- 投稿日:2019-12-12T20:54:57+09:00
TypeScript×Nodeを勉強した時に参考にしたソースまとめ
- 投稿日:2019-12-12T19:22:19+09:00
掃除当番つぶやきボットを作ってみた
はじめに
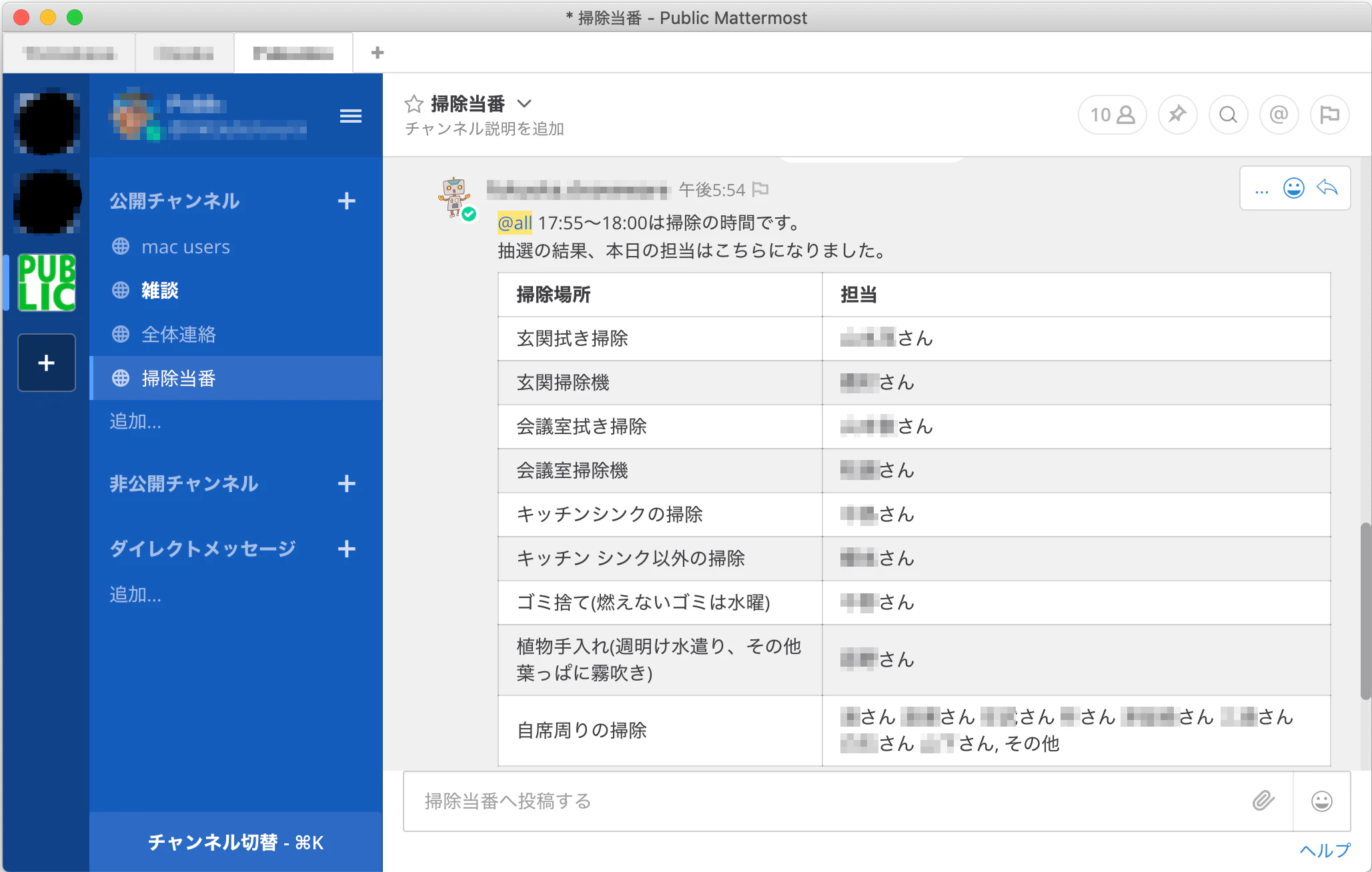
お掃除当番を抽選し、Mattermostに発言するボットです。
抽選されるとちょっとした楽しみになりますよ。
インストール
GitHubからファイル一式をクローンもしくはダウンロードする
Mattermostにボット用のアカウントを登録する
Node.jsをインストールする
モジュールをインストールする
$ npm ci
app/environment.tsファイルを設定するビルドする
$ npm run build発言させる
$ npm start定時実行させたい時はcronなどを利用してください。
利用しているモジュール
- @types/node
- request
- typescript
さいごに
よければいいねをお願いします。
- 投稿日:2019-12-12T18:50:25+09:00
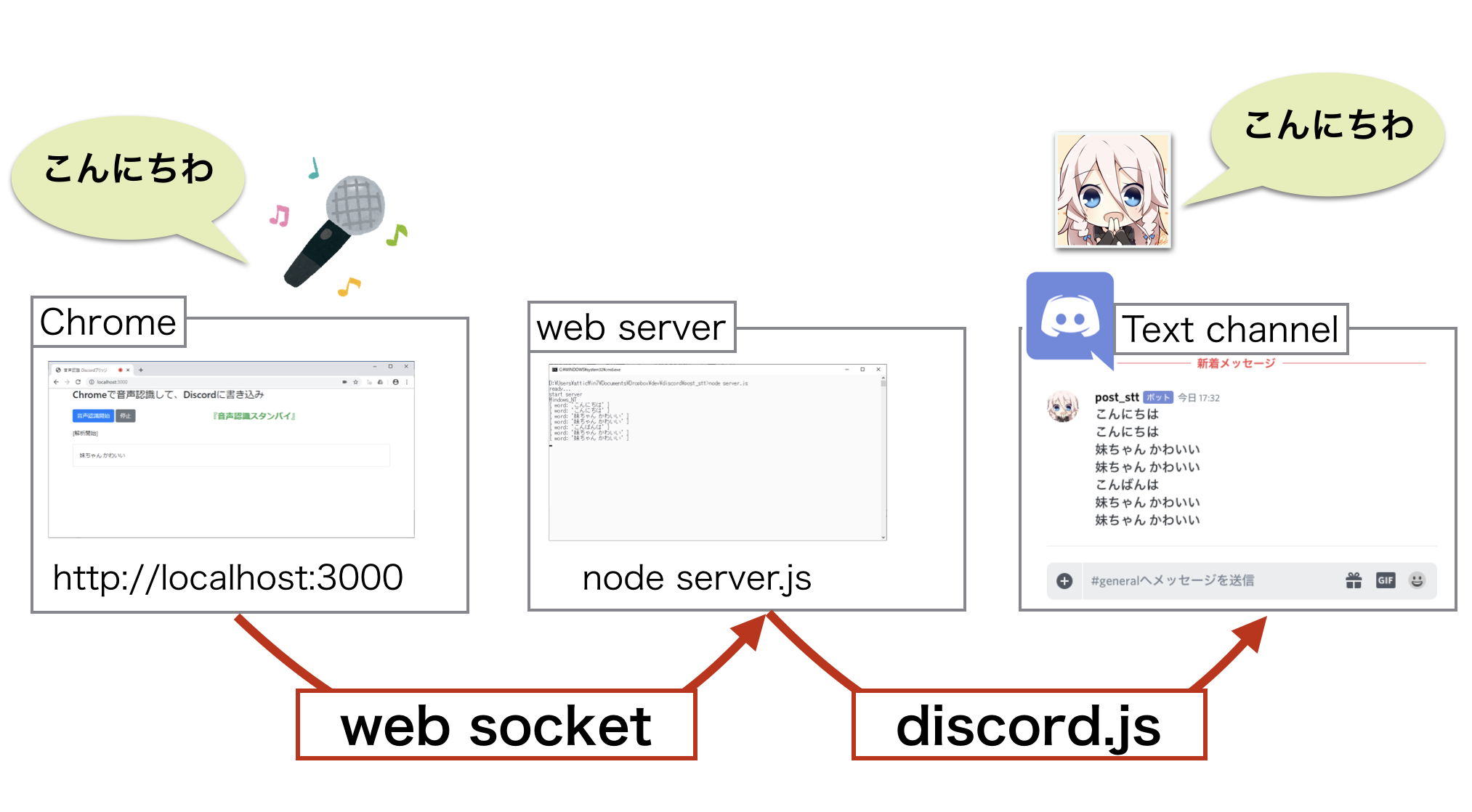
Chromeで音声認識して、Discordに書き込み
1. 概要
Google Chromeの Web Speech API を利用して音声認識し、結果を Discordのテキストチャンネルに書き込みをする方法を紹介します。
やっていることは、NAMAROIDの音声認識をChromeでやってみた とほぼ同様ですが、本記事では実装面を解説します。本実装は Webサーバを介した、クライアント・サーバ形式で、相互のメッセージングに socket.ioを利用しています。
socket.ioを利用することにより、Web APIに比べて実装が簡単で、送受信の高速化が期待できます。
アイコンはおむ烈 様のフリーアイコンをお借りしております!参考記事
- Discord Bot の登録方法
Discord Botアカウント初期設定ガイド for Developer動作環境
- OS: Windows 10
- node: v9.11.1
- chrome: 78.X
ソースコード
https://bitbucket.org/YoshikazuOota/post_stt
2. 使い方
2.1 ライブラリのインストール
初回のみ
npm install(setting.bat) を実行して2.2 Discord Bot・テキストチャンネルの設定
config/discord.jsonで下記の2つを指定する
- Botのトークン
- 書き込み先のテキストチャンネル2.3 サーバサイドの実行
node server.js実行(start.bat) を実行- ブラウザで http://localhost:4000 を開く
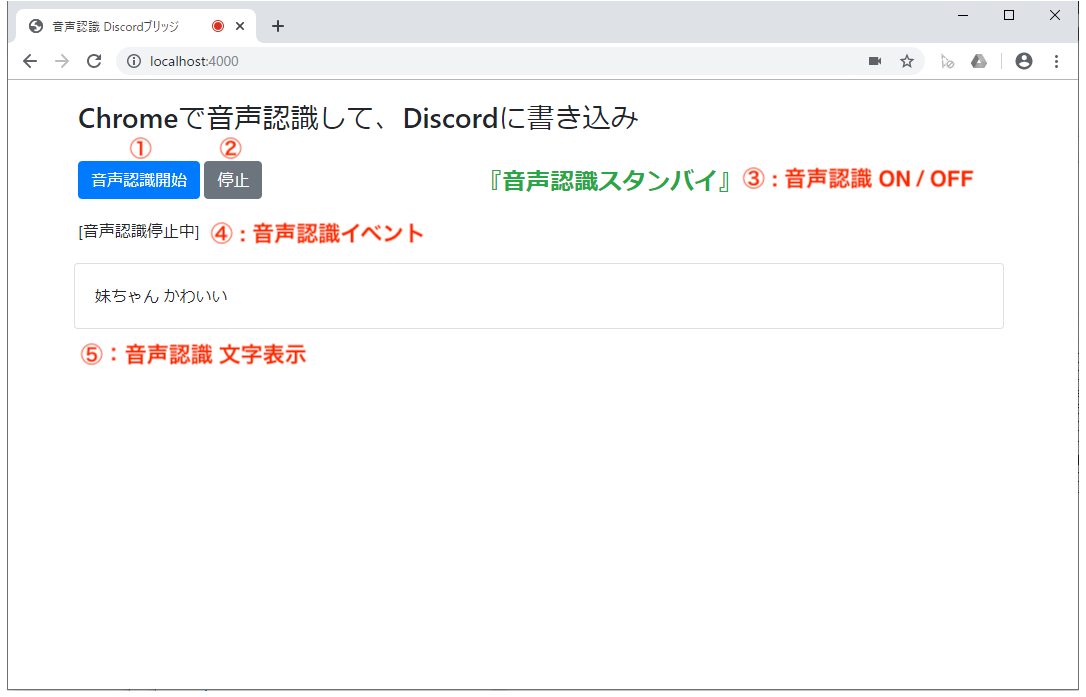
2.4 ブラウザ操作
- 『音声認識開始』ボタンをクリックして、音声認識かいし
- 『停止』ボタンで音声認識を終了
補足
音声入力がうまく出来ていないときは、マイクの使用許可設定が適切か確認してください。3. 実装の解説
3.A クライアントサイド(index.html)
Chrome で音声認識して、サーバにテキストを送る
'server.js' を起動すると、
http://localhost:4000で 'index.html' にアクセスすることができます。
このindex.htmlがクライアントサイドになります。音声認識のメイン処理は
speech_recognition.jsで行われます。index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>音声認識 Discordブリッジ</title> <link rel="stylesheet" href="assets/bootstrap/css/bootstrap.min.css" > <link rel="stylesheet" href="assets/bootstrap/css/bootstrap-grid.min.css" > <link rel="stylesheet" href="assets/bootstrap/css/bootstrap-reboot.min.css" > <script src="assets/lib_js/jquery-3.3.1.min.js" ></script> <script src="assets/bootstrap/js/bootstrap.js" ></script> <script src="/socket.io/socket.io.js"></script> <!-- socket.io を読み込み --> <script src="assets/js/speech_recognition.js"></script> <!-- メインロジック --> <style> .row { margin-top: 20px;} </style> </head> <body> <div class="container"> <div class="row"> <div class="col-sm-12"> <h3>Chromeで音声認識して、Discordに書き込み</h3> </div> </div> <div class="row"> <div class="col-sm-5"> <button class="btn btn-primary" id="start_btn">音声認識開始</button> <!-- 音声認識開始ボタン --> <button class="btn btn-secondary" id="end_btn">停止</button> <!-- 音声認識停止ボタン --> </div> <div class="col-sm-7 d-flex align-items-center"> <strong><span id="status" style="font-size: 24px"></span></strong> <!-- 音声認識 ON/OFF 表示 --> </div> </div> <div class="row"> <div class="col-sm-12"> <div class="card-text"> <span id="prosess"></span> <!-- 音声認識イベント表示 --> </div> </div> </div> <div class="row"> <div class="col-sm-12"> <div class="card"> <div class="card-body"> <div class="card-text" id="content"></div> <!-- 認識したテキスト表示 --> </div> </div> </div> </div> </div> </body> </html>speech_recognition.jsconst socket = io.connect(); // ソケットio const speech = new webkitSpeechRecognition(); // 音声認識APIの使用 speech.lang = "ja"; // 言語を日本語に設定 let keep_standby = false; function update_prosess(text) { $("#prosess").text(text); } // 音声認識 スタンバイ/停止 表示 function update_status(text) { $("#status").html(text); } // 音声認識 イベント 表示 // 音声認識した文字表示 function update_result_text(text) { update_prosess('[結果表示]'); $("#content").text(text); console.log(text); } // 音声認識の結果取得時の処理 speech.onresult = result => { const text = result.results[0][0].transcript; update_result_text(text); socket.emit('get_word', {word: text}); // 認識文字を socket.io 経由でサーバに送信する }; // 音声認識の継続継続処理 speech.onend = () => { if (keep_standby) speech.start(); else speech.stop(); }; speech.onspeechstart = () => update_prosess('[音声取得開始]'); speech.onspeechend = () => update_prosess('[解析開始]'); $(function () { $("#start_btn").on('click', () => { update_status('<span class="text-success">『音声認識スタンバイ』</span>'); keep_standby = true; speech.start(); }); $("#end_btn").on('click', () => { update_status('<span class="text-danger">『停止中』</span>'); update_prosess('[音声認識停止中]'); keep_standby = false; speech.stop(); }); $("#end_btn").trigger('click'); // 初期 $("#start_btn").trigger('click'); // 自動スタート });音声認識の処理フロー
1. index.html:
socket.io,speech_recognition.jsを読み込み
/socket.io/socket.io.jsの実態ファイルがソースコード一式にないため、不思議な感じですが、このファイルはserver.jsでsocket.ioの設定をすると勝手に用意してくれます。<script src="/socket.io/socket.io.js"></script> <!-- socket.io を読み込み --> <script src="assets/js/speech_recognition.js"></script> <!-- メインロジック -->2. speech_recognition.js: socket.io オブジェクト取得
サーバ側(server.js)へのテキスト送信はこのオブジェクトを介して行います。const socket = io.connect(); // ソケットio3. speech_recognition.js: "音声認識APIの使用"
音声認識のオブジェクト(speech)を取得します。
音声認識に関わる処理はこちらを介して行います。
その際、speech.lang = "ja"をお忘れなく。const speech = new webkitSpeechRecognition(); // 音声認識APIの使用 speech.lang = "ja";4. speech_recognition.js:
$("#start_btn").on
index.html で表示している、『音声認識開始』ボタンをクリックした時のイベント。
ここのspeech.start();で音声認識が開始されます。
以降、音声認識処理が完了するとspeech.onresultで、音声認識した文字列を取得出来ます。$("#start_btn").on('click', () => { update_status('<span class="text-success">『音声認識スタンバイ』</span>'); keep_standby = true; speech.start(); });5. speech_recognition.js:
speech.onresultでサーバ(server.js)への文字送信
音声認識した文字列はresult.results[0][0].transcript;に格納されています。大抵このまま決め打ちでいいようです。
細かい仕様は https://wicg.github.io/speech-api/#speechreco-result を参照してください。6. speech_recognition.js:
speech.onendで音声認識を継続
処理を継続するための処理です。
5でkeep_standby = trueとして、このフラグがtrueであれば、speech.start()をコールして継続処理をします。B. サーバーサイド(server.js)
音声認識文字を受け取り、Discord の テキストチャンネル書き込む
server.jsでは クライアント側のspeech_recognition.jsのsocket.emitで送信される文字を取得して、Discord のテキストチャンネルに書き込みをします。server.jsconst PORT = 4000; const express = require('express'); const os = require('os'); const app = express(); app.use(express.static(__dirname)); const server = require('http').createServer(app).listen(PORT); const io = require('socket.io').listen(server); // ログイン処理 const config = require("./config/discord"); const Discord = require('discord.js'); const client = new Discord.Client(); const token = config.token; client.on('ready', () => { console.log('start server'); console.log(`open chrome: http://localhost:${PORT}`); const targetTextChannel = client.channels.find(val => val.id === config.channel_id); // 指定テキストチャンネルを取得 io.sockets.on('connection', function(socket) { socket.on('get_word', function (data) { if(data === undefined || data === "" || data === null) return; console.log(data); targetTextChannel.send(data.word); }); }); }); client.login(token);音声認識の文字取得・テキストチャンネル書き込み処理フロー
1. Webサーバー
expressを利用して index.html 用の Webサーバを立ち上げ、Webサーバに socket.ioを追加する。server.jsconst app = express(); app.use(express.static(__dirname)); const server = require('http').createServer(app).listen(PORT); const io = require('socket.io').listen(server);2. Discord Botの設定
