- 投稿日:2020-08-08T12:36:37+09:00
【TPU】【Transformers】爆速でBERTを作る
こないだ参加したコンペでTPU + Transformersを使ってめちゃめちゃ簡単にBERT系のモデルを構築できたのでシェアします。
とにかく速度優先で最近のNLPのトレンドであるBERTを作っていきます。
BERT
Googleが考案した汎用言語モデルです。
今回はBERTよりも軽くて速い蒸留モデルであるDistilBERTを使った時短レシピでいきます。
Pretrainモデルはバンダイナムコ研究所が公開している日本語モデルを使います。TPU
TPU(Tensor Processing Unit)はGoogleが自社開発した機械学習周りの計算に特化したプロセッサです。
演算回路を32bitから8 or 16bitに置き換えたり、メモリの読み書きをせずに演算回路間で値を渡したりすることで汎用プロセッサよりも高速に行列演算ができるそうです。
最近だとGCPで利用できたり、Raspberry piに搭載可能なEdge用のTPUがあったりします。今回はGoogle Colab上でTPUを使い、学習時間を爆上げします。
Transformers
Hugging Face社が提供しているTransformer系のモデルに特化したDeep Learningのフレームワークです。
Transformer系のモデルを作成するのに必要なTokenizerやPretrainモデルをHugging Face社のHP上に公開されたものから簡単にロードすることが出来ます。
(もちろん、ローカルに保存したモデルも参照可能です。)
開発当初はPytorchにしか対応していませんでしたが、現在ではTensorflowにも対応しています。
今回はI/FのシンプルさとTPUの使いやすさを考慮してTensorflow(Keras)用のモデルをロードして構築します。
(PytorchでTPUを使う場合、XLAを使ったり、multi-processingを書いたりと色々面倒なのでそこら辺が比較的簡単なTensorflowを使います。)構築
今回はベタですが、みんな大好きLivedoorコーパスを使って多クラス分類器を作ります。
準備
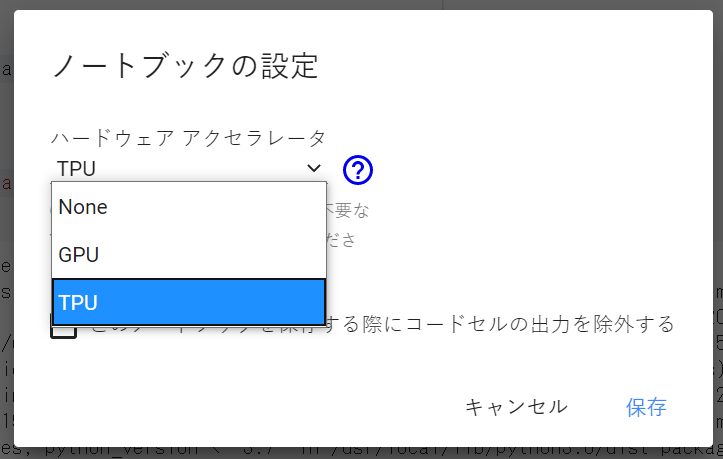
Notebookの[ランタイム] -> [ランタイムのタイプを変更]からランタイムをTPUに変更します。
(デフォルトはNone)
Colabの環境にはtransfomersは入っていないのでpipで落としてきます。
また、今回使用するTokenizerがMecabを使うのでそれも一緒にインストールしておきます。!pip install transformers !apt install aptitude !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3==0.7 from google.colab import drive drive.mount('/gdrive') %cd "/gdrive/My Drive/workspace/python/bakusoku"データの前処理
今回、AutoTokenizerを使います。
Pretrainモデルを指定してするとそのモデルに適したTokenizerを自動でロードしてくれます。
(今回の場合はBertJapaneseTokenizerのインスタンスをロードしています。)
tokenizeメソッドで文をトークン化できます。
今回のTokenizerはWord Piece単位で分割します。(他にもsentencepieceなどの分割方法があります。)from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking") print(tokenizer.tokenize('爆速でBERTを作る')) # ['爆', '##速', 'で', 'BE', '##R', '##T', 'を', '作る']学習にあたっては文を単語IDのシーケンスに変換する必要があるため、以下のメソッドで変換します。
import numpy as np def encode_texts(texts, tokenizer, maxlen=512): enc_di = tokenizer.batch_encode_plus( texts, return_attention_masks=False, return_token_type_ids=False, pad_to_max_length=True, max_length=maxlen ) return np.array(enc_di['input_ids']) x_train = encode_texts(train_df['text'].values, tokenizer) x_valid = encode_texts(valid_df['text'].values, tokenizer) x_test = encode_texts(test_df['text'].values, tokenizer) print(x_train) # [[ 2 281 306 ... 2478 9 3] # [ 2 1519 7 ... 15 16 3] # [ 2 11634 3217 ... 2478 7 3] # ... # [ 2 6093 16562 ... 0 0 0] # [ 2 885 2149 ... 0 0 0] # [ 2 5563 2037 ... 0 0 0]]正解ラベルもone-hotエンコーディングしておきます。
