- 投稿日:2020-07-26T23:44:19+09:00
やらかしJS先生がみたMapをObject的に扱ってハマった話⭕❌
Overview
過去にバグになってしまったものを忘れないよう書き留めておくシリーズです。
今回の題材はMapです。以下は私が最初にさらりと書いたコードです。
これを基に❌な部分を修正していきます。const map = new Map(); if (!map["1"]) { map["1"] = "⭕"; } for(const {key, value} of map) { console.log(`key:${key}, value:${value}`); }Target reader
- この結果がわからない方
Prerequisite
- JavaScriptを一通り理解している
- 今回はChromeで実行したが、Node.js等、環境によって出力結果が異なることがあることに注意。
Body
少しだけ言い訳をしたい

いつもはJSONでファイル出力することが多いため、どうしてもそのまま出力できるObjectを利用することが多い。
そんな折、ファイル出力ないものがあったので、久しぶりにMapを使ったらずいぶん忘れていただけ。
今はもう大丈夫なんで答え合わせ
正解はこうなる。
terminal何も出ないが正解
そもそも、MapはMapにあるメソッドを使って値を扱い必要がある。
https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Global_Objects/Map
Map オブジェクトに対してオブジェクトプロパティを設定すると正しく動作しますが、混乱を催すことが考えられます。
要するに、Object的な扱いもできる故に、Mapにデータ入れたと思ったらハマりますよってことで。
詳しくは上記URL参照のこと。ということで、Object的な扱いを一つ一つ是正していく。
const map = new Map(); if (!map.has("1")) { // ❌ !map["1"] map.set("1", "⭕"); // ❌ map["1"] = "⭕"; } for(const {key, value} of map.entries()) { console.log(`key:${key}, value:${value}`); }これで正しくMapのデータ構造にデータを入れれたはず…答えはこうだ。
terminal何も出ない
よく見ると、
of mapではなくof map.entries()でkey-valueのペアを受け取らないといけなかった!const map = new Map(); if (!map.has("1")) { // ❌ !map["1"] map.set("1", "⭕"); // ❌ map["1"] = "⭕"; } for(const {key, value} of map.entries()) { // ❌ map console.log(`key:${key}, value:${value}`); }これで正しくMapのデータ構造にデータを入れれたはず…答えはこうだ。
terminal> "key:undefined, value:undefined"値がない
そういえば、
map.entries()ってkey-valueのペアだからオブジェクトから取り出しではない!const map = new Map(); if (!map.has("1")) { // ❌ !map["1"] map.set("1", "⭕"); // ❌ map["1"] = "⭕"; } for(const [key, value] of map.entries()) { // ❌ map, ❌ {key, value} console.log(`key:${key}, value:${value}`); }これで正しくMapのデータ構造にデータを入れれたはず…答えはこうだ。
terminal> "key:1, value:⭕"動いた
ちなみに、以下のように、値のセットをObjectとして処理し、存在チェックをMapで処理すると…
const map = new Map(); map["1"] = "❌"; if (!map.has("1")) { map.set("1", "⭕"); } for(const [key, value] of map.entries()) { console.log(`key:${key}, value:${value}`); }terminal> "key:1, value:⭕"本来なら❌が出力され、⭕での上書きを防止するはずがそれを防げないという厄介なバグに発展するので要注意。
Conclusion
MapはObjectと似ているように見えるが、使い方が異なるのでうろ覚えでの使用には注意!
