- 投稿日:2020-03-18T23:29:00+09:00
Windows10ProでAWS SAMでHelloWorld(サンプルはnode.js)
初めに
Windows10ProでAWS SAMを使ってHelloWorldしようと思ったら意外と大変だったので自分用メモ。
何も入っていない前提ですが、Dockerとかnodeとか入っている場合は飛ばしてください(特にこだわりがなければこの機会にすべて最新化をおススメします)執筆時の各バージョン
GitBash
v2.25.1
Docker
v2.2.0.4
node.js
v12.16.1
aws sam
v0.45.0
必要なものインストール/設定
Git for Windowsインストール
Git for Windows公式からダウンロードし、インストールする。
(特にチェック付けなくて大丈夫です)Dockerのインストール/設定
Docker公式からStableバージョンをダウンロードしてインストーラーをクリック。
インストールすると再起動を促されるので、再起動する。
再起動後にタスクバーのDockerアイコンを右クリック
-> Settings -> Resourses -> FILE SHARINGでCにチェックを付け、Aplly&Restertを押下する。(AWS SAMを実行するドライブ)
node.jsのインストール
nodejs公式で最新のLTSをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)AWS SAMのインストール
AWS SAMをクリックしてインストーラーをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)SAMサンプルアプリでHelloWorld
1.コマンドプロンプトで
sam initと入力する。
2.Choice: で1と入力する(サンプルアプリ作成)
3.Runtime:で1と入力する(nodejs12.xで作成)出力例
> sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore2.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8 13 - dotnetcore2.0 14 - dotnetcore1.0 Runtime: 1 Project name [sam-app]: hello-world Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git ----------------------- Generating application: ----------------------- Name: hello-world Runtime: nodejs12.x Dependency Manager: npm Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./hello-world/README.md4.
cd hello-worldと入力する(作成したサンプルアプリルートへ移動)
5.sam local start-apiと入力する(ローカルでサンプルアプリを起動)サンプルアプリ起動出力例
>sam local start-api Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET] You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template 2020-03-18 23:26:19 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)6.http://127.0.0.1:3000/helloにアクセスする(hello world!!!!1)
参考リンク
終わりに
不明点/修正点あれば気軽にコメントください!
Twitterを細々とやっています_:(´ཀ`」 ∠):!?


- 投稿日:2020-03-18T23:29:00+09:00
Windows10ProでAWS SAMを使ってHelloWorld(サンプルはnode.js)
初めに
Windows10ProでAWS SAMを使ってHelloWorldしようと思ったら意外と大変だったので自分用メモ。
何も入っていない前提ですが、Dockerとかnodeとか入っている場合は飛ばしてください(特にこだわりがなければこの機会にすべて最新化をおススメします)執筆時の各バージョン
GitBash
v2.25.1
Docker
v2.2.0.4
node.js
v12.16.1
aws sam
v0.45.0
必要なものインストール/設定
Git for Windowsインストール
Git for Windows公式からダウンロードし、インストールする。
(特にチェック付けなくて大丈夫です)Dockerのインストール/設定
Docker公式からStableバージョンをダウンロードしてインストーラーをクリック。
インストールすると再起動を促されるので、再起動する。
再起動後にタスクバーのDockerアイコンを右クリック
-> Settings -> Resourses -> FILE SHARINGでCにチェックを付け、Aplly&Restertを押下する。(AWS SAMを実行するドライブ)
node.jsのインストール
nodejs公式で最新のLTSをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)AWS SAMのインストール
AWS SAMをクリックしてインストーラーをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)SAMサンプルアプリでHelloWorld
1.コマンドプロンプトで
sam initと入力する。
2.Choice: で1と入力する(サンプルアプリ作成)
3.Runtime:で1と入力する(nodejs12.xで作成)出力例
> sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore2.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8 13 - dotnetcore2.0 14 - dotnetcore1.0 Runtime: 1 Project name [sam-app]: hello-world Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git ----------------------- Generating application: ----------------------- Name: hello-world Runtime: nodejs12.x Dependency Manager: npm Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./hello-world/README.md4.
cd hello-worldと入力する(作成したサンプルアプリルートへ移動)
5.sam local start-apiと入力する(ローカルでサンプルアプリを起動)サンプルアプリ起動出力例
>sam local start-api Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET] You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template 2020-03-18 23:26:19 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)6.http://127.0.0.1:3000/helloにアクセスする(hello world!!!!1)
参考リンク
終わりに
不明点/修正点あれば気軽にコメントください!
Twitterを細々とやっています_:(´ཀ`」 ∠):!?
- 投稿日:2020-03-18T23:29:00+09:00
Windows10ProでAWS SAMを使ってローカルでHelloWorld(サンプルはnode.js)
初めに
Windows10ProでAWS SAMを使ってHelloWorldしようと思ったら意外と大変だったので自分用メモ。
何も入っていない前提ですが、Dockerやnode等が入っている場合は飛ばしてください(特にこだわりがなければこの機会にすべて最新化をおススメします)この記事ですること
- node.jsを使ってローカルでHelloWorldする
この記事でしないこと
- AWS上にソースをアップロードする
- node.js以外を使ってHelloWorldする
執筆時の各バージョン
GitBash
v2.25.1
Docker
v2.2.0.4
node.js
v12.16.1
aws sam
v0.45.0
必要なものインストール/設定
Git for Windowsインストール
Git for Windows公式からダウンロードし、インストールする。
(特にチェック付けなくて大丈夫です)Dockerのインストール/設定
Docker公式からStableバージョンをダウンロードしてインストーラーをクリック。
インストールすると再起動を促されるので、再起動する。
再起動後にタスクバーのDockerアイコンを右クリック
-> Settings -> Resourses -> FILE SHARINGでCにチェックを付け、Aplly&Restertを押下する(AWS SAMを実行するドライブ)
node.jsのインストール
nodejs公式で最新のLTSをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)AWS SAMのインストール
AWS SAMをクリックしてインストーラーをダウンロードし、ライセンスに同意してインストールする。
(ライセンス以外はチェック付けなくて大丈夫です)SAMサンプルアプリでHelloWorld
1.コマンドプロンプトで
sam initと入力する。
2.Choice: で1と入力する(サンプルアプリ作成)
3.Runtime:で1と入力する(nodejs12.xで作成)出力例
> sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.7 4 - go1.x 5 - java11 6 - dotnetcore2.1 7 - nodejs10.x 8 - python3.7 9 - python3.6 10 - python2.7 11 - ruby2.5 12 - java8 13 - dotnetcore2.0 14 - dotnetcore1.0 Runtime: 1 Project name [sam-app]: hello-world Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git ----------------------- Generating application: ----------------------- Name: hello-world Runtime: nodejs12.x Dependency Manager: npm Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./hello-world/README.md4.
cd hello-worldと入力する(作成したサンプルアプリルートへ移動)
5.sam local start-apiと入力する(ローカルでサンプルアプリを起動)サンプルアプリ起動時出力例
>sam local start-api Mounting HelloWorldFunction at http://127.0.0.1:3000/hello [GET] You can now browse to the above endpoints to invoke your functions. You do not need to restart/reload SAM CLI while working on your functions, changes will be reflected instantly/automatically. You only need to restart SAM CLI if you update your AWS SAM template 2020-03-18 23:26:19 * Running on http://127.0.0.1:3000/ (Press CTRL+C to quit)6.http://127.0.0.1:3000/helloにアクセスする(hello world!!!!1)
参考リンク
終わりに
不明点/修正点あれば気軽にコメントください!
Twitterを細々とやっています_:(´ཀ`」 ∠):!?
- 投稿日:2020-03-18T19:51:44+09:00
アロー演算子で使う()と{}の違い
本の写経していたら
=> ()と=> {}の違いについて知らなかったので調べてわかったことを書きます(^^)
=> ()returnの明示が不要で、最後に評価された値をreuturnしてくれますが、(if)文を書けない。
> [1, 3].map((value, i) => ( value )) [ 1, 3 ][1, 3].map((value, i) => ( if(true){ value } )) ^^ SyntaxError: Unexpected token ifz
=> {}returnの明示が必要で、(if)文を書ける。
> [1, 3].map((value, i) => { value }) [ undefined, undefined ]> [1, 3].map((value, i) => { if(true){ return value } }) [ 1, 3 ]まとめ
値だけを返すようなシンプルな時は、
=> ()を使って、条件分岐したい時は=> {}を使う。といいと思いました。nodeむずかしいです(^^)よくわからなかったこと
=> ()はどういうルールで文法が制限されているか知っている人がいたら教えて下さいm(_ _)m
- 投稿日:2020-03-18T19:22:26+09:00
LINE Messaging APIの新機能でLINE公式アカウントのアイコンを変更する
概要
先日(2020/03/17)、LINE公式アカウントのアイコンをメッセージ送信ごとに変更できる機能が一般開放されました。
これを使うことにより、ボットの機能や担当者ごとにアイコンを切り替えたりできるようになります。詳細はこちらの公式サイト( https://developers.line.biz/ja/docs/messaging-api/icon-nickname-switch/#%E6%A6%82%E8%A6%81 ) をご覧ください。
イメージ
こんな感じで、1つの公式アカウントで複数のアイコンを使い分けれます。
使い方
※ そもそもメッセージの送信の仕方を知らないという方はこちら( https://qiita.com/fkooo/items/d07a7b717e120e661093 )などを参考にしてください。
使い方は簡単でこれまで
{ "type": "text", "text": "ただいま混み合っています。1時間後くらいにこちらからメッセージさせていただきます。" }みたいになっていたメッセージオブジェクトにsenderプロパティをつけて、
sender.nameに表示名、sender.iconUrlにアイコン画像をつけるだけです。{ "type": "text", "text": "ただいま混み合っています。1時間後くらいにこちらからメッセージさせていただきます。", "sender": { "name": "bot", "iconUrl": "https://rsasage.s3-ap-northeast-1.amazonaws.com/qiita/omocha_robot-square.png" } }コード
全体のコードは下記のようになります。
index.jsconst line = require('@line/bot-sdk') const config = { channelAccessToken: 'YOUR_CHANNEL_ACCESS_TOKEN' } client = new line.Client(config) client.pushMessage('YOUR_ACCOUNT_DESTINATION_ID', [ { type: "text", text: "ただいま混み合っています。1時間後くらいにこちらからメッセージさせていただきます。", sender: { name: "bot", iconUrl: "https://rsasage.s3-ap-northeast-1.amazonaws.com/qiita/omocha_robot-square.png" } } ])簡単ですね。
用途を考えてみた。
#1 チャットノベル
登場人物を増やせるので、別のアイコン同士で会話させて、たまにユーザに選択肢を与えたりすると面白いかもしれません。
#2 カスタマーサポート
人間による対応と自動通知による対応をアイコンを変えることでわかりやすくできます。
営業時間外はボットモードにして、営業時間内は人が対応することにしたり、ボットモードでも人間が対応できるように管理画面を自作したり、することになりますね。#3 複数人プレイのゲーム
ユーザからメッセージをwebhookで受け取った時にそれをそのまま他のユーザに流してやると、擬似的にグループチャットのようなことが実現できるはずです。
グループチャットにボットを追加するのと同じですが、不特定多数とプレイできるのとリッチメニューを利用できる点が違います。
ただ、PUSHメッセージをたくさん送ることになりかねないのでお財布的に課題はあるかもしれません。終わりに
他にもいろいろ工夫のしようがありそうですね。
Messaging APIを触ったことのある方なら簡単に導入できると思います。





- 投稿日:2020-03-18T18:25:22+09:00
レジの店員を呼ぶアプリをつくた android cordova ハイブリッドアプリ
成果物
https://play.google.com/store/apps/details?id=com.itsumen.regi&hl=ja
リポジトリ
https://github.com/yuzuru2/regi_apuri_sozai
環境
- node.js 12.14.0
- cordova 9.0.0
- java 1.8.0
※javaとandroidのsdkは各自インスコしてパスを通しておいてください。
コマンド
$ npm i -g cordova $ cordova create sample com.example.sample sample $ cd sample $ cordova platform add android $ cordova plugin add cordova-plugin-volume-control $ rm -rf www/* $ cd www $ git clone https://github.com/yuzuru2/regi_apuri_sozai.git . $ cd .. $ cordova run android
- 投稿日:2020-03-18T18:09:37+09:00
Vue.js セットアップメモ(Mac)
この記事の目的
Vue.jsの学習を始める際に実施したセットアップ手順のメモです。
開発環境、必要なもの
- Mac OS Catalina 10.15.2 ←自分の場合(参考程度)
セットアップ
ndenvのインストール
- 複数バージョンのNodeを切り替えて使用することになると思いますので、
ndenvをインストールします。$ brew install ndenv
- PATHを追加します
echo 'export PATH="$HOME/.ndenv/bin:$PATH"' echo 'eval "$(ndenv init -)"'
- Nodeをインストールするために
node-buildをインストールします。$ git clone https://github.com/riywo/node-build.git $(ndenv root)/plugins/node-buildNode.jsのインストール
- インストールできるNode.jsバージョンを確認
$ ndenv install -l
- Node.jsのインストール
$ ndenv install v12.16.1 #LTS版がおすすめ
- 使用するNode.jsの設定
$ ndenv versions # インストールしているNode.jsのバージョンを確認する $ ndenv global v12.16.1 # デフォルトバージョンを設定するとき $ ndenv local v12.16.1 # プロジェクトごとに変更するとき
- Node.jsのバージョン確認
$ node --versionVue.jsのインストール
- Vue CLIのインストール
$ npm install -g @vue/cli
- Vue cli-service-globalのインストール
$ npm install -g @vue/cli-service-global動作確認
- vueファイルを作成します。
$ cat app.vue <template> <div id="app"> <h1>Hello World</h1> </div> </template>
- 実行する
$ vue serve
- ブラウザで確認する。
- http://localhost:8080 にアクセスしてみてください。
- 期待通りにブラウザに表示されていたら、セットアップ完了です!
