-be4f9f158850 Duration: 36 ms Billed Duration: 100 ms Memory Size: 1536 MB Max Memory Used: 19 MB "[LOCAL]: {\"foo\": \"bar\"}"このように出ていれば成功です!
実行上の注意
Dockerコンテナをrunする時、
レイヤーを割り当てるディレクトリには注意が必要です。公式にはレイヤーを割り当てる際、以下のようなオプションを付けるよう書いてありますが、
[-v <layer_dir>:/opt]例えばPythonでは、以下のように割り当てる必要があります。
[-v <layer_dir>:/opt/python]まとめ
今回は、環境変数&Lambdaレイヤーまで再現できるLambdaローカル環境を作りました。
このLambCIを使うと、ENVやLayer機能含めた
非常に実機に近い形で動かすことができるので、ぜひお試しください!?
- 投稿日:2019-04-25T09:31:42+09:00
サーバの運用管理をPythonで自動化する
サーバの運用管理業務では定型作業も少なくないと思うが、その自動化はどうしているだろう。
ターミナルソフト(PuTTY、Tera Term、Rlogin、etc)が備えるマクロにやらせるのも良いが、ここではPythonで実現してみようと思う。よくあるケース
- サーバまたはネットワーク機器でコマンドを実行し、結果をクライアント(Windows PC)にダウンロード
- クライアント(Windows PC)からファイルをアップロードし、サーバまたはネットワーク機器でコマンドを実行
というケースが多いのではなかろうか。
ここでは後者のサンプルコードを示す。必要なパッケージ
SSHv2プロトコルのPython実装であるParamikoと、scpを導入する。
pip install paramiko pip install scpサンプルコード
ファイルをscpで転送し、sshでコマンドを実行する必要最小限のコード。
パスワード認証方式の場合は、pkeyの代わりにpasswordを指定すること。import paramiko import scp def exec_cmd(cmd, ssh): print('# ' + cmd) stdin, stdout, stderr = ssh.exec_command(cmd) for out_line in stdout: print(out_line.strip('\n')) # 標準出力 for err_line in stderr: print(err_line.strip('\n')) # 標準エラー出力 with paramiko.SSHClient() as ssh: ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) pkey = paramiko.RSAKey.from_private_key_file('秘密鍵ファイル') # 今回はパスフレーズ無し ssh.connect(hostname='192.168.10.1', port=22, username='myuser', pkey=pkey) with scp.SCPClient(ssh.get_transport()) as scp: scp.put('foo.csv', '/tmp/foo.csv') # ファイルをアップロード time.sleep(1) # 念の為、待ち時間を挿入 exec_cmd('./bar.sh /tmp/foo.csv', ssh) # サーバでシェルを実行おまけ
せっかくPythonで書くのだから、実行結果もメールで自動送信してみよう。
CSVファイルをメールに添付して送信するサンプルコードを示す。import smtplib from email.mime.text import MIMEText from email import Encoders from email.mime.base import MIMEBase from email.mime.multipart import MIMEMultipart from_addr = 'XXXXX@gmail.com' to_addr = 'YYYYY@aaaaa.co.jp' bcc_addr = 'ZZZZZ@aaaaa.co.jp' # カンマ区切りで複数指定可 rcpt = bcc_addr.split(',') + [to_addr] msg = MIMEMultipart() msg['Subject'] = '【XXサーバ】コマンド実行結果' msg['From'] = '名無し' msg['To'] = to_addr msg.attach(MIMEText(''' 関係各位 お疲れさまです。 本日のコマンド実行結果を添付しますのでご確認ください。 '''.strip()) attachment = MIMEBase('application', 'csv') # 添付ファイルの種類に応じて適宜変更すること file = open('/tmp/results.csv', 'rb+') attachment.set_payload(file.read()) file.close() Encoders.encode_base64(attachment) attachment.add_header('Content-Disposition', 'attachment', filename='results.csv') msg.attach(attachment) smtp = smtplib.SMTP('smtp.gmail.com', 587) # Gmailの場合 smtp.starttls() smtp.login(from_addr, 'password') smtp.sendmail(from_addr, rcpt, msg.as_string()) smtp.close()