特に存在チェックとセットメソッドを混在して利用する等すると泥沼。
- 投稿日:2020-07-26T17:22:24+09:00
クライアントアプリから Google Cloud Speech-to-Text を使ってみた(マイク編)
前回の記事のつづきです。前提の環境やソースコードなどはすべて前回の記事とおなじなので、そちらを先にご参照ください。
今回のコンテンツ
入門ガイドにある「ストリーミング入力の音声文字変換」 をやってみましょう。
TL;DR
- MacでもWindowsでもマイクによる音声認識が可能でした
- ただ SoX - Sound eXchange というライブラリをOSごとにインストールする方式なので、WEB開発むけという意味だとこの方式は採用しないかな、、。。
ライブラリのインストールなど環境設定
Node.jsのクライアントアプリケーションからOSのマイクデバイスにアクセスするには、SoX - Sound eXchange のインストールなどが必要です。基本はすべてチュートリアルに説明があるのでインストールできればなんでもOKなのですが、一応作業メモを。
Mac
Macの環境構築はシンプルです
brew install soxするだけ。
Windows
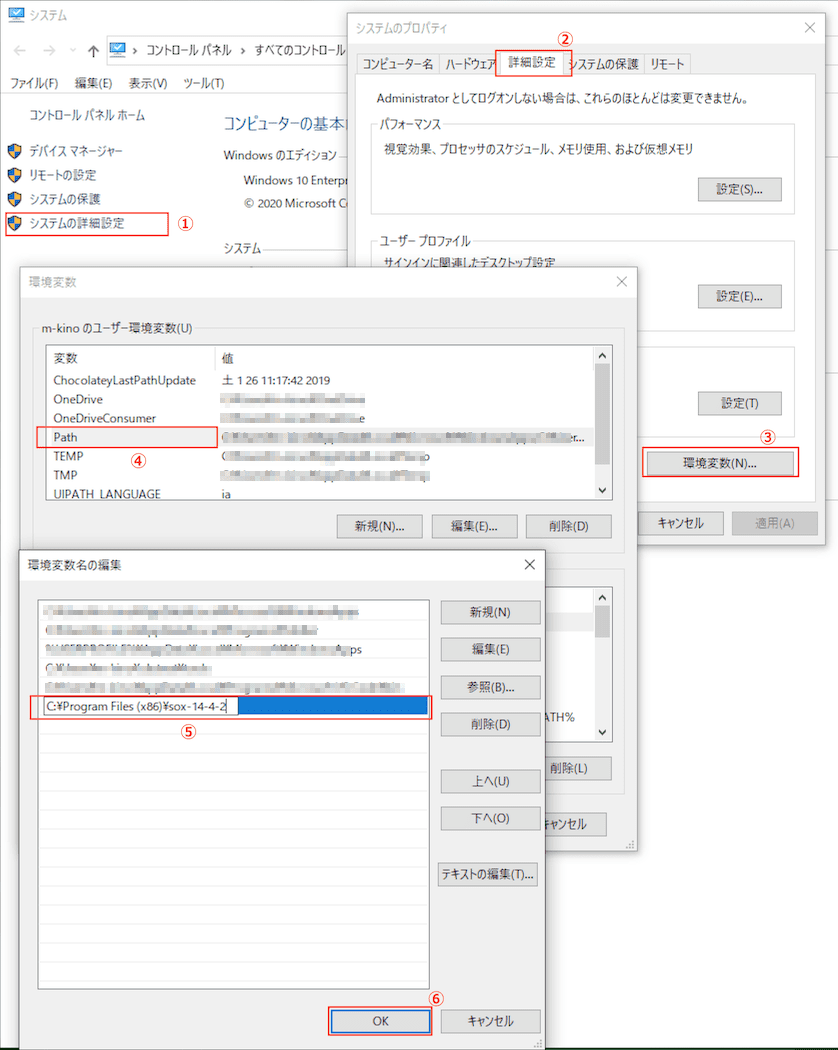
バイナリをインストールして、パスを通すなどが必要です。ハマりました。
バイナリへの直リンクはココ でです。
ダウンロードしたモノをインストールしたのち、下記の通りインストールディレクトリC:\Program Files (x86)\sox-14-4-2へパスを通します。
さらにさらに環境によるかもしれませんが、こちらでやった限り Error: spawn rec ENOENT の現象が発生し、
sample_ts\node_modules\node-record-lpcm16\recorders\sox.jsに手修正が必要でした、、、。let args = [ '--type', 'waveaudio', // audio type <-この1行を追加 '--default-device', '--no-show-progress', // show no progress '--rate', options.sampleRate, // sample rate '--channels', options.channels, // channels '--encoding', 'signed-integer', // sample encoding '--bits', '16', // precision (bits) '--type', options.audioType, // audio type '-' // pipe ]うーん、とても「簡単」とはいかないですね、、メンドクサイ。
やってみる
コードは前回の記事で取得済なので、実行するだけです。
Mac
% pwd /xxx/speech_node_samples/sample_ts % export GOOGLE_APPLICATION_CREDENTIALS="`pwd`/firebase-adminsdk.json" % % npx ts-node src/index3.ts Listening, press Ctrl+C to stop. Transcription: テストをしています Transcription: もう一度テストです (終了するにはCtrl-C) ^C %ちゃんと音声認識できていますね!
