- 投稿日:2020-01-04T23:43:31+09:00
言語処理100本ノック 2015をやったら結構Python基礎力がついた 第1章
はじめに
今更ですが、Pythonの勉強がてら言語処理100本ノック 2015をやってみました。最初は何も見ずにやってみて、その後、他の方の100本ノックの書き方を参考に、より良い(スマートな)書き方でやり直してみます。
より良い書き方の参考文献は最後にまとめて記載しています。
第1章: 準備運動
00. 文字列の逆順
文字列"stressed"の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.
コードinput_str = 'stressed' result = input_str[::-1] print(result)出力結果dessertsより良いコード
スライスのステップに負の値を設定すると末尾から見てくれる。これより大きく変わるのはなさそう。
01. 「パタトクカシーー」
「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.
コードinput_str = 'パタトクカシーー' result = '' for index, s in enumerate(input_str): if index % 2 == 0: result += s print(result)出力結果パトカーより良いコード
これもスライスでOK。
コードinput_str = 'パタトクカシーー' result = input_str[::2] print(result)02. 「パトカー」+「タクシー」=「パタトクカシーー」
「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ.
コードp = 'パトカー' t = 'タクシー' result = '' for i in range(len(p)): result += p[i] result += t[i] print(result)出力結果パタトクカシーーより良いコード
['パタ', 'トク', 'カシ', 'ーー']というリストを作ってjoin()する。コードp = 'パトカー' t = 'タクシー' result = ''.join([char1 + char2 for char1, char2 in zip(p, t)]) print(result)03. 円周率
"Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics."という文を単語に分解し,各単語の(アルファベットの)文字数を先頭から出現順に並べたリストを作成せよ.
コードinput_str = 'Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.' result = [] input_str = input_str.replace(',', '').replace('.', '').split(' ') for s in input_str: result.append(len(s)) print(result)出力結果[3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 9]より良いコード
split()の引数はデフォルトで' 'のため指定不要。コードinput_str = 'Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.' result = [] input_str = input_str.replace(',', '').replace('.', '').split() for s in input_str: result.append(len(s)) print(result)04. 元素記号
"Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can."という文を単語に分解し,1, 5, 6, 7, 8, 9, 15, 16, 19番目の単語は先頭の1文字,それ以外の単語は先頭に2文字を取り出し,取り出した文字列から単語の位置(先頭から何番目の単語か)への連想配列(辞書型もしくはマップ型)を作成せよ.
コードinput_str = 'Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can.' single_ary = [1, 5, 6, 7, 8, 9, 15, 16, 19] result = {} input_str = input_str.replace('.', '').split(' ') for index, s in enumerate(input_str): if index + 1 in single_ary: result[s[0]] = index else: result[s[0] + s[1]] = index print(result)出力結果{'H': 0, 'He': 1, 'Li': 2, 'Be': 3, 'B': 4, 'C': 5, 'N': 6, 'O': 7, 'F': 8, 'Ne': 9, 'Na': 10, 'Mi': 11, 'Al': 12, 'Si': 13, 'P': 14, 'S': 15, 'Cl': 16, 'Ar': 17, 'K': 18, 'Ca': 19}より良いコード
if文を三項演算子に。リストにaryって命名もよくなさそうなので修正。
コードinput_str = 'Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can.' single_list = [1, 5, 6, 7, 8, 9, 15, 16, 19] result = {} input_str = input_str.split() for index, s in enumerate(input_str): l = 1 if index + 1 in single_list else 2 result[s[:l]] = index print(result)05. n-gram
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,"I am an NLPer"という文から単語bi-gram,文字bi-gramを得よ.
コードinput_str = 'I am an NLPer' def create_word_n_gram(input_str, num): str_list = input_str.split(' ') results = [] for i in range(len(str_list) - num + 1): ngram = '' for j in range(num): ngram += str_list[j + i] results.append(ngram) return results def create_char_n_gram(input_str, num): str_no_space = input_str.replace(' ', '') results = [] for i in range(len(str_no_space) - num + 1): ngram = '' for j in range(num): ngram += str_no_space[j + i] results.append(ngram) return results print(create_word_n_gram(input_str, 2)) print(create_char_n_gram(input_str, 2))出力結果['Iam', 'aman', 'anNLPer'] ['Ia', 'am', 'ma', 'an', 'nN', 'NL', 'LP', 'Pe', 'er']より良いコード
文字n-gramはスペースも含む。ずっと勘違いしていた。。。
単語n-gramも出力形式がいけていないので修正。コードinput_str = 'I am an NLPer' def create_word_n_gram(input_str, num): str_list = input_str.split(' ') results = [] for i in range(len(str_list) - num + 1): results.append(str_list[i:i + num]) return results def create_char_n_gram(input_str, num): results = [] for i in range(len(input_str) - num + 1): results.append(input_str[i:i + num]) return results print(create_word_n_gram(input_str, 2)) print(create_char_n_gram(input_str, 2))出力結果[['I', 'am'], ['am', 'an'], ['an', 'NLPer']] ['I ', ' a', 'am', 'm ', ' a', 'an', 'n ', ' N', 'NL', 'LP', 'Pe', 'er']06. 集合
"paraparaparadise"と"paragraph"に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.さらに,'se'というbi-gramがXおよびYに含まれるかどうかを調べよ.
コードinput_str_x = 'paraparaparadise' input_str_y = 'paragraph' word = 'se' def create_char_n_gram(input_str, num): str_no_space = input_str.replace(' ', '') results = [] for i in range(len(str_no_space) - num + 1): ngram = '' for j in range(num): ngram += str_no_space[j + i] results.append(ngram) return results def calculate_union(list_x, list_y): list_union = list(set(list_x + list_y)) return list_union def calculate_intersection(list_x, list_y): list_sum = list_x + list_y list_intersection = [elem for elem in set(list_sum) if list_sum.count(elem) > 1] return list_intersection def calculate_difference(list_x, list_y): list_intersection = calculate_intersection(list_x, list_y) list_sum = list_x + list_intersection list_difference = [elem for elem in set(list_sum) if list_sum.count(elem) == 1] return list_difference def check_including_word(word_list, word): if word in word_list: return True else: return False x = create_char_n_gram(input_str_x, 2) y = create_char_n_gram(input_str_y, 2) print(calculate_union(x, y)) print(calculate_intersection(x, y)) print(calculate_difference(x, y)) print(check_including_word(x, word)) print(check_including_word(y, word))出力結果['ar', 'ag', 'gr', 'is', 'ph', 'se', 'pa', 'di', 'ap', 'ad', 'ra'] ['ar', 'pa', 'ap', 'ra'] ['is', 'se', 'di', 'ad'] True Falseより良いコード
setにしてしまえば集合演算が可能。関数なんていらなかった・・・
チェック関数もかなり冗長。こっちは書いている最中に気付くべき。コードinput_str_x = 'paraparaparadise' input_str_y = 'paragraph' word = 'se' def create_char_n_gram(input_str, num): results = [] for i in range(len(input_str) - num + 1): results.append(input_str[i:i + num]) return results x = set(create_char_n_gram(input_str_x, 2)) y = set(create_char_n_gram(input_str_y, 2)) print(x | y) print(x - y) print(x & y) print(word in x) print(word in y)07. テンプレートによる文生成
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y="気温", z=22.4として,実行結果を確認せよ.
コードx = 12 y = '気温' z = 22.4 def create_str(x, y, z): return str(x) + '時の' + y + 'は' + str(z) print(create_str(x, y, z))出力結果12時の気温は22.4より良いコード
文字列の足し方はいろいろあると思うが、これより大きく変わるのはなさそう。
08. 暗号文
与えられた文字列の各文字を,以下の仕様で変換する関数cipherを実装せよ.
英小文字ならば(219 - 文字コード)の文字に置換
その他の文字はそのまま出力
この関数を用い,英語のメッセージを暗号化・復号化せよ.コードinput_str = 'Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.' def cipher(input_str): result = list(map(lambda e: chr(219 - ord(e)) if e.islower() else e, input_str)) return ''.join(result) print(cipher(input_str)) print(cipher(cipher(input_str)))出力結果Nld I mvvw z wirmp, zoxlslorx lu xlfihv, zugvi gsv svzeb ovxgfivh rmeloermt jfzmgfn nvxszmrxh. Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.より良いコード
これより大きく変わるのはなさそう。
正しくは「復号化」ではなく「復号」。と思ったけど、今は「復号化」も普通に使われているらしい・・・※一瞬、同じ操作で暗号化と復号を両方やるのは不可能だと思ってしまったが、
219 - x = yなら、219 - y = xになるのは当然だった。219は他の数字でもよい。09. Typoglycemia
スペースで区切られた単語列に対して,各単語の先頭と末尾の文字は残し,それ以外の文字の順序をランダムに並び替えるプログラムを作成せよ.ただし,長さが4以下の単語は並び替えないこととする.適当な英語の文(例えば"I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind .")を与え,その実行結果を確認せよ.
コードimport random input_str = "I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind ." def create_typoglycemia(input_str): input_str_list = input_str.split(' ') result = [] for word in input_str_list: length = len(word) if length > 4: first_char = word[0] last_char = word[length - 1] random_str = ''.join(random.sample(list(word[1:length - 1]), length - 2)) result.append(word[0] + random_str + word[length - 1]) else: result.append(word) return ' '.join(result) print(create_typoglycemia(input_str))出力結果I cunldo't biveele that I culod aclatluy urdseanntd what I was rdineag : the pehaneomnl pewor of the huamn mind .より良いコード
定義したくせに一度しか使っていない変数や、定義したくせに全く使っていない変数を削除。
コードimport random input_str = "I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind ." def create_typoglycemia(input_str): result = [] for word in input_str.split(' '): length = len(word) if length > 4: random_str = ''.join(random.sample(word[1:length - 1], length - 2)) result.append(word[0] + random_str + word[length - 1]) else: result.append(word) return ' '.join(result) print(create_typoglycemia(input_str))おわりに
参考とさせていただいた、Qiitaに上がっている言語処理100本ノック2015(Python)の記事をまとめておきます。
- 投稿日:2020-01-04T23:34:29+09:00
Pythonによる AI・機械学習について学んだ内容(3)
はじめに
この本を使って勉強しています
Pythonによる AI・機械学習・深層学習アプリのつくり方scikit-learn
Python向けの機械学習フレームワークの定番
http://scikit-learn.org/次の特徴がある
- 機械学習で使われるさまざまなアルゴリズムに対応
- すぐに機械学習を試すことができるようにサンプルデータが含まれる
- 機械学習の結果を検証する機能を持っている
- 機械学習でよく使われる他のライブラリ(Pnadas, Numpy, scipy, Matplotlib etc)と親和性が高い
- BSDライセンスのオープンソースのため無料で商用利用可能
アルゴリズムを選択する
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
どのような機械学習をしたいか、どのようなデータを準備しているのかなどの条件をたどっていくとアルゴリズムを選択できるようになっている。AND演算を機械学習する
and.py# ライブラリをインポートする from sklearn.svm import LinearSVC # LinearSVC アルゴリズムを利用するためのパッケージ(sklearn.svm.LinearSVC) from sklearn.metrics import accuracy_score # テスト結果を評価するためのパッケージ(sklearn.metrics.accuracy_score) #学習データを用意 learn_data = [[0, 0], [1, 0], [0, 1], [1, 1]] # 学習用の入力データ(AND の入力値) learn_label = [0, 0, 0, 1] # 学習用の結果データ(AND の出力値) # アルゴリズムの指定 clf = LinearSVC() # 学習する(学習用の入力データと結果データを渡す) clf.fit(learn_data, learn_label) # 学習用の入力データと結果データを渡す # 学習を検証する test_data = [[0, 0], [1, 0], [0, 1], [1, 1]] # テストデータの入力データを用意 test_label = clf.predict(test_data) # テストデータの結果を取得 # テストデータの結果を表示 print(test_data, "の予測結果", test_label) # 正解率を表示 Accuracy_rate= accuracy_score([0, 0, 0, 1], test_label) # accuracy_score(正解データ, テストの結果) print("正解率:", Accuracy_rate)[[0, 0], [1, 0], [0, 1], [1, 1]] の予測結果 [0 0 0 1] 正解率: 1.0AND論理演算を正しく学習している。
線形に分類できるものは、LinearSVCアルゴリズムで解決できる。
でも、XORは?使用される単語
SVM(Support Vector Machine)
「本当に予測に必要となる一部のデータ」のこと
このサイトがわかりやすいLinear SVM Classification ... 線形 SVM 分類
accuracy ... 精度・正確さ
classification ... 分類
classifier ... 分類器
fit ... 学習する(適合する)
predict ... 予測する
XOR演算を機械学習する
xor.py# ライブラリをインポートする from sklearn.svm import LinearSVC # LinearSVC アルゴリズムを利用するためのパッケージ(sklearn.svm.LinearSVC) from sklearn.metrics import accuracy_score # テスト結果を評価するためのパッケージ(sklearn.metrics.accuracy_score) #学習データを用意 learn_data = [[0, 0], [1, 0], [0, 1], [1, 1]] # 学習用の入力データ(XORの入力値) learn_label = [0, 1, 1, 0] # 学習用の結果データ(XORの出力値) # アルゴリズムの指定 clf = LinearSVC() # 学習する(学習用の入力データと結果データを渡す) clf.fit(learn_data, learn_label) # 学習用の入力データと結果データを渡す # 学習を検証する test_data = [[0, 0], [1, 0], [0, 1], [1, 1]] # テストデータの入力データを用意 test_label = clf.predict(test_data) # テストデータの結果を取得 # テストデータの結果を表示 print(test_data, "の予測結果", test_label) # 正解率を表示 Accuracy_rate= accuracy_score([0, 1, 1, 0], test_label) # accuracy_score(正解データ, テストの結果) print("正解率:", Accuracy_rate)[[0, 0], [1, 0], [0, 1], [1, 1]] の予測結果 [0 0 0 0] 正解率: 0.5うーん、線形では正しく分類できない。
xor2.py# ライブラリをインポートする from sklearn.neighbors import KNeighborsClassifier # LinearSVC アルゴリズムを利用するためのパッケージ(sklearn.svm.LinearSVC) from sklearn.metrics import accuracy_score # テスト結果を評価するためのパッケージ(sklearn.metrics.accuracy_score) #学習データを用意 learn_data = [[0, 0], [1, 0], [0, 1], [1, 1]] # 学習用の入力データ(XORの入力値) learn_label = [0, 1, 1, 0] # 学習用の結果データ(XORの出力値) # アルゴリズムの指定 clf = KNeighborsClassifier(n_neighbors = 1) # 学習する(学習用の入力データと結果データを渡す) clf.fit(learn_data, learn_label) # 学習用の入力データと結果データを渡す # 学習を検証する test_data = [[0, 0], [1, 0], [0, 1], [1, 1]] # テストデータの入力データを用意 test_label = clf.predict(test_data) # テストデータの結果を取得 # テストデータの結果を表示 print(test_data, "の予測結果", test_label) # 正解率を表示 Accuracy_rate= accuracy_score([0, 1, 1, 0], test_label) # accuracy_score(正解データ, テストの結果) print("正解率:", Accuracy_rate)[[0, 0], [1, 0], [0, 1], [1, 1]] の予測結果 [0 1 1 0] 正解率: 1.0KNeighborsClassifierアルゴリズムを使うと学習できた。

- 投稿日:2020-01-04T22:47:38+09:00
Homebrewのエラー
Python update時、venvをリセットする時でたエラー
$ brew cleanupで下記のWarningがありました。
Warning: Skipping python: most recent version 3.7.6_1 not installed
アップデートします。
$ brew upgradeで下記のエラー...
Traceback (most recent call last):
4: from /usr/local/Homebrew/Library/Homebrew/brew.rb:23:in `<main>'
3: from /usr/local/Homebrew/Library/Homebrew/brew.rb:23:in `require_relative'
2: from /usr/local/Homebrew/Library/Homebrew/global.rb:13:in `<top (required)>'
1: from /System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require'
/System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require': cannot load such file -- active_support/core_ext/object/blank (LoadError)
$ brew update-resetでブランチのリセットとアップデート
==> Fetching /usr/local/Homebrew...
==> Resetting /usr/local/Homebrew...
Branch 'master' set up to track remote branch 'master' from 'origin'.
Reset branch 'master'
brew upgradeで問題なくアップデートしましたが、Warningもありました。
Warning: Building python from source:
The bottle needs the Apple Command Line Tools to be installed.
You can install them, if desired, with:
xcode-select --install
$ xcode-select --installでまだ下記のエラー...
xcode-select: note: install requested for command line developer tools以上で全部解決。
- 投稿日:2020-01-04T22:29:18+09:00
Python で初めての単回帰分析
単回帰分析の意味は調べればいくらでも出てきますが、自分で実際にプログラムを書いてみることで、理解が深まればいいかなと思い、Python を使って試してみたいと思っています。
一応、単回帰分析に対する説明としては、以下のような例があります。
1. 1つの目的変数(y)を1つの説明変数(x)で予測するもの。
2. それらの関係性を y = ax + b という一次方程式の形であらわす。
※ a は傾き、b は切片テスト環境は、(いつインストールしたかも覚えていない) Jupyter Notebook を使います。
使用したバージョンは以下です。The version of the notebook server is: 6.0.0 Python 3.7.3 (default, Mar 27 2019, 22:11:17) [GCC 7.3.0]pandas
pandas(パンダス、パンダズまたはパンダ)はデータを変換したり解析したりするためのライブラリ。
これを使って、データを読み込んでいきます。
使用したバージョンは以下です。import pandas as pd print(pd.__version__) # 0.24.2データ読み込み
今回は、48名分の身長(x)と体重(y)のデータ(sample.csv)を使用してみます。
sample.csvx,y 152,57 173,78 172,83 178,58 166,63 175,66 158,66 163,74 157,64 165,68 176,68 165,60 147,63 153,63 146,47 156,49 145,59 181,66 160,74 140,55 152,55 165,56 170,65 159,51 151,52 167,51 177,82 155,63 159,45 170,66 154,56 163,60 161,70 165,70 150,57 158,53 163,67 186,69 168,68 170,74 155,60 159,49 170,87 163,50 166,58 161,69 159,60 171,71sample.csv ファイルを読み込み、最初の3行を出力してみます。
以下のように読み込めているようです。df = pd.read_csv('sample.csv') df.head(3) x y 0 152 57 1 173 78 2 172 83pandas.read_csv でデータを読み込むと、DataFrame という型でデータが作成されるようです。
pandas.read_csv
DataFrameそれぞれの列データを変数x, y に格納しておきます。
x = df.x y = df.ymatplotlib
matplotlib(マットプロットリブ)は、グラフ描画ライブラリ。
使用したバージョンは以下です。import matplotlib matplotlib.__version__ # '3.1.0'グラフ描画
import matplotlib.pyplot as plt plt.plot(x, y) plt.show()
全ての点が線でつながれたグラフが表示されました。
期待していたのは点だけが表示されているグラフでしたので、以下のように修正します。import matplotlib.pyplot as plt plt.plot(x, y, 'o') plt.show()
scikit-learn
scikit-learn(サイキット・ラーン)は、科学技術計算を行うためのPythonパッケージ NumPy(ナンパイまたはナムパイ)と SciPy(サイパイ)の上で構築されている機械学習用ライブラリ。
使用したバージョンは以下です。import sklearn print(sklearn.__version__) # 0.21.2scikit-learn を使うことでお手軽に単回帰分析することが出来そうです。
LinearRegressionデータの学習
線形回帰モデル(LinearRegression)のインスタンスを生成し、データを学習(fit)させます。
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(x, y) # ValueError: Expected 2D array, got 1D array instead:と思ったら、エラーが出てしまいました。2次元配列が必要なところ、1次元配列を与えているようです。
x, y の格納の仕方を変更して、改めて学習してみます。x = df[['x']] y = df[['y']]from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(x, y) # LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)今度は取り込んでくれたようです。
ここの部分は、元の x と y のままでも以下のように定義すれば動いてくれるはずです。# values で numpy.ndarray 型に変換し、np.reshape(-1, 1)でn行1列に変換する model.fit(x.values.reshape(-1,1), y.values.reshape(-1,1))データの予測
それでは予測(predict)させてみます。
plt.plot(x, y, 'o') plt.plot(x, model.predict(x), linestyle="solid") plt.show()
説明変数(x) から、目的変数(y) を予測した結果、右肩上がり(身長が増えるほど、体重が増える)の線が引かれました。この直線の"傾き"と"切片"については、それぞれ coef_ と intercept_ 属性が保持しているようですので、それらを出力してみると、直線の方程式を得ることができます。
print('y = %.2fx + %.2f' % (model.coef_ , model.intercept_)) # y = 0.52x + -20.94以上のことから、a(傾き)と b(切片)が分かることで、x(身長)から y(体重)を予測することができる、即ち"単回帰分析"が実現出来たということになります。



- 投稿日:2020-01-04T22:28:32+09:00
deeplearningで柴犬の写真からうちの子かどうか判定(2) データ増量・転移学習・ファインチューニング
はじめに
- こちらは私自身の機械学習やディープラーニングの勉強記録のアウトプットです。
- 前回のdeeplearningで柴犬の写真からうちの子かどうか判定(1)に引き続き、Google Colaboratoryで画像データの2種分類を行います。
- 様々なエラーでつまずいた箇所などもなるべく記述し、なるべく誰でも再現がしやすいように記載します。
この記事の対象者・参考にした文献
前回と同じです。詳細はこちら。
私について
- 現職は事務職。2019年9月にJDLA Deep Learning for Engeneer 2019#2を取得。
- 2020年4月からデータサイエンスの仕事にジョブチェンジをしたいと考え、転職活動を開始しました。 詳細はこちら。
前回(1)の分析の概要
- 愛犬(柴犬)の写真60枚、(愛犬以外の)柴犬の写真の写真を60枚、計120枚の画像ファイル(jpg)を集め、それらを deep learning で2分類しました。
- モデルを学習させて、テストデータで検証した結果、精度は75~76%程度に留まりました。
今回(2)の手順概要
手順1 分析データ量を増加し(写真を倍の枚数に増やす)、Google Driveにアップロード
手順2 Google Drive上に作業用フォルダを作成し、データを解凍、コピーする
手順3 モデル構築・学習・結果
手順4 ImageNetのモデル(VGG16)で転移学習
手順5 ImageNetのモデル(VGG16)でファインチューニング手順1 分析データ量を増加し(写真を倍の枚数に増やす)、Google Driveにアップロード
(1) 写真データの増量
前回の分析で、分類精度が7割台に留まった原因はいろいろあると思いますが、その最たるものは、やはり学習用データが60データと少量であったためであると思います。データを増やすのはなかなか大変ですが、今回の分類のため、写真の枚数を愛犬120枚、愛犬以外の柴120枚、計240枚に増量しました。このデータファイルを基に、再度分類を行います。
愛犬のjpgファイル(120枚) 新たに追加した写真例 ⇒ mydog2.zipにまとめる
愛犬以外の柴犬のjpgファイル(120枚) 新たに追加した写真例 → otherdogs2.zipにまとめる
(2) Google drive内のデータ格納用フォルダを整備する
前回の分析を実施した際に、データを格納するフォルダを次のとおり作成しました。(図は私のフォルダ構成例)
データファイルが増えた(120データ→240データ)ことにより、今回の分析を行う前に前回使用したデータファイルは一旦丸ごと削除して、新たに入れ替えることにします。そのため、具体的にはGoogle Drive上の操作で、"use_data"フォルダ内の赤字で示した"train","validation","test"の3つのフォルダについては、格納データごとすべて削除します。
(3) データファイルのアップロード
- "mydog2.zip" "otherdogs2.zip"の2つのzipファイルをGoogle Drive("original_data"フォルダ)にアップロードします。
- "mydog2.zip" "otherdogs2.zip"の2つのzipファイルについては、私のgithubに掲載しています。
手順2 Google Drive上に作業用フォルダを作成し、データを解凍、コピーする
- 今回はtrainデータに各60枚、validationデータに各30枚、testデータに各30枚を割り当てます。
- ここからはGoogle Colaboratoryを起動してColab上で操作していきます。
- 以下の内容は前回の実装と共通する部分が大半のため、ここでのコードについてはjupyternotebook形式で私のgithubに掲載しています。
- ファイル名:mydog_or_otherdogs2_1(120data_input320px).ipynb
注)ColaboratoryとGoogle Driveとの間の連携に関するタイムラグについて これは注意点というより、メモ書きに近いのですが、ColaboratoryとGoogle Driveとの連携にはタイムラグがあるように思います。安全に処理を実施するには、作業用フォルダ作成、コピー等の各処理は一気通貫に行うのではなく、ワンステップずつ、各処理が完了しているのを確認しながら進めたほうがよさそうだと思います。私の試行だと、ColaboratoryからGoogle Driveに命令を出した後、それが実際に反映するのにちょっと時間を要しています。そのため、タイミングにもよるかもしれませんが、反映前に次の処理を走らせるとエラーになる場合がありました。一気通貫でうまくいかない場合には、処理を何ステップかに分けて進めてみるとよいと思います。
手順3 モデル構築・学習・結果
(1) データオーギュメンテーションなしでの学習の結果
- 訓練の結果は、次のグラフのとおりとなりました。accuracy, lossともに過学習の兆候が出ていて、目立った改善はありません。

(2) テストデータへの適用(データオーギュメンテーションなし)
テストデータに適用した検証結果については次のとおりとなりました。サンプルデータ数を増やしたことが精度の向上につながり、accuracyも8割程度に到達しています。
test loss: 1.7524430536416669
test acc: 0.8166666567325592(3) データオーギュメンテーションありでの学習の結果
続いてデータオーギュメンテーションありで学習させました。訓練の結果は、次のグラフのとおりとなりました。
(4) テストデータへの適用(データオーギュメンテーションあり)
次にImageGeneratorの設定を画像データの水増しありにした場合のテストデータの検証結果は次のとおりです(水増し条件は前回の試行の設定と同じで、結果表示のみ)。こちらの方がaccuracyがより高くなっています。
test loss: 1.382319548305386
test acc: 0.8666666634877522手順4 ImageNetのモデル(VGG16)で転移学習
今度は転移学習を実施します。代表的なモデルであるImageNetの学習済みモデル (VGG16) をkerasのライブラリからインポートして使用します。VGG16モデルからは、学習済み畳み込みベースのみを利用し、汎用性の高い局所的な特徴マップを抽出させます。その出力に「(柴犬用)うちの子-よその子」分類器を接続することで、分類精度の向上を図ります。
(1) VGG16について
- VGG16は、畳み込み13層、全結合層3層、計16層からなる多層ニューラルネットワーク。公開されているモデルはImageNetと呼ばれる大規模な画像セットを用いて訓練されたもの。
- Kerasのライブラリとして keras.applications.vgg16 モジュールに実装されている。
(2) モデルの読み込み
- 以下は、Google Drive内にデータの格納フォルダ、作業用フォルダが生成されており、分析用画像データが格納されていることを前提に進めて行きます。(これまでの分析環境そのままで実施します)
- 変数conv_baseにVGG16モデルを読み込みます。
# VGG16の読み込み from keras.applications import VGG16 conv_base = VGG16(weights='imagenet', # 重みの種類を指定(ここではImagenetで学習した重みを指定) include_top=False, # NWの出力側にある全結合分類器を含めるかどうか(ここでは自作の全結合分類器を使用するので含まない設定とする) input_shape=(320, 320, 3)) # NWに供給する画像テンソルの形状でImageNet標準は(224, 224 3) (今回は320pxl*320pxlのRGB画像を指定) conv_base.summary()読み込んだVGG16の該当部分について、次のようなモデル構造が表示されます。
Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_2 (InputLayer) (None, 320, 320, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 320, 320, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 320, 320, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 160, 160, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 160, 160, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 160, 160, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 80, 80, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 80, 80, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 80, 80, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 80, 80, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 40, 40, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 40, 40, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 40, 40, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 40, 40, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 20, 20, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 20, 20, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 20, 20, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 20, 20, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 10, 10, 512) 0 ================================================================= Total params: 14,714,688 Trainable params: 14,714,688 Non-trainable params: 0 _________________________________________________________________(3) モデルの構築
conv_baseに今回の2値分類用の全結合層を結合し、モデルを構築します。
from keras import models from keras import layers model = models.Sequential() model.add(conv_base) model.add(layers.Flatten()) model.add(layers.Dense(256, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.summary()次のようなモデル構造が表示されます。
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= vgg16 (Model) (None, 10, 10, 512) 14714688 _________________________________________________________________ flatten_1 (Flatten) (None, 51200) 0 _________________________________________________________________ dense_1 (Dense) (None, 256) 13107456 _________________________________________________________________ dense_2 (Dense) (None, 1) 257 ================================================================= Total params: 27,822,401 Trainable params: 27,822,401 Non-trainable params: 0 _________________________________________________________________(4) 訓練可能な重みの数を確認します
# conv_baseを凍結する前の状態で訓練可能な重みの数 print('conv_baseを凍結する前の状態で訓練可能な重みの数:' ,len(model.trainable_weights))実行すると「30」という結果が表示されます。
(5) conv_baseの重みのみを訓練不可能に設定し、設定結果を確認します
# conv_baseの重みのみ訓練不可能に設定する conv_base.trainable = False # 訓練可能な重みの数の確認 print('conv_base凍結後の状態で訓練可能な重みの数:' ,len(model.trainable_weights))実行すると、訓練可能な重みの数は「4」という結果に変更されて表示されます。このセットアップ状態でモデルの学習を実施します。
(5) 画像のテンソル化、学習
以下のコードで実施します。
from keras.preprocessing.image import ImageDataGenerator from keras import optimizers # trainデータのジェネレータ設定 水増し:あり train_datagen = ImageDataGenerator( rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest') # validationデータ、testデータ用のジェネレータ設定 水増し:なし\(validationデータとtestデータのジェネレータは共通とする) test_datagen = ImageDataGenerator(rescale=1./255) # trainデータのテンソル化 train_generator = train_datagen.flow_from_directory( # target directory train_dir, # size 320x320 target_size=(320, 320), batch_size=20, # 損失関数としてbinary_crossentropyを使用するため、二値のラベルが必要 class_mode='binary') # validationデータのテンソル化 validation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(320, 320), batch_size=32, class_mode='binary') # モデルのコンパイル model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=2e-5), metrics=['acc']) # 学習 history = model.fit_generator( train_generator, steps_per_epoch=100, epochs=30, validation_data=validation_generator, validation_steps=50, verbose=2)実行後のモデルは保存します。
model.save('mydog_or_otherdogs_02a.h5')(6) 実行結果
- 訓練結果のグラフは次のとおりです。

グラフの形状に変化が出てきました。accuracyは0.88あたりで始まり、0.93から0.96あたりまで改善しています。lossは0.3あたりから始まり、0.1から0.2の範囲を推移しています。過学習状態から少し改善の兆候が出てきました。
続いて、テストデータでこのモデルの分類結果を検証します。(コードは前回記事を参照)
test loss: 0.274524162985399
test acc: 0.9333333373069763転移学習の結果、分類性能は改善しています。accuracyが初めて9割を超えました。
この試行では、畳み込みベースにVGG16の学習済みモジュールのみを使用しましたが、ImageNetでのトレーニングにより得られた汎用性の高い局所的な特徴マップの抽出能力が、分類性能に大きく貢献しているであろうことが確認できます。
手順5 ImageNetのモデル(VGG16)でファインチューニング
(1) ファインチューニングの概要
ファインチューニングは特徴抽出に使用される凍結された畳み込みベースの出力側の層をいくつか解凍し、モデルの新しく追加された部分(この場合は全結合分類器)と解凍した層の両方で訓練を行う、という仕組みになっています。
(2) ファインチューニングの実施手順
- 訓練済みのベースネットワークの最後にカスタムネットワークを追加する
- ベースネットワークを凍結する
- 追加した部分の学習を行う
- ベースネットワークの一部の層を解凍する
- 解凍した層と追加した部分の訓練を同時に行う
※(1)(2)の記載については、『PythonとKerasによるディープラーニング』Francois Chollet著 株式会社クイープ訳 巣籠悠輔監訳 株式会社マイナビ出版刊より、該当部分を引用
(3) 訓練可能な重みの設定
- 次のコードでファインチューニングの実施に際して訓練可能な重みを設定します。
- block5_conv1, block5_conv2, block5_conv3の3つの層のみ、訓練可能に設定します。
conv_base.trainable = True set_trainable = False for layer in conv_base.layers: if layer.name == 'block5_conv1': set_trainable = True if set_trainable: layer.trainable = True else: layer.trainable = False(4) ファインチューニングの実行
次のコードで学習をさせます。
# オプティマイザにRMSpropを選択し、かなり低い設定の学習率を使用 # 更新値が大きいとファインチューニングの対象層3つの表現を傷つけてしまうため model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-5), metrics=['acc']) history = model.fit_generator( train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)訓練後のモデルは保存します。
model.save('mydog_or_otherdogs_02b.h5')(5) 結果グラフ
結果のグラフは次のとおりです。
次のコードでグラフのスムース化を行います。# プロットのスムージング def smooth_curve(points, factor=0.8): smoothed_points = [] for point in points: if smoothed_points: previous = smoothed_points[-1] smoothed_points.append(previous * factor + point * (1 - factor)) else: smoothed_points.append(point) return smoothed_points plt.plot(epochs, smooth_curve(acc), 'bo', label='Smoothed training acc') plt.plot(epochs, smooth_curve(val_acc), 'b', label='Smoothed validation acc') plt.title('Training and validation accuracy') plt.legend() plt.figure() plt.plot(epochs, smooth_curve(loss), 'bo', label='Smoothed training loss') plt.plot(epochs, smooth_curve(val_loss), 'b', label='Smoothed validation loss') plt.title('Training and validation loss') plt.legend() plt.show()グラフは次のとおりとなります。validationの状況を見ると、エポックの回数が増えるごとに性能が上がっている様子ではないものの、以前に比べて、グラフの変化の幅がより狭い範囲で表示されているため、精度が改善されていることが期待できます。
(6) 学習済みモデルをテストデータに適用して分類精度を確認します
テストデータに適用した検証結果については次のとおりとなりました。
test loss: 0.5482699687112941
test acc: 0.9499999916553498ファインチューニングの結果、分類性能をさらに向上させることができました。さらなる精度の向上へ向けて、まだ試していないアプローチもいろいろ実施してみたいところです。今回の検証ではここまでで一区切りとします。













- 投稿日:2020-01-04T22:14:07+09:00
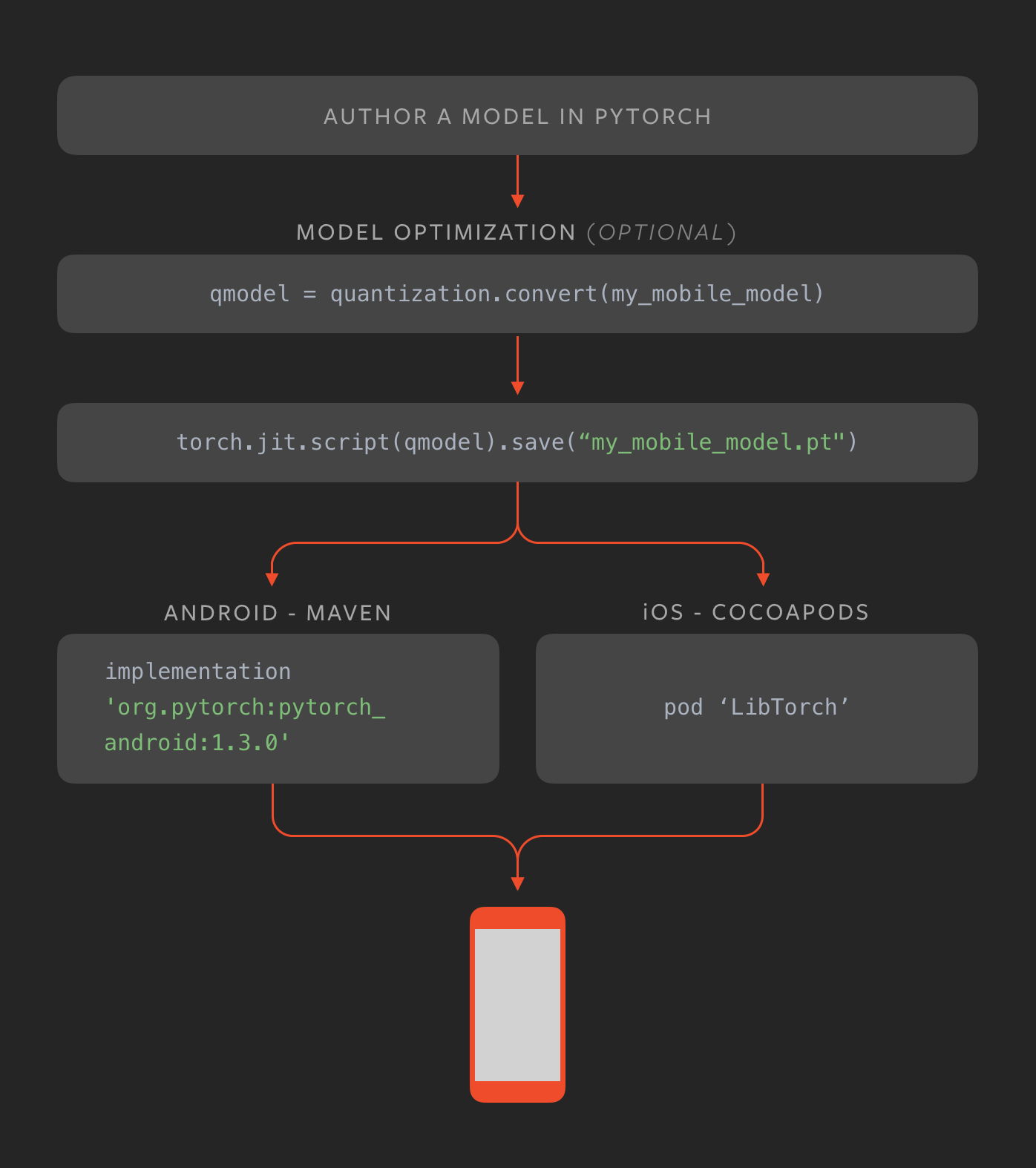
[kotlin] アンドロイドで画像分類をする(Pytorch Mobile)
PyTorch Mobile
去年(2019年)の10月くらいに出た。Tensolflow Liteとかではandroid iosでも機械学習ができたが、やっとpytorch 1.3からモバイル向けが登場した。tensorflow よりpytorch使う側からすると最高だね!
