- 投稿日:2019-03-01T23:58:43+09:00
シンプルなトランプ用Class(Python)
プログラミング入門者からの卒業試験は『ブラックジャック』を開発すべし
の記事を見かけ、自分も入門者から卒業目指してチャレンジしてみることに。
第一歩として、シンプルなトランプ用クラス作成。
(Deck=シャッフルされたトランプの山)内部のデータは扱いやすいように整数、
表示は絵文字を使った形式に。import random class Card: SUITS = '♤♡♢♧' RANKS = '0 A 2 3 4 5 6 7 8 9 10 J Q K'.split() def __init__(self, suit, rank): self.suit, self.rank = suit, rank def __repr__(self): return f'{Card.SUITS[self.suit]}{Card.RANKS[self.rank]}' class Deck: def __init__(self): self.cards = [Card(suit, rank) for suit in range(4) for rank in range(1, 14)] random.shuffle(self.cards) @property def next_card(self): return self.cards.pop()表示のテスト:
d=Deck() print(d.next_card) print(d.next_card) print(d.next_card)output:
♡Q
♢6
♢7
- 投稿日:2019-03-01T23:38:56+09:00
【機械学習入門】「PCA主成分分析;多変量解析」の軸変換をプロットで見える化♬
今回はわかりやすいと思うので、ちょっと理論から入ることとする。
データを$x_i=(x_{i1},…,x_{id})^T$, $(i=1,…,N)$、ここで$d$は独立な測定項目の次元である。
データ行列を $X=(x_i,…,x_{N})^T$ 、原点を平均 $\bar{x} = \sum_{i=1}^{N}x_{i}$としたデータ行列を $\bar{X}=(x_i−\bar{x},…,x_{N}−\bar{x})^{T}$とすると、PCA主成分分析は$S=\frac{1}{N}\bar{X}^{T} \bar{X}$という共分散行列を使って、以下のようないわゆる固有値問題となる。Su=λuを解いて固有値を求めて$S$を対角化し、新たな主軸(分散の大きい順に第一主成分、第二主成分。。。)を求めることである。
ここでこの固有ベクトルが新たな主軸の軸方向を示しており、この固有ベクトルを利用すると、P^{-1}SPと対角化できる。そして、元の方程式は以下のように変形でき、変換テンソルPは固有ベクトル$u_1,u_2,u_3...$で以下のように書けることが分かる。
P^{-1}SP P^{-1}u=λP^{-1}u \\ P=(u_1,u_2,u_3...)つまり、このPを使って、新たな主軸(基底という)における各座標が
P^{-1}uで求められることが分かる。
また、この固有値を$s_k$とすると、各成分の寄与は以下のようになる。c_k=\frac{s_k}{V_{total}}ここで重要なことは、上記の共分散行列の各行列要素は比例していないことが前提となる。すなわち測定項目間の相関が無いかあるいはあっても小さいことが前提条件になる。
今回はこの対角化の様子を多変量解析についてグラフ化して見える化することを試みる。
手法は前回の3D見える化と同じであるが、上式の新たな座標上の点への座標変換$P^{-1}u$を利用して示そうと思う。
【参考】
・[Python][Scikit-learn]主成分分析を用いた次元削減、主成分ベクトルを用いた予測と線形回帰による予測の比較
・主成分分析と固有値問題@Aidemy Blog
・固有値問題・固有空間・スペクトル分解@武内修@筑波大やったこと
・最初の一歩2次元
・三次元でGifアニメーション
・六次元を3DGifアニメーション今回のコードは以下に置きました
・MachineLearning/pca_exaple.py
・MachineLearning/out_gif.py・最初の一歩2次元
説明はこの2次元の場合が分かりやすい。
import numpy as np from sklearn.decomposition import PCA import matplotlib.pyplot as pltデータはscikit_learnの例から以下のとおりのものを使う。
【参考】
・sklearn.decomposition.PCAX = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])まず、2次元のPCA分析を実施する。
そして、その結果として、主成分方向のベクトルv_pca0と第二主成分方向のベクトルv_pca1が以下のとおり、得られる。pca = PCA(n_components=2) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1]このベクトルはそれぞれ以下のとおり求められる。
X_pca0=[0,1*v_pca0[0]] Y_pca0=[0,1*v_pca0[1]] X_pca1=[0,1*v_pca1[0]] Y_pca1=[0,1*v_pca1[1]]元々の空間で入力座標をプロットする。
さらに、上記で求めた第一主成分(赤)と第二主成分(青)のベクトルをプロットする。plt.scatter(X[:,0],X[:,1],c="g",marker = "*") plt.plot(X_pca0,Y_pca0,c="r",marker = "o") plt.plot(X_pca1,Y_pca1,c="b",marker = "o") plt.savefig('k-means/pca_example/pca_data_scatter.jpg') plt.pause(1) plt.close()第一主成分が赤い線の方向、第二主成分が青い線の方向である。
次に固有値ベクトルを利用して、測定点Xと主成分ベクトルYを変換して、変換された座標上にプロットする。この変換はscikit-learnではPCAの関数pca.transform()を利用して以下のとおり変換できる。Y=np.array([[0,0],[v_pca0[0],v_pca0[1]],[v_pca1[0],v_pca1[1]]]) pcatran_X = pca.transform(X) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y))そして、変換された座標上に以下のとおりプロットする。
plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[0,1]],[pcatran_Y[2,0],pcatran_Y[2,1]],c="b") plt.plot([pcatran_Y[2,0],pcatran_Y[2,1]],[pcatran_Y[0,0],pcatran_Y[0,1]],c="r") #,marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter.jpg') plt.pause(1) plt.close()まともな方向にプロットされ、新しい座標軸も第一主成分及び第二主成分方向になった。
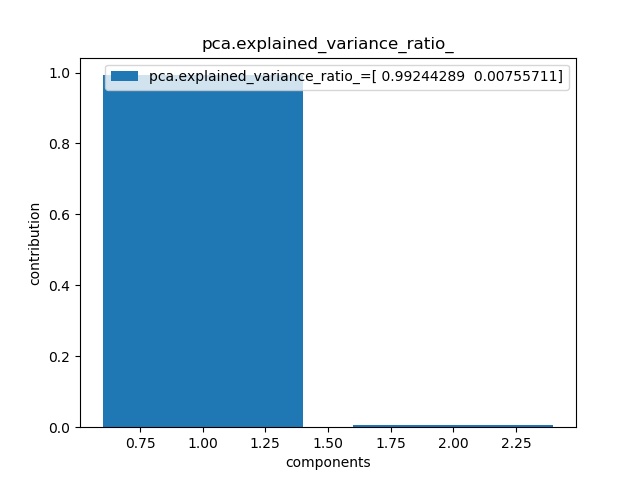
次に、これらの成分の寄与を以下のように求める。s=2 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca2d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()
・三次元でGifアニメーション
次元が増えるだけで、同じ流れで進みます。
データは、以下のようにmake_blobsで生成しました。from sklearn.datasets import make_blobs X, Y = make_blobs(random_state=8, n_samples=100, n_features=3, cluster_std=4, centers=3)PCA分析の成分は3とします。そして、3つの成分ベクトルが求まります。
そして、それぞれの方向のベクトルを定義します。pca = PCA(n_components=3) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]]座標軸は3次元なので、以下のように立体的に描画します。
def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca3d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)
3次元でも同じようにYを定義して、一括変換して新たな座標上のベクトルを求め、スナップを書いてみます。Y=np.array([[0,0,0],[10*v_pca0[0],10*v_pca0[1],10*v_pca0[2]],[10*v_pca1[0],10*v_pca1[1],10*v_pca1[2]],[10*v_pca2[0],10*v_pca2[1],10*v_pca2[2]]]) print(Y) pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y)) plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[1,0]],[pcatran_Y[0,1],pcatran_Y[1,1]],c="b",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[2,0]],[pcatran_Y[0,1],pcatran_Y[2,1]],c="r",marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter3.jpg') plt.pause(1) plt.close()
次に新しい座標軸上に3dプロットします。def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca3d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)今回は変換された軸上にプロットしているので、軸の記載はしていません。
最後に寄与のグラフは以下のとおりになっています。s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca3d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()第一主成分とそん色なく第二主成分や第三主成分の広がりがあるように見えますが、寄与は以下のとおり、70%,19%,11%程度になっています。
・六次元を3DGifアニメーション
次元、広がり、そして3中心(n_features=6,cluster_std=4,centers=3)で生成しました。
s=6 X, Y = make_blobs(random_state=8, n_samples=100, n_features=6, cluster_std=4, centers=3)上と同じように、固有ベクトルはとりあえず第三主成分まで求めます。
pca = PCA(n_components=6) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]]そして、以下のように三次元プロットをします。
def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca6d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)
今回も同じように固有ベクトルで変換し、3dプロットします。pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca6d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)
以下のようにそれぞれの成分の寄与を見ます。print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3,4,5,6], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca6d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()第三成分までで、45%,25%,10%で80%程度をカバーしています。
まとめ
・固有値問題としてのPCA分析の理論を見た
・二次元、三次元、そして六次元の場合について座標変換の様子を見た
・こうして次元圧縮の様子が分かった・これをベースにさらなるクラスタリング手法と利用を見ていく
おまけ
【参考】
・機械学習 〜 データセット生成 〜import numpy as np from sklearn.decomposition import PCA import matplotlib.pyplot as plt from pandas.tools import plotting # 高度なプロットを行うツールのインポート import pandas as pd from mpl_toolkits.mplot3d import Axes3D X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) pca = PCA(n_components=2) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] X_pca0=[0,1*v_pca0[0]] Y_pca0=[0,1*v_pca0[1]] X_pca1=[0,1*v_pca1[0]] Y_pca1=[0,1*v_pca1[1]] plt.scatter(X[:,0],X[:,1],c="g",marker = "*") plt.plot(X_pca0,Y_pca0,c="r",marker = "o") plt.plot(X_pca1,Y_pca1,c="b",marker = "o") plt.savefig('k-means/pca_example/pca_data_scatter.jpg') plt.pause(1) plt.close() print(v_pca0[0],v_pca0[1]) Y=np.array([[0,0],[v_pca0[0],v_pca0[1]],[v_pca1[0],v_pca1[1]]]) print(Y) pcatran_X = pca.transform(X) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y)) plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[0,1]],[pcatran_Y[2,0],pcatran_Y[2,1]],c="b") plt.plot([pcatran_Y[2,0],pcatran_Y[2,1]],[pcatran_Y[0,0],pcatran_Y[0,1]],c="r") #,marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter.jpg') plt.pause(1) plt.close() print("v_pca0={},v_pca1={}".format(v_pca0,v_pca1)) s=2 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca2d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() print("pca.singular_values_={}".format(pca.singular_values_)) from sklearn.datasets import make_regression #X, Y, coef = make_regression(random_state=12, n_samples=100, n_features=3, n_informative=2, noise=10.0, bias=-0.0, coef=True) from sklearn.datasets import make_blobs X, Y = make_blobs(random_state=8, n_samples=100, n_features=3, cluster_std=4, centers=3) pca = PCA(n_components=3) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]] def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) #for kx, ky,kz, name in zip(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], labels): #ax.text(kx, ky,kz, name, alpha=0.8, size=20) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) #ax.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], c = "b", marker = "*", s = 100) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca3d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print(v_pca0[0],v_pca0[1],v_pca0[2]) Y=np.array([[0,0,0],[10*v_pca0[0],10*v_pca0[1],10*v_pca0[2]],[10*v_pca1[0],10*v_pca1[1],10*v_pca1[2]],[10*v_pca2[0],10*v_pca2[1],10*v_pca2[2]]]) print(Y) pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y)) plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[1,0]],[pcatran_Y[0,1],pcatran_Y[1,1]],c="b",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[2,0]],[pcatran_Y[0,1],pcatran_Y[2,1]],c="r",marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter3.jpg') plt.pause(1) plt.close() def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca3d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca3d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() print("pca.singular_values_={}".format(pca.singular_values_)) s=6 X, Y = make_blobs(random_state=8, n_samples=100, n_features=6, cluster_std=4, centers=3) pca = PCA(n_components=6) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]] def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) #for kx, ky,kz, name in zip(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], labels): #ax.text(kx, ky,kz, name, alpha=0.8, size=20) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) #ax.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], c = "b", marker = "*", s = 100) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca6d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print(v_pca0[0],v_pca0[1],v_pca0[2]) pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca6d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3,4,5,6], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca6d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() print("pca.singular_values_={}".format(pca.singular_values_))









- 投稿日:2019-03-01T23:38:56+09:00
【機械学習入門】「PCA主成分分析;多変量解析」の軸変換を3Dプロットで見える化♬
今回はわかりやすいと思うので、ちょっと理論から入ることとする。
データを$x_i=(x_{i1},…,x_{id})^T$, $(i=1,…,N)$、ここで$d$は独立な測定項目の次元である。
データ行列を $X=(x_i,…,x_{N})^T$ 、原点を平均 $\bar{x} = \sum_{i=1}^{N}x_{i}$としたデータ行列を $\bar{X}=(x_i−\bar{x},…,x_{N}−\bar{x})^{T}$とすると、PCA主成分分析は$S=\frac{1}{N}\bar{X}^{T} \bar{X}$という共分散行列を使って、以下のようないわゆる固有値問題となる。Su=λuを解いて固有値を求めて$S$を対角化し、新たな主軸(分散の大きい順に第一主成分、第二主成分。。。)を求めることである。
ここでこの固有ベクトルが新たな主軸の軸方向を示しており、この固有ベクトルを利用すると、P^{-1}SPと対角化できる。そして、元の方程式は以下のように変形でき、変換テンソルPは固有ベクトル$u_1,u_2,u_3...$で以下のように書けることが分かる。
P^{-1}SP P^{-1}u=λP^{-1}u \\ P=(u_1,u_2,u_3...)つまり、このPを使って、新たな主軸(基底という)における各座標が
P^{-1}uで求められることが分かる。
また、この固有値を$s_k$とすると、各成分の寄与は以下のようになる。c_k=\frac{s_k}{V_{total}}ここで重要なことは、上記の共分散行列の各行列要素は比例していないことが前提となる。すなわち測定項目間の相関が無いかあるいはあっても小さいことが前提条件になる。
今回はこの対角化の様子を多変量解析についてグラフ化して見える化することを試みる。
手法は前回の3D見える化と同じであるが、上式の新たな座標上の点への座標変換$P^{-1}u$を利用して示そうと思う。
【参考】
・[Python][Scikit-learn]主成分分析を用いた次元削減、主成分ベクトルを用いた予測と線形回帰による予測の比較
・主成分分析と固有値問題@Aidemy Blog
・固有値問題・固有空間・スペクトル分解@武内修@筑波大やったこと
・最初の一歩2次元
・三次元でGifアニメーション
・六次元を3DGifアニメーション今回のコードは以下に置きました
・MachineLearning/pca_exaple.py
・MachineLearning/out_gif.py・最初の一歩2次元
説明はこの2次元の場合が分かりやすい。
import numpy as np from sklearn.decomposition import PCA import matplotlib.pyplot as pltデータはscikit_learnの例から以下のとおりのものを使う。
【参考】
・sklearn.decomposition.PCAX = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])まず、2次元のPCA分析を実施する。
そして、その結果として、主成分方向のベクトルv_pca0と第二主成分方向のベクトルv_pca1が以下のとおり、得られる。pca = PCA(n_components=2) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1]このベクトルはそれぞれ以下のとおり求められる。
X_pca0=[0,1*v_pca0[0]] Y_pca0=[0,1*v_pca0[1]] X_pca1=[0,1*v_pca1[0]] Y_pca1=[0,1*v_pca1[1]]元々の空間で入力座標をプロットする。
さらに、上記で求めた第一主成分(赤)と第二主成分(青)のベクトルをプロットする。plt.scatter(X[:,0],X[:,1],c="g",marker = "*") plt.plot(X_pca0,Y_pca0,c="r",marker = "o") plt.plot(X_pca1,Y_pca1,c="b",marker = "o") plt.savefig('k-means/pca_example/pca_data_scatter.jpg') plt.pause(1) plt.close()第一主成分が赤い線の方向、第二主成分が青い線の方向である。
次に固有値ベクトルを利用して、測定点Xと主成分ベクトルYを変換して、変換された座標上にプロットする。この変換はscikit-learnではPCAの関数pca.transform()を利用して以下のとおり変換できる。Y=np.array([[0,0],[v_pca0[0],v_pca0[1]],[v_pca1[0],v_pca1[1]]]) pcatran_X = pca.transform(X) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y))そして、変換された座標上に以下のとおりプロットする。
plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[0,1]],[pcatran_Y[2,0],pcatran_Y[2,1]],c="b") plt.plot([pcatran_Y[2,0],pcatran_Y[2,1]],[pcatran_Y[0,0],pcatran_Y[0,1]],c="r") #,marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter.jpg') plt.pause(1) plt.close()まともな方向にプロットされ、新しい座標軸も第一主成分及び第二主成分方向になった。
次に、これらの成分の寄与を以下のように求める。s=2 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca2d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()
・三次元でGifアニメーション
次元が増えるだけで、同じ流れで進みます。
データは、以下のようにmake_blobsで生成しました。from sklearn.datasets import make_blobs X, Y = make_blobs(random_state=8, n_samples=100, n_features=3, cluster_std=4, centers=3)PCA分析の成分は3とします。そして、3つの成分ベクトルが求まります。
そして、それぞれの方向のベクトルを定義します。pca = PCA(n_components=3) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]]座標軸は3次元なので、以下のように立体的に描画します。
def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca3d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)
3次元でも同じようにYを定義して、一括変換して新たな座標上のベクトルを求め、スナップを書いてみます。Y=np.array([[0,0,0],[10*v_pca0[0],10*v_pca0[1],10*v_pca0[2]],[10*v_pca1[0],10*v_pca1[1],10*v_pca1[2]],[10*v_pca2[0],10*v_pca2[1],10*v_pca2[2]]]) print(Y) pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y)) plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[1,0]],[pcatran_Y[0,1],pcatran_Y[1,1]],c="b",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[2,0]],[pcatran_Y[0,1],pcatran_Y[2,1]],c="r",marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter3.jpg') plt.pause(1) plt.close()
次に新しい座標軸上に3dプロットします。def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca3d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)今回は変換された軸上にプロットしているので、軸の記載はしていません。
最後に寄与のグラフは以下のとおりになっています。s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca3d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()第一主成分とそん色なく第二主成分や第三主成分の広がりがあるように見えますが、寄与は以下のとおり、70%,19%,11%程度になっています。
・六次元を3DGifアニメーション
次元、広がり、そして3中心(n_features=6,cluster_std=4,centers=3)で生成しました。
s=6 X, Y = make_blobs(random_state=8, n_samples=100, n_features=6, cluster_std=4, centers=3)上と同じように、固有ベクトルはとりあえず第三主成分まで求めます。
pca = PCA(n_components=6) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]]そして、以下のように三次元プロットをします。
def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca6d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)
今回も同じように固有ベクトルで変換し、3dプロットします。pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca6d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)
以下のようにそれぞれの成分の寄与を見ます。print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3,4,5,6], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca6d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()第三成分までで、45%,25%,10%で80%程度をカバーしています。
まとめ
・固有値問題としてのPCA分析の理論を見た
・二次元、三次元、そして六次元の場合について座標変換の様子を見た
・こうして次元圧縮の様子が分かった・これをベースにさらなるクラスタリング手法と利用を見ていく
おまけ
【参考】
・機械学習 〜 データセット生成 〜import numpy as np from sklearn.decomposition import PCA import matplotlib.pyplot as plt from pandas.tools import plotting # 高度なプロットを行うツールのインポート import pandas as pd from mpl_toolkits.mplot3d import Axes3D X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) pca = PCA(n_components=2) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] X_pca0=[0,1*v_pca0[0]] Y_pca0=[0,1*v_pca0[1]] X_pca1=[0,1*v_pca1[0]] Y_pca1=[0,1*v_pca1[1]] plt.scatter(X[:,0],X[:,1],c="g",marker = "*") plt.plot(X_pca0,Y_pca0,c="r",marker = "o") plt.plot(X_pca1,Y_pca1,c="b",marker = "o") plt.savefig('k-means/pca_example/pca_data_scatter.jpg') plt.pause(1) plt.close() print(v_pca0[0],v_pca0[1]) Y=np.array([[0,0],[v_pca0[0],v_pca0[1]],[v_pca1[0],v_pca1[1]]]) print(Y) pcatran_X = pca.transform(X) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y)) plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[0,1]],[pcatran_Y[2,0],pcatran_Y[2,1]],c="b") plt.plot([pcatran_Y[2,0],pcatran_Y[2,1]],[pcatran_Y[0,0],pcatran_Y[0,1]],c="r") #,marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter.jpg') plt.pause(1) plt.close() print("v_pca0={},v_pca1={}".format(v_pca0,v_pca1)) s=2 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca2d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() print("pca.singular_values_={}".format(pca.singular_values_)) from sklearn.datasets import make_regression #X, Y, coef = make_regression(random_state=12, n_samples=100, n_features=3, n_informative=2, noise=10.0, bias=-0.0, coef=True) from sklearn.datasets import make_blobs X, Y = make_blobs(random_state=8, n_samples=100, n_features=3, cluster_std=4, centers=3) pca = PCA(n_components=3) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]] def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) #for kx, ky,kz, name in zip(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], labels): #ax.text(kx, ky,kz, name, alpha=0.8, size=20) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) #ax.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], c = "b", marker = "*", s = 100) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca3d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print(v_pca0[0],v_pca0[1],v_pca0[2]) Y=np.array([[0,0,0],[10*v_pca0[0],10*v_pca0[1],10*v_pca0[2]],[10*v_pca1[0],10*v_pca1[1],10*v_pca1[2]],[10*v_pca2[0],10*v_pca2[1],10*v_pca2[2]]]) print(Y) pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y)) plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[1,0]],[pcatran_Y[0,1],pcatran_Y[1,1]],c="b",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[2,0]],[pcatran_Y[0,1],pcatran_Y[2,1]],c="r",marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter3.jpg') plt.pause(1) plt.close() def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca3d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca3d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() print("pca.singular_values_={}".format(pca.singular_values_)) s=6 X, Y = make_blobs(random_state=8, n_samples=100, n_features=6, cluster_std=4, centers=3) pca = PCA(n_components=6) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]] def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) #for kx, ky,kz, name in zip(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], labels): #ax.text(kx, ky,kz, name, alpha=0.8, size=20) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) #ax.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], c = "b", marker = "*", s = 100) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca6d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print(v_pca0[0],v_pca0[1],v_pca0[2]) pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca6d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3,4,5,6], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca6d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() print("pca.singular_values_={}".format(pca.singular_values_))