- 投稿日:2019-04-25T08:53:39+09:00
pandasでDataFrameから特定の条件で抽出する方法
例えばデータフレームdfから、ある列aの値に'e'を含む、あるいは、からはじまる、あるいは、で終わるものを取り出したい場合は以下のようにするとできます。
sample.pydf[ df['a'].str.contains('e') ] df[ df['a'].str.startswith('e') ] df[ df['a'].str.endswith('e') ]以下にjupyter notebookでのサンプルデータと実行結果を載せます。
また特定のインデックスまたは特定の値のデータを抽出するには以下のようにdf[]の中にtrueであれば抽出する条件を書いたり、.loc[[(インデックス番号)]]を使えば可能です。最後の.isin(num)は'b'列の値がnumの中にあれば抽出するという条件です。

- 投稿日:2019-04-25T08:46:59+09:00
楽天ウェブ自動検索システムを作りました
楽天で検索するとポイントがザックリたまるんですよ。そこで、自動化するプログラムをpythonで書きました。
ウェブ検索画面→ランダムにキーワード入力→検索
という順番にプログラムを回しています。
楽天の検索システムは楽天ウェブ検索ツールバーを通して数回単語検索すると、最大「30口」たまり、最大「5ポイント」楽天スーパーポイントにたまるシステムです。
125万ポイント山分け!とありますが、最大1日30口までです。
1日5ポイント…30日で150ポイントか…。と思った方もいることでしょう。
実は月に1万5000円積立投資をして、ポイントをもらう金額と同じなのです。
複利として150ポイント×12ヶ月=1800ポイントとなります。
まぁ…続けてみましょう笑
今回はInternet Explorer を使います。google chromeだと拡張機能を使わなくてはなりませんし、最大5口(1ポイント)しかたまりません。
今回はログイン済みを対象としています。
Internet Explorerで楽天にログインすると、ログアウトするまでずっと会員情報を保持しているようです。
さて、準備です。
①IEDriverServerをダウンロードしてDドライブ直下にdriverフォルダを作り、そこにIEDriverServer.exeファイルを入れてください。
下記のリンクから太字の32bit.verを選択してください。
IEDriverServerDownloads
www.seleniumhq.org
The Internet Explorer Driver Server
This is required if you want to make use of the latest and greatest features of the WebDriver InternetExplorerDriver. Please make sure that this is available on your $PATH (or %PATH% on Windows) in order for the IE Driver to work as expected.
Download version 3.14.0 for (recommended) 32 bit Windows IE or 64 bit Windows IE
CHANGELOG
②楽天ツールバーをInternet Explorerにダウンロード。③IDELを起動して、コードをコピーペーストして、適当な名前をつけて保存。
④pyファイルを起動し実行。
以上になります。簡単でしょう。最下部にコードの詳細があります。
ここからは、コードを作成するまでの概要になります。参考にしたい人は見て下さい。飛ばしたい方は下にスクロールして下さい。
1、ログイン情報ページから自動で入る
自動で入るコードはこちらになります。
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.keys import Keys driver = webdriver.Ie("c:/driver/IEDriverServer.exe") driver.get("https://grp03.id.rakuten.co.jp/rms/nid/login?service_id=r12&return_url=login?tool_id=1&tp=&id=") elem_search_word = driver.find_element_by_name("u") elem_search_word.send_keys("※※※※※") password = driver.find_element_by_name('p') password.send_keys("※※※※") elem_search_word = driver.find_element_by_name("submit").click() 下記※にあなたのID elem_search_word = driver.find_element_by_name("u") elem_search_word.send_keys("※※※※※") 下記※にあなたのパスワード password = driver.find_element_by_name('p') password.send_keys("※※※※")これで自動で入れます。
