- 投稿日:2020-10-10T22:44:58+09:00
【俺得】SAM CLIでデプロイする迄
AWS CLIインストール
pythonとpipのpath追記 ※前段作業
・pythonとpipのPath確認方法
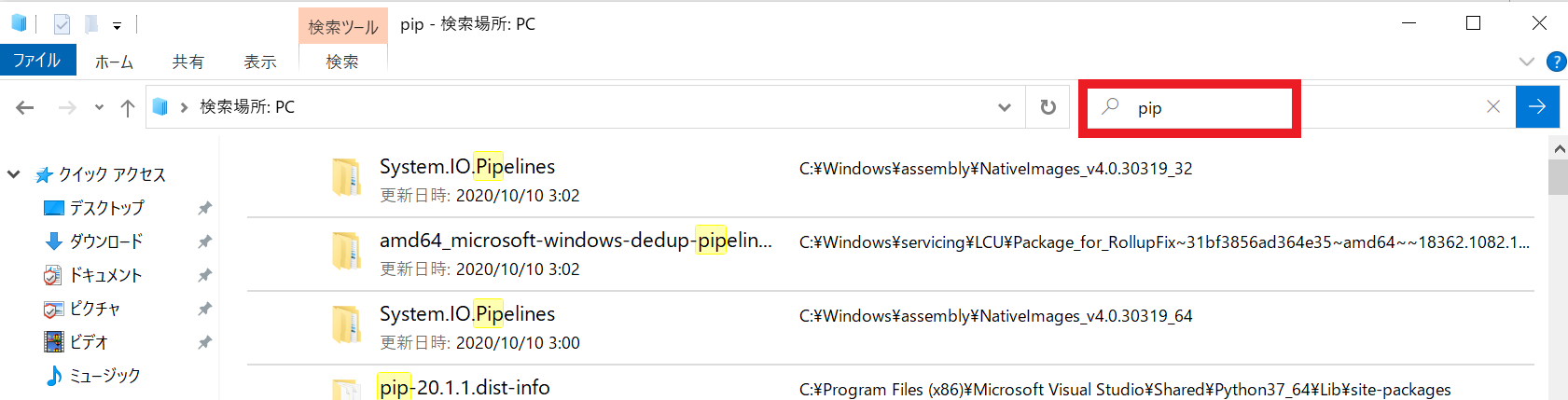
エクスプローラで確認
・pathの追記
コマンドプロンプトから下記を開いていく
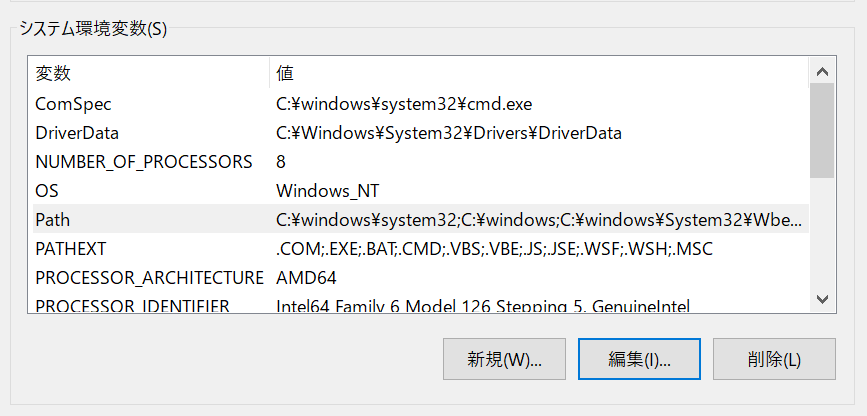
システムとセキュリティ→システム→システムの詳細設定→環境変数
システム環境変数の一覧からPathを選択し、編集をクリック
pythonとpipのPathがなければ新規にて作成
AWS CLIインストール
C:\Users\USER>pip install awscli Defaulting to user installation because normal site-packages is not writeable Collecting awscli Downloading awscli-1.18.157-py2.py3-none-any.whl (3.4 MB) |████████████████████████████████| 3.4 MB 504 kB/s Installing collected packages: six, python-dateutil, jmespath, urllib3, botocore, PyYAML, pyasn1, rsa, s3transfer, colorama, docutils, awscli WARNING: The scripts pyrsa-decrypt.exe, pyrsa-encrypt.exe, pyrsa-keygen.exe, pyrsa-priv2pub.exe, pyrsa-sign.exe and pyrsa-verify.exe are installed in 'C:\Users\USER\AppData\Roaming\Python\Python37\Scripts' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location. Successfully installed PyYAML-5.3.1 awscli-1.18.157 botocore-1.18.16 colorama-0.4.3 docutils-0.15.2 jmespath-0.10.0 pyasn1-0.4.8 python-dateutil-2.8.1 rsa-4.5 s3transfer-0.3.3 six-1.15.0 urllib3-1.25.10 WARNING: You are using pip version 20.1.1; however, version 20.2.3 is available. You should consider upgrading via the 'c:\program files (x86)\microsoft visual studio\shared\python37_64\python.exe -m pip install --upgrade pip' command.WARNINGの一つ目はPathが通っていないため追記が必要
追加するPathはWARNINGに記載ありWARNINGの二つ目は単純なpipのupgradeで最新版にできるという案内
AWS CLI設定
C:\Users\USER>aws configure --profile IoT
AWS Access Key ID [None]: ###
AWS Secret Access Key [None]: ###
Default region name [None]: ap-northeast-1
Default output format [None]: json設定後の確認
ec2の確認aws ec2 describe-instances --instance-ids ${instance-id} --profile IoTS3の確認
C:\Users\USER>aws s3 ls --profile IoT 2020-10-10 14:46:01 test7712121AWS SAM CLIインストール
Dockerのインストール ※前段作業
まずはタスクマネージャー→パフォーマンスタブ→CPUの
右下の「仮想」の欄が有効になっていることを確認。
Dockerのを入れるにあたりWindows10HomeではDokcer Desktop for Windows が入らないため
今回は代わりにDocker Toolboxをインストールすることにしました。
下記サイトから「Install Docker Toolbox for Windows」からv19.03.1をインストール
https://docs.docker.com/toolbox/overview/
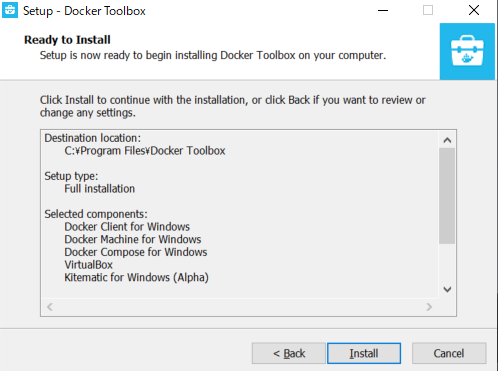
特に内容は変更せずインストールを行いました。
Dockerのインストールの途中で下記がインストールが表示された場合はインストールする。
AWS SAM CLIインストール
以下よりインストーラをダウンロード
https://github.com/awslabs/aws-sam-cli/releases/download/v0.6.2/AWS_SAM_CLI_64_PY3.msiバージョンの確認コマンド
C:\Users\USER>sam --version SAM CLI, version 0.6.2initが考えていた挙動とは違い指定等ができなかったが
buildをしようとするとできない状態が発生!!実はインストーラのバージョンが古い為だと判明したため、
最新のSAMをインストールすると無事解決!ビルドとデプロイ
まずはsam initでAWS SAM テンプレートを使用して
サーバーレスアプリケーションを初期化します。
ちなみにプロジェクトを変える時などの初回時だけで大丈夫。今回の設定は
: 1 - AWS Quick Start Templates
言語 : 8 - python3.7
Project name : test2
templates : 1 - Hello World ExampleC:\Users\USER\test>sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore3.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8.al2 13 - java8 14 - dotnetcore2.1 Runtime: 8 Project name [sam-app]: test2 Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git AWS quick start application templates: 1 - Hello World Example 2 - EventBridge Hello World 3 - EventBridge App from scratch (100+ Event Schemas) 4 - Step Functions Sample App (Stock Trader) Template selection: Template selection: 1 ----------------------- Generating application: ----------------------- Name: test2 Runtime: python3.7 Dependency Manager: pip Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./test2/README.md今回は思っていた通り指定等ができたので
初回に必要な--guided オプションをつけて実行し、
biludしdeploy開始した結果がこちらなんですが、またもエラーが・・・C:\Users\USER\sam_test>sam build Building codeuri: hello_world/ runtime: python3.7 metadata: {} functions: ['HelloWorldFunction'] Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam\build Built Template : .aws-sam\build\template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guidedsam deploy --guided --profile IoT Configuring SAM deploy ====================== Looking for config file [samconfig.toml] : Not found Setting default arguments for 'sam deploy' ========================================= Stack Name [sam-app]: sam_test AWS Region [us-east-1]: ap-northeast-1 #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [y/N]: N #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: Y HelloWorldFunction may not have authorization defined, Is this okay? [y/N]: y Save arguments to configuration file [Y/n]: Y SAM configuration file [samconfig.toml]: SAM configuration environment [default]: Looking for resources needed for deployment: Not found. Creating the required resources... Successfully created! Initiating deployment ===================== HelloWorldFunction may not have authorization defined. Uploading to sam_test/25efe53b4bac655770621572b615acba.template 1132 / 1132.0 (100.00%) Error: Failed to create changeset for the stack: sam_test, An error occurred (ValidationError) when calling the CreateChangeSet operation: 1 validation error detected: Value 'sam_test' at 'stackName' failed to satisfy constraint: Member must satisfy regular expression pattern: [a-zA-Z][-a-zA-Z0-9]*|arn:[-a-zA-Z0-9:/._+]*実際には簡単なミスでstackName に 「_」を使用できないためのエラーだったので
samconfig.tomlのファイルの中身を編集して解決した。
修正後、buildしdeployしてみると成功。

- 投稿日:2020-10-10T22:42:29+09:00
aws初学者がCIDR表記を調べてみて
- 投稿日:2020-10-10T22:35:29+09:00
昨今のエンジニアのインフラ技術を料理で無理矢理例えてみた。
はじめに
この記事の想定対象者は
- 自分はエンジニア(開発者)ではありません
- でも、エンジニアと関わります。(企画とかマネジメントとか)
- そのため、最低限エンジニアのインフラ知識ないとエンジニアの皆様に『そんなことも知らねーのかよ勉強して出直せ』と怒られます
- でも、少しググったけど何もわからないんです
という人々です人類どんな人がいようと食べない人はいないだろうということで、無理矢理料理で例える努力をしてみました。
ので、日頃サーバー触っているエンジニアの方々はあまり対象ではありません
もしかしたらプログラミングはできるけどインフラ周り何もわからないっていう人の助けにはなるかもしれません。
ならないかもしれません。具体的な技術について
- クラウド(いわゆるパブリッククラウド。AWS/Azure/GCP...)
- コンテナ(Docker)
- Kubernetes
についてかるーく触れます
雰囲気が伝わることをめざしています。ので超厳密にいうと少し違うかもしれません。
ご了承ください嘘は書いてないつもりです。ここ違うよ!ってところがあればコメントいただけますと幸いです。
本題
では、本題です。
1. 従来
あなたは料理人です(エンジニア)
料理をします(コーディング/プログラミング)
ただそれだけだとお客様に提供がきません(デプロイできません)
まず、テーブル(物理サーバ)を用意して、お皿(ライブラリ等)を用意して、そこに料理(コード)を盛り付けて初めて提供できます(デプロイ)なので、毎回テーブルとお皿を用意しなければいけません.。
特にテーブルを毎回用意するのは面倒です。重いし高いし。2. クラウド
そこで生まれたのがクラウドです
クラウドとは、テーブル(物理サーバ)を1000台以上並べた上に、でっかい真っ白なテーブルクロスを引いたものです
なので中身はテーブルの集合ですが、上から見たら真っ白な巨大なテーブルでしかありませんその巨大テーブルに仕切りを作って、1つ1つの空間に切り分けます。以後この1つの空間をテーブル(仮)とします。(仮想サーバ/EC2インスタンス)。ちょっとイメージしにくいかもしれませんが、テーブル(仮)は物理的なテーブルだと思ってください。
それを料理人に提供します。「いくつテーブル(仮)が必要ですか」「ここはあなたのテーブル(仮)です」「好きに使ってください」「レンタル料は1テーブル(仮)あたり1ヶ月いくらです」って貸し出すのがクラウド事業者(AWS/Azure/GCP…)ですただ、結局そのテーブル(仮)上にお皿(ライブラリ等)は用意しなければいけません。複数のテーブル(仮)に提供したい場合は、それごとにお皿(ライブラリ等)を買ってきて置いて、その上でそれぞれ料理(コード)を並べることになります。綺麗な盛り付けも必要です。面倒です。
3. コンテナ
そこで生まれたのがコンテナです
コンテナとは、出前用の箱だと思ってください。岡持ちです。その箱の中にお皿と料理を詰めます。綺麗な盛り付けもここで終わらせます。
ので、一度岡持ちを作ってしまえば、それをテーブルの上に置くだけで済みます。(コンテナ自体は物理サーバでも仮想サーバでも動きます。なぜこの順番で説明しているかは一番下の番外編をご覧ください)
そして、ここからが現実と違うところですが、この岡持ちは全く同じものが複製できます。
ここいい例え思いつきませんでした。この岡持ちに入ったら超科学で3dプリンターが使えるとか思ってください。ので、複数のテーブルに提供したい場合も、その複製した岡持ちごとおけば全て解決します。毎回お皿(ライブラリ等)を買って来る必要はありません。
このコンテナという技術のうち一番有名なものがDockerと呼ばれますコンテナです。
しかし、ここでも問題があります。それは、テーブルが壊れれば(割れるとか足が折れるとか)、その上においてある岡持ち(コンテナ)は当然一緒に落ちる、ということです
例えば、そこがバイキング/ビュッフェとかだったら一大事。
常に料理をお客様に提供しなければならないのに、壊れてしまったら、別のテーブルの上にまた岡持ち(コンテナ)を置くまで料理の提供ができなくなります。(そんな簡単に壊れねーだろと思うかもしれませんが、壊れた時が本当に一大事なので絶対に避けたいのがインフラエンジニアの方々だったりします)
4. Kubernetes
そこで生まれたのがKubernetesです。(略してk8s)
Kubernetesは、なんか、ウエイターです。スーパーウエイターです。
ウエイターは自分の店内にある全てのテーブル(物理/仮想サーバー)を常に見ています。
そして、料理人(エンジニア)はウエイターに置きたい料理が入った岡持ち(コンテナ)を渡します。
例えば「この野菜炒めの岡持ちを置いて欲しい」とかです。
ウエイターは「かしこまりました」と言い、1つのテーブルの上に野菜炒めの岡持ちを置きます。そこで、そのテーブルが壊れたとしましょう。当然野菜炒めは落ちます。食べられません。
従来なら、料理人が時間差で気づき、慌てて他の空きのあるテーブルの上に新しい「野菜炒めの岡持ち」を置いてお客様に提供するところです。
(この壊れてから新しいテーブルの上に岡持ちを置くまで=お客様に料理を提供できていない時間がダウンタイムです。いわゆるシステム障害と呼ばれWebサービス等に接続できない状態のことを指します。エンジニアからすると恐怖ですね。絶対に嫌です。)しかしスーパーウエイター(kubernetes)はそんな手を煩わせません。ウエイターが即座に気づき、自動的に空きのあるテーブルを探し、そこに新しい「野菜炒めの岡持ち」を置きます。そのため、そのままお客様に提供し続けることが可能になります。
そうすることで、料理人は料理に集中できるのです。番外編: オートスケール
ちなみに、たまに聞くかもしれない「オートスケール」とは、2で出てきたテーブル(仮)が,あらかじめ用意していた分では足らなくなった時、勝手に新しいテーブル(仮)を用意してくれる仕組みのことです。
これがクラウドという超巨大テーブルの最大の強みの1つだったりします。ので、例えば4のウエイター(kubernetes)がとあるテーブル(仮想サーバ)が壊れていることに気づき、「野菜炒めの岡持ち(コンテナ)」を別のテーブルに置きたいけど空きのあるテーブルがない!やばい!どうしよう!ってなった時。
オートスケール機能をつけておけば、なんとびっくり。新しいテーブル(仮)が自動的に使えるようになります。
ので、晴れてウエイターは新しいテーブル(仮)に「野菜炒めの岡持ち」を置くことができるのです。そのため、kubernetesとクラウドを同時に使われることが多い(と勝手に思ってる)のです
終わりに
いかがだったでしょうか。
この記事は、弊社で最近 Kubernetes! Kubernetes! と叫ばれることが多く、開発者ではない大先輩の方々が「Kubernetesとはなんじゃ...」と思っている節があり、そういう人たちが少しでもイメージしやすくなるといいなと思って書きました割と勢いで書きました。正直お酒飲んでます
ので、あんまり批判が多かったら冷静になった僕が消すかもしれません兎にも角にも、ここまで読んでくださりありがとうございました。
- 投稿日:2020-10-10T21:29:46+09:00