from tensorflow.keras.utils import to_categorical y_train = to_categorical(train_df['label'].values) y_valid = to_categorical(valid_df['label'].values) print(y_train) # [[1. 0. 0. ... 0. 0. 0.] # [1. 0. 0. ... 0. 0. 0.] # [1. 0. 0. ... 0. 0. 0.] # ... # [0. 0. 0. ... 0. 0. 1.] # [0. 0. 0. ... 0. 0. 1.] # [0. 0. 0. ... 0. 0. 1.]]TPUの利用準備
切り替えただけで使えるGPUランタイムと違ってTPUランタイムは以下のようなコード書いてあげる必要があります。
ほぼおまじないレベルですが、バッチサイズはTPUのコア数に併せて変えてあげたほうが早くなります。import tensorflow as tf try: tpu = tf.distribute.cluster_resolver.TPUClusterResolver() print('Running on TPU ', tpu.master()) except ValueError: tpu = None if tpu: tf.config.experimental_connect_to_cluster(tpu) tf.tpu.experimental.initialize_tpu_system(tpu) strategy = tf.distribute.experimental.TPUStrategy(tpu) else: strategy = tf.distribute.get_strategy() num_replicas = strategy.num_replicas_in_sync print("REPLICAS: ", num_replicas) # REPLICAS: 8 BATCH_SIZE = 16 * num_replicas # 128モデル構築
今回はDistilBERTをエンコーダにした多クラス分類器を作ります。
エンコーダの出力のうち、1トークン目([CLS]という文頭を示す特殊なトークン)に対応するものをHEAD(Softmaxによる出力層)に接続します。
エンコーダの出力全体をGlobalPoolingしてから接続するのもありだと思います。from tensorflow.keras.layers import Dense, Input from tensorflow.keras.optimizers import Adam from tensorflow.keras.models import Model def build_model(transformer, num_cls=1, max_len=512): input_word_ids = Input(shape=(max_len,), dtype=tf.int32, name="input_word_ids") sequence_output = transformer(input_word_ids)[0] cls_token = sequence_output[:, 0, :] out = Dense(num_cls, activation='softmax')(cls_token) model = Model(inputs=input_word_ids, outputs=out) model.compile(Adam(lr=2e-4), loss='categorical_crossentropy', metrics=['accuracy']) # lr = 5e-5 * 4 return modelHugging FaceのHP上に公開されているPretrainモデルをロードして上述のモデルを作ります。
Tokenizer同様、TFAutoModelを使ってpretrainモデルをTPU上にロードします。
(今回の場合はTFDistilBertModelのインスタンスをロードしています。)
※ バンダイナムコ研究所が公開しているモデルはPytorchモデルなのでfrom_ptをTrueにします。from transformers import TFAutoModel with strategy.scope(): transformer_layer = (TFAutoModel.from_pretrained('bandainamco-mirai/distilbert-base-japanese', from_pt=True)) model = build_model(transformer_layer, num_cls=9, max_len=512) model.summary() # Model: "model_1" # _________________________________________________________________ # Layer (type) Output Shape Param # # ================================================================= # input_word_ids (InputLayer) [(None, 512)] 0 # _________________________________________________________________ # tf_distil_bert_model_1 (TFDi ((None, 512, 768), ((None 67497984 # _________________________________________________________________ # tf_op_layer_strided_slice_1 [(None, 768)] 0 # _________________________________________________________________ # dense_1 (Dense) (None, 9) 6921 # ================================================================= # Total params: 67,504,905 # Trainable params: 67,504,905 # Non-trainable params: 0 # _________________________________________________________________fine-tuning