終わりに
- 最低限のセットアップになりますが、上記の手順で一通りの実行環境は整います。
- editor用のプラグインの設定等の設定も追記予定です。
補足
- Google Chrome用に
vue-devtoolsをインストールしておくのも必須のようです。
- 投稿日:2020-03-18T14:53:46+09:00
nodebrewでNode.jsをインストール(デザイナー向け)
nodebrewとは
Node.js のバージョンを管理するツールです。
なぜNode.js のバージョンを管理するのか
それは Node.js が現在も開発中のプログラミング言語だからです。
日々様々な改善が行われ、新バージョンで機能が変更される、ということもあります。
今まで利用していた機能が、次のバージョンで使えなくなるということもあるのです。
そのようなことを防止するために、どのバージョンの Node.js を利用しているのかを明確にし、そして必要に応じてバージョンを切り替えたりできると便利なのです。nodebrewのインストール
…の前に豆知識(?)
ターミナルでコマンドを実行したけどきちんと処理されているの?
やたら時間が掛かっているけどいつ処理が終わるの?
…という方。
処理の後に、以下が出たら処理が終わった合図(次のコマンドを打っても良い)です。自分のPCの名前 ~ %それではnodebrewのインストールを始めましょう。
1.ターミナルで以下を実行
curl -L git.io/nodebrew | perl - setup2.以下が表示されます
% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0 0 0 0 0 0 0 0 0 --:--:-- 0:00:01 --:--:-- 0 0 0 0 0 0 0 0 0 --:--:-- 0:00:01 --:--:-- 0 100 24634 100 24634 0 0 10473 0 0:00:02 0:00:02 --:--:-- 174k Fetching nodebrew... Installed nodebrew in $HOME/.nodebrew ======================================== Export a path to nodebrew: export PATH=$HOME/.nodebrew/current/bin:$PATH ========================================3.以下を実行します
echo 'export PATH=$HOME/.nodebrew/current/bin:$PATH' >> ~/.profile4.以下を実行します
source ~/.profile5.以下を実行します
nodebrew6.以下のような情報(バージョン情報)が表示されたらnodebrewのインストール成功です
nodebrew 1.0.1 Usage: nodebrew help Show this message nodebrew install <version> Download and install <version> (from binary) ...nodebrewでNode.jsをローカルインストール
…の前に豆知識(?)
- グローバルインストール
自動的に実行ファイルをパスが通るのでパスを指定しなくて実行できる
ただし、バージョンアップ等で、動作しなくなるプロジェクトが発生する場合があるので注意- ローカルインストール
プロジェクト単位でバージョンを管理できる
プロジェクトごとなため、 容量がとられることがあるが、基本的にはローカルインストールを利用すべきそれではNode.jsのローカルインストールを始めましょう。
1.以下を実行します
安定版(Node.js公式サイトに「推奨版」と記載があるバージョン)をインストールするコマンドです。
nodebrew installでインストールすると時間が掛かるので以下を実行してください。nodebrew install-binary stable2.以下を実行します
nodebrew ls3.以下のような情報(バージョン情報)が表示されたらNode.jsのローカルインストール成功です
v12.16.1 current: none4.以下を実行します(どのバージョンを使用するかの指定:必須)
nodebrew use v12.16.15.完了
次回はgulpとgulp-sassの設定を行います。
参考サイト
- 投稿日:2020-03-18T11:57:22+09:00
Node.jsの設計をつらつらと概観する
株式会社Global Mobility ServiceでソフトウェアエンジニアのインターンをさせてもらっているShirubaです。グローバルな環境で利用されている社会的サービスの開発の一端を担いたい志ある方は、ぜひ緩くお話ししましょう〜。バックエンドはNode.jsを使っています。?♂️→ 採用ページ
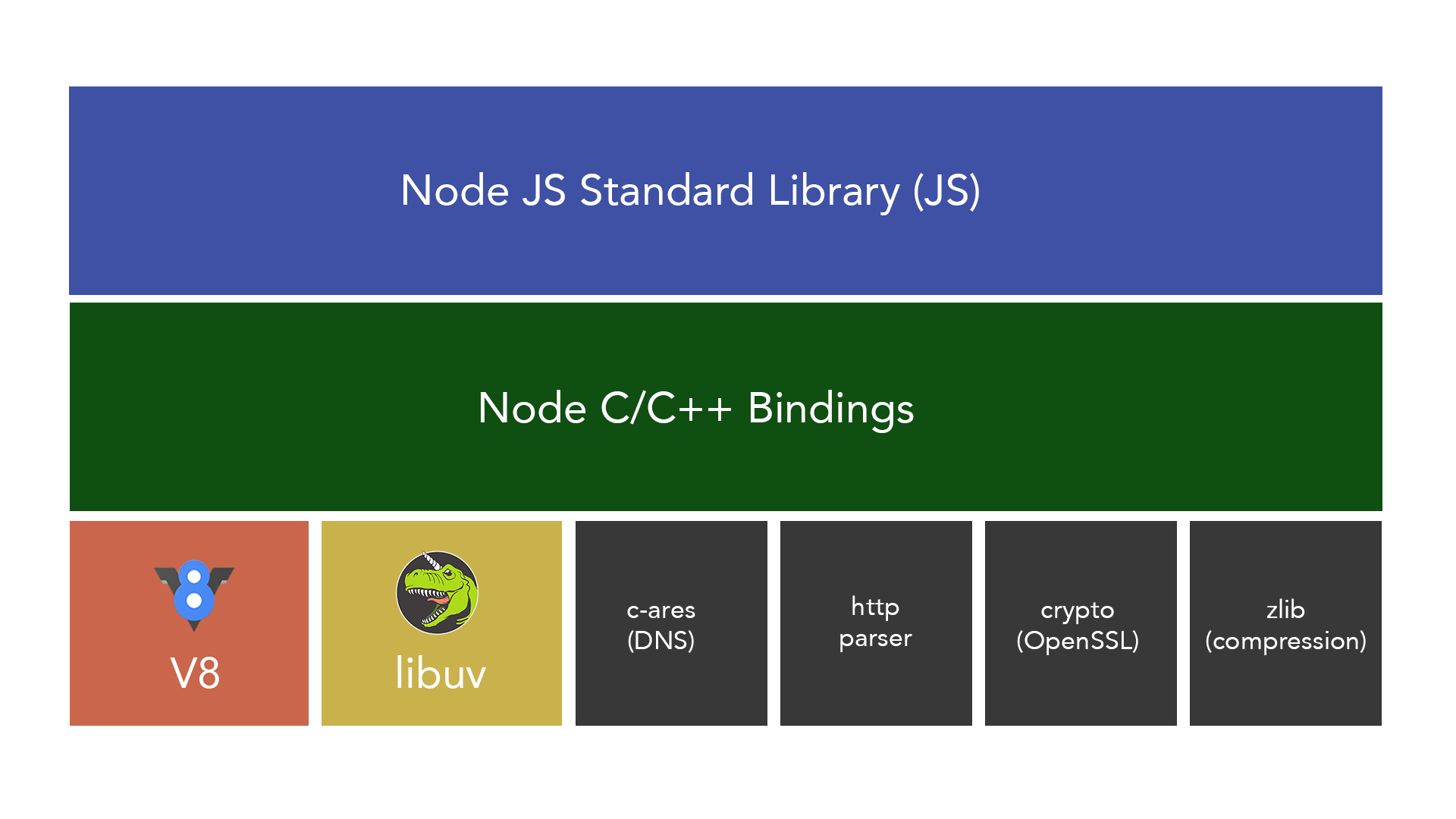
Node.jsについて色々資料を読んでメモをとったりしていたので、一度まとめておきたくて、この記事を書くことにしました。V8やLibuvなど低レイヤ技術の設計をベースにNode.jsを概観していきます。
Node.jsとは
Node.js公式によるNode.jsの定義は以下です。
Node.js はスケーラブルなネットワークアプリケーションを構築するために設計された非同期型のイベント駆動の JavaScript 環境です。
https://nodejs.org/ja/about/Node.jsを理解する上で重要な特徴を定義から抽出すると、以下の3つです。
- スケーラブル
- 非同期型
- イベント駆動
この3つの特徴については後で触れていきます。
Node.jsの内部構造
画像引用:https://blog.insiderattack.net/event-loop-and-the-big-picture-nodejs-event-loop-part-1-1cb67a182810Node.jsは、いくつかのモジュールを組み合わせて構成されています。Node.jsを理解する上で重要なのは「V8」と「Libuv」です。この2つが、サーバーサイドでのJavascript実行環境を作っています。(クライアントサイドでは、chrome組み込みのv8とhtml5(イベントループ等を提供)でJavascript実行環境が実現されているそう。)
V8
どうでもいいですが、V8の読み方は「ヴィーエイト」です。謎に「ブイハチ」って読んでた自分を恥じたい。
V8の定義を公式から引用します。
V8 is Google’s open source high-performance JavaScript and WebAssembly engine, written in C++. It is used in Chrome and in Node.js, among others. It implements ECMAScript and WebAssembly, and runs on Windows 7 or later, macOS 10.12+, and Linux systems that use x64, IA-32, ARM, or MIPS processors. V8 can run standalone, or can be embedded into any C++ application.
