- 投稿日:2020-05-21T21:06:51+09:00
AWS IoTボタンを押すと動物の鳴き声をgoogle homeで再生する2歳児向けおもちゃを作ってみた
AWS IoTボタンを押すと動物の鳴き声を再生する2歳児向けおもちゃを作ってみました。
きっかけは動物好きな子どもが親の真似をして 「おけーぐるぐる ぞうの声」 とgoogle homeに向かって何度もしゃべっても認識できない
→親に「おけーぐるぐる ぞうの声 っていって」と何度も言われるような状況がうまれ、しんどい。。。
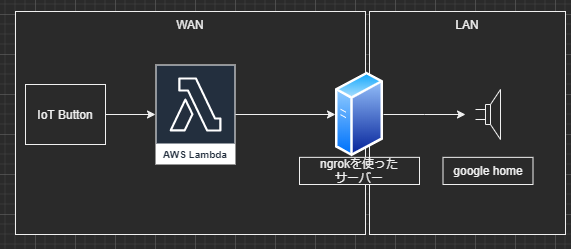
そこでボタン押すだけなら操作なら2歳児でもできるでしょ!と思い作成しました。構成
構成はこんな感じです。
1.Amazon IoTボタンを押す
2.ラムダ関数が起動(ただGETメソッドを実行するだけ)
3.ローカルのサーバーが起動(ngrokを使うことでインターネット上に公開)
4.google homeがしゃべる!作成手順
作成手順はこんな感じです。
1.LAN環境でgoogle homeをしゃべらせる
2.サーバーをngrokを使ってLambdaからgoogle homeをしゃべらせる
3.Amazon IoTボタンとLambdaを連携し、google homeをしゃべらせる1.LAN環境でgoogle homeをしゃべらせる
google-home-notifierというライブラリを使ってgoogle homeをしゃべらせてみました!(windows環境)
設定編
。。。。
。。。
エラーがたくさん出て長かったです。
まずは npm install google-home-notifier を実行
npm install google-home-notifierエラーが出る
gyp ERR! find VS gyp ERR! find VS msvs_version not set from command line or npm config gyp ERR! find VS VCINSTALLDIR not set, not running in VS Command Prompt gyp ERR! find VS could not use PowerShell to find Visual Studio 2017 or newer gyp ERR! find VS looking for Visual Studio 2015 gyp ERR! find VS - not found gyp ERR! find VS not looking for VS2013 as it is only supported up to Node.js 8 gyp ERR! find VS gyp ERR! find VS ************************************************************** gyp ERR! find VS You need to install the latest version of Visual Studio gyp ERR! find VS including the "Desktop development with C++" workload. gyp ERR! find VS For more information consult the documentation at: gyp ERR! find VS https://github.com/nodejs/node-gyp#on-windows gyp ERR! find VS ************************************************************** gyp ERR! find VS gyp ERR! configure error gyp ERR! stack Error: Could not find any Visual Studio installation to useWindows10にてNode環境構築によくあるエラーこちらを参考にしました。
→対処 PowerShellを管理者権限で起動し、下記のコマンドを発行する
npm install --global --production windows-build-tools
windows-build-toolsを入れるとよさげなのでインストール実施!※結構時間がかかりますNow configuring the Visual Studio Build Tools and Python... All done!こうなったら終わりです。
再度npm installを実行!
c:\github\google-home-notifier\node_modules\mdns\src\mdns.hpp(32): fatal error C1083: include ファイルを開けません。'dns_sd.h':No such file or directory (ソース ファイルをコンパイルしています ..\src\txt_record_buffer_to_object.cpp) [C:\github\google-home-notifier\nod e_modules\mdns\build\dns_sd_bindings.vcxproj]はい、次のエラーが出ました。
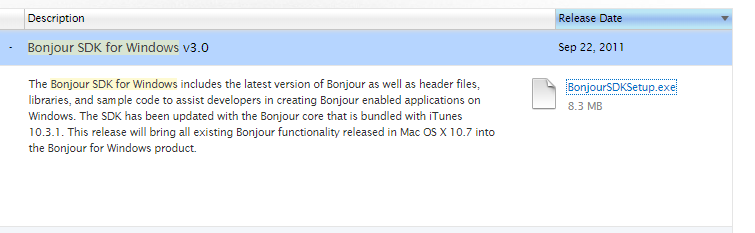
Bonjourのインストールをします。
これをダウンロード&インストール
やっと環境設定が完了しました!
まずは動かしてみる。
googlehome = require('google-home-notifier'); googlehome.device('Google-Home', 'ja'); this.googlehome.notify('test', function(res) { console.log(res); });で実行!
をしてみたのですが、またもやエラー。。。google-tts-apiのバージョンを上げないといけないらしい」です
package.json の google-tts-api を 0.0.4 に設定します。node_modules/google-home-notifier/package.json"bundleDependencies": false, "dependencies": { "body-parser": "^1.15.2", "castv2-client": "^1.1.2", "express": "^4.14.0", - "google-tts-api": "https://github.com/darrencruse/google-tts/tarball/british-voice", + "google-tts-api": "0.0.4", "mdns": "^2.3.3", "ngrok": "^2.2.4" },そしてアップデート
npm update google-tts-api
ようやくしゃべりました!