- 投稿日:2019-03-01T23:38:56+09:00
【機械学習入門】「PCA主成分分析;多変量解析」をグラフで見える化♬
今回はわかりやすいと思うので、ちょっと理論から入ることとする。
データを$x_i=(x_{i1},…,x_{id})^T$, $(i=1,…,N)$、ここで$d$は独立な測定項目の次元である。
データ行列を $X=(x_i,…,x_{N})^T$ 、原点を平均 $\bar{x} = \sum_{i=1}^{N}x_{i}$としたデータ行列を $\bar{X}=(x_i−\bar{x},…,x_{N}−\bar{x})^{T}$とすると、PCA主成分分析は$S=\frac{1}{N}\bar{X}^{T} \bar{X}$という共分散行列を使って、以下のようないわゆる固有値問題となる。Su=λuを解いて固有値を求めて$S$を対角化し、新たな主軸(分散の大きい順に第一主成分、第二主成分。。。)を求めることである。
ここでこの固有ベクトルが新たな主軸の軸方向を示しており、この固有ベクトルを利用すると、P^{-1}SPと対角化できる。そして、元の方程式は以下のように変形でき、変換テンソルPは固有ベクトル$u_1,u_2,u_3...$で以下のように書けることが分かる。
P^{-1}SP P^{-1}u=λP^{-1}u \\ P=(u_1,u_2,u_3...)つまり、このPを使って、新たな主軸(基底という)における各座標が
P^{-1}uで求められることが分かる。
また、この固有値を$s_k$とすると、各成分の寄与は以下のようになる。c_k=\frac{s_k}{V_{total}}ここで重要なことは、上記の共分散行列の各行列要素は比例していないことが前提となる。すなわち測定項目間の相関が無いかあるいはあっても小さいことが前提条件になる。
今回はこの対角化の様子を多変量解析についてグラフ化して見える化することを試みる。
手法は前回の3D見える化と同じであるが、上式の新たな座標上の点への座標変換$P^{-1}u$を利用して示そうと思う。
【参考】
・[Python][Scikit-learn]主成分分析を用いた次元削減、主成分ベクトルを用いた予測と線形回帰による予測の比較
・主成分分析と固有値問題@Aidemy Blog
・固有値問題・固有空間・スペクトル分解@武内修@筑波大やったこと
・最初の一歩2次元
・三次元でGifアニメーション
・六次元を3DGifアニメーション・最初の一歩2次元
説明はこの2次元の場合が分かりやすい。
import numpy as np from sklearn.decomposition import PCA import matplotlib.pyplot as pltデータはscikit_learnの例から以下のとおりのものを使う。
【参考】
・sklearn.decomposition.PCAX = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])まず、2次元のPCA分析を実施する。
そして、その結果として、主成分方向のベクトルv_pca0と第二主成分方向のベクトルv_pca1が以下のとおり、得られる。pca = PCA(n_components=2) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1]このベクトルはそれぞれ以下のとおり求められる。
X_pca0=[0,1*v_pca0[0]] Y_pca0=[0,1*v_pca0[1]] X_pca1=[0,1*v_pca1[0]] Y_pca1=[0,1*v_pca1[1]]元々の空間で入力座標をプロットする。
さらに、上記で求めた第一主成分(赤)と第二主成分(青)のベクトルをプロットする。plt.scatter(X[:,0],X[:,1],c="g",marker = "*") plt.plot(X_pca0,Y_pca0,c="r",marker = "o") plt.plot(X_pca1,Y_pca1,c="b",marker = "o") plt.savefig('k-means/pca_example/pca_data_scatter.jpg') plt.pause(1) plt.close()第一主成分が赤い線の方向、第二主成分が青い線の方向である。
次に固有値ベクトルを利用して、測定点Xと主成分ベクトルYを変換して、変換された座標上にプロットする。この変換はscikit-learnではPCAの関数pca.transform()を利用して以下のとおり変換できる。Y=np.array([[0,0],[v_pca0[0],v_pca0[1]],[v_pca1[0],v_pca1[1]]]) pcatran_X = pca.transform(X) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y))そして、変換された座標上に以下のとおりプロットする。
plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[0,1]],[pcatran_Y[2,0],pcatran_Y[2,1]],c="b") plt.plot([pcatran_Y[2,0],pcatran_Y[2,1]],[pcatran_Y[0,0],pcatran_Y[0,1]],c="r") #,marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter.jpg') plt.pause(1) plt.close()まともな方向にプロットされ、新しい座標軸も第一主成分及び第二主成分方向になった。
次に、これらの成分の寄与を以下のように求める。s=2 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca2d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()
・三次元でGifアニメーション
次元が増えるだけで、同じ流れで進みます。
データは、以下のようにmake_blobsで生成しました。from sklearn.datasets import make_blobs X, Y = make_blobs(random_state=8, n_samples=100, n_features=3, cluster_std=4, centers=3)PCA分析の成分は3とします。そして、3つの成分ベクトルが求まります。
そして、それぞれの方向のベクトルを定義します。pca = PCA(n_components=3) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]]座標軸は3次元なので、以下のように立体的に描画します。
def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca3d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)
3次元でも同じようにYを定義して、一括変換して新たな座標上のベクトルを求め、スナップを書いてみます。Y=np.array([[0,0,0],[10*v_pca0[0],10*v_pca0[1],10*v_pca0[2]],[10*v_pca1[0],10*v_pca1[1],10*v_pca1[2]],[10*v_pca2[0],10*v_pca2[1],10*v_pca2[2]]]) print(Y) pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y)) plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[1,0]],[pcatran_Y[0,1],pcatran_Y[1,1]],c="b",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[2,0]],[pcatran_Y[0,1],pcatran_Y[2,1]],c="r",marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter3.jpg') plt.pause(1) plt.close()
次に新しい座標軸上に3dプロットします。def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca3d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)今回は変換された軸上にプロットしているので、軸の記載はしていません。
最後に寄与のグラフは以下のとおりになっています。s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca3d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()第一主成分とそん色なく第二主成分や第三主成分の広がりがあるように見えますが、寄与は以下のとおり、70%,19%,11%程度になっています。
・六次元を3DGifアニメーション
次元、広がり、そして3中心(n_features=6,cluster_std=4,centers=3)で生成しました。
s=6 X, Y = make_blobs(random_state=8, n_samples=100, n_features=6, cluster_std=4, centers=3)上と同じように、固有ベクトルはとりあえず第三主成分まで求めます。
pca = PCA(n_components=6) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]]そして、以下のように三次元プロットをします。
def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca6d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)
今回も同じように固有ベクトルで変換し、3dプロットします。pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca6d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle)
以下のようにそれぞれの成分の寄与を見ます。print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3,4,5,6], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca6d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close()第三成分までで、45%,25%,10%で80%程度をカバーしています。
まとめ
・固有値問題としてのPCA分析の理論を見た
・二次元、三次元、そして六次元の場合について座標変換の様子を見た
・こうして次元圧縮の様子が分かった・これをベースにさらなるクラスタリング手法と利用を見ていく
おまけ
【参考】
・機械学習 〜 データセット生成 〜import numpy as np from sklearn.decomposition import PCA import matplotlib.pyplot as plt from pandas.tools import plotting # 高度なプロットを行うツールのインポート import pandas as pd from mpl_toolkits.mplot3d import Axes3D X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) pca = PCA(n_components=2) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] X_pca0=[0,1*v_pca0[0]] Y_pca0=[0,1*v_pca0[1]] X_pca1=[0,1*v_pca1[0]] Y_pca1=[0,1*v_pca1[1]] plt.scatter(X[:,0],X[:,1],c="g",marker = "*") plt.plot(X_pca0,Y_pca0,c="r",marker = "o") plt.plot(X_pca1,Y_pca1,c="b",marker = "o") plt.savefig('k-means/pca_example/pca_data_scatter.jpg') plt.pause(1) plt.close() print(v_pca0[0],v_pca0[1]) Y=np.array([[0,0],[v_pca0[0],v_pca0[1]],[v_pca1[0],v_pca1[1]]]) print(Y) pcatran_X = pca.transform(X) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y)) plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[0,1]],[pcatran_Y[2,0],pcatran_Y[2,1]],c="b") plt.plot([pcatran_Y[2,0],pcatran_Y[2,1]],[pcatran_Y[0,0],pcatran_Y[0,1]],c="r") #,marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter.jpg') plt.pause(1) plt.close() print("v_pca0={},v_pca1={}".format(v_pca0,v_pca1)) s=2 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca2d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() print("pca.singular_values_={}".format(pca.singular_values_)) from sklearn.datasets import make_regression #X, Y, coef = make_regression(random_state=12, n_samples=100, n_features=3, n_informative=2, noise=10.0, bias=-0.0, coef=True) from sklearn.datasets import make_blobs X, Y = make_blobs(random_state=8, n_samples=100, n_features=3, cluster_std=4, centers=3) pca = PCA(n_components=3) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]] def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) #for kx, ky,kz, name in zip(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], labels): #ax.text(kx, ky,kz, name, alpha=0.8, size=20) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) #ax.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], c = "b", marker = "*", s = 100) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca3d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print(v_pca0[0],v_pca0[1],v_pca0[2]) Y=np.array([[0,0,0],[10*v_pca0[0],10*v_pca0[1],10*v_pca0[2]],[10*v_pca1[0],10*v_pca1[1],10*v_pca1[2]],[10*v_pca2[0],10*v_pca2[1],10*v_pca2[2]]]) print(Y) pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) pcatran_Y = pca.transform(Y) print("pcatran_Y={}".format(pcatran_Y)) plt.scatter(pcatran_X[:,0],pcatran_X[:,1],c="g",marker = "*") plt.scatter(pcatran_Y[:,0],pcatran_Y[:,1],c="r",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[1,0]],[pcatran_Y[0,1],pcatran_Y[1,1]],c="b",marker = "o") plt.plot([pcatran_Y[0,0],pcatran_Y[2,0]],[pcatran_Y[0,1],pcatran_Y[2,1]],c="r",marker = "o") plt.savefig('k-means/pca_example/pca_tran_scatter3.jpg') plt.pause(1) plt.close() def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca3d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca3d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() print("pca.singular_values_={}".format(pca.singular_values_)) s=6 X, Y = make_blobs(random_state=8, n_samples=100, n_features=6, cluster_std=4, centers=3) pca = PCA(n_components=6) pca.fit(X) v_pca0=pca.components_[0] v_pca1=pca.components_[1] v_pca2=pca.components_[2] X_pca0=[0,10*v_pca0[0]] Y_pca0=[0,10*v_pca0[1]] Z_pca0=[0,10*v_pca0[2]] X_pca1=[0,10*v_pca1[0]] Y_pca1=[0,10*v_pca1[1]] Z_pca1=[0,10*v_pca1[2]] X_pca2=[0,10*v_pca2[0]] Y_pca2=[0,10*v_pca2[1]] Z_pca2=[0,10*v_pca2[2]] def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) #for kx, ky,kz, name in zip(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], labels): #ax.text(kx, ky,kz, name, alpha=0.8, size=20) ax.plot(X_pca0,Y_pca0,Z_pca0, c='b', marker='o', alpha=0.5, label='1st pricipal') ax.plot(X_pca1,Y_pca1,Z_pca1, c='r', marker='o', alpha=0.5, label='2nd principal') ax.plot(X_pca2,Y_pca2,Z_pca2, c='g', marker='o', alpha=0.5, label='3rd principal') ax.scatter(X[:, 0], X[:, 1], X[:, 2], c="b", marker='o', alpha=1) #ax.scatter(kmeans_model.cluster_centers_[:,0], kmeans_model.cluster_centers_[:,1], kmeans_model.cluster_centers_[:,2], c = "b", marker = "*", s = 100) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_zlabel('z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/pca6d/keiba3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print(v_pca0[0],v_pca0[1],v_pca0[2]) pcatran_X = pca.transform(X) print("pcatran_X={}".format(pcatran_X)) def show_with_angle(angle): fig = plt.figure() ax = fig.add_subplot(111, projection='3d') ax.view_init(elev = 10., azim = angle) ax.scatter(pcatran_X[:, 0], pcatran_X[:, 1], pcatran_X[:, 2], c="b", marker='o', alpha=1) ax.set_xlabel('tran_x') ax.set_ylabel('tran_y') ax.set_zlabel('tran_z') ax.legend() plt.pause(0.01) plt.savefig('k-means/pca_example/tran_pca6d/pca3_PCA3d_angle_'+str(angle)+'.jpg') plt.close() for angle in range(0, 360, 5): show_with_angle(angle) print("v_pca0={},v_pca1={},v_pca2={}".format(v_pca0,v_pca1,v_pca2)) s=3 print("pca.explained_variance_ratio_{}".format(pca.explained_variance_ratio_)) plt.bar([1, 2,3,4,5,6], pca.explained_variance_ratio_, align = "center",label="pca.explained_variance_ratio_={}".format(pca.explained_variance_ratio_)) plt.title("pca.explained_variance_ratio_") plt.xlabel("components") plt.ylabel("contribution") plt.legend() plt.savefig('k-means/pca_example/pca6d_contribution_PCA12_plotSn'+str(s)+'.jpg') plt.pause(1) plt.close() print("pca.singular_values_={}".format(pca.singular_values_))
- 投稿日:2019-03-01T23:34:39+09:00
Pythonによるフィボナッチ数列の色々な求め方(一般項、反復法、再帰法)
はじめに
その性質からプログラミング入門によく使われるフィボナッチ数列。私はこのフィボナッチ数列が大好きで、プログラミングを楽しいと感じたきっかけであるとさえ思っています。
さて、個人的な話はさておき、今回はPython3でフィボナッチ数列を以下に示す3通りの方法で求めてみます。各々の求め方の話はネット上に転がっていますが、それらがまとまった解説ページは(私が探した限りでは)見つからなかったので、個人的な備忘録も兼ねて書いてみました。
- 一般項から求める方法
- 反復的な(forで回す)解法
- 再帰的な解法(メモ化も含む)
フィボナッチ数列の定義
フィボナッチ数列とは二つの初期条件(初項$F_0=0$,第二項$F_1=1$)を持つ 1 漸化式$F_n=F_{n-1}+F_{n-2}$で表される数列です。具体的には0,1,1,2,3,5,8,13,21,34,55,...です。
この数列はもちろん数学的にも重要な意味を持つのですが、for構文や再帰関数の理解に最適なため、プログラミング入門で扱うのに適しています。一般項から求める方法
フィボナッチ数列には一般項があり、それは以下の数式で表されます。
F_n=\frac{1}{\sqrt{5}}\left\{\left(\frac{1+\sqrt{5}}{2}\right)^n-\left(\frac{1-\sqrt{5}}{2}\right)^n\right\}ではこの式を使ってフィボナッチ数列の第n項を求めてみましょう。ただし、第n項のフィボナッチ数は$F_{n-1}$であることに注意しましょう。
Pythonでこういうことをするときは大抵の場合、高機能数値計算モジュールであるnumpyを使うと思います。この記事でもnumpyを使えばよいのでしょうが、独自性を出すため&個人的にsympyの方がなじみ深いため、代数計算モジュールであるsympyを使います。general_term.pyimport sympy as sym #sympyのインポート def Fib(n): x = sym.symbols('x',nonnegative=True,integer=True) #変数xの宣言(非負の整数) Fib=1/sym.sqrt(5)*(((1+sym.sqrt(5))/2)**(n-1)-((1-sym.sqrt(5))/2)**(n-1)) #一般項の式 result=Fib.subs(x,n) #xにnを代入 result=result.evalf() #式を浮動小数点数として評価 return int(result)試しにn=1,2,...,10で計算してみます。
Fiblist=[] for n in range(1,10): Fiblist+=[Fib(n)] print(Fiblist) # [0, 1, 1, 2, 3, 5, 8, 13, 21]実際の値と一致しているので成功してそうです。
ちなみに リスト内法表記 を使うと以下のように書けます。こちらの方が簡略なので以降はこちらを使います。
print([Fib(n) for n in range(1,10)]) # [0, 1, 1, 2, 3, 5, 8, 13, 21]プログラミングのロジックとしてはこの数値計算をするだけの方法が最も簡単です。裏を返せばプログラミング入門には向かないということですが。
精度について
実装した関数の精度について検証してみましょう。ただ、これはこの記事の本質ではないので読み飛ばしてもらって構いません。
以下の記述は フィボナッチ数列の一般項について を参考にしました。101番目のフィボナッチ数
では101番目のフィボナッチ数を求めてみます。
print(Fib(101)) # 354224848179261931520101 番目の本当のフィボナッチ数は $354224848179261915075$ ですから、参考記事と同様に値が違ってしまいます。
精度の改善
それでは精度を改善していきましょう。
参考記事では計算方法を変えていますが、本記事ではsympyで実装しているのでsympyの便利な機能が使えます。さきほど示したコード内でも使用している浮動小数点数評価の関数evalf()は引数に任意の自然数をとり、有効数字を指定することができます。これを使うと任意精度でフィボナッチ数をフィボナッチ数を求められるというわけです。
しかし、この方法にはこんな問題があります。例えば100番目のフィボナッチ数は21桁なのでevalf(21)とすれば必要十分な精度が得られます。ただ、3番目のフィボナッチ数を求めるのに21桁の精度は必要ありません。また1000番目のフィボナッチ数を求めるのに21桁では精度が足りません。任意精度で結果が得られるのは良いものの、必要な精度が分からないのです。
この記事を書くにあたって オンライン整数列大辞典のフィボナッチ数列の項目のグラフ を見ていると、解決の手掛かりが得られました。フィボナッチ数列の桁数は線形的に増加し、その係数は$\frac{3}{14}$程度であるということが分かったのです。
改善版のコードは以下の通りです。general_term_improved.pyimport sympy as sym def FibRe(n): x = sym.symbols('x',nonnegative=True,integer=True) Fib=1/sym.sqrt(5)*(((1+sym.sqrt(5))/2)**(n-1)-((1-sym.sqrt(5))/2)**(n-1)) result=Fib.subs(x,n) result=result.evalf(int(n*3/14)+1) #精度の指定 return int(result)精度を確かめましょう。
print(FibRe(101)) # 354224848179261915075 import sys sys.setrecursionlimit(15000) #再帰計算の上限を指定(詳しくは参考記事参照) print(FibRe(10001)) # 336447648764...(中略)...7366875 (2090桁)101番目に関しては先ほど示した真値と一致しています。
また、こちらのサイトで確認したところ、10001番目でも正確な値が得られているようです。一般項の求解
sympyには漸化式(階差方程式)の解を求めることができる機能があるので、もし一般項の式を知らなくても導出してしまえばよいのです。
import sympy as sym f = sym.simplify("f(n)") #求める解 s = sym.simplify("f(n)-f(n-1)-f(n-2)") #漸化式(s=0となるように記述する) ini = sym.simplify({"f(0)":0,"f(1)":1}) #初期条件({0:0,1:1}としても良い) FibGeneralTerm = sym.rsolve(s,f,ini) #初期条件iniの漸化式sをfについて解く print(FibGeneralTerm) # sqrt(5)*(1/2 + sqrt(5)/2)**n/5 - sqrt(5)*(-sqrt(5)/2 + 1/2)**n/5このように一般項の求解ができます。
反復的な(forで回す)解法
これがプログラミング入門としてフィボナッチ数列を扱う際の最もオーソドックスな解法でしょう。
私たちが「n番目のフィボナッチ数列を求めて」と言われて暗算する時も大抵はこの方法を使うと思います。
Python3では以下のように書くことができます。repetition.pydef Fib(n): a, b = 0, 1 if n == 1: return a elif n == 2: return b else: for i in range(n-2): a, b = b, a + b return b出力を確認してみましょう。
print([Fib(n) for n in range(1,10)]) # [0, 1, 1, 2, 3, 5, 8, 13, 21]一般式を用いた方法と違い、整数の計算なので何番目であろうと誤差はありません。
引数をとる自作関数が含まれ、if文やfor文の理解が不可欠なこのコードはやはりプログラミング入門に最適でしょう。
再帰的な解法
そもそもフィボナッチ数列は漸化式で再帰的に定義されているので、最も可読性の高いコードを書くことができるのはこの解法だと思います。
Pythonの基礎文法を学んだあとに少し発展的な内容として再帰関数を学ぶのに最適な解法です。recursion.pydef Fib(n): if n == 1: return 0 elif n == 2: return 1 else: return Fib(n-1)+Fib(n-2)初期条件2つと漸化式を記述するだけなので(慣れれば)簡単です。
出力を確認してみます。print([Fib(n) for n in range(1,10)]) # [0, 1, 1, 2, 3, 5, 8, 13, 21]それぞれの方法の演算速度
方法によって演算速度が異なります。それらを比較してみましょう。
演算速度はtimeモジュールを使うことで以下のように調べられます。import time start=time.time() hoge() #速度を調べたい処理 end=time.time() print(f'処理にかかった時間は{end-start}秒です。')前述した3通りの方法2でn回
Fib(40)を計算して平均値を出します。
用いるコードは以下の通りです。import time n=10 # 再帰法以外ではn=1000とする(処理時間が短くうまく計測できないため) start=time.time() for i in range(n): Fib(40) end=time.time() print(f'処理にかかった平均時間は{(end-start)/n}秒です。')結果を以下の表にまとめました。
方法 処理にかかった平均時間(秒) 一般項を用いる解法 1.228e-03 反復的な解法 1.995e-06 再帰的な解法 24.52 環境によって速度は異なるのでこの値は絶対ではありませんが、重要なのはそれぞれの方法の相対的な処理時間です。
表を見ると再帰法が圧倒的に遅いことが分かります。再帰法は何故遅い?