discord.jsを利用して Botを起動させる。
その際、config/discord.jsonにDiscord Bot トークンと、書き込みをするDiscordテキストチャンネルIDを記載する。{ "token": "Discord bot token", "channel_id": "テキストチェンネルID" }
client.login(token)で Botが起動して、起動完了後client.on('ready', () => {})がコールされます。server.jsconst config = require("./config/discord"); const Discord = require('discord.js'); const client = new Discord.Client(); const token = config.token; ... client.login(token);3. 指定のテキストチャンネルを取得
config.channel_idに一致する channelを取得します。
find(val => val.name === 'チャンネル名')とすると、チャンネル名でチャンネルを取得できます。server.jsconst targetTextChannel = client.channels.find(val => val.id === config.channel_id); // 指定テキストチャンネルを取得4. socket.io の接続待ち
index.html側で socket.ioに接続するのを待ち、接続があった場合はio.sockets.on('connection', () => {})が実行されます。
この処理は index.htmlを開いたページ毎にコールされ、音声入力する index.htmlは複数でも対応可能です。5. 取得文字をテキストチャンネルにポスト
index.html側でget_wordイベントを発火すると、下記のget_wordがコールされます。
data.wordに音声認識した文字列が格納されているので、それを送信するだけで、テキストチャンネルに書き込みをします。server.jssocket.on('get_word', function (data) { if(data === undefined || data === "" || data === null) return; console.log(data); targetTextChannel.send(data.word); });最後に
google chromeの音声認識は無料で、APIなどを発行する必要もないので、個人利用するのであればすごく便利ですね。
google Cloud の STT(Speech-to-Text)も低料金で利用できるのですが、音声処理周りの実装やAPI利用のための設定が大変ですですので、Chromeの Web Speechが一番楽です。音声入力は未来感があって、筆者はとてもワクワクするインターフェイスだと思っています!
- 投稿日:2019-12-12T18:42:16+09:00
YouTubeのJukeboxを作ってみた
どんなもの
YouTubeのURLを登録しておくと指定した時間帯にランダム再生するジュークボックスです。
音専用で、映像は流れません。
ブラウザでサーバにアクセスし、曲登録や編集ができます。
注意事項
- ssl設定はしていないので、VPNやローカルネットワークなどのセキュアなネットワーク内で利用してください
- 著作権は守ってください。ご自分の演奏動画などが推奨されます。
構成
インストール
GitHubからファイル一式をクローンするかダウンロードしてください。
バックエンド
Node.jsをインストールしてください
MongoDBをインストールしてください
back/app/environment.tsを環境に合わせて編集してください下記のコマンドを実行しプラグインをインストールしてください
$ npm install下記のコマンドを実行すると起動します
$ npm startフロントエンド
Angular7をインストールしてください
front/src/environments/environment.tsを環境に合わせて編集してください下記のコマンドを実行しプラグインをインストールしてください
$ npm install下記どちらかの方法でWEBページを公開してください
- 下記のコマンドを実行するとnginxやapacheなしでWEBページが公開されます
$ ng serve --host 0.0.0.0
下記のコマンドを実行すると
distディレクトリにindex.htmlやjs, css一式が生成されるので、apacheやnginxでWEBページを公開してください$ ng build利用しているモジュール
バックエンド
- @microlink/youtube-dl
- @types/express
- @types/mongodb
- @types/node
- body-parser
- cluster
- crypto
- express
- moment
- mongodb
- node-cron
- typescript
フロントエンド
- angular


- 投稿日:2019-12-12T18:08:41+09:00
JavaScriptで木構造をラクに扱う
はじめに
この記事はJavaScriptで木構造をラクに扱う方法について、ロゴスウェア株式会社の社内勉強会で取り上げたものです。
1. 木構造を楽に扱うためのライブラリ
以下の2つがオススメです。
- tree-model-js
- list-to-tree
2. tree-model-js
木構造のデータについて、ノードの検索やフィルタ等々の操作をうまいことやってくれるライブラリです。
2-1. 呼び出し方
const TreeModel = require('tree-model'); const tree = new TreeModel();2-2. 期待するデータの形式
tree-model-jsでは、入れ子になっている木構造のオブジェクトを入力にとります。
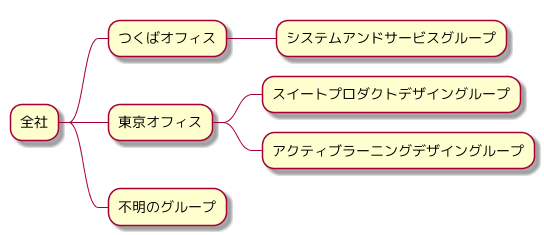
ここでは以下のような組織図の木構造のデータを例にします。組織図
上記組織図を表すオブジェクト
以下のように
childrenプロパティの配列に子組織のオブジェクトを入れて表現します。const treeDataStructure = { id: 1, name: '全社', children: [ { id: 11, name: 'つくばオフィス' children: [ { id: 111, name: 'システムアンドサービスグループ' } ] }, { id: 12, name: '東京オフィス', children: [ { id: 121, name: 'スイートプロダクトデザイングループ' }, { id: 122, name: 'アクティブ・ラーニングデザイングループ' } ] }, { id: 13, name: '不明のグループ' } ] };2-3. Rootノードオブジェクトを作成する
tree-model-jsのparseヘルパーに上記の入れ子のデータを入れて、対象の木構造のRootノードのオブジェクトを作成します。// 木構造のオブジェクトをパースしてRootノードオブジェクトを作成 const root = tree.parse(treeDataStructure);2-4. ノードを検索する
idが121のノードを検索してノードを取得する例です。
const node121 = root.first(node => node.model.id === 121); console.log(node121.model); // modelプロパティを使えば、ノードのプロパティを取得できる。 // -> { id: 121, name: 'SPD' }2-5. ノードをフィルターする
idが100以上のノードを全て取得する例です。
const nodesGt100 = root.all(node => node.model.id > 100);2-6. ノードを走査する
ツリーを上から辿って、ノードのidを順番に出力する例です。
root.walk(node => { console.log(node.model.id) }); /* 1 11 111 12 121 122 13 */2-7. 探索アルゴリズムを指定する
上記いずれのAPI(first, all, walk)も、オプションを指定すれば探索アルゴリズムを指定できます。
root.walk({ strategy: 'breadth' /* 幅優先探索 */ }, node => { console.log(node.model.id) }); /* 1 11 12 13 111 121 122 */以下の3種類がサポートされています。
種類 オプション 幅優先探索 { strategy: 'breadth' } 深さ優先探索(ルートから) { strategy: 'pre' } 深さ優先探索(末端から) { strategy: 'post' } 3. list-to-tree
フラットなリストから、
2-2. 期待するデータの形式で記載した 入れ子になっている木構造のオブジェクト に変換するライブラリです。const LTT = require('list-to-tree'); const nodeList = [ { id: 1, parent: 0 }, { id: 11, parent: 1 }, { id: 111, parent: 11 } ]; const treeDataStructure = new LTT( nodes, { key_id: 'id', key_parent: 'parent', key_child: 'children' } ).GetTree()[0]; console.log(JSON.stringfy(treeDataStructure, null, 2)); /* { "children": [ { "children": [ { "id": 111, "parent": 11 } ], "id": 11, "parent": 1 } ], "id": 1, "parent": 0 } */4. tree-model-js と list-to-tree を組み合わせる
2つを組み合わせれば、
1. フラットな木構造のデータから
2. 入れ子になっている木構造のオブジェクトに変換し、
3.tree-model-jsのRootノードオブジェクトを作成できます。const TreeModel = require('tree-model'); const LTT = require('list-to-tree'); // 1. フラットな木構造のデータ const nodeList = [ { id: 1, parent: 0 }, { id: 11, parent: 1 }, { id: 111, parent: 11 } ]; // 2. 入れ子になっている木構造のオブジェクト const treeDataStructure = new LTT( nodes, { key_id: 'id', key_parent: 'parent', key_child: 'children' } ).GetTree()[0]; // 3. tree-model-jsのRootノードオブジェクトを作成 const root = tree.parse(treeDataStructure);最後に
間違いや改善点等があればご指摘ください。
参考リンク
- tree-model-js
- list-to-tree
- 投稿日:2019-12-12T17:27:27+09:00
Node.jsでLINE BRAIN OCR APIを使う #linebrain #ood2019
先日のLINE DEVDAYでbeta公開されていたLINE BRAIN COR APIをNode.jsで利用してみます。
LINE BRAIN & LINE BRAIN COR API
LINE BRAINとは
企業がチャットボット・OCR・音声認識・音声合成・画像認識などの AI技術をより簡単に利用できる、各種サービスの総称らしいです。 AIがどんどん民主化されて嬉しい限りです。公式サイトから引用 https://www.linebrain.ai/
LINE BRAIN OCR APIはLINE BRAINのサービス群の一つというイメージですね。
汚い字でも読み込んでくれた
実際にDEMOページで試してみたら、手書きの結構汚い字でもちゃんと読み込んでくれました。
GCPなどでもOCRはあると思いますが、その辺の精度の違いは僕は比較してないのでよく分かりません。
instagram https://www.instagram.com/p/B57Yq7ijJg2/OCR APIはまだベータ版
2019/12/12時点ではまだベータ版で、ベータ版のエンドポイントは
https://ocr-devday19.linebrain.ai/v1/となっています。URLから分かる通りLINE DEVDAY 2019に参加した人だけに公開されたっぽい雰囲気です。利用料金なども現時点では分かりません。(既にどこかで公開されてるかもしれないですが)
ドキュメント画面はこんな雰囲気です。ドキュメントのURLは非公開かもしれないので載せないでおきます。
DetectionとRecognition
大きく分けるとこの二つの機能になっているみたいで、
- Detection - 文字領域の検出のみを行います。
- Recognition - 文字認識のみを行います。もしくは、文字領域の検出と認識を順に行います。
CURLで試す (ローカルファイル)
Recognitionの方を試してみました。
以下のようなコマンドで結果が返ってきます。ここで書いてるサービスIDの
PMqTDgBsucfsyvi7pJEsbIxMIUeNQWDgはドキュメントに書いてあるサンプル例なので、このまま書いても使えません。LINE DEV DAY 2019で登録した人はメールでサービスIDが届いてると思います。curl -X POST https://ocr-devday19.linebrain.ai/v1/recognition \ -H 'X-ClovaOCR-Service-ID: PMqTDgBsucfsyvi7pJEsbIxMIUeNQWDg' \ -H "Content-Type: multipart/form-data" \ -F "image=@./image.png" \ -F "entrance=detection" \ -F "language=jp" \ -F "segments=false" \CURLから試すが画像URL指定がうまくいかなかった
ドキュメントにあるサンプルリクエストを見るとこんな感じで画像URL指定でも使えそうでした。
curl -X POST https://ocr-devday19.linebrain.ai/v1/recognition \ -H 'X-ClovaOCR-Service-ID: PMqTDgBsucfsyvi7pJEsbIxMIUeNQWDg' \ -H "Content-Type: application/json" \ -d '{ "imageURL":["https://xxxx/images/ocr_sample.jpg"], "entrance":"detection", "scaling":false, "segments":false }'ただ、Gyazoに載せた画像URLを指定した場合に