“Beyond the Twelve-Factor App” & “The Twelve-Factor App”から学びAWSで実践する (2)APIファースト
解説
本ファクターはオリジナルにはなく、Beyondで追加されたものです。最近のアプリケーション開発においてAPIは重要性を増しており、非常に重要なファクターになります。APIファーストの良い点を以下のようにまとめています。
- アプリケーションの機能要件はAPIの利用を通じてすべて満たされる。UI部分はWebやモバイルアプリといった様々な形式で自由に提供できる
あらゆる機能をAPIで実装し、UIはそのAPIを利用して構築するというのはすでに当然の構成です。AndroidやiOSといったモバイル端末、Webブラウザ、PC用のデスクトップアプリケーションと同じアプリケーションを提供するとしても、対象端末ごとに最適なユーザーエクスペリエンスを提供するためには、それぞれに適したUI実装が必要となります。その中で、機能要件は共通なロジックとしてAPIで提供されるのはしかるべき構成になります。- ステークホルダー(内部チーム、顧客、APIを利用する他の組織のチーム)と、APIの仕様をベースに議論することができる
RESTful APIで設計することは、ドメイン駆動設計におけるエンティティの定義と似たような設計になります。ドメイン駆動設計ではユビキタス言語でステークホルダーたちと会話しドメインの定義をしていくことがベースにあります。これと同様で、API仕様を通して議論することで。内部の設計やアーキテクチャにとらわれることなく本質的な議論が可能となります。- APIを開発するためにはAPI BlueprintやApirayを使用する
最近だとOpenAPI/Swaggerがこの世界のデファクトになったと思いますのでその利用を推奨します。いまさら独自のフォーマットでAPI仕様書を作成し提供するのはやめましょう。- CIにより仕様を維持していくことが容易になる。各サービスチームはそれぞれのサービス開発に注力できる
APIをテストするのは非常に簡単で開発コストが低いです。逆にUIからの機能テストはCIでやるにしても非常に開発コストが高くテストコードを保守していくだけでも一苦労です。APIで全機能が実現されているのであれば、全機能のテストがAPIベースで実施でき、容易にCIで自動化できます。これにより、サービスの外部機能仕様の維持ができることになります。外部仕様が維持されれば、各サービスチームは自由に、サービス内の仕様変更や仕様追加ができることになります。- ウォーターフォールによるモノリシックなアプリケーション開発から解放される
APIファーストによりマイクロサービス化されたアプリケーションは、それぞれがアジャイル的に開発されるべきであることが暗に述べられています。アジャイルで言われている自己組織化された各サービスチームがそれぞれの担当サービスを進化させていくことで各サービスは最良のアーキテクチャで進化していくことになり、それらが集まることで、アプリケーション全体が適切に進化していくことになるということが今のトレンドであるといえます。実践
ドメイン駆動設計、RESTful APIの設計、マイクロサービス、アジャイル開発とAPIファーストの裏には多くの開発トレンドがひしめいています。本記事では、これらをどう進めるかというよりは、具体的なAPIの実装方法にフォーカスを当てたいと思います。APIファーストでの実装を始めるにあたり、AWSではAPI Gatewayを利用するのが最適です。APIのライフサイクル管理、流量制限、ロギング、認証・認可などAPIに必要な要素がマネージドサービスで提供されている便利なサービスになります。
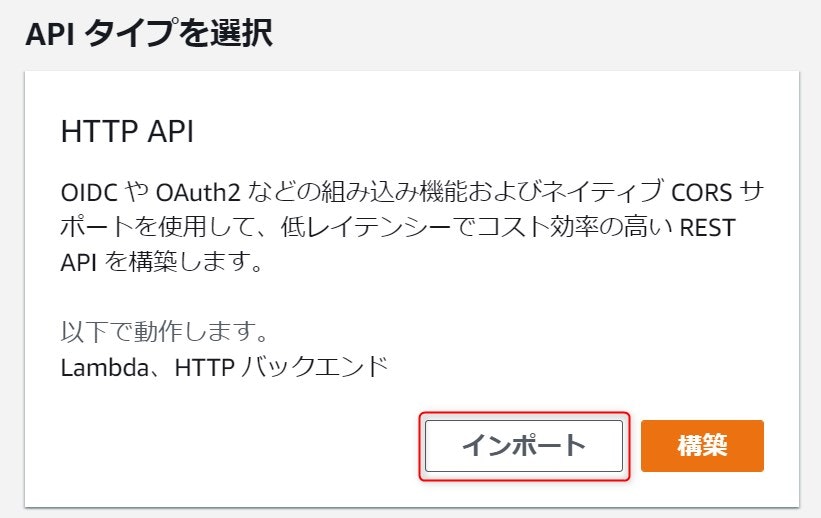
HTTP API + Lambda統合
API Gatewayにはいくつかの実装形態がありますが、今後主流になるであろうHTTP APIの形式で実装の流れを見ていきたいと思います。また、APIのバックエンドとしてはLambdaを利用します。こちらも最近の主流であるサーバレスアプリケーションの構成になります。APIを実装するアプリケーションの構成としては最初にこの構成で実現できないか考えましょう。サーバレスの構成は圧倒的に低コストでサービスを実現できますし、管理も非常に楽です。24時間常時高負荷で高いトランザクションを処理しないといけない」、「バックエンドがRDB」など、Lambdaと相性が悪い一部の例外を除けばとても有用な構成です。
OpenAPI 3.0によるRESTfull API設計
API GatewayのHTTP APIでは、OpenAPI 3.0で定義したAPIをインポートできます。本記事のテーマであるAPIファーストを実現するためには、APIの設計をOpenAPIで定義された仕様ベースで行い議論することが可能です。細かい仕様に関しては公式のドキュメントから確認できますので、参考にしてください。
それでは早速APIの定義をしていきたいと思います。今回定義するリソースは「本」とします。RESTfull APIで設計すると下記のようになります。多くのリソースの設計は、この検索系+CRUDの5APIになるかと思います。「本」のIDはISBNという国際規格で決まっていますのでその値を使うことにしています。
URL メソッド アクション /books GET 本の一覧を取得する(検索) /books POST 新規に本を登録する(C) /books/{isbn} GET isbnで指定した本の情報を取得する(R) /books/{isbn} PUT isbnで指定した本の情報を書き換える(U) /books/{isbn} DELETE isbnで指定した本を削除する(D) これを実際に定義していきます。ちなみに私はVisual Studio Codeにプラグイン(OpenAPI (Swagger) EditorとYAML)を入れて実装をしています。YAMLで定義を書き、SwaggerUIで表示して確認するというのを簡単に行うことができます。また、YAMLプラグインの以下設定を行うと、入力支援が行われるようになるので多少定義作業が楽になります。/openapi/フォルダ配下の*.yamlファイルに対して有効になる設定なので、ファイルを作る際はそのルールに則り作る必要がある点はご注意ください。
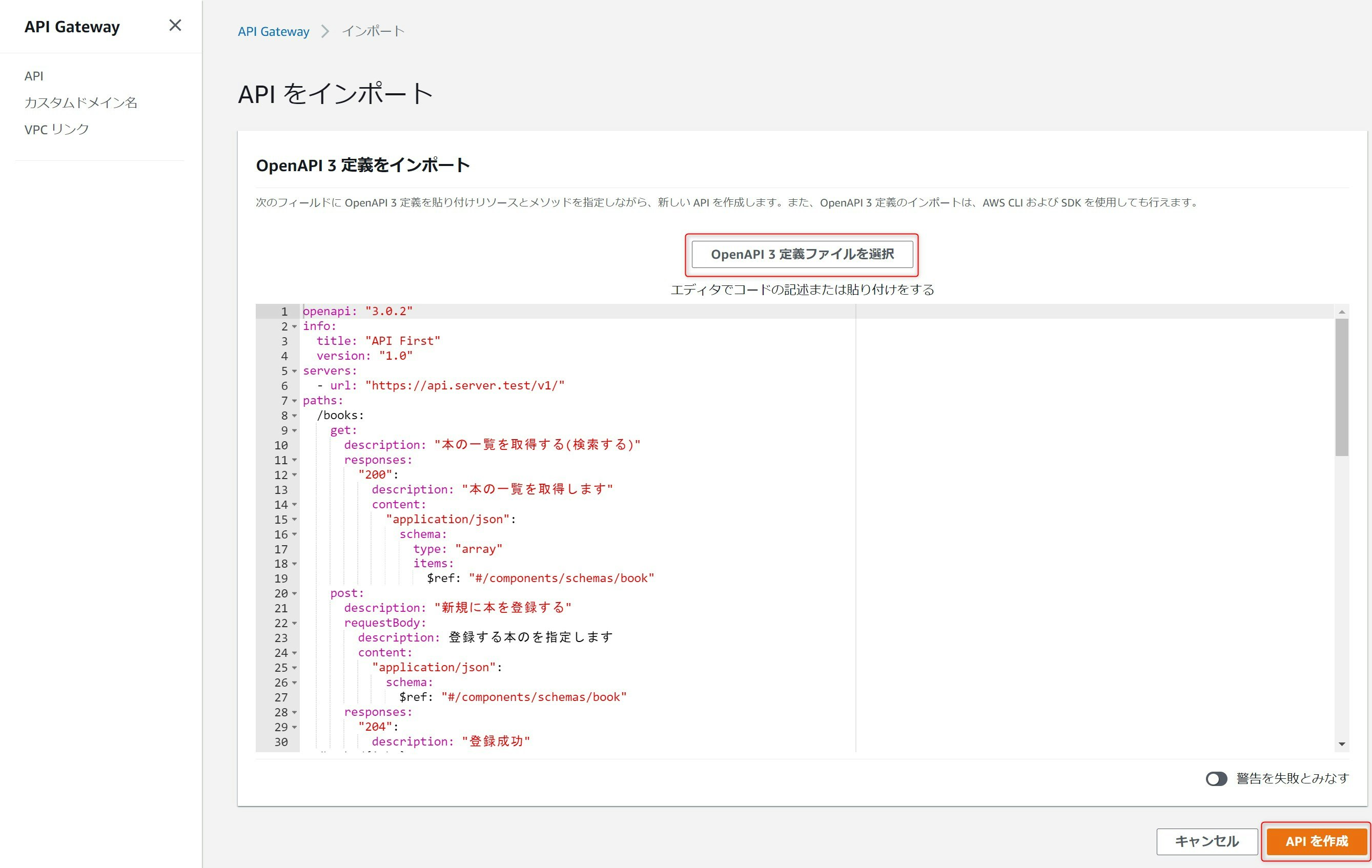
"yaml.schemas": { "https://raw.githubusercontent.com/OAI/OpenAPI-Specification/master/schemas/v3.0/schema.json": [ "/openapi/*.yaml" ] },以下が先ほど定義したメソッド+αを実際に実装したOpenAPI 3.0のYAMLファイルです。以下の定義だけで、すでにAPI Gatewayにインポートすることが可能になっています。
openapi: "3.0.2" info: title: "API First" version: "1.0" servers: - url: "https://api.server.test/v1/" paths: /books: get: description: "本の一覧を取得する(検索する)" responses: "200": description: "本の一覧を取得します" content: "application/json": schema: type: "array" items: $ref: "#/components/schemas/book" post: description: "新規に本を登録する" requestBody: description: 登録する本のを指定します content: "application/json": schema: $ref: "#/components/schemas/book" responses: "204": description: "登録成功" /books/{isbn}: get: description: "ISBNで指定した本の情報を取得する" parameters: - name: "isbn" in: "path" description: "ISBN" required: true schema: type: "string" responses: "200": description: "OK" content: "application/json": schema: $ref: "#/components/schemas/book" put: description: "ISBNで指定した本の情報を書き換える" parameters: - name: "isbn" in: "path" description: "ISBN" required: true schema: type: "string" requestBody: description: 登録する本の情報を指定します。isbnは書き換えられません。 content: "appication/json": schema: $ref: "#/components/schemas/book" responses: "200": description: "OK" delete: description: "ISBNで指定した本を削除する" parameters: - name: "isbn" in: "path" description: "ISBN" required: true schema: type: "string" responses: "204": description: "削除成功" components: schemas: book: type: "object" properties: "isbn": type: "string" description: "ISBN" "title": type: "string" description: "タイトル" "price": type: "integer" description: "税抜き価格"APIファーストではこれをベースに仕様の議論をし設計・実装を進めましょう。上の例では。メソッドの定義に加えて、本の属性をどうするかという議論を行い、ISBNとタイトルと税抜き価格を持つようにしようと決めて定義しています。また、ISBNは本のIDであるので、PUTでも書き換えられないようにしようといった設計も記載しています。さらに議論を深めるとすると、/booksのget時にフィルタ条件(例えば、タイトルの部分一致や税抜き価格の範囲指定)を持たせたいよねといったことや、一覧取得だけどデータが1万とかあった場合どうする?といったことがすぐに考え付きます。このAPIを見ているだけで様々な仕様を決めていくことができますし、同時に機能仕様書が完成していきます。
API Gatewayへのインポート
AWSマネージメントコンソールを使って、API GatewayでAPIを構築していきます。
APIのAPIを作成を押下します。
HTTP APIを選択し、インポートを押下します。
OpenAPI3定義ファイルを選択で先ほど作成したYAMLファイルをアップロードし、APIを作成を押下します。
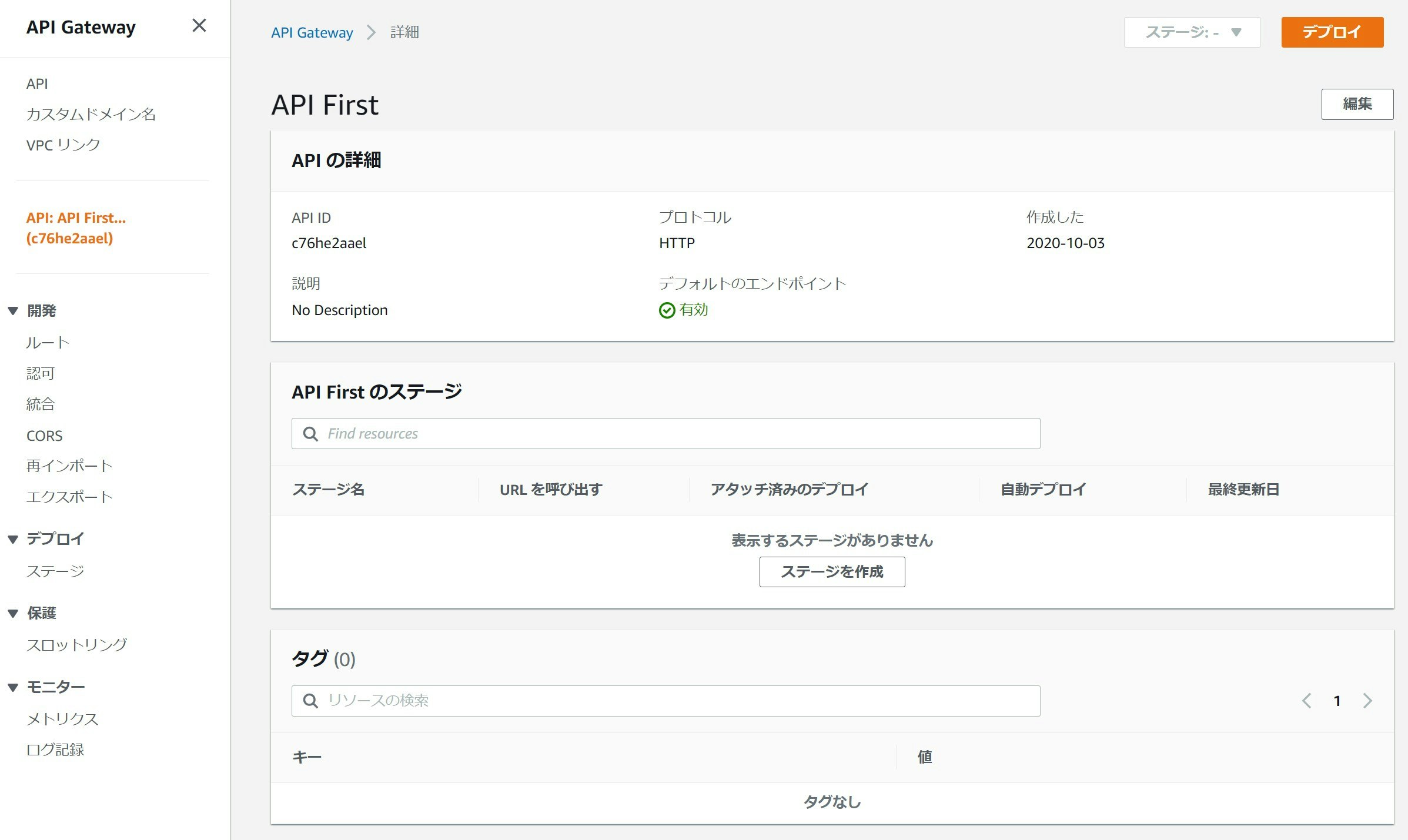
以上でAPIのインポートが完了しました。
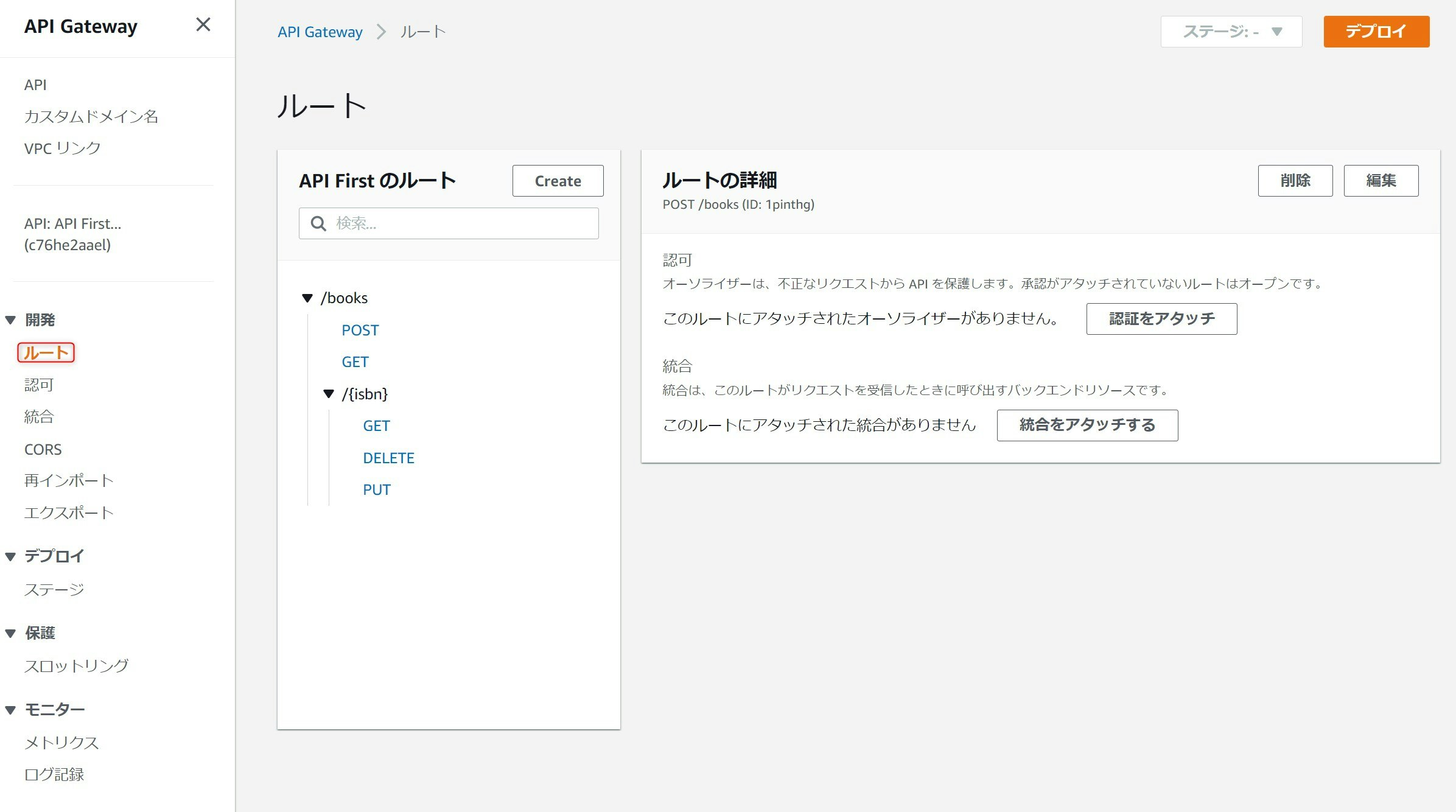
開発 > ルートで確認すると、/booksにPOSTとGET、/books/{isbn}にGET、DELETE、PUTのメソッドがYAML定義通り作成されていることがわかります。
Lambdaによるロジックの実装
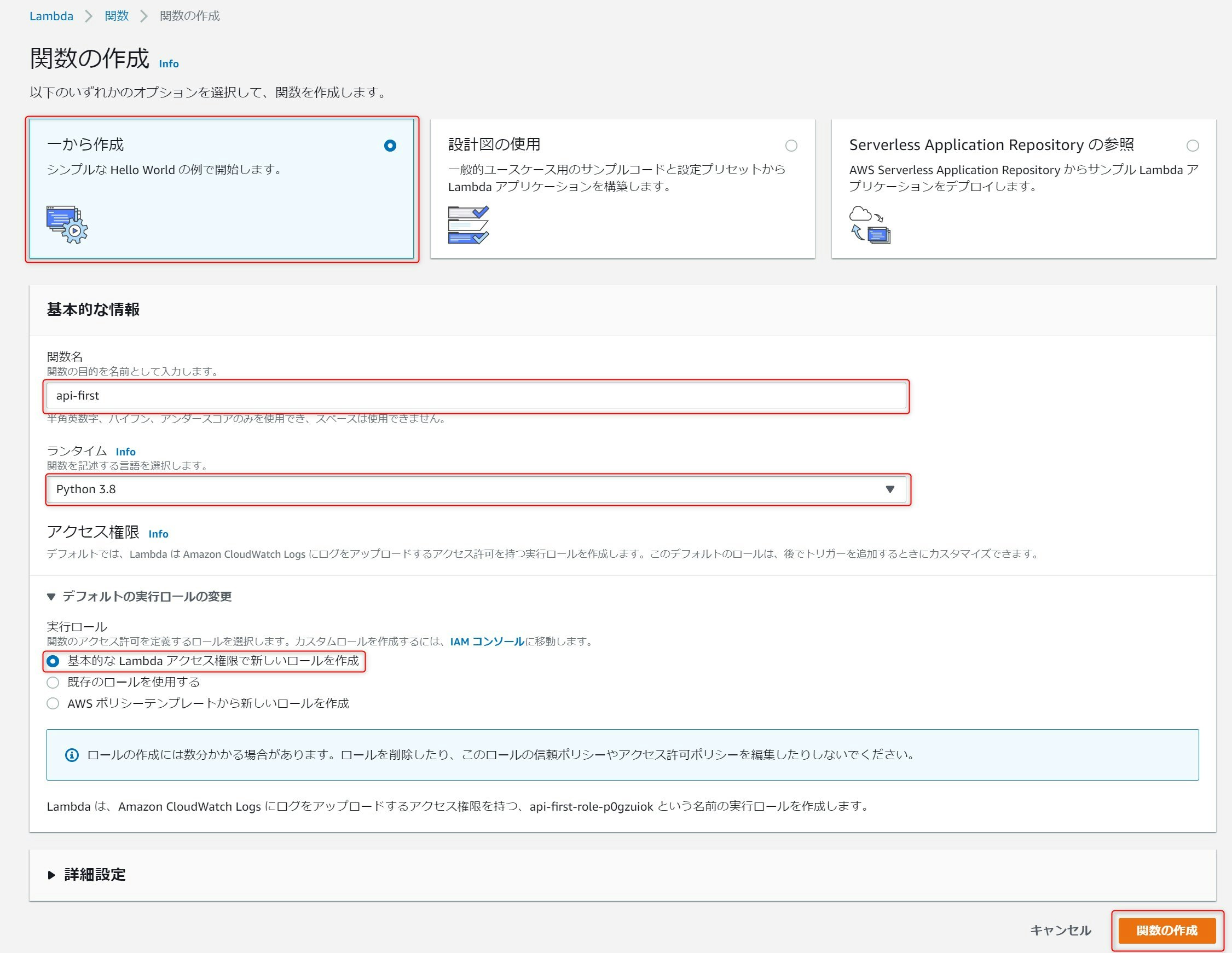
AWSマネージコンソールでAWS Lamdaを開き、関数 > 関数の作成を選択します。
一から作成を選択し、関数名に任意の値を設定します。また、ランタイムは各自が実装したいものを選択すればよいですが、今回は
Python 3.8を選択します。実行ロールに基本的なLambdaアクセス権限で新しいロールを作成を選び、関数の作成を押下します。
デフォルトの実装として、APIにステータス200、レスポンスに"Hello from Lambda!"を返却するものができるので、他はいじらず完了します。
API Gatewayへの統合
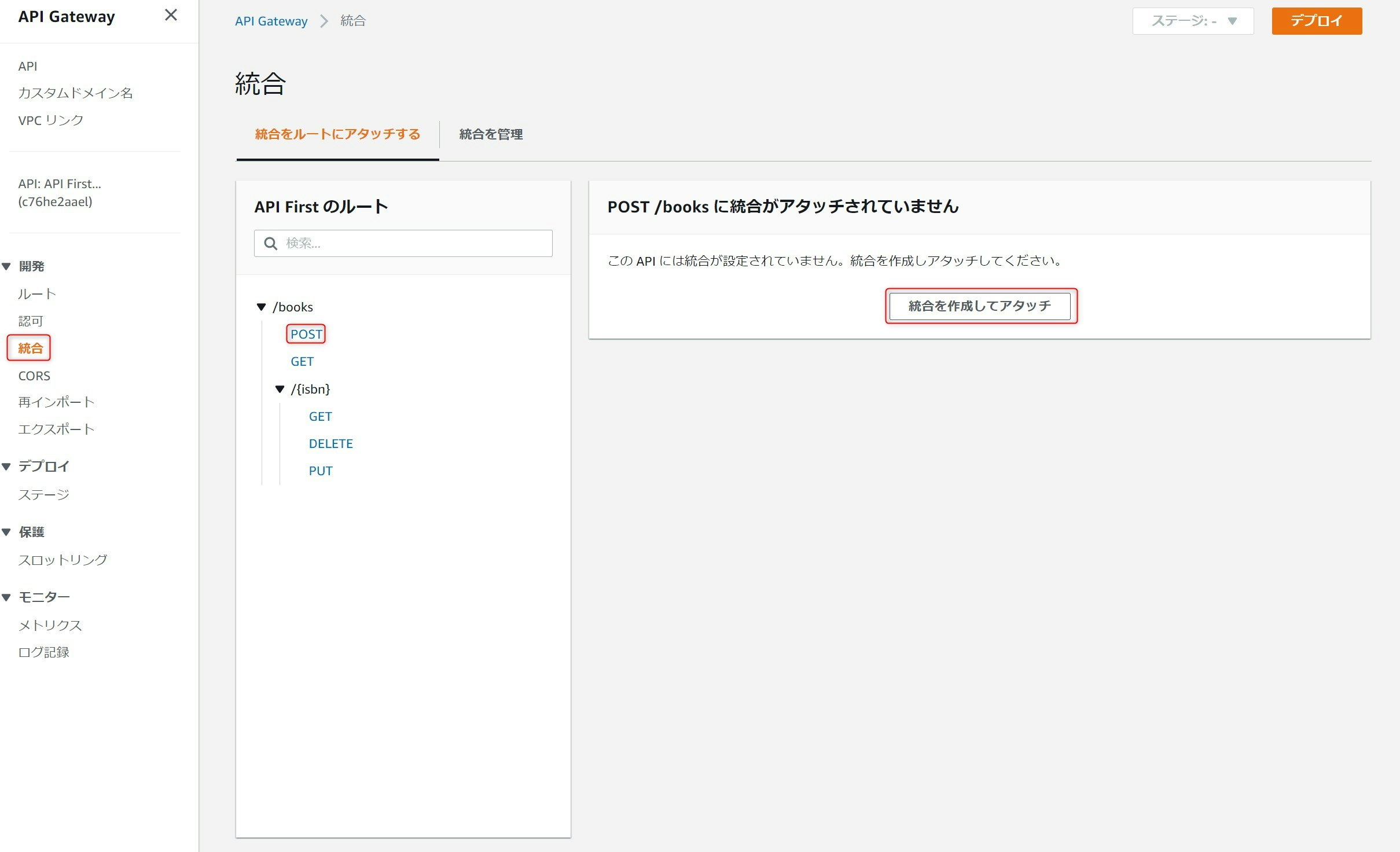
引き続きAPI GatewayからLambdaを起動する設定を行います。
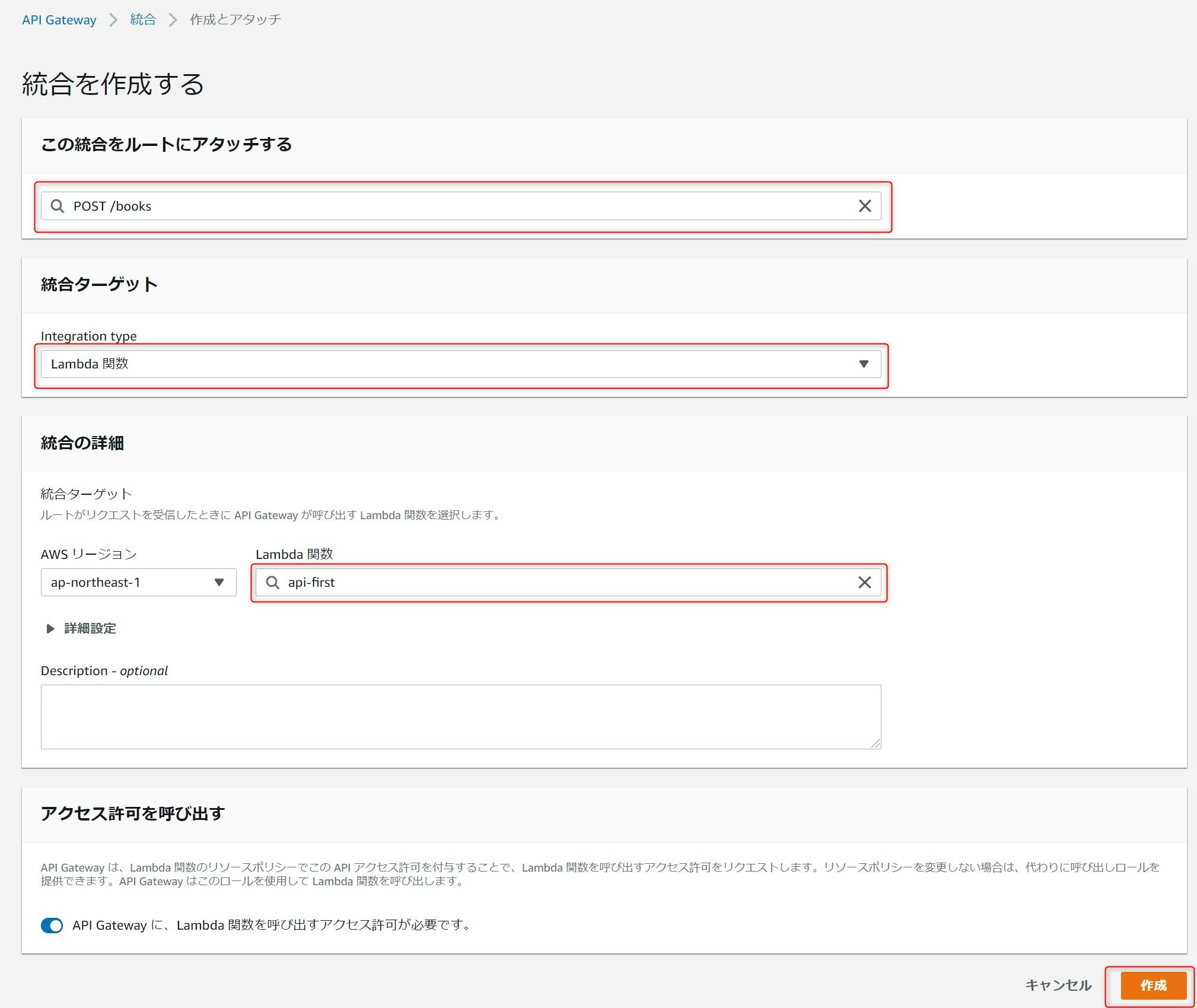
AWSマネージメントコンソールで、先ほど作成したAPIを開き、開発 > 統合を選択します。Lambdaの統合を設定するAPIを選択します。今回はまず/booksのPOSTを選択しています。その状態で統合を作成してアタッチを押下します。
統合を作成する画面にて、統合ターゲットにLambda関数を選択し、先ほど選択したAPIを選び作成を押下します。
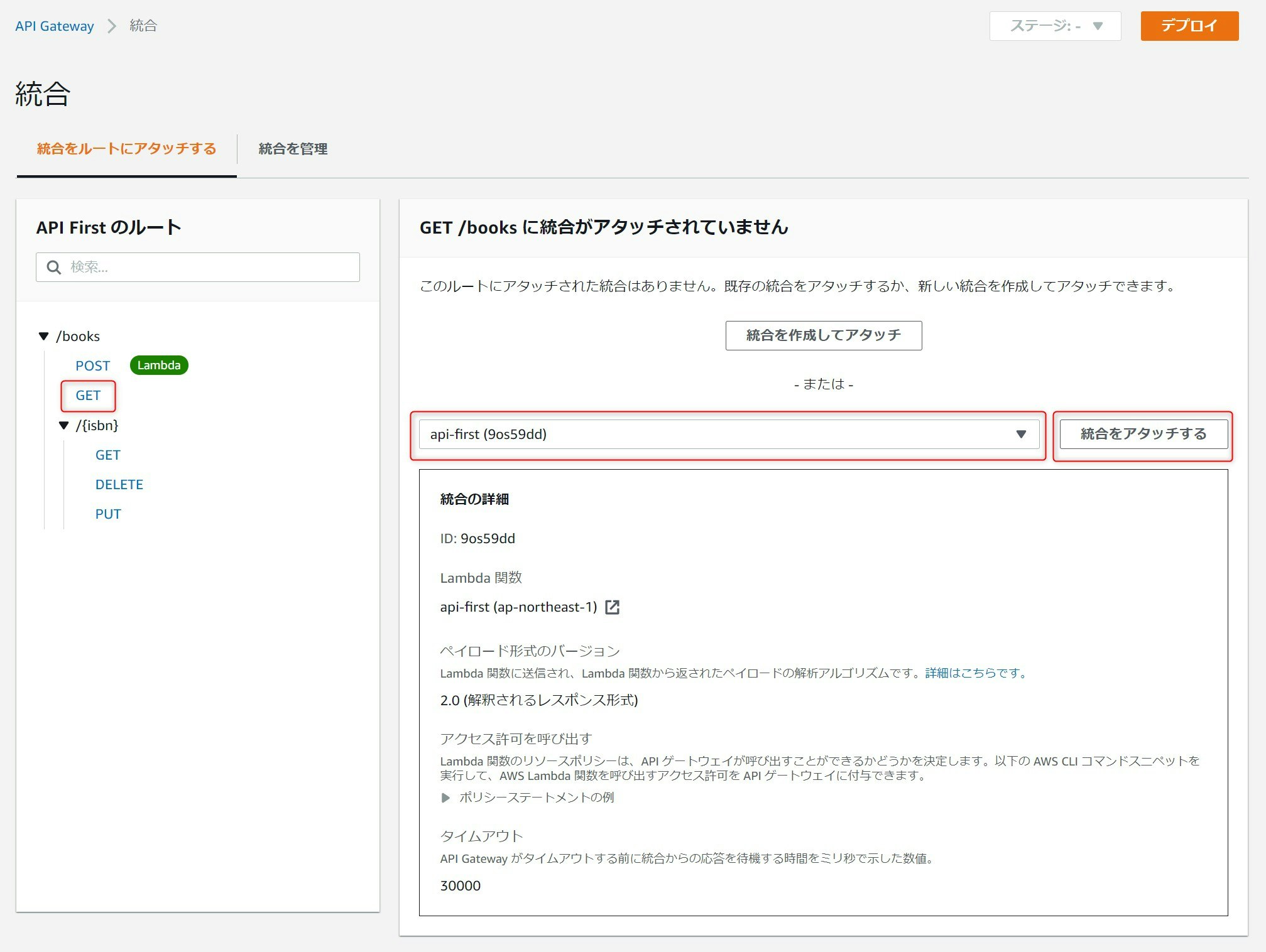
すべてのメソッドを順次選択し、先ほど作ったものと同Lambda統合をアタッチしていきます。LambdaはAPI毎に作成することも可能ですが、ある程度まとめて一つのLambdaとするのがハンドリングがしやすいと思います。Lambda関数側で、呼び出されたときのURLのパスやメソッドの種類がわかりますので、どのAPIに対する処理をするべきか判断しロジックを切り替えられます。
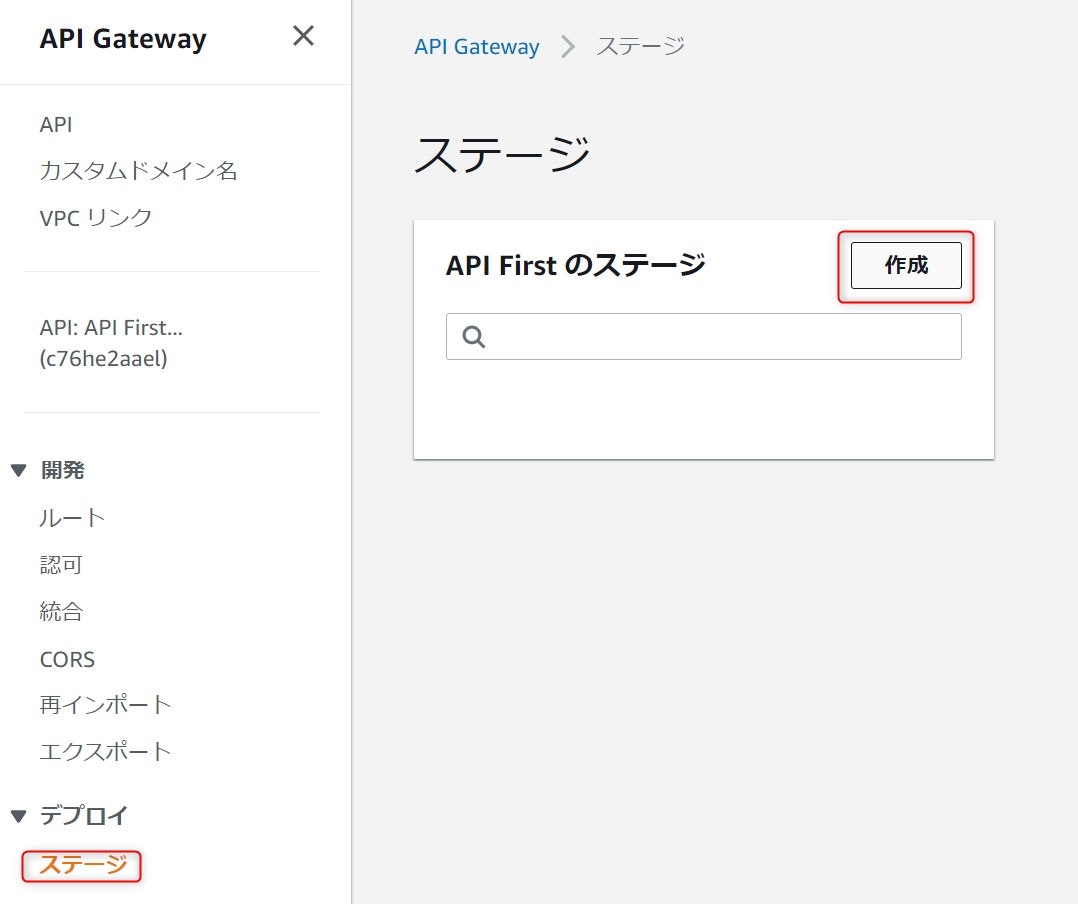
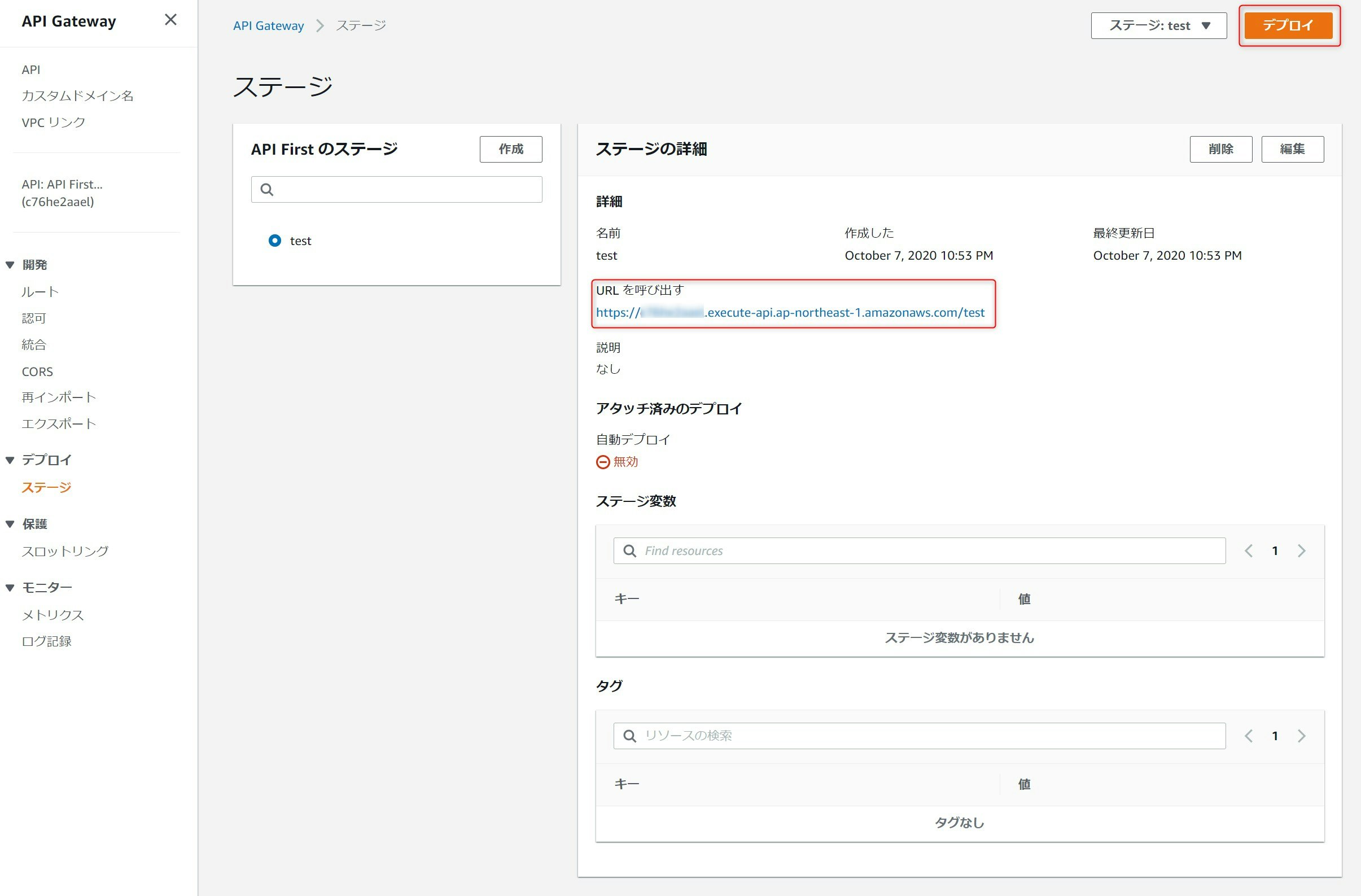
最後に作成したAPIをホストして公開します。APIのデプロイ > ステージを選択し、作成を押下します。
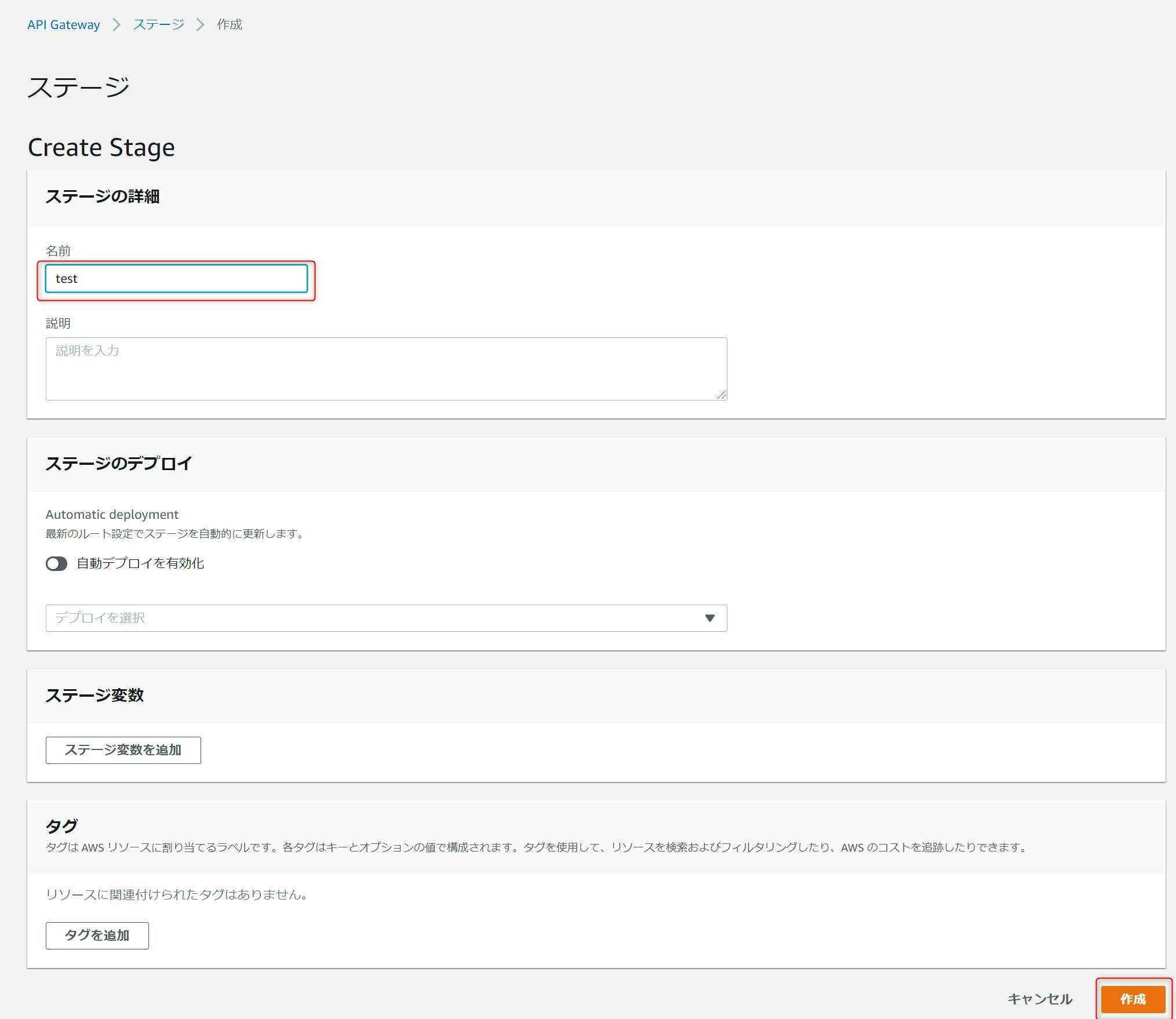
ステージの作成画面で名前に任意の値を入力し作成を押下します。
先ほど入力した名前がAPIのルートパスになりステージが作成されます。引き続き、作成したステージにAPIをデプロイするため、デプロイボタンを押下します。
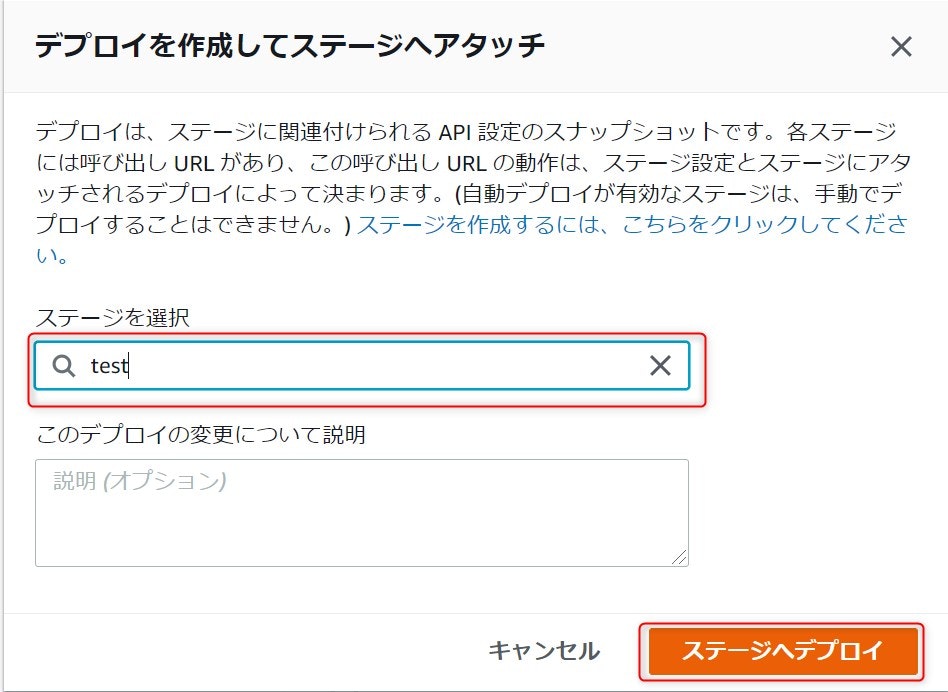
作成したステージを選択し、ステージへデプロイを押下します。これでAPIが公開されます。
以上でAPIの公開開始です。先ほどの画面で表示されたURLをブラウザで開くと、
/booksへのGET呼び出しとなり、"Hello from Lambda!"が画面に表示されます。まとめ
第二のファクターとして、APIファーストによる開発の考えと、AWS API GatewayとLamdaを使った実装方法の話を進めました。今後のアプリケーション開発において、API Gateway+Lamdaでの開発は相当力を発揮すると思いますし、APIファーストを実現するのがとても楽なのでぜひ使ってみてください。
次回は「((3)依存関係管理 / 依存関係 - 依存関係を明示的に宣言し分離する」です。
本シリーズの目次
全シリーズの目次


- 投稿日:2020-10-10T20:26:09+09:00
`% terraform init` で `* hashicorp/aws: version = "~> 3.10.0"` とエラーが表示される場合
IaCに憧れてTerraformを勉強中の新米エンジニアよしこです。
AWS EC2にVPCを構築するのにTerraformを使用しているときに以下のログに遭遇しました
> terraform init Initializing the backend... Initializing provider plugins... - Using previously-installed hashicorp/aws v3.10.0 The following providers do not have any version constraints in configuration, so the latest version was installed. To prevent automatic upgrades to new major versions that may contain breaking changes, we recommend adding version constraints in a required_providers block in your configuration, with the constraint strings suggested below. * hashicorp/aws: version = "~> 3.10.0" Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.日本語のケースワークが少なかったので解消方法を共有します
環境
> terraform -v Terraform v0.13.4 + provider registry.terraform.io/hashicorp/aws v3.10.0解決策
ログにもしっかり書かれていますが、
hashicorp/aws: version = "~> 3.10.0"のようにバージョンの記述をmain.tfへ追加することでエラーが解消します。Terraformのドキュメントを参考に以下のように記述しました。
https://registry.terraform.io/providers/hashicorp/aws/latest/docsmain.tfvariable "access_key" {} variable "secret_key" {} variable "region" {} terraform { required_providers { aws = { source = "hashicorp/aws" version = "~> 3.10" } } } # Configure the AWS Provider provider "aws" { access_key = var.access_key secret_key = var.sevret_key region = var.region } # Create a VPC resource "aws_vpc" "vpc-1" { cidr_block = "10.0.0.0/16" tags = { Name = "vpc-1" } }こちらはterraformのバージョン0.13 以降の記述になります。
バージョン0.12 以前の場合は以下のように記述します。
main.tf# Configure the AWS Provider provider "aws" { version = "~> 3.0" region = "us-east-1" } # Create a VPC resource "aws_vpc" "example" { cidr_block = "10.0.0.0/16" }変更前
参考程度に、変更前はこのように記述していました