再帰法が遅い理由は端的に言うと「演算回数が多いから」です。この図をみてください。
これは再帰法によるFib(5)の演算の概念図です。Fib(n)のnが大きくなると爆発的な勢いで演算回数が多くなります。では他の方法はどうなのでしょうか。それぞれの方法のnに応じた演算回数の特徴を表にまとめました。
方法 演算回数の特徴 一般項を用いる解法 (内容は複雑だが)どんなnに対しても1回 反復的な解法 nに応じて演算回数が線形的に増加する 再帰的な解法 nに応じて演算回数が指数関数的に増加する この特徴から、反復法より一般項の方が速いんじゃないかと思う人がいると思いますが、一般項の計算に用いている方法は全く最適化していないので反復法より遅いです(
Fib(10000)でも試してみましたが、それでも反復法の方が5倍くらい速いです)。誰か最適化の方法を知っている人は教えてください。さて、反復法は速く、再帰法は遅いというのが分かりました。でも再帰法は「あること」をすることで反復法並み、もしくはそれ以上の速さを手に入れることができます。それはメモ化です。
メモ化
再帰法はさきほど概念図に示した通り、何度も同じ関数を呼び出しています。その呼び出しのたびに演算をするため、処理が遅いのです。この問題を解決するのが「メモ化」です。
メモ化の理念
一度呼び出した関数を再び使う時に再演算しなくて済むように、一度呼び出した関数の戻り値をメモに保存しておいて、2回目以降呼び出されたときはメモに書かれた値を使う、というのがメモ化の理念です。
例えば、先ほど示した概念図をみて分かる通りFib(4)は4回、Fib(5)は8回関数を呼び出します。そのため、メモ化無しだとFib(6)を計算するのに12回関数を呼び出す必要があります。しかし、Fib(5)はすでに求めたFib(4)をわざわざもう一回求めなおしています。このFib(4)の戻り値をメモに保存して以降はそれを使うようにすると、Fib(6)は9回の呼び出しで済みます(Fib(3)もメモ化することで8回となります)。メモ化の実装
関数が呼び出されたらメモに既にその関数の戻り値が保存されてないかを確認し、保存されていたらメモの値を返し、保存されていなかったらメモにその戻り値を書き込む。これがメモ化の根幹のアルゴリズムです。
実装例1
Pythonで再帰フィボナッチのメモ化 で見た方法です。空リストと入れ子構造になったdefを使ってメモ化を実現しています。参照記事のコードを本記事の他コードと整合するように少し書き換えたものがこちらです。
recursion_memo1.pydef fib_memo(n): memo=["EMPTY"]*(n+1) def _fib(n): if n == 1: return 0 elif n == 2: return 1 elif memo[n] != "EMPTY": return memo[n] else: memo[n] = _fib(n-1)+_fib(n-2) return memo[n] return _fib(n)10000回
Fib(40)を計算して平均値をとると、その平均処理速度は1.999e-05秒でした。単純な再帰法よりかなり速くなっています(構造が複雑な分、反復法よりは劣りますが)。実装例2
辞書型を使う方法もあります。また、defを入れ子にせずとも、2つ引数を持つ関数にすればメモを保持できます。この方法は事前にメモがあればそれを使えるというメリットがあります。
recursion_memo2.pydef Fib(n, memo={}): if n == 1: return 0 elif n == 2: return 1 elif n in memo: return memo[n] else: memo[n] = Fib(n-1,memo)+Fib(n-2,memo) return memo[n]同様に10000回
Fib(40)を計算して平均値をとると、その平均処理速度は1.998e-07秒でした。
実装例1より単純な(速く計算できる)構造なため、反復法より速く演算できています。実装例3
Pythonにはfunctoolsモジュールという高階関数用のモジュールがあり、それを使えば非常に簡単にメモ化が実装できます。ただ、ブラックボックスなのでメモ化のアルゴリズムの勉強にはなりません(モジュールのソースコードを読める人なら別ですが)。
recursion_memo3.pyfrom functools import lru_cache @lru_cache(maxsize=None) def Fib(n): if n == 1: return 0 elif n == 2: return 1 else: return Fib(n-1) + Fib(n-2)同様に10000回
Fib(40)を計算して平均値をとると、その平均処理速度は1.199e-07秒でした。
どの実装例よりも速く演算できています。実用的にはこの方法が最適でしょう。補足:行列を使ったフィボナッチ数列の求め方
とある2*2行列のべき乗を使うとフィボナッチ数列を計算することができます。それには自然数nについて成り立つ以下の定理を用います。
A = \left(\begin{array}{rrr}1 & 1 \\1 & 0\end{array}\right)においてA^{n-1}の1行1列要素はF_nと等しいこれを用いてフィボナッチ数列を求めるプログラムをsympyで実装しましょう。ただし、第n項のフィボナッチ数は$F_{n-1}$であることに注意しましょう。
array.pyimport sympy as sym def Fib(n): if n==1: return 0 else: A = sym.Matrix([ [1,1], [1,0] ]) FibArray=A**(n-2) return FibArray[0,0] #試しに計算してみる print([Fib(n) for n in range(1,10)]) # [0, 1, 1, 2, 3, 5, 8, 13, 21]10000回
Fib(40)を計算して平均値をとると、その平均処理速度は1.699e-04秒でした。反復法に一歩及ばないといったところでしょうか。逐次平方というメモ化に似たテクニックを使えばもっと速くなると思います。おわりに
この記事ではPythonでフィボナッチ数列を求める色々な方法をまとめて紹介しました。フィボナッチ数列の面白さやプログラミングの楽しさが共有できたならば幸いです。
個人的な話をすると、この記事が私の初投稿なのですが、Markdown記法に慣れず、調べながら書いたので思ったより時間がかかってしまいました。
誤字脱字や誤った記述、更に良いアルゴリズム、気づいたこと、感想などがあればぜひコメントをください。記事中に示したもの以外の参考文献
フィボナッチ数 - Wikipedia
sympyで「フィボナッチ数(Fibonacci number)」の一般項を出力してみた
1.2.4 べき乗 - SCIP
フィボナッチ数列の任意の項を高速に計算する方法
問題解決のPythonプログラミング

- 投稿日:2019-03-01T22:55:44+09:00
CNN with Layer Reuseの論文を読んだので要点まとめ
CNNの畳み込み層を再利用することにより、パラメータ数とメモリ使用量の大幅な削減を可能にする論文を読んだので要点をまとめます
論文リンク
最初にリンクを貼っておきます
https://arxiv.org/pdf/1901.09615.pdf
github
https://github.com/okankop/CNN-layer-reuse/tree/master/models論文の概要
1. Introduction
AlexNetの最初の層の重みを可視化すると、色付けしたところのように、かなり似た重みが多い(Fig 2)
そのため、多くのConvolution層を用意してもそれは無駄なのではないか?
下の図のように、Convolution層を再利用すれば、パラメータの数やメモリ使用量の削減に繋がるのではないか? (Fig 1)
これを以降、Layer Reuse Network (LruNet) と呼ぶことにする。
2. Approach
2.1 Layer Reuse (LRU)
層の再利用(Layer Reuse)は以下のように行う(Fig 3)
DwConvとPwConvを順に作用させ、それと入力をconcatさせて、Channelをシャッフルする
- PwConvの
group=8は実験的に求められた値であるChannel Shuffleは、suffleNet を参考にしたが、元々の実装では最初と最後のチャンネルがシャッフルされないままだったので、単純にチャンネルの前半と後半を入れ替えてシャッフルした(注) DwConvとPxConvについて参考
DwConv(depth wise convolution)
https://www.robotech-note.com/entry/2017/12/27/084952
PxConv(pixel wise convolution)
https://www.robotech-note.com/entry/2017/12/24/191936
2.2 NetworkArchitecture
LruNetのアーキテクチャは以下のようになっている (Table 1)
- Nは何回LRU Blockを繰り返すかを示している。
- この表には記載されていないが、$\alpha$(width multiplier)という変数があり、これは最初のConv層の出力を何倍にconcatして広げるかという値である。(githubに
width_multという変数名で書かれているのでそちらを参照するとわかりやすい)これらをまとめて、N-LruNet- αxという名前で呼ぶこととする。
3. Experiments
Table 2は各種類のLruNetのCIFAR10での精度を示している。
14-LruNet-1xがもっとも精度が良く、それ以上にNを大きくしても精度の向上は見られなかった。
Convolution層のパラメータ数はどれも等しく125kであるが、Nの値が大きくなるにつれパラメータ数が増加しているのは、Bach Normalization層が増えていくからである。
Table 3はchannel shufflingを加えた場合を加えなかった場合の精度を示している。
channel shufflingを行なったほうが精度が良くなることがわかる。
Table 4: パラメータ数をかなり抑えて同等の精度が出せる
Table 5: CIFER-100で実行した結果
width multiplierを2にしてdropoutを0.7にあげて実行している
Table 6: Fashion MNISTでの結果
Table 7:各データセットでの実行結果のまとめ
LruNetはパラメータ数は小さいが、ほかのモデルとほぼ同等の性能を持っている










- 投稿日:2019-03-01T20:31:36+09:00
No.042【Python】pprintの使い方
今回は、pprintの使いかたについて書いていきます。
I'll write about "how to use "pprint"
■ pprintモジュール
リスト(list型)や辞書(dict型)などのオブジェクトを綺麗に出力・表示、 また、文字列(str型オブジェクト)に変換することが可能。 You can output and indicate objects such as lists and dictionaries with better loonking.>>> # pprintの使い方 >>> >>> >>> import pprint >>> l = [{"Name": "Youtarin XXX", "Age":18, "Points":[70, 30]},{"Name": "No-tarin YYY", "Age":19, "Points":[40, 60]},{"Name": "tarin ZZZ", "Age":20, "Points":[50, 50]}] >>> >>> print(l) [{'Name': 'Youtarin XXX', 'Age': 18, 'Points': [70, 30]}, {'Name': 'No-tarin YYY', 'Age': 19, 'Points': [40, 60]}, {'Name': 'tarin ZZZ', 'Age': 20, 'Points': [50, 50]}]■ 出力幅を指定:width
Indicate the number of strings:width
>>> # 文字数を引数widthで指定することが可能 >>> >>> pprint.pprint(l, width=40) [{'Age': 18, 'Name': 'Youtarin XXX', 'Points': [70, 30]}, {'Age': 19, 'Name': 'No-tarin YYY', 'Points': [40, 60]}, {'Age': 20, 'Name': 'tarin ZZZ', 'Points': [50, 50]}]>>> # 大きな値を指定すると、改行挿入されずprint()と同様の出力となる >>> >>> pprint.pprint(l, width=150) [{'Age': 18, 'Name': 'Youtarin XXX', 'Points': [70, 30]}, {'Age': 19, 'Name': 'No-tarin YYY', 'Points': [40, 60]}, {'Age': 20, 'Name': 'tarin ZZZ', 'Points': [50, 50]}]>>> # 改行されるのはリストや辞書の要素ごと >>> # keyとvalueで改行、数値の途中で改行されしない >>> >>> pprint.pprint(l, width = 1) [{'Age': 18, 'Name': 'Youtarin ' 'XXX', 'Points': [70, 30]}, {'Age': 19, 'Name': 'No-tarin ' 'YYY', 'Points': [40, 60]}, {'Age': 20, 'Name': 'tarin ' 'ZZZ', 'Points': [50, 50]}] >>> # ↑ 文字列は単語ごとに改行される■ 出力要素の深さを指定:depth
Indicate the depth of output factors
>>> # 指定した値より深い要素は省略記号にて出力される >>> >>> pprint.pprint(l, depth = 1) [{...}, {...}, {...}] >>> >>> pprint.pprint(l, depth = 2) [{'Age': 18, 'Name': 'Youtarin XXX', 'Points': [...]}, {'Age': 19, 'Name': 'No-tarin YYY', 'Points': [...]}, {'Age': 20, 'Name': 'tarin ZZZ', 'Points': [...]}] >>> >>> # デフォルトはdepth=Noneで全ての要素が省略されず出力される>>> # widthの組み合わせでも可能 >>> # 改行される場所は width で指定する文字数に依存する >>> >>> pprint.pprint(l, depth = 2, width = 40) [{'Age': 18, 'Name': 'Youtarin XXX', 'Points': [...]}, {'Age': 19, 'Name': 'No-tarin YYY', 'Points': [...]}, {'Age': 20, 'Name': 'tarin ZZZ', 'Points': [...]}]■ インデント幅の指定:indent
Indicate indent width
>>> # インデント幅を引数 indentで指定できる >>> # デフォルトは indent = 1 >>> >>> pprint.pprint(l, indent = 4, width = 4) [ { 'Age': 18, 'Name': 'Youtarin ' 'XXX', 'Points': [ 70, 30]}, { 'Age': 19, 'Name': 'No-tarin ' 'YYY', 'Points': [ 40, 60]}, { 'Age': 20, 'Name': 'tarin ' 'ZZZ', 'Points': [ 50, 50]}]■ 改行を最小限にする:compact
Minimize new lines:compact
>>> # デフォルトで width に収まらない場合、全ての要素は改行される >>> >>> l_long = [list(range(10)), list(range(100, 120))] >>> >>> print(l_long) [[0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119]]>>> # compactを"True"とすると"width"に収まらない分改行される >>> # 要素数の多いリストがある場合、compact = Trueの方が見やすい >>> >>> pprint.pprint(l_long, width = 40, compact = True) [[0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119]]■ 文字列に変換: pprint.pformat()
Convert to strings
>>> # 辞書やリストはstr( )で文字列に変換できる >>> >>> s_normal = str(l) >>> >>> print(s_normal) [{'Name': 'Youtarin XXX', 'Age': 18, 'Points': [70, 30]}, {'Name': 'No-tarin YYY', 'Age': 19, 'Points': [40, 60]}, {'Name': 'tarin ZZZ', 'Age': 20, 'Points': [50, 50]}] >>> >>> print(type(s_normal)) <class 'str'>>>> # pprint.pformat():適宜改行が挿入され、整形された文字列として取得可能 >>> >>> s_pp = pprint.pformat(l) >>> >>> print(s_pp) [{'Age': 18, 'Name': 'Youtarin XXX', 'Points': [70, 30]}, {'Age': 19, 'Name': 'No-tarin YYY', 'Points': [40, 60]}, {'Age': 20, 'Name': 'tarin ZZZ', 'Points': [50, 50]}] >>> >>> print(type(s_pp)) <class 'str'>>>> # pprint.pformat() = pprint.pprint() >>> >>> s_pp = pprint.pformat(l, depth = 2, width = 40, indent = 2) >>> >>> print(s_pp) [ { 'Age': 18, 'Name': 'Youtarin XXX', 'Points': [...]}, { 'Age': 19, 'Name': 'No-tarin YYY', 'Points': [...]}, { 'Age': 20, 'Name': 'tarin ZZZ', 'Points': [...]}]■ 二次元配列の整形
Shaping a two-dimensional array
>>> # pprintは二次元配列表示の際は便利 >>> >>> l_2d = [list(range(10)), list(range(10)), list(range(10))] >>> >>> print(l_2d) [[0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]] >>> >>> pprint.pprint(l_2d) [[0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]>>> # 要素数が少ない場合、デフォルトのwidth = 80 に収まるため改行されない >>> >>> l_2d = [[0, 1, 2], [3, 4, 5], [6, 7, 8]] >>> >>> print(l_2d) [[0, 1, 2], [3, 4, 5], [6, 7, 8]] >>> >>> pprint.pprint(l_2d) [[0, 1, 2], [3, 4, 5], [6, 7, 8]]>>> # 改行表示したい場合 widthを適宜指定する >>> >>> pprint.pprint(l_2d, width = 20) [[0, 1, 2], [3, 4, 5], [6, 7, 8]] >>> >>> # 文字列として取得したい場合:pprint.pformat( ) >>> >>> s = pprint.pformat(l_2d, width = 20) >>> >>> print(s) [[0, 1, 2], [3, 4, 5], [6, 7, 8]] >>> >>> print(type(s)) <class 'str'>随時に更新していきますので、
定期的な購読をよろしくお願いします。
I'll update my article at all times.
So, please subscribe my articles from now on.本記事について、
何か要望等ありましたら、気軽にメッセージをください!