tensorflow Liteと同様にandroid ios で利用できるようになっている。詳細はこちら
PyTorch Mobile公式サイト : https://pytorch.org/mobile/home/公式サイトより
今回やること
公式サイトで紹介されているチュートリアルをやる。Kotlinで書く!
resNetの学習済みモデルを使って画像の分類を行う。(推論のみ)github載せてます https://github.com/SY-BETA/PyTorchMobile
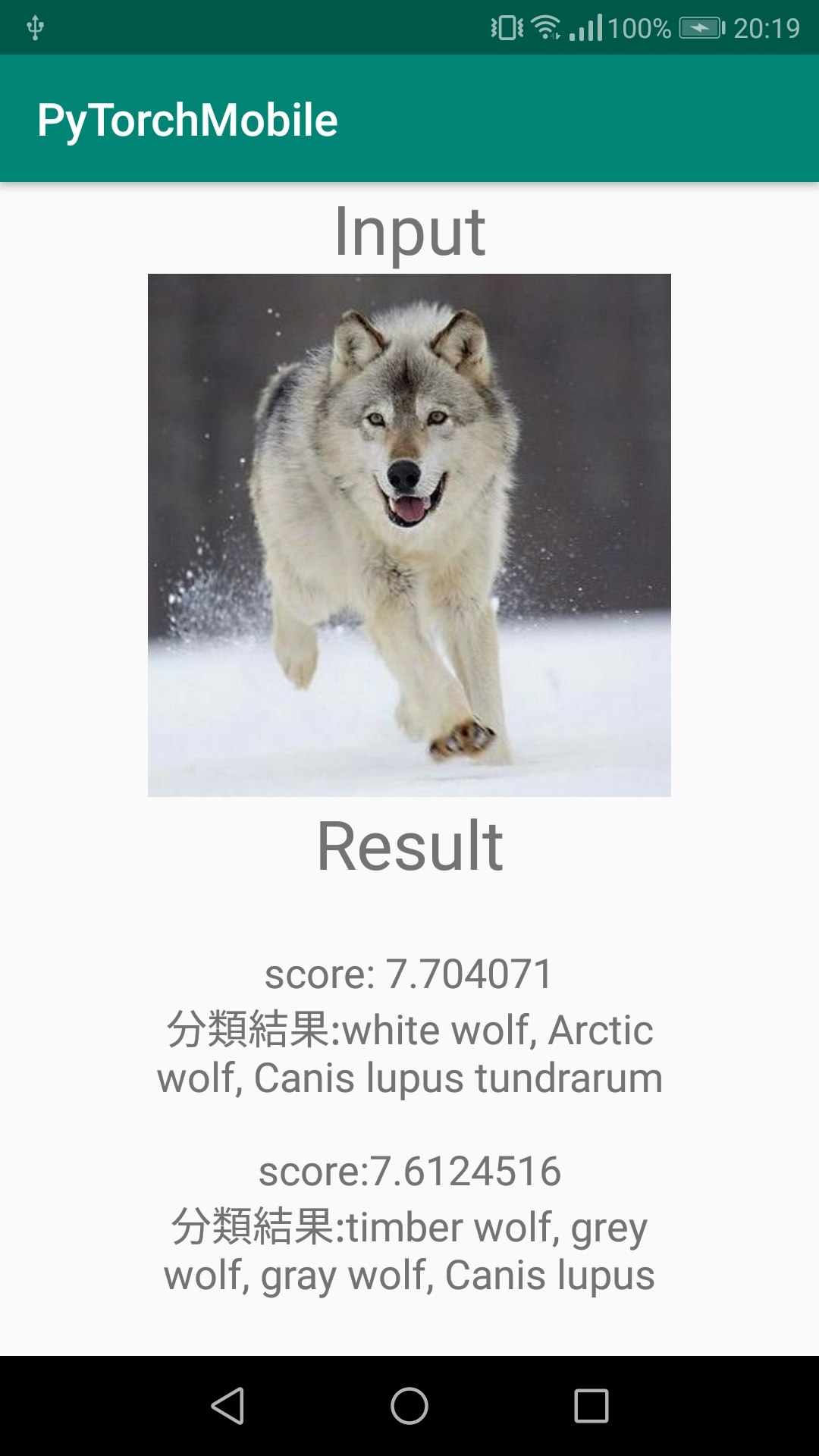
こんな感じ ↓
分類する画像と上位二つの分類結果とそのスコアを表示するだけの簡単なもの。(Canis lupusってなんだろ?)必要なもの
- python の実行環境 (自分はjupyter notebookでやった)
- pytorch, torchVision(最新版推奨)
- android studio
こんだけ
ResNetモデルのダウンロード
まずandroid studio で新規プロジェクトを作成する。
そのプロジェクトにassetsフォルダを作成する。(「UI左のapp右クリック-> 新規 -> フォルダ -> assetsフォルダ」 でできる)
作成したらそのプロジェクトのappフォルダと同じ階層で以下のpythonコードを実行するcreateModel.pyimport torch import torchvision # resnetモデルを利用 model = torchvision.models.resnet18(pretrained=True) # 推論modeに model.eval() example = torch.rand(1, 3, 224, 224) traced_script_module = torch.jit.trace(model, example) traced_script_module.save("app/src/main/assets/resnet.pt")うまく実行できると先ほど作ったassetsフォルダに
resnet.ptというファイルが追加される。assetsフォルダとdrawableフォルダに以下のサンプル画像を
image.jpgの名前で保存する
実装
依存関係
gradleに以下を追加(2020年1月4日時点)
dependencies { implementation 'org.pytorch:pytorch_android:1.3.0' implementation 'org.pytorch:pytorch_android_torchvision:1.3.0' }android studio でレイアウトを作る
適当にレイアウト作成
縦に画像が1個とテキストが6個あるだけのレイアウトactivity_main.xml<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <TextView android:id="@+id/textView" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Input" android:textSize="30sp" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toTopOf="parent" /> <ImageView android:id="@+id/imageView" android:layout_width="wrap_content" android:layout_height="230dp" android:scaleType="fitCenter" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/textView" app:srcCompat="@drawable/image" /> <TextView android:id="@+id/textView2" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Result" android:textSize="30sp" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/imageView" /> <TextView android:id="@+id/result1Score" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="32dp" android:text="TextView" android:textSize="18sp" app:layout_constraintBottom_toTopOf="@+id/result1Class" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintHorizontal_bias="0.5" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/textView2" /> <TextView android:id="@+id/result1Class" android:layout_width="250dp" android:layout_height="wrap_content" android:layout_marginStart="40dp" android:layout_marginTop="8dp" android:layout_marginEnd="40dp" android:gravity="center" android:text="TextView" android:textSize="18sp" app:layout_constraintBottom_toTopOf="@+id/result2Score" app:layout_constraintEnd_toEndOf="@+id/result1Score" app:layout_constraintHorizontal_bias="0.5" app:layout_constraintStart_toStartOf="@+id/result1Score" app:layout_constraintTop_toBottomOf="@+id/result1Score" /> <TextView android:id="@+id/result2Score" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="24dp" android:text="TextView" android:textSize="18sp" app:layout_constraintBottom_toTopOf="@+id/result2Class" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintHorizontal_bias="0.5" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/result1Class" app:layout_constraintVertical_bias="0.94" /> <TextView android:id="@+id/result2Class" android:layout_width="250dp" android:layout_height="wrap_content" android:layout_marginStart="40dp" android:layout_marginTop="8dp" android:layout_marginEnd="40dp" android:layout_marginBottom="32dp" android:gravity="center" android:text="TextView" android:textSize="18sp" app:layout_constraintBottom_toBottomOf="parent" app:layout_constraintEnd_toEndOf="@+id/result2Score" app:layout_constraintHorizontal_bias="0.5" app:layout_constraintStart_toStartOf="@+id/result2Score" app:layout_constraintTop_toBottomOf="@+id/result2Score" /> </androidx.constraintlayout.widget.ConstraintLayout>モデルのロード
先に作成した
resnet.ptをロードするMainActivity.ktoverride fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) //// assetファイルからパスを取得する関数 fun assetFilePath(context: Context, assetName: String): String { val file = File(context.filesDir, assetName) if (file.exists() && file.length() > 0) { return file.absolutePath } context.assets.open(assetName).use { inputStream -> FileOutputStream(file).use { outputStream -> val buffer = ByteArray(4 * 1024) var read: Int while (inputStream.read(buffer).also { read = it } != -1) { outputStream.write(buffer, 0, read) } outputStream.flush() } return file.absolutePath } } /// モデルと画像をロード /// シリアル化されたモデルをロード val bitmap = BitmapFactory.decodeStream(assets.open("image.jpg")) val module = Module.load(assetFilePath(this, "resnet.pt")) }assetsフォルダから画像やモデルをロードするのは結構面倒な書き方をするので注意
推論
dependenciesに追加したモジュールとresnetを使ってサンプル画像を入力して結果を出力する
MainActivity.kt/// テンソルに変換 val inputTensor = TensorImageUtils.bitmapToFloat32Tensor( bitmap, TensorImageUtils.TORCHVISION_NORM_MEAN_RGB, TensorImageUtils.TORCHVISION_NORM_STD_RGB ) /// 推論とその結果 /// フォワードプロパゲーション val outputTensor = module.forward(IValue.from(inputTensor)).toTensor() val scores = outputTensor.dataAsFloatArray推論結果
上位のscoreを取り出す
MainActivity.kt/// scoreを格納する変数 var maxScore: Float = 0F var maxScoreIdx = -1 var maxSecondScore: Float = 0F var maxSecondScoreIdx = -1 /// scoreが高いものを上から2個とる for (i in scores.indices) { if (scores[i] > maxScore) { maxSecondScore = maxScore maxSecondScoreIdx = maxScoreIdx maxScore = scores[i] maxScoreIdx = i } }分類クラス
分類するクラスの名前
すごく長いので省略 (imageNetの1000クラス分類のアレです)
githubに載せてるのでImageNetClasses.ktの中身をコピペしてくださいgithub クラス名リスト(ImageNetClasses.kt)
ImageNetClasses.ktclass ImageNetClasses { var IMAGENET_CLASSES = arrayOf( "tench, Tinca tinca", "goldfish, Carassius auratus", //~~~~~~~~~~~~~~略(githubからコピペしてください)~~~~~~~~~~~~~~~~// "toilet tissue, toilet paper, bathroom tissue" ) }結果を表示
インデックスから推論したクラス名を取得し、
最後に推論結果をレイアウトに表示するMainActivity.kt/// インデックスから分類したクラス名を取得 val className = ImageNetClasses().IMAGENET_CLASSES[maxScoreIdx] val className2 = ImageNetClasses().IMAGENET_CLASSES[maxSecondScoreIdx] result1Score.text = "score: $maxScore" result1Class.text = "分類結果:$className" result2Score.text = "score:$maxSecondScore" result2Class.text = "分類結果:$className2"完了!!ビルドすれば冒頭のような画面ができるはず。
いろんな写真入れて遊んでみてください。おわり
ライブラリって便利。画像分類がこんだけでできるとは。
tensorに変換とかが少しひっかかるなって感じだったけど、これでpytorchでもandroid に使えるようになった。
あと余談で、最初pytorchのバージョンが最新じゃなくてモデルのロードのときエラー出て全くできかったところと、assetsフォルダのパスの取得で結構ハマった。

- 投稿日:2020-01-04T22:04:42+09:00
Pythonによる AI・機械学習について学んでいます(2)
はじめに
この本を使って勉強しています
Pythonによる AI・機械学習・深層学習アプリのつくり方1-4 Google Colaboratory
Google が提供している Colaboratory を使うとインストール不要で機械学習の開発を始めることができます。必要なのは、HTML5に対応したWebブラウザだけです!
Colaboratory を使うメリット
Python 環境をインストール不要、最初からよく使うライブラリの一式がインストール済み。
サーバのOS は、Ubuntu(Linux)なのでUbuntuで動作するツールやライブラリであれば自由にインストールして使用可能。
仕組みは、Colaboratoryのサーバで計算が行われ、結果だけがWebブラウザに返されて表示される。Google Colaboratory を開く
https://colab.research.google.com/
GPUをアサイン
メニュー ランタイム > ランタイムのタイプを変更 で、 ノートブックの設定 を開く
ハードウェア・アクセラレータに GPU を選択し 保存 するどんなサーバーなの?
次のコマンドを実行するとわかるよ
- !cat /proc/cpuinfo
- !cat /proc/meminfo
- !cat /etc/issue
- !df -h
- !free -h
- !cat /proc/cpuinfo
- !nvcc -v
- !nvidia-smi
Sat Jan 4 12:04:20 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.44 Driver Version: 418.67 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 | | N/A 37C P8 9W / 70W | 0MiB / 15079MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+Tesla T4だって!
AI専用サーバーを構築しようと思ったけどやめました。制約
- 最大利用時間は12時間
- 最大利用時間を超えると全部初期化されて消えてしまう
Google Drive をマウントするといい
Colaboratory の左にある > からドライブをマウントをクリックすると Google Drive を
/content/drive/My Drive/ 以下にマウントすることができる。
必要なファイルは、Google Drive にアップロードすればすぐにみられる。
12時間を超えてもちゃんとファイルは保存されてる。ディレクトリの移動は、cd で行える。
ちなみに ls ll などのコマンドも使える。ちょっとグラフを描いてみる
import numpy as np import matplotlib.pyplot as plt x = np.arange(0, 10, 0.1) y = np.sin(x) plt.plot(x, y) plt.show()

- 投稿日:2020-01-04T22:04:42+09:00
Pythonによる AI・機械学習について学んだ内容(2)
はじめに
この本を使って勉強しています
Pythonによる AI・機械学習・深層学習アプリのつくり方1-4 Google Colaboratory
Google が提供している Colaboratory を使うとインストール不要で機械学習の開発を始めることができます。必要なのは、HTML5に対応したWebブラウザだけです!
Colaboratory を使うメリット
Python 環境をインストール不要、最初からよく使うライブラリの一式がインストール済み。
サーバのOS は、Ubuntu(Linux)なのでUbuntuで動作するツールやライブラリであれば自由にインストールして使用可能。
仕組みは、Colaboratoryのサーバで計算が行われ、結果だけがWebブラウザに返されて表示される。Google Colaboratory を開く
https://colab.research.google.com/
GPUをアサイン
メニュー ランタイム > ランタイムのタイプを変更 で、 ノートブックの設定 を開く
ハードウェア・アクセラレータに GPU を選択し 保存 するどんなサーバーなの?
次のコマンドを実行するとわかるよ
- !cat /proc/cpuinfo
- !cat /proc/meminfo
- !cat /etc/issue
- !df -h
- !free -h
- !cat /proc/cpuinfo
- !nvcc -v
- !nvidia-smi
Sat Jan 4 12:04:20 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.44 Driver Version: 418.67 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 | | N/A 37C P8 9W / 70W | 0MiB / 15079MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+Tesla T4だって!
AI専用サーバーを構築しようと思ったけどやめました。制約
- 最大利用時間は12時間
- 最大利用時間を超えると全部初期化されて消えてしまう
Google Drive をマウントするといい
Colaboratory の左にある > からドライブをマウントをクリックすると Google Drive を
/content/drive/My Drive/ 以下にマウントすることができる。
必要なファイルは、Google Drive にアップロードすればすぐにみられる。
12時間を超えてもちゃんとファイルは保存されてる。ディレクトリの移動は、cd で行える。
ちなみに ls ll などのコマンドも使える。ちょっとグラフを描いてみる
import numpy as np import matplotlib.pyplot as plt x = np.arange(0, 10, 0.1) y = np.sin(x) plt.plot(x, y) plt.show()
- 投稿日:2020-01-04T21:34:57+09:00
【初心者向け】自然言語処理ツール「GiNZA」を用いた言語解析入門(形態素解析からベクトル化まで)
はじめに
最近、Pythonの言語処理ツール「GiNZA」を使い始めました。これまではMeCabを使っていましたが、なにやら最先端の機械学習技術を取り入れたライブラリがPythonにあるというのを(恥ずかしながら)最近知ったので、現在GiNZAに移行中です。今回は初めてのGiNZAということもあり、いろいろなサイトを参考にしながら備忘録として処理の流れをまとめてみました。筆者は自然言語解析の初学者で至らぬ箇所も多々ありますので、より深く学習したい方は公式ドキュメントなどを参考にしてください。この記事は、筆者と同じ初学者が「GiNZAってこんなことが出来るんだ!自分も使ってみよう!」と思ってくれればいいなと思いながら書いています。
GiNZAについて
既に多くの方が記事にされていますが、GiNZAはリクルートのAI研究機関であるMegagon Labsと国立国語研究所との共同研究成果の学習モデルを用いた自然言語処理ライブラリです。
「GiNZA」の概要
「GiNZA」は、ワンステップでの導入、高速・高精度な解析処理、単語依存構造解析レベルの国際化対応などの特長を備えた日本語自然言語処理オープンソースライブラリです。「GiNZA」は、最先端の機械学習技術を取り入れた自然言語処理ライブラリ「spaCy」(※5)をフレームワークとして利用しており、また、オープンソース形態素解析器「SudachiPy」(※6)を内部に組み込み、トークン化処理に利用しています。「GiNZA日本語UDモデル」にはMegagon Labsと国立国語研究所の共同研究成果が組み込まれています。https://www.recruit.co.jp/newsroom/2019/0402_18331.htmlより引用
GiNZAの内部では言語処理ライブラリ「spaCy」を利用しているようですね。こちらに記載されているように、GiNZAはspaCyを日本語対応にしたライブラリであるとざっくり解釈しています。また、形態素解析には「SudachiPy」を利用しています。この記事を読む多くの方が日本語の解析を望んでいるはずなので、Pythonユーザーにとって魅力的なライブラリですね!
開発環境
- Ubuntu 16.04
- Python 3.6.7
- GiNZA 2.2.0
(2020/01/04現在、GiNZAの最新バージョンは2.2.1です。)
GiNZAはpipコマンド一行でインストール出来ます。
$ pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"形態素解析
まずは基本の形態素解析を行います。
係り受け解析import spacy nlp = spacy.load('ja_ginza') doc = nlp('今年の干支は庚子です。東京オリンピックたのしみだなあ。') for sent in doc.sents: for token in sent: print(token.i, token.orth_, token.lemma_, token.pos_, token.tag_, token.dep_, token.head.i)出力結果
0 今年 今年 NOUN 名詞-普通名詞-副詞可能 nmod 2 1 の の ADP 助詞-格助詞 case 0 2 干支 干支 NOUN 名詞-普通名詞-一般 nsubj 4 3 は は ADP 助詞-係助詞 case 2 4 庚子 庚子 NOUN 名詞-普通名詞-一般 ROOT 4 5 です です AUX 助動詞 aux 4 6 。 。 PUNCT 補助記号-句点 punct 4 7 東京 東京 PROPN 名詞-固有名詞-地名-一般 compound 9 8 オリンピック オリンピック NOUN 名詞-普通名詞-一般 compound 9 9 たのしみ 楽しみ NOUN 名詞-普通名詞-一般 ROOT 9 10 だ だ AUX 助動詞 cop 9 11 なあ な PART 助詞-終助詞 aux 9 12 。 。 PUNCT 補助記号-句点 punct 9上手く形態素に分割できています。左から「入力語」「見出し語(基本形)」「品詞」「品詞詳細」です(tokenの詳細はspaCyのAPIを参照してください)。GiNZAでは依存構造解析にも対応しており、依存関係にある単語番号とその単語との関係も推定されています(token.dep_の詳細はこちらを参照してください)。
GiNZAでは依存関係をグラフで可視化することも可能です。可視化には
displacyを使います。依存関係の可視化from spacy import displacy displacy.serve(doc, style='dep', options={'compact':True})実行後、
Serving on http://0.0.0.0:5000 ...と表示されるので、アクセスすると図が表示されます。
MeCabしか使ってこなかったので、一行で構造を図示してくれるのは素晴らしいの一言です。可視化手法の詳細はspaCyのVisualizersを参照してください 。
テキストのベクトル化
単語ベクトルの推定法はいくつか提案されていますが、GiNZAには既に学習済みの単語ベクトルが用意されており、
Tokenのvector属性で参照することが出来ます。単語ベクトルdoc = nlp('あきらめたらそこで試合終了だ') token = doc[4] print(token) print(token.vector) print(token.vector.shape)実行結果
試合 [-1.7299166 1.3438352 0.51212436 0.8338855 0.42193085 -1.4436126 4.331309 -0.59857213 2.091658 3.1512427 -2.0446565 -0.41324708 ... 1.1213776 1.1430703 -1.231743 -2.3723211 ] (100,)単語ベクトルの次元数は100次元です。
また、similarity()メソッドを使用することで単語ベクトル間のコサイン類似度をはかることが出来ます。similarityword1 = nlp('おむすび') word2 = nlp('おにぎり') word3 = nlp('カレー') print(word1.similarity(word2)) #0.8016603151410209 print(word1.similarity(word3)) #0.5304326270109458コサイン類似度は0-1の範囲を取り、1に近いほど単語同士が似ているという意味になります。実際に、おむすびはカレーよりおにぎりに近いです。また、単語ではなく文書の場合でも同じ手順でベクトル化とコサイン類似度の計算が出来ます。文書のベクトルは、その文を構成する単語ベクトルの平均を返しているようです。
最後に、単語や文書をベクトルで表現できたのでこれらをベクトル空間に図示してみます。ベクトルの次元は100次元なので今回は主成分分析を用いて2次元まで落としてからプロットします。
plotimport numpy as np import matplotlib.pyplot as plt from sklearn.decomposition import PCA #text2vector vec1 = nlp('あけましておめでとうございます').vector vec2 = nlp('昨日キャベツを買った').vector vec3 = nlp('映画を観に行こう').vector vec4 = nlp('カレーが食べたい').vector vec5 = nlp('買い物しようと町まで出かけた').vector vec6 = nlp('昨日食べたチョコレート').vector #pca vectors = np.vstack((vec1, vec2, vec3, vec4, vec5, vec6)) pca = PCA(n_components=2).fit(vectors) trans = pca.fit_transform(vectors) pc_ratio = pca.explained_variance_ratio_ #plot plt.figure() plt.scatter(trans[:,0], trans[:,1]) i = 0 for txt in ['text1','text2','text3','text4','text5','text6']: plt.text(trans[i,0]-0.2, trans[i,1]+0.1, txt) i += 1 plt.hlines(0, min(trans[:,0]), max(trans[:,0]), linestyle='dashed', linewidth=1) plt.vlines(0, min(trans[:,1]), max(trans[:,1]), linestyle='dashed', linewidth=1) plt.xlabel('PC1 ('+str(round(pc_ratio[0]*100,2))+'%)') plt.ylabel('PC2 ('+str(round(pc_ratio[1]*100,2))+'%)') plt.tight_layout() plt.show()実行結果
情報量は落ちていますが、大量のデータを扱うにはこちらの方が認識しやすいかと思います。この図を見るとtext3と5が、text4と6がそれぞれ近いようですね。肌感覚でもそんな気がします。
最後に
自然言語処理初学者でしたが、GiNZAを利用することで形態素解析からベクトル化まで簡単に解析することが出来ました。これから言語処理を始めたい方にぜひオススメです。もし間違っている箇所やおかしな表現などありましたらご指摘をいただけますと幸いです。
参考サイト


- 投稿日:2020-01-04T21:34:57+09:00
【初心者向け】自然言語処理ツール「GiNZA」を用いた言語解析(形態素解析からベクトル化まで)
はじめに
最近、Pythonの言語処理ツール「GiNZA」を使い始めました。これまではMeCabを使っていましたが、なにやら最先端の機械学習技術を取り入れたライブラリがPythonにあるというのを(恥ずかしながら)最近知ったので、現在GiNZAに移行中です。今回は初めてのGiNZAということもあり、いろいろなサイトを参考にしながら備忘録として処理の流れをまとめてみました。筆者は自然言語解析の初学者で至らぬ箇所も多々ありますので、より深く学習したい方は公式ドキュメントなどを参考にしてください。この記事は、筆者と同じ初学者が「GiNZAってこんなことが出来るんだ!自分も使ってみよう!」と思ってくれればいいなと思いながら書いています。
GiNZAについて
既に多くの方が記事にされていますが、GiNZAはリクルートのAI研究機関であるMegagon Labsと国立国語研究所との共同研究成果の学習モデルを用いた自然言語処理ライブラリです。
「GiNZA」の概要
「GiNZA」は、ワンステップでの導入、高速・高精度な解析処理、単語依存構造解析レベルの国際化対応などの特長を備えた日本語自然言語処理オープンソースライブラリです。「GiNZA」は、最先端の機械学習技術を取り入れた自然言語処理ライブラリ「spaCy」(※5)をフレームワークとして利用しており、また、オープンソース形態素解析器「SudachiPy」(※6)を内部に組み込み、トークン化処理に利用しています。「GiNZA日本語UDモデル」にはMegagon Labsと国立国語研究所の共同研究成果が組み込まれています。https://www.recruit.co.jp/newsroom/2019/0402_18331.htmlより引用
GiNZAの内部では言語処理ライブラリ「spaCy」を利用しているようですね。こちらに記載されているように、GiNZAはspaCyを日本語対応にしたライブラリであるとざっくり解釈しています。また、形態素解析には「SudachiPy」を利用しています。この記事を読む多くの方が日本語の解析を望んでいるはずなので、Pythonユーザーにとって魅力的なライブラリですね!