https://v8.dev
- V8っていうのは、Javascript Engineを指します。要するに、Javascriptで書かれているソースコードを受け取って、機械語に変換してOS上で実行してくれるのがV8です。
- chromeとnode.jsはJavascript EngineとしてV8を採用していますが、それ以外は違います。例えばSafariではV8ではなくJavascriptCoreを採用しています。
ちなみに、EngineだとかRuntimeだとか単語がややこしいのですが、Javascript Engine、 Javascript Runtime、A compiler、Virtual Machineは全てV8を指すと考えて良いそうです。(参考:https://www.youtube.com/watch?v=PsDqH_RKvyc)
また、V8の定義に「ECMAScript」という単語が入っているので定義を引用しておきます。
ECMAScript(エクマスクリプト)は、JavaScriptの標準であり、Ecma Internationalのもとで標準化手続きなどが行われている。
引用:https://ja.wikipedia.org/wiki/ECMAScript要するに、Javascirptの文法の標準がECMAScriptです。「(Javacsriptで書かれている)ソースコードが何を意味しているのか」を表します。V8が受け取る、Javascriptで書かれているソースコードは極論ただのテキストの塊です。V8は、Javascriptで書かれたソースコードをECMAScriptを用いて解析しています。
V8を理解していなくてもNode.jsのアーキテクチャは理解できるので、V8は後回しにして、この記事の最後で見ていきます。
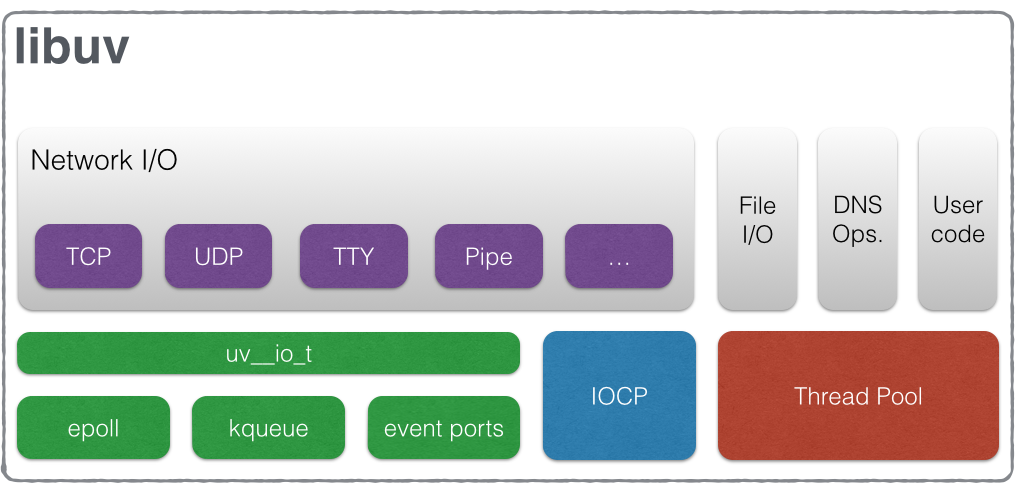
Libuv
Libuvの定義を引用します。
libuv is a multi-platform support library with a focus on asynchronous I/O. It was primarily developed for use by Node.js, but it’s also used by Luvit, Julia, pyuv, and others.
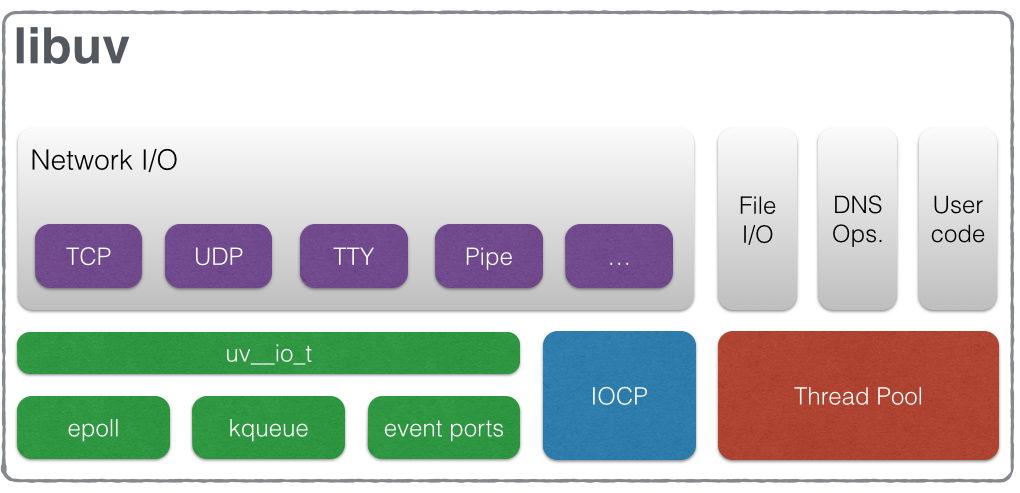
引用:http://docs.libuv.org/en/v1.x/#overview非同期I/Oは、OSごとに実現方法が異なります。epollを使うOSがあったり、kqueueを使うOSがあったり。(非同期I/Oについては後述。)そこでepollやkqueueなど低レイヤの技術を抽象化したインタフェースを作って、OSを気にすることなく非同期I/Oを使えるようにしようとして作られたのがLibuvです。
Libuvの内部は以下のようにデザインされています。
画像引用:http://docs.libuv.org/en/v1.x/design.html#design-overviewちなみにNode.jsで使われているイベントループを提供してくれているのもLibuvです。
Node.js Bindings
これは、概念的なものです。
v8やlibuvはc++で書かれている一方で、Node.jsを使ってapplicationを作るときに私たちはjavascriptを用います。これがNode.jsの旨みでもあるのですが、私たちはJavascriptで開発しているのに、内部的にはc++で記述されているv8とかlibuvを利用できるのです。
このJavascriptと他のプログラミング言語の橋渡しをしているのがNode.js Bindingsです。
ちなみにNode.js Bindingsは、「Language Bindings」のことを指しています。ということで、「Language Bindings」の定義をwikipediaから引用します。
In computing, a binding is an application programming interface (API) that provides glue code specifically made to allow a programming language to use a foreign library or operating systemservice (one that is not native to that language).
Binding generally refers to a mapping of one thing to another. In the context of software libraries, bindings are wrapper libraries that bridge two programming languages, so that a library written for one language can be used in another language.[1] Many software libraries are written in system programming languages such as C or C++. To use such libraries from another language, usually of higher-level, such as Java, Common Lisp, Scheme, Python, or Lua, a binding to the library must be created in that language, possibly requiring recompiling the language's code, depending on the amount of modification needed.[2] However, most languages offer a foreign function interface, such as Python's and OCaml's ctypes, and Embeddable Common Lisp's cffi and uffi.[3][4][5]
https://en.wikipedia.org/wiki/Language_bindingNode.js Bindingsについて詳しくは触れませんが、Internals of Node- Advance node ✌️が面白かったです。