main.tfvariable "access_key" {} variable "secret_key" {} variable "region" {} provider "aws" { access_key = var.access_key secret_key = var.secret_key region = var.region } resource "aws_vpc" "vpc-1" { cidr_block = "10.0.0.0/16" tags = { Name = "vpc-1" } }
- 投稿日:2020-10-10T19:54:24+09:00
新人エンジニアが AWS Black Belt オンラインセミナー の魅力を語ってみた
はじめに
約3ヶ月間、それなりにボリュームのある新規開発で AWS周りをガッツリやらせてもらいました。
AWS や新規開発について学ぶことが多かったので何回かに分けてまとめてみたいと思います。
これから AWS をガッツリ使っていこうと思っている方の参考になれば幸いです。バックナンバーはこちらからどうぞ!
今回はその第2回、 AWS Black Belt オンラインセミナー 編です?
AWS Black Belt オンラインセミナー とは?
AWS Black Belt Online Seminar シリーズは、製品・サービス別、ソリューション別、業種別のそれぞれのテーマに分かれて、アマゾン ウェブ サービス ジャパン株式会社が主催するオンラインセミナーシリーズです。
https://aws.amazon.com/jp/about-aws/events/webinars/
何が良いのか?
- YouTube でいつでも好きなように見られる(https://www.youtube.com/playlist?list=PLzWGOASvSx6FIwIC2X1nObr1KcMCBBlqY)
- 公式情報であることの信頼性
- 体系的な情報
- 分かりやすい説明
- 頭の中にインデックスを作るのに最適
YouTube でいつでも好きなように見られる
これはオンラインセミナーならでは。当然ですが、非常に助かります。
動画だからこそ難しいところは巻き戻してじっくり聞いても良し、必要なパートだけをサクッと確認するも良し。
公式情報であることの信頼性
オンライン記事も参考になることが非常に多いのですが、情報が古くなっていたり間違っていたりすることがあるのはご存知の通りです。
もちろん公式でも情報は古くなりますし、動画という特性上、ドキュメントと違ってアップデートがしにくいかと思います。
しかし信頼性に関してはかなり高いレベルで担保できるので、考慮するのが情報の新鮮度だけになります。それに、動画の冒頭では必ず免責事項として 20xx年〇〇月〇〇日 時点の情報です、とアナウンスがありますのでそこだけ見ればOKです。
余談ですが、多少小難しい言い回しをされたとしても出来る限り最初から公式リソースを使って学習するのが結局効率良いと思っている派です?
体系的な情報
AWS もビジネスです。自分たちの製品を使ってもらおうというマーケティングの一部としてこのようなコンテンツを公開しています。
なのでそもそもの前提知識が抜けたまま進まないように配慮されていて、非常に体系的です。大体基礎から始まり、最後の方はコストなど管理者向けの話になっていくことが多いように思います。
新しいサービスを学ぶ時にはまず王道を体系的に学んでみてからそれぞれのユースケースに応用してみてはいかがでしょうか?
分かりやすい説明
ブラックベルトとはすなわち黒帯なので、結構難しいんじゃないかという印象を持たれる方も多いと思います。
確かに後半は少し難しい話が出てくる場合も多いのですが、それも含めて非常に分かりやすく説明してくれています。おそらく資料も発表の仕方も含めて分かりやすくなるようなノウハウが AWS 社内で共有されており、それに従って担当者の方が発表してくださっているんだと思います。
どの発表も分かりやすく、説明する人によっての質のバラつきが少ないのが印象的です。「そもそもどうしてこのサービスが必要なのか?」というところから分かりやすく説明してくれますよ?
頭の中にインデックスを作るのに最適
このように素晴らしいオンラインセミナーですが、デメリットもあります。
それは動画コンテンツなのでリファレンスとしては使えないということです。なので役割分担としては必然的に、
- オンラインんセミナーで頭の中にインデックスを作る
- 開発を進める中での細かいことなどはドキュメントを見る
ということになると思います。
まずは頭の中にざっくりしたインデックスを作ってあとはとにかく実際に手を動かす というのは学習で非常に大切ですよね!!
先ほども述べたように体系的かつ割と網羅的なのでインデックスを作るのに適しているコンテンツだと思います
自分流 AWS 学習ステップをまとめてみた
学習方法は人それぞれに合ったものが1番ですが、参考になればということで偉そうに書いておきたいと思います?
- AWS Black Belt オンラインセミナー をメモを取りながら1回見る(頭の中にインデックスを作るのが目的)
- そのサービスはどんな場合に有効なのか、よく使われるのか、ネット上の記事を見ながらざっくり把握
- AWS マネージドコンソールから そのサービスを使ってみて設定する必要のあるプロパティなどを見てみる(コード化しない)
- 実際に使う(ここからは基本公式ドキュメントを参照する)
という感じで大体いけるはずです。公式のチュートリアルが用意されているサービスも多いのでそちらもやってみても良いかもしれません?
おわりに
AWS Black Belt オンラインセミナー のおかげで AWS の右も左も分からない状態から幅広いサービスを習得して実務で使えるまでになりました。
本当に良いコンテンツだと思いますので、新しい AWS サービスを学習する際には是非活用してみて下さいね!!

- 投稿日:2020-10-10T19:51:02+09:00
【らくちんAWS】 LightSailからはじめるAWSエンジニア (前編) 【EC2よりカンタン】
【らくちんAWS】LightSailからはじめるAWSエンジニア (後編)【完全に理解した】(作成中)
この記事について
この記事は、「AWSは難しくて嫌だ!」と感じる人の苦手意識を克服するために、
とっても簡単に使えるAWS LightSailというサービスを紹介させていただく記事になります。
後編では、LightSail基準で見るAWSの各種サービスの紹介をさせていただきますので、
今までよりも簡単に、AWSの理解を広げていけると思います。※AWSのデファクトスタンダードである「EC2」を基準に各サービスの理解を広げることができる方は、この記事を読む必要はありません。
※LightSailをWordPress環境として構築する使い方が主流のようですが、この記事ではシンプルなWEBサーバーとして使用することを想定しています。自己紹介と、記事を書いたきっかけ
わたしは世間で言うところの「駆け出しエンジニア」になります。
HTML/CSS、JavaScript、PHPなどを経験してきて、もうすぐ2年弱になります。
技術力が強いエンジニアではありませんが、挫折しなかった駆け出しエンジニアとして、
「未習得の方にとってわかりやすい記事」をコンセプトに、Qiitaを書かせていただいてます!わたしはエンジニアのタイプでいうと、
「ものづくりタイプ(作る物が好きな方)」「解決思考タイプ」のエンジニアです。
AWSを学ぶ際も「どんな物が作れそうか」「何が解決できそうか」に注目しておりました。
わたしの制作の規模で考えると、AWSはその点が他サービスと比べてどう優れているのかよくわからないし、掘り下げるのが難しいというのが正直な感想でした。
「技術好きタイプ」や「職業人タイプ」とは違い、
「技術的に面白いか」「次のプロジェクトで使うか」の基準で学習のモチベーションを保つことは難しいため、AWSは、気になるけど手をつけにくい存在となっていました。仕事上、AWSの基本的なサービス(EC2など)に触れる機会はありましたが、
個人で開発・学習のために使うとなると
「支払い総額がわからない」
「(詳しく調べないと)使い方もわからない」
「使ったところで、どんなメリットがあるかもわからない」
と、ないないづくしの印象を持っていました。そんなときに知ったのが、AWS LightSailでした。
「月額固定料金」
「ぱっと見ただけで使い方がわかるUI」
「必要な機能がすべてセットになっている」
そんなLightSailと出会い、わたしの興味は一気に惹きつけられました!当初は、LightSail以外のサービスには一切興味がなく、
ひたすらLightSailの使い方・使いやすさ・口コミなどばかり調べていました。
そんな中、AWSマンガと出会いました。
第1話で紹介されるサービスがLightSailだったので、
LightSailを基準にAWSを深く知ることができる!と歓喜しました。
読みすすめると、物語中の開発規模は壮大で、一生使うことがなさそうなサービスもたくさん紹介されていましたが、
それでもAWSの入り口が、ぐぐっと広がった気がしました!
紹介されていたサービスや、紹介されなかったサービスを、より詳しく知りたくなって、
読破後の興奮冷めやらぬまま、ひたすらAWSを調べてメモをしていきました。
このとき調べた知識を共有することで、
わたしと同じようにAWSに苦手意識を持っている駆け出しエンジニアのみなさんも、
AWSの扉を開くことができたらいいな、と思い記事にまとめました。長い内容になりますが、小分けにしながら読み進めていただければと思います。
よろしくお願いいたします!記事のコンセプト
記事のターゲット層について
この記事は、フロントエンドからデビューした駆け出しエンジニアをメインターゲットとしております。
自分で知識を広げられる段階までもっていくことを最優先と考えているため、
記事の中には、できるだけカンタンに説明するための独特な表現(=正確ではない表現)があるかもしれません。この記事の内容を理解したあとは、
他の情報や、記事のコメントなどを参考にして、より知識を深めていただければと思います。記事タイトルについて
記事タイトルで掲げている「AWSエンジニア」というのは「AWSが使えるエンジニア」という意味であり、
「AWSのプロフェッショナル」という意味ではありません。LightSailとは
AWS LightSailは、クラウド上に自分専用のサーバーをつくれるサービスです。
一般的に「VPS」や「レンタルサーバー」と呼ばれる類のサービスになります。AWSは本来、AWSの各サービスを組み合わせて構築していくのが特徴なのですが、
LightSailは、各サービスをいい感じのセットにして提供してくれています。
そのため、余計なことを考えなくていい、わかりやすさ重視のサービスとなっています。LightSailについて調べると、よくEC2を中心としたAWSの各サービスと比較されていますが、
本来は、他社のレンタルサーバー(さくらのVPS、GMOクラウドVPS、ロリポップ!等)や、
サービスを簡単にWEBに公開することを目的とした HerokuやFirebaseなどのサービスが比較対象として適しているのではないかと思います。わかりやすさ重視なので、インフラの管理に時間を割けない個人開発や、少数開発にぴったりです!
パッケージされているサービスなので、費用が高いのでは?と思うかもしれませんが、
AWSの他サービスを利用するときにかかる時間と手間を時給に換算して考えれば、
圧倒的にコスパは良いと思います!ただし、最近できたサービスであるのと、
もともとAWSに手を付けていた層が「難しい技術大歓迎!」なエンジニアが多いかと思うので、
LightSail自体の認知度が低く、QiitaやGoogleで探しても情報が見つかりにくいのが欠点です。
この記事で、たくさんの人がLightSailに興味を持って、もっともっと情報共有が盛んになることを祈ってます!公式ドキュメントでも、EC2ではなくLightSailを使う手順を解説するようになったそうなので、
公式としても、まずは簡単なLightSailから初めて、必要になったらEC2などを利用する流れにした方がわかりやすいと考えているのかと思います。サーバーとは
さきほど説明したように、LightSailはあくまでサーバーを提供するサービスです。
そのため、サーバーでできること・やることについては、わたしたちがあらかじめ把握しておく必要があります。
もし、あなたが「そもそもサーバーのことを知らない」「サーバーを使ってやりたい事がわからない」という場合は、
LightSailを始めるまえに、サーバーについて勉強してください。サーバーで出来ることをイメージできない方には、以前わたしが書いた記事をオススメさせていただきます。
記事を読んで、サーバーを使う目的が決められるようになってから、LightSailをはじめましょう。
参考: 駆け出しエンジニア「サーバーサイド言語を勉強したら、何ができるようになるの?」メリット・デメリットについて
2020年現在、ネットでLightSailを調べると出てくるメリット・デメリットの情報は、
AWSの各サービス(というかEC2)と比較した上での情報が多く、
AWSを使い慣れてない人にとっては誤解しやすい表現が多いと感じたので、補足させていただきます。拡張性は、高いです。
LightSailのデメリットを調べるとよく見かける「拡張性が低い」という情報がありますが、
ここでいう「拡張性が低い」は、EC2と比較したときの話です。EC2ではなく他社サービスと比べて考えると、むしろ拡張性は高いと言えます。
サーバーにSSH接続してアプリのインストールができるので、
それができないHerokuやFirebaseと比べると圧倒的に拡張性が高いですし、
EC2への移行ができる点や、LightSailにパッケージされている各AWS機能が使えることを考えると、
他社のVPSと比べても拡張性はかなり高いと思います。では、ここで低いと言われている「拡張性」とは何なのか?という疑問がでてくると思います。
これについて、わたしは「他のAWSのサービスと組み合わせて使えるかどうか」という意味なのだと解釈しました。たとえば、AWSにはEC2のような仮想コンピュータ機能以外にも、
以下のようなサービスがあります。
- Connect: 自動電話対応窓口(=コンタクトセンター)の作成。
- Pinpoint: ユーザーの行動(アプリの使用日時など)と連動してスマホへのプッシュ通知などを行う。
- SES: メールの送受信サービス。メールマガジン配信など。
- Athena: AWSのストレージサービス内に保存されたCSV形式などのファイルの内容を、SQL文を使って取得できる。
- Lambda: バッチ処理の管理&実行。
これらとの連携ができない可能性があるという意味で「拡張性が低い」と言われているのでしょう。
(上記はあくまで「AWSの他サービスの例」であり、実際にLightSailと連携できないかどうかは未確認です。)そして、勘違いしてはいけないのが、もし仮に上記のサービスとの連携ができない場合でも、
「LightSailで作ったサーバーでは上記のようなことができない」という意味ではない事です。
(AWSのサービスを使わない方法で実装することや、
AWSの想定した方法以外のやりかたで連携できるのであれば、実装は可能ということです。)また、データベースやロードバランサー、CDNや独自ドメインなどの機能は利用可能だと公言されていますし、
AWSの一部サービス(Cloud9など)と連携できている前例もあるため、
「AWSの他サービスとまったく連携ができない」わけではないのです。カスタマイズ性は、低いです。
LightSailで作れるサーバーは、一般的なバランスのスペックのものしか用意されていないため、
「データの保存を大量に行うから、ストレージ容量が沢山ほしい」とか、
「AIやディープラーニングなどを行うのでCPUが強いサーバーを使いたい」など、
一般的なバランスとは違ったスペックを求める場合、LightSailはオススメできません。費用は、安いです。
※わたし自身、LightSailでの本格的な運用や、長期的な運用の経験がないので、情報が正確ではない可能性があります。あくまで、軽く調べてみた感想であることをご了承ください。
EC2で運用した場合と比べて安く済むのか高くつくのかは、正直わかりません。
ネットで調べても誰に聞いても具体的な答えは返ってこないので、答えはどこにも無いものと認識しています。
もし、詳しい方がいらっしゃいましたら、コメントをお願いいたします。ふつう、あらゆるサービスがパッケージ化されていると聞くと、高いのだろうと考えるのが当然ですが、
ざっくりAWSでざっくり計算したところ、
LightSailの$3.5プランの上限転送量(=1TB)をEC2やS3で達成した場合、
1万円を余裕で超える費用が算出されます。ざっくりAWSの信憑性を置いといても、AWSの他サービスをLightsailに移行して費用を1/10にしたやAWSで10万円溶かした話という記事があるように、
パッケージサービスだから高い、と安直に考えるのは間違いのようです。また、安いか高いかにかかわらず、AWSの他サービスは基本的に基本料金+従量課金制であり、
どういう使い方をすると費用が高くなりやすいか等をあらかじめ勉強し、管理しなければ安心して使えないものがほとんどです。
「利用するサービスの数に比例して、必要学習時間や考慮すべきリスクが増える」ということですので、
このリスクを無くせるLightSailは、個人開発はもちろんのこと、仕事上でも導入するメリットが大きいかと思います。しかし、LightSailは未経験向けのくせに無料で使い続けられるプランがなく、
無料期間も1ヶ月と、他のAWSサービスと比べるとしょぼいので、
これはLightSailが普及しない原因のひとつかと思います。料金を比較して考える
LightSailの一番安いプランと、他サービスの月額費用を比べてみた感想です。
各社の料金の決め方がバラバラで、まったく同じ条件での比較ができないため、
ざっくりご理解いただければと思います。ちなみに、$3.5プランのスペックは下記です。
メモリ: 512MB / CPU: 1コアプロセッサ / ストレージ: 20GB SSDディスク / 転送量: 1TB(=1000GB)
(無料期間: 1ヶ月間)AWS(ざっくりAWSにて計算)
- EC2: t2.microプランだと、容量20GBで781円。1000GBの転送料は12,596円。
- S3: 容量20GBで52円。1000GBの転送料は12,068円。VPS、クラウドサーバー
- さくらのVPS: 512MB/1コア/25GBの最安プランが、585円。無料期間は14日間。
- GMOクラウドVPS: 1GB/2コア/50GB/転送量無制限の最安プランが、780円(1年契約の場合)。無料期間は15日間。
- ロリポップ!: スペック非公開のため比較できず。最安プランは100円、大量アクセスでも高速表示できるハイスピードプランは500円。
◯aaS系サービス
- Heroku: 無料プランあり。メモリ512MBのプロダクションプランは \$25~。
- Firebase: 月20GBのストレージ利用で \$0.39。ホスティングサービスの1000GBの転送料は \$149。
メリット・デメリットの説明は以上です。
どうでしょう?LightSailを使ってみたくなったでしょうか?