開発環境
- Ubuntu 16.04
- Python 3.6.7
- GiNZA 2.2.0
(2020/01/04現在、GiNZAの最新バージョンは2.2.1です。)
GiNZAはpipコマンド一行でインストール出来ます。
$ pip install "https://github.com/megagonlabs/ginza/releases/download/latest/ginza-latest.tar.gz"形態素解析
まずは基本の形態素解析を行います。
係り受け解析import spacy nlp = spacy.load('ja_ginza') doc = nlp('今年の干支は庚子です。東京オリンピックたのしみだなあ。') for sent in doc.sents: for token in sent: print(token.i, token.orth_, token.lemma_, token.pos_, token.tag_, token.dep_, token.head.i)出力結果
0 今年 今年 NOUN 名詞-普通名詞-副詞可能 nmod 2 1 の の ADP 助詞-格助詞 case 0 2 干支 干支 NOUN 名詞-普通名詞-一般 nsubj 4 3 は は ADP 助詞-係助詞 case 2 4 庚子 庚子 NOUN 名詞-普通名詞-一般 ROOT 4 5 です です AUX 助動詞 aux 4 6 。 。 PUNCT 補助記号-句点 punct 4 7 東京 東京 PROPN 名詞-固有名詞-地名-一般 compound 9 8 オリンピック オリンピック NOUN 名詞-普通名詞-一般 compound 9 9 たのしみ 楽しみ NOUN 名詞-普通名詞-一般 ROOT 9 10 だ だ AUX 助動詞 cop 9 11 なあ な PART 助詞-終助詞 aux 9 12 。 。 PUNCT 補助記号-句点 punct 9上手く形態素に分割できています。左から「入力語」「見出し語(基本形)」「品詞」「品詞詳細」です(tokenの詳細はspaCyのAPIを参照してください)。GiNZAでは依存構造解析にも対応しており、依存関係にある単語番号とその単語との関係も推定されています(token.dep_の詳細はこちらを参照してください)。
GiNZAでは依存関係をグラフで可視化することも可能です。可視化には
displacyを使います。依存関係の可視化from spacy import displacy displacy.serve(doc, style='dep', options={'compact':True})実行後、
Serving on http://0.0.0.0:5000 ...と表示されるので、アクセスすると図が表示されます。
MeCabしか使ってこなかったので、一行で構造を図示してくれるのは素晴らしいの一言です。可視化手法の詳細はspaCyのVisualizersを参照してください 。
テキストのベクトル化
単語ベクトルの推定法はいくつか提案されていますが、GiNZAには既に学習済みの単語ベクトルが用意されており、
Tokenのvector属性で参照することが出来ます。単語ベクトルdoc = nlp('あきらめたらそこで試合終了だ') token = doc[4] print(token) print(token.vector) print(token.vector.shape)実行結果
試合 [-1.7299166 1.3438352 0.51212436 0.8338855 0.42193085 -1.4436126 4.331309 -0.59857213 2.091658 3.1512427 -2.0446565 -0.41324708 ... 1.1213776 1.1430703 -1.231743 -2.3723211 ] (100,)単語ベクトルの次元数は100次元です。
また、similarity()メソッドを使用することで単語ベクトル間のコサイン類似度をはかることが出来ます。similarityword1 = nlp('おむすび') word2 = nlp('おにぎり') word3 = nlp('カレー') print(word1.similarity(word2)) #0.8016603151410209 print(word1.similarity(word3)) #0.5304326270109458コサイン類似度は0-1の範囲を取り、1に近いほど単語同士が似ているという意味になります。実際に、おむすびはカレーよりおにぎりに近いです。また、単語ではなく文書の場合でも同じ手順でベクトル化とコサイン類似度の計算が出来ます。文書のベクトルは、その文を構成する単語ベクトルの平均を返しているようです。
最後に、単語や文書をベクトルで表現できたのでこれらをベクトル空間に図示してみます。ベクトルの次元は100次元なので今回は主成分分析を用いて2次元まで落としてからプロットします。
plotimport numpy as np import matplotlib.pyplot as plt from sklearn.decomposition import PCA #text2vector vec1 = nlp('あけましておめでとうございます').vector vec2 = nlp('昨日キャベツを買った').vector vec3 = nlp('映画を観に行こう').vector vec4 = nlp('カレーが食べたい').vector vec5 = nlp('買い物しようと町まで出かけた').vector vec6 = nlp('昨日食べたチョコレート').vector #pca vectors = np.vstack((vec1, vec2, vec3, vec4, vec5, vec6)) pca = PCA(n_components=2).fit(vectors) trans = pca.fit_transform(vectors) pc_ratio = pca.explained_variance_ratio_ #plot plt.figure() plt.scatter(trans[:,0], trans[:,1]) i = 0 for txt in ['text1','text2','text3','text4','text5','text6']: plt.text(trans[i,0]-0.2, trans[i,1]+0.1, txt) i += 1 plt.hlines(0, min(trans[:,0]), max(trans[:,0]), linestyle='dashed', linewidth=1) plt.vlines(0, min(trans[:,1]), max(trans[:,1]), linestyle='dashed', linewidth=1) plt.xlabel('PC1 ('+str(round(pc_ratio[0]*100,2))+'%)') plt.ylabel('PC2 ('+str(round(pc_ratio[1]*100,2))+'%)') plt.tight_layout() plt.show()実行結果
情報量は落ちていますが、大量のデータを扱うにはこちらの方が認識しやすいかと思います。この図を見るとtext3と5が、text4と6がそれぞれ近いようですね。肌感覚でもそんな気がします。
最後に
自然言語処理初学者でしたが、GiNZAを利用することで形態素解析からベクトル化まで簡単に解析することが出来ました。これから言語処理を始めたい方にぜひオススメです。もし間違っている箇所やおかしな表現などありましたらご指摘をいただけますと幸いです。
参考サイト
- 投稿日:2020-01-04T21:26:38+09:00
実験系でもPythonで効率化したい(4)try構文を用いてエラーを吐いたときにser.close()するようにする
前回までのあらすじ
前回までで測定を自動化できるようになりました。今回は測定装置が機嫌が悪い時に、エラーを吐いてしまうのでそれに対応します。
Windows COMポート二桁以上許容されない問題
- マイクロソフトサポートページ
- 上記サイトでも言及されている通り、WindowsではCOMポートが、接続デバイスが増えるごとに増殖し続けるにも関わらず、10以上になると不具合が出ることがあります。私の環境ではADVANTEST社のR6441が、USBハブなどを用いて接続しているときに、COMポートが10以上だと測定に失敗することがあります。
try構文を用いて解決する
exceptのあとに例外の名前(エラーのときに出力される)を書いておくと、失敗したときの挙動を決められます。今回は、ser.close()するようにします。try: while 1: if pulse >= MAX: ## 位置がMAXまで来ている場合while文を終了 break ## 現在位置の情報を記録 pulse_list.append(pulse/2) ## 電流を測定する(5回とって平均したものをその位置での値とする) for i in range(5): ser = serial.Serial(COMampere,bitRate,timeout=0.1) ser.write(b"F5, R0,PR2\r\n") time.sleep(1) ser.write(b"MD?\r\n") time.sleep(1) tmp = ser.read_all() # 電流が取れていない場合はスキップする if len(tmp)== 0: ser.close() continue ampere = float(tmp.split()[2]) ampere_average_list.append(ampere) time.sleep(1) ser.close() ## 電流とpulse(位置)をlistに追加 ampere_list.append(sum(ampere_average_list)/len(ampere_average_list)) ampere_average_list = [] ## 光学台を動かす pulse += 1000 position = "A:2+P"+str(pulse)+"\r\n" ser = serial.Serial(COMpulse,bitRate,timeout=0.1) ser.write(bytes(position, 'UTF-8')) time.sleep(1) ser.write(b"G:\r\n") ser.close() ## リストをdataframeに変える print(ampere_list) print(pulse_list) df = pd.DataFrame({'ampere(A)':ampere_list,'pulse':pulse_list}) def pulseToMilliMeter(pulse): return pulse*0.006 df["position(mm)"] = df["pulse"].map(pulseToMilliMeter) df.to_csv('./csv/result.csv',index=False) plt.figure() df.plot(x='position(mm)',y='ampere(A)',marker='o') plt.savefig('./img/sample.png') plt.close('all') except IndexError: ser.close()
- 投稿日:2020-01-04T21:25:42+09:00
実験系でもPythonで効率化したい(5)slackAPIで実験終了時に通知を送りたい
前回までのあらすじ
前回まででエラーも考慮して自動測定ができるようになりました。今回はslackのAPIを用いて、測定の終了をslackに通知できるようにします。他のチャットツール(Discord ,Lineなど)であっても、トークンを取得してAPIに要求を送るという流れは同じなので、様々な用途に利用できると思います。
環境
- Windows10
- Anaconda(3.x)
- (2)でpySerialを
conda installしましたやっていること
pythonのslackclientパッケージが私の環境では動かなかったので、
- Slackにpythonからメッセージを送信する - Qiita
- Pythonを使ってSlackに送信する方法 - Qiitaなどを参考にして、
- requests パッケージを用いて
- slackのwebページで取得したトークンを用いて
slackAPIを使って任意のメッセージを、任意のチャンネルに送れます。以下のコードで変更すべき点は
- token
- send_message("ココ", ココ(チャンネル名))
のみで、送れるはずです
mentionの付け方は
このサイトを参考にしてください
import serial import time import pandas as pd ## 定数指定 MAX = 40000 COMampere = "COM10" COMpulse = "COM9" bitRate = 9600 ## 変数初期化 pulse = 0 ampere_list = [] pulse_list = [] ampere_average_list =[] ## 奥原点移動(初期化) ser = serial.Serial(COMsigma, bitRate, timeout=0.1) ser.write(b"H:2-\r\n") # time.sleep(0.1) # print(ser.read_all()) ser.close() import requests class SlackDriver: def __init__(self, _token): self._token = _token # api_token self._headers = {'Content-Type': 'application/json'} def send_message(self, message, channel): params = {"token": self._token, "channel": channel, "text": message} r = requests.get('https://slack.com/api/chat.postMessage', headers=self._headers, params=params) print("return ", r.json()) token = 'xxxx-oooooooooooo-000000000000-hogehoge' # この部分を取得したトークンにしてください slack = SlackDriver(token) # 計測開始 try: while 1: if pulse >= MAX: ## 位置がMAXまで来ている場合while文を終了 break if pulse ==2000: slack.send_message("<@IDhogehoge> 1000おわったよ", "#bot-test") # 取得したIDは<>でくくってください if pulse ==30000: slack.send_message("<@IDhogehoge> 15000おわったよ", "#bot-test") ## 現在位置の情報を記録 pulse_list.append(pulse/2) ## 電流を測定する(5回とって平均したものをその位置での値とする) for i in range(5): ser = serial.Serial(COMampere,bitRate,timeout=0.1) ser.write(b"F5, R0,PR2\r\n") time.sleep(1) ser.write(b"MD?\r\n") time.sleep(1) tmp = ser.read_all() # 電流が取れていない場合はスキップする if len(tmp)== 0: ser.close() continue ampere = float(tmp.split()[2]) ampere_average_list.append(ampere) time.sleep(1) ser.close() ## 電流とpulse(位置)をlistに追加 ampere_list.append(sum(ampere_average_list)/len(ampere_average_list)) ampere_average_list = [] ## 光学台を動かす pulse += 1000 position = "A:2+P"+str(pulse)+"\r\n" ser = serial.Serial(COMpulse,bitRate,timeout=0.1) ser.write(bytes(position, 'UTF-8')) time.sleep(1) ser.write(b"G:\r\n") ser.close() ## リストをdataframeに変える print(ampere_list) print(pulse_list) df = pd.DataFrame({'ampere(A)':ampere_list,'pulse':pulse_list}) def pulseToMilliMeter(pulse): return pulse*0.006 df["position(mm)"] = df["pulse"].map(pulseToMilliMeter) df.to_csv('./csv/result.csv',index=False) plt.figure() df.plot(x='position(mm)',y='ampere(A)',marker='o') plt.savefig('./img/sample.png') plt.close('all') except IndexError: ser.close() slack.send_message("<@IDhogehoge> 測定失敗してるよ", "#bot-test") # slackに通知したい slack.send_message("<@IDhogehoge> 測定終わったよ", "#bot-test") ## 変数初期化 pulse = 0 ampere_list = [] pulse_list = [] ampere_average_list =[] ## 奥原点移動(初期化) ser = serial.Serial(COMpulse, bitRate, timeout=0.1) ser.write(b"H:2-\r\n") time.sleep(0.1) print(ser.read_all()) ser.close()
- 投稿日:2020-01-04T21:09:33+09:00
Raspberry PiでGrove Pi+スターターキットとカメラを使う初期設定
概要
ハッカソンでRaspberry Piとカメラ、Grove Pi+スターターキット、kintoneを活用することになり、Raspberry Piのセットアップと初期設定について調べました。
結果、OpenCVをPython3で使う設定とGrove Pi+設定でトラブルはありましたが、Raspberry Piとカメラ、Grove Pi+スターターキット、Python library to access kintone の設定ができました。使用する機器について(2020/01/03 Amazonで調査)
最新のRaspberry Pi 4はGrove Piのサポートに含まれないため、今回はRaspberry Pi 3を使用しています。
そもそもRaspberry Pi 4は高価で、今回の用途にはそこまでのスペックが必要ないでしょう。今回の調査で用いた機器(一部同等品含む)
Amazonで全て購入して20,408円前後で試すことができます。
Raspberry Pi3 Model B ボード&ケースセット 3ple Decker対応 (Clear)-Physical Computing Lab(6,100円)
https://www.amazon.co.jp/dp/B01CSFZ4JG/
SanDisk microSDHC ULTRA 16GB 80MB/s SDSQUNS-016G Class10(465円)
https://www.amazon.co.jp/dp/B074B4P7KD/
Grove Pi+ スターターキット 初心者向け Raspberry Pi A+,B,B+&2,3適用 CE認証(6,100円)
https://www.amazon.co.jp/dp/B07H9PFWHW/
US電源アダプタ オン/オフスイッチ ケーブル 5V 2.5A ラズベリーパイ3に対応 軽量 携帯便利(464円)
https://www.amazon.co.jp/dp/B07CYNGG4C/
カメラモジュール 感光チップOV5647センサー 5M画素 Raspberry Pi 1 2 3 Model B B A+対応(780円)
https://www.amazon.co.jp/dp/B07G572B3R/Raspberry Piの設定
OSのセットアップ
以下より最新のOSをダウンロードしました。
https://www.raspberrypi.org/downloads/raspbian/使用したOSイメージは以下です。
Raspbian Buster with desktop
・Version: September 2019
・Release date: 2019-09-26
・Kernel version: 4.19OSをSDカードにセットアップする方法などは省略します。
詳しく知りたい方は以下を参照ください。Raspberry Pi 初期設定 Windows( @sigma7641 さん)
https://qiita.com/sigma7641/items/995c7bb07eab408b9d0e
Raspberry Pi 初期設定 Mac( @skkojiko さん)
https://qiita.com/skkojiko/items/a7e342a8ab53b409fe6aコマンドラインテキストエディタについて
作業はsshで接続し、コマンドラインで行います。
コマンドラインのテキストエディタはnanoで説明しますが、使い方は以下を参照ください。GNU nanoを使いこなす( @snct_hu さん)
https://qiita.com/snct_hu/items/971d512c26dd8b3a3b3c固定IPの設定
先ず最初にsshで接続しやすくするため固定IPを設定します。
$ sudo nano /etc/dhcpcd.conf (IPアドレスは適切な内容に変更して、以下の設定を追加) interface eth0 static ip_address=192.168.0.111/24 static routers=192.168.0.1 static domain_name_servers=192.168.0.1 8.8.8.8無線LANの設定は以下を参照ください。
Raspberry Piの無線LAN設定をコマンドラインで行う( @mym さん)
https://qiita.com/mym/items/468d2cdb30d756b6df24OSの基本設定
OSの基本設定はraspi-configを使って行います。
$ sudo raspi-config今回は、以下を設定しています。
1 Change User Password
4 Localisation Options
-> I1 Change Locale -> ja_JP.UTF-8 UTF-8
-> I2 Change Timezone -> Asia -> Tokyo
-> I3 Change Keyboard Layout -> 適宜
-> I4 Change Wi-fi Country -> JP Japan5 Interfacing Options
-> P1 Camera -> Enable
-> P4 SPI -> Enable
-> P5 I2C -> Enable8 Update
設定後はOSを最新の状態にUPDATEします。
$ sudo apt-get update $ sudo apt-get upgradeRaspberry Pi カメラ設定
Raspberry Pi カメラの設定は以下を参照ください。
Raspberry Pi カメラで写真・ビデオを撮影する
https://iotdiyclub.net/raspberry-pi-using-camera-1/基本的な設定完了後、PythonのOpenCV(画像編集ライブラリィ)用の設定を行います。
$ sudo modprobe bcm2835-v4l2 $ sudo nano /etc/modules bcm2835-v4l2 $ sudo apt-get install libopencv-dev python-opencvOpenCVの詳細については以下を参照ください。
OpenCV
https://opencv.org/
Python版 OpenCVの基本
https://cvtech.cc/py-opencv/
画像処理入門講座 : OpenCVとPythonで始める画像処理
https://postd.cc/image-processing-101/Python3を使う場合は以下の設定を行います。
$ sudo apt-get install libhdf5-dev libhdf5-serial-dev libhdf5-103 $ sudo apt-get install libqtgui4 libqtwebkit4 libqt4-test python3-pyqt5 $ sudo apt-get install libatlas-base-dev $ sudo apt-get install libjasper-dev $ pip3 install opencv-pythonOpenCVをPython3でそのまま利用すると import cv2 でエラーになります。
このエラーを回避するため、ロードするライブラリィを追加します。$ nano .bashrc export LD_PRELOAD=/usr/lib/arm-linux-gnueabihf/libatomic.so.1 $ source .bashrcGrove Pi+の設定
Grove Pi+のRaspberry Pi への取り付けは以下を参考にしてください。
GrovePi+
https://www.switch-science.com/catalog/2129/Grove Pi+のソフトウェアの設定は以下を参考に行います。
Setting Up The Software
https://www.dexterindustries.com/GrovePi/get-started-with-the-grovepi/setting-software/$ curl -kL dexterindustries.com/update_grovepi | bash $ sudo reboot $ cd /home/pi/Dexter $ git clone https://github.com/DexterInd/GrovePi $ cd /home/pi/Dexter/GrovePi/Script $ sudo chmod +x install.sh $ sudo ./install.shインストール後に問題なければi2cdetectコマンドで以下のようにI2Cの04ポートが確認できます。
$ sudo i2cdetect -y 1 0 1 2 3 4 5 6 7 8 9 a b c d e f 00: -- 04 -- -- -- -- -- -- -- -- -- -- -- 10: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 20: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 30: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 40: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 50: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 60: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 70: -- -- -- -- -- -- -- --Grove Pi+設定後、OSやインストール済のソフト更新を行う apt-get upgrade でパッケージ依存関係に問題が発生しエラーになります。
このエラーを回避するため、以下を実行します。$ sudo apt-get --fix-broken upgrade実際に動くか試験するため、以下を参考に付属のGrove LEDをGrove Pi+のD4ポートに配線します。
http://wiki.seeedstudio.com/Grove-Red_LED/#play-with-raspberry-pi-with-grovepi_plus
配線後に、以下のバージョン表示や、LEDの点滅を試験して問題がないか確認します。
$ python /home/pi/Dexter/GrovePi/Software/Python/grovepi.py library supports this fw versions: 1.3.0 $ python /home/pi/Dexter/GrovePi/Software/Python/grove_led_blink.py This example will blink a Grove LED connected to the GrovePi+ on the port labeled D4. If you're having trouble seeing the LED blink, be sure to check the LED connection and the port number. You may also try reversing the direction of the LED on the sensor. Connect the LED to the port labele D4! LED ON! LED OFF! LED ON! LED OFF! LED ON! LED OFF!Grove Pi+のライブラリィ不具合
2020/02/02 時点で以下のGrove Pi+のライブラリィ 1.3.0 のファイルに不具合があり、多くのサンプルが動きません。
/home/pi/Dexter/GrovePi/Software/Python/grovepi.py
https://github.com/DexterInd/GrovePi/blob/master/Software/Python/grovepi.py例えば grove_button.py は、0でボタンOFF、1でボタンONを表示するプログラムですが、実行すると以下の表示になります。
$ python /home/pi/Dexter/GrovePi/Software/Python/grove_button.py 255 255 255 255 255 255grovepi.pyのI2Cの読み込み部分に不具合があり、修正する必要があります。
以下にgrovepi.pyの修正箇所を説明します。227行目read_identified_i2c_block()while文が永久ループするため削除
grovepi.pydef read_identified_i2c_block(read_command_id, no_bytes): data = [-1] data = read_i2c_block(no_bytes + 1) return data246行目analogRead()のnumber配列要素番号を修正
grovepi.py# Read analog value from Pin def analogRead(pin): write_i2c_block(aRead_cmd + [pin, unused, unused]) number = read_identified_i2c_block(aRead_cmd, no_bytes = 2) return number[1] * 256 + number[2]284行目ultrasonicRead()のnumber配列要素番号を修正
grovepi.py# Read value from Grove Ultrasonic def ultrasonicRead(pin): write_i2c_block(uRead_cmd + [pin, unused, unused]) number = read_identified_i2c_block(uRead_cmd, no_bytes = 2) return (number[1] * 256 + number[2])320行目dht()のnumber配列要素番号、no_bytes変数値を修正
grovepi.py# Read and return temperature and humidity from Grove DHT Pro def dht(pin, module_type): write_i2c_block(dht_temp_cmd + [pin, module_type, unused]) number = read_identified_i2c_block(dht_temp_cmd, no_bytes = 9) if p_version==2: h='' for element in (number[1:5]): h+=chr(element) t_val=struct.unpack('f', h) t = round(t_val[0], 2) h = '' for element in (number[5:9]): h+=chr(element) hum_val=struct.unpack('f',h) hum = round(hum_val[0], 2) else: t_val=bytearray(number[1:5]) h_val=bytearray(number[5:9]) t=round(struct.unpack('f',t_val)[0],2) hum=round(struct.unpack('f',h_val)[0],2) if t > -100.0 and t <150.0 and hum >= 0.0 and hum<=100.0: return [t, hum] else: return [float('nan'),float('nan')]上記の修正後に以下を実行すると、期待通りの結果を得ることができました。
$ python /home/pi/Dexter/GrovePi/Software/Python/grove_button.py 0 0 1 1 1 0 0Python library to access kintoneの設定
$ pip install pykintone $ pip3 install pykintonenode-redの設定(必要な場合のみ)
node-redの設定は以下のように行います。
$ sudo apt-get install nodered $ sudo systemctl enable nodered.service $ sudo service nodered startブラウザで http://Raspberry PiのIPアドレス:1880/ にアクセスするとnode-redが利用できます。
詳細は以下を参照ください。
Node-RED Raspberry Piで実行する
https://nodered.jp/docs/getting-started/raspberrypiリモートディスクトップの設定(必要な場合のみ)
リモートディスクトップの設定は以下のように行います。
$ sudo apt-get install xrdp $ cd /etc/xrdp/ $ sudo wget http://w.vmeta.jp/temp/km-0411.ini $ sudo ln -s km-0411.ini km-e0010411.ini $ sudo ln -s km-0411.ini km-e0200411.ini $ sudo ln -s km-0411.ini km-e0210411.ini $ sudo service xrdp restartRaspberry PiのIPアドレスで以下のようにリモートディスクトップに接続できます。
詳細は以下を参照ください。
Windowsパソコンからraspberrypi3にリモートデスクトップで接続する( @t114 さん)
https://qiita.com/t114/items/bfac508504b9a6b7570d参考
ラズパイでpython3にopencvを入れたらエラーが出た【対処法】( @XM03 さん)
https://qiita.com/XM03/items/48463fd910470b226f22Raspberry Pi Projects for the GrovePi.