長かった。
開発編
nodejs、expressでAPIサーバーを作りました。
├ mp3/ ├ node_modules/ ├ app.js └ googoleHomeApp.jsapp.jsconst express = require('express'); const app = express(); const speech=require('./googleHomeApp.js'); const conf=require('config'); const speechObj= new speech(conf.ipaddress,conf.portNo); app.use(express.static('mp3')); app.use(express.static('public')); app.use(express.static('js')); app.get('/speech', (req, res) => { speechObj.speech(req.query.value); res.send('speechOK') }); app.get('/animalVoice', (req, res) => { speechObj.speechAnimalVoice(); res.send('animalVoice') }); app.listen(conf.portNo, () => console.log('Listening on port '+conf.portNo));googoleHomeAppがメインのクラスです。
speechAnimalVoiceメソッドではmp3フォルダの中身をランダムに再生するようにしています。googoleHomeApp.jsmodule.exports =class { constructor(ipaddress,portNo){ this.googlehome = require('google-home-notifier'); this.fs = require('fs'); this.language = 'ja'; this.googlehome.device('Google-Home', this.language); this.rootUrl="http://"+ipaddress+":"+portNo; } speech(value) { this.googlehome.notify(value, function(res) { console.log(res); }); } speechAnimalVoice() { const allDirents = this.fs.readdirSync('./mp3', { withFileTypes: true }); const mp3value=allDirents[Math.floor(Math.random() * allDirents.length)]; console.log(this.rootUrl); this.googlehome.play(this.rootUrl +'/'+ mp3value, function(res) { console.log(res); }); } }2.サーバーをngrokを使ってLambdaからgoogle homeをしゃべらせる
ngrokの設定
続いてngrokを以下を参考に設定