errorConnection reset by peerなどのエラーが出たり、エラーが出た時のメッセージからどこに問題があるのかの判断がつきにくいとこが現時点ではありました。
取り急ぎの原因は不明で、時間があれば再調査しますが、とりあえずローカルファイルを投げつけてみます。
Node.jsから扱ってみる
ということで実際のアプリケーションに組み込みやすいようにNode.jsから扱ってみます。
環境や準備など
こちらで書いた内容がそのまま使えます。
axiosの準備をしましょう。
コード
post.js'use strict'; const fs = require('fs'); const axios = require('axios'); const FormData = require('form-data'); const OCR_SERVICE_URL = `https://ocr-devday19.linebrain.ai/v1/recognition`; const OCR_SERVICE_ID = `PMqTDgBsucfsyvi7pJEsbIxMIUeNQWDg`; //サービスID const IMAGE_PATH = `./public/image.png`; // 画像パス const file = fs.createReadStream(IMAGE_PATH); const form = new FormData(); form.append('image', file); form.append('entrance', 'detection'); const config = { headers: { 'X-ClovaOCR-Service-ID': OCR_SERVICE_ID, ...form.getHeaders(), } } axios.post(OCR_SERVICE_URL, form, config) .then(res => console.log(res.data)) //成功時 .catch(err => console.log(err)); //失敗時ちなみに、entranceをdetectionにしないとうまいこと文字が抽出されませんでした。
実行結果
$ node post.js { words: [ { boundingBox: [Array], text: '斎場御獄', confidence: 0.6916899085044861, lineBreak: false, segments: [Array] } ] }元画像はこちらですね。
斎場御獄という文字が抽出されました。
instagram https://www.instagram.com/p/B57Yq7ijJg2/所感
使い勝手は割と直感的なAPIで分かりやすい気がしました。
他社のOCR系のAPIと比較してどうなのか、どこかの誰かが検証してくれると幸いです。
画像URLからOCR APIに投げつけたかった問題はまたどこかで...



- 投稿日:2019-12-12T16:36:53+09:00
Azure Searchのハイライト機能 & ハイライト機能の癖を回避した実装について
Azure Searchのハイライト機能 & ハイライト機能の癖を回避した実装について
はじめに
Azure Searchの検索結果はデフォルトだと、キーワードにヒットした本文をハイライトしてくれません
なのでAzure Searchの検索結果のハイライトを実装したいと思います。ハイライト機能はやや癖があるので、癖を回避した実装について書きます
<ハイライトを使用しない場合の検索結果イメージ>
基礎部分の作成
npm install
npm install npm express ejs request --save
index.js ※Azure Searchの設定関連は未入力状態になっています
// ///////////////////////////////////////////////////////////////////////////////////// // Azure Searchの設定関連 // ///////////////////////////////////////////////////////////////////////////////////// // Azure Searchのサービス名 const searchServiceName=''; // Azure Searchのクエリキー const queryKey= ''; // Azure Searchのインデクス名 const indexName=''; // コンテンツを保持しているフィールド名(ほとんどの場合はcontent、OCRのマージフィールドを指定する場合はmerged_content) const content_field_name = "content"; // ///////////////////////////////////////////////////////////////////////////////////// // 定義関連 // ///////////////////////////////////////////////////////////////////////////////////// // MVCフレームワークとしてexpressを利用するための設定 var express = require('express'); var app = express(); // ejsをビューに使う為の設定 app.set('view engine', 'ejs'); // 非同期処理における例外発生時にエラーに繋ぐためのラッパー const asyncwrap = fn => (req, res, next) => fn(req, res, next).catch(next); // 静的コンテンツを外部ファイル化(publicフォルダ配下を<ROOT>/staticでアクセス許可) app.use('/static', express.static('public')); // ///////////////////////////////////////////////////////////////////////////////////// // 検索の初期表示 と 検索実施 // http://localhost:8080/にアクセスしたときの処理 // ///////////////////////////////////////////////////////////////////////////////////// app.get('/', asyncwrap(async (req, res) => { // 画面から投げた検索キーワードの設定。 キーワードが投げられていない場合はワイルドカード(*=条件未指定)を設定する const q = req.query.keyword || '*'; console.log(q); // キーワードをエンコードして設定 const query = encodeURIComponent(q) + '&count=true&searchMode=all'; // 検索実行 var searchResult = await new Promise((resolve, reject) => { const request = require('request'); request({ method: 'GET', url: `https://${searchServiceName}.search.windows.net/indexes/${indexName}/docs?api-version=2019-05-06&search=${query}`, headers: { 'Content-type': 'application/json', 'api-key': queryKey }, json: true, }, function (err, res, body) { if (err) { reject(err); } else { resolve(body); } }); }); // 通常の検索結果とハイライト付の検索結果はそれぞれ異なるフィールドに設定されるので、ハイライトを優先的に取得します var result = []; for( var i = 0; i < searchResult.value.length; i++ ) { // 1.タイトル(ファイル名)の取得 var title = searchResult.value[i].metadata_storage_name; // 2.本文の取得 var body = searchResult.value[i][`${content_field_name}`]; result.push({'title':title, 'body':body}); } // index.ejsに検索結果を渡して画面描画 res.render('index', { searchResult: result, inputKeyword: q}); })); // ///////////////////////////////////////////////////////////////////////////////////// // 起動 // ///////////////////////////////////////////////////////////////////////////////////// app.listen(8080, () => console.log('access -> http://localhost:8080/'))
index.ejs ※viewsフォルダ配下に入れましょう
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <link rel="stylesheet" media="all" href="./static/style.css" /> <title>ハイライト</title> </head> <body> <% //************************************************ %> <% // 検索条件を設定し、検索を行う為のフォームエリア %> <% // *********************************************** %> <form style="position:relative; margin-bottom:20px;" action="/"> <% // キーワード入力 %> <input id="keyword" class="keyword" name="keyword" type="text" placeholder="キーワードを入力" value="<%= inputKeyword %>" /> <% // 検索ボタン %> <input type="submit" class="submitsearch" value="検索" /> </form> <% //************************************************ %> <% // 検索結果表示 %> <% // *********************************************** %> <% for(var i=0;i<searchResult.length;i++){ %> <% // ファイル名 %> <p class="filename"> <%= searchResult[i].title %> </p> <% // 本文 %> <p id="a<%= i %>" class="docmain"> <%- searchResult[i].body %> </p> <% // 隙間調整 %> <br> <% } %> </body> </html>
style.css ※publicフォルダ配下に入れましょう
.docmain{ width:850px;margin: 0 0 0 0;padding: 12px 15px;color: #777;background: #fafafa;border: 1px solid #ddd; position:relative; left:40px; } .keyword{ outline:0;height:50px;padding:0 10px;left:0;top:0; width:230px;border-radius:2px;background:#eee; } .submitsearch{ width:70px;height:50px; left:260px; top:0;border-radius:2px;background:#7fbfff;color:#fff;font-weight:bold;font-size:16px;border:none; }
ハイライトの実装
ハイライトの実装に必要な要素は大きく2つです。
1つ目がハイライト検索を行う為のクエリの作成です
ハイライトの要求はクエリで行う為、クエリに以下の3つのパラメータを追加します。
パラメータ 説明 例 highlight どのフィールドをハイライトしたいか 本記事ではcontentフィールド等を指定 highlightPreTag ハイライト開始に指定したいタグ 本記事ではmarkタグを指定 highlightPostTag ハイライトの終了に指定したタグ 本記事では/markタグを指定 ※markタグは囲った文字列をマーカー調にハイライトしてくれます
クエリ周りを以下のように実装します// Azure Searchのハイライトは以下のようにクエリで指定します。 // ハイライトの設定(検索結果に含まれるキーワードを<mark>タグで囲うように設定) var highlight = `&highlight=${content_field_name}-3&highlightPreTag=<mark>&highlightPostTag=</mark>`; // キーワードをエンコードして設定 const query = encodeURIComponent(q) + '&count=true&searchMode=all' + highlight;
2つ目がハイライトされた検索結果の取得です
ハイライトされた文字列は、本文とは異なるフィールドにマップされる為
以下のような実装が必要になります。ハイライトされている場合 → ハイライトフィールドをサマリとして活用
ハイライトされていない場合 → デフォルトフィールドをサマリとして活用// 2.本文の取得 var body = null; if(searchResult.value[i]['@search.highlights'] != undefined){ // ハイライトが存在する場合 let highlights = searchResult.value[i]['@search.highlights']; body = highlights[`${content_field_name}`].join('\n'); } else { // ハイライトが存在しない場合 body = searchResult.value[i][`${content_field_name}`]; }ハイライトの動作確認をします
キーワードにマッチする本文がハイライトされていることがわかります
しかしハイライトされているのは一部で本文全体がハイライトされているわけではありません。
<ハイライト機能をさくっと実装した際のイメージ>
ハイライト処理のカスタマイズ
本文全体の中からマッチするワードをハイライトするようにカスタマイズします
一番オーソドックスなやりかたとしては
①『ハイライト文章』からハイライトタグを除去して、『未ハイライト文章』を作成