https://www.dexterindustries.com/GrovePi/projects-for-the-raspberry-pi/
https://www.dexterindustries.com/GrovePi/get-started-with-the-grovepi/setting-software/Grove - LED
https://www.seeedstudio.com/Grove-Green-LED.html
http://wiki.seeedstudio.com/Grove-Red_LED/#play-with-raspberry-pi-with-grovepi_plusGrove - Button(ボタン)
https://www.seeedstudio.com/Grove-Button.html
http://wiki.seeedstudio.com/Grove-Button/#play-with-raspberry-piwith-grovepi_plusNode-RED Raspberry Piで実行する
https://nodered.jp/docs/getting-started/raspberrypiWindowsパソコンからraspberrypi3にリモートデスクトップで接続する( @t114 さん)
https://qiita.com/t114/items/bfac508504b9a6b7570dGitHub icoxfog417/pykintone
https://github.com/icoxfog417/pykintonegrovepi.py の不具合修正(227行以降)
(Y.K Bug fixes) の記載部分に修正ありgrovepi.py(前略) # Read I2C block from the GrovePi def read_i2c_block(no_bytes = max_recv_size): data = data_not_available_cmd counter = 0 while data[0] in [data_not_available_cmd[0], 255] and counter < 3: try: data = i2c.read_list(reg = None, len = no_bytes) time.sleep(0.002 + additional_waiting) if counter > 0: counter = 0 except: counter += 1 time.sleep(0.003) return data # (Y.K Bug fixes) def read_identified_i2c_block(read_command_id, no_bytes): data = [-1] data = read_i2c_block(no_bytes + 1) return data # Arduino Digital Read def digitalRead(pin): write_i2c_block(dRead_cmd + [pin, unused, unused]) data = read_identified_i2c_block( dRead_cmd, no_bytes = 1)[0] return data # Arduino Digital Write def digitalWrite(pin, value): write_i2c_block(dWrite_cmd + [pin, value, unused]) read_i2c_block(no_bytes = 1) return 1 # Read analog value from Pin (Y.K Bug fixes) def analogRead(pin): write_i2c_block(aRead_cmd + [pin, unused, unused]) number = read_identified_i2c_block(aRead_cmd, no_bytes = 2) return number[1] * 256 + number[2] # Write PWM def analogWrite(pin, value): write_i2c_block(aWrite_cmd + [pin, value, unused]) read_i2c_block(no_bytes = 1) return 1 # Setting Up Pin mode on Arduino def pinMode(pin, mode): if mode == "OUTPUT": write_i2c_block(pMode_cmd + [pin, 1, unused]) elif mode == "INPUT": write_i2c_block(pMode_cmd + [pin, 0, unused]) read_i2c_block(no_bytes = 1) return 1 # Read temp in Celsius from Grove Temperature Sensor def temp(pin, model = '1.0'): # each of the sensor revisions use different thermistors, each with their own B value constant if model == '1.2': bValue = 4250 # sensor v1.2 uses thermistor ??? (assuming NCP18WF104F03RC until SeeedStudio clarifies) elif model == '1.1': bValue = 4250 # sensor v1.1 uses thermistor NCP18WF104F03RC else: bValue = 3975 # sensor v1.0 uses thermistor TTC3A103*39H a = analogRead(pin) resistance = (float)(1023 - a) * 10000 / a t = (float)(1 / (math.log(resistance / 10000) / bValue + 1 / 298.15) - 273.15) return t # Read value from Grove Ultrasonic (Y.K Bug fixes) def ultrasonicRead(pin): write_i2c_block(uRead_cmd + [pin, unused, unused]) number = read_identified_i2c_block(uRead_cmd, no_bytes = 2) return (number[1] * 256 + number[2]) # Read the firmware version def version(): write_i2c_block(version_cmd + [unused, unused, unused]) number = read_identified_i2c_block(version_cmd, no_bytes = 3) return "%s.%s.%s" % (number[0], number[1], number[2]) # Read Grove Accelerometer (+/- 1.5g) XYZ value # Need to investigate why this reports what was read with the previous command # Doesn't look to be implemented on the GrovePi def acc_xyz(): write_i2c_block(acc_xyz_cmd + [unused, unused, unused]) number = read_identified_i2c_block(acc_xyz_cmd, no_bytes = 3) if number[1] > 32: number[1] = - (number[1] - 224) if number[2] > 32: number[2] = - (number[2] - 224) if number[3] > 32: number[3] = - (number[3] - 224) return (number[0], number[1], number[2]) # Read from Grove RTC # Doesn't look to be implemented on the GrovePi def rtc_getTime(): write_i2c_block(rtc_getTime_cmd + [unused, unused, unused]) number = read_i2c_block() return number # Read and return temperature and humidity from Grove DHT Pro (Y.K Bug fixes) def dht(pin, module_type): write_i2c_block(dht_temp_cmd + [pin, module_type, unused]) number = read_identified_i2c_block(dht_temp_cmd, no_bytes = 9) if p_version==2: h='' for element in (number[1:5]): h+=chr(element) t_val=struct.unpack('f', h) t = round(t_val[0], 2) h = '' for element in (number[5:9]): h+=chr(element) hum_val=struct.unpack('f',h) hum = round(hum_val[0], 2) else: t_val=bytearray(number[1:5]) h_val=bytearray(number[5:9]) t=round(struct.unpack('f',t_val)[0],2) hum=round(struct.unpack('f',h_val)[0],2) if t > -100.0 and t <150.0 and hum >= 0.0 and hum<=100.0: return [t, hum] else: return [float('nan'),float('nan')] (後略)



- 投稿日:2020-01-04T21:07:19+09:00
自分用 Anaconda + JupyterLab 構築メモ
anaconda ダウンロード
https://www.anaconda.com/distribution/ からダウンロード
インストール確認
以下のディレクトリが存在することを確認
/opt/anaconda3/JupyterLab 起動
以下のコマンドを実行
$ jupyter lab実行すると、ブラウザが立ち上がりJupyterLab が表示される。
- 投稿日:2020-01-04T20:53:32+09:00
numpyのarrayの要素をforで回さないで済むようにする方法チェックリスト
※コメントいただいたので追記します。諸事情によりpython2からアップデートできない状況でして、コードもpython2になってます。大きく結論が変わるわけではないと思いますが、文法が異なるところは適宜ご自身の環境に合わせて読み替えてください。
numpy.arrayの要素をfor文で回すと実行速度がかなり落ちる。
これをもうちょっと早くするために試す対処として、
- list内包表記にする
- 条件が複雑ならnp.whereを使う
- np.frompyfuncを使う
というのを学んだのでその備忘録。
list内包表記
これはもうどこにでも書いてあるけど、
import numpy as np a = np.array(range(10)) a2 = [] for x in a: a2.append(x*2)とかやるくらいなら、
a2 = [x*2 for x in a]にしなさいよ、という話。体感でもかなり早くなる。
条件が複雑ならnp.whereを使う
たとえば、いじりたいのは配列aだけど、条件は配列bの要素で決めたい、みたいな場合。
例として、配列bの要素が偶数なら配列aの要素を2倍、それ以外だったら配列aの要素を3倍にするケースを考えてみる。
ついC++的にインデックス使ってforで回したくなってしまうのをぐっとこらえて、np.whereを使う。
import numpy as np a = np.array(range(10)) print "a = ", a b = a + 100 print "b = ", b # インデックス使っちゃうとこんな感じ result1 = [] for i in range(10) : answer = a[i]*2 if b[i]%2 == 0 else a[i]*3 result1.append(answer) print np.array(result1) # np.whereと関数を使えば1行で書けて速い def func_double(x) : return x*2 def func_triple(x) : return x*3 result2 = np.where(b%2 == 0, func_double(a), func_triple(a)) print result2なお、コメントにいただいた通り、この程度の関数であればリスト内包表記にそのまま関数を埋め込んでも良いと思います。
(ただ、個人的にはリスト内包表記に関数を直書きで埋め込むのはあまり好きではないです…あとから色々変更しにくいし、変更忘れたりするし、ファーストランゲージがpython世代の若い学生さんがリスト内包表記内にクソ長いコード書いてきたりすると、「すっげえ読みにくいィィッ!!!」とキレそうになるから(笑))
np.frompyfuncを使う
もうちょっと速くならないか、と探していたら以下のページを見つけたので、有難く使わせていただいた。
Pythonのリストの全要素に任意の関数をapplyする最速の方法
Python高速化実験~map関数とか~というわけで、frompyfuncを使ってみる。
import numpy as np # prepare input arrays a = np.array(range(10)) print "array a is", a b = a + 100 print "array b is", b def addition(x, y): return x + y np_addition = np.frompyfunc(addition, 2, 1) print "print a + b using frompyfunc" print np_addition(a, b) print "print a + 1 using frompyfunc" print np_addition(a, 1) print "print 1 + b using frompyfunc" print np_addition(1, b) np_subtruction = np.frompyfunc(subtruction, 2, 1) print "using np.where and frompyfuncs" result2 = np.where(b%2 == 0, np_addition(a, b), np_subtruction(a, b)) print result2frompyfuncで作ったユニバーサル関数の引数は、1つ目が関数オブジェクト、2つ目が引数の数、3つ目が戻り値の数。これを使うと、ユニバーサル関数の引数に配列を突っ込めば、それぞれの要素に関数を適用した結果を配列として返してくれる。
なんだ、こんな便利なものがあるなら、さっさと使えばよかった。
体感でも、list内包表記より3割くらい速い感じがする。で、なにを確かめたかったかというと、このfrompyfuncで作ったユニバーサル関数の引数に、一部だけ配列を渡し、残りはただのfloatにする、とかいうことが可能なのか? という話。
結果は、全然問題なし!
つまり、配列を渡した部分だけを要素ごとに変更しながら、計算した結果を返してくれるのである。
しかも、どの引数を配列にしようが、勝手に判断してくれる。スバラシイ!!
さらに、np.whereとの併用も問題がないことを確認。
(追記)この先要検討でした!(汗)np.whereとfrompyfuncで作ったユニバーサル関数の併用の場合、下記のとおり動くことは確認しましたが、場合によっては激遅になって、リスト内包表記で回しながら直接スカラー引数用の関数を呼んだ方が速かった。テストプログラムと実際の解析プログラムと遅くなり方が違うので、どういうときに激遅になるのかまだ不明。というか、要するに、原理わからずに使ってるからこういうことになるんだな(苦笑)。でもあまり速度関係ない場面なら使えるかもしれない。
実は、このケースだと別にnp.whereの引数にわざわざユニバーサル関数を使う必要はなく、ダイレクトにスカラー引数用のaddition, subtruction関数を突っ込んでも同じ結果になる。
しかし、あえてユニバーサル関数を使うことの利点として、C++でいう関数オーバーロードっぽいことができることが考えられる。
つまり、pythonでは、そもそも関数の引数に厳密な型指定がないために、たとえば引数のうちの一つを配列でもfloatでもOKにして振る舞いを変えたければ、関数の中で型チェックをしてif分岐するしかないわけです。それはあまり美しくない。
もちろん、引数名を配列の場合とfloatの場合で変えて定義して振る舞いを変えるなんてのはもっとやりたくない(使用側のコードの変更が必要になるから)。
python楽チンだけど、たまには、C++みたいな厳密な型指定ができて関数オーバーロードできりゃいいのに、と思うことはある(まあ、いわゆるpythonっぽいコードの書き方ができていないせいでしょうが)。しかし、たとえば、あるケースではxは配列だけど、別のケースではxは固定したい、みたいなシンプルなケースの場合には、上の実験から、スカラー引数の場合の関数一つ作ってfrompyfuncでユニバーサル関数にするだけで、全てのケースに勝手に対応してくれる。
これは、パラメタ変数を一個ずつ固定して残りを動かしながら結果の推移を見る、みたいなケースとか、パラメタ全部動かすと計算が重いから一時的に変数一つだけ固定しちゃえ、みたいな場合に大変有用なんではないかという気がする。というわけで、これから今いじっているコードのlist内包表記を駆逐してみて、どのくらい使用感が変わるかみてみようと思います。
- 投稿日:2020-01-04T20:43:14+09:00
Pythonによる AI・機械学習について学んでいます
はじめに
この本を使って勉強しています
Pythonによる AI・機械学習・深層学習アプリのつくり方1-1 機械学習で何ができる?
分類(classification) ... 与えられたデータを分類
データの特徴を調べて分類する回帰(regression) ... 過去の実績から未来の値を予測
過去のデータを学習して将来の数値予測を行うクラスタリング(clustering) ... データを似たものの集合に分類
分類と違うのはあらかじめ決まっている項目に分けるのではなく似たもの区分けする推薦(recommendation) ... データの関連情報を導き出す
ネットショッピングでユーザの嗜好にあったものを推薦するデータの次元数を削減(dimensionality reduction) ... データの特徴を残して削減
大きな次元から特徴的なデータを特定して次元を削減し、効率的にデータを分析する何に適用できる?
- 画像解析 画像の物体を判定
- 音声解析 音声からテキストに変換、どんな音なのか判定
- テキスト解析 文章のカテゴリ分け、特定表現の抽出・構文解析
機械学習の種類
- 教師あり学習(Supervised Learning)
- データとともに正解が与えられる
- 未知のデータに対して予測を行う
- 教師なし学習(Unsupervised Learning)
- 正解は与えられていない
- 未知のデータから規則性を見出す
- 強化学習(Reinforcement Learning)
- 行動により部分的に正解が与えられる
- データから適切な買いを見つける
1-2 どのようなシナリオで機械学習を行うのか
1. ゴールの決定
2. データの収集
3. データの整形・加工
4. データを学習
1. 機械学習の手法を選択
2. パラメータの調整
3. データを学習してモデルを構築
5. モデルを評価
6. 十分な精度がでなければ4.に戻る
7. 業務で活用1-3 機械学習で利用するデータの作り方
機械学習で役に立つ汎用的なデータフォーマット
- カンマ区切りデータ CSV 形式
- ini ファイル形式
- XML
- JSON(JavaScriptのオブジェクト形式を元に考案された構造化データ)
- YAML
その他、Numpy保存形式、Pythonオブジェクトをそのまま書き込むことができる pickleなど
- 投稿日:2020-01-04T20:43:14+09:00
Pythonによる AI・機械学習について学んでいます(1)
はじめに
この本を使って勉強しています
Pythonによる AI・機械学習・深層学習アプリのつくり方1-1 機械学習で何ができる?
分類(classification) ... 与えられたデータを分類
データの特徴を調べて分類する回帰(regression) ... 過去の実績から未来の値を予測
過去のデータを学習して将来の数値予測を行うクラスタリング(clustering) ... データを似たものの集合に分類
分類と違うのはあらかじめ決まっている項目に分けるのではなく似たもの区分けする推薦(recommendation) ... データの関連情報を導き出す
ネットショッピングでユーザの嗜好にあったものを推薦するデータの次元数を削減(dimensionality reduction) ... データの特徴を残して削減
大きな次元から特徴的なデータを特定して次元を削減し、効率的にデータを分析する何に適用できる?
- 画像解析 画像の物体を判定
- 音声解析 音声からテキストに変換、どんな音なのか判定
- テキスト解析 文章のカテゴリ分け、特定表現の抽出・構文解析
機械学習の種類
- 教師あり学習(Supervised Learning)
- データとともに正解が与えられる
- 未知のデータに対して予測を行う
- 教師なし学習(Unsupervised Learning)
- 正解は与えられていない
- 未知のデータから規則性を見出す
- 強化学習(Reinforcement Learning)
- 行動により部分的に正解が与えられる
- データから適切な買いを見つける
1-2 どのようなシナリオで機械学習を行うのか
1. ゴールの決定
2. データの収集
3. データの整形・加工
4. データを学習
1. 機械学習の手法を選択
2. パラメータの調整
3. データを学習してモデルを構築
5. モデルを評価
6. 十分な精度がでなければ4.に戻る
7. 業務で活用1-3 機械学習で利用するデータの作り方
機械学習で役に立つ汎用的なデータフォーマット
- カンマ区切りデータ CSV 形式
- ini ファイル形式
- XML
- JSON(JavaScriptのオブジェクト形式を元に考案された構造化データ)
- YAML
その他、Numpy保存形式、Pythonオブジェクトをそのまま書き込むことができる pickleなど
- 投稿日:2020-01-04T20:43:14+09:00
Pythonによる AI・機械学習について学んだ内容
はじめに
この本を使って勉強しています
Pythonによる AI・機械学習・深層学習アプリのつくり方1-1 機械学習で何ができる?
分類(classification) ... 与えられたデータを分類
データの特徴を調べて分類する回帰(regression) ... 過去の実績から未来の値を予測
過去のデータを学習して将来の数値予測を行うクラスタリング(clustering) ... データを似たものの集合に分類
分類と違うのはあらかじめ決まっている項目に分けるのではなく似たもの区分けする推薦(recommendation) ... データの関連情報を導き出す
ネットショッピングでユーザの嗜好にあったものを推薦するデータの次元数を削減(dimensionality reduction) ... データの特徴を残して削減
大きな次元から特徴的なデータを特定して次元を削減し、効率的にデータを分析する何に適用できる?
- 画像解析 画像の物体を判定
- 音声解析 音声からテキストに変換、どんな音なのか判定
- テキスト解析 文章のカテゴリ分け、特定表現の抽出・構文解析
機械学習の種類
- 教師あり学習(Supervised Learning)
- データとともに正解が与えられる
- 未知のデータに対して予測を行う
- 教師なし学習(Unsupervised Learning)
- 正解は与えられていない
- 未知のデータから規則性を見出す
- 強化学習(Reinforcement Learning)
- 行動により部分的に正解が与えられる
- データから適切な買いを見つける
1-2 どのようなシナリオで機械学習を行うのか
1. ゴールの決定
2. データの収集
3. データの整形・加工
4. データを学習
1. 機械学習の手法を選択
2. パラメータの調整
3. データを学習してモデルを構築
5. モデルを評価
6. 十分な精度がでなければ4.に戻る
7. 業務で活用1-3 機械学習で利用するデータの作り方
機械学習で役に立つ汎用的なデータフォーマット
- カンマ区切りデータ CSV 形式
- ini ファイル形式
- XML
- JSON(JavaScriptのオブジェクト形式を元に考案された構造化データ)
- YAML
その他、Numpy保存形式、Pythonオブジェクトをそのまま書き込むことができる pickleなど
- 投稿日:2020-01-04T20:43:14+09:00
Pythonによる AI・機械学習について学んだ内容(1)
はじめに
この本を使って勉強しています
Pythonによる AI・機械学習・深層学習アプリのつくり方1-1 機械学習で何ができる?
分類(classification) ... 与えられたデータを分類
データの特徴を調べて分類する回帰(regression) ... 過去の実績から未来の値を予測
過去のデータを学習して将来の数値予測を行うクラスタリング(clustering) ... データを似たものの集合に分類
分類と違うのはあらかじめ決まっている項目に分けるのではなく似たもの区分けする推薦(recommendation) ... データの関連情報を導き出す
ネットショッピングでユーザの嗜好にあったものを推薦するデータの次元数を削減(dimensionality reduction) ... データの特徴を残して削減
大きな次元から特徴的なデータを特定して次元を削減し、効率的にデータを分析する何に適用できる?
- 画像解析 画像の物体を判定
- 音声解析 音声からテキストに変換、どんな音なのか判定
- テキスト解析 文章のカテゴリ分け、特定表現の抽出・構文解析
機械学習の種類
- 教師あり学習(Supervised Learning)
- データとともに正解が与えられる
- 未知のデータに対して予測を行う
- 教師なし学習(Unsupervised Learning)
- 正解は与えられていない
- 未知のデータから規則性を見出す
- 強化学習(Reinforcement Learning)
- 行動により部分的に正解が与えられる
- データから適切な買いを見つける
1-2 どのようなシナリオで機械学習を行うのか
1. ゴールの決定
2. データの収集
3. データの整形・加工
4. データを学習
1. 機械学習の手法を選択
2. パラメータの調整
3. データを学習してモデルを構築
5. モデルを評価
6. 十分な精度がでなければ4.に戻る
7. 業務で活用1-3 機械学習で利用するデータの作り方
機械学習で役に立つ汎用的なデータフォーマット
- カンマ区切りデータ CSV 形式
- ini ファイル形式
- XML
- JSON(JavaScriptのオブジェクト形式を元に考案された構造化データ)
- YAML
その他、Numpy保存形式、Pythonオブジェクトをそのまま書き込むことができる pickleなど
- 投稿日:2020-01-04T20:19:05+09:00
Python基本文法メモ
コメント
- コメントは
#。 3重のクォーテーションで、複数行コメントとして使える。print関数
- 改行しないようにする
print(引数1, 引数2, ... , end="")変数
- 変数名は、
sample_colorのように、_で区切るのが一般的。- 代入演算子は、
+= -= *= /=が使える。++ --は使えない。- キーボードから入力するには、
str = input("入力してください:")のようにして、文字列型が返却される。float("160.5")で文字列型をfloat型に変換できる。- Pythonの数値型は、整数型(int)、浮動小数点型(float)、複素数型(complex)の3種類。
type()関数で、型を調べられる。- リテラル、
5はint、5.0はfloat、0xff = 255は16進数、0o23 = 19は8進数、0b1111 = 15は2進数。- 指数表現
9.5e3 = 9.5 * 10^3- 文字列型は、シングルクォーテーションかダブルクォーテーションで囲む。
\でエスケープ。- 複数の行の文字列を記述するには、3重クオーテーションで囲む。
int("5")で文字型から整数型に変換。int("FFF",16)で16進数を整数型に変換。str(数値)で数値型から文字型に変換する。hex()oct()bin()を使うと、それぞれ16進数、8進数、2進数の文字型に変換する。id(オブジェクト)でオブジェクトのid番号を調べられる。シーケンス型
height = [180, 165, 159, 171, 155]のようにしてリスト型を作成する。height[0]のようにして、リスト型の中身を取り出す。height[1] = 182のようにして、中身を変更できる。height[-1]で一番右の値を取り出す。len(height)でリストの長さを返す。height_tuple = (180, 165, 159, 171, 155)のようにしてタプル型を作成する。タプルは値が変更不可なリスト。()は省略可。値の取り出し方はリストと同じ。list()tuple()で相互変換可能。- リスト、タプル、文字列型(str)は、シーケンス型で、インデックスで取り出し可能。
import
import モジュール名でモジュールのインポートをする。モジュール名.コンストラクタを呼び出すことにより、クラスのインスタンスを作成する。インスタンス変数.メソッド名(引数, ...)でメソッドを呼び出す。import calendar cal = calendar.TextCalendar() cal.prmonth(2016, 1)
from モジュール名 import クラス名1, クラス名2, ...と指定すれば、クラスを呼ぶ時のモジュール名を省略できる。from calendar import TextCalendar cal = TextCalendar() cal.prmonth(2016, 1)
- 関数のモジュールをインポートする(クラスのインポートと同じ)
import モジュール名の時、モジュール名.関数名で関数を呼び出せる。from モジュール名 import 関数名1, 関数名2, ...の時は、関数名を直接呼び出せる。from モジュール名 import *で全ての関数を読み込む。乱数の利用
import randomrandint(0,3)で、0以上3以下の整数の乱数を生成する。randrange(3)で。0以上3未満の整数の乱数を生成する。if文
if 条件式A: 処理1 elif 条件式B: 処理2 else: 処理3
- 論理演算子は、
andorを使う。- 条件式は、
3 <= month < 5のように書ける。- リストやタプルは、
inで含まれるかを判定できる3 in [1, 2, 3, 4]not inで含まれないかを判定できる3 not in [1, 2, 3, 4]innot inは文字列にも使える"日" in "月火水木金土日"- Pythonには、switch文はない。
- 以下のように3項演算子を使える。
値1 if 条件式 else 値2 msg = "こんにちは" if hour < 18 else "こんばんは"ループ処理
- Pythonに、do〜whileループはない
- range([開始,] 終了[, ステップ])
# for文 for l in list: 処理 # 10回繰り返す(i=1〜9) for i in range(10): 処理 # rangeオブジェクトをリストに変換 l = list(range(0, 31, 10)) # i=[0, 10, 20, 30] # while while 条件式: 処理
- enumerate()関数を使うと、インデックスと要素のペアが取り出せる。
countries = ["フランス", "アメリカ", "中国" , "ドイツ" , "日本"] for index, country in enumerate(countries): print(str(index + 1) + ":", country)
- zip(リスト1, リスト2, ...)関数を使うと、複数のリストの値を、一番短いリストの要素がなくなるまで、タプルとして順に取り出せる。
weekday1 = ["Sun", "Mon", "Tue" , "Wed" , "Thu"] weekday2 = ["日", "月", "火" , "水" , "木", "金", "土"] for (eng, jap) in enumerate(weekday1, weekday1): print(eng + ":" + jap)
- elseで、forループが終了した時の処理を書ける。ただし、breakで抜けた時は実行されない。
for 変数 in イテレート可能なオブジェクト: ループ本体 else: 完了した時に実行されるブロック例外処理
- exceptで、例外を指定しないと、任意の例外を捕まえることができる。
- exceptで、タプルを使って、複数の例外を指定することができる。
- elseで、例外が発生しなかった場合の処理を記述できる。
try: 例外が発生する可能性がある処理 except 例外: 例外が発生した場合の処理 else: 例外が発生しなかった場合の処理文字列の活用
"python".upper()で大文字を出力する。"python".lower()で小文字を出力する。"python".count("y")で指定した文字列の出現回数をカウントする。"/python/".startswith("/")で指定した文字列で終わるかどうかをTrue/Falseで返す。"/python/".endswith("/")で指定した文字列で終わるかどうかをTrue/Falseで返す。"python".find("t")で指定した文字列が含まれるかどうかをTrue/Falseで返す。",".join(リスト)で指定した文字列とリストを連結して返す。"Python".replace("n", "a") # Pythoa"Apple Orange Pineapple".split(" ") # ['Apple', 'Orange', 'Pineapple']セパレータで区切る。"Pineapple"[4:9] # apple0から始まる4番目から9−1=8番目を取り出す。[開始値:]、[:終了位置]で開始値または終了位置を省略できる。"月" in "月火水木金土日" # Trueinで含まれるかどうか調べる。"abcde".find("d")) # 3find()で文字列が見つかった位置を返す。みつからなければ-1を返す。"こんにちは{}の世界へようこそ{}月{}日".format("Python", 12, 24) # こんにちはPythonの世界へようこそ12月24日formatで、{}の中に文字や数字を埋め込むことができる。"こんにちは{2}の世界へようこそ{0}月{1}日".format(12, 24, "Python") # こんにちはPythonの世界へようこそ12月24日{}の中の数字で、順番を指定することができる。{引数の番号:.桁f}で小数点の桁数を指定できる。{引数の番号:,}で3桁区切りでカンマを挿入できる。リストやタプルの基本操作
+でリストを結合する。["春", "夏"] + ["秋", "冬"] # ['春', '夏', '秋', '冬'](新たなリストを作成する)*でリストを繰り返す。["春", "夏"] * 3 # ['春', '夏', '春', '夏', '春', '夏'](新たなリストを作成する)リスト[0から始まる開始位置:0から始まる終了位置の次の番号]で要素を取り出す。[::ステップ数]でステップ数ごとに要素を取り出せる。探したい要素 in リストで、存在するかどうかをTrue/Falseで返す。not inで存在しないことを返す。リスト.index(探したい要素)で順番を返すが、見つからない場合はValueError例外を返す。リスト[インデックス] = 値でリストの値を変更する。インデックスが見つからなければIndexError例外が発生する。リスト.append(追加したい値)でリストに値を追加できる。リストを追加した時は1つの要素として追加され、リストが入れ子になる。リスト.remove(削除したい値)で、値に一致する最初の要素を削除できる。(一致しても2番目以降は削除されない)del リスト[インデックス]で、指定したインデックスの要素を削除できる。del リスト[1:4]で、インデックス1〜3が削除できる。リスト.reverse()で、リストを破壊的に反転させる。max(リスト) min(リスト) sum(リスト)で、それぞれ最大、最小、合計値を返す。リスト.sort()で破壊的にソートする。リスト.sort(reverse=True)で破壊的に逆順ソートする。sorted(リスト)でソートしたリストを返す。- リスト同士が同じ値かを調べるには、
==演算子を使う。オブジェクトか同じかどうかは、is演算子を使う。コマンドライン引数
- コマンドライン引数は、
sys.argvからリストが取れ、0番目は実行プログラムファイル名で、1番目〜から取得する。import sys # インデックス番号を取得するためにenumerate()関数を使用する for i,a in enumerate(sys.argv): print(i,a)辞書と集合
- 辞書
{キー1:値1, キー2:値2, キー3:値3, ...}- 要素数は、
len(辞書)- 値を取り出す
辞書[キー]- 値を更新する
辞書[キー] = 新しい値- ペアを追加する
辞書[追加するキー] = 追加する値- ペアを削除する
del 辞書[キー]
- 存在しないキーを指定すると、
KeyError例外が発生する- キーが存在するかどうか調べる
キー in 辞書- for文などで使用する(イテレート)
- キーの一覧を取得する
辞書.keys()- 値の一覧を取得する
辞書.values()- ペアの一覧を取得する
辞書.items()- 文字列の中に出てくるフルーツの数をカウントするプログラム
fruits = "apple orange strawberry banana orange apple grape strawberry apple" count = {} fruits_list = fruits.split(" ") for f in fruits_list: if f in count: count[f] += 1 else: count[f] = 1 for k, v in count.items(): print(k, v) # apple 3 # orange 2 # strawberry 2 # banana 1 # grape 1集合(set)
- 重複を許さないリストは、集合(set)で、
{要素1, 要素2, 要素3, ...}で作る。set(リスト)でリストから集合が作ることができる、重複はなくなる。集合.add(追加する要素)で要素を追加する。集合.remove(削除する要素)で要素を削除する。集合.clear()で全ての要素を削除する。inで含まれるか調査する。set1 | set2で両方を含む、新たな集合を返す。set1 & set2で両方に共通した要素をもつ、新たな集合を返す。set1 - set2でset1に含まれ、かつset2に含まれない、新たな集合を返す。set1 ^ set2でset1とset2のどちらか一方に含まれる、新たな集合を返す。内包表記
[式 for 変数 in イテレート可能なオブジェクト]リストを作成するl = [num ** 2 for num in range(0, 21, 2)] # [0, 4, 16, 36, 64, 100, 144, 196, 256, 324, 400] dolls = [1,55,243,445,178] rate = 106 yens = [d * rate for d in dolls] # [106, 5830, 25758, 47170, 18868]
ifの追加[式 for 変数 in イテレート可能なオブジェクト if 条件式]address = ["東京都千代田区", "東京都世田谷区", "埼玉県さいたま市", "神奈川県横浜市", "東京都足立区"] # 東京都のみ取り出す tokyo = [a for a in address if a.startswith("東京都")] # ['東京都千代田区', '東京都世田谷区', '東京都足立区'] people = [("鈴木", "女"), ("山田", "男"), ("高橋", "女"), ("佐藤", "男")] # 男のみの名前を取り出す man = [p[0] for p in people if p[1] == "男"]
- 辞書の内包表記
{キー:値 for 変数 in イテレート可能なオブジェクト}en = ["apple", "orange", "cherry", "banana"] jp = ["りんご", "オレンジ", "さくらんぼ", "バナナ"] fruits = {k: v for k, v in zip(en, jp)} # {'apple': 'りんご', 'orange': 'オレンジ', 'cherry': 'さくらんぼ', 'banana': 'バナナ'}
- 集合の内包表記
(式 for 変数 in イテレート可能なオブジェクト}- タプルの内包表記はない。
関数
def 変数名(引数1, 引数2, ...): 処理 return 戻り値
- キーワード引数 呼び出し側:
f(p1=100, p2=200)- デフォルト引数 関数定義側:
f(a=1, b="empty"):- 関数に渡された引数は、関数内で変更しても呼び出し側には反映されないが、関数にミュータブルな引数を渡すと変更が反映される(appendなどの破壊的メソッドのみ)
def change(a): a.append(4) a = [1, 2, 3] change(a) print(a) # [1, 2, 3, 4]変数のスコープ
- グローバルスコープ 関数の外部で作成された変数 プログラム全体で有効
- ローカルスコープ 関数の内部で作成された変数
- 同じ名前がある場合は、ローカルスコープが優先されるため、関数内でグローバル変数に代入したい場合は、
global グローバル変数名で定義する必要がある。可変長引数
- 可変長引数を定義する場合は、変数名の前に
*をつける。def(*objects, sep = ''):可変長変数の後ろの引数は、キーワード引数にする。(どこまでが可変長引数かわからないため)- 可変長引数はタプルとして受け取る。
キーワード引数を辞書として受け取る
- 仮引数名の前に
**をつけると、キーワード指定された任意の数の引数を辞書として受け取れる。def dic(**a): print(a) dic(height=100, width=80, depth=50) # {'height': 100, 'width': 80, 'depth': 50}### 関数もオブジェクト
hello(a)は、my_func = helloと代入すれば、my_func(a)として呼び出し可能。ラムダ式
lambda 引数1, 引数2, 引数3, ... : 処理- キーワード引数やデフォルト値、可変長引数、も使用可。
smaller = lambda n1, n2: n2 if n1 > n2 else n1 print(smaller(9, 2)) # 2 print(smaller(1, 11)) # 1 ave = lambda *n : sum(n) / len(n) print(ave(1, 5, 10, 50, 1000, 5000, 10000)) # 2295.1428571428573リストの要素をまとめて処理する
map()関数
map(関数, リスト)mapオブジェクトで返す。(イテレート可能なオブジェクト)list(map(関数, リスト))リストで返すdef cm(inch): return inch*2.54 inches = map(cm, [1, 2, 5, 10, 100]) for i in inches: print(i) print(list(map(cm, inches))) # [2.54, 5.08, 12.7, 25.4, 254.0] # 以下のように書いても同じ print(list(map(lambda inch: inch*2.54, [1, 2, 5, 10, 100]))) # [2.54, 5.08, 12.7, 25.4, 254.0] # 内包表記 print([n*2.54 for n in [1, 2, 5, 10, 100]]) # [2.54, 5.08, 12.7, 25.4, 254.0]リストの値をフィルタリングする
filter()関数
filter(関数, リスト)関数でTrueとなる要素をイテレート可能なオブジェクトで返すprint(list(filter(lambda n: n % 2 == 0, range(0, 10)))) # [0, 2, 4, 6, 8] # 内包表記 print([n for n in range(0, 10) if n % 2 == 0]) # [0, 2, 4, 6, 8]リストをソートする
ソートされたリスト = sorted(ソートする前のリスト)ソートされたリスト = sorted(ソートする前のリスト, key=str.upper)大文字としてソートするソートされたリスト = sorted(key=関数)関数の結果でソートする辞書をソートする
names = {"taro": 2, "jiro": 4, "saburo": 1, "shiro": 3} # 値でソートする print(sorted(names.items(), key=lambda n: n[1])) # [('saburo', 1), ('taro', 2), ('shiro', 3), ('jiro', 4)] # 値でソートする(逆順) print(sorted(names.items(), key=lambda n: n[1], reverse=True)) # [('jiro', 4), ('shiro', 3), ('taro', 2), ('saburo', 1)]ジェネレータ関数
- returnの代わりに
yieldで値を返すnext()関数で次を取り出す。forで取り出せば例外は発生しない。def gen(str): for c in str.upper(): yield c yes = gen("yes") print(next(yes)) # Y print(next(yes)) # E print(next(yes)) # S print(next(yes)) # StopIteration例外 for h in gen("hello"): print(h, end="") # HELLOジェネレータ式
(式 for 変数 in イテレート可能なオブジェクト)- 一見するとタプルの内包表記に見えるが、タプルの内包表記はない。
gen = (c for c in "hello".upper()) for g in gen: print(g, end="")クラス
- クラス名は慣習的に、
MyClassのようなアッパーキャメルケースを用いる- コンストラクタ
def __init__(self, 引数1, 引数2, ...):- インスタンス変数に値を入れる
self.インスタンス変数名 = 値- インスタンスの生成
変数 = クラス名(引数, ...)コンストラクタの第一引数selfには、自動的に自分自身が入るので、第二引数以降を指定する。- コンストラクタで値を代入した変数がインスタンス変数、メソッドの外部で値を代入したものがクラス変数となる
- メソッドの定義は、
def メソッド名(self, 引数, ...):- privateメソッドは、メソッド名の前に
__をつける。 外部からアクセスできるが、アクセスしてほしくないメソッドは_をつける- getter, setterメソッドは慣習的に
get_nameset_nameのように命名する。プロパティ名 = propery([セッターメソッド[,ゲッターメソッド]])でプロパティを設定するモジュール
- モジュール名は、ファイル名から拡張子
.pyを除いた名前になる。
- ファイル名が
customer_m1.pyのとき、customer_m1がモジュール名となる。- モジュール名、ファイル名は慣習的に小文字とアンダースコアが推奨される。
if __name__ == "__main__":のブロックは、ファイル名のみが指定されたときに呼ばれる。クラスの継承
class サブクラス名(スーパークラス名)で定義する。super().__init__(引数)でスーパークラスのコンストラクタを呼び出す
- 投稿日:2020-01-04T20:09:15+09:00
[モデル構築編] ロイター通信のデータセットを用いて、ニュースをトピックに分類するモデル(MLP)をkerasで作る(TensorFlow 2系)
前回の前処理編!