つぎは、実際にLightSailを使ってみましょう。はじめ方
先にお伝えしたように、LightSailはわかりやすさを重視したサービスです。
画面を見れば、だいたいの使い方はわかるかと思うので、かなり大雑把に解説していきます。インスタンスの作成
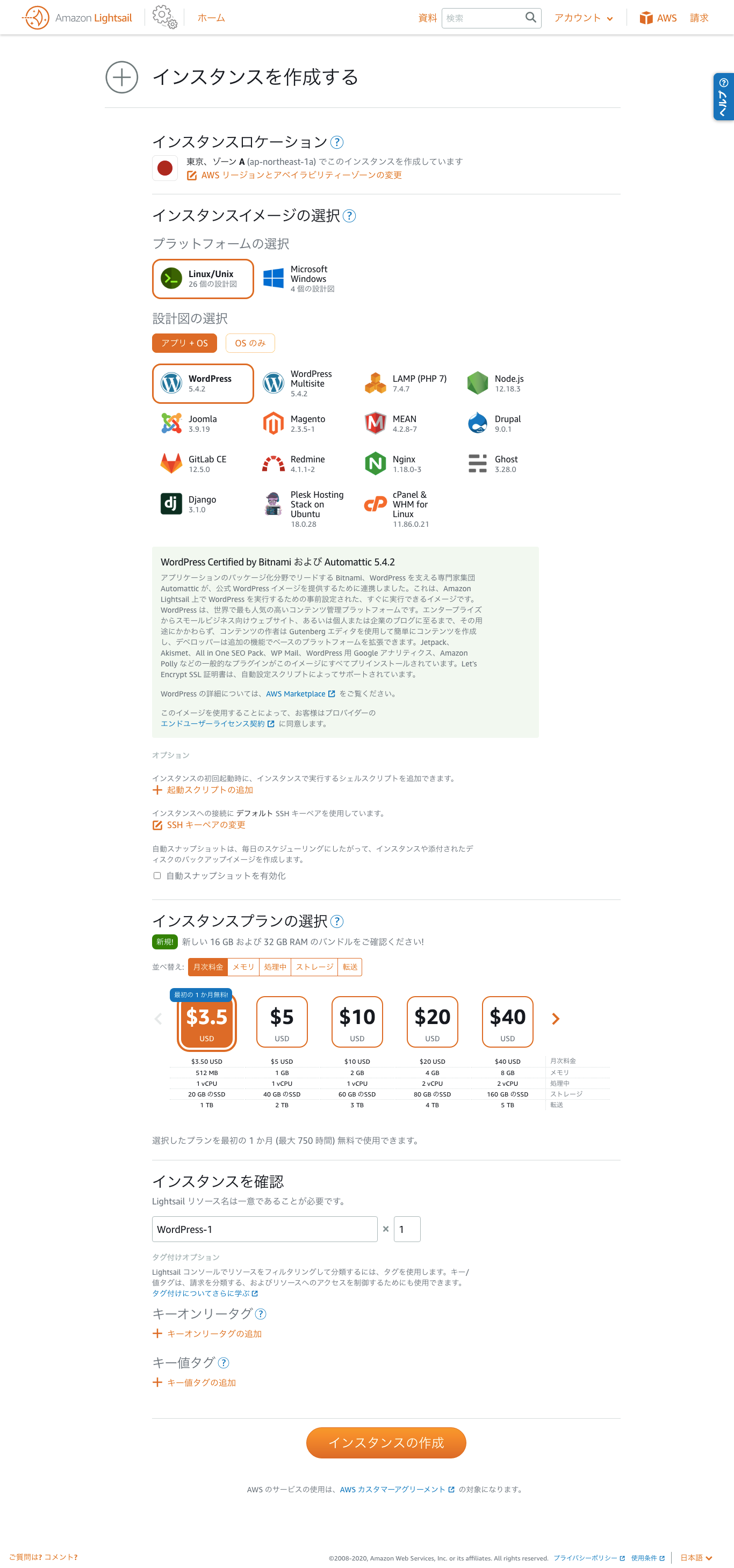
まずは(インスタンスの作成画面)をご覧ください!
はい!!
もう説明はいらないかもしれませんが、簡潔に補足させていただきます。※AWSでよく出てくる「インスタンス」という言葉は、LightSailにおいては「サーバー」と同じ意味で考えて大丈夫です。(厳密に言えば、AWSの「サーバー」はたくさんのユーザーがつくったサーバーを動かしている大元のPC(=親機)のことで、それと区別するための呼び方が「インスタンス」となります。)
インスタンスロケーション
意味:
物理的な意味で、どこに置いてあるPCにサーバーを構築するかどうかです。
決め方:
サーバーの所在地は、アクセス速度に影響します。
日本向けのサービスを作るなら、東京がベストです。インスタンスイメージの選択
意味:
サーバーのOSと、あらかじめ導入しておくアプリを選びます。
決め方:
メジャーなプラットフォームはLinux/Unix、
メジャーなアプリはWEBサーバーならLAMP、Node.js、Nginxなどです。インスタンスプランの選択
意味:
サーバーのスペックです。
決め方:
後々変更する方法があるので、よくわからなければ一番安いプランにしましょう。インスタンスを確認
意味:
今回つくるサーバーの名前と数を指定します。
決め方:
今後何台もサーバーを作る可能性があるならば、サーバー名が一覧表示されたときに、
目的のサーバーを間違えずに見つけられるような名前をつけてあげてください。インスタンスの作成
上記項目を入力したら「インスタンスの作成」ボタンを押してください。
無事、サーバーを作ることができたと思います!静的IPの作成
IPアドレスについては皆さんご存知でしょうか?(ご存知出ない方は、調べてみてください。)
「静的IP」というものについてざっくり説明すると、
たとえばAWSの他サービス(というかEC2)は、インスタンスを停止するたびにIPが変わってしまうので、ElasticIPという「固定IP(=静的IP)」の設定をする必要があります。
LightSailも、同じ仕組みなので、停止・再起動したあとも同じIPアドレスでサーバーを使用したい場合は、
静的IPを設定しておく必要があります。
同じIPアドレスでサーバーを使用したい場合というのは、主にサーバーに独自ドメイン(URL)でアクセスできるように設定する場合などですね。作り方はカンタンです。
管理画面(=AWSコンソール)の「ネットワーキング」メニューから「静的IPの作成」ボタンをクリックし、
さきほど作ったサーバーを選択して、静的IPを作成してください。作成されたIPアドレスをブラウザのアドレスバーに入力すれば、自身のサーバーにアクセスできると思います。
SSH接続
SSH接続とは、サーバーを操作するために、サーバーのCUIに接続する方法のことです。
(CUIとは、Macでいう「Terminal」、Windowsでいう「コマンドプロンプト」や「PowerShell」のことです)通常サーバーにSSH接続するためには鍵となるファイルを作成してユーザー作成を行う必要があるのですが、
AWSの場合はそれが不要になります!
LightSailのコンソールから「SSHを使用して接続」ボタンを押すだけでSSH接続ができます!感動!!
もちろん、あなたのPCのターミナルアプリを利用してSSH接続することも可能ですので、やりたかったら調べてみてください。(順次追記予定…)
おわり
いかがでしょうか?
LightSailの管理画面を触っていただいて、
AWSの他サービスより格段にわかりやすく作られているという実感ができたのではないでしょうか?
SSH接続ができるようになれば、このサーバーを使って何をつくるかはあなた次第です!
これにてLightSailの説明は以上となります。後編では、LightSailしか知らない人でも理解しやすいように、AWSの各種サービスを説明させていただきます。
AWSの理解を広げるために、ぜひ読んでみてください!
【らくちんAWS】LightSailからはじめるAWSエンジニア (後編)【完全に理解した】(作成中)


- 投稿日:2020-10-10T19:28:02+09:00
AWSでAwstatsのインストール
AWSでAwstatsのインストールをしたので、メモ代わりに投稿します。
Awstatsって、まだ需要あるのかな?Awstatsのインストールと設定方法
apacheのログの形式を変更
Awstatsをインストールする前に、先にapacheのログの形式を変更。$ vi /etc/httpd/conf/httpd.conf以下の様に、変更。
CustomLog logs/access_log common ↓ CustomLog logs/access_log combined次はAWstatsのダウンロード。
最新版は7.8。$ wget http://prdownloads.sourceforge.net/awstats/awstats-7.8.tar.gzダウンロードしたファイルを解凍。
$ tar zxvf awstats-7.8.tar.gz解凍したディレクトリのcgi-binディレクトリに移動。
$ cd awstats-7.8/wwwroot/cgi-binこのディレクトリ内のファイルを全てapacheのcgiが動作するディレクトリにコピー。AWSだと場所は/var/www/cgi-bin/
$ cp -r * /var/www/cgi-bin/一つ上のディレクトリに移動して、iconディレクトリを/var/www/html/にコピー。
$ cd ../ $ cp -r icon/ /var/www/html/cgi-binディレクトリに移動。
$ cd /var/www/cgi-bin/awstats.model.confをawstats.ドメイン.confという名前でコピー。
たとえば、ドメイン名がnewstweet.jpの場合は、awstats.newstweet.jp.confという名前でコピー。$ cp awstats.model.conf awstats.newstweet.jp.conf次は、今作成した設定ファイルの編集。
$ vi awstats.newstweet.jp.conf次はLogFileを自分のログファイルの位置に変更。
# Example: "/var/log/access_log.%YYYY-0%MM-0%DD-0.log" # Example: "C:/WINNT/system32/LogFiles/W3SVC1/ex%YY-24%MM-24%DD-24.log" # You can also use a pipe if log file come from a pipe : # Example: "gzip -d </var/log/apache/access.log.gz |" # If there are several log files from load balancing servers : # Example: "/pathtotools/logresolvemerge.pl *.log |" # LogFile="/var/log/httpd/mylog.log" ↓ LogFile="/var/log/httpd/access_log"(自分のアクセスログを指定)LogTypeの値を確認。 今回はwebのログを取得するのでWのままでOK。
# Enter the log file type you want to analyze. # Possible values: # W - For a web log file # S - For a streaming log file # M - For a mail log file # F - For a ftp log file # Example: W # Default: W # LogType=W次に、LogTypeの値を確認。 最初にログの形式をcombinedに変更しているので、1であるかを確認。
# Examples for Apache combined logs (following two examples are equivalent): # LogFormat = 1 # LogFormat = "%host %other %logname %time1 %methodurl %code %bytesd %refererquot %uaquot" # # Example for IIS: # LogFormat = 2 # LogFormat=1Sitedomainには自分のドメインを入れる。
# If analyzing mail log, enter here the domain name of mail server. # Example: "myintranetserver" # Example: "www.domain.com" # Example: "ftp.domain.com" # Example: "domain.com" # SiteDomain="" ↓ SiteDomain="newstweet.jp"(自分のドメイン名を入れる)DNSLookupの値を1に変更。
# Possible values: # 0 - No DNS Lookup # 1 - DNS Lookup is fully enabled # 2 - DNS Lookup is made only from static DNS cache file (if it exists) # Default: 2 # DNSLookup=2 ↓ DNSLookup=1apacheのログのパーミッションを変更
$ sudo chmod 755 /var/log/httpd $ sudo chmod 644 /var/log/httpd/access_logその他の項目はそのままでOK。 解析後データはawstats.plと同じディレクトリに置かれる。(今回の場合は /var/www/cgi-bin/)
基本的な設定はここまで。
次に統計の作成を行う。$ perl awstats.pl -config=newstweet.jp -updatenewstweet.jpの部分を自分のドメイン名に変更して実行することで統計が作成。
Create/Update database for config "./awstats.newstweet.jp.conf" by AWStats version 7.8 (build 20200416) From data in log file "/var/log/httpd/access_log"... (省略)上記の様なメッセージが表示されれば成功。
統計が作成できたらブラウザからhttp://newstweet.jp/cgi-bin/awstats.plにアクセスし、統計情報が見られるか確認。
統計情報が見られればAWstatsの導入は完了。cronに定期的(1分毎)に解析を行うように設定
最後に1分毎に自動更新の設定
cronを行います。crontab -e以下を追加「-config=」には/etc/awstats/にある設定ファイル名ではなく、awstats設定ファイル内の「SiteDomain」に定義されたドメイン名を設定。
*/01 * * * * perl /var/www/cgi-bin/awstats.pl -config=newstweet.jp -update > /dev/null 2>&1これで1分ごとに解析が行われているはず。
最後に・・・
今回、インストールしたAwstatsのアクセス解析を公開しているので、参考にどうぞ!
newstweet.jpのアクセス解析アクセス解析を見て、アクセスの少なさに同情した方は、こちらをお願いします。
NewsTweet|Twitterで注目されているニュースが分かる参考にしたサイト
Awstatsのインストールと設定方法 - Denet Tech Lib.
Apacheログ解析ツールAwstatsの導入
AWStats:/var/log/apache2/access.logにアクセスできません
- 投稿日:2020-10-10T18:44:51+09:00
AWSでSlackへのPOST先を限定する仕組みを構築する話(失敗ルート)
0. はじめに
今年の7月にAWSアソシをギリで取得した初心者が、AWSでそれっぽいことをする奮闘記である。
言いたいことは、AWS初心者でも調べる&触るを繰り返せば、それっぽいこと出来ちゃうよ、やってみよう!ってこと。ちなみに、これはうまくいかなかった失敗ルートです。
失敗ルートを歩んだけど、HPが0になってゲームオーバーになったわけじゃないから、そこで得た経験値はありがたく自分のものになったので、セーブしとこう。1. やりたいこと
情報流出を防ぐために、みんなで作るLambdaのPOST先をSlackだけにシステム的に絞りたい。
ただし、いくつかの条件がある。(この条件も調べてから知った)条件
- SlackのIPアドレスの範囲は非公開のため、L4レイヤによるIPアドレスのフィルタリングでは難しい。
- 現在、AWSサービスでWebフィルタリングする機能はない。(出口側)
2. 絵にする
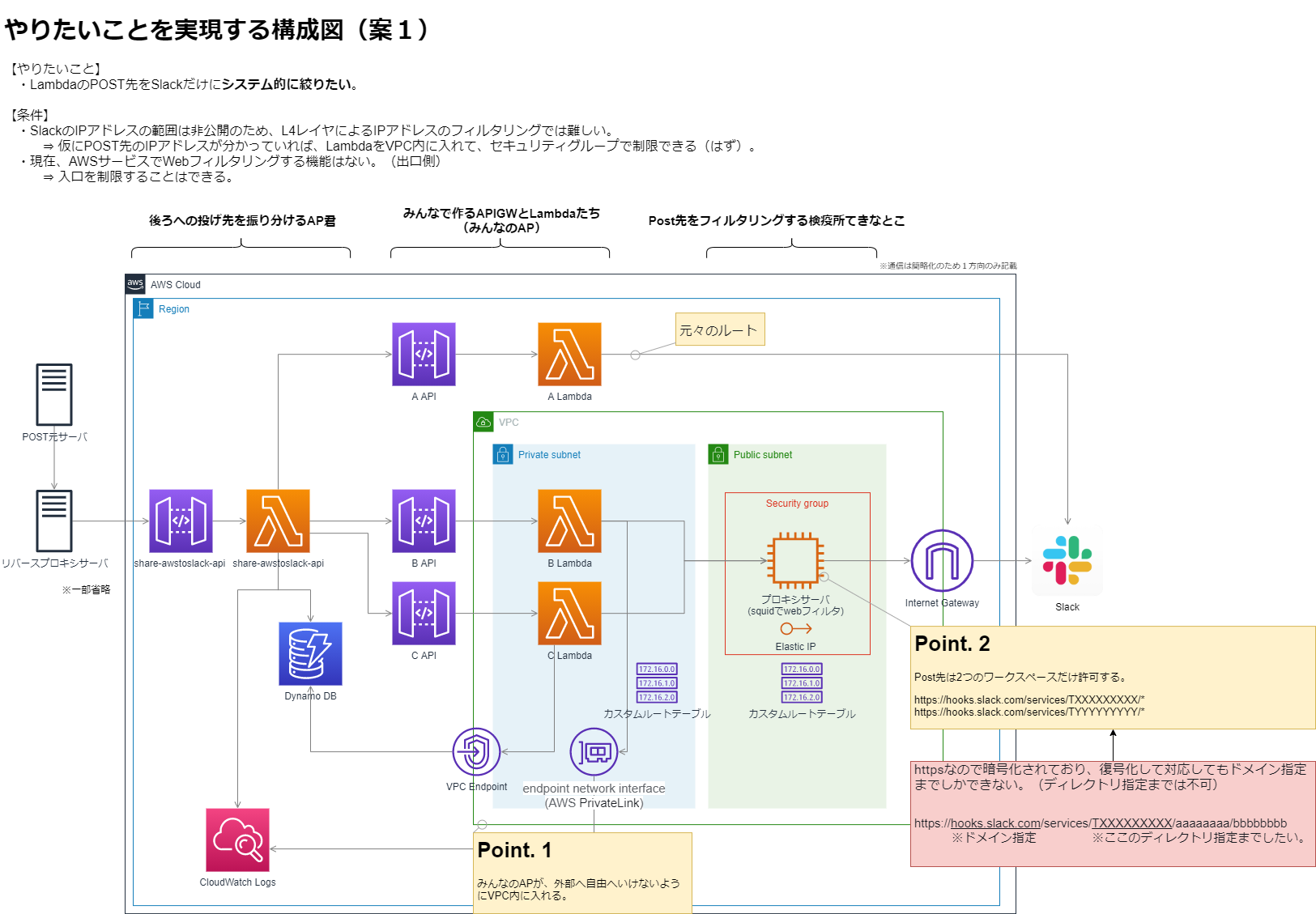
いきなりこれが出来たわけではないけど、こんな構成図を考えました。
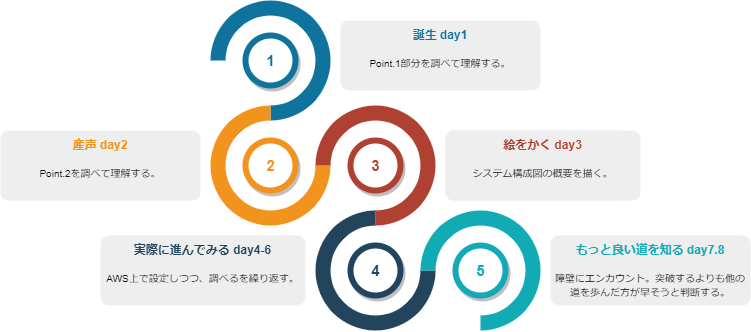
3. 歩んだ道
やりたいことと「LambdaをVPCに入れたら出来るんじゃない」っていう話を聞いてから、どんな道を歩んだのか、ってのを絵を交えてダラダラと書きます。
① 誕生 : day1
誕生である、さぁ道を進もう、、いえいえ生まれたて。
なんとなく出来そうってのは分かってたけど、概念レベル。
セキュリティグループで簡単に出来るんじゃない?って、生まれたて。ようこそ!
そもそも、LambdaをVPC内に入れて、やりたいことがなんで出来るんだっけ?っていう状態。
上の構成図のPoint1の部分。
- その時のメモたち:まずLambdaってデフォルトはVPCの外にあるんだ!そんなところから。
APIのエンドポイントタイプをリージョン ⇒ プライベートにするのかな? ん?違う?VPCからアクセスしたいわけではないよな。。。つまり最初はパブリックで良い。で、その連携Lambdaもパブリック。 LambdaもAPIGWもDyanamoも全部VPCの外にいる・・・から? ん?VPCでの制御云々ではないはず。 https://qiita.com/saitotak/items/d2ede050e7a2224da46d VPC Lambdaならその名の通り、VPCだけど。。 https://dev.classmethod.jp/articles/dynamodb-vpc-endpoint-lambda/ 仮にVPC内にLambdaを配置すると、インターネットへのアクセスには、これが必要。 ・プライベートサブネット&パブリックサブネット用意 ・プライベートいらなくないか?いや、IP固定にはいるのか?? ・「Amazon VPC NAT gateway」 ・プライベートいらないなら、これもいらない。 ・VPC エンドポイントを設定する。(cloudwthchとかDyanamodbとか) ・ENI(Elastic Network Interface)の作成権限をLambdaに与える必要があります ・VPCにインターネットGW ・セキュリティグループのインターネット間とのトラフィックを許可している。 ・これだと出来ない。IP指定しかできないのでは?AWSにプロキシ必要なんじゃね?? ・フォワードプロキシおいて、そこ通すようにする? ・NATGWではなく、NATインスタンス/プロキシ設定② 産声:day2
生まれたので、何しよう。よし、泣こう!おぎゃぁおぎゃぁ。
プロキシサーバってヒントを得たので、そこを中心的に調べてみる。
上の構成図のPoint.2の部分。ようやくちょっと霧が晴れた。
フィルタリングの仕組みもないか調査したり(Amazon GuardDuty使ってみる?とか)と、
ここまでは、ひたすらググってメモに残してく活動って感じ。
利用してるのは、タスク管理ツールとTypora。
その時のメモたち:Webフィルタリングをなんとなーく理解
疑問点 ・プロキシサーバを用意する理由は? ・NATインスタンスなどでは、L7レイヤのURL制御ができない。 ・プロキシサーバなら…??? ← ここが?? ・⇒ URLフィルタリングはProxyサーバにSquidを用いて実装 ・プロキシを設定する方法は? ・pythonのRequest オブジェクト内でset_proxyやればよさげ。 https://maku77.github.io/python/web/http-request.html ・Webフィルタリングしたいけど… ・AWSサービスでWebフィルタリングする機能はない https://dev.classmethod.jp/articles/web-filtering-on-workspaces/ > また、AWS が提供する他のサービスでも Web フィルタリングを行うためのサービスはありません今思うと、ここをもっとちゃんと調べりゃよかったっていう話もあるけど、それは過去の話。
③ 絵を書く:day3
さーて、進むべき絵でも描くか。急成長である。
今までの内容を図にすることで頭の整理と、俯瞰することで気付きを見つけようの期間。
頭の整理途中の具体例は、
エンドポイントって2種類あるけど、なにが違うんだ?(GW型とインターフェース型)→ 調べる。
- AWSのサービスによって違うのね。DynamoとS3はGW型。
NATインスタンスの図は置かないでいいのか? → 調べる。
- プロキシサーバにパブリックIPを付与するから、不要。
API-GWはVPC内に入れるのか?外なのか? → 調べる。
- 外。
利用してるのは、draw.io。
意外とここはdraw.ioのおかげだなって思った。
勿論、AWSのサービスの図があるから、とても楽ちん。ってのはあるけど、
サービスの図を選ぶときに、「え?2つあるけど、どっちを選べば良いんだ?」ってなり、そこから調査して理解するっていう流れが数度あった。俯瞰してみると、やっぱりSlack側のIPさえ分かれば、別にこの仕組みいらないよなー。
って思い、調べる。が、やはり進むべきは間違ってなさそう、そんな結論になった。https://stackoverflow.com/questions/38759599/slack-webhook-which-ips-should-i-open > 同じ問題に直面し、IP範囲をホワイトリスト化することしかできませんでした。 残念ながら、Slack APIのこのツイートによると、プラットフォームはAWSにあり、 固定IP範囲を持っていません。何らかのプロキシを使わないと通れないかもしれません。④ 実際に進んでみる:day4~6
もう歩いちゃう。さーさー、いざ参らん。
構成もある程度決まったので、構築を始める。きゅきゅっとまとめると3日間くらい?
実際は他のことをやったり、待ちだったりとで、8日間くらいはこの状態かな。
- VPC足りない問題(上限:リージョンあたり5)
- Elastic-IP足りない問題(上限:リージョンあたり5)
- カスタムルートテーブルとか、そもそも何を設定したらいいんだ?
進め方のポイントは、満足ポイントを如何に早め&定期的に得るかってこと。
まぁ切り分けをやりやすくなるしね。
- ざっと全体にモノを配置していって、満足ポイントを獲得する。
- 部分的に疎通していって、設定があってそうかってのを確認していく。
- 例:B-API ⇔ B LambdaやB Lambda ⇔ CloudWatch Logsとか
この期間が一番スキルとしては収穫デカいところ。
VPCのIPアドレス体系どうしようかな…とか基本的なところから、
実際にモノ触って初めて分かること多すぎる。これ、ググれる環境ないとマジ無理だ。こんなところに引っかかった。
Lambda
VPCを設定しようとすると、エラー起こる。
The provided execution role does not have permissions to call CreateNetworkInterface on EC2実際はEC2ではなくVPCの権限。
- 解決策はこれ。LambdaをVPCにぶち込むときの実行ロールが足りない。 https://blog.i-tale.jp/2020/06/11/
解決策は公式解説どおりですが、 Lambda の実行ロールに管理ポリシーである AWSLambdaVPCAccessExecutionRole これを付与することです。
Cloudwatch logs
https://qiita.com/akhkyamada/items/7e2fa8f9f8d4b7e78878
- Cloudwatch logs のエンドポイント設定しようとしたけど、エラー
VPC エンドポイントの作成でエラーが発生しました Enabling private DNS requires both enableDnsSupport and enableDnsHostnames VPC attributes set to true for vpc-xxxxxxxxxxxxxxxxxはいはい、DNSホスト名を有効化するのね。→ 作れた。
https://dev.classmethod.jp/articles/rdp-windows-deny-all-inbound-access/⑤ もっと良い道を知る:day7,8
なんとなーく感づいてたけど、行く先に大きな石ころが転がってた!さて、どうしよう。
そう、一番大事な箇所であるWebフィルタリングの部分。(squidのconfファイルのところ)
squidとか初めて触るし、ネットワーク周りは苦手…うまくいかない…これは厳しい…。
でも、きっと、こっちから見たら大きいけど実は薄ーい石なんでしょ?って思いつつ、調査。ん?httpsでは、URLフィルタリングできない?
https://milestone-of-se.nesuke.com/sv-advanced/server-software/https-url-filter/ > 暗号化によりhttpヘッダの中身を見ることができません。 やり方はいくつかあるけど、どれも完璧にそのままでは出来なそう。 > この方式の問題点は、CONNECT と同様サブディレクトリが識別できないことです。 https://xtech.nikkei.com/it/atcl/column/16/052300113/052300008/ > プロキシーサーバーでは、ドメイン単位(https://www.google.co.jp/)での フィルタリングはできたが、ディレクトリー単位(https://www.google.co.jp/intl/ja/drive/)はできなかった。なるほど、、、確かに他のwebフィルタリングの記事を見ると、httpのことしか書いてない。
UTMっていう「ぎんがのつるぎ」※を入手するってのも1つの手だけど、いかんせんそこには色んなハードルがある。
※ ドラクエをまともにやったことがないので、こういう時に大変。 https://game8.jp/dq11/277926ということで、相談をして、他の道を推奨。ってことで、そちらの道を歩むことにした。
それはまた、別のお話で。
- 投稿日:2020-10-10T18:04:02+09:00
AWS Certified Security - Specialtyに合格したよ!
AWS Certified Security - Specialty合格したよ!
※記載内容に間違いあったらすいません
前提
私はこれが六つ目のAWS認定で、これを受ける前にアソシエイトとプロフェッショナルの資格を全て保持していました。
今回受験した理由として、AWSでシステムアーキテクチャを考える上でセキュリティの観点で1から勉強したく取得に踏み切りました。本記事では私がAWS 認定セキュリティを受験するに当たって勉強した内容、教材と受けた感想を共有させて頂き、少しでもこれから受験する人の役に立てばと良いなと思ってます!
試験内容
AWS 認定セキュリティ – 専門知識は、最低 2 年間の AWS のワークロードの保護に関する実務経験を持つセキュリティ担当者である個人を対象としています。
認定によって検証される能力
- 専門的なデータ分類と AWS におけるデータ保護メカニズムについての理解
- データ暗号化メソッドと、AWS におけるその実装メカニズムについての理解
- 安全なインターネットプロトコルと、AWS におけるその実装メカニズムについての理解
- 安全な本番環境を実現するための、AWS のセキュリティサービスと機能についての実務知識
- AWS のセキュリティ関連のサービスと機能の使用に関する、2 年以上の本番デプロイ経験から得るコンピテンシー
- 一連のアプリケーション要件が指定された状況で、コスト、セキュリティ、デプロイの煩雑さについてトレードオフを考慮した決定を下せる能力
- セキュリティの運用とリスクについての理解
推奨される知識と経験
- AWS ワークロードの保護に関する最低 2 年間の実践経験
- AWS でのワークロードのセキュリティコントロール
- IT セキュリティ分野でセキュリティソリューションの設計と実装に従事した最低 5 年間の経験
KMS認定試験と言い換えても良いくらいKMSについて聞かれます(ちょい盛り)
基本的なIAMやS3のセキュリティ設計やWebアプリのセキュリティーなどについて聞かれ、SAPに似ていますがこちらの方が問題が易しかったです。教材リスト
- Exam Readiness: AWS Certified Security - Specialty (Japanese)
- 試験の内容を確認するのに活用しました。
- AWSの認定はどれもこのシリーズでまずは勉強してみるのが良いかと思います
- 要点整理から攻略する『AWS認定 セキュリティ-専門知識』
- 対象サービスの概要のおさらいと章末にある対策問題を活用させていただきました!
- 各サービスについて重要な機能についてまとまっていて非常に読みやすいです。
- tutorial dojo
- 各サービスの対比やサービス毎に押さえるべき内容が整理されているので、試験の前に自分の知識の確認に使用しました。
- AWSの薄い本 IAMのマニアックな話
- 試験ではIAMなどのポリシーのJSONでの書き方について問われることがわかっていたので、それ対策で読みました。
- 大変よくIAMについてまとまっているので試験とは関係なく、業務でIAMを利用する人には是非読んでいただきたいです!
- 模擬試験
- Jon-Bonsoさんが作成している模擬試験で、問題毎に公式リファレンスのリンクと詳細な解答が記述されているので、非常におすすめです。
- 受験する二週間くらい前から解いて、解答を確認のサイクルを繰り返し行ってました。
勉強方法
- まずはセキュリティ認定がどのくらいの難易度でどのようにAWSについて聞かれるかを把握するためExam Readiness: AWS Certified Security - Specialty (Japanese)を一周しました。
- その後出題範囲のサービスについて確認するため要点整理から攻略する『AWS認定 セキュリティ-専門知識』こちらを読ませて頂きました。ここで全てを理解しようとはせず、「ふむふむ、あ〜〜完全に理解したわ」くらいになればOKです。
- その後模擬試験を通じてBlackbeltや各サービスのユーザガイド、開発者ガイドを読み込み知識の補完を行いました。その際に公式ドキュメントから忘れそうなことを下記のようにコピペしてメモりながらあとで見返せるようにしていました。
- 認定試験前に自身でまとめたものを確認して終わり!