https://qiita.com/mininobu/items/b45dbc70faedf30f484e
こんなにも簡単にローカルのサーバーがインターネット公開できるとは。。。
セキュリティ面が気になりますが、いったん動かすレベルではこれでよいかなと思いました。
node.jslambda関数の設定(ただGETメソッドを実行するだけ)
ngrokで公開されたURLにrequestを送るだけのlambda関数を作成しました。
Lambdaとか初心者なので require('request') を使うためにzipをアップロードするのに手間取りました。。。exports.handler = async (event) => { const request = require('request'); var URL = 'http://XXXXX.ngrok.io/animalVoice'; request.get({ uri: URL }, function(err, req, data){ const response = { statusCode: 200, body: JSON.stringify('OK'), }; return response; }); };3.Amazon IoTボタンとLambdaを連携し、google homeをしゃべらせる
Lambda関数の設定
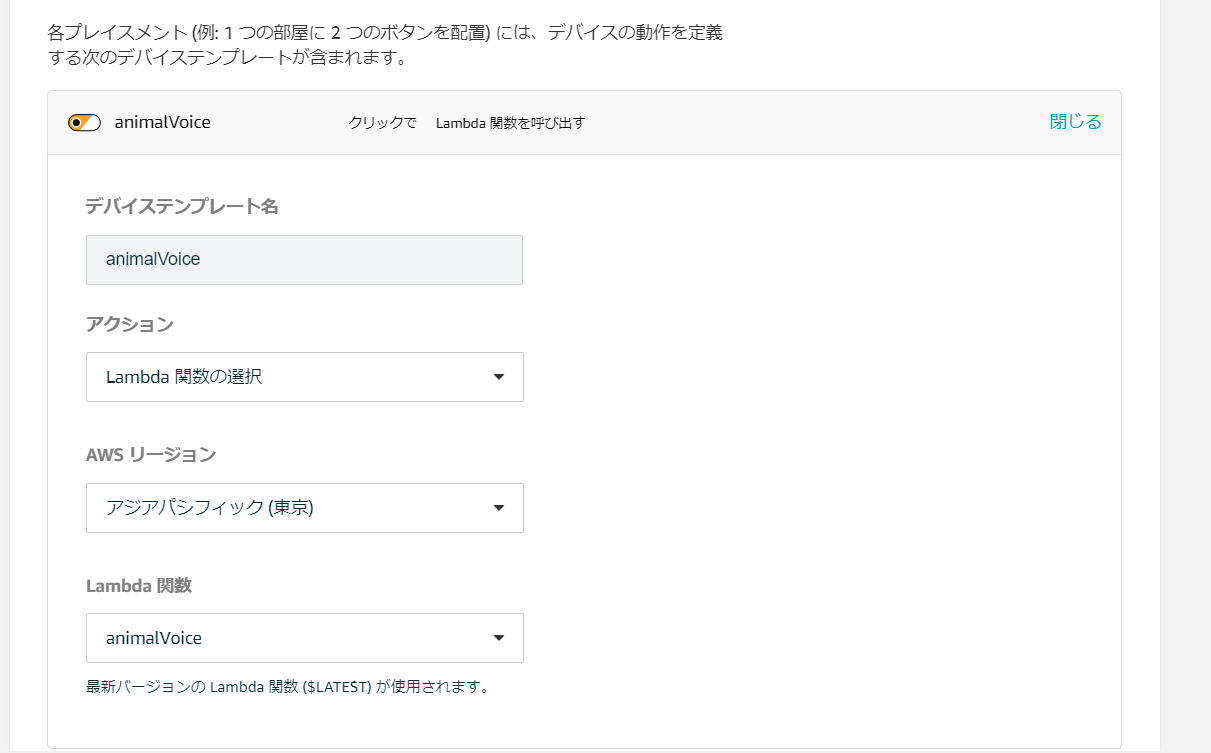
AWS IoT 1-Clickを選んで、プロジェクトを選択→lambda関数を指定
デバイスの設定
アプリをダウンロードして設定しました。
ノリと勢いで何とかなります。
android
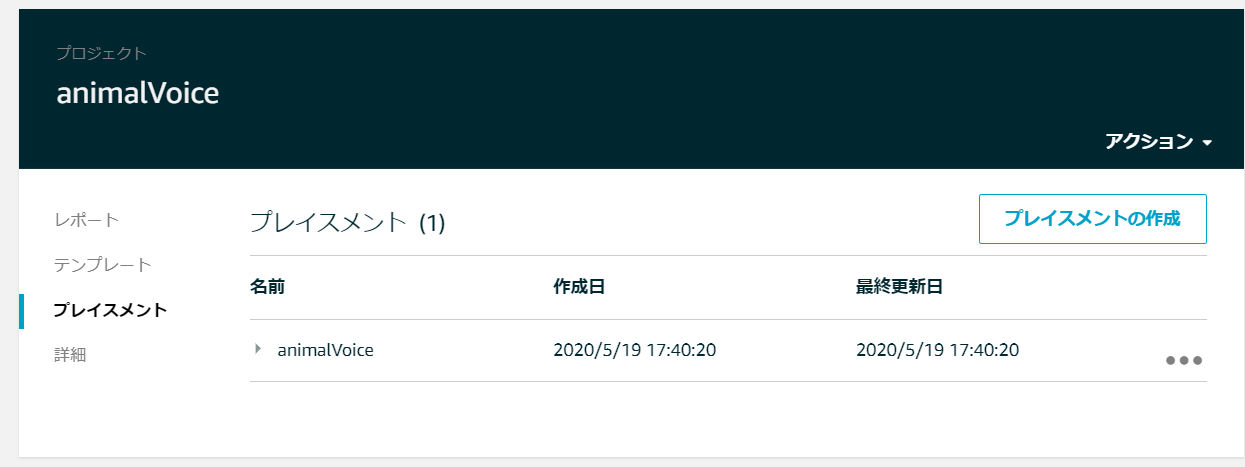
iosデバイスとプロジェクトの紐づけ
プレイスメントを選択し、デバイスとプロジェクトを紐づけます。
以上で終了です!
感想
ngrokのURLが固定じゃなかったり、ローカルPCで立ち上げているため、毎回いろいろと設定が必要なのは課題ですが、いったん作れてよかったです!
AWS,nodejsなんとなく使ったことあるレベルだったので何かプロダクトを作りたい!と思いやってみました。
動くと楽しいですね!あと思いのほか子供がいい反応をしてくれてやってよかったなぁと思ってます。
ただ、ボタンを押してからしゃべるまでタイムラグがあるのがちょっといけてないなぁと思っています。また何か思いついたらプロダクトを作りたいと思います。
あとaws,nodejsも独学なので、こうしたほうが良いよ!というご指摘等あればいただきたいです。ソースコードは以下にあります!(実はgithubをちゃんと使うのも初めてです)
https://github.com/tayack/googlehome
- 投稿日:2020-05-21T15:37:27+09:00
Visual Studio Code で GAS のコードを編集する環境を作ってみた(Windowsだよ)
はじめに
なにやら世の中には「VSCode」という素晴らしいものがあることを今更知った。orz
なんだか、TypeScriptで書けて、JavaScriptに変換までしてくれるらしいのですが!?
GASでこういう↓ものを作成したので、だったら「VSCode」で書けないのかしらん?