コアモジュール
Node.jsには組み込みのコアモジュールというものが存在します。コアモジュールは沢山あるので、それぞれの重要度とかはNode.js徹底攻略 ─ ヤフーのノウハウに学ぶ、パフォーマンス劣化やコールバック地獄との戦い方を参考にされたし。
サーバのアーキテクチャ
Node.jsの内部を雑に見渡したところで、Node.jsの設計を見ていきます。
Node.jsで特徴的なのが、採用しているサーバアーキテクチャです。サーバーのアーキテクチャには、一般的に「Thread Based」と「Event Driven」があります。Node.jsの採用しているサーバアーキテクチャは「Event Driven」、つまり「イベント駆動型」です。(参考:Server Architectures)
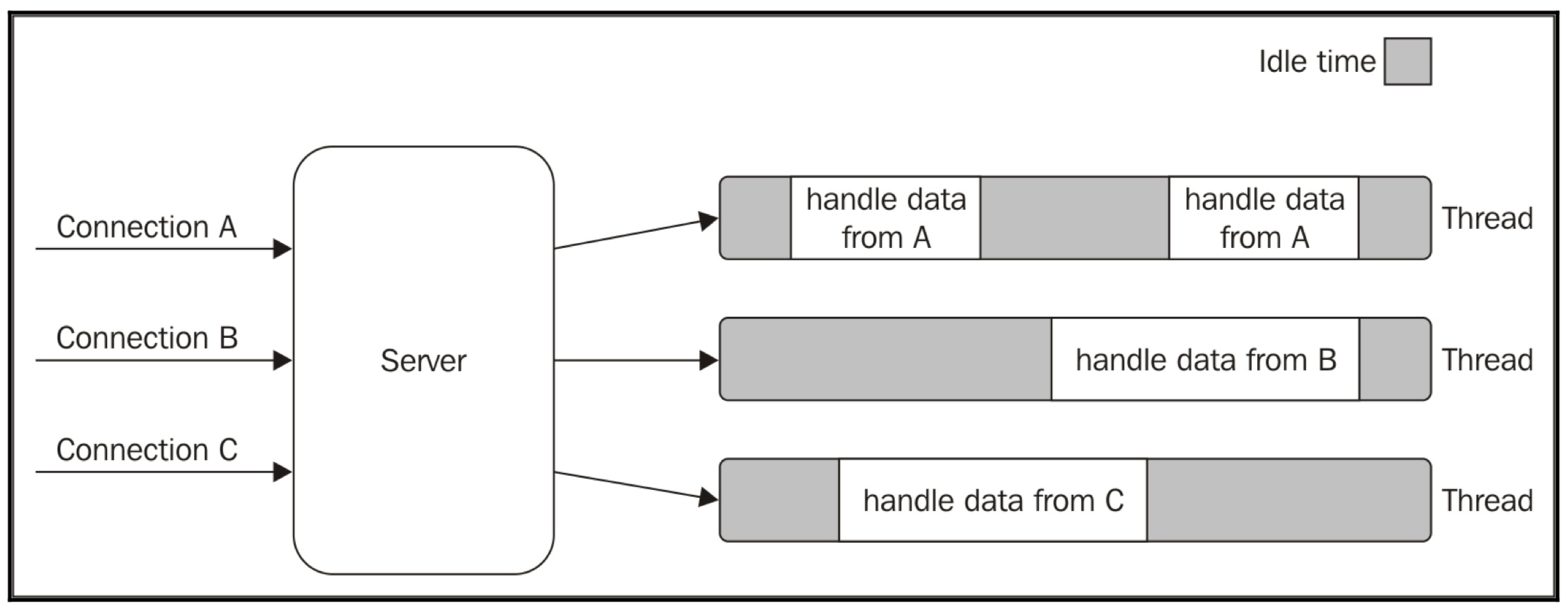
Thread-based
Thread Basedの場合のサーバの典型的なコードは以下のようになる。
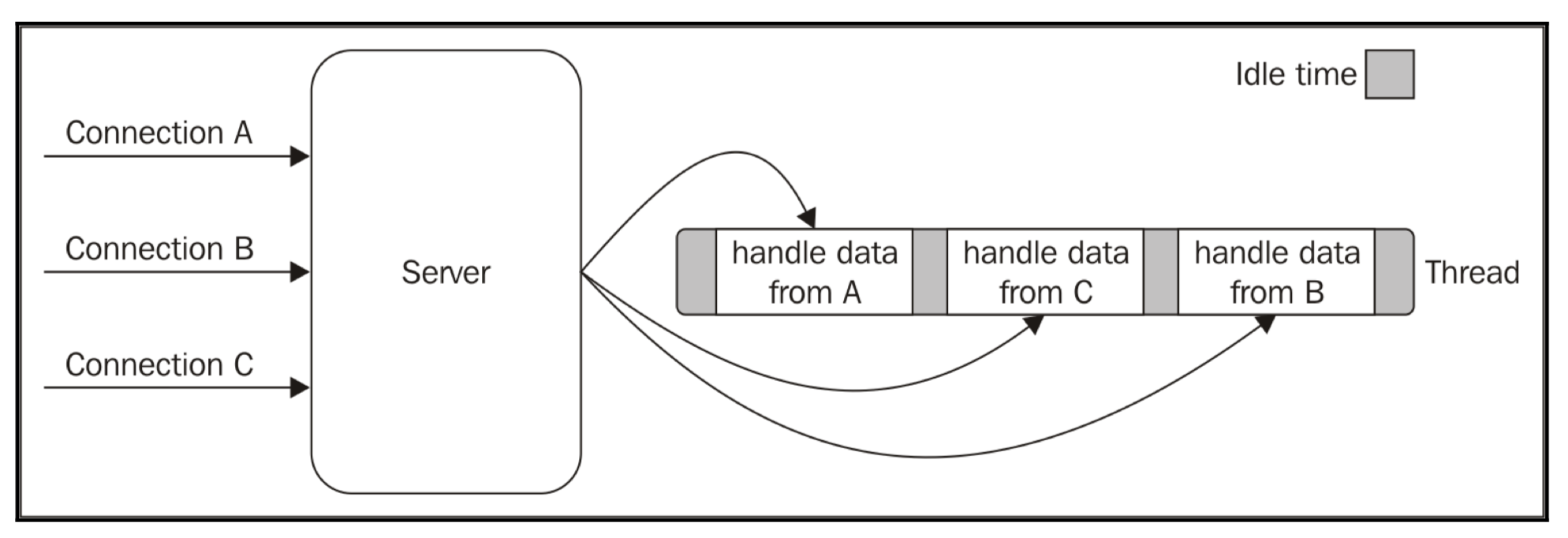
[画像引用:https://www.slideshare.net/NodejsFoundation/nodes-event-loop-from-the-inside-out-sam-roberts-ibm]acceptというシステムコールを通して接続されたコネクションをpthread_createで別のスレッドに渡して、別のスレッドでそのコネクションを処理させます。メインスレッドは、acceptでのブロッキング状態にすぐに戻り、ユーザーからの新しい接続に備えるという流れです。
つまり、ユーザーからのコネクション1つにつきスレッドを1つ作成して、そのスレッドでコネクションに対応しているという訳です。これだとスレッドの無駄使いだし、コンテキストスイッチも発生してしまいます。
このサーバアーキテクチャを図で表すと以下のようになります。
[画像引用:Node.jsデザインパターン第2版]Idle timeも多くなってしまっていることが分かります。このサーバアーキテクチャで出現した問題が「c10k問題」。c10k問題はThe c10k Problemを参考されたし。
wikipediaからc10k問題の定義を引用しときます。
C10K問題(英語: C10K problem)とは、Apache HTTP ServerなどのWebサーバソフトウェアとクライアントの通信において、クライアントが約1万台に達すると、Webサーバーのハードウェア性能に余裕があるにも関わらず、レスポンス性能が大きく下がる問題である。
引用:https://ja.wikipedia.org/wiki/C10K問題またまた引用します。
preforkモデルのApatchでは、クライアントの接続要求から始まる一連の処理を各プロセスで1接続ずつ処理します。そのため大量の接続を同時に処理するにはその分だけプロセス(またはスレッド)を起動しなければなりません。これでも複数の接続を並行して処理することはできますが、あまり大量のプロセスを起動するとプロセス間コンテキストスイッチのオーバーヘッドが大きくなって性能が劣化します。これがC10K問題の本質です。
引用: nginx実践入門このc10k問題を解決するのが、非同期I/Oであり、非同期I/Oを用いたサーバアーキテクチャである「Event-Driven」(イベント駆動型)です。
Event-Driven
イベント駆動型のサーバアーキテクチャを理解するためには、まず「非同期I/O」を理解する必要があります。
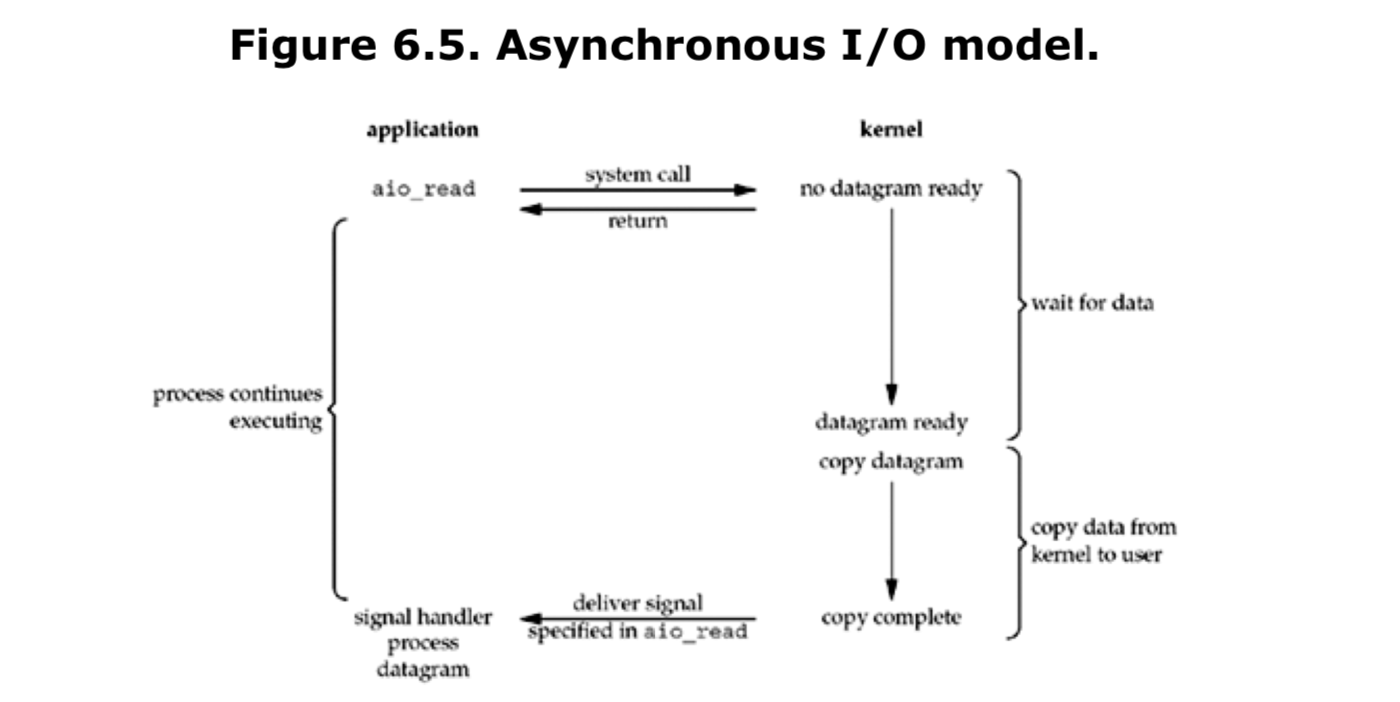
非同期I/O
Unixには、以下の5種類のI/Oモデルが存在します。
- ブロッキングI/O
- 非ブロッキングI/O
- I/Oの多重化(selectとpoll)
- シグナル駆動I/O(SIGIO)
- 非同期I/O(Posix.1のaio_関数群)
Node.jsで使われているのは「非同期I/O」です。
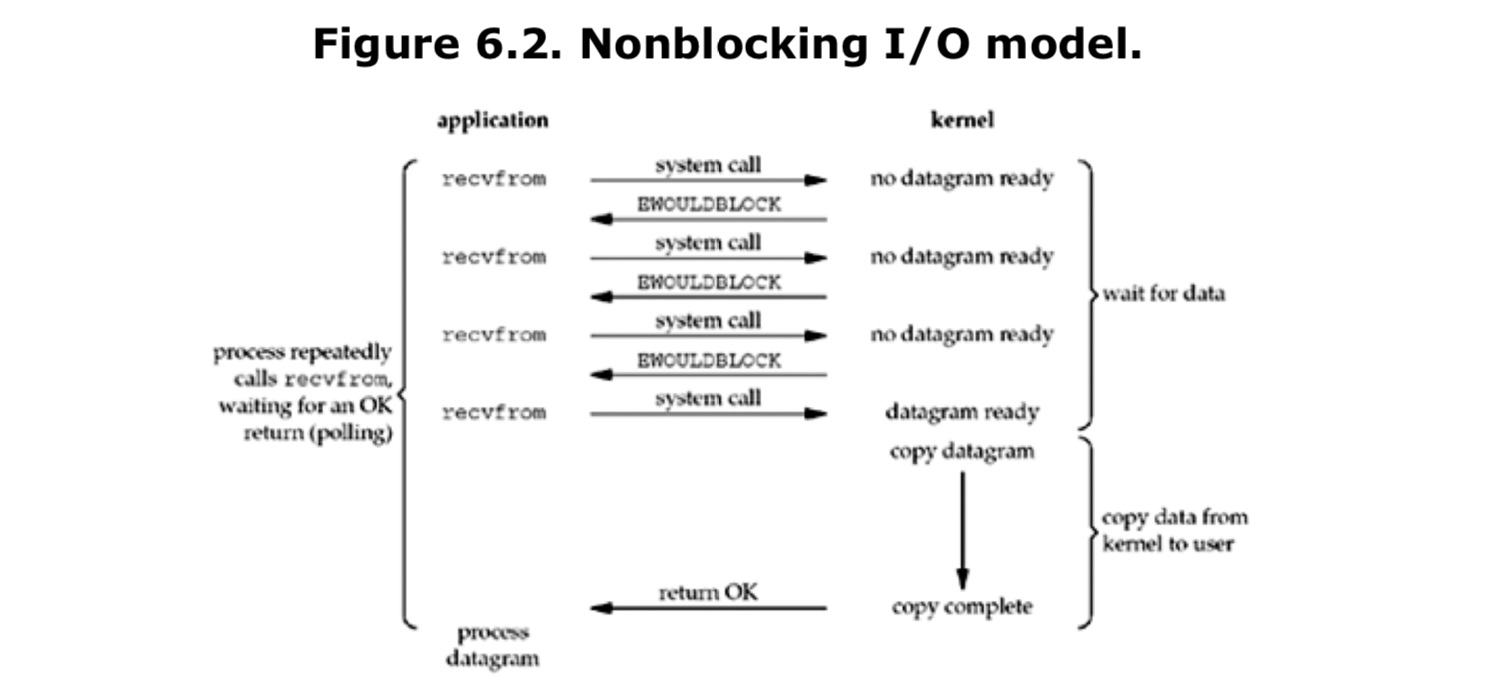
処理をカーネルに任せ、処理が完了したらカーネルが元のスレッドに通知をよこすというI/Oモデルです。ちなみによく聞く「ノンブロッキングI/O」は以下のようなI/Oモデルです。
図から分かるように、アプリケーション側からカーネルに「データの準備が完了したか」を尋ねる作業をループで繰り返す必要があり、リソースが勿体無いので、イベント駆動型では非同期I/Oモデルが採用されています。
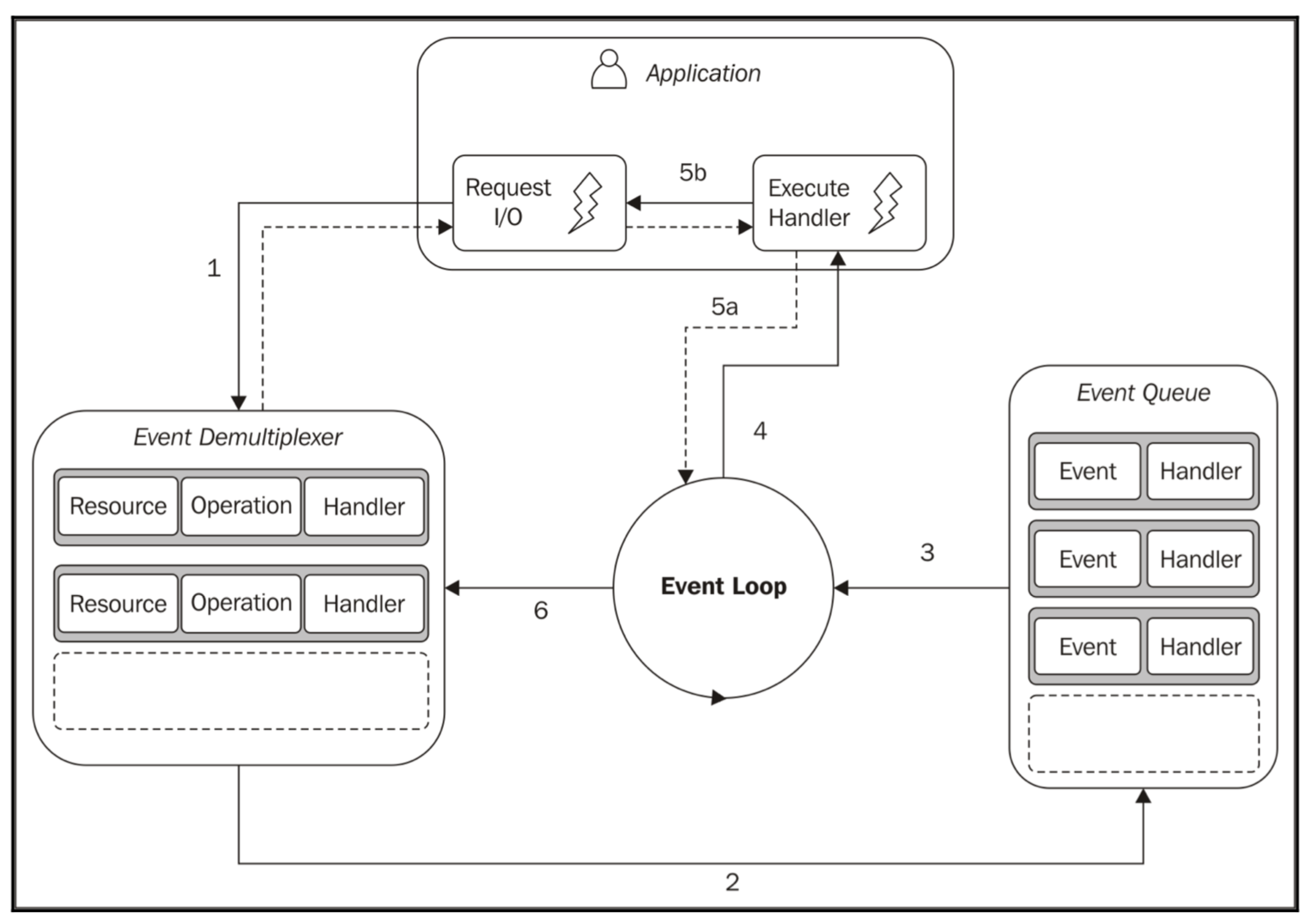
この非同期I/Oモデルを用いることで実現されるのが「イベントループ」です。通知を発生させるイベントを常にループ文で監視していることから「イベントループ」です。また、このおかげでユーザーからのコネクションをシングルスレッドで処理することが可能になります。
画像引用:Node.jsデザインパターン第2版リアクタパターン
このイベントループを用いたイベント駆動型モデルは、リアクタパターンと呼ばれます。(非同期I/Oを用いたイベント駆動型モデルなので、プロアクタパターンと呼ぶのだろうか。「Node.jsデザインパターン第2版」に沿って、ここではリアクタパターンと呼ぶことにします。)
リアクタパターンの定義は以下。
リアクタパターンではI/Oの処理はいったんブロックされる。監視対象のリソース(群)で新しいイベントが発生することでブロックが解消され、この時、イベントに結びつけられたハンドラ(コールバック関数)に制御を渡すことで呼び出し側に反応(react)する。
引用:Node.jsデザインパターン第2版Node.jsでは、非同期処理を使う場合、イベントにコールバックを持たせて、イベントが終了したものからコールバックを実行しています。ちなみに、Javascriptの関数は第1級オブジェクトなので、関数にコールバック関数を持たせるのが非常に容易です。
リアクタパターンを図で表すと以下のようになる。
画像引用:Node.jsデザインパターン第2版Node.jsでは、ここで説明した「イベント駆動型」モデルが採用されています。ただ、注意したいのは、Node.jsで用いられているイベントループのデザインはこれとは少し異なるということです。
まずNode.jsでは、非同期I/Oを使っている処理もありますが、内部的にスレッドプールを使っている処理もあります。そして2つにNode.jsではイベントキューが複数存在するということです。全てのイベントのハンドラが同一のイベントキューに入れられていくのではなく、イベントの種類に応じて積まれていくイベントキューが異なります。