この記事は[前処理編]に続く続編です。
[前処理編] ロイター通信のデータセットを用いて、ニュースをトピックに分類するモデル(MLP)をkerasで作る(TensorFlow 2系)動作環境についても前処理編をご参照ください。
モデルの学習
前処理をしたニュース記事のテキスト
x_trainとニュースのラベルy_trainを使ってモデルを作ります。今回は単純なモデルとして、2層のMLP(マルチレイヤーパーセプトロン)とします。
Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 512) 512512 _________________________________________________________________ dropout (Dropout) (None, 512) 0 _________________________________________________________________ dense_2 (Dense) (None, 46) 23598 =================================================================モデルを組んでいきます1。
In [92]: import tensorflow as tf In [93]: from tensorflow.keras import layers In [96]: model = keras.Sequential( ...: [ ...: layers.Dense(512, input_shape=(1000,), activation=tf.nn.relu), ...: layers.Dropout(0.5), ...: layers.Dense(number_of_classes, activation=tf.nn.softmax), ...: ] ...: )
input_shape=(1000,)というのは、モデルに入力されるニュースの記事は前処理で長さを1000に揃えているからです- 出力層は
number_of_classes個あるうち、一番値が大きいものをラベルとして返すようにsoftmaxを取っています学習に入る前のcompileです。
In [99]: model.compile( ...: loss="categorical_crossentropy", ...: optimizer=keras.optimizers.Adam(), ...: metrics=["accuracy"], ...: )多クラス分類なので、
lossに"categorical_crossentropy"を指定、optimizerはAdamで、指標にaccuracy(正解率)を指定します。モデルを学習させましょう。
In [100]: history = model.fit( ...: x_train, ...: y_train, ...: batch_size=32, ...: epochs=5, ...: verbose=1, ...: validation_split=0.1, ...: ) Train on 8083 samples, validate on 899 samples Epoch 1/5 8083/8083 [==============================] - 2s 192us/sample - loss: 1.4148 - accuracy: 0.6828 - val_loss: 1.0709 - val_accuracy: 0.7653 Epoch 2/5 8083/8083 [==============================] - 1s 104us/sample - loss: 0.7804 - accuracy: 0.8169 - val_loss: 0.9457 - val_accuracy: 0.7920 Epoch 3/5 8083/8083 [==============================] - 1s 102us/sample - loss: 0.5557 - accuracy: 0.8659 - val_loss: 0.8587 - val_accuracy: 0.8076 Epoch 4/5 8083/8083 [==============================] - 1s 100us/sample - loss: 0.4175 - accuracy: 0.8976 - val_loss: 0.8491 - val_accuracy: 0.8176 Epoch 5/5 8083/8083 [==============================] - 1s 103us/sample - loss: 0.3269 - accuracy: 0.9171 - val_loss: 0.8689 - val_accuracy: 0.8065学習用データのうち1割をバリデーションデータとし、これを学習に使わずにaccuracyの確認に使っています。
5エポック学習させたところ、学習用データについてはlossが減少し続けていますが、バリデーションデータについてはlossが増加を始めており、過学習し始めたような印象です。
- 学習用データについての正解率は、◯で表されています。エポック数が増え、学習が進むにつれて、正解率も上昇しています
- バリデーションデータについての正解率は、実線で表されています。4エポック目で頭打ちになり、5エポック目では4エポック目より小さくなっています
モデルの性能確認
sklearn.metrics.accuracy_score(ドキュメント)を使って正解率を算出します。まず、学習に使ったデータについて性能を確認します。
※accuracy_scoreを求めるのにone-hot表現にする前のデータを再度読み込んでいます
(load_dataメソッドのseed引数にデフォルト値が指定されているので、再現性は確保されています)In [101]: pred_train = model.predict_classes(x_train) In [109]: from sklearn.metrics import accuracy_score In [114]: (_, y_train), (_, y_test) = reuters.load_data(num_words=1000) In [115]: accuracy_score(y_train, pred_train) Out[115]: 0.9380984190603429学習に使ったデータについては正解率は93%と9割を超えており、学習はできていそうです。
続いて、学習に使っていないデータ(テスト用データ)について性能を確認します。
In [116]: pred = model.predict_classes(x_test) In [117]: accuracy_score(y_test, pred) Out[117]: 0.7916295636687445学習に使っていないデータでは正解率は79%でした。
シンプルなMLPではまずまずという感想です。分類結果の確認
ニュース記事に3と4が多いという偏りがあったので、ラベルごとの正解率を確認します。
filter関数(ドキュメント)を使って該当する要素を抽出します。
その返り値をリストに変換してからlenを取ることで、該当する個数を求めています。In [126]: for label in range(46): ...: train_count = len(list(filter(lambda x: x==label, y_train))) ...: pred_train_count = len(list(filter(lambda x: x==label, pred_train))) ...: train_correct = len(list(filter(lambda pair: pair[0]==label and ...: pair[0]==pair[1], zip(y_train, pred_train)))) ...: test_count = len(list(filter(lambda x: x==label, y_test))) ...: pred_count = len(list(filter(lambda x: x==label, pred))) ...: test_correct = len(list(filter(lambda pair: pair[0]==label and ...: pair[0]==pair[1], zip(y_test, pred)))) ...: print(f'{label}, {train_count}, {pred_train_count}, {train_corr ...: ect}({train_correct/train_count:.4f}), {test_count}, {pred_count}, ...: {test_correct}({test_correct/test_count:.4f})') ...: # ラベル(※整数), 学習用データに含まれる数, モデルが学習用データで予測した数(※誤り含む), 学習用データでモデルの予測が正解した数(正解率), # テスト用データに含まれる数, モデルがテスト用データで予測した数(※誤り含む), テスト用データでモデルの予測が正解した数(正解率) 0, 55, 58, 52(0.9455), 12, 11, 9(0.7500) 1, 432, 426, 397(0.9190), 105, 104, 78(0.7429) 2, 74, 75, 70(0.9459), 20, 13, 10(0.5000) 3, 3159, 3196, 3072(0.9725), 813, 837, 765(0.9410) 4, 1949, 2018, 1873(0.9610), 474, 525, 418(0.8819) 5, 17, 14, 13(0.7647), 5, 1, 1(0.2000) 6, 48, 46, 46(0.9583), 14, 11, 11(0.7857) 7, 16, 15, 14(0.8750), 3, 2, 1(0.3333) 8, 139, 149, 125(0.8993), 38, 42, 27(0.7105) 9, 101, 109, 99(0.9802), 25, 23, 20(0.8000) 10, 124, 121, 113(0.9113), 30, 30, 27(0.9000) 11, 390, 395, 366(0.9385), 83, 104, 62(0.7470) 12, 49, 42, 42(0.8571), 13, 8, 5(0.3846) 13, 172, 184, 161(0.9360), 37, 60, 24(0.6486) 14, 26, 19, 18(0.6923), 2, 0, 0(0.0000) 15, 20, 19, 19(0.9500), 9, 2, 1(0.1111) 16, 444, 442, 404(0.9099), 99, 124, 76(0.7677) 17, 39, 36, 36(0.9231), 12, 6, 5(0.4167) 18, 66, 61, 61(0.9242), 20, 12, 10(0.5000) 19, 549, 519, 481(0.8761), 133, 108, 84(0.6316) 20, 269, 252, 223(0.8290), 70, 67, 37(0.5286) 21, 100, 96, 93(0.9300), 27, 34, 22(0.8148) 22, 15, 11, 10(0.6667), 7, 0, 0(0.0000) 23, 41, 33, 33(0.8049), 12, 7, 3(0.2500) 24, 62, 65, 57(0.9194), 19, 20, 9(0.4737) 25, 92, 93, 87(0.9457), 31, 26, 22(0.7097) 26, 24, 20, 20(0.8333), 8, 1, 1(0.1250) 27, 15, 11, 11(0.7333), 4, 1, 1(0.2500) 28, 48, 47, 45(0.9375), 10, 4, 2(0.2000) 29, 19, 16, 16(0.8421), 4, 4, 3(0.7500) 30, 45, 43, 40(0.8889), 12, 7, 7(0.5833) 31, 39, 40, 37(0.9487), 13, 9, 6(0.4615) 32, 32, 32, 31(0.9688), 10, 5, 5(0.5000) 33, 11, 10, 10(0.9091), 5, 4, 3(0.6000) 34, 50, 48, 47(0.9400), 7, 3, 3(0.4286) 35, 10, 9, 9(0.9000), 6, 2, 2(0.3333) 36, 49, 39, 37(0.7551), 11, 7, 4(0.3636) 37, 19, 18, 16(0.8421), 2, 0, 0(0.0000) 38, 19, 15, 15(0.7895), 3, 0, 0(0.0000) 39, 24, 17, 17(0.7083), 5, 3, 0(0.0000) 40, 36, 39, 30(0.8333), 10, 5, 3(0.3000) 41, 30, 25, 23(0.7667), 8, 1, 0(0.0000) 42, 13, 10, 10(0.7692), 3, 0, 0(0.0000) 43, 21, 22, 20(0.9524), 6, 8, 6(1.0000) 44, 12, 10, 10(0.8333), 5, 4, 4(0.8000) 45, 18, 17, 17(0.9444), 1, 1, 1(1.0000)含まれるニュースの数が多い3や4というラベルは、テスト用データでも高い正解率を出しています。
一方、含まれるニュースの数が少ないラベルでは、テスト用データへの正解率が低いものが見られ(0%もあります)、まだまだモデルの改良余地があるように思われます。
該当するラベルのテキストを確認し、特徴量の作り方を検討してもいいかもしれません。コード全容
スクリプトで実行できるように書いたコードも共有します。
- Qiitaに書いた内容を関数にまとめているので、完全に同じというわけではありません
- スクリプトの冒頭の定数を変えることで、ハイパーパラメタを変えたモデルを試せるようにしています(『直感 Deep Learning』で見たコードを参考にしました)
keras_mlp.pyimport matplotlib.pyplot as plt import numpy as np import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from tensorflow.keras.datasets import reuters from tensorflow.keras.preprocessing.text import Tokenizer np.random.seed(42) tf.random.set_seed(1234) MAX_WORDS = 1000 DROPOUT = 0.5 OPTIMIZER = keras.optimizers.Adam() BATCH_SIZE = 32 EPOCHS = 5 class IndexWordMapper: def __init__(self, index_word_map): self.index_word_map = index_word_map @staticmethod def initialize_index_word_map(): word_index = reuters.get_word_index() index_word_map = { index + 3: word for word, index in word_index.items() } index_word_map[0] = "[padding]" index_word_map[1] = "[start]" index_word_map[2] = "[oov]" return index_word_map def print_original_sentence(self, indices_of_words): for index in indices_of_words: print(self.index_word_map[index], end=" ") class TokenizePreprocessor: def __init__(self, tokenizer): self.tokenizer = tokenizer @staticmethod def initialize_tokenizer(max_words): return Tokenizer(num_words=max_words) def convert_text_to_matrix(self, texts, mode): return self.tokenizer.sequences_to_matrix(texts, mode=mode) def convert_to_onehot(labels, number_of_classes): return keras.utils.to_categorical(labels, number_of_classes) def build_model(number_of_classes, max_words, drop_out, optimizer): model = keras.Sequential( [ layers.Dense(512, input_shape=(max_words,), activation=tf.nn.relu), layers.Dropout(drop_out), layers.Dense(number_of_classes, activation=tf.nn.softmax), ] ) model.compile( loss="categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"], ) return model def plot_accuracy(history): accuracy = history["accuracy"] val_accuracy = history["val_accuracy"] epochs = range(1, len(accuracy) + 1) plt.plot(epochs, accuracy, "bo", label="Training accuracy") plt.plot(epochs, val_accuracy, "b", label="Validation accuracy") plt.title("Training and Validation accuracy") plt.legend() plt.savefig("accuracy.png") if __name__ == "__main__": index_word_map = IndexWordMapper.initialize_index_word_map() index_word_mapper = IndexWordMapper(index_word_map) (x_train, y_train), (x_test, y_test) = reuters.load_data( num_words=MAX_WORDS ) number_of_classes = np.max(y_train) + 1 tokenizer = TokenizePreprocessor.initialize_tokenizer(MAX_WORDS) preprocessor = TokenizePreprocessor(tokenizer) x_train = preprocessor.convert_text_to_matrix(x_train, "binary") x_test = preprocessor.convert_text_to_matrix(x_test, "binary") y_train = convert_to_onehot(y_train, number_of_classes) y_test = convert_to_onehot(y_test, number_of_classes) model = build_model(number_of_classes, MAX_WORDS, DROPOUT, OPTIMIZER) history = model.fit( x_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, verbose=1, validation_split=0.1, ) score = model.evaluate(x_test, y_test, batch_size=BATCH_SIZE, verbose=0) print(score) plot_accuracy(history.history$ python keras_mlp.py Train on 8083 samples, validate on 899 samples Epoch 1/5 8083/8083 [==============================] - 1s 161us/sample - loss: 1.4255 - accuracy: 0.6828 - val_loss: 1.0781 - val_accuracy: 0.7631 Epoch 2/5 8083/8083 [==============================] - 1s 102us/sample - loss: 0.7915 - accuracy: 0.8122 - val_loss: 0.9229 - val_accuracy: 0.7942 Epoch 3/5 8083/8083 [==============================] - 1s 99us/sample - loss: 0.5530 - accuracy: 0.8689 - val_loss: 0.8850 - val_accuracy: 0.8042 Epoch 4/5 8083/8083 [==============================] - 1s 99us/sample - loss: 0.4072 - accuracy: 0.8983 - val_loss: 0.8857 - val_accuracy: 0.8087 Epoch 5/5 8083/8083 [==============================] - 1s 99us/sample - loss: 0.3336 - accuracy: 0.9150 - val_loss: 0.9134 - val_accuracy: 0.8053 [0.9012499411830069, 0.7907391]Sequentialモデルの
evaluateメソッド(ドキュメント)をテスト用データに適用した結果を出力しています。Returns the loss value & metrics values for the model in test mode.
ですので、1つ目(
score[0])がlossの値で、2つ目(score[1])がaccuracyです(コンパイルで指定したメトリクス)。再現性の確保
スクリプトにまとめるに当たり、再現性確保のためのシードの固定にハマりました。
TensorFlow 2系でのシードの固定の情報が少ない2ように思われます。結論としては、以下の2点を行いました。
np.random.seed(42) tf.random.set_seed(1234)今後手を動かしたい事項
- モデルを変える
- 手を動かす中で「Embedding layer」を見つけたので試してみたい
- ref: https://machinelearningmastery.com/use-word-embedding-layers-deep-learning-keras/
- ハイパーパラメタのグリッドサーチ
- optimizerやドロップアウト率、バッチサイズ、エポック数
- 取り出すのは上位1000語でいいか
- 前処理深堀り(count, tfidf, freqを試す)
- 記事間での数の偏りへの対処が必要かデータを確認
今回のアウトプットを下地に色々と試していこうと思います。
本記事のまとめ
- シンプルなモデルとして2層のMLPを構築
- 性能を確認したところ、テスト用データに対して79%の正解率。ラベルに含まれるニュースの数により正解率にはムラがある
- スクリプトにした際、
TensorFlow2系向けの再現性の確保(2行)が必要だった
このモデルを作った後、
model.summary()を実行すると、前掲のモデルの層が確認できます ↩再現性の確保からは脱線ですが、短時間で学習が終わるならシードを固定するのではなく繰り返して、統計的な値で評価するという方法も見つかりました ref: https://machinelearningmastery.com/reproducible-results-neural-networks-keras/ ↩
ref: https://stackoverflow.com/a/58639060 。
tensorflow.set_random_seedは2系ではなくなったようです ↩
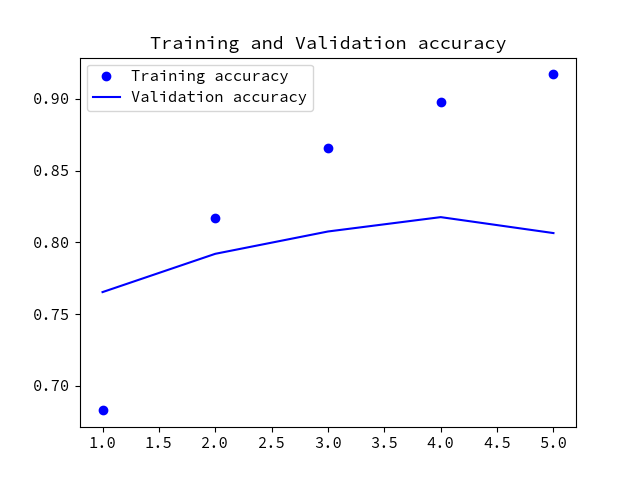
- 投稿日:2020-01-04T18:45:49+09:00
【簡単】PythonでWikipediaをWebスクレイピングしてみよう【初心者向け】
こんにちは。
せら⇒だいひょー?です。
僕のTwitterアカウント
(https://twitter.com/seradaihyo)
では、未経験からエンジニアを目指す方に向けて日々発信しています。
今回はPythonでWikipediaのスクレイピングを行う方法を記事にしたいと思います。
それでは始めていきましょう。
Pythonでスクレイピングをする上で必ず使うサードパーティ製ライブラリが二つあります。
それが
・Requests
・BeautifulSoupです。
それぞれ簡単に説明すると、
Requests
⇒URLを開くためのライブラリBeautifulSoup
⇒HTMLからデータを抽出するといった感じです。
Requestsでページを開いて、BeautifulSoupでデータを取ってくるイメージです。
Pythonコードの先頭に、この二つのライブラリをインポートするためのコードを書いておきます。
wikipedia.pyimport requests,bs4■WikipediaのPython記事をスクレイピング
今回は、wikipediaのPython記事をスクレイピングして目次を表示するアプリを作ります。
アプリと言っても記述するコードはたったの7行なので、安心してください。
まず、wikipediaでPythonの記事を検索します。
このURLをコピーして、以下のようにURLの変数に入れます。
wikipedia.pyurl = 'https://ja.wikipedia.org/wiki/Python'そしてそのURLのページを開く次の呪文を唱えます。
wikipedia.pyres = requests.get(url)resは変数なので名前は自由です。
勿論1と2は次のように一行で書くことも可能です。wikipedia.pyres = requests.get('https://ja.wikipedia.org/wiki/Python')次にこのURLからHTMLを取ってくる次の呪文を唱えます。
wikipedia.pysoup = bs4.BeautifulSoup(res.text, "html.parser")因みにhtml.parserとは、htmlのタグ情報から情報を解釈するプログラムです。
初めのうちは、htmlを扱いやすくしてくれるという解釈でOKです。
次に、wikipediaの目次の部分にカーソルを持ってきます。
そこで右クリックをし、「検証」をクリックします。
すると、次のようなhtmlのコードが出てきます。
目次を囲っているdivタグのidを確認すると、tocとなっていますね。
なので、このdivタグ”toc”内の全ての要素を次のように引っ張ってきます。
wikipedia.pyindex = soup.select('#toc')(この場合idなので「#」が付いていますが、classの場合は「.」を付けてください)
これでindexというリストに目次の要素が入れられました。
※なぜリストなの?後は、for文を使ってindexの中身を表示させます。
wikipedia.pyfor i in index: print(i.getText()).getText()を付けることで、HTMLのタグを取り除くことができます。
これまで書いたコード
wikipedia.pyimport requests,bs4 url = 'https://ja.wikipedia.org/wiki/Python' res = requests.get(url) soup = bs4.BeautifulSoup(res.text, "html.parser") index = soup.select('#toc') for i in index: print(i.getText())これを実行すると、
このように、目次を表示する事ができます。
※リストになって返される理由は、select()メソッドがすべての要素を返すメソッドだからです。
一つだけ要素を返したい場合はselect_one()メソッドを使います。というわけで、今回はPythonでスクレイピングを行う方法を簡単に説明させていただきました。
最後まで読んでいただきありがとうございました!