スプレッドシートをDB代わりにGASのWebアプリを作成しデータ更新させてみた。Vue版 その1~~
ということで調べ、まとめてみました。
「間違ってるぞ。」「動かないぞ。」というときは優しくご指摘くださいm(_'_)m参考にさせていただいたサイト
・【Google Apps Script】claspを使ってローカル環境で開発する
こちら↑を見ればできます。わからないこと
- Googleのアカウントを複数持っていた場合の挙動
インストールと設定手順
No 対象 設定方法 1 VSCode こちらからWindows用インストーラをダウンロードしてexeを起動する。インストール後、VSCodeは閉じておく(念のため) 2 Node.js こちらからWindows Installerを選択してダウンロード。msiファイルを実行する。 3 clasp コマンドプロンプトを管理者で起動する。
「npm install @google/clasp -g」を実行する。4 GoogleAPI Googleに任意のアカウントでログインしておきます。
そして、こちらでAPIをオンに変更します。これで下準備は完了です。
まっさらでVSCodeから始める場合
※スプレッドシートの作成から・・・
No やること 1 ローカルパソコンでソースなどを保存する用のフォルダを作成しておく。
フォルダの名称でスプレッドシートのファイル名が作成されるようなので、ちょっと注意。2 VSCodeを起動する。 3 VSCode内で、ファイル>フォルダを開く で上記のフォルダを開く。 4 ターミナル>ターミナルを開く でターミナルを表示する。 5 ターミナルに、「clasp login」と入力しエンター。 6 ブラウザが開きアカウント選択⇒スマホに連絡が来たので許可などする。 7 ブラウザを閉じてVSCodeに戻る 8 ターミナルに「clasp create --rootDir ./src」と入力し、エンター。 9 上下キーでsheetsを選択⇒エンター。 10 すると、vsCodeで選択していたフォルダの名前でスプレッドシートのファイルが作成される。 11 左側の階層で「src」で右クリックをして「New File」を選択する。 12 ファイル名は、なんでもいいが、拡張子は「.ts」にする。 13 作成したファイルにfunction test() {
console.log('test')
}
と書いてみる。14 ターミナルに「clasp push」と入力しエンター。
するとGAS側に反映される。15 ターミナルに「clasp open」と入力しエンター。
するとブラウザが起動しスクリプトのエディタ画面が表示され、上記のソースが確認できる。16 確認できない場合は、F5を押すなりしてリフレッシュさせると更新が確認できるはず。 ※「.ts」が「.gs」になったりと臨機応変にやってくれているようです。
GASは存在していてVSCodeでこれから書いてみようとする場合
No やること 1 ローカルパソコンでソースなどを保存する用のフォルダを作成しておく。 2 VSCodeを起動する。 3 VSCode内で、ファイル>フォルダを開く で上記のフォルダを開く。 4 ターミナル>ターミナルを開く でターミナルを表示する。 5 ブラウザを開き、Googleにログインする。 6 GASのあるスプレッドシートを開く。 7 ファイル>プロジェクトのプロパティ から、「スクリプトID」をメモる(コピる) 8 VSCodeに戻る。 9 ターミナルに「clasp clone xxxxxxxxxxxxxxx」と入力しエンター。
「xxxxxxxx」は前の「スクリプトID」を入力する。10 すると、ファイル類が出来上がる。 11 ※しかし、新規に作成したような「src」フォルダは作成されない。 そのあとの使い方(たぶん共通)
やること その後は、Loginしなくても、スクリプトIDは入れなくても以降の処理はできる。 ターミナルに「clasp pull」と入力しエンターでGAS側から引っ張ってこれる。 ブラウザ側でのファイルのrenameは、vscodeでpullすると新しいファイルとして認識される模様。 vscode側でのファイルのrename後に、vscodeでpushするとファイル名が変わったように認識される模様。(※delete⇒insertなのかぁ) ターミナルで「npm init --y」
「npm i @types/google-apps-script --save-dev」を実行しておくと便利らしい。拡張機能を入れると便利
・VSCode に必ず入れておきたい拡張機能
簡単に拡張できてすごく便利ですね入れてみました。
感想
プッシュする際に毎回「clasp push」と打つのが面倒に感じますね。
十字キーを使えばいいんでしょうが、なんかそれも何度もだと面倒に感じて・・・
ボタンがあったらうれしいのになぁ。でも、見やすくなっていい感じ。
でわでわ。
- 投稿日:2020-05-21T13:07:06+09:00
CloudWatch Synthetics & Puppeteer ことはじめ
今さらながらCloudWatch SyntheticsでWebサイトの監視をしたのでまとめます。
この記事の内容
- CloudWatch Syntheticsのために手動でS3バケットとIAM Roleを作る
- ローカル環境にPuppeteerをインストールしてNode.jsのコードを書く
- Googleのトップページに「猫 wikipedia」を入力して検索する
- トップにWikipediaの記事が出てこなかったら異常事態なのでスクショを撮ってCloudWatchでアラートを上げることにする
- このコードをCloudWatch Syntheticsに持って行ってCanaryを作成する
きちんとした環境構築などはしていません。非常に意識の低い内容となっています。。
まず最初に:勝手にバケットやIAMを作ってほしくない
最初のセットアップで
s3://cw-syn-results-999999999999-ap-northeast-1というS3バケット、CloudWatchSyntheticsRole-canary-123-4567890abcdeというIAM Roleが勝手に作られるのでちょっと気分が良くありません。手動で作ることにします。(気にしない人は次へ進みましょう)
IAM Role作成手順
空のIAM Roleを作る
IAM RoleのPathは
/service-role/である必要があるようです。現状コンソールからはそのようなIAM Roleを作成することはできない(無条件で/になる)のでCLIを叩きましょう。このようなJSONを作っておいて、