Libuvが提供する非同期処理のアーキテクチャ
Node.jsで用いられる「イベントループ」を提供しているのがLibuvです。ここではLibuvが提供する以下の概念について見ていきます。
- Event Loop
- Handles
- Requests
- Thread Pool
イベントループ
イベントループの定義を公式から引用します。
The event loop is what allows Node.js to perform non-blocking I/O operations — despite the fact that JavaScript is single-threaded — by offloading operations to the system kernel whenever possible.
Since most modern kernels are multi-threaded, they can handle multiple operations executing in the background. When one of these operations completes, the kernel tells Node.js so that the appropriate callback may be added to the poll queue to eventually be executed.
引用:The Node.js Event Loop, Timers, and process.nextTick先ほど紹介したように、「非同期I/O」を可能にするのが「イベントループ」です。ちなみに、イベントループはNode.jsのメインスレッドで、ひたすらクルクル回っています。(ループ文)
メインスレッドを止めてしまうようなタスク(I/Oに関するタスクなど)を入れてしまうと、その処理に時間を食ってしまい、そこでイベントループが止まってしまい、他の処理ができなくなります。そのため、そういった処理に関しては、カーネル内のマルチスレッドを使った非同期I/Oモデルに処理を依頼する訳です。そして依頼したI/O処理が完了したら、登録しておいたハンドラ(コールバック関数)を実行する訳ですが、このハンドラはqueueに入って、メインスレッド(イベントループが回っているスレッド)で順次実行されていきます。この挙動によって、Node.jsの非同期I/Oでは、「競合状態」を気にせずに開発することができます。
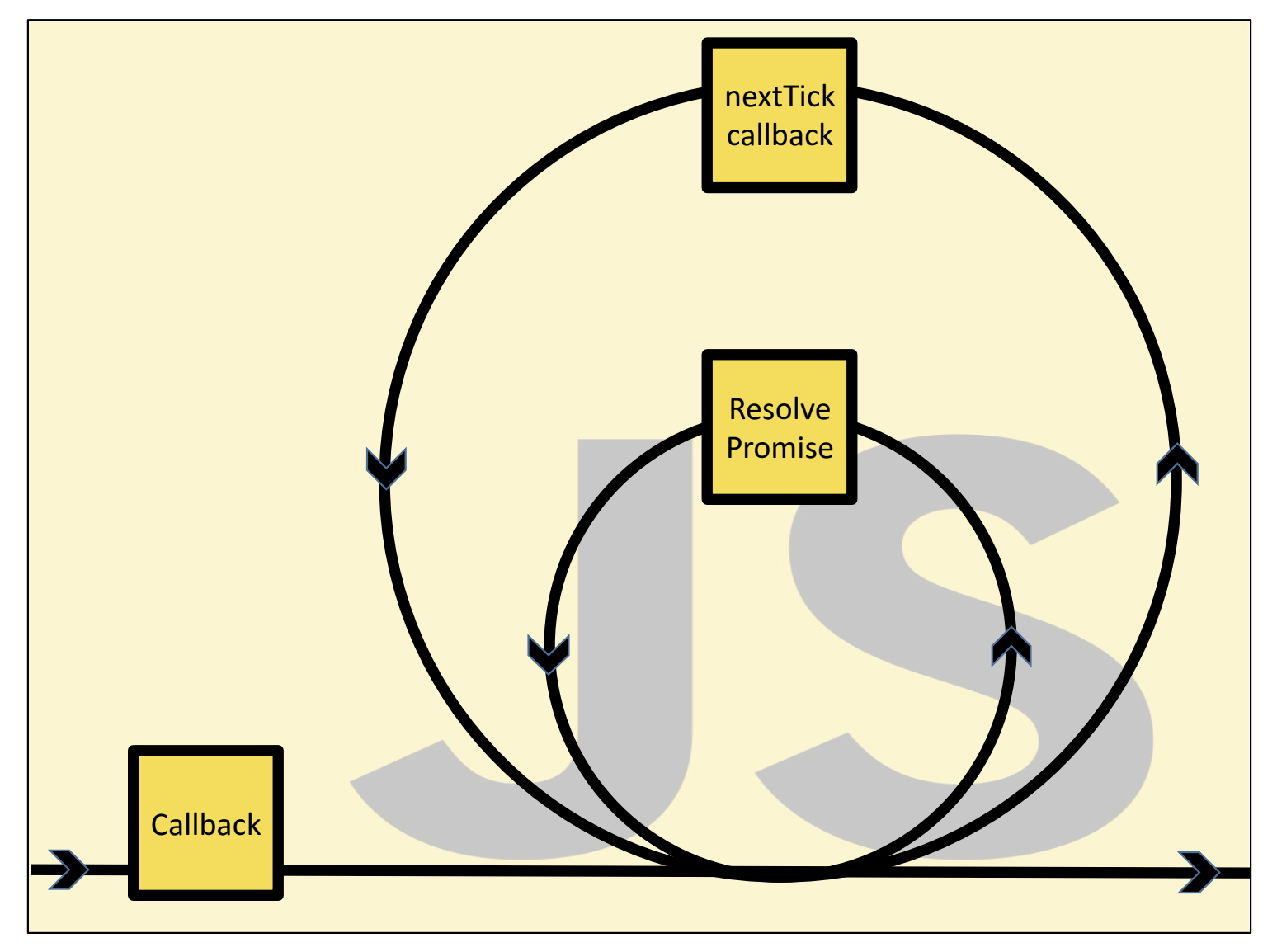
Node.jsのイベントループは、いくつかのフェーズから構成されています。このフェーズごとの挙動は、ここでは省略させてもらいます。イベントループに関する分かりやすかった図を載せておきます。
[画像引用:https://drive.google.com/file/d/0B1ENiZwmJ_J2a09DUmZROV9oSGc/view]この図内の「黄色いJSの箱」の部分を詳細に見ると以下のようなループになっています。
[画像引用:https://drive.google.com/file/d/0B1ENiZwmJ_J2a09DUmZROV9oSGc/view]Node.jsのサーバを開始する際にも、イベントループが利用されています。公式ドキュメントの、Node.jsを使ったサーバーを作るためのコードを引用します。
const http = require('http'); const hostname = '127.0.0.1'; const port = 3000; const server = http.createServer((req, res) => { res.statusCode = 200; res.setHeader('Content-Type', 'text/plain'); res.end('Hello World\n'); }); server.listen(port, hostname, () => { console.log(`Server running at http://${hostname}:${port}/`); });server.listenで内部的にepollなど非同期I/Oが用いられています。ハンドラは、arrow関数の部分ですね。tcp connectionをacceptした時のコールバックとしてアプリケーションが非同期に実行されるようにコードが書かれています。
HandleとRequest
イベントループ内で処理されるタスクはHandleオブジェクトとRequestオブジェクトの2種類存在します。
Handleは長期間存在することができるオブジェクトで、I/Oが発生していない時でもイベントループを維持します。Requestは短期間存在するオブジェクトで、I/Oが発生している時のみイベントループを維持します。
イベントループは、アクティブなHandlesもしくはRequestsがなければ止まります。
スレッドプール
Node.jsはイベント駆動型のサーバアーキテクチャを採用していることからも、よく「シングルスレッド」だと表現されます。しかしここで注意しておきたいのですが、Node.jsは処理によって、内部的にスレッドプールを使った並行処理を行なっています。
ここから動画「The Node.js Event Loop: Not So Single Threaded」から画像を大量拝借しています。(すごく分かりやすかった。)
例えばCPU intensiveな処理であるcryptモジュールを使ったコードを見てみます。
[画像引用:https://www.slideshare.net/nebrius/the-nodejs-event-loop-not-so-single-threaded]ここでcrypt.pdkdf2は非同期に実行されています。(引数の最後に、非同期処理特有のcallbackであるarrow関数が見られます。これが無ければcrypt.pdkdf2は同期処理で実行されます。)for文でループさせてcrypt.pdkdf2を2回使用していることに注意して下さい。これをマルチコアで実行すると、実行にかかる時間は以下のようになります。
[画像引用:https://www.slideshare.net/nebrius/the-nodejs-event-loop-not-so-single-threaded]同じくマルチコア環境で、今度は繰り返し回数を4回にしてみると以下のようになります。