If you have some requests, please leave some messages! by You-Tarin

- 投稿日:2019-03-01T20:26:13+09:00
Python-Selenium-Chrome でユーザープロフィールを指定してChromeを起動させたい
Python-Selenium-Chromeで、下記のページを参考に、既にChrome上で設定済みのユーザープロフィールを指定してChromeを起動させたいです。
【参考ページ】
Python + Selenium + Chrome で自動ログインいくつか
の『既存のユーザプロファイルを使う』の部分しかし、以下のようなコードでChromeを起動させると、下記のエラーが出てしまいます。
何が原因か、ご教示いただけたら幸いです。
よろしくfrom selenium import webdriver chrome_user_data_dir_path = 'C:\\Users\\[UserName]\\AppData\\Local\\Google\\Chrome\\User Data' chrome_user_profile_directory = 'Profile 1' options = webdriver.ChromeOptions() options.add_argument('--user-data-dir=' + chrome_user_data_dir_path) options.add_argument('--profile-directory=' + chrome_user_profile_directory) browser = webdriver.Chrome(options=options)[14396:9608:0301/174908.325:ERROR:cache_util_win.cc(19)] Unable to move the cache: 0 [14396:9608:0301/174908.328:ERROR:cache_util.cc(140)] Unable to move cache folder C:\Users\[UserName]\AppData\Local\Google\Chrome\User Data\ShaderCache\GPUCache to C:\Users\[UserName]\AppData\Local\Google\Chrome\User Data\ShaderCache\old_GPUCache_000 [14396:9608:0301/174908.329:ERROR:disk_cache.cc(184)] Unable to create cache [14396:9608:0301/174908.333:ERROR:shader_disk_cache.cc(622)] Shader Cache Creation failed: -2 Traceback (most recent call last): File "create_new_account.py", line 105, in <module> browser = webdriver.Chrome(options=options) File "C:\Users\[UserName]\Anaconda3\envs\py37\lib\site-packages\selenium\webdriver\chrome\webdriver.py", line 75, in __init__ desired_capabilities=desired_capabilities) File "C:\Users\[UserName]\Anaconda3\envs\py37\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 156, in __init__ self.start_session(capabilities, browser_profile) File "C:\Users\[UserName]\Anaconda3\envs\py37\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 251, in start_session response = self.execute(Command.NEW_SESSION, parameters) File "C:\Users\[UserName]\Anaconda3\envs\py37\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 320, in execute self.error_handler.check_response(response) File "C:\Users\[UserName]\Anaconda3\envs\py37\lib\site-packages\selenium\webdriver\remote\errorhandler.py", line 242, in check_response raise exception_class(message, screen, stacktrace) selenium.common.exceptions.InvalidArgumentException: Message: invalid argument: user data directory is already in use, please specify a unique value for --user-data-dir argument, or don't use --user-data-dir【バージョン】
OS:Windows 7(64 ビット)
Python 3.7.0
Chrome:72.0.3626.119(64 ビット)
- 投稿日:2019-03-01T19:18:21+09:00
openCV pythonチュートリアルの画像中の注目領域(ROI)において
opencv チュートリアル 「画像上の基本的な処理」のチュートリアル内の
画像中の注目領域(ROI)におけるNumpyのインデックス指定で少し戸惑ったので備忘録書きます。
ball = img[280:340, 330:390]
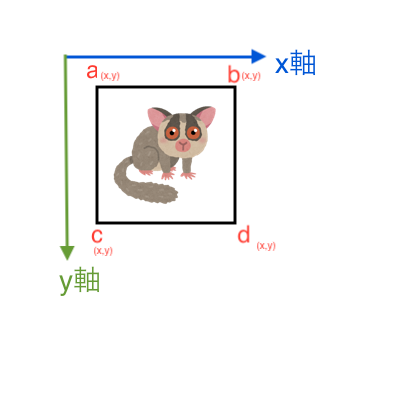
img[273:333, 100:160] = ballopencvは左上原点らしく、なので
この画像だとimg[Xa:Ya,Xd:Yd]だと勘違いしました。
実際はimg[Ya:Yd,Xa:Xd]だったみたいです。チュートリアルで実行してると???となったので書いときます。
以上!
- 投稿日:2019-03-01T18:57:51+09:00
PysparkのDataFrameで横持ちデータを縦持ちに変換する
はじめに
PysparkのDataFrameで縦→横の変換は簡単だけど、逆は結構難しいので備忘のために記載。
解決策
PySQLのbuldin関数のstackを使う。
引数は、stack(行数, クエリ1, クエリ2, ...)。
stackで指定した行数分、後続のクエリで指定した列を集計して、行数を膨らませるような処理を行う。このstack関数は、pysparkのfunctionでは提供されていない?ようなので、selectExprでSQLのselectクエリを記述して実行する。
サンプル
横持ち→縦持ちfrom pyspark.sql import functions as F # 横持ちで各列のNull値の件数を集計 null_count_pivot = df.select([F.count(F.when(F.col(c).isNull(), c).otherwise(None)) for c in df.columns]) # 横持ちを縦持ちに変換 null_count_unpivot = ( null_count_pivot .selectExpr( f""" stack( {len(df.columns)}, {', '.join(f'"{c}", {c}' for c in df.columns)} ) as (column, null_count) """ ) )参考
- 投稿日:2019-03-01T18:30:33+09:00
pythonでgRPC サーバを作る
前回の続きで、サーバ側を作ってみます
サーバを作ろう
サンプルを見るのが分かりやすい。前回生成した
xx_grpc.pyファイルを元に実装していきます。├── proto │ ├── __init__.py │ ├── create_proto.py │ ├── my_if.proto │ ├── my_if_pb2.py │ └── my_if_pb2_grpc.py └── server.py全ソースはgithubに。
# my_if_pb2_grpc.py # Generated by the gRPC Python protocol compiler plugin. DO NOT EDIT! import grpc from . import my_if_pb2 as my__if__pb2 # エラーになったので`from .`を追加しています # 中略 class MyGrpcServicer(object): """サンプルサービス """ def GetSomething(self, request, context): """なにかを受け取るRPC """ context.set_code(grpc.StatusCode.UNIMPLEMENTED) context.set_details('Method not implemented!') raise NotImplementedError('Method not implemented!') def add_MyGrpcServicer_to_server(servicer, server): rpc_method_handlers = { 'GetSomething': grpc.unary_unary_rpc_method_handler( servicer.GetSomething, request_deserializer=my__if__pb2.MyReq.FromString, response_serializer=my__if__pb2.MyResp.SerializeToString, ), } generic_handler = grpc.method_handlers_generic_handler( 'MyGrpc', rpc_method_handlers) server.add_generic_rpc_handlers((generic_handler,))# server.py from concurrent import futures import time import grpc from proto import my_if_pb2 from proto import my_if_pb2_grpc _ONE_DAY_IN_SECONDS = 60 * 60 * 24 # my_if_pb2_grpcのMyGrpcServicer()を実装 class MyGrpc(my_if_pb2_grpc.MyGrpcServicer): def GetSomething(self, request, context): # いろんな処理はここで print("Someone requested something!") # データ取得は`request.xxx`でできて分かりやすい print(f'int_param: {request.int_param}') print(f'str_param: {request.str_param}') # 必ず設定したresponseを返却する response = my_if_pb2.MyResp(status=200, message="Great message.") return response def serve(): server = grpc.server(futures.ThreadPoolExecutor(max_workers=10)) # MyGrpc()を使うよ!と登録しているかんじ my_if_pb2_grpc.add_MyGrpcServicer_to_server(MyGrpc(), server) # portの設定 server.add_insecure_port('[::]:50051') server.start() try: while True: time.sleep(_ONE_DAY_IN_SECONDS) except KeyboardInterrupt: server.stop(0) if __name__ == '__main__': print("start") serve()サンプルとだいたい一緒になりました(シンプルなことしかしてないので当然だけど)
/code/grpc_practice ❯ python server.py start疎通確認できてませんがとりあえず起動はおーけー
- 投稿日:2019-03-01T18:24:15+09:00
ラスボス系後輩ヒロインAIチャットボットを作りたい・環境の構築〜Pythonの基礎③
※この記事はQrunchにもクロス投稿しています。
前回の続きから行きます。コメントは
#を先頭につける。これはPHPもRubyも昨日書いたVagrantfileも同じなのでよし。
#の名称について、本文に「オクトソープと言うとちょっと不気味な感じだ」、注釈に「あの8本足の緑色の生き物のような。ほら、あなたの後ろにいる」と記述があり、流れ的にクトゥルフか何かかと思っているのですが未履修なのでわからず。背後にいる確率が一番高い8本足は蜘蛛では……?そういえばこの時点でまだコンソール入力なのだけどファイル実行の方法はやらないのかしらと思って先の方パラパラ見てみたところ、見つからなかったのでここに追記しておきます。
Pythonファイルの実行
$ python cabocha.py なんでも => できる できる => ラスボス系後輩なのです ラスボス系後輩なのです => None上記の例は係り受け解析器にBBちゃんのセリフを突っ込んだの図。スクリプトの中身はMeCabとCaboChaです。
別に読まなくていい係り受け解析器の中身
\# -*- coding: utf-8 -*- import CaboCha import itertools def chunk_by(func, col): ''' `func`の要素が正のアイテムで区切る ''' result = [] for item in col: if func(item): result.append([]) else: result[len(result) - 1].append(item) return result def has_chunk(token): ''' チャンクがあるかどうか チャンクがある場合、その単語が先頭になる ''' return token.chunk is not None def to_tokens(tree): ''' 解析済みの木からトークンを取得する ''' return [tree.token(i) for i in range(0, tree.size())] def concat_tokens(i, tokens, lasts): ''' 単語を意味のある単位にまとめる ''' if i == -1: return None word = tokens[i].surface last_words = [x.surface for x in lasts[i]] return word + ''.join(last_words) raw_string = u'なんでもできるラスボス系後輩なのです' cp = CaboCha.Parser('-n 0') tree = cp.parse(raw_string) tokens = to_tokens(tree) head_tokens = [token for token in tokens if has_chunk(token)] lasts = chunk_by(has_chunk, tokens) links = [x.chunk.link for x in head_tokens] link_words = [concat_tokens(x, head_tokens, lasts) for x in links] for (i, to_word) in enumerate(link_words): from_word = concat_tokens(i, head_tokens, lasts) print("{0} => {1}".format(from_word, to_word))自分で書いたわけではなく、Python2のコードが公開されてたのをPython3対応コードに書き換えただけです。
そして今確認したら参考サイト無くなってるっぽいですね。予想当たってやんのわはは。分岐
分岐は
if, elif, elseで管理する。elif。初めてのパターン。>>> hoge = False >>> fuga = True >>> if hoge: ... print('hoge') ... elif fuga: ... print('fuga') ... else: ... print('piyo') ... fugaちなみに
hoge = trueって書いたら怒られてちょっとびっくりしました。>>> hoge = true Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'true' is not defined本文中の例、「毛皮に包まれてて小さければ猫!小さくなければ熊!毛皮に包まれていなくて小さければ蛇!小さくなければ人間、もしくは禿げた熊」の雑さに笑ってしまった。禿げた熊。
比較演算子はふつう、どっちかって言うと
andとorの方が珍しいように思う。読み下しやすくてすてき。あと>>> x = 7 >>> 5 < x < 10 Trueみたいな複数の比較ができるのもとてもよい。いちいち
andでつなぐのダルいもんな……繰り返し
whileがあり、breakがあり、continueがあり、forがある。eachは無く、for-inがある。
forとwhileにはelseがある。正常終了された場合(処理途中でbreakされなかった場合)elseに入ってくる。for gem in gems: print(gem) break else: print('break!')正常終了したときのみの処理。ちょっとぱっとは思いつかない。不思議だ。
本文においては「何かを探すためにループを使い、それが見つからなかったときにelseが呼び出されると思えばいい」とあり、うーん。何かを探すのにわざわざループを使う状況……。zip()を使った繰り返し
>>> days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'] >>> staples = ['Rice', 'Bread', 'Pasta', 'Pizza', 'Burger'] >>> drinks = ['Juice', 'Coffee', 'Tea', 'Milk', 'Water'] >>> fluits = ['Orange', 'Apple', 'Strawberry', 'Banana', 'Peach'] >>> for day, staple, drink, fluit in zip(days, staples, drinks, fluits): >>> print("day:" + day + " staple:" + staple + " drink:" + drink + " fluit:" + fluit) day:Monday staple:Rice drink:Juice fluit:Orange day:Tuesday staple:Bread drink:Coffee fluit:Apple day:Wednesday staple:Pasta drink:Tea fluit:Strawberry day:Thursday staple:Pizza drink:Milk fluit:Banana day:Friday staple:Burger drink:Water fluit:Peachああーいいですね。いいですねこれ。
for(int i=0;i<arr.length;i++)でやるのウザいと思ってたとこです。さすがです。zipとdictを組み合わせることで小さな日英辞書が出来上がる。
>>> japanese = ['月曜日', '火曜日', '水曜日', '木曜日', '金曜日'] >>> english = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'] >>> dict(zip(japanese, english)) {'月曜日': 'Monday', '火曜日': 'Tuesday', '水曜日': 'Wednesday', '木曜日': 'Thursday', '金曜日': 'Friday'}ちなみにこれ3つ渡したらどうなるかなと思ったら怒られました。
>>> japanese = ['月曜日', '火曜日', '水曜日', '木曜日', '金曜日'] >>> english = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'] >>> french = ['Lundi', 'Mardi', 'Mercredi', 'Jeudi', 'Vendredi'] >>> dict(zip(japanese, english, french)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: dictionary update sequence element #0 has length 3; 2 is requiredzipはタプルを生成するもので、dictが引数に取るのは「2要素のシーケンス」なのでそりゃそうですね。
リスト内包表記
[expression for item in iterable]Σ急にわからなくなった……?!
……と思ったけどその後のプログラム読んだらわかりました。やはり言葉は難しい。
>>> number_list = [number for number in range(1, 6)] [1, 2, 3, 4, 5]Railsのアレっぽいですね、mapとか。
number_list = Range.new(1, 6).map{ | number | number } => [1, 2, 3, 4, 5, 6]ifが付くこともある。
>>> number_list = [number for number in range(1, 6) if number %2 == 0] [2, 4]number_list = Range.new(1, 6).map{ | number | number if number %2 == 0 } => [nil, 2, nil, 4, nil, 6]Railsのmapは未だに使いこなせていない感がある……nil……
6が入ってくるかどうかも結構大きな違いですね。混乱しそう。辞書にも集合にも同じく内包表記がありますが、同じなので割愛。
ジェネレータ内包表記
わからない。わかるけどわからない。書き方はわかったけれど用例がわからない……ので、検索する。
Pythonのジェネレーターってなんのためにあるのかをなるべく分かりやすく説明しようと試みた - Qiitaふーむ……?シングルトンで管理するみたいなもの……?ちょっと違うか?
こういうときはサンプル書いてみるのが一番なんで、書いてみましょう。# -*- coding: utf-8 -*- def generator_sample(maximum): num = 2 while num < maximum: if (not [divisor for divisor in list(range(num - 1, 1, -1)) if num % divisor == 0]): yield num num += 1 for prime in generator_sample(100): print(prime)引数以下の素数を出力するプログラム。
結果がこう
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97んん。「書き方はわかるけど用例はわからない」からあまり進んでいないような……
関数
位置引数とキーワード引数
listとtupleだと理解した。割といつも通り。メッセージ式は便利でいいよね。OC以外でメッセージ式って言い方するかはわからないけど。Railsにもキーワード引数がありますね。シンボルはなかなか和解出来なんだ……。
*による位置引数のタプル化
午前中リストとかタプルとかやったときにも触れたんですけど、*を使った位置引数のタプル化で可変長の引数を取ることができます。
まあでも何が入ってくるかわからないって点では使いどころが微妙かな……セキュリティホールになりそう。少なくともユーザーの入力をこれで受け取るのはやめた方がいいですね(printするだけとかならともかく(それでもscriptタグとか入れられたらつらい**によるキーワード引数の辞書化
これも。Railsでいうところの
params.require.permitみたいにに便利に使えそうですけど、バリデーションちゃんとしないと怖い感じ。なんでも何個でも入るというのはこわいですね……。一人前のオブジェクトとしての関数
関数自体がオブジェクトになります。可変関数みたいなものかな? と思ったんですがどうもちょっと違うっぽい。
def answer(): ''' これO'Railly本のサンプルそのままなんですけど名前がanswerで答えが42なのわらう。 銀河ヒッチハイクガイドだ ''' print(42) def runner(func): func() runner(answer) runner("answer") # 試す$ python func.py 42 Traceback (most recent call last): File "func.py", line 24, in <module> runner("answer") File "func.py", line 21, in runner func() TypeError: 'str' object is not callableふーむ。私はどうもこのオブジェクト概念が苦手なようで、インスタンス化しないのにオブジェクトというのが未だにちょっと馴染みません。answerが呼び出されるのはrunnerの中の
func()時点での話なのだろうけど……オブジェクト……?
どうでもいいですけどRailsに慣れたせいで引数を取らない関数の()を省く癖がついてしまってちょいちょい怒られる。慣れるものだなあ……ちょっと記事伸び過ぎたので切ります。次回、関数内関数から。
- 投稿日:2019-03-01T18:24:00+09:00
【Python】インストール方法
概要
Pythonのインストール方法について説明する.
データ分析などに使うことを考え,Anacondaディストリビューションを利用する.
Pythonを直接インストールする場合は,他のサイトを参考にして頂きたい.Pythonとは
Pythonは,プログラミング言語の一種である.プログラミング言語のうちスクリプト言語という種類に分類される.Pythonは以下のような長所を持つ.
1. 文法(=プログラミング言語が持つルール)がとてもシンプルである. ➡覚えやすい・使いやすい.可読性が高い.
2. 標準ライブラリ,外部ライブラリが充実している. ➡簡単に高度なプログラムを作ることができる.Pythonのインストール
バージョン
Pythonには,2系と3系という2つのバージョンが存在する.この二つには後方互換性がなく,Python 3系で書いたプログラムがPython 2系では実行できないといったことが起こる.よって,Python 3系を使うことをおすすめする.
ディストリビューション
ユーザが一括してインストールできるように,ライブラリなどがひとつにまとめ上げられたものをディストリビューションという.ここでは,データ分析に重点を置いたAnacondaというディストリビューションを利用する.AnacondaにはNumPy(=数値計算のためのライブラリ)やMatplotlib(=グラフ描画のためのライブラリ)など,データ分析に有用なライブラリが含まれている.リンクより,ディストリビューションをダウンロードし,インストールを行う.
参考文献
- 斎藤 康毅, "ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装," 株式会社オライリー・ジャパン, 2016
- 柴田淳, "みんなのPython 第3版," SBクリエイティブ株式会社, 2012
- 投稿日:2019-03-01T18:21:22+09:00
mlflowコマンドが見つからない時の解決方法
問題
この記事でも書いたんですが、macOSにpyenvとanacondaを使ってインストールしたMLflowのmlflowコマンドが見つからないという問題です。
$ mlflow ui -bash: mlflow: command not found結論
パスが通ってないだけでした。。。
今回の対処手順
しょうがないから再インストールしてみるか、ということで再インストールしました。
$ pip --no-cache-dir install -I mlflow --userそしたら以下のような表示が!
