- 投稿日:2020-09-13T23:47:43+09:00
New Relic APMをNode.jsのアプリケーションに導入してパフォーマンス解析をする
背景
- Webアプリケーションのパフォーマンスチューニングコンテスト「ISUCON10」の予選に参加した。
→ チームメイトの参加ブログ- New Relicから ISUCON10参加チーム向けNew Relic特別無料ライセンス が提供されていたので使ってみた。
導入方法
前提として、NewRelicのAPMライセンス適用済みのアカウントが作成されていること
- NewRelicポータル > APM > Add More で
Node jsを選択- 画面の案内に沿って導入する
- アプリケーション名を決めて入力する
- Node.jsアプリケーションのディレクトリでnewrelicのNPMパッケージを導入
$ npm install newrelic --save- NewRelicの設定ファイル(newrelic.js)をダウンロードし、Node.jsアプリケーションのディレクトリ直下に配置
(NewRelicのライセンスキーと1.で入力したアプリケーション名が記載されている)- Node.jsのアプリケーション本体(app.jsなど)にrequireを追加する
require('newrelic');- Node.jsのアプリケーションを再起動する。(
$npm startなど)
どんな情報が見えるのか?
ISUCONの中でどのようなパフォーマンス解析に使っていたかのメモです。
(アプリケーションはコンテスト中で改修した後のもの)Summary
- アプリケーションのトランザクション処理時間のグラフが確認できる。
- トランザクション全体の時間の中でMySQLの処理時間の割合がわかる
- スループット、エラーレート、Apdexスコア(レスポンスタイムベースのユーザ満足度)
- 下部にはアプリケーションを処理しているサーバ別のレスポンス・スループット・エラーレート・CPU使用率・メモリ使用率の平均値が表示される。

Distributed Tracing
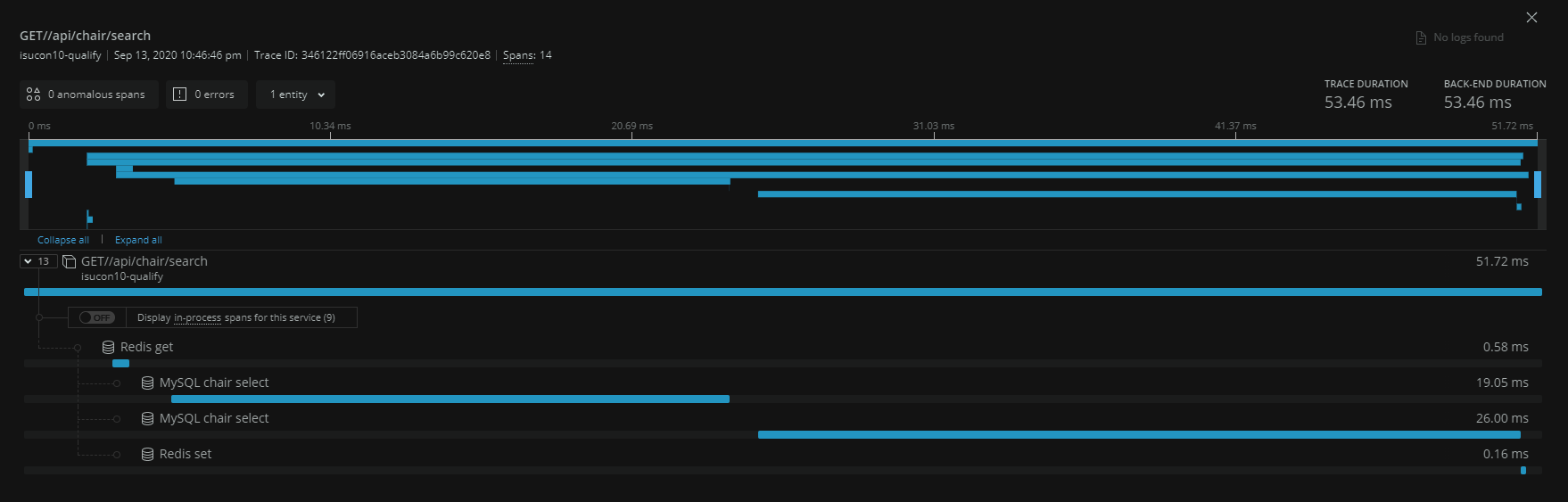
- アプリケーションのトランザクションのサンプリング一覧を表示する。
全体の処理時間・バックエンドの処理時間でソートし遅いトランザクションを特定することができる。- 更にドリルダウンすることでトランザクションの中でのバックエンドの呼び出し時間の割合(MySQLならテーブル単位)を確認することができる。キャプチャの例ではトランザクション中でMySQLのchairテーブルに2回selectを発行し、Redisに1回setしていることがわかる。
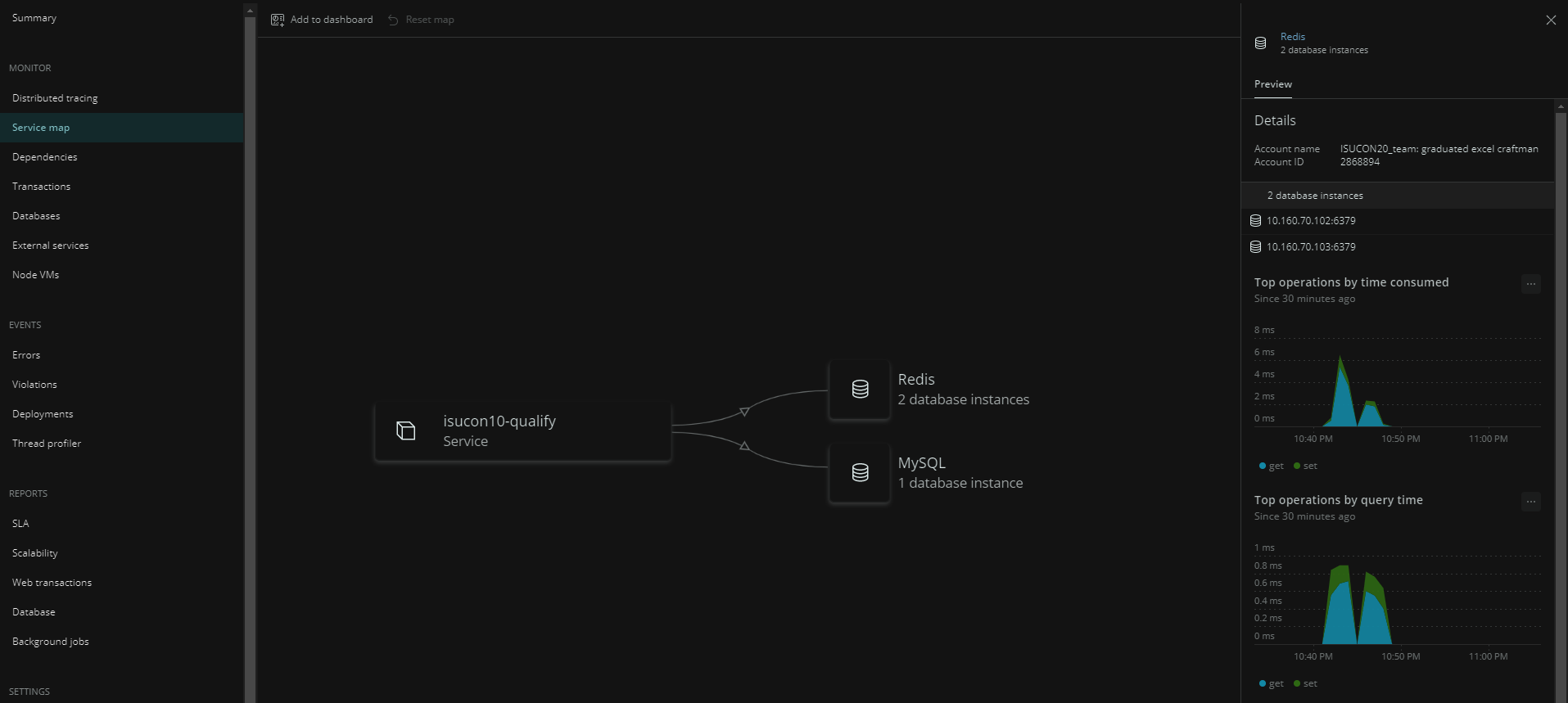
Service Map
- アプリケーションが依存している外部サービスがマップ上に表示される。
- キャプチャの例ではアプリケーションから2ノードのRedisと1ノードのMySQLにアクセスしていることがわかる
- データベースをクリックするとクエリの処理時間のグラフも表示される
Dependencies
- Service Mapに表示されていた外部サービスが一覧表示される
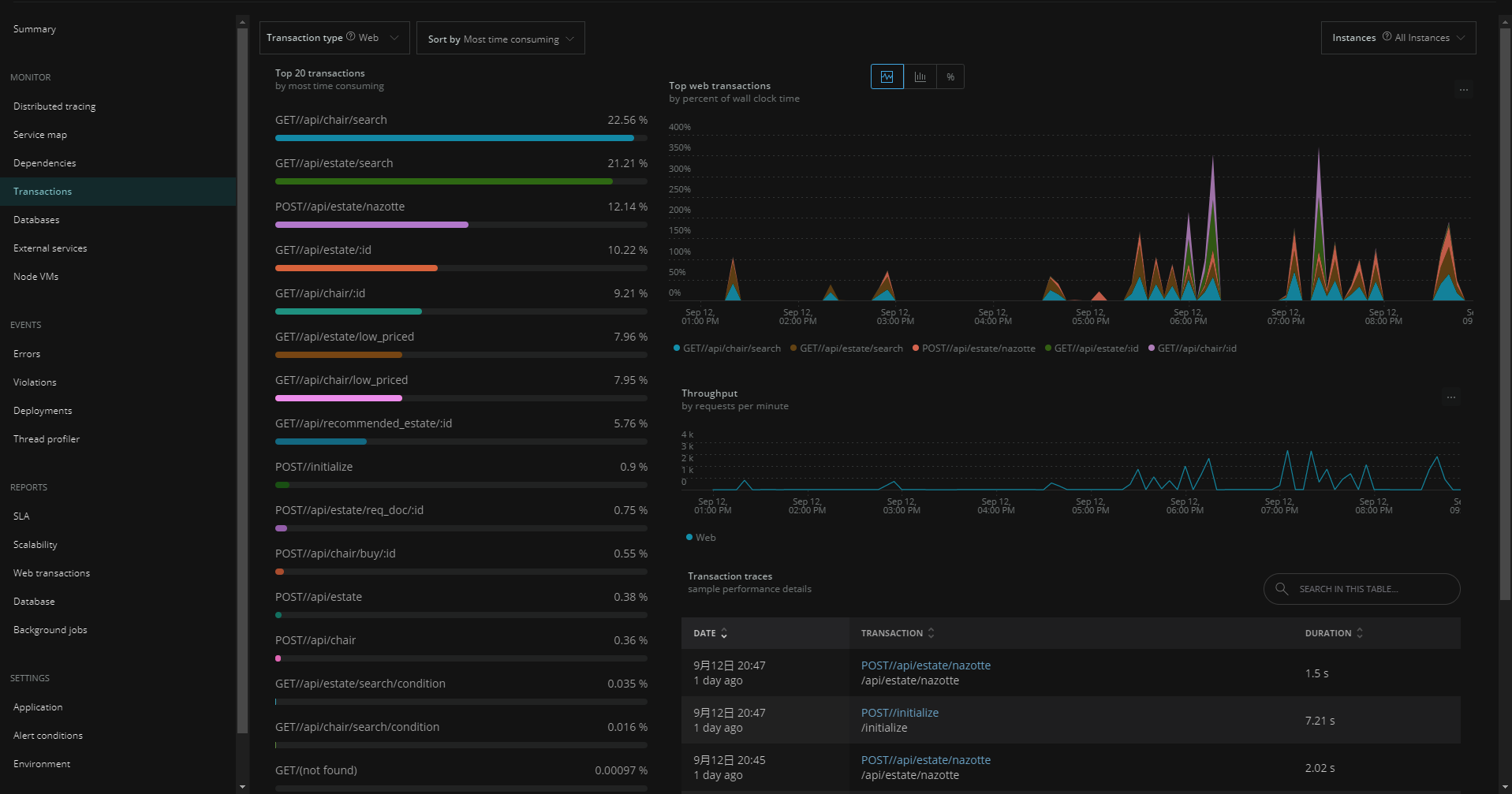
Transactions
- 初期表示の「Sort by Most time consuming」でアプリケーションのトランザクションの中で「処理時間 × リクエスト数」が多い順に表示される。(キャプチャ1枚目)
- 特定機能にフォーカスすると処理時間の内訳がグラフ表示される。キャプチャ2枚目の例ではMySQLのchairテーブルのselectが支配的なことがわかる。
- パフォーマンス改善の効果が高い機能を特定しチューニングの方向性を決めるために利用できる。
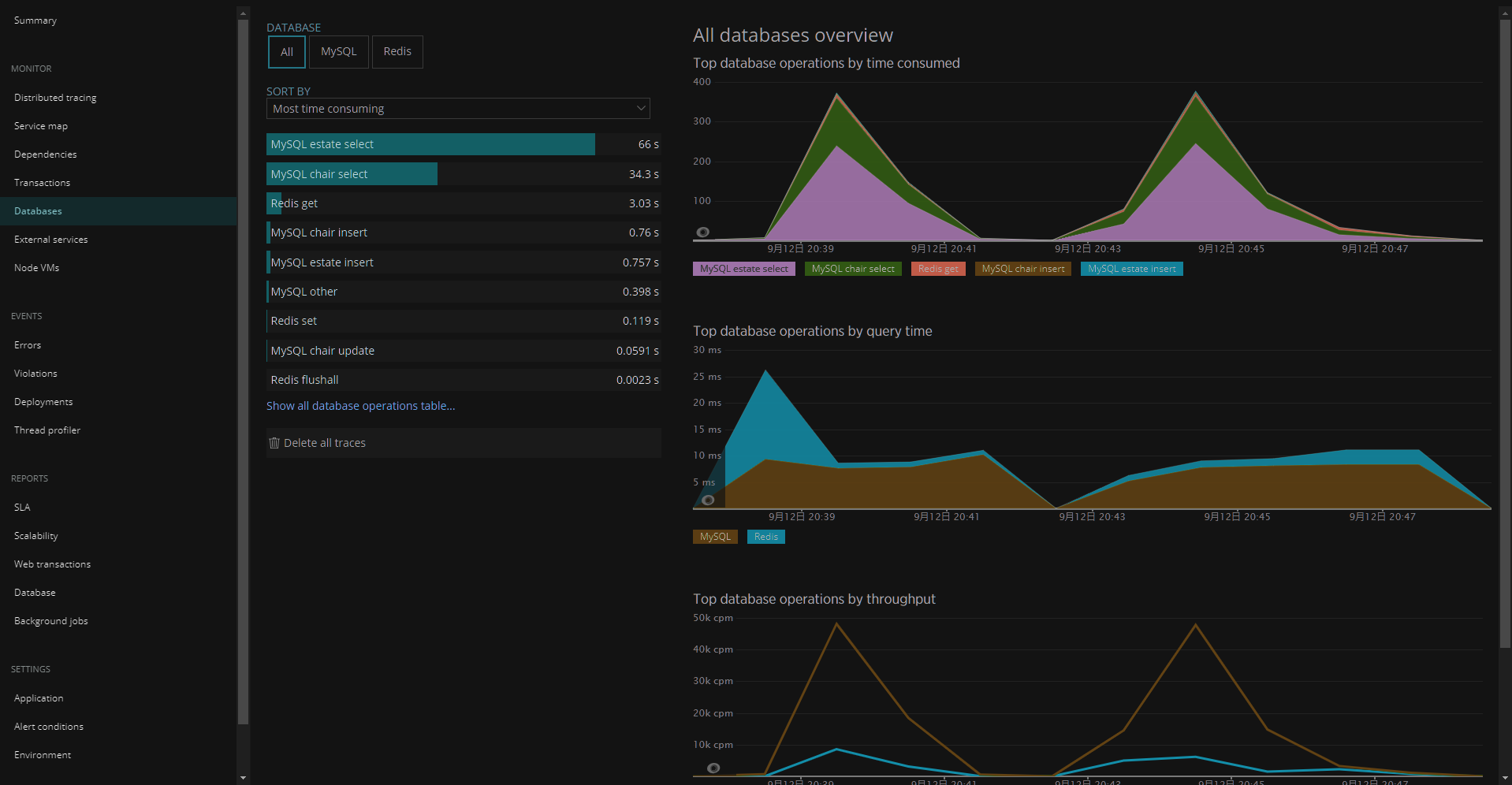
Databases
- 初期表示の「Sort by Most time consuming」でアプリケーションが接続しているデータベースのクエリの「処理時間 × リクエスト数」が多い順に表示される。
- テーブル単位のselect/insertの処理時間の外観をつかむことができるのでDBチューニングの方向性を決めるために利用できる。
感想
- NewRelicの導入簡単すぎ。(Node.jsの場合)
- アプリケーションの機能単位での処理時間、データベースのテーブル単位のselect/insertの処理時間が確認できるため、パフォーマンス低下の原因を速やかに特定できる。とても便利。
- ISUCONのスコアベースでは100-200点程度の影響しかなかったので、New Relic APM Agentによるパフォーマンス影響よりも可観測性のメリットの方が大きいと思われる。(競技の最終盤では外しましたが)本番運用しているアプリケーションではNewRelicでモニタリングし続けたほうがいいと思いました。



- 投稿日:2020-09-13T22:19:23+09:00
GitHub Actionsを使ってWebサイト(EC2)の更新を自動化する
GitHub Actionsを使ってWebサイトの更新を自動化する手法を備忘録がてらにご紹介します。
この記事を読むことで、下記の作業を自動化できます。
- Node.jsを用いた静的アセット(html,css,js)のビルド
- scpを用いたビルドアーティファクトのAWS EC2インスタンスへのデプロイ
- slackへの通知
技術・ツール

前提となる技術とツールをご紹介します。
Node.js、EC2インスタンス、slackは既に用意されているものとして説明します。
名前 GitHub Actions AWS EC2 Node.js(v12.18.3) slack GitHub Actions を始める前に
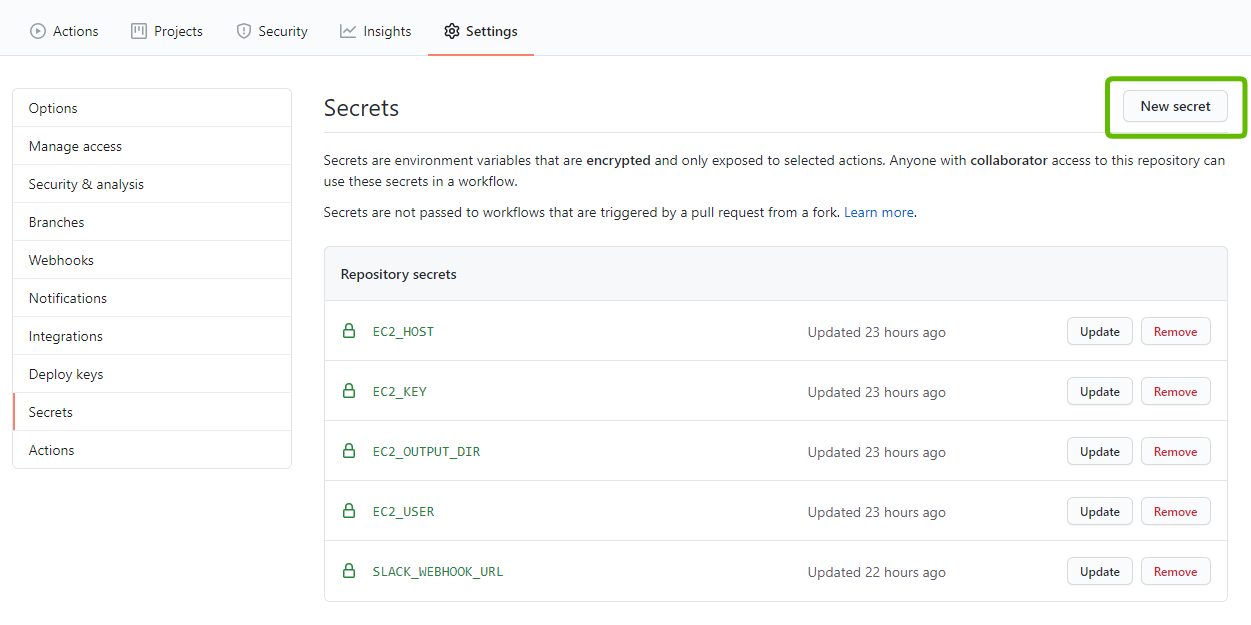
slackへの通知やEC2インスタンスへのssh接続が必要となるため、GitHubのsecretsを使用して秘匿情報を隠蔽します。
[ Settings > Secrets > New secret ]より、下記のsecretsを追加してください。
名前 用途 EC2_HOST EC2インスタンスへ接続するためのホスト名です。 EC2_KEY EC2インスタンスへ接続するための秘密鍵です。 EC2_OUTPUT_DIR 実際に公開されるサイトのドキュメントルートです( /var/www/htmlが一般的ですが、各種Webサーバの設定に依存します)。EC2_USER EC2インスタンスへ接続するためのユーザー名です。 SLACK_WEBHOOK_URL slackのAppディレクトリで確認できるIncoming WebhookのURLです。詳しくはこちらをご確認ください。 GitHub Actions の用意
詳細な説明が不要な場合は、下記のymlファイルをコピペすれば問題なく動くと思います(たぶん)。
GitHub Actionsを使うには、リポジトリのルートディレクトリに
.github/workflows/file-name.ymlというファイルを追加する必要があります。このymlファイルの構文は公式のリファレンスを参考にするのが良いと思います。