[画像引用:https://www.slideshare.net/nebrius/the-nodejs-event-loop-not-so-single-threaded]マルチコアで実行しているため前の場合と比べて2倍の時間がかかってしまっていることに注意です。また、preemptiveなマルチタスクとして処理されている(それぞれのタスクを割り当てられたtime sliceごとに実行していく)ので、4回全て同じくらいの処理時間で終了しています。
今度は繰り返し回数を6回にすると実行時間は以下のようになります。
[画像引用:https://www.slideshare.net/nebrius/the-nodejs-event-loop-not-so-single-threaded]なぜこのようになるかというと、Node.jsが内部的に4つのthread poolをデフォルトで持っているからです。4つのタスクは4つのスレッドを用いてマルチタスクで処理され同時に終わっていますが、後の2つはスレッドが空いてから実行されます。(このthread poolはLibuvによって提供されているもので、環境変数UV_THREADPOOL_SIZEをいじることでthread poolの個数を変えることができます。)
これでNode.jsでは内部的にスレッドプールが用いられていることが分かりました。一方で、先に紹介した通り非同期I/Oも用いられています。非同期I/Oを示すためにhttpsモジュールを使った例も動画で紹介されていたので、見ていきます。
[画像引用:https://www.slideshare.net/nebrius/the-nodejs-event-loop-not-so-single-threaded](上のスライドではfor文を2回繰り返していますが、)for文を6回繰り返した場合の実行時間は以下です。
[画像引用:https://www.slideshare.net/nebrius/the-nodejs-event-loop-not-so-single-threaded]httpモジュールは、thread poolを使わず、OSに依頼してepollなどを使っているため、6 Requestsの場合でもほぼ同時にタスクが終了しています。
では、どの処理がthread poolを使って、どの処理がepollやkqueueなど非同期I/Oを使うのかっていう話になりますが、以下の画像を参照してください。
[画像引用:https://www.slideshare.net/nebrius/the-nodejs-event-loop-not-so-single-threaded]基本的にはthread poolではなく、OSが提供する非同期I/Oが使われます。じゃあ何故全てOSの非同期I/Oを使わずにthread poolを使う必要があるのか。それは設計上の難しさがあったからだそうです。詳しくはasynchronous disk I/Oを参考にしてください。
繰り返しますが、このthread poolはLibuvが提供しています。Libuvのデザインの画像をよく見ると右にthread poolと載っています。
V8
Libuvを一通り見たところで、次はV8を見ていきます。V8は、Javascirptで書かれているソースコードを受け取って、それを解析しcompileして実行します。
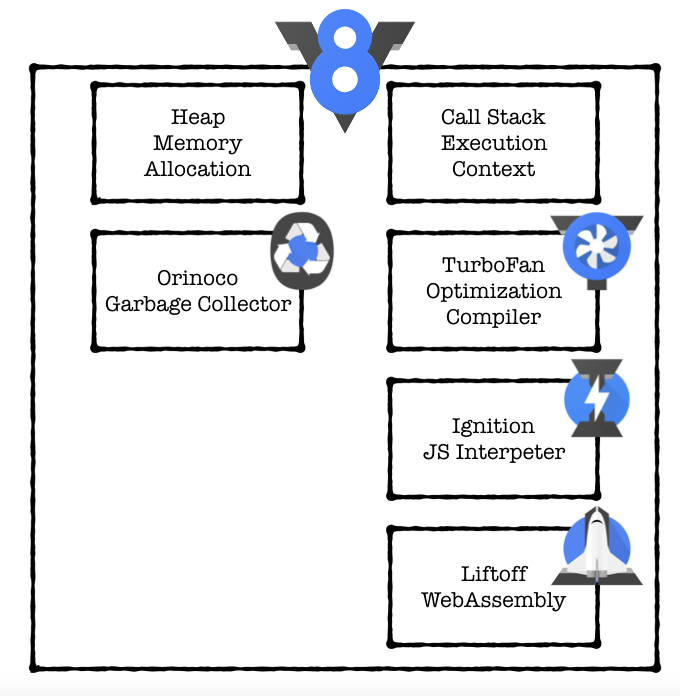
V8の機能群
[画像引用:JavaScript V8 Engine Explained]
- コードを実行する環境として、call stackとheapという概念があります。Javascriptはシングルスレッドで実行される言語であり、call stackは1つだけです。また、オブジェクトをheapに割り当てたりするわけですが、オブジェクトを使い終わったのに割り当てたメモリを解放しないとメモリリークが起きちゃいます。そこでOrinocoというGarbage Collectorの出番となります。
- V8はJavascriptで書かれたソースコードを受け取って、それを機械語にする必要があります。その際に使われるのがIgnitionというインタプリタとTurboFanという最適化コンパイラです。
(Liftoffについてはこの記事では触れていません。)
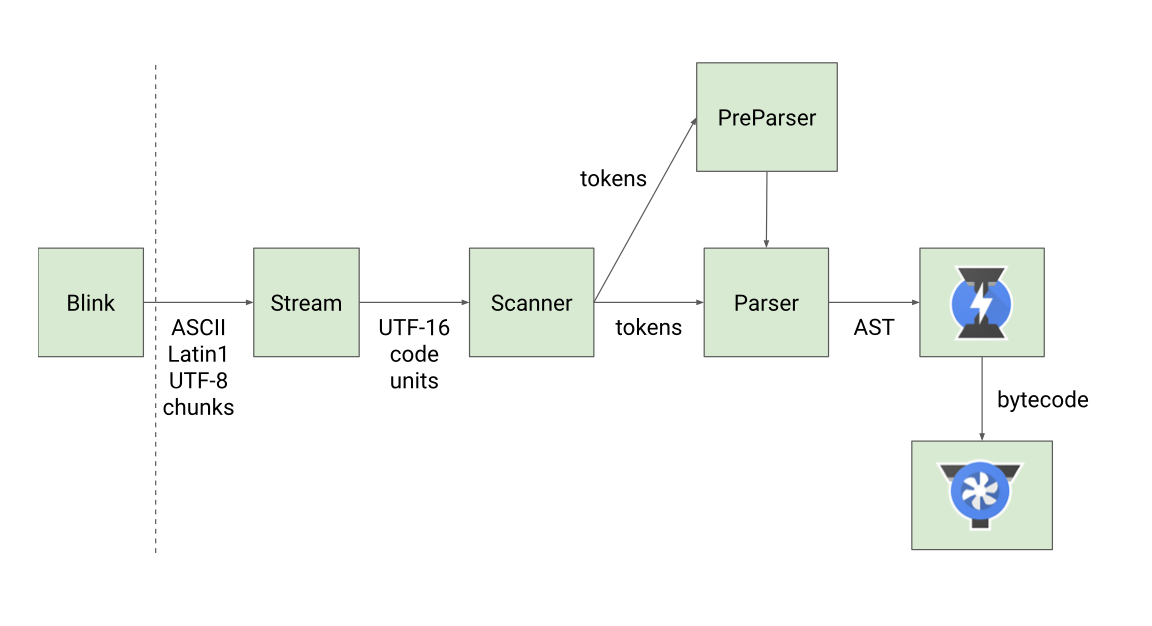
V8の処理の流れ
[画像引用:Understanding V8’s Bytecode]
- ソースコードをV8に渡す
- Perserを使ってソースコードを解析。そしてASTという抽象構文木を作る。
- IgnitionというInterpreterを使ってASTをBytecodeに変換する。(変換されたBytecodeは同じくIgnitionによって実行される。)
- IgnitionはASTをBytecodeに変換しつつ、その時の変換情報を蓄えている。(Profiilng)
- 特定の条件下でコードを最適化するために、Ignitionは、蓄えた情報とBytecodeをTurboFanに渡す。
- TurboFanは、そのコードを最適化された機械語に変換して実行
IgnitionとTurboFanの部分が少しややこしいので、別の画像でも確認しておきましょう。
[画像引用:Parsing JavaScript - better lazy than eager? ]ASTがBytecode generatorによってBytecodeになり、それがIgnitionによって実行されます。(ASTをBytecodeに変換するBytecode generatorと、Bytecodeを実行するBytecode Handlerを合わせてIgnitionと総称しているぽいです。)
TurboFanは、Bytecodeを受け取り、機械語を生成し、それをそのまま実行しています。ScannerとParserとAST
Scanner
[画像引用:Blazingly fast parsing, part 1: optimizing the scanner]Scannerは、V8に渡されたJavascriptソースコードを字句解析(tokenizer/ lexical analysis )して、tokenに分解します。tokenの定義は以下。
Tokens are blocks of one or more characters that have a single semantic meaning: a string, an identifier, an operator like ++.