The script chardetect is installed in '/Users/panda531/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.完全に見落としてました…
ということで
~/.bashrcに以下の記述を追加しました。export PATH=$PATH:/Users/panda531/.local/binそして
source ~/.bashrcこれで無事にパスが通るようになりました。
ただ、
~/.local/binじゃなくて仮想環境の下(~/.pyenv/versions/anaconda3-5.0.1/envs/envname/bin/)に入ってほしいんですけどどうなんでしょうか。。。
- 投稿日:2019-03-01T17:56:51+09:00
[Python] if __name__ == '__main__'の意味するところ
はじめに
Pythonをやっている人ならこの「おまじない」のようなものをどこかで見たことがあると思います。
今回はこれが実際どんな意味を表しているか、詳しく見ていきたいと思います。
なんのためにあるのか
一言でいうと、この
if __name__ == '__main__'はこのPythonファイルが$ python ファイル名.pyというように実行されているのかを判定するif文です。
ないと何が困るのか
ためしに
if __name__ == '__main__'のないPythonファイルを作ってみます。hello_world.pydef main(): print('Hello World!') main()これを実行すると当然ですが、
$ python hello_world.py Hello World!と表示されます。
しかし・・・
この同じディレクトリでこのPythonファイルをimportしてみると、
$ python >>> import hello_world Hello World!というように「Hello World!」が表示されてしまいます。。
Pythonでは、importされたファイルの中身は実行されてしまうのでこのようなことがおきてしまうのです。
本題
では
__name__には何が入っているのでしょうか?これは特殊な変数で、このPythonファイルのモジュール名が文字列で入っています。
たとえば、import hello_worldとされた場合、hello_world.py内部での
__name__はhello_worldという文字列になります。そして、python hello_world.pyとして実行した場合は、
__name__は__main__という文字列になります。これを実際に確認してみましょう。
先程のhello_world.pyを少し書き換えます。
hello_world.pydef main(): print('Hello World!') main() print(f'__name__: {__name__}')これを先程と同じように2通りの方法で実行してみましょう。
まず、普通に実行してみます
$ python hello_world.py Hello World! __name__: __main__次に、importして試してみます。
$ python >>> import hello_world Hello World! __name__: hello_worldちゃんと両方とも期待どおりの結果になり、結果を確認することができました。
おわりに
またひとつ自分の中の疑問が解決されました。
最後まで読んでいただきありがとうございます。
- 投稿日:2019-03-01T17:48:20+09:00
予測精度評価指標をPythonで実装する
構築したアルゴリズムの予測結果を評価するための誤差について
以下の誤差を紹介します。
略称 日本語 Mean Absolute Error MAE 平均絶対誤差 Mean Absolute Persentage Error MAPE 平均絶対誤差率 Root Mean Squared Error RMSE 平均平方二乗誤差 Root Mean Squared Persentage Error RMSPE 平均平方二乗誤差率 Mean Absolute Error
基本。
\dfrac {1}{N} \sum ^{N}_{i=1}\left| y_{i}- \widehat {y_{i}}\right|from sklearn.metrics import mean_absolute_error mean_absolute_error(true, pred)Mean Absolute Persentage Error
異なるスケール間の誤差を比較できる。
\dfrac {100}{N}\sum ^{N}_{i=1}\left| \frac{ y_{i}- \widehat {y_{i}}}{\widehat {y_{i}}}\right|import numpy as np np.mean(np.abs((true - pred) / true)) * 100Root Mean Squared Error
MAEに比べ誤差の影響が大きい。
\left(\dfrac {1}{N}\sum ^{N}_{i=1}\left( y_{i}- \widehat {y_{i}}\right)^2\right)^{\frac{1}{2}}import numpy as np from sklearn.metrics import mean_squared_error np.sqrt(mean_squared_error(true, pred))Root Mean Squared Persentage Error
誤差の影響を大きく反映し、かつ異なるスケール間の誤差を比較できる。
100\left(\dfrac {1}{N}\sum ^{N}_{i=1}\left( \frac{y_{i}- \widehat {y_{i}} }{\widehat {y_{i}}}\right)^2\right)^{\frac{1}{2}}import numpy as np np.sqrt(np.mean(((true - pred) / true)**2))*100これすごい
手書きの式をTeX式にしてくれます。
https://webdemo.myscript.com/views/math/index.html
- 投稿日:2019-03-01T17:35:16+09:00
最小二乗法で回帰直線を求めてみよう
まえがき
こんな散布図を考えてみましょう。
以下のように作ります。import matplotlib.pyplot as plt x = [1,2,4,6,7] y = [1,3,3,5,4] plt.scatter(x, y) plt.show()この散布図を近似する表現する直線が欲しい。こういうの↓。
これを最小二乗法を使って求めてみましょう。統計学を簡単に
目的の直線を
y = ax型の関数と仮定します。
この関数では$x$地点でのy座標は$ax$になります。実際のy座標との誤差はax- yですね。
統計学では誤差はだいたい二乗して扱います。(ax - y)^2これを全要素に対して行うので
E = \sum ^n _ {i = 1}(ax_i - y)^2こうですね。これを最小化できるようにaを調整すればいいわけです。
そのためにaで微分してみましょう。\frac{\partial E}{\partial a} = \sum 2x_i (ax _i - y_i)\\ = 2(a\sum x_i^2 - \sum x_iy_i)これが0の時最小値なので
a = {\sum x_i y_i \over \sum x_i^2} = {\mathbf{x}^T \mathbf{y} \over ||\mathbf{x}||^2}これを計算すればEが最小となるaが求まります。
実装してみよう
Pythonに実装すると以下のようになります。
import numpy as np #np.dot(x, y) xyの内積をとる関数。 import matplotlib.pyplot as plt x = np.array([1,2,4,6,7]) # 内積計算のためにnp.arrayで作る。 y = np.array([1,3,3,5,4]) def reg1dim(x, y): a = np.dot(x, y)/ (x ** 2).sum() return a a = reg1dim(x, y) plt.scatter(x, y, color="k") plt.plot([0,x.max()], [0, a * x.max()]) # x.max() 配列xの最大値まで plt.show()できたグラフがこちら。
いい感じの直線が引けました。
まとめ
$y = ax$型の関数は簡単な式変形で最小二乗法を適用できる。
次回は$y = ax +b$型を見てみましょう。『機械学習のエッセンス』という本を参考にしました。この本についてまとめていきます。
前回:数理最適化問題
https://qiita.com/NNNiNiNNN/items/57e409e5dbcfac9897ec


- 投稿日:2019-03-01T17:35:16+09:00
Pythonで最小二乗法をしてみよう
まえがき
こんな散布図を考えてみましょう。
以下のように作ります。import matplotlib.pyplot as plt x = [1,2,4,6,7] y = [1,3,3,5,4] plt.scatter(x, y) plt.show()この散布図を近似する表現する直線が欲しい。こういうの↓。
これを最小二乗法を使って求めてみましょう。統計学を簡単に
目的の直線を
y = ax型の関数と仮定します。
この関数では$x$地点でのy座標は$ax$になります。実際のy座標との誤差はax- yですね。
統計学では誤差はだいたい二乗して扱います。(ax - y)^2これを全要素に対して行うので
E = \sum ^n _ {i = 1}(ax_i - y)^2こうですね。これを最小化できるようにaを調整すればいいわけです。
そのためにaで微分してみましょう。\frac{\partial E}{\partial a} = \sum 2x_i (ax _i - y_i)\\ = 2(a\sum x_i^2 - \sum x_iy_i)これが0の時最小値なので
a = {\sum x_i y_i \over \sum x_i^2} = {\mathbf{x}^T \mathbf{y} \over ||\mathbf{x}||^2}これを計算すればEが最小となるaが求まります。
実装してみよう
Pythonに実装すると以下のようになります。
import numpy as np #np.dot(x, y) xyの内積をとる関数。 import matplotlib.pyplot as plt x = np.array([1,2,4,6,7]) # 内積計算のためにnp.arrayで作る。 y = np.array([1,3,3,5,4]) def reg1dim(x, y): a = np.dot(x, y)/ (x ** 2).sum() return a a = reg1dim(x, y) plt.scatter(x, y, color="k") plt.plot([0,x.max()], [0, a * x.max()]) # x.max() 配列xの最大値まで plt.show()できたグラフがこちら。
いい感じの直線が引けました。
まとめ
$y = ax$型の関数は簡単な式変形で最小二乗法を適用できる。
次回は$y = ax +b$型を見てみましょう。『機械学習のエッセンス』という本を参考にしました。この本についてまとめていきます。
前回:数理最適化問題
https://qiita.com/NNNiNiNNN/items/57e409e5dbcfac9897ec
- 投稿日:2019-03-01T17:29:39+09:00
ルービックキューブを深層強化学習で解いてみる
以前の記事で、組合せ最適化問題を深層強化学習を用いて解く一例を、関連論文に沿ってご紹介しました(巡回セールスマン問題を深層強化学習で解いてみる)。今回もある種の組合せ最適化問題と考えられる、ルービックキューブを深層強化学習を用いて解く試みをご紹介しようと思います。
ルービックキューブと強化学習
皆さんご存知のルービックキューブは、各面を次々に回転させることによって解の状態を得るパズルゲームです。小さい頃に慣れ親しんだ方も多いと思いますが、私も学生時代に置換群に関連して少々調べたことがあり、思い入れのあるパズルでした1。このルービックキューブは、ある任意の状態から解にたどり着くまでの最適な回転手続きの組合せを見つける組合せ最適化問題として考えることもできます。
可能な組合せ数が爆発することから、ナイーブに全探索するのが現実的でないことは以前の巡回セールスマン問題と同様です。この様な問題に対して、様々なヒューリスティクな解法が提案されているのも同様で、群論を基礎にしたKociemba's algorithmや、探索ベースのKorf's algorithmなどが代表的なアルゴリズムになっているようです。
この問題に対して、深層強化学習を用いて妥当な求解アルゴリズムをデータから構築するのが今回ご紹介する試みです。
以前の記事でも記載した様に、強化学習や機械学習の手法を用いることで、既存の手法が持つ長所、短所のトレードオフを解決することを目指すものです。
また、特に強化学習を用いるメリットは、ルールや達成したい目的のみから、supervisionやドメイン知識無しで自律的に学習を進めることができる点で、ヒューリスティクスに準ずる(もしくは置き換わる)ような求解パターンを、ルールのみからスクラッチ学習しようという試みとなっています。この試みに関して、一年ほど前にUCIのグループから論文「Solving the Rubik's Cube Without Human Knowledge」が出ており、今回はその概要を簡単な実装例と実験結果を通してご紹介させていただきます。
強化学習アルゴリズムについて
強化学習の基礎学習アルゴリズムとして今回は、「モデルフリー」で「方策学習」ベースの
A2Cアルゴリズム2を用いました。一方、上記参照論文では「モデルベース」で「方策学習」ベースの(動的計画法の一種である)Policy Iteration3に基づいたアルゴリズムを用いています。加えて、それら基礎アルゴリズムで学習された方策に「モデルベース」のMonte Calro Tree Search(MCTS)アルゴリズムをポストプロセスとして組み合わせ、予測の更なる精度向上を図っています。強化学習アルゴリズムは、各アルゴリズムの特徴に基づき、対象課題の特性に沿って選択、組み合わされます。その意味でもアルゴリズムの大きな分類を把握できていると全体の見通しが良くなるかと思いますので、以下に今回関連している代表的な分類である、価値/方策学習、モデルフリー/ベースに関して簡単に纏め、今回の手法選択の背景をご説明することにします。(他にも方策オン/オフ、前方/後方観測などの重要な分類もありますが今回は割愛することにします。)
価値学習か、方策学習か
手法 典型例 長所 短所 価値学習 DQN, DDQN - 学習が安定しやすい - "方策"は状態価値から二次的に表現 方策学習 REINFORCE - 最終目的である"方策"を直接的に表現 - 局所解に陥りやすい
- 「価値学習」アルゴリズムは、各状態(+行動)の価値を、今後獲得される(であろう)報酬に基づき学習することを目指します。学習に際して、状態価値が局所的に無矛盾に表現できているか(ベルマン誤差)を保証するように学習を進めるため、学習が安定しやすくなっています。一方、当初の目的である”各状態においてどのような行動を取るべきか”を与える方策は、状態価値関数に基づき、より良い行動を取るように間接的に表現されます。
- 一方、「方策学習」アルゴリズムは、方策に基づいて行動を進めた際に獲得される(であろう)報酬を最大化するように、より良い方策を(関数変換等なく)直接的に学習します。本来の目的である”方策”を直接的に学習する一方で、学習データへの依存(バリアンス)が大きくなる傾向があり、ハイパーパラメタへの依存性が大きくなったり、局所解に陥り易くなる傾向があります。
近年、互いの欠点を補うようなより良い学習アルゴリズムが検討される中で、一定条件下での「価値学習」と「方策学習」の等価性が示されている様に4、実はどちらの学習法でも本質的には同様の表現が可能であることが分かってきています。一方、課題応用に際しては、求められる表現や加えたい制約条件、実装的な制約などに基づき、対象課題を扱いやすいアルゴリズムが選択されているように伺えます。特に、
1. ターン制のボードゲームなど、複雑で戦略的な行動選択が求められる課題
2. ロボットアームのアクチュエータの連続制御など、高次元で行動自由度の高い課題
に対しては、方策の表現を直接的に保持、評価、工夫するメリットが大きくなり、方策学習に基づいたアルゴリズムが選ばれる傾向が強くなっています。本ルービックキューブの課題においては、上記1.(下記モデルベース手法との組合せ観点を含む)を鑑みて、方策ネットワークを直接的に学習するActor-Criticアルゴリズム3(A2C)を採用しました。モデルフリーか、モデルベースか
手法 典型例 長所 短所 モデルフリー A2C, DQN - 環境に依存せず、限られたデータのみから学習が可能 - 詳細な学習には時間が掛かる モデルベース MCTS, 動的計画法 - 環境に沿った詳細な学習が可能 - 学習データの網羅的な探索が求められる
- 「モデルフリー」アルゴリズムは、エージェントが環境の詳細(遷移確率)を知ることなく、行動による環境への働きかけとその返り値である報酬や次の状態のみから学習を進めるアルゴリズムです。環境を常にブラックボックスの学習対象として扱い、環境の(確率的)反応も内包した方策や状態価値を学習していきます。特定の環境に依存しない汎用性の高い学習が限られたデータのみから可能である一方、データ効率が悪く詳細な学習にはより多くのデータを必要とし、学習に時間が掛かる傾向にあります。
- 一方、「モデルベース」アルゴリズムは、対象の環境が明示的にモデル化されている/モデル化することを前提とし、モデル化された環境を活用し先を予測したり、状態系列を戻したりしながら、方策や状態価値の学習を進めます。環境に寄り添ったデータ効率の良い詳細な学習が可能になる一方、環境をモデル化するために網羅的な状態探索が必要になる傾向にあります。
今回の様な小さい課題(可能な行動選択も考慮すべき行動系列も10オーダー)に対しては、網羅探索の計算コストが小さいため「モデルベース」の手法が用いられ易く、そのため、上記参照論文では実際、「モデルベース」の手法が基礎学習手法として用いられています。一方、囲碁や将棋のような大きな課題に対しては、「モデルフリー」のアルゴリズムが基礎になることが多くなっています。今回の取り組みでは、今後のより複雑な課題への発展も考慮し、「モデルフリー」のアルゴリズム(A2C)を基礎とすることにしました。
実際の課題応用においては、これらも組み合わせれて用いられることが多く、実際AlphaGo5では、「モデルベース」のMCTSアルゴリズムが(学習された方策ネットワークに基づき)さらに高精度の将来予測を行うためのポストプロセスとして活用され、戦略決定アルゴリズムの重要な一部分を担っています。同様に、上記参照論文でも、MCTSアルゴリズムをポストプロセスとして用いることで行動選択の精度を大幅に向上させています。今回の取り組みでも、MCTSをポストプロセスとして活用し、基礎方策のみに基づくナイーブな戦略に対し、確かに精度向上が見られるかを確認することにしました。
実装例
実装例の全体は Githubを参照いただくとして、実装の基礎となる内容のみ簡単に記載します。
シミュレーター環境について
まず、強化学習の学習の基礎となるシミュレーターについてです。様々な方がルービックキューブのシミュレーターの実装を公開していらっしゃいますが、今回は、状態空間の試行錯誤や自身の理解のためにも、OpenAI Gymの枠組みで簡単に自前実装することにしました。今回は簡単のため、3x3x3、2x2x2のキューブ (order = 3, 2) のみ想定していますが、より大きなキューブへの拡張も容易かと思います。
今回実装したシミュレーターの各要素の概要は以下の通りです。
概要 表現 状態 (state) 各面の各タイルセグメントにどの色付きタイルが配置されているかの状態 タイルの色をone-hotで表現した、 order x order x 6(face) x 6(color)次元のベクトル行動 (action) グローバル回転を除外した(固定ブロック/軸を保持した)、可能な面/スライスの回転操作(上図参照) - 2x2x2: (F, R, U),
- 3x3x3:(F, R, U, B, L, D)
+ 逆回転(反時計回り), etc.報酬 (reward) 状態に応じた報酬 - 終端であれば +1
- それ以外は-1終端 (done) 解けた状態かどうか - 解けたら True
- それ以外はFalse回転操作の実装としては、操作に関係する周辺タイルを一度
(order+2, order+2)の行列にマップし、numpyの操作を用いて90°回転を行っています。また、操作の対称性を考慮し、キューブ全体を回転させるようなグローバルな回転は実装しておらず、指定面(スライス)を回転させる操作のみを考えています。
対称性やキューブ構造の制約に伴って、本来は考慮すべき状態ベクトルもより小さい次元での表現が可能となりますが、今回は簡単のため、冗長ですが最も単純な上記の様なone-hot表現を用いました。
以下の試行では、2x2x2のルービックキューブに対して、
(F, F', R, R', U, U')(Xの逆回転操作をX'で表現)という6つの90°回転操作を行う環境("quarter-turn metric"と呼ばれる6)を採用し実験を行いました。構築ネットワークと学習について
A2Cアルゴリズムでは、方策ネットワークと価値ネットワークを更新・学習しますが、今回はシェアされた共通ネットワークをもち、入力であるキューブ状態から、方策(次の各行動の確率)と価値(入力状態の価値)を与える二つのヘッドを持つ一つのネットワークを学習することにしました。
オリジナルのAlphaGoでは、教師あり学習による事前学習結果の転移活用も考慮に入れ、別ネットワークとしていましたが、(事前学習を用いない)AlphaGo Zeroの論文7では、別々のネットワークを用いる場合と比較して、計算効率や複数の目的に跨る(汎用性の高い)共通の表現の獲得によってより良い結果が得られたことが報告されています。切り替えは容易ではありますが、今回はその単純さから2ヘッドのネットワークを活用しました。
学習ターゲットであるデータの生成(探索)に関しては、解かれた状態から(可能な回転操作の中から)ランダムに選択された回転操作を指定回数だけ行い、その状態から強化学習の試行錯誤の探索手続きを実行しました。ランダム操作の回数は、参照論文に従い、より解に近い(回数が少ない)サンプルが多くなるように(
1/操作回数の重みで)生成しました。(この重みづけによって、確かにより精度の高い方策が学習できることも確かめられました。)A2Cの学習アルゴリズムの概要を記載すると以下のようになります。現在の方策ネットワークに基づき(方策オンで)行動選択を行い、環境にアクセスしながら自身で探索を行い(self-play)、獲得した報酬の情報を用いて、方策や価値ネットワークの重みを更新します。今回の課題のような手続き系列の学習に際しては、(TD$(0)$ではなくTD$(\lambda)$の様に)系列情報を明示的に保持して学習に活用することが、学習効率を向上させるために一層重要になります。今回は、episode内の獲得報酬情報を保持し、ネットワークの更新の際に重み付き報酬和($G_T$)を明示的に再構成する、いわゆる前方観測によって更新を行いました。
pseudo-codeimport tensorflow as tf import RubiksCubeEnv, ActorCriticAgent, Memory # --- PRE-PROCESS --- # session start sess = tf.Session() # make instances env = RubiksCubeEnv() agent = ActorCriticAgent() memory = Memory() # --- TRAIN MAIN --- # episode loop for i_episode in range(n_episodes): # reset environment env.reset() # initial cube scramble _, state = env.apply_scramble() # step loop for i_step in range(n_steps): # obtain action prediction from policy network action = agent.get_action(sess, state) # obtain reward for the action next_state, reward, done, _ = env.step(action) # memory push memory.push(state, action, reward, next_state, done) state = next_state if done: break # --- POST-PROCESS (EPISODE) --- # retrieve episode data memory_data = memory.get_memory_data() # update model with the episodic data _args = zip(*memory_data) losses = agent.update_model(sess, *_args) # reset memory for next episode memory.reset() class ActorCriticAgent(object): def __init__(self): ... def update_model(self, sess, state, action, reward, next_state, done): ... # calculate value target & TD error # TD(0) if 0: next_st_val = self.predict_value(sess, next_state) target_val = reward + self.gamma * next_st_val # TD(\lambda) if 1: # re-order rewards to construct Gt target_val = [] for i_step in range(len(reward)): reward_seq = [self.gamma**i * i_reward[0] for i, i_reward in enumerate(reward[i_step:])] g_t = np.sum(reward_seq) target_val.append([g_t]) st_val = self.predict_value(sess, state) td_error = target_val - st_val # define feed_dict feed_dict = {input: state, val_obs: target_val, td_err: td_error, act_obs: action_idx} # update value network _, losses = sess.run([self.value_optim, self.losses], feed_dict) # update policy network _, losses = sess.run([self.policy_optim, self.losses], feed_dict) return losses方策学習後のポストプロセスについて
次に、A2Cアルゴリズムによって学習された方策ネットワークを用いた予測に関してです。
前項で述べた様に、方策ネットワークを直接用いる予測よりも、追加の探索時間は必要となりますが、MCTSをポストプロセスとして追加することで、精度が大きく向上することが報告されています。今回用いたMCTSは、
PUCTアルゴリズムと呼ばれる(rolloutを用いない)学習ネットワークを全面的に信頼、活用したアルゴリズムで、AlphaGo Zeroでも用いられているものです。(ただしAlphaGo Zeroではポストプロセスだけではなく、self-playによる学習ターゲットの生成にも同様のMCTSを用いています。)本MCTSの概要を記載すると以下のようになります。