2、キーワードを取得する
熟語が羅列されてるサイトなら何でも良いのですが、価格ドットコムのランキングから取りました。
下記がプログラムです。タグを巡回するコードにしました。
#access to kakaku.com from selenium import webdriver driver = webdriver.Chrome("c:/driver/chromedriver.exe") driver.get("https://kakaku.com/keyword/") for a in driver.find_elements_by_tag_name("a"): print(a.text) driver.quit()[uploading-0]()
3、取得したキーワードをエクセルに貼り整形する。
行列の入れ替えをして
メモにコピー&ペーストします。
検索置換で検索を「空白(タブ)」をコピーしてペーストします。
置換は「”,”」を入力。
結果、内包リストの出来上がりです。
上記の説明は補足説明で、実際にコードを写したりする必要はありません。すでにコード中にキーワードリストは記載してあります。
製作環境:win7 32bit python3.7.2 IDLE
下記をコピーペーストしてください。
# coding: utf-8 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.keys import Keys from time import sleep import random #楽天ウェブ検索に接続 driver = webdriver.Ie("c:/driver/IEDriverServer.exe") driver.get("https://websearch.rakuten.co.jp/?l-id=header_left_top_logo") driver.implicitly_wait(10) #キーワードを30回自動入力して検索 for i in range(32): #200のキーワードからランダムに抽出 keywordlist = ["ホーム","ポケトーク","4kチューナー","ipad","ipad mini","ネックスピーカー","α7iii","airpods","ipad air","翻訳機","ps4","windows10","ps4 本体","防犯カメラ ワイヤレス 屋外","ウェアラブルネックスピーカー","デジタルサイネージ ディスプレイ","モバイルディスプレイ","液晶テレビ 50インチ","血糖値測定器","ps4pro 本体","物置","プリンター","電気温水器","psvr","ipadmini","sv12ff","三輪 電動アシスト自転車","145r12 6pr","家庭用防犯カメラ","プロジェクター","ワイヤレスインターホン 無線インターホン","ポータブル電源","iphone8","bwv80c","ルンバ","surface go","SRS-WS1","フロントラインプラス","ドライブレコーダー バイク 防水","ミニ耕運機","apple pencil","ジャンプスターター","ログハウス キット","電話 録音機","50インチ モニター","フォーマル ミセス スーツ 50代","surface pro","セグウェイ","紙折り機","コンクリート 平板","キャノン 純正インク","枝 粉砕機","nebs1500","TS8230","ニンテンドースイッチ 本体","カラオケ 機器 家庭用","gopro","ipad pro","bwv70c","パーリーゲイツ キャディーバッグ","ドクターエア","手元スピーカー ワイヤレス","ウォークマン","夢ゲンクール","自転車通学 カッパ","4kテレビ 50インチ","フル電動自転車","ドクターシーラボ 200g","ca-dr150","60代 フォーマル ミセス 結婚式","物置 屋外","真空包装機 業務用","dyson v10","ウォシュレット","人工芝 ロール","シュレッダー 家庭用","ドローン カメラ付き","折りたたみ 自転車 超軽量","パルスオキシメーター","ドアスコープ カメラ","レ・ー・ダ・ー 探知器","おしゃれ 倉庫 屋外 物置","th55fz950","ipad mini キーボード","ダイソン","ps4 pro","タイヤチェンジャー","階段 昇降機","RX0","波板 トタン","auto-vox","ポータブル電源 suaoki","4tc50aj1","bwv100c","D850","シャワーヘッド マイクロバブル","bluetooth トランスミッター","mrovs8","タイヤ空気圧 モニタリングシステム","物置 倉庫","スピーカーセレクター","ポケトーク","夢ゲンクール","α7iii","棒寒天","血糖値測定器","電話 