先程、作ったモデルを学習させます。
以下の例だと5,500件 - 4epochで70秒ぐらいで学習が終わります。AUTO = tf.data.experimental.AUTOTUNE train_dataset = ( tf.data.Dataset .from_tensor_slices((x_train, y_train)) .repeat() .shuffle(2048) .batch(BATCH_SIZE) .prefetch(AUTO) ) valid_dataset = ( tf.data.Dataset .from_tensor_slices((x_valid, y_valid)) .batch(BATCH_SIZE) .cache() .prefetch(AUTO) ) test_dataset = ( tf.data.Dataset .from_tensor_slices(x_test) .batch(BATCH_SIZE) ) n_steps = x_train.shape[0] // BATCH_SIZE train_history = model.fit( train_dataset, steps_per_epoch=n_steps, validation_data=valid_dataset, epochs=4 ) # Epoch 1/4 # 43/43 [==============================] - 31s 715ms/step - accuracy: 0.2473 - loss: 2.0548 - val_accuracy: 0.3355 - val_loss: 1.9584 # Epoch 2/4 # 43/43 [==============================] - 13s 308ms/step - accuracy: 0.6726 - loss: 1.4064 - val_accuracy: 0.6612 - val_loss: 1.1878 # Epoch 3/4 # 43/43 [==============================] - 13s 309ms/step - accuracy: 0.8803 - loss: 0.7522 - val_accuracy: 0.7877 - val_loss: 0.8257 # Epoch 4/4 # 43/43 [==============================] - 13s 309ms/step - accuracy: 0.9304 - loss: 0.4401 - val_accuracy: 0.8181 - val_loss: 0.6747評価
Accuracyが81%・・・ビミョーな結果になりました。
データのクレンジングとかEncoder以降のモデル構造とかをもう少し工夫すると精度は上がると思います。from sklearn.metrics import classification_report test_df['predict'] = model.predict(test_dataset, verbose=1).argmax(axis=1) print(classification_report(test_df['label'], test_df['predict'], target_names=target_names)) # 12/12 [==============================] - 11s 890ms/step # precision recall f1-score support # # dokujo-tsushin 0.73 0.95 0.83 174 # it-life-hack 0.66 0.91 0.76 174 # kaden-channel 0.79 0.47 0.59 173 # livedoor-homme 0.91 0.31 0.47 102 # movie-enter 0.81 0.96 0.88 174 # peachy 0.81 0.71 0.76 169 # smax 0.91 0.97 0.94 174 # sports-watch 0.88 1.00 0.94 180 # topic-news 0.91 0.75 0.83 154 # # accuracy 0.81 1474 # macro avg 0.83 0.78 0.78 1474 # weighted avg 0.82 0.81 0.79 1474
- 投稿日:2020-08-08T02:23:11+09:00
module 'tensorflow' has no attribute '〇〇' の対処法
TensorFlowのバージョンの問題なことが多いです。
TensorFlowはバージョンアップが頻繁で、
バージョンアップでattributeの名前も変わったりしています。
必要なバージョンをドキュメントで調べてインストールしましょう。pip uninstall -y tensorflow pip install tensorflow==1.14 //必要なversionCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。