引用:https://v8.dev/blog/scannerパフォーマンス向上のためにScannerで使われている仕組みなど、詳細はBlazingly fast parsing, part 1: optimizing the scannerを参照して下さい。
Parser
字句解析を終えてparserに流れてきたtokenを、ECMAScriptで決められている構文に沿ってabstract syntax tree(AST)にします。この作業をparseといいます。
AST(Abstract Syntax Tree)っていうのは、抽象構文木のことで、プログラムの構造を示すオブジェクトです。
このASTは、Engineのみでなく、transpilerや静的解析にも使われるものです。V8では、このASTを基にBytecodeがIginitionによって作成されます。
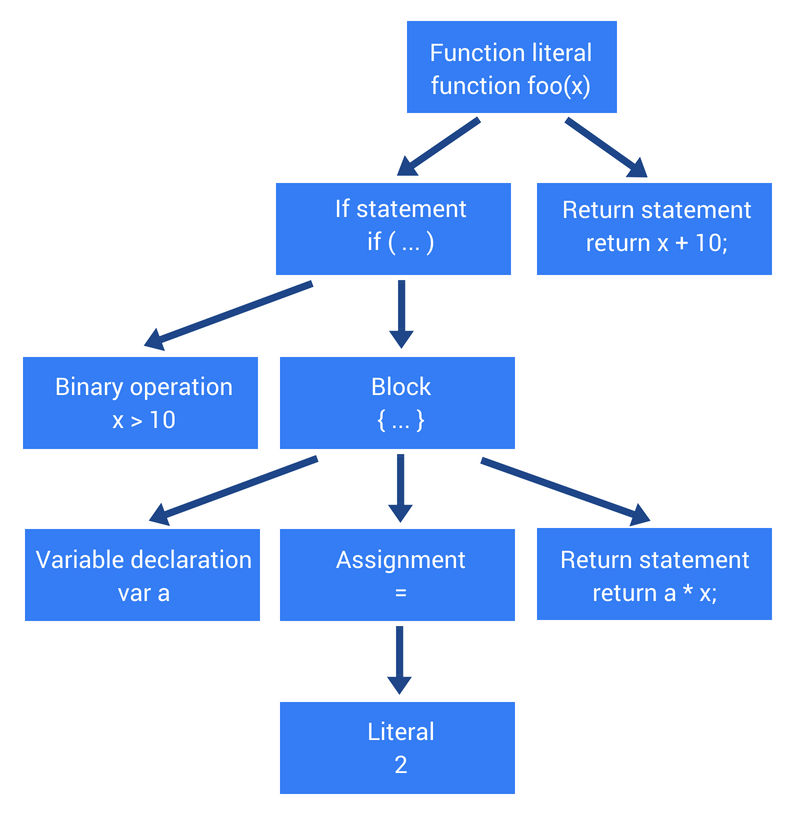
ASTの例を1つ見ておきます。(参考:How JavaScript works: Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse time)
以下のJavascriptコードをASTにします。
function foo(x) { if (x > 10) { var a = 2; return a * x; } return x + 10; }ASTは以下。
[画像引用:
How JavaScript works: Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse time]ちなみに以下のサイトで、JavascriptコードをASTに変換して見ることができます。
ASTに変換するこのParse作業っていうのは結構時間を食うものらしくて、最適化が重要になってきます。以下の画像は、どれだけParseに時間がかかっているかを示す画像。
そこでParseを最適化するために「Preparser」と「Parser」の2つのParserがV8では使われています。
関数を除く、トップレベルに記述されているコードは、全て実行されるのでparse作業をしてASTに変換します。一方で関数にはトップレベルに書かれていたとしても結局呼ばれない関数も存在します。その結局実行されない関数に対して、フルでparse作業をすると、parseにかかる時間もメモリも無駄なのです。そこで「Preparse」の出番です。
Preparseでは、ASTを作ったりせず、とりあえず最低限必要な情報だけ作っておき、あとで関数が実際に呼び出されたらフルでParseします。
ちなみに、以下のようなJavascriptソースコードは、Parseという観点では非効率なコードです。
function sayHi(name){ var message = "Hi " + name + "!" print(message) } sayHi("Sparkle")このようなコードでは、関数をPreparseした後、その関数をすぐ呼び出すことになるのでフルでParseされます。つまりすぐにParseするのに一度Preparseさせてしまっているのです。詳しくは、How JavaScript works: Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse timeを参照して下さい。
また、Preparserについて詳しく知りたい方は、公式のBlazingly fast parsing, part 2: lazy parsingを参照してください。
IgnitionとTurbofan
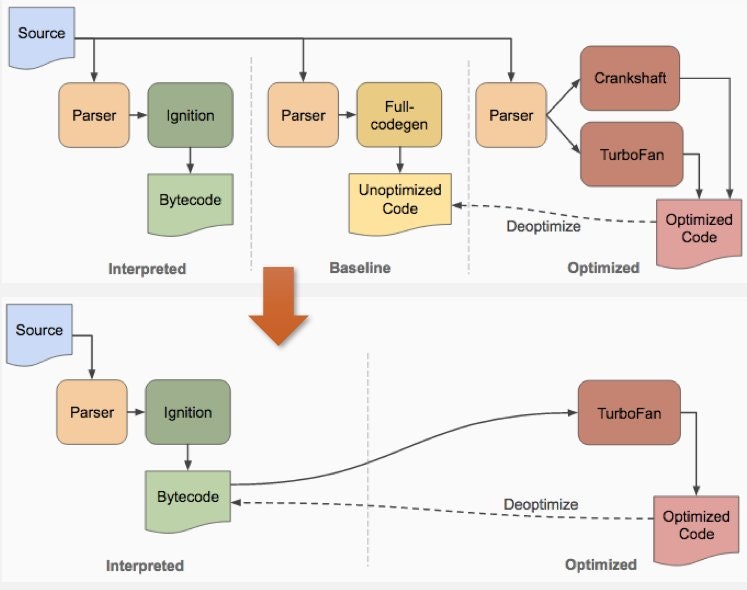
CranksahftとFull-codegen
V8ではInterpreterとCompilerとしてCrankshaftとFull-codegenが使われてきたけど、それらがIgnitionとTurbofanに変わりました。
[画像引用:Node8.3.0でデフォルトになるTF/Iに関わるベンチマークについて]Crankshaftはtryスコープ、ES2015の最適化(e.g. scope, class literal, for of, etc…)などができなかったことや、低レイヤと高レイヤとの分離がうまくできておらずV8チームがアーキテクチャ依存のコードを大量生成しなければいけなかったことなどから、TurboFanに代わったそうです。
またFull-codegenは機械語にコンパイルするため、メモリを食うこと、またIgnitionが生成するBytecodeが最適化に利用できてそのスピードがFull-codegenよりも早かったことからIgnitionに代わったそうです。
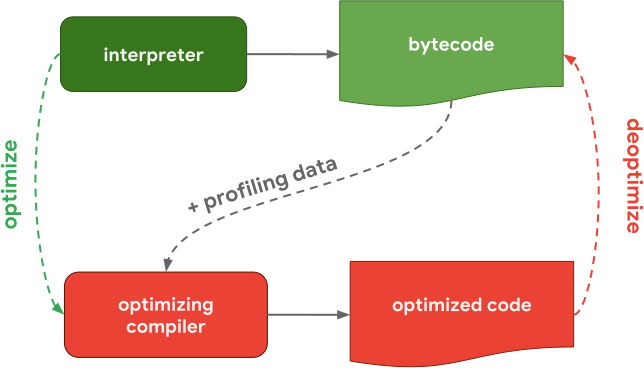
処理の流れ
- まずASTがIgnitionに渡され、そしてBytecode(機械語を抽象化したコード)が生成され、実行が開始されます。最適化はされていないにしてもIgnitionが素早くBytecodeを生成するため、アプリケーションは素早く動作し始めることができます。
- Profilerがコードを監視していて、何度も繰り返しコンパイルされている部分、つまり最適化できると推測される部分を見つけます。ここではinline cachesという最適化手法が利用されています。
- 最適化できる場合は、Ignitionもその情報を活用し最適化しますが、Turbofanも活用します。TurboFanにBytecodeが渡され、speculative optimizationという最適化手法を用いて、最適化された機械語が生成されます。最適化できるという推測が間違っていた場合は、deoptimizeされます。
- profilerとcompilerのおかげで、徐々にJavascriptの実行が改善されていきます。
[画像引用:JavaScript engine fundamentals: Shapes and Inline Caches]Bytecodeっていうのは、機械語を抽象化したものです。
[画像引用:Understanding V8’s Bytecode]BytecodeについてV8の人の説明を引用しておきます。
Bytecode is an abstraction of machine code. Compiling bytecode to machine code is easier if the bytecode was designed with the same computational model as the physical CPU. This is why interpreters are often register or stack machines. Ignition is a register machine with an accumulator register.
引用:Understanding V8’s Bytecodeまとめると、Ignitionは、Bytecode(抽象化された機械語)を素早く生成できるけど、最適化はされていません。Bytecodeは、メモリをあまり食わないという特徴もあります。一方でTurboFanは、最適化に少し時間はかかるけど、最適化された機械語を生成できます。生成されるのが機械語なので、抽象化された機械語であるBytecodeよりもメモリを多く使います。
またIgnitionとTurbofanには様々な最適化テクが使われていますが、ここでは省略します。
- Speculative Optimization
- Hidden Classes
- inline caches
Call stack と Heap
Call stackの定義をwikipediaから引用します。
コールスタック (Call Stack)は、プログラムで実行中のサブルーチンに関する情報を格納するスタックである。実行中のサブルーチンとは、呼び出されたが処理を完了していないサブルーチンを意味する。
引用:https://ja.wikipedia.org/wiki/コールスタックCall Stackは、コードが実行されていくにつれ、Stack Frameが積み重なっていきます。Call Stackを見ることで、プログラムが今どこにいるのか分かります。一方でHeapは、オブジェクトなどStack Frameのスコープを超えて保持すべきデータに対してメモリが割り当てられる場所です。
[画像引用:Confused about Stack and Heap?]Javascriptをブラウザで実行する際に、以下のようなエラー画面を見たことがあると思います。
(画像引用:How JavaScript works: an overview of the engine, the runtime, and the call stack)これはCall Stackを表していて、この場合だと以下のようなコードが順次Stack Frameとして積み重なっていったということになります。
function foo() { throw new Error('SessionStack will help you resolve crashes :)'); } function bar() { foo(); } function start() { bar(); } start();最後に
4月からNode.jsを離れることになるので、ここまで読んだ記事とか知ったこととかをまとめてみました。間違っている部分とかあれば、指摘くださるとありがたいです。
参考
Node.js(Libuv含む)
Event Loop and the Big Picture — NodeJS Event Loop Part1 https://blog.insiderattack.net/event-loop-and-the-big-picture-nodejs-event-loop-part-1-1cb67a182810?
Don't Block the Event Loop (or the Worker Pool)
https://nodejs.org/ja/docs/guides/dont-block-the-event-loop/Node.js徹底攻略 ─ ヤフーのノウハウに学ぶ、パフォーマンス劣化やコールバック地獄との戦い方
https://employment.en-japan.com/engineerhub/entry/2019/08/08/103000The Node.js Event Loop, Timers, and process.nextTick()
https://nodejs.org/en/docs/guides/event-loop-timers-and-nexttick/#event-loop-explainedそうだったのか! よくわかる process.nextTick() node.jsのイベントループを理解する
https://www.slideshare.net/shigeki_ohtsu/processnext-tick-nodejsasynchronous disk I/O
https://blog.libtorrent.org/2012/10/asynchronous-disk-io/http://nikhilm.github.io/uvbook/
Node.jsでのイベントループの仕組みとタイマーについて
https://blog.hiroppy.me/entry/nodejs-event-loop#Poll-PhaseNode.js event loop architecture
https://medium.com/preezma/node-js-event-loop-architecture-go-deeper-node-core-c96b4cec7aa4今日から始めるNode.jsコードリーディング - libuv / V8 JavaScriptエンジン / Node.jsによるスクリプトの実行
https://blog.otakumode.com/2014/08/14/nodejs-code-reading-startup-script/Nonblocking I/O
https://medium.com/@copyconstruct/nonblocking-i-o-99948ad7c957process.nextTick()
https://www.slideshare.net/shigeki_ohtsu/processnext-tick-nodejsNode.jsでのイベントループの仕組みとタイマーについて
https://blog.hiroppy.me/entry/nodejs-event-loopループの中で
https://www.youtube.com/watch?v=cCOL7MC4Pl0&t=1011slibuv
https://www.youtube.com/watch?v=nGn60vDSxQ4Node's Event Loop From the Inside Out by Sam Roberts, IBM
https://www.youtube.com/watch?v=P9csgxBgaZ8イベントループとは一体何ですか? | Philip Roberts | JSConf EU
https://www.youtube.com/watch?v=8aGhZQkoFbQV8
JavaScript V8 Engine Explained
https://hackernoon.com/javascript-v8-engine-explained-3f940148d4efUnderstanding V8’s Bytecode
https://medium.com/dailyjs/understanding-v8s-bytecode-317d46c94775Explaining JavaScript VMs in JavaScript - Inline Caches
https://mrale.ph/blog/2012/06/03/explaining-js-vms-in-js-inline-caches.htmlAn Introduction to Speculative Optimization in V8
https://benediktmeurer.de/2017/12/13/an-introduction-to-speculative-optimization-in-v8/How JavaScript works: an overview of the engine, the runtime, and the call stack
https://blog.sessionstack.com/how-does-javascript-actually-work-part-1-b0bacc073cfHow JavaScript works: Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse time
https://blog.sessionstack.com/how-javascript-works-parsing-abstract-syntax-trees-asts-5-tips-on-how-to-minimize-parse-time-abfcf7e8a0c8Confused about Stack and Heap?