だいたい試験の1ヶ月くらい前から勉強を初めて、全部で15〜20時間くらい費やしました。
サービス別要点整理
VPC
VPCフローログ
送信元と送信先の IP アドレス、ポート、プロトコル、開始時刻と終了時刻、パケット数とバイト数、アクションをキャプチャする個々のレコードで構成されています。
これらは抽象化されたレコードであるため、完全なパケットの再構築はできません。
フローログの例
- アカウント
123456789010のネットワークインターフェイスeni-1235b8ca123456789への SSH トラフィック (宛先ポート 22、TCP プロトコル) が許可されています。2 123456789010 eni-1235b8ca123456789 172.31.16.139 172.31.16.21 20641 22 6 20 4249 1418530010 1418530070 ACCEPT OK
- アカウント
123456789010のネットワークインターフェイスeni-1235b8ca123456789への RDP トラフィック (宛先ポート 3389、TCP プロトコル) が拒否されています。2 123456789010 eni-1235b8ca123456789 172.31.9.69 172.31.9.12 49761 3389 6 20 4249 1418530010 1418530070 REJECT OKAmazon S3
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/security-best-practices.html#transit
データアクセス保護
- オブジェクトACL
- ここのオブジェクトへのアクセス権限を付与
- 別のアカウントが所有するオブジェクトにアクセスする
- バケットACL
- ログ配信グループにバケットへの書き込みアクセスを付与する
- バケットポリシー
- バケットACLよりも幅広いアクセス権限を付与する
- バケットへのクロスアカウントアクセスを許可する
- IAMユーザーポリシー
- ユーザとグループを作成し、ポリシーを添付してアクセス権限を管理する
デフォルトの暗号化
バケットにデフォルトの暗号化を設定することで、バケットに保存されているときにすべてのオブジェクトが暗号化されるようにすることができます。
オブジェクトは、Amazon S3管理鍵(SSE-S3)またはAWS Key Management Service(AWS KMS)、顧客マスター鍵(CMKs)のいずれかを使用してサーバーサイド暗号化を使用して暗号化されます。サーバーサイド暗号化を使用する場合、Amazon S3はオブジェクトをデータセンターのディスクに保存する前に暗号化し、オブジェクトをダウンロードする際に復号化します。
デフォルトの暗号化は、既存のすべてのAmazon S3バケットと新しいAmazon S3バケットで動作します。
デフォルトの暗号化がない場合は、バケットに保存されているすべてのオブジェクトを、オブジェクトの保存要求ごとに暗号化するための暗号化情報を含める必要があります。また、暗号化情報を含まないストレージリクエストを拒否するために、Amazon S3バケットポリシーを設定する必要があります。
セキュアにアクセスしてるか確認
- バケットポリシーでHTTPまたはHTTPSリクエストを判断するには、キー「aws:SecureTransport」をチェックする条件を使用。
"Condition": { "Bool": { "aws:SecureTransport": "false" }Amazon S3 Glacier
アーカイブデータの長期保存とオブジェクトの迅速な取得
- 自動データ転送を対象とするAmazon S3ライフサイクルルール
- データは取得後24時間使用が可能
- データは一括で、またはセグメント単位で取得が可能
ボールトロック
- 時間ベースの保持
- MFA認証のサポート
- ロック後はポリシーの変更不可
- Write Once Read Many(WORM)のサポート
Amazon RDS
転送中のデータ保護
- TLSとネイティブ暗号化クライアントを使用
- AmazonRDSがアクセス認証を処理
保管中の保護
- AES-256暗号化アルゴリズムを使用
- DBの作成時に暗号化を有効にすること可能
- 作成後は有効にすることができない
- 特定のDBエンジンでTDEをサポート
Amazon DynamoDB
転送中のデータ保護
- TLSで暗号化されたエンドポイントを使用
- HMAC-SHA256署名付きのリクエストのみを許可
保管中の保護
- CSEまたはSSE暗号化オプションをサポート
- AES-256暗号化アルゴリズムを使用
- テーブルとインデックスを暗号化
Amazon DynamoDB Encryption Client
- テーブルデータをAmazon DynamoDBに送信する前にテーブルデータを保護するのに役立つソフトウェアライブラリ
- トランジット時と休止時に機密データを暗号化することで、平文データがAWSなどの第三者に公開されないようにすることができます
- クライアント側の暗号化をサポートしており、テーブルデータをDynamoDBに送信する前にテーブルデータを暗号化します
- デフォルトでは、DynamoDBはDynamoDBサービスアカウントでAWS所有のCMKを使用しますが、一部またはすべてのテーブルにAWS管理されたCMKをアカウントで使用することを選択することができます
Amazon Cognito
Amazon Cognito Identity Pool(認可)
ユーザーが一時的にAWSの資格情報を取得して、Amazon S3やDynamoDBなどのAWSサービスにアクセスすることを可能にします。アイデンティティプールは匿名のゲストユーザーをサポートしているほか、プールのユーザーを認証するために使用できる様々なアイデンティティプロバイダをサポートしています。
アイデンティティプールを利用してユーザーに固有のアイデンティティを作成し、他のAWSサービスへのアクセス権を与えることができます。
Amazon Cognito User Pool(認証)
Amazon Cognitoのユーザーディレクトリです。ユーザープールを使用すると、ユーザーはAmazon Cognitoを介してWebまたはモバイルアプリにサインインしたり、サードパーティのIDプロバイダ(IdP)を介してフェデレートすることができます。ユーザーが直接サインインしても、サードパーティを介してサインインしても、ユーザープールのすべてのメンバーはディレクトリプロファイルを持っており、SDKを介してアクセスできます。
グループの作成と管理、グループへのユーザーの追加、グループからのユーザーの削除を可能にする「グループ」をサポートしています。グループを使用して、ユーザーの権限を管理するためのユーザーのコレクションを作成したり、異なるタイプのユーザーを代表するために使用します。グループにAWS Identity and Access Management(IAM)ロールを割り当てて、グループのメンバーのパーミッションを定義することができます。グループを使用してユーザープールにユーザーの集合体を作成することができますが、これは、そのユーザーのパーミッションを設定するために行われることが多いです。
Amazon Route53
DNS
- 高い可用性と信頼性
- 他のAWSサービスと連携できる
- 優れた柔軟性とスケーラビリティ
- 安全性
Amazon CloudFront
低レイテンシーで安全にデータを配信する高速コンテンツ配信ネットワークサービス(CDN)
- 高速アンドグローバル
- エッジでのセキュリティ
- 高度なプログラムが可能
- 様々なAWSサービスとの統合が可能
ACM証明書の使用
- Amazon CloudFrontでACM証明書を使用するには、US East(N. Virginia)リージョンで証明書をリクエストするか、インポートする必要があります
- CloudFrontのディストリビューションに関連付けられたこのリージョンのACM証明書は、そのディストリビューションに設定されたすべての地理的ロケーションに配布されます
AWS WAF
ウェブアプリケーションの保護に役立つファイアウォール
- ウェブ攻撃からの保護の強化
- AWSの他のサービスと統合したセキュリティ
- 向上したウェブトラフィック可視性
- マネージドルールによるセキュリティ強化
AWS Shield
AWSのすべての顧客を追加料金なしで保護
- ほとんどのネットワークおよびトランスポートレイヤーへの攻撃を防御
- セキュリティを高めるために、AWS Shield Advancedを追加することもできる($3000)
- マネージド型の分散型サービス(DDoS)保護サービス
- 常時検知機能と自動インラインミティゲーション機能を提供し、アプリケーションのダウンタイムやレイテンシを最小限に抑える
Advanced
- Standardに搭載されているネットワーク層とトランスポート層の保護に加えて、大規模かつ高度なDDoS攻撃に対する検知と緩和、攻撃に対するほぼリアルタイムの可視性、WebアプリケーションファイアウォールであるAWS WAFとの統合が可能。
AWS Config
リソースが独自のセキュリティポリシー、業界のベストプラクティス、準拠企画に準拠しているかどうかを確認できるようにする
- リソースの全設定変更についての詳細情報を継続的にキャプチャ
- コンプライアンスモニタリングとセキュリティ分析を有効化
- セキュリティを侵害するような設定変更を特定し、影響を軽減できる
すべてのリソースのリストを取得できる
AWSマネージドルール
- AWSによる定義と管理
- 設定は最小限または不要
カスタムルール
- Lambdaの使用
- お客様による管理が必須
Amazon SES
暗号化について
- Amazon SESは、TLSで暗号化された接続を確立するための2つのメカニズムをサポートしています
- STARTTLS
- TLS Wrapper
- TARTTLSは、暗号化されていない接続を暗号化された接続にアップグレードするための手段です。STARTTLS接続をセットアップするには、SMTPクライアントはポート25、587、または2587のAmazon SES SMTPエンドポイントに接続し、EHLOコマンドを発行し、サーバーがSTARTTLS SMTP拡張をサポートしていることをアナウンスするのを待ちます。クライアントはSTARTTLSコマンドを発行し、TLSネゴシエーションを開始します。ネゴシエーションが完了すると、クライアントは新しい暗号化された接続上でEHLOコマンドを発行し、SMTPセッションは正常に進行します。
AWS CloudTrail
https://docs.aws.amazon.com/ja_jp/awscloudtrail/latest/userguide/best-practices-security.html
ユーザー、ロール、またはAWSサービスによって行われたアクションは、CloudTrailにイベントとして記録されます。イベントには、AWS Management Console、AWS Command Line Interface、AWS SDKやAPIで行われたアクションが含まれます。
- CloudTrailはAWSアカウント作成時に有効になる
- 過去90日間のアクティビティを表示、検索、ダウンロードができる
- CloudTrailで記録できるイベントには、管理イベントとデータイベントの2種類があり、デフォルトでは、トレイルには管理イベントは記録されますが、データイベントは記録されません。
ログファイルの暗号化
- CloudTrailからバケットに配信されるログファイルは、Amazon S3が管理する暗号化キー(SSE-S3)を使用したAmazonサーバーサイド暗号化で暗号化されています
- AWS KMS管理鍵(SSE-KMS)によるサーバーサイド暗号化を有効にすると、ログファイルは暗号化されますが、SSE-KMSを使用したダイジェストファイルは暗号化されないことに注意してください。
- ダイジェストファイルはAmazon S3管理暗号化キー(SSE-S3)で暗号化されます
- ユーザーは、ログファイルが格納されているバケットのS3読み取り権限を持っている必要があります
- ユーザーはCMKポリシーで復号化のパーミッションを許可するポリシーまたはロールを適用している必要があります
- 選択したCMKは、ログファイルを受け取るAmazon S3バケットと同じAWSリージョンに作成する必要があります
- https://docs.aws.amazon.com/ja_jp/awscloudtrail/latest/userguide/encrypting-cloudtrail-log-files-with-aws-kms.html
CloudTrailのTrail
Read/Write events
- 証跡情報のログを記録する場合は [All]、[Read-only]、[Write-only]、または [None] を選択して、[Save] を選択します。デフォルトでは、証跡はすべての管理イベントを記録します。詳細については、「管理イベント」を参照してください。
AWS KMS イベントの記録
- 通常、
Encrypt、Decrypt、GenerateDataKeyなどの AWS KMS アクションは、大容量イベント (99% 以上) を生成します。これらのアクションは、[Read (読み取り)] イベントとしてログに記録されるようになりました。Disable、Delete、ScheduleKeyなどの少量の関連する AWS KMS アクション (通常は AWS KMS イベントボリュームの 0.5% 未満) は、[Write (書き込み)] イベントとしてログに記録されます。
Encrypt、Decrypt、GenerateDataKeyなどの大容量イベントを除外するが、Disable、Delete、ScheduleKeyなどの関連イベントを引き続きログに記録するには、[書き込み専用] 管理イベントをログに記録するよう選択し、[Log AWS KMS events] で [はい] を選択します。Trailの種類
すべてのリージョンに適用するトレイル
- CloudTrailは各リージョンのイベントを記録し、CloudTrailのイベントログファイルを指定したS3バケットに配信する。
- すべてのリージョンに適用するトレイルを作成した後にリージョンを追加すると、その新しいリージョンが自動的に含まれ、そのリージョン内のイベントが記録される
1つのリージョンに適用されるトレイル
- CloudTrailはそのリージョン内のイベントのみを記録します。その後、CloudTrailのイベントログファイルは、指定したAmazon S3バケットに配信されます。
- 追加の単一トレイルを作成した場合、CloudTrailイベントログファイルを同じAmazon S3バケットに配信したり、別のバケットに配信したりすることができます。これは、AWS CLIまたはCloudTrail APIを使用してトレイルを作成する際のデフォルトのオプション。
AWS Organizationsで組織を作成している場合は、その組織内のすべてのAWSアカウントのすべてのイベントをログに記録するトレイルを作成することもできます。
Cloud wathe Logs
- イベントをCloudWatch Logsに送信するようにトレイルを設定することができる
- CloudWatch Logsを使用して、特定のAPIの呼び出しやイベントについてアカウントを監視することができます。イベントをCloudWatch Logsのロググループに送信するようにトレイル(すべてのリージョンに適用される)を設定した場合、CloudTrailはすべてのリージョンのイベントを1つのロググループに送信することに注意
- トレイルのログを監視し、特定のアクティビティが発生したときに通知を受けることができる
AWS GuardDuty
脅威検知サービス
- CloudTrail,DNSログ,VPCフローログからデータを収集
- 悪意のある操作や不正な動作を継続的にモニタリングし、AWSアカウントとワークフローを保護
脅威の可能性が検出されると、GuardDutyコンソールとCloudWatchに詳細なセキュリティアラートが配信さる
複数のアカウント間での有効化と管理を容易にします。マルチアカウント機能により、すべてのメンバーアカウントの調査結果をGuardDuty管理者アカウントで集約することができます。これにより、セキュリティチームは、組織全体からのすべてのGuardDutyの調査結果を1つのアカウントで管理することができます。集計された調査結果はCloudWatch Eventsでも利用できるため、既存の企業イベント管理システムとの統合が容易になります。
AWS環境のEC2インスタンスがブルートフォース攻撃に関与したことを通知することができます。これにより、Linuxベースのシステム上でSSHサービスのパスワードを取得することを目的とした攻撃からAWSのリソースを保護することができます。
アカウントの招待
他のアカウントを招待してGuardDutyを有効にし、自分のAWSアカウントと関連付けられるようにすることができます。
- 招待を受け入れると、自分のアカウントがマスターのGuardDutyアカウントとして指定されます。
- 招待を受け入れたアカウントは、マスターアカウントに関連付けられたメンバーアカウントになります。
- マスター アカウントのユーザーは、GuardDuty を設定したり、自分のアカウントと関連するすべてのメン バー アカウントの GuardDuty の調査結果を表示および管理したりすることができます。
- マスターアカウントはメンバー アカウントに代わって GuardDuty の調査結果を表示し、管理することができます。GuardDutyでは、マスターアカウント(リージョンごと)に最大1000個のメンバーアカウントを持つことができます。
マスターアカウントができること
- GuardDuty を設定したり、自分のアカウントと関連するすべてのメン バー アカウントの GuardDuty の調査結果を表示および管理したりすることができます。
- 自分のアカウントでサンプル調査結果を生成できます。マスター アカウントのユーザーは、メンバーのアカウントにサンプル調査結果を生成することはできません。
- 自分のアカウントとすべてのメンバーアカウントの調査結果をアーカイブすることができます。
- 自分のアカウントで信頼できる IP リストと脅威リストをアップロードして管理することができます。
メンバーアカウントができることできないこと
- メンバー アカウントのユーザは、GuardDuty を構成したり、アカウント内の GuardDuty の調査結果を表示および管理したりできます。
- GuardDuty を構成したり、マスター アカウントや他のメンバー アカウントの所見を表示したり管理したりすることはできません。
- 自分のアカウント、マスターのアカウント、または他のメンバー アカウントに調査結果をアーカイブすることはできません。
- 信頼できるIPリストおよび脅威リストをアップロードしたり、管理したりすることができません。
- マスター アカウントによってアップロードされた信頼できる IP リストと脅威リストは、メンバー アカウントの GuardDuty 機能に課せられます。
AWS Inspetor
AWS上に展開されたアプリケーションのセキュリティとコンプライアンスの向上を支援する自動セキュリティ評価サービスです。Amazon Inspectorは、アプリケーションの暴露、脆弱性、ベストプラクティスからの逸脱がないかどうかを自動的に評価します。評価を実行すると、Amazon Inspectorはセキュリティに関する調査結果の詳細なリストを作成し、重要度のレベル別に優先順位を付けて表示します。これらの調査結果は、直接確認することも、Amazon InspectorのコンソールやAPIから入手できる詳細なアセスメントレポートの一部として確認することもできます。
EC2に対してセキュリティ検査が可能
- 共通脆弱性識別子(CVE)
- CISベンチマーク
- セキュリティのベストプラクティス
- ランタイム動作分析
Amazon Macie
Amazon S3に保存されているセンシティブなデータを自動的に検出、分類、保護することで、データの損失を防ぐことができる、MLを活用したセキュリティサービスです。Amazon Macieは機械学習を使用して、個人を特定できる情報(PII)や知的財産などのセンシティブなデータを認識し、ビジネス価値を割り当て、このデータがどこに保存されているか、組織内でどのように使用されているかを可視化します。
データアクセスアクティビティの異常を継続的に監視し、不正アクセスや不注意によるデータ漏洩のリスクを検知した場合にはアラートを配信します。Amazon Macieは、機密データに不用意に設定されたグローバルなアクセス許可を検出したり、ソースコード内のAPIキーのアップロードを検出したり、機密性の高い顧客データがコンプライアンス基準を満たす方法で保存およびアクセスされているかどうかを検証したりする機能を備えています。
AWS Key Management Service
AWS KMSは、キーの保管と管理、およびデータの暗号化を目的とするマネージド型の暗号化サービスである。
- エンベロープ暗号化を使用した2層のキー階層
- キーを一元的に管理し、セキュリティを保護
キーを使用できるユーザを使用ポリシーで決定
- 暗号鍵に付与されるDefaultPolicyはrootアカウントに対してすべての権限を持つ
キーをインポートする
- キーをエクスポートすることはできない
- 256ビットの対象鍵のみインポート可能
- インポートした鍵は自動ローテーションできない
- リージョン障害の場合、自動復旧されない
既存の CMK キーはそのままローテーションできない
キーローテーションが無効になっている場合でも、CMKのすべてのバッキングキーを保持します。バッキングキーが削除されるのは、CMKが削除されたときだけです。
顧客管理のCMKでは、自動キーローテーションはデフォルトで無効になっています。キーローテーションを有効化(または再有効化)すると、AWS KMSは有効化日から365日後、それ以降は365日ごとにCMKを自動的にローテーションします。
RDSの暗号化について
- Amazon RDSリソースの暗号化と復号化に使用する鍵を管理するには、AWS Key Management Service (AWS KMS)を使用します。
- Amazon RDSで暗号化されたDBインスタンスの場合、ログ、バックアップ、スナップショットはすべて暗号化されています。
- Amazon RDSで暗号化されたインスタンスのリードレプリカも、両方が同じAWSリージョン内にある場合は、マスターインスタンスと同じ鍵を使って暗号化されます。マスターとリードレプリカが異なるAWSリージョンにある場合は、そのAWSリージョンの暗号化キーを使用して暗号化します。
- AWS KMSで生成されたキーは、作成されたリージョンにのみ保存され、使用されます。他のリージョンに転送することはできません。例えば、EU-Central (Frankfurt)リージョンで作成された鍵は、EU-Central (Frankfurt)リージョン内でのみ保存・使用されます。
転送中のデータの保護
トラフィックが暗号化され、HTTPS経由でデータの整合性が認証される
- クライアントとサービスエンドポイント間にTLSセッションを確立する
- パブリックキーインフラストラクチャ(PKI)内でX.509証明書を使用する
- 証明書によりサーバのアイデンティティを検証し、改竄や偽造を防止する
暗号処理手順
- データキーを作成
- KMSはデータキーと暗号化されたデータキーの両方を返す
- データキーはアプリケーションのメモリ上に配置し、データの暗号化に利用
- データキーの管理はアプリケーション側
- 平文のデータキーは、決してディスクに置いてはならない
- 暗号化処理が終了したら即座に削除
- 暗号化されたデータキーは暗号化されたデータとともに保存する
- 管理を容易にするため
複合処理手順
- アプリケーションから暗号化されたデータキーをKMSに送信
- KMSは該当するマスターキーを利用してデータキーを複合し、アプリケーションに返す
- アプリケーションでデータキーを使ってデータを複合する
- この際に平文のデータキーの取扱注意
データの暗号化の選択肢
- Client-Side Encryption
- ユーザアプリケーションでのデータ暗号化にKMSを利用
- 各種AWSSDKを利用する
- より上位のSDKやクライアントを利用するレバ、Envelop Encryptionを容易にバンドル可能
- Server-Side Encryption
- AWSの各種サービスとインテグレーションされている
- AWSサービスでデータが受信された後にサービスがKMSを利用してデータを暗号化
AWS Certificate Manager
- 単一のインターフェイスを備え、パブリック証明書とプライベート証明書の両方を管理する
- 証明書のデプロイを容易にする
- プライベート証明書を保護および保存する
- 自動更新によりダウンタイムを最小限に抑える
Amazon Sercets Manager
AWS Secrets Managerは、アプリケーション、サービス、ITリソースへのアクセスに必要なシークレットの保護に役立ちます
- シークレットを安全にローテする
- アクセスの管理
- 一元的なセキュリティと監査
- 従量課金制
RDS のクレデンシャル
- クレデンシャルのタイプとしてCredentials for RDSデータベースを使用してローテーションを有効にすると、Secrets Managerは自動的にLambdaローテーション関数を作成して設定します。
- その後、関数の Amazon リソース名 (ARN) をクレデンシャルに装備します。
- Secrets Manager は、関数に関連付けられた IAM ロールを作成し、必要なすべての権限を持つロールを設定します。または、別のシークレットで同じローテーション戦略を使用していて、新しいシークレットで同じローテーションを使用したい場合は、既存の関数の ARN を指定して、両方のシークレットで使用することができます。
AWS System Manger
AWS Systems Manager Patch Manager
管理されているインスタンスにセキュリティ関連のアップデートのパッチを適用するプロセスを自動化します。Linuxベースのインスタンスの場合は、セキュリティ関連以外のアップデートのパッチをインストールすることも可能です。Amazon EC2インスタンスのフリートやオンプレミスのサーバーや仮想マシン(VM)に、オペレーティングシステムの種類ごとにパッチを適用することができます。
インスタンスをスキャンして欠落しているパッチのレポートのみを表示することも、スキャンして欠落しているすべてのパッチを自動的にインストールすることもできます。
AWS Systems Manager Parameter Store
セキュアな文字列パラメータを作成することができます。セキュアな文字列パラメータとは、平文のパラメータ名と暗号化されたパラメータ値を持つパラメータのことです。Parameter Storeでは、AWS KMSを利用して、セキュアな文字列パラメータのパラメータ値を暗号化・復号化します。
機密性の高いデータを管理するために、セキュアな文字列パラメータを作成することができます。AWS KMSのカスタマーマスターキー(CMK)を使用して、セキュアな文字列パラメータの作成時や変更時にパラメータ値を暗号化します。また、アクセスした際にもCMKを使用してパラメータ値を復号化します。Parameter Storeがアカウント用に作成したAWS管理のCMKを使用することもできますし、独自の顧客管理CMKを指定することもできます。Parameter Storeは対称CMKのみをサポートしています。非対称CMKを使用してパラメータを暗号化することはできません。
CMKに関連したParameterStoreの失敗原因
- アプリケーションが使用している資格情報がCMKで指定されたアクションを実行する権限を持っていない
- 別の資格情報でアプリケーションを実行するか、操作を妨げているIAMまたはキーポリシーを修正する
- CMK が見つかりません
- CMK に誤った識別子を使用した場合に発生します。CMK の正しい識別子を見つけて、コマンドを再試行する
- CMKが有効になっていない
- これが発生すると、パラメータストアはInvalidKeyId例外を返し、AWS KMSから詳細なエラーメッセージが表示されます。CMKの状態がDisabledの場合は、有効にしてください。インポートを保留中の場合は、インポート手順を完了させます。キーの状態が Pending Deletion の場合は、キーの削除をキャンセルするか、別の CMK を使用する
- アカウントに割り当てられたAWS管理CMKの代わりに顧客管理CMKを使用するには、--key-idパラメータを使用してキーを指定する必要がある。
セキュリティ別対応例
IAMキーの流出
認証情報を失効させる
- 公開された認証情報を無効化
- 必要に応じてアクセスキーを削除
IAMの許可を取り消す
- IAMを拒否するポリシーをユーザにアタッチする
- 未処理のセッションを全て取り消す
IAMアクセスキーのソースを確認
- どのユーザに割り当てられているか
- そのキーのポリシーの範囲を調査
整合性を確認して、影響範囲を調査
- CloudTrailとAWS Configを使用して、変更されたものがないか確認
- 他のIAMアクセスキーや認証情報が問題にならないかチェック
Amazon CloudWatch Logのクエリを使用してAPIの履歴を検索する
特定の EC2 インスタンス間で送受信されるトラフィックの完全なパケット分析を実行したい
- バケットキャプチャとルートテーブルをサポートするAWS Market placeのAMIを使用してトラフィックをルーティングする必要がある
- VPCフローログだと完全なバケットの再構築をできない
PCを紛失して、SSHキーが流出したときの対処
- AWS Systems ManagerのRunコマンドを使用して、影響を受けたすべてのEC2インスタンスの
~/.ssh/authorized_keysファイルを修正します。- SSH秘密鍵に関連付けられているファイル内のすべての公開鍵を削除します。
具体的な手順:https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/replacing-lost-key-pair.html
IAM /Userのアクセスキーの期限付き削除方法
- AWS Configを使って古いアクセスキーを検出することもできる。ただし、アクセスキーを無効にするためには、Systems Manager Automationを使用してカスタムの修復アクションを作成する必要がある
- AWS Configが監視して通知してくれるのは、アカウント内に不適合なキーがある場合のみ
- AWS Configにはaccess-keys-rotatedという管理ルールがあり、maxAccessKeyAgeで指定した日数内にアクティブなアクセスキーがローテーションされているかどうかをチェックしています。アクセスキーがmaxAccessKeyAgeで指定した日数以上ローテーションされていない場合、ルールは非準拠としてタグ付けされます。
- GenerateCredentialReport APIを呼び出してクレデンシャル・レポートを生成するLambda関数を開発する
- GetCredentialReport APIを使用してレポートをダウンロードし、CSVファイルを解析し、user_creation_timeが90日以上の鍵をチェックするように関数を構成し、UpdateAccessKey APIを使用して古いアクセスキーを無効にします
CloudWatch Logs AgentがAmazon CloudWatch Logsへのログデータのプッシュを停止した場合
/var/log/awslogs.log ファイルを確認。エラーメッセージをチェック。
ログファイルに情報メッセージのみが含まれる場合は、エージェント構成ファイルの logging_config_file オプションに低いロギングレベルを指定
ログのローテーション後にログがプッシュされなくなった場合は、サポートされているログのローテーション方法を確認
awslogsエージェントを再起動した後、ログが短時間しかプッシュされない場合は、エージェント設定ファイルの[logstream]セクションで重複していないか確認、各セクションには一意の名前を付ける必要あり
https://aws.amazon.com/jp/premiumsupport/knowledge-center/push-log-data-cloudwatch-awslogs/
サードパーティが組織のAWSリソースへのアクセスを必要とする場合
- IAMロールを使用してアクセスを委任することができる
- [クロスアカウントアクセスのロール]-[所有しているAWSアカウント間のアクセスを提供します]を選択し、許可するアカウントのIDを入力してIAMロールを作成
AWS KMSキーを含むアップロードリクエストで大きなファイルをS3バケットにアップロードしようとしたときにAccess Deniedエラーが発生する
- オブジェクトを暗号化するために使用しているAWS KMSキーに対してkms:Decryptアクションを実行する権限を持っていることを確認する必要がある
- kms:Encrypt、kms:ReEncrypt*、kms:GenerateDataKey*、kms:DescribeKeyのアクションに対しても権限が必要
セキュリティグループとネットワークACLが受信トラフィックを許可しているのに、サービスに接続できない場合
- インスタンスで実行されているサービスへの接続を有効にするには、関連付けられたネットワークACLで、サービスがリッスンしているポートでの受信トラフィックと、エフェメラルポートからの送信トラフィックの両方を許可する必要があります。
- クライアントがサーバーに接続すると、一時ポート範囲(1024〜65535)のランダムなポートがクライアントのソースポートになります。
- 指定された一時ポートは、サービスからの戻りトラフィックの宛先ポートになるため、一時ポートからの送信トラフィックはネットワークACLで許可する必要があります。
Amazon RDS データベースシークレットのローテーションを有効にする場合
- Lambda 関数は、データベースと通信できる必要がある
- Lambda 関数は、Secrets Manager サービスエンドポイントと通信できる必要がある
受験した感想
認定試験の結果は831点で合格でした!!