policy.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }これで希望通りのPathを持った空のIAM Roleが作成できます。
aws iam create-role --role-name cloudwatch-synthetics --path /service-role/ --assume-role-policy-document file://policy.jsonIAM Policyをアタッチする
必要な権限を記述したインラインポリシーをアタッチして終わりです。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetBucketLocation" ], "Resource": [ "arn:aws:s3:::YOUR-BUCKET-NAME/*" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:PutLogEvents", "logs:CreateLogGroup" ], "Resource": [ "arn:aws:logs:ap-northeast-1:999999999999:log-group:/aws/lambda/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListAllMyBuckets" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Resource": "*", "Action": "cloudwatch:PutMetricData", "Condition": { "StringEquals": { "cloudwatch:namespace": "CloudWatchSynthetics" } } } ] }スクリプトの文法が良く分からんしテスト実行が遅い
CloudWatch Syntheticsの実体はAWS Lambda (Node.js)で、裏でHeadless ChromeをPuppeteer経由で動かしています。遅いのも当然ですしスクリーンショットに日本語が出てこないのも当然です(フォントを入れるにはLambdaの容量制限が厳しすぎます)。そこでローカルでコードを書いてから持って行くのが良さそうなのでその準備をします。なお今回Dockerは使っていませんのでよろしくお願いします。
ローカルでPuppeteerを動かす準備をする
新しめのNode.js をインストールする
n packageを使う方法が最もお手軽ですが、一時的に動かなかったという報告があったのでうまくやってください。なお2020/5/20時点においてCloudWatch SyntheticsはNode.js v10を利用しているそうです。そんなに複雑な文法を使わなければv12でもまあ問題はないでしょう。
依存モジュールをインストールする
公式の手順にある通り、必要なものを全部突っ込みます。勢いが大切です。
Debian/Ubuntusudo apt install ca-certificates fonts-liberation gconf-service libappindicator1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgbm1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 lsb-release wget xdg-utilsCentOSsudo yum install alsa-lib.x86_64 atk.x86_64 cups-libs.x86_64 GConf2.x86_64 gtk3.x86_64 ipa-gothic-fonts libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXrandr.x86_64 libXScrnSaver.x86_64 libXtst.x86_64 pango.x86_64 xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-fonts-cyrillic xorg-x11-fonts-misc xorg-x11-fonts-Type1 xorg-x11-utils空のディレクトリを作って初期化する
mkdir hello-puppeteer; cd $_; npm init -yPuppeteerをインストールする
npm install --save puppeteerサンプルコードを書いて実行してみる
公式のサンプルコードをちょっと変更して持ってきました。
index.jsconst puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://www.google.com'); await page.screenshot({path: 'example.png'}); await browser.close(); })();さっそく実行しましょう。
node index.jsうまく行けば同じディレクトリの中にGoogleのトップページのスクリーンショット、
example.pngという画像ファイルが生成されているはずです。
おめでとうございます! ここまでで最低限のコードは書けるようになりました!(フォントがないので日本語は全部文字「?」になってしまっています。どうせAWSに持って行くとこれは避けられないので諦めましょう)
CSS SelectorとXPath
単なる死活監視ならこれでオッケーですが、検索や検索結果検証を行うためにはHTML内の要素を探し出して取得する必要があります。そのために必要な武器がCSS Selectorです。XPathに慣れている人はXPathでもいいです。どちらもHTMLのツリー構造をたどり、必要な要素――文字を入力したりボタンを押したり文字列を探し出したり――を探し出すのに使うことができます。こちらの記事がとても参考になりました。
puppeteerでの要素の取得方法 - Qiita (@go_sagawaさん)
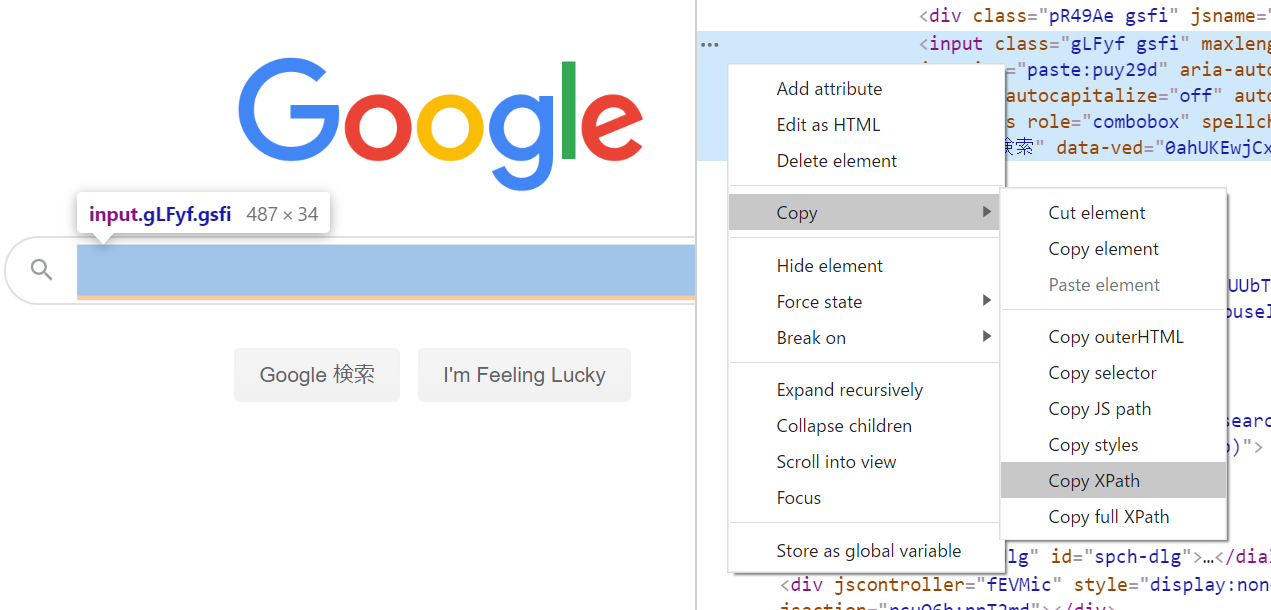
XPathの文法はそれなりに複雑ですし、スクレイピングを柔軟に1行うためにはある程度きちんと書く必要がありますが、対象のWebサイトの構造が固定であるという前提があれば何も覚える必要はありません。Chromeで対象の要素を右クリックし、「要素を調査」で開発者ツールを開き、対象の要素がハイライトされていることを確認したら、そこでさらに右クリックして「Copy XPath」をクリックするだけです。
コードを書いてみよう
XPath版