- 投稿日:2020-01-04T18:33:32+09:00
多変量正規分布をPythonでplotして理解する
はじめに
統計を勉強していた際に出てきた「多変量正規分布」のイメージを掴むためpythonでplotしてみました。今回は可視化して際にわかりやすいよう$n$数を2にして二次元正規分布をplotしています。
参考
多変量正規分布の理解とそのplotを行うに当たって下記を参考にさせていただきました。
多変量正規分布の概要
$n$変数の多変量正規分布は下記のように表されます。
f(\vec{x}) = \frac{1}{\sqrt{(2\pi)^n |\sum|}}exp \left \{-\frac{1}{2}{}^t (\vec{x}-\vec{\mu}) {\sum}^{-1} (\vec{x}-\vec{\mu}) \right \}変数が$n$個あるためデータを$n$次元ベクトル表記で表します。さらに平均値$\mu$も変数の数だけ存在するため同様にベクトル表記で表します。
{ \begin{equation}\vec{x}=\begin{pmatrix}x_1 \\ x_2 \\ \vdots \\ x_n \\ \end{pmatrix}, \vec{\mu}=\begin{pmatrix}\mu_1 \\ \mu_2 \\ \vdots \\ \mu_n \\ \end{pmatrix} \end{equation} }ある一つの要素$x_{i}$が確率変数$X_{i}$のデータを表し、平均値$\mu_i$が確率変数$X_{i}$の平均値を表します。
続いて分散についてですが、多変量となる場合は各データの分布のみならずデータ間の相関を考慮する必要があるため分散共分散行列$\sum$を用います。{ \begin{equation}\ \ \ \Sigma = \begin{pmatrix} \sigma_{1}^2 & \cdots & \sigma_{1i} & \cdots & \sigma_{1n}\\ \vdots & \ddots & & & \vdots \\ \sigma_{i1} & & \sigma_{i}^2 & & \sigma_{in} \\ \vdots & & & \ddots & \vdots \\ \sigma_{n1} & \cdots & \sigma_{ni} & \cdots & \sigma_{n}^2 \end{pmatrix} \end{equation} }$\sigma^2_i$は$i$番目の変数の分散で、$\sigma_{ij} =\sigma_{ji} (i≠j)$は$i$番目と$j$番目の変数間の共分散になっています。
そして$n$が$2$の時の二次元正規分布は下記のように表されます。N_2 \left ( \begin{pmatrix} \mu_x \\ \mu_y \\ \end{pmatrix} , \begin{pmatrix} \sigma_{x}^2 & \sigma_{xy}\\ \sigma_{xy} & \sigma_{y}^2\\ \end{pmatrix} \right )それでは二次元正規分布をplotしてみたいと思います。
二次元正規分布のplot
二次元正規分布をplotするスクリプトが下記になります。
まずは2変数とも標準正規分布に従い、互いに独立な場合で出力してみます。import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import axes3d from matplotlib import cm #関数に投入するデータを作成 x = y = np.arange(-20, 20, 0.5) X, Y = np.meshgrid(x, y) z = np.c_[X.ravel(),Y.ravel()] #二次元正規分布の確率密度を返す関数 def gaussian(x): #分散共分散行列の行列式 det = np.linalg.det(sigma) print(det) #分散共分散行列の逆行列 inv = np.linalg.inv(sigma) n = x.ndim print(inv) return np.exp(-np.diag((x - mu)@inv@(x - mu).T)/2.0) / (np.sqrt((2 * np.pi) ** n * det)) #2変数の平均値を指定 mu = np.array([0,0]) #2変数の分散共分散行列を指定 sigma = np.array([[1,0],[0,1]]) Z = gaussian(z) shape = X.shape Z = Z.reshape(shape) #二次元正規分布をplot fig = plt.figure(figsize = (15, 15)) ax = fig.add_subplot(111, projection='3d') ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap=cm.coolwarm) plt.show()出力結果は下記です。2変数とも正規分布のため偏りのない尖ったグラフになります。
それでは異なる形のグラフもplotします。
2変数の分布が下記となる場合の二次元正規分布をplotしてみましょう。#2変数の平均値を指定 mu = np.array([3,1]) #2変数の分散共分散行列を指定 sigma = np.array([[10,5],[5,10]])下記は先ほどのplotと同様です。
Z = gaussian(z) shape = X.shape Z = Z.reshape(shape) #二次元正規分布をplot fig = plt.figure(figsize = (15, 15)) ax = fig.add_subplot(111, projection='3d') ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap=cm.coolwarm) plt.show()出力結果は下記になります。今回は互いに相関している分布をplotしたため、少し斜めに歪んだ形になっていることがわかります。
数式上ではわかりにくかったことも、こうやって可視化するとイメージが掴みやすいですね。
Next
統計を勉強していると中々数式だけでイメージが掴めないことも多いので、pythonで自分で書いてみたりplotして可視化するのを積極的にやっていきたいと思います。


- 投稿日:2020-01-04T17:51:42+09:00
ケモインフォマティクスで学ぶPythonのデータ構造
はじめに
ケモインフォマティクスで学ぶPythonの変数とデータ型に引き続き、リピドミクス(脂質の網羅解析)を題材として「データ構造」について解説していきます。
ケモインフォマティクスの実践例を中心に説明していきますので、基本を確認したいという人は以下の記事を読んでからこの記事を読んでみてください。製薬企業研究者がPythonのデータ構造についてまとめてみた
リスト
リストの作成、要素の値の参照、更新
リスト(list)は、複数の要素を格納したデータ型で、
リスト名 = [要素1, 要素2, ・・・]で作ることができます。
以下の例は文字列のみを格納したリストですが、数値や真偽値を入れることもできますし、同じ値の要素を複数入れたり、複数のデータ型を混在させたりすることもできます。
リストの中の要素は、リスト名[インデックス番号]で値を参照することができます。
インデックス番号は1からではなく、0から始まることに注意する必要があります。fatty_acids = ['FA 16:0', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3'] print(fatty_acids[0]) # 1番目(最初)の要素 print(fatty_acids[1]) # 2番目の要素 print(fatty_acids[-1]) # 後ろから1番目(最後)の要素 print(fatty_acids[2:4]) # 3番目から4番目の要素 print(fatty_acids[3:]) # 4番目以降の要素 print(fatty_acids[:3]) # 4番目までの要素 print(fatty_acids[:-2]) # 後ろから2番目までの要素
リスト名[インデックス番号] = 値とすることで、指定したインデックス番号の要素を更新することができます。fatty_acids[3] = 'FA 18:2 (6Z, 9Z)' print(fatty_acids)ちなみに、
(6Z, 9Z)は、二重結合の位置と様式を表しています。6と9はカルボン酸とは反対側の炭素原子から数えて何番目の炭素原子が二重結合を形成しているかを示し、Zというのは二重結合がcisであることを示しています。Eだとtransということになります。
リノール酸の構造など詳しくは、以下のリンク先を見てください。
Linoleic acid (FA 18:2)
二重結合がある場合は、本来であれば上記のように二重結合の位置や結合様式を明示する必要があるわけですが、少し長くなってしまうので、以降では省略することとします。リストの要素の数の取得
リストに含まれる要素の数は
lenで確認することができます。
ちなみに、lenは「length」の略です。print(len(fatty_acids))リストの演算
リストの演算でよく使うのは、
+と*です。
+でリスト同士を結合することができ、*で同じ要素を指定個数持つリストを作成することができます。saturated_fatty_acids = ['FA 16:0', 'FA 18:0'] # 飽和脂肪酸(二重結合がない脂肪酸) unsaturated_fatty_acids = ['FA 18:1', 'FA 18:2', 'FA 18:3'] # 不飽和脂肪酸(二重結合がある脂肪酸) fatty_acids = saturated_fatty_acids + unsaturated_fatty_acids # リストの結合 print(fatty_acids) number_carbons = [16] + [18]*4 # リストの結合と複製 print(number_carbons)
number_carbonsは、リストfatty_acidsの炭素原子数だけ取り出したものになっています。
fatty_acidsには、炭素原子数18の分子種が4つ含まれているので、*で複製しています。リストのメソッド
リストでよく使うメソッドを以下で紹介します。
fatty_acids = ['FA 16:0', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3'] fatty_acids_copy = fatty_acids.copy() # コピーを作成 print(fatty_acids_copy) fatty_acids.append('FA 20:4') # 末尾に要素を追加 print(fatty_acids) fatty_acids.extend(['FA 20:5', 'FA 22:6']) # 末尾に要素(複数)を追加 print(fatty_acids) fatty_acids.insert(1, 'FA 16:1') # 指定したインデックス番号に要素を追加 print(fatty_acids) fatty_acids.remove('FA 18:3') # 指定した要素を削除 print(fatty_acids) print(fatty_acids.pop()) # 最後の要素を削除し、削除した要素を出力 print(fatty_acids.pop(2)) # 3番目の要素を削除し、削除した要素を出力 fatty_acids.sort(key=None, reverse=True) # 要素を降順に並び替え print(fatty_acids) fatty_acids.sort(key=None, reverse=False) # 要素を昇順に並び替え print(fatty_acids) print(fatty_acids.index('FA 18:2')) # 指定した要素のインデックス番号 print(fatty_acids.count('FA 18:2')) # 指定した要素の個数
.extend(['FA 20:5', 'FA 22:6')は、.append(['FA 20:5', 'FA 22:6'])と書いても良さそうですが、実行結果が変わってきます。
extendを使った場合は、'FA 20:5'と'FA 22:6'という2つの要素が追加されますが、appendを使った場合は、['FA 20:5', 'FA 22:6']というリストが1つの要素として追加されます。つまり、appendを使った場合は、リストの中にリストが含まれるという状態になるわけです。
appendとextendの使い分けには注意が必要です。文字列の扱い
文字列もリストと同じように扱うことができます。文字列を単一文字のリストと考えて、前から5文字目を参照する、といったことができます。
palmitic_acid = fatty_acids[0] # リスト「fatty_acid」の1番目の要素 print(palmitic_acid) # FA 16:0 print(palmitic_acid[0]) # 「FA 16:0」という文字列の1文字目、すなわち「F」 print(len(palmitic_acid)) # 文字数 lipid_class = palmitic_acid[0:2] print(lipid_class) # FA Cn = int(palmitic_acid[3:5]) print(Cn) # 16(数値) Un = int(palmitic_acid[6]) print(Un) # 0(数値)応用:SMILES記法
応用編として、SMILES記法で脂肪酸の炭素原子や二重結合の数を数えるということを考えます。
smiles_la = 'OC(CCCCCCC/C=C\C/C=C\CCCCC)=O' # リノール酸のSMILES Cn = smiles_la.count('C') # 炭素原子の数 Un = smiles_la.count('=') - 1 # 炭素鎖の中の二重結合の数 linoleic_acid = f'FA {Cn}:{Un}' # f-string print(linoleic_acid)タプル
タプル(tupple)はリストに似たデータ型で、
タプル名 = (要素1, 要素2, ・・・)で作ることができます。
リストと同様に、タプル名[インデックス番号]で値を参照することはできますが、値の更新をすることはできません。
なので、値を書き換えたくないデータを配列にしたい場合は、タプルを使うと良いです。fatty_acids = ('FA 16:0', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3') print(fatty_acids[0]) # 1番目の要素 print(fatty_acids[1]) # 2番目の要素 print(fatty_acids[-1]) # 後ろから1番目の要素 print(fatty_acids[2:4]) # 3番目から4番目の要素 print(fatty_acids[3:]) # 4番目以降の要素 print(fatty_acids[:3]) # 4番目までの要素 print(fatty_acids[:-2]) # 後ろから2番目までの要素辞書
辞書の作成
辞書(dictionary)というのは、「キー」と「値」を1対1に対応させ、このキーと値の組合せを配列にしたものです。
辞書名 = {キー1: 値1, キー2: 値2, ・・・}で作成することができます。Cn = 18 # 脂肪酸の炭素原子数(鎖長) Un = 2 # 二重結合数(不飽和度) num_C = Cn # 分子全体の炭素原子数 num_H = Cn * 2 - Un * 2 # 分子全体の水素原子の数 num_O = 2 # 分子全体の酸素原子の数 molecular_formula = {'C': num_C, 'H': num_H, 'O': num_O}辞書の要素の参照
上の例では、元素記号をキーに、原子数を値とした辞書を作成しています。
辞書に含まれる全てのキーや値を参照するには、以下のようにします。print(molecular_formula.keys()) # キーのリスト print(molecular_formula.values()) # 値のリスト print(molecular_formula.items()) # キーと値のタプルのリスト辞書の要素の更新、追加
辞書名[キー] = 値とすると、辞書の中にキーが既にあった場合は値が更新され、キーがなかった場合は新しくキーと値が追加されます。molecular_formula['C'] = 16 # 値の書き換え molecular_formula['H'] = 32 # 値の書き換え molecular_formula['N'] = 0 # 新たなキーと値の追加 print(molecular_formula)集合
集合(set)は、
集合名 = {}で作成することができます。
順番といった概念はなく、インデックス番号で要素を指定せずに、特定の要素があるかないかなどを判定するときに使います。fatty_acids = {'FA 16:0', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3'}まとめ
ここでは、Pythonのデータ構造について、ケモインフォマティクスで使える実践的な知識を中心に解説しました。
もう一度要点をおさらいしておきましょう。
- リストは、複数の要素を格納できるほか、文字列をリストのように扱うこともできます。SMILES記法で記述された化合物の構造を取り扱うことにも応用できます。
- 辞書は、キーと値を対応させて複数のデータを格納できます。化合物の組成式の情報などを格納するのに使えます。
次回は、Pythonの制御文(条件分岐、反復処理など)について解説する予定です。
参考資料・リンク
- 投稿日:2020-01-04T16:38:04+09:00
【StyleGAN入門】style_mixing「眼鏡をはずす女性」で遊んでみた♬
StyleGAN二日目は、以下の参考①にある、StyleGANで画像生成する3つの方法のうち二つの方法について解説して、いろいろなStyle_Mixing画像生成をやってみようと思う。なお、StyleGANについての良い解説が参考②にあるので参照するとこの記事の解説もわかりやすいと思う。
【参考】
①NVlabs/stylegan
②StyleGAN解説 CVPR2019読み会@DeNAやったこと
・まず2つの方法とは
・コードにしてみる
・LatentMixing;潜在空間$z$でMixingをやってみる
・StyleMixing;写像された潜在空間$w$でMixingしてみる
・StyleMixing_2;写像された潜在空間$w$でstyle属性を入れ替えて画像生成する
・StyleMixing_3;写像潜在空間$w$の個別Style属性をMixingして画像生成する・まず2つの方法とは
簡単に直訳すると以下のとおりである。
事前学習済みのジェネレーターを使用するには、次の3つの方法があります。
$1. 入力と出力がnumpy配列である即時モード操作にはGs.run()を使用します.$
訳注)前回はこの手法を使いました# Pick latent vector. rnd = np.random.RandomState(5) latents = rnd.randn(1, Gs.input_shape[1]) # Generate image. fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) images = Gs.run(latents, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt)最初の引数は、形状[num、512]の潜在ベクトルのバッチです。 2番目の引数はクラスラベル用に予約されています(StyleGANでは使用されません)
残りのキーワード引数はオプションであり、操作をさらに変更するために使用できます(以下を参照)。出力は画像のバッチであり、その形式はoutput_transform引数によって決定されます。
訳注)以下参照のオプション(truncation_psi=0.7, randomize_noise=True)については参考①を参照してください$2.$Use $Gs$.get_output_for() to incorporate the generator as a part of a larger TensorFlow expression:
訳注)これは今回使用しないので飛ばします。
...
$3.Gs.components.mappingおよびGs.components.synthesis$を検索して、ジェネレーターの個々のサブネットワークにアクセスします。$G$と同様に、サブネットワークは$dnnlib.tflib.Network$の独立したインスタンスとして表されます。:
訳注)今回は生成画像Mixingでこの手法を利用しますsrc_latents = np.stack(np.random.RandomState(seed).randn(Gs.input_shape[1]) for seed in src_seeds) src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component] src_images = Gs.components.synthesis.run(src_dlatents, randomize_noise=False, **synthesis_kwargs)・コードにしてみる
上記の手法を用いて実際の最も簡単なコードは以下のとおり記述できます。
import os import pickle import numpy as np import PIL.Image import dnnlib import dnnlib.tflib as tflib import config from PIL import Image, ImageDraw import numpy as np import matplotlib.pyplot as plt import tensorflow as tf synthesis_kwargs = dict(output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True), minibatch_size=8) def main(): # Initialize TensorFlow. tflib.init_tf() fpath = './weight_files/tensorflow/karras2019stylegan-ffhq-1024x1024.pkl' with open(fpath, mode='rb') as f: _G, _D, Gs = pickle.load(f) #方法1. 入力と出力がnumpy配列である即時モード操作にはGs.run()を使用 # Pick latent vector. rnd = np.random.RandomState(5) latents1 = rnd.randn(1, Gs.input_shape[1]) # Generate image. fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) images = Gs.run(latents1, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt) plt.imshow(images.reshape(1024,1024,3)) plt.pause(1) plt.savefig("./results/simple1_.png") plt.close() #方法3.Gs.components.mappingおよびGs.components.synthesisを検索して、ジェネレーターの個々のサブネットワークにアクセスします #Gと同様に、サブネットワークはdnnlib.tflib.Networkの独立したインスタンスとして表されます。 src_seeds = [5] src_latents = np.stack(np.random.RandomState(seed).randn(Gs.input_shape[1]) for seed in src_seeds) src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component] src_images = Gs.components.synthesis.run(src_dlatents, randomize_noise=False, **synthesis_kwargs) plt.imshow(src_images[0].reshape(1024,1024,3)) plt.pause(1) plt.savefig("./results/simple3_.png") plt.close() if __name__ == "__main__": main()このコードだとどちらの手法も同じ画像を生成しそうですが、実際にやってみると以下のとおり少し異なりました。
手法1 手法2 潜在テンソル z=latents1 z=src_latents, w=src_dlatents size (1,512) (1,512), (1,18,512) これらの潜在テンソルはそれぞれ以下の図の$z$と$w$に対応しています。
つまり、Latent $z$は512のパラメータを持つベクトルで、その写像潜在空間$W$のテンソル$w$は(18,512)の次元を持っているということです。
すなわちSynthesis networkへの入力Aは18ヶ所あり(参考③参照)、これがそれぞれStyleの元となっているテンソル$w$というわけです。
【参考】
③Style-mixingをやってみる@StyleGANの学習済みモデルでサクッと遊んでみる
つまり、上記の手法1と3の説明は以下のように言い換えることができます。
- 手法1. 潜在ベクトル$z$から画像生成しているものです
- 手法2. 潜在ベクトル$z$から一度写像潜在空間のテンソル$w$を求めて、さらにそこから対応するsynthesys networkの$A$を探索して、それぞれが独立なネットワークとして計算しつつ画像生成しているということです
・LatentMixing;潜在空間 zでMixingをやってみる
これは前回やった通りですが、上記を反映して潜在ベクトル$z$の求め方として二通りで実施します。
主要なコードは以下のとおりです。simple_method1.pydef main(): # Initialize TensorFlow. tflib.init_tf() fpath = './weight_files/tensorflow/karras2019stylegan-ffhq-1024x1024.pkl' with open(fpath, mode='rb') as f: _G, _D, Gs = pickle.load(f) # Pick latent vector. rnd = np.random.RandomState(5) #5 latents1 = rnd.randn(1, Gs.input_shape[1]) print(latents1.shape) # Generate image. fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) images = Gs.run(latents1, None, truncation_psi=1, randomize_noise=False, output_transform=fmt) # Pick latent vector2 src_seeds=[6] src_latents = np.stack(np.random.RandomState(seed).randn(Gs.input_shape[1]) for seed in src_seeds) # Generate image2 src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component] src_images = Gs.components.synthesis.run(src_dlatents, randomize_noise=False, **synthesis_kwargs) for i in range(1,101,4): # mixing latent vetor_1-2 latents = i/100*latents1+(1-i/100)*src_latents[0].reshape(1,512) # Generate image for mixing vector by method1. fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) images = Gs.run(latents, None, truncation_psi=1, randomize_noise=False, output_transform=fmt) # Save image. os.makedirs(config.result_dir, exist_ok=True) png_filename = os.path.join(config.result_dir, 'example{}.png'.format(i)) PIL.Image.fromarray(images[0], 'RGB').save(png_filename)結果は以下のとおりとなります。
Latent z mixing ここで、「コードにしてみる」のところで両者の出力が異なっていましたが、これはtruncation_psi, randomize_noiseというパラメータの所為でした。そこでここでは再現性を確実にするために、それぞれ1, Falseと変更しています。
感想)この動画見てると二人のお子さんの顔が見えるようで怖い...・StyleMixing; 写像された潜在空間wでMixingしてみる
今度は上と同じように、しかし写像潜在空間$w$によるMixingをやってみます。
コードの主要な部分は以下のとおりです。simple_method2.pysynthesis_kwargs = dict(output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True), minibatch_size=8) def main(): # Initialize TensorFlow. tflib.init_tf() fpath = './weight_files/tensorflow/karras2019stylegan-ffhq-1024x1024.pkl' with open(fpath, mode='rb') as f: _G, _D, Gs = pickle.load(f) # Pick latent vector. rnd = np.random.RandomState(5) #5 latents1 = rnd.randn(1, Gs.input_shape[1]) # Generate image. dlatents1 = Gs.components.mapping.run(latents1, None) # [seed, layer, component] images = Gs.components.synthesis.run(dlatents1, randomize_noise=False, **synthesis_kwargs) src_seeds=[6] src_latents = np.stack(np.random.RandomState(seed).randn(Gs.input_shape[1]) for seed in src_seeds) src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component] src_images = Gs.components.synthesis.run(src_dlatents, randomize_noise=False, **synthesis_kwargs) for i in range(1,101,4): dlatents = i/100*dlatents1+(1-i/100)*src_dlatents # Generate image. images = Gs.components.synthesis.run(dlatents, randomize_noise=False, **synthesis_kwargs) # Save image. os.makedirs(config.result_dir, exist_ok=True) png_filename = os.path.join(config.result_dir, 'example{}.png'.format(i)) PIL.Image.fromarray(images[0], 'RGB').save(png_filename)結果は以下のとおりとなりました。
一見して、結果は異なっています。
Style mixing in projected space 入力の潜在ベクトル$z$で線形補間するのと、その非線形(多段MLP)写像空間でのStyleベクトル$w$のそれぞれを線形補間するのと異なるのは当然である。
結果は、ウワンが見る限りだと写像空間でのStyleベクトルの線形補間の方が眼鏡が長持ちするという意味で好ましい気がします。
ここで、次からはこの線形補間は、補間という意味ではまだまだ粗いというのを見ていこうと思います。・StyleMixing_2;写像された潜在空間wでstyle属性を入れ替えて画像生成する
この手法は論文にも出ていて最も有名な画像変化の例です。
早速、コードを示します。このコードは参考③のコードを参考にしています。
※関数の構成を変更しているのでほぼ全体を載せますordinary_style_mixising.pyimport os import pickle import numpy as np import PIL.Image import dnnlib import dnnlib.tflib as tflib import config import matplotlib.pyplot as plt synthesis_kwargs = dict(output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True), minibatch_size=8) def load_Gs(): fpath = './weight_files/tensorflow/karras2019stylegan-ffhq-1024x1024.pkl' with open(fpath, mode='rb') as f: _G, _D, Gs = pickle.load(f) return Gs def draw_style_mixing_figure(png, Gs, w, h, src_seeds, dst_seeds, style_ranges): print(png) src_latents = np.stack(np.random.RandomState(seed).randn(Gs.input_shape[1]) for seed in src_seeds) src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component] # Pick latent vector. rnd = np.random.RandomState(5) #5 latents1 = rnd.randn(1, Gs.input_shape[1]) print(latents1.shape) # Generate image. dlatents1 = Gs.components.mapping.run(latents1, None) # [seed, layer, component] images = Gs.components.synthesis.run(dlatents1, randomize_noise=False, **synthesis_kwargs) dst_dlatents = np.zeros((6,18,512)) for j in range(6): dst_dlatents[j] = dlatents1 src_images = Gs.components.synthesis.run(src_dlatents, randomize_noise=False, **synthesis_kwargs) dst_images = Gs.components.synthesis.run(dst_dlatents, randomize_noise=False, **synthesis_kwargs) print(dst_images.shape) canvas = PIL.Image.new('RGB', (w * (len(src_seeds) + 1), h * (len(dst_seeds) + 1)), 'white') for col, src_image in enumerate(list(src_images)): canvas.paste(PIL.Image.fromarray(src_image, 'RGB'), ((col + 1) * w, 0)) for row, dst_image in enumerate(list(dst_images)): canvas.paste(PIL.Image.fromarray(dst_image, 'RGB'), (0, (row + 1) * h)) row_dlatents = np.stack([dst_dlatents[row]] * len(src_seeds)) row_dlatents[:, style_ranges[row]] = src_dlatents[:, style_ranges[row]] row_images = Gs.components.synthesis.run(row_dlatents, randomize_noise=False, **synthesis_kwargs) for col, image in enumerate(list(row_images)): canvas.paste(PIL.Image.fromarray(image, 'RGB'), ((col + 1) * w, (row + 1) * h)) canvas.save(png) def main(): tflib.init_tf() os.makedirs(config.result_dir, exist_ok=True) draw_style_mixing_figure(os.path.join(config.result_dir, 'style-mixing.png'), load_Gs(), w=1024, h=1024, src_seeds=[6,701,687,615,2268], dst_seeds=[0,0,0,0,0,0], style_ranges=[range(0,8)]+[range(1,8)]+[range(2,8)]+[range(1,18)]+[range(4,18)]+[range(5,18)]) if __name__ == "__main__": main()結果は以下のとおりとなります。
※なお、掲載サイズのために上記出力1024x1024を256x256に縮小しています
コードからこれらの図は以下のStyle変換で生成されています。
style_ranges=[range(0,8)]+[range(1,8)]+[range(2,8)]+[range(1,18)]+[range(4,18)]+[range(5,18)]
row_dlatents[:, style_ranges[row]] = src_dlatents[:, style_ranges[row]]
すなわち、Style[0,18]のうち上段から以下のStyleの変換だけでこれだけの画像変換ができるということです。
※おじさん側から見て、以下のRange部分を女性のStyleに変更しています
おじさんを維持するには少なくともrange[0,4]を維持する必要があるということです
[range(0,8)] 同上 [range(1,8)] 同上 [range(2,8)] 同上 [range(1,18)] 同上 [range(4,18)] 同上 [range(5,18)] 逆に女性から言えば、2-4段目を見るとrange[0]が無いだけで眼鏡は外され女性らしさもかなりボーイッシュな感じに変化させられています。特に4段目はrange[0]以外すべて同じなのにかなりの変化をしています。
・StyleMixing_3;写像潜在空間wの個別Style属性をMixingして画像生成する
ということで、先ほどのコードを使ってこのrange[0]のStyleをMixingすることにより、この変化を見てみようと思います。
simple_method2.pyの当該コード部分を以下に置き換えると実現できます。individual_mixing_style.pyfor i in range(1,26,1): dlatents=src_dlatents dlatents[0][0] = i/100*dlatents1[0][0]+(1-i/100)*src_dlatents[0][0]
Individual style mixing in projected space 今回は示しませんが、この手法だとStyle空間の任意のパラメータをMixingできることにより、よりきめ細かなMixingが出来ます。
まとめ
・「眼鏡をはずす女性」をやってみた
・それぞれの特性に特化してMixing出来るようになった
・この手法だとnpyで与えられた画像についても同様に実施できる・独自画像を学習して独自なStyle画像を生成したい















- 投稿日:2020-01-04T16:34:25+09:00
【Django Rest Framework】Django-Filterを使ってフィルタ機能をカスタマイズする
概要
この記事は初心者の自分がRESTfulなAPIとswiftでiPhone向けのクーポン配信サービスを開発した手順を順番に記事にしています。技術要素を1つずつ調べながら実装したため、とても遠回りな実装となっております。
前回の Django Rest Framework で 特定のデータだけレスポンスするようにフィルタを設定する で、 Generic Filtering を使って指定したフィールドのパラメータに一致するデータをフィルタリングできました。しかしこの方法では指定したパラメータに対して 「以上」、「以下」という条件でフィルタリングする事が出来ません。
そこで今回は日付について「〜より前」「〜より後」といった条件で有効期限を判定するフィルタ機能を実装します。
Django-Filterをインストールされていない場合は前回の記事を参考にインストールしてください。参考
環境
Mac OS 10.15
VSCode 1.39.2
pipenv 2018.11.26
Python 3.7.4
Django 2.2.6手順
- views.py にFilterSetのクラスを作る
- 既存のViewSetでFilterSetを呼ぶ処理を追加
- 試してみる
views.py にFilterSetのクラスを作る
django_filter の FilterSetクラスを継承してオリジナルのフィルターセットを作ります。
まずFilterSetクラスをインポートするための処理を追加します。from django_filters import rest_framework as filters次に、ViewSetのクラスの前にオリジナルのフィルターセットを実装します。
class CustomFilter(filters.FilterSet): # フィルタの定義 deadline = filters.DateFilter(field_name='deadline', lookup_expr='gte') class Meta: model = Coupon fields = ['deadline'] #定義したフィルタを列挙下記の部分がフィルタの設定になります。今回はDateFilterを使いますが、他にも文字列のフィルターや数値のフィルターなど、沢山あります。詳しくは公式ドキュメントで!
deadline = filters.DateFilter(field_name='deadline', lookup_expr='gte')補足
上記のfield_name = ‘ ‘は フィルタリングしたいモデルフィールドの名前を指定します。ここへ名前を指定しない場合はフィルタ定義の名前(上記のコードだとdeadlineの部分)がフィルタリング対象のモデルフィールドの名前として扱われます。(サンプルコードには
field_nameを指定していますが、フィルタ定義の名前と同じであれば実は不要です)リクエストする際のパラメータ名はフィルタ定義の名前になります。つまり、リクエストする際のパラメータ名をモデルフィールドの名前と異なる名前にしたい場合は field_name の設定が必要です。
下記の
model = ~には、フィルタリングしたデータのモデル名を設定します。
Fields = [~]には、フィルタ定義の名前を列挙します。class Meta: model = Coupon fields = ['deadline']既存のViewSetでFilterSetを呼ぶ処理を追加
上記で実装したフィルタクラスをfilter_classとして呼ぶだけです。
filter_class = CustomFilter試してみる
見積5分 → 5分
リクエストパラメータとして、クーポンの有効期限を示す
deadlineを指定しない場合と、する場合で GETできるデータの違いを比較します。パラメータ deadline を指定しない場合
リクエスト
curl -X GET http://127.0.0.1:8000/api/coupons/レスポンス
[{"id":1,"code":"0001","benefit":"お会計から1,000円割引","explanation":"5,000円以上ご利用のお客様限定。他クーポンとの併用不可。","store":"全店","start":"2019-10-01","deadline":"2019-12-31","status":true},{"id":2,"code":"0002","benefit":"お会計を10%オフ!","explanation":"他クーポンとの併用不可","store":"有楽町店","start":"2019-10-01","deadline":"2019-12-31","status":true},{"id":3,"code":"0003","benefit":"【ハロウィン限定】仮装して来店すると30%オフ","explanation":"全身の50%以上を仮装されているお客様限定(判断はスタッフの感覚とさせて頂きます)。他クーポンとの併用不可","store":"神田店","start":"2019-10-31","deadline":"2019-10-31","status":true},{"id":4,"code":"0004","benefit":"【9月限定】お月見団子サービス","explanation":"ご希望のお客様に月見団子をプレゼント! 他クーポンとの併用可能です!","store":"全店","start":"2019-09-01","deadline":"2019-09-30","status":true},{"id":5,"code":"0005","benefit":"【雨の日限定】お会計から15%オフ","explanation":"クーポンが配信された時だけ利用可能です。他クーポンとの併用不可","store":"全店","start":"2019-10-01","deadline":"2019-12-31","status":false},{"id":6,"code":"0006","benefit":"【日曜日限定】乾杯テキーラサービス","explanation":"テキーラを人数分サービスします。他クーポンとの併用可。","store":"神田店","start":"2019-11-03","deadline":"2019-12-01","status":true},{"id":7,"code":"0007","benefit":"お会計から19%引き","explanation":"12月29日~12月31日限定。他のクーポンとの併用不可","store":"神田店","start":"2019-12-29","deadline":"2019-12-31","status":true}]
deadlineを指定する場合
リクエスト(有効期限が12月5日以降のクーポンだけリクエスト)
curl -X GET http://127.0.0.1:8000/api/coupons/?deadline=2019-12-05レスポンス
[{"id":1,"code":"0001","benefit":"お会計から1,000円割引","explanation":"5,000円以上ご利用のお客様限定。他クーポンとの併用不可。","store":"全店","start":"2019-10-01","deadline":"2019-12-31","status":true},{"id":2,"code":"0002","benefit":"お会計を10%オフ!","explanation":"他クーポンとの併用不可","store":"有楽町店","start":"2019-10-01","deadline":"2019-12-31","status":true},{"id":5,"code":"0005","benefit":"【雨の日限定】お会計から15%オフ","explanation":"クーポンが配信された時だけ利用可能です。他クーポンとの併用不可","store":"全店","start":"2019-10-01","deadline":"2019-12-31","status":false},{"id":7,"code":"0007","benefit":"お会計から19%引き","explanation":"12月29日~12月31日限定。他のクーポンとの併用不可","store":"神田店","start":"2019-12-29","deadline":"2019-12-31","status":true}]
有効期限が12月5日以降のクーポンのみGET出来ました。
- 投稿日:2020-01-04T16:33:05+09:00
【機械学習】決定木を使ってFX予測をする
機械学習とFX
こんにちは。Qiitaにまともな記事を投稿するのは初めてです。
最近機械学習のお勉強をはじめました。
機械学習、もはや言うまでもないけど、いろんなところで使われますね。
スパムメールのフィルタリングや商品のレコメンドなどなど...実例を挙げればきりがないですね。
そんな中でも僕は機械学習を使った株価とかFXの予測に興味を持ったので、今日は
機械学習の1つである決定木を用いてFXを予測してみたいと思います。
もし良い精度で株価とかFXの予測できれば何もしなくても儲けることができるので非常に夢がある話ですよね。
ただ実際にはそんなに簡単に予測できるほど甘いものではないので、勝つ、儲けるというよりも最近勉強した機械学習を何かに適用したいというのが一番のモチベーションです。
なので最初に言っておきますが、もしこの記事を読んでる人で「機械学習とかどうでもいいからAIでFXを予測して明日のドル円が上がるか下がるか教えてくれ!」という人にとってはまったく有益な情報はないです。機械学習やFX予測に興味がある人にとってはもしかしたら少しだけ楽しめるかもしれません。その程度です。FXって?