② 本文から『未ハイライト文章』を検索して、『ハイライト文章』で置換します①②を繰り返すことで、本文全体の中からマッチするワードがハイライトされるようになります。
// 2.本文の取得 body = searchResult.value[i][`${content_field_name}`]; if(searchResult.value[i]['@search.highlights'] != undefined){ // ハイライトが存在する場合、本文にハイライトを設定する let highlights = searchResult.value[i]['@search.highlights']; for( var j = 0; j < highlights[`${content_field_name}`].length; j++ ) { // ハイライトを1つずつ取得 let highlight = highlights[`${content_field_name}`][j]; // ハイライトタグを除去して、未ハイライト文章を作成する let notHighlight = highlight.replace(/<mark>/g, '').replace(/<\/mark>/g, ''); // 本文から未ハイライト文章を検索し、ハイライト済文章で置換する body = body.replace(notHighlight, highlight); } }
カスタマイズしたハイライトの動作確認をします
本文全体がハイライトされていることが確認できました
<ハイライト機能の癖を回避した実装のイメージ>
↑ 構造が複雑なPDFファイル等をこの手法でハイライトする場合は
構造データが本文フィールドに混じる場合があり、ハイライトフィールドには混じらないことがあるので
そういった場合は、もう1工夫が必要です。(上記手法だけだと、置換の為の検索対象が本文に存在しないので、置換がうまくいかない場合があります。)
※現時点ではそうなってしまう状態ですが、バージョンアップでいずれ解消するかもしれません。
最終的なindex.jsのソースです
// ///////////////////////////////////////////////////////////////////////////////////// // Azure Searchの設定関連 // ///////////////////////////////////////////////////////////////////////////////////// // Azure Searchのサービス名 const searchServiceName='makineko2-as3rjz26u7sx4bu'; // Azure Searchのクエリキー const queryKey= '230918AB65B8167F94F422A83890FBA8'; // Azure Searchのインデクス名 const indexName='azureblob-index'; // コンテンツを保持しているフィールド名(ほとんどの場合はcontent、OCRのマージフィールドを指定する場合はmerged_content) const content_field_name = "content"; // ///////////////////////////////////////////////////////////////////////////////////// // 定義関連 // ///////////////////////////////////////////////////////////////////////////////////// // MVCフレームワークとしてexpressを利用するための設定 var express = require('express'); var app = express(); // ejsをビューに使う為の設定 app.set('view engine', 'ejs'); // 非同期処理における例外発生時にエラーに繋ぐためのラッパー const asyncwrap = fn => (req, res, next) => fn(req, res, next).catch(next); // 静的コンテンツを外部ファイル化(publicフォルダ配下を<ROOT>/staticでアクセス許可) app.use('/static', express.static('public')); // ///////////////////////////////////////////////////////////////////////////////////// // 検索の初期表示 と 検索実施 // http://localhost:8080/にアクセスしたときの処理 // ///////////////////////////////////////////////////////////////////////////////////// app.get('/', asyncwrap(async (req, res) => { // 画面から投げた検索キーワードの設定。 キーワードが投げられていない場合はワイルドカード(*=条件未指定)を設定する const q = req.query.keyword || '*'; console.log(q); // Azure Searchのハイライトは以下のようにクエリで指定します。 // ハイライトの設定(検索結果に含まれるキーワードを<mark>タグで囲うように設定) var highlight = `&highlight=${content_field_name}-3&highlightPreTag=<mark>&highlightPostTag=</mark>`; // キーワードをエンコードして設定 const query = encodeURIComponent(q) + '&count=true&searchMode=all' + highlight; // 検索実行 var searchResult = await new Promise((resolve, reject) => { const request = require('request'); request({ method: 'GET', url: `https://${searchServiceName}.search.windows.net/indexes/${indexName}/docs?api-version=2019-05-06&search=${query}`, headers: { 'Content-type': 'application/json', 'api-key': queryKey }, json: true, }, function (err, res, body) { if (err) { reject(err); } else { resolve(body); } }); }); // 通常の検索結果とハイライト付の検索結果はそれぞれ異なるフィールドに設定されるので、ハイライトを優先的に取得します var result = []; for( var i = 0; i < searchResult.value.length; i++ ) { // 1.タイトル(ファイル名)の取得 var title = searchResult.value[i].metadata_storage_name; // 2.本文の取得 body = searchResult.value[i][`${content_field_name}`]; if(searchResult.value[i]['@search.highlights'] != undefined){ // ハイライトが存在する場合、本文にハイライトを設定する let highlights = searchResult.value[i]['@search.highlights']; for( var j = 0; j < highlights[`${content_field_name}`].length; j++ ) { // ハイライトを1つずつ取得 let highlight = highlights[`${content_field_name}`][j]; // ハイライトタグを除去して、未ハイライト文章を作成する let notHighlight = highlight.replace(/<mark>/g, '').replace(/<\/mark>/g, ''); // 本文から未ハイライト文章を検索し、ハイライト済文章で置換する body = body.replace(notHighlight, highlight); } } const MarkovChain = require('./modules/MarkovChain'); const markovChain = new MarkovChain(); var chain = markovChain.chain(null); console.log(chain); result.push({'title':title, 'body':body}); } // index.ejsに検索結果を渡して画面描画 res.render('index', { searchResult: result, inputKeyword: q}); })); // ///////////////////////////////////////////////////////////////////////////////////// // 起動 // ///////////////////////////////////////////////////////////////////////////////////// app.listen(8080, () => console.log('access -> http://localhost:8080/'))



- 投稿日:2019-12-12T16:05:46+09:00
LINE Clova を使って怠惰なDrink Bar を開発する
この記事の概要
この記事では、6/25に開催された「スマートスピーカーを遊びたおす会 vol.6」の登壇ネタとして開発した『LINE Clova Drink Bar』のコンセプトや実装内容について解説します。
また、LINE Clova Drink Bar はヒーローズ・リーグのVUI 部門決勝にノミネートいただきました。ありがとうございました。
LINE Clova Drink Bar のコンセプト
LINE Clova Drink Bar(以下、Drink Bar)は、「怠惰」を目指した作品です。
VUI として、Drink Bar というサービスをどこまで人の手を使わずに声だけで操作できるかを試しています。単純に指示したドリンクを抽出するだけはなく、怠惰のためには人間からの指示を状況に応じて置き換えることもあります。
出来ること
音声操作で好みのドリンクを抽出
これは単純に指示されたドリンクを抽出する機能です。
カスタムスロット「DRINK」として麦茶やオレンジジュースなどをスロットタイプに追加しておき、Clova で認識できるようにしておきます。
- お茶・ジュースなど複数から選択できる
- スロット値のドリンク(麦茶、コーラなど)に応じ、抽出するドリンクを切り替える
同種のドリンクで代替して抽出
Drink Bar とはいえ在庫がないドリンクもあります。そんな時でも変わりのドリンクを提供するための機能です。
予めドリンクをグルーピング(麦茶、緑茶などはTEAグループ、オレンジジュース、りんごジュースはSOFTDRINKグループ など)しておき、在庫がないドリンクを指示されても同じグループ(同種)で在庫があるドリンクを抽出する機能です。例えば、以下のように置き換えます。
- 緑茶が在庫に無ければ、同じお茶で在庫のある麦茶を抽出する
- 同様にオレンジジュースが無ければ、りんごジュースを抽出する
市販の銘柄でも認識可能
もう一つの置き換え機能が、市販されている商品名でもドリンクとして認識できるものです。
コーラを飲みたいと頭で考えていても、思わず「ペプシをちょうだい」と指示してしまうこともあります。そんな時にこの銘柄認識機能が役に立ちます。例えば、以下のように認識します。
- 緑茶として認識する語句
- 伊右衛門、生茶、綾鷹
- オレンジジュースとして認識する語句
- なっちゃんオレンジ、つぶつぶみかん
- コーラとして認識する語句
- ペプシ、ドクターペッパー、メッツコーラ
デモ動画
言葉で説明しても難しいので、デモ動画を見ていただければ分かっていただけると思います。
システム構成
Drink Bar のシステム構成です。
スキル側はnode.js で実装し、ngrok で開発PC をサーバーとして動かしています。
実際にドリンクを抽出するハードウェア部分はobniz とエアーポンプ(DC モーター)、シリコンチューブを組み合わせた構成となっています。
スキルの実装はシンプル
スキル部分はとてもシンプルです。
カスタムインテントは、飲みたいドリンクを指示する「DispenseDrinkIntent」のみです。DispenseDrinkIntent では「麦茶をちょうだい」「オレンジジュースをいれて」などの指示を受け付けます。
あとは認識したドリンクを基に、JSON で定義しておいたDrinkModel で在庫有無や、どのエアーポンプを動かせば抽出されるかの情報を取得します。
在庫があればそのまま、なければ同種で在庫があるドリンクに置き換えて、抽出するためのエアーポンプを動作させるだけです。clova.js(抜粋)let messageText = ''; let d = findDrinkById(drink); if (d['available'] === true) { // ドリンクバーに設置されているドリンクの場合 messageText = `わかりました。${d['name']} をついでおくね!` } else { let sameTypeDrink = findSameTypeDrinkModel(d['type']); if (sameTypeDrink) { // 同じ種類のドリンクが設置されている場合はそちらを注ぐ messageText = `おっと、${d['name']} が無かったので、同じ種類の${sameTypeDrink['name']}をついでおくね!`; } else { // ドリンクが設置されてない場合は断りのメッセージを返す messageText = `ごめんなさい。${d['name']}を用意してなかったよ。他の飲みたいドリンクを教えてね。`; } d = sameTypeDrink; } // Clova のセリフを組み立てる const speechList = []; // 注ぐセリフ speechList.push( clova.SpeechBuilder.createSpeechText(messageText) );DrinkModel.json(抜粋){ "list": [ { "available": false, "id": "OolongTea", "name": "ウーロン茶", "slot": 0, "type": "TEA" }, { "available": false, "id": "GreenTea", "name": "緑茶", "slot": 0, "type": "TEA" }, { "available": true, "id": "BarleyTea", "name": "麦茶", "slot": 0, "type": "TEA" }, { "available": false, "id": "BrownRiceTea", "name": "玄米茶", "slot": 0, "type": "TEA" }, { "available": false, "id": "JasmineTea", "name": "ジャスミン茶", "slot": 0, "type": "TEA" }, { "available": true, "id": "OrangeJuice", "name": "オレンジジュース", "slot": 1, "type": "SOFTDRINK" }, { "available": false, "id": "AppleJuice", "name": "リンゴジュース", "slot": 1, "type": "SOFTDRINK" }, ...後略市販銘柄の認識は同義語をひたすら登録する