必要なXPathが入手できたので実際にコードを書いてみます。
index.js (XPathバージョン)const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); const searchTextboxXPath = '//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input'; const firstSearchResultXPath = '//*[@id="rso"]/div[1]/div/div/div[1]/a/h3'; await page.goto("https://www.google.com"); // 検索テキストボックスが見つかるまで待つ(タイムアウト3秒) await page.waitForXPath(searchTextboxXPath, { timeout: 3000 }); // テキストボックスを取得(XPathでは配列で結果が返るので最初の要素を取る) const textbox = (await page.$x(searchTextboxXPath))[0]; // フォーカスを合わせるために1回クリックしておく await textbox.click(); // ディレイを入れつつキー入力 await page.keyboard.type("猫 wikipedia", { delay: 100 }); // エンターキーを押す。検索画面に移動するはず await page.keyboard.press('Enter'); // 見出しが出てくるまで待つ(タイムアウト3秒) await page.waitForXPath(firstSearchResultXPath, { timeout: 3000 }); // 見出しを取得(これも配列なので最初の1個を取る) const firstSearchResult = (await page.$x(firstSearchResultXPath))[0]; // 文字列を取得するためのやり方 const result = await (await firstSearchResult.getProperty('textContent')).jsonValue(); await page.screenshot({ path: "example.png" }); if (result !== "ネコ - Wikipedia") { throw new Error("Wikipedia dokka itta nya!!!"); } await browser.close(); })();CSS Selector版
ほとんど変わりませんがCSS Selector版も書いておきます。
index.js (CSS Selectorバージョン)const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); const searchTextboxSelector = '#tsf input[type="text"]'; const firstSearchResultSelector = '#rso div.r > a > h3'; await page.goto("https://www.google.com"); // 検索テキストボックスが見つかるまで待つ(タイムアウト3秒) await page.waitFor(searchTextboxSelector, { timeout: 3000 }); // テキストボックスを取得 const textbox = (await page.$(searchTextboxSelector)); // フォーカスを合わせるために1回クリックしておく await textbox.click(); // ディレイを入れつつキー入力 await page.keyboard.type("猫 wikipedia", { delay: 100 }); // エンターキーを押す。検索画面に移動するはず await page.keyboard.press('Enter'); // 見出しが出てくるまで待つ(タイムアウト3秒) await page.waitFor(firstSearchResultSelector, { timeout: 3000 }); // 見出しを取得 const firstSearchResult = (await page.$(firstSearchResultSelector)); // 文字列を取得するためのやり方 const result = await (await firstSearchResult.getProperty('textContent')).jsonValue(); // スクショを取っておく await page.screenshot({ path: "example.png" }); // 求める値になっているかチェック if (result !== "ネコ - Wikipedia") { throw new Error("Wikipedia dokka itta nya!!!"); } await browser.close(); })();CloudWatch Syntheticsにコピペしよう
「ハートビートのモニタリング」を選ぶとひな形のコードが出てきます。
var synthetics = require('Synthetics'); const log = require('SyntheticsLogger'); const pageLoadBlueprint = async function () { // INSERT URL here const URL = "https://google.com"; let page = await synthetics.getPage(); // 中略 }; exports.handler = async () => { return await pageLoadBlueprint(); };
pageオブジェクトは既に与えられているので、セレクタ宣言部分からawait browser.close()手前までをコピペすればいいですね。またスクリーンショットはローカルに保存することはできないのでawait synthetics.takeScreenshot("hoge"); await synthetics.takeScreenshot("fuga", "piyo");などとSyntheticsの提供するメソッドを使う必要があります。(引数に与えた文字列がハイフンで結合されてファイル名になり、png形式で保存されます)
CloudWatchのアラームを作成する