録音機","クリスチャンオリビエ バック","ポータブル電源","パルスイクロス","翻訳機","育苗器","プリンター","一本満足","ha-sd70bt","セグウェイ","モバイルディスプレイ","電気温水器","アイコス","液晶テレビ 50インチ","ドライブレコーダー バイク 防水","紙折り機","宅配ボックス","sv12ff","cbdオイル","コンクリート 平板","WH-1000XM3","EX-LD321DB","eos kiss x10","防草シート","枝 粉砕機","診断機 自動車","デジタルサイネージ ディスプレイ","ブラウン 洗浄液","絵の具 セット 小学校","人工芝 ロール","SSD 2tb","自転車通学 カッパ","ミニ耕運機","gopro","太陽光発電 ソーラーパネル","階段 昇降機","ジャージ上下 メンズ","酸素濃度計","遺伝子検査キット","145r12 6pr","ミラー型ドライブレコーダー","ipad 2018","surface go","グッドラックソファ","ウォシュレット","波板 トタン","頭皮マッサージ機","dmrbw550","シックスパッド","網戸 お掃除ローラー","TS8230","無線機 アマチュア無線","自転車通学 カッパ リュック","薬 フィラリア","ポケトーク 翻訳機","口臭チェッカー","リチウムイオン充電池 18650","コックリング","auto-vox","a3 複合機","bwv100c","メスティン","冷凍ストッカー 業務用","UNX-9130","レーザー彫刻機","ipad キーボード カバー","windows10","物置","耐火レンガ","キャノン 純正インク","タイヤ空気圧 モニタリングシステム","サイクルポート","ps vr","ケイカル板","ポータブル電源 suaoki","iphone8","レ・ー・ダ・ー 探知器","ワイヤレスインターホン 無線インターホン","ドクターエア","ポータブル電源 大容量","玄関ドア","ジンバル","ipad mini キーボード","5セカンズシャイン","200m 黒マルチ","家庭用防犯カメラ","ゲーミングモニター","iphone10","iphone7","navx9900","ワイヤレスマイク bluetooth","gps ロガー","麻雀卓 折りたたみ","土留め"] sleep(2) search_word = driver.find_element_by_name("qt") sleep(2) search_word.send_keys(random.choice(keywordlist)) sleep(3) search_word.send_keys(Keys.ENTER) sleep(4) search_erase_icon = driver.find_element_by_xpath("//*[@id='cbtn']").click() sleep(5) print("終了")IEでは重たい動作が続いたり不安定になることもあります。
その際は一度閉じて、やり直しをかけるか、スリープモジュールのsleep(2)を(4)にしたり少し秒数を変えてみたりして調節してみてください。
※筆者はいかなる利益・責任を負うことはできません。
予めご了承願います。

- 投稿日:2019-04-25T08:40:23+09:00
自分用勉強メモ5日目
調べた知識
pcap (Packet CAPture)
パケットを扱うAPI.
WinPcap(for Windows)やlibpcap(for Linux)というライブラリで実装されている.
これを利用する有名なツールにtcpdumpやWireSharkがある.tcpdumpのオプションの違い(xとか)
紛らわしいと思ったので,書き留める.
- -x 系のオプションをつけるとパケットの中身も出力してくれる.
- 2文字連ねると,データリンク層のヘッダを含める.
- 大文字にすると,16進数表記からASCIIに変換したものも出力する.
表にまとめると下のような感じ.
リンク層ヘッダなし あり ASCII表記なし -x -xx あり -X -XX ハッシュ関数
よく使われるものについて,メモ書き程度に.
- MD5
- ビット長: 128
- 16進表記の長さ: 32文字
- 既知の脆弱性があるため,手元のファイルの同一性チェック程度の使用に留めたほうがいい.(パスワードのハッシュとかに使用しない.)
- SHA1
- ビット長: 160
- 16進表記の長さ: 40文字
- MD5に比べれば頑健だが,これを効率解く方法はすでに存在する.
- 多くの場面で使用されているが,今後実装するならSHA-2系を使用するほうが安全.
- SHA256
- ビット長: 256
- 16進表記の長さ: 64文字
- SHA-2系の一種.xxxビット長でSHAxxxと表記する.
- 3つの中では最もセキュア.
参考:Hash関数まとめ(md5, sha1, sha2, crc32, PBKDF2)
f文字列
フォーマット済み文字列リテラル.
Python3.6から導入された仕組み.
formatメソッドに似ている.
今までずっとformatを使用していたので,これからは代用していく.cpawCTF
Q11.[Network]pcap
pcapファイルにフラグが隠されている.