数秒無音が続くと音声認識が実行されて画面に結果が表示され、また待ち状態になります。Windows
(cloneしたコードは
t:\speech_node_samples\sample_ts\に展開されているとします)T:\speech_node_samples\sample_ts> set GOOGLE_APPLICATION_CREDENTIALS=t:\speech_node_samples\sample_ts\firebase-adminsdk.json T:\speech_node_samples\sample_ts> npx ts-node src\index3.ts Listening, press Ctrl+C to stop. Transcription: テストをしています Transcription: もう一度テストです (終了するにはCtrl-C) ^Cバッチ ジョブを終了しますか (Y/N)? y T:\speech_node_samples\sample_ts>Windowsでも、(環境設定はメンドクサかったですが) ちゃんと音声認識できていますね!
コードの中身
コードを見ておきましょう。これもストリーミング入力の音声文字変換のほぼまんまですが。
src/index3.tsimport speech from '@google-cloud/speech' const recorder = require('node-record-lpcm16'); async function main() { // Creates a client const client = new speech.SpeechClient() const sampleRateHertz = 16000 const config = { encoding: 'LINEAR16', languageCode: 'ja-JP', model: 'default', sampleRateHertz: sampleRateHertz, interimResults: false, // If you want interim results, set this to true } const request: any = { config: config, } // Create a recognize stream const recognizeStream = client .streamingRecognize(request) .on('error', console.error) .on('data', (data) => process.stdout.write( data.results[0] && data.results[0].alternatives[0] ? `Transcription: ${data.results[0].alternatives[0].transcript}\n` : '\n\nReached transcription time limit, press Ctrl+C\n', ), ) // Start recording and send the microphone input to the Speech API. // Ensure SoX is installed, see https://www.npmjs.com/package/node-record-lpcm16#dependencies recorder .record({ sampleRateHertz: sampleRateHertz, threshold: 0, // Other options, see https://www.npmjs.com/package/node-record-lpcm16#options verbose: false, recordProgram: 'rec', // Try also "arecord" or "sox" silence: '10.0', }) .stream() .on('error', console.error) .pipe(recognizeStream) console.log('Listening, press Ctrl+C to stop.') } if (!module.parent) { main().catch(console.error) }流れとしては
@google-cloud/speechライブラリのstreamingRecognizeメソッドで、音声認識をおこなうStreamを作成し、認識結果を受信したときの挙動を設定しておきます(結果を画面に表示するだけ)node-record-lpcm16ライブラリをつかってマイクからの音声を受信し、先ほどのStreamをセットしておくとなります。
以上で「マイクからの音声をもとに、クライアントアプリケーションから、ライブラリを用いて音声認識する」ことができました。まとめ
前回までのコンテンツも含めて、以下のことができるようになりました。
- 音声ファイルをもとに、クライアントアプリケーションから、ライブラリを用いて音声認識する ことができました。
- 音声ファイルをもとに、クライアントアプリケーションから、RESTを用いて音声認識する ことができました。
- マイクからの音声をもとに、クライアントアプリケーションから、ライブラリを用いて音声認識する ことができました。