株の場合、株を購入して株価が上がれば儲かる、下がれば損をする、というのは誰でも知っていると思います。FXについてはもしかしたら知らない方もいるかもしれないので一応説明しておきます。
例えば1ドル100円で取引されていたとします。この状態で1ドルの「買い」注文を入れたとしましょう。
明日この1ドルが
- 110円に上がる→10円の利益
- 90円に下がる→しまえば10円の損失
ですよね。このような為替の取引のことをFXと言います。
FXの場合はレバレッジというものをかけることができるので、例えばレバレッジを10倍にすれば10倍のお金を動かすことができます。この場合利益も10倍、損失も10倍なので注意が必要です。
ドルと円の取引の場合はドル円と呼ばれ。1ドル100円->110円のようにドルの価値が上がればドル高(円安)となり、逆に1ドル100円->90円のようにドルの価値が下がればドル安(円高)となります。
FXについてはわかりやすく説明している本やサイトなどが腐る程あるのでこれ以上は説明しませんが、要は株と同じように上がるか、下がるかを予測できれば利益を生むことができるということです。参考にしたサイト
ここを参考にしました。決定木の丁寧な説明もここに載っているので、この記事ではあまり詳しい解説はしないです。
一言で説明すれば、決定木には標準化と呼ばれる特徴量をスケーリングする作業がいらなかったり、どういう過程でその結果が得られたのかという解釈がしやすい(意味解釈性がある)などの利点があります。
リンク先のページで行われていることをざっくりとまとめます。
- 2018年時点での500日分の日足のドル円データを使って明日のドル円が上がるか下がるかを予測する
- 決定木を使う
- 他の分類器は使っていない。Grid Searchや交差検証などは行なっていない
- 素性として使ったのはドル円の「始値」「終値」「高値」「安値」
- トレーニングデータ(学習データ)とテストデータを8:2で分割している
- testデータに適用した結果、適合率は約50%だった。(あんまりうまく予測できてない)
といった感じです。
本気で予測するよりもあくまで機械学習(決定木)をFXに適用する方法を紹介することをメインとしているので、予測精度はそんなに高くないですね。このページでやりたいこと
- 上で紹介したページと同様の方法を自分の環境で適用する
- 2019年終わりまでの最新の日足データを使う
- 何日分のデータを使うと精度がよくなるのかを調べたい(500日?200日?)
- 素性を増やすと精度が向上するかを確かめたい
- grid searchを使って決定木の最適なパラメータを求めたい
- 交差検証をちゃんと行う
といったところです。素性を増やすことについては、上のページでは数百日分のデータを学習していますが、実際に予測する際の素性として使っているのは「始値」「終値」「高値」「安値」の4つのみなんですよね。
つまり明日のドル円が上がるか下がるかを決める際に”その日の”ローソク足のみで判断して決めているわけです。
でも、実際にトレーダーが判断する際には移動平均(過去n日の平均値)やボリンジャーバンドやMACDなどと呼ばれるさまざまなテクニカル指標ってやつを使うことが多いんですよね。
そんなわけで、今回は以上の4つの素性に加えて「5日、25日、50日、75日の終値の平均と分散」、「過去3日までの始値、終値、高値、安値」などを新たに加えたいと思います。これらの値はさきほど言及したテクニカル指標に関連しています。
何を言っているかよくわからないって?
明日のドル円を予測する際に今日の値動きだけじゃなくて、過去数日〜数週間の平均値やどれくらいばらつきがあったかも参考にした方がいい予測ができるよね?ってことです。
すごくわかりづらい例えで言うと、
「今日のご飯はお母さんが作ってくれたカレーライスだった。過去の傾向からカレーライスの次の日のご飯はハンバーグである確率が高いので明日はハンバーグだ!」
と予測するのが上でやっている方法です。僕がやりたいのは
「今日のご飯はカレーライスだった。昨日は肉じゃが、先週は中華料理が多かった。今日のメニューと直近数週間の傾向から推測すると...明日はハンバーグ!」
って感じです。わかりづらいですね。jupyterで実装してみる
前準備
上のページと同じようにjupyterでPythonを使ってごりごり書きます。
途中までは上で紹介したページとほぼ同じですが、順番にやっていこうと思います。
まずは必要なライブラリをいろいろとimportします。import pandas as pd import numpy as np # データ可視化のライブラリ import matplotlib.pyplot as plt # 機械学習ライブラリ from sklearn.tree import DecisionTreeClassifier from sklearn import tree from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score # graphvizのインポート import graphviz #grid searchとcross validation用 from sklearn.model_selection import cross_val_score from sklearn.model_selection import GridSearchCV下2つはgrid searchや交差検証を行うときに必要です。次にデータを読み込みます。
今回は2017年から2019年までの2年分のcsvデータを用意しました。
僕はMT4というソフトで取引を行なっているのですが、そこで提供されているデータをcsv形式で持ってきました。# CSVファイルの読み込み。2017-2019の2年分 df = pd.read_csv('usd_jpy_api_2017_2019.csv') # 最後の5行を確認 df.tail()最初の5行はこんな感じです。それぞれ取引が行われた時間、終値、始値、高値、安値、取引量を表してます。
ここらへんまでの作業は上で紹介したページなのでざっくりと飛ばしていきますが、ついの日の終値が上がるかどうかで正解ラベルを0, 1で付与します。
# 翌日終値 - 当日終値で差分を計算 #shift(-1)でcloseを上に1つずらす df['close+1'] = df.close.shift(-1) df['diff'] = df['close+1'] - df['close'] #最終日はclose+1がNaNになるので削る df = df[:-1]一応上昇、下降データの割合を確認してみます。
# 上昇と下降のデータ割合を確認 m = len(df['close']) #df['diff']>0で全行に対してtrueかfalseで返してくれる。df[(df['diff'] > 0)]でdff>0に絞って全てのカラムを出力 print(len(df[(df['diff'] > 0)]) / m * 100) print(len(df[(df['diff'] < 0)]) / m * 100)52.16284987277354 47.837150127226465わずかに上昇した日の方が多いですね。次に不要な列を削除してラベルの名前をtargetにします。
- targetと書いてあるのが学習する際に必要な正解のクラスラベルにあたる
- 次の日の終値が上がる場合は1、下がる場合は0が割り当てられている
df.rename(columns={"diff" : "target"}, inplace=True) # 不要なカラムを削除 del df['close+1'] del df['time'] # カラムの並び替え df = df[['target', 'volume', 'open', 'high', 'low', 'close']] # 最初の5行を出力 df.head()
素性の追加
ここから新しい素性を計算してゴリゴリ追加していきます。
#移動平均の計算、5日、25日、50日、75日 #ついでにstdも計算する。(=ボリンジャーバンドと同等の情報を持ってる) #75日分のデータ確保 for i in range(1, 75): df['close-'+str(i)] = df.close.shift(+i) #移動平均の値とstdを計算する, skipnaの設定で一つでもNanがあるやつはNanを返すようにする nclose = 5 df['MA5'] = df.iloc[:, np.arange(nclose, nclose+5)].mean(axis='columns', skipna=False) df['MA25'] = df.iloc[:, np.arange(nclose, nclose+25)].mean(axis='columns', skipna=False) df['MA50'] = df.iloc[:, np.arange(nclose, nclose+50)].mean(axis='columns', skipna=False) df['MA75'] = df.iloc[:, np.arange(nclose, nclose+75)].mean(axis='columns', skipna=False) df['STD5'] = df.iloc[:, np.arange(nclose, nclose+5)].std(axis='columns', skipna=False) df['STD25'] = df.iloc[:, np.arange(nclose, nclose+25)].std(axis='columns', skipna=False) df['STD50'] = df.iloc[:, np.arange(nclose, nclose+50)].std(axis='columns', skipna=False) df['STD75'] = df.iloc[:, np.arange(nclose, nclose+75)].std(axis='columns', skipna=False) #計算終わったら余分な列は削除 for i in range(1, 75): del df['close-'+str(i)] #それぞれの平均線の前日からの変化(移動平均線が上向か、下向きかわかる) #shift(-1)でcloseを上に1つずらす df['diff_MA5'] = df['MA5'] - df.MA5.shift(1) df['diff_MA25'] = df['MA25'] - df.MA25.shift(1) df['diff_MA50'] = df['MA50'] - df.MA50.shift(1) df['diff_MA75'] = df['MA50'] - df.MA50.shift(1) #3日前までのopen, close, high, lowも素性に加えたい for i in range(1, 4): df['close-'+str(i)] = df.close.shift(+i) df['open-'+str(i)] = df.open.shift(+i) df['high-'+str(i)] = df.high.shift(+i) df['low-'+str(i)] = df.low.shift(+i) #NaNを含む行を削除 df = df.dropna() #何日分使うか決める nday = 500 df = df[-nday:] #df.head() df
右の方見切れてますが、こんな感じです。
- MAと書いてあるのは移動平均。例えばMA5はその日から過去5日間での終値の平均
- close-nはn日前の終値を表す(openやhigh、lowも同様)
- STDとかいてあるのは標準偏差
- 移動平均が上を向いているのか、下を向いているのかも知りたかったので前日からの変化もdiff_という名前で加えた
とりあえず500日分のデータを選びました。
最初にデータを読み込んだ時に指定してもよかったんですが、75日平均を計算するときなどは75日分遡ったデータが必要となるので、一通り計算が済んでから500日分のデータを使っています。これで500行30列のデータができあがりました。決定木の学習
準備は整ったので、trainとtestに分割して評価していこう。
n = df.shape[0] p = df.shape[1] print(n,p) # 訓練データとテストデータへ分割。シャッフルはしない train_start = 0 train_end = int(np.floor(0.8*n)) test_start = train_end + 1 test_end = n data_train = np.arange(train_start, train_end) data_train = df.iloc[np.arange(train_start, train_end), :] data_test = df.iloc[np.arange(test_start, test_end), :] # 訓練データとテストデータのサイズを確認 print(data_train.shape) print(data_test.shape)今回は8:2で分割しました。
(400, 30) (99, 30)次に正解ラベルの部分を分離して、決定木で学習を行なっていきます。
木の深さを表すハイパーパラメータであるmax_depthはとりあえず5にしてありますが、適切な値はこの後grid searchで決定します。#targetを分離 X_train = data_train.iloc[:, 1:] y_train = data_train.iloc[:, 0] X_test = data_test.iloc[:, 1:] y_test = data_test.iloc[:, 0] # 決定技モデルの訓練 clf_2 = DecisionTreeClassifier(max_depth=5)ようやく決定木が出てきましたね。k=10の交差検証とgrid searchを行います。
# grid searchでmax_depthの最適なパラメータを決める #k=10のk分割交差検証も行う params = {'max_depth': [2, 5, 10, 20]} grid = GridSearchCV(estimator=clf_2, param_grid=params, cv=10, scoring='roc_auc') grid.fit(X_train, y_train) for r, _ in enumerate(grid.cv_results_['mean_test_score']): print("%0.3f +/- %0.2f %r" % (grid.cv_results_['mean_test_score'][r], grid.cv_results_['std_test_score'][r] / 2.0, grid.cv_results_['params'][r])) print('Best parameters: %s' % grid.best_params_) print('Accuracy: %.2f' % grid.best_score_)出力はこんな感じ。深さ10の時が一番正答率高くで69%と出ていますね。
0.630 +/- 0.05 {'max_depth': 2} 0.679 +/- 0.06 {'max_depth': 5} 0.690 +/- 0.06 {'max_depth': 10} 0.665 +/- 0.05 {'max_depth': 20} Best parameters: {'max_depth': 10} Accuracy: 0.69テストデータでの評価
上で出てきた正答率はあくまで学習データでの正答率なので、testデータを予測できるか試してみます。
#grid searchで最適だったパラメータを使って学習する clf_2 = grid.best_estimator_ clf_2 = clf_2.fit(X_train, y_train) clf_2パラメータはこんな感じで設定されていることがわかる。
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=10, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter='best')せっかくなので可視化してみよう。max_depth=10なのでえぐいことになっとる。。
一番上の部分だけ切り取るとこんな感じ。
この場合だと3日前の高値が82.068以上なのか以下なのかで最初に分割を行い、次に当日の安値でしきい値を決めて分割してってるのがわかる。
giniと買いてあるのは、gini不純度という値が小さくなるように分割を行なっているという意味。
value=の部分は上昇、下降それぞれいくつあるかを表す。
testの正答率を調べてみよう。
pred_test_2 = clf_2.predict(X_test) #テストデータ 正解率 accuracy_score(y_test, pred_test_2)0.555555555555うーん。。いろいろ頑張った割には..って感じだけど、まあこんなもんか。
どの素性が重要なのか(feature impotance)もみてみよう。#重要度の高い素性を表示 importances = clf_2.feature_importances_ indices = np.argsort(importances)[::-1] for f in range(X_train.shape[1]): print("%2d) %-*s %f" % (f + 1, 30, df.columns[1+indices[f]], importances[indices[f]]))移動平均とか色々計算してはみたけど、結局当日とか前日の値動きが重要みたいね。
1) low 0.407248 2) close 0.184738 3) low-1 0.078743 4) high-3 0.069653 5) high 0.043982 6) diff_MA5 0.039119 7) close-3 0.035420 8) STD50 0.035032 9) diff_MA25 0.029473 10) MA75 0.028125 11) MA50 0.009830 12) open-3 0.009540 13) STD25 0.009159 14) low-3 0.007632 15) high-1 0.007632 16) volume 0.004674 以下0なので略いろいろ値をいじってみる
今回の検証の条件を今一度まとめてみよう
- 集計期間:2019年12月31日までの500日分
- 分類器:決定木
- パラメータ:max_depth=10
- 交差検証:10分割
- トレーニングとテストの分割:8:2
結果:正答率0.55
ここで決定木のパラメータはgrid searchで決めたのでいいとして、集計期間や分割の比率などはいじれそうなので試してみました。分割比率を9:1に変えた結果 → 正答率:61% (max_depth=20)
集計期間を200日にした結果 → 正答率:56% (max_depth=10)
となりました。正答率は50-60%くらいってとこですかね。
grid searchは条件を変えるたびにやり直してますが、だいたいmax_depth=10-20くらいが一番いいスコアでした。今回わかったこと
- ドル円の日足データから決定木でいろいろ頑張って予測するととだいたい50-60%くらいの精度がでる
今後やりたいこと
- 決定木以外の分類器で試す (ロジスティック回帰、kNN、etc.)
- アンサンブルの手法を使う (いくつかの分類機を組み合わせる。)
- 次元削減などを適切に行う (今回は決定木の性質上あまり必要なかった)
- 素性を考える (もっといい特徴量があるかも...??)
思ったより長くなってしまった。。
おわり




- 投稿日:2020-01-04T16:28:15+09:00
iTunesで再生中の曲の歌詞をPythonで自動表示させよう(改良版)
はじめに
以前作った「iTunesで再生中の曲の歌詞をPythonで自動表示させよう」に大幅に機能を追加しました。
改良箇所
- 曲のスキップに対応
- 表示の高速化
- アプリの制御
- 自動スクロール
- 歌詞検索精度の向上
曲のスキップに対応
一度曲の歌詞ページを開いたらその曲が終わるまでそのページを表示し続ける仕様だったのを、次の曲にスキップしたら歌詞も次の曲を表示させるようにしました。
変更前while True: start = time.time() # delete # ~~~~~~~~ time.sleep(music_time - (time.time() - start)) # delete変更後prev_track_name = "" # add while True: # 再生中の曲名、アルバム名、アーティスト名、曲の長さ name = music.current_track.name.get() artist = music.current_track.artist.get() album = music.current_track.album.get() music_time = music.current_track.time.get() # m:s の str # add-start if name == prev_track_name: time.sleep(1) continue prev_track_name = name # add-end # ~~~~~~~~ time.sleep(1) # add表示の高速化
歌詞ページの表示が完了するまでに時間がかかっていたため、タイムアウトを設定しました。
変更後driver = webdriver.Chrome(executable_path="chromedriver") driver.get("https://www.google.com/") # 初期タブ driver.set_page_load_timeout(5) # 読み込みの最大待ち時間(この場合 5 秒間) # add歌詞自体は 5 秒もあれば読み込みができますが、それ以外の画像等に時間がかかってページ読み込み時間が長くなってしまうため、5 秒を過ぎたら強制的に終了させます。ついでに「歌詞の位置までスクロール」も、歌詞の位置を探してその位置までスクロールするように変更しました。
変更前while True: # ~~~~~~~~ try: # ~~~~~~~~ # 新しいタブで開く driver.execute_script("window.open()") driver.switch_to.window(driver.window_handles[1]) driver.get("https://www.uta-net.com/" + name_url) driver.execute_script("window.scrollTo(0, 380);") # 歌詞の位置までスクロール # 前のタブを閉じる driver.switch_to.window(driver.window_handles[0]) driver.close() driver.switch_to.window(driver.window_handles[0])変更後while True: # ~~~~~~~~ try: # ~~~~~~~~ # 新しいタブで開く driver.execute_script("window.open()") driver.switch_to.window(driver.window_handles[1]) # add-start try: driver.get("https://www.uta-net.com/" + name_url) except: pass # 歌詞の位置までスクロール driver.execute_script("arguments[0].scrollIntoView();", driver.find_element_by_id("view_kashi")) # add-end # 前のタブを閉じる driver.switch_to.window(driver.window_handles[0]) driver.close() driver.switch_to.window(driver.window_handles[0])アプリの制御
ほぼおまけですが、ターミナル上でも「再生」「次の曲へ」などを制御できるようにしました。
まず基本的な操作です。基本操作music = appscript.app("Music") # 再生 music.play() # 一時停止 music.pause() # 再生・一時停止 music.playpause() # 前のトラックへ music.previous_track() # 次のトラックへ music.next_track()これをそのまま使います。
また、通常のinput()だと入力が行われるまで待機して他の処理を行うことができないため、タイムアウト付き入力を利用しました。タイムアウト付き入力from select import select import sys # 引数は順に「読み込み」「書き込み」「例外」「待機時間」で、今回は読み込みのみ使用 # 待機時間は 0.5 秒に指定 # 0.5 秒経って入力がなければ空のリストが返される read, _, _ = select([sys.stdin], [], [], 0.5) if read: command = sys.stdin.readline().strip() else: command = ""以上をそのままコードの中に入れていきます。
変更後while True: # Music アプリにアクセスする music = appscript.app("Music") # add-start # ---- アプリ制御 ---- # タイムアウト付き入力 read, _, _ = select([sys.stdin], [], [], 0.5) if read: command = sys.stdin.readline().strip() else: command = "" if command == "b": # 前のトラックへ music.previous_track() elif command == "p": # 再生・一時停止 music.playpause() elif command == "n": # 次のトラックへ music.next_track() # add-end # ~~~~~~~~自動スクロール
歌詞全体が表示できないこともあるため、歌詞が自動でスクロールされるようにしました。
変更後while True: # ~~~~~~~~ if name == prev_track_name: time.sleep(1) # add-start count += 1 if count % 5 == 0: driver.execute_script( "window.scrollTo(window.pageXOffset, window.pageYOffset + " + str(kashi_length // music_time * 5) + ");" ) # add-end continue # ~~~~~~~~ # 新しいタブで開く driver.execute_script("window.open()") driver.switch_to.window(driver.window_handles[1]) try: driver.get("https://www.uta-net.com/" + name_url) except: pass # 歌詞の位置までスクロール driver.execute_script("arguments[0].scrollIntoView();", driver.find_element_by_id("view_kashi")) # add-start # ページ上の歌詞部分の長さ kashi_length = driver.find_element_by_id("view_mylink").location["y"] - \ driver.find_element_by_id("view_kashi").location["y"] # add-end # 前のタブを閉じる driver.switch_to.window(driver.window_handles[0]) driver.close() driver.switch_to.window(driver.window_handles[0])ページ内の歌詞部分の長さを取得し、 (歌詞の長さ / 曲の長さ) * 5 下にスクロール を 5 秒おきに実行することで程良いペースでスクロールしています。
歌詞検索精度の向上
まずは全角アルファベットを半角に変換します。また、検索の際に「完全一致」だったのを「が含まれる」に変更しました。
変更後while True: # ~~~~~~~~ # ---- 歌詞サイトにアクセス ---- # 全角を半角に # add name = str(name).translate(str.maketrans({chr(0xFF01 + i): chr(0x21 + i) for i in range(94)})) name = parse.quote(name) # パーセントエンコーディング url = "https://www.uta-net.com/search/?Aselect=2&Keyword=" + name + "&Bselect=3&x=0&y=0" # Bselect=4 を Bselect=3 にまたアクセス数の多いページに付く王冠マークの影響で歌手名の位置がずれることがあるため、修正しました。
変更後while True: # ~~~~~~~~ try: # ~~~~~~~~ name_url = "" flag = False for tag_tr in tr: a = tag_tr.find_all("a") for i, tag_a in enumerate(a): if i == 0: # 曲名 name_url = tag_a.get("href") elif i == 1 or i == 2: # 歌手名 # 1 だけだったところに 2 を追加 if tag_a.string == artist: flag = True break if flag: breakコード全体
import time import sys from select import select import appscript from urllib import request, parse from bs4 import BeautifulSoup from selenium import webdriver driver = webdriver.Chrome(executable_path="chromedriver") driver.get("https://www.google.com/") # 初期タブ driver.set_page_load_timeout(5) # 回線の速さによってはもっと短くても大丈夫 music_time = 0 prev_track_name = "" count = 0 kashi_length = 0 while True: # Music アプリにアクセスする music = appscript.app("Music") # ---- アプリ制御 ---- # タイムアウト付き入力 read, _, _ = select([sys.stdin], [], [], 0.5) if read: command = sys.stdin.readline().strip() else: command = "" if command == "b": # 前のトラックへ music.previous_track() elif command == "p": # 再生・一時停止 music.playpause() elif command == "n": # 次のトラックへ music.next_track() # ---- 曲名取得 ---- # 再生中の曲名、アルバム名、アーティスト名、曲の長さ name = music.current_track.name.get() artist = music.current_track.artist.get() album = music.current_track.album.get() music_time = music.current_track.time.get() # m:s の str # music_time を秒数に music_time = music_time.split(":") music_time = int(music_time[0]) * 60 + int(music_time[1]) if name == prev_track_name: time.sleep(1) count += 1 if count % 5 == 0: driver.execute_script( "window.scrollTo(window.pageXOffset, window.pageYOffset + " + str(kashi_length // music_time * 5) + ");" ) continue prev_track_name = name print("{} / {} / {}".format(name, artist, album)) # ---- 歌詞サイトにアクセス ---- # 全角を半角に name = str(name).translate(str.maketrans({chr(0xFF01 + i): chr(0x21 + i) for i in range(94)})) name = parse.quote(name) # パーセントエンコーディング url = "https://www.uta-net.com/search/?Aselect=2&Keyword=" + name + "&Bselect=3&x=0&y=0" try: html = request.urlopen(url) soup = BeautifulSoup(html, "html.parser") tr = soup.find_all("tr") name_url = "" flag = False for tag_tr in tr: a = tag_tr.find_all("a") for i, tag_a in enumerate(a): if i == 0: # 曲名 name_url = tag_a.get("href") elif i == 1 or i == 2: # 歌手名 if tag_a.string == artist: flag = True break if flag: break # 新しいタブで開く driver.execute_script("window.open()") driver.switch_to.window(driver.window_handles[1]) try: driver.get("https://www.uta-net.com/" + name_url) except: pass # 歌詞の位置までスクロール driver.execute_script("arguments[0].scrollIntoView();", driver.find_element_by_id("view_kashi")) kashi_length = driver.find_element_by_id("view_mylink").location["y"] - \ driver.find_element_by_id("view_kashi").location["y"] # 前のタブを閉じる driver.switch_to.window(driver.window_handles[0]) driver.close() driver.switch_to.window(driver.window_handles[0]) except: pass print("b:前 | p:再生・一時停止 | n:次") print() time.sleep(1)
- 投稿日:2020-01-04T16:05:01+09:00
量子情報理論の基本:データ圧縮(1)
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
前々回の記事で「ホレボー限界」を取り上げ、量子通信チャネルの限界について説明しました。そのときの想定は、古典情報を量子ビットで符号化して送信し、受信側でPOVM測定することで古典情報を復号するという、「古典-量子-古典」という通信路のお話でした。今回、取り上げたいのは、そうではなくて、量子状態そのものを「情報」として伝送するお話です。古典的なシャノンの情報理論において、情報源の性質(確率分布)がわかったら、最低限必要な通信容量が決まるという有名な定理がありますが、その定理の量子版がシューマッハによって証明されています。そのあたりの理解まで何とか行きたいと思っています。ちょっと長くなりそうなので、2回に分けます。1回目の今回は、まず前提知識として、古典情報理論における「雑音のないチャネルにおけるシャノンの符号化定理」について説明し、2回目の次回に、本題である「雑音のない量子チャネルにおけるシューマッハの符号化定理」を説明します。各回、理解ができたところで、Pythonプログラムで、その符号化動作をシミュレーションしてみます1。
参考にさせていただいたのは、以下の文献です。
i.i.d.情報源
これから考えていきたいのは、一言で言うと、情報源の性質がこうだったときに、原理的にどれだけのデータ圧縮ができるだろうかという疑問への答えです。そのため、情報というある種つかみどころのないものを抽象化して、モデル化して、数学的に扱える形にしておく必要があります。本質を捉えるための単純化によって、現実の情報から多少外れてしまう可能性もありますが、実用上有益な結果が得られるのであれば、それも良しとします。という考え方で、まず、情報源というものを抽象化・モデル化します。
例えば、アルファベット文字列からなる英文のテキスト情報をイメージしてみてください。"I have a dream."という英文があったときに、アルファベット文字は"I","$\space$","h","a","v","e"...という具合に、時系列順に生起するという見方ができます。世の中に英文というのは、これ以外にも大量にあって、それらを見ると生起しやすい文字("e"とか"a"とか)とあまり生起しない文字("q"とか"z"とか)がありますので2、各時点で生起するアルファベット文字を確率変数と考えてみるというのが、一つの抽象化・モデル化のアイデアになります3。このアルファベット文字に関する確率は、どんな時点でも共通であるというのは自然な仮定としてあり得そうですし、さらに、異なる時点で発生したアルファベット文字同士は、互いに無関係に発生するという仮定を置いても、良さそうです4。このように、情報源から別々に発生した値は互いに独立(independent)で、同一分布(identically distributed)に従うという仮定をおいた情報源のことを「i.i.d.情報源(independent and identically distributed information source)」と呼びます。これを前提に以降の議論を進めていきます。
典型系列
シャノンの符号化定理の前に、「典型系列」「非典型系列」という概念について説明しておく必要があります。いま、i.i.d.情報源が確率変数$X_1,X_2,X_3, \cdots$を作り出すとします。例えば、コインを投げて表が出るか裏が出るかという事象を確率変数と見立て、それを何度も繰り返して表裏の系列つくるようなことをイメージしてもらえば良いです。表の場合"0"、裏の場合"1"という数値を割り当てると、その系列は2進数の系列になります。普通のコインであれば表も裏もどちらも確率1/2で生起しますが、なるべく一般的に議論したいので、表が出る確率が$p$であるように作られているコインであるとしておきます。という想定だとしても、毎回同じコインを投げるので、「同一分布(identically distributed)」であるというのは自然な仮定です。また、どっちが出るかは、過去の結果に依存しない(例えば、前回「表」だったので今回「表」が出やすくなる、わけではない)ので、「独立(independent)」というのも変な仮定ではありません。というわけで、コイン投げで得られる情報は、i.i.d.情報源と見なしても良いです。
このi.i.d.情報源の無限の系列の中から$n$個の確率変数$X_1,X_2,\cdots,X_n$を取り出してみると、その実際の値$x_1,x_2,\cdots,x_n$にはいろんな可能性があるのですが、生起しやすい系列パターンとめったに生起しない系列パターンに分けることができます。生起しやすい系列を「典型系列(typical sequence)」、めったに生起しない系列を「非典型系列(atypical sequence)」と呼びます。0が出る確率を$p=1/4$として、取り出す系列の数を$n=100$とします。そうすると、0が出る回数は、だいたい25回あたりになることが想像できます。この100個のサンプリングを何度も繰り返したとしても、おそらく多少の揺れはあるでしょうか、0が出る回数は、25回あたりに集中するはずです。逆に、5回しかないとか、85回もあったら、これは非常に珍しい現象が起きたか、コイン投げをする人がイカサマ師であるかのどちらかです。いまの例で言うと、0が出る回数が25回くらいになっている系列のことを「典型系列」と言います。