CloudWatch Syntheticsからも直接アラームは作成できますが、アラームの名前が勝手に決まってしまうためちょっとイケていません。アラームを作ったらChatbot経由でSlack通知をするなどしたら監視は完成です。
Chromeが生成するXPathをそのまま使うとちょっと要素が増減したりしただけで動かなくなったりします ↩
- 投稿日:2020-05-21T10:07:53+09:00
[Node.js]Firestoreのコレクションにサーバーサイドから最速でドキュメントを書き込む書き方
Overview
Firestoreの一つのコレクションに1万件ほどデータを書き込んでいたが2分は要して遅かった。
公式ドキュメントのみではなかなか最速にたどり着けないためメモとして残しておく。Target reader
- Firestoreでコレクションへのサーバーサイドからへの書き込みをNode.jsを問わず高速にしたい方。
Prerequisite
- SDKはNode.jsのものを使用するが、他の言語でも同様になると考える。
- Node.jsのバージョンはGoogle Cloud Function(GCF)に依存し、現時点ではV10系とする。
- Firestoreのインポートによる書き込みは調査対象外です。読む限り大量のデータを書き込む用途ではなくリストア向けに見えたこと、特に速度面で有利になる記述がなかったため。
Body
理論上の限界値を把握する
まずは公式ドキュメントから上限値を把握する。
https://firebase.google.com/docs/firestore/quotas?hl=ja#writes_and_transactions
データベースあたりの最大書き込み回数/秒 10,000(最大 10 MiB/秒)
ドキュメントへの最大書き込み速度 1 秒あたり 1
コレクションへの最大書き込み速度(コレクションに含まれているドキュメントのインデックス付きフィールドには順次値が含まれている) 1 秒あたり 500
Commit オペレーションに渡すか、トランザクションで実行することができる書き込みの最大数 5001つのコレクションに対して書き込める速度は500ドキュメント/sだと理解。
コレクションを分けても10,00ドキュメント/sだと理解。
DBが重要なプロジェクトではなかったため把握してなかったが、意外にも少ないというのが正直な感想。
これを意識して設計する必要があり、実際はこれより低いと考えておいた方が安全だろう。バッチ書き込み
500ドキュメント/sを目指して高速化していく。
Firestoreがバッチ書き込みできることを知っていれば、公式ドキュメントの該当ページを読むことになる。
読んでみると不可思議な記述にたどり着く。https://firebase.google.com/docs/firestore/manage-data/transactions#batched-writes
注: データを一括入力するには、並列化された個別の書き込みでサーバー クライアント ライブラリを使用します。バッチ書き込みは、シリアル化された書き込みより優れたパフォーマンスを発揮しますが、並列書き込みほど優れてはいません。一括データ オペレーションには、モバイル / ウェブ SDK ではなく、サーバー クライアント ライブラリを使用する必要があります。
つまり、サーバーサイドにおいては 並列化された個別の書き込み > バッチ書き込み > シリアルでの書き込み ということか。
ここでつまずいたのがサーバー クライアント ライブラリでの書き込みは、専用のメソッドがあるのか、それともPromise.all()による並列書き込みなのかわからなかった。
SDKを漁るがどうも専用メソッドはなく、どうやらPromise.all()であることは予測できたが、果たして多数の並列書き込みでバッチを超えれるのかという疑問があった。ぐぐる
並列書き込みのアンサーを探すのに苦労したが、stackoverflowに回答があった。
async function testParallelIndividualWrites(datas) { await Promise.all(datas.map((data) => collection.add(data))); }結論としてはこれが最速。だが、これでは実用的ではないので実用性を加えていく。
これを1万ドキュメントに適用すると以下のようなエラーになる。terminalError: 10 ABORTED: Too much contention on these documents. Please try again.そう、コレクションは500doc/sだから1万ドキュメントも並列化したらエラーになるのは当然のこと。
FaaSのような環境ではソケットが枯渇する可能性も考えられる。batch書き込みでも同様にエラーになる。おまけとして実際に使ったコードは以下。
const updateDocuments = async (collectionName, documents) => { const batches = []; // Firestoreのドキュメント数の上限に抵触しないように小さく書き込んでいく while (documents.length) { const batch = db.batch(); batches.push(batch); documents.splice(0, 500).forEach( v => batch.set(db.collection(collectionName).doc(v.id), v) ); } // Error: 10 ABORTED: Too much contention on these documents. Please try again. await Promise.all(batches.map((batch) => batch.commit())); }無制限の並列化はエラーを避けられないため、何らかの方法でこれをコントロールする必要がある。
ちなみに
splice(0, 500)の部分をsplice(0, 250)にして、かつ後述の書き込み数コントロールのsleepを導入すると約97秒を要した。
500ドキュメントを同時実行できるようになったとしても半分の約48秒になることが予想され、理論値に程遠いと予測できる。
Firestoreの公式ドキュメントでもバッチはトランザクションと類似扱いされていることから、簡易トランザクションであり速度面では最速とはなりえさそうだ。最速級コード
500doc/sにするには主に二つの選択肢がある。
- 書き込み側で500doc/sにコントロールする
- 無制限で書き込みつつ、エラーになったら書き込みタイミングをコントロールしてリトライする