- 今回のマイクからの音声受信は、各OSにSoxというプログラムのインストールが必要だったり、WEBアプリなどからは利用できなそう、ということがわかりました。
おつかれさまでしたー。
関連リンク
- 投稿日:2020-07-26T15:41:16+09:00
データ収集めんどくさいからプログラム書いちゃお
はじめに
私はゼミで統計経済を研究しており、日々エクセルやスプレッドシートとにらめっこしています。
その中で複雑な絞り込みや検索が既存機能だけではできないことがあったので、
この際プログラム書いたほうが「楽だし早いんじゃないかなあ」と思い、Node.jsを用いてやってみました。
また当初はGASでやろうかと考えていたのですが、今後データ収集でスクレイピングをするためにクローラーなどを使用することを考えてNode.jsで統一することにしました。
(VBAを0から触る時間がなかったので今回はパスです、、、)この記事でわかること
Node.jsでエクセルファイルを扱う方法
今回すること
今回は特許データを使用して、その中から特定の企業の
①特許総出願数
②特許共同出願数
③特許単独出願数
をそれぞれ計算するというものです。エクセルなどの既存機能では、特許総出願数をフィルターや検索を用いて割り出すことができるのですが、共同出願か単独出願かを見分けるには該当のセルと前後のセルの状態と見比べる必要があるのでプログラムを書く他なさそうでした(多分)。
以下の図のようになっていて、空欄箇所がある場合前後の特許と同じものすなわち共同出願しているとみなすことができるという見方です。
なのでロジックとしては以下です。
①検索時にひかかる数→総出願数
②タイトル(変数名)がある→次のセルのタイトルが空欄である→共同出願数
③タイトルがある→次のセルのタイトルが空欄ではない→単独出願数
④タイトルがない→共同出願数これにしたがって実装すると、、、
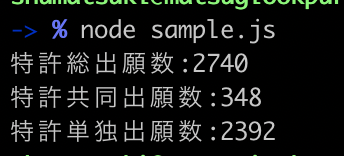
ほんの2~3秒で処理が終わって結果を出力してくれました。環境
macOS Catalina 10.15.4
npm: 6.4.1
node: v10.15.3実装
実装自体は難しくなく、ほぼNode.jsでエクセルファイルをどう扱うのかということだと思いますが、モジュールが用意されていてそれをJSONオブジェクトに置換できるので簡単だと思います!
参考記事や公式リポジトリのリンクを掲載しておきますのでそちらで確認して見てください。
Node.jsでExcelファイルのread/write
リポジトリconst XLSX = require("xlsx"); // 対象ファイルの読み込み const book = XLSX.readFile("Sample.xlsx"); // 対象シートの読み込み const sheet = book.Sheets["Results"]; // JSONオブジェクトとして取得 let sheet_json = XLSX.utils.sheet_to_json( sheet ); //検索したい企業のID const searchCompanyId = "JP9011101031552"; //固定変数名 const APPLICANT_BVD_ID_NUMBER_VALIABLE = "Applicant(s) BvD ID Number(s)" const TITLE_VALIABLE = "Title" var jointPatentNumber = 0; var simplePatentNumber = 0; var totalPatentNumber = 0; let cellNumber = 0; searchCompanyId(searchCompanyId); function serchPatentNumber(id) { for( let cell of sheet_json){ cellNumber++; if(cell[APPLICANT_BVD_ID_NUMBER_VALIABLE] == id) { totalPatentNumber++; if (cell[TITLE_VALIABLE] == undefined) { //共同特許の場合:タイトルが空欄ということは共同出願としてみなすことができる jointPatentNumber++; } else { var nextCell = sheet_json[cellNumber+1]; if (nextCell[TITLE_VALIABLE] == undefined) { //共同特許の場合:現在のセルの特許タイトルがあったとしも、次のセルの特許タイトルがない場合共同特許としてみなすことができる jointPatentNumber++; } else { //単独同特許の場合:現在のセルの特許タイトルがあり、次のセルの特許タイトルもある場合単独特許としてみなすことができる simplePatentNumber++; } } } } console.log("特許総出願数:" + totalPatentNumber); console.log("特許共同出願数:" + jointPatentNumber); console.log("特許単独出願数:" + simplePatentNumber); }終わりに
一度このようなプログラムを書いてしまえば使い回せるし、自分好みにカスタマイズできるのでやってよかったなと思いました。