パケットデータも今後扱うと見込んでスクリプトを書いてみた.from scapy.all import rdpcap from subprocess import run import sys class MyPackets: def __init__(self, pcap_path): self.__packets = rdpcap(pcap_path) def size(self): return len(self.__packets) def raws(self): raw_data = '' for pac in self.__packets: raw_data += pac['Raw'].show(dump=True) return raw_data def useful_strings(self): us_list = [] offset = len('load = ') raw_data = self.raws() raw_list = raw_data.split('\n') for r in raw_list: str_index = r.find('load') if str_index < 0: continue us_list.append(r[str_index+offset:]) return '\n'.join(us_list) if __name__ == '__main__': packets = MyPackets(sys.argv[1]) print('num of packets: {}'.format(packets.size())) print(packets.useful_strings())useful_stringsメソッドでパケットの中身から有用な文字列を抽出する.
今回はstringsを実行するだけでもフラグが取れたが,Pythonに慣れるためにも手を動かしてみた.Q12.[Crypto]HashHashHash!
ヒント通り,検索すれば答えが出てくる.
Q14.[PPC]並べ替えろ!
整数をソートする問題.
import sys input_line = sys.argv[1] num_list = input_line.split(',') sorted_list = sorted(num_list, key=int, reverse=True) flag = ''.join(sorted_list) print(f'cpaw{{{flag}}}')f文字列を初めて使用してみた.
載せるほどでもないが,プログラミング力向上のために.Q13.[Stego]隠されたフラグ
画像のすみにモールス符号が書かれている.
検索して変換すればいいが,自作してみた.import sys MORSE_DICT = { '.-': 'A', '-...': 'B', '-.-.': 'C', '-..': 'D', '.': 'E', '..-.': 'F', '--.': 'G', '....': 'H', '..': 'I', '.---': 'J', '-.-': 'K', '.-..': 'L', '--': 'M', '-.': 'N', '---': 'O', '.--.': 'P', '--.-': 'Q', '.-.': 'R', '...': 'S', '-': 'T', '..-': 'U', '...-': 'V', '.--': 'W', '-..-': 'X', '-.--': 'Y', '--..': 'Z', '-----': '0', '.----': '1', '..---': '2', '...--': '3', '....-': '4', '.....': '5', '-....': '6', '--...': '7', '---..': '8', '----.': '9', '.-.-.-': '.', '--..--': ',', '..--..': '?', '-.-.--': '!', '-....-': '-', '-..-.': '/', '.--.-.': '@', '-.--.': '(', '-.--.-': ')', '.-..-. ': '"', '..--.-': '_', '---...': ':', '.----.': "'", '.-.-.': '+', '-...-': '=', '-.-.-.': ';', '...-..-': '$', } input_code = sys.argv ans = '' for index, hyphen_dot in enumerate(input_code): if index == 0: continue try: ans += MORSE_DICT[hyphen_dot] except: ans += ' ' print(f'cpaw{{{ans.lower()}}}'){}の中にも"cpaw"という文字列が出てくるので,それを削除して入力すれば通る.
Q15.[Web] Redirect
与えられたURLをクリックすると別のサイトにリダイレクトされる.
ブラウザ上で右クリック→「要素を調査」→「ネットワーク」を開いた状態で,先のURLをクリックすると,HTTPヘッダを読むことができる.
ヘッダ内にフラグが隠されている.参考:CTF初心者によるCpawCTF Lv2のWriteUp
Q16.[Network+Forensic]HTTP Traffic
write-upを参考にして解いた.
Wiresharkを使えば,HTTPオブジェクトを取り出すことができる.
手順としては以下の通り,
- pcapファイルをWiresharkで開く.
- HTTPオブジェクトを取り出して保存する.
- 拡張子のないファイルが2つあるので,fileコマンドで調べるとHTMLドキュメントであることがわかる.
- ブラウザで開く.
- ボタン機能がうまく動作していないので,HTMLを見てみると,
./js/button2.jsに配置しなければならないことがわかるので,jsディレクトリをHTMLソースと同じ階層に作成し,button2.js を配置すればうまく動作する.- フラグを取得.