出来ることで挙げていた「市販の銘柄でも認識可能」ですが、こちらはカスタムスロットの同義語としてひたすら登録します。
怠惰のためには地道な作業もこなします。
ひたすら画面に入力するのも大変なので、Google スプレッドシートなどを活用してTSV ファイルとして出力し、Clova Developer Center のアップロード機能を活用すると少し楽ができます。
アップロードファイル例
OolongTea ウーロン茶 烏龍茶 うーろん茶 黒烏龍茶 GreenTea 緑茶 りょくちゃ おちゃ お茶 伊右衛門 いえもん 綾鷹 あやたか 生茶 なまちゃ おーいお茶 贅沢緑茶 特茶 ヘルシア緑茶 濃い茶 BarleyTea 麦茶 むぎちゃ ミネラル麦茶 ゴマ麦茶 胡麻麦茶 むぎ茶 健康ミネラル麦茶 六畳麦茶 六条麦茶 やさしい麦茶 香り薫るむぎ茶 BrownRiceTea 玄米茶 げんまい茶 げんまいちゃ JasmineTea ジャスミン茶 ジャスミンティー ジャスミンアップロード機能はサンプル発話の登録にも有効
アップロード機能はサンプル発話の登録にも有効です。
サンプル発話のテンプレートを決めて、そこにタグとドリンク名を連結してサンプル発話の文字列を一挙に生成します。アップロードファイル例
[INTENT SLOT] Drink DRINK [INTENT EXPRESSION] <Drink>ウーロン茶</Drink>を頂戴 <Drink>烏龍茶</Drink>を頂戴 <Drink>うーろん茶</Drink>を頂戴 <Drink>黒烏龍茶</Drink>を頂戴 <Drink>緑茶</Drink>を頂戴 <Drink>りょくちゃ</Drink>を頂戴 <Drink>おちゃ</Drink>を頂戴 <Drink>お茶</Drink>を頂戴 <Drink>伊右衛門</Drink>を頂戴 <Drink>いえもん</Drink>を頂戴 <Drink>綾鷹</Drink>を頂戴 <Drink>あやたか</Drink>を頂戴 <Drink>生茶</Drink>を頂戴 <Drink>なまちゃ</Drink>を頂戴 <Drink>おーいお茶</Drink>を頂戴 <Drink>贅沢緑茶</Drink>を頂戴 <Drink>特茶</Drink>を頂戴 <Drink>ヘルシア緑茶</Drink>を頂戴obniz を使ってドリンクを抽出する
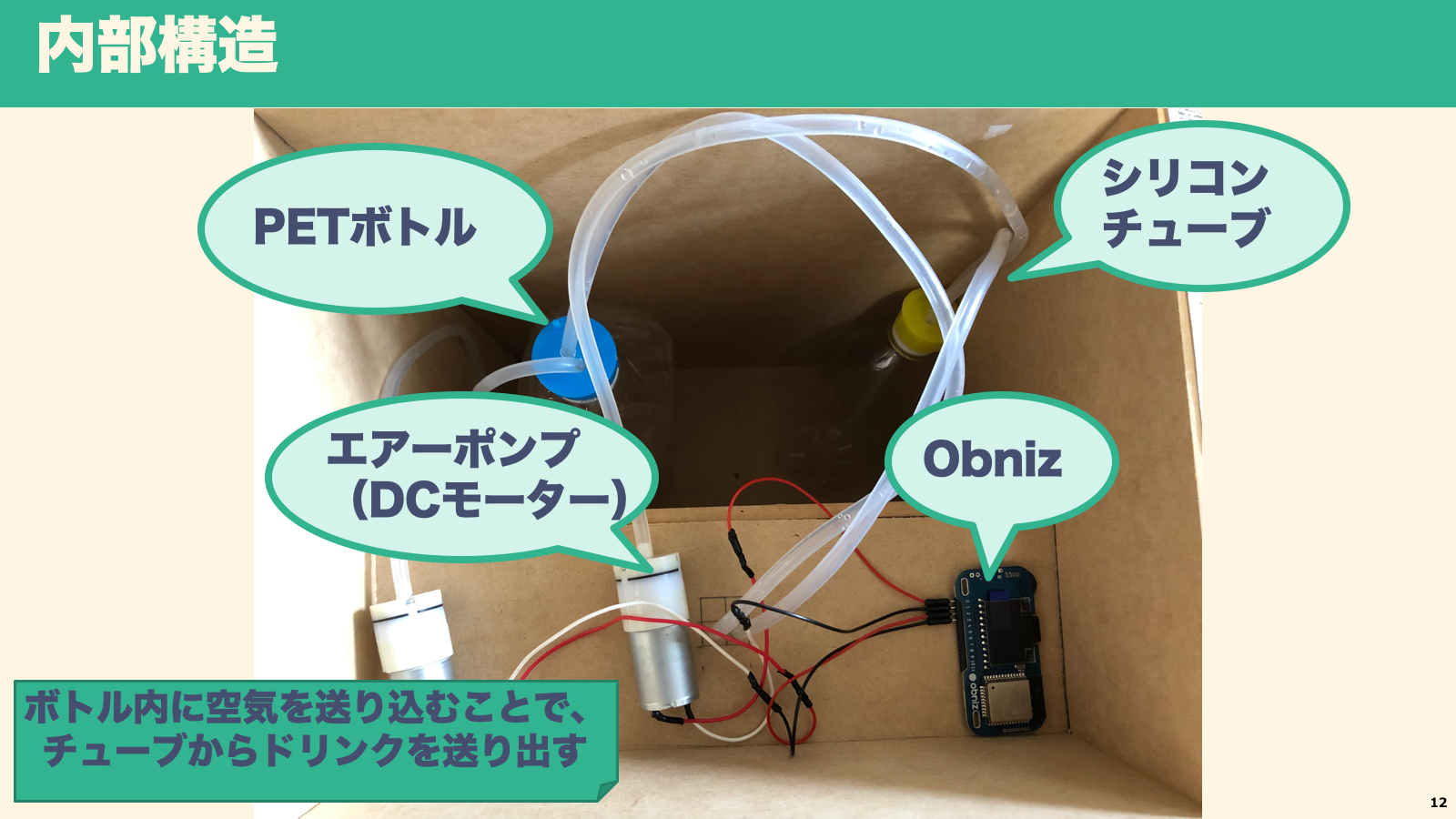
ハードウェア構成もシンプルです。まずはobniz とエアーポンプを繋ぎます。
エアーポンプに繋いだシリコンチューブと、ドリンクが出てくる側のシリコンチューブをPET ボトルキャップに接続します。接続できるようにPET ボトルキャップに電気ドリルで穴を開けています。
うまくドリンクを抽出するポイントはボトルの気密を保つことです。チューブ外径にぴったりな穴が開けられない場合は、ホットボンドで穴とチューブを接着したり、キャップにパッキンを装着するなどして気密を保ってください。
以上で実装は終わりです。
とてもシンプルな作りとなっています。あとは外装などにこだわるのも良いですね。まとめ
実はこの「LINE Clova Drink Bar」は最初から作ろうと思っていたのではなく、別で作成していた「LINE Things Drink Bar」というLINE Things とLINE Pay を組み合わせた作品のスピンオフとして生まれた作品でした。
もう少し明かすと、「スマートスピーカーを遊びたおす会 vol.6」の登壇ネタに困っていた筆者が、時間かけずに作れるネタがないものか、という怠惰な発想から生まれた怠惰な作品なのでした。
実際の実装時間も半日程度です。怠惰ですませたいという気持ちを持っていると、作業効率の良い作品が生まれるのかもしれません。そんな怠惰な作品が日本最大級のスマートスピーカーコミュニティでの登壇ネタとなり、日本最大級の開発コンテストの部門決勝にノミネートされてしまい、とても恐縮です。
あの有名なミステリーの女王 アガサ・クリスティが「発明は怠惰から生まれる」と言っていたように、怠惰にしたいがために動いていれば良い作品が生まれるのかもしれませんね。




- 投稿日:2019-12-12T13:57:21+09:00
Node.jsから画像をmultipart/form-dataでPOSTするメモ (axios利用)
某APIを試していて、少しハマったのでメモ。
axiosで画像POSTとかを調べると、最近はVue.jsだったりフロントエンド側からPOSTする記事が多く、Node.js側から送るサンプルはあまりヒットしない印象です。環境
Node.js v13.2.0
準備
mkdir myapp cd myapp npm init -y npm i axios form-dataこんな感じでaxiosとform-dataを追加インストールです。
コード
post.js'use strict'; const fs = require('fs'); const FormData = require('form-data'); const axios = require('axios'); const url = `https://hogehoge.com/hogehoge`; //ポスト先のエンドポイントURL const imagePath = `./public/image.png`; //画像のパス const file = fs.createReadStream(imagePath); const form = new FormData(); form.append('image', file); const config = { headers: { 'X-HOGEHOGE-HEADER': 'xxxxxxx', //APIごとのヘッダーなど ...form.getHeaders(), } } axios.post(url, form, config) .then(res => console.log(res.data)) //成功時 .catch(err => console.log(err)); //失敗時所感
参考にさせてもらった記事にもありましたが、色々調べてて
form.getHeaders()の箇所が直感的ではないのでちょっとハマりました。参考
- 投稿日:2019-12-12T11:21:39+09:00
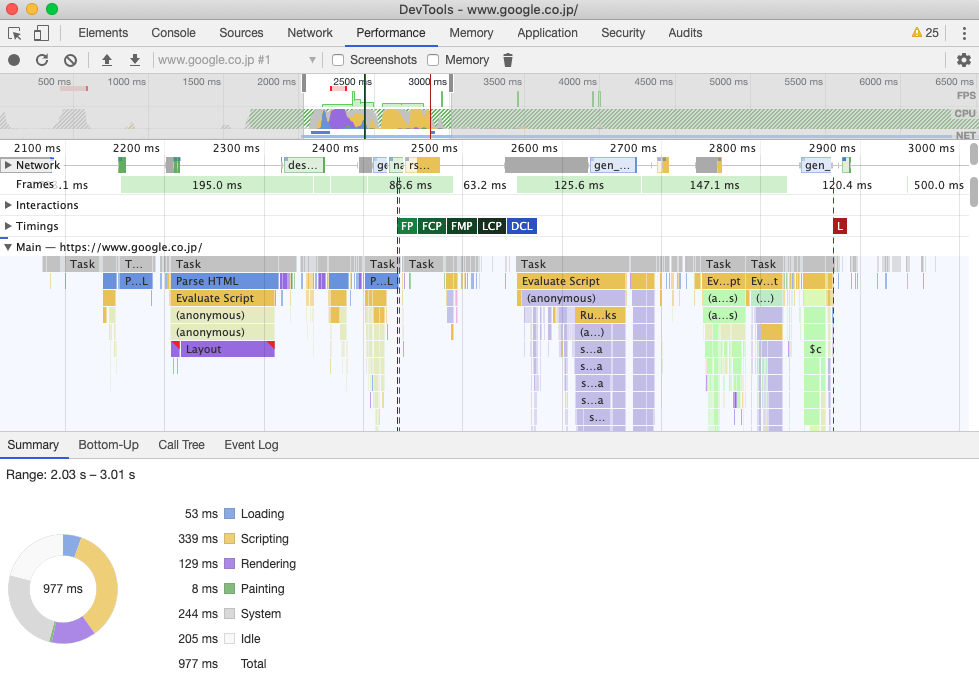
puppeteerでSPAのページ表示速度を計測してみた
普段はテスト自動化、ちょっとだけ開発を行なっています。
自動化繋がり(?)で、手動で行なっているページ表示速度の取得を自動化をすることなりました。やりたいこと
・手動でやっているページ表示速度(ボタンクリック→画面が全て表示されるまで)を定期的に自動で取得したい
・対象はSPA(シングルページアプリケーション)
・リロードの時間も計測したい
・毎日数時間おきに計測して比較したい
・Puppeteer使いたい (Node.jsのライブラリでプログラムからAPIでChromeの操作ができる。詳しくはこちら)計測方法の検討
Puppeteer + Navigation Timing API
Puppeteer + Navigation Timing API で簡単にできそうと思ったけど、SPAだと計測できなかった(計測できたのは初期表示時だけ。。)
Puppeteer + speedline
手動で計測する場合は、Chrome DevToolsのPerformanceパネルでのパフォーマンス計測を行なっているという情報を得たため、同じようにできないか調査。(左上のRecordボタンで計測できき、左下のような結果が得られる)
Puppeteerを使用することで、Chrome DevToolsのPerformanceパネルでのパフォーマンス計測でexportできるprofileが取れることがわかったため、これを利用することとした
ただし、profileの解析は別でやる必要があるため、別ライブラリ(speedline)を使用することとした
ボタンのクリック後、ページが表示されたタイミングが取れなかったため、
対象画面が表示される直前までマスクがかかっていることを利用し、マスクが外れたタイミング=表示されたとした具体的な計測方法
1. Puppeteerで遷移元のページを表示する
2. recordを開始
3. ボタンのクリックを行う
4. マスクが表示されるまで待つ(ボタンクリック後マスクがかかるまでタイムラグがあるため)
5. マスクが表示されなくなるまで待つ
6. recordを終了
7. recoed結果をspeedlineで解析して、結果を取得するSpeedMeasure.jsconst puppeteer = require('puppeteer'); const speedline = require('speedline'); const filename = 'trace.json'; (async () => { const browser = await puppeteer.launch({ devtools: true, }); try { let page = (await browser.pages())[0]; // 1. puppterで遷移元のページを表示する await page.goto("http://xxxxxx.com", { timeout: 300000, waitUntil: 'networkidle0' }); // 2. recordを開始 await page.tracing.start({ path: filename , screenshots: true}); // 3. ボタンのクリックを行う // 4. マスクが表示されるまで待つ(ボタンクリック後マスクがかかるまでタイムラグがあるため) await Promise.all([ page.waitForXPath("マスクが表示状態時のxpath", 300000), (await page.$x("ボタンのxpath"))[0].click() ]); // 5. マスクが表示されなくなるまで待つ await page.waitForXPath("マスクが非表示状態のxpath", 300000); // 6. recordを終了 await page.tracing.stop(); // 7. 結果をspeedlineで解析して、結果を取得する const result = await speedline(filename); console.log(result.duration) } catch (e) { console.error(e); } finally { browser.close(); } })();最後に
手動と比べたら若干の誤差はありますが、毎日同じ時間に計測し、比較するという目的は満たせているのでよしとしました。
実際にはJenkinsで数時間ごとに実行、結果をスプレットシートに自動で書き込みまでやっています。
- 投稿日:2019-12-12T09:16:59+09:00
続・実録 Node-REDノード作成 24時
こんにちは、ポキオです。
IoTLT Advent Calendar 2019とenebular Advent Calendar 2019の15日目の記事です。
手抜きです、ごめんなさい。
tl;dr
- 京急ノードを作ってみました
- Node-REDのノードライブラリに反映されるまで時間がかかることがあります
- 一度公開したあとも、ノードのメンテは必須です
- Node-RED、だぁいすき!
話の発端:Node-RED向けの京急ノードを作りたかった
この記事をご覧の諸兄姉にとっては釈迦に説法かもしれませんが、Node-REDはグラフィカルなUIで、ノンコーディングでもプログラミングができてしまう、素晴らしいツールでございます。
Node-REDで部品として動くパーツであるノードは色々準備されていたり、ノードライブラリでも種々のノードが公開されていて、Node-REDの可能性を無限に広げてくれています。
ただし、なかなか日本向けのノードがないのに玉に瑕で、だからこそ自分でノードを作って公開しようというモチベーションが湧いてきたわけです。とりわけ、私は京急が大好きなので、京急にまつわるノードを作ろうと思い立ったわけです。
で、作ったのがこれです。
node-red-contrib-keikyu
https://flows.nodered.org/node/node-red-contrib-keikyu
京急の運行情報が取得できる、すばらしいノードに仕上がっています(笑)
問題①:なかなか公開できない!
詳しい経緯はこちらで公開していますが、公開作業をしている段階で一つの問題にぶち当たりました。
ノードがノードライブラリで公開されるまで、やることは色々あるわけですが、とりあえずコーディングやnpmjs.comでの公開までは順調に進んだわけです。
ただ、npmjs.comでnpmモジュールとしてノードを公開したあと、なかなかノードライブラリに反映されないという問題に陥りました。通常は数時間で反映されるわけなのですが、そのときは全く反映されませんでした。
よくある原因としては、
- package.jsonのkeywordsに「node-red」がない
- プレフィックス「node-red-contrib-」を用いて命名されてない
- README.mdがない
- LICENSEがない
- npmで公開されてない
- npm versionしたあとにgit pushし忘れてる
などなどありますが、それはすべてOK。結局、npmjs.comから一度ノードを削除して、再度公開しました・・・。削除後は24時間経たないと再公開できないという制限がありましたが、なんとか再公開後にノードライブラリに反映されました・・・。もし同じようなことで困っている方がいらっしゃいましたら、お試しくださいませ。
問題②:京急ノードが動かなくなった!
公開して、一安心してたんですが、ある日突然ノードが使えなくなっていました。
結論から言ってしまえば、京急の運行情報ページのレイアウトが更新されていて、いままで使っていたパースのロジックがワークしなくなり、運行情報の取得ができなくなっていました・・・。
もともとパースのロジックは、かなりのクソコードだったので致し方ないとおもいつつ、とりあえずコードを修正して、再度公開しました。
また、二度と同じようなことがないように、自分が作ったノードが正しく動作しているか、enebular上でCIのように定期的に動かし、ノードの状態を監視する仕組みを作りました。
こんな感じでステータスが表示されます。これで完璧ですね!(笑)
現在平常通り運転しています。
というわけで、今年もいろいろとお世話になりました。
来年もポキオと京急を何卒よろしくおねがいします!宣伝
ポキオとドライブをしながらIoTとかTechな話をする、ポキオ・カープール。
ぜひご覧ください!
一緒にドライブしながら喋ってくれる方も大募集中です!