書き込みが一か所からでしか行われないなら前者を採用可能。
書き込みが複数なら、後者を採用しないといけないだろう。
私のケースではバッチ処理で同時に複数からの書き込みはないため前者を採用する。const updateDocuments = async (collectionName, documents) => { let start = Date.now(); // Firestoreのドキュメント数の上限に抵触しないように数を制限して書き込む while (documents.length) { await Promise.all( documents.splice(0, 500) .map((v) => db.collection(collectionName).doc(v.id).set(v)) ); // 最低1秒の間隔を保つ start = await sleepForProtection(1000, start); } } const sleepForProtection = async (duration, start) => { const sleepTime = start + duration - Date.now(); if (sleepTime > 0) { console.log('sleep...'); await sleep(sleepTime); } return Date.now(); }
sleepForProtection()により最低1秒の間隔をキープしつつ、500ドキュメントずつ書き込む。
splice()は参照先のデータ自体を変更するため、updateDocuments()が終了したら配列は空になる。
これを避けたい場合は、const documents = [..._documents](関数の引数は_documentsに変更したとする)のような感じにするといい。このコードにより、約12500ドキュメントを約28.7秒で書き込み完了できるようになった。
約435doc/sと理論値500doc/sと比較して約87%とお手軽なコードのわりにはまずまずの結果になった。
理論値が25秒なのでこれで作業は終了した。
お手軽に書いたが、厳密に1秒に近づけるならmap()の戻り値を直接Promise.all()に投入せず変数に入れ、そのあとstartを更新したほうが正確性が増す。注意事項として、このコードは失敗しないことを前提にしているため、本番コードはエラーを考慮する必要がある。
まず、Promise.all()はいずれかが失敗するとそこで終了するため、そこに対してフォローが必要になる。
具体的にはNode.jsのバージョンが12.10以上ならPromise.allSettled()に変更したほうがよさそう。
https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Global_Objects/Promise/allSettled
個別の処理結果を取得できるようになるため、失敗した処理へのフォローが簡単にできるようになるはず。(私使ったことないので予想)
(v) => db.collection(collectionName).doc(v.id).set(v)の配列変数を作ってPromise.allSettled()に投入し、rejectのインデックスに対応したドキュメントを再投入にまわすということになるかな?
完全なコードを示せず申し訳ないです最後の見せ場は残しておきます
GCFだと現状v10で
Promise.allSettled()が存在しないので、shimるのが手っ取り早いですね
https://www.npmjs.com/package/promise.allsettledConclusion
最速コードがBatch書き込みではなく、通常の
set()をPromise.all()で実行することで約435doc/sという結果になりました。
そうなってくると、サーバーSDKのBatchの存在意義って…クライアントSDKでは通信回数が格段に減るのでそれだけでも存在意義があるけど。
Have a great day!
- 投稿日:2020-05-21T01:12:28+09:00
2020年から始めるAzure Cosmos DB - 目次

- 投稿日:2020-05-21T01:03:56+09:00
node.jsとnpmとwebpack、nodenvとanyenvとは(初心者向け)
ここら辺の用語が今だに混乱するのでこの機会にまとめておきます。
node.js
昔node.jsでExpressを使ってシステムを組んだりした関係でJavaScriptをサーバサイドで使えるようにするもの、ぐらいの理解だったので、なぜフロントエンドでnode.jsが必要なのかわからなかった。
以下の方の説明がわかりやすかった。
https://qiita.com/kobalab/items/e0c2a3d5a9f4c172bad0Node.jsとは、Google Chromeに搭載されている高速なJavaScriptエンジンV8をコマンドラインから使えるようにしたJavaScript言語処理系
要はjavaコマンドやperlコマンドと同じです。node hoge.js で hoge.js に書かれたJavaScriptのプログラムを実行します。node とだけタイプすると対話モードに入るので、インタフェースはshに近いといえるかもしれません。つまり本来はブラウザでの動作に特化したJavascriptをJavaScriptエンジンV8を使ってUnix系で使うときに必要なもの。上記のインタープリター機能やnpmも含まれている。
なぜフロントエンド開発でもnode.jsが必要なのか調べたところ、
大量のフロントエンド向けjavaScriptのモジュールが下記のnpm向けに開発されていて、それを利用するためにnode.jsが必要だから、ということらしいnpmとは
node.jsのモジュール、パッケージ管理ツール。
パッケージ管理システムでNode Package Managerの意。
Node.jsをインストールすると一緒にくっついてくる。Ruby的に言えば、npmはBundler、パッケージはGem、package.jsonはGemfileのようなもの?
例えばwebpackなどを管理する。webpackとは
機能や関数単位ごとに別れたJavaScriptモジュールを一つのファイルに統合(バンドル)してくれるツールモジュールバンドラーと呼ばれています。
また、JavaScriptだけでなく、CSSや画像などのバンドルも可能。nodenvとは
node.jsのバージョン管理ツール
anyenv
node.jsのnodenvやrubyのrbenvなどのバージョン管理ツールをまとめて管理してくれるツール。