今回は、ビルド・デプロイ・slack通知を自動化したいので、下記のようなymlファイルを書きます。build-deploy-notify.ymlname: Build and Deploy to EC2 on: push: branches: - master env: SSH_PRIVATE_KEY: ${{ secrets.EC2_KEY }} REMOTE_HOST: ${{ secrets.EC2_HOST }} REMOTE_USER: ${{ secrets.EC2_USER }} TARGET: ${{ secrets.EC2_OUTPUT_DIR }} SOURCE: 'public' SLACK_WEBHOOK: ${{ secrets.SLACK_WEBHOOK_URL }} SLACK_CHANNEL: ci jobs: build-and-deploy: name: Build and Deploy runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Use Node.js v12.18.3 uses: actions/setup-node@v1 with: node-version: '12.18.3' - name: Build run: | npm install npm run build - name: Deploy to EC2 uses: easingthemes/ssh-deploy@v2.1.1 - name: Slack Notification on Success if: success() uses: rtCamp/action-slack-notify@v2.0.2 env: SLACK_TITLE: Deploy Success SLACK_COLOR: good - name: Slack Notification on Failure if: failure() uses: rtCamp/action-slack-notify@v2.0.2 env: SLACK_TITLE: Deploy Failure SLACK_COLOR: dangeryml ファイルの詳解
nameWorkflowの名前となり、実際にGitHub上のActionsページにて表示される名前です。処理に直接的な影響は及ぼしません。
onWorkflowが実行される条件の部分です。
今回はmasterブランチにpushされたイベントを検知して、Workflowが実行されるようになっています。
push以外にも様々なイベントをトリガーとして設定可能で、ブランチも複数選択可能です。build-deploy-notify.yml# workflowの名前です。 name: Build and Deploy to EC2 # masterブランチにpushしたときのイベントをトリガーにしています。 on: push: branches: - master
envこのWorkflowにおける環境変数です。
${{ secrets.SOME_SECRET }}で [ Settings > Secrets ]で設定した値を使用することができます。
後述しますが、今回いくつかの外部Actionを使用しており、ここで設定した環境変数は外部のActionを使用する際に必須のパラメータとなります。GitHub ActionsはMarketplaceに公開されている外部のアクションを使用することができます。build-deploy-notify.ymlenv: SSH_PRIVATE_KEY: ${{ secrets.EC2_KEY }} REMOTE_HOST: ${{ secrets.EC2_HOST }} REMOTE_USER: ${{ secrets.EC2_USER }} TARGET: ${{ secrets.EC2_OUTPUT_DIR }} # publicはビルドアーティファクトが出力されるディレクトリです。 # このプロジェクトではWebpackを使って、静的アセットをpublicディレクトリに出力しています。 SOURCE: 'public' SLACK_WEBHOOK: ${{ secrets.SLACK_WEBHOOK_URL }} SLACK_CHANNEL: ci
jobs実際の処理群を記述する場所です。
stepsにビルド・デプロイ・通知などの処理をそれぞれ記述しています。
Use Node.js v12.18.3で、Node.jsとnpmのセットアップ、Buildでnpm scriptsを実行、Deploy EC2でEC2インスタンスへのデプロイ、Slack Notification on Success(or Failure)でslackへの通知作業を行っています。ここまでの記述でわかるとおり、実際の処理はほとんど書いていません。これはusesに記述している外部のアクションを用いているからです。
easingthemes/ssh-deploy@v2.1.1では、scpを用いた静的アセットの輸送を、rtCamp/action-slack-notify@v2.0.2では、Incoming Webhookを用いたSlackへの通知をそれぞれ担っています。また、環境変数envは各ステップごとにも設定することが可能で、slackへの通知では成功・失敗でそれぞれメッセージや文字色を分けるよう設定しています。いずれかのstep中にエラーが発生すると当該のWorkflowは失敗となります。
ビルドやデプロイなど、失敗する可能性が0%ではない処理を含んでいる場合は、成功・失敗の条件分岐をさせることも可能で、今回はSlackの通知をそれぞれ成功・失敗で出し分けられるようにしています。
if:failure()もしくはif:success()で条件分岐させています。build-deploy-notify.ymljobs: build-and-deploy: name: Build and Deploy runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Use Node.js v12.18.3 uses: actions/setup-node@v1 with: node-version: '12.18.3' - name: Build run: | npm install npm run build - name: Deploy to EC2 uses: easingthemes/ssh-deploy@v2.1.1 - name: Slack Notification on Success if: success() uses: rtCamp/action-slack-notify@v2.0.2 env: SLACK_TITLE: Deploy Success SLACK_COLOR: good - name: Slack Notification on Failure if: failure() uses: rtCamp/action-slack-notify@v2.0.2 env: SLACK_TITLE: Deploy Failure SLACK_COLOR: dangerまとめ
EC2にデプロイする場合は、AWSのCodePipeLine(CodeBuild,CodeDeploy)を使うことが一般的かと思いますが、今回はあえてGitHub Actionsを使ってみました。それぞれメリット・デメリットがあるので、プロジェクトにあった技術を選定するのが良いと思います。GitHub Actionsを使えば、デプロイ先をEC2以外にすることもできますし、通知先をSlack以外にすることも可能かと思いますので、可用性や汎用性といった部分が非常に高いように感じました。価格も無料ですし、コードのテストを追加したいといった場合にCI的に扱えることも魅力の一つかなと思います。