- 投稿日:2019-12-12T03:28:58+09:00
wordpress投稿データをcontentfulに移植するスクリプトを公開しました。
最近contentfulを業務で使うことが多くなった上に、非エンジニアの方々にcontentfulを教える作業が辛くなったため、エディタをwordpress、データベース・APIをcontentfulにと役割分担させるべく「wordpressで書いた記事をcontentfulに同期しちゃう」というスクリプトを書きました。
その際、contentfulのfieldsの仕組みを鑑みてwordpressの記事投稿は通常投稿(post)を許容せず、いわゆるカスタム投稿(custom post type)のみを許容するようにしました。
正直、通常記事しかないとしたらcontentfulの高機能なAPIを使うこともないと思うので、wordpress rest apiでゴニョゴニョして運用した方がいいと思います。
早速使ってみる
Githubからzipなりpullなり適当にダウンロードしてもらって、ローカルで下準備をします。
必要なもの
とりあえず、必要なものは
Wordpress Information
- "Wordpress rest url"(ex: https://example.com/wp-json/wp/v2)
- "Wordpress custom post type slug names"(ex: ["example_slug1","example_slug2", ...])
Or (Only one of these two)
- "Wordpress custom posts and custom post type slug names of those" (ex:
{ "example_slug1": ["example_post1", ...], ... } )Contentful Information
以上になります。(githubから横流しですみません)
日本語で軽く説明しますと、
wordpress rest apiからデータをとるため、rest apiのurl(これは、wp-json/wp/v2という末尾を考えています)、データの対象であるslugsやposts・slugsのペアのいずれかが必要になります。(どっちもはダメです)
次に、contentfulにデータをアップロードする際に諸々の情報が必要になりますが、基本的にググれば出るので割愛します。気をつけることとしては、management apiとdelivery apiが割と区別されているので惑わされないようにするくらいです。(management apiは作成とかで、delivery apiは閲覧専門的な感じです)wordpress側の設定と入力事項
今回テスト環境に適当なwordpressをインストールして、rest apiは全て公開するというノンセキュアな環境のみで実行しています。そのため、セキュリティプラグインが邪魔するなどの方は、リポジトリを改変するかセキュリティプラグインの設定をうまくrest apiが使えるようにチューニングしてください。
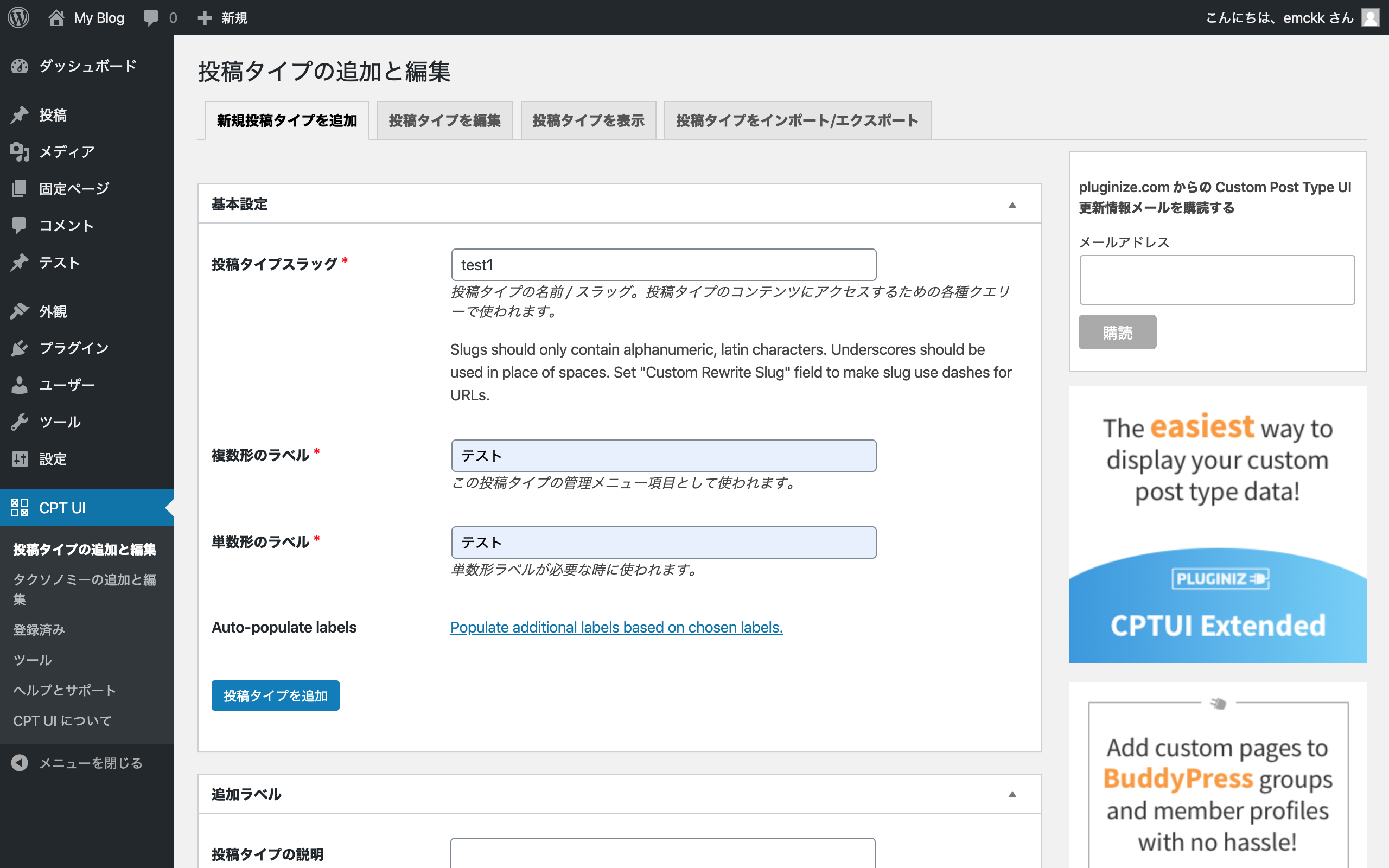
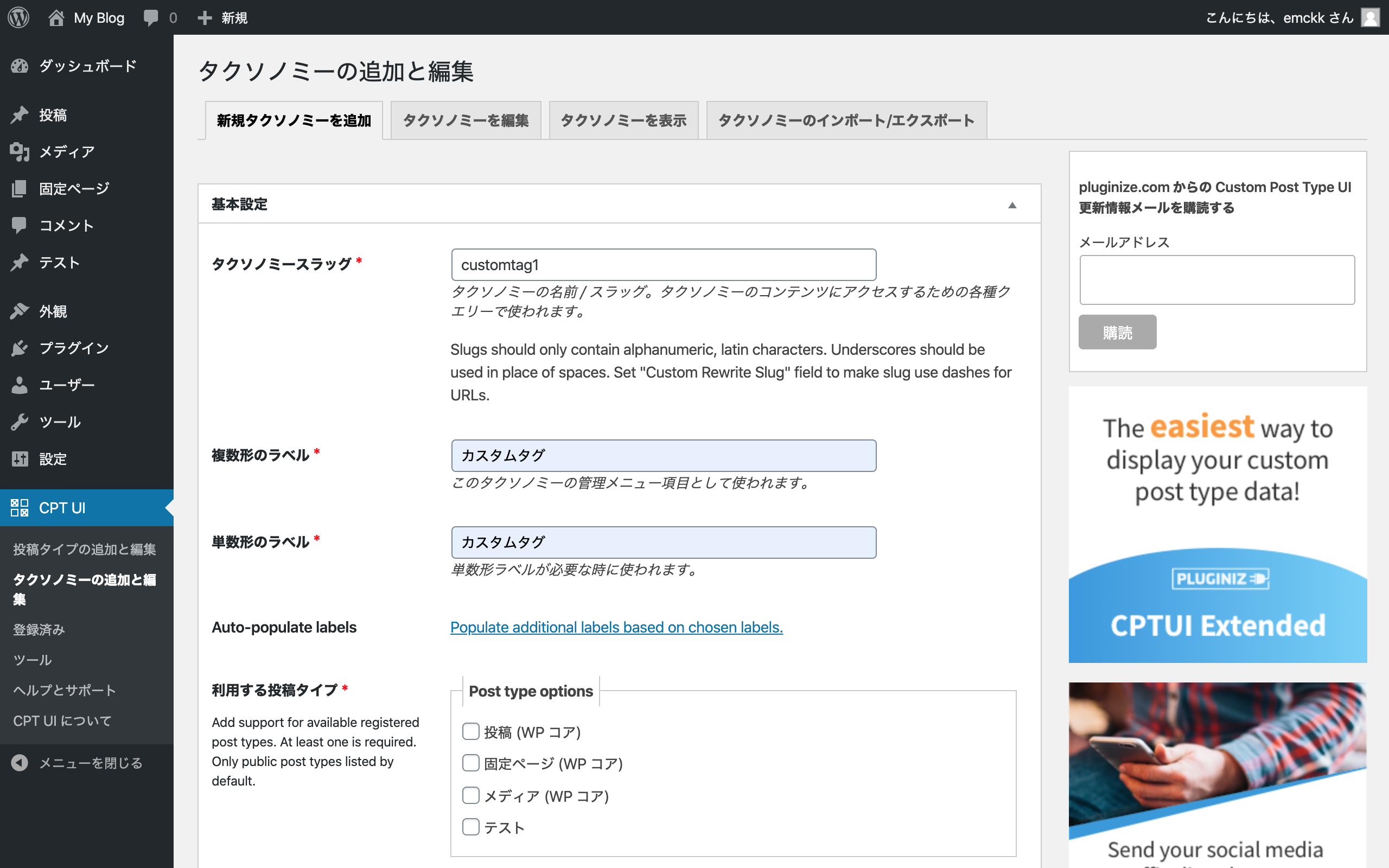
wordpressに Custom Post Type UIを入れてカスタム投稿量産体制を整える
このプラグインを使用すると、カスタム投稿がボタンぽちぽちするだけで作れて、カスタムタクソノミーもボタンぽちぽちで瞬時に作れます。
とりあえず、テストというカスタム投稿とカスタムタグ、カスタムカテゴリーを作成しちゃいます。
(同様にカスタムカテゴリー。写真略)
脱線しますが、wordpressって無料プラグインのくせにあり得ないほどの高機能なプラグインがあったりしてたまに怖いです。その中でもこのプラグインはシンプルさと高機能・カスタマイズ性の高さがすごいので是非この機会に今後も使ってもらいたいですね。wordpress上でデータを作っとく
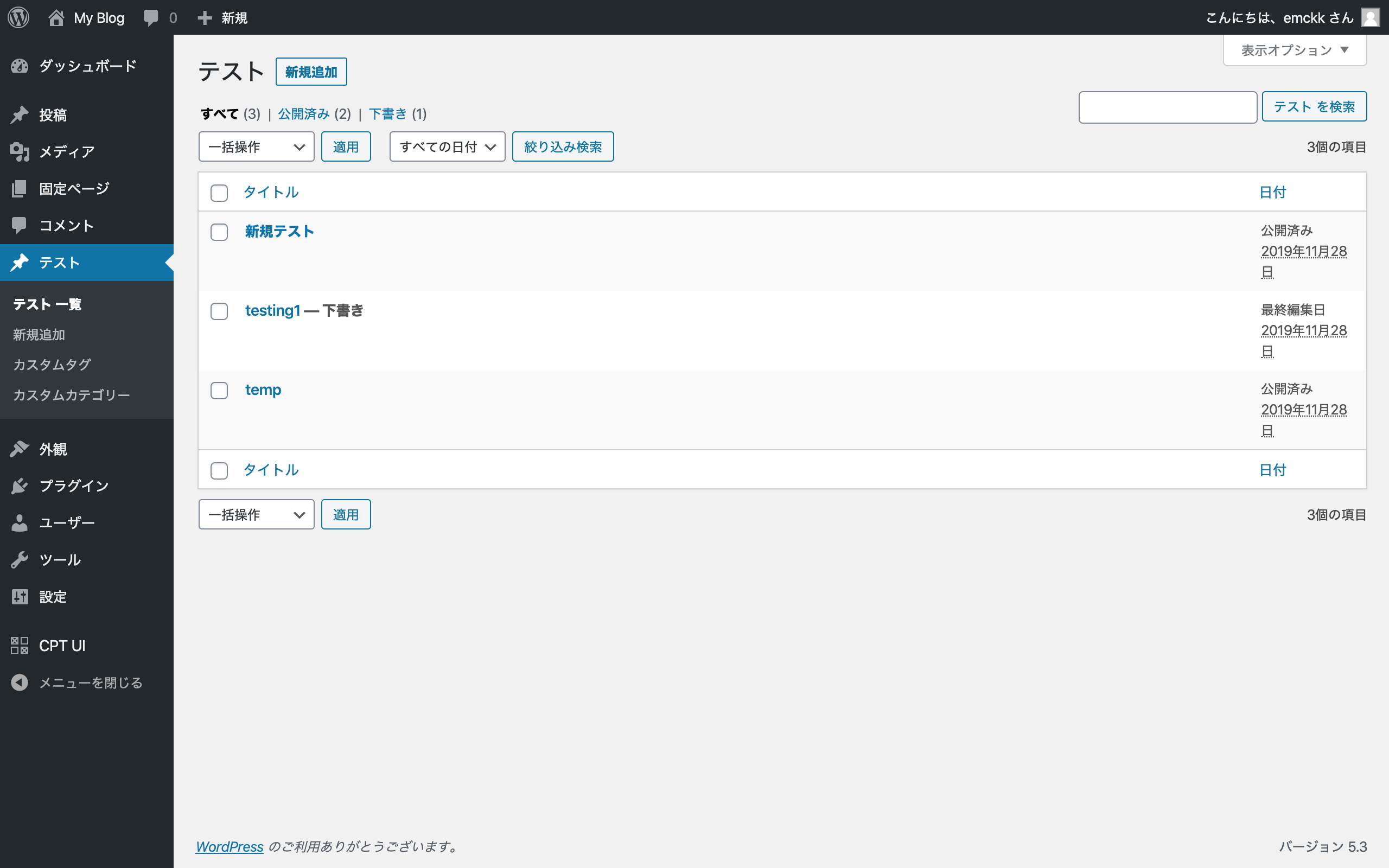
僕は、以下のようにデータを作っときました。
下書きを入れているのは、テスト用で、下書きはrest api上で取得できないです。そのためcontentfulへのデータ移植は公開済みのものしか対応していません。Contentfulでapiを取得する
contentfulアカウント作成→スペース作成(スペースIDが後に必要)→Delivery api keyを取得(後に必要)→management api keyを取得(後に必要)→地域設定が必要なら済ませてdefault areaを設定(後に必要)
加えて、ENVIRONMENT_IDも必要だったりしますが、基本的にmasterで問題ないはずです。スクリプトを実行する
二通りのパターンで実行できるようにしましたが、今回は楽チンに設定ファイルで済ませてしまいます。
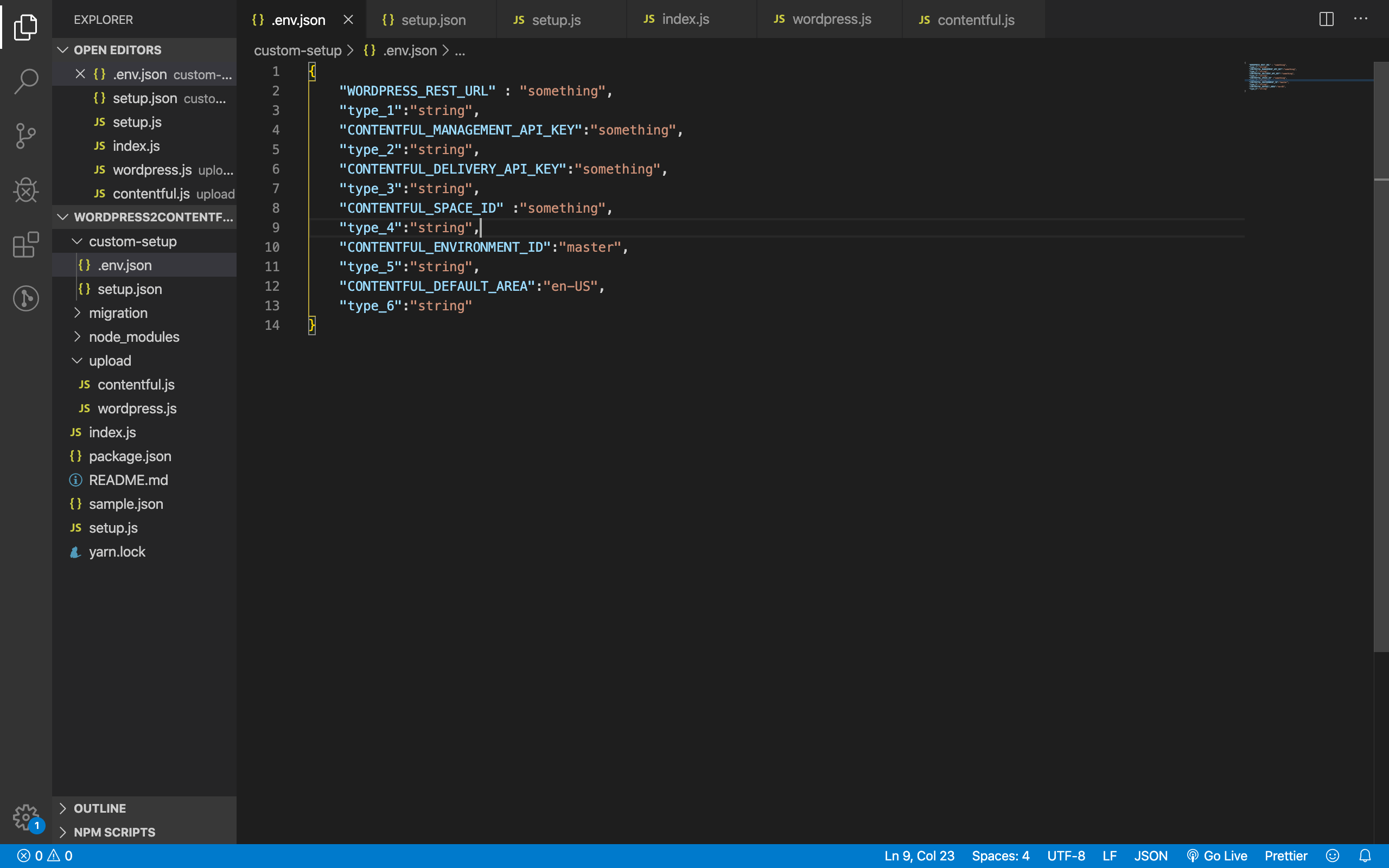
.env.jsonに直接環境設定を記載。ローカル環境なのでこうしています。
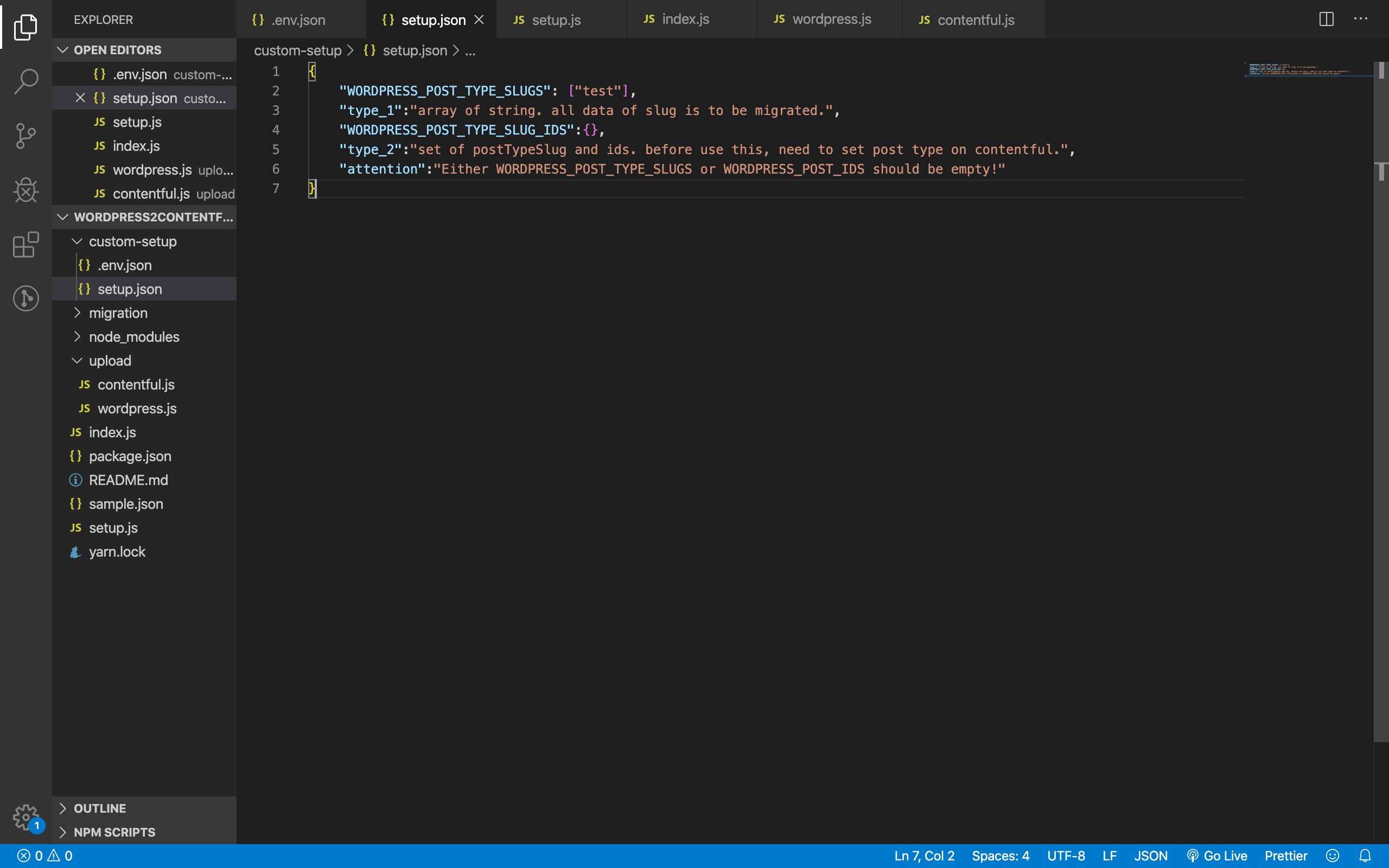
setup.jsonにwordpress側の欲しいデータの設定を記載。
なお、WORDPRESS_POST_TYPE_SLUGSとWORDPRESS_POST_TYPE_SLUG_IDSの片方は空でないといけないようにしました。両方を考慮するパターンは、需要がなさそうな上に処理が煩雑になったためです。
run script
node index.jsで実行。
色々出力していますが、終わってcontentfulを確認して中身がいい感じなら完了です。
なお、後半忙しくなって、entry titleを設定してないので、最後にそれだけ設定してしまいましょう。Entry Titleの設定
Content Modelに入って、作成したcontent modelをクリックします。