AWSを扱う上で共有責任モデルの私たち側で守るべき要件について再度見直すことができ、仕事に生かせる良い認定試験だと感じました!次はData Analytics認定を受けようかと考えています!
- 投稿日:2020-10-10T16:48:49+09:00
Amazon Timestreamの結果をグラフにしてみた
Timestreamの検索をSDKを使ってやってみました。
クエリーをする最小のコードはこんな感じ。
import boto3 from botocore.config import Config query = """ SELECT fleet, truck_id, fuel_capacity, model, load_capacity, make, measure_name, CREATE_TIME_SERIES(time, measure_value::double) as measure FROM "IoT-sample"."IoT" WHERE measure_value::double IS NOT NULL AND measure_name = 'speed' GROUP BY fleet, truck_id, fuel_capacity, model, load_capacity, make, measure_name ORDER BY fleet, truck_id, fuel_capacity, model, load_capacity, make, measure_name LIMIT 2 """ config = Config(region_name = 'us-east-1') config.endpoint_discovery_enabled = True client = boto3.client('timestream-query', config=config) result = client.query(QueryString=query)
resultはこんな感じ
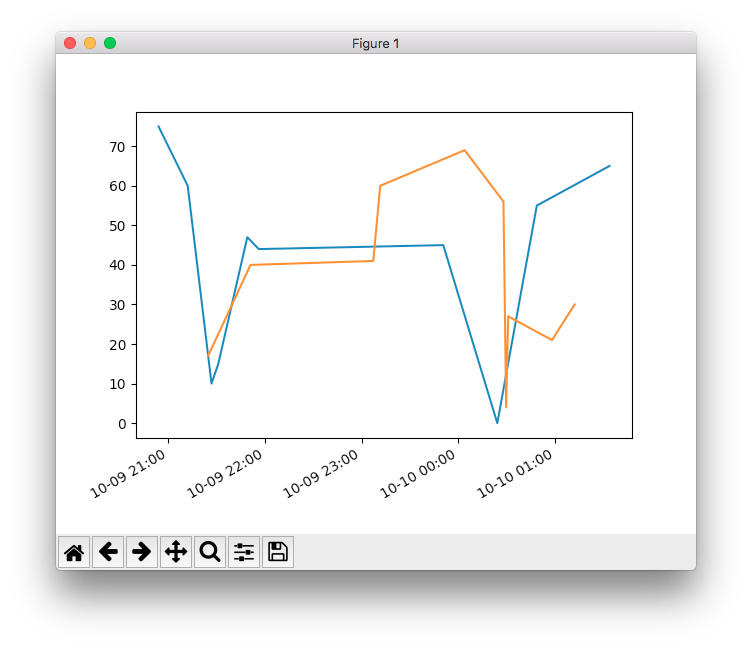
{ "QueryId": "AEBQEAMXPVS6RHIUBHJXW6H4BRUINE7GFNEMJMP2AYZFQHAUJLR5ZO4PABHEU2A", "Rows": [ { "Data": [ { "ScalarValue": "Alpha" }, { "ScalarValue": "1234546252" }, { "ScalarValue": "150" }, { "ScalarValue": "W925" }, { "ScalarValue": "1000" }, { "ScalarValue": "Kenworth" }, { "ScalarValue": "speed" }, { "TimeSeriesValue": [ { "Time": "2020-10-09 20:53:57.273000000", "Value": { "ScalarValue": "75.0" } }, { "Time": "2020-10-09 21:12:02.919000000", "Value": { "ScalarValue": "60.0" } }, { "Time": "2020-10-09 21:26:49.334000000", "Value": { "ScalarValue": "10.0" } }, { "Time": "2020-10-09 21:31:01.641000000", "Value": { "ScalarValue": "15.0" } }, { "Time": "2020-10-09 21:49:01.249000000", "Value": { "ScalarValue": "47.0" } }, { "Time": "2020-10-09 21:56:08.380000000", "Value": { "ScalarValue": "44.0" } }, { "Time": "2020-10-09 23:50:37.597000000", "Value": { "ScalarValue": "45.0" } }, { "Time": "2020-10-10 00:24:09.414000000", "Value": { "ScalarValue": "0.0" } }, { "Time": "2020-10-10 00:48:40.046000000", "Value": { "ScalarValue": "55.0" } }, { "Time": "2020-10-10 01:33:44.347000000", "Value": { "ScalarValue": "65.0" } } ] } ] }, { "Data": [ { "ScalarValue": "Alpha" }, { "ScalarValue": "1575739296" }, { "ScalarValue": "100" }, { "ScalarValue": "359" }, { "ScalarValue": "1000" }, { "ScalarValue": "Peterbilt" }, { "ScalarValue": "speed" }, { "TimeSeriesValue": [ { "Time": "2020-10-09 21:24:41.479000000", "Value": { "ScalarValue": "17.0" } }, { "Time": "2020-10-09 21:51:00.847000000", "Value": { "ScalarValue": "40.0" } }, { "Time": "2020-10-09 23:07:10.695000000", "Value": { "ScalarValue": "41.0" } }, { "Time": "2020-10-09 23:11:31.029000000", "Value": { "ScalarValue": "60.0" } }, { "Time": "2020-10-10 00:03:54.235000000", "Value": { "ScalarValue": "69.0" } }, { "Time": "2020-10-10 00:27:58.341000000", "Value": { "ScalarValue": "56.0" } }, { "Time": "2020-10-10 00:29:38.188000000", "Value": { "ScalarValue": "4.0" } }, { "Time": "2020-10-10 00:30:54.110000000", "Value": { "ScalarValue": "27.0" } }, { "Time": "2020-10-10 00:58:07.005000000", "Value": { "ScalarValue": "21.0" } }, { "Time": "2020-10-10 01:12:06.518000000", "Value": { "ScalarValue": "30.0" } } ] } ] } ], "ColumnInfo": [ { "Name": "fleet", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "truck_id", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "fuel_capacity", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "model", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "load_capacity", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "make", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "measure_name", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "measure", "Type": { "TimeSeriesMeasureValueColumnInfo": { "Type": { "ScalarType": "DOUBLE" } } } } ], "ResponseMetadata": { "RequestId": "JRJDO6RN63OVLGZ6ZX52GCCPF4", "HTTPStatusCode": 200, "HTTPHeaders": { "x-amzn-requestid": "JRJDO6RN63OVLGZ6ZX52GCCPF4", "content-type": "application/x-amz-json-1.0", "content-length": "2413", "date": "Sat, 10 Oct 2020 07:33:29 GMT" }, "RetryAttempts": 0 } }
result['Rows'][0]['Data'][0]に検索結果が入っています。
そのままではグラフにしづらいので、変形しました。timeがISO 8601形式のUTC時刻で扱いづらいので、datetimeに変換しています。def convert_callback(x): dt = datetime.fromisoformat(x[:26]) dt = dt.replace(tzinfo= timezone.utc) return dt rows = result['Rows'] for row in rows: measure = row['Data'][7]['TimeSeriesValue'] time = list(map(lambda x: (convert_callback(x['Time'])), measure)) value = list(map(lambda x: (float(x['Value']['ScalarValue'])), measure))あとはこいつをグラフにします。
register_matplotlib_converters() fig = plt.figure() ax = fig.add_subplot(1, 1, 1) ax.plot(time, value) daysFmt = mdates.DateFormatter('%m-%d %H:%M') ax.xaxis.set_major_formatter(daysFmt) fig.autofmt_xdate() plt.show()
めでたしめでたし。あまり派手なグラフではありませんが。。
コードの全体はこちら。
import json from datetime import datetime, timezone import boto3 import matplotlib.dates as mdates import matplotlib.pyplot as plt import pandas as pd from botocore.config import Config from pandas.plotting import register_matplotlib_converters query = """ SELECT fleet, truck_id, fuel_capacity, model, load_capacity, make, measure_name, CREATE_TIME_SERIES(time, measure_value::double) as measure FROM "IoT-sample"."IoT" WHERE measure_value::double IS NOT NULL AND measure_name = 'speed' GROUP BY fleet, truck_id, fuel_capacity, model, load_capacity, make, measure_name ORDER BY fleet, truck_id, fuel_capacity, model, load_capacity, make, measure_name LIMIT 2 """ def create_client(): config = Config(region_name = 'us-east-1') config.endpoint_discovery_enabled = True client = boto3.client('timestream-query', config=config) return client def convert_callback(x): dt = datetime.fromisoformat(x[:26]) dt = dt.replace(tzinfo= timezone.utc) return dt if __name__ == "__main__": client = create_client() result = client.query(QueryString=query) rows = result['Rows'] register_matplotlib_converters() fig = plt.figure() ax = fig.add_subplot(1, 1, 1) for row in rows: measure = row['Data'][7]['TimeSeriesValue'] time = list(map(lambda x: (convert_callback(x['Time'])), measure)) value = list(map(lambda x: (float(x['Value']['ScalarValue'])), measure)) ax.plot(time, value) daysFmt = mdates.DateFormatter('%m-%d %H:%M') ax.xaxis.set_major_formatter(daysFmt) fig.autofmt_xdate() plt.show()
- 投稿日:2020-10-10T14:11:54+09:00
ECSからLambdaを実行するときに必要なIAMロール
やりたいこと
ECS TaskからLambdaを呼び出したい。
ECSとそれに付与するIAMロールはCloudFormationで定義しているが、IAMロールが正しいところに対して設定できていないとエラーが発生する。
エラーの例
message:Unable to locate credentials環境
- 起動タイプ
- Fargate
- OS
- linux(alpine)
書き方
詳細については後述
sample.ymlAWSTemplateFormatVersion: 2010-09-09 Resources: TaskRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - ecs-tasks.amazonaws.com Action: - sts:AssumeRole RoleName: TaskRoleNameHoge RolePolicy: Type: AWS::IAM::Policy Properties: PolicyName: TaskRolePolicyNameHoge PolicyDocument: Version: 2012-10-17 Statement: - Sid: Hoge Effect: Allow Action: - lambda:InvokeFunction Resource: - <実行したいLambdaのArn> Roles: - TaskRoleNameHoge TaskDefinition: ExecutionRoleArn: ecsTaskExecutionRole TaskRoleArn : !Ref TaskRole <その他TaskDefinition省略>ExecutionRoleとTaskRoleとTargetRoleの違い
TaskDefinitionの中でRoleを指定するところは
- ExecutionRoleArn
- TaskRoleArn
がある。
さらにECSタスクにスケジュール設定する場合は
- Targets: RoleArn
もある。
このどこにLambda実行ポリシーをつければいいかわかっていなかったためにかなり迷走したので本記事を書いた。
(まず前提として このあたり が混乱していたのも迷走の一因)結論としては上記のsampleに書いた通り、TaskRoleArnに指定すれば良い。
それはそれとしてExecutionRoleとTaskRoleとTargetsRoleはどう違うのか。イメージはこんなかんじ
ExecutionRole
Amazon ECSコンテナエージェント、あるいはFargateエージェントにAWS APIの呼び出しを代行する権限を付与するタスク実行ロール。
目的やサービスごとに複数のタスク実行ロールを持つことができる。Fargateを利用しているのであれば、主にコンテナイメージをプルし、コンテナログを Amazon CloudWatch に出力する権限が付与されていれば良い。
ECSコンソール初回実行にecsTaskExecutionRoleというRoleが自動生成されるので、基本のpolicyとなるAmazonECSTaskExecutionRolePolicyなどを必要に応じてアタッチして使うと良い。また このようにECSへSSMから機密情報を受け渡す 場合には、ここにssmへの権限もアタッチしておく必要がある。
コンテナインスタンス上で実行されているコンテナは、コンテナインスタンスプロファイルに供給された資格情報にアクセスすることはできないため、ここは最小限の権限にとどめたほうが良い。
参考:開発者ガイド Amazon ECS タスク実行 IAM ロール
TaskRole
ECSタスクの実体となるコンテナに AWS API を呼び出す許可を与えるIAMロールのARN。
AWSのクレデンシャルを作成してコンテナに配布したり、EC2インスタンスのロールを使用する代わりに、ECSのタスク定義やRunTask APIの操作にIAMロールを関連付けることができる。このロールを使ってタスクのコンテナ内のアプリケーションは、AWS SDKやCLIを使用して、認可されたAWSサービスへのAPIリクエストを行うことができる。
だから今回の「ECS TaskからLambdaを呼び出したい」のためには、ここにLambda実行権限を付与すれば良い。
AWS::Events::Rule Targets配下のRole
ルールがトリガーされたときに、そのターゲットに使用されるIAMロールのARN。
1つのルールが複数のターゲットをトリガーする場合、ターゲットごとに異なるIAMロールを使用することができる。別のアカウントのイベントバスをターゲットとして設定していて、そのアカウントがアカウントIDによって直接ではなく組織を介してアカウントに権限を付与している場合は、このパラメータで適切な権限を持つRoleArnをここに指定する必要がある。
参考:ユーザーガイド AWS::Events::Rule Target
参考
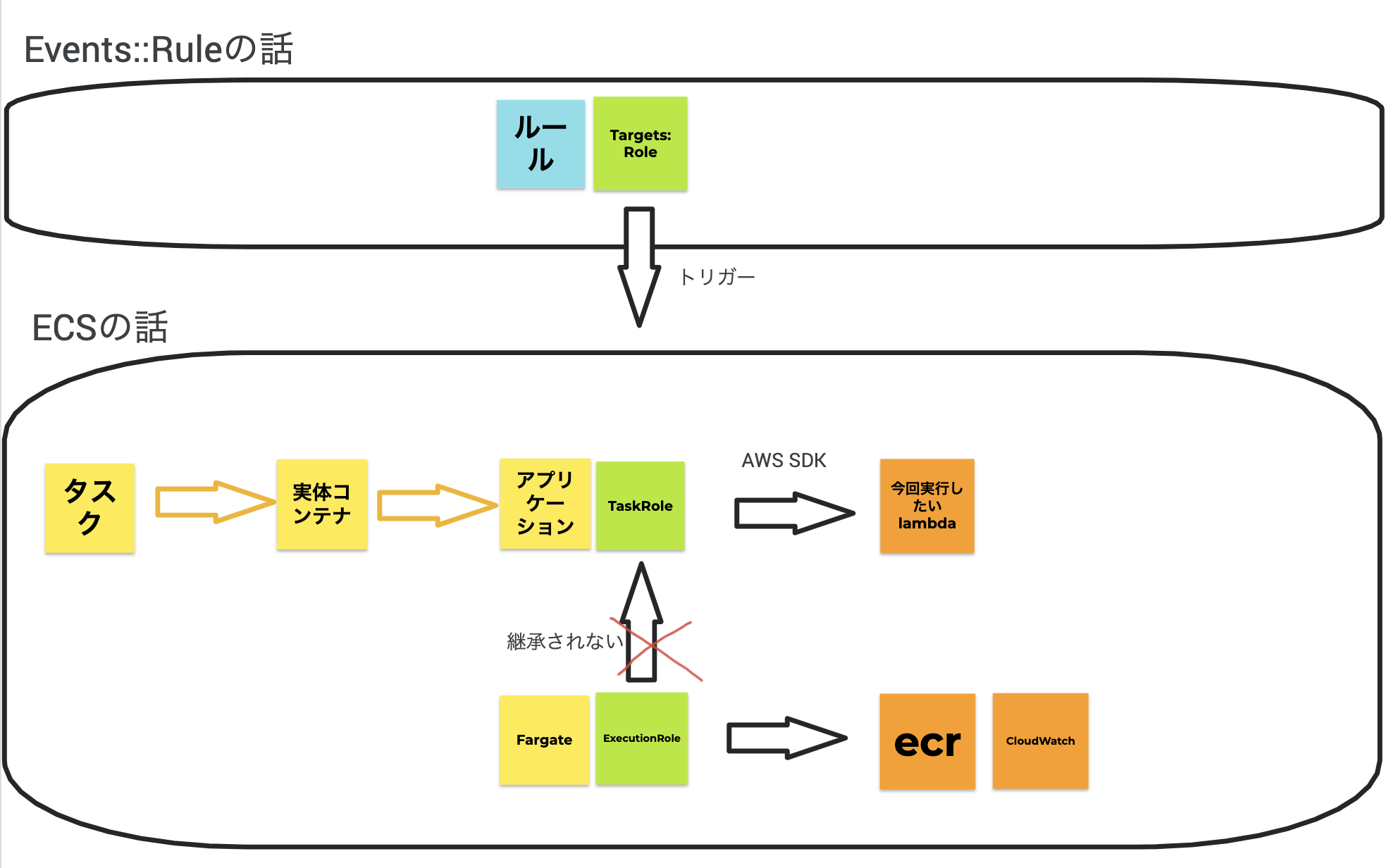
- 投稿日:2020-10-10T13:35:40+09:00
sam deployの新しいオプション(--config-env,--config-file)を動作検証する
0.前置き
少し前にsam deployの仕様が整理され、samconfig.tomlを参照してデプロイするようになりました。
https://dev.classmethod.jp/articles/aws-sam-simplifies-deployment/つい3週間ほど前に--config-envと--config-fileというオプションが追加されたようです。
https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-config.html#rules
https://github.com/aws/aws-sam-cli/pull/2176動作検証します。
A.結論
下記です。
オプション 仮説 --config-env [environment] samconfig.tomlに記述した環境別の設定を読み込む --config-file [filename] [filename]を設定ファイルとして読み込む ※組み合わせ可
1.基本情報
1−1.環境
項目 バージョン macOS mojave 10.14.6 anaconca 4.8.3 python 3.6 aws-sam-cli 1.6.2 ※使おうと思ってる直近の案件にあわせてpython3.6
1−2.検証手順
No 分類 コマンド 概要 1 default sam deploy デフォルト設定ファイルのdefaultを実行 2 test1 sam deploy --config-env test1 デフォルト設定ファイルのtest1を実行 3 test2 sam deploy --config-file another-config.toml 追加の設定ファイルのdefaultを実行 4 test3 sam deploy --config-file another-config.toml --config-env test3 追加の設定ファイルのtest3を実行 1−3.設定ファイル
設定群のヘッダーに[environment.command.parameters]を記述します。
--config-envをつけない場合は、environmentがdefaultになります。
environmentには任意の文字列を設定します。
commandのところは、利用するコマンドを指定します。1−3−1.デフォルト設定ファイル
samconfig.tomlversion = 1.0 [default.deploy.parameters] stack_name = "default-stack" s3_bucket = "sam-deploy-option-bucket-1" region = "ap-southeast-1" profile = "default-stack" confirm_changeset = true capabilities = "CAPABILITY_IAM" parameter_overrides="Environment=default" [test1.deploy.parameters] stack_name = "test1-stack" s3_bucket = "sam-deploy-option-bucket-1" region = "ap-southeast-1" profile = "test-sam1" confirm_changeset = true capabilities = "CAPABILITY_IAM" parameter_overrides="Environment=test1"1−3−2.追加の設定ファイル
another-config.tomlversion = 1.0 [default.deploy.parameters] stack_name = "test2-stack" s3_bucket = "sam-deploy-option-bucket-3" region = "ap-southeast-1" profile = "test-sam2" confirm_changeset = true capabilities = "CAPABILITY_IAM" parameter_overrides="Environment=test2" [test3.deploy.parameters] stack_name = "test3-stack" s3_bucket = "sam-deploy-option-bucket-4" region = "ap-southeast-1" profile = "test-sam3" confirm_changeset = true capabilities = "CAPABILITY_IAM" parameter_overrides="Environment=test3"2.検証
2−1.デフォルト設定ファイルのdefaultを実行
オプションを指定しないで実行します。
$ sam deploydefault-stackを呼び出すはずです。
Deploying with following values =============================== Stack name : default-stack Region : ap-southeast-1 Confirm changeset : True Deployment s3 bucket : sam-deploy-option-bucket-1 Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {'Environment': 'default'}default-stackが呼び出されています。
2−2.デフォルト設定ファイルのtest1を実行
--config-envでtest1を指定します。
$ sam deploy --config-env test1test1-stackが呼び出されるはずです。
Deploying with following values =============================== Stack name : test1-stack Region : ap-southeast-1 Confirm changeset : True Deployment s3 bucket : sam-deploy-option-bucket-2 Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {'Environment': 'test1'}test1-stackが呼び出されています。
2−3.追加の設定ファイルのdefaultを実行
$ sam deploy --config-file another-config.tomlanother-config.tomlのdefaultなので、test2-stackになるはずです。
Deploying with following values =============================== Stack name : test2-stack Region : ap-southeast-1 Confirm changeset : True Deployment s3 bucket : sam-deploy-option-bucket-3 Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {'Environment': 'test2'}test2-stackが呼び出されています。
2−4.追加の設定ファイルのtest3を実行
sam deploy --config-file another-config.toml --config-env test32つのオプションのあわせ技です。test3-stackになるはずです。
Deploying with following values =============================== Stack name : test3-stack Region : ap-southeast-1 Confirm changeset : True Deployment s3 bucket : sam-deploy-option-bucket-4 Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {'Environment': 'test3'}test3-stackが呼び出されています。
3.生成されたスタックの確認
別々のスタックが生成されています。
4.結論
下記の通りでした。
オプション 仮説 --config-env [environment] samconfig.tomlに記述した環境別の設定を読み込む --config-file [filename] [filename]を設定ファイルとして読み込む ※組み合わせ可
一つの設定ファイルに環境別の設定を記述してもいいし、環境ファイルを別々に用意してもよくなりました。
ほしかった機能が正式に実装されたので素直にうれしいですね。X.余談
今回のネタは、英語版のドキュメントを眺めていたらたまたま見つけました。まだ日本語版には載っていません。(2020/10/10現在)
こういう翻訳版の更新の遅さに加えて、awsのドキュメントが自動翻訳に頼り始めているのか、ファンキーな日本語になっているものがあります。たとえば、下記のKMSの記事です。
https://docs.aws.amazon.com/ja_jp/kms/latest/developerguide/concepts.html
原文で読める英語力を身につけるか、英語の記事をchromeで開いて日本語翻訳して読むことにします。

- 投稿日:2020-10-10T13:10:09+09:00
Amazon Lightsailでサーバー構築
Amazon Lightsailとは?