もし他の人の参考にもなればいいなと思います。

- 投稿日:2020-07-26T10:50:45+09:00
PyCharmのインタープリタ�等の設定方法
この記事の内容:PyCharmの開発環境ごとの設定方法
開発環境(本番・ステージング・開発等)ごとにPyCharmの設定を分けると開発が楽に進む。しかし、PyCharmの設定はいろいろあって分かりづらい。そこで、PyCharmのディレクトリ構造・Project interpreter・Project structure・Run/Debug Config・Virtualenvあたりについて、個人的におすすめの設定方法を書き残しておく。
前提となる環境
フロントエンドとバックエンドを分けて開発していること。
- 以下では例として、フロントエンドはnode、Vue、Axiosで、バックエンドはPython、Django、DRF等を用いて説明する。
- なお、ベースとなるリポトリとしてakiyoko/drf-vue-sampleを用いた。このリポジトリとの差分は、フロントエンドとバックエンドの分離の仕方のみ。
達成したいPyCharmの設定
- 環境の分離
- 開発・ステージング・本番等という開発ステージごとの設定の分離
- フロントエンド単体、バックエンド単体、結合状態それぞれのモジュールごとの設定の分離
設定方法
ディレクトリ構造
frontendとbackendを分離。トップレベルのtestで結合テストを実施。結合テストの設定ファイルは(pythonの場合は)./requiremetns.txtに書いておく。drf-vue-sample2. ├── backend │ ├── apiv1 │ ├── config │ ├── db.sqlite3 │ ├── manage.py │ ├── requirements.txt │ ├── shop │ ├── static │ ├── tests │ └── templates ├── frontend │ ├── babel.config.js │ ├── node_modules │ ├── package-lock.json │ ├── package.json │ ├── public │ ├── src │ ├── tests │ └── vue.config.js ├── requirements.txt └── tests本番・ステージング・開発等の環境設定
環境ラベル
- 環境変数名は
$DEPLOY_ENVで、ラベルは下記の通り。
- 開発ローカルサーバー:
dvl- 開発リモートサーバー:
dvr- ステージングリモート:
stg- 本番リモート:
prd* 開発環境だけはローカルとリモートの環境を2つ用意してある。理想的には
devに統一してDocker使ったほうが良い。Virtualenvs設定
~/.virtualenvs/drf-vue-sample2/bin/activateの最後に以下を追加する。export $DEPLOY_ENV=環境ラベルこうすると、ターミナルで行う
manage.py系統の処理(例:python manage.py makemigrations)にも環境ラベルが反映されるのでとても便利。逆に言えば、Run/Dedebug ConfigurationやInterpreterの設定をいじってもmanage.py系の処理はターミナルから行う限り失敗する。PyCharmのProject interpreter
2つ用意する。
- 結合テスト(
drf-vue-sample2/test)を行うpythonインタープリター
drf-vue-sample2-integration
- Seleniumを動かす等に用いる。
- バックエンドのサーバー立ち上げ、またはテストを行うインタープリター
drf-vue-sample2-backendPyCharmのRun/Debug Configuration
3つ用意する。
結合テスト用の設定
integration_${開発ラベル}
- テンプレートはpython tests
- script pathは
drf-vue-sample2/testsを指定する。- インタープリターは
drf-vue-sample2-integrationバックエンド用の設定
backend_${開発ラベル}
- テンプレートはDjango server
- 環境変数に、
${DEPLOY_ENV}と${DJANGO_SETINGS_MODULE}を追加フロントエンド用の設定
frontend_${開発ラベル}
- テンプレートはnpm
- 実行する前に、
fronendのディレクトリで、npm installしておく。Project Structure
backendとfrontendの両方をsrcに足しておく。←意外と重要。
- こうすると両者が混ざることで若干環境依存性を生むが、こうしないとインスペクション(エディタレベルでエラーやワーニングを出してくれる機能のこと)がうまく行かないのでこのように設定する。
以上の設定で一旦目標としていた状態(環境分離)は達成できるはず。
まとめ
- PyCharmで環境を分けるには、最低限、
Project Interpreter(フロント/バック/結合)と、Run/Debug Configuration(インタープリター種類✕{dev/prd/stg等})で分離するとよい。