1. Select:既存の探索木の中から、各ノードの価値(V)と選択確率(P)に基づいた一定の選択条件によって子ノードを順次選択しながら報酬情報を収集
2. Expand:終端ノードに達したら更なる子ノードを展開し、各ノードの選択確率(P)を”推定方策”に基づいて付与
3. Evaluate and Backup:通ってきた行動経路/列によって得られた報酬情報や終端ノードの”推定状態価値”を用いて、該当経路の価値を評価し、関連各ノードの価値(V)を更新
4. Repeat:1へ戻るこれを繰り返し木探索を終了条件が満たされるまで繰り返します。”推定方策”や"推定状態価値"に既に学習された方策、価値ネットワークを用いることで、探索木を全探索することなく目ぼしいノードに絞りながら状態の探索と評価を効率的に進めることが可能になります。
ノード選択条件の詳細などは上記論文などを参照いただくとして、基本的な方針は、上記P、Vに基づき各ノードに対して算出される 平均状態価値 ($Q(s, a) \propto $ 累積報酬総和/ノード訪問数) と ノード探索価値 ($U(s, a) \propto $ 選択確率/ノード訪問数) から、$a_t = \text{argmax}_a (Q(s_t,a_t)+U(s_t,a_t))$ によって、探索と活用のバランスを取りながら選択していきます。
pseudo-code# Class of Monte Carlo Tree Search class MCTS(object): # constructor def __init__(self, agent): self.env = RubiksCubeEnv() self.agent = agent # run search to find best path def run_search(self, sess, root_state): # --- PRE-PROCESS --- # create root node of this search root_node = Node(None, None, None) # record best path best_reward = float('-inf') best_solved = False best_actions = [] # --- SEARCH MAIN --- start_time = time.time() # loop of search runs while True: # initialization node = root_node state = root_state self.env.set_state(root_state) weighted_reward = 0.0 done = [False] actions = [] # drill down existing tree nodes with a selecting rule until its terminal n_depth = 0 while node.child_nodes: # select a node among child nodes node = self._select_next_node(node.child_nodes) # evaluate the node next_state, reward, done, _ = self.env.step(node.action) weighted_reward += self.gamma**n_depth * reward[0] n_depth += 1 state = next_state actions.append(node.action) # expand the terminal node when its not done if not done[0]: # calc probs of each action at the terminal node action_probs = self.agent.predict_policy(sess, [state]) # expand child nodes from the terminal node.child_nodes = [Node(node, act, act_prob) for act, act_prob in zip(self.action_list, action_probs[0])] # evaluate the terminal state value when its not done if not done[0]: # utilize state value of the terminal node, (no rollout) _v_s = self.agent.predict_value(sess, [state]) weighted_reward += self.gamma**n_depth * _v_s[0][0] # non-complete penalty weighted_reward += self.unsolved_penalty # update node params, following back the node path while node: node.n += 1 node.v += weighted_reward node = node.parent_node # update best path if best_reward < weighted_reward: best_reward = weighted_reward best_solved = done[0] best_actions = actions # termination criteria duration = time.time() - start_time if duration >= self.time_limit: break return best_reward, best_solved, best_actions # Class of Node Container class Node(object): def __init__(self, parent, action, prob): # its parent node self.parent_node = parent # action taken to arrive self.action = action # probability to arrive at this node from parent self.p = prob # state value of this node self.v = 0.0 # number of visits of this node self.n = 0 # child nodes associated to this node self.child_nodes = []試行結果
ここまでご紹介したアルゴリズムに基づいて、2x2x2のルービックキューブの学習を進めた結果、以下の様な結果が得られました。今回は各アルゴリズム紹介と基本傾向の把握を主としているため、学習は簡易的に行っています。
A2Cアルゴリズムによる学習/推定結果
まず、A2Cアルゴリズムによる方策/価値ネットワークの学習を行いました。簡単のため、学習はローカルラップトップで1時間程度で終了するepisode数で行いました。左下図に平均損失と平均報酬の推移を示しています。ランダムな方策からスタートし、確かにepisodeの進行によって期待報酬が向上しているのが確認できます。また、今回は、episode毎でのネットワーク更新(バッチサイズ15(ステップ)程度)を行っていますが、価値ネットワーク(ベースライン)の導入によって、ある程度バリアンスが抑えられた学習が行えていることも分かります。
学習された方策ネットワークを用いて、別のテストデータに対して、どの程度ルービックキューブが確かに解かれ得るかをプロットしたものが右図になります。今回は学習された方策ネットワークのみを用い、各状態に対して方策ネットワークの出力確率に基づき、次の行動を選択して状態を推移させています。横軸は解状態からランダムに回転操作した回数で、縦軸はそのうち実際に解けた割合を表しています。学習プロットから分かる通り、1, 2回の操作に対してはよく解を導けているものの、6, 7回辺りからは5割程度しか解けていないのが分かります。(ランダム方策では、凡そ $(1/6)^n = (0.17)^n$ になることにも留意ください。)
実際の遷移サンプルを示したものが以下になります。右向きの遷移がランダムに回転操作を行なった際の記録で、左向きの遷移が方策ネットワークによって選択された回転操作です。また各状態には、価値ネットワークが与える状態価値の値も記載しています。
解けている例:
以下、簡単のため全てコマンドラインにて表現していきます。Scrambles: 2, 536/536 G | --[R']--> --[F']--> | S G | <--[R]-- (1.31) <--[F]-- (0.29) | S Scrambles: 4, 496/518 G | --[R]--> --[U]--> --[U]--> --[F]--> | S G | <--[R']-- (1.21) <--[U']-- (0.57) <--[U']-- (-0.43) <--[F']-- (-10.02) | S Scrambles: 6, 342/486 G | --[F]--> --[F]--> --[F']--> --[U']--> --[U']--> --[F']--> | S G | <--[F']-- (1.13) <--[U]-- (2.01) <--[U]-- (-1.22) <--[F]-- (-12.02) | S Scrambles: 8, 248/498 G | --[R']--> --[U]--> --[U]--> --[F']--> --[U]--> --[R']--> --[F']--> --[F]--> | S G | <--[R]-- (1.31) <--[U']-- (0.20) <--[U']-- (-0.06) <--[F]-- (-10.18) <--[U]-- (-12.67) <--[U]-- (-11.84) <--[U]-- (-17.50) <--[R]-- (-16.78) | S多回転操作で解けているものは、(X+X')のような冗長な操作が含まれ、実質少ない操作で解けるものが多くまれていました。また、選択操作についてもUx3(=U')など冗長な表現も含まれがちです。
解けていない例:
Scrambles: 4, 22/518 G | --[R]--> --[F']--> --[U']--> --[R']--> | S * <--[R]-- (-8.44) <--[R]-- (-10.68) <--[U']-- (-3.49) <--[U]-- (-10.68) <--[R']-- (-8.44) <--[R]-- (-10.68) <--[F]-- (-10.60) <--[U]-- (-12.93) <--[F']-- (-10.13) <--[F]-- (-12.93) <--[F]-- (-11.18) <--[R]-- (-10.36) <--[U]-- (-7.00) <--[U]-- (-13.74) <--[U]-- (-7.81) | S Scrambles: 6, 144/486 G | --[F']--> --[R]--> --[R]--> --[U]--> --[F]--> --[U']--> | S * <--[R']-- (-12.14) <--[U]-- (-12.96) <--[U']-- (-12.14) <--[R]-- (-15.32) <--[R']-- (-12.14) <--[R]-- (-15.32) <--[F]-- (-15.66) <--[U]-- (-13.88) <--[U]-- (-12.74) <--[U]-- (-11.92) <--[F]-- (-8.69) <--[F']-- (-11.92) <--[F']-- (-10.07) <--[U]-- (-11.29) <--[R]-- (-15.29) | S Scrambles: 8, 250/498 G | --[U]--> --[R]--> --[R]--> --[R]--> --[R']--> --[U]--> --[R]--> --[U']--> | S * <--[R']-- (-9.04) <--[R]-- (-8.03) <--[R']-- (-9.04) <--[R]-- (-8.03) <--[R']-- (-9.04) <--[R]-- (-8.03) <--[R']-- (-9.04) <--[R]-- (-8.03) <--[R']-- (-9.04) <--[U']-- (-10.61) <--[R']-- (-6.85) <--[R']-- (-10.02) <--[U']-- (-9.74) <--[R]-- (-12.29) <--[U]-- (-11.78) | S今回の報酬の定義を考慮すれば、状態価値(や方策)が正しく推定されていれば、各状態価値は解から離れるにしたがっておおよそ
-1で減少していくことが期待されます。一方、上記例からは、2、3回の操作を越えると、それら期待される値から大きく乖離した状態価値が各状態に付与されており、それらの状態の価値がネットワークによって(まだ)正しく推定できてないことが分かります。特に、解けていない例においては、行動操作によって状態価値が上昇しておらず、各状態に対してその価値や適切な方策が正しく推定できていなことが、顕著に伺えます。一層学習を進め、これらの価値を正しく推定できる様になっていくことを通して、上記解答率曲線が改善していくことが予想されます。A2C + MCTSアルゴリズムによる推定結果
次に、テストデータに対して、A2Cで学習された方策/価値ネットワークに基づいてMCTSアルゴリズムによるポストプロセス処理を行い、得られた結果が以下のプロットになります。
解答率の曲線が明らかに大きく向上しているのが見て取れるかと思います。上記と同様にこの時の遷移サンプルを示したものが以下になります。
解けている例:
Scrambles: 6, 504/526 G | --[F']--> --[R']--> --[U]--> --[R']--> --[R']--> --[U]--> | S G | <--[F]-- (0.89) <--[R]-- (0.06) <--[U']-- (-0.29) <--[R']-- (-11.72) <--[R']-- (-14.34) <--[U']-- (-19.36) | S Scrambles: 7, 471/515 G | --[F']--> --[F']--> --[R']--> --[F']--> --[R]--> --[R]--> --[U']--> | S G | <--[F']-- (1.13) <--[F']-- (0.14) <--[R]-- (-1.69) <--[F]-- (-7.61) <--[R']-- (-10.43) <--[R']-- (-9.58) <--[U]-- (-12.97) | S Scrambles: 8, 440/527 G | --[F]--> --[F]--> --[R']--> --[F']--> --[U]--> --[F]--> --[R]--> --[U']--> | S G | <--[F]-- (0.89) <--[U']-- (0.78) <--[R']-- (-0.87) <--[U]-- (-8.39) <--[F]-- (-12.67) <--[U]-- (-15.65) | S Scrambles: 9, 358/472 G | --[F]--> --[R']--> --[R]--> --[U']--> --[U']--> --[U']--> --[R']--> --[R']--> --[F]--> | S G | <--[F']-- (1.13) <--[U']-- (-0.04) <--[R']-- (-1.04) <--[R']-- (-7.84) <--[F']-- (-15.58) | S状態価値の評価の不十分さに伴って、一時的に状態価値が減少する様な操作も含みながら、長い操作列や冗長な操作列に対しても、より効率的な操作手順(U'x3をUで対応)を推定できていることが見て取れます。また、8回転操作の例では、逆順とは異なる、より短い操作列(6操作)を見つけられていることも分かります。
解けていない例:
Scrambles: 7, 44/515 G | --[U']--> --[R']--> --[F]--> --[U]--> --[F']--> --[R]--> --[U']--> | S * <--[U']-- (-7.49) <--[F]-- (-12.53) <--[U]-- (-16.16) | S Scrambles: 8, 87/527 G | --[F']--> --[U]--> --[U]--> --[F']--> --[R]--> --[R]--> --[F]--> --[F]--> | S * <--[F']-- (-7.45) <--[U']-- (-5.17) <--[F']-- (-6.55) <--[U]-- (-6.71) <--[F']-- (-10.45) <--[U]-- (-14.78) <--[R]-- (-10.14) <--[F']-- (-19.06) | S Scrambles: 9, 114/472 G | --[U']--> --[R]--> --[U']--> --[F']--> --[F']--> --[U]--> --[U']--> --[U']--> --[U']--> | S * <--[F']-- (-4.30) <--[U']-- (-3.19) <--[F]-- (-5.79) <--[F]-- (-6.82) <--[U']-- (-12.63) <--[R']-- (-12.41) <--[U']-- (-19.56) | S Scrambles: 10, 179/495 G | --[U]--> --[F]--> --[R]--> --[R]--> --[F]--> --[R']--> --[U]--> --[U]--> --[R]--> --[F]--> | S * <--[R']-- (-2.27) <--[F]-- (-8.30) <--[U']-- (-5.89) <--[F]-- (-8.38) <--[U]-- (-15.96) <--[U]-- (-16.01) | S一方、上記の様に解を発見できていない系列も未だある程度見受けられました。しかしながら、最終状態の状態価値の値を見る限り、ネットワークの改善やハイパラ調整、探索時間の延長などで改善が見込める様に伺えます。
前記のナイーブな推定の際と同様に、ネットワークによる状態価値の推定は未だ不十分である状況ですが、今回の様に、木探索による適切な活用と探索を行うことによって、微妙な状態価値の差を考慮(活用)したり、時には価値が悪化する方向に振る(探索)ことによって、期待される解の遷移を効果的に発見し得ることが分かります。(結果は活用と探索の重みパラメタ、探索時間などハイパーパラメターに大きく依存することにご留意ください。今回の探索時間に関しては、ネットワークによる解推定
0.1 [s]に対して、MCTSでは10倍の1.0 [s]程度の探索・推定を許す様な環境に設定しています。)この様に、学習された方策が大まかでも、それらをMCTSに活用することである程度の質の解が得られ、性能を大きく改善し得ることが伺えました。AlphaGo Zeroではこの性質をより積極的に活用し、方策・価値ネットワーク学習のターゲット生成に際してもMCTSを活用し、協力的に学習を進めるアイディアが活用されています(まとめ章の図参照)。
これら以上の結果は、上記参照論文でも同様なことが報告されており、学習方策基づいてMCTSを用いた解推定を行うことで初めて、推定精度や推定速度の両観点から既存のベストヒューリスティクスを凌駕する性能を発揮することが報告されています。ちなみに、ルービックキューブに関しては、網羅探索によって、God's Numberと呼ばれる、任意シャッフル状態を解くために必要となる回転操作数の上限値が示されています5。論文でもその観点から、得られた解がヒューリスティクス解に対し、いかにより良い解を与えているかの比較も行われており、大変興味深い結果が示されています。また、学習された解の中によく知られた定石パターンが多く含まれてることも示されており、ご興味のある方は一読いただけると面白いかと思います。
教師あり学習による学習/推定結果
最後に、A2Cによる方策学習の比較対象として、方策ネットワークについて教師あり学習を行なった結果を示しておこうと思います。教師としてはランダム回転させた際の各回転を各状態に対しる解として保持し、学習を行いました。強化学習と同様、解に近いサンプルの適当な重みづけは必要でしたが、A2Cと同程度のサンプル数のデータに対して得られた結果は、以下の様な曲線でした。
予想通り、教師あり学習の強化学習(A2C)に対するデータ効率の良さが見て取れます。AlphaGo Zeroの報告でも、教師あり学習の初期学習効率の良さが示されています。実課題適用を考える際に、まず初期アプローチとして(AlphaGoの例のように)教師あり学習を用いて方策を明示的に学習するのは筋が良さそうです。一方、最終的には強化学習が教師に依存しない、無駄の少ないより良い戦略を獲得する様になることが報告されています。今回の課題でも、上記サンプルで既に一部見られたように、必ずしも回転させる手続きを逆に辿る行動系列が最適とは限らず、より詳細を探ってゆくことで同様の傾向が得られることが十分予想されます。また、今回は教師ありとの比較でしたが、参照論文で用いられたpolicy iterationとのデータ効率の比較も興味深いかと思います。
最後に、今回簡易的に得られた結果をより改善していくためのアプローチとしては、
■ ロングランや非同期化などによって学習データを増やし、そもそもの方策・価値ネットワークを賢くしていく
■ 今回は学習の振舞いを確認しながらざっくり行なったA2C、MCTSのハイパーパラメタの調整
■ 学習データの工夫(例:X+X'の様な冗長な組合せを除外。実は今回の環境では1/6の確率で逆操作となるため、10回操作すると80%以上は必ず冗長な手続きを含んでしまう。)
■ AlphaGo Zeroの様に学習過程(ターゲット)にMCTSを用いる
などが挙げられ、今後適宜検討していこうと思っています。まとめ
今回はルービックキューブのパズルを、機械学習、特に強化学習で解くアプローチをご紹介しました。簡易的に試行したのみではありますが、身近なパズルに対しても、機械学習によるアプローチが検討され得ることをご理解いただければ幸いです。この例のように、機械学習によって、既存のドメイン知識をデータに基づいて再構築し直したり、互いに補うことで、より有効なビジネス活用を模索するケースは今後も増えてくるのではないかと考えています。
また、各アルゴリズムの紹介でも度々登場するしているように、今回の参照論文もAlphaGo7 8のアプローチに大きく影響を受けており、各構成要素は基本的には同様なものとなっています。
参考:AlpahGo Zeroの学習アルゴリズム概要図8
今回のご紹介したアルゴリズムを、非同期化するなど適宜拡張・効率化していただくことで、より複雑な対戦ボードゲームやハイパーパラメターチューニングの様な、多様な行動選択を重ねて最適解を目指す課題に対しても、効率的に課題を解くアプローチとして検討いただけるのではないかと思います。実際、先日の最新のAlphaZeroのリリース9においても、広く様々なボードゲームに対して、強化学習による方策/状態価値の学習によって探索が桁違いに効率化されたことが強調されています。
その意味でも今回のルービックキューブの課題は、良い基礎を与える課題と感じ、取り組みをご紹介させていただきました。これら強化学習アルゴリズムや探索アルゴリズムは、より効率的な手法の模索が現在も精力的に続けられており10、また開発コミュニティの活発な貢献によって、実装の敷居も大きく下がってきています11。今後もそれらの掛け算でより良い求解アルゴリズムが提案、実装されていくと思われます。引き続きこれらの発展を注意深く見守って行くとともに、その実務応用可能性を模索していきたいと考えています。
Combining policy gradient and Q-learning, Bridging the Gap Between Value and Policy Based Reinforcement Learning, Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor ↩
90°(X), 270°(X')回転のみでなく180°回転(X+X)も1操作とする"half-turn metric"という基準も存在 ↩
Mastering the game of Go with Deep Neural Networks & Tree Search ↩
AlphaZero: Shedding new light on the grand games of chess, shogi and Go ↩





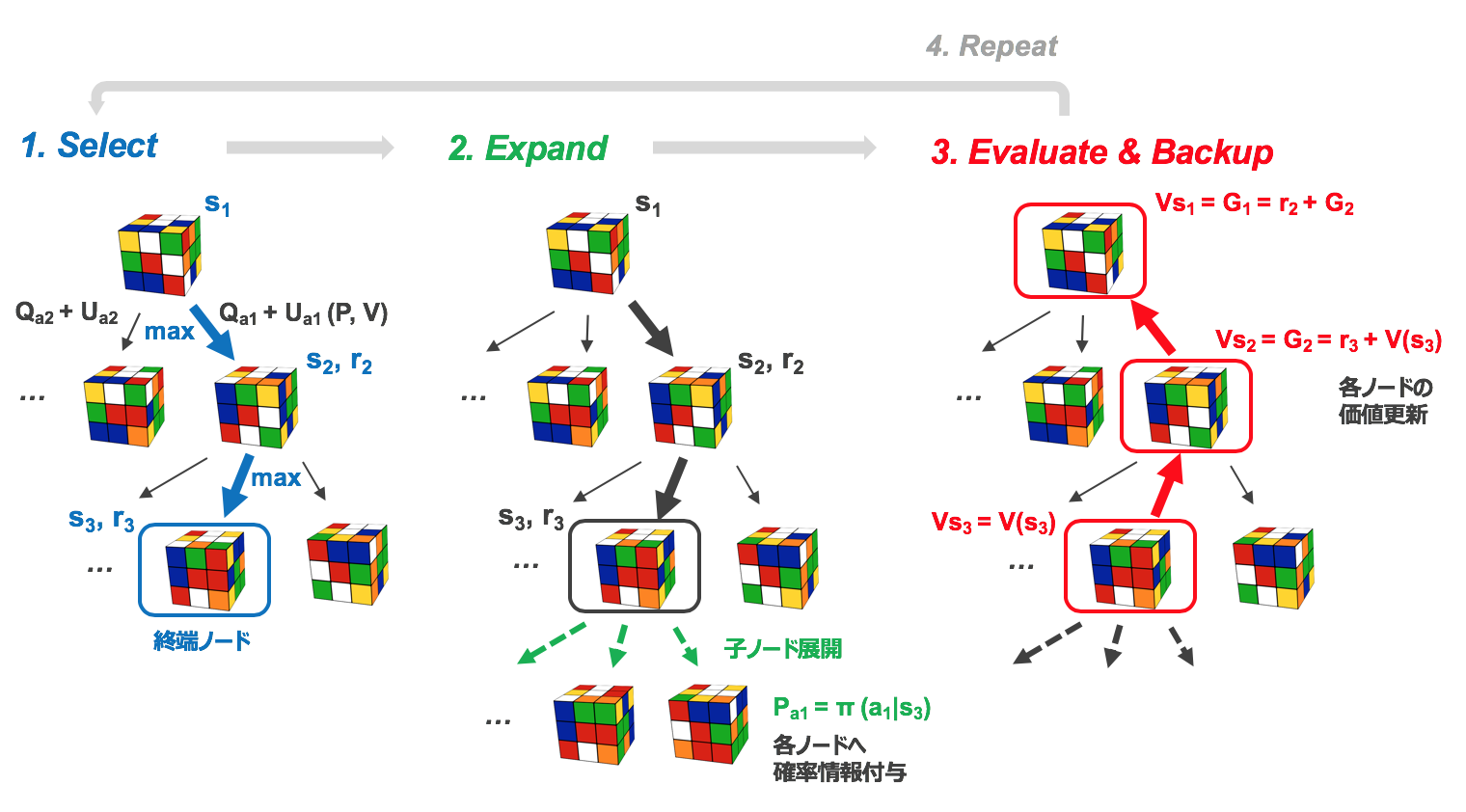






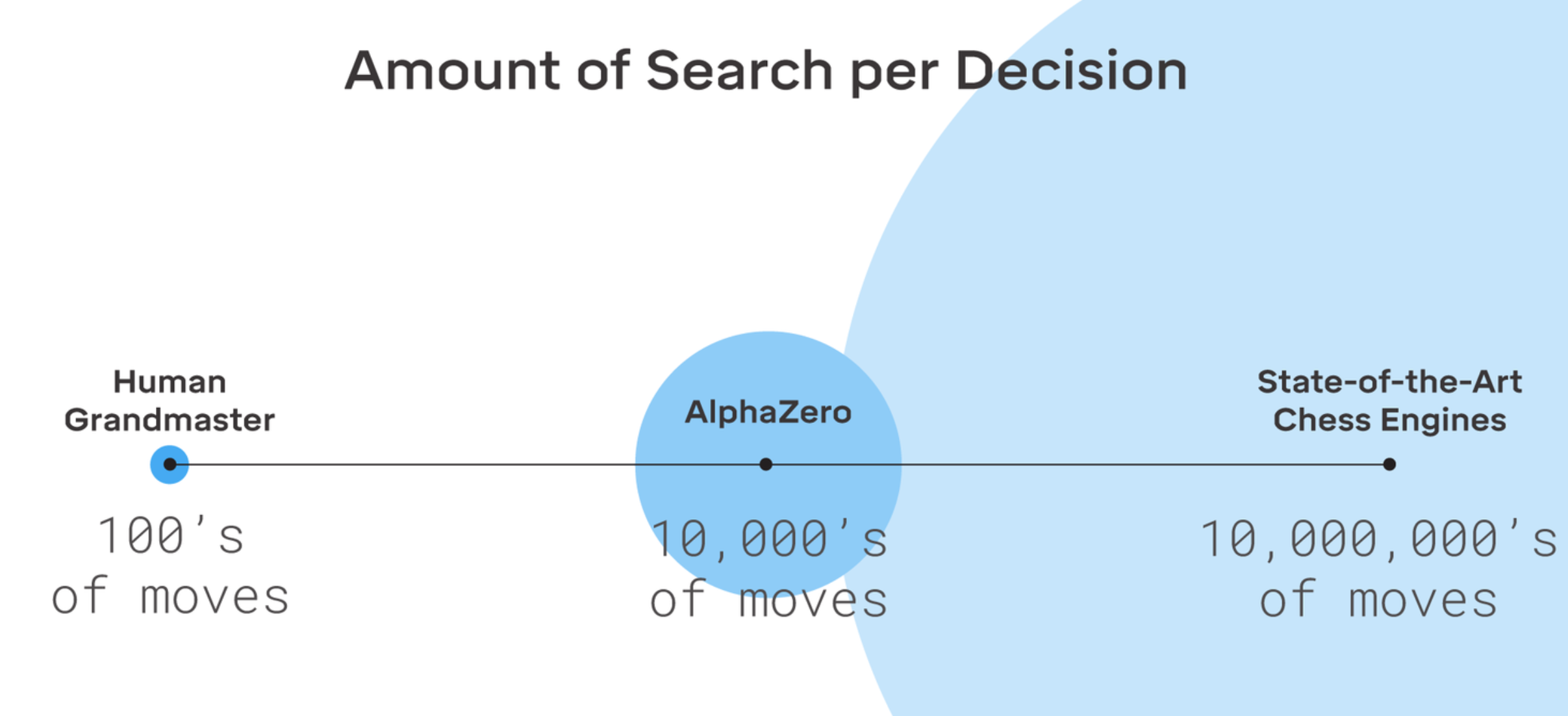
- 投稿日:2019-03-01T17:28:28+09:00
ヒト変異のHGVS表記の変換(vep api)
変異のHGVS表記の相互変換
これまでに、ヒトゲノムの変異のHGVSの変換を行うために、変異のHGVS表記の相互変換(Ensembl variant_recoder)や変異のHGVS表記の変換(Python hgvs)等を試してみた
しかし、お手軽さの点ではvep apiを利用するのにかなわないようだ
vep restful api のvariant recoderを利用する
変異のHGVS表記の相互変換(Ensembl variant_recoder)のオプション指定と統一するため、下記のようなコードをpythonで作成
Pythonのrequests モジュールを予めインストールしておいてください
variant_recoder_rest.pyfrom __future__ import print_function import argparse import json import requests server_grch37 = "https://grch37.rest.ensembl.org" server_grch38 = "https://rest.ensembl.org" variant_recoder = "/variant_recoder/human" def variant_recoder(input_data, grch37, pretty): server = server_grch38 if not grch37 else server_grch37 api_url = server + variant_recoder + '/' + input_data result = requests.get(api_url, headers={"Content-Type": "application/json"}) if result.status_code != requests.codes.ok: header = result.headers ratelimit_remaining = int(header['X-RateLimit-Remaining']) if ratelimit_remaining == 0: print("You are not allowd to submit any request.") raise ValueError( "You've reached the rate limit of api. Please wait {} seconds.".format(header['X-RateLimit-Reset'])) raise ValueError(api_url) if pretty: print(json.dumps(result.json(), indent=4)) else: print(json.dumps(result.json())) def parse_args(): parser = argparse.ArgumentParser(description='vep recoder with ensembl vep API.') parser.add_argument('--input_data', nargs=1, required=True, help='hgvs string to convert') parser.add_argument('--grch37', action='store_true', help='Set genome version to GRCh37. (Default version is GRCh38)') parser.add_argument('--pretty', action='store_true', help="Prettify JSON result") return parser.parse_args() if __name__ == "__main__": args = parse_args() input_data = args.input_data[0] grch37 = args.grch37 pretty = args.pretty variant_recoder(input_data=input_data, grch37=grch37, pretty=pretty)前回同様指定可能なオプションは下記の通り