- 投稿日:2020-09-13T22:07:02+09:00
Node.jsでナイーブベイズ分類器を使った分類を行う
ナイーブベイズ分類器のBayesモジュールを使う
ナイーブベイズ分類器は、次のようなことができます。
- スパムメールの判定
- ニュース記事やブログ記事のカテゴリー判定
ごく簡単にいうと、学習に必要なのはカテゴリーに関連する単語をたくさん登録するだけです。カテゴリーのわかっている文章を単語に分解して登録します。判定するときには、カテゴリーに関わる単語の出現率で判定されます。
もちろん、もっと正しい理解をしたほうがいいですが、bayesモジュールを使うならこの程度のイメージを持っておくだけで使えて、なかなか有益な結果を得られます。詳しく知りたい方は末尾のリンク先を参照してください。1
使い方(イメージ)
// 学習 classifier.learn('カテゴリーAに関する長文・・・・・', 'カテゴリーA') classifier.learn('カテゴリーBに関する長文・・・・・', 'カテゴリーB') classifier.learn('カテゴリーCに関する長文・・・・・', 'カテゴリーC') // 判定 const category = classifier.categorize('カテゴリーを判定したい文章')準備(予備知識)
分かち書き
先に示したように、bayesモジュールのlearnメソッドを使ってカテゴリーのわかっている文章を学習させます。英語であれば自動で単語に分割して登録されるのですが、日本語の場合は単語への分割がうまくいきません。そこで、bayesが日本語の文章の単語への分割=分かち書きができるようにその機能を持ったメソッドを渡してあげます。分かち書きの機能を提供するtiny-segmenterモジュールを使って次のようにします。(イメージを掴むために、こちらのサイトでtiny-segmenterの動作を見ておくとよいです。)
const segmenter = new TinySegmenter() var classifier = bayes({ tokenizer: function (text) { return segmenter.segment(text); } });async/await
また、最初の使い方イメージでは省略しましたが、bayesのlearnメソッドとcategorizeメソッドはasyncで提供されているため、簡単に使用するにはawaitをつけて呼び出す必要があります。awaitはaysncメソッド内でしか使えません。そのため下記のサンプルコードではasyncが使われています。
データ準備
学習に使う文章はWikipediaからもってきましょう。以下のURLでアクセスするとXMLデータが得られます。2
https://ja.wikipedia.org/wiki/特別:データ書き出し/キーワード得られるデータにはちょっと無駄な情報が多いですが簡単に済ますために今回はこれをこのまま使いましょう。ブラウザで以下の3つのURLにアクセスして、それぞれyoritomo.txt、takauji.txt、ieyasu.txtとして保存してください。
yoritomo.txtとして保存https://ja.wikipedia.org/wiki/特別:データ書き出し/源頼朝takauji.txtとして保存https://ja.wikipedia.org/wiki/特別:データ書き出し/足利尊氏ieyasu.txtとして保存https://ja.wikipedia.org/wiki/特別:データ書き出し/徳川家康これで準備は完了です。
インストール
bayesのインストールnpm install bayestiny-segmenterのインストールnpm install tiny-segmenterデモ・コード
実行結果は次の通りです。
実行結果$ node bayes-demo.js 判定=[源頼朝] -- 日本で最初に幕府を開いた人物で、妻は尼将軍としても有名な北条政子である。 判定=[源頼朝] -- 後鳥羽天皇によって征夷大将軍に任ぜられた。 判定=[源頼朝] -- 奥州を平定した。 判定=[足利尊氏] -- 室町幕府を開いた。 判定=[足利尊氏] -- 鎌倉幕府の滅亡後、鎮守府将軍・左兵衛督に任ぜられた。 判定=[足利尊氏] -- 歌人としても知られる。 判定=[徳川家康] -- 幼少時代を人質として過ごした。 判定=[徳川家康] -- 室町幕府最後の将軍足利義昭が信長包囲網を企てたとき、協力要請を受けたがこれを無視した。これがデモ・コードです。ぐだぐだ説明する必要もないと思います。シンプル。
bayes-demo.jsvar bayes = require('bayes'); const TinySegmenter = require('tiny-segmenter') const fs = require('fs') // 分かち書きの機能を使うため const segmenter = new TinySegmenter() // 学習用文章の読み込み var txt_yoritomo = fs.readFileSync('yoritomo.txt', 'utf-8') var txt_takauji = fs.readFileSync('takauji.txt', 'utf-8') var txt_ieyasu = fs.readFileSync('ieyasu.txt', 'utf-8') // 分かち書き機能の設定 var classifier = bayes({ tokenizer: function (text) { return segmenter.segment(text); } }); async function demo() { // 学習 await classifier.learn(txt_yoritomo, '源頼朝'); await classifier.learn(txt_takauji, '足利尊氏'); await classifier.learn(txt_ieyasu, '徳川家康'); // 判定して結果を表示 async function categorize(text) { // 判定 var r = await classifier.categorize(text); console.log("判定=[" + r + "] -- " + text); } // 文章のカテゴリーを判定する(分類する) categorize('日本で最初に幕府を開いた人物で、妻は尼将軍としても有名な北条政子である。'); categorize('後鳥羽天皇によって征夷大将軍に任ぜられた。'); categorize('奥州を平定した。'); categorize('室町幕府を開いた。'); categorize('鎌倉幕府の滅亡後、鎮守府将軍・左兵衛督に任ぜられた。'); categorize('歌人としても知られる。'); categorize('幼少時代を人質として過ごした。'); categorize('室町幕府最後の将軍足利義昭が信長包囲網を企てたとき、協力要請を受けたがこれを無視した。'); } demo()bayesモジュールのコードを読む(わずか271行!)