https://fhinkel.rocks/2017/10/30/Confused-about-Stack-and-Heap/JavaScript Internals: Under The Hood of a Browser
https://medium.com/better-programming/javascript-internals-under-the-hood-of-a-browser-f357378cc922JavaScript Internals: Execution Context
https://medium.com/better-programming/javascript-internals-execution-context-bdeee6986b3bHow Does JavaScript Really Work? (Part 1)
https://blog.bitsrc.io/how-does-javascript-really-work-part-1-7681dd54a36dHow JavaScript works: Optimizing the V8 compiler for efficiency
https://blog.logrocket.com/how-javascript-works-optimizing-the-v8-compiler-for-efficiency/V8のIgnition Interpreterについて
https://speakerdeck.com/brn/v8falseignition-interpreternituite?slide=14V8 javascript engine for フロントエンドデベロッパー
https://www.slideshare.net/ssuser6f246f/v8-javascript-engine-forJavaScript engines - how do they even? | JSConf EU
https://www.youtube.com/watch?v=p-iiEDtpy6I&feature=youtu.be&t=722V8: an open source JavaScript engine
https://www.youtube.com/watch?v=hWhMKalEicY&feature=emb_titleMarja Hölttä: Parsing JavaScript - better lazy than eager? | JSConf EU 2017
https://www.youtube.com/watch?v=Fg7niTmNNLgV8公式
https://v8.dev/blog






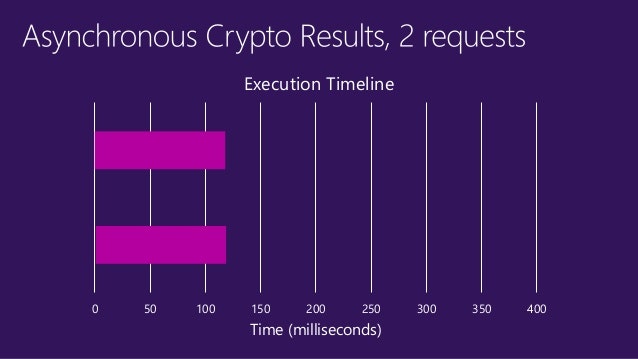
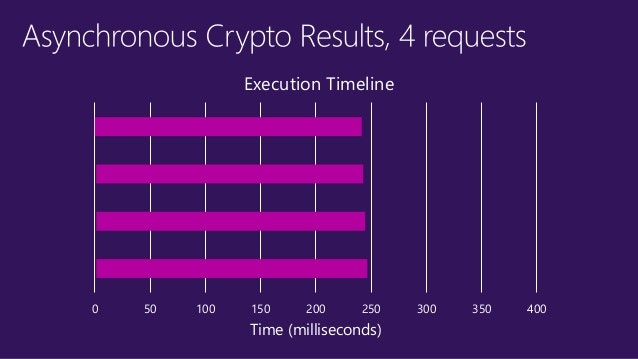
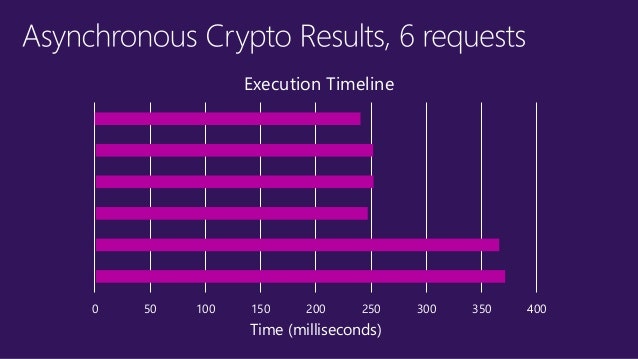

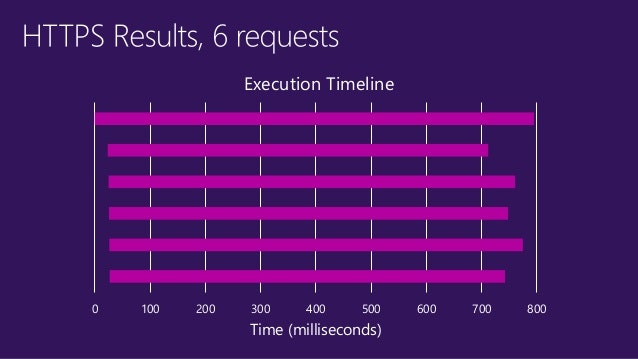







- 投稿日:2020-03-18T11:32:07+09:00
Firebaseのアプリケーションで複数のプロジェクトを使用する場合、Firebase app named "xxx" already exists.エラーが出る
はじめに
一つのアプリケーションで複数のFirebaseプロジェクトを利用する際に、最初にServiceAccountを使って初期化するのですが、次に別のファイルとかで使用する際に、同じように初期化しようとすると、すでに同一名で初期化されているとエラーが出ます。
再利用の仕方をドキュメントで見つけられなかったので、備忘録で...参考
環境
- Node v13.9.0
- npm 6.14.1
現象
'Firebase app named "dest" already exists. This means you called initializeApp() more than once with the same app name as the second argument. Make sure you provide a unique name every time you call initializeApp().'
とエラーが出る。コード公式(2つ目の別プロジェクトの設定読み込み)(databaseをfirestoreに変更)
var admin = require("firebase-admin"); var serviceAccount = require("path/to/serviceAccountKey.json"); var secondaryAppConfig = { credential: admin.credential.cert(serviceAccount), databaseURL: "https://<DATABASE_NAME>.firebaseio.com" }; // Initialize another app with a different config var secondary = firebase.initializeApp(secondaryAppConfig, "secondary"); // Retrieve the database. var secondaryDatabase = secondary.firestore();上記のsecondaryDatabaseを別のファイルで利用する
var admin = require('firebase-admin'); var secondaryDatabase = admin.app("secondary").firestore();以上
- 投稿日:2020-03-18T02:09:52+09:00
Node.jsのworker_threadsに何を渡すべきか
久々にScalaの世界からJSの世界に帰ってきました。
1. 本日の課題
本来Node.jsは非同期処理をストイックに突き詰めることでマルチスレッドやマルチプロセスのようなオーバーヘッドを伴う方法よりも高効率に並列処理を実現しているわけです。
ただし、それが有効なのは頻繁に「待ち」≒「I/O処理」が発生する場合に限られます。
ひたすらI/OなしでCPUをぶん回す処理、を複数同時にやれって言われたらシングルスレッドなNodeはマルチスレッドに勝てません。ですがですが、Nodeにだってマルチスレッド/マルチプロセスの仕組みはあります。
さて今回は、
- 数百MB~数GB程度のデータ構造(変数として持っている)に対して
- 秒オーダーの時間をかけておこなう検索処理を
- 複数回おこなう
- 元のデータ構造は更新しない(Read Only)
という要件で、この「複数回おこなう」というところをマルチスレッドかマルチプロセスで並列化して時間を短縮したい、というお題になります。1
2.候補
child_process/cluster
どちらもマルチプロセスなアプローチです。
マルチプロセスなので、メモリは各自が持ちます2。GB単位のメモリをそれぞれのプロセスが持ってたらちょっともったいないですね3。ということで早々に候補から排除。worker_threads
今回の本命です。
本家にはこのように書いてあります。child_processやclusterとは異なり、worker_threadsはメモリを共有できます。
ふむふむ、スレッドですからね。そりゃそうですよね。ですが続けてこうも書いてあります。
これは、ArrayBufferインスタンスを転送するか、SharedArrayBufferインスタンスを共有することにより行われます。
What's?
つまり、何も考えなくてもメモリが共有されるわけじゃないようですよ。
それが今回の本題というわけです。3. Bufferを使うということ
ArrayBuffer/SharedArrayBufferというのはつまり中身はバイナリですから、
{ "こんな": 1, "好き勝手な": "aaa", "形をした": [ "JSONから", "作った", "object/arrayなんか", ], "面倒みないよ": true }てなもんですよ。最後のtrueがなんだかムカつきますね。
なんとかBufferの基本的な使い方は、Uint32ArrayみたいなTypedArrayをViewとして使うことが多いんではないかと思います。4メモリは大事にしたい(共有したい)、JSON-likeな構造も扱いたい、そんなわがままに答えてくれるものはないでしょうか。
JSON
メインスレッドでJSON.stringifyしてBufferに載せて、ワーカースレッドでJSON.parseする・・・えーと、parseしてしまったらメモリの共有になってません。ダメです。
JSON以外のシリアライザ
messagePackとかありますね。これもデコードせねばならないのでメモリの共有にはなりません。messagePackならJSONよりエンコード状態のサイズが若干小さいという利点はありますが、デコードしてしまうのでささいな差ですね。5
4. ないものは自分で作ればいいじゃない
そう、それ!
やっと本題だ。
要するに、
- SharedArrayBufferに載せられて
- デコードせずとも中身にObjectやArrayのようにアクセスできる
何かを作ってしまえばいいじゃないか、という話。
「デコードせずとも中身にObjectやArrayのようにアクセスできる」?は?
と思ったあなた!
あるんですよ、JSにはいにしえより伝わる黒魔術、その名もProxyが。
つまり、「Object(あるいはArray)に見える」Proxyが動的にBufferをデコードしてあげればいいんじゃないか、と思ったわけです。この用途だとJSONやmessagePackなどのシリアライザでエンコードしておいて、SharedArrayBufferに載せて、ワーカー側では全体のデコードは「せず」に読み出しの時だけ必要部分をエンコードするようにすればいいわけですが、ここでもう一つ問題が。
JSONは、全体をスキャンしないと、構造が分からない。keyがあるのかどうか、あった場合に何byte目に入っているのかは、先頭から順に追っていかないとわからない。メモリが節約できても、それではあまりに遅すぎる。messagePackも「ほぼバイナリ形式のJSON」であり同じこと。そういうわけですから、
- Objectならkeyの有無、Arrayなら配列のサイズがすぐに分かって、
- 値の格納場所にダイレクトにたどり着ける
そんなデータ構造のシリアライザが欲しい!
ということで作ってみましたよ。使い方(sample.js)もGistに載せてますが一応再掲。
一般的なシリアライザ(JSON/messagePack等)と同じようにごくシンプル。sample.jsconst roJson = require('./roJson'); const buffer = roJson.encode({a: "Hello roJson.", b: 1, c: [0, 100, 200]}); const proxiedObject = roJson.getProxy(buffer); console.log(proxiedObject.a); // "Hello roJson." console.log(proxiedObject.c[1]); // 100長くなったのでいったんここまで。
工夫ポイント、ベンチマークなどは次回!
そんなヘビーな用途にNode.jsを使うなんて、なんてツッコミはなしの方向で。 ↩
OSの機能でプロセス間共有メモリってのがありますからそういうので共有できないことはないです。Node.jsから使う猛者がいるかどうかは知りませんが。 ↩
昔の知識なので最新は違うかもしれないしOSにもよるんでしょうが、プロセスをforkするとすぐにはメモリはコピーされなくて(つまり共有されていて)、書き込んだ時点でページ単位でコピーしてそれぞれの道を歩むようになってました。大部分のメモリに書き込みが発生しないならそれに頼るのも一つの見識ですね。 ↩
そういうデータを使うのって機械学習とかCG系とかのイメージ。そういう用途Node.js使いますかね・・・。 ↩
あと、JSON.stringify/parseはJSエンジンネイティブ実装だし、最適化されまくってるので速さで勝てません。憎いです。 ↩