AWSのサービスの一つであり、レンタルサーバーのようなものです。
類似サービスにEC2がありますが、相違点としては使用料が月額3.5$からの固定であることや、アプリケーションやフレームワークのインストールが非常に容易であることが挙げられます。使ってみよう
AWSのサービス検索フォームでlightsailを検索しましょう。
遷移先の画面でインスタンスを作成します。
すごく魅力的な画面になります。以下の画像に表示しているものが全てインストール可能です。
今回はwordpressを使いたいだけなのでLinuxとwordpressを選択しました。
続いて契約プランの選択です。
作成するインスタンスのスペックが高いほど料金は高額となります。
画面下部の「インスタンスの作成」を押下すれば前準備は完了です。
インスタンスにアクセスする
前述の作業でインスタンスが既に出来ていると思います。
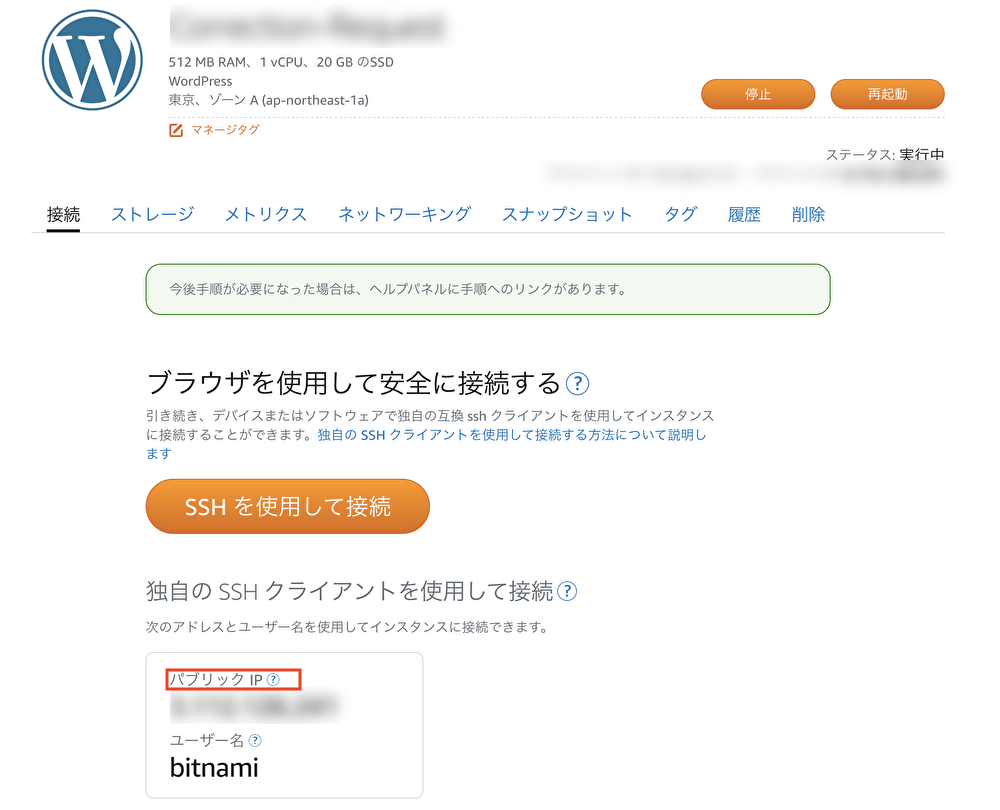
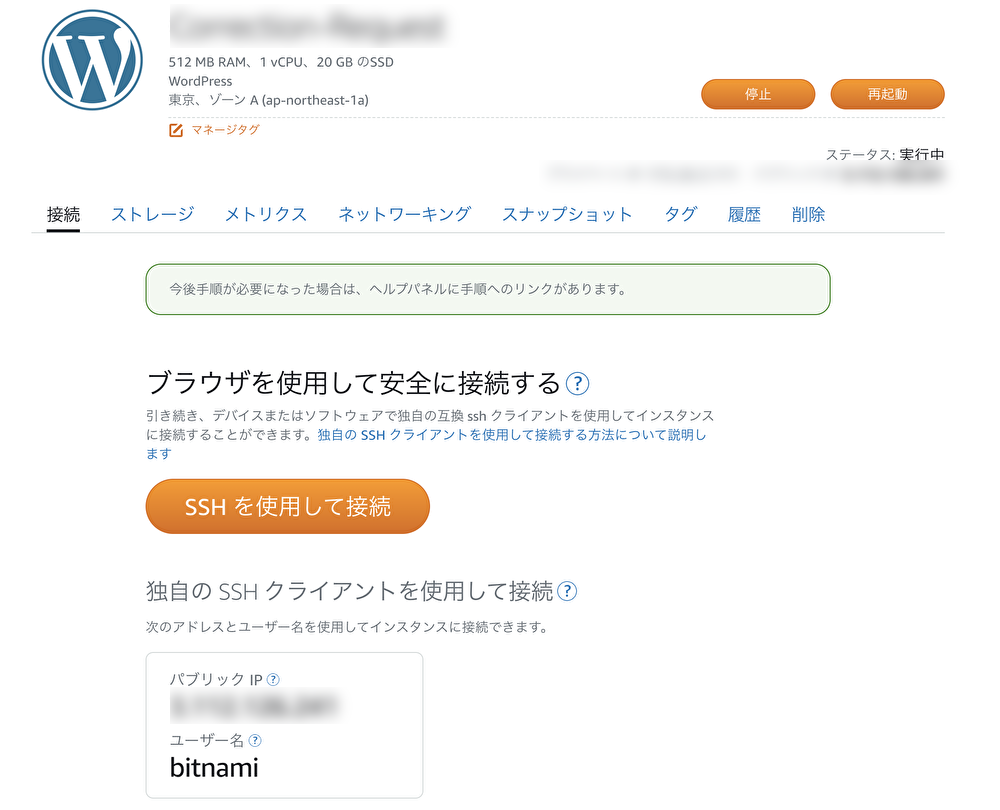
続いて、インスタンス名をクリックして詳細画面を確認しましょう。
赤枠で囲ってあるパブリックIPにアクセスしてみましょう。
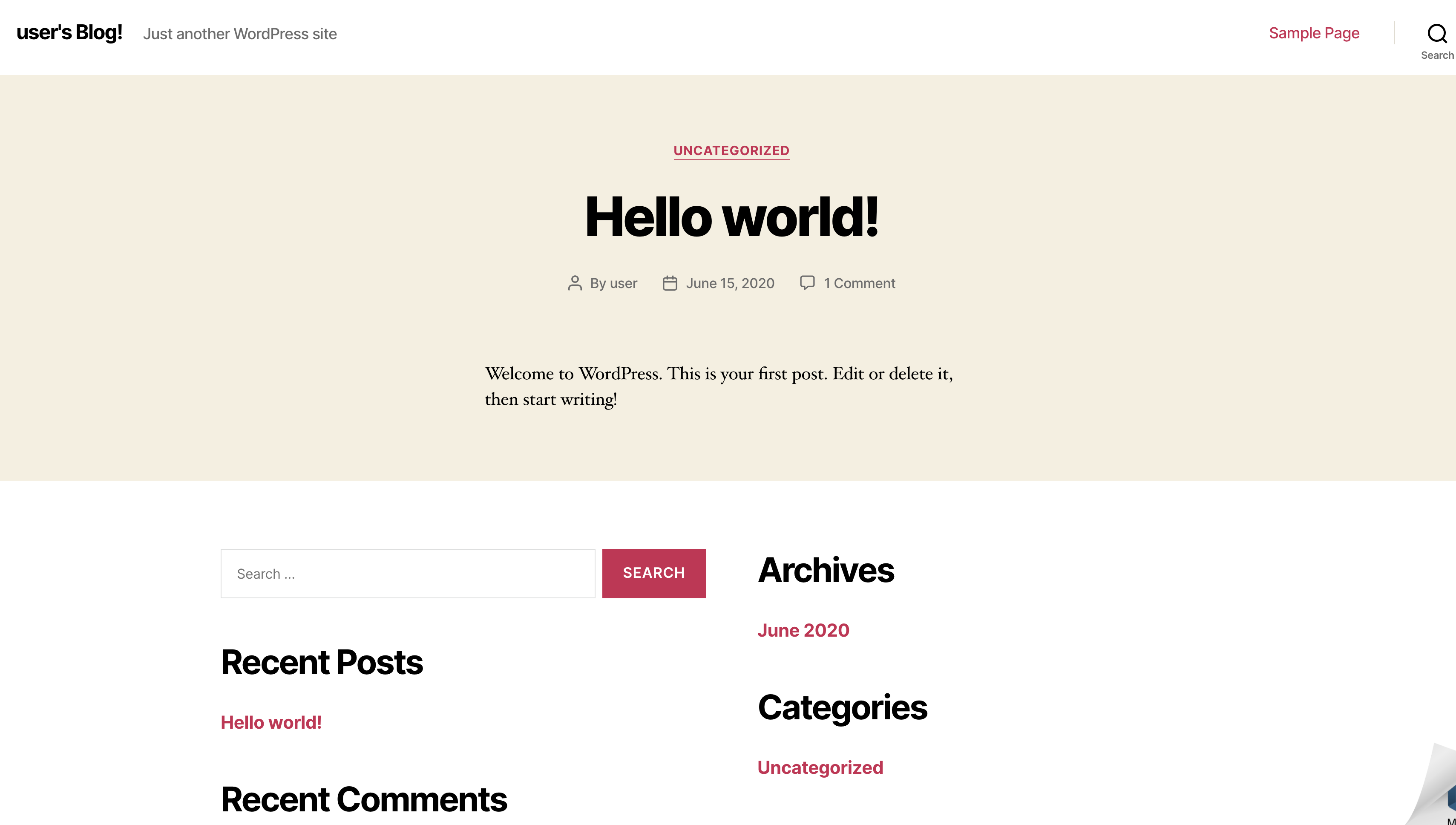
既にwordpressが起動している状態なので、デフォルトの画面が表示されます。
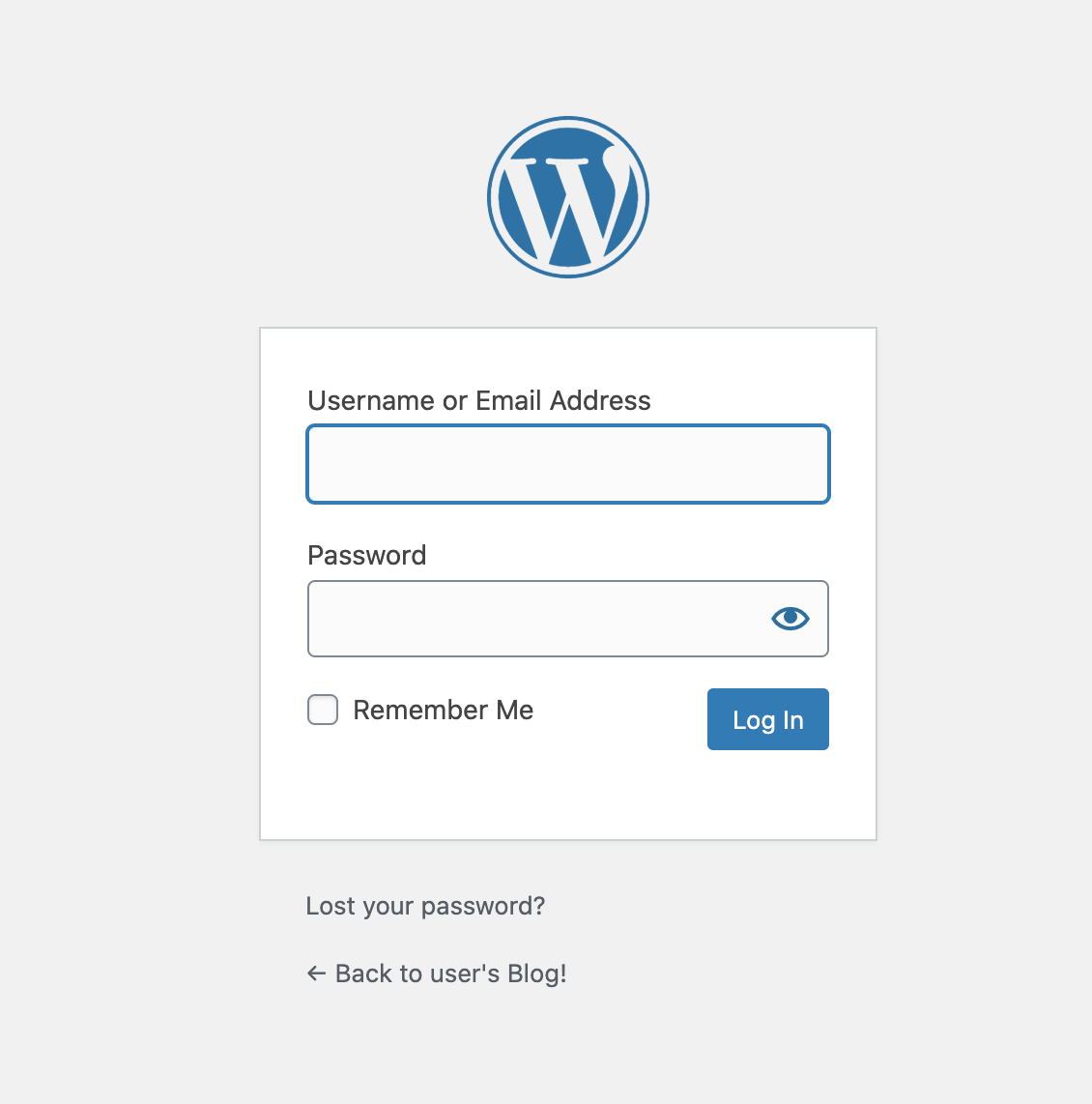
ログイン画面には パブリックIP/wp-admin でアクセスすることができます。
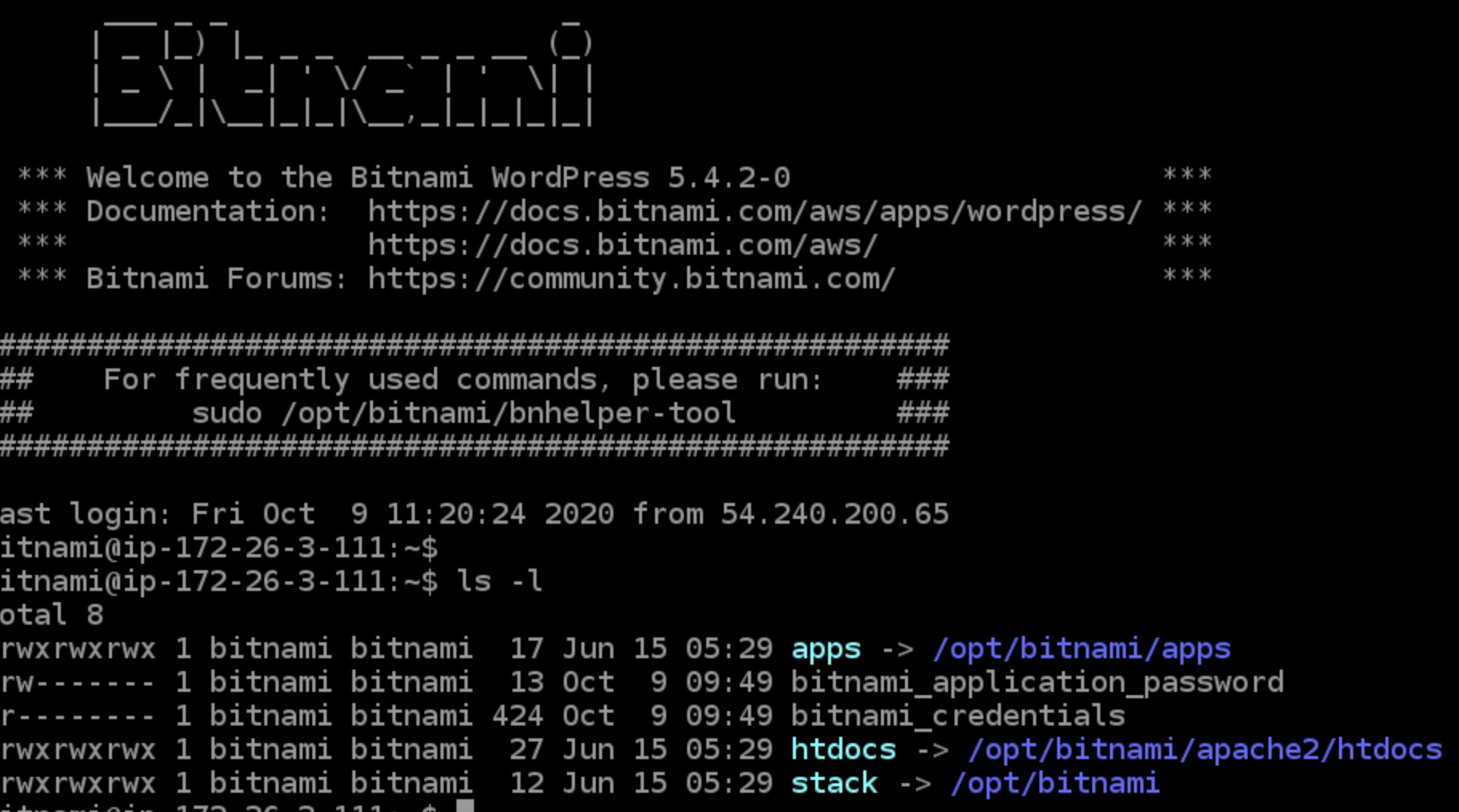
ログインパスワードは「SSHを使用して接続」から確認することが可能です。
ターミナルでlsコマンドを実行すると「bitnami_application_password」というファイルがあることを確認できます。
このファイルにパスワードが記載されています。
というわけで、ログインIDとパスワードは以下になります。
ログインID: user (これがデフォルト)
パスワード: 「bitnami_application_password」に記載これでログインできました!
今回の記事は以上です!
半分くらいwordpress記事になってしまいましたが、Lightsailは様々な用途に利用可能です。
ぜひ一度使ってみてください!


- 投稿日:2020-10-10T12:25:04+09:00
AWS 認定ソリューションアーキテクト – プロフェッショナル資格試験に向けた知識の整理 IAMポリシーサンプル
概要
AWS 認定ソリューションアーキテクト – プロフェッショナル資格試験に向けた小ネタ集。
今回は様々なところで出題されるIAMポリシーで制限可能などの問題や設問に対し、具体的にIAMポリシーをどう書いたらいいかわからず調べてみたいくつかのIAMポリシーのサンプルです。[2020年10月]
2回目の受験でついにプロフェッショナル試験に合格しました!
合格体験記/勉強法を以下で投稿しているので良かったら読んでください。
試験受ける予定がある方の少しでも役に立てればと思います(^^)AWS初心者がAWS 認定ソリューションアーキテクト – プロフェッショナル資格試験に合格した時の勉強法
EC2 インスタンスや EBS ボリュームの作成において、指定可能なタグを制限する方法
- https://aws.amazon.com/jp/premiumsupport/knowledge-center/iam-policy-tags-restrict/
- SCP や IAMポリシーでaws:RequestTag/aws:TagKeys(TagKeysは大文字と小文字の区別可能)、ForAllValues(すべて)/ForAnyValue(いずれか)を定義してタグを強要する。
- 次の例は、「key1/value1」 and 「key2/value2」 の指定のみ OK
- 「KEY1/value1」 and 「key2/value2」 は 指定NGとする指定方法。
"Condition": { "StringEquals": { "aws:RequestTag/key1": "value1", "aws:RequestTag/key2": "value2" }, "ForAllValues:StringEquals": { "aws:TagKeys": [ "key1", "key2" ] } }特定の VPC エンドポイントへのアクセスの制限
- https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/example-bucket-policies-vpc-endpoint.html
- 次の例は、特定のバケット (awsexamplebucket1) に対するアクセスを ID が vpce-1a2b3c4d の VPC エンドポイントからのアクセスのみに制限します。
{ "Version": "2012-10-17", "Id": "Policy1415115909152", "Statement": [ { "Sid": "Access-to-specific-VPCE-only", "Principal": "*", "Action": "s3:*", "Effect": "Deny", "Resource": ["arn:aws:s3:::awsexamplebucket1", "arn:aws:s3:::awsexamplebucket1/*"], "Condition": { "StringNotEquals": { "aws:SourceVpce": "vpce-1a2b3c4d" } } } ] }指定した IP アドレス範囲アクセスからCodeCommitリポジトリに接続するユーザーを許可
- https://docs.aws.amazon.com/ja_jp/codecommit/latest/userguide/auth-and-access-control-iam-identity-based-access-control.html
- 次の例は、特定のIPアドレスレンジ (203.0.113.0/16) からのアクセスのみに制限します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Deny", "Action": [ "codecommit:*" ], "Resource": "*", "Condition": { "NotIpAddress": { "aws:SourceIp": [ "203.0.113.0/16" ] } } } ] }AssumeRoleを利用した様々な外部アクセスの許可
- https://dev.classmethod.jp/articles/iam-role-and-assumerole/
- 他のAWSアカウントを信頼する(クロスアカウントアクセスを許可する)。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "AWS": [ "123456789012" ] // ← AWSアカウントを信頼 }, "Action": "sts:AssumeRole" } ] }
- AWSサービスからアクセスを許可する。
{ "Version" : "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "ec2.amazonaws.com" ] // ← EC2サービスを信頼 }, "Action": "sts:AssumeRole" } ] }
- Facebookユーザのアクセスを許可する。
- PrincipalとConditionを利用して、Facebookの外部IDを指定する。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRoleWithWebIdentity", "Principal": { "Federated": "graph.facebook.com" }, "Condition": { "StringEquals": { "graph.facebook.com:app_id": "012345678901234" // ← FacebookアプリケーションID } } } ] }ウェブ ID フェデレーションを使用したユーザーの識別
- https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_roles_providers_oidc_user-id.html
- 次の例は、バケットのプレフィックスが文字列に一致する場合にのみ、Amazon S3 のバケットへのアクセスを許可するアクセス許可ポリシーを示します。
- 例えば、「myBucket/Amazon/mynumbersgame/user1」
- この例では、ユーザーが Login with Amazon を使用してサインインし、mynumbersgame というをアプリを使用していると仮定しています。
- ユーザーの一意の ID は、user_id と呼ばれる属性として表示されます。
- Resourceにユーザー専用のバケットパスを指定します。
- ConditionにユーザーのIDを指定します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": ["s3:ListBucket"], "Resource": ["arn:aws:s3:::myBucket"], "Condition": {"StringLike": {"s3:prefix": ["Amazon/mynumbersgame/${www.amazon.com:user_id}/*"]}} }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::myBucket/amazon/mynumbersgame/${www.amazon.com:user_id}", "arn:aws:s3:::myBucket/amazon/mynumbersgame/${www.amazon.com:user_id}/*" ] } ] }EC2 の IAMロールとインスタンスプロファイルの関連
- https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/iam-roles-for-amazon-ec2.html
- IAMポリシーではないが、インスタンスプロファイルとIAMロールの具体例
- create-instance-profile コマンドを使用して、s3access-profile という名前のインスタンスプロファイルを作成します。
- aws iam create-instance-profile --instance-profile-name s3access-profile
{ "InstanceProfile": { "InstanceProfileId": "AIPAJTLBPJLEGREXAMPLE", "Roles": [], "CreateDate": "2013-12-12T23:53:34.093Z", "InstanceProfileName": "s3access-profile", "Path": "/", "Arn": "arn:aws:iam::123456789012:instance-profile/s3access-profile" } }
- 次のコマンドで s3access-profile インスタンスプロファイルに s3access ロールを追加します。
- aws iam add-role-to-instance-profile --instance-profile-name s3access-profile --role-name s3access
- このコマンド実行で上記のインスタンスプロファイルのRolesに s3access ロールが設定されるはず。
その他参考
アソシエイト資格の勉強法は以下を参照
AWS初心者がAWS 認定ソリューションアーキテクト – アソシエイト資格試験に合格した時の勉強法
プロフェッショナル資格の勉強法は以下を参照
AWS初心者がAWS 認定ソリューションアーキテクト – プロフェッショナル資格試験に合格した時の勉強法
その他のプロフェッショナルの小ネタは以下を参照
プロレベルのTips
フェデレーションとDDoS対策
IAMポリシー
DR対策
IAMポリシーサンプル(本記事)
- 投稿日:2020-10-10T11:24:37+09:00
AWS Certified Security Specialty(SCS)合格体験談
前書き
- 試験の概要については、AWS 公式サイトや他の記事に委ねますので、ここでは割愛します。
- 自分の試験対策方法をここで簡単にご紹介します。とは言え、あくまで自分のやり方なので、すべての人に適応できるとは限りません。ご自身に一番合う手法やペースで頑張りましょう。
受験結果
- 2020/10/08 に一発で合格、スコアは 774
- 五つのセクションのうち、「ログと監視」と「インフラストラクチャのセキュリティ」については再学習の必要ありだとレポートに叩かれました(ややショックだった、インフラの部分一番自信あるのにな。。。
)
受験者スペック
- 新卒で IT 業界に入りエンジニアとしてのキャリアは今年で 5 年目、AWS 歴は 2 年
- 受験時に以下の資格を保有:
- AWS Certified Cloud Practitioner
- AWS Certified Solutions Architect - Associate
- AWS Certified Developer - Associate
- 最初は EC2 や DMS などを用いて弊社製品 COMPANY のデータ移行ツールの開発に携わっており、使ってるサービスはそれほど多種多様なわけではないが、今年に入ってからCOMPANYとは違う自社開発のWebアプリケーションの環境設計・構築大臣になり、そこで AWS のベストプラクティスに沿う王道的な設計パターンを学び続けてきました。同時にセキュリティ周りの需要も段々出てきて、それで今回受験の決意に至りました。
試験対策
対策本として利用したのは『AWS認定 セキュリティ-専門知識』
https://www.amazon.co.jp/gp/product/4839970947/ref=ppx_yo_dt_b_asin_title_o04_s00?ie=UTF8&psc=1
比較的新しく出版された本であって、内容も体系的に書かれており、とても分かりやすかったです。試験ガイドラインで示された 5 つの分野に沿い、それぞれに対してどのようなサービスを利用すれば「安全」だと言えるのか、ユースケースも含めて説明してくれました。
さらに、40 問ほどの練習問題も用意してくれて、試験前のリハーサルとしてかなり有用です。本番ほどの長文や難易度ではないが、大事なポイントをそこそこカバーしており、回答も丁寧に書かれております。
試験までにはこの本を 2 周しまして、だいたいの勉強時間は前後で 50 時間くらい。模擬試験
AWS 公式で提供されている模擬試験です。以前の認定試験合格の特典でもらったクーポンを使って無料で 2 回受けました(ちなみに 2 回とも全く同じ問題文でした)。難易度的には上記対策本の練習問題とほぼ同レベルで、本番よりは低い。受験後即時に簡単な結果レポートをメールで送ってくれるんで、それを参照して自分の弱いところを補うのは良いでしょう。実際に手を動かす
これ対策と言えるかどうかちょっと微妙ですが、正直今回一番ためになったのは実際の仕事経験です。前述の通り、受験前にすでに仕事で社内サービスのアーキテクチャを設計・構築したことがあって、各種 AWS サービスのコンセプトや利用方法をそこそこ身に付けておりました。本番の試験問題を見たら、「これうちが作った Web アプリと一緒じゃねえ?!」みたいなデジャブが多々ありました。なので実践こそ、試験合格の一番の近道かもしれません。
試験の難易度比較
★★★★★ 本番試験
★★★★ AWS 公式模擬試験、対策本の模擬試験さらに、あくまで個人感覚ですが、他の Associate 認定試験と比べると、
SAA < DVA ≒ SCSコンセプト的には、
【SAA】開発や運用の要件を達成し、かつ AWS Well-Architected を満たすためにどのサービス(あるいはサービスの組み合わせ)がベストなのか
【DVA】上記よりさらに一歩進んで、そのサービス(あるいはサービスの組み合わせ)をどのように実装・設定・運用すれば良いか
【SCS】上記よりさらに一歩進んで、そのサービス(あるいはサービスの組み合わせ)をどのように実装・設定・運用すれば「安全」と言えるか試験について
- 全 65 問の中、問題文がユースケース中心で長文の割合が高く、1 行や 2 行で完結する問題はほんのわずか、なので意外と疲れます。集中力保持のために前日はきちんと寝ましょう。時間配分をそこそこ意識できれば、再検査の時間は十分に確保できるはず。
- 今回の試験でテストセンターがメモ用紙も用意してくれました(前の DVA を受けたときはなかったけど、なぜでしょうかね
)。思考が混乱するとき、メモ用紙でちゃんと構造図とかを描いてみたら意外とスッキリするかも。
対策本であんまり言及されていないが確認したほうが良いポイント
- CLB から ALB に移行するとき発生する認証エラーのトラブルシューティング
- SES の SMTP インターフェース、TLS 暗号化
- GuardDuty の信頼できる IP リスト
- Secrets Manager の自動更新
最後に
本当は DVA の体験談も書きたかったけど、結局ずっと後回しにしていて、試験の内容をほとんど忘れてしまい書けなくなった。。。一つだけ覚えているのは、サーバーレスに関する問題の割合が物凄く高いこと。多分それがこれからのトレンドですかね。
次は Professional 認定にチャレンジします。
- 投稿日:2020-10-10T08:31:10+09:00
【AWS】APIGatewayにキャッシュを設定する際にハマったこと
はじめに
先日APIGatewayにキャッシュを設定しようとしてハマったので記事にしておきます。
キャッシュを無効化させたくない!
エンドポイントへのHTTPリクエストヘッダに[Cache-Control: max-age=0]が含まれていた場合も、APIGatewayの後ろに控えたLambdaを実行させたくない!キャッシュがある場合は必ずキャッシュを受け取ってほしい。
APIGateway設定
キャッシュの設定自体はキャッシュ有効化にチェックをつけ、キャパシティーやTTL等を自由に設定しておしまいです。
キャッシュコントロールヘッダについての設定は「キーごとのキャッシュの無効化」にあたります。
画像の設定では「認可されたリクエストで無ければ、HTTPリクエストに[Cache-Control: max-age=0]が含まれていた場合403エラーとして返すよ」という状態。キャッシュ無効化できる…!?
この状態でターミナルから以下curlコマンドを叩いても、何事も無かったかのように応答が返ってきます。
ついでにCloudWatchでログを見るとキャッシュが効いていないログが確認できます。curl <APIGatewayエンドポイントURL> -H "Cache-Control: max-age=0"HTTPリクエストメソッド単位の設定が必要
先ほどキャッシュを設定した画面ですが、実はステージ単位だけではなくHTTPリクエストメソッド単位でも設定できるようになっています。
ここでステージ単位の設定を上書きしてしまっていたことが原因でした。
認可が必要にチェックが入っていないのでキャッシュ無効化し放題です。解決!