その後titleのSettingsをクリックして、Field optionsというところにあるThis field represents the Entry titleにチェックをつければ完了です。注意点とまとめ
基本的に、個人的なスクリプトなので共通して雑に作成しています。暇な方はプルリク投げてくれると仕事した感が出るのでお願いします。
注意点
今回個人的な使用目的に限定しているためいくつかの制約があります。
・カスタム投稿しか使えない
・カスタムフィールドとかに対応していない
・カスタムタクソノミーがcontent modelのshort textのlistとして扱われる(※1)
・親カテゴリーなどに対応していない
などなど
個人的には、通常投稿で固めていてカスタムフィールドをデータベースとして使用している方も多い印象なので、そうした方々はそれらデータをエクスポートしてカスタム投稿とカスタムタクソノミーに合うように工夫してもらうとかがいいかと思います。例えば、wordpressダッシュボードのツールからエクスポートして、ローカルでそのファイルのpost名をカスタム投稿のpost名に置換してインポートするとカスタム投稿として複製されます。まとめ
用途が限られるかもしれませんが、簡易的なサイトであったり個人用サイトではこのスクリプトで物足りることは多い気もします。保守メンテはとても暇な際にやる予定なので、エラーが出たりしたら一応共有して頂けると嬉しいです。
※1:contentfulの仕様的に、いわゆるタグやカテゴリーを実現するには、1.content modelに作成するパターンと2.fieldsに書いてしまうパターンの二つがあります。1のパターンだと絞り込みでgetする際にrelationから取得しますが、2のパターンだと標準のfieldsの絞り込みapiで実現できます。好き好きではありますが、個人的にcontentfulの無料枠がasset 5000まで(1だとasset扱いにならざるをない)なのでケチな私は2しか選べなかっただけです。すみません。
- 投稿日:2019-12-12T00:34:22+09:00
TypeScriptでステップ実行するときの設定の自分用のまとめ
私はTypeScript初心者です。よろしくお願いします。m(_ _)m
今回
tsconfig.jsonはこのような設定で行いました。
sourceMapはtrueに設定しておきます。tsconfig.json{ "compilerOptions": { "target": "es6", "module": "commonjs", "sourceMap": true, "outDir": "./dist", "strict": true }, "include": [ "src" ], "exclode": [ "node_modules" ] }ステップ実行するコードは、こちらの簡単なコードで行います。
https://gist.github.com/okumurakengo/8433019b8b525dd241c08cb357c414e7
src/index.tsfunction fizzbuzz(n: number): number|"Fizz"|"Buzz"|"FizzBuzz" { if (n % 15 === 0) { return "FizzBuzz"; } if (n % 3 === 0) { return "Fizz"; } if (n % 5 === 0) { return "Buzz"; } return n; } let a: number = 1; console.log(fizzbuzz(a++)); console.log(fizzbuzz(a++)); console.log(fizzbuzz(a++)); console.log(fizzbuzz(a++)); console.log(fizzbuzz(a++)); // ...chromeでステップ実行する用にhtmlも作成
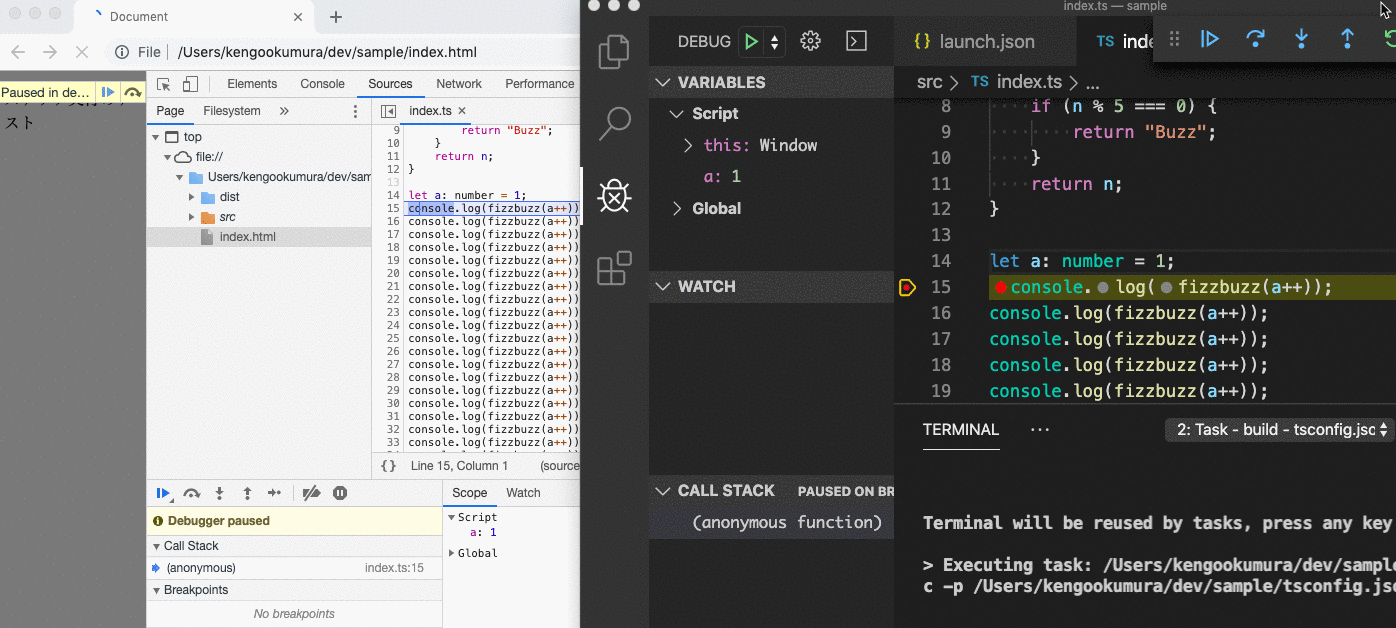
index.html<!DOCTYPE html> <meta charset="UTF-8"> <title>Document</title> <script src="dist/index.js" defer></script> <p>ステップ実行のテスト</p>1-1. chromeでステップ実行をしてみた
yarn add -D typescript yarn tsc # src/index.ts をコンパイルして、 dist/index.js が出力
index.htmlを開き、開発者ツールのSourcesパネルでtypescriptのコードを確認できるので、ブレークポイントを設定してステップ実行することができました。
1-2. chromeでNode.jsのコードのステップ実行してみた
参考: ChromeDevToolを使ってNodeJSのデバッグ - Qiita
nodeで実行するときに
--inspectフラグをつけて実行することで、chromeでステップ実行することができます。node --inspect index.js参考の通りに、ts-nodeを指定すると、typescriptをts-nodeで実行して、chromeでステップ実行することができました。
--inspect-brkをつけると、1行目にブレークポイントをつけたように実行してくれるようなので、それもつけておきました。$ yarn add -D typescript ts-node $ node --inspect --inspect-brk --require ts-node/register src/index.ts Debugger listening on ws://127.0.0.1:9229/d715288d-7d07-4576-834e-4787eecadb0bchrome://inspect を開いて、Remote Targetの部分にある、
inspectを押すと、開発者ツールが開いてステップ実行できました。