bayesモジュールのソースコードを見てみると、わずか271行しかない比較的簡単な内容となっている。読んで理解するにはさすがに少しナイーブベイズ分類器について理解を深めておいたほうがよい。ナイーブベイズ分類器の良い解説記事はたくさんあるので探して読んでください。1
leanメソッドが学習部分です。
naive_bayes.js抜粋/** * textがどのcategoryに対応しているか学習することで、ナイーブベイズ分類器を訓練する * * @param {String} text * @param {Promise<String>} class */ Naivebayes.prototype.learn = async function (text, category) { var self = this //はじめてのカテゴリの場合は、カテゴリのデータ構造を初期化する self.initializeCategory(category) //カテゴリにマップされたドキュメント数をカウントする self.docCount[category]++ //学習したドキュメントの総数をカウント self.totalDocuments++ //テキストを単語に分割して配列にする var tokens = await self.tokenizer(text)learnメソッドの後半では、各単語の出現回数をカウントしています。カウントしているのは、カテゴリ中の単語出現回数(wordFreqencyCount)と、カテゴリーの総単語数(wordCount)です。
naive_bayes.js抜粋//テキスト内の各トークンの頻度カウントを取得します。 //get a frequency count for each token in the text var frequencyTable = self.frequencyTable(tokens) /* このカテゴリの語彙数と単語数を更新します。 Update our vocabulary and our word frequency count for this category */ Object .keys(frequencyTable) .forEach(function (token) { //この単語がない場合は、私たちの語彙に追加します。 //add this word to our vocabulary if not already existing if (!self.vocabulary[token]) { self.vocabulary[token] = true self.vocabularySize++ } var frequencyInText = frequencyTable[token] //このカテゴリのこの単語の頻度情報を更新する //update the frequency information for this word in this category if (!self.wordFrequencyCount[category][token]) self.wordFrequencyCount[category][token] = frequencyInText else self.wordFrequencyCount[category][token] += frequencyInText //このカテゴリにマップされたすべての単語のカウントを更新します。 //update the count of all words we have seen mapped to this category self.wordCount[category] += frequencyInText }) return self }categorizeメソッドは与えられたテキストのカテゴリーを判定します。すべてのカテゴリーごとに可能性を調べて、最も高い可能性のカテゴリーを選択します。可能性の算出は、テキスト中の各単語について、各単語の確率を加算するという方法です。非常にシンプルですね。
naive_bayes.js抜粋/** * テキストがどのカテゴリに属するかを決定する * * @param {String} text * @return {Promise<string>} category */ Naivebayes.prototype.categorize = async function (text) { var self = this , maxProbability = -Infinity , chosenCategory = null var tokens = await self.tokenizer(text) var frequencyTable = self.frequencyTable(tokens) //カテゴリを反復処理して、最も確率の高いカテゴリを求める Object .keys(self.categories) .forEach(function (category) { // このカテゴリの全体的な確率を計算することから始める // => 学習したすべての文書のうち、このカテゴリのものはどれくらいあったか var categoryProbability = self.docCount[category] / self.totalDocuments //アンダーフロー対策に対数(log)を取る var logProbability = Math.log(categoryProbability) //テキスト中の各単語 `w` について P( w | c ) を決定する Object .keys(frequencyTable) .forEach(function (token) { var frequencyInText = frequencyTable[token] var tokenProbability = self.tokenProbability(token, category) // console.log('token: %s category: `%s` tokenProbability: %d', token, category, tokenProbability) //この単語のP( w | c )の対数(log)を求める logProbability += frequencyInText * Math.log(tokenProbability) }) if (logProbability > maxProbability) { maxProbability = logProbability chosenCategory = category } }) return chosenCategory }以上
- 投稿日:2020-09-13T21:45:47+09:00
第6回:Node.jsの環境構築
第6回:Node.jsの環境構築
今回からNode.jsを利用しバックエンドを作成していきます。
Node.jsパッケージを作成する
下記のコマンドでプロジェクトのディレクトリを生成し、Node.jsのプロジェクト生成コマンドを実行します。
$ mkdir back $ cd back $ npm initパッケージの設定を問われますが、後で変更可能なので全て省略で構いません。
This utility will walk you through creating a package.json file. It only covers the most common items, and tries to guess sensible defaults. See `npm help init` for definitive documentation on these fields and exactly what they do. Use `npm install <pkg>` afterwards to install a package and save it as a dependency in the package.json file. Press ^C at any time to quit. package name: (back) version: (1.0.0) description: entry point: (index.js) test command: git repository: keywords: author: license: (ISC) About to write to /Users/radiance/git/web-learning-loadmap/back/package.json: { "name": "back", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC" } Is this OK? (yes) yesディレクトリ内にpackage.jsonだけ生成されます。
これがNode.jsパッケージの設定ファイルになります。Node.jsでJavaScriptを実行する
1) back/index.jsファイルを作成し、下記の内容を記載します。
console.log('Hello World !');2) 作成したJavaScriptを実行する
Node.jsでJavaScriptを実行するには下記のコマンドを実行します。$ node index.jsJavaScriptが実行され、標準出力に文字が出力されます。
Hello World !パッケージのスクリプト機能を利用して実行してみる
Node.jsパッケージにはコマンドラインをスクリプトとして登録し実行を簡単にする機能があります。
1) package.jsonを開き、scriptsを下記のように修正します。"scripts": { "start": "node index.js" },2) スクリプトを実行してみる
スクリプトとして登録した"start"のキーワードを呼び出してみます。$ npm run startnode index.jsが実行され、JavaScriptが動作します。
> node index.js Hello World !キーワード"start"は特別で、runを省略して実行することができます。
$ npm startindex.jsはもう利用しませんので削除してください。
TypeScriptを利用する
より綺麗で再利用可能なプログラムを書くために、TypeScriptを利用します。
TypeSciptはNode.jsのモジュールで、独自の記法のTypeSciptファイルをJavaScriptファイルにビルドする機能を提供します。
1) Node.jsのtypescriptモジュールをパッケージにインストールします。$ npm install typescriptpackage.jsonにモジュールが追加されました。
"dependencies": { "typescript": "^4.0.2" }node_modulesディレクトリ配下にインストールされたモジュールの本体がダウンロードされています。
2) TypeScriptの設定ファイルを作成する。
pacakge.jsonと同じ階層にtsconfig.jsonを作成します。
内容は下記のように記載します。{ "compilerOptions": { "module": "commonjs", "target": "es2017", "sourceMap": true, "outDir": "./build", "types": ["node"] }, "exclude": [ "node_modules" ] }3) 最初に起動するTypeScriptファイルを作成する
app/main.tsを作成し、下記の内容を記載します。console.log('Hello World !');TypeScriptはクラスを利用した構文で書きますが、一番最初に起動されるファイルはJavaSciprtと同じ記載方法です。
4) ビルドする
下記のコマンドを実行し、TypeScriptで記載したコードをビルドします。$ node_modules/typescript/bin/tsc下記のエラーが発生するので、@types/nodeモジュールをインストールします。
error TS2688: Cannot find type definition file for 'node'.$ npm install @types/node再度ビルドするとエラーは解消します。
ビルド結果はbuildディレクトリ配下に出力されます。
5) ビルドしてできたJavaScriptファイルを実行する
$ node build/main.js Hello World !6) ビルド、実行を行うスクリプトを追加する
package.jsonにビルド、実行を行うスクリプトを追加します。
"scripts": { "build": "tsc", "start": "node build/main.js" },package.jsonのscriptsではnode_modules/{パッケージ名}/bin/の下にある実行ファイルはパスを省略して実行することができます。
ビルド
$ npm run build > tsc実行
$ npm start > node build/main.js Hello World !ビルドと実行を一度のコマンドで動かすには、scriptを下記のように
&&で連結して記載します。"scripts": { "build": "tsc", "start": "tsc && node build/main.js" },最後に
今回はバックエンドの環境を構築しました。次回はニュースフィード一覧を取得するREST APIを作成します。
今回開発したソースコードはGitHubに入っています。

- 投稿日:2020-09-13T21:45:21+09:00
npm install --save について
はじめに
本投稿は
npm installコマンドの--saveオプションについてですが、すでにnpmでパッケージをインストールする際、ネットを検索すると
--saveというオプションをよく見かける。
ex)axios をインストールする場合$ npm install axios --save
-gでグローバルにインストールする際には見ないのだが、何者なのか調べてみた。npm install --save オプションについて
package.jsonのdependenciesに登録してくれるようだ。何がうれしいのか
git にコミットする際、パッケージをインストールしているフォルダ
node_modulesは.gitignoreによって除外されます。
違う開発環境を git からクローンして構築する場合、package.jsonを元に復元します。
よって、同じパッケージ環境を簡単に構築することができます。結論:
--saveオプションは必要か現在の環境では
--saveオプションは不要です。
2017-05-30にリリースされたnpm5.0.0以降ではデフォルトで--saveがつくようになりました。
よって、現在では古い環境を除いて基本的に不要です。参考
https://yosuke-furukawa.hatenablog.com/entry/2017/05/30/090602
https://blog.npmjs.org/post/161081169345/v500
https://nodejs.org/ja/download/releases/
- 投稿日:2020-09-13T19:34:01+09:00
実行できて見栄えも良いMarkdown手順書で快適な運用ライフを送ろう!
実行できる手順書(LC4RI)ってのご存じでしょうか?
ドキュメントとコマンドが混じって書いてあって、コマンド部分は実行できて、
その実行結果が載っています。
なので、手順書として読めて、かつ実行した内容とその時の出力がエビデンスとしてとれるもので
運用作業者にとってはExcel手順書の置き換えにぴったしなんですねそういう書き方が出来るツールとしてjupyter notebookが良く使われているんですけど、
これが運用してみるとドキュメントの並び替えとか、編集が意外と面倒だったりする。もっと普通のエディタで書けたら・・そう思ってました。したらヒラめいた!
VSCodeのmarkdown編集機能を実行できるようにすれば良いんだ!!