オプション 説明 コメント --input_data 変換元のhgvsで表記された文字列 ダブルクオーテーション又はシングルクオーテーションで区切る --grch37 ヒトゲノムのバージョン指定 無指定であればGRCh38(hg38)が利用される --pretty JSON表記を見やすく整形表示する GRCh37で取得
変異のhgvs表記'NM_000603.4:c.894T>G'から変換結果を取得してみる
$ python variant_recoder_rest.py \ --input_data 'NM_000603.4:c.894T>G' \ --grch37 \ --pretty結果は下記の通り
[ { "hgvsp": [ "ENSP00000297494.3:p.Asp298Glu", "ENSP00000417143.1:p.Asp92Glu", "ENSP00000420551.1:p.Asp298Glu", "ENSP00000420215.1:p.Asp298Glu", "NP_000594.2:p.Asp298Glu", "NP_001153581.1:p.Asp298Glu", "NP_001153582.1:p.Asp298Glu", "NP_001153583.1:p.Asp298Glu" ], "id": [ "rs1799983", "CM981388" ], "hgvsg": [ "NC_000007.13:g.150696111T>G" ], "hgvsc": [ "ENST00000297494.3:c.894T>G", "ENST00000461406.1:c.276T>G", "ENST00000467517.1:c.894T>G", "ENST00000484524.1:c.894T>G", "NM_000603.4:c.894T>G", "NM_001160109.1:c.894T>G", "NM_001160110.1:c.894T>G", "NM_001160111.1:c.894T>G" ], "input": "NM_000603.4:c.894T>G" } ]GRCh38で取得
--grch37オプションを省略した場合にはGRCh38上での変換結果が出力される$ python variant_recoder_rest.py \ --input_data 'NM_000603.4:c.894T>G' \ --pretty[ { "hgvsc": [ "ENST00000297494.7:c.894T>G", "ENST00000461406.5:c.276T>G", "ENST00000467517.1:c.894T>G", "ENST00000484524.5:c.894T>G", "NM_000603.4:c.894T>G", "NM_001160109.1:c.894T>G", "NM_001160110.1:c.894T>G", "NM_001160111.1:c.894T>G" ], "input": "NM_000603.4:c.894T>G", "hgvsp": [ "ENSP00000297494.3:p.Asp298Glu", "ENSP00000417143.1:p.Asp92Glu", "ENSP00000420551.1:p.Asp298Glu", "ENSP00000420215.1:p.Asp298Glu", "cds46555.1:p.Asp298Glu", "cds46558.1:p.Asp298Glu", "cds46557.1:p.Asp298Glu", "cds46556.1:p.Asp298Glu" ], "hgvsg": [ "NC_000007.14:g.150999023T>G" ], "id": [ "rs1799983", "CM981388" ] } ]hgvsg の結果をみると
- GRCh37
- "NC_000007.13:g.150696111T>G"
- GRCh38
- "NC_000007.14:g.150999023T>G"
となっていて、指定したゲノム上で変換が行われている事が確認できる
単位時間あたりのリクエストの制限
EnsemblのAPIの利用には単位時間あたりの利用制限が設けられている
通常、上限が3600秒間に55000回となっているので、リミットに達する事は無いと思えるけれど、もしリミットに達してしまった場合には何秒間待てば再開できるかという情報を表示してエラーとなる今回はここまで
- 投稿日:2019-03-01T16:31:58+09:00
PythonプログラムをExeファイル化出来なくて1日費やしたときには
もし私がフリーザ様なら
地球は消えていたでしょう。
表題の件はそれくらい、久しぶりにハマりました。さて、Pythonでプログラムを記述して、使ってもらおうと思っても、
専門的な知識がない人に、コマンド画面を叩いて.pyファイルを実行させることはおろか、
Pythonとは、ANACONDAとは、インストール?パス?はて?
と、直接展開には高いハードルが立ちふさがります。そこでPythonには記述したプログラムをExeファイル化してくれる方法がいくつか存在しており
その中でもポピュラーな【pyinstaller】というものがあります。
コマンド画面で、記述したファイルを指定して、実行するだけでExeファイルが出来ます。
ExeファイルであればPythonがインストールされていないPCでも
プログラムを実行することが出来ます。実は今までの私はただ運がよかっただけで、何不自由なくExe化できていました。
しかし、ある日突然pyinstallerは牙を剥きました。備忘録の意味も含め記述します。
※分かりにくい箇所はご指摘ください。目次
■原因はMatplotlib
■涙が出そうなRecursionError: maximum recursion depth exceeded
■それでも明日はUnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 130: invalid start byteちなみに、PyQt5がインストールされていないことがあるので、
コマンドpip install PyQt5こちらのインストールも忘れないようにしましょう。
■原因はMatplotlib
かいつまんでお話ししますので、かなりの部分を割愛していますが、
Matplotlibを使用しており、そのplot部分でExeプログラムは断りもなく強制終了していました。
黙って終了するのはクソです。
Webとかで【Python Exe エラー】とか【Python Exe Matplotlib】で
調べてみたら結構出てきました。
でも、理由が分かりません。■RecursionError: maximum recursion depth exceeded
訳【再帰エラー:最大再帰深さを超えました】らしいです。
はっ?あの、すみません、日本語で言ってもらえませんか?日本語に訳したのに、意味が分からない日本語ってすごいですね。
コマンド画面の最終行に書かれていたので調べてみるとteratailで見つけました。teratail:pyinstallerでのexe化に失敗します
これだけ見るとなんのこっちゃなんですが、
ベストアンサーで紹介されているstackoverflowの先に
対応方法が書いていました。(英語なので翻訳などしてください)この部分に注目して下さい。
例えば、Hello.pyというPythonのファイルをExe化しようとしたとき
pyinstallerを実行すると、Hello.pyのファイルと同じディレクトリにHello.specという
specファイルが最初に出来、その後エラーが発生するとExe化は中止されます。
※specファイルはメモ帳とかにドラッグすると普通に中を見ることが出来ます。そのspecファイルの一番最初の行に
specファイルimport sys sys.setrecursionlimit(5000)と書き込み、上書き保存します。
コマンド画面に戻り、
今まではコマンド画面pyinstaller Hello.pyだったのを
コマンド画面pyinstaller Hello.specで実行すると再帰エラーはなくなります。
■UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 130: invalid start byte
こいつはやばかった。ドドリアさんはもうすでに逃げ出していた。
どうも、デコードが上手くいってないエラーだというのはなんとなくわかる。
でもutf-8で記述しているし、特別へんてこりんなことはしてない。
大体それまで普通通り動いてたのです。後々、もう少しコマンド画面をよく見れば、解決は早かったのかもしれないです。
さて、途方に暮れてteratailで質問しようと思い
質問文を書く前に、【Matplotlib EXE】で検索してみたが、それらしいものは無く、
ダメ元で【Seaborn EXE】で検索。これが大当たり。teratail:python3のpyinstallerを使用したexe化について
回答者の方が回答内容を勘違いしていたのですが
そのあとに回答していたないが大当たり。
本当にバグ取り作業並みの小ささ。
anaconda3\lib\site-packages\PyInstallerフォルダ内の
compat.pyファイルの370行目の
out = out.decode(encoding, errors='ignore')に書き換えてという指示。
質問者の方もこれを実施し、Exe化出来たとあります。これPythonファイルの一部を書き換える作業です(画像矢印のところ)
ここを書き換えて保存。もう少しコマンド画面をよく見ていればと思ったのは
この作業が終わってコマンド画面を見てみると、
ちゃんとそれっぽいのが出ていますね。その後、pyinstallerで一旦.pyファイルを実行すると意外と通りました。
でも、念のためspecファイルで再実行し
ようやく思い通りのExeが出来た。しかし、compat.pyの改修は本当にやばかった。
新しいバージョンになってこの辺りはちゃんと手入れされているのでしょうか。
そもそも、なんでMatplotlibと仲良くやってくれないのでしょうか。でも、つくづく思うのはPython利用者が爆発的に増え、
それに伴うバグの質問や対応の情報量もとても豊富にあるので、
とても助かりました。teratailの質問者の方、回答者の方
stuckoverflowの質問者の方、回答者の方
ありがとうございます。



- 投稿日:2019-03-01T16:29:56+09:00
pythonで音声をいじったり出力したりする方法まとめ
目的
ディープラーニングで声を変換したくて、とりあえず音声をpythonでいじったりする方法を調べたので(自分用に)まとめる。
まとめること一覧
- 形式変換して保存
- メル周波数ケプストラム係数(MFCC)
- 録音してある音声の出力
- リアルタイム入出力
形式変換して保存
import pydub sound = pydub.AudioSegment.from_file('ファイル', '拡張子') sound.export('ファイル.wav', format='wav') # 以下ちょっとした音声情報を調べる from matplotlib import pyplot as plt channel_count = sound.channels fps = sound.frame_rate duration = sound.duration_seconds print(channel_count) # チャンネル数(1:mono, 2:stereo) print(fps) # サンプルレート(Hz) print(duration) # 再生時間(秒) # 波形を表示 samples = sound.get_array_of_samples() plt.plot(samples) plt.show()メル周波数ケプストラム係数(MFCC)
import librosa x, sampling_rate = librosa.load('ファイル.wav') mfcc = librosa.feature.mfcc(x, sr=sampling_rate) # 以下視覚化 from librosa import display from matplotlib import pyplot as plt import numpy as np display.specshow(mfcc, sr=sampling_rate, x_axis='time') plt.colorbar() plt.show() # mfccはnumpy arrayなのでnumpyでいろいろできる print(mfcc.shape)録音してある音声の出力
import pydub from pydub.playback import play sound = pydub.AudioSegment.from_wav('ファイル.wav') play(sound)リアルタイム入出力
import pyaudio chunk = 1024 # * 2 処理の重さによって値を変える sr = 48000 # 小さくしていくと音質が悪くなる speaker = pyaudio.PyAudio() stream = speaker.open( format=pyaudio.paInt16, channels=1, rate=sr, frames_per_buffer=chunk, input=True, output=True ) while stream.is_active(): I = stream.read(chunk) # I = 何かしらの処理(I) 処理を加えるときはchunkをいくらか大きくする O = stream.write(I) stream.stop_stream() stream.close() speaker.terminate()以上。またいろいろわかり次第まとめていく。
- 投稿日:2019-03-01T15:57:35+09:00
openpyxlで別ブックにシートをコピーする
Introduction
この記事ではopenpyxlで別ブックにあるシートをコピーする方法を掲載しています。
openpyxlでは基本的には別ブックにあるシートを丸ごとコピーすることはできません(リンク先参照)。ですが、シートにある値であれば、コピーすることができます。Pythonスクリプト
Pythonのコード例を以下に示します。以下の例ではfgo.xlsxのシート1の内容を読み込み、新規作成したfgo_2.xlsxのclassというシートにコピーしています。
sheet_copy.py''' sheet_copy.py purpose: make new xlsx and copy sheet ''' import pandas as pd import os import openpyxl as xl # set input file name inputfile = 'fgo.xlsx' # set output file name outfile = 'fgo_2.xlsx' # set output sheet title sheettitle = 'class' # read tmp xlsx wb1 = xl.load_workbook(filename=inputfile) ws1 = wb1.worksheets[0] # create new xlsx file wb2 = xl.Workbook() ws2 = wb2.worksheets[0] ws2.title = sheettitle # write to sheet in output file for row in ws1: for cell in row: ws2[cell.coordinate].value = cell.value # save target xlsx file wb2.save(outfile)最後の方の
# write to sheet in output file for row in ws1: for cell in row: ws2[cell.coordinate].value = cell.valueの部分でws1(fgo.xlsxのシート1)のcellの値を、逐次的にws2(fgo_2.xlsxのclassシート)のcellに代入しています。
同様の方法を使えば、塗りつぶしの色やフォントなどの体裁もコピーできそうです。
- 投稿日:2019-03-01T15:56:15+09:00
stanfordnlp PermanentlyFailedExceptionが出た時にやったこと
概要
stanfordnlpを使って、serverを立ち上げた時に出るこのエラーを回避したのでメモしておきます。
ちなみに、CoreNLPサーバーを立ち上げる方法は、公式のGitHubのデモに記載があるのでそちらを確認してください。
https://github.com/stanfordnlp/stanfordnlp/blob/master/demo/corenlp.pyエラー
$ stanfordnlp.server.client.PermanentlyFailedException: Timed out waiting for service to come alive.timeoutの時間を伸ばしてくださいとのことです。デフォルトが30000msらしいので、適当に長さを伸ばせば解決します。適当にtimeoutを設定すれば大丈夫です。該当のコードはここです。
with CoreNLPClient(annotators=['tokenize','ssplit','pos','lemma','ner','depparse','coref'], timeout=10000000, memory='16G') as client:せっかくなので、中身をみてみるとなんのことはありません。
class CoreNLPClient(RobustService): """ A CoreNLP client to the Stanford CoreNLP server. """ DEFAULT_ANNOTATORS = "tokenize ssplit lemma pos ner depparse".split() DEFAULT_PROPERTIES = {} DEFAULT_OUTPUT_FORMAT = "serialized" def __init__(self, start_server=True, endpoint="http://localhost:9000", timeout=30000, threads=5, annotators=None, properties=None, output_format=None, stdout=sys.stdout, stderr=sys.stderr, memory="4G", be_quiet=True, max_char_length=100000 ): if isinstance(annotators, str): annotators = annotators.split() if start_server: host, port = urlparse(endpoint).netloc.split(":") assert host == "localhost", "If starting a server, endpoint must be localhost" assert os.getenv("CORENLP_HOME") is not None, "Please define $CORENLP_HOME where your CoreNLP Java checkout is" start_cmd = "java -Xmx{memory} -cp '{corenlp_home}/*' edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port {port} -timeout {timeout} -threads {threads} -maxCharLength {max_char_length}".format( corenlp_home=os.getenv("CORENLP_HOME"), port=port, memory=memory, timeout=timeout, threads=threads, max_char_length=max_char_length) stop_cmd = None else: start_cmd = stop_cmd = None super(CoreNLPClient, self).__init__(start_cmd, stop_cmd, endpoint, stdout, stderr, be_quiet) self.timeout = timeout self.default_annotators = annotators or self.DEFAULT_ANNOTATORS self.default_properties = properties or self.DEFAULT_PROPERTIES self.default_output_format = output_format or self.DEFAULT_OUTPUT_FORMATjavaのコマンド叩いてるだけなので、ローカルの環境で再現したい場合は、これを穴埋めして叩けばいいです。READMEで
export CORENLP_HOME='path/to/stanfordnlp'をしておかないと確かにエラー吐きますね。"java -Xmx{memory} -cp '{corenlp_home}/*' edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port {port} -timeout {timeout} -threads {threads} -maxCharLength {max_char_length}".format( corenlp_home=os.getenv("CORENLP_HOME"), port=port, memory=memory, timeout=timeout, threads=threads, max_char_length=max_char_length参考
https://github.com/stanfordnlp/python-stanford-corenlp/issues/9
- 投稿日:2019-03-01T15:19:53+09:00
回帰分析を行う際の曜日と休日のダミー変数
回帰分析を行う際の{曜日、休日、祝日}など、人の行動に関与するダミー変数を作成したので共有する。
以下画像はデータ例
以下ソースコード
import numpy as np import pandas as df import sys from datetime import * from time import * import csv # 祝日のデータを読み込む def import_Pholiday(): get_data = [] #祝日データ読み込み先のパス path = './import_data/holiday_data.csv' with open(path,'r',encoding="utf-8_sig") as f: reader = csv.reader(f) for row in reader: get_data.append(row) return get_data # csv出力先 def write_csv(data): # ソースと同じディレクトリにsome.csvとして書き出す with open('some.csv', 'w') as f: writer = csv.writer(f, lineterminator='\n') for i in range(0,len(data)): writer.writerow(data[i]) def main(): #作成するトレンド日数 trendDay = 1860 # [日付,月,火,水,木,金,土,日,祝日,祝日の名前,休] trend = [[]] arr = ["日付","月","火","水","木","金","土","日","祝日","祝日の名前","休日","年末年始"] # 今日の日付を選択 day_now = datetime.today() ph_day = import_Pholiday() for i in range(len(ph_day)): ph_day[i][1] = datetime.strptime(ph_day[i][1], '%Y/%m/%d') ph_day[i][1] = datetime.strftime(ph_day[i][1], '%Y%m%d') # 日付のフォーマット型を整形 first_day = day_now.replace(day=1) day = datetime.strftime(first_day, '%Y%m%d') print(day) trend[0] =arr # 各日にちのトレンドデータを作成 for i in range(0,trendDay): trend.append([0]*12) first_day = first_day - timedelta(days=1) day = datetime.strftime(first_day, '%Y%m%d') trend[i][0] = day if first_day.weekday() == 0: trend[i][1] = 1 elif first_day.weekday() == 1: trend[i][2] = 1 elif first_day.weekday() == 2: trend[i][3] = 1 elif first_day.weekday() == 3: trend[i][4] = 1 elif first_day.weekday() == 4: trend[i][5] = 1 elif first_day.weekday() == 5: trend[i][6] = 1 elif first_day.weekday() == 6: trend[i][7] = 1 if str(day) in str(ph_day): trend[i][8] = 1 for j in range(len(ph_day)): if str(day) == str(ph_day[j][1]): trend[i][9] = str(ph_day[j][3]) if str(trend[i][0]).endswith('1231') or str(trend[i][0]).endswith('1231') or str(trend[i][0]).endswith('0101') or str(trend[i][0]).endswith('0102') or str(trend[i][0]).endswith('0103'): trend[i][11] = 1 if trend[i][6] == 1 or trend[i][7] == 1 or trend[i][8] == 1 or trend[i][11]: trend[i][10] = 1 #print(trend[i]) #print(trend[0]) #print(trend[1]) write_csv(trend) if __name__ == '__main__': main()githubに作成したcsvなども置いてあります。
https://github.com/Baya-Non/-Linear_regression_trend

- 投稿日:2019-03-01T14:05:41+09:00
nginx + djangoで adminページのsvgが表示されないやつを直す
初心者です
nginxとかに関しては全くの初心者で、そんな中引っかかった問題を書く。
環境
Docker: 2.0.0.3
django: 2.1.7
nginx: 1.15.9問題
- なんとかDockerでdjango + nginx + postgreの環境を整えて、デフォルトページが表示できた。
- cssとかは動いているのにsvgだけ読み込まんのはなんで????