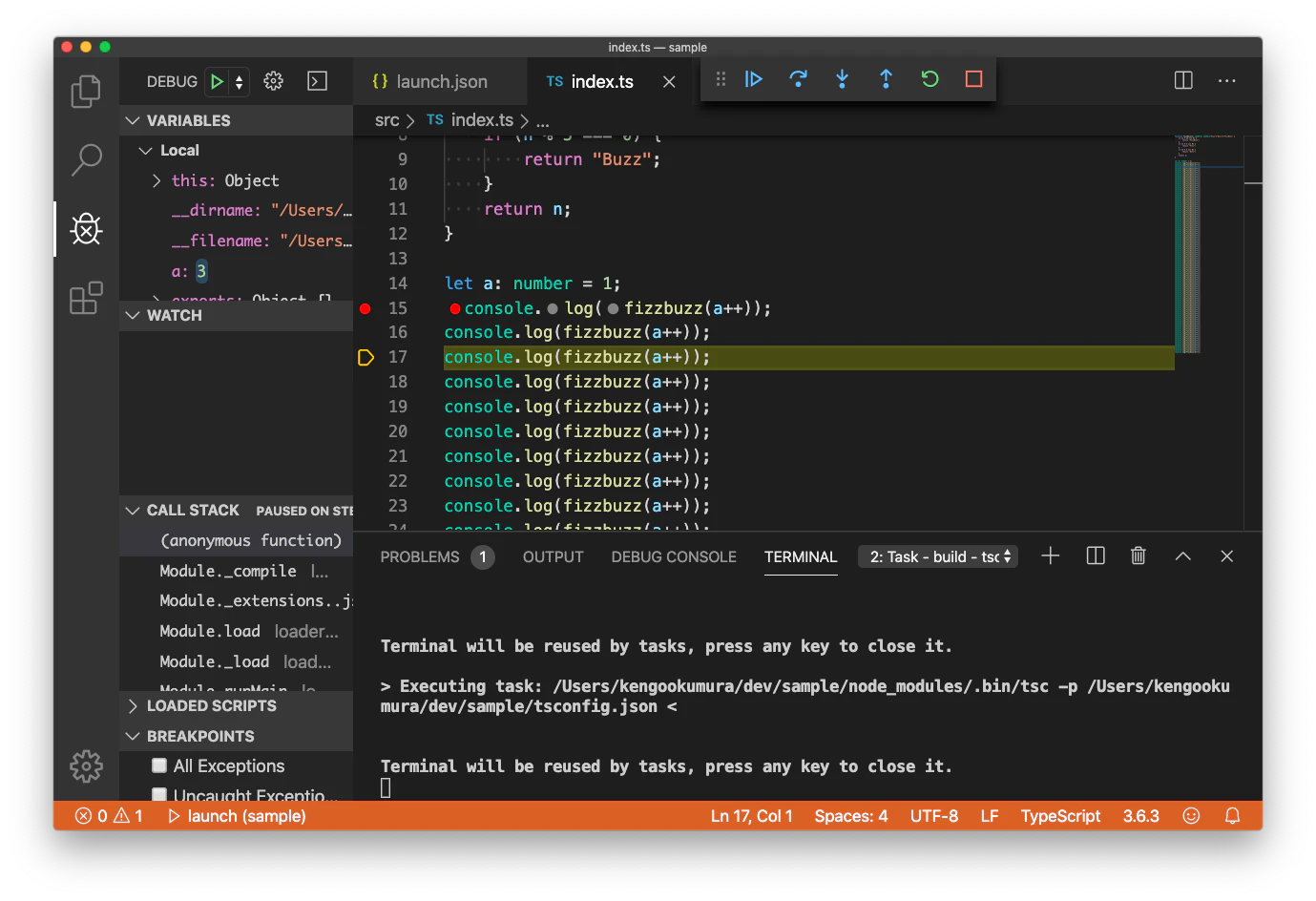
2-1. vscodeでステップ実行してみた
参考:https://code.visualstudio.com/docs/typescript/typescript-debugging
vscodeの左の虫のマークを押して、左上の歯車を押すと、
launch.jsonが開きます。
参考ページの
launch.jsonを自分のディレクトリに合わせて設定します。launch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "type": "node", "request": "launch", "name": "launch", "program": "${workspaceFolder}/src/index.ts", "preLaunchTask": "tsc: build - tsconfig.json", "outFiles": ["${workspaceFolder}/dist/**/*.js"] } ] }この状態で左上にある緑色の三角の実行ボタンを押すとステップ実行できました。
2-2. vscodeでクライアントコードのステップ実行してみた
vscode拡張の Debugger for Chrome をインストールする
launchi.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "type": "chrome", "request": "launch", "name": "Launch local file", "preLaunchTask": "tsc: build - tsconfig.json", "url": "file:///Users/kengookumura/dev/sample/index.html", "webRoot": "${workspaceFolder}" } ] }この状態でデバッグの実行ボタンを押すと、chromeが起動し、デバッグすることができました。
↑の設定だと、ローカルファイルとしてデバッグしているので、例えば、自分でローカルサーバを起動していて、
http://localhost:8000/として実行したい場合は、launch.jsonの設定を変更するか、追加すると実行できます。launch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "type": "chrome", "request": "launch", "name": "Launch local file", "preLaunchTask": "tsc: build - tsconfig.json", "url": "file:///Users/kengookumura/dev/sample/index.html", "webRoot": "${workspaceFolder}" }, { "type": "chrome", "request": "launch", "name": "Launch localhost", "preLaunchTask": "tsc: build - tsconfig.json", "url": "http://localhost:8000", "webRoot": "${workspaceFolder}" } ] }jsonの
"name"の部分でどれを実行できるか指定できるので、Launch localhostを指定した状態で実行すると
http://localhost:8000/を指定して、vscodeでクライアントコードのデバッグができました。
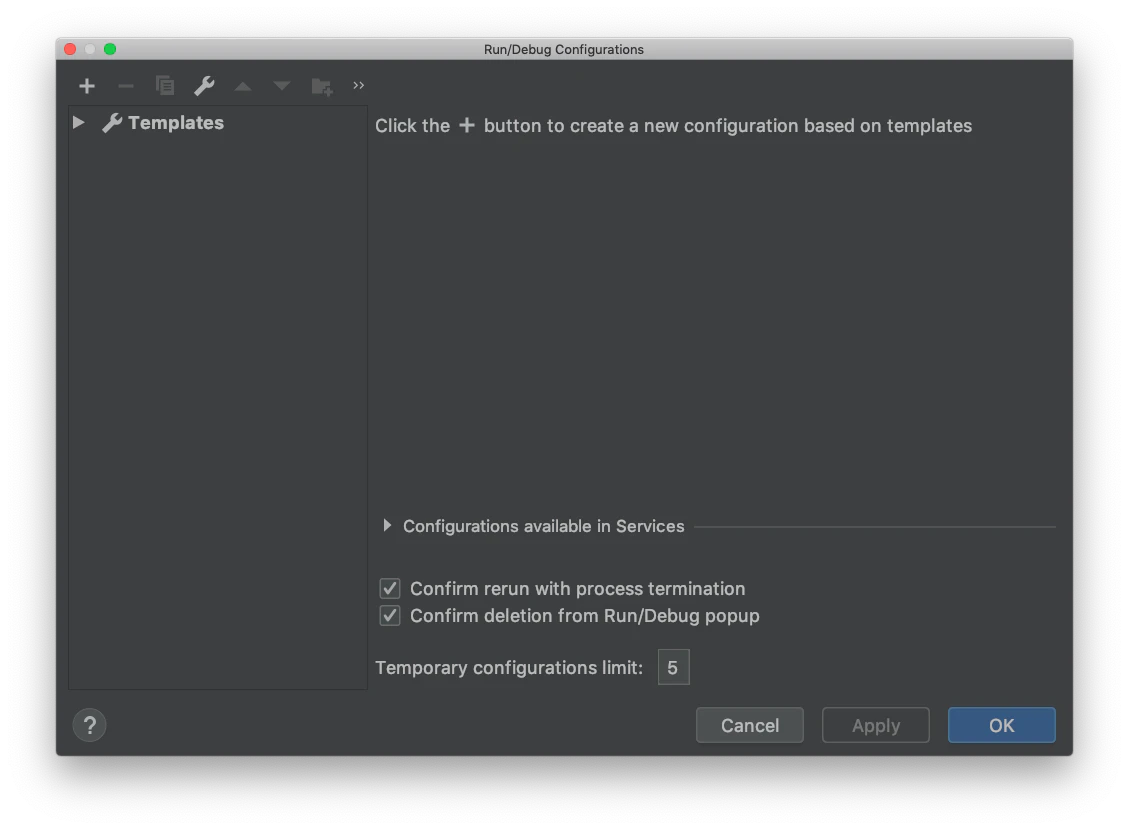
3-1. WebStormでステップ実行してみた
参考
- Getting started with Typescript debugging with Webstorm breakpoints
- TypeScriptの実行とデバッグ - ヘルプ | WebStorm
- Can support WebStorm breakpoint ? · Issue #188 · TypeStrong/ts-node
右上の「Add Configulation」を押す
左上の「+」を押して、「Node.js」 を選択
- Working directory
- JavaScript file
をそれぞれコンパイル後のJavaScriptを指定する。
Before launch: activate tool window に
Compile TypeScriptを指定すると、
最初の一回はコマンドでtscと実行し(※最初の1回目をWebStormで実行するとdist/index.jsがないとエラーになる)、
それ以降WebStormで実行するときは自動でTypeScriptをコンパイル後にデバッグ実行してくれました。
この状態で右上のデバッグ実行のボタンを押すと、ステップ実行できました。
※私の環境ではなぜか不安定で、ブレークポイントを2つ設定しないと止まってくれなかったり、普通に動いてくれることもあったりで、よくわかりませんでした。
3-2. WebStormでクライアントコードのステップ実行してみた
右上の「Edit Configulation」から、
左上の「+」を押して、「JavaScript Debug」 を選択URLに
http://localhost:63342/<index.htmlへのパス>で設定すると、WebStormの組み込みのWebサーバーからステップ実行してくれました。
※もちろんhttp://localhost:8000などとして自分のローカルサーバーを指定しても大丈夫でした。先ほどと同じように、Before launch: activate tool window に
Compile TypeScriptを指定すると、
デバッグ実行するときは毎回自動でTypeScriptをコンパイルした後にデバッグ実行してくれました。
以上です。見ていただいてありがとうございました。m(_ _)m