つくってみたわ
VScodeのマーケットプレイスからインストールするならこちら
こっちGit。
つかいかた
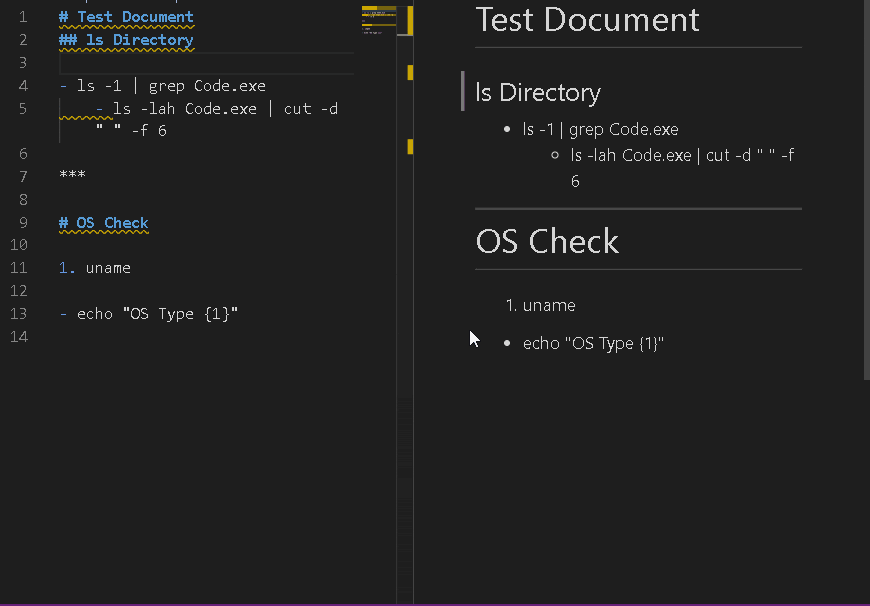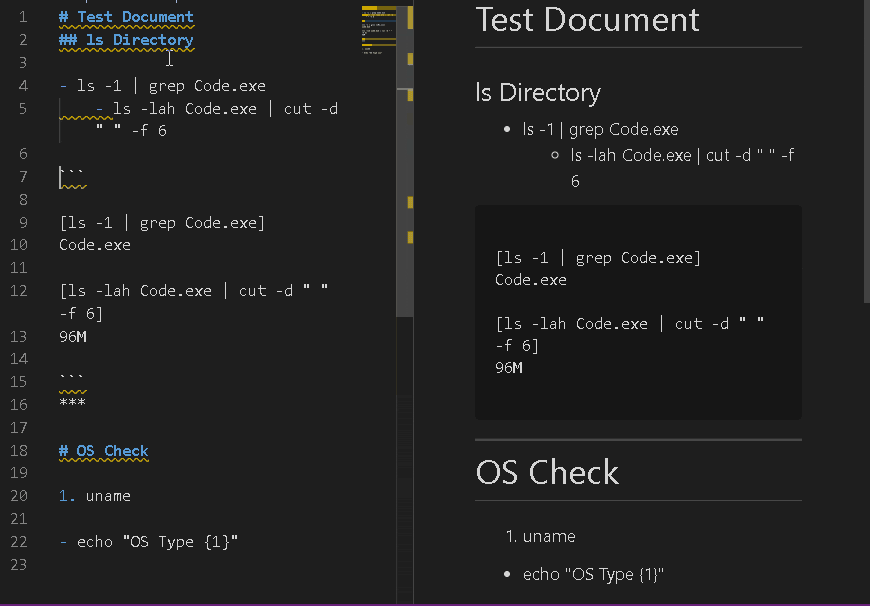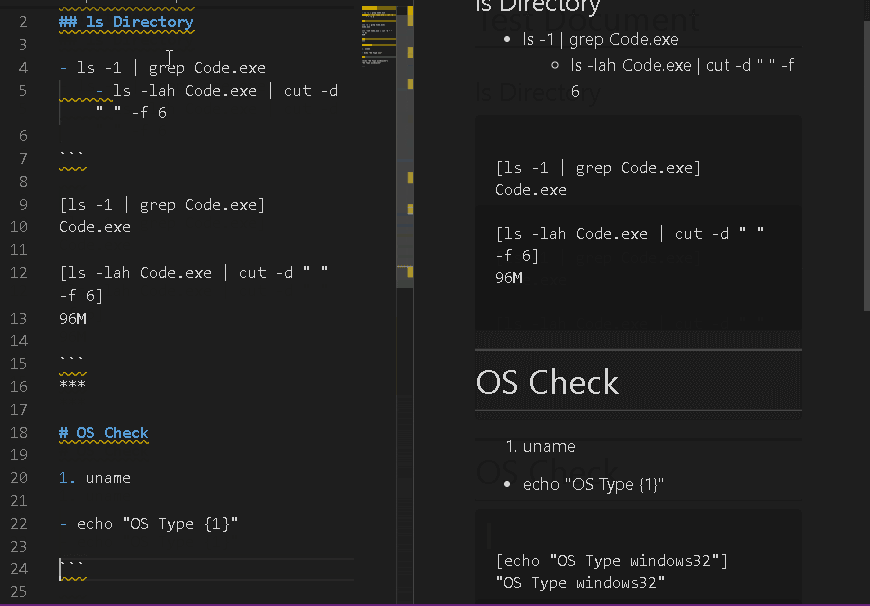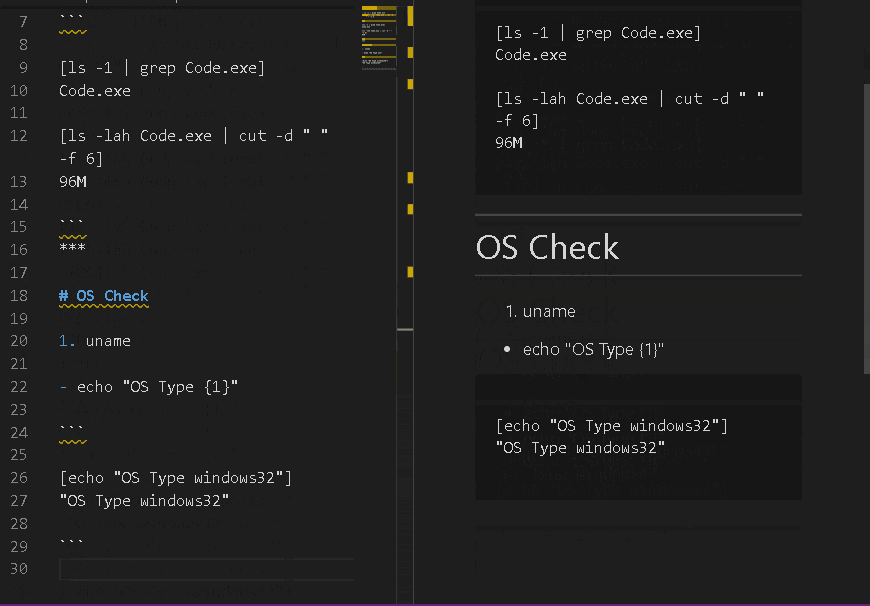
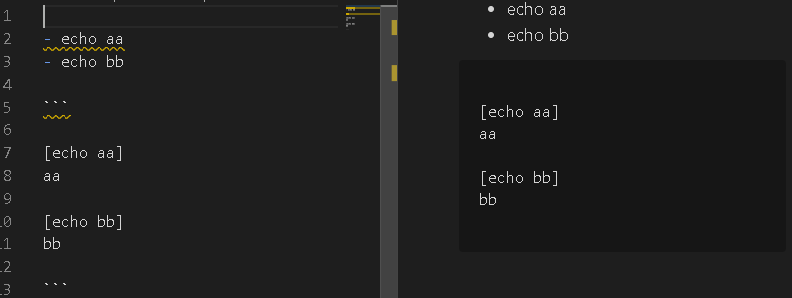
基本は普通のmarkdownと同じ書きっぷりです。リストと水平線と番号リストで変わります。
VSCodeのカーソル位置から下にあるコマンドを実行していきます。
なので、実行したい部分までカーソルを持ってってこの拡張機能を動かしてください。
(ショートカットキーに拡張機能の実行を割り当てると超便利ですよ!)リスト
実行したいコマンドを書きます。
タブでインデントをずらすとAND条件になります。
つまり、
- - ls existsfile.txt
- - rm existsfile.txt
でexistsfile.txtが無ければ削除しない、みたいな書き方ができます。
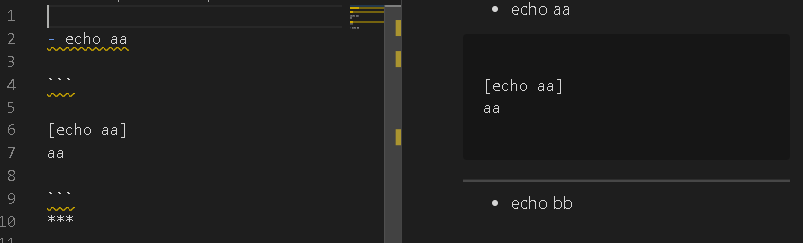
水平線
コマンドの実行範囲を区切ります。区切らないとリスト表記のを上から順に実行しちゃいます。
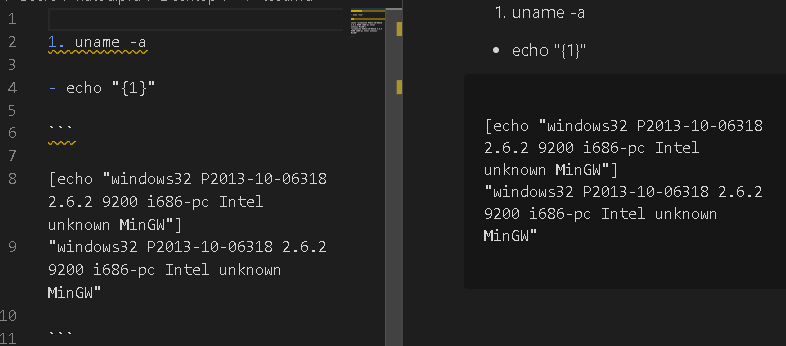
番号リスト
変数をもてます。1.~9.の範囲で実行結果の出力を変数として格納します。
重いコマンドとか何度も実行したくないものは結果を格納して使いまわせます。あとがき
VSCodeのエコシステムが使えるので文章校正とか他の拡張機能の恩恵も受けれますね!