リクエストメソッド単位でもステージ単位と同様にキャッシュの設定を行うことで、[Cache-Control: max-age=0]付きのcurlコマンドを実行すると無事エラーで応答されるようになりました。
以上です。お疲れ様でした
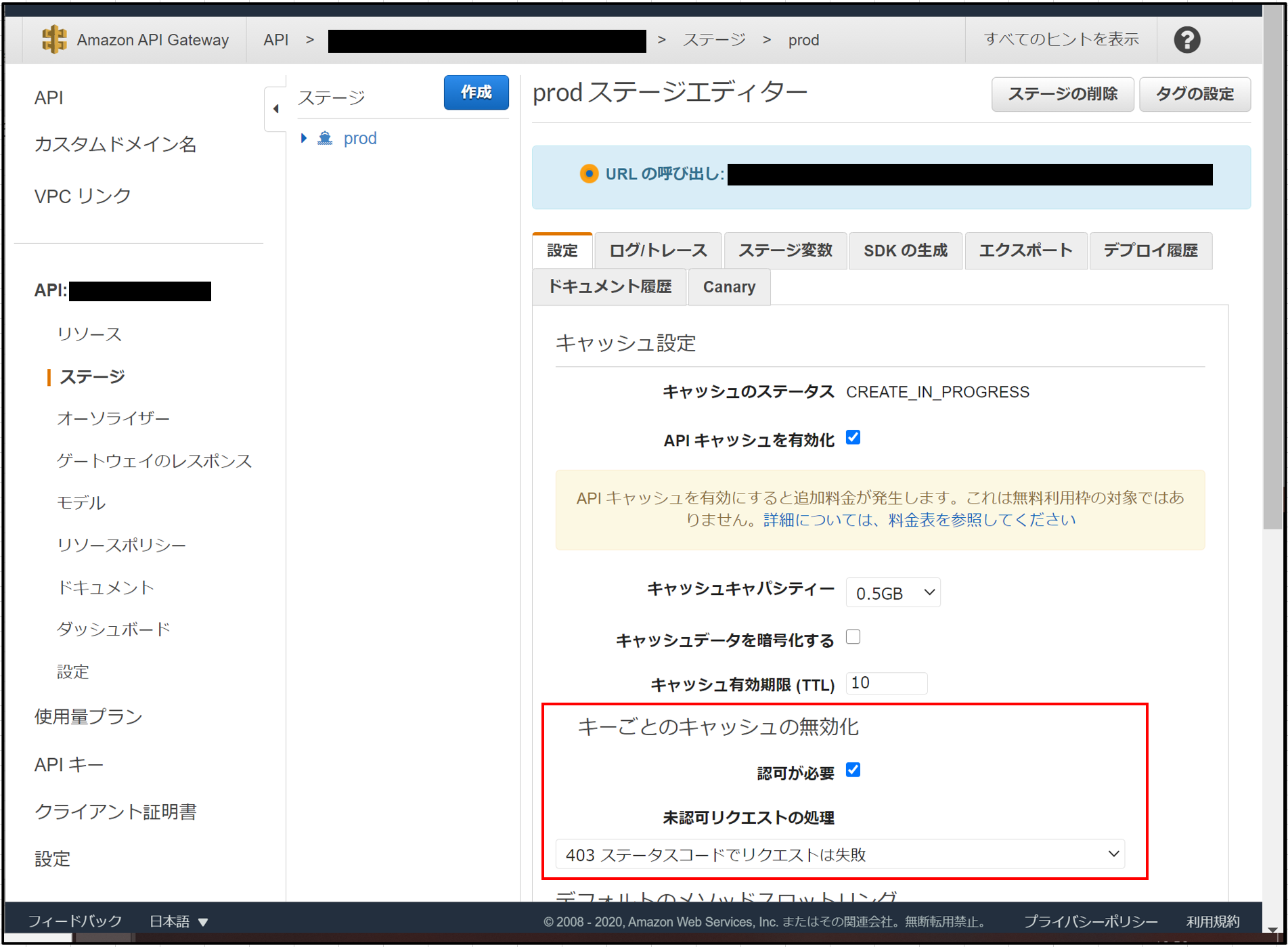
- 投稿日:2020-10-10T02:58:52+09:00
LaravelでAWS Elastic Cashe Redisを使ってみた
LaravelのSchedulerにてonOneServerを使用したかったので、共通のキャッシュサーバーとしてAWSのElastic Cache Redisを使った時のメモ。
先にキャッシュサーバー用のセキュリティーグループを作成しておく。
port6379を開け、ソースにプライベートサブネットにおいたEC2のセキュリティグループを選択し保存
ElasticCacheのダッシュボードから作成をクリック
redisを選択。ロケーションはクラウド
Redisの設定、エンジンバージョンの互換性とパラメータグループはデフォの設定
ノードのタイプは用途に合わせてサイズ選択。今回は極小。
配置するVPCサブネットを選択しサブネットグループを作成
以下はとりあえずデフォ
接続テスト
対象のEC2インスタンスに入り、ping
EC2ping your-elastic-cache-host環境変数設定
.envREDIS_HOST=your-elastic-chache-host REDIS_PASSWORD=null // 今回はAUTH設定していないため REDIS_PORT=6379laravelから接続テスト
適当なコマンドを作成して、操作可能かチェック
EC2cd to/your/dir php artisan make:command RedisConnectionSampleRedisConnectionSample.phpnamespace App\Console\Commands; use Illuminate\Console\Command; use Illuminate\Support\Facades\Redis; class RedisConnectionSample extends Command { /** * The name and signature of the console command. * * @var string */ protected $signature = 'connect:redis'; /** * The console command description. * * @var string */ protected $description = 'Command description'; /** * Create a new command instance. * * @return void */ public function __construct() { parent::__construct(); } /** * Execute the console command. * * @return mixed */ public function handle() { Redis::set('key', 'value'); $data = Redis::get('key'); var_dump($data); } }EC2php artisan connect:redisうまくいかない時には、phpredisかpredisが入っていないケースがあるので、その場合には入れる。amazon linux 2の場合にはextrasから入手可能。
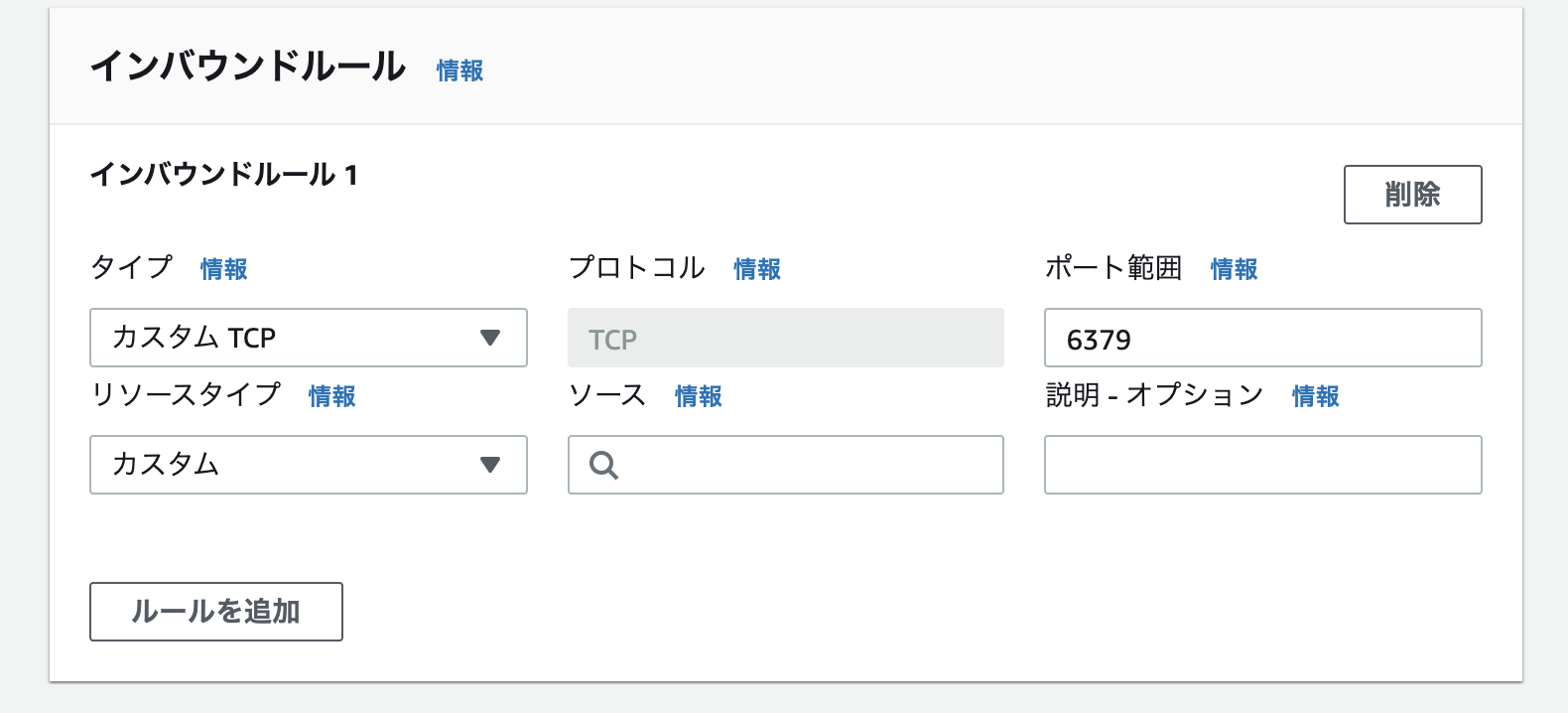

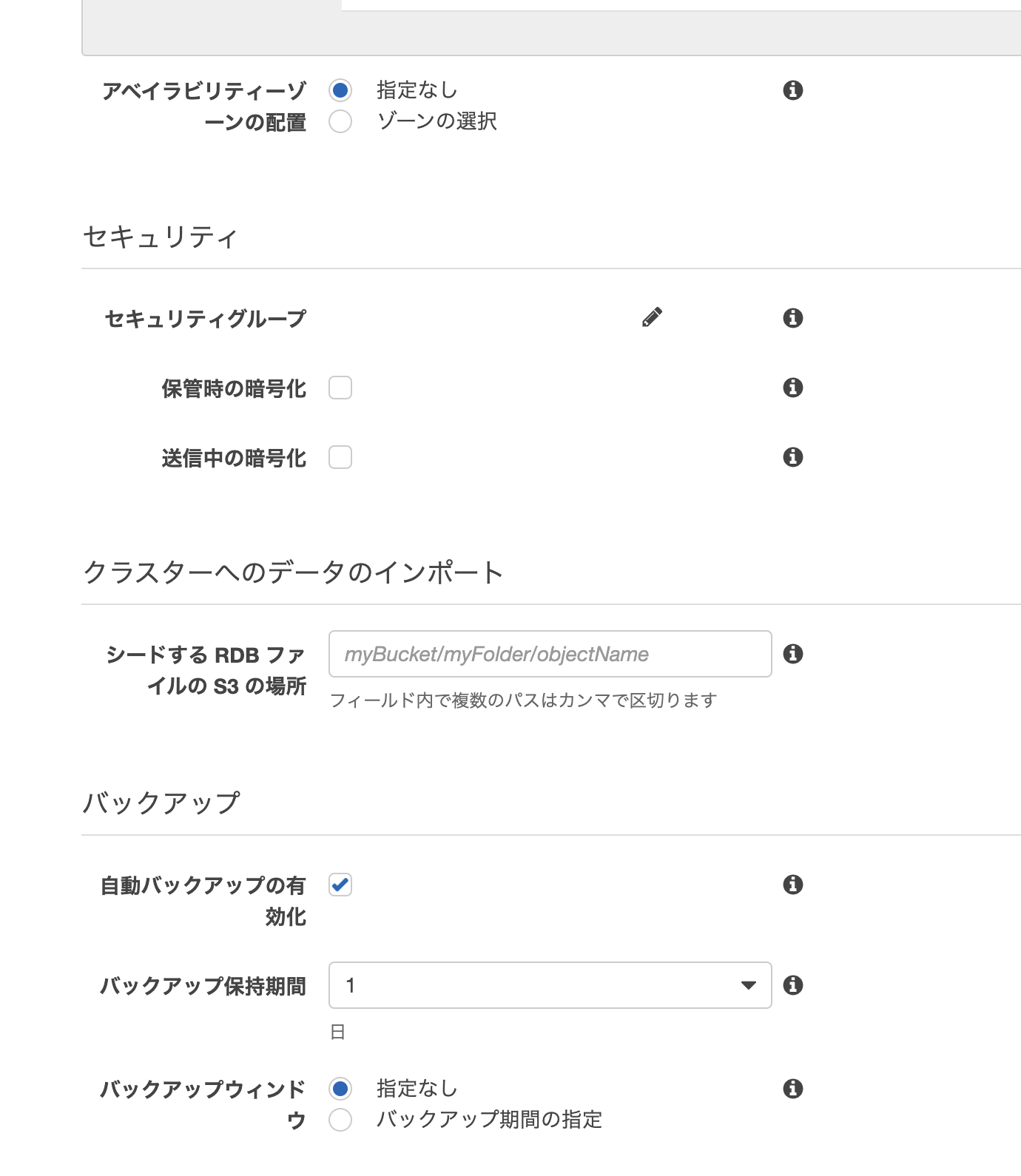
- 投稿日:2020-10-10T02:34:29+09:00
Amazon Linux 2 にphp-pecl-redis入れる
LaravelにてRedisを使う必要があり、phpredisかpredisいれてねとのことだったのでその時の備忘録
Laravel6.xのドキュメントにあるように、predisはもうLaravelに含めないようにしますとのことだったので、phpredisを入れる方向で検討
remiを使えとの記事が多かったがよくよく見ればamazon-linux-extrasにすでにあるようなのでそちらから入れた。
AmazonLinux2sudo yum install php-pecl-redis sudo systemctl restart php-fpmうまくいかない場合にはお使いのPHPのバージョンのrepoが有効化されているか確認して下さい。
- 投稿日:2020-10-10T00:38:23+09:00
Amazon Timestreamにいろいろなクエリーを投げてみた。
GAリリースされたAmazon Timestreamにいろいろなクエリーを投げてみました。
サンプルデータ
Timestreamのデータベースを作成する際に、サンプルデータが入ったものを作成することができます。
今回はこちらを使ってクエリーを投げてみました。
fleet truck_id fuel_capacity model load_capacity make measure_value::double measure_value::varchar measure_name time Alpha 7128555298 100 359 1000 Peterbilt 7.842702716127531 - fuel-reading 2020-10-09 14:11:54.267000000 Alpha 1641688615 100 359 1000 Peterbilt - 36.1627° N, 86.7816° W location 2020-10-09 14:11:52.086000000 Alpha 9355060257 100 Wrecker 500 Peterbilt 12.0 - speed 2020-10-09 14:11:48.210000000 Alpha 7219245711 100 Wrecker 500 Peterbilt 19.78241022554396 - fuel-reading 2020-10-09 14:11:44.294000000 Alpha 21135517 100 359 1000 Peterbilt 74.1987909949444 - fuel-reading 2020-10-09 14:11:27.965000000 Alpha 433496933 100 Wrecker 500 Peterbilt 112.0 - load 2020-10-09 14:11:27.788000000 Alpha 3496454495 150 W925 1000 Kenworth - 36.1627° N, 86.7816° W location 2020-10-09 14:11:27.742000000 Alpha 4354044937 100 359 1000 Peterbilt 69.50232420155284 - fuel-reading 2020-10-09 14:11:25.140000000 Alpha 5644432615 150 W925 1000 Kenworth 101.12753874492175 - fuel-reading 2020-10-09 14:11:24.987000000 Alpha 7602194211 100 359 1000 Peterbilt 138.0 - load 2020-10-09 14:11:18.528000000
timeに時刻、measure_name測定値の名前が入り、measure_value::doubleまたはmeasure_value::varcharに計測値が入ってます。
fleetやtruck_idなどは属性値で、Dimensionと呼ぶようです。SQL
いわゆる通常のSQLが使えます。サブクエリも使えるとのことです。
SELECT * FROM "IoT-Sample"."IoT" WHERE truck_id = '4132246625' AND measure_name = 'speed' ORDER BY time DESC LIMIT 10
fleet truck_id fuel_capacity model load_capacity make measure_value::double measure_value::varchar measure_name time Alpha 4132246625 100 359 1000 Peterbilt 67.0 - speed 2020-10-09 14:09:21.208000000 Alpha 4132246625 100 359 1000 Peterbilt 73.0 - speed 2020-10-09 12:24:41.422000000 Alpha 4132246625 100 359 1000 Peterbilt 16.0 - speed 2020-10-09 12:16:49.933000000 Alpha 4132246625 100 359 1000 Peterbilt 3.0 - speed 2020-10-09 12:00:57.192000000 Alpha 4132246625 100 359 1000 Peterbilt 35.0 - speed 2020-10-09 11:51:33.847000000 Alpha 4132246625 100 359 1000 Peterbilt 49.0 - speed 2020-10-09 11:48:21.102000000 Alpha 4132246625 100 359 1000 Peterbilt 50.0 - speed 2020-10-09 11:47:10.982000000 Alpha 4132246625 100 359 1000 Peterbilt 52.0 - speed 2020-10-09 11:01:30.840000000 Alpha 4132246625 100 359 1000 Peterbilt 54.0 - speed 2020-10-09 09:22:08.533000000 Alpha 4132246625 100 359 1000 Peterbilt 19.0 - speed 2020-10-09 09:03:11.096000000 Date / Time Functions
時系列データベースというので、時刻関係の関数が用意されており、
bin(timestamp, X unit)関数はX unitに切り捨てしてくれます。
例えば30分ごとの平均を取得。SELECT truck_id, avg(measure_value::double) as avg_speed, BIN(time, 30m) as binned_time FROM "IoT-Sample"."IoT" WHERE truck_id = '4132246625' AND measure_name = 'speed' GROUP BY truck_id, BIN(time, 30m) ORDER BY binned_time DESC LIMIT 10
truck_id avg_speed binned_time 4132246625 67.0 2020-10-09 14:00:00.000000000 4132246625 30.666666666666668 2020-10-09 12:00:00.000000000 4132246625 44.666666666666664 2020-10-09 11:30:00.000000000 4132246625 52.0 2020-10-09 11:00:00.000000000 4132246625 36.5 2020-10-09 09:00:00.000000000 Timeseries views
Timestreamでは、
timeseriesというデータタイプが用意されいて、CREATE_TIME_SERIES関数を使うことで、timeseries型に変換できます。
timeseries型のデータは、時刻と計測値のペアがJSON形式で格納されます。SELECT truck_id, CREATE_TIME_SERIES(time, measure_value::double) as speed FROM "IoT-Sample"."IoT" WHERE measure_name = 'speed' GROUP BY truck_id ORDER BY truck_id LIMIT 10
truck_id speed 1234546252 [
{ time: 2020-10-09 09:45:32.192000000, value: 65.0 },
{ time: 2020-10-09 11:16:40.034000000, value: 45.0 }...
View 8 more row(s)
]1575739296 [
{ time: 2020-10-09 09:15:07.856000000, value: 56.0 },
{ time: 2020-10-09 10:29:40.381000000, value: 30.0 }...
View 8 more row(s)
]1588092325 [
{ time: 2020-10-09 09:01:49.081000000, value: 19.0 },
{ time: 2020-10-09 09:22:57.346000000, value: 67.0 }...
View 8 more row(s)
]1641688615 [
{ time: 2020-10-09 09:49:20.010000000, value: 37.0 },
{ time: 2020-10-09 10:14:42.971000000, value: 42.0 }...
View 8 more row(s)
]1682738967 [
{ time: 2020-10-09 09:07:58.814000000, value: 75.0 },
{ time: 2020-10-09 09:28:31.453000000, value: 8.0 }...
View 8 more row(s)
]1712492054 [
{ time: 2020-10-09 09:36:27.020000000, value: 44.0 },
{ time: 2020-10-09 09:49:04.039000000, value: 65.0 }...
View 8 more row(s)
]1836816173 [
{ time: 2020-10-09 08:59:28.330000000, value: 29.0 },
{ time: 2020-10-09 09:21:43.510000000, value: 15.0 }...
View 8 more row(s)
]199744055 [
{ time: 2020-10-09 09:16:35.398000000, value: 42.0 },
{ time: 2020-10-09 09:23:48.835000000, value: 46.0 }...
View 8 more row(s)
]2062792987 [
{ time: 2020-10-09 09:30:31.074000000, value: 45.0 },
{ time: 2020-10-09 09:54:24.573000000, value: 50.0 }...
View 8 more row(s)
]21135517 [
{ time: 2020-10-09 09:23:58.552000000, value: 64.0 },
{ time: 2020-10-09 10:43:06.367000000, value: 48.0 }...
View 8 more row(s)
]
View X more row(s)の部分はマネジメントコンソールでは省略して表示されており、クリックすると、詳細が表示されます。
time value 2020-10-09 09:45:32.192000000 65.0 2020-10-09 11:16:40.034000000 45.0 2020-10-09 11:28:41.938000000 47.0 2020-10-09 11:33:45.047000000 55.0 2020-10-09 12:19:13.367000000 75.0 2020-10-09 12:36:46.970000000 10.0 2020-10-09 13:30:40.722000000 44.0 2020-10-09 13:56:28.837000000 60.0 2020-10-09 14:01:50.177000000 15.0 2020-10-09 14:03:38.020000000 0.0 Time series functions
時系列データに対する関数も用意されています。例えば、
INTERPOLATE_LINEAR関数は値を埋めてくれます。Fills in missing data using linear interpolation.
下の例は、30分ごとのデータを線形補間で生成しています。
sequence(start, stop, step)関数で生成する値の間隔を指定していますが、startとstopは実際の値の範囲内じゃないとだめっぽいです。SELECT truck_id, INTERPOLATE_LINEAR( CREATE_TIME_SERIES(time, measure_value::double), SEQUENCE(min(time), max(time), 30m) ) as speed FROM "IoT-Sample"."IoT" WHERE measure_name = 'speed' GROUP BY truck_id ORDER BY truck_id LIMIT 10
truck_id speed 1234546252 [
{ time: 2020-10-09 09:45:32.192000000, value: 65.0 },
{ time: 2020-10-09 10:15:32.192000000, value: 58.416049695656895 }...
View 7 more row(s)
]1575739296 [
{ time: 2020-10-09 09:15:07.856000000, value: 56.0 },
{ time: 2020-10-09 09:45:07.856000000, value: 45.53611215141335 }...
View 8 more row(s)
]1588092325 [
{ time: 2020-10-09 09:01:49.081000000, value: 19.0 },
{ time: 2020-10-09 09:31:49.081000000, value: 68.91556160771218 }...
View 7 more row(s)
]1641688615 [
{ time: 2020-10-09 09:49:20.010000000, value: 37.0 },
{ time: 2020-10-09 10:19:20.010000000, value: 47.34174652449723 }...
View 7 more row(s)
]1682738967 [
{ time: 2020-10-09 09:07:58.814000000, value: 75.0 },
{ time: 2020-10-09 09:37:58.814000000, value: 9.162118557623112 }...
View 7 more row(s)
]1712492054 [
{ time: 2020-10-09 09:36:27.020000000, value: 44.0 },
{ time: 2020-10-09 10:06:27.020000000, value: 34.61657724615213 }...
View 6 more row(s)
]1836816173 [
{ time: 2020-10-09 08:59:28.330000000, value: 29.0 },
{ time: 2020-10-09 09:29:28.330000000, value: 31.383254052802055 }...
View 8 more row(s)
]199744055 [
{ time: 2020-10-09 09:16:35.398000000, value: 42.0 },
{ time: 2020-10-09 09:46:35.398000000, value: 13.60871678326465 }...
View 6 more row(s)
]2062792987 [
{ time: 2020-10-09 09:30:31.074000000, value: 45.0 },
{ time: 2020-10-09 10:00:31.074000000, value: 52.07211022782296 }...
View 7 more row(s)
]21135517 [
{ time: 2020-10-09 09:23:58.552000000, value: 64.0 },
{ time: 2020-10-09 09:53:58.552000000, value: 57.93405176907693 }...
View 8 more row(s)
]データが30分おきになっています。
time value 2020-10-09 09:45:32.192000000 65.0 2020-10-09 10:15:32.192000000 58.416049695656895 2020-10-09 10:45:32.192000000 51.83209939131379 2020-10-09 11:15:32.192000000 45.248149086970685 2020-10-09 11:45:32.192000000 60.18373944405349 2020-10-09 12:15:32.192000000 73.37867258972554 2020-10-09 12:45:32.192000000 15.522237945272241 2020-10-09 13:15:32.192000000 34.44762245218557 2020-10-09 13:45:32.192000000 53.213475743081105
min(time)からの30分間隔は少し気持ちが悪いので、00分、30分ごとにするにはこんな感じでしょうかSELECT truck_id, INTERPOLATE_LINEAR( CREATE_TIME_SERIES(time, measure_value::double), SEQUENCE(bin(min(time)+ 1h ,1h), max(time), 30m) ) as speed FROM "IoT-Sample"."IoT" WHERE measure_name = 'speed' GROUP BY truck_id ORDER BY truck_id LIMIT 10
truck_id speed 1234546252 [
{ time: 2020-10-09 10:00:00.000000000, value: 61.82577514127146 },
{ time: 2020-10-09 10:30:00.000000000, value: 55.24182483692835 }...
View 7 more row(s)
]1575739296 [
{ time: 2020-10-09 10:00:00.000000000, value: 40.34983728430808 },
{ time: 2020-10-09 10:30:00.000000000, value: 29.77482942057512 }...
View 6 more row(s)
]1588092325 [
{ time: 2020-10-09 10:00:00.000000000, value: 46.790964648508535 },
{ time: 2020-10-09 10:30:00.000000000, value: 63.37907403508092 }...
View 5 more row(s)
]1641688615 [
{ time: 2020-10-09 10:00:00.000000000, value: 39.1011371926136 },
{ time: 2020-10-09 10:30:00.000000000, value: 59.68175770780711 }...
View 6 more row(s)
]1682738967 [
{ time: 2020-10-09 10:00:00.000000000, value: 16.966425157908184 },
{ time: 2020-10-09 10:30:00.000000000, value: 70.67966775160798 }...
View 6 more row(s)
]1712492054 [
{ time: 2020-10-09 10:00:00.000000000, value: 45.89098423361806 },
{ time: 2020-10-09 10:30:00.000000000, value: 12.212910765588772 }...
View 5 more row(s)
]1836816173 [
{ time: 2020-10-09 09:00:00.000000000, value: 28.667924923980287 },
{ time: 2020-10-09 09:30:00.000000000, value: 32.49950906732863 }...
View 8 more row(s)
]199744055 [
{ time: 2020-10-09 10:00:00.000000000, value: 45.46459879696737 },
{ time: 2020-10-09 10:30:00.000000000, value: 3.39022689038606 }...
View 4 more row(s)
]2062792987 [
{ time: 2020-10-09 10:00:00.000000000, value: 50.54843613050327 },
{ time: 2020-10-09 10:30:00.000000000, value: 21.4323793899003 }...
View 6 more row(s)
]21135517 [
{ time: 2020-10-09 10:00:00.000000000, value: 56.71598240453767 },
{ time: 2020-10-09 10:30:00.000000000, value: 50.6500341736146 }...
View 6 more row(s)
]
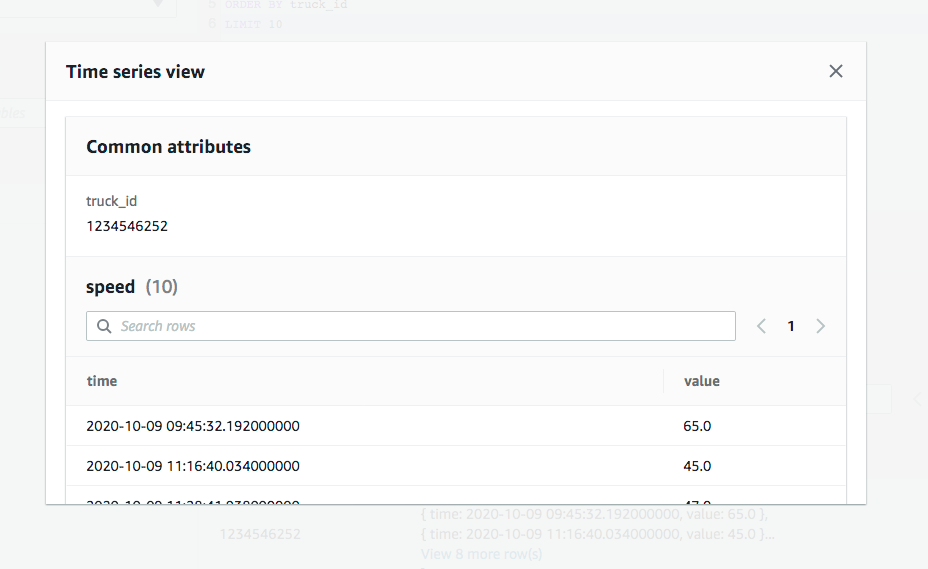
- 投稿日:2020-10-10T00:10:38+09:00
【Rails】Nginx, Puma な環境によるデプロイ&サーバーの勉強【AWS EC2】
はじめに
個人開発アプリを
WEBサーバー:Nginx
アプリケーションサーバー:Puma
を利用し、AWS EC2にデプロイしました。Ruby 2.5.3
Rails 5.2.4.2
MacOS:Catalina 10.15.6AWSの設定は既出の優れた記事通りで理解を進めながらOKだったのですが、駆け出したばかりである為、特にNginxの設定(nginx.conf等)が難しく感じ、幾つものエラーを乗り越え、試行錯誤してクリアしました。
最近はPumaをアプリケーションサーバーに選ぶ方が多いかと思います。
デプロイで必要になるnginx.conf,yourapp.confの設定2つを載せている記事がなかった為、誰かのためになるかと思い作成しました。
エラーに躓き、調べることでサーバーへの理解が深まったのでよしとしますが、恐らくチャレンジする皆さまも同じところで躓きそうなので、自分の場合はこのような設定でデプロイ出来ましたよ、という体で記事にしたいと思います。
1 NginxとPumaについて整理
自分自身、復習の意味を込めて両者について整理します(相違点があれば是非ご教示願います!)。
【Nginx】...WEBサーバー。ブラウザからのコンテンツリクエストを受け取り、ブラウザにレスポンスする。静的コンテンツ(画像など)のリクエストの場合、WEBサーバーが処理する。動的コンテンツはアプリケーションサーバーが担当する。WEBサーバーの代表はApache,Nginxなど
【Puma】...アプリケーションサーバー。NginxがWEBサーバーで静的コンテンツ処理に対し、こちらはNginxでは処理できない動的コンテンツを捌く。WEBサーバーからリクエスト→アプリケーションサーバー受け→Railsアプリケーションの処理結果を、WEBサーバーに返す。代表例としてUnicorn,Pumaなど。現在RailsはPumaをデフォルトのアプリケーションサーバーとして採用している。
PumaとUnicornの選択ですが前者はマルチスレッド、後者はマルチプロセスの違いがあるようです。Pumaの方がより多くのリクエストを効率的に捌ける利点があるようですが、通常使用ではさほど変わりはないという意見もあります。私はRailsで推奨されているPumaを選択しました。
2 puma.rbの設定
次にpuma.rbの設定です。以下が私の設定です。
puma.rb(local)# アプリケーションディレクトリ app_dir = File.expand_path("../../", __FILE__) # ソケット通信を図る為bindでURI指定 bind "unix://#{app_dir}/tmp/sockets/puma.sock" # PIDファイル所在(プロセスID) pidfile "#{app_dir}/tmp/pids/puma.pid" # stateファイルはpumactlコマンドでサーバーを操作する。その所在。 state_path "#{app_dir}/tmp/pids/puma.state" # 標準出力/標準エラーを出力するファイルの所在。 stdout_redirect "#{app_dir}/log/puma.stdout.log", "#{app_dir}/log/puma.stderr.log", true threads_count = ENV.fetch("RAILS_MAX_THREADS") { 5 } threads threads_count, threads_count #port ENV.fetch("PORT") { 3000 } environment ENV.fetch("RAILS_ENV") { "development" } plugin :tmp_restartportは使用しない為、コメントアウトしました。
PumaとNginxはソケット通信させる為、2行目のbindで指定します。
bindでは下記のようにURIでパスを指定します。bind "unix://#{app_dir}/tmp/sockets/puma.sock"3 nginx.confの設定
Nginxは主に2つのファイルを変更します。
1 nginx.conf...Nginx自体の設定ファイル
2 yourapp.conf...アプリケーション毎のNginx設定ファイル下記が私のnginx.conf設定です
(EC2)etc/nginx/nginx.confuser nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /var/run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; include /etc/nginx/conf.d/*.conf; index index.html index.htm; upstream puma { server unix:///var/www/rails/yourapp/shared/tmp/sockets/puma.sock; } server { listen 80 default_server; listen [::]:80 default_server; server_name Elastic IP(URL); root /var/www/rails/yourapp/current/public; location / { try_files $uri $uri/index.html $uri.html @webapp; } location @webapp { proxy_read_timeout 300; proxy_connect_timeout 300; proxy_redirect off; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_pass http://puma; } error_page 404 /404.html; location = /40x.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } } server { listen 443 ssl; server_name Elastic IP(URL); location @webapp { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://puma; } } }4 yourapp.confの設定
yourapp.confとしていますが、yourappにはあなたが作っているアプリケーション名が入ります。
(EC2)/etc/nginx/conf.d/yourapp.conf# log directory error_log /var/www/rails/yourapp/shared/log/nginx.error.log; access_log /var/www/rails/yourapp/shared/nginx.access.log; upstream app_server { # for UNIX domain socket setups server unix:/var/www/rails/yourapp/shared/tmp/sockets/yourapp-puma.sock fail_timeout=0; } server { listen 80; server_name ; # nginx so increasing this is generally safe... # path for static files root /var/www/rails/yourapp/current/public; # page cache loading try_files $uri/index.html $uri @app_server; location / { # HTTP headers proxy_pass http://app_server; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; } # Rails error pages error_page 500 502 503 504 /500.html; location = /500.html { root /var/www/rails/yourapp/current/public; } client_max_body_size 4G; keepalive_timeout 5; }私がデプロイする際に参考にした記事を載せます。
Rails5+Puma+Nginxな環境をCapistrano3でEC2にデプロイする(後編)
Rails5アプリケーションのAWSによるネットワーク構築 Nginx+Puma+Capistranoな環境とAWS構築(VPC EC2 RDS CloudFlont Route53 etc)
インフラ初心者がNginx+PumaのRails5アプリケーションをCapistrano3でデプロイした話
所感
サーバーの扱いに慣れていなかったため、EC2へのデプロイに当たってAWS等の設定よりも、上記NginxとPumaの設定に苦慮した次第です。最終的にCapistrano、CircleCIを利用してAWS EC2にデプロイすることができました。
CDについては先人たちの記事通りに進めていけば難なくできるかと思います。
エラーが多発している時は参りますが、新機能の実装やエラー解決できた時の嬉しさが勝るのでやめられません!