わかったこと
- nginx側で静的ファイルをいい感じに振り分けていた。(djangoで/static/...のURIだったときはnginxの方にリクエストを流す)
- どうやら
mime.typesというファイルに、レスポンスするファイルのMIMEをすべて書き連ねないといかんらしい。- そうしないと
nginx.confで設定されているapplication/octet-streamでヘッダが組まれてしまいいい感じにやってくれない↓どっからかコピペした
nginx.confnginx.conf...略 http { include /etc/nginx/mime.types; default_type application/octet-stream; access_log /tmp/nginx.access.log combined; sendfile on; ...全略 }どうやらmime.typesに書かれていないMIMEが要求された時、ここの
default_typeとやらに勝手になってしまって、正常にMIMEを認識してくれない -> svgとして読み取らんからレスポンスが無い。というわけでまたまたどっかからコピペしたmime.typesにsvgのMIMEを調べて追加
mime.typestypes { text/html html htm shtml; text/css css; text/xml xml rss; image/gif gif; image/jpeg jpeg jpg; image/svg+xml svg; # <-ココ application/x-javascript js; text/plain txt; }無事にsvgが表示されるようになったとさ
- 投稿日:2019-03-01T14:04:24+09:00
ラスボス系後輩ヒロインAIチャットボットを作りたい・環境の構築〜Pythonの基礎②
※この記事はQrunchにもクロス投稿しています。
前回の続きから行きます。そういえばRubyで
str[n]を見たときはぎょっとしたんですけど、あれ考えてみればchar[]の扱いをStringに取り込んだだけなのでそんな変な動きでもないですね。char[]の存在自体忘れてたけど……char*とか懐かしすぎる……リストとタプルと辞書と集合
名前 書式 注釈 リスト [val] 順番が保証される。重複した値も許可する。上書き可能。 タプル (val) 順番が保証される。重複した値も許可する。上書きできない。 辞書 {key:val} 順番は保証されない。キーが一意となる。上書き可能。 集合 {val} 順番は保証されない。重複した値は入らない。上書き可能。 「二通りの意味でPythonicな」という記述に首を傾げてコードを眺めていたのですが、なるほどMonty PythonとPythonのダブルミーニングか……
Monty PythonはあれかなイギリスのTeam Nacsって認識でいいかな。怒られるかな。タプル、一回読んだだけだとちょっと理解できなかったけどPHPのlist()みたいなことができると思えばだいたい合ってるっぽい?
php > $arr = ['ruby', 'diamond', 'perl']; php > list($a, $b, $c) = $arr; php > echo $a; ruby php > echo $b; diamond php > echo $c; perl>>> a, b, c = {'ruby', 'diamond', 'perl'} >>> a 'ruby' >>> b 'diamond' >>> c 'perl'ただケツカンマだけはちょっと受け付けない。まあ要素一個のタプルなんて使わないでしょうし別にいいけど。
可変長の引数を取る関数には*argsてきなことをやるらしい。リストの方はざっと見た感じ「どう書いても動くな……」という印象。
index, count, join, sort, len, copyと欲しいものがだいたいあり、脳死状態で書いても安定して動いてくれそう。
中でも「マーベラス!!!」とテンション爆上げ&内心スタンディングオベーションしたのがin構文。>>> 'fizz' in ['hoge', 'fuga', 'poyo'] Falseこの構文すっごい素敵。エンジニアの手に馴染みやすく英語としてそのまま読み下すこともできる! 最強では?! 好き!
辞書はだいたい連想配列、ハッシュマップと似たようなものなので違和感も疑問も特に無い。dict()を使った変換はCSV読み込みあたりで使いそう?
foreach($line as $key => $val){ $arr[$key] = $val; }みたいなこと書かないで済むのは地味に便利っぽい。
辞書のupdate関数はなんでupdate? と思ったけど要は「Aの辞書をBの辞書で上書きする」みたいなことだと思えばよさそう。Bの辞書に無いものは上書きされない。
こちらもdel, keys, values, items, copyと大体必要そうなものが揃っていて便利っぽい。updateがあってinsertが無いのちょっともやっとするけど。集合は数学の集合だと思えばいいらしい。和集合、差集合、積集合、排他的論理和などが取れる。
名前 記号 例 意味 和集合 & a & b 積集合 | a|b 差集合 - a-b 排他的論理和 ^ a^b 部分集合 <= a<=b aはbの部分集合である 真部分集合 < a<b aはbの真部分集合である 上位集合 >= a>=b aはbの上位集合である 真上位集合 > a>b aはbの真上位集合である 半角パイプ入れられなかった……
>>> language = {'python', 'ruby', 'perl', 'java'} >>> gem = {'sapphire', 'ruby', 'diamond', 'quartz'} >>> language & gem {'ruby'} >>> language ^ gem {'diamond', 'perl', 'quartz', 'python', 'sapphire', 'java'} >>> language | gem {'diamond', 'perl', 'quartz', 'python', 'ruby', 'sapphire', 'java'} >>> language < gem Falseというわけで割合サクッと三章が終わってしまった(見積もりが下手!)ので四章に行きます。
- 投稿日:2019-03-01T13:42:30+09:00
BERTでエンコードした文リストをfaissで検索
BERTをエンコーダとして使ったらどうなるか検証するために、文をエンコードし、それをfaissへ入れて類似性検索を行います。
そもそもBERTにおける文ベクトルってあるの?
BERT Vector Space shows issues with unknown words
https://github.com/google-research/bert/issues/164
@jacobdevlin-google (bert開発者)
"I'm not sure what these vectors are, since BERT does not generate meaningful sentence vectors. It seems that this is is doing average pooling over the word tokens to get a sentence vector, but we never suggested that this will generate meaningful sentence representations. And even if they are decent representations when fed into a DNN trained for a downstream task, it doesn't mean that they will be meaningful in terms of cosine distance. (Since cosine distance is a linear space where all dimensions are weighted equally)."
訳:"BERTは意味のある文ベクトルを生成しないので、これらのベクトルが何であるのかについて確証はない。 文ベクトルを取得するためのワードトークンに対する平均プーリングをやっているように見えるが、我々はこの方法が意味のある文表現を生成するとは示唆しない。 そして、たとえ下流のタスクのために訓練されたDNNに供給されたときにそれらがまともな表現であったとしても、それらがコサイン距離の観点から意味があるという意味ではない。 (コサイン距離は、すべての次元が等しく重み付けされている線形空間であるため)。"
Features extracted from layer -1 represent sentence embedding for a sentence?
https://github.com/google-research/bert/issues/71
@jacobdevlin-google (bert開発者)
"-1 means the last hidden layer. There are 12 or 24 hidden layers, so -1,-2,-3,-4 means 12,11,10,9 (for BERT-Base.) It's extracted for each token. There is not any "sentence embedding" in BERT (the hidden state of the first token is not a good sentence representation). If you want sentence representation that you don't want to train, your best bet would just to be to average all the final hidden layers of all of the tokens in the sentence (or second-to-last hidden layers, i.e., -2, would be better)."訳: "-1は最終層を意味します。隠れ層が12か24あるので、-1,-2,-3,-4は12,11,10,9層目です。それぞれのトークンに対して展開されます。BERTには「文エンベディング」のようなものはありません(最初のトークンの隠れ層の状態は良い分表現とは言えません)。もし、文表現を獲得したい場合、最も良い方法となりそうなのは、最終層のすべてのトークンの平均です。(または、最後から2番目の層も良くなるかもしれません。)"
実行
文リストをエンコード
エンコードのスクリプトは以下で共有します。
https://github.com/sugiyamath/bert_and_faiss_experiments/blob/master/bert/extract_features.pyなお、このエンコードスクリプトを使うより、bert-as-serviceを使ったほうが高速だと思います。エンコードのやり方は省略します。
faissにぶち込む
1ファイル1文としてエンコードしたjsonファイルを読み込み、最終層の各トークンベクトルの平均をfaissへ格納します。
import os import json import numpy as np from tqdm import tqdm import faiss files = list(map(lambda x: os.path.join(".",x), os.scandir("enc_outputs/"))) files[0] data = [] for file in tqdm(files): with open(file) as f: tmp = json.load(f) tmp = np.mean([d['layers'][0]['values'] for d in tmp['features']], axis=0) data.append(tmp) index = faiss.IndexFlatL2(data[0].shape[0]) index.add(np.array(data, dtype=np.float32)) faiss.write_index(index, "faiss_bert.faiss")検索する
from gensim.models.doc2vec import Doc2Vec import numpy as np import faiss import sys if __name__ == "__main__": doc_num = int(sys.argv[1]) with open("postlist.txt") as f: data = [line.strip() for line in f] print("[target doc:", data[doc_num], "]\n") index = faiss.read_index("./faiss_bert.faiss") vec = index.reconstruct(doc_num) D,I = index.search(np.array([vec]), k=30) for i in I[0]: print(data[i])[実行方法]
python <スクリプト名> <類似性検索したいドキュメント番号>実行結果 (1行1投稿)
タグを投稿する形式のSNSを想定します。1投稿に複数タグが投稿できます。
target doc は類似性検索する対象のドキュメントです。このドキュメントに似た投稿を検索します。
python bert_faiss_search.py 20000[target doc: 極楽鳥 横浜 鶏ラーメン えりな増し 太麺と細麺 ] 極楽鳥 横浜 鶏ラーメン えりな増し 太麺と細麺 煮干し中華 らーめん 麺や城 青森 フェスめし 小籠包 担々麺 餃子 マグロ寿司 麻婆焼鳥 麺屋宗 金色香味塩らぁ麺 仁久屋 松阪牛肉汁餃子 麺や庄の 燻し焼きチャーシューメン 神龍 神龍餃子 小豆島ラーメンHISHIO 醤 丸満 福包み揚げ焼き餃子 世界が麺で満ちる時 名古屋コーチン黄金醤油ラーメン 浜太郎 浜松餃子 つけ麺 らーめん ラーメン 魚介豚骨 武骨屋 武骨屋恵比寿 恵比寿家系ラーメン 恵比寿ラーメン 麺類 中太麺 現場飯 コスパ飯 プチプラ飯 やじー 矢嶋巧 ラーメン 麺スタグラム 麺肆秀膽 塩ラーメン 塩つけ麺 大盛り 京都北白川ラーメン魁力屋 ラーメン 餃子 ランチ 味玉追加 辛子味噌 麺屋又兵衛 名古屋 塩ラーメン チャーシュー 鰹節 らーめん 中華そば ラーメン 麺スタグラム ラーメンインスタグラマー ラーメン好きと繋がりたい ラーメン女子 らーめん ラーメン 豚骨ラーメン 豚骨 麺 ハリガネ チャーシュー もやし 替え玉 ラーメン好き 今年初 麺スタグラム めし ランチ おいしかった 味噌ラーメン 麺 麺スタグラム 拉麺 ラーメン ラーメン部 ramen noodles スープ ルーロー飯 魯肉飯 丼 大阪 コッチネッラ coccinella 美味しい 華丸ラーメン らーめん 焼干しらーめん 醤油ラーメン 青森 つけ麺 ラーメン 麺野郎 うどん 丸亀製麺 牡蠣づくし玉子あんかけ 麺者すぐれ 白つけ麺 三種の肉 穴子天ぷら カネキッチンヌードル 東長崎 ラーメン らーめん 中華そば 醤油ラーメン らぁ麺 麺活 ラーメンいんすたグラマー ラーメン大好き 麺すたぐらむ ラーメン好き女子 麺スタグラム ラーメン 江古田 ヤマン らはめん 根っからくいしん坊 20190203 品川やきいもテラス 塩やきいも 品達 麺屋翔 塩ラーメン 東京スカイツリー キングダムハーツ 光と闇の塔 星乃珈琲 パンケーキ 京都 クックドゥー 担々麺 ピーマン 稲庭うどん 麺屋三郎 札幌味噌 限定 塩らぅめんリベンジ 関西 京都 祇園 同伴 ディナー 大好物 和食 割烹 ミシュラン2つ星 三玄茶 舞扇 にしむら 鉄板割烹 一道 中華 にしぶち飯店 白椀竹快樓 おばんざい イタリアン オバタリアン ご馳走様でした つけ麺 ラーメン 麺類好き うまし めん奏心 特製煮干しそば ラーメン 麺navi東海 めん奏心 簡単 茶碗蒸し 作った ぷるぷる どん兵衛 カップ麺 カップラーメン ラーメン 拉麺 広島県 広島 尾道 尾道ラーメン しんたく 餃子 海鮮巻 料理 ドラえもん お箸 富山 富山県 ディズニー ツムツム お皿 ラーメン らーめん 拉麺 ラーメン屋 とんこつラーメン 豚骨ラーメン とんこつ 麺 ハリガネ 紅生姜 たっぷり めし 麺スタグラム ランチ おいしかった ラーメン らーめん 拉麺 noodles 塩 ラーメン花月嵐 天下一品 ラーメン こってりネギ多め チャーシュー麺 麺散 表参道 究極の釜揚げうどん バリカタぶっかけスタイル 黒木啓司 純手打ち麺と未来 麺と未来 下北沢 ラーメン ラーメン部 醤油ラーメン 東京ラーメン 東京グルメ 1人飯 女性が入りやすいラーメン屋 恵比寿ラーメン 恵比寿ランチ 神座 ラーメン 中華そば しょうゆラーメン らーめん ラーメン女子 麺スタグラム らーめん部 ラー活 麺活 ramenいい感じではないでしょうか。
参考
- 投稿日:2019-03-01T11:10:07+09:00
Adversarial Validationについてメモ
概要
Adversarial Validationとは、学習データとテストデータが大きく異なる場合、
学習データをそのまま使ってもいい検証結果が得られないから、
テストデータに似た学習データを作ろうという手法みたいです。元ネタ
http://fastml.com/adversarial-validation-part-one/
http://fastml.com/adversarial-validation-part-two/手順
取り込んだ学習データとテストデータが判別できるラベルを追加します。
train = pd.DataFrame({'A': [1,2,3,4,5,6,7,8,9,10]}) test = pd.DataFrame({'A': [100,200,300,400,3,1,200]}) train['TARGET'] = 1 test['TARGET'] = 0学習データとテストデータをくっつけます。
data = pd.concat(( train, test )) x = data.drop( [ 'TARGET' ], axis = 1 ) y = data.TARGETデータを分割します。
from sklearn.model_selection import train_test_split num_train = 5 x_train, x_test, y_train, y_test = train_test_split( x, y, train_size = num_train )作成した、テストデータと検証データで、分類モデルを作成、評価します。
from sklearn.ensemble import RandomForestClassifier clf = RandomForestClassifier(random_state=0) clf = clf.fit(x_train, y_train) yy = clf.predict(x_train)テストデータに似ているスコアでソートします
y_sorted = np.sort(yy, axis=0) plt.plot(y_sorted)
x_sorted = np.sort(x_train, axis=0) plt.plot(x_sorted)
ソートしたデータから60%を学習データとして使用します。
sixty = int(num_train * .6) sixty = num_train - sixty thresh = x_sorted[sixty, 0] #このグラフだと200とかになりました # threshより大きい値を学習データにする以上、Adversarial Validationの考え方のメモです。
分類モデルはCNNや、他のアルゴリズムでも問題ないです。
KaggleでPublic LBとLocalCVの結果が大幅に違う場合、試してみる価値ありかと。
めっちゃわかりやすい記事ありました!
https://blog.amedama.jp/entry/adversarial-validation


- 投稿日:2019-03-01T10:30:23+09:00
Pandasでデータを操る。ある列に特定の文字(文字列)を含んだ行を削除編
タイトルの通り、「ある列に特定の文字(文字列)が含まれている場合、それを行ごと削除したい」という願いを叶えるPythonスクリプトをご紹介します。
Pythonスクリプト
nonG.py''' nonG.py purpose: delete G row in ALT column ''' import os import pandas as pd import argparse import sys def main(): # make parser parser = argparse.ArgumentParser() # add argument parser.add_argument('input') parser.add_argument('output') # analize arguments args = parser.parse_args() # set input filename and the number of vcf header inputfile = args.input print(inputfile) # if inputfile does not exist, print error message and program done if os.path.exists(inputfile) == False: print(inputfile+' does not exist. Please check file name.') sys.exit(1) # set output filename outputfile = args.output # if outputfile already exists, print error message and program done if os.path.exists(outputfile) == True: print(outputfile+' already exists. Please delete or rename.') sys.exit(1) # input tsv data = pd.read_csv(inputfile, delimiter='\t') # delete row contains G in ALT column data = data[~data['ALT'].str.contains('G')] # output data to outputfile data.to_csv(outputfile, index=False, mode='a', sep='\t') if __name__ == '__main__': main()テストデータには以下のようなinput.tsvファイルを用います。
このスクリプトを実行するにはターミナルで以下のようにタイプしてください。
$ python nonG.py input.tsv output.tsv結果がoutput.tsvとして出力されます。
スクリプト詳細
最初の方はinput.tsvを読み込む作業をしているので無視して、本題のデータ操作を説明したいと思います。
# delete row contains G in ALT column data = data[~data['ALT'].str.contains('G')]このたった1行で「'ALT'列にある、'G'を含む行を削除」しています。
data['ALT'].str.contains('G')でdataの中の'ALT'列の中で、文字(文字列)'G'を含むものを抽出しています。そこに否定を意味する演算子 ~ をつけ、
~data['ALT'].str.contains('G')とすることで、文字(文字列)'G'を含まないものを抽出することができます。このようにすることで、特定の文字を含む行を削除したデータテーブルを簡単に作成することができます。結果は以下のようになります。
'ALT'列から文字(文字列)'G'を含む行が削除されていることがわかります。