これで運用作業ドキュメントも見栄え良く、使いやすくなるものと思います。

- 投稿日:2020-09-13T19:17:10+09:00
ウソ穴 Ver 6 の作り方
はじめに
個人開発
ウソ穴の作り方を紹介します。ウソ穴とは
ウソ穴は、ライブ映像 or 動画とARを組み合わせて、壁に穴が空いた錯覚を作り出します。Webサイトなので、ユーザーはアプリのインストール無くウソ穴を使用できます。ウソ穴 Ver 6
今回は、Android端末でも動作実績のある Ver 6 を紹介します。
デモ映像
ウソ穴 Ver 6 Type B で顔に穴を開けてみました。
見た目の涼を演出しようと、顔に穴をあけたのですが、『涼しい』って感じにならなかった。シースルーより貫通の方が涼しく見えると思ったのですが、、#ウソ穴 #AR #protoout #なんか違う pic.twitter.com/jCjkVYfN1a
— j4amountain (@zsipparu) August 29, 2020ウソ穴 Ver 6 Type A で壁に穴を開け、外のベランダの様子を見ました。
今日も危険な暑さなので、ウソ穴で窓を開けずに外が見えるようにしました。 #ウソ穴 #AR #protoout pic.twitter.com/5NZXFrkk5a
— j4amountain (@zsipparu) August 30, 2020ウソ穴 Ver 6 Type A,B,C タイプ別の特徴
ウソ穴 Ver 6 は、TypeA,B,C の3種類あります。
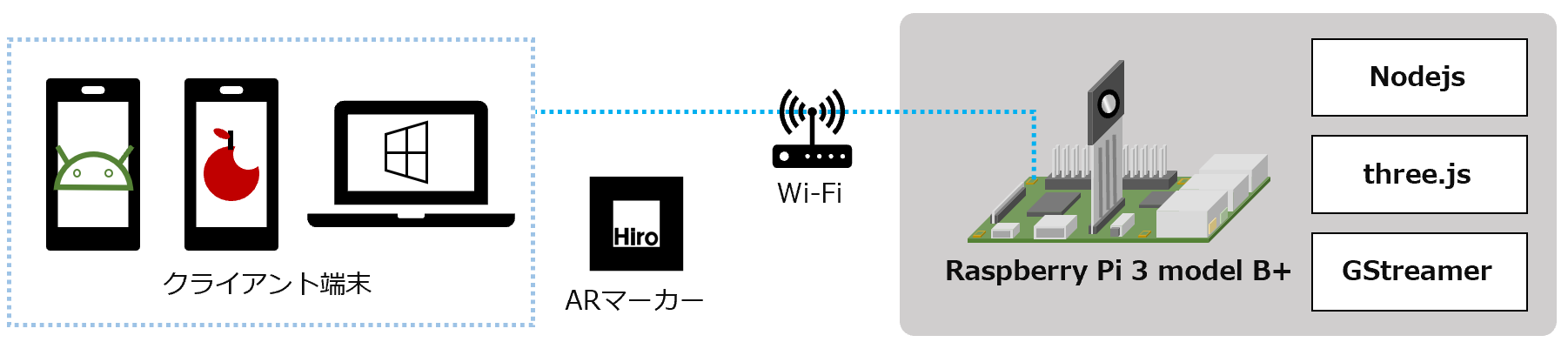
- ウソ穴 Type A / GStreamer
- ライブ配信と組み合わせたウソ穴
- ライブ配信はGStreamerを使用
- 映像遅延 : ライブ配信の遅延に依存
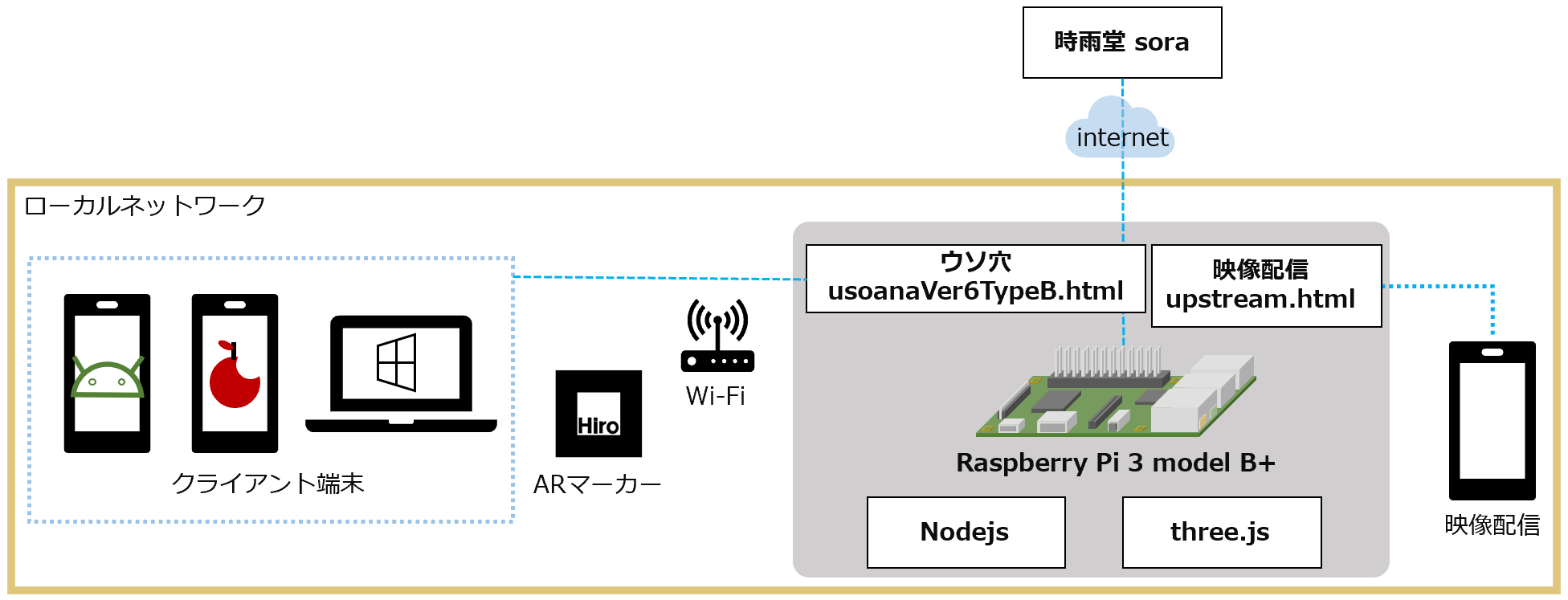
- ウソ穴 Type B / 時雨堂 sora
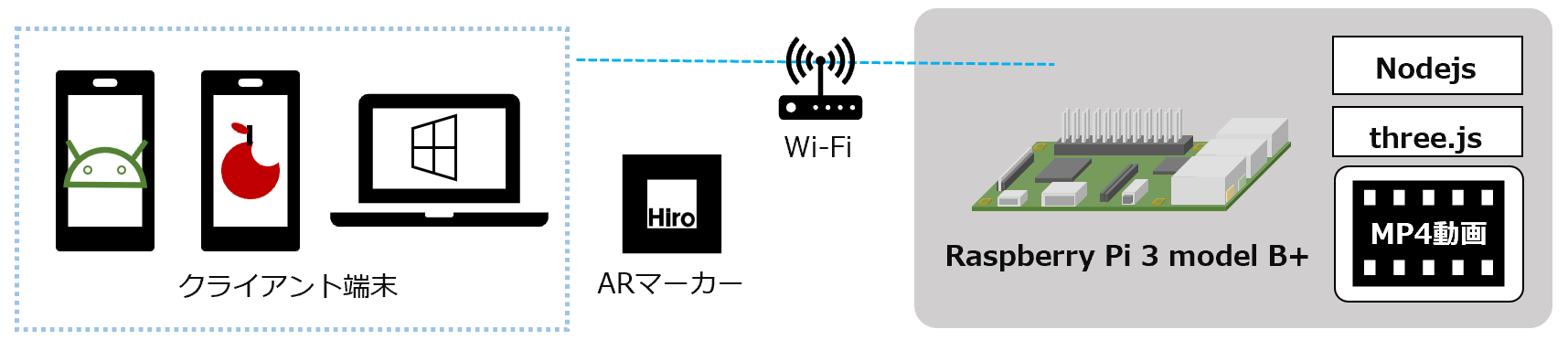
- ウソ穴 Type C / MP4動画
- 動画と組み合わせたウソ穴
- 映像遅延 : 動画ファイル読み込みの時間が必要
構成図
それぞれの構成図を紹介します。
ウソ穴 Ver 6 Type A / GStreamer
ウソ穴 Ver 6 Type B / 時雨堂 sora
ウソ穴 Ver 6 Type C / MP4動画
ソース
ソースは、githubに置きました。
作り方
作り方は、ウソ穴 Ver 5 と同じです。それぞれのリンクは以下です。
ウソ穴 Ver 6 Type A / GStreamer
作り方 -> ウソ穴 Ver 5 Type A / GStreamer
ウソ穴 Ver 6 Type B / 時雨堂 sora
作り方 -> ウソ穴 Ver 5 Type B / 時雨堂 Sora
ウソ穴 Ver 6 Type C / MP4動画
作り方 -> ウソ穴 Ver 5 Type C / MP4動画
ウソ穴の開発はつづく

- 投稿日:2020-09-13T17:43:05+09:00
[メモ] TypeScript で hello-world!


はじめに
TypeScriptを仕事で使うことになったので最近勉強を始めました。
そのときのメモです。TypeScriptをインストールする
公式サイトにインストールの手順が書いてあります。
自分の環境では以下のコマンドを使いました。
--save-devでTypeScriptコンパイラをローカル(プロジェクトフォルダ内)にインストールしています。npm init -y npm install typescript --save-devTypeScriptプロジェクトの設定 (tsconfig.json)
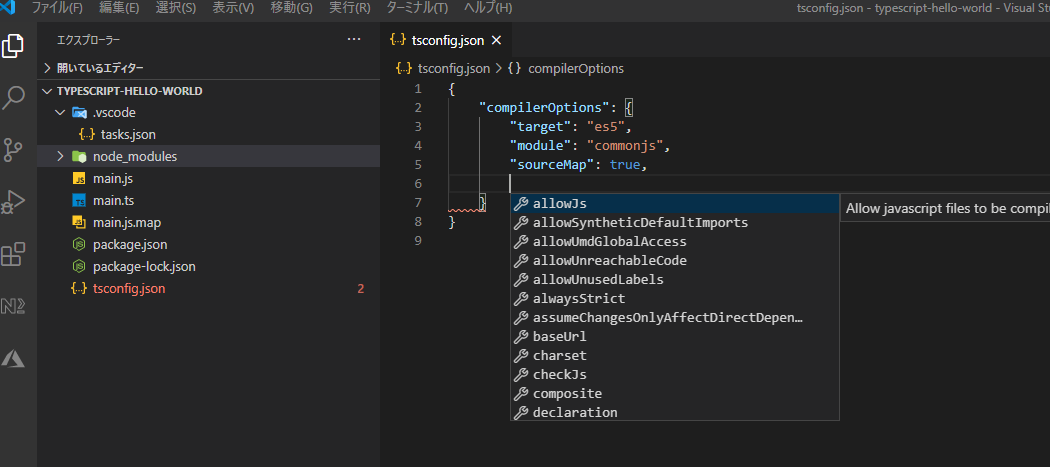
npx tsc --initを実行してtsconfig.jsonを作ります。
tsconfig.jsonにはコンパイラオプションなどの設定を書きます。
詳しくはこちらを参照。tsconfig.json{ "compilerOptions": { "target": "es5", "module": "commonjs", "sourceMap": true } }インテリセンスが効いているので
Ctr+Spaceで入力候補を表示してその中から選ぶと良さそうです。
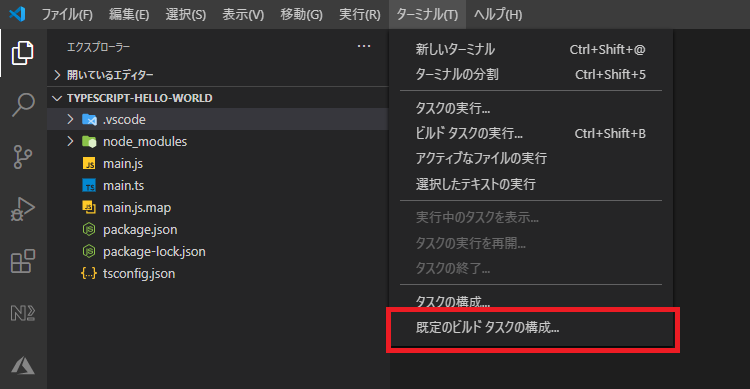
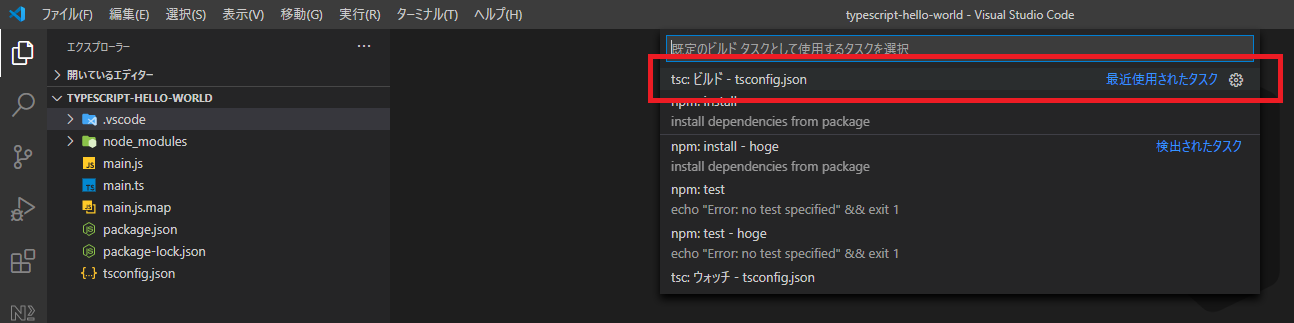
ビルドタスクを構成する
ターミナル(T) -> 既定のビルドタスクの構成...からtsc: ビルド tsconfig.jsonを選択します。
ビルドタスクの設定(tasks.json)は.vscodeフォルダ中にあります。
.vscode>tasks.json{ "version": "2.0.0", "tasks": [ { "type": "typescript", "tsconfig": "tsconfig.json", "problemMatcher": [ "$tsc" ], "group": { "kind": "build", "isDefault": true }, "label": "tsc: ビルド - tsconfig.json" } ] }TypeScriptのコード
見ての通りです。
TypeScriptのことはまだよく分かっていないのでこれだけにしてきます。main.tsclass Message { constructor(public message: string) {} greet() { return this.message; } } console.log(new Message("hello-world!").greet());ビルド
Ctr+Shift+Bでビルドタスクを実行します。
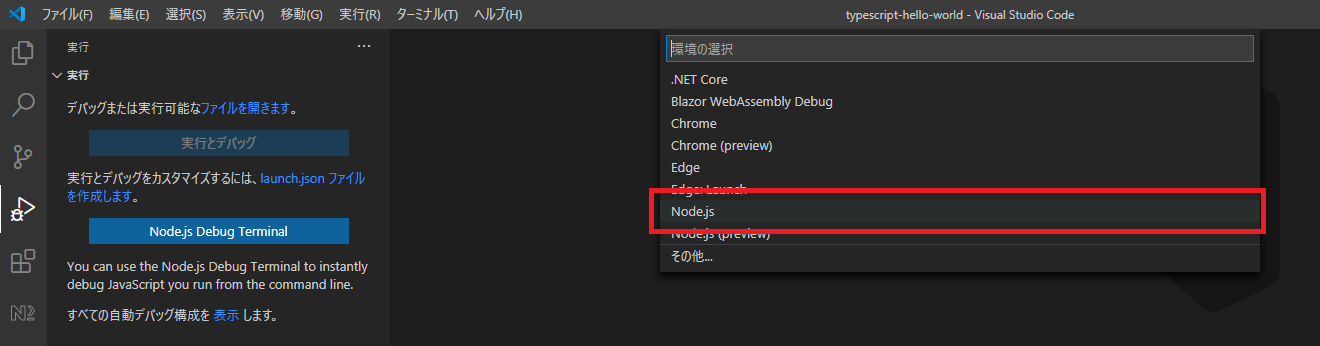
プロジェクトフォルダ内のTypeScriptのコード(.ts)がJavaScriptのコードに変換され、デバッグ用のmapファイルが出力されます。デバッグ
デバッグビュー > launch.jsonファイルを作成します。(リンク)からNode.jsを選ぶだけです。
他の言語の場合と大体同じ手順です。
デバッグ構成の詳細はこちらを参照。
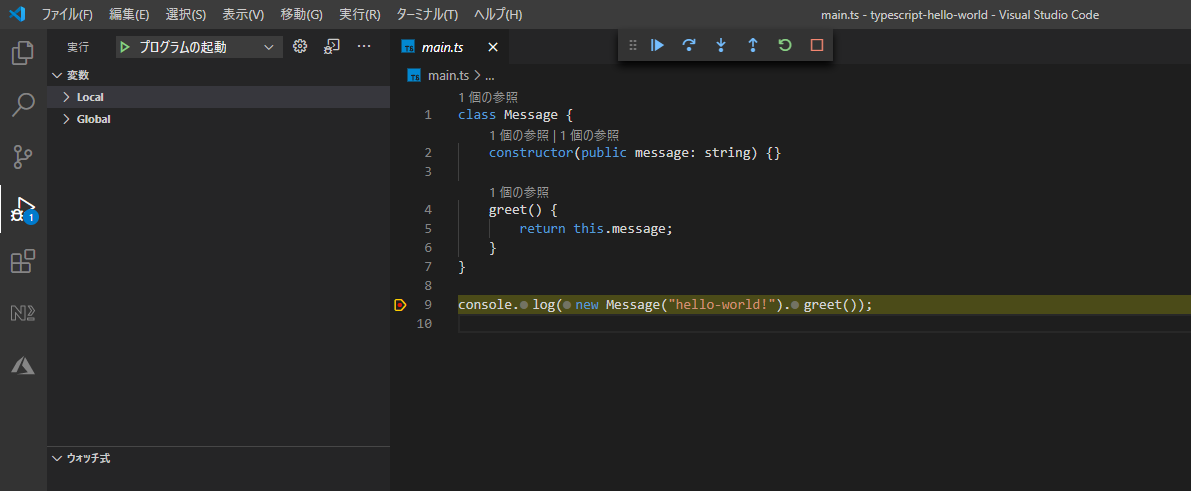
.vscode>launch.json{ // IntelliSense を使用して利用可能な属性を学べます。 // 既存の属性の説明をホバーして表示します。 // 詳細情報は次を確認してください: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "type": "node", "request": "launch", "name": "プログラムの起動", "skipFiles": [ "<node_internals>/**" ], "program": "${workspaceFolder}\\main.js" } ] }hello-worldを出力するファイルの名前を
main.tsにしたので"program"のファイル名をデフォルトの"index.js"から"main.js"に変更しました。これでプログラムの起動、デバッグができます。

- 投稿日:2020-09-13T17:42:17+09:00
気象庁アメダス観測データのAPI「JJWD」をきちんと作り直した
長らく停止しておりましたが2020年9月、再始動しました。
https://jjwd.info/
JJWD とは / 作り直した動機
JSONized Japanse Weather Dataの略で、気象庁が公開しているCSV形式のアメダス観測値データを使いやすいJSON形式に変換して提供するAPIサービスです。
当初は2017年のアドベントカレンダーに間に合わせるために構築したAPIでした。
停止したにもかかわらず、記事にコンスタントにLGTMがついておりました。
需要はあるものを放置したくはないですし、データを必要としている人も多いと思ったのできちんと使える形で整備した次第です。
使い方
使用に際して
気象業務法に抵触しない範囲で使用してください。
観測された値を基に何らかの処理を行って独自の予測を行う場合、資格ならびに気象庁の許可が必要です(観測されたままの値や、発表された気象予報を第三者に伝達することは問題ありません)。また、気象庁以外が「警報」「注意報」などを発表することは許可されていません。
観測所検索
GET
https://jjwd.info/api/v2/stations/search?URL に以下のパラメータを付与して検索できます。
stn_name_ja: 観測所名 日本語(部分一致)stn_name_en: 観測所名 英語(部分一致)pref_ja: 都府県振興局 日本語(部分一致)pref_en: 都府県振興局 英語(部分一致)address: 住所 日本語(部分一致)たとえば
https://jjwd.info/api/v2/stations/search?pref_ja=東京&address=世田谷
では、都府県振興局に東京を含み、なおかつ住所に世田谷を含む観測所が取得できます。北海道は振興局単位なのでご注意ください。
/api/v2/stations/search?pref_ja=東京&address=世田谷{ "about": "JJWD - JSONized Japanese Weather Data: https://jjwd.info/", "datasource": "https://www.data.jma.go.jp/obd/stats/data/mdrr/", "author": "Original data are from Japan Meteorological Agency. API data are modified by jjwd.info .", "version": "v2.0", "stations": [ { "stn_num": 44126, "pref_ja": "東京", "pref_en": "Tokyo", "stn_type": "RobotRain", "stn_name_ja": "世田谷", "stn_name_ja_kana": "セタガヤ", "stn_name_en": "SETAGAYA", "stn_multipoint": false, "target_main_ja": null, "target_sub_ja": null, "target_main_en": null, "target_sub_en": null, "stn_temp": false, "stn_daylight": true, "address": "世田谷区岡本", "address_sub": null, "lat": 35.6267, "lng": 139.62, "lat_sub": null, "lng_sub": null, "elevation": 35, "alt_anemometer": null, "alt_thermometer": null, "elevation_sub": null, "alt_anemometer_sub": null, "alt_thermometer_sub": null, "start_date_rain": "1974-11-01", "start_date_multi": null, "snow_stn_num": null, "updatedAt": "2020-09-11T19:00:32.933Z", "preall": { "year": 2020, "month": 9, "day": 12, "hour": 19, "minute": 