典型系列は生起しやすい系列であると言いいましたが、では、その確率はどのように定量化できるでしょうか。確率変数系列の中から、n個のサンプリングをして、系列$x_1,x_2,\cdots,x_n$を得る確率を$p(x_1,x_2,\cdots,x_n)$とすると、i.i.d.情報源なので、
p(x_1,x_2,\cdots,x_n) = p(x_1)p(x_2) \cdots p(x_n) \approx p^{np} (1-p)^{n(1-p)} \tag{1}となります。両辺の対数をとると、
-\log p(x_1,x_2,\cdots,x_n) \approx -np \log p - n(1-p) \log (1-p) = n H(X) \tag{2}なので、
p(x_1,x_2,\cdots,x_n) \approx 2^{-nH(X)} \tag{3}という具合にエントロピーを使って近似できます。ここでは、確率変数が"0"と"1"という値しかとらない2値をイメージして、式(3)を導きましたが、多値の場合でも成り立ちます。証明してみます。
【証明】
確率変数$X_i \space (i=1,2,\cdots)$において生起するシンボルが$A=\{ a_1,a_2,\cdots,a_{|A|}\}$のいずれかだったとします。$|A|$は集合$A$の要素数を表します。確率変数系列からn個をサンプリングし、その値が$\{ x_1,x_2,\cdots,x_n\}$だった確率は、i.i.d.情報源を前提としているので、以下のように、各確率の積で表すことができます。
p(x_1,x_2,\cdots,x_n) = p(x_1)p(x_2) \cdots p(x_n) \tag{4}また、$p(x_i)$の関数形は同一です。$x_i=a_{\mu}$のときの確率$p(a_{\mu})$は、$n$個の系列の中で$a_{\mu}$が登場する回数を$N(a_{\mu})$と書くとすると、
p(a_{\mu}) \approx \frac{N(a_{\mu})}{n} \tag{5}と近似できます。そうすると、
p(x_1,x_2,\cdots,x_n) \approx \prod_{\mu=1}^{|A|} p(a_{\mu})^{N(a_{\mu})} = \prod_{\mu=1}^{|A|} p(a_{\mu})^{np(a_{\mu})} \tag{6}となります。両辺の対数をとると、
- \log p(x_1,x_2,\cdots,x_n) \approx \sum_{\mu=1}^{|A|} np(a_\mu) \log p(a_{\mu}) = nH(X) \tag{7}なので、
p(x_1,x_2,\cdots,x_n) \approx 2^{-nH(X)} \tag{8}となり、式(3)が同様に証明できました。(証明終)
確率の逆数が、それが生起する場合の数なので、典型系列の数はだいたい$2^{nH(X)}$くらいと思っておけば良いです。ということは、情報源をn個のブロックに区切って符号化することを考えると、$nH(X)$ビットの符号を用意しておけばほとんどの情報は間違いなく伝送できるということになります。もちろん、非典型系列が発生する場合もあるので、その場合は、諦めて適当な符号を割り当てます。とすると、一定の割合で伝送誤差が発生しますが、nを十分に大きくすると、その割合を十分に小さくすることができて、結局、信頼できる通信を実現することが可能になります。シャノンが証明したのは、まさにこのことです。この証明に入る前に、典型系列について、もう少し、深い理解が必要なので、それについて説明します。
$\epsilon > 0$が与えられたとき、
2^{-n(H(X)+\epsilon)} \leq p(x_1,x_2,\cdots,x_n) \leq 2^{-n(H(X)-\epsilon)} \tag{9}を満たす系列$x_1,x_2,\cdots,x_n$を「$\epsilon$典型系列」と言います。長さ$n$のそのようなすべての$\epsilon$典型系列の集合を$T(n,\epsilon)$と表します。式(9)は、
| \frac{1}{n} \log \frac{1}{p(x_1,x_2,\cdots,x_n)} - H(X) | \leq \epsilon \tag{10}のように書きかえられます。これで、漠然と定義してきた典型系列を数学的に扱えるように一応定量化できました。ということで、次に、典型系列に関する3つの定理について順に説明していきます。
典型系列の定理(1)
ニールセン、チャンの記載をそのまま引用します。
「$\epsilon > 0$を固定する。任意の$\delta > 0$、十分大きな$n$に対して文字列が$\epsilon$典型的である確率は少なくとも$1-\delta$である。」
さて、何を言っているのかさっぱりわかりません、という人も多いかと思うので、少し噛み砕きます。$\epsilon$というのは、典型系列の範囲を決める$\epsilon$です。いまこの$\epsilon$を固定したとします。頭の中で何か適当な正の数字(例えば、0.1とか)を思い浮かべてください。で、もうひとつ$\delta$というのが登場します。これは任意の正の値として設定しても良いです。この定理が主張しているのは、どんな$\delta>0$を決めたとしても、十分に大きな$n$をとれば、長さ$n$の系列が、$\epsilon$典型系列になる確率は、少なくとも$1-\delta$である、ということです。例えば、$\delta$を割と大きい値(0.999とか)にすると、この定理の主張はかなり自明な感じがします。なぜなら、$\epsilon$典型になる確率はとても小さい=とてもゆるい条件になるので、そんなに大きな$n$でなくても成り立ちそうな気がします。一方、$\delta$の値が非常に小さい値だとするとどうでしょうか(例えば、0.000001とか)?この定理の主張は非常に厳しい条件になります。なぜなら、$\epsilon$典型になる確率は、ほぼ1であると言っているので。しかし、$n$の値は十分に大きな値をとれます。十分大きな$n$をとれば、$\epsilon$典型になる確率を$1-\delta$以上にすること(すなわち十分1に近づけること)ができます。ということを、この定理は言っています。ざっくり一言で言うと、とても簡単な話で、十分大きな$n$をとれば、どんな系列も$\epsilon$典型系列になるということです。サイコロを転がして出る目を記録していく実験を考えてみてください。10回転がした程度では、典型系列になっていなかったとしても、100回とか1000回とか転がせば、きっと典型系列になっているに違いありません。ということを数学的に厳密に言っているだけですね。では、証明してみます。
【証明】
$X_1,X_2,\cdots$はi.i.d.情報源から得られる確率変数系列とします。$p(X_i)$は独立で同一分布なので、$-\log p(X_i)$も独立で同一分布です。ということは、$-\log p(X)$の期待値$E(-log p(X))$は、十分大きな$n$個の$-\log p(X_i)$を取り出したときの平均値に近似することができます。すなわち、任意の$\epsilon > 0, \delta > 0$に対して、
p(| \sum_{i=1}^{n} \frac{- \log p(X_i)}{n} - E(- \log p(X)) | \leq \epsilon) \geq 1-\delta \tag{11}が成り立つ$n>0$が必ず存在します。これは大丈夫でしょうか。どんなに小さな$\epsilon$や$\delta$をとったとしても、十分に大きな$n$をとれば、上の式を満たすことができます、ということです。つまり、十分大きな$n$をとれば$E(- \log p(X)) = \sum_{i=1}^{n} \frac{- \log p(X_i)}{n}$にできるということで、これは、いわゆる「大数の法則」の言い換えに過ぎません。
ここで、
\begin{align} & E(- \log p(X)) = H(X) \\ & \sum_{i=1}^{n} \log p(X_i) = \log(p(X_1,X_2,\cdots,X_n)) \tag{12} \end{align}なので、式(11)は、
p(| - \frac{\log(p(X_1,X_2,\cdots,X_n))}{n} - H(X) | \leq \epsilon) \geq 1-\delta \tag{13}となります。この左辺の$p$の中身は$\epsilon$典型系列の定義そのものなので、式(13)は、$\epsilon$典型系列である確率が少なくとも$1-\delta$であることを言い表しています。ということで、証明ができました。(証明終)
典型系列の定理(2)
ニールセン、チャンの記載を引用します。
「任意の固定した$\epsilon >0$、$\delta >0$、十分大きな$n$に対して$\epsilon$典型系列の数$|T(n,\epsilon)|$は次式を満たす。
(1-\delta) 2^{n(H(X)-\epsilon)} \leq |T(n,\epsilon)| \leq 2^{n(H(X)+\epsilon)} \tag{14}」
ざっくり言い換えると、$\epsilon \to 0$、$\delta \to 0$の極限で、十分大きな$n$をとれば、$|T(n,\epsilon)| \approx 2^{n(H(X)}$に近似できる、ということです。先程、式(8)の下あたりで「典型系列の数はだいたい$2^{nH(X)}$くらい」と言いましたが、そのことを数学的に厳密に表現すると、こんな定理になります。では、証明します。
【証明】
系列$x=(x_1,x_2,\cdots,x_n)$が生起する確率に対する式(9)と確率が1を超えないことから、
1 \geq \sum_{x \in T(n,\epsilon)} p(x) \geq \sum_{x \in T(n,\epsilon)} 2^{-n(H(X)+\epsilon)} = |T(n,\epsilon)| 2^{-n(H(X)+\epsilon)} \tag{15}なので、
|T(n,\epsilon)| \leq 2^{n(H(X)+\epsilon)} \tag{16}が成り立ちます。これで、式(14)の右側の不等号が証明できました。次に左側の不等号についてです。
典型系列の定理(1)および式(9)より、
1-\delta \leq \sum_{x \in T(n,\epsilon)} p(x) \leq \sum_{x \in T(n,\epsilon)} 2^{-n(H(X)-\epsilon)} = |T(n,\epsilon)| 2^{-n(H(X)-\epsilon)} \tag{17}なので、
(1-\delta) 2^{n(H(X)-\epsilon)} \leq |T(n,\epsilon)| \tag{18}が成り立ちます。式(16)と式(18)を合わせると、式(14)になります。(証明終)
典型系列の定理(3)
ニールセン、チャンの記載を引用します。
「$S(n)$は情報源からの長さ$n$の文字列の集まりで、その大きさはたかだか$2^{nR}$であるとする。ここで$R<H(X)$は固定されている。このとき任意の$\delta>0$と十分大きな$n$に対して次式が成り立つ。
\sum_{x \in S(n)} p(x) \leq \delta \tag{19}」
典型系列の数は、近似的に$2^{nH(X)}$くらいですが、$H(X)$よりも小さい$R$を使って、$2^{nR}$個くらいしかない部分集合$S(n)$を考えるわけです。$n$を十分に大きくしていくと、長さ$n$の系列集合の中に含まれる$S(n)$の割合が十分に小さくなるということを主張しています。$n \to \infty$の極限で、その割合は0に収束します。ホントですか?と言いたくなるかもしれませんが、ホントです。以下で証明してみます。2のべき乗の威力をご堪能ください。
【証明】
$S(n)$の文字列を典型系列と非典型系列に分けて考えます。典型系列の定理(1)より、$n$が十分に大きいとき、長さ$n$の系列集合に含まれる非典型系列の数は十分に小さくなるので、その部分集合である$S(n)$に含まれる非典型系列の数も十分に小さくなります。$n \to \infty$の極限では0になります。
一方、$S(n)$の中に含まれる典型系列の数は、$S(n)$に含まれる系列数以下です。つまり、たただか$2^{nR}$です。典型系列の出現確率は、$2^{-nH(X)}$だったので、$S(n)$が出現する確率は、たかだか、$2^{n(R-H(X))}$となります。つまり、十分大きな$n$に対して、
\sum_{x \in S(n)} p(x) \leq 2^{n(R-H(X))} \tag{20}です。いま、$R < H(X)$だったので、任意の$\delta > 0$に対して
\sum_{x \in S(n)} p(x) \leq \delta \tag{21}を満たす、$n>0$が存在するということになります。つまり、$n \to \infty$の極限で、
\sum_{x \in S(n)} p(x) \to 0 \tag{22}が成り立ちます。(証明終)
雑音のないチャネルにおけるシャノンの符号化定理
さて、それでは本日のメイン・イベントであるシャノンの定理を証明する準備が整いました。またまた、ニールセン、チャンの記載を引用します。
「$\{ X_i \}$はエントロピー$H(X)$のi.i.d.情報源であるとする。$R>H(X)$とする。このときこの情報源に対してレート$R$の信頼できる圧縮法が存在する。逆にもし$R<H(X)$ならば如何なる圧縮法も信頼性が高くない。」
一言で言うと、情報源のエントロピーよりも、ちょっとでも大きい伝送レートを用意しさえすれば、この情報を正確に伝送する圧縮法を構築することができるということです。では、証明してみます。
【証明】
まず、$R>H(X)$の場合です。
$H(X)+\epsilon \leq R$を満たすような$\epsilon$を選び、その$\epsilon$で$\epsilon$典型系列の集合$T(n,\epsilon)$を考えます。典型系列の定理(1)と(2)および$R>H(X)$という前提より、任意の$\delta>0$と十分大きな$n$に対して、
|T(n,\epsilon)| \leq 2^{n(H(X)+\epsilon)} \leq 2^{nR} \tag{23}が成り立ちます。つまり、典型系列の個数は、たかだか$2^{nR}$個で、そのような系列を生起させる確率は、少なくとも$1-\delta$です。もう少し噛み砕いて言うと、十分に大きな$n$をとれば、その系列は確率$1$で典型系列となり、かつ、その個数は$2^{nR}$個です5。従って、$n$個からなる系列を$nR$ビット使って符号化すれば、十分正確に伝送できるということになります。これを称して「レートRの信頼できる圧縮法が存在する」という言い方をしています。
次に、$R<H(X)$の場合です。
典型系列の定理(3)より、$R<H(X)$のとき、情報源から出力された系列が$2^{nR}$個の系列集合$S(n)$に含まれる確率は、十分大きな$n$に対して$0$になります。従って、正確に伝送できる圧縮方法は存在しません。(証明終)
符号化シミュレーション
情報源のエントロピーに相当する伝送レート近くにまで可逆にデータを圧縮する方法として、「ハフマン符号」とか「算術符号」とか色々提案されていますが、ここでは、シャノンの定理を実感してみることのみを目的として、非常に原始的な符号化を実装することにします。すなわち、十分に大きな$n$をとれば、信頼できるデータ圧縮が実現できるということだったので、$n$を変化させることで伝送誤差がきちんと小さくなっていくということをシミュレーションにより確認してみます6。
今回、前提とした情報源は、$\{ 0,1 \}$からなるバイナリ系列です。圧縮法はとても簡単です。伝送したいバイナリ系列全体を$n$個のシンボルからなるブロックに分けます。各ブロックに含まれるバイナリ系列が典型系列かどうかを判定し、典型系列であれば$nR$ビットの符号を典型系列に対して一意になるように割り当てます。そうでなければ諦めて「不明」を表す符号を割り当てます。
実装
全体のPythonコードを示します。
import random import numpy as np from collections import Counter def generator(prob, N): return [0 if random.random() < prob else 1 for i in range(N)] def entropy_exp(s): prb_0 = list(s).count('0') / len(s) prb_1 = 1.0 - prb_0 if prb_0 == 1.0 or prb_1 == 1.0: ent_exp = 0.0 else: ent_exp = - prb_0*np.log2(prb_0)- prb_1*np.log2(prb_1) return ent_exp def coder(data, blk, ent, eps, rat): # binary data to symbols (= message) # ex) [0,1,1,0,1,0,0,1,...] -> ['0110','1001',...] (for blk = 4) message = [''.join(map(str,data[i:i+blk])) for i in range(0,len(data),blk)] # histogram syms = list(Counter(message).keys()) frqs = list(Counter(message).values()) prbs = [frqs[i]/len(message) for i in range(len(frqs))] hist = dict(zip(syms, prbs)) # codebook index = 0 digits = int(rat*blk) # number of digits for each code codebook = {} for s,p in hist.items(): ent_exp = entropy_exp(s) if abs(ent_exp - ent) <= eps and index < 2**digits-1: codebook[s] = '{:0{digits}b}'.format(index, digits=digits) index += 1 codebook[False] = '{:0{digits}b}'.format(index, digits=digits) # coding (message -> codes) codes = [codebook[s] if s in codebook else codebook[False] for s in message] # decodebook decodebook = {} for k,v in codebook.items(): decodebook[v] = k return (codes, decodebook) def decoder(codes, decodebook, block): message = [decodebook[c] for c in codes] blocks = [list(s) if s != False else generator(0.5,block) for s in message] data_str = sum(blocks, []) return [int(d) for d in data_str] def error_rate(data_in, data_out): N = len(data_in) count = 0 for i in range(N): if data_in[i] != data_out[i]: count += 1 return count / N if __name__ == "__main__": # settings BLK = 10 # block size NUM = BLK * 1000 # number of binary data sequence PRB = 0.8 # probability to generate '0' ENT = - PRB * np.log2(PRB) - (1-PRB) * np.log2(1-PRB) # entropy (= 0.7219..) RAT = 0.9 # transmission rate (RAT > ENT) EPS = 0.15 # eplsilon for typical sequence print("NUM = ", NUM) print("BLK = ", BLK) print("ENT = ", ENT) print("RAT = ", RAT) # generate data sequence data_in = generator(PRB, NUM) # code the data (codes, decodebook) = coder(data_in, BLK, ENT, EPS, RAT) # decode the data data_out = decoder(codes, decodebook, BLK) # evaluate error rate err_rate = error_rate(data_in, data_out) print("error rate = ", err_rate)何をやっているか説明します。main処理部を見てください。
# settings BLK = 10 # block size NUM = BLK * 1000 # number of binary data sequence PRB = 0.8 # probability to generate '0' ENT = - PRB * np.log2(PRB) - (1-PRB) * np.log2(1-PRB) # entropy (= 0.7219..) RAT = 0.9 # transmission rate (RAT > ENT) EPS = 0.15 # eplsilon for typical sequenceここは各種パラメータを設定する部分です。BLKはブロックのサイズ、すなわち1ブロックに含まれるバイナリ値の数です。NUMは、伝送したい全体のバイナリ値の数です(ブロック1000個分のバイナリ値を伝送する想定にしました)。PRBは"0"が生起する確率です(0.8としました)。ENTは1シンボルあたりのエントロピーです(PRBの値0.8で計算すると、0.7219..になります)。RATは伝送レートです。0.7219..よりも大きくして、かつ、1.0よりも小さくしないとデータ圧縮にならないので、適当な値0.9としました。EPSは典型系列を判定するためのしきい値$\epsilon$の値です。適度に小さい値にしないといけないのですが7、小さくしすぎると、とても大きな$n$を設定しないと誤差が小さくならないので、適当な値として0.15を選びました。
# generate data sequence data_in = generator(PRB, NUM)まず、関数generatorで、伝送すべきバイナリ値の系列を作成します。PRBで設定した確率に従って"0"または"1"という整数値をランダムに生成して、長さNUMのリストを出力します。詳細は、関数定義を見てください。
# code the data (codes, decodebook) = coder(data_in, BLK, ENT, EPS, RAT)関数coderで、data_inを符号化して、符号系列codesと復号化のための辞書decodebookを出力します。関数の中身を見てみます。
# binary data to symbols (= message) # ex) [0,1,1,0,1,0,0,1,...] -> ['0110','1001',...] (for blk = 4) message = [''.join(map(str,data[i:i+blk])) for i in range(0,len(data),blk)]伝送するデータは"0","1"という整数値からなるリストなので、それをブロックごとに文字列にしてmessageというリストにします。ブロックサイズ4の場合の例をコメントに記載しておきました。
# histogram syms = list(Counter(message).keys()) frqs = list(Counter(message).values()) prbs = [frqs[i]/len(message) for i in range(len(frqs))] hist = dict(zip(syms, prbs))messageに含まれる要素からヒストグラムを作成し、histという辞書に格納します。
# codebook index = 0 digits = int(rat*blk) # number of digits for each code codebook = {} for s,p in hist.items(): ent_exp = entropy_exp(s) if abs(ent_exp - ent) <= eps and index < 2**digits-1: codebook[s] = '{:0{digits}b}'.format(index, digits=digits) index += 1 codebook[False] = '{:0{digits}b}'.format(index, digits=digits)登場するmessageの要素、すなわち、n個のシンボルからなる系列がわかったので、その各々にどんな符号を割り当てるかを決めて、それをcodebookという辞書データに格納します。上記、forループでヒストグラムに含まれているシンボル系列sが典型系列かどうかを判定すべく、関数entropy_expでこの系列に対するエントロピーを計算します。そのエントロピーと真のエントロピーとの差が$\epsilon$以下になっている場合、典型系列とみなし、0.9*nビットの符号indexを0から順に割り当てます。非典型系列の場合、「不明」という意味でFalseとおき、それに対する符号としてindexの最大値を割り当てます。
# coding (message -> codes) codes = [codebook[s] if s in codebook else codebook[False] for s in message]で、得られたコードブックを使って、messageを符号語のリストcodesに変換します。
# decodebook decodebook = {} for k,v in codebook.items(): decodebook[v] = k復号化の際に使えるようにcodebookの逆変換に相当する辞書decodebookを作成します。
return (codes, decodebook)で、codesとdecodebookをリターンします。
main処理部に戻ります。
# decode the data data_out = decoder(codes, decodebook, BLK)関数decoderで、codesを復号化します。その際、decodebookを使います。関数定義を見ればわかると思いますが、decodebookを参照しながら復号するのですが、復号した結果、Falseだった場合、誤差覚悟でランダムな系列を発生します。
復号化が完了したら、
# evaluate error rate err_rate = error_rate(data_in, data_out) print("error rate = ", err_rate)error_rate関数で、エラー率を計算して、表示します。
動作確認
では、ブロックサイズ($n$の値)をいくつか変えてエラー率がどうなるか試してみます。まず、$n=10$の場合です。
NUM = 10000 BLK = 10 ENT = 0.7219280948873623 RAT = 0.9 error rate = 0.3499エラー率は、とても大きいです。約35%がエラーです。次に、$n=100$の場合です。
NUM = 100000 BLK = 100 ENT = 0.7219280948873623 RAT = 0.9 error rate = 0.03194先程と比べ、1桁減って、3.2%くらいになりました。最後に、$n=200$の場合です。
NUM = 200000 BLK = 200 ENT = 0.7219280948873623 RAT = 0.9 error rate = 0.00454さらに1桁減り、0.45%くらいになりました。
ということで、$\epsilon$の値を固定して、$n$の値を大きくしていくと、エラー率がどんどん減っていくことがわかりました。シャノンの定理が主張しているのは、この極限において、エラー率がゼロになるということです。
おわりに
今回は、古典情報理論のお話だったので、量子計算シミュレータqlazyは使っていません。コードをコピペすれば、お使いのPython環境でも動作すると思いますので、ご興味あれば、遊んでみてください。
次回は、「はじめに」で述べた通り、シャノンの定理の量子版である「雑音のない量子チャネルにおけるシューマッハの符号化定理」を説明します。典型系列に類似した概念として「典型部分空間」というものが出てきますが、今回の議論と同じような流れで、その定理が導かれます。量子情報でも古典と同様に圧縮でき、限界性能も量子エントロピーであるというのは、興味深いです。
以上
ちなみに、いま「符号化」という言葉を使いましたが、「データ圧縮」と同義と思っていただいて良いです。「符号化」というのは情報をビット列に変換することです。その際、できるだけ効率的に、つまり必要なリソースを少なくして「通信」したり「蓄積」したいわけです。そのため、情報をできるだけ「圧縮」したいというモチベーションが生まれ、シャノン以降、長年研究がなされてきました。ちょっとうるさいことを言うと、正確には、「データ圧縮」は「符号化」の目的の一つだと思うのですが、非常に大きな目的なので、色々な文脈の中で、ほぼ同じ意味で使われているというのが現状かと思います。また、今回、「雑音のない」という限定をつけていますが、当然、「雑音のある」場合もあります。未勉強なので、理解できたら機会を改めて、紹介したいと思います(予定は未定です)。 ↩
"I have a dream."というのは、マーチン・ルーサー・キング・ジュニアの有名なスピーチの一節で、英語の授業で読んだり、聞いたりした人は多いと思います。何度聞いても、そのスピーチは感動的で、彼が何を言わんとしていたのか、この"I have a dream."という一節を見るだけで、伝わってくるものがあります。そういった一切の含意を捨てて、抽象化して、ひたすら数学的な対象として、情報を捉えましょう、ということをこれから説明していくわけです。シャノンがはじめた情報理論がそれです。とてもクールな立場ですが、これによって世界は大きく変わりました。スピーチの動画、リンク張っておきます。"I have a dream."を連呼し始めるのは、11分40秒あたりからです。【日本語字幕】キング牧師演説"私には夢がある" - Martin Luther King "I Have A Dream" ↩
英文をイメージすると、正確には違います。例えば、"t"の後に”h”が来る確率は、他の場合と比べて多いです。が、多くの情報源おいて、大雑把にこんな仮定をしても、そう外れた仮定ではなさそうです。また、もっともシンプルな仮定からはじめて、次第に複雑なものを考えていくのが、理論構築をする常套手段です。というわけで、まずこのようなシンプルな仮定から議論をはじめます。 ↩
$\epsilon$とか$\delta$が出てくる数学の言い回しは独特で最初面食らうと思いますが、厳密な言い方をしようとすると、どうしてもこうなってしまいます。が、よく吟味すると、意外とやさしいことを言っていることも多々あります。今の場合、サイコロを十分に何度も転がせば、それは典型系列になっていて、かつ、その典型系列の個数はたかだか$2^{nR}$個(ただし$R$はサイコロ1回転がしの場合のエントロピーよりも少し大きい値)になりますと言っています。 ↩
ということで、ここで実装する符号化は可逆ではないですし、非可逆としても効率向上の工夫は一切やっていないので、ほぼ実用性のない手法だと思ってください。 ↩
$H(X)+\epsilon \leq R$を満たす$\epsilon$にする必要があります。 ↩
- 投稿日:2020-01-04T15:44:36+09:00
Pythonのフレームワークを理解するために必要な知識メモ
Pythonの本を読んで学んだことをメモしてきます
Pythonの勉強中です。読んだ本に関しては、以下ブログ記事参照下さい。
内容的には、この記事では、特にPythonで書かれたフレームワーク(具体的にはTensorFlow、PyTorch等のディープラーニングのフレームワーク)を理解するのに必要だった知識を中心にメモしています。
以下は前提です。
- 当方、永遠の初心者です。優しくして下さい
- Pythonの基礎中の基礎は理解している読者を想定しています
#行は、出力結果を意味します- コメント、編集リクエスト歓迎です
しばらくは、随時追加、修正していく予定です。
全体的な話
Pythonは全てがオブジェクト
Pythonは全てがオブジェクトらしいです。雰囲気でオブジェクト指向をやっているので、あんまり意味がわかってないです。
クラスすらオブジェクトらしいですが、それがどういうことなのかも良くわからないです。以下を読んでもよく分からないです。
Pythonのオブジェクトとクラスのビジュアルガイド – 全てがオブジェクトであるということ
当面、理解できなくてもプログラムを読み書きはできているのですが、このことを意識しておくと、いつか悟りをひらけそうな気がするので、最初に書いておきます。
公式ドキュメント読むの大切です
当たり前のことのようですが、結構公式ドキュメントを読んでない人多いと思います(すみません、私もあんまり読んでませんでした)。
いくつかPython本を読んで気づいてたのですが、本も結構間違っていたり、初心者向けに理解しやすくするために、省略している部分があったりするので、ドキュメントを読むのが大切ですね。日本語もあります。
全部を隅から隅まで読むのは、厳しいと思いますが、コーディングルールを記載していある、PEP8とかは、さらっと目を通しておくと良さそうです。
PEP 8 -- Style Guide for Python Code
クラス関係
特殊メソッド
__hoge__に関してよく見る
__hoge__って表現、一体何なの?という人は、以下記事読むと幸せになりそうです。Python初心者でも
__hoge__使いたい!〜特殊属性,特殊メソッドの使い方〜
__call__メソッドでインスタンスを関数のように使う以下みたいな書き方ができます。
class Function: def __call__(self, x): return 2*x f = Function() print(f(2)) # 4あれ?これって関数なの?メソッドでは?と思ったら
__call__を確認すると良いかもしれません。ディープラーングのフレームワークでは、結構使われているイメージです。
データ構造
リスト・タプル・辞書・集合(セット)
Pythonで複数のデータを扱うときに使われるのが以下4つです。
- リスト:
[ ]- タプル:
( )- 集合(set):
{ }- 辞書:
{ }一人で簡単なプログラムを書くときには、大体リストを使えばこと足りてしまいますが、ディープラーニングのフレームワークでは、当然リスト以外のものもよく使われます。具体的には、教師データのラベルとファイルの対応に辞書が使われたりしますね。
コードを読むときや、自分で使うときは、これらがどう違うのか、理解しておく必要があります。また、この後、説明しますがタプルの実体は実はカッコでなく、カンマなので注意して下さい。
タプルを作るのはカンマ(カッコは省略可能だけどカンマは省略できない)
要素が1個のタプルは、以下のように書く必要があります。
tuple = (1, ) print(tuple) # (1,)それどころか、そもそもタプルは以下のようにカンマだけでOKです。
tuple = 1, print(tuple) # (1,)入門書では、リストは
[]でタプルは()って書いてあるだけのことが多いので、実はタプルを作るのはカンマ(,)というのは、地味に衝撃でした。また、Pythonは、アンパック代入と呼ばれる、要素を複数の変数に展開して代入する手法があります(以下のコードだと、
a, b = b, aの箇所)が、実はこれPythonの内部的にはタプルという扱いになります。a = 1 b = 2 a, b = b, a print(a,b) # 2 1これも、全然意識せず使っていたので、驚きました。
参考:Pythonで要素が1個のタプルには末尾にカンマが必要
内包表記:
リストに関して、内包表記と呼ばれる以下のような書き方ができます。
test = [i for i in range(5)] print(test) # [0, 1, 2, 3, 4]内包表記は、集合に対しても使用可能です。
test = {i for i in range(5)} print(test) # {0, 1, 2, 3, 4}
ifつかって、条件に合うものだけ取り出したりもできるので、色々使い勝手が良いです。イテレータ・ジェネレータ
仕様だけみると「こんなん何に使うの?」という感じなのですが、ディープラーニングのフレームワークだと、データセット(教師データの集まり)のローダとして大活躍します。TensorFlow(Keras)だとImageDataGenerator、PyTorchだとDataLoaderですね。
ディープラーニングは、バッチ(小さいデータのかたまり)に分けて学習を進めていくので、まさにこのイテレータの仕組みが大活躍するわけですね。なので、イテレータの仕組みを理解しないままデータローダを使うとよく分からなくなるので、基本を理解するのが良いです。
Qiita記事だと以下などが分かりやすいと思いました。
テストに関して
何か問題あったとき、テストプログラムを活用できると効率的に問題を切り分けられる場合があるので、知っておくと良いかと思います。
unittest --- ユニットテストフレームワーク オフィシャルドキュメント
Python標準のunittestの使い方メモ
Pythonのunittestでハマったところと、もっと早くに知りたかったことその他
あんまりフレームワークとは関係ないけど、知っておくとPythonを読み書きするときに便利なTIPS。
enumerateを使ってループにインデックスを付ける
ループの回数にインデックスが必要な場合、enumerateを使うと以下のように簡潔に書けます。
test = ['a', 'b', 'c', 'd', 'e'] for i, x in enumerate(test): print(i, x) # 0 a # 1 b # 2 c # 3 d # 4 e大したことではないですが、よく使われるので、知っておくとコードを読み書きするとき便利です。
modfで数値の整数部と小数部を同時取得
正確な値取得しようとすると、ちょっと面倒臭いので知っておくと便利です。
import math print(math.modf(1.5)) # (0.5, 1.0) print(type(math.modf(1.5))) # <class 'tuple'>参考:Python, math.modfで数値の整数部と小数部を同時に取得
Pythonでのアスタリスク
*の意味アスタリスクは、CやC++だと、ポインタなので嫌な思い出しかないのですが、Pythonは全然違うので安心(?)です。以下のまとめをみておくと良さそうです(困った時に調べる感じでも良いかとは思いますが)。
@で行列の積を計算できる
@で行列の積を計算できます。Python3.5, NumPy1.10.0以降でないと使用できないので注意して下さい。import numpy as np x = np.array([1, 2]) y = np.array([1],[2]) x @ y # array([5])
np.matmul(x,y)でも同じ結果になります。np.dot(x,y)というのもあるのですが、こちらは3次元以上の配列になると、結果が変わってくるようです(2次元だと、matmul,@と同じ結果)。機械学習系だと、行列の積はよく使われるので、見かけることもあるかと思います。
まとめ
Pythonで学んだことを、フレームワークへの理解を深める知識という観点で簡単にまとめました。他のテーマでも忘れないようにメモしていこうかなと考えています。