50, "precip_1h_new_record_month": null, "precip_1h_new_record_in_decade": null, "precip_3h_new_record_month": null, "precip_3h_new_record_in_decade": null, "precip_6h_new_record_month": null, "precip_6h_new_record_in_decade": null, "precip_12h_new_record_month": null, "precip_12h_new_record_in_decade": null, "precip_24h_new_record_month": null, "precip_24h_new_record_in_decade": null, "precip_48h_new_record_month": null, "precip_48h_new_record_in_decade": null, "precip_72h_new_record_month": null, "precip_72h_new_record_in_decade": null, "precip_daily_new_record_month": null, "precip_daily_new_record_in_decade": null, "precip_1h": 0.5, "precip_1h_q": 8, "precip_1h_daily_max": 13, "precip_1h_daily_max_q": 5, "precip_3h": 0.5, "precip_3h_q": 8, "precip_3h_daily_max": 24, "precip_3h_daily_max_q": 4, "precip_6h": 1, "precip_6h_q": 8, "precip_6h_daily_max": 24, "precip_6h_daily_max_q": 4, "precip_12h": 5, "precip_12h_q": 8, "precip_12h_daily_max": 26.5, "precip_12h_daily_max_q": 4, "precip_24h": 29, "precip_24h_q": 8, "precip_24h_daily_max": 29, "precip_24h_daily_max_q": 4, "precip_48h": 29, "precip_48h_q": 8, "precip_48h_daily_max": 29, "precip_48h_daily_max_q": 4, "precip_72h": 29.5, "precip_72h_q": 8, "precip_72h_daily_max": 29.5, "precip_72h_daily_max_q": 4, "precip_daily": 28.5, "precip_daily_q": 4, "updatedAt": "2020-09-12T11:13:41.878Z" }, "max_wind": null, "max_gust": null, "max_temp": null, "min_temp": null } ] }観測所番号を指定して取得
GET
https://jjwd.info/api/v2/station/{stn_num}観測所番号がわかっている場合はこちらを使用することができます。
/api/v2/station/46046{ "about": "JJWD - JSONized Japanese Weather Data: https://jjwd.info/", "datasource": "https://www.data.jma.go.jp/obd/stats/data/mdrr/", "author": "Original data are from Japan Meteorological Agency. API data are modified by jjwd.info .", "version": "v2.0", "station": { "stn_num": 46046, "pref_ja": "神奈川", "pref_en": "Kanagawa", "stn_type": "RobotRain", "stn_name_ja": "相模原中央", "stn_name_ja_kana": "サガミハラチュウオウ", "stn_name_en": "SAGAMIHARACHUO", "stn_multipoint": false, "target_main_ja": null, "target_sub_ja": null, "target_main_en": null, "target_sub_en": null, "stn_temp": false, "stn_daylight": true, "address": "相模原市中央区中央", "address_sub": null, "lat": 35.5717, "lng": 139.37, "lat_sub": null, "lng_sub": null, "elevation": 149, "alt_anemometer": null, "alt_thermometer": null, "elevation_sub": null, "alt_anemometer_sub": null, "alt_thermometer_sub": null, "start_date_rain": "1975-05-16", "start_date_multi": "1975-05-16", "snow_stn_num": null, "createdAt": "2020-08-29T15:44:50.463Z", "updatedAt": "2020-09-11T19:00:32.937Z", "preall": { "year": 2020, "month": 9, "day": 12, "hour": 19, "minute": 50, "precip_1h_new_record_month": null, "precip_1h_new_record_in_decade": null, "precip_3h_new_record_month": null, "precip_3h_new_record_in_decade": null, "precip_6h_new_record_month": null, "precip_6h_new_record_in_decade": null, "precip_12h_new_record_month": null, "precip_12h_new_record_in_decade": null, "precip_24h_new_record_month": null, "precip_24h_new_record_in_decade": null, "precip_48h_new_record_month": null, "precip_48h_new_record_in_decade": null, "precip_72h_new_record_month": null, "precip_72h_new_record_in_decade": null, "precip_daily_new_record_month": null, "precip_daily_new_record_in_decade": null, "precip_1h": 0, "precip_1h_q": 8, "precip_1h_daily_max": 10, "precip_1h_daily_max_q": 5, "precip_3h": 0.5, "precip_3h_q": 8, "precip_3h_daily_max": 10.5, "precip_3h_daily_max_q": 4, "precip_6h": 2, "precip_6h_q": 8, "precip_6h_daily_max": 13.5, "precip_6h_daily_max_q": 4, "precip_12h": 5, "precip_12h_q": 8, "precip_12h_daily_max": 16, "precip_12h_daily_max_q": 4, "precip_24h": 18.5, "precip_24h_q": 8, "precip_24h_daily_max": 18.5, "precip_24h_daily_max_q": 4, "precip_48h": 18.5, "precip_48h_q": 8, "precip_48h_daily_max": 18.5, "precip_48h_daily_max_q": 4, "precip_72h": 19, "precip_72h_q": 8, "precip_72h_daily_max": 19, "precip_72h_daily_max_q": 4, "precip_daily": 17.5, "precip_daily_q": 4, "updatedAt": "2020-09-12T11:13:41.884Z" }, "max_wind": null, "max_gust": null, "max_temp": null, "min_temp": null } }各パラメータの意味など、詳細はドキュメントをご参照ください
https://jjwd.info/doc-ja.htmlデータソース
基地局データ
気象庁の地域気象観測所一覧 [ZIP圧縮形式]から取得しています。
ZIP形式の中にCSVが格納されているのですが、開発中に提供されているファイルの名前が変わってしまい、取得できなくなるエラーが発生しました(気象庁さん、配布するファイルの名称は固定してほしい……)。観測値データ
「最新の気象データ」CSVダウンロードから取得しています。データのつらさは相変わらずです。その辺は前回と同じようになんとかしました。
実装
Node.js + Express.js + Sequelize の無難な構成です。
ざっくりとしたディレクトリ構成/ | - /schedule | - | - fetch_amedas_stations.js | - | - fetch_csv_files.js | - /models | - /public | - | - /css | - | - /js | - app.js | - package.jsonデータベース
Heroku Postgresを使用しています。件数的にはHobby devに収まるので無料の枠内で運用しています。
アクセス数が増えたら Connection Limit などを緩和するために Standard 0 などにアップグレードする必要がありそうです(Hobby Basicは行数の制限緩和のみなので)。
データの更新
Heroku Scheduler でNodeのスクリプトを走らせてUpsertしています。
Heroku Scheduler を使うと、Herokuにデプロイした repository 上にあるスクリプトを定時に走らせる事が可能です。DBのモデルやnpmパッケージも本体と共用できるので便利です。観測値データの更新は 10 分おきに取得しています。
基地局データの更新は 1 日おきに取得しています。ただし、生の CSV データが配布されている観測値と異なり、基地局データは元データが zip で圧縮されているので/tmpにデータをダウンロードした上で展開する処理を挟んでいます(Heroku では/tmpや/log以外にファイルを書き込めないので要注意です)。静的ページ(ドキュメント)
シンプルに
app.use(express.static(__dirname + '/public'));で配信しています。デザインには Tailwind.css を使用しています。
便利なCSSフレームワークですが、何もしないとファイルサイズが巨大なので、デプロイ前にpurgeやminifyしましょう。また、軽くCSSアニメーションを入れたかったのでanimistaを使用しています。
デプロイ
Heroku を使用しています。
独自ドメインを使用したかったので、いまのところ月額7ドルの Hobby Dyno を使用しています。独自ドメイン
公式ドキュメントを参考に、バリュードメインで以下のように CNAME で設定しています。
ドメイン設定cname @ ****************.herokudns.com.
- 投稿日:2020-09-13T15:54:52+09:00
Jestとpuppeteerで複数ページへの同じテストをすっきりまとめたサンプル
Jestとpuppeteerでe2eテストを書いています。大量のページに対してページのtitleをチェックしています。配列に対象ページのURLとtitleをまとめると、すっきり書けたのでメモしておきます。
配列
検査したい要素、titleとurlをまとめて指定しています。
const pages = [ { 'title': 'はじめに - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/introduction/', }, { 'title': 'ダウンロード - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/download/', }, { 'title': 'ファイル構成 - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/contents/', }, ];テスト部分
testを配列のループで囲んでいます。ページを取得してtitleを照合しています。
for (const i in pages) { const title = pages[i].title; const url = pages[i].url; it('should be titled "' + title + '"', async () => { await page.goto(url); await expect(page.title()).resolves.toMatch(title); }); }
- 投稿日:2020-09-13T15:54:52+09:00
Jestとpuppetterで繰り返しテストをarrayにまとめたサンプル
Jestとpuppeteerでe2eテストを書いています。大量のページに対してページのtitleをチェックしています。配列に対象ページのURLとtitleをまとめると、すっきり書けたのでメモしておきます。
配列
検査したい要素、titleとurlをまとめて指定しています。
const pages = [ { 'title': 'はじめに - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/introduction/', }, { 'title': 'ダウンロード - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/download/', }, { 'title': 'ファイル構成 - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/contents/', }, ];テスト
testを配列のループで囲んでいます。ページを取得してtitleを照合しています。
for (const i in pages) { const title = pages[i].title; const url = pages[i].url; it('should be titled "' + title + '"', async () => { await page.goto(url); await expect(page.title()).resolves.toMatch(title); }); }コード全体
loop.test.jsconst pages = [ { 'title': 'はじめに - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/introduction/', }, { 'title': 'ダウンロード - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/download/', }, { 'title': 'ファイル構成 - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/contents/', }, ]; describe('LOOP', () => { beforeAll(async () => { await page.setDefaultNavigationTimeout(0); }); for (const i in pages) { const title = pages[i].title; const url = pages[i].url; it('should be titled "' + title + '"', async () => { await page.goto(url); await expect(page.title()).resolves.toMatch(title); }); } });実行結果
% jest loop.test.js PASS ./loop.test.js LOOP ✓ should be titled "はじめに - Bootstrap 4.5 - 日本語リファレンス" (696 ms) ✓ should be titled "ダウンロード - Bootstrap 4.5 - 日本語リファレンス" (331 ms) ✓ should be titled "ファイル構成 - Bootstrap 4.5 - 日本語リファレンス" (515 ms) Test Suites: 1 passed, 1 total Tests: 3 passed, 3 total Snapshots: 0 total Time: 2.251 s, estimated 9 s Ran all test suites matching /loop.test.js/i.
- 投稿日:2020-09-13T15:54:52+09:00
Jestとpuppetterで同じテストをarrayにまとめたサンプル
Jestとpuppeteerでe2eテストを書いています。大量のページに対してページのtitleをチェックしています。配列に対象ページのURLとtitleをまとめると、すっきり書けたのでメモしておきます。
配列
検査したい要素、titleとurlをまとめて指定しています。
const pages = [ { 'title': 'はじめに - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/introduction/', }, { 'title': 'ダウンロード - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/download/', }, { 'title': 'ファイル構成 - Bootstrap 4.5 - 日本語リファレンス', 'url': 'https://getbootstrap.jp/docs/4.5/getting-started/contents/', }, ];テスト部分
testを配列のループで囲んでいます。ページを取得してtitleを照合しています。
for (const i in pages) { const title = pages[i].title; const url = pages[i].url; it('should be titled "' + title + '"', async () => { await page.goto(url); await expect(page.title()).resolves.toMatch(title); }); }
- 投稿日:2020-09-13T11:55:08+09:00
かんたん Appleのヘルスデータをエクスポート、解析、csvに変換する方法
はじめに
みなさんは iOS アプリ Healthをつかってますか?
そんなみなさんは、体重や睡眠時間、歩数などの健康データはApple Healthのアプリ上に記録されていると思います。
このアプリは、健康状態の情報を記録し、アプリ上ではみえますが、実際には自分でデータ分析を行うことはできません。
データ分析とデータの可視化にはいろんな形式があると思いますが。今回はExcelやGoogle Sheetsのようなスプレッドシートアプリケーションを使って、解析するためにcsv 出力したいです。
今回、そんなみなさんにぴったりのCLIを作ったのでご紹介させていただきます.Apple health dataの抽出方法
まずはこの動画を開いてみてください
- iPhoneでHealthを開きます。
- 上隅にあるプロフィールのアイコンをタップすしてください。
- ヘルスのプロフィールの一番下までスクロールして、"Export All Health Data"をタップします。
- 更に"Export"をタップすると、データをエクスポートすることを確認してエクスポート処理を開始します(完了するまでに少し時間がかかる場合があります)
- 上記で抽出したファイルをローカルやGoogle Driveに保存してください
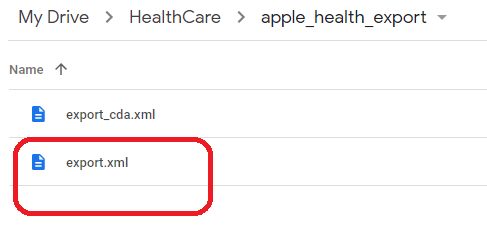
抽出したファイル
抽出したなら、その中の export.xml を使いますNodejs環境設定
本当の初心者のためのNode.js超入門 ~環境構築編~
などを参考にローカルにNodejsの環境を構築してくださいコマンドインストール方法
下記のコマンドを叩いてahcdというコマンドをインストールしてください
$ npm i -g ahcd使い方
$ ahcd ================================================================================ Apple Health Care Data convert xml to csv Author : Fumikazu Fujiwara Homepage : https://github.com/freddiefujiwara/ahcd#readme LICENSE : MIT Report bugs: https://github.com/freddiefujiwara/ahcd/issues ================================================================================ Usage: ahcd [-h] <file> [-t <type>] [-d <dir>]
- 引数の<file>は必ずexport.xmlを指定してください
- -t は特定のcsvだけ出力します (例えば -t BodyMass など)
- -d は出力先のディレクトリを指定します (例えば -d /path/to など)
実際に使ってみると
$ ahcd -d . export.xml Read export.xml Analyze export.xml Wrote ./Height.csv (1 records) Wrote ./HeartRate.csv (87 records) Wrote ./BodyMassIndex.csv (50 records) Wrote ./BloodPressureDiastolic.csv (165 records) Wrote ./BodyMass.csv (51 records) Wrote ./BodyFatPercentage.csv (50 records) Wrote ./FlightsClimbed.csv (1045 records) Wrote ./BloodPressureSystolic.csv (165 records) Wrote ./SleepAnalysis.csv (1193 records) Wrote ./StepCount.csv (12032 records) Wrote ./DistanceWalkingRunning.csv (13631 records)最後に
さぁ ちょっと長かったですが、
これで、Excelなどのシートで解析できますね
またahcdはpull request大歓迎です
